
Serie S2300G & S3300G | Manual CLI
Versão deste manual: 1.0.0
Serie S2300G & S3300G | Manual CLI
Parabéns, você acaba de adquirir um produto com a qualidade e segurança Intelbras.
Estes produtos são homologados pela Anatel, o número de homologação se encontra na etiqueta dos produtos, para consultas utilize o link sistemas.anatel.gov.br/sch
O Manual de Linha de Comandos do Usuário, está divido em 12 capítulos para melhor oranização e compreenção do contéudo. Segue a lista com redirecionamento para URL de cada capítulo.
- 01 Configurações Fundamentais
- 02 Configurações de tecnologias virtuais
- 03 Configurando as interfaces Ethernet
- 04 Configuração de servições IP
- 05 Roteamento Unicast
- 06 Configuração de Multicast
- 07 ACL e QoS
- 08 Configuração de segurança
- 09 Guia de configuração de alta disponibilidade
- 10 Guia de configuração de gerenciamento e monitoramento de rede
- 11 Telemetria
- 12 OpenFlow
01 - Configurações Fundamentais
Usando a CLI
Sobre a CLI
Na interface de linha de comando (CLI), você pode inserir comandos de texto para configurar, gerenciar e monitorar o dispositivo.
Você pode usar diferentes métodos para fazer login na CLI. Por exemplo, é possível fazer login pela porta do console ou pela Telnet. Para obter mais informações sobre os métodos de login, consulte "Visão geral do login".
Uso de exibições da CLI
Sobre as exibições da CLI
Os comandos são agrupados em diferentes visualizações por recurso. Para usar um comando, você deve entrar em sua visualização.
As exibições da CLI são organizadas hierarquicamente, conforme mostrado na Figura 1. Cada visualização tem um prompt exclusivo, a partir do qual é possível identificar onde você está e o que pode fazer. Por exemplo , o prompt [Sysname-vlan100] mostra que você está na visualização VLAN 100 e pode configurar atributos para essa VLAN.
Figura 1 Visualizações da CLI
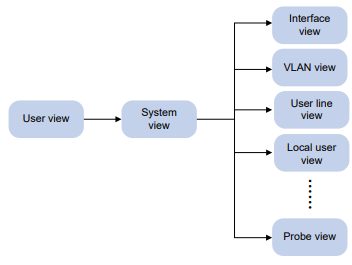
Você é colocado na visualização do usuário imediatamente após fazer login na CLI. Na visualização do usuário, é possível executar as seguintes tarefas:
- Realizar operações básicas, incluindo exibição, depuração, gerenciamento de arquivos, FTP, Telnet e configuração de relógio e reiniciar.
- Entre na visualização do sistema.
Na visualização do sistema, você pode executar as seguintes tarefas:
- Defina as configurações que afetam o dispositivo como um todo, como o horário de verão, banners e teclas de atalho.
- Insira visualizações de recursos.
Por exemplo, você pode executar as seguintes tarefas:
- Entre na visualização da interface para configurar os parâmetros da interface.
- Entre no modo de exibição VLAN para adicionar portas à VLAN.
- Entre na visualização da linha do usuário para configurar os atributos do usuário de login.
Uma visualização de recurso pode ter visualizações secundárias. Por exemplo, a visualização de operação NQA tem a visualização secundária de operação HTTP.
- Entre na visualização de sonda usando o comando probe.
A visualização da sonda fornece comandos de exibição, depuração e manutenção, que são usados principalmente por desenvolvedores e testadores para diagnóstico de falhas do sistema e monitoramento da operação do sistema.
 CUIDADO:
CUIDADO:
Use os comandos na visualização da sonda sob a orientação de engenheiros para evitar exceções do sistema causadas por operações incorretas.
Para obter mais informações sobre os comandos na visualização da sonda, consulte o manual de comandos da sonda para cada recurso.
Para exibir todos os comandos disponíveis em uma visualização, digite um ponto de interrogação (?) no prompt da visualização.
Entrar na visualização do sistema a partir da visualização do usuário
Para entrar na visualização do sistema a partir da visualização do usuário, execute o seguinte comando:
system-viewRetornar à visualização de nível superior a partir de uma visualização
Restrições e diretrizes
A execução do comando quit na visualização do usuário encerra sua conexão com o dispositivo.
Para retornar da visualização da chave pública para a visualização do sistema, você deve usar o comando
peer-public-key endProcedimento
Para retornar à visualização de nível superior a partir de uma visualização, execute o seguinte comando:
quitRetornar à visualização do usuário
Sobre o retorno à visualização do usuário
Esse recurso permite que você retorne à visualização do usuário a partir de qualquer visualização executando uma única operação, eliminando a necessidade de executar o comando quit várias vezes.
Procedimento
Para retornar diretamente à visualização do usuário a partir de qualquer outra visualização (exceto a visualização de configuração Tcl e o shell Python), use um dos seguintes métodos:
- Execute o comando return em qualquer visualização.
- Pressione Ctrl+Z em qualquer exibição.
Para retornar à visualização do usuário a partir da visualização de configuração Tcl, execute o comando tclquit na visualização de configuração Tcl.
Para retornar à visualização do usuário a partir do shell Python, execute o comando exit() no shell Python.
Acesso à ajuda on-line da CLI
A ajuda on-line da CLI é sensível ao contexto. Digite um ponto de interrogação em qualquer prompt ou em qualquer posição de um comando para exibir todas as opções disponíveis.
Para acessar a ajuda on-line da CLI, use um dos métodos a seguir:
- Digite um ponto de interrogação em um prompt de visualização para exibir a primeira palavra-chave de cada comando disponível na visualização. Por exemplo:
<Sysname> ?User view commands:archive Archive configurationarp Address Resolution Protocol (ARP) modulebackup Backup the startup configuration file to a TFTP serverboot-loader Software image file management...
- Digite um espaço e um ponto de interrogação após uma palavra-chave de comando para exibir todas as palavras-chave e argumentos disponíveis.
- Se o ponto de interrogação estiver no lugar de uma palavra-chave, a CLI exibirá todas as palavras-chave possíveis, cada uma com uma breve descrição. Por exemplo:
<Sysname> terminal ?debugging Enable to display debugging logs on the current terminallogging Display logs on the current terminalmonitor Enable to display logs on the current terminal
- Se o ponto de interrogação estiver no lugar de um argumento, a CLI exibirá a descrição do argumento. Por exemplo:
<Sysname> system-view[Sysname] interface vlan-interface ?<1-4094> Vlan-interface interface number[Sysname] interface vlan-interface 1 ?<cr>[Sysname] interface vlan-interface 1
- Digite uma cadeia de palavras-chave incompleta seguida de um ponto de interrogação para exibir todas as palavras-chave que começam com essa cadeia. A CLI também exibe as descrições das palavras-chave. Por exemplo:
<Sysname> f?fdisk Partition a storage mediumfixdisk Check and repair a storage mediumformat Format a storage mediumfree Release a connectionftp Open an FTP connection<Sysname> display ftp?ftp FTP moduleftp-server FTP server informationftp-user FTP user information
Usando a forma de desfazer de um comando
A maioria dos comandos de configuração tem um formulário de desfazer para as seguintes tarefas:
- Cancelamento de uma configuração.
- Restaurar o padrão.
- Desativar um recurso.
Por exemplo, o comando info-center enable habilita o centro de informações. O comando
undo info-center enable desativa o centro de informações.
Inserção de um comando
Ao inserir um comando, você pode executar as seguintes tarefas:
- Use teclas ou teclas de atalho para editar a linha de comando.
- Use palavras-chave abreviadas ou aliases de palavras-chave.
Edição de uma linha de comando
Para editar uma linha de comando, use as teclas listadas na Tabela 1 ou as teclas de atalho listadas na Tabela 4. Quando terminar, pressione Enter para executar o comando.
O buffer de edição de comandos pode conter um máximo de 511 caracteres. Se o comprimento total de uma linha de comando exceder o limite depois que você pressionar Tab para concluir a última palavra-chave ou argumento, o sistema não concluirá a palavra-chave.
Tabela 1 Teclas de edição da linha de comando
O dispositivo suporta os seguintes comandos especiais:
- #Usado pelo sistema em um arquivo de configuração como separadores para seções adjacentes.
- version - Usado pelo sistema em um arquivo de configuração para indicar as informações da versão do software. Por exemplo, versão 7.1. xxx, Release xxx.
Esses comandos são especiais pelos seguintes motivos:
- Esses comandos não se destinam a ser usados na CLI.
- Você pode digitar o comando # em qualquer visualização ou o comando version na visualização do sistema, ou digitar qualquer valor para eles. Por exemplo, você pode digitar # abc ou versão abc. No entanto, as configurações não entram em vigor.
- O dispositivo não fornece nenhuma informação de ajuda on-line para esses comandos.
Inserção de um valor do tipo texto ou cadeia de caracteres para um argumento
Um valor de argumento do tipo texto pode conter qualquer caractere, exceto pontos de interrogação (?).
Um valor de argumento do tipo string pode conter qualquer caractere imprimível, exceto pontos de interrogação (?).
- Para incluir uma aspa (") ou uma barra invertida (\) em um valor de argumento do tipo cadeia de caracteres, prefixe o caractere com uma tecla de escape (\), por exemplo, \" e \\.
- Para incluir um espaço em branco em um valor de argumento do tipo string, coloque o valor entre aspas, por exemplo, ''my device''.
Um argumento específico pode ter mais requisitos. Para obter mais informações, consulte a referência do comando relevante.
Para inserir um caractere imprimível, você pode inserir o caractere ou seu código ASCII no intervalo de 32 a 126.
Inserção de um tipo de interface
Você pode inserir um tipo de interface em um dos seguintes formatos:
- Ortografia completa do tipo de interface.
- Uma abreviação que identifica exclusivamente o tipo de interface.
- Acrônimo do tipo de interface.
Em uma linha de comando, todos os tipos de interface não diferenciam maiúsculas de minúsculas. A Tabela 2 mostra a grafia completa e os acrônimos dos tipos de interface.
Por exemplo, para usar o comando interface para entrar na visualização da interface GigabitEthernet 1/0/1, você pode inserir a linha de comando nos seguintes formatos:
- interface gigabitethernet 1/0/1
- interface g 1/0/1
- interface ge 1/0/1
Não são necessários espaços entre os tipos de interface e as interfaces.
Tabela 2 Grafia completa e acrônimos dos tipos de interface
| Ortografia completa | Acrônimo |
| Bridge-Aggregation | BAGG |
| Ethernet | Ética |
| GigabitEthernet | GE |
| InLoopBack | InLoop |
| LoopBack | Loop |
| M-Ethernet | ME |
| NULO | NULO |
| Dez GigabitEthernet | XGE |
| Interface Vlan | Vlan-int |
Abreviação de comandos
Você pode entrar em uma linha de comando rapidamente digitando palavras-chave incompletas que identificam exclusivamente o comando completo. Na visualização do usuário, por exemplo, os comandos que começam com s incluem startup saved-configuration e system-view. Para inserir o comando system-view, você precisa digitar apenas sy. Para acessar o comando startup saved-configuration, digite st s.
Você também pode pressionar Tab para completar uma palavra-chave incompleta.
Configuração e uso de aliases de comando
Sobre aliases de comando
Você pode configurar um ou mais aliases para um comando ou para as palavras-chave iniciais dos comandos. Em seguida, você pode usar os aliases para executar o comando ou os comandos. Se o comando ou os comandos tiverem formulários de desfazer, você também poderá usar os aliases para executar o comando ou os comandos de desfazer.
Por exemplo, se você configurar o alias shiprt para display ip routing-table, poderá digitar shiprt para executar o comando display ip routing-table. Se você configurar o alias ship para display ip, poderá usar ship para executar todos os comandos que começam com display ip, inclusive:
- Digite ship routing-table para executar o comando display ip routing-table.
- Digite ship interface para executar o comando display ip interface. O dispositivo fornece um conjunto de aliases de comando definidos pelo sistema, conforme listado na Tabela 3. Tabela 3 Aliases de comando definidos pelo sistema
| Alias de comando | Comando ou palavra-chave de comando |
| lista de acesso | acl |
| final | retorno |
| apagar | excluir |
| saída | sair |
| nome do host | nome do sistema |
| registro | Centro de informações |
| não | desfazer |
| show | exibição |
| escrever | salvar |
Restrições e diretrizes
Um alias de comando pode ser usado apenas como a primeira palavra-chave de um comando ou como a segunda palavra-chave do comando
desfazer a forma de um comando.
Depois que você executa um comando com sucesso usando um alias, o sistema salva o comando, em vez do alias, na configuração em execução.
A cadeia de comando pode incluir até nove parâmetros. Cada parâmetro começa com o cifrão ($) e
um número de sequência no intervalo de 1 a 9. Por exemplo, você pode configurar o alias shinc para o comando display ip $1 | include $2. Em seguida, para executar o comando display ip routing-table | include Static, você precisa digitar apenas shinc routing-table Static.
Para usar um alias para um comando que tenha parâmetros, você deve especificar um valor para cada parâmetro. Se isso não for feito, o sistema informará que o comando está incompleto e exibirá a cadeia de comandos representada pelo alias.
Os aliases de comando definidos pelo sistema não podem ser excluídos.
Procedimento
- Entre na visualização do sistema.
system-view- Configurar um alias de comando.
alias alias commandPor padrão, o dispositivo tem um conjunto de aliases de comando, conforme listado na Tabela 3.
- (Opcional.) Exibir aliases de comando.
display alias [ alias ]Esse comando está disponível em qualquer visualização.
Configuração e uso de teclas de atalho
Sobre as teclas de atalho
O dispositivo suporta um conjunto de teclas de atalho. Pressionar uma tecla de atalho executa o comando ou a função atribuída à tecla de atalho. A Tabela 4 mostra as teclas de atalho e suas definições padrão. Você pode configurar todas as teclas de atalho, exceto Ctrl+].
Se uma tecla de atalho também for definida pelo software de terminal que estiver usando para interagir com o dispositivo, você poderá reconfigurar a tecla de atalho ou removê-la.
Restrições e diretrizes
Uma tecla de atalho pode corresponder a apenas um comando ou função. Se você atribuir vários comandos ou funções à mesma tecla de atalho, o comando ou função atribuído mais recentemente terá efeito.
Um comando ou função pode ser atribuído a várias teclas de atalho. Você pode usar qualquer uma das teclas de atalho para executar o comando ou a função.
Se uma tecla de atalho também for definida pelo software do terminal que você está usando para interagir com o dispositivo, a definição do software do terminal terá efeito.
Procedimento
- Entre na visualização do sistema.
system-view- Atribuir um comando a uma tecla de atalho.
hotkey hotkey { command | function function | none }A Tabela 4 mostra as definições padrão para as teclas de atalho.
- (Opcional.) Exibir teclas de atalho.
display hotkeyEsse comando está disponível em qualquer visualização.
Tabela 4 Definições padrão para teclas de atalho
| Tecla de atalho | Função ou comando |
| Ctrl+A | move_the_cursor_to_the_beginning_of_the_line: Move o cursor para o início de uma linha. |
| Ctrl+B | move_the_cursor_one_character_to_the_left: Move o cursor um caractere para a esquerda. |
| Tecla de atalho | Função ou comando |
| Ctrl+C | stop_the_current_command: Interrompe o comando atual. |
| Ctrl+D | erase_the_character_at_the_cursor: Apaga o caractere no cursor. |
| Ctrl+E | move_the_cursor_to_the_end_of_the_line: Move o cursor para o final de uma linha. |
| Ctrl+F | move_the_cursor_one_character_to_the_right: Move o cursor um caractere para a direita. |
| Ctrl+G | display current-configuration: Exibe a configuração em execução. |
| Ctrl+H | erase_the_character_to_the_left_of_the_cursor: Apaga o caractere à esquerda do cursor. |
| Ctrl+L | display ip routing-table: Exibe as informações da tabela de roteamento IPv4. |
| Ctrl+N | display_the_next_command_in_the_history_buffer: Exibe o próximo comando no buffer do histórico. |
| Ctrl+O | undo debugging all: Desabilita todas as funções de depuração. |
| Ctrl+P | display_the_previous_command_in_the_history_buffer: Exibe o comando anterior no buffer do histórico. |
| Ctrl+R | redisplay_the_current_line: Exibe novamente a linha atual. |
| Ctrl+T | N/A |
| Ctrl+U | N/A |
| Ctrl+W | delete_the_word_to_the_left_of_the_cursor: Exclui a palavra à esquerda do cursor. |
| Ctrl+X | delete_all_characters_from_the_beginning_of_the_line_to_the_cursor: Exclui todos os caracteres à esquerda do cursor. |
| Ctrl+Y | delete_all_characters_from_the_cursor_to_the_end_of_the_line: Exclui todos os caracteres do cursor até o final da linha. |
| Ctrl+Z | return_to_the_User_View: Retorna à visualização do usuário. |
| Ctrl+] | kill_incoming_connection_or_redirect_connection: Termina a conexão atual. |
| Esc+B | move_the_cursor_back_one_word: move o cursor uma palavra para trás. |
| Esc+D | delete_all_characters_from_the_cursor_to_the_end_of_the_word: Exclui todos os caracteres do cursor até o final da palavra. |
| Esc+F | move_the_cursor_forward_one_word: move o cursor uma palavra para frente. |
Ativação da reexibição de comandos inseridos, mas não enviados
Sobre a reexibição de comandos inseridos, mas não enviados
Sua entrada pode ser interrompida pela saída de informações do sistema. Se a reexibição de comandos inseridos, mas não enviados, estiver ativada, o sistema reexibirá sua entrada após terminar a saída. Você poderá continuar a digitar a linha de comando.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a reexibição de comandos inseridos, mas não enviados.
info-center synchronousPor padrão, o sistema não exibe novamente os comandos inseridos, mas não enviados.
Para obter mais informações sobre esse comando, consulte Referência de comandos de monitoramento e gerenciamento de rede.
Compreensão das mensagens de erro de sintaxe da linha de comando
Depois que você pressiona Enter para enviar um comando, o interpretador de linha de comando examina a sintaxe do comando.
- Se o comando for aprovado na verificação de sintaxe, a CLI executará o comando.
- Se o comando não passar na verificação de sintaxe, a CLI exibirá uma mensagem de erro.
Tabela 5 Mensagens comuns de erro de sintaxe da linha de comando
| Mensagem de erro de sintaxe | Causa |
| % Comando não reconhecido encontrado na posição '^'. | A palavra-chave na posição marcada é inválida. |
| % Comando incompleto encontrado na posição '^'. | Uma ou mais palavras-chave ou argumentos necessários estão faltando. |
| Comando ambíguo encontrado na posição '^'. | A sequência de caracteres inserida corresponde a mais de um comando. |
| % Too many parameters found at '^' position. | A sequência de caracteres inserida contém palavras- chave ou argumentos em excesso. |
| % Parâmetro incorreto encontrado na posição '^'. | O argumento na posição marcada é inválido. |
Uso do recurso de histórico de comandos
Sobre os buffers do histórico de comandos
O sistema salva automaticamente os comandos executados com êxito por um usuário de login nos dois buffers de histórico de comandos a seguir:
- Buffer do histórico de comandos para a linha do usuário.
- Buffer do histórico de comandos para todas as linhas de usuário.
Tabela 6 Comparação entre os dois tipos de buffers de histórico de comandos
| Item | Buffer do histórico de comandos para uma linha de usuário | Buffer do histórico de comandos para todas as linhas do usuário |
| Quais comandos são salvos no buffer? | Comandos executados com sucesso pelo usuário atual da linha do usuário. | Comandos executados com sucesso por todos os usuários de login. |
| Os comandos no buffer podem ser exibidos? | Sim. | Sim. |
| Os comandos no buffer podem ser recuperados? | Sim. | Não. |
| Item | Buffer do histórico de comandos para uma linha de usuário | Buffer do histórico de comandos para todas as linhas do usuário |
| Os comandos armazenados em buffer são apagados quando o usuário faz logout? | Sim. | Não. |
| O tamanho do buffer é ajustável? | Sim. | Não. O tamanho do buffer é fixado em 1024. |
Regras de buffer de comando
O sistema segue essas regras ao armazenar comandos em buffer:
- Se você usar palavras-chave incompletas ao inserir um comando, o sistema armazenará o comando na forma exata que você usou.
- Se você usar um alias ao inserir um comando, o sistema transformará o alias no comando representado ou nas palavras-chave do comando antes de armazenar o comando em buffer.
- Se você inserir um comando no mesmo formato várias vezes seguidas, o sistema armazenará o comando em buffer apenas uma vez. Se você digitar um comando em diferentes formatos várias vezes, o sistema armazenará em buffer cada formato de comando.
Por exemplo, display cu e displaycurrent-configuration são armazenados em buffer como duas entradas, mas repetições sucessivas de exibir cu criar apenas uma entrada.
- Para armazenar em buffer um novo comando quando um buffer estiver cheio, o sistema exclui a entrada de comando mais antiga em o buffer.
Gerenciar e usar os buffers do histórico de comandos
Exibição dos comandos nos buffers do histórico de comandos
Para exibir os comandos nos buffers do histórico de comandos, execute os seguintes comandos em qualquer visualização:
- Exibe os comandos nos buffers do histórico de comandos de uma linha de usuário.
display history-command- Exibe os comandos nos buffers do histórico de comandos para todas as linhas de usuário.
display history-command allRecuperação de comandos no buffer do histórico de comandos para uma linha de usuário
Use as teclas de seta para cima e para baixo para navegar até o comando e pressione Enter.
Definição do tamanho do buffer do histórico de comandos para uma linha de usuário
Use o comando history-command max-size na visualização de linha de usuário ou de classe de linha de usuário. Para obter mais informações, consulte Referência de comandos básicos.
Repetição de comandos no buffer do histórico de comandos para uma linha de usuário
Sobre a repetição de comandos no buffer do histórico de comandos para uma linha de usuário
É possível recuperar e executar comandos no buffer do histórico de comandos para a linha de usuário atual várias vezes.
Restrições e diretrizes
O comando de repetição está disponível em qualquer visualização. No entanto, para repetir um comando, você deve primeiro entrar na visualização do comando. Para repetir vários comandos, você deve primeiro entrar na visualização do primeiro comando.
O comando repeat executa os comandos na ordem em que foram executados. O sistema aguarda a sua interação quando repete um comando interativo.
Procedimento
Para repetir comandos no buffer do histórico de comandos para a linha do usuário atual, execute o seguinte comando:
repeat [ number ] [ count times ] [ delay seconds ]Controle da saída da CLI
Esta seção descreve os recursos de controle de saída da CLI que o ajudam a identificar a saída desejada.
Pausa entre telas de saída
Sobre a pausa entre telas de saída
O dispositivo pode pausar automaticamente após a exibição de um número específico de linhas se a saída for muito longa para caber em uma tela. Em uma pausa, o dispositivo exibe ----more----
. Você pode usar as teclas descritas na Tabela 7 para exibir mais informações ou interromper a exibição.
Também é possível desativar a pausa entre as telas de saída da sessão atual. Assim, toda a saída é exibida de uma só vez e a tela é atualizada continuamente até que a tela final seja exibida.
Tabela 7 Teclas de controle de saída
| Chaves | Função |
| Espaço | Exibe a próxima tela. |
| Entrar | Exibe a próxima linha. |
| Ctrl+C | Interrompe a exibição e cancela a execução do comando. |
| <PageUp> | Exibe a página anterior. |
| <PageDown> | Exibe a próxima página. |
Desativar a pausa entre as telas de saída
Para desativar a pausa entre as telas de saída, execute o seguinte comando na visualização do usuário:
screen-length disable
O padrão depende das configurações do comando screen-length na visualização da linha do usuário. A seguir estão as configurações padrão do comando screen-length:
- A pausa entre as telas de saída está ativada.
- O número máximo de linhas a serem exibidas por vez é 24.
Para obter mais informações sobre o comando screen-length, consulte Fundamentals Command Reference.
Esse comando é único e tem efeito apenas na sessão atual da CLI.
Numeração de cada linha de saída de um comando de exibição
Sobre a numeração da linha de saída do comando display
Para facilitar a identificação, você pode usar a opção | by-linenum para exibir um número para cada linha de saída de um comando de exibição.
Cada número de linha é exibido como uma cadeia de 5 caracteres e pode ser seguido por dois pontos (:) ou hífen (-). Se você especificar | by-linenum e | begin regular- expression para um comando display , será exibido um hífen para todas as linhas que não corresponderem à expressão regular.
Procedimento
Para numerar cada linha de saída de um comando de exibição, execute o seguinte comando em qualquer visualização:
comando display | by-linenum
Exemplo
# Exibir informações sobre a VLAN 999, numerando cada linha de saída.
<Sysname> display vlan 999 | by-linenum1: VLAN ID: 9992: VLAN type: Static3: Route interface: Configured4: IPv4 address: 192.168.2.15: IPv4 subnet mask: 255.255.255.06: Description: For LAN Access7: Name: VLAN 09998: Tagged ports: None9: Untagged ports: None
Filtragem da saída de um comando de exibição
Sobre a filtragem da saída do comando display
Você pode usar a opção [ | [ by-linenum ] { begin | exclude | include } regular-expression ]&<1-128> para filtrar a saída de um comando display.
- Você pode usar a opção para especificar um máximo de 128 condições de filtro. O sistema exibe apenas as linhas de saída que atendem a todas as condições.
- by-linenum - Exibe um número antes de cada linha de saída. Você precisa especificar essa palavra-chave em apenas uma condição de filtro.
- begin - Exibe a primeira linha que corresponde à expressão regular especificada e todas as linhas subsequentes.
- exclude - Exibe todas as linhas que não correspondem à expressão regular especificada.
- include - Exibe todas as linhas que correspondem à expressão regular especificada.
- expressão regular - Uma cadeia de caracteres com distinção entre maiúsculas e minúsculas de 1 a 256 caracteres, que pode conter os caracteres especiais descritos na tabela 8.
Tabela 8 Caracteres especiais suportados em uma expressão regular
| Personagens | Significado | Exemplos |
| ^ | Corresponde ao início de uma linha. | "^u" corresponde a todas as linhas que começam com "u". Uma linha que começa com "Au" não é correspondida. |
| $ | Corresponde ao final de uma linha. | "u$" corresponde a todas as linhas que terminam com "u". Uma linha |
| Personagens | Significado | Exemplos |
| que termina com "uA" não é correspondido. | ||
| . (período) | Corresponde a qualquer caractere único. | ".s" corresponde a "as" e "bs". |
| * | Corresponde ao caractere ou à cadeia de caracteres anterior zero, uma ou várias vezes. | "zo*" corresponde a "z" e "zoo", e "(zo)*" corresponde a "zo" e "zozo". |
| + | Corresponde ao caractere ou à cadeia de caracteres anterior uma ou várias vezes. | "zo+" corresponde a "zo" e "zoo", mas não a "z". |
| | | Corresponde à cadeia de caracteres anterior ou posterior. | "def|int" corresponde a uma linha que contém "def" ou "int". |
| ( ) | Corresponde à cadeia de caracteres entre parênteses, geralmente usada junto com o sinal de adição (+) ou o sinal de asterisco (*). | "(123A)" corresponde a "123A". "408(12)+" corresponde a "40812" e "408121212", mas não "408". |
| \N | Corresponde às cadeias de caracteres anteriores entre parênteses, com a enésima cadeia de caracteres repetida uma vez. | "(string)\1" corresponde a uma string que contém "stringstring". "(string1)(string2)\2" corresponde a uma string que contém "string1string2string2". "(string1)(string2)\1\2" corresponde a uma string que contém " string1string2string1string2". |
| [ ] | Corresponde a um único caractere entre colchetes. | "[16A]" corresponde a uma cadeia de caracteres contendo 1, 6 ou A; "[1-36A]" corresponde a uma cadeia de caracteres contendo 1, 2, 3, 6 ou A (- é um hífen). Para corresponder ao caractere "]", coloque-o imediatamente após "[", por exemplo, []abc]. Não existe esse limite para "[". |
| [^] | Corresponde a um único caractere que não está entre colchetes. | "[^16A]" corresponde a uma cadeia de caracteres que contém um ou mais caracteres, exceto 1, 6 ou A, como "abc". Uma correspondência também pode conter 1, 6 ou A (como "m16"), mas não pode conter apenas esses três caracteres (como 1, 16 ou 16A). |
| {n} | Corresponde ao caractere anterior n vezes. O número n deve ser um número inteiro não negativo. | "o{2}" corresponde a "food", mas não a "Bob". |
| {n,} | Corresponde ao caractere anterior n vezes ou mais. O número n deve ser um número inteiro não negativo. | "o{2,}" corresponde a "foooood", mas não a "Bob". |
| {n,m} | Corresponde ao caractere anterior n a m vezes ou mais. Os números n e m devem ser números inteiros não negativos e n não pode ser maior que m. | " o{1,3}" corresponde a "fod", "food" e "foooood", mas não a "fd". |
| \< | Corresponde a uma cadeia de caracteres que começa com o padrão seguinte a \<. Uma cadeia de caracteres que contém o padrão também é uma correspondência se os caracteres que precedem o padrão não forem dígitos, letras ou sublinhados. | "\<do" corresponde a "domain" e "doa". |
| \> | Corresponde a uma cadeia de caracteres que termina com o padrão anterior a \>. Uma cadeia de caracteres que contém o padrão também é uma correspondência se os caracteres que seguem o padrão não forem dígitos, letras ou sublinhados. | "do\>" corresponde a "undo" e "cdo". |
| \b | Corresponde a uma palavra que começa com o padrão seguinte a \b ou termina com o padrão | "er\b" corresponde a "never", mas não a "verb" ou "erase". |
| Personagens | Significado | Exemplos |
| padrão anterior a \b. | "\ber" corresponde a "erase" (apagar), mas não a "verb" (verbo) ou "never" (nunca). | |
| \B | Corresponde a uma palavra que contém o padrão, mas não começa nem termina com o padrão. | "er\B" corresponde a "verbo", mas não a "never" ou "erase". |
| \w | Igual a [A-Za-z0-9_], corresponde a um dígito, letra ou sublinhado. | "v\w" corresponde a "vlan" e "service". |
| \W | Igual a [^A-Za-z0-9_], corresponde a um caractere que não é um dígito, letra ou sublinhado. | "\Wa" corresponde a "-a", mas não a "2a" ou "ba". |
| \ | Caractere de escape. Se um caractere especial listado nesta tabela vier depois de \, o significado específico do caractere será removido. | "\\" corresponde a uma cadeia de caracteres que contém "\", "\^" corresponde a uma cadeia de caracteres que contém "^" e "\\b" corresponde a uma cadeia de caracteres que contém "\b". |
Restrições e diretrizes
O tempo de filtragem necessário aumenta com a complexidade da expressão regular. Para interromper o processo de filtragem, pressione Ctrl+C.
Exemplos
<Sysname> display current-configuration | begin lineline class auxuser-role network-admin#line class vtyuser-role network-operator#line aux 0user-role network-admin#line vty 0 63authentication-mode noneuser-role network-adminuser-role network-operator#...
# Exibir informações breves sobre interfaces em estado ativo.
<Sysname> display interface brief | exclude DOWNBrief information on interfaces in route mode:Link: ADM - administratively down; Stby - standbyProtocol: (s) - spoofingInterface Link Protocol Primary IP DescriptionInLoop0 UP UP(s) --NULL0 UP UP(s) --Vlan1 UP UP 192.168.1.83Brief information on interfaces in bridge mode:Link: ADM - administratively down; Stby - standby15Speed: (a) - autoDuplex: (a)/A - auto; H - half; F - fullType: A - access; T - trunk; H - hybridInterface Link Speed Duplex Type PVID DescriptionGE1/0/1 UP 1000M(a) F(a) A 1
# Exibir linhas de configuração em execução relacionadas ao SNMP.
<Sysname> display logbuffer | include SHELL | include VTY%Sep 6 10:38:12:320 2018 Sysname SHELL/5/SHELL_LOGIN: VTY logged in from 169.254.100.171.%Sep 6 10:52:32:576 2018 Sysname SHELL/5/SHELL_LOGOUT: VTY logged out from 169.254.100.171.%Sep 6 16:03:27:100 2018 Sysname SHELL/5/SHELL_LOGIN: VTY logged in from 169.254.100.171.%Sep 6 16:44:18:113 2018 Sysname SHELL/5/SHELL_LOGOUT: VTY logged out from 169.254.100.171.
Salvando a saída de um comando de exibição em um arquivo
Sobre o salvamento da saída do comando de exibição
Um comando display mostra determinadas informações de configuração e operação do dispositivo. Sua saída pode variar com o tempo ou com a configuração ou operação do usuário. Você pode salvar a saída em um arquivo para recuperação futura ou solução de problemas.
Use um dos métodos a seguir para salvar a saída de um comando display:
- Salve a saída em um arquivo separado. Use esse método se quiser usar um arquivo para um comando display.
- Anexa a saída ao final de um arquivo. Use esse método se quiser usar um arquivo para várias comandos display.
Procedimento
Para salvar a saída de um comando display em um arquivo, use um dos seguintes comandos em qualquer visualização:
- Salve a saída de um comando display em um arquivo separado.
display command > filename
- Anexa a saída de um comando de exibição ao final de um arquivo.
display command >> filename
Exemplos
# Salve as configurações da VLAN 1 em um arquivo separado chamado vlan.txt.
# Verifique se as configurações da VLAN 1 foram salvas no arquivo vlan.txt.
<Sysname> more vlan.txt
VLAN ID: 1
VLAN type: Static
16
Route interface: Not configured
Description: VLAN 0001
Name: VLAN 0001
Tagged ports: None
Untagged ports: None# Acrescente as configurações da VLAN 999 ao final do arquivo vlan.txt.
<Sysname> display vlan 999 >> vlan.txt<Sysname> more vlan.txt
VLAN ID: 1
VLAN type: Static
Route interface: Not configured
Description: VLAN 0001
Name: VLAN 0001
Tagged ports: None
Untagged ports: None
VLAN ID: 999
VLAN type: Static
Route interface: Configured
IP address: 192.168.2.1
Subnet mask: 255.255.255.0
Description: For LAN Access
Name: VLAN 0999
Tagged ports: None
Untagged ports: NoneVisualizar e gerenciar a saída de um comando de exibição de forma eficaz
Você pode usar os seguintes métodos em combinação para filtrar e gerenciar a saída de um displaycomando:
- Numeração de cada linha de saída de um comando de exibição
- Filtragem da saída de um comando de exibição
- Salvando a saída de um comando de exibição em um arquivo
Procedimento
Para usar várias medidas para visualizar e gerenciar a saída de um comando de exibição de
forma eficaz, execute o seguinte comando em qualquer exibição:
display command [ | [ by-linenum ] { begin | exclude | include }
regular-expression ]&<1-128> [ > filename | >> filename ]Exemplos
# Salve a configuração em execução em um arquivo separado chamado test.txt, com cada linha numerada.
<Sysname> display current-configuration | by-linenum > test.txt# Acrescente linhas que incluam snmp na configuração em execução ao arquivo test.txt.
<Sysname> display current-configuration | include snmp >> test.txt# Exibir a primeira linha que começa com user-group na configuração em execução e todas as linhas seguintes.
<Sysname> display current-configuration | by-linenum begin user-group
114: user-group system
115- #
116- return// Os dois pontos (:) após um número de linha indicam que a linha contém a string user-group. O hífen (-) após um número de linha indica que a linha não contém a string user-group.
Configuração do RBAC
Sobre o RBAC
O RBAC (Role-based access control) controla as permissões de acesso dos usuários com base nas funções do usuário.
O RBAC atribui permissões de acesso às funções de usuário que são criadas para diferentes funções de trabalho. Os usuários recebem permissão para acessar um conjunto de itens e recursos com base nas funções de usuário dos usuários. Separar as permissões dos usuários permite o gerenciamento simples da autorização de permissões.
Atribuição de permissão
Use os seguintes métodos para atribuir permissões a uma função de usuário:
- Defina um conjunto de regras para determinar itens acessíveis ou inacessíveis para a função do usuário. (Consulte "Regras de função do usuário").
- Configure políticas de acesso a recursos para especificar quais recursos são acessíveis à função do usuário. (Consulte "Políticas de acesso a recursos").
Para usar um comando relacionado a um recurso do sistema, uma função de usuário deve ter acesso tanto ao comando quanto ao recurso.
Por exemplo, uma função de usuário tem acesso ao comando vlan e acesso somente à VLAN
10. Quando a função de usuário é atribuída, você pode usar o comando vlan para criar a VLAN 10 e entrar em sua visualização. No entanto, não é possível criar outras VLANs. Se a função de usuário tiver acesso à VLAN 10, mas não tiver acesso ao comando vlan, não será possível usar o comando para entrar na visualização da VLAN 10.
Quando um usuário faz login no dispositivo com qualquer função de usuário e digita <?> em uma visualização, as informações de ajuda são exibidas para os aliases de comando definidos pelo sistema na visualização. No entanto, o usuário pode não ter permissão para acessar os aliases de comando. Se o usuário pode acessar os aliases de comando depende da permissão da função do usuário para os comandos correspondentes aos aliases. Para obter informações sobre aliases de comando, consulte "Usando a CLI".
Um usuário que faz login no dispositivo com qualquer função de usuário tem acesso às funções de
visualização do sistema, sair e comandos de saída.
Regras de função do usuário
As regras de função do usuário permitem ou negam o acesso aos itens, incluindo comandos, páginas da Web, elementos XML ou nós MIB. É possível definir os seguintes tipos de regras para diferentes granularidades de controle de acesso:
- Regra de comando - Controla o acesso a um comando ou a um conjunto de comandos que correspondem a uma expressão regular.
- Regra de recurso - Controla o acesso aos comandos de um recurso por tipo de comando.
- Regra de grupo de recursos - Controla o acesso aos comandos de recursos em um grupo de recursos por tipo de comando.
- Regra do menu da Web - Controla o acesso às páginas da Web usadas para configurar o dispositivo. Essas páginas da Web são chamadas de menus da Web.
- Regra de elemento XML - Controla o acesso aos elementos XML usados para configurar o dispositivo.
- Regra OID - Controla o acesso SNMP a um nó MIB e seus nós filhos. Um OID é uma
cadeia numérica pontilhada que identifica exclusivamente o caminho do nó raiz para um nó folha.
Os itens (comandos, menus da Web, elementos XML e nós MIB) são controlados com base nos seguintes tipos:
- Read-Itens que exibem informações de configuração e manutenção. Por exemplo, o comandos de exibição e o comando dir.
- Gravação - Itens que configuram os recursos do sistema. Por exemplo, o comando info-center enable e o comando debugging.
- Execute - Itens que executam funções específicas. Por exemplo, o comando ping e o comando ftp
comando.
Uma função de usuário pode acessar o conjunto de itens permitidos especificados nas regras de função de usuário. As regras de função de usuário incluem regras de função de usuário predefinidas (identificadas por sys-n) e definidas pelo usuário. Para obter mais informações sobre a prioridade da regra de função do usuário, consulte "Configuração das regras de função do usuário".
Políticas de acesso a recursos
As políticas de acesso a recursos controlam o acesso de uma função de usuário aos recursos do sistema e incluem os seguintes tipos:
- Política de interface - Controla o acesso às interfaces.
- Política de VLAN - Controla o acesso às VLANs.
As políticas de acesso a recursos não controlam o acesso às opções de interface ou VLAN nos comandos de exibição. É possível especificar essas opções nos comandos de exibição se elas forem permitidas por qualquer regra de função de usuário.
Funções de usuário predefinidas
O sistema fornece funções de usuário predefinidas. Essas funções de usuário têm acesso a todos os recursos do sistema. Entretanto, suas permissões de acesso são diferentes, conforme mostrado na Tabela 1.
Entre todas as funções de usuário predefinidas, somente network-admin e level-15 podem criar, modificar e excluir usuários locais e grupos de usuários locais. As outras funções de usuário só podem modificar suas próprias senhas se tiverem permissões para configurar usuários locais e grupos de usuários locais.
As permissões de acesso das funções de usuário de nível 0 a nível 14 podem ser modificadas por meio de regras de função de usuário e políticas de acesso a recursos. No entanto, não é possível fazer alterações nas permissões de acesso predefinidas dessas funções de usuário. Por exemplo, não é possível alterar a permissão de acesso dessas funções de usuário para o comando display history-command all.
Tabela 1 Matriz de funções e permissões predefinidas
| Nome da função do usuário | Permissões |
| administrador de rede | Acessa todos os recursos e funções do sistema, exceto os comandos display security-logfile summary, info-center security-logfile directory e security-logfile save. |
| operador de rede | Acessa os comandos de exibição de recursos e funções no sistema. Para exibir todos os comandos acessíveis da função do usuário, use o comando display role. Permite que os usuários de login de autenticação local alterem suas próprias senhas. Acessa o comando usado para entrar na visualização XML. Acessa todos os itens de menu da Web do tipo leitura. Acessa todos os elementos XML do tipo leitura. Acessa todos os nós MIB do tipo leitura. |
| nível-n (n = 0 a 15) | level-0 - Tem acesso a comandos como ping, tracert, ssh2, telnet e super. Os direitos de acesso do nível 0 são configuráveis. Nível 1 - Tem acesso aos comandos de exibição de recursos e funções no sistema. A função de usuário de nível 1 também tem todos os direitos de acesso da função de usuário de nível 0. Os direitos de acesso do nível 1 são configuráveis. nível 2 a nível 8 e nível 10 a nível 14 - Não têm direitos de acesso por padrão. Os direitos de acesso são configuráveis. |
| Nome da função do usuário | Permissões |
| Nível 9 - Tem acesso à maioria dos recursos e funções do sistema. Se você estiver conectado com uma conta de usuário local que tenha uma função de usuário de nível 9, poderá alterar a senha na conta de usuário local. Veja a seguir os principais recursos e comandos que a função de usuário de nível 9 não pode acessar: Comandos de não depuração do RBAC. Usuários locais. Gerenciamento de arquivos. Gerenciamento de dispositivos. O comando display history-command all. level-15 - Tem os mesmos direitos que network-admin. | |
| auditoria de segurança | Gerente de registro de segurança. A função de usuário tem os seguintes direitos de acesso aos arquivos de log de segurança: Acessa os comandos para exibir e manter os arquivos de registro de segurança (por exemplo, os comandos dir, display security-logfile summary e outros). Acessa os comandos para gerenciar arquivos de log de segurança e o sistema de arquivos de log de segurança (por exemplo, os comandos info-center security-logfile directory, mkdir e security-logfile save). Para obter mais informações sobre o gerenciamento de registros de segurança, consulte o Guia de configuração de monitoramento e gerenciamento de rede. Para obter mais informações sobre o gerenciamento do sistema de arquivos, consulte "Gerenciamento de sistemas de arquivos". IMPORTANTE: Somente a função de usuário security-audit tem acesso aos arquivos de registro de segurança. Não é possível atribuir a função de usuário de auditoria de segurança a usuários de autenticação não AAA. |
Atribuição de função de usuário
Os direitos de acesso a um usuário são atribuídos por meio da atribuição de, no mínimo, uma função de usuário. O usuário pode usar o conjunto de itens e recursos acessíveis a todas as funções de usuário atribuídas a ele. Por exemplo, você pode acessar qualquer interface para usar o comando qos apply policy se lhe forem atribuídas as seguintes funções de usuário:
- A função de usuário A nega o acesso ao comando qos apply policy e permite o acesso somente à interface GigabitEthernet 1/0/1.
- A função de usuário B permite o acesso ao comando qos apply policy e a todas as interfaces. Dependendo do método de autenticação, a atribuição de função de
Usuário tem os seguintes métodos:
- Autorização AAA - Se a autenticação de esquema for usada, o módulo AAA tratará da atribuição de função do usuário.
- Se o usuário for aprovado na autorização local, o dispositivo atribuirá as funções de usuário especificadas na conta de usuário local.
- Se o usuário for aprovado na autorização remota, o servidor AAA remoto atribuirá as funções de usuário especificadas no servidor. O servidor AAA pode ser um servidor RADIUS ou HWTACACS.
- Autorização não AAA - Quando o usuário acessa o dispositivo sem autenticação ou passando a autenticação por senha em uma linha de usuário, o dispositivo atribui funções de usuário especificadas na linha de usuário. Esse método também se aplica a clientes SSH que usam autenticação de chave pública ou de senha-pública. As funções de usuário atribuídas a esses clientes SSH são especificadas em suas respectivas contas de usuário de gerenciamento do dispositivo.
Para obter mais informações sobre AAA e SSH, consulte o Guia de configuração de segurança. Para obter mais informações sobre linhas de usuário, consulte "Visão geral do login" e "Configuração do login da CLI".
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não- FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de Configuração de Segurança.
Criação de uma função de usuário
Sobre a criação de funções de usuário
Além das funções de usuário predefinidas, é possível criar um máximo de 64 funções de usuário personalizadas para controle de acesso granular.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma função de usuário e insira sua visualização.
role name role-namePor padrão, o sistema tem as seguintes funções de usuário predefinidas:
- network-admin
- network-operator.
- level-n (em que n é igual a um número inteiro no intervalo de 0 a 15).
- security-audit.
Entre essas funções de usuário, somente as permissões e descrições das funções de usuário de nível 0 a nível 14 são configuráveis.
- (Opcional.) Configure uma descrição para a função do usuário.
description textPor padrão, uma função de usuário não tem uma descrição.
Configuração das regras de função do usuário
Sobre as regras de função do usuário
É possível configurar regras de função de usuário para permitir ou negar o acesso de uma função de usuário a comandos, páginas da Web, elementos XML e nós MIB específicos.
As diretrizes a seguir se aplicam a regras não-OID:
- Se duas regras definidas pelo usuário do mesmo tipo entrarem em conflito, a regra com a ID mais alta entrará em vigor. Por exemplo, uma função de usuário pode usar o comando tracert, mas não o comando ping, se a função de usuário contiver regras configuradas usando os seguintes comandos:
- rule 1 permit command ping
- rule 2 permit command tracert
- rule 3 deny command ping
- Se uma regra de função de usuário predefinida e uma regra de função de usuário definida pelo usuário entrarem em conflito, a regra de função de usuário definida pelo usuário entrará em vigor.
- O sistema compara um OID com os OIDs especificados nas regras de função do usuário e usa o princípio da correspondência mais longa para selecionar uma regra para o OID. Por exemplo, uma função de usuário não pode acessar o nó MIB com o OID 1.3.6.1.4.1.25506.141.3.0.1 se a função de usuário contiver regras configuradas com os seguintes comandos:
- rule 1 permit read write oid 1.3.6
- rule 2 deny read write oid 1.3.6.1.4.1
- rule 3 permit read write oid 1.3.6.1.4
- Se o mesmo OID for especificado em várias regras, a regra com o ID mais alto terá efeito. Por exemplo, uma função de usuário pode acessar o nó MIB com o OID 1.3.6.1.4.1.25506.141.3.0.1 se a função de usuário contiver regras configuradas com os seguintes comandos:
- rule 1 permit read write oid 1.3.6
- rule 2 deny read write oid 1.3.6.1.4.1
- rule 3 permit read write oid 1.3.6.1.4.1
As diretrizes a seguir se aplicam às regras de OID:
Restrições e diretrizes
- Somente as funções de usuário network-admin e level-15 têm acesso aos seguintes comandos:
- O comando display history-command all.
- Todos os comandos que começam com a função display, reboot, startup configuração salva, e undo startup saved-configuration.
- Todos os comandos que começam com as palavras-chave role, undo role, super, undo super, password-recovery e undo password-recovery na visualização do sistema.
- Todos os comandos que começam com as palavras-chave snmp-agent community,
- O comando display history-command all.
- Todos os comandos que começam com a função display, reboot, startup configuração salva, e undo startup saved-configuration.
- Todos os comandos que começam com as palavras-chave role, undo role, super, undo super, password-recovery e undo password-recovery na visualização do sistema.
- Todos os comandos que começam com as palavras-chave snmp-agent community,
undo snmp-agent community, snmp-agent usm-user, undo snmp-agent usm-user, snmp-agent group e undo snmp-agent group na visualização do sistema.
- Todos os comandos que começam com user-role, undo user-role, authentication-mode, undo authentication-mode, set authentication
e undo set authentication password na visualização de linha de usuário ou de classe de linha de usuário.
- Todos os comandos que começam com as palavras-chave user-role e undo user- role na exibição de agenda ou na exibição de política definida pela CLI.
- É possível configurar um máximo de 256 regras definidas pelo usuário para uma função de usuário. O número total de regras de função de usuário definidas pelo usuário não pode exceder 1024.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização da função do usuário.
role name role-name- Configure regras para a função do usuário. Escolha as opções para configurar conforme necessário:
- Configurar uma regra de comando.
rule number { deny | permit } command command-string- Configure uma regra de recurso.
rule number { deny | permit } { execute | read | write } * feature[ feature-name ]- Configure uma regra de grupo de recursos.
rule number { deny | permit } { execute | read | write } * feature-group feature-group-nameUma regra de grupo de recursos entra em vigor somente depois que o grupo de recursos é criado.
- Configure uma regra de menu da Web.
rule number { deny | permit } { execute | read | write } * web-menu [ web-string ]- Configure uma regra de elemento XML.
rule number { deny | permit } { execute | read | write } * xml-element [ xml-string ]- Configurar uma regra de OID.
rule number { deny | permit } { execute | read | write } * oid oid-stringConfiguração de um Grupo de Recursos
Sobre Grupos de Recursos
Use grupos de recursos para atribuir em massa permissões de acesso a comandos a conjuntos de recursos. Além dos grupos de recursos predefinidos, você pode criar um máximo de 64 grupos de recursos personalizados e atribuir um recurso a vários grupos de recursos.
Procedimento
- Entre na visualização do sistema.
system-viewrole feature-group name feature-group-namePor padrão, o sistema tem os seguintes grupos de recursos predefinidos, que não podem ser excluídos ou modificados:
- L2 - Inclui todos os comandos da Camada 2.
- L3 - Inclui todos os comandos da Camada 3.
feature feature-namePor padrão, um grupo de recursos não tem nenhum recurso.
Configuração de políticas de acesso a recursos
Sobre as políticas de acesso a recursos
Cada função de usuário tem uma política de interface e uma política de VLAN. Por padrão, essas políticas permitem que uma função de usuário acesse quaisquer recursos do sistema. É possível configurar as políticas de uma função de usuário definida pelo usuário ou de uma função de usuário de nível n predefinida para limitar seu acesso a quaisquer recursos.
Restrições e diretrizes para a configuração da política de acesso a recursos
A configuração da política entra em vigor somente para os usuários que estiverem conectados com a função de usuário após a configuração do .
Configuração da política de interface de função do usuário
system-view- Insira a visualização da função do usuário.
role name role-name- Entre na visualização da política de interface de função do usuário.
interface policy denyPor padrão, a política de interface da função de usuário permite o acesso a todas as interfaces.
 CUIDADO:
CUIDADO:
Esse comando nega o acesso da função de usuário a qualquer interface se você não especificar as interfaces acessíveis usando o comando permit interface.
- (Opcional.) Especifique uma lista de interfaces acessíveis à função de usuário.
permit interface interface-listPor padrão, nenhuma interface acessível é configurada na visualização da política de interface de função do usuário. Repita esta etapa para adicionar várias interfaces acessíveis.
Configuração da política de VLAN de função de usuário
- Entre na visualização do sistema.
system-view- Insira a visualização da função do usuário.
role name role-name- Entre na visualização da política de VLAN da função do usuário.
vlan policy denyPor padrão, a política de VLAN da função de usuário permite o acesso a todas as VLANs.
 CUIDADO:
CUIDADO:
Esse comando nega o acesso da função de usuário a quaisquer VLANs se você não especificar as VLANs acessíveis usando o comando permit vlan.
- (Opcional.) Especifique uma lista de VLANs acessíveis à função de usuário.
permit vlan vlan-id-listPor padrão, nenhuma VLAN acessível é configurada na visualização da política de VLAN da função do usuário. Repita esta etapa para adicionar várias VLANs acessíveis.
Atribuição de funções de usuário
Restrições e diretrizes para a atribuição de funções de usuário
Para controlar o acesso do usuário ao sistema, é necessário atribuir no mínimo uma função de usuário. Certifique-se de que exista no dispositivo pelo menos uma função de usuário entre as funções de usuário atribuídas pelo servidor.
Ativação do recurso de função de usuário padrão
Sobre o recurso de função de usuário padrão
O recurso de função de usuário padrão atribui a função de usuário padrão aos usuários autenticados por AAA se o servidor de autenticação (local ou remoto) não atribuir nenhuma função de usuário aos usuários. Esses usuários têm permissão para acessar o sistema com a função de usuário padrão.
Você pode especificar qualquer função de usuário existente no sistema como a função de usuário padrão.
Procedimento
- Entre na visualização do sistema.
system-view- Ative o recurso de função de usuário padrão.
role default-role enable [ nome da função ]Por padrão, o recurso de função de usuário padrão está desativado.
Se você não usar o comando authorization-attribute user role para atribuir funções de usuário a usuários locais, deverá ativar o recurso de função de usuário padrão. Para obter informações sobre o comando authorization-attribute user role, consulte Comandos AAA em Referência de comandos de segurança.
Atribuição de funções de usuário a usuários de autenticação AAA remota
Para usuários de autenticação AAA remota, as funções de usuário são configuradas no servidor de autenticação remota. Para obter informações sobre a configuração de funções de usuário para usuários RADIUS, consulte a documentação do servidor RADIUS. Para usuários HWTACACS, a configuração de função deve usar o formato roles="role-1 role-2 ... role-n", em que as funções de usuário são separadas por espaço. Por exemplo, configure roles="level-0 level-1 level-2" para atribuir level-0, level-1 e level-2 a um usuário HWTACACS.
Se o servidor AAA atribuir a função de usuário de auditoria de segurança e outras funções de usuário ao mesmo usuário, somente a função de usuário de auditoria de segurança terá efeito.
Atribuição de funções de usuário a usuários de autenticação AAA local
Sobre a atribuição de função de usuário a usuários de autenticação AAA local
Configure as funções de usuário para usuários de autenticação AAA local em suas contas de usuário locais. Para obter informações sobre AAA e configuração de usuário local, consulte Configuração de AAA no Guia de configuração de segurança.
Restrições e diretrizes
- Cada usuário local tem uma função de usuário padrão. Se essa função de usuário padrão não for adequada, remova-a.
- Se um usuário local for o único usuário com a função de usuário de auditoria de segurança, o usuário não poderá ser excluído.
- A função de usuário de auditoria de segurança é mutuamente exclusiva de outras funções de usuário.
- Quando você atribui a função de usuário de auditoria de segurança a um usuário local, o sistema solicita confirmação para remover todas as outras funções de usuário do usuário.
- Quando você atribui as outras funções de usuário a um usuário local que tem a função de usuário de auditoria de segurança, o sistema solicita confirmação para remover a função de auditoria de segurança do usuário.
- É possível atribuir um máximo de 64 funções de usuário a um usuário local.
Procedimento
- Entre na visualização do sistema.
system-viewlocal-user user-name class { manage | network }authorization-attribute user-role role role-namePor padrão, a função de usuário network-operator é atribuída a usuários locais criados por um usuário network-admin ou de nível 15.
Atribuição de funções de usuário a usuários de autenticação não AAA em linhas de usuário
Sobre a atribuição de função de usuário a usuários de autenticação não AAA
Especifique as funções de usuário para os dois tipos de usuários de login a seguir nas linhas de usuário:
- Usuários não SSH que usam autenticação por senha ou nenhuma autenticação.
- Clientes SSH que usam autenticação de chave pública ou senha-chave pública. As funções de usuário atribuídas a esses clientes SSH são especificadas em suas respectivas contas de usuário de gerenciamento de dispositivos.
Para obter mais informações sobre as linhas de usuário, consulte "Visão geral do login" e "Configuração do login da CLI". Para obter mais informações sobre SSH em , consulte o Guia de configuração de segurança.
Restrições e diretrizes
- É possível atribuir um máximo de 64 funções de usuário a um usuário de autenticação não AAA em uma linha de usuário.
- Não é possível atribuir a função de usuário de auditoria de segurança a usuários de autenticação não AAA em linhas de usuário.
Procedimento
- Entre na visualização do sistema.
system-viewline { first-num1 [ last-num1 ] | { aux | vty } first-num2 [ last-num2 ] }line class { aux | vty }Para obter informações sobre a ordem de prioridade e o escopo de aplicação das configurações na visualização de linha de usuário e na visualização de classe de linha de usuário, consulte "Configuração do login da CLI".
user-role role-namePor padrão, a função de usuário administrador de rede é especificada na linha de usuário AUX, e a função de usuário operador de rede é especificada em qualquer outra linha de usuário.
Configuração da autorização temporária da função do usuário
Sobre a autorização temporária de função de usuário
A autorização temporária de função de usuário permite que você obtenha outra função de usuário sem se reconectar ao dispositivo. Esse recurso é útil quando se deseja usar uma função de usuário temporariamente para configurar um recurso.
A autorização temporária de função de usuário só é válida para o login atual. Esse recurso não altera as configurações de função do usuário na conta de usuário com a qual você fez login. Na próxima vez em que você fizer login com a conta de usuário, as configurações originais de função de usuário entrarão em vigor.
Para permitir que um usuário obtenha outra função de usuário sem se reconectar ao dispositivo, é necessário configurar a autenticação da função de usuário. A Tabela 2 descreve os modos de autenticação disponíveis e os requisitos de configuração.
Tabela 2 Modos de autenticação de função de usuário
| Palavras- chave | Modo de autenticação | Descrição |
| local | Apenas autenticação por senha local (local- only) | O dispositivo usa a senha configurada localmente para autenticação. Se nenhuma senha local estiver configurada para uma função de usuário nesse modo, um usuário AUX poderá obter a função de usuário inserindo uma cadeia de caracteres ou não inserindo nada. |
| esquema | Autenticação AAA remota por meio de HWTACACS ou RADIUS (somente remoto) | O dispositivo envia o nome de usuário e a senha para o servidor HWTACACS ou RADIUS para autenticação remota. Para usar esse modo, você deve executar as seguintes tarefas de configuração: Configure o esquema HWTACACS ou RADIUS necessário e configure o domínio ISP para usar o esquema para o usuário. Para obter mais informações, consulte o Guia de configuração de segurança. Adicione a conta de usuário e a senha no servidor HWTACACS ou RADIUS. |
| esquema local | Primeiro a autenticação por senha local e, em seguida, a autenticação AAA remota (local-então-remoto) | A autenticação por senha local é realizada primeiro. Se nenhuma senha local for configurada para a função de usuário nesse modo: O dispositivo executa a autenticação AAA remota para usuários VTY. Um usuário AUX pode obter outra função de usuário inserindo uma string ou não inserindo nada. |
| Palavras- chave | Modo de autenticação | Descrição |
| esquem a local | Primeiro, a autenticação AAA remota e, em seguida, a autenticação por senha local (remote-then-local) | A autenticação AAA remota é realizada primeiro. A autenticação por senha local é realizada em uma das seguintes situações: O servidor HWTACACS ou RADIUS não responde. A configuração AAA remota no dispositivo é inválida. |
Restrições e diretrizes para autorização temporária de função de usuário
Se a autenticação HWTACACS for usada, as seguintes regras se aplicam:
- Se o dispositivo não estiver ativado para obter automaticamente o nome de usuário de login como o nome de usuário de autenticação, será necessário inserir um nome de usuário para solicitar a autenticação de função.
- O dispositivo envia o nome de usuário para o servidor no nome de usuário ou username@domain-nameformato. A inclusão do nome de domínio no nome de usuário depende do comando user-name-format no esquema HWTACACS.
- Para obter uma função de usuário de nível n, a conta de usuário no servidor deve ter o nível de função de usuário de destino ou um nível superior ao da função de usuário de destino. Uma conta de usuário que obtém a função de usuário de nível n pode obter qualquer função de usuário do nível 0 ao nível n.
- Para obter uma função de usuário não-level-n, certifique-se de que a conta de usuário no servidor atenda aos seguintes requisitos:
- A conta tem um nível de privilégio de usuário.
- O atributo personalizado HWTACACS é configurado para a conta na forma de allowed-roles="role". A variável role representa a função do usuário de destino.
Se a autenticação RADIUS for usada, as seguintes regras se aplicam:
- O dispositivo não usa o nome de usuário que você digita ou o nome de usuário de login obtido automaticamente para solicitar a autenticação da função do usuário. Ele usa um nome de usuário no formato $enabn$. A variável n representa um nível de função de usuário, e um nome de domínio não é incluído no nome de usuário. Sempre é possível passar na autenticação de função de usuário quando a senha estiver correta.
- Para obter uma função de usuário de nível n, é necessário criar uma conta de usuário para a função de usuário de nível n no formato $enabn$ no servidor RADIUS. A variável n representa o nível da função de usuário de destino. Por exemplo, para obter a função de usuário de nível 3, é possível inserir qualquer nome de usuário. O dispositivo usa o nome de usuário $enab3$ para solicitar a autenticação da função de usuário ao servidor.
- Para obter uma função de usuário não-level-n, é necessário executar as seguintes tarefas:
- Crie uma conta de usuário chamada $enab0$ no servidor.
- Configure o atributo cisco-av-pair para a conta na forma de allowed-roles="role". A variável role representa a função do usuário de destino.
O dispositivo seleciona um domínio de autenticação para autenticação de função de usuário na seguinte ordem:
- O domínio do ISP incluído no nome de usuário inserido.
- O domínio padrão do ISP.
Se você executar o comando quit depois de obter autorização para a função de usuário, será desconectado do dispositivo.
Definição do modo de autenticação para autorização temporária de função de usuário
- Entre na visualização do sistema.
system-view- Definir o modo de autenticação.
super authentication-mode { local | scheme } *Por padrão, aplica-se a autenticação somente local.
Especificação da função de usuário de destino padrão para autorização temporária de função de usuário
- Entre na visualização do sistema.
system-view- Especifique a função de usuário de destino padrão para autorização temporária de função de usuário.
super default role role-namePor padrão, a função de usuário de destino padrão é network-admin.
Definição de uma senha de autenticação para autorização temporária de função de usuário
Sobre senhas de autenticação
As senhas de autenticação são necessárias apenas para autenticação por senha local.
Procedimento
- Entre na visualização do sistema.
system-view- Defina uma senha de autenticação local para uma função de usuário. No modo não-FIPS:
super password [ role role-name ] [ { hash | simple } string ]No modo FIPS:
super password [ role role-name ]Por padrão, nenhuma senha é definida.
Se você não especificar a opção role role-name, o comando definirá uma senha para a função de usuário de destino padrão .
Obtenção automática do nome de usuário de login para autorização temporária de função de usuário
Sobre a obtenção automática do nome de usuário de login para autorização temporária de função de usuário
Esse recurso é aplicável somente ao login de uma linha de usuário que usa autenticação de esquema, que exige um nome de usuário para o login. Esse recurso permite que o dispositivo obtenha automaticamente o nome de usuário de login quando o usuário de login solicita uma autorização temporária de função de usuário de um servidor de autenticação remoto.
Restrições e diretrizes
Se o usuário tiver efetuado login a partir de uma linha de usuário que usa autenticação por senha ou nenhuma autenticação, o dispositivo não poderá obter o nome de usuário de login. A solicitação de autorização temporária de função de usuário de um servidor de autenticação remoto falhará.
Esse recurso não tem efeito sobre a autenticação de senha local para autorização temporária de função de usuário.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o dispositivo para obter automaticamente o nome de usuário de login quando um usuário de login solicitar autorização temporária de função de usuário de um servidor de autenticação remoto.
super use-login-usernamePor padrão, o dispositivo solicita um nome de usuário quando um usuário de login solicita autorização temporária de função de usuário de um servidor de autenticação remoto.
Obtenção de autorização temporária de função de usuário
Restrições e diretrizes
A operação de obtenção de autorização temporária de função de usuário falha após três tentativas consecutivas de autenticação sem sucesso.
Poderá haver falha na mudança para uma função de usuário não nível n se ambas as condições a seguir existirem:
- A autenticação de troca de função do usuário é realizada no mesmo domínio ISP que o usuário de login atual.
- A autenticação de troca de função do usuário usa um método AAA diferente do método de autorização de login configurado para o domínio ISP.
Para resolver esse problema, certifique-se de que os métodos AAA configurados usando o comando authentication super sejam consistentes com aqueles configurados usando o comando authorization login para o domínio ISP.
Para obter mais informações sobre AAA, consulte o Guia de configuração de segurança.
Pré-requisitos
Antes de obter autorização temporária de função de usuário, certifique-se de que a conta de usuário atual tenha permissão para executar o comando super para obter autorização temporária de função de usuário.
Procedimento
Para obter a autorização temporária para usar uma função de usuário, execute o seguinte comando na visualização do usuário:
super [ role-name ]Se você não especificar o argumento role-name, obterá a função de usuário de destino padrão para autorização temporária de função de usuário.
Comandos de exibição e manutenção para RBAC
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações sobre a função do usuário. | display role [ name role-name ] |
| Tarefa | Comando |
| Exibir informações sobre o recurso de função do usuário. | display role feature [ name feature-name | verbose ] |
| Exibir informações do grupo de recursos da função do usuário. | display role feature-group [ name feature-group-name ] [ verbose ] |
Exemplos de configuração do RBAC
Exemplo: Configuração de RBAC para usuários de autenticação AAA local
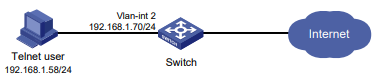
Configuração de rede
Conforme mostrado na Figura 1, o switch executa a autenticação AAA local para o usuário Telnet. A conta de usuário para o usuário Telnet é user1@bbb, à qual é atribuída a função de usuário role1.
Configure a função1 para ter as seguintes permissões:
- Executar os comandos de leitura de qualquer recurso.
- Acesso às VLANs 10 a 20. O acesso a quaisquer outras VLANs é negado.
Figura 1 Diagrama de rede
Procedimento
# Atribua um endereço IP à interface VLAN 2 (a interface conectada ao usuário Telnet).
<Switch> system-view
[Interface vlan-interface 2]
ip address 192.168.1.70 255.255.255.0
[Switch-Vlan-interface2] quit# Habilite o servidor Telnet.
[Switch] telnet server enable# Habilite a autenticação de esquema nas linhas de usuário para usuários de Telnet.
[Linha vty 0 63]
[Switch-line-vty0-63] authentication-mode scheme [Switch-line-vty0-63] quit# Habilite a autenticação e a autorização locais para o domínio ISP bbb.
[Switch] line vty 0 63
[Switch-line-vty0-63] authentication-mode scheme
[Switch-line-vty0-63] quit# Crie uma função de usuário chamada role1.
[Switch] role name role1# Configure a regra 1 para permitir que a função de usuário acesse os comandos de leitura de todos os recursos.
[Switch-role-role1] rule 1 permit read feature# Configure a regra 2 para permitir que a função de usuário crie VLANs e acesse comandos na visualização de VLAN.
[Switch-role-role1] rule 2 permit command system-view ; vlan *# Altere a política de VLAN para permitir que a função de usuário configure apenas as VLANs 10 a 20.
[Switch-role-role1] vlan policy deny
[Switch-role-role1-vlanpolicy] permit vlan 10 to 20
[Switch-role-role1-vlanpolicy] quit
[Switch-role-role1] quit# Crie um usuário de gerenciamento de dispositivos chamado user1 e entre na visualização de usuário local.
[Switch] local-user user1 class manage# Defina uma senha de texto simples de 123456TESTplat&! para o usuário. [Switch-luser-manage-user1] password simple 123456TESTplat&!
[Switch-luser-manage-user1] password simple 123456TESTplat&!# Defina o tipo de serviço como Telnet. [Switch-luser-manage-user1] service-type telnet
[Switch-luser-manage-user1] service-type telnet# Atribua a função1 ao usuário.
[Switch-luser-manage-user1] authorization-attribute user-role role1# Remova a função de usuário padrão (network-operator) do usuário. Essa operação garante que o usuário tenha apenas as permissões da função1.
[Switch-luser-manage-user1] undo authorization-attribute user-role network-operator
[Switch-luser-manage-user1] quitVerificação da configuração
# Faça Telnet no switch e digite o nome de usuário e a senha para acessar o switch. (Detalhes não mostrados).
# Verifique se você pode criar VLANs de 10 a 20. Este exemplo usa a VLAN 10.
<Switch> system-view
[Switch] vlan 10
[Switch-vlan10] quit# Verifique se você não pode criar nenhuma VLAN além das VLANs 10 a 20. Este exemplo usa a VLAN 30.
[Switch] vlan 30
Permission denied.# Verifique se você pode usar todos os comandos de leitura de qualquer recurso. Este exemplo usa
[Switch] display clock
09:31:56.258 UTC Sun 01/01/2017
[Switch] quit# Verifique se você não pode usar os comandos de gravação ou execução de qualquer recurso.
<Switch> debugging role all
Permission denied.
<Switch> ping 192.168.1.58
Permission denied.Exemplo: Configuração de RBAC para usuários de autenticação RADIUS
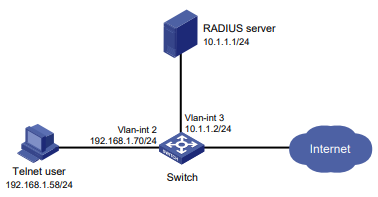
Configuração de rede
Conforme mostrado na Figura 2, o switch usa o servidor FreeRADIUS para fornecer serviço AAA para usuários de login, incluindo o usuário Telnet. A conta de usuário para o usuário Telnet é hello@bbb, à qual é atribuída a função de usuário role2.
A função de usuário role2 tem as seguintes permissões:
- Use todos os comandos na visualização do domínio ISP.
- Use os comandos de leitura e gravação dos recursos arp e radius.
- Não é possível acessar os comandos de leitura do recurso acl.
- Configure as VLANs 1 a 20 e as interfaces GigabitEthernet 1/0/1 a GigabitEthernet 1/0/4. O acesso a quaisquer outras VLANs e interfaces é negado.
O switch e o servidor FreeRADIUS usam uma chave compartilhada de expert e a porta de autenticação 1812. O switch fornece nomes de usuário com seus nomes de domínio para o servidor.
Figura 2 Diagrama de rede
Procedimento
Verifique se as configurações do switch e do servidor RADIUS correspondem.
- Configure o switch:
# Atribua à interface VLAN 2 um endereço IP da mesma sub-rede que o usuário Telnet.
<Switch> system-view
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ip address 192.168.1.70 255.255.255.0
[Switch-Vlan-interface2] quit# Atribua à interface VLAN 3 um endereço IP da mesma sub-rede que o servidor RADIUS.
[Switch] interface vlan-interface 3
[Switch-Vlan-interface3] ip address 10.1.1.2 255.255.255.0
[Switch-Vlan-interface3] quit# Habilite o servidor Telnet.
[Switch] telnet server enable# Habilite a autenticação de esquema nas linhas de usuário para usuários de Telnet.
[Switch] line vty 0 63
[Switch-line-vty0-63] authentication-mode scheme
[Switch-line-vty0-63] quit# Crie o esquema RADIUS rad e entre na visualização do esquema RADIUS.
[Switch] radius scheme rad# Especifique o endereço do servidor primário e a porta de serviço no esquema.
[Switch-radius-rad] primary authentication 10.1.1.1 1812# Defina a chave compartilhada como expert no esquema para que o switch se autentique no servidor.
[Switch-radius-rad] key authentication simple expert
[Switch-radius-rad] quit# Especifique o esquema rad como os esquemas de autenticação e autorização para o domínio ISP bbb e configure o domínio ISP para não realizar a contabilidade dos usuários de login.
 IMPORTANTE:
IMPORTANTE:
Como as informações de autorização de usuário do RADIUS são transferidas para as respostas de autenticação, os métodos de autenticação e autorização devem usar o mesmo esquema RADIUS.
[Switch] domain bbb
[Switch-isp-bbb] authentication login radius-scheme rad
[Switch-isp-bbb] authorization login radius-scheme rad
[Switch-isp-bbb] accounting login none
[Switch-isp-bbb] quit# Criar o grupo de recursos fgroup1.
[Switch] role feature-group name fgroup1# Adicione os recursos arp e radius ao grupo de recursos.
[Switch-featuregrp-fgroup1] feature arp
[Switch-featuregrp-fgroup1] feature radius
[Switch-featuregrp-fgroup1] quit# Criar função de usuário role2.
[Switch] role name role2# Configure a regra 1 para permitir que a função de usuário use todos os comandos disponíveis na visualização do domínio ISP.
[Switch-role-role2] rule 1 permit command system-view ; domain *# Configure a regra 2 para permitir que a função de usuário use os comandos de leitura e gravação de todos os recursos em fgroup1
[Switch-role-role2] rule 2 permit read write feature-group fgroup1Configure a regra 3 para desativar o acesso aos comandos de leitura do recurso
[Switch-role-role2] rule 3 deny read feature acl# Configure a regra 4 para permitir que a função de usuário crie VLANs e use todos os comandos disponíveis na visualização de VLAN.
[Switch-role-role2] rule 4 permit command system-view ; vlan *# Configure a regra 5 para permitir que a função de usuário entre na visualização da interface e use todos os comandos disponíveis na visualização da interface.
[Switch-role-role2] rule 5 permit command system-view ; interface *# Configure a política de VLAN da função de usuário para desativar a configuração de qualquer VLAN, exceto as VLANs 1 a 20.
[Switch-role-role2] vlan policy deny
[Switch-role-role2-vlanpolicy] permit vlan 1 to 20
[Switch-role-role2-vlanpolicy] quit# Configure a política de interface de função do usuário para desativar a configuração de qualquer interface, exceto GigabitEthernet 1/0/1 a GigabitEthernet 1/0/4.
[Switch-role-role2] interface policy deny
18
[Switch-role-role2-ifpolicy] permit interface gigabitethernet 1/0/1 to gigabitethernet 1/0/4
[Switch-role-role2-ifpolicy] quit
[Switch-role-role2] quit- Configure o servidor RADIUS:
# Adicione um dos atributos de função do usuário ao arquivo de dicionário do servidor FreeRADIUS.
Cisco-AVPair = "shell:roles=\"role2\""
Cisco-AVPair = "shell:roles*\"role2\""# Defina as configurações necessárias para que o servidor FreeRADIUS se comunique com o switch.
(Detalhes não mostrados.)
Verificação da configuração
# Faça Telnet no switch e digite o nome de usuário e a senha para acessar o switch. (Detalhes não mostrados).
# Verifique se você pode usar todos os comandos disponíveis na visualização do domínio ISP.
<Switch> system-view
[Switch] domain abc
[Switch-isp-abc] authentication login radius-scheme abc
[Switch-isp-abc] quit# Verifique se você pode usar todos os comandos de leitura e gravação dos recursos radius e arp. Este exemplo usa o radius.
[Switch] radius scheme rad
[Switch-radius-rad] primary authentication 2.2.2.2
[Switch-radius-rad] display radius scheme rad# Verifique se você não pode configurar nenhuma VLAN, exceto as VLANs 1 a 20. Este exemplo usa a VLAN 10 e a VLAN 30.
[Switch] vlan 10
[Switch-vlan10] quit
[Switch] vlan 30
Permission denied.# Verifique se você não pode configurar nenhuma interface, exceto GigabitEthernet 1/0/1 a GigabitEthernet 1/0/4. Este exemplo usa a GigabitEthernet 1/0/2 e a GigabitEthernet 1/0/5.
[Switch] vlan 10
[Switch-vlan10] port gigabitethernet 1/0/2
[Switch-vlan10] port gigabitethernet 1/0/5
Permission denied.Exemplo: Configuração da autorização temporária de função de usuário RBAC (autenticação HWTACACS)
Configuração de rede
Conforme mostrado na Figura 3, o switch usa a autenticação HWTACACS para usuários de login, incluindo o usuário Telnet. A conta de usuário para o usuário Telnet é test@bbb, à qual é atribuída a função de usuário nível 0.
Configure o modo de autenticação remote-then-local para autorização temporária da função do usuário. O switch usa o servidor HWTACACS para fornecer autenticação para alterar a função do
usuário entre o nível 0 e o nível 3 ou alterar a função do usuário para administrador de rede. Se a configuração AAA for inválida ou o servidor HWTACACS não responder, o switch executará a autenticação local.
Figura 3 Diagrama de rede
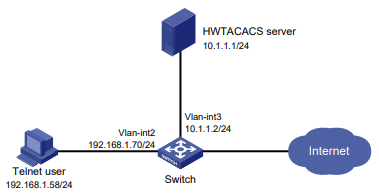
Procedimento
- Configure o switch:
# Atribua um endereço IP à interface VLAN 2 (a interface conectada ao usuário Telnet).
<Switch> system-view
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ip address 192.168.1.70 255.255.255.0
[Switch-Vlan-interface2] quit# Atribua um endereço IP à interface VLAN 3 (a interface conectada ao servidor HWTACACS).
[Switch] interface vlan-interface 3
[Switch-Vlan-interface3] ip address 10.1.1.2 255.255.255.0
[Switch-Vlan-interface3] quit# Habilite o servidor Telnet.
[Switch] telnet server enable# Habilite a autenticação de esquema nas linhas de usuário para usuários de Telnet.
[Switch] line vty 0 63
[Switch-line-vty0-63] authentication-mode scheme
[Switch-line-vty0-63] quit# Habilite a autenticação remote-then-local para autorização temporária da função do usuário.
[Switch] super authentication-mode scheme local# Crie um esquema HWTACACS chamado hwtac e entre na visualização do esquema HWTACACS.
[Switch] hwtacacs scheme hwtac# Especifique o endereço do servidor de autenticação principal e a porta de serviço no esquema.
[Switch-hwtacacs-hwtac] primary authentication 10.1.1.1 49# Especifique o endereço do servidor de autorização principal e a porta de serviço no esquema.
[Switch-hwtacacs-hwtac] primary authorization 10.1.1.1 49# Defina a chave compartilhada como expert no esquema para que o switch faça a autenticação no servidor de autenticação.
[Switch-hwtacacs-hwtac] key authentication simple expert# Defina a chave compartilhada como expert no esquema para que o switch se autentique no servidor de autorização.
[Switch-hwtacacs-hwtac] key authorization simple expert# Exclua os nomes de domínio do ISP dos nomes de usuário enviados ao servidor HWTACACS.
[Switch-hwtacacs-hwtac] user-name-format without-domain
[Switch-hwtacacs-hwtac] quit# Crie o domínio ISP bbb e entre na visualização do domínio ISP.
[Switch] domain bbb# Configure o domínio ISP bbb para usar o esquema HWTACACS hwtac para autenticação de usuário de login.
[Switch-isp-bbb] authentication login hwtacacs-scheme hwtac# Configure o domínio ISP bbb para usar o esquema HWTACACS hwtac para autorização de usuário de login.
[Switch-isp-bbb] authorization login hwtacacs-scheme hwtac# Configure o domínio bbb do ISP para não realizar a contabilidade dos usuários de login.
[Switch-isp-bbb] accounting login none# Aplique o esquema HWTACACS hwtac ao domínio ISP para autenticação de função de usuário.
[Switch-isp-bbb] authentication super hwtacacs-scheme hwtac
[Switch-isp-bbb] quit# Defina a senha de autenticação local como 654321TESTplat&! para a função de usuário nível 3.
[Switch] super password role level-3 simple 654321TESTplat&!# Defina a senha de autenticação local como 654321TESTplat&! para a função de usuário
network-admin.
[Switch] super password role network-admin simple 654321TESTplat&!
[Switch] quit- Configure o servidor HWTACACS: Este exemplo usa o ACSv4.0.
Este exemplo fornece apenas as principais etapas de configuração. Para obter mais informações sobre a configuração de um servidor HWTACACS, consulte a documentação do servidor.
- Acesse a página User Setup (Configuração do usuário).
- Adicione uma conta de usuário chamada test e defina sua senha como
123456TESTplat&!. (Detalhes não mostrados).
- Na área Advanced TACACS+ Settings (Configurações avançadas do TACACS+), configure os seguintes parâmetros:
- Selecione Nível 3 para a opção Privilégio máximo para qualquer cliente AAA.
Se a função de usuário de destino for apenas administrador de rede para autorização temporária de função de usuário, você poderá selecionar qualquer nível para a opção.
- Selecione a opção Usar senha separada e especifique enabpass como a senha.
Figura 4 Configuração de definições avançadas do TACACS+
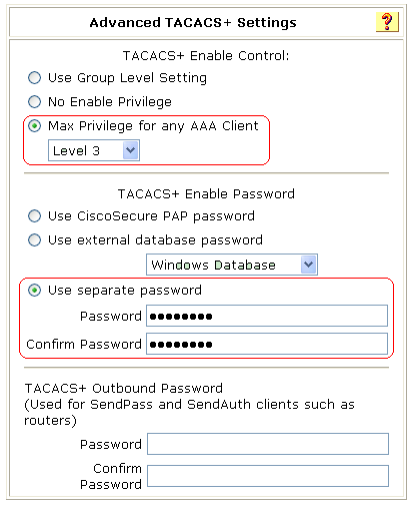
- Selecione Shell (exec) e Custom attributes e digite allowed-roles="network-admin"
no campo Atributos personalizados.
Use um espaço em branco para separar as funções permitidas.
Figura 5 Configuração de atributos personalizados para o usuário Telnet
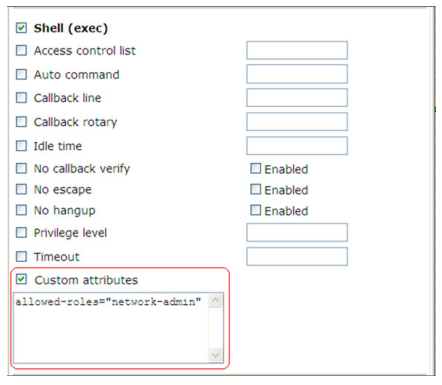
Verificação da configuração
- Faça Telnet no switch e digite o nome de usuário test@bbb e a senha 123456TESTplat&! para acessar o switch. Verifique se você tem acesso aos comandos de diagnóstico.
<Switch> telnet 192.168.1.70
Trying 192.168.1.70 ...
Press CTRL+K to abort
Connected to 192.168.1.70 ...
******************************************************************************
* Copyright (c) 2004-2017 New Intelbras Technologies Co., Ltd. All rights reserved.*
* Without the owner's prior written consent, *
* no decompiling or reverse-engineering shall be allowed. *
******************************************************************************
login: test@bbb
Password:
<Switch>?
User view commands:
ping Ping function
quit Exit from current command view
ssh2 Establish a secure shell client connection
super Switch to a user role
system-view Enter the System View
telnet Establish a telnet connection
tracert Tracert function
<Switch>- Verifique se você pode obter a função de usuário de nível 3:
# Use a super senha para obter a função de usuário de nível 3. Quando o sistema solicitar um nome de usuário e uma senha, digite o nome de usuário test@bbb e a senha enabpass.
<Switch> super level-3
Username: test@bbb
Password:A saída a seguir mostra que você obteve a função de usuário de nível 3.
A função de privilégio do usuário é de nível 3, e somente os comandos autorizados para a função podem ser usados.
# Se o servidor ACS não responder, digite a senha de autenticação local 654321TESTplat&!
no prompt.
Configuração inválida ou nenhuma resposta do servidor de autenticação. Altere o modo de autenticação para local.
Senha:
A função de privilégio do usuário é de nível 3, e somente os comandos autorizados para a função podem ser usados.
O resultado mostra que você obteve a função de usuário de nível 3.
- Use o método da etapa 2 para verificar se é possível obter as funções de usuário de nível 0, nível 1, nível 2 e administrador de rede. (Detalhes não mostrados).
Exemplo: Configuração de autorização temporária de função de usuário RBAC (autenticação RADIUS)
Configuração de rede
Conforme mostrado na Figura 6, o switch usa a autenticação RADIUS para usuários de login, incluindo o usuário Telnet. A conta de usuário para o usuário Telnet é test@bbb, à qual é atribuída a função de usuário nível 0.
Configure o modo de autenticação remote-then-local para autorização temporária da função de usuário. O switch usa o servidor RADIUS para fornecer autenticação para a função de usuário network-admin. Se a configuração AAA for inválida ou o servidor RADIUS não responder, o switch executará a autenticação local.
Figura 6 Diagrama de rede
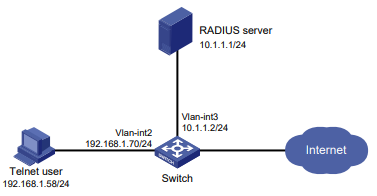
Procedimento
- Configure o switch:
# Atribua um endereço IP à interface VLAN 2 (a interface conectada ao usuário Telnet).
<Switch> system-view
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ip address 192.168.1.70 255.255.255.0
[Switch-Vlan-interface2] quit# Atribua um endereço IP à interface VLAN 3 (a interface conectada ao servidor RADIUS).
[Switch] interface vlan-interface 3
[Switch-Vlan-interface3] ip address 10.1.1.2 255.255.255.0
[Switch-Vlan-interface3] quit# Habilite o servidor Telnet.
[Switch] telnet server enable# Habilite a autenticação de esquema nas linhas de usuário para usuários de Telnet.
[Switch] line vty 0 15
[Switch-line-vty0-15] authentication-mode scheme
[Switch-line-vty0-15] quit# Habilite a autenticação remote-then-local para autorização temporária da função do usuário.
[Switch] super authentication-mode scheme local# Crie o esquema RADIUS radius e entre na visualização do esquema RADIUS.
[Switch] radius scheme radius# Especifique o endereço do servidor de autenticação primária e a chave compartilhada no esquema para a comunicação segura entre o switch e o servidor.
[Switch-radius-radius] primary authentication 10.1.1.1 key simple expert# Crie o domínio ISP bbb e entre na visualização do domínio ISP.
[Switch] domain bbb# Configure o domínio bbb do ISP para usar o esquema radius do RADIUS para autenticação do usuário de login.
[Switch-isp-bbb] authentication login radius-scheme radius# Configure o domínio bbb do ISP para usar o esquema radius do RADIUS para autorização do usuário de login.
[Switch-isp-bbb] authorization login radius-scheme radius# Configure o domínio bbb do ISP para não realizar a contabilidade dos usuários de login.
[Switch-isp-bbb] accounting login none# Aplique o esquema RADIUS radius ao domínio ISP para autenticação de função de usuário.
[Switch-isp-bbb] authentication super radius-scheme radius [Switch-isp-bbb] quit# Defina a senha de autenticação local como abcdef654321 para a função de usuário
[Switch] super password role network-admin simple abcdef654321
[Switch] quit
- Configure o servidor RADIUS: Este exemplo usa o ACSv4.2.
Este exemplo fornece apenas as principais etapas de configuração. Para obter mais informações sobre a configuração de um servidor RADIUS, consulte a documentação do servidor.
- Adicione uma conta de usuário Telnet para autenticação de login. Defina o nome de usuário como test@bbb e a senha como 123456TESTplat&!. (Detalhes não mostrados).
- Adicione uma conta de usuário para autorização temporária de função de usuário. Defina o nome de usuário como
$enab0$ e a senha para 123456. (Detalhes não mostrados).
- Acesse a página Atributos RADIUS do Cisco IOS/PIX 6.x.
- Configure o atributo cisco-av-pair, conforme mostrado na Figura 7.
Figura 7 Configuração do atributo cisco-av-pair
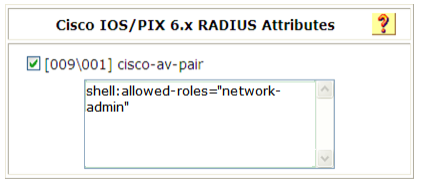
Verificação da configuração
- Faça telnet no switch e digite o nome de usuário test@bbb e a senha 123456TESTplat&! para acessar o switch. Verifique se você tem acesso aos comandos de diagnóstico.
<Switch> telnet 192.168.1.70
Trying 192.168.1.70 ...
Press CTRL+K to abort
Connected to 192.168.1.70 ...
******************************************************************************
* Copyright (c) 2004-2017 New Intelbras Technologies Co., Ltd. All rights reserved.*
* Without the owner's prior written consent, *
* no decompiling or reverse-engineering shall be allowed. *
******************************************************************************
login: test@bbb
Password:
<Switch>?
User view commands:
ping Ping function
quit Exit from current command view
ssh2 Establish a secure shell client connection
super Switch to a user role
system-view Enter the System View
telnet Establish a telnet connection
tracert Tracert function
<switch>
- Verifique se é possível obter a função de usuário network-admin:
# Use a super senha para obter a função de usuário administrador da rede. Quando o sistema solicitar um nome de usuário e uma senha, digite o nome de usuário test@bbb e a senha 123456.
<Switch> super network-admin
Username: test@bbb
Password:
A saída a seguir mostra que você obteve a função de usuário network-admin.
A função de privilégio do usuário é administrador de rede, e somente os comandos
autorizados para a função podem ser usados.
# Se o servidor ACS não responder, digite a senha de autenticação local abcdef654321 no prompt.
Configuração inválida ou nenhuma resposta do servidor de autenticação. Altere o modo de autenticação para local.
Senha:
A função de privilégio do usuário é administrador de rede, e somente os comandos autorizados para a função podem ser usados.
A saída mostra que você obteve a função de usuário network-admin.
Solução de problemas de RBAC
Esta seção descreve vários problemas típicos do RBAC e suas soluções.
Os usuários locais têm mais permissões de acesso do que o pretendido
Sintoma
Análise
Solução
Um usuário local pode usar mais comandos do que o permitido pelas funções de usuário atribuídas.
O usuário local pode ter sido atribuído a funções de usuário sem o seu conhecimento. Por exemplo, o usuário local é automaticamente atribuído à função de usuário padrão quando você cria o usuário.
Para resolver o problema:
- Use o comando display local-user para examinar as contas de usuário locais em busca de funções de usuário indesejáveis e removê-las.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
As tentativas de login dos usuários do RADIUS sempre falham
Sintoma
Análise
Solução
As tentativas de um usuário RADIUS de fazer login no dispositivo de acesso à rede sempre falham, mesmo que as seguintes condições existam:
- O dispositivo de acesso à rede e o servidor RADIUS podem se comunicar entre si.
- Todas as configurações AAA estão corretas.
O RBAC exige que um usuário de login tenha no mínimo uma função de usuário. Se o servidor RADIUS não autorizar o usuário de login a usar qualquer função de usuário, ele não poderá fazer login no dispositivo.
Para resolver o problema:
- Use um dos métodos a seguir:
- Configure o comando role default-role enable. Um usuário RADIUS pode fazer login com a função de usuário padrão quando nenhuma função de usuário é atribuída pelo servidor RADIUS.
- Adicione os atributos de autorização da função do usuário no servidor RADIUS.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Visão geral do login
O dispositivo suporta os seguintes tipos de métodos de login:
- Conecte-se à porta do console.
- Use o Telnet.
- Use SSH.
- Login na Web - Por meio da interface da Web, você pode configurar e gerenciar o dispositivo visualmente.
Antes do primeiro login na Web, obtenha o endereço IP de gerenciamento, o nome de usuário e a senha no dispositivo. Em seguida, execute um navegador da Web, digite o endereço IP de gerenciamento na barra de endereços e pressione Enter para acessar a interface da Web para fazer login no dispositivo.
- Para as outras séries de switches, só é possível fazer login na CLI por meio da porta do console, a menos que o dispositivo seja configurado automaticamente na inicialização.
- Se o dispositivo for iniciado com os padrões de fábrica, a autenticação do esquema estará ativada. São necessários o nome de usuário e a senha, que podem ser obtidos no dispositivo.
- Se o dispositivo for iniciado com a configuração inicial, a autenticação será desativada.
- Na outra série de switches, a autenticação está desativada.
Para obter mais informações sobre a configuração inicial e os padrões de fábrica, consulte "Gerenciamento de arquivos de configuração".
Após o login, é possível alterar os parâmetros de login do console ou configurar outros métodos de acesso.
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não- FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de configuração de segurança.
Telnet, login na Web baseado em HTTP e acesso RESTful baseado em HTTP não são compatíveis com o modo FIPS.
Uso da porta do console para o primeiro acesso ao dispositivo
Sobre o uso da porta do console para o primeiro acesso ao dispositivo
O login no console é o método de login fundamental.
Pré-requisitos
Para fazer login pela porta do console, prepare um terminal de console, por exemplo, um PC. Certifique-se de que o terminal do console tenha um programa de emulação de terminal, como o HyperTerminal ou o PuTTY. Para obter informações sobre como usar programas de emulação de terminal, consulte os guias do usuário dos programas.
Procedimento
As portas seriais dos PCs não são compatíveis com hot swapping. Antes de conectar ou desconectar um cabo de uma porta serial em um PC, é necessário desligar o PC.
- Localize o cabo do console fornecido com o dispositivo e conecte o conector fêmea DB-9 do cabo do console à porta serial do PC.
- Identifique cuidadosamente a porta do console do dispositivo e conecte o conector RJ-45 do cabo do console à porta do console.
 IMPORTANTE:
IMPORTANTE:
Para conectar um PC a um dispositivo operacional, primeiro conecte a extremidade do PC. Para desconectar um PC de um dispositivo operacional, primeiro desconecte a extremidade do dispositivo.
Figura 1 Conexão de um terminal à porta do console
- Ligue o PC.
- No PC, inicie o programa de emulação de terminal e crie uma conexão que use a porta serial conectada ao dispositivo. Defina as propriedades da porta de modo que elas correspondam às seguintes configurações padrão da porta do console:
- Bits por segundo - 9600 bps.
- Controle de fluxo - Nenhum.
- Paridade - Nenhuma.
- Bits de parada-1.
- Bits de dados-8.
- Ligue o dispositivo. O método para acessar a CLI varia de acordo com o modelo do dispositivo.
O prompt de visualização do usuário é exibido. Você pode inserir comandos para configurar ou gerenciar o dispositivo. Para obter ajuda, digite um ponto de interrogação (?).
Configuração do login da CLI
Sobre o login da CLI
O dispositivo usa linhas de usuário (também chamadas de interfaces de usuário) para gerenciar sessões de CLI e monitorar o comportamento do usuário. Para uma linha de usuário, é possível definir as configurações de controle de acesso, incluindo o método de autenticação de login e as funções do usuário.
Linhas de usuário
Tipos de linha do usuário
O dispositivo suporta os tipos de linhas de usuário listados na Tabela 1. Diferentes linhas de usuário exigem diferentes métodos de login .
Tabela 1 Método de login da CLI e matriz de linhas de usuário
| Linha do usuário | Método de login |
| Linha AUX | Porta do console. |
| Linha de terminal de tipo virtual (VTY) | Telnet ou SSH. |
Numeração da linha do usuário
Uma linha de usuário tem um número absoluto e um número relativo.
Um número absoluto identifica exclusivamente uma linha de usuário entre todas as linhas de usuário. As linhas de usuário são numeradas a partir de 0 e incrementadas em 1, na sequência de linhas AUX, VTY e USB. É possível usar o comando display line sem nenhum parâmetro para visualizar as linhas de usuário compatíveis e seus números absolutos.
Um número relativo identifica de forma exclusiva uma linha de usuário entre todas as linhas de usuário do mesmo tipo. O formato do número é tipo de linha de usuário + número. Todos os tipos de linhas de usuário são numerados a partir de 0 e incrementados em 1. Por exemplo, a primeira linha VTY é VTY 0.
Atribuição de linha de usuário
O dispositivo atribui linhas de usuário aos usuários de login da CLI, dependendo de seus métodos de login, conforme mostrado na Tabela
1. Quando um usuário faz login, o dispositivo verifica as linhas de usuário ociosas para o método de login e atribui a linha de usuário com o número mais baixo ao usuário. Por exemplo, se a VTY 0 e a VTY 3 estiverem ociosas quando um usuário se conectar ao dispositivo, o dispositivo atribuirá a VTY 0 ao usuário.
Cada linha de usuário pode ser atribuída somente a um usuário por vez. Se nenhuma linha de usuário estiver disponível, uma tentativa de login na CLI será rejeitada.
Modos de autenticação de login
Você pode configurar a autenticação de login para impedir o acesso ilegal à CLI do dispositivo. No modo não-FIPS, o dispositivo suporta os seguintes modos de autenticação de login:
- None - desativa a autenticação. Esse modo permite o acesso sem autenticação e é inseguro.
- Senha - Requer autenticação por senha. O usuário deve fornecer a senha correta no login.
- Esquema - Usa o módulo AAA para fornecer autenticação de login local ou remoto. Um usuário deve fornecer o nome de usuário e a senha corretos no login.
No modo FIPS, o dispositivo suporta apenas o modo de autenticação de esquema.
Diferentes modos de autenticação de login exigem diferentes configurações de linha de usuário, conforme mostrado na Tabela 2.
Tabela 2 Configuração necessária para diferentes modos de autenticação de login
| Modo de autenticação | Tarefas de configuração |
| Nenhum | Defina o modo de autenticação como nenhum. |
| Senha | Defina o modo de autenticação como senha. Defina uma senha. |
| Esquema | Defina o modo de autenticação como esquema. Configure os métodos de autenticação de login na visualização de domínio do ISP. Para obter mais informações, consulte o Guia de configuração de segurança. |
Funções do usuário
As funções de usuário são atribuídas a um usuário no login. As funções de usuário controlam os comandos disponíveis para o usuário. Para obter mais informações sobre funções de usuário, consulte "Configuração do RBAC".
O dispositivo atribui funções de usuário com base no modo de autenticação de login e no tipo de usuário.
- No modo de autenticação sem senha ou com senha, o dispositivo atribui as funções de usuário especificadas para a linha de usuário.
- No modo de autenticação de esquema, o dispositivo usa as seguintes regras para atribuir funções de usuário:
- Para um usuário de login SSH que usa autenticação publickey ou password-publickey, o dispositivo atribui as funções de usuário especificadas para o usuário de gerenciamento de dispositivo local com o mesmo nome.
- Para outros usuários, o dispositivo atribui funções de usuário de acordo com a configuração da função de usuário do módulo AAA. Se o servidor AAA não atribuir nenhuma função de usuário e o recurso de função de usuário padrão estiver desativado, um usuário de autenticação AAA remota não poderá fazer login.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não- FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de configuração de segurança.
O login Telnet não é compatível com o modo FIPS.
Restrições e diretrizes: Configuração de login da CLI
Para comandos disponíveis na visualização de linha de usuário e na visualização de classe de linha de usuário, aplicam-se as seguintes regras:
- Uma configuração na visualização de linha de usuário aplica-se somente à linha de usuário. Uma configuração na visualização de classe de linha de usuário se aplica a todas as linhas de usuário da classe.
- Uma configuração não padrão em uma das visualizações tem precedência sobre a configuração padrão na outra visualização. Uma configuração não padrão na visualização de linha de usuário tem precedência sobre a configuração não padrão na visualização de classe de linha de usuário.
- Uma configuração na visualização de classe de linha de usuário entra em vigor somente para os usuários que fizerem login depois que a configuração for feita. Ela não afeta os usuários que já estão on-line quando a configuração é feita.
Configuração do login no console
Sobre o login no console
É possível conectar um terminal à porta do console do dispositivo para fazer login e gerenciar o dispositivo, conforme mostrado na Figura 2. Para obter informações sobre o procedimento de login, consulte "Uso da porta do console para o primeiro acesso ao dispositivo".
Figura 2 Fazer login pela porta do console

As configurações padrão para o login do console são as seguintes:
- Se o dispositivo for iniciado com os padrões de fábrica, a autenticação de esquema estará ativada.
- Se o dispositivo for iniciado com a configuração inicial, a autenticação será desativada. A função do usuário é network-admin para um usuário de console.
- Na outra série de switches, a autenticação está desativada. A função do usuário é network-admin para um usuário de console.
Para obter mais informações sobre a configuração inicial e os padrões de fábrica, consulte "Gerenciamento de arquivos de configuração".
Para aumentar a segurança do dispositivo, configure a autenticação por senha ou esquema imediatamente após fazer login no dispositivo pela primeira vez.
Restrições e diretrizes
Uma alteração na configuração de login do console entra em vigor apenas para os usuários que fizerem login após a alteração ser feita. Ela não afeta os usuários que já estão on-line quando a alteração é feita.
No modo FIPS, o dispositivo suporta apenas a autenticação de esquema. Não é possível desativar a autenticação ou configurar a autenticação por senha.
Visão geral das tarefas de configuração do login do console e do USB
Para configurar o login no console, execute as seguintes tarefas:
- Configuração da autenticação de login do console
- Desativação da autenticação para login no console
- Configuração da autenticação por senha para login no console
- Configuração da autenticação de esquema para login no console
- (Opcional.) Definição de configurações comuns de login no console
Configuração da autenticação de login do console
Desativação da autenticação para login no console
- Entre na visualização do sistema.
system-view- Entre na visualização de linha AUX ou na visualização de classe.
- Entre na visualização de linha AUX.
line { aux | } first-number [ last-number ]- Entre na visualização da classe de linha AUX.
line class { aux }- Desativar a autenticação.
authentication-mode none (modo de autenticação nenhum)O modo de autenticação padrão para login no console é o seguinte:
- Se o dispositivo for iniciado com os padrões de fábrica, a autenticação de esquema estará ativada.
- Se o dispositivo for iniciado com a configuração inicial, a autenticação será desativada.
Para obter mais informações sobre a configuração inicial e os padrões de fábrica, consulte "Gerenciamento de arquivos de configuração".
 CUIDADO:
CUIDADO:
Quando a autenticação é desativada, os usuários podem fazer login no dispositivo por meio da linha ou da classe de linha sem autenticação. Para fins de segurança, desative a autenticação com cuidado.
Atribua uma função de usuário.
user-role role-namePor padrão, um usuário de console recebe a função de usuário administrador de rede.
Configuração da autenticação por senha para login no console
- Entre na visualização do sistema.
system-view- Entre na visualização de linha AUX.
line{ aux | usb } first-number [ last-number ] line class { aux | usb }authentication-mode passwordModo de autenticação senha
O modo de autenticação padrão para login no console é o seguinte:
- Defina uma senha.
set authentication password { hash | simple } passwordPor padrão, nenhuma senha é definida.
user-role role-namePor padrão, um usuário de console recebe a função de usuário administrador de rede.
Configuração da autenticação de esquema para login no console
- Entre na visualização do sistema.
system-view- Entre na visualização de linha AUX.
line { aux | } first-number [ last-number ]line class { aux | usb }- No modo não-FIPS:
authentication-mode schemeauthentication-mode schemePor padrão, a autenticação de esquema está ativada.
 CUIDADO:
CUIDADO:
Ao ativar a autenticação de esquema, certifique-se de que uma conta de usuário de autenticação esteja disponível. Se nenhuma conta de usuário de autenticação estiver disponível, não será possível fazer login no dispositivo por meio da linha ou da classe de linha na próxima vez.
Para usar a autenticação local, configure um usuário local e defina os atributos relevantes. Para usar a autenticação remota, configure um esquema RADIUS, LDAP ou HWTACACS. Para obter mais informações, consulte AAA no Guia de configuração de segurança.
Definição de configurações comuns de login no console
Restrições e diretrizes
Algumas configurações comuns de login de console entram em vigor imediatamente e podem interromper a sessão atual. Use um método de login diferente do login do console ou do USB para fazer login no dispositivo antes de alterar as configurações de login do console ou do USB.
Depois de alterar as configurações de login do console, ajuste as configurações no terminal de configuração de acordo para que o login seja bem-sucedido.
Procedimento
- Entre na visualização do sistema.
system-viewline { aux } first-number [ last-number ]line class { aux | usb }- Defina a taxa de transmissão.
speed speed-valuePor padrão, a taxa de transmissão é de 9600 bps.
Esse comando não está disponível na visualização de classe da linha do usuário.
parity { even | mark | none | odd | space }Por padrão, uma linha de usuário não usa paridade.
Esse comando não está disponível na visualização de classe da linha do usuário.
flow-control { hardware | none | software }Por padrão, o dispositivo não executa o controle de fluxo. Esse comando não está disponível na visualização de classe de linha do usuário.
databits { 5 | 6 | 7 | 8 }Esse comando não está disponível na visualização de classe da linha do usuário.
| Parâmetro | Descrição |
| 7 | Usa caracteres ASCII padrão. |
| 8 | Usa caracteres ASCII estendidos. |
| 5 e 6 | Disponível somente para discagem por modem. |
stopbits { 1 | 1.5 | 2 }O padrão é 1.
Os bits de parada indicam o fim de um caractere. Quanto maior o número de bits de parada, mais lenta será a transmissão.
Esse comando não está disponível na visualização de classe da linha do usuário.
- Habilite o serviço de terminal.
shellPor padrão, o serviço de terminal é ativado em todas as linhas de usuário. O comando undo shell não está disponível na visualização de linha AUX.
O dispositivo é compatível com os tipos de exibição de terminal ANSI e VT100. Como prática recomendada, especifique o tipo VT100 tanto no dispositivo quanto no terminal de configuração. Você também pode especificar o tipo ANSI para ambos os lados, mas poderá ocorrer um problema de exibição se a linha de comando tiver mais de 80 caracteres.
screen-length screen-lengthPor padrão, o dispositivo envia um máximo de 24 linhas ao terminal por vez. Para desativar a pausa entre as telas de saída, defina o valor como 0.
history-command max-size valuePor padrão, o tamanho do buffer é 10. O buffer de uma linha de usuário pode salvar no máximo 10 comandos de histórico.
idle-timeout minutes [ seconds ]Por padrão, o temporizador de tempo ocioso da conexão CLI é de 10 minutos.
Se não ocorrer nenhuma interação entre o dispositivo e o usuário dentro do intervalo de tempo ocioso, o sistema encerrará automaticamente a conexão do usuário na linha do usuário.
Se você definir o cronômetro de tempo limite como 0, a conexão não será envelhecida.
auto-execute command commandPor padrão, nenhum comando é especificado para execução automática.
 CUIDADO:
CUIDADO:
Use esse comando com cuidado. Se esse comando for usado em uma linha de usuário, os usuários que fizerem login no dispositivo por meio dessa linha de usuário poderão não conseguir configurar o sistema.
O dispositivo executará automaticamente o comando especificado quando um usuário fizer login pela linha do usuário e fechará a conexão do usuário depois que o comando for executado.
Esse comando não está disponível na visualização de linha AUX ou na visualização de classe de linha AUX.
- Especifique a chave de ativação da sessão do terminal.
activation-key characterPor padrão, pressionar Enter inicia a sessão do terminal.
escape-key { caractere | padrão }Por padrão, pressionar Ctrl+C encerra um comando.
lock-key key-stringPor padrão, nenhuma chave de bloqueio de linha de usuário é definida.
Configuração do login Telnet
Sobre o login Telnet
O dispositivo pode atuar como um servidor Telnet para permitir o login Telnet ou como um cliente Telnet para fazer Telnet em outros dispositivos.
Restrições e diretrizes
O login Telnet não é compatível com o modo FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de configuração de segurança.
Uma alteração na configuração de login do Telnet entra em vigor somente para os usuários que fizerem login depois que a alteração for feita. Ela não afeta os usuários que já estão on-line quando a alteração é feita.
Configuração do dispositivo como um servidor Telnet
Ativação do servidor Telnet
- Entre na visualização do sistema.
system-viewtelnet server enableServidor telnet habilitado
Por padrão, o servidor Telnet está desativado.
Desativação da autenticação para login Telnet
- Entre na visualização do sistema.
system-view- Entre na visualização de linha VTY.
first-number [ last-number ] line class vtyauthentication-mode none (modo de autenticação nenhum)Por padrão, a autenticação por senha é ativada para o login Telnet.
 CUIDADO:
CUIDADO:
Quando a autenticação está desativada, os usuários podem fazer login no dispositivo por meio da linha ou da classe de linha sem autenticação. Para fins de segurança, desative a autenticação com cuidado.
Na visualização de linha VTY, esse comando está associado ao comando de entrada de protocolo. Se um comando tiver uma configuração não padrão na visualização de linha VTY, o outro comando usará sua configuração na visualização de linha VTY, independentemente de sua configuração na visualização de classe de linha VTY.
user-role role-namePor padrão, um usuário de linha VTY recebe a função de usuário operador de rede.
Configuração da autenticação de senha para login Telnet
- Entre na visualização do sistema.
system-view- Entre na visualização de linha VTY.
line vty first-number [ last-number ]line class vtyauthentication-mode passwordPor padrão, a autenticação por senha é ativada para o login Telnet.
 CUIDADO:
CUIDADO:
Ao ativar a autenticação por senha, você também deve configurar uma senha de autenticação para a linha ou classe de linha. Se nenhuma senha de autenticação for configurada, não será possível fazer login no dispositivo por meio da linha ou da classe de linha na próxima vez.
Na visualização de linha VTY, esse comando está associado ao comando de entrada de protocolo. Se um comando tiver uma configuração não padrão na visualização de linha VTY, o outro comando usará sua configuração na visualização de linha VTY , independentemente de sua configuração na visualização de classe de linha VTY.
set authentication password { hash | simple } passwordPor padrão, nenhuma senha é definida.
user-role role-namePor padrão, um usuário de linha VTY recebe a função de usuário operador de rede.
Configuração da autenticação de esquema para login Telnet
- Entre na visualização do sistema.
system-view- Entre na visualização de linha VTY.
line vty first-number [ last-number ]line class vtyauthentication-mode schemePor padrão, a autenticação por senha é ativada para o login Telnet.
 CUIDADO:
CUIDADO:
Ao ativar a autenticação de esquema, certifique-se de que uma conta de usuário de autenticação esteja disponível. Se nenhuma conta de usuário de autenticação estiver disponível, não será possível fazer login no dispositivo por meio da linha ou da classe de linha na próxima vez.
Na visualização de linha VTY, esse comando está associado ao comando de entrada de protocolo. Se um comando tiver uma configuração não padrão na visualização de linha VTY, o outro comando usará sua configuração na visualização de linha VTY, independentemente de sua configuração na visualização de classe de linha VTY.
Para usar a autenticação remota, configure um esquema RADIUS, LDAP ou HWTACACS. Para obter mais informações, consulte AAA no Guia de configuração de segurança.
Definição de configurações comuns do servidor Telnet
- Entre na visualização do sistema.
system-view- IPv4:
telnet server dscp dscp-valuetelnet server ipv6 dscp dscp-valuePor padrão, o valor DSCP é 48.
- IPv4:
telnet server port port-numbertelnet server ipv6 port port-numberPor padrão, o número da porta do serviço Telnet é 23.
aaa session-limit telnet max-sessionsPor padrão, o número máximo de usuários Telnet simultâneos é 32.
A alteração dessa configuração não afeta os usuários que estão on-line no momento. Se o novo limite for menor que o número de usuários Telnet on-line, nenhum usuário adicional poderá fazer Telnet até que o número caia abaixo do novo limite.
Para obter mais informações sobre esse comando, consulte Referência de comandos de segurança.
Definição das configurações comuns da linha VTY
- Entre na visualização do sistema.
system-view- Entre na visualização de linha VTY.
line vty first-number [ last-number ]line class vty- Habilite o serviço de terminal.
shellPor padrão, o serviço de terminal é ativado em todas as linhas de usuário.
terminal type { ansi | vt100 }screen-length screen-lengthPor padrão, o dispositivo envia um máximo de 24 linhas ao terminal por vez. Para desativar a pausa entre as telas de saída, defina o valor como 0.
history-command max-size valuePor padrão, o temporizador de tempo ocioso da conexão CLI é de 10 minutos.
idle-timeout minutes [ seconds ]Se não ocorrer nenhuma interação entre o dispositivo e o usuário dentro do intervalo de tempo ocioso, o sistema encerrará automaticamente a conexão do usuário na linha do usuário.
Se você definir o cronômetro de tempo limite como 0, a conexão não será envelhecida.
protocol inbound { all | ssh | telnet }Por padrão, Telnet e SSH são compatíveis.
Uma alteração de protocolo entra em vigor somente para os usuários que fizerem login depois que a configuração for feita. Ela não afeta os usuários que já estão on-line quando a configuração é feita.
Na visualização de linha VTY, esse comando está associado ao comando authentication- mode. Se um comando tiver uma configuração não padrão na visualização de linha VTY, o outro comando usará sua configuração na visualização de linha VTY, independentemente de sua configuração na visualização de classe de linha VTY.
auto-execute command commandPor padrão, nenhum comando é especificado para execução automática.
 IMPORTANTE:
IMPORTANTE:
Antes de executar esse comando e salvar a configuração, verifique se é possível acessar a CLI para modificar a configuração por meio de outras linhas VTY ou AUX.
Para uma linha VTY, é possível especificar um comando que deve ser executado automaticamente quando um usuário fizer login. Após a execução do comando especificado, o sistema desconecta automaticamente a sessão Telnet do .
- Especifique a tecla de atalho para encerrar
escape-key { character | default }A configuração padrão é Ctrl+C.
lock-key key-stringPor padrão, nenhuma chave de bloqueio de linha de usuário é definida.
Uso do dispositivo para fazer login em um servidor Telnet
Sobre como usar o dispositivo para fazer login em um servidor Telnet
Você pode usar o dispositivo como um cliente Telnet para fazer login em um servidor Telnet.
Figura 3 Conexão via Telnet do dispositivo a um servidor Telnet

Pré-requisitos
Atribua um endereço IP ao dispositivo e obtenha o endereço IP do servidor Telnet. Se o dispositivo residir em uma sub-rede diferente da do servidor Telnet, certifique-se de que o dispositivo e o servidor Telnet possam alcançar um ao outro.
Procedimento
- Entre na visualização do sistema.
system-viewtelnet client source { interface interface-type interface-number |ip ip-address }Por padrão, nenhum endereço IPv4 de origem ou interface de origem é especificado. O dispositivo usa o endereço IPv4 primário da interface de saída como endereço de origem para os pacotes Telnet de saída.
quittelnet remote-host [ service-port ] [ source { interface interface-type interface-number | ip ip-address } |dscp dscp- value ] *IPv6:
telnet ipv6 remote-host [ -i interface-type interface-number ][ port-number ] [ source { interface interface-type interface-number |ipv6 ipv6-address } | dscp dscp-value ] *Configuração do login SSH
Sobre o login SSH
O SSH oferece um método seguro de login remoto. Ao fornecer criptografia e autenticação forte, ele protege os dispositivos contra ataques como falsificação de IP e interceptação de senhas de texto simples. Para obter mais informações, consulte o Guia de configuração de segurança.
O dispositivo pode atuar como um servidor SSH para permitir o login Telnet ou como um cliente SSH para fazer login em um servidor SSH.
Configuração do dispositivo como um servidor SSH
Sobre o procedimento de configuração do servidor SSH
Esta seção fornece o procedimento de configuração do servidor SSH usado quando o método de autenticação do cliente SSH é a senha. Para obter mais informações sobre a autenticação SSH e publickey configuração, consulte o Guia de configuração de segurança.
Procedimento
- Entre na visualização do sistema.
system-viewpublic-key local create { dsa | ecdsa [ secp192r1 | secp256r1 | secp384r1 | secp521r1 ] | rsa } [ name key-name ]No modo FIPS:
public-key local create { dsa | ecdsa [ secp256r1 | secp384r1 | secp521r1 ] | rsa } [ name key-name ]Ativação do servidor sshPor padrão, o servidor SSH está desativado.
ssh user username service-type stelnet authentication-type password- Entre na visualização de linha VTY.
line vty first-number [ last-number ]classe de linha vtyauthentication-mode schemePor padrão, a autenticação por senha é ativada para as linhas VTY.
Na visualização de linha VTY, esse comando está associado ao comando de entrada de protocolo. Se um comando tiver uma configuração não padrão na visualização de linha VTY, o outro comando usará sua configuração na visualização de linha VTY, independentemente de sua configuração na visualização de classe de linha VTY.
No modo FIPS:
authentication-mode schemePor padrão, a autenticação de esquema é ativada para linhas VTY.
Na visualização de linha VTY, esse comando está associado ao comando de entrada de protocolo. Se um comando tiver uma configuração não padrão na visualização de linha VTY, o outro comando usará sua configuração na visualização de linha VTY, independentemente de sua configuração na visualização de classe de linha VTY.
 CUIDADO:
CUIDADO:
Ao ativar a autenticação de esquema, verifique se há uma conta de usuário de autenticação disponível. Se nenhuma conta de usuário de autenticação estiver disponível, não será possível fazer login no dispositivo por meio da linha ou da classe de linha na próxima vez.
No modo não-FIPS:
protocol inbound { all | ssh | telnet }Por padrão, Telnet e SSH são compatíveis.
Uma alteração de protocolo entra em vigor somente para os usuários que fizerem login depois que a configuração for feita. Ela não afeta os usuários que já estão on-line quando a configuração é feita.
Na visualização de linha VTY, esse comando está associado ao comando authentication-mode. Se um comando tiver uma configuração não padrão na visualização de linha VTY, o outro comando usará sua configuração na visualização de linha VTY, independentemente de sua configuração na visualização de classe de linha VTY.
No modo FIPS:
protocolo de entrada sshPor padrão, há suporte para SSH.
Uma alteração de protocolo entra em vigor somente para os usuários que fizerem login depois que a configuração for feita. Ela não afeta os usuários que já estão on-line quando a configuração é feita.
Na visualização de linha VTY, esse comando está associado ao comando authentication-mode. Se um comando tiver uma configuração não padrão na visualização de linha VTY, o outro comando usará sua configuração na visualização de linha VTY, independentemente de sua configuração na visualização de classe de linha VTY.
aaa session-limit ssh max-sessionsPor padrão, o número máximo de usuários SSH simultâneos é 32.
A alteração dessa configuração não afeta os usuários que estão on-line no momento. Se o novo limite for menor que o número de usuários SSH on-line, nenhum usuário SSH adicional poderá fazer login até que o número caia abaixo do novo limite.
Para obter mais informações sobre esse comando, consulte Referência de comandos de segurança.
quitUso do dispositivo para fazer login em um servidor SSH
Sobre como usar o dispositivo para fazer login em um servidor SSH
Você pode usar o dispositivo como um cliente SSH para fazer login em um servidor SSH.
Figura 4 Fazer login em um servidor SSH a partir do dispositivo

Pré-requisitos
Atribua um endereço IP ao dispositivo e obtenha o endereço IP do servidor SSH. Se o dispositivo residir em uma sub-rede diferente da do servidor SSH, certifique-se de que o dispositivo e o
servidor SSH possam se comunicar.
Procedimento
Para usar o dispositivo para fazer login em um servidor SSH, execute um dos seguintes comandos na visualização do usuário:
IPv4:
ssh2 serverIPv6:
ssh2 ipv6 serverPara trabalhar com o servidor SSH, talvez seja necessário especificar um conjunto de parâmetros.
Comandos de exibição e manutenção para login na CLI
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | Observações |
| Exibir informações da linha do usuário. | display line [ num1 | { aux | usb | vty } num2 ] [ summary ] | N/A |
| Exibir a configuração da origem do pacote para o cliente Telnet. | display telnet client | N/A |
| Exibir usuários da CLI on-line. | display users [ all ] | N/A |
| Libere uma linha de usuário. | free line { num1 | { aux | usb | vty } num2 } | Vários usuários podem fazer login no dispositivo para configurá-lo simultaneamente. Quando necessário, você pode executar esse comando para liberar algumas conexões. Não é possível usar esse comando para liberar a conexão que você está usando ou uma conexão Telnet redirecionada. Esse comando está disponível na visualização do usuário. |
| Bloqueia a linha do usuário atual e define a senha para desbloquear a linha. | lock | Por padrão, o sistema não bloqueia nenhuma linha de usuário. Esse comando não é compatível com o modo FIPS. Esse comando está disponível na visualização do usuário. |
| Bloqueie a linha do usuário atual e ative a autenticação de desbloqueio. | lock reauthentication | Por padrão, o sistema não bloqueia nenhuma linha de usuário nem inicia a reautenticação. Para desbloquear a linha de usuário bloqueada, pressione Enter e forneça a senha de login para passar pela reautenticação. Esse comando está disponível em qualquer visualização. |
| Enviar mensagens para as linhas do usuário. | send { all | num1 | { aux | usb | vty } num2 } | Esse comando está disponível na visualização do usuário. |
Configuração do login na Web
Sobre o login na Web
O dispositivo fornece um servidor da Web integrado que suporta HTTP 1.0, HTTP 1.1 e HTTPS. Você pode usar um navegador da Web para fazer login e configurar o dispositivo.
O HTTPS usa SSL para garantir a integridade e a segurança dos dados trocados entre o cliente e o servidor, e é mais seguro que o HTTP. É possível definir uma política de controle de acesso baseada em certificados para permitir que apenas clientes legais acessem a interface da Web.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não-FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de configuração de segurança.
O HTTP não é compatível com o modo FIPS.
Restrições e diretrizes: Configuração de login na Web
Para aumentar a segurança do dispositivo, o sistema ativa automaticamente o serviço HTTPS quando você ativa o serviço HTTP. Quando o serviço HTTP está ativado, você não pode desativar o serviço HTTPS.
Pré-requisitos para o login na Web
Antes de fazer login na interface da Web do dispositivo, faça login no dispositivo usando qualquer outro método e atribua um endereço IP ao dispositivo. Certifique-se de que o terminal de configuração e o dispositivo possam se comunicar pela rede IP.
Configuração do login HTTP
- (Opcional.) Especifique um código de verificação fixo para o login na Web.
código de verificação de captcha da webPor padrão, nenhum código de verificação fixo é especificado. Um usuário da Web deve inserir o código de verificação exibido na página de login no momento do login.
Execute esse comando na visualização do usuário.
system-viewip http enable- Se o dispositivo for iniciado com os padrões de fábrica, o serviço HTTP estará ativado.
- Se o dispositivo for iniciado com a configuração inicial, o serviço HTTP será desativado.
ip http port port-numberO número padrão da porta de serviço HTTP é 80.
Configuração do login HTTPS
Sobre o login HTTPS
O dispositivo suporta os seguintes modos de login HTTPS:
- Modo simplificado: O dispositivo usa um certificado autoassinado (um certificado que é gerado e assinado pelo próprio dispositivo) e as configurações SSL padrão. O dispositivo opera no modo simplificado depois que você ativa o serviço HTTPS no dispositivo.
- Modo seguro: O dispositivo usa um certificado assinado por uma CA e um conjunto de configurações de proteção de segurança definidas pelo usuário para garantir a segurança. Para que o dispositivo opere no modo seguro, você deve executar as seguintes tarefas:
- Habilite o serviço HTTPS no dispositivo.
- Especifique uma política de servidor SSL para o serviço.
- Configurar parâmetros relacionados ao domínio PKI.
Restrições e diretrizes
- Para associar uma política de servidor SSL diferente ao serviço HTTPS, você deve executar as seguintes tarefas:
- Desative o serviço HTTP e o serviço HTTPS antes de associar a nova política de servidor SSL.
- Habilite o serviço HTTP e o serviço HTTPS novamente após a associação.
Se você não concluir as tarefas necessárias, a nova política de servidor SSL não entrará em vigor.
- Para que o serviço HTTP use seu certificado autoassinado depois que você associar uma política de servidor SSL ao serviço HTTPS, é necessário seguir estas etapas:
- Desative o serviço HTTP e o serviço HTTPS.
- Execute o comando undo ip https ssl-server-policy para remover a associação de política de servidor SSL existente.
- Habilite novamente o serviço HTTP e o serviço HTTPS.
- A ativação do serviço HTTPS aciona o processo de negociação do handshake SSL.
- Se o dispositivo tiver um certificado local, a negociação do handshake SSL será bem-sucedida e o serviço HTTPS será iniciado.
- Se o dispositivo não tiver um certificado local, o processo de aplicação do certificado será iniciado. Como o processo de aplicação do certificado leva muito tempo, a negociação do handshake SSL pode falhar e o serviço HTTPS pode não ser iniciado. Para resolver o problema, execute o comando ip https enable novamente até que o serviço HTTPS seja ativado.
- Para usar uma política de controle de acesso baseada em certificado para controlar o acesso HTTPS, é necessário executar as seguintes tarefas:
- Execute o comando client-verify enable na política do servidor SSL que está associada ao serviço HTTPS.
- Configure no mínimo uma regra de permissão na política de controle de acesso baseada em certificado. Se você não concluir as tarefas necessárias, os clientes HTTPS não poderão fazer login.
Procedimento
- (Opcional.) Especifique um código de verificação fixo para o login na Web.
código de verificação de captcha da webPor padrão, nenhum código de verificação fixo é configurado. Um usuário da Web deve inserir o código de verificação exibido na página de login no momento do login.
system-view- Aplicar uma política de servidor SSL.
ip https ssl-server-policy policy-namePor padrão, nenhuma política de servidor SSL está associada. O serviço HTTP usa um certificado autoassinado.
- Aplique uma política de controle de acesso baseada em certificado para controlar o acesso HTTPS.
ip https certificate access-control-policy policy-namePor padrão, nenhuma política de controle de acesso baseada em certificado é aplicada.
Para obter mais informações sobre políticas de controle de acesso baseadas em certificados, consulte PKI no Guia de Configuração de Segurança.
ip https enableip https port port-numberO número da porta padrão do serviço HTTPS é 443.
web https-authorization mode { auto | manual }Por padrão, o modo de autenticação manual é usado para login HTTPS.
Configuração de um usuário local de login na Web
- Entre na visualização do sistema.
system-viewlocal-useruser-name [class manage]
- (Opcional.) Configure uma senha para o usuário local. No modo não-FIPS:
password [ { hash | simple } password ]Por padrão, nenhuma senha é configurada para um usuário local. O usuário local pode passar na autenticação depois de inserir o nome de usuário correto e passar nas verificações de atributos.
No modo FIPS:
passwordPor padrão, nenhuma senha é configurada para um usuário local. O usuário local não pode ser aprovado na autenticação.
- Atribua uma função de usuário ao usuário local.
authorization-attribute user-role user-roleA função de usuário padrão é network-operator para um usuário da Web.
- Especifique o tipo de serviço para o usuário local.
service-type { http | https }Por padrão, nenhum tipo de serviço é especificado para um usuário local.
Gerenciamento de conexões da Web
Configuração do temporizador de tempo ocioso da conexão com a Web
- Entre na visualização do sistema.
system-viewminutos de tempo de inatividade da webPor padrão, o temporizador de tempo ocioso da conexão à Web é de 10 minutos.
Especificação do número máximo de usuários HTTP ou HTTPS on-line
- Entre na visualização do sistema.
system-viewaaa session-limit{http|https} max-sessions
Por padrão, o dispositivo suporta um número máximo de 32 usuários HTTP on-line e 32 usuários HTTPS on-line.
A alteração dessa configuração não afeta os usuários que estão on-line no momento. Se a nova configuração for menor que o número
usuários HTTP ou HTTPS on-line, nenhum usuário HTTP ou HTTPS adicional poderá fazer logon
até que o número caia abaixo do novo limite. Para obter mais informações sobre esse comando, consulte
Referência de comandos de segurança.
Fazer logoff de usuários da Web
Para fazer logoff de usuários da Web, execute o seguinte comando na visualização do usuário:
free web users { all | user-id user-id | user-name user-name }Ativação do registro de operações na Web
- Entre na visualização do sistema.
system-viewwebui log enablePor padrão, o registro de operações na Web está desativado.
Comandos de exibição e manutenção para login na Web
Executar comandos de exibiçãoção em qualquer visualização.
| Tarefa | Comando |
| Exibir informações de configuração e status do serviço HTTP. | display ip http |
| Exibir informações de configuração e status do serviço HTTPS. | display ip https |
| Exibir informações da árvore de navegação da interface da Web. | display web menu |
| Exibir usuários da Web on-line. | display web users |
Exemplos de configuração de login na Web
Exemplo: Configuração do login HTTP
Configuração de rede
Conforme mostrado na Figura 5, o PC e o dispositivo podem se comunicar pela rede IP. Configure o dispositivo para permitir que o PC faça login usando HTTP.
Figura 5 Diagrama de rede

Procedimento
# Crie um usuário local chamado admin. Defina a senha como hello12345, o tipo de serviço como HTTP e a função do usuário como network-admin.
[Sysname] local-user admin
[Sysname-luser-manage-admin] service-type http
[Sysname-luser-manage-admin] authorization-attribute user-role network-admin
[Sysname-luser-manage-admin] password simple hello12345
[Sysname-luser-manage-admin] quit
# Habilite o HTTP.
[Sysname] ip http enableVerificação da configuração
- No PC, execute um navegador da Web e digite o endereço IP do dispositivo na barra de endereços.
- Na página de login, digite o nome de usuário, a senha e o código de verificação. Selecione Inglês e clique em Login.
Depois de passar pela autenticação, a página inicial é exibida e você pode configurar o dispositivo.
Exemplo: Configuração do login HTTPS
Configuração de rede
Conforme mostrado na Figura 6, o host, o dispositivo e a CA podem se comunicar pela rede IP.
Execute as seguintes tarefas para permitir que apenas usuários autorizados acessem a interface da Web do dispositivo:
Figura 6 Diagrama de rede
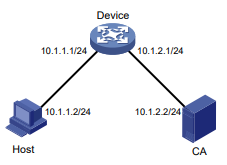
Dispositivo
Hospedeiro CA
Procedimento
# No exemplo, a CA executa o Windows Server e tem o complemento SCEP instalado.
# Configure o dispositivo (servidor HTTPS):
<Device> system-view
[Device] pki entity en
[Device-pki-entity-en] common-name http-server1
[Device-pki-entity-en] fqdn ssl.security.com
[Device-pki-entity-en] quit
[Device] pki domain 1
[Device-pki-domain-1] ca identifier new-ca
[Device-pki-domain-1] url de solicitação de certificado http://10.1.2.2/certsrv/mscep/mscep.dll
[Device-pki-domain-1] certificate request from ra
[Device-pki-domain-1] certificate request entity en
[Device-pki-domain-1] public-key rsa general name hostkey length 1024
[Device-pki-domain-1] quit
[Device] public-key local create rsa
[Device] pki retrieve-certificate domain 1 ca
[Device] pki request-certificate domain 1
[Dispositivo] ssl server-policy myssl
[Device-ssl-server-policy-myssl] pki-domain 1
[Device-ssl-server-policy-myssl] client-verify enable
[Device-ssl-server-policy-myssl] quit
[Device-pki-cert-attribute-group-mygroup1] attribute 1 issuer-name dn ctn new-ca
[Device] pki certificate access-control-policy myacp
[Device-pki-cert-acp-myacp] rule 1 permit mygroup1
[Device-pki-cert-acp-myacp] quit
[Device] ip https ssl-server-policy myssl
[Dispositivo] ip https certificate access-control-policy myacp
[Device] ip https enable
[Device] local-user usera
[Device-luser-usera] password simple hello12345
[Device-luser-usera] service-type https
[Device-luser-usera] authorization-attribute user-role network-admin
# No host, execute um navegador da Web e digite http://10.1.2.2/certsrv na barra de endereços. Solicite um certificado para o host conforme solicitado.
# Verificação da configuração:
# No host, digite https://10.1.1.1 na barra de endereços do navegador da Web e selecione o certificado emitido por new-ca.
# Quando a página de login na Web for exibida, digite o nome de usuário usera e a senha hello12345 para fazer login na interface da Web.
# Para obter mais informações sobre os comandos de configuração de PKI e SSL e o comando
# public-key local create rsa, consulte Referência de comandos de segurança.Acesso ao dispositivo por meio de SNMP
É possível executar o SNMP em um NMS para acessar o MIB do dispositivo e realizar operações Get e Set para configurar e gerenciar o dispositivo.
Figura 7 Diagrama de acesso SNMP
Configuração do acesso RESTful
Sobre o acesso RESTful
O dispositivo fornece a interface de programação de aplicativos Representational State Transfer (API RESTful). Com base nessa API, você pode usar linguagens de programação como Python, Ruby ou Java para escrever programas para executar as seguintes tarefas:
- Envie solicitações RESTful ao dispositivo para passar a autenticação.
- Use as operações da API RESTful para configurar e gerenciar o dispositivo. As operações da API RESTful incluem Get, Put, Post e Delete.
O dispositivo suporta o uso de HTTP ou HTTPS para transferir pacotes RESTful.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não- FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de configuração de segurança.
O acesso RESTful por HTTP não é compatível com o modo FIPS.
Configuração do acesso RESTful por HTTP
- Entre na visualização do sistema.
system-viewRestful http enablePor padrão, o acesso RESTful por HTTP está desativado.
local-user user-name [ class manage ]senha [ { hash | simples} senha ] authorization-attribute user-role user-roleA função de usuário padrão é network-operator para um usuário de acesso RESTful.
service-type httpPor padrão, nenhum tipo de serviço é especificado para um usuário local.
Configuração do acesso RESTful por HTTPS
- Entre na visualização do sistema.
system-viewRestful https enablePor padrão, o acesso RESTful por HTTPS está desativado.
local-user user-name [ class manage ]password [ { hash | simple } password ]No modo FIPS:
password
authorization-attribute user-role user-roleA função de usuário padrão é network-operator para um usuário de acesso RESTful.
service-type httpsPor padrão, nenhum tipo de serviço é especificado para um usuário local.
Controle do acesso do usuário ao dispositivo
Sobre o controle de acesso do usuário de login
Use ACLs para impedir o acesso não autorizado e configure a autorização de comandos e a contabilidade para monitorar e controlar o comportamento do usuário.
Se uma ACL aplicada não existir ou não tiver nenhuma regra, nenhuma restrição de login de usuário será aplicada. Se a ACL existir e tiver regras, somente os usuários permitidos pela ACL poderão acessar o dispositivo.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não- FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de configuração de segurança.
Telnet e HTTP não são compatíveis com o modo FIPS.
Controle de logins Telnet e SSH
Controle de logins Telnet
- Entre na visualização do sistema.
system-view- Aplique uma ACL para controlar os logins Telnet. IPv4:
telnet server acl { advanced-acl-number | basic-acl-number | mac mac-acl-number }IPv6:
telnet server ipv6 acl { ipv6 { advanced-acl-number | basic-acl-number } | mac mac-acl-number }Por padrão, nenhuma ACL é usada para controlar os logins Telnet.
- (Opcional.) Ative o registro das tentativas de login do Telnet que são negadas pela ACL de controle de login do Telnet.
server telnet acl-deny-log enablePor padrão, o registro é desativado para tentativas de login do Telnet que são negadas pela ACL de controle de login do Telnet.
Controle de logins SSH
- Entre na visualização do sistema.
system-view- Aplique uma ACL para controlar os logins SSH. IPv4:
ssh server acl { advanced-acl-number | basic-acl-number | macmac-acl-number }IPv6:
ssh server ipv6 acl { ipv6 { advanced-acl-number | basic-acl-number } mac mac-acl-number }
Por padrão, nenhuma ACL é usada para controlar os logins SSH.
- (Opcional.) Ative o registro de tentativas de login SSH que são negadas pela ACL de controle de login SSH.
Servidor ssh acl-deny-log enablePor padrão, o registro é desativado para tentativas de login SSH que são negadas pela ACL de controle de login SSH.
Para obter mais informações sobre os comandos ssh, consulte Referência de comandos de segurança.
Exemplo: Controle do login Telnet
Configuração de rede
Conforme mostrado na Figura 8, o dispositivo é um servidor Telnet.
Configure o dispositivo para permitir somente pacotes Telnet originados do Host A e do Host B.
Figura 8 Diagrama de rede
Host B 10.110.100.52
Procedimento
# Configure uma ACL para permitir pacotes provenientes do Host A e do Host B.
<Sysname> system-view
[Sysname] acl basic 2000 match-order config
[Sysname-acl-ipv4-basic-2000] rule 1 permit source 10.110.100.52 0
[Sysname-acl-ipv4-basic-2000] rule 2 permit source 10.110.100.46 0
[Sysname-acl-ipv4-basic-2000] quit
# Aplique a ACL para filtrar os logins Telnet.
[Sysname] telnet server acl 2000Controle de logins da Web
Configuração do controle de login na Web com base no IP de origem
- Entre na visualização do sistema.
system-view- Aplique uma ACL básica para controlar os logins na Web.
- Controle os logins HTTP.
ip http acl { acl-número | nome acl-nome }- Controle os logins HTTPS.
ip https acl { acl-número | nome acl-nome }Por padrão, nenhuma ACL é aplicada para controlar os logins na Web.
Exemplo: Controle do login na Web
Configuração de rede
Conforme mostrado na Figura 9, o dispositivo é um servidor HTTP. Configure o dispositivo para fornecer serviço HTTP somente ao Host B.
Figura 9 Diagrama de rede
Procedimento
# Crie uma ACL e configure a regra 1 para permitir pacotes provenientes do Host B.
<Sysname> system-view
[Sysname] acl basic 2030 match-order config
[Sysname-acl-ipv4-basic-2030] rule 1 permit source 10.110.100.52 0# Aplique a ACL ao serviço HTTP para que somente um usuário da Web no Host B possa acessar o dispositivo.
[Sysname] ip http acl 2030Controle do acesso SNMP
Sobre o controle de acesso SNMP
Para obter informações sobre o controle de acesso SNMP, consulte SNMP no Guia de configuração de monitoramento e gerenciamento de rede.
Exemplo: Controle do acesso SNMP
Configuração de rede
Conforme mostrado na Figura 10, o dispositivo está executando o SNMP.
Configure o dispositivo para permitir que o Host A e o Host B acessem o dispositivo por meio de SNMP.
Figura 10 Diagrama de rede
Procedimento
# Crie uma ACL para permitir pacotes provenientes do Host A e do Host B.
<Sysname> system-view
[Sysname] acl basic 2000 match-order config
[Sysname-acl-ipv4-basic-2000] rule 1 permit source 10.110.100.52 0
[Sysname-acl-ipv4-basic-2000] rule 2 permit source 10.110.100.46 0
[Sysname-acl-ipv4-basic-2000] quit# Associe a ACL à comunidade SNMP e ao grupo SNMP.
[Sysname] snmp-agent community read aaa acl 2000
[Sysname] snmp-agent group v2c groupa acl 2000
[Sysname] snmp-agent usm-user v2c usera groupa acl 2000Configuração da autorização de comando
Sobre a autorização de comandos
Por padrão, os comandos disponíveis para um usuário dependem apenas das funções de usuário do usuário. Quando o modo de autenticação é o esquema, você pode configurar o recurso de autorização de comando para controlar ainda mais o acesso aos comandos.
Depois de ativar a autorização de comando, um usuário pode usar somente os comandos permitidos pelo esquema AAA e pelas funções de usuário.
Restrições e diretrizes
O método de autorização de comando pode ser diferente do método de autorização de login do usuário.
Para que o recurso de autorização de comando entre em vigor, você deve configurar um método de autorização de comando na visualização de domínio do ISP. Para obter mais informações, consulte o Guia de configuração de segurança.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização de linha de usuário ou na visualização de classe de linha de usuário.
- Entre na visualização da linha do usuário.
line { first-number1 [ last-number1 ] | { aux | usb | vty }primeiro-número2 [ último-número2 ] }- Entre na visualização da classe de linha do usuário.
classe de linha { aux | usb |vty }Uma configuração na visualização de linha de usuário aplica-se somente à linha de usuário. Uma configuração na visualização de classe de linha de usuário se aplica a todas as linhas de usuário da classe. Uma configuração não padrão em qualquer uma das visualizações tem precedência sobre a configuração padrão na outra visualização. Uma configuração não padrão na visualização de linha de usuário tem precedência sobre a configuração não padrão na visualização de classe de linha de usuário.
Uma configuração na visualização de classe de linha de usuário entra em vigor somente para os usuários que fizerem login depois que a configuração for feita. Ela não afeta os usuários que já estão on-line quando a configuração é feita.
- Ativar a autenticação do esquema. No modo não-FIPS:
esquema de modo de autenticação
Por padrão, a autenticação por senha é ativada para o login no VTY. O modo de autenticação padrão para login no console é o seguinte:
- Se o dispositivo for iniciado com os padrões de fábrica, a autenticação de esquema estará ativada.
- Se o dispositivo for iniciado com a configuração inicial, a autenticação será desativada.
- Na outra série de switches, a autenticação está desativada.
- Ativar a autorização de comando.
Para obter mais informações sobre a configuração inicial e os padrões de fábrica, consulte "Gerenciamento de arquivos de configuração".
Na visualização de linha VTY, esse comando está associado ao comando de entrada de protocolo. Se um comando tiver uma configuração não padrão na visualização de linha VTY, o outro comando usará sua configuração na visualização de linha VTY, independentemente de sua configuração na visualização de classe de linha VTY.
No modo FIPS:
esquema de modo de autenticação
Por padrão, a autenticação de esquema está ativada.
Na visualização de linha VTY, esse comando está associado ao comando de entrada de protocolo. Se um comando tiver uma configuração não padrão na visualização de linha VTY, o outro comando usará sua configuração na visualização de linha VTY, independentemente de sua configuração na visualização de classe de linha VTY.
 CUIDADO:
CUIDADO:
Ao ativar a autenticação de esquema, certifique-se de que uma conta de usuário de autenticação esteja disponível. Se nenhuma conta de usuário de autenticação estiver disponível, não será possível fazer login no dispositivo por meio da linha ou da classe de linha na próxima vez.
autorização de comando
Por padrão, a autorização de comando está desativada e os comandos disponíveis para um usuário dependem apenas da função do usuário.
Se o comando de autorização de comando for executado na visualização de classe da linha de usuário, a autorização de comando será ativada em todas as linhas de usuário da classe. Não é possível executar o comando desfazer autorização de comando na visualização de uma linha de usuário na classe.
Exemplo: Configuração da autorização de comando
Configuração de rede
Conforme mostrado na Figura 11, o Host A precisa fazer login no dispositivo para gerenciá-lo. Configure o dispositivo para executar as seguintes operações:
- Permitir que o Host A faça Telnet após a autenticação.
- Use o servidor HWTACACS para controlar os comandos que o usuário pode executar.
- Se o servidor HWTACACS não estiver disponível, use a autorização local.
Figura 11 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces relevantes. Certifique-se de que o dispositivo e o servidor HWTACACS possam se comunicar. Certifique-se de que o dispositivo e o Host A possam se comunicar.
# Habilite o servidor Telnet.
<Device> system-view
[Device] telnet server enable# Habilite a autenticação de esquema para as linhas de usuário VTY 0 a VTY 4.
[Device] line vty 0 4
[Device-line-vty0-4] authentication-mode scheme# Habilite a autorização de comando para as linhas de usuário. [Device-line-vty0-4] command authorization [Device-line-vty0-4] quit
# Criar o esquema HWTACACS tac.
[Device] hwtacacs scheme tac# Configure o esquema para usar o servidor HWTACACS em 192.168.2.20:49 para autenticação e autorização.
[Device-hwtacacs-tac] primary authentication 192.168.2.20 49[Device-hwtacacs-tac] primary authorization 192.168.2.20 49# Defina as chaves compartilhadas como expert.
[Device-hwtacacs-tac] key authentication simple expert[Device-hwtacacs-tac] key authorization simple expert# Remova os nomes de domínio dos nomes de usuário enviados ao servidor HWTACACS.
[Device-hwtacacs-tac] user-name-format without-domain[Device-hwtacacs-tac] quit# Configure o domínio definido pelo sistema (sistema).
[Device] domain system# Use o esquema tac do HWTACACS para autenticação de usuário de login e autorização de comando. Use a autenticação local e a autorização local como método de backup.
[Device-isp-system] authentication login hwtacacs-scheme tac local[Device-isp-system] authorization command hwtacacs-scheme tac local[Device-isp-system] quit# Crie um monitor de usuário local. Defina a senha simples como hello12345, o tipo de serviço como Telnet e a função de usuário padrão como level-1.
[Device] local-user monitor[Device-luser-manage-monitor] password simple hello12345[Device-luser-manage-monitor] service-type telnet[Device-luser-manage-monitor] authorization-attribute user-role level-1Configuração da contabilidade de comandos
Sobre a contabilidade de comandos
A contabilidade de comandos usa o servidor HWTACACS para registrar todos os comandos executados para monitorar o comportamento do usuário no dispositivo.
Se a contabilidade de comandos estiver ativada, mas a autorização de comandos não estiver, todos os comandos executados serão registrados. Se a contabilidade e a autorização de comandos estiverem ativadas, somente os comandos autorizados que forem executados serão registrados.
Restrições e diretrizes
O método de contabilização de comandos pode ser igual ou diferente do método de autorização de comandos e do método de autorização de login do usuário.
Para que o recurso de contabilização de comandos entre em vigor, você deve configurar um método de contabilização de comandos na visualização de domínio do ISP. Para obter mais informações, consulte o Guia de configuração de segurança.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da linha do usuário.
line { first-number1 [ last-number1 | { aux | usb | vty } first-number2 [ last-number2 ] }- Entre na visualização da classe de linha do usuário.
line class { aux | usb |vty }Uma configuração na visualização de linha de usuário aplica-se somente à linha de usuário. Uma configuração na visualização de classe de linha de usuário se aplica a todas as linhas de usuário da classe. Uma configuração não padrão em qualquer uma das visualizações tem precedência sobre a configuração padrão na outra visualização. Uma configuração não padrão na visualização de linha de usuário tem precedência sobre a configuração não padrão na visualização de classe de linha de usuário.
Uma configuração na visualização de classe de linha de usuário entra em vigor somente para os usuários que fizerem login depois que a configuração for feita. Ela não afeta os usuários que já estão on-line quando a configuração é feita.
authentication-mode schemePor padrão, a autenticação por senha é ativada para o login no VTY. O modo de autenticação padrão para login no console é o seguinte:
- Se o dispositivo for iniciado com os padrões de fábrica, a autenticação de esquema estará ativada.
- Se o dispositivo for iniciado com a configuração inicial, a autenticação será desativada.
- Na outra série de switches, a autenticação está desativada.
Para obter mais informações sobre a configuração inicial e os padrões de fábrica, consulte "Gerenciamento de arquivos de configuração".
Na visualização de linha VTY, esse comando está associado ao comando de entrada de protocolo. Se um comando tiver uma configuração não padrão na visualização de linha VTY, o outro comando usará sua configuração na visualização de linha VTY, independentemente de sua configuração na visualização de classe de linha VTY.
No modo FIPS:
authentication-mode schemePor padrão, a autenticação de esquema está ativada.
Na visualização de linha VTY, esse comando está associado ao comando de entrada de protocolo. Se um comando tiver uma configuração não padrão na visualização de linha VTY, o outro comando usará sua configuração na visualização de linha VTY, independentemente de sua configuração na visualização de classe de linha VTY.
 CUIDADO:
CUIDADO:
Ao ativar a autenticação de esquema, certifique-se de que uma conta de usuário de autenticação esteja disponível. Se nenhuma conta de usuário de autenticação estiver disponível, não será possível fazer login no dispositivo por meio da linha ou da classe de linha na próxima vez.
command accountingPor padrão, a contabilização de comandos está desativada. O servidor de contabilidade não registra os comandos executados pelos usuários.
Se o comando command accounting for executado na visualização de classe da linha de usuário, o command accounting será ativado em todas as linhas de usuário da classe. Não é possível executar o comando undo command accounting na visualização de uma linha de usuário da classe.
Exemplo: Configuração da contabilidade de comandos
Configuração de rede
Conforme mostrado na Figura 12, os usuários precisam fazer login no dispositivo para gerenciá-lo.
Configure o dispositivo para enviar comandos executados pelos usuários ao servidor HWTACACS para monitorar e controlar as operações do usuário no dispositivo.
Figura 12 Diagrama de rede
Procedimento
# Habilite o servidor Telnet.
<Device> system-view [Device] telnet server enable# Habilite a contabilidade de comandos para a linha de usuário AUX 0.
[Device] line aux 0[Device-line-aux0] command accounting [Device-line-aux0] quit# Habilite a contabilidade de comandos para as linhas de usuário VTY 0 a VTY 63.
[Device] line vty 0 63[Device-line-vty0-63] command accounting [Device-line-vty0-63] quit# Criar o esquema HWTACACS tac.
[Device] hwtacacs scheme tac# Configure o esquema para usar o servidor HWTACACS em 192.168.2.20:49 para contabilidade.
[Device-hwtacacs-tac] primary accounting 192.168.2.20 49# Defina a chave compartilhada como expert.
[Device-hwtacacs-tac] key accounting simple expert# Remova os nomes de domínio dos nomes de usuário enviados ao servidor HWTACACS.
[Device-hwtacacs-tac] user-name-format without-domain[Device-hwtacacs-tac] quit# Configure o domínio definido pelo sistema (sistema) para usar o esquema HWTACACS para a contabilidade de comandos.
[Device] domain system[Device-isp-system] accounting command hwtacacs-scheme tac [Device-isp-system] quitConfiguração de FTP
Sobre o FTP
O File Transfer Protocol (FTP) é um protocolo de camada de aplicativo para transferência de arquivos de um host para outro em uma rede IP. Ele usa a porta TCP 20 para transferir dados e a porta TCP 21 para transferir comandos de controle.
O FTP é baseado no modelo cliente/servidor. O dispositivo pode atuar como servidor FTP ou cliente FTP.
Modos de transferência de arquivos FTP
O FTP é compatível com os seguintes modos de transferência:
- Modo binário - Usado para arquivos não textuais, como arquivos .app, .bin e .btm.
- Modo ASCII - Usado para transferir arquivos de texto, como arquivos .txt, .bat e .cfg.
Quando o dispositivo atua como cliente de FTP, você pode definir o modo de transferência (binário por padrão). Quando o dispositivo atua como servidor de FTP, o modo de transferência é determinado pelo cliente de FTP.
Modos de operação de FTP
O FTP pode operar em um dos seguintes modos:
- Modo ativo (PORT) - O servidor FTP inicia a conexão TCP. Esse modo não é adequado quando o cliente FTP está atrás de um firewall, por exemplo, quando o cliente FTP reside em uma rede privada.
- Modo passivo (PASV) - O cliente FTP inicia a conexão TCP. Esse modo não é adequado quando o servidor não permite que o cliente use uma porta aleatória sem privilégios maior que 1024.
O modo de operação de FTP varia de acordo com o programa cliente de FTP.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não- FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de configuração de segurança.
Não há suporte para FTP no modo FIPS.
Uso do dispositivo como um servidor FTP
Para usar o dispositivo como um servidor FTP, você deve ativar o servidor FTP e configurar a autenticação e a autorização no dispositivo. Outros comandos são opcionais.
Ativação do servidor FTP
- Entre na visualização do sistema.
system-viewftp server enablePor padrão, o servidor FTP está desativado.
Configuração da autenticação e autorização do cliente
Execute esta tarefa no servidor FTP para autenticar clientes FTP e definir os diretórios autorizados que os clientes autenticados podem acessar.
Os seguintes modos de autenticação estão disponíveis:
- Autenticação local - O dispositivo procura o nome de usuário e a senha do cliente no banco de dados da conta de usuário local. Se for encontrada uma correspondência, a autenticação será bem-sucedida.
- Autenticação remota - O dispositivo envia o nome de usuário e a senha do cliente a um servidor de autenticação remota para autenticação. A conta de usuário é configurada no servidor de autenticação remota e não no dispositivo.
Os seguintes modos de autorização estão disponíveis:
- Autorização local - O dispositivo atribui diretórios autorizados a clientes FTP com base nos atributos de autorização configurados localmente.
- Autorização remota - Um servidor de autorização remota atribui diretórios autorizados no dispositivo a clientes FTP.
Para obter mais informações sobre como configurar a autenticação e a autorização, consulte AAA no Security Configuration Guide.
Configuração do controle de acesso ao servidor FTP
Sobre o controle de acesso ao servidor FTP
Use ACLs para impedir o acesso não autorizado. Se uma ACL aplicada não existir ou não tiver nenhuma regra, nenhuma restrição de login de usuário será aplicada. Se a ACL existir e tiver regras, somente os clientes FTP permitidos pela ACL poderão acessar o dispositivo.
Restrições e diretrizes
Essa configuração entra em vigor somente para conexões FTP a serem estabelecidas. Ela não afeta as conexões FTP existentes.
Se você configurar o controle de acesso ao servidor FTP várias vezes, a configuração mais recente entrará em vigor.
Procedimento
- Entre na visualização do sistema.
system-viewftp server acl { advanced-acl-number | basic-acl-number | ipv6 { advanced-acl-number | basic-acl-number } }Por padrão, nenhuma ACL é usada para controle de acesso.
ftp server acl-deny-log enablePor padrão, o registro em log é desativado para tentativas de login de FTP que são negadas pelo controle de login de FTP ACL.
Configuração dos parâmetros de gerenciamento de conexão
- Entre na visualização do sistema.
system-viewftp timeout minutesPor padrão, o temporizador de tempo ocioso da conexão FTP é de 30 minutos.
Se não ocorrer nenhuma transferência de dados em uma conexão FTP antes que o temporizador de tempo ocioso expire, o servidor FTP fechará a conexão FTP.
aaa session-limit ftp max-sessionsPor padrão, o número máximo de usuários de FTP simultâneos é 32.
A alteração dessa configuração não afeta os usuários que estão on-line no momento. Se o novo limite for menor que o número de usuários de FTP on-line, nenhum usuário de FTP adicional poderá fazer login até que o número caia abaixo do novo limite. Para obter mais informações sobre esse comando, consulte Security Command Reference.
Especificação de uma política de servidor SSL para conexões SFTP
Sobre a especificação de uma política de servidor SSL para conexões SFTP
Depois que você associar uma política de servidor SSL ao dispositivo, um cliente compatível com SFTP estabelecerá uma conexão segura com o dispositivo para garantir a segurança dos dados.
Procedimento
- Entre na visualização do sistema.
system-viewftp server ssl-server-policy policy-namePor padrão, nenhuma política de servidor SSL está associada ao servidor FTP.
Configuração do valor DSCP para pacotes FTP de saída
- Entre na visualização do sistema.
system-viewIPv4:
ftp server dscp dscp-valueIPv6:
ftp server ipv6 dscp dscp-valuePor padrão, o valor DSCP é 0.
Liberação manual de conexões FTP
Para liberar manualmente as conexões FTP, execute os seguintes comandos na visualização do usuário:
- Libere a conexão FTP estabelecida usando uma conta de usuário específica:
free ftp user usernamefree ftp user-ip [ ipv6 ] ip-address [ port port ]Comandos de exibição e manutenção do servidor FTP
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações de configuração e status do servidor FTP. | display ftp-server |
| Exibir informações detalhadas sobre os usuários de FTP on-line. | display ftp-user |
Exemplo: Uso do dispositivo como um servidor FTP
Configuração de rede
- Configure a malha IRF como um servidor FTP.
- Crie uma conta de usuário local chamada abc no servidor FTP. Defina a senha como hello12345 .
- Use a conta de usuário para fazer login no servidor FTP a partir do cliente FTP.
- Faça upload do arquivo temp.bin do cliente FTP para o servidor FTP.
Figura 1 Diagrama de rede
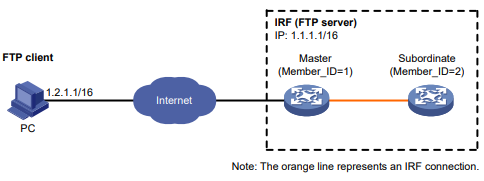
Procedimento
- Configure os endereços IP conforme mostrado na Figura 1. Certifique-se de que a malha IRF e o PC possam se comunicar. (Detalhes não mostrados.)
- Configure o servidor FTP:
# Examine o espaço de armazenamento nos dispositivos membros. Se o espaço livre for insuficiente, use a função comando {delete/unreserved file } para excluir arquivos não utilizados.(Detalhes não mostrados.)
# Crie um usuário local com nome de usuário abc e senha hello12345.
<Sysname> system-view[Sysname] local-user abc class manage[Sysname-luser-manage-abc] password simples hello12345# Atribua a função de usuário administrador de rede ao usuário. Defina o diretório de trabalho como o diretório raiz da memória flash no mestre. (Para definir o diretório de trabalho como o diretório raiz da memória flash no membro subordinado, você deve incluir o número do slot no caminho do diretório).
[Sysname-luser-manage-abc] authorization-attribute user-role network-admin work-directory flash:/# Atribua o tipo de serviço FTP ao usuário.
[Sysname-luser-manage-abc] service-type ftp [Sysname-luser-manage-abc] quit# Habilite o servidor FTP.
[Sysname] ftp server enable [Sysname] quit# Faça login no servidor FTP em 1.1.1.1 usando o nome de usuário abc e a senha hello12345.
c:\> ftp 1.1.1.1Connected to 1.1.1.1.220 FTP service ready. User(1.1.1.1:(none)):abc331 Password required for abc. Password:230 User logged in.# Use o modo ASCII para fazer download do arquivo de configuração config.cfg do servidor FTP para o PC para backup.
ftp> ascii200 TYPE is now ASCIIftp> get config.cfg back-config.cfg# Use o modo binário para carregar o arquivo temp.bin do PC para o diretório raiz da memória flash no mestre.
ftp> binary200 TYPE is now 8-bit binary ftp> put temp.bin# Sair do FTP.
ftp> byeUso do dispositivo como um cliente FTP
Estabelecimento de uma conexão FTP
Lista de tarefas de estabelecimento de conexão FTP
Para estabelecer uma conexão FTP, execute as seguintes tarefas:
- (Opcional.) Especificação de um endereço IP de origem para pacotes FTP de saída
- Estabelecimento de uma conexão FTP
- Configuração do modo de transferência de arquivos FTP e do modo de operação
Restrições e diretrizes
O endereço IP de origem especificado no comando ftp tem precedência sobre aquele definido pelo comando ftp client source.
O endereço IP de origem especificado no comando ftp ipv6 tem precedência sobre aquele definido pelo comando ftp client ipv6 source.
Especificação de um endereço IP de origem para pacotes FTP de saída
- Entre na visualização do sistema.
system-viewIPv4:
ftp client source { interface interface-type interface-number | ip source-ip-address }Por padrão, nenhum endereço IP de origem é especificado. O dispositivo usa o endereço IP primário da interface de saída como endereço IP de origem.
IPv6:
ftp client ipv6 source { interface interface-type interface-number | ipv6 source-ipv6-address }Por padrão, nenhum endereço IPv6 de origem é especificado. O endereço de origem é selecionado automaticamente, conforme definido na RFC 3484.
Estabelecimento de uma conexão FTP
- Faça login no servidor FTP a partir da visualização do usuário.
IPv4:
ftp [ ftp-server [ service-port ] [ dscp dscp-value | source { interface interface-type interface-number | ip source-ip-address } | -d ] * ]IPv6:
ftp ipv6 [ ftp-server [ service-port ] [ dscp dscp-value | source { interface interface-type interface-number | ipv6 source-ipv6-address } | -d ] * [ -i interface-type interface-number ] ]- Entre na visualização do cliente FTP.
ftp [ ipv6 ]open server-address [ service-port ]Configuração do modo de transferência de arquivos FTP e do modo de operação
- Entre na visualização do cliente FTP a partir da visualização do usuário.
ftp- Defina o modo de transferência de arquivos como ASCII.
asciibinaryO modo padrão de transferência de arquivos é binário.
passiveO modo de operação padrão do FTP é passivo.
Exibição de informações de ajuda do comando
- Entre na visualização do cliente FTP a partir da visualização do usuário.
ftphelp [ command-name ]? [ command-name ]Exibição de diretórios e arquivos no servidor FTP
- Entre na visualização do cliente FTP a partir da visualização do usuário.
ftpdir [ remotefile [ localfile ] ]ls [ remotefile [ localfile ] ]Gerenciamento de diretórios no servidor FTP
Pré-requisitos
Use o comando dir ou ls para exibir os diretórios e arquivos no servidor FTP.
Procedimento
- Entre na visualização do cliente FTP a partir da visualização do usuário.
ftp- Exibir o diretório de trabalho que está sendo acessado no servidor FTP.
pwdcd { directory | .. | / }cdupmkdir directoryrmdir directory CUIDADO:
CUIDADO:
Exclua um diretório do servidor FTP com cuidado. Quando você excluir um diretório do servidor FTP, certifique-se de que o diretório não esteja mais em uso.
Gerenciamento de diretórios no cliente FTP
- Entre na visualização do cliente FTP a partir da visualização do usuário.
ftplcd [ directory | / ]Para fazer upload de um arquivo, use esse comando para mudar para o diretório em que o arquivo reside. Os arquivos baixados são salvos no diretório de trabalho.
Trabalho com arquivos no servidor FTP
Pré-requisitos
Use o comando dir ou ls para exibir os diretórios e arquivos no servidor FTP.
Procedimento
- Entre na visualização do cliente FTP a partir da visualização do usuário.
ftp- Excluir permanentemente um arquivo do servidor FTP.
delete remotefile CUIDADO:
CUIDADO:
Exclua um arquivo do servidor FTP permanentemente com cuidado. Quando você excluir um arquivo do servidor FTP permanentemente, certifique-se de que o arquivo não esteja mais em uso.
Esse comando requer que você tenha o direito de exclusão.
rename [ oldfilename [ newfilename ] ]put localfile [ remotefile ]get remotefile [ localfile ]append localfile [ remotefile ]restart markerUse esse comando junto com o comando put, get ou append.
newer remotefilereget remotefile [ localfile ]Mudança para outra conta de usuário
Sobre a mudança para outra conta de usuário
Depois de fazer login no servidor FTP, você pode iniciar uma autenticação FTP para mudar para uma nova conta. Ao mudar para uma nova conta, você pode obter um privilégio diferente sem restabelecer a conexão FTP.
Restrições e diretrizes
Para que a alteração da conta seja bem-sucedida, é necessário inserir o novo nome de usuário e a senha corretamente. Um nome de usuário ou senha incorretos no site pode fazer com que a conexão FTP seja desconectada.
Procedimento
- Entre na visualização do cliente FTP a partir da visualização do usuário.
ftpuser username [ password ]Manutenção e solução de problemas da conexão FTP
Sobre a manutenção e a solução de problemas da conexão FTP
Depois de usar o dispositivo para estabelecer uma conexão FTP com o servidor FTP, use os comandos desta seção para localizar e solucionar problemas relacionados à conexão FTP.
Procedimento
- Entre na visualização do cliente FTP a partir da visualização do usuário.
ftp- Exibir comandos FTP compatíveis com o servidor FTP.
rhelprhelp protocol-commandrstatusrstatus remotefilestatussystemverbosePor padrão, essa função está ativada.
debugPor padrão, a depuração do cliente FTP está desativada.
resetEncerramento da conexão FTP
- Entre na visualização do cliente FTP a partir da visualização do usuário.
ftp- Encerrar a conexão com o servidor FTP sem sair da visualização do cliente FTP.
disconnect closebyequitComandos de exibição e manutenção para o cliente FTP
Execute o comando display em qualquer visualização.
| Tarefa | Comando |
| Exibir informações sobre o endereço IP de origem no cliente FTP. | exibir a origem do cliente ftp |
Exemplo: Uso do dispositivo como um cliente FTP
Configuração de rede
Conforme mostrado na Figura 2, o PC está atuando como um servidor FTP. Uma conta de usuário com nome de usuário abc e senha hello12345 foi criada no PC.
- Use a malha IRF como um cliente FTP para fazer login no servidor FTP.
- Faça o download do arquivo temp.bin do servidor FTP para o cliente FTP.
Figura 2 Diagrama de rede
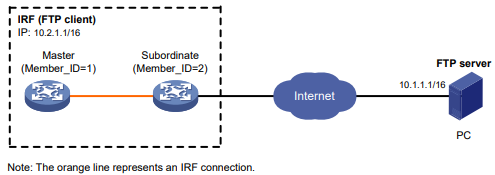
Procedimento
# Configure os endereços IP conforme mostrado na Figura 2. Certifique-se de que a malha IRF e o PC possam se comunicar. (Detalhes não mostrados.)
# Examine o espaço de armazenamento nos dispositivos membros. Se o espaço livre for insuficiente, use a função
comando delete/unreserved file para excluir arquivos não utilizados. (Detalhes não mostrados.) # Faça login no servidor FTP em 10.1.1.1 usando o nome de usuário abc e a senha hello12345.
<Sysname> ftp 10.1.1.1
Press CTRL+C to abort.
Connected to 10.1.1.1 (10.1.1.1).
220 WFTPD 2.0 service (by Texas Imperial Software) ready for new user
User (10.1.1.1:(none)): abc
331 Give me your password, please
Password:
230 Logged in successfully
Remote system type is MSDOS.
ftp># Defina o modo de transferência de arquivos como binário.
ftp> binary
200 TYPE is now 8-bit binary# Faça o download do arquivo temp.bin do PC para o diretório raiz da memória flash no dispositivo mestre.
ftp> get temp.bin
local: temp.bin remote: temp.bin
150 Connecting to port 47457
226 File successfully transferred
23951480 bytes received in 95.399 seconds (251.0 kbyte/s)# Faça o download do arquivo temp.bin do PC para o diretório raiz da memória flash n o membro subordinado (com ID de membro 2).
ftp> get temp.bin slot2#flash:/temp.bin# Use o modo ASCII para carregar o arquivo de configuração config.cfg da malha IRF para o PC para backup.
ftp> ascii
200 TYPE is now ASCII
ftp> put config.cfg back-config.cfg
local: config.cfg remote: back-config.cfg
150 Connecting to port 47461
226 File successfully transferred
3494 bytes sent in 5.646 seconds (618.00 kbyte/s)
ftp> bye
221-Goodbye. You uploaded 2 and downloaded 2 kbytes.
221 Logout.
<Sysname>Configuração de TFTP
Sobre o TFTP
O Trivial File Transfer Protocol (TFTP) é uma versão simplificada do FTP para transferência de arquivos em redes seguras e confiáveis. O TFTP usa a porta UDP 69 para a transmissão de dados. Em contraste com o FTP baseado em TCP, o TFTP não exige autenticação nem trocas de mensagens complexas e é mais fácil de implantar. O TFTP é adequado para ambientes de rede confiáveis.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não- FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de configuração de segurança.
O TFTP não é compatível com o modo FIPS.
Restrições e diretrizes: Configuração de TFTP
Você pode fazer upload de um arquivo do dispositivo para o servidor TFTP ou fazer download de um arquivo do servidor TFTP para o dispositivo.
Como prática recomendada para fazer download de um arquivo, especifique um nome de arquivo inexistente como o nome do arquivo de destino. Se você fizer download de um arquivo com um nome de arquivo existente no diretório de destino, o dispositivo excluirá o arquivo existente e salvará o novo. Se o download do arquivo falhar devido à desconexão da rede ou por outros motivos, o arquivo original não poderá ser restaurado.
O dispositivo pode atuar apenas como um cliente TFTP.
Configuração e uso do cliente TFTP IPv4
- Entre na visualização do sistema.
system-viewtftp-server acl acl-numberPor padrão, nenhuma ACL é usada para controle de acesso.
tftp client source { interface interface-type interface-number | ip source-ip-address }Por padrão, nenhum endereço IP de origem é especificado. O dispositivo usa o endereço IP primário da interface de saída como endereço IP de origem.
quittftp tftp-server { get | put | sget } source-filename [ destination-filename ] [ dscp dscp-value | source { interface interface-type interface-number | ip source-ip-address } ] *O endereço IP de origem especificado nesse comando tem precedência sobre o endereço IP de origem definido com o uso do comando:
tftp client source Configuração e uso do cliente TFTP IPv6
- Entre na visualização do sistema.
system-viewtftp-server ipv6 acl ipv6-acl-numberPor padrão, nenhuma ACL é usada para controle de acesso.
tftp client ipv6 source { interface interface-type interface-number | ipv6 source-ipv6-address } Por padrão, nenhum endereço IPv6 de origem é especificado. O endereço de origem é selecionado automaticamente , conforme definido na RFC 3484.
quittftp ipv6 tftp-server [ -i interface-type interface-number ] { get | put | sget } source-filename [ destination-filename ] [ dscp dscp-value | source { interface interface-type interface-number | ipv6 source-ipv6-address } ] *O endereço IP de origem especificado nesse comando tem precedência sobre o endereço definido pelo comando:
tftp client ipv6 sourceGerenciamento de sistemas de arquivos
Este capítulo descreve como gerenciar sistemas de arquivos.
Sobre o gerenciamento do sistema de arquivos
Mídia de armazenamento e sistemas de arquivos
O dispositivo suporta mídia de armazenamento fixa (a memória flash) e hot swappable (disco USB).
- A mídia de armazenamento fixo tem um sistema de arquivos.
- A mídia de armazenamento hot swappable pode ser particionada. Cada mídia de armazenamento não particionada tem um sistema de arquivos. Em uma mídia de armazenamento particionada, cada partição tem um sistema de arquivos.
Convenções de nomenclatura de mídia de armazenamento e sistema de arquivos
O sistema de arquivos na memória flash tem o mesmo nome que a memória flash. O nome tem as seguintes partes:
- Tipo de mídia de armazenamento flash.
- Dois pontos (:).
O nome de um disco USB e os nomes do sistema de arquivos compartilham as seguintes partes:
- Tipo de mídia de armazenamento usb.
- Número de sequência, uma letra minúscula em inglês, como a, b ou c.
- Número da partição, um dígito que começa em 0 e aumenta em 1. Se a mídia de armazenamento não estiver particionada, o sistema determinará que a mídia de armazenamento tem uma partição. (O nome da mídia de armazenamento não contém um número de partição).
- Dois pontos (:).
Por exemplo, o primeiro disco USB é denominado usba: e o sistema de arquivos na primeira partição do primeiro disco USB é denominado usba0:.
 IMPORTANTE:
IMPORTANTE:
Os nomes de sistemas de arquivos diferenciam maiúsculas de minúsculas e devem ser inseridos em minúsculas.
Localização do sistema de arquivos
Para identificar um sistema de arquivos no dispositivo mestre, não é necessário especificar o local do sistema de arquivos. Para identificar um sistema de arquivos em um dispositivo membro subordinado, é necessário especificar o local do sistema de arquivos no formato slotn#. O argumento n representa a ID de membro IRF do dispositivo membro. Por exemplo, o local é slot2# para um sistema de arquivos que reside no dispositivo membro 2.
 IMPORTANTE:
IMPORTANTE:
A cadeia de caracteres de localização do sistema de arquivos diferencia maiúsculas de minúsculas e deve ser inserida em minúsculas.
Sistema de arquivos padrão
Por padrão, você trabalha com o sistema de arquivos padrão depois de fazer login. Para especificar um arquivo ou diretório no sistema de arquivos padrão, não é necessário especificar o nome do sistema de arquivos. Por exemplo, você não precisa especificar nenhuma informação de
local se quiser salvar a configuração em execução no diretório raiz do sistema de arquivos padrão.
Para alterar o sistema de arquivos padrão, use o menu Boot ROM. Para obter mais informações, consulte as notas de versão do software.
Diretórios
Os diretórios em um sistema de arquivos são estruturados em forma de árvore.
Diretório raiz
O diretório raiz é representado por uma barra de encaminhamento (/). Por exemplo, flash:/
representa o diretório raiz da memória flash.
Diretório de trabalho
O diretório de trabalho também é chamado de diretório atual.
Convenções de nomenclatura de diretórios
Quando você especificar um nome para um diretório, siga estas convenções:
- Um nome de diretório pode conter letras, dígitos e caracteres especiais, exceto asteriscos (*), barras verticais (|), barras inclinadas para frente (/), barras inclinadas para trás (\), pontos de interrogação (?), colchetes angulares esquerdos (<), colchetes angulares direitos (>), aspas (") e dois pontos (:).
- Um diretório cujo nome começa com um caractere de ponto (.) é um diretório oculto. Para evitar que o sistema oculte um diretório, certifique-se de que o nome do diretório não comece com um caractere de ponto.
Diretórios comumente usados
O dispositivo tem alguns diretórios padrão de fábrica. O sistema cria diretórios automaticamente durante a operação. Esses diretórios incluem:
- diagfile - Armazena arquivos de informações de diagnóstico.
- logfile - Armazena arquivos de registro.
- seclog - >Armazena arquivos de registro de segurança.
- versionInfo- Armazena arquivos de informações sobre a versão do software.
Arquivos
Convenções de nomenclatura de arquivos
Quando você especificar um nome para um arquivo, siga estas convenções:
- Um nome de arquivo pode conter letras, dígitos e caracteres especiais, exceto asteriscos (*), barras verticais (|), barras inclinadas para frente (/), barras inclinadas para trás (\), pontos de interrogação (?), colchetes angulares esquerdos (<), colchetes angulares direitos (>), aspas (") e dois pontos (:).
- Um arquivo cujo nome começa com um caractere de ponto (.) é um arquivo oculto. Para evitar que o sistema oculte um arquivo, certifique-se de que o nome do arquivo não comece com um caractere de ponto.
Tipos de arquivos comuns
O dispositivo é fornecido com alguns arquivos. O sistema cria arquivos automaticamente durante a operação. Os tipos desses arquivos incluem:
- .ipe file - arquivo de pacote de imagem de software compactado.
- .bin file - Arquivo de imagem de software.
- .cfg file - Arquivo de configuração.
- .mdb file - arquivo de configuração binário.
- .log file - Arquivo de registro.
Especificação de um nome de diretório ou nome de arquivo
Especificação de um nome de diretório
Para especificar um diretório, você pode usar o caminho absoluto ou um caminho relativo. Por exemplo, o diretório de trabalho é flash:/. Para especificar o diretório test2 na Figura 1, você pode usar os seguintes métodos:
- flash:/test/test1/test2 (caminho absoluto)
- flash:/test/test1/test2/ (caminho absoluto)
- test/test1/test2 (caminho relativo)
- test/test1/test2/ (caminho relativo)
Figura 1 Exemplo de hierarquia de diretório
Especificação de um nome de arquivo
Para especificar um arquivo, use os seguintes métodos:
- Digite o caminho absoluto do arquivo e o nome do arquivo no formato filesystem/directory1/directory2/.../directoryn/filename, em que directoryn é o diretório em que o arquivo reside.
- Digite o caminho relativo do arquivo e o nome do arquivo.
Por exemplo, o diretório de trabalho é flash:/. O arquivo samplefile.cfg está no diretório test2
mostrado na Figura 1. Para especificar o arquivo, você pode usar os seguintes métodos:
- flash:/test/test1/test2/samplefile.cfg
- test/test1/test2/samplefile.cfg
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não- FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de Configuração de Segurança.
Restrições e diretrizes: Gerenciamento do sistema de arquivos
Para evitar a corrupção do sistema de arquivos, não execute as seguintes tarefas durante o gerenciamento do sistema de arquivos:
- Instale ou remova a mídia de armazenamento.
- Realizar uma troca de mestre/subordinado.
Se você remover uma mídia de armazenamento enquanto um diretório ou arquivo na mídia estiver sendo acessado, o dispositivo poderá não reconhecer a mídia quando você a reinstalar. Para reinstalar esse tipo de mídia de armazenamento, execute uma das seguintes tarefas:
- Se você estava acessando um diretório na mídia de armazenamento, altere o diretório de trabalho.
- Se você estava acessando um arquivo na mídia de armazenamento, feche o arquivo.
- Se outro administrador estiver acessando a mídia de armazenamento, desmonte todas as partições da mídia de armazenamento.
Certifique-se de que um disco USB não esteja protegido contra gravação antes de uma operação que exija o direito de gravação no disco.
Não é possível acessar uma mídia de armazenamento que está sendo particionada ou um sistema de arquivos que está sendo formatado ou reparado.
Antes de gerenciar sistemas de arquivos, diretórios e arquivos, certifique-se de conhecer o possível impacto.
Gerenciamento de mídia de armazenamento e sistemas de arquivos
Particionamento de uma mídia de armazenamento
Sobre o particionamento de uma mídia de armazenamento
Uma mídia de armazenamento pode ser dividida em dispositivos lógicos chamados partições. As operações em uma partição não afetam as outras partições.
Restrições e diretrizes
 IMPORTANTE:
IMPORTANTE:
O particionamento de uma mídia de armazenamento limpa todos os dados da mídia.
A memória flash não é compatível com o particionamento.
Antes de particionar uma mídia de armazenamento, execute as seguintes tarefas:
- Certifique-se de que nenhum outro usuário esteja acessando o meio.
- Para particionar um disco USB, certifique-se de que o disco não esteja protegido contra gravação. Se o disco estiver protegido contra gravação, a operação de partição falhará. Para restaurar o acesso ao disco USB, é necessário reinstalar o disco ou remontar os sistemas de arquivos no disco.
Uma partição deve ter um mínimo de 32 MB de espaço de armazenamento.
O tamanho real da partição e o tamanho especificado da partição podem ter uma diferença de menos de 5% do tamanho total da mídia de armazenamento.
Pré-requisitos
Faça backup dos arquivos na mídia de armazenamento.
Procedimento
Para particionar uma mídia de armazenamento, execute o seguinte comando na visualização do usuário:
fdisk medium [ partition-number ]Para particionar uma mídia de armazenamento uniformemente, especifique o argumento partition-number. Para personalizar os tamanhos das partições, não especifique o argumento número da partição. O comando solicitará que você especifique um tamanho para cada partição.
Montagem ou desmontagem de um sistema de arquivos
Restrições e diretrizes
Você só pode montar ou desmontar um sistema de arquivos que esteja em uma mídia de armazenamento hot-swappable. Só é possível desmontar um sistema de arquivos quando
nenhum outro usuário estiver acessando o sistema de arquivos.
Para evitar que um disco USB e a interface USB sejam danificados, certifique-se de que os seguintes requisitos sejam atendidos antes de desmontar os sistemas de arquivos no disco USB:
- O sistema reconheceu o disco USB.
- O LED do disco USB não está piscando.
Montagem de um sistema de arquivos
Para montar um sistema de arquivos, execute o seguinte comando na visualização do usuário:
mount filesystemOs sistemas de arquivos em uma mídia de armazenamento hot-swappable são montados automaticamente quando a mídia de armazenamento é conectada ao dispositivo. Se o sistema não reconhecer um sistema de arquivos, será necessário montá-lo antes de poder acessá-lo.
Desmontagem de um sistema de arquivos
Para desmontar um sistema de arquivos, execute o seguinte comando na visualização do usuário:
umount filesystemPara remover uma mídia de armazenamento hot-swappable do dispositivo, primeiro é necessário desmontar todos os sistemas de arquivos na mídia de armazenamento para desconectar a mídia do dispositivo. A remoção de uma mídia de armazenamento hot-swappable conectada pode danificar os arquivos na mídia de armazenamento ou até mesmo a própria mídia de armazenamento.
Formatação de um sistema de arquivos
Restrições e diretrizes
É possível formatar um sistema de arquivos somente quando nenhum outro usuário estiver acessando o sistema de arquivos.
Procedimento
Para formatar um sistema de arquivos, execute o seguinte comando na visualização do usuário:
format filesystem CUIDADO:
CUIDADO:
A formatação de um sistema de arquivos exclui permanentemente todos os arquivos e diretórios do sistema de arquivos. Não é possível restaurar os arquivos ou diretórios excluídos. Se houver um arquivo de configuração de inicialização no sistema de arquivos, faça o backup do arquivo, se necessário.
Reparo de um sistema de arquivos
Restrições e diretrizes
Se parte de um sistema de arquivos estiver inacessível, use esta tarefa para examinar e reparar o sistema de arquivos. Só é possível reparar um sistema de arquivos quando nenhum outro usuário estiver acessando o sistema de arquivos.
Procedimento
Para reparar um sistema de arquivos, execute o seguinte comando na visualização do usuário:
fixdisk filesystemGerenciamento de arquivos e diretórios
Definição do modo de operação para arquivos e diretórios
Sobre os modos de operação de arquivos e diretórios
O dispositivo suporta os seguintes modos de operação:
- alerta - O >sistema solicita confirmação quando a operação pode causar problemas como corrupção de arquivos ou perda de dados. Esse modo oferece uma oportunidade para você cancelar uma operação que cause transtornos.
- silencioso - O sistema não solicita confirmação quando você executa uma operação de arquivo ou diretório , exceto a operação de esvaziamento da lixeira.
Procedimento
- Entre na visualização do sistema.
system-viewfile prompt { alert | quiet }O modo padrão é alerta.
Exibição de informações sobre arquivos e diretórios
Para exibir informações sobre arquivos e diretórios, execute o seguinte comando na visualização do usuário:
dir [ /all ] [ file | directory | /all-filesystems ]Se vários usuários realizarem operações de arquivo (por exemplo, criar ou excluir arquivos ou diretórios) ao mesmo tempo, a saída desse comando poderá estar incorreta.
Exibição do conteúdo de um arquivo de texto
Para exibir o conteúdo de um arquivo de texto, execute o seguinte comando na visualização do usuário:
more fileExibição do diretório de trabalho
Para exibir o diretório de trabalho, execute o seguinte comando na visualização do usuário:
pwdAlteração do diretório de trabalho
Sobre a alteração do diretório de trabalho
O diretório de trabalho padrão é o diretório raiz do sistema de arquivos padrão no dispositivo mestre.
Procedimento
Para alterar o diretório de trabalho, execute o seguinte comando na visualização do usuário:
cd { directory | .. }Criação de um diretório
Para criar um diretório, execute o seguinte comando na visualização do usuário:
mkdir directoryRenomear um arquivo ou diretório
Para renomear um arquivo ou diretório, execute o seguinte comando na visualização do usuário:
rename { source-file | source-directory } { dest-file | dest-directory }Cópia de um arquivo
Para copiar um arquivo, execute o comando na visualização do usuário. No modo não-FIPS:
copy source-file { dest-file | dest-directory } [ source interface interface-type interface-number ]No modo FIPS:
copy source-file { dest-file | dest-directory }Mover um arquivo
Para mover um arquivo, execute o seguinte comando na visualização do usuário:
move source-file { dest-file | dest-directory }Exclusão e restauração de arquivos
Sobre a exclusão e a restauração de um arquivo
Você pode excluir um arquivo permanentemente ou movê-lo para a lixeira do sistema de arquivos. Um arquivo movido para a lixeira pode ser restaurado, mas um arquivo excluído permanentemente não pode.
Cada sistema de arquivos tem uma lixeira. A lixeira é um diretório chamado .trash no diretório raiz do sistema de arquivos .
Restrições e diretrizes
Os arquivos na lixeira ocupam espaço de armazenamento. Para liberar o espaço de armazenamento ocupado, exclua os arquivos da lixeira.
Para excluir arquivos da lixeira, use o comando reset recycle-bin. Se você usar o comando
delete, a lixeira pode não funcionar corretamente. Para exibir os arquivos em uma lixeira, use um dos métodos a seguir:
- Acesse o diretório raiz do sistema de arquivos e execute o comando dir /all .trash.
- Acesse o diretório da lixeira do sistema de arquivos e execute o comando dir.
Exclusão de um arquivo
Para excluir um arquivo, execute um dos seguintes comandos na visualização do usuário:
- Exclua um arquivo movendo-o para a lixeira.
delete file- Excluir um arquivo permanentemente.
delete /unreserved file CUIDADO:
CUIDADO:
O comando delete /unreserved file exclui um arquivo permanentemente. O arquivo não pode ser restaurado.
- Excluir arquivos da lixeira.
reset recycle-bin [ /force ] CUIDADO:
CUIDADO:
Os arquivos em uma lixeira podem ser restaurados usando o comando undelete. Se você excluir um arquivo da lixeira, esse arquivo não poderá ser restaurado. Antes de excluir arquivos de uma lixeira, certifique-se de que os arquivos não estejam mais em uso.
Restauração de um arquivo
Para restaurar um arquivo da lixeira, execute o seguinte comando na visualização do usuário:
undelete fileExclusão de um diretório
Para excluir um diretório, execute o seguinte comando na visualização do usuário:
rmdir directory CUIDADO:
CUIDADO:
Para excluir um diretório, você deve primeiro excluir permanentemente todos os arquivos e subdiretórios do diretório ou movê-los para a lixeira. Se você os mover para a lixeira, a execução do comando rmdir para excluir o diretório os excluirá permanentemente. Antes de usar o comando rmdir para excluir um diretório, é necessário certificar-se de que o diretório e seus arquivos e subdiretórios não estejam mais em uso.
Arquivamento de arquivos e diretórios
Sobre o arquivamento de arquivos e diretórios
Você pode arquivar arquivos e diretórios em um único arquivo para fins como backup de arquivos. Os arquivos e diretórios originais ainda existem.
Ao arquivar arquivos e diretórios, você pode optar por compactar os arquivos para que eles usem menos espaço de armazenamento.
Procedimento
Para arquivar arquivos e diretórios, execute o seguinte comando na visualização do usuário:
tar create [ gz ] archive-file dest-file [ verbose ] source { source-file | source-directory }&<1-5>Extração de arquivos e diretórios
Sobre a extração de arquivos e diretórios
Use esse recurso para extrair arquivos e diretórios de arquivos compactados.
Restrições e diretrizes
Para especificar a palavra-chave screen para o comando tar extract, primeiro use o comando tar list para identificar os tipos de arquivos arquivados. Como prática recomendada, especifique a palavra-chave somente se todos os arquivos arquivados forem arquivos de texto. A exibição do conteúdo de um arquivo arquivado que não seja de texto e que contenha caracteres de controle de terminal pode resultar em caracteres distorcidos e até mesmo fazer com que o terminal não funcione corretamente. Para usar o terminal novamente, você deve fechar a conexão atual e fazer login no dispositivo novamente.
Procedimento
Para extrair arquivos e diretórios, execute os seguintes comandos na visualização do usuário:
- (Opcional.) Exibir arquivos e diretórios arquivados.
tar list archive-file file- Extraia arquivos e diretórios.
tar extract archive-file file [ verbose ] [ screen | to directory ]Compressão de um arquivo
Para compactar um arquivo, execute o seguinte comando na visualização do usuário:
gzip fileDescompactando um arquivo
Para descompactar um arquivo, execute o seguinte comando na visualização do usuário:
gunzip fileCálculo do arquivo digest
Sobre os resumos de arquivos
Os resumos de arquivos são usados para verificar a integridade dos arquivos.
Procedimento
Para calcular o resumo de um arquivo, execute um dos seguintes comandos na visualização do usuário:
- Use o algoritmo SHA-256.
sha256sum file- Use o algoritmo MD5.
md5sum fileExecução de um arquivo em lote
Sobre o arquivo de lote e a execução do arquivo de lote
Um arquivo de lote contém um conjunto de comandos. A execução de um arquivo de lote executa os comandos do arquivo um a um.
Restrições e diretrizes
Para executar um arquivo de lote no dispositivo, crie um arquivo de lote em um PC e carregue o arquivo de lote no dispositivo.
Como prática recomendada, experimente todos os comandos no dispositivo para garantir que a linha de comando possa ser executada corretamente antes de adicionar o comando a um arquivo em lote. Se um comando for inválido ou uma condição para a execução do comando não for atendida, o comando falhará e o sistema continuará a executar o próximo comando.
Ao executar um comando interativo em um arquivo em lote, o sistema usa as entradas padrão.
Procedimento
- Entre na visualização do sistema.
system-viewexecute filenameGerenciamento de arquivos de configuração
Sobre o gerenciamento de arquivos de configuração
Você pode gerenciar os arquivos de configuração a partir da CLI ou do menu BootWare. As informações a seguir explicam como gerenciar arquivos de configuração a partir da CLI.
Um arquivo de configuração salva um conjunto de comandos para a configuração de recursos de software no dispositivo. Você pode salvar qualquer configuração em um arquivo de configuração para que a configuração possa sobreviver a uma reinicialização. Também é possível fazer backup dos arquivos de configuração em um host para uso futuro.
Tipos de configuração
Configuração inicial
A configuração inicial é o conjunto de configurações padrão iniciais para os comandos de configuração no software.
O dispositivo será iniciado com a configuração inicial se você acessar o menu BootWare e selecionar a opção Skip Current System Configuration (Ignorar configuração atual do sistema). Nessa situação, o dispositivo também pode ser descrito como sendo iniciado com a configuração vazia.
Nenhum comando está disponível para exibir a configuração inicial. Para visualizar as definições padrão iniciais dos comandos de configuração, consulte as seções Padrão nas referências de comando.
Padrões de fábrica
Os padrões de fábrica são configurações básicas personalizadas que acompanham o dispositivo. Os padrões de fábrica variam de acordo com o modelo do dispositivo e podem ser diferentes das configurações padrão iniciais dos comandos.
O dispositivo será iniciado com os padrões de fábrica se não houver arquivos de configuração de próxima inicialização disponíveis. Para exibir os padrões de fábrica, use o comando display default-configuration.
Configuração de inicialização
O dispositivo usa a configuração de inicialização para configurar os recursos do software durante a inicialização. Após a inicialização do dispositivo, você pode especificar o arquivo de configuração a ser carregado na próxima inicialização. Esse arquivo de configuração é chamado de arquivo de configuração de próxima inicialização. O arquivo de configuração que foi carregado é chamado de arquivo de configuração de inicialização atual.
Você pode exibir a configuração de inicialização usando um dos seguintes métodos:
- Para exibir o conteúdo do arquivo de configuração de inicialização atual, execute o comando display current-configuration antes de alterar a configuração após a reinicialização do dispositivo.
- Para exibir o conteúdo do arquivo de configuração da próxima inicialização, use o comando display saved-configuration.
- Use o comando display startup para exibir os nomes do arquivo de configuração de
inicialização atual e dos arquivos de configuração da próxima inicialização. Em seguida, você pode usar o comando more para exibir o conteúdo do arquivo de configuração de inicialização especificado.
Configuração em execução
A configuração em execução inclui configurações de inicialização inalteradas e novas configurações. A configuração em execução é armazenada na memória e é apagada em uma reinicialização ou desligamento do dispositivo. Para usar a configuração em execução após um ciclo de energia ou reinicialização, salve-a em um arquivo de configuração.
Para exibir a configuração em execução, use o comando display current-configuration.
Tipos de arquivos de configuração e processo de seleção de arquivos na inicialização
Quando você salva a configuração, o sistema salva as definições em um arquivo de configuração
.cfg e em um arquivo .mdb.
- Um arquivo de configuração .cfg é um arquivo de texto legível por humanos e seu conteúdo pode ser exibido com o uso do comando more. Os arquivos de configuração que você especificar para salvar a configuração devem usar a extensão .cfg.
- Um arquivo .mdb é um arquivo binário inacessível ao usuário que tem o mesmo nome do arquivo .cfg. O dispositivo carrega um arquivo .mdb mais rapidamente do que um arquivo .cfg.
Na inicialização, o dispositivo usa o seguinte procedimento para identificar o arquivo de configuração a ser carregado:
- O dispositivo procura um arquivo de configuração de próxima inicialização .cfg válido. Para obter mais informações sobre as regras de seleção de arquivos, consulte "Redundância do arquivo de configuração da próxima inicialização".
- Se for encontrado um arquivo de configuração de próxima inicialização .cfg válido, o dispositivo procurará um arquivo .mdb que tenha o mesmo nome e soma de verificação do arquivo .cfg.
- Se for encontrado um arquivo .mdb correspondente, o dispositivo será iniciado com o arquivo .mdb. Se nenhum for encontrado, o dispositivo será iniciado com o arquivo .cfg.
Se não houver arquivos de configuração .cfg next-startup disponíveis, o dispositivo será iniciado com os padrões de fábrica.
Salvo indicação em contrário, o termo "arquivo de configuração" neste documento refere-se a um arquivo de configuração .cfg.
Redundância do arquivo de configuração da próxima inicialização
Você pode especificar um arquivo de configuração de próxima inicialização principal e um arquivo de configuração de próxima inicialização de backup para redundância.
Na inicialização, o dispositivo tenta selecionar a configuração de inicialização .cfg na seguinte ordem:
- O principal arquivo de configuração da próxima inicialização.
- O arquivo de configuração de próxima inicialização de backup se o arquivo de configuração de próxima inicialização principal não existir ou estiver corrompido.
Se não houver arquivos de configuração de próxima inicialização disponíveis, o dispositivo será iniciado com os padrões de fábrica.
Organização e formato do conteúdo do arquivo de configuração
 IMPORTANTE:
IMPORTANTE:
Para ser executado no dispositivo, um arquivo de configuração deve atender aos requisitos de conteúdo e formato. Para garantir o sucesso do carregamento, da reversão ou da restauração da configuração, use um arquivo de configuração criado no dispositivo. Se você editar o arquivo de configuração, certifique-se de que todas as edições estejam em conformidade com os requisitos.
Um arquivo de configuração deve atender aos seguintes requisitos:
- Todos os comandos são salvos em sua forma completa.
- Nenhuma linha de comando contém caracteres inválidos.
 IMPORTANTE:
IMPORTANTE:
Algumas linhas de comando (por exemplo, o comando sysname) não podem conter pontos de interrogação (?) ou tabulações horizontais (\t). Se o sistema carregar um arquivo de configuração que contenha a linha de comando sysname abc?? na inicialização, o sistema ignorará a linha de comando e usará o nome padrão do sistema. Se o sistema usar esse arquivo de configuração para reverter ou restaurar a configuração, o nome do sistema não será revertido ou restaurado.
- Os comandos são classificados em seções por diferentes visualizações de comando, incluindo visualização do sistema, visualizações de interface, visualizações de protocolo e visualizações de linha do usuário.
- Duas seções adjacentes são separadas por um sinal de libra (#).
- O arquivo de configuração termina com a palavra return.
A seguir, um exemplo de trecho de arquivo de configuração:
#
local-user root class manage
password hash
$h$6$Twd73mLrN8O2vvD5$Cz1vgdpR4KoTiRQNE9pg33gU14Br2p1VguczLSVyJLO2huV5Syx/LfDIf8ROLtV
ErJ/C31oq2rFtmNuyZf4STw==
service-type ssh telnet terminal
authorization-attribute user-role network-admin
authorization-attribute user-role network-operator
#
interface Vlan-interface1
ip address 192.168.1.84 255.255.255.0
#
Reversão da configuração
A reversão da configuração p e r m i t e substituir a configuração em execução pela configuração em um arquivo de configuração sem reinicializar o dispositivo. Você pode usar esse recurso para as seguintes finalidades:
- Reverter para um estado de configuração anterior.
- Adaptação da configuração em execução a diferentes ambientes de rede.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não- FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de configuração de segurança.
Ativação da criptografia de configuração
Sobre a criptografia de configuração
A criptografia de configuração permite que o dispositivo criptografe um arquivo de configuração de inicialização automaticamente quando ele salva a configuração em execução. Todos os dispositivos que executam o software Comware 7 usam a mesma chave privada ou pública para criptografar os arquivos de configuração.
Restrições e diretrizes
Todos os dispositivos que executam o software Comware 7 podem descriptografar os arquivos de configuração criptografados. Para evitar que um arquivo criptografado seja decodificado por usuários não autorizados, certifique-se de que o arquivo seja acessível somente a usuários autorizados.
Não é possível usar o comando more para visualizar o conteúdo de um arquivo de configuração criptografado.
Procedimento
- Entre na visualização do sistema.
system-viewconfiguration encrypt { private-key | public-key }Por padrão, a criptografia de configuração está desativada.
Desativação das operações automáticas do arquivo de configuração da próxima inicialização em todo o sistema
Sobre as operações automáticas do arquivo de configuração da próxima inicialização em todo o sistema
Por padrão, as operações automáticas do arquivo de configuração da próxima inicialização em todo o sistema estão ativadas. O sistema executa as seguintes operações em todos os dispositivos subordinados IRF, além do dispositivo mestre:
- Salva a configuração em execução no arquivo de configuração da próxima inicialização em cada dispositivo membro quando você executa o comando:
save [ safely ] [ backup | main ] [ force ] [ changed ] reset saved-configurationSe você desativar as operações automáticas do arquivo de configuração da próxima inicialização em todo o sistema, o sistema salvará a configuração em execução ou excluirá o arquivo de configuração da próxima inicialização somente no dispositivo mestre.
As operações automáticas em todo o sistema garantem a consistência do arquivo de configuração de inicialização entre os dispositivos mestre e subordinados. No entanto, uma operação em todo o sistema leva mais tempo do que uma operação realizada apenas no dispositivo mestre. Além disso, o tempo necessário para concluir uma operação de configuração em todo o sistema aumenta à medida que a quantidade de dados de configuração cresce.
Se você estiver desativando as operações automáticas em todo o sistema para salvar a configuração mais rapidamente, saiba que os arquivos de configuração da próxima inicialização serão inconsistentes entre o dispositivo mestre e os dispositivos subordinados.
Procedimento
- Entre na visualização do sistema.
system-view- Desative as operações automáticas do arquivo de configuração da próxima inicialização em todo o sistema.
undo standby auto-update configPor padrão, as operações do arquivo de configuração da próxima inicialização são sincronizadas automaticamente em todo o sistema .
Salvando a configuração em execução
Sobre os métodos de salvamento da configuração em execução
Ao salvar a configuração em execução em um arquivo de configuração .cfg, você pode especificar o arquivo como um arquivo de configuração da próxima inicialização ou não.
Se você estiver especificando o arquivo como um arquivo de configuração de próxima inicialização .cfg, use um dos seguintes métodos para salvar a configuração:
- Modo rápido - Use o comando save sem a palavra-chave safely. Nesse modo, o dispositivo substitui diretamente o arquivo de configuração de próxima inicialização de
- Modo de segurança - Use o comando save com a palavra-chave safely. O modo de segurança é mais lento que o modo rápido, mas é mais seguro. No modo de segurança, o sistema salva a configuração em um arquivo temporário e começa a substituir o arquivo de configuração de destino da próxima inicialização após a conclusão da operação de salvamento. Se ocorrer uma reinicialização ou falha de energia durante a operação de salvamento, o arquivo de configuração da próxima inicialização
destino. Se ocorrer uma reinicialização ou falha de energia durante esse processo, o arquivo de configuração da próxima inicialização será perdido. Você deve especificar um novo arquivo de configuração de inicialização depois que o dispositivo for reinicializado (consulte "Especificação de um arquivo de configuração de próxima inicialização").
O arquivo de configuração ainda é mantido. Use o modo de segurança se a fonte de alimentação não for confiável ou se você estiver configurando o dispositivo remotamente.
Restrições e diretrizes
Para evitar a perda da configuração da próxima inicialização, certifique-se de que ninguém reinicie ou faça um ciclo de energia no dispositivo enquanto ele estiver salvando a configuração em execução.
Quando um dispositivo membro da IRF se separa da malha IRF, suas definições são mantidas na memória, mas removidas da configuração em execução na malha IRF. Salvar a configuração em execução antes que a malha IRF se recupere removerá as definições do dispositivo membro do arquivo de configuração da próxima inicialização.
Se você salvou a configuração em execução antes de o dispositivo membro voltar a integrar a malha IRF, execute as seguintes etapas para restaurar as configurações do dispositivo membro para o arquivo de configuração da próxima inicialização:
- Resolver a questão da divisão.
- Reinicialize o dispositivo membro para voltar a participar da malha IRF.
- Depois que o dispositivo membro se juntar novamente à malha IRF, execute o comando:
display current-configuration Para verificar se as configurações do dispositivo membro foram restauradas da memória para a configuração em execução.
 IMPORTANTE:
IMPORTANTE:
Para garantir uma restauração bem-sucedida da configuração, certifique-se de que a malha IRF não tenha sido reinicializada após a saída do dispositivo membro.
Por padrão, o comando
save [ safely ] [ backup | main ] [ force ] [ changed ]Procedimento
Para salvar a configuração em execução, execute uma das seguintes tarefas em qualquer visualização:
- Salve a configuração em execução em um arquivo de configuração sem especificar o arquivo como um arquivo de configuração da próxima inicialização.
save file-url [ all | slot slot-number ]save [ safely ] [ backup | main ] [ force ] [ changed ]Como prática recomendada, especifique a palavra-chave safely para salvar a configuração de forma confiável.
 CUIDADO:
CUIDADO:
Use o comando save com cuidado. Esse comando substituirá as configurações no arquivo de configuração de destino. Leia atentamente as mensagens geradas no dispositivo quando você usar esse comando e certifique-se de que compreendeu totalmente o impacto desse comando ao executá-lo.
Comparação de configurações quanto às suas diferenças
Sobre a comparação de configurações
Você pode comparar arquivos de configuração ou comparar um arquivo de configuração com a configuração em execução para verificar suas diferenças.
Se você especificar a configuração da próxima inicialização para uma comparação, o sistema selecionará o arquivo de configuração da próxima inicialização a ser comparado na seguinte ordem:
- O principal arquivo de configuração da próxima inicialização.
- O arquivo de configuração de backup da próxima inicialização se o arquivo de configuração principal da próxima inicialização não estiver disponível.
Se ambos os arquivos de configuração não estiverem disponíveis, o sistema exibirá uma mensagem indicando que não existem arquivos de configuração da próxima inicialização.
Procedimento
Para comparar as diferenças entre as configurações, execute uma das seguintes tarefas em qualquer visualização:
- Exibe as diferenças que um arquivo de configuração, a configuração em execução ou a configuração da próxima inicialização tem em comparação com o arquivo de configuração de origem especificado.
display diff configfile file-name-s { configfile file-name-d | current-configuration | startup-configuration }display diff current-configuration { configfile file-name-d | startup-configuration }display diff startup-configuration configfile file-name-d- Método 1:
display diff startup-configuration current-configurationdisplay current-configuration diffConfiguração da reversão da configuração
Visão geral das tarefas de reversão de configuração
Para configurar a reversão da configuração, execute as seguintes tarefas:
- Definição dos parâmetros do arquivo de configuração
- Arquivamento da configuração em execução
- Ativação do arquivamento automático da configuração
- Arquivamento manual da configuração em execução
- Reversão da configuração
Definição dos parâmetros do arquivo de configuração
Sobre a definição dos parâmetros do arquivo de configuração
Antes de arquivar a configuração em execução, é necessário definir um diretório de arquivos e um prefixo de nome de arquivo para os arquivos de configuração.
O diretório do arquivo pode estar localizado no dispositivo local ou em um servidor SCP remoto.
Se você usar o arquivamento local, os arquivos de configuração serão nomeados no formato prefix_serial number.cfg, por exemplo, archive_1.cfg e archive_2.cfg. O número de série é atribuído automaticamente de 1 a 1000, aumentando de 1 em 1. Depois que o número de série chega a 1000, ele é reiniciado a partir de 1.
Se você alterar o diretório do arquivo ou o prefixo do nome do arquivo no dispositivo local, ocorrerão os seguintes eventos:
- Os arquivos de configuração antigos são alterados para arquivos de configuração comuns.
- O contador do arquivo de configuração é reiniciado. O número de série dos novos arquivos de configuração começa em 1.
- O comando display archive configuration não exibe mais os arquivos de configuração antigos.
O contador de arquivos de configuração não é reiniciado quando o usuário exclui arquivos de configuração do diretório de arquivos. Entretanto, se o dispositivo for reinicializado depois que todos os arquivos de configuração tiverem sido excluídos, o contador de arquivos de configuração será reiniciado. O número de série dos novos arquivos de configuração começa em 1.
Se você arquivar a configuração em execução em um servidor SCP remoto, os arquivos de configuração serão nomeados no formato prefix_YYYYMMDD_HHMMSS.cfg, por exemplo, archive_20170526_203430.cfg.
Se você alterar o diretório do arquivo ou o prefixo do nome do arquivo no servidor SCP remoto, o comando display archive configuration não exibirá mais os arquivos de configuração antigos salvos antes da alteração.
Restrições e diretrizes para definir os parâmetros do arquivo de configuração
O arquivamento local (archive configuration location) e o arquivamento remoto (archive configuration server) são mutuamente exclusivos. Não é possível usar os dois recursos ao mesmo tempo.
 IMPORTANTE:
IMPORTANTE:
No modo FIPS, o dispositivo não suporta o arquivamento da configuração em execução em um servidor SCP remoto.
Com o arquivamento de configuração local, o sistema exclui o arquivo mais antigo para abrir espaço para o novo arquivo depois que o número máximo de arquivos de configuração é atingido.
O número máximo de arquivos de configuração em um servidor SCP remoto depende da configuração do servidor SCP e não é restringido pelo comando archive configuration max.
O comando undo archive configuration location remove o diretório do arquivo de configuração local e as definições do prefixo do nome do arquivo, mas não exclui os arquivos de configuração do dispositivo. O comando também executa as seguintes operações:
- Desativa os recursos de arquivamento manual e automático da configuração.
- Restaura as configurações padrão dos comandos:
archive configuration interval archive configuration max display archive configurationO comando undo archive configuration server remove o diretório do arquivo de configuração remota e as definições do prefixo do nome do arquivo, mas não exclui os arquivos de configuração no servidor. O comando também executa as seguintes operações:
- Desativa os recursos de arquivamento manual e automático da configuração.
- Restaura a configuração padrão do comando:
archive configuration intervaldisplay archive configurationConfiguração dos parâmetros de arquivamento local
- Entre na visualização do sistema.
system-viewarchive configuration location directory filename-prefix filename-prefixPor padrão, nenhum caminho ou prefixo de nome de arquivo é definido para os arquivos de configuração no dispositivo, e o sistema não salva regularmente a configuração.
Em uma malha IRF, o diretório do arquivo de configuração já deve existir no dispositivo mestre e não pode incluir um ID de membro.
archive configuration max file-numberO número padrão é 5.
Altere a configuração de acordo com a quantidade de armazenamento disponível no dispositivo.
Configuração de parâmetros de arquivamento remoto
- Entre na visualização do sistema.
system-viewarchive configuration server scp { ipv4-address | ipv6 ipv6-address } [ port port-number ] [ directory directory ] filename-prefix filename-prefixPor padrão, nenhum caminho ou prefixo de nome de arquivo é definido para arquivar a configuração em execução em um servidor SCP remoto.
- Configure o nome de usuário.
archive configuration server user user-namePor padrão, nenhum nome de usuário é configurado para acessar o servidor SCP.
archive configuration server password { cipher | simple } stringPor padrão, nenhuma senha é configurada para acessar o servidor SCP.
Certifique-se de que o nome de usuário e a senha sejam os mesmos das configurações da conta SCP no servidor SCP .
Arquivamento da configuração em execução
Sobre o arquivamento da configuração em execução
Veja a seguir os métodos para arquivar a configuração em execução:
- Arquivamento automático da configuração - O sistema arquiva automaticamente a configuração em execução em intervalos, conforme configurado.
- Arquivamento manual da configuração - Você pode desativar o arquivamento automático da configuração e arquivar manualmente a configuração em execução se a configuração não for alterada com muita frequência. Você também pode usar esse método antes de executar tarefas de configuração complicadas. Se a tentativa de configuração falhar, você poderá usar o arquivo para recuperar a configuração.
Restrições e diretrizes para arquivar a configuração em execução
Se você usar o arquivamento local, o recurso de arquivamento de configuração salvará a configuração em execução somente no dispositivo mestre. Para garantir que o sistema possa arquivar a configuração em execução após uma alternância mestre/subordinado, crie o diretório de arquivamento de configuração em todos os membros da IRF.
Se um arquivamento local tiver sido iniciado com base nos parâmetros de arquivamento existentes, quando um parâmetro de arquivamento for alterado, o arquivo ainda será mantido no diretório antigo. No entanto, o comando display archive configuration não exibirá o registro sobre esse arquivamento.
Ao modificar os parâmetros (por exemplo, o nome de usuário ou a senha) para arquivamento remoto, verifique se as alterações são consistentes entre o dispositivo e o servidor. Um arquivamento remoto manual ou automático falhará se tiver sido iniciado antes de você alterar as configurações do dispositivo e do servidor para que sejam consistentes.
Ativação do arquivamento automático da configuração
- Entre na visualização do sistema.
system-viewarchive configuration interval intervalPor padrão, o arquivamento automático da configuração está desativado.
Arquivamento manual da configuração em execução
Arquive manualmente a configuração em execução na visualização do usuário.
archive configurationReversão da configuração
Sobre a reversão da configuração
O recurso de reversão de configuração compara a configuração em execução com o arquivo de configuração de substituição especificado e trata as diferenças de configuração da seguinte forma:
- Se um comando na configuração em execução não estiver no arquivo de substituição, o recurso de reversão executará a forma de desfazer do comando.
- Se um comando no arquivo de substituição não estiver na configuração em execução, o recurso de reversão adicionará o comando à configuração em execução.
- Se um comando tiver configurações diferentes na configuração em execução e no arquivo de substituição, o recurso de reversão substituirá a configuração do comando em execução pela configuração do arquivo de substituição.
Restrições e diretrizes
Para garantir que a reversão seja bem-sucedida, não execute uma alternância mestre/subordinado enquanto o sistema estiver fazendo a reversão da configuração.
O recurso de reversão de configuração pode falhar ao reconfigurar alguns comandos na configuração em execução por um dos seguintes motivos:
- Um comando não pode ser desfeito porque a prefixação da palavra-chave undo ao comando não resulta em um comando undo válido. Por exemplo, se a forma de desfazer criada para o comando A [B] C for undo A C, o recurso de reversão de configuração não poderá desfazer o comando A B C. Isso ocorre porque o sistema não reconhece o comando undo A B C. Isso ocorre porque o sistema não reconhece o comando undo A B C.
- Um comando (por exemplo, um comando dependente de hardware) não pode ser excluído, sobrescrito ou desfeito devido a restrições do sistema.
- Os comandos em diferentes visualizações são dependentes uns dos outros.
- Não é possível adicionar à configuração em execução comandos ou configurações de comando que não sejam compatíveis com o dispositivo.
Certifique-se de que o arquivo de configuração de substituição seja criado usando o recurso de arquivamento de configuração ou o comando save no dispositivo local. Se o arquivo de configuração não for criado no dispositivo local, verifique se as linhas de comando no arquivo de configuração são totalmente compatíveis com o dispositivo local.
Se o arquivo de configuração de substituição estiver criptografado, verifique se o dispositivo pode descriptografá-lo.
Procedimento
- Entre na visualização do sistema.
system-viewconfiguration replace file filename CUIDADO:
CUIDADO:
O recurso de reversão de configuração substitui a configuração em execução pela configuração em um arquivo de configuração sem reinicializar o dispositivo. Essa operação fará com que as configurações que não estão no arquivo de configuração de substituição sejam perdidas, o que pode causar interrupção do serviço. Ao executar a reversão da configuração, certifique-se de compreender totalmente o impacto na rede.
O arquivo de configuração especificado deve ser salvo no sistema local.
Configuração do atraso de confirmação da configuração
Sobre o atraso no commit da configuração
Esse recurso permite que o sistema remova automaticamente as configurações feitas durante um intervalo de atraso de confirmação de configuração se você não as tiver confirmado manualmente.
Você especifica o intervalo de atraso de confirmação da configuração usando o temporizador de atraso de confirmação da configuração. O sistema cria um ponto de reversão para registrar o status da configuração quando você inicia o temporizador de atraso de confirmação da configuração. As definições feitas durante o intervalo de atraso de confirmação da configuração entram em vigor imediatamente. Entretanto, essas configurações serão removidas automaticamente se você não as tiver confirmado manualmente antes que o temporizador de atraso de confirmação da configuração expire. Em seguida, o sistema retorna ao status de configuração quando o temporizador de atraso de confirmação da configuração foi iniciado.
Esse recurso evita que uma configuração incorreta cause a impossibilidade de acessar o dispositivo e é especialmente útil quando você configura o dispositivo remotamente.
Restrições e diretrizes
Quando você usar esse recurso, siga estas restrições e diretrizes:
- Em um contexto multiusuário, certifique-se de que ninguém mais esteja configurando o dispositivo.
- Para evitar erros inesperados, não execute nenhuma operação durante a reversão da configuração.
- Você pode reconfigurar o temporizador de atraso de confirmação de configuração antes que ele expire para reduzir ou estender o intervalo de atraso de confirmação. No entanto, o ponto de reversão não será alterado.
- O recurso de atraso de confirmação de configuração é uma configuração única. O recurso é desativado com o ponto de reversão removido quando o cronômetro de atraso de confirmação expira ou após a execução de uma operação de confirmação manual . Para usar esse recurso novamente, é necessário reiniciar o cronômetro.
Procedimento
- Entre na visualização do sistema.
system-viewconfiguration commit delay delay-timeconfiguration commitEspecificação de um arquivo de configuração de próxima inicialização
Restrições e diretrizes
 CUIDADO:
CUIDADO:
O uso do comando undo startup saved-configuration pode causar uma divisão da IRF após a reinicialização da malha IRF ou de um membro da IRF. Ao executar esse comando, certifique-se de compreender o impacto dele na rede.
Como prática recomendada, especifique arquivos diferentes como os arquivos de configuração principal e de backup da próxima inicialização.
O comando undo startup saved-configuration altera o atributo do arquivo de configuração de próxima inicialização principal ou de backup para NULL, em vez de excluir o arquivo.
Pré-requisitos
Em uma malha IRF, certifique-se de que o arquivo de configuração especificado seja válido e tenha sido salvo no diretório raiz de uma mídia de armazenamento em cada dispositivo membro. Além disso, verifique se a mídia de armazenamento é do mesmo tipo em todos os dispositivos membros da IRF.
Procedimento
- Especifique um arquivo de configuração para a próxima inicialização. Escolha um dos seguintes métodos:
- Execute o seguinte comando na visualização do usuário para especificar um arquivo de configuração de próxima inicialização:
startup saved-configuration cfgfile [ backup | main ]Por padrão, nenhum arquivo de configuração de próxima inicialização é especificado.
save [ safely ] [ backup | main ] [ force ]Para obter mais informações sobre esse comando, consulte "Salvando a configuração em execução".
Se você não especificar a palavra-chave backup ou main, esse comando especificará o arquivo de configuração como o arquivo principal de configuração da próxima inicialização.
- Exibe os nomes dos arquivos de configuração para esta inicialização e para a próxima inicialização.
display startupdisplay saved-configurationFazendo backup e restaurando o arquivo de configuração principal da próxima inicialização
Sobre o backup e a restauração do arquivo de configuração
principal da próxima inicialização
Você pode fazer backup do arquivo de configuração principal da próxima inicialização em um servidor TFTP ou restaurar o arquivo de configuração principal da próxima inicialização a partir de um servidor TFTP.
Restrições e diretrizes para backup e restauração de configurações
Não há suporte para backup e restauração de configuração no modo FIPS.
Pré-requisitos para backup e restauração da configuração
Antes de fazer backup ou restaurar o arquivo principal de configuração da próxima inicialização, execute as seguintes tarefas:
- Certifique-se de que os seguintes requisitos sejam atendidos:
- O servidor pode ser acessado.
- O servidor está ativado com o serviço TFTP.
- Você tem permissões de leitura e gravação no servidor.
- Para o backup da configuração, use o comando display startup para verificar se o arquivo de configuração principal de próxima inicialização foi especificado na visualização do usuário. Se nenhum arquivo de configuração de próxima inicialização tiver sido especificado ou se o arquivo de configuração especificado não existir, a operação de backup falhará.
Fazendo backup do arquivo de configuração principal da próxima inicialização em um servidor TFTP
Para fazer backup do arquivo principal de configuração da próxima inicialização em um servidor TFTP, execute o seguinte comando na visualização do usuário:
backup startup-configuration to { ipv4-server | ipv6 ipv6-server } [ dest-filename ]Restaurar o arquivo de configuração principal da próxima inicialização a partir de um servidor TFTP
- Restaurar o arquivo de configuração principal da próxima inicialização de um servidor TFTP na visualização do usuário.
restore startup-configuration from { ipv4-server | ipv6 ipv6-server } src-filename- Exibe os nomes dos arquivos de configuração para esta inicialização e para a próxima inicialização.
display startupdisplay saved-configurationExclusão de um arquivo de configuração de próxima inicialização
Sobre a exclusão de um arquivo de configuração de próxima inicialização
Você pode executar essa tarefa para excluir um arquivo de configuração da próxima inicialização.
Se os arquivos de configuração principal e de backup da próxima inicialização forem excluídos, o dispositivo usará os padrões de fábrica na próxima inicialização.
Para excluir um arquivo definido como arquivos de configuração de próxima inicialização principal e de backup, é necessário executar o comando reset saved-configuration backup e o comando reset saved-configuration main. O uso de apenas um dos comandos remove o atributo de arquivo especificado em vez de excluir o arquivo.
Por exemplo, se o comando reset saved-configuration backup for executado, a definição do arquivo de configuração de backup da próxima inicialização será definida como NULL. No entanto, o arquivo ainda é usado como o arquivo principal. Para excluir o arquivo, você também deve executar o comando reset saved-configuration main.
Restrições e diretrizes
 CUIDADO:
CUIDADO:
Por padrão, essa tarefa exclui permanentemente um arquivo de configuração da próxima inicialização de todos os dispositivos membros da IRF. Para excluir o arquivo de configuração somente do dispositivo mestre, desative as operações automáticas do arquivo de configuração da próxima inicialização em todo o sistema. Para obter mais informações, consulte "Desativação das operações automáticas do arquivo de configuração da próxima inicialização".
operações de arquivo de configuração de próxima inicialização em todo o sistema".
Se você não especificar a palavra-chave backup ou main ao executar essa tarefa, a configuração principal da próxima inicialização do será excluída.
Procedimento
Para excluir um arquivo de configuração de próxima inicialização, execute o seguinte comando na visualização do usuário:
reset saved-configuration [ backup | main ]Comandos de exibição e manutenção de arquivos de configuração
Execute comandos de display em qualquer visualização e os comandos de reset na visualização do usuário.
| Tarefa | Comando |
| Exibir informações do arquivo de configuração. | display archive configuration |
| Exibir a configuração em execução. | display current-configuration [ [ configuration [ module-name ] | interface [ interface-type [ interface-number ] ] ] [ all ] | slot slot-number ] |
| Exibe as diferenças que a configuração em execução tem em comparação com a configuração da próxima inicialização. | display current-configuration diff |
| Exibir os padrões de fábrica. | display default-configuration |
| Exibir as diferenças entre as configurações. |
|
__________________________________________________________________________________________________________________
| Tarefa | Comando |
| Exibir o conteúdo do arquivo de configuração para a próxima inicialização do sistema. | display saved-configuration |
| Exibe os nomes dos arquivos de configuração para esta inicialização e para a próxima inicialização. | display startup |
| Exibe a configuração válida na visualização atual. | display this [ all ] |
| Excluir arquivos de configuração da próxima inicialização. | reset saved-configuration [ backup | main ] |
Atualização de software
Sobre a atualização do software
O upgrade de software permite que você atualize uma versão de software, adicione novos recursos e corrija bugs de software. Este capítulo descreve os tipos de software e as formas de liberação, compara os métodos de atualização de software e fornece os procedimentos para atualização de software a partir da CLI.
Tipos de software
Os seguintes tipos de software estão disponíveis:
- Imagem do BootWare - Também chamada de imagem da ROM de inicialização. Essa imagem contém um segmento básico e um segmento estendido.
- O segmento básico é o código mínimo que inicializa o sistema.
- O segmento estendido permite a inicialização do hardware e fornece menus de gerenciamento do sistema. Quando o dispositivo não consegue iniciar corretamente, você pode usar os menus para carregar o software e o arquivo de configuração de inicialização ou gerenciar arquivos.
- Imagem do Comware - Inclui as seguintes subcategorias de imagem:
- Imagem de inicialização - Um arquivo .bin que contém o kernel do sistema operacional Linux. Ele fornece gerenciamento de processos, gerenciamento de memória e gerenciamento do sistema de arquivos.
- Imagem do sistema - Um arquivo .bin que contém o kernel do Comware e os recursos padrão, incluindo gerenciamento de dispositivos, gerenciamento de interface, gerenciamento de configuração e roteamento.
- Imagem de recurso - Um arquivo .bin que contém recursos avançados ou personalizados do software. Você pode adquirir imagens de recursos conforme necessário.
- Imagem de correção - Um arquivo .bin que é liberado para corrigir erros sem reiniciar o dispositivo. Uma imagem de patch não adiciona ou remove recursos.
- Imagens de correção incrementais - Uma nova imagem de correção pode cobrir todas, parte ou nenhuma das funções fornecidas por uma imagem de patch antiga. Uma nova imagem de patch pode coexistir com uma imagem de patch antiga no dispositivo somente quando a primeira não cobrir nenhuma das funções fornecidas pela segunda.
- Imagens de correção não incrementais - Uma nova imagem de correção não incremental abrange todas as funções fornecidas por uma imagem de patch não incremental antiga. Cada imagem de inicialização, sistema ou recurso pode ter uma imagem de patch não incremental, e essas imagens de patch podem coexistir no dispositivo. O dispositivo desinstala a imagem de patch não incremental antiga antes de instalar uma nova imagem de patch não incremental.
Normalmente, a imagem do BootWare é integrada à imagem de inicialização para evitar erros de compatibilidade de software.
As imagens de patches têm os seguintes tipos:
Uma imagem de correção incremental e uma imagem de patch não incremental podem coexistir no dispositivo.
As imagens de comware que foram carregadas são chamadas de imagens de software atuais. As imagens de comware especificadas para serem carregadas na próxima inicialização são chamadas de imagens de software de inicialização.
A imagem do BootWare, a imagem de inicialização e a imagem do sistema são necessárias para o funcionamento do dispositivo.
Você pode instalar até 32 arquivos .bin no dispositivo, incluindo um arquivo de imagem de inicialização, um arquivo de imagem do sistema e até 30 arquivos de imagem de recursos e patches.
Formulários de liberação de software
As imagens de software são liberadas em uma das seguintes formas:
- Arquivos .bin separados. Você deve verificar a compatibilidade entre as imagens de software.
- Como um todo em um arquivo de pacote .ipe. As imagens em um arquivo de pacote .ipe são compatíveis. O sistema descompacta o arquivo automaticamente, carrega as imagens .bin e as define como imagens de software de inicialização.
OBSERVAÇÃO:
Os nomes dos arquivos de imagem de software usam o formato model-comware version- image type-release. Este documento usa boot.bin e system.bin como nomes de arquivo de imagem de inicialização e de sistema.
Métodos de atualização
| Método de atualização | Tipos de software | Observações |
| Atualização a partir da CLI usando o método do carregador de inicialização |
|
Esse método é prejudicial. É necessário reinicializar todo o dispositivo para concluir a atualização. |
| Atualização pelo menu BootWare |
|
Use esse método quando o dispositivo não puder ser iniciado corretamente. Para usar esse método, primeiro conecte-se à porta do console e desligue o dispositivo. Em seguida, pressione Ctrl+B no prompt para acessar o menu BootWare. Para obter mais informações sobre o upgrade de software no menu BootWare, consulte as notas de versão da versão do software. IMPORTANTE: Use esse método somente quando não tiver outra opção. |
Este capítulo aborda apenas a atualização de software da CLI usando o método do carregador de inicialização.
Carregamento de imagens de software
Imagens de software de inicialização
Para atualizar o software, você deve especificar os arquivos de atualização como imagens de software de inicialização para que o dispositivo seja carregado na próxima inicialização. Você pode especificar duas listas de imagens de software: uma principal e outra de backup. O dispositivo carrega primeiro as imagens do software de inicialização principal. Se as imagens do software de inicialização principal não estiverem disponíveis, o dispositivo carregará as imagens do software de inicialização de backup.
Processo de carregamento de imagens na inicialização
Na inicialização, o dispositivo executa as seguintes operações depois de carregar e inicializar o BootWare:
- Carrega as imagens principais.
- Se alguma imagem principal não existir ou for inválida, carrega as imagens de backup.
- Se alguma imagem de backup não existir ou for inválida, o dispositivo não poderá ser iniciado.
Restrições e diretrizes: Atualização de software
Como prática recomendada, armazene as imagens de inicialização em uma mídia de armazenamento fixa. Se armazenar as imagens de inicialização em uma mídia de armazenamento hot swappable, não remova a mídia de armazenamento hot swappable durante o processo de inicialização.
Atualização do software do dispositivo usando o método do carregador de inicialização
Visão geral das tarefas de atualização de software
Para atualizar o software, execute uma das seguintes tarefas:
- Faça upgrade da malha IRF:
- (Opcional.) Faça o pré-carregamento da imagem do BootWare para o BootWare
- Especificação de imagens de inicialização e conclusão do upgrade
- (Opcional.) Sincronização de imagens de inicialização do dispositivo mestre para os dispositivos subordinados
Se for necessário um upgrade do BootWare, você poderá executar essa tarefa para reduzir o tempo de upgrade subsequente. Essa tarefa ajuda a reduzir os problemas de atualização causados por uma falha inesperada de energia. Se você ignorar essa tarefa, o dispositivo atualizará o BootWare automaticamente quando atualizar as imagens do software de inicialização.
Execute essa tarefa quando as imagens de inicialização nos dispositivos subordinados não forem da mesma versão que as do dispositivo mestre.
Pré-requisitos
- Use o comando display version para verificar a versão atual da imagem do BootWare e a versão do software de inicialização.
- Use as notas de versão da versão do software de upgrade para avaliar o impacto do upgrade em sua rede e verificar os seguintes itens:
- Compatibilidade de software e hardware.
- Versão e tamanho do software de upgrade.
- Compatibilidade do software de upgrade com a imagem atual do BootWare e a imagem do software de inicialização.
- Use o comando dir para verificar se todos os dispositivos membros da IRF têm espaço de armazenamento suficiente para as imagens de upgrade. Se o espaço de armazenamento não for suficiente, exclua os arquivos não utilizados usando o comando delete. Para obter mais informações, consulte "Gerenciamento de sistemas de arquivos".
- Use FTP ou TFTP para transferir o arquivo de imagem de upgrade para o diretório raiz de um sistema de arquivos. Para obter mais informações sobre FTP e TFTP, consulte "Configuração de FTP" ou "Configuração de TFTP". Para obter mais informações sobre sistemas de arquivos, consulte "Gerenciamento de sistemas de arquivos".
Pré-carregamento da imagem do BootWare no BootWare
Para carregar a imagem de upgrade do BootWare na área Normal do BootWare, execute o seguinte comando na visualização do usuário:
bootrom update file file slot slot-number-listEspecifique o arquivo de imagem do software baixado para o argumento arquivo.
A nova imagem do BootWare entra em vigor em uma reinicialização.
Especificação de imagens de inicialização e conclusão do upgrade
Execute as etapas a seguir na visualização do usuário:
- Especifique imagens de inicialização principais ou de backup para todos os dispositivos membros.
- Use um arquivo .ipe:
boot-loader file ipe-filename [ patch filename&<1-16> ] { all | slot slot-number } { backup | main }boot-loader file boot filename system filename [ feature filename&<1-30> ] [ patch filename&<1-16> ] { all | slot slot-number } { backup | main }Como prática recomendada em uma malha IRF com vários chassis, especifique a palavra- chave all para o comando. Se você usar a opção slot slot-number para atualizar os dispositivos membros um a um, ocorrerão inconsistências de versão entre os dispositivos membros durante a atualização.
saveEssa etapa garante que qualquer configuração que você tenha feito possa sobreviver a uma reinicialização.
rebootdisplay boot-loader [ slot slot-number ]Verifique se as imagens de software atuais são as mesmas que as imagens de software de inicialização.
Sincronização de imagens de inicialização do dispositivo mestre para os dispositivos subordinados
Sobre a sincronização da imagem de inicialização
Execute essa tarefa quando as imagens de inicialização nos dispositivos subordinados não forem da mesma versão que as do dispositivo mestre.
Essa tarefa sincroniza as imagens de inicialização que estão sendo executadas no dispositivo mestre com os dispositivos subordinados. Se alguma das imagens de inicialização não existir ou for inválida, a sincronização falhará.
As imagens de inicialização sincronizadas com dispositivos subordinados são definidas como imagens de inicialização principais, independentemente de as imagens de inicialização de origem serem principais ou de backup.
Restrições e diretrizes
Se uma instalação de patch tiver sido realizada no dispositivo mestre, use o comando install commit para atualizar o conjunto de imagens de inicialização principais no dispositivo mestre antes da sincronização do software. Esse comando garante a consistência da imagem de
inicialização entre o dispositivo mestre e os subordinados.
Procedimento
Execute as etapas a seguir na visualização do usuário:
- Sincronizar imagens de inicialização do mestre para os dispositivos subordinados.
boot-loader update { all | slot slot-number }reboot slot slot-number [ force ]Instalação ou desinstalação de recursos e patches
Sobre a instalação ou desinstalação de recursos e patches
Você pode instalar um novo recurso ou imagem de patch, ou atualizar uma imagem de recurso existente.
Restrições e diretrizes
Para garantir que a instalação ou o upgrade da imagem seja bem-sucedido, não reinicie o dispositivo nem execute uma alternância entre mestre e subordinado durante a instalação ou o upgrade da imagem.
Depois de instalar uma imagem de recurso, você deve fazer login no dispositivo novamente para usar os comandos fornecidos na imagem.
Pré-requisitos
Use os comandos FTP ou TFTP para transferir o arquivo de imagem para o sistema de arquivos padrão no dispositivo mestre. Não é necessário transferir ou copiar o arquivo de imagem para os dispositivos membros subordinados. O sistema copiará automaticamente o arquivo de imagem para os membros subordinados quando você ativar as imagens neles. Para obter mais informações sobre FTP e TFTP, consulte "Configuração de FTP" e "Configuração de TFTP".
Instalação ou atualização de recursos
- Ativar recursos nos arquivos especificados.
install activate feature filename&<1-30> slot slot-numberinstall commitPara que as alterações na imagem entrem em vigor após uma reinicialização, você deve executar uma operação de confirmação.
Instalação de patches
- Ativar patches em um arquivo.
install activate patch filename { all | slot slot-number }Você pode especificar apenas um arquivo de imagem de patch para esse comando por vez. No entanto, você pode executar esse comando várias vezes para instalar vários arquivos de imagem de patch.
O comando install activate patch filename allinstala as imagens de patch especificadas em todo o hardware e as imagens podem sobreviver a uma reinicialização. Não é necessário executar o comando install commit para a instalação.
install commitAs imagens são executadas na memória imediatamente após serem ativadas. Entretanto, somente as imagens de patch ativadas com o comando install activate patch filename all podem sobreviver a uma reinicialização. Para que outras imagens tenham efeito após uma reinicialização, você deve executar esse comando para confirmar a alteração do software.
Desinstalação de recursos ou patches
Restrições e diretrizes
Depois de desinstalar uma imagem de recurso, você deve fazer login no dispositivo novamente para que os comandos da imagem sejam removidos.
Procedimento
- Desativar os recursos ou patches instalados a partir de um arquivo de imagem.
install deactivate feature filename&<1-30> slot slot-numberinstall deactivate patch filename { all | slot slot-number }Você pode especificar apenas um arquivo de imagem de patch para esse comando por vez. No entanto, você pode executar esse comando várias vezes para desativar vários arquivos de imagem de patch.
As imagens desativadas com o comando install deactivate patch filename all não são executadas após a reinicialização. Para evitar que outras imagens desativadas sejam executadas após uma reinicialização, você deve confirmar a alteração do software usando o comando install commit.
- Confirmar a alteração do software.
install commitEssa etapa remove o arquivo de imagem da lista de imagens de inicialização, mas não exclui o arquivo de imagem do sistema de arquivos padrão.
O dispositivo não carregará recursos e patches dos arquivos de imagem na inicialização.
Comandos de exibição e manutenção para configurações de imagem de software
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir imagens de software atuais e imagens de software de inicialização. | display boot-loader [ slot slot-number ] |
Exemplos de atualização de software
Exemplo: Atualização do software do dispositivo
Configuração de rede
Conforme mostrado na Figura 1, use o arquivo startup-a2105.ipe para atualizar as imagens de software para a malha IRF.
Figura 1 Diagrama de rede
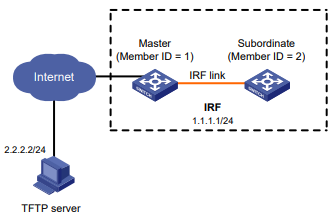
Procedimento
# Configure endereços IP e rotas. Certifique-se de que o dispositivo e o servidor TFTP possam se comunicar. (Detalhes não mostrados.)
# Defina as configurações de TFTP no dispositivo e no servidor TFTP. (Detalhes não mostrados.) # Exibir informações sobre as imagens de software atuais.
<Sysname> display version# Faça o backup das imagens atuais do software.
<Sysname> copy boot.bin boot_backup.bin
<Sysname> copy system.bin system_backup.bin
# Especifique boot_backup.bin e system_backup.bin como arquivos de imagem de inicialização de backup para todos os dispositivos membros da IRF.
<Sysname> boot-loader file boot flash:/boot_backup.bin system flash:/system_backup.bin slot 1 backup
<Sysname> boot-loader file boot flash:/boot_backup.bin system flash:/system_backup.bin slot 2 backup
# Use o TFTP para fazer o download do arquivo de imagem startup-a2105.ipe do servidor TFTP para o diretório raiz da memória flash no dispositivo mestre.
<Sysname> tftp 2.2.2.2 get startup-a2105.ipe# Especifique startup-a2105.ipe como o arquivo de imagem de inicialização principal para todos os dispositivos membros da IRF.
<Sysname> boot-loader file flash:/startup-a2105.ipe slot 1 main
<Sysname> boot-loader file flash:/startup-a2105.ipe slot 2 main
# Verificar as configurações da imagem de inicialização.
<Sysname> display boot-loader# Reinicialize o dispositivo para concluir a atualização.
<Sysname> reboot# Verifique se o dispositivo está executando o software correto.
<Sysname> display versionGerenciando o dispositivo
Configuração do nome do dispositivo
Sobre o nome do dispositivo
Um nome de dispositivo (também chamado de nome de host) identifica um dispositivo em uma rede e é usado nos prompts de exibição da CLI. Por exemplo, se o nome do dispositivo for Sysname, o prompt de exibição do usuário será <Sysname>.
Restrições e diretrizes
Em uma rede de subcamada, o dispositivo usa o nome de dispositivo que você configurou para ele. Se você não configurar um nome de dispositivo para o dispositivo, mas a implementação automatizada de rede de subcamada estiver ativada, o dispositivo usará o nome de dispositivo atribuído pelo recurso de malha VCF. Para obter mais informações sobre a malha VCF, consulte Configuração da malha VCF no Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
system-viewsysname sysnamePor padrão, o nome do dispositivo é Intelbras.
Configuração da hora do sistema
Sobre a hora do sistema
A hora correta do sistema é essencial para o gerenciamento e a comunicação da rede. Configure a hora do sistema corretamente antes de executar o dispositivo na rede.
O dispositivo pode usar um dos seguintes métodos para obter a hora do sistema:
- Usa a hora do sistema definida localmente e, em seguida, usa os sinais de relógio gerados por seu oscilador de cristal integrado para manter a hora do sistema.
- Obtém periodicamente a hora UTC de uma fonte NTP e usa a hora UTC, o fuso horário e o horário de verão para calcular a hora do sistema. Para obter mais informações sobre NTP, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
A hora do sistema calculada usando a hora UTC de uma fonte de hora é mais precisa.
Restrições e diretrizes para configurar a hora do sistema
Depois que você executar o comando clock protocol none, o comando clock datetime determinará a hora do sistema, independentemente de o fuso horário ou o horário de verão ter sido configurado ou não.
Se você configurar ou alterar o fuso horário ou o horário de verão depois que o dispositivo obtiver a hora do sistema, o dispositivo recalculará a hora do sistema. Para visualizar a hora do sistema, use o comando display clock.
Visão geral das tarefas de configuração do tempo do sistema
Para configurar a hora do sistema, execute as seguintes tarefas:
- Configuração da hora do sistema
- Definição da hora do sistema na CLI
- Obtenção da hora UTC por meio de um protocolo de horário
- (Opcional.) Definição do fuso horário
- (Opcional.) Configuração do horário de verão
Escolha uma das tarefas a seguir:
Certifique-se de que cada dispositivo de rede use o fuso horário do local onde o dispositivo reside.
Certifique-se de que cada dispositivo de rede use os parâmetros de horário de verão do local onde o dispositivo reside.
Definição da hora do sistema na CLI
- Entre na visualização do sistema.
system-viewclock protocol nonePor padrão, o dispositivo usa a fonte de horário NTP.
Se você executar o comando clock protocol várias vezes, a configuração mais recente entrará em vigor.
quitclock datetime time datePor padrão, a hora do sistema é a hora UTC 00:00:00 01/01/2013.
 CUIDADO:
CUIDADO:
Esse comando altera a hora do sistema, o que afeta a execução de recursos relacionados à hora do sistema (por exemplo, tarefas agendadas) e operações colaborativas do dispositivo com outros dispositivos (por exemplo, relatórios de registro e coleta de estatísticas). Antes de executar esse comando, certifique-se de compreender totalmente o impacto dele em sua rede ativa.
Obtenção da hora UTC por meio de um protocolo de horário
- Entre na visualização do sistema.
system-viewclock protocol ntpPor padrão, o dispositivo usa a fonte de horário NTP.
Se você executar esse comando várias vezes, a configuração mais recente entrará em vigor.
Para obter mais informações sobre a configuração do NTP, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Definição do fuso horário
- Entre na visualização do sistema.
system-viewclock timezone zone-name { add | minus } zone-offsetPor padrão, o sistema usa o fuso horário UTC.
Configuração do horário de verão
- Entre na visualização do sistema.
system-viewclock summer-time name start-time start-date end-time end-date add-timePor padrão, o horário de verão não é definido.
Permitir a exibição da declaração de direitos autorais
Sobre a exibição da declaração de direitos autorais
Esse recurso permite que o dispositivo exiba a declaração de direitos autorais nas seguintes situações:
- Quando um usuário de Telnet ou SSH faz login.
- Quando um usuário do console sai da visualização do usuário. Isso ocorre porque o dispositivo tenta reiniciar automaticamente a sessão do usuário.
Se você desativar a exibição da declaração de direitos autorais, o dispositivo não exibirá a declaração de direitos autorais em nenhuma situação.
Procedimento
- Entre na visualização do sistema.
system-viewcopyright-info enablePor padrão, a exibição da declaração de direitos autorais está ativada.
Configuração de banners
Sobre banners
Os banners são mensagens que o sistema exibe quando um usuário faz login. O sistema suporta os seguintes banners:
- Banner jurídico - Aparece após a declaração de direitos autorais. Para continuar o login, o usuário deve digitar Y ou pressione Enter. Para encerrar o processo, o usuário deve digitar N. Y e N não diferenciam maiúsculas de minúsculas.
- Banner Mensagem do dia (MOTD) - Aparece após o banner jurídico e antes do banner de login.
- Banner de login - É exibido somente quando a autenticação por senha ou esquema está configurada.
- Banner Shell - Aparece quando um usuário acessa a visualização do usuário.
O sistema exibe os banners na seguinte ordem: banner legal, banner MOTD, banner de login, e banner de shell.
Métodos de entrada de banner
Você pode configurar um banner usando um dos seguintes métodos:
- Insira toda a linha de comando em uma única linha.
O banner não pode conter retornos de carro. A linha de comando inteira, incluindo as palavras- chave de comando, o banner e os delimitadores, pode ter no máximo 511 caracteres. Os delimitadores do banner podem ser qualquer caractere imprimível, mas devem ser os mesmos. Não é possível pressionar Enter antes de inserir o delimitador final.
Por exemplo, você pode configurar o banner do shell "Have a nice day." da seguinte forma:
<Sysname> system-view
[System] header shell %Have a nice day.%
O banner pode conter retornos de carro. Um retorno de carro é contado como dois caracteres.
Para inserir uma linha de comando de configuração de banner em várias linhas, use um dos métodos a seguir:
- Pressione Enter após a palavra-chave final do comando, digite o banner e termine a linha final com o caractere delimitador %. O banner mais o delimitador podem ter um máximo de 1999 caracteres.
Por exemplo, você pode configurar o banner "Have a nice day." da seguinte forma:
<Sysname> system-view [System] header shell
Please input banner content, and quit with the character '%'.
Have a nice day.%
Por exemplo, você pode configurar o banner "Have a nice day." da seguinte forma:
<Sysname> system-view [System] header shell A
Please input banner content, and quit with the character 'A'.
Have a nice day.A
Por exemplo, você pode configurar o banner "Have a nice day." da seguinte forma:
<Sysname> system-view
[System] header shell AHave a nice day.
Please input banner content, and quit with the character 'A'.
A
Procedimento
- Entre na visualização do sistema.
system-viewheader legal textheader motd textheader login textheader shell textDesativar o recurso de recuperação de senha
Sobre o recurso de recuperação de senha
O recurso de recuperação de senha controla o acesso do usuário do console à configuração do dispositivo e à SDRAM a partir dos menus do BootWare. Para obter mais informações sobre os menus do BootWare, consulte as notas de versão.
Se o recurso de recuperação de senha estiver ativado, um usuário do console poderá acessar a configuração do dispositivo sem autenticação para configurar uma nova senha.
Se o recurso de recuperação de senha estiver desativado, os usuários do console deverão restaurar a configuração padrão de fábrica antes de poderem configurar novas senhas. A restauração da configuração padrão de fábrica exclui os arquivos de configuração da próxima inicialização.
Para aumentar a segurança do sistema, desative o recurso de recuperação de senha.
Restrições e diretrizes Procedimento
- Entre na visualização do sistema.
system-viewundo password-recovery enablePor padrão, o recurso de recuperação de senha está ativado.
Configuração do temporizador de detecção do status da porta
Sobre o temporizador de detecção de status da porta
O dispositivo inicia um cronômetro de detecção de status da porta quando uma porta é desligada por um protocolo. Quando o cronômetro expira, o dispositivo ativa a porta para que o status da porta reflita o status físico da porta.
Procedimento
- Entre na visualização do sistema.
system-viewsystem-viewA configuração padrão é 30 segundos.
Monitoramento do uso da CPU
Sobre o monitoramento do uso da CPU
Para monitorar o uso da CPU, o dispositivo executa as seguintes operações:
- Faz a amostragem do uso da CPU em intervalos de 1 minuto e compara as amostras com os limites de uso da CPU para identificar o status de uso da CPU e enviar alarmes ou notificações de acordo.
- Amostras e salva o uso da CPU em um intervalo configurável se o rastreamento do uso da CPU estiver ativado. Você pode usar o comando display cpu-usage history para exibir as estatísticas históricas de uso da CPU em um sistema de coordenadas.
O dispositivo suporta os seguintes limites de uso da CPU:
- Limite menor - Se o uso da CPU aumentar até o limite menor ou acima dele, mas for menor que o limite grave, o uso da CPU entrará no estado de alarme menor. O dispositivo envia alarmes menores periodicamente até que a utilização da CPU aumente acima do limite grave ou o alarme menor seja removido.
- Limite severo - Se o uso da CPU aumentar acima do limite severo, o uso da CPU entrará no estado de alarme severo. O dispositivo envia alarmes graves periodicamente até que o alarme grave seja removido.
- Limite de recuperação - Se o uso da CPU diminuir abaixo do limite de recuperação, o uso da CPU entrará no estado de recuperação. O dispositivo envia uma notificação de recuperação.
Os alarmes e as notificações de uso da CPU podem ser enviados ao NETCONF, ao SNMP e ao centro de informações para serem encapsulados como eventos do NETCONF, traps e informes do SNMP e mensagens de registro. Para obter mais informações
informações, consulte NETCONF, SNMP e centro de informações no Guia de configuração de monitoramento e gerenciamento de rede.
Figura 1 Alarmes de CPU e notificações de alarme removido
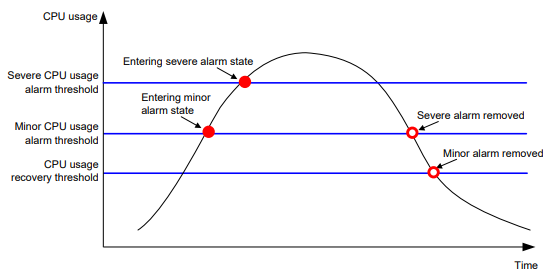
Procedimento
- Entre na visualização do sistema.
system-viewmonitor cpu-usage threshold severe-threshold minor-threshold minor-threshold recovery-threshold recovery-threshold [ slot slot-number [ cpu cpu-number ] ]As configurações padrão são as seguintes:
- Limite de alarme de uso grave da CPU - 99%.
- Limite de alarme de uso de CPU menor - 98%.
- Limite de recuperação do uso da CPU - 50%.
 CUIDADO:
CUIDADO:
Se você definir o limite do alarme de uso grave da CPU com um valor muito baixo, o dispositivo atingirá o limite facilmente. Os serviços normais serão afetados.
monitor resend cpu-usage { minor-interval minor-interval | severe-interval severe-interval } * [ slot slot-number [ cpu cpu-number ] ]Por padrão, o intervalo de reenvio de alarmes menores é de 300 segundos e o intervalo de reenvio de alarmes graves é de 60 segundos.
monitor cpu-usage interval interval [ slot slot-number [ cpu cpu-number ] ]Por padrão, o intervalo de amostragem para o rastreamento do uso da CPU é de 1 minuto.
monitor cpu-usage enable [ slot slot-number [ cpu cpu-number ] ]Por padrão, o rastreamento do uso da CPU está ativado.
Definição dos limites de alarme de memória
Sobre os limites de alarme de memória
Para garantir a operação correta e melhorar a eficiência da memória, o sistema monitora a quantidade de espaço livre na memória em tempo real. Se a quantidade de espaço livre na memória exceder um limite de alarme, o sistema emitirá um alarme para os módulos e processos de serviço afetados.
(Em dispositivos que não suportam pouca memória.) Você pode usar o comando display memory para exibir informações sobre o uso da memória.
(Em dispositivos que suportam pouca memória.) O sistema monitora apenas a quantidade de espaço livre de pouca memória. Você pode usar o comando display memory para exibir informações sobre o uso da memória.
(Em dispositivos com slots que suportam pouca memória.) Para slots que suportam pouca memória, o sistema monitora apenas a quantidade de espaço livre de pouca memória. Você pode usar o comando display memory para exibir informações sobre o uso da memória. Se o campo LowMem for exibido para um slot, isso significa que o slot suporta pouca memória.
Conforme mostrado na Tabela 1, o sistema suporta os seguintes limites de memória livre:
- Limite de estado normal.
- Limite de alarme menor.
- Limite de alarme grave.
- Limite de alarme crítico.
Tabela 1 Notificações de alarme de memória e notificações de alarme de memória removida
| Notificação | Condição de acionamento | Observações |
| Notificação de alerta antecipado | A quantidade de espaço livre na memória diminui abaixo do limite de alerta precoce. | Depois de gerar e enviar um notificação de alerta antecipado, o sistema não gera nem envia nenhuma notificação de alerta antecipado adicional até que o alerta antecipado seja removido. |
| Notificação de alarme menor | A quantidade de espaço livre na memória diminui abaixo do limite de alarme menor. | Depois de gerar e enviar uma notificação de alarme secundário, o sistema não gera nem envia nenhuma notificação de alarme secundário adicional até que o alarme secundário seja removido. |
| Notificação de alarme grave | A quantidade de espaço livre na memória diminui abaixo do limite de alarme grave. | Depois de gerar e enviar uma notificação de alarme grave, o sistema não gera nem envia nenhuma notificação de alarme grave adicional até que o alarme grave seja removido. |
| Notificação de alarme crítico | A quantidade de espaço livre na memória diminui abaixo do limite crítico do alarme. | Depois de gerar e enviar uma notificação de alarme crítico, o sistema não gera nem envia nenhuma notificação de alarme crítico adicional até que o alarme crítico seja removido. |
| Notificação de alarme crítico removido | A quantidade de espaço livre na memória aumenta acima do limite de alarme grave. | N/A |
| Notificação de alarme grave removido | A quantidade de espaço livre na memória aumenta acima do limite de alarme menor. | N/A |
| Notificação de alarme menor removido | A quantidade de espaço livre na memória aumenta acima do valor de | N/A |
| limiar do estado normal. | ||
| Notificação de aviso prévio removida | A quantidade de espaço livre na memória aumenta acima do limite de memória suficiente. | N/A |
Figura 2 Notificações de alarme de memória e notificações de alarme removido
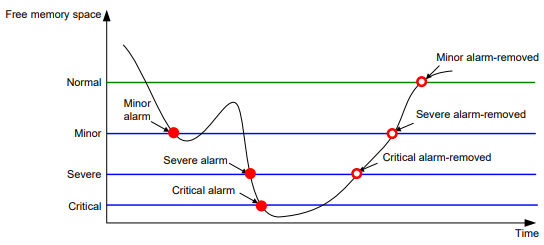
Restrições e diretrizes
Se ocorrer um alarme de memória, exclua os itens de configuração não utilizados ou desative alguns recursos para aumentar o espaço livre na memória. Como o espaço de memória é insuficiente, alguns itens de configuração podem não poder ser excluídos.
Procedimento
- Entre na visualização do sistema.
system-viewmemory-threshold [ slot slot-number [ cpu cpu-number ] ] usage memory-thresholdPor padrão, o limite de uso de memória é 100%.
memory-threshold [ slot slot-number [ cpu cpu-number ] ] [ ratio ] minor minor-value severe severe-value critical critical-value normal normal-valueAs configurações padrão são as seguintes:
- Limite de alarme menor - 60 MB.
- Limite de alarme grave - 56 MB.
- Limite de alarme crítico - 52 MB.
- Limite de estado normal - 64 MB.
monitor resend memory-threshold { critical-interval critical-interval | minor-interval minor-interval | severe-interval severe-interval } * [ slot slot-number [ cpu cpu-number ] ]As configurações padrão são as seguintes:
- Intervalo de reenvio de alarme menor - 12 horas.
- Intervalo de reenvio de alarme grave - 3 horas.
- Intervalo de reenvio de alarme crítico - 1 hora.
Configuração do monitoramento do uso do disco
Sobre o monitoramento do uso do disco
Esse recurso permite que o dispositivo faça uma amostragem periódica do uso de um disco e compare o uso com o limite. Se o uso do disco exceder o limite, o dispositivo enviará um alarme de alto uso de disco para o módulo NETCONF. Para obter mais informações sobre o módulo NETCONF, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Versão do software e compatibilidade de recursos
Esse recurso está disponível somente na versão 6348P01 e posteriores.
Procedimento
- Entre na visualização do sistema.
system-viewmonitor disk-usage interval intervalPor padrão, o intervalo de amostragem de uso de disco é de 300 segundos.
monitor disk-usage [ slot slot-number ] disk disk-name threshold threshold-valuePor padrão, o limite de uso do disco é de 95%.
Definição dos limites do alarme de temperatura
Sobre os limites de alarme de temperatura
O dispositivo monitora sua temperatura com base nos seguintes limites:
- Limite de baixa temperatura.
- Limite de aviso de alta temperatura.
- Limite de alarme de alta temperatura.
Quando a temperatura do dispositivo cai abaixo do limite de baixa temperatura ou atinge o limite de alerta ou alarme de alta temperatura, o dispositivo executa as seguintes operações:
- Envia mensagens de registro e traps.
- Define os LEDs no painel do dispositivo.
Procedimento
- Entre na visualização do sistema.
system-viewtemperature-limit slot slot-number hotspot sensor-number lowlimit warninglimit [ alarmlimit ]Os padrões variam de acordo com o modelo do sensor de temperatura. Para visualizar os padrões, execute os comandos undo temperature-limit e display environment, respectivamente.
O limite de alarme de alta temperatura deve ser maior do que o limite de aviso de alta temperatura, e o limite de aviso de alta temperatura deve ser maior do que o limite de alarme de alta temperatura.
limiar de baixa temperatura.
Configuração do alarme de desligamento do dispositivo
Sobre o alarme de desligamento do dispositivo
Esse recurso permite que o dispositivo detecte um evento de desligamento do dispositivo e emita um alarme de desligamento enviando notificações SNMP ou mensagens de registro.
Compatibilidade de hardware
Esse recurso é compatível apenas com os seguintes dispositivos:
- dispositivos PoE e dispositivos não PoE de 52 portas.
- Dispositivos que suportam fontes de alimentação com hot-swap.
Procedimento
- Entre na visualização do sistema.
system-viewdying-gasp source interface-type { interface-number | interface-number.subnumber }Por padrão, nenhuma interface de origem é especificada. Em uma rede IPv4, o dispositivo usa o endereço IPv4 primário da interface de saída da rota para o host de destino como endereço de origem. Em uma rede IPv6, o dispositivo seleciona um endereço IPv6 de origem, conforme definido na RFC 3484.
dying-gasp host { ip-address | ipv6 ipv6-address } snmp-trap version { v1 | v2c } securityname security-stringPor padrão, nenhuma configuração de host de destino de notificação SNMP é configurada.
Você pode configurar o dispositivo para enviar notificações SNMP de alarme de desligamento para vários hosts de destino.
dying-gasp host { ip-address | ipv6 ipv6-address } syslogPor padrão, nenhuma configuraçãoS de host de destino de mensagem de registro é configurada.
É possível configurar o dispositivo para enviar as mensagens de registro de alarme de desligamento para vários hosts de destino.
Verificação e diagnóstico de módulos transceptores
Verificação dos módulos transceptores
Sobre a verificação do módulo transceptor
Você pode usar um dos métodos a seguir para verificar a autenticidade de um módulo transceptor:
- Exibir os principais parâmetros de um módulo transceptor, incluindo o tipo de transceptor, o tipo de conector, o comprimento de onda central do laser de transmissão, a distância de transferência e o nome do fornecedor.
- Exibir a etiqueta eletrônica. A etiqueta eletrônica é um perfil do módulo transceptor e contém a configuração permanente, incluindo o número de série, a data de fabricação e o nome do fornecedor. Os dados foram gravados no módulo transceptor ou no componente de armazenamento do dispositivo durante a depuração ou o teste do módulo transceptor ou do dispositivo.
O dispositivo verifica regularmente os módulos transceptores quanto aos nomes de seus fornecedores. Se um módulo transceptor não tiver um nome de fornecedor ou se o nome do fornecedor não for Intelbras, o dispositivo emitirá repetidamente traps e mensagens de registro. Para obter informações sobre regras de registro, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
Para verificar os módulos do transceptor, execute os seguintes comandos em qualquer visualização:
- Exibir os principais parâmetros dos módulos transceptores.
display transceiver interface [ interface-type interface-number ]display transceiver manuinfo interface [ interface-type interface-number ]Diagnóstico de módulos transceptores
Sobre o diagnóstico do módulo transceptor
O dispositivo fornece as funções de alarme e diagnóstico digital para módulos transceptores. Quando um módulo transceptor falha ou não está funcionando corretamente, você pode executar as seguintes tarefas:
- Verifique os alarmes existentes no módulo transceptor para identificar a origem da falha.
- Examine os principais parâmetros monitorados pela função de diagnóstico digital, incluindo a temperatura, a tensão, a corrente de polarização do laser, a potência TX e a potência RX.
Procedimento
Para diagnosticar os módulos do transceptor, execute os seguintes comandos em qualquer visualização:
- Exibir alarmes do transceptor.
display transceiver alarm interface [ interface-type interface-number ]display transceiver diagnosis interface [ interface-type interface-number ]Configuração do monitoramento do transceptor
Sobre o monitoramento do transceptor
Depois que o monitoramento do transceptor é ativado, o dispositivo coleta amostras dos parâmetros dos módulos do transceptor periodicamente, incluindo a potência de entrada e a potência de saída dos módulos do transceptor. Se um valor amostrado atingir o limite de alarme, o dispositivo gera um registro para notificar os usuários.
Versão do software e compatibilidade de recursos
Esse recurso está disponível somente na versão 6343P08 e posteriores.
Procedimento
- Entre na visualização do sistema.
system-viewtransceiver monitor interval intervalPor padrão, o intervalo de monitoramento do transceptor é de 600 segundos.
transceiver monitor enablePor padrão, o monitoramento do transceptor está desativado.
Configuração do transceptor antifalsificação
Sobre o transceptor antifalsificação
Esse recurso detecta automaticamente os módulos transceptores da Intelbras.
- Após a detecção de um módulo transceptor Intelbras, o sistema emite um registro que recomenda que o usuário verifique a autenticidade do transceptor no site oficial da Intelbras www.Intelbras.com. Selecione Support > Intelbras Product Anti-Counterfeit Query no site e, em seguida, digite o código de barras do módulo transceptor. Para obter o código de barras do módulo do transceptor, consulte a etiqueta no módulo do transceptor ou execute o comando manuinfo do dispositivo de exibição.
- O sistema emite um registro após a detecção de um módulo transceptor Intelbras possivelmente falsificado para notificar o usuário. O registro contém informações sobre quais módulos de transceptor são possivelmente falsificados. Para um transceptor Intelbras falsificado, o comando display transceiver diagnosis não exibe nenhuma informação sobre ele.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6342 e posteriores.
Agendamento de uma tarefa
Sobre o agendamento de tarefas
Você pode programar o dispositivo para executar automaticamente um comando ou um conjunto de comandos sem interferência administrativa.
Você pode configurar uma programação periódica ou não periódica. Uma agenda não periódica não é salva no arquivo de configuração e é perdida quando o dispositivo é reinicializado. Uma agenda periódica é salva no arquivo de configuração de inicialização e é executada periodicamente de forma automática.
Restrições e diretrizes
- A hora padrão do sistema é sempre restaurada na reinicialização. Para garantir que um cronograma de tarefas possa ser executado conforme o esperado, reconfigure a hora do sistema ou configure o NTP após a reinicialização do dispositivo. Para obter mais informações sobre NTP, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
- Para atribuir um comando (comando A) a um trabalho, você deve primeiro atribuir ao trabalho o comando ou comandos para entrar na visualização do comando A.
- Certifique-se de que todos os comandos em uma programação estejam em conformidade com a sintaxe do comando. O sistema não verifica a sintaxe quando você atribui um comando a um trabalho.
- Uma agenda não pode conter nenhum destes comandos: telnet, ftp, ssh2 e monitor process.
- Uma programação não suporta a interação do usuário. Se um comando exigir uma resposta do tipo "sim" ou "não", o sistema sempre presumirá que Y ou Yes foi inserido. Se um comando exigir a entrada de uma cadeia de caracteres, o sistema presumirá que a cadeia de caracteres padrão (se houver) ou uma cadeia nula foi inserida.
- Uma agenda é executada em segundo plano e nenhuma saída (exceto logs, traps e informações de depuração) é exibida para a agenda.
Procedimento
- Entre na visualização do sistema.
system-viewscheduler job job-namecommand id commandPor padrão, nenhum comando é atribuído a um trabalho.
Você pode atribuir vários comandos a um trabalho. Um comando com uma ID menor é executado primeiro.
quitscheduler schedule schedule-namejob job-namePor padrão, nenhum trabalho é atribuído a uma agenda.
Você pode atribuir vários trabalhos a um agendamento. Os trabalhos serão executados simultaneamente.
user-role role-namePor padrão, uma agenda tem a função de usuário do criador da agenda.
É possível atribuir um máximo de 64 funções de usuário a uma agenda. Um comando em uma agenda pode ser executado se for permitido por uma ou mais funções de usuário da agenda.
- Executar o cronograma em momentos específicos.
time at time datetime once at time [ month-date month-day | week-day week-day&<1-7> ]time once delay timetime repeating at time [ month-date [ month-day | last ] | week-day week-day&<1-7> ]time repeating [ at time [date ] ] interval intervalPor padrão, nenhum tempo de execução é especificado para uma agenda.
Os comandos de tempo se sobrepõem uns aos outros. O comando executado mais recentemente tem efeito.
scheduler logfile size valuePor padrão, o limite de tamanho do arquivo de registro de agendamento é de 16 KB.
O arquivo de log de programação armazena mensagens de log para resultados de execução de comandos em trabalhos. Depois que o limite é atingido, o sistema exclui as mensagens de log mais antigas para armazenar as novas mensagens de log. Se o espaço restante do arquivo de log não for suficiente para uma única mensagem de log, o sistema trunca a mensagem e não armazena a parte extra.
Exemplo: Agendamento de uma tarefa
Configuração de rede
Conforme mostrado na Figura 3, duas interfaces do dispositivo estão conectadas aos usuários. Para economizar energia, configure o dispositivo para executar as seguintes operações:
- Ative as interfaces às 8:00 da manhã, de segunda a sexta-feira.
- Desative as interfaces às 18:00 horas, de segunda a sexta-feira.
Figura 3 Diagrama de rede
Procedimento
# Entre na visualização do sistema.
<Sysname> system-view# Configure um trabalho para desativar a interface GigabitEthernet 1/0/1.
[Sysname] scheduler job shutdown-GigabitEthernet1/0/1
[Sysname-job-shutdown-GigabitEthernet1/0/1] command 1 system-view
[Sysname-job-shutdown-GigabitEthernet1/0/1] command 2 interface gigabitethernet 1/0/1
[Sysname-job-shutdown-GigabitEthernet1/0/1] command 3 shutdown
[Sysname-job-shutdown-GigabitEthernet1/0/1] quit
# Configure um trabalho para ativar a interface GigabitEthernet 1/0/1.
[Sysname] scheduler job start-GigabitEthernet1/0/1
[Sysname-job-start-GigabitEthernet1/0/1] command 1 system-view
[Sysname-job-start-GigabitEthernet1/0/1] command 2 interface gigabitethernet 1/0/1
[Sysname-job-start-GigabitEthernet1/0/1] command 3 undo shutdown
[Sysname-job-start-GigabitEthernet1/0/1] quit
# Configure um trabalho para desativar a interface GigabitEthernet 1/0/2.
[Sysname] scheduler job shutdown-GigabitEthernet1/0/2
[Sysname-job-shutdown-GigabitEthernet1/0/2] command 1 system-view
[Sysname-job-shutdown-GigabitEthernet1/0/2] command 2 interface gigabitethernet 1/0/2
[Sysname-job-shutdown-GigabitEthernet1/0/2] command 3 shutdown
[Sysname-job-shutdown-GigabitEthernet1/0/2] quit
# Configure um trabalho para ativar a interface GigabitEthernet 1/0/2.
[Sysname] scheduler job start-GigabitEthernet1/0/2
[Sysname-job-start-GigabitEthernet1/0/2] command 1 system-view
[Sysname-job-start-GigabitEthernet1/0/2] command 2 interface gigabitethernet 1/0/2
[Sysname-job-start-GigabitEthernet1/0/2] command 3 undo shutdown
[Sysname-job-start-GigabitEthernet1/0/2] quit
# Configure uma programação periódica para ativar as interfaces às 8:00 da manhã, de segunda a sexta-feira.
[Sysname] scheduler schedule START-pc1/pc2
[Sysname-schedule-START-pc1/pc2] job start-GigabitEthernet1/0/1
[Sysname-schedule-START-pc1/pc2] job start-GigabitEthernet1/0/2
[Sysname-schedule-START-pc1/pc2] time repeating at 8:00 week-day mon tue wed thu fri
[Sysname-schedule-START-pc1/pc2] quit
# Configure uma programação periódica para desativar as interfaces às 18:00, de segunda a sexta-feira.
[Sysname] scheduler schedule STOP-pc1/pc2
[Sysname-schedule-STOP-pc1/pc2] job shutdown-GigabitEthernet1/0/1
[Sysname-schedule-STOP-pc1/pc2] job shutdown-GigabitEthernet1/0/2
[Sysname-schedule-STOP-pc1/pc2] time repeating at 18:00 week-day mon tue wed thu fri
[Sysname-schedule-STOP-pc1/pc2] quit
Verificação da configuração
# Exibir as informações de configuração de todos os trabalhos.
[Sysname] display scheduler job
Job name: shutdown-GigabitEthernet1/0/1
system-view
interface gigabitethernet 1/0/1
shutdown
Job name: shutdown-GigabitEthernet1/0/2
system-view
interface gigabitethernet 1/0/2
shutdown
Job name: start-GigabitEthernet1/0/1
system-view
interface gigabitethernet 1/0/1
undo shutdown
Job name: start-GigabitEthernet1/0/2
system-view
interface gigabitethernet 1/0/2
undo shutdown
# Exibir as informações da programação. [Sysname] display scheduler schedule Nome da programação : START-pc1/pc2
[Sysname] display scheduler schedule
Schedule name : START-pc1/pc2
Schedule type : Run on every Mon Tue Wed Thu Fri at 08:00:00
Start time : Wed Sep 28 08:00:00 2011
Last execution time : Wed Sep 28 08:00:00 2011
Last completion time : Wed Sep 28 08:00:03 2011
Execution counts : 1
------------------------------------------------------------------------------------------
Job name Last execution status
start-GigabitEthernet1/0/1 Successful
start-GigabitEthernet1/0/2 Successful
Schedule name : STOP-pc1/pc2
Schedule type : Run on every Mon Tue Wed Thu Fri at 18:00:00
Start time : Wed Sep 28 18:00:00 2011
Last execution time : Wed Sep 28 18:00:00 2011
Last completion time : Wed Sep 28 18:00:01 2011
Execution counts : 1
------------------------------------------------------------------------------------------
Job name Last execution status
shutdown-GigabitEthernet1/0/1 Successful
shutdown-GigabitEthernet1/0/2 Successful
# Exibir informações de registro de programação.
[Sysname] display scheduler logfile
Job name : start-GigabitEthernet1/0/1
Schedule name : START-pc1/pc2
Execution time : Wed Sep 28 08:00:00 2011
Completion time : Wed Sep 28 08:00:02 2011
------------------------------------------------------------------------------------------
<Sysname>system-view
System View: return to User View with Ctrl+Z.
[Sysname]interface gigabitethernet 1/0/1
[Sysname-GigabitEthernet1/0/1]undo shutdown
Job name : start-GigabitEthernet1/0/2
Schedule name : START-pc1/pc2
Execution time : Wed Sep 28 08:00:00 2011
Completion time : Wed Sep 28 08:00:02 2011
------------------------------------------------------------------------------------------
<Sysname>system-view
System View: return to User View with Ctrl+Z.
[Sysname]interface gigabitethernet 1/0/2
[Sysname-GigabitEthernet1/0/2]undo shutdown
Job name : shutdown-GigabitEthernet1/0/1
Schedule name : STOP-pc1/pc2
Execution time : Wed Sep 28 18:00:00 2011
Completion time : Wed Sep 28 18:00:01 2011
------------------------------------------------------------------------------------------
<Sysname>system-view
System View: return to User View with Ctrl+Z.
[Sysname]interface gigabitethernet 1/0/1
[Sysname-GigabitEthernet1/0/1]shutdown
Job name : shutdown-GigabitEthernet1/0/2
Schedule name : STOP-pc1/pc2
Execution time : Wed Sep 28 18:00:00 2011
Completion time : Wed Sep 28 18:00:01 2011
------------------------------------------------------------------------------------------
<Sysname>system-view
System View: return to User View with Ctrl+Z.
[Sysname]interface gigabitethernet 1/0/2
[Sysname-GigabitEthernet1/0/2]shutdown
Reinicialização do dispositivo
Sobre a reinicialização do dispositivo
Os seguintes métodos de reinicialização do dispositivo estão disponíveis:
- Programe uma reinicialização na CLI, para que o dispositivo seja reinicializado automaticamente no horário especificado ou após o período de tempo especificado.
- Reinicialize imediatamente o dispositivo na CLI.
- Reinicia todos os seus chips.
- Usa o BootWare para verificar o pacote de software de inicialização, descompactar o pacote e carregar as imagens.
- Inicializa o sistema.
- Desligue e, em seguida, ligue o dispositivo. Esse método pode causar perda de dados e é o método menos preferido.
Esse método permite que você reinicie o dispositivo remotamente.
Durante o processo de reinicialização, o dispositivo executa as seguintes operações:
Usando a CLI, você pode reinicializar o dispositivo a partir de um host remoto.
Restrições e diretrizes para reinicialização do dispositivo
Para a segurança dos dados, o dispositivo não é reinicializado enquanto estiver executando operações de arquivo.
Reinicialização imediata do dispositivo na CLI
Pré-requisitos
Execute as etapas a seguir em qualquer visualização:
- Verifique se o arquivo de configuração da próxima inicialização está especificado corretamente.
display startupPara obter mais informações sobre o comando display startup, consulte Fundamentals Command Reference.
display boot-loaderSe um arquivo de imagem de inicialização principal estiver danificado ou não existir, você deverá especificar outro arquivo de imagem de inicialização principal antes de reiniciar o dispositivo.
Para obter mais informações sobre o comando display boot-loader, consulte
Referência de comandos básicos.
savePara evitar a perda de configuração, salve a configuração em execução antes da reinicialização.
Para obter mais informações sobre o comando save, consulte Referência de comandos dos fundamentos.
Procedimento
Para reinicializar o dispositivo imediatamente na CLI, execute o seguinte comando na visualização do usuário:
reboot [ slot slot-number ] [ force ] CUIDADO:
CUIDADO:
- A reinicialização do dispositivo pode causar interrupção do serviço. Antes de executar esse comando, certifique-se de compreender totalmente o impacto dele em sua rede ativa.
- Use a palavra-chave force para reinicializar o dispositivo somente quando o sistema estiver com defeito ou não conseguir iniciar normalmente. Uma reinicialização forçada do dispositivo pode causar danos ao sistema de arquivos. Antes de usar a palavra-chave force para reinicializar o dispositivo, certifique-se de que você entenda seu impacto.
Agendamento de uma reinicialização do dispositivo
Restrições e diretrizes
A configuração de reinicialização automática entra em vigor em todos os dispositivos membros. Ela será cancelada se ocorrer uma troca de mestre/subordinado.
O dispositivo suporta apenas um agendamento de reinicialização do dispositivo. Se você executar o agendamento de reinicialização
várias vezes, a configuração mais recente entra em vigor.
Procedimento
Para agendar uma reinicialização, execute um dos seguintes comandos na visualização do usuário:
scheduler reboot at time [ date ]scheduler reboot delay timePor padrão, nenhum tempo de reinicialização do dispositivo é especificado.
 CUIDADO:
CUIDADO:
Essa tarefa permite que o dispositivo seja reinicializado em um horário programado, o que causa a interrupção do serviço. Antes de configurar essa tarefa, certifique-se de compreender totalmente o impacto dela em sua rede ativa.
Restauração da configuração padrão de fábrica
Sobre a restauração da configuração padrão de fábrica
Se quiser usar o dispositivo em um cenário diferente ou se não conseguir solucionar o problema usando outros métodos, use esta tarefa para restaurar a configuração padrão de fábrica.
Essa tarefa não exclui arquivos .bin.
Restrições e diretrizes
Esse recurso é perturbador.
Procedimento
- Execute o seguinte comando na visualização do usuário para restaurar a configuração padrão de fábrica do dispositivo:
restore factory-defaultrebootQuando o comando solicitar que você escolha se deseja salvar a configuração em execução, digite N. Se você optar por salvar a configuração em execução, o dispositivo carregará a configuração salva na inicialização.
 CUIDADO:
CUIDADO:
Esse comando restaura o dispositivo para as configurações padrão de fábrica. Antes de usar esse comando, certifique-se de entender completamente o impacto dele em sua rede ativa.
Comandos de exibição e manutenção para configuração do gerenciamento de dispositivos
Executar comandos de exibição em qualquer visualização. Execute o comando reset scheduler logfile na visualização do usuário. Execute o comando reset version-update-record na visualização do sistema.
| Tarefa | Comando |
| Exibir a hora do sistema, a data, o fuso horário e o horário de verão. | display clock |
| Exibir a declaração de direitos autorais. | display copyright |
| Exibir estatísticas de uso da CPU. | display cpu-usage [ summary ] [ slot slot-number [ cpu cpu-number [ core { core-number | all } ] ] ] |
| Exibir as configurações de monitoramento do uso da CPU. | display cpu-usage configuration [ slot slot-number [ cpu cpu-number ] ] |
| Exibir as estatísticas históricas de uso da CPU em um sistema de coordenadas. | display cpu-usage history [ job job-id ] [ slot slot-number [ cpu cpu-number ] ] |
| Exibir informações de hardware. | display device [ flash | usb ] [ slot slot-number | verbose ] |
| Exibir informações da etiqueta eletrônica do dispositivo. | display device manuinfo [ slot slot-number ] |
| Exibir informações da etiqueta eletrônica de uma fonte de alimentação. | display device manuinfo slot slot-number power power-id |
| Exibir ou salvar informações operacionais de recursos e módulos de hardware. | display diagnostic-information [ hardware | infrastructure | l2 | l3 | service ] [ key-info ] [ filename ] |
| Exibir as configurações do host de destino do alarme de desligamento. | display dying-gasp host |
| Exibir informações sobre a temperatura do dispositivo. | display environment [ slot slot-number ] |
| Exibir os estados operacionais das bandejas de ventiladores. | display fan [ slot slot-number [ fan-id ] ] |
| Exibir estatísticas de uso da memória. | display memory [ summary ] [ slot slot-number [ cpu cpu-number ] ] |
| Exibir limites e estatísticas de alarme de memória. | display memory-threshold [ slot slot-number [ cpu cpu-number ] ] |
| Exibir informações sobre a fonte de alimentação. | display power [ slot slot-number [ power-id ] ] |
| Exibir informações de configuração do trabalho. | display scheduler job [ job-name ] |
| Exibir informações do registro de execução do trabalho. | display scheduler logfile |
| Exibir a programação de reinicialização automática. | display scheduler reboot |
| Exibir informações de programação. | display scheduler schedule [ schedule-name ] |
| Exibir informações de estabilidade e status do sistema. | display system stable state |
| Exibir informações sobre a versão do sistema. | display version |
| Exibir registros de atualização da imagem do software de inicialização. | display version-update-record |
| Limpar informações do registro de execução do trabalho. | reset scheduler logfile |
| Limpe os registros de atualização da imagem do software de inicialização. | reset version-update-record |
Usando Tcl
Sobre o Tcl
O Comware V7 oferece um interpretador de linguagem de comando de ferramenta (Tcl) integrado. Na visualização do usuário, você pode usar o comando tclsh para entrar na visualização de configuração Tcl e executar os seguintes comandos:
- Comandos Tcl 8.5.
- Comandos do Comware.
A visualização de configuração Tcl é equivalente à visualização do usuário. Você pode usar os comandos do Comware na visualização de configuração Tcl da mesma forma que são usados na visualização do usuário.
Restrições e diretrizes: Tcl
Para retornar de uma subvisualização na visualização de configuração Tcl para a visualização de nível superior, use o comando quit
comando.
Para retornar de uma subvisualização na visualização de configuração Tcl para a visualização de configuração Tcl, pressione Ctrl+Z.
Uso de comandos Tcl para configurar o dispositivo
Restrições e diretrizes
Quando você usar o Tcl para configurar o dispositivo, siga estas restrições e diretrizes:
- Você pode aplicar variáveis de ambiente Tcl aos comandos do Comware.
- Nenhuma informação de ajuda on-line é fornecida para os comandos Tcl.
- Não é possível pressionar Tab para concluir um comando Tcl abreviado.
- Verifique se os comandos Tcl podem ser executados corretamente.
- Como prática recomendada, faça login por meio de Telnet ou SSH. Você não pode interromper os comandos Tcl usando uma tecla de atalho ou um comando da CLI. Se ocorrer um problema quando os comandos Tcl estiverem sendo executados, você poderá encerrar o processo fechando a conexão se tiver feito login por meio de Telnet ou SSH. Se tiver efetuado login pela porta do console, deverá executar uma das seguintes tarefas:
- Reinicie o dispositivo.
- Faça login no dispositivo usando um método diferente e use o comando free line para liberar o console ou a linha AUX. Para obter mais informações sobre o comando, consulte Referência de comandos básicos.
- Você pode pressionar Ctrl+D para interromper o comando Tcl read stdin.
Procedimento
- Entre na visualização de configuração Tcl a partir da visualização do usuário.
tclshTcl commandtclquitquitExecução de comandos Comware na visualização de configuração Tcl
Sobre a execução de comandos do Comware na visualização de configuração Tcl
Para executar um comando Comware na visualização de configuração Tcl, use um dos métodos a seguir:
- Digite o comando Comware diretamente. Se um comando Tcl usar a mesma string de comando que o comando Comware, o comando Tcl será executado.
- Prefixe o comando Comware com a palavra-chave cli. Se um comando Tcl usar a mesma cadeia de comando que o comando Comware, o comando Comware será executado.
Restrições e diretrizes
Siga estas restrições e diretrizes ao executar comandos Comware na visualização de configuração Tcl:
- Para especificar uma cadeia de caracteres entre aspas (") ou chaves ({ e }), é necessário usar o caractere de escape (\) antes das aspas ou chaves. Por exemplo, para especificar "a" como a descrição de uma interface, você deve digitar description \"a\". Se você digitar description "a", a descrição será a.
- Para os comandos do Comware, você pode digitar ? para obter ajuda on-line ou pressionar Tab para concluir um comando abreviado. Para obter mais informações, consulte "Uso da CLI".
- O comando cli é um comando Tcl, portanto, você não pode digitar ? para obter ajuda on- line ou pressionar Tab para concluir um comando abreviado.
- Os comandos do Comware executados com êxito são salvos nos buffers do histórico de comandos. Você pode usar a seta superior ou a seta inferior para obter os comandos executados.
- Para executar vários comandos do Comware em uma única operação, use um dos métodos a seguir:
- Insira vários comandos do Comware separados por ponto e vírgula para executar os comandos na ordem em que foram inseridos. Por exemplo, vlan 2;description Tech.
- Especifique vários comandos do Comware para o comando cli, coloque-os entre aspas e separe-os com um espaço e um ponto e vírgula. Por exemplo, cli "vlan 2 ;cli description Tech".
- Especifique um comando Comware para cada comando cli e separe-os com um espaço e um ponto e vírgula. Por exemplo, cli vlan 2 ;cli description Tech.
Procedimento
- Entrar na visualização da configuração Tcl
tclsh- Executar comandos do Comware diretamente.
Commandcli commandtclquitquitUsando Python
Sobre o Python
O Comware 7 oferece um interpretador Python integrado. Você pode usar o Python para executar as seguintes tarefas:
- Execute scripts Python para implementar a configuração automática do dispositivo.
- Entre no shell Python para configurar o dispositivo usando os itens a seguir:
- Comandos do Python 2.7.
- API padrão do Python 2.7.
- API estendida. Para obter mais informações sobre a API estendida, consulte "API Python estendida do Comware 7 ".
Execução de um script Python
Para executar um script Python, use o seguinte comando na visualização do usuário:
python filenameEntrando no shell do Python
Para entrar no shell Python a partir da visualização do usuário, execute o seguinte comando:
pythonImportando e usando a API estendida do Python
Para usar a API estendida do Python, você deve primeiro importar a API para o Python.
Importação de toda a API estendida e uso da API
Procedimento
- Entre no shell Python a partir da visualização do usuário.
pythonimport comwarecomware.apiExemplo
# Use a função Transfer da API estendida para fazer download do arquivo test.cfg do servidor TFTP 192.168.1.26.
<Sysname> python
Python 2.7.3 (default)
[GCC 4.4.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import comware
>>> comware.Transfer('tftp', '192.168.1.26', 'test.cfg', 'flash:/test.cfg', user='', password='')
<comware.Transfer object at 0xb7eab0e0>
Importação de uma função de API estendida e uso da função
Procedimento
- Entre no shell Python a partir da visualização do usuário.
pythonfrom comware import api-nameapi-functionExemplo
# Use a função Transfer da API estendida para fazer download do arquivo test.cfg do servidor TFTP 192.168.1.26.
<Sysname> python
Python 2.7.3 (default)
[GCC 4.4.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> from comware import Transfer
>>> Transfer('tftp', '192.168.1.26', 'test.cfg', 'flash:/test.cfg', user='', password='')
<comware.Transfer object at 0xb7e5e0e0>
Sair do shell Python
Para sair do shell do Python, execute o seguinte comando no shell do Python.
exit()Exemplos de uso do Python
Exemplo: Uso de um script Python para configuração do dispositivo
Configuração de rede
Use um script Python para executar as seguintes tarefas:
- Faça o download dos arquivos de configuração main.cfg e backup.cfg para o dispositivo.
- Configure os arquivos como os arquivos de configuração principal e de backup para a próxima inicialização.
Figura 1 Diagrama de rede

Procedimento
# Use um editor de texto no PC para configurar o script Python test.py da seguinte forma:
#!usr/bin/python
import comware
comware.Transfer('tftp', '192.168.1.26', 'main.cfg', 'flash:/main.cfg')
comware.Transfer('tftp', '192.168.1.26', 'backup.cfg', 'flash:/backup.cfg')
comware.CLI('startup saved-configuration flash:/main.cfg main ;startup
saved-configuration flash:/backup.cfg backup')
# Use o TFTP para fazer o download do script para o dispositivo.
<Sysname> tftp 192.168.1.26 get test.py# Execute o script.
<Sysname> python flash:/test.py
<Sysname>startup saved-configuration flash:/main.cfg main
Please wait.......Done.
<Sysname>startup saved-configuration flash:/backup.cfg backup
Please wait.......Done.
Verificação da configuração
# Exibir arquivos de configuração de inicialização.
<Sysname> display startup
Current startup saved-configuration file: flash:/startup.cfg
Next main startup saved-configuration file: flash:/main.cfg
Next backup startup saved-configuration file: flash:/backup.cfg
API Python estendida do Comware 7
CLI
A API Python estendida do Comware 7 é compatível com a sintaxe Python.
Sintax e
Use a CLI para executar comandos da CLI do Comware 7 e criar objetos da CLI.
CLI(command='', do_print=True)Parâmetros
command: Especifica os comandos a serem executados. Para inserir vários comandos, use um espaço e um ponto e vírgula (;) como delimitador. Para inserir um comando em uma visualização diferente da visualização do usuário, é necessário primeiro inserir os comandos usados para entrar na visualização. Por exemplo, é necessário digitar 'system-view ;local-user test class manage' para executar o comando local-user test class manage.
do_print: Especifica se o resultado da execução deve ser emitido:
- True - Emite o resultado da execução. Esse valor é o padrão.
- False - Não gera o resultado da execução.
Diretrizes de uso
Essa função da API é compatível apenas com os comandos do Comware. Ela não é compatível com comandos do Linux, Python ou Tcl.
Devoluções
Objetos da CLI
Exemplos
# Adicione um usuário local chamado test.
<Sysname> python
Python 2.7.3 (default)
[GCC 4.4.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import comware
>>> comware.CLI('system-view ;local-user test class manage')
Saída de amostra
<Sysname> system-view
System View: return to User View with Ctrl+Z.
[Sysname] local-user test class manage
New local user added.
<comware.CLI object at 0xb7f680a0>
get_error
Use get_error para obter as informações de erro da operação de download.
Sintaxe
Transfer.get_error()Retorno
Informações de erro (se não houver informações de erro, None será retornado)
Exemplos
# Faça o download do arquivo test.cfg do servidor TFTP 1.1.1.1 e obtenha as informações de erro da operação.
<Sysname> python
Python 2.7.3 (default)
[GCC 4.4.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import comware
>>> c = comware.Transfer('tftp', '1.1.1.1', 'test.cfg', 'flash:/test.cfg', user='', password='')
>>> c.get_error()
Saída de amostra
"Timeout was reached”get_output
Use get_output para obter a saída dos comandos executados.
Sintaxe
CLI.get_output()Retorno
Saída de comandos executados
Exemplos
# Adicione um usuário local e obtenha a saída do comando.
<Sysname> python
Python 2.7.3 (default)
[GCC 4.4.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import comware
>>> c = comware.CLI('system-view ;local-user test class manage', False)
>>> c.get_output()
Saída de amostra
['<Sysname>system-view', 'System View: return to User View with Ctrl+Z.',
'[Sysname]local-user test class manage', 'New local user added.']get_self_slot
Use get_self_slot para obter a ID de membro do dispositivo mestre.
Sintaxe
get_self_slot()Retorno
Um objeto de lista no formato [-1,slot-number]. O número do slot indica a ID do membro d o dispositivo mestre.
Exemplos
# Obtenha o ID do membro do dispositivo mestre.
<Sysname> python
Python 2.7.3 (default)
[GCC 4.4.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import comware
>>> comware.get_self_slot()
Saída de amostra
[-1,0]get_slot_info
Use get_slot_info para obter informações sobre um dispositivo membro.
Sintaxe
get_slot_info()
Retorno
Um objeto de dicionário no formato {'Slot': número do slot, 'Status': 'status', 'Chassis': número do chassi, 'Role': 'role', 'Cpu': CPU-number }. O argumento slot-number indica a ID do membro do dispositivo. O argumento status indica o status do dispositivo membro. Os argumentos chassis- number e CPU-number são fixados em 0. O argumento role indica a função do dispositivo membro.
Exemplos
# Obter informações sobre o dispositivo ou um dispositivo membro.
<Sysname> python
Python 2.7.3 (default)
[GCC 4.4.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import comware
>>> comware.get_slot_info(1)
Saída de amostra
{'Slot': 1, 'Status': 'Normal', 'Chassis': 0, 'Role': 'Master', 'Cpu': 0}get_slot_range
Use get_slot_range para obter o intervalo de ID de membro IRF
Sintaxe
get_slo t_range ()Retorno
Um objeto de dicionári o no formato {'MaxSl ot': max- slot- number, 'MinSlot' min- slot- number >}. O argumen to max- slot- number indica a ID máxima do membro. O argumen to min- slot- number indica a ID mínima do membro.
Exemplos
# Obtenha o intervalo de IDs de membros IRF suportados.
<Sysname> python
Python 2.7.3 (default)
[GCC 4.4.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import comware
>>> comware.get_slot_range()
Saída de amostra
{'MaxSlot': 10, 'MinSlot': 1}get_standby_slot
Use get_standby_slot para obter as IDs de membro dos dispositivos subordinados.
Sintaxe
get_standby_slot()Retorno
Um objeto de lista em um dos seguintes formatos:
- [ ] - A malha IRF não tem um dispositivo subordinado.
- [[-1,slot-number]] - A malha IRF tem apenas um dispositivo subordinado.
- [[-1,slot-number1],[-1,slot-number2],...] - A malha IRF tem vários dispositivos subordinados.
Os argumentos slot-number indicam as IDs de membro dos dispositivos subordinados.
Exemplos
# Obtenha as IDs de membro dos dispositivos subordinados.
<Sysname> python
Python 2.7.3 (default)
[GCC 4.4.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import comware
>>> comware.get_standby_slot()
Saída de amostra
[[-1, 1], [-1, 2]]Transferência
Use Transfer para fazer download de um arquivo de um servidor.
Sintaxe
Transfer(protocol='', host='', source='', dest='',login_timeout=10, user='', password='')Parâmetros
protocol: Especifica o protocolo usado para fazer download de um arquivo:
- ftp - Usa o FTP.
- tftp - Usa TFTP.
- http - Usa HTTP.
host: especifica o endereço IP do servidor remoto.
fonte: Especifica o nome do arquivo a ser baixado do servidor remoto.
dest: Especifica um nome para o arquivo baixado.
login_timeout: Especifica o tempo limite da operação, em segundos. O padrão é 10.
usuário: Especifica o nome de usuário para fazer login no servidor.
password: Especifica a senha de login.
Retorno
Objeto de transferência
Exemplos
# Faça o download do arquivo test.cfg do servidor TFTP 192.168.1.26.
<Sysname> python
Python 2.7.3 (default)
[GCC 4.4.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import comware
>>> comware.Transfer('tftp', '192.168.1.26', 'test.cfg', 'flash:/test.cfg', user='', password='')
Saída de amostra
<comware.Transfer object at 0xb7f700e0>Uso da configuração automática
Sobre a configuração automática
Quando o dispositivo é iniciado sem um arquivo de configuração de próxima inicialização válido, o dispositivo procura no diretório raiz de seu sistema de arquivos padrão os arquivos autocfg.py, autocfg.tcl e autocfg.cfg. Apenas um dos arquivos pode existir no diretório raiz. Se qualquer um dos arquivos existir, o dispositivo carregará o arquivo. Se nenhum dos arquivos existir, o dispositivo usará o recurso de configuração automática para obter um conjunto de definições de configuração.
Com o recurso de configuração automática, o dispositivo pode obter automaticamente um conjunto de definições de configuração na inicialização. Esse recurso simplifica a configuração e a manutenção da rede.
A configuração automática pode ser implementada usando os métodos de implementação da Tabela 1.
Tabela 1 Métodos de implementação de configuração automática
| Método de implementação | Local do arquivo de configuração | Cenários de aplicativos |
| Configuração automática baseada em servidor | Servidor de arquivos | Vários dispositivos distribuídos geograficamente precisam ser configurados. |
Uso da configuração automática baseada no servidor
Sobre a configuração automática baseada em servidor
Com a configuração automática baseada em servidor, um dispositivo sem um arquivo de configuração pode executar o cliente DHCP para obter um arquivo de configuração de um servidor de arquivos na inicialização.
Você pode implementar a configuração automática baseada em servidor em redes IPv4 e IPv6 usando o mesmo método. Este capítulo descreve as tarefas de implementação da configuração automática baseada em servidor em uma rede IPv4.
Rede típica de configuração automática baseada em servidor
Conforme mostrado na Figura 1, uma rede típica de configuração automática baseada em servidor consiste nos seguintes servidores:
- Servidor DHCP.
- Servidor de arquivos (servidor TFTP ou HTTP).
- (Opcional.) Servidor DNS.
Figura 1 Diagrama de rede da configuração automática baseada em servidor
Visão geral das tarefas de configuração automática baseadas no servidor
Para configurar a configuração automática baseada no servidor, execute as seguintes tarefas:
- Configuração do servidor de arquivos
- Prepare os arquivos para a configuração automática:
- Preparação dos arquivos de configuração
- Preparação de arquivos de script
- Configuração do servidor DHCP
- (Opcional.) Configuração do servidor DNS
- (Opcional.) Configuração do gateway
- Preparar a interface usada para a configuração automática
- Início e conclusão da configuração automática
Configuração do servidor de arquivos
Para que os dispositivos obtenham informações de configuração de um servidor TFTP, inicie o serviço TFTP no servidor de arquivos.
Para que os dispositivos obtenham informações de configuração de um servidor HTTP, inicie o serviço HTTP no servidor de arquivos .
Preparação dos arquivos de configuração
Tipos de arquivos de configuração
O dispositivo é compatível com os tipos de arquivos de configuração listados na Tabela 2.
Tabela 2 Tipos de arquivos de configuração
| Tipo de arquivo de configuração | Objetos de aplicativos | Requisitos de nome de arquivo | Tipos de servidores de arquivos compatíveis |
| Arquivo de configuração dedicado | Dispositivos que exigem configurações diferentes | File name.cfg Para nome de arquivo simples identificação, use nomes de arquivos de configuração que não contenham espaços. |
|
| Arquivo de configuração comum | Dispositivos que compartilham todas ou algumas configurações | File name.cfg |
|
| Arquivo de configuração padrão | Outros dispositivos. O arquivo contém apenas as configurações comuns que os dispositivos usam para iniciar. |
device.cfg |
|
Identificação de requisitos e preparação de arquivos de configuração
- Identifique os requisitos dos dispositivos para os arquivos de configuração.
- Para dispositivos que exigem configurações diferentes, prepare um arquivo de configuração para cada um deles e salve o arquivo no servidor de arquivos.
- Para dispositivos que compartilham todas ou algumas configurações, salve as configurações comuns em um arquivo .cfg no servidor de arquivos.
- Se for usado um servidor de arquivos TFTP, você poderá salvar as configurações comuns que os dispositivos usam para iniciar no arquivo device.cfg no servidor. O arquivo é atribuído a um dispositivo somente quando o dispositivo não tem nenhum outro arquivo de configuração para usar.
Preparação do arquivo de nome de host no servidor TFTP
Se for usado um servidor TFTP e o servidor DHCP não atribuir nomes de arquivos de configuração, você poderá configurar um arquivo de nome de host no servidor TFTP. O arquivo de nome de host contém os mapeamentos de nome de host e endereço IP dos dispositivos a serem configurados automaticamente.
Para preparar o arquivo de nome do host:
- Crie um arquivo de nome de host chamado network.cfg.
- Adicione cada entrada de mapeamento no formato ip host host-name ip-address em uma linha separada. Por exemplo:
ip host host1 101.101.101.101
ip host host2 101.101.101.102
ip host client1 101.101.101.103
ip host client2 101.101.101.104 IMPORTANTE:
IMPORTANTE:
O nome do host de um dispositivo deve ser o mesmo que o nome do arquivo de configuração configurado para o dispositivo.
Preparação de arquivos de script
Sobre arquivos de script
Os arquivos de script podem ser usados para atualização automática de software e configuração automática.
O dispositivo suporta scripts Python (arquivos.py) e scripts Tcl (arquivos.tcl). Para obter mais informações sobre scripts Python e Tcl, consulte "Usando Python" e "Usando Tcl".
O dispositivo suporta arquivos de script dedicados e arquivos de script dedicados comuns. Ele não é compatível com o uso de um arquivo de script padrão. Para obter informações sobre arquivos de script dedicados e arquivos de script dedicados comuns, consulte a Tabela 2.
Quando são usados arquivos de script, não é possível usar um arquivo de nome de host para fornecer os mapeamentos de nome de host e endereço IP para dispositivos.
Restrições e diretrizes
Para usar um script Tcl, verifique se todos os comandos do script são compatíveis e estão configurados corretamente. Qualquer erro em um comando faz com que o processo de configuração automática seja encerrado.
Procedimento
- Para dispositivos que compartilham todas ou algumas configurações, crie um arquivo de script que contenha as configurações comuns.
- Para os outros dispositivos, crie um arquivo de script separado para cada um deles.
Configuração do servidor DHCP
Sobre o servidor DHCP
O servidor DHCP atribui os seguintes itens aos dispositivos que precisam ser configurados automaticamente:
- Endereços IP.
- Caminhos dos arquivos de configuração ou de script.
Restrições e diretrizes
Quando você configurar o servidor DHCP, siga estas diretrizes:
- Para dispositivos para os quais você preparou arquivos de configuração diferentes, execute as seguintes tarefas para cada um dos dispositivos no servidor DHCP:
- Criar um pool de endereços DHCP.
- Configure uma vinculação de endereço estático.
- Especifique um arquivo de configuração ou de script.
- Para dispositivos para os quais você preparou o mesmo arquivo de configuração, use um dos seguintes métodos:
- Método 1:
- Crie um pool de endereços DHCP para os dispositivos.
- Configure uma vinculação de endereço estático para cada um dos dispositivos no pool de endereços.
- Especifique o arquivo de configuração para os dispositivos.
- Método 2:
- Crie um pool de endereços DHCP para os dispositivos.
- Especifique a sub-rede para alocação dinâmica.
- Especifique o servidor TFTP.
- Especifique o arquivo de configuração para os dispositivos.
- Se todos os dispositivos em uma sub-rede compartilharem o mesmo arquivo de configuração ou arquivo de script, execute as seguintes tarefas no servidor DHCP:
- Configurar a alocação dinâmica de endereços.
- Especifique o arquivo de configuração ou o arquivo de script para os dispositivos.
Como um pool de endereços pode usar apenas um arquivo de configuração, você pode especificar apenas uma associação de endereço estático para um pool de endereços.
O arquivo de configuração pode conter apenas as configurações comuns dos dispositivos. Você pode fornecer um método para os administradores de dispositivos alterarem as configurações após a inicialização dos dispositivos.
Configuração do servidor DHCP quando um servidor de arquivos HTTP é usado
- Entre na visualização do sistema.
system-viewdhcp enablePor padrão, o DHCP está desativado.
dhcp server ip-pool pool-nameEscolha as opções para configurar conforme necessário:
- Especifique a sub-rede primária para o pool de endereços:
network network-address [ mask-length | mask mask ] Por padrão, nenhuma sub-rede primária é especificada.
static-bind ip-address ip-address [ mask-length | mask mask ] { client-identifier client-identifier | hardware-address hardware-address [ ethernet | token-ring ] } Por padrão, nenhuma associação estática é configurada.
Você pode configurar vários vínculos estáticos. No entanto, um endereço IP pode ser vinculado a apenas um cliente. Para alterar a associação de um cliente DHCP, você deve remover a associação e reconfigurar uma associação.
bootfile-name urlPor padrão, nenhum URL de arquivo de configuração ou script é especificado.
Configuração do servidor DHCP quando um servidor de arquivos TFTP é usado
- Entre na visualização do sistema.
system-viewdhcp enablePor padrão, o DHCP está desativado.
dhcp server ip-pool pool-nameEscolha as opções para configurar conforme necessário:
- Especifique a sub-rede primária para o pool de endereços:
network network-address [ mask-length | mask mask ] Por padrão, nenhuma sub-rede primária é especificada.
static-bind ip-address ip-address [ mask-length | mask mask ] { client-identifier client-identifier | hardware-address hardware-address [ ethernet | token-ring ] } Por padrão, nenhuma associação estática é configurada.
Você pode configurar vários vínculos estáticos. No entanto, um endereço IP pode ser vinculado a apenas um cliente. Para alterar a associação de um cliente DHCP, você deve remover a associação e reconfigurar uma associação.
TFTP. Escolha uma opção conforme necessário:
- Especifique o endereço IP do servidor TFTP:
tftp-server ip-address ip-addressPor padrão, nenhum endereço IP do servidor TFTP é especificado.
tftp-server domain-name domain-namePor padrão, nenhum nome de servidor TFTP é especificado.
Se você especificar um servidor TFTP por seu nome, será necessário um servidor DNS na rede.
bootfile-name bootfile-namePor padrão, nenhum nome de arquivo de configuração ou de script é especificado.
Configuração do servidor DNS
Um servidor DNS é necessário nas seguintes situações:
- O servidor TFTP não tem um arquivo de nome de host.
- O servidor DHCP atribui o nome de domínio do servidor TFTP por meio da mensagem de resposta do DHCP. Os dispositivos devem usar o nome de domínio para obter o endereço IP do servidor TFTP.
Os dispositivos precisam fornecer ao servidor DNS seus endereços IP para obter seus nomes de host. Em seguida, os dispositivos podem obter arquivos de configuração nomeados no formato host name.cfg do servidor TFTP.
Configuração do gateway
Se os dispositivos a serem configurados automaticamente e os servidores para configuração automática residirem em segmentos de rede diferentes, você deverá executar as seguintes tarefas:
- Implante um gateway e certifique-se de que os dispositivos possam se comunicar com os servidores.
- Configure o recurso de agente de retransmissão DHCP no gateway.
- Configure o recurso auxiliar de UDP no gateway.
- A resposta do DHCP não contém o endereço IP ou o nome de domínio do servidor TFTP.
- O endereço IP ou o nome de domínio do servidor TFTP é inválido.
Essa tarefa é necessária se os dispositivos enviarem solicitações a um servidor TFTP usando pacotes de difusão. Um dispositivo usa pacotes de difusão para enviar solicitações a um servidor TFTP nas seguintes situações:
O auxiliar UDP transforma um pacote de difusão em um pacote unicast e encaminha o pacote unicast para o servidor de arquivos. Para obter mais informações sobre o auxiliar UDP, consulte o Guia de Configuração de Serviços de Camada 3 IP.
Preparar a interface usada para a configuração automática
O dispositivo usa as seguintes etapas para selecionar a interface para configuração automática:
- Identifica o status da interface Ethernet de gerenciamento na Camada 2. Se o status for "up", o dispositivo usará a interface Ethernet de gerenciamento.
- Identifica o status das interfaces Ethernet de camada 2. Se uma ou mais interfaces Ethernet de camada 2 estiverem em estado ativo, o dispositivo usará a interface VLAN da VLAN padrão.
- Se nenhuma interface Ethernet de camada 2 estiver em estado ativo, o dispositivo aguardará 30 segundos e voltará à etapa 1 para tentar novamente.
Para uma configuração automática rápida do dispositivo, conecte à rede apenas a interface Ethernet de gerenciamento de cada dispositivo.
Início e conclusão da configuração automática
- Ligue os dispositivos a serem configurados automaticamente.
- Se o dispositivo obtiver um arquivo de configuração e executá-lo com êxito, o processo de configuração automática será encerrado.
- Se uma tentativa falhar, o dispositivo tentará novamente até que o número máximo de tentativas seja atingido. Para interromper o processo, pressione Ctrl+C ou Ctrl+D.
- Salve a configuração em execução.
Se um dispositivo não encontrar um arquivo de configuração de próxima inicialização localmente, ele iniciará o processo de configuração automática para obter um arquivo de configuração.
Se o dispositivo não conseguir obter um arquivo de configuração, ele será iniciado sem carregar nenhuma configuração.
salvarO dispositivo não salva localmente o arquivo de configuração obtido. Se você não salvar a configuração em execução, o dispositivo deverá usar o recurso de configuração automática novamente após uma reinicialização.
Para obter mais informações sobre o comando save, consulte Referência de comandos dos fundamentos.
Exemplos de configuração automática baseada em servidor
Exemplo: Uso de um servidor TFTP para configuração automática
Configuração de rede
Conforme mostrado na Figura 2, dois departamentos de uma empresa estão conectados à rede por meio de gateways (Switch B e Switch C). Os dispositivos de acesso Switch D, Switch E, Switch F e Switch G não têm um arquivo de configuração.
Configure os servidores e gateways para que os dispositivos de acesso possam obter um arquivo de configuração para concluir as tarefas de configuração a seguir:
- Permitir que os administradores de dispositivos de acesso façam Telnet e gerenciem seus respectivos dispositivos de acesso.
- Exigir que os administradores digitem seus respectivos nomes de usuário e senhas no login.
Figura 2 Diagrama de rede
Procedimento
- Configure o servidor DHCP:
# Crie uma interface VLAN e atribua um endereço IP à interface.
<SwitchA> system-view
[SwitchA] vlan 2
[SwitchA-vlan2] port gigabitethernet 1/0/1
[SwitchA-vlan2] quit
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 192.168.1.42 24
[SwitchA-Vlan-interface2] quit
# Habilite o DHCP.
[SwitchA] dhcp enable# Habilite o servidor DHCP na interface VLAN 2. [SwitchA] interface vlan-interface 2 [SwitchA-Vlan-interface2] dhcp select server [SwitchA-Vlan-interface2] quit
SwitchA] interface vlan-interface 2 [SwitchA-Vlan-interface2] dhcp select server [SwitchA-Vlan-interface2] quit# Configure o pool de endereços market para atribuir endereços IP na sub-rede 192.168.2.0/24 aos clientes do departamento de Marketing. Especifique o servidor TFTP, o gateway e o nome do arquivo de configuração para os clientes.
[SwitchA] dhcp server ip-pool market
[SwitchA-dhcp-pool-market] network 192.168.2.0 24
[SwitchA-dhcp-pool-market] tftp-server ip-address 192.168.1.40
[SwitchA-dhcp-pool-market] gateway-list 192.168.2.1
[SwitchA-dhcp-pool-market] bootfile-name market.cfg
[SwitchA-dhcp-pool-market] quit
# Configure o pool de endereços rd para atribuir endereços IP na sub-rede 192.168.3.0/24 aos clientes em
[SwitchA] dhcp server ip-pool rd
[SwitchA-dhcp-pool-rd] network 192.168.3.0 24
[SwitchA-dhcp-pool-rd] tftp-server ip-address 192.168.1.40
[SwitchA-dhcp-pool-rd] gateway-list 192.168.3.1
[SwitchA-dhcp-pool-rd] bootfile-name rd.cfg
[SwitchA-dhcp-pool-rd] quit
# Configure rotas estáticas para os agentes de retransmissão DHCP.
[SwitchA] ip route-static 192.168.2.0 24 192.168.1.41
[SwitchA] ip route-static 192.168.3.0 24 192.168.1.43
[SwitchA] quit
# Crie interfaces de VLAN e atribua endereços IP às interfaces.
<SwitchB> system-view
[SwitchB] vlan 2
[SwitchB-vlan2] port gigabitethernet 1/0/3
[SwitchB-vlan2] quit
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address 192.168.1.41 24
[SwitchB-Vlan-interface2] quit
[SwitchB] vlan 3
[SwitchB-vlan3] port gigabitethernet 1/0/1
[SwitchB-vlan3] port gigabitethernet 1/0/2
[SwitchB-vlan3] quit
[SwitchB] interface vlan-interface 3
[SwitchB-Vlan-interface3] ip address 192.168.2.1 24
[SwitchB-Vlan-interface3] quit
# Habilite o DHCP.
[SwitchB] dhcp enable# Habilite o agente de retransmissão DHCP na interface VLAN 3.
SwitchB] interface vlan-interface 3 # Especifique o endereço do servidor DHCP.
[SwitchB-Vlan-interface3] dhcp relay server-address 192.168.1.42# Crie interfaces de VLAN e atribua endereços IP às interfaces.
<SwitchC> system-view
[SwitchC] vlan 2
[SwitchC-vlan2] port gigabitethernet 1/0/3
[SwitchC-vlan2] quit
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] ip address 192.168.1.43 24
[SwitchC-Vlan-interface2] quit
[SwitchC] vlan 3
[SwitchC-vlan3] port gigabitethernet 1/0/1
[SwitchC-vlan3] port gigabitethernet 1/0/2
[SwitchC-vlan3] quit
[SwitchC] interface vlan-interface 3
[SwitchC-Vlan-interface3] ip address 192.168.3.1 24
[SwitchC-Vlan-interface3] quit
# Habilite o DHCP.
[SwitchC] dhcp enable# Habilite o agente de retransmissão DHCP na interface VLAN 3.
[SwitchC] interface vlan-interface 3 [SwitchC-Vlan-interface3] dhcp select relay # Especifique o endereço do servidor DHCP.
[SwitchC-Vlan-interface3] dhcp relay server-address 192.168.1.42# No servidor TFTP, crie um arquivo de configuração chamado market.cfg.
#
sysname Market
#
telnet server enable
#
vlan 3
#
local-user market
password simple market
service-type telnet
quit
#
interface Vlan-interface3
ip address dhcp-alloc
quit
#
interface gigabitethernet 1/0/1
port access vlan 3
quit
#
user-interface vty 0 63
authentication-mode scheme
user-role network-admin
#
return
# No servidor TFTP, crie um arquivo de configuração chamado rd.cfg.
#
sysname RD
#
telnet server enable
#
vlan 3 #
local-user rd
password simple rd
service-type telnet
quit
#
interface Vlan-interface3
ip address dhcp-alloc
quit
#
interface gigabitethernet 1/0/1
port access vlan 3
quit
#
user-interface vty 0 63
authentication-mode scheme
user-role network-admin
#
return
# Inicie o software do serviço TFTP e especifique a pasta em que os dois arquivos de configuração residem como o diretório de trabalho. (Detalhes não mostrados.)
# Verifique se o servidor TFTP e os agentes de retransmissão DHCP podem se comunicar. (Detalhes não mostrados.)
Verificação da configuração
- Ligue o Switch D, Switch E, Switch F e o Switch G
- Após a inicialização dos dispositivos de acesso, exiba os endereços IP atribuídos no Switch A.
<SwitchA> display dhcp server ip-in-use
IP address Client-identifier/ Lease expiration Type
Hardware address
192.168.2.2 3030-3066-2e65-3233- May 6 05:21:25 2013 Auto(C)
642e-3561-6633-2d56-
6c61-6e2d-696e-7465-
7266-6163-6533
192.168.2.3 3030-3066-2e65-3230- May 6 05:22:50 2013 Auto(C)
302e-3232-3033-2d56-
6c61-6e2d-696e-7465-
7266-6163-6533
192.168.3.2 3030-6530-2e66-6330- May 6 05:23:15 2013 Auto(C)
302e-3335-3131-2d56-
6c61-6e2d-696e-7465-
7266-6163-6531
192.168.3.3 3030-6530-2e66-6330- May 6 05:24:10 2013 Auto(C)
302e-3335-3135-2d56-
6c61-6e2d-696e-7465-
7266-6163-6532
<SwitchA> telnet 192.168.2.2Você está conectado ao Switch D ou Switch E.
Exemplo: Uso de um servidor HTTP e scripts Tcl para configuração automática
Configuração de rede
Conforme mostrado na Figura 3, o Switch A não tem um arquivo de configuração.
Configure os servidores para que o Switch A possa obter um script Tcl para concluir as seguintes tarefas de configuração:
- Permitir que o administrador faça Telnet no Switch A para gerenciar o Switch A.
- Exigir que o administrador digite o nome de usuário e a senha corretos no login.
Figura 3 Diagrama de rede
Procedimento
- Configure o servidor DHCP:
# Habilite o DHCP.
<DeviceA> system-view
[DeviceA] dhcp enable# Configure o pool de endereços 1 para atribuir endereços IP na sub-rede 192.168.1.0/24 aos clientes.
[DeviceA] dhcp server ip-pool 1
[DeviceA-dhcp-pool-1] network 192.168.1.0 24
# Especifique o URL do arquivo de script para os clientes.
[DeviceA-dhcp-pool-1] bootfile-name http://192.168.1.40/device.tcl# Crie um arquivo de configuração chamado device.tcl no servidor HTTP.
system-view
telnet server enable
local-user user
password simple abcabc
service-type telnet
quit
user-interface vty 0 63
authentication-mode scheme
user-role network-admin
quit
interface Vlan-interface 1
ip address dhcp-alloc
return
# Inicie o software de serviço HTTP e ative o serviço HTTP. (Detalhes não mostrados).
Verificação da configuração
- Ligue o Switch A.
- Após a inicialização do Switch A, exiba os endereços IP atribuídos no Dispositivo A.
<DeviceA> display dhcp server ip-in-use
IP address Client identifier/ Lease expiration Type
Hardware address
192.168.1.2 0030-3030-632e-3239- Dec 12 17:41:15 2013 Auto(C)
3035-2e36-3736-622d-
4574-6830-2f30-2f32
telnet 192.168.1.2 Você está conectado ao Switch A.
Exemplo: Usando um servidor HTTP e scripts Python para configuração automática
Configuração de rede
Conforme mostrado na Figura 4, o Switch A não tem um arquivo de configuração.
Configure os servidores para que o Switch A possa obter um script Python para concluir as seguintes tarefas de configuração:
- Permitir que o administrador faça Telnet no Switch A para gerenciar o Switch A.
- Exigir que o administrador digite o nome de usuário e a senha corretos no login.
Figura 4 Diagrama de rede
Procedimento
- Configure o servidor DHCP:
# Habilite o DHCP.
<DeviceA> system-view
[DeviceA] dhcp enable# Configure o pool de endereços 1 para atribuir endereços IP na sub-rede 192.168.1.0/24 aos clientes.
[DeviceA] dhcp server ip-pool 1
[DeviceA-dhcp-pool-1] network 192.168.1.0 24
# Especifique o URL do arquivo de script para os clientes.
[DeviceA-dhcp-pool-1] bootfile-name http://192.168.1.40/device.py# Crie um arquivo de configuração chamado device.py no servidor HTTP.
#!usr/bin/python
import comware
comware.CLI('system-view ;telnet server enable ;local-user user ;password simple
abcabc ;service-type telnet ;quit ;user-interface vty 0 63 ;authentication-mode
scheme ;user-role network-admin ;quit ;interface Vlan-interface 1 ;ip address
dhcp-alloc ;return')
# Inicie o software de serviço HTTP e ative o serviço HTTP. (Detalhes não mostrados).
Verificação da configuração
- Ligue o Switch A.
- Após a inicialização do Switch A, exiba os endereços IP atribuídos no Dispositivo A.
<DeviceA> display dhcp server ip-in-use
IP address Client identifier/ Lease expiration Type
Hardware address
192.168.1.2 0030-3030-632e-3239- Dec 12 17:41:15 2013 Auto(C)
3035-2e36-3736-622d-
4574-6830-2f30-2f32
<DeviceA> telnet 192.168.1.2Exemplo: Configuração de uma malha IRF
Configuração de rede
Conforme mostrado na Figura 5, o Switch A e o Switch B não têm um arquivo de configuração.
Configure os servidores para que os switches possam obter um script Python para concluir suas respectivas configurações e formar uma malha IRF.
Figura 5 Diagrama de rede
Procedimento
- Atribua endereços IP às interfaces. Certifique-se de que os dispositivos possam se comunicar entre si. (Detalhes não mostrados).
- Configure os seguintes arquivos no servidor HTTP:
- (Opcional.) Verifique se a memória flash tem espaço suficiente para os arquivos a serem baixados.
- Faça o download do arquivo de configuração e sn.txt.
- (Opcional.) Faça o download do arquivo de imagem do software e especifique-o como o arquivo de imagem de inicialização principal.
- Resolva o sn.txt e atribua um ID de membro IRF exclusivo a cada SN.
- Especifique o arquivo de configuração como o principal arquivo de configuração da próxima inicialização.
- Reinicialize os switches membros.
- Configure o Dispositivo A como o servidor DHCP:
| Arquivo | Conteúdo | Observações |
| Arquivo de configuração .cfg | Comandos necessários para a configuração da IRF. | Você pode criar um arquivo de configuração copiando e modificando o arquivo de configuração de uma malha IRF existente. |
| sn.txt | Números de série dos switches membros. | Cada SN identifica um switch de forma exclusiva. Esses SNs serão usados para atribuir um ID de membro IRF exclusivo a cada switch membro. |
| (Opcional.) Arquivo de imagem de software .ipe ou .bin | Imagens de software. | Se os switches membros estiverem executando versões de software diferentes, você deverá preparar o arquivo de imagem de software usado para o upgrade de software. |
| .py Arquivo de script Python | Comandos Python que realizam as seguintes tarefas:
|
Para obter mais informações sobre a configuração de scripts Python, consulte "Usando Python". |
# Habilite o DHCP.
<DeviceA> system-view
[DeviceA] dhcp enable
# Configure o pool de endereços 1 para atribuir endereços IP na sub-rede 192.168.1.0/24 aos clientes.
[DeviceA] dhcp server ip-pool 1
[DeviceA-dhcp-pool-1] network 192.168.1.0 24
# Especifique o URL do arquivo de script para os clientes.
[DeviceA-dhcp-pool-1] bootfile-name http://192.168.1.40/device.py
[DeviceA-dhcp-pool-1] quit
# Habilite o servidor DHCP na GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] dhcp select server
[DeviceA-GigabitEthernet1/0/1] quit
O Switch A e o Switch B obterão o arquivo de script Python do servidor DHCP e executarão o script. Após concluir a configuração do IRF, o Switch A e o Switch B são reinicializados.
O Switch A e o Switch B elegerão um membro mestre. O membro subordinado será reinicializado para se juntar à malha IRF.
Verificação da configuração
# No Switch A, exiba os dispositivos membros da IRF. Você também pode usar o comando display irf no Switch B para exibir os dispositivos membros da IRF.
<Switch A> display irf
MemberID Slot Role Priority CPU-Mac Description
1 1 Standby 1 00e0-fc0f-8c02 ---
*+2 1 Master 30 00e0-fc0f-8c14 ---
----------------------------------------------------------------
* indicates the device is the master.
+ indicates the device through which the user logs in.
The Bridge MAC of the IRF is: 000c-1000-1111
Auto upgrade : yes
Mac persistent : always
Domain ID : 0
Auto merge : yes
A saída mostra que os switches formaram uma malha IRF.
Gerenciamento de licenças
Sobre as licenças
Para usar os recursos baseados em licença, você deve adquirir licenças da Intelbras e instalá-las.
Para obter informações sobre os recursos baseados em licença, seu status de licenciamento e a disponibilidade de licenças, execute o comando display license feature no dispositivo. Em seguida, você pode comprar e instalar licenças conforme necessário.
Para instalar uma licença formal para um recurso:
- Adquirir um certificado de licença de software por meio de um canal oficial.
- Acesse a plataforma de gerenciamento de licenças da Intelbras em http://www.Intelbras.com/en/License e, em seguida, insira a chave de licença no certificado e as informações necessárias do dispositivo para obter um arquivo de ativação.
- Instale o arquivo de ativação no dispositivo.
Conceitos básicos
As informações a seguir descrevem os conceitos básicos que você pode encontrar ao registrar, instalar e gerenciar licenças.
Plataforma de gerenciamento de licenças da Intelbras
A plataforma de gerenciamento de licenças da Intelbras fornece serviços de licenciamento de produtos para os clientes da Intelbras. Você pode acessar esse sistema para obter um arquivo de ativação.
A plataforma de gerenciamento de licenças da Intelbras pode ser acessada em http://www.Intelbras.com/en/License/.
Certificado de licença de software
Um certificado de licença de software permite que os usuários usem um recurso baseado em licença. Ele contém a chave de licença, a capacidade da licença e outras informações.
Chave de licença
Uma chave de licença identifica exclusivamente uma licença.
Para obter uma chave de licença formal, adquira um certificado de licença de software. O número de série da autorização no certificado de licença do software é a chave de licença.
Número de série do dispositivo
Um número de série do dispositivo (SN ou S/N) é um código de barras que identifica exclusivamente um dispositivo. Ele vem com o dispositivo e deve ser fornecido quando você solicita uma licença na plataforma de gerenciamento de licenças da Intelbras.
ID do dispositivo (DID) e arquivo DID
Um DID é uma cadeia de caracteres que identifica exclusivamente um dispositivo de hardware. Um arquivo DID armazena o DID e outras informações. O dispositivo vem com um arquivo DID ou DID. Você deve fornecer o arquivo DID ou DID ao solicitar uma licença para o dispositivo na plataforma de gerenciamento de licenças da Intelbras.
Arquivo de ativação
Para usar um recurso baseado em licença em um sistema, é necessário executar as seguintes tarefas:
- Use a chave de licença e as informações de SN e DID do sistema para obter um arquivo de ativação da plataforma de gerenciamento de licenças da Intelbras.
- Instale o arquivo de ativação no sistema.
Chave de desinstalação e arquivo de desinstalação
Quando você desinstala uma licença, é criado um arquivo Uninstall que contém uma chave Uninstall. A chave Uninstall é necessária para a transferência da licença.
Armazenamento de licenças
O armazenamento de licenças é um armazenamento persistente de tamanho fixo para armazenar informações de licenciamento. Essas informações incluem o estado da licença, o período de validade, a chave de desinstalação ou o arquivo de desinstalação e outras informações relacionadas.
Os dados no armazenamento de licenças persistem durante a reinicialização. Isso garante a precisão e a continuidade do licenciamento.
Restrições e diretrizes: Gerenciamento de licenças
Restrições de operações de gerenciamento
- Adquira licenças nos canais oficiais da Intelbras.
- Para licenças que foram instaladas no dispositivo, execute o comando display license para visualizar o período de validade da licença. Para usar um recurso baseado em licença continuamente, instale uma nova licença para o recurso antes que a licença antiga expire.
- Normalmente, as licenças são bloqueadas por dispositivo. Para garantir um licenciamento bem-sucedido, use as seguintes diretrizes de licenciamento:
- Ao adquirir um certificado de licença, verifique os seguintes itens:
- Certifique-se de que a licença seja compatível com o dispositivo de destino.
- Certifique-se de que a funcionalidade e a capacidade licenciadas atendam às suas necessidades.
- Ao obter um arquivo de ativação, verifique se a chave de licença fornecida e as informações de hardware estão corretas.
- Instale o arquivo de ativação no dispositivo de destino correto.
- Certifique-se de que ninguém mais esteja executando tarefas de gerenciamento de licenças enquanto você estiver gerenciando licenças no dispositivo.
Restrições de operação de arquivos
Ao gerenciar arquivos DID, arquivos de ativação ou arquivos de desinstalação, siga estas restrições e diretrizes:
- Para evitar erros de licenciamento, não modifique o nome de um arquivo DID, arquivo de ativação ou arquivo de desinstalação, nem edite o conteúdo do arquivo.
- Antes de instalar um arquivo de ativação, faça o download do arquivo de ativação para a mídia de armazenamento do dispositivo, como a memória flash. Ao instalar um arquivo de ativação, o dispositivo copia automaticamente o arquivo de ativação para a pasta de licenças no diretório raiz da mídia de armazenamento. A pasta de licenças armazena arquivos importantes para o licenciamento. Para que os recursos licenciados funcionem corretamente, não exclua nem modifique a pasta de licenças ou os arquivos dessa pasta.
Configuração do licenciamento local
Sobre o licenciamento local
O licenciamento local requer a ativação da licença dispositivo por dispositivo. É aplicável a redes de pequeno porte. Para instalar uma licença em um dispositivo:
- Obtenha a chave de licença, o SN do dispositivo e as informações de DID do dispositivo.
- Acesse a plataforma de gerenciamento de licenças da Intelbras para solicitar um arquivo de ativação com base na chave de licença e nas informações de SN e DID do dispositivo.
- Instale o arquivo de ativação no dispositivo para ativar a licença.
O arquivo de ativação de uma licença está bloqueado por dispositivo. Não é possível instalar o arquivo de ativação de um dispositivo para ativar a licença em outro dispositivo.
Registro e instalação de uma licença
Fluxo de trabalho de registro e instalação de licenças
Este capítulo descreve apenas as operações realizadas no dispositivo e na plataforma de gerenciamento de licenças da Intelbras. Para obter mais informações, consulte o guia de licenciamento do dispositivo.
Identificação do armazenamento de licenças
Para identificar o espaço livre do armazenamento de licenças, execute o seguinte comando em qualquer visualização:
display license featureNa saída do comando, visualize os campos Total e Uso para examinar se o armazenamento de licenças restante é suficiente para a instalação de novas licenças. Se o armazenamento de licenças restante não for suficiente, comprima o armazenamento de licenças.
Compactação do armazenamento de licenças
Sobre esta tarefa
O armazenamento de licenças armazena informações de licenciamento e tem um tamanho fixo.
Você pode compactar o armazenamento de licenças para excluir informações de licenças expiradas e desinstaladas e garantir espaço de armazenamento suficiente para a instalação de novas licenças.
Se nenhuma licença tiver sido instalada no dispositivo, não será necessário compactar o armazenamento de licenças.
Pré-requisitos
Faça o backup das chaves de desinstalação ou dos arquivos de desinstalação das licenças desinstaladas para transferência ou desinstalação subsequente de licenças.
Se houver licenças desinstaladas ou expiradas no dispositivo, a operação de compactação fará com que o arquivo DID ou DID seja alterado. Você não conseguirá instalar o arquivo de ativação obtido usando o arquivo DID ou DID antigo no dispositivo. Como prática recomendada, instale todos os arquivos de ativação registrados com o arquivo DID ou DID antigo antes de executar uma compactação.
Se você não tiver instalado um arquivo de ativação registrado com o DID antigo, execute as seguintes ações:
- Se o armazenamento da licença for suficiente, instale o arquivo de ativação no dispositivo.
- Se o armazenamento da licença for insuficiente e o arquivo de ativação não puder ser instalado após a compactação , entre em contato com o Suporte da Intelbras.
Procedimento
- Entre na visualização do sistema.
system-viewlicense compress slot slot-numberObtenção das informações necessárias para o registro da licença
Para obter as informações de SN e DID, execute o seguinte comando em qualquer visualização:
display license device-id slot slot-numberRegistro de uma licença na plataforma de gerenciamento de licenças da Intelbras
Sobre o registro de uma licença
O registro da licença tem os seguintes procedimentos:
- Registro de licenças pela primeira vez - Registre uma licença para um dispositivo que não tenha sido registrado anteriormente.
- Registro de licenças de upgrade - Registre licenças para expansão de capacidade, aprimoramento de recursos ou extensão de tempo. Esse procedimento também se aplica ao cenário em que você registra uma nova licença para um dispositivo com licenças expiradas ou desinstaladas.
Se você não souber qual procedimento de registro deve ser usado, selecione o registro de licenças pela primeira vez. Se a seleção não estiver correta, o site exibirá mensagens para a escolha correta do registro depois que você inserir as informações necessárias.
Restrições e diretrizes
Se não for possível fazer o download do arquivo de ativação devido a problemas como erros no sistema operacional e no navegador, tente registrar novamente a licença. Se o problema persistir, entre em contato com o Suporte da Intelbras.
Registro de licenças pela primeira vez
- Visite o site da Intelbras em http://www.Intelbras.com/en/License/.
- Selecione Registrar a primeira vez.
- Digite o número de série da autorização no campo Input the license key e clique em Submit .
- Na caixa de diálogo, selecione uma categoria de produto na lista suspensa Product category e clique em OK.
- Digite o SN do dispositivo.
- Digite o DID ou carregue o arquivo DID.
- Digite as informações de contato necessárias e o código de verificação, selecione I accept all terms of Intelbras Legal Statement e clique em Get activation key or file.
- Faça o download do arquivo de ativação para o PC.
Uma caixa de diálogo é aberta, exibindo as categorias de produtos que correspondem à chave de licença.
Uma cópia do arquivo de ativação também será enviada para o endereço de e-mail informado nas informações de contato.
Registro de licenças de upgrade
- Visite o site da Intelbras em http://www.Intelbras.com/en/License/.
- Selecione Registrar licenças de upgrade.
- Digite o número de série da autorização no campo Input the license key e clique em Submit.
- Na caixa de diálogo, selecione uma categoria de produto na lista suspensa Product category e clique em OK.
- Digite o SN do dispositivo.
- Digite o DID ou carregue o arquivo DID e clique em Submit.
- Digite as informações de contato necessárias e o código de verificação, selecione I accept all terms of Intelbras Legal Statement e clique em Get activation key or file.
- Faça o download do arquivo de ativação para o PC.
Uma caixa de diálogo é aberta, exibindo as categorias de produtos que correspondem à chave de licença.
Uma cópia do arquivo de ativação também será enviada para o endereço de e-mail informado nas informações de contato.
Instalação de um arquivo de ativação
Sobre esta tarefa
 CUIDADO:
CUIDADO:
Faça backup de um arquivo de ativação antes de instalá-lo. Se o arquivo de
ativação for excluído inadvertidamente ou ficar indisponível por algum outro motivo, você poderá
usar o arquivo de ativação de backup para restaurar a licença.
Para obter uma licença, instale um arquivo de ativação para a licença no dispositivo.
Pré-requisitos
Use FTP ou TFTP para carregar o arquivo de ativação a ser instalado no dispositivo. Se o FTP for usado para transferir o arquivo de ativação, defina-o no modo binário.
Procedimento
- Entre na visualização do sistema.
system-viewlicense activation-file install file-name slot slot-numberÉ possível instalar um único arquivo .ak ou vários arquivos .ak em uma única operação. Para instalar vários arquivos .ak, salve todos os arquivos de ativação no mesmo diretório e especifique o diretório como o valor do argumento nome do arquivo.
Transferência de uma licença
Sobre esta tarefa
Execute esta tarefa para transferir uma licença que não tenha expirado de um dispositivo para outro da mesma série de produtos.
Fluxo de trabalho de transferência de licenças
Este capítulo descreve apenas as operações realizadas no dispositivo de origem. Para as operações realizadas no dispositivo de destino, consulte "Registro e instalação de uma licença". Para obter mais informações sobre a transferência de licenças, entre em contato com o Suporte da Intelbras.
Obtenção de um arquivo de desinstalação
- Execute o comando display license para visualizar o arquivo de ativação a ser desinstalado.
- Entre na visualização do sistema.
system-viewlicense activation-file uninstall license-file slot slot-numberÉ possível desinstalar um único arquivo .ak ou vários arquivos .ak em uma única operação. Para desinstalar vários arquivos .ak, salve todos os arquivos de ativação no mesmo diretório e especifique o diretório como o valor do argumento license-file.
Desinstalação de uma licença
Sobre a desinstalação da licença
Uma chave de licença é vinculada a um dispositivo quando você ativa a chave de licença na plataforma de gerenciamento de licenças da Intelbras. Não é possível vincular essa chave de licença a outro dispositivo. Para desvincular uma chave de licença de uma licença que não tenha expirado em um dispositivo, obtenha a chave de desinstalação ou o arquivo de desinstalação da licença no dispositivo. Em seguida, entre em contato com o Suporte da Intelbras para concluir a desinstalação da licença.
Para restaurar a licença no dispositivo local ou transferir a licença para outro dispositivo, é necessário entrar em contato com o Suporte da Intelbras para obter um novo arquivo de ativação para a licença. Em seguida, instale o novo arquivo de ativação no dispositivo de destino.
Fluxo de trabalho de desinstalação da licença
Para obter informações sobre como obter o arquivo de desinstalação, consulte "Obtenção de um arquivo de desinstalação". Para obter mais informações sobre a desinstalação da licença, entre em contato com o Suporte da Intelbras.
Recuperação de um arquivo de ativação
Se você excluir por engano um arquivo de ativação, use o procedimento a seguir para recuperar o arquivo de ativação:
- Use o comando copy para copiar o arquivo de ativação de backup para a pasta de licenças no diretório raiz da mídia de armazenamento.
- Use o comando display license para verificar se o estado do arquivo de ativação recuperado é Em uso
- Reinicie o dispositivo se o estado da licença for Em uso, mas o recurso licenciado não puder funcionar corretamente.
Comandos de exibição e manutenção para gerenciamento de licenças
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações detalhadas sobre a licença. | display license [ activation-file ] [ slot slot-number ] |
| Exibir as informações de SN e DID. | display license device-id slot slot-number |
| Exibir informações breves sobre a licença do recurso. | display license feature |
02 - Virtual Tecnologies
Configuração de uma malha IRF
Sobre a IRF
A tecnologia Intelligent Resilient Framework (IRF) virtualiza vários dispositivos físicos na mesma camada em uma malha virtual para oferecer disponibilidade e escalabilidade de classe de data center. A tecnologia de virtualização IRF oferece capacidade de processamento, interação, gerenciamento unificado e manutenção ininterrupta de vários dispositivos.
Modelo de rede IRF
A Figura 1 mostra uma malha IRF com dois dispositivos, que aparecem como um único nó para os dispositivos da camada superior e da camada inferior.
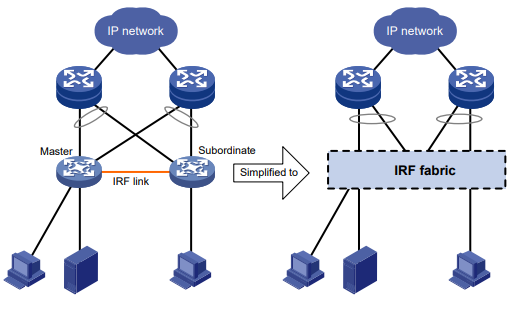
Figura 1 Cenário de aplicação da IRF
Benefícios da IRF
O IRF oferece os seguintes benefícios:
- Topologia simplificada e gerenciamento fácil - Uma malha IRF aparece como um nó e é acessível em um único endereço IP na rede. Você pode usar esse endereço IP para fazer login em qualquer dispositivo membro e gerenciar todos os membros da malha IRF. Além disso, não é necessário executar o recurso spanning tree entre os membros da IRF.
- Redundância 1:N - Em uma malha IRF, um membro atua como mestre para gerenciar e controlar toda a malha IRF. Todos os outros membros processam serviços enquanto fazem o backup do mestre. Quando o mestre falha, todos os outros dispositivos membros elegem um novo mestre entre eles para assumir o controle sem interromper os serviços.
- Agregação de links IRF - Você pode atribuir vários links físicos entre membros vizinhos às suas portas IRF para criar uma conexão IRF agregada com balanceamento de carga e redundância.
- Agregação de link de vários chassis - Você pode usar o recurso de agregação de link Ethernet para agregar os links físicos entre a malha da IRF e seus dispositivos upstream ou downstream entre os membros da IRF.
- Escalabilidade e resiliência da rede - A capacidade de processamento de uma malha IRF é igual à capacidade total de processamento de todos os membros. Você pode aumentar as portas, a largura de banda da rede e a capacidade de processamento de uma malha IRF simplesmente adicionando dispositivos membros sem alterar a topologia da rede .
Conceitos básicos
Funções dos membros da IRF
A IRF usa duas funções de membro: mestre e reserva (chamada de subordinada em toda a documentação).
Quando os dispositivos formam uma malha IRF, eles elegem um mestre para gerenciar e controlar a malha IRF, e todos os outros dispositivos fazem backup do mestre. Quando o dispositivo mestre falha, os outros dispositivos elegem automaticamente um novo mestre. Para obter mais informações sobre a eleição do mestre, consulte "Eleição do mestre".
ID de membro da IRF
Uma malha IRF usa IDs de membro para identificar e gerenciar exclusivamente seus membros. Essas informações de ID de membro são incluídas como a primeira parte dos números de interface e dos caminhos de arquivo para identificar exclusivamente as interfaces e os arquivos em uma malha IRF. Dois dispositivos não poderão formar uma malha IRF se usarem a mesma ID de membro. Um dispositivo não poderá ingressar em uma malha IRF se sua ID de membro tiver sido usada na malha.
Prioridade do membro
A prioridade do membro determina a possibilidade de um dispositivo membro ser eleito o mestre. Um membro com prioridade mais alta tem mais chances de ser eleito o mestre.
Porta IRF
Uma porta IRF é uma interface lógica que conecta dispositivos membros da IRF. Cada dispositivo compatível com IRF tem duas portas IRF.
As portas IRF são denominadas IRF-port n/1 e IRF-port n/2, em que n é a ID de membro do dispositivo. As duas portas IRF são chamadas de IRF-port 1 e IRF-port 2.
Para usar uma porta IRF, você deve vincular no mínimo uma interface física a ela. As interfaces físicas atribuídas a uma porta IRF formam automaticamente um link IRF agregado. Uma porta IRF fica inoperante quando todas as suas interfaces físicas IRF ficam inoperantes.
Interface física IRF
As interfaces físicas IRF conectam os dispositivos membros da IRF e devem ser vinculadas a uma porta IRF. Elas encaminham o tráfego entre os dispositivos membros, inclusive os pacotes de protocolo IRF e os pacotes de dados que devem trafegar entre os dispositivos membros da IRF.
Divisão do IRF
A divisão da IRF ocorre quando uma malha IRF se divide em várias malhas IRF devido a falhas no link da IRF, conforme mostrado na Figura 2. Os fabrics IRF divididos operam com o mesmo endereço IP. A divisão da IRF causa problemas de roteamento e encaminhamento na rede. Para detectar rapidamente uma colisão multiativa, configure no site um mínimo de um mecanismo MAD (consulte "Configuração do MAD").
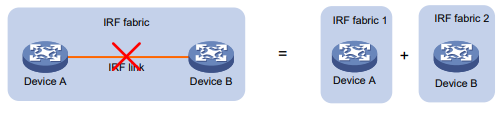
Figura 2 Divisão da IRF
A fusão de IRF ocorre quando duas malhas IRF divididas se reúnem ou quando duas malhas IRF independentes são unidas, conforme mostrado na Figura 3.
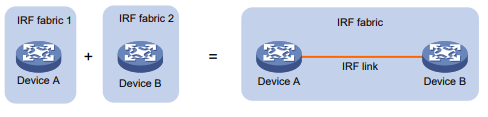
Figura 3 Fusão de IRF
MAD
Uma falha no link IRF faz com que uma malha IRF se divida em duas malhas IRF que operam com as mesmas configurações da Camada 3, incluindo o mesmo endereço IP. Para evitar colisões de endereços IP e problemas de rede, o IRF usa mecanismos de detecção multiativa (MAD) para detectar a presença de vários fabrics IRF idênticos, lidar com colisões e recuperar-se de falhas.
ID do domínio IRF
Uma malha IRF forma um domínio IRF. A IRF usa IDs de domínio IRF para identificar exclusivamente as malhas IRF e evitar que as malhas IRF interfiram umas nas outras.
Conforme mostrado na Figura 4, a malha IRF 1 contém o Dispositivo A e o Dispositivo B, e a malha IRF 2 contém o Dispositivo C e o Dispositivo D. Ambas as malhas usam os links agregados LACP entre elas para MAD. Quando um dispositivo membro recebe um LACPDU estendido para MAD, ele verifica a ID do domínio para determinar se o pacote é da malha IRF local. Em seguida, o dispositivo membro pode tratar o pacote corretamente.
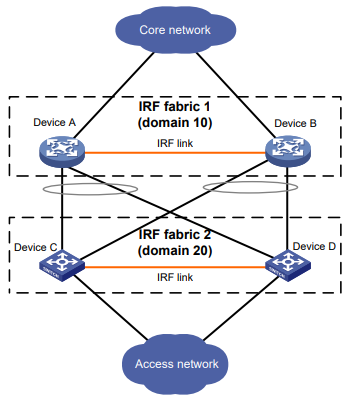
Figura 4 Uma rede que contém dois domínios IRF
Topologia da rede IRF
Uma malha IRF pode usar uma topologia em cadeia ou em anel. Conforme mostrado na Figura 5, a topologia em anel é mais confiável. Na topologia em anel, a falha de um link IRF não faz com que a malha IRF se divida como na topologia em cadeia. Em vez disso, a malha IRF muda para uma topologia de cadeia de margaridas sem interromper os serviços de rede .
Figura 5 Topologia em cadeia vs. topologia em anel
Eleição de mestre
A eleição do mestre ocorre sempre que a topologia da malha IRF é alterada nas seguintes situações:
- A malha IRF é estabelecida.
- O dispositivo mestre falha ou é removido.
- A malha IRF se divide.
- Fusão de tecidos de IRFs independentes.
OBSERVAÇÃO:
A eleição do mestre não ocorre quando as malhas IRF divididas se fundem. Para obter informações sobre o dispositivo mestre da malha IRF mesclada, consulte "Recuperação de falhas".
A eleição do mestre seleciona um mestre em ordem decrescente:
- Mestre atual, mesmo que um novo membro tenha prioridade mais alta.
- Membro com prioridade mais alta.
- Membro com o maior tempo de atividade do sistema.
- Membro com o endereço MAC mais baixo da CPU.
Quando uma malha IRF está sendo formada, todos os membros se consideram o mestre. Essa regra é ignorada.
Considera-se que dois membros iniciam ao mesmo tempo se a diferença entre seus tempos de inicialização for igual ou inferior a 10 minutos. Para esses membros, aplica-se o próximo critério de desempate.
Para a configuração de uma nova malha IRF, os dispositivos subordinados devem ser reinicializados para concluir a configuração após a eleição do mestre.
Para uma mesclagem de IRF, os dispositivos devem ser reinicializados se estiverem na malha IRF que falhar na eleição do mestre.
Convenções de nomenclatura de interface
Uma interface física é numerada no formato chassis-number/slot-number/interface-index.
- chassis-number - ID de membro do dispositivo. O valor padrão para esse argumento é 1. Qualquer alteração na ID do membro entra em vigor após uma reinicialização.
- slot-number - Número do slot da interface. O número do slot é fixo em 0.
- interface-index - índice da interface no dispositivo. O índice da interface depende do número de interfaces físicas disponíveis no dispositivo. Para identificar o índice de uma interface física, examine sua marca de índice no chassi.
Por exemplo, a GigabitEthernet 3/0/1 representa a primeira interface física no dispositivo membro 3. Defina seu tipo de link como tronco, como segue:
<Sysname> system-view
[Sysname] interface gigabitethernet 3/0/1
[Sysname-GigabitEthernet3/0/1] port link-type trunkConvenções de nomenclatura do sistema de arquivos
Em uma malha de chassi único, é possível usar o nome do dispositivo de armazenamento para acessar o sistema de arquivos.
Em uma malha IRF com vários chassis, é possível usar o nome do dispositivo de armazenamento para acessar o sistema de arquivos do mestre. Para acessar o sistema de arquivos de qualquer outro dispositivo membro, use o nome no formato slotmember-ID#storage-device-name.
Para obter mais informações sobre as convenções de nomenclatura de dispositivos de armazenamento, consulte o Fundamentals Configuration Guide.
Por exemplo:
- Para criar e acessar a pasta de teste no diretório raiz da memória flash no switch mestre:
<Master> mkdir test
Criando o diretório flash:/test... Concluído.
<Master> cd test
<Master> dir
Diretório do flash:/test O diretório está vazio.
251904 KB total (70964 KB livres)- Para criar e acessar a pasta de teste no diretório raiz da memória flash no dispositivo membro 3:
<Master> mkdir slot3#flash:/test
Criando o diretório slot3#flash:/test... Concluído.
<Master> cd slot3#flash:/test
<Master> dir
Diretório do slot3#flash:/test O diretório está vazio.
251904 KB total (70964 KB livres)Sincronização de configuração
O IRF usa um mecanismo rigoroso de sincronização de configuração em execução. Em uma malha IRF, todos os dispositivos obtêm e executam a configuração em execução do mestre. As alterações de configuração são propagadas automaticamente do mestre para os demais dispositivos. Os arquivos de configuração desses dispositivos são mantidos, mas não entram em vigor. Os dispositivos usam seus próprios arquivos de configuração de inicialização somente depois de serem removidos da malha IRF.
Como prática recomendada, faça backup do arquivo de configuração da próxima inicialização em um dispositivo antes de adicionar o dispositivo a uma malha IRF como subordinado.
O arquivo de configuração de próxima inicialização de um dispositivo subordinado poderá ser sobrescrito se o mestre e o subordinado usarem o mesmo nome de arquivo para seus arquivos de configuração de próxima inicialização. Você pode usar o arquivo de backup para restaurar a configuração original depois de remover o subordinado da malha IRF.
Para obter mais informações sobre o gerenciamento de configuração, consulte o Fundamentals Configuration Guide.
Procedimento de manuseio multiativo
O procedimento de tratamento multiativo inclui detecção, tratamento de colisões e recuperação de falhas.
Detecção
O IRF fornece mecanismos MAD estendendo o LACP, o BFD, o ARP e o IPv6 ND para detectar colisões multiativas. Como prática recomendada, configure no mínimo um mecanismo MAD em uma malha IRF. Para obter mais informações sobre os mecanismos MAD e seus cenários de aplicação, consulte "Mecanismos MAD".
Para obter informações sobre o LACP, consulte Agregação de links Ethernet no Guia de Configuração de Switching de LAN de Camada 2. Para obter informações sobre o BFD, consulte o Guia de configuração de alta disponibilidade. Para obter informações sobre ARP, consulte o Guia de configuração de serviços da camada 3IP. Para obter informações sobre ND, consulte Noções básicas de IPv6 no Guia de configuração de serviços de IP de camada 3.
Manuseio de colisões
Ao detectar uma colisão multiativa, a MAD desativa todas as malhas IRF, exceto uma, do encaminhamento de tráfego de dados, colocando-as no estado de recuperação. As fabrics IRF colocadas no estado de recuperação são chamadas de fabrics IRF inativas. A malha IRF que continua a encaminhar o tráfego é chamada de malha IRF ativa.
O LACP MAD e o BFD MAD usam o seguinte processo para lidar com uma colisão multiativa:
- Compare o número de membros em cada tecido.
- Defina todas as malhas para o estado de recuperação, exceto a que tiver mais membros.
- Compare as IDs de membros dos mestres se todas as malhas IRF tiverem o mesmo número de membros.
- Defina todas as malhas para o estado de recuperação, exceto a que tiver o mestre com o número mais baixo.
- Desligue todas as interfaces de rede comuns nas malhas em estado de recuperação, exceto as seguintes interfaces:
- Interfaces automaticamente excluídas do desligamento pelo sistema.
- Interfaces especificadas pelo uso do comando mad exclude interface. O ARP MAD e o ND MAD usam o seguinte processo para lidar com uma colisão multiativa:
- Compare as IDs de membro dos mestres nas malhas IRF.
- Defina todas as malhas para o estado de recuperação, exceto a que tiver o mestre com o número mais baixo.
- Tome a mesma ação que LACP MAD e BFD MAD nas interfaces de rede em fabrics em estado de recuperação.
Recuperação de falhas
Para mesclar duas malhas IRF divididas, primeiro repare o link IRF com falha e remova a falha do link IRF.
Quando o link IRF com falha entre duas malhas IRF divididas é recuperado, todos os dispositivos membros da malha IRF inativa são reinicializados automaticamente para se juntarem à malha IRF ativa como membros subordinados. As interfaces de rede que foram desligadas pela MAD restauram automaticamente seu estado original, conforme mostrado na Figura 6.
Figura 6 Recuperação da malha IRF
Se a malha IRF ativa falhar antes que o link IRF seja recuperado (consulte a Figura 7), use o comando mad restore na malha IRF inativa para recuperar a malha IRF inativa. Esse comando ativa todas as interfaces de rede que foram desligadas pela MAD. Depois que o link da IRF for reparado, mescle as duas partes em uma malha IRF unificada.
Figure 7 Active IRF fabric fails before the IRF link is recovered
Mecanismos MAD
O IRF fornece mecanismos de MAD ampliando o LACP, o BFD, o ARP e o IPv6 ND. A Tabela 1 compara os mecanismos MAD e seus cenários de aplicação.
Tabela 1 Comparação dos mecanismos de DAM
| MAD mecanismo | Vantagens | Desvantagens | Cenários de aplicativos |
| LACP MAD | A velocidade de detecção é rápida. Funciona em links agregados existentes sem exigir links físicos dedicados ao MAD ou interfaces de camada 3. | Requer um dispositivo intermediário que suporte LACP estendido para MAD. | A agregação de links é usada entre a malha IRF e seu dispositivo upstream ou downstream. |
| BFD MAD | A velocidade de detecção é rápida. O dispositivo intermediário, se usado, pode ser de qualquer fornecedor. | Requer links físicos dedicados MAD e interfaces de camada 3, que não podem ser usados para transmitir o tráfego do usuário. | Não há requisitos especiais para cenários de rede. Se nenhum dispositivo intermediário for usado, esse mecanismo só será adequado para malhas IRF que tenham apenas dois membros geograficamente próximos um do outro. |
| ARP MAD | Não é necessário nenhum dispositivo intermediário. O dispositivo intermediário, se usado, pode ser de qualquer fornecedor. Não requer portas dedicadas ao MAD. | A velocidade de detecção é mais lenta que a do BFD MAD e do LACP MAD. O recurso spanning tree deve ser ativado se portas Ethernet comuns forem usadas para links ARP MAD. | Cenários de rede IPv4 sem agregação de links. Cenários de rede IPv4 sem agregação de link habilitados para Spanning Tree se forem usadas portas Ethernet comuns. |
| ND MAD | Não é necessário nenhum dispositivo intermediário. O dispositivo intermediário, se usado, pode ser de qualquer fornecedor. Não requer portas dedicadas ao MAD. | A velocidade de detecção é mais lenta que a do BFD MAD e do LACP MAD. O recurso spanning tree deve ser ativado se portas Ethernet comuns forem usadas para links ND MAD. | Cenários de rede IPv6 sem agregação de links. Cenários de rede IPv6 sem agregação de link habilitados para Spanning Tree se forem usadas portas Ethernet comuns. |
LACP MAD
Conforme mostrado na Figura 8, o LACP MAD tem os seguintes requisitos:
- Todo membro da IRF deve ter um link com um dispositivo intermediário.
- Todos os links formam um grupo de agregação de links dinâmicos.
- O dispositivo intermediário deve ser um dispositivo que ofereça suporte a LACP estendido para MAD.
- Se as IDs de domínio e as IDs ativas enviadas por todos os dispositivos membros forem as mesmas, a malha IRF estará integrada.
- Se os LACPDUs estendidos transmitirem o mesmo ID de domínio, mas IDs ativos diferentes, ocorreu uma divisão . O LACP MAD lida com essa situação conforme descrito em "Tratamento de colisões".
Os dispositivos membros da IRF enviam LACPDUs estendidos que transmitem uma ID de domínio e uma ID ativa (a ID de membro do mestre). O dispositivo intermediário encaminha de forma transparente os LACPDUs estendidos recebidos de um dispositivo membro para todos os outros dispositivos membros.
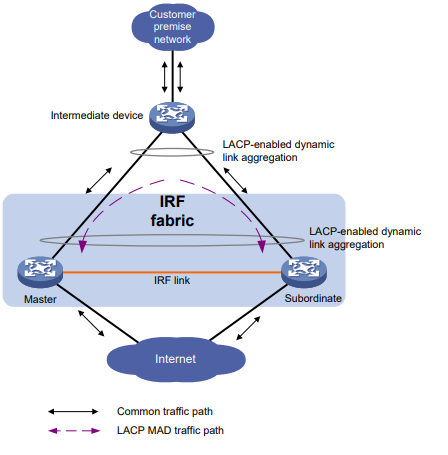
Figura 8 Cenário LACP MAD
BFD MAD
O BFD MAD detecta colisões multiativas usando o BFD.
Você pode usar portas Ethernet comuns ou de gerenciamento para BFD MAD. Para evitar que problemas de plano de dados afetem o BFD MAD, use as portas Ethernet de gerenciamento (se houver) para o BFD MAD pelo maior tempo possível.
Se forem usadas portas Ethernet de gerenciamento, o BFD MAD tem os seguintes requisitos:
- É necessário um dispositivo intermediário e cada dispositivo membro da IRF deve ter um link BFD MAD para o dispositivo intermediário.
- Cada dispositivo membro recebe um endereço IP MAD na porta Ethernet de gerenciamento do mestre.
- Como prática recomendada, use as portas Ethernet de gerenciamento para BFD MAD somente se não for acessar o dispositivo por meio das portas Ethernet de gerenciamento para gerenciamento fora de banda.
- Você pode estabelecer links BFD diretos entre as portas de gerenciamento somente se a malha IRF tiver dois dispositivos membros.
- Se você conectar diretamente as portas de gerenciamento em uma malha IRF de dois membros, não será possível acessar o dispositivo no endereço IP das portas de gerenciamento para gerenciamento fora de banda. Para acessar o dispositivo remotamente, você deve se conectar ao endereço IP de uma interface comum da Camada 3 para gerenciamento em banda.
- Como prática recomendada, não acesse o dispositivo pelo endereço IP das portas de gerenciamento depois que elas forem usadas para BFD MAD. Isso pode causar problemas inesperados e interferência com
Siga estas diretrizes ao usar portas Ethernet de gerenciamento para BFD MAD:
BFD MAD. Para acessar o dispositivo, conecte-se ao endereço IP de uma interface comum da Camada 3 para gerenciamento em banda.
Se forem usadas portas Ethernet comuns, o BFD MAD tem os seguintes requisitos:
- Se for usado um dispositivo intermediário, cada dispositivo membro deverá ter um link BFD MAD para o dispositivo intermediário. Se nenhum dispositivo intermediário for usado, todos os dispositivos membros deverão ter um link BFD MAD entre si. Como prática recomendada, use um dispositivo intermediário para conectar os dispositivos membros da IRF se a malha da IRF tiver mais de dois dispositivos membros. Uma malha completa de membros da IRF pode causar loops de transmissão.
- As portas nos links BFD MAD são atribuídas à mesma VLAN. Cada dispositivo membro recebe um endereço IP MAD na interface da VLAN.
Os links BFD MAD e a VLAN BFD MAD devem ser dedicados. Não use os links BFD MAD ou a VLAN BFD MAD para nenhum outro fim.
OBSERVAÇÃO:
- Os endereços MAD identificam os dispositivos membros e devem pertencer à mesma sub-rede.
- De todas as portas Ethernet de gerenciamento em uma malha IRF, somente a porta Ethernet de gerenciamento do mestre é acessivel
A Figura 9 mostra um cenário típico de BFD MAD que usa um dispositivo intermediário. No dispositivo intermediário, atribua as portas nos links BFD MAD à mesma VLAN.
A Figura 10 mostra um cenário típico de BFD MAD que não usa um dispositivo intermediário.
Com o BFD MAD, o mestre tenta estabelecer sessões BFD com outros dispositivos membros usando seu endereço IP MAD como endereço IP de origem.
- Se a malha IRF estiver integrada, somente o endereço IP MAD do mestre terá efeito. O mestre não pode estabelecer uma sessão BFD com nenhum outro membro. Se você executar o comando display bfd session, o estado das sessões BFD será Down.
- Quando a malha IRF se divide, os endereços IP dos mestres nas malhas IRF divididas entram em vigor. Os mestres podem estabelecer uma sessão BFD. Se você executar o comando display bfd session, o estado da sessão BFD entre os dois dispositivos será Up.
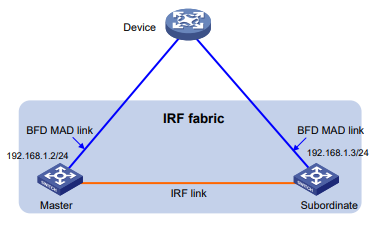
Figura 9 Cenário BFD MAD com um dispositivo intermediário
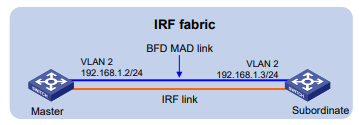
Figura 10 Cenário BFD MAD sem um dispositivo intermediário
ARP MAD
O ARP MAD detecta colisões multiativas usando pacotes ARP estendidos que transmitem a ID de domínio IRF e a ID ativa.
Você pode usar portas Ethernet comuns ou de gerenciamento para o ARP MAD.
Se forem usadas portas Ethernet de gerenciamento, o ARP MAD deverá funcionar com um dispositivo intermediário. Certifique-se de que os seguintes requisitos sejam atendidos:
- Conecte uma porta Ethernet de gerenciamento em cada dispositivo membro ao dispositivo intermediário.
- No dispositivo intermediário, você deve atribuir as portas usadas para ARP MAD à mesma VLAN. Siga estas diretrizes ao usar portas Ethernet de gerenciamento para ARP MAD:
- Como prática recomendada, use as portas Ethernet de gerenciamento para ARP MAD somente se não for acessar,o dispositivo por meio das portas Ethernet de gerenciamento para gerenciamento fora de banda.
- Você pode estabelecer links ARP MAD diretos entre as portas de gerenciamento somente se a malha IRF tiver dois dispositivos membros.
- Se você conectar diretamente as portas de gerenciamento em uma malha IRF de dois membros, não será possível acessar o dispositivo no endereço IP das portas de gerenciamento para gerenciamento fora de banda. Para acessar o dispositivo remotamente, é necessário conectar-se ao endereço IP de uma interface comum de Camada 3 para gerenciamento em banda.
- Como prática recomendada, não acesse o dispositivo pelo endereço IP das portas de gerenciamento depois que elas forem usadas para ARP MAD. Fazer isso pode causar problemas inesperados e interferência com o ARP MAD. Para acessar o dispositivo, conecte-se ao endereço IP de uma interface comum de Camada 3 para gerenciamento em banda.
Se forem usadas portas Ethernet comuns, o ARP MAD pode funcionar com ou sem um dispositivo intermediário. Certifique-se de que os seguintes requisitos sejam atendidos:
- Se for usado um dispositivo intermediário, conecte cada dispositivo membro da IRF ao dispositivo intermediário, conforme mostrado na Figura 11. Execute o recurso spanning tree entre a malha IRF e o dispositivo intermediário. Nessa situação, podem ser usados links de dados.
- Se nenhum dispositivo intermediário for usado, conecte cada dispositivo membro da IRF a todos os outros dispositivos membros. Nessa situação, os links IRF não podem ser usados para ARP MAD.
Cada membro da IRF compara o ID de domínio e o ID ativo (o ID de membro do mestre) nos pacotes ARP estendidos de entrada com seu ID de domínio e ID ativo.
- Se as IDs de domínio forem diferentes, o pacote ARP estendido é de uma malha IRF diferente. O dispositivo não continua a processar o pacote com o mecanismo MAD.
- Se as IDs de domínio forem as mesmas, o dispositivo comparará as IDs ativas.
- Se as IDs ativas forem diferentes, a malha IRF se dividiu.
- Se as IDs ativas forem as mesmas, a malha IRF estará integrada.
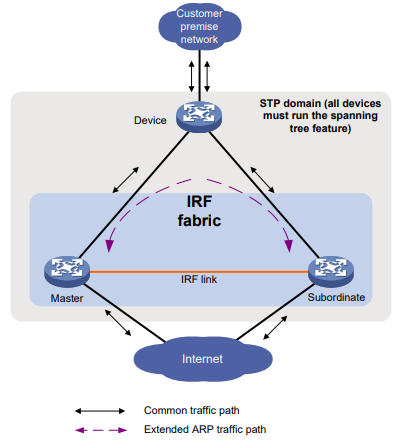
Figura 11 Cenário ARP MAD (portas Ethernet comuns)
ND MAD
O ND MAD detecta colisões multiativas usando pacotes NS para transmitir a ID de domínio IRF e a ID ativa.
Você pode usar portas Ethernet comuns ou de gerenciamento para o ND MAD.
Se forem usadas portas Ethernet de gerenciamento, o ND MAD deverá funcionar com um dispositivo intermediário. Certifique-se de que os seguintes requisitos sejam atendidos:
- Conecte uma porta Ethernet de gerenciamento em cada dispositivo membro ao dispositivo intermediário.
- No dispositivo intermediário, você deve atribuir as portas usadas para ND MAD à mesma VLAN. Siga estas diretrizes ao usar portas Ethernet de gerenciamento para ND MAD:
- Como prática recomendada, use as portas Ethernet de gerenciamento para ND MAD somente se não for acessar o dispositivo por meio das portas Ethernet de gerenciamento para gerenciamento fora de banda.
- Você pode estabelecer links ND MAD diretos entre as portas de gerenciamento somente se a malha IRF tiver dois dispositivos membros.
- Se você conectar diretamente as portas de gerenciamento em uma malha IRF de dois membros, não será possível acessar o dispositivo no endereço IP das portas de gerenciamento para gerenciamento fora de banda. Para acessar o dispositivo remotamente, é necessário conectar-se ao endereço IP de uma interface comum de Camada 3 para gerenciamento em banda.
- Como prática recomendada, não acesse o dispositivo pelo endereço IP das portas de gerenciamento depois que elas forem usadas para ND MAD. Fazer isso pode causar problemas inesperados e interferência com o ND MAD. Para acessar o dispositivo, conecte-se ao endereço IP de uma interface comum de Camada 3 para gerenciamento em banda.
Se forem usadas portas Ethernet comuns, o ND MAD pode funcionar com ou sem um dispositivo intermediário. Certifique-se de que os seguintes requisitos sejam atendidos:
- Se for usado um dispositivo intermediário, conecte cada dispositivo membro da IRF ao dispositivo intermediário, conforme mostrado na Figura 12. Execute o recurso spanning tree entre a malha IRF e o dispositivo intermediário. Nessa situação, podem ser usados links de dados.
- Se nenhum dispositivo intermediário for usado, conecte cada dispositivo membro da IRF a todos os outros dispositivos membros. Nessa situação, os links IRF não podem ser usados para ND MAD.
Cada dispositivo membro da IRF compara o ID de domínio e o ID ativo (o ID de membro do mestre) nos pacotes NS recebidos com seu ID de domínio e ID ativo.
- Se as IDs de domínio forem diferentes, o pacote NS é de uma malha IRF diferente. O dispositivo não continua a processar o pacote com o mecanismo MAD.
- Se as IDs de domínio forem as mesmas, o dispositivo comparará as IDs ativas.
- Se as IDs ativas forem diferentes, a malha IRF se dividiu.
- Se as IDs ativas forem as mesmas, a malha IRF estará integrada.
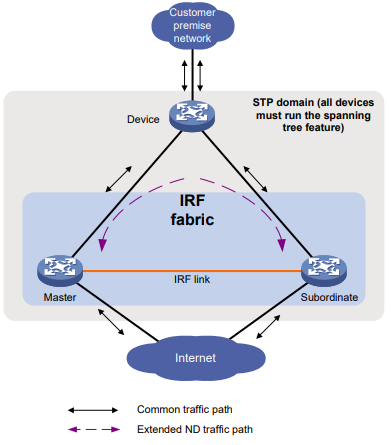
Figura 12 Cenário ND MAD (portas Ethernet comuns)
Restrições e diretrizes: Configuração da IRF
Requisitos de software para IRF
Todos os dispositivos membros da IRF devem executar a mesma versão de imagem de software. Certifique-se de que o recurso de atualização automática do software esteja ativado em todos os dispositivos membros.
Interfaces físicas IRF candidatas
Você pode usar portas Ethernet 10G ou 1G como interfaces físicas IRF, dependendo do modelo do dispositivo.
- As portas Ethernet 10G ou 1G devem operar a 10 Gbps ou 1 Gbps, respectivamente, quando forem usadas como interfaces físicas IRF.
- As portas vinculadas a uma porta IRF devem pertencer ao mesmo grupo de portas. Entretanto, as portas do mesmo grupo podem ser vinculadas a diferentes portas IRF. Para obter as informações do grupo de portas, execute o comando debug port mapping na visualização de sonda e visualize o valor da unidade de cada porta. As portas em um grupo de portas têm o mesmo valor de unidade.
Para obter mais informações sobre as portas que podem ser usadas como interfaces físicas IRF, as informações do grupo de portas e os módulos e cabos transceptores disponíveis, consulte Configuração da malha IRF no switch guia de instalação.
Conexão da porta IRF
Quando você conectar dois membros vizinhos da IRF, siga estas restrições e diretrizes:
- Você deve conectar as interfaces físicas da porta IRF 1 em um membro às interfaces físicas da porta IRF 2 no outro.
- Para obter alta disponibilidade, associe várias interfaces físicas a uma porta IRF. Você pode vincular um máximo de oito interfaces físicas a uma porta IRF. Devido a restrições de hardware, talvez não seja possível vincular até oito interfaces físicas a uma porta IRF.
Figura 13 Conexão de interfaces físicas IRF
Restrições e diretrizes de configuração da interface física IRF
Restrições de configuração do comando
Em uma interface física vinculada a uma porta IRF, você pode executar apenas os seguintes comandos:
- Comandos básicos de interface, incluindo shutdown e descrição. Para obter mais informações sobre esses comandos, consulte Comandos de interface Ethernet em Layer 2-LAN Switching Command Reference.
- O comando flow-interval, que define o intervalo de sondagem de estatísticas em uma interface. Para obter mais informações sobre esse comando, consulte Comandos de interface Ethernet em Layer 2-LAN Switching Command Reference.
- O comando port link-flap protect enable, que habilita a proteção contra flapping de link em uma interface. Para evitar que o link flapping da IRF afete o desempenho do sistema, a proteção contra link flapping atua de forma diferente nas interfaces físicas da IRF e nas interfaces de rede comuns, como segue:
- A proteção contra flapping de link é ativada por padrão nas interfaces físicas IRF. Esse recurso entra em vigor em uma interface física IRF desde que esteja ativado nessa interface, independentemente de a proteção contra flapping de link ter sido ativada globalmente.
- Se o número de flapings de link em uma interface física IRF ultrapassar o limite de flapping de link durante um intervalo de detecção de flapping, o sistema exibirá mensagens de evento. Entretanto, o sistema não desliga essa interface física IRF como faria com uma interface de rede comum.
Para obter mais informações sobre esse comando, consulte Comandos da interface Ethernet em Layer 2-LAN Switching Command Reference.
- O comando mirroring-group reflector-port, que especifica a interface física como uma porta refletora para espelhamento remoto. Para obter mais informações sobre esse comando, consulte espelhamento de porta em Referência de comandos de gerenciamento e monitoramento de rede.
Não execute o comando mirroring-group reflector-port em uma interface física IRF se essa interface for a única interface membro de uma porta IRF. Isso dividirá a malha IRF, pois esse comando também remove a vinculação da interface física e da porta IRF..
Supressão de notificações SNMP de quedas de pacotes em interfaces físicas IRF
Antes de um dispositivo membro da IRF encaminhar um pacote, ele examina seu caminho de encaminhamento na malha da IRF em busca de um loop. Se houver um loop, o dispositivo descarta o pacote na interface de origem do caminho com loop. Esse mecanismo de eliminação de loop descartará um grande número de pacotes de broadcast nas interfaces físicas da IRF.
Para suprimir as notificações SNMP de quedas de pacotes que não requerem atenção, não monitore o encaminhamento de pacotes nas interfaces físicas da IRF.
Restrições de reversão de configuração
O recurso de reversão de configuração não pode reverter as seguintes configurações de IRF:
- Descrição do dispositivo membro (definida com o comando irf member description).
- Prioridade do dispositivo membro (definida com o comando irf member priority).
- Interface física IRF e associações de portas IRF (definidas usando a interface de grupo de portascomando).
Para obter mais informações sobre o recurso de reversão de configuração, consulte gerenciamento de arquivos de configuração em
Visão geral das tarefas da IRF
Para configurar o IRF, execute as seguintes tarefas:
- Configuração de uma malha IRF
- Configuração da DAM
Configure um mínimo de um mecanismo MAD em uma malha IRF. Para saber sobre a compatibilidade do MAD, consulte "Compatibilidade do mecanismo MAD".
- Configuração do LACP MAD
- Configuração de BFD MAD
- Configuração de ARP MAD
- Configuração de ND MAD
- Exclusão de interfaces da ação de desligamento após a detecção de colisão multiativa
Esse recurso exclui uma interface da ação de desligamento para fins de gerenciamento ou outros fins especiais quando uma malha IRF passa para o estado de recuperação.
- Recuperação de uma malha IRF
- (Opcional.) Otimização das configurações de IRF para uma malha IRF
- Configuração de uma descrição de dispositivo membro
- Configuração das definições de endereço MAC da ponte IRF
- Ativação da atualização automática de software para sincronização de imagens de software
Esse recurso sincroniza automaticamente as imagens de software atuais do mestre com os dispositivos que estão tentando ingressar na malha IRF.
- Configuração do atraso do relatório de alteração do status do link IRF
Planejamento da configuração da malha IRF
Considere os seguintes itens ao planejar uma malha IRF:
- Compatibilidade e restrições de hardware.
- Tamanho do tecido IRF.
- Dispositivo mestre.
- ID de membro e esquema de atribuição de prioridade.
- Topologia de malha e esquema de cabeamento.
- Interfaces físicas IRF.
Configuração de uma malha IRF
Visão geral das tarefas de configuração do IRF
Para configurar uma malha IRF, execute as seguintes tarefas:
- Configure IDs de membros, prioridades e interfaces físicas IRF separadamente.
- Atribuição de um ID de membro a cada dispositivo membro da IRF
- (Opcional.) Especificar uma prioridade para cada dispositivo membro
- Vinculação de interfaces físicas a portas IRF
- Configuração em massa das configurações básicas da IRF para um dispositivo membro
- Conexão de interfaces físicas IRF
- Acesso à malha IRF
Ignore essas tarefas se você configurar IDs de membros, prioridades, ID de domínio e interfaces físicas IRF em massa.
Ignore esta tarefa se você configurar separadamente as IDs de membros, as prioridades, a ID de domínio e as interfaces físicas IRF.
Atribuição de um ID de membro a cada dispositivo membro da IRF
Restrições e diretrizes
Uma alteração no ID de membro da IRF pode invalidar as configurações relacionadas ao ID de membro e causar perda de dados. Certifique-se de compreender totalmente o impacto em sua rede ativa.
Para criar uma malha IRF, você deve atribuir um ID de membro IRF exclusivo a cada dispositivo membro.
A nova ID de membro de um dispositivo entra em vigor em uma reinicialização. Após a reinicialização do dispositivo, as configurações em todos os recursos físicos relacionados ao ID de membro (incluindo interfaces de rede físicas comuns) são removidas, independentemente de você ter salvo a configuração.
Procedimento
- Entre na visualização do sistema.
System Viewirf member member-id renumber new-member-idA ID padrão do membro da IRF é 1.
Uma alteração no ID de membro da IRF pode invalidar as configurações relacionadas ao ID de membro e causar perda de dados. Certifique-se de compreender totalmente o impacto em sua rede ativa.
saveSe você tiver vinculado interfaces físicas a portas IRF ou atribuído prioridade de membro, deverá executar essa etapa para que essas configurações tenham efeito após a reinicialização.
quitreboot [ slot slot-número ] [ force ]Especificação de uma prioridade para cada dispositivo membro
Sobre a especificação da prioridade de um membro da IRF
A prioridade do membro IRF representa a possibilidade de um dispositivo ser eleito o mestre em uma malha IRF. Um valor de prioridade maior indica uma prioridade mais alta.
Uma alteração na prioridade do membro afeta o resultado da eleição na próxima eleição do mestre, mas não causa uma reeleição imediata do mestre.
Procedimento
- Entre na visualização do sistema.
System Viewirf member member-id priority priorityA prioridade padrão do membro da IRF é 1.
Vinculação de interfaces físicas a portas IRF
Restrições e diretrizes
Selecione interfaces físicas qualificadas como interfaces físicas IRF, conforme descrito em "Interfaces físicas IRF candidatas".
Depois de vincular interfaces físicas a portas IRF pela primeira vez, você deve usar o comando
comando irf-port-configuration active para ativar as configurações nas portas IRF. O sistema ativa as configurações da porta IRF automaticamente somente nas seguintes situações:
- O arquivo de configuração com o qual o dispositivo é iniciado contém associações de portas IRF.
- Você está adicionando interfaces físicas a uma porta IRF (no estado UP) depois que uma malha IRF é formada.
Procedimento
- Entre na visualização do sistema.
- Entre na visualização da interface ou da faixa de interfaces.
- Entre na visualização da interface.
- Entre na visualização de intervalo de interface. Escolha um dos seguintes comandos:
System View
interface interface-type interface-number
interface range { interface-type interface-number [ to
interface-type interface-number ] } &<1-24>
interface range name name [ interface { interface-type
interface-number [ to interface-type interface-number ] } &<1-24> ]Para desligar um intervalo de interfaces físicas IRF, entre na visualização de intervalo de interfaces. Para desligar uma interface física IRF, entre na visualização da interface.
shutdownPor padrão, uma interface física não está administrativamente inativa.
quitirf-port member-id/irf-port-numberport group interface interface-type interface-numberPor padrão, nenhuma interface física é vinculada a uma porta IRF.
Repita esta etapa para atribuir várias interfaces físicas à porta IRF.
quitinterface interface-type interface-numberinterface range { interface-type interface-number [ to interface-type interface-number ] } &<1-24>
interface range name name [ interface { interface-type interface-number [ to interface-type interface-number ] } &<1-24> ]
undo shutdownquitsaveA ativação das configurações da porta IRF causa a fusão e a reinicialização da IRF. Para evitar a perda de dados, salve a configuração em execução no arquivo de configuração de inicialização antes de executar a operação.
irf-port-configuration activeConfiguração em massa das configurações básicas da IRF para um dispositivo membro
Sobre a IRF fácil
Use o recurso IRF fácil para configurar em massa as definições básicas de IRF para um dispositivo membro, incluindo o ID do membro, o ID do domínio, a prioridade e as associações de portas IRF.
O recurso IRF fácil oferece os seguintes métodos de configuração:
- Método interativo - Insira o comando easy-irf sem parâmetros. O sistema o guiará na definição dos parâmetros, passo a passo.
- Método não interativo - Insira o comando easy-irf com parâmetros. Como prática recomendada, use o método interativo se você for novo no IRF.
Restrições e diretrizes
O dispositivo membro é reinicializado imediatamente após você especificar um novo ID de membro para ele. Certifique-se de que você está ciente do impacto na rede.
Se você executar o comando easy-irf várias vezes, as seguintes configurações terão efeito:
- As configurações mais recentes de ID de membro, ID de domínio e prioridade.
- Ligações de portas IRF adicionadas por meio de repetidas execuções do comando. Para remover uma interface física IRF de uma porta IRF, você deve usar o comando undo port group interface na visualização da porta IRF.
Se você especificar interfaces físicas IRF usando o método interativo, também deverá seguir essas restrições e diretrizes:
- Não insira espaços entre o tipo de interface e o número da interface.
- Use uma vírgula (,) para separar duas interfaces físicas. Não são permitidos espaços entre as interfaces.
Procedimento
- Entre na visualização do sistema.
System Vieweasy-irf [ member member-id [ renumber new-member-id ] domain domain-id [ priority priority ] [ irf-port1 interface-list1 ] [ irf-port2 interface-list2 ]Certifique-se de que o novo ID de membro seja exclusivo na malha IRF à qual o dispositivo será adicionado.
Conexão de interfaces físicas IRF
Siga as restrições em "Conexão de porta IRF" para conectar as interfaces físicas IRF, bem como com base na topologia e no esquema de cabeamento. Os dispositivos realizam a eleição do mestre. Os dispositivos membros que falharem na eleição do mestre são reinicializados automaticamente para formar uma malha IRF com o dispositivo mestre.
Acesso à malha IRF
A malha IRF aparece como um único dispositivo após ser formada. Você configura e gerencia todos os membros da IRF na CLI do mestre. Todas as configurações que você fez são automaticamente propagadas para os membros da IRF.
Os seguintes métodos estão disponíveis para acessar uma malha IRF:
- Login local - Faça login pela porta do console de qualquer dispositivo membro.
- Login remoto - Faça login em uma interface da Camada 3 em qualquer dispositivo membro usando métodos como Telnet e SNMP.
Ao fazer login em uma malha IRF, você é colocado na CLI do mestre, independentemente do dispositivo membro em que estiver conectado.
Para obter mais informações, consulte a configuração de login no Fundamentals Configuration Guide.
Configuração da MAD
Restrições e diretrizes para a configuração da MAD
Compatibilidade de hardware com MAD
Alguns modelos não têm portas Ethernet de gerenciamento. Eles não suportam a configuração do MAD em uma porta Ethernet de gerenciamento. Para obter informações sobre esses modelos, consulte o guia de instalação.
Compatibilidade do mecanismo MAD
Como prática recomendada, configure no mínimo um mecanismo MAD em uma malha IRF para detecção imediata de divisão IRF. Como os mecanismos MAD usam processos diferentes de tratamento de colisões, siga estas restrições e diretrizes ao configurar vários mecanismos MAD em uma malha IRF:
- Não configure o LACP MAD junto com o ARP MAD ou o ND MAD.
- Não configure o BFD MAD junto com o ARP MAD ou o ND MAD.
Atribuição de IDs de domínio IRF
Uma malha IRF tem apenas uma ID de domínio IRF. Você pode alterar a ID do domínio IRF usando os seguintes comandos: irf domain, mad enable, mad arp enable ou mad nd enable. As IDs de domínio IRF configuradas por meio desses comandos se sobrepõem umas às outras.
Se LACP MAD, ARP MAD ou ND MAD for executado entre duas malhas IRF, atribua a cada malha uma ID de domínio IRF exclusiva. (Para BFD MAD, essa tarefa é opcional).
Ações em interfaces fechadas pela MAD
Para evitar que uma colisão multiativa cause problemas na rede, evite usar o comando undo shutdown para ativar as interfaces desligadas por um mecanismo MAD em uma malha IRF em estado de recuperação .
Configuração do LACP MAD
- Entre na visualização do sistema.
- Atribua uma ID de domínio à malha IRF.
System View
irf domain domain-idA ID de domínio IRF padrão é 0.
A alteração do ID de domínio IRF de um dispositivo membro IRF removerá esse dispositivo membro da malha IRF. Esse dispositivo membro não poderá trocar pacotes de protocolo IRF com os dispositivos membros restantes na malha IRF.
interface bridge-aggregation interface-numberlink-aggregation mode dynamicPor padrão, um grupo de agregação opera no modo de agregação estática. O LACP MAD entra em vigor somente em interfaces de agregação dinâmica.
Execute essa etapa também no dispositivo intermediário.
mad enablePor padrão, o LACP MAD está desativado.
quit- Entre na visualização da interface Ethernet.
interface interface-type interface-numberinterface range { interface-type interface-number [ to interface-type interface-number ] } &<1-24>interface range name name [ interface { interface-type interface-number [ to interface-type interface-number ] } &<1-24> ]Para atribuir um intervalo de portas ao grupo de agregação, entre na visualização de intervalo de interfaces. Para atribuir uma porta ao grupo de agregação, entre na visualização da interface Ethernet.
port link-aggregation group group-idA agregação de links de vários chassis é permitida.
Execute essa etapa também no dispositivo intermediário.
Configuração de BFD MAD
Restrições e diretrizes para configurar o BFD MAD
Como prática recomendada, use o procedimento a seguir para configurar o BFD MAD:
- Escolha um esquema de link BFD MAD conforme descrito em "BFD MAD".
- Configurar o BFD MAD.
- Conecte os links BFD MAD.
Ao configurar o BFD MAD em uma interface VLAN, siga estas restrições e diretrizes:
| Categoria | Restrições e diretrizes |
| BFD MAD VLAN | Não habilite o BFD MAD na interface VLAN 1. Se estiver usando um dispositivo intermediário, execute as seguintes tarefas: Na malha IRF e no dispositivo intermediário, crie uma VLAN para o BFD MAD. Na malha IRF e no dispositivo intermediário, atribua as portas dos links BFD MAD à VLAN BFD MAD. Na malha IRF, crie uma interface VLAN para a VLAN MAD do BFD. Certifique-se de que as malhas IRF na rede usem VLANs BFD MAD diferentes. Certifique-se de que a VLAN BFD MAD contenha apenas portas nos links BFD MAD. Exclua uma porta da VLAN BFD MAD se essa porta não estiver em um link BFD MAD. Se você tiver atribuído essa porta a todas as VLANs usando o comando port trunk permit vlan all, use o comando undo port trunk permit para excluir essa porta da VLAN BFD MAD. |
| BFD MAD VLAN e Compatibilidade de recursos | Não use a VLAN BFD MAD e suas portas membros para nenhuma outra finalidade que não seja a configuração do BFD MAD. Use somente os comandos mad bfd enable e mad ip address na interface VLAN habilitada para BFD MAD. Se você configurar outros recursos, o BFD MAD e outros recursos na interface poderão ser executados incorretamente. Desative o recurso de árvore de abrangência em todas as portas Ethernet de camada 2 na VLAN MAD do BFD. O recurso MAD é mutuamente exclusivo do recurso de árvore de abrangência. |
| Endereço IP do MAD | Para evitar problemas de rede, use apenas o comando mad ip address para configurar endereços IP na interface de VLAN habilitada para BFD MAD. Não configure um endereço IP usando o comando ip address nem configure um endereço virtual VRRP na interface de VLAN habilitada para BFD MAD. Certifique-se de que todos os endereços IP do MAD estejam na mesma sub-rede. |
Ao configurar o BFD MAD em uma porta Ethernet de gerenciamento, siga estas restrições e diretrizes:
| Categoria | Restrições e diretrizes |
| Portas Ethernet de gerenciamento para BFD MAD | Conecte uma porta Ethernet de gerenciamento em cada dispositivo membro da IRF às portas Ethernet comuns no dispositivo intermediário. |
| BFD MAD VLAN | No dispositivo intermediário, crie uma VLAN para BFD MAD e atribua as portas usadas para BFD MAD à VLAN. Na malha IRF, não é necessário atribuir as portas Ethernet de gerenciamento à VLAN. Certifique-se de que as malhas IRF na rede usem VLANs BFD MAD diferentes. Certifique-se de que a VLAN BFD MAD no dispositivo intermediário contenha apenas portas nos links BFD MAD. |
| Endereço IP do MAD | Use o comando mad ip address em vez do comando ip address para configurar endereços IP MAD nas portas Ethernet de gerenciamento habilitadas para BFD MAD. Certifique-se de que todos os endereços IP do MAD estejam na mesma sub-rede. |
Configuração do BFD MAD em uma interface VLAN
- Entre na visualização do sistema.
System Viewirf domain domain-idPor padrão, a ID de domínio de uma malha IRF é 0.
A alteração do ID de domínio IRF de um dispositivo membro IRF removerá esse dispositivo membro da malha IRF. Esse dispositivo membro não poderá trocar pacotes de protocolo IRF com os dispositivos membros restantes na malha IRF.
vlan vlan-idPor padrão, existe apenas a VLAN 1.
Não habilite o BFD MAD na interface VLAN 1.
Execute essa etapa também no dispositivo intermediário (se houver).
quit- Entre na visualização da interface Ethernet.
interface interface-type interface-numberinterface range { interface-type interface-number [ to interface-type interface-number ] } <1-24>interface range name name [ interface { interface-typeinterface-number [ to interface-type interface-number ] } <1-24> ]Para atribuir um intervalo de portas à VLAN BFD MAD, entre no modo de exibição de intervalo de interface. Para atribuir uma porta à VLAN BFD MAD, entre na visualização da interface Ethernet.
- Atribua a porta ou o intervalo de portas à VLAN BFD MAD.
- Atribua as portas à VLAN como portas de acesso.
vlan de acesso à porta vlan-idport trunk permit vlan vlan-idport hybrid vlan vlan-id { tagged | untagged }O tipo de link das portas BFD MAD pode ser de acesso, tronco ou híbrido. O tipo de link padrão de uma porta é acesso.
Execute essa etapa também no dispositivo intermediário (se houver).
quitinterface vlan-interface vlan-interface-idmad bfd enablePor padrão, o BFD MAD está desativado.
mad ip address ip-address { mask | mask-length } member member-idPor padrão, nenhum endereço IP MAD é configurado em nenhuma interface de VLAN.
Repita esta etapa para atribuir um endereço IP MAD a cada dispositivo membro na interface da VLAN.
Configuração do BFD MAD em uma porta Ethernet de gerenciamento
Entre na visualização do sistema.
system-view2. (Opcional) Atribua um ID de domínio à IRF fabric.
irf domain domain-idPor padrão, o ID de domínio de uma IRF fabric é 0.
Alterar o ID de domínio IRF de um dispositivo membro IRF removerá esse dispositivo membro da IRF fabric. Esse dispositivo membro não poderá trocar pacotes de protocolo IRF com os dispositivos membros restantes na IRF fabric.
3. Entre na visualização da interface Ethernet de gerenciamento.
interface m-gigabitethernet interface-numberDe todas as portas Ethernet de gerenciamento em uma IRF fabric, apenas a porta Ethernet de gerenciamento do mestre é acessível.
4. Ative o BFD MAD.
mad bfd enablePor padrão, o BFD MAD está desativado.
5. Atribua um endereço IP MAD a cada dispositivo membro.
mad ip address ip-address { mask | mask-length } member member-idPor padrão, nenhum endereço IP MAD está configurado.
Configurando ARP MAD
Restrições e diretrizes para configurar ARP MAD
Como prática recomendada, use o seguinte procedimento para configurar ARP MAD:
1. Escolha um esquema de link ARP MAD conforme descrito em "ARP MAD".
2. Configure o ARP MAD.
3. Conecte os links ARP MAD se você não estiver usando links de dados existentes como links ARP MAD.
Ao configurar ARP MAD em uma interface VLAN, siga estas restrições e diretrizes:
| Categoria | Restrições e diretrizes |
| ARP MAD VLAN | Não habilite o ARP MAD na interface VLAN 1. Se estiver usando um dispositivo intermediário, execute as seguintes tarefas: Na malha IRF e no dispositivo intermediário, crie uma VLAN para ARP MAD. Na malha IRF e no dispositivo intermediário, atribua as portas dos links ARP MAD à VLAN ARP MAD. Na malha IRF, crie uma interface VLAN para a VLAN ARP MAD. Não use a VLAN ARP MAD para nenhuma outra finalidade. |
| ARP MAD e configuração de recursos | Se for usado um dispositivo intermediário, certifique-se de que os seguintes requisitos sejam atendidos: Execute o recurso spanning tree entre a malha IRF e o dispositivo intermediário para garantir que haja apenas um link ARP MAD em estado de encaminhamento. Para obter mais informações sobre o recurso spanning tree |
| Categoria | Restrições e diretrizes |
| e sua configuração, consulte o Layer 2-LAN Switching Configuration Guide. Permitir que a malha IRF altere seu endereço MAC de ponte assim que o proprietário do endereço sair. Se o dispositivo intermediário também for uma malha IRF, atribua às duas malhas IRF IDs de domínio diferentes para a detecção correta da divisão. |
Ao configurar o ARP MAD em uma porta Ethernet de gerenciamento, siga estas restrições e diretrizes:
| Categoria | Restrições e diretrizes |
| Portas Ethernet de gerenciamento para ARP MAD | Conecte uma porta Ethernet de gerenciamento em cada dispositivo membro às portas Ethernet comuns no dispositivo intermediário. |
| ARP MAD VLAN | No dispositivo intermediário, crie uma VLAN para ARP MAD e atribua as portas usadas para ARP MAD à VLAN. Na malha IRF, não é necessário atribuir as portas Ethernet de gerenciamento à VLAN. |
| ARP MAD e configuração de recursos | Permitir que a malha IRF altere seu endereço MAC de ponte assim que o proprietário do endereço sair. Se o dispositivo intermediário também for uma malha IRF, atribua às duas malhas IRF IDs de domínio diferentes para a detecção correta da divisão. |
Configurando ARP MAD em uma interface VLAN
1. Entre na visualização do sistema.
system-view2. Atribua um ID de domínio à IRF fabric.
irf domain domain-idO ID de domínio IRF padrão é 0.
Alterar o ID de domínio IRF de um dispositivo membro IRF removerá esse dispositivo membro da IRF fabric. Esse dispositivo membro não poderá trocar pacotes de protocolo IRF com os dispositivos membros restantes na IRF fabric.
3. Configure o endereço MAC da ponte IRF para mudar assim que o proprietário do endereço sair.
undo irf mac-address persistentPor padrão, o endereço MAC da ponte IRF permanece inalterado por 6 minutos após o proprietário do endereço sair.
A mudança do endereço MAC da ponte IRF causará uma interrupção transitória no tráfego.
4. Crie uma VLAN dedicada ao ARP MAD.
vlan vlan-idPor padrão, apenas a VLAN 1 existe.
Não configure o ARP MAD na VLAN-interface 1.
Realize esta tarefa também no dispositivo intermediário (se houver).
5. Retorne à visualização do sistema.
quit6. Entre na visualização da interface Ethernet ou na visualização de intervalo de interfaces.
28- Entre na visualização da interface Ethernet.
interface interface-type interface-numberinterface range { interface-type interface-number [ to
interface-type interface-number ] } <1-24>interface range name name [ interface { interface-type
interface-number [ to interface-type interface-number ] } <1-24> ]Para atribuir uma faixa de portas à VLAN ARP MAD, entre na visualização de intervalo de interfaces. Para atribuir uma porta à VLAN ARP MAD, entre na visualização da interface Ethernet.
7. Atribua a porta ou a faixa de portas à VLAN ARP MAD.
- Atribua as portas à VLAN como portas de acesso.
port access vlan vlan-idport trunk permit vlan vlan-idport hybrid vlan vlan-id { tagged | untagged }O tipo de link das portas ARP MAD pode ser acesso, tronco ou híbrido. O tipo de link padrão de uma porta é acesso. Realize esta tarefa também no dispositivo intermediário (se houver).
8. Retorne à visualização do sistema.
quit9. Entre na visualização da interface VLAN.
interface vlan-interface vlan-interface-id10. Atribua à interface um endereço IP.
ip address ip-address { mask | mask-length }Por padrão, nenhum endereço IP é atribuído a nenhuma interface VLAN.
11. Ative o ARP MAD.
mad arp enablePor padrão, o ARP MAD está desativado.
Configurando ARP MAD em uma porta de gerenciamento Ethernet
1. Entre na visualização do sistema.
system-view2. Atribua um ID de domínio à IRF fabric.
irf domain domain-idO ID de domínio IRF padrão é 0.
Alterar o ID de domínio IRF de um dispositivo membro IRF removerá esse dispositivo membro da IRF fabric. Esse dispositivo membro não poderá trocar pacotes de protocolo IRF com os dispositivos membros restantes na IRF fabric.
3. Configure o endereço MAC da ponte IRF para mudar assim que o proprietário do endereço sair.
undo irf mac-address persistentPor padrão, o endereço MAC da ponte IRF permanece inalterado por 6 minutos após o proprietário do endereço sair.
A mudança do endereço MAC da ponte IRF causará uma interrupção transitória no tráfego.
4. Entre na visualização da interface de gerenciamento Ethernet.
interface m-gigabitethernet interface-numberDe todas as portas de gerenciamento Ethernet em uma IRF fabric, apenas a porta de gerenciamento Ethernet do mestre é acessível.
5. Atribua um endereço IP à porta de gerenciamento Ethernet.
ip address ip-address { mask | mask-length }Por padrão, nenhum endereço IP é configurado.
6. Ative o ARP MAD.
mad arp enablePor padrão, o ARP MAD está desativado.
Configurando ND MAD
Restrições e diretrizes para configurar ND MAD
Como prática recomendada, use o seguinte procedimento para configurar ND MAD:
1. Escolha um esquema de link ND MAD conforme descrito em "ND MAD."
2. Configure ND MAD.
3. Conecte os links ND MAD se você não estiver usando links de dados existentes como links ND MAD.
Ao configurar ND MAD em uma interface VLAN, siga estas restrições e diretrizes:
| Categoria | Restrições e diretrizes |
| ND MAD VLAN | Não habilite o ND MAD na interface VLAN 1. Se estiver usando um dispositivo intermediário, execute as seguintes tarefas: Na malha IRF e no dispositivo intermediário, crie uma VLAN para o ND MAD. Na malha IRF e no dispositivo intermediário, atribua as portas dos links ND MAD à VLAN ND MAD. Na malha IRF, crie uma interface VLAN para a VLAN ND MAD. Não use a VLAN ND MAD para nenhuma outra finalidade. |
| ND MAD e configuração de recursos | Se for usado um dispositivo intermediário, certifique-se de que os seguintes requisitos sejam atendidos: Execute o recurso spanning tree entre a malha IRF e o dispositivo intermediário para garantir que haja apenas um link ND MAD em estado de encaminhamento. Para obter mais informações sobre o recurso spanning tree e sua configuração, consulte o Layer 2-LAN Switching Configuration Guide. Permitir que a malha IRF altere seu endereço MAC de ponte assim que o proprietário do endereço sair. Se o dispositivo intermediário também for uma malha IRF, atribua às duas malhas IRF IDs de domínio diferentes para a detecção correta da divisão. |
Ao configurar o ND MAD em uma porta Ethernet de gerenciamento, siga estas restrições e diretrizes:
| Categoria | Restrições e diretrizes |
| Portas Ethernet de gerenciamento para ND MAD | Conecte uma porta Ethernet de gerenciamento em cada dispositivo membro às portas Ethernet comuns no dispositivo intermediário. |
| Categoria | Restrições e diretrizes |
| ND MAD VLAN | No dispositivo intermediário, crie uma VLAN para ND MAD e atribua as portas usadas para ND MAD à VLAN. Na malha IRF, não é necessário atribuir as portas Ethernet de gerenciamento à VLAN. |
| ND MAD e configuração de recursos | Permitir que a malha IRF altere seu endereço MAC de ponte assim que o proprietário do endereço sair. Se o dispositivo intermediário também for uma malha IRF, atribua às duas malhas IRF IDs de domínio diferentes para a detecção correta da divisão. |
Configuração de ND MAD em uma interface VLAN
1. Acesse a visualização do sistema.
system-view2. Atribua um ID de domínio à IRF fabric.
irf domain domain-idO ID de domínio padrão da IRF fabric é 0.
Alterar o ID de domínio da IRF de um dispositivo membro removerá esse dispositivo membro da fabric IRF. Este dispositivo membro será incapaz de trocar pacotes de protocolo IRF com os dispositivos membros restantes na fabric IRF.
3. Configure o endereço MAC da ponte IRF para ser alterado assim que o proprietário do endereço sair.
undo irf mac-address persistentPor padrão, o endereço MAC da ponte IRF permanece inalterado por 6 minutos após o proprietário do endereço sair da fabric.
A alteração do endereço MAC da ponte IRF causará uma interrupção temporária no tráfego.
4. Crie uma VLAN dedicada ao ND MAD.
vlan vlan-idPor padrão, apenas a VLAN 1 existe.
Não configure o ND MAD na VLAN-interface 1.
Realize esta tarefa também no dispositivo intermediário (se houver).
5. Retorne à visualização do sistema.
quit6. Acesse a visualização da interface Ethernet ou a visualização da faixa de interface.
- Acesse a visualização da interface Ethernet.
interface interface-type interface-numberinterface range { interface-type interface-number [ to
interface-type interface-number ] } <1-24>interface range name name [ interface { interface-type
interface-number [ to interface-type interface-number ] } <1-24> ]Para atribuir uma faixa de portas à VLAN ND MAD, acesse a visualização da faixa de interface. Para atribuir uma porta à VLAN ND MAD, acesse a visualização da interface Ethernet.
7. Atribua a porta ou a faixa de portas à VLAN ND MAD.
- Atribua as portas à VLAN como portas de acesso.
port access vlan vlan-idport trunk permit vlan vlan-idport hybrid vlan vlan-id { tagged | untagged }O tipo de link das portas ND MAD pode ser acesso, tronco ou híbrido. O tipo de link padrão de uma porta é acesso.
Realize esta tarefa também no dispositivo intermediário (se houver).
8. Retorne à visualização do sistema.
quit9. Acesse a visualização da interface VLAN.
interface vlan-interface interface-number10. Atribua à interface um endereço IPv6.
ipv6 address { ipv6-address/prefix-length | ipv6-address
prefix-length }Por padrão, nenhum endereço IPv6 é atribuído a uma interface VLAN.
11. Ative o ND MAD.
mad nd enablePor padrão, o ND MAD está desativado.
Configuração de ND MAD em uma porta Ethernet de gerenciamento
Configurando ND MAD em uma porta Ethernet de gerenciamento
1. Acesse a visualização do sistema.
system-view2. Atribua um ID de domínio à IRF fabric.
irf domain domain-idO ID de domínio padrão da IRF fabric é 0.
Alterar o ID de domínio da IRF de um dispositivo membro removerá esse dispositivo membro da fabric IRF. Este dispositivo membro será incapaz de trocar pacotes de protocolo IRF com os dispositivos membros restantes na fabric IRF.
3. Configure o endereço MAC da ponte IRF para ser alterado assim que o proprietário do endereço sair.
undo irf mac-address persistentPor padrão, o endereço MAC da ponte IRF permanece inalterado por 6 minutos após o proprietário do endereço sair da fabric.
A alteração do endereço MAC da ponte IRF causará uma interrupção temporária no tráfego.
4. Acesse a visualização da interface Ethernet de gerenciamento.
interface m-gigabitethernet interface-numberDe todas as portas de Ethernet de gerenciamento em uma fabric IRF, apenas a porta de Ethernet de gerenciamento do mestre é acessível.
5. Atribua um endereço IPv6 à porta de Ethernet de gerenciamento.
ipv6 address { ipv6-address/pre-length | ipv6 address pre-length }Por padrão, nenhum endereço IPv6 é atribuído a uma porta de Ethernet de gerenciamento.
6. Ative o ND MAD.
mad nd enablePor padrão, o ND MAD está desativado.
Excluindo interfaces da ação de desligamento ao detectar colisão multiativa
Sobre a exclusão de interfaces do desligamento
Quando uma fabric IRF transita para o estado de Recuperação, o sistema exclui automaticamente as seguintes interfaces de rede do desligamento:
- Interfaces físicas IRF.
- Interfaces usadas para o BFD MAD.
- Interfaces de membros de uma interface agregada se a interface agregada estiver excluída do desligamento.
Você pode excluir uma interface da ação de desligamento para fins de gerenciamento ou outros fins especiais. Por exemplo:
- Exclua uma porta da ação de desligamento para que você possa acessar a porta via Telnet para gerenciar o dispositivo.
- Exclua uma interface de VLAN e suas portas de Camada 2 da ação de desligamento para que você possa fazer login através da interface VLAN.
Restrições e diretrizes
Se as portas de Camada 2 de uma interface VLAN estiverem distribuídas em vários dispositivos membros, a operação de exclusão pode introduzir riscos de colisão de IP. A interface VLAN pode ficar ativa em ambas as fabrics IRF ativas e inativas.
Procedimento
1. Acesse a visualização do sistema.
system-view2. Configure uma interface para não ser desligada quando a fabric IRF transitar para o estado de Recuperação.
mad exclude interface interface-type interface-numberPor padrão, todas as interfaces de rede em uma fabric IRF no estado de Recuperação são desligadas, exceto pelas interfaces de rede excluídas automaticamente pelo sistema.
Recuperando uma fabric IRF
Sobre a recuperação de uma fabric IRF
Se a fabric IRF ativa falhar antes da recuperação do link IRF, execute esta tarefa na fabric IRF inativa para recuperar a fabric IRF inativa para o encaminhamento de tráfego. A operação de recuperação manual faz com que todas as interfaces desligadas pelo MAD na fabric IRF inativa sejam ativadas.
Procedimento
1. Acesse a visualização do sistema.
system-view2. Recupere a fabric IRF inativa.
mad restoreOtimização das configurações de IRF para uma malha IRF
Configuração de uma descrição de dispositivo membro
1. Acesse a visualização do sistema.
system-view2. Configure uma descrição para um dispositivo membro.
irf member member-id description textPor padrão, nenhuma descrição de dispositivo membro é configurada.
Configurando as configurações do endereço MAC da ponte IRF
Sobre a configuração do endereço MAC da ponte IRF
O endereço MAC da ponte de um sistema deve ser único em uma LAN comutada. O endereço MAC da ponte IRF identifica uma fabric IRF pelos protocolos de Camada 2 (por exemplo, LACP) em uma LAN comutada.
Por padrão, uma fabric IRF usa o endereço MAC da ponte do mestre como o endereço MAC da ponte IRF. Após a saída do mestre, o endereço MAC da ponte IRF persiste por um período de tempo ou permanentemente, dependendo da configuração de persistência do endereço MAC da ponte IRF. Quando o temporizador de persistência do endereço MAC da ponte IRF expira, a fabric IRF usa o endereço MAC da ponte do mestre atual como o endereço MAC da ponte IRF.
Se ocorrer a fusão de fabric IRF, o IRF determina o endereço MAC da ponte IRF da fabric IRF fundida da seguinte forma:
- Ao ocorrer a fusão de fabric IRF, o IRF ignora os endereços MAC da ponte IRF e verifica o endereço MAC da ponte de cada dispositivo membro nas fabrics IRF. A fusão IRF falha se dois dispositivos membros tiverem o mesmo endereço MAC da ponte.
- Após a fusão das fabrics IRF, a fabric IRF fundida usa o endereço MAC da ponte da fabric IRF que venceu a eleição de mestre como o endereço MAC da ponte IRF.
Restrições e diretrizes para a configuração do endereço MAC da ponte IRF
CAUTION: A mudança do endereço MAC da ponte causará uma interrupção transitória no tráfego.
Ao configurar a persistência do endereço MAC da ponte IRF, siga estas restrições e diretrizes:
- Se ARP MAD ou ND MAD for usado com o recurso de spanning tree, você deve desativar a persistência do endereço MAC da ponte IRF usando o comando
undo irf mac-address persistent. - Se a fabric IRF tiver links agregados multichassi, não use o comando
undo irf mac-address persistent. O uso deste comando pode causar interrupção no tráfego.
Configuração da persistência de MAC da ponte IRF
1. Acesse a visualização do sistema.
system-view2. Configure a persistência do endereço MAC da ponte IRF.
- Retenha o endereço MAC da ponte permanentemente, mesmo que o proprietário do endereço tenha saído da fabric.
irf mac-address persistent alwaysirf mac-address persistent timerundo irf mac-address persistentPor padrão, o endereço MAC da ponte IRF permanece inalterado por 6 minutos após o proprietário do endereço deixar a fabric.
O comando irf mac-address persistent timer evita alterações desnecessárias no endereço MAC da ponte causadas pelo reinício do dispositivo, falha transitória no link ou desconexão intencional do link.
Ativação da atualização automática de software para sincronização de imagens de software
Sobre a atualização automática do software IRF
O recurso de atualização automática de software sincroniza automaticamente as imagens de software atuais do mestre para dispositivos que estão tentando ingressar na fabric IRF.
Para ingressar em uma fabric IRF, um dispositivo deve utilizar as mesmas imagens de software do mestre na fabric.
Ao adicionar um dispositivo à fabric IRF, a atualização automática de software compara as imagens de software de inicialização do dispositivo com as imagens de software atuais do mestre IRF. Se os dois conjuntos de imagens forem diferentes, o dispositivo realiza automaticamente as seguintes operações:
- Faz o download das imagens de software atuais do mestre.
- Define as imagens baixadas como suas imagens de inicialização principais.
- Reinicia com as novas imagens de software para se reconectar à fabric IRF.
Você deve atualizar manualmente o novo dispositivo com as imagens de software em execução na fabric IRF se a atualização automática de software estiver desativada.
Restrições e diretrizes:
- Para garantir uma atualização automática bem-sucedida em um ambiente de vários usuários, evite reiniciar os dispositivos membros durante o processo de atualização automática. Para informar os administradores sobre o status da atualização automática, configure o centro de informações para enviar mensagens de status para os terminais de configuração (consulte o Guia de Configuração de Gerenciamento e Monitoramento de Rede).
- Assegure-se de que o dispositivo que está sendo adicionado à fabric IRF tenha espaço de armazenamento suficiente para as novas imagens de software.
- Se não houver espaço de armazenamento suficiente, o dispositivo exclui automaticamente as imagens de software atuais. Se o espaço recuperado ainda for insuficiente, o dispositivo não conseguirá concluir a atualização automática. Você deve reiniciar o dispositivo e, em seguida, acessar o menu BootWare para excluir arquivos.
Procedimento:
- Acesse a visualização do sistema.
system-viewirf auto-update enablePor padrão, a atualização automática de software está ativada.
Configurando o atraso no relatório de alteração do status do link IRF
Sobre o atraso no relatório de alteração do status do link IRF
Para evitar divisões e fusões frequentes do IRF durante oscilações do link, configure as portas IRF para atrasar a emissão de eventos de alteração de status do link.
Uma porta IRF não relata imediatamente um evento de alteração de status do link para a fabric IRF logo após a mudança do estado de cima para baixo ou de baixo para cima. Se a alteração no estado do link persistir quando o atraso é atingido, a porta relata a alteração para a fabric IRF.
O dispositivo atrasa a emissão de eventos de alteração de status do link de uma porta IRF, mas não atrasa a emissão de eventos de alteração de status do link de uma interface física IRF.
Restrições e diretrizes
Assegure-se de que o atraso no relatório de alteração do status do link IRF seja menor que as configurações de tempo limite de heartbeat ou hello dos protocolos de camada superior (por exemplo, CFD e OSPF). Se o atraso de relatório for maior que a configuração de tempo limite de um protocolo, recálculos desnecessários podem ocorrer.
Defina o atraso como 0 segundos nas seguintes situações:
- A fabric IRF requer uma alternância rápida entre mestre/subordinado ou link IRF.
- O recurso RRPP, BFD ou GR é utilizado.
- Você deseja desativar uma interface física IRF ou reiniciar um dispositivo membro IRF. (Após concluir a operação, reconfigure o atraso dependendo da condição da rede.)
O recurso de atualização automática de software sincroniza automaticamente as imagens de software atuais do mestre com os dispositivos que estão tentando ingressar na malha IRF.
Para participar de uma malha IRF, um dispositivo deve usar as mesmas imagens de software que o mestre na malha.
Quando você adiciona um dispositivo à malha IRF, a atualização automática do software compara as imagens de software de inicialização do dispositivo com as imagens de software atuais do mestre IRF. Se os dois conjuntos de imagens forem diferentes, o dispositivo executará automaticamente as seguintes operações:
- Faz o download das imagens de software atuais do mestre.
- Define as imagens baixadas como suas principais imagens de software de inicialização.
- Reinicializa com as novas imagens de software para se juntar novamente à malha IRF.
Você deve atualizar manualmente o novo dispositivo com as imagens de software em execução na malha IRF se a atualização automática do software estiver desativada.
Restrições e diretrizes
Para garantir que a atualização automática do software seja bem-sucedida em um ambiente com vários usuários, evite que qualquer pessoa reinicie os dispositivos membros durante o processo de atualização automática. Para informar os administradores sobre o status da atualização automática, configure o centro de informações para enviar as mensagens de status aos terminais de configuração (consulte o Guia de configuração de monitoramento e gerenciamento de rede).
Certifique-se de que o dispositivo que você está adicionando à malha IRF tenha espaço de armazenamento suficiente para as novas imagens de software.
Se não houver espaço de armazenamento suficiente disponível, o dispositivo excluirá automaticamente as imagens de software atuais. Se o espaço recuperado ainda for insuficiente, o dispositivo não poderá concluir a atualização automática. É necessário reinicializar o dispositivo e, em seguida, acessar o menu BootWare para excluir os arquivos.
Procedimento
Entrar na visualização do sistema.
system-viewConfigurar o atraso de relatório de alteração de status de link do IRF.
irf link-delay intervalO atraso padrão para relatório de alteração de status de link do IRF é de 4 segundos.
Comandos de exibição e manutenção para IRF
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações sobre todos os membros da IRF. | display irf |
| Exibir a topologia da malha IRF. | display irf topology |
| Exibir informações do link IRF. | display irf link |
| Exibir a configuração da IRF. | display irf configuration |
| Exibir a configuração do MAD. | display mad [ verbose ] |
Exemplos de configuração de IRF
Os exemplos de configuração da IRF mostram como configurar malhas IRF que usam diferentes mecanismos MAD.
Exemplo: Configuração de uma malha IRF habilitada para LACP MAD
Configuração de rede
Conforme mostrado na Figura 14, configure uma malha IRF de quatro chassis na camada de acesso da rede corporativa. Configure o LACP MAD na agregação de vários chassis para o Dispositivo E, que é compatível com o LACP estendido.
Figura 14 Diagrama de rede
Procedimento
- Configurar o dispositivo A:
# Desligar as interfaces físicas usadas para links IRF. Neste exemplo, as interfaces físicas são desligadas em lote. Para obter mais informações, consulte o Layer 2-LAN Switching Configuration Guide.
<Sysname< system-view
[Sysname] interface range ten-gigabitethernet 1/0/49 to ten-gigabitethernet 1/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Desligar as interfaces físicas usadas para links IRF. Neste exemplo, as interfaces físicas são desligadas em lote. Para obter mais informações, consulte o Layer 2-LAN Switching Configuration Guide.
<Sysname< system-view
[Sysname] interface range ten-gigabitethernet 1/0/49 to ten-gigabitethernet 1/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit# Vincule a Ten-GigabitEthernet 1/0/51 e a Ten-GigabitEthernet 1/0/52 à porta IRF 1/2.
[Sysname] irf-port 1/1
[Sysname-irf-port1/1] port group interface ten-gigabitethernet 1/0/49
[Sysname-irf-port1/1] port group interface ten-gigabitethernet 1/0/50
[Sysname-irf-port1/1] quit# Vincular Ten-GigabitEthernet 1/0/51 e Ten-GigabitEthernet 1/0/52 ao IRF-port 1/2.
[Sysname] irf-port 1/2
[Sysname-irf-port1/2] port group interface ten-gigabitethernet 1/0/51
[Sysname-irf-port1/2] port group interface ten-gigabitethernet 1/0/52
[Sysname-irf-port1/2] quit# Ativar as interfaces físicas e salvar a configuração.
[Sysname] interface range ten-gigabitethernet 1/0/49 to ten-gigabitethernet 1/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save# Ativar a configuração da porta IRF.
[Sysname] irf-port-configuration active- Configurar o dispositivo B:
# Alterar o ID do membro do Dispositivo B para 2 e reiniciar o dispositivo para que a alteração tenha efeito.
<Sysname< system-view
[Sysname] irf member 1 renumber 2
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]:y
[Sysname] quit
<Sysname< rebootConecte o Dispositivo B ao Dispositivo A conforme mostrado na Figura 14 e faça login no Dispositivo B. (Detalhes não mostrados.)
# Desative as interfaces físicas para os links IRF.
<Sysname< system-view
[Sysname] interface range ten-gigabitethernet 2/0/49 to ten-gigabitethernet 2/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincule a Ten-GigabitEthernet 2/0/49 e Ten-GigabitEthernet 2/0/50 à IRF-port 2/1.
<Sysname< irf-port 2/1
[Sysname-irf-port2/1] port group interface ten-gigabitethernet 2/0/49
[Sysname-irf-port2/1] port group interface ten-gigabitethernet 2/0/50
[Sysname-irf-port2/1] quit
# Vincule a Ten-GigabitEthernet 2/0/51 e Ten-GigabitEthernet 2/0/52 à IRF-port 2/2.
<Sysname< irf-port 2/2
[Sysname-irf-port2/2] port group interface ten-gigabitethernet 2/0/51
[Sysname-irf-port2/2] port group interface ten-gigabitethernet 2/0/52
[Sysname-irf-port2/2] quit
# Ative as interfaces físicas e salve a configuração.
<Sysname< interface range ten-gigabitethernet 2/0/49 to ten-gigabitethernet 2/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
# Ative a configuração da porta IRF.
[Sysname] irf-port-configuration activeOs dois dispositivos realizam a eleição do mestre, e aquele que perdeu a eleição reinicia para formar um IRF fabric com o mestre.
3. Configurar o Dispositivo C:
# Altere o ID do membro do Dispositivo C para 3 e reinicie o dispositivo para que a alteração tenha efeito.
<Sysname< system-view
[Sysname] irf member 1 renumber 3
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]:y
[Sysname] quit
<Sysname< reboot
Conecte o Dispositivo C ao Dispositivo A conforme mostrado na Figura 14 e faça login no Dispositivo C. (Detalhes não mostrados.)
# Desative as interfaces físicas para os links IRF.
<Sysname< system-view
[Sysname] interface range ten-gigabitethernet 3/0/49 to ten-gigabitethernet 3/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincule Ten-GigabitEthernet 3/0/49 e Ten-GigabitEthernet 3/0/50 ao IRF-port 3/1.
[Sysname] irf-port 3/1
[Sysname-irf-port3/1] port group interface ten-gigabitethernet 3/0/49
[Sysname-irf-port3/1] port group interface ten-gigabitethernet 3/0/50
[Sysname-irf-port3/1] quit
# Vincule Ten-GigabitEthernet 3/0/51 e Ten-GigabitEthernet 3/0/52 ao IRF-port 3/2.
[Sysname] irf-port 3/2
[Sysname-irf-port3/2] port group interface ten-gigabitethernet 3/0/51
[Sysname-irf-port3/2] port group interface ten-gigabitethernet 3/0/52
[Sysname-irf-port3/2] quit
# Ative as interfaces físicas e salve a configuração.
[Sysname] interface range ten-gigabitethernet 3/0/49 to ten-gigabitethernet 3/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
# Ative a configuração da porta IRF.
[Sysname] irf-port-configuration active
O Dispositivo C reinicia para se juntar ao IRF fabric.
Configurar o dispositivo C:
# Alterar o ID do membro do Dispositivo D para 4 e reiniciar o dispositivo para que a alteração tenha efeito.
[Sysname] system-view
[Sysname] irf member 1 renumber 4
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]:y
[Sysname] quit
<Sysname< reboot
Conectar o Dispositivo D ao Dispositivo B e ao Dispositivo C, conforme mostrado na Figura 14, e fazer login no Dispositivo D. (Detalhes não mostrados.)
# Desativar as interfaces físicas.
<Sysname< system-view
[Sysname] interface range ten-gigabitethernet 4/0/49 to ten-gigabitethernet 4/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincular Ten-GigabitEthernet 4/0/49 e Ten-GigabitEthernet 4/0/50 ao IRF-port 4/1.
[Sysname] irf-port 4/1
[Sysname-irf-port4/1] port group interface ten-gigabitethernet 4/0/49
[Sysname-irf-port4/1] port group interface ten-gigabitethernet 4/0/50
[Sysname-irf-port4/1] quit
# Vincular Ten-GigabitEthernet 4/0/51 e Ten-GigabitEthernet 4/0/52 ao IRF-port 4/2.
[Sysname] irf-port 4/2
[Sysname-irf-port4/2] port group interface ten-gigabitethernet 4/0/51
[Sysname-irf-port4/2] port group interface ten-gigabitethernet 4/0/52
[Sysname-irf-port4/2] quit
# Ativar as interfaces físicas e salvar a configuração.
[Sysname] interface range ten-gigabitethernet 4/0/49 to ten-gigabitethernet 4/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
# Ativar a configuração da porta IRF.
[Sysname] irf-port-configuration active
Configurar o dispositivo D:
Configure LACP MAD on the IRF fabric:
Defina o ID de domínio do IRF fabric como 1.
[Sysname] system-view
[Sysname] irf domain 1
# Crie uma interface de agregação dinâmica e ative o LACP MAD.
[Sysname] interface bridge-aggregation 2
[Sysname-Bridge-Aggregation2] link-aggregation mode dynamic
[Sysname-Bridge-Aggregation2] mad enable
Você precisa atribuir um ID de domínio (intervalo: 0-4294967295)
[Current domain ID is: 1]:
O ID de domínio atribuído é: 1
[Sysname-Bridge-Aggregation2] quit
# Atribua GigabitEthernet 1/0/1, GigabitEthernet 2/0/1, GigabitEthernet 3/0/1 e GigabitEthernet 4/0/1 à interface de agregação.
[Sysname] interface range gigabitethernet 1/0/1 gigabitethernet 2/0/1
gigabitethernet 3/0/1 gigabitethernet 4/0/1
[Sysname-if-range] port link-aggregation group 2
[Sysname-if-range] quit
Se o dispositivo intermediário também estiver em uma malha IRF, atribua às duas malhas IRF IDs de domínio diferentes para a detecção correta da divisão. A falsa detecção causa a divisão da IRF.
# Crie uma interface de agregação dinâmica.
[Sysname] system-view
[Sysname] interface bridge-aggregation 2
[Sysname-Bridge-Aggregation2] link-aggregation mode dynamic
[Sysname-Bridge-Aggregation2] quit
# Atribua GigabitEthernet 1/0/1, GigabitEthernet 1/0/2, GigabitEthernet 1/0/3 e GigabitEthernet 1/0/4 à interface de agregação.
[Sysname] interface range gigabitethernet 1/0/1 to gigabitethernet 1/0/4
[Sysname-if-range] port link-aggregation group 2
[Sysname-if-range] quit
Exemplo: Configuração de uma malha IRF habilitada para BFD MAD
Configuração de rede
Conforme mostrado na Figura 15, configure uma malha IRF de quatro chassis na camada de distribuição da rede corporativa.
- Configure o BFD MAD na malha IRF e estabeleça links BFD MAD entre cada dispositivo membro e o dispositivo intermediário.
- Desative o recurso de spanning tree nas portas usadas para BFD MAD, pois os dois recursos entram em conflito entre si.
Figura 15 Diagrama de rede
Procedimento
Configurar o dispositivo A:
# Desativar as interfaces físicas usadas para os links IRF.
<Sysname< system-view
[Sysname] interface range ten-gigabitethernet 1/0/49 to ten-gigabitethernet 1/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincular Ten-GigabitEthernet 1/0/49 e Ten-GigabitEthernet 1/0/50 ao IRF-port 1/1.
[Sysname] irf-port 1/1
[Sysname-irf-port1/1] port group interface ten-gigabitethernet 1/0/49
[Sysname-irf-port1/1] port group interface ten-gigabitethernet 1/0/50
[Sysname-irf-port1/1] quit
# Vincular Ten-GigabitEthernet 1/0/51 e Ten-GigabitEthernet 1/0/52 ao IRF-port 1/2.
[Sysname] irf-port 1/2
[Sysname-irf-port1/2] port group interface ten-gigabitethernet 1/0/51
[Sysname-irf-port1/2] port group interface ten-gigabitethernet 1/0/52
[Sysname-irf-port1/2] quit
# Ativar as interfaces físicas e salvar a configuração.
[Sysname] interface range ten-gigabitethernet 1/0/49 to ten-gigabitethernet 1/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
# Ativar a configuração da porta IRF.
[Sysname] irf-port-configuration active
Configurar o dispositivo B:
# Alterar o ID do membro do Dispositivo B para 2 e reiniciar o dispositivo para que a alteração tenha efeito.
<Sysname< system-view
[Sysname] irf member 1 renumber 2
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]:y
[Sysname] quit
<Sysname< reboot
# Conectar o Dispositivo B ao Dispositivo A conforme mostrado na Figura 15 e fazer login no Dispositivo B. (Detalhes não mostrados.)
<Sysname< system-view
[Sysname] interface range ten-gigabitethernet 2/0/49 to ten-gigabitethernet 2/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincular Ten-GigabitEthernet 2/0/49 e Ten-GigabitEthernet 2/0/50 ao IRF-port 2/1.
[Sysname] irf-port 2/1
[Sysname-irf-port2/1] port group interface ten-gigabitethernet 2/0/49
[Sysname-irf-port2/1] port group interface ten-gigabitethernet 2/0/50
[Sysname-irf-port2/1] quit
# Vincular Ten-GigabitEthernet 2/0/51 e Ten-GigabitEthernet 2/0/52 ao IRF-port 2/2.
[Sysname] irf-port 2/2
[Sysname-irf-port2/2] port group interface ten-gigabitethernet 2/0/51
[Sysname-irf-port2/2] port group interface ten-gigabitethernet 2/0/52
[Sysname-irf-port2/2] quit
# Ativar as interfaces físicas e salvar a configuração.
[Sysname] interface range ten-gigabitethernet 2/0/49 to ten-gigabitethernet 2/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
# Ativar a configuração da porta IRF.
[Sysname] irf-port-configuration active
Os dois dispositivos realizam a eleição do mestre, e aquele que perdeu a eleição reinicia para formar uma rede IRF com o mestre.
Configurar o dispositivo C:
# Alterar o ID do membro do Dispositivo C para 3 e reiniciar o dispositivo para que a alteração tenha efeito.
<Sysname< system-view
[Sysname] irf member 1 renumber 3
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]:y
[Sysname] quit
<Sysname< reboot
#Conectar o Dispositivo C ao Dispositivo A conforme mostrado na Figura 15 e fazer login no Dispositivo C. (Detalhes não mostrados.)
<Sysname< system-view
[Sysname] interface range ten-gigabitethernet 3/0/49 to ten-gigabitethernet 3/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincular Ten-GigabitEthernet 3/0/49 e Ten-GigabitEthernet 3/0/50 ao IRF-port 3/1.
[Sysname] irf-port 3/1
[Sysname-irf-port3/1] port group interface ten-gigabitethernet 3/0/49
[Sysname-irf-port3/1] port group interface ten-gigabitethernet 3/0/50
[Sysname-irf-port3/1] quit
# Vincular Ten-GigabitEthernet 3/0/51 e Ten-GigabitEthernet 3/0/52 ao IRF-port 3/2.
[Sysname] irf-port 3/2
[Sysname-irf-port3/2] port group interface ten-gigabitethernet 3/0/51
[Sysname-irf-port3/2] port group interface ten-gigabitethernet 3/0/52
[Sysname-irf-port3/2] quit
#Ativar as interfaces físicas e salvar a configuração.
[Sysname] interface range ten-gigabitethernet 3/0/49 to ten-gigabitethernet 3/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
# Ativar a configuração da porta IRF.
[Sysname] irf-port-configuration active
O Dispositivo C reinicia para se juntar à rede IRF.
Configurar o dispositivo D:
# Alterar o ID do membro do Dispositivo D para 4 e reiniciar o dispositivo para que a alteração tenha efeito.
<Sysname< system-view
[Sysname] irf member 1 renumber 4
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]:y
[Sysname] quit
<Sysname< reboot
# Conectar o Dispositivo D ao Dispositivo B e ao Dispositivo C conforme mostrado na Figura 15 e fazer login no Dispositivo D. (Detalhes não mostrados.)
<Sysname< system-view
[Sysname] interface range ten-gigabitethernet 4/0/49 to ten-gigabitethernet 4/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincular Ten-GigabitEthernet 4/0/49 e Ten-GigabitEthernet 4/0/50 ao IRF-port 4/1.
[Sysname] irf-port 4/1
[Sysname-irf-port4/1] port group interface ten-gigabitethernet 4/0/49
[Sysname-irf-port4/1] port group interface ten-gigabitethernet 4/0/50
[Sysname-irf-port4/1] quit
# Vincular Ten-GigabitEthernet 4/0/51 e Ten-GigabitEthernet 4/0/52 ao IRF-port 4/2.
[Sysname] irf-port 4/2
[Sysname-irf-port4/2] port group interface ten-gigabitethernet 4/0/51
[Sysname-irf-port4/2] port group interface ten-gigabitethernet 4/0/52
[Sysname-irf-port4/2] quit
# Ativar as interfaces físicas e salvar a configuração.
[Sysname] interface range ten-gigabitethernet 4/0/49 to ten-gigabitethernet 4/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
Ativar a configuração da porta IRF.
[Sysname] irf-port-configuration active
O Dispositivo D reinicia para se juntar à rede IRF. Uma rede IRF de quatro chassi é formada.
Configure o BFD MAD na malha IRF:
# Criar a VLAN 3 e adicionar GigabitEthernet 1/0/1, GigabitEthernet 2/0/1, GigabitEthernet 3/0/1 e GigabitEthernet 4/0/1 à VLAN 3.
[Sysname] vlan 3
[Sysname-vlan3] port gigabitethernet 1/0/1 gigabitethernet 2/0/1 gigabitethernet 3/0/1 gigabitethernet 4/0/1
[Sysname-vlan3] quit
#Criar a VLAN-interface 3 e configurar um endereço IP MAD para cada dispositivo membro na interface VLAN.
[Sysname] interface vlan-interface 3
[Sysname-Vlan-interface3] mad bfd enable
[Sysname-Vlan-interface3] mad ip address 192.168.2.1 24 member 1
[Sysname-Vlan-interface3] mad ip address 192.168.2.2 24 member 2
[Sysname-Vlan-interface3] mad ip address 192.168.2.3 24 member 3
[Sysname-Vlan-interface3] mad ip address 192.168.2.4 24 member 4
[Sysname-Vlan-interface3] quit
# Desativar o recurso de spanning tree em GigabitEthernet 1/0/1, GigabitEthernet 2/0/1, GigabitEthernet 3/0/1 e GigabitEthernet 4/0/1.
[Sysname] interface range gigabitethernet 1/0/1 gigabitethernet 2/0/1 gigabitethernet 3/0/1 gigabitethernet 4/0/1
[Sysname-if-range] undo stp enable
[Sysname-if-range] quit
# Criar VLAN 3 e atribuir GigabitEthernet 1/0/1, GigabitEthernet 1/0/2, GigabitEthernet 1/0/3 e GigabitEthernet 1/0/4 à VLAN 3 para encaminhar pacotes BFD MAD.
<DeviceE> system-view
[DeviceE] vlan 3
[DeviceE-vlan3] port gigabitethernet 1/0/1 to gigabitethernet 1/0/4
[DeviceE-vlan3] quit
Exemplo: Configuração de uma malha IRF habilitada para ARP MAD
- Configure o ARP MAD na malha IRF e use os links conectados ao Dispositivo E para transmitir pacotes ARP MAD.
- Para evitar loops, execute o recurso spanning tree entre o Dispositivo E e a malha IRF.
Configuração de rede
Conforme mostrado na Figura 16, configure uma malha IRF de quatro chassis na rede corporativa.
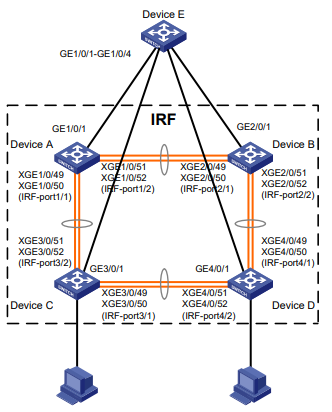
Figura 16 Diagrama de rede
Procedimento
Configurar o dispositivo A:
# Desativar as interfaces físicas usadas para links IRF.
<Sysname> system-view
[Sysname] interface range ten-gigabitethernet 1/0/49 to ten-gigabitethernet 1/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincular Ten-GigabitEthernet 1/0/49 e Ten-GigabitEthernet 1/0/50 ao IRF-port 1/1.
<Sysname> irf-port 1/1
[Sysname-irf-port1/1] port group interface ten-gigabitethernet 1/0/49
[Sysname-irf-port1/1] port group interface ten-gigabitethernet 1/0/50
[Sysname-irf-port1/1] quit
# Vincular Ten-GigabitEthernet 1/0/51 e Ten-GigabitEthernet 1/0/52 ao IRF-port 1/2.
<Sysname> irf-port 1/2
[Sysname-irf-port1/2] port group interface ten-gigabitethernet 1/0/51
[Sysname-irf-port1/2] port group interface ten-gigabitethernet 1/0/52
[Sysname-irf-port1/2] quit
# Ativar a configuração da porta IRF.
<Sysname> interface range ten-gigabitethernet 1/0/49 to ten-gigabitethernet 1/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
[Sysname] irf-port-configuration active
Configurar o dispositivo B:
# Alterar o ID do membro do Dispositivo B para 2 e reiniciar o dispositivo para que a alteração tenha efeito.
<Sysname> system-view
[Sysname] irf member 1 renumber 2
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]: y
[Sysname] quit
[Sysname] reboot
# Conectar o Dispositivo B ao Dispositivo A, conforme mostrado na Figura 16, e fazer login no Dispositivo B. (Detalhes não mostrados.)
<Sysname> system-view
[Sysname] interface range ten-gigabitethernet 2/0/49 to ten-gigabitethernet 2/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincular Ten-GigabitEthernet 2/0/49 e Ten-GigabitEthernet 2/0/50 ao IRF-port 2/1.
<Sysname> irf-port 2/1
[Sysname-irf-port2/1] port group interface ten-gigabitethernet 2/0/49
[Sysname-irf-port2/1] port group interface ten-gigabitethernet 2/0/50
[Sysname-irf-port2/1] quit
# Vincular Ten-GigabitEthernet 2/0/51 e Ten-GigabitEthernet 2/0/52 ao IRF-port 2/2.
<Sysname> irf-port 2/2
[Sysname-irf-port2/2] port group interface ten-gigabitethernet 2/0/51
[Sysname-irf-port2/2] port group interface ten-gigabitethernet 2/0/52
[Sysname-irf-port2/2] quit
# Ativar a configuração da porta IRF.
<Sysname> interface range ten-gigabitethernet 2/0/49 to ten-gigabitethernet 2/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
[Sysname] irf-port-configuration active
Os dois dispositivos realizam a eleição do mestre, e aquele que perdeu a eleição reinicia para formar uma malha IRF com o mestre.
Configurar o dispositivo C:
# Alterar o ID do membro do Dispositivo C para 3 e reiniciar o dispositivo para que a alteração tenha efeito.
<Sysname> system-view
[Sysname] irf member 1 renumber 3
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]: y
[Sysname] quit
[Sysname] reboot
# Conectar o Dispositivo C ao Dispositivo A, conforme mostrado na Figura 16, e fazer login no Dispositivo C. (Detalhes não mostrados.)
<Sysname> system-view
[Sysname] interface range ten-gigabitethernet 3/0/49 to ten-gigabitethernet 3/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincular Ten-GigabitEthernet 3/0/49 e Ten-GigabitEthernet 3/0/50 ao IRF-port 3/1.
<Sysname> irf-port 3/1
[Sysname-irf-port3/1] port group interface ten-gigabitethernet 3/0/49
[Sysname-irf-port3/1] port group interface ten-gigabitethernet 3/0/50
[Sysname-irf-port3/1] quit
# Vincular Ten-GigabitEthernet 3/0/51 e Ten-GigabitEthernet 3/0/52 ao IRF-port 3/2.
<Sysname> irf-port 3/2
[Sysname-irf-port3/2] port group interface ten-gigabitethernet 3/0/51
[Sysname-irf-port3/2] port group interface ten-gigabitethernet 3/0/52
[Sysname-irf-port3/2] quit
# Ativar a configuração da porta IRF.
<Sysname> interface range ten-gigabitethernet 3/0/49 to ten-gigabitethernet 3/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
[Sysname] irf-port-configuration active
O Dispositivo C reinicia para ingressar na malha IRF.
Configurar o dispositivo D:
# Alterar o ID do membro do Dispositivo D para 4 e reiniciar o dispositivo para que a alteração tenha efeito.
<Sysname> system-view
[Sysname] irf member 1 renumber 4
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]: y
[Sysname] quit
[Sysname] reboot
# Conectar o Dispositivo D ao Dispositivo B e ao Dispositivo C, conforme mostrado na Figura 16, e fazer login no Dispositivo D. (Detalhes não mostrados.)
<Sysname> system-view
[Sysname] interface range ten-gigabitethernet 4/0/49 to ten-gigabitethernet 4/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincular Ten-GigabitEthernet 4/0/49 e Ten-GigabitEthernet 4/0/50 ao IRF-port 4/1.
<Sysname> irf-port 4/1
[Sysname-irf-port4/1] port group interface ten-gigabitethernet 4/0/49
[Sysname-irf-port4/1] port group interface ten-gigabitethernet 4/0/50
[Sysname-irf-port4/1] quit
# Vincular Ten-GigabitEthernet 4/0/51 e Ten-GigabitEthernet 4/0/52 ao IRF-port 4/2.
<Sysname> irf-port 4/2
[Sysname-irf-port4/2] port group interface ten-gigabitethernet 4/0/51
[Sysname-irf-port4/2] port group interface ten-gigabitethernet 4/0/52
[Sysname-irf-port4/2] quit
# Ativar a configuração da porta IRF.
<Sysname> interface range ten-gigabitethernet 4/0/49 to ten-gigabitethernet 4/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
[Sysname] irf-port-configuration active
O Dispositivo D reinicia para ingressar na malha IRF. Uma malha IRF de quatro chassi é formada.
# Habilitar globalmente a funcionalidade de spanning tree. Mapear a VLAN ARP MAD para MSTI 1 na região MST.
<Sysname> system-view
[Sysname] stp global enable
[Sysname] stp region-configuration
[Sysname-mst-region] region-name arpmad
[Sysname-mst-region] instance 1 vlan 3
[Sysname-mst-region] active region-configuration
[Sysname-mst-region] quit
# Configurar a malha IRF para alterar seu endereço MAC de ponte assim que o proprietário do endereço sair.
<Sysname> undo irf mac-address persistent# Definir o ID do domínio da malha IRF como 1.
<Sysname> irf domain 1# Criar VLAN 3 e atribuir GigabitEthernet 1/0/1, GigabitEthernet 2/0/1, GigabitEthernet 3/0/1 e GigabitEthernet 4/0/1 à VLAN 3.
<Sysname> vlan 3
[Sysname-vlan3] port gigabitethernet 1/0/1 gigabitethernet 2/0/1 gigabitethernet 3/0/1 gigabitethernet 4/0/1
[Sysname-vlan3] quit
# Criar a VLAN-interface 3, atribuir um endereço IP e habilitar o ARP MAD na interface.
<Sysname> interface vlan-interface 3
[Sysname-Vlan-interface3] ip address 192.168.2.1 24
[Sysname-Vlan-interface3] mad arp enable
You need to assign a domain ID (range: 0-4294967295)
[Current domain is: 1]:
The assigned domain ID is: 1
Se o dispositivo intermediário também estiver em uma malha IRF, atribua às duas malhas IRF IDs de domínio diferentes para a detecção correta da divisão. A falsa detecção causa a divisão da IRF.
# Habilitar globalmente a funcionalidade de spanning tree. Mapear a VLAN ARP MAD para MSTI 1 na região MST.
<DeviceE> system-view
[DeviceE] stp global enable
[DeviceE] stp region-configuration
[DeviceE-mst-region] region-name arpmad
[DeviceE-mst-region] instance 1 vlan 3
[DeviceE-mst-region] active region-configuration
[DeviceE-mst-region] quit
# Criar a VLAN 3 e atribuir GigabitEthernet 1/0/1, GigabitEthernet 1/0/2, GigabitEthernet 1/0/3 e GigabitEthernet 1/0/4 à VLAN 3 para encaminhamento de pacotes ARP MAD.
<DeviceE> vlan 3
[DeviceE-vlan3] port gigabitethernet 1/0/1 to gigabitethernet 1/0/4
[DeviceE-vlan3] quit
Exemplo: Configuração de uma malha IRF habilitada para ND MAD
Configuração de rede
Conforme mostrado na Figura 17, configure uma malha IRF de quatro chassis na rede corporativa IPv6.
- Configure o ND MAD na malha IRF e use os links conectados ao Dispositivo E para transmitir pacotes ND MAD.
- Para evitar loops, execute o recurso spanning tree entre o Dispositivo E e a malha IRF.
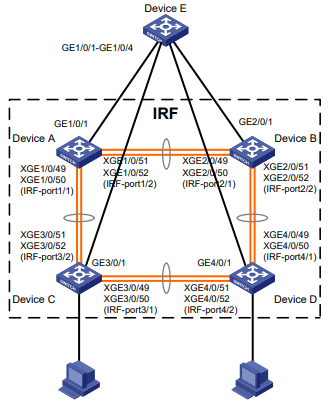
Figura 17 Diagrama de rede
Procedimento
- Configurar o dispositivo A:
# Desativar as interfaces físicas usadas para links IRF.
<Sysname> system-view
[Sysname] interface range ten-gigabitethernet 1/0/49 to ten-gigabitethernet 1/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
#Vincular Ten-GigabitEthernet 1/0/49 e Ten-GigabitEthernet 1/0/50 ao IRF-port 1/1.
<Sysname> irf-port 1/1
[Sysname-irf-port1/1] port group interface ten-gigabitethernet 1/0/49
[Sysname-irf-port1/1] port group interface ten-gigabitethernet 1/0/50
[Sysname-irf-port1/1] quit
# Vincular Ten-GigabitEthernet 1/0/51 e Ten-GigabitEthernet 1/0/52 ao IRF-port 1/2.
<Sysname> irf-port 1/2
[Sysname-irf-port1/2] port group interface ten-gigabitethernet 1/0/51
[Sysname-irf-port1/2] port group interface ten-gigabitethernet 1/0/52
[Sysname-irf-port1/2] quit
# Ativar as interfaces físicas e salvar a configuração do IRF.
<Sysname> interface range ten-gigabitethernet 1/0/49 to ten-gigabitethernet 1/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
[Sysname] irf-port-configuration active
Configurar o dispositivo B:
# Alterar o ID do membro do Device B para 2 e reiniciar o dispositivo para aplicar a alteração.
<Sysname> system-view
[Sysname] irf member 1 renumber 2
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]:y
[Sysname] quit
[Sysname] reboot
Conectar o Device B ao Device A conforme mostrado na Figura 17 e fazer login no Device B. (Detalhes não mostrados.)
# Desativar as interfaces físicas usadas para os links IRF.
<Sysname> system-view
[Sysname] interface range ten-gigabitethernet 2/0/49 to ten-gigabitethernet 2/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincular Ten-GigabitEthernet 2/0/49 e Ten-GigabitEthernet 2/0/50 ao IRF-port 2/1.
<Sysname> irf-port 2/1
[Sysname-irf-port2/1] port group interface ten-gigabitethernet 2/0/49
[Sysname-irf-port2/1] port group interface ten-gigabitethernet 2/0/50
[Sysname-irf-port2/1] quit
# Vincular Ten-GigabitEthernet 2/0/51 e Ten-GigabitEthernet 2/0/52 ao IRF-port 2/2.
<Sysname> irf-port 2/2
[Sysname-irf-port2/2] port group interface ten-gigabitethernet 2/0/51
[Sysname-irf-port2/2] port group interface ten-gigabitethernet 2/0/52
[Sysname-irf-port2/2] quit
# Ativar as interfaces físicas e salvar a configuração.
<Sysname> interface range ten-gigabitethernet 2/0/49 to ten-gigabitethernet 2/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
[Sysname] irf-port-configuration active
Os dois dispositivos realizam a eleição do mestre, e aquele que perdeu a eleição reinicia para formar uma malha IRF com o mestre.
Configurar o dispositivo C:
# Alterar o ID do membro do Device C para 3 e reiniciar o dispositivo para aplicar a alteração.
<Sysname> system-view
[Sysname] irf member 1 renumber 3
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]:y
[Sysname] quit
[Sysname] reboot
Conectar o Device C ao Device A conforme mostrado na Figura 17 e fazer login no Device C. (Detalhes não mostrados.)
# Desativar as interfaces físicas usadas para os links IRF.
<Sysname> system-view
[Sysname] interface range ten-gigabitethernet 3/0/49 to ten-gigabitethernet 3/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincular Ten-GigabitEthernet 3/0/49 e Ten-GigabitEthernet 3/0/50 ao IRF-port 3/1.
<Sysname> irf-port 3/1
[Sysname-irf-port3/1] port group interface ten-gigabitethernet 3/0/49
[Sysname-irf-port3/1] port group interface ten-gigabitethernet 3/0/50
[Sysname-irf-port3/1] quit
# Vincular Ten-GigabitEthernet 3/0/51 e Ten-GigabitEthernet 3/0/52 ao IRF-port 3/2.
<Sysname> irf-port 3/2
[Sysname-irf-port3/2] port group interface ten-gigabitethernet 3/0/51
[Sysname-irf-port3/2] port group interface ten-gigabitethernet 3/0/52
[Sysname-irf-port3/2] quit
# Ativar as interfaces físicas e salvar a configuração.
<Sysname> interface range ten-gigabitethernet 3/0/49 to ten-gigabitethernet 3/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
[Sysname] irf-port-configuration active
O Device C reinicia para ingressar na malha IRF.
Configurar o dispositivo D:
# Alterar o ID do membro do Device D para 4 e reiniciar o dispositivo para aplicar a alteração.
<Sysname> system-view
[Sysname] irf member 1 renumber 4
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]:y
[Sysname] quit
[Sysname] reboot
Conectar o Device D ao Device B e Device C conforme mostrado na Figura 17 e fazer login no Device D. (Detalhes não mostrados.)
# Desativar as interfaces físicas usadas para os links IRF.
<Sysname> system-view
[Sysname] interface range ten-gigabitethernet 4/0/49 to ten-gigabitethernet 4/0/52
[Sysname-if-range] shutdown
[Sysname-if-range] quit
# Vincular Ten-GigabitEthernet 4/0/49 e Ten-GigabitEthernet 4/0/50 ao IRF-port 4/1.
<Sysname> irf-port 4/1
[Sysname-irf-port4/1] port group interface ten-gigabitethernet 4/0/49
[Sysname-irf-port4/1] port group interface ten-gigabitethernet 4/0/50
[Sysname-irf-port4/1] quit
# Vincular Ten-GigabitEthernet 4/0/51 e Ten-GigabitEthernet 4/0/52 ao IRF-port 4/2.
<Sysname> irf-port 4/2
[Sysname-irf-port4/2] port group interface ten-gigabitethernet 4/0/51
[Sysname-irf-port4/2] port group interface ten-gigabitethernet 4/0/52
[Sysname-irf-port4/2] quit
# Ativar as interfaces físicas e salvar a configuração.
<Sysname> interface range ten-gigabitethernet 4/0/49 to ten-gigabitethernet 4/0/52
[Sysname-if-range] undo shutdown
[Sysname-if-range] quit
[Sysname] save
[Sysname] irf-port-configuration active
O Device D reinicia para ingressar na malha IRF. Uma malha IRF de quatro chassi é formada.
# Habilitar globalmente a funcionalidade de spanning tree. Mapear a VLAN ND MAD para o MSTI 1 na região MST.
<Sysname> system-view
[Sysname] stp global enable
[Sysname] stp region-configuration
[Sysname-mst-region] region-name ndmad
[Sysname-mst-region] instance 1 vlan 3
[Sysname-mst-region] active region-configuration
[Sysname-mst-region] quit
# Configurar a malha IRF para alterar seu endereço MAC de ponte assim que o proprietário do endereço sair.
<Sysname> undo irf mac-address persistent# Definir o ID de domínio da malha IRF como 1.
<Sysname> irf domain 1# Criar a VLAN 3 e adicionar GigabitEthernet 1/0/1, GigabitEthernet 2/0/1, GigabitEthernet 3/0/1 e GigabitEthernet 4/0/1 à VLAN 3.
<Sysname> vlan 3
[Sysname-vlan3] port gigabitethernet 1/0/1 gigabitethernet 2/0/1 gigabitethernet 3/0/1 gigabitethernet 4/0/1
[Sysname-vlan3] quit
# Criar a interface VLAN 3, atribuir um endereço IPv6 e habilitar o ND MAD na interface.
<Sysname> interface vlan-interface 3
[Sysname-Vlan-interface3] ipv6 address 2001::1 64
[Sysname-Vlan-interface3] mad nd enable
You need to assign a domain ID (range: 0-4294967295)
[Current domain is: 1]:
The assigned domain ID is: 1
Se o dispositivo intermediário também estiver em uma malha IRF, atribua às duas malhas IRF IDs de domínio diferentes para a detecção correta da divisão. A falsa detecção causa a divisão da IRF.
# Habilitar globalmente a funcionalidade de spanning tree. Mapear a VLAN ND MAD para o MSTI 1 na região MST.
<DeviceE> system-view
[DeviceE] stp global enable
[DeviceE] stp region-configuration
[DeviceE-mst-region] region-name ndmad
[DeviceE-mst-region] instance 1 vlan 3
[DeviceE-mst-region] active region-configuration
[DeviceE-mst-region] quit
# Criar a VLAN 3 e adicionar GigabitEthernet 1/0/1, GigabitEthernet 1/0/2, GigabitEthernet 1/0/3 e GigabitEthernet 1/0/4 à VLAN 3 para encaminhar pacotes ND MAD.
<DeviceE> vlan 3
[DeviceE-vlan3] port gigabitethernet 1/0/1 to gigabitethernet 1/0/4
[DeviceE-vlan3] quit
03 - Configurando as interfaces Ethernet
Confifurando interfaces Ethernet
Sobre a interface Ethernet
A série de switches é compatível com interfaces Ethernet e interfaces de console. Para saber os tipos de interface e o número de interfaces suportadas por um modelo de switch, consulte o guia de instalação.
Este capítulo descreve como configurar as interfaces Ethernet de gerenciamento e as interfaces Ethernet.
Convenções de nomenclatura de interface Ethernet
As interfaces Ethernet são nomeadas no formato de tipo de interface A/B/C. As letras que seguem o tipo de interface representam os seguintes elementos:
ID do membro A-IRF. Se o switch não estiver em uma malha IRF, A será 1 por padrão.
Número do slot do cartão B. 0 indica que a interface é uma interface fixa do switch.
Índice da porta C.
Configuração de definições comuns da interface Ethernet
Configuração do tipo físico para uma interface combinada (interface combinada única)
Sobre a interface combo
Uma interface combo é uma interface lógica que compreende fisicamente uma porta combo de fibra e uma porta combo de cobre. As duas portas compartilham um canal de encaminhamento e uma visualização de interface. Como resultado, elas não podem funcionar simultaneamente. Quando você ativa uma porta, a outra porta é automaticamente desativada. Se você executar o comando combo enable auto em uma interface combo, a interface identificará automaticamente a mídia inserida e ativará a porta combo correspondente. Na visualização da interface, você pode ativar a porta combo de fibra ou de cobre e configurar outros atributos da porta, como a taxa de interface e o modo duplex.
Restrições e diretrizes de configuração
Esse recurso está disponível somente em dispositivos que suportam interfaces combinadas.
Pré-requisitos
Antes de configurar as interfaces combo, conclua as seguintes tarefas:
Determine as interfaces combinadas em seu dispositivo. Identifique as duas interfaces físicas que pertencem a cada interface combinada de acordo com as marcas no painel do dispositivo.
Use o comando display interface para determinar qual porta (fibra ou cobre) de cada interface combo está ativa:
Se a porta de cobre estiver ativa, a saída incluirá "O tipo de mídia é par trançado".
Se a porta de fibra estiver ativa, a saída não incluirá essas informações.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberAtivar a porta combo de cobre ou a porta combo de fibra. combo enable { auto | copper | fiber } O padrão é auto.
Configuração das definições básicas de uma interface Ethernet
Sobre as configurações básicas da interface Ethernet
Você pode configurar uma interface Ethernet para operar em um dos seguintes modos duplex:
Modo full-duplex - A interface pode enviar e receber pacotes simultaneamente.
Modo half-duplex - A interface só pode enviar ou receber pacotes em um determinado momento.
Modo de negociação automática - A interface negocia um modo duplex com seu par.
Você pode definir a velocidade de uma interface Ethernet ou permitir que ela negocie automaticamente uma velocidade com seu par. Para uma interface Ethernet de camada 2 de 100 Mbps ou 1000 Mbps, você também pode definir opções de velocidade para negociação automática. As duas extremidades podem selecionar uma velocidade somente entre as opções disponíveis. Para obter mais informações, consulte "Definição de opções de velocidade para autonegociação em uma interface Ethernet".
Restrições e diretrizes
O comando shutdown não pode ser configurado em uma interface em um teste de loopback.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberDefina a descrição da interface Ethernet.
description text A configuração padrão é interface-nome da interface. Por exemplo, GigabitEthernet1/0/1 Interface.
Defina o modo duplex para a interface Ethernet.
duplex { auto | full | half } Por padrão, o modo duplex é automático para interfaces Ethernet.
As portas de cobre Ethernet que operam em 1000 Mbps ou 10000 Mbps e as portas de fibra não suportam a palavra-chave half.
Defina a velocidade da interface Ethernet.
speed { 10 | 100 | 1000 | 2500 | 5000 | 10000 | auto }Por padrão, uma interface Ethernet negocia uma velocidade com seu par.
Defina a largura de banda esperada para a interface Ethernet.
Por padrão, a largura de banda esperada (em kbps) é a taxa de transmissão da interface dividida por 1000.
Abra a interface Ethernet.
undo shutdownPor padrão, as interfaces Ethernet estão no estado "up".
Ativação da negociação automática para redução de velocidade
Sobre a negociação automática para redução de velocidade
Execute esta tarefa para permitir que as interfaces em duas extremidades de um link negociem automaticamente o downgrade de velocidade quando houver as seguintes condições:
As interfaces negociam automaticamente uma velocidade de 1000 Mbps.
As interfaces não podem operar a 1000 Mbps devido a restrições de link.
Restrições e diretrizes
Esse recurso está disponível apenas em interfaces GE.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberHabilitar a negociação automática para redução de velocidade.
speed auto downgradePor padrão, a negociação automática para redução de velocidade está ativada.
Configuração do suporte a jumbo frame
Sobre o jumbo frame
Os quadros Jumbo são quadros maiores que 1522 bytes e normalmente são recebidos por uma interface Ethernet durante trocas de dados de alto rendimento, como transferências de arquivos.
A interface Ethernet processa os quadros jumbo das seguintes maneiras:
Quando a interface Ethernet está configurada para negar quadros jumbo (usando o comando undo jumboframe enable), a interface Ethernet descarta os quadros jumbo.
Quando a interface Ethernet é configurada com suporte a jumbo frame, a interface Ethernet executa as seguintes operações:
Processa quadros jumbo com o comprimento especificado.
Descarta os quadros jumbo que excedem o comprimento especificado.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberConfigurar o suporte a jumbo frame.
jumboframe enable [ size ]Por padrão, o dispositivo permite a passagem de quadros jumbo de até 10240 bytes.
Se você definir o argumento size várias vezes, a configuração mais recente entrará em vigor.
Configuração da supressão de alterações de estado físico em uma interface Ethernet
Sobre a supressão da mudança de estado físico
O estado do link físico de uma interface Ethernet é ativo ou inativo. Toda vez que o link físico de uma interface é ativado ou desativado, a interface informa imediatamente a alteração à CPU. Em seguida, a CPU executa as seguintes operações:
Notifica os módulos de protocolo da camada superior (como os módulos de roteamento e encaminhamento) sobre a alteração para orientar o encaminhamento de pacotes.
Gera automaticamente traps e logs para informar os usuários para que tomem as medidas corretas.
Para evitar que a oscilação frequente de links físicos afete o desempenho do sistema, configure a supressão de alterações de estado físico. Você pode configurar esse recurso para suprimir somente eventos de link-down, somente eventos de link-up ou ambos. Se um evento do tipo especificado ainda existir quando o intervalo de supressão expirar, o sistema informará o evento à CPU.
Você pode configurar diferentes intervalos de supressão para eventos de link-up e link-down.
Se você executar o comando link-delay várias vezes em uma interface, as regras a seguir serão aplicadas:
Você pode configurar os intervalos de supressão para eventos de link-up e link-down separadamente.
Se você configurar o intervalo de supressão várias vezes para eventos de link-up ou link-down, a configuração mais recente entrará em vigor.
Os comandos link-delay, dampening e port link-flap protect enable são mutuamente exclusivos em uma interface Ethernet.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberConfigurar a supressão da alteração do estado físico.
link-delay { down | up } [ msec ] delay-timePor padrão, toda vez que o link físico de uma interface sobe ou desce, a interface informa imediatamente a alteração à CPU.
Configuração do amortecimento em uma interface Ethernet
Sobre o amortecimento
O recurso de amortecimento de interface usa um mecanismo de decaimento exponencial para evitar que eventos de oscilação excessiva de interface afetem negativamente os protocolos de roteamento e as tabelas de roteamento na rede. A supressão dos eventos de alteração de estado da interface protege os recursos do sistema.
Se uma interface não for atenuada, suas alterações de estado serão relatadas. Para cada alteração de estado, o sistema também gera uma mensagem de registro e uma armadilha SNMP.
Depois que uma interface de flapping é atenuada, ela não informa suas alterações de estado à CPU. Para eventos de alteração de estado, a interface gera apenas mensagens de registro e de interceptação de SNMP.
Parâmetros
Penalidade - A interface tem uma penalidade inicial de 0. Quando a interface se move, a penalidade aumenta em 1.000 para cada evento de descida até que o teto seja atingido. Ela não aumenta para eventos de subida. Quando a interface para de se movimentar, a penalidade diminui pela metade a cada vez que o cronômetro de meia-vida expira, até que a penalidade caia para o limite de reutilização.
Teto - A penalidade para de aumentar quando atinge o teto.
Suppress-limit - A penalidade acumulada que aciona o dispositivo para atenuar a interface. No estado amortecido, a interface não informa suas alterações de estado à CPU. Para eventos de alteração de estado, a interface gera apenas traps SNMP e mensagens de registro.
Limite de reutilização - Quando a penalidade acumulada diminui para esse limite de reutilização, a interface não é atenuada. As alterações de estado da interface são informadas às camadas superiores. Para cada alteração de estado, o sistema também gera uma armadilha SNMP e uma mensagem de registro.
Decaimento - O período de tempo (em segundos) após o qual uma penalidade é reduzida.
Max-suppress-time - O período máximo de tempo em que a interface pode ser atenuada. Se a penalidade ainda for maior do que o limite de reutilização quando esse temporizador expirar, a penalidade deixará de aumentar para eventos de inatividade. A penalidade começa a diminuir até ficar abaixo do limite de reutilização.
Ao executar o comando de amortecimento, siga estas regras para definir os valores mencionados acima:
O teto é igual a 2(Max-suppress-time/Decay) × reuse-limit. Não é configurável pelo usuário.
O limite de supressão configurado é menor ou igual ao teto.
O teto é menor ou igual ao limite máximo de supressão suportado.
A Figura 1 mostra a regra de alteração do valor da penalidade. As linhas t0 e t2 indicam a hora de início e a hora de término da supressão, respectivamente. O período de t0 a t2 indica o período de supressão, t0 a t1 indica o tempo máximo de supressão e t1 a t2 indica o período de decaimento completo.
Figura 1 Regra de alteração do valor da penalidade
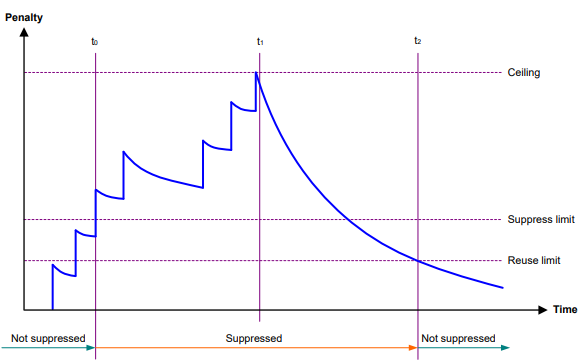
Restrições e diretrizes
Os comandos dampening, link-delay e port link-flap protect enable são mutuamente exclusivos em uma interface.
O comando de atenuação não tem efeito sobre os eventos de inatividade administrativa. Quando você executa o comando shutdown, a penalidade é restaurada para 0 e a interface informa o evento de inatividade aos protocolos da camada superior.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberAtivar o amortecimento na interface.
dampening [ half-life reuse suppress max-suppress-time ]Por padrão, o amortecimento da interface é desativado nas interfaces Ethernet.
Ativação da proteção contra flapping de link em uma interface
Sobre a proteção contra oscilação do link
A oscilação de link em uma interface altera a topologia da rede e aumenta a sobrecarga do sistema. Por exemplo, em um cenário de link ativo/em espera, quando o status da interface no link ativo muda entre UP e DOWN, o tráfego alterna entre os links ativo e em espera. Para resolver esse problema, configure esse recurso na interface.
Com esse recurso ativado em uma interface, quando a interface é desativada, o sistema ativa a detecção de flapping de link. Durante o intervalo de detecção de flapping de link, se o número de flaps detectados atingir ou exceder o limite de detecção de flapping de link, o sistema desligará a interface.
Restrições e diretrizes
Esse recurso só terá efeito se for configurado na visualização do sistema e na visualização da interface Ethernet.
A estabilidade do sistema IRF pode ser afetada pelo flapping do link físico IRF. Para a estabilidade do sistema da IRF, esse recurso é ativado por padrão nas interfaces físicas da IRF e o status de ativação desse recurso não é afetado pelo status da proteção global contra flapping de link. Quando o número de flaps detectados em uma interface física IRF excede o limite dentro do intervalo de detecção, o dispositivo emite um registro em vez de desligar a interface física IRF.
Os comandos dampening, link-delay e port link-flap protect enable são mutuamente exclusivos em uma interface Ethernet.
Para ativar uma interface que tenha sido desligada pela proteção de flapping de link, execute o comando undo shutdown.
Na saída do comando Exibir interface, o valor Link-Flap DOWN do estado atual
indica que a interface foi desligada por proteção contra flapping de link.
Procedimento
Entre na visualização do sistema.
System ViewHabilite a proteção contra flapping de link globalmente.
link-flap protect enablePor padrão, a proteção contra flapping de link é desativada globalmente.
Entre na visualização da interface Ethernet.
interface interface-type interface-numberHabilite a proteção contra flapping de link na interface Ethernet.
port link-flap protect enable [ interval interval | threshold
threshold ] *Por padrão, a proteção contra flapping de link é desativada em uma interface Ethernet.
Configuração da supressão de tempestades
Sobre a supressão de tempestades
O recurso de supressão de tempestades garante que o tamanho de um tipo específico de tráfego (broadcast, multicast ou tráfego unicast desconhecido) não exceda o limite em uma interface. Quando o tráfego de broadcast, multicast ou unicast desconhecido na interface excede esse limite, o sistema descarta os pacotes até que o tráfego caia abaixo desse limite.
Tanto a supressão quanto o controle de tempestades podem suprimir tempestades em uma interface. A supressão de tempestades usa o chip para suprimir o tráfego. A supressão de tempestades tem menos impacto sobre o desempenho do dispositivo do que o controle de tempestades , que usa software para suprimir o tráfego.
Restrições e diretrizes
Para que o resultado da supressão de tráfego seja determinado, não configure o controle de tempestade juntamente com a supressão de tempestade para o mesmo tipo de tráfego. Para obter mais informações sobre o controle de tempestade, consulte "Configuração do controle de tempestade em uma interface Ethernet".
Quando você configura o limite de supressão em kbps, o limite de supressão real pode ser diferente do configurado, como segue:
Se o valor configurado for menor que 64, o valor de 64 entrará em vigor.
Se o valor configurado for maior que 64, mas não for um múltiplo inteiro de 64, o múltiplo inteiro de 64 que for maior e mais próximo do valor configurado entrará em vigor.
Para saber o limite de supressão que entra em vigor, consulte o prompt no dispositivo.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberHabilite a supressão de broadcast e defina o limite de supressão de broadcast. broadcast-suppression { ratio | pps max-pps | kbps max-kbps } Por padrão, a supressão de broadcast está desativada.
Habilite a supressão de multicast e defina o limite de supressão de multicast. multicast-suppression { ratio | pps max-pps | kbps max-kbps } Por padrão, a supressão de multicast está desativada.
Habilite a supressão de unicast desconhecido e defina o limite de supressão de unicast desconhecido.
unicast-suppression { ratio | pps max-pps | kbps max-kbps }Por padrão, a supressão de unicast desconhecido está desativada.
Configuração do controle de fluxo genérico em uma interface Ethernet
Sobre o controle de fluxo genérico
Para evitar o descarte de pacotes em um link, é possível ativar o controle de fluxo genérico em ambas as extremidades do link. Quando ocorre congestionamento de tráfego na extremidade receptora, esta envia um controle de fluxo (Pausa)
para solicitar que a extremidade de envio suspenda o envio de pacotes. O controle de fluxo genérico inclui os seguintes tipos:
Controle de fluxo genérico no modo TxRx - Ativado com o uso do comando flow-control. Com o controle de fluxo genérico no modo TxRx ativado, uma interface pode enviar e receber quadros de controle de fluxo:
Quando ocorre um congestionamento, a interface envia um quadro de controle de fluxo ao seu par.
Quando a interface recebe um quadro de controle de fluxo de seu par, ela suspende o envio de pacotes para seu par.
Controle de fluxo genérico no modo Rx - Ativado com o uso do comando flow-control receive enable. Com o controle de fluxo genérico no modo Rx ativado, uma interface pode receber quadros de controle de fluxo, mas não pode enviar quadros de controle de fluxo:
Quando ocorre um congestionamento, a interface não pode enviar quadros de controle de fluxo para seu par.
Quando a interface recebe um quadro de controle de fluxo de seu par, ela suspende o envio de pacotes para seu par.
Para lidar com o congestionamento de tráfego unidirecional em um link, configure o comando flow-control receive enable em uma extremidade e o comando flow-control na outra extremidade. Para permitir que ambas as extremidades de um link lidem com o congestionamento de tráfego, configure o comando flow-control em ambas as extremidades.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberHabilita o controle de fluxo genérico.
Habilita o controle de fluxo genérico no modo TxRx.
flow-controlHabilita o controle de fluxo genérico no modo Rx.
flow-control receive enable lPor padrão, o controle de fluxo genérico é desativado em uma interface Ethernet.
Ativação de recursos de economia de energia em uma interface Ethernet
Sobre os recursos de economia de energia em uma interface Ethernet
Esse recurso contém desligamento automático e Energy Efficient Ethernet (EEE) em uma interface Ethernet.
Quando uma interface Ethernet com desligamento automático ativado fica inativa por um determinado período de tempo, ocorrem os dois eventos a seguir:
O dispositivo interrompe automaticamente o fornecimento de energia à interface Ethernet.
A interface Ethernet entra no modo de economia de energia.
O período de tempo depende das especificações do chip e não é configurável. Quando a interface Ethernet é ativada, ocorrem os dois eventos a seguir:
O dispositivo restaura automaticamente a fonte de alimentação da interface Ethernet.
A interface Ethernet volta ao seu estado normal.
Com o Energy Efficient Ethernet (EEE) ativado, uma interface de link-up entra no estado de baixo consumo de energia se não tiver recebido nenhum pacote por um período de tempo. O período de tempo depende das especificações do chip e não é configurável. Quando um pacote chega mais tarde, o dispositivo restaura automaticamente o fornecimento de energia à interface e ela volta ao estado normal.
Restrições e diretrizes
As portas de fibra não são compatíveis com esse recurso.
Configuração do desligamento automático em uma interface Ethernet
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberAtivar o desligamento automático na interface Ethernet.
port auto-power-down Por padrão, o desligamento automático é desativado em uma interface Ethernet.
Configuração do EEE em uma interface Ethernet
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberHabilite o EEE na interface Ethernet.
eee enablePor padrão, o EEE está desativado em uma interface Ethernet.
Configuração do intervalo de sondagem de estatísticas
Sobre o intervalo de sondagem de estatísticas
Para exibir as estatísticas da interface coletadas no último intervalo de sondagem de estatísticas, use o comando display interface. Para limpar as estatísticas da interface, use o comando reset counters interface.
Um dispositivo é compatível com as configurações de visualização do sistema ou com as configurações de visualização da interface Ethernet.
O intervalo de sondagem de estatísticas configurado na visualização do sistema entra em vigor em todas as interfaces Ethernet.
O intervalo de sondagem de estatísticas configurado na visualização da interface Ethernet tem efeito apenas na interface atual.
Para uma interface Ethernet, o intervalo de sondagem de estatísticas configurado na visualização da interface Ethernet tem prioridade.
Restrições e diretrizes para a configuração do intervalo de sondagem de estatísticas
A configuração do intervalo de sondagem de estatísticas na visualização do sistema é compatível apenas com a versão 6328 e posteriores.
Como prática recomendada, use a configuração padrão ao definir o intervalo de sondagem de estatísticas na visualização do sistema. Um intervalo curto de sondagem de estatísticas pode diminuir o desempenho do sistema e resultar em estatísticas imprecisas.
Definição do intervalo de sondagem de estatísticas na visualização do sistema
Entre na visualização do sistema.
System ViewDefina o intervalo de sondagem de estatísticas. intervalo de intervalo de fluxo A configuração padrão é 300 segundos.
Configuração do intervalo de sondagem de estatísticas na visualização da interface Ethernet
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberDefina o intervalo de sondagem de estatísticas para a interface Ethernet.
flow-interval interval Por padrão, o intervalo de sondagem de estatísticas é de 300 segundos.
Ativação do teste de loopback em uma interface Ethernet
Sobre o teste de loopback
Execute essa tarefa para determinar se um link Ethernet funciona corretamente. O teste de loopback inclui os seguintes tipos:
Teste de loopback interno - Testa o dispositivo onde reside a interface Ethernet. O teste
A interface Ethernet envia pacotes de saída de volta para o dispositivo local. Se o dispositivo não conseguir receber os pacotes, ele falhará.
Teste de loopback externo - Testa a função de hardware da interface Ethernet. A interface Ethernet envia pacotes de saída para o dispositivo local por meio de um plugue de loop automático. Se o dispositivo não receber os pacotes, haverá falha na função de hardware da interface Ethernet.
Restrições e diretrizes
Depois que você ativar esse recurso em uma interface Ethernet, a interface não encaminhará o tráfego de dados.
Uma interface Ethernet em um teste de loopback não pode encaminhar corretamente os pacotes de dados.
Não é possível executar um teste de loopback em interfaces Ethernet desativadas manualmente (exibidas como no estado ADM ou Administratively DOWN).
Os comandos speed, duplex, mdix-mode e shutdown não podem ser configurados em uma interface Ethernet em um teste de loopback.
Depois de ativar esse recurso em uma interface Ethernet, a interface Ethernet muda para o modo full duplex. Depois de desativar esse recurso, a interface Ethernet volta à sua configuração duplex.
Os comandos shutdown, port up-mode e loopback são mutuamente exclusivos.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberConfigure o teste de loopback na interface Ethernet.
Ativar o teste de loopback na interface Ethernet.
loopback{ external | internal }Por padrão, o teste de loopback é desativado em uma interface Ethernet.
Realize um teste de loopback.
loopback-test{ external | internal }OBSERVAÇÃO:
Esse comando é compatível apenas com a versão 6346 e posteriores.
Ativação forçada de uma porta de fibra
Sobre esta tarefa
Conforme mostrado na Figura 2, uma porta de fibra usa fibras separadas para transmitir e receber pacotes. O estado físico da porta de fibra está ativo somente quando as fibras de transmissão e recepção estão fisicamente conectadas. Se uma das fibras estiver desconectada, a porta de fibra não funcionará.
Para permitir que uma porta de fibra encaminhe o tráfego por um único link, você pode usar o comando port up-mode. Esse comando força a ativação de uma porta de fibra, mesmo quando não há links de fibra ou módulos transceptores presentes para a porta de fibra. Quando um link de fibra está presente e ativo, a porta de fibra pode encaminhar pacotes pelo link de forma unidirecional.
Figura 2 Ativação forçada de uma porta de fibra
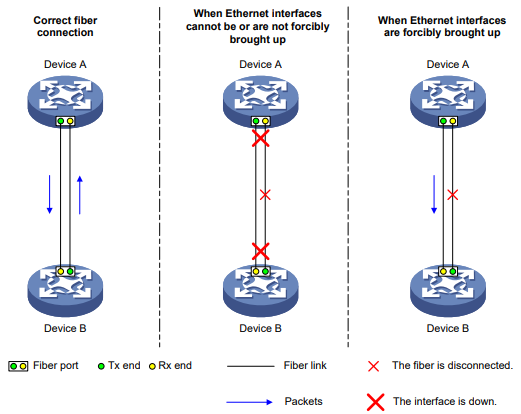
Restrições e diretrizes
As portas de cobre e as interfaces combinadas não são compatíveis com esse recurso. Esse recurso é compatível apenas com a versão 6312 e posteriores.
Os comandos de modo de atividade, desligamento e loopback da porta são mutuamente exclusivos. Uma porta de fibra não é compatível com esse recurso se a porta se unir a um grupo de agregação da Camada 2.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberAbra a porta de fibra à força.
port up-mode Por padrão, uma porta de fibra não é ativada à força.
Configuração das funções de alarme da interface
Sobre esta tarefa
Com as funções de alarme de interface ativadas, quando o número de pacotes de erro em uma interface em estado normal dentro do intervalo especificado excede o limite superior, a interface gera um alarme de excesso de limite superior e entra no estado de alarme. Quando o número de pacotes de erro em uma interface no estado de alarme dentro do intervalo especificado cai abaixo do limite inferior, a interface gera um alarme de recuperação e volta ao estado normal.
Compatibilidade de software e recursos
Esse recurso é compatível apenas com a versão 6342 e posteriores.
Restrições e diretrizes
Você pode configurar os parâmetros do alarme de pacote de erro na visualização do sistema e na visualização da interface.
A configuração na visualização do sistema entra em vigor em todas as interfaces do slot especificado. A configuração na visualização da interface tem efeito apenas na interface atual.
Para uma interface, a configuração na visualização da interface tem prioridade, e a configuração na visualização do sistema é usada somente quando nenhuma configuração é feita na visualização da interface.
Uma interface que é desligada devido a alarmes de pacotes de erros não pode se recuperar automaticamente. Para ativar a interface, execute o comando undo shutdown na interface.
Para que as estatísticas de pacotes de erros sejam precisas, defina o intervalo de coleta e comparação de estatísticas como superior a 7 segundos usando a palavra-chave interval interval.
Ativação das funções de alarme da interface
Entre na visualização do sistema.
System ViewAtivar funções de alarme para o módulo de monitoramento de interface.
snmp-agent trap enable ifmonitor [ crc-error | input-error | output-error ] * Por padrão, todas as funções de alarme são ativadas para as interfaces.
Configuração dos parâmetros do pacote de erro CRC
Entre na visualização do sistema.
System ViewConfigurar parâmetros globais de alarme de pacote de erro de CRC.
ifmonitor crc-error slot slot-number high-threshold high-value
low-threshold low-value interval interval [ shutdown ] Por padrão, o limite superior é 1000, o limite inferior é 100 e o intervalo de coleta e comparação de estatísticas é de 10 segundos para pacotes de erro CRC.
Entre na visualização da interface Ethernet.
interface interface-type interface-numberConfigurar parâmetros de alarme de pacote de erro de CRC para a interface.
port ifmonitor crc-error high-threshold high-value low-threshold low-value interval interval [ shutdown ] Por padrão, uma interface usa os parâmetros globais de alarme de pacote de erro de CRC.
Configuração dos parâmetros de alarme do pacote de erros de entrada
Entre na visualização do sistema.
System ViewConfigurar parâmetros globais de alarme de pacote de erros de entrada.
ifmonitor input-error slot slot-number high-threshold high-value low-threshold low-value interval interval [ shutdown ] Por padrão, o limite superior é 1000, o limite inferior é 100 e o intervalo de coleta e comparação de estatísticas é de 10 segundos para pacotes de erros de entrada.
Entre na visualização da interface Ethernet.
interface interface-type interface-numberConfigurar parâmetros de alarme de pacote de erro de entrada para a interface.
port ifmonitor input-error high-threshold high-value low-threshold low-value interval interval [ shutdown ] Por padrão, uma interface usa os parâmetros globais de alarme de pacote de erro de entrada.
Configuração dos parâmetros de alarme do pacote de erros de saída
Entre na visualização do sistema.
System ViewConfigurar parâmetros globais de alarme de pacote de erro de saída.
ifmonitor output-error slot slot-number high-threshold high-value low-threshold low-value interval interval [ shutdown ] Por padrão, o limite superior é 1000, o limite inferior é 100 e a coleta de estatísticas e o intervalo de comparação é de 10 segundos para pacotes de erro de saída.
Entre na visualização da interface Ethernet.
interface interface-type interface-numberConfigurar os parâmetros de alarme do pacote de erros de saída.
port ifmonitor output-error high-threshold high-value low-threshold low-value interval interval [ shutdown ]Por padrão, uma interface usa os parâmetros globais de alarme de pacote de erro de saída.
Restaurar as configurações padrão de uma interface
Restrições e diretrizes
Esse recurso pode interromper os serviços de rede em andamento. Certifique-se de estar totalmente ciente dos impactos desse recurso ao usá-lo em uma rede ativa.
Esse recurso pode não conseguir restaurar as configurações padrão de alguns comandos devido a dependências de comandos ou restrições do sistema. Você pode usar o comando display this na visualização da interface para verificar esses comandos e executar suas formas de desfazer ou seguir a referência do comando para restaurar suas configurações padrão. Se a tentativa de restauração ainda falhar, siga a mensagem de erro para resolver o problema.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberRestaurar as configurações padrão da interface.
defaultConfiguração de uma interface Ethernet de camada 2
Configuração das opções de velocidade para autonegociação em uma interface Ethernet
Sobre as opções de velocidade para autonegociação
Por padrão, a autonegociação de velocidade permite que uma interface Ethernet negocie com seu par a velocidade mais alta que ambas as extremidades suportam. Você pode restringir a lista de opções de velocidade para negociação.
Figura 3 Cenário de aplicação da autonegociação de velocidade
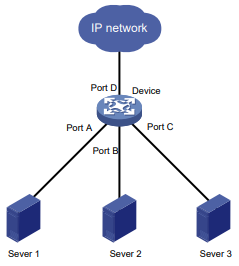
Conforme mostrado na Figura 3:
Todas as interfaces do dispositivo estão operando no modo de autonegociação de velocidade, com a velocidade mais alta de 1000 Mbps.
A porta D fornece acesso à Internet para os servidores.
Se a taxa de transmissão de cada servidor no cluster de servidores for de 1000 Mbps, a taxa de transmissão total excederá a capacidade da Porta D.
Para evitar congestionamento na Porta D, configure 100 Mbps como a única opção disponível para negociação de velocidade nas interfaces Porta A, Porta B e Porta C. Como resultado, a taxa de transmissão em cada interface conectada a um servidor é limitada a 100 Mbps.
Restrições e diretrizes
Os comandos speed e speed auto substituem um ao outro, e o que for configurado por último entra em vigor.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberDefinir opções de velocidade para autonegociação.
speed auto { 10 | 100 | 1000 } *Nenhuma opção de velocidade é definida para a negociação automática.
Configuração do modo MDIX de uma interface Ethernet
As portas de fibra não são compatíveis com a configuração do modo MDIX.
Sobre o modo MDIX
Uma interface Ethernet física tem oito pinos, cada um dos quais desempenha uma função específica. Por exemplo, os pinos 1 e 2 transmitem sinais e os pinos 3 e 6 recebem sinais. Você pode usar cabos Ethernet cruzados e diretos para conectar interfaces Ethernet de cobre. Para acomodar esses tipos de cabos, uma interface Ethernet de cobre pode operar em um dos seguintes modos MDIX (Medium Dependent Interface-Crossover):
Modo MDIX - Os pinos 1 e 2 são pinos de recepção e os pinos 3 e 6 são pinos de transmissão.
Modo MDI - Os pinos 1 e 2 são pinos de transmissão e os pinos 3 e 6 são pinos de recepção.
Modo AutoMDIX - A interface negocia as funções de pino com seu par.
OBSERVAÇÃO:
Esse recurso não tem efeito nos pinos 4, 5, 7 e 8 das interfaces Ethernet físicas.
Os pinos 4, 5, 7 e 8 das interfaces que operam a 10 Mbps ou 100 Mbps não recebem nem transmitem sinais.
Os pinos 4, 5, 7 e 8 das interfaces que operam com taxas de 1000 Mbps ou mais recebem e transmitem sinais.
Restrições e diretrizes
Para permitir que uma interface Ethernet de cobre se comunique com seu par, defina o modo MDIX da interface seguindo estas diretrizes:
Normalmente, defina o modo MDIX da interface como AutoMDIX. Defina o modo MDIX da interface como MDI ou MDIX somente quando o dispositivo não puder determinar o tipo de cabo.
Quando um cabo direto for usado, configure a interface para operar em um modo MDIX diferente do seu par.
Quando um cabo crossover for usado, execute uma das seguintes tarefas:
Configure a interface para operar no mesmo modo MDIX que seu par.
Configure uma das extremidades para operar no modo AutoMDIX.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberDefinir o modo MDIX da interface Ethernet.
mdix-mode { automdix | mdi | mdix }Por padrão, uma interface Ethernet de cobre opera no modo automático para negociar funções de pino com seu par.
Configuração do controle de tempestades em uma interface Ethernet
Sobre o controle de tempestades
O controle de tempestades compara o tráfego de broadcast, multicast e unicast desconhecido regularmente com seus respectivos limites de tráfego em uma interface Ethernet. Para cada tipo de tráfego, o controle de tempestade fornece um limite inferior e um limite superior.
Dependendo de sua configuração, quando um tipo específico de tráfego excede o limite superior, a interface executa uma das seguintes operações:
Bloqueia esse tipo de tráfego e encaminha outros tipos de tráfego - Mesmo que a interface não encaminhe o tráfego bloqueado, ela ainda conta o tráfego. Quando o tráfego bloqueado cai abaixo do limite inferior, a interface começa a encaminhar o tráfego.
Desativa-se automaticamente - A interface se desativa automaticamente e deixa de encaminhar qualquer tráfego. Quando o tráfego bloqueado cai abaixo do limite inferior, a interface não é ativada automaticamente. Para ativar a interface, use o comando undo shutdown ou desative o recurso de controle de tempestade.
Você pode configurar uma interface Ethernet para emitir traps de eventos de limite e mensagens de registro quando o tráfego monitorado atender a uma das seguintes condições:
Excede o limite superior.
Cai abaixo do limite inferior.
Tanto a supressão quanto o controle de tempestades podem suprimir tempestades em uma interface. A supressão de tempestades usa o chip para suprimir o tráfego. A supressão de tempestades tem menos impacto sobre o desempenho do dispositivo do que o controle de tempestades, que usa software para suprimir o tráfego. Para obter mais informações sobre a supressão de tempestades, consulte "Configuração da supressão de tempestades".
O controle de tempestade usa um ciclo completo de sondagem para coletar dados de tráfego e analisa os dados no próximo ciclo. Uma interface leva de um a dois intervalos de sondagem para tomar uma ação de controle de tempestade.
Restrições e diretrizes
Para que o resultado da supressão de tráfego seja determinado, não configure o controle de tempestade juntamente com a supressão de tempestade para o mesmo tipo de tráfego.
Procedimento
Entre na visualização do sistema.
System View(Opcional.) Defina o intervalo de sondagem de estatísticas do módulo de controle de tempestade.
intervalo de restrição de tempestade intervalo
A configuração padrão é de 10 segundos.
Para estabilidade da rede, use o padrão ou defina um intervalo de sondagem de estatísticas mais longo.
Entre na visualização da interface Ethernet.
interface interface-type interface-numberHabilite o controle de tempestades e defina os limites inferior e superior para tráfego de broadcast, multicast ou unicast desconhecido.
storm-constrain { broadcast | multicast | unicast } { pps | kbps | ratio } upperlimit lowerlimit Por padrão, o controle de tempestade está desativado.
Defina a ação de controle a ser tomada quando o tráfego monitorado exceder o limite superior.
storm-constrain control { block | shutdown }Por padrão, o controle de tempestade está desativado.
Habilite a interface Ethernet para emitir mensagens de registro quando detectar eventos de limite de controle de tempestade.
storm-constrain enable logPor padrão, a interface Ethernet emite mensagens de registro quando o tráfego monitorado excede o limite superior ou cai abaixo do limite inferior a partir de um valor acima do limite superior.
Habilite a interface Ethernet para enviar traps de eventos de limite de controle de tempestade.
storm-constrain enable trapPor padrão, a interface Ethernet envia traps quando o tráfego monitorado excede o limite superior ou cai abaixo do limite inferior a partir do limite superior de um valor acima do limite superior .
Teste da conexão do cabo de uma interface Ethernet
Se o link de uma interface Ethernet estiver ativo, o teste da conexão do cabo fará com que o link caia e depois volte a funcionar.
Sobre como testar a conexão do cabo de uma interface Ethernet
Esse recurso testa a conexão do cabo de uma interface Ethernet e exibe o resultado do teste do cabo em 5 segundos. O resultado do teste inclui o status do cabo e alguns parâmetros físicos. Se alguma falha for detectada, o resultado do teste mostrará o comprimento da porta local até o ponto defeituoso.
Restrições e diretrizes
As portas de fibra não são compatíveis com esse recurso.
Procedimento
Digite qualquer visualização.
Realize um teste para o cabo conectado a uma interface Ethernet.
virtual-cable-test interface [ interface-type interface-number | interface-name ]A interface [ interface-type interface-number | interface-name ]
é compatível apenas com as versões R6350 e posteriores.
Ao executar essa operação em uma interface Ethernet, o link será automaticamente desativado e ativado uma vez, se já estiver ativado.
Ativação de bridging em uma interface Ethernet
Sobre a ativação de bridging em uma interface Ethernet
Por padrão, o dispositivo descarta os pacotes cuja interface de saída e a interface de entrada são as mesmas.
Para permitir que o dispositivo encaminhe esses pacotes em vez de descartá-los, ative o recurso de ponte na visualização da interface Ethernet.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberHabilite a ponte na interface Ethernet.
port bridge enable Por padrão, o bridging é desativado em uma interface Ethernet.
Configurando as interfaces loopback, nulas e inloopback
Sobre interfaces de loopback, nulas e inloopback
Sobre as interfaces de loopback
Uma interface de loopback é uma interface virtual. O estado da camada física de uma interface de loopback está sempre ativo, a menos que a interface de loopback seja desligada manualmente. Devido a esse benefício, as interfaces de loopback são amplamente usadas nos seguintes cenários:
Configuração de um endereço de interface de loopback como o endereço de origem dos pacotes IP gerados pelo dispositivo - Como os endereços de interface de loopback são endereços unicast estáveis, geralmente são usados como identificações de dispositivos.
Ao configurar uma regra em um servidor de autenticação ou de segurança, você pode configurá-la para permitir ou negar pacotes que tenham o endereço da interface de loopback de um dispositivo. Isso simplifica sua configuração e obtém o efeito de permitir ou negar os pacotes gerados pelo dispositivo. Para usar um endereço de interface de loopback como endereço de origem de pacotes IP, certifique-se de que a interface de loopback seja acessível a partir do par, executando a configuração de roteamento. Todos os pacotes de dados enviados para a interface de loopback são considerados pacotes enviados para o próprio dispositivo, portanto, o dispositivo não encaminha esses pacotes.
Uso de uma interface de loopback em protocolos de roteamento dinâmico - Sem nenhuma ID de roteador configurada para um protocolo de roteamento dinâmico, o sistema seleciona o endereço IP mais alto da interface de loopback como ID de roteador.
Sobre interfaces nulas
Uma interface nula é uma interface virtual e está sempre ativa, mas você não pode usá-la para encaminhar pacotes de dados nem configurá-la com um endereço IP ou protocolo de camada de link. A interface nula oferece uma maneira mais simples de filtrar pacotes do que a ACL. Você pode filtrar o tráfego indesejado transmitindo-o para uma interface nula em vez de aplicar uma ACL. Por exemplo, se você especificar uma interface nula como o próximo salto de uma rota estática para um segmento de rede , todos os pacotes roteados para o segmento de rede serão descartados.
Sobre as interfaces inloopback
Uma interface inloopback é uma interface virtual criada pelo sistema, que não pode ser configurada ou excluída. Os estados do protocolo da camada física e da camada de link de uma interface de inloopback estão sempre ativos. Todos os pacotes IP enviados para uma interface inloopback são considerados pacotes enviados para o próprio dispositivo e não são encaminhados.
Configuração de uma interface de loopback
Entre na visualização do sistema.
System ViewCrie uma interface de loopback e entre na visualização da interface de loopback.
interface loopback interface-number Configure a descrição da interface.
description text A configuração padrão é o nome da interface Interface (por exemplo, Interface LoopBack1).
Configure a largura de banda esperada da interface de loopback.
bandwidth bandwidth-valuePor padrão, a largura de banda esperada de uma interface de loopback é de 0 kbps.
Ative a interface de loopback.
undo shutdown Por padrão, uma interface de loopback está ativa.
Configuração de uma interface nula
Entre na visualização do sistema.
System ViewEntre na visualização de interface nula.
interface null 0 A Interface Null 0 é a interface nula padrão do dispositivo e não pode ser criada ou removida manualmente.
Somente uma interface nula, Null 0, é compatível com o dispositivo. O número da interface nula é sempre 0.
Configure a descrição da interface.
description text A configuração padrão é Interface NULL0.
Restaurar as configurações padrão de uma interface
Restrições e diretrizes
Esse recurso pode interromper os serviços de rede em andamento. Certifique-se de estar totalmente ciente do impacto desse recurso ao usá-lo em uma rede ativa.
Esse recurso pode não conseguir restaurar as configurações padrão de alguns comandos devido a dependências de comandos ou restrições do sistema. Você pode usar o comando display this na visualização da interface para verificar esses comandos e executar suas formas de desfazer ou seguir a referência do comando para restaurar suas configurações padrão. Se a tentativa de restauração ainda falhar, siga a mensagem de erro para resolver o problema.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface de loopback ou da interface nula.
interface loopback interface-number interface nula 0
Restaurar as configurações padrão da interface.
defaultConfigurando as interfaces em massa
Sobre a configuração em massa da interface
Você pode entrar na visualização de intervalo de interfaces para configurar em massa várias interfaces com o mesmo recurso, em vez de configurá-las uma a uma. Por exemplo, você pode executar o comando shutdown na visualização de intervalo de interfaces para desligar um intervalo de interfaces.
Para configurar interfaces em massa, você deve configurar um intervalo de interfaces e entrar em sua visualização usando a opção
comando de intervalo de interface ou nome do intervalo de interface.
O intervalo de interfaces criado com o uso do comando de intervalo de interfaces não é salvo na configuração em execução. Não é possível usar o intervalo de interface repetidamente. Para criar um intervalo de interface que possa ser usado repetidamente, use o comando nome do intervalo de interface.
Restrições e diretrizes: Configuração de interface em massa
Quando você configurar interfaces em bloco na visualização de intervalo de interfaces, siga estas restrições e diretrizes:
Na visualização de intervalo de interfaces, somente os comandos suportados pela primeira interface na lista de interfaces especificada (em ordem alfabética) estão disponíveis para configuração.
Antes de configurar uma interface como a primeira interface em um intervalo de interfaces, certifique-se de que é possível entrar na visualização da interface usando o comando interface interface-type
comando interface-número.
Não atribua uma interface agregada e nenhuma de suas interfaces membros a um intervalo de interface. Alguns comandos, depois de serem executados em uma interface agregada e em suas interfaces membros, podem interromper a agregação.
Entenda que quanto mais interfaces você especificar, maior será o tempo de execução do comando.
Para garantir o desempenho da configuração da interface em massa, configure menos de 1.000 nomes de intervalos de interface.
O dispositivo não emite mensagens de alerta ou alarme durante o processo de configuração da interface em massa. Certifique-se de que você está totalmente ciente dos impactos da configuração da interface em massa.
Depois que um comando é executado na visualização de intervalo de interface, pode ocorrer uma das seguintes situações:
O sistema exibe uma mensagem de erro e permanece na visualização do intervalo de interfaces. Isso significa que a execução falhou em uma ou várias interfaces de membro.
Se a execução falhar na primeira interface membro, o comando não será executado em nenhuma interface membro.
Se a execução falhar em uma interface de membro que não seja a primeira, o comando entrará em vigor nas interfaces de membro restantes.
O sistema retorna à visualização do sistema. Isso significa que:
O comando é compatível tanto com a visualização do sistema quanto com a visualização da interface.
A execução falhou em uma interface membro na visualização do intervalo de interfaces e foi bem-sucedida na visualização do sistema.
O comando não é executado nas interfaces de membro subsequentes.
Você pode usar o comando display this para verificar a configuração na visualização da interface de cada interface membro. Além disso, se a configuração na visualização do sistema não for necessária, use a forma undo do comando para remover a configuração.
Procedimento
Entre na visualização do sistema.
System ViewCrie um intervalo de interface e entre na visualização de intervalo de interface.
Criar um intervalo de interface sem especificar um nome.
interface range { interface-type interface-number [ to interface-type interface-number ] } &<1-24>Crie um intervalo de interface nomeado.
interface range name name [ interface { interface-type interface-number [ to interface-type interface-number ] } &<1-24> ](Opcional.) Exibir comandos disponíveis para a primeira interface no intervalo de interfaces. Digite um ponto de interrogação (?) no prompt do intervalo de interfaces.
Use os comandos disponíveis para configurar as interfaces. Os comandos disponíveis dependem da interface.
(Opcional.) Verifique a configuração.
display thisConfigurando a tabela de endereços MAC
Sobre a tabela de endereços MAC
Um dispositivo Ethernet usa uma tabela de endereços MAC para encaminhar quadros. Uma entrada de endereço MAC inclui um endereço MAC de destino, uma interface de saída e um ID de VLAN. Quando o dispositivo recebe um quadro, ele usa o endereço MAC de destino do quadro para procurar uma correspondência na tabela de endereços MAC.
O dispositivo encaminha o quadro para fora da interface de saída na entrada correspondente se for encontrada uma correspondência.
O dispositivo inunda o quadro na VLAN do quadro se nenhuma correspondência for encontrada.
Como uma entrada de endereço MAC é criada
As entradas na tabela de endereços MAC incluem entradas aprendidas automaticamente pelo dispositivo e entradas adicionadas manualmente.
Aprendizado de endereço MAC
O dispositivo pode preencher automaticamente sua tabela de endereços MAC aprendendo os endereços MAC de origem dos quadros de entrada em cada interface.
O dispositivo executa as seguintes operações para saber o endereço MAC de origem dos pacotes de entrada:
Verifica o endereço MAC de origem (por exemplo, MAC-SOURCE) do quadro.
Procura o endereço MAC de origem na tabela de endereços MAC.
O dispositivo atualiza a entrada se for encontrada uma entrada.
O dispositivo adiciona uma entrada para MAC-SOURCE e a porta de entrada se nenhuma entrada for encontrada.
Quando o dispositivo recebe um quadro destinado ao MAC-SOURCE depois de aprender esse endereço MAC de origem, o dispositivo executa as seguintes operações:
Localiza a entrada MAC-SOURCE na tabela de endereços MAC.
Encaminha o quadro para fora da porta na entrada.
O dispositivo executa o processo de aprendizado para cada quadro de entrada com um endereço MAC de origem desconhecida até que a tabela esteja totalmente preenchida.
Configuração manual de entradas de endereço MAC
O aprendizado dinâmico de endereço MAC não faz distinção entre quadros ilegítimos e legítimos, o que pode acarretar riscos à segurança. Quando o host A estiver conectado à porta A, uma entrada de endereço MAC será aprendida para o endereço MAC do host A (por exemplo, MAC A). Quando um usuário ilegal envia quadros com MAC A como endereço MAC de origem para a Porta B, o dispositivo executa as seguintes operações:
Aprende uma nova entrada de endereço MAC com a Porta B como interface de saída e sobrescreve a antiga entrada para o MAC A.
Encaminha os quadros destinados ao MAC A para fora da porta B para o usuário ilegal.
Como resultado, o usuário ilegal obtém os dados do Host A. Para aumentar a segurança do Host A, configure manualmente uma entrada estática para vincular o Host A à Porta A. Em seguida, os quadros destinados ao Host A são sempre enviados pela Porta A. Outros hosts que usam o endereço MAC forjado do Host A não podem obter os quadros destinados ao Host A.
Tipos de entradas de endereço MAC
Uma tabela de endereços MAC pode conter os seguintes tipos de entradas:
Entradas estáticas - Uma entrada estática é adicionada manualmente para encaminhar quadros com um endereço MAC de destino específico para fora da interface associada e nunca se esgota. Uma entrada estática tem prioridade mais alta do que uma entrada aprendida dinamicamente.
Entradas dinâmicas - Uma entrada dinâmica pode ser configurada manualmente ou aprendida dinamicamente para encaminhar quadros com um endereço MAC de destino específico para fora da interface associada. Uma entrada dinâmica pode envelhecer. Uma entrada dinâmica configurada manualmente tem a mesma prioridade que uma entrada aprendida dinamicamente.
Entradas de blackhole - Uma entrada de blackhole é configurada manualmente e nunca se esgota. Uma entrada de blackhole é configurada para filtrar quadros com um endereço MAC de origem ou destino específico. Por exemplo, para bloquear todos os quadros destinados a um usuário ou originados por ele, é possível configurar o endereço MAC do usuário como uma entrada de endereço MAC blackhole. Uma entrada de blackhole tem prioridade mais alta do que uma entrada aprendida dinamicamente.
Entradas unicast multiportas - Uma entrada unicast multiportas é adicionada manualmente para enviar quadros com um endereço MAC de destino unicast específico a partir de várias portas e nunca se esgota. Uma entrada unicast multiportas tem prioridade mais alta do que uma entrada aprendida dinamicamente.
Uma entrada de endereço MAC unicast estático, blackhole ou multiportas pode sobrescrever uma entrada de endereço MAC dinâmico, mas não vice-versa. Uma entrada estática, uma entrada blackhole e uma entrada unicast multiportas não podem se sobrepor umas às outras.
Este documento não abrange a configuração de entradas de endereço MAC multicast estático. Para obter mais informações sobre a configuração de entradas de endereço MAC de multicast estático, consulte IGMP snooping no Guia de configuração de multicast IP.
Configuração de entradas de endereço MAC
Sobre o encaminhamento de quadros baseado em entradas de endereço MAC
Um quadro cujo endereço MAC de origem corresponde a diferentes tipos de entradas de endereço MAC é processado de forma diferente.
Restrições e diretrizes para a configuração de entradas de endereços MAC
Uma entrada de endereço MAC dinâmico configurada manualmente substituirá uma entrada aprendida que já exista com uma interface de saída diferente para o endereço MAC.
As entradas de endereço MAC unicast estático, blackhole e multiportas configuradas manualmente não sobreviverão a uma reinicialização se você não salvar a configuração. As entradas de endereço MAC dinâmico configuradas manualmente são perdidas após a reinicialização, independentemente de você salvar ou não a configuração.
Não configure os endereços MAC reservados do dispositivo como endereços MAC unicast estáticos, dinâmicos, blackhole ou multiportas. Os endereços MAC reservados de um dispositivo são endereços MAC do endereço MAC de ponte do dispositivo até o endereço MAC de ponte mais 95. Para obter informações sobre endereços MAC de ponte, consulte IRF no Guia de Configuração de Tecnologias Virtuais.
Pré-requisitos para a configuração da entrada de endereço MAC
Antes de configurar manualmente uma entrada de endereço MAC para uma interface, certifique-se de que a VLAN na entrada tenha sido criada.
Adição ou modificação de uma entrada de endereço MAC estático ou dinâmico
Adição ou modificação de uma entrada de endereço MAC estático ou dinâmico globalmente
Entre na visualização do sistema.
System ViewAdicionar ou modificar uma entrada de endereço MAC estático ou dinâmico.
mac-address { dynamic | static } mac-address interface interface-type interface-number vlan vlan-idPor padrão, nenhuma entrada de endereço MAC é configurada globalmente. Certifique-se de ter atribuído a interface à VLAN.
Adição ou modificação de uma entrada de endereço MAC estático ou dinâmico em uma interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberAdicionar ou modificar uma entrada de endereço MAC estático ou dinâmico.
mac-address { dynamic | static } mac-address vlan vlan-idPor padrão, nenhuma entrada de endereço MAC é configurada em uma interface. Certifique-se de ter atribuído a interface à VLAN.
Adição ou modificação de uma entrada de endereço MAC de blackhole
Entre na visualização do sistema.
System ViewAdicionar ou modificar uma entrada de endereço MAC de blackhole.
mac-address blackhole mac-address vlan vlan-idPor padrão, nenhuma entrada de endereço MAC de blackhole é configurada.
Adição ou modificação de uma entrada de endereço MAC unicast multiportas
Sobre a configuração de entrada de endereço MAC unicast multiportas
Você pode configurar uma entrada de endereço MAC unicast multiportas para associar um endereço MAC de destino unicast a várias portas. O quadro com um endereço MAC de destino que corresponda à entrada é enviado por várias portas.
Por exemplo, no modo unicast NLB (consulte a Figura 1):
Todos os servidores em um cluster usam o endereço MAC do cluster como seu próprio endereço.
Os quadros destinados ao cluster são encaminhados a todos os servidores do grupo.
Nesse caso, você pode configurar uma entrada de endereço MAC unicast multiportas no dispositivo conectado ao grupo de servidores. Em seguida, o dispositivo encaminha o quadro destinado ao grupo de servidores para cada servidor por meio de todas as portas conectadas aos servidores dentro do cluster.
Figura 1 Cluster NLB
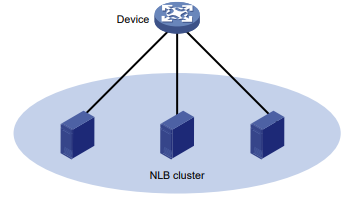
É possível configurar uma entrada de endereço MAC unicast multiportas globalmente ou em uma interface.
Configuração de uma entrada de endereço MAC unicast multiportas globalmente
Entre na visualização do sistema.
System ViewAdicionar ou modificar uma entrada de endereço MAC unicast multiportas.
mac-address multiport mac-address interface interface-list vlanPor padrão, nenhuma entrada de endereço MAC unicast multiportas é configurada globalmente. Certifique-se de ter atribuído a interface à VLAN.
Configuração de uma entrada de endereço MAC unicast multiportas em uma interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberAdicione a interface a uma entrada de endereço MAC unicast multiportas.
mac-address multiport mac-address vlan vlan-idPor padrão, nenhuma entrada de endereço MAC unicast multiportas é configurada em uma interface. Certifique-se de ter atribuído a interface à VLAN.
Configuração do timer de envelhecimento para entradas dinâmicas de endereço MAC
Sobre o cronômetro de envelhecimento para entradas de endereço MAC dinâmico
Para segurança e uso eficiente do espaço da tabela, a tabela de endereços MAC usa um cronômetro de envelhecimento para cada entrada de endereço MAC dinâmico. Se uma entrada de endereço MAC dinâmico não for atualizada antes que o cronômetro de envelhecimento expire, o dispositivo excluirá a entrada. Esse mecanismo de envelhecimento garante que a tabela de endereços MAC possa ser atualizada prontamente para acomodar as últimas alterações na topologia da rede.
Uma rede estável requer um intervalo de envelhecimento mais longo, e uma rede instável requer um intervalo de envelhecimento mais curto.
Um intervalo de envelhecimento muito longo pode fazer com que a tabela de endereços MAC retenha entradas desatualizadas. Como resultado, os recursos da tabela de endereços MAC podem se esgotar e a tabela de endereços MAC pode não conseguir atualizar suas entradas para acomodar as alterações mais recentes na rede.
Um intervalo muito curto pode resultar na remoção de entradas válidas, o que causaria inundações desnecessárias e possivelmente afetaria o desempenho do dispositivo.
Para reduzir as inundações em uma rede estável, defina um temporizador de envelhecimento longo ou desative o temporizador para evitar que as entradas dinâmicas envelheçam desnecessariamente. A redução das inundações melhora o desempenho da rede. A redução das inundações também melhora a segurança, pois reduz as chances de um quadro de dados chegar a destinos não intencionais.
Procedimento
Entre na visualização do sistema.
System ViewDefina o cronômetro de envelhecimento para entradas de endereço MAC dinâmico.
mac-address timer { aging seconds | no-aging }Por padrão, o cronômetro de envelhecimento é de 300 segundos para entradas de endereço MAC dinâmico.
Desativação do aprendizado de endereço MAC
Sobre a desativação do aprendizado de endereço MAC
O aprendizado de endereço MAC é ativado por padrão. Para evitar que a tabela de endereços MAC fique saturada quando o dispositivo estiver sofrendo ataques, desative o aprendizado de endereços MAC. Por exemplo, você pode desativar o aprendizado de endereço MAC para evitar que o dispositivo seja atacado por uma grande quantidade de quadros com diferentes endereços MAC de origem.
Depois que o aprendizado de endereço MAC é desativado, o dispositivo exclui imediatamente as entradas de endereço MAC dinâmico existentes.
Desativação do aprendizado global de endereço MAC
Restrições e diretrizes
Depois que você desativar o aprendizado de endereço MAC global, o dispositivo não poderá aprender endereços MAC em nenhuma interface .
Procedimento
Entre na visualização do sistema.
System ViewDesativar o aprendizado global de endereço MAC.
undo mac-address mac-learning enablePor padrão, o aprendizado global de endereço MAC está ativado.
Desativar o aprendizado de endereço MAC em uma interface
Sobre como desativar o aprendizado de endereço MAC em uma interface
Quando o aprendizado de endereço MAC global está ativado, é possível desativar o aprendizado de endereço MAC em uma única interface.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDesativar o aprendizado de endereço MAC na interface.
undo mac-address mac-learning enablePor padrão, o aprendizado de endereço MAC é ativado em uma interface.
Desativação do aprendizado de endereço MAC em uma VLAN
Sobre como desativar o aprendizado de endereço MAC em uma VLAN
Quando o aprendizado de endereço MAC global está ativado, você pode desativar o aprendizado de endereço MAC por VLAN.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização de VLAN.
vlan vlan-idDesativar o aprendizado de endereço MAC na VLAN.
undo mac-address mac-learning enablePor padrão, o aprendizado de endereço MAC na VLAN está ativado.
Configuração do limite de aprendizagem de MAC
Sobre o limite de aprendizado MAC baseado em interface
Esse recurso limita o tamanho da tabela de endereços MAC. Uma tabela de endereços MAC grande prejudicará o desempenho do encaminhamento .
Restrições e diretrizes
O limite de aprendizagem de MAC não controla o número de endereços MAC aprendidos em Voice Vlan. Para obter mais informações, consulte "Configuração de Voice Vlan".
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberDefinir o limite de aprendizado de MAC na interface.
mac-address max-mac-count countPor padrão, nenhum limite de aprendizagem de MAC é configurado em uma interface.
Configuração da regra de encaminhamento de quadros desconhecidos após o limite de aprendizagem de MAC ser atingido
Neste documento, os quadros desconhecidos referem-se a quadros cujos endereços MAC de origem não estão na tabela de endereços MAC.
Sobre a configuração da regra de encaminhamento de quadros desconhecidos
Você pode ativar ou desativar o encaminhamento de quadros desconhecidos depois que o limite de aprendizagem de MAC for atingido.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure o dispositivo para encaminhar quadros desconhecidos recebidos na interface depois que o limite de aprendizado de MAC na interface for atingido.
mac-address max-mac-count enable-forwardingPor padrão, o dispositivo pode encaminhar quadros desconhecidos recebidos em uma interface depois que o limite de aprendizagem de MAC na interface for atingido.
Ativação da sincronização de endereços MAC
Sobre a sincronização de endereços MAC
Para evitar inundações desnecessárias e aumentar a velocidade de encaminhamento, certifique-se de que todos os dispositivos membros tenham a mesma tabela de endereços MAC. Depois que você ativa a sincronização de endereços MAC, cada dispositivo membro anuncia as entradas de endereços MAC aprendidos para outros dispositivos membros.
Conforme mostrado na Figura 2:
Figura 2 Tabelas de endereços MAC de dispositivos quando o cliente A acessa o AP C
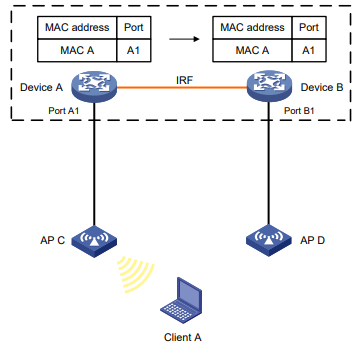
Procedimento
Entre na visualização do sistema.
System ViewAtivar a sincronização de endereços MAC.
mac-address mac-roaming enablePor padrão, a sincronização de endereços MAC está desativada.
Configuração de notificações e supressão de movimentação de endereço MAC
Sobre notificações e supressão de movimentação de endereço MAC
A interface de saída de uma entrada de endereço MAC aprendida na interface A é alterada para a interface B quando existem as seguintes condições:
A interface B recebe um pacote com o endereço MAC como endereço MAC de origem.
A interface B pertence à mesma VLAN que a interface A.
Nesse caso, o endereço MAC é movido da interface A para a interface B, e ocorre uma movimentação de endereço MAC.
O recurso de notificações de movimentação de endereço MAC permite que o dispositivo emita registros de movimentação de endereço MAC quando forem detectadas movimentações de endereço MAC.
Se um endereço MAC for movido continuamente entre as duas interfaces, poderão ocorrer loops de camada 2. Para detectar e localizar loops, você pode visualizar as informações de movimentação do endereço MAC. Para exibir os registros de movimentação de endereço MAC depois que o dispositivo for iniciado, use o comando display mac-address mac-move.
Se o sistema detectar que as movimentações de endereço MAC ocorrem com frequência em uma interface, você poderá configurar a supressão de movimentação de endereço MAC para desligar a interface. A interface é ativada automaticamente após um intervalo de supressão. Ou você pode ativar manualmente a interface.
Restrições e diretrizes
Depois de configurar as notificações de movimentação de endereço MAC, o sistema envia apenas mensagens de registro para o módulo do centro de informações. Se o dispositivo também estiver configurado com o comando snmp-agent trap enable mac-address, o sistema também enviará notificações de SNMP para o módulo SNMP.
Procedimento
Entre na visualização do sistema.
System ViewHabilite as notificações de movimentação de endereço MAC e, opcionalmente, especifique um intervalo de detecção de movimentação de MAC.
mac-address notification mac-move [ interval interval ]Por padrão, as notificações de mudança de endereço MAC estão desativadas.
(Opcional.) Defina os parâmetros de supressão de movimentação de endereço MAC.
mac-address notification mac-move suppression { interval interval | threshold threshold }Por padrão, o intervalo de supressão é de 30 segundos e o limite de supressão é 3.
Para que os parâmetros de supressão de movimentação de endereço MAC tenham efeito, ative a supressão de movimentação de endereço MAC em uma porta.
Entre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberAtivar a supressão de movimentação de endereço MAC.
mac-address notification mac-move suppression Por padrão, a supressão de movimentação de endereço MAC está desativada.
Ativação da atualização rápida do ARP para mudanças de endereço MAC
Sobre a atualização rápida de ARP para mudanças de endereço MAC
A atualização rápida de ARP para mudanças de endereço MAC permite que o dispositivo atualize uma entrada ARP imediatamente após a mudança da interface de saída de um endereço MAC. Esse recurso garante a conexão de dados sem interrupção.
Conforme mostrado na Figura 4, um laptop de usuário móvel acessa a rede conectando-se ao AP 1 ou AP 2. Quando o AP ao qual o usuário se conecta muda, o dispositivo atualiza a entrada ARP para o usuário imediatamente após detectar uma mudança de endereço MAC.
Figura 4 Cenário do aplicativo de atualização rápida de ARP
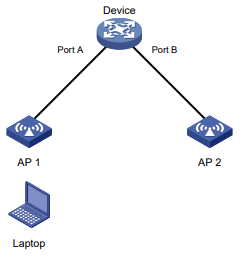
Procedimento
Entre na visualização do sistema.
System ViewHabilite a atualização rápida do ARP para mudanças de endereço MAC.
mac-address mac-move fast-updatePor padrão, a atualização rápida do ARP para mudanças de endereço MAC está desativada.
Configuração do tamanho do intervalo de hash da tabela de endereços MAC
Sobre o tamanho do intervalo de hash da tabela de endereços MAC
O dispositivo salva a tabela de endereços MAC por meio de cadeias de hash. Se vários endereços MAC obtiverem a mesma chave por meio de hash, ocorrerão conflitos de hash de endereço MAC, e o dispositivo não poderá aprender alguns desses endereços MAC. O dispositivo transmitirá o tráfego destinado aos endereços MAC desconhecidos, o que consome largura de banda e recursos.
Você pode aumentar o tamanho do intervalo de hash da tabela de endereços MAC para reduzir os conflitos de hash de endereços MAC. Um tamanho maior do intervalo de hash requer mais recursos do sistema. Defina o tamanho do intervalo de hash
adequadamente, dependendo dos recursos do sistema. Você pode usar o comando display mac-address hash-bucket-size para visualizar o tamanho atual do hash bucket e o tamanho do hash bucket que entrará em vigor na próxima inicialização.
Restrições e diretrizes
O tamanho do intervalo de hash definido entra em vigor na próxima inicialização.
Procedimento
Entre na visualização do sistema.
System ViewDefina o tamanho do intervalo de hash da tabela de endereços MAC.
mac-address hash-bucket-size sizePor padrão, o tamanho do intervalo de hash da tabela de endereços MAC é 4.
Ativação do registro de conflitos de hashing de MAC
Sobre esta tarefa
O registro de conflitos de hashing de MAC permite que o dispositivo gere mensagens de registro para os conflitos de hashing de MAC que ocorrem no aprendizado de endereços MAC. Você pode usar esse recurso para identificar os endereços MAC que o dispositivo não consegue aprender devido a conflitos de hashing. Para exibir as mensagens de registro geradas para conflitos de hashing de MAC, execute o comando display mac-address hash-conflict-record.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6328 e posteriores.
Restrições e diretrizes
Esse recurso consome recursos do sistema. Ao ativá-lo no dispositivo, certifique-se de estar totalmente ciente do impacto no desempenho do dispositivo.
Procedimento
Entre na visualização do sistema.
System ViewHabilite o registro de conflitos de hashing de MAC.
mac-address hash-conflict-record enable slot slot-numberPor padrão, o registro de conflitos de hashing de MAC está desativado.
Desativar o filtro de pacotes quando o endereço MAC de origem for um endereço MAC de multicast ou broadcast
Sobre esta tarefa
Por padrão, o dispositivo descartará um quadro cujo endereço MAC de origem seja um endereço MAC de multicast ou broadcast. Para evitar a perda de tráfego do usuário e garantir que o tráfego do usuário seja encaminhado corretamente nesse cenário, você pode desativar o filtro de pacotes no dispositivo quando o endereço MAC de origem for um endereço MAC de multicast ou broadcast.
Procedimento
Entre na visualização do sistema.
System ViewDesative o filtro de pacotes quando o endereço MAC de origem for um endereço MAC de multicast ou broadcast.
undo mac-address multicast-source packet-filterPor padrão, o filtro de pacotes é ativado no dispositivo em que o endereço MAC de origem é um endereço MAC de multicast ou broadcast.
Ativação de notificações SNMP para a tabela de endereços MAC
Sobre as notificações SNMP para a tabela de endereços MAC
Para relatar eventos críticos de movimentação de endereço MAC a um NMS, ative as notificações de SNMP para a tabela de endereços MAC. Para que as notificações de eventos de mudança de endereço MAC sejam enviadas corretamente, você também deve configurar o SNMP no dispositivo.
Quando as notificações SNMP estão desativadas para a tabela de endereços MAC, o dispositivo envia os registros gerados para o centro de informações. Para exibir os registros, configure o destino do registro e a configuração da regra de saída no centro de informações.
Para obter mais informações sobre o SNMP e a configuração do centro de informações, consulte o guia de configuração de monitoramento e gerenciamento de rede do dispositivo.
Procedimento
Entre na visualização do sistema.
System ViewAtive as notificações SNMP para a tabela de endereços MAC.
snmp-agent trap enable mac-address [ mac-move ]Por padrão, as notificações SNMP são ativadas para a tabela de endereços MAC.
Quando as notificações SNMP são desativadas para a tabela de endereços MAC, as mensagens syslog são enviadas para notificar eventos importantes no módulo da tabela de endereços MAC.
Exemplos de configuração da tabela de endereços MAC
Configuração de rede
Conforme mostrado na Figura 5:
O host A com endereço MAC 000f-e235-dc71 está conectado à GigabitEthernet 1/0/1 do dispositivo e pertence à VLAN 1.
O host B com endereço MAC 000f-e235-abcd, que se comportou de forma suspeita na rede, também pertence à VLAN 1.
Configure a tabela de endereços MAC da seguinte forma:
Para evitar a falsificação de endereços MAC, adicione uma entrada estática para o Host A na tabela de endereços MAC do Device.
Para descartar todos os quadros destinados ao Host B, adicione uma entrada de endereço MAC blackhole para o Host B.
Defina o cronômetro de envelhecimento como 500 segundos para entradas dinâmicas de endereço MAC.
Figura 5 Diagrama de rede

Procedimento
# Adicione uma entrada de endereço MAC estático para o endereço MAC 000f-e235-dc71 na GigabitEthernet 1/0/1 que pertence à VLAN 1.
<Device> system-view
[Device] mac-address static 000f-e235-dc71 interface gigabitethernet 1/0/1 vlan 1 # Adicione uma entrada de endereço MAC blackhole para o endereço MAC 000f-e235-abcd que pertence à VLAN 1.
[Dispositivo] mac-address blackhole 000f-e235-abcd vlan 1# Defina o cronômetro de envelhecimento para 500 segundos para entradas de endereço MAC dinâmico.
[Dispositivo] mac-address timer aging 500Verificação da configuração
# Exibir as entradas de endereço MAC estático para GigabitEthernet 1/0/1.
[Exibir mac-address static interface gigabitethernet 1/0/1# Exibir o tempo de envelhecimento das entradas de endereço MAC dinâmico.
[Device] display mac-address aging-time Tempo de envelhecimento do endereço MAC: 500s.Configuração de informações de MAC
Configurando as informações MAC
Sobre as informações do MAC
O recurso Informações de MAC pode gerar mensagens de syslog ou notificações de SNMP quando as entradas de endereço MAC são aprendidas ou excluídas. Você pode usar essas mensagens para monitorar a saída ou entrada de usuários na rede e analisar o tráfego da rede.
O recurso Informações de MAC armazena em uma fila as mensagens de syslog de alteração de MAC ou as notificações de SNMP. O dispositivo substitui a alteração de endereço MAC mais antiga gravada na fila pela alteração de endereço MAC mais recente quando existem as seguintes condições:
O intervalo de notificação de alteração de MAC não expira.
A fila foi esgotada.
Para enviar uma mensagem syslog ou uma notificação SNMP imediatamente após sua criação, defina o comprimento da fila como zero.
Ativação de informações de MAC
Restrições e diretrizes
Para que as informações de MAC tenham efeito, você deve ativar as informações de MAC globalmente e nas interfaces.
Procedimento
Entre na visualização do sistema.
System ViewAtivar informações de MAC globalmente.
mac-address information enable Por padrão, as informações de MAC são desativadas globalmente.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberAtivar informações de MAC na interface.
mac-address information enable { added | deleted }Por padrão, as informações de MAC são desativadas em uma interface.
Configuração do modo de informações do MAC
Sobre os modos de informações do MAC
Os seguintes modos de informações de MAC estão disponíveis para o envio de alterações de endereço MAC:
Syslog - O dispositivo envia mensagens syslog para notificar alterações de endereço MAC. O dispositivo envia mensagens syslog para o centro de informações, que as envia para o terminal de monitoramento. Para obter mais informações sobre a central de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Trap - O dispositivo envia notificações SNMP para notificar alterações de endereço MAC. O dispositivo envia notificações de SNMP para o NMS. Para obter mais informações sobre SNMP, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
Entre na visualização do sistema.
System ViewConfigure o modo de informações do MAC.
mac-address information mode { syslog | trap } A configuração padrão é trap.
Configuração do intervalo de notificação de alteração de MAC
Sobre o intervalo de notificação de alteração de MAC
Para evitar que as mensagens de syslog ou as notificações de SNMP sejam enviadas com muita frequência, você pode definir o intervalo de notificação de alteração de MAC para um valor maior.
Procedimento
Entre na visualização do sistema.
System ViewDefina o intervalo de notificação de alteração de MAC.
mac-address information interval intervalA configuração padrão é de 1 segundo.
Configuração do comprimento da fila de informações do MAC
Sobre o comprimento da fila de informações MAC
Se o comprimento da fila de informações de MAC for 0, o dispositivo enviará uma mensagem syslog ou uma notificação SNMP imediatamente após o aprendizado ou a exclusão de um endereço MAC.
Se o comprimento da fila de informações de MAC não for 0, o dispositivo armazenará as alterações de MAC na fila:
O dispositivo substitui a alteração de MAC mais antiga gravada na fila pela alteração de MAC mais recente quando existem as seguintes condições:
O intervalo de notificação de alteração de MAC não expira.
A fila foi esgotada.
O dispositivo envia mensagens de syslog ou notificações de SNMP somente se o intervalo de notificação de alteração de MAC expirar.
Procedimento
Entre na visualização do sistema.
System ViewDefina o comprimento da fila de informações do MAC.
mac-address information queue-length value A configuração padrão é 50.
Exemplos de configuração de informações de MAC
Configuração de rede
Ative as informações de MAC na GigabitEthernet 1/0/1 no dispositivo da Figura 6 para enviar alterações de endereço MAC em mensagens de syslog para o host de registro, Host B, por meio da interface GigabitEthernet 1/0/2.
Figura 6 Diagrama de rede
Restrições e diretrizes
Quando você editar o arquivo /etc/syslog.conf, siga estas restrições e diretrizes:
Os comentários devem estar em uma linha separada e devem começar com um sinal de libra (#).
Não são permitidos espaços redundantes após o nome do arquivo.
O nome do recurso de registro e o nível de gravidade especificados no arquivo /etc/syslog.conf devem ser os mesmos que os configurados no dispositivo. Caso contrário, as informações de registro podem não ser enviadas corretamente para o host de registro. O nome do recurso de registro e o nível de gravidade são configurados usando os comandos info-center loghost e info-center source, respectivamente.
Procedimento
Configure o dispositivo para enviar mensagens de syslog ao Host B: # Habilite o centro de informações.
<Device> system-view
[Device] info-center enable # Especifique o host de registro 192.168.1.2/24 e especifique local4 como o recurso de registro.
[Device] info-center loghost 192.168.1.2 facility local4# Desativar a saída de registro para o host de registro.
[Device] info-center source default loghost denyPara evitar a saída de informações desnecessárias, desative a saída de logs de todos os módulos para o destino especificado (loghost, neste exemplo) antes de configurar uma regra de saída.
# Configure uma regra de saída para enviar ao host de registro os registros de endereço MAC que tenham um nível de gravidade não inferior a informativo.
[Device] info-center source mac loghost level informationalConfigure o host de registro, Host B:
Configure o Solaris da seguinte forma. Configure outros sistemas operacionais UNIX da mesma forma que o Solaris.
Faça login no host de registro como usuário root.
Crie um subdiretório chamado Device no diretório /var/log/.
# mkdir /var/log/Device Crie o arquivo info.log no diretório do dispositivo para salvar os registros do dispositivo.
# touch /var/log/Device/info.log Edite o arquivo syslog.conf no diretório /etc/ e adicione o seguinte conteúdo:
# Mensagens de configuração do dispositivo local4.info /var/log/Device/info.log
Nessa configuração, local4 é o nome do recurso de registro que o host de registro usa para receber os registros e info é o nível informativo. O sistema UNIX registra as informações de log que têm um nível de gravidade não inferior a informational no arquivo
# Device configuration messages
local4.info /var/log/Device/info.log Exibir a ID do processo do syslogd, encerrar o processo do syslogd e, em seguida, reiniciar o syslogd
usando a opção -r para que a nova configuração entre em vigor.
# ps -ae | grep syslogd
147
# kill -HUP 147
# syslogd -r & O dispositivo pode enviar os registros de endereços MAC para o host de registro, que armazena os registros no arquivo especificado.
Ativar informações de MAC no dispositivo: # Habilitar informações de MAC globalmente.
[Device] mac-address information enable # Configure o modo de informações do MAC como syslog.
[Device] mac-address information mode syslog # Habilite as informações de MAC na GigabitEthernet 1/0/1 para permitir que a porta registre as informações de alteração de endereço MAC quando a interface executar uma das seguintes operações:
Aprende um novo endereço MAC.
Exclui um endereço MAC existente.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] mac-address information enable added
[Device-GigabitEthernet1/0/1] mac-address information enable deleted
[Device-GigabitEthernet1/0/1] quit # Defina o comprimento da fila de informações do MAC como 100.
[Device] mac-address information queue-length 100Configuração da agregação de links Ethernet
Sobre a agregação de links Ethernet
A agregação de links Ethernet agrupa vários links Ethernet físicos em um único link lógico (chamado de link agregado). A agregação de links oferece os seguintes benefícios:
Maior largura de banda além dos limites de um único link individual. Em um link agregado, o tráfego é distribuído entre as portas membros.
Maior confiabilidade do link. As portas membros fazem backup dinamicamente umas das outras. Quando uma porta membro falha, seu tráfego é automaticamente transferido para outras portas membro.
Cenário de aplicação de agregação de link Ethernet
Conforme mostrado na Figura 1, o Dispositivo A e o Dispositivo B estão conectados por três links físicos de Ethernet. Esses links Ethernet físicos são combinados em um link agregado chamado agregação de link 1. A largura de banda desse link agregado pode atingir até a largura de banda total dos três links Ethernet físicos. Ao mesmo tempo, os três links Ethernet fazem backup um do outro. Quando um link Ethernet físico falha, o tráfego transmitido no link com falha é alternado para os outros dois links.
Figura 1 Diagrama de agregação de link Ethernet

Interface agregada, grupo de agregação e porta membro
Cada agregação de link é representada por uma interface de agregação lógica. Cada interface agregada tem um grupo de agregação criado automaticamente, que contém portas-membro a serem usadas para a agregação . O tipo e o número de um grupo de agregação são os mesmos de sua interface agregada.
Tipos de interface agregada compatíveis
O dispositivo suporta interfaces agregadas de camada 2. Uma interface agregada de camada 2 é criada manualmente. As portas membros em um grupo de agregação de camada 2 só podem ser interfaces Ethernet de camada 2.
A taxa de porta de uma interface agregada é igual à taxa total de suas portas membros selecionadas. Seu modo duplex é o mesmo das portas membros selecionadas. Para obter mais informações sobre as portas membro selecionadas, consulte "Estados de agregação das portas membro em um grupo de agregação".
Estados de agregação das portas membros em um grupo de agregação
Uma porta membro em um grupo de agregação pode estar em qualquer um dos seguintes estados de agregação:
Selected - Uma porta selecionada pode encaminhar tráfego.
Unselected (Não selecionado) - Uma porta não selecionada não pode encaminhar tráfego.
Individual - Uma porta Individual pode encaminhar o tráfego como uma porta física normal. Esse estado é peculiar às portas membros das interfaces agregadas de borda. Uma porta membro é colocada no estado Individual se não tiver recebido LACPDUs antes da primeira expiração do cronômetro de tempo limite do LACP após a ocorrência de um dos eventos a seguir:
A interface agregada é configurada como uma interface agregada de borda.
A porta membro fica inativa e volta a funcionar depois de ser colocada no estado Unselected (não selecionado) ou Selected (selecionado).
Para obter mais informações sobre interfaces agregadas de borda, consulte "Interface agregada de borda".
Chave operacional
Ao agregar portas, o sistema atribui automaticamente a cada porta uma chave operacional com base nas informações da porta, como a taxa da porta e o modo duplex. Qualquer alteração nessas informações aciona um novo cálculo da chave operacional.
Em um grupo de agregação, todas as portas selecionadas têm a mesma chave operacional.
Tipos de configuração
A configuração da porta inclui a configuração do atributo e a configuração do protocolo. A configuração do atributo afeta o estado de agregação da porta, mas a configuração do protocolo não.
Configuração de atributos
Para se tornar uma porta selecionada, uma porta membro deve ter a mesma configuração de atributos que a interface agregada. A Tabela 1 descreve a configuração de atributos.
Tabela 1 Configuração de atributos
Configuração do protocolo
A configuração do protocolo de uma porta membro não afeta o estado de agregação da porta membro. As configurações de aprendizado de endereço MAC e Spanning Tree são exemplos de configuração de protocolo.
Modos de agregação de links
Um grupo de agregação opera em um dos seguintes modos:
A agregação estática é estável. Um grupo de agregação em modo estático é chamado de grupo de agregação estática. Os estados de agregação das portas membros em um grupo de agregação estática não são afetados pelas portas pares.
Dinâmico - Um grupo de agregação em modo dinâmico é chamado de grupo de agregação dinâmica. A agregação dinâmica é implementada por meio do protocolo de controle de agregação de links IEEE 802.3ad
(LACP). O sistema local e o sistema par mantêm automaticamente os estados de agregação das portas membros. A agregação dinâmica de links reduz a carga de trabalho dos administradores.
Agregação dinâmica de links
Sobre o LACP
A agregação dinâmica é implementada por meio do protocolo de controle de agregação de links (LACP) IEEE 802.3ad.
O LACP usa LACPDUs para trocar informações de agregação entre dispositivos habilitados para LACP. Cada porta membro em um grupo de agregação dinâmica pode trocar informações com seu par. Quando uma porta membro recebe um LACPDU, ela compara as informações recebidas com as informações recebidas
nas outras portas membros. Dessa forma, os dois sistemas chegam a um acordo sobre quais portas são colocadas no estado Selecionado.
Funções do LACP
O LACP oferece funções básicas do LACP e funções estendidas do LACP, conforme descrito na Tabela 2.
Tabela 2 Funções básicas e estendidas do LACP
Modos de operação do LACP
O LACP pode operar em modo ativo ou passivo.
Quando o LACP está operando em modo passivo em uma porta membro local e em sua porta par, ambas as portas não podem enviar LACPDUs. Quando o LACP está operando em modo ativo em qualquer extremidade de um link, ambas as portas podem enviar LACPDUs.
Prioridades do LACP
As prioridades do LACP incluem a prioridade do sistema LACP e a prioridade da porta, conforme descrito na Tabela 3. Quanto menor o valor da prioridade, maior a prioridade.
Tabela 3 Prioridades do LACP
Intervalo de tempo limite do LACP
O intervalo de tempo limite do LACP especifica o tempo que uma porta membro aguarda para receber LACPDUs da porta par. Se uma porta membro local não tiver recebido LACPDUs do par dentro do intervalo de tempo limite do LACP mais 3 segundos, a porta membro considerará o par como falho.
O intervalo de tempo limite do LACP também determina a taxa de envio de LACPDUs do par. Os intervalos de tempo limite do LACP incluem os seguintes tipos:
Intervalo de tempo limite curto - 3 segundos. Se você usar o intervalo de tempo limite curto, o par enviará um LACPDU por segundo.
Intervalo de tempo limite longo - 90 segundos. Se você usar o intervalo de tempo limite longo, o par enviará um LACPDU a cada 30 segundos.
Métodos para atribuir interfaces a um grupo de agregação de links dinâmicos
Você pode usar um dos métodos a seguir para atribuir interfaces a um grupo de agregação dinâmica de links:
Atribuição manual - Atribui manualmente as interfaces ao grupo de agregação dinâmica de links.
Atribuição automática - Habilite a atribuição automática em interfaces para que elas entrem automaticamente em um grupo de agregação de links dinâmicos, dependendo das informações de pares nos LACPDUs recebidos.
OBSERVAÇÃO:
Quando você usa a atribuição automática em uma extremidade, deve usar a atribuição manual na outra extremidade.
Como alternativa, você pode usar a agregação automática de links para que dois dispositivos criem automaticamente uma agregação de links dinâmicos entre eles usando o LLDP.
Atribuição automática de porta membro
Esse recurso automatiza a atribuição de portas de membros de agregação a um grupo de agregação. Você pode usar esse recurso ao configurar um link de agregação para um servidor.
Conforme mostrado na Figura 3, uma interface habilitada com atribuição automática entra em um grupo de agregação dinâmica com base nas informações do par nos LACPDUs recebidos do par de agregação. Se nenhum dos grupos de agregação dinâmica existentes for qualificado, o dispositivo criará automaticamente um novo grupo de agregação dinâmica. Em seguida, o dispositivo atribui a interface a esse grupo e sincroniza as configurações de atributos da interface com a interface agregada.
Um grupo de agregação dinâmica que contém portas-membro atribuídas automaticamente seleciona uma porta de referência e portas selecionadas, conforme descrito em "Como funciona a agregação dinâmica de links". Os métodos de atribuição de portas-membro não alteram os processos de seleção de porta de referência e de seleção de porta selecionada.
Figura 3 Processo de atribuição automática de porta membro
Agregação automática de links
A agregação automática de links permite que dois dispositivos criem automaticamente uma agregação dinâmica de links entre eles usando o LLDP.
Depois que você ativar a agregação automática de links e o LLDP em dois dispositivos conectados, eles estabelecerão automaticamente uma agregação dinâmica de links com base nas informações dos quadros LLDP recebidos. Cada um dos dispositivos cria automaticamente uma interface agregada dinâmica e atribui as portas redundantes conectadas ao par ao grupo de agregação dessa interface. Ao atribuir a primeira porta membro ao grupo agregado, o dispositivo sincroniza a configuração de atributos da porta membro com a interface agregada.
Um grupo de agregação dinâmica criado automaticamente seleciona uma porta de referência e portas selecionadas, conforme descrito em "Como funciona a agregação dinâmica de links". Os métodos de criação de grupos de agregação não alteram os processos de seleção da porta de referência e da porta selecionada.
Como prática recomendada para garantir a operação correta dos grupos de agregação dinâmica, não use a agregação automática de links e a atribuição automática de porta membro juntas.
Como funciona a agregação dinâmica de links
Escolha de uma porta de referência
O sistema escolhe uma porta de referência entre as portas membro em estado ativo. Uma porta selecionada deve ter as mesmas configurações de chave operacional e atributo que a porta de referência.
O sistema local (o ator) e o sistema par (o parceiro) negociam uma porta de referência usando o seguinte fluxo de trabalho:
Os dois sistemas determinam o sistema com a ID de sistema menor.
Um ID do sistema contém a prioridade do sistema LACP e o endereço MAC do sistema.
Os dois sistemas comparam seus valores de prioridade LACP.
Quanto menor for a prioridade do LACP, menor será a ID do sistema. Se os valores de prioridade do LACP forem os mesmos, os dois sistemas prosseguirão para a etapa b.
Os dois sistemas comparam seus endereços MAC.
Quanto menor for o endereço MAC, menor será a ID do sistema.
O sistema com a menor ID de sistema escolhe a porta com a menor ID de porta como a porta de referência.
Um ID de porta contém uma prioridade de porta e um número de porta. Quanto mais baixa for a prioridade da porta, menor será a ID da porta .
O sistema escolhe a porta com o valor de prioridade mais baixo como a porta de referência. Se as portas tiverem a mesma prioridade, o sistema prossegue para a etapa b.
O sistema compara seus números de porta.
Quanto menor for o número da porta, menor será a ID da porta.
A porta com o menor número de porta e as mesmas configurações de atributo que a interface agregada é escolhida como a porta de referência.
OBSERVAÇÃO:
Para identificar os números das portas dos membros da agregação, execute o comando display
comando link-aggregation verbose e examine o campo Index na saída do comando.
Configuração do estado de agregação de cada porta membro
Depois que a porta de referência é escolhida, o sistema com a ID de sistema menor define o estado de cada porta membro em seu lado.
Figura 4 Configuração do estado de uma porta membro em um grupo de agregação dinâmica
O sistema com o maior ID de sistema pode detectar as alterações de estado de agregação no sistema par. O sistema com o ID de sistema maior define o estado de agregação das portas membros locais da mesma forma que as portas pares.
Quando você agregar interfaces no modo dinâmico, siga estas diretrizes:
Um grupo de agregação dinâmica de links escolhe apenas portas full-duplex como portas selecionadas.
Para obter uma agregação estável e a continuidade do serviço, não altere a chave operacional ou as configurações de atributo em nenhuma porta membro.
Quando uma porta membro muda para o estado Selecionado ou Não selecionado, sua porta par muda para o mesmo estado de agregação.
Depois que o limite de portas selecionadas for atingido, uma porta recém-ingressada se tornará uma porta selecionada se for mais qualificada do que uma porta selecionada atual.
S-MLAG
A agregação de link simples de vários chassis (S-MLAG) aprimora a agregação de link dinâmico para estabelecer uma agregação que abrange vários dispositivos em um dispositivo remoto.
Uma agregação de vários chassis S-MLAG conecta uma interface agregada dinâmica de camada 2 em cada dispositivo S-MLAG ao dispositivo remoto, conforme mostrado na Figura 5.
O S-MLAG usa um grupo S-MLAG para gerenciar as interfaces agregadas para cada agregação e executa o LACP para manter cada agregação, assim como a agregação dinâmica de links. Para o dispositivo remoto, os dispositivos S-MLAG aparecem como um sistema de agregação de pares.
Figura 5 Cenário de aplicação do S-MLAG
Configuração de uma agregação manual de links
Restrições e diretrizes para a configuração do grupo de agregação
Restrições do grupo de agregação da camada 2
Não é possível atribuir uma interface a um grupo de agregação de camada 2 se algum recurso da Tabela 4 estiver configurado nessa interface.
Tabela 4 Recursos incompatíveis com portas de membro de agregação de camada 2
Restrições da porta do membro de agregação
A exclusão de uma interface agregada também exclui seu grupo de agregação e faz com que todas as portas membros deixem o grupo de agregação.
Uma interface não poderá participar de um grupo de agregação se tiver configurações de atributos diferentes das da interface agregada. Após ingressar em um grupo de agregação, uma interface herda as configurações de atributos da interface agregada. Você pode modificar as configurações de atributos somente na interface agregada.
Não atribua uma porta refletora para espelhamento de porta a um grupo de agregação. Para obter mais informações sobre portas refletoras, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Restrições de configuração de atributos e protocolos
Em um grupo de agregação de links, as configurações de atributos são configuráveis somente na interface de agregação e são automaticamente sincronizadas com todas as portas membros. Não é possível definir as configurações de atributos em uma porta membro até que ela seja removida do grupo de agregação de links. As configurações que foram sincronizadas a partir da interface agregada são mantidas nas portas membros mesmo depois que a interface agregada é excluída.
Se uma configuração de atributo na interface agregada não for sincronizada com uma porta membro selecionada, a porta poderá mudar para o estado não selecionado.
As configurações de protocolo de uma interface agregada têm efeito apenas na interface agregada atual. As configurações de protocolo de uma porta membro entram em vigor somente quando a porta deixa o grupo de agregação.
Requisitos de consistência de configuração
Você deve configurar o mesmo modo de agregação nas duas extremidades de um link agregado.
Para que a agregação estática seja bem-sucedida, certifique-se de que as portas em ambas as extremidades de cada link estejam no mesmo estado de agregação.
Para uma agregação dinâmica bem-sucedida:
Certifique-se de que as portas em ambas as extremidades de um link estejam atribuídas ao grupo de agregação correto. As duas extremidades podem negociar automaticamente o estado de agregação de cada porta membro.
Se você usar a atribuição automática de interface em uma extremidade, deverá usar a atribuição manual na outra extremidade.
Configuração de um grupo de agregação de camada 2
Configuração de um grupo de agregação estática de camada 2
Entre na visualização do sistema.
System ViewCrie uma interface agregada de camada 2 e entre na visualização da interface agregada de camada 2.
interface bridge-aggregation interface-numberQuando você cria uma interface agregada de camada 2, o sistema cria automaticamente um grupo de agregação estática de camada 2 com o mesmo número dessa interface.
Retornar à visualização do sistema.
quitAtribuir uma interface ao grupo de agregação da Camada 2:
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberAtribua a interface ao grupo de agregação da Camada 2.
port link-aggregation group group-id [ force ]
Repita as subetapas para atribuir mais interfaces ao grupo de agregação.
Para sincronizar as configurações de atributo da interface agregada quando a interface atual ingressar no grupo de agregação, especifique a palavra-chave force.
(Opcional.) Defina a prioridade da porta da interface.
link-aggregation port-priority priority A prioridade de porta padrão de uma interface é 32768.
Configuração de um grupo de agregação dinâmica de camada 2
Entre na visualização do sistema.
System ViewDefinir a prioridade do sistema LACP.
lacp system-priority priority (prioridade do sistema lacp)Por padrão, a prioridade do sistema LACP é 32768.
A alteração da prioridade do sistema LACP pode afetar os estados de agregação das portas em um grupo de agregação dinâmica.
Crie uma interface agregada de camada 2 e entre na visualização da interface agregada de camada 2.
interface bridge-aggregation interface-numberQuando você cria uma interface agregada de camada 2, o sistema cria automaticamente um grupo de agregação estática de camada 2 com o mesmo número dessa interface.
Configure o grupo de agregação para operar no modo dinâmico.
link-aggregation mode dynamic Por padrão, um grupo de agregação opera em modo estático.
Retornar à visualização do sistema.
quitAtribuir uma interface ao grupo de agregação da Camada 2:
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberAtribua a interface ao grupo de agregação da Camada 2 ou ative a atribuição automática nessa interface.
port link-aggregation group { group-id [ force ] | auto [ group-id ] }Repita essas duas subetapas para atribuir mais interfaces Ethernet de camada 2 ao grupo de agregação.
Para sincronizar as configurações de atributo da interface agregada quando a interface atual entrar no grupo de agregação, especifique a palavra-chave force.
Para ativar a atribuição automática, especifique a palavra-chave auto. Como prática recomendada, não modifique a configuração em uma interface agregada criada automaticamente ou em suas portas membros.
Definir o modo de operação do LACP para a interface.
Defina o modo de operação do LACP como passivo.
lacp mode passive Defina o modo de operação do LACP como ativo.
undo lacp modePor padrão, o LACP está operando no modo ativo.
(Opcional.) Defina a prioridade da porta para a interface.
link-aggregation port-priority priority A configuração padrão é 32768.
(Opcional.) Defina o intervalo de tempo limite curto do LACP (3 segundos) para a interface.
lacp period short Por padrão, o intervalo de tempo limite longo do LACP (90 segundos) é usado pela interface.
Configuração do S-MLAG
Restrições e diretrizes
Use o S-MLAG para configurar agregações de link somente com servidores.
O S-MLAG foi projetado para um ambiente não IRF. Não o configure em uma malha IRF. Para obter mais informações sobre IRF, consulte o Guia de configuração de tecnologias virtuais.
Cada grupo S-MLAG pode conter apenas uma interface agregada em cada dispositivo. Não defina as seguintes configurações nos dispositivos S-MLAG:
LACP MAD.
Redirecionamento de tráfego de agregação de links.
Número máximo ou mínimo de portas selecionadas.
Atribuição automática de porta membro.
Como prática recomendada, mantenha a consistência entre os dispositivos S-MLAG na configuração dos recursos de serviço.
Pré-requisitos
Defina as configurações de agregação de link que não sejam as configurações do S-MLAG em cada dispositivo S-MLAG. Certifique-se de que as configurações sejam consistentes entre os dispositivos S-MLAG.
Procedimento
Entre na visualização do sistema.
System ViewDefina o endereço MAC do sistema LACP.
lacp system-mac mac-addressPor padrão, o endereço MAC do sistema LACP é o endereço MAC da ponte do dispositivo. Todos os dispositivos S-MLAG devem usar o mesmo endereço MAC do sistema LACP.
Definir a prioridade do sistema LACP.
lacp system-priority priority (prioridade do sistema lacp)Por padrão, a prioridade do sistema LACP é 32768.
Todos os dispositivos S-MLAG devem usar a mesma prioridade de sistema LACP.
Defina o número do sistema LACP.
lacp system-number number numberPor padrão, o número do sistema LACP não é definido.
Você deve atribuir um número de sistema LACP exclusivo a cada dispositivo S-MLAG.
Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefina o modo de agregação de link como dinâmico.
link-aggregation mode dynamic Por padrão, um grupo de agregação opera em modo estático.
Atribuir a interface agregada a um grupo S-MLAG.
port s-mlag group group-idPor padrão, uma interface agregada não é atribuída a nenhum grupo S-MLAG.
Configuração de uma interface agregada
A maioria das configurações que podem ser feitas nas interfaces Ethernet de camada 2 também pode ser feita nas interfaces agregadas de camada 2.
Configuração da descrição de uma interface agregada
Sobre a descrição da interface agregada
Você pode configurar a descrição de uma interface agregada para fins administrativos, por exemplo, descrevendo a finalidade da interface.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-numberConfigure a descrição da interface.
description text Por padrão, a descrição de uma interface é interface-name Interface.
Configuração do suporte a jumbo frame
Sobre os quadros jumbo
Uma interface agregada pode receber quadros maiores que 1522 bytes durante trocas de dados de alto rendimento, como transferências de arquivos. Esses quadros são chamados de quadros jumbo.
O modo como uma interface agregada processa os quadros jumbo depende do fato de o suporte a quadros jumbo estar ativado na interface.
Se estiver configurada para negar quadros jumbo, a interface agregada descartará os quadros jumbo.
Se estiver habilitada com suporte a jumbo frame, a interface agregada executará as seguintes operações:
Processa quadros jumbo que estão dentro do comprimento permitido.
Descarta os quadros jumbo que excedem o comprimento permitido.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberPermitir quadros jumbo.
jumboframe enable [ size ]Por padrão, uma interface agregada permite a passagem de jumbo frames com um comprimento máximo de 10240 bytes.
Se você executar esse comando várias vezes, a configuração mais recente entrará em vigor.
Definição da largura de banda esperada para uma interface agregada
Sobre a largura de banda esperada
A largura de banda esperada é um parâmetro informativo usado apenas por protocolos de camada superior para cálculo. Não é possível ajustar a largura de banda real de uma interface com a execução dessa tarefa.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefina a largura de banda esperada para a interface.
Por padrão, a largura de banda esperada (em kbps) é a taxa de transmissão da interface dividida por 1000.
Configuração de uma interface agregada de borda
Restrições e diretrizes
Você só pode configurar uma interface agregada no modo dinâmico como uma interface de borda.
Configure apenas as interfaces de agregação conectadas a pontos de extremidade, como servidores, como interfaces de agregação de borda. Não conecte interfaces de agregação de borda a dispositivos de rede.
O redirecionamento de tráfego de agregação de links não pode funcionar corretamente em uma interface agregada de borda. Para obter mais informações sobre o redirecionamento de tráfego de agregação de links, consulte "Como ativar o redirecionamento de tráfego de agregação de links".
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-numberConfigure a interface agregada como uma interface agregada de borda.
lacp edge-portPor padrão, uma interface agregada não funciona como uma interface agregada de borda.
Configuração da supressão de alterações de estado físico em uma interface agregada
Sobre a supressão da mudança de estado físico
O estado do link físico de uma interface agregada é ativo ou inativo. Toda vez que o link físico de uma interface é ativado ou desativado, o sistema informa imediatamente a alteração à CPU. Em seguida, a CPU executa as seguintes operações:
Notifica os módulos de protocolo da camada superior (como os módulos de roteamento e encaminhamento) sobre a alteração para orientar o encaminhamento de pacotes.
Gera automaticamente traps e logs para informar os usuários para que tomem as medidas corretas.
Para evitar que a oscilação frequente de links físicos afete o desempenho do sistema, configure a supressão de alterações de estado físico. Você pode configurar esse recurso para suprimir eventos de link-down, eventos de link-up ou ambos. Se um evento do tipo especificado ainda existir quando o intervalo de supressão expirar, o sistema informará o evento à CPU.
Restrições e diretrizes
Não use esse recurso em combinação com o S-MLAG.
Ao usar esse recurso em uma interface agregada, verifique se o par dela também é uma interface agregada. Além disso, você deve definir o intervalo de supressão de alteração de estado físico com o mesmo valor nessas interfaces agregadas.
Em uma interface, é possível configurar diferentes intervalos de supressão para eventos de link-up e link-down. Se você executar o comando link-delay várias vezes para um tipo de evento, a configuração mais recente terá efeito sobre esse tipo de evento.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberConfigurar a supressão da alteração do estado físico.
link-delay { down | up } [ msec ] delay-timePor padrão, sempre que o link físico de uma interface agregada sobe ou desce, o sistema informa imediatamente a alteração à CPU.
Desligamento de uma interface agregada
Restrições e diretrizes
O comando shutdown desconectará todos os links estabelecidos em uma interface. Certifique-se de estar totalmente ciente dos impactos desse comando ao usá-lo em uma rede ativa.
O desligamento ou a ativação de uma interface de agregação afeta os estados de agregação e os estados de link das portas membros no grupo de agregação correspondente, como segue:
Quando uma interface agregada é desligada, todas as suas portas selecionadas se tornam não selecionadas e todas as portas membros são desligadas.
Quando uma interface agregada é ativada, os estados de agregação de todas as suas portas membros são recalculados.
Quando você desliga ou ativa uma interface agregada de camada 3, todas as suas subinterfaces agregadas também são desligadas ou ativadas. O desligamento ou a ativação de uma subinterface agregada de camada 3 não afeta o estado da interface agregada principal.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDesligue a interface.
ShutdownRestauração das configurações padrão de uma interface agregada
Restrições e diretrizes
O comando padrão pode interromper os serviços de rede em andamento. Certifique-se de estar totalmente ciente dos impactos desse comando ao executá-lo em uma rede ativa.
O comando padrão pode não conseguir restaurar as configurações padrão de alguns comandos por motivos como dependências de comandos e restrições do sistema.
Para resolver esse problema:
Use o comando display this na visualização da interface para identificar esses comandos.
Use seus formulários de desfazer ou siga a referência do comando para restaurar suas configurações padrão.
Se a tentativa de restauração ainda falhar, siga as instruções da mensagem de erro para resolver o problema.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberRestaurar as configurações padrão da interface agregada.
defaultConfiguração dos números mínimo e máximo de portas selecionadas para um grupo de agregação
Sobre os números mínimo e máximo de portas selecionadas para um grupo de agregação
A largura de banda de um link agregado aumenta à medida que aumenta o número de portas membros selecionadas. Para evitar congestionamento, você pode definir o número mínimo de portas selecionadas necessárias para ativar uma interface agregada.
Essa configuração de limite mínimo afeta os estados de agregação das portas membros da agregação e o estado da interface agregada.
Quando o número de portas membro qualificadas para serem portas selecionadas é menor do que o limite mínimo, ocorrem os seguintes eventos:
As portas membros elegíveis são colocadas no estado Não selecionado.
O estado da camada de link da interface agregada fica inativo.
Quando o número de portas membro qualificadas para serem portas selecionadas atinge ou excede o limite mínimo, ocorrem os seguintes eventos:
Os portos membros elegíveis são colocados em Estado selecionado.
O estado da camada de link da interface agregada torna-se ativo.
O número máximo de portas selecionadas permitidas em um grupo de agregação é limitado pela configuração manual ou pela limitação de hardware, o que for menor.
Você pode implementar o backup entre duas portas executando as seguintes tarefas:
Atribuição de duas portas a um grupo de agregação.
Definir o número máximo de portas selecionadas como 1 para o grupo de agregação.
Então, somente uma porta selecionada é permitida no grupo de agregação, e a porta não selecionada atua como uma porta de backup.
Restrições e diretrizes
Depois que você definir a porcentagem mínima de portas selecionadas para um grupo de agregação, poderá ocorrer oscilação na interface agregada quando as portas entrarem ou saírem de um grupo de agregação. Certifique-se de que esteja totalmente ciente dos impactos dessa configuração ao configurá-la em uma rede ativa.
Você pode definir o número mínimo ou a porcentagem mínima de portas selecionadas para um grupo de agregação. Se você definir as duas configurações em uma interface de agregação, o limite mais alto do número de portas selecionadas terá efeito.
Os números mínimo e máximo de portas selecionadas devem ser os mesmos entre as duas extremidades de um link agregado.
A porcentagem mínima de portas selecionadas deve ser a mesma entre as duas extremidades de um link agregado.
Para um grupo de agregação, o número máximo de portas selecionadas deve ser igual ou superior ao número mínimo de portas selecionadas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-numberDefina o número mínimo de portas selecionadas para o grupo de agregação. Escolha um dos métodos a seguir:
Defina o número mínimo de portas selecionadas.
link-aggregation selected-port minimum min-numberDefina a porcentagem mínima de portas selecionadas.
link-aggregation selected-port minimum min-number Por padrão, o número mínimo de portas selecionadas não é especificado para um grupo de agregação.
Defina o número máximo de portas selecionadas para o grupo de agregação.
link-aggregation selected-port maximum max-numberPor padrão, um grupo de agregação pode ter um máximo de 8 portas selecionadas.
Desativar a ação padrão de selecionar uma porta selecionada para grupos de agregação dinâmica que não tenham recebido LACPDUs
Sobre a ação de seleção de porta padrão
A ação de seleção de porta padrão se aplica a grupos de agregação dinâmica.
Essa ação escolhe automaticamente a porta com o ID mais baixo entre todas as portas membros em funcionamento como uma porta selecionada se nenhuma delas tiver recebido LACPDUs antes que o intervalo de tempo limite do LACP expire.
Depois que essa ação for desativada, um grupo de agregação dinâmica não terá nenhuma porta selecionada para encaminhar o tráfego se não tiver recebido LACPDUs antes que o intervalo de tempo limite do LACP expire.
Procedimento
Entre na visualização do sistema.
System ViewDesativar a ação de seleção de porta padrão.
lacp default-selected-port disablePor padrão, a ação de seleção de porta padrão é ativada para grupos de agregação dinâmica.
Configuração de um grupo de agregação dinâmica para usar a velocidade da porta como critério prioritário para a seleção da porta de referência
Sobre a priorização da velocidade da porta na seleção da porta de referência
Execute esta tarefa para garantir que um grupo de agregação dinâmica selecione uma porta membro de alta velocidade como a porta de referência. Depois que você executar essa tarefa, a porta de referência será selecionada com base nos critérios em ordem de ID do dispositivo, velocidade da porta e ID da porta.
Compatibilidade de recursos e versões de software
Esse recurso é compatível apenas com a versão 6348P01 e versões posteriores.
Restrições e diretrizes
A alteração dos critérios de seleção da porta de referência pode causar interrupção transitória do tráfego. Certifique-se de compreender o impacto dessa tarefa em sua rede.
Você deve executar essa tarefa em ambas as extremidades do link agregado para que os sistemas de agregação de pares usem os mesmos critérios para a seleção da porta de referência.
Como prática recomendada, desligue as interfaces de agregação de pares antes de executar esse comando e ative as interfaces depois que esse comando for executado em ambas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberEspecifique a velocidade da porta como o critério priorizado para a seleção da porta de referência.
lacp select speedPor padrão, o ID da porta é o critério priorizado para a seleção da porta de referência de um grupo de agregação dinâmica .
Configuração do compartilhamento de carga para grupos de agregação de links
Configuração dos modos de compartilhamento de carga para grupos de agregação de links
Sobre os modos de compartilhamento de carga
É possível definir um modo de compartilhamento de carga global para todos os grupos de agregação de links.
Restrições e diretrizes
Os modos de compartilhamento de carga global suportados no dispositivo são os seguintes:
O modo de compartilhamento de carga é determinado automaticamente com base no tipo de pacote.
- IP de origem.
- IP de destino.
- Fonte MAC.
- MAC de destino.
- Porta de origem.
- Porta de destino.
- Porta de entrada.
Qualquer combinação de porta de entrada, IP de origem, porta de origem, IP de destino e porta de destino.
Qualquer combinação de porta de entrada, porta de origem, MAC de origem, porta de destino e MAC de destino .
Procedimento
Entre na visualização do sistema.
System ViewDefinir o modo de compartilhamento de carga de agregação de links global.
link-aggregation global load-sharing mode { destination-ip | destination-mac | destination-port | ingress-port | source-ip | source-mac | source-port } *Por padrão, os pacotes são compartilhados com base nas seguintes informações:
- Endereços IP de origem e destino.
- Endereços MAC de origem e destino.
Habilitação do compartilhamento de carga local-primeiro para agregação de links
Sobre o compartilhamento de carga local-primeiro para agregação de links
Use o compartilhamento de carga local-primeiro em um cenário de agregação de link de vários dispositivos para distribuir o tráfego preferencialmente entre as portas dos membros no slot de entrada.
Quando você agrega portas em diferentes dispositivos membros em uma malha IRF, pode usar o compartilhamento de carga local primeiro para reduzir o tráfego nos links IRF, conforme mostrado na Figura 6. Para obter mais informações sobre IRF, consulte o Guia de Configuração de Tecnologias Virtuais.
Figura 6 Compartilhamento de carga para agregação de links de vários dispositivos em uma malha IRF
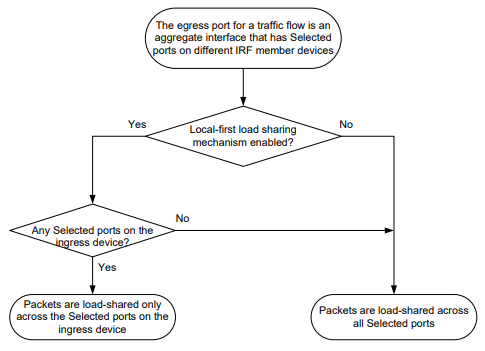
Ativação do compartilhamento de carga local-primeiro para agregação de links globalmente
Entre na visualização do sistema.
System ViewHabilite o compartilhamento de carga local-primeiro para a agregação de links globalmente.
link-aggregation load-sharing mode local-first Por padrão, o compartilhamento de carga local-first é ativado globalmente.
Ativação do redirecionamento de tráfego de agregação de links
Sobre o redirecionamento de tráfego de agregação de links
Esse recurso opera em grupos de agregação de links dinâmicos. Ele redireciona o tráfego em uma porta selecionada para as portas selecionadas disponíveis restantes de um grupo de agregação se ocorrer um dos eventos a seguir:
A porta é desligada usando o comando shutdown.
O slot que hospeda a porta é reinicializado e o grupo de agregação abrange vários slots.
OBSERVAÇÃO:
O dispositivo não redireciona o tráfego para as portas membro que se tornam selecionadas durante o processo de redirecionamento de tráfego.
Esse recurso garante perda zero de pacotes para tráfego unicast conhecido, mas não protege o tráfego unicast desconhecido.
Você pode ativar o redirecionamento de tráfego de agregação de links globalmente ou para um grupo de agregação. As configurações globais de redirecionamento de tráfego de agregação de links têm efeito em todos os grupos de agregação. Um grupo de agregação de links usa preferencialmente as configurações de redirecionamento de tráfego de agregação de links específicas do grupo. Se o redirecionamento de tráfego de agregação de links específico do grupo não estiver configurado, o grupo usará as configurações globais de redirecionamento de tráfego de agregação de links.
Restrições e diretrizes para redirecionamento de tráfego de agregação de links
O redirecionamento de tráfego de agregação de links aplica-se somente a grupos de agregação de links dinâmicos.
Como prática recomendada, ative o redirecionamento de tráfego de agregação de links por interface. Se você ativar esse recurso globalmente, a comunicação com um dispositivo par de terceiros poderá ser afetada se o par não for compatível com esse recurso.
Para evitar a interrupção do tráfego, ative o redirecionamento do tráfego de agregação de links em ambas as extremidades do link agregado.
Para evitar a perda de pacotes que pode ocorrer em uma reinicialização de slot, não ative o recurso spanning tree junto com o redirecionamento de tráfego de agregação de links.
O redirecionamento de tráfego de agregação de links não funciona corretamente em uma interface agregada de borda.
Ativação do redirecionamento de tráfego de agregação de links globalmente
Entre na visualização do sistema.
System ViewAtivar o redirecionamento de tráfego de agregação de links globalmente.
link-aggregation lacp traffic-redirect-notification enable Por padrão, o redirecionamento de tráfego de agregação de links é desativado globalmente.
Ativação do redirecionamento de tráfego de agregação de links para um grupo de agregação
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberAtivar o redirecionamento de tráfego de agregação de links para o grupo de agregação.
link-aggregation lacp traffic-redirect-notification enable Por padrão, o redirecionamento de tráfego de agregação de links é desativado para um grupo de agregação.
Ativação do BFD para um grupo de agregação
Sobre o BFD para agregação de links Ethernet
Você pode usar o BFD para monitorar o status do link do membro em um grupo de agregação. Depois de ativar o BFD em uma interface de agregação, cada porta selecionada no grupo de agregação estabelece uma sessão BFD com sua porta par. O BFD funciona de forma diferente, dependendo do modo de agregação.
BFD em uma agregação estática - Quando o BFD detecta uma falha de link, o BFD notifica o módulo de agregação de link Ethernet de que a porta par não pode ser acessada. A porta local é então colocada no estado Não selecionado. No entanto, a sessão BFD entre as portas local e de pares permanece e a porta local continua enviando pacotes BFD. Quando o BFD na porta local recebe pacotes da porta de par após a recuperação do link, o BFD notifica o módulo de agregação de link Ethernet de que a porta de par está acessível. Em seguida, a porta local é colocada novamente no estado Selecionado. Esse mecanismo garante que as portas locais e pares de um link agregado estático tenham o mesmo estado de agregação.
BFD em uma agregação dinâmica - Quando o BFD detecta uma falha de link, o BFD notifica o módulo de agregação de link Ethernet de que a porta do par não pode ser acessada. Ao mesmo tempo, o BFD limpa a sessão e interrompe o envio de pacotes BFD. Quando a porta local é colocada no estado Selecionado novamente após a recuperação do link, a porta local estabelece uma nova sessão com a porta par e o BFD notifica o módulo de agregação de link Ethernet de que a porta par está acessível. Como o BFD oferece detecção rápida de falhas, os sistemas locais e pares de um link agregado dinâmico podem negociar mais rapidamente o estado de agregação de suas portas membros.
Para obter mais informações sobre o BFD, consulte o Guia de configuração de alta disponibilidade.
Restrições e diretrizes
Quando você ativar o BFD para um grupo de agregação, siga estas restrições e diretrizes:
Certifique-se de que os endereços IP de origem e destino estejam invertidos entre as duas extremidades de um link agregado. Por exemplo, se você executar link-aggregation bfd ipv4 source
1.1.1.1 destino 2.2.2.2 na extremidade local, execute link-aggregation bfd ipv4 fonte 2.2.2.2 destino 1.1.1.1 na extremidade do par. Os endereços IP de origem e destino não podem ser os mesmos.
Os parâmetros de BFD configurados em uma interface agregada têm efeito em todas as sessões de BFD estabelecidas pelas portas membros em seu grupo de agregação. O BFD em um link agregado suporta apenas o modo de pacote de controle para o estabelecimento e a manutenção da sessão. As duas extremidades de uma sessão BFD estabelecida só podem operar no modo assíncrono.
Como prática recomendada, não configure o BFD para nenhum protocolo em uma interface agregada habilitada para BFD.
Certifique-se de que o número de portas-membro em um grupo de agregação habilitado para BFD seja menor ou idêntico ao número de sessões BFD suportadas pelo dispositivo. Se o grupo de agregação contiver mais portas-membro do que as sessões suportadas, algumas portas selecionadas poderão mudar para o estado Não selecionado.
Se o número de sessões BFD for diferente entre as duas extremidades de um link agregado, verifique se há inconsistência nas configurações do número máximo de portas selecionadas. Você deve se certificar de que as duas extremidades tenham a mesma configuração para o número máximo de portas selecionadas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberHabilite o BFD para o grupo de agregação.
link-aggregation bfd ipv4 source ip-address destination ip-addressPor padrão, o BFD está desativado para um grupo de agregação.
Exemplos de configuração de agregação de link Ethernet
Exemplo: Configuração de um grupo de agregação estática de camada 2
Configuração de rede
Na rede mostrada na Figura 7, execute as seguintes tarefas:
Configure um grupo de agregação estática de camada 2 no dispositivo A e no dispositivo B.
Habilite a VLAN 10 em uma extremidade do link agregado para se comunicar com a VLAN 10 na outra extremidade.
Habilite a VLAN 20 em uma extremidade do link agregado para se comunicar com a VLAN 20 na outra extremidade .
Figura 7 Diagrama de rede
Procedimento
Configurar o dispositivo A:
# Crie a VLAN 10 e atribua a porta GigabitEthernet 1/0/4 à VLAN 10.
<DeviceA> system-view
[DeviceA] vlan 10
[DeviceA-vlan10] port gigabitethernet 1/0/4
[DeviceA-vlan10] quit# Crie a VLAN 20 e atribua a porta GigabitEthernet 1/0/5 à VLAN 20.
[DeviceA] vlan 20
[DeviceA-vlan20] port gigabitethernet 1/0/5
[DeviceA-vlan20] quit # Criar interface agregada de camada 2 Bridge-Aggregation 1.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] quit # Atribua as portas GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 ao grupo de agregação de links 1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-aggregation group 1
[DeviceA-GigabitEthernet1/0/1] quit
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-aggregation group 1
[DeviceA-GigabitEthernet1/0/2] quit
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port link-aggregation group 1
[DeviceA-GigabitEthernet1/0/3] quit# Configure a interface agregada de camada 2 Bridge-Aggregation 1 como uma porta tronco e atribua-a às VLANs 10 e 20.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] port link-type trunk
[DeviceA-Bridge-Aggregation1] port trunk permit vlan 10 20
[DeviceA-Bridge-Aggregation1] quitConfigure o Dispositivo B da mesma forma que o Dispositivo A está configurado. (Detalhes não mostrados).
Verificação da configuração
# Exibir informações detalhadas sobre todos os grupos de agregação no Dispositivo A.
[DeviceA] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Port: A -- Auto port, M -- Management port, R -- Reference port
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Bridge-Aggregation1
Aggregation Mode: Static
Loadsharing Type: Shar
Management VLANs: None
Port Status Priority Oper-Key
GE1/0/1(R) S 32768 1
GE1/0/2 S 32768 1
GE1/0/3 S 32768 1A saída mostra que o grupo de agregação de links 1 é um grupo de agregação estática de camada 2 que contém três portas selecionadas.
Exemplo: Configuração de um grupo de agregação dinâmica de camada 2
Configuração de rede
Na rede mostrada na Figura 8, execute as seguintes tarefas:
Configure um grupo de agregação dinâmica de camada 2 no Dispositivo A e no Dispositivo B.
Habilite a VLAN 10 em uma extremidade do link agregado para se comunicar com a VLAN 10 na outra extremidade.
Habilite a VLAN 20 em uma extremidade do link agregado para se comunicar com a VLAN 20 na outra extremidade.
Figura 8 Diagrama de rede
Procedimento
Configurar o dispositivo A:
# Crie a VLAN 10 e atribua a porta GigabitEthernet 1/0/4 à VLAN 10.
<DeviceA>
system-view [DeviceA] vlan 10
[DeviceA-vlan10] port gigabitethernet 1/0/4
[DeviceA-vlan10] quit# Crie a VLAN 20 e atribua a porta GigabitEthernet 1/0/5 à VLAN 20.
[DeviceA] vlan 20
[DeviceA-vlan20] port gigabitethernet 1/0/5
[DeviceA-vlan20] quit# Crie a interface agregada de camada 2 Bridge-Aggregation 1 e defina o modo de agregação de link como dinâmico.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] link-aggregation mode dynamic
[DeviceA-Bridge-Aggregation1] quit# Atribua as portas GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 ao grupo de agregação de links 1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-aggregation group 1
[DeviceA-GigabitEthernet1/0/1] quit
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-aggregation group 1
[DeviceA-GigabitEthernet1/0/2] quit
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port link-aggregation group 1
[DeviceA-GigabitEthernet1/0/3] quit# Configure a interface agregada de camada 2 Bridge-Aggregation 1 como uma porta tronco e atribua-a às VLANs 10 e 20.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] port link-type trunk
[DeviceA-Bridge-Aggregation1] port trunk permit vlan 10 20
[DeviceA-Bridge-Aggregation1] quitConfigure o Dispositivo B da mesma forma que o Dispositivo A está configurado. (Detalhes não mostrados).
Verificação da configuração
# Exibir informações detalhadas sobre todos os grupos de agregação no Dispositivo A.
[DeviceA] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Port: A -- Auto port, M -- Management port, R -- Reference port
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Bridge-Aggregation1
Aggregation Mode: Static
Loadsharing Type: Shar
Management VLANs: None
Port Status Priority Oper-Key
GE1/0/1(R) S 32768 1
GE1/0/2 S 32768 1
GE1/0/3 S 32768 1
A saída mostra que o grupo de agregação de links 1 é um grupo de agregação dinâmica de camada 2 que contém três portas selecionadas.
Exemplo: Configuração de uma interface agregada de borda de camada 2
Configuração de rede
Conforme mostrado na Figura 9, um grupo de agregação dinâmica de camada 2 está configurado no dispositivo. O servidor não está configurado com agregação dinâmica de links.
Configure uma interface agregada de borda de modo que tanto a GigabitEthernet 1/0/1 quanto a GigabitEthernet 1/0/2 possam encaminhar o tráfego para aumentar a confiabilidade do link.
Figura 9 Diagrama de rede

Procedimento
# Crie a interface agregada de camada 2 Bridge-Aggregation 1 e defina o modo de agregação de link como dinâmico.
<Device> system-view
[DeviceA] vlan 10
[DeviceA-vlan10] port gigabitethernet 1/0/4
[DeviceA-vlan10] quit # Configure a interface de agregação da camada 2 Bridge-Aggregation 1 como uma interface de agregação de borda.
[DeviceA] vlan 20
[DeviceA-vlan20] port gigabitethernet 1/0/5
[DeviceA-vlan20] quit# Atribua as portas GigabitEthernet 1/0/1 e GigabitEthernet 1/0/2 ao grupo de agregação de links 1.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] link-aggregation mode dynamic
[DeviceA-Bridge-Aggregation1] quitVerificação da configuração
# Exibir informações detalhadas sobre todos os grupos de agregação no dispositivo quando o servidor não estiver configurado com agregação dinâmica de links.
[Device] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Port: A -- Auto port, M -- Management port, R -- Reference port
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Bridge-Aggregation1
Creation Mode: Manual
Aggregation Mode: Dynamic
Loadsharing Type: Shar
Management VLANs: None
System ID: 0x8000, 000f-e267-6c6a
Local:
Port Status Priority Index Oper-Key
GE1/0/1 I 32768 11 1
GE1/0/2 I 32768 12 1
Remote:
Actor Priority Index Oper-Key SystemID Flag
GE1/0/1 32768 81 0 0x8000, 0000-0000-0000 {DEF}
32768
GE1/0/2 32768 82 0 0x8000, 0000-0000-0000 {DEF}
A saída mostra que a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 estão no estado Individual quando não recebem LACPDUs do servidor. Tanto a GigabitEthernet 1/0/1 quanto a GigabitEthernet 1/0/2 podem encaminhar tráfego. Quando uma porta falha, seu tráfego é automaticamente transferido para a outra porta.
Exemplo: Configuração do S-MLAG
Configuração de rede
Conforme mostrado na Figura 10, configure o Dispositivo B, o Dispositivo C e o Dispositivo D como dispositivos S-MLAG para estabelecer um link agregado de vários dispositivos com o Dispositivo A.
Figura 10 Diagrama de rede
Procedimento
Configure o dispositivo A:
# Crie a interface agregada de camada 2 Bridge-Aggregation 10 e defina o modo de agregação de link como dinâmico.
<DeviceA> system-view
[DeviceA] interface bridge-aggregation 10
[DeviceA-Bridge-Aggregation10] link-aggregation mode dynamic
[DeviceA-Bridge-Aggregation10] quit# Atribuir GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 ao grupo de agregação 10.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-aggregation group 10
[DeviceA-GigabitEthernet1/0/1] quit
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-aggregation group 10
[DeviceA-GigabitEthernet1/0/2] quit
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port link-aggregation group 10
[DeviceA-GigabitEthernet1/0/3] quit Configurar o dispositivo B:
# Defina o endereço MAC do sistema LACP como 0001-0001-0001.
<DeviceB> system-view [DeviceB] lacp system-mac 1-1-1# Defina a prioridade do sistema LACP como 123.
[DeviceB] lacp system-priority 123 # Defina o número do sistema LACP como 1.
[DeviceB] lacp system-number 1# Crie uma interface de agregação de camada 2 Bridge-Aggregation 2 e defina o modo de agregação de link como dinâmico.
[DeviceB] interface bridge-aggregation 2
[DeviceB-Bridge-Aggregation2] link-aggregation mode dynamic # Atribua a Bridge-Aggregation 2 ao grupo S-MLAG 100. [Atribuir GigabitEthernet 1/0/1 ao grupo de agregação 2. [DeviceB] interface gigabitethernet 1/0/1
[DeviceB-Bridge-Aggregation2] port s-mlag group 100Configurar o dispositivo C:
# Defina o endereço MAC do sistema LACP como 0001-0001-0001.
<Device> system-view
[DeviceC] lacp system-mac 1-1-1 # Defina a prioridade do sistema LACP como 123. [Defina o número do sistema LACP como 2.
[DeviceC] lacp system-number 2# Crie uma interface de agregação de camada 2 Bridge-Aggregation 3 e defina o modo de agregação de link como dinâmico.
[DeviceC] interface bridge-aggregation 3
[DeviceC-Bridge-Aggregation3] link-aggregation mode dynamic# Atribua a Bridge-Aggregation 3 ao grupo S-MLAG 100.
[DeviceC-Bridge-Aggregation3] port s-mlag group 100Configurar o dispositivo D:
# Defina o endereço MAC do sistema LACP como 0001-0001-0001.
<DeviceD> system-view
[DeviceD] lacp system-mac 1-1-1# Defina a prioridade do sistema LACP como 123.
[DeviceD] lacp system-priority 123# Crie a interface agregada de camada 2 Bridge-Aggregation 4 e defina o modo de agregação de link como dinâmico.
[DeviceD] interface bridge-aggregation 4
[DeviceD-Bridge-Aggregation4] link-aggregation mode dynamic# Atribua a Bridge-Aggregation 4 ao grupo S-MLAG 100. [Atribuir GigabitEthernet 1/0/1 ao grupo de agregação 4. [DeviceD] interface gigabitethernet 1/0/1
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] port link-aggregation group 4
[DeviceD-GigabitEthernet1/0/1] quitVerificação da configuração
# Verifique se as portas GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 no Dispositivo A são portas selecionadas.
[DeviceA] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Port: A -- Auto port, M -- Management port, R -- Reference port
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Bridge-Aggregation10
Creation Mode: Manual
Aggregation Mode: Dynamic
Loadsharing Type: Shar
Management VLANs: None
System ID: 0x8000, 40fa-264f-0100
Local:
Port Status Priority Index Oper-Key Flag
GE1/0/1(R) S 32768 1 1 {ACDEF}
GE1/0/2 S 32768 2 1 {ACDEF}
GE1/0/3 S 32768 3 1 {ACDEF}
Remote:
Actor Priority Index Oper-Key SystemID Flag
GE1/0/1 32768 16385 50100 0x7b , 0001-0001-0001 {ACDEF}
GE1/0/2 32768 32769 50100 0x7b , 0001-0001-0001 {ACDEF}
GE1/0/3 32768 49153 50100 0x7b , 0001-0001-0001 {ACDEF}
Configuração do isolamento de portas
Sobre o isolamento de portas
O recurso de isolamento de porta isola o tráfego da Camada 2 para privacidade e segurança dos dados sem usar VLANs.
As portas em um grupo de isolamento não podem se comunicar umas com as outras. No entanto, elas podem se comunicar com portas fora do grupo de isolamento.
Atribuição de uma porta a um grupo de isolamento
Sobre a atribuição de portas a um grupo de isolamento
O dispositivo suporta vários grupos de isolamento, que podem ser configurados manualmente. O número de portas atribuídas a um grupo de isolamento não é limitado.
Restrições e diretrizes
Você pode atribuir uma porta a apenas um grupo de isolamento. Se você executar o comando port-isolate enable group várias vezes, a configuração mais recente entrará em vigor.
A configuração na visualização da interface Ethernet de camada 2 se aplica somente à interface.
A configuração na visualização da interface agregada da Camada 2 aplica-se à interface agregada da Camada 2 e às suas portas-membro de agregação. Se o dispositivo não conseguir aplicar a configuração à interface agregada, ele não atribuirá nenhuma porta membro de agregação ao grupo de isolamento. Se a falha ocorrer em uma porta membro de agregação, o dispositivo ignorará a porta e continuará a atribuir outras portas membros de agregação ao grupo de isolamento.
Procedimento
Entre na visualização do sistema.
System ViewCrie um grupo de isolamento.
port-isolate group group-idEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberAtribuir a porta ao grupo de isolamento.
Entre na visualização da interface Ethernet de camada 2.
port-isolate enable group group-idPor padrão, a porta não está em nenhum grupo de isolamento.
Exemplos de configuração de isolamento de porta
Exemplo: Configuração do isolamento de portas
Configuração de rede
Conforme mostrado na Figura 1:
Os usuários da LAN Host A, Host B e Host C estão conectados à GigabitEthernet 1/0/1, GigabitEthernet 1/0/2 e GigabitEthernet 1/0/3 no dispositivo, respectivamente.
O dispositivo se conecta à Internet por meio da GigabitEthernet 1/0/4.
Configure o dispositivo para fornecer acesso à Internet para os hosts e isole-os uns dos outros na Camada 2.
Figura 1 Diagrama de rede
Procedimento
# Criar o grupo de isolamento 2.
<Device> system-view
[Device] port-isolate group 2# Atribuir GigabitEthernet 1/0/1, GigabitEthernet 1/0/2 e GigabitEthernet 1/0/3 ao grupo de isolamento 2.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] port-isolate enable group 2
[Device-GigabitEthernet1/0/1] quit
[Device] interface gigabitethernet 1/0/2
[Device-GigabitEthernet1/0/2] port-isolate enable group 2
[Device-GigabitEthernet1/0/2] quit
[Device] interface gigabitethernet 1/0/3
[Device-GigabitEthernet1/0/3] port-isolate enable group 2
[Device-GigabitEthernet1/0/3] quitVerificação da configuração
# Exibir informações sobre o grupo de isolamento 2.
[Device] display port-isolate group 2
Port isolation group information:
Group ID: 2
Group members:
GigabitEthernet1/0/1 GigabitEthernet1/0/2 GigabitEthernet1/0/3A saída mostra que a GigabitEthernet 1/0/1, a GigabitEthernet 1/0/2 e a GigabitEthernet 1/0/3 estão atribuídas ao grupo de isolamento 2. Como resultado, o host A, o host B e o host C estão isolados uns dos outros na camada 2.
Visão geral do protocolo Spanning Tree
Sobre a STP
O STP foi desenvolvido com base no padrão 802.1d do IEEE para eliminar loops na camada de link de dados em uma LAN. As redes geralmente têm links redundantes como backups em caso de falhas, mas os loops são um problema muito sério. Os dispositivos que executam o STP detectam loops na rede trocando informações entre si. Eles eliminam os loops bloqueando seletivamente determinadas portas para podar a estrutura de loop em uma estrutura de árvore sem loop. Isso evita a proliferação e o ciclo infinito de pacotes que ocorreriam em uma rede com loop.
Em um sentido restrito, STP refere-se ao IEEE 802.1d STP. Em um sentido amplo, STP refere-se ao IEEE 802.1d STP e a vários protocolos de spanning tree aprimorados derivados desse protocolo.
Quadros do protocolo STP
O STP usa unidades de dados de protocolo de ponte (BPDUs), também conhecidas como mensagens de configuração, como seus quadros de protocolo. Este capítulo usa BPDUs para representar todos os tipos de quadros de protocolo Spanning Tree.
Os dispositivos habilitados para STP trocam BPDUs para estabelecer uma árvore de abrangência. Os BPDUs contêm informações suficientes para que os dispositivos concluam o cálculo da árvore de abrangência.
O STP usa dois tipos de BPDUs, BPDUs de configuração e BPDUs de notificação de alteração de topologia (TCN).
BPDUs de configuração
Os dispositivos trocam BPDUs de configuração para eleger a ponte raiz e determinar as funções das portas. A Figura 1 mostra o formato do BPDU de configuração.
Figura 1 Formato do BPDU de configuração
Os dispositivos usam o ID da ponte raiz, o custo do caminho da raiz, o ID da ponte designada, o ID da porta designada, a idade da mensagem, a idade máxima, o tempo de espera e o atraso de encaminhamento para o cálculo da árvore de abrangência.
BPDUs TCN
Os dispositivos usam TCN BPDUs para anunciar alterações na topologia da rede. A Figura 2 mostra o formato do TCN BPDU.
Figura 2 Formato TCN BPDU
DMA: Endereço MAC de destino SMA: Endereço MAC de origem L/T: Comprimento do quadro
Cabeçalho LLC: Cabeçalho de controle de link lógico Carga útil: Dados BPDU
A carga útil de uma BPDU TCN inclui os seguintes campos:
ID do protocolo - Fixado em 0x0000, que representa o IEEE 802.1d.
ID da versão do protocolo - ID da versão do protocolo da árvore de planejamento. A ID da versão do protocolo para STP é 0x00.
Tipo de BPDU - Tipo de BPDU. O valor é 0x80 para um BPDU TCN.
Uma ponte não raiz envia BPDUs TCN quando um dos eventos a seguir ocorre na ponte:
Uma porta passa para o estado de encaminhamento, e a ponte tem no mínimo uma porta designada.
Uma porta passa do estado de encaminhamento ou aprendizado para o estado de bloqueio.
A ponte não raiz usa BPDUs TCN para notificar a ponte raiz quando a topologia da rede é alterada. A ponte raiz define o sinalizador TC em sua configuração BPDU e o propaga para as outras pontes.
Conceitos básicos do STP
Ponte raiz
Uma rede em árvore deve ter uma ponte raiz. A rede inteira contém apenas uma ponte raiz, e todas as outras pontes da rede são chamadas de nós folha. A ponte raiz não é permanente, mas pode mudar com as alterações na topologia da rede.
Após a inicialização de uma rede, cada dispositivo gera e envia periodicamente BPDUs de configuração, sendo ele próprio a ponte raiz. Após a convergência da rede, somente a ponte raiz gera e envia periodicamente BPDUs de configuração. Os outros dispositivos apenas encaminham os BPDUs.
Porta raiz
Em uma ponte não raiz, a porta mais próxima da ponte raiz é a porta raiz. A porta raiz se comunica com a ponte raiz. Cada ponte não-raiz tem apenas uma porta raiz. A ponte raiz não tem porta raiz.
Ponte designada e porto designado
Conforme mostrado na Figura 3, o Dispositivo B e o Dispositivo C estão diretamente conectados a uma LAN.
Se o Dispositivo A encaminhar BPDUs ao Dispositivo B pela porta A1, a ponte designada e a porta designada serão as seguintes:
A ponte designada para o Dispositivo B é o Dispositivo A.
A porta designada para o Dispositivo B é a porta A1 no Dispositivo A.
Se o dispositivo B encaminhar BPDUs para a LAN, a ponte designada e a porta designada serão as seguintes:
A ponte designada para a LAN é o Dispositivo B.
A porta designada para a LAN é a porta B2 no Dispositivo B.
Figura 3 Pontes designadas e portas designadas
O custo do caminho é um valor de referência usado para a seleção de links no STP. Para podar a rede em uma árvore sem loop, o STP calcula os custos de caminho para selecionar os links mais robustos e bloquear os links redundantes que são menos robustos.
Processo de cálculo do algoritmo STP
No cálculo do STP, um dispositivo compara as prioridades dos BPDUs de configuração recebidos de diferentes portas e elege a ponte raiz, as portas raiz e as portas designadas. Quando o cálculo da spanning tree é concluído, forma-se uma topologia em forma de árvore.
O processo de cálculo da árvore de abrangência descrito nas seções a seguir é um exemplo de um processo simplificado.
Inicialização da rede
Após a inicialização de um dispositivo, cada porta gera um BPDU com o seguinte conteúdo:
A porta como a porta designada.
O dispositivo como ponte raiz.
0 como o custo do caminho da raiz.
A ID do dispositivo como a ID da ponte designada.
Seleção da ponte raiz
A ponte raiz pode ser selecionada pelos seguintes métodos:
Eleição automática - Inicialmente, cada dispositivo habilitado para STP na rede assume ser a ponte raiz, com seu próprio ID de dispositivo como o ID da ponte raiz. Ao trocar BPDUs de configuração, os dispositivos comparam seus IDs de root bridge para eleger o dispositivo com o menor ID de root bridge como root bridge.
Atribuição manual - Você pode configurar um dispositivo como root bridge ou root bridge secundária de uma spanning tree.
Uma árvore de abrangência pode ter apenas uma ponte raiz. Se você configurar vários dispositivos como root bridge para uma spanning tree, o dispositivo com o endereço MAC mais baixo será selecionado.
Você pode configurar uma ou várias pontes raiz secundárias para uma árvore de abrangência. Quando a ponte raiz falha ou é desligada, uma ponte raiz secundária pode assumir o controle. Se várias pontes raiz secundárias estiverem configuradas, a que tiver o endereço MAC mais baixo será selecionada. Entretanto, se uma nova ponte raiz for configurada, a ponte raiz secundária não será selecionada.
Seleção da porta raiz e das portas designadas nas pontes não raiz
Quando a topologia da rede está estável, somente a porta raiz e as portas designadas encaminham o tráfego do usuário. As outras portas estão todas no estado de bloqueio para receber BPDUs, mas não para encaminhar BPDUs ou tráfego de usuários.
Tabela 2 Seleção da configuração ideal BPDU
A seguir, os princípios da comparação de BPDUs de configuração:
O BPDU de configuração com o ID de ponte raiz mais baixo tem a prioridade mais alta.
Se os BPDUs de configuração tiverem o mesmo ID de ponte raiz, seus custos de caminho raiz serão comparados. Por exemplo, o custo do caminho raiz em um BPDU de configuração mais o custo do caminho de uma porta receptora é S. O BPDU de configuração com o menor valor S tem a prioridade mais alta.
Se todos os BPDUs de configuração tiverem o mesmo ID de ponte raiz e valor S, os seguintes atributos serão comparados em sequência:
IDs de pontes designadas.
IDs de portas designadas.
IDs das portas de recebimento.
O BPDU de configuração que contém uma ID de ponte designada, ID de porta designada ou ID de porta receptora menor é selecionado.
Uma topologia em forma de árvore se forma quando a ponte raiz, as portas raiz e as portas designadas são selecionadas.
O mecanismo de encaminhamento de BPDU de configuração do STP
Os BPDUs de configuração do STP são encaminhados de acordo com essas diretrizes:
Após o início da rede, cada dispositivo se considera a ponte raiz e gera BPDUs de configuração com ele mesmo como raiz. Em seguida, ele envia os BPDUs de configuração em um intervalo regular de "hello".
Se a porta raiz receber um BPDU de configuração superior ao BPDU de configuração da porta, o dispositivo executará as seguintes operações:
Aumenta a idade da mensagem transportada no BPDU de configuração.
Inicia um cronômetro para cronometrar o BPDU de configuração.
Envia esse BPDU de configuração pela porta designada.
Se uma porta designada receber um BPDU de configuração com uma prioridade mais baixa do que seu BPDU de configuração, a porta responderá imediatamente com seu BPDU de configuração.
Se um caminho falhar, a porta raiz nesse caminho não receberá mais novos BPDUs de configuração e os BPDUs de configuração antigos serão descartados devido ao tempo limite. O dispositivo gera um BPDU de configuração com ele mesmo como a raiz e envia os BPDUs e os BPDUs TCN. Isso aciona um novo processo de cálculo da spanning tree para estabelecer um novo caminho e restaurar a conectividade da rede.
No entanto, a BPDU de configuração recém-calculada não pode ser propagada imediatamente por toda a rede. Como resultado, as portas raiz antigas e as portas designadas que não detectaram a mudança de topologia continuam encaminhando dados pelo caminho antigo. Se as novas portas raiz e as portas designadas começarem a encaminhar dados assim que forem eleitas, poderá ocorrer um loop temporário.
Temporizadores STP
Os parâmetros de tempo mais importantes no cálculo do STP são o atraso de encaminhamento, o tempo de espera e a idade máxima.
Atraso de encaminhamento
O atraso de encaminhamento é o tempo de atraso para a transição do estado da porta. Por padrão, o atraso de encaminhamento é de 15 segundos.
Uma falha de caminho pode causar o recálculo da árvore de abrangência para adaptar a estrutura da árvore de abrangência à alteração. No entanto, a nova configuração BPDU resultante não pode se propagar pela rede imediatamente. Se as portas-raiz recém-eleitas e as portas designadas começarem a encaminhar dados imediatamente, provavelmente ocorrerá um loop temporário.
As portas raiz recém-eleitas ou as portas designadas devem passar pelos estados de escuta e aprendizado antes de passar para o estado de encaminhamento. Isso requer o dobro do tempo de atraso de encaminhamento e permite que a nova configuração BPDU se propague por toda a rede.
Olá, hora
O dispositivo envia BPDUs de configuração no intervalo de tempo hello para os dispositivos vizinhos para garantir que os caminhos estejam livres de falhas. Por padrão, o hello time é de 2 segundos. Se o dispositivo não receber BPDUs de configuração dentro do período de tempo limite, ele recalculará a árvore de abrangência. A fórmula para calcular o período de tempo limite é: período de tempo limite = fator de tempo limite × 3 × hello time.
Idade máxima
O dispositivo usa a idade máxima para determinar se um BPDU de configuração armazenado expirou e o descarta se a idade máxima for excedida. Por padrão, a idade máxima é de 20 segundos. No CIST de uma rede MSTP, o dispositivo usa o timer de idade máxima para determinar se um BPDU de configuração recebido por uma porta expirou. Se ele tiver expirado, um novo processo de cálculo da árvore de abrangência será iniciado. O timer de idade máxima não entra em vigor nos MSTIs.
Se uma porta não receber nenhum BPDU de configuração dentro do período de tempo limite, a porta passa para o estado de escuta. O dispositivo recalculará a árvore de abrangência. A porta leva 50 segundos para voltar ao estado de encaminhamento. Esse período inclui 20 segundos para a idade máxima, 15 segundos para o estado de escuta e 15 segundos para o estado de aprendizado.
Para garantir uma convergência rápida da topologia, certifique-se de que as configurações do temporizador atendam às seguintes fórmulas:
2 × (atraso de encaminhamento - 1 segundo) ≥ idade máxima
Idade máxima ≥ 2 × (tempo de espera + 1 segundo)
Sobre o RSTP
O RSTP consegue uma convergência rápida da rede, permitindo que uma porta raiz recém-eleita ou uma porta designada entre no estado de encaminhamento muito mais rapidamente do que o STP.
Quadros do protocolo RSTP
Um BPDU RSTP usa o mesmo formato de um BPDU STP, exceto pelo fato de que um campo de comprimento da versão 1 é adicionado à carga útil dos BPDUs RSTP. As diferenças entre um BPDU RSTP e um BPDU STP são as seguintes:
ID da versão do protocolo - O valor é 0x02 para RSTP.
Tipo de BPDU - O valor é 0x02 para BPDUs RSTP.
Flags - Todos os 8 bits são usados.
Comprimento da versão 1 - O valor é 0x00, o que significa que não há informações sobre o protocolo da versão 1.
O RSTP não usa BPDUs TCN para anunciar alterações de topologia. O RSTP inunda BPDUs com o sinalizador TC definido na rede para anunciar alterações de topologia.
Conceitos básicos do RSTP
Funções de porta
Além da porta raiz e da porta designada, o RSTP também usa as seguintes funções de porta:
Porta alternativa - Atua como porta de backup para uma porta raiz. Quando a porta raiz é bloqueada, a porta alternativa assume o controle.
Porta de backup - Atua como porta de backup de uma porta designada. Quando a porta designada é inválida, a porta de backup torna-se a nova porta designada. Um loop ocorre quando duas portas do mesmo dispositivo de spanning tree estão conectadas, de modo que o dispositivo bloqueia uma das portas. A porta bloqueada é a porta de backup.
Porta de borda - conecta-se diretamente a um host de usuário em vez de a um dispositivo de rede ou segmento de rede.
Estados das portas
O RSTP usa o estado de descarte para substituir os estados de desativação, bloqueio e escuta no STP. A Tabela 5 mostra as diferenças entre os estados das portas no RSTP e no STP.
Tabela 5 Diferenças de estado de porta entre RSTP e STP
Como o RSTP funciona
Durante o cálculo do RSTP, ocorrem os seguintes eventos:
Se uma porta em estado de descarte se tornar uma porta alternativa, ela manterá seu estado.
Se uma porta no estado de descarte for eleita como porta raiz ou porta designada, ela entrará no estado de aprendizado após o atraso no encaminhamento. A porta aprende os endereços MAC e entra no estado de encaminhamento após outro atraso de encaminhamento.
Uma porta raiz RSTP recém-eleita entra rapidamente no estado de encaminhamento se os seguintes requisitos forem atendidos:
A porta raiz antiga do dispositivo parou de encaminhar dados.
A porta designada upstream começou a encaminhar dados.
Uma porta designada RSTP recém-eleita entra rapidamente no estado de encaminhamento se um dos requisitos a seguir for atendido:
A porta designada é configurada como uma porta de borda que se conecta diretamente a um terminal de usuário.
A porta designada se conecta a um link ponto a ponto e recebe uma resposta de handshake do dispositivo conectado diretamente.
Processamento de BPDUs RSTP
No RSTP, uma ponte não raiz envia ativamente BPDUs RSTP no momento do "hello" por meio de portas designadas, sem esperar que a ponte raiz envie BPDUs RSTP. Isso permite que o RSTP detecte rapidamente o link
falhas. Se um dispositivo não receber nenhum BPDU RSTP em uma porta dentro do triplo do tempo de espera, o dispositivo considerará que ocorreu uma falha de link. Após a expiração do BPDU de configuração armazenada, o dispositivo inunda BPDUs RSTP com o sinalizador TC definido para iniciar um novo cálculo RSTP.
No RSTP, uma porta em estado de bloqueio pode responder imediatamente a um BPDU do RSTP com uma prioridade mais baixa do que seu próprio BPDU.
Conforme mostrado na Figura 6, o Dispositivo A é a ponte raiz. A prioridade do Dispositivo B é maior que a prioridade do Dispositivo C. A porta C2 no Dispositivo C está bloqueada.
Quando o link entre o Dispositivo A e o Dispositivo B falha, ocorrem os seguintes eventos:
O dispositivo B envia um BPDU RSTP com ele mesmo como a ponte raiz para o dispositivo C.
O dispositivo C compara o BPDU do RSTP com seu próprio BPDU.
Como o BPDU RSTP do Dispositivo B tem uma prioridade mais baixa, o Dispositivo C envia seu próprio BPDU para Dispositivo B.
O dispositivo B considera que a porta B2 é a porta raiz e para de enviar BPDUs RSTP para o dispositivo C.
Figura 6 Processamento de BPDU no RSTP
Sobre o PVST
Em uma LAN habilitada para STP ou RSTP, todas as pontes compartilham uma árvore de abrangência. O tráfego de todas as VLANs é encaminhado ao longo da árvore de abrangência, e as portas não podem ser bloqueadas por VLAN para podar loops.
O PVST permite que cada VLAN tenha sua própria spanning tree, o que aumenta o uso de links e largura de banda. Como cada VLAN executa o RSTP de forma independente, uma árvore de abrangência atende apenas à sua VLAN.
Um dispositivo INTELBRAS habilitado para PVST pode se comunicar com um dispositivo de terceiros que esteja executando Rapid PVST ou PVST. O dispositivo INTELBRAS habilitado para PVST suporta convergência de rede rápida como RSTP quando conectado a dispositivos INTELBRAS habilitados para PVST ou a dispositivos de terceiros habilitados com Rapid PVST.
Quadros do protocolo PVST
Conforme mostrado na Figura 7, um BPDU PVST usa o mesmo formato de um BPDU RSTP, exceto pelas seguintes diferenças:
O endereço MAC de destino de um BPDU PVST é 01-00-0c-cc-cc-cd, que é um endereço MAC privado.
Cada BPDU PVST contém uma tag de VLAN. A tag de VLAN identifica a VLAN à qual o BPDU PVST pertence.
Os campos de código de organização e PID são adicionados ao cabeçalho LLC do BPDU PVST.
Figura 7 Formato BPDU do PVST
O tipo de link de uma porta determina o tipo de BPDUs que a porta envia.
Uma porta de acesso envia BPDUs RSTP.
Uma porta tronco ou híbrida envia BPDUs RSTP na VLAN padrão e envia BPDUs PVST em outras VLANs.
Como o PVST funciona
O PVST implementa o cálculo da árvore de abrangência por VLAN mapeando cada VLAN para um MSTI. No PVST, cada VLAN executa o RSTP de forma independente para manter sua própria árvore de abrangência sem afetar as árvores de abrangência de outras VLANs. Dessa forma, os loops em cada VLAN são eliminados e o tráfego de diferentes VLANs é compartilhado por links. O PVST usa BPDUs do RSTP na VLAN padrão e BPDUs do PVST em outras VLANs para o cálculo da árvore de abrangência.
O PVST usa as mesmas funções e estados de porta que o RSTP para a transição rápida. Para obter mais informações, consulte "Conceitos básicos do RSTP".
Sobre a MSTP
Recursos do MSTP
Desenvolvido com base no IEEE 802.1s, o MSTP supera as limitações do STP, RSTP e PVST. Além de dar suporte à rápida convergência da rede, ele permite que os fluxos de dados de diferentes VLANs sejam encaminhados por caminhos separados. Isso proporciona um melhor mecanismo de compartilhamento de carga para links redundantes.
O MSTP oferece os seguintes recursos:
O MSTP divide uma rede comutada em várias regiões, cada uma das quais contém várias spanning trees independentes umas das outras.
O MSTP suporta o mapeamento de VLANs para instâncias de spanning tree por meio de uma tabela de mapeamento de VLAN para instância. O MSTP pode reduzir as despesas gerais de comunicação e o uso de recursos mapeando várias VLANs para uma instância.
O MSTP poda uma rede de loop em uma árvore sem loop, o que evita a proliferação e o ciclo interminável de quadros em uma rede de loop. Além disso, ele oferece suporte ao balanceamento de carga de dados de VLAN, fornecendo vários caminhos redundantes para o encaminhamento de dados.
O MSTP é compatível com o STP e o RSTP, e parcialmente compatível com o PVST.
Conceitos básicos do MSTP
A Figura 9 mostra uma rede comutada que contém quatro regiões MST, cada região MST contendo quatro dispositivos MSTP. A Figura 10 mostra a topologia de rede da região 3 da MST.
Figura 9 Conceitos básicos do MSTP
Figura 10 Diagrama de rede e topologia da região 3 do MST
Para a região 4 da MST
Região MST
Uma região Spanning Tree múltipla (região MST) consiste em vários dispositivos em uma rede comutada e nos segmentos de rede entre eles. Todos esses dispositivos têm as seguintes características:
Um protocolo de spanning tree ativado
Mesmo nome de região
Mesma configuração de mapeamento de VLAN para instância
Mesmo nível de revisão do MSTP
Fisicamente ligados entre si
Podem existir várias regiões MST em uma rede comutada. Você pode atribuir vários dispositivos à mesma região MST.
A rede comutada contém quatro regiões MST, da região MST 1 à região MST 4.
Todos os dispositivos em cada região MST têm a mesma configuração de região MST.
MSTI
O MSTP pode gerar várias spanning trees independentes em uma região MST, e cada spanning tree é mapeada para VLANs específicas. Cada árvore de abrangência é chamada de instância Spanning Tree múltipla (MSTI).
Tabela de mapeamento de VLAN para instância
Como atributo de uma região MST, a tabela de mapeamento VLAN-para-instância descreve as relações de mapeamento entre VLANs e MSTIs.
O MSTP realiza o balanceamento de carga por meio da tabela de mapeamento de VLAN para instância.
CST
A árvore de abrangência comum (CST) é uma única árvore de abrangência que conecta todas as regiões MST em uma rede comutada. Se você considerar cada região MST como um dispositivo, a CST é uma árvore de abrangência calculada por esses dispositivos por meio do STP ou do RSTP.
Uma árvore de abrangência interna (IST) é uma árvore de abrangência que é executada em uma região MST. Também é chamada de MSTI 0, uma MSTI especial para a qual todas as VLANs são mapeadas por padrão.
A árvore de abrangência comum e interna (CIST) é uma única árvore de abrangência que conecta todos os dispositivos em uma rede comutada. Ela consiste nas ISTs em todas as regiões MST e na CST.
Raiz regional
A ponte raiz do IST ou de um MSTI em uma região MST é a raiz regional do IST ou do MSTI. Com base na topologia, diferentes spanning trees em uma região MST podem ter diferentes raízes regionais, conforme mostrado na região MST 3
Ponte raiz comum
A ponte raiz comum é a ponte raiz do CIST.
Funções de porta
Uma porta pode desempenhar diferentes funções em diferentes MSTIs. Conforme mostrado na Figura 11, uma região MST contém o Dispositivo A, o Dispositivo B, o Dispositivo C e o Dispositivo D. A porta A1 e a porta A2 do Dispositivo A se conectam à ponte raiz comum. A porta B2 e a porta B3 do Dispositivo B formam um loop. Porta C3 e Porta C4 do Dispositivo C conectam-se a outras regiões MST. A porta D3 do dispositivo D se conecta diretamente a um host.
Figura 11 Funções da porta
Para a raiz comum
Porta raiz Porta designada Porta alternativa
Porta de backup
Porta de borda Porta mestre Porta de limite Link normal Link bloqueado
Para outras regiões MST
O cálculo do MSTP envolve as seguintes funções de porta:
Porta raiz - encaminha dados de uma ponte não raiz para a ponte raiz. A ponte raiz não tem nenhuma porta raiz.
Porta designada - encaminha dados para o segmento de rede ou dispositivo downstream.
Porta alternativa - Atua como porta de backup para uma porta raiz ou porta principal. Quando a porta raiz ou a porta principal é bloqueada, a porta alternativa assume o controle.
Porta de backup - Atua como porta de backup de uma porta designada. Quando a porta designada é inválida, a porta de backup torna-se a nova porta designada. Um loop ocorre quando duas portas do mesmo dispositivo de spanning tree estão conectadas, de modo que o dispositivo bloqueia uma das portas. A porta bloqueada atua como backup.
Porta de borda - conecta-se diretamente a um host de usuário em vez de a um dispositivo de rede ou segmento de rede.
Porta mestre - Atua como uma porta no caminho mais curto da região MST local até a ponte raiz comum. A porta mestre nem sempre está localizada na raiz regional. Ela é uma porta raiz no IST ou CIST e ainda é uma porta mestre nos outros MSTIs.
Porta de limite - Conecta uma região MST a outra região MST ou a um dispositivo em execução STP/RSTP. No cálculo do MSTP, a função de uma porta de limite em um MSTI é consistente com sua função na região MST.
Estados das portas
CIST. Entretanto, isso não é verdade com as portas mestras. Uma porta mestre em MSTIs é uma porta raiz no CIST.
No MSTP, uma porta pode estar em um dos seguintes estados:
Encaminhamento - A porta recebe e envia BPDUs, aprende endereços MAC e encaminha o tráfego de usuários.
Aprendizagem - A porta recebe e envia BPDUs, aprende endereços MAC, mas não encaminha tráfego de usuário. O aprendizado é um estado intermediário da porta.
Descarte - A porta recebe e envia BPDUs, mas não aprende endereços MAC nem encaminha tráfego de usuários.
OBSERVAÇÃO:
Quando em MSTIs diferentes, uma porta pode estar em estados diferentes.
Um estado de porta não está associado exclusivamente a uma função de porta. A Tabela 6 lista os estados de porta que cada função de porta suporta. (Uma marca de seleção [√] indica que a porta é compatível com esse estado, enquanto um traço [-] indica que a porta não é compatível com esse estado).
Tabela 6 Estados de porta que diferentes funções de porta suportam
Como o MSTP funciona
O MSTP divide toda uma rede de Camada 2 em várias regiões MST, que são conectadas por um CST calculado. Dentro de uma região MST, são calculadas várias spanning trees, chamadas MSTIs. Entre essas MSTIs, a MSTI 0 é a IST.
Assim como o STP, o MSTP usa BPDUs de configuração para calcular as árvores de abrangência. Uma diferença importante é que um BPDU MSTP carrega a configuração MSTP da ponte da qual o BPDU é enviado.
Cálculo do CIST
Durante o cálculo do CIST, ocorre o seguinte processo:
O dispositivo com a prioridade mais alta é eleito como a ponte raiz do CIST.
O MSTP gera um IST em cada região MST por meio de cálculos.
O MSTP considera cada região MST como um único dispositivo e gera um CST entre essas regiões MST por meio de cálculos.
O CST e os ISTs constituem o CIST de toda a rede.
Cálculo de MSTI
Em uma região MST, o MSTP gera MSTIs diferentes para VLANs diferentes com base nos mapeamentos de VLAN para instância. Para cada árvore de abrangência, o MSTP executa um processo de cálculo separado semelhante ao cálculo da árvore de abrangência no STP. Para obter mais informações, consulte "Processo de cálculo do algoritmo STP".
No MSTP, um quadro de VLAN é encaminhado pelos seguintes caminhos:
Em uma região MST, o quadro é encaminhado ao longo do MSTI correspondente.
Entre duas regiões MST, o quadro é encaminhado ao longo da CST.
Implementação do MSTP em dispositivos
O MSTP é compatível com o STP e o RSTP. Os dispositivos que estão executando o MSTP e que são usados para o cálculo da árvore de abrangência podem identificar os quadros dos protocolos STP e RSTP.
Além dos recursos básicos do MSTP, os seguintes recursos são fornecidos para facilitar o gerenciamento:
Retenção da ponte raiz.
Backup da ponte raiz.
Proteção da raiz.
Proteção de BPDU.
Proteção do laço.
Proteção TC-BPDU.
Restrição de função de porta.
Restrição de transmissão TC-BPDU.
Mecanismo de transição rápida
No STP, uma porta deve esperar o dobro do atraso de encaminhamento (30 segundos por padrão) antes de passar do estado de bloqueio para o estado de encaminhamento. O atraso de encaminhamento está relacionado ao hello time e ao diâmetro da rede. Se o atraso de encaminhamento for muito curto, poderão ocorrer loops. Isso afeta a estabilidade da rede.
O RSTP, o PVST e o MSTP usam o mecanismo de transição rápida para acelerar a transição do estado da porta para portas de borda, portas raiz e portas designadas. O mecanismo de transição rápida para portas designadas também é conhecido como transição de proposta/acordo (P/A).
Transição rápida da porta de borda
Conforme mostrado na Figura 12, a porta C3 é uma porta de borda conectada a um host. Quando ocorre uma mudança na topologia da rede, a porta pode transitar imediatamente do estado de bloqueio para o estado de encaminhamento, pois não será causado nenhum loop.
Como um dispositivo não pode determinar se uma porta está diretamente conectada a um terminal, você deve configurar manualmente a porta como uma porta de borda.
Figura 12 Transição rápida da porta de borda
Transição rápida da porta raiz
Quando uma porta raiz for bloqueada, a ponte elegerá a porta alternativa com a prioridade mais alta como a nova porta raiz. Se o par da nova porta raiz estiver no estado de encaminhamento, a nova porta raiz passará imediatamente para o estado de encaminhamento.
Conforme mostrado na Figura 13, a porta C2 no dispositivo C é uma porta raiz e a porta C1 é uma porta alternativa. Quando a porta C2 passa para o estado de bloqueio, a porta C1 é eleita como a porta raiz e passa imediatamente para o estado de encaminhamento .
Figura 13 Transição rápida da porta raiz
Transição P/A
A transição P/A permite que uma porta designada passe rapidamente para o estado de encaminhamento após um handshake com seu par. A transição P/A aplica-se somente a links ponto a ponto.
Transição P/A para RSTP e PVST.
No RSTP ou PVST, as portas em um novo link ou em um link recuperado são portas designadas em estado de bloqueio. Quando uma das portas designadas passa para o estado de descarte ou aprendizado, ela define o sinalizador de proposta em seu BPDU. Sua ponte par recebe o BPDU e determina se a porta receptora é a porta raiz. Se for a porta raiz, a ponte bloqueia as outras portas, exceto as portas de borda. Em seguida, a ponte responde um BPDU de acordo para a porta designada. A porta designada passa imediatamente para o estado de encaminhamento ao receber o BPDU de acordo. Se a porta designada não receber o BPDU de acordo, ela aguardará o dobro do atraso de encaminhamento para passar para o estado de encaminhamento.
Conforme mostrado na Figura 14, a transição P/A funciona da seguinte forma:
O dispositivo A envia uma proposta BPDU ao dispositivo B por meio da porta A1.
O dispositivo B recebe a proposta BPDU na porta B2. A porta B2 é eleita como a porta raiz.
O dispositivo B bloqueia sua porta designada, a porta B1, e a porta alternativa, a porta B3, para eliminar os loops.
A porta raiz, a porta B2, passa para o estado de encaminhamento e envia um BPDU de acordo para o dispositivo A.
A porta designada Porta A1 no Dispositivo A passa imediatamente para o estado de encaminhamento após receber o BPDU de acordo.
Figura 14 Transição P/A para RSTP e PVST
Transição P/A para MSTP.
No MSTP, uma ponte upstream define os sinalizadores de proposta e de acordo em seu BPDU. Se uma ponte downstream receber o BPDU e sua porta receptora for eleita como a porta raiz, a ponte bloqueará todas as outras portas, exceto as portas de borda. Em seguida, a ponte de downstream responde um BPDU de acordo para a ponte de upstream. A porta upstream passa imediatamente para o estado de encaminhamento ao receber o BPDU de acordo. Se a porta upstream não receber o BPDU de acordo, ela aguardará o dobro do atraso de encaminhamento para passar para o estado de encaminhamento.
Conforme mostrado na Figura 15, a transição P/A funciona da seguinte forma:
O dispositivo A define os sinalizadores de proposta e acordo em seu BPDU e o envia ao dispositivo B por meio da porta A1 do .
O dispositivo B recebe o BPDU. A porta B1 do dispositivo B é eleita como a porta raiz.
O dispositivo B bloqueia todas as suas portas, exceto as portas de borda.
A porta raiz Porta B1 do Dispositivo B passa para o estado de encaminhamento e envia um acordo BPDU para o Dispositivo A.
A porta A1 do dispositivo A passa imediatamente para o estado de encaminhamento ao receber o acordo BPDU.
Figura 15 Transição P/A para MSTP
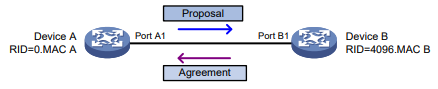
Protocolos e padrões
O MSTP está documentado nos seguintes protocolos e padrões:
IEEE 802.1d, pontes de controle de acesso à mídia (MAC)
IEEE 802.1w, Parte 3: Pontes de controle de acesso ao meio (MAC) - Alteração 2: Reconfiguração rápida
IEEE 802.1s, redes locais com pontes virtuais - Alteração 3: múltiplas árvores de varredura
IEEE 802.1Q-REV/D1.3, pontes de controle de acesso a mídia (MAC) e redes locais com pontes virtuais - Cláusula 13: Protocolos Spanning Tree
Configuração dos protocolos de spanning tree
Configurando o protocolo Spanning Tree
Restrições e diretrizes: configuração do protocolo spanning tree
Restrições: Configuração da interface
Alguns recursos da árvore de abrangência são suportados na visualização da interface Ethernet da Camada 2 e na visualização da interface agregada da Camada 2. Salvo indicação em contrário, essas visualizações são coletivamente chamadas de visualização de interface neste documento. O BPDU drop pode ser configurado somente na visualização da interface Ethernet da camada 2.
As configurações feitas na visualização do sistema entram em vigor globalmente. As configurações feitas na visualização da interface Ethernet de camada 2 têm efeito apenas na interface. As configurações feitas na visualização da interface agregada da camada 2 têm efeito apenas na interface agregada. As configurações feitas em uma porta de membro de agregação podem entrar em vigor somente depois que a porta for removida do grupo de agregação.
Depois que você ativa um protocolo Spanning Tree em uma interface agregada da Camada 2, o sistema executa o cálculo da árvore de abrangência na interface agregada da Camada 2. Ele não realiza o cálculo da árvore de abrangência nas portas-membro de agregação. O estado de ativação do protocolo spanning tree e o estado de encaminhamento de cada porta membro selecionada são consistentes com os da interface agregada de camada 2 correspondente.
As portas membros de um grupo de agregação não participam do cálculo da árvore de abrangência. No entanto, as portas ainda reservam suas configurações Spanning Tree para participar do cálculo da árvore de abrangência após deixarem o grupo de agregação.
Configuração do modo Spanning Tree
Sobre o modo spanning tree
Os modos Spanning Tree incluem:
Modo STP - Todas as portas do dispositivo enviam BPDUs STP. Selecione esse modo quando o dispositivo par de uma porta for compatível apenas com STP.
Modo RSTP - Todas as portas do dispositivo enviam BPDUs RSTP. Uma porta nesse modo passa automaticamente para o modo STP quando recebe BPDUs STP do dispositivo par. Uma porta nesse modo não passa para o modo MSTP quando recebe BPDUs MSTP do dispositivo par.
Modo PVST - Todas as portas do dispositivo enviam BPDUs PVST. Cada VLAN mantém uma árvore de abrangência. Em uma rede, a quantidade de árvores de abrangência mantidas por todos os dispositivos é igual ao número de VLANs habilitadas para PVST multiplicado pelo número de portas habilitadas para PVST. Se a quantidade de spanning trees exceder a capacidade da rede, as CPUs dos dispositivos ficarão sobrecarregadas. O encaminhamento de pacotes será interrompido e a rede se tornará instável. O dispositivo pode manter árvores de abrangência para 128 VLANs.
Modo MSTP - Todas as portas do dispositivo enviam BPDUs MSTP. Uma porta nesse modo passa automaticamente para o modo STP quando recebe BPDUs STP do dispositivo par. Uma porta nesse modo não passa para o modo RSTP quando recebe BPDUs RSTP do dispositivo par.
Restrições e diretrizes
O modo MSTP é compatível com o modo RSTP, e o modo RSTP é compatível com o modo STP.
A compatibilidade do modo PVST depende do tipo de link de uma porta.
Em uma porta de acesso, o modo PVST é compatível com outros modos de spanning tree em todas as VLANs.
Em uma porta tronco ou porta híbrida, o modo PVST é compatível com outros modos de spanning tree somente na VLAN padrão.
Procedimento
Entre na visualização do sistema.
System ViewDefinir o modo Spanning Tree.
stp mode { mstp | pvst | rstp | stp }A configuração padrão é o modo MSTP.
Configuração de uma região MST
Sobre a região MST
Os dispositivos Spanning Tree pertencem à mesma região MST se ambos estiverem conectados por meio de um link físico e configurados com os seguintes detalhes:
Seletor de formato (0 por padrão, não configurável).
Nome da região MST.
Nível de revisão da região MST.
Entradas de mapeamento de VLAN para instância na região MST.
A configuração dos parâmetros relacionados à região MST (especialmente a tabela de mapeamento VLAN-para-instância) pode fazer com que o MSTP inicie um novo cálculo Spanning Tree. Para reduzir a possibilidade de instabilidade da topologia, a configuração da região MST entra em vigor somente depois de ser ativada por meio de uma das ações a seguir:
Use o comando active region-configuration.
Ative um protocolo Spanning Tree usando o comando stp global enable se o protocolo Spanning Tree estiver desativado.
Restrições e diretrizes
No modo STP, RSTP ou PVST, as configurações de região MST não têm efeito.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da região MST.
stp region-configuration Configure o nome da região MST.
region-name name A configuração padrão é o endereço MAC.
Configure a tabela de mapeamento de VLAN para instância. Escolha uma opção conforme necessário:
Mapear uma lista de VLANs para um MSTI.
instance instance-id vlan vlan-id-listCrie rapidamente uma tabela de mapeamento de VLAN para instância.
vlan-mapping modulo moduloPor padrão, todas as VLANs em uma região MST são mapeadas para o CIST (ou MSTI 0).
Configure o nível de revisão MSTP da região MST.
revision-level levelA configuração padrão é 0.
(Opcional.) Exibe as configurações de região MST que ainda não foram ativadas.
check region-configuration Ativar manualmente a configuração da região MST.
active region-configurationConfiguração da ponte raiz ou de uma ponte raiz secundária
Restrições e diretrizes
Você pode fazer com que o protocolo da árvore de abrangência determine a ponte raiz de uma árvore de abrangência por meio de cálculo. Você também pode especificar um dispositivo como root bridge ou como root bridge secundária.
Quando você especificar um dispositivo como root bridge ou como root bridge secundário, siga estas restrições e diretrizes:
Um dispositivo tem funções independentes em diferentes spanning trees. Ele pode atuar como root bridge em uma spanning tree e como root bridge secundária em outra. Entretanto, um dispositivo não pode ser a ponte raiz e uma ponte raiz secundária na mesma árvore de abrangência.
Se você especificar a root bridge para uma spanning tree, nenhuma nova root bridge será eleita de acordo com as configurações de prioridade do dispositivo. Depois de especificar um dispositivo como root bridge ou root bridge secundária, você não poderá alterar a prioridade do dispositivo.
Você pode configurar um dispositivo como a ponte raiz definindo a prioridade do dispositivo como 0. Para a configuração da prioridade do dispositivo, consulte "Configuração da prioridade do dispositivo".
Configuração do dispositivo como a ponte raiz de uma árvore de abrangência
Entre na visualização do sistema.
System ViewConfigure o dispositivo como a ponte raiz.
No modo STP/RSTP:
stp root primary No modo PVST:
stp vlan vlan-id-list root primaryNo modo MSTP:
stp [ instance instance-list ] root primaryPor padrão, o dispositivo não é uma ponte raiz.
Configuração do dispositivo como uma ponte raiz secundária de uma árvore de abrangência
Entre na visualização do sistema.
System ViewConfigure o dispositivo como uma ponte raiz secundária.
No modo STP/RSTP:
stp root secondaryNo modo PVST:
stp vlan vlan-id-list root secondaryNo modo MSTP:
stp [ instance instance-list ] root secondaryPor padrão, o dispositivo não é uma ponte raiz secundária.
Configuração da prioridade do dispositivo
Sobre a prioridade do dispositivo
A prioridade do dispositivo é um fator no cálculo da árvore de abrangência. A prioridade de um dispositivo determina se ele pode ser eleito como a ponte raiz de uma árvore de abrangência. Um valor mais baixo indica uma prioridade mais alta. Você pode definir a prioridade de um dispositivo com um valor baixo para especificar o dispositivo como a ponte raiz da árvore de abrangência. Um dispositivo Spanning Tree pode ter prioridades diferentes em árvores de abrangência diferentes.
Durante a seleção da root bridge, se todos os dispositivos em uma spanning tree tiverem a mesma prioridade, será selecionado aquele com o endereço MAC mais baixo. Não é possível alterar a prioridade de um dispositivo depois que ele estiver configurado como root bridge ou como root bridge secundária.
Procedimento
Entre na visualização do sistema.
System ViewConfigure a prioridade do dispositivo.
No modo STP/RSTP:
stp priority priorityNo modo PVST:
stp vlan vlan-id-list priority priorityNo modo MSTP:
stp [ instance instance-list ] priority priorityA configuração padrão é 32768.
Configuração do número máximo de saltos de uma região MST
Sobre o número máximo de saltos de uma região MST
Restrinja o tamanho da região definindo o máximo de saltos de uma região MST. O limite de saltos configurado na ponte raiz regional é usado como o limite de saltos para a região MST.
Os BPDUs de configuração enviados pela ponte raiz regional sempre têm uma contagem de saltos definida como o valor máximo. Quando um dispositivo recebe esse BPDU de configuração, ele diminui a contagem de saltos em um e usa a nova contagem de saltos nos BPDUs que propaga. Quando a contagem de saltos de um BPDU chega a zero, ele é descartado pelo dispositivo que o recebeu. Os dispositivos além do alcance do máximo de saltos não podem mais participar dos cálculos da spanning tree, portanto o tamanho da região MST é limitado.
Restrições e diretrizes
Faça essa configuração somente na ponte raiz. Todos os outros dispositivos na região MST usam o valor de salto máximo definido para a ponte raiz.
Você pode configurar o máximo de hops de uma região MST com base no tamanho da rede STP. Como prática recomendada, defina o máximo de saltos para um valor maior do que o máximo de saltos de cada dispositivo de borda para a ponte raiz.
Procedimento
Entre na visualização do sistema.
System ViewConfigure o número máximo de saltos da região MST.
stp max-hops hopsA configuração padrão é 20.
Configuração do diâmetro da rede de uma rede comutada
Sobre o diâmetro da rede
Quaisquer dois dispositivos terminais em uma rede comutada podem alcançar um ao outro por meio de um caminho específico, e há uma série de dispositivos no caminho. O diâmetro da rede comutada é o número máximo de dispositivos no caminho para um dispositivo de borda alcançar outro dispositivo na rede comutada por meio da ponte raiz. O diâmetro da rede indica o tamanho da rede. Quanto maior o diâmetro, maior o tamanho da rede.
Com base no diâmetro da rede que você configurou, o sistema define automaticamente um hello time, um forward delay e um max age ideais para o dispositivo.
No modo STP, RSTP ou MSTP, cada região MST é considerada um dispositivo. O diâmetro de rede configurado entra em vigor somente no CIST (ou na ponte raiz comum), mas não em outros MSTIs.
No modo PVST, o diâmetro de rede configurado entra em vigor somente nas pontes-raiz das VLANs especificadas.
Procedimento
Entre na visualização do sistema.
System ViewConfigure o diâmetro da rede comutada.
No modo STP/RSTP/MSTP:
stp bridge-diameter diameterNo modo PVST:
stp vlan vlan-id-list bridge-diameter diameterA configuração padrão é 7.
Configuração de temporizadores de spanning tree
Sobre os temporizadores de spanning tree
Os seguintes temporizadores são usados para o cálculo da árvore de abrangência:
Atraso de encaminhamento - Tempo de atraso para a transição do estado da porta. Para evitar loops temporários em uma rede, o recurso spanning tree define um estado de porta intermediário (o estado de aprendizagem) antes que ela transite do estado de descarte para o estado de encaminhamento. O recurso também exige que a porta transite em seu estado após um cronômetro de atraso de encaminhamento. Isso garante que a transição de estado da porta local permaneça sincronizada com o par.
Hello time-Intervalo no qual o dispositivo envia BPDUs de configuração para detectar falhas de link. Se o dispositivo não receber BPDUs de configuração dentro do período de tempo limite, ele recalculará a árvore de abrangência. A fórmula para calcular o período de tempo limite é: período de tempo limite = fator de tempo limite × 3 × tempo de espera.
Idade máxima-No CIST de uma rede MSTP, o dispositivo usa o timer de idade máxima para determinar se um BPDU de configuração recebido por uma porta expirou. Se ele tiver expirado, um novo processo de cálculo da árvore de abrangência será iniciado. O cronômetro de idade máxima não entra em vigor nos MSTIs.
Para garantir uma convergência rápida da topologia, certifique-se de que as configurações do timer atendam às seguintes fórmulas:
2 × (atraso de encaminhamento - 1 segundo) ≥ idade máxima
Idade máxima ≥ 2 × (tempo de espera + 1 segundo)
Como prática recomendada, especifique o diâmetro da rede e deixe que os protocolos Spanning Tree calculem automaticamente os timers com base no diâmetro da rede, em vez de definir manualmente os timers da árvore de abrangência. Se o diâmetro da rede usar o valor padrão, os temporizadores também usarão seus valores padrão.
Defina os temporizadores somente na ponte raiz. As configurações de temporizador na ponte raiz se aplicam a todos os dispositivos em toda a rede comutada.
Restrições e diretrizes
A duração do atraso de encaminhamento está relacionada ao diâmetro da rede comutada. Quanto maior for o diâmetro da rede, maior deverá ser o tempo de atraso de encaminhamento. Como prática recomendada, use o valor calculado automaticamente porque a configuração inadequada do atraso de encaminhamento pode causar caminhos redundantes temporários ou aumentar o tempo de convergência da rede.
Uma configuração adequada do hello time permite que o dispositivo detecte prontamente falhas de link na rede sem usar recursos excessivos da rede. Se o hello time for muito longo, o dispositivo confunde a perda de pacotes com uma falha de link e aciona um novo processo de cálculo da spanning tree. Se o hello time for muito curto, o dispositivo enviará frequentemente os mesmos BPDUs de configuração, o que desperdiça recursos do dispositivo e da rede. Como prática recomendada, use o valor calculado automaticamente.
Se o timer de idade máxima for muito curto, o dispositivo iniciará frequentemente os cálculos da árvore de abrangência e poderá confundir o congestionamento da rede com uma falha de link. Se o timer de idade máxima for muito longo, o dispositivo poderá não conseguir detectar prontamente as falhas de link e iniciar rapidamente os cálculos da árvore de abrangência, reduzindo
Procedimento
o recurso de detecção automática da rede. Como prática recomendada, use o valor calculado automaticamente.
Entre na visualização do sistema.
System ViewDefina o cronômetro de atraso de encaminhamento.
No modo STP/RSTP/MSTP:
stp timer forward-delay timeNo modo PVST:
stp vlan vlan-id-list timer forward-delay timeA configuração padrão é de 15 segundos.
Defina o temporizador de "hello".
No modo STP/RSTP/MSTP:
stp timer hello timeNo modo PVST:
stp vlan vlan-id-list timer hello timeA configuração padrão é de 2 segundos.
Defina o cronômetro de idade máxima.
No modo STP/RSTP/MSTP:
stp timer max-age timeNo modo PVST:
stp vlan vlan-id-list timer max-age timeA configuração padrão é de 20 segundos.
Configuração do fator de tempo limite
Sobre o fator de tempo limite
O fator de tempo limite é um parâmetro usado para decidir o período de tempo limite. A fórmula para calcular o período de tempo limite é: período de tempo limite = fator de tempo limite × 3 × tempo de espera.
Em uma rede estável, cada dispositivo não raiz-ponte encaminha BPDUs de configuração para os dispositivos downstream no intervalo de tempo hello para detectar falhas de link. Se um dispositivo não receber um BPDU do dispositivo upstream em um intervalo de nove vezes o tempo de "hello", ele presumirá que o dispositivo upstream falhou. Em seguida, ele inicia um novo processo de cálculo da spanning tree.
Restrições e diretrizes
Como prática recomendada, defina o fator de tempo limite como 5, 6 ou 7 nas seguintes situações:
Para evitar cálculos indesejados da spanning tree. Um dispositivo upstream pode estar ocupado demais para encaminhar BPDUs de configuração a tempo; por exemplo, muitas interfaces de camada 2 estão configuradas no dispositivo upstream. Nesse caso, o dispositivo downstream não recebe um BPDU dentro do período de tempo limite e, em seguida, inicia um cálculo indesejado da árvore de abrangência.
Para economizar recursos de rede em uma rede estável.
Procedimento
Entre na visualização do sistema.
System ViewDefina o fator de tempo limite do dispositivo.
stp timer-factor factorA configuração padrão é 3.
Configuração da taxa de transmissão de BPDU
Sobre a taxa de transmissão de BPDU
O número máximo de BPDUs que uma porta pode enviar em cada hello time é igual à taxa de transmissão de BPDU mais o valor do temporizador de hello.
Quanto mais alta for a taxa de transmissão de BPDU, mais BPDUs serão enviados em cada hello time e mais recursos do sistema serão usados. Ao definir uma taxa de transmissão de BPDU apropriada, você pode limitar a taxa na qual a porta envia BPDUs. A definição de uma taxa adequada também evita que os protocolos Spanning Tree usem recursos de rede excessivos quando a topologia da rede muda.
Restrições e diretrizes
A taxa de transmissão de BPDU depende do status físico da porta e da estrutura da rede. Como prática recomendada, use a configuração padrão.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure a taxa de transmissão de BPDU das portas.
stp transmit-limit limitA configuração padrão é 10.
Configuração de portas de borda
Sobre a porta de borda
Se uma porta se conectar diretamente a um terminal de usuário em vez de a outro dispositivo ou a um segmento de LAN compartilhado, essa porta será considerada uma porta de borda. Quando ocorrer uma mudança na topologia da rede, uma porta de borda não causará um loop temporário. Como um dispositivo não determina se uma porta está diretamente conectada a um terminal, você deve configurar manualmente a porta como uma porta de borda. Depois disso, a porta pode transitar rapidamente do estado de bloqueio para o estado de encaminhamento.
Restrições e diretrizes
Se a proteção de BPDU estiver desativada em uma porta configurada como uma porta de borda, ela se tornará uma porta não de borda novamente se receber um BPDU de outra porta. Para restaurar a porta de borda, reative-a.
Se uma porta se conectar diretamente a um terminal de usuário, configure-a como uma porta de borda e ative a proteção de BPDU para ela. Isso permite que a porta passe rapidamente para o estado de encaminhamento ao garantir a segurança da rede.
Em uma porta, o recurso de proteção de loop e a configuração de porta de borda são mutuamente exclusivos.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure a porta como uma porta de borda.
stp edged-portPor padrão, todas as portas são portas sem borda.
Configuração dos custos de caminho das portas
Sobre o custo do caminho
O custo do caminho é um parâmetro relacionado à velocidade do link de uma porta. Em um dispositivo spanning tree, uma porta pode ter diferentes custos de caminho em diferentes MSTIs. A definição de custos de caminho apropriados permite que os fluxos de tráfego de VLAN sejam encaminhados ao longo de diferentes links físicos, alcançando o balanceamento de carga baseado em VLAN.
Você pode fazer com que o dispositivo calcule automaticamente o custo padrão do caminho ou pode configurar o custo do caminho para as portas.
Especificação de um padrão para o cálculo do custo do caminho padrão
Sobre o padrão para o cálculo do custo do caminho padrão
Você pode especificar um padrão para o dispositivo usar no cálculo automático do custo do caminho padrão
Restrições e diretrizes
Se você alterar o padrão para o cálculo do custo do caminho padrão, os custos do caminho serão restaurados para o padrão.
Quando o dispositivo calcula o custo do caminho para uma interface agregada, o IEEE 802.1t leva em conta o número de portas selecionadas em seu grupo de agregação. Entretanto, o IEEE 802.1d-1998 não leva em conta o número de portas selecionadas. A fórmula de cálculo do IEEE 802.1t é: Custo do caminho = 200.000.000/velocidade do link (em 100 kbps). A velocidade do link é a soma dos valores de velocidade do link das portas selecionadas no grupo de agregação.
Procedimento
Entre na visualização do sistema.
System ViewEspecifique um padrão para o cálculo de custos de caminho padrão.
stp pathcost-standard { dot1d-1998 | dot1t | legacy }Por padrão, o dispositivo usa o legado para calcular os custos de caminho padrão de suas portas.
Configuração de custos de caminho das portas
Restrições e diretrizes
Quando o custo do caminho de uma porta muda, o sistema recalcula a função da porta e inicia uma transição de estado.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure o custo do caminho das portas.
No modo STP/RSTP:
stp cost cost-valueNo modo PVST:
stp vlan vlan-id-list cost cost-valueNo modo MSTP:
stp [ instance instance-list ] cost cost-valuePor padrão, o sistema calcula automaticamente o custo do caminho de cada porta.
Configuração da prioridade da porta
Sobre a prioridade da porta
A prioridade de uma porta é um fator que determina se a porta pode ser eleita como a porta raiz de um dispositivo. Se todas as outras condições forem as mesmas, a porta com a prioridade mais alta será eleita como a porta raiz.
Em um dispositivo Spanning Tree, uma porta pode ter prioridades diferentes e desempenhar funções diferentes em árvores de abrangência diferentes. Como resultado, os dados de diferentes VLANs podem ser propagados por diferentes caminhos físicos, implementando o balanceamento de carga por VLAN. Você pode definir valores de prioridade de porta com base nos requisitos reais de rede.
Restrições e diretrizes
Quando a prioridade de uma porta muda, o sistema recalcula a função da porta e inicia uma transição de estado. Prepare-se para a alteração da topologia da rede antes de configurar a prioridade da porta.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigurar a prioridade da porta.
No modo STP/RSTP:
stp port priority priority No modo PVST:
stp vlan vlan-id-list port priority priority No modo MSTP:
stp [ instance instance-list ] port priority priorityA configuração padrão é 128 para todas as portas.
Configuração do tipo de link de porta
Sobre o tipo de link de porta
Um link ponto a ponto conecta diretamente dois dispositivos. Se duas portas-raiz ou portas designadas estiverem conectadas em um link ponto a ponto, elas poderão passar rapidamente para o estado de encaminhamento após um processo de handshake de proposta e acordo .
Restrições e diretrizes
Você pode configurar o tipo de link como ponto a ponto para uma interface agregada de Camada 2 ou uma porta que opere no modo full duplex. Como prática recomendada, use a configuração padrão e deixe que o dispositivo detecte automaticamente o tipo de link da porta.
No modo PVST ou MSTP, os comandos stp point-to-point force-false ou stp
O comando force-true ponto a ponto configurado em uma porta entra em vigor em todas as VLANs ou em todos os MSTIs.
Antes de definir o tipo de link de uma porta como ponto a ponto, certifique-se de que a porta esteja conectada a um link ponto a ponto . Caso contrário, poderá ocorrer um loop temporário.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure o tipo de link da porta.
stp ponto a ponto { auto | force-false | force-true }Por padrão, o tipo de link é automático, em que a porta detecta automaticamente o tipo de link.
Configuração do modo que uma porta usa para reconhecer e enviar quadros MSTP
Sobre o formato de quadro MSTP
Uma porta pode receber e enviar quadros MSTP nos seguintes formatos:
formato padrão compatível com dot1s-802.1s
Formato compatível com o legado
Por padrão, o modo de reconhecimento de formato de quadro de uma porta é automático. A porta distingue automaticamente os dois formatos de quadro MSTP e determina o formato dos quadros que enviará com base no formato reconhecido.
Você pode configurar o formato de quadro MSTP em uma porta. Em seguida, a porta envia somente quadros MSTP do formato configurado para se comunicar com dispositivos que enviam quadros do mesmo formato.
Por padrão, uma porta no modo automático envia quadros MSTP 802.1s. Quando a porta recebe um quadro MSTP de um formato legado, ela começa a enviar quadros somente do formato legado. Isso evita que a porta altere frequentemente o formato dos quadros enviados. Para configurar a porta para enviar quadros MSTP 802.1s, desligue e, em seguida, abra a porta.
Restrições e diretrizes
Quando o número de MSTIs existentes for superior a 48, a porta poderá enviar somente quadros MSTP 802.1s.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure o modo que a porta usa para reconhecer/enviar quadros MSTP.
stp compliance { auto | dot1s | legacy }A configuração padrão é automática.
Ativação da saída de informações sobre a transição do estado da porta
Sobre a saída de informações de transição de estado da porta
Em uma rede spanning tree de grande escala, você pode permitir que os dispositivos emitam as informações de transição do estado da porta. Assim, você pode monitorar os estados das portas em tempo real.
Procedimento
Entre na visualização do sistema.
System ViewHabilita a saída de informações sobre a transição do estado da porta.
No modo STP/RSTP:
stp port-log instance 0 No modo PVST:
stp port-log vlan vlan-id-list No modo MSTP:
stp port-log { all | instance instance-list } O padrão varia de acordo com a versão do software, conforme mostrado abaixo:
Para obter mais informações sobre a configuração inicial e os padrões de fábrica, consulte o gerenciamento de arquivos de configuração no Guia de Configuração dos Fundamentos.
Ativação do recurso spanning tree
Restrições e diretrizes
Você deve ativar o recurso Spanning Tree para o dispositivo antes que qualquer outra configuração relacionada à árvore de abrangência possa ter efeito. No modo STP, RSTP ou MSTP, certifique-se de que o recurso de spanning tree esteja ativado globalmente e nas portas desejadas. No modo PVST, certifique-se de que o recurso Spanning Tree esteja ativado globalmente, nas VLANs desejadas e nas portas desejadas.
Para excluir portas específicas do cálculo da árvore de abrangência e economizar recursos da CPU, desative o recurso Spanning Tree para essas portas com o comando undo stp enable. Certifique-se de que não ocorram loops na rede depois que você desativar o recurso de spanning tree nessas portas.
Ativação do recurso spanning tree no modo STP/RSTP/MSTP
Entre na visualização do sistema.
System ViewHabilite o recurso Spanning Tree.
stp global enablePara as séries de switches S5000V3-EI, S5000V5-EI, S5000E-X, S5000X-EI e WAS6000, o recurso spanning tree é desativado globalmente por padrão.
Para outras séries de switches:
Quando o dispositivo é iniciado com as configurações iniciais, o recurso spanning tree é desativado globalmente por padrão.
Quando o dispositivo é iniciado com os padrões de fábrica, o recurso spanning tree é ativado globalmente por padrão.
Para obter mais informações sobre as configurações iniciais e os padrões de fábrica, consulte o Fundamentals Configuration Guide.
Entre na visualização da interface.
interface interface-type interface-numberAtivar o recurso de spanning tree para a porta.
stp enable Por padrão, o recurso spanning tree está ativado em todas as portas.
Ativação do recurso de spanning tree no modo PVST
Entre na visualização do sistema.
System ViewAtivar o recurso Spanning Tree.
stp global enableQuando o dispositivo é iniciado com as configurações iniciais, o recurso spanning tree é desativado globalmente por padrão.
Quando o dispositivo é iniciado com os padrões de fábrica, o recurso spanning tree é ativado globalmente por padrão.
Para obter mais informações sobre as configurações iniciais e os padrões de fábrica, consulte o Fundamentals Configuration Guide.
Habilite o recurso Spanning Tree em VLANs.
stp vlan vlan-id-list enablePor padrão, o recurso spanning tree é ativado nas VLANs.
Entre na visualização da interface.
interface interface-type interface-numberAtivar o recurso de spanning tree na porta.
stp enable Por padrão, o recurso spanning tree está ativado em todas as portas.
Execução do mCheck
Sobre o mCheck
O recurso mCheck permite a intervenção do usuário no processo de transição do estado da porta.
Quando uma porta em um dispositivo MSTP, RSTP ou PVST se conecta a um dispositivo STP e recebe BPDUs STP, a porta passa automaticamente para o modo STP. Entretanto, a porta não pode voltar automaticamente ao modo original quando as seguintes condições existirem:
O dispositivo STP par é desligado ou removido.
A porta não consegue detectar a alteração.
Para forçar a porta a operar no modo original, você pode executar uma operação mCheck.
Por exemplo, o Dispositivo A, o Dispositivo B e o Dispositivo C estão conectados em sequência. O dispositivo A executa o STP, o dispositivo B não executa nenhum protocolo de spanning tree e o dispositivo C executa o RSTP, o PVST ou o MSTP. Nesse caso, quando o Dispositivo C recebe um BPDU STP transmitido de forma transparente pelo Dispositivo B, a porta receptora passa para o modo STP. Se você configurar o Dispositivo B para executar RSTP, PVST ou MSTP com o Dispositivo C, deverá executar operações de mCheck nas portas que interconectam o Dispositivo B e o Dispositivo C.
Restrições e diretrizes
A operação mCheck entra em vigor em dispositivos que operam no modo MSTP, PVST ou RSTP.
Executando o mCheck globalmente
Entre na visualização do sistema.
System ViewExecute o mCheck.
stp global mcheckExecução do mCheck na visualização da interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberExecute o mCheck.
stp mcheck Desativação da proteção PVID inconsistente
Sobre a proteção PVID inconsistente
No PVST, se duas portas conectadas usarem PVIDs diferentes, poderão ocorrer erros de cálculo do PVST. Por padrão, a proteção de PVID inconsistente é ativada para evitar erros de cálculo de PVST. Se a inconsistência do PVID for detectada em uma porta, o sistema bloqueará a porta.
Restrições e diretrizes
Se forem necessários PVIDs diferentes em duas portas conectadas, desative a proteção de PVID inconsistente nos dispositivos que hospedam as portas. Para evitar erros de cálculo do PVST, certifique-se de que os seguintes requisitos sejam atendidos:
Certifique-se de que as VLANs em um dispositivo não usem o mesmo ID que o PVID de sua porta par (exceto a VLAN padrão) em outro dispositivo.
Se a porta local ou seu par for uma porta híbrida, não configure as portas local e do par como membros sem marcação da mesma VLAN.
Desative a proteção PVID inconsistente no dispositivo local e no dispositivo par. Esse recurso entra em vigor somente quando o dispositivo está operando no modo PVST.
Procedimento
Entre na visualização do sistema.
System ViewDesative o recurso de proteção de PVID inconsistente.
stp ignore-pvid-inconsistencyPor padrão, o recurso de proteção de PVID inconsistente está ativado.
Configuração do Digest Snooping
Sobre o Digest Snooping
Conforme definido no IEEE 802.1s, os dispositivos conectados estão na mesma região somente quando têm as mesmas configurações relacionadas à região MST, incluindo:
Nome da região.
Nível de revisão.
Mapeamentos de VLAN para instância.
Um dispositivo de spanning tree identifica dispositivos na mesma região MST determinando o ID de configuração em BPDUs. O ID de configuração inclui o nome da região, o nível de revisão e o resumo da configuração. Ele tem 16 bytes de comprimento e é o resultado calculado pelo algoritmo HMAC-MD5 com base nos mapeamentos de VLAN para instância.
Como as implementações de spanning tree variam de acordo com o fornecedor, os resumos de configuração calculados por meio de chaves privadas são diferentes. Os dispositivos de diferentes fornecedores na mesma região MST não podem se comunicar entre si.
Para permitir a comunicação entre um dispositivo INTELBRAS e um dispositivo de terceiros na mesma região MST, ative o Digest Snooping na porta do dispositivo INTELBRAS que os conecta.
Restrições e diretrizes
Tenha cuidado com o Digest Snooping global nas seguintes situações:
Quando você modifica os mapeamentos de VLAN para instância.
Quando você restaura a configuração padrão da região MST.
Se o dispositivo local tiver mapeamentos de VLAN para instância diferentes dos dispositivos vizinhos, ocorrerão loops ou interrupção do tráfego.
Antes de ativar o Digest Snooping, certifique-se de que os dispositivos associados de diferentes fornecedores estejam conectados e executem protocolos de spanning tree.
Com o Digest Snooping ativado, a verificação na mesma região não requer a comparação do resumo da configuração. Os mapeamentos de VLAN para instância devem ser os mesmos nas portas associadas.
Para que o Digest Snooping entre em vigor, você deve ativar o Digest Snooping globalmente e nas portas associadas. Como prática recomendada, ative primeiro o Digest Snooping em todas as portas associadas e, em seguida, ative-o globalmente. Isso fará com que a configuração tenha efeito em todas as portas configuradas e reduzirá o impacto na rede.
Para evitar loops, não ative o Digest Snooping nas portas de borda da região MST.
Como prática recomendada, ative o Digest Snooping primeiro e, em seguida, ative o recurso de spanning tree. Para evitar a interrupção do tráfego, não configure o Digest Snooping quando a rede já estiver funcionando bem.
Pré-requisitos
Antes de configurar o Digest Snooping, você precisa se certificar de que o dispositivo INTELBRAS e o dispositivo de terceiros executam corretamente os protocolos de spanning tree.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberAtivar o Digest Snooping na interface.
stp config-digest-snoopingPor padrão, o Digest Snooping está desativado nas portas.
Retornar à visualização do sistema.
quitHabilite o Digest Snooping globalmente.
stp global config-digest-snoopingPor padrão, o Digest Snooping é desativado globalmente.
Configuração da verificação de ausência de acordo
Sobre o No Agreement Check
No RSTP e no MSTP, os seguintes tipos de mensagens são usados para a rápida transição de estado nas portas designadas:
Proposta - Enviada por portos designados para solicitar uma transição rápida
Acordo - Usado para reconhecer solicitações de transição rápida
Os dispositivos RSTP e MSTP podem realizar a transição rápida em uma porta designada somente quando a porta recebe um pacote de acordo do dispositivo downstream. Os dispositivos RSTP e MSTP têm as seguintes diferenças:
Para o MSTP, a porta raiz do dispositivo downstream envia um pacote de acordo somente depois de receber um pacote de acordo do dispositivo upstream.
Para o RSTP, o dispositivo downstream envia um pacote de acordo, independentemente de ter recebido ou não um pacote de acordo do dispositivo upstream.
Figura 16 Transição rápida de estado de uma porta designada MSTP
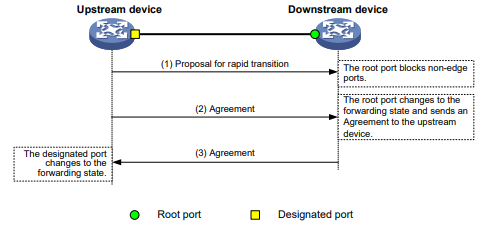
Figura 17 Transição rápida de estado de uma porta designada RSTP
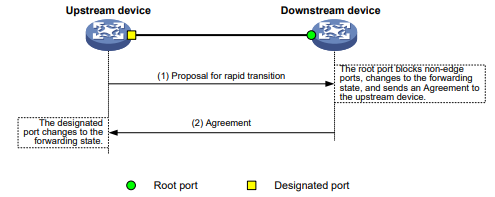
Se o dispositivo upstream for um dispositivo de terceiros, a implementação da transição rápida de estado poderá ser limitada da seguinte forma:
O dispositivo upstream usa um mecanismo de transição rápida semelhante ao do RSTP.
O dispositivo downstream executa o MSTP e não opera no modo RSTP. Nesse caso, ocorre o seguinte:
A porta raiz no dispositivo downstream não recebe nenhum acordo do dispositivo upstream.
Ele não envia nenhum acordo para o dispositivo upstream.
Como resultado, a porta designada do dispositivo upstream pode passar para o estado de encaminhamento somente após um período duas vezes maior que o atraso de encaminhamento.
Para permitir que a porta designada do dispositivo upstream transite rapidamente em seu estado, ative No Agreement Check na porta do dispositivo downstream.
Restrições e diretrizes
Configure No Agreement Check na porta raiz de seu dispositivo, pois esse recurso entra em vigor somente se estiver configurado nas portas raiz.
Pré-requisitos
Antes de configurar o recurso No Agreement Check, conclua as seguintes tarefas:
Conecte um dispositivo a um dispositivo upstream de terceiros que ofereça suporte a protocolos de spanning tree por meio de um link ponto a ponto.
Configure o mesmo nome de região, nível de revisão e mapeamentos de VLAN para instância nos dois dispositivos.
Procedimento
Habilite o recurso No Agreement Check na porta raiz.
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberAtivar a verificação de ausência de acordo.
stp no-agreement-checkPor padrão, No Agreement Check está desativado.
Configuração do TC Snooping
Sobre o TC Snooping
Conforme mostrado na Figura 18, uma malha IRF se conecta a duas redes de usuários por meio de links duplos.
O dispositivo A e o dispositivo B formam a malha IRF.
O recurso spanning tree está desativado no Dispositivo A e no Dispositivo B e ativado em todos os dispositivos da rede de usuários 1 e da rede de usuários 2.
A malha IRF transmite BPDUs de forma transparente para ambas as redes de usuários e não está envolvida no cálculo das árvores de abrangência.
Quando a topologia da rede muda, leva tempo para que a malha IRF atualize sua tabela de endereços MAC e a tabela ARP. Durante esse período, o tráfego na rede pode ser interrompido.
Figura 18 Cenário do aplicativo TC Snooping
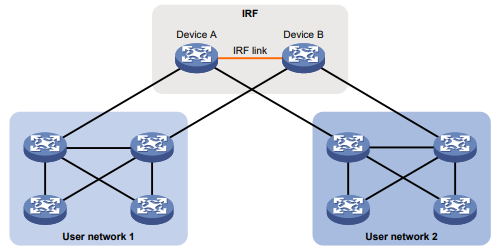
Para evitar a interrupção do tráfego, você pode ativar o TC Snooping na malha IRF. Após receber um TC-BPDU por meio de uma porta, a malha IRF atualiza a tabela de endereços MAC e as entradas da tabela ARP associadas à VLAN da porta. Dessa forma, o TC Snooping evita que a mudança de topologia interrompa o encaminhamento de tráfego na rede. Para obter mais informações sobre a tabela de endereços MAC e a tabela ARP, consulte "Configuração da tabela de endereços MAC" e o Guia de configuração de serviços de IP de camada 3.
Restrições e diretrizes
O TC Snooping e o recurso Spanning Tree são mutuamente exclusivos. Você deve desativar globalmente o recurso de spanning tree antes de ativar o TC Snooping.
A prioridade do tunelamento de BPDU é maior do que a do TC Snooping. Quando o tunelamento de BPDU é ativado em uma porta, o recurso TC Snooping não entra em vigor na porta.
O TC Snooping não é compatível com o modo PVST.
Procedimento
Entre na visualização do sistema.
System ViewDesativar globalmente o recurso de spanning tree.
undo stp global enablePara as séries de switches S5000V3-EI, S5000V5-EI, S5000E-X, S5000X-EI e WAS6000, o recurso spanning tree é desativado globalmente por padrão.
Para outras séries de switches:
Quando o dispositivo é iniciado com as configurações iniciais, o recurso spanning tree é desativado globalmente por padrão.
Quando o dispositivo é iniciado com os padrões de fábrica, o recurso spanning tree é ativado globalmente por padrão.
Para obter mais informações sobre as configurações iniciais e os padrões de fábrica, consulte o Fundamentals Configuration Guide.
Ativar o TC Snooping.
stp tc-snoopingPor padrão, o TC Snooping está desativado.
Configuração de recursos de proteção
Configuração da proteção BPDU
Sobre a proteção de BPDU
Para dispositivos da camada de acesso, as portas de acesso podem se conectar diretamente aos terminais de usuário (como PCs) ou servidores de arquivos. As portas de acesso são configuradas como portas de borda para permitir uma transição rápida. Quando essas portas recebem BPDUs de configuração, o sistema define automaticamente as portas como portas que não são de borda e inicia um novo processo de cálculo da árvore de abrangência. Isso causa uma alteração na topologia da rede. Em condições normais, essas portas não devem receber BPDUs de configuração. Entretanto, se alguém usar BPDUs de configuração de forma maliciosa para atacar os dispositivos, a rede se tornará instável.
O protocolo spanning tree fornece o recurso BPDU guard para proteger o sistema contra esses ataques. Quando as portas com o BPDU guard ativado recebem BPDUs de configuração em um dispositivo, o dispositivo executa as seguintes operações:
Fecha essas portas.
Notifica o NMS de que essas portas foram fechadas pelo protocolo spanning tree.
O dispositivo reativa as portas que foram desligadas quando o temporizador de detecção de status da porta expira. Você pode definir esse cronômetro usando o comando shutdown-interval. Para obter mais informações sobre esse comando, consulte os comandos de gerenciamento de dispositivos na Referência de comandos básicos.
Restrições e diretrizes
Você pode configurar o recurso de proteção de BPDU na visualização do sistema ou por porta. Uma porta usa preferencialmente a configuração de proteção de BPDU específica da porta. Se a configuração de proteção de BPDU específica da porta não estiver disponível, a porta usará a configuração de proteção de BPDU global.
A configuração global de proteção de BPDU entra em vigor somente nas portas de borda configuradas com o comando stp edged-port. Para que a configuração de proteção de BPDU tenha efeito em portas que não sejam de borda, é necessário configurar o recurso por porta. A configuração de proteção de BPDU específica da porta entra em vigor tanto nas portas de borda quanto nas que não são de borda.
Configure o BPDU guard nas portas que se conectam diretamente a um terminal de usuário em vez de outro dispositivo ou segmento de LAN compartilhado.
O BPDU guard não entra em vigor nas portas habilitadas para teste de loopback. Para obter mais informações sobre o teste de loopback do site , consulte Configuração da interface Ethernet no Guia de Configuração da Interface.
Ativação da proteção BPDU na visualização do sistema
Entre na visualização do sistema.
System ViewAtivar a proteção de BPDU globalmente.
stp bpdu-protectionPor padrão, a proteção de BPDU está globalmente desativada.
Configuração do BPDU guard na visualização da interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigurar a proteção de BPDU.
stp port bpdu-protection { enable | disable }Por padrão, o status de ativação do BPDU guard em uma interface é o mesmo do BPDU guard global, e o BPDU guard não é configurado para portas que não sejam de borda.
Ativação da proteção de raiz
Sobre o root guard
Configure o root guard em uma porta designada.
A root bridge e a root bridge secundária de uma spanning tree devem estar localizadas na mesma região MST. Especialmente no caso do CIST, a root bridge e a root bridge secundária são colocadas em uma região central de alta largura de banda durante o projeto da rede. Entretanto, devido a possíveis erros de configuração ou ataques mal-intencionados na rede, a ponte raiz legal pode receber um BPDU de configuração com prioridade mais alta. Outro dispositivo substitui a atual ponte raiz legal, causando uma alteração indesejada na topologia da rede. O tráfego que deveria passar por links de alta velocidade é transferido para links de baixa velocidade, resultando em congestionamento da rede.
Para evitar essa situação, o MSTP oferece o recurso de root guard. Se o root guard estiver ativado em uma porta de uma ponte raiz, essa porta desempenhará a função de porta designada em todos os MSTIs. Depois que essa porta recebe um BPDU de configuração com uma prioridade mais alta de um MSTI, ela executa as seguintes operações:
Define imediatamente essa porta para o estado de escuta no MSTI.
Não encaminha os dados de usuário recebidos.
Isso equivale a desconectar o link conectado a essa porta no MSTI. Se a porta não receber BPDUs com prioridade mais alta dentro do dobro do atraso de encaminhamento, ela voltará ao seu estado original.
Restrições e diretrizes
Em uma porta, o recurso de proteção de loop e o recurso de proteção de raiz são mutuamente exclusivos.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberHabilite o recurso de proteção de raiz.
stp root-protectionPor padrão, a proteção de raiz está desativada.
Ativação da proteção de loop
Sobre o loop guard
Configure o loop guard na porta raiz e nas portas alternativas de um dispositivo.
Ao continuar a receber BPDUs do dispositivo upstream, um dispositivo pode manter o estado da porta raiz e das portas bloqueadas. Entretanto, o congestionamento do link ou as falhas unidirecionais do link podem fazer com que essas portas não recebam BPDUs dos dispositivos upstream. Nessa situação, o dispositivo seleciona novamente as seguintes funções de porta:
As portas em estado de encaminhamento que não conseguiram receber BPDUs de upstream tornam-se portas designadas.
As portas bloqueadas passam para o estado de encaminhamento.
Como resultado, ocorrem loops na rede comutada. O recurso de proteção de loop pode suprimir a ocorrência desses loops.
O estado inicial de uma porta habilitada para proteção de loop é o descarte em cada MSTI. Quando a porta recebe BPDUs, ela muda de estado. Caso contrário, ela permanece no estado de descarte para evitar loops temporários.
Restrições e diretrizes
Não ative o loop guard em uma porta que conecte terminais de usuários. Caso contrário, a porta permanecerá no estado de descarte em todos os MSTIs porque não poderá receber BPDUs.
Em uma porta, o recurso de proteção de loop é mutuamente exclusivo do recurso de proteção de raiz ou da configuração da porta de borda.
Uma interface habilitada para proteção de loop pode receber BPDUs e passar do estado de descarte para o estado de encaminhamento após dois atrasos de encaminhamento se ocorrer um dos eventos a seguir:
O estado da interface muda de baixo para cima.
O recurso de spanning tree está ativado na interface up.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberHabilite o recurso de proteção de loop.
stp loop-protectionPor padrão, a proteção de loop está desativada.
Configuração da restrição de função de porta
Sobre a restrição de função de porta
Faça essa configuração na porta que se conecta à rede de acesso do usuário.
A alteração da bridge ID de um dispositivo na rede de acesso do usuário pode causar uma alteração na topologia da spanning tree na rede principal. Para evitar esse problema, você pode ativar a restrição de função de porta em uma porta. Com esse recurso ativado, quando a porta recebe um BPDU superior, ela se torna uma porta alternativa em vez de uma porta raiz.
Restrições e diretrizes
Use esse recurso com cuidado, pois a ativação da restrição de função de porta em uma porta pode afetar a conectividade da topologia da árvore de abrangência.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberAtivar restrição de função de porta.
stp role-restrictionPor padrão, a restrição de função de porta está desativada.
Configuração da restrição de transmissão TC-BPDU
Sobre a restrição de transmissão TC-BPDU
Faça essa configuração na porta que se conecta à rede de acesso do usuário.
A alteração da topologia da rede de acesso do usuário pode causar alterações no endereço de encaminhamento da rede principal. Quando a topologia da rede de acesso do usuário é instável, a rede de acesso do usuário pode afetar a rede principal. Para evitar esse problema, você pode ativar a restrição de transmissão TC-BPDU em
uma porta. Com esse recurso ativado, quando a porta recebe um TC-BPDU, ela não encaminha o TC-BPDU para outras portas.
Restrições e diretrizes
A ativação da restrição de transmissão TC-BPDU em uma porta pode fazer com que a tabela de endereços de encaminhamento anterior não seja atualizada quando a topologia for alterada.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberAtivar a restrição de transmissão TC-BPDU.
stp tc-restrictionPor padrão, a restrição de transmissão TC-BPDU está desativada.
Ativação da proteção TC-BPDU
Sobre a proteção TC-BPDU
Quando um dispositivo recebe BPDUs de alteração de topologia (TC) (os BPDUs que notificam os dispositivos sobre alterações de topologia), ele libera suas entradas de endereço de encaminhamento. Se alguém usar TC-BPDUs para atacar o dispositivo, ele receberá um grande número de TC-BPDUs em um curto espaço de tempo. Em seguida, o dispositivo estará ocupado com a descarga de entradas de endereços de encaminhamento. Isso afeta a estabilidade da rede.
O TC-BPDU guard permite definir o número máximo de descargas imediatas de entradas de endereços de encaminhamento realizadas dentro de 10 segundos após o dispositivo receber o primeiro TC-BPDU. Para TC-BPDUs recebidos além do limite, o dispositivo executa uma limpeza de entrada de endereço de encaminhamento quando o período de tempo expira. Isso evita a descarga frequente de entradas de endereços de encaminhamento.
Restrições e diretrizes
Como prática recomendada, ative a proteção TC-BPDU.
Procedimento
Entre na visualização do sistema.
System ViewAtivar o recurso de proteção TC-BPDU.
stp tc-protectionPor padrão, a proteção TC-BPDU está ativada.
(Opcional.) Configure o número máximo de descargas de entradas de endereços de encaminhamento que o dispositivo pode executar a cada 10 segundos.
stp tc-protection threshold numberA configuração padrão é 6.
Habilitação de queda de BPDU
Sobre a queda de BPDU
Em uma rede spanning tree, cada BPDU que chega ao dispositivo aciona um processo de cálculo STP e, em seguida, é encaminhado para outros dispositivos na rede. Os invasores mal-intencionados podem usar a vulnerabilidade para atacar a rede forjando BPDUs. Ao enviar continuamente BPDUs forjados, eles podem fazer com que todos os dispositivos da rede continuem executando cálculos STP. Como resultado, ocorrem problemas como sobrecarga da CPU e erros de status do protocolo BPDU.
Para evitar esse problema, você pode ativar o BPDU drop nas portas. Uma porta com BPDU drop ativado não recebe BPDUs e é invulnerável a ataques de BPDUs forjados.
Restrições e diretrizes
Esse recurso permite que o dispositivo descarte BPDUs de STP, RSTP, MSTP, PVST, LACP e LLDP. Certifique-se de estar totalmente ciente do impacto desse recurso ao usá-lo em uma rede ativa.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberHabilita a queda de BPDU na interface.
bpdu-drop anyPor padrão, o BPDU drop está desativado.
Ativação da proteção BPDU do PVST
Sobre a proteção BPDU do PVST
Esse recurso entra em vigor somente quando o dispositivo está operando no modo MSTP.
Um dispositivo habilitado para MSTP encaminha BPDUs PVST como tráfego de dados porque não pode reconhecer BPDUs PVST. Se um dispositivo habilitado para PVST em outra rede independente receber os BPDUs PVST, poderá ocorrer um erro de cálculo de PVST. Para evitar erros de cálculo de PVST, habilite o PVST BPDU guard em o dispositivo habilitado para MSTP. O dispositivo desliga uma porta se ela receber BPDUs PVST.
Procedimento
Entre na visualização do sistema.
System ViewAtivar a proteção BPDU do PVST.
stp pvst-bpdu-protectionPor padrão, a proteção BPDU do PVST está desativada.
Desativação da proteção contra disputas
Sobre a proteção contra disputas
O Dispute Guard pode ser acionado por falhas de link unidirecional. Se uma porta upstream receber BPDUs inferiores de uma porta designada downstream em estado de encaminhamento ou aprendizado devido a uma falha de link unidirecional, será exibido um loop. O Dispute Guard bloqueia a porta designada upstream para evitar o loop.
Conforme mostrado na Figura 19, em condições normais, o resultado do cálculo da árvore de abrangência é o seguinte:
O dispositivo A é a ponte raiz e a porta A1 é uma porta designada.
A porta B1 está bloqueada.
Quando o link entre a porta A1 e a porta B1 falha na direção da porta A1 para a porta B1 e se torna unidirecional, ocorrem os seguintes eventos:
A porta A1 só pode receber BPDUs e não pode enviar BPDUs para a porta B1.
A porta B1 não recebe BPDUs da porta A1 por um determinado período de tempo.
O dispositivo B se determina como a ponte raiz.
A porta B1 envia seus BPDUs para a porta A1.
A porta A1 determina que os BPDUs recebidos são inferiores aos seus próprios BPDUs. Uma disputa é detectada.
O Dispute Guard é acionado e bloqueia a porta A1 para evitar um loop.
Figura 19 Cenário de acionamento da proteção contra disputas
No entanto, o dispute guard pode interromper a conectividade da rede. Você pode desativar o dispute guard para evitar a perda de conectividade em redes VLAN. Conforme mostrado na Figura 20, o recurso spanning tree está desativado no Dispositivo B e ativado no Dispositivo A e no Dispositivo C. O Dispositivo B transmite BPDUs de forma transparente.
O dispositivo C não pode receber BPDUs superiores da VLAN 1 do dispositivo A porque a porta B1 do dispositivo B está configurada para negar pacotes da VLAN 1. O dispositivo C se determina como a ponte raiz após um determinado período de tempo. Em seguida, a porta C1 envia um BPDU inferior da VLAN 100 para o dispositivo A.
Quando o Dispositivo A recebe o BPDU inferior, o dispute guard bloqueia a Porta A1, o que causa a interrupção do tráfego. Para garantir a continuidade do serviço, você pode desativar o dispute guard no Dispositivo A para evitar que o link seja bloqueado.
Figura 20 Cenário de desativação do aplicativo de proteção contra disputas
Restrições e diretrizes
Você pode desativar o dispute guard se a rede não tiver falhas de link unidirecionais.
Procedimento
Entre na visualização do sistema.
System ViewDesativar a proteção contra disputas.
undo stp dispute-protectionPor padrão, a proteção contra disputas está ativada.
Habilitação do dispositivo para registrar eventos de detecção ou recebimento de BPDUs TC
Sobre o registro de eventos TC BPDU da árvore de abrangência
Esse recurso permite que o dispositivo gere registros quando detecta ou recebe BPDUs TC. Esse recurso se aplica somente ao modo PVST.
Procedimento
Entre na visualização do sistema.
System ViewPermita que o dispositivo registre eventos de recebimento ou detecção de BPDUs TC.
stp log enable tcPor padrão, o dispositivo não gera registros quando detecta ou recebe TC BPDUs.
Desativação do dispositivo para reativar portas de borda desligadas pela proteção de BPDU
Sobre a desativação do dispositivo para reativar as portas de borda desligadas pela proteção de BPDU
O BPDU guard desliga as portas de borda que receberam BPDUs de configuração e notifica o NMS sobre o evento de desligamento.
O dispositivo reativa as portas que foram desligadas quando o temporizador de detecção de status da porta expira. Você pode definir esse cronômetro usando o comando shutdown-interval. Para obter mais informações sobre esse comando, consulte os comandos de gerenciamento de dispositivos em Referência de comandos básicos.
Restrições e diretrizes
Esse recurso impede que o dispositivo reative as portas de borda desligadas pelo BPDU Guard depois que esse recurso for configurado. O dispositivo não ativará as portas desligadas se você executar o comando undo stp port shutdown permanent. Para ativar essas portas, use o comando undo shutdown.
Procedimento
Entre na visualização do sistema.
System ViewDesative o dispositivo para reativar as portas de borda desligadas pela proteção de BPDU.
stp port shutdown permanentPor padrão, o dispositivo reativa uma porta de borda desligada pela proteção de BPDU depois que o temporizador de detecção de status da porta expira.
Ativação de notificações SNMP para eleição de nova raiz e eventos de alteração de topologia
Sobre as notificações SNMP de spanning tree
Essa tarefa permite que o dispositivo gere registros e relate eventos de eleição de nova raiz ou alterações na topologia da árvore de abrangência para o SNMP. Para que as notificações de eventos sejam enviadas corretamente, você também deve configurar o SNMP no dispositivo. Para obter mais informações sobre a configuração do SNMP, consulte o guia de configuração de monitoramento e gerenciamento de rede do dispositivo.
Quando você usar o comando snmp-agent trap enable stp [ new-root | tc ], siga estas diretrizes:
A palavra-chave new-root se aplica somente aos modos STP, MSTP e RSTP.
A palavra-chave tc se aplica somente ao modo PVST.
No modo STP, MSTP ou RSTP, o comando snmp-agent trap enable stp ativa as notificações SNMP para eventos de eleição de nova raiz.
No modo PVST, o comando snmp-agent trap enable stp ativa as notificações SNMP para alterações na topologia da árvore de abrangência.
Procedimento
Entre na visualização do sistema.
System ViewHabilite as notificações SNMP para eventos de eleição de novo root e de alteração de topologia.
snmp-agent trap enable stp [ new-root | tc ]As configurações padrão são as seguintes:
As notificações SNMP são desativadas para eventos de eleição de nova raiz.
No modo MSTP, as notificações SNMP são ativadas no MSTI 0 e desativadas em outros MSTIs para alterações na topologia da árvore de abrangência.
No modo PVST, as notificações SNMP são desativadas para alterações na topologia da árvore de abrangência em todas as VLANs.
Exemplos de configuração Spanning Tree
Exemplo: Configuração do MSTP
Configuração de rede
Conforme mostrado na Figura 21, todos os dispositivos da rede estão na mesma região MST. O dispositivo A e o dispositivo B trabalham na camada de distribuição. O dispositivo C e o dispositivo D trabalham na camada de acesso.
Configure o MSTP para que os quadros de diferentes VLANs sejam encaminhados por diferentes spanning trees.
Os quadros da VLAN 10 são encaminhados ao longo da MSTI 1.
Os quadros da VLAN 30 são encaminhados ao longo da MSTI 3.
Os quadros da VLAN 40 são encaminhados ao longo da MSTI 4.
Os quadros da VLAN 20 são encaminhados ao longo da MSTI 0.
A VLAN 10 e a VLAN 30 são terminadas nos dispositivos da camada de distribuição e a VLAN 40 é terminada nos dispositivos da camada de acesso. As pontes raiz da MSTI 1 e da MSTI 3 são os dispositivos A e B, respectivamente, e a ponte raiz da MSTI 4 é o dispositivo C.
Figura 21 Diagrama de rede
Procedimento
Configurar VLANs e portas membros da VLAN. (Detalhes não mostrados.)
Crie a VLAN 10, a VLAN 20 e a VLAN 30 no Dispositivo A e no Dispositivo B.
Crie a VLAN 10, a VLAN 20 e a VLAN 40 no dispositivo C.
Crie a VLAN 20, a VLAN 30 e a VLAN 40 no dispositivo D.
Configure as portas desses dispositivos como portas tronco e atribua-as às VLANs relacionadas.
Configurar o dispositivo A:
# Entre na visualização da região MST e configure o nome da região MST como exemplo.
<DeviceA> system-view
[DeviceA] stp region-configuration
[DeviceA-mst-region] region-name example # Mapeie a VLAN 10, a VLAN 30 e a VLAN 40 para MSTI 1, MSTI 3 e MSTI 4, respectivamente.
[DeviceA-mst-region] instance 1 vlan 10
[DeviceA-mst-region] instance 3 vlan 30
[DeviceA-mst-region] instance 4 vlan 40 # Configure o nível de revisão da região MST como 0.
[DeviceA-mst-region] revision-level 0 # Ativar a configuração da região MST.
[DeviceA-mst-region] active region-configuration
[DeviceA-mst-region] quit# Configure o dispositivo A como a ponte raiz do MSTI 1.
[DeviceA] stp instance 1 root primary# Habilite o recurso de spanning tree globalmente.
[DeviceA] stp global enableConfigurar o dispositivo B:
# Entre na visualização da região MST e configure o nome da região MST como exemplo.
<DeviceB> system-view
[DeviceB] stp region-configuration
[DeviceB-mst-region] region-name example# Mapeie a VLAN 10, a VLAN 30 e a VLAN 40 para MSTI 1, MSTI 3 e MSTI 4, respectivamente.
[DeviceB-mst-region] instance 1 vlan 10
[DeviceB-mst-region] instance 3 vlan 30
[DeviceB-mst-region] instance 4 vlan 40
# Configure o nível de revisão da região MST como 0.
[DeviceB-mst-region] revision-level 0# Ativar a configuração da região MST.
[DeviceB-mst-region] active region-configuration
[DeviceB-mst-region] quit# Configure o dispositivo B como a ponte raiz da MSTI 3.
[DeviceB] stp instance 3 root primary Configurar o dispositivo C:
# Entre na visualização da região MST e configure o nome da região MST como exemplo.
<DeviceC> system-view
[DeviceC] stp region-configuration
[DeviceC-mst-region] region-name example # Mapeie a VLAN 10, a VLAN 30 e a VLAN 40 para MSTI 1, MSTI 3 e MSTI 4, respectivamente.
[DeviceC-mst-region] instance 1 vlan 10
[DeviceC-mst-region] instance 3 vlan 30
[DeviceC-mst-region] instance 4 vlan 40 # Configure o nível de revisão da região MST como 0.
[DeviceC-mst-region] revision-level 0# Ativar a configuração da região MST.
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit # Configure o dispositivo C como a ponte raiz da MSTI 4.
[DeviceC] stp instance 4 root primaryConfigurar o dispositivo D:
# Entre na visualização da região MST e configure o nome da região MST como exemplo.
<DeviceD> system-view
[DeviceD] stp region-configuration
[DeviceD-mst-region] region-name example# Mapeie a VLAN 10, a VLAN 30 e a VLAN 40 para MSTI 1, MSTI 3 e MSTI 4, respectivamente.
[DeviceD-mst-region] instance 1 vlan 10
[DeviceD-mst-region] instance 3 vlan 30
[DeviceD-mst-region] instance 4 vlan 40 # Configure o nível de revisão da região MST como 0.
[DeviceD-mst-region] nível de revisão 0# Ativar a configuração da região MST.
[DeviceD-mst-region] active region-configuration
[DeviceD-mst-region] quit# Habilite o recurso Spanning Tree globalmente.
[DeviceD] stp global enableVerificação da configuração
Neste exemplo, o Dispositivo B tem o ID de ponte raiz mais baixo. Como resultado, o Dispositivo B é eleito como a ponte raiz no MSTI 0.
Quando a rede estiver estável, você poderá usar o comando display stp brief para exibir informações breves sobre a árvore de abrangência em cada dispositivo.
# Exibir informações breves sobre a árvore de abrangência no Dispositivo A.
[DeviceA] display stp brief
MST ID Port Role STP State Protection
0 GigabitEthernet1/0/1 ALTE DISCARDING NONE
0 GigabitEthernet1/0/2 DESI FORWARDING NONE
0 GigabitEthernet1/0/3 ROOT FORWARDING NONE
1 GigabitEthernet1/0/1 DESI FORWARDING NONE
1 GigabitEthernet1/0/3 DESI FORWARDING NONE
3 GigabitEthernet1/0/2 DESI FORWARDING NONE
3 GigabitEthernet1/0/3 ROOT FORWARDING NONE# Exibir informações breves sobre a árvore de abrangência no Dispositivo B.
[DeviceB] display stp brief
MST ID Port Role STP State Protection
0 GigabitEthernet1/0/1 ALTE DISCARDING NONE
0 GigabitEthernet1/0/2 DESI FORWARDING NONE
0 GigabitEthernet1/0/3 ROOT FORWARDING NONE
1 GigabitEthernet1/0/1 DESI FORWARDING NONE
1 GigabitEthernet1/0/3 DESI FORWARDING NONE
3 GigabitEthernet1/0/2 DESI FORWARDING NONE
3 GigabitEthernet1/0/3 ROOT FORWARDING NONE# Exibir informações breves sobre a árvore de abrangência no Dispositivo C.
[DeviceC] display stp brief
MST ID Port Role STP State Protection
0 GigabitEthernet1/0/1 ALTE DISCARDING NONE
0 GigabitEthernet1/0/2 DESI FORWARDING NONE
0 GigabitEthernet1/0/3 ROOT FORWARDING NONE
1 GigabitEthernet1/0/1 DESI FORWARDING NONE
1 GigabitEthernet1/0/3 DESI FORWARDING NONE
3 GigabitEthernet1/0/2 DESI FORWARDING NONE
3 GigabitEthernet1/0/3 ROOT FORWARDING NONE# Exibir informações breves sobre a árvore de abrangência no Dispositivo D.
[DeviceD] display stp brief
MST ID Port Role STP State Protection
0 GigabitEthernet1/0/1 ALTE DISCARDING NONE
0 GigabitEthernet1/0/2 DESI FORWARDING NONE
0 GigabitEthernet1/0/3 ROOT FORWARDING NONE
1 GigabitEthernet1/0/1 DESI FORWARDING NONE
1 GigabitEthernet1/0/3 DESI FORWARDING NONE
3 GigabitEthernet1/0/2 DESI FORWARDING NONE
3 GigabitEthernet1/0/3 ROOT FORWARDING NONECom base na saída, você pode desenhar cada MSTI mapeado para cada VLAN, conforme mostrado na Figura 22.
Figura 22 MSTIs mapeados para diferentes VLANs
Exemplo: Configuração do PVST
Configuração de rede
Conforme mostrado na Figura 23, o Dispositivo A e o Dispositivo B funcionam na camada de distribuição, e o Dispositivo C e o Dispositivo D funcionam na camada de acesso.
Configure o PVST para atender aos seguintes requisitos:
Os quadros de uma VLAN são encaminhados ao longo das árvores de abrangência da VLAN.
A VLAN 10, a VLAN 20 e a VLAN 30 são terminadas nos dispositivos da camada de distribuição e a VLAN 40 é terminada nos dispositivos da camada de acesso.
A ponte raiz da VLAN 10 e da VLAN 20 é o Dispositivo A.
A ponte raiz da VLAN 30 é o Dispositivo B.
A ponte raiz da VLAN 40 é o Dispositivo C.
Figura 23 Diagrama de rede
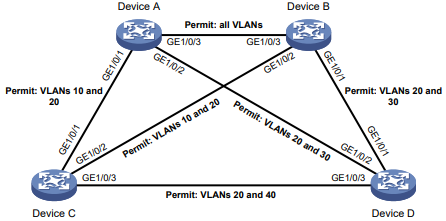
Procedimento
Configurar VLANs e portas membros da VLAN. (Detalhes não mostrados).
Crie a VLAN 10, a VLAN 20 e a VLAN 30 no Dispositivo A e no Dispositivo B.
Crie a VLAN 10, a VLAN 20 e a VLAN 40 no dispositivo C.
Crie a VLAN 20, a VLAN 30 e a VLAN 40 no dispositivo D.
Configure as portas desses dispositivos como portas tronco e atribua-as às VLANs relacionadas.
Configurar o dispositivo A:
# Defina o modo Spanning Tree como PVST.
<DeviceA> system-view
[DeviceA] stp mode pvst# Configure o dispositivo como a ponte raiz da VLAN 10 e da VLAN 20.
[DeviceA] stp vlan 10 20 root primary# Habilite o recurso spanning tree globalmente e na VLAN 10, VLAN 20 e VLAN 30.
[DeviceA] stp global enable [DeviceA] stp vlan 10 20 30 enableConfigurar o dispositivo B:
# Defina o modo Spanning Tree como PVST.
<DeviceB> system-view
[DeviceB] stp mode pvst# Configure o dispositivo como a ponte raiz da VLAN 30.
[DeviceB] stp vlan 30 root primary# Habilite o recurso spanning tree globalmente e na VLAN 10, VLAN 20 e VLAN 30.
[DeviceB] stp global enable
[DeviceB] stp vlan 10 20 30 enableConfigurar o dispositivo C:
# Defina o modo Spanning Tree como PVST.
<DeviceC> system-view
[DeviceC] stp mode pvst# Configure o dispositivo como a ponte raiz da VLAN 40.
[DeviceC] stp vlan 40 root primary# Habilite o recurso spanning tree globalmente e na VLAN 10, VLAN 20 e VLAN 40.
[DeviceC] stp global enable
[DeviceC] stp vlan 10 20 40 enable Configurar o dispositivo D:
# Defina o modo Spanning Tree como PVST.
<DeviceD> system-view
[DeviceD] stp mode pvst # Habilite o recurso spanning tree globalmente e na VLAN 20, VLAN 30 e VLAN 40.
[DeviceD] stp global enable
[DeviceD] stp vlan 20 30 40 enable Verificação da configuração
Quando a rede estiver estável, você poderá usar o comando display stp brief para exibir informações breves sobre a árvore de abrangência em cada dispositivo.
# Exibir informações breves sobre a árvore de abrangência no Dispositivo A.
[DeviceA] display stp brief
VLAN ID Port Role STP State Protection
10 GigabitEthernet1/0/1 DESI FORWARDING NONE
10 GigabitEthernet1/0/3 DESI FORWARDING NONE
20 GigabitEthernet1/0/1 DESI FORWARDING NONE
20 GigabitEthernet1/0/2 DESI FORWARDING NONE
20 GigabitEthernet1/0/3 DESI FORWARDING NONE
30 GigabitEthernet1/0/2 DESI FORWARDING NONE
30 GigabitEthernet1/0/3 ROOT FORWARDING NONE# Exibir informações breves sobre a árvore de abrangência no Dispositivo B.
[DeviceB] display stp brief
VLAN ID Port Role STP State Protection
10 GigabitEthernet1/0/2 DESI FORWARDING NONE
10 GigabitEthernet1/0/3 ROOT FORWARDING NONE
20 GigabitEthernet1/0/1 DESI FORWARDING NONE
20 GigabitEthernet1/0/2 DESI FORWARDING NONE
20 GigabitEthernet1/0/3 ROOT FORWARDING NONE
30 GigabitEthernet1/0/1 DESI FORWARDING NONE
30 GigabitEthernet1/0/3 DESI FORWARDING NONE # Exibir informações breves sobre a árvore de abrangência no Dispositivo C.
[DeviceC] display stp brief
VLAN ID Port Role STP State Protection
10 GigabitEthernet1/0/1 ROOT FORWARDING NONE
10 GigabitEthernet1/0/2 ALTE DISCARDING NONE
20 GigabitEthernet1/0/1 ROOT FORWARDING NONE
20 GigabitEthernet1/0/2 ALTE DISCARDING NONE
20 GigabitEthernet1/0/3 DESI FORWARDING NONE
40 GigabitEthernet1/0/3 DESI FORWARDING NONE # Exibir informações breves sobre a árvore de abrangência no Dispositivo D.
[DeviceD] display stp brief
Com base na saída, você pode desenhar uma topologia para cada árvore de abrangência de VLAN, conforme mostrado na Figura 24.
Figura 24 Topologias Spanning Tree de VLAN
Configuração da detecção de loop
Sobre a detecção de loop
O mecanismo de detecção de loop realiza verificações periódicas de loops da Camada 2. O mecanismo gera imediatamente um registro quando ocorre um loop, para que você seja imediatamente notificado para ajustar as conexões e configurações da rede. Você pode configurar a detecção de loop para desligar a porta com loop. Os registros são mantidos no centro de informações. Para obter mais informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Mecanismo de detecção de loop
O dispositivo detecta loops enviando quadros de detecção e verificando se esses quadros retornam a qualquer porta do dispositivo. Se isso acontecer, o dispositivo considera que a porta está em um link com loop.
A detecção de loop geralmente funciona dentro de uma VLAN. Se um quadro de detecção for devolvido com uma tag de VLAN diferente daquela com a qual foi enviado, ocorreu um loop entre VLANs. Para remover o loop, examine a configuração de mapeamento de QinQ ou VLAN em busca de configurações incorretas. Para obter mais informações sobre QinQ e mapeamento de VLAN, consulte "Configuração de QinQ" e "Configuração de mapeamento de VLAN".
Figura 1 Cabeçalho do quadro Ethernet para detecção de loop
O cabeçalho do quadro Ethernet de um pacote de detecção de loop contém os seguintes campos:
DMAC - Endereço MAC de destino do quadro, que é o endereço MAC multicast.
010f-e200-0007. Quando um dispositivo habilitado para detecção de loop recebe um quadro com esse endereço MAC de destino, ele executa as seguintes operações:
Envia o quadro para a CPU.
Inunda o quadro na VLAN da qual o quadro foi originalmente recebido.
SMAC - Endereço MAC de origem do quadro, que é o endereço MAC da ponte do dispositivo de envio.
TPID-Tipo de tag de VLAN, com o valor de 0x8100.
TCI-Informações da tag de VLAN, incluindo a prioridade e o ID da VLAN.
Type - Tipo de protocolo, com o valor 0x8918.
Figura 2 Cabeçalho interno do quadro para detecção de loop

O cabeçalho interno do quadro de um pacote de detecção de loop contém os seguintes campos:
Subtipo Code-Protocol, que é 0x0001, indicando o protocolo de detecção de loop.
Versão - versão do protocolo, que é sempre 0x0000.
Comprimento - Comprimento do quadro. O valor inclui o cabeçalho interno, mas exclui o cabeçalho Ethernet.
Reservado - Esse campo é reservado.
Os quadros para detecção de loop são encapsulados como tripletos de TLV.
Intervalo de detecção de loop
A detecção de loop é um processo contínuo à medida que a rede muda. Os quadros de detecção de loop são enviados no intervalo de detecção de loop para determinar se ocorrem loops nas portas e se os loops são removidos.
Ações de proteção de loop
Quando o dispositivo detecta um loop em uma porta, ele gera um registro, mas não executa nenhuma ação na porta por padrão. Você pode configurar o dispositivo para executar uma das seguintes ações:
Block (Bloquear) - Desabilita a porta de aprender endereços MAC e bloqueia a porta.
Sem aprendizado - Desabilita a porta de aprender endereços MAC.
Shutdown - Desativa a porta para impedir que ela receba e envie quadros.
Recuperação automática do status da porta
Quando o dispositivo configurado com a ação de loop de bloqueio ou de não aprendizado detecta um loop em uma porta, ele executa a ação e aguarda três intervalos de detecção de loop. Se o dispositivo não receber um quadro de detecção de loop em três intervalos de detecção de loop, ele executará as seguintes operações:
Define automaticamente a porta para o estado de encaminhamento.
Notifica o usuário sobre o evento.
Quando o dispositivo configurado com a ação de desligamento detecta um loop em uma porta, ocorrem os seguintes eventos:
O dispositivo desliga automaticamente a porta.
O dispositivo define automaticamente a porta para o estado de encaminhamento após a expiração do cronômetro de detecção definido com o uso do comando shutdown-interval. Para obter mais informações sobre o comando shutdown-interval, consulte a Referência de comandos básicos.
O dispositivo desligará a porta novamente se um loop ainda for detectado na porta quando o cronômetro de detecção expirar.
Esse processo é repetido até que o loop seja removido.
OBSERVAÇÃO:
Pode ocorrer uma recuperação incorreta quando os quadros de detecção de loop são descartados para reduzir a carga. Para evitar isso, use a ação de desligamento ou remova manualmente o loop.
Ativação da detecção de loop
Restrições e diretrizes para a configuração da detecção de loop
Você pode ativar a detecção de loop globalmente ou por porta. Quando uma porta recebe um quadro de detecção em qualquer VLAN, a ação de proteção de loop é acionada nessa porta, independentemente de a detecção de loop estar ativada nela.
O recurso de detecção de loop é mutuamente exclusivo dos recursos de prevenção de loop da Camada 2, inclusive:
O recurso Spanning Tree.
RRPP.
ERPS.
Para evitar problemas inesperados na rede, não use o recurso de detecção de loop e nenhum desses recursos de prevenção de loop da Camada 2 juntos. Para obter mais informações sobre o recurso spanning tree, consulte "Configuração dos protocolos spanning tree". Para obter mais informações sobre RRPP e ERPS, consulte o High Availability Configuration Guide.
Ativação da detecção de loop globalmente
Entre na visualização do sistema.
System ViewAtivar globalmente a detecção de loop.
loopback-detection global enable vlan { vlan-id--list | all }Por padrão, a detecção de loop está globalmente desativada.
Ativação da detecção de loop em uma porta
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2 ou na visualização da interface agregada de camada 2.
interface interface-type interface-numberAtivar a detecção de loop na porta.
loopback-detection enable vlan { vlan-id--list | all }Por padrão, a detecção de loop está desativada nas portas.
Configuração da ação de proteção de loop
Restrições e diretrizes para a configuração da ação de proteção de loop
Você pode definir a ação de proteção de loop globalmente ou por porta. A ação global se aplica a todas as portas. A ação por porta se aplica às portas individuais. A ação por porta tem precedência sobre a ação global.
Definição da ação de proteção de loop global
Entre na visualização do sistema.
System ViewDefina a ação de proteção de loop global.
loopback-detection global action shutdownPor padrão, o dispositivo gera um registro, mas não executa nenhuma ação na porta em que um loop é detectado.
Configuração da ação de proteção de loop em uma interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberDefina a ação de proteção de loop na interface.
loopback-detection action { block | no-learning | shutdown }Por padrão, o dispositivo gera um registro, mas não executa nenhuma ação na porta em que um loop é detectado.
O suporte para as palavras-chave desse comando varia de acordo com o tipo de interface. Para obter mais informações, consulte
Referência de comandos de switching de LAN de camada 2.
Configuração do intervalo de detecção de loop
Sobre o intervalo de detecção de loop
Com a detecção de loop ativada, o dispositivo envia quadros de detecção de loop no intervalo de detecção de loopback. Um intervalo mais curto oferece uma detecção mais sensível, mas consome mais recursos. Considere o desempenho do sistema e a velocidade de detecção de loop ao definir o intervalo de detecção de loop.
Procedimento
Entre na visualização do sistema.
System ViewDefina o intervalo de detecção de loop.
loopback-detection interval-time intervalA configuração padrão é de 30 segundos.
Exemplos de configuração de detecção de loop
Exemplo: Configuração das funções básicas de detecção de loop
Configuração de rede
Conforme mostrado na Figura 3, configure a detecção de loop no Dispositivo A para atender aos seguintes requisitos:
O dispositivo A gera um registro como uma notificação.
O dispositivo A desliga automaticamente a porta na qual foi detectado um loop.
Figura 3 Diagrama de rede
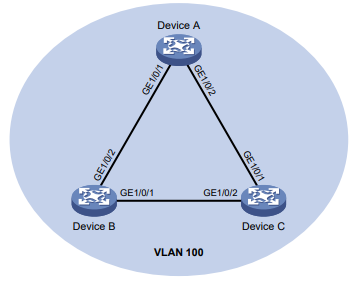
Procedimento
Configurar o dispositivo A:
# Crie a VLAN 100 e ative globalmente a detecção de loop para a VLAN.
<DeviceA> system-view
[DeviceA] vlan 100
[DeviceA-vlan100] quit
[DeviceA] loopback-detection global enable vlan 100# Configure a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 como portas tronco e atribua-as à VLAN 100.
[DeviceA] interface GigabitEthernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type trunk
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan 100
[DeviceA-GigabitEthernet1/0/1] quit
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 100
[DeviceA-GigabitEthernet1/0/2] quit# Defina a ação de proteção de loop global como desligamento.
[DeviceA] loopback-detection global action shutdown # Defina o intervalo de detecção de loop para 35 segundos.
[DeviceA] loopback-detection interval-time 35 Configure o dispositivo B:
# Criar VLAN 100.
<DeviceB> system-view
[DeviceB] vlan 100
[DeviceB–vlan100] quit
# Configure a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 como portas tronco e atribua-as à VLAN 100.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type trunk
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 100
[DeviceB-GigabitEthernet1/0/1] quit
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 100
[DeviceB-GigabitEthernet1/0/2] quit
Configure o dispositivo C:
# Criar VLAN 100.
<DeviceC> system-view
[DeviceC] vlan 100
[DeviceC–vlan100] quit
# Configure a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 como portas tronco e atribua-as à VLAN 100.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] port link-type trunk
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 100
[DeviceC-GigabitEthernet1/0/1] quit
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan 100
[DeviceC-GigabitEthernet1/0/2] quit
Verificação da configuração
# View the system logs on devices, for example, Device A.
[DispositivoA]
%Feb 24 15:04:29:663 2013 DeviceA LPDT/4/LPDT_LOOPED: Foi detectado um loop na GigabitEthernet1/0/1.
%Feb 24 15:04:29:664 2013 DeviceA LPDT/4/LPDT_VLAN_LOOPED: Foi detectado um loop na GigabitEthernet1/0/1 na VLAN 100.
%Feb 24 15:04:29:667 2013 DeviceA LPDT/4/LPDT_LOOPED: Foi detectado um loop na GigabitEthernet1/0/2.
%Feb 24 15:04:29:668 2013 DeviceA LPDT/4/LPDT_VLAN_LOOPED: Foi detectado um loop na GigabitEthernet1/0/2 na VLAN 100.
%Feb 24 15:04:44:243 2013 DeviceA LPDT/5/LPDT_VLAN_RECOVERED: Um loop foi removido na GigabitEthernet1/0/1 na VLAN 100.
%Feb 24 15:04:44:243 2013 DeviceA LPDT/5/LPDT_RECOVERED: Todos os loops foram removidos em GigabitEthernet1/0/1.
%Feb 24 15:04:44:248 2013 DeviceA LPDT/5/LPDT_VLAN_RECOVERED: Um loop foi removido na GigabitEthernet1/0/2 na VLAN 100.
%Feb 24 15:04:44:248 2013 DeviceA LPDT/5/LPDT_RECOVERED: Todos os loops foram removidos em GigabitEthernet1/0/2.O resultado mostra as seguintes informações:
O dispositivo A detectou loops na GigabitEthernet 1/0/1 e na GigabitEthernet 1/0/2 em um intervalo de detecção de loop.
Os loops na GigabitEthernet 1/0/1 e na GigabitEthernet 1/0/2 foram removidos.
# Use o comando display loopback-detection para exibir a configuração e o status da detecção de loop nos dispositivos, por exemplo, no Dispositivo A.
[DeviceA] display loopback-detection
Loop detection is enabled.
Loop detection interval is 35 second(s).
Loop is detected on following interfaces:
Interface Action mode VLANs
GigabitEthernet1/0/1 Shutdown 100
GigabitEthernet1/0/2 Shutdown 100
A saída mostra que o dispositivo removeu os loops da GigabitEthernet 1/0/1 e da GigabitEthernet 1/0/2 de acordo com a ação de desligamento.
# Exibir o status da GigabitEthernet 1/0/1 nos dispositivos, por exemplo, no Dispositivo A.
[DeviceA] display interface gigabitethernet 1/0/1
GigabitEthernet1/0/1 current state: DOWN (Loop detection down)
...A saída mostra que a GigabitEthernet 1/0/1 já foi desligada pelo módulo de detecção de loop.
# Exibir o status da GigabitEthernet 1/0/2 nos dispositivos, por exemplo, no Dispositivo A.
[DeviceA] display interface gigabitethernet 1/0/2
GigabitEthernet1/0/2 current state: DOWN (Loop detection down) A saída mostra que a GigabitEthernet 1/0/2 já foi desligada pelo módulo de detecção de loop.
Configuração de VLANs
Sobre VLANs
A tecnologia de rede local virtual (VLAN) divide uma LAN física em várias LANs lógicas. Ela tem os seguintes benefícios:
Segurança - Os hosts da mesma VLAN podem se comunicar entre si na Camada 2, mas são isolados dos hosts de outras VLANs na Camada 2.
Isolamento de tráfego de broadcast - Cada VLAN é um domínio de broadcast que limita a transmissão de pacotes de broadcast.
Flexibilidade - Uma VLAN pode ser dividida logicamente com base em um grupo de trabalho. Os hosts do mesmo grupo de trabalho podem ser atribuídos à mesma VLAN, independentemente de suas localizações físicas.
Encapsulamento de quadros VLAN
Para identificar quadros Ethernet de VLANs diferentes, o IEEE 802.1Q insere uma tag de VLAN de quatro bytes entre o campo de endereço MAC de destino e de origem (DA&SA) e o campo Type.
Figura 1 Posicionamento e formato da tag VLAN

Uma tag de VLAN inclui os seguintes campos:
TPID - identificador de protocolo de tag de 16 bits que indica se um quadro é marcado por VLAN. Por padrão, o valor hexadecimal TPID 8100 identifica um quadro com marcação de VLAN. Um fornecedor de dispositivos pode definir o TPID com um valor diferente. Para fins de compatibilidade com um dispositivo vizinho, defina o valor TPID no dispositivo para ser o mesmo que o do dispositivo vizinho. Para obter mais informações sobre como definir o valor TPID, consulte os comandos QinQ em Layer 2-LAN Switching Command Reference.
Prioridade - 3 bits de comprimento, identifica a prioridade 802.1p do quadro. Para obter mais informações, consulte o Guia de configuração de ACL e QoS.
CFI - indicador de formato canônico longo de 1 bit que indica se os endereços MAC são encapsulados no formato padrão quando os pacotes são transmitidos por diferentes mídias. Os valores disponíveis incluem:
0 (padrão) - Os endereços MAC são encapsulados no formato padrão.
1 - Os endereços MAC são encapsulados em um formato não padrão. Esse campo é sempre definido como 0 para Ethernet.
VLAN ID - 12 bits de comprimento, identifica a VLAN à qual o quadro pertence. O intervalo de VLAN ID é de 0 a 4095. As VLAN IDs 0 e 4095 são reservadas e as VLAN IDs 1 a 4094 são configuráveis pelo usuário.
A maneira como um dispositivo de rede trata um quadro de entrada depende do fato de o quadro ter uma tag de VLAN e do valor da tag de VLAN (se houver).
A Ethernet é compatível com os formatos de encapsulamento Ethernet II, 802.3/802.2 LLC, 802.3/802.2 SNAP e
802.3 raw. O formato de encapsulamento Ethernet II é usado aqui. Para obter informações sobre os campos de tag de VLAN em outros formatos de encapsulamento de quadros, consulte os protocolos e padrões relacionados.
Para um quadro que tenha várias tags de VLAN, o dispositivo o trata de acordo com a tag de VLAN mais externa e transmite as tags de VLAN internas como carga útil.
VLANs baseadas em portas
As VLANs baseadas em portas agrupam os membros da VLAN por porta. Uma porta encaminha pacotes de uma VLAN somente depois de ser atribuída à VLAN.
Tipo de link de porta
Você pode definir o tipo de link de uma porta como acesso, tronco ou híbrido. O tipo de link da porta determina se a porta pode ser atribuída a várias VLANs. Os tipos de link usam os seguintes métodos de manipulação de tags de VLAN:
Acesso - Uma porta de acesso pode encaminhar pacotes somente de uma VLAN e enviar esses pacotes sem marcação. Uma porta de acesso é normalmente usada nas seguintes condições:
Conexão a um dispositivo terminal que não oferece suporte a pacotes VLAN.
Em cenários que não distinguem VLANs.
Tronco - Uma porta tronco pode encaminhar pacotes de várias VLANs. Com exceção dos pacotes da porta VLAN ID (PVID), os pacotes enviados por uma porta tronco são marcados com VLAN. As portas que conectam dispositivos de rede geralmente são configuradas como portas tronco.
Híbrida - Uma porta híbrida pode encaminhar pacotes de várias VLANs. O status de marcação dos pacotes encaminhados por uma porta híbrida depende da configuração da porta. No mapeamento de VLAN de uma para duas, as portas híbridas são usadas para remover as tags de SVLAN do tráfego de downlink. Para obter mais informações sobre o mapeamento de VLAN de uma para duas, consulte "Configuração do mapeamento de VLAN".
PVID
O PVID identifica a VLAN padrão de uma porta. Os pacotes não marcados recebidos em uma porta são considerados como pacotes do PVID da porta.
Uma porta de acesso pode participar de apenas uma VLAN. A VLAN à qual a porta de acesso pertence é o PVID da porta. Uma porta tronco ou híbrida suporta várias VLANs e a configuração do PVID.
VLANs baseadas em MAC
O recurso de VLAN baseada em MAC atribui hosts a uma VLAN com base em seus endereços MAC. Esse recurso também é chamado de VLAN baseada no usuário porque a configuração da VLAN permanece a mesma, independentemente da localização física do usuário.
Atribuição estática de VLAN baseada em MAC
Use a atribuição estática de VLAN baseada em MAC em redes que tenham um pequeno número de usuários de VLAN. Para configurar a atribuição estática de VLAN baseada em MAC em uma porta, execute as seguintes tarefas:
Criar entradas de MAC para VLAN.
Habilite o recurso de VLAN baseada em MAC na porta.
Atribuir a porta à VLAN baseada em MAC.
Uma porta configurada com atribuição estática de VLAN baseada em MAC processa um quadro recebido da seguinte forma antes de enviá-lo:
Para um quadro sem marcação, a porta determina sua VLAN ID no seguinte fluxo de trabalho:
A porta realiza primeiro uma correspondência exata. Ela procura entradas de MAC para VLAN cujas máscaras sejam todas Fs. Se o endereço MAC de origem do quadro corresponder exatamente ao endereço MAC de uma entrada MAC-para-VLAN, a porta marcará o quadro com a VLAN ID específica dessa entrada.
Se a correspondência exata falhar, a porta executará um fuzzy da seguinte forma:
Procura as entradas de MAC para VLAN cujas máscaras não sejam todas Fs.
Executa uma operação AND lógica no endereço MAC de origem e em cada uma dessas máscaras.
Se o resultado de uma operação AND corresponder ao endereço MAC em uma entrada MAC-to-VLAN, a porta marca o quadro com a VLAN ID específica dessa entrada.
Se nenhuma VLAN ID correspondente for encontrada, a porta determinará a VLAN para o pacote usando a seguinte ordem de correspondência:
VLAN baseada em sub-rede IP.
VLAN baseada em protocolo.
VLAN baseada em porta.
Quando uma correspondência é encontrada, a porta marca o pacote com a VLAN ID correspondente.
Para um quadro marcado, a porta determina se a VLAN ID do quadro é permitida na porta.
Se a VLAN ID do quadro for permitida na porta, a porta encaminhará o quadro.
Se a VLAN ID do quadro não for permitida na porta, a porta descartará o quadro.
Atribuição dinâmica de VLAN baseada em MAC
Quando você não puder determinar as VLANs de destino baseadas em MAC de uma porta, use a atribuição dinâmica de VLAN baseada em MAC na porta. Para usar a atribuição dinâmica de VLAN baseada em MAC, execute as seguintes tarefas:
Criar entradas de MAC para VLAN.
Habilite o recurso de VLAN baseada em MAC na porta.
Ativar a atribuição dinâmica de VLAN baseada em MAC na porta.
A atribuição dinâmica de VLAN baseada em MAC usa o seguinte fluxo de trabalho, conforme mostrado na Figura 2:
Quando uma porta recebe um quadro, ela primeiro determina se o quadro está marcado.
Se o quadro estiver marcado, a porta receberá o endereço MAC de origem do quadro.
Se o quadro não estiver marcado, a porta seleciona uma VLAN para o quadro usando a seguinte ordem de correspondência:
VLAN baseada em MAC (correspondência de endereço MAC difusa e exata).
VLAN baseada em sub-rede IP.
VLAN baseada em protocolo.
VLAN baseada em porta.
Depois de marcar o quadro com a VLAN selecionada, a porta obtém o endereço MAC de origem do quadro.
A porta usa o endereço MAC de origem e a VLAN do quadro para fazer a correspondência entre as entradas MAC e VLAN.
Se o endereço MAC de origem do quadro corresponder exatamente ao endereço MAC em um
MAC-para-VLAN, a porta verifica se a VLAN ID do quadro corresponde à VLAN na entrada.
Se as duas VLAN IDs coincidirem, a porta se juntará à VLAN e encaminhará o quadro.
Se as duas VLAN IDs não corresponderem, a porta descarta o quadro.
Se o endereço MAC de origem do quadro não corresponder exatamente a nenhum endereço MAC nas entradas MAC-to-VLAN, a porta verificará se o VLAN ID do quadro é seu PVID.
Se o VLAN ID do quadro for o PVID da porta, a porta determinará se permite o PVID.
Se o PVID for permitido, a porta encaminhará o quadro dentro do PVID. Se o PVID não for permitido, a porta descarta o quadro.
Se o VLAN ID do quadro não for o PVID da porta, a porta determinará se o VLAN ID é o VLAN ID primário e o PVID da porta é um VLAN ID secundário. Em caso afirmativo, a porta encaminha o quadro. Caso contrário, a porta descarta o quadro.
Figura 2 Fluxograma para o processamento de um quadro na atribuição dinâmica de VLAN baseada em MAC
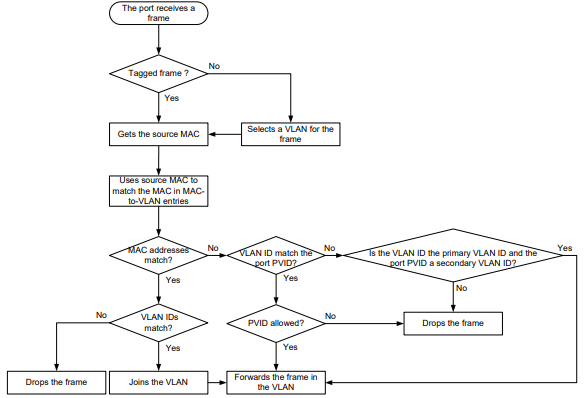
VLAN baseada em MAC atribuída ao servidor
Use esse recurso com autenticação de acesso, como a autenticação 802.1X baseada em MAC, para implementar um acesso seguro e flexível ao terminal.
Para implementar a VLAN baseada em MAC atribuída ao servidor, execute as seguintes tarefas:
Configure o recurso de VLAN baseada em MAC atribuído pelo servidor no dispositivo de acesso.
Configure as entradas de nome de usuário para VLAN no servidor de autenticação de acesso.
Quando um usuário passa na autenticação do servidor de autenticação de acesso, o servidor atribui ao dispositivo as informações da VLAN de autorização do usuário. Em seguida, o dispositivo executa as seguintes operações :
Gera uma entrada MAC para VLAN usando o endereço MAC de origem do pacote do usuário e as informações da VLAN de autorização. A VLAN de autorização é uma VLAN baseada em MAC.
A entrada MAC-para-VLAN gerada não pode entrar em conflito com as entradas estáticas MAC-para-VLAN existentes. Se houver um conflito, a entrada dinâmica de MAC para VLAN não poderá ser gerada.
Atribui a porta que conecta o usuário à VLAN baseada em MAC.
Quando o usuário fica off-line, o dispositivo exclui automaticamente a entrada MAC-to-VLAN e remove a porta da VLAN baseada em MAC. Para obter mais informações sobre a autenticação 802.1X e MAC, consulte o Guia de configuração de segurança.
VLANs baseadas em sub-rede IP
O recurso de VLAN baseada em sub-rede IP atribui pacotes não marcados a VLANs com base em seus endereços IP de origem e máscaras de sub-rede.
Use esse recurso quando os pacotes sem marcação de uma sub-rede IP ou endereço IP precisarem ser transmitidos em uma VLAN.
VLANs baseadas em protocolos
O recurso de VLAN baseada em protocolo atribui pacotes de entrada a diferentes VLANs com base em seus tipos de protocolo e formatos de encapsulamento. Os protocolos disponíveis para atribuição de VLAN incluem IP, IPX e AT. Os formatos de encapsulamento incluem Ethernet II, 802.3 raw, 802.2 LLC e 802.2 SNAP.
Esse recurso associa os tipos de serviço de rede disponíveis às VLANs e facilita o gerenciamento e a manutenção da rede.
Comunicação de camada 3 entre VLANs
Os hosts de diferentes VLANs usam interfaces de VLAN para se comunicar na Camada 3. As interfaces de VLAN são interfaces virtuais que não existem como entidades físicas nos dispositivos. Para cada VLAN, você pode criar uma interface de VLAN e atribuir um endereço IP a ela. A interface de VLAN atua como gateway da VLAN para encaminhar pacotes destinados a outra sub-rede IP na Camada 3.
Protocolos e padrões
IEEE 802.1Q, padrão IEEE para redes locais e metropolitanas: Redes locais com ponte virtual
Configuração de uma VLAN
Restrições e diretrizes
Como a VLAN padrão do sistema, a VLAN 1 não pode ser criada ou excluída.
Antes de excluir uma VLAN dinâmica ou uma VLAN bloqueada por um aplicativo, você deve primeiro remover a configuração da VLAN.
Criação de VLANs
Entre na visualização do sistema.
System ViewCrie uma ou várias VLANs.
Crie uma VLAN e entre em sua visualização.
vlan vlan-idCrie várias VLANs e entre na visualização de VLAN. Criar VLANs.
vlan { vlan-id-list | all }Entre no modo de exibição VLAN.
vlan vlan-idPor padrão, existe apenas a VLAN padrão do sistema (VLAN 1).
(Opcional.) Defina um nome para a VLAN.
name textPor padrão, o nome de uma VLAN é VLAN vlan-id. O argumento vlan-id especifica a VLAN ID em um formato de quatro dígitos. Se a VLAN ID tiver menos de quatro dígitos, serão adicionados zeros à esquerda. Por exemplo, o nome da VLAN 100 é VLAN 0100.
(Opcional.) Configure a descrição da VLAN.
description text Por padrão, a descrição de uma VLAN é VLAN vlan-id. O argumento vlan-id especifica a VLAN ID em um formato de quatro dígitos. Se a VLAN ID tiver menos de quatro dígitos, serão adicionados zeros à esquerda. Por exemplo, a descrição padrão da VLAN 100 é VLAN 0100.
Configuração de VLANs baseadas em portas
Restrições e diretrizes para VLANs baseadas em portas
Quando você usa o comando undo vlan para excluir o PVID de uma porta, ocorre um dos seguintes eventos, dependendo do tipo de link da porta:
Para uma porta de acesso, o PVID da porta muda para a VLAN 1.
Para uma porta híbrida ou tronco, a configuração PVID da porta não é alterada.
Você pode usar uma VLAN inexistente como PVID para uma porta híbrida ou tronco, mas não para uma porta de acesso.
Como prática recomendada, defina o mesmo PVID para uma porta local e seu par.
Para evitar que uma porta descarte pacotes não marcados ou pacotes marcados com PVID, atribua à porta seu PVID.
Atribuição de uma porta de acesso a uma VLAN
Sobre a atribuição de uma porta de acesso a uma VLAN
Você pode atribuir uma porta de acesso a uma VLAN na visualização de VLAN ou na visualização de interface.
Atribuição de uma ou várias portas de acesso a uma VLAN na visualização de VLAN
Entre na visualização do sistema.
System ViewEntre na visualização de VLAN.
vlan vlan-idAtribua uma ou várias portas de acesso à VLAN.
port interface-listPor padrão, todas as portas pertencem à VLAN 1.
Atribuição de uma porta de acesso a uma VLAN na visualização da interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefina o tipo de link da porta como acesso.
port link-type accessPor padrão, todas as portas são portas de acesso.
Atribuir a porta de acesso a uma VLAN.
port access vlan vlan-id Por padrão, todas as portas de acesso pertencem à VLAN 1.
Atribuição de uma porta tronco a uma VLAN
Sobre a atribuição de uma porta tronco a uma VLAN
Uma porta tronco suporta várias VLANs. Você pode atribuí-la a uma VLAN na visualização da interface.
Restrições e diretrizes
Para alterar o tipo de link de uma porta de tronco para híbrido, defina primeiro o tipo de link como acesso.
Para permitir que uma porta tronco transmita pacotes de seu PVID, você deve atribuir a porta tronco ao PVID usando o comando port trunk permit vlan.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefina o tipo de link da porta como tronco.
port link-type trunkPor padrão, todas as portas são portas de acesso.
Atribuir a porta tronco às VLANs especificadas.
port trunk permit vlan { vlan-id-list | all }Por padrão, uma porta tronco permite apenas a VLAN 1.
(Opcional.) Defina o PVID para a porta tronco.
port trunk pvid vlan vlan-idA configuração padrão é VLAN 1.
Atribuição de uma porta híbrida a uma VLAN
Sobre a atribuição de uma porta híbrida a uma VLAN
Uma porta híbrida suporta várias VLANs. Você pode atribuí-la às VLANs especificadas na visualização da interface. Certifique-se de que as VLANs tenham sido criadas.
Restrições e diretrizes
Para alterar o tipo de link de uma porta de tronco para híbrido, defina primeiro o tipo de link como acesso.
Para permitir que uma porta híbrida transmita pacotes de seu PVID, você deve atribuir a porta híbrida ao PVID usando o comando port hybrid vlan.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-numberDefina o tipo de link da porta como híbrido.
port link-type hybridPor padrão, todas as portas são portas de acesso.
Atribuir a porta híbrida às VLANs especificadas.
port hybrid vlan vlan-id-list { tagged | untagged }Por padrão, a porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é access.
(Opcional.) Defina o PVID para a porta híbrida.
port hybrid pvid vlan vlan-id Por padrão, o PVID de uma porta híbrida é o ID da VLAN à qual a porta pertence quando seu tipo de link é de acesso.
Configuração de VLANs baseadas em MAC
Restrições e diretrizes para VLANs baseadas em MAC
As VLANs baseadas em MAC estão disponíveis somente em portas híbridas.
O recurso de VLAN baseada em MAC é configurado principalmente nas portas de downlink dos dispositivos de acesso do usuário. Não use esse recurso com agregação de links.
Configuração da atribuição estática de VLAN baseada em MAC
Entre na visualização do sistema.
System ViewCriar uma entrada de MAC para VLAN.
mac-vlan mac-address mac-address [ mask mac-mask ] vlan vlan-id [ dot1p priority ]Por padrão, não existem entradas de MAC para VLAN.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberDefina o tipo de link da porta como híbrido.
port link-type hybridPor padrão, todas as portas são portas de acesso.
Atribuir a porta híbrida às VLANs baseadas em MAC.
port hybrid vlan vlan-id-list { tagged | untagged }Por padrão, uma porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é de acesso.
Habilite o recurso de VLAN baseada em MAC.
mac-vlan enablePor padrão, esse recurso está desativado.
(Opcional.) Configure o sistema para atribuir preferencialmente VLANs com base no endereço MAC.
vlan precedence mac-vlanPor padrão, o sistema atribui VLANs com base no endereço MAC preferencialmente quando tanto a VLAN baseada em MAC quanto a VLAN baseada em sub-rede IP estão configuradas em uma porta.
Configuração da atribuição dinâmica de VLAN baseada em MAC
Sobre a atribuição dinâmica de VLAN baseada em MAC
Para que a atribuição dinâmica de VLAN baseada em MAC seja bem-sucedida, use VLANs estáticas ao criar entradas de MAC para VLAN.
Quando uma porta se junta a uma VLAN especificada na entrada MAC-to-VLAN, ocorre um dos seguintes eventos, dependendo da configuração da porta:
Se a porta não tiver sido configurada para permitir a passagem de pacotes da VLAN, ela se juntará à VLAN como um membro sem marcação.
Se a porta tiver sido configurada para permitir a passagem de pacotes da VLAN, a configuração da porta permanecerá a mesma.
A prioridade 802.1p da VLAN em uma entrada MAC para VLAN determina a prioridade de transmissão dos pacotes correspondentes.
Restrições e diretrizes
Se você configurar atribuições de VLAN estáticas e dinâmicas baseadas em MAC em uma porta, a atribuição dinâmica de VLAN baseada em MAC entrará em vigor.
Como prática recomendada para garantir a operação correta da autenticação 802.1X e MAC, não use a atribuição dinâmica de VLAN baseada em MAC com a autenticação 802.1X ou MAC.
Como prática recomendada, não configure a atribuição dinâmica de VLAN baseada em MAC e desative o aprendizado de endereço MAC em uma porta. Se os dois recursos forem configurados juntos em uma porta, ela encaminhará apenas os pacotes que correspondem exatamente às entradas de MAC para VLAN e descartará os pacotes que não correspondem exatamente.
Como prática recomendada, não configure a atribuição dinâmica de VLAN baseada em MAC e o limite de aprendizado de MAC em uma porta.
Se os dois recursos forem configurados juntos em uma porta e a porta aprender o número máximo configurado de entradas de endereço MAC, a porta processará os pacotes da seguinte forma:
Encaminha apenas os pacotes que correspondem às entradas de endereço MAC aprendidas pela porta.
Descarta pacotes não correspondentes.
Como prática recomendada, não use a atribuição dinâmica de VLAN baseada em MAC com o MSTP. No modo MSTP, se uma porta estiver bloqueada no MSTI de sua VLAN de destino, ela descartará os pacotes recebidos em vez de entregá-los à CPU. Como resultado, a porta não será atribuída dinamicamente à VLAN de destino.
Como prática recomendada, não use a atribuição dinâmica de VLAN baseada em MAC com o PVST. No modo PVST, se a VLAN de destino de uma porta não for permitida na porta, ela será colocada em estado de bloqueio. A porta descarta os pacotes recebidos em vez de entregá-los à CPU. Como resultado, a porta não será atribuída dinamicamente à VLAN de destino.
Como prática recomendada, não configure a atribuição dinâmica de VLAN baseada em MAC e o modo de atribuição automática de Voice Vlan em uma porta. Eles podem ter um impacto negativo um sobre o outro.
Procedimento
Entre na visualização do sistema.
System ViewCriar uma entrada de MAC para VLAN.
mac-vlan mac-address mac-address vlan vlan-id [ dot1p priority ]Por padrão, não existem entradas de MAC para VLAN.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberDefina o tipo de link da porta como híbrido.
port link-type hybridPor padrão, todas as portas são portas de acesso.
Habilite o recurso de VLAN baseada em MAC.
mac-vlan enablePor padrão, a VLAN baseada em MAC está desativada.
Ativar a atribuição dinâmica de VLAN baseada em MAC.
mac-vlan trigger enablePor padrão, a atribuição dinâmica de VLAN baseada em MAC está desativada.
A atribuição de VLAN para uma porta é acionada somente quando o endereço MAC de origem do pacote recebido corresponde exatamente ao endereço MAC em uma entrada MAC para VLAN.
(Opcional.) Configure o sistema para atribuir preferencialmente VLANs com base no endereço MAC.
vlan precedence mac-vlanPor padrão, o sistema atribui VLANs com base no endereço MAC preferencialmente quando tanto a VLAN baseada em MAC quanto a VLAN baseada em sub-rede IP estão configuradas em uma porta.
(Opcional.) Desative a porta para que não encaminhe pacotes que não correspondam ao endereço MAC exato em seu PVID.
port pvid forbidden Por padrão, quando uma porta recebe pacotes cujos endereços MAC de origem não correspondem à correspondência exata, a porta os encaminha em seu PVID.
Configuração de VLAN baseada em MAC atribuída ao servidor
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberDefina o tipo de link da porta como híbrido.
port link-type hybridPor padrão, todas as portas são portas de acesso.
Atribuir a porta híbrida às VLANs baseadas em MAC.
port hybrid vlan vlan-id-list { tagged | untagged }Por padrão, uma porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é access.
Habilite o recurso de VLAN baseada em MAC.
mac-vlan enablePor padrão, a VLAN baseada em MAC está desativada.
Configure a autenticação 802.1X ou MAC.
Para obter mais informações, consulte Referência de comandos de segurança.
Configuração de VLANs baseadas em sub-rede IP
Restrições e diretrizes
Esse recurso está disponível somente em portas híbridas e processa apenas pacotes sem marcação.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização de VLAN.
vlan vlan-idAssocie a VLAN a uma sub-rede IP ou a um endereço IP.
ip-subnet-vlan [ ip-subnet-index ] ip ip-address [ mask ]Por padrão, uma VLAN não está associada a uma sub-rede IP ou a um endereço IP.
Uma sub-rede multicast ou um endereço multicast não pode ser associado a uma VLAN.
Retornar à visualização do sistema.
quitEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefina o tipo de link da porta como híbrido.
port link-type hybridPor padrão, todas as portas são portas de acesso.
Atribuir a porta híbrida às VLANs baseadas em sub-rede IP especificadas.
port hybrid vlan vlan-id-list { tagged | untagged }Por padrão, uma porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é access.
Associar a porta híbrida à VLAN baseada em sub-rede IP especificada.
port hybrid ip-subnet-vlan vlan vlan-idPor padrão, uma porta híbrida não está associada a uma VLAN baseada em sub-rede.
Configuração de um grupo de VLAN
Sobre um grupo de VLAN
Um grupo de VLANs inclui um conjunto de VLANs.
Em um servidor de autenticação, um nome de grupo de VLAN representa um grupo de VLANs de autorização. Quando um usuário de autenticação 802.1X ou MAC é aprovado na autenticação, o servidor de autenticação atribui um nome de grupo de VLAN ao dispositivo. Em seguida, o dispositivo usa o nome do grupo de VLAN recebido para fazer a correspondência com os nomes de grupos de VLAN configurados localmente. Se for encontrada uma correspondência, o dispositivo selecionará uma VLAN do grupo e atribuirá a VLAN ao usuário. Para obter mais informações sobre a autenticação 802.1X e MAC, consulte Security Configuration Guide.
Procedimento
Entre na visualização do sistema.
System ViewCrie um grupo de VLAN e entre em sua visualização.
vlan-group group-nameAdicione VLANs ao grupo de VLANs.
vlan-list vlan-id-listPor padrão, não existem VLANs em um grupo de VLANs.
Você pode adicionar várias listas de VLAN a um grupo de VLAN.
Configuração de interfaces VLAN
Restrições e diretrizes
Você não pode criar interfaces de VLAN para VLANs secundárias que tenham as seguintes características:
Associado à mesma VLAN primária.
Ativado com comunicação de camada 3 na visualização da interface de VLAN da interface de VLAN primária. Para obter mais informações sobre VLANs secundárias, consulte "Configuração de VLAN privada".
Criação de uma interface VLAN
Entre na visualização do sistema.
System ViewCrie uma interface VLAN e entre em sua visualização.
interface vlan-interface interface-númeroAtribua um endereço IP à interface da VLAN.
ip address ip-address { mask | mask-length } [ sub ]Por padrão, nenhum endereço IP é atribuído a uma interface de VLAN.
(Opcional.) Configure a descrição da interface de VLAN.
description text A configuração padrão é o nome da interface da VLAN. Por exemplo, Interface Vlan-interface1.
(Opcional.) Defina o MTU para a interface VLAN.
mtu sizePor padrão, o MTU de uma interface VLAN é de 1500 bytes.
(Opcional.) Defina a largura de banda esperada para a interface.
bandwidth bandwidth-valuePor padrão, a largura de banda esperada (em kbps) é a taxa de transmissão da interface dividida por 1000.
Abra a interface da VLAN.
undo shutdown Por padrão, uma interface de VLAN não é desligada manualmente. O status da interface de VLAN depende do status das portas membros da VLAN.
Restaurar as configurações padrão da interface VLAN
Restrições e diretrizes
Esse recurso pode não conseguir restaurar as configurações padrão de alguns comandos por motivos como dependências de comandos ou restrições do sistema. Use o comando display this na visualização da interface para identificar esses comandos e, em seguida, use suas formas de desfazer ou siga a referência do comando para restaurar suas configurações padrão. Se a tentativa de restauração ainda falhar, siga as instruções da mensagem de erro para resolver o problema.
Procedimento
Entre na visualização do sistema.
System ViewEntre em uma visualização de interface de VLAN.
interface vlan-interface interface-númeroRestaurar as configurações padrão da interface VLAN.
defaultEsse recurso pode interromper os serviços de rede em andamento. Certifique-se de estar totalmente ciente do impacto desse recurso ao usá-lo em uma rede ativa.
Exemplos de configuração VLAN
Exemplo: Configuração de VLANs baseadas em portas
Configuração de rede
Conforme mostrado na Figura 3:
Configure VLANs baseadas em portas para que somente os hosts do mesmo departamento possam se comunicar entre si.
Figura 3 Diagrama de rede
Procedimento
Configurar o dispositivo A:
# Crie a VLAN 100 e atribua a GigabitEthernet 1/0/1 à VLAN 100.
<DeviceA> system-view
[DeviceA] vlan 100
[DeviceA-vlan100] port gigabitethernet 1/0/1
[DeviceA-vlan100] quit# Crie a VLAN 200 e atribua a GigabitEthernet 1/0/2 à VLAN 200.
[DeviceA] vlan 200
[DeviceA-vlan200] port gigabitethernet 1/0/2
[DeviceA-vlan200] quit # Configure a GigabitEthernet 1/0/3 como uma porta tronco e atribua a porta às VLANs 100 e 200.
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port link-type trunk
[DeviceA-GigabitEthernet1/0/3] port trunk permit vlan 100 200
Please wait... Done Configure o Dispositivo B da mesma forma que o Dispositivo A está configurado. (Detalhes não mostrados).
Configurar hosts:
Configure o Host A e o Host C para estarem na mesma sub-rede IP. Por exemplo, 192.168.100.0/24.
Configure o Host B e o Host D para que estejam na mesma sub-rede IP. Por exemplo, 192.168.200.0/24.
Verificação da configuração
# Verifique se o Host A e o Host C conseguem fazer o ping um do outro, mas ambos não conseguem fazer o ping do Host B e do Host D. (Os detalhes não são mostrados).
# Verifique se o Host B e o Host D conseguem executar o ping um do outro, mas ambos não conseguem executar o ping do Host A e do Host C. (Os detalhes não são mostrados).
# Verifique se as VLANs 100 e 200 estão configuradas corretamente no dispositivo A.
[DeviceA-GigabitEthernet1/0/3] display vlan 100
VLAN ID: 100
VLAN type: Static
Route interface: Not configured
Description: VLAN 0100
Name: VLAN 0100
Tagged ports:
GigabitEthernet1/0/3
Untagged ports:
GigabitEthernet1/0/1
[DeviceA-GigabitEthernet1/0/3] display vlan 200
VLAN ID: 200
VLAN type: Static
Route interface: Not configured
Description: VLAN 0200
Name: VLAN 0200
Tagged ports:
GigabitEthernet1/0/3
Untagged ports:
GigabitEthernet1/0/2Exemplo: Configuração de VLANs baseadas em MAC
Configuração de rede
Conforme mostrado na Figura 4:
A GigabitEthernet 1/0/1 do Dispositivo A e o Dispositivo C estão conectados a uma sala de reunião. O Laptop 1 e o Laptop 2 são usados para reuniões e podem ser usados em qualquer uma das duas salas de reunião.
Um departamento usa a VLAN 100 e possui o laptop 1. O outro departamento usa a VLAN 200 e possui o laptop 2.
Configure VLANs baseadas em MAC, de modo que o Laptop 1 e o Laptop 2 possam acessar o Servidor 1 e o Servidor 2, respectivamente, independentemente da sala de reunião em que estejam sendo usados.
Figura 4 Diagrama de rede
Procedimento
Configure o dispositivo A:
# Crie as VLANs 100 e 200.
<DeviceA> system-view
[DeviceA] vlan 100
[DeviceA-vlan100] quit
[DeviceA] vlan 200
[DeviceA-vlan200] quit [DeviceA] mac-vlan mac-address 000d-88f8-4e71 vlan 100
[DeviceA] mac-vlan mac-address 0014-222c-aa69 vlan 200 # Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua-a às VLANs 100 e 200 como um membro de VLAN sem marcação.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type hybrid
[DeviceA-GigabitEthernet1/0/1] port hybrid vlan 100 200 untagged # Configure a porta de uplink (GigabitEthernet 1/0/2) como uma porta tronco e atribua-a às VLANs 100 e 200.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 100 200
[DeviceA-GigabitEthernet1/0/2] quitConfigurar o dispositivo B:
# Crie a VLAN 100 e atribua a GigabitEthernet 1/0/3 à VLAN 100.
<DeviceA> system-view
[DeviceB] vlan 100
[DeviceB-vlan100] port gigabitethernet 1/0/3
[DeviceB-vlan100] quit # Crie a VLAN 200 e atribua a GigabitEthernet 1/0/4 à VLAN 200.
[DeviceB] vlan 200
[DeviceB-vlan200] port gigabitethernet 1/0/4
[DeviceB-vlan200] quit # Configure a GigabitEthernet 1/0/1 como uma porta tronco e atribua a porta às VLANs 100 e 200.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type trunk
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 100 200
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco e atribua a porta às VLANs 100 e 200.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 100 200
[DeviceB-GigabitEthernet1/0/2] quit Configure o Dispositivo C da mesma forma que o Dispositivo A está configurado. (Detalhes não mostrados.)
Verificação da configuração
# Verifique se o laptop 1 pode acessar somente o servidor 1 e se o laptop 2 pode acessar somente o servidor 2. (Os detalhes não são mostrados).
# Verifique as entradas MAC-to-VLAN no Dispositivo A e no Dispositivo C, por exemplo, no Dispositivo A.
[DeviceA] display mac-vlan all
The following MAC VLAN addresses exist:
S:Static D:Dynamic
MAC address Mask VLAN ID Dot1p State
000d-88f8-4e71 ffff-ffff-ffff 100 0 S
0014-222c-aa69 ffff-ffff-ffff 200 0 S
Total MAC VLAN address count: 2Exemplo: Configuração de VLANs baseadas em sub-rede IP
Configuração de rede
Conforme mostrado na Figura 5, os hosts do escritório pertencem a diferentes sub-redes IP.
Configure o Dispositivo C para transmitir pacotes de 192.168.5.0/24 e 192.168.50.0/24 nas VLANs 100 e 200, respectivamente.
Figura 5 Diagrama de rede
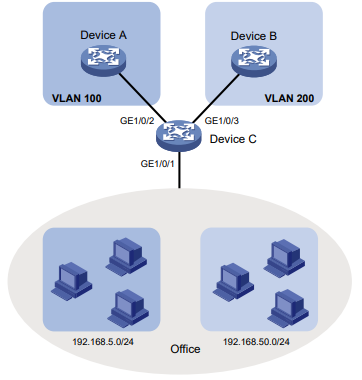
Procedimento
Configurar o dispositivo C:
# Associe a sub-rede IP 192.168.5.0/24 à VLAN 100.
<DeviceC> system-view
[DeviceC] vlan 100
[DeviceC-vlan100] ip-subnet-vlan ip 192.168.5.0 255.255.255.0
[DeviceC-vlan100] quit# Associe a sub-rede IP 192.168.50.0/24 à VLAN 200.
[DeviceC] vlan 200
[DeviceC-vlan200] ip-subnet-vlan ip 192.168.50.0 255.255.255.0
[DeviceC-vlan200] quit# Configure a GigabitEthernet 1/0/2 como uma porta híbrida e atribua-a à VLAN 100 como membro de uma VLAN marcada.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] port link-type hybrid
[DeviceC-GigabitEthernet1/0/2] port hybrid vlan 100 tagged
[DeviceC-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 como uma porta híbrida e atribua-a à VLAN 200 como membro de uma VLAN marcada.
[DeviceC] interface gigabitethernet 1/0/3
[DeviceC-GigabitEthernet1/0/3] port link-type hybrid
[DeviceC-GigabitEthernet1/0/3] port hybrid vlan 200 tagged
[DeviceC-GigabitEthernet1/0/3] quit# Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua-a às VLANs 100 e 200 como uma porta híbrida membro de VLAN sem marcação.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] port link-type hybrid
[DeviceC-GigabitEthernet1/0/1] port hybrid vlan 100 200 untagged# Associe a GigabitEthernet 1/0/1 às VLANs 100 e 200 baseadas em sub-rede IP.
[DeviceC-GigabitEthernet1/0/1] port hybrid ip-subnet-vlan vlan 100
[DeviceC-GigabitEthernet1/0/1] port hybrid ip-subnet-vlan vlan 200
[DeviceC-GigabitEthernet1/0/1] quitConfigure o Dispositivo A e o Dispositivo B para encaminhar pacotes das VLANs 100 e 200, respectivamente. (Detalhes não mostrados).
Verificação da configuração
# Verifique a configuração da VLAN baseada em sub-rede IP no Dispositivo C.
[DeviceC] display ip-subnet-vlan vlan all
VLAN ID: 100
Subnet index IP address Subnet mask
0 192.168.5.0 255.255.255.0
VLAN ID: 200
Subnet index IP address Subnet mask
0 192.168.50.0 255.255.255.0# Verifique a configuração da VLAN baseada em sub-rede IP na GigabitEthernet 1/0/1 do Dispositivo C.
[DeviceC] display ip-subnet-vlan interface gigabitethernet 1/0/1
Interface: GigabitEthernet1/0/1Exemplo: Configuração de VLANs baseadas em protocolo
Configuração de rede
Conforme mostrado na Figura 6:
A maioria dos hosts em um ambiente de laboratório executa o protocolo IPv4.
Os outros hosts executam o protocolo IPv6 para fins didáticos.
Para isolar o tráfego IPv4 e IPv6 na Camada 2, configure VLANs baseadas em protocolo para associar os protocolos IPv4 e ARP à VLAN 100 e associar o protocolo IPv6 à VLAN 200.
Figura 6 Diagrama de rede
Procedimento
Neste exemplo, o Comutador L2 A e o Comutador L2 B usam a configuração de fábrica.
Configurar dispositivo:
# Crie a VLAN 100 e configure a descrição da VLAN 100 como VLAN de protocolo para IPv4.
<Device> system-view
[Device] vlan 100
[Device-vlan100] description protocol VLAN for IPv4
# Atribua a GigabitEthernet 1/0/3 à VLAN 100. [Device-vlan100] port gigabitethernet 1/0/3 [Device-vlan100] quit
# Crie a VLAN 200 e configure a descrição da VLAN 200 como VLAN de protocolo para IPv6.
[Device-vlan100] port gigabitethernet 1/0/3
[Device-vlan100] quit# Atribua a GigabitEthernet 1/0/4 à VLAN 200.
[Device-vlan200] port gigabitethernet 1/0/4# Configure a VLAN 200 como uma VLAN baseada em protocolo e crie um modelo de protocolo IPv6 com o índice 1 para a VLAN 200.
[Device-vlan200] protocol-vlan 1 ipv6
[Device-vlan200] quit# Configure a VLAN 100 como uma VLAN baseada em protocolo. Crie um modelo de protocolo IPv4 com o parâmetro
índice 1 e crie um modelo de protocolo ARP com o índice 2. (No encapsulamento Ethernet II, o ID do tipo de protocolo para ARP é 0806 em notação hexadecimal).
[Device] vlan 100
[Device-vlan100] protocol-vlan 1 ipv4
[Device-vlan100] protocol-vlan 2 mode ethernetii etype 0806
[Device-vlan100] quit# Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua-a às VLANs 100 e 200 como um membro de VLAN sem marcação.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] port link-type hybrid
[Device-GigabitEthernet1/0/1] port hybrid vlan 100 200 untagged # Associe a GigabitEthernet 1/0/1 aos modelos de protocolo IPv4 e ARP da VLAN 100 e ao modelo de protocolo IPv6 da VLAN 200.
[Device-GigabitEthernet1/0/1] port hybrid protocol-vlan vlan 100 1 to 2
[Device-GigabitEthernet1/0/1] port hybrid protocol-vlan vlan 200 1
[Device-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta híbrida e atribua-a às VLANs 100 e 200 como um membro de VLAN sem marcação.
[Device] interface gigabitethernet 1/0/2
[Device-GigabitEthernet1/0/2] port link-type hybrid
[Device-GigabitEthernet1/0/2] port hybrid vlan 100 200 untagged # Associe a GigabitEthernet 1/0/2 aos modelos de protocolo IPv4 e ARP da VLAN 100 e ao modelo de protocolo IPv6 da VLAN 200.
[Device-GigabitEthernet1/0/2] port hybrid protocol-vlan vlan 100 1 to 2
[Device-GigabitEthernet1/0/2] port hybrid protocol-vlan vlan 200 1
[Device-GigabitEthernet1/0/2] quit Configurar hosts e servidores:
Configure o host IPv4 A, o host IPv4 B e o servidor IPv4 para que estejam no mesmo segmento de rede (192.168.100.0/24, por exemplo). (Detalhes não mostrados.)
Configure o Host A IPv6, o Host B IPv6 e o servidor IPv6 para que estejam no mesmo segmento de rede (2001::1/64, por exemplo). (Detalhes não mostrados.)
Verificação da configuração
Verifique o seguinte:
Os hosts e o servidor na VLAN 100 podem fazer ping entre si com sucesso. (Detalhes não mostrados.)
Os hosts e o servidor na VLAN 200 podem fazer ping entre si com êxito. (Detalhes não mostrados.)
Os hosts ou o servidor da VLAN 100 não podem fazer ping nos hosts ou no servidor da VLAN 200. (Detalhes não mostrados.)
Verifique a configuração da VLAN baseada em protocolo: # Exibir VLANs baseadas em protocolo no dispositivo.
[Device] display protocol-vlan vlan all
VLAN ID: 100
Protocol index Protocol type
1 IPv4
2 Ethernet II Etype 0x0806
VLAN ID: 200
Protocol index Protocol type
1 IPv6
# Exibir VLANs baseadas em protocolo nas portas do dispositivo.
[Device] display protocol-vlan interface all
Interface: GigabitEthernet1/0/1
VLAN ID Protocol index Protocol type
Status
100 1 IPv4 Active
100 2 Ethernet II Etype 0x0806 Active
200 1 IPv6 Active
Interface: GigabitEthernet 1/0/2
VLAN ID Protocol index Protocol type Status
100 1 IPv4 Active
100 2 Ethernet II Etype 0x0806 Active
200 1 IPv6 Active
Configurando VLANs privadas
Sobre a VLAN privada
A tecnologia VLAN oferece um método para isolar o tráfego dos clientes. Na camada de acesso de uma rede, o tráfego de clientes deve ser isolado para fins de segurança ou contabilidade. Se as VLANs forem atribuídas por usuário, será necessário um grande número de VLANs.
O recurso de VLAN privada economiza recursos de VLAN. Ele usa uma estrutura de VLAN de dois níveis, como segue:
VLAN primária - Usada para conectar o dispositivo upstream. Uma VLAN primária pode ser associada a várias VLANs secundárias. O dispositivo upstream identifica apenas a VLAN primária.
VLANs secundárias - Usadas para conectar usuários. As VLANs secundárias são isoladas na Camada 2. Para implementar a comunicação na camada 3 entre as VLANs secundárias associadas à VLAN primária, ative o proxy ARP local ou ND no dispositivo upstream (por exemplo, o dispositivo L3 A na Figura 7).
Conforme mostrado na Figura 7, o recurso de VLAN privada está ativado no Dispositivo L2 B. A VLAN 10 é a VLAN primária. As VLANs 2, 5 e 8 são VLANs secundárias associadas à VLAN 10. O dispositivo L3 A está ciente apenas da VLAN 10.
Figura 7 Exemplo de VLAN privada
Se o recurso de VLAN privada estiver configurado em um dispositivo de Camada 3, use um dos seguintes métodos no dispositivo de Camada 3 para ativar a comunicação de Camada 3. A comunicação da Camada 3 pode ser necessária entre VLANs secundárias associadas à mesma VLAN primária ou entre VLANs secundárias e outras redes.
Método 1:
Crie interfaces de VLAN para as VLANs secundárias.
Atribua endereços IP às interfaces de VLAN secundárias.
Método 2:
Habilite a comunicação da Camada 3 entre as VLANs secundárias associadas à VLAN primária .
Crie a interface de VLAN para a VLAN primária e atribua um endereço IP a ela. (Não crie interfaces de VLAN secundárias se você usar esse método).
Habilite o proxy ARP ou ND local na interface VLAN primária.
Restrições e diretrizes: Configuração de VLAN privada
Certifique-se de que os seguintes requisitos sejam atendidos:
Para uma porta promíscua:
A VLAN primária é o PVID da porta.
A porta é um membro sem marcação da VLAN primária e das VLANs secundárias.
Para uma porta de host:
O PVID da porta é uma VLAN secundária.
A porta é um membro sem marcação da VLAN primária e da VLAN secundária.
Uma porta tronco promíscua ou porta tronco secundária deve ser um membro marcado das VLANs primária e secundária.
A VLAN 1 (VLAN padrão do sistema) não é compatível com a configuração de VLAN privada.
Criação de uma VLAN primária
Entre na visualização do sistema.
System ViewCrie uma VLAN e entre na visualização de VLAN.
vlan vlan-idConfigure a VLAN como uma VLAN primária.
private-vlan primaryPor padrão, uma VLAN não é uma VLAN primária.
Criação de VLANs secundárias
Entre na visualização do sistema.
System ViewCrie uma ou várias VLANs secundárias.
vlan { vlan-id-list | all }Associação da VLAN primária com VLANs secundárias
Entre na visualização do sistema.
System ViewCrie uma visualização de VLAN da VLAN primária.
vlan vlan-idAssocie a VLAN primária às VLANs secundárias.
private-vlan secondary vlan-id-listPor padrão, uma VLAN primária não está associada a nenhuma VLAN secundária.
Configuração da porta de uplink
Sobre a porta de uplink
Configure a porta de uplink (por exemplo, a porta que conecta o dispositivo L2 B ao dispositivo L3 A na Figura 7) da seguinte forma:
Se a porta permitir apenas uma VLAN primária, configure-a como uma porta promíscua da VLAN primária. A porta promíscua pode ser atribuída automaticamente à VLAN primária e às suas VLANs secundárias associadas.
Se a porta permitir várias VLANs primárias, configure-a como uma porta promíscua de tronco das VLANs primárias. A porta promíscua de tronco pode ser automaticamente atribuída às VLANs primárias e às VLANs secundárias associadas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface da porta de uplink.
interface interface-type interface-numberConfigure a porta de uplink como uma porta promíscua ou tronco promíscuo das VLANs especificadas.
Configure a porta de uplink como uma porta promíscua da VLAN especificada.
port private-vlan vlan-id promiscuousConfigure a porta de uplink como uma porta promíscua de tronco das VLANs especificadas.
port private-vlan vlan-id-list trunk promiscuousPor padrão, uma porta não é uma porta promíscua ou tronco promíscuo de nenhuma VLAN.
Configuração de uma porta de downlink
Sobre a porta de downlink
Configure uma porta de downlink da seguinte forma:
Se uma porta de downlink permitir apenas uma VLAN secundária (por exemplo, a porta que conecta o Dispositivo L2 B a um host na Figura 7), configure a porta como uma porta de host. A porta do host pode ser atribuída automaticamente à VLAN secundária e à VLAN primária associada.
Se uma porta de downlink permitir várias VLANs secundárias, configure a porta como uma porta secundária tronco. A porta secundária tronco pode ser atribuída automaticamente às VLANs secundárias e às VLANs primárias associadas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface da porta de downlink.
interface interface-type interface-numberAtribuir a porta de downlink a VLANs secundárias.
Definir o tipo de link da porta.
port link-type { access | hybrid | trunk }Atribuir a porta de acesso à VLAN especificada.
port access vlan vlan-id Atribuir a porta tronco às VLANs especificadas.
port trunk permit vlan { vlan-id-list | all }Atribuir a porta híbrida às VLANs especificadas.
port hybrid vlan vlan-id-list { tagged | untagged }Selecione a subetapa b, c ou d, dependendo do tipo de link de porta.
Configure a porta de downlink como uma porta secundária de host ou de tronco.
Configure a porta de downlink como uma porta de host.
port private-vlan hostConfigure a porta de downlink como uma porta secundária de tronco das VLANs especificadas.
port trunk permit vlan { vlan-id-list | all } Por padrão, uma porta não é uma porta secundária de host ou de tronco.
Retornar à visualização do sistema.
quitEntre na visualização de VLAN de uma VLAN secundária.
vlan vlan-id(Opcional.) Habilite a comunicação da Camada 2 para portas na mesma VLAN secundária. Escolha um comando conforme necessário:
undo private-vlan isolated private-vlan communityPor padrão, as portas na mesma VLAN secundária podem se comunicar entre si na Camada 2.
Configuração da comunicação da camada 3 para VLANs secundárias
Entre na visualização do sistema.
System ViewEntre na visualização da interface de VLAN da interface de VLAN primária.
interface vlan-interface interface-númeroHabilita a comunicação da Camada 3 entre VLANs secundárias associadas à VLAN primária.
private-vlan secondary vlan-id-listPor padrão, as VLANs secundárias não podem se comunicar entre si na Camada 3.
Atribua um endereço IP à interface VLAN primária.
IPv4:
ip address ip-address { mask-length | mask } [ sub IPv6:
ipv6 address { ipv6-address prefix-length | ipv6-address/prefix-length }padrão, nenhum endereço IP é configurado para uma interface VLAN.
Habilite o proxy local ARP ou ND. IPv4:
local-proxy-arp enablePor padrão, o proxy ARP local está desativado.
Para obter mais informações sobre o ARP de proxy local, consulte o Guia de configuração de serviços de IP de camada 3. IPv6:
local-proxy-nd enablePor padrão, o proxy local ND está desativado.
Para obter mais informações sobre o proxy local ND, consulte o Guia de Configuração de Serviços de Camada 3 IP.
Comandos de exibição e manutenção para a VLAN privada
display private-vlan [ primary-vlan-id ]Executar comandos de exibição em qualquer visualização.
Exemplos de configuração de VLAN privada
Exemplo: Configuração de portas promíscuas
Configuração de rede
Conforme mostrado na Figura 8, configure o recurso de VLAN privada para atender aos seguintes requisitos:
No Dispositivo B, a VLAN 5 é uma VLAN primária associada às VLANs secundárias 2 e 3. A GigabitEthernet 1/0/5 está na VLAN 5. A GigabitEthernet 1/0/2 está na VLAN 2. A GigabitEthernet 1/0/3 está na VLAN 3.
No Dispositivo C, a VLAN 6 é uma VLAN primária associada às VLANs secundárias 3 e 4. A GigabitEthernet 1/0/5 está na VLAN 6. A GigabitEthernet 1/0/3 está na VLAN 3. A GigabitEthernet 1/0/4 está na VLAN 4.
O dispositivo A está ciente apenas da VLAN 5 no dispositivo B e da VLAN 6 no dispositivo C.
Figura 8 Diagrama de rede
Procedimento
Este exemplo descreve as configurações no Dispositivo B e no Dispositivo C.
Configurar o dispositivo B:
# Configure a VLAN 5 e 10 VLANS primária.
<DeviceB> system-view
[DeviceB] vlan 5
[DeviceB-vlan5] private-vlan primary
[DeviceB-vlan5] quit # Crie as VLANs 2 e 3.
[DeviceB] vlan 2 a 3# Associe as VLANs secundárias 2 e 3 à VLAN primária 5.
[DeviceB] vlan 5
[DeviceB-vlan5] private-vlan secondary 2 to 3
[DeviceB-vlan5] quit # Configure a porta de uplink (GigabitEthernet 1/0/5) como uma porta promíscua da VLAN 5.
[DeviceB] interface gigabitethernet 1/0/5
[DeviceB-GigabitEthernet1/0/5] port private-vlan 5 promiscuous
[DeviceB-GigabitEthernet1/0/5] quit# Atribua a porta de downlink GigabitEthernet 1/0/2 à VLAN 2 e configure a porta como uma porta de host.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port access vlan 2
[DeviceB-GigabitEthernet1/0/2] port private-vlan host
[DeviceB-GigabitEthernet1/0/2] quit # Atribua a porta de downlink GigabitEthernet 1/0/3 à VLAN 3 e configure a porta como uma porta de host.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] port access vlan 3
[DeviceB-GigabitEthernet1/0/3] port private-vlan host
[DeviceB-GigabitEthernet1/0/3] quit Configurar o dispositivo C:
# Configure a VLAN 6 como uma VLAN primária.
<DeviceC> system-view
[DeviceC] vlan 6
[DeviceC–vlan6] private-vlan primary
[DeviceC–vlan6] quit# Crie as VLANs 3 e 4.
[DeviceC] vlan 3 to 4 # Associe as VLANs secundárias 3 e 4 à VLAN primária 6.
[DeviceC] vlan 6
[DeviceC-vlan6] private-vlan secondary 3 to 4
[DeviceC-vlan6] quit
# Configure a porta de uplink (GigabitEthernet 1/0/5) como uma porta promíscua da VLAN 6.
[DeviceC] interface gigabitethernet 1/0/5
[DeviceC-GigabitEthernet1/0/5] port private-vlan 6 promiscuous
[DeviceC-GigabitEthernet1/0/5] quit
# Atribua a porta de downlink GigabitEthernet 1/0/3 à VLAN 3 e configure a porta como uma porta de host.
[DeviceC] interface gigabitethernet 1/0/3
[DeviceC-GigabitEthernet1/0/3] port access vlan 3
[DeviceC-GigabitEthernet1/0/3] port private-vlan host
[DeviceC-GigabitEthernet1/0/3] quit
# Atribua a porta de downlink GigabitEthernet 1/0/4 à VLAN 4 e configure a porta como uma porta de host.
[DeviceC] interface gigabitethernet 1/0/4
[DeviceC-GigabitEthernet1/0/4] port access vlan 4
[DeviceC-GigabitEthernet1/0/4] port private-vlan host
[DeviceC-GigabitEthernet1/0/4] quit
Verificação da configuração
# Verifique as configurações de VLAN privada nos dispositivos, por exemplo, no Dispositivo B.
[DeviceB] display private-vlan
Primary VLAN ID: 5
Secondary VLAN ID: 2-3
VLAN ID: 5
VLAN type: Static
Private VLAN type: Primary
Route interface: Not configured
Description: VLAN 0005
Name: VLAN 0005
Tagged ports:
None
Untagged ports:
GigabitEthernet1/0/2
GigabitEthernet1/0/3
GigabitEthernet1/0/5
VLAN ID: 2
VLAN type: Static
Private VLAN type: Secondary
31
Route interface: Not configured
Description: VLAN 0002
Name: VLAN 0002
Tagged ports:
None
Untagged ports:
GigabitEthernet1/0/2
GigabitEthernet1/0/5
VLAN ID: 3
VLAN type: Static
Private VLAN type: Secondary
Route interface: Not configured
Description: VLAN 0003
Name: VLAN 0003
Tagged Ports:
None
Untagged Ports:
GigabitEthernet1/0/3
GigabitEthernet1/0/5
O resultado mostra isso:
A porta promíscua (GigabitEthernet 1/0/5) é um membro sem marcação da VLAN 5 primária e das VLANs 2 e 3 secundárias.
A porta do host GigabitEthernet 1/0/2 é um membro sem marcação da VLAN 5 primária e da VLAN 2 secundária.
A porta do host GigabitEthernet 1/0/3 é um membro sem marcação da VLAN 5 primária e da VLAN 3 secundária.
Exemplo: Configuração de portas promíscuas de tronco
Configuração de rede
Conforme mostrado na Figura 9, configure o recurso de VLAN privada para atender aos seguintes requisitos:
As VLANs 5 e 10 são VLANs primárias no Dispositivo B. A porta de uplink (GigabitEthernet 1/0/1) no Dispositivo B permite que os pacotes das VLANs 5 e 10 passem marcados.
No Dispositivo B, a porta de downlink GigabitEthernet 1/0/2 permite a VLAN 2 secundária. A porta de downlink GigabitEthernet 1/0/3 permite a VLAN secundária 3. As VLANs secundárias 2 e 3 estão associadas à VLAN primária 5.
No Dispositivo B, a porta de downlink GigabitEthernet 1/0/4 permite a VLAN secundária 6. A porta de downlink GigabitEthernet 1/0/5 permite a VLAN secundária 8. As VLANs secundárias 6 e 8 estão associadas à VLAN primária 10.
O dispositivo A está ciente apenas das VLANs 5 e 10 no dispositivo B.
Figura 9 Diagrama de rede
Procedimento
Configurar o dispositivo B:
# Configure as VLANs 5 como VLANs primárias.
<DeviceB> system-view
[DeviceB] vlan 5
[DeviceB-vlan5] private-vlan primary
[DeviceB-vlan5] quit# Crie as VLANs 2, 3
[DeviceB] vlan 2 to 3# Associe as VLANs secundárias 2 e 3 à VLAN primária 5.
[DeviceB] vlan 5
[DeviceB-vlan5] private-vlan secondary 2 to 3
[DeviceB-vlan5] quit # Associe as VLANs secundárias 6 e 8 à VLAN primária 10.
[DeviceB] vlan 10
[DeviceB-vlan10] private-vlan secondary 6 8 [DeviceB-vlan10] quit
# Configure a porta de uplink (GigabitEthernet 1/0/1) como uma porta promíscua de tronco das VLANs 5 e 10.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port private-vlan 5 10 trunk promiscuous [DeviceB-GigabitEthernet1/0/1] quit
# Atribua a porta de downlink GigabitEthernet 1/0/2 à VLAN 2 e configure a porta como uma porta de host.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port access vlan 2
[DeviceB-GigabitEthernet1/0/2] port private-vlan host
[DeviceB-GigabitEthernet1/0/2] quit # Atribua a porta de downlink GigabitEthernet 1/0/3 à VLAN 3 e configure a porta como uma porta de host.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] port access vlan 3
[DeviceB-GigabitEthernet1/0/3] port private-vlan host
[DeviceB-GigabitEthernet1/0/3] quit # Atribua a porta de downlink GigabitEthernet 1/0/4 à VLAN 6 e configure a porta como uma porta de host.
[DeviceB] interface gigabitethernet 1/0/4
[DeviceB-GigabitEthernet1/0/4] port access vlan 6
[DeviceB-GigabitEthernet1/0/4] port private-vlan host
[DeviceB-GigabitEthernet1/0/4] quit # Atribua a porta de downlink GigabitEthernet 1/0/5 à VLAN 8 e configure a porta como uma porta de host.
[DeviceB] interface gigabitethernet 1/0/5
[DeviceB-GigabitEthernet1/0/5] port access vlan 8
[DeviceB-GigabitEthernet1/0/5] port private-vlan host
[DeviceB-GigabitEthernet1/0/5] quitConfigure o dispositivo A:
# Crie as VLANs 5 e 10.
[DeviceA] vlan 5
[DeviceA-vlan5] quit
[DeviceA] vlan 10
[DeviceA-vlan10] quit # Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua-a às VLANs 5 e 10 como um membro de VLAN marcada.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type hybrid
[DeviceA-GigabitEthernet1/0/1] port hybrid vlan 5 10 tagged
[DeviceA-GigabitEthernet1/0/1] quit Verificação da configuração
# Verifique as configurações da VLAN primária no Dispositivo B. A saída a seguir usa a VLAN primária 5 como exemplo.
[DeviceB] display private-vlan 5
Primary VLAN ID: 5
Secondary VLAN ID: 2-3
VLAN ID: 5
VLAN type: Static
Private VLAN type: Primary
Route interface: Not configured
Description: VLAN 0005
Name: VLAN 0005
Tagged ports:
GigabitEthernet1/0/1
Untagged ports:
GigabitEthernet1/0/2
GigabitEthernet1/0/3
VLAN ID: 2
VLAN type: Static
Private VLAN type: Secondary
Route interface: Not configured
Description: VLAN 0002
Name: VLAN 0002
Tagged ports:
GigabitEthernet1/0/1
Untagged ports:
GigabitEthernet1/0/2
VLAN ID: 3
VLAN type: Static
Private VLAN type: Secondary
Route interface: Not configured
Description: VLAN 0003
Name: VLAN 0003
Tagged ports:
GigabitEthernet1/0/1
Untagged ports:
GigabitEthernet1/0/3
O resultado mostra isso:
A porta promíscua do tronco (GigabitEthernet 1/0/1) é um membro marcado da VLAN 5 primária e das VLANs 2 e 3 secundárias.
A porta do host GigabitEthernet 1/0/2 é um membro sem marcação da VLAN 5 primária e da VLAN 2 secundária.
A porta do host GigabitEthernet 1/0/3 é um membro sem marcação da VLAN 5 primária e da VLAN 3 secundária.
Exemplo: Configuração de portas tronco promíscuas e tronco secundárias
Configuração de rede
Conforme mostrado na Figura 10, configure o recurso de VLAN privada para atender aos seguintes requisitos:
As VLANs 10 e 20 são VLANs primárias no Dispositivo A. A porta de uplink (GigabitEthernet 1/0/5) no Dispositivo A permite que os pacotes das VLANs 10 e 20 passem marcados.
As VLANs 11, 12, 21 e 22 são VLANs secundárias no Dispositivo A.
A porta de downlink GigabitEthernet 1/0/2 permite que os pacotes das VLANs secundárias 11 e 21 passem com tags.
A porta de downlink GigabitEthernet 1/0/1 permite a VLAN 22 secundária.
A porta de downlink GigabitEthernet 1/0/3 permite a VLAN 12 secundária.
As VLANs secundárias 11 e 12 estão associadas à VLAN primária 10.
As VLANs secundárias 21 e 22 estão associadas à VLAN primária 20.
Figura 10 Diagrama de rede
Procedimento
Configurar o dispositivo A:
# Configure as VLANs 10 e 20 como VLANs primárias.
<DeviceA> system-view
[DeviceA] vlan 10
[DeviceA-vlan10] private-vlan primary
[DeviceA-vlan10] quit
[DeviceA] vlan 20
[DeviceA-vlan20] private-vlan primary
[DeviceA-vlan20] quit # Crie as VLANs 11, 12, 21 e 22.
[DeviceA] vlan 11 to 12
[DeviceA] vlan 21 to 22 # Associe as VLANs secundárias 11 e 12 à VLAN primária 10.
[DeviceA] vlan 10
[DeviceA-vlan10] private-vlan secondary 11 12
[DeviceA-vlan10] quit # Associe as VLANs secundárias 21 e 22 à VLAN primária 20.
[DeviceA] vlan 20
[DeviceA-vlan20] private-vlan secondary 21 22
[DeviceA-vlan20] quit # Configure a porta de uplink (GigabitEthernet 1/0/5) como uma porta promíscua de tronco das VLANs 10 e 20.
[DeviceA] interface gigabitethernet 1/0/5
[DeviceA-GigabitEthernet1/0/5] port private-vlan 10 20 trunk promiscuous
[DeviceA-GigabitEthernet1/0/5] quit # Atribua a porta de downlink GigabitEthernet 1/0/1 à VLAN 22 e configure a porta como uma porta de host.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port access vlan 22
[DeviceA-GigabitEthernet1/0/1] port private-vlan host
[DeviceA-GigabitEthernet1/0/1] quit# Atribua a porta de downlink GigabitEthernet 1/0/3 à VLAN 12 e configure a porta como uma porta de host.
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port access vlan 12
[DeviceA-GigabitEthernet1/0/3] port private-vlan host
[DeviceA-GigabitEthernet1/0/3] quit # Configure a porta de downlink GigabitEthernet 1/0/2 como uma porta tronco secundária das VLANs 11 e 21.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port private-vlan 11 21 trunk secondary
[DeviceA-GigabitEthernet1/0/2] quit Configurar o dispositivo B:
# Crie as VLANs 11 e 21.
<DeviceB> system-view
[DeviceB] vlan 11
[DeviceB-vlan11] quit
[DeviceB] vlan 21
[DeviceB-vlan21] quit # Configure a GigabitEthernet 1/0/2 como uma porta híbrida e atribua-a às VLANs 11 e 21 como um membro de VLAN marcada.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type hybrid
[DeviceB-GigabitEthernet1/0/2] port hybrid vlan 11 21 tagged
[DeviceB-GigabitEthernet1/0/2] quit# Atribua a GigabitEthernet 1/0/3 à VLAN 11.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] port access vlan 11
[DeviceB-GigabitEthernet1/0/3] quit# Atribua a GigabitEthernet 1/0/4 à VLAN 21.
[DeviceB] interface gigabitethernet 1/0/4
[DeviceB-GigabitEthernet1/0/4] port access vlan 21
[DeviceB-GigabitEthernet1/0/4] quitConfigurar o dispositivo C:
# Crie as VLANs 10 e 20.
<DeviceC> system-view
[DeviceC] vlan 10
[DeviceC-vlan10] quit
[DeviceC] vlan 20
[DeviceC-vlan20] quit # Configure a GigabitEthernet 1/0/5 como uma porta híbrida e atribua-a às VLANs 10 e 20 como um membro de VLAN marcada.
[DeviceC] interface gigabitethernet 1/0/5
[DeviceC-GigabitEthernet1/0/5] port link-type hybrid
[DeviceC-GigabitEthernet1/0/5] port hybrid vlan 10 20 tagged
[DeviceC-GigabitEthernet1/0/5] quitVerificação da configuração
# Verifique as configurações da VLAN primária no dispositivo A. A saída a seguir usa a VLAN primária 10 como exemplo.
[DeviceA] display private-vlan 10
Primary VLAN ID: 10
Secondary VLAN ID: 11-12
VLAN ID: 10
VLAN type: Static
Private-vlan type: Primary
Route interface: Not configured
Description: VLAN 0010
Name: VLAN 0010
Tagged ports:
GigabitEthernet1/0/2
GigabitEthernet1/0/5
Untagged ports:
GigabitEthernet1/0/3
VLAN ID: 11
VLAN type: Static
Private-vlan type: Secondary
Route interface: Not configured
Description: VLAN 0011
Name: VLAN 0011
Tagged ports:
GigabitEthernet1/0/2
GigabitEthernet1/0/5
Untagged ports: None
VLAN ID: 12
VLAN type: Static
Private-vlan type: Secondary
Route interface: Not configured
Description: VLAN 0012
Name: VLAN 0012
Tagged ports:
GigabitEthernet1/0/5
Untagged ports:
GigabitEthernet1/0/3O resultado mostra isso:
A porta promíscua do tronco (GigabitEthernet 1/0/5) é um membro marcado da VLAN 10 primária e das VLANs 11 e 12 secundárias.
A porta tronco secundária (GigabitEthernet 1/0/2) é um membro marcado da VLAN 10 primária e da VLAN 11 secundária.
A porta do host (GigabitEthernet 1/0/3) é um membro sem marcação da VLAN 10 primária e da VLAN 12 secundária.
Exemplo: Configuração da comunicação da camada 3 para VLANs secundárias
Configuração de rede
Conforme mostrado na Figura 11, configure o recurso de VLAN privada para atender aos seguintes requisitos:
A VLAN primária 10 no Dispositivo A está associada às VLANs secundárias 2 e 3. O endereço IP da interface VLAN 10 é 192.168.1.1/24.
A GigabitEthernet 1/0/1 pertence à VLAN 10. A GigabitEthernet 1/0/2 e a GigabitEthernet 1/0/3 pertencem à VLAN 2 e à VLAN 3, respectivamente.
As VLANs secundárias são isoladas na Camada 2, mas interoperáveis na Camada 3.
Figura 11 Diagrama de rede
Procedimento
# Crie a VLAN 10 e configure-a como uma VLAN primária.
<DeviceA> system-view
[DeviceA] vlan 10
[DeviceA-vlan10] private-vlan primary
[DeviceA-vlan10] quit# Crie as VLANs 2 e 3.
<DeviceA> system-view
[DeviceA] vlan 2 to 3 # Associe a VLAN 10 primária às VLANs 2 e 3 secundárias.
[DeviceA] vlan 10
[DeviceA-vlan10] private-vlan primary
[DeviceA-vlan10] private-vlan secondary 2 3
[DeviceA-vlan10] quit # Configure a porta de uplink (GigabitEthernet 1/0/1) como uma porta promíscua da VLAN 10.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port private-vlan 10 promiscuous
[DeviceA-GigabitEthernet1/0/1] quit# Atribua a porta de downlink GigabitEthernet 1/0/2 à VLAN 2 e configure a porta como uma porta de host.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port access vlan 2
[DeviceA-GigabitEthernet1/0/2] port private-vlan host
[DeviceA-GigabitEthernet1/0/2] quit# Atribua a porta de downlink GigabitEthernet 1/0/3 à VLAN 3 e configure a porta como uma porta de host.
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port access vlan 3
[DeviceA-GigabitEthernet1/0/3] port private-vlan host
[DeviceA-GigabitEthernet1/0/3] quit# Habilite a comunicação de camada 3 entre as VLANs secundárias 2 e 3 que estão associadas à VLAN primária 10.
[DeviceA] interface vlan-interface 10
[DeviceA-Vlan-interface10] private-vlan secondary 2 3 # Atribua o endereço IP 192.168.1.1/24 à interface VLAN 10.
[DeviceA-Vlan-interface10] ip address 192.168.1.1 255.255.255.0# Habilite o proxy ARP local na interface VLAN 10. [DeviceA-Vlan-interface10] local-proxy-arp enable [DeviceA-Vlan-interface10] quit
Verificação da configuração
# Exibir a configuração da VLAN 10 primária.
[DeviceA] display private-vlan 10
Primary VLAN ID: 10
Secondary VLAN ID: 2-3
VLAN ID: 10
VLAN type: Static
Private VLAN type: Primary
Route interface: Configured
IPv4 address: 192.168.1.1
IPv4 subnet mask: 255.255.255.0
Description: VLAN 0010
Name: VLAN 0010
Tagged ports: None
Untagged ports:
GigabitEthernet1/0/1
GigabitEthernet1/0/2
GigabitEthernet1/0/3
VLAN ID: 2
VLAN type: Static
Private VLAN type: Secondary
Route interface: Configured
IPv4 address: 192.168.1.1
IPv4 subnet mask: 255.255.255.0
Description: VLAN 0002
Name: VLAN 0002
Tagged ports: None
Untagged ports:
GigabitEthernet1/0/1
GigabitEthernet1/0/2
VLAN ID: 3
VLAN type: Static
Private VLAN type: Secondary
Route interface: Configured
IPv4 address: 192.168.1.1
IPv4 subnet mask: 255.255.255.0
Description: VLAN 0003
Name: VLAN 0003
Tagged ports: None
Untagged ports:
GigabitEthernet1/0/1
GigabitEthernet1/0/3 O campo Interface de rota na saída é Configurado, indicando que as VLANs secundárias 2 e 3 são interoperáveis na Camada 3.
Configuração de Voice Vlan
Sobre a Voice Vlan
Uma Voice Vlan é usada para transmitir tráfego de voz. O dispositivo pode configurar parâmetros de QoS para pacotes de voz para garantir maior prioridade de transmissão dos pacotes de voz.
Os dispositivos de voz comuns incluem telefones IP e dispositivos de acesso integrado (IADs). Este capítulo usa como exemplo os telefones IP .
Mecanismo de trabalho
Quando um telefone IP acessa um dispositivo, o dispositivo executa as seguintes operações:
Identifica o telefone IP na rede e obtém o endereço MAC do telefone IP.
Anuncia as informações da Voice Vlan para o telefone IP.
Após receber as informações da Voice Vlan, o telefone IP realiza a configuração automática. Os pacotes de voz enviados pelo telefone IP podem ser transmitidos dentro da Voice Vlan.
Métodos de identificação de telefones IP
Os dispositivos podem usar os endereços OUI ou LLDP para identificar os telefones IP.
Identificação de telefones IP por meio de endereços OUI
Um dispositivo identifica os pacotes de voz com base em seus endereços MAC de origem. Um pacote cujo endereço MAC de origem esteja de acordo com um endereço OUI (Organizationally Unique Identifier) do dispositivo é considerado um pacote de voz.
Você pode usar os endereços OUI padrão do sistema (consulte a Tabela 1) ou configurar endereços OUI para o dispositivo. Você pode remover ou adicionar manualmente os endereços OUI padrão do sistema.
Tabela 1 Endereços OUI padrão
Normalmente, um endereço OUI refere-se aos primeiros 24 bits de um endereço MAC (em notação binária) e é um identificador globalmente exclusivo que o IEEE atribui a um fornecedor. No entanto, os endereços OUI deste capítulo são endereços que o sistema usa para identificar os pacotes de voz. Eles são os resultados lógicos AND dos argumentos mac-address e oui-mask no comando voice-vlan mac-address.
Identificação automática de telefones IP por meio de LLDP
Se os telefones IP forem compatíveis com LLDP, configure o LLDP para a descoberta automática de telefones IP no dispositivo. O dispositivo pode então descobrir automaticamente o par por meio do LLDP e trocar TLVs LLDP com o par.
Se o LLDP System Capabilities TLV recebido em uma porta indicar que o par pode atuar como um telefone, o dispositivo executará as seguintes operações:
Envia um LLDP TLV com a configuração da Voice Vlan para o par.
Atribui a porta receptora à Voice Vlan.
Aumenta a prioridade de transmissão dos pacotes de voz enviados pelo telefone IP.
Adiciona o endereço MAC do telefone IP à tabela de endereços MAC para garantir que o telefone IP possa passar pela autenticação.
Use o LLDP em vez da lista OUI para identificar telefones IP se a rede tiver mais categorias de telefones IP do que o número máximo de endereços OUI suportados pelo dispositivo. O LLDP tem prioridade mais alta do que a lista OUI.
Para obter mais informações sobre o LLDP, consulte "Configuração do LLDP".
Anunciar as informações da Voice Vlan para os telefones IP
A Figura 12 mostra o fluxo de trabalho da publicidade das informações da Voice Vlan para os telefones IP.
Figura 12 Fluxo de trabalho da publicidade das informações da Voice Vlan para telefones IP
Métodos de acesso ao telefone IP
Conectando o host e o telefone IP em série
Conforme mostrado na Figura 13, o host está conectado ao telefone IP e o telefone IP está conectado ao dispositivo. Nesse cenário, os seguintes requisitos devem ser atendidos:
O host e o telefone IP usam VLANs diferentes.
O telefone IP pode enviar pacotes com marcação de VLAN, para que o dispositivo possa diferenciar o tráfego do host e do telefone IP.
A porta que se conecta ao telefone IP encaminha pacotes da Voice Vlan e do PVID.
Figura 13 Conexão do host e do telefone IP em série
Conexão do telefone IP ao dispositivo
Conforme mostrado na Figura 14, os telefones IP são conectados ao dispositivo sem a presença do host. Use esse método de conexão quando os telefones IP enviarem pacotes de voz não marcados. Nesse cenário, você deve configurar a Voice Vlan como o PVID da porta de acesso do telefone IP e configurar a porta para encaminhar os pacotes do PVID.
Figura 14 Conexão do telefone IP ao dispositivo
Modos de atribuição de Voice Vlan
Uma porta pode ser atribuída a uma Voice Vlan automática ou manualmente.
Modo automático
Use o modo automático quando os PCs e os telefones IP estiverem conectados em série para acessar a rede por meio do dispositivo, conforme mostrado na Figura 13. As portas do dispositivo transmitem tráfego de voz e tráfego de dados.
Quando um telefone IP é ligado, ele envia pacotes de protocolo. Depois de receber esses pacotes de protocolo, o dispositivo usa o endereço MAC de origem dos pacotes de protocolo para fazer a correspondência com seus endereços OUI. Se a correspondência for bem-sucedida, o dispositivo executará as seguintes operações:
Atribui a porta receptora dos pacotes de protocolo à Voice Vlan.
Emite regras de ACL para definir a precedência do pacote.
Inicia o cronômetro de envelhecimento da Voice Vlan.
Se nenhum pacote de voz for recebido da porta antes da expiração do cronômetro de envelhecimento, o dispositivo removerá a porta da Voice Vlan. O cronômetro de envelhecimento também é configurável.
Quando o telefone IP é reinicializado, a porta é reatribuída à Voice Vlan para garantir a operação correta das conexões de voz existentes. A reatribuição ocorre automaticamente sem ser acionada pelo tráfego de voz, desde que a Voice Vlan funcione corretamente.
Modo manual
Use o modo manual quando apenas os telefones IP acessarem a rede por meio do dispositivo, conforme mostrado na Figura
14. Nesse modo, as portas são atribuídas a uma Voice Vlan que transmite exclusivamente o tráfego de voz. Nenhum tráfego de dados afeta a transmissão do tráfego de voz.
Você deve atribuir manualmente a porta que se conecta ao telefone IP a uma Voice Vlan. O dispositivo usa o endereço MAC de origem dos pacotes de voz recebidos para fazer a correspondência com seus endereços OUI. Se a correspondência for bem-sucedida, o dispositivo emitirá regras de ACL para definir a precedência do pacote.
Para remover a porta da Voice Vlan, você deve removê-la manualmente.
Cooperação dos modos de atribuição de Voice Vlan e telefones IP
Alguns telefones IP enviam pacotes com marcação de VLAN e outros enviam apenas pacotes sem marcação. Para o processamento correto dos pacotes, as portas de diferentes tipos de links devem atender a requisitos específicos de configuração em diferentes modos de atribuição de Voice Vlan.
Se um telefone IP enviar tráfego de voz marcado e sua porta de acesso estiver configurada com autenticação 802.1X, VLAN de convidado, VLAN de falha de autenticação ou VLAN crítica, as IDs de VLAN deverão ser diferentes para as seguintes VLANs:
Voice Vlan.
PVID da porta de acesso.
802.1X guest, Auth-Fail ou VLAN crítica.
Se um telefone IP enviar tráfego de voz sem marcação, o PVID da porta de acesso deverá ser a Voice Vlan. Nesse cenário, não há suporte para a autenticação 802.1X.
As portas de acesso não transmitem pacotes marcados.
Requisitos de configuração para a transmissão de tráfego de voz com tags
Requisitos de configuração para a transmissão de tráfego de voz sem marcação
Quando os telefones IP enviam pacotes não marcados, você deve definir o modo de atribuição de Voice Vlan como manual.
Tabela 2 Requisitos de configuração para portas no modo manual para suportar tráfego de voz sem marcação
Modo de segurança e modo normal de Voice Vlan
Dependendo dos mecanismos de filtragem dos pacotes de entrada, uma porta habilitada para Voice Vlan pode operar em um dos seguintes modos:
Modo normal - A porta recebe pacotes com marcação de Voice Vlan e os encaminha para a Voice Vlan sem examinar seus endereços MAC. Se o PVID da porta for a Voice Vlan e a porta operar no modo de atribuição manual de VLAN, a porta encaminhará todos os pacotes não marcados recebidos na Voice Vlan.
Nesse modo, as Voice Vlan são vulneráveis a ataques de tráfego. Usuários mal-intencionados podem enviar um grande número de pacotes falsificados com ou sem marcação de Voice Vlan para afetar a comunicação de voz.
Modo de segurança - A porta usa os endereços MAC de origem dos pacotes de voz para corresponder aos endereços OUI do dispositivo. Os pacotes que não corresponderem serão descartados.
Em uma rede segura, você pode configurar as Voice Vlan para operar no modo normal. Esse modo reduz o consumo de recursos do sistema na verificação do endereço MAC de origem.
Em ambos os modos, o dispositivo modifica a prioridade de transmissão somente para pacotes de Voice Vlan cujos endereços MAC de origem correspondam aos endereços OUI do dispositivo.
Como prática recomendada, não transmita tráfego de voz e tráfego que não seja de voz em uma Voice Vlan. Se for necessário transmitir tráfego diferente em uma Voice Vlan, verifique se o modo de segurança da Voice Vlan está desativado.
Tabela 3 Processamento de pacotes em uma porta habilitada para Voice Vlan no modo normal ou de segurança
Restrições e diretrizes: Configuração da Voice Vlan
O cronômetro de envelhecimento de uma Voice Vlan começa somente quando a entrada de endereço MAC dinâmico da Voice Vlan se esgota. O período de envelhecimento da Voice Vlan é igual à soma do temporizador de envelhecimento da Voice Vlan e do temporizador de envelhecimento de sua entrada de endereço MAC dinâmico. Para obter mais informações sobre o cronômetro de envelhecimento das entradas de endereço MAC dinâmico, consulte "Configuração da tabela de endereços MAC".
Como prática recomendada, não configure a Voice Vlan e desative o aprendizado de endereço MAC em uma porta. Se os dois recursos forem configurados juntos em uma porta, ela encaminhará somente os pacotes que correspondem exatamente aos endereços OUI e descartará os pacotes que não correspondem exatamente.
Como prática recomendada, não configure a Voice Vlan e o limite de aprendizagem de MAC em uma porta. Se os dois recursos forem configurados juntos em uma porta e a porta aprender o número máximo configurado de entradas de endereço MAC, a porta processará os pacotes da seguinte forma:
Encaminha apenas os pacotes que correspondem às entradas de endereço MAC aprendidas pela porta e pelos endereços OUI.
Descarta pacotes não correspondentes.
Configuração dos modos de atribuição de Voice Vlan para uma porta
Configuração de uma porta para operar no modo de atribuição automática de Voice Vlan
Restrições e diretrizes
Não configure uma VLAN como uma Voice Vlan e uma VLAN baseada em protocolo.
Uma Voice Vlan em modo automático em uma porta híbrida processa apenas o tráfego de voz de entrada marcado.
Uma VLAN baseada em protocolo em uma porta híbrida processa somente os pacotes de entrada não marcados. Para obter mais informações sobre VLANs baseadas em protocolo, consulte "Configuração de VLANs baseadas em protocolo".
Como prática recomendada, não use esse modo com MSTP. No modo MSTP, se uma porta estiver bloqueada no MSTI da Voice Vlan de destino, a porta descartará os pacotes recebidos em vez de entregá-los à CPU. Como resultado, a porta não será atribuída dinamicamente à Voice Vlan.
Como prática recomendada, não use esse modo com PVST. No modo PVST, se a Voice Vlan de destino não for permitida em uma porta, ela será colocada em estado bloqueado. A porta descarta os pacotes recebidos em vez de entregá-los à CPU. Como resultado, a porta não será atribuída dinamicamente à Voice Vlan.
Como prática recomendada, não configure a atribuição dinâmica de VLAN baseada em MAC e o modo de atribuição automática de Voice Vlan em uma porta. Eles podem ter um impacto negativo um sobre o outro.
Procedimento
Entre na visualização do sistema.
System View(Opcional.) Defina o cronômetro de envelhecimento da Voice Vlan.
voice-vlan aging minutes Por padrão, o cronômetro de envelhecimento de uma Voice Vlan é de 1440 minutos.
O cronômetro de envelhecimento da Voice Vlan entra em vigor somente nas portas no modo de atribuição automática de Voice Vlan.
(Opcional.) Habilite o modo de segurança da Voice Vlan.
voice-vlan security enablePor padrão, o modo de segurança da Voice Vlan está ativado.
(Opcional.) Adicione um endereço OUI para identificação do pacote de voz.
voice-vlan mac-address oui mask oui-mask [ description text ]Por padrão, existem endereços OUI padrão do sistema. Para obter mais informações, consulte a Tabela 1.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure o tipo de link da porta.
porta link-type tronco
porta tipo link híbrido
Configure a porta para operar no modo de atribuição automática de Voice Vlan.
voice-vlan mode autoPor padrão, o modo de atribuição automática de Voice Vlan está ativado.
Habilite o recurso de Voice Vlan na porta.
voice-vlan vlan-id enablePor padrão, o recurso de Voice Vlan está desativado.
Antes de executar esse comando, verifique se a VLAN especificada já existe.
Configuração de uma porta para operar no modo de atribuição manual de Voice Vlan
Restrições e diretrizes
Você pode configurar Voice Vlan diferentes para portas diferentes no mesmo dispositivo. Certifique-se de que os seguintes requisitos sejam atendidos:
Uma porta pode ser configurada com apenas uma Voice Vlan.
As Voice Vlan devem ser VLANs estáticas existentes.
Não ative a Voice Vlan nas portas membros de um grupo de agregação de links. Para obter mais informações sobre agregação de links, consulte "Configuração da agregação de links Ethernet".
Para que uma Voice Vlan entre em vigor em uma porta operando no modo manual, é necessário atribuir manualmente a porta à Voice Vlan.
Procedimento
Entre na visualização do sistema.
System View(Opcional.) Habilite o modo de segurança da Voice Vlan.
voice-vlan security enablePor padrão, o modo de segurança da Voice Vlan está ativado.
(Opcional.) Adicione um endereço OUI para identificação do pacote de voz.
voice-vlan mac-address oui mask oui-mask [ description text ]Por padrão, existem endereços OUI padrão do sistema. Para obter mais informações, consulte a Tabela 1.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure a porta para operar no modo de atribuição manual de Voice Vlan.
undo voice-vlan mode autoPor padrão, uma porta opera no modo de atribuição automática de Voice Vlan.
Atribua a porta de acesso, tronco ou híbrida à Voice Vlan.
Para a porta de acesso, consulte "Atribuição de uma porta de acesso a uma VLAN".
Para a porta tronco, consulte "Atribuição de uma porta tronco a uma VLAN".
Para a porta híbrida, consulte "Atribuição de uma porta híbrida a uma VLAN".
Depois que você atribuir uma porta de acesso à Voice Vlan, a Voice Vlan se tornará o PVID da porta .
(Opcional.) Configure a Voice Vlan como o PVID do tronco ou da porta híbrida.
Para a porta tronco, consulte "Atribuição de uma porta tronco a uma VLAN".
Para a porta híbrida, consulte "Atribuição de uma porta híbrida a uma VLAN".
Essa etapa é necessária para o tráfego de voz de entrada sem tags e proibida para o tráfego de voz de entrada com tags.
Habilite o recurso de Voice Vlan na porta.
voice-vlan vlan-id enablePor padrão, o recurso de Voice Vlan está desativado.
Antes de executar esse comando, verifique se a VLAN especificada já existe.
Ativação do LLDP para descoberta automática de telefones IP
Restrições e diretrizes
Antes de ativar esse recurso, ative o LLDP globalmente e nas portas de acesso.
Use esse recurso somente com o modo de atribuição automática de Voice Vlan.
Se você usar esse recurso junto com a compatibilidade com CDP, as configurações de Voice Vlan serão excluídas quando os vizinhos de CDP forem excluídos, o que faz com que os telefones IP descobertos automaticamente por meio de LLDP fiquem off-line. Não use esse recurso junto com a compatibilidade com CDP.
Depois que você ativar esse recurso no dispositivo, cada porta do dispositivo poderá ser conectada a um máximo de cinco telefones IP.
Procedimento
Entre na visualização do sistema.
System ViewHabilite o LLDP para a descoberta automática de telefones IP.
voice-vlan track lldpPor padrão, esse recurso está desativado.
Configuração de LLDP ou CDP para anunciar uma Voice Vlan
Sobre a configuração do LLDP para anunciar uma Voice Vlan
Para telefones IP compatíveis com LLDP, o dispositivo anuncia as informações da Voice Vlan para os telefones IP por meio dos TLVs LLDP-MED.
Pré-requisitos
Antes de configurar esse recurso, ative o LLDP globalmente e nas portas de acesso.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure uma VLAN ID de voz anunciada.
lldp tlv-enable med-tlv network-policy vlan-idPor padrão, nenhuma VLAN ID de voz anunciada é configurada.
Para obter mais informações sobre o comando, consulte Layer 2-LAN Switching Command Reference.
(Opcional.) Exibir a Voice Vlan anunciada pelo LLDP.
display lldp local-informationPara obter mais informações sobre o comando, consulte Layer 2-LAN Switching Command Reference.
Configuração do CDP para anunciar uma Voice Vlan
Sobre como configurar o CDP para anunciar uma Voice Vlan
Se um telefone IP for compatível com CDP, mas não com LLDP, ele enviará pacotes CDP ao dispositivo para solicitar a VLAN ID de voz. Se o telefone IP não receber a VLAN ID de voz em um determinado período de tempo, ele enviará pacotes sem marcação. O dispositivo não pode diferenciar os pacotes de voz sem marcação de outros tipos de pacotes.
Você pode configurar a compatibilidade do CDP no dispositivo para permitir que ele execute as seguintes operações:
Receber e identificar pacotes CDP do telefone IP.
Envie pacotes CDP para o telefone IP. As informações da Voice Vlan são transportadas nos pacotes CDP.
Após receber as informações da VLAN anunciada, o telefone IP executa a configuração automática da Voice Vlan. Os pacotes do telefone IP serão transmitidos na Voice Vlan dedicada.
Os pacotes LLDP enviados pelo dispositivo contêm as informações de prioridade. Os pacotes CDP enviados pelo dispositivo não contêm as informações de prioridade.
Pré-requisitos
Antes de configurar esse recurso, ative o LLDP globalmente e nas portas de acesso.
Procedimento
Entre na visualização do sistema.
System ViewHabilitar a compatibilidade com CDP.
cdp de conformidade lldpPor padrão, a compatibilidade com CDP está desativada.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure o LLDP compatível com CDP para operar no modo TxRx.
lldp compliance admin-status cdp txrxPor padrão, o LLDP compatível com CDP opera no modo Disable (Desativado).
Configure uma VLAN ID de voz anunciada.
cdp voice-vlan vlan-idPor padrão, nenhuma VLAN ID de voz anunciada é configurada.
Para obter mais informações sobre o comando, consulte Layer 2-LAN Switching Command Reference.
Exemplos de configuração de Voice Vlan
Exemplo: Configuração do modo de atribuição automática de Voice Vlan
Configuração de rede
Conforme mostrado na Figura 15, o Dispositivo A transmite o tráfego de telefones IP e hosts. Para a transmissão correta do tráfego de voz, execute as seguintes tarefas no Dispositivo A:
Configure as Voice Vlan 2 e 3 para transmitir pacotes de voz do telefone IP A e do telefone IP B,
respectivamente.
Configure a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 para operar no modo de atribuição automática de Voice Vlan.
Adicione os endereços MAC dos telefones IP A e B ao dispositivo para identificação dos pacotes de voz. A máscara dos dois endereços MAC é FFFF-FF00-0000.
Defina um cronômetro de envelhecimento para Voice Vlan.
Figura 15 Diagrama de rede
Procedimento
Configure as Voice Vlan:
# Crie as VLANs 2 e 3.
<DeviceA> system-view
[DeviceA] vlan 2 to 3 # Defina o cronômetro de envelhecimento da Voice Vlan para 30 minutos.
[DeviceA] voice-vlan aging 30# Ativar o modo de segurança para Voice Vlan.
[DeviceA] voice-vlan security enable# Adicione os endereços MAC dos telefones IP A e B ao dispositivo com a máscara FFFF-FF00-0000.
[DeviceA] voice-vlan mac-address 0011-1100-0001 mask ffff-ff00-0000 description IP phone A
[DeviceA] voice-vlan mac-address 0011-2200-0001 mask ffff-ff00-0000 description IP phone BConfigure a GigabitEthernet 1/0/1:
# Configure a GigabitEthernet 1/0/1 como uma porta híbrida.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type hybrid# Configure a GigabitEthernet 1/0/1 para operar no modo de atribuição automática de Voice Vlan.
[DeviceA-GigabitEthernet1/0/1] voice-vlan mode auto# Habilite a Voice Vlan na GigabitEthernet 1/0/1 e configure a VLAN 2 como a Voice Vlan para ela.
[DeviceA-GigabitEthernet1/0/1] voice-vlan 2 enable
[DeviceA-GigabitEthernet1/0/1] quitConfigure a GigabitEthernet 1/0/2:
# Configure a GigabitEthernet 1/0/2 como uma porta híbrida.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type hybrid# Configure a GigabitEthernet 1/0/2 para operar no modo de atribuição automática de Voice Vlan.
[DeviceA-GigabitEthernet1/0/2] voice-vlan mode auto# Habilite a Voice Vlan na GigabitEthernet 1/0/2 e configure a VLAN 3 como a Voice Vlan para ela.
[DeviceA-GigabitEthernet1/0/2] voice-vlan 3 enable
[DeviceA-GigabitEthernet1/0/2] quitVerificação da configuração
# Exibir os endereços OUI compatíveis com o dispositivo A.
[DeviceA] display voice-vlan mac-address
OUI Address
Mask
Description
0001-e300-0000 ffff-ff00-0000 Siemens phone
0003-6b00-0000 ffff-ff00-0000 Cisco phone
0004-0d00-0000 ffff-ff00-0000 Avaya phone
000f-e200-0000 ffff-ff00-0000 INTELBRAS Aolynk phone
0011-1100-0000 ffff-ff00-0000 IP phone A
0011-2200-0000 ffff-ff00-0000 IP phone B
0060-b900-0000 ffff-ff00-0000 Philips/NEC phone
00d0-1e00-0000 ffff-ff00-0000 Pingtel phone
00e0-7500-0000 ffff-ff00-0000 Polycom phone
00e0-bb00-0000 ffff-ff00-0000 3Com phone# Exibir o estado da Voice Vlan.
[DeviceA] display voice-vlan state
Current voice VLANs: 2
Voice VLAN security mode: Security
Voice VLAN aging time: 30 minutes
Voice VLAN enabled ports and their modes:
Port VLAN Mode CoS DSCP
GE1/0/1 2 Auto 6 46
GE1/0/2 3 Auto 6 46
Exemplo: Configuração do modo de atribuição manual de Voice Vlan
Configuração de rede
Conforme mostrado na Figura 16, o telefone IP A envia tráfego de voz sem marcação.
Para ativar a GigabitEthernet 1/0/1 para transmitir somente pacotes de voz, execute as seguintes tarefas no Dispositivo A:
Crie a VLAN 2. Essa VLAN será usada como uma Voice Vlan.
Configure a GigabitEthernet 1/0/1 para operar no modo de atribuição manual de Voice Vlan e adicione-a à VLAN 2.
Adicione o endereço OUI do telefone IP A à lista OUI do dispositivo A.
Figura 16 Diagrama de rede
Procedimento
# Habilitar o modo de segurança para Voice Vlan.
<DeviceA> system-view
[DeviceA] voice-vlan security enable# Adicione o endereço MAC 0011-2200-0001 com a máscara FFFF-FF00-0000.
[DeviceA] voice-vlan mac-address 0011-2200-0001 mask ffff-ff00-0000 description test # Criar a VLAN 2.
[DeviceA] vlan 2
[DeviceA-vlan2] quit
# Configure a GigabitEthernet 1/0/1 para operar no modo de atribuição manual de Voice Vlan.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] undo voice-vlan mode auto # Configure a GigabitEthernet 1/0/1 como uma porta híbrida.
[DeviceA-GigabitEthernet1/0/1] port link-type hybrid# Defina o PVID da GigabitEthernet 1/0/1 como VLAN 2.
[DeviceA-GigabitEthernet1/0/1] port hybrid pvid vlan 2# Atribua a GigabitEthernet 1/0/1 à VLAN 2 como um membro de VLAN sem marcação.
[DeviceA-GigabitEthernet1/0/1] port hybrid vlan 2 untagged# Habilite a Voice Vlan e configure a VLAN 2 como a Voice Vlan na GigabitEthernet 1/0/1.
[DeviceA-GigabitEthernet1/0/1] voice-vlan 2 enable [DeviceA-GigabitEthernet1/0/1] quitVerificação da configuração
# Exibir os endereços OUI compatíveis com o dispositivo A.
[DeviceA] display voice-vlan mac-address
OUI Address
Mask
Description
0001-e300-0000 ffff-ff00-0000 Siemens phone
0003-6b00-0000 ffff-ff00-0000 Cisco phone
0004-0d00-0000 ffff-ff00-0000 Avaya phone
000f-e200-0000 ffff-ff00-0000 INTELBRAS Aolynk phone
0011-1100-0000 ffff-ff00-0000 IP phone A
0011-2200-0000 ffff-ff00-0000 IP phone B
0060-b900-0000 ffff-ff00-0000 Philips/NEC phone
00d0-1e00-0000 ffff-ff00-0000 Pingtel phone
00e0-7500-0000 ffff-ff00-0000 Polycom phone
00e0-bb00-0000 ffff-ff00-0000 3Com phone# Exibir o estado da Voice Vlan.
[DeviceA] display voice-vlan state Voice Vlan atuais: 1
Modo de segurança da Voice Vlan: Segurança Tempo de envelhecimento da Voice Vlan: 1440 minutos
Portas habilitadas para Voice VLAN e seus modos:
Configuração do MVRP
Sobre a MVRP
O MRP (Multiple Registration Protocol) é um protocolo de registro de atributos usado para transmitir valores de atributos. O protocolo de registro de múltiplas VLANs (MVRP) é um aplicativo MRP típico. Ele sincroniza as informações de VLAN entre os dispositivos e reduz bastante a carga de trabalho dos administradores de rede.
Implementação do MRP
Uma porta habilitada para MRP é chamada de participante de MRP. Uma porta habilitada para MVRP é chamada de participante de MVRP.
Conforme mostrado na Figura 1, um participante do MRP envia declarações e retiradas para notificar outros participantes a registrar e cancelar o registro de seus valores de atributo. Ele também registra e cancela o registro dos valores de atributos de outros participantes de acordo com as declarações e retiradas recebidas. O MRP propaga rapidamente as informações de configuração de um participante do MRP por toda a LAN.
Figura 1 Implementação do MRP
Por exemplo, o MRP registra e cancela o registro de atributos de VLAN da seguinte forma:
Quando uma porta recebe uma declaração para uma VLAN, a porta registra a VLAN e entra na VLAN.
Quando uma porta recebe uma retirada para uma VLAN, a porta cancela o registro da VLAN e sai da VLAN.
O MRP permite que os dispositivos na mesma LAN transmitam valores de atributos por MSTI. A Figura 1 mostra uma implementação simples de MRP em um MSTI. Em uma rede com vários MSTIs, o MRP realiza o registro e o cancelamento do registro de atributos por MSTI. Para obter mais informações sobre MSTIs, consulte "Configuração de protocolos Spanning Tree".
Mensagens MRP
As mensagens MRP incluem os seguintes tipos:
Declaração - Inclui mensagens de ingresso e novas mensagens.
Retirada-Inclui as mensagens Leave e LeaveAll.
Junte-se à mensagem
Um participante do MRP envia uma mensagem Join para solicitar que o participante par registre atributos na mensagem Join.
Ao receber uma mensagem Join do participante par, um participante MRP executa as seguintes tarefas:
Registra os atributos na mensagem Join.
Propaga a mensagem Join para todos os outros participantes no dispositivo.
Depois de receber a mensagem Join, os outros participantes enviam a mensagem Join para seus respectivos pares de participantes.
As mensagens de ingresso enviadas de um participante local para seu participante par incluem os seguintes tipos:
JoinEmpty-Declara um atributo não registrado. Por exemplo, quando um participante do MRP se junta a uma VLAN estática não registrada, ele envia uma mensagem JoinEmpty.
As VLANs criadas manual e localmente são chamadas de VLANs estáticas. As VLANs aprendidas por meio do MRP são chamadas de VLANs dinâmicas.
JoinIn - Declara um atributo registrado. Uma mensagem JoinIn é usada em uma das seguintes situações:
Um participante do MRP se junta a uma VLAN estática existente e envia uma mensagem JoinIn após registrar a VLAN.
O participante do MRP recebe uma mensagem Join propagada por outro participante no dispositivo e envia uma mensagem JoinIn após registrar a VLAN.
Nova mensagem
Semelhante a uma mensagem Join, uma mensagem New permite que os participantes do MRP registrem atributos.
Quando a topologia do MSTP muda, um participante do MRP envia uma mensagem New ao participante par para declarar a mudança de topologia.
Ao receber uma mensagem New do participante par, um participante MRP executa as seguintes tarefas:
Registra os atributos na mensagem.
Propaga a mensagem Nova para todos os outros participantes no dispositivo.
Depois de receber a mensagem New, os outros participantes enviam a mensagem New para seus respectivos participantes pares.
Deixar mensagem
Um participante MRP envia uma mensagem Leave (Deixar) para o participante par quando deseja que o participante par cancele o registro de atributos que ele cancelou.
Quando o participante par recebe a mensagem Leave, ele executa as seguintes tarefas:
Cancela o registro do atributo na mensagem de saída.
Propaga a mensagem Leave (Sair) para todos os outros participantes no dispositivo.
Depois que um participante no dispositivo recebe a mensagem Leave (Sair), ele determina se deve enviar a mensagem Leave (Sair) para o participante par, dependendo do status do atributo no dispositivo.
Se a VLAN na mensagem Leave for uma VLAN dinâmica não registrada por nenhum participante no dispositivo, ocorrerão os dois eventos a seguir:
A VLAN é excluída no dispositivo.
O participante envia a mensagem Leave (Sair) para o participante par.
Se a VLAN na mensagem Leave for uma VLAN estática, o participante não enviará a mensagem Leave para o participante par.
Mensagem LeaveAll
Cada participante do MRP inicia seu cronômetro LeaveAll ao iniciar. Quando o cronômetro expira, o participante MRP envia mensagens LeaveAll para o participante par.
Ao enviar ou receber uma mensagem LeaveAll, o participante local inicia o cronômetro Leave. O participante local determina se deve enviar uma mensagem Join dependendo de seu status de atributo. Um participante pode registrar novamente os atributos na mensagem Join recebida antes que o temporizador Leave expire.
Quando o temporizador Leave expira, um participante cancela o registro de todos os atributos que não foram registrados novamente para limpar periodicamente os atributos inúteis na rede.
Temporizadores MRP
O MRP usa os seguintes temporizadores para controlar a transmissão de mensagens.
Temporizador periódico
O timer Periodic controla a transmissão de mensagens MRP. Um participante do MRP inicia seu próprio timer Periodic na inicialização e armazena mensagens MRP a serem enviadas antes que o timer Periodic expire. Quando o timer Periodic expira, o MRP envia mensagens MRP armazenadas no menor número possível de quadros MRP e reinicia o timer Periodic. Esse mecanismo reduz o número de quadros MRP enviados.
Você pode ativar ou desativar o timer Periodic. Quando o timer Periodic está desativado, o MRP não envia mensagens MRP periodicamente. Em vez disso, um participante do MRP envia mensagens MRP quando o temporizador LeaveAll expira ou quando o participante recebe uma mensagem LeaveAll do participante par.
Aderir ao cronômetro
O temporizador de associação controla a transmissão de mensagens de associação. Um participante do MRP inicia o cronômetro de associação depois de enviar uma mensagem de associação ao participante par. Antes que o cronômetro de Join expire, o participante não reenvia a mensagem Join quando as condições a seguir existem:
O participante recebe uma mensagem JoinIn do participante par.
A mensagem JoinIn recebida tem os mesmos atributos da mensagem Join enviada.
Quando o cronômetro de ingresso e o cronômetro periódico expiram, o participante reenvia a mensagem de ingresso.
Deixar o cronômetro
O temporizador Leave controla o cancelamento do registro de atributos.
Um participante do MRP inicia o cronômetro de licença em uma das seguintes condições:
O participante recebe uma mensagem Leave (Sair) de seu colega participante.
O participante recebe ou envia uma mensagem LeaveAll.
O participante do MRP não cancela o registro dos atributos na mensagem Leave ou LeaveAll se as seguintes condições existirem:
O participante recebe uma mensagem Join antes que o cronômetro Leave expire.
A mensagem Join inclui os atributos que foram encapsulados na mensagem Leave ou LeaveAll.
Se o participante não receber uma mensagem Join para esses atributos antes que o temporizador Leave expire, o MRP cancela o registro dos atributos.
Temporizador LeaveAll
Após a inicialização, um participante do MRP inicia seu próprio cronômetro LeaveAll. Quando o cronômetro LeaveAll expira, o participante do MRP envia uma mensagem LeaveAll e reinicia o cronômetro LeaveAll.
Ao receber a mensagem LeaveAll, os outros participantes reiniciam o cronômetro LeaveAll. O valor do cronômetro LeaveAll é selecionado aleatoriamente entre o cronômetro LeaveAll e 1,5 vezes o cronômetro LeaveAll. Esse mecanismo oferece os seguintes benefícios:
Reduz efetivamente o número de mensagens LeaveAll na rede.
Impede que o cronômetro LeaveAll de um determinado participante expire sempre primeiro.
Modos de registro do MVRP
As informações de VLAN propagadas pelo MVRP incluem informações de VLAN dinâmicas de outros dispositivos e informações de VLAN estáticas locais.
Com base em como um participante do MVRP lida com o registro de VLANs dinâmicas, o MVRP tem os seguintes modos de registro:
Normal - Um participante do MVRP no modo de registro normal registra e cancela o registro de VLANs dinâmicas.
Fixo - Um participante do MVRP no modo de registro fixo desativa o cancelamento do registro de VLANs dinâmicas e descarta os quadros MVRP recebidos. O participante do MVRP não cancela o registro de VLANs dinâmicas nem registra novas VLANs dinâmicas.
Forbidden (Proibido) - Um participante do MVRP no modo de registro proibido desativa o registro de VLANs dinâmicas e descarta os quadros MVRP recebidos. Quando você define o modo de registro proibido para uma porta, a VLAN 1 da porta é mantida e todas as VLANs registradas dinamicamente da porta são excluídas.
Protocolos e padrões
IEEE 802.1ak, Padrão IEEE para redes locais e metropolitanas: Virtual Bridged Local Area Networks - Emenda 07: Protocolo de registro múltiplo
Restrições e diretrizes: Configuração do MVRP
Quando você configurar o MVRP, siga estas restrições e diretrizes:
O MVRP pode funcionar com STP, RSTP ou MSTP. As portas bloqueadas pelo STP, RSTP ou MSTP podem receber e enviar quadros MVRP. Não configure o MVRP com outros protocolos de topologia de camada de link, como PVST, RRPP e Smart Link.
Para obter mais informações sobre STP, RSTP, MSTP e PVST, consulte "Configuração de protocolos de spanning tree". Para obter mais informações sobre RRPP e Smart Link, consulte o Guia de configuração de alta disponibilidade.
Não configure o MVRP e o espelhamento de porta remota em uma porta. Caso contrário, o MVRP poderá registrar a VLAN da sonda remota com portas incorretas, o que faria com que a porta do monitor recebesse cópias indesejadas. Para obter mais informações sobre espelhamento de porta, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
A ativação do MVRP em uma interface agregada de camada 2 tem efeito na interface agregada e em todas as portas membros selecionadas no grupo de agregação de links.
A configuração do MVRP feita em uma porta membro do grupo de agregação entra em vigor somente depois que a porta é removida do grupo de agregação.
Visão geral das tarefas do MVRP
Para configurar o MVRP, execute as seguintes tarefas:
Ativação do MVRP
Configuração de um modo de registro MVRP
(Opcional.) Configuração de temporizadores MRP
(Opcional.) Ativação da compatibilidade com GVRP
Pré-requisitos
Antes de configurar o MVRP, conclua as seguintes tarefas:
Mapeie cada MSTI usado pelo MVRP para uma VLAN existente em cada dispositivo da rede.
Defina o tipo de link de porta dos participantes do MVRP como tronco, pois o MVRP tem efeito somente nas portas tronco. Para obter mais informações sobre portas tronco, consulte "Configuração de VLANs".
Ativação do MVRP
Entre na visualização do sistema.
System ViewAtivar o MVRP globalmente.
mvrp global enablePor padrão, o MVRP está globalmente desativado.
Para que o MVRP entre em vigor em uma porta, ative o MVRP na porta e globalmente.
Entre na visualização da interface Ethernet de camada 2 ou na visualização da interface agregada de camada 2.
interface interface-type interface-numberConfigure a porta como uma porta tronco.
port link-type trunkPor padrão, cada porta é uma porta de acesso. Para obter mais informações sobre o comando port link-type trunk, consulte Referência de comandos de comutação de Layer 2-LAN.
Configure a porta tronco para permitir as VLANs especificadas. port trunk permit vlan { vlan-id-list | all } Por padrão, uma porta tronco permite apenas a VLAN 1.
Certifique-se de que a porta tronco permita todas as VLANs registradas.
Para obter mais informações sobre o comando port trunk permit vlan, consulte Layer 2-LAN Switching Command Reference.
Habilita o MVRP na porta.
mvrp enablePor padrão, o MVRP está desativado em uma porta.
Configuração de um modo de registro MVRP
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet da Camada 2 ou na visualização da interface agregada da Camada 2.
interface interface-type interface-numberDefina um modo de registro MVRP para a porta.
registro mvrp { fixo | proibido | normal }
A configuração padrão é o modo de registro normal.
Configuração de temporizadores MRP
Restrições e diretrizes
Quando você definir os temporizadores MVRP, siga estas restrições e diretrizes:
Siga os requisitos de intervalo de valores para os temporizadores Join, Leave e LeaveAll e suas dependências, conforme descrito na Tabela 1. Se você definir um temporizador com um valor além do intervalo de valores permitido, sua configuração falhará. Você pode definir um temporizador ajustando o valor de qualquer outro temporizador. O valor de cada timer deve ser um número inteiro múltiplo de 20 centissegundos.
Tabela 1 Dependências dos temporizadores Join, Leave e LeaveAll
Para evitar registros e cancelamentos de registros de VLAN frequentes, use os mesmos temporizadores MRP em toda a rede.
Cada porta mantém seus próprios timers Periodic, Join e LeaveAll, e cada atributo de uma porta mantém um timer Leave.
Como prática recomendada, restaure os cronômetros na ordem de Join, Leave e LeaveAll ao restaurar esses cronômetros para seus valores padrão.
Você pode restaurar o timer Periodic ao seu valor padrão a qualquer momento.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2 ou na visualização da interface agregada de camada 2.
interface interface-type interface-numberDefina o cronômetro LeaveAll.
mrp timer leaveall timer-valueA configuração padrão é 1000 centissegundos.
mrp timer join timer-value Valor do timer de ingresso no timer do mrp
A configuração padrão é 20 centissegundos.
Defina o cronômetro de licença.
mrp timer leave timer-valueA configuração padrão é 60 centissegundos.
Defina o cronômetro Periodic.
mrp timer periodic timer-value A configuração padrão é 100 centissegundos.
Ativação da compatibilidade com GVRP
Sobre a compatibilidade com GVRP
Execute esta tarefa para permitir que o dispositivo receba e envie quadros MVRP e GVRP quando o dispositivo par suportar GVRP. Para obter mais informações sobre o GVRP, consulte o padrão IEEE 802.1Q.
Restrições e diretrizes
Quando você ativar a compatibilidade com GVRP, siga estas restrições e diretrizes:
A compatibilidade do GVRP permite que o MVRP funcione com o STP ou o RSTP, mas não com o MSTP.
Quando o sistema estiver ocupado, desative o timer Period para evitar que o participante registre ou cancele o registro de atributos com frequência.
Procedimento
Entre na visualização do sistema.
System ViewHabilitar a compatibilidade com GVRP.
mvrp gvrp-compliance enablePor padrão, a compatibilidade com GVRP está desativada.
Exemplos de configuração de MVRP
Exemplo: Configuração das funções básicas do MVRP
Configuração de rede
Conforme mostrado na Figura 2:
Crie a VLAN 10 no dispositivo A e a VLAN 20 no dispositivo B.
Configure o MSTP, mapeie a VLAN 10 para o MSTI 1, mapeie a VLAN 20 para o MSTI 2 e mapeie as outras VLANs para o MSTI 0.
Configure o MVRP no Dispositivo A, Dispositivo B, Dispositivo C e Dispositivo D para atender aos seguintes requisitos:
Os dispositivos podem registrar e cancelar o registro de VLANs dinâmicas.
Os dispositivos podem manter configurações de VLAN idênticas para cada MSTI.
Figura 2 Diagrama de rede
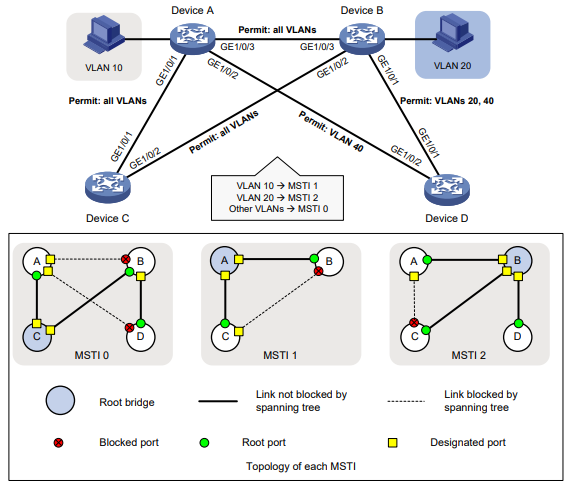
Procedimento
Configurar o dispositivo A:
# Entre na visualização da região MST.
<DeviceA> system-view
[DeviceA] stp region-configuration# Configure o nome da região MST, os mapeamentos de VLAN para instância e o nível de revisão.
[DeviceA-mst-region] region-name example
[DeviceA-mst-region] instance 1 vlan 10
[DeviceA-mst-region] instance 2 vlan 20
[DeviceA-mst-region] revision-level 0 # Ativar manualmente a configuração da região MST.
[DeviceA-mst-region] active region-configuration
[DeviceA-mst-region] quit # Configure o dispositivo A como a ponte raiz primária do MSTI 1.
[DeviceA] stp instance 1 root primary # Ativa globalmente o recurso de spanning tree.
[DeviceA] stp global enable# Ativar globalmente o MVRP.
[DeviceA] mvrp global enable# Configure a GigabitEthernet 1/0/1 como uma porta tronco e configure-a para permitir todas as VLANs.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type trunk
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan all # Configure a GigabitEthernet 1/0/2 como uma porta tronco e configure-a para permitir a VLAN 40.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 40 # Enable MVRP on GigabitEthernet 1/0/2.
[DeviceA-GigabitEthernet1/0/2] mvrp enable
[DeviceA-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 como uma porta tronco e configure-a para permitir todas as VLANs.
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port link-type trunk
[DeviceA-GigabitEthernet1/0/3] port trunk permit vlan all# Habilite o MVRP na GigabitEthernet 1/0/3.
[DeviceA-GigabitEthernet1/0/3] mvrp enable
[DeviceA-GigabitEthernet1/0/3] quit# Criar a VLAN 10
[DeviceA] vlan 10
[DeviceA-vlan10] quitConfigurar o dispositivo B:
# Entre na visualização da região MST.
<DeviceB> system-view
[DeviceB] stp region-configuration# Configure o nome da região MST, os mapeamentos de VLAN para instância e o nível de revisão.
[DeviceB-mst-region] region-name example
[DeviceB-mst-region] instance 1 vlan 10
[DeviceB-mst-region] instance 2 vlan 20
[DeviceB-mst-region] revision-level 0# Ativar manualmente a configuração da região MST.
[DeviceB-mst-region] active region-configuration
[DeviceB-mst-region] quit# Configure o dispositivo B como a ponte raiz primária do MSTI 2.
[DeviceB] stp instance 2 root primary# Habilita globalmente o recurso de spanning tree.
[DeviceB] stp global enable # Ativar globalmente o MVRP.
[DeviceB] mvrp global enable # Configure a GigabitEthernet 1/0/1 como uma porta tronco e configure-a para permitir as VLANs 20 e 40.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type trunk
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 20 40# Habilite o MVRP na GigabitEthernet 1/0/1.
[DeviceB-GigabitEthernet1/0/1] mvrp enable
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco e configure-a para permitir todas as VLANs.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan all# Habilite o MVRP na GigabitEthernet 1/0/2.
[DeviceB-GigabitEthernet1/0/2] mvrp enable
[DeviceB-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 como uma porta tronco e configure-a para permitir todas as VLANs.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] port link-type trunk
[DeviceB-GigabitEthernet1/0/3] port trunk permit vlan all# Habilite o MVRP na GigabitEthernet 1/0/3.
[DeviceB-GigabitEthernet1/0/3] mvrp enable
[DeviceB-GigabitEthernet1/0/3] quit# Criar VLAN 20.
[DeviceB] vlan 20 [DeviceB-vlan20] quiConfigurar o dispositivo C:
# Entre na visualização da região MST.
<DeviceC> system-view
[DeviceC] stp region-configuration# Configure o nome da região MST, os mapeamentos de VLAN para instância e o nível de revisão.
[DeviceC-mst-region] region-name example
[DeviceC-mst-region] instance 1 vlan 10
[DeviceC-mst-region] instance 2 vlan 20
[DeviceC-mst-region] revision-level 0# Ativar manualmente a configuração da região MST.
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit# Configure o dispositivo C como a ponte raiz do MSTI 0.
[DeviceC] stp instance 0 root primary# Habilita globalmente o recurso de spanning tree.
[DeviceC] stp global enable# Ativar globalmente o MVRP.
[DeviceC] mvrp global enable# Configure a GigabitEthernet 1/0/1 como uma porta tronco e configure-a para permitir todas as VLANs.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] port link-type trunk
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan all# Configure a GigabitEthernet 1/0/2 como uma porta tronco e configure-a para permitir todas as VLANs.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan all# Habilite o MVRP na GigabitEthernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] mvrp enable
[DeviceC-GigabitEthernet1/0/2] quitConfigurar o dispositivo D:
# Entre na visualização da região MST.
><DeviceD> system-view
[DeviceD] stp region-configuration # Configure o nome da região MST, os mapeamentos de VLAN para instância e o nível de revisão.
[DeviceD-mst-region] region-name example
[DeviceD-mst-region] instance 1 vlan 10
[DeviceD-mst-region] instance 2 vlan 20
[DeviceD-mst-region] revision-level 0# Ativar manualmente a configuração da região MST.
[DeviceD-mst-region] active region-configuration
[DeviceD-mst-region] quit# Ativar globalmente o recurso Spanning Tree.
[Ativar globalmente o MVRP. [DeviceD] mvrp global enable# Configure a GigabitEthernet 1/0/1 como uma porta tronco e configure-a para permitir as VLANs 20 e 40.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] port link-type trunk
[DeviceD-GigabitEthernet1/0/1] port trunk permit vlan 20 40# Habilite o MVRP na GigabitEthernet 1/0/1.
[DeviceD-GigabitEthernet1/0/1] mvrp enable
[DeviceD-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco e configure-a para permitir a VLAN 40.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] port link-type trunk
[DeviceD-GigabitEthernet1/0/2] port trunk permit vlan 40Verificação da configuração
Verifique a configuração do modo de registro normal. # Exibir informações da VLAN local no Dispositivo A.
[DeviceA] display mvrp running-status
-------[MVRP Global Info]-------
Global Status : Enabled
Compliance-GVRP : False
----[GigabitEthernet1/0/1]----
Config Status : Enabled
Running Status : Enabled
Join Timer : 20 (centiseconds)
Leave Timer : 60 (centiseconds)
Periodic Timer : 100 (centiseconds)
LeaveAll Timer : 100 (centiseconds)
Registration Type : Normal
Registered VLANs :
1(default)
Declared VLANs :
1(default), 10, 20
Propagated VLANs :
1(default)
----[GigabitEthernet1/0/2]----
Config Status : Enabled
Running Status : Enabled
Join Timer : 20 (centiseconds)
Leave Timer : 60 (centiseconds)
Periodic Timer : 100 (centiseconds)
LeaveAll Timer : 1000 (centiseconds)
Registration Type : Normal
Registered VLANs :
None
Declared VLANs :
1(default)
Propagated VLANs :
None
----[GigabitEthernet1/0/3]----
Config Status : Enabled
Running Status : Enabled
Join Timer : 20 (centiseconds)
Leave Timer : 60 (centiseconds)
Periodic Timer : 100 (centiseconds)
LeaveAll Timer : 1000 (centiseconds)
Registration Type : Normal
Registered VLANs :
20
Declared VLANs :
1(default) 10
Propagated VLANs :
20
A saída mostra que os seguintes eventos ocorreram:
A GigabitEthernet 1/0/1 registrou a VLAN 1, declarou a VLAN 1, a VLAN 10 e a VLAN 20, e propagou a VLAN 1 por meio do MVRP.
A GigabitEthernet 1/0/2 declarou a VLAN 1 e não registrou e propagou nenhuma VLAN.
A GigabitEthernet 1/0/3 registrou a VLAN 20, declarou a VLAN 1 e a VLAN 10 e propagou a VLAN 20 por meio do MVRP.
Configuração do QinQ
Sobre a QinQ
Aplicavel somente a Serie S3300G
O Q-in-802.1Q (QinQ) adiciona uma tag 802.1Q ao tráfego de clientes com tags 802.1Q. Ele permite que um provedor de serviços estenda as conexões de camada 2 em uma rede Ethernet entre os sites dos clientes.
Benefícios do QinQ
O QinQ oferece os seguintes benefícios:
Permite que um provedor de serviços use uma única SVLAN para transmitir várias CVLANs para um cliente.
Permite que os clientes planejem CVLANs sem entrar em conflito com SVLANs.
Permite que os clientes mantenham seus esquemas de atribuição de VLAN inalterados quando o provedor de serviços altera seu esquema de atribuição de VLAN.
Permite que clientes diferentes usem CVLAN IDs sobrepostas. Os dispositivos na rede do provedor de serviços tomam decisões de encaminhamento com base em SVLAN IDs em vez de CVLAN IDs.
Como o QinQ funciona
Conforme mostrado na Figura 1, um quadro QinQ transmitido pela rede do provedor de serviços contém as seguintes tags:
Etiqueta CVLAN - Identifica a VLAN à qual o quadro pertence quando é transmitido na rede do cliente.
Etiqueta SVLAN - Identifica a VLAN à qual o quadro QinQ pertence quando é transmitido na rede do provedor de serviços. O provedor de serviços aloca a tag SVLAN para o cliente.
Os dispositivos na rede do provedor de serviços encaminham um quadro com tag de acordo apenas com sua tag SVLAN. A tag CVLAN é transmitida como parte da carga útil do quadro.
Figura 1 Cabeçalho de quadro Ethernet com marcação única e cabeçalho de quadro Ethernet com marcação dupla
Conforme mostrado na Figura 2, o cliente A tem sites remotos CE 1 e CE 4. O cliente B tem sites remotos CE 2 e CE 3. As CVLANs dos dois clientes se sobrepõem. O provedor de serviços atribui SVLANs 3 e 4 aos clientes A e B, respectivamente.
Quando um quadro Ethernet marcado do CE 1 chega ao PE 1, o PE marca o quadro com SVLAN 3. O quadro Ethernet com marcação dupla viaja pela rede do provedor de serviços até chegar ao PE 2. O PE 2 remove a tag SVLAN do quadro e, em seguida, envia o quadro para o CE 4.
Figura 2 Cenário típico de aplicação do QinQ
Implementações de QinQ
O QinQ é ativado por porta. O tipo de link de uma porta habilitada para QinQ pode ser de acesso, híbrido ou tronco. Os comportamentos de marcação de QinQ são os mesmos entre esses tipos de portas.
Uma porta habilitada para QinQ marca todos os quadros de entrada (marcados ou não marcados) com a tag PVID.
Se um quadro de entrada já tiver uma tag, ele se tornará um quadro com tag dupla.
Se o quadro não tiver nenhuma tag 802.1Q, ele se tornará um quadro marcado com o PVID.
O QinQ fornece o método mais básico de manipulação de VLAN para marcar todos os quadros de entrada (marcados ou não marcados) com a marca PVID. Para realizar manipulações avançadas de VLAN, use mapeamentos de VLAN ou políticas de QoS da seguinte forma:
Para adicionar SVLANs diferentes para tags de CVLAN diferentes, use mapeamentos de VLAN um para dois.
Para usar critérios diferentes do CVLAN ID para combinar pacotes para marcação de SVLAN, use a ação de aninhamento de QoS. A ação de aninhamento de QoS também pode ser usada com outras ações no mesmo comportamento de tráfego.
Para obter mais informações sobre mapeamentos de VLAN, consulte "Configuração do mapeamento de VLAN". Para obter mais informações sobre QoS no site , consulte o Guia de configuração de ACL e QoS.
Restrições e diretrizes: Configuração do QinQ
Quando você configurar o QinQ, siga estas restrições e diretrizes:
A etiqueta 802.1Q interna dos quadros QinQ é tratada como parte da carga útil. Como prática recomendada para garantir a transmissão correta de quadros QinQ, defina o MTU para um mínimo de 1504 bytes para cada porta em seu caminho de encaminhamento. Esse valor é a soma do MTU padrão da interface Ethernet (1500 bytes) com o comprimento (4 bytes) de uma tag de VLAN.
É possível usar um mapeamento de VLAN e QinQ em uma porta para manipulação de tags de VLAN. Se suas configurações entrarem em conflito, o mapeamento de VLAN terá prioridade mais alta.
Não ative o QinQ e aplique uma política de QoS que contenha uma ação de aninhamento na mesma interface. Caso contrário, o QinQ ou a política de QoS poderá não entrar em vigor.
Ativação do QinQ
Sobre a habilitação do QinQ
Habilite o QinQ nas portas do lado do cliente dos PEs. Uma porta habilitada para QinQ marca um quadro de entrada com seu PVID.
Restrições e diretrizes
Antes de ativar ou desativar o QinQ em uma porta, você deve remover qualquer mapeamento de VLAN na porta. Para obter mais informações sobre mapeamento de VLAN, consulte o Layer 2-LAN Switching Configuration Guide.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2 ou na visualização da interface agregada de camada 2.
interface interface-type interface-numberDefinir o tipo de link da porta.
port link-type { access | hybrid | trunk }Por padrão, o tipo de link de uma porta é acesso.
Configure a porta para permitir a passagem de pacotes de seu PVID.
Atribuir a porta de acesso à VLAN especificada.
port access vlan vlan-id Por padrão, todas as portas de acesso pertencem à VLAN 1.
O PVID de uma porta de acesso é a VLAN à qual a porta pertence. A porta envia pacotes da VLAN sem marcação.
Configure a porta híbrida para enviar pacotes de seu PVID sem marcação.
port hybrid vlan vlan-id-list untaggedPor padrão, a porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é de acesso.
Configure a porta tronco para permitir a passagem de pacotes de seu PVID.
port trunk permit vlan { vlan-id-list | all }Por padrão, uma porta tronco permite a passagem de pacotes apenas da VLAN 1.
Habilite o QinQ na porta.
qinq enablePor padrão, o QinQ está desativado na porta.
Configuração da transmissão para VLANs transparentes
Sobre a VLAN transparente
É possível excluir uma VLAN (por exemplo, a VLAN de gerenciamento) da ação de marcação QinQ em uma porta do lado do cliente. Essa VLAN é chamada de VLAN transparente.
Restrições e diretrizes
Não configure nenhuma outra ação de manipulação de VLAN para a VLAN transparente na porta.
Certifique-se de que todas as portas no caminho do tráfego permitam a passagem da VLAN transparente.
Se você usar VLANs transparentes e mapeamentos de VLAN em uma interface, as VLANs transparentes não poderão ser as seguintes VLANs:
VLANs originais ou traduzidas de mapeamentos de VLANs um-para-um, um-para-dois e muitos-para-um.
VLANs externas originais ou traduzidas de mapeamentos de VLAN de duas para duas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2 ou na visualização da interface agregada de camada 2.
interface interface-type interface-numberDefinir o tipo de link da porta.
port link-type { hybrid | trunk }Por padrão, o tipo de link de uma porta é acesso.
Configure a porta para permitir a passagem de pacotes das VLANs transparentes.
Configure a porta híbrida para permitir a passagem de pacotes das VLANs transparentes.
port hybrid vlan vlan-id-list { tagged | untagged }Por padrão, uma porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é de acesso.
Configure a porta tronco para permitir a passagem de pacotes das VLANs transparentes.
port trunk permit vlan { vlan-id-list | all }Por padrão, uma porta tronco permite a passagem de pacotes apenas da VLAN 1.
Especificar VLANs transparentes para a porta.
qinq transparent-vlan vlan-id-listPor padrão, a transmissão transparente não é configurada para nenhuma VLAN.
Configuração do TPID para tags de VLAN
Sobre a TPID
O TPID identifica um quadro como um quadro marcado com 802.1Q. O valor do TPID varia de acordo com o fornecedor. Em um dispositivo INTELBRAS, o TPID na etiqueta 802.1Q adicionada em uma porta habilitada para QinQ é 0x8100 por padrão, em
conformidade com o IEEE 802.1Q. Em uma rede de vários fornecedores, certifique-se de que a configuração TPID seja a mesma entre os dispositivos conectados diretamente para que os quadros marcados com 802.1Q possam ser identificados corretamente.
As configurações de TPID incluem CVLAN TPID e SVLAN TPID.
Uma porta habilitada para QinQ usa o TPID da CVLAN para corresponder aos quadros marcados que chegam. Um quadro de entrada é tratado como não marcado se seu TPID for diferente do TPID da CVLAN.
Os SVLAN TPIDs são configuráveis por porta. Uma porta do lado do provedor de serviços usa o SVLAN TPID para substituir o TPID nas etiquetas SVLAN dos quadros de saída e corresponder aos quadros etiquetados de entrada. Um quadro de entrada é tratado como não marcado se o TPID em sua etiqueta de VLAN externa for diferente do SVLAN TPID.
Por exemplo, um dispositivo PE está conectado a um dispositivo de cliente que usa o TPID 0x8200 e a um dispositivo de provedor que usa o TPID 0x9100. Para o processamento correto dos pacotes, você deve definir o CVLAN TPID e o SVLAN TPID como 0x8200 e 0x9100 no PE, respectivamente.
O campo TPID está na mesma posição que o campo EtherType em um quadro Ethernet não marcado. Para garantir a identificação correta do tipo de pacote, não defina o valor TPID como nenhum dos valores listados na Tabela 1.
Tabela 1 Valores reservados do EtherType
Restrições e diretrizes
O valor TPID nas tags CVLAN é normalmente configurado nos PEs. O valor TPID nas tags SVLAN é normalmente configurado nas portas do lado do provedor de serviços dos PEs.
Configuração do TPID para tags CVLAN
Entre na visualização do sistema.
System ViewDefina o TPID para tags CVLAN.
qinq ethernet-type customer-tag hex-valuePor padrão, o TPID é 0x8100 para tags CVLAN.
Configuração do TPID para tags SVLAN
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet da Camada 2 ou na visualização da interface agregada da Camada 2.
interface interface-type interface-numberDefina o TPID para tags SVLAN.
qinq ethernet-type service-tag hex-valuePor padrão, o TPID é 0x8100 para tags SVLAN.
Exemplos de configuração do QinQ
Configuração de rede
Conforme mostrado na Figura 3:
O provedor de serviços atribui a VLAN 100 às VLANs 10 a 70 da Empresa A.
O provedor de serviços atribui a VLAN 200 às VLANs 30 a 90 da Empresa B.
Os dispositivos entre o PE 1 e o PE 2 na rede do provedor de serviços usam um valor TPID de 0x8200.
Configure o QinQ no PE 1 e no PE 2 para transmitir o tráfego nas VLANs 100 e 200 para a Empresa A e a Empresa B, respectivamente.
Para que os quadros QinQ sejam identificados corretamente, defina o SVLAN TPID como 0x8200 nas portas do lado do provedor de serviços do PE 1 e do PE 2.
Figura 3 Diagrama de rede
Procedimento
Configurar o PE 1:
# Configure a GigabitEthernet 1/0/1 como uma porta tronco e atribua-a à VLAN 100.
<PE1> system-view
[PE1] interface gigabitethernet 1/0/1
[PE1-GigabitEthernet1/0/1] port link-type trunk
[PE1-GigabitEthernet1/0/1] port trunk permit vlan 100# Defina o PVID da GigabitEthernet 1/0/1 como VLAN 100.
[PE1-GigabitEthernet1/0/1] porta tronco pvid vlan 100# Habilite o QinQ na GigabitEthernet 1/0/1.
[PE1-GigabitEthernet1/0/1] qinq enable
[PE1-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco e atribua-a às VLANs 100 e 200.
[PE1] interface gigabitethernet 1/0/2
[PE1-GigabitEthernet1/0/2] port link-type trunk
[PE1-GigabitEthernet1/0/2] port trunk permit vlan 100 200# Defina o valor TPID nas tags SVLAN como 0x8200 na GigabitEthernet 1/0/2.
[PE1-GigabitEthernet1/0/2] qinq ethernet-type service-tag 8200
[PE1-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 como uma porta tronco e atribua-a à VLAN 200.
system-view
[PE2] interface gigabitethernet 1/0/1
[PE2-GigabitEthernet1/0/1] port link-type trunk
[PE2-GigabitEthernet1/0/1] port trunk permit vlan 200 # Defina o PVID da GigabitEthernet 1/0/3 como VLAN 200.
[PE2-GigabitEthernet1/0/1] port trunk pvid vlan 200 # Habilite o QinQ na GigabitEthernet 1/0/3.
[PE2-GigabitEthernet1/0/1] qinq enable
[PE2-GigabitEthernet1/0/1] quitConfigurar o PE 2:
# Configure a GigabitEthernet 1/0/1 como uma porta tronco e atribua-a à VLAN 200.
[PE2] interface gigabitethernet 1/0/2
[PE2-GigabitEthernet1/0/2] port link-type trunk
[PE2-GigabitEthernet1/0/2] port trunk permit vlan 100 200# Defina o PVID da GigabitEthernet 1/0/1 como VLAN 200.
[PE2-GigabitEthernet1/0/1] porta tronco pvid vlan 200# Habilite o QinQ na GigabitEthernet 1/0/1.
[PE2-GigabitEthernet1/0/1] qinq
enable [PE2-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco e atribua-a às VLANs 100 e 200.
[PE2] interface gigabitethernet 1/0/3
[PE2-GigabitEthernet1/0/3] port link-type trunk
[PE2-GigabitEthernet1/0/3] port trunk permit vlan 100# Defina o valor TPID nas tags SVLAN como 0x8200 na GigabitEthernet 1/0/2.
[PE2-GigabitEthernet1/0/2] qinq ethernet-type service-tag 8200
[PE2-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 como uma porta tronco e atribua-a à VLAN 100.
[PE2] interface gigabitethernet 1/0/3
[PE2-GigabitEthernet1/0/3] port link-type trunk
[PE2-GigabitEthernet1/0/3] port trunk permit vlan 100# Defina o PVID da GigabitEthernet 1/0/3 como VLAN 100.
[PE2-GigabitEthernet1/0/3] port trunk pvid vlan 100# Habilite o QinQ na GigabitEthernet 1/0/3.
[PE2-GigabitEthernet1/0/3] qinq enable
[PE2-GigabitEthernet1/0/3] quitConfigure os dispositivos entre o PE 1 e o PE 2:
# Defina o MTU para um mínimo de 1504 bytes para cada porta no caminho dos quadros QinQ. (Detalhes não mostrados.)
# Configure todas as portas no caminho de encaminhamento para permitir que os quadros das VLANs 100 e 200 passem sem remover a tag da VLAN. (Detalhes não mostrados.)
Exemplo: Configuração da Transmissão Transparente de VLAN
Configuração de Rede
Conforme mostrado na Figura 4:
- O provedor de serviços atribui a VLAN 100 às VLANs 10 a 50 de uma empresa.
- A VLAN 3000 é a VLAN dedicada da empresa na rede do provedor de serviços.
- Configure o QinQ no PE 1 e no PE 2 para fornecer conectividade de camada 2 para as CVLANs 10 a 50 na rede do provedor de serviços.
- Configure a transmissão transparente de VLAN para a VLAN 3000 no PE 1 e no PE 2 para permitir que os hosts na VLAN 3000 se comuniquem sem usar uma SVLAN.
Figura 4: Diagrama de Rede
Procedimento
Configurar o PE 1:
<PE1> system-view
[PE1] interface gigabitethernet 1/0/1
[PE1-GigabitEthernet1/0/1] port link-type trunk
[PE1-GigabitEthernet1/0/1] port trunk permit vlan 100 3000
[PE1-GigabitEthernet1/0/1] port trunk pvid vlan 100
[PE1-GigabitEthernet1/0/1] qinq enable
[PE1-GigabitEthernet1/0/1] qinq transparent-vlan 3000
[PE1-GigabitEthernet1/0/1] quit
Configurar o PE 2:
<PE2> system-view
[PE2] interface gigabitethernet 1/0/1
[PE2-GigabitEthernet1/0/1] port link-type trunk
[PE2-GigabitEthernet1/0/1] port trunk permit vlan 100 3000
[PE2-GigabitEthernet1/0/1] port trunk pvid vlan 100
[PE2-GigabitEthernet1/0/1] qinq enable
[PE2-GigabitEthernet1/0/1] qinq transparent-vlan 3000
[PE2-GigabitEthernet1/0/1] quit
- Defina o MTU para um mínimo de 1504 bytes para cada porta no caminho dos quadros QinQ. (Detalhes não mostrados.)
- Configure todas as portas no caminho de encaminhamento para permitir a passagem de quadros das VLANs 100 e 3000 sem remover a tag da VLAN. (Detalhes não mostrados.)
Configuração do mapeamento de VLAN
Sobre o mapeamento de VLAN
O mapeamento de VLAN remarca o tráfego de VLAN com novas VLAN IDs.
Tipos de mapeamento de VLAN
A INTELBRAS oferece os seguintes tipos de mapeamento de VLAN:
Mapeamento de VLAN um para um - Substitui uma tag de VLAN por outra.
Mapeamento de VLAN de muitos para um - Substitui várias tags de VLAN pela mesma tag de VLAN.
Mapeamento de uma para duas VLANs - Marca pacotes com uma única tag com uma tag de VLAN externa.
Cenários de aplicativos de mapeamento de VLAN
Mapeamento de VLAN um para um e muitos para um
O mapeamento de VLANs um para um e muitos para um é normalmente usado por uma comunidade para acesso à Internet de banda larga, conforme mostrado na Figura 1.
Figura 1 Cenário de aplicação do mapeamento de VLANs um-para-um e muitos-para-um
Conforme mostrado na Figura 1, a rede é implementada da seguinte forma:
Cada gateway doméstico usa VLANs diferentes para transmitir os serviços de PC, VoD e VoIP.
Para subclassificar ainda mais cada tipo de tráfego por cliente, configure o mapeamento de VLAN um para um nos switches do conjunto de fiação. Esse recurso atribui uma VLAN separada a cada tipo de tráfego de cada cliente. O número total necessário de VLANs na rede pode ser muito grande.
Para evitar que o número máximo de VLANs seja excedido no dispositivo da camada de distribuição, configure o mapeamento de VLANs muitas para uma no switch do campus. Esse recurso atribui a mesma VLAN ao mesmo tipo de tráfego de clientes diferentes.
Mapeamento de VLAN um para dois
Conforme mostrado na Figura 2, o mapeamento de uma para duas VLANs é usado para transmitir diferentes tipos de pacotes CVLAN com diferentes tags SVLAN pela rede do provedor de serviços.
Figura 2 Cenário de aplicação do mapeamento de uma para duas VLANs
Conforme mostrado na Figura 2, os usuários do Site 1 e do Site 2 estão na VLAN 10 e na VLAN 20. O provedor de serviços atribui a VLAN 100 e a VLAN 200 à rede do cliente. Quando os pacotes do Site 1 chegam ao PE 1, o PE 1 adiciona uma tag SVLAN aos pacotes com base no tipo de pacote.
O mapeamento de uma para duas VLANs permite que o cliente planeje CVLANs sem entrar em conflito com SVLANs. O provedor de serviços pode distinguir o tráfego da rede do cliente com diferentes SVLANs e aplicar políticas de transmissão ao tráfego do cliente.
Implementações de mapeamento de VLAN
A Figura 3 mostra uma rede simplificada que ilustra os termos básicos de mapeamento de VLAN. Os termos básicos de mapeamento de VLAN incluem o seguinte:
Tráfego de uplink - Tráfego transmitido da rede do cliente para a rede do provedor de serviços.
Tráfego de downlink - Tráfego transmitido da rede do provedor de serviços para a rede do cliente.
Porta do lado da rede - Uma porta conectada à rede do provedor de serviços ou mais próxima a ela.
Porta do lado do cliente - Uma porta conectada à rede do cliente ou mais próxima a ela.
Figura 3 Termos básicos de mapeamento de VLAN
Mapeamento de VLAN um a um
Conforme mostrado na Figura 4, o mapeamento de VLAN um para um é implementado na porta do lado do cliente e substitui as tags de VLAN da seguinte forma:
Substitui a CVLAN pela SVLAN para o tráfego de uplink.
Substitui a SVLAN pela CVLAN para o tráfego de downlink.
Figura 4 Implementação de mapeamento de VLAN um para um
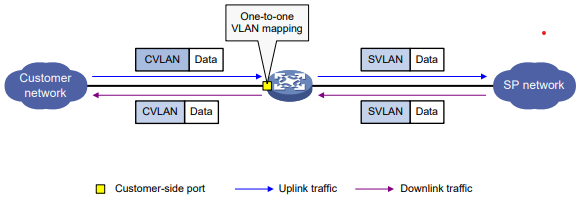
Porta do lado do cliente Tráfego de uplink Tráfego de downlink
Mapeamento de VLANs muitos para um
Conforme mostrado na Figura 5, o mapeamento de VLANs muitos-para-um é implementado nas portas do lado do cliente e do lado da rede, como segue:
Para o tráfego de uplink, o mapeamento de VLANs muitas para uma no lado do cliente substitui várias CVLANs pela mesma SVLAN.
Para o tráfego de downlink, o dispositivo executa as seguintes operações:
Procura na tabela de endereços MAC uma entrada que corresponda ao endereço MAC de destino dos pacotes de downlink.
Substitui a tag SVLAN por uma tag CVLAN com base na entrada de mapeamento correspondente de muitos para um.
Para obter mais informações sobre a tabela de endereços MAC, consulte "Configuração da tabela de endereços MAC".
Figura 5 Implementação do mapeamento de VLANs muitos-para-um
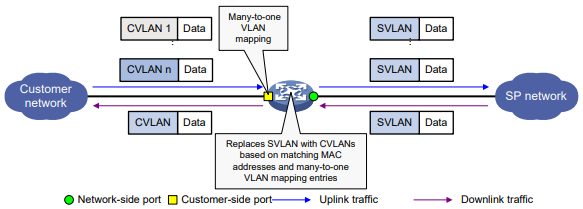
Mapeamento de VLAN um para dois
Conforme mostrado na Figura 6, o mapeamento de uma para duas VLANs é implementado na porta do lado do cliente para adicionar a tag SVLAN ao tráfego de uplink.
Para que o tráfego de downlink seja enviado corretamente para a rede do cliente, certifique-se de que a tag SVLAN seja removida na porta do lado do cliente antes da transmissão. Use um dos métodos a seguir para remover a tag SVLAN do tráfego de downlink:
Configure a porta do lado do cliente como uma porta híbrida e atribua a porta à SVLAN como um membro sem marcação.
Configure a porta do lado do cliente como uma porta tronco e defina o PVID da porta como SVLAN.
Figura 6 Implementação de mapeamento de VLAN um para dois
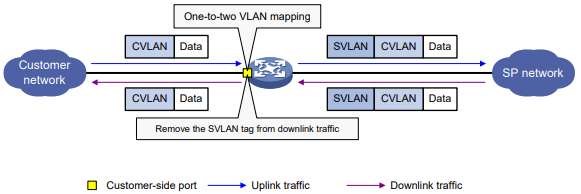
Restrições e diretrizes: Configuração de mapeamento de VLAN
Para adicionar tags de VLAN aos pacotes, você pode configurar o mapeamento de VLAN e o QinQ. O mapeamento de VLAN entra em vigor se ocorrer um conflito de configuração. Para obter mais informações sobre QinQ, consulte "Configuração de QinQ".
Para adicionar ou substituir tags de VLAN para pacotes, você pode configurar o mapeamento de VLAN e uma política de QoS. O mapeamento de VLAN entra em vigor se ocorrer um conflito de configuração. Para obter informações sobre políticas de QoS, consulte ACL and QoS Configuration Guide.
Configuração do Mapeamento de VLAN um para um
Sobre o Mapeamento de VLAN um para um
Configure o mapeamento de VLANs um a um nas portas do lado do cliente dos switches do gabinete de fiação (consulte Figura 1) para isolar o tráfego do mesmo tipo de serviço de residências diferentes.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefinir o tipo de link da porta.
port link-type { hybrid | trunk } Por padrão, o tipo de link de uma porta é acesso.
Atribua a porta à VLAN original e à VLAN traduzida.
Atribua a porta tronco à VLAN original e à VLAN traduzida.
port trunk permit vlan vlan-id-listPor padrão, uma porta tronco é atribuída à VLAN 1.
Atribua a porta híbrida à VLAN original e a VLAN traduzida como um membro marcado.
port hybrid vlan vlan-id-list taggedPor padrão, uma porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é de acesso.
Configure um mapeamento de VLAN um para um.
vlan mapping vlan-id translated-vlan vlan-idPor padrão, nenhum mapeamento de VLAN é configurado em uma interface.
Configuração do Mapeamento de VLANs Muitos para Um
Sobre o Mapeamento de VLANs Muitos para Um
Para conservar os recursos de VLAN, configure o mapeamento de VLANs muitos-para-um nos switches do campus (consulte a Figura 1) para transmitir o mesmo tipo de tráfego de diferentes usuários em uma VLAN.
Compatibilidade de Recursos e Versões de Software
Esse recurso é compatível apenas com as versões R6350 e superiores.
Restrições e Diretrizes para o Mapeamento de VLANs Muitos-para-Um
Para garantir o encaminhamento correto do tráfego da rede do provedor de serviços para a rede do cliente, não configure mapeamentos de VLAN muitos para um junto com os seguintes recursos:
- Desativar o aprendizado de endereço MAC.
- Configuração do limite de aprendizagem de MAC.
Para obter mais informações sobre o aprendizado de endereços MAC, consulte "Configuração da Tabela de Endereços MAC".
Para estabelecer a conectividade de rede com êxito em um ambiente de mapeamento de VLANs muitos-para-um, certifique-se de que as solicitações ARP sejam enviadas do lado do cliente para acionar a conexão com o lado da rede.
Visão Geral das Tarefas de Mapeamento de VLANs Muitas para Uma
Configuração da Porta do Lado do Cliente
Configuração da Porta do Lado da Rede
Configuração da Porta do Lado do Cliente
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefina o tipo de link da porta como híbrido ou tronco.
port link-type { hybrid | trunk } Por padrão, o tipo de link de uma porta é acesso.
Atribua a porta às VLANs originais.
Atribua a porta tronco às VLANs originais.
port trunk permit vlan vlan-id-list
Atribua a porta híbrida às VLANs originais como um membro marcado.
port hybrid vlan vlan-id-list tagged
Configure um mapeamento de VLAN muitos-para-um.
vlan mapping uni { range vlan-range-list | single vlan-id-list } translated-vlan vlan-id
Configuração da Porta do Lado da Rede
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-numberDefina o tipo de link da porta como híbrido ou tronco.
port link-type { hybrid | trunk } Por padrão, o tipo de link de uma porta é acesso.
Atribua a porta à VLAN traduzida.
port trunk permit vlan vlan-id-list
Atribua a porta híbrida à VLAN traduzida como um membro marcado.
port hybrid vlan vlan-id-list tagged
Configuração do mapeamento de VLAN um para dois
Sobre o mapeamento de VLAN um para dois
Configure o mapeamento de VLAN um para dois nas portas do lado do cliente dos dispositivos de borda a partir dos quais o tráfego do cliente entra nas redes SP, por exemplo, nos PEs 1 e 4 da Figura 2. O mapeamento de VLAN de uma para duas permite que os dispositivos de borda adicionem uma tag SVLAN a cada pacote recebido.
Restrições e diretrizes
Somente uma tag SVLAN pode ser adicionada a pacotes da mesma CVLAN. Para adicionar diferentes tags de SVLAN a diferentes pacotes de CVLAN em uma porta, defina o tipo de link da porta como híbrido e configure vários mapeamentos de VLAN de um para dois.
O MTU de uma interface é de 1500 bytes por padrão. Depois que uma tag de VLAN é adicionada a um pacote, o comprimento do pacote é acrescido de 4 bytes. Como prática recomendada, defina o MTU para um mínimo de 1504 bytes para as portas no caminho de encaminhamento do pacote na rede do provedor de serviços.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefinir o tipo de link da porta.
port link-type { hybrid | trunk }Por padrão, o tipo de link de uma porta é acesso.
Configure a porta para permitir que os pacotes da SVLAN passem sem marcação.
Configure a SVLAN como o PVID da porta tronco e atribua a porta tronco à SVLAN.
porta tronco pvid vlan vlan-idport trunk permit vlan { vlan-id-list | all }Atribuir a porta híbrida à SVLAN como um membro sem marcação.
port hybrid vlan vlan-id-list untaggedConfigure um mapeamento de VLAN de uma para duas.
vlan mapping nest { range vlan-range-list | single vlan-id-list }nested-vlan vlan-idPor padrão, nenhum mapeamento de VLAN é configurado em uma interface.
Exemplos de configuração de mapeamento VLAN
Exemplo: Configuração do Mapeamento de VLANs um para um
Procedimento
Configure o Switch A:
# Criar as VLANs originais.
<SwitchA> system-view
[SwitchA] vlan 2 a 3# Crie as VLANs traduzidas.
# Configure a porta GigabitEthernet 1/0/1 do lado do cliente como uma porta tronco.
<SwitchA> system-view
[Interface gigabitethernet 1/0/1
[SwitchA-GigabitEthernet1/0/1] port link-type trunk
[SwitchA-GigabitEthernet1/0/1] port trunk permit vlan 1 2 3 101 201 301
[SwitchA-GigabitEthernet1/0/1] vlan mapping 1 translated-vlan 101
[SwitchA-GigabitEthernet1/0/1] vlan mapping 2 translated-vlan 201
[SwitchA-GigabitEthernet1/0/1] vlan mapping 3 translated-vlan 301
[SwitchA-GigabitEthernet1/0/1] quit# Configure a porta GigabitEthernet 1/0/2 do lado do cliente como uma porta tronco.
[Interface gigabitethernet 1/0/2
[SwitchA-GigabitEthernet1/0/2] port link-type trunk
[SwitchA-GigabitEthernet1/0/2] port trunk permit vlan 1 2 3 102 202 302
[SwitchA-GigabitEthernet1/0/2] vlan mapping 1 translated-vlan 102
[SwitchA-GigabitEthernet1/0/2] vlan mapping 2 translated-vlan 202
[SwitchA-GigabitEthernet1/0/2] vlan mapping 3 translated-vlan 302
[SwitchA-GigabitEthernet1/0/2] quit# Configure a porta do lado da rede (GigabitEthernet 1/0/3) como uma porta tronco.
[SwitchA] interface gigabitethernet 1/0/3
[SwitchA-GigabitEthernet1/0/3] port link-type trunk
[SwitchA-GigabitEthernet1/0/3] port trunk permit vlan 101 201 301 102 202 302
[SwitchA-GigabitEthernet1/0/3] quitConfigure o Switch B da mesma forma que o Switch A está configurado. (Os detalhes não são mostrados).
Verificação da Configuração
# Verifique as informações de mapeamento de VLAN nos switches do conjunto de fiação, por exemplo, Switch A.
[SwitchA] display vlan mapping
Interface GigabitEthernet1/0/1:
Interface GigabitEthernet1/0/2:Exemplo: Configuração do Mapeamento de VLANs Muitos para Um
Configuração de Rede
Conforme mostrado na Figura 8:
- Crie a VLAN 2, a VLAN 3 e a VLAN 4 nos switches do gabinete de fiação para isolar o tráfego do mesmo tipo de serviço de diferentes residências.
- Configure mapeamentos de VLAN muitos para um no switch do campus para atribuir uma VLAN para transportar todos os tipos de tráfego de diferentes residências. Neste exemplo, mapeie as VLANs 2 a 4 para a VLAN 10.
Figura 8: Diagrama de Rede
Procedimento
Configure o Switch A:
- Criar VLAN 2.
<SwitchA> system-view
[SwitchA] vlan 2
[SwitchA-vlan2] quit- Atribua as portas GigabitEthernet 1/0/1 e GigabitEthernet 1/0/2 à VLAN 2.
[SwitchA] interface range gigabitethernet 1/0/1 to gigabitethernet 1/0/2
[SwitchA-if-range] port access vlan 2
[SwitchA-if-range] quitConfigure o Switch B e o Switch C da mesma forma que o Switch A está configurado. (Os detalhes não são mostrados).
Configurar o Switch D:
- Crie as VLANs 2, 3 e 4.
- Atribuir as portas GigabitEthernet 1/0/1 à VLAN 2, GigabitEthernet 1/0/2 à VLAN 3 e GigabitEthernet 1/0/3 para a VLAN 4.
- Configure a porta GigabitEthernet 1/0/4 como uma porta tronco e atribua-a às VLANs 2 a 4.
Configurar o Switch E:
- Crie as VLANs 2, 3 e 4 (as VLANs originais no mapeamento de VLAN a ser criado).
- Configure a porta do lado do cliente (GigabitEthernet 1/0/1) como uma porta tronco e atribua-a às VLANs originais.
- Configure o mapeamento de VLANs muitos para um na GigabitEthernet 1/0/1, que substitui a tag de VLAN 2 até a tag de VLAN 4 pela tag de VLAN 10.
<SwitchE> system-view
[SwitchE] interface gigabitethernet 1/0/1
[SwitchE-GigabitEthernet1/0/1] port link-type trunk
[SwitchE-GigabitEthernet1/0/1] port trunk permit vlan 2 to 4
[SwitchE-GigabitEthernet1/0/1] vlan mapping uni range 2 to 4 translated-vlan 10
[SwitchE-GigabitEthernet1/0/1] quitVerificação da Configuração
# Verificar as informações de mapeamento de VLAN no Switch E.
[SwitchE] display vlan mapping
Interface GigabitEthernet1/0/1:Exemplo: Configuração do Mapeamento de Uma para Duas VLANs
Configuração de Rede
Conforme mostrado na Figura 9, o Site 1 e o Site 2 de uma empresa usam a VLAN 10 e a VLAN 20 para transmitir o tráfego de VoIP e de PC, respectivamente. O provedor de serviços atribui a VLAN 100 e a VLAN 200 à rede do cliente.
Configure mapeamentos de VLAN um para dois para permitir que a rede do provedor de serviços transmita tráfego de VoIP e PC com SVLAN 100 e SVLAN 200, respectivamente.
Figura 9: Diagrama de Rede
Procedimento
Configurar o PE 1:
- Crie as VLANs 10, 20, 100 e 200.
<PE1> system-view
[PE1] vlan 10
[PE1-vlan10] quit
[PE1] vlan 20
[PE1-vlan20] quit
[PE1] vlan 100
[PE1-vlan100] quit
[PE1] vlan 200
[PE1-vlan200] quit- Configure um mapeamento de VLAN de um para dois na porta do lado do cliente (GigabitEthernet 1/0/1) para adicionar a tag SVLAN 100 aos pacotes da CVLAN 10.
[PE1] interface gigabitethernet 1/0/1
[PE1-GigabitEthernet1/0/1] vlan mapping nest single 10 nested-vlan 100- Configure um mapeamento de VLAN de um para dois na GigabitEthernet 1/0/1 para adicionar a tag SVLAN 200 aos pacotes da CVLAN 20.
[PE1-GigabitEthernet1/0/1] vlan mapping nest single 20 nested-vlan 200- Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua-a às VLANs 100 e 200 como um membro untagged.
[PE1-GigabitEthernet1/0/1] port link-type hybrid
[PE1-GigabitEthernet1/0/1] port hybrid vlan 100 200 untagged
[PE1-GigabitEthernet1/0/1] quit- Configure a porta do lado da rede (GigabitEthernet 1/0/2) como uma porta tronco e atribua a porta às VLANs 100 e 200.
[PE1] interface gigabitethernet 1/0/2
[PE1-GigabitEthernet1/0/2] port link-type trunk
[PE1-GigabitEthernet1/0/2] port trunk permit vlan 100 200
[PE1-GigabitEthernet1/0/2] quitConfigure o PE 2 da mesma forma que o PE 1 está configurado. (Detalhes não mostrados).
Verificação da Configuração
# Verificar as informações de mapeamento de VLAN no PE 1.
[PE1] display vlan mapping Interface GigabitEthernet1/0/1:# Verificar as informações de mapeamento de VLAN no PE 2.
[PE2] display vlan mapping Interface GigabitEthernet1/0/2:Configuração do LLDP
Sobre o LLDP
O Link Layer Discovery Protocol (LLDP) é um protocolo de camada de link padrão que permite que dispositivos de rede de diferentes fornecedores descubram vizinhos e troquem informações de sistema e configuração.
Em uma rede habilitada para LLDP, um dispositivo anuncia informações sobre o dispositivo local em unidades de dados LLDP (LLDPDUs) para os dispositivos diretamente conectados. As informações distribuídas por meio do LLDP são armazenadas por seus destinatários em MIBs padrão, possibilitando que as informações sejam acessadas por um sistema de gerenciamento de rede (NMS) por meio de SNMP.
As informações que podem ser distribuídas por meio do LLDP incluem (mas não se limitam a):
Principais recursos do sistema.
Endereço IP de gerenciamento do sistema.
ID do dispositivo.
ID da porta.
Agentes LLDP e modos de ponte
Um agente LLDP é um mapeamento de uma entidade de protocolo que implementa o LLDP. Vários agentes LLDP podem ser executados na mesma interface.
Os agentes LLDP são classificados nos seguintes tipos:
Agente de ponte mais próximo.
Agente de ponte do cliente mais próximo.
Agente de ponte não-TPMR mais próximo.
Um MAC Relay de duas portas (TPMR) é um tipo de ponte que tem apenas duas portas de ponte acessíveis externamente. Ele é compatível com um subconjunto dos recursos de uma ponte MAC. Um TPMR é transparente para todos os protocolos independentes de mídia baseados em quadros, exceto para os seguintes protocolos:
Protocolos destinados ao TPMR.
Protocolos destinados a endereços MAC reservados que o recurso de retransmissão do TPMR está configurado para não encaminhar.
O LLDP troca pacotes entre agentes vizinhos e cria e mantém informações de vizinhança para eles. A Figura 1 mostra as relações de vizinhança para esses agentes LLDP.
Figura 1 Relações de vizinhança LLDP
Os tipos de agentes LLDP suportados variam de acordo com o modo de ponte em que o LLDP opera. O LLDP suporta os seguintes modos de ponte: ponte de cliente (CB) e ponte de serviço (SB).
Modo de ponte do cliente - O LLDP suporta o agente de ponte mais próximo, o agente de ponte não TPMR mais próximo e o agente de ponte do cliente mais próximo. O LLDP processa os quadros LLDP com endereços MAC de destino para esses agentes e transmite de forma transparente os quadros LLDP com outros endereços MAC de destino em VLANs.
Modo de ponte de serviço - O LLDP suporta o agente de ponte mais próximo e o agente de ponte não-TPMR mais próximo. O LLDP processa os quadros LLDP com endereços MAC de destino para esses agentes e o transmite de forma transparente os quadros LLDP com outros endereços MAC de destino em VLANs.
Formatos de quadros LLDP
O LLDP envia informações do dispositivo em quadros LLDP. Os quadros LLDP são encapsulados no formato Ethernet II ou SNAP (Subnetwork Access Protocol).
Quadro LLDP encapsulado em Ethernet II
Figura 2 Quadro LLDP encapsulado em Ethernet II
LLDPDUs
Cada quadro LLDP contém uma LLDPDU. Cada LLDPDU é uma sequência de estruturas do tipo valor-comprimento-valor (TLV) .
Figura 4 Formato de encapsulamento da LLDPDU

TLVs
Conforme mostrado na Figura 4, cada LLDPDU começa com os seguintes TLVs obrigatórios: TLV de ID do chassi, TLV de ID da porta e TLV de tempo de vida. As TLVs obrigatórias são seguidas por um máximo de 29 TLVs opcionais.
Um TLV é um elemento de informação que contém os campos de tipo, comprimento e valor. As TLVs da LLDPDU incluem as seguintes categorias:
TLVs de gerenciamento básico.
TLVs específicos da organização (IEEE 802.1 e IEEE 802.3).
TLVs LLDP-MED (descoberta de ponto final de mídia).
Os TLVs de gerenciamento básico são essenciais para o gerenciamento do dispositivo.
TLVs específicos da organização e TLVs LLDP-MED são usados para o gerenciamento aprimorado do dispositivo. Eles são definidos pela padronização ou por outras organizações e são opcionais para LLDPDUs.
TLVs de gerenciamento básico
A Tabela 3 lista os tipos de TLV de gerenciamento básico. Alguns deles são obrigatórios para LLDPDUs.
Tabela 3 TLVs de gerenciamento básico
TLVs específicos da organização IEEE 802.1
A Tabela 4 lista os TLVs específicos da organização do IEEE 802.1.
O dispositivo pode receber TLVs de identidade de protocolo e TLVs de resumo de uso de VID, mas não pode enviar esses TLVs.
Tabela 4 TLVs específicos da organização IEEE 802.1
TLVs específicos da organização IEEE 802.3
A Tabela 5 mostra os TLVs específicos da organização do IEEE 802.3.
A TLV de controle de estado de energia é definida no IEEE P802.3at D1.0 e não é compatível com versões posteriores. O dispositivo envia esse tipo de TLVs somente depois de recebê-los.
Tabela 5 TLVs específicos da organização IEEE 802.3
TLVs LLDP-MED
As TLVs LLDP-MED oferecem vários aplicativos avançados para voz sobre IP (VoIP), como configuração básica, configuração de políticas de rede e gerenciamento de endereços e diretórios. As TLVs LLDP-MED oferecem uma solução econômica e fácil de usar para a implementação de dispositivos de voz na Ethernet. As TLVs LLDP-MED são mostradas na Tabela 6.
Se o TLV de configuração/status do MAC/PHY não for anunciável, nenhum dos TLVs do LLDP-MED será anunciado, mesmo que seja anunciável.
Se o TLV de recursos do LLDP-MED não for anunciável, os outros TLVs do LLDP-MED não serão anunciados, mesmo que sejam anunciáveis.
Tabela 6 TLVs LLDP-MED
TLVs proprietários da INTELBRAS
Os TLVs proprietários da INTELBRAS são usados para atender a requisitos específicos de transmissão no gerenciamento de rede. Os dispositivos de outros fornecedores não podem identificar os TLVs proprietários da INTELBRAS transportados no LLDPDUS.
Somente os TLVs de potência real são compatíveis com a versão atual do software. Esse tipo de TLVs fornece informações sobre a potência PoE em uma interface.
Endereço de gerenciamento
O sistema de gerenciamento de rede usa o endereço de gerenciamento de um dispositivo para identificar e gerenciar o dispositivo para manutenção da topologia e gerenciamento da rede. O endereço de gerenciamento é encapsulado no endereço de gerenciamento TLV.
Modos de operação do LLDP
Um agente LLDP pode operar em um dos seguintes modos:
Modo TxRx - Um agente LLDP nesse modo pode enviar e receber quadros LLDP.
Modo Tx - Um agente LLDP nesse modo só pode enviar quadros LLDP.
Modo Rx - Um agente LLDP nesse modo só pode receber quadros LLDP.
Modo desativado - Um agente LLDP nesse modo não pode enviar ou receber quadros LLDP.
Toda vez que o modo operacional de um agente LLDP é alterado, sua máquina de estado do protocolo LLDP é reinicializada. Um atraso de reinicialização configurável evita inicializações frequentes causadas por alterações frequentes no modo de operação. Se você configurar o atraso de reinicialização, um agente LLDP deverá aguardar o período de tempo especificado para inicializar o LLDP depois que o modo operacional do LLDP for alterado.
Transmissão e recebimento de quadros LLDP
Transmissão de quadros LLDP
Um agente LLDP operando no modo TxRx ou no modo Tx envia quadros LLDP para seus dispositivos diretamente conectados periodicamente e quando a configuração local é alterada. Para evitar que os quadros LLDP sobrecarreguem a rede durante os períodos de alterações frequentes nas informações do dispositivo local, o LLDP usa o mecanismo de token bucket para limitar a taxa de quadros LLDP. Para obter mais informações sobre o mecanismo de token bucket, consulte o Guia de configuração de ACL e QoS.
O LLDP ativa automaticamente o mecanismo de transmissão rápida de quadros LLDP em qualquer um dos seguintes casos:
Um novo quadro LLDP é recebido e contém novas informações sobre o dispositivo local.
O modo de operação LLDP do agente LLDP muda de Disable ou Rx para TxRx ou Tx.
O mecanismo de transmissão rápida de quadros LLDP envia sucessivamente o número especificado de quadros LLDP em um intervalo configurável de transmissão rápida de quadros LLDP. O mecanismo ajuda os vizinhos LLDP a descobrir o dispositivo local o mais rápido possível. Em seguida, o intervalo normal de transmissão de quadros LLDP é retomado.
Recebimento de quadros LLDP
Um agente LLDP operando no modo TxRx ou no modo Rx confirma a validade dos TLVs transportados em cada quadro LLDP recebido. Se os TLVs forem válidos, o agente LLDP salvará as informações e iniciará um cronômetro de envelhecimento. O valor inicial do cronômetro de envelhecimento é igual ao valor TTL no TLV Time To Live transportado no quadro LLDP. Quando o agente LLDP recebe um novo quadro LLDP, o cronômetro de envelhecimento é reiniciado. Quando o cronômetro de envelhecimento chega a zero, todas as informações salvas envelhecem.
Colaboração com a trilha
Você pode configurar uma entrada de rastreamento e associá-la a uma interface LLDP. O módulo LLDP verifica a disponibilidade de vizinhos da interface LLDP e informa o resultado da verificação ao módulo Track. O módulo Track altera o status da entrada de rastreamento adequadamente para que o módulo de aplicativo associado possa tomar as medidas corretas.
O módulo Track altera o status da entrada de rastreamento com base na disponibilidade de vizinhos de uma interface LLDP monitorada da seguinte forma:
Se o vizinho da interface LLDP estiver disponível, o módulo Track define a entrada da trilha para o estado Positivo.
Se o vizinho da interface LLDP não estiver disponível, o módulo Track definirá a entrada da trilha para o estado Negativo.
Para obter mais informações sobre a colaboração entre o Track e o LLDP, consulte a configuração do track em
Protocolos e padrões
IEEE 802.1AB-2005, descoberta de conectividade de controle de acesso a mídia e estação
IEEE 802.1AB-2009, descoberta de conectividade de controle de acesso a mídia e estação
ANSI/TIA-1057, Protocolo de descoberta de camada de enlace para dispositivos de ponto de extremidade de mídia
IEEE Std 802.1Qaz-2011, pontes de controle de acesso a mídia (MAC) e redes locais com pontes virtuais - Alteração 18: seleção de transmissão aprimorada para compartilhamento de largura de banda entre classes de tráfego
Restrições e diretrizes: Configuração do LLDP
Quando você configurar o LLDP, siga estas restrições e diretrizes:
Algumas das tarefas de configuração do LLDP estão disponíveis em diferentes visualizações de interface (consulte a Tabela 7).
Tabela 7 Suporte das tarefas de configuração do LLDP em diferentes visualizações
Para usar o LLDP junto com o OpenFlow, você deve ativar o LLDP globalmente nos switches OpenFlow. Para evitar que o LLDP afete a descoberta de topologia dos controladores OpenFlow, desative o LLDP nas portas das instâncias OpenFlow. Para obter mais informações sobre o OpenFlow, consulte o Guia de configuração do OpenFlow.
Ativação do LLDP
Restrições e diretrizes
Para que o LLDP entre em vigor em portas específicas, você deve ativar o LLDP globalmente e nessas portas.
Procedimento
Entre na visualização do sistema.
System ViewHabilite o LLDP globalmente. lldp global enable Por padrão:
Se o dispositivo for iniciado com a configuração inicial, o LLDP será desativado globalmente.
Se o dispositivo for iniciado com os padrões de fábrica, o LLDP será ativado globalmente.
Para obter mais informações sobre a inicialização do dispositivo com a configuração inicial ou os padrões de fábrica, consulte
Guia de configuração de fundamentos.
Entre na visualização da interface.
interface interface-type interface-numberHabilitar LLDP.
lldp enablePor padrão, o LLDP está ativado em uma porta.
Configuração do modo de ponte LLDP
Entre na visualização do sistema.
System ViewDefinir o modo de ponte LLDP.
Defina o modo de ponte LLDP como ponte de serviço.
lldp mode service-bridgePor padrão, o LLDP opera no modo de ponte do cliente.
Defina o modo de ponte LLDP como ponte de cliente.
undo lldp modePor padrão, o LLDP opera no modo de ponte do cliente.
Configuração do Modo de Operação LLDP
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberDefinir o modo de operação do LLDP.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp [ agent { nearest-customer | nearest-nontpmr } ] admin-status { disable | rx | tx | txrx }Na visualização da interface Ethernet, se você não especificar um tipo de agente, o comando definirá o modo de operação do agente de ponte mais próximo.
Na visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr } admin-status { disable | rx | tx | txrx }Por padrão:
- O agente de ponte mais próximo opera no modo TxRx.
- O agente de ponte de cliente mais próximo e o agente de ponte não TPMR mais próximo operam no modo Desativado.
Configuração do Atraso de Reinicialização do LLDP
Sobre o Atraso de Reinicialização do LLDP
Quando o modo operacional do LLDP muda em uma porta, ela inicializa as máquinas de estado do protocolo após um atraso de reinicialização do LLDP. Ao ajustar o atraso, você pode evitar inicializações frequentes causadas por alterações frequentes no modo de operação LLDP em uma porta.
Procedimento:
Entre na visualização do sistema.
System ViewDefina o atraso de reinicialização do LLDP.
lldp reinit-delay timer-delayO atraso padrão de reinicialização do LLDP é de 2 segundos.
Configuração dos TLVs anunciáveis
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure os TLVs anunciáveis.
Na visualização da interface Ethernet de camada 2:
lldp tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ipv6 ] [ ip-address | interface loopback interface-number ] } | Dot1-tlv { all | port-vlan-id | link-aggregation | protocol-vlan-id [ vlan-id ] | vlan-name [ vlan-id ] | management-vid [ mvlan-id ] } | Dot3-tlv { all | link-aggregation | mac-physic | max-frame-size | power } | med-tlv { all | capability | inventory | network-policy [ vlan-id ] | power-over-ethernet | location-id { civic-address device-type country-code { ca-type ca-value }<1-10> | elin-address tel-number } } }lldp tlv-enable private-tlv actual-powerOs dispositivos não PoE não são compatíveis com o comando lldp tlv-enable private-tlv actual-power.
O comando lldp tlv-enable private-tlv actual-power está disponível somente na versão 6343P08 e posteriores.
Por padrão, o agente de ponte mais próximo anuncia todos os TLVs suportados, exceto os seguintes TLVs:
- TLVs de identificação de local.
- TLVs de VLAN ID de porta e protocolo.
- TLVs de nome de VLAN.
- TLVs de ID da VLAN de gerenciamento.
lldp agent nearest-nontpmr tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ipv6 ] [ ip-address ] } | dot1-tlv { all | port-vlan-id | link-aggregation } dot3-tlv { all | port-vlan-id | link-aggregation } link-aggregation } }lldp tlv-enable dot1-tlv { protocol-vlan-id [ vlan-id ] | vlan-name [ vlan-id ] | management-vid [ mvlan-id ] }lldp agent nearest-nontpmr tlv-enable private-tlv actual-powerOs dispositivos não PoE não são compatíveis com o comando lldp tlv-enable private-tlv actual-power.
O comando lldp tlv-enable private-tlv actual-power está disponível somente na versão 6343P08 e posteriores.
Por padrão, o agente de ponte não TPMR mais próximo não anuncia nenhum TLV.
lldp agent nearest-customer tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ipv6 ] [ ip-address ] } | dot1-tlv { all | port-vlan-id | link-aggregation } | dot3-tlv { all | link-aggregation } }lldp tlv-enable dot1-tlv { protocol-vlan-id [ vlan-id ] | vlan-name [ vlan-id ] | management-vid [ mvlan-id ] }lldp agent nearest-customer tlv-enable private-tlv actual-powerOs dispositivos não PoE não são compatíveis com o comando lldp agent nearest-customer tlv-enable private-tlv actual-power.
O comando lldp agent nearest-customer tlv-enable private-tlv actual-power está disponível somente na versão 6343P08 e posteriores.
Por padrão, o agente de ponte do cliente mais próximo anuncia todos os TLVs de gerenciamento básico suportados e os TLVs específicos da organização IEEE 802.1.
Na visualização da interface Ethernet de gerenciamento:
lldp tlv-enable { basic-tlv { all | port-description | capacidade do sistema | descrição do sistema | nome do sistema | management-address-tlv [ ipv6 ] [ ip-address ] } | Dot1-tlv { all | link-aggregation } | dot3-tlv { all | link-aggregation | mac-physic | max-frame-size | power } | med-tlv { all | capability | inventory | power-over-ethernet | location-id { civic-address device-type country-code { ca-type ca-value }<1-10> | elin-address tel-number } } }Por padrão, o agente de ponte mais próximo anuncia os seguintes TLVs:
- TLVs de agregação de links no conjunto de TLVs específicos da organização 802.1.
- Todos os TLVs específicos da organização 802.3 suportados.
- Todos os TLVs LLDP-MED suportados, exceto os TLVs de política de rede.
lldp agent { nearest-nontpmr | nearest-customer } tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ipv6 ] [ ip-address ] } | Dot1-tlv { all | link-aggregation } | dot3-tlv { all | link-aggregation } }Por padrão:
- O agente de ponte não-TPMR mais próximo não anuncia nenhumTLV.
- O agente de ponte do cliente mais próximo anuncia todos os TLVs de gerenciamento básico e TLVs de agregação de links suportados no conjunto de TLVs específicos da organização IEEE 802.1.
Na visualização da interface agregada da Camada 2:
lldp tlv-enable dot1-tlv { protocol-vlan-id [ vlan-id ] | vlan-name [ vlan-id ] | management-vid [ mvlan-id ] }lldp agent nearest-nontpmr tlv-enable { basic-tlv { all | management-address-tlv [ ipv6 ] [ ip-address ] | port-description | system-capability | system-description | system-name } | dot1-tlv { all | port-vlan-id } }lldp agent nearest-customer tlv-enable { basic-tlv { all | management-address-tlv [ ipv6 ] [ ip-address ] | port-description | system-capability | system-description | system-name } | dot1-tlv { all | port-vlan-id } }Por padrão, o agente de ponte do cliente mais próximo anuncia todos os TLVs de gerenciamento básico suportados e os seguintes TLVs específicos da organização IEEE 802.1:
- TLVs de VLAN ID de porta e protocolo.
- TLVs de nome de VLAN.
- TLVs de ID da VLAN de gerenciamento.
Não há suporte para o agente de ponte mais próximo.
Configuração do anúncio do endereço de gerenciamento TLV
Sobre o anúncio do endereço de gerenciamento TLV
O LLDP codifica endereços de gerenciamento em formato numérico ou de cadeia de caracteres em TLVs de endereço de gerenciamento.
Se um vizinho codificar seu endereço de gerenciamento em formato de cadeia de caracteres, defina o formato de codificação do endereço de gerenciamento como cadeia de caracteres na porta de conexão. Isso garante a comunicação normal com o vizinho.
Você pode configurar o anúncio do endereço de gerenciamento TLV globalmente ou por interface. O dispositivo seleciona a configuração de anúncio de TLV de endereço de gerenciamento para uma interface na seguinte ordem:
Definição baseada na interface, configurada pelo uso do comando lldp tlv-enable com a opção
palavra-chave management-address-tlv.
Definição global, configurada com o comando lldp global tlv-enable basic-tlv management-address-tlv.
Configuração padrão para a interface. Por padrão:
Procedimento
O agente de ponte mais próximo e o agente de ponte do cliente mais próximo anunciam o endereço de gerenciamento TLV.
O agente de ponte não-TPMR mais próximo não anuncia o endereço de gerenciamento TLV.
Entre na visualização do sistema.
System ViewHabilite o anúncio do endereço de gerenciamento TLV globalmente e defina o endereço de gerenciamento a ser anunciado.
lldp [ agent { nearest-customer | nearest-nontpmr } ] global tlv-enable
basic-tlv management-address-tlv [ ipv6 ] { ip-address | interface
loopback interface-number | interface m-gigabitethernet
interface-number | interface vlan-interface interface-number }Por padrão, o anúncio do endereço de gerenciamento TLV é desativado globalmente.
Entre na visualização da interface.
interface interface-type interface-numberHabilite o anúncio do endereço de gerenciamento TLV na interface e defina o endereço de gerenciamento a ser anunciado.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp tlv-enable basic-tlv management-address-tlv [ ipv6 ]
[ ip-address | interface loopback interface-number ]
lldp agent { nearest-customer | nearest-nontpmr } tlv-enable
basic-tlv management-address-tlv [ ipv6 ] [ ip-address ]Na visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr } tlv-enable
basic-tlv management-address-tlv [ ipv6 ] [ ip-address ]Por padrão:
O agente de ponte mais próximo e o agente de ponte do cliente mais próximo anunciam os TLVs de endereço de gerenciamento.
O agente de ponte não-TPMR mais próximo não anuncia o endereço de gerenciamento TLV. O dispositivo suporta apenas o formato de codificação numérica para endereços de gerenciamento IPv6.
Defina o formato de codificação do endereço de gerenciamento como string.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp [ agent { nearest-customer | nearest-nontpmr } ]
management-address-format stringNa visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr }
management-address-format string O formato padrão de codificação do endereço de gerenciamento é numérico.
Configuração do formato de encapsulamento para quadros LLDP
Sobre a configuração do formato de encapsulamento do quadro LLDP
As versões anteriores do LLDP exigem o mesmo formato de encapsulamento em ambas as extremidades para processar os quadros LLDP. Para se comunicar com sucesso com um dispositivo vizinho que esteja executando uma versão anterior do LLDP, o dispositivo local deve ser configurado com o mesmo formato de encapsulamento.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberDefina o formato de encapsulamento dos quadros LLDP como SNAP.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp [ agente { nearest-customer | nearest-nontpmr } ] encapsulamento snap Na visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr } encapsulation snap Por padrão, é usado o formato de encapsulamento Ethernet II.
Configuração dos parâmetros de transmissão de quadros LLDP
Sobre a configuração dos parâmetros de transmissão de quadros LLDP
O TLV Time to Live transportado em um LLDPDU determina por quanto tempo as informações do dispositivo transportadas no LLDPDU podem ser salvas em um dispositivo destinatário.
Ao definir o multiplicador de TTL, você pode configurar o TTL dos LLDPDUs enviados localmente. O TTL é expresso por meio da seguinte fórmula:
TTL = Mínimo (65535, (multiplicador TTL × intervalo de transmissão do quadro LLDP + 1))
Como mostra a expressão, o TTL pode ser de até 65535 segundos. Os TTLs maiores que 65535 serão arredondados para 65535 segundos.
Procedimento
Entre na visualização do sistema.
System ViewDefina o multiplicador TTL.
lldp hold-multiplier valueA configuração padrão é 4.
Defina o intervalo de transmissão de quadros LLDP. lldp timer tx-interval interval A configuração padrão é 30 segundos.
Defina o tamanho do bloco de tokens para o envio de quadros LLDP.
lldp max-credit valor de créditoA configuração padrão é 5.
Defina o número de quadros LLDP enviados sempre que a transmissão rápida de quadros LLDP for acionada.
lldp fast-count count countA configuração padrão é 4.
Defina o intervalo de transmissão rápida de quadros LLDP. lldp timer fast-interval interval A configuração padrão é 1 segundo.
Configuração do tipo de TLVs de ID de porta anunciados pelo LLDP
Sobre esta tarefa
Esta tarefa permite que um dispositivo INTELBRAS anuncie apenas TLVs de ID de porta que contenham nomes de interface. Por padrão, um dispositivo INTELBRAS anuncia TLVs de ID de porta que contêm endereços MAC de interface ou nomes de interface. Os dispositivos de mídia de alguns fornecedores podem obter informações de interface dos dispositivos INTELBRAS somente por meio de LLDP. Para que os dispositivos de mídia obtenham os nomes das interfaces, é necessário configurar os dispositivos INTELBRAS para gerar TLVs de ID de porta com base nos nomes das interfaces.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6331 e posteriores.
Restrições e diretrizes
Execute essa tarefa somente quando os vizinhos LLDP precisarem obter nomes de interface de LLDPDUs. Não execute essa tarefa em nenhum outro cenário.
Você pode configurar o tipo de porta ID TLV na visualização do sistema ou da interface. A configuração específica da interface tem precedência sobre a configuração global.
Configuração do tipo de TLVs de ID de porta anunciados pelo LLDP globalmente
Entre na visualização do sistema.
System ViewConfigure o tipo de TLVs de ID de porta anunciados pelo LLDP.
lldp [ agent { nearest-customer | nearest-nontpmr } ] global tlv-config basic-tlv port-id type-idPor padrão, uma interface anuncia TLVs de ID de porta que contêm endereços MAC de interface se receber TLVs LLDP-MED e anuncia TLVs de ID de porta que contêm nomes de interface se nenhum TLV LLDP-MED for recebido.
Configuração do tipo de TLVs de ID de porta anunciados pelo LLDP em uma interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure o tipo de TLVs de ID de porta anunciados pelo LLDP.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp [ agent { nearest-customer | nearest-nontpmr } ] tlv-config basic-tlv port-id type-idNa visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr } tlv-config basic-tlv port-id type-idPor padrão, a configuração global do tipo de TLV de ID de porta entra em vigor.
Ativação da exibição de informações locais do LLDP sobre todas as interfaces
Sobre esta tarefa
Essa tarefa ativa o comando display lldp local-information para exibir informações locais do LLDP sobre todas as interfaces.
Por padrão, o comando display lldp local-information exibe informações sobre as interfaces fisicamente ativas. Os dispositivos de mídia de alguns fornecedores podem obter informações de interface dos dispositivos INTELBRAS somente por meio de LLDP. Para que os dispositivos de mídia obtenham todas as informações da interface, ative o comando display lldp local-information para exibir informações locais do LLDP sobre todas as interfaces.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6331 e posteriores.
Restrições e diretrizes
Execute essa tarefa somente quando os vizinhos do LLDP puderem obter informações sobre a interface do dispositivo por meio do LLDP.
Procedimento
Entre na visualização do sistema.
System ViewPermitir a exibição de informações locais do LLDP sobre todas as interfaces.
lldp local-information all-interfacePor padrão, o comando display lldp local-information exibe informações sobre interfaces fisicamente ativas.
Ativação de sondagem LLDP
Sobre a sondagem LLDP
Com o polling LLDP ativado, um dispositivo procura periodicamente por alterações na configuração local. Quando o dispositivo detecta uma alteração de configuração, ele envia quadros LLDP para informar os dispositivos vizinhos sobre a alteração.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberHabilite a sondagem LLDP e defina o intervalo de sondagem.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp [ agent { nearest-customer | nearest-nontpmr } ]intervalo de intervalo de alteração de verificação
Na visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr }intervalo de intervalo de alteração de verificação
Por padrão, o polling LLDP está desativado.
Desativação da verificação de inconsistência do PVID do LLDP
Sobre a verificação de inconsistência do PVID do LLDP
Por padrão, quando o sistema recebe um pacote LLDP, ele compara o valor do PVID contido no pacote com o PVID configurado na interface receptora. Se os dois PVIDs não corresponderem, será impressa uma mensagem de registro para notificar o usuário.
Você pode desativar a verificação de inconsistência de PVID se forem necessários PVIDs diferentes em um link.
Procedimento
Entre na visualização do sistema.
System ViewDesativar a verificação de inconsistência do PVID do LLDP.
lldp ignore-pvid-inconsistencyPor padrão, a verificação de inconsistência do PVID do LLDP está ativada.
Configuração da compatibilidade do CDP
Sobre a compatibilidade do CDP
Para permitir que seu dispositivo troque informações com um dispositivo Cisco conectado diretamente que suporte apenas CDP, você deve ativar a compatibilidade com CDP.
A compatibilidade com o CDP permite que seu dispositivo receba e reconheça os pacotes CDP do dispositivo CDP vizinho e envie pacotes CDP para o dispositivo vizinho. Os pacotes CDP enviados ao dispositivo CDP vizinho contêm as seguintes informações:
ID do dispositivo.
ID da porta que se conecta ao dispositivo vizinho.
Endereço IP da porta.
TTL.
O endereço IP da porta é o endereço IP primário de uma interface de VLAN em estado ativo. A VLAN ID da interface VLAN deve ser a mais baixa entre as VLANs permitidas na porta. Se não for atribuído um endereço IP a nenhuma interface VLAN das VLANs permitidas ou se todas as interfaces VLAN estiverem inativas, nenhum endereço IP de porta será anunciado.
Você pode visualizar as informações do dispositivo CDP vizinho que podem ser reconhecidas pelo dispositivo na saída do comando display lldp neighbor-information. Para obter mais informações sobre o comando display lldp neighbor-information, consulte Comandos LLDP em Layer 2-LAN Switching Command Reference.
Para que seu dispositivo funcione com os telefones IP da Cisco, é necessário ativar a compatibilidade com o CDP.
Se o seu dispositivo habilitado para LLDP não puder reconhecer os pacotes CDP, ele não responderá às solicitações dos telefones IP da Cisco para a VLAN ID de voz configurada no dispositivo. Como resultado, um telefone IP Cisco solicitante envia tráfego de voz sem nenhuma tag para o seu dispositivo. Seu dispositivo não consegue diferenciar o tráfego de voz de outros tipos de tráfego.
A compatibilidade com CDP permite que seu dispositivo receba e reconheça os pacotes CDP de um telefone IP da Cisco e responda com pacotes CDP que contenham TLVs com a Voice Vlan configurada. Se nenhuma Voice Vlan estiver configurada para pacotes CDP, os pacotes CDP transportarão a Voice Vlan da porta ou a Voice Vlan atribuída pelo servidor RADIUS. A Voice Vlan atribuída tem uma prioridade mais alta. De acordo com os TLVs com a configuração da Voice Vlan, o telefone IP configura automaticamente a Voice Vlan. Como resultado, o tráfego de voz é confinado na Voice Vlan configurada e é diferenciado de outros tipos de tráfego.
Para obter mais informações sobre Voice Vlan, consulte "Configuração de Voice Vlan".
Quando o dispositivo está conectado a um telefone IP da Cisco que tem um host conectado à sua porta de dados, o host deve acessar a rede por meio do telefone IP da Cisco. Se a porta de dados cair, o telefone IP enviará um pacote CDP ao dispositivo para que ele possa fazer o logout do usuário.
O LLDP compatível com CDP opera em um dos seguintes modos:
Os pacotes TxRx-CDP podem ser transmitidos e recebidos.
Os pacotes Rx-CDP podem ser recebidos, mas não podem ser transmitidos.
Desativar - os pacotes CDP não podem ser transmitidos ou recebidos.
Restrições e diretrizes
Quando você configurar a compatibilidade de CDP para LLDP, siga estas restrições e diretrizes:
Para que o LLDP compatível com CDP entre em vigor em uma porta, siga estas etapas:
Habilitar LLDP compatível com CDP globalmente.
Configure o LLDP compatível com CDP para operar no modo TxRx na porta.
O valor máximo de TTL permitido pelo CDP é de 255 segundos. Para que o LLDP compatível com CDP funcione corretamente com os telefones IP da Cisco, configure o intervalo de transmissão do quadro LLDP para que não seja superior a 1/3 do valor TTL.
Pré-requisitos
Antes de configurar a compatibilidade do CDP, conclua as seguintes tarefas:
Ativar globalmente o LLDP.
Habilite o LLDP na porta que se conecta a um dispositivo CDP.
Configure o LLDP para operar no modo TxRx na porta.
Procedimento
Entre na visualização do sistema.
System ViewHabilite a compatibilidade do CDP globalmente.
cdp de conformidade lldpPor padrão, a compatibilidade do CDP é desativada globalmente.
Entre na visualização da interface Ethernet de camada 2 ou na visualização da interface Ethernet de gerenciamento.
interface interface-type interface-numberConfigure o LLDP compatível com CDP para operar no modo TxRx.
lldp compliance admin-status cdp txrxPor padrão, o LLDP compatível com CDP opera no modo de desativação .
Defina a VLAN ID de voz transportada nos pacotes CDP.
cdp voice-vlan vlan-idPor padrão, nenhuma VLAN ID de voz é configurada para ser transportada em pacotes CDP.
Configuração do trapping LLDP e do trapping LLDP-MED
Sobre o trapping LLDP e o trapping LLDP-MED
O trapping LLDP ou o trapping LLDP-MED notifica o sistema de gerenciamento de rede sobre eventos, como dispositivos vizinhos recém-detectados e falhas de link.
Para evitar o envio excessivo de traps LLDP quando a topologia estiver instável, defina um intervalo de transmissão de traps para LLDP.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberAtivar o rastreamento de LLDP.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp [ agent { nearest-customer | nearest-nontpmr } ] notification remote-change enableNa visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr } notification remote-change enablePor padrão, o rastreamento de LLDP está desativado.
(Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento.) Habilite o rastreamento LLDP-MED.
lldp notification med-topology-change enablePor padrão, o rastreamento LLDP-MED está desativado.
Retornar à visualização do sistema.
quit(Opcional.) Defina o intervalo de transmissão de interceptação LLDP.
lldp timer notification-interval intervalA configuração padrão é de 30 segundos.
Configuração do aprendizado de endereço MAC para DCN
Definição do endereço MAC de origem dos quadros LLDP
Sobre a configuração do endereço MAC de origem dos quadros LLDP
Na visualização da interface Ethernet de camada 2, esse recurso deve ser configurado com a geração de entradas ARP ou ND para TLVs de endereço de gerenciamento recebidos para atender aos seguintes requisitos:
O endereço MAC de origem dos quadros LLDP de saída é o endereço MAC de uma interface VLAN, em vez do endereço MAC da interface de saída.
O dispositivo vizinho pode gerar entradas ARP ou ND corretas para o dispositivo local.
Na visualização da interface Ethernet de camada 2, esse recurso define o endereço MAC de origem dos quadros LLDP de saída como o endereço MAC de uma interface VLAN à qual pertence a VLAN ID especificada. O endereço MAC de origem dos quadros LLDP de saída é o endereço MAC da interface Ethernet de camada 2 nas seguintes situações:
A VLAN especificada ou a interface VLAN correspondente não existe.
A interface da VLAN à qual pertence a VLAN ID está fisicamente inativa.
Restrições e diretrizes
Na visualização da interface Ethernet de camada 2, você deve configurar esse recurso para que a interface possa usar o endereço MAC de uma interface VLAN em vez de seu próprio endereço MAC como o endereço MAC de origem do LLDP
frames. Isso garante que o dispositivo vizinho possa gerar entradas ARP ou ND corretas para o dispositivo local.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberDefina o endereço MAC de origem dos quadros LLDP como o endereço MAC de uma interface VLAN.
lldp source-mac vlan vlan-idPor padrão, o endereço MAC de origem dos quadros LLDP é o endereço MAC da interface de saída .
Ativação da geração de entradas ARP ou ND para TLVs de endereço de gerenciamento recebidos
Sobre a geração de entradas ARP ou ND para TLVs de endereço de gerenciamento recebidos
Esse recurso permite que o dispositivo gere uma entrada ARP ou ND após receber um quadro LLDP contendo um endereço de gerenciamento TLV em uma interface. A entrada ARP ou ND mapeia o endereço de gerenciamento anunciado para o endereço MAC de origem do quadro.
Você pode ativar a geração de entradas ARP e ND em uma interface. Se o endereço de gerenciamento TLV contiver um endereço IPv4, o dispositivo gerará uma entrada ARP. Se o endereço de gerenciamento TLV contiver um endereço IPv6, o dispositivo gerará uma entrada ND.
Na visualização da interface Ethernet de Camada 2, esse recurso define a interface Ethernet de Camada 2 como a interface de saída nas entradas geradas. A VLAN à qual as entradas pertencem é a VLAN especificada por esse recurso. O dispositivo não pode gerar entradas ARP ou ND em uma das seguintes situações:
A VLAN especificada ou a interface VLAN correspondente não existe.
A interface da VLAN à qual pertence a VLAN ID está fisicamente inativa.
Restrições e diretrizes
Na visualização da interface Ethernet de camada 2, você deve configurar a interface para usar o endereço MAC de uma interface VLAN em vez de seu próprio endereço MAC como endereço MAC de origem dos quadros LLDP. Esse garante que o dispositivo vizinho possa gerar entradas ARP ou ND corretas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberHabilita a geração de entradas ARP ou ND para TLVs de endereço de gerenciamento recebidos na interface.
lldp management-address { arp-learning | nd-learning } vlan vlan-id
Por padrão, a geração de entradas ARP ou ND para TLVs de endereços de gerenciamento recebidos é desativada em uma interface.
Na visualização da interface Ethernet de camada 2, a opção vlan vlan-id especifica a ID da VLAN à qual pertence a entrada ARP ou ND gerada. Para evitar que as entradas ARP ou ND se sobreponham umas às outras, não especifique a mesma ID de VLAN para diferentes interfaces Ethernet de camada 2.
Você pode ativar a geração de entradas ARP e ND em uma interface.
Exemplos de configuração LLDP
Exemplo: Configuração das funções básicas do LLDP
Configuração de rede
Conforme mostrado na Figura 5, habilite o LLDP globalmente no Switch A e no Switch B para realizar as seguintes tarefas:
- Monitore o link entre o Switch A e o Switch B no NMS.
- Monitore o link entre o Switch A e o dispositivo MED no NMS.
Figura 5 Diagrama de rede
Procedimento
Configure o Switch A:
# Habilite o LLDP globalmente.
<SwitchA> system-view
[SwitchA] lldp enable global# Habilite o LLDP na GigabitEthernet 1/0/1. Por padrão, o LLDP está ativado nas portas.
[SwitchA] interface gigabitethernet 1/0/1
[SwitchA-GigabitEthernet1/0/1] lldp enable# Defina o modo de operação LLDP como Rx na GigabitEthernet 1/0/1.
[SwitchA-GigabitEthernet1/0/1] lldp admin-status rx
[SwitchA-GigabitEthernet1/0/1] quit# Habilite o LLDP na GigabitEthernet 1/0/2. Por padrão, o LLDP está habilitado nas portas.
[SwitchA] interface gigabitethernet1/2
[SwitchA-GigabitEthernet1/0/2] lldp enable# Defina o modo de operação LLDP como Rx na GigabitEthernet 1/0/2.
[SwitchA-GigabitEthernet1/0/2] lldp admin-status rx
[SwitchA-GigabitEthernet1/0/2] quitConfigurar o Switch B:
# Habilite o LLDP globalmente.
<SwitchB> system-view
[SwitchB] lldp enable global# Habilite o LLDP na GigabitEthernet 1/0/1. Por padrão, o LLDP está ativado nas portas.
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] lldp enable# Defina o modo de operação do LLDP como Tx na GigabitEthernet 1/0/1.
[SwitchB-GigabitEthernet1/0/1] lldp admin-status tx
[SwitchB-GigabitEthernet1/0/1] quitVerificação da configuração
# Verifique os seguintes itens:
- A GigabitEthernet 1/0/1 do Switch A se conecta a um dispositivo MED.
- A GigabitEthernet 1/0/2 do Switch A se conecta a um dispositivo não-MED.
- Ambas as portas operam no modo Rx e podem receber quadros LLDP, mas não podem enviar quadros LLDP.
[SwitchA] display lldp status
LLDP global status: Enable
LLDP bridge mode: customer-bridge
Current number of LLDP neighbors: 2
Current number of CDP neighbors: 0
Last LLDP neighbor information change: 0 days, 0 hours, 4 minutes, 40 seconds
Transmission interval: 30s
Rapid transmission interval: 1s
Maximum transmission credit: 5
Retention multiplier: 4
Reinitialization delay: 2s
Trap interval: 30s
Quick start times: 4# Remova o link entre o Switch A e o Switch B.
# Verifique se a GigabitEthernet 1/0/2 do Switch A não se conecta a nenhum dispositivo vizinho.
[SwitchA] display lldp status
LLDP global status: Enable (Activate)
Current number of LLDP neighbors: 1
Current number of CDP neighbors: 0
Last LLDP neighbor information change: 0 days, 0 hours, 5 minutes, 20 seconds
Transmission interval: 30s
Rapid transmission interval: 1s
Maximum transmission credit: 5
Retention multiplier: 4
Reinitialization delay: 2s
Trap interval: 30s
Quick start times: 4Configuração do L2PT
Sobre a L2PT
O L2PT (Layer 2 Protocol Tunneling) pode enviar pacotes de protocolo de camada 2 de forma transparente a partir de redes de clientes geograficamente dispersas em uma rede de provedor de serviços ou descartá-los.
Cenário do aplicativo L2PT
As linhas dedicadas são usadas em uma rede de provedor de serviços para criar redes de Camada 2 específicas do usuário. Como resultado, uma rede de clientes contém sites localizados em lados diferentes da rede do provedor de serviços.
Conforme mostrado na Figura 1, a rede do Cliente A é dividida em rede 1 e rede 2, que são conectadas pela rede do provedor de serviços. Para que a rede do Cliente A implemente os cálculos do protocolo da Camada 2, os pacotes do protocolo da Camada 2 devem ser transmitidos pela rede do provedor de serviços.
Ao receber um pacote de protocolo de camada 2, os PEs não podem determinar se o pacote é da rede do cliente ou da rede do provedor de serviços. Eles devem entregar o pacote à CPU para processamento. Nesse caso, o cálculo do protocolo da Camada 2 na rede do Cliente A é misturado com o cálculo do protocolo da Camada 2 na rede do provedor de serviços. Nem a rede do cliente nem a rede do provedor de serviços podem implementar cálculos de protocolo de Camada 2 independentes.
Figura 1 Cenário do aplicativo L2PT
O L2PT foi introduzido para resolver o problema. O L2PT oferece as seguintes funções:
Multicasts de pacotes de protocolo de Camada 2 de uma rede de clientes em uma VLAN. As redes de clientes dispersas podem concluir um cálculo de protocolo de camada 2 independente, que é transparente para a rede do provedor de serviços.
Isola os pacotes de protocolo da Camada 2 de diferentes redes de clientes por meio de diferentes VLANs.
Mecanismo operacional L2PT
Conforme mostrado na Figura 2, o L2PT funciona da seguinte forma:
Quando uma porta do PE 1 recebe um pacote de protocolo de camada 2 da rede do cliente em uma VLAN, ela executa as seguintes operações:
Multicasts o pacote para fora de todas as portas voltadas para o cliente na VLAN, exceto a porta receptora.
Encapsula o pacote com um endereço multicast de destino especificado e o envia para todas as portas voltadas para o ISP na VLAN. O pacote encapsulado é chamado de pacote com túnel BPDU.
Quando uma porta do PE 2 na VLAN recebe o pacote com túnel da rede do provedor de serviços, ela executa as seguintes operações:
Multicasts o pacote para fora de todas as portas voltadas para o ISP na VLAN, exceto a porta receptora.
Decapsula o pacote e faz multicasts do pacote decapsulado para todas as portas voltadas para o cliente na VLAN.
Figura 2 Mecanismo operacional do L2PT
Por exemplo, conforme mostrado na Figura 3, o PE 1 recebe um pacote STP (BPDU) da rede 1 para a rede 2. Os CEs são os dispositivos de borda na rede do cliente e os PEs são os dispositivos de borda na rede do provedor de serviços. O L2PT processa o pacote da seguinte forma:
O PE 1 realiza as seguintes operações:
Encapsula o pacote com um endereço MAC multicast de destino especificado (010f-e200-0003 por padrão).
Envia o pacote com túnel para fora de todas as portas voltadas para o ISP na VLAN do pacote.
Ao receber o pacote tunelado, o PE 2 decapsula o pacote e envia o BPDU para o CE 2.
Por meio do L2PT, tanto a rede do ISP quanto a rede do Cliente A podem realizar cálculos independentes de spanning tree.
Figura 3 Diagrama de rede L2PT
Visão geral das tarefas do L2PT
Para configurar o L2PT, execute as seguintes tarefas:
Ativação do L2PT
Esse recurso é aplicável somente a portas voltadas para o cliente.
(Opcional.) Configuração do endereço MAC multicast de destino para pacotes tunelados
Ativação do L2PT
Restrições e diretrizes para L2PT
Para ativar o L2PT para um protocolo de camada 2 em uma porta, execute as seguintes tarefas:
Habilite o protocolo no EC conectado e desabilite o protocolo na porta.
Quando um PE estabelece uma conexão com um dispositivo de rede dentro da rede do provedor de serviços por meio do CDP, você deve ativar a compatibilidade do CDP para LLDP no PE. A compatibilidade de CDP para LLDP só pode ser ativada globalmente e não pode ser desativada separadamente nas interfaces voltadas para o cliente. Como resultado, os pacotes CDP do CE não podem ser transmitidos de forma transparente dentro da rede do provedor de serviços. Nesse caso, como prática recomendada, não habilite o L2PT para CDP no PE. Para que o L2PT tenha efeito sobre o CDP no PE, você deve desativar a compatibilidade do CDP para LLDP globalmente no PE, o que fará com que o PE não consiga se comunicar com os dispositivos de rede dentro da rede do provedor de serviços por meio do CDP. Antes de desativar a compatibilidade de CDP para LLDP no PE, certifique-se de conhecer sua influência na rede. Para obter mais informações sobre a compatibilidade de CDP do LLDP, consulte "Configuração do LLDP".
Desative o protocolo (por exemplo, STP) nas portas PE que se conectam a uma interface agregada em um CE quando houver as seguintes condições:
O protocolo está sendo executado na interface agregada do CE.
A interface agregada no CE conecta-se a uma porta habilitada para L2PT no PE.
Ativar o L2PT nas portas PE conectadas a uma rede de clientes. Se você ativar o L2PT nas portas conectadas à rede do provedor de serviços, o L2PT determinará que as portas estão conectadas a uma rede do cliente.
Certifique-se de que as tags de VLAN dos pacotes de protocolo da Camada 2 não sejam alteradas ou excluídas para que os pacotes tunelados sejam transmitidos corretamente pela rede do provedor de serviços.
O L2PT para LLDP suporta pacotes LLDP somente dos agentes de ponte mais próximos.
É possível ativar o L2PT em uma porta membro de um grupo de agregação de Camada 2, mas a configuração não tem efeito.
Ativação do L2PT para um protocolo na visualização da interface Ethernet de camada 2
Restrições e diretrizes
O LACP e o EOAM exigem transmissão ponto a ponto. Se você ativar o L2PT em uma interface Ethernet de Camada 2 para LACP ou EOAM, o L2PT fará multicasts de pacotes LACP ou EOAM para fora das portas voltadas para o cliente. Como resultado, a transmissão entre dois CEs não é ponto a ponto. Para garantir a transmissão ponto a ponto dos pacotes LACP ou EOAM, você deve configurar outros recursos (por exemplo, VLAN).
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberAtivar o L2PT para um protocolo.
l2protocol { cdp | cfd | dldp | dtp | eoam | gvrp | lacp | lldp | mvrp | pagp
| pvst | stp | udld | vtp } tunnel dot1q Por padrão, o L2PT está desativado para todos os protocolos.
As palavras-chave dtp e cfd são compatíveis apenas com a versão 6331 e posteriores.
Ativação do L2PT para um protocolo na visualização da interface agregada da Camada 2
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-type interface-number
Ativar o L2PT para um protocolo.
l2protocol { cdp | cfd | gvrp | lacp | lldp | mvrp | pagp | pvst | stp
| udld | vtp } tunnel dot1qPor padrão, o L2PT está desativado para todos os protocolos.
A palavra-chave cfd é compatível apenas com a versão 6331 e posteriores.
Configuração do endereço MAC multicast de destino para pacotes com túnel
Sobre o endereço MAC multicast de destino para pacotes tunelados
O endereço MAC multicast de destino padrão para pacotes com túnel é 010f-e200-0003. Você pode modificar o endereço MAC multicast de destino para pacotes com túnel de um protocolo específico ou de todos os protocolos.
Restrições e diretrizes
O comando l2protocol tunnel-dmac define o endereço MAC multicast de destino para pacotes com túnel de todos os protocolos. O comando l2protocol type tunnel-dmac define o endereço
endereço MAC multicast de destino para pacotes com túnel do protocolo especificado. Se ambos os comandos forem executados, o comando l2protocol type tunnel-dmac terá prioridade.
Para que os pacotes tunelados sejam reconhecidos, defina os mesmos endereços MAC multicast de destino para pacotes do mesmo protocolo em PEs que estejam conectados à mesma rede de clientes.
Como prática recomendada, defina endereços MAC multicast de destino diferentes em PEs conectados a redes de clientes diferentes. Isso evita que o L2PT envie pacotes de uma rede de clientes para outra rede de clientes.
Procedimento
Entre na visualização do sistema.
System ViewExecute pelo menos uma das seguintes tarefas:
Defina o endereço MAC multicast de destino para pacotes tunelados de todos os protocolos.
l2protocol tunnel-dmac mac-addressDefine o endereço MAC multicast de destino para pacotes tunelados do protocolo especificado.
l2protocol type { cdp | cfd | dldp | dtp | eoam | gvrp | lacp | lldp
| mvrp | pagp | pvst | stp | udld | vtp } tunnel-dmac mac-address Esse comando é compatível apenas com a versão 6331 e posteriores.
Por padrão, 010f-e200-0003 é usado para pacotes com túnel.
Exemplos de configuração L2PT
Exemplo: Configuração de L2PT para STP
Configuração de rede
Conforme mostrado na Figura 4, os endereços MAC de CE 1 e CE 2 são 00e0-fc02-5800 e 00e0-fc02-5802, respectivamente. O MSTP está ativado na rede do Cliente A e as configurações padrão do MSTP são usadas.
Execute as seguintes tarefas nos PEs:
- Configure as portas que se conectam aos CEs como portas de acesso e configure as portas na rede do provedor de serviços como portas tronco. Configure as portas na rede do provedor de serviços para permitir a passagem de pacotes de qualquer VLAN.
- Ative o L2PT para STP para permitir que a rede do Cliente A implemente o cálculo independente da árvore de abrangência na rede do provedor de serviços.
- Defina o endereço MAC multicast de destino como 0100-0ccd-cdd0 para pacotes com túnel.
Figura 4 Diagrama de rede
Procedimento
Configurar o PE 1:
# Defina o endereço multicast de destino como 0100-0ccd-cdd0 para pacotes com túnel.
<PE1> system-view
[PE1] l2protocol tunnel-dmac 0100-0ccd-cdd0# Crie a VLAN 2.
[PE1] vlan 2
[PE1-vlan2] quit# Configure a GigabitEthernet 1/0/1 como uma porta de acesso e atribua a porta à VLAN 2.
[PE1] interface gigabitethernet 1/0/1
[PE1-GigabitEthernet1/0/1] port access vlan 2# Desative o STP e ative o L2PT para STP na GigabitEthernet 1/0/1.
[PE1-GigabitEthernet1/0/1] undo stp enable
[PE1-GigabitEthernet1/0/1] l2protocol-tunnel stp enable# Configure a GigabitEthernet 1/0/2 conectada à rede do provedor de serviços como uma porta tronco e atribua a porta a todas as VLANs.
[PE1] interface gigabitethernet 1/0/2
[PE1-GigabitEthernet1/0/2] port link-type trunk
[PE1-GigabitEthernet1/0/2] port trunk permit vlan allConfigure o PE 2 da mesma forma que o PE 1 está configurado. (Detalhes não mostrados).
Verificação da configuração
# Verifique se a ponte raiz da rede do cliente A é a CE 1.
<CE2> display stp rootMST ID Root Bridge ID ExtPathCost IntPathCost Root Port
0 32768.00e0-fc02-5800 0 0
# Verificar se a ponte raiz da rede do provedor de serviços não é a CE 1.
[PE1] display stp rootMST ID Root Bridge ID ExtPathCost IntPathCost Root Port
0 32768.0cda-41c5-ba50 0 0
Exemplo: Configuração de L2PT para LACP
Configuração de rede
Conforme mostrado na Figura 5, os endereços MAC de CE 1 e CE 2 são 0001-0000-0000 e 0004-0000-0000, respectivamente.
Execute as seguintes tarefas:
- Configure a agregação do link Ethernet no CE 1 e no CE 2.
- Configure a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 no CE 1 para formar links agregados com a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 no CE 2, respectivamente.
- Habilite o L2PT para LACP para permitir que o CE 1 e o CE 2 implementem a agregação de links Ethernet na rede do provedor de serviços.
Figura 5 Diagrama de rede
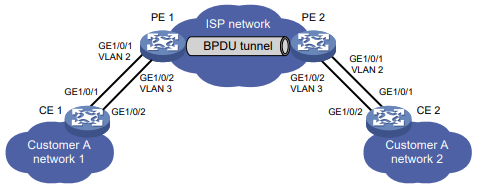
Análise de requisitos
Para atender aos requisitos de rede, execute as seguintes tarefas:
- Para que a agregação de links Ethernet funcione corretamente, configure as VLANs nos PEs para garantir a transmissão ponto a ponto entre o CE 1 e o CE 2 em um grupo de agregação.
- Defina os PVIDs como VLAN 2 e VLAN 3 para GigabitEthernet 1/0/1 e GigabitEthernet 1/0/2 no PE 1, respectivamente.
- Configure o PE 2 da mesma forma que o PE 1 está configurado.
- Configure as portas que se conectam aos CEs como portas tronco.
- Para manter a tag de VLAN da rede do cliente, ative o QinQ na GigabitEthernet 1/0/1 e na GigabitEthernet 1/0/2 no PE 1 e no PE 2.
- Para que os pacotes de qualquer VLAN sejam transmitidos, configure todas as portas da rede do provedor de serviços como portas tronco.
Procedimento
Configurar o CE 1:
# Configure o grupo de agregação da camada 2 Bridge-Aggregation 1 para operar no modo de agregação dinâmica.
<CE1> system-view
[CE1] interface bridge-aggregation 1
[CE1-Bridge-Aggregation1] port link-type access
[CE1-Bridge-Aggregation1] link-aggregation mode dynamic
[CE1-Bridge-Aggregation1] quit# Atribua a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 ao Bridge-Aggregation 1.
[CE1] interface gigabitethernet 1/0/1
[CE1-GigabitEthernet1/0/1] port link-aggregation group 1
[CE1-GigabitEthernet1/0/1] quit
[CE1] interface gigabitethernet 1/0/2
[CE1-GigabitEthernet1/0/2] port link-aggregation group 1
[CE1-GigabitEthernet1/0/2] quitConfigure o CE 2 da mesma forma que o CE 1 está configurado. (Os detalhes não são mostrados).
Configurar o PE 1:
# Crie as VLANs 2 e 3.
<PE1> system-view
[PE1] vlan 2
[PE1-vlan2] quit
[PE1] vlan 3
[PE1-vlan3] quit# Configure a GigabitEthernet 1/0/1 como uma porta tronco, atribua a porta à VLAN 2 e defina o PVID como VLAN 2.
[PE1] interface gigabitethernet 1/0/1
[PE1-GigabitEthernet1/0/1] port link-mode bridge
[PE1-GigabitEthernet1/0/1] port link-type trunk
[PE1-GigabitEthernet1/0/1] port trunk permit vlan 2
[PE1-GigabitEthernet1/0/1] port trunk pvid vlan 2
[PE1-GigabitEthernet1/0/1] qinq enable
[PE1-GigabitEthernet1/0/1] l2protocol lacp tunnel dot1q
[PE1-GigabitEthernet1/0/1] quit# Habilite o L2PT para LACP na GigabitEthernet 1/0/1.
[PE1-GigabitEthernet1/0/1] l2protocol-tunnel lacp enable# Configure a GigabitEthernet 1/0/2 como uma porta tronco, atribua a porta à VLAN 3 e defina o PVID para a VLAN 3.
[PE1] interface gigabitethernet 1/0/2
[PE1-GigabitEthernet1/0/2] port link-mode bridge
[PE1-GigabitEthernet1/0/2] port link-type trunk
[PE1-GigabitEthernet1/0/2] port trunk permit vlan 3
[PE1-GigabitEthernet1/0/2] port trunk pvid vlan 3
[PE1-GigabitEthernet1/0/2] qinq enable
[PE1-GigabitEthernet1/0/2] l2protocol-tunnel lacp enable
[PE1-GigabitEthernet1/0/2] quitConfigure o PE 2 da mesma forma que o PE 1 está configurado. (Detalhes não mostrados).
Verificação da configuração
# Verifique se o CE 1 e o CE 2 concluíram a agregação do link Ethernet com êxito.
[CE1] display link-aggregation verbose Bridge-Aggregation1[CE2] display link-aggregation verbose Bridge-Aggregation1Configuração do relé PPPoE
Sobre o PPPoE
O PPPoE (Point-to-Point Protocol over Ethernet) amplia o PPP transportando quadros PPP encapsulados em Ethernet por links ponto a ponto.
O PPPoE especifica os métodos para estabelecer sessões PPPoE e encapsular quadros PPP sobre Ethernet. O PPPoE requer uma relação ponto a ponto entre pares, em vez de uma relação ponto a multiponto como em ambientes de acesso múltiplo, como a Ethernet. O PPPoE fornece acesso à Internet para os hosts em uma Ethernet por meio de um dispositivo de acesso remoto e implementa controle de acesso, autenticação e contabilidade por host. Integrando o baixo custo da Ethernet e as funções de escalabilidade e gerenciamento do PPP, o PPPoE ganhou popularidade em vários ambientes de aplicativos, como redes de acesso residencial.
Para obter mais informações sobre o PPPoE, consulte a RFC 2516.
Estrutura de rede PPPoE
O PPPoE usa o modelo cliente/servidor. O cliente PPPoE inicia uma solicitação de conexão com o servidor PPPoE. Após a conclusão da negociação da sessão entre eles, uma sessão é estabelecida entre eles e o servidor PPPoE fornece controle de acesso, autenticação e contabilidade ao cliente PPPoE.
Para gerenciar de forma granular os clientes PPPoE com base em suas informações de localização, você pode implantar um relé PPPoE entre os clientes PPPoE e o servidor PPPoE.
As estruturas de rede PPPoE são classificadas em estruturas de rede iniciadas pelo roteador e iniciadas pelo host, dependendo do ponto de partida da sessão PPPoE.
Estrutura de rede iniciada pelo roteador
Conforme mostrado na Figura 1, a sessão PPPoE é estabelecida entre os roteadores (Roteador A e Roteador B). Todos os hosts compartilham uma sessão PPPoE para a transmissão de dados sem que seja instalado um software cliente PPPoE. Essa estrutura de rede é normalmente usada por empresas.
Figura 1 Estrutura de rede iniciada por roteador
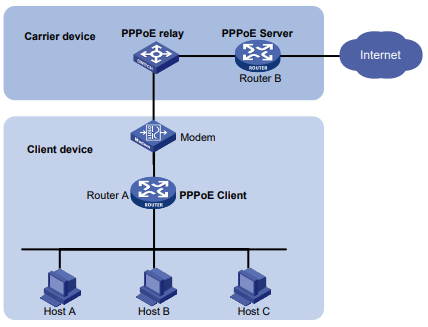
Estrutura de rede iniciada pelo host
Conforme mostrado na Figura 2, uma sessão PPPoE é estabelecida entre cada host (cliente PPPoE) e o roteador da operadora (servidor PPPoE). O provedor de serviços atribui uma conta a cada host para cobrança e controle. O host deve ser instalado com o software cliente PPPoE.
Figura 2 Estrutura de rede iniciada pelo host
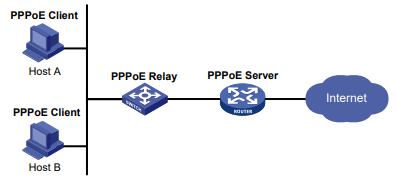
Fundamentos do relé PPPoE
O relé PPPoE controla o encaminhamento de pacotes de protocolo por meio do monitoramento da troca de pacotes de protocolo entre o cliente PPPoE e o servidor PPPoE. A Figura 3 mostra o processo detalhado.
Figura 3 Procedimento de acesso do cliente PPPoE em uma rede de retransmissão PPPoE
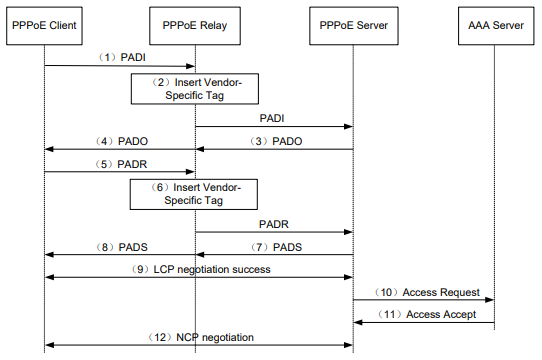
O cliente PPPoE transmite um pacote PADI.
Ao receber o pacote PADI, o relé PPPoE adiciona o campo de tag específico do fornecedor ao pacote PADI e transmite o pacote para todas as portas confiáveis.
A tag específica do fornecedor em um pacote PPPoE identifica as informações de localização (por exemplo, a porta de acesso e as VLANs) de um cliente PPPoE.
Ao receber os pacotes PADI, o servidor PPPoE responde com um pacote PADO para o cliente PPPoE.
Ao receber o pacote PADO, o relé PPPoE encaminha o pacote para o cliente PPPoE.
Ao receber o pacote PADO, o cliente PPPoE envia um pacote PADR para o servidor PPPoE para solicitar o serviço PPPoE.
Ao receber o pacote PADR, o relé PPPoE adiciona a tag específica do fornecedor ao pacote e procura uma interface de saída com base no endereço MAC de destino do pacote PADR.
Se a interface de saída for uma porta confiável, o relé PPPoE encaminhará o pacote para fora da porta.
Se a interface de saída for uma porta não confiável, o relé PPPoE descartará o pacote PADR.
Ao receber o pacote PADR, o servidor PPPoE atribui um ID de sessão ao cliente PPPoE e vincula o ID de sessão à tag específica do fornecedor. Em seguida, o servidor PPPoE responde com um pacote PADS para o cliente PPPoE.
Ao receber o pacote PADS, o relé PPPoE encaminha o pacote para o cliente PPPoE.
Ao receber o pacote PADS, o cliente PPPoE inicia a negociação LCP e a autenticação com o servidor PPPoE.
Durante a fase de autenticação, o servidor PPPoE enviará as informações de localização, o nome de usuário e a senha do cliente PPPoE ao servidor RADIUS para autenticação.
O servidor RADIUS compara as informações de localização, o nome de usuário e a senha salvos no banco de dados com os do cliente PPPoE. Se forem iguais, o cliente PPPoE passa na autenticação.
Depois que o cliente PPPoE passa pela autenticação, o cliente PPPoE inicia a negociação NCP com o servidor PPPoE. Depois que a negociação NCP for bem-sucedida, o cliente PPPoE ficará on-line com êxito.
Configuração do relé PPPoE
Visão geral das tarefas de retransmissão do PPPoE
Para configurar o relé PPPoE, execute as seguintes tarefas:
Ativação da função de retransmissão PPPoE
Configuração de portas confiáveis de retransmissão PPPoE
(Opcional.) Ativação de uma interface para remover as tags específicas do fornecedor dos pacotes do lado do servidor PPPoE
(Opcional.) Configuração dos formatos de preenchimento do ID do circuito e do ID remoto para os pacotes PPPoE do lado do cliente no relé PPPoE
(Opcional.) Configuração da política de processamento de tags específicas do fornecedor para os pacotes PPPoE do lado do cliente no relé PPPoE
Ativação da função de retransmissão PPPoE
Sobre a função de retransmissão PPPoE
Para que as configurações relacionadas ao relé PPPoE tenham efeito, você deve ativar a função de relé PPPoE.
Procedimento
Entre na visualização do sistema.
System ViewAtivar a função de retransmissão PPPoE.
pppoe-relay enable
Por padrão, a função de retransmissão PPPoE está desativada.
Configuração de portas confiáveis de retransmissão PPPoE
Sobre as portas confiáveis de retransmissão PPPoE
Um dispositivo habilitado para retransmissão PPPoE processa os pacotes do protocolo PPPoE da seguinte forma:
Ao receber PADI, PADR e PADT em portas não confiáveis, o dispositivo pode encaminhar os pacotes apenas para as portas confiáveis.
Ao receber pacotes PADO e PADS em portas não confiáveis, o dispositivo descarta diretamente os pacotes.
Ao receber pacotes PADO, PADS e PADT em portas confiáveis, o dispositivo pode encaminhar os pacotes para qualquer porta.
Ao receber pacotes PADI e PADR em portas confiáveis, o dispositivo pode encaminhar os pacotes somente para as portas confiáveis.
Para que um relé PPPoE encaminhe e processe corretamente os pacotes do protocolo PPPoE, você deve configurar as interfaces voltadas para o servidor PPPoE no relé PPPoE como portas confiáveis e configurar as interfaces voltadas para o cliente PPPoE no relé PPPoE como portas não confiáveis.
Restrições e diretrizes
Esse comando não é compatível com as portas membro do grupo de agregação da Camada 2. Se uma interface Ethernet de camada 2 for configurada com esse comando antes de entrar em um grupo de agregação de camada 2, o comando será apagado na porta membro depois que ela entrar no grupo de agregação.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure a interface como uma porta confiável de retransmissão PPPoE.
pppoe-relay trustPor padrão, uma interface não é configurada como uma porta confiável de retransmissão PPPoE.
Ativação de uma interface para remover as tags específicas do fornecedor dos pacotes do lado do servidor PPPoE
Sobre a remoção das tags específicas do fornecedor dos pacotes do lado do servidor PPPoE
Quando o retransmissor PPPoE recebe pacotes PADO e PADS do servidor PPPoE em uma porta confiável do retransmissor PPPoE com esse recurso ativado, o retransmissor PPPoE remove as tags específicas do fornecedor dos pacotes antes de encaminhá-los.
Restrições e diretrizes
Esse recurso entra em vigor somente em pacotes recebidos em portas confiáveis de retransmissão PPPoE.
Esse comando não é compatível com as portas membro do grupo de agregação da Camada 2. Se uma interface Ethernet de camada 2 for configurada com esse comando antes de entrar em um grupo de agregação de camada 2, o comando será apagado na porta membro depois que ela entrar no grupo de agregação.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberHabilite a interface para remover as tags específicas do fornecedor dos pacotes do lado do servidor PPPoE.
faixa específica do fornecedor de informações do servidor de pppoe-relay
Por padrão, a função de remoção de tags específicas do fornecedor dos pacotes do lado do servidor PPPoE está desativada.
Configuração dos formatos de preenchimento do ID do circuito e do ID remoto para os pacotes PPPoE do lado do cliente no relé PPPoE
Sobre os formatos de preenchimento de ID de circuito e ID remota para os pacotes PPPoE do lado do cliente no relé PPPoE
Quando o relé PPPoE recebe pacotes PPPoE do cliente PPPoE, o relé PPPoE preenche a ID do circuito e a ID remota com o conteúdo no formato configurado usando esse comando.
Tanto a ID do circuito quanto a ID remota têm até 63 caracteres. Quando o conteúdo a ser preenchido exceder 63 caracteres, os primeiros 63 caracteres serão preenchidos.
Procedimento
Entre na visualização do sistema.
System ViewConfigure os formatos de preenchimento do ID do circuito e do ID remoto para os pacotes PPPoE do lado do cliente no relé PPPoE.
pppoe-relay client-information format { circuit-id | remote-id }
{ ascii | hex | user-defined text } Por padrão, tanto o formato de preenchimento do ID do circuito quanto o formato de preenchimento do ID remoto para os pacotes PPPoE do lado do cliente são o formato de cadeia ASCII no relé PPPoE.
Configuração da política de processamento de tags específicas do fornecedor para os pacotes PPPoE do lado do cliente no relé PPPoE
Sobre a política de processamento de tags específicas do fornecedor para os pacotes PPPoE do lado do cliente no relé PPPoE
Quando o retransmissor PPPoE recebe pacotes PADI ou PADR, o retransmissor PPPoE processa o pacote de acordo com o fato de os pacotes conterem a etiqueta específica do fornecedor e a política de processamento de etiqueta específica do fornecedor configurada. Em seguida, o relé PPPoE envia os pacotes para o servidor PPPoE. A Tabela 1 mostra o processo detalhado.
Tabela 1 Política de processamento de tags específica do fornecedor no relé PPPoE
Restrições e diretrizes
Esse recurso pode ser configurado tanto na visualização do sistema quanto na visualização da interface. A configuração na visualização do sistema tem efeito em todas as interfaces. A configuração na visualização da interface tem efeito apenas na interface atual. A configuração na visualização da interface tem precedência sobre a configuração na visualização do sistema.
A política de processamento entra em vigor somente nos pacotes de entrada das interfaces.
Esse comando não é compatível com as portas membro do grupo de agregação da Camada 2. Se uma interface Ethernet de camada 2 for configurada com esse comando antes de entrar em um grupo de agregação de camada 2, o comando será apagado na porta membro depois que ela entrar no grupo de agregação.
Configuração da política global de processamento de tags específicas do fornecedor para os pacotes PADI e PADR do lado do cliente no relé PPPoE
Entre na visualização do sistema.
System ViewConfigure a política global de processamento de tags específicas do fornecedor para os pacotes PADI e PADR do lado do cliente no relé PPPoE.
pppoe-relay client-information strategy { drop | keep | replace }Por padrão, a política de processamento de tag específica do fornecedor global para os pacotes PADI e PADR do lado do cliente no relé PPPoE é substituir.
Configuração de uma política de processamento de tags específica do fornecedor em nível de interface para os pacotes PADI e PADR do lado do cliente no relé PPPoE
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure a política de processamento de tags específica do fornecedor para os pacotes PADI e PADR do lado do cliente para a interface no relé PPPoE.
pppoe-relay client-information strategy { drop | keep | replace }Por padrão, nenhuma política de processamento de tags específica do fornecedor para os pacotes PADI e PADR do lado do cliente é configurada para uma interface no relé PPPoE.
Exemplos de configuração PPPoE
Exemplo: Configuração do relé PPPoE
Configuração de rede
O host usa o método de acesso PPPoE para se conectar ao roteador por meio do switch. O switch atua como retransmissor de PPPoE. O roteador atua como servidor PPPoE e atribui endereços IPv4 ao cliente PPPoE por meio de um pool de endereços PPP.
Figura 4 Diagrama de rede
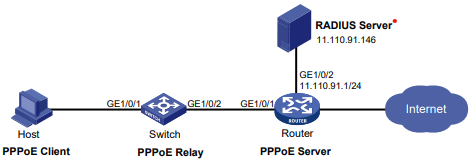
Procedimento
Configure o switch como o relé PPPoE:
# Habilite a função de retransmissão do PPPoE.
<Switch> system-view
[Switch] pppoe-relay enable# Configure a interface GigabitEthernet 1/0/2 voltada para o servidor como uma porta confiável de retransmissão de PPPoE.
[Interface GigabitEthernet 1/0/2
[Switch-GigabitEthernet1/0/2] pppoe-relay trustConfigure o roteador como um servidor PPPoE:
# Crie um usuário PPPoE.
<Router> system-view
[Router] local-user user1 class network
[Router-luser-network-user1] password simple pass1
[Router-luser-network-user1] service-type ppp
[Router-luser-network-user1] quit# Configure o Virtual-Template 1 para usar CHAP para autenticação e usar um pool de endereços PPP para atribuição de endereços IP. Defina o endereço IP do servidor DNS para o par.
[Interface virtual-template 1
[Router-Virtual-Template1] ppp authentication-mode chap domain system
[Router-Virtual-Template1] ppp chap user user1
[Router-Virtual-Template1] remote address pool 1
[Router-Virtual-Template1] ppp ipcp dns 8.8.8.8
[Router-Virtual-Template1] quit# Configure um pool de endereços PPP que contenha nove endereços IP atribuíveis e configure um endereço de gateway para o pool de endereços PPP.
[Router] ip pool 1 1.1.1.2 1.1.1.10
[Router] ip pool 1 gateway 1.1.1.1# Habilite o servidor PPPoE na GigabitEthernet 1/0/1 e vincule a interface ao Virtual-Template 1.
[Interface gigabitethernet 1/0/1
[Router-GigabitEthernet1/0/1] pppoe-server bind virtual-template 1
[Router-GigabitEthernet1/0/1] quit# Configure o domínio ISP padrão (sistema) para usar o esquema RADIUS para autenticação, autorização e contabilidade.
[Router] domain system
[Router-isp-system] authentication ppp radius-scheme rs1
[Router-isp-system] authorization ppp radius-scheme rs1
[Router-isp-system] accounting ppp radius-scheme rs1
[Router-isp-system] quit# Configure um esquema RADIUS e especifique o servidor de autenticação principal e o servidor de contabilidade principal.
[Router] radius scheme rs1
[Router-radius-rs1] primary authentication 11.110.91.146
[Router-radius-rs1] primary accounting 11.110.91.146
[Router-radius-rs1] key authentication simple expert
[Router-radius-rs1] key accounting simple expert
[Router-radius-rs1] quitConfigure o servidor RADIUS:
# Configure as senhas de autenticação e contabilidade como especialista.
# Adicione um usuário PPPoE com nome de usuário user1 e senha 123456. Para obter mais informações, consulte o manual do usuário do servidor RADIUS.
Verificação da configuração
# Instale o software cliente PPPoE e configure o nome de usuário e a senha (user1 e pass1 neste exemplo) nos hosts. Em seguida, os hosts podem usar o PPPoE para acessar a Internet por meio do roteador.
04 Layer 3 — IP Services Configuration Guide
Configuração de ARP
Sobre a ARP
O ARP resolve endereços IP em endereços MAC em redes Ethernet.
Formato da mensagem ARP
O ARP usa dois tipos de mensagens: Solicitação ARP e resposta ARP. A Figura 1 mostra o formato das mensagens de solicitação/resposta do ARP. Os números na figura referem-se ao comprimento dos campos.
Figura 1 Formato da mensagem ARP

- Tipo de hardware-Tipo de endereço de hardware. O valor 1 representa Ethernet.
- Tipo de protocolo - Tipo de endereço de protocolo a ser mapeado. O valor hexadecimal 0x0800 representa IP.
- Comprimento do endereço de hardware e comprimento do endereço de protocolo - Comprimento, em bytes, de um endereço de hardware e de um endereço de protocolo. Para um endereço Ethernet, o valor do campo de comprimento do endereço de hardware é 6. Para um endereço IPv4, o valor do campo de comprimento do endereço de protocolo é 4.
- OP-Código de operação, que descreve o tipo de mensagem ARP. O valor 1 representa uma solicitação ARP e o valor 2 representa uma resposta ARP.
- Endereço de hardware do remetente - Endereço de hardware do dispositivo que está enviando a mensagem.
- Endereço de protocolo do remetente - Endereço de protocolo do dispositivo que está enviando a mensagem.
- Endereço de hardware de destino - Endereço de hardware do dispositivo para o qual a mensagem está sendo enviada.
- Endereço de protocolo de destino - Endereço de protocolo do dispositivo para o qual a mensagem está sendo enviada.
Mecanismo operacional do ARP
Conforme mostrado na Figura 2, o Host A e o Host B estão na mesma sub-rede. O host A envia um pacote para o host B da seguinte forma:
- O host A procura na tabela ARP uma entrada ARP para o host B. Se for encontrada uma entrada, o host A usa o endereço MAC na entrada para encapsular o pacote IP em um quadro da camada de enlace de dados. Em seguida, o host A envia o quadro para o host B.
- Se o Host A não encontrar nenhuma entrada para o Host B, o Host A armazenará o pacote em um buffer e transmitirá uma solicitação ARP. A carga útil da solicitação ARP contém as seguintes informações:
- Endereço IP do remetente e endereço MAC do remetente - Endereço IP e endereço MAC do host A.
- Endereço IP de destino-O endereço IP do host B.
- Endereço MAC de destino - Um endereço MAC totalmente zero.
Todos os hosts dessa sub-rede podem receber a solicitação de difusão, mas somente o host solicitado (Host B) processa a solicitação.
- O host B compara seu próprio endereço IP com o endereço IP de destino na solicitação ARP. Se eles forem iguais, o Host B opera da seguinte forma:
- Adiciona o endereço IP do remetente e o endereço MAC do remetente em sua tabela ARP.
- Encapsula seu endereço MAC em uma resposta ARP.
- Transmite a resposta ARP para o host A.
- Depois de receber a resposta do ARP, o host A opera da seguinte forma:
- Adiciona o endereço MAC do Host B em sua tabela ARP.
- Encapsula o endereço MAC no pacote e envia o pacote para o Host B.
Figura 2 Processo de resolução de endereços ARP

Se o host A e o host B estiverem em sub-redes diferentes, o host A enviará um pacote para o host B da seguinte forma:
- O host A transmite uma solicitação ARP em que o endereço IP de destino é o endereço IP do gateway.
- O gateway responde com seu endereço MAC em uma resposta ARP ao Host A.
- O host A usa o endereço MAC do gateway para encapsular o pacote e, em seguida, envia o pacote para o gateway.
- Se o gateway tiver uma entrada ARP para o Host B, ele encaminhará o pacote diretamente para o Host B. Caso contrário, o gateway transmite uma solicitação ARP, na qual o endereço IP de destino é o endereço IP do Host B.
- Depois que o gateway obtém o endereço MAC do Host B, ele envia o pacote para o Host B.
Tipos de entrada ARP
Uma tabela ARP armazena entradas ARP dinâmicas, entradas ARP OpenFlow, entradas ARP Rule e entradas ARP estáticas.
Entrada ARP dinâmica
O ARP cria e atualiza automaticamente entradas dinâmicas. Uma entrada dinâmica de ARP é removida quando o cronômetro de envelhecimento expira ou a interface de saída é desativada. Além disso, uma entrada ARP dinâmica pode ser substituída por uma entrada ARP estática.
Entrada ARP estática
Uma entrada ARP estática é configurada e mantida manualmente. Ela não envelhece e não pode ser substituída por nenhuma entrada ARP dinâmica.
As entradas de ARP estático protegem a comunicação entre dispositivos porque os pacotes de ataque não podem modificar o mapeamento de IP para MAC em uma entrada de ARP estático.
O dispositivo suporta os seguintes tipos de entradas ARP estáticas:
- Entrada ARP estática longa - É usada diretamente para encaminhar pacotes. Uma entrada longa de ARP estático contém o endereço IP, o endereço MAC, a VLAN e a interface de saída.
- Entrada ARP estática curta - Contém apenas o endereço IP e o endereço MAC.
Se a interface de saída for uma interface VLAN, o dispositivo enviará uma solicitação ARP cujo endereço IP de destino é o endereço IP da entrada curta. Se os endereços IP e MAC do remetente na resposta ARP recebida corresponderem à entrada ARP estática curta, o dispositivo executará as seguintes operações:
- Adiciona a interface que recebeu a resposta ARP à entrada ARP estática curta.
- Usa a entrada ARP estática curta resolvida para encaminhar pacotes IP.
- Entrada ARP multiportas - Contém o endereço IP, o endereço MAC e as informações de VLAN.
O dispositivo pode usar uma entrada ARP multiportas que tenha o mesmo endereço MAC e VLAN que uma entrada de endereço MAC unicast multicast ou multiportas para o encaminhamento de pacotes. Uma entrada ARP multiportas é configurada manualmente. Ela não envelhece e não pode ser substituída por nenhuma entrada ARP dinâmica.
Para se comunicar com um host usando um mapeamento fixo de IP para MAC, configure uma entrada ARP estática curta no dispositivo. Para se comunicar com um host usando um mapeamento fixo de IP para MAC por meio de uma interface em uma VLAN, configure uma entrada ARP estática longa no dispositivo.
Entrada ARP do OpenFlow
O ARP cria entradas ARP OpenFlow aprendendo com o módulo OpenFlow. Uma entrada ARP do OpenFlow não envelhece e não pode ser atualizada. Uma entrada ARP do OpenFlow pode ser usada diretamente para encaminhar pacotes. Para obter mais informações sobre o OpenFlow, consulte o Guia de configuração do OpenFlow.
Regra de entrada ARP
As entradas do Rule ARP podem ser usadas diretamente para o encaminhamento de pacotes. Uma entrada Rule ARP não envelhece e não pode ser atualizada. Ela pode ser substituída por uma entrada ARP estática.
O ARP cria entradas de Rule ARP aprendendo com o módulo de autenticação do portal. Para obter mais informações sobre a autenticação do portal, consulte a configuração da autenticação do portal no Security Configuration Guide.
Configuração de uma entrada ARP estática
As entradas de ARP estático são efetivas quando o dispositivo funciona corretamente.
Configuração de uma entrada ARP estática curta
Restrições e diretrizes
Uma entrada ARP estática curta resolvida deixa de ser resolvida em determinados eventos, por exemplo, quando a interface de saída resolvida fica inoperante ou a VLAN ou a interface de VLAN correspondente é excluída.
Procedimento
system-view- Configure uma entrada ARP estática curta.
arp static ip-address mac-addressConfiguração de uma entrada ARP estática longa
Sobre entradas longas de ARP estático
As entradas ARP estáticas longas podem ser eficazes ou ineficazes. As entradas de ARP estático longo ineficazes não podem ser usadas para o encaminhamento de pacotes. Uma entrada de ARP estático longo é ineficaz quando existe uma das seguintes condições:
- O endereço IP na entrada entra em conflito com um endereço IP local.
- Nenhuma interface local tem um endereço IP na mesma sub-rede que o endereço IP na entrada ARP. Uma entrada ARP estática longa para uma VLAN será excluída se a VLAN ou a interface da VLAN for excluída.
Procedimento
- Entre na visualização do sistema.
system-view- Configure uma entrada ARP estática longa.
arp static ip-address mac-address [ vlan-id interface-type interface-number ]Configuração de uma entrada ARP multiportas
Sobre entradas ARP multiportas
Uma entrada ARP multiportas contém um endereço IP, endereço MAC, interface de saída e informações de ID de VLAN. A VLAN e as interfaces de saída são especificadas por uma entrada de endereço MAC unicast multiportas ou uma entrada de endereço MAC multicast. Para obter mais informações sobre entradas de endereço MAC unicast multiportas, consulte o Layer-2 LAN Switching Configuration Guide. Para obter mais informações sobre entradas de endereço MAC multicast, consulte o Guia de configuração de IP Multicast.
Uma entrada ARP multiportas pode sobrescrever uma entrada ARP dinâmica, estática curta ou estática longa. Por outro lado, uma entrada ARP estática curta ou estática longa pode sobrescrever uma entrada ARP multiportas.
Restrições e diretrizes
Para que uma entrada ARP multiportas seja eficaz para o encaminhamento de pacotes, certifique-se de que as seguintes condições sejam atendidas:
- Existe uma entrada de endereço MAC unicast multiportas ou uma entrada de endereço MAC multicast.
- A entrada ARP multiportas deve ter o mesmo endereço MAC que a entrada de endereço MAC unicast multiportas ou a entrada de endereço MAC multicast.
- O endereço IP na entrada ARP multiportas deve residir na mesma sub-rede que a interface VLAN da VLAN especificada.
Se uma interface agregada for a interface de saída de uma entrada e suas portas membros residirem em vários dispositivos membros da IRF, o dispositivo não poderá usar a entrada para encaminhar pacotes. Para resolver esse problema, defina o modo de compartilhamento de carga de agregação de link global para um modo diferente do baseado em endereço MAC de origem ou destino usando o comando link-aggregation global load-sharing mode. Para obter mais informações sobre esse comando, consulte Agregação de links Ethernet em Layer 2-LAN Switching Command Reference.
Procedimento
- Entre na visualização do sistema.
system-view- Configure uma entrada de endereço MAC unicast multiportas ou uma entrada de endereço MAC multicast.
- Em uma rede comum, configure uma entrada de endereço MAC unicast multiportas.
mac-address multiport mac-address interface interface-list vlan vlan-id- Em uma rede comum, configure uma entrada de endereço MAC multicast.
mac-address multicast mac-address interface interface-list vlan
vlan-id- Configurar uma entrada ARP multiportas.
arp multiport ip-address mac-address vlan-idConfiguração de recursos para entradas ARP dinâmicas
Definição do limite de aprendizado dinâmico de ARP para um dispositivo
Sobre o limite de aprendizado dinâmico de ARP para um dispositivo
Um dispositivo pode aprender dinamicamente as entradas ARP. Para evitar que um dispositivo mantenha muitas entradas ARP, você pode definir o número máximo de entradas ARP dinâmicas que o dispositivo pode aprender. Quando o limite é atingido, o dispositivo interrompe o aprendizado de ARP.
Se você definir um valor menor do que o número de entradas ARP dinâmicas existentes, o dispositivo não excluirá as entradas existentes, a menos que elas se esgotem. Você pode usar o comando reset arp dynamic para limpar as entradas de ARP dinâmico.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o limite de aprendizado dinâmico de ARP para o dispositivo.
arp max-learning-number max-number slot slot-numberA configuração padrão varia de acordo com o modelo do dispositivo. Para obter mais informações, consulte a referência do comando. Para desativar o aprendizado dinâmico de ARP do dispositivo, defina o valor como 0.
Configuração do limite de aprendizado dinâmico de ARP para uma interface
Sobre a configuração do limite de aprendizado dinâmico de ARP para uma interface
Uma interface pode aprender dinamicamente entradas ARP. Para evitar que uma interface mantenha muitas entradas ARP, você pode definir o número máximo de entradas ARP dinâmicas que a interface pode aprender. Quando o limite é atingido, a interface interrompe o aprendizado de ARP.
Você pode definir limites para uma interface de camada 2 e para a interface VLAN para uma VLAN permitida na interface de camada 2. A interface da camada 2 aprende uma entrada ARP somente quando nenhum dos limites é atingido.
O limite total de aprendizado dinâmico de ARP para todas as interfaces não será maior do que o limite de aprendizado dinâmico de ARP do dispositivo.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Definir o limite de aprendizado dinâmico de ARP para a interface.
arp max-learning-num max-number [ alarm alarm-threshold ]A configuração padrão varia de acordo com o modelo do dispositivo. Para obter mais informações, consulte a referência de comandos. Para desativar o aprendizado dinâmico de ARP da interface, defina o valor como 0.
Configuração do cronômetro de envelhecimento para entradas ARP dinâmicas
Sobre o cronômetro de envelhecimento para entradas ARP dinâmicas
Cada entrada ARP dinâmica na tabela ARP tem uma vida útil limitada, chamada de cronômetro de envelhecimento. O cronômetro de envelhecimento de uma entrada de ARP dinâmico é redefinido sempre que a entrada de ARP dinâmico é atualizada. Uma entrada de ARP dinâmico que não é atualizada antes que seu cronômetro de envelhecimento expire é excluída da tabela ARP.
É possível definir o cronômetro de envelhecimento para entradas ARP dinâmicas na visualização do sistema ou na visualização da interface. O cronômetro de envelhecimento definido na visualização da interface tem precedência sobre o cronômetro de envelhecimento definido na visualização do sistema.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o cronômetro de envelhecimento para entradas ARP dinâmicas.
- Defina o cronômetro de envelhecimento para entradas ARP dinâmicas na visualização do sistema.
aarp timer aging { aging-minutes | second aging-seconds }Por padrão, o cronômetro de envelhecimento para entradas ARP dinâmicas na visualização do sistema é de 20 minutos.
- Execute os comandos a seguir em sequência para definir o cronômetro de envelhecimento para entradas ARP dinâmicas na visualização da interface:
interface interface-type interface-numberaarp timer aging { aging-minutes | second aging-seconds }Por padrão, o cronômetro de envelhecimento para entradas ARP dinâmicas na visualização de interface é o cronômetro de envelhecimento definido na visualização do sistema.
Configuração do número máximo de sondas para entradas ARP dinâmicas
Sobre o número máximo de sondagens para entradas ARP dinâmicas
Esse mecanismo de sondagem mantém válidas as entradas dinâmicas legais de ARP e evita a resolução desnecessária de ARP durante o encaminhamento posterior do tráfego. Ele envia solicitações ARP para o endereço IP em uma entrada ARP dinâmica.
- Se o dispositivo receber uma resposta ARP antes que o cronômetro de envelhecimento da entrada expire, o dispositivo redefinirá o cronômetro de envelhecimento.
- Se o dispositivo não receber nenhuma resposta ARP após o número máximo de sondagens, o dispositivo excluirá a entrada quando o cronômetro de envelhecimento da entrada expirar.
Você pode definir o número máximo de sondas na visualização do sistema ou na visualização da interface. A contagem de sondas definida na visualização da interface tem precedência sobre a contagem de sondas definida na visualização do sistema.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o número máximo de sondas para entradas ARP dinâmicas.
- Defina o número máximo de sondas para entradas ARP dinâmicas na visualização do sistema.
arp timer aging probe-interval intervalPor padrão, o número máximo de sondas na visualização do sistema para entradas ARP dinâmicas é 3.
- Execute os comandos a seguir em sequência para definir o número máximo de sondas para entradas ARP dinâmicas:
interface interface-type interface-numberarp timer aging probe-interval intervalPor padrão, o número máximo de sondas na visualização da interface para entradas ARP dinâmicas é o número máximo de sondas definido na visualização do sistema.
Configuração do intervalo para sondagem de entradas ARP dinâmicas
Sobre o intervalo para sondagem de entradas ARP dinâmicas
O recurso de sondagem mantém válidas as entradas dinâmicas legais de ARP e evita a resolução desnecessária de ARP durante o encaminhamento posterior do tráfego.
Antes que uma entrada ARP dinâmica seja envelhecida, o dispositivo envia solicitações ARP para o endereço IP na entrada ARP.
- Se o dispositivo receber uma resposta ARP durante o intervalo da sonda, ele redefinirá o cronômetro de envelhecimento.
- Se o dispositivo não receber nenhuma resposta ARP durante o intervalo da sonda, ele iniciará uma nova sonda.
- Se o número máximo de sondagens for feito e nenhuma resposta ARP for recebida, o dispositivo excluirá a entrada.
Você pode definir o intervalo da sonda na visualização do sistema e na visualização da interface. O intervalo da sonda na interface tem precedência sobre o intervalo da sonda na visualização do sistema.
Restrições e diretrizes
- Se houver tráfego intenso na rede, defina um intervalo longo.
- Durante o processo de sondagem da entrada ARP dinâmica, uma entrada ARP dinâmica não será excluída se o tempo de envelhecimento expirar. Se uma resposta for recebida durante a sondagem, o cronômetro de envelhecimento da entrada ARP será redefinido.
- Para que o dispositivo execute o número especificado de sondas, certifique-se de que os requisitos a seguir sejam atendidos:
Tempo de envelhecimento das entradas ARP dinâmicas > o número máximo de sondas × intervalo de sonda
Procedimento
- Entre na visualização do sistema.
system-view- Defina o intervalo para sondagem de entradas ARP dinâmicas.
- Defina o intervalo para sondagem de entradas ARP dinâmicas na visualização do sistema.
arp timer aging probe-interval intervalPor padrão, o intervalo da sonda é de 5 segundos.
- Execute os seguintes comandos em sequência para definir o intervalo de sondagem das entradas ARP dinâmicas:
interface interface-type interface-numberarp timer aging probe-interval intervalPor padrão, o intervalo da sonda depende da configuração na visualização do sistema.
Ativação da verificação dinâmica de entradas ARP
Sobre a verificação dinâmica de entradas ARP
O recurso de verificação de entrada ARP dinâmica impede que o dispositivo ofereça suporte a entradas ARP dinâmicas que contenham endereços MAC multicast. O dispositivo não pode aprender entradas ARP dinâmicas que contenham endereços MAC multicast. Não é possível adicionar manualmente entradas ARP estáticas que contenham endereços MAC multicast.
Quando a verificação dinâmica de entradas ARP está desativada, há suporte para entradas ARP que contêm endereços MAC multicast. O dispositivo pode aprender entradas ARP dinâmicas contendo endereços MAC multicast obtidos dos pacotes ARP originados de um endereço MAC unicast. Você também pode adicionar manualmente entradas ARP estáticas contendo endereços MAC multicast.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a verificação dinâmica de entradas ARP.
arp check enablePor padrão, a verificação dinâmica de entrada ARP está ativada.
Sincronização de entradas ARP em todos os dispositivos membros
Sobre a sincronização de entradas ARP
Essa tarefa garante que todos os dispositivos membros da IRF em uma malha IRF tenham as mesmas entradas ARP.
Restrições e diretrizes
Para sincronizar as entradas ARP em todos os dispositivos membros em tempo hábil, você pode programar o dispositivo para executar automaticamente o comando arp smooth. Para obter informações sobre o agendamento de uma tarefa, consulte a configuração de gerenciamento de dispositivos no Guia de Configuração dos Fundamentos.
Procedimento
Para sincronizar as entradas ARP do dispositivo mestre com todos os dispositivos subordinados, execute o seguinte comando na visualização do usuário:
arp smoothAtivação do registro de conflitos de endereço IP do usuário
Sobre o registro de conflitos de endereço IP do usuário
Esse recurso permite que o dispositivo detecte e registre conflitos de endereço IP do usuário. O dispositivo determina que ocorre um conflito se um pacote ARP não gratuito de entrada tiver o mesmo endereço IP de remetente que uma entrada ARP existente, mas um endereço MAC de remetente diferente. O dispositivo gera um registro de conflito de endereço IP do usuário, registra o conflito e envia o registro para o centro de informações. Para obter informações sobre o destino do registro e a configuração da regra de saída na central de informações, consulte a central de informações no Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o registro de conflitos de endereço IP do usuário.
arp user-ip-conflict record enableAtivação da verificação de consistência da interface entre ARP e entradas de endereço MAC
Sobre a verificação de consistência da interface entre as entradas de endereço ARP e MAC
Em uma rede instável, a interface de recebimento de pacotes de um usuário pode mudar. A interface na entrada de endereço MAC pode ser atualizada imediatamente, enquanto a interface na entrada ARP não pode. Nesse caso, os pacotes que correspondem à entrada ARP serão enviados por uma interface incorreta. Para resolver esse problema, você pode usar esse recurso para verificar periodicamente a consistência da interface entre a entrada de endereço ARP e MAC de um usuário. Se as interfaces não forem as mesmas, o ARP enviará solicitações ARP na VLAN da entrada ARP e atualizará a entrada com a interface de recebimento da resposta ARP.
Use display mac-address para exibir entradas de endereço MAC. Para obter mais informações sobre esse comando, consulte Tabela de endereços MAC em Layer 2-LAN Switching Command Reference.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a verificação de consistência da interface entre as entradas de endereço ARP e MAC.
arp mac-interface-consistency check enablePor padrão, a verificação de consistência da interface entre as entradas de endereço ARP e MAC está desativada.
Ativação do registro de migrações de portas de usuários
Sobre o registro de migrações de portas de usuários
Esse recurso permite que o dispositivo detecte e registre eventos de migração de porta de usuário. Uma porta de usuário migra se um pacote ARP de entrada tiver o mesmo endereço IP de remetente e endereço MAC de remetente que uma entrada ARP existente, mas uma porta de entrada diferente. O dispositivo gera um registro de migração de porta de usuário, registra o evento de migração, envia o registro para o centro de informações e atualiza a interface da entrada ARP. Para obter informações sobre o destino do registro e a configuração da regra de saída no centro de informações, consulte o centro de informações no Guia de configuração de gerenciamento de rede e monitoramento .
Restrições e diretrizes
Para evitar a degradação do desempenho do dispositivo, desative o registro de migrações de portas de usuário se forem gerados muitos logs de migração de portas de usuário.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o registro de migrações de portas de usuários.
arp user-move record enablePor padrão, o registro das migrações de porta do usuário está desativado.
Ativação do registro de ARP
Sobre o registro de ARP
Esse recurso permite que um dispositivo registre eventos de ARP quando o ARP não consegue resolver corretamente os endereços IP. As informações de registro ajudam os administradores a localizar e resolver problemas. O dispositivo pode registrar os seguintes eventos ARP:
- Em uma interface proxy com ARP desativado, o endereço IP de destino de um pacote ARP recebido não é um dos seguintes endereços IP:
- O endereço IP da interface de recebimento.
- O endereço IP virtual do grupo VRRP.
- O endereço IP do remetente de uma resposta ARP recebida está em conflito com um dos seguintes endereços IP:
- O endereço IP da interface de recebimento.
- O endereço IP virtual do grupo VRRP.
O dispositivo envia mensagens de registro ARP para o centro de informações. Você pode usar o comando info-center source para especificar as regras de saída de log para o centro de informações. Para obter mais informações sobre o centro de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o registro de ARP.
arp check log enablePor padrão, o registro de ARP está desativado.
Comandos de exibição e manutenção para ARP
A limpeza de entradas ARP da tabela ARP pode causar falhas de comunicação. Certifique-se de que as entradas a serem apagadas não afetem as comunicações atuais.
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir entradas ARP. | display arp [ [ all | dynamic | multiport | static ] [ slot slot-number ] | vlan vlan-id | interface interface-type interface-número ] [ count | verbose ] |
| Exibe o número máximo de entradas ARP que um dispositivo suporta. | display arp entry-limit |
| Exibir a entrada ARP de um endereço IP. | display arp ip-address [ slot slot-número ] [ verbose ] |
| Exibe o número de entradas ARP do OpenFlow. | display arp openflow count [ slot slot-number ] |
| Exibir o cronômetro de envelhecimento de entradas ARP dinâmicas. | display arp timer aging |
| Exibir conflitos de endereço IP do usuário. | display arp user-ip-conflict record [ slot slot-number ] |
| Exibir migrações de porta de usuário. | display arp user-move record [ slot slot-number ] |
| Limpar entradas ARP da tabela ARP. | reset arp { all | dynamic | interface interface-type interface-number | multiportas | slot slot-number | static } |
Exemplos de configuração de ARP
Exemplo: Configuração de uma entrada ARP estática longa
Configuração de rede
Conforme mostrado na Figura 3, os hosts estão conectados ao Dispositivo B. O Dispositivo B está conectado ao Dispositivo A por meio da interface GigabitEthernet 1/0/1 na VLAN 10.
Para garantir comunicações seguras entre o Dispositivo A e o Dispositivo B, configure uma entrada ARP estática longa para o Dispositivo A no Dispositivo B.
Figura 3 Diagrama de rede
Procedimento
# Criar a VLAN 10.
<DeviceB> system-view
[DeviceB] vlan 10
[DeviceB-vlan10] quit# Adicione a interface GigabitEthernet 1/0/1 à VLAN 10.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port access vlan 10
[DeviceB-GigabitEthernet1/0/1] quit# Crie a interface VLAN 10 e configure seu endereço IP.
[DeviceB] interface vlan-interface 10
[DeviceB-vlan-interface10] ip address 192.168.1.2 8
[DeviceB-vlan-interface10] quit# Configure uma entrada ARP estática longa que tenha o endereço IP 192.168.1.1, o endereço MAC 00e0-fc01-0000 e a interface de saída GigabitEthernet 1/0/1 na VLAN 10.
[DeviceB] arp static 192.168.1.1 00e0-fc01-0000 10 gigabitethernet 1/0/1Verificação da configuração
# Verifique se o dispositivo B tem uma entrada ARP estática longa para o dispositivo A.
[DeviceB] display arp static
Type: S-Static D-Dynamic O-Openflow R-Rule M-Multiport I-Invalid
IP address MAC address VLAN/VSI Interface Aging Type
192.168.1.1 00e0-fc01-0000 10 GE1/0/1 -- SExemplo: Configuração de uma entrada ARP estática curta
Configuração de rede
Conforme mostrado na Figura 4, os hosts estão conectados ao Dispositivo B. O Dispositivo B está conectado ao Dispositivo A por meio da interface GigabitEthernet 1/0/2.
Para garantir comunicações seguras entre o Dispositivo A e o Dispositivo B, configure uma entrada ARP estática curta para o Dispositivo A no Dispositivo B.
Figura 4 Diagrama de rede
Procedimento
# Configure um endereço IP para a GigabitEthernet 1/0/2.
<DeviceB> system-view system-view
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] ip address 192.168.1.2 24
[DeviceB-GigabitEthernet1/0/2] quit
# Configure uma entrada ARP estática curta que tenha o endereço IP 192.168.1.1 e o endereço MAC 00e0-fc01-001f.
[DeviceB] arp static 192.168.1.1 00e0-fc01-001f
Verificação da configuração
# Verificar se o dispositivo B tem uma entrada ARP estática curta para o dispositivo A
[DeviceB] display arp static
Type: S-Static D-Dynamic O-Openflow R-Rule M-Multiport I-Invalid
IP address MAC address VLAN/VSI Interface Aging Type
192.168.1.1 00e0-fc01-001f -- -- -- SExemplo: Configuração de uma entrada ARP multiportas
Configuração de rede
Conforme mostrado na Figura 5, um dispositivo se conecta a três servidores por meio das interfaces GigabitEthernet 1/0/1, GigabitEthernet 1/0/2 e GigabitEthernet 1/0/3 na VLAN 10. Os servidores compartilham o endereço IP 192.168.1.1/24 e o endereço MAC 00e0-fc01-0000.
Configure uma entrada ARP multiportas para que o dispositivo envie pacotes IP com o endereço IP de destino 192.168.1.1 para os três servidores.
Figura 5 Diagrama de rede
Procedimento
# Criar a VLAN 10.
<Device> system-view
[Device] vlan 10
[Device-vlan10] quit# Adicione GigabitEthernet 1/0/1, GigabitEthernet 1/0/2 e GigabitEthernet 1/0/3 à VLAN 10.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] port access vlan 10
[Device-GigabitEthernet1/0/1] quit
[Device] interface gigabitethernet 1/0/2
[Device-GigabitEthernet1/0/2] port access vlan 10
[Device-GigabitEthernet1/0/2] quit
[Device] interface gigabitethernet 1/0/3
[Device-GigabitEthernet1/0/3] port access vlan 10
[Device-GigabitEthernet1/0/3] quit# Crie a interface VLAN 10 e especifique seu endereço IP.
[Device] interface vlan-interface 10
[Device-vlan-interface10] ip address 192.168.1.2 24
[Device-vlan-interface10] quit# Configure uma entrada de endereço MAC unicast multiportas que tenha o endereço MAC 00e0-fc01-0000 e as interfaces de saída GigabitEthernet 1/0/1, GigabitEthernet 1/0/2 e GigabitEthernet 1/0/3 na VLAN 10.
[Device] mac-address multiport 00e0-fc01-0000 interface gigabitethernet 1/0/1 to
gigabitethernet 1/0/3 vlan 10# Configure uma entrada ARP multiportas com o endereço IP 192.168.1.1 e o endereço MAC 00e0-fc01-0000.
[Device] arp multiport 192.168.1.1 00e0-fc01-0000 10Verificação da configuração
# Verifique se o dispositivo tem uma entrada ARP multiportas com o endereço IP 192.168.1.1 e o endereço MAC 00e0-fc01-0000.
[Device] display arp
Type: S-Static D-Dynamic O-Openflow R-Rule M-Multiport I-Invalid
IP address MAC address VLAN/VSI Interface Aging Type
192.168.1.1 00e0-fc01-0000 10 -- -- M Configuração do ARP gratuito
Sobre o ARP gratuito
Em um pacote ARP gratuito, o endereço IP do remetente e o endereço IP de destino são os endereços IP do dispositivo de envio.
Um dispositivo envia um pacote ARP gratuito para uma das seguintes finalidades:
- Determinar se seu endereço IP já está sendo usado por outro dispositivo. Se o endereço IP já estiver sendo usado, o dispositivo será informado do conflito por uma resposta ARP.
- Informar outros dispositivos sobre uma alteração de endereço MAC.
Detecção de conflitos de IP
Quando uma interface obtém um endereço IP, o dispositivo transmite pacotes ARP gratuitos na LAN em que a interface reside. Se o dispositivo receber uma resposta ARP, seu endereço IP entrará em conflito com o endereço IP de outro dispositivo na LAN. O dispositivo exibe uma mensagem de registro sobre o conflito e informa ao administrador para alterar o endereço IP. O dispositivo não usará o endereço IP conflitante. Se nenhuma resposta ARP for recebida, o dispositivo usará o endereço IP.
Aprendizado gratuito de pacotes ARP
Esse recurso permite que um dispositivo crie ou atualize entradas ARP usando os endereços IP e MAC do remetente nos pacotes ARP gratuitos recebidos.
Quando esse recurso está desativado, o dispositivo usa os pacotes ARP gratuitos recebidos apenas para atualizar as entradas ARP existentes. As entradas ARP não são criadas com base nos pacotes ARP gratuitos recebidos, o que economiza espaço na tabela ARP.
Envio periódico de pacotes ARP gratuitos
O envio periódico de pacotes ARP gratuitos ajuda os dispositivos downstream a atualizar as entradas ARP ou MAC em tempo hábil.
Esse recurso pode implementar as seguintes funções:
- Evite a falsificação de gateway.
A falsificação de gateway ocorre quando um invasor usa o endereço do gateway para enviar pacotes ARP gratuitos para os hosts em uma rede. Em vez disso, o tráfego destinado ao gateway dos hosts é enviado ao invasor. Como resultado, os hosts não conseguem acessar a rede externa.
Para evitar esses ataques de falsificação de gateway, você pode habilitar o gateway para enviar pacotes ARP gratuitos em intervalos. Os pacotes ARP gratuitos contêm o endereço IP primário e os endereços IP secundários configurados manualmente do gateway, para que os hosts possam saber as informações corretas do gateway.
- Evite que as entradas ARP envelheçam.
Se o tráfego de rede for intenso ou se o uso da CPU do host for alto, os pacotes ARP recebidos poderão ser descartados ou não serão processados imediatamente. Eventualmente, as entradas dinâmicas de ARP no host receptor se esgotam. O tráfego entre o host e os dispositivos correspondentes é interrompido até que o host recrie as entradas ARP.
Para evitar esse problema, você pode habilitar o gateway para enviar pacotes ARP gratuitos periodicamente. Os pacotes ARP gratuitos contêm o endereço IP primário e o endereço IP configurado manualmente.
endereços IP secundários do gateway, para que os hosts receptores possam atualizar as entradas ARP em tempo hábil.
- Impedir que o endereço IP virtual de um grupo VRRP seja usado por um host.
O roteador mestre de um grupo VRRP pode enviar periodicamente pacotes ARP gratuitos para os hosts da rede local. Os hosts podem então atualizar as entradas ARP locais e evitar o uso do endereço IP virtual do grupo VRRP. O endereço MAC do remetente no pacote ARP gratuito é o endereço MAC virtual do roteador virtual. Para obter mais informações sobre o VRRP, consulte o Guia de configuração de alta disponibilidade.
Visão geral das tarefas ARP gratuitas
Todas as tarefas de ARP gratuito são opcionais. Se todos os recursos a seguir estiverem desativados, o ARP gratuito ainda fornecerá a função de detecção de conflito de IP.
- Ativação da notificação de conflito de IP
- Ativação do aprendizado gratuito de pacotes ARP
- Ativação do envio periódico de pacotes ARP gratuitos
- Ativação do envio de pacotes ARP gratuitos para solicitações ARP com endereço IP do remetente em uma sub-rede diferente
- Configuração da retransmissão gratuita de pacotes ARP para a alteração do endereço MAC do dispositivo
Ativação da notificação de conflito de IP
Sobre a notificação de conflito de IP
Ao detectar um conflito de IP, o dispositivo enviará uma solicitação ARP gratuita. Por padrão, o dispositivo exibe uma mensagem de erro somente depois de receber uma resposta ARP. Você pode ativar esse recurso para permitir que o dispositivo exiba uma mensagem de erro imediatamente após a detecção de um conflito de IP.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a notificação de conflito de IP.
arp ip-conflict log promptO padrão varia de acordo com a versão do software, conforme mostrado abaixo:
| Versões | Configuração padrão |
| Versões anteriores à versão 6350 | A notificação de conflito de IP está desativada. |
| Versão 6350 e posterior | Se o dispositivo for iniciado com a configuração inicial, a notificação de conflito de IP será desativada. Se o dispositivo for iniciado com os padrões de fábrica, a notificação de conflito de IP estará ativada. |
Ativação do aprendizado gratuito de pacotes ARP
- Entre na visualização do sistema.
system-view- Ativar o aprendizado gratuito de pacotes ARP.
gratuitous-arp-learning enablePor padrão, o aprendizado gratuito de pacotes ARP está ativado.
Ativação do envio periódico de pacotes ARP gratuitos
Restrições e diretrizes
- Você pode ativar o envio periódico de pacotes ARP gratuitos em um máximo de 1024 interfaces.
- O envio periódico de pacotes ARP gratuitos só tem efeito em uma interface quando as seguintes condições são atendidas:
- O estado da camada de enlace de dados da interface está ativo.
- A interface tem um endereço IP.
- Se você alterar o intervalo de envio de pacotes ARP gratuitos, a configuração entrará em vigor no próximo intervalo de envio.
- O intervalo de envio de pacotes ARP gratuitos pode ser muito maior do que o intervalo de envio especificado em qualquer uma das seguintes circunstâncias:
- Esse recurso está ativado em várias interfaces.
- Cada interface é configurada com vários endereços IP secundários.
- Um pequeno intervalo de envio é configurado quando as duas condições anteriores existem.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar o envio periódico de pacotes ARP gratuitos.
arp send-gratuitous-arp [ interval interval ]Por padrão, o envio periódico de pacotes ARP gratuitos está desativado.
Ativação do envio de pacotes ARP gratuitos para solicitações ARP com endereço IP do remetente em uma sub-rede diferente
- Entre na visualização do sistema.
system-view- Habilite o dispositivo a enviar pacotes ARP gratuitos ao receber solicitações ARP cujo endereço IP do remetente pertença a uma sub-rede diferente.
gratuitous-arp-sending enablePor padrão, um dispositivo não envia pacotes ARP gratuitos ao receber solicitações ARP cujo endereço IP do remetente pertence a uma sub-rede diferente.
Configuração da retransmissão gratuita de pacotes ARP para a alteração do endereço MAC do dispositivo
Sobre a retransmissão gratuita de pacotes ARP para a alteração do endereço MAC do dispositivo
O dispositivo envia um pacote ARP gratuito para informar outros dispositivos sobre a alteração de seu endereço MAC. No entanto, os outros dispositivos podem não receber o pacote porque o dispositivo envia o pacote ARP gratuito apenas uma vez por padrão. Configure o recurso de retransmissão do pacote ARP gratuito para garantir que os outros dispositivos possam receber o pacote.
Procedimento
- Entre na visualização do sistema.
system-view- Defina os horários e o intervalo para retransmitir um pacote ARP gratuito para a alteração do endereço MAC do dispositivo.
gratuitous-arp mac-change retransmit times interval secondsPor padrão, o dispositivo envia um pacote gratuito para informar sua alteração de endereço MAC apenas uma vez.
Configuração de ARP proxy
Sobre o proxy ARP
O ARP proxy permite que um dispositivo em uma rede responda a solicitações de ARP para um endereço IP em outra rede. Com o ARP proxy, os hosts em diferentes domínios de broadcast podem se comunicar entre si como se estivessem no mesmo domínio de broadcast.
O proxy ARP inclui o proxy ARP comum e o proxy ARP local.
- ARP de proxy comum - Permite a comunicação entre hosts que se conectam a diferentes interfaces da Camada 3 e residem em diferentes domínios de broadcast.
- ARP de proxy local - Permite a comunicação entre hosts que se conectam à mesma interface da Camada 3 e residem em diferentes domínios de broadcast.
Ativação do proxy ARP comum
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-numberSomente interfaces VLAN são compatíveis.
- Ativar o proxy ARP comum.
proxy-arp enablePor padrão, o proxy ARP comum está desativado.
Ativação do proxy ARP local
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-numberSomente interfaces VLAN são compatíveis.
- Ativar o proxy ARP local.
local-proxy-arp enable [ ip-range start-ip-address to end-ip-address ]Por padrão, o proxy ARP local está desativado.
Comandos de exibição e manutenção para ARP proxy
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir ARP de proxy comum | display proxy-arp [ interface interface-type] |
| status. | interface-number ] |
| Exibir o status do ARP do proxy local. | display local-proxy-arp [ interface interface-type interface-number ] |
Exemplo de configuração de ARP de proxy comum
Exemplo: Configuração de ARP de proxy comum
Configuração de rede
Conforme mostrado na Figura 6, o Host A e o Host D têm o mesmo prefixo e máscara IP, mas estão localizados em sub-redes diferentes separadas pelo switch. O host A pertence à VLAN 1 e o host D pertence à VLAN 2. Nenhum gateway padrão está configurado no Host A e no Host D.
Configure o proxy ARP comum no switch para permitir a comunicação entre os dois hosts.
Figura 6 Diagrama de rede
Procedimento
# Criar VLAN 2.
<Switch> system-view
[Switch] vlan 2
[Switch-vlan2] quit# Configure o endereço IP da interface VLAN 1.
[Switch] interface vlan-interface 1
[Switch-Vlan-interface1] ip address 192.168.10.99 255.255.255.0
# Habilite o proxy ARP comum na interface VLAN 1.
[Switch-Vlan-interface1] proxy-arp enable
[Switch-Vlan-interface1] quit# Configure o endereço IP da interface VLAN 2.
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ip address 192.168.20.99 255.255.255.0# Habilite o proxy ARP comum na interface VLAN 2.
[Switch-Vlan-interface2] proxy-arp enable.Verificação da configuração
# Verifique se o host A e o host D podem fazer ping um do outro.
Configuração do ARP snooping
Sobre o ARP snooping
O ARP snooping é usado em redes de comutação da Camada 2. Ele cria entradas de snooping ARP usando as informações dos pacotes ARP. A MFF pode usar as entradas de snooping ARP. Para obter mais informações sobre o MFF, consulte o Guia de Configuração de Segurança.
Criação de entradas de ARP snooping
Se você ativar o ARP snooping para uma VLAN, os pacotes ARP recebidos na VLAN serão redirecionados para a CPU. Para a VLAN, a CPU usa os endereços IP e MAC do remetente dos pacotes ARP, bem como a VLAN e a porta receptoras para criar entradas de snooping ARP.
Envelhecimento de entradas de ARP snooping
O cronômetro de envelhecimento e o período válido de uma entrada do ARP snooping são de 25 minutos e 15 minutos. Se uma entrada de ARP snooping não for atualizada em 12 minutos, o dispositivo enviará uma solicitação ARP. A solicitação ARP usa o endereço IP da entrada como o endereço IP de destino. Se uma entrada do ARP snooping não for atualizada em 15 minutos, ela se tornará inválida e não poderá ser usada. Depois disso, se um pacote ARP correspondente à entrada for recebido, a entrada se tornará válida e seu cronômetro de envelhecimento será reiniciado.
Se o cronômetro de envelhecimento de uma entrada do ARP snooping expirar, a entrada será removida.
Proteção para ARP snooping
Ocorre um ataque se um pacote ARP tiver o mesmo endereço IP de remetente que uma entrada de snooping ARP válida, mas um endereço MAC de remetente diferente. A entrada do ARP snooping torna-se inválida e é removida em 1 minuto.
Ativação do ARP snooping para uma VLAN
- Entre na visualização do sistema.
system-view- Entre na visualização de VLAN.
vlan vlan-id- Habilite o ARP snooping para a VLAN.
arp snooping enablePor padrão, o ARP snooping está desativado para uma VLAN.
Comandos de exibição e manutenção para ARP snooping
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir entradas de ARP snooping. | display arp snooping vlan [ vlan-id ] [ slot slot-number ] [ count ] display arp snooping vlan ip ip-address [ slot slot-number ] |
| Excluir entradas de ARP snooping. | reset arp snooping vlan [ vlan-id ] reset arp snooping vlan ip ip-address |
Configuração do anúncio de rota direta ARP
Sobre o anúncio de rota direta ARP
Esse recurso gera rotas de host com base em entradas ARP para encaminhamento de pacotes e anúncio de rotas.
Ativação do anúncio de rota direta ARP
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilite o recurso de anúncio de rota direta ARP.
arp route-direct advertisePor padrão, o recurso de anúncio de rota direta ARP está desativado.
Configuração do endereçamento IP
Sobre o endereçamento IP
Os endereços IP neste capítulo referem-se a endereços IPv4, a menos que especificado de outra forma.
Representação e classes de endereços IP
O endereçamento IP usa um endereço de 32 bits para identificar cada host em uma rede IPv4. Para facilitar a leitura, os endereços são escritos em notação decimal com pontos, sendo que cada endereço tem quatro octetos de comprimento. Por exemplo, o endereço 00001010000000010000000100000001 em binário é escrito como 10.1.1.1.
Cada endereço IP é dividido nas seguintes seções:
- ID de rede - identifica uma rede. Os primeiros bits de uma ID de rede, conhecidos como campo de classe ou bits de classe, identificam a classe do endereço IP.
- ID do host - Identifica um host em uma rede.
Os endereços IP são divididos em cinco classes, conforme mostrado na Figura 1. As áreas sombreadas representam a classe de endereço . As três primeiras classes são mais comumente usadas.
Figura 1 Classes de endereços IP
Tabela 1 Classes e intervalos de endereços IP
| Classe | Faixa de endereços | Observações |
| A | 0.0.0.0 a 127.255.255.255 | O endereço IP 0.0.0.0 é usado por um host na inicialização para comunicação temporária. Esse endereço nunca é um endereço de destino válido. Os endereços que começam com 127 são reservados para teste de loopback. Os pacotes destinados a esses endereços são processados localmente como pacotes de entrada em vez de serem enviados ao link. |
| B | 128.0.0.0 a 191.255.255.255 | N/A |
| C | 192.0.0.0 a 223.255.255.255 | N/A |
| D | 224.0.0.0 a 239.255.255.255 | Endereços multicast. |
| E | 240.0.0.0 a 255.255.255.255 | Reservado para uso futuro, exceto para o endereço de broadcast 255.255.255.255. |
Endereços IP especiais
Os endereços IP a seguir são para uso especial e não podem ser usados como endereços IP de host:
- Endereço IP com um ID de rede totalmente zero - Identifica um host na rede local. Por exemplo, o endereço IP 0.0.0.16 indica o host com um ID de host 16 na rede local.
- Endereço IP com um ID de host totalmente zero - identifica uma rede.
- Endereço IP com um ID de host único - Identifica um endereço de broadcast direcionado. Por exemplo, um pacote com o endereço de destino 192.168.1.255 será transmitido para todos os hosts da rede 192.168.1.0.
Sub-rede e mascaramento
A sub-rede divide uma rede em redes menores, chamadas sub-redes, usando alguns bits da ID do host para criar uma ID de sub-rede.
O mascaramento identifica o limite entre o ID do host e a combinação de ID de rede e ID de sub-rede.
Cada máscara de sub-rede é composta de 32 bits que correspondem aos bits em um endereço IP. Em uma máscara de sub-rede, os uns consecutivos representam a ID da rede e a ID da sub-rede, e os zeros consecutivos representam a ID do host.
Antes de serem sub-redeadas, as redes de classe A, B e C usam essas máscaras padrão (também chamadas de máscaras naturais): 255.0.0.0, 255.255.0.0 e 255.255.255.0, respectivamente.
Figura 2 Sub-rede de uma rede Classe B
A sub-rede aumenta o número de endereços que não podem ser atribuídos a hosts. Portanto, usar sub-redes significa acomodar menos hosts.
Por exemplo, uma rede de classe B sem sub-rede pode acomodar 1.022 hosts a mais do que a mesma rede com 512 sub-redes.
- Sem sub-rede - 65534 (216 - 2) hosts. (Os dois endereços deduzidos são o endereço de broadcast, que tem um ID de host totalmente um, e o endereço de rede, que tem um ID de host totalmente zero).
- Com sub-rede - O uso dos primeiros nove bits do ID do host para a sub-rede fornece 512 (29 ) sub-redes. No entanto, apenas sete bits permanecem disponíveis para o ID do host. Isso permite 126 (27 - 2) hosts em cada sub-rede, um total de 64512 (512 × 126) hosts.
Atribuição de endereço IP
Veja a seguir os métodos disponíveis para atribuir um endereço IP a uma interface:
- Atribuição manual. Este capítulo descreve apenas a atribuição manual de endereços IP para interfaces.
- BOOTP. Para obter informações sobre o BOOTP, consulte "Configuração do cliente BOOTP".
- DHCP. Para obter informações sobre o DHCP, consulte "Configuração do cliente DHCP".
Esses métodos são mutuamente exclusivos. Se você alterar o método de atribuição de endereço IP, o novo endereço IP substituirá o anterior.
Atribuição de um endereço IP a uma interface
Sobre a atribuição manual de endereços IP
Uma interface pode ter um endereço primário e vários endereços secundários.
Normalmente, você precisa configurar um endereço IP primário para uma interface. Se a interface se conectar a várias sub-redes, configure os endereços IP primário e secundário na interface para que as sub-redes possam se comunicar entre si por meio da interface.
Em uma malha IRF, é possível atribuir um endereço IP à porta Ethernet de gerenciamento de cada membro na visualização da porta Ethernet de gerenciamento do mestre. Somente o endereço IP atribuído à porta Ethernet de gerenciamento do mestre tem efeito. Após uma divisão da malha IRF, os endereços IP atribuídos às portas Ethernet de gerenciamento dos novos mestres (subordinados originais) entram em vigor. Em seguida, você pode usar esses endereços IP para fazer login nos novos mestres para solucionar problemas.
Restrições e diretrizes
- Uma interface pode ter apenas um endereço IP primário. Se você executar o comando ip address várias vezes para especificar diferentes endereços IP primários em uma interface, a configuração mais recente terá efeito.
- Não é possível atribuir endereços IP secundários a uma interface que obtém um endereço IP por meio de IP não numerado, BOOTP ou DHCP.
- Os endereços IP primário e secundário atribuídos à interface podem estar localizados no mesmo segmento de rede. Interfaces diferentes em seu dispositivo devem residir em segmentos de rede diferentes.
- Após uma divisão da IRF, as informações de roteamento no mestre original podem não ser atualizadas imediatamente. Como resultado, a porta Ethernet de gerenciamento do mestre original não pode receber um ping do mestre (subordinado original) em outra malha IRF. Para resolver o problema, aguarde até que a sincronização de rotas entre os dispositivos seja concluída ou ative o NSR para o protocolo de roteamento. Para obter informações sobre NSR, consulte o Guia de Configuração de Roteamento IP de Camada 3.
- Os comandos a seguir são mutuamente exclusivos. Você pode configurar apenas um desses comandos para atribuir um endereço IP à porta Ethernet de gerenciamento do IRF master.
- O comando ip address com a opção irf-member member-id que especifica o mestre.
- O comando ip address que não contém a opção irf-member member-id.
- O comando ip address dhcp-alloc.
- Você pode atribuir às interfaces endereços IP com máscaras diferentes, mas que tenham o mesmo endereço de rede se forem combinados com a máscara mais curta. Por exemplo, 1.1.1.1/16 e 1.1.2.1/24 têm o mesmo endereço de rede 1.1.0.0 se forem combinados com 255.255.0.0. Você pode atribuir os endereços IP a duas interfaces no dispositivo. Por padrão, os usuários conectados às duas interfaces não podem se comunicar entre si. Para que os usuários possam se comunicar, é necessário configurar o proxy ARP comum no dispositivo. Para obter mais informações, consulte "Configuração do proxy ARP".
- Entre na visualização do sistema.
Procedimento
system-view- Entre na visualização da interface.
interface interface-type interface-number- Atribuir um endereço IP à interface.
ip address ip-address { mask-length | mask } [ irf-member member-id |
sub ]Por padrão, nenhum endereço IP é atribuído à interface.
Para atribuir um endereço IP à porta Ethernet de gerenciamento de um dispositivo membro da IRF, entre na visualização da porta Ethernet de gerenciamento do mestre e especifique a opção irf-member member-id.
Configuração de IP não numerado
Sobre o IP não numerado
Você pode configurar uma interface para emprestar um endereço IP de outras interfaces. Isso é chamado de IP não numerado, e a interface que toma emprestado o endereço IP é chamada de interface IP não numerada.
Você pode usar o IP não numerado para economizar endereços IP quando os endereços IP disponíveis forem inadequados ou quando uma interface for usada apenas ocasionalmente.
Restrições e diretrizes
- As interfaces de loopback não podem emprestar endereços IP de outras interfaces, mas outras interfaces podem emprestar endereços IP de interfaces de loopback.
- Uma interface não pode pegar emprestado um endereço IP de uma interface não numerada.
- Várias interfaces podem usar o mesmo endereço IP não numerado.
- Se uma interface tiver vários endereços IP configurados manualmente, somente o endereço IP primário configurado manualmente poderá ser emprestado.
- Um protocolo de roteamento dinâmico não pode ser ativado na interface em que o IP unnumbered está configurado. Para permitir que a interface se comunique com outros dispositivos, configure uma rota estática para o dispositivo par na interface.
Pré-requisitos
Atribua um endereço IP à interface da qual você deseja obter o endereço IP. Como alternativa, você pode configurar a interface para obter um endereço por meio de BOOTP ou DHCP.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique a interface para pedir emprestado o endereço IP da interface especificada.
ip address unnumbered interface interface-type interface-number
Por padrão, a interface não toma emprestado endereços IP de outras interfaces.
Comandos de exibição e manutenção para endereçamento IP
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir a configuração e as estatísticas de IP para a interface especificada ou para todas as interfaces da Camada 3. | display ip interface [ interface-type interface-number ] |
| Exibir uma breve configuração de IP para as interfaces da Camada 3. | display ip interface [ interface-type [ número da interface ] ] brief [ descrição ] |
Exemplos de configuração de endereçamento IP
Exemplo: Especificação manual de um endereço IP
Configuração de rede
Conforme mostrado na Figura 3, uma porta na VLAN 1 em um switch está conectada a uma LAN composta por dois segmentos: 172.16.1.0/24 e 172.16.2.0/24.
Para permitir que os hosts nos dois segmentos de rede se comuniquem com a rede externa por meio do switch e para permitir que os hosts na LAN se comuniquem entre si:
- Atribua um endereço IP primário e um endereço IP secundário à interface 1 da VLAN no switch.
- Defina o endereço IP primário do switch como o endereço de gateway dos PCs na sub-rede 172.16.1.0/24 e defina o endereço IP secundário do switch como o endereço de gateway dos PCs na sub-rede 172.16.2.0/24.
Figura 3 Diagrama de rede
Procedimento
# Atribua um endereço IP primário e um endereço IP secundário à interface VLAN 1.
<Switch> system-view
[Switch] interface vlan-interface 1
[Switch-Vlan-interface1] ip address 172.16.1.1 255.255.255.0
[Switch-Vlan-interface1] ip address 172.16.2.1 255.255.255.0 sub# Defina o endereço do gateway para 172.16.1.1 nos PCs conectados à sub-rede 172.16.1.0/24 e para
172.16.2.1 nos PCs conectados à sub-rede 172.16.2.0/24.
Verificação da configuração
# Verifique a conectividade entre um host na sub-rede 172.16.1.0/24 e o switch.
<Switch> ping 172.16.1.2
Ping 172.16.1.2 (172.16.1.2): 56 data bytes, press CTRL_C to break
56 bytes from 172.16.1.2: icmp_seq=0 ttl=128 time=7.000 ms
56 bytes from 172.16.1.2: icmp_seq=1 ttl=128 time=2.000 ms
56 bytes from 172.16.1.2: icmp_seq=2 ttl=128 time=1.000 ms
56 bytes from 172.16.1.2: icmp_seq=3 ttl=128 time=1.000 ms
56 bytes from 172.16.1.2: icmp_seq=4 ttl=128 time=2.000 ms
--- Ping statistics for 172.16.1.2 ---
5 packet(s) transmitted, 5 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 1.000/2.600/7.000/2.245 ms# Verifique a conectividade entre um host na sub-rede 172.16.2.0/24 e o switch.
<Switch> ping 172.16.2.2
Ping 172.16.2.2 (172.16.2.2): 56 data bytes, press CTRL_C to break
56 bytes from 172.16.2.2: icmp_seq=0 ttl=128 time=2.000 ms
56 bytes from 172.16.2.2: icmp_seq=1 ttl=128 time=7.000 ms
56 bytes from 172.16.2.2: icmp_seq=2 ttl=128 time=1.000 ms
56 bytes from 172.16.2.2: icmp_seq=3 ttl=128 time=2.000 ms
56 bytes from 172.16.2.2: icmp_seq=4 ttl=128 time=1.000 ms
--- Ping statistics for 172.16.2.2 ---
5 packet(s) transmitted, 5 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 1.000/2.600/7.000/2.245 ms# Verifique a conectividade entre um host na sub-rede 172.16.1.0/24 e um host na sub-rede 172.16.2.0/24. A operação de ping foi bem-sucedida.
Visão geral do DHCP
Modelo de rede DHCP
O DHCP (Dynamic Host Configuration Protocol) fornece uma estrutura para atribuir informações de configuração a dispositivos de rede.
A Figura 1 mostra um cenário típico de aplicativo DHCP em que os clientes DHCP e o servidor DHCP residem na mesma sub-rede. Os clientes DHCP também podem obter parâmetros de configuração de um servidor DHCP em outra sub-rede por meio de um agente de retransmissão DHCP. Para obter mais informações sobre o agente de retransmissão DHCP , consulte "Configuração do agente de retransmissão DHCP".
Figura 1 Um aplicativo DHCP típico
Alocação de endereços DHCP
Mecanismos de alocação
O DHCP oferece suporte aos seguintes mecanismos de alocação:
- Alocação estática - O administrador da rede atribui um endereço IP a um cliente, como um servidor WWW, e o DHCP transmite o endereço atribuído ao cliente.
- Alocação automática - o DHCP atribui um endereço IP permanente a um cliente.
- Alocação dinâmica - o DHCP atribui um endereço IP a um cliente por um período limitado de tempo, o que é chamado de concessão. A maioria dos clientes DHCP obtém seus endereços dessa forma.
Processo de alocação de endereços IP
Figura 2 Processo de alocação de endereços IP
Conforme mostrado na Figura 2, um servidor DHCP atribui um endereço IP a um cliente DHCP no seguinte processo :
- O cliente transmite uma mensagem DHCP-DISCOVER para localizar um servidor DHCP.
- Cada servidor DHCP oferece parâmetros de configuração, como um endereço IP, ao cliente em uma mensagem DHCP-OFFER. O modo de envio do DHCP-OFFER é determinado pelo campo de sinalização na mensagem DHCP-DISCOVER. Para obter mais informações, consulte "Formato da mensagem DHCP".
- Se o cliente receber várias ofertas, ele aceitará a primeira oferta recebida e a transmitirá em uma mensagem DHCP-REQUEST para solicitar formalmente o endereço IP. (Os endereços IP oferecidos por outros servidores DHCP podem ser atribuídos a outros clientes).
- Todos os servidores DHCP recebem a mensagem DHCP-REQUEST. Entretanto, somente o servidor selecionado pelo cliente realiza uma das seguintes operações:
- Retorna uma mensagem DHCP-ACK para confirmar que o endereço IP foi alocado para o cliente.
- Retorna uma mensagem DHCP-NAK para negar a alocação do endereço IP.
Após receber a mensagem DHCP-ACK, o cliente verifica os seguintes detalhes antes de usar o endereço IP atribuído:
- O endereço IP atribuído não está em uso. Para verificar isso, o cliente transmite um pacote ARP gratuito. O endereço IP atribuído não estará em uso se nenhuma resposta for recebida dentro do tempo especificado.
- O endereço IP atribuído não está na mesma sub-rede que qualquer endereço IP em uso no cliente.
Caso contrário, o cliente envia uma mensagem DHCP-DECLINE ao servidor para solicitar um endereço IP novamente.
Extensão da concessão do endereço IP
Um endereço IP atribuído dinamicamente tem uma concessão. Quando a concessão expira, o endereço IP é recuperado pelo servidor DHCP. Para continuar usando o endereço IP, o cliente deve estender a duração da concessão.
Quando cerca de metade da duração da concessão termina, o cliente DHCP envia um DHCP-REQUEST ao servidor DHCP para estender a concessão. Dependendo da disponibilidade do endereço IP, o servidor DHCP retorna uma das seguintes mensagens:
- Um unicast DHCP-ACK confirmando que a duração da concessão do cliente foi estendida.
- Um unicast DHCP-NAK negando a solicitação.
Se o cliente não receber resposta, ele transmitirá outra mensagem DHCP-REQUEST para extensão do contrato de arrendamento quando sete oitavos da duração do contrato de arrendamento tiverem se passado. Novamente, dependendo da disponibilidade do endereço IP, o servidor DHCP retorna um unicast DHCP-ACK ou um unicast DHCP-NAK.
Formato da mensagem DHCP
A Figura 3 mostra o formato da mensagem DHCP. O DHCP usa alguns dos campos de maneiras significativamente diferentes . Os números entre parênteses indicam o tamanho de cada campo em bytes.
Figura 3 Formato da mensagem DHCP
- op - Tipo de mensagem definido no campo de opções. 1 = SOLICITAÇÃO, 2 = RESPOSTA
- htype, hlen-Tipo de endereço de hardware e comprimento do cliente DHCP.
- hops-Número de agentes de retransmissão que uma mensagem de solicitação percorreu.
- xid - ID da transação, um número aleatório escolhido pelo cliente para identificar uma alocação de endereço IP.
- secs - Preenchido pelo cliente, o número de segundos decorridos desde que o cliente iniciou o processo de aquisição ou renovação de endereços. Esse campo é reservado e definido como 0.
- flags - O bit mais à esquerda é definido como o sinalizador BROADCAST (B). Se esse sinalizador for definido como 0, o servidor DHCP enviou uma resposta de volta por unicast. Se esse sinalizador for definido como 1, o servidor DHCP enviará uma resposta de volta por broadcast. Os bits restantes do campo flags são reservados para uso futuro.
- ciaddr - Endereço IP do cliente se o cliente tiver um endereço IP válido e utilizável. Caso contrário, defina como zero. (O cliente não usa esse campo para solicitar um endereço IP para concessão).
- yiaddr-Seu endereço IP. É um endereço IP atribuído pelo servidor DHCP ao cliente DHCP.
- siaddr - Endereço IP do servidor, do qual o cliente obteve os parâmetros de configuração.
- giaddr-Endereço IP do gateway. É o endereço IP do primeiro agente de retransmissão para o qual uma mensagem de solicitação é encaminhada.
- chaddr - Endereço de hardware do cliente.
- sname-Nome do host do servidor, do qual o cliente obteve os parâmetros de configuração.
- file - Nome do arquivo de inicialização (também chamado de imagem do software do sistema) e informações de caminho, definidas pelo servidor para o cliente.
- options - Campo de parâmetros opcionais que tem comprimento variável. Os parâmetros opcionais incluem o tipo de mensagem, a duração da concessão, a máscara de sub-rede, o endereço IP do servidor de nomes de domínio e o endereço IP do WINS.
Opções de DHCP
O DHCP amplia o formato da mensagem como uma extensão do BOOTP para fins de compatibilidade. O DHCP usa o campo de opções para transportar informações para alocação dinâmica de endereços e fornecer informações adicionais de configuração para os clientes.
Figura 4 Formato da opção DHCP
Opções comuns de DHCP
As opções comuns de DHCP são as seguintes:
- Opção 3 - Opção de roteador. Especifica o endereço do gateway a ser atribuído aos clientes.
- Opção 6 - Opção de servidor DNS. Especifica o endereço IP do servidor DNS a ser atribuído aos clientes.
- Opção 33 - Opção de rota estática. Especifica uma lista de rotas estáticas com classe (os endereços de destino nessas rotas estáticas são com classe) que um cliente deve adicionar à sua tabela de roteamento. Se a Opção 33 e a Opção 121 existirem, a Opção 33 será ignorada.
- Opção 51 - Opção de concessão de endereço IP.
- Opção 53 - Opção de tipo de mensagem DHCP. Identifica o tipo de mensagem DHCP.
- Opção 55 - Opção de lista de solicitação de parâmetro. É usada por um cliente DHCP para solicitar parâmetros de configuração especificados. A opção inclui valores que correspondem aos parâmetros solicitados pelo cliente.
- Opção 60 - Opção de identificador de classe do fornecedor. Um cliente DHCP usa essa opção para identificar seu fornecedor. Um servidor DHCP usa essa opção para distinguir os clientes DHCP e atribui endereços IP a eles.
- Opção 66 - Opção de nome do servidor TFTP. Especifica o nome de domínio do servidor TFTP a ser atribuído aos clientes.
- Opção 67 - Opção de nome de arquivo de inicialização. Especifica o nome do arquivo de inicialização a ser atribuído ao cliente.
- Opção 121 - Opção de rota sem classe. Especifica uma lista de rotas estáticas sem classe (os endereços de destino nessas rotas estáticas não têm classe) que um cliente deve adicionar à sua tabela de roteamento. Se a Opção 33 e a Opção 121 existirem, a Opção 33 será ignorada.
- Opção 150 - Opção de endereço IP do servidor TFTP. Especifica o endereço IP do servidor TFTP a ser atribuído aos clientes.
Para obter mais informações sobre as opções de DHCP, consulte as RFC 2132 e RFC 3442.
Opções personalizadas de DHCP
Algumas opções, como a Opção 43, a Opção 82 e a Opção 184, não têm definições padrão na RFC 2132.
Opção específica do fornecedor (Opção 43)
Função da opção 43
Os servidores e clientes DHCP usam a Opção 43 para trocar informações de configuração específicas do fornecedor. O cliente DHCP pode obter as seguintes informações por meio da Option 43:
- Parâmetros do ACS, incluindo o URL do ACS, o nome de usuário e a senha.
- Identificador do provedor de serviços, que é adquirido pelo CPE do servidor DHCP e enviado ao ACS para selecionar configurações e parâmetros específicos do vendedor. Para obter mais informações sobre o CPE e o ACS, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
- Endereço do servidor PXE, que é usado para obter o arquivo de inicialização ou outras informações de controle do servidor PXE.
Formato da opção 43
Figura 5 Formato da opção 43
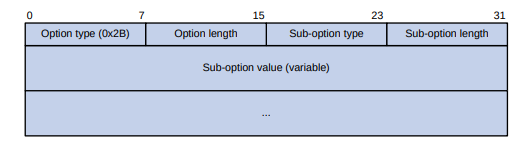
Os parâmetros de configuração de rede são transportados em diferentes subopções da Opção 43, conforme mostrado na Figura 5.
- Tipo de subopção - O valor do campo pode ser 0x01 (subopção de parâmetro ACS), 0x02 (subopção de identificador de provedor de serviços) ou 0x80 (subopção de endereço de servidor PXE).
- Comprimento da subopção - Exclui os campos de tipo de subopção e comprimento da subopção.
- Valor da subopção - O formato do valor varia de acordo com a subopção.
Formato do campo de valor da subopção
- Campo de valor da subopção do parâmetro ACS - Inclui o URL do ACS, o nome de usuário e a senha separados por espaços (número hexadecimal 20), conforme mostrado na Figura 6.
Figura 6 Campo de valor da subopção do parâmetro ACS

- Campo de valor da subopção do identificador do provedor de serviços - Inclui o identificador do provedor de serviços.
- Campo de valor da subopção de endereço do servidor PXE - Inclui o tipo de servidor PXE, que só pode ser 0, o número do servidor, que indica o número de servidores PXE contidos na subopção, e os endereços IP do servidor, conforme mostrado na Figura 7.
Figura 7 Campo de valor da subopção do endereço do servidor PXE
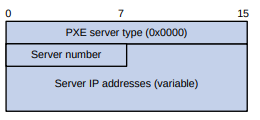
Opção de agente de retransmissão (Opção 82)
A opção 82 é a opção do agente de retransmissão. Ela registra as informações de localização sobre o cliente DHCP. Quando um agente de retransmissão DHCP ou um dispositivo DHCP snooping recebe a solicitação de um cliente, ele adiciona a Opção 82 à solicitação e a envia ao servidor.
O administrador pode usar a Opção 82 para localizar o cliente DHCP e implementar ainda mais o controle de segurança e a contabilidade. O servidor DHCP pode usar a Opção 82 para fornecer políticas de configuração individuais para os clientes.
A opção 82 pode incluir um máximo de 255 subopções e deve incluir um mínimo de uma subopção. A opção 82 suporta as seguintes subopções: subopção 1 (ID do circuito), subopção 2 (ID remota), subopção 5 (seleção de link) e subopção 9 (específica do fornecedor). A opção 82 não tem definição padrão. Seus formatos de preenchimento variam de acordo com o fornecedor.
- O Circuit ID tem os seguintes modos de preenchimento:
- Modo de preenchimento de cadeia - Inclui uma cadeia de caracteres especificada pelo usuário.
- Modo de preenchimento normal - Inclui a VLAN ID e o número da interface que recebe a solicitação do cliente.
- Modo de preenchimento detalhado - Inclui o identificador do nó de acesso especificado pelo usuário e o ID da VLAN, o número da interface e o tipo de interface da interface que recebe a solicitação do cliente.
- A ID remota tem os seguintes modos de preenchimento:
- Modo de preenchimento de cadeia - Inclui uma cadeia de caracteres especificada pelo usuário.
- Modo de preenchimento normal - Inclui o endereço MAC da interface do agente de retransmissão DHCP ou o endereço MAC do dispositivo DHCP snooping que recebe a solicitação do cliente.
- Sysname padding mode - Inclui o nome do dispositivo. Para definir o nome do dispositivo, use o comando sysname na visualização do sistema.
- A subopção Link Selection carrega o endereço IP no campo giaddr ou o endereço IP de uma interface de retransmissão. Se você usar o comando dhcp relay source-address { ip-address | interface interface-type interface-number }, deverá habilitar o agente de retransmissão DHCP para dar suporte à Opção 82. Essa subopção será então incluída na Opção 82.
- A subopção Vendor-Specific suporta apenas o modo de preenchimento básico. O conteúdo do preenchimento inclui o identificador do nó de acesso configurado pelo usuário e o ID da VLAN, o número da interface e o tipo de interface da interface que recebe a solicitação do cliente. Essa subopção é suportada somente em dispositivos DHCP snooping.
Opção 184
A opção 184 é uma opção reservada. Você pode definir os parâmetros na opção conforme necessário. O dispositivo é compatível com a opção 184 que contém parâmetros relacionados à voz, de modo que um cliente DHCP com funções de voz pode obter parâmetros de voz do servidor DHCP.
A opção 184 tem as seguintes subopções:
- Subopção 1 - Especifica o endereço IP do processador primário de chamadas de rede. O processador primário atua como a fonte de controle de chamada de rede e fornece serviços de download de programas. Para a Opção 184, você deve definir a subopção 1 para que as outras subopções tenham efeito.
- Subopção 2 - Especifica o endereço IP do processador de chamadas de rede de backup. Os clientes DHCP entram em contato com o processador de backup quando o processador principal não pode ser acessado.
- Subopção 3 - Especifica a ID da VLAN de voz e o resultado, se o cliente DHCP considera essa VLAN como a VLAN de voz.
- Subopção 4 - Especifica a rota de failover que inclui o endereço IP e o número do usuário de destino. Um usuário VoIP SIP usa esse endereço IP e esse número para estabelecer diretamente uma conexão com o usuário SIP de destino quando os processadores de chamadas primário e de backup não puderem ser acessados.
Protocolos e padrões
- RFC 2131, Protocolo de configuração dinâmica de host
- RFC 2132, Opções de DHCP e extensões de fornecedor de BOOTP
- RFC 1542, Esclarecimentos e extensões para o protocolo Bootstrap
- RFC 3046, Opção de informações do agente de retransmissão DHCP
- RFC 3442, The Classless Static Route Option for Dynamic Host Configuration Protocol (DHCP) versão 4
Configuração do servidor DHCP
Sobre o servidor DHCP
Um servidor DHCP gerencia um pool de endereços IP e parâmetros de configuração do cliente. Ele seleciona um endereço IP e parâmetros de configuração do pool de endereços e os aloca a um cliente DHCP solicitante.
Mecanismos de atribuição de endereços DHCP
Configure os seguintes mecanismos de atribuição de endereços, conforme necessário:
- Alocação de endereço estático - Vincule manualmente o endereço MAC ou a ID de um cliente a um endereço IP em um pool de endereços DHCP. Quando o cliente solicita um endereço IP, o servidor DHCP atribui ao cliente o endereço IP na associação estática.
- Alocação dinâmica de endereços - Especifique intervalos de endereços IP em um pool de endereços DHCP. Ao receber uma solicitação de DHCP, o servidor DHCP seleciona dinamicamente um endereço IP do intervalo de endereços IP correspondente no pool de endereços.
Você pode especificar intervalos de endereços IP em um pool de endereços usando um dos seguintes métodos:
- Método 1 - Uma sub-rede primária sendo dividida em vários intervalos de endereços em um pool de endereços
- Método 2 - Uma sub-rede primária e várias sub-redes secundárias em um pool de endereços
Uma sub-rede primária sendo dividida em vários intervalos de endereços em um pool de endereços
Um intervalo de endereços inclui um intervalo de endereços IP comum e intervalos de endereços IP para classes de usuários DHCP.
Ao receber uma solicitação de DHCP, o servidor DHCP encontra uma classe de usuário correspondente ao cliente e seleciona um endereço IP no intervalo de endereços da classe de usuário para o cliente. Uma classe de usuário pode incluir várias regras de correspondência, e um cliente corresponde à classe de usuário desde que corresponda a qualquer uma das regras. Na visualização do pool de endereços, é possível especificar diferentes intervalos de endereços para diferentes classes de usuários.
O servidor DHCP seleciona um endereço IP para um cliente executando as seguintes etapas:
- O servidor DHCP compara o cliente com as classes de usuário do DHCP na ordem em que foram configuradas.
- Se o cliente corresponder a uma classe de usuário, o servidor DHCP selecionará um endereço IP do intervalo de endereços da classe de usuário.
- Se a classe de usuário correspondente não tiver endereços atribuíveis, o servidor DHCP compara o cliente com a próxima classe de usuário. Se todas as classes de usuários correspondentes não tiverem endereços atribuíveis, o servidor DHCP selecionará um endereço IP do intervalo de endereços comum.
- Se o cliente DHCP não corresponder a nenhuma classe de usuário DHCP, o servidor DHCP selecionará um endereço no intervalo de endereços IP especificado pelo comando de intervalo de endereços. Se o intervalo de endereços não tiver endereços IP atribuíveis ou não estiver configurado, a alocação de endereços falhará.
OBSERVAÇÃO:
Todos os intervalos de endereços devem pertencer à sub-rede primária. Se um intervalo de endereços não residir na sub-rede primária, o DHCP não poderá atribuir os endereços no intervalo de endereços.
Uma sub-rede primária e várias sub-redes secundárias em um pool de endereços
O servidor DHCP seleciona primeiro um endereço IP da sub-rede primária. Se não houver nenhum endereço IP atribuível na sub-rede primária, o servidor DHCP selecionará um endereço IP das sub-redes secundárias na ordem em que forem configuradas.
Princípios para a seleção de um pool de endereços
O servidor DHCP observa os seguintes princípios para selecionar um pool de endereços para um cliente:
- Se houver um pool de endereços em que um endereço IP esteja estaticamente vinculado ao endereço MAC ou à ID do cliente, o servidor DHCP selecionará esse pool de endereços e atribuirá o endereço IP estaticamente vinculado e outros parâmetros de configuração ao cliente.
- Se a interface receptora tiver uma política de DHCP e o cliente DHCP corresponder a uma classe de usuário, o servidor DHCP selecionará o pool de endereços que está vinculado à classe de usuário correspondente. Se não for encontrada nenhuma classe de usuário correspondente, o servidor atribuirá um endereço IP e outros parâmetros do pool de endereços DHCP padrão. Se nenhum pool de endereços padrão for especificado ou se o pool de endereços padrão não tiver endereços IP atribuíveis, a atribuição de endereços falhará.
- Se a interface receptora tiver um pool de endereços aplicado, o servidor DHCP selecionará um endereço IP e outros parâmetros de configuração desse pool de endereços.
- Se as condições acima não forem atendidas, o servidor DHCP selecionará um pool de endereços dependendo da localização do cliente.
- Cliente na mesma sub-rede que o servidor - O servidor DHCP compara o endereço IP da interface receptora com as sub-redes primárias de todos os pools de endereços.
- Se for encontrada uma correspondência, o servidor selecionará o pool de endereços com a sub-rede primária de correspondência mais longa.
- Se não for encontrada nenhuma correspondência, o servidor DHCP comparará o endereço IP com as sub-redes secundárias de todos os pools de endereços. O servidor seleciona o pool de endereços com a sub-rede secundária com a correspondência mais longa.
- Cliente em uma sub-rede diferente da do servidor - O servidor DHCP compara o endereço IP no campo giaddr da solicitação DHCP com as sub-redes primárias de todos os pools de endereços.
- Se for encontrada uma correspondência, o servidor selecionará o pool de endereços com a sub-rede primária de correspondência mais longa.
- Se não for encontrada nenhuma correspondência, o servidor DHCP comparará o endereço IP com as sub-redes secundárias de todos os pools de endereços. O servidor seleciona o pool de endereços com a sub-rede secundária com a correspondência mais longa.
Por exemplo, dois pools de endereços 1.1.1.0/24 e 1.1.1.0/25 estão configurados, mas não são aplicados a nenhuma interface do servidor DHCP.
- Se o endereço IP da interface receptora for 1.1.1.1/25, o servidor DHCP selecionará o pool de endereços 1.1.1.0/25. Se o pool de endereços não tiver endereços IP disponíveis, o servidor DHCP não selecionará o outro pool e a alocação de endereços falhará.
- Se o endereço IP da interface receptora for 1.1.1.130/25, o servidor DHCP selecionará o pool de endereços 1.1.1.0/24.
Para garantir a alocação correta de endereços, mantenha os endereços IP usados para alocação dinâmica em uma das sub-redes:
- Clientes na mesma sub-rede que o servidor-Sub-rede em que reside a interface de recepção do servidor DHCP.
- Clientes em uma sub-rede diferente da do servidor - Sub-rede em que reside a primeira interface de retransmissão DHCP voltada para os clientes.
OBSERVAÇÃO:
Como prática recomendada, configure no mínimo uma sub-rede primária correspondente em sua rede. Caso contrário, o servidor DHCP selecionará apenas a primeira sub-rede secundária correspondente para alocação de endereços. Se a rede tiver mais clientes DHCP do que os endereços IP atribuíveis na sub-rede secundária, nem todos os clientes DHCP poderão obter endereços IP.
Sequência de alocação de endereços IP
O servidor DHCP seleciona um endereço IP para um cliente na seguinte sequência:
- Endereço IP vinculado estaticamente ao endereço MAC ou ID do cliente.
- Endereço IP que já foi atribuído ao cliente.
- Endereço IP designado pelo campo Option 50 na mensagem DHCP-DISCOVER enviada pelo cliente.
A opção 50 é a opção Requested IP Address (Endereço IP solicitado). O cliente usa essa opção para especificar o endereço IP desejado em uma mensagem DHCP-DISCOVER. O conteúdo da Option 50 é definido pelo usuário.
- Primeiro endereço IP atribuível encontrado na forma discutida em "Mecanismos de atribuição de endereços DHCP" e "Princípios para selecionar um pool de endereços".
- Endereço IP que foi um conflito ou que ultrapassou o período de concessão. Se nenhum endereço IP puder ser atribuído, o servidor não responderá.
OBSERVAÇÃO:
- Se um cliente mudar para outra sub-rede, o servidor DHCP selecionará um endereço IP no pool de endereços correspondente à nova sub-rede. Ele não atribui o endereço IP que já foi atribuído ao cliente.
- Os endereços IP conflitantes podem ser atribuídos a outros clientes DHCP somente depois que os endereços estiverem em conflito por uma hora.
Visão geral das tarefas do servidor DHCP
Para configurar o servidor DHCP, execute as seguintes tarefas:
- (Opcional.) Criação de uma classe de usuário DHCP
- Configuração de um pool de endereços no servidor DHCP
- (Opcional.) Modificar o método de seleção do pool de endereços no servidor DHCP
- Aplicação de um pool de endereços a uma interface
- Configuração de uma política DHCP para atribuição dinâmica
- Ativação do DHCP
- Ativação do servidor DHCP em uma interface
- (Opcional.) Configuração de recursos avançados de DHCP
- Configuração da detecção de conflitos de endereços IP
- Ativação do manuseio da Opção 82
- Configuração dos recursos de segurança do servidor DHCP
- Configuração da compatibilidade do servidor DHCP
- Configuração do valor DSCP para pacotes DHCP enviados pelo servidor DHCP
- Configuração do backup automático de vinculação DHCP
- Ativação da detecção off-line do cliente no servidor DHCP
- (Opcional.) Configuração da notificação e do registro de SNMP
- Configuração de alarmes de uso do pool de endereços
- Ativação do registro de DHCP no servidor DHCP
Criação de uma classe de usuário DHCP
Sobre a classe de usuário DHCP
O servidor DHCP classifica os usuários DHCP em diferentes classes de usuários de acordo com o endereço de hardware, as informações de opção ou o campo giaddr nas solicitações DHCP recebidas. O servidor aloca endereços IP e parâmetros de configuração para clientes DHCP em diferentes classes de usuários.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma classe de usuário DHCP e entre na visualização da classe de usuário DHCP.
dhcp class class-name- Configure uma regra de correspondência para a classe de usuário DHCP.
if-match rule rule-number { hardware-address hardware-address mask
hardware-address-mask | option option-code [ ascii ascii-string
[ offset offset | partial ] | hex hex-string [ mask mask | offset offset
length length | partial ] ] | relay-agent gateway-address }Por padrão, nenhuma regra de correspondência é configurada para uma classe de usuário DHCP.
Configuração de um pool de endereços no servidor DHCP
Visão geral das tarefas do pool de endereços DHCP
Para configurar um pool de endereços DHCP, execute as seguintes tarefas:
- Criação de um pool de endereços DHCP
- Especificação de intervalos de endereços IP em um pool de endereços DHCP
Em um pool de endereços DHCP, os dois métodos de alocação dinâmica não podem ser configurados, mas as alocações de endereços estáticos e dinâmicos podem ser implementadas.
- Especificação de uma sub-rede primária e de vários intervalos de endereços em um pool de endereços DHCP
- Especificação de uma sub-rede primária e de várias sub-redes secundárias em um pool de endereços DHCP
- Configuração de uma associação estática em um pool de endereços DHCP
- Especificação de outros parâmetros de configuração a serem atribuídos aos clientes DHCP
- Especificação de gateways para clientes DHCP
- Especificação de um sufixo de nome de domínio para clientes DHCP
- Especificação de servidores DNS para clientes DHCP
- Especificação de servidores WINS e tipo de nó NetBIOS para clientes DHCP
- Especificação do servidor BIMS para clientes DHCP
- Especificação do arquivo de configuração para a configuração automática do cliente DHCP
- Especificação de um servidor para clientes DHCP
- Configuração dos parâmetros da Option 184 para clientes DHCP
- Personalização das opções de DHCP
- (Opcional.) Configuração da lista branca de classes de usuários DHCP
Criação de um pool de endereços DHCP
system-view- Crie um pool de endereços DHCP e entre em sua visualização.
dhcp server ip-pool pool-nameEspecificação de uma sub-rede primária e de vários intervalos de endereços em um pool de endereços DHCP
Sobre uma sub-rede primária e vários intervalos de endereços em um pool de endereços DHCP
Alguns cenários precisam classificar os clientes DHCP na mesma sub-rede em grupos de endereços diferentes. Para atender a essa necessidade, você pode configurar classes de usuários DHCP e especificar diferentes intervalos de endereços para as classes. Os clientes que correspondem a uma classe de usuário podem, então, obter os endereços IP de um intervalo de endereços. Além disso, é possível especificar um intervalo de endereços comum para os clientes que não correspondem a nenhuma classe de usuário. Se nenhum intervalo de endereços comum for especificado, esses clientes não conseguirão obter endereços IP.
Se não houver necessidade de classificar clientes, não será necessário configurar classes de usuários DHCP ou seus intervalos de endereços .
Restrições e diretrizes
- Se você executar o comando de rede ou de intervalo de endereços várias vezes para o mesmo pool de endereços, a configuração mais recente entrará em vigor.
- Se você executar o comando forbidden-ip várias vezes, estará excluindo vários intervalos de endereços da alocação dinâmica.
- Os endereços IP especificados pelo comando forbidden-ip não podem ser atribuídos no pool de endereços atual, mas podem ser atribuídos em outros pools de endereços. Os endereços IP especificados pelo comando forbidden-ip do servidor dhcp não podem ser atribuídos em nenhum pool de endereços.
- Você pode usar o intervalo de classes para modificar um intervalo de endereços existente, e o novo intervalo de endereços pode incluir endereços IP que estão sendo usados por clientes. Ao receber uma solicitação de extensão de concessão para esse endereço IP, o servidor DHCP aloca um novo endereço IP para o cliente solicitante. Mas a concessão original continua envelhecendo no pool de endereços e será liberada quando a duração da concessão for atingida. Para liberar essa concessão sem aguardar o tempo limite, execute o comando reset dhcp server ip-in-use.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Especifique a sub-rede primária no pool de endereços.
network network-address [ mask-length | mask mask ]Por padrão, nenhuma sub-rede primária é especificada.
- (Opcional.) Especifique o intervalo de endereços comuns.
address range start-ip-address end-ip-addressPor padrão, nenhum intervalo de endereços IP é especificado.
- (Opcional.) Especifique um intervalo de endereços IP para uma classe de usuário DHCP.
class class-name range start-ip-address end-ip-addressPor padrão, nenhum intervalo de endereços IP é especificado para uma classe de usuário.
A classe de usuário DHCP já deve ter sido criada usando o comando dhcp class.
- (Opcional.) Defina a duração do aluguel do endereço.
expired { day day [ hour hour [ minute minute [ second second ] ] ] |
unlimited }A configuração padrão é 1 dia.
- (Opcional.) Exclua da alocação dinâmica os endereços IP especificados no pool de endereços.
forbidden-ip ip-address&<1-8>
Por padrão, todos os endereços IP no pool de endereços DHCP podem ser atribuídos.
- (Opcional.) Exclua os endereços IP especificados da alocação automática na visualização do sistema.
- Retornar à visualização do sistema.
quit- Excluir os endereços IP especificados da alocação automática em nível global.
dhcp server forbidden-ip start-ip-address [ end-ip-address ]Por padrão, com exceção do endereço IP da interface do servidor DHCP, os endereços IP em todos os pools de endereços podem ser atribuídos.
Especificação de uma sub-rede primária e de várias sub-redes secundárias em um pool de endereços DHCP
Sobre uma sub-rede primária e várias sub-redes secundárias em um pool de endereços DHCP
Se um pool de endereços tiver uma sub-rede primária e várias sub-redes secundárias, o servidor atribuirá endereços IP em uma sub-rede secundária quando a sub-rede primária não tiver endereços IP atribuíveis.
Restrições e diretrizes
Os endereços IP especificados pelo comando forbidden-ip não podem ser atribuídos no pool de endereços atual, mas podem ser atribuídos em outros pools de endereços. Os endereços IP especificados pelo comando dhcp server forbidden-ip não podem ser atribuídos em nenhum pool de endereços.
Especificação de uma sub-rede primária e de várias sub-redes secundárias
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Especifique a sub-rede primária.
network network-address [ mask-length | mask mask ]Por padrão, nenhuma sub-rede primária é especificada.
Você pode especificar apenas uma sub-rede primária em cada pool de endereços. Se você executar a função de rede
várias vezes, a configuração mais recente entra em vigor.
- (Opcional.) Especifique uma sub-rede secundária.
network network-address [ mask-length | mask mask ] secondaryPor padrão, nenhuma sub-rede secundária é especificada.
É possível especificar um máximo de 32 sub-redes secundárias em um pool de endereços.
- (Opcional.) Retorne à visualização do pool de endereços.
quitDefinição da duração da concessão para endereços IP alocados dinamicamente
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Defina a duração do aluguel do endereço.
expired { day day [ hour hour [ minute minute [ second second ] ] ] |
unlimited }A configuração padrão é 1 dia.
Exclusão de endereços IP da alocação dinâmica
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Excluir os endereços IP especificados da alocação dinâmica.
forbidden-ip ip-address&<1-8>
Por padrão, todos os endereços IP no pool de endereços DHCP podem ser atribuídos.
Para excluir vários intervalos de endereços do pool de endereços, repita esta etapa.
- (Opcional.) Exclua os endereços IP especificados da alocação dinâmica na visualização do sistema.
- Retornar à visualização do sistema.
quit- Excluir os endereços IP especificados da alocação dinâmica em nível global.
dhcp server forbidden-ip start-ip-address [ end-ip-address ]Por padrão, com exceção do endereço IP da interface do servidor DHCP, os endereços IP em todos os pools de endereços podem ser atribuídos.
Para excluir vários intervalos de endereços globalmente, repita esta etapa.
Configuração de uma associação estática em um pool de endereços DHCP
Sobre a vinculação estática em um pool de endereços DHCP
Alguns clientes DHCP, como um servidor WWW, precisam de endereços IP fixos. Para fornecer um endereço IP fixo para um cliente, você pode vincular estaticamente o endereço MAC ou a ID do cliente a um endereço IP em um pool de endereços DHCP. Quando o cliente solicita um endereço IP, o servidor DHCP atribui o endereço IP em a associação estática ao cliente.
Restrições e diretrizes
- O endereço IP de uma associação estática não pode ser o endereço da interface do servidor DHCP. Caso contrário, ocorrerá um conflito de endereço IP e o cliente vinculado não poderá obter um endereço IP corretamente.
- Várias interfaces no mesmo dispositivo podem usar o DHCP para solicitar um endereço IP estático. Nesse caso, use IDs de cliente em vez do endereço MAC do dispositivo para identificar as interfaces. Caso contrário, a alocação do endereço IP falhará.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Configure uma ligação estática.
static-bind ip-address ip-address [ mask-length | mask mask ] { client-identifier client-identifier | hardware-address hardware-address [ ethernet | token-ring ] }Por padrão, nenhuma ligação estática é configurada.
Um endereço IP pode ser vinculado a apenas um MAC de cliente ou ID de cliente. Não é possível modificar as associações que foram criadas. Para alterar a associação de um cliente DHCP, primeiro você deve excluir a associação existente.
- (Opcional.) Defina a duração do aluguel do endereço IP.
expired { day day [ hour hour [ minute minute [ second second ] ] ] | unlimited }Por padrão, a duração do arrendamento é de 1 dia.
Especificação de gateways para clientes DHCP
Sobre gateways para clientes DHCP
Os clientes DHCP enviam pacotes destinados a outras redes para um gateway. O servidor DHCP pode atribuir o endereço do gateway aos clientes DHCP.
Restrições e diretrizes
Você pode especificar endereços de gateway em cada pool de endereços no servidor DHCP. É possível especificar um máximo de 64 gateways na visualização do pool de endereços DHCP ou na visualização da sub-rede secundária.
O servidor DHCP atribui endereços de gateway a clientes em uma sub-rede secundária das seguintes maneiras:
- Se os gateways forem especificados no modo de exibição de pool de endereços e no modo de exibição de sub-rede secundária, o DHCP atribuirá aqueles especificados no modo de exibição de sub-rede secundária.
- Se os gateways forem especificados no modo de exibição de pool de endereços, mas não no modo de exibição de sub-rede secundária, o DHCP atribuirá aqueles especificados no modo de exibição de pool de endereços.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Especifique os gateways.
gateway-list ip-address&<1-64>Por padrão, nenhum gateway é especificado.
- (Opcional.) Especifique gateways na visualização de sub-rede secundária.
- Entre na visualização da sub-rede secundária.
network network-address [ mask-length | mask mask ] secondary- Especifique os gateways.
gateway-list ip-address&<1-64>Por padrão, nenhum gateway é especificado.
Especificação de um sufixo de nome de domínio para clientes DHCP
Sobre o sufixo do nome de domínio para clientes DHCP
Você pode especificar um sufixo de nome de domínio em um pool de endereços DHCP no servidor DHCP. Com esse sufixo atribuído, o cliente só precisa inserir parte de um nome de domínio, e o sistema adiciona o sufixo de nome de domínio para resolução de nomes. Para obter mais informações sobre DNS, consulte "Configuração de DNS".
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Especifique um sufixo de nome de domínio.
domain-name domain-namePor padrão, nenhum nome de domínio é especificado.
Especificação de servidores DNS para clientes DHCP
Sobre servidores DNS para clientes DHCP
Para acessar hosts na Internet por meio de nomes de domínio, um cliente DHCP deve entrar em contato com um servidor DNS para resolver os nomes. É possível especificar até oito servidores DNS em um pool de endereços DHCP.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Especifique os servidores DNS.
dns-list ip-address&<1-8>Por padrão, nenhum servidor DNS é especificado.
Especificação de servidores WINS e tipo de nó NetBIOS para clientes DHCP
Sobre servidores WINS e tipo de nó NetBIOS para clientes DHCP
Um cliente Microsoft DHCP que usa o protocolo NetBIOS deve entrar em contato com um servidor WINS para a resolução de nomes. Além disso, você deve especificar um dos seguintes tipos de nó NetBIOS para abordar a resolução de nomes:
- b (broadcast) - nó - Um cliente de nó b envia o nome do destino em uma mensagem de broadcast.
O destino retorna seu endereço IP para o cliente após receber a mensagem.
- p (peer-to-peer) - nó - Um cliente de nó p envia o nome do destino em uma mensagem unicast para o servidor WINS. O servidor WINS retorna o endereço IP de destino.
- m (mixed)-node - Um cliente de nó m transmite o nome do destino. Se não receber resposta, ele unicausa o nome de destino para o servidor WINS para obter o endereço IP de destino.
- nó h (híbrido) - Um cliente de nó h transmite o nome de destino ao servidor WINS. Se não receber resposta, ele transmite o nome de destino para obter o endereço IP de destino.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-namePor padrão, não existe nenhum pool de endereços DHCP.
- Especifique os servidores WINS.
nbns-list ip-address&<1-8>Por padrão, nenhum servidor WINS é especificado.
Essa etapa é opcional para o nó b. Você pode especificar um máximo de oito servidores WINS para esses clientes em um pool de endereços DHCP.
- Especifique o tipo de nó NetBIOS.
netbios-type { b-node | h-node | m-node | p-node }Por padrão, nenhum tipo de nó NetBIOS é especificado.
Especificação do servidor BIMS para clientes DHCP
Sobre o servidor BIMS para clientes DHCP
Execute essa tarefa para fornecer o endereço IP do servidor BIMS, o número da porta e a chave compartilhada para os clientes. Os clientes DHCP entram em contato com o servidor BIMS para obter arquivos de configuração e realizar atualização e backup de software.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Especifique o endereço IP do servidor BIMS, o número da porta e a chave compartilhada.
bims-server ip ip-address [ port port-number ] sharekey { cipher |
simple } stringPor padrão, nenhuma informação do servidor BIMS é especificada.
Especificação do arquivo de configuração para a configuração automática do cliente DHCP
Sobre o arquivo de configuração para a configuração automática do cliente DHCP
A configuração automática permite que um dispositivo obtenha automaticamente um conjunto de definições de configuração na inicialização. A configuração automática baseada em servidor requer a cooperação do servidor DHCP e do servidor de arquivos (servidor TFTP ou HTTP). O dispositivo usa os parâmetros obtidos para entrar em contato com o servidor de arquivos e obter o arquivo de configuração. Para obter mais informações sobre a configuração automática, consulte o Fundamentals Configuration Guide (Guia de configuração básica).
Especificação do arquivo de configuração em um servidor de arquivos TFTP
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-namePor padrão, não existe nenhum pool de endereços DHCP.
- Especifique o endereço IP ou o nome de um servidor TFTP.
- Especifique o endereço IP do servidor TFTP.
tftp-server ip-address ip-addressPor padrão, nenhum endereço IP do servidor TFTP é especificado.
- Especifique o nome do servidor TFTP.
tftp-server domain-name domain-namePor padrão, nenhum nome de servidor TFTP é especificado.
- Especifique o nome do arquivo de configuração.
bootfile-name bootfile-namePor padrão, nenhum nome de arquivo de configuração é especificado.
Especificar o URL do arquivo de configuração em um servidor de arquivos HTTP
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Especifique o URL do arquivo de configuração.
bootfile-name urlPor padrão, nenhum URL de arquivo de configuração é especificado.
Especificação de um servidor para clientes DHCP
Sobre um servidor para clientes DHCP
Alguns clientes DHCP precisam obter informações de configuração de um servidor, como um servidor TFTP. Você pode especificar o endereço IP desse servidor. O servidor DHCP envia o endereço IP do servidor para clientes DHCP juntamente com outras informações de configuração.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Especifique o endereço IP de um servidor. next-server ip-address Por padrão, nenhum servidor é especificado.
Configuração dos parâmetros da Option 184 para clientes DHCP
Sobre os parâmetros da Opção 184 para clientes DHCP
Para atribuir parâmetros de chamada a clientes DHCP com serviço de voz, você deve configurar a Opção 184 no servidor DHCP. Para obter mais informações sobre a Opção 184, consulte "Opção 184".
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Especifique o endereço IP do processador de chamada de rede principal.
voice-config ncp-ip ip-addressPor padrão, nenhum processador de chamada de rede primária é especificado.
Depois que você configurar esse comando, os outros parâmetros da Opção 184 entrarão em vigor.
- (Opcional.) Especifique o endereço IP do servidor de backup.
voice-config as-ip ip-addressPor padrão, nenhum processador de chamada de rede de backup é especificado.
- (Opcional.) Configure a VLAN de voz.
voice-config voice-vlan vlan-id { disable | enable }Por padrão, nenhuma VLAN de voz é configurada.
- (Opcional.) Especifique o endereço IP de failover e a cadeia de discagem.
voice-config fail-over ip-address dialer-stringPor padrão, nenhum endereço IP de failover ou cadeia de discagem é especificado.
Personalização das opções de DHCP
Aplicativos de personalização de opções DHCP
Você pode personalizar as opções de DHCP para as seguintes finalidades:
- Adicionar opções recém-lançadas.
- Adicione opções para as quais o fornecedor define o conteúdo, por exemplo, Opção 43.
- Adicionar opções para as quais a CLI não fornece um comando de configuração dedicado. Por exemplo, você pode usar o comando ip-address 1.1.1.1 da opção 4 para definir o endereço do servidor de horário 1.1.1.1 para clientes DHCP.
- Adicione todos os valores de opção se o requisito real exceder o limite de um comando de configuração de opção dedicado. Por exemplo, o comando dns-list pode especificar até oito servidores DNS. Para especificar mais de oito servidores DNS, você deve usar o comando option 6 para definir todos os servidores DNS.
Opções comuns de DHCP
A Tabela 1 lista as opções comuns do DHCP e seus parâmetros.
Tabela 1 Opções comuns do DHCP
| Opção | Nome da opção | Comando correspondente | Parâmetro recomendado no comando de opção |
| 3 | Opção de roteador | Lista de gateway | endereço IP |
| 6 | Opção de servidor de nomes de domínio | lista de dns | endereço IP |
| 15 | Nome de domínio | nome do domínio | ascii |
| 44 | Opção de servidor de nomes NetBIOS sobre TCP/IP | lista de nbns | endereço IP |
| 46 | Opção de tipo de nó NetBIOS sobre TCP/IP | tipo netbios | hexadecimal |
| 66 | Nome do servidor TFTP | Servidor tftp | ascii |
| 67 | Nome do arquivo de inicialização | nome do arquivo de inicialização | ascii |
| Opção | Nome da opção | Comando correspondente | Parâmetro recomendado no comando de opção |
| 43 | Informações específicas do fornecedor | N/A | hexadecimal |
Restrições e diretrizes
Tenha cuidado ao personalizar as opções de DHCP, pois a configuração pode afetar a operação do DHCP.
Você pode personalizar uma opção DHCP em um pool de endereços DHCP
É possível personalizar uma opção DHCP em um grupo de opções DHCP e especificar o grupo de opções para uma classe de usuário em um pool de endereços. Um cliente DHCP na classe de usuário obterá a configuração da opção.
Personalização de uma opção DHCP em um pool de endereços DHCP
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Personalizar uma opção DHCP.
option code { ascii ascii-string | hex hex-string | ip-address
ip-address&<1-8> }Por padrão, nenhuma opção DHCP é personalizada em um pool de endereços DHCP.
As opções DHCP especificadas nos grupos de opções DHCP têm precedência sobre as especificadas nos pools de endereços DHCP.
Personalização de uma opção DHCP em um grupo de opções DHCP
- Entre na visualização do sistema.
system-view- Crie um grupo de opções DHCP e entre na visualização do grupo de opções DHCP.
dhcp option-group option-group-number- Personalizar uma opção DHCP.
option code { ascii ascii-string | hex hex-string | ip-address
ip-address&<1-8> }Por padrão, nenhuma opção DHCP é personalizada em um grupo de opções DHCP.
Se vários grupos de opções DHCP tiverem a mesma opção, o servidor selecionará a opção no grupo de opções DHCP que corresponda primeiro à classe do usuário.
- Retornar à visualização do sistema.
quit- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Especifique o grupo de opções DHCP para a classe de usuário DHCP.
class class-name option-group option-group-numberPor padrão, nenhum grupo de opções DHCP é especificado para uma classe de usuário DHCP.
Configuração da lista branca de classes de usuários DHCP
Sobre a lista branca de classes de usuários DHCP
A lista de permissões da classe de usuário DHCP permite que o servidor DHCP processe solicitações somente de clientes na lista de permissões da classe de usuário DHCP.
Restrições e diretrizes
A lista branca não tem efeito sobre os clientes que solicitam endereços IP estáticos, e o servidor sempre processa suas solicitações.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- Habilite a lista branca de classes de usuários DHCP.
verify classPor padrão, a lista branca da classe de usuário DHCP está desativada.
- Adicione classes de usuários DHCP à lista de permissões de classes de usuários DHCP.
valid class class-name&<1-8>Por padrão, nenhuma classe de usuário DHCP está na lista de permissões da classe de usuário DHCP.
Aplicação de um pool de endereços a uma interface
Sobre a aplicação de um pool de endereços a uma interface
Execute esta tarefa para aplicar um pool de endereços DHCP a uma interface.
Ao receber uma solicitação de DHCP da interface, o servidor DHCP realiza a alocação de endereços das seguintes maneiras:
- Se for encontrada uma associação estática para o cliente, o servidor atribuirá o endereço IP estático e os parâmetros de configuração do pool de endereços que contém a associação estática.
- Se não for encontrada nenhuma associação estática para o cliente, o servidor usará o pool de endereços aplicado à interface para alocação de endereços e parâmetros de configuração.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Aplicar um pool de endereços à interface.
dhcp server apply ip-pool pool-namePor padrão, nenhum pool de endereços é aplicado a uma interface.
Se o pool de endereços aplicado não existir, o servidor DHCP não conseguirá realizar a alocação dinâmica de endereços.
Configuração de uma política DHCP para atribuição dinâmica
Sobre uma política de DHCP para atribuição dinâmica
Em uma política DHCP, cada classe de usuário DHCP tem um pool de endereços DHCP vinculado. Os clientes que correspondem a diferentes classes de usuários obtêm endereços IP e outros parâmetros de diferentes pools de endereços. A política de DHCP deve ser aplicada à interface que atua como servidor DHCP. Ao receber uma solicitação de DHCP, o servidor DHCP compara o pacote com as classes de usuário na ordem em que foram configuradas.
- Se for encontrada uma classe de usuário correspondente e o pool de endereços vinculado tiver endereços IP atribuíveis, o servidor atribuirá um endereço IP e outros parâmetros do pool de endereços. Se o pool de endereços não tiver endereços IP atribuíveis, a atribuição de endereços falhará.
- Se não for encontrada nenhuma correspondência, o servidor atribuirá um endereço IP e outros parâmetros do pool de endereços DHCP padrão. Se nenhum pool de endereços padrão for especificado ou se o pool de endereços padrão não tiver endereços IP atribuíveis, a atribuição de endereços falhará.
Para que a atribuição de endereços seja bem-sucedida, certifique-se de que a política DHCP aplicada e o endereço vinculado pools existam.
Restrições e diretrizes
Uma política de DHCP entra em vigor somente depois de ser aplicada a uma interface.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma política de DHCP e entre na visualização da política de DHCP.
dhcp policy policy-name- Especifique um pool de endereços DHCP para uma classe de usuário DHCP.
class class-name ip-pool pool-namePor padrão, nenhum pool de endereços é especificado para uma classe de usuário.
- Especifique o pool de endereços DHCP padrão.
default ip-pool pool-namePor padrão, nenhum pool de endereços padrão é especificado.
- Retornar à visualização do sistema.
quit- Entre na visualização da interface.
interface interface-type interface-number- Aplicar a política de DHCP à interface.
dhcp apply-policy policy-namePor padrão, nenhuma política de DHCP é aplicada a uma interface.
Ativação do DHCP
Restrições e diretrizes
Você deve ativar o DHCP para que outras configurações do DHCP tenham efeito.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar DHCP.
dhcp enablePor padrão, o DHCP está desativado.
Ativação do servidor DHCP em uma interface
Sobre a ativação do servidor DHCP em uma interface
Execute esta tarefa para ativar o servidor DHCP em uma interface. Ao receber uma solicitação de DHCP na interface, o servidor DHCP atribui ao cliente um endereço IP e outros parâmetros de configuração de um pool de endereços DHCP.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar o servidor DHCP na interface.
dhcp select serverPor padrão, o servidor DHCP está ativado na interface.
Configuração da detecção de conflito de endereços IP
Sobre a detecção de conflitos de endereços IP
Antes de atribuir um endereço IP, o servidor DHCP faz o ping desse endereço IP.
- Se o servidor receber uma resposta dentro do período especificado, ele seleciona e faz ping em outro endereço IP.
- Se não receber resposta, o servidor continuará a executar o ping no endereço IP até que o número máximo de pacotes de ping seja enviado. Se ainda assim não houver resposta, o servidor atribuirá o endereço IP ao cliente solicitante. O cliente DHCP usa ARP gratuito para realizar a detecção de conflitos de endereços IP.
Procedimento
- Entre na visualização do sistema.
system-view- (Opcional.) Defina o número máximo de pacotes de ping a serem enviados para detecção de conflitos.
dhcp server ping packets numberA configuração padrão é um.
Para desativar a detecção de conflito de endereços IP, defina o valor como 0.
- (Opcional.) Defina o tempo limite do ping.
dhcp server ping timeout millisecondsA configuração padrão é 500 ms.
Para desativar a detecção de conflito de endereço IP, defina o valor como 0.
Ativação do manuseio da Opção 82
Sobre o manuseio da Opção 82
Execute essa tarefa para habilitar o servidor DHCP a lidar com a Opção 82. Ao receber uma solicitação DHCP que contém a Opção 82, o servidor DHCP adiciona a Opção 82 à resposta DHCP.
Se você desativar o DHCP para lidar com a Opção 82, ele não adicionará a Opção 82 à mensagem de resposta.
Você deve ativar o tratamento da Opção 82 no servidor DHCP e no agente de retransmissão DHCP para garantir o processamento correto da Opção 82. Para obter informações sobre como ativar o processamento da Option 82 no agente de retransmissão DHCP, consulte "Configuração do suporte do agente de retransmissão DHCP para a Option 82 ".
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o servidor para lidar com a Option 82.
dhcp server relay information enablePor padrão, o tratamento da Opção 82 está ativado.
Configuração dos recursos de segurança do servidor DHCP
Restrições e diretrizes
Os recursos de segurança do servidor DHCP não são aplicáveis se houver um agente de retransmissão DHCP na rede. Isso ocorre porque o endereço MAC do agente de retransmissão DHCP é encapsulado como o endereço MAC de origem na solicitação DHCP recebida pelo servidor DHCP. Nesse caso, você deve configurar os recursos de segurança do agente de retransmissão DHCP. Para obter mais informações, consulte "Configuração dos recursos de segurança do agente de retransmissão DHCP".
Configuração da proteção contra ataques de inanição do DHCP
Sobre a proteção contra ataques de inanição de DHCP
Um ataque de inanição de DHCP ocorre quando um invasor envia constantemente solicitações forjadas de DHCP usando diferentes endereços MAC no campo chaddr para um servidor DHCP. Isso esgota os recursos de endereço IP do servidor DHCP, de modo que os clientes DHCP legítimos não conseguem obter endereços IP. O servidor DHCP também pode deixar de funcionar devido ao esgotamento dos recursos do sistema. Para obter informações sobre os campos nas mensagens DHCP, consulte "Formato da mensagem DHCP".
Os métodos a seguir estão disponíveis para aliviar ou impedir esses ataques.
- Para aliviar um ataque de inanição de DHCP que usa pacotes DHCP encapsulados com diferentes endereços MAC de origem, faça a seguinte configuração em uma interface:
- Execute o comando mac-address max-mac-count para definir o limite de aprendizado de MAC. Para obter mais informações sobre esse comando, consulte Referência de comandos de comutação da camada 2-LAN.
- Desative o encaminhamento de quadros desconhecidos quando o limite de aprendizado MAC for atingido.
- Para evitar um ataque de inanição de DHCP que usa solicitações de DHCP encapsuladas com o mesmo endereço MAC de origem, você pode ativar a verificação de endereço MAC no servidor DHCP. O servidor DHCP compara o campo chaddr de uma solicitação DHCP recebida com o endereço MAC de origem no cabeçalho do quadro. Se eles forem iguais, o servidor DHCP verificará se a solicitação é legal e a processará. Se não forem iguais, o servidor descartará a solicitação DHCP.
- Entre na visualização do sistema.
Procedimento
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar a verificação de endereço MAC.
dhcp server check mac-addressPor padrão, a verificação de endereço MAC está desativada.
Configuração da compatibilidade do servidor DHCP
Execute esta tarefa para permitir que o servidor DHCP ofereça suporte a clientes DHCP que não estejam em conformidade com a RFC.
Configuração do servidor DHCP para sempre transmitir respostas
Sobre a configuração do servidor DHCP para sempre transmitir respostas
Por padrão, o servidor DHCP transmite uma resposta somente quando o sinalizador de transmissão na solicitação DHCP está definido como 1. Você pode configurar o servidor DHCP para ignorar o sinalizador de transmissão e sempre transmitir uma resposta. Esse recurso é útil quando alguns clientes definem o sinalizador de difusão como 0, mas não aceitam respostas unicast.
O servidor DHCP sempre unicausa uma resposta nas seguintes situações, independentemente de esse recurso estar configurado ou não:
- A solicitação DHCP é de um cliente DHCP que tem um endereço IP (o campo ciaddr não é 0).
- A solicitação DHCP é encaminhada por um agente de retransmissão DHCP de um cliente DHCP (o campo giaddr não é 0).
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o servidor DHCP para sempre transmitir todas as respostas.
dhcp server always-broadcastPor padrão, o servidor DHCP lê o sinalizador de broadcast para decidir se deve transmitir ou unicast uma resposta.
Retorno de uma mensagem DHCP-NAK quando o cliente percebe que os endereços IP estão incorretos
Sobre a devolução de uma mensagem DHCP-NAK quando o cliente percebe endereços IP incorretos
Um cliente DHCP pode enviar uma mensagem DHCP-REQUEST diretamente ou ao receber uma mensagem DHCP-OFFER. Ao receber a solicitação, o servidor DHCP verificará se a noção do cliente sobre seu endereço IP está correta. Se o endereço IP solicitado for diferente do alocado ou não tiver um registro de concessão correspondente, o servidor DHCP permanecerá em silêncio por padrão. Depois que a concessão do endereço IP alocado para o cliente expirar, o servidor DHCP responderá à solicitação do cliente.
Esse recurso permite que o servidor DHCP retorne mensagens DHCP-NAK se as noções do cliente sobre seus endereços IP estiverem incorretas. Após receber a mensagem DHCP-NAK, o cliente DHCP solicitará um endereço IP novamente.
Procedimento
- Entre na visualização do sistema.
system-view- Permita que o servidor DHCP retorne uma mensagem DHCP-NAK se as noções dos clientes sobre seus endereços IP estiverem incorretas.
dhcp server request-ip-address checkPor padrão, o servidor DHCP não retorna uma mensagem DHCP-NAK se as noções dos clientes sobre seus endereços IP estiverem incorretas.
Configuração do servidor DHCP para ignorar solicitações de BOOTP
Sobre como configurar o servidor DHCP para ignorar solicitações de BOOTP
A duração da concessão dos endereços IP obtidos pelos clientes BOOTP é ilimitada. Em alguns cenários que não permitem concessões ilimitadas, você pode configurar o servidor DHCP para ignorar as solicitações de BOOTP.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o servidor DHCP para ignorar as solicitações de BOOTP.
dhcp server bootp ignorePor padrão, o servidor DHCP processa solicitações BOOTP.
Configuração do servidor DHCP para enviar respostas BOOTP no formato RFC 1048
Sobre a configuração do servidor DHCP para enviar respostas BOOTP no formato RFC 1048
Nem todos os clientes BOOTP podem enviar solicitações compatíveis com a RFC 1048. Por padrão, o servidor DHCP não processa o campo Vend das solicitações em conformidade com a RFC 1048, mas copia o campo Vend nas respostas.
Esse recurso permite que o servidor DHCP preencha o campo Vend no formato compatível com a RFC 1048 nas respostas do DHCP às solicitações não compatíveis com a RFC 1048 enviadas pelos clientes BOOTP.
Procedimento
- Entre na visualização do sistema.
system-view- Permitir que o servidor DHCP envie respostas BOOTP no formato RFC 1048 para as solicitações BOOTP que não estejam em conformidade com a RFC 1048.
dhcp server bootp reply-rfc-1048Por padrão, o servidor DHCP copia diretamente o campo Vend de tais solicitações para as respostas.
Configuração do valor DSCP para pacotes DHCP enviados pelo servidor DHCP
Sobre o valor DSCP para pacotes DHCP
O valor DSCP de um pacote especifica o nível de prioridade do pacote e afeta a prioridade de transmissão do pacote.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o valor DSCP para pacotes DHCP enviados pelo servidor DHCP.
dhcp dscp dscp-valuePor padrão, o valor DSCP nos pacotes DHCP enviados pelo servidor DHCP é 56.
Configuração do backup automático de vinculação DHCP
Sobre o backup automático de vinculação DHCP
O recurso de backup automático salva as associações em um arquivo de backup e permite que o servidor DHCP faça o download das associações do arquivo de backup na reinicialização do servidor. As associações incluem as associações de concessão e os endereços IP conflitantes. Elas não sobrevivem a uma reinicialização no servidor DHCP.
O servidor DHCP não fornece serviços durante o processo de download. Se ocorrer um erro de conexão durante o processo e não puder ser reparado em um curto espaço de tempo, você poderá encerrar a operação de download. A interrupção manual permite que o servidor DHCP forneça serviços sem esperar que a conexão seja reparada.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o servidor DHCP para fazer backup das associações em um arquivo.
dhcp server database filename { filename | url url [ username username [ password { cipher | simple } string ] ] }Por padrão, o servidor DHCP não faz backup dos vínculos de DHCP.
Com esse comando executado, o servidor DHCP faz o backup de suas associações imediatamente e executa o backup automático.
- (Opcional.) Salve manualmente as associações de DHCP no arquivo de backup.
dhcp server database update now- (Opcional.) Defina o tempo de espera após uma alteração de associação DHCP para que o servidor DHCP atualize o arquivo de backup.
dhcp server database update interval intervalPor padrão, o servidor DHCP aguarda 300 segundos para atualizar o arquivo de backup após uma alteração na associação DHCP . Se nenhuma associação de DHCP for alterada, o arquivo de backup não será atualizado.
- (Opcional.) Encerre o download das associações de DHCP do arquivo de backup.
dhcp server database update stopEsse comando aciona apenas uma terminação.
Ativação da detecção off-line do cliente no servidor DHCP
Sobre a detecção off-line do cliente no servidor DHCP
O recurso de detecção de cliente off-line recupera um endereço IP atribuído e exclui a entrada de associação quando a entrada ARP para o endereço IP se esgota.
Restrições e diretrizes
O recurso não funcionará se uma entrada ARP for excluída manualmente.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar a detecção off-line do cliente.
dhcp client-detect
Por padrão, a detecção off-line do cliente está desativada no servidor DHCP.
Configuração de alarmes de uso do pool de endereços
Sobre o alarme de uso do pool de endereços
Execute esta tarefa para definir o limite do alarme de uso do pool de endereços. Quando o limite é excedido, o sistema envia mensagens de registro para o centro de informações. De acordo com as informações de registro, é possível otimizar a configuração do pool de endereços. Para obter mais informações sobre o centro de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCP.
dhcp server ip-pool pool-name- (Opcional.) Defina o limite para o alarme de uso do pool de endereços.
ip-in-use threshold threshold-valueO limite padrão é 100%.
Ativação do registro de DHCP no servidor DHCP
Sobre o registro de DHCP no servidor DHCP
O recurso de registro de DHCP permite que o servidor DHCP gere registros de DHCP e os envie para o centro de informações. As informações ajudam os administradores a localizar e resolver problemas. Para obter informações sobre o destino do registro e a configuração da regra de saída no centro de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Restrições e diretrizes
Como prática recomendada, desative esse recurso se a geração de registros afetar o desempenho do dispositivo ou reduzir a eficiência da alocação de endereços. Por exemplo, essa situação pode ocorrer quando um grande número de clientes fica on-line ou off-line com frequência.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o registro de DHCP.
dhcp log enablePor padrão, o registro de DHCP está desativado.
Comandos de exibição e manutenção do servidor DHCP
A reinicialização do servidor DHCP ou a execução do comando reset dhcp server ip-in-use exclui todas as informações de concessão. O servidor DHCP nega qualquer solicitação de extensão de concessão do DHCP e o cliente deve solicitar um endereço IP novamente.
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações sobre conflitos de endereços IP. | display dhcp server conflict [ ip ip-address ] |
| Exibir informações sobre o backup automático de vinculação DHCP. | display dhcp server database |
| Exibir informações sobre endereços IP com contrato de arrendamento expirado. | display dhcp server expired [ ip ip-address | pool pool-name ] |
| Exibir informações sobre endereços IP atribuíveis. | display dhcp server free-ip [ pool pool-name ] |
| Exibir informações sobre endereços IP atribuídos. | display dhcp server ip-in-use [ ip ip-address | pool pool-name ] |
| Exibir informações sobre os pools de endereços DHCP. | display dhcp server pool [ pool-name ] |
| Exibir estatísticas do servidor DHCP. | display dhcp server statistics [ pool pool-name ] |
| Limpar informações sobre conflitos de endereço IP. | reset dhcp server conflict [ ip ip-address ] |
| Limpar informações sobre endereços IP com contrato de arrendamento expirado. | reset dhcp server expired [ ip ip-address | pool pool-name ] |
| Limpar informações sobre endereços IP atribuídos. | reset dhcp server ip-in-use [ ip ip-address | pool pool-name ] |
| Limpar estatísticas do servidor DHCP. | reset dhcp server statistics |
Exemplos de configuração do servidor DHCP
Exemplo: Configuração da atribuição de endereço IP estático
Configuração de rede
Conforme mostrado na Figura 8, o Switch B (cliente DHCP) e o Switch C (cliente BOOTP) obtêm o endereço IP, o endereço do servidor DNS e o endereço do gateway do Switch A (servidor DHCP).
Ocliente ID de em Switch é 0030-3030-662e-6532-3030-2e30-3030-322d-4574-6865-726e-6574.
O endereço MAC da interface VLAN 2 no Switch C é 000f-e200-01c0.
Figura 8 Diagrama de rede
Procedimento
- Especifique um endereço IP para a interface VLAN 2 no Switch A.
<SwitchA> system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 10.1.1.1 25
[SwitchA-Vlan-interface2] quit- Configure o servidor DHCP:
# Criar o pool de endereços DHCP 0.
[SwitchA] dhcp server ip-pool 0# Configure uma ligação estática para o Switch B.
[SwitchA-dhcp-pool-0] static-bind ip-address 10.1.1.5 25 client-identifier
0030-3030-662e-6532-3030-2e30-3030-322d-4574-6865-726e-6574# Configure uma ligação estática para o Switch C.
[SwitchA-dhcp-pool-0] static-bind ip-address 10.1.1.6 25 hardware-address
000f-e200-01c0# Especifique o endereço do servidor DNS e o endereço do gateway.
[SwitchA-dhcp-pool-0] dns-list 10.1.1.2
[SwitchA-dhcp-pool-0] gateway-list 10.1.1.126
[SwitchA-dhcp-pool-0] quit
[SwitchA]# Habilite o DHCP.
[SwitchA] dhcp enable# Habilite o servidor DHCP na interface VLAN 2.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] dhcp select server
[SwitchA-Vlan-interface2] quitVerificação da configuração
# Verifique se o Switch B pode obter o endereço IP 10.1.1.5 e todos os outros parâmetros de rede do Switch A. (Os detalhes não são mostrados).
# Verifique se o Switch C pode obter o endereço IP 10.1.1.6 e todos os outros parâmetros de rede do Switch A. (Os detalhes não são mostrados).
# No servidor DHCP, exiba os endereços IP atribuídos aos clientes.
[SwitchA] display dhcp server ip-in-use
IP address Client-identifier/ Lease expiration Type
Hardware address
10.1.1.5 0030-3030-662e-6532- Jan 21 14:27:27 2014 Static(C)
3030-2e30-3030-322d-
4574-6865-726e-6574
10.1.1.6 000f-e200-01c0 Unlimited Static(C)
Exemplo: Configuração da atribuição dinâmica de endereços IP
Configuração de rede
Conforme mostrado na Figura 9, o servidor DHCP (Switch A) atribui endereços IP a clientes na sub-rede 10.1.1.0/24, que é subdividida em 10.1.1.0/25 e 10.1.1.128/25.
Configure o servidor DHCP no Switch A para implementar o seguinte esquema de atribuição.
Tabela 2 Esquema de atribuição
| Clientes DHCP | Endereço IP | Arrendamento | Outros parâmetros de configuração |
| Clientes conectados à interface VLAN 10 | Endereços IP na sub-rede 10.1.1.0/25 | 10 dias e 12 horas | Gateway: 10.1.1.126/25 Servidor DNS: 10.1.1.2/25 Nome do domínio: aabbcc.com Servidor WINS: 10.1.1.4/25 |
| Clientes conectados à interface VLAN 20 | Endereços IP na sub-rede 10.1.1.128/25 | Cinco dias | Gateway: 10.1.1.254/25 Servidor DNS: 10.1.1.2/25 Nome do domínio: aabbcc.com |
Figura 9 Diagrama de rede
Procedimento
- Especifique os endereços IP para as interfaces de VLAN. (Detalhes não mostrados).
- Configure o servidor DHCP:
# Excluir o endereço do servidor DNS, o endereço do servidor WINS e os endereços de gateway da alocação dinâmica.
<SwitchA> system-view
[SwitchA] dhcp server forbidden-ip 10.1.1.2
[SwitchA] dhcp server forbidden-ip 10.1.1.4
[SwitchA] dhcp server forbidden-ip 10.1.1.126
[SwitchA] dhcp server forbidden-ip 10.1.1.254# Configure o pool de endereços DHCP 1 para atribuir endereços IP e outros parâmetros de configuração a clientes na sub-rede 10.1.1.0/25.
[SwitchA] dhcp server ip-pool 1
[SwitchA-dhcp-pool-1] network 10.1.1.0 mask 255.255.255.128
[SwitchA-dhcp-pool-1] expired day 10 hour 12
[SwitchA-dhcp-pool-1] domain-name aabbcc.com
[SwitchA-dhcp-pool-1] dns-list 10.1.1.2
[SwitchA-dhcp-pool-1] gateway-list 10.1.1.126
[SwitchA-dhcp-pool-1] nbns-list 10.1.1.4
[SwitchA-dhcp-pool-1] quit# Configure o pool de endereços DHCP 2 para atribuir endereços IP e outros parâmetros de configuração
para clientes na sub-rede 10.1.1.128/25.
[SwitchA] dhcp server ip-pool 2
[SwitchA-dhcp-pool-2] network 10.1.1.128 mask 255.255.255.128
[SwitchA-dhcp-pool-2] expired day 5
[SwitchA-dhcp-pool-2] domain-name aabbcc.com
[SwitchA-dhcp-pool-2] dns-list 10.1.1.2
[SwitchA-dhcp-pool-2] gateway-list 10.1.1.254
[SwitchA-dhcp-pool-2] quit# Habilite o DHCP.
[SwitchA] dhcp enable# Habilite o servidor DHCP na interface VLAN 10 e na interface VLAN 20.
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] dhcp select server
[SwitchA-Vlan-interface10] quit
[SwitchA] interface vlan-interface 20
[SwitchA-Vlan-interface20] dhcp select server
[SwitchA-Vlan-interface20] quitVerificação da configuração
# Verifique se os clientes das sub-redes 10.1.1.0/25 e 10.1.1.128/25 conseguem obter os endereços IP corretos e todos os outros parâmetros de rede do Switch A. (Os detalhes não são mostrados).
# No servidor DHCP, exiba os endereços IP atribuídos aos clientes.
[SwitchA] display dhcp server ip-in-use
IP address Client-identifier/ Lease expiration Type
Hardware address
10.1.1.3 0031-3865-392e-6262- Jan 14 22:25:03 2015 Auto(C)
3363-2e30-3230-352d-
4745-302f-30
10.1.1.5 0031-fe65-4203-7e02- Jan 14 22:25:03 2015 Auto(C)
3063-5b30-3230-4702-
620e-712f-5e
10.1.1.130 3030-3030-2e30-3030- Jan 9 10:45:11 2015 Auto(C)
662e-3030-3033-2d45-
7568-6572-1e
10.1.1.131 3030-0020-fe02-3020- Jan 9 10:45:11 2015 Auto(C)
7052-0201-2013-1e02
0201-9068-23
10.1.1.132 2020-1220-1102-3021- Jan 9 10:45:11 2015 Auto(C)
7e52-0211-2025-3402
0201-9068-9a
10.1.1.133 2021-d012-0202-4221- Jan 9 10:45:11 2015 Auto(C)
8852-0203-2022-55e0
3921-0104-31Exemplo: Configuração da classe de usuário DHCP
Requisitos de rede
Conforme mostrado na Figura 10, o agente de retransmissão DHCP (Switch A) encaminha pacotes DHCP entre os clientes DHCP e o servidor DHCP (Switch B). Habilite o switch A para suportar a Opção 82, de modo que o switch A possa adicionar a Opção 82 nas solicitações de DHCP enviadas pelos clientes DHCP.
Configure o esquema de alocação de endereços da seguinte forma:
| Atribuir endereços IP | Para os clientes |
| 10.10.1.2 a 10.10.1.10 | A solicitação DHCP contém a Opção 82. |
| 10.10.1.11 a 10.10.1.26 | O endereço de hardware na solicitação tem seis bytes de comprimento e começa com aabb-aabb-aab. |
Para clientes na sub-rede 10.10.1.0/24, o endereço do servidor DNS é 10.10.1.20/24 e o endereço do gateway é 10.10.1.254/24.
Figura 10 Diagrama de rede
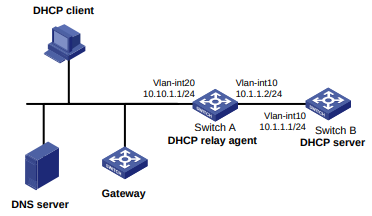
Procedimento
- Especificar endereços IP para interfaces no servidor DHCP e no agente de retransmissão DHCP. (Detalhes não mostrados).
- Configurar serviços DHCP:
# Crie a classe de usuário DHCP tt e configure uma regra de correspondência para corresponder às solicitações do cliente com a Opção 82.
<SwitchB> system-view
[SwitchB] dhcp class tt
[SwitchB-dhcp-class-tt] if-match rule 1 option 82
[SwitchB-dhcp-class-tt] quit
# Crie a classe de usuário DHCP ss e configure uma regra de correspondência para corresponder às solicitações de DHCP nas quais o endereço de hardware tem seis bytes e começa com aabb-aabb-aab.
[SwitchB] dhcp class ss
[SwitchB-dhcp-class-ss] if-match rule 1 hardware-address aabb-aabb-aab0 mask
ffff-ffff-fff0
[SwitchB-dhcp-class-ss] quit
# Criar o pool de endereços DHCP aa.
[SwitchB] dhcp server ip-pool aa# Especifique a sub-rede para alocação dinâmica.
[SwitchB-dhcp-pool-aa] network 10.10.1.0 mask 255.255.255.0# Especifique o intervalo de endereços para alocação dinâmica.
[SwitchB-dhcp-pool-aa] address range 10.10.1.2 10.10.1.100# Especifique o intervalo de endereços para a classe de usuário tt.
[SwitchB-dhcp-pool-aa] class tt range 10.10.1.2 10.10.1.10# Especifique o intervalo de endereços para a classe de usuário ss.
[SwitchB-dhcp-pool-aa] class ss range 10.10.1.11 10.10.1.26# Especifique o endereço do gateway e o endereço do servidor DNS.
[SwitchB-dhcp-pool-aa] gateway-list 10.10.1.254
[SwitchB-dhcp-pool-aa] dns-list 10.10.1.20
[SwitchB-dhcp-pool-aa] quit# Habilite o DHCP e configure o servidor DHCP para lidar com a Opção 82.
[SwitchB] dhcp enable
[SwitchB] dhcp server relay information enable
# Habilite o servidor DHCP na interface VLAN 10.
[SwitchB] interface vlan-interface 10
[SwitchB-Vlan-interface10] dhcp select server
[SwitchB-Vlan-interface10] quit
Verificação da configuração
# Verifique se os clientes que correspondem às classes de usuários podem obter endereços IP nos intervalos especificados e todos os outros parâmetros de configuração do servidor DHCP. (Detalhes não mostrados).
# Exibir o endereço IP atribuído pelo servidor DHCP.
[SwitchB] display dhcp server ip-in-use
IP address Client-identifier/ Lease expiration Type
Hardware address
10.10.1.2 0031-3865-392e-6262- Jan 14 22:25:03 2015 Auto(C)
3363-2e30-3230-352d-
4745-302f-30
10.10.1.11 aabb-aabb-aab1 Jan 14 22:25:03 2015 Auto(C)
Exemplo: Configuração da lista branca de classes de usuários DHCP
Configuração de rede
Conforme mostrado na Figura 11, configure a lista de permissões da classe de usuário DHCP para permitir que o servidor DHCP atribua endereços IP a clientes cujos endereços de hardware tenham seis bytes e comecem com aabb-aabb.
Figura 11 Diagrama de rede

Procedimento
- Especifique os endereços IP para as interfaces no servidor DHCP. (Detalhes não mostrados).
- Configurar DHCP:
# Crie a classe de usuário DHCP ss e configure uma regra de correspondência para corresponder às solicitações de DHCP nas quais o endereço de hardware tem seis bytes e começa com aabb-aabb.
<SwitchB> system-view
[SwitchB] dhcp class ss
[SwitchB-dhcp-class-ss] if-match rule 1 hardware-address aabb-aabb-0000 mask
ffff-ffff-0000
[SwitchB-dhcp-class-ss] quit# Criar o pool de endereços DHCP aa.
[SwitchB] dhcp server ip-pool aa# Especifique a sub-rede para alocação dinâmica.
[SwitchB-dhcp-pool-aa] network 10.1.1.0 mask 255.255.255.0# Habilite a lista branca de classes de usuários DHCP.
[SwitchB-dhcp-pool-aa] verify class# Adicione a classe de usuário DHCP ss à lista de permissões da classe de usuário DHCP.
[SwitchB-dhcp-pool-aa] valid class ss
[SwitchB-dhcp-pool-aa] quit# Habilite o DHCP.
[SwitchB] dhcp enable# Habilite o servidor DHCP na interface VLAN 2.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] dhcp select server
[SwitchB-Vlan-interface2] quit
Verificação da configuração
# Verifique se os clientes que correspondem à classe de usuário DHCP podem obter endereços IP na sub-rede 10.1.1.0/24 do servidor DHCP. (Detalhes não mostrados.)
# No servidor DHCP, exiba os endereços IP atribuídos aos clientes.
[SwitchB] display dhcp server ip-in-use
IP address Client-identifier/ Lease expiration Type
Hardware address
10.1.1.2 aabb-aabb-ab01 Jan 14 22:25:03 2015 Auto(C)
Exemplo: Configuração de sub-redes primárias e secundárias
Configuração de rede
Conforme mostrado na Figura 12, o servidor DHCP (Switch A) atribui dinamicamente endereços IP a clientes na LAN.
Configure duas sub-redes no pool de endereços no servidor DHCP: 10.1.1.0/24 como a sub-rede primária e 10.1.2.0/24 como a sub-rede secundária. O servidor DHCP seleciona endereços IP da sub-rede secundária quando a sub-rede primária não tem endereços atribuíveis.
O switch A atribui os seguintes parâmetros:
- O gateway padrão 10.1.1.254/24 para clientes na sub-rede 10.1.1.0/24.
- O gateway padrão 10.1.2.254/24 para clientes na sub-rede 10.1.2.0/24.
Figura 12 Diagrama de rede
Procedimento
# Criar o pool de endereços DHCP aa.
lt;SwitchA> system-view
[SwitchA] dhcp server ip-pool aa
# Especifique a sub-rede primária e o endereço do gateway para alocação dinâmica.
[SwitchA-dhcp-pool-aa] network 10.1.1.0 mask 255.255.255.0
[SwitchA-dhcp-pool-aa] gateway-list 10.1.1.254
# Especifique a sub-rede secundária e o endereço do gateway para alocação dinâmica.
[SwitchA-dhcp-pool-aa] network 10.1.2.0 mask 255.255.255.0 secondary
[SwitchA-dhcp-pool-aa-secondary] gateway-list 10.1.2.254
[SwitchA-dhcp-pool-aa-secondary] quit
[SwitchA-dhcp-pool-aa] quit
# Habilite o DHCP.
[SwitchA] dhcp enable# Configure os endereços IP primário e secundário da interface VLAN 10.
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ip address 10.1.1.1 24
[SwitchA-Vlan-interface10] ip address 10.1.2.1 24 sub
# Habilite o servidor DHCP na interface VLAN 10.
[SwitchA-Vlan-interface10] dhcp select server
[SwitchA-Vlan-interface10] quit
Verificação da configuração
# Verifique se o servidor DHCP atribui aos clientes endereços IP e endereço de gateway da sub-rede secundária quando nenhum endereço está disponível na sub-rede primária. (Detalhes não mostrados.)
# Exibir os endereços IP de sub-rede primária e secundária que o servidor DHCP atribuiu. A seguir, parte da saída do comando.
[SwitchA] display dhcp server ip-in-use
IP address Client-identifier/ Lease expiration Type
Hardware address
10.1.1.2 0031-3865-392e-6262- Jan 14 22:25:03 2015 Auto(C)
3363-2e30-3230-352d-
4745-302f-30
10.1.2.2 3030-3030-2e30-3030- Jan 14 22:25:03 2015 Auto(C)
662e-3030-3033-2d45-
7568-6572-1e
Exemplo: Personalização da opção DHCP
Configuração de rede
Conforme mostrado na Figura 13, os clientes DHCP obtêm endereços IP e endereços de servidor PXE do servidor DHCP (Switch A). A sub-rede para alocação de endereços é 10.1.1.0/24.
Configure o esquema de alocação de endereços da seguinte forma:
| Atribuir endereços PXE | Para os clientes |
| 2.3.4.5 e 3.3.3.3 | O endereço de hardware na solicitação tem seis bytes de comprimento e começa com aabb-aabb. |
| 1.2.3.4 e 2.2.2.2. | Outros clientes. |
O servidor DHCP atribui endereços de servidor PXE a clientes DHCP por meio da Opção 43, uma opção personalizada. O formato da Opção 43 e o da subopção de endereço do servidor PXE são mostrados na Figura 5 e na Figura 7. Por exemplo, o valor da Opção 43 configurado no pool de endereços DHCP é 80 0B 00 00 02 01 02 03 04 02 02 02 02 02.
- O número 80 é o valor do tipo de subopção.
- O número 0B é o valor do comprimento da subopção.
- Os números 00 00 00 são o valor do tipo de servidor PXE.
- O número 02 indica o número de servidores.
- Os números 01 02 03 04 02 02 02 02 indicam que os endereços do servidor PXE são 1.2.3.4 e 2.2.2.2.
Figura 13 Diagrama de rede
Procedimento
- Especifique os endereços IP para as interfaces. (Detalhes não mostrados).
- Configure o servidor DHCP:
# Crie a classe de usuário DHCP ss e configure uma regra de correspondência para corresponder às solicitações de DHCP nas quais o endereço de hardware tem seis bytes e começa com aabb-aabb.
<SwitchA> system-view
[SwitchA] dhcp class ss
[SwitchA-dhcp-class-ss] if-match rule 1 hardware-address aabb-aabb-0000 mask
ffff-ffff-0000
[SwitchA-dhcp-class-ss] quit
# Crie o grupo de opções 1 do DHCP e personalize a opção 43.
[SwitchA] dhcp option-group 1
[SwitchA-dhcp-option-group-1] option 43 hex 800B0000020203040503030303
# Habilite o servidor DHCP na interface VLAN 2.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] dhcp select server
[SwitchA-Vlan-interface2] quit# Criar o pool de endereços DHCP 0.
[SwitchA] dhcp server ip-pool 0# Especifique a sub-rede para alocação dinâmica de endereços.
[SwitchA-dhcp-pool-0] network 10.1.1.0 mask 255.255.255.0
# Personalize a opção 43.
[SwitchA-dhcp-pool-0] option 43 hex 800B0000020102030402020202# Associe a classe de usuário DHCP ss ao grupo de opções 1.
[SwitchA-dhcp-pool-0] class ss option-group 1
[SwitchA-dhcp-pool-0] quit# Habilite o DHCP.
[SwitchA] dhcp enableVerificação da configuração
# Verifique se o Switch B pode obter um endereço IP na sub-rede 10.1.1.0/24 e os endereços de servidor PXE correspondentes do Switch A. (Detalhes não mostrados).
# No servidor DHCP, exiba os endereços IP atribuídos aos clientes.
[SwitchA] display dhcp server ip-in-use
IP address Client-identifier/ Lease expiration Type
Hardware address
10.1.1.2 aabb-aabb-ab01 Jan 14 22:25:03 2015 Auto(C)Solução de problemas de configuração do servidor DHCP
Não obtenção de um endereço IP não conflitante
Sintoma
O endereço IP de um cliente obtido do servidor DHCP entra em conflito com um endereço IP de outro host.
Solução
Outro host na sub-rede pode ter o mesmo endereço IP. Para resolver o problema:
- Desative o adaptador de rede do cliente ou desconecte o cabo de rede do cliente. Faça ping no IP
do cliente de outro host para verificar se há um host usando o mesmo endereço IP.
- Se for recebida uma resposta de ping, o endereço IP foi configurado manualmente em um host. Execute o comando dhcp server forbidden-ip no servidor DHCP para excluir o endereço IP da alocação dinâmica.
- Ative o adaptador de rede ou conecte o cabo de rede, libere o endereço IP e obtenha outro no cliente. Por exemplo, para liberar o endereço IP e obter outro em um cliente DHCP do Windows XP:
- No ambiente Windows, execute o comando cmd para entrar no ambiente DOS.
- Digite ipconfig /release para liberar o endereço IP.
- Digite ipconfig /renew para obter outro endereço IP.
Configuração do agente de retransmissão DHCP
Sobre o agente de retransmissão DHCP
O agente de retransmissão DHCP permite que os clientes obtenham endereços IP e parâmetros de configuração de um servidor DHCP em outra sub-rede.
A Figura 14 mostra um aplicativo típico do agente de retransmissão DHCP.
Figura 14 Aplicativo do agente de retransmissão DHCP
Operação do agente de retransmissão DHCP
O servidor e o cliente DHCP interagem entre si da mesma forma, independentemente da existência ou não do agente de retransmissão. Para obter detalhes sobre a interação, consulte "Processo de alocação de endereços IP". A seguir, descrevemos apenas as etapas relacionadas ao agente de retransmissão DHCP:
- Depois de receber uma mensagem de difusão DHCP-DISCOVER ou DHCP-REQUEST de um cliente DHCP, o agente de retransmissão DHCP processa a mensagem da seguinte forma:
- Preenche o campo giaddr da mensagem com seu endereço IP.
- Unicasts a mensagem para o servidor DHCP designado.
- Com base no campo giaddr, o servidor DHCP retorna um endereço IP e outros parâmetros de configuração em uma resposta.
- O agente de retransmissão transmite a resposta ao cliente.
Figura 15 Operação do agente de retransmissão DHCP
Suporte do agente de retransmissão DHCP para a Opção 82
A opção 82 registra as informações de localização sobre o cliente DHCP. Ela permite que o administrador execute as seguintes tarefas:
- Localize o cliente DHCP para fins de segurança e contabilidade.
- Atribuir endereços IP em um intervalo específico aos clientes.
Para obter mais informações sobre a Opção 82, consulte "Opção de agente de retransmissão (Opção 82)".
Se o agente de retransmissão DHCP for compatível com a Opção 82, ele tratará as solicitações de DHCP seguindo as estratégias descritas na Tabela 3.
Se uma resposta retornada pelo servidor DHCP contiver a Opção 82, o agente de retransmissão DHCP removerá a Opção 82 antes de encaminhar a resposta ao cliente.
Tabela 3 Estratégias de manuseio do agente de retransmissão DHCP
| Se uma solicitação DHCP tiver... | Estratégia de manuseio | O agente de retransmissão DHCP... |
| Opção 82 | Queda | Desiste da mensagem. |
| Manter | Encaminha a mensagem sem alterar a Opção 82. | |
| Substituir | Encaminha a mensagem após substituir a Opção 82 original pela Opção 82 preenchida de acordo com o formato de preenchimento configurado, o conteúdo de preenchimento e o tipo de código. | |
| Nenhuma opção 82 | N/A | Encaminha a mensagem após adicionar a Opção 82 com preenchimento de acordo com o formato de preenchimento configurado, o conteúdo de preenchimento e o tipo de código. |
Visão geral das tarefas do agente de retransmissão DHCP
Para configurar um agente de retransmissão DHCP, execute as seguintes tarefas:
- Ativação do DHCP
- Ativação do agente de retransmissão DHCP em uma interface
- Especificação de servidores DHCP
- (Opcional.) Configuração de recursos avançados:
- Especificação de um pool de endereços de retransmissão DHCP para clientes DHCP
- Configuração dos recursos de segurança do agente de retransmissão DHCP
- Configuração do agente de retransmissão DHCP para liberar um endereço IP
- Configuração do suporte do agente de retransmissão DHCP para a Opção 82
- Configuração do valor DSCP para pacotes DHCP enviados pelo agente de retransmissão DHCP
- Especificando o endereço do agente de retransmissão DHCP para o campo giaddr
- Especificação do endereço IP de origem para solicitações DHCP retransmitidas
Ativação do DHCP
Restrições e diretrizes
Você deve ativar o DHCP para que outras configurações do agente de retransmissão DHCP tenham efeito.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar DHCP.
dhcp enable
Por padrão, o DHCP está desativado.
Ativação do agente de retransmissão DHCP em uma interface
Sobre a ativação do agente de retransmissão DHCP em uma interface
Com o agente de retransmissão DHCP ativado, uma interface encaminha as solicitações de DHCP recebidas para um servidor DHCP.
Um pool de endereços IP que contenha o endereço IP da interface de retransmissão DHCP deve ser configurado no servidor DHCP. Caso contrário, os clientes DHCP conectados ao agente de retransmissão não poderão obter os endereços IP corretos.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar o agente de retransmissão DHCP.
dhcp select relayPor padrão, quando o DHCP está ativado, uma interface opera no modo de servidor DHCP.
Especificação de servidores DHCP
Especificação de servidores DHCP em um agente de retransmissão
Sobre a especificação de servidores DHCP em um agente de retransmissão
Para aumentar a disponibilidade, você pode especificar vários servidores DHCP no agente de retransmissão DHCP. Quando a interface recebe mensagens de solicitação de clientes, o agente retransmissor as encaminha a todos os servidores DHCP.
Restrições e diretrizes
O endereço IP de qualquer servidor DHCP especificado não deve residir na mesma sub-rede que o endereço IP da interface de retransmissão. Caso contrário, os clientes poderão não conseguir obter endereços IP.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique um endereço de servidor DHCP no agente de retransmissão.
dhcp relay server-address ip-address [ class class-name ]Por padrão, nenhum endereço de servidor DHCP é especificado no agente de retransmissão.
Para especificar vários endereços de servidor DHCP, repita esta etapa. Você pode especificar um máximo de oito servidores DHCP.
Especificação de servidores DHCP em um pool de endereços de retransmissão DHCP
Sobre a especificação de servidores DHCP em um pool de endereços de retransmissão DHCP
Os pools de endereços DHCP criados em um agente de retransmissão DHCP são chamados de pools de endereços de retransmissão DHCP. Você pode criar um pool de endereços de retransmissão e especificar servidores DHCP nesse pool de endereços. Esse recurso permite que os clientes DHCP do mesmo tipo obtenham endereços IP e outros parâmetros de configuração dos servidores DHCP especificados no pool de endereços de retransmissão DHCP correspondente.
Aplica-se a cenários em que o agente de retransmissão DHCP se conecta a clientes do mesmo tipo de acesso, mas classificados em tipos diferentes por suas localizações. Nesse caso, a interface de retransmissão normalmente não tem endereço IP configurado. Você pode usar o comando gateway-list para especificar endereços de gateway para clientes que correspondam ao mesmo pool de endereços de retransmissão de DHCP e vincular os endereços de gateway ao endereço MAC do dispositivo.
Ao receber um DHCP DISCOVER ou REQUEST de um cliente que corresponde a um pool de endereços de retransmissão DHCP, o agente de retransmissão processa o pacote da seguinte forma:
- Preenche o campo giaddr do pacote com um endereço de gateway especificado.
- Encaminha o pacote para todos os servidores DHCP no pool de endereços de retransmissão DHCP correspondente. Os servidores DHCP selecionam um pool de endereços de retransmissão DHCP de acordo com o endereço do gateway.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um pool de endereços de retransmissão DHCP e entre em sua visualização.
dhcp server ip-pool pool-name- Especifique os gateways no pool de endereços de retransmissão DHCP.
gateway-list ip-address&<1-64>Por padrão, nenhum endereço de gateway é especificado.
- Especifique os servidores DHCP no pool de endereços de retransmissão DHCP.
remote-server ip-address&<1-8>Por padrão, nenhum servidor DHCP é especificado no pool de endereços de retransmissão DHCP.
É possível especificar um máximo de oito servidores DHCP em um pool de endereços de retransmissão DHCP para alta disponibilidade.
Especificação do algoritmo de seleção do servidor DHCP
Sobre o algoritmo de seleção do servidor DHCP
O agente de retransmissão DHCP é compatível com os algoritmos de seleção de servidor DHCP de polling e master-backup.
Por padrão, o agente de retransmissão DHCP usa o algoritmo de sondagem. Ele encaminha solicitações de DHCP a todos os servidores DHCP. Os clientes DHCP selecionam o servidor DHCP do qual vem a primeira resposta DHCP recebida.
Se o agente de retransmissão DHCP usar o algoritmo mestre-backup, ele encaminhará as solicitações de DHCP primeiro para o servidor DHCP mestre. Se o servidor DHCP mestre não estiver disponível, o agente de retransmissão encaminha as solicitações DHCP subsequentes para um servidor DHCP de backup. Se o servidor DHCP de backup não estiver disponível, o agente de retransmissão seleciona o próximo servidor DHCP de backup e assim por diante. Se nenhum servidor DHCP de backup estiver disponível, o processo será repetido a partir do servidor DHCP mestre.
O servidor DHCP mestre é determinado de uma das seguintes maneiras:
- Em uma rede comum em que vários endereços de servidor DHCP são especificados na interface de retransmissão DHCP, o primeiro servidor DHCP especificado é o mestre. Os outros servidores DHCP são backups.
- Em uma rede em que os pools de endereços de retransmissão DHCP estão configurados no agente de retransmissão DHCP, o primeiro servidor DHCP especificado em um pool de endereços de retransmissão DHCP é o mestre. Os outros servidores DHCP no pool de endereços de retransmissão DHCP são backups.
A seleção do servidor DHCP suporta as seguintes funções:
- Tempo limite de resposta do servidor DHCP - O agente de retransmissão DHCP determina que um servidor DHCP não está disponível se não receber nenhuma resposta do servidor dentro do tempo limite de resposta do servidor DHCP. O tempo limite de resposta do servidor DHCP é configurável e o padrão é 30 segundos.
- Comutação de servidor DHCP - Se o agente de retransmissão DHCP selecionar um servidor DHCP de backup, ele não alterna de volta para o servidor DHCP mestre por padrão. Você pode configurar o agente de retransmissão DHCP para retornar ao servidor DHCP mestre após um atraso. Se o servidor DHCP mestre estiver disponível, o agente de retransmissão DHCP encaminhará as solicitações de DHCP para o servidor DHCP mestre. Se o servidor DHCP mestre não estiver disponível, o agente de retransmissão DHCP ainda usará o servidor DHCP de backup.
Especificação do algoritmo de seleção do servidor DHCP na visualização da interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique o algoritmo de seleção do servidor DHCP.
dhcp relay server-address algorithm { master-backup | polling }Por padrão, é usado o algoritmo de sondagem. O agente de retransmissão DHCP encaminha as solicitações de DHCP para todos os servidores DHCP.
- (Opcional.) Defina o tempo limite de resposta do servidor DHCP para a troca de servidor DHCP.
dhcp relay dhcp-server timeout timePor padrão, o tempo limite de resposta do servidor DHCP é de 30 segundos.
- (Opcional.) Ative o retorno ao servidor DHCP mestre e defina o tempo de atraso.
dhcp relay master-server switch-delay delay-timePor padrão, o agente de retransmissão DHCP não alterna de volta para o servidor DHCP mestre.
Especificar o algoritmo de seleção do servidor DHCP na visualização do pool de endereços de retransmissão DHCP
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços de retransmissão DHCP.
dhcp server ip-pool pool-name- Especifique o algoritmo de seleção do servidor DHCP.
dhcp relay server-address algorithm { master-backup | polling }Por padrão, o algoritmo de sondagem é usado. O agente de retransmissão DHCP encaminha solicitações de DHCP a todos os servidores DHCP.
- (Opcional.) Defina o tempo limite de resposta do servidor DHCP para a troca de servidor DHCP.
dhcp-server timeout timePor padrão, o tempo limite de resposta do servidor DHCP é de 30 segundos.
- (Opcional.) Ative o retorno ao servidor DHCP mestre e defina o tempo de atraso.
master-server switch-delay delay-timePor padrão, o agente de retransmissão DHCP não alterna de volta para o servidor DHCP mestre.
Especificação de um pool de endereços de retransmissão DHCP para clientes DHCP
Sobre a especificação de um pool de endereços de retransmissão DHCP para clientes DHCP
Depois de configurar vários pools de endereços de retransmissão DHCP em um agente de retransmissão DHCP, é possível especificar esses pools em uma interface. Para combinar clientes DHCP com base em opções, você pode definir configurações de opções ao especificar os pools de endereços de retransmissão.
Se você especificar vários pools de endereços de retransmissão DHCP em uma interface, o agente de retransmissão selecionará um pool de endereços de retransmissão DHCP para um cliente DHCP da seguinte forma:
- Compara os valores de opção na solicitação DHCP em ordem decrescente com os valores de opção nos pools de endereços de retransmissão DHCP.
- Se for encontrada uma correspondência (diferente de 60), o processo de correspondência será interrompido e o agente de retransmissão selecionará o pool de endereços de retransmissão correspondente.
- Se o valor da opção correspondente for 60, o agente de retransmissão continuará a comparar o conteúdo da Opção 60 na solicitação e a string da Opção 60 no pool de endereços de retransmissão:
- Se o conteúdo da Option 60 corresponder à string, o pool de endereços de retransmissão será selecionado.
- Se o conteúdo da Opção 60 não corresponder à cadeia de caracteres, o pool de endereços do relé não será selecionado. Se outro pool de endereços de retransmissão for especificado para corresponder à Opção 60, mas não tiver a cadeia de caracteres da Opção 60 definida, o agente de retransmissão selecionará esse pool de endereços de retransmissão.
- Se ainda não houver correspondência com nenhum pool de endereços de retransmissão DHCP, o agente de retransmissão selecionará o pool de endereços de retransmissão DHCP sem opções especificadas.
- Especifique os pools de endereços de retransmissão DHCP usando o comando dhcp relay pool.
- Especifique os servidores DHCP diretamente em uma interface usando a opção dhcp relay server-address
Restrições e diretrizes
Se você especificar servidores DHCP configurando os dois métodos a seguir em uma interface, a configuração do pool de endereços de retransmissão DHCP entrará em vigor.
comando.
Quando você especificar um pool de endereços de retransmissão DHCP em uma interface para definir os servidores DHCP, certifique-se de que o comando remote-server esteja configurado no pool de endereços de retransmissão DHCP. Caso contrário, o agente de retransmissão rejeitará as solicitações de DHCP. As solicitações de DHCP não são encaminhadas a nenhum servidor DHCP, mesmo que o comando dhcp relay server-address esteja configurado.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um pool de endereços de retransmissão DHCP e entre em sua visualização.
dhcp server ip-pool pool-namePor padrão, não existem pools de endereços de retransmissão DHCP.
- Especifique os servidores DHCP no pool de endereços de retransmissão DHCP.
remote-server ip-address&<1-8>Por padrão, nenhum servidor DHCP é especificado no pool de endereços de retransmissão DHCP.
- Especifique os endereços de gateway para os clientes que correspondem ao pool de endereços de retransmissão DHCP.
gateway-list ip-address&<1-64>Por padrão, nenhum endereço de gateway é especificado.
- Especifique o algoritmo de seleção do servidor DHCP.
remote-server algorithm { master-backup | polling }Por padrão, o algoritmo de sondagem é usado. O agente de retransmissão DHCP encaminha solicitações de DHCP a todos os servidores DHCP ao mesmo tempo.
- Retornar à visualização do sistema.
quit- Entre na visualização da interface.
interface interface-type interface-number- Especifique um pool de endereços de retransmissão DHCP para clientes DHCP.
dhcp relay pool pool-name [ option { 60 [ option-text ] | code } ]Por padrão, nenhum pool de endereços de retransmissão DHCP é especificado para clientes DHCP.
Configuração dos recursos de segurança do agente de retransmissão DHCP
Ativação do agente de retransmissão DHCP para registrar entradas de retransmissão
Sobre como habilitar o agente de retransmissão DHCP para registrar entradas de retransmissão
Execute esta tarefa para permitir que o agente de retransmissão DHCP registre automaticamente as associações de IP para MAC dos clientes (entradas de retransmissão) depois que eles obtiverem endereços IP por meio do DHCP.
Alguns recursos de segurança usam as entradas de retransmissão para verificar os pacotes recebidos e bloquear os pacotes que não correspondem a nenhuma entrada. Dessa forma, os hosts ilegais não conseguem acessar redes externas por meio do agente de retransmissão. Exemplos de recursos de segurança são verificação de endereço ARP, ARP autorizado e proteção de origem IP.
Restrições e diretrizes
O agente de retransmissão DHCP não registra as associações de IP a MAC para clientes DHCP executados em interfaces seriais síncronas/assíncronas.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o agente de retransmissão a registrar entradas de retransmissão.
dhcp relay client-information recordPor padrão, o agente de retransmissão não registra entradas de retransmissão.
Ativação da atualização periódica de entradas de retransmissão dinâmica
Sobre como ativar a atualização periódica de entradas de retransmissão dinâmica
Um cliente DHCP envia uma mensagem DHCP-RELEASE para o servidor DHCP para liberar seu endereço IP. O agente de retransmissão DHCP transmite a mensagem ao servidor DHCP e não remove a entrada IP-para-MAC do cliente.
Com esse recurso, o agente de retransmissão DHCP usa o endereço IP de uma entrada de retransmissão para enviar periodicamente uma mensagem DHCP-REQUEST para o servidor DHCP.
O agente de retransmissão mantém as entradas de retransmissão dependendo do que recebe do servidor DHCP:
- Se o servidor retornar uma mensagem DHCP-ACK ou não retornar nenhuma mensagem em um intervalo, o agente de retransmissão DHCP removerá a entrada de retransmissão. Além disso, ao receber a mensagem DHCP-ACK, o agente de retransmissão envia uma mensagem DHCP-RELEASE para liberar o endereço IP.
- Se o servidor retornar uma mensagem DHCP-NAK, o agente de retransmissão manterá a entrada de retransmissão.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a atualização periódica das entradas de retransmissão dinâmica.
dhcp relay client-information refresh enablePor padrão, a atualização periódica das entradas de retransmissão dinâmica está ativada.
- (Opcional.) Defina o intervalo de atualização.
dhcp relay client-information refresh [ auto | interval interval ]Por padrão, o intervalo de atualização é automático, que é calculado com base no número total de entradas do relé .
Ativação da proteção contra ataques de inanição de DHCP
Sobre a proteção contra ataques de inanição de DHCP
Um ataque de inanição de DHCP ocorre quando um invasor envia constantemente solicitações forjadas de DHCP usando diferentes endereços MAC no campo chaddr para um servidor DHCP. Isso esgota os recursos de endereço IP do servidor DHCP, de modo que os clientes DHCP legítimos não conseguem obter endereços IP. O servidor DHCP também pode deixar de funcionar devido ao esgotamento dos recursos do sistema. Os métodos a seguir estão disponíveis para aliviar ou impedir esses ataques.
- Para aliviar um ataque de inanição de DHCP que usa pacotes DHCP encapsulados com diferentes endereços MAC de origem, você pode usar um dos métodos a seguir:
- Limite o número de entradas ARP que uma interface de Camada 3 pode aprender.
- Defina o limite de aprendizado de MAC para uma porta da Camada 2 e desative o encaminhamento de quadros desconhecidos quando o limite de aprendizado de MAC for atingido.
- Para evitar um ataque de inanição de DHCP que usa solicitações de DHCP encapsuladas com o mesmo endereço MAC de origem, você pode ativar a verificação de endereço MAC no agente de retransmissão DHCP. O agente de retransmissão DHCP compara o campo chaddr de uma solicitação DHCP recebida com o endereço MAC de origem no cabeçalho do quadro. Se eles forem iguais, o agente de retransmissão DHCP encaminhará a solicitação ao servidor DHCP. Caso contrário, o agente de retransmissão descarta a solicitação.
- A entrada envelhece.
Habilite a verificação de endereço MAC somente no agente de retransmissão DHCP diretamente conectado aos clientes DHCP. Um agente de retransmissão DHCP altera o endereço MAC de origem dos pacotes DHCP antes de enviá-los.
Uma entrada de verificação de endereço MAC tem um tempo de envelhecimento. Quando o tempo de envelhecimento expira, ocorrem as duas situações a seguir:
- O agente de retransmissão DHCP verifica novamente a validade das solicitações DHCP enviadas do endereço MAC na entrada.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o tempo de envelhecimento das entradas de verificação de endereço MAC.
dhcp relay check mac-address aging-time timeO tempo de envelhecimento padrão é de 30 segundos.
Esse comando só tem efeito depois que você executa o comando dhcp relay check mac-address
comando.
- Entre na visualização da interface.
interface interface-type interface-number- Ativar a verificação de endereço MAC.
dhcp relay check mac-addressPor padrão, a verificação de endereço MAC está desativada.
Ativação do proxy do servidor DHCP no agente de retransmissão DHCP
Sobre a ativação do proxy do servidor DHCP no agente de retransmissão DHCP
O recurso de proxy de servidor DHCP isola os servidores DHCP dos clientes DHCP e protege os servidores DHCP contra ataques.
Ao receber uma resposta do servidor, o proxy do servidor DHCP modifica o endereço IP do servidor como o endereço IP da interface de retransmissão antes de enviar a resposta. O cliente DHCP considera o agente de retransmissão DHCP como o servidor DHCP.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar o agente de retransmissão DHCP e o proxy do servidor DHCP na interface.
dhcp select relay proxyPor padrão, a interface opera no modo de servidor DHCP depois que o DHCP é ativado.
Ativação da detecção off-line do cliente no agente de retransmissão DHCP
Sobre a detecção de cliente off-line no agente de retransmissão DHCP
A detecção de cliente off-line no agente de retransmissão DHCP detecta o status on-line do usuário com base no envelhecimento da entrada ARP. Quando uma entrada ARP se esgota, o recurso de detecção de cliente DHCP off-line exclui a entrada de retransmissão do endereço IP e envia uma mensagem RELEASE ao servidor DHCP.
Se o agente de retransmissão DHCP e o DHCP snooping estiverem configurados no mesmo dispositivo, o módulo de DHCP snooping excluirá suas entradas de DHCP snooping depois de obter as mensagens RELEASE do módulo de agente de retransmissão.
Restrições e diretrizes
O recurso não funcionará se uma entrada ARP for excluída manualmente.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o agente de retransmissão a registrar entradas de retransmissão.
dhcp relay client-information recordPor padrão, o agente de retransmissão não registra entradas de retransmissão.
Sem entradas de retransmissão, a detecção off-line do cliente não pode funcionar corretamente.
- Entre na visualização da interface.
interface interface-type interface-number- Ativar o agente de retransmissão DHCP.
dhcp select relayPor padrão, quando o DHCP está ativado, uma interface opera no modo de servidor DHCP.
- Ativar a detecção off-line do cliente.
dhcp client-detect
Por padrão, a detecção off-line do cliente está desativada no agente de retransmissão DHCP.
Configuração do agente de retransmissão DHCP para liberar um endereço IP
Sobre como configurar o agente de retransmissão DHCP para liberar um endereço IP
Configure o agente de retransmissão para liberar o endereço IP de uma entrada de retransmissão. O agente de retransmissão envia uma mensagem DHCP-RELEASE para o servidor e, enquanto isso, exclui a entrada de retransmissão. Ao receber a mensagem DHCP-RELEASE, o servidor DHCP libera o endereço IP.
Esse comando pode liberar apenas os endereços IP nas entradas de retransmissão registradas.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o agente de retransmissão DHCP para liberar um endereço IP.
dhcp relay release ip ip-address
Configuração do suporte do agente de retransmissão DHCP para a Opção 82
Para oferecer suporte à Opção 82, você deve executar a configuração relacionada no servidor DHCP e no agente de retransmissão . Para a configuração da Opção 82 do servidor DHCP, consulte "Ativação do manuseio da Opção 82".
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilite o agente de retransmissão para lidar com a Opção 82.
Informações de retransmissão de dhcp
Por padrão, o tratamento da Opção 82 está desativado.
- (Opcional.) Configure a estratégia para lidar com solicitações DHCP que contenham a Opção 82.
dhcp relay information strategy { drop | keep | replace }Por padrão, a estratégia de tratamento é substituir.
Se a estratégia de tratamento for substituir, configure um modo de preenchimento e um formato de preenchimento para a opção
82. Se a estratégia de tratamento for manter ou soltar, não será necessário configurar um modo de preenchimento ou um formato de preenchimento para a Opção 82.
- (Opcional.) Configure o modo de preenchimento e o formato de preenchimento para a subopção Circuit ID.
dhcp relay information circuit-id { bas | string circuit-id | { normal |
verbose [ node-identifier { mac | sysname | user-defined
node-identifier } ] [ interface ] } [ format { ascii | hex } ] }
identificador de nó } ] [ interface ] } [ formato { ascii | hex } ] }
Por padrão, o modo de preenchimento da subopção Circuit ID é normal, e o formato de preenchimento é
hex.
O nome do dispositivo (sysname) não deve incluir espaços se estiver configurado como conteúdo de preenchimento para a subopção 1. Caso contrário, o agente de retransmissão DHCP falhará ao adicionar ou substituir a Opção 82.
- (Opcional.) Configure o modo de preenchimento e o formato de preenchimento para a subopção ID remota.
dhcp relay information remote-id { normal [ format { ascii | hex } ] |
string remote-id | sysname }
Por padrão, o modo de preenchimento da subopção Remote ID é normal, e o formato de preenchimento é hex.
Configuração do valor DSCP para pacotes DHCP enviados pelo agente de retransmissão DHCP
Sobre o valor DSCP para pacotes DHCP enviados pelo agente de retransmissão DHCP
O valor DSCP de um pacote especifica o nível de prioridade do pacote e afeta a prioridade de transmissão do pacote.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o valor DSCP para pacotes DHCP enviados pelo agente de retransmissão DHCP.
dhcp dscp dscp-valuePor padrão, o valor DSCP nos pacotes DHCP enviados pelo agente de retransmissão DHCP é 56.
Especificando o endereço do agente de retransmissão DHCP para o campo giaddr
Especificar manualmente o endereço do agente de retransmissão DHCP para o campo giaddr
Sobre a especificação manual do endereço do agente de retransmissão DHCP para o campo giaddr
Essa tarefa permite que você especifique os endereços IP a serem encapsulados no campo giaddr das solicitações DHCP. Se você não especificar nenhum endereço de agente de retransmissão DHCP, o endereço IP primário da interface de retransmissão DHCP será encapsulado no campo giaddr das solicitações DHCP.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique o endereço do agente de retransmissão DHCP a ser encapsulado nas solicitações DHCP retransmitidas.
dhcp relay gateway ip-addressPor padrão, o endereço IP primário da interface de retransmissão de DHCP é encapsulado nas solicitações de DHCP retransmitidas.
Configuração de retransmissão inteligente para especificar o endereço do agente de retransmissão DHCP para o campo giaddr
Sobre o smart relay
Por padrão, o agente de retransmissão encapsula apenas o endereço IP primário no campo giaddr de todas as solicitações antes de retransmiti-las ao servidor DHCP. Em seguida, o servidor DHCP seleciona um endereço IP na mesma sub-rede que o endereço no campo giaddr. Se nenhum endereço atribuível na sub-rede estiver disponível, o servidor DHCP não atribuirá nenhum endereço IP. O recurso de retransmissão inteligente de DHCP foi introduzido para permitir que o agente de retransmissão de DHCP encapsule endereços IP secundários quando o servidor DHCP não enviar de volta uma mensagem DHCP-OFFER.
O agente de retransmissão inicialmente encapsula seu endereço IP primário no campo giaddr antes de encaminhar uma solicitação ao servidor DHCP. Se nenhum DHCP-OFFER for recebido, o agente de retransmissão permitirá que o cliente envie no máximo duas solicitações ao servidor DHCP usando o endereço IP primário. Se nenhum DHCP-OFFER for retornado após duas tentativas, o agente de retransmissão mudará para um endereço IP secundário. Se o servidor DHCP ainda não responder, o próximo endereço IP secundário será usado. Depois que todos os endereços IP secundários forem tentados e o servidor DHCP não responder, o agente de retransmissão repetirá o processo começando pelo endereço IP primário.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o recurso de retransmissão inteligente de DHCP.
dhcp smart-relay enablePor padrão, o recurso de retransmissão inteligente de DHCP está desativado.
Especificação do endereço IP de origem para solicitações DHCP retransmitidas
Sobre a especificação do endereço IP de origem para solicitações DHCP retransmitidas
Essa tarefa é necessária se várias interfaces de retransmissão compartilharem o mesmo endereço IP ou se uma interface de retransmissão não tiver rotas para servidores DHCP. Você pode especificar um endereço IP ou o endereço IP de outra interface, normalmente a interface de loopback, no agente de retransmissão DHCP como o endereço IP de origem para solicitações DHCP. A interface de retransmissão insere o endereço IP de origem no campo de endereço IP de origem, bem como o campo giaddr nas solicitações de DHCP.
Se várias interfaces de retransmissão compartilharem o mesmo endereço IP, você também deverá configurar a interface de retransmissão para dar suporte à Opção 82. Ao receber uma solicitação de DHCP, a interface de retransmissão insere as informações de sub-rede na subopção 5 da Opção 82. O servidor DHCP atribui um endereço IP de acordo com
subopção 5. O agente de retransmissão DHCP procura a interface de saída na tabela de endereços MAC para encaminhar a resposta DHCP.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique o endereço IP de origem para solicitações de DHCP.
dhcp relay source-address { ip-address | interface interface-type
interface-number }
Por padrão, o agente de retransmissão DHCP usa o endereço IP primário da interface que se conecta ao servidor DHCP como o endereço IP de origem para solicitações DHCP retransmitidas. Se essa interface não tiver um endereço IP, o agente de retransmissão DHCP usará um endereço IP que compartilhe a mesma sub-rede com o servidor DHCP.
É possível especificar apenas um endereço IP de origem para solicitações de DHCP em uma interface.
Comandos de exibição e manutenção do agente de retransmissão DHCP
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir entradas de verificação de endereço MAC no agente de retransmissão DHCP. | display dhcp relay check mac-address |
| Exibir entradas de retransmissão no agente de retransmissão DHCP. | display dhcp relay client-information [ interface interface-type interface-number | ip ip-address ] |
| Exibir informações de configuração da Opção 82 no agente de retransmissão DHCP. | display dhcp relay information [ interface interface-type interface-number ] |
| Exibir informações sobre servidores DHCP em uma interface. | display dhcp relay server-address [ interface interface-type interface-number ] |
| Exibir estatísticas de pacotes no agente de retransmissão DHCP. | exibir estatísticas de retransmissão de dhcp [ interface interface-type interface-number ] |
| Limpar entradas de retransmissão no agente de retransmissão DHCP. | reset dhcp relay client-information [ interface interface-type interface-number | ip ip-address ] |
| Limpar estatísticas de pacotes no agente de retransmissão DHCP. | reset dhcp relay statistics [ interface interface-type interface-number ] |
Exemplos de configuração do agente de retransmissão DHCP
Exemplo: Configuração do agente de retransmissão DHCP básico
Configuração de rede
Conforme mostrado na Figura 16, configure o agente de retransmissão DHCP no Switch A. O agente de retransmissão DHCP permite que os clientes DHCP obtenham endereços IP e outros parâmetros de configuração do servidor DHCP em outra sub-rede.
O agente de retransmissão DHCP e o servidor estão em sub-redes diferentes. Configure o roteamento estático ou dinâmico para torná-los acessíveis um ao outro.
Realize a configuração no servidor DHCP para garantir a comunicação cliente-servidor. Para obter informações sobre a configuração do servidor DHCP, consulte "Exemplos de configuração do servidor DHCP".
Figura 16 Diagrama de rede
Procedimento
# Especifique os endereços IP para as interfaces. (Detalhes não mostrados.) # Habilite o DHCP.
<SwitchA> system-view
[SwitchA] dhcp enable
# Habilite o agente de retransmissão DHCP na interface VLAN 10.
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] dhcp select relay
# Especifique o endereço IP do servidor DHCP no agente de retransmissão.
[SwitchA-Vlan-interface10] dhcp relay server-address 10.1.1.1
Verificação da configuração
# Verifique se os clientes DHCP podem obter endereços IP e todos os outros parâmetros de rede do servidor DHCP por meio do agente de retransmissão DHCP. (Detalhes não mostrados.)
# Exibir as estatísticas dos pacotes DHCP encaminhados pelo agente de retransmissão DHCP.
[SwitchA] display dhcp relay statistics# Exibir entradas de retransmissão se você tiver ativado o registro de entrada de retransmissão no agente de retransmissão DHCP.
[SwitchA] display dhcp relay client-informationExemplo: Configuração da opção 82
Configuração de rede
Conforme mostrado na Figura 16, o agente de retransmissão DHCP (Switch A) substitui a Opção 82 nas solicitações DHCP antes de encaminhá-las ao servidor DHCP (Switch B).
- A subopção de ID do circuito é company001.
- A subopção Remote ID é device001.
Para usar a Opção 82, você também deve habilitar o servidor DHCP para lidar com a Opção 82.
Procedimento
# Especifique os endereços IP para as interfaces. (Detalhes não mostrados.) # Habilite o DHCP.
<SwitchA> system-view
[SwitchA] dhcp enable
# Habilite o agente de retransmissão DHCP na interface VLAN 10.
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] dhcp select relay
# Especifique o endereço IP do servidor DHCP.
[SwitchA-Vlan-interface10] dhcp relay server-address 10.1.1.1
# Configure as estratégias de manuseio e o conteúdo de preenchimento da Opção 82.
[SwitchA-Vlan-interface10] dhcp relay information enable
[SwitchA-Vlan-interface10] dhcp relay information strategy replace
[SwitchA-Vlan-interface10] dhcp relay information circuit-id string company001
[SwitchA-Vlan-interface10] dhcp relay information remote-id string device001Exemplo: Configuração da seleção do servidor DHCP
Configuração de rede
Conforme mostrado na Figura 17, o cliente DHCP e os servidores DHCP estão em sub-redes diferentes. Tanto o servidor DHCP 1 quanto o servidor DHCP 2 têm um pool de endereços DHCP que contém endereços IP na sub-rede 22.22.22.0/24, mas nenhum deles tem o DHCP ativado.
Configure o agente de retransmissão DHCP para que o cliente DHCP obtenha um endereço IP na sub-rede 22.22.22.0/24 e outros parâmetros de configuração de um servidor DHCP. O agente de retransmissão DHCP está conectado ao cliente DHCP por meio da interface VLAN 2, ao servidor DHCP 1 por meio da interface VLAN 3 e ao servidor DHCP 2 por meio da interface VLAN 4.
Figura 17 Diagrama de rede
Procedimento
- Atribua endereços IP às interfaces nos switches. (Detalhes não mostrados).
- Configure o Switch B e o Switch C como servidores DHCP. (Detalhes não mostrados.)
- Configure o agente de retransmissão DHCP no Switch A: # Habilite o DHCP.
<SwitchA> system-view
[SwitchA] dhcp enable# Habilite o agente de retransmissão DHCP na interface VLAN 2.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] dhcp select relay# Especifique os endereços IP dos servidores DHCP.
[SwitchA-Vlan-interface2] dhcp relay server-address 1.1.1.1
[SwitchA-Vlan-interface2] dhcp relay server-address 2.2.2.2# Especifique o algoritmo de seleção do servidor DHCP como master-backup.
[SwitchA-Vlan-interface2] dhcp relay server-address algorithm master-backup# Configure o agente de retransmissão DHCP para voltar ao servidor DHCP mestre 3 minutos depois de mudar para o servidor DHCP de backup.
[SwitchA-Vlan-interface2] dhcp relay master-server switch-delay 3Verificação da configuração
# Verifique se o cliente DHCP não consegue obter um endereço IP e se o seguinte registro é gerado em cerca de 30 segundos.
DHCPR/3/DHCPR_SWITCHMASTER:
Switched to the master DHCP server at 1.1.1.1.# Habilite o DHCP no servidor DHCP em 1.1.1.1. (Detalhes não mostrados.)
# Verifique se o cliente DHCP não consegue obter um endereço IP e se o seguinte registro é gerado em cerca de 3 minutos.
DHCPR/3/DHCPR_SWITCHMASTER:
Comutado para o servidor DHCP mestre em 1.1.1.1.
# Verifique se o cliente DHCP obtém um endereço IP. (Detalhes não mostrados.)
Solução de problemas de configuração do agente de retransmissão DHCP
Falha dos clientes DHCP em obter parâmetros de configuração por meio do agente de retransmissão DHCP
Sintoma
Os clientes DHCP não podem obter parâmetros de configuração por meio do agente de retransmissão DHCP.
Solução
Alguns problemas podem ocorrer com o agente de retransmissão DHCP ou com a configuração do servidor.
Para localizar o problema, ative a depuração e execute o comando display no agente de retransmissão DHCP para visualizar as informações de depuração e as informações de estado da interface.
Verifique isso:
- O DHCP está ativado no servidor DHCP e no agente de retransmissão.
- O servidor DHCP tem um pool de endereços na mesma sub-rede que os clientes DHCP.
- O servidor DHCP e o agente de retransmissão DHCP podem se comunicar entre si.
- O endereço do servidor DHCP especificado na interface de retransmissão DHCP conectada aos clientes DHCP está correto.
Configuração do cliente DHCP
Sobre o cliente DHCP
Com o cliente DHCP ativado, uma interface usa o DHCP para obter parâmetros de configuração do servidor DHCP , por exemplo, um endereço IP.
Restrições e diretrizes: Configuração do cliente DHCP
A configuração do cliente DHCP é compatível apenas com interfaces VLAN.
Visão geral das tarefas do cliente DHCP
Para configurar um cliente DHCP, execute as seguintes tarefas:
- Ativação do cliente DHCP em uma interface
- Configuração de uma ID de cliente DHCP para uma interface
Execute essa tarefa se o cliente DHCP usar o ID do cliente para obter endereços IP.
- (Opcional.) Ativação da detecção de endereços duplicados
- (Opcional.) Configuração do valor DSCP para pacotes DHCP enviados pelo cliente DHCP
- (Opcional.) Configuração da opção 60 para solicitações DHCP
Ativação do cliente DHCP em uma interface
Restrições e diretrizes
- Se o número de falhas na solicitação de endereço IP atingir a quantidade definida pelo sistema, a interface habilitada para o cliente DHCP usará um endereço IP padrão.
- Uma interface pode ser configurada para adquirir um endereço IP de várias maneiras. A nova configuração substitui a antiga.
- Os endereços IP secundários não podem ser configurados em uma interface que esteja ativada com o cliente DHCP.
- Se a interface obtiver um endereço IP no mesmo segmento que outra interface no dispositivo, a interface não usará o endereço atribuído. Em vez disso, ela solicita um novo endereço IP ao servidor DHCP .
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure uma interface para usar o DHCP para aquisição de endereços IP.
ip address dhcp-alloc
Configuração de uma ID de cliente DHCP para uma interface
Sobre a ID do cliente DHCP
Um ID de cliente DHCP é adicionado à opção 61 do DHCP para identificar exclusivamente um cliente DHCP. Um servidor DHCP pode atribuir endereços IP a clientes com base em suas IDs de cliente DHCP.
A ID do cliente DHCP inclui um tipo de ID e um valor de tipo. Cada tipo de ID tem um valor de tipo fixo. Você pode especificar uma ID de cliente DHCP usando um dos métodos a seguir:
- Use uma cadeia ASCII como ID do cliente. Se for usada uma cadeia ASCII, o valor do tipo será 00.
- Use um número hexadecimal como ID do cliente. Se for usado um número hexadecimal, o valor do tipo será os dois primeiros caracteres do número.
- Usar o endereço MAC de uma interface para gerar uma ID de cliente. Se esse método for usado, o valor do tipo será 01.
O valor do tipo de uma ID de cliente DHCP pode ser exibido com a instrução display dhcp server ip-in-use
ou comando display dhcp client.
Restrições e diretrizes
Certifique-se de que a ID de cada cliente DHCP seja exclusiva.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure uma ID de cliente DHCP para a interface.
dhcp client identifier { ascii ascii-string | hex hex-string | mac
interface-type interface-number }
Por padrão, uma interface gera a ID de cliente DHCP com base em seu endereço MAC. Se a interface não tiver endereço MAC, ela usará o endereço MAC da primeira interface Ethernet para gerar sua ID de cliente.
Ativação da detecção de endereços duplicados
Sobre a detecção de endereços duplicados
O cliente DHCP detecta conflitos de endereço IP por meio de pacotes ARP. Um invasor pode agir como o proprietário do endereço IP para enviar uma resposta ARP. O ataque de falsificação faz com que o cliente não consiga usar o endereço IP
atribuído pelo servidor. Como prática recomendada, desative a detecção de endereços duplicados quando houver ataques ARP na rede.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a detecção de endereços duplicados.
dhcp client dad enable
Por padrão, o recurso de detecção de endereços duplicados é ativado em uma interface.
Configuração do valor DSCP para pacotes DHCP enviados pelo cliente DHCP
Sobre a configuração do valor DSCP para pacotes DHCP enviados pelo cliente DHCP
O valor DSCP de um pacote especifica o nível de prioridade do pacote e afeta a prioridade de transmissão do pacote.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o valor DSCP para pacotes DHCP enviados pelo cliente DHCP.
dhcp client dscp dscp-value
Por padrão, o valor DSCP nos pacotes DHCP enviados pelo cliente DHCP é 56.
Configuração da opção 60 para solicitações DHCP
Sobre esta tarefa
A opção 60 atua como um identificador de classe de fornecedor (VCI). Você pode configurar um cliente DHCP para enviar uma solicitação com a Opção 60 para que o servidor DHCP faça a atribuição de endereços IP com base em classe. Quando o servidor DHCP recebe uma solicitação com a Opção 60 de um cliente, o servidor identifica a classe de usuário do cliente. Em seguida, o servidor atribui ao cliente um endereço IP do intervalo de IPs especificado para a classe de usuário.
Por padrão, a Opção 60 contém o nome do fornecedor e o nome do produto. Para definir essa opção para as solicitações de DHCP do site , execute esta tarefa.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6340 e posteriores.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure a Option 60 para solicitações DHCP.
dhcp client class-id { ascii ascii-string | hex hex-string }Por padrão, a Opção 60 contém o nome do fornecedor e o nome do produto.
Comandos de exibição e manutenção para o cliente DHCP
Executar o comando de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações do cliente DHCP. | display dhcp client [ verbose ] [ interface interface-type interface-number ] |
Exemplos de configuração do cliente DHCP
Exemplo: Configuração do cliente DHCP
Configuração de rede
Conforme mostrado na Figura 19, em uma LAN, o Switch B entra em contato com o servidor DHCP por meio da interface VLAN 2 para obter um endereço IP, um endereço de servidor DNS e informações de rota estática. O endereço IP do cliente DHCP reside na sub-rede 10.1.1.0/24. O endereço do servidor DNS é 20.1.1.1. O próximo salto da rota estática para a sub-rede 20.1.1.0/24 é 10.1.1.2.
O servidor DHCP usa a Option 121 para atribuir informações de rota estática aos clientes DHCP. A Figura 18 mostra o formato da Option 121. O campo descritor de destino contém as seguintes partes: comprimento da máscara de sub-rede e endereço de rede de destino, ambos em notação hexadecimal. Neste exemplo, o descritor de destino é 18 14 01 01 (o comprimento da máscara de sub-rede é 24 e o endereço de rede é
20.1.1.0 em notação decimal com pontos). O endereço do próximo salto é 0A 01 01 02 (10.1.1.2 em notação decimal pontilhada ).
Figura 18 Formato da opção 121

Figura 19 Diagrama de rede
Procedimento
- Configure o Switch A:
# Especifique um endereço IP para a interface VLAN 2.
<SwitchA> system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 10.1.1.1 24
[SwitchA-Vlan-interface2] quit# Excluir um endereço IP da alocação dinâmica.
[SwitchA] dhcp server forbidden-ip 10.1.1.2# Configure o pool de endereços DHCP 0. Especifique a sub-rede, a duração da concessão, o endereço do servidor DNS e uma rota estática para a sub-rede 20.1.1.0/24.
[SwitchA] dhcp server ip-pool 0
[SwitchA-dhcp-pool-0] network 10.1.1.0 mask 255.255.255.0
[SwitchA-dhcp-pool-0] expired day 10
[SwitchA-dhcp-pool-0] dns-list 20.1.1.1
[SwitchA-dhcp-pool-0] option 121 hex 18 14 01 01 0A 01 01 02
[SwitchA-dhcp-pool-0] quit# Habilite o DHCP.
[SwitchA] dhcp enable- Configure o Switch B:
# Configure a interface VLAN 2 para usar o DHCP para aquisição de endereços IP.
<SwitchB> system-view
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address dhcp-alloc
[SwitchB-Vlan-interface2] quitVerificação da configuração
# Exibir o endereço IP e outros parâmetros de rede atribuídos ao Switch B.
[SwitchB-Vlan-interface2] display dhcp client verbose
Vlan-interface2 DHCP client information:
Current state: BOUND
Allocated IP: 10.1.1.3 255.255.255.0
Allocated lease: 864000 seconds, T1: 331858 seconds, T2: 756000 seconds
Lease from May 21 19:00:29 2012 to May 31 19:00:29 2012
DHCP server: 10.1.1.1
Transaction ID: 0xcde72232
Classless static routes:
Destination: 20.1.1.0, Mask: 255.255.255.0, NextHop: 10.1.1.2
DNS servers: 20.1.1.1
Client ID type: acsii(type value=00)
Client ID value: 000c.29d3.8659-Vlan2
Client ID (with type) hex: 0030-3030-632e-3239-
6433-2e38-3635-392d-
4574-6830-2f30-2f32
T1 will timeout in 3 days 19 hours 48 minutes 43 seconds# Exiba as informações de rota no Switch B. A saída mostra que uma rota estática para a sub-rede 20.1.1.0/24 foi adicionada à tabela de roteamento.
[SwitchB] display ip routing-table
Destinations : 11 Routes : 11
Destination/Mask Proto Pre Cost NextHop Interface
10.1.1.0/24 Direct 0 0 10.1.1.3 Vlan2
10.1.1.3/32 Direct 0 0 127.0.0.1 InLoop0
20.1.1.0/24 Static 70 0 10.1.1.2 Vlan2
10.1.1.255/32 Direct 0 0 10.1.1.3 Vlan2
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
127.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
224.0.0.0/4 Direct 0 0 0.0.0.0 NULL0
224.0.0.0/24 Direct 0 0 0.0.0.0 NULL0
255.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0Configuração do DHCP snooping
Sobre o DHCP snooping
O DHCP snooping é um recurso de segurança do DHCP.
O DHCP snooping funciona entre o cliente e o servidor DHCP ou entre o cliente DHCP e o agente de retransmissão DHCP. Ele garante que os clientes DHCP obtenham endereços IP de servidores DHCP autorizados. Além disso, ele registra as associações de IP a MAC dos clientes DHCP (chamadas de entradas de snooping DHCP) para fins de segurança.
O DHCP snooping define portas confiáveis e não confiáveis para garantir que os clientes obtenham endereços IP somente de servidores DHCP autorizados.
∙ Confiável - Uma porta confiável pode encaminhar mensagens DHCP corretamente para garantir que os clientes obtenham endereços IP de servidores DHCP autorizados.
∙ Não confiável - Uma porta não confiável não pode encaminhar solicitações de DHCP para o servidor DHCP. Ela descarta as mensagens DHCP-ACK e DHCP-OFFER recebidas para evitar que servidores não autorizados atribuam endereços IP.
O snooping DHCP lê mensagens DHCP-ACK recebidas de portas confiáveis e mensagens DHCP-REQUEST para criar entradas de snooping DHCP. Uma entrada de DHCP snooping inclui os endereços MAC e IP de um cliente, a porta que se conecta ao cliente DHCP e a VLAN.
Os recursos a seguir precisam usar entradas de DHCP snooping:
∙ Detecção de ataque ARP - Usa entradas de DHCP snooping para filtrar pacotes ARP de clientes não autorizados. Para obter mais informações, consulte o Guia de configuração de segurança.
∙ Encaminhamento forçado por MAC (MFF) - O modo automático do MFF executa as seguintes tarefas:
⚪ Intercepta solicitações ARP de clientes.
⚪ Usa entradas de DHCP snooping para encontrar o endereço do gateway.
⚪ Retorna o endereço MAC do gateway para os clientes.
Esse recurso força o cliente a enviar todo o tráfego para o gateway, de modo que o gateway possa monitorar o tráfego do cliente para evitar ataques mal-intencionados entre os clientes. Para obter mais informações, consulte o Guia de configuração de segurança.
∙ IP source guard - Usa entradas de DHCP snooping para filtrar pacotes ilegais por porta. Para obter mais informações, consulte o Guia de configuração de segurança.
∙ Mapeamento de VLAN - Usa entradas de DHCP snooping para substituir a VLAN do provedor de serviços em pacotes pela VLAN do cliente antes de enviar os pacotes aos clientes. Para obter mais informações, consulte o Layer 2-LAN Switching Configuration Guide.
Aplicação de portas confiáveis e não confiáveis
Configure as portas voltadas para o servidor DHCP como portas confiáveis e configure outras portas como portas não confiáveis.
Conforme mostrado na Figura 20, configure a porta do dispositivo de DHCP snooping que está conectada ao servidor DHCP como uma porta confiável. A porta confiável encaminha mensagens de resposta do servidor DHCP para o cliente. A porta não confiável conectada ao servidor DHCP não autorizado descarta as mensagens de resposta DHCP recebidas.
Figura 20 Portas confiáveis e não confiáveis
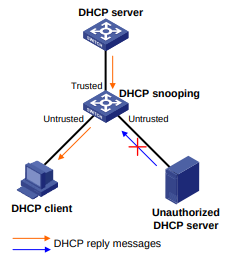
Em uma rede em cascata, conforme mostrado na Figura 21, configure as portas dos dispositivos de snooping DHCP voltadas para o servidor DHCP como portas confiáveis. Para economizar recursos do sistema, você pode habilitar apenas as portas não confiáveis diretamente conectadas aos clientes DHCP para registrar entradas de snooping DHCP.
Figura 21 Portas confiáveis e não confiáveis em uma rede em cascata
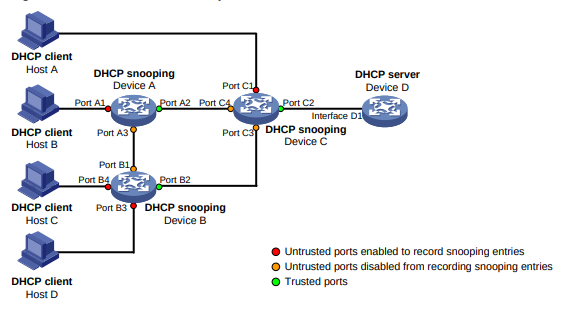
Suporte a DHCP snooping para a Opção 82
A opção 82 registra as informações de localização sobre o cliente DHCP para que o administrador possa localizar o cliente DHCP para fins de segurança e contabilidade. Para obter mais informações sobre a Opção 82, consulte "Opção de agente de retransmissão (Opção 82)".
A subopção 9 (específica do fornecedor) na Opção 82 é suportada somente em dispositivos DHCP snooping. Cada dispositivo DHCP snooping com a estratégia de manipulação append Option 82 adiciona as seguintes informações à subopção na solicitação DHCP recebida:
Identificador de nó do dispositivo DHCP snooping atual.
Informações sobre a interface do lado do cliente.
∙ VLAN do cliente DHCP.
Depois que o dispositivo de gerenciamento recebe a solicitação DHCP, ele pode determinar a topologia de rede que a solicitação percorreu e localizar o cliente DHCP.
O snooping DHCP usa as mesmas estratégias que o agente de retransmissão DHCP para lidar com a Opção 82 para mensagens de solicitação DHCP, conforme mostrado na Tabela 4. Se uma resposta retornada pelo servidor DHCP contiver a Opção 82, o snooping DHCP removerá a Opção 82 antes de encaminhar a resposta ao cliente. Se a resposta não contiver nenhuma Opção 82, o snooping DHCP a encaminhará diretamente.
Tabela 4 Estratégias de manuseio
| Se uma solicitação DHCP tiver... | Estratégia de manuseio | DHCP snooping... |
| Opção 82 | Anexar | Encaminha a mensagem depois de preencher a subopção Vendor-Specific com o conteúdo especificado no comando dhcp snooping information vendor-specific. Encaminha a mensagem sem alterar a Opção 82 se o Informações de dhcp snooping o comando específico do fornecedor não está configurado. |
| Queda | Desiste da mensagem. | |
| Manter | Encaminha a mensagem sem alterar a Opção 82. | |
| Substituir | Encaminha a mensagem após substituir a Opção 82 original pela Opção 82 preenchida de acordo com o formato de preenchimento configurado, o conteúdo de preenchimento e o tipo de código. | |
| Nenhuma opção 82 | N/A | Encaminha a mensagem depois de adicionar a Opção 82 com preenchimento de acordo com o formato de preenchimento configurado, o conteúdo de preenchimento e o tipo de código. |
Restrições e diretrizes: Configuração do DHCP snooping
∙ A configuração do DHCP snooping não entra em vigor em uma interface Ethernet de camada 2 que seja uma porta membro de agregação. A configuração entra em vigor quando a interface deixa o grupo de agregação.
∙ Especifique as portas conectadas a servidores DHCP autorizados como portas confiáveis para garantir que os clientes DHCP possam obter endereços IP válidos. As portas confiáveis e as portas conectadas aos clientes DHCP devem estar na mesma VLAN.
∙ Você pode especificar as seguintes interfaces como portas confiáveis: Interfaces Ethernet de camada 2 e interfaces agregadas de camada 2. Para obter mais informações sobre interfaces agregadas, consulte Agregação de links Ethernet no Guia de configuração de comutação de LAN de camada 2.
Visão geral das tarefas do DHCP snooping
Para configurar o DHCP snooping, execute as seguintes tarefas:
- Configuração dos recursos básicos do DHCP snooping
- (Opcional.) Configuração do suporte do DHCP snooping para a opção 82
- (Opcional.) Configuração do backup automático de entradas do DHCP snooping
- (Opcional.) Configuração do número máximo de entradas de DHCP snooping
- (Opcional.) Configuração do limite de taxa de pacotes DHCP
- (Opcional.) Configuração dos recursos de segurança do DHCP snooping
- (Opcional.) Ativação do registro de DHCP snooping
- (Opcional.) Desativar o DHCP snooping em uma interface
Configuração dos recursos básicos do DHCP snooping
Configuração de recursos básicos de DHCP snooping em uma rede comum
Sobre os recursos básicos de DHCP snooping em uma rede comum
Os recursos básicos do DHCP snooping referem-se ao seguinte:
∙ Ativação do DHCP snooping.
∙ Configuração de portas confiáveis do DHCP snooping.
∙ Ativação do registro de informações do cliente em entradas de DHCP snooping.
Se você ativar o DHCP snooping globalmente, o DHCP snooping será ativado em todas as interfaces do dispositivo.
Você também pode ativar o snooping DHCP para VLANs específicas. Depois de ativar o DHCP snooping para uma VLAN, você pode configurar os outros recursos básicos do DHCP snooping na VLAN.
Restrições e diretrizes
Se os recursos básicos do DHCP snooping estiverem configurados globalmente, você só poderá usar a forma undo dos comandos de configuração global para desativar as configurações globalmente. Os comandos de configuração específicos da VLAN não podem desativar as configurações.
Se os recursos básicos do DHCP snooping estiverem configurados em uma VLAN, você só poderá usar a forma undo dos comandos de configuração específicos da VLAN para desativar as configurações na VLAN. O comando de configuração global não pode desativar as configurações.
Configuração dos recursos básicos do DHCP snooping globalmente
- Entre na visualização do sistema.
system-view- Ativar o DHCP snooping globalmente.
dhcp snooping enablePor padrão, o DHCP snooping é desativado globalmente.
- Entre na visualização da interface.
interface interface-type interface-numberEssa interface deve se conectar ao servidor DHCP.
- Especifique a porta como uma porta confiável.
dhcp snooping trustPor padrão, todas as portas são portas não confiáveis depois que o DHCP snooping é ativado.
- (Opcional.) Habilite o registro de entradas de DHCP snooping.
- Retornar à visualização do sistema.
quit- Entre na visualização da interface.
interface interface-type interface-numberEssa interface deve se conectar ao cliente DHCP.
- Habilite o registro de entradas de DHCP snooping.
dhcp snooping binding recordPor padrão, o registro de entradas de DHCP snooping está desativado.
Configuração de recursos básicos do DHCP snooping para VLANs
- Entre na visualização do sistema.
system-view- Habilite o DHCP snooping para VLANs.
dhcp snooping enable vlan vlan-id-listPor padrão, o DHCP snooping está desativado para todas as VLANs.
- Entrar na visualização de VLAN
vlan vlan-idCertifique-se de que o DHCP snooping esteja ativado para a VLAN.
- Configure uma interface na VLAN como uma porta confiável.
dhcp snooping trust interface interface-type interface-numberPor padrão, todas as interfaces da VLAN são portas não confiáveis.
- (Opcional.) Habilite o registro das informações do cliente nas entradas do DHCP snooping.
dhcp snooping binding recordPor padrão, o registro das informações do cliente nas entradas do DHCP snooping está desativado.
Configuração do suporte do DHCP snooping para a opção 82
Restrições e diretrizes
∙ A configuração da Opção 82 em uma interface Ethernet de camada 2 que tenha sido adicionada a um grupo de agregação não entra em vigor a menos que a interface saia do grupo de agregação.
∙ Para oferecer suporte à Opção 82, você deve configurar a Opção 82 no servidor DHCP e no dispositivo DHCP snooping. Para obter informações sobre como configurar a Option 82 no servidor DHCP, consulte "Ativação do manuseio da Option 82".
∙ Se a Opção 82 contiver o nome do dispositivo, o nome do dispositivo não poderá conter espaços. Caso contrário, o DHCP snooping rejeita a mensagem. Você pode usar o comando sysname para especificar o nome do dispositivo. Para obter mais informações sobre esse comando, consulte Referência de comandos básicos.
∙ O DHCP snooping usa "outer VLAN tag.inner VLAN tag" para preencher o campo VLAN ID da subopção 1 no formato de preenchimento detalhado se houver uma das seguintes condições:
⚪ O DHCP snooping e o QinQ trabalham juntos.
⚪ O DHCP snooping recebe um pacote DHCP com duas tags de VLAN.
Por exemplo, se a tag de VLAN externa for 10 e a tag de VLAN interna for 20, o campo VLAN ID será 000a.0014. O dígito hexadecimal a representa a tag 10 da VLAN externa e o dígito hexadecimal 14 representa a tag 20 da VLAN interna.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface ou da VLAN.
- Entre na visualização da interface.
interface interface-type interface-number- Entre na visualização de VLAN.
vlan vlan-idOBSERVAÇÃO:
A visualização de VLAN é compatível apenas com a versão 6348P01 e posteriores.
- Habilite o DHCP snooping para dar suporte à Opção 82.
dhcp snooping information enablePor padrão, o DHCP snooping não é compatível com a Option 82.
- (Opcional.) Configure uma estratégia de tratamento para solicitações DHCP que contenham a Opção 82.
dhcp snooping information strategy { append | drop | keep | replace }Por padrão, a estratégia de tratamento é substituir.
Se a estratégia de tratamento for anexar ou substituir, configure um modo de preenchimento e um formato de preenchimento para a Opção 82. Se a estratégia de tratamento for manter ou soltar, você não precisará configurar nenhum modo ou formato de preenchimento para a Opção 82.
- (Opcional.) Configure o modo de preenchimento e o formato de preenchimento para a subopção Circuit ID.
dhcp snooping information circuit-id { normal-extended | [ vlan
vlan-id ] string circuit-id | { normal | verbose [ node-identifier { mac |
sysname | user-defined node-identifier } ] } [ format { ascii | hex } ] }Por padrão, o modo de preenchimento é normal e o formato de preenchimento é hexadecimal para a subopção Circuit ID.
Se o nome do dispositivo (sysname) estiver configurado como conteúdo de preenchimento para a subopção 1, certifique-se de que o nome do dispositivo não inclua espaços. Caso contrário, o dispositivo DHCP snooping não conseguirá adicionar ou substituir a Opção 82.
Quando você usa esse comando na visualização de VLAN, não há suporte para a opção vlan vlan-id. A palavra-chave normal-extended é compatível apenas com a versão 6328 e posteriores.
- (Opcional.) Configure o modo de preenchimento e o formato de preenchimento para a subopção ID remota.
dhcp snooping information remote-id { normal [ format { ascii | hex } ] |
[ vlan vlan-id ] string remote-id | sysname }Por padrão, o modo de preenchimento é normal e o formato de preenchimento é hexadecimal para a subopção Remote ID.
Quando você usa esse comando na visualização de VLAN, não há suporte para a opção vlan vlan-id. Esse comando é compatível apenas com a versão 6348P01 e posteriores.
- (Opcional.) Configure o modo de preenchimento para a subopção Vendor-Specific.
dhcp snooping information vendor-specific [ vlan vlan-id ] bas
[ node-identifier { mac | sysname | user-defined string } ]
Por padrão, o dispositivo não preenche a subopção Vendor-Specific.
Quando você usa esse comando na visualização de VLAN, a opção vlan vlan-id não é suportada.
Configuração do backup automático de entradas do DHCP snooping
Sobre o backup automático de entradas do DHCP snooping
O recurso de backup automático salva as entradas do DHCP snooping em um arquivo de backup e permite que o dispositivo de DHCP snooping faça o download das entradas do arquivo de backup na reinicialização do dispositivo. As entradas no dispositivo de snooping DHCP não sobrevivem a uma reinicialização. O backup automático ajuda os recursos de segurança a fornecer serviços se esses recursos (como o IP source guard) precisarem usar entradas do DHCP snooping para autenticação do usuário.
Restrições e diretrizes
Se você desativar o snooping DHCP com o comando undo dhcp snooping enable, o dispositivo excluirá todas as entradas do snooping DHCP, mas as entradas armazenadas no arquivo de backup ainda existirão. Elas serão excluídas na próxima vez que o dispositivo atualizar o arquivo de backup.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o dispositivo de snooping DHCP para fazer backup das entradas de snooping DHCP em um arquivo.
dhcp snooping binding database filename { filename | url url [ username
username [ password { cipher | simple } string ] ] }
Por padrão, o dispositivo de snooping DHCP não faz backup das entradas de snooping DHCP.
Com esse comando executado, o dispositivo de snooping DHCP faz o backup das entradas de snooping DHCP imediatamente e executa o backup automático.
Esse comando cria automaticamente o arquivo se você especificar um arquivo inexistente.
- (Opcional.) Salve manualmente as entradas do DHCP snooping no arquivo de backup.
dhcp snooping binding database update now- (Opcional.) Defina o tempo de espera após a alteração de uma entrada de DHCP snooping para que o dispositivo de DHCP snooping atualize o arquivo de backup.
dhcp snooping binding database update interval intervalPor padrão, o dispositivo de snooping DHCP aguarda 300 segundos para atualizar o arquivo de backup após a alteração de uma entrada de snooping DHCP. Se nenhuma entrada do DHCP snooping for alterada, o arquivo de backup não será atualizado.
Definição do número máximo de entradas de DHCP snooping
Sobre a configuração do número máximo de entradas do DHCP snooping
Execute essa tarefa para evitar que os recursos do sistema sejam usados em excesso.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o número máximo de entradas de DHCP snooping para a interface aprender.
dhcp snooping max-learning-num max-numberPor padrão, o número de entradas de DHCP snooping a serem aprendidas por uma interface é ilimitado.
Configuração do limite de taxa de pacotes DHCP
Sobre o limite de taxa de pacotes DHCP
Execute esta tarefa para definir a taxa máxima na qual uma interface pode receber pacotes DHCP. Esse recurso descarta os pacotes DHCP excedentes para evitar ataques que enviam um grande número de pacotes DHCP.
Restrições e diretrizes
A taxa definida na interface agregada da Camada 2 aplica-se a todos os membros da interface agregada. Se uma interface membro deixar o grupo de agregação, ela usará a taxa definida em sua visualização de interface Ethernet.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilite o limite de taxa de pacotes do DHCP snooping em uma interface e defina o valor do limite.
dhcp snooping rate-limit ratePor padrão, o limite de taxa de pacotes do DHCP snooping é desativado em uma interface.
Configuração dos recursos de segurança do DHCP snooping
Ativação da proteção contra ataques de inanição de DHCP
Sobre a proteção contra ataques de inanição de DHCP
Um ataque de inanição de DHCP ocorre quando um invasor envia constantemente solicitações de DHCP forjadas que contêm endereços MAC de remetente idênticos ou diferentes no campo chaddr para um servidor DHCP. Esse ataque esgota os recursos de endereço IP do servidor DHCP para que os clientes DHCP legítimos não possam obter endereços IP. O servidor DHCP também pode deixar de funcionar devido ao esgotamento dos recursos do sistema. Para obter informações sobre os campos do pacote DHCP, consulte "Formato da mensagem DHCP".
Você pode evitar ataques de inanição de DHCP das seguintes maneiras:
∙ Se as solicitações forjadas de DHCP contiverem endereços MAC de remetentes diferentes, use o comando mac-address max-mac-count para definir o limite de aprendizado de MAC em uma porta da Camada 2. Para obter mais informações sobre o comando, consulte Referência de comandos de comutação da camada 2-LAN.
∙ Se as solicitações forjadas de DHCP contiverem o mesmo endereço MAC do remetente, execute esta tarefa para ativar a verificação de endereço MAC para o DHCP snooping. Esse recurso compara o campo chaddr de uma solicitação DHCP recebida com o campo de endereço MAC de origem no cabeçalho do quadro. Se eles forem iguais, a solicitação será considerada válida e encaminhada ao servidor DHCP. Caso contrário, a solicitação será descartada.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar a verificação de endereço MAC.
dhcp snooping check mac-addressPor padrão, a verificação de endereço MAC está desativada.
Ativação da proteção contra ataques DHCP-REQUEST
Sobre a proteção contra ataques DHCP-REQUEST
As mensagens DHCP-REQUEST incluem pacotes de renovação de concessão de DHCP, pacotes DHCP-DECLINE e pacotes DHCP-RELEASE. Esse recurso impede que clientes não autorizados que falsificam as mensagens DHCP-REQUEST ataquem o servidor DHCP.
Os invasores podem forjar pacotes de renovação de concessão de DHCP para renovar concessões para clientes DHCP legítimos que não precisam mais dos endereços IP. Essas mensagens forjadas impedem que o servidor DHCP da vítima libere os endereços IP.
Os invasores também podem forjar pacotes DHCP-DECLINE ou DHCP-RELEASE para encerrar concessões para clientes DHCP legítimos que ainda precisam dos endereços IP.
Para evitar esses ataques, você pode ativar a verificação DHCP-REQUEST. Esse recurso usa entradas do DHCP snooping para verificar as mensagens DHCP-REQUEST recebidas.
∙ Se for encontrada uma entrada correspondente a uma mensagem, esse recurso comparará a entrada com as informações da mensagem.
⚪ Se forem consistentes, a mensagem será considerada válida e encaminhada ao servidor DHCP.
⚪ Se forem diferentes, a mensagem é considerada forjada e é descartada.
∙ Se não for encontrada nenhuma entrada correspondente, a mensagem será considerada válida e encaminhada ao servidor DHCP.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar a verificação de DHCP-REQUEST.
dhcp snooping check request-messagePor padrão, a verificação DHCP-REQUEST está desativada.
Configuração de uma porta de bloqueio de pacotes DHCP
Sobre a porta de bloqueio de pacotes DHCP
Execute esta tarefa para configurar uma porta como uma porta de bloqueio de pacotes DHCP. Essa porta de bloqueio descarta todas as solicitações DHCP de entrada.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure a porta para bloquear solicitações de DHCP.
dhcp snooping denyPor padrão, a porta não bloqueia solicitações de DHCP.
Para evitar falhas na aquisição de endereços IP, configure uma porta para bloquear pacotes DHCP somente se nenhum cliente DHCP estiver conectado a ela.
Ativação do registro do DHCP snooping
Sobre o registro do DHCP snooping
O recurso de registro de snooping DHCP permite que o dispositivo de snooping DHCP gere registros de snooping DHCP e os envie para o centro de informações. As informações ajudam os administradores a localizar e resolver problemas. Para obter informações sobre o destino do registro e a configuração da regra de saída no centro de informações , consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Restrições e diretrizes
Como prática recomendada, desative esse recurso se a geração de registros afetar o desempenho do dispositivo.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o registro do DHCP snooping.
dhcp snooping log enablePor padrão, o registro do DHCP snooping está desativado.
Desativação do DHCP snooping em uma interface
Sobre a desativação do DHCP snooping em uma interface
Esse recurso permite restringir o intervalo de interfaces em que o snooping DHCP entra em vigor. Por exemplo, para ativar o snooping DHCP globalmente, exceto para uma interface específica, você pode ativar o snooping DHCP globalmente e desativar o snooping DHCP na interface de destino.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Desativar o DHCP snooping na interface.
dhcp snooping disablePor padrão:
- Se você ativar o DHCP snooping globalmente ou para uma VLAN, o DHCP snooping será ativado em todas as interfaces do dispositivo ou em todas as interfaces da VLAN.
- Se você não ativar o DHCP snooping globalmente ou para uma VLAN, o DHCP snooping será desativado em todas as interfaces do dispositivo ou em todas as interfaces da VLAN.
Comandos de exibição e manutenção para DHCP snooping
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir entradas de DHCP snooping. | display dhcp snooping binding [ ip ip-address [ vlan vlan-id ] ] [ verbose ] |
| Tarefa | Comando |
| Exibir informações sobre o arquivo que armazena as entradas do DHCP snooping. | exibir banco de dados de vinculação do dhcp snooping |
| Exibir informações de configuração da Opção 82 no dispositivo DHCP snooping. | display dhcp snooping information { all | interface interface-type interface-number } |
| Exibir estatísticas de pacotes DHCP no dispositivo DHCP snooping. | exibir estatísticas de pacotes do dhcp snooping [ slot slot-número ] |
| Exibir informações sobre portas confiáveis. | display dhcp snooping trust |
| Limpar entradas de DHCP snooping. | reset dhcp snooping binding { all | ip ip-address [ vlan vlan-id ] } |
| Limpar as estatísticas de pacotes DHCP no dispositivo DHCP snooping. | reset dhcp snooping packet statistics [ slot slot-number ] |
Exemplos de configuração do DHCP snooping
Exemplo: Configuração global dos recursos básicos do DHCP snooping
Configuração de rede
Conforme mostrado na Figura 22, o Switch B está conectado ao servidor DHCP autorizado por meio da GigabitEthernet 1/0/1, ao servidor DHCP não autorizado por meio da GigabitEthernet 1/0/3 e ao cliente DHCP por meio da GigabitEthernet 1/0/2.
Configure somente a porta conectada ao servidor DHCP autorizado para encaminhar as respostas do servidor DHCP. Habilite o dispositivo DHCP snooping para registrar as associações de IP para MAC dos clientes lendo as mensagens DHCP-ACK recebidas da porta confiável e as mensagens DHCP-REQUEST.
Figura 22 Diagrama de rede
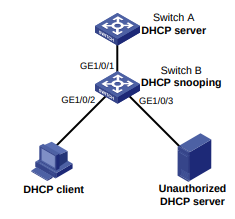
Procedimento
# Habilite o DHCP snooping globalmente.
<SwitchB> system-view
[SwitchB] dhcp snooping enable# Configure a GigabitEthernet 1/0/1 como uma porta confiável.
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] dhcp snooping trust
[SwitchB-GigabitEthernet1/0/1] quit# Habilite o registro das associações de IP para MAC dos clientes na GigabitEthernet 1/0/2.
[SwitchB] interface gigabitethernet 1/0/2
[SwitchB-GigabitEthernet1/0/2] dhcp snooping binding record
[SwitchB-GigabitEthernet1/0/2] quitVerificação da configuração
# Verifique se o cliente DHCP pode obter um endereço IP e outros parâmetros de configuração somente do servidor DHCP autorizado. (Detalhes não mostrados.)
# Exibir a entrada de DHCP snooping registrada para o cliente.
[SwitchB] display dhcp snooping bindingExemplo: Configuração de recursos básicos de DHCP snooping para uma VLAN
Configuração de rede
Conforme mostrado na Figura 23, o Switch B está conectado ao servidor DHCP autorizado por meio da GigabitEthernet 1/0/1, ao servidor DHCP não autorizado por meio da GigabitEthernet 1/0/3 e ao cliente DHCP por meio da GigabitEthernet 1/0/2.
Configure apenas a porta na VLAN 100 conectada ao servidor DHCP autorizado para encaminhar as respostas do servidor DHCP. Habilite a porta na VLAN 100 para registrar as associações de IP para MAC dos clientes lendo as mensagens DHCP-ACK recebidas da porta confiável e as mensagens DHCP-REQUEST.
Figura 23 Diagrama de rede
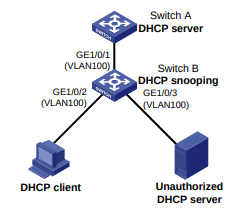
Procedimento
# Atribuir GigabitEthernet 1/0/1, GigabitEthernet 1/0/2 e GigabitEthernet 1/0/3 à VLAN 100.
<SwitchB> system-view
[SwitchB] vlan 100
[SwitchB-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/3
[SwitchB-vlan100] quit# Habilite o DHCP snooping para a VLAN 100.
[SwitchB] dhcp snooping enable vlan 100# Configure a GigabitEthernet 1/0/1 como porta confiável de DHCP snooping.
[SwitchB] vlan 100
[SwitchB-vlan100] dhcp snooping trust interface gigabitethernet 1/0/1# Habilite o registro das associações de IP para MAC dos clientes na VLAN 100.
[SwitchB-vlan100] dhcp snooping binding record
[SwitchB-vlan100] quitVerificação da configuração
# Verifique se o cliente DHCP pode obter um endereço IP e outros parâmetros de configuração somente do servidor DHCP autorizado. (Detalhes não mostrados.)
# Exibir a entrada de DHCP snooping registrada para o cliente.
[SwitchB] display dhcp snooping bindingExemplo: Configuração do suporte do DHCP snooping para a Opção 82
Configuração de rede
Conforme mostrado na Figura 24, ative o DHCP snooping e configure a Opção 82 no Switch B da seguinte forma:
∙ Configure a estratégia de tratamento das solicitações DHCP que contêm a Opção 82 como substituta.
∙ Na GigabitEthernet 1/0/2, configure o conteúdo de preenchimento da subopção Circuit ID como
company001 e para a subopção Remote ID como device001.
∙ Na GigabitEthernet 1/0/3, configure o modo de preenchimento da subopção Circuit ID como verbose, o identificador do nó de acesso como sysname e o formato de preenchimento como ascii. Configure o conteúdo de preenchimento da subopção Remote ID como device001.
Figura 24 Diagrama de rede
Procedimento
# Habilite o DHCP snooping.
<SwitchB> system-view
[SwitchB] dhcp snooping enable# Configure a GigabitEthernet 1/0/1 como uma porta confiável.
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] dhcp snooping trust
[SwitchB-GigabitEthernet1/0/1] quit# Configure a opção 82 na GigabitEthernet 1/0/2.
[SwitchB] interface gigabitethernet 1/0/2
[SwitchB-GigabitEthernet1/0/2] dhcp snooping information enable
[SwitchB-GigabitEthernet1/0/2] dhcp snooping information strategy replace
[SwitchB-GigabitEthernet1/0/2] dhcp snooping information circuit-id string company001
[SwitchB-GigabitEthernet1/0/2] dhcp snooping information remote-id string device001
[SwitchB-GigabitEthernet1/0/2] quit# Configure a opção 82 na GigabitEthernet 1/0/3.
[SwitchB] interface gigabitethernet 1/0/3
[SwitchB-GigabitEthernet1/0/3] dhcp snooping information enable
[SwitchB-GigabitEthernet1/0/3] dhcp snooping information strategy replace
[SwitchB-GigabitEthernet1/0/3] dhcp snooping information circuit-id verbose
node-identifier sysname format ascii
[SwitchB-GigabitEthernet1/0/3] dhcp snooping information remote-id string device001
Verificação da configuração
# Exibir informações de configuração da Option 82 na GigabitEthernet 1/0/2 e na GigabitEthernet 1/0/3 no dispositivo DHCP snooping.
[SwitchB] display dhcp snooping information
Configuração do cliente BOOTP
Sobre o cliente BOOTP
Aplicativo cliente BOOTP
Uma interface que atua como cliente BOOTP pode usar o BOOTP para obter informações (como endereço IP) do servidor BOOTP.
Para usar o BOOTP, o administrador deve configurar um arquivo de parâmetros BOOTP para cada cliente BOOTP no servidor BOOTP. O arquivo de parâmetros contém informações como o endereço MAC e o endereço IP de um cliente BOOTP. Quando um cliente BOOTP envia uma solicitação ao servidor BOOTP, o servidor BOOTP procura o arquivo de parâmetros BOOTP e retorna as informações de configuração correspondentes.
O BOOTP é normalmente usado em ambientes relativamente estáveis. Em ambientes de rede que mudam com frequência, o DHCP é mais adequado.
Como um servidor DHCP pode interagir com um cliente BOOTP, você pode usar o servidor DHCP para atribuir um endereço IP ao cliente BOOTP. Não é necessário configurar um servidor BOOTP. O servidor DHCP atribuirá um endereço IP ao cliente BOOTP com base na sequência de alocação de endereços IP.
Obtenção de um endereço IP dinamicamente
Um cliente BOOTP obtém dinamicamente um endereço IP de um servidor BOOTP da seguinte forma:
- O cliente BOOTP transmite uma solicitação BOOTP, que contém seu próprio endereço MAC.
- Ao receber a solicitação, o servidor BOOTP procura no arquivo de configuração o endereço IP e outras informações de acordo com o endereço MAC do cliente BOOTP.
- O servidor BOOTP retorna uma resposta BOOTP para o cliente BOOTP.
- O cliente BOOTP obtém o endereço IP a partir da resposta recebida.
Um servidor DHCP pode substituir o servidor BOOTP na seguinte aquisição de endereço IP dinâmico.
Protocolos e padrões
∙ RFC 951, Protocolo de bootstrap (BOOTP)
∙ RFC 2132, Opções de DHCP e extensões de fornecedor de BOOTP
∙ RFC 1542, Esclarecimentos e extensões para o protocolo Bootstrap
Configuração de uma interface para usar o BOOTP para aquisição de endereços IP
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-numberA configuração do cliente BOOTP se aplica somente às interfaces VLAN.
- Configure uma interface para usar o BOOTP para aquisição de endereços IP.
ip address bootp-allocPor padrão, uma interface não usa BOOTP para aquisição de endereços IP.
Comandos de exibição e manutenção para o cliente BOOTP
Executar o comando de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações do cliente BOOTP. | exibir cliente bootp [ interface interface-type interface-number ] |
Exemplos de configuração do cliente BOOTP
Exemplo: Configuração do cliente BOOTP
Configuração de rede
Conforme mostrado na Figura 9, a porta do Switch B pertencente à VLAN 10 está conectada à LAN. A interface VLAN 10 obtém um endereço IP do servidor DHCP usando BOOTP.
Para fazer com que o cliente BOOTP obtenha um endereço IP do servidor DHCP, você deve executar a configuração no servidor DHCP. Para obter mais informações, consulte "Configuração do servidor DHCP examples".
Procedimento
A seguir, descrevemos a configuração no Switch B, que atua como cliente.
# Configure a interface VLAN 10 para obter dinamicamente um endereço IP do servidor DHCP.
<SwitchB> system-view
[SwitchB] interface vlan-interface 10
[SwitchB-Vlan-interface10] ip address bootp-allocVerificação da configuração
# Exibir o endereço IP atribuído ao cliente BOOTP.
[SwitchB] display bootp clientConfiguração do DNS
Sobre o DNS
O DNS (Domain Name System, sistema de nomes de domínio) é um banco de dados distribuído usado por aplicativos TCP/IP para traduzir nomes de domínio em endereços IP. O mapeamento de nome de domínio para endereço IP é chamado de entrada de DNS.
Tipos de serviços de DNS
Os serviços de DNS podem ser estáticos ou dinâmicos. Depois que um usuário especifica um nome, o dispositivo verifica se há um endereço IP na tabela de resolução de nomes estáticos. Se nenhum endereço IP estiver disponível, ele entrará em contato com o servidor DNS para resolução dinâmica de nomes, o que leva mais tempo do que a resolução estática de nomes. Para aumentar a eficiência, você pode colocar os mapeamentos de nome para endereço IP consultados com frequência na tabela local de resolução de nomes estáticos .
Resolução estática de nomes de domínio
Resolução estática de nomes de domínio significa criar manualmente mapeamentos entre nomes de domínio e endereços IP. Por exemplo, você pode criar um mapeamento de DNS estático para um dispositivo de modo que possa fazer Telnet no dispositivo usando o nome de domínio.
Resolução dinâmica de nomes de domínio
Arquitetura
A Figura 1 mostra a relação entre o programa do usuário, o cliente DNS e o servidor DNS. O cliente DNS inclui o resolvedor e o cache. O programa do usuário e o cliente DNS podem ser executados no mesmo dispositivo ou em dispositivos diferentes. O servidor DNS e o cliente DNS geralmente são executados em dispositivos diferentes.
Figura 1 Resolução dinâmica de nomes de domínio
O dispositivo pode funcionar como um cliente DNS, mas não como um servidor DNS.
Se um alias estiver configurado para um nome de domínio no servidor DNS, o dispositivo poderá resolver o alias para o endereço IP do host.
Processo de resolução
O processo de resolução dinâmica de nomes de domínio é o seguinte:
- Um programa de usuário envia uma consulta de nome para o resolvedor do cliente DNS.
Armazenamento em cache
- O resolvedor de DNS procura uma correspondência no cache de nomes de domínio local. Se o resolvedor encontrar uma correspondência, ele envia de volta o endereço IP correspondente. Caso contrário, ele envia uma consulta ao servidor DNS.
- O servidor DNS procura o endereço IP correspondente ao nome de domínio em seu banco de dados DNS. Se nenhuma correspondência for encontrada, o servidor envia uma consulta a outros servidores DNS. Esse processo continua até que um resultado, bem-sucedido ou não, seja retornado.
- Depois de receber uma resposta do servidor DNS, o cliente DNS retorna o resultado da resolução para o programa do usuário.
A resolução dinâmica de nomes de domínio permite que o cliente DNS armazene as entradas de DNS mais recentes no cache do DNS. O cliente de DNS não precisa enviar uma solicitação ao servidor de DNS para uma consulta repetida dentro do tempo de envelhecimento. Para garantir que as entradas do servidor DNS estejam atualizadas, uma entrada de DNS é removida quando o tempo de envelhecimento expira. O servidor DNS determina por quanto tempo um mapeamento é válido, e o cliente DNS obtém as informações de envelhecimento das respostas do DNS.
Sufixos DNS
Você pode configurar uma lista de sufixos de nome de domínio para que o resolvedor possa usar a lista para fornecer a parte ausente de um nome incompleto.
Por exemplo, você pode configurar com como o sufixo de aabbcc.com. O usuário só precisa digitar aabbcc para obter o endereço IP de aabbcc.com. O resolvedor adiciona o sufixo e o delimitador antes de passar o nome para o servidor DNS.
O resolvedor de nomes trata as consultas com base nos nomes de domínio que o usuário insere:
∙ Se o usuário inserir um nome de domínio sem um ponto (.) (por exemplo, aabbcc), o resolvedor considerará o nome de domínio como um nome de host. Ele adiciona um sufixo DNS ao nome do host antes de executar a operação de consulta. Se nenhuma correspondência for encontrada para qualquer combinação de nome de host e sufixo, o resolvedor usará o nome de domínio inserido pelo usuário (por exemplo, aabbcc) para a consulta de endereço IP.
∙ Se o usuário inserir um nome de domínio com um ponto (.) entre as letras (por exemplo, www.aabbcc), o resolvedor usará diretamente esse nome de domínio para a operação de consulta. Se a consulta falhar, o resolvedor adicionará um sufixo de DNS para outra operação de consulta.
∙ Se o usuário digitar um nome de domínio com um ponto (.) no final (por exemplo, aabbcc.com.), o resolvedor considerará o nome de domínio como um FQDN e retornará o resultado da consulta com êxito ou com falha. O ponto no final do nome de domínio é considerado um símbolo de terminação.
Proxy DNS
O proxy DNS executa as seguintes funções:
∙ Encaminha a solicitação do cliente DNS para o servidor DNS designado.
∙ Transmite a resposta do servidor DNS para o cliente.
O proxy de DNS simplifica o gerenciamento da rede. Quando o endereço do servidor DNS é alterado, você pode alterar a configuração apenas no proxy DNS em vez de em cada cliente DNS.
A Figura 2 mostra o aplicativo proxy de DNS típico.
Figura 2 Aplicativo de proxy DNS
Um proxy DNS funciona da seguinte forma:
- Um cliente de DNS considera o proxy de DNS como o servidor de DNS e envia uma solicitação de DNS ao proxy de DNS. O endereço de destino da solicitação é o endereço IP do proxy de DNS.
- O proxy de DNS pesquisa a tabela de resolução de nomes de domínio estático local e o cache de resolução de nomes de domínio dinâmico após receber a solicitação. Se as informações solicitadas forem encontradas, o proxy de DNS retornará uma resposta de DNS ao cliente.
- Se as informações solicitadas não forem encontradas, o proxy DNS enviará a solicitação ao servidor DNS designado para resolução do nome de domínio.
- Depois de receber uma resposta do servidor DNS, o proxy DNS registra o mapeamento de endereço IP para nome de domínio e encaminha a resposta para o cliente DNS.
Se nenhum servidor DNS for designado ou se nenhuma rota estiver disponível para o servidor DNS designado, o proxy DNS não encaminhará solicitações de DNS.
Falsificação de DNS
Conforme mostrado na Figura 3, a falsificação de DNS é aplicada à rede dial-up.
∙ O dispositivo se conecta a uma rede PSTN/ISDN por meio de uma interface dial-up. O dispositivo aciona o estabelecimento de uma conexão dial-up somente quando os pacotes devem ser encaminhados pela interface dial-up.
∙ O dispositivo atua como um proxy de DNS e é especificado como um servidor de DNS nos hosts. Depois que a conexão dial-up é estabelecida, o dispositivo obtém dinamicamente o endereço do servidor DNS por meio de DHCP ou outro mecanismo de autoconfiguração.
Figura 3 Aplicativo de falsificação de DNS
O proxy DNS não tem o endereço do servidor DNS ou não consegue acessar o servidor DNS após a inicialização. Um host acessa o servidor HTTP nas seguintes etapas:
- O host envia uma solicitação de DNS ao dispositivo para resolver o nome de domínio do servidor HTTP em um endereço IP.
- Ao receber a solicitação, o dispositivo pesquisa as entradas locais de DNS estático e dinâmico em busca de uma correspondência. Como nenhuma correspondência é encontrada, o dispositivo falsifica o host respondendo com um endereço IP configurado. O dispositivo deve ter uma rota para o endereço IP com a interface dial-up como interface de saída.
O endereço IP configurado para falsificação de DNS não é o endereço IP real do nome de domínio solicitado. Portanto, o campo TTL é definido como 0 na resposta do DNS. Quando o cliente de DNS recebe a resposta, ele cria uma entrada de DNS e a envelhece imediatamente.
- Ao receber a resposta, o host envia uma solicitação HTTP para o endereço IP respondido.
- Ao encaminhar a solicitação HTTP por meio da interface dial-up, o dispositivo executa as seguintes operações:
- Estabelece uma conexão dial-up com a rede.
- Obtém dinamicamente o endereço do servidor DNS por meio de DHCP ou outro mecanismo de autoconfiguração.
- Como a entrada de DNS se esgota imediatamente após a criação, o host envia outra solicitação de DNS ao dispositivo para resolver o nome de domínio do servidor HTTP.
- O dispositivo funciona da mesma forma que um proxy de DNS. Para obter mais informações, consulte "Proxy DNS".
- Depois de obter o endereço IP do servidor HTTP, o host pode acessar o servidor HTTP.
Sem falsificação de DNS, o dispositivo encaminha as solicitações de DNS do host para o servidor DNS se não conseguir encontrar uma entrada de DNS local correspondente. No entanto, o dispositivo não pode obter o endereço do servidor DNS, pois não há conexão discada estabelecida. Portanto, o dispositivo não pode encaminhar ou responder às solicitações do cliente. A resolução de DNS falha e o cliente não consegue acessar o servidor HTTP.
Visão geral das tarefas do DNS
Para configurar o DNS, execute as seguintes tarefas:
- Configuração do cliente DNS
Escolha as seguintes tarefas, conforme necessário:
- Configuração da resolução estática de nomes de domínio
- Configuração da resolução dinâmica de nomes de domínio
- (Opcional.) Configuração do proxy DNS
Esse recurso é aplicado à rede dial-up.
- (Opcional.) Especificar a interface de origem para pacotes DNS
- (Opcional.) Configuração da interface confiável do DNS
- (Opcional.) Configuração do valor DSCP para pacotes DNS de saída
Configuração do cliente DNS
Configuração da resolução estática de nomes de domínio
Restrições e diretrizes
Cada nome de host é mapeado para apenas um endereço IPv4 e um endereço IPv6. É possível configurar um máximo de 2048 entradas de DNS.
Procedimento
- Entre na visualização do sistema.
system-view- Configure um mapeamento de nome de host para endereço. Escolha as opções para configurar conforme necessário: IPv4:
ip host host-name ip-addressIPv6:
ipv6 host host-name ipv6-addressConfiguração da resolução dinâmica de nomes de domínio
Restrições e diretrizes
∙ O limite do número de servidores DNS no dispositivo é o seguinte:
⚪ Na visualização do sistema, você pode especificar um máximo de seis endereços IPv4 de servidor DNS.
⚪ Na visualização do sistema, você pode especificar um máximo de seis endereços IPv6 de servidor DNS.
⚪ Na visualização da interface, você pode especificar no máximo seis endereços IPv4 de servidor DNS.
∙ É necessário um endereço de servidor DNS para que as consultas de DNS possam ser enviadas a um servidor correto para resolução. Se você especificar um endereço IPv4 e um endereço IPv6, o dispositivo executará as seguintes operações:
⚪ Envia uma consulta de DNS IPv4 primeiro para os endereços IPv4 do servidor DNS. Se a consulta falhar, o dispositivo se voltará para os endereços IPv6 do servidor DNS.
⚪ Envia uma consulta de DNS IPv6 primeiro para os endereços IPv6 do servidor DNS. Se a consulta falhar, os dispositivos se voltam para os endereços IPv4 do servidor DNS.
∙ Um endereço de servidor DNS especificado na visualização do sistema tem prioridade sobre um endereço de servidor DNS especificado na visualização da interface. Um endereço de servidor DNS especificado anteriormente tem prioridade mais alta. Um endereço de servidor DNS especificado manualmente tem prioridade sobre um endereço de servidor DNS obtido dinamicamente, por exemplo, por meio de DHCP. O dispositivo envia primeiro uma consulta de DNS para o endereço de servidor DNS de maior prioridade. Se a primeira consulta falhar, ele enviará a consulta de DNS para o endereço de servidor DNS de segunda prioridade mais alta e assim por diante.
∙ É possível configurar um sufixo DNS que o sistema adiciona automaticamente ao nome de domínio incompleto inserido por um usuário.
⚪ Você pode configurar um máximo de 16 sufixos de DNS.
⚪ Um sufixo DNS configurado manualmente tem prioridade sobre um sufixo DNS obtido dinamicamente, por exemplo, por meio de DHCP. Um sufixo DNS configurado anteriormente tem uma prioridade mais alta. O dispositivo usa primeiro o sufixo que tem a prioridade mais alta. Se a consulta falhar, o dispositivo usará o sufixo com a segunda prioridade mais alta, e assim por diante.
Procedimento
- Entre na visualização do sistema.
system-view- (Opcional.) Configure um sufixo DNS.
dns domain domain-namePor padrão, nenhum sufixo DNS é configurado e somente o nome de domínio inserido pelo usuário é resolvido.
- Especifique um endereço de servidor DNS. IPv4:
dns server ip-addressIPv6:
ipv6 dns server ipv6-address [ interface-type interface-number ]sEm versões anteriores à versão 6348P01, nas configurações padrão de fábrica, nenhum endereço de servidor DNS é especificado.
Na versão 6348P01 e posteriores:
- Na configuração inicial, nenhum endereço de servidor DNS é especificado.
- Nas configurações padrão de fábrica, é especificado um servidor DNS com endereço IP 114.114.114.114.
Para obter mais informações sobre a configuração inicial e as configurações padrão de fábrica, consulte o gerenciamento de arquivos de configuração no Guia de Configuração Básica.
Configuração do proxy DNS
Restrições e diretrizes
Você pode especificar vários servidores DNS. O proxy de DNS encaminha uma solicitação ao servidor de DNS que tem a prioridade mais alta. Se não tiver recebido uma resposta, ele encaminhará a solicitação ao servidor DNS que tiver a segunda prioridade mais alta e assim por diante.
Você pode especificar um endereço IPv4 e um endereço IPv6.
∙ Um proxy de DNS encaminha uma consulta de nome IPv4 primeiro para servidores DNS IPv4. Se nenhuma resposta for recebida, ele encaminha a solicitação aos servidores DNS IPv6.
∙ Um proxy de DNS encaminha uma consulta de nome IPv6 primeiro para servidores DNS IPv6. Se nenhuma resposta for recebida, ele encaminha a solicitação aos servidores DNS IPv4.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar proxy DNS.
dns proxy enablePor padrão, o proxy DNS está desativado.
- Especifique um endereço de servidor DNS. IPv4:
dns server ip-addressIPv6:
ipv6 dns server ipv6-address [ interface-type interface-number ]sPor padrão, nenhum endereço de servidor DNS é especificado.
Configuração de spoofing de DNS
Restrições e diretrizes
∙ Você pode configurar apenas um endereço IPv4 respondido e um endereço IPv6 respondido. Se você executar o comando várias vezes, a configuração mais recente terá efeito.
∙ Depois que a falsificação de DNS entra em vigor, o dispositivo falsifica uma solicitação de DNS mesmo que exista uma entrada de DNS estático correspondente.
Pré-requisitos
O proxy DNS está ativado no dispositivo.
Nenhum servidor DNS ou rota para qualquer servidor DNS está especificado no dispositivo.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar proxy DNS.
dns proxy enablePor padrão, o proxy DNS está desativado.
- Habilite a falsificação de DNS e especifique o endereço IP usado para falsificar solicitações de DNS. Escolha uma opção conforme necessário:
IPv4:
dns spoofing ip-addressIPv6:
ipv6 dns spoofing ipv6-addressPor padrão, a falsificação de DNS está desativada.
Especificação da interface de origem para pacotes DNS
Sobre a interface de origem dos pacotes DNS
Essa tarefa permite que o dispositivo sempre use o endereço IP primário da interface de origem especificada como o endereço IP de origem dos pacotes DNS de saída. Esse recurso se aplica a cenários em que o servidor DNS responde apenas a solicitações de DNS originadas de um endereço IP específico. Se nenhum endereço IP estiver configurado na interface de origem, nenhum pacote DNS poderá ser enviado.
Restrições e diretrizes
Ao enviar uma solicitação de DNS IPv6, o dispositivo segue o método definido na RFC 3484 para selecionar um endereço IPv6 da interface de origem.
Você pode configurar apenas uma interface de origem.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique a interface de origem dos pacotes DNS.
dns source-interface interface-type interface-numberPor padrão, nenhuma interface de origem para pacotes DNS é especificada.
Configuração da interface confiável do DNS
Sobre a interface confiável do DNS
Essa tarefa permite que o dispositivo use apenas o sufixo DNS e as informações do servidor de nomes de domínio obtidas por meio da interface confiável. O dispositivo pode então obter o endereço IP resolvido correto. Esse recurso protege o dispositivo contra invasores que atuam como servidor DHCP para atribuir sufixo DNS e endereço de servidor de nome de domínio incorretos.
Restrições e diretrizes
Você pode configurar um máximo de 128 interfaces confiáveis de DNS.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique a interface confiável do DNS.
dns trust-interface interface-type interface-numberPor padrão, nenhuma interface confiável de DNS é especificada.
Configuração do valor DSCP para pacotes DNS de saída
Sobre o valor DSCP para pacotes DNS de saída
O valor DSCP de um pacote especifica o nível de prioridade do pacote e afeta a prioridade de transmissão do pacote. Um valor DSCP maior representa uma prioridade mais alta.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o valor DSCP para pacotes DNS enviados por um cliente DNS ou um proxy DNS. IPv4:
dns dscp dscp-valuePor padrão, o valor DSCP é 0 nos pacotes DNS IPv4 enviados por um cliente DNS ou um proxy DNS. IPv6:
ipv6 dns dscp dscp-valuePor padrão, o valor DSCP é 0 nos pacotes DNS IPv6 enviados por um cliente DNS ou um proxy DNS.
Comandos de exibição e manutenção do DNS
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir sufixos DNS. | exibir domínio dns [ dinâmico ] |
| Exibir a tabela de resolução de nomes de domínio. | exibir host dns [ ip | ipv6 ] |
| Exibir informações do servidor DNS IPv4. | exibir servidor dns [ dinâmico ] |
| Exibir informações do servidor DNS IPv6. | exibir servidor ipv6 dns [ dinâmico ] |
| Limpar entradas de DNS dinâmico. | reset dns host [ ip | ipv6 ] |
Exemplos de configuração do DNS IPv4
Exemplo: Configuração da resolução estática de nomes de domínio
Configuração de rede
Conforme mostrado na Figura 4, o host em 10.1.1.2 tem o nome de host.com. Configure o DNS IPv4 estático no dispositivo para que ele possa usar o nome de domínio fácil de lembrar em vez do endereço IP para acessar o host.
Figura 4 Diagrama de rede

Procedimento
# Configure um mapeamento entre o nome do host host.com e o endereço IP 10.1.1.2.
<Sysname> system-view
[Sysname] ip host host.com 10.1.1.2
# Verifique se o dispositivo pode usar a resolução de nome de domínio estático para resolver o nome de domínio host.com
no endereço IP 10.1.1.2.
[Sysname] ping host.com
Ping host.com (10.1.1.2): 56 data bytes, press CTRL_C to break
56 bytes from 10.1.1.2: icmp_seq=0 ttl=255 time=1.000 ms
56 bytes from 10.1.1.2: icmp_seq=1 ttl=255 time=1.000 ms
56 bytes from 10.1.1.2: icmp_seq=2 ttl=255 time=1.000 ms
56 bytes from 10.1.1.2: icmp_seq=3 ttl=255 time=1.000 ms
56 bytes from 10.1.1.2: icmp_seq=4 ttl=255 time=2.000 ms
--- Ping statistics for host.com ---
5 packet(s) transmitted, 5 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 1.000/1.200/2.000/0.400 msExemplo: Configuração da resolução dinâmica de nomes de domínio
Configuração de rede
Conforme mostrado na Figura 5, configure o servidor DNS para armazenar o mapeamento entre o nome de domínio host do host e o endereço IPv4 3.1.1.1/16 no domínio com. Configure o DNS IPv4 dinâmico e o sufixo DNS com no dispositivo para que ele possa usar o nome de domínio host para acessar o host.
Figura 5 Diagrama de rede
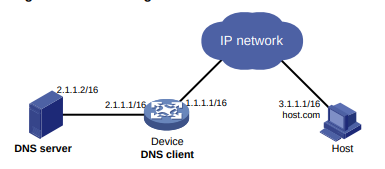
Procedimento
Antes de realizar a configuração a seguir, certifique-se de que:
∙ O dispositivo e o host podem se comunicar entre si.
∙ Os endereços IP das interfaces são configurados conforme mostrado na Figura 5.
- Configure o servidor DNS:
A configuração pode variar de acordo com o servidor DNS. A configuração a seguir é realizada em um PC com Windows Server 2008 R2.
- Selecione Iniciar > Programas > Ferramentas administrativas > DNS.
A página de configuração do servidor DNS é exibida, conforme mostrado na Figura 6.
- Clique com o botão direito do mouse em Forward Lookup Zones, selecione New Zone e siga o assistente para criar uma nova zona chamada com.
Figura 6 Criação de uma zona
- Na página de configuração do servidor DNS, clique com o botão direito do mouse na zona com e selecione New Host.
Figura 7: Adição de um host
- Na página que aparece, digite o nome do host e o endereço IP 3.1.1.1.
- Clique em Add Host.
O mapeamento entre o endereço IP e o nome do host é criado.
Figura 8: Adição de um mapeamento entre o nome de domínio e o endereço IP
- Configure o cliente DNS:
# Especifique o servidor DNS 2.1.1.2.
<Sysname> system-view
[Sysname] dns server 2.1.1.2
Verificação da configuração
# Verifique se o dispositivo pode usar a resolução dinâmica de nome de domínio para resolver o nome de domínio
[Sysname] ping host
Ping host.com (3.1.1.1): 56 data bytes, press CTRL_C to break
56 bytes from 3.1.1.1: icmp_seq=0 ttl=255 time=1.000 ms
56 bytes from 3.1.1.1: icmp_seq=1 ttl=255 time=1.000 ms
56 bytes from 3.1.1.1: icmp_seq=2 ttl=255 time=1.000 ms
56 bytes from 3.1.1.1: icmp_seq=3 ttl=255 time=1.000 ms
56 bytes from 3.1.1.1: icmp_seq=4 ttl=255 time=2.000 ms
--- Ping statistics for host ---
5 packet(s) transmitted, 5 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 1.000/1.200/2.000/0.400 ms
Exemplo: Configuração do proxy DNS
Configuração de rede
Conforme mostrado na Figura 9, configure o Dispositivo A como proxy de DNS para encaminhar pacotes de DNS entre o cliente de DNS (Dispositivo B) e o servidor de DNS em 4.1.1.1.
Figura 9 Diagrama de rede
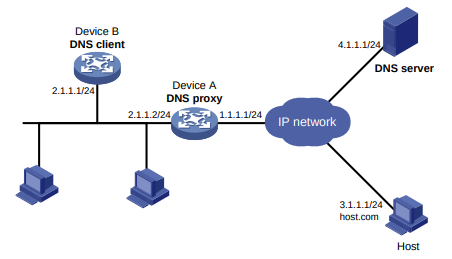
Procedimento
Antes de realizar a configuração a seguir, certifique-se de que:
∙ O dispositivo A, o servidor DNS e o host podem se comunicar entre si.
∙ Os endereços IP das interfaces são configurados conforme mostrado na Figura 9.
- Configure o servidor DNS:
A configuração pode variar de acordo com o servidor DNS. Quando um PC que executa o Windows Server 2008 R2 atua como servidor DNS, consulte "Exemplo: Configuração da resolução dinâmica de nomes de domínio" para obter informações de configuração.
- Configure o proxy DNS:
# Especifique o servidor DNS 4.1.1.1.
<DeviceA> system-view
[DeviceA] dns server 4.1.1.1
# Habilite o proxy DNS.
[DeviceA] dns proxy enable- Configure o cliente DNS:
<DeviceB> system-viewe# Especifique o servidor DNS 2.1.1.2.
[DeviceB] dns server 2.1.1.2Verificação da configuração
# Verifique se o proxy DNS no dispositivo A funciona.
[DeviceB] ping host.com
Ping host.com (3.1.1.1): 56 data bytes, press CTRL_C to break
56 bytes from 3.1.1.1: icmp_seq=0 ttl=255 time=1.000 ms
56 bytes from 3.1.1.1: icmp_seq=1 ttl=255 time=1.000 ms
56 bytes from 3.1.1.1: icmp_seq=2 ttl=255 time=1.000 ms
56 bytes from 3.1.1.1: icmp_seq=3 ttl=255 time=1.000 ms
56 bytes from 3.1.1.1: icmp_seq=4 ttl=255 time=2.000 ms
--- Ping statistics for host.com ---
5 packet(s) transmitted, 5 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 1.000/1.200/2.000/0.400 msExemplos de configuração do DNS IPv6
Exemplo: Configuração da resolução estática de nomes de domínio
Configuração de rede
Conforme mostrado na Figura 10, o host em 1::2 tem o nome de host.com. Configure o DNS IPv6 estático no dispositivo para que ele possa usar o nome de domínio fácil de lembrar em vez do endereço IPv6 para acessar o host.
Figura 10 Diagrama de rede

Procedimento
# Configure um mapeamento entre o nome do host host.com e o endereço IPv6 1::2.
<Device> system-view
[Device] ipv6 host host.com 1::2# Verifique se o dispositivo pode usar a resolução de nome de domínio estático para resolver o nome de domínio host.com
no endereço IPv6 1::2.
[Sysname] ping ipv6 host.com
Ping6(56 data bytes) 1::1 --> 1::2, press CTRL_C to break
56 bytes from 1::2, icmp_seq=0 hlim=128 time=1.000 ms
56 bytes from 1::2, icmp_seq=1 hlim=128 time=0.000 ms
56 bytes from 1::2, icmp_seq=2 hlim=128 time=1.000 ms
56 bytes from 1::2, icmp_seq=3 hlim=128 time=1.000 ms
56 bytes from 1::2, icmp_seq=4 hlim=128 time=0.000 ms
--- Ping6 statistics for host.com ---
5 packet(s) transmitted, 5 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 0.000/0.600/1.000/0.490 ms
Exemplo: Configuração da resolução dinâmica de nomes de domínio
Configuração de rede
Conforme mostrado na Figura 11, configure o servidor DNS para armazenar o mapeamento entre o nome de domínio host do host e o endereço IPv6 1::1/64 no domínio com. Configure o DNS IPv6 dinâmico e o sufixo DNS com no dispositivo para que ele possa usar o nome de domínio host para acessar o host.
Figura 11 Diagrama de rede
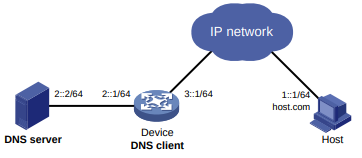
Procedimento
Antes de realizar a configuração a seguir, certifique-se de que:
∙ O dispositivo e o host podem se comunicar entre si.
∙ Os endereços IPv6 das interfaces são configurados conforme mostrado na Figura 11.
- Configure o servidor DNS:
A configuração pode variar de acordo com o servidor DNS. A configuração a seguir é realizada em um PC com o Windows Server 2008 R2. Certifique-se de que o servidor DNS ofereça suporte ao DNS IPv6 para que o servidor possa processar pacotes DNS IPv6 e suas interfaces possam encaminhar pacotes IPv6.
- Selecione Iniciar > Programas > Ferramentas administrativas > DNS.
A página de configuração do servidor DNS é exibida, conforme mostrado na Figura 12.
- Clique com o botão direito do mouse em Forward Lookup Zones, selecione New Zone e siga o assistente para criar uma nova zona chamada com.
Figura 12 Criação de uma zona
- Na página de configuração do servidor DNS, clique com o botão direito do mouse na zona com e selecione New Host.
Figura 13 Adição de um host
- Na página que aparece, digite o nome do host e o endereço IPv6 1::1.
- Clique em Add Host.
O mapeamento entre o endereço IPv6 e o nome do host é criado.
Figura 14: Adição de um mapeamento entre o nome de domínio e o endereço IPv6
- Configure o cliente DNS:
# Especifique o servidor DNS 2::2.
<Device> system-view
[Device] ipv6 dns server 2::2# Configure com como o sufixo DNS.
[Device] dns domain comVerificação da configuração
# Verifique se o dispositivo pode usar a resolução dinâmica de nomes de domínio para resolver o nome de domínio
host.com no endereço IP 1::1.
[Device] ping ipv6 host
Ping6(56 data bytes) 3::1 --> 1::1, press CTRL_C to break
56 bytes from 1::1, icmp_seq=0 hlim=128 time=1.000 ms
56 bytes from 1::1, icmp_seq=1 hlim=128 time=0.000 ms
56 bytes from 1::1, icmp_seq=2 hlim=128 time=1.000 ms
56 bytes from 1::1, icmp_seq=3 hlim=128 time=1.000 ms
56 bytes from 1::1, icmp_seq=4 hlim=128 time=0.000 ms
--- Ping6 statistics for host ---
5 packet(s) transmitted, 5 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 0.000/0.600/1.000/0.490 ms
Exemplo: Configuração do proxy DNS
Configuração de rede
Conforme mostrado na Figura 15, configure o Dispositivo A como proxy de DNS para encaminhar pacotes de DNS entre o cliente de DNS (Dispositivo B) e o servidor de DNS em 4000::1.
Figura 15 Diagrama de rede
Procedimento
Antes de realizar a configuração a seguir, certifique-se de que:
∙ O dispositivo A, o servidor DNS e o host podem ser acessados entre si.
∙ Os endereços IPv6 das interfaces são configurados conforme mostrado na Figura 15.
- Configure o servidor DNS:
Essa configuração pode variar de acordo com o servidor DNS. Quando um PC que executa o Windows Server 2008 R2 atua como servidor DNS, consulte "Exemplo: Configuração da resolução dinâmica de nomes de domínio" para obter informações de configuração.
- Configure o proxy DNS:
# Especifique o servidor DNS 4000::1.
<DeviceA> system-view
[DeviceA] ipv6 dns server 4000::1
# Habilite o proxy DNS.
[DeviceA] dns proxy enable- Configure o cliente DNS:
# Especifique o servidor DNS 2000::2.
<DeviceB> system-viewe
[DeviceB] ipv6 dns server 2000::2
Verificação da configuração
# Verifique se o proxy DNS no dispositivo A funciona.
[DeviceB] ping host.com
Ping6(56 data bytes) 2000::1 --> 3000::1, press CTRL_C to break
56 bytes from 3000::1, icmp_seq=0 hlim=128 time=1.000 ms
56 bytes from 3000::1, icmp_seq=1 hlim=128 time=0.000 ms
56 bytes from 3000::1, icmp_seq=2 hlim=128 time=1.000 ms
56 bytes from 3000::1, icmp_seq=3 hlim=128 time=1.000 ms
56 bytes from 3000::1, icmp_seq=4 hlim=128 time=0.000 ms
--- Ping6 statistics for host.com ---
5 packet(s) transmitted, 5 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 0.000/0.600/1.000/0.490 ms
Solução de problemas de configuração do DNS
Falha na resolução de endereços IPv4
Sintoma
Depois de ativar a resolução dinâmica de nomes de domínio, o usuário não consegue obter o endereço IP correto.
Solução
Para resolver o problema:
- Use o comando display dns host ip para verificar se o nome de domínio especificado está no cache.
- Se o nome de domínio especificado não existir, verifique se o cliente DNS pode se comunicar com o servidor DNS.
- Se o nome de domínio especificado estiver no cache, mas o endereço IP estiver incorreto, verifique se o cliente DNS tem o endereço IP correto do servidor DNS.
- Verifique se o mapeamento entre o nome de domínio e o endereço IP está correto no servidor DNS.
Falha na resolução de endereços IPv6
Sintoma
Depois de ativar a resolução dinâmica de nomes de domínio, o usuário não consegue obter o endereço IPv6 correto.
Solução
Para resolver o problema:
- Use o comando display dns host ipv6 para verificar se o nome de domínio especificado está no cache.
- Se o nome de domínio especificado não existir, verifique se a resolução dinâmica de nomes de domínio está ativada e se o cliente DNS pode se comunicar com o servidor DNS.
- Se o nome de domínio especificado estiver no cache, mas o endereço IPv6 estiver incorreto, verifique se o cliente DNS tem o endereço IPv6 correto do servidor DNS.
- Verifique se o mapeamento entre o nome de domínio e o endereço IPv6 está correto no servidor DNS.
Configuração das definições básicas de encaminhamento de IP
Sobre a tabela FIB
Um dispositivo usa a tabela FIB para tomar decisões de encaminhamento de pacotes.
Um dispositivo seleciona as rotas ideais da tabela de roteamento e as coloca na tabela FIB. Cada entrada FIB especifica o endereço IP do próximo salto e a interface de saída para pacotes destinados a uma sub-rede ou host específico.
Para obter mais informações sobre a tabela de roteamento, consulte o Guia de configuração de roteamento de IP de camada 3.
Use o comando display fib para exibir a tabela FIB. O exemplo a seguir exibe a tabela FIB inteira.
<Sysname> display fib
Destination count: 8 FIB entry count: 8
Flag:
U:Usable G:Gateway H:Host B:Blackhole D:Dynamic S:Static
R:Relay F:FRR
Destination/Mask Nexthop Flag OutInterface/Token Label
0.0.0.0/32 127.0.0.1 UH InLoop0 Null
127.0.0.0/8 127.0.0.1 U InLoop0 Null
127.0.0.0/32 127.0.0.1 UH InLoop0 Null
127.0.0.1/32 127.0.0.1 UH InLoop0 Null
127.255.255.255/32 127.0.0.1 UH InLoop0 Null
224.0.0.0/4 0.0.0.0 UB NULL0 Null
224.0.0.0/24 0.0.0.0 UB NULL0 Null
255.255.255.255/32 127.0.0.1 UH InLoop0 NullUma entrada FIB inclui os seguintes itens:
∙ Endereço IP de destino.
∙ Máscara - Máscara de rede. A máscara e o endereço de destino identificam a rede de destino. Uma operação lógica AND entre o endereço de destino e a máscara de rede produz o endereço da rede de destino. Por exemplo, se o endereço de destino for 192.168.1.40 e a máscara for 255.255.255.0, o endereço da rede de destino será 192.168.1.0. Uma máscara de rede inclui um determinado número de 1s consecutivos. Ela pode ser expressa no formato decimal com pontos ou pelo número de 1s.
∙ Nexthop - endereço IP do próximo salto.
∙ Bandeira - bandeira de rota.
∙ OutInterface - Interface de saída.
∙ Número de índice do caminho comutado de rótulos Token-MPLS.
∙ Etiqueta - Etiqueta interna.
Salvando as entradas de encaminhamento de IP em um arquivo
Restrições e diretrizes
O recurso cria automaticamente o arquivo se você especificar um arquivo inexistente. Se o arquivo já existir, esse recurso substituirá o conteúdo do arquivo.
Esse recurso aciona o salvamento único das entradas de encaminhamento de IP.
Para salvar automaticamente as entradas de encaminhamento de IP periodicamente, configure uma programação para que o dispositivo execute automaticamente o comando ip forwarding-table save. Para obter informações sobre agendamento de uma tarefa, consulte o Fundamentals Configuration Guide.
Procedimento
Para salvar as entradas de encaminhamento de IP em um arquivo, execute o seguinte comando em qualquer visualização:
ip forwarding-table save filename filename
Comandos de exibição e manutenção da tabela FIB
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir entradas FIB. | display fib [ ip-address [ mask | mask-length ] ] ] |
Configuração do avanço rápido
Sobre o avanço rápido
O encaminhamento rápido reduz o tempo de pesquisa de rota e melhora a eficiência do encaminhamento de pacotes usando um cache de alta velocidade e tecnologia baseada em fluxo de dados. Ele identifica um fluxo de dados usando os seguintes campos: endereço IP de origem, número da porta de origem, endereço IP de destino, número da porta de destino e número do protocolo. Depois que o primeiro pacote de um fluxo é encaminhado pela tabela de roteamento, o encaminhamento rápido cria uma entrada e usa essa entrada para encaminhar os pacotes subsequentes do fluxo.
Restrições e diretrizes: Configuração de avanço rápido
O encaminhamento rápido pode processar pacotes IP fragmentados, mas não fragmenta os pacotes IP.
Configuração do tempo de envelhecimento para entradas de avanço rápido
Sobre o tempo de envelhecimento para entradas de avanço rápido
A tabela de encaminhamento rápido usa um cronômetro de envelhecimento para cada entrada de encaminhamento. Se uma entrada não for atualizada antes da expiração do cronômetro, o dispositivo excluirá a entrada. Se uma entrada tiver um acerto dentro do tempo de envelhecimento, o cronômetro de envelhecimento será reiniciado.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o tempo de envelhecimento para entradas de avanço rápido.
ip fast-forwarding aging-time aging-timePor padrão, o tempo de envelhecimento é de 30 segundos.
Configuração do compartilhamento de carga de encaminhamento rápido
Sobre o avanço rápido do compartilhamento de carga
O compartilhamento de carga de encaminhamento rápido permite que o dispositivo identifique um fluxo de dados usando as informações do pacote.
Se o compartilhamento de carga de encaminhamento rápido estiver desativado, o dispositivo identificará um fluxo de dados pelas informações do pacote e pela interface de entrada.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o compartilhamento de carga de encaminhamento rápido. Escolha uma opção conforme necessário:
- Habilite o compartilhamento de carga de avanço rápido.
ip fast-forwarding load-sharing- Desative o compartilhamento de carga de encaminhamento rápido.
undo ip fast-forwarding load-sharingPor padrão, o compartilhamento de carga de avanço rápido está ativado.
Comandos de exibição e manutenção para avanço rápido
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibe o tempo de envelhecimento dos registros de avanço rápido. | display ip fast-forwarding aging-time |
| Exibir entradas de avanço rápido. | display ip fast-forwarding cache [ ip-address ] [ slot slot-number ] |
| Exibir entradas de encaminhamento rápido sobre pacotes fragmentados. | display ip fast-forwarding fragcache [ ip-address ] [ slot slot-número do slot ] |
| Limpar a tabela de avanço rápido. | reset ip fast-forwarding cache [ slot slot-number ] |
Otimização de performance IP
Ativação de uma interface para encaminhar transmissões direcionadas destinadas à rede diretamente conectada
Sobre o encaminhamento de transmissões destinadas à rede diretamente conectada
Um pacote de difusão direcionada é destinado a todos os hosts em uma rede específica. No endereço IP de destino do broadcast direcionado, o ID da rede identifica a rede de destino e o ID do host é composto de todos os uns.
Se uma interface tiver permissão para encaminhar transmissões direcionadas destinadas à rede diretamente conectada, os hackers poderão explorar essa vulnerabilidade para atacar a rede de destino. Em alguns cenários, entretanto, uma interface deve enviar esses pacotes de broadcast direcionado para oferecer suporte aos seguintes recursos:
∙ UDP helper - Converte os broadcasts direcionados em unicasts e os encaminha para um servidor específico.
Wake on LAN - Envia as transmissões direcionadas para despertar os hosts na rede de destino.
Você pode configurar essa função para permitir que a interface encaminhe pacotes de difusão direcionada destinados à rede diretamente conectada.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilite a interface para encaminhar broadcasts direcionados para a rede diretamente conectada.
ip forward-broadcast [ acl acl-number ]Por padrão, uma interface não pode encaminhar transmissões direcionadas destinadas à rede diretamente conectada.
Exemplo: Habilitação de uma interface para encaminhar transmissões direcionadas destinadas à rede diretamente conectada
Configuração de rede
Conforme mostrado na Figura 1, o gateway padrão do host é o endereço IP 1.1.1.2/24 da interface VLAN 3 do Switch A.
O switch B pode receber broadcasts direcionados do host para o endereço IP 2.2.2.255.
Figura 1 Diagrama de rede

Procedimento
- Configure o Switch A:
# Especifique os endereços IP para a interface VLAN 3 e a interface VLAN 2.
<SwitchA> system-view
[SwitchA] interface vlan-interface 3
[SwitchA-Vlan-interface3] ip address 1.1.1.2 24
[SwitchA-Vlan-interface3] quit
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 2.2.2.2 24
# Habilite a interface VLAN 2 para encaminhar broadcasts direcionados para a rede diretamente conectada.
[SwitchA-Vlan-interface2] ip forward-broadcast- Configurar o Switch B:
# Configure uma rota estática para o host.
<SwitchB> system-view
[SwitchB] ip route-static 1.1.1.1 24 2.2.2.2Especifique um endereço IP para a interface VLAN 2.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address 2.2.2.1 24Verificação da configuração
Após a conclusão das configurações, se você fizer ping no endereço de broadcast direcionado à sub-rede 2.2.2.255 no host, a interface VLAN 2 do Switch B poderá receber os pacotes de ping. Se você excluir a configuração ip forward-broadcast em qualquer switch, a interface não poderá receber os pacotes de ping.
Configuração do MTU da interface para pacotes IPv4
Sobre a configuração do MTU da interface para pacotes IPv4
A MTU da interface para pacotes IPv4 define o maior tamanho de um pacote IPv4 que uma interface pode transmitir sem fragmentação. Quando um pacote excede a MTU da interface de envio, o dispositivo processa o pacote de uma das seguintes maneiras:
Se o pacote não permitir a fragmentação, o dispositivo o descartará.
Se o pacote permitir a fragmentação, o dispositivo o fragmentará e encaminhará os fragmentos.
A fragmentação e a remontagem consomem recursos do sistema, portanto, defina o MTU com base no ambiente de rede para evitar a fragmentação.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o MTU da interface para pacotes IPv4.
ip mtu mtu-sizePor padrão, o MTU da interface não é definido.
Ativação da remontagem de fragmentos locais IPv4
Sobre a remontagem de fragmentos locais IPv4
Use esse recurso em uma malha IRF com vários chassis para melhorar a eficiência da remontagem de fragmentos. Esse recurso permite que um subordinado remonte os fragmentos IPv4 de um pacote se todos os fragmentos chegarem a ele. Se esse recurso estiver desativado, todos os fragmentos IPv4 serão entregues ao dispositivo mestre para remontagem. O recurso se aplica somente a fragmentos destinados ao mesmo subordinado.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a remontagem de fragmentos locais IPv4.
ip reassemble local enablePor padrão, a remontagem de fragmentos locais IPv4 está desativada.
Ativação do envio de mensagens de erro ICMP
Sobre o envio de mensagens de erro ICMP
As mensagens ICMP são usadas pelos protocolos da camada de rede e da camada de transporte para comunicar atualizações e erros a outros dispositivos, facilitando o gerenciamento da rede.
O envio excessivo de mensagens ICMP aumenta o tráfego da rede. O desempenho do dispositivo será prejudicado se ele receber muitas mensagens ICMP mal-intencionadas que o levem a responder com mensagens de erro ICMP. Para evitar esses problemas, o envio de mensagens de erro ICMP é desativado por padrão. Você pode ativar o envio de mensagens de erro ICMP de diferentes tipos, conforme necessário.
As mensagens de erro ICMP incluem mensagens de redirecionamento, mensagens de tempo excedido e mensagens de destino inalcançável.
Ativação do envio de mensagens de redirecionamento ICMP
Sobre as mensagens de redirecionamento ICMP
Um host que tenha apenas uma rota padrão envia todos os pacotes para o gateway padrão. O gateway padrão envia uma mensagem de redirecionamento ICMP para informar o host sobre o próximo salto correto, seguindo estas regras:
∙ As interfaces de recebimento e envio são as mesmas.
∙ O endereço IP de origem do pacote e o endereço IP da interface de recebimento do pacote estão no mesmo segmento.
∙ Não há opção de rota de origem no pacote recebido.
As mensagens de redirecionamento ICMP simplificam o gerenciamento do host e permitem que os hosts otimizem gradualmente sua tabela de roteamento.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o envio de mensagens de redirecionamento ICMP.
ip redirects enablePor padrão, o envio de mensagens de redirecionamento ICMP está desativado.
Ativação do envio de mensagens ICMP de tempo excedido
Sobre as mensagens ICMP de tempo excedido
Um dispositivo envia mensagens ICMP de tempo excedido seguindo estas regras:
∙ O dispositivo envia à origem uma mensagem ICMP TTL exceeded in transit quando as seguintes condições são atendidas:
⚪ O pacote recebido não é destinado ao dispositivo.
⚪ O campo TTL do pacote é 1.
∙ Quando o dispositivo recebe o primeiro fragmento de um datagrama IP destinado a ele, inicia um cronômetro. Se o cronômetro expirar antes que todos os fragmentos do datagrama sejam recebidos, o dispositivo enviará uma mensagem ICMP fragment reassembly time exceeded para a origem.
Restrições e diretrizes
Se o envio de mensagens ICMP de tempo excedido estiver desativado, o dispositivo não enviará mensagens ICMP de TTL excedido em trânsito. No entanto, ele ainda pode enviar mensagens ICMP de tempo excedido de remontagem de fragmento.
Procedimento
- Entre na visualização do sistema.
system-view- Habilita o envio de mensagens ICMP de tempo excedido.
ip ttl-expires enablePor padrão, o envio de mensagens ICMP de tempo excedido está desativado.
Ativar o envio de mensagens ICMP de destino inalcançável
Sobre as mensagens ICMP de destino inalcançável
Um dispositivo envia mensagens ICMP de destino inalcançável seguindo estas regras:
∙ O dispositivo envia à origem uma mensagem ICMP de rede inacessível quando as seguintes condições são atendidas:
⚪ O pacote não corresponde a nenhuma rota.
⚪ Não existe rota padrão na tabela de roteamento.
∙ O dispositivo envia à origem uma mensagem de protocolo ICMP inacessível quando as seguintes condições são atendidas:
⚪ O pacote é destinado ao dispositivo.
⚪ O protocolo da camada de transporte do pacote não é compatível com o dispositivo.
∙ O dispositivo envia à origem uma mensagem ICMP de porta inalcançável quando as seguintes condições são atendidas:
⚪ O pacote UDP é destinado ao dispositivo.
⚪ O número da porta do pacote não corresponde ao processo correspondente.
∙ O dispositivo envia à origem uma mensagem ICMP source route failed quando as seguintes condições são atendidas:
⚪ A origem usa o Strict Source Routing para enviar pacotes.
⚪ O dispositivo intermediário descobre que o próximo salto especificado pela origem não está diretamente conectado.
∙ O dispositivo envia à origem uma mensagem ICMP fragmentation needed e DF set quando as seguintes condições são atendidas:
⚪ O MTU da interface de envio é menor do que o pacote.
⚪ O pacote tem DF definido.
Restrições e diretrizes
Se um dispositivo habilitado para DHCP receber uma resposta de eco ICMP sem enviar nenhuma solicitação de eco ICMP, o dispositivo não enviará nenhuma mensagem de protocolo ICMP inalcançável para a origem. Para obter mais informações sobre o DHCP no site , consulte o Guia de configuração de serviços de IP de camada 3.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o envio de mensagens ICMP de destino inalcançável.
ip unreachables enablePor padrão, o envio de mensagens ICMP de destino inalcançável está desativado.
Configuração do limite de taxa para mensagens de erro ICMP
Sobre o algoritmo de token bucket
Para evitar o envio de mensagens de erro ICMP excessivas em um curto período, o que pode causar congestionamento na rede, é possível limitar a taxa de envio de mensagens de erro ICMP. Um algoritmo de token bucket é usado com um token representando uma mensagem de erro ICMP.
Um token é colocado no balde em intervalos até que o número máximo de tokens que o balde pode conter seja atingido.
Um token é removido do compartimento quando uma mensagem de erro ICMP é enviada. Quando o compartimento está vazio, as mensagens de erro ICMP não são enviadas até que um novo token seja colocado no compartimento.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o intervalo para que os tokens cheguem ao compartimento e o tamanho do compartimento para mensagens de erro ICMP.
ip icmp error-interval interval [ bucketsize ]Por padrão, um token é colocado no compartimento em intervalos de 100 milissegundos e o compartimento permite um máximo de 10 tokens.
Para desativar o limite de taxa de ICMP, defina o intervalo como 0 milissegundos.
Desativação do encaminhamento de fragmentos ICMP
Restrições e diretrizes
A desativação do encaminhamento de fragmentos ICMP pode proteger seu dispositivo contra ataques de fragmentos ICMP.
Procedimento
- Entre na visualização do sistema.
system-view- Desativar o encaminhamento de fragmentos ICMP.
ip icmp fragment discarding (descarte de fragmento ip icmp)
Por padrão, o encaminhamento de fragmentos ICMP está ativado.
Especificação do endereço de origem para pacotes ICMP
Sobre a especificação do endereço de origem para pacotes ICMP
A especificação do endereço IP de origem para solicitações de eco de ping de saída e mensagens de erro ICMP ajuda os usuários a localizar facilmente o dispositivo de envio. Como prática recomendada, especifique o endereço IP da interface de loopback como o endereço IP de origem.
Restrições e diretrizes
Se você especificar um endereço IP no comando ping, as solicitações de ping echo usarão o endereço especificado como endereço IP de origem em vez do endereço IP especificado pelo comando ip icmp source.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique o endereço de origem dos pacotes ICMP de saída.
ip icmp fragment discardingPor padrão, nenhum endereço de origem é especificado para pacotes ICMP de saída. Nenhum endereço de origem é especificado para os pacotes ICMP de saída. Os endereços IP de origem padrão para diferentes tipos de pacotes ICMP variam da seguinte forma:
- Para uma mensagem de erro ICMP, o endereço IP de origem é o endereço IP da interface receptora do pacote que aciona a mensagem de erro ICMP. As mensagens de erro ICMP incluem as mensagens Time Exceeded (Tempo excedido), Port Unreachable (Porta inalcançável) e Parameter Problem (Problema de parâmetro).
- Para uma solicitação de eco ICMP, o endereço IP de origem é o endereço IP da interface de envio.
- Para uma resposta de eco ICMP, o endereço IP de origem é o endereço IP de destino da solicitação de eco ICMP específica para essa resposta.
Desativar o envio de um tipo específico de mensagens ICMP
Sobre esta tarefa
Por padrão, o dispositivo envia todos os tipos de mensagens ICMP, exceto Destination Unreachable, Time Exceeded e Redirect. Os invasores podem obter informações de tipos específicos de mensagens ICMP, causando problemas de segurança.
Para fins de segurança, você pode executar essa tarefa desativando o envio de mensagens ICMP de tipos específicos.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com o R6348P01 e versões posteriores.
Restrições e diretrizes
A desativação do envio de mensagens ICMP de um tipo específico pode afetar a operação da rede. Use esse recurso com cautela.
Para ativar o envio de mensagens Destination Unreachable, Time Exceeded ou Redirect, você pode executar uma das seguintes tarefas:
∙ Execute o comando ip icmp send enable.
∙ Execute um dos seguintes comandos, conforme necessário:
⚪ ip unreachables enable
⚪ ip ttl-expires enable
⚪ ip redirects enable
Procedimento
- Entre na visualização do sistema.
system-view- Desative o envio de um tipo específico de mensagens ICMP pelo dispositivo.
undo ip icmp { name icmp-name | type icmp-type code icmp-code } send
enablePor padrão, o dispositivo envia todos os tipos de mensagens ICMP, exceto as mensagens Destination Unreachable (Destino inalcançável), Time Exceeded (Tempo excedido) e Redirect (Redirecionamento).
Desativar o recebimento de um tipo específico de mensagens ICMP
Sobre esta tarefa
Por padrão, o dispositivo recebe todos os tipos de mensagens ICMP. Essa configuração poderá afetar o desempenho do dispositivo se um grande número de respostas ICMP for recebido em um curto espaço de tempo. Para resolver esse problema, você pode executar esta tarefa para desativar o recebimento pelo dispositivo de um tipo específico de mensagens ICMP .
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com o R6348P01 e versões posteriores.
Restrições e diretrizes
A desativação do recebimento de mensagens ICMP de um tipo específico pode afetar a operação da rede. Use esse recurso com cautela.
Procedimento
- Entre na visualização do sistema.
system-view- Desative o recebimento de um tipo específico de mensagens ICMP pelo dispositivo.
undo ip icmp { name icmp-name | type icmp-type code icmp-code } receive
enablePor padrão, o dispositivo recebe todos os tipos de mensagens ICMP.
Configuração do TCP MSS para uma interface
Sobre o TCP MSS
A opção de tamanho máximo de segmento (MSS) informa ao receptor o maior segmento que o remetente pode aceitar. Cada extremidade anuncia seu MSS durante o estabelecimento da conexão TCP. Se o tamanho de um segmento TCP for menor que o MSS do receptor, o TCP enviará o segmento TCP sem fragmentação. Caso contrário, ele fragmenta o segmento de acordo com o MSS do receptor.
Restrições e diretrizes
∙ Se você definir o TCP MSS em uma interface, o tamanho de cada segmento TCP recebido ou enviado na interface não poderá exceder o valor do MSS.
∙ Essa configuração entra em vigor somente para conexões TCP estabelecidas após a configuração, e não para as conexões TCP já existentes.
∙ Essa configuração é eficaz apenas para pacotes IP.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o TCP MSS para a interface.
tcp mss valuePor padrão, o TCP MSS não é definido.
Configuração da descoberta de MTU de caminho TCP
Sobre a descoberta de MTU de caminho TCP
A descoberta de MTU de caminho TCP (na RFC 1191) descobre o MTU de caminho entre as extremidades de origem e destino de uma conexão TCP. O dispositivo usa o MTU do caminho para calcular o MSS a fim de evitar a fragmentação do IP. O MTU de caminho usa um mecanismo de envelhecimento para garantir que o dispositivo de origem possa aumentar o MTU de caminho quando o MTU de link mínimo no caminho aumentar.
A descoberta de MTU de caminho TCP funciona da seguinte forma:
- Um dispositivo de origem TCP envia um pacote com o bit Don't Fragment (DF) definido.
- Um roteador descarta o pacote que excede o MTU da interface de saída e retorna uma mensagem de erro ICMP. A mensagem de erro contém o MTU da interface de saída.
- Ao receber a mensagem ICMP, o dispositivo de origem do TCP calcula o MTU do caminho atual da conexão TCP.
- O dispositivo de origem do TCP envia segmentos TCP subsequentes, cada um deles menor que o MSS (MSS = MTU do caminho - comprimento do cabeçalho IP - comprimento do cabeçalho TCP).
Se o dispositivo de origem do TCP ainda receber mensagens de erro ICMP quando o MSS for menor que 32 bytes, o dispositivo de origem do TCP fragmentará os pacotes.
Uma mensagem de erro ICMP recebida de um roteador que não é compatível com a RFC 1191 tem o MTU da interface de saída definido como 0. Ao receber a mensagem ICMP, o dispositivo de origem do TCP seleciona o MTU do caminho menor que o MTU do caminho atual na tabela MTU, conforme descrito na RFC 1191. Com base na MTU de caminho selecionada, o dispositivo de origem do TCP calcula o TCP MSS. A tabela MTU contém MTUs de 68, 296, 508, 1006, 1280, 1492, 2002, 4352, 8166, 17914, 32000 e 65535 bytes.
Como o MSS mínimo do TCP especificado pelo sistema é de 32 bytes, o MTU mínimo real é de 72 bytes.
O mecanismo de envelhecimento da MTU do caminho é o seguinte:
∙ Quando o dispositivo de origem do TCP recebe uma mensagem de erro ICMP, ele reduz o MTU do caminho e inicia um cronômetro de envelhecimento para o MTU do caminho.
∙ Depois que o cronômetro de envelhecimento expira, o dispositivo de origem usa um MSS maior na tabela MTU, conforme descrito na RFC 1191.
∙ Se nenhuma mensagem de erro ICMP for recebida em dois minutos, o dispositivo de origem aumentará o MSS novamente até atingir o MSS negociado durante o handshake de três vias do TCP.
Pré-requisitos
Certifique-se de que todos os dispositivos em uma conexão TCP estejam habilitados para enviar mensagens de erro ICMP usando o comando
comando ip unreachables enable.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a descoberta de MTU de caminho TCP.
tcp path-mtu-discovery [ aging age-time | no-aging ]Por padrão, a descoberta de MTU de caminho TCP está desativada.
Ativação do cookie SYN
Sobre o SYN Cookie
Uma conexão TCP é estabelecida por meio de um handshake de três vias. Um invasor pode explorar esse mecanismo para montar ataques SYN Flood. O invasor envia um grande número de pacotes SYN, mas não responde aos pacotes SYN ACK do servidor. Como resultado, o servidor estabelece um grande número de semiconexões TCP e não consegue mais lidar com serviços normais.
O SYN Cookie pode proteger o servidor contra ataques de SYN Flood. Quando o servidor recebe um pacote SYN, ele responde com um pacote SYN ACK sem estabelecer uma semiconexão TCP. O servidor estabelece uma conexão TCP e entra no estado ESTABLISHED somente quando recebe um pacote ACK do cliente.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar cookie SYN.
tcp syn-cookie enablePor padrão, o cookie SYN está desativado.
Configuração do tamanho do buffer TCP
- Entre na visualização do sistema.
system-view- Definir o tamanho do buffer de recebimento/envio do TCP.
tcp window window-sizeO tamanho padrão do buffer é de 63 KB.
Configuração de temporizadores TCP
Sobre os temporizadores TCP
Você pode definir os seguintes temporizadores TCP:
∙ Timer de espera SYN - O TCP inicia o timer de espera SYN depois de enviar um pacote SYN. Dentro do temporizador de espera SYN, se nenhuma resposta for recebida ou se o limite superior de tentativas de conexão TCP for atingido, o TCP não conseguirá estabelecer a conexão.
∙ Temporizador de espera FIN - O TCP inicia o temporizador de espera FIN quando altera o estado da conexão para FIN_WAIT_2. Se nenhum pacote FIN for recebido dentro do intervalo do cronômetro, o TCP encerrará a conexão. Se um pacote FIN for recebido, o TCP mudará o estado da conexão para TIME_WAIT. Se um pacote não FIN for recebido, o TCP reiniciará o cronômetro e encerrará a conexão quando o cronômetro expirar.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o cronômetro de espera do TCP SYN.
tcp timer syn-timeout time-valuePor padrão, o temporizador de espera do TCP SYN é de 75 segundos.
- Defina o cronômetro de espera TCP FIN.
tcp timer syn-timeout time-valuePor padrão, o temporizador de espera TCP FIN é de 675 segundos.
Ativação do encapsulamento da opção Timestamps em pacotes TCP de saída
Sobre o encapsulamento da opção Timestamps em pacotes TCP de saída
Os dispositivos em cada extremidade da conexão TCP podem calcular o valor do RTT usando a opção de carimbos de data/hora do TCP contida nos pacotes TCP. Para fins de segurança em algumas redes, você pode desativar esse recurso em uma extremidade da conexão TCP para evitar que dispositivos intermediários obtenham as informações da opção Timestamps.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o dispositivo para encapsular a opção TCP Timestamps nos pacotes TCP de saída.
tcp timestamps enablePor padrão, a opção de carimbos de data/hora TCP é encapsulada em pacotes TCP de saída.
Comandos de exibição e manutenção para otimização do desempenho IP
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir estatísticas de ICMP. | display icmp statistics [ slot slot-number ] |
| Exibir estatísticas de pacotes IP. | display ip statistics [ slot slot-number ] |
| Exibir informações breves sobre as conexões RawIP. | display rawip [ slot slot-número ] |
| Exibir informações detalhadas sobre conexões RawIP. | display rawip verbose [ slot slot-number [ pcb pcb-index ] ] |
| Exibir informações breves sobre conexões TCP. | display tcp [ slot slot-número ] |
| Exibir estatísticas de tráfego TCP. | display tcp statistics [ slot slot-number ] |
| Exibir informações detalhadas sobre conexões TCP. | display tcp verbose [ slot slot-number [ pcb pcb-index ] ] |
| Exibir informações breves sobre conexões UDP. | display udp [ slot slot-número ] |
| Exibir estatísticas de tráfego UDP. | display udp statistics [ slot slot-number ] |
| Exibir informações detalhadas sobre conexões UDP. | display udp verbose [ slot slot-number [ pcb pcb-index ] ] |
| Limpar estatísticas de pacotes IP. | reset ip statistics [ slot slot-number ] |
| Limpar estatísticas de tráfego TCP. | reset tcp statistics |
| Limpar estatísticas de tráfego UDP. | reset udp statistics |
Configuração do auxiliar UDP
Sobre o auxiliar UDP
O UDP helper pode fornecer os seguintes serviços de conversão de pacotes para pacotes com números de porta de destino UDP específicos:
∙ Converter broadcast em unicast e encaminhar os pacotes unicast para destinos específicos.
∙ Converter broadcast em multicast e encaminhar os pacotes multicast.
Configuração do auxiliar UDP para converter broadcast em unicast
Sobre a conversão de broadcast para unicast
Você pode configurar o UDP helper para converter pacotes de difusão com números de porta UDP específicos em pacotes unicast.
Ao receber um pacote de difusão UDP, o UDP helper usa as portas UDP configuradas para corresponder ao número da porta de destino UDP do pacote.
Se for encontrada uma correspondência, o auxiliar UDP duplicará o pacote e modificará o endereço IP de destino da cópia para o endereço unicast configurado. Em seguida, o UDP helper encaminha o pacote unicast para o endereço unicast.
Se não for encontrada nenhuma correspondência, o auxiliar UDP não processará o pacote.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o auxiliar UDP.
udp-helper enablePor padrão, o auxiliar UDP está desativado.
- Especifique um número de porta UDP para o auxiliar UDP.
udp-helper port { port-number | dns | netbios-ds | netbios-ns | tacacs | tftp | time }Por padrão, nenhum número de porta UDP é especificado para o UDP helper.
Não defina as portas UDP 67 e 68 para o auxiliar UDP, pois o auxiliar UDP não pode encaminhar pacotes de difusão DHCP.
Você pode especificar um máximo de 256 portas UDP para o UDP helper.
- Entre na visualização da interface.
interface interface-type interface-number- Especifique um servidor de destino para que o auxiliar UDP converta broadcast em unicast.
udp-helper server ip-addressPor padrão, nenhum servidor de destino é especificado.
Use esse comando na interface que recebe os pacotes de difusão.
Você pode especificar um máximo de 20 endereços unicast e multicast para que o UDP helper converta pacotes de broadcast em uma interface.
Configuração do auxiliar UDP para converter broadcast em multicast
Sobre a conversão de broadcast para multicast
Você pode configurar o UDP helper para converter pacotes de broadcast com números de porta UDP específicos em pacotes multicast.
Ao receber um pacote de difusão UDP, o UDP helper usa as portas UDP configuradas para corresponder ao número da porta de destino UDP do pacote.
∙ Se for encontrada uma correspondência, o auxiliar UDP duplicará o pacote e modificará o endereço IP de destino da cópia para o endereço de multicast configurado. Em seguida, o UDP helper encaminha o pacote para o grupo multicast.
∙ Se não for encontrada nenhuma correspondência, o auxiliar UDP não processará o pacote.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o auxiliar UDP.
udp-helper enablePor padrão, o auxiliar UDP está desativado.
- Especifique um número de porta UDP para o auxiliar UDP.
udp-helper port { port-number | dns | netbios-ds | netbios-ns | tacacs |
tftp | time }Por padrão, nenhum número de porta UDP é especificado para o UDP helper.
Não defina as portas UDP 67 e 68 para o auxiliar UDP, pois o auxiliar UDP não pode encaminhar pacotes de difusão DHCP.
Você pode especificar um máximo de 256 portas UDP para o UDP helper.
- Entre na visualização da interface.
interface interface-type interface-number- Especifique um endereço multicast de destino para que o auxiliar UDP converta broadcast em multicast.
udp-helper broadcast-map multicast-address [ acl acl-number ]Por padrão, nenhum endereço multicast de destino é especificado para o UDP helper. Use esse comando na interface que recebe pacotes de difusão.
Você pode especificar um máximo de 20 endereços unicast e multicast para que o UDP helper converta pacotes de broadcast em uma interface.
Comandos de exibição e manutenção para o auxiliar UDP
Execute o comando de exibição em qualquer visualização e redefina os comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações sobre a conversão de broadcast em unicast pelo auxiliar UDP em uma interface. | exibir interface udp-helper interface-type interface-number |
| Limpar estatísticas de pacotes para o auxiliar UDP. | reset udp-helper statistics |
Exemplos de configuração do auxiliar UDP
Exemplo: Configuração do auxiliar UDP para converter broadcast em unicast
Configuração de rede
Conforme mostrado na Figura 1, configure o UDP helper para converter broadcast em unicast na interface VLAN 1 do Switch A. Esse recurso permite que o Switch A encaminhe pacotes de broadcast com porta de destino UDP número 55 para o servidor de destino 10.2.1.1/16.
Figura 1 Diagrama de rede
Procedimento
Certifique-se de que o Switch A possa acessar a sub-rede 10.2.0.0/16. # Habilite o auxiliar UDP.
[SwitchA] System-view
[SwitchA] udp-helper enable# Habilite a porta UDP 55 para o auxiliar UDP.
[SwitchA] udp-helper port 55# Especifique o servidor de destino 10.2.1.1 para o auxiliar UDP para converter broadcast em unicast na interface VLAN 1.
[SwitchA] interface vlan-interface 1
[SwitchA-Vlan-interface1] ip address 10.110.1.1 16
[SwitchA-Vlan-interface1] udp-helper server 10.2.1.1Verificação da configuração
# Exibir informações sobre a conversão de broadcast em unicast pelo auxiliar UDP na interface VLAN 1.
[SwitchA-Vlan-interface1] display udp-helper interface vlan-interface 1
Interface Server VPN instance Server address Packets sent
Vlan-interface1 N/A 10.2.1.1 5Exemplo: Configuração do auxiliar UDP para converter broadcast em multicast
Configuração de rede
Conforme mostrado na Figura 2, a interface VLAN 1 do Switch B pode receber pacotes multicast destinados a 225.1.1.1.
Configure o UDP helper para converter broadcast em multicast na interface 1 da VLAN do Switch A. Esse recurso permite que o Switch A encaminhe pacotes de broadcast com porta de destino UDP número 55 para o grupo multicast 225.1.1.1 do site .
Figura 2 Diagrama de rede
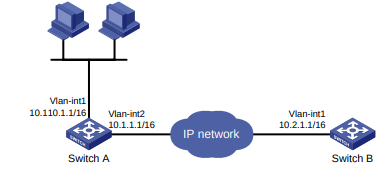
Procedimento
Certifique-se de que o Switch A possa acessar a sub-rede 10.2. 0.0/16.
- Configure o Switch A:
# Habilite o auxiliar UDP.
<SwitchA> system-view
[SwitchA] udp-helper enable# Habilite a porta UDP 55 para o auxiliar UDP.
[SwitchA] udp-helper port 55# Configure o UDP helper para converter pacotes de broadcast em pacotes multicast destinados a 225.1.1.1.
[SwitchA] interface vlan-interface 1
[SwitchA-Vlan-interface1] ip address 10.110.1.1 16
[SwitchA-Vlan-interface1] udp-helper broadcast-map 225.1.1.1
[SwitchA-Vlan-interface1] quit# Habilite o roteamento multicast de IP globalmente.
[SwitchA] multicast routing
[SwitchA-mrib] quitHabilite o PIM-DM na interface VLAN 1.
[SwitchA] interface vlan-interface 1
[SwitchA-Vlan-interface1] pim dm
[SwitchA-Vlan-interface1] quit# Habilite o PIM-DM e o IGMP na interface VLAN 2.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] pim dm
[SwitchA-Vlan-interface2] igmp enable
# Configure a interface VLAN 2 como um membro estático do grupo multicast 225.1.1.1.
[SwitchA-Vlan-interface2] igmp static-group 225.1.1.1
- Configurar o Switch B:
# Habilite o roteamento multicast de IP globalmente.
<SwitchB> system-view
[SwitchB] multicast routing
[SwitchB-mrib] quit# Habilite o PIM-DM e o IGMP na interface VLAN 1.
[SwitchB] interface vlan-interface 1
[SwitchB-Vlan-interface1] pim dm
[SwitchB-Vlan-interface1] igmp enable# Configure a interface VLAN 1 como um membro estático do grupo multicast 225.1.1.1.
[SwitchB-Vlan-interface1] igmp static-group 225.1.1.1
Verificação da configuração
Verifique se você pode capturar pacotes multicast do Switch A no Switch B.
Configuração de definições básicas de IPv6
Sobre o IPv6
O IPv6, também chamado de IP next generation (IPng), foi projetado pela IETF como o sucessor do IPv4. Uma diferença significativa entre o IPv6 e o IPv4 é que o IPv6 aumenta o tamanho do endereço IP de 32 bits para 128 bits.
Recursos do IPv6
Formato de cabeçalho simplificado
O IPv6 remove vários campos do cabeçalho IPv4 ou os move para os cabeçalhos de extensão IPv6 para reduzir o comprimento do cabeçalho básico do pacote IPv6. O cabeçalho básico do pacote IPv6 tem um comprimento fixo de 40 bytes para simplificar o manuseio do pacote IPv6 e melhorar a eficiência do encaminhamento. Embora o tamanho do endereço IPv6 seja quatro vezes maior que o tamanho do endereço IPv4, o tamanho do cabeçalho do pacote IPv6 básico é apenas duas vezes maior que o tamanho do cabeçalho do pacote IPv4 sem opções.
Figura 1 Formato do cabeçalho do pacote IPv4 e formato básico do cabeçalho do pacote IPv6
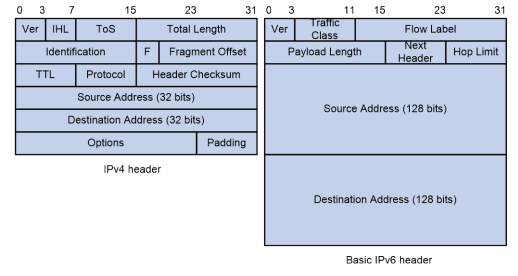
Espaço de endereço maior
O IPv6 pode fornecer 3,4 x 1038 endereços para atender aos requisitos de atribuição hierárquica de endereços para redes públicas e privadas.
Estrutura hierárquica de endereços
O IPv6 usa uma estrutura de endereços hierárquicos para acelerar a pesquisa de rotas e reduzir o tamanho da tabela de roteamento IPv6 por meio da agregação de rotas.
Autoconfiguração de endereços
Para simplificar a configuração do host, o IPv6 oferece suporte à autoconfiguração de endereços com e sem estado.
∙ A autoconfiguração de endereço com estado permite que um host adquira um endereço IPv6 e outras informações de configuração de um servidor (por exemplo, um servidor DHCPv6). Para obter mais informações sobre o servidor DHCPv6, consulte "Configuração do servidor DHCPv6".
∙ A autoconfiguração de endereço sem estado permite que um host gere automaticamente um endereço IPv6 e outras informações de configuração usando seu endereço de camada de link e as informações de prefixo anunciadas por um roteador.
Para se comunicar com outros hosts no mesmo link, um host gera automaticamente um endereço local de link com base em seu endereço de camada de link e no prefixo de endereço local de link (FE80::/10).
Segurança incorporada
O IPv6 define cabeçalhos de extensão para dar suporte ao IPsec. O IPsec oferece segurança de ponta a ponta e aprimora a interoperabilidade entre diferentes aplicativos IPv6.
Suporte a QoS
O campo Flow Label (rótulo de fluxo) no cabeçalho do IPv6 permite que o dispositivo rotule os pacotes de um fluxo específico para tratamento especial.
Mecanismo aprimorado de descoberta de vizinhos
O protocolo de descoberta de vizinhos IPv6 usa um grupo de mensagens ICMPv6 para gerenciar a troca de informações entre nós vizinhos no mesmo link. O grupo de mensagens ICMPv6 substitui as mensagens ARP, as mensagens ICMPv4 de descoberta de roteador e as mensagens ICMPv4 de redirecionamento e oferece uma série de outras funções.
Cabeçalhos de extensão flexíveis
O IPv6 elimina o campo Opções no cabeçalho e introduz cabeçalhos de extensão opcionais para oferecer escalabilidade e aumentar a eficiência. O campo Opções no cabeçalho do pacote IPv4 contém no máximo 40 bytes, enquanto os cabeçalhos de extensão IPv6 estão restritos ao tamanho máximo dos pacotes IPv6.
Endereços IPv6
Formato de endereço IPv6
Um endereço IPv6 é representado como um conjunto de hexadecimais de 16 bits separados por dois pontos (:). Um endereço IPv6 é dividido em oito grupos, e cada grupo de 16 bits é representado por quatro números hexadecimais, por exemplo, 2001:0000:130F:0000:0000:0000:09C0:876A:130B.
Para simplificar a representação de endereços IPv6, você pode lidar com zeros em endereços IPv6 usando os seguintes métodos:
∙ Os zeros à esquerda em cada grupo podem ser removidos. Por exemplo, o endereço acima pode ser representado em um formato mais curto como 2001:0:130F:0:0:0:9C0:876A:130B.
Se um endereço IPv6 contiver um ou mais grupos consecutivos de zeros, eles poderão ser substituídos por dois pontos (::). Por exemplo, o endereço acima pode ser representado no formato mais curto como 2001:0:130F::9C0:876A:130B.
Os dois pontos duplos podem aparecer uma vez ou não aparecer em um endereço IPv6. Esse limite permite que o dispositivo determine quantos zeros os dois pontos representam e os converta corretamente em zeros para restaurar um endereço IPv6 de 128 bits.
Um endereço IPv6 consiste em um prefixo de endereço e um ID de interface, que são equivalentes ao ID de rede e ao ID de host de um endereço IPv4.
Um prefixo de endereço IPv6 é escrito na notação IPv6-address/prefix-length. O comprimento do prefixo é um número decimal que indica quantos bits mais à esquerda do endereço IPv6 estão no prefixo do endereço.
Tipos de endereços IPv6
Os endereços IPv6 incluem os seguintes tipos:
∙ Endereço unicast - Um identificador para uma única interface, semelhante a um endereço IPv4 unicast. Um pacote enviado para um endereço unicast é entregue à interface identificada por esse endereço.
∙ Endereço multicast - Um identificador para um conjunto de interfaces (normalmente pertencentes a nós diferentes), semelhante a um endereço multicast IPv4. Um pacote enviado para um endereço multicast é entregue a todas as interfaces identificadas por esse endereço.
Os endereços de difusão são substituídos por endereços multicast no IPv6.
∙ Endereço anycast - Um identificador para um conjunto de interfaces (normalmente pertencentes a nós diferentes). Um pacote enviado a um endereço anycast é entregue à interface mais próxima entre as interfaces identificadas por esse endereço. A interface mais próxima é escolhida de acordo com a medida de distância do protocolo de roteamento.
O tipo de um endereço IPv6 é designado pelos primeiros bits, chamados de prefixo de formato.
Tabela 1 Mapeamentos entre tipos de endereço e prefixos de formato
| Tipo | Prefixo do formato (binário) | ID do prefixo IPv6 | |
| Endereço unicast | Endereço não especificado | 00...0 (128 bits) | ::/128 |
| Endereço de loopback | 00...1 (128 bits) | ::1/128 | |
| Endereço local do link | 1111111010 | FE80::/10 | |
| Endereço unicast global | Outras formas | N/A | |
| Endereço multicast | 11111111 | FF00::/8 | |
| Endereço anycast | Os endereços anycast usam o espaço de endereço unicast e têm a mesma estrutura dos endereços unicast. |
Endereços unicast
Os endereços unicast incluem endereços unicast globais, endereços unicast link-local, o endereço de loopback e o endereço não especificado.
∙ Endereços unicast globais - Equivalentes aos endereços IPv4 públicos, os endereços unicast globais são fornecidos para os provedores de serviços de Internet. Esse tipo de endereço permite a agregação de prefixos para restringir o número de entradas de roteamento global.
∙ Endereços link-local - Usados para comunicação entre nós link-local para descoberta de vizinhos e autoconfiguração sem estado. Os pacotes com endereços de origem ou destino link-local não são encaminhados para outros links.
∙ Um endereço de loopback-0:0:0:0:0:0:0:0:0:1 (ou ::1). Ele tem a mesma função que o endereço de loopback no IPv4. Não pode ser atribuído a nenhuma interface física. Um nó usa esse endereço para enviar um pacote IPv6 para si mesmo.
∙ Um endereço não especificado-0:0:0:0:0:0:0:0:0:0:0 (ou ::). Não pode ser atribuído a nenhum nó. Antes de adquirir um endereço IPv6 válido, um nó preenche esse endereço no campo de endereço de origem dos pacotes IPv6 . O endereço não especificado não pode ser usado como endereço IPv6 de destino.
Endereços multicast
Os endereços multicast IPv6 listados na Tabela 2 são reservados para fins especiais.
Tabela 2 Endereços multicast IPv6 reservados
| Endereço | Aplicativo |
| FF01::1 | Endereço multicast de todos os nós com escopo local de nó. |
| FF02::1 | Endereço multicast de todos os nós com escopo link-local. |
| FF01::2 | Endereço multicast de todos os roteadores com escopo local de nó. |
| FF02::2 | Endereço multicast de todos os roteadores de escopo local de link. |
Os endereços multicast também incluem endereços de nós solicitados. Um nó usa um endereço multicast de nó solicitado para adquirir o endereço da camada de link de um nó vizinho no mesmo link e para detectar
endereços duplicados. Cada endereço IPv6 unicast ou anycast tem um endereço de nó solicitado correspondente. O formato de um endereço multicast de nó solicitado é FF02:0:0:0:0:0:1:FFXX:XXXX. FF02:0:0:0:0:0:1:FF é fixo e consiste em 104 bits, e XX:XXXX são os últimos 24 bits de um endereço IPv6 unicast ou anycast.
Identificadores de interface baseados em endereços EUI-64
Um identificador de interface tem 64 bits de comprimento e identifica exclusivamente uma interface em um link.
Em uma interface IEEE 802 (como uma interface VLAN), o identificador de interface é derivado do endereço da camada de link (normalmente um endereço MAC) da interface. O endereço MAC tem 48 bits de comprimento.
Para obter um identificador de interface baseado em endereço EUI-64, siga estas etapas:
- Insira o número binário de 16 bits 1111111111111110 (valor hexadecimal de FFFE) atrás do 24º bit de ordem alta do endereço MAC.
- Inverter o bit universal/local (U/L) (o sétimo bit de ordem alta). Essa operação faz com que o identificador de interface tenha o mesmo significado local ou global que o endereço MAC.
Figura 2 Conversão de um endereço MAC em um identificador de interface baseado em endereço EUI-64
Descoberta de MTU de caminho IPv6
Os links pelos quais um pacote passa de uma origem para um destino podem ter MTUs diferentes, entre os quais o MTU mínimo é o MTU do caminho. Se um pacote exceder o MTU do caminho, a extremidade da origem fragmenta o pacote para reduzir a pressão de processamento nos dispositivos intermediários e para usar os recursos da rede de forma eficaz.
Uma extremidade de origem usa a descoberta de MTU de caminho para encontrar o MTU de caminho para um destino, conforme mostrado na Figura 3.
- O host de origem envia um pacote não maior que sua MTU para o host de destino.
- Se o MTU da interface de saída de um dispositivo intermediário for menor que o pacote, o dispositivo executará as seguintes operações:
- Descarta o pacote.
- Retorna uma mensagem de erro ICMPv6 contendo o MTU da interface para o host de origem.
- Ao receber a mensagem de erro ICMPv6, o host de origem executa as seguintes operações:
- Usa o MTU retornado para limitar o tamanho do pacote.
- Executa a fragmentação.
- Envia os fragmentos para o host de destino.
- As etapas 2 e 3 são repetidas até que o host de destino receba o pacote. Dessa forma, o host de origem encontra o MTU mínimo de todos os links no caminho para o host de destino.
Figura 3 Processo de descoberta do Path MTU
Tecnologias de transição para o IPv6
As tecnologias de transição do IPv6 permitem a comunicação entre redes IPv4 e IPv6.
Pilha dupla
A pilha dupla é a abordagem de transição mais direta. Um nó de rede compatível com IPv4 e IPv6 é um nó de pilha dupla. Um nó de pilha dupla configurado com um endereço IPv4 e um endereço IPv6 pode encaminhar pacotes IPv4 e IPv6. Um aplicativo compatível com IPv4 e IPv6 prefere o IPv6 na camada de rede.
A pilha dupla é adequada para a comunicação entre nós IPv4 ou entre nós IPv6. Ela é a base de todas as tecnologias de transição. No entanto, ela não resolve o problema de esgotamento de endereços IPv4 porque cada nó de pilha dupla deve ter um endereço IPv4 globalmente exclusivo.
NAT-PT
O NAT-PT (Network Address Translation - Protocol Translation) permite a comunicação entre nós IPv4 e IPv6 por meio da tradução entre pacotes IPv4 e IPv6. Ele realiza a tradução de endereços IP e, de acordo com diferentes protocolos, realiza a tradução semântica dos pacotes. Essa tecnologia é adequada apenas para a comunicação entre um nó IPv4 puro e um nó IPv6 puro.
Protocolos e padrões
∙ RFC 1881, Gerenciamento de alocação de endereços IPv6
∙ RFC 1887, Uma arquitetura para alocação de endereços unicast IPv6
∙ RFC 1981, Path MTU Discovery para IP versão 6
∙ RFC 2375, Atribuições de endereços IPv6 Multicast
∙ RFC 2460, Especificação do Protocolo da Internet, Versão 6 (IPv6)
∙ RFC 2464, Transmissão de pacotes IPv6 em redes Ethernet
∙ RFC 2526, Endereços Anycast de sub-rede IPv6 reservados
∙ RFC 3307, Diretrizes de alocação para endereços IPv6 multicast
∙ RFC 4191, Preferências do roteador padrão e rotas mais específicas
∙ RFC 4291, Arquitetura de endereçamento IP versão 6
∙ RFC 4443, Protocolo de Mensagens de Controle da Internet (ICMPv6) para a Especificação do Protocolo da Internet Versão 6 (IPv6)
Visão geral das tarefas básicas do IPv6
Para definir as configurações básicas de IPv6, execute as seguintes tarefas:
Escolha as seguintes tarefas, conforme necessário:
- Configuração de um endereço unicast global IPv6
- Configuração de um endereço IPv6 link-local
- Configuração de um endereço anycast IPv6
- (Opcional.) Configuração da descoberta do MTU do caminho
- Configuração do MTU da interface para pacotes IPv6
- Definição de um MTU de caminho estático para um endereço IPv6
- Configuração do tempo de envelhecimento para MTUs de caminho dinâmico
- (Opcional.) Controle do envio de mensagens ICMPv6
- Configuração do limite de taxa para mensagens de erro ICMPv6
- Ativação da resposta a solicitações de eco multicast
- Ativação do envio de mensagens ICMPv6 de destino inalcançável
- Ativação do envio de mensagens ICMPv6 de tempo excedido
- Ativação do envio de mensagens de redirecionamento ICMPv6
- (Opcional.) Ativação da remontagem do fragmento local do IPv6
Configuração de um endereço unicast global IPv6
Sobre o endereço unicast global do IPv6
Use um dos métodos a seguir para configurar um endereço unicast global IPv6 para uma interface:
∙ Endereço IPv6 EUI-64 - O prefixo do endereço IPv6 da interface é configurado manualmente e o ID da interface é gerado automaticamente pela interface.
∙ Configuração manual - O endereço unicast global IPv6 é configurado manualmente.
∙ Autoconfiguração de endereço sem estado - O endereço unicast global IPv6 é gerado automaticamente com base nas informações de prefixo de endereço contidas na mensagem RA.
∙ Autoconfiguração de endereço específico de prefixo - O endereço unicast global IPv6 é gerado automaticamente com base no prefixo especificado por seu ID. O prefixo pode ser configurado manualmente ou obtido por meio do DHCPv6.
É possível configurar vários endereços unicast globais IPv6 em uma interface.
Os endereços globais unicast configurados manualmente (inclusive os endereços IPv6 EUI-64) têm precedência sobre os gerados automaticamente. Se você configurar manualmente um endereço global unicast com o mesmo prefixo de endereço que um endereço global unicast existente em uma interface, o endereço configurado manualmente entrará em vigor. Entretanto, ele não substitui o endereço gerado automaticamente. Se você excluir o endereço global unicast configurado manualmente , o dispositivo usará o endereço gerado automaticamente.
Geração de um endereço IPv6 EUI-64
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure um endereço IPv6 EUI-64 na interface.
ipv6 address { ipv6-address prefix-length |
ipv6-address/prefix-length } eui-64Por padrão, nenhum endereço IPv6 EUI-64 é configurado em uma interface.
Atribuição manual de um endereço IPv6 global unicast
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Atribuir um endereço unicast global IPv6 à interface.
ipv6 address { ipv6-address prefix-length |
ipv6-address/prefix-length }
Por padrão, nenhum endereço unicast global IPv6 é configurado em uma interface.
Autoconfiguração de endereço sem estado
Sobre a autoconfiguração de endereço sem estado e o endereço temporário
A autoconfiguração de endereço sem estado permite que uma interface gere automaticamente um endereço unicast global IPv6 usando o prefixo do endereço na mensagem RA recebida e o ID da interface. Em uma interface IEEE 802 (como uma interface Ethernet ou uma interface VLAN), a ID da interface é gerada com base no endereço MAC da interface e é globalmente exclusiva. Um invasor pode explorar essa regra para identificar facilmente o dispositivo de envio.
Para corrigir a vulnerabilidade, você pode configurar o recurso de endereço temporário. Com esse recurso, uma interface IEEE 802 gera os seguintes endereços:
∙ Endereço IPv6 público-Inclui o prefixo do endereço na mensagem RA e uma ID de interface fixa gerada com base no endereço MAC da interface.
∙ Endereço IPv6 temporário - Inclui o prefixo do endereço na mensagem RA e um ID de interface aleatório gerado por MD5.
Você também pode configurar a interface para usar preferencialmente o endereço IPv6 temporário como endereço de origem dos pacotes enviados. Quando o tempo de vida válido do endereço IPv6 temporário expira, a interface exclui o endereço e gera um novo. Esse recurso permite que o sistema envie pacotes com diferentes endereços de origem pela mesma interface. Se o endereço IPv6 temporário não puder ser usado devido a um conflito de DAD, será usado o endereço IPv6 público.
O tempo de vida preferencial e o tempo de vida válido para um endereço IPv6 temporário são determinados da seguinte forma:
∙ O tempo de vida preferencial de um endereço IPv6 temporário assume o menor dos seguintes valores:
⚪ O tempo de vida preferido do prefixo de endereço na mensagem RA.
⚪ O tempo de vida preferencial configurado para endereços IPv6 temporários menos DESYNC_FACTOR (um número aleatório no intervalo de 0 a 600 segundos).
∙ O tempo de vida válido de um endereço IPv6 temporário assume o menor dos seguintes valores:
⚪ O tempo de vida válido do prefixo do endereço.
⚪ O tempo de vida válido configurado para endereços IPv6 temporários.
Restrições e diretrizes
Se o prefixo IPv6 na mensagem RA não tiver 64 bits, a autoconfiguração de endereço stateless não conseguirá gerar um endereço IPv6 global unicast.
Para gerar um endereço temporário, uma interface deve estar ativada com a autoconfiguração de endereço sem estado. Os endereços IPv6 temporários não substituem os endereços IPv6 públicos, portanto, uma interface pode ter vários endereços IPv6 com o mesmo prefixo de endereço, mas com IDs de interface diferentes.
Se uma interface não conseguir gerar um endereço IPv6 público devido a um conflito de prefixo ou a outros motivos, ela não gerará nenhum endereço IPv6 temporário.
A execução do comando undo ipv6 address auto em uma interface exclui todos os endereços IPv6 unicast globais e endereços link-local gerados automaticamente na interface.
Ativação da autoconfiguração de endereços sem estado
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ative a autoconfiguração de endereço sem estado em uma interface, para que ela possa gerar automaticamente um endereço unicast global.
ipv6 address autoPor padrão, o recurso de autoconfiguração de endereço sem estado está desativado em uma interface.
Configurar o recurso de endereço temporário e usar preferencialmente o endereço IPv6 temporário como o endereço de origem dos pacotes de saída
- Entre na visualização do sistema.
system-view- Habilite o recurso de endereço IPv6 temporário.
ipv6 temporary-address [ valid-lifetime preferred-lifetime ]
Por padrão, o recurso de endereço IPv6 temporário está desativado.
- Habilite o sistema para usar preferencialmente o endereço IPv6 temporário como o endereço de origem dos pacotes de saída.
ipv6 prefer temporary-addressPor padrão, o sistema não usa preferencialmente o endereço IPv6 temporário como endereço de origem dos pacotes de saída.
Configuração da autoconfiguração de endereços específicos de prefixo
- Entre na visualização do sistema.
system-view- Configure um prefixo IPv6. Escolha uma opção conforme necessário:
- Configurar um prefixo IPv6 estático.
ipv6 prefix prefix-number ipv6-prefix/prefix-lengthPor padrão, não existem prefixos IPv6 estáticos.
- Use o DHCPv6 para obter um prefixo IPv6 dinâmico.
Para obter mais informações sobre a aquisição de prefixos IPv6, consulte "Configuração do cliente DHCPv6".
- Entre na visualização da interface.
interface interface-type interface-number- Especifique um prefixo IPv6 para que uma interface gere automaticamente um endereço unicast global IPv6 e anuncie o prefixo.
ipv6 address prefix-number sub-prefix/prefix-lengthPor padrão, nenhum prefixo IPv6 é especificado para que a interface gere automaticamente um endereço unicast global IPv6.
Configuração de um endereço IPv6 link-local
Sobre o endereço IPv6 link-local
Configure os endereços IPv6 link-local usando um dos métodos a seguir:
∙ Geração automática - O dispositivo gera automaticamente um endereço local de link para uma interface de acordo com o prefixo do endereço local de link (FE80::/10) e o endereço da camada de link da interface.
∙ Atribuição manual - Configure manualmente um endereço IPv6 link-local para uma interface.
Restrições e diretrizes
Depois que você configura um endereço unicast global IPv6 para uma interface, a interface gera automaticamente um endereço local de link. Esse endereço de link-local é o mesmo gerado com o uso do comando ipv6 address auto link-local. Se um endereço link-local for atribuído manualmente a uma interface, esse endereço link-local atribuído manualmente entrará em vigor. Se o endereço link-local atribuído manualmente for excluído, o endereço link-local gerado automaticamente entrará em vigor.
O uso do comando undo ipv6 address auto link-local em uma interface exclui apenas o endereço link-local gerado pelo comando ipv6 address auto link-local. Se a interface tiver um endereço unicast global IPv6, ela ainda terá um endereço link-local. Se a interface não tiver um endereço unicast global IPv6, ela não terá um endereço link-local.
Uma interface pode ter apenas um endereço local de link. Como prática recomendada, use o método de geração automática para evitar conflitos de endereços link-local. Se forem usados os métodos de geração automática e de atribuição manual, a atribuição manual terá precedência.
∙ Se você usar primeiro a geração automática e depois a atribuição manual, o endereço link-local atribuído manualmente substituirá o gerado automaticamente.
∙ Se você usar primeiro a atribuição manual e depois a geração automática, ocorrerão as duas situações a seguir:
⚪ O endereço local do link ainda é o atribuído manualmente.
⚪ O endereço local de link gerado automaticamente não entra em vigor. Se você excluir o endereço atribuído manualmente, o endereço local de link gerado automaticamente entrará em vigor.
Configuração da geração automática de um endereço IPv6 link-local para uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure a interface para gerar automaticamente um endereço IPv6 link-local.
ipv6 address auto link-localPor padrão, nenhum endereço link-local é configurado em uma interface.
Depois que um endereço unicast global IPv6 é configurado na interface, um endereço local de link é gerado automaticamente.
Atribuição manual de um endereço IPv6 link-local a uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Atribuir manualmente um endereço IPv6 link-local à interface.
ipv6 address { ipv6-address [ prefix-length ] |
ipv6-address/prefix-length } link-localPor padrão, nenhum endereço link-local é configurado em uma interface.
Configuração de um endereço anycast IPv6
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure um endereço anycast IPv6.
ipv6 address { ipv6-address prefix-length |
ipv6-address/prefix-length } anycast
Por padrão, nenhum endereço anycast IPv6 é configurado em uma interface.
Configuração da descoberta de MTU de caminho
Configuração do MTU da interface para pacotes IPv6
Sobre o MTU da interface para pacotes IPv6
Se o tamanho de um pacote exceder a MTU da interface de envio, o dispositivo descartará o pacote. Se o dispositivo for um dispositivo intermediário, ele também enviará ao host de origem uma mensagem ICMPv6 Packet Too Big com o MTU da interface de envio. O host de origem fragmenta os pacotes de acordo com o MTU. Para evitar essa situação, defina um MTU de interface adequado.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o MTU da interface para pacotes IPv6.
ipv6 mtu size
Por padrão, nenhum MTU de interface é definido.
Definição de um MTU de caminho estático para um endereço IPv6
Sobre o MTU de caminho estático para um endereço IPv6
Você pode definir uma MTU de caminho estático para um endereço IPv6. Antes de enviar um pacote para o endereço IPv6, o dispositivo compara a MTU da interface de saída com a MTU do caminho estático. Se o tamanho do pacote exceder a
menor um dos dois valores, o dispositivo fragmenta o pacote de acordo com o valor menor. Depois de enviar os pacotes fragmentados, o dispositivo encontra dinamicamente o MTU do caminho para um host de destino (consulte "Descoberta de MTU de caminho IPv6").
Procedimento
- Entre na visualização do sistema.
system-view- Defina um MTU de caminho estático para um endereço IPv6.
ipv6 pathmtu ipv6-address valuePor padrão, nenhum MTU de caminho é definido para qualquer endereço IPv6.
Configuração do tempo de envelhecimento para MTUs de caminho dinâmico
Sobre o tempo de envelhecimento para MTUs de caminho dinâmico
Depois que o dispositivo descobre dinamicamente o MTU do caminho para um host de destino (consulte "Descoberta de MTU de caminho IPv6"), ele executa as seguintes operações:
∙ Envia pacotes para o host de destino com base nesse MTU de caminho.
∙ Inicia o cronômetro de envelhecimento para esse MTU de caminho.
Quando o cronômetro de envelhecimento expira, o dispositivo remove o MTU de caminho dinâmico e descobre o MTU de caminho novamente.
Restrições e diretrizes
O tempo de envelhecimento é inválido para uma MTU de caminho estático.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o tempo de envelhecimento para MTUs de caminho dinâmico.
ipv6 pathmtu age age-timeA configuração padrão é 10 minutos.
Controle do envio de mensagens ICMPv6
Configuração do limite de taxa para mensagens de erro ICMPv6
Sobre o limite de taxa para mensagens de erro ICMPv6
Para evitar o envio de mensagens de erro ICMPv6 excessivas em um curto período, o que pode causar congestionamento na rede, é possível limitar a taxa de envio de mensagens de erro ICMPv6. Um algoritmo de token bucket é usado com um token representando uma mensagem de erro ICMPv6.
Um token é colocado no balde em intervalos até que o número máximo de tokens que o balde pode conter seja atingido.
Um token é removido do compartimento quando uma mensagem de erro ICMPv6 é enviada. Quando o compartimento está vazio, as mensagens de erro ICMPv6 não são enviadas até que um novo token seja colocado no compartimento.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o tamanho do compartimento e o intervalo para que os tokens cheguem ao compartimento para mensagens de erro ICMPv6.
ipv6 icmpv6 error-interval interval [ bucketsize ]Por padrão, o compartimento permite um máximo de 10 tokens. Um token é colocado no compartimento em um intervalo de 100 milissegundos.
Para desativar o limite de taxa de ICMPv6, defina o intervalo como 0 milissegundos.
Ativação da resposta a solicitações de eco multicast
- Entre na visualização do sistema.
system-view- Habilitar a resposta a solicitações de eco multicast.
ipv6 icmpv6 multicast-echo-reply enablePor padrão, esse recurso está desativado.
Ativação do envio de mensagens ICMPv6 de destino inalcançável
Sobre o envio de mensagens ICMPv6 de destino inalcançável
O dispositivo envia à origem as seguintes mensagens ICMPv6 de destino inalcançável:
∙ Mensagem ICMPv6 No Route to Destination - Um pacote a ser encaminhado não corresponde a nenhuma rota.
∙ Mensagem ICMPv6 Communication with Destination Administratively Prohibited - Uma proibição administrativa está impedindo a comunicação bem-sucedida com o destino. Normalmente, isso é causado por um firewall ou uma ACL no dispositivo.
∙ Mensagem ICMPv6 Beyond Scope of Source Address (Além do escopo do endereço de origem) - O destino está além do escopo do endereço IPv6 de origem. Por exemplo, o endereço IPv6 de origem de um pacote é um endereço local de link e o endereço IPv6 de destino é um endereço unicast global.
∙ Mensagem ICMPv6 Address Unreachable - O dispositivo não consegue resolver o endereço da camada de link para o endereço IPv6 de destino de um pacote.
∙ Mensagem ICMPv6 Port Unreachable - Não existe nenhum processo de porta no dispositivo de destino para um pacote UDP recebido.
Restrições e diretrizes
Uma mensagem ICMPv6 destination unreachable indica que o destino não pode ser acessado pelo dispositivo de origem. Os invasores podem lançar ataques maliciosos para fazer com que o dispositivo gere mensagens ICMPv6 de destino inalcançável incorretas, o que afetará a função da rede. Para proteger a rede contra ataques mal-intencionados e reduzir o tráfego de rede desnecessário, você pode desativar o envio de mensagens ICMPv6 de destino inalcançável.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o envio de mensagens ICMPv6 de destino inalcançável.
ipv6 unreachables enablePor padrão, esse recurso está desativado.
Ativação do envio de mensagens ICMPv6 de tempo excedido
Sobre o envio de mensagens ICMPv6 de tempo excedido
O dispositivo envia as mensagens ICMPv6 de origem com tempo excedido da seguinte forma:
∙ Se um pacote recebido não for destinado ao dispositivo e seu limite de salto for 1, o dispositivo enviará uma mensagem ICMPv6 hop limit exceeded in transit (limite de salto excedido em trânsito) para a origem.
∙ Ao receber o primeiro fragmento de um datagrama IPv6 destinado ao dispositivo, o dispositivo inicia um cronômetro. Se o cronômetro expirar antes que todos os fragmentos cheguem, o dispositivo enviará uma mensagem ICMPv6 fragment reassembly time exceeded para a origem.
Restrições e diretrizes
Se o dispositivo receber um grande número de pacotes maliciosos, seu desempenho será bastante prejudicado porque ele precisará enviar de volta mensagens ICMP de tempo excedido. Para evitar esses ataques, desative o para enviar mensagens ICMPv6 de tempo excedido.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o envio de mensagens ICMPv6 de tempo excedido.
ipv6 hoplimit-expires enablePor padrão, o envio de mensagens ICMPv6 de tempo excedido está ativado.
Ativação do envio de mensagens de redirecionamento ICMPv6
Sobre o envio de mensagens de redirecionamento ICMPv6
Ao receber um pacote de um host, o dispositivo envia uma mensagem de redirecionamento ICMPv6 para informar ao host sobre um próximo salto melhor quando as seguintes condições forem atendidas:
∙ A interface que recebe o pacote é a interface que encaminha o pacote.
∙ A rota selecionada não é criada ou modificada por nenhuma mensagem de redirecionamento ICMPv6.
∙ A rota selecionada não é uma rota padrão.
∙ O pacote encaminhado não contém o cabeçalho de extensão de roteamento.
O recurso de redirecionamento ICMPv6 simplifica o gerenciamento de hosts, permitindo que os hosts com poucas rotas otimizem sua tabela de roteamento gradualmente. No entanto, para evitar a adição de muitas rotas nos hosts, esse recurso é desativado por padrão.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o envio de mensagens de redirecionamento ICMPv6.
ipv6 redirects enablePor padrão, o envio de mensagens de redirecionamento ICMPv6 está desativado.
Especificação do endereço IPv6 de origem para pacotes ICMPv6 não solicitados
Sobre a especificação do endereço IPv6 de origem para pacotes ICMPv6 não solicitados
Execute esta tarefa para especificar o endereço IPv6 de origem para solicitações de eco de ping de saída e mensagens de erro ICMPv6. É uma boa prática especificar o endereço IPv6 de uma interface de loopback como o endereço IPv6 de origem. Esse recurso ajuda os usuários a localizar facilmente o dispositivo de envio.
Restrições e diretrizes
Para solicitações de eco ICMPv6, o endereço IPv6 de origem especificado no comando ping ipv6 tem prioridade mais alta do que o endereço IPv6 de origem especificado no comando ipv6 icmpv6 source.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique um endereço IPv6 de origem para pacotes ICMPv6 não solicitados.
ipv6 icmpv6 source ipv6-addressPor padrão, nenhum endereço de origem é especificado para pacotes ICMPv6 não solicitados.
Ativação da remontagem de fragmentos locais IPv6
Sobre a remontagem de fragmentos locais do IPv6
Use esse recurso em uma malha IRF com vários chassis para melhorar a eficiência da remontagem de fragmentos. Esse recurso permite que um subordinado remonte os fragmentos IPv6 de um pacote se todos os fragmentos chegarem a ele. Se esse recurso estiver desativado, todos os fragmentos IPv6 serão entregues ao dispositivo mestre para remontagem.
Restrições e diretrizes
O recurso de remontagem de fragmentos locais do IPv6 aplica-se somente a fragmentos destinados ao mesmo subordinado.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a remontagem de fragmentos locais IPv6.
ipv6 reassemble local enablePor padrão, a remontagem de fragmentos locais do IPv6 está desativada.
Comandos de exibição e manutenção para noções básicas de IPv6
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
Para obter informações sobre os comandos display tcp statistics, display udp statistics, reset tcp statistics e reset udp statistics, consulte os comandos de desempenho de IP na Referência de comandos de serviços IP de camada 3.
| Tarefa | Comando |
| Exibir entradas de FIB IPv6. | display ipv6 fib [ ipv6-address |
| Tarefa | Comando |
| [ prefix-length ] ] | |
| Exibir estatísticas de tráfego ICMPv6. | display ipv6 icmp statistics [ slot slot-number ] |
| Exibir informações de IPv6 sobre a interface. | display ipv6 interface [ interface-type [ número da interface ] ] [ brief ] |
| Exibir informações de prefixo IPv6 sobre a interface. | display ipv6 interface interface-type interface-number prefix |
| Exibir as informações de MTU do caminho IPv6. | display ipv6 pathmtu { ipv6-address | { all | dinâmico | estático } [ count ] } |
| Exibir as informações do prefixo IPv6. | display ipv6 prefix [ prefix-number ] |
| Exibir informações breves sobre conexões IPv6 RawIP. | display ipv6 rawip [ slot slot-número ] |
| Exibir informações detalhadas sobre conexões IPv6 RawIP. | display ipv6 rawip verbose [ slot número do slot [ pcb pcb-index ] ] ] |
| Exibir estatísticas de pacotes IPv6 e ICMPv6. | display ipv6 statistics [ slot slot-number ] |
| Exibir informações breves sobre conexões TCP IPv6. | display ipv6 tcp [ slot slot-número ] |
| Exibir informações detalhadas sobre conexões TCP IPv6. | display ipv6 tcp verbose [ slot slot-number [ pcb pcb-index ] ] |
| Exibir informações breves sobre conexões UDP IPv6. | display ipv6 udp [ slot slot-número ] |
| Exibir informações detalhadas sobre conexões IPv6 UDP. | display ipv6 udp verbose [ slot slot-number [ pcb pcb-index ] ] |
| Exibir estatísticas de tráfego TCP IPv6. | display tcp statistics [ slot slot-number ] |
| Exibir estatísticas de tráfego UDP IPv6. | display udp statistics [ slot slot-number ] |
| Limpar MTUs de caminho. | reset ipv6 pathmtu { all | dynamic | static } |
| Limpar estatísticas de pacotes IPv6 e ICMPv6. | reset ipv6 statistics [ slot slot-number ] |
| Limpar estatísticas de tráfego TCP IPv6. | reset tcp statistics |
| Limpar estatísticas de tráfego UDP IPv6. | reset udp statistics |
Exemplos de configuração de definições básicas de IPv6
Exemplo: Configuração de definições básicas de IPv6
Configuração de rede
Conforme mostrado na Figura 4, um host, o Switch A e o Switch B estão conectados por meio de portas Ethernet. Adicione as portas Ethernet às VLANs correspondentes. Configure endereços IPv6 para as interfaces de VLAN e verifique se elas estão conectadas. O Switch B pode acessar o host.
Habilite o IPv6 no host para obter automaticamente um endereço IPv6 por meio do IPv6 ND.
Figura 4 Diagrama de rede

Procedimento
Este exemplo pressupõe que as interfaces de VLAN tenham sido criadas nos switches.
- Configure o Switch A:
# Especifique um endereço unicast global para a interface VLAN 2.
<SwitchA> system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ipv6 address 3001::1/64
[SwitchA-Vlan-interface2] quit# Especifique um endereço unicast global para a interface VLAN 1 e permita que ela anuncie mensagens RA (nenhuma interface anuncia mensagens RA por padrão).
[SwitchA] interface vlan-interface 1
[SwitchA-Vlan-interface1] ipv6 address 2001::1/64
[SwitchA-Vlan-interface1] undo ipv6 nd ra halt
[SwitchA-Vlan-interface1] quit- Configurar o Switch B:
# Configure um endereço unicast global para a interface VLAN 2.
<SwitchB> system-view
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ipv6 address 3001::2/64
[SwitchB-Vlan-interface2] quit# Configure uma rota estática IPv6 com o endereço IPv6 de destino 2001::/64 e o endereço do próximo salto 3001::1.
[SwitchB] ipv6 route-static 2001:: 64 3001::1- Configure o host:
Habilite o IPv6 para que o host obtenha automaticamente um endereço IPv6 por meio do IPv6 ND.
# Exibir informações de vizinhança para GigabitEthernet 1/0/2 no Switch A.
[SwitchA] display ipv6 neighbors interface gigabitethernet 1/0/2
Type: S-Static D-Dynamic O-Openflow R-Rule IS-Invalid static
IPv6 address MAC address VID Interface State T Aging
FE80::215:E9FF:FEA6:7D14 0015-e9a6-7d14 1 GE1/0/2 STALE D 1238
2001::15B:E0EA:3524:E791 0015-e9a6-7d14 1 GE1/0/2 STALE D 1248Verificação da configuração
# Exibir as configurações da interface IPv6 no Switch A. São exibidos todos os endereços unicast globais IPv6 configurados na interface.
[SwitchA] display ipv6 interface vlan-interface 2
Vlan-interface2 current state: UP
Line protocol current state: UP
IPv6 is enabled, link-local address is FE80::20F:E2FF:FE00:2
Global unicast address(es):
3001::1, subnet is 3001::/64
Switch A Switch B
Vlan-int2
3001::1/64
Vlan-int2
3001::2/64
Vlan-int1
2001::1/64
GE1/0/2 GE1/0/1 GE1/0/1
17
Joined group address(es):
FF02::1
FF02::2
FF02::1:FF00:1
FF02::1:FF00:2
MTU is 1500 bytes
ND DAD is enabled, number of DAD attempts: 1
ND reachable time is 30000 milliseconds
ND retransmit interval is 1000 milliseconds
Hosts use stateless autoconfig for addresses
IPv6 Packet statistics:
InReceives: 25829
InTooShorts: 0
InTruncatedPkts: 0
InHopLimitExceeds: 0
InBadHeaders: 0
InBadOptions: 0
ReasmReqds: 0
ReasmOKs: 0
InFragDrops: 0
InFragTimeouts: 0
OutFragFails: 0
InUnknownProtos: 0
InDelivers: 47
OutRequests: 89
OutForwDatagrams: 48
InNoRoutes: 0
InTooBigErrors: 0
OutFragOKs: 0
OutFragCreates: 0
InMcastPkts: 6
InMcastNotMembers: 25747
OutMcastPkts: 48
InAddrErrors: 0
InDiscards: 0
OutDiscards: 0
[SwitchA] display ipv6 interface vlan-interface 1
Vlan-interface1 current state: UP
Line protocol current state: UP
IPv6 is enabled, link-local address is FE80::20F:E2FF:FE00:1C0
Global unicast address(es):
2001::1, subnet is 2001::/64
Joined group address(es):
FF02::1
FF02::2
FF02::1:FF00:1
FF02::1:FF00:1C0
MTU is 1500 bytes
ND DAD is enabled, number of DAD attempts: 1
ND reachable time is 30000 milliseconds
ND retransmit interval is 1000 milliseconds
ND advertised reachable time is 0 milliseconds
ND advertised retransmit interval is 0 milliseconds
ND router advertisements are sent every 600 seconds
ND router advertisements live for 1800 seconds
Hosts use stateless autoconfig for addresses
IPv6 Packet statistics:
InReceives: 272
InTooShorts: 0
InTruncatedPkts: 0
InHopLimitExceeds: 0
InBadHeaders: 0
InBadOptions: 0
ReasmReqds: 0
ReasmOKs: 0
InFragDrops: 0
InFragTimeouts: 0
OutFragFails: 0
InUnknownProtos: 0
InDelivers: 159
OutRequests: 1012
OutForwDatagrams: 35
InNoRoutes: 0
InTooBigErrors: 0
OutFragOKs: 0
OutFragCreates: 0
InMcastPkts: 79
InMcastNotMembers: 65
OutMcastPkts: 938
InAddrErrors: 0
InDiscards: 0
OutDiscards: 0# Exibir as configurações da interface IPv6 no Switch B. São exibidos todos os endereços unicast globais IPv6 configurados na interface.
[SwitchB] display ipv6 interface vlan-interface 2
Vlan-interface2 current state :UP
Line protocol current state :UP
IPv6 is enabled, link-local address is FE80::20F:E2FF:FE00:1234
Global unicast address(es):
3001::2, subnet is 3001::/64
Joined group address(es):
FF02::1
FF02::2
FF02::1:FF00:2
FF02::1:FF00:1234
MTU is 1500 bytes
19
ND DAD is enabled, number of DAD attempts: 1
ND reachable time is 30000 milliseconds
ND retransmit interval is 1000 milliseconds
Hosts use stateless autoconfig for addresses
IPv6 Packet statistics:
InReceives: 117
InTooShorts: 0
InTruncatedPkts: 0
InHopLimitExceeds: 0
InBadHeaders: 0
InBadOptions: 0
ReasmReqds: 0
ReasmOKs: 0
InFragDrops: 0
InFragTimeouts: 0
OutFragFails: 0
InUnknownProtos: 0
InDelivers: 117
OutRequests: 83
OutForwDatagrams: 0
InNoRoutes: 0
InTooBigErrors: 0
OutFragOKs: 0
OutFragCreates: 0
InMcastPkts: 28
InMcastNotMembers: 0
OutMcastPkts: 7
InAddrErrors: 0
InDiscards: 0
OutDiscards: 0
# Pingue o Switch A e o Switch B no host e pingue o Switch A e o host no Switch B para verificar se estão conectados.
OBSERVAÇÃO:
Quando você fizer ping em um endereço local de link, use o parâmetro -i para especificar uma interface para o endereço local de link.
[SwitchB] ping ipv6 -c 1 3001::1
Ping6(56 data bytes) 3001::2 --> 3001::1, press CTRL_C to break
56 bytes from 3001::1, icmp_seq=0 hlim=64 time=4.404 ms
--- Ping6 statistics for 3001::1 ---
1 packet(s) transmitted, 1 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 4.404/4.404/4.404/0.000 ms
[SwitchB] ping ipv6 -c 1 2001::15B:E0EA:3524:E791
Ping6(56 data bytes) 3001::2 --> 2001::15B:E0EA:3524:E791, press CTRL_C to break
56 bytes from 2001::15B:E0EA:3524:E791, icmp_seq=0 hlim=64 time=5.404 ms
--- Ping6 statistics for 2001::15B:E0EA:3524:E791 ---
1 packet(s) transmitted, 1 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 5.404/5.404/5.404/0.000 msConfiguração da descoberta de vizinhos IPv6
Sobre a descoberta de vizinhos IPv6
Mensagens ICMPv6 usadas pela descoberta de vizinhos IPv6
O processo de descoberta de vizinhos (ND) do IPv6 usa mensagens ICMP para resolução de endereços, verificação de acessibilidade de vizinhos e rastreamento de dispositivos vizinhos.
A Tabela 3 descreve as mensagens ICMPv6 usadas pelo protocolo IPv6 ND.
Tabela 3 Mensagens ICMPv6 usadas pelo ND
| Mensagem ICMPv6 | Tipo | Função |
| Solicitação de vizinho (NS) | 135 | Adquire o endereço da camada de link de um vizinho no link local. Verifica a acessibilidade de um vizinho. Detecta endereços duplicados. |
| Anúncio de vizinho (NA) | 136 | Responde a uma mensagem NS. Notifica os nós vizinhos sobre alterações na camada de link. |
| Solicitação de roteador (RS) | 133 | Solicita um prefixo de endereço e outras informações de configuração para autoconfiguração após a inicialização. |
| Anúncio de roteador (RA) | 134 | Responde a uma mensagem RS. Anuncia informações, como as opções de informações de prefixo e os bits de sinalização. |
| Redirecionamento | 137 | Informa o host de origem sobre um próximo salto melhor no caminho para um destino específico quando determinadas condições são atendidas. |
Resolução de endereços
Essa função é semelhante ao ARP no IPv4. Um nó IPv6 adquire os endereços da camada de link dos nós vizinhos no mesmo link por meio de mensagens NS e NA.
A Figura 5 mostra como o host A adquire o endereço da camada de link do host B no mesmo link. O procedimento de resolução do endereço é o seguinte:
- O host A envia uma mensagem NS por multicasts. O endereço de origem da mensagem NS é o endereço IPv6 da interface de envio do Host A. O endereço de destino é o endereço multicast do nó solicitado do Host B. O corpo da mensagem NS contém o endereço da camada de link do Host A e o endereço IPv6 de destino .
- Após receber a mensagem NS, o host B determina se o endereço de destino do pacote é seu endereço IPv6. Se for, o host B descobre o endereço da camada de link do host A e, em seguida, unicausa uma mensagem NA contendo seu endereço da camada de link.
- O host A adquire o endereço da camada de link do host B a partir da mensagem NA.
Figura 5 Resolução de endereços
Detecção de acessibilidade do vizinho
Depois que o host A adquire o endereço da camada de link do host B vizinho, o host A pode usar as mensagens NS e NA para testar a acessibilidade do host B da seguinte forma:
- O host A envia uma mensagem NS cujo endereço de destino é o endereço IPv6 do host B.
- Se o host A receber uma mensagem NA do host B, o host A decide que o host B está acessível. Caso contrário, o host B não pode ser acessado.
Detecção de endereços duplicados
Depois que o host A adquire um endereço IPv6, ele executa a detecção de endereços duplicados (DAD) para verificar se o endereço está sendo usado por outro nó. Isso é semelhante ao ARP gratuito no IPv4. A DAD é realizada por meio de mensagens NS e NA.
O procedimento do DAD é o seguinte:
- O host A envia uma mensagem NS. O endereço de origem é o endereço não especificado e o endereço de destino é o endereço multicast de nó solicitado correspondente do endereço IPv6 a ser detectado. O corpo da mensagem NS contém o endereço IPv6 detectado.
- Se o host B usar esse endereço IPv6, o host B retornará uma mensagem NA que contém seu endereço IPv6.
- O host A sabe que o endereço IPv6 está sendo usado pelo host B depois de receber a mensagem NA do host B. Se não receber nenhuma mensagem NA, o host A decide que o endereço IPv6 não está em uso e usa esse endereço.
Figura 6 Detecção de endereços duplicados
Descoberta de roteador/prefixo e autoconfiguração de endereço sem estado
A descoberta de roteador/prefixo permite que um nó IPv6 encontre os roteadores vizinhos e aprenda o prefixo e os parâmetros de configuração da rede a partir do recebimento de mensagens RA.
A autoconfiguração de endereço sem estado permite que um nó IPv6 gere automaticamente um endereço IPv6 com base nas informações obtidas por meio da descoberta de roteador/prefixo.
Um nó executa a descoberta de roteador/prefixo e a autoconfiguração de endereço sem estado da seguinte forma:
- Na inicialização, um nó envia uma mensagem RS para solicitar informações de configuração de um roteador.
- O roteador retorna uma mensagem RA contendo a opção Prefix Information e outras informações de configuração. (O roteador também envia periodicamente uma mensagem RA).
- O nó gera automaticamente um endereço IPv6 e outros parâmetros de configuração de acordo com as informações de configuração na mensagem RA.
A opção Informações de prefixo contém um prefixo de endereço e o tempo de vida preferido e válido do prefixo de endereço. Um nó atualiza o tempo de vida preferido e o tempo de vida válido ao receber uma mensagem RA periódica.
O endereço IPv6 gerado é válido dentro do tempo de vida válido e se torna inválido quando o tempo de vida válido expira.
Após a expiração do tempo de vida preferencial, o nó não poderá usar o endereço IPv6 gerado para estabelecer novas conexões, mas poderá receber pacotes destinados ao endereço IPv6. O tempo de vida preferencial não pode ser maior que o tempo de vida válido.
Redirecionamento
Ao receber um pacote de um host, o gateway envia uma mensagem de redirecionamento ICMPv6 para informar ao host sobre um próximo salto melhor quando as seguintes condições forem atendidas:
∙ A interface que recebe o pacote é a mesma que encaminha o pacote.
∙ A rota selecionada não é criada ou modificada por uma mensagem de redirecionamento ICMPv6.
∙ A rota selecionada não é uma rota padrão no dispositivo.
∙ O pacote IPv6 encaminhado não contém o cabeçalho de extensão de roteamento.
Protocolos e padrões
∙ RFC 4861, Descoberta de vizinho para IP versão 6 (IPv6)
∙ RFC 4862, Autoconfiguração de endereços sem estado do IPv6
∙ RFC 8106, Opções de anúncio de roteador IPv6 para configuração de DNS
Visão geral das tarefas de descoberta de vizinhos IPv6
Todas as tarefas de descoberta de vizinhos IPv6 são opcionais.
∙ Configuração dos recursos relacionados à entrada ND
⚪ Configuração de uma entrada de vizinho estático
⚪ Definição do limite de aprendizagem dinâmica de vizinhos em uma interface
⚪ Definição do cronômetro de envelhecimento para entradas ND em estado obsoleto
⚪ Minimização de entradas ND link-local
∙ Definição do limite de salto
∙ Configuração de parâmetros e envio de mensagens RA
∙ Definição do número máximo de tentativas de envio de uma mensagem NS para DAD
∙ Configuração do snooping ND
⚪ Configuração do ND snooping em uma VLAN
∙ Ativação do proxy ND
∙ Configuração do registro de informações do usuário
⚪ Habilitação do registro de conflitos de endereços IPv6 do usuário
⚪ Habilitação da gravação de migrações de portas de usuários
⚪ Ativação do registro de ND para eventos on-line e off-line do usuário
Configuração de uma entrada de vizinho estático
Sobre entradas de vizinhos estáticos
Uma entrada de vizinho armazena informações sobre um nó local de link. A entrada pode ser criada dinamicamente por meio de mensagens NS e NA ou configurada estaticamente.
O dispositivo identifica com exclusividade uma entrada de vizinho estático usando o endereço IPv6 do vizinho e o número da interface da Camada 3 que se conecta ao vizinho. Você pode configurar uma entrada de vizinho estático usando um dos seguintes métodos:
∙ Método 1 - Associar o endereço IPv6 e o endereço da camada de link de um vizinho à interface local da Camada 3.
∙ Método 2 - Associar o endereço IPv6 e o endereço da camada de link de um vizinho a uma porta da Camada 2 em uma VLAN.
Restrições e diretrizes
Você pode usar qualquer um dos métodos para configurar uma entrada de vizinho estático para uma interface VLAN.
∙ Se você usar o Método 1, o dispositivo deverá resolver a porta da Camada 2 na VLAN relacionada.
∙ Se você usar o Método 2, verifique se a porta da Camada 2 pertence à VLAN especificada e se a interface da VLAN correspondente já existe. Após a configuração, o dispositivo associa a interface de VLAN ao endereço IPv6 do vizinho para identificar a entrada de vizinho estático.
Procedimento
- Entre na visualização do sistema.
system-view- Configurar uma entrada de vizinho estático.
ipv6 neighbor ipv6-address mac-address { vlan-id port-type port-number | interface interface-type interface-number }Por padrão, não existem entradas de vizinhos estáticos.
Configuração do limite de aprendizagem dinâmica de vizinhos em uma interface
Sobre o limite de aprendizagem dinâmica de vizinhos em uma interface
O dispositivo pode adquirir dinamicamente o endereço da camada de link de um nó vizinho por meio de mensagens NS e NA e adicioná-lo à tabela de vizinhos. Quando o número de entradas de vizinhos dinâmicos atinge o limite, a interface para de aprender informações de vizinhos.
Esse recurso limita o tamanho da tabela de vizinhos. Uma tabela de vizinhos grande prejudicará o desempenho do encaminhamento.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Definir o limite de aprendizagem dinâmica de vizinhos na interface.
ipv6 neighbors max-learning-num max-number
A configuração padrão varia de acordo com o modelo do dispositivo. Para obter mais informações sobre os valores padrão do argumento max-number, consulte esse comando na referência de comandos.
Configuração do timer de envelhecimento para entradas ND em estado obsoleto
Sobre o cronômetro de envelhecimento para entradas ND em estado obsoleto
As entradas de ND no estado obsoleto têm um cronômetro de envelhecimento. Se uma entrada de ND em estado obsoleto não for atualizada antes que o cronômetro expire, a entrada de ND mudará para o estado de atraso. Se ainda não for atualizada em 5 segundos, a entrada ND mudará para o estado de sondagem e o dispositivo enviará uma mensagem NS três vezes. Se nenhuma resposta for recebida, o dispositivo excluirá a entrada ND.
Restrições e diretrizes
É possível definir o cronômetro de envelhecimento para entradas ND em estado obsoleto na visualização do sistema e na visualização da interface. Para entradas ND em estado obsoleto em uma interface, o timer de envelhecimento na visualização da interface tem prioridade mais alta do que o timer de envelhecimento na visualização do sistema.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o cronômetro de envelhecimento para entradas ND em estado obsoleto.
- Defina o cronômetro de envelhecimento para entradas ND em estado obsoleto na visualização do sistema.
ipv6 neighbor stale-aging aging-time
A configuração padrão é 240 minutos.
- Execute os seguintes comandos em sequência para definir o cronômetro de envelhecimento na visualização da interface.
interface interface-type interface-number
ipv6 neighbor timer stale-aging aging-time
Por padrão, o timer de envelhecimento das entradas ND em estado obsoleto não é configurado em uma interface. O cronômetro de envelhecimento é determinado pela configuração do comando ipv6 neighbor stale-aging na visualização do sistema.
Minimização de entradas ND link-local
Sobre a minimização de entradas ND link-local
Execute esta tarefa para minimizar as entradas de ND link-local atribuídas ao hardware. As entradas de ND link-local referem-se a entradas de ND que contêm endereços link-local.
Por padrão, o dispositivo atribui todas as entradas de ND ao hardware. Com esse recurso ativado, as entradas de ND link-local recém-aprendidas não serão atribuídas ao hardware se os endereços link-local das entradas não forem os próximos hops de nenhuma rota. Esse recurso economiza recursos de hardware.
Esse recurso entra em vigor somente nas entradas de ND link-local recém-aprendidas.
Procedimento
- Entre na visualização do sistema.
system-view- Minimizar as entradas de ND link-local.
ipv6 neighbor link-local minimize
Por padrão, o dispositivo atribui todas as entradas de ND ao hardware.
Definição do limite de salto
Sobre o limite de salto
Você pode definir o valor do limite de salto para preencher o campo Limite de salto dos pacotes IPv6 a serem enviados.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o valor do campo Hop Limit no cabeçalho IP.
ipv6 hop-limit value
A configuração padrão é 64.
Configuração de parâmetros e envio de mensagens RA
Sobre os parâmetros da mensagem RA
Você pode habilitar uma interface para enviar mensagens RA e configurar o intervalo para o envio de mensagens RA e os parâmetros nas mensagens RA. Após receber uma mensagem RA, um host pode usar esses parâmetros para executar as operações correspondentes. A Tabela 4 descreve os parâmetros configuráveis em uma mensagem RA.
Tabela 4 Parâmetros em uma mensagem RA e suas descrições
| Parâmetro | Descrição |
| Limite de salto | Número máximo de saltos em mensagens RA. Um host que recebe a mensagem RA preenche o valor no campo Hop Limit dos pacotes IPv6 enviados. |
| Informações sobre o prefixo | Depois de receber as informações do prefixo, os hosts no mesmo link podem executar a autoconfiguração sem estado. |
| MTU | Garante que todos os nós do link usem o mesmo MTU. |
| URL do arquivo de inicialização | Especifica o endereço de URL para fazer download do arquivo de inicialização nas mensagens RA. O dispositivo pode usar o protocolo ND para obter o endereço IPv6 e o URL do arquivo de inicialização para configuração automática em vez de usar o DHCPv6. |
| Bandeira M | Determina se um host usa a autoconfiguração com estado para obter um endereço IPv6. Se o sinalizador M estiver definido como 1, o host usará a autoconfiguração com estado (por exemplo, de um servidor DHCPv6) para obter um endereço IPv6. Caso contrário, o host usará a autoconfiguração sem estado para gerar um endereço IPv6 de acordo com seu endereço de camada de link e as informações de prefixo na mensagem RA. |
| O sinalizador | Determina se um host usa a autoconfiguração com estado para obter informações de configuração que não sejam o endereço IPv6. |
| Parâmetro | Descrição |
| Se o sinalizador O for definido como 1, o host usará a autoconfiguração com estado (por exemplo, de um servidor DHCPv6) para obter informações de configuração que não sejam o endereço IPv6. Caso contrário, o host usará a autoconfiguração sem estado. | |
| Vida útil do roteador | Informa aos hosts receptores quanto tempo o roteador de publicidade pode durar. Se o tempo de vida de um roteador for 0, ele não poderá ser usado como gateway padrão. |
| Temporizador de retransmissão | Se o dispositivo não receber uma mensagem de resposta dentro do tempo especificado após o envio de uma mensagem NS, ele retransmitirá a mensagem NS. |
| Tempo de alcance | Se a detecção da capacidade de alcance do vizinho mostrar que um vizinho está acessível, o dispositivo considerará o vizinho acessível dentro do tempo de alcance especificado. Se o dispositivo precisar enviar um pacote ao vizinho depois que o tempo de alcance especificado expirar, o dispositivo confirmará novamente se o vizinho está acessível. |
| Preferência de roteador | Especifica a preferência do roteador em uma mensagem RA. Um host seleciona um roteador como gateway padrão de acordo com a preferência do roteador. Se as preferências do roteador forem as mesmas, o host selecionará o roteador do qual a primeira mensagem RA for recebida. |
| Opção de servidor DNS | Informações do servidor DNS para hosts IPv6. Os hosts podem obter informações do servidor DNS a partir de mensagens RA recebidas em vez de usar o DHCPv6. |
| Informações de sufixo DNS na opção Lista de pesquisa DNS (DNSSL) | Informações de sufixo DNS para hosts IPv6. Os hosts podem obter informações de sufixo DNS a partir de mensagens RA recebidas em vez de usar o DHCPv6. |
Restrições e diretrizes
O intervalo máximo para o envio de mensagens RA deve ser menor (ou igual) ao tempo de vida do roteador nas mensagens RA. Dessa forma, o roteador pode ser atualizado por uma mensagem RA antes da expiração.
Os valores do timer de retransmissão NS e o tempo alcançável configurado para uma interface são enviados em mensagens RA para hosts. Essa interface envia mensagens NS no intervalo do timer de retransmissão NS e considera um vizinho alcançável dentro do tempo alcançável.
Ativação do envio de mensagens RA
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar o envio de mensagens RA.
undo ipv6 nd ra halt
A configuração padrão é desativada.
- Defina os intervalos máximo e mínimo para o envio de mensagens RA.
ipv6 nd ra interval max-interval min-intervalPor padrão, o intervalo máximo para o envio de mensagens RA é de 600 segundos, e o intervalo mínimo é de 200 segundos.
O dispositivo envia mensagens RA em intervalos aleatórios entre o intervalo máximo e o intervalo mínimo.
O intervalo mínimo deve ser menor ou igual a 0,75 vezes o intervalo máximo.
Configuração de parâmetros para mensagens RA
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configurar as informações de prefixo nas mensagens RA.
ipv6 nd ra prefix { ipv6-prefix prefix-length |
ipv6-prefix/prefix-length } [ valid-lifetime preferred-lifetime
[ no-autoconfig | off-link | prefix-preference level ] * |
no-advertise ]Por padrão, nenhuma informação de prefixo é configurada para mensagens RA, e o endereço IPv6 da interface que envia mensagens RA é usado como informação de prefixo. Se o endereço IPv6 for configurado manualmente, o prefixo usará um tempo de vida válido fixo de 2592000 segundos (30 dias) e um tempo de vida preferencial de 604800 segundos (7 dias). Se o endereço IPv6 for obtido automaticamente, o prefixo usará o tempo de vida válido e o tempo de vida preferencial configurados para o endereço IPv6.
- Configurar as definições padrão para prefixos anunciados em mensagens RA.
ipv6 nd ra prefix default [ valid-lifetime preferred-lifetime
[ no-autoconfig | off-link ] * | no-advertise ]
Por padrão, nenhuma configuração padrão é definida para os prefixos anunciados nas mensagens RA.
- Desative a opção MTU nas mensagens RA.
ipv6 nd ra no-advlinkmtu
Por padrão, as mensagens RA contêm a opção MTU.
- Especificar hops ilimitados nas mensagens RA.
ipv6 nd ra hop-limit unspecifiedPor padrão, o número máximo de saltos nas mensagens RA é 64.
- Especifique o URL do arquivo de inicialização nas mensagens RA.
ipv6 nd ra boot-file-url url-stringPor padrão, as mensagens RA não contêm o URL do arquivo de inicialização.
- Defina o bit do sinalizador M como 1.
ipv6 nd autoconfig managed-address-flagPor padrão, o bit do sinalizador M é definido como 0 nos anúncios RA. Os hosts que receberem os anúncios obterão endereços IPv6 por meio de autoconfiguração sem estado.
- Defina o bit do sinalizador O como 1.
ipv6 nd autoconfig other-flagPor padrão, o bit do sinalizador O é definido como 0 nos anúncios RA. Os hosts que receberem os anúncios adquirirão outras informações de configuração por meio da autoconfiguração sem estado.
- Definir o tempo de vida do roteador em mensagens RA.
ipv6 nd ra router-lifetime timePor padrão, o tempo de vida do roteador é três vezes maior que o intervalo máximo para anunciar mensagens RA.
- Defina o cronômetro de retransmissão NS.
ipv6 nd ns retrans-timer valuePor padrão, uma interface envia mensagens NS a cada 1.000 milissegundos, e o valor do campo Retrans Timer nas mensagens RA é 0.
- Definir a preferência do roteador nas mensagens RA.
ipv6 nd router-preference { high | low | medium }Por padrão, a preferência do roteador é média.
- Defina o tempo de alcance.
ipv6 nd nud reachable-time timePor padrão, o tempo de alcance do vizinho é de 1.200.000 milissegundos, e o valor do campo Reachable Time nas mensagens RA enviadas é 0.
Especificação de informações do servidor DNS em mensagens RA
Sobre a especificação de informações do servidor DNS em mensagens RA
As opções do servidor DNS nas mensagens RA fornecem informações do servidor DNS para hosts IPv6. As mensagens RA permitem que os hosts obtenham seus endereços IPv6 e o servidor DNS por meio de autoconfiguração sem estado. Esse método é útil em uma rede em que a infraestrutura DHCPv6 não é fornecida.
Uma opção de servidor DNS contém um servidor DNS. Todas as opções de servidor DNS são classificadas em ordem crescente do número de sequência do servidor DNS.
Depois que você executa o comando ipv6 nd ra dns server, o dispositivo envia imediatamente uma mensagem RA com as informações do servidor DNS existente e recém-especificado.
Depois que você executa o comando undo ipv6 nd ra dns server, o dispositivo envia imediatamente duas mensagens RA.
∙ A primeira mensagem RA contém informações sobre todos os servidores DNS, inclusive os servidores DNS especificados no comando undo com o tempo de vida definido como 0 segundos.
∙ A segunda mensagem RA contém informações sobre os servidores DNS restantes.
Sempre que o dispositivo envia uma mensagem RA de uma interface, ele atualiza imediatamente o intervalo de anúncio da mensagem RA para essa interface.
Restrições e diretrizes
É possível configurar um máximo de oito servidores DNS em uma interface.
O tempo de vida padrão de um servidor DNS é três vezes o intervalo máximo para anunciar mensagens RA. Para definir o intervalo máximo, use o comando ipv6 nd ra interval.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique as informações do servidor DNS a serem anunciadas nas mensagens RA.
ipv6 nd ra dns server ipv6-address [ seconds | infinite ] sequence
seqnoPor padrão, nenhuma informação de servidor DNS é especificada e as mensagens RA não contêm opções de servidor DNS.
Especificação de informações de sufixo DNS em mensagens RA
Sobre a especificação de informações de sufixo DNS em mensagens RA
A opção DNSSL nas mensagens RA fornece informações de sufixo para hosts IPv6. As mensagens RA permitem que os hosts obtenham seus endereços IPv6 e o sufixo DNS por meio de autoconfiguração sem estado. Esse método é útil em uma rede em que a infraestrutura DHCPv6 não é fornecida.
Uma opção DNSSL contém um sufixo DNS. Todas as opções DNSSL são classificadas em ordem crescente do número de sequência do sufixo DNS.
Depois que você executa o comando ipv6 nd ra dns search-list, o dispositivo envia imediatamente uma mensagem RA com as informações de sufixo DNS existentes e recém-especificadas.
Depois que você executa o comando undo ipv6 nd ra dns search-list, o dispositivo envia imediatamente duas mensagens RA.
∙ A primeira mensagem RA contém informações sobre todos os sufixos DNS, inclusive os sufixos DNS especificados no comando undo com o tempo de vida definido como 0 segundos.
∙ A segunda mensagem RA contém informações sobre os sufixos DNS restantes.
Sempre que o dispositivo envia uma mensagem RA de uma interface, ele atualiza imediatamente o intervalo de anúncio da mensagem RA para essa interface.
Restrições e diretrizes
É possível configurar um máximo de oito sufixos DNS em uma interface.
O tempo de vida padrão de um sufixo de DNS é três vezes o intervalo máximo para anunciar mensagens RA. Para definir o intervalo máximo, use o comando ipv6 nd ra interval.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique as informações de sufixo DNS a serem anunciadas nas mensagens RA.
ipv6 nd ra dns server ipv6-address [ seconds | infinite ] sequence
seqnoPor padrão, nenhuma informação de sufixo DNS é especificada e as mensagens RA não contêm sufixo DNS opções.
Supressão da publicidade de informações de DNS em mensagens RA
Sobre a supressão da publicidade de informações de DNS em mensagens RA
Execute esta tarefa para impedir que o dispositivo anuncie informações sobre endereços de servidores DNS e sufixos DNS em mensagens RA.
O fato de a ativação desse recurso em uma interface acionar o envio imediato de mensagens RA para atualização do servidor DNS depende da configuração da interface:
∙ Se a interface tiver sido configurada com informações do servidor DNS ou tiver obtido um
Se o endereço do servidor DNS autorizado por AAA, o dispositivo envia imediatamente duas mensagens RA. Na primeira mensagem, o tempo de vida dos endereços de servidor DNS é de 0 segundos. A segunda mensagem RA não contém nenhuma opção de servidor DNS.
∙ Se a interface não tiver nenhuma informação de servidor DNS especificada ou nenhum endereço de servidor DNS autorizado pelo AAA atribuído, nenhuma mensagem RA será acionada.
∙ você especificar um novo servidor DNS ou remover um servidor DNS, o dispositivo enviará imediatamente uma mensagem RA sem nenhuma opção de endereço de servidor DNS.
O fato de a desativação desse recurso em uma interface acionar o envio imediato de mensagens RA para atualização do servidor DNS depende da configuração da interface:
∙ Se a interface tiver sido configurada com as informações do servidor DNS ou tiver obtido um
endereço de servidor DNS autorizado pelo AAA, o dispositivo envia imediatamente uma mensagem RA com as informações do servidor DNS.
∙ Se a interface não tiver nenhuma informação de servidor DNS especificada ou nenhum endereço de servidor DNS autorizado pelo AAA atribuído, nenhuma mensagem RA será acionada.
Sempre que o dispositivo envia uma mensagem RA de uma interface, ele atualiza imediatamente o intervalo de anúncio da mensagem RA para essa interface.
O mesmo mecanismo de supressão se aplica quando você ativa ou desativa a supressão de sufixo DNS em mensagens RA.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar a supressão do servidor DNS nas mensagens RA.
ipv6 nd ra dns server suppress
Por padrão, a supressão do servidor DNS nas mensagens RA está desativada.
- Ativar a supressão do sufixo DNS nas mensagens RA.
ipv6 nd ra dns search-list suppressPor padrão, a supressão do sufixo DNS nas mensagens RA está desativada.
Definição do número máximo de tentativas de envio de uma mensagem NS para DAD
Sobre o número máximo de tentativas de envio de uma mensagem NS para DAD
Uma interface envia uma mensagem NS para DAD para um endereço IPv6 obtido. A interface reenvia a mensagem NS se não receber uma resposta dentro do tempo especificado pelo comando ipv6 nd ns retrans-timer. Se a interface não receber nenhuma resposta depois de fazer o máximo de tentativas especificadas pelo comando ipv6 nd dad attempts, a interface usará o endereço IPv6.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o número de tentativas de envio de uma mensagem NS para DAD.
ipv6 nd dad attempts timesA configuração padrão é 1. Quando o argumento times é definido como 0, o DAD é desativado.
Configuração do ND snooping em uma VLAN
Sobre o ND snooping em uma VLAN
O recurso de snooping ND é usado em redes de comutação da Camada 2. Ele aprende os endereços MAC de origem, os endereços IPv6 de origem, as interfaces de entrada e as VLANs das mensagens ND e dos pacotes de dados que chegam para criar a tabela de snooping ND.
As entradas de snooping de ND podem ser usadas pela detecção de ND para evitar ataques de spoofing.
A detecção de ND processa as mensagens ND recebidas em interfaces ND confiáveis e não confiáveis da seguinte forma:
A detecção de ND encaminha todas as mensagens ND recebidas em uma interface ND confiável.
∙ A detecção de ND compara todas as mensagens ND recebidas em uma interface ND não confiável com as entradas do ND snooping, exceto as mensagens RA e de redirecionamento.
Você pode usar o comando ipv6 nd detection trust para especificar uma porta agregada ou Ethernet de camada 2 como uma interface confiável de ND. Para obter mais informações sobre o comando ipv6 nd detection trust, consulte Referência de comandos de segurança.
As entradas do ND snooping podem ser usadas pelo IPv6 source guard para evitar ataques de spoofing. Para obter mais informações sobre o IPv6 source guard, consulte o Security Configuration Guide.
O snooping ND fornece rastreamento da atividade do dispositivo para que a tabela de snooping ND possa ser atualizada em tempo hábil. Depois que o snooping ND é ativado para uma VLAN, o dispositivo usa os seguintes mecanismos para criar, atualizar e excluir entradas de snooping ND. O exemplo a seguir usa mensagens ND para fins ilustrativos.
Criação de entradas de ND snooping
Ao receber uma mensagem ND ou um pacote de dados de uma fonte desconhecida, o dispositivo cria uma entrada de snooping ND no status INVALID e executa o DAD para o endereço IPv6 de origem. O dispositivo envia mensagens NS das interfaces confiáveis ND na VLAN receptora duas vezes. O intervalo de envio é definido pelo comando ipv6 nd snooping dad retrans-timer.
∙ Se o dispositivo não receber uma mensagem NA dentro do tempo de vida da entrada inválida (definido pelo comando ipv6 nd snooping lifetime invalid), a entrada se tornará válida.
Se o dispositivo receber uma mensagem NA dentro do tempo de vida da entrada inválida, ele excluirá essa entrada.
Atualização de entradas do ND snooping
Quando a interface não confiável ND que recebe uma mensagem ND é diferente da que está na entrada de um endereço IPv6, o dispositivo executa o DAD para a entrada. Ele envia mensagens NS duas vezes. O intervalo de envio é definido pelo comando ipv6 nd snooping dad retrans-timer.
Se o dispositivo não receber uma mensagem NA dentro do tempo de vida da entrada inválida, ele atualizará a entrada com a nova interface de recebimento.
∙ Se o dispositivo receber uma mensagem NA dentro do tempo de vida da entrada inválida, a entrada do ND snooping permanecerá inalterada.
Exclusão de entradas do ND snooping
∙ Quando uma interface ND confiável na VLAN recebe uma mensagem ND do endereço IPv6 em uma entrada ND snooping aprendida, ela executa o DAD para a entrada. O dispositivo envia mensagens NS duas vezes. O intervalo de envio é definido pelo comando ipv6 nd snooping dad retrans-timer.
⚪ Se o dispositivo não receber uma mensagem NA dentro do tempo de vida da entrada inválida, ele excluirá a entrada.
⚪ Se o dispositivo receber uma mensagem NA dentro do tempo de vida da entrada inválida, a entrada do ND snooping permanecerá inalterada.
∙ Se uma entrada do ND snooping não tiver mensagens ND correspondentes dentro do tempo de vida válido da entrada (definido pelo comando ipv6 nd snooping lifetime valid), a entrada se tornará inválida. Em seguida, o dispositivo executa o DAD para a entrada enviando duas vezes mensagens NS para fora da interface da entrada. O intervalo de envio é definido pelo comando ipv6 nd snooping dad retrans-timer.
⚪ Se o dispositivo não receber uma mensagem NA dentro do tempo de vida da entrada inválida, ele excluirá a entrada.
⚪ Se o dispositivo receber uma mensagem NA dentro do tempo de vida da entrada inválida, a entrada do ND snooping permanecerá inalterada e se tornará válida.
Ativação do snooping ND
- Entre na visualização do sistema.
system-view- Entre na visualização de VLAN.
vlan vlan-id- Habilite o snooping ND para endereços IPv6. Escolha as opções para configurar conforme necessário:
- Habilite o snooping ND para endereços unicast globais.
ipv6 nd snooping enable global- Habilite o snooping de ND para endereços link-local.
ipv6 nd snooping enable link-localPor padrão, o snooping ND está desativado para endereços unicast globais IPv6 e endereços link-local.
- (Opcional.) Ative o snooping ND para pacotes de dados de fontes desconhecidas.
ipv6 nd snooping glean sourcePor padrão, o snooping ND é desativado para pacotes de dados de fontes desconhecidas.
Antes de executar esse comando em uma VLAN, você deve configurar o IPv6 source guard em todas as interfaces não confiáveis na mesma VLAN. Essa operação garante o encaminhamento correto dos pacotes de dados recebidos por todas essas interfaces.
- Retornar à visualização do sistema.
quitConfiguração do número máximo de entradas do ND snooping
- Entre na visualização do sistema.
system-view- Entre na visualização da interface agregada da Camada 2 ou Ethernet da Camada 2.
interface interface-type interface-number- (Opcional.) Defina o número máximo de entradas de ND snooping que uma interface pode aprender.
ipv6 nd snooping max-learning-num max-numberPor padrão, uma interface pode aprender um máximo de 1024 entradas de ND snooping.
Configuração dos parâmetros relacionados à entrada do ND snooping
- Entre na visualização do sistema.
system-view- Entre na visualização da interface agregada da Camada 2 ou Ethernet da Camada 2.
interface interface-type interface-number- (Opcional.) Configure a porta como uma porta de uplink de snooping ND. A porta de uplink do ND snooping não pode aprender entradas do ND snooping.
ipv6 nd snooping uplinkPor padrão, a porta não é uma porta de uplink de snooping ND. Depois que o ND snooping é ativado, a porta pode aprender entradas de ND snooping.
- Retornar à visualização do sistema.
quit- (Opcional.) Defina temporizadores de tempo limite para entradas do ND snooping.
ipv6 nd snooping lifetime { invalid invalid-lifetime | valid
valid-lifetime }As configurações padrão são as seguintes:
- O cronômetro de tempo limite para entradas do ND snooping em status INVALID (TENTATIVE, TESTING_TPLT ou TESTING_VP) é de 500 milissegundos.
- O cronômetro de tempo limite para entradas de ND snooping no status VALID é de 300 segundos.
- (Opcional.) Defina o intervalo para retransmissão de uma mensagem NS para DAD.
ipv6 nd snooping dad retrans-timer intervalO valor padrão é 250 milissegundos.
Ativação do proxy ND
Sobre o proxy ND
O proxy ND permite que um dispositivo responda a uma mensagem NS solicitando o endereço de hardware de um host em outra rede. Com o proxy ND, os hosts em diferentes domínios de broadcast podem se comunicar entre si como se estivessem na mesma rede.
O proxy ND inclui o proxy ND comum e o proxy ND local.
Proxy ND comum
Conforme mostrado na Figura 7, a Interface A com endereço IPv6 4:1::99/64 e a Interface B com endereço IPv6 4:2::99/64 pertencem a sub-redes diferentes. O host A e o host B residem na mesma rede, mas em domínios de broadcast diferentes .
Figura 7 Ambiente de aplicativo do proxy ND
Como o endereço IPv6 do Host A está na mesma sub-rede que o do Host B, o Host A envia diretamente uma mensagem NS para obter o endereço MAC do Host B. No entanto, o host B não pode receber a mensagem NS porque eles pertencem a domínios de broadcast diferentes.
Para resolver esse problema, ative o proxy ND comum na Interface A e na Interface B do dispositivo. O dispositivo responde à mensagem NS do Host A e encaminha os pacotes de outros hosts para o Host B.
Proxy ND local
Conforme mostrado na Figura 8, o Host A pertence à VLAN 2 e o Host B pertence à VLAN 3. O host A e o host B se conectam à porta B1 e à porta B3, respectivamente.
Figura 8 Ambiente de aplicativos do proxy ND local
Como o endereço IPv6 do Host A está na mesma sub-rede que o do Host B, o Host A envia diretamente uma mensagem NS para obter o endereço MAC do Host B. No entanto, o host B não pode receber a mensagem NS porque eles pertencem a VLANs diferentes.
Para resolver esse problema, ative o proxy ND local na Interface A do Dispositivo A para que o Dispositivo A possa encaminhar mensagens entre o Host A e o Host B.
O proxy ND local implementa a comunicação da Camada 3 para dois hosts nos seguintes casos:
∙ Os dois hosts se conectam a portas do mesmo dispositivo e as portas devem estar em VLANs diferentes.
∙ Os dois hosts se conectam a portas isoladas da Camada 2 no mesmo grupo de isolamento de uma VLAN.
∙ Se a VLAN privada for usada, os dois hosts deverão pertencer a VLANs secundárias diferentes.
Habilitação de proxy ND comum
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilitar o proxy ND comum.
proxy-nd enablePor padrão, o proxy ND comum está desativado.
Ativação do proxy ND local
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar o proxy ND local.
local-proxy-nd enablePor padrão, o proxy ND local está desativado.
Ativação do registro de conflitos de endereços IPv6 do usuário
Sobre o registro de conflitos de endereços IPv6 do usuário
Esse recurso detecta e registra conflitos de endereços IPv6 do usuário. Um conflito ocorre se um pacote NA de entrada tiver o mesmo endereço IP de origem de uma entrada ND existente, mas um endereço MAC de origem diferente. O dispositivo gera um registro de conflito de endereço IPv6 do usuário, registra o conflito e envia o registro para o centro de informações. Para obter informações sobre o destino do registro e a configuração da regra de saída na central de informações, consulte a central de informações no Guia de configuração de monitoramento e gerenciamento de rede .
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o registro de conflitos de endereços IPv6 do usuário.
ipv6 nd user-ip-conflict record enablePor padrão, o registro de conflitos de endereços IPv6 do usuário está desativado.
Ativação do registro de migrações de portas de usuários
Sobre o registro de migrações de portas de usuários
Esse recurso permite que o dispositivo detecte e registre migrações de portas de usuários. Uma porta de usuário migra se um pacote NA de entrada tiver o mesmo endereço IPv6 de origem e o mesmo endereço MAC de origem que uma entrada ND existente, mas uma porta de entrada diferente. O dispositivo gera um registro de migração de porta de usuário, registra o evento de migração e envia o registro para o centro de informações. Para obter informações sobre o destino do registro e a configuração da regra de saída no centro de informações, consulte o centro de informações em Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o registro de migrações de portas de usuários.
ipv6 nd user-move record enablePor padrão, o registro das migrações de porta do usuário está desativado.
Ativação do registro de ND para eventos on-line e off-line do usuário
Sobre o registro de ND para eventos on-line e off-line do usuário
Esse recurso permite que o dispositivo gere logs on-line ou off-line do usuário em tais eventos e envie esses logs para o centro de informações. Para obter informações sobre o destino do registro e a configuração da regra de saída na central de informações, consulte a central de informações no Guia de configuração de monitoramento e gerenciamento de rede.
Restrições e diretrizes
Uma taxa de saída de log mais alta consome mais recursos da CPU. Ajuste a taxa de saída de registros com base no desempenho e no uso da CPU.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o registro ND para eventos on-line e off-line do usuário.
ipv6 nd online-offline-log enable [ rate rate ]Por padrão, o registro de ND para eventos on-line e off-line do usuário está desativado.
Comandos de exibição e manutenção para IPv6 ND
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibe o número de entradas de snooping IPv6 ND em VLANs. | display ipv6 nd snooping count vlan [ interface interface-type interface-number ] |
| Exibir entradas de snooping IPv6 ND em VLANs. | display ipv6 nd snooping vlan [ [ vlan-id | interface interface-type interface-number ] [ global | link-local ] | ipv6-address ] [ verbose ] |
| Exibir registros de conflito de endereços IPv6 do usuário. | display ipv6 nd user-ip-conflict record [slot slot-number ] |
| Exibir registros de migração de porta de usuário. | display ipv6 nd user-move record [ slot slot-number ] |
| Exibe o número total de entradas vizinhas. | display ipv6 neighbors { { all | dynamic | static } [ slot slot-number ] | interface-type interface-number | vlan vlan-id } count |
| Exibir informações sobre vizinhos. | display ipv6 neighbors { { ipv6-address | all | dinâmico | estático } [ slot slot-number ] | interface-type interface-number | vlan vlan-id } [ verbose ] |
| Exibe o número máximo de entradas ND que um dispositivo suporta. | exibir ipv6 neighbors entry-limit |
| Limpar entradas de snooping IPv6 ND em uma VLAN. | reset ipv6 nd snooping vlan { [ vlan-id ] [ global | link-local ] | vlan-id ipv6-address } |
| Limpar informações de vizinhos IPv6. | reset ipv6 neighbors { all | dynamic | interface interface-type interface-number | slot slot-number | static } |
Exemplos de configuração do IPv6 ND
Exemplo: Configuração do snooping ND
Configuração de rede
Conforme mostrado na Figura 9, o Host A e o Host B estão conectados ao gateway por meio do Dispositivo B. Ative o snooping de ND no Dispositivo B para obter entradas de snooping de ND sobre o Host A e o Host B.
Figura 9 Diagrama de rede
Procedimento
- Configure o dispositivo A: # Crie a VLAN 10.
<DeviceA> system-view
[DeviceA] vlan 10
[DeviceA-vlan10] quit# Configure a GigabitEthernet 1/0/3 para a VLAN 10 do tronco.
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port link-type trunk
[DeviceA-GigabitEthernet1/0/3] port trunk permit vlan 10
[DeviceA-GigabitEthernet1/0/3] quit# Atribuir o endereço IPv6 10::1/64 à interface VLAN 10.
[DeviceA] interface vlan-interface 10
[DeviceA-Vlan-interface10] ipv6 address 10::1/64
[DeviceA-Vlan-interface10] quit- Configurar o dispositivo B:
# Criar a VLAN 10.
[DeviceB] vlan 10
[DeviceB-vlan10] quit# Configure a GigabitEthernet 1/0/1, a GigabitEthernet 1/0/2 e a GigabitEthernet 1/0/3 para a VLAN 10 do tronco.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type access
[DeviceB-GigabitEthernet1/0/1] port access vlan 10
[DeviceB-GigabitEthernet1/0/1] quit
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type access
[DeviceB-GigabitEthernet1/0/2] port access vlan 10
[DeviceB-GigabitEthernet1/0/2] quit
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] port link-type trunk
[DeviceB-GigabitEthernet1/0/3] port trunk permit vlan 10
[DeviceB-GigabitEthernet1/0/3] quit# Habilite o snooping ND para endereços unicast globais e endereços link-local na VLAN 10.
[DeviceB] vlan 10
[DeviceB-vlan10] ipv6 nd snooping enable global
[DeviceB-vlan10] ipv6 nd snooping enable link-local# Habilite o snooping ND para pacotes de dados de fontes desconhecidas na VLAN 10.
[DeviceB-vlan10] ipv6 nd snooping glean source
[DeviceB-vlan10] quit# Configure a GigabitEthernet 1/0/3 como interface confiável ND.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] ipv6 nd detection trust
[DeviceB-GigabitEthernet1/0/3] quit# Configure a GigabitEthernet 1/0/1 para aprender um número máximo de 200 entradas de ND snooping.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] ipv6 nd snooping max-learning-num 200
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 para aprender um número máximo de 200 entradas de ND snooping.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] ipv6 nd snooping max-learning-num 200
[DeviceB-GigabitEthernet1/0/2] quitVerificação da configuração
# Verifique se o dispositivo B aprendeu as entradas de snooping ND para o host A e o host B.
[DeviceB] display ipv6 nd snooping vlan 10
IPv6 address MAC address VID Interface Status Age
10::5 0001-0203-0405 10 GE1/0/1 VALID 157
10::6 0001-0203-0607 10 GE1/0/2 VALID 105Visão geral do DHCPv6
Atribuição de endereço/prefixo DHCPv6
Um processo de atribuição de endereço/prefixo envolve duas ou quatro mensagens.
Atribuição rápida envolvendo duas mensagens
Conforme mostrado na Figura 1, a atribuição rápida funciona nas seguintes etapas:
- O cliente DHCPv6 envia ao servidor DHCPv6 uma mensagem Solicit que contém uma opção Rapid Commit para preferir a atribuição rápida.
- Se o servidor DHCPv6 suportar a atribuição rápida, ele responderá com uma mensagem de resposta contendo o endereço/prefixo IPv6 atribuído e outros parâmetros de configuração. Se o servidor DHCPv6 não for compatível com a atribuição rápida, será realizada uma atribuição que envolve quatro mensagens.
Figura 1 Atribuição rápida envolvendo duas mensagens
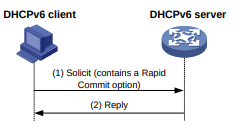
Atribuição envolvendo quatro mensagens
Conforme mostrado na Figura 2, a atribuição de quatro mensagens funciona usando as seguintes etapas:
- O cliente DHCPv6 envia uma mensagem Solicit para solicitar um endereço/prefixo IPv6 e outros parâmetros de configuração.
- O servidor DHCPv6 responde com uma mensagem Advertise que contém o endereço/prefixo atribuível e outros parâmetros de configuração se houver uma das seguintes condições:
- A mensagem Solicit não contém uma opção Rapid Commit.
- O servidor DHCPv6 não oferece suporte à atribuição rápida, mesmo que a mensagem Solicit contenha uma opção Rapid Commit.
- O cliente DHCPv6 pode receber várias mensagens Advertise oferecidas por diferentes servidores DHCPv6. Ele seleciona uma oferta de acordo com a sequência de recebimento e a prioridade do servidor e envia uma mensagem Request ao servidor selecionado para confirmação.
- O servidor DHCPv6 envia uma mensagem de resposta ao cliente, confirmando que o endereço/prefixo e outros parâmetros de configuração foram atribuídos ao cliente.
Figura 2 Atribuição envolvendo quatro mensagens
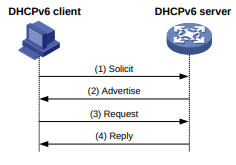
Renovação de leasing de endereço/prefixo
Um endereço/prefixo IPv6 atribuído por um servidor DHCPv6 tem uma vida útil válida. Após a expiração da vida útil válida, o cliente DHCPv6 não poderá usar o endereço/prefixo IPv6. Para usar o endereço/prefixo IPv6, o cliente DHCPv6 deve renovar o tempo de concessão.
Figura 3: Uso da mensagem Renew para renovação de leasing de endereço/prefixo
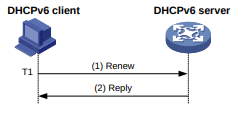
Conforme mostrado na Figura 3, em T1, o cliente DHCPv6 envia uma mensagem Renew para o servidor DHCPv6. O valor recomendado de T1 é a metade do tempo de vida preferido. O servidor DHCPv6 responde com uma mensagem Reply , informando ao cliente se o arrendamento foi renovado.
Figura 4: Uso da mensagem Rebind para renovação de leasing de endereço/prefixo
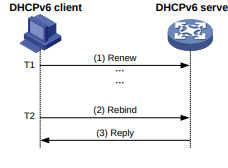
Conforme mostrado na Figura 4:
∙ Se o cliente DHCPv6 não receber uma resposta do servidor DHCPv6 após o envio de uma mensagem Renew (Renovar) em T1, ele enviará uma mensagem Rebind (Reagrupar) para todos os servidores DHCPv6 em T2. Normalmente, o valor de T2 é 0,8 vezes o tempo de vida preferencial.
∙ O servidor DHCPv6 responde com uma mensagem de resposta, informando ao cliente se o arrendamento foi renovado.
∙ Se o cliente DHCPv6 não receber uma resposta de nenhum servidor DHCPv6 antes que o tempo de vida válido expire, o cliente deixará de usar o endereço/prefixo.
Para obter mais informações sobre o tempo de vida válido e o tempo de vida preferencial, consulte "Definição das configurações básicas de IPv6".
DHCPv6 sem estado
O DHCPv6 sem estado permite que um dispositivo que tenha obtido um endereço/prefixo IPv6 obtenha outros parâmetros de configuração de um servidor DHCPv6.
O dispositivo executará o DHCPv6 sem estado se uma mensagem RA com os seguintes sinalizadores for recebida do roteador durante a autoconfiguração de endereço sem estado:
∙ O sinalizador de configuração de endereço gerenciado (sinalizador M) é definido como 0.
∙ O outro sinalizador de configuração com estado (sinalizador O) é definido como 1.
Figura 5 Operação DHCPv6 sem estado

Conforme mostrado na Figura 5, o DHCPv6 sem estado funciona nas seguintes etapas:
- O cliente DHCPv6 envia uma mensagem de solicitação de informações para o endereço multicast de todos os servidores DHCPv6 e agentes de retransmissão DHCPv6. A mensagem Information-request contém uma opção Option Request que especifica os parâmetros de configuração solicitados.
- O servidor DHCPv6 retorna ao cliente uma mensagem de resposta contendo os parâmetros de configuração solicitados.
- O cliente verifica a mensagem de resposta. Se os parâmetros de configuração obtidos corresponderem aos solicitados na mensagem Information-request, o cliente usará esses parâmetros para concluir a configuração. Caso contrário, o cliente ignora os parâmetros de configuração. Se o cliente receber várias respostas com parâmetros de configuração que correspondam aos solicitados na mensagem
mensagem de solicitação de informações, ele usa a primeira resposta recebida.
Opções do DHCPv6
Opção 18
A opção 18, também chamada de opção interface-ID, é usada pelo agente de retransmissão DHCPv6 para determinar a interface a ser usada para encaminhar a mensagem RELAY-REPLY.
O dispositivo snooping DHCPv6 adiciona a Opção 18 à mensagem de solicitação DHCPv6 recebida antes de encaminhá-la ao servidor DHCPv6. Em seguida, o servidor atribui o endereço IP ao cliente com base nas informações do cliente na Opção 18.
Figura 6 Formato da opção 18
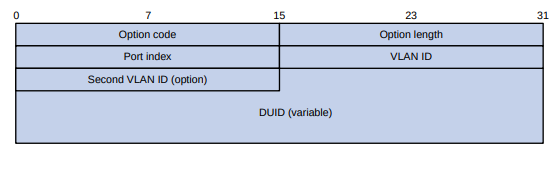
A Figura 6 mostra o formato da Opção 18, que inclui os seguintes campos:
∙ Código da opção - Código da opção. O valor é 18.
∙ Comprimento da opção-Tamanho dos dados da opção.
∙ Índice da porta - Porta que recebe a solicitação DHCPv6 do cliente.
∙ VLAN ID - ID da VLAN externa.
∙ Segunda VLAN ID - ID da VLAN interna. Esse campo é opcional. Se a solicitação DHCPv6 recebida não contiver uma segunda VLAN, a Opção 18 também não a conterá.
∙ DUID-DUID do cliente DHCPv6.
Opção 37
A opção 37, também chamada de opção remote-ID, é usada para identificar o cliente.
O dispositivo snooping DHCPv6 adiciona a Opção 37 à mensagem de solicitação DHCPv6 recebida antes de encaminhá-la ao servidor DHCPv6. Essa opção fornece informações ao cliente sobre a alocação de endereços.
Figura 7 Formato da opção 37
A Figura 7 mostra o formato da Opção 37, que inclui os seguintes campos:
∙ Código da opção - Código da opção. O valor é 37.
∙ Comprimento da opção-Tamanho dos dados da opção.
∙ Número da empresa - Número da empresa.
∙ Índice da porta - Porta que recebe a solicitação DHCPv6 do cliente.
∙ VLAN ID - ID da VLAN externa.
∙ Second VLAN ID - ID da VLAN interna. Esse campo é opcional. Se a solicitação DHCPv6 recebida não contiver uma segunda VLAN, a Opção 37 também não a conterá.
∙ DUID-DUID do cliente DHCPv6.
Opção 79
A opção 79, também chamada de opção de endereço da camada de link do cliente, é usada para registrar o endereço MAC do cliente DHCPv6. O primeiro agente de retransmissão pelo qual passa uma solicitação DHCPv6 descobre o endereço MAC do cliente e encapsula esse endereço na Opção 79 na mensagem Relay-Forward da solicitação. O servidor DHCPv6 verifica o cliente ou atribui endereço/prefixo IPv6 ao cliente com base no endereço MAC do cliente.
Figura 8 Formato da opção 79

A Figura 8 mostra o formato da Opção 79, que inclui os seguintes campos:
∙ Código da opção - Código da opção. O valor é 79.
∙ Comprimento da opção-Tamanho dos dados da opção.
∙ Link-layer type-Tipo de endereço de camada de link do cliente.
∙ Link-layer address-Endereço de camada de link do cliente.
Protocolos e padrões
∙ RFC 3736, Serviço de protocolo de configuração dinâmica de host (DHCP) sem estado para IPv6
∙ RFC 3315, Protocolo de configuração dinâmica de host para IPv6 (DHCPv6)
∙ RFC 2462, Autoconfiguração de endereço sem estado do IPv6
∙ RFC 3633, Opções de prefixo IPv6 para DHCP (Dynamic Host Configuration Protocol) versão 6
∙ RFC 6939, Opção de endereço da camada de link do cliente no DHCPv6
Configuração do servidor DHCPv6
Sobre o servidor DHCPv6
Um servidor DHCPv6 pode atribuir endereços IPv6, prefixos IPv6 e outros parâmetros de configuração a clientes DHCPv6.
Atribuição de endereços IPv6
Conforme mostrado na Figura 9, o servidor DHCPv6 atribui endereços IPv6, sufixos de nome de domínio, endereços de servidor DNS e outros parâmetros de configuração aos clientes DHCPv6.
Os endereços IPv6 atribuídos aos clientes incluem os seguintes tipos:
∙ Endereços IPv6 temporários: alterados com frequência sem renovação do contrato de aluguel.
∙ Endereços IPv6 não temporários - usados corretamente por clientes DHCPv6, com renovação de leasing.
Figura 9 Atribuição de endereços IPv6
Atribuição de prefixo IPv6
Conforme mostrado na Figura 10, o servidor DHCPv6 atribui um prefixo IPv6 ao cliente DHCPv6. O cliente anuncia as informações do prefixo em uma mensagem RA multicast para que os hosts da sub-rede possam configurar automaticamente seus endereços IPv6 usando o prefixo.
Figura 10 Atribuição de prefixo IPv6
Conceitos
Endereços multicast usados pelo DHCPv6
O DHCPv6 usa o endereço multicast FF05::1:3 para identificar todos os servidores DHCPv6 locais. Ele usa o endereço multicast FF02::1:2 para identificar todos os servidores DHCPv6 locais de link e agentes de retransmissão.
DUID
Um identificador exclusivo DHCP (DUID) identifica exclusivamente um dispositivo DHCPv6 (cliente DHCPv6, servidor ou agente de retransmissão ). Um dispositivo DHCPv6 adiciona seu DUID em um pacote enviado.
Figura 11 Formato DUID-LL
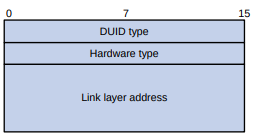
O dispositivo é compatível com o formato DUID baseado no endereço da camada de link (DUID-LL) definido na RFC 3315. A Figura 11 mostra o formato DUID-LL, que inclui os seguintes campos:
- Tipo de DUID - O dispositivo suporta o tipo de DUID de DUID-LL com o valor de 0x0003.
- Tipo de hardware - O dispositivo suporta o tipo de hardware Ethernet com o valor 0x0001.
- Endereço da camada de link - Assume o valor do endereço MAC da ponte do dispositivo.
Identificada por um IAID, uma associação de identidade (IA) fornece uma estrutura por meio da qual um cliente gerencia os endereços obtidos, os prefixos e outros parâmetros de configuração. Um cliente pode ter várias IAs, por exemplo, uma para cada uma de suas interfaces.
Um IAID identifica de forma exclusiva um IA. Ele é escolhido pelo cliente e deve ser exclusivo no cliente.
O servidor DHCPv6 cria uma delegação de prefixo (PD) para cada prefixo atribuído para registrar os seguintes detalhes:
- Prefixo IPv6.
- DUID do cliente.
- IAID.
- Vida útil válida.
- Vida útil preferida.
- Prazo de validade do aluguel.
- Endereço IPv6 do cliente solicitante.
Pool de endereços DHCPv6
O servidor DHCP seleciona endereços IPv6, prefixos IPv6 e outros parâmetros de um pool de endereços e os atribui aos clientes DHCP.
Mecanismos de alocação de endereços
O DHCPv6 oferece suporte aos seguintes mecanismos de alocação de endereços:
- Alocação estática de endereços - Para implementar a alocação estática de endereços para um cliente, crie um pool de endereços DHCPv6 e vincule manualmente o DUID e o IAID do cliente a um endereço IPv6 no pool de endereços DHCPv6. Quando o cliente solicita um endereço IPv6, o servidor DHCPv6 atribui ao cliente o endereço IPv6 na associação estática.
- Alocação dinâmica de endereços - Para implementar a alocação dinâmica de endereços para clientes, crie um pool de endereços DHCPv6, especifique uma sub-rede para o pool e divida a sub-rede em intervalos de endereços IPv6 temporários e não temporários. Ao receber uma solicitação DHCP, o servidor DHCPv6 seleciona um endereço IPv6 do intervalo de endereços IPv6 temporários ou não temporários com base no tipo de endereço na solicitação do cliente.
Mecanismos de alocação de prefixos
O DHCPv6 oferece suporte aos seguintes mecanismos de alocação de prefixo:
- Alocação estática de prefixo - Para implementar a alocação estática de prefixo para um cliente, crie um pool de endereços DHCPv6 e vincule manualmente o DUID e o IAID do cliente a um prefixo IPv6 no pool de endereços DHCPv6. Quando o cliente solicita um prefixo IPv6, o servidor DHCPv6 atribui ao cliente o prefixo IPv6 na associação estática.
- Alocação dinâmica de prefixos - Para implementar a alocação dinâmica de prefixos para clientes, crie um pool de endereços DHCPv6 e um pool de prefixos, especifique uma sub-rede para o pool de endereços e aplique o pool de prefixos ao pool de endereços. Ao receber uma solicitação de DHCP, o servidor DHCPv6 seleciona dinamicamente um prefixo IPv6 do pool de prefixos no pool de endereços.
Seleção do pool de endereços
O servidor DHCPv6 observa os seguintes princípios ao selecionar um endereço ou prefixo IPv6 para um cliente:
- Se houver um pool de endereços em que um endereço IPv6 esteja estaticamente vinculado ao DUID ou IAID do cliente, o servidor DHCPv6 selecionará esse pool de endereços. Ele atribui o endereço ou prefixo IPv6 vinculado estaticamente e outros parâmetros de configuração ao cliente.
- Se a interface receptora tiver uma política de DHCP e o cliente DHCP corresponder a uma classe de usuário, o servidor DHCP selecionará o pool de endereços vinculado à classe de usuário correspondente. Se não for encontrada nenhuma classe de usuário correspondente, o servidor atribuirá um endereço IP e outros parâmetros do pool de endereços DHCP padrão. Se nenhum pool de endereços padrão for especificado ou se o pool de endereços padrão não tiver endereços IP atribuíveis, a atribuição de endereços falhará.
- Se a interface receptora tiver um pool de endereços aplicado, o servidor DHCP selecionará um endereço ou prefixo IPv6 e outros parâmetros de configuração desse pool de endereços.
- Se as condições acima não forem atendidas, o servidor DHCPv6 selecionará um pool de endereços dependendo da localização do cliente.
- Cliente na mesma sub-rede que o servidor - O servidor DHCPv6 compara o endereço IPv6 da interface receptora com as sub-redes de todos os pools de endereços. Ele seleciona o pool de endereços com a sub-rede correspondente mais longa.
- Cliente em uma sub-rede diferente da do servidor - O servidor DHCPv6 compara o endereço IPv6 da interface do agente de retransmissão DHCPv6 mais próxima do cliente com as sub-redes de todos os pools de endereços. Ele também seleciona o pool de endereços com a sub-rede correspondente mais longa.
Para garantir que a alocação de endereços IPv6 funcione corretamente, mantenha a sub-rede usada para atribuição dinâmica consistente com a sub-rede em que reside a interface do servidor DHCPv6 ou do agente de retransmissão DHCPv6.
Sequência de alocação de endereços/prefixos IPv6
O servidor DHCPv6 seleciona um endereço/prefixo IPv6 para um cliente na seguinte sequência:
- Endereço/prefixo IPv6 vinculado estaticamente ao DUID e IAID do cliente e esperado pelo cliente.
- Endereço/prefixo IPv6 vinculado estaticamente ao DUID e IAID do cliente.
- Endereço/prefixo IPv6 vinculado estaticamente ao DUID do cliente e esperado pelo cliente.
- Endereço/prefixo IPv6 vinculado estaticamente ao DUID do cliente.
- Endereço IPv6 EUI-64 gerado com base no endereço MAC do cliente se a alocação de endereços EUI-64 estiver ativada.
- Endereço/prefixo IPv6 atribuível no pool de endereços/prefixo esperado pelo cliente.
- Endereço/prefixo IPv6 que já foi atribuído ao cliente.
- Endereço/prefixo IPv6 atribuível no pool de endereços/prefixo.
- Endereço/prefixo IPv6 que estava em conflito ou que ultrapassou a duração da concessão. Se não for possível atribuir nenhum endereço/prefixo IPv6, o servidor não responderá.
Se um cliente mudar para outra sub-rede, o servidor DHCPv6 selecionará um endereço/prefixo IPv6 do pool de endereços que corresponda à nova sub-rede.
Os endereços IPv6 conflitantes podem ser atribuídos a outros clientes DHCPv6 somente depois que os endereços estiverem em conflito por uma hora.
Visão geral das tarefas do servidor DHCPv6
Para configurar o servidor DHCPv6, execute as seguintes tarefas:
- Configuração do servidor DHCPv6 para atribuir prefixos IPv6, endereços IPv6 e outros parâmetros de rede
Escolha as seguintes tarefas, conforme necessário:
- Configuração da atribuição de prefixo IPv6
- Configuração da atribuição de endereços IPv6
- Configuração da atribuição de parâmetros de rede
- Modificação do método de seleção do pool de endereços no servidor DHCPv6 Escolha as seguintes tarefas conforme necessário:
- Configuração do servidor DHCPv6 em uma interface
- Configuração de uma política DHCPv6 para atribuição de endereços e prefixos IPv6
- (Opcional.) Configuração do valor DSCP para pacotes DHCPv6 enviados pelo servidor DHCPv6
Configuração da atribuição de prefixo IPv6
Sobre a atribuição de prefixo IPv6
Use os seguintes métodos para configurar a atribuição de prefixo IPv6:
- Configurar uma vinculação de prefixo IPv6 estático em um pool de endereços - Se você vincular um DUID e um IAID a um prefixo IPv6, o DUID e o IAID em uma solicitação deverão corresponder aos da vinculação antes que o
O servidor DHCPv6 pode atribuir o prefixo IPv6 ao cliente DHCPv6. Se você associar apenas um DUID a um prefixo IPv6, o DUID na solicitação deverá corresponder ao DUID na associação antes que o servidor DHCPv6 possa atribuir o prefixo IPv6 ao cliente DHCPv6.
- Aplicar um pool de prefixos a um pool de endereços - O servidor DHCPv6 atribui dinamicamente um prefixo IPv6 do pool de prefixos no pool de endereços a um cliente DHCPv6.
Restrições e diretrizes
Quando você configurar a atribuição de prefixo IPv6, siga estas restrições e diretrizes:
- Um prefixo IPv6 pode ser vinculado a apenas um cliente DHCPv6. Não é possível modificar as associações que foram criadas. Para alterar a associação de um cliente DHCPv6, primeiro você deve excluir a associação existente.
- Um pool de endereços pode ter apenas um pool de prefixos aplicado. Não é possível modificar os pools de prefixos que já foram aplicados. Para alterar o pool de prefixos de um pool de endereços, primeiro é necessário remover a aplicação do pool de prefixos.
- É possível aplicar um pool de prefixos que não tenha sido criado a um pool de endereços. A configuração entra em vigor depois que o pool de prefixos é criado.
Procedimento
- Entre na visualização do sistema.
system-view- (Opcional.) Especifique os prefixos IPv6 excluídos da atribuição dinâmica.
ipv6 dhcp server forbidden-prefix start-prefix/prefix-len
[ end-prefix/prefix-len ]
Por padrão, nenhum prefixo IPv6 do pool de prefixos é excluído da atribuição dinâmica.
Se o prefixo IPv6 excluído estiver em uma associação estática, o prefixo ainda poderá ser atribuído ao cliente.
- Criar um pool de prefixos.
ipv6 dhcp prefix-pool prefix-pool-number prefix { prefix-number |
prefix/prefix-len } assign-len assign-len
Essa etapa é necessária para a atribuição dinâmica de prefixos.
Se você especificar um prefixo IPv6 por sua ID, verifique se o prefixo IPv6 está em vigor. Caso contrário, a configuração não terá efeito.
- Entre na visualização do pool de endereços DHCP.
ipv6 dhcp pool pool-name
- Especifique uma sub-rede IPv6 para atribuição dinâmica.
network { prefix/prefix-length | prefix prefix-number
[ sub-prefix/sub-prefix-length ] } [ preferred-lifetime
preferred-lifetime valid-lifetime valid-lifetime ]Por padrão, nenhuma sub-rede IPv6 é especificada para atribuição dinâmica. As sub-redes IPv6 não podem ser as mesmas em pools de endereços diferentes.
Se você especificar um prefixo IPv6 por sua ID, certifique-se de que o prefixo IPv6 esteja em vigor. Caso contrário, a configuração do não terá efeito.
- Configure a atribuição do prefixo. Escolha as opções para configurar conforme necessário:
- Configurar uma vinculação de prefixo estático:
static-bind prefix prefix/prefix-len duid duid [ iaid iaid ] [ preferred-lifetime preferred-lifetime valid-lifetime valid-lifetime ]
Por padrão, nenhum vínculo de prefixo estático é configurado.
Para adicionar várias associações de prefixo IPv6 estático, repita esta etapa.
- Aplique o pool de prefixos ao pool de endereços:
prefix-pool prefix-pool-number [ preferred-lifetime
preferred-lifetime valid-lifetime valid-lifetime ]
Por padrão, a atribuição de prefixo estático ou dinâmico não é configurada para um pool de endereços.
Configuração da atribuição de endereços IPv6
Sobre a atribuição de endereços IPv6
Use um dos métodos a seguir para configurar a atribuição de endereços IPv6:
- Configure uma vinculação de endereço IPv6 estático em um pool de endereços.
Se você associar um DUID e um IAID a um endereço IPv6, o DUID e o IAID em uma solicitação deverão corresponder àqueles na associação antes que o servidor DHCPv6 possa atribuir o endereço IPv6 ao cliente solicitante. Se você associar apenas um DUID a um endereço IPv6, o DUID em uma solicitação deverá corresponder ao DUID na associação antes que o servidor DHCPv6 possa atribuir o endereço IPv6 ao cliente solicitante.
- Especifique uma sub-rede e intervalos de endereços em um pool de endereços.
- Atribuição de endereços não temporários - O servidor seleciona endereços do intervalo de endereços não temporários especificado pelo comando de intervalo de endereços. Se não houver
se for especificado um intervalo de endereços não temporário, o servidor selecionará os endereços na sub-rede especificada pelo comando network.
- Atribuição de endereço temporário - O servidor seleciona endereços do intervalo de endereços temporários especificado pelo comando de intervalo de endereços temporários. Se nenhum intervalo de endereços temporários for especificado no pool de endereços, o servidor DHCPv6 não poderá atribuir endereços temporários aos clientes.
Restrições e diretrizes
- É possível especificar apenas um intervalo de endereços não temporário e um intervalo de endereços temporário em um pool de endereços.
- Os intervalos de endereços especificados pelos comandos de intervalo de endereços e intervalo de endereços temporário devem estar na sub-rede especificada pelo comando network. Caso contrário, os endereços não poderão ser atribuídos.
- Um endereço IPv6 pode ser vinculado a apenas um cliente DHCPv6. Não é possível modificar as associações que foram criadas. Para alterar a associação de um cliente DHCPv6, você deve excluir primeiro a associação existente.
- Somente uma sub-rede pode ser especificada em um pool de endereços. Se você usar o comando network várias vezes em um pool de endereços DHCPv6, a configuração mais recente entrará em vigor. Se você usar esse comando para especificar somente novos tempos de vida, as configurações não afetarão as concessões existentes. Os endereços IPv6 atribuídos após a modificação usarão os novos tempos de vida.
Procedimento
- Entre na visualização do sistema.
system-view- (Opcional.) Especifique os endereços IPv6 excluídos da atribuição dinâmica.
ipv6 dhcp server forbidden-address start-ipv6-address
[ end-ipv6-address ]
Por padrão, todos os endereços IPv6, exceto o endereço IP do servidor DHCPv6 em um pool de endereços DHCPv6, podem ser atribuídos.
Se o endereço IPv6 excluído estiver em uma associação estática, o endereço ainda poderá ser atribuído ao cliente.
- Entre na visualização do pool de endereços DHCPv6.
ipv6 dhcp pool pool-name
- Especifique uma sub-rede IPv6 para atribuição dinâmica.
network { prefix/prefix-length | prefix prefix-number
[ sub-prefix/sub-prefix-length ] } [ preferred-lifetime
preferred-lifetime valid-lifetime valid-lifetime ]Por padrão, nenhuma sub-rede de endereço IPv6 é especificada.
As sub-redes IPv6 não podem ser as mesmas em pools de endereços diferentes.
Se você especificar um prefixo IPv6 por sua ID, verifique se o prefixo IPv6 está em vigor. Caso contrário, a configuração não terá efeito.
- (Opcional.) Especifique um intervalo de endereços IPv6 não temporário.
static-bind prefix prefix/prefix-len duid duid [ iaid iaid ]
[ preferred-lifetime preferred-lifetime valid-lifetime
valid-lifetime ]
Por padrão, nenhum intervalo de endereços IPv6 não temporário é especificado, e todos os endereços unicast na sub-rede são atribuíveis.
- (Opcional.) Especifique um intervalo de endereços IPv6 temporário.
prefix-pool prefix-pool-number [ preferred-lifetime
preferred-lifetime valid-lifetime valid-lifetime ]
Por padrão, nenhum intervalo de endereços IPv6 temporários é especificado, e o servidor DHCPv6 não pode atribuir endereços IPv6 temporários.
- (Opcional.) Ative o modo de alocação de endereços EUI-64.
address-alloc-mode eui-64Por padrão, o modo de alocação de endereços EUI-64 está desativado.
Esse recurso permite que o servidor DHCPv6 obtenha o endereço MAC do cliente na solicitação DHCP e gere um endereço IPv6 EUI-64 para atribuir ao cliente.
- (Opcional.) Crie uma ligação estática.
static-bind address ipv6-address/addr-prefix-length duid duid [ iaid
iaid ] [ preferred-lifetime preferred-lifetime valid-lifetime
valid-lifetime ]
Por padrão, nenhuma ligação estática é configurada.
Para adicionar mais vínculos estáticos, repita esta etapa.
Configuração da atribuição de parâmetros de rede
Sobre a atribuição de parâmetros de rede
Além dos prefixos IPv6 e dos endereços IPv6, você pode configurar os seguintes parâmetros de rede em um pool de endereços:
- Um máximo de oito endereços de servidor DNS.
- Um nome de domínio.
- Um máximo de oito endereços de servidor SIP.
- Um máximo de oito nomes de domínio de servidor SIP.
Você pode configurar os parâmetros de rede em um servidor DHCPv6 usando um dos métodos a seguir:
- Configure os parâmetros de rede em um pool de endereços DHCPv6.
- Configure os parâmetros de rede em um grupo de opções DHCPv6 e especifique o grupo de opções para um pool de endereços DHCPv6.
Os parâmetros de rede configurados em um pool de endereços DHCPv6 têm precedência sobre aqueles configurados em um grupo de opções DHCPv6.
Configuração de parâmetros de rede em um pool de endereços DHCPv6
- Entre na visualização do sistema.
system-view- Entre na visualização do pool de endereços DHCPv6.
ipv6 dhcp pool pool-name
- Especifique uma sub-rede IPv6 para atribuição dinâmica.
network { prefix/prefix-length | prefix prefix-number
[ sub-prefix/sub-prefix-length ] } [ preferred-lifetime
preferred-lifetime valid-lifetime valid-lifetime ]Por padrão, nenhuma sub-rede IPv6 é especificada.
As sub-redes IPv6 não podem ser as mesmas em pools de endereços diferentes.
Se você especificar um prefixo IPv6 por sua ID, verifique se o prefixo IPv6 está em vigor. Caso contrário, a configuração não terá efeito.
- Especifique um endereço de servidor DNS.
dns-server ipv6-address
Por padrão, nenhum endereço de servidor DNS é especificado.
- Especifique um nome de domínio.
domain-name domain-namePor padrão, nenhum nome de domínio é especificado.
- Especifique um endereço de servidor SIP ou nome de domínio.
sip-server { address ipv6-address | domain-name domain-name }
Por padrão, nenhum endereço de servidor SIP ou nome de domínio é especificado.
- Configurar uma opção DHCPv6 autodefinida.
option code hex hex-string
Por padrão, nenhuma opção DHCPv6 autodefinida é configurada.
Configuração de parâmetros de rede em um grupo de opções DHCPv6
Sobre a atribuição de parâmetros de rede em um grupo de opções DHCPv6
Um grupo de opções DHCPv6 pode ser criado usando os seguintes métodos:
- Crie um grupo de opções DHCPv6 estático usando o comando ipv6 dhcp option-group. O grupo de opções estático do DHCPv6 tem precedência sobre o grupo de opções dinâmico do DHCPv6.
- Quando o dispositivo atua como um cliente DHCPv6, ele cria automaticamente um grupo de opções DHCPv6 dinâmico para salvar os parâmetros obtidos. Para obter mais informações sobre a criação de um grupo de opções dinâmico DHCPv6, consulte "Configuração do cliente DHCPv6".
Procedimento
- Entre na visualização do sistema.
system-view- Crie um grupo de opções DHCPv6 estático e entre em sua visualização.
ipv6 dhcp option-group option-group-number
- Especifique um endereço de servidor DNS.
dns-server ipv6-address
Por padrão, nenhum endereço de servidor DNS é especificado.
- Especifique um sufixo de nome de domínio.
domain-name domain-namePor padrão, nenhum sufixo de nome de domínio é especificado.
- Especifique um endereço de servidor SIP ou nome de domínio.
sip-server { address ipv6-address | domain-name domain-name }
Por padrão, nenhum endereço de servidor SIP ou nome de domínio é especificado.
- Configurar uma opção DHCPv6 autodefinida.
option code hex hex-string
Por padrão, nenhuma opção DHCPv6 autodefinida é configurada.
- Retornar à visualização do sistema.
quit- Entre na visualização do pool de endereços DHCPv6.
ipv6 dhcp pool pool-name
- Especifique um grupo de opções DHCPv6.
option-group option-group-numberPor padrão, nenhum grupo de opções DHCPv6 é especificado.
Configuração do servidor DHCPv6 em uma interface
Sobre a configuração do servidor DHCPv6 em uma interface
Ative o servidor DHCP e configure um dos seguintes métodos de atribuição de endereço/prefixo em uma interface:
- Aplicar um pool de endereços na interface - O servidor DHCPv6 seleciona um endereço/prefixo IPv6 do pool de endereços aplicado para um cliente solicitante. Se não houver nenhum endereço/prefixo IPv6 atribuível no pool de endereços, o servidor DHCPv6 não poderá atribuir um endereço/prefixo IPv6 a um cliente.
- Configurar atribuição de endereço global na interface - O servidor DHCPv6 seleciona um endereço/prefixo IPv6 no pool de endereços DHCPv6 global que corresponde ao endereço da interface do servidor ou ao endereço do agente de retransmissão DHCPv6 para um cliente solicitante.
Se você configurar os dois métodos em uma interface, o servidor DHCPv6 usará o pool de endereços especificado para a atribuição de endereços sem realizar a atribuição global de endereços.
Restrições e diretrizes
- Uma interface não pode atuar como servidor DHCPv6 e agente de retransmissão DHCPv6 ao mesmo tempo.
- Não ative o servidor DHCPv6 e o cliente DHCPv6 na mesma interface.
- Você pode aplicar um pool de endereços que ainda não foi criado a uma interface. A configuração entra em vigor depois que o pool de endereços é criado.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar o servidor DHCPv6 na interface.
ipv6 dhcp select serverPor padrão, a interface não atua como servidor DHCP ou agente de retransmissão DHCP e descarta os pacotes DHCPv6 dos clientes DHCPv6.
- Configure um método de atribuição.
- Configurar a atribuição de endereços globais.
ipv6 dhcp server { allow-hint | preference preference-value |
rapid-commit } *Por padrão, a atribuição de endereço/prefixo desejado e a atribuição rápida estão desativadas, e a preferência padrão é 0.
- Aplicar um pool de endereços DHCPv6 à interface.
ipv6 dhcp server apply pool pool-name [ allow-hint | preference
preference-value | rapid-commit ] *Configuração de uma política DHCPv6 para atribuição de endereços e prefixos IPv6
Sobre a política DHCPv6 para atribuição de endereços e prefixos IPv6
Em uma política DHCPv6, cada classe de usuário DHCPv6 tem um pool de endereços DHCPv6 vinculado. Os clientes que correspondem a diferentes classes de usuários obtêm endereços IPv6, prefixos IPv6 e outros parâmetros de diferentes pools de endereços. Ao receber uma solicitação de DHCPv6, o servidor DHCPv6 compara o pacote com as classes de usuário na ordem em que foram configuradas.
Se for encontrada uma correspondência e o pool de endereços vinculado tiver endereços ou prefixos IPv6 atribuíveis, o servidor usará o pool de endereços para atribuição. Se o pool de endereços vinculado não tiver endereços ou prefixos IPv6 atribuíveis, a atribuição falhará.
Se não for encontrada nenhuma correspondência, o servidor usará o pool de endereços DHCPv6 padrão para a atribuição. Se nenhum pool de endereços padrão for especificado ou se o pool de endereços padrão não tiver endereços ou prefixos IPv6 atribuíveis, a atribuição falhará.
Para que a atribuição seja bem-sucedida, certifique-se de que a política DHCPv6 aplicada e os pools de endereços vinculados existam.
Uma regra de correspondência não pode corresponder a uma opção adicionada pelo dispositivo DHCPv6, por exemplo, Option 18 ou Option 37.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma classe de usuário DHCPv6 e entre na visualização da classe de usuário DHCPv6.
ipv6 dhcp class class-name- Configure uma regra de correspondência para a classe de usuário DHCPv6.
if-match rule rule-number { option option-code [ ascii ascii-string
[ offset offset | partial ] | hex hex-string [ mask mask | offset offset
length length | partial ] ] | relay-agent gateway-ipv6-address }Por padrão, nenhuma regra de correspondência é configurada para uma classe de usuário DHCPv6.
- Retornar à visualização do sistema.
quit- Crie uma política DHCPv6 e entre na visualização da política DHCPv6.
ipv6 dhcp policy policy-nameA política DHCPv6 entra em vigor somente depois de ser aplicada à interface que atua como servidor DHCPv6.
- Especifique um pool de endereços DHCPv6 para uma classe de usuário DHCPv6.
class class-name pool pool-namePor padrão, nenhum pool de endereços é especificado para uma classe de usuário.
- (Opcional.) Especifique o pool de endereços DHCPv6 padrão.
pool padrão nome do pool
Por padrão, o pool de endereços padrão não é especificado.
- Retornar à visualização do sistema.
quit- Entre na visualização da interface.
interface interface-type interface-number- Aplique a política DHCPv6 à interface.
ipv6 dhcp apply-policy policy-namePor padrão, nenhuma política de DHCPv6 é aplicada a uma interface.
Configuração do valor DSCP para pacotes DHCPv6 enviados pelo servidor DHCPv6
Sobre a configuração do valor DSCP para pacotes DHCPv6 enviados pelo servidor DHCPv6
O valor DSCP de um pacote especifica o nível de prioridade do pacote e afeta a prioridade de transmissão do pacote.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o valor DSCP para pacotes DHCPv6 enviados pelo servidor DHCPv6.
ipv6 dhcp dscp dscp-valuePor padrão, o valor DSCP nos pacotes DHCPv6 enviados pelo servidor DHCPv6 é 56.
Configuração do backup automático de vinculação DHCPv6
Sobre o backup automático da associação DHCPv6
O recurso de backup automático salva as associações de DHCPv6 em um arquivo de backup e permite que o servidor DHCPv6 faça download das associações do arquivo de backup na reinicialização do servidor. As associações incluem as associações de concessão e os endereços IPv6 conflitantes. Elas não podem sobreviver a uma reinicialização no servidor DHCPv6.
O servidor DHCPv6 não fornece serviços durante o processo de download. Se ocorrer um erro de conexão durante o processo e não puder ser reparado em um curto espaço de tempo, você poderá encerrar a operação de download. A interrupção manual permite que o servidor DHCPv6 forneça serviços sem esperar que a conexão seja reparada.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o servidor DHCPv6 para fazer backup das associações em um arquivo.
ipv6 dhcp server database filename { filename | url url [ username
username [ password { cipher | simple } string ] ] }
Por padrão, o servidor DHCPv6 não faz backup das associações de DHCPv6.
Com esse comando executado, o servidor DHCPv6 faz o backup de suas associações imediatamente e executa o backup automático .
- (Opcional.) Salve manualmente as associações de DHCPv6 no arquivo de backup.
ipv6 dhcp server database update now
- (Opcional.) Defina o tempo de espera após uma alteração de associação DHCPv6 para que o servidor DHCPv6 atualize o arquivo de backup.
ipv6 dhcp server database update interval interval
Por padrão, o servidor DHCP aguarda 300 segundos para atualizar o arquivo de backup após uma alteração de associação de DHCP. Se nenhuma associação de DHCP for alterada, o arquivo de backup não será atualizado.
- (Opcional.) Encerre o download das associações de DHCPv6 do arquivo de backup.
ipv6 dhcp server database update stop
Esse comando aciona apenas uma terminação.
Ativação do servidor DHCPv6 para anunciar prefixos IPv6
Sobre o anúncio de prefixos IPv6
Um cliente DHCPv6 pode obter um prefixo IPv6 por meio do DHCPv6 e usar esse prefixo IPv6 para atribuir endereços IPv6 a clientes em uma rede downstream. Se o prefixo IPv6 estiver em uma sub-rede diferente do endereço IPv6 da interface upstream do cliente DHCPv6, os clientes na rede downstream não poderão acessar a rede externa. Se o servidor DHCPv6 estiver no mesmo link que o cliente DHCPv6, habilite o servidor DHCPv6 para anunciar o prefixo IPv6.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o servidor DHCPv6 para anunciar prefixos IPv6.
ipv6 dhcp advertise pd-route
Por padrão, o servidor DHCPv6 não anuncia prefixos IPv6.
Ativação do registro de DHCPv6 no servidor DHCPv6
Sobre o registro do servidor DHCPv6
O recurso de registro de DHCPv6 permite que o servidor DHCPv6 gere registros de DHCPv6 e os envie para o centro de informações. As informações ajudam os administradores a localizar e resolver problemas. Para obter informações sobre o destino do registro e a configuração da regra de saída no centro de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Restrições e diretrizes
Como prática recomendada, desative esse recurso se a geração de registros afetar o desempenho do dispositivo ou reduzir a eficiência da alocação de endereços e prefixos. Por exemplo, essa situação pode ocorrer quando um grande número de clientes fica on-line ou off-line com frequência.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o registro de DHCPv6.
ipv6 dhcp log enable
Por padrão, o registro de DHCPv6 está desativado.
Comandos de exibição e manutenção do servidor DHCPv6
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibe o DUID do dispositivo local. | display ipv6 dhcp duid |
| Exibir informações sobre um grupo de opções DHCPv6. | display ipv6 dhcp option-group [ option-group-number ] |
| Exibir informações do pool de endereços DHCPv6. | display ipv6 dhcp pool [ pool-name ] |
| Exibir informações do pool de prefixos. | display ipv6 dhcp prefix-pool [ prefix-pool-number ] |
| Exibir informações do servidor DHCPv6 em uma interface. | display ipv6 dhcp server [ interface interface-type interface-number ] |
| Exibir informações sobre conflitos de endereços IPv6. | display ipv6 dhcp server conflict [ address ipv6-address ] |
| Exibir informações sobre o backup automático da associação DHCPv6 | display ipv6 dhcp server database |
| Exibir informações sobre endereços IPv6 expirados. | display ipv6 dhcp server expired [ address ipv6-address | pool pool-name ] |
| Exibir informações sobre associações de endereços IPv6. | display ipv6 dhcp server ip-in-use [ address ipv6-address | pool pool-name ] |
| Exibir informações sobre as associações de prefixo IPv6. | display ipv6 dhcp server pd-in-use [ pool nome do pool | [ prefixo prefixo/prefixo-len ] ] ] |
| Exibir estatísticas de pacotes no servidor DHCPv6. | display ipv6 dhcp server statistics [ pool pool-name ] |
| Limpar informações sobre conflitos de endereços IPv6. | reset ipv6 dhcp server conflict [ endereço ipv6-address ] |
| Limpar informações sobre associações de endereços IPv6 expiradas. | reset ipv6 dhcp server expired [ endereço ipv6-address | pool pool-name ] |
| Limpar informações sobre associações de endereços IPv6. | reset ipv6 dhcp server ip-in-use [ endereço ipv6-address | pool pool-name ] |
| Limpar informações sobre as associações de prefixo IPv6. | reset ipv6 dhcp server pd-in-use [ pool nome do pool | prefixo prefixo/prefixo-len ] |
| Limpar estatísticas de pacotes no servidor DHCPv6. | reset ipv6 dhcp server statistics |
Exemplos de configuração do servidor DHCPv6
Exemplo: Configuração da atribuição dinâmica de prefixo IPv6
Configuração de rede
Conforme mostrado na Figura 12, o switch atua como um servidor DHCPv6 para atribuir um prefixo IPv6, um endereço de servidor DNS, um nome de domínio, um endereço de servidor SIP e um nome de servidor SIP a cada cliente DHCPv6.
O switch atribui o prefixo 2001:0410:0201::/48 ao cliente cujo DUID é 00030001CA0006A40000 e atribui prefixos no intervalo de 2001:0410::/48 a 2001:0410:FFFF::/48 (excluindo 2001:0410:0201::/48) a outros clientes. O endereço do servidor DNS é 2::2:3. Os clientes DHCPv6 residem no domínio aaa.com. O endereço do servidor SIP é 2:2::4 e o nome do servidor SIP é bbb.com.
Figura 12 Diagrama de rede
Procedimento
# Especifique um endereço IPv6 para a interface VLAN 2.
<Switch> system-view
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ipv6 address 1::1/64
# Desative a supressão de mensagens RA na interface VLAN 2.
[Switch-Vlan-interface2] undo ipv6 nd ra halt
# Defina o sinalizador M como 1 nos anúncios RA a serem enviados na interface VLAN 2. Os hosts que receberem os anúncios RA obterão endereços IPv6 por meio do DHCPv6.
[Switch-Vlan-interface2] ipv6 nd autoconfig managed-address-flag
# Defina o sinalizador O como 1 nos anúncios RA a serem enviados na interface VLAN 2. Os hosts que receberem os anúncios RA obterão outras informações além do endereço IPv6 por meio do DHCPv6.
[Switch-Vlan-interface2] ipv6 nd autoconfig other-flag
[Switch-Vlan-interface2] quit
# Crie o pool de prefixos 1 e especifique o prefixo 2001:0410::/32 com o comprimento de prefixo atribuído 48.
[Switch] ipv6 dhcp prefix-pool 1 prefix 2001:0410::/32 assign-len 48
# Criar o pool de endereços 1.
[Switch] ipv6 dhcp pool 1
# No pool de endereços 1, configure a sub-rede 1::/64 onde reside a interface-2 da VLAN.
[Switch-dhcp6-pool-1] network 1::/64
# Aplique o pool de prefixos 1 ao pool de endereços 1 e defina o tempo de vida preferencial como um dia e o tempo de vida válido como três dias.
[Switch-dhcp6-pool-1] prefix-pool 1 preferred-lifetime 86400 valid-lifetime 259200
# No pool de endereços 1, associe o prefixo 2001:0410:0201::/48 ao DUID do cliente 00030001CA0006A40000 e defina o tempo de vida preferencial como um dia e o tempo de vida válido como três dias.
[Switch-dhcp6-pool-1] static-bind prefix 2001:0410:0201::/48 duid 00030001CA0006A40000
preferred-lifetime 86400 valid-lifetime 259200
# Configure o endereço do servidor DNS 2:2::3.
[Switch-dhcp6-pool-1] dns-server 2:2::3
# Configure o nome de domínio como aaa.com.
[Switch-dhcp6-pool-1] domain-name aaa.com
# Configure o endereço do servidor SIP como 2:2::4 e o nome do servidor SIP como bbb.com.
[Switch-dhcp6-pool-1] sip-server address 2:2::4
[Switch-dhcp6-pool-1] sip-server domain-name bbb.com
[Switch-dhcp6-pool-1] quit
# Habilite o servidor DHCPv6 na interface VLAN 2, habilite a atribuição do prefixo desejado e a atribuição rápida do prefixo e defina a preferência como a mais alta.
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ipv6 dhcp select server
[Switch-Vlan-interface2] ipv6 dhcp server allow-hint preference 255 rapid-commit
Verificação da configuração
# Exibir a configuração do servidor DHCPv6 na interface VLAN 2.
[Switch-Vlan-interface2] display ipv6 dhcp server interface vlan-interface 2
Using pool: global
Preference value: 255
Allow-hint: Enabled
Rapid-commit: Enabled
# Exibir informações sobre o pool de endereços 1.
[Switch-Vlan-interface2] display ipv6 dhcp pool 1
DHCPv6 pool: 1
Network: 1::/64
Preferred lifetime 604800 seconds, valid lifetime 2592000 seconds
Prefix pool: 1
Preferred lifetime 86400 seconds, valid lifetime 259200 seconds
Static bindings:
DUID: 00030001ca0006a40000
IAID: Not configured
Prefix: 2001:410:201::/48
Preferred lifetime 86400 seconds, valid lifetime 259200 seconds
DNS server addresses:
2:2::3
Domain name:
aaa.com
SIP server addresses:
2:2::4
SIP server domain names:
bbb.com
# Exibir informações sobre o pool de prefixos 1.
[Switch-Vlan-interface2] display ipv6 dhcp prefix-pool 1
Prefix: 2001:410::/32
Assigned length: 48
Total prefix number: 65536
Available: 65535
In-use: 0
Static: 1
# Depois que o cliente com o DUID 00030001CA0006A40000 obtiver um prefixo IPv6, exiba as informações de associação no servidor DHCPv6.
[Switch-Vlan-interface2] display ipv6 dhcp server pd-in-use
Pool: 1
IPv6 prefix Type Lease expiration
2001:410:201::/48 Static(C) Jul 10 19:45:01 2009
# Depois que o outro cliente obtiver um prefixo IPv6, exiba as informações de vinculação no servidor DHCPv6.
[Switch-Vlan-interface2] display ipv6 dhcp server pd-in-use
Pool: 1
IPv6 prefix Type Lease expiration
2001:410:201::/48 Static(C) Jul 10 19:45:01 2009
Exemplo: Configuração da atribuição dinâmica de endereços IPv6
Configuração de rede
Conforme mostrado na Figura 13, o Switch A atua como um servidor DHCPv6 para atribuir endereços IPv6 aos clientes nas sub-redes 1::1:0:0:0/96 e 1::2:0:0:0/96.
No Switch A, configure o endereço IPv6 1::1:0:0:1/96 para a interface de VLAN 10 e 1::2:0:0:0:1/96 para a interface de VLAN 20. A duração da concessão dos endereços na sub-rede 1::1:0:0:0/96 é de 172800 segundos (dois dias), o tempo válido é de 345600 segundos (quatro dias), o sufixo do nome de domínio é aabbcc.com e o endereço do servidor DNS é 1::1:0:0:2/96. A duração da concessão dos endereços na sub-rede 1::2:0:0:0/96 é de 432000 segundos (cinco dias), o tempo válido é de 864000 segundos (dez dias), o nome de domínio é aabbcc.com e o endereço do servidor DNS é 1::2:0:0:2/96.
Figura 13 Diagrama de rede
Procedimento
- Configure as interfaces no servidor DHCPv6:
# Especifique um endereço IPv6 para a interface VLAN 10.
<SwitchA> system-view
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ipv6 address 1::1:0:0:1/96
# Desative a supressão de mensagens RA na interface VLAN 10.
[SwitchA-Vlan-interface10] undo ipv6 nd ra halt
# Defina o sinalizador M como 1 nos anúncios RA a serem enviados na interface VLAN 10. Os hosts que receberem os anúncios RA obterão endereços IPv6 por meio do DHCPv6.
[SwitchA-Vlan-interface10] ipv6 nd autoconfig managed-address-flag
# Defina o sinalizador O como 1 nos anúncios RA a serem enviados na interface VLAN 10. Os hosts que receberem os anúncios RA obterão outras informações além do endereço IPv6 por meio do DHCPv6.
[SwitchA-Vlan-interface10] ipv6 nd autoconfig other-flag
[SwitchA-Vlan-interface10] quit
# Especifique um endereço IPv6 para a interface VLAN 20.
[SwitchA] interface vlan-interface 20
[SwitchA-Vlan-interface20] ipv6 address 1::2:0:0:1/96
# Desative a supressão de mensagens RA na interface VLAN 20.
[SwitchA-Vlan-interface20] undo ipv6 nd ra halt
# Defina o sinalizador M como 1 nos anúncios RA a serem enviados na interface VLAN 20. Os hosts que receberem os anúncios RA obterão endereços IPv6 por meio do DHCPv6.
[SwitchA-Vlan-interface20] ipv6 nd autoconfig managed-address-flag
# Defina o sinalizador O como 1 nos anúncios RA a serem enviados na interface VLAN 20. Os hosts que receberem os anúncios RA obterão outras informações além do endereço IPv6 por meio do DHCPv6.
[SwitchA-Vlan-interface20] ipv6 nd autoconfig other-flag
[SwitchA-Vlan-interface20] quit
- Ativar DHCPv6:
# Habilite o servidor DHCPv6 na interface VLAN 10 e na interface VLAN 20.
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ipv6 dhcp select server
[SwitchA-Vlan-interface10] quit
[SwitchA] interface vlan-interface 20
[SwitchA-Vlan-interface20] ipv6 dhcp select server
[SwitchA-Vlan-interface20] quit
# Excluir os endereços do servidor DNS da atribuição dinâmica.
[SwitchA] ipv6 dhcp server forbidden-address 1::1:0:0:2
[SwitchA] ipv6 dhcp server forbidden-address 1::2:0:0:2
# Configure o pool de endereços DHCPv6 1 para atribuir endereços IPv6 e outros parâmetros de configuração a clientes na sub-rede 1::1:0:0:0/96.
[SwitchA] ipv6 dhcp pool 1
[SwitchA-dhcp6-pool-1] network 1::1:0:0:0/96 preferred-lifetime 172800
valid-lifetime 345600
[SwitchA-dhcp6-pool-1] domain-name aabbcc.com
[SwitchA-dhcp6-pool-1] dns-server 1::1:0:0:2
[SwitchA-dhcp6-pool-1] quit
# Configure o pool de endereços DHCPv6 2 para atribuir endereços IPv6 e outras configurações
para clientes na sub-rede 1::2:0:0:0/96.
[SwitchA] ipv6 dhcp pool 2
[SwitchA-dhcp6-pool-2] network 1::2:0:0:0/96 preferred-lifetime 432000
valid-lifetime 864000
[SwitchA-dhcp6-pool-2] domain-name aabbcc.com
[SwitchA-dhcp6-pool-2] dns-server 1::2:0:0:2
[SwitchA-dhcp6-pool-2] quitVerificação da configuração
# Verifique se os clientes das sub-redes 1::1:0:0:0/96 e 1::2:0:0:0:0/96 podem obter endereços IPv6 e todos os outros parâmetros de configuração do servidor DHCPv6 (Switch A). (Detalhes não mostrados.)
# No servidor DHCPv6, exiba os endereços IPv6 atribuídos aos clientes DHCPv6.
[SwitchA] display ipv6 dhcp server ip-in-useConfiguração do agente de retransmissão DHCPv6
Sobre o agente de retransmissão DHCPv6
Aplicação típica
Um cliente DHCPv6 geralmente usa um endereço multicast para entrar em contato com o servidor DHCPv6 no link local para obter um endereço IPv6 e outros parâmetros de configuração. Conforme mostrado na Figura 14, se o servidor DHCPv6 residir em outra sub-rede, os clientes DHCPv6 precisarão de um agente de retransmissão DHCPv6 para entrar em contato com o servidor. O recurso de agente de retransmissão evita a implantação de um servidor DHCPv6 em cada sub-rede.
Figura 14 Aplicativo típico de agente de retransmissão DHCPv6
Processo operacional do agente de retransmissão DHCPv6
Conforme mostrado na Figura 15, um cliente DHCPv6 obtém um endereço IPv6 e outros parâmetros de configuração de rede de um servidor DHCPv6 por meio de um agente de retransmissão DHCPv6. O exemplo a seguir usa a atribuição rápida para descrever o processo:
- O cliente DHCPv6 envia uma mensagem Solicit contendo a opção Rapid Commit para o endereço multicast FF02::1:2 de todos os servidores DHCPv6 e agentes de retransmissão.
- Depois de receber a mensagem Solicit, o agente de retransmissão DHCPv6 encapsula a mensagem na opção Relay Message de uma mensagem Relay-forward e envia a mensagem para o servidor DHCPv6.
- Depois de obter a mensagem Solicit da mensagem Relay-forward, o servidor DHCPv6 executa as seguintes tarefas:
- Seleciona um endereço IPv6 e outros parâmetros necessários.
- Adiciona-os a uma resposta encapsulada na opção Relay Message de uma mensagem Relay-reply.
- Envia a mensagem Relay-reply para o agente de retransmissão DHCPv6.
- O agente de retransmissão DHCPv6 obtém a resposta da mensagem Relay-reply e envia a resposta ao cliente DHCPv6.
- O cliente DHCPv6 usa o endereço IPv6 e outros parâmetros de rede atribuídos pelo servidor DHCPv6 para concluir a configuração da rede.
Figura 15 Processo operacional de um agente de retransmissão DHCPv6
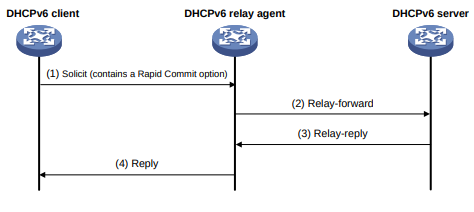
Visão geral das tarefas do agente de retransmissão DHCPv6
Para configurar um agente de retransmissão DHCPv6, execute as seguintes tarefas:
- Ativação do agente de retransmissão DHCPv6 em uma interface
- Especificação de servidores DHCPv6 no agente de retransmissão
- (Opcional.) Especificação de um endereço de gateway para clientes DHCPv6
- (Opcional.) Configuração do valor DSCP para pacotes DHCPv6 enviados pelo agente de retransmissão DHCPv6
- (Opcional.) Especificar um modo de preenchimento para a opção Interface-ID
- (Opcional.) Ativação do agente de retransmissão DHCPv6 para dar suporte à Opção 79
- (Opcional.) Ativação do agente de retransmissão DHCPv6 para anunciar prefixos IPv6
- (Opcional.) Ativação do agente de retransmissão DHCPv6 para anunciar rotas de host para endereços IPv6 atribuídos
- (Opcional.) Especificar o endereço IPv6 de origem para solicitações DHCPv6 retransmitidas
Ativação do agente de retransmissão DHCPv6 em uma interface
Restrições e diretrizes
Como prática recomendada, não ative o agente de retransmissão DHCPv6 e o cliente DHCPv6 na mesma interface.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar o agente de retransmissão DHCPv6 na interface.
ipv6 dhcp select relayPor padrão, o agente de retransmissão DHCPv6 está desativado na interface.
Especificação de servidores DHCPv6 no agente de retransmissão
Especificação de endereços IP do servidor DHCPv6
Restrições e diretrizes
- Você pode usar o comando ipv6 dhcp relay server-address para especificar um máximo de oito servidores DHCPv6 na interface do agente de retransmissão DHCPv6. O agente de retransmissão DHCPv6 encaminha solicitações de DHCP para todos os servidores DHCPv6 especificados.
- Se um endereço de servidor DHCPv6 for um endereço local de link ou um endereço multicast, você deverá especificar uma interface de saída usando a palavra-chave interface nesse comando. Caso contrário, os pacotes DHCPv6 podem não chegar ao servidor DHCPv6.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique um servidor DHCPv6.
ipv6 dhcp relay server-address ipv6-address [ interface interface-type
interface-number ]
Por padrão, nenhum servidor DHCPv6 é especificado.
Especificação de servidores DHCPv6 para um pool de endereços DHCPv6 no agente de retransmissão DHCPv6
Sobre a especificação de servidores DHCPv6 para um pool de endereços DHCPv6 no agente de retransmissão DHCPv6
Esse recurso permite que clientes DHCPv6 do mesmo tipo obtenham endereços IPv6, prefixos IPv6 e outros parâmetros de configuração dos servidores DHCPv6 no pool de endereços DHCPv6 correspondente.
Aplica-se a cenários em que o agente de retransmissão DHCPv6 se conecta a clientes do mesmo tipo de acesso, mas classificados em tipos diferentes por suas localizações. Nesse caso, a interface de retransmissão normalmente não tem endereço IPv6 configurado. Você pode usar o comando gateway-list para especificar os endereços de gateway para clientes que correspondem ao mesmo pool de endereços DHCPv6.
Ao receber uma Solicitação ou Pedido de DHCPv6 de um cliente que corresponde a um pool de endereços DHCPv6, o agente de retransmissão processa o pacote da seguinte forma:
- Preenche o campo link-address do pacote com um endereço de gateway especificado.
- Encaminha o pacote para todos os servidores DHCPv6 no pool de endereços DHCPv6 correspondente. Os servidores DHCPv6 selecionam um pool de endereços DHCPv6 de acordo com o endereço do gateway.
Restrições e diretrizes
- Você pode especificar um máximo de oito servidores DHCPv6 para um pool de endereços DHCPv6 para alta disponibilidade. O agente de retransmissão encaminha os pacotes DHCPv6 Solicit e Request para todos os servidores DHCPv6 no pool de endereços DHCPv6.
- Se esse recurso for usado no cenário PPPoE, execute o comando ipv6 dhcp relay
comando client-information record para permitir que o agente de retransmissão DHCPv6 registre as entradas de retransmissão. Quando um usuário PPPoE fica off-line, o agente de retransmissão DHCPv6 localiza a entrada de retransmissão correspondente e envia uma mensagem de liberação para o servidor DHCPv6.
- Se esse recurso for usado no cenário PPPoE, não será necessário executar o comando ipv6 dhcp select relay. Isso ocorre porque o comando remote-server é obrigatório nessa tarefa de configuração e implica que esse dispositivo é um dispositivo de retransmissão.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um pool de endereços DHCPv6 e entre em sua visualização.
ipv6 dhcp pool pool-name
- Especifique os endereços de gateway para os clientes que correspondem ao pool de endereços DHCPv6.
gateway-list ipv6-address&<1-8>
Por padrão, nenhum endereço de gateway é especificado.
- Especificar servidores DHCPv6 para o pool de endereços DHCPv6.
gremote-server ipv6-address [ interface interface-type
interface-number ]
Por padrão, nenhum servidor DHCPv6 é especificado para o pool de endereços DHCPv6.
Especificação de um endereço de gateway para clientes DHCPv6
Sobre a especificação de um endereço de gateway para o cliente DHCPv6
Por padrão, o agente de retransmissão DHCPv6 preenche o campo link-address dos pacotes DHCPv6 Solicit e Request com o primeiro endereço IPv6 da interface de retransmissão. Você pode especificar um endereço de gateway no agente de retransmissão para clientes DHCPv6. O agente de retransmissão DHCPv6 usa o endereço de gateway especificado para preencher o campo link-address dos pacotes DHCPv6 Solicit e Request.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique um endereço de gateway para clientes DHCPv6.
ipv6 dhcp relay gateway ipv6-address
Por padrão, o agente de retransmissão DHCPv6 usa o primeiro endereço IPv6 da interface de retransmissão como endereço de gateway dos clientes.
Configuração do valor DSCP para pacotes DHCPv6 enviados pelo agente de retransmissão DHCPv6
Sobre a configuração do valor DSCP para pacotes DHCPv6
O valor DSCP de um pacote especifica o nível de prioridade do pacote e afeta a prioridade de transmissão do pacote.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o valor DSCP para pacotes DHCPv6 enviados pelo agente de retransmissão DHCPv6.
ipv6 dhcp dscp dscp-valueO valor DSCP padrão é 56.
Especificação de um modo de preenchimento para a opção Interface-ID
Sobre a especificação de um modo de preenchimento para a opção Interface-ID
Esse recurso permite que o agente de retransmissão preencha a opção Interface-ID no modo especificado. Ao receber um pacote DHCPv6 de um cliente, o agente de retransmissão preenche a opção Interface-ID no modo e, em seguida, encaminha o pacote para o servidor DHCPv6.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique um modo de preenchimento para a opção Interface-ID.
ipv6 dhcp relay interface-id { bas | interface }
Por padrão, o agente de retransmissão preenche a opção Interface-ID com o índice da interface.
Habilitação do agente de retransmissão DHCPv6 para suportar a Opção 79
Sobre a ativação do agente de retransmissão DHCPv6 para dar suporte à Opção 79
Se houver agentes de retransmissão DHCPv6 na rede, o servidor DHCPv6 precisará do endereço MAC do cliente DHCPv6 para autenticação ou para atribuição de endereço ou prefixo IPv6. Para atender ao requisito, habilite o agente de retransmissão DHCPv6 pelo qual o cliente passa primeiro para oferecer suporte à Opção 79. Esse recurso permite que o agente de retransmissão DHCPv6 saiba o endereço MAC na solicitação do cliente. Quando o agente de retransmissão gera um pacote Relay-Forward para a solicitação, ele preenche o endereço MAC do cliente na Opção 79. O pacote Relay-Forward é então encaminhado para o servidor DHCPv6.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilite o agente de retransmissão DHCPv6 para dar suporte à Opção 79.
ipv6 dhcp relay client-link-address enable
Por padrão, o agente de retransmissão DHCPv6 não é compatível com a Opção 79.
Ativação do agente de retransmissão DHCPv6 para anunciar prefixos IPv6
Sobre como habilitar o agente de retransmissão DHCPv6 para anunciar prefixos IPv6
Um cliente DHCPv6 pode obter um prefixo IPv6 por meio do DHCPv6 e usar esse prefixo IPv6 para atribuir endereços IPv6 a clientes em uma rede downstream. Se o prefixo IPv6 estiver em uma sub-rede diferente da sub-rede IPv6
Se o endereço IPv6 da interface upstream do cliente DHCPv6 não for anunciado, os clientes na rede downstream não poderão acessar a rede externa. Você pode ativar o agente de retransmissão DHCPv6 que está no mesmo link que o cliente DHCPv6 para anunciar o prefixo IPv6.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o agente de retransmissão DHCPv6 para anunciar prefixos IPv6.
ipv6 dhcp advertise pd-route
Por padrão, o agente de retransmissão DHCPv6 não anuncia prefixos IPv6.
Antes de usar esse comando, certifique-se de que o agente de retransmissão DHCPv6 esteja ativado para registrar entradas de retransmissão DHCPv6.
Ativação do agente de retransmissão DHCPv6 para anunciar rotas de host para endereços IPv6 atribuídos
Sobre como habilitar o agente de retransmissão DHCPv6 para anunciar rotas de host para endereços IPv6 atribuídos
Em uma rede em que a ND não pode resolver endereços unicast globais, os dispositivos de rede não podem gerar entradas ND para todos os endereços unicast globais. Se um cliente DHCPv6 obtiver um endereço global de unicast, os dispositivos vizinhos não terão as entradas de ND para esse endereço global de unicast e, portanto, não poderão encaminhar os pacotes destinados ao cliente. Para resolver esse problema, ative o agente de retransmissão DHCPv6 para anunciar rotas de host para endereços IPv6 atribuídos nas respostas DHCPv6. As informações da rota anunciada são as seguintes:
- O endereço IP de destino é o endereço IPv6 atribuído.
- O próximo salto é o endereço local do link do cliente DHCPv6.
- A interface de saída é a interface que encaminha a resposta.
Depois que o agente de retransmissão recebe um pacote destinado ao endereço IPv6 atribuído, ele procura na tabela de roteamento o próximo salto. A resolução ND pode ser bem-sucedida porque o próximo salto é o endereço local do link do cliente. O agente de retransmissão procura na tabela de ND o endereço MAC do cliente com base no próximo salto e, em seguida, encaminha o pacote.
Restrições e diretrizes
Antes de usar esse recurso no agente de retransmissão DHCPv6, ative o agente de retransmissão DHCPv6 para registrar entradas de retransmissão DHCPv6 primeiro.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o agente de retransmissão DHCPv6 para anunciar rotas de host para endereços IPv6 atribuídos a clientes DHCPv6.
ipv6 dhcp advertise pd-route
Por padrão, o agente de retransmissão DHCPv6 não anuncia rotas de host para endereços IPv6 atribuídos a clientes DHCPv6.
Especificação do endereço IPv6 de origem para solicitações DHCPv6 retransmitidas
Sobre a especificação do endereço IPv6 de origem para solicitações DHCPv6 retransmitidas
Essa tarefa é necessária se uma interface de retransmissão não tiver rotas para servidores DHCPv6. Você pode especificar um endereço unicast global ou o endereço IPv6 de outra interface (normalmente a interface de loopback) como o endereço IPv6 de origem para solicitações de DHCPv6. A interface de retransmissão insere o endereço IPv6 de origem no campo de endereço IPv6 de origem das solicitações de DHCPv6.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique o endereço IPv6 de origem para solicitações DHCPv6 retransmitidas.
ipv6 dhcp relay source-address { ipv6-address | interface
interface-type interface-number }
Por padrão, o agente de retransmissão DHCPv6 usa o endereço unicast global IPv6 da interface que se conecta ao servidor DHCPv6 como endereço IPv6 de origem para solicitações DHCPv6 retransmitidas.
Se a interface especificada não tiver um endereço unicast global IPv6, o endereço IPv6 da interface de saída será usado como endereço de origem para solicitações DHCPv6 retransmitidas.
Comandos de exibição e manutenção do agente de retransmissão DHCPv6
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibe o DUID do dispositivo local. | exibir ipv6 dhcp duid |
| Exibir entradas de retransmissão DHCPv6 que registram as informações de endereço IPv6 dos clientes. | exibir ipv6 dhcp relay endereço de informações do cliente [ número da interface do tipo interface | ipv6 endereço ipv6 ] |
| Exibir entradas de retransmissão DHCPv6 que registram as informações de prefixo IPv6 dos clientes. | exibir ipv6 dhcp relay pd de informações do cliente [ número da interface do tipo interface | prefixo prefixo/prefixo-len ] |
| Exibir endereços de servidor DHCPv6 especificados no agente de retransmissão DHCPv6. | display ipv6 dhcp relay server-address [ interface tipo interface-número da interface ] |
| Exibir estatísticas de pacotes no agente de retransmissão DHCPv6. | display ipv6 dhcp relay statistics [ interface interface-type interface-number ] |
| Limpe as entradas de retransmissão de DHCPv6 que registram as informações de endereço IPv6 dos clientes. | reset ipv6 dhcp relay client-information address [ interface interface-type |
| Tarefa | Comando |
| número da interface | ipv6 ipv6-address ] | |
| Limpe as entradas de retransmissão DHCPv6 que registram as informações de prefixo IPv6 dos clientes. | reset ipv6 dhcp relay client-information pd [ interface interface-type número da interface | prefixo prefixo/prefixo-len ] |
| Limpar estatísticas de pacotes no agente de retransmissão DHCPv6. | reset ipv6 dhcp relay statistics [ interface interface-type interface-number ] |
Exemplos de configuração do agente de retransmissão DHCPv6
Exemplo: Configuração do agente de retransmissão DHCPv6
Configuração de rede
Conforme mostrado na Figura 16, configure o agente de retransmissão DHCPv6 no Switch A para retransmitir pacotes DHCPv6 entre os clientes DHCPv6 e o servidor DHCPv6.
O switch A atua como gateway da rede 1::/64. Ele envia mensagens RA para notificar os hosts para que obtenham endereços IPv6 e outros parâmetros de configuração por meio do DHCPv6. Para obter mais informações sobre mensagens RA, consulte "Configuração das definições básicas de IPv6".
Figura 16 Diagrama de rede
Procedimento
# Especifique os endereços IPv6 para a interface de VLAN 2 e a interface de VLAN 3.
<SwitchA> system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ipv6 address 2::1 64
[SwitchA-Vlan-interface2] quit
[SwitchA] interface vlan-interface 3
[SwitchA-Vlan-interface3] ipv6 address 1::1 64
# Desativar a supressão de mensagens RA na interface VLAN 3.
[SwitchA-Vlan-interface3] undo ipv6 nd ra halt
# Defina o sinalizador M como 1 nos anúncios RA a serem enviados na interface VLAN 3. Os hosts que receberem os anúncios RA obterão endereços IPv6 por meio do DHCPv6.
[SwitchA-Vlan-interface3] ipv6 nd autoconfig managed-address-flag
# Defina o sinalizador O como 1 nos anúncios RA a serem enviados na interface VLAN 3. Os hosts que receberem os anúncios RA obterão outras informações além do endereço IPv6 por meio do DHCPv6.
[SwitchA-Vlan-interface3] ipv6 nd autoconfig other-flag
# Habilite o agente de retransmissão DHCPv6 na interface VLAN 3 e especifique o servidor DHCPv6 no agente de retransmissão.
[SwitchA-Vlan-interface3] ipv6 dhcp select relay
[SwitchA-Vlan-interface3] ipv6 dhcp relay server-address 2::2
Verificação da configuração
# Exibir informações de endereço do servidor DHCPv6 no Switch A.
[SwitchA-Vlan-interface3] display ipv6 dhcp relay server-address
Interface: Vlan-interface3
Server address Outgoing Interface Public/VRF name
2::2 --/--
# Exibir estatísticas de pacotes no agente de retransmissão DHCPv6.
[SwitchA-Vlan-interface3] display ipv6 dhcp relay statistics
Packets dropped : 0
Packets received : 14
Solicit : 0
Request : 0
Confirm : 0
Renew : 0
Rebind : 0
Release : 0
Decline : 0
Information-request : 7
Relay-forward : 0
Relay-reply : 7
Packets sent : 14
Advertise : 0
Reconfigure : 0
Reply : 7
Relay-forward : 7
Relay-reply : 0
Configuração do cliente DHCPv6
Sobre o cliente DHCPv6
Com o cliente DHCPv6 configurado, uma interface pode obter parâmetros de configuração do servidor DHCPv6.
Um cliente DHCPv6 pode usar o DHCPv6 para realizar as seguintes funções:
- Obter um endereço IPv6, um prefixo IPv6, ou ambos, e obter outros parâmetros de configuração. Se o servidor DHCPv6 estiver ativado no dispositivo, o cliente poderá salvar automaticamente os parâmetros obtidos em um grupo de opções DHCPv6. Com o prefixo IPv6 obtido, o cliente pode gerar seu endereço unicast global.
- Suporta DHCPv6 sem estado para obter parâmetros de configuração, exceto o endereço IPv6 e o prefixo IPv6. O cliente obtém um endereço IPv6 por meio da autoconfiguração de endereço IPv6 sem estado. Se o cliente receber uma mensagem RA com o sinalizador M definido como 0 e o sinalizador O definido como 1 durante a aquisição do endereço , o DHCPv6 sem estado será iniciado.
Restrições e diretrizes: Configuração do cliente DHCPv6
Não configure o cliente DHCPv6 na mesma interface que o servidor DHCPv6 ou o agente de retransmissão DHCPv6.
Visão geral das tarefas do cliente DHCPv6
Para configurar um cliente DHCPv6, execute as seguintes tarefas:
- (Opcional.) Configuração do DUID do cliente DHCPv6
- Configuração do cliente DHCPv6 para obter endereços IPv6, prefixos IPv6 e outros parâmetros de rede
Escolha as seguintes tarefas, conforme necessário:
- Configuração da aquisição de endereços IPv6
- Configuração da aquisição de prefixos IPv6
- Configuração da aquisição de endereços e prefixos IPv6
- Configuração da aquisição de parâmetros de configuração, exceto endereços IP e prefixos
- (Opcional.) Configuração do valor DSCP para pacotes DHCPv6 enviados pelo cliente DHCPv6
Configuração do DUID do cliente DHCPv6
Sobre o DUID do cliente DHCPv6
O DUID de um cliente DHCPv6 é o identificador globalmente exclusivo do cliente. O cliente insere seu DUID na Opção 1 do pacote DHCPv6 que envia ao servidor DHCPv6. O servidor DHCPv6 pode atribuir endereços ou prefixos IPv6 específicos a clientes DHCPv6 com DUIDs específicos.
Restrições e diretrizes
Certifique-se de que o DUID que você configurou seja exclusivo.
Procedimento
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o DUID do cliente DHCPv6.
ipv6 dhcp client duid { ascii ascii-string | hex hex-string | mac
interface-type interface-number }
Por padrão, a interface usa o endereço MAC da ponte do dispositivo para gerar o DUID do cliente DHCPv6.
Configuração da aquisição de endereços IPv6
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure a interface para usar o DHCPv6 para obter endereços IPv6 e outras configurações de rede.
ipv6 address dhcp-alloc [ option-group group-number | rapid-commit ] *Em uma versão anterior à R6348P01, uma interface não usa o DHCPv6 para obter endereços IPv6 e outras configurações de rede por padrão.
No R6348P01 ou posterior, a configuração padrão desse comando varia de acordo com o método de inicialização do dispositivo, como segue:
- Quando o dispositivo é iniciado com a configuração inicial, uma interface usa as configurações padrão dos recursos de software e não usa o DHCPv6 para obter endereços IPv6 e outras configurações de rede.
- Quando o dispositivo é iniciado com os padrões de fábrica, somente a interface VLAN 1 suporta o uso de DHCPv6 para obter endereços IPv6 e outras configurações de rede. As outras interfaces não usam DHCPv6 para obter endereços IPv6 e outras configurações de rede.
Para obter mais informações sobre a configuração inicial e os padrões de fábrica, consulte o arquivo de configuração management no Fundamentals Configuration Guide.
Configuração da aquisição de prefixos IPv6
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure a interface para usar o DHCPv6 para obter um prefixo IPv6 e outros parâmetros de configuração.
ipv6 dhcp client stateful prefix prefix-number [ option-group
option-group-number | rapid-commit ] *
Por padrão, a interface não usa o DHCPv6 para aquisição de prefixo IPv6.
Configuração da aquisição de endereços e prefixos IPv6
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure a interface para usar o DHCPv6 para obter um endereço IPv6, um prefixo IPv6 e outros parâmetros de configuração.
ipv6 dhcp client stateful prefix prefix-number [ option-group
option-group-number | rapid-commit ] *
Por padrão, a interface não usa o DHCPv6 para aquisição de endereços e prefixos IPv6.
Configuração da aquisição de parâmetros de configuração, exceto endereços IP e prefixos
Sobre a aquisição de parâmetros de configuração, exceto endereços IP e prefixos
Quando um cliente DHCPv6 tiver obtido um endereço IPv6 e um prefixo, você poderá configurar os seguintes métodos para que o cliente obtenha outros parâmetros de configuração de rede:
- Execute o comando ipv6 address auto para permitir que uma interface gere automaticamente um endereço unicast global IPv6 e um endereço local de link. Em seguida, o DHCPv6 sem estado será acionado quando o sinalizador M for definido como 0 e o sinalizador O for definido como 1 em uma mensagem RA recebida. Para obter mais informações sobre os comandos, consulte Referência de comandos de serviços IP de camada 3.
- A execução do comando ipv6 dhcp client stateless enable em uma interface permite que a interface atue como cliente DHCPv6 para obter parâmetros de configuração de um servidor DHCPv6.
Se você executar tanto o ip address auto quanto o ipv6 dhcp client stateless enable
a interface age da seguinte forma:
- Gerar um endereço unicast global e um endereço local de link.
- Obter outros parâmetros de configuração de um servidor DHCPv6.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure a interface para suportar DHCPv6 sem estado. Escolha as opções para configurar conforme necessário:
- Ativar a autoconfiguração de endereço IPv6 sem estado:
ipv6 address auto- Configure o cliente para obter parâmetros de rede dos servidores DHCPv6:
ipv6 dhcp client stateless enable
Por padrão, a interface não oferece suporte a DHCPv6 sem estado.
Configuração do valor DSCP para pacotes DHCPv6 enviados pelo cliente DHCPv6
Sobre a configuração do valor DSCP para pacotes DHCPv6
O valor DSCP de um pacote especifica o nível de prioridade do pacote e afeta a prioridade de transmissão do pacote.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o valor DSCP para pacotes DHCPv6 enviados pelo cliente DHCPv6.
ipv6 dhcp client dscp dscp-value
Por padrão, o valor DSCP nos pacotes DHCPv6 enviados pelo cliente DHCPv6 é 56.
Comandos de exibição e manutenção para o cliente DHCPv6
Execute os comandos de exibição em qualquer visualização e execute o comando de redefinição na visualização do usuário.
| Tarefa | Comando |
| Exibir as informações do cliente DHCPv6. | exibir cliente ipv6 dhcp [ interface interface-type interface-number ] |
| Exibir as estatísticas do cliente DHCPv6. | display ipv6 dhcp client statistics [ interface interface-type interface-number ] |
| Limpar as estatísticas do cliente DHCPv6. | reset ipv6 dhcp client statistics [ interface interface-type interface-number ] |
Exemplos de configuração de cliente DHCPv6
Exemplo: Configuração da aquisição de endereços IPv6
Configuração de rede
Conforme mostrado na Figura 17, configure o switch para usar o DHCPv6 para obter parâmetros de configuração do servidor DHCPv6. Os parâmetros incluem o endereço IPv6, o endereço do servidor DNS, o sufixo do nome de domínio, o endereço do servidor SIP e o nome de domínio do servidor SIP.
Figura 17 Diagrama de rede
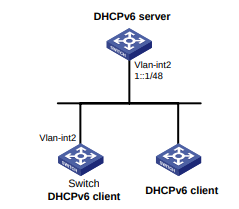
Procedimento
Você deve configurar o servidor DHCPv6 antes de configurar o cliente DHCPv6. Para obter informações sobre a configuração do servidor DHCPv6, consulte "Configuração do servidor DHCPv6".
# Configure a interface VLAN 2 como um cliente DHCPv6 para aquisição de endereços IPv6. Configure o cliente DHCPv6 para oferecer suporte à atribuição rápida de endereços DHCPv6. Configure o cliente DHCPv6 para criar um grupo de opções DHCPv6 dinâmico para salvar os parâmetros de configuração.
<Switch> system-view
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ipv6 address dhcp-alloc rapid-commit option-group 1
[Switch-Vlan-interface2] quit
Verificação da configuração
# Verificar se o cliente obteve um endereço IPv6 e outros parâmetros de configuração do servidor.
[Switch] display ipv6 dhcp client
Vlan-interface2:
Type: Stateful client requesting address
State: OPEN
Client DUID: 0003000100e002000000
Preferred server:
Reachable via address: FE80::2E0:1FF:FE00:18
Server DUID: 0003000100e001000000
IA_NA: IAID 0x00000642, T1 50 sec, T2 80 sec
Address: 1:1::2/128
Preferred lifetime 100 sec, valid lifetime 200 sec
Will expire on Mar 27 2014 at 08:06:57 (198 seconds left)
DNS server addresses:
2000::FF
Domain name:
example.com
SIP server addresses:
2:2::4
SIP server domain names:
bbb.com
# Depois que o servidor DHCPv6 for ativado no dispositivo, verifique se os parâmetros de configuração estão salvos em um grupo de opções DHCPv6 dinâmico.
[Switch] display ipv6 dhcp option-group 1
DHCPv6 option group: 1
DNS server addresses:
Type: Dynamic (DHCPv6 address allocation)
Interface: Vlan-interface2
2000::FF
Domain name:
Type: Dynamic (DHCPv6 address allocation)
Interface: Vlan-interface2
example.com
SIP server addresses:
Type: Dynamic (DHCPv6 address allocation)
Interface: Vlan-interface2
2:2::4
SIP server domain names:
Type: Dynamic (DHCPv6 address allocation)
Interface: Vlan-interface2
bbb.com
# Verifique se o cliente DHCPv6 obteve um endereço IPv6.
[Switch] display ipv6 interface brief
*down: administratively down
(s): spoofing
Interface Physical Protocol IPv6 Address
Vlan-interface2 up up 1:1::2
Exemplo: Configuração da aquisição de prefixos IPv6
Configuração de rede
Conforme mostrado na Figura 18, configure o switch para usar o DHCPv6 para obter parâmetros de configuração do servidor DHCPv6. Os parâmetros incluem o prefixo IPv6, o endereço do servidor DNS, o sufixo do nome de domínio, o endereço do servidor SIP e o nome de domínio do servidor SIP.
Figura 18 Diagrama de rede
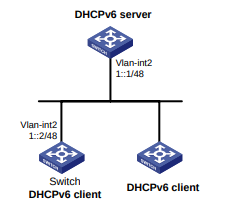
Procedimento
Você deve configurar o servidor DHCPv6 antes de configurar o cliente DHCPv6. Para obter informações sobre a configuração do servidor DHCPv6, consulte "Configuração do servidor DHCPv6".
# Configure um endereço IPv6 para a interface VLAN 2 que está conectada ao servidor DHCPv6.
<Switch> system-view
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ipv6 address 1::2/48
# Configure a interface VLAN 2 como um cliente DHCPv6 para aquisição de prefixo IPv6. Configure o cliente DHCPv6 para oferecer suporte à atribuição rápida de prefixo DHCPv6. Configure o cliente DHCPv6 para atribuir um ID ao prefixo IPv6 obtido e crie um grupo de opções DHCPv6 dinâmico para salvar os parâmetros de configuração.
[Switch-Vlan-interface2] ipv6 dhcp client pd 1 rapid-commit option-group 1
[Switch-Vlan-interface2] quit
Verificação da configuração
# Verifique se o cliente DHCPv6 obteve um prefixo IPv6 e outros parâmetros de configuração do servidor DHCPv6.
[Switch] display ipv6 dhcp client
Vlan-interface2:
Type: Stateful client requesting prefix
State: OPEN
Client DUID: 0003000100e002000000
Preferred server:
Reachable via address: FE80::2E0:1FF:FE00:18
Server DUID: 0003000100e001000000
IA_PD: IAID 0x00000642, T1 50 sec, T2 80 sec
Prefix: 12:34::/48
Preferred lifetime 100 sec, valid lifetime 200 sec
Will expire on Feb 4 2014 at 15:37:20(80 seconds left)
DNS server addresses:
2000::FF
Domain name:
example.com
SIP server addresses:
2:2::4
SIP server domain names:
bbb.com
# Verificar se o cliente obteve um prefixo IPv6.
[Switch] display ipv6 prefix 1
Number: 1
Type : Dynamic
Prefix: 12:34::/48
Preferred lifetime 100 sec, valid lifetime 200 sec
# Depois que o servidor DHCPv6 for ativado no dispositivo, verifique se os parâmetros de configuração estão salvos em um grupo de opções DHCPv6 dinâmico.
[Switch] display ipv6 dhcp option-group 1
DHCPv6 option group: 1
DNS server addresses:
Type: Dynamic (DHCPv6 prefix allocation)
Interface: Vlan-interface2
2000::FF
Domain name:
Type: Dynamic (DHCPv6 prefix allocation)
Interface: Vlan-interface2
example.com
SIP server addresses:
Type: Dynamic (DHCPv6 prefix allocation)
Interface: Vlan-interface2
2:2::4
SIP server domain names:
Type: Dynamic (DHCPv6 prefix allocation)
Interface: Vlan-interface2
bbb.com
Exemplo: Configuração da aquisição de endereços e prefixos IPv6
Configuração de rede
Conforme mostrado na Figura 19, configure o switch para usar o DHCPv6 para obter parâmetros de configuração do servidor DHCPv6. Os parâmetros incluem o endereço IPv6, o prefixo IPv6, o endereço do servidor DNS, o sufixo do nome do domínio , o endereço do servidor SIP e o nome do domínio do servidor SIP.
Figura 19 Diagrama de rede
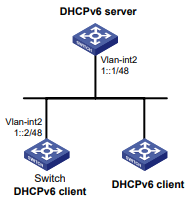
Procedimento
Você deve configurar o servidor DHCPv6 antes de configurar o cliente DHCPv6. Para obter informações sobre a configuração do servidor DHCPv6, consulte "Configuração do servidor DHCPv6".
# Configure um endereço IPv6 para a interface VLAN 2 que está conectada ao servidor DHCPv6.
<Switch> system-view
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ipv6 address 1::2/48
# Configure a interface VLAN 2 como um cliente DHCPv6 para aquisição de endereços e prefixos IPv6. Especifique IDs para o prefixo IPv6 dinâmico e o grupo de opções DHCPv6 dinâmico e configure o cliente para oferecer suporte à atribuição rápida de endereços e prefixos.
[Switch-Vlan-interface2] ipv6 dhcp client stateful prefix 1 rapid-commit option-group 1
[Switch-Vlan-interface2] quit
Verificação da configuração
# Verifique se o cliente DHCPv6 obteve um endereço IPv6, um prefixo IPv6 e outros parâmetros de configuração do servidor DHCPv6.
[Switch] display ipv6 dhcp client
DHCPv6 server
Switch
DHCPv6 client
Vlan-int2
1::1/48
DHCPv6 client
Vlan-int2
1::2/48
Vlan-interface2:
Type: Stateful client requesting address and prefix
State: OPEN
Client DUID: 0003000100e002000000
Preferred server:
Reachable via address: FE80::2E0:1FF:FE00:18
Server DUID: 0003000100e001000000
IA_NA: IAID 0x00000642, T1 50 sec, T2 80 sec
Address: 1:1::2/128
Preferred lifetime 100 sec, valid lifetime 200 sec
Will expire on Mar 27 2014 at 08:02:00 (199 seconds left)
IA_PD: IAID 0x00000642, T1 50 sec, T2 80 sec
Prefix: 12:34::/48
Preferred lifetime 100 sec, valid lifetime 200 sec
Will expire on Mar 27 2014 at 08:02:00 (199 seconds left)
DNS server addresses:
2000::FF
Domain name:
example.com
SIP server addresses:
2:2::4
SIP server domain names:
bbb.com
# Verificar se o cliente DHCPv6 obteve um endereço IPv6.
[Switch] display ipv6 interface brief
*down: administratively down
(s): spoofing
Interface Physical Protocol IPv6 Address
Vlan-interface2 up up 1:1::2
# Verificar se o cliente obteve um prefixo IPv6.
[Switch] display ipv6 prefix 1
Number: 1
Type : Dynamic
Prefix: 12:34::/48
Preferred lifetime 100 sec, valid lifetime 200 sec
# Depois que o servidor DHCPv6 for ativado no dispositivo, verifique se os parâmetros de configuração estão salvos em um grupo de opções DHCPv6 dinâmico.
[Switch] display ipv6 dhcp option-group 1
DNS server addresses:
Type: Dynamic (DHCPv6 address and prefix allocation)
Interface: Vlan-interface2
2000::FF
Domain name:
Type: Dynamic (DHCPv6 address and prefix allocation)
Interface: Vlan-interface2
example.com
SIP server addresses:
Type: Dynamic (DHCPv6 address and prefix allocation)
Interface: Vlan-interface2
2:2::4
SIP server domain names:
Type: Dynamic (DHCPv6 address and prefix allocation)
Interface: Vlan-interface2
bbb.com
Exemplo: Configuração de DHCPv6 sem estado
Configuração de rede
Conforme mostrado na Figura 20, configure o Switch A para usar o DHCPv6 sem estado para obter parâmetros de configuração, exceto o endereço IPv6 e o prefixo IPv6. O switch B atua como gateway e anuncia mensagens RA periodicamente.
Figura 20 Diagrama de rede
Procedimento
Você deve configurar o servidor DHCPv6 antes de configurar o cliente DHCPv6. Para obter informações sobre a configuração do servidor DHCPv6, consulte "Configuração do servidor DHCPv6".
- Configure o gateway Switch B.
# Configure um endereço IPv6 para a interface VLAN 2.
<SwitchB> system-view
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ipv6 address 1::1 64
# Defina o sinalizador O como 1 nos anúncios RA a serem enviados na interface VLAN 2. Os hosts que receberem os anúncios RA obterão outras informações além do endereço IPv6 por meio do DHCPv6.
[SwitchB-Vlan-interface2] ipv6 nd autoconfig other-flag
# Desative a supressão de mensagens RA na interface VLAN 2.
[SwitchB-Vlan-interface2] undo ipv6 nd ra halt- Configurar o cliente DHCPv6 Switch A.
# Habilite a autoconfiguração de endereço IPv6 sem estado na interface VLAN 2.
<SwitchA> system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ipv6 address autoCom a autoconfiguração de endereço IPv6 stateless ativada, mas sem nenhum endereço IPv6 configurado para a interface VLAN 2, o Switch A gera automaticamente um endereço link-local. Ele envia uma mensagem RS ao Switch B para solicitar informações de configuração para a geração de endereços IPv6. Ao receber a mensagem RS, o Switch B envia de volta uma mensagem RA. Depois de receber uma mensagem RA com o sinalizador M definido como 0 e o sinalizador O definido como 1, o Switch A executa o DHCPv6 sem estado para obter outros parâmetros de configuração.
Verificação da configuração
# Exibir as informações do cliente DHCPv6.
[SwitchA-Vlan-interface2] display ipv6 dhcp client interface vlan-interface 2
Vlan-interface2:
Type: Stateless client
State: OPEN
Client DUID: 00030001000fe2ff0000
Preferred server:
Reachable via address: FE80::213:7FFF:FEF6:C818
Server DUID: 0003000100137ff6c818
DNS server addresses:
1:2:4::5
1:2:4::7
Domain name:
abc.com# Exibir as estatísticas do cliente DHCPv6.
[SwitchA-Vlan-interface2] display ipv6 dhcp client statistics
Interface : Vlan-interface2
Packets received : 1
Reply : 1
Advertise : 0
Reconfigure : 0
Invalid : 0
Packets sent : 5
Solicit : 0
Request : 0
Renew : 0
Rebind : 0
Information-request : 5
Release : 0
Decline : 0Configuração do DHCPv6 snooping
Sobre o snooping DHCPv6
Ele garante que os clientes DHCPv6 obtenham endereços ou prefixos IPv6 de servidores DHCPv6 autorizados. Além disso, ele registra as associações de IP a MAC de clientes DHCPv6 (chamadas de entradas de endereço de snooping DHCPv6) e as associações de prefixo a porta de clientes DHCPv6 (chamadas de entradas de prefixo de snooping DHCPv6) para fins de segurança.
O snooping DHCPv6 define portas confiáveis e não confiáveis para garantir que os clientes obtenham endereços IPv6 somente de servidores DHCPv6 autorizados.
- Confiável - Uma porta confiável pode encaminhar mensagens DHCPv6 corretamente para garantir que os clientes obtenham endereços IPv6 de servidores DHCPv6 autorizados.
- Não confiável - Uma porta não confiável descarta as mensagens recebidas enviadas por servidores DHCPv6 para evitar que servidores não autorizados atribuam endereços IPv6.
O snooping DHCPv6 lê as mensagens DHCP-ACK recebidas de portas confiáveis e as mensagens DHCP-REQUEST para criar entradas de snooping DHCPv6. Uma entrada de snooping DHCPv6 pode ser uma entrada de endereço ou uma entrada de prefixo.
- Uma entrada de endereço DHCPv6 inclui os endereços MAC e IP de um cliente, a porta que se conecta ao cliente DHCPv6 e a VLAN. Você pode usar o comando display ipv6 dhcp snooping binding para exibir os endereços IP dos usuários para gerenciamento.
- Uma entrada de prefixo DHCPv6 inclui o prefixo e as informações de concessão atribuídas ao cliente, a porta que se conecta ao cliente DHCPv6 e a VLAN. Você pode usar o comando display ipv6 dhcp snooping pd binding para exibir os prefixos dos usuários para gerenciamento.
Aplicação de portas confiáveis e não confiáveis
Configure as portas voltadas para o servidor DHCPv6 como portas confiáveis e configure outras portas como portas não confiáveis.
Conforme mostrado na Figura 21, configure a porta do dispositivo de snooping DHCPv6 que está conectada ao servidor DHCPv6 como uma porta confiável. A porta confiável encaminha mensagens de resposta do servidor DHCPv6 para o cliente. A porta não confiável conectada ao servidor DHCPv6 não autorizado descarta as mensagens de resposta DHCPv6 recebidas.
Figura 21 Portas confiáveis e não confiáveis
Restrições e diretrizes: Configuração do DHCPv6 snooping
O snooping do DHCPv6 funciona entre o cliente e o servidor DHCPv6 ou entre o cliente DHCPv6 e o agente de retransmissão DHCPv6.
O snooping DHCPv6 não funciona entre o servidor DHCPv6 e o agente de retransmissão DHCPv6.
Para garantir que os clientes DHCPv6 possam obter endereços IPv6 válidos, especifique as portas conectadas aos servidores DHCPv6 autorizados como portas confiáveis. As portas confiáveis e as portas conectadas aos clientes DHCPv6 devem estar na mesma VLAN.
Se você definir as configurações do DHCPv6 snooping em uma interface Ethernet de camada 2 que seja uma porta membro de uma interface agregada de camada 2, as configurações não terão efeito, a menos que a interface seja removida do grupo de agregação.
Visão geral das tarefas de snooping do DHCPv6
Para configurar o DHCPv6 snooping, execute as seguintes tarefas:
- Configuração dos recursos básicos do DHCPv6 snooping
- (Opcional.) Configuração do suporte do DHCP snooping para a Opção 18
- (Opcional.) Configuração do suporte do DHCP snooping para a Opção 37
- (Opcional.) Configuração do backup automático de entradas do DHCPv6 snooping
- (Opcional.) Configuração do número máximo de entradas do DHCPv6 snooping
- (Opcional.) Configuração do limite de taxa de pacotes DHCPv6
- (Opcional.) Configuração dos recursos de segurança do DHCPv6 snooping
- (Opcional.) Ativação do registro e do alarme do DHCPv6 snooping
- (Opcional.) Desativar o DHCPv6 snooping em uma interface
Configuração dos recursos básicos do DHCPv6 snooping
Configuração de recursos básicos de DHCPv6 snooping em uma rede comum
Sobre os recursos básicos do DHCPv6 snooping em uma rede comum
Os recursos básicos do snooping DHCPv6 incluem a ativação do snooping DHCPv6, a configuração de portas confiáveis e a ativação do registro de entradas do snooping DHCPv6.
Quando você ativa o snooping do DHCPv6 globalmente em um dispositivo, o snooping do DHCPv6 também é ativado em todas as VLANs do dispositivo. Ative o snooping em VLANs específicas se você não precisar ativar o snooping DHCPv6 globalmente em algumas redes. Você também pode usar outros recursos básicos de snooping DHCP nessas VLANs.
Restrições e diretrizes
Se os recursos básicos do DHCPv6 snooping estiverem configurados globalmente, você só poderá usar a forma undo dos comandos de configuração global para desativar as configurações globalmente. Os comandos de configuração específicos da VLAN não podem desativar as configurações.
Se os recursos básicos do DHCPv6 snooping estiverem configurados em uma VLAN, você só poderá usar a forma undo dos comandos de configuração específicos da VLAN para desativar as configurações na VLAN. O comando de configuração global não pode desativar as configurações.
Configuração dos recursos básicos do DHCPv6 snooping globalmente
- Entre na visualização do sistema.
system-view- Ativar o snooping DHCPv6 globalmente.
ipv6 dhcp snooping enable
Por padrão, o DHCPv6 snooping é desativado globalmente.
- Entre na visualização da interface.
interface interface-type interface-numberEssa interface deve se conectar ao servidor DHCPv6.
- Especifique a porta como uma porta confiável.
ipv6 dhcp snooping trust
Por padrão, todas as portas são portas não confiáveis depois que o DHCPv6 snooping é ativado.
- Ativar o registro de entradas de DHCPv6 snooping.
- Retornar à visualização do sistema.
quit- Entre na visualização da interface.
interface interface-type interface-numberEssa interface deve se conectar ao cliente DHCPv6.
- Habilite o registro de entradas de snooping DHCPv6. Selecione as seguintes tarefas, conforme necessário:
- Habilite o registro de entradas de endereço do DHCPv6 snooping.
ipv6 dhcp snooping binding record
Por padrão, o registro das entradas de endereço do DHCPv6 snooping está desativado.
- Habilite o registro de entradas de prefixo do DHCPv6 snooping.
ipv6 dhcp snooping pd binding record
Por padrão, o registro das entradas de prefixo do DHCPv6 snooping está desativado.
Configuração dos recursos básicos do DHCPv6 snooping para VLANs
- Entre na visualização do sistema.
system-view- Ativar o DHCPv6 snooping para VLANs.
ipv6 dhcp snooping enable vlan vlan-id-listPor padrão, o DHCPv6 snooping está desativado em todas as VLANs.
- Entre na visualização de VLAN.
vlan vlan-idCertifique-se de que o DHCP snooping esteja ativado para a VLAN.
- Especifique uma porta como uma porta confiável.
ipv6 dhcp snooping trust interface interface-type interface-numberPor padrão, todas as portas são portas não confiáveis depois que o DHCPv6 snooping é ativado.
- (Opcional.) Habilite o registro de entradas de DHCPv6 snooping na VLAN. Selecione as seguintes tarefas, conforme necessário:
- Habilite o registro de entradas de endereço do DHCPv6 snooping.
ipv6 dhcp snooping binding record
Por padrão, o registro das entradas de endereço do DHCPv6 snooping é desativado em uma VLAN.
- Habilite o registro de entradas de prefixo do DHCPv6 snooping.
ipv6 dhcp snooping pd binding record
Por padrão, o registro das entradas de prefixo do DHCPv6 snooping é desativado em uma VLAN.
Configuração do suporte do DHCP snooping para a Opção 18
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilite o suporte a DHCP snooping para a Opção 18.
ipv6 dhcp snooping option interface-id enable
Por padrão, o suporte do DHCP snooping para a Opção 18 está desativado.
- (Opcional.) Especifique o conteúdo como a ID da interface.
ipv6 dhcp snooping option interface-id [ vlan vlan-id ] string
interface-id
Por padrão, o dispositivo de snooping DHCPv6 usa seu DUID como conteúdo da Opção 18.
Configuração do suporte do DHCP snooping para a Opção 37
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilite o suporte a DHCP snooping para a Opção 37.
ipv6 dhcp snooping option remote-id enable
Por padrão, o suporte do DHCP snooping para a Opção 37 está desativado.
- (Opcional.) Especifique o conteúdo como a ID remota.
ipv6 dhcp snooping option remote-id [ vlan vlan-id ] string remote-id
Por padrão, o dispositivo de snooping DHCPv6 usa seu DUID como conteúdo da Opção 37.
Configuração do backup automático de entradas do DHCPv6 snooping
Sobre o backup automático de entradas do DHCPv6 snooping
O recurso de backup automático salva as entradas do snooping do DHCPv6 em um arquivo de backup e permite que o dispositivo de snooping do DHCPv6 faça o download das entradas do arquivo de backup na reinicialização. As entradas no dispositivo de snooping do DHCPv6 não sobrevivem a uma reinicialização. O backup automático ajuda os recursos de segurança a fornecer serviços se esses recursos (como o IP source guard) precisarem usar entradas de snooping do DHCPv6 para autenticação do usuário.
Restrições e diretrizes
- Se você desativar o snooping DHCPv6 com o comando undo ipv6 dhcp snooping enable, o dispositivo excluirá todas as entradas do snooping DHCPv6, inclusive as armazenadas no arquivo de backup.
- Se você executar o comando ipv6 dhcp snooping binding database filename, o dispositivo de snooping DHCPv6 fará o backup das entradas de snooping DHCPv6 imediatamente e executará o backup automático. Esse comando cria automaticamente o arquivo se você especificar um arquivo inexistente.
- O período de espera começa quando uma entrada do snooping DHCPv6 é aprendida, atualizada ou removida. O dispositivo de snooping DHCPv6 atualiza o arquivo de backup quando o período de espera especificado é atingido. Todas as entradas alteradas durante o período serão salvas no arquivo de backup. Se nenhuma entrada do snooping DHCPv6 for alterada, o arquivo de backup não será atualizado.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o dispositivo de snooping DHCPv6 para fazer backup das entradas de snooping DHCPv6 em um arquivo.
ipv6 dhcp snooping binding database filename { filename | url url
[ username username [ password { cipher | simple } string ] ] }
Por padrão, o dispositivo de snooping DHCPv6 não faz backup das entradas de snooping DHCPv6.
- (Opcional.) Salve manualmente as entradas do snooping DHCPv6 no arquivo de backup.
ipv6 dhcp snooping binding database update now
- (Opcional.) Defina o tempo de espera após a alteração de uma entrada de snooping DHCPv6 para que o dispositivo de snooping DHCPv6 atualize o arquivo de backup.
ipv6 dhcp snooping binding database update interval interval
Por padrão, o dispositivo de snooping DHCP aguarda 300 segundos para atualizar o arquivo de backup após a alteração de uma entrada de snooping DHCP. Se nenhuma entrada do DHCP snooping for alterada, o arquivo de backup não será atualizado.
Configuração do número máximo de entradas de snooping DHCPv6
Sobre a configuração do número máximo de entradas de snooping DHCPv6
Execute essa tarefa para evitar que os recursos do sistema sejam usados em excesso.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o número máximo de entradas de DHCPv6 snooping para a interface aprender.
ipv6 dhcp snooping max-learning-num max-number
Por padrão, o número de entradas de DHCPv6 snooping a serem aprendidas por uma interface não é limitado.
Configuração do limite de taxa de pacotes DHCPv6
Sobre o limite de taxa de pacotes DHCPv6
Esse recurso de limite de taxa de pacotes DHCPv6 descarta os pacotes DHCPv6 excedentes para evitar ataques que enviam um grande número de pacotes DHCPv6.
Restrições e diretrizes
A taxa definida na interface agregada da Camada 2 aplica-se a todos os membros da interface agregada. Se uma interface membro deixar o grupo de agregação, ela usará a taxa definida em sua visualização de interface Ethernet.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina a taxa máxima na qual uma interface pode receber pacotes DHCPv6.
ipv6 dhcp snooping rate-limit rate
Por padrão, os pacotes DHCPv6 de entrada em uma interface não são limitados por taxa.
Configuração dos recursos de segurança do DHCPv6 snooping
Ativação da verificação DHCPv6-REQUEST
Sobre a verificação do DHCPv6-REQUEST
Execute esta tarefa para usar o recurso de verificação DHCPv6-REQUEST para proteger o servidor DHCPv6 contra ataques de falsificação de clientes DHCPv6. Os invasores podem falsificar mensagens DHCPv6-RENEW para renovar concessões para clientes DHCPv6 legítimos que não precisam mais dos endereços IP. As mensagens forjadas impedem que o servidor DHCPv6 da vítima libere os endereços IP. Os invasores também podem forjar mensagens DHCPv6-DECLINE ou DHCPv6-RELEASE para encerrar concessões para clientes DHCPv6 legítimos que ainda precisam dos endereços IP.
O recurso de verificação DHCPv6-REQUEST permite que o dispositivo de snooping DHCPv6 verifique cada mensagem DHCPv6-RENEW, DHCPv6-DECLINE ou DHCPv6-RELEASE recebida em relação às entradas de snooping DHCPv6.
- Se algum critério em uma entrada for correspondido, o dispositivo comparará a entrada com as informações da mensagem.
- Se forem consistentes, o dispositivo considerará a mensagem válida e a encaminhará ao servidor DHCPv6.
- Se forem diferentes, o dispositivo considerará a mensagem forjada e a descartará.
- Se nenhuma entrada correspondente for encontrada, o dispositivo encaminhará a mensagem para o servidor DHCPv6.
- Entre na visualização do sistema.
Procedimento
system-viewinterface interface-type interface-number- Ativar a verificação DHCPv6-REQUEST.
ipv6 dhcp snooping check request-message
Por padrão, a verificação DHCPv6-REQUEST está desativada.
Configuração de uma porta de bloqueio de pacotes DHCPv6
Sobre a porta de bloqueio de pacotes DHCPv6
Execute esta tarefa para configurar uma porta como uma porta de bloqueio de pacotes DHCPv6. A porta de bloqueio de pacotes DHCPv6 descarta todas as solicitações de DHCP recebidas.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure a porta para bloquear solicitações de DHCPv6.
ipv6 dhcp snooping deny
Por padrão, a porta não bloqueia solicitações de DHCPv6.
Para evitar falhas na aquisição de endereços e prefixos IPv6, configure uma porta para bloquear pacotes DHCPv6 somente se nenhum cliente DHCPv6 estiver conectado a ela.
Ativação de alarme e registro de snooping DHCPv6
Ativação do registro de snooping DHCPv6
Sobre o registro de snooping DHCPv6
O recurso de registro de snooping do DHCPv6 permite que o dispositivo de snooping do DHCPv6 gere registros de snooping do DHCPv6 e os envie para o centro de informações. As informações ajudam os administradores a localizar e resolver problemas. Para obter informações sobre o destino do registro e a configuração da regra de saída no centro de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Restrições e diretrizes
Como prática recomendada, desative esse recurso se a geração de registros afetar o desempenho do dispositivo.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o registro de snooping DHCPv6.
ipv6 dhcp snooping log enable
Por padrão, o registro de snooping DHCPv6 está desativado.
Desativação do DHCPv6 snooping em uma interface
Sobre a desativação do DHCPv6 snooping em uma interface
Esse recurso permite restringir o intervalo de interfaces em que o snooping do DHCPv6 entra em vigor. Por exemplo, para ativar o snooping DHCPv6 globalmente, exceto para uma interface específica, você pode ativar o snooping DHCPv6 globalmente e desativar o snooping DHCPv6 na interface de destino.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar na visualização da interface
interface interface-type interface-number- Desativar o snooping DHCPv6 na interface.
ipv6 dhcp snooping disable
Por padrão:
- Se você ativar o DHCPv6 snooping globalmente ou para uma VLAN, o DHCPv6 snooping será ativado em todas as interfaces do dispositivo ou em todas as interfaces da VLAN.
- Se você não ativar o DHCPv6 snooping globalmente ou para uma VLAN, o DHCPv6 snooping será desativado em todas as interfaces do dispositivo ou em todas as interfaces da VLAN.
Comandos de exibição e manutenção para DHCPv6 snooping
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir entradas de endereço de snooping DHCPv6. | display ipv6 dhcp snooping binding [ address ipv6-address [ vlan vlan-id ] ] |
| Exibir informações sobre o arquivo que armazena entradas de snooping DHCPv6. | display ipv6 dhcp snooping binding database |
| Exibir estatísticas de pacotes DHCPv6 para DHCPv6 snooping. | display ipv6 dhcp snooping packet statistics [ slot slot-number ] |
| Exibir entradas de prefixo do DHCPv6 snooping. | display ipv6 dhcp snooping pd binding [ prefix prefix/prefix-length [ vlan vlan-id ] ] |
| Exibir informações sobre portas confiáveis. | display ipv6 dhcp snooping trust |
| Tarefa | Comando |
| Limpar entradas de endereço de snooping DHCPv6. | reset ipv6 dhcp snooping binding { all | address ipv6-address [ vlan vlan-id ] } |
| Limpar estatísticas de pacotes DHCPv6 para DHCPv6 snooping. | reset ipv6 dhcp snooping packet statistics [ slot slot-number ] |
| Limpar entradas de prefixo do DHCPv6 snooping. | reset ipv6 dhcp snooping pd binding { all | prefix prefix/prefix-length [ vlan vlan-id ] } |
Exemplos de configuração do DHCPv6 snooping
Exemplo: Configuração global do DHCPv6 snooping
Configuração de rede
Conforme mostrado na Figura 22, o Switch B está conectado ao servidor DHCPv6 autorizado por meio da GigabitEthernet 1/0/1, ao servidor DHCPv6 não autorizado por meio da GigabitEthernet 1/0/3 e ao cliente DHCPv6 por meio da GigabitEthernet 1/0/2.
Configure somente a porta conectada ao servidor DHCPv6 autorizado para encaminhar as respostas do servidor DHCPv6. Habilite o dispositivo de snooping do DHCPv6 para registrar entradas de endereço de snooping do DHCPv6.
Figura 22 Diagrama de rede
Procedimento
# Habilite o DHCPv6 snooping.
<SwitchB> system-view
[SwitchB] ipv6 dhcp snooping enable# Especifique a GigabitEthernet 1/0/1 como uma porta confiável.
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] ipv6 dhcp snooping trust
[SwitchB-GigabitEthernet1/0/1] quit# Habilite o registro de entradas de endereço do DHCPv6 snooping na GigabitEthernet 1/0/2.
[SwitchB]interface gigabitethernet 1/0/2
[SwitchB-GigabitEthernet1/0/2] ipv6 dhcp snooping binding record
[SwitchB-GigabitEthernet1/0/2] quitVerificação da configuração
# Verifique se o cliente DHCPv6 obtém um endereço IPv6 e todos os outros parâmetros de configuração somente do servidor DHCPv6 autorizado. (Detalhes não mostrados.)
# Exibir entradas de endereço de snooping DHCPv6 no dispositivo de snooping DHCPv6.
[SwitchB] display ipv6 dhcp snooping bindingExemplo: Configuração de DHCPv6 snooping para uma VLAN
Configuração de rede
Conforme mostrado na Figura 23, o Switch B está conectado ao servidor DHCPv6 autorizado por meio da GigabitEthernet 1/0/1, ao servidor DHCPv6 não autorizado por meio da GigabitEthernet 1/0/3 e ao cliente DHCPv6 por meio da GigabitEthernet 1/0/2.
Na VLAN 100, configure somente a porta conectada ao servidor DHCPv6 autorizado para encaminhar as respostas do servidor DHCPv6. Ative o dispositivo de snooping do DHCPv6 para registrar entradas de endereço de snooping do DHCPv6.
Figura 23 Diagrama de rede
Procedimento
# Atribua as portas de acesso GigabitEthernet 1/0/1, GigabitEthernet 1/0/2 e GigabitEthernet 1/0/3 à VLAN 100.
<SwitchB> system-view
[SwitchB] vlan 100
[SwitchB-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/3
[SwitchB-vlan100] quit# Habilite o DHCPv6 snooping para a VLAN 100.
[SwitchB] ipv6 dhcp snooping enable vlan 100# Configure a GigabitEthernet 1/0/1 como uma porta confiável na VLAN 100.
[SwitchB] vlan 100
[SwitchB-vlan100] ipv6 dhcp snooping trust interface gigabitethernet 1/0/1
# Habilite o registro de entradas de snooping DHCPv6 na VLAN 100.
[SwitchB-vlan100] ipv6 dhcp snooping binding record
[SwitchB-vlan100] quit
Verificação da configuração
# Verifique se o cliente DHCPv6 obtém um endereço IPv6 e todos os outros parâmetros de configuração somente do servidor DHCPv6 autorizado. (Detalhes não mostrados.)
# Exibir entradas de endereço de snooping DHCPv6 no dispositivo de snooping DHCPv6.
[SwitchB] display ipv6 dhcp snooping bindingConfiguração da proteção DHCPv6
Sobre a proteção DHCPv6
O recurso de proteção do DHCPv6 filtra as mensagens de anúncio e resposta do DHCPv6 usando as políticas de proteção do DHCPv6 para garantir que os clientes DHCPv6 obtenham endereços/prefixos de servidores DHCPv6 autorizados. Para fornecer um nível mais refinado de granularidade de filtragem, você pode especificar os seguintes parâmetros para uma política de proteção do DHCPv6:
- Função do dispositivo conectado à interface ou VLAN de destino. A interface ou VLAN à qual a política de proteção DHCPv6 é aplicada é chamada de interface ou VLAN de destino.
- Critério de correspondência do servidor DHCPv6.
- Critério de correspondência para endereços/prefixos IPv6 atribuídos por servidores DHCPv6.
- Faixa de preferência de servidor DHCPv6 permitida.
Para atender aos requisitos de clientes DHCPv6 em diferentes locais, aplique políticas de proteção DHCPv6 para diferentes interfaces ou VLANs no mesmo dispositivo.
Mecanismo operacional de proteção do DHCPv6
Ao receber uma mensagem DHCPv6 Solicit ou Request, o dispositivo de proteção DHCPv6 encaminha a mensagem sem executar a verificação da política de proteção DHCPv6.
Ao receber uma resposta DHCPv6, o dispositivo de proteção DHCPv6 executa a verificação da política de proteção DHCPv6 na seguinte ordem:
- Examina se a porta receptora é uma porta confiável. O dispositivo encaminha a mensagem se ela vier de uma porta confiável.
Configure portas confiáveis em uma política de proteção DHCPv6 somente em uma das seguintes condições:
- A porta à qual a política de proteção DHCPv6 se aplica está conectada a um servidor autorizado.
- Todas as portas da VLAN às quais a política de proteção DHCPv6 se aplica estão conectadas a servidores autorizados.
- Examina a mensagem com base na função do dispositivo:
- Se a mensagem for recebida do dispositivo com a função de dispositivo cliente DHCPv6, o dispositivo descartará a mensagem.
Se a interface à qual a política de proteção DHCPv6 se aplica não estiver conectada a nenhum servidor DHCPv6 autorizado, defina a função do dispositivo como cliente para a política, conforme mostrado na Figura 24.
Figura 24 Definição da função do dispositivo como cliente
- Se a mensagem for recebida do dispositivo com a função de dispositivo servidor DHCPv6, o dispositivo examinará a mensagem da seguinte forma:
- Para uma mensagem Advertise, a mensagem passa na verificação de política se o endereço IP de origem na mensagem for permitido pela ACL e a preferência do servidor estiver no intervalo de correspondência.
- Para uma mensagem de resposta, a mensagem passa na verificação de política se os endereços/prefixos IPv6 atribuídos na mensagem forem permitidos pela ACL.
Se a interface à qual a política de proteção DHCPv6 se aplica estiver conectada a um servidor DHCPv6 autorizado, defina a função do dispositivo como servidor para a política, conforme mostrado na Figura 25.
Figura 25 Definição da função do dispositivo como servidor
O dispositivo encaminha a resposta depois que a mensagem passa pela verificação da política de proteção do DHCPv6.
Restrições e diretrizes: Configuração de proteção DHCPv6
O recurso de proteção do DHCPv6 opera corretamente somente quando o dispositivo está localizado entre o cliente DHCPv6 e o servidor DHCPv6 ou entre o cliente DHCPv6 e o agente de retransmissão DHCPv6. Se o dispositivo estiver localizado entre o servidor DHCPv6 e o agente de retransmissão DHCPv6, o recurso de proteção DHCPv6 não poderá funcionar corretamente.
Quando o recurso DHCPv6 guard é configurado em um dispositivo de DHCPv6 snooping, ambos os recursos podem ter efeito. O dispositivo encaminha pacotes de resposta DHCPv6 recebidos em uma porta confiável de snooping DHCPv6 somente se eles passarem na verificação de proteção DHCPv6. Esses pacotes serão descartados se não passarem na verificação de proteção do DHCPv6 .
Visão geral das tarefas de proteção do DHCPv6
Para configurar a proteção DHCPv6, execute as seguintes tarefas:
- Configuração de uma política de proteção DHCPv6
- Aplicação da política de proteção DHCPv6 Escolha as seguintes tarefas, conforme necessário:
- Aplicação de uma política de proteção DHCPv6 a uma interface
- Aplicação de uma política de proteção DHCPv6 a uma VLAN
Se as políticas de proteção do DHCPv6 forem aplicadas a uma interface e à VLAN da interface, a política específica da interface será usada na interface.
Configuração de uma política de proteção DHCPv6
- Entre na visualização do sistema.
system-view- Crie uma política de proteção DHCPv6 e entre em sua visualização.
ipv6 dhcp guard policy policy-name
- Especifique a função do dispositivo conectado à interface ou VLAN de destino.
device-role { client | server }
Por padrão, a função do dispositivo é cliente DHCPv6 para o dispositivo conectado à interface de destino ou à VLAN .
- Configure uma política de proteção DHCPv6.
- Configure um critério de correspondência de servidor DHCPv6.
if-match server acl { acl-number | name acl-name }
Por padrão, nenhum critério de correspondência de servidor DHCPv6 é configurado, e todos os servidores DHCPv6 são autorizados.
- Configure um critério de correspondência para os endereços/prefixos IPv6 atribuídos.
if-match reply acl { acl-number | name acl-name }
Por padrão, nenhum critério de correspondência é configurado para os endereços/prefixos IPv6 atribuídos, e todos os endereços/prefixos IPv6 atribuídos podem passar na verificação de endereço/prefixo.
- Configure um intervalo de preferências de servidor DHCPv6 permitido.
preference { max max-value | min min-value } *
Por padrão, nenhum intervalo de preferências de servidor DHCPv6 é configurado, e os servidores DHCPv6 com preferências de 1 a 255 podem passar na verificação de preferências.
- Configure a porta à qual a política se aplica como uma porta confiável para a política.
trust port
Por padrão, nenhuma porta confiável é configurada para uma política de proteção DHCPv6.
Aplicação de uma política de proteção DHCPv6 a uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface da Camada 2.
interface interface-type interface-number- Aplique uma política de proteção DHCPv6 à interface.
ipv6 dhcp guard apply policy policy-name
Por padrão, nenhuma política de proteção DHCPv6 é aplicada à interface.
Aplicação de uma política de proteção DHCPv6 a uma VLAN
- Entre na visualização do sistema.
system-view- Crie uma VLAN e entre em sua visualização.
vlan vlan-número
- Aplique uma política de proteção DHCPv6 à VLAN.
ipv6 dhcp guard apply policy policy-name
Por padrão, nenhuma política de proteção DHCPv6 é aplicada à VLAN.
Comandos de exibição e manutenção do DHCPv6 guard
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações sobre as políticas de proteção do DHCPv6. | exibir política de proteção ipv6 dhcp [ policy-name ] |
Exemplos de configuração do DHCPv6 guard
Exemplo: Configuração da proteção DHCPv6
Configuração de rede
Conforme mostrado na Figura 26, todos os servidores e clientes DHCPv6 estão na VLAN 100. Os intervalos de endereços IPv6 atribuíveis no servidor DHCPv6 1, no servidor 2 e no servidor 3 são 2001::/64, 2001::/64 e 2002::/64, respectivamente.
Configure a proteção DHCPv6 no switch para que ele encaminhe somente respostas DHCPv6 com o endereço IPv6 de origem no intervalo de FE80::/12 e prefixos atribuídos no intervalo de 2001::/16.
Figura 26 Diagrama de rede
Procedimento
Antes de configurar o DHCPv6 guard, conclua a configuração nos servidores DHCPv6.
# Crie a VLAN 100 e atribua GigabitEthernet 1/0/1, GigabitEthernet 1/0/2, GigabitEthernet 1/0/3 e GigabitEthernet 1/0/4 à VLAN 100.
<Switch> system-view
[Switch] vlan 100
[Switch-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/4
[Switch-vlan100] quit
# Criar uma ACL básica IPv6 numerada como 2001.
[Switch] acl ipv6 number 2001
# Crie a regra 1 para permitir somente pacotes com endereços IPv6 de origem no intervalo FE80::/12.
[Switch-acl-ipv6-basic-2001] rule 1 permit source fe80:: 12
[Switch-acl-ipv6-basic-2001] quit
# Crie uma ACL básica IPv6 numerada como 2002.
[Switch] acl ipv6 number 2002
# Crie a regra 1 para permitir apenas pacotes com endereços IPv6 de origem no intervalo de 2001::/16.
[Switch-acl-ipv6-basic-2002] rule 1 permit source 2001:: 16
[Switch-acl-ipv6-basic-2002] quit
# Criar política de proteção DHCPv6 denominada p1.
[Switch] ipv6 dhcp guard policy p1
# Defina a função do dispositivo como servidor DHCPv6 para o dispositivo conectado à VLAN de destino.
[Switch-dhcp6-guard-policy-p1] device-role server
# Especifique a ACL 2001 para corresponder aos servidores DHCPv6.
[Switch-dhcp6-guard-policy-p1] if-match server acl 2001
# Especifique a ACL 2002 para corresponder aos endereços/prefixos IPv6 atribuídos pelos servidores DHCPv6.
[Switch-dhcp6-guard-policy-p1] if-match reply acl 2002
[Switch-dhcp6-guard-policy-p1] quit
# Criar política de proteção DHCPv6 chamada p2.
[Switch] ipv6 dhcp guard policy p2
# Defina a função do dispositivo como cliente DHCPv6 para o dispositivo conectado à interface de destino.
[Switch-dhcp6-guard-policy-p2] device-role client
[Switch-dhcp6-guard-policy-p2] quit
# Aplique a política de proteção DHCPv6 p1 à VLAN 100.
[Switch] vlan 100
[Switch-vlan100] ipv6 dhcp guard apply policy p1
[Switch-vlan100] quit
# Aplique a política de proteção DHCPv6 p2 à GigabitEthernet 1/0/4.
[Switch]interface gigabitethernet 1/0/4
[Switch-GigabitEthernet1/0/4] ipv6 dhcp guard apply policy p2
[Switch-GigabitEthernet1/0/4] quit
Verificação da configuração
Verifique se o switch encaminha respostas DHCPv6 com o endereço IPv6 de origem no intervalo de FE80::/12 e os prefixos IPv6 atribuídos no intervalo de 2001::/16. O switch encaminha as respostas DHCPv6 do servidor DHCPv6 1 e descarta as respostas dos servidores DHCPv6 2 e 3.
Configuração do encaminhamento rápido de IPv6
Sobre o avanço rápido do IPv6
O encaminhamento rápido reduz o tempo de pesquisa de rota e melhora a eficiência do encaminhamento de pacotes usando um cache de alta velocidade e tecnologia baseada em fluxo de dados. Ele identifica um fluxo de dados usando os seguintes campos:
- Endereço IPv6 de origem.
- Endereço IPv6 de destino.
- Número da porta de origem.
- Número da porta de destino.
- Número de protocolo.
Depois que o primeiro pacote de um fluxo é encaminhado pela tabela de roteamento, o encaminhamento rápido cria uma entrada e usa essa entrada para encaminhar os pacotes subsequentes do fluxo.
Configuração do tempo de envelhecimento para entradas de encaminhamento rápido de IPv6
Sobre o tempo de envelhecimento das entradas de encaminhamento rápido do IPv6
A tabela de encaminhamento rápido IPv6 usa um cronômetro de envelhecimento para cada entrada de encaminhamento. Se uma entrada não for atualizada antes da expiração do cronômetro, o dispositivo excluirá a entrada. Se uma entrada tiver um acerto dentro do tempo de envelhecimento, o cronômetro de envelhecimento será reiniciado.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o tempo de envelhecimento para entradas de encaminhamento rápido de IPv6.
ipv6 fast-forwarding aging-time aging-time
Por padrão, o tempo de envelhecimento é de 30 segundos.
Configuração do compartilhamento de carga de encaminhamento rápido IPv6
Sobre o compartilhamento de carga de encaminhamento rápido IPv6
O compartilhamento de carga de encaminhamento rápido IPv6 permite que o dispositivo identifique um fluxo de dados usando as informações do pacote.
Se o compartilhamento de carga do encaminhamento rápido IPv6 estiver desativado, o dispositivo identificará um fluxo de dados pelas informações do pacote e pela interface de entrada.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o compartilhamento de carga de encaminhamento rápido de IPv6. Escolha uma opção conforme necessário:
- Habilite o compartilhamento de carga de encaminhamento rápido de IPv6.
Ipv6 fast-forwarding load-sharing
- Desative o compartilhamento de carga de encaminhamento rápido de IPv6.
undo ipv6 fast-forwarding load-sharing
Por padrão, o compartilhamento de carga de encaminhamento rápido IPv6 está ativado.
Comandos de exibição e manutenção para encaminhamento rápido de IPv6
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir o tempo de envelhecimento das entradas de encaminhamento rápido de IPv6. | exibir ipv6 fast-forwarding aging-time |
| Exibir entradas de encaminhamento rápido de IPv6. | display ipv6 fast-forwarding cache [ ipv6-address ] [ slot slot-number ] |
| Limpar a tabela de encaminhamento rápido de IPv6. | reset ipv6 fast-forwarding cache [ slot slot-number ] |
Configuração do redirecionamento de HTTP
Sobre o redirecionamento de HTTP
O redirecionamento de HTTP é um método para redirecionar as solicitações HTTP ou HTTPS dos usuários para um URL específico. Ele é usado nos seguintes recursos:
- Atribuição de URL de redirecionamento em autenticação 802.1X, autenticação MAC, autenticação Web e segurança de porta.
- Redirecionamento de URL do assistente do EAD na autenticação 802.1X.
- Serviços de redirecionamento de URL no portal.
Restrições e diretrizes: Configuração de redirecionamento de HTTP
Para que o redirecionamento de URL funcione corretamente na autenticação 802.1X, autenticação MAC, autenticação Web, segurança de porta e assistente EAD, certifique-se de que as VLANs de entrada de pacotes tenham interfaces de Camada 3 (interfaces VLAN) configuradas. Caso contrário, o redirecionamento de solicitações HTTPS falhará.
Visão geral das tarefas de redirecionamento de HTTP
Não é necessária nenhuma configuração para redirecionar solicitações HTTP. Para redirecionar solicitações HTTPS, execute as seguintes tarefas:
- Especificação do número da porta de escuta do redirecionamento HTTPS
- (Opcional.) Associar uma política de servidor SSL ao serviço de redirecionamento de HTTPS
Especificação do número da porta de escuta do redirecionamento HTTPS
Sobre o número da porta de escuta do redirecionamento HTTPS
O dispositivo pode redirecionar as solicitações de HTTPS somente depois que você especificar o número da porta TCP na qual o serviço de redirecionamento de HTTPS escuta as solicitações de HTTPS.
Restrições e diretrizes
Para evitar a indisponibilidade do serviço causada por conflito de portas, não especifique um número de porta TCP usado por um protocolo bem conhecido ou usado por qualquer outro serviço baseado em TCP. Para exibir os números de porta TCP que foram usados pelos serviços, use o comando display tcp. Para obter mais informações sobre esse comando, consulte Comandos de otimização de desempenho de IP na Referência de comandos de serviços de IP de camada 3.
Se você executar essa tarefa várias vezes, a configuração mais recente entrará em vigor.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique o número da porta de escuta do redirecionamento HTTPS.
http-redirect https-port port-number
Por padrão, o número da porta de escuta do redirecionamento HTTPS é 6654.
Associação de uma política de servidor SSL ao serviço de redirecionamento de HTTPS
Sobre a associação de uma política de servidor SSL com o serviço de redirecionamento de HTTPS
Para aumentar a segurança do redirecionamento de HTTPS, você pode associar uma política de servidor SSL ao serviço de redirecionamento de HTTPS. Para obter mais informações sobre a configuração da política do servidor SSL, consulte SSL no Guia de Configuração de Segurança.
Restrições e diretrizes
O redirecionamento de HTTPS não estará disponível se a política de servidor SSL associada não existir. Primeiro, você pode associar uma política de servidor SSL inexistente ao serviço de redirecionamento de HTTPS e, em seguida, configurar a política de servidor SSL.
Se você alterar a política de servidor SSL associada ao serviço de redirecionamento de HTTPS, a nova política entrará em vigor imediatamente.
Se você executar essa tarefa várias vezes, a configuração mais recente entrará em vigor.
Procedimento
- Entre na visualização do sistema.
system-view- Associe uma política de servidor SSL ao serviço de redirecionamento de HTTPS.
http-redirect ssl-server-policy policy-name
Por padrão, nenhuma política de servidor SSL está associada ao serviço de redirecionamento de HTTPS. O serviço de redirecionamento de HTTPS usa o certificado autoatribuído e os parâmetros SSL padrão.
Visão geral do NAT
Conceitos básicos de NAT
O Network Address Translation (NAT) traduz um endereço IP no cabeçalho do pacote IP para outro endereço IP. Normalmente, o NAT é configurado em gateways para permitir que hosts privados acessem redes externas e hosts externos acessem recursos de rede privada, como um servidor Web.
A seguir, descrevemos os conceitos básicos de NAT:
- Dispositivo NAT - Um dispositivo configurado com NAT. Normalmente, o NAT é configurado no dispositivo de borda que conecta as redes interna e externa.
- Interface NAT - Uma interface configurada com NAT.
- Endereço NAT - Um endereço IP público usado para conversão de endereços, e esse endereço pode ser acessado pela rede externa.
- Entrada NAT - Armazena o mapeamento entre um endereço IP privado e um endereço IP público.
Mecanismo operacional básico de NAT
A Figura 1 mostra o mecanismo básico de operação do NAT.
- Ao receber uma solicitação do host para o servidor, o NAT traduz o endereço de origem privado 192.168.1.3 para o endereço público 20.1.1.1 e encaminha o pacote NATed. O NAT adiciona um mapeamento para os dois endereços em sua tabela NAT.
- Ao receber uma resposta do servidor, o NAT converte o endereço público de destino para o endereço privado e encaminha o pacote para o host.
A operação de NAT é transparente para os terminais (o host e o servidor). O NAT oculta a rede privada dos usuários externos e mostra que o endereço IP do host interno é 20.1.1.1.
Figura 1 Operação básica do NAT
Restrições: Compatibilidade de versão de software com NAT
O recurso NAT é compatível apenas com a versão 6328 e posteriores.
Configuração de NAT estático de saída um para um
Sobre esta tarefa
O NAT estático cria um mapeamento fixo entre um endereço privado e um endereço público. Ele oferece suporte a conexões iniciadas por usuários internos para a rede externa e de usuários externos para a rede interna. A NAT estática se aplica a comunicações regulares.
Para a conversão de endereços de um endereço IP privado para um endereço IP público, configure o NAT estático de saída um para um na interface conectada à rede externa.
- Quando o endereço IP de origem de um pacote de saída corresponde ao local-ip, o endereço IP de origem é traduzido para o global-ip.
- Quando o endereço IP de destino de um pacote de entrada corresponde ao global-ip, o endereço IP de destino é traduzido para o local-ip.
Restrições e diretrizes
Se você configurar a configuração modular de QoS (MQC) em um dispositivo habilitado com NAT estático, os pacotes que correspondem a uma regra de ACL serão enviados à CPU. Se os endereços IP dos pacotes corresponderem a uma regra NAT, o dispositivo gerará sessões NAT e realizará o encaminhamento no software, o que poderá causar perda de pacotes de sessões NAT estabelecidas.
Procedimento
- Entre na visualização do sistema.
system-view- Configure um mapeamento de um para um para NAT estático de saída.
nat static outbound local-ip global-ip
- Entre na visualização da interface.
interface interface-type interface-number- Habilite o NAT estático na interface.
nat static enable
Por padrão, o NAT estático está desativado.
Comandos de exibição e manutenção para NAT
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir sessões NAT. | display nat session [ { source-ip source-ip | destination-ip destination-ip } * ] [ slot slot-number ] [ verbose ] |
| Exibir mapeamentos NAT estáticos. | display nat static |
| Limpar sessões NAT. | redefinir sessão nat |
Exemplos de configuração de NAT
Exemplo: Configuração de NAT estático de saída um para um
Configuração de rede
Configure o NAT estático para permitir que o host em 10.110.10.8/24 acesse a Internet.
Figura 2 Diagrama de rede

Procedimento
# Especifique os endereços IP para as interfaces no dispositivo. (Detalhes não mostrados).
# Configure um mapeamento NAT estático de um para um entre o endereço privado 10.110.10.8 e o endereço público 202.38.1.100.
<Device> system-view
[Device] nat static outbound 10.110.10.8 202.38.1.100
# Habilite o NAT estático na interface VLAN 200.
[Device] interface vlan-interface 200
[Device-Vlan-interface200] nat static enable
[Device-Vlan-interface200] quit
Verificação da configuração
# Verifique se o host em 10.110.10.8/24 pode acessar o servidor na Internet. (Detalhes não mostrados.) # Exibir a configuração NAT estática.
[Device] display nat static
Static NAT mappings:
Totally 1 outbound static NAT mappings.
IP-to-IP:
Local IP : 10.110.10.8
Global IP : 202.38.1.100
Config status: Active
Interfaces enabled with static NAT:
Totally 1 interfaces enabled with static NAT.
Interface: Vlan-interface200
Service card : ---
Config status: Active
# Exibir informações da sessão NAT. [Device] display nat session verbose Iniciador:
[Device] display nat session verbose
Initiator:
Source IP/port: 10.110.10.8/42496
Destination IP/port: 202.38.1.111/2048
DS-Lite tunnel peer: -
VPN instance/VLAN ID/VLL ID: -/-/-
Host
10.110.10.8/24
Server
Internet
Vlan-int100
10.110.10.1/24
Vlan-int200
202.38.1.100/16
Device
4
Protocol: ICMP(1)
Inbound interface: Vlan-interface100
Responder:
Source IP/port: 202.38.1.111/42496
Destination IP/port: 202.38.1.100/0
DS-Lite tunnel peer: -
VPN instance/VLAN ID/VLL ID: -/-/-
Protocol: ICMP(1)
Inbound interface: Vlan-interface200
State: ICMP_REPLY
Application: INVALID
Start time: 2021-04-13 09:30:49 TTL: 27s
Initiator->Responder: 5 packets 420 bytes
Responder->Initiator: 5 packets 420 bytes
Total sessions found: 1
05 - Roteamento Unicast
Configuração do roteamento IP básico
Sobre o roteamento IP
O roteamento IP direciona o encaminhamento de pacotes IP nos roteadores. Com base no endereço IP de destino do pacote, um roteador procura uma rota para o pacote em uma tabela de roteamento e encaminha o pacote para o próximo salto. As rotas são informações de caminho usadas para direcionar os pacotes IP.
Tabela de roteamento
Um RIB contém as informações de roteamento global e as informações relacionadas, inclusive informações de recursão de rota, redistribuição de rota e extensão de rota. O roteador seleciona as rotas ideais da tabela de roteamento e as coloca na tabela FIB. Ele usa a tabela FIB para encaminhar os pacotes. Para obter mais informações sobre a tabela FIB, consulte o Guia de configuração de serviços de IP de camada 3.
Categorias de rotas
A Tabela 1 categoriza as rotas de acordo com diferentes critérios.
Tabela 1 Categorias de rotas
| Critério | Categorias |
| Origem | Rota direta - Uma rota direta é descoberta pelo protocolo de link de dados em uma interface e também é chamada de rota de interface. Rota estática - Uma rota estática é configurada manualmente por um administrador. Rota dinâmica - Uma rota dinâmica é descoberta dinamicamente por um protocolo de roteamento. |
| Destino | Rota de rede - O destino é uma rede. A máscara de sub-rede tem menos de 32 bits. Rota de host - O destino é um host. A máscara de sub-rede é de 32 bits. |
| Se o destino está diretamente conectado | Rota direta - O destino está diretamente conectado. Rota indireta - O destino está conectado indiretamente. |
Protocolos de roteamento dinâmico
As rotas estáticas funcionam bem em redes pequenas e estáveis. Elas são fáceis de configurar e exigem menos recursos do sistema. Entretanto, em redes em que as mudanças de topologia ocorrem com frequência, uma prática comum é configurar um protocolo de roteamento dinâmico. Em comparação com o roteamento estático, um protocolo de roteamento dinâmico é complicado de configurar, exige mais recursos do roteador e consome mais recursos da rede.
Os protocolos de roteamento dinâmico coletam e relatam dinamicamente informações de acessibilidade para se adaptar às mudanças na topologia. Eles são adequados para redes grandes.
Os protocolos de roteamento dinâmico podem ser classificados de acordo com diferentes critérios, conforme mostrado na Tabela 2.
Tabela 2 Categorias de protocolos de roteamento dinâmico
| Critério | Categorias |
| Escopo da operação | IGPs - Funcionam em um AS. Os exemplos incluem RIP, OSPF e IS-IS. EGPs - Trabalham entre ASs. O EGP mais popular é o BGP. |
| Algoritmo de roteamento | Protocolos de vetor de distância - Exemplos incluem RIP e BGP. O BGP também é considerado um protocolo de vetor de caminho. Protocolos de estado de link - Exemplos incluem OSPF e IS-IS. |
| Tipo de endereço de destino | Protocolos de roteamento unicast - Exemplos incluem RIP, OSPF, BGP e IS-IS. Protocolos de roteamento multicast - Exemplos incluem PIM-SM e PIM-DM. |
| Versão IP | Protocolos de roteamento IPv4 - Exemplos incluem RIP, OSPF, BGP e IS-IS. Protocolos de roteamento IPv6 - Exemplos incluem RIPng, OSPFv3, IPv6 BGP e IPv6 IS-IS. |
Um AS refere-se a um grupo de roteadores que usam a mesma política de roteamento e trabalham sob a mesma administração.
Preferência de rota
Os protocolos de roteamento, inclusive o roteamento estático e direto, têm, por padrão, uma preferência. Se eles encontrarem várias rotas para o mesmo destino, o roteador selecionará a rota com a maior preferência como a rota ideal.
A preferência de uma rota direta é sempre 0 e não pode ser alterada. Você pode configurar uma preferência para cada rota estática e cada protocolo de roteamento dinâmico. A tabela a seguir lista os tipos de rota e as preferências padrão. Quanto menor o valor, maior a preferência.
Tabela 3 Tipos de rota e preferências de rota padrão
| Tipo de rota | Preferência |
| Rota direta | 0 |
| Rota estática de multicast | 1 |
| OSPF | 10 |
| IS-IS | 15 |
| Rota estática unicast | 60 |
| RIP | 100 |
| OSPF ASE | 150 |
| OSPF NSSA | 150 |
| IBGP | 255 |
| EBGP | 255 |
| Desconhecido (rota de uma fonte não confiável) | 256 |
Backup de rota
O backup de rotas pode aumentar a disponibilidade da rede. Entre várias rotas para o mesmo destino, a rota com a prioridade mais alta é a rota primária e as outras são rotas secundárias.
O roteador encaminha os pacotes correspondentes por meio da rota primária. Quando a rota primária falha, a rota com a maior preferência entre as rotas secundárias é selecionada para encaminhar os pacotes. Quando a rota primária se recupera, o roteador a utiliza para encaminhar os pacotes.
Recursão de rota
Para usar uma rota BGP, estática ou RIP que tenha um próximo salto conectado indiretamente, um roteador deve executar a recursão de rota para encontrar a interface de saída para alcançar o próximo salto.
Os protocolos de roteamento link-state, como OSPF e IS-IS, não precisam de recursão de rota, pois obtêm os próximos saltos diretamente conectados por meio do cálculo da rota.
O RIB registra e salva informações de recursão de rota, incluindo informações breves sobre rotas relacionadas, caminhos recursivos e profundidade de recursão.
Redistribuição de rotas
A redistribuição de rotas permite que os protocolos de roteamento aprendam informações de roteamento uns dos outros. Um protocolo de roteamento dinâmico pode redistribuir rotas de outros protocolos de roteamento, inclusive roteamento direto e estático. Para obter mais informações, consulte os respectivos capítulos sobre esses protocolos de roteamento neste guia de configuração.
O RIB registra as relações de redistribuição dos protocolos de roteamento.
Redistribuição de atributos de extensão
A redistribuição de atributos de extensão permite que os protocolos de roteamento aprendam atributos de extensão de rota entre si, incluindo atributos de comunidade estendida BGP, IDs de área OSPF, tipos de rota e IDs de roteador.
O RIB registra os atributos estendidos de cada protocolo de roteamento e as relações de redistribuição dos diferentes atributos estendidos do protocolo de roteamento.
Definição do tempo de vida máximo para rotas e rótulos na RIB
Sobre a configuração do tempo de vida máximo para rotas e rótulos na RIB
Execute essa tarefa para evitar que as rotas de um determinado protocolo sejam envelhecidas devido à lentidão do protocolo convergência resultante de um grande número de entradas de rota ou de um longo período de GR.
Restrições e diretrizes
A configuração entra em vigor na próxima troca de protocolo ou de processo RIB.
Procedimento (IPv4)
- Entre na visualização do sistema.
system-view- Entre na visualização RIB.
rib- Crie a família de endereços IPv4 do RIB e entre em sua visualização.
address-family ipv4- Defina o tempo de vida máximo para rotas e rótulos IPv4 no RIB.
protocol protocol [ instance instance-name ] lifetime secondsPor padrão, a duração máxima das rotas e rótulos na RIB é de 480 segundos.
Procedimento (IPv6)
- Entre na visualização do sistema.
system-view- Entre na visualização RIB.
rib- Crie a família de endereços IPv6 do RIB e entre em sua visualização.
address-family ipv6- Defina o tempo de vida máximo para rotas e rótulos IPv6 no RIB.
protocol protocol [ instance instance-name ] lifetime secondsPor padrão, a duração máxima das rotas e rótulos na RIB é de 480 segundos.
Definição da duração máxima das rotas na FIB
Sobre a configuração da duração máxima das rotas na FIB
Quando GR ou NSR está desativado, as entradas FIB devem ser mantidas por algum tempo após a troca de processo de protocolo ou troca de processo RIB. Quando GR ou NSR está ativado, as entradas FIB devem ser removidas imediatamente após uma troca de protocolo ou de processo RIB para evitar problemas de roteamento. Execute esta tarefa para atender a esses requisitos.
Procedimento (IPv4)
- Entre na visualização do sistema.
system-view- Entre na visualização RIB.
rib- Crie a família de endereços IPv4 do RIB e entre em sua visualização.
address-family ipv4- Definir o tempo de vida máximo das rotas IPv4 na FIB.
fib lifetime secondsPor padrão, a duração máxima das rotas na FIB é de 600 segundos.
Procedimento (IPv6)
- Entre na visualização do sistema.
system-view- Entre na visualização RIB.
rib- Crie a família de endereços IPv6 do RIB e entre em sua visualização.
address-family ipv6- Definir o tempo de vida máximo das rotas IPv6 na FIB.
fib lifetime secondsPor padrão, a duração máxima das rotas na FIB é de 600 segundos.
Configuração de RIB NSR
Sobre a RIB NSR
Quando ocorre uma alternância entre ativo e em espera, o roteamento ininterrupto (NSR) faz o backup das informações de roteamento do processo ativo para o processo em espera, a fim de evitar oscilações no roteamento e garantir a continuidade do encaminhamento.
O RIB NSR oferece convergência de rota mais rápida do que o protocolo NSR durante uma alternância ativo/em espera.
Restrições e diretrizes
Use esse recurso com o protocolo GR ou NSR para evitar tempos limite de rota e interrupção do tráfego.
Procedimento (IPv4)
- Entre na visualização do sistema.
system-view- Entre na visualização RIB.
rib- Crie a família de endereços IPv4 do RIB e entre em sua visualização.
address-family ipv4- Ativar IPv4 RIB NSR.
non-stop-routingPor padrão, o RIB NSR está desativado.
Procedimento (IPv6)
- Entre na visualização do sistema.
system-view- Entre na visualização RIB.
rib- Crie a família de endereços IPv6 do RIB e entre em sua visualização.
address-family ipv6- Ativar IPv6 RIB NSR.
non-stop-routingPor padrão, o RIB NSR está desativado.
Configuração de FRR entre protocolos
Sobre FRR entre protocolos
O FRR (Inter-protocol fast reroute) permite o redirecionamento rápido entre rotas de diferentes protocolos. Um próximo salto de backup é selecionado automaticamente para reduzir o tempo de interrupção do serviço causado por próximos saltos inalcançáveis. Quando o próximo salto do link principal falha, o tráfego é redirecionado para o próximo salto de backup.
Entre as rotas para o mesmo destino na RIB, um roteador adiciona a rota com a maior preferência à tabela FIB. Por exemplo, se uma rota estática e uma rota OSPF no RIB tiverem o mesmo destino, o roteador adiciona a rota OSPF à tabela FIB por padrão. O próximo salto da rota estática é selecionado como o próximo salto de backup para a rota OSPF. Quando o próximo salto da rota OSPF estiver inacessível, o próximo salto de backup será usado.
Restrições e diretrizes
Esse recurso usa o próximo salto de uma rota de um protocolo diferente como o próximo salto de backup, o que pode causar loops.
Procedimento (IPv4)
- Entre na visualização do sistema.
system-view- Entre na visualização RIB.
rib- Crie a família de endereços IPv4 do RIB e entre em sua visualização.
address-family ipv4- Ativar o FRR interprotocolo do RIB IPv4.
inter-protocol fast-reroutePor padrão, o FRR interprotocolo está desativado.
Procedimento (IPv6)
- Entre na visualização do sistema.
system-view- Entre na visualização RIB.
rib- Crie a família de endereços IPv6 do RIB e entre em sua visualização.
address-family ipv6- Ativar o FRR interprotocolo da RIB IPv6.
inter-protocol fast-reroutePor padrão, o FRR interprotocolo está desativado.
Ativação da troca rápida de rotas
Sobre a ativação da comutação rápida de rotas
Esse recurso se aplica a um dispositivo que fornece a mesma interface de saída física para um grande número de rotas, inclusive rotas primárias/secundárias. Quando ocorre uma falha de link na interface, o dispositivo deve executar as seguintes tarefas antes de alternar o tráfego para outra rota:
- Exclui todas as entradas ARP ou ND do link.
- Instrui o FIB a excluir as entradas FIB associadas.
Esse procedimento é demorado e interrompe o tráfego por um longo período. Para resolver esse problema, você pode ativar a troca rápida de rota. Esse recurso permite que o dispositivo instrua o FIB a excluir primeiro as entradas inválidas do FIB para a troca de rota.
Procedimento (IPv4)
- Entre na visualização do sistema.
system-view- Ativar a troca rápida de rotas IPv4.
ip route fast-switchover enablePor padrão, a troca rápida de rotas IPv4 está desativada.
Procedimento (IPv6)
- Entre na visualização do sistema.
system-view- Ativar a troca rápida de rotas IPv6.
ipv6 route fast-switchover enablePor padrão, a troca rápida de rotas IPv6 está desativada.
Configuração da pesquisa recursiva baseada em políticas de roteamento
Sobre a pesquisa recursiva baseada em políticas de roteamento
Configure a pesquisa recursiva baseada na política de roteamento para controlar os resultados da recursão de rotas. Por exemplo, quando uma rota muda, o protocolo de roteamento precisa executar uma recursão de rota se o próximo salto estiver conectado indiretamente. O protocolo de roteamento pode selecionar um caminho incorreto, o que pode causar perda de tráfego. Para resolver esse problema, você pode usar uma política de roteamento para filtrar as rotas incorretas. As rotas que passarem pela filtragem da política de roteamento serão usadas para a recursão de rota.
Restrições e diretrizes
As cláusulas de aplicação na política de roteamento especificada não podem entrar em vigor.
Certifique-se de que pelo menos uma rota relacionada possa corresponder à política de roteamento para o encaminhamento correto do tráfego.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização RIB.
rib- Crie a família de endereços IPv4 do RIB e entre em sua visualização.
address-family ipv4- Configure a pesquisa recursiva baseada em políticas de roteamento.
protocol protocol nexthop recursive-lookup route-policy
route-policy-namePor padrão, a pesquisa recursiva baseada em políticas de roteamento não está configurada.
Definição do número máximo de rotas ativas suportadas pelo dispositivo
Sobre a configuração do número máximo de rotas ativas suportadas pelo dispositivo
O recurso permite que você defina o número máximo de rotas IPv4/IPv6 ativas suportadas pelo dispositivo. Quando o número máximo de rotas IPv4/IPv6 ativas é excedido, o dispositivo ainda aceita novas rotas ativas, mas gera uma mensagem de registro do sistema. Você pode executar ações relevantes com base na mensagem para economizar recursos do sistema.
Procedimento (IPv4)
- Entre na visualização do sistema.
system-view- Entre na visualização RIB.
rib- Crie a família de endereços IPv4 do RIB e entre em sua visualização.
address-family ipv4- Defina o número máximo de rotas IPv4 ativas suportadas pelo dispositivo.
routing-table limit number simply-alertPor padrão, o número máximo de rotas IPv4 ativas não é definido para o dispositivo.
A configuração na visualização da família de endereços IPv4 do RIB limita o número de rotas IPv4 ativas para a rede pública.
Procedimento (IPv6)
- Entre na visualização do sistema.
system-view- Entre na visualização RIB.
rib- Crie a família de endereços IPv6 do RIB e entre em sua visualização.
address-family ipv6- Defina o número máximo de rotas IPv6 ativas suportadas pelo dispositivo.
routing-table limit number simply-alertPor padrão, o número máximo de rotas IPv6 ativas não é definido para o dispositivo.
A configuração na visualização da família de endereços IPv6 do RIB limita o número de rotas IPv6 ativas para a rede pública.
Ativação do MTP
Sobre esta tarefa
Use a sonda de manutenção (MTP) para localizar falhas nos protocolos de roteamento, dependendo dos requisitos de manutenção da rede. O MTP permite que o dispositivo execute automaticamente as seguintes operações após a expiração do temporizador de espera de um vizinho:
- Faça ping no vizinho ou rastreie a rota até o vizinho.
- Registre os resultados do ping ou do tracert.
Para exibir informações sobre falhas, use os comandos de exibição de protocolos de roteamento, por exemplo, o comando display ospf troubleshooting. Para exibir informações detalhadas sobre o MTP, use o comando display logbuffer.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar MTP.
maintenance-probe enablePor padrão, o MTP está desativado.
Comandos de exibição e manutenção para roteamento IP básico
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações da tabela de roteamento. | display ip routing-table [ verbose ] display ip routing-table [ all-routes ] |
| Exibir informações sobre as rotas permitidas por uma ACL básica IPv4. | display ip routing-table acl ipv4-acl-number [ verbose ] |
| Exibir informações sobre rotas para um endereço de destino específico. | display ip routing-table ip-address [ mask-length | mask ] [ longer-match ] [ verbose ] |
| Exibir informações sobre rotas para um intervalo de endereços de destino. | display ip routing-table ip-address1 to ip-address2 [ verbose ] |
| Exibir informações sobre rotas permitidas por uma lista de prefixos IP. | display ip routing-table prefix-list nome da lista de prefixos [ verbose ] |
| Exibir informações sobre rotas instaladas por um protocolo. | display ip routing-table protocol protocol [ inactive | verbose ] |
| Exibir estatísticas de rota IPv4. | display ip routing-table [ all-routes ] estatísticas |
| Exibir informações resumidas da tabela de roteamento IPv4. | display ip routing-table summary |
| Exibir informações sobre o estado do RIB GR IPv6. | display ipv6 rib graceful-restart |
| Exibir as informações do próximo salto no RIB do IPv6. | display ipv6 rib nib [ self-originated ] [ nib-id ] [ verbose ] display ipv6 rib nib protocol protocol [ verbose ] |
| Exibir informações de próximo salto para rotas diretas IPv6. | display ipv6 route-direct nib [ nib-id ] [ verbose ] |
| Exibir informações da tabela de roteamento IPv6. | display ipv6 routing-table [ verbose ] display ipv6 routing-table [ all-routes ] |
| Exibir informações sobre as rotas permitidas por uma ACL básica IPv6. | display ipv6 routing-table acl ipv6-acl-number [ verbose ] |
| Exibir informações sobre rotas para um endereço de destino IPv6. | display ipv6 routing-table ipv6-address [ prefix-length ] [ longer-match ] [ verbose ] |
| Exibir informações sobre rotas para um intervalo de endereços de destino IPv6. | display ipv6 routing-table ipv6-address1 to ipv6-address2 [ verbose ] |
| Exibir informações sobre rotas permitidas por uma lista de prefixos IPv6. | display ipv6 routing-table prefix-list nome da lista de prefixos [ verbose ] |
| Exibir informações sobre rotas instaladas por um protocolo IPv6. | display ipv6 routing-table protocol protocol [ inactive | verbose ] |
| Exibir estatísticas de rota IPv6. | display ipv6 routing-table [ all-routes ] estatísticas |
| Exibir informações resumidas da tabela de roteamento IPv6. | display ipv6 routing-table summary |
| Exibir informações sobre o estado do RIB GR. | display rib graceful-restart |
| Exibir as informações do próximo salto no RIB. | display rib nib [ self-originated ] [ nib-id ] [ verbose ] display rib nib protocol protocol [ verbose ] |
| Exibir informações de próximo salto para rotas diretas. | display route-direct nib [ nib-id ] [ verbose ] |
| Limpar estatísticas de rota IPv4. | reset ip routing-table statistics protocol { protocol | all } reset ip routing-table [ all-routes ] statistics protocol { protocol | all } |
| Limpar estatísticas de rota IPv6. | reset ipv6 routing-table statistics protocol { protocol | all } reset ipv6 routing-table [ all-routes ] statistics protocol { protocol | all } |
Configuração de roteamento estático
Sobre rotas estáticas
As rotas estáticas são configuradas manualmente. Se a topologia de uma rede for simples, basta configurar as rotas estáticas para que a rede funcione corretamente.
As rotas estáticas não podem se adaptar às mudanças na topologia da rede. Se ocorrer uma falha ou uma alteração topológica em a rede, o administrador da rede deverá modificar as rotas estáticas manualmente.
Configuração de uma rota estática
- Entre na visualização do sistema.
system-view- Configurar uma rota estática.
ip route-static dest-address { mask-length | mask } { interface-type
interface-number [ next-hop-address [ nexthop-index index-string ] ]
| next-hop-address [ nexthop-index index-string ] [ recursive-lookup
host-route ] } [ permanent | track track-entry-number ] [ preference
preference ] [ tag tag-value ] [ description text ]Por padrão, nenhuma rota estática é configurada.
Você pode associar o Track a uma rota estática para monitorar a capacidade de alcance dos próximos saltos. Para obter mais informações sobre o Track, consulte o Guia de configuração de alta disponibilidade.
- (Opcional.) Ative o envio periódico de solicitações ARP para os próximos saltos de rotas estáticas.
ip route-static arp-request interval intervalPor padrão, o dispositivo não envia solicitações ARP para os próximos saltos de rotas estáticas.
- (Opcional.) Configure a preferência padrão para rotas estáticas.
ip route-static default-preference default-preferenceA configuração padrão é 60.
Configuração de um grupo de rotas estáticas
Sobre grupos de rotas estáticas
Essa tarefa permite que você crie em lote rotas estáticas com prefixos diferentes, mas com a mesma interface de saída e o mesmo próximo salto.
Você pode criar um grupo de rotas estáticas e especificar o grupo estático no comando ip route-static. Todos os prefixos do grupo de rotas estáticas receberão o próximo salto e a interface de saída especificados no comando ip route-static.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um grupo de rotas estáticas e entre em sua visualização.
ip route-static-group group-namePor padrão, nenhum grupo de rotas estáticas está configurado.
prefix dest-address { mask-length | mask }Por padrão, nenhum prefixo de rota estática é adicionado ao grupo de rotas estáticas.
- Retornar à visualização do sistema.
quit- Configurar uma rota estática.
ip route-static group group-name { interface-type interface-number
[ next-hop-address ] | next-hop-address [ recursive-lookup
host-route ] } [ permanent | track track-entry-number ] [ preference
preference ] [ tag tag-value ] [ description text ]Por padrão, nenhuma rota estática é configurada.
Exclusão de rotas estáticas
Sobre a exclusão de rotas estáticas
Para excluir uma rota estática, use o comando undo ip route-static. Para excluir todas as rotas estáticas, inclusive a rota padrão, use o comando delete static-routes all.
Procedimento
- Entre na visualização do sistema.
system-view- Excluir todas as rotas estáticas.
delete static-routes allEsse comando pode interromper a comunicação da rede e causar falha no encaminhamento de pacotes. Antes de executar o comando, certifique-se de compreender totalmente o possível impacto na rede.
Configuração de BFD para rotas estáticas
A ativação do BFD para uma rota com flapping pode piorar a situação.
Sobre a BFD
O BFD oferece um mecanismo de detecção rápida de falhas de uso geral, padrão, independente de meio e protocolo. Ele pode detectar de maneira uniforme e rápida as falhas dos caminhos de encaminhamento bidirecional entre dois roteadores para protocolos, como protocolos de roteamento.
Para obter mais informações sobre o BFD, consulte o Guia de configuração de alta disponibilidade.
Configuração do modo de pacote de controle BFD
Sobre o modo de pacote de controle BFD
Esse modo usa pacotes de controle BFD para detectar o status de um link bidirecionalmente em um nível de milissegundos.
O modo de pacote de controle BFD pode ser aplicado a rotas estáticas com um próximo salto direto ou com um próximo salto indireto.
Restrições e diretrizes para o modo de pacote de controle BFD
Se você usar o modo de pacote de controle BFD na extremidade local, deverá usar esse modo também na extremidade do par.
Configuração do modo de pacote de controle BFD para uma rota estática (próximo salto direto)
- Entre na visualização do sistema.
system-view- Configure o modo de pacote de controle BFD para uma rota estática.
ip route-static dest-address { mask-length | mask } interface-type
interface-number next-hop-address bfd control-packet [ preference
preference ] [ tag tag-value ] [ description text ]
Por padrão, o modo de pacote de controle BFD para uma rota estática não está configurado.
Configuração do modo de pacote de controle BFD para uma rota estática (próximo salto indireto)
- Entre na visualização do sistema.
system-view- Configure o modo de pacote de controle BFD para uma rota estática.
ip route-static dest-address { mask-length | mask } { next-hop-address
bfd control-packet bfd-source ip-address [ preference preference ]
[ tag tag-value ] [ description text ] }
Por padrão, o modo de pacote de controle BFD para uma rota estática não está configurado.
Configuração do modo de pacote de eco BFD
Sobre o modo de pacote de eco BFD
Com o modo de pacote de eco BFD ativado para uma rota estática, a interface de saída envia pacotes de eco BFD para o dispositivo de destino, que retorna os pacotes em loop para testar a capacidade de alcance do link.
Restrições e diretrizes
Não é necessário configurar o modo de pacote de eco BFD na extremidade do par.
Não use o BFD para uma rota estática com a interface de saída em estado de spoofing.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o endereço de origem dos pacotes de eco.
bfd echo-source-ip ip-addressPor padrão, o endereço de origem dos pacotes de eco não é configurado.
Para obter mais informações sobre esse comando, consulte Referência de comandos de alta disponibilidade.
- Configurar o modo de pacote de eco BFD para uma rota estática.
Por padrão, o modo de pacote de eco BFD para uma rota estática não está configurado.
Configuração de rota estática FRR
Sobre a rota estática FRR
Uma falha de link ou de roteador em um caminho pode causar perda de pacotes. O FRR (fast reroute) de rota estática permite o redirecionamento rápido para minimizar o impacto de falhas de links ou nós.
Figura 1 Diagrama de rede
Conforme mostrado na Figura 1, em uma falha de link, os pacotes são direcionados para o próximo salto de backup para evitar a interrupção do tráfego. Você pode especificar um próximo salto de backup para a FRR ou ativar a FRR para selecionar automaticamente um próximo salto de backup (que deve ser configurado com antecedência).
Restrições e diretrizes para a rota estática FRR
- Não use FRR de rota estática e BFD (para uma rota estática) ao mesmo tempo.
- Além da rota estática configurada para FRR, o dispositivo deve ter outra rota para chegar ao destino.
Quando o estado do link primário (com as interfaces da camada 3 permanecendo ativas) muda de bidirecional para unidirecional ou para baixo, a rota estática FRR redireciona rapidamente o tráfego para o próximo salto de backup. Quando as interfaces da Camada 3 do link primário estão inativas, a FRR de rota estática redireciona temporariamente o tráfego para o próximo salto de backup. Além disso, o dispositivo procura outra rota para chegar ao destino e redireciona o tráfego para o novo caminho se for encontrada uma rota. Se nenhuma rota for encontrada, ocorrerá a interrupção do tráfego .
Configuração de FRR de rota estática especificando um próximo salto de backup
Restrições e diretrizes
Uma rota estática não entra em vigor quando a interface de saída de backup não está disponível.
Para alterar a interface de saída de backup ou o próximo salto, você deve primeiro remover a configuração atual. A interface de saída de backup e o next hop devem ser diferentes da interface de saída primária e do next hop.
Procedimento
- Entre na visualização do sistema.
system-view- Configurar a rota estática FRR.
ip route-static dest-address { mask-length | mask } interface-type
interface-number [ next-hop-address [ backup-interface interface-type
interface-number [ backup-nexthop backup-nexthop-address ] ] ]
[ permanent ] [ preference preference ] [ tag tag-value ] [ description
text ]Por padrão, a FRR de rota estática está desativada.
Configuração de FRR de rota estática para selecionar automaticamente um próximo salto de backup
- Entre na visualização do sistema.
system-view- Configure a rota estática FRR para selecionar automaticamente um próximo salto de backup.
ip route-static fast-reroute auto]Por padrão, o FRR de rota estática é desativado para selecionar automaticamente um próximo salto de backup.
Ativação do modo de pacote de eco BFD para FRR de rota estática
Sobre o modo de pacote de eco BFD
Por padrão, o FRR de rota estática usa ARP para detectar falhas no link primário. Execute esta tarefa para habilitar a FRR de rota estática a usar o modo de pacote de eco BFD para detecção rápida de falhas no link primário.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o endereço IP de origem dos pacotes de eco BFD.
bfd echo-source-ip ip-addressPor padrão, o endereço IP de origem dos pacotes de eco do BFD não é configurado.
O endereço IP de origem não pode estar no mesmo segmento de rede que o endereço IP de qualquer interface local.
Para obter mais informações sobre esse comando, consulte Referência de comandos de alta disponibilidade.
- Ativar o modo de pacote de eco BFD para FRR de rota estática.
ip route-static primary-path-detect bfd echoPor padrão, o modo de pacote de eco BFD para FRR de rota estática está desativado.
Comandos de exibição e manutenção para roteamento estático
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações de rota estática. | display ip routing-table protocol static [ inactive | verbose ] |
| Exibir informações do próximo salto da rota estática. | display route-static nib [ nib-id ] [ verbose ] |
| Exibir informações da tabela de roteamento estático. | display route-static routing-table [ ip-address { mask-length | mask } ] |
Exemplos de configuração de rota estática
Exemplo: Configuração basica de rota estática
Configuração de rede
Conforme mostrado na Figura 2, configure rotas estáticas nos switches para interconexões entre dois hosts quaisquer.
Figura 2 Diagrama de rede
Procedimento
- Configurar endereços IP para interfaces. (Detalhes não mostrados).
- Configurar rotas estáticas:
# Configure uma rota padrão no Switch A.
<SwitchA> system-view
[SwitchA] ip route-static 0.0.0.0 0.0.0.0 1.1.4.2# Configure duas rotas estáticas no Switch B.
<SwitchB> system-view
[SwitchB] ip route-static 1.1.2.0 255.255.255.0 1.1.4.1
[SwitchB] ip route-static 1.1.3.0 255.255.255.0 1.1.5.6# Configure uma rota padrão no Switch C.
<SwitchC> system-view
[SwitchC] ip route-static 0.0.0.0 0.0.0.0 1.1.5.5- Configure os gateways padrão do Host A, Host B e Host C como 1.1.2.3, 1.1.6.1 e 1.1.3.1. (Detalhes não mostrados.)
Verificação da configuração
# Exibir rotas estáticas no Switch A.
[SwitchA] display ip routing-table protocol static
Summary count : 1
Static Routing table status : <Active>
Summary count : 1
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/0 Static 60 0 1.1.4.2 Vlan500
Static Routing table status : <Inativo>
Summary count : 0# Exibir rotas estáticas no Switch B.
[SwitchB] display ip routing-table protocol static
Summary count : 2
Static Routing table status : <Active>
Summary count : 2
Destination/Mask Proto Pre Cost NextHop Interface
1.1.2.0/24 Static 60 0 1.1.4.1 Vlan500
Static Routing table status : lt;Inativo>
Summary count : 0# Use o comando ping no host B para testar a acessibilidade do host A (o Windows XP é executado nos dois hosts).
C:\Documents and Settings\Administrator>ping 1.1.2.2
Pinging 1.1.2.2 with 32 bytes of data:
Reply from 1.1.2.2: bytes=32 time=1ms TTL=126
Reply from 1.1.2.2: bytes=32 time=1ms TTL=126
Reply from 1.1.2.2: bytes=32 time=1ms TTL=126
Reply from 1.1.2.2: bytes=32 time=1ms TTL=126
Ping statistics for 1.1.2.2:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 1ms, Maximum = 1ms, Average = 1ms# Use o comando tracert no host B para testar a acessibilidade do host A.
C:\Documents and Settings\Administrator>tracert 1.1.2.2 Rastreamento da rota para 1.1.2.2 em um máximo de 30 saltos
C:\Documents and Settings\Administrator>tracert 1.1.2.2
Tracing route to 1.1.2.2 over a maximum of 30 hops
1 <1 ms <1 ms <1 ms 1.1.6.1
2 <1 ms <1 ms <1 ms 1.1.4.1
3 1 ms <1 ms <1 ms 1.1.2.2
Trace complete.Exemplo: Configuração de BFD para rotas estáticas (próximo salto direto)
Configuração de rede
Configure o seguinte, conforme mostrado na Figura 3:
- Configure uma rota estática para a sub-rede 120.1.1.0/24 no Switch A.
- Configure uma rota estática para a sub-rede 121.1.1.0/24 no Switch B.
- Habilite o BFD para ambas as rotas.
- Configure uma rota estática para a sub-rede 120.1.1.0/24 e uma rota estática para a sub-rede 121.1.1.0/24 no Switch C.
Quando o link entre o switch A e o switch B através do switch de camada 2 falha, o BFD pode detectar a falha imediatamente. O switch A então se comunica com o switch B por meio do switch C.
Figura 3 Diagrama de rede
Tabela 1 Atribuição de interface e endereço IP
| Dispositivo | Interface | Endereço IP |
| Chave A | Interface VLAN 10 | 12.1.1.1/24 |
| Chave A | Interface VLAN 11 | 10.1.1.102/24 |
| Chave B | Interface VLAN 10 | 12.1.1.2/24 |
| Chave B | Interface VLAN 13 | 13.1.1.1/24 |
| Chave C | Interface VLAN 11 | 10.1.1.100/24 |
| Chave C | Interface VLAN 13 | 13.1.1.2/24 |
Procedimento
- Configure os endereços IP para as interfaces. (Detalhes não mostrados).
- Configurar rotas estáticas e BFD:
# Configure rotas estáticas no Switch A e ative o modo de pacote de controle BFD para a rota estática que atravessa o switch de Camada 2.
<SwitchA> system-view
[SwitchA] interface vlan-interface 10
[SwitchA-vlan-interface10] bfd min-transmit-interval 500
[SwitchA-vlan-interface10] bfd min-receive-interval 500
[SwitchA-vlan-interface10] bfd detect-multiplier 9
[SwitchA-vlan-interface10] quit
[SwitchA] ip route-static 120.1.1.0 24 vlan-interface 10 12.1.1.2 bfd control-packet
[SwitchA] ip route-static 120.1.1.0 24 vlan-interface 11 10.1.1.100 preference 65
[SwitchA] quit# Configure rotas estáticas no Switch B e ative o modo de pacote de controle BFD para a rota estática que atravessa o switch de Camada 2.
<SwitchB> system-view
[SwitchB] interface vlan-interface 10
[SwitchB-vlan-interface10] bfd min-transmit-interval 500
[SwitchB-vlan-interface10] bfd min-receive-interval 500
[SwitchB-vlan-interface10] bfd detect-multiplier 9
[SwitchB-vlan-interface10] quit
[SwitchB] ip route-static 121.1.1.0 24 vlan-interface 10 12.1.1.1 bfd control-packet
[SwitchB] ip route-static 121.1.1.0 24 vlan-interface 13 13.1.1.2 preference 65
[SwitchB] quit# Configure rotas estáticas no Switch C.
<SwitchC> system-view
[SwitchC] ip route-static 120.1.1.0 24 13.1.1.1
[SwitchC] ip route-static 121.1.1.0 24 10.1.1.102Verificação da configuração
# Exibir sessões BFD no Switch A.
<SwitchA> display bfd session
Total Session Num: 1 Up Session Num: 1 Init Mode: Active
IPv4 Session Working Under Ctrl Mode:
LD/RD SourceAddr DestAddr State Holdtime Interface
4/7 12.1.1.1 12.1.1.2 Up 2000ms Vlan10A saída mostra que a sessão BFD foi criada.
# Exibir as rotas estáticas no Switch A.
<SwitchA> display ip routing-table protocol static
Summary count : 1
Static Routing table status : <Active>
Summary count : 1
Destination/Mask Proto Pre Cost NextHop Interface
120.1.1.0/24 Static 60 0 12.1.1.2 Vlan10
Static Routing table status : <Inativo>
Summary count : 0A saída mostra que o Switch A se comunica com o Switch B por meio da interface de VLAN 10. Em seguida, o link na interface VLAN 10 falha.
# Exibir rotas estáticas no Switch A.
<SwitchA> display ip routing-table protocol static
Summary count : 1
Static Routing table status : <Active>
Summary count : 1
Destination/Mask Proto Pre Cost NextHop Interface
120.1.1.0/24 Static 65 0 10.1.1.100 Vlan11
Static Routing table status : <Inativo>
Summary count : 0A saída mostra que o Switch A se comunica com o Switch B por meio da interface VLAN 11.
Exemplo: Configuração do BFD para rotas estáticas (próximo salto indireto)
Configuração de rede
A Figura 4 mostra a topologia da rede da seguinte forma:
- O Switch A tem uma rota para a interface Loopback 1 (2.2.2.9/32) no Switch B, com a interface de saída VLAN-interface 10.
- O Switch B tem uma rota para a interface Loopback 1 (1.1.1.9/32) no Switch A, com a interface de saída VLAN-interface 12.
- O switch D tem uma rota para 1.1.1.9/32, com a interface de saída VLAN-interface 10, e uma rota para 2.2.2.9/32, com a interface de saída VLAN-interface 12.
Configure o seguinte:
- Configure uma rota estática para a sub-rede 120.1.1.0/24 no Switch A.
- Configure uma rota estática para a sub-rede 121.1.1.0/24 no Switch B.
- Habilite o BFD para ambas as rotas.
- Configure uma rota estática para a sub-rede 120.1.1.0/24 e uma rota estática para a sub-rede 121.1.1.0/24 no Switch C e no Switch D.
Quando o link entre o switch A e o switch B através do switch D falha, o BFD pode detectar a falha imediatamente. O switch A então se comunica com o switch B por meio do switch C.
Figura 4 Diagrama de rede
Tabela 2 Atribuição de interface e endereço IP
| Dispositivo | Interface | Endereço IP |
| Chave A | Interface VLAN 10 | 12.1.1.1/24 |
| Chave A | Interface VLAN 11 | 10.1.1.102/24 |
| Chave A | Loopback 1 | 1.1.1.9/32 |
| Chave B | Interface VLAN 12 | 11.1.1.1/24 |
| Chave B | Interface VLAN 13 | 13.1.1.1/24 |
| Chave B | Loopback 1 | 2.2.2.9/32 |
| Chave C | Interface VLAN 11 | 10.1.1.100/24 |
| Chave C | Interface VLAN 13 | 13.1.1.2/24 |
| Chave D | Interface VLAN 10 | 12.1.1.2/24 |
| Chave D | Interface VLAN 12 | 11.1.1.2/24 |
Procedimento
- Configurar endereços IP para interfaces. (Detalhes não mostrados).
- Configurar rotas estáticas e BFD:
# Configure rotas estáticas no Switch A e ative o modo de pacote de controle BFD para a rota estática que atravessa o Switch D.
<SwitchA> system-view
[SwitchA] bfd multi-hop min-transmit-interval 500
[SwitchA] bfd multi-hop min-receive-interval 500
[SwitchA] bfd multi-hop detect-multiplier 9
[SwitchA] ip route-static 120.1.1.0 24 2.2.2.9 bfd control-packet bfd-source 1.1.1.9
[SwitchA] ip route-static 120.1.1.0 24 vlan-interface 11 10.1.1.100 preference 65
[SwitchA] quit# Configure rotas estáticas no Switch B e ative o modo de pacote de controle BFD para a rota estática que atravessa o Switch D.
<SwitchB> system-view
[SwitchB] bfd multi-hop min-transmit-interval 500
[SwitchB] bfd multi-hop min-receive-interval 500
[SwitchB] bfd multi-hop detect-multiplier 9
[SwitchB] ip route-static 121.1.1.0 24 1.1.1.9 bfd control-packet bfd-source 2.2.2.9
[SwitchB] ip route-static 121.1.1.0 24 vlan-interface 13 13.1.1.2 preference 65
[SwitchB] quit# Configurar rotas estáticas no Switch C.
<SwitchC> system-view
[SwitchC] ip route-static 120.1.1.0 24 13.1.1.1
[SwitchC] ip route-static 121.1.1.0 24 10.1.1.102# Configure rotas estáticas no Switch D.
<SwitchD> system-view
[SwitchD] ip route-static 120.1.1.0 24 11.1.1.1
[SwitchD] ip route-static 121.1.1.0 24 12.1.1.1
Verificação da configuração
# Exibir sessões BFD no Switch A.
<SwitchA> display bfd session
Total Session Num: 1 Up Session Num: 1 Init Mode: Active
IPv4 Session Working Under Ctrl Mode:
LD/RD SourceAddr DestAddr State Holdtime Interface
4/7 1.1.1.9 2.2.2.9 Up 2000ms N/A
A saída mostra que a sessão BFD foi criada. # Exibir as rotas estáticas no Switch A.
<SwitchA> display ip routing-table protocol static
Summary count : 1
Static Routing table status : <Active>
Summary count : 1
Destination/Mask Proto Pre Cost NextHop Interface
120.1.1.0/24 Static 60 0 12.1.1.2 Vlan10
Static Routing table status : <Inativo>
Summary count : 0A saída mostra que o Switch A se comunica com o Switch B por meio da interface de VLAN 10. Em seguida, o link na interface VLAN 10 falha.
# Exibir rotas estáticas no Switch A.
<SwitchA> display ip routing-table protocol static
Summary count : 1
Static Routing table status : <Active>
Summary count : 1
Destination/Mask Proto Pre Cost NextHop Interface
120.1.1.0/24 Static 65 0 10.1.1.100 Vlan11
Static Routing table status : <Inativo>
Summary count : 0A saída mostra que o Switch A se comunica com o Switch B por meio da interface VLAN 11.
Exemplo: Configuração de rota estática FRR
Configuração de rede
Conforme mostrado na Figura 5, configure rotas estáticas no Switch A, Switch B e Switch C e configure a rota estática FRR. Quando o Link A se torna unidirecional, o tráfego pode ser transferido para o Link B imediatamente.
Figura 5 Diagrama de rede
Tabela 3 Atribuição de interface e endereço IP
| Dispositivo | Interface | Endereço IP |
| Chave A | Interface VLAN 100 | 12.12.12.1/24 |
| Chave A | Interface VLAN 200 | 13.13.13.1/24 |
| Chave A | Loopback 0 | 1.1.1.1/32 |
| Chave B | Interface VLAN 101 | 24.24.24.4/24 |
| Chave B | Interface VLAN 200 | 13.13.13.2/24 |
| Chave B | Loopback 0 | 4.4.4.4/32 |
| Chave C | Interface VLAN 100 | 12.12.12.2/24 |
| Chave C | Interface VLAN 101 | 24.24.24.2/24 |
Procedimento
- Configurar endereços IP para interfaces. (Detalhes não mostrados).
- Configure a rota estática FRR no link A usando um dos métodos a seguir:
- (Método 1.) Especifique um próximo salto de backup para a rota estática FRR:
# Configure uma rota estática no Switch A e especifique a interface VLAN 100 como a interface de saída de backup e 12.12.12.2 como o próximo salto de backup.
<SwitchA> system-view
[SwitchA] ip route-static 4.4.4.4 32 vlan-interface 200 13.13.13.2
backup-interface vlan-interface 100 backup-nexthop 12.12.12.2
# Configure uma rota estática no Switch B e especifique a interface VLAN 101 como a interface de saída de backup e 24.24.24.2 como o próximo salto de backup.
<SwitchB> system-view
[SwitchB] ip route-static 1.1.1.1 32 vlan-interface 200 13.13.13.1
backup-interface vlan-interface 101 backup-nexthop 24.24.24.2
- (Método 2.) Configure a rota estática FRR para selecionar automaticamente um próximo salto de backup: # Configure rotas estáticas no Switch A e ative a FRR de rota estática.
<SwitchA> system-view
[SwitchA] ip route-static 4.4.4.4 32 vlan-interface 200 13.13.13.2
[SwitchA] ip route-static 4.4.4.4 32 vlan-interface 100 12.12.12.2 preference 70
[SwitchA] ip route-static fast-reroute auto
# Configure rotas estáticas no Switch B e ative a FRR de rota estática.
<SwitchB> system-view
[SwitchB] ip route-static 1.1.1.1 32 vlan-interface 200 13.13.13.1
[SwitchB] ip route-static 1.1.1.1 32 vlan-interface 101 24.24.24.2 preference 70
[SwitchB] ip route-static fast-reroute auto
- Configurar rotas estáticas no Switch C.
<SwitchC> system-view
[SwitchC] ip route-static 4.4.4.4 32 vlan-interface 101 24.24.24.4
[SwitchC] ip route-static 1.1.1.1 32 vlan-interface 100 12.12.12.1
Verificação da configuração
# Exibir a rota 4.4.4.4/32 no Switch A para ver as informações do próximo salto de backup.
[SwitchA] display ip routing-table 4.4.4.4 verbose
Summary count : 1
Destination: 4.4.4.4/32
Protocol: Static
Process ID: 0
SubProtID: 0x0 Age: 04h20m37s
Cost: 0 Preference: 60
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 0
NibID: 0x26000002 LastAs: 0
AttrID: 0xffffffff Neighbor: 0.0.0.0
Flags: 0x1008c OrigNextHop: 13.13.13.2
Label: NULL RealNextHop: 13.13.13.2
BkLabel: NULL BkNextHop: 12.12.12.2
SRLabel: NULL BkSRLabel: NULL
Tunnel ID: Invalid Interface: Vlan-interface200
BkTunnel ID: Invalid BkInterface: Vlan-interface100
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0
# Exibir a rota 1.1.1.1/32 no Switch B para ver as informações do próximo salto de backup.
[SwitchB] display ip routing-table 1.1.1.1 verbose
Summary count : 1
Destination: 1.1.1.1/32
Protocol: Static
Process ID: 0
SubProtID: 0x0 Age: 04h20m37s
Cost: 0 Preference: 60
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 0
NibID: 0x26000002 LastAs: 0
AttrID: 0xffffffff Neighbor: 0.0.0.0
Flags: 0x1008c OrigNextHop: 13.13.13.1
Label: NULL RealNextHop: 13.13.13.1
15
BkLabel: NULL BkNextHop: 24.24.24.2
SRLabel: NULL BkSRLabel: NULL
Tunnel ID: Invalid Interface: Vlan-interface200
BkTunnel ID: Invalid BkInterface: Vlan-interface101
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0
Configuração de uma rota padrão
Sobre a configuração de uma rota padrão
Uma rota padrão é usada para encaminhar pacotes que não correspondem a nenhuma entrada de roteamento específica na tabela de roteamento. Sem uma rota padrão, os pacotes que não correspondem a nenhuma entrada de roteamento são descartados e um pacote ICMP destination-unreachable é enviado à origem.
Uma rota padrão pode ser configurada de uma das seguintes maneiras:
- O administrador de rede pode configurar uma rota padrão com o destino e a máscara sendo 0.0.0.0. Para obter mais informações, consulte "Configuração de roteamento estático".
- Alguns protocolos de roteamento dinâmico (como OSPF e RIP) podem gerar uma rota padrão. Por exemplo, um roteador upstream que executa o OSPF pode gerar uma rota padrão e anunciá-la a outros roteadores. Esses roteadores instalam a rota padrão com o próximo salto sendo o roteador upstream. Para obter mais informações, consulte os respectivos capítulos sobre esses protocolos de roteamento neste guia de configuração.
Configuração do RIP
Sobre a RIP
O RIP (Routing Information Protocol) é um IGP de vetor de distância adequado a redes de pequeno porte. Ele emprega UDP para trocar informações de rota por meio da porta 520.
Métricas de roteamento RIP
O RIP usa uma contagem de saltos para medir a distância até um destino. A contagem de saltos de um roteador para uma rede diretamente conectada é 0. A contagem de saltos de um roteador para um roteador diretamente conectado é 1. Para limitar o tempo de convergência, o RIP restringe o intervalo de valores da métrica de 0 a 15. Um destino com um valor de métrica de 16 (ou maior) é considerado inalcançável. Por esse motivo, o RIP não é adequado para redes de grande porte.
Entradas de rota RIP
O RIP armazena entradas de roteamento em um banco de dados. Cada entrada de roteamento contém os seguintes elementos:
- Endereço de destino - endereço IP de um host de destino ou de uma rede.
- Próximo salto - endereço IP do próximo salto.
- Interface de saída - Interface de saída da rota.
- Métrica - custo do roteador local até o destino.
- Route time-Tempo decorrido desde a última atualização. O tempo é redefinido para 0 quando a entrada de roteamento é atualizada.
- Route tag - Usada para controle de rota. Para obter mais informações, consulte "Configuração de políticas de roteamento".
Operação RIP
O RIP funciona da seguinte forma:
- O RIP envia mensagens de solicitação aos roteadores vizinhos. Os roteadores vizinhos retornam mensagens de resposta que contêm suas tabelas de roteamento.
- O RIP usa as respostas recebidas para atualizar a tabela de roteamento local e envia mensagens de atualização acionadas para seus vizinhos. Todos os roteadores RIP da rede fazem isso para obter as informações de roteamento mais recentes.
- O RIP envia periodicamente a tabela de roteamento local para seus vizinhos. Depois que um vizinho RIP recebe a mensagem, ele atualiza sua tabela de roteamento, seleciona rotas ideais e envia uma atualização para outros vizinhos. O RIP envelhece as rotas para manter apenas as rotas válidas.
Prevenção de loop de roteamento
O RIP usa os seguintes mecanismos para evitar loops de roteamento:
- Contagem até o infinito - Um destino com um valor de métrica de 16 é considerado inalcançável. Quando ocorrer um loop de roteamento, o valor da métrica de uma rota será incrementado para 16 para evitar looping infinito.
- Atualizações acionadas - o RIP anuncia imediatamente atualizações acionadas para alterações na topologia, a fim de reduzir a possibilidade de loops de roteamento e acelerar a convergência.
- Split horizon - Desativa o envio de rotas pelo RIP através da interface em que as rotas foram aprendidas para evitar loops de roteamento e economizar largura de banda.
- Poison reverse - Habilita o RIP a definir a métrica das rotas recebidas de um vizinho como 16 e envia essas rotas de volta ao vizinho. O vizinho pode excluir essas informações de sua tabela de roteamento para evitar loops de roteamento.
Versões RIP
Há duas versões de RIP, RIPv1 e RIPv2.
O RIPv1 é um protocolo de roteamento classful. Ele anuncia mensagens somente por meio de broadcast. As mensagens do RIPv1 não contêm informações de máscara, portanto, o RIPv1 só pode reconhecer redes naturais, como as classes A, B e C. Por esse motivo, o RIPv1 não oferece suporte a sub-redes descontínuas.
O RIPv2 é um protocolo de roteamento sem classe. Ele tem as seguintes vantagens em relação ao RIPv1:
- Oferece suporte a tags de rota para implementar o controle flexível de rotas por meio de políticas de roteamento.
- Oferece suporte a máscaras, sumarização de rotas e CIDR.
- Oferece suporte a próximos saltos designados para selecionar os melhores em redes de transmissão.
- Oferece suporte a atualizações de rotas por multicast, de modo que somente os roteadores RIPv2 possam receber essas atualizações para reduzir o consumo de recursos.
- Suporta autenticação de texto simples e autenticação MD5 para aumentar a segurança.
O RIPv2 oferece suporte a dois modos de transmissão: broadcast e multicast. Multicast é o modo padrão, usando 224.0.0.9 como endereço multicast. Uma interface operando no modo de transmissão RIPv2 também pode receber mensagens RIPv1.
Protocolos e padrões
- RFC 1058, Protocolo de Informações de Roteamento
- RFC 1723, RIP Versão 2 - Transportando informações adicionais
- RFC 1721, Análise do Protocolo RIP Versão 2
- RFC 1722, Declaração de aplicabilidade do protocolo RIP versão 2
- RFC 1724, Extensão MIB do RIP Versão 2
- RFC 2082, Autenticação MD5 do RIPv2
- RFC 2091, Extensões acionadas do RIP para suportar circuitos de demanda
- RFC 2453, RIP Versão 2
Visão geral das tarefas RIP
Para configurar o RIP, execute as seguintes tarefas:
- Configuração do RIP básico
- Ativação do RIP
- (Opcional.) Controle da recepção e do anúncio de RIP nas interfaces
- (Opcional.) Configuração de uma versão RIP
- Especificação de um vizinho RIP
Para ativar o RIP em um link que não oferece suporte a broadcast ou multicast, é necessário especificar manualmente um vizinho RIP.
Configuração do RIP básico
Restrições e diretrizes para a configuração do RIP básico
Para ativar vários processos RIP em um roteador, é necessário especificar um ID para cada processo. Uma ID de processo RIP tem significado apenas local. Dois roteadores RIP com IDs de processo diferentes também podem trocar pacotes RIP.
Ativação do RIP
Sobre a ativação do RIP
Você pode ativar o RIP em uma rede e especificar uma máscara curinga para a rede. Depois disso, somente a interface conectada à rede executa o RIP.
Restrições e diretrizes
Se você definir as configurações de RIP na visualização da interface antes de ativar o RIP, as configurações não terão efeito até que o RIP seja ativado.
Se uma interface física estiver conectada a várias redes, você não poderá anunciar essas redes em diferentes processos RIP.
Não é possível ativar vários processos RIP em uma interface física.
O comando rip enable tem precedência sobre o comando network.
Ativação do RIP em uma rede
- Entre na visualização do sistema.
system-view- Habilite o RIP e entre no modo de exibição RIP.
rip [ process-id ]Por padrão, o RIP está desativado.
- Habilite o RIP em uma rede.
network network-address [ wildcard-mask ]Por padrão, o RIP está desativado em uma rede.
O comando network 0.0.0.0 pode ativar o RIP em todas as interfaces em um único processo, mas não se aplica a vários processos RIP.
Ativação do RIP em uma interface
- Entre na visualização do sistema.
system-view- Habilite o RIP e entre no modo de exibição RIP.
rip [ process-id ]Por padrão, o RIP está desativado.
- Retornar à visualização do sistema.
quit- Entre na visualização da interface.
interface interface-type interface-number- Habilite o RIP na interface.
rip process-id enable [ exclude-subip ]Por padrão, o RIP está desativado em uma interface.
Controle da recepção e do anúncio de RIP nas interfaces
Sobre a recepção de RIP e o controle de anúncios em interfaces
Você pode executar essa tarefa para configurar os seguintes recursos:
- Supressão de uma interface. A interface suprimida pode receber mensagens RIP, mas não pode enviar mensagens RIP.
- Desativar o envio de mensagens RIP por uma interface.
- Desativar o recebimento de mensagens RIP por uma interface.
Restrições e diretrizes para recepção de RIP e controle de anúncios em interfaces
Uma interface suprimida pelo uso do comando silent-interface só pode receber mensagens RIP. Ela não pode enviar mensagens RIP. Você pode usar o comando silent-interface all para suprimir todas as interfaces. O comando silent-interface tem precedência sobre os comandos rip input e rip output.
Supressão de uma interface
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Suprimir uma interface.
silent-interface { interface-type interface-number | all }Por padrão, todas as interfaces habilitadas para RIP podem enviar mensagens RIP.
A interface suprimida ainda pode receber mensagens RIP e responder a solicitações unicast contendo portas desconhecidas.
Desativar o recebimento de mensagens RIP por uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Desabilitar uma interface para que não receba mensagens RIP.
undo rip inputPor padrão, uma interface habilitada para RIP pode receber mensagens RIP.
Desativar o envio de mensagens RIP por uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Desabilitar uma interface para que não envie mensagens RIP.
undo rip outputPor padrão, uma interface habilitada para RIP pode enviar mensagens RIP.
Configuração de uma versão RIP
Sobre a configuração da versão RIP
Você pode configurar uma versão RIP global na visualização RIP ou uma versão RIP específica da interface na visualização da interface.
Uma interface usa preferencialmente a versão RIP específica da interface. Se nenhuma versão específica da interface for especificada, a interface usará a versão global do RIP. Se não for configurada uma versão RIP global ou específica da interface, a interface enviará transmissões RIPv1 e poderá receber as seguintes:
- RIPv1 broadcasts e unicasts.
- RIPv2 broadcasts, multicasts e unicasts.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique uma versão RIP.
- Execute os seguintes comandos em sequência para especificar uma versão global do RIP:
rip [ process-id ]
version { 1 | 2 }Por padrão, nenhuma versão global é especificada. Uma interface envia transmissões RIPv1 e pode receber transmissões e unicasts RIPv1 e transmissões, multicasts e unicasts RIPv2.
- Execute os seguintes comandos em sequência para especificar uma versão RIP em uma interface:
interface interface-type interface-number
rip version { 1 | 2 [ broadcast | multicast ] }Por padrão, nenhuma versão RIP específica da interface é especificada. A interface envia transmissões RIPv1 e pode receber transmissões e unicasts RIPv1 e transmissões RIPv2, multicasts e unicasts.
Especificação de um vizinho RIP
Sobre os vizinhos RIP
Normalmente, as mensagens RIP são enviadas em broadcast ou multicast. Para ativar o RIP em um link que não suporta broadcast ou multicast, é necessário especificar manualmente um vizinho RIP.
Restrições e diretrizes
Como prática recomendada, não use o comando peer ip-address para especificar um vizinho conectado diretamente. O vizinho pode receber uma atualização de rota em mensagens unicast e multicast (ou broadcast) do dispositivo.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Especifique um vizinho RIP.
peer ip-addressPor padrão, o RIP não envia atualizações por unicast para nenhum par.
- Desativar a verificação do endereço IP de origem nas atualizações RIP de entrada.
undo validate-source-addressPor padrão, a verificação do endereço IP de origem está ativada nas atualizações RIP de entrada.
Se o vizinho especificado não estiver diretamente conectado, desative a verificação do endereço de origem nas atualizações recebidas.
Configuração do controle de rotas RIP
Configuração de uma métrica de roteamento adicional
Sobre métricas de roteamento adicionais
Uma métrica de roteamento adicional (contagem de saltos) pode ser adicionada à métrica de uma rota RIP de entrada ou saída.
- Uma métrica adicional de saída é adicionada à métrica de uma rota enviada e não altera a métrica da rota na tabela de roteamento.
- Uma métrica adicional de entrada é adicionada à métrica de uma rota recebida antes que a rota seja adicionada à tabela de roteamento, e a métrica da rota é alterada. Se a soma da métrica adicional e da métrica original for maior que 16, a métrica da rota será 16.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique uma métrica de roteamento adicional de entrada.
rip metricin [ route-policy route-policy-name ] valuePor padrão, a métrica adicional de uma rota de entrada é 0.
- Especifique uma métrica de roteamento adicional de saída.
rip metricout [ route-policy route-policy-name ] valuePor padrão, a métrica adicional de uma rota de saída é 1.
Configuração da compactação de rotas RIPv2
Sobre a compactação de rotas RIPv2
Execute essa tarefa para resumir sub-redes contíguas em uma rede resumida e envie a rede para os vizinhos. A menor métrica entre todas as rotas resumidas é usada como a métrica da rota resumida.
Você pode usar os seguintes métodos para resumir rotas no RIPv2:
- Sumarização automática - Configure o RIPv2 para gerar uma rede natural para sub-redes contíguas. Por exemplo, suponha que haja três rotas de sub-rede 10.1.1.0/24, 10.1.2.0/24 e 10.1.3.0/24. A compactação automática cria e anuncia automaticamente uma rota de resumo 10.0.0.0/8 em vez das rotas mais específicas.
- Sumarização manual - Configure manualmente uma rota de resumo. O RIPv2 anuncia a rota resumida em vez de rotas mais específicas. Por exemplo, suponha que as rotas de sub-redes contíguas 10.1.1.0/24, 10.1.2.0/24 e 10.1.3.0/24 existam na tabela de roteamento. Você pode criar uma rota de resumo 10.1.0.0/16 na GigabitEthernet 1/0/1 para anunciar a rota de resumo em vez das rotas mais específicas. Por padrão, as máscaras naturais são usadas para anunciar rotas de resumo. Para configurar manualmente uma rota de resumo em uma interface, é necessário primeiro desativar a sumarização automática de rotas RIPv2.
Restrições e diretrizes
Para evitar loops causados pela sumarização de rotas, crie uma rota de buraco negro especificando a interface NULL 0 como a interface de saída da rota de resumo. Os pacotes que correspondem à rota black hole são descartados.
Ativação da compactação automática de rotas RIPv2
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Ativar o resumo automático de rotas RIPv2.
summaryPor padrão, a compactação automática de rotas RIPv2 está ativada.
Se as sub-redes na tabela de roteamento não forem contíguas, desative a sumarização automática de rotas para anunciar rotas mais específicas.
Anunciar uma rota resumida
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Desativar o resumo automático de rotas RIPv2.
undo summaryPor padrão, a compactação automática de rotas RIPv2 está ativada.
- Retornar à visualização do sistema.
quit- Entre na visualização da interface.
interface interface-type interface-number- Configurar uma rota de resumo.
rip summary-address ip-address { mask-length | mask }Por padrão, nenhuma rota resumida é configurada.
Desativação da recepção de rotas do host
Sobre a desativação da recepção da rota do host
Essa tarefa desativa o RIPv2 de receber rotas de host da mesma rede para economizar recursos de rede. Esse recurso não se aplica ao RIPv1.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Desative o recebimento de rotas de host pelo RIP.
undo host-routePor padrão, o RIP recebe rotas de host.
Anunciar uma rota padrão
Sobre o anúncio de rota padrão
Você pode anunciar uma rota padrão em todas as interfaces RIP na visualização RIP ou em uma interface RIP específica na visualização de interface. A configuração da visualização de interface tem precedência sobre as configurações da visualização RIP.
Para impedir que uma interface anuncie uma rota padrão, use o comando rip default-route no-originate na interface.
O roteador habilitado para anunciar uma rota padrão não aceita rotas padrão de vizinhos RIP.
Procedimento
- Entre na visualização do sistema.
system-view- Anunciar uma rota padrão.
- Execute os seguintes comandos em sequência para configurar o RIP para anunciar uma rota padrão:
rip [ process-id ] default-route { only | originate } [ cost cost-value | route-policy route-policy-name ] *Por padrão, o RIP não anuncia uma rota padrão.
- Execute os seguintes comandos em sequência para configurar uma interface RIP para anunciar uma rota padrão:
interface interface-type interface-number
rip default-route { { only | originate } [ cost cost-value |
route-policy route-policy-name ] * | no-originate }Por padrão, uma interface RIP pode anunciar uma rota padrão se o processo RIP estiver habilitado para anunciar uma rota padrão.
Configuração da filtragem de rotas recebidas/redistribuídas
Sobre a filtragem de rotas recebidas/redistribuídas
Essa tarefa permite que você crie uma política para filtrar rotas recebidas ou redistribuídas que correspondam a critérios específicos, como uma ACL ou uma lista de prefixos IP.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Configurar a filtragem de rotas recebidas.
filter-policy { ipv4-acl-number | gateway prefix-list-name |
prefix-list prefix-list-name [ gateway prefix-list-name ] } import
[ interface-type interface-number ]Por padrão, a filtragem de rotas recebidas não é configurada.
Esse comando filtra as rotas recebidas. As rotas filtradas não são instaladas na tabela de roteamento nem anunciadas aos vizinhos.
- Configurar a filtragem de rotas redistribuídas.
filter-policy { ipv4-acl-number | prefix-list prefix-list-name }
export [ protocol [ process-id ] | interface-type interface-number ]Por padrão, a filtragem de rotas redistribuídas não é configurada.
Esse comando filtra as rotas redistribuídas, incluindo as rotas redistribuídas com o comando comando import-route.
Definição de uma preferência para RIP
Sobre a configuração de uma preferência para RIP
Se vários IGPs encontrarem rotas para o mesmo destino, a rota encontrada pelo IGP que tiver a prioridade mais alta será selecionada como a rota ideal. Execute esta tarefa para atribuir uma preferência ao RIP. Quanto menor o valor da preferência, maior a prioridade.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Definir uma preferência para RIP.
preference { preference | route-policy route-policy-name } *A preferência padrão para o RIP é 100.
Configuração da redistribuição de rotas RIP
Sobre a redistribuição de rotas RIP
Execute esta tarefa para configurar o RIP para redistribuir rotas de outros protocolos de roteamento, incluindo OSPF, static e direct.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Redistribuir rotas de outro protocolo de roteamento.
- Redistribuir rotas diretas ou estáticas.
import-route { direct | static } [ cost cost-value | route-policy
route-policy-name | tag tag ] *- Redistribuir rotas do OSPF ou de outros processos RIP.
import-route { ospf | rip } [ process-id | all-processes ]
[ allow-direct | cost cost-value | route-policy route-policy-name |
tag tag ] *Por padrão, a redistribuição de rotas RIP está desativada.
Esse comando pode redistribuir apenas rotas ativas. Para visualizar as rotas ativas, use o comando display ip routing-table protocol.
- (Opcional.) Defina um custo padrão para rotas redistribuídas.
default cost cost-valueO custo padrão para rotas redistribuídas é 0.
Ajuste e otimização de redes RIP
Configuração de temporizadores RIP
Sobre os temporizadores RIP
Você pode alterar a velocidade de convergência da rede RIP ajustando os seguintes temporizadores RIP:
- Timer de atualização - Especifica o intervalo entre as atualizações de rota.
- Temporizador de tempo limite - Especifica o tempo de envelhecimento da rota. Se nenhuma atualização para uma rota for recebida dentro do tempo de envelhecimento, a métrica da rota será definida como 16.
- Temporizador de supressão - Especifica por quanto tempo uma rota RIP permanece no estado suprimido. Quando a métrica de uma rota é 16, a rota entra no estado suprimido. Uma rota suprimida pode ser substituída por uma rota atualizada que seja recebida do mesmo vizinho antes que o timer de supressão expire e tenha uma métrica menor que 16.
- Temporizador de coleta de lixo - Especifica o intervalo entre o momento em que a métrica de uma rota se torna 16 e o momento em que ela é excluída da tabela de roteamento. O RIP anuncia a rota com uma métrica de 16. Se nenhuma atualização for anunciada para essa rota antes da expiração do cronômetro de coleta de lixo, a rota será excluída da tabela de roteamento.
Restrições e diretrizes
Para evitar tráfego desnecessário ou oscilação de rota, defina configurações idênticas de timer RIP nos roteadores RIP.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Definir temporizadores RIP.
timers { garbage-collect garbage-collect-value | suppress
suppress-value | timeout timeout-value | update update-value } *
As configurações padrão são as seguintes:
- O cronômetro de coleta de lixo é de 120 segundos.
- O cronômetro de supressão é de 120 segundos.
- O cronômetro de tempo limite é de 180 segundos.
- O cronômetro de atualização é de 30 segundos.
Habilitação de split horizon e poison reverse
Sobre o split horizon e o poison reverse
Os recursos split horizon e poison reverse podem evitar loops de roteamento.
- O horizonte dividido impede que o RIP envie rotas pela interface em que as rotas foram aprendidas para evitar loops de roteamento entre roteadores adjacentes.
- O Poison reverse permite que o RIP envie rotas pela interface em que as rotas foram aprendidas. A métrica dessas rotas é sempre definida como 16 (inalcançável) para evitar loops de roteamento entre vizinhos.
Restrições e diretrizes
Se tanto o split horizon quanto o poison reverse estiverem configurados, somente o recurso poison reverse terá efeito.
Ativação do horizonte dividido
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar o horizonte dividido.
rip split-horizonPor padrão, o horizonte dividido está ativado.
Ativação de poison reverse
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilitar o poison reverse.
rip poison-reversePor padrão, o poison reverse está desativado.
Configuração do intervalo de atualização acionado pelo RIP
Sobre o intervalo de atualização acionado pelo RIP
Execute essa tarefa para evitar a sobrecarga da rede e reduzir o consumo de recursos do sistema causado por atualizações frequentes acionadas pelo RIP.
Você pode usar o comando timer triggered para definir o intervalo máximo, o intervalo mínimo e o intervalo incremental para o envio de atualizações acionadas por RIP.
- Para uma rede estável, é usado o intervalo mínimo.
- Se as alterações na rede se tornarem frequentes, o intervalo incremental incremental-intervalo é usado para estender o intervalo de envio da atualização acionada até que o intervalo máximo seja atingido.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Defina o intervalo de atualização acionado pelo RIP.
timer triggered maximum-interval [ minimum-interval
[ incremental-interval ] ]
As configurações padrão são as seguintes:
- O intervalo máximo é de 5 segundos.
- O intervalo mínimo é de 50 milissegundos.
- O intervalo incremental é de 200 milissegundos.
Configuração da taxa de envio de pacotes RIP
Sobre a configuração da taxa de envio de pacotes RIP
Execute esta tarefa para definir o intervalo de envio de pacotes RIP e o número máximo de pacotes RIP que podem ser enviados em cada intervalo. Esse recurso pode evitar que o excesso de pacotes RIP afete o desempenho do sistema e consuma muita largura de banda.
Procedimento
- Entre na visualização do sistema.
system-view- Configurar a taxa de envio de pacotes RIP.
- Execute os comandos a seguir em sequência para configurar a taxa de envio de pacotes RIP para todas as interfaces:
rip [ process-id ]output-delay time count countPor padrão, uma interface envia até três pacotes RIP a cada 20 milissegundos.
- Execute os seguintes comandos em sequência para configurar a taxa de envio de pacotes RIP para uma interface:
interface interface-type interface-numberrip output-delay time count countPor padrão, a interface usa a taxa de envio de pacotes RIP configurada para o processo RIP que a interface executa.
Configuração do comprimento máximo dos pacotes RIP
Sobre a configuração do comprimento máximo dos pacotes RIP
O comprimento dos pacotes RIP determina quantas rotas podem ser transportadas em um pacote RIP. Defina o comprimento máximo dos pacotes RIP para fazer bom uso da largura de banda do link.
Quando a autenticação estiver ativada, siga estas diretrizes para garantir o encaminhamento de pacotes:
- Para autenticação simples, o comprimento máximo dos pacotes RIP não pode ser inferior a 52 bytes.
- Para autenticação MD5 (com formato de pacote definido na RFC 2453), o comprimento máximo dos pacotes RIP não pode ser inferior a 56 bytes.
- Para autenticação MD5 (com formato de pacote definido na RFC 2082), o comprimento máximo dos pacotes RIP não pode ser inferior a 72 bytes.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o comprimento máximo dos pacotes RIP.
rip max-packet-length valuePor padrão, o comprimento máximo dos pacotes RIP é de 512 bytes.
Configuração do valor DSCP para pacotes RIP de saída
Sobre o valor DSCP
O valor DSCP especifica a precedência dos pacotes de saída.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Defina o valor DSCP para pacotes RIP de saída.
dscp dscp-valuePor padrão, o valor DSCP para pacotes RIP de saída é 48.
Configuração do gerenciamento de rede RIP
Sobre o gerenciamento de rede RIP
Você pode usar o software de gerenciamento de rede para gerenciar o processo RIP ao qual o MIB está vinculado.
Procedimento
- Entre na visualização do sistema.
system-view- Vincular o MIB a um processo RIP.
rip mib-binding process-idPor padrão, o MIB é vinculado ao processo RIP com a menor ID de processo.
Configuração do RIP GR
Sobre a RIP GR
O GR garante a continuidade do encaminhamento quando um protocolo de roteamento é reiniciado ou quando ocorre uma alternância ativo/em espera.
São necessários dois roteadores para concluir um processo de GR. Veja a seguir as funções do roteador em um processo de GR:
- GR restarter - Roteador de reinicialização gradual. Ele deve ter capacidade de GR.
- Ajudante de GR - Um vizinho do reiniciador de GR. Ele ajuda o reiniciador de GR a concluir o processo de GR.
Depois que o RIP é reiniciado em um roteador, ele precisa aprender novamente as rotas RIP e atualizar sua tabela FIB, o que causa desconexões de rede e reconvergência de rotas.
Com o recurso GR, o roteador que está reiniciando (conhecido como GR restarter) pode notificar o evento aos seus vizinhos habilitados para GR. Os vizinhos com capacidade de GR (conhecidos como GR helpers) mantêm suas adjacências com o roteador em um intervalo de GR. Durante esse processo, a tabela FIB do roteador não é alterada. Após a reinicialização, o roteador entra em contato com seus vizinhos para recuperar sua FIB.
Por padrão, um dispositivo habilitado para RIP atua como auxiliar de GR. Execute esta tarefa no restarter GR.
Restrições e diretrizes
Não é possível ativar o RIP NSR em um dispositivo que atua como reiniciador de GR.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Habilitar GR para RIP.
graceful-restartPor padrão, o RIP GR está desativado.
- (Opcional.) Defina o intervalo de GR.
graceful-restart interval intervalPor padrão, o intervalo de GR é de 60 segundos.
Ativação do RIP NSR
Sobre a RIP NSR
O Nonstop Routing (NSR) permite que o dispositivo faça backup das informações de roteamento do processo RIP ativo para o processo RIP em espera. Após uma alternância entre ativo e em espera, o NSR pode concluir a regeneração de rotas sem derrubar adjacências ou afetar os serviços de encaminhamento.
O NSR não exige a cooperação de dispositivos vizinhos para recuperar informações de roteamento e, normalmente, é usado com mais frequência do que o GR.
Restrições e diretrizes
Um dispositivo que tenha o RIP NSR ativado não pode atuar como reiniciador de GR.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Habilitar RIP NSR.
non-stop-routingPor padrão, o RIP NSR está desativado.
O RIP NSR ativado para um processo RIP tem efeito apenas nesse processo. Como prática recomendada, ative o RIP NSR para cada processo se houver vários processos RIP.
Configuração de BFD para RIP
Sobre o BFD para RIP
O RIP detecta falhas de rota enviando solicitações periodicamente. Se não receber nenhuma resposta para uma rota em um determinado período, o RIP considera a rota inacessível. Para acelerar a convergência, execute esta tarefa para ativar o BFD para RIP. Para obter mais informações sobre o BFD, consulte o Guia de configuração de alta disponibilidade.
O RIP suporta os seguintes modos de detecção de BFD:
- Detecção de eco de salto único - Modo de detecção para um vizinho conectado diretamente. Nesse modo, uma sessão BFD é estabelecida somente quando o vizinho diretamente conectado tem informações de rota para enviar.
- Detecção de eco de salto único para um destino específico - Modo de detecção para um vizinho conectado diretamente. Nesse modo, uma sessão BFD é estabelecida para o vizinho RIP especificado quando o RIP está ativado na interface local. Quando o BFD detecta um link unidirecional, o dispositivo local não recebe nem envia nenhum pacote RIP pela interface para aumentar a velocidade de convergência. Quando o link for recuperado, a interface poderá enviar pacotes RIP novamente.
- Bidirectional control detection (Detecção de controle bidirecional) - Modo de detecção de vizinhos conectados indiretamente. Nesse modo, uma sessão BFD é estabelecida somente quando ambas as extremidades têm rotas para enviar e o BFD está ativado na interface de recebimento.
Restrições e diretrizes
Os comandos rip bfd enable e rip bfd enable destination são mutuamente exclusivos.
Configuração da detecção de eco de salto único (para um vizinho RIP conectado diretamente)
- Entre na visualização do sistema.
system-view- Configure o endereço IP de origem dos pacotes de eco do BFD.
bfd echo-source-ip ip-addressPor padrão, o endereço IP de origem dos pacotes de eco do BFD não é configurado.
- Entre na visualização da interface.
interface interface-type interface-number- Habilitar BFD para RIP.
rip bfd enablePor padrão, o BFD para RIP está desativado.
Configuração da detecção de eco de salto único (para um destino específico)
Restrições e diretrizes
Esse recurso se aplica somente aos vizinhos RIP que estão diretamente conectados.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o endereço IP de origem dos pacotes de eco BFD.
bfd echo-source-ip ip-addressPor padrão, nenhum endereço IP de origem é configurado para os pacotes de eco do BFD.
- Entre na visualização da interface.
interface interface-type interface-number- Habilitar BFD para RIP.
rip bfd enable destination ip-addressPor padrão, o BFD para RIP está desativado.
Configuração da detecção de controle bidirecional
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Especifique um vizinho RIP.
peer ip-addressPor padrão, o RIP não envia atualizações por unicast para nenhum par.
Como o comando undo peer não remove a relação de vizinhança imediatamente, a execução do comando não pode derrubar a sessão BFD imediatamente.
- Entre na visualização da interface.
interface interface-type interface-number- Habilitar BFD para RIP.
rip bfd enablePor padrão, o BFD para RIP está desativado.
Configuração do RIP FRR
Sobre a RIP FRR
Uma falha de link ou de roteador em um caminho pode causar perda de pacotes e até mesmo loop de roteamento até que o RIP conclua a convergência de roteamento com base na nova topologia de rede. O FRR permite o redirecionamento rápido para minimizar o impacto das falhas de links ou nós.
Figura 1 Diagrama de rede para RIP FRR
Conforme mostrado na Figura 1, configure o FRR no Roteador B usando uma política de roteamento para especificar um próximo salto de backup. Quando o link primário falha, o RIP direciona os pacotes para o próximo salto de backup. Ao mesmo tempo, o RIP calcula o caminho mais curto com base na nova topologia da rede e encaminha os pacotes por esse caminho após a convergência da rede.
Restrições e diretrizes para RIP FRR
O RIP FRR entra em vigor somente para rotas RIP aprendidas de vizinhos diretamente conectados.
O RIP FRR está disponível somente quando o estado do link primário (com as interfaces da Camada 3 permanecendo em funcionamento) muda de bidirecional para unidirecional ou para baixo.
Ativação do RIP FRR
- Entre na visualização do sistema.
system-view- Configure uma política de roteamento para FRR.
Você deve especificar um próximo salto usando a opção apply fast-reroute backup-interface
na política de roteamento.
Para obter mais informações sobre a configuração da política de roteamento, consulte "Configuração de políticas de roteamento".
- Entre no modo de exibição RIP.
rip [ process-id ]- Habilitar RIP FRR.
fast-reroute route-policy route-policy-namePor padrão, o RIP FRR está desativado.
Habilitação de BFD para RIP FRR
Sobre a detecção de eco de salto único BFD
Por padrão, o RIP FRR não usa o BFD para detectar falhas no link primário. Para um RIP FRR mais rápido, use o BFD single-hop echo detection no link primário de links redundantes para detectar falhas de link.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o endereço IP de origem dos pacotes de eco do BFD.
bfd echo-source-ip ip-addressPor padrão, o endereço IP de origem dos pacotes de eco do BFD não é configurado.
O endereço IP de origem não pode estar no mesmo segmento de rede que qualquer interface local. Para obter mais informações sobre esse comando, consulte Referência de comandos de alta disponibilidade.
- Entre na visualização da interface.
interface interface-type interface-number- Habilitar BFD para RIP FRR.
frip primary-path-detect bfd echoPor padrão, o BFD para RIP FRR está desativado.
Aprimoramento da segurança RIP
Ativação da verificação de campo zero para mensagens RIPv1 de entrada
Sobre a verificação de campo zero para mensagens RIPv1 de entrada
Alguns campos da mensagem RIPv1 devem ser definidos como zero. Esses campos são chamados de "campos zero". Você pode ativar a verificação de campo zero para mensagens RIPv1 de entrada. Se um campo zero de uma mensagem contiver um valor diferente de zero, o RIP não processará a mensagem. Se você tiver certeza de que todas as mensagens são confiáveis, desative a verificação de campo zero para economizar recursos da CPU.
Esse recurso não se aplica aos pacotes RIPv2, pois eles não têm campos zero.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Ativar a verificação de campo zero para mensagens RIPv1 de entrada.
checkzeroPor padrão, a verificação de campo zero é desativada para mensagens RIPv1 de entrada.
Ativação da verificação do endereço IP de origem para atualizações RIP de entrada
Sobre a verificação do endereço IP de origem para atualizações RIP de entrada
Execute esta tarefa para ativar a verificação do endereço IP de origem para atualizações RIP de entrada.
- Ao receber uma mensagem em uma interface Ethernet, o RIP compara o endereço IP de origem da mensagem com o endereço IP da interface. Se eles não estiverem no mesmo segmento de rede, o RIP descartará a mensagem.
- Ao receber uma mensagem em uma interface PPP, o RIP verifica se o endereço de origem da mensagem é o endereço IP da interface par. Caso contrário, o RIP descarta a mensagem.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIP.
rip [ process-id ]- Ativar a verificação do endereço IP de origem para mensagens RIP recebidas.
validate-source-addressPor padrão, a verificação do endereço IP de origem está desativada para atualizações RIP de entrada.
Configuração da autenticação de mensagens RIPv2
Sobre a autenticação de mensagens RIPv2
Execute esta tarefa para ativar a autenticação em mensagens RIPv2. O RIPv2 suporta autenticação simples e autenticação MD5.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configurar a autenticação RIPv2.
rip authentication-mode { md5 { rfc2082 { cipher | plain } string key-id
| rfc2453 { cipher | plain } string } | simple { cipher | plain } string }Por padrão, a autenticação RIPv2 não é configurada.
O RIPv1 não oferece suporte à autenticação. Embora você possa especificar um modo de autenticação para o RIPv1 na visualização da interface, a configuração não tem efeito.
Comandos de exibição e manutenção para RIP
Execute comandos de exibição em qualquer visualização e execute comandos de redefinição na visualização do usuário.
| Tarefa | Comando |
| Exibir o status atual do RIP e as informações de configuração. | display rip [ process-id ] |
| Exibir informações do RIP GR. | display rip [ process-id ] reinício gracioso |
| Exibir informações do RIP NSR. | display rip [ process-id ] roteamento ininterrupto |
| Exibir rotas ativas no banco de dados RIP. | display rip process-id database [ ip-address { mask-length | mask } ] |
| Exibir informações da interface RIP. | display rip process-id interface [ número da interface do tipo interface ] |
| Exibir informações de vizinhos para um processo RIP. | display rip process-id neighbor [ número da interface do tipo interface ] |
| Exibir informações de roteamento de um processo RIP. | display rip process-id route [ ip-address { mask-length | mask } [ verbose ] | peer ip-address | statistics ] |
| Redefinir um processo RIP. | reset rip process-id process |
| Limpar as estatísticas de um processo RIP. | reset rip process-id statistics |
Exemplos de configuração de RIP
Exemplo: Configuração basica RIP
Configuração de rede
Conforme mostrado na Figura 2, habilite o RIPv2 em todas as interfaces do Switch A e do Switch B. Configure o Switch B para não anunciar a rota 10.2.1.0/24 para o Switch A e para aceitar somente a rota 2.1.1.0/24 do Switch A.
Figura 2 Diagrama de rede
Procedimento
- Configure os endereços IP para as interfaces. (Detalhes não mostrados).
- Ativar RIP.
# Habilite o RIP nas redes especificadas no Switch A.
<SwitchA> system-view
[SwitchA] rip
[SwitchA-rip-1] network 1.0.0.0
[SwitchA-rip-1] network 2.0.0.0
[SwitchA-rip-1] network 3.0.0.0
[SwitchA-rip-1] quit# Habilite o RIP nas interfaces especificadas no Switch B.
<SwitchB> system-view
[SwitchB] rip
[SwitchB-rip-1] quit
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] rip 1 enable
[SwitchB-Vlan-interface100] quit
[SwitchB] interface vlan-interface 101
[SwitchB-Vlan-interface101] rip 1 enable
[SwitchB-Vlan-interface101] quit
[SwitchB] interface vlan-interface 102
[SwitchB-Vlan-interface102] rip 1 enable
[SwitchB-Vlan-interface102] quit# Exibir a tabela de roteamento RIP do Switch A.
[SwitchA] display rip 1 route
Route Flags: R - RIP, T - TRIP
P - Permanent, A - Aging, S - Suppressed, G - Garbage-collect
D - Direct, O - Optimal, F - Flush to RIB
----------------------------------------------------------------------------
Peer 1.1.1.2 on Vlan-interface100
Destination/Mask Nexthop Cost Tag Flags Sec
Destination/Mask Nexthop Cost Tag Flags Sec
1.1.1.0/24 0.0.0.0 0 0 RDOF -
2.1.1.0/24 0.0.0.0 0 0 RDOF -
3.1.1.0/24 0.0.0.0 0 0 RDOF -A saída mostra que o RIPv1 usa uma máscara natural.
- Configurar uma versão RIP:
# Configure o RIPv2 no Switch A.
[SwitchA] rip
[SwitchA-rip-1] version 2
[SwitchA-rip-1] undo summary
[SwitchA-rip-1] quit# Configure o RIPv2 no Switch B.
[SwitchB] rip
[SwitchB-rip-1] version 2
[SwitchB-rip-1] undo summary
[SwitchB-rip-1] quit# Exibir a tabela de roteamento RIP no Switch A.
[SwitchA] display rip 1 route
Route Flags: R - RIP, T - TRIP
P - Permanent, A - Aging, S - Suppressed, G - Garbage-collect
D - Direct, O - Optimal, F - Flush to RIB
----------------------------------------------------------------------------
Peer 1.1.1.2 on Vlan-interface100
Destination/Mask Nexthop Cost Tag Flags Sec
10.0.0.0/8 1.1.1.2 1 0 RAOF 50
10.2.1.0/24 1.1.1.2 1 0 RAOF 16
10.1.1.0/24 1.1.1.2 1 0 RAOF 16
Local route
Destination/Mask Nexthop Cost Tag Flags Sec
1.1.1.0/24 0.0.0.0 0 0 RDOF -
2.1.1.0/24 0.0.0.0 0 0 RDOF -
3.1.1.0/24 0.0.0.0 0 0 RDOF -A saída mostra que o RIPv2 usa máscaras de sub-rede sem classe.
OBSERVAÇÃO:
Depois que o RIPv2 é configurado, as rotas RIPv1 podem continuar existindo na tabela de roteamento até que sejam eliminadas.
# Exibir a tabela de roteamento RIP no Switch B.
[SwitchB] display rip 1 route
Route Flags: R - RIP, T - TRIP
P - Permanent, A - Aging, S - Suppressed, G - Garbage-collect
D - Direct, O - Optimal, F - Flush to RIB
----------------------------------------------------------------------------
Peer 1.1.1.1 on Vlan-interface100
Destination/Mask Nexthop Cost Tag Flags Sec
2.1.1.0/24 1.1.1.1 1 0 RAOF 19
3.1.1.0/24 1.1.1.1 1 0 RAOF 19
Local route
Destination/Mask Nexthop Cost Tag Flags Sec
1.1.1.0/24 0.0.0.0 0 0 RDOF -
10.1.1.0/24 0.0.0.0 0 0 RDOF -
10.2.1.0/24 0.0.0.0 0 0 RDOF -- Configurar a filtragem de rotas:
# Faça referência às listas de prefixos IP no Switch B para filtrar as rotas recebidas e redistribuídas.
[SwitchB] ip prefix-list aaa index 10 permit 2.1.1.0 24
[SwitchB] ip prefix-list bbb index 10 deny 10.2.1.0 24
[SwitchB] ip prefix-list bbb index 11 permit 0.0.0.0 0 less-equal 32
[SwitchB] rip 1
[SwitchB-rip-1] filter-policy prefix-list aaa import
[SwitchB-rip-1] filter-policy prefix-list bbb export
[SwitchB-rip-1] quit# Exibir a tabela de roteamento RIP no Switch A.
[SwitchA] display rip 100 route
Route Flags: R - RIP, T - TRIP
P - Permanent, A - Aging, S - Suppressed, G - Garbage-collect
----------------------------------------------------------------------------
Peer 1.1.1.2 on Vlan-interface100
Destination/Mask Nexthop Cost Tag Flags Sec
10.1.1.0/24 1.1.1.2 1 0 RAOF 19
Local route
Destination/Mask Nexthop Cost Tag Flags Sec
1.1.1.0/24 0.0.0.0 0 0 RDOF -
2.1.1.0/24 0.0.0.0 0 0 RDOF -
3.1.1.0/24 0.0.0.0 0 0 RDOF -
# Exibir a tabela de roteamento RIP no Switch B.
[SwitchB] display rip 1 route
Route Flags: R - RIP, T - TRIP
P - Permanent, A - Aging, S - Suppressed, G - Garbage-collect
D - Direct, O - Optimal, F - Flush to RIB
----------------------------------------------------------------------------
Peer 1.1.1.1 on Vlan-interface100
Destination/Mask Nexthop Cost Tag Flags Sec
2.1.1.0/24 1.1.1.1 1 0 RAOF 19
Local route
Destination/Mask Nexthop Cost Tag Flags Sec
1.1.1.0/24 0.0.0.0 0 0 RDOF -
10.1.1.0/24 0.0.0.0 0 0 RDOF -
10.2.1.0/24 0.0.0.0 0 0 RDOF -
Exemplo: Configuração da redistribuição de rotas RIP
Configuração de rede
Conforme mostrado na Figura 3, o Switch B se comunica com o Switch A por meio do RIP 100 e com o Switch C por meio do RIP 200.
Configure o RIP 200 para redistribuir rotas diretas e rotas do RIP 100 no Switch B, de modo que o Switch C possa aprender rotas destinadas a 10.2.1.0/24 e 11.1.1.0/24. O switch A não pode aprender rotas destinadas a 12.3.1.0/24 e 16.4.1.0/24.
Figura 3 Diagrama de rede
Procedimento
- Configure os endereços IP para as interfaces. (Detalhes não mostrados).
- Configurar definições básicas de RIP:
# Habilite o RIP 100 e configure o RIPv2 no Switch A.
<SwitchA> system-view
[SwitchA] rip 100
[SwitchA-rip-100] network 10.0.0.0
[SwitchA-rip-100] network 11.0.0.0
[SwitchA-rip-100] version 2
[SwitchA-rip-100] undo summary
[SwitchA-rip-100] quit
# Habilite o RIP 100 e o RIP 200 e configure o RIPv2 no Switch B.
<SwitchB> system-view
[SwitchB] rip 100
[SwitchB-rip-100] network 11.0.0.0
[SwitchB-rip-100] version 2
[SwitchB-rip-100] undo summary
[SwitchB-rip-100] quit
[SwitchB] rip 200
[SwitchB-rip-200] network 12.0.0.0
[SwitchB-rip-200] version 2
[SwitchB-rip-200] undo summary
[SwitchB-rip-200] quit
# Habilite o RIP 200 e configure o RIPv2 no Switch C.
<SwitchC> system-view
[SwitchC] rip 200
[SwitchC-rip-200] network 12.0.0.0
[SwitchC-rip-200] network 16.0.0.0
[SwitchC-rip-200] version 2
[SwitchC-rip-200] undo summary
[SwitchC-rip-200] quit
# Exibir a tabela de roteamento IP no Switch C.
[SwitchC] display ip routing-table
Destinations : 13 Routes : 13
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
12.3.1.0/24 Direct 0 0 12.3.1.2 Vlan200
12.3.1.0/32 Direct 0 0 12.3.1.2 Vlan200
12.3.1.2/32 Direct 0 0 127.0.0.1 InLoop0
12.3.1.255/32 Direct 0 0 12.3.1.2 Vlan200
16.4.1.0/24 Direct 0 0 16.4.1.1 Vlan400
16.4.1.0/32 Direct 0 0 16.4.1.1 Vlan400
16.4.1.1/32 Direct 0 0 127.0.0.1 InLoop0
16.4.1.255/32 Direct 0 0 16.4.1.1 Vlan400
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
127.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
- Configurar a redistribuição de rotas:
# Configure o RIP 200 para redistribuir rotas do RIP 100 e direcionar rotas no Switch B.
[SwitchB] rip 200
[SwitchB-rip-200] import-route rip 100
[SwitchB-rip-200] import-route direct
[SwitchB-rip-200] quit
# Exibir a tabela de roteamento IP no Switch C.
[SwitchC] display ip routing-table
Destinations : 15 Routes : 15
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
10.2.1.0/24 RIP 100 1 12.3.1.1 Vlan200
11.1.1.0/24 RIP 100 1 12.3.1.1 Vlan200
12.3.1.0/24 Direct 0 0 12.3.1.2 Vlan200
12.3.1.0/32 Direct 0 0 12.3.1.2 Vlan200
12.3.1.2/32 Direct 0 0 127.0.0.1 InLoop0
12.3.1.255/32 Direct 0 0 12.3.1.2 Vlan200
16.4.1.0/24 Direct 0 0 16.4.1.1 Vlan400
16.4.1.0/32 Direct 0 0 16.4.1.1 Vlan400
16.4.1.1/32 Direct 0 0 127.0.0.1 InLoop0
16.4.1.255/32 Direct 0 0 16.4.1.1 Vlan400
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
127.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
Exemplo: Configuração de uma métrica adicional para uma interface RIP
Configuração de rede
Conforme mostrado na Figura 4, execute o RIPv2 em todas as interfaces do Switch A, Switch B, Switch C, Switch D e Switch E.
O Switch A tem dois links para o Switch D. O link do Switch B para o Switch D é mais estável do que o do Switch C para o Switch D. Configure uma métrica adicional para rotas RIP recebidas da interface VLAN 200 no Switch A, de modo que o Switch A prefira a rota 1.1.5.0/24 obtida do Switch B.
Figura 4 Diagrama de rede
Procedimento
- Configure os endereços IP para as interfaces. (Detalhes não mostrados).
- Configure as definições básicas de RIP: # Configurar o Switch A.
<SwitchA> system-view
[SwitchA] rip 1
[SwitchA-rip-1] network 1.0.0.0
[SwitchA-rip-1] version 2
[SwitchA-rip-1] undo summary
[SwitchA-rip-1] quit
# Configure o Switch B.
<SwitchB> system-view
[SwitchB] rip 1
[SwitchB-rip-1] network 1.0.0.0
[SwitchB-rip-1] version 2
[SwitchB-rip-1] undo summary
# Configure o Switch C.
<SwitchC> system-view
[SwitchB] rip 1
[SwitchC-rip-1] network 1.0.0.0
[SwitchC-rip-1] version 2
[SwitchC-rip-1] undo summary
# Configure o Switch D.
<SwitchD> system-view
[SwitchD] rip 1
[SwitchD-rip-1] network 1.0.0.0
[SwitchD-rip-1] version 2
[SwitchD-rip-1] undo summary
# Configure o Switch E.
<SwitchE> system-view
[SwitchE] rip 1
[SwitchE-rip-1] network 1.0.0.0
[SwitchE-rip-1] version 2
[SwitchE-rip-1] undo summary
# Exibir todas as rotas ativas no banco de dados RIP do Switch A.
[SwitchA] display rip 1 database
1.0.0.0/8, auto-summary
1.1.1.0/24, cost 0, nexthop 1.1.1.1, RIP-interface
1.1.2.0/24, cost 0, nexthop 1.1.2.1, RIP-interface
1.1.3.0/24, cost 1, nexthop 1.1.1.2
1.1.4.0/24, cost 1, nexthop 1.1.2.2
1.1.5.0/24, cost 2, nexthop 1.1.1.2
1.1.5.0/24, cost 2, nexthop 1.1.2.2
A saída mostra duas rotas RIP destinadas à rede 1.1.5.0/24, com os próximos saltos como Switch B (1.1.1.2) e Switch C (1.1.2.2), e com o mesmo custo de 2.
- Configurar uma métrica adicional para uma interface RIP:
# Configure uma métrica adicional de entrada de 3 para a interface habilitada para RIP VLAN-interface 200 no Switch A.
[SwitchA] interface vlan-interface 200
[SwitchA-Vlan-interface200] rip metricin 3
# Exibir todas as rotas ativas no banco de dados RIP do Switch A.
[SwitchA-Vlan-interface200] display rip 1 database
1.0.0.0/8, auto-summary
1.1.1.0/24, cost 0, nexthop 1.1.1.1, RIP-interface
1.1.2.0/24, cost 0, nexthop 1.1.2.1, RIP-interface
1.1.3.0/24, cost 1, nexthop 1.1.1.2
1.1.4.0/24, cost 2, nexthop 1.1.1.2
1.1.5.0/24, cost 2, nexthop 1.1.1.2
O resultado mostra que apenas uma rota RIP chega à rede 1.1.5.0/24, com o próximo salto sendo o Switch B (1.1.1.2) e um custo de 2.
Exemplo: Configuração do RIP para anunciar uma rota resumida
Configuração de rede
Conforme mostrado na Figura 5, os Comutadores A e B executam OSPF, o Comutador D executa RIP e o Comutador C executa OSPF e RIP. Configure o RIP para redistribuir rotas OSPF no Comutador C para que o Comutador D possa aprender rotas destinadas às redes 10.1.1.0/24, 10.2.1.0/24, 10.5.1.0/24 e 10.6.1.0/24.
Para reduzir o tamanho da tabela de roteamento do Switch D, configure a sumarização de rotas no Switch C para anunciar apenas a rota de resumo 10.0.0.0/8 para o Switch D.
Figura 5 Diagrama de rede
Procedimento
- Configurar endereços IP para as interfaces. (Detalhes não mostrado).
- Configurar as definições básicas do OSPF:
# Configure o switch A.
<SwitchA> system-view
[SwitchA] ospf
[SwitchA-ospf-1] area 0
[SwitchA-ospf-1-area-0.0.0.0] network 10.5.1.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.0] network 10.2.1.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.0] quit# Configure o Switch B.
<SwitchB> system-view
[SwitchB] ospf
[SwitchB-ospf-1] area 0
[SwitchB-ospf-1-area-0.0.0.0] network 10.1.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] network 10.6.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] quit# Configurar o switch C.
<SwitchC> system-view
[SwitchC] ospf
[SwitchC-ospf-1] area 0
[SwitchC-ospf-1-area-0.0.0.0] network 10.1.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.0] network 10.2.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.0] quit
[SwitchC-ospf-1] quit# Configurar o switch C.
[SwitchC] rip 1
[SwitchC-rip-1] network 11.3.1.0
[SwitchC-rip-1] version 2
[SwitchC-rip-1] undo summary# Configure o Switch D.
<SwitchD> system-view
[SwitchD] rip 1
[SwitchD-rip-1] network 11.0.0.0
[SwitchD-rip-1] version 2
[SwitchD-rip-1] undo summary
[SwitchD-rip-1] quit
# Configure o RIP para redistribuir rotas do processo 1 do OSPF e direcionar rotas no Switch C.
[SwitchC-rip-1] import-route direct
[SwitchC-rip-1] import-route ospf 1
[SwitchC-rip-1] quit
# Exibir a tabela de roteamento IP no Switch D.
[SwitchD] display ip routing-table
Destinations : 15 Routes : 15
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
10.1.1.0/24 RIP 100 1 11.3.1.1 Vlan300
10.2.1.0/24 RIP 100 1 11.3.1.1 Vlan300
10.5.1.0/24 RIP 100 1 11.3.1.1 Vlan300
10.6.1.0/24 RIP 100 1 11.3.1.1 Vlan300
11.3.1.0/24 Direct 0 0 11.3.1.2 Vlan300
11.3.1.0/32 Direct 0 0 11.3.1.2 Vlan300
11.3.1.2/32 Direct 0 0 127.0.0.1 InLoop0
11.4.1.0/24 Direct 0 0 11.4.1.2 Vlan400
11.4.1.0/32 Direct 0 0 11.4.1.2 Vlan400
11.4.1.2/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
127.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
- Configurar a compactação de rotas:
# Configure a sumarização de rotas no Switch C e anuncie apenas a rota de resumo 10.0.0.0/8.
[SwitchC] interface vlan-interface 300
[SwitchC-Vlan-interface300] rip summary-address 10.0.0.0 8
# Exibir a tabela de roteamento IP no Switch D.
[SwitchD] display ip routing-table
Destinations : 12 Routes : 12
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
10.0.0.0/8 RIP 100 1 11.3.1.1 Vlan300
11.3.1.0/24 Direct 0 0 11.3.1.2 Vlan300
11.3.1.0/32 Direct 0 0 11.3.1.2 Vlan300
11.3.1.2/32 Direct 0 0 127.0.0.1 InLoop0
11.4.1.0/24 Direct 0 0 11.4.1.2 Vlan400
11.4.1.0/32 Direct 0 0 11.4.1.2 Vlan400
11.4.1.2/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
127.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
Exemplo: Configuração do RIP GR
Configuração de rede
Conforme mostrado na Figura 6, o Switch A, o Switch B e o Switch C executam o RIPv2.
- Habilite o GR no Switch A. O Switch A atua como reiniciador do GR.
- Os comutadores B e C atuam como auxiliares de GR para sincronizar suas tabelas de roteamento com o comutador A pelo usando GR.
Figura 6 Diagrama de rede
Procedimento
- Configure os endereços IP e as máscaras de sub-rede para as interfaces nos switches. (Detalhes não mostrados).
- Configure o RIPv2 nos switches para garantir o seguinte: (Detalhes não mostrados).
- O Switch A, o Switch B e o Switch C podem se comunicar entre si na Camada 3.
- A atualização dinâmica de rotas pode ser implementada entre eles com o RIPv2.
- Habilite o RIP GR no Switch A.
<SwitchA> system-view
[SwitchA] rip
[SwitchA-rip-1] graceful-restart
Verificação da configuração
# Reinicie o RIP ou acione uma alternância ativo/em espera e, em seguida, exiba o status do GR no Switch A.
<SwitchA> display rip graceful-restart
RIP process: 1
Graceful Restart capability : Enabled
Current GR state : Normal
Graceful Restart period : 60 seconds
Graceful Restart remaining time : 0 seconds
Exemplo: Configuração do RIP NSR
Configuração de rede
Conforme mostrado na Figura 7, o Switch A, o Switch B e o Switch S executam o RIPv2.
Habilite o RIP NSR no Switch S para garantir o roteamento correto quando ocorrer uma alternância ativo/em espera no Switch S.
Figura 7 Diagrama de rede

Procedimento
- O Switch A, o Switch B e o Switch S podem se comunicar entre si na Camada 3.
- A atualização dinâmica de rotas pode ser implementada entre eles com o RIPv2.
- Habilite o RIP NSR no Switch S.
<SwitchS> system-view
[SwitchS] rip 100
[SwitchS-rip-100] non-stop-routing
[SwitchS-rip-100] quit
Verificação da configuração
# Executar uma alternância entre ativo e em espera no Switch S.
[SwitchS] placement reoptimize
Predicted changes to the placement
Program Current location New location
---------------------------------------------------------------------
lb 0/0 0/0
lsm 0/0 0/0
slsp 0/0 0/0
rib6 0/0 0/0
routepolicy 0/0 0/0
rib 0/0 0/0
staticroute6 0/0 0/0
staticroute 0/0 0/0
eviisis 0/0 0/0
ospf 0/0 1/0
Continue? [y/n]:y
Re-optimization of the placement start. You will be notified on completion
Re-optimization of the placement complete. Use 'display placement' to view the new
placement
# Exibir informações de vizinhos e de rotas no Switch A.
[SwitchA] display rip 1 neighbor
Neighbor Address: 12.12.12.2
Interface : Vlan-interface200
Version : RIPv2 Last update: 00h00m13s
Relay nbr : No BFD session: None
Bad packets: 0 Bad routes : 0
Loop 0
22.22.22.22/32 Vlan-int100
12.12.12.1/24
Vlan-int100
12.12.12.2/24
Vlan-int200
14.14.14.2/24
Vlan-int200
14.14.14.1/24
Loop 0
Switch S 44.44.44.44/32
Switch A Switch B
[SwitchA] display rip 1 route
Route Flags: R - RIP, T - TRIP
P - Permanent, A - Aging, S - Suppressed, G - Garbage-collect
D - Direct, O - Optimal, F - Flush to RIB
----------------------------------------------------------------------------
Peer 12.12.12.2 on Vlan-interface200
Destination/Mask Nexthop Cost Tag Flags Sec
14.0.0.0/8 12.12.12.2 1 0 RAOF 16
44.0.0.0/8 12.12.12.2 2 0 RAOF 16
Local route
Destination/Mask Nexthop Cost Tag Flags Sec
12.12.12.0/24 0.0.0.0 0 0 RDOF -
22.22.22.22/32 0.0.0.0 0 0 RDOF -# Exibir informações de vizinhos e de rotas no Switch B.
[SwitchB] display rip 1 neighbor
Neighbor Address: 14.14.14.2
Interface : Vlan-interface200
Version : RIPv2 Last update: 00h00m32s
Relay nbr : No BFD session: None
Bad packets: 0 Bad routes : 0
[SwitchB] display rip 1 route
Route Flags: R - RIP, T - TRIP
P - Permanent, A - Aging, S - Suppressed, G - Garbage-collect
D - Direct, O - Optimal, F - Flush to RIB
----------------------------------------------------------------------------
Peer 14.14.14.2 on Vlan-interface200
Destination/Mask Nexthop Cost Tag Flags Sec
12.0.0.0/8 14.14.14.2 1 0 RAOF 1
22.0.0.0/8 14.14.14.2 2 0 RAOF 1
Local route
Destination/Mask Nexthop Cost Tag Flags Sec
44.44.44.44/32 0.0.0.0 0 0 RDOF -
14.14.14.0/24 0.0.0.0 0 0 RDOF -A saída mostra que as informações de vizinhança e rota no Switch A e no Switch B permanecem inalteradas durante a alternância ativo/em espera no Switch S. O tráfego do Switch A para o Switch B não foi afetado.
Exemplo: Configuração de BFD para RIP (detecção de eco de salto único para um vizinho conectado diretamente)
Configuração de rede
Conforme mostrado na Figura 8, a interface VLAN 100 do comutador A e do comutador C executa o processo RIP 1. A interface de VLAN 200 do switch A executa o processo RIP 2. A interface de VLAN 300 do switch C e as interfaces de VLAN 200 e 300 do switch B executam o processo RIP 1.
Configure uma rota estática destinada a 100.1.1.1/24 e ative a redistribuição de rotas estáticas para o RIP no Switch C. Isso permite que o Switch A aprenda duas rotas destinadas a 100.1.1.1/24 por meio de
VLAN-interface 100 e VLAN-interface 200, respectivamente, e usa a que passa pela VLAN-interface 100.
∙ Habilite o BFD para RIP na interface VLAN 100 do Switch A. Quando o link na interface VLAN 100 falhar, o BFD poderá detectar rapidamente a falha e notificar o RIP. O RIP exclui a relação de vizinhança e as informações de rota aprendidas na interface de VLAN 100 e usa a rota destinada a 100.1.1.1 24 por meio da interface de VLAN 200.
Figura 8 Diagrama de rede
Procedimento
<SwitchA> system-view
[SwitchA] rip 1
[SwitchA-rip-1] version 2
[SwitchA-rip-1] undo summary
[SwitchA-rip-1] network 192.168.1.0
[SwitchA-rip-1] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] rip bfd enable
[SwitchA-Vlan-interface100] quit
[SwitchA] rip 2
[SwitchA-rip-2] version 2
[SwitchA-rip-2] undo summary
[SwitchA-rip-2] network 192.168.2.0
[SwitchA-rip-2] quit# Configure o Switch B.
<SwitchB> system-view
[SwitchB] rip 1
[SwitchB-rip-1] version 2
[SwitchB-rip-1] undo summary
[SwitchB-rip-1] network 192.168.2.0
[SwitchB-rip-1] network 192.168.3.0
[SwitchB-rip-1] quit# Configurar o switch C.
<SwitchC> system-view
[SwitchC] rip 1
Vlan-int100
192.168.1.1/24
BFD Switch A Switch C
Vlan-int100
192.168.1.2/24
L2 switch
Vlan-int300
192.168.3.1/24
Vlan-int300
192.168.3.2/24
Vlan-int200
192.168.2.2/24
Vlan-int200
192.168.2.1/24
Switch B
33
[SwitchC-rip-1] version 2
[SwitchC-rip-1] undo summary
[SwitchC-rip-1] network 192.168.1.0
[SwitchC-rip-1] network 192.168.3.0
[SwitchC-rip-1] import-route static
[SwitchC-rip-1] quit- Configure os parâmetros de BFD na interface VLAN 100 do Switch A.
[SwitchA] bfd echo-source-ip 11.11.11.11
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] bfd min-echo-receive-interval 500
[SwitchA-Vlan-interface100] bfd detect-multiplier 7
[SwitchA-Vlan-interface100] quit
[SwitchA] quit- Configure uma rota estática no Switch C.
[SwitchC] ip route-static 120.1.1.1 24 null 0Verificação da configuração
# Exibir as informações da sessão BFD no Switch A.
<SwitchA> display bfd session
Total Session Num: 1 Up Session Num: 1 Init Mode: Active
IPv4 Session Working Under Echo Mode:
LD SourceAddr DestAddr State Holdtime Interface
4 192.168.1.1 192.168.1.2 Up 2000ms Vlan100
# Exibir rotas RIP destinadas a 120.1.1.0/24 no Switch A.
<SwitchA> display ip routing-table 120.1.1.0 24
Summary count : 1
Destination/Mask Proto Pre Cost NextHop Interface
120.1.1.0/24 RIP 100 1 192.168.1.2 Vlan-interface100
# Exibir rotas RIP destinadas a 120.1.1.0/24 no Switch A.
<SwitchA> display ip routing-table 120.1.1.0 24
Summary count : 1
Destination/Mask Proto Pre Cost NextHop Interface
120.1.1.0/24 RIP 100 1 192.168.2.2 Vlan-interface200
Exemplo: Configuração de BFD para RIP (detecção de eco de salto único para um destino específico)
Configuração de rede
Conforme mostrado na Figura 9, a interface VLAN 100 do Switch A e do Switch B executa o processo RIP 1. A interface de VLAN 200 do comutador B e do comutador C executa o processo RIP 1.
∙ Configure uma rota estática com destino a 100.1.1.0/24 e ative a redistribuição de rotas estáticas para o RIP tanto no Switch A quanto no Switch C. Isso permite que o Switch B aprenda duas rotas com destino a 100.1.1.0/24 por meio da interface de VLAN 100 e da interface de VLAN 200. A rota redistribuída pelo Switch A tem um custo menor do que a redistribuída pelo Switch C, portanto o Switch B usa a rota pela interface de VLAN 200.
∙ Habilite o BFD para RIP na interface VLAN 100 do Switch A e especifique a interface VLAN 100 do Switch B como destino. Quando ocorre um link unidirecional entre o Switch A e o Switch B, o BFD pode detectar rapidamente a falha do link e notificar o RIP. O Switch B exclui o relacionamento de vizinhança e as informações de rota aprendidas na interface VLAN 100. Ele não recebe ou envia nenhum pacote da interface VLAN 100. Quando a rota aprendida do Switch A se esgota, o Switch B usa a rota destinada a 100.1.1.1 24 por meio da interface de VLAN 200.
Figura 9 Diagrama de rede
Procedimento
- Configure os endereços IP para as interfaces. (Detalhes não mostrados).
- Configure as definições básicas de RIP e ative o BFD nas interfaces: # Configure o Switch A.
<SwitchA> system-view
[SwitchA] rip 1
[SwitchA-rip-1] network 192.168.2.0
[SwitchA-rip-1] import-route static
[SwitchA-rip-1] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] rip bfd enable destination 192.168.2.2
[SwitchA-Vlan-interface100] quit
# Configure o Switch B.
<SwitchB> system-view
[SwitchB] rip 1
[SwitchB-rip-1] network 192.168.2.0
[SwitchB-rip-1] network 192.168.3.0
[SwitchB-rip-1] quit
# Configurar o switch C.
<SwitchC> system-view
[SwitchC] rip 1
[SwitchC-rip-1] network 192.168.3.0
[SwitchC-rip-1] import-route static cost 3
[SwitchC-rip-1] quit
- Configure os parâmetros de BFD na interface VLAN 100 do Switch A.
[SwitchA] bfd echo-source-ip 11.11.11.11
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] bfd min-echo-receive-interval 500
[SwitchA-Vlan-interface100] return
- Configurar rotas estáticas:
# Configure uma rota estática no Switch A.
[SwitchA] ip route-static 100.1.1.0 24 null 0
# Configure uma rota estática no Switch C.
[SwitchA] ip route-static 100.1.1.0 24 null 0
Verificação da configuração
# Exibir informações sobre a sessão BFD no Switch A.
lt;SwitchA> display bfd session
Total Session Num: 1 Up Session Num: 1 Init Mode: Active
IPv4 session working under Echo mode:
LD SourceAddr DestAddr State Holdtime Interface
3 192.168.2.1 192.168.2.2 Up 2000ms vlan100# Exibir rotas destinadas a 100.1.1.0/24 no Switch B.
display ip routing-table 100.1.1.0 24 verbose
Summary Count : 1
Destination: 100.1.1.0/24
Protocol: RIP
Process ID: 1
SubProtID: 0x1 Age: 00h02m47s
Cost: 1 Preference: 100
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 0
NibID: 0x12000002 LastAs: 0
AttrID: 0xffffffff Neighbor: 192.168.2.1
Flags: 0x1008c OrigNextHop: 192.168.2.1
Label: NULL RealNextHop: 192.168.2.1
BkLabel: NULL BkNextHop: N/A
SRLabel: NULL BkSRLabel: NULL
Tunnel ID: Invalid Interface: vlan-interface 100
BkTunnel ID: Invalid BkInterface: N/A
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0 # Exibir rotas destinadas a 100.1.1.0/24 no Switch B quando o link entre o Switch A e o Switch B falhar.
<SwitchB> display ip routing-table 100.1.1.0 24 verbose
Summary Count : 1
Destination: 100.1.1.0/24
Protocol: RIP
Process ID: 1
SubProtID: 0x1 Age: 00h21m23s
Cost: 4 Preference: 100
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 0
NibID: 0x12000002 LastAs: 0
AttrID: 0xffffffff Neighbor: 192.168.3.2
Flags: 0x1008c OrigNextHop: 192.168.3.2
Label: NULL RealNextHop: 192.168.3.2
BkLabel: NULL BkNextHop: N/A
SRLabel: NULL BkSRLabel: NULL
Tunnel ID: Invalid Interface: vlan-interface 200
BkTunnel ID: Invalid BkInterface: N/A
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0
Exemplo: Configuração de BFD para RIP (detecção bidirecional no modo de pacote de controle BFD)
Configuração de rede
Conforme mostrado na Figura 10, a interface VLAN 100 do Switch A e a interface VLAN 200 do Switch C executam o processo RIP 1.
A interface VLAN 300 do Switch A executa o processo RIP 2. A interface de VLAN 400 do Switch C e a interface de VLAN 300 e a interface de VLAN 400 do Switch D executam o processo RIP 1.
∙ Configure uma rota estática com destino a 100.1.1.0/24 no Switch A.
∙ Configure uma rota estática com destino a 101.1.1.0/24 no Switch C.
∙ Habilite a redistribuição de rotas estáticas para o RIP no Switch A e no Switch C. Isso permite que o Switch A aprenda duas rotas destinadas a 100.1.1.0/24 por meio da interface de VLAN 100 e da interface de VLAN 300. Ele usa a rota pela interface de VLAN 100.
∙ Habilite o BFD na interface de VLAN 100 do Switch A e na interface de VLAN 200 do Switch C.
Quando o link da interface VLAN 100 falha, o BFD pode detectar rapidamente a falha do link e notificar o RIP. O RIP exclui o relacionamento de vizinhança e as informações de rota recebidas aprendidas na interface VLAN
100. Ele usa a rota destinada a 100.1.1.0/24 por meio da interface VLAN 300.
Figura 10 Diagrama de rede
Tabela 1 Atribuição de interface e endereço IP
| Dispositivo | Interface | Endereço IP |
| Chave A | Interface VLAN 300 | 192.168.3.1/24 |
| Chave A | Interface VLAN 100 | 192.168.1.1/24 |
| Chave B | Interface VLAN 100 | 192.168.1.2/24 |
| Chave B | Interface VLAN 200 | 192.168.2.1/24 |
| Chave C | Interface VLAN 200 | 192.168.2.2/24 |
| Chave C | Interface VLAN 400 | 192.168.4.2/24 |
| Chave D | Interface VLAN 300 | 192.168.3.2/24 |
| Chave D | Interface VLAN 400 | 192.168.4.1/24 |
Procedimento
- Configure os endereços IP para as interfaces. (Detalhes não mostrados).
- Defina as configurações básicas do RIP e ative a redistribuição de rotas estáticas no RIP para que o Switch A e o Switch C tenham rotas para enviar um ao outro:
# Configure o switch A.
<SwitchA> system-view
[SwitchA] rip 1
[SwitchA-rip-1] version 2
[SwitchA-rip-1] undo summary
[SwitchA-rip-1] network 192.168.1.0
[SwitchA-rip-1] network 101.1.1.0
[SwitchA-rip-1] peer 192.168.2.2
[SwitchA-rip-1] undo validate-source-address
[SwitchA-rip-1] import-route static
[SwitchA-rip-1] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] rip bfd enable
[SwitchA-Vlan-interface100] quit
[SwitchA-rip-2] undo summary
[SwitchA-rip-2] network 192.168.3.0
[SwitchA-rip-2] quit# Configurar o switch C.
<SwitchC> system-view
[SwitchC] rip 1
[SwitchC-rip-1] version 2
[SwitchC-rip-1] undo summary
[SwitchC-rip-1] network 192.168.2.0
[SwitchC-rip-1] network 192.168.4.0
[SwitchC-rip-1] network 100.1.1.0
[SwitchC-rip-1] peer 192.168.1.1
[SwitchC-rip-1] undo validate-source-address
[SwitchC-rip-1] import-route static
[SwitchC-rip-1] quit
[SwitchC] interface vlan-interface 200
[SwitchC-Vlan-interface200] rip bfd enable
[SwitchC-Vlan-interface200] quit# Configurar o switch D.
<SwitchD> system-view
[SwitchD] rip 1
[SwitchD-rip-1] version 2
[SwitchD-rip-1] undo summary
[SwitchD-rip-1] network 192.168.3.0
[SwitchD-rip-1] network 192.168.4.0
- Configure os parâmetros do BFD:
# Configurar o Switch A.
[SwitchA] bfd session init-mode active
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] bfd min-transmit-interval 500
[SwitchA-Vlan-interface100] bfd min-receive-interval 500
[SwitchA-Vlan-interface100] bfd detect-multiplier 7
[SwitchA-Vlan-interface100] quit# Configurar o switch C.
[SwitchC] bfd session init-mode active
[SwitchC] interface vlan-interface 200
[SwitchC-Vlan-interface200] bfd min-transmit-interval 500
[SwitchC-Vlan-interface200] bfd min-receive-interval 500
[SwitchC-Vlan-interface200] bfd detect-multiplier 7
[SwitchC-Vlan-interface200] quit
- Configurar rotas estáticas:
# Configure uma rota estática para o Switch C no Switch A.
[SwitchA] ip route-static 192.168.2.0 24 vlan-interface 100 192.168.1.2
[SwitchA] quit
# Configure uma rota estática para o Switch A no Switch C.
[SwitchC] ip route-static 192.168.1.0 24 vlan-interface 200 192.168.2.1
Verificação da configuração
# Exibir as informações da sessão BFD no Switch A.
<SwitchA> display bfd session
Total Session Num: 1 Up Session Num: 1 Init Mode: Active
IPv4 session working under Ctrl mode:
LD/RD SourceAddr DestAddr State Holdtime Interface
513/513 192.168.1.1 192.168.2.2 Up 1700ms vlan100
# Exibir rotas RIP destinadas a 100.1.1.0/24 no Switch A.
display ip routing-table 100.1.1.0 24
Summary count : 1
Destination/Mask Proto Pre Cost NextHop Interface
100.1.1.0/24 RIP 100 1 192.168.2.2 vlan-interface 100
A saída mostra que o Switch A se comunica com o Switch C por meio da interface de VLAN 100. Em seguida, o link na interface VLAN 100 falha.
# Exibir rotas RIP destinadas a 100.1.1.0/24 no Switch A.
<SwitchA> display ip routing-table 100.1.1.0 24
Summary count : 1
Destination/Mask Proto Pre Cost NextHop Interface
100.1.1.0/24 RIP 100 2 192.168.3.2 vlan-interface 300
A saída mostra que o Switch A se comunica com o Switch C por meio da interface VLAN 300.
Exemplo: Configuração de RIP FRR
Configuração de rede
Conforme mostrado na Figura 11, o Switch A, o Switch B e o Switch C executam o RIPv2. Configure o RIP FRR para que quando o Link A se tornar unidirecional, os serviços possam ser alternados para o Link B imediatamente.
Figura 11 Diagrama de rede
Tabela 2 Atribuição de interface e endereço IP
| Dispositivo | Interface | Endereço IP |
| Chave A | Interface VLAN 100 | 12.12.12.1/24 |
| Chave A | Interface VLAN 200 | 13.13.13.1/24 |
| Chave A | Loopback 0 | 1.1.1.1/32 |
| Chave B | Interface VLAN 101 | 24.24.24.4/24 |
| Chave B | Interface VLAN 200 | 13.13.13.2/24 |
| Chave B | Loopback 0 | 4.4.4.4/32 |
| Chave C | Interface VLAN 100 | 12.12.12.2/24 |
| Chave C | Interface VLAN 101 | 24.24.24.2/24 |
Procedimento
- Configure os endereços IP e as máscaras de sub-rede para as interfaces nos switches. (Detalhes não mostrados).
- Configure o RIPv2 nos switches para garantir que o Switch A, o Switch B e o Switch C possam se comunicar entre si na Camada 3. (Detalhes não mostrados).
- Configurar o RIP FRR: # Configurar o Switch A.
<SwitchA> system-view
[SwitchA] ip prefix-list abc index 10 permit 4.4.4.4 32
[SwitchA] route-policy frr permit node 10
[SwitchA-route-policy-frr-10] if-match ip address prefix-list abc
[SwitchA-route-policy-frr-10] apply fast-reroute backup-interface vlan-interface
100 backup-nexthop 12.12.12.2
[SwitchA-route-policy-frr-10] quit
[SwitchA] rip 1
[SwitchA-rip-1] fast-reroute route-policy frr
[SwitchA-rip-1] quit
# Configure o Switch B.
<SwitchB> system-view
[SwitchB] ip prefix-list abc index 10 permit 1.1.1.1 32
[SwitchB] route-policy frr permit node 10
[SwitchB-route-policy-frr-10] if-match ip address prefix-list abc
[SwitchB-route-policy-frr-10] apply fast-reroute backup-interface vlan-interface
101 backup-nexthop 24.24.24.2
[SwitchB-route-policy-frr-10] quit
[SwitchB] rip 1
[SwitchB-rip-1] fast-reroute route-policy frr
[SwitchB-rip-1] quit
Verificação da configuração
# Exibir a rota 4.4.4.4/32 no Switch A para ver as informações do próximo salto de backup.
[SwitchA] display ip routing-table 4.4.4.4 verbose
Summary Count : 1
Destination: 4.4.4.4/32
Protocol: RIP
Process ID: 1
41
SubProtID: 0x1 Age: 04h20m37s
Cost: 1 Preference: 100
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 0
NibID: 0x26000002 LastAs: 0
AttrID: 0xffffffff Neighbor: 13.13.13.2
Flags: 0x1008c OrigNextHop: 13.13.13.2
Label: NULL RealNextHop: 13.13.13.2
BkLabel: NULL BkNextHop: 12.12.12.2
Tunnel ID: Invalid Interface: Vlan-interface200
BkTunnel ID: Invalid BkInterface: Vlan-interface100
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0
# Exibir a rota 1.1.1.1/32 no Switch B para ver as informações do próximo salto de backup.
[SwitchB] display ip routing-table 1.1.1.1 verbose
Summary Count : 1
Destination: 1.1.1.1/32
Protocol: RIP
Process ID: 1
SubProtID: 0x1 Age: 04h20m37s
Cost: 1 Preference: 100
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 0
NibID: 0x26000002 LastAs: 0
AttrID: 0xffffffff Neighbor: 13.13.13.1
Flags: 0x1008c OrigNextHop: 13.13.13.1
Label: NULL RealNextHop: 13.13.13.1
BkLabel: NULL BkNextHop: 24.24.24.2
Tunnel ID: Invalid Interface: Vlan-interface200
BkTunnel ID: Invalid BkInterface: Vlan-interface101
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0
Configuração do OSPF
Sobre o OSPF
O Open Shortest Path First (OSPF) é um IGP de estado de link desenvolvido pelo grupo de trabalho OSPF do IETF. O OSPF versão 2 é usado para IPv4. Neste capítulo, OSPF se refere a OSPFv2.
Aplicavel somente a Serie S3300G
Recursos do OSPF
O OSPF tem os seguintes recursos:
∙ Amplo escopo - suporta vários tamanhos de rede e várias centenas de roteadores em um domínio de roteamento OSPF.
∙ Convergência rápida: anuncia atualizações de roteamento instantaneamente após alterações na topologia da rede.
∙ Loop free - calcula rotas com o algoritmo SPF para evitar loops de roteamento.
∙ Partição de rede baseada em área - divide um AS em várias áreas para facilitar o gerenciamento. Esse recurso reduz o tamanho do LSDB nos roteadores para economizar memória e recursos de CPU e reduz as atualizações de rota transmitidas entre as áreas para economizar largura de banda.
∙ Hierarquia de roteamento - Suporta uma hierarquia de roteamento de 4 níveis que prioriza as rotas em rotas intra-área, inter-área, externas Tipo 1 e externas Tipo 2.
∙ Autenticação - Oferece suporte à autenticação de pacotes baseada em área e interface para garantir a troca segura de pacotes.
∙ Suporte para multicasting - pacotes de protocolo multicast em alguns tipos de links para evitar o impacto em outros dispositivos.
Pacotes OSPF
As mensagens OSPF são transportadas diretamente pelo IP. O número do protocolo é 89. O OSPF usa os seguintes tipos de pacotes:
∙ Hello-Enviado periodicamente para localizar e manter vizinhos, contendo valores de timer, informações
sobre o DR, o BDR e os vizinhos conhecidos.
∙ Descrição do banco de dados (DD) - Descreve o resumo de cada LSA no LSDB, trocado entre dois roteadores para sincronização de dados.
∙ Solicitação de estado de link (LSR) - Solicita LSAs necessários de um vizinho. Depois de trocar os pacotes DD, os dois roteadores sabem quais LSAs do vizinho estão faltando em seus LSDBs. Em seguida, eles trocam pacotes LSR solicitando os LSAs ausentes. Os pacotes LSR contêm o resumo dos LSAs ausentes.
∙ Atualização do estado do link (LSU): transmite os LSAs solicitados para o vizinho.
∙ Confirmação de estado do link (LSAck) - Confirma pacotes LSU recebidos. Ele contém os cabeçalhos dos LSAs recebidos (um pacote LSAck pode confirmar vários LSAs).
Tipos de LSA
O OSPF anuncia informações de roteamento em anúncios de estado de link (LSAs). Os seguintes LSAs são comumente usados:
∙ LSA de roteador - LSA do tipo 1, originado por todos os roteadores e inundado somente em uma única área. Esse LSA descreve os estados coletados das interfaces do roteador em uma área.
∙ LSA de rede - LSA do tipo 2, originado para redes de broadcast e NBMA pelo roteador designado e inundado somente em uma única área. Esse LSA contém a lista de roteadores conectados à rede.
∙ Network Summary LSA (LSA de resumo de rede) - LSA do tipo 3, originado pelos ABRs (Area Border Routers, roteadores de borda de área) e inundado em toda a área associada ao LSA. Cada summary-LSA descreve uma rota para um destino fora da área, mas ainda dentro do AS (uma rota interárea).
∙ ASBR Summary LSA (LSA de resumo ASBR) - LSA do tipo 4, originado por ABRs e inundado em toda a área associada ao LSA. Os LSAs de resumo do tipo 4 descrevem rotas para o ASBR (Autonomous System Boundary Router, roteador de limite de sistema autônomo).
∙ AS External LSA - LSA do tipo 5, originado por ASBRs e inundado em todo o AS (exceto áreas stub e NSSA). Cada AS-external-LSA descreve uma rota para outro AS.
∙ NSSA LSA - LSA do tipo 7, conforme definido na RFC 1587, originado por ASBRs em NSSAs e inundado em uma única NSSA. Os LSAs da NSSA descrevem rotas para outros ASs.
∙ LSA-LSA opaco para extensões OSPF. Seu formato consiste em um cabeçalho LSA padrão e informações específicas do aplicativo. O LSA opaco inclui o Tipo 9, o Tipo 10 e o Tipo 11. O LSA opaco do Tipo 9 é inundado na sub-rede local. O Grace LSA, usado pelo graceful restart, é o LSA Tipo 9. O Tipo 10 é transmitido para a área local. O Tipo 11 é transmitido para todo o AS.
Áreas OSPF
Partição de rede OSPF baseada em área
Em grandes domínios de roteamento OSPF, os cálculos de rota SPF consomem muitos recursos de armazenamento e CPU, e os enormes pacotes OSPF gerados para sincronização de rotas ocupam uma largura de banda excessiva.
Para resolver esses problemas, o OSPF divide um AS em várias áreas. Cada área é identificada por um ID de área. Os limites entre as áreas são roteadores e não links. Um segmento de rede (ou um link) só pode residir em uma área, conforme mostrado na Figura 1.
Você pode configurar a compactação de rotas nos ABRs para reduzir o número de LSAs anunciados para outras áreas e minimizar o efeito das alterações na topologia.
Figura 1 Partição de rede OSPF baseada em área
Área de backbone
Cada AS tem uma área de backbone que distribui informações de roteamento entre áreas não-backbone. As informações de roteamento entre áreas não-backbone devem ser encaminhadas pela área de backbone. O OSPF tem os seguintes requisitos:
Todas as áreas não-backbone devem manter a conectividade com a área de backbone.
A área de backbone deve manter a conectividade dentro de si mesma.
Na prática, esses requisitos podem não ser atendidos devido à falta de links físicos. Os links virtuais do OSPF podem resolver esse problema.
Links virtuais
Um link virtual é estabelecido entre dois ABRs por meio de uma área não-backbone. Ele deve ser configurado em ambos os ABRs para ter efeito. A área não-backbone é chamada de área de trânsito.
Conforme mostrado na Figura 2, a Área 2 não tem um link físico direto para a Área 0 do backbone. Você pode configurar um link virtual entre os dois ABRs para conectar a Área 2 à área de backbone.
Figura 2 Aplicativo de link virtual 1
Os links virtuais também podem ser usados como links redundantes. Se uma falha no link físico interromper a conectividade interna da área de backbone, você poderá configurar um link virtual para substituir o link físico com falha, conforme mostrado na Figura 3.
Figura 3 Aplicativo de link virtual 2
O link virtual entre os dois ABRs funciona como uma conexão ponto a ponto. Você pode configurar os parâmetros da interface, como o intervalo de espera, no link virtual, da mesma forma que são configurados em uma interface física.
Os dois ABRs no link virtual enviam pacotes OSPF unicast um para o outro, e os roteadores OSPF intermediários transmitem esses pacotes OSPF como pacotes IP normais.
Área de stub e área totalmente stub
Uma área de stub não distribui LSAs do Tipo 5 para reduzir o tamanho da tabela de roteamento e os LSAs anunciados dentro da área. O ABR da área de stub anuncia uma rota padrão em um LSA Tipo 3 para que os roteadores da área possam acessar redes externas por meio da rota padrão.
Para reduzir ainda mais o tamanho da tabela de roteamento e os LSAs anunciados, você pode configurar a área de stub como uma área totalmente stub. O ABR de uma área de stub total não anuncia rotas interáreas ou LSAs externas.
rotas. Ele anuncia uma rota padrão em um LSA Tipo 3 para que os roteadores da área possam acessar redes externas por meio da rota padrão.
Área NSSA e área totalmente NSSA
Uma área NSSA não importa LSAs externos de AS (LSAs Tipo 5), mas pode importar LSAs Tipo 7 gerados pelo NSSA ASBR. O NSSA ABR converte LSAs do Tipo 7 em LSAs do Tipo 5 e anuncia os LSAs do Tipo 5 para outras áreas.
Conforme mostrado na Figura 4, o AS OSPF contém a Área 1, a Área 2 e a Área 0. Os outros dois ASs executam RIP. A Área 1 é uma área NSSA em que o ASBR redistribui rotas RIP em LSAs do tipo 7 para a Área 1. Ao receber os LSAs do tipo 7, o ABR NSSA os converte em LSAs do tipo 5 e anuncia os LSAs do tipo 5 para a Área 0.
O ASBR da Área 2 redistribui rotas RIP em LSAs do Tipo 5 para o domínio de roteamento OSPF. No entanto, a Área 1 não recebe LSAs do Tipo 5 porque é uma área NSSA.
Figura 4 Área da NSSA
Tipos de roteadores
Conforme mostrado na Figura 5, os roteadores OSPF são classificados em diferentes tipos, incluindo roteadores internos, ABRs, roteadores de backbone e ASBRs.
Figura 5 Tipos de roteadores OSPF
Roteador interno
Todas as interfaces em um roteador interno pertencem a uma área OSPF.
ABR
Um ABR pertence a mais de duas áreas, uma das quais deve ser a área de backbone. O ABR conecta a área de backbone a uma área que não é de backbone. Um ABR e a área de backbone podem ser conectados por meio de um link físico ou lógico.
Roteador de backbone
Pelo menos uma interface de um roteador de backbone deve residir na área de backbone. Todos os ABRs e roteadores internos na Área 0 são roteadores de backbone.
ASBR
Um ASBR troca informações de roteamento com outro AS. Um ASBR pode não residir na borda do AS. Ele pode ser um roteador interno ou um ABR.
Tipos de rota
O OSPF prioriza as rotas nos seguintes níveis de rota:
∙ Rota dentro da área.
∙ Rota entre áreas.
∙ Rota externa tipo 1.
∙ Rota externa tipo 2.
As rotas intra-área e inter-área descrevem a topologia de rede do AS. As rotas externas descrevem as rotas para ASs externos.
Uma rota externa Tipo 1 tem alta credibilidade. O custo de uma rota externa Tipo 1 = o custo do roteador até o ASBR correspondente + o custo do ASBR até o destino da rota externa.
Uma rota externa do Tipo 2 tem baixa credibilidade. O OSPF considera que o custo do ASBR até o destino de uma rota externa Tipo 2 é muito maior do que o custo do ASBR até um roteador interno do OSPF. O custo de uma rota externa Tipo 2 = o custo do ASBR até o destino da rota externa Tipo 2. Se duas rotas do Tipo 2 para o mesmo destino tiverem o mesmo custo, o OSPF levará em consideração o custo do roteador até o ASBR para determinar a melhor rota.
ID do roteador
Um ID de roteador identifica de forma exclusiva um roteador em um AS. Para que um roteador execute o OSPF, ele deve ter uma ID de roteador. Você pode especificar manualmente uma ID de roteador ou usar a ID de roteador global para um processo OSPF.
Configuração manual
Ao criar um processo OSPF, você pode especificar manualmente um ID de roteador. Para garantir que a ID do roteador seja exclusiva no AS, você pode especificar o endereço IP de uma interface no roteador como a ID do roteador.
Usando a ID do roteador global
Se você não especificar uma ID de roteador ao criar um processo OSPF, será usada a ID de roteador global. Como prática recomendada, especifique manualmente uma ID de roteador ou habilite o processo OSPF para obter automaticamente uma ID de roteador ao criar o processo OSPF.
Cálculo da rota
O OSPF calcula as rotas em uma área da seguinte forma:
∙ Cada roteador gera LSAs com base na topologia da rede ao seu redor e os envia a outros roteadores em pacotes de atualização.
Cada roteador OSPF coleta LSAs de outros roteadores para compor um LSDB. Um LSA descreve a topologia de rede em torno de um roteador, e o LSDB descreve toda a topologia de rede da área.
∙ Cada roteador transforma o LSDB em um gráfico direcionado ponderado que mostra a topologia da área. Todos os roteadores da área têm o mesmo gráfico.
∙ Cada roteador usa o algoritmo SPF para calcular uma árvore de caminho mais curto que mostra as rotas para os nós da área. O próprio roteador é a raiz da árvore.
Tipos de rede OSPF
O OSPF classifica as redes nos seguintes tipos, dependendo dos diferentes protocolos da camada de link:
∙ Broadcast - Se o protocolo da camada de link for Ethernet ou FDDI, o OSPF considerará o tipo de rede como broadcast por padrão. Em uma rede de broadcast, os pacotes hello, LSU e LSAck são multicast para
224.0.0.5, que identifica todos os roteadores OSPF, ou para 224.0.0.6, que identifica o DR e o BDR. Os pacotes DD e os pacotes LSR são unicast.
- NBMA - Se o protocolo da camada de link for Frame Relay, ATM ou X.25, o OSPF considerará o tipo de rede como NBMA por padrão. Os pacotes OSPF são unicast em uma rede NBMA.
- P2MP - Nenhum link é do tipo P2MP por padrão. O P2MP deve ser uma conversão de outros tipos de rede, como NBMA. Em uma rede P2MP, os pacotes OSPF são multicast para 224.0.0.5.
- P2P - Se o protocolo da camada de link for PPP ou HDLC, o OSPF considerará o tipo de rede como P2P. Em uma rede P2P, os pacotes OSPF são multicast para 224.0.0.5.
Veja a seguir as diferenças entre as redes NBMA e P2MP:
- As redes NBMA são totalmente mescladas. Não é necessário que as redes P2MP tenham malha completa.
- As redes NBMA exigem a eleição de DR e BDR. As redes P2MP não têm DR ou BDR.
- Em uma rede NBMA, os pacotes OSPF são unicast e os vizinhos são configurados manualmente. Em uma rede P2MP, os pacotes OSPF são multicast por padrão, e você pode configurar o OSPF para pacotes de protocolo unicast.
DR e BDR
Mecanismo DR e BDR
Em uma rede broadcast ou NBMA, dois roteadores quaisquer devem estabelecer uma adjacência para trocar informações de roteamento entre si. Se houver n roteadores na rede, serão estabelecidas n(n-1)/2 adjacências. Qualquer alteração na topologia da rede resulta em um aumento no tráfego para sincronização de rotas, o que consome uma grande quantidade de recursos do sistema e de largura de banda.
O uso dos mecanismos DR e BDR pode resolver esse problema.
- DR - Eleito para anunciar informações de roteamento entre outros roteadores. Se o DR falhar, os roteadores da rede deverão eleger outro DR e sincronizar as informações com o novo DR. O uso desse mecanismo sem o BDR consome muito tempo e está sujeito a erros de cálculo de rota.
- BDR-Eleito junto com o DR para estabelecer adjacências com todos os outros roteadores. Se o DR falhar, o BDR se tornará imediatamente o novo DR, e os outros roteadores elegerão um novo BDR.
Os roteadores que não sejam o DR e o BDR são chamados de DR Others. Eles não estabelecem adjacências entre si, portanto, o número de adjacências é reduzido.
A função de um roteador é específica da sub-rede (ou interface). Ele pode ser um DR em uma interface e um BDR ou DR Outro em outra interface.
Conforme mostrado na Figura 6, as linhas sólidas são links físicos Ethernet e as linhas tracejadas representam as adjacências OSPF. Com o DR e o BDR, apenas sete adjacências são estabelecidas.
Figura 6 DR e BDR em uma rede
OBSERVAÇÃO:
No OSPF, vizinho e adjacência são conceitos diferentes. Após a inicialização, o OSPF envia um pacote hello em cada interface OSPF. Um roteador receptor verifica os parâmetros no pacote. Se os parâmetros corresponderem aos seus, o roteador receptor considera o roteador remetente um vizinho OSPF. Dois vizinhos OSPF estabelecem uma relação de adjacência depois de sincronizarem seus LSDBs por meio da troca de pacotes DD e LSAs.
Eleição de DR e BDR
A eleição de DR é realizada em redes broadcast ou NBMA, mas não em redes P2P e P2MP.
Os roteadores em uma rede de broadcast ou NBMA elegem o DR e o BDR por prioridade e ID do roteador. Os roteadores com um valor de prioridade de roteador maior que 0 são candidatos à eleição de DR e BDR.
Os votos da eleição são pacotes hello. Cada roteador envia o DR eleito por ele mesmo em um pacote hello para todos os outros roteadores. Se dois roteadores na rede se declararem como DR, o roteador com a prioridade mais alta vence. Se as prioridades do roteador forem as mesmas, o roteador com o ID de roteador mais alto vence.
Se um roteador com prioridade mais alta se tornar ativo após a eleição do DR e do BDR, ele não poderá substituir o DR ou o BDR até que uma nova eleição seja realizada. Portanto, o DR de uma rede pode não ser o roteador com a prioridade mais alta, e o BDR pode não ser o roteador com a segunda prioridade mais alta.
Protocolos e padrões
- RFC 1245, análise do protocolo OSPF
- RFC 1246, Experiência com o protocolo OSPF
- RFC 1370, Declaração de aplicabilidade para OSPF
- RFC 1765, Estouro de banco de dados OSPF
- RFC 1793, Extensão do OSPF para suportar circuitos de demanda
- RFC 2154, OSPF com assinaturas digitais
- RFC 2328, OSPF Versão 2
- RFC 3101, opção NSSA (Not-So-Stubby Area) do OSPF
- RFC 3166, solicitação para mover a RFC 1403 para o status histórico
- RFC 3509, Implementações alternativas de roteadores de borda de área OSPF
- RFC 4167, Relatório de implementação de reinício gracioso do OSPF
- RFC 4750, Base de informações de gerenciamento do OSPF versão 2
- RFC 4811, Ressincronização LSDB fora de banda do OSPF
- RFC 4812, Sinalização de reinício do OSPF
- RFC 5088, Extensões do protocolo OSPF para descoberta de elementos de computação de caminho (PCE)
- RFC 5250, A opção OSPF Opaque LSA
- RFC 5613, Sinalização de Link-Local OSPF
- RFC 5642, Mecanismo de troca dinâmica de nomes de host para OSPF
- RFC 5709, Autenticação criptográfica HMAC-SHA do OSPFv2
- RFC 5786, Anunciando os endereços locais de um roteador nas extensões de engenharia de tráfego (TE) do OSPF
- RFC 6571, Aplicabilidade do LFA (Loop-Free Alternate) em redes de provedores de serviços (SP)
- RFC 6860, Ocultando redes somente de trânsito no OSPF
- RFC 6987, anúncio de roteador de stub do OSPF
Visão geral das tarefas do OSPF
Para configurar o OSPF, execute as seguintes tarefas:
- Configuração das funções básicas do OSPF
- Ativação de um processo OSPF
- Criação de uma área OSPF
- Ativação do OSPF
- (Opcional.) Configuração das áreas stub e NSSA do OSPF
- Configuração de uma área de stub
- Configuração de uma área NSSA
- Configuração de um link virtual
- (Opcional.) Configuração dos tipos de rede OSPF
- Configuração do tipo de rede de broadcast para uma interface
- Configuração do tipo de rede NBMA para uma interface
- Configuração do tipo de rede P2MP para uma interface
- Configuração do tipo de rede P2P para uma interface
- (Opcional.) Configuração do controle de rota OSPF
- Configuração da compactação de rotas entre áreas do OSPF
- Configuração da compactação de rotas redistribuídas
- Configuração da filtragem de rotas OSPF recebidas
- Configuração da filtragem de LSA tipo 3
- Definição de um custo OSPF para uma interface
- Configuração da preferência OSPF
- Configuração de rotas de descarte para redes de resumo
- Redistribuição de rotas de outro protocolo de roteamento
- Redistribuição de uma rota padrão
- Anunciar uma rota de host
- (Opcional.) Configuração dos temporizadores OSPF
- Configuração de temporizadores de pacotes OSPF
- Configuração do atraso de transmissão de LSA
- Definição do intervalo de cálculo do SPF
- Configuração do intervalo mínimo de chegada de LSA
- Configuração do intervalo de geração de LSA
- Configuração do intervalo de estouro de saída do OSPF
- (Opcional.) Configuração dos parâmetros de pacotes OSPF
- Desativar o recebimento e o envio de pacotes OSPF pelas interfaces
- Adição do MTU da interface aos pacotes DD
- Configuração do valor DSCP para pacotes OSPF de saída
- Configuração do comprimento máximo dos pacotes OSPF que podem ser enviados por uma interface
- Configuração da taxa de transmissão da LSU
- (Opcional.) Controle da geração, do anúncio e da recepção de LSA
- Configuração do número máximo de LSAs externos no LSDB
- Filtragem de LSAs de saída em uma interface
- Filtragem de LSAs para o vizinho especificado
- (Opcional.) Aceleração da velocidade de convergência do OSPF
- Ativação do OSPF ISPF
- Configuração da supressão de prefixo
- Configuração da priorização de prefixos
- Configuração do OSPF PIC
- (Opcional.) Configuração de recursos avançados do OSPF
- Configuração de roteadores stub
- Compatibilidade com a RFC 1583
- (Opcional.) Aumentar a disponibilidade do OSPF
- Configuração do OSPF GR
- Configuração do NSR do OSPF
- Configuração de BFD para OSPF
- Configuração de OSPF FRR
- (Opcional.) Configuração dos recursos de segurança do OSPF
- Configuração da autenticação OSPF
- Configuração do GTSM para OSPF
- (Opcional.) Configuração do registro OSPF e das notificações SNMP
- Registro de alterações no estado do vizinho
- Configuração do recurso de registro do OSPF
- Configuração do gerenciamento de rede OSPF
- Configuração do número máximo de entradas de solução de problemas de relacionamento com vizinhos OSPF
Configuração das funções básicas do OSPF
Ativação de um processo OSPF
- Entre na visualização do sistema.
system-view- (Opcional.) Configure uma ID de roteador global.
router id router-idPor padrão, nenhuma ID de roteador global é configurada.
Se nenhuma ID de roteador global estiver configurada, o endereço IP mais alto da interface de loopback, se houver, será usado como ID de roteador. Se nenhum endereço IP de interface de loopback estiver disponível, o endereço IP mais alto da interface física será usado, independentemente do status da interface (ativo ou inativo).
- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *Por padrão, o OSPF está desativado.
- (Opcional.) Configure uma descrição para o processo OSPF.
description textPor padrão, nenhuma descrição é configurada para o processo OSPF.
Como prática recomendada, configure uma descrição para cada processo OSPF.
Criação de uma área OSPF
- Entre na visualização do sistema.
system-view- (Opcional.) Configure uma ID de roteador global.
router id router-idPor padrão, nenhum ID de roteador global é configurado.
- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *Por padrão, o OSPF está desativado.
- (Opcional.) Configure uma descrição para o processo OSPF.
description textPor padrão, nenhuma descrição é configurada para o processo OSPF.
Como prática recomendada, configure uma descrição para cada processo OSPF.
- Crie uma área OSPF e entre na visualização de área OSPF.
area area-id- (Opcional.) Configure uma descrição para a área.
description textPor padrão, nenhuma descrição é configurada para a área.
Como prática recomendada, configure uma descrição para cada área OSPF.
- (Opcional.) Excluir interfaces na área OSPF da topologia de base:
capability default-exclusionPor padrão, as interfaces em uma área OSPF pertencem à topologia de base.
Para estabelecer corretamente a relação de vizinhança, execute essa tarefa tanto no dispositivo local quanto no dispositivo vizinho.
Ativação do OSPF
Sobre vários processos e VPNs
Para ativar o OSPF em um roteador, é necessário executar as seguintes tarefas:
- Crie um processo OSPF.
- Crie uma área OSPF para o processo.
- Especifique uma rede na área.
A interface conectada à rede executará o processo OSPF na área. O OSPF anuncia rotas diretas da interface.
O OSPF é compatível com vários processos. Para executar vários processos OSPF, você deve especificar um ID para cada processo. As IDs de processo entram em vigor localmente e não influenciam a troca de pacotes entre os roteadores . Dois roteadores com IDs de processo diferentes podem trocar pacotes.
Restrições e diretrizes para ativar o OSPF
Ao configurar o OSPF em uma interface, siga estas restrições e diretrizes:
- Você pode ativar o OSPF na rede em que a interface reside ou ativar diretamente o OSPF nessa interface. Se você configurar ambos, o último terá precedência.
- Se o processo e a área OSPF especificados não existirem, a operação criará um processo e uma área OSPF para a interface. A desativação de um processo OSPF em uma interface não exclui o processo OSPF ou a área.
Ativação do OSPF em uma rede
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Entre na visualização de área OSPF.
area area-id- Especifique uma rede para permitir que a interface anexada à rede execute o processo OSPF na área.
network ip-address wildcard-maskPor padrão, nenhuma rede é especificada para ativar o OSPF na interface anexada à rede. Uma rede pode ser adicionada a apenas uma área.
Ativação do OSPF em uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilite um processo OSPF na interface.
ospf process-id area area-id [ exclude-subip ]Por padrão, o OSPF está desativado em uma interface.
Configuração das áreas stub e NSSA do OSPF
Sobre a configuração da área de stub e NSSA do OSPF
Esta tarefa permite que você configure uma área OSPF como área stub ou área NSSA. Também permite que você crie um link virtual se não for possível obter conectividade entre uma área não-backbone e uma área backbone ou na área backbone.
Configuração de uma área de stub
Sobre a configuração da área de stub
É possível configurar uma área não-backbone em uma borda de AS como uma área stub. Para isso, execute o comando stub em todos os roteadores anexados à área. O tamanho da tabela de roteamento é reduzido porque os LSAs do tipo 5 não serão inundados dentro da área stub. O ABR gera uma rota padrão para a área de stub, de modo que todos os pacotes destinados a fora do AS são enviados por meio da rota padrão.
Para reduzir ainda mais o tamanho da tabela de roteamento e as informações de roteamento trocadas na área de stub, configure uma área totalmente stub usando o comando stub no-summary no ABR. As rotas externas AS e as rotas interáreas não serão distribuídas para a área. Todos os pacotes destinados a fora do AS ou da área serão enviados ao ABR para encaminhamento.
Uma área stub ou totalmente stub não pode ter um ASBR porque as rotas externas não podem ser distribuídas para a área.
Restrições e diretrizes
Não configure a área de backbone como uma área de stub ou totalmente stub.
Para configurar uma área como uma área de stub, execute o comando stub em todos os roteadores anexados à área.
Para configurar uma área como uma área totalmente stub, execute o comando stub em todos os roteadores anexados à área e execute o comando stub no-summary no ABR.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Entrar na visualização de área.
area area-id- Configure a área como uma área de stub.
stub [ default-route-advertise-always | no-summary ] *Por padrão, nenhuma área de stub está configurada.
- (Opcional.) Defina um custo para a rota padrão anunciada para a área de stub.
default cost cost-valuePor padrão, o custo da rota padrão anunciada para a área de stub é 1.
Esse comando só tem efeito no ABR de uma área stub ou de uma área totalmente stub.
Configuração de uma área NSSA
Sobre a configuração da área NSSA
Uma área de stub não pode importar rotas externas, mas uma área NSSA pode importar rotas externas para o domínio de roteamento OSPF e, ao mesmo tempo, manter outras características da área de stub.
Para configurar uma área como uma área totalmente NSSA, use o comando nssa no-summary. O ABR da área não anuncia rotas entre áreas para a área.
Restrições e diretrizes
Não configure a área de backbone como uma área NSSA ou totalmente NSSA.
Para configurar uma área NSSA, configure o comando nssa em todos os roteadores anexados à área.
Para configurar uma área totalmente NSSA, configure o comando nssa em todos os roteadores anexados à área e configure o comando nssa no-summary no ABR.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Entrar na visualização de área.
area area-id- Configure a área como uma área NSSA.
nssa [ default-route-advertise [ cost cost-value | nssa-only |
route-policy route-policy-name | type type ] * | no-import-route |
no-summary | suppress-fa | [ [ [ translate-always ]
[ translate-ignore-checking-backbone ] ] | translate-never ] |
translator-stability-interval value ] *Por padrão, nenhuma área é configurada como uma área NSSA.
- (Opcional.) Defina um custo para a rota padrão anunciada para a área NSSA.
default cost cost-valuePor padrão, o custo da rota padrão anunciada para a área NSSA é 1.
Esse comando só tem efeito no ABR/ASBR em uma área NSSA ou em uma área totalmente NSSA.
Configuração de um link virtual
Sobre a configuração do link virtual
Você pode configurar um link virtual para manter a conectividade entre uma área não-backbone e o backbone, ou no próprio backbone.
Restrições e diretrizes
Um link virtual não pode atravessar uma área stub, uma área totalmente stub, uma área NSSA ou uma área totalmente NSSA.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Entre na visualização de área OSPF.
area area-id- Configurar um link virtual.
vlink-peer router-id [ dead seconds | hello seconds | { { hmac-md5 | md5 }
key-id { cipher | plain } string | simple { cipher | plain } string } |
retransmit seconds | trans-delay seconds ] *Configure esse comando em ambas as extremidades de um link virtual. Os intervalos hello e dead devem ser idênticos em ambas as extremidades do link virtual.
Configuração dos tipos de rede OSPF
Com base no protocolo da camada de link, o OSPF classifica as redes em diferentes tipos, incluindo broadcast, NBMA, P2MP e P2P.
Restrições e diretrizes para a configuração de tipos de rede OSPF
Se algum roteador em uma rede de broadcast não for compatível com multicasting, altere o tipo de rede para NBMA.
Se houver apenas dois roteadores executando OSPF em um segmento de rede, você poderá alterar o tipo de rede para P2P para economizar custos.
Duas interfaces de transmissão, NBMA e P2MP podem estabelecer uma relação de vizinhança somente quando estiverem no mesmo segmento de rede.
Configuração do tipo de rede de broadcast para uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o tipo de rede OSPF para a interface como broadcast.
ospf network-type broadcastPor padrão, o tipo de rede de uma interface é broadcast.
- (Opcional.) Defina uma prioridade de roteador para a interface.
ospf dr-priority priorityA prioridade padrão do roteador é 1.
Configuração do tipo de rede NBMA para uma interface
Restrições e diretrizes
Depois de configurar o tipo de rede como NBMA, você deve especificar os vizinhos e suas prioridades de roteador, pois as interfaces NBMA não podem encontrar vizinhos por meio da transmissão de pacotes hello.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o tipo de rede OSPF para a interface como NBMA.
ospf network-type nbmaPor padrão, o tipo de rede de uma interface é broadcast.
- (Opcional.) Defina uma prioridade de roteador para a interface.
ospf dr-priority priorityA prioridade padrão do roteador para uma interface é 1.
A prioridade do roteador configurada com esse comando é para a eleição do DR.
- Retornar à visualização do sistema.
quit- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Especifique um vizinho NBMA.
peer ip-address [ dr-priority priority ]Por padrão, nenhum vizinho é especificado.
A prioridade configurada com esse comando indica se um vizinho tem o direito de eleição ou não. Se você configurar a prioridade do roteador para um vizinho como 0, o roteador local determinará que o vizinho não tem direito de escolha. Ele não enviará pacotes hello para esse vizinho. No entanto, se o roteador local for o DR ou o BDR, ele ainda enviará pacotes hello ao vizinho para estabelecer uma relação de vizinhança.
Configuração do tipo de rede P2MP para uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o tipo de rede OSPF para a interface como P2MP.
ospf network-type p2mp [ unicast ]Por padrão, o tipo de rede de uma interface é broadcast.
- Retornar à visualização do sistema.
quit- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Especifique um vizinho P2MP.
peer ip-address [ cost cost-value ]Por padrão, nenhum vizinho é especificado
Essa etapa é necessária se o tipo de rede da interface for P2MP unicast.
Configuração do tipo de rede P2P para uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o tipo de rede OSPF para a interface como P2P.
ospf network-type p2p [ peer-address-check ]Por padrão, o tipo de rede de uma interface é broadcast.
Configuração do controle de rotas OSPF
Esta seção descreve como controlar o anúncio e o recebimento de informações de roteamento do OSPF, bem como a redistribuição de rotas de outros protocolos.
Configuração da compactação de rotas entre áreas do OSPF
Sobre a compactação de rotas entre áreas do OSPF
A sumarização de rotas entre áreas do OSPF reduz as informações de roteamento trocadas entre as áreas e o tamanho das tabelas de roteamento, além de melhorar o desempenho do roteamento.
A sumarização de rotas interáreas do OSPF permite que um ABR sumarize redes contíguas em uma única rede e anuncie a rede para outras áreas. Por exemplo, três redes internas 19.1.1.0/24, 19.1.2.0/24 e 19.1.3.0/24 estão disponíveis em uma área. Você pode configurar o ABR para resumir as três redes na rede 19.1.0.0/16 e anunciar a rede resumida para outras áreas em um LSA Tipo 3. Essa configuração reduz a escala de LSDBs em roteadores de outras áreas e a influência de alterações na topologia.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Entre na visualização de área OSPF.
area area-id- Configurar a compactação de rotas ABR.
abr-summary ip-address { mask-length | mask } [ advertise |
not-advertise ] [ cost cost-value ]Por padrão, a compactação de rotas não é configurada em um ABR.
Configuração da compactação de rotas redistribuídas
Sobre a compactação de rotas redistribuídas
Execute esta tarefa para permitir que um ASBR sumarize rotas externas dentro do intervalo de endereços especificado em uma única rota. O ASBR anuncia somente LSAs do tipo 5 para reduzir o número de LSAs no LSDB.
Um ASBR pode resumir rotas nos seguintes LSAs:
- LSAs do tipo 5.
- LSAs do tipo 7 em uma área NSSA.
Restrições e diretrizes
Se um ASBR (também um ABR) for um tradutor em uma área NSSA, ele resumirá as rotas em LSAs do Tipo 5 traduzidos de LSAs do Tipo 7. Se não for um tradutor, ele não resumirá rotas em LSAs do tipo 5 traduzidos de LSAs do tipo 7.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Configurar a sumarização de rotas ASBR.
asbr-summary ip-address { mask-length | mask } [ cost cost-value |
not-advertise | nssa-only | tag tag ] *Por padrão, a compactação de rotas não é configurada em um ASBR.
Configuração da filtragem de rotas OSPF recebidas
Sobre os métodos de filtragem
Execute essa tarefa para filtrar rotas calculadas usando LSAs recebidos. Os seguintes métodos de filtragem estão disponíveis:
- Use uma ACL ou uma lista de prefixos IP para filtrar as informações de roteamento por endereço de destino.
- Use a opção gateway prefix-list-name para filtrar as informações de roteamento pelo próximo salto.
- Use uma ACL ou uma lista de prefixos IP para filtrar as informações de roteamento por endereço de destino. Ao mesmo tempo, use a opção gateway prefix-list-name para filtrar as informações de roteamento pelo próximo salto.
- Use a opção route-policy route-policy-name para filtrar as informações de roteamento.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Configure o OSPF para filtrar rotas calculadas usando LSAs recebidos.
filter-policy { ipv4-acl-number [ gateway prefix-list-name ] | gateway
prefix-list-name | prefix-list prefix-list-name [ gateway
prefix-list-name ] | route-policy route-policy-name } import
Por padrão, o OSPF aceita todas as rotas calculadas usando LSAs recebidos.
Configuração da filtragem de LSA tipo 3
Sobre a filtragem de LSA tipo 3
Execute esta tarefa para filtrar os LSAs do tipo 3 anunciados na área local ou em outras áreas em um ABR.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Entre na visualização de área OSPF.
area area-id- Configurar a filtragem de LSA tipo 3.
filter-policy { ipv4-acl-number [ gateway prefix-list-name ] | gateway
prefix-list-name | prefix-list prefix-list-name [ gateway
prefix-list-name ] | route-policy route-policy-name } importPor padrão, o ABR não filtra LSAs do tipo 3.
Definição de um custo OSPF para uma interface
Sobre a configuração de um custo OSPF para uma interface
Defina um custo OSPF para uma interface usando um dos métodos a seguir:
- Defina o valor do custo na visualização da interface.
- Defina um valor de referência de largura de banda para a interface. O OSPF calcula o custo com esta fórmula: Custo OSPF da interface = Valor de referência da largura de banda (100 Mbps) / Largura de banda esperada da interface (Mbps). A largura de banda esperada de uma interface é configurada com o comando bandwidth (consulte Referência de comandos de interface).
- Se o custo calculado for maior que 65535, o valor de 65535 será usado. Se o custo calculado for menor que 1, será usado o valor 1.
- Se nenhum valor de referência de custo ou largura de banda estiver configurado para uma interface, o OSPF calculará o custo da interface com base na largura de banda da interface e no valor padrão de referência de largura de banda.
Definição de um custo OSPF para uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Definir um custo OSPF para a interface.
ospf cost cost-valuePor padrão, o custo do OSPF é calculado de acordo com a largura de banda da interface. Para uma interface de loopback, o custo do OSPF é 0 por padrão.
Definição de um valor de referência de largura de banda
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Defina um valor de referência de largura de banda.
bandwidth-reference valueA configuração padrão é 100 Mbps.
Configuração da preferência OSPF
Sobre a preferência OSPF
Um roteador pode executar vários protocolos de roteamento, e a cada protocolo é atribuída uma preferência. Se houver várias rotas disponíveis para o mesmo destino, a que tiver a preferência de protocolo mais alta será selecionada como a melhor rota.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Defina uma preferência para OSPF.
preference [ ase ] { preference | route-policy route-policy-name } *Por padrão, a preferência das rotas internas do OSPF é 10 e a preferência das rotas externas do OSPF é 150.
Configuração de rotas de descarte para redes de resumo
Sobre o descarte de rotas para redes de resumo
Execute esta tarefa em um ABR ou ASBR para especificar se deve gerar rotas de descarte para redes de resumo. Você também pode especificar uma preferência para as rotas de descarte.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Configurar rotas de descarte para redes de resumo.
discard-route { external { preference | suppression } | internal
{ preference | suppression } } *
Por padrão, o ABR ou ASBR gera rotas de descarte para redes de resumo e a preferência padrão de rotas de descarte é 255.
Redistribuição de rotas de outro protocolo de roteamento
Sobre a redistribuição de rotas de outro protocolo de roteamento
Em um roteador que executa o OSPF e outros protocolos de roteamento, é possível configurar o OSPF para redistribuir rotas de outros protocolos. O OSPF anuncia as rotas em LSAs do tipo 5 ou LSAs do tipo 7. Além disso, você pode configurar o OSPF para filtrar as rotas redistribuídas, de modo que o OSPF anuncie somente as rotas permitidas.
Restrições e diretrizes
O OSPF redistribui apenas as rotas ativas. Para visualizar as informações de status da rota, use o comando display ip routing-table protocol.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Configure o OSPF para redistribuir rotas de outro protocolo de roteamento.
import-route { direct | static } [ cost cost-value | nssa-only |
route-policy route-policy-name | tag tag | type type ] *
import-route { ospf | rip } [ process-id | all-processes ] [ allow-direct
| cost cost-value | nssa-only | route-policy route-policy-name | tag
tag | type type ] *
Por padrão, nenhuma redistribuição de rota é configurada.
- (Opcional.) Configure o OSPF para filtrar rotas redistribuídas.
filter-policy { ipv4-acl-number | prefix-list prefix-list-name }
export [ protocol [ process-id ] ]
Por padrão, o OSPF aceita todas as rotas redistribuídas.
- Configure os parâmetros padrão para rotas redistribuídas (custo, tag e tipo).
default { cost cost-value | tag tag | type type } *
Por padrão, o custo é 1, a tag é 1 e o tipo de rota é 2
Redistribuição de uma rota padrão
Sobre a redistribuição de rotas padrão
O comando import-route não pode redistribuir uma rota externa padrão. Execute esta tarefa para redistribuir uma rota padrão.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Redistribuir uma rota padrão.
default-route-advertise [ [ always | permit-calculate-other ] | cost
cost-value | route-policy route-policy-name | type type ] *
Por padrão, nenhuma rota padrão é redistribuída.
- Configure os parâmetros padrão para rotas redistribuídas (custo, tag e tipo).
default { cost cost-value | tag tag | type type } *
Por padrão, o custo é 1, a tag é 1 e o tipo de rota é 2
Anunciar uma rota de host
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Entrar na visualização de área.
area area-id- Anunciar uma rota de host.
host-advertise ip-address costPor padrão, o OSPF não anuncia rotas de host que não estejam na área.
Configuração de temporizadores OSPF
Sobre a configuração de temporizadores OSPF
Essa tarefa permite que você altere os temporizadores de pacotes OSPF para ajustar a velocidade de convergência e a carga da rede e ajustar o tempo de atraso para o envio de LSAs em links de baixa velocidade.
Configuração de temporizadores de pacotes OSPF
Sobre os temporizadores de pacotes OSPF
Uma interface OSPF inclui os seguintes cronômetros:
- Hello timer - Intervalo para envio de pacotes hello. Ele deve ser idêntico nos vizinhos OSPF.
- Timer de sondagem - Intervalo para envio de pacotes hello a um vizinho que esteja inativo na rede NBMA.
- Dead timer - Intervalo durante o qual, se a interface não receber nenhum pacote hello do vizinho, ela declara que o vizinho está inativo.
- Timer de retransmissão de LSA - Intervalo durante o qual, se a interface não receber nenhum pacote de reconhecimento depois de enviar um LSA ao vizinho, ela retransmite o LSA.
Restrições e diretrizes
O valor padrão para o hello interval e o neighbor dead interval depende do tipo de rede. Quando o tipo de rede de uma interface é alterado, o hello interval e o neighbor dead interval padrão são restaurados. Certifique-se de que duas interfaces vizinhas estejam configuradas com o mesmo hello interval e neighbor dead interval. Configurações inconsistentes afetarão a relação de vizinhança OSPF estabelecimento.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o intervalo de espera.
ospf timer hello secondsO intervalo padrão de hello nas interfaces P2P e de broadcast é de 10 segundos. O intervalo padrão do hello nas interfaces P2MP e NBMA é de 30 segundos.
- Defina o intervalo de sondagem.
ospf timer poll seconds
A configuração padrão é 120 segundos.
O intervalo de sondagem é, no mínimo, quatro vezes maior que o intervalo de espera.
- Defina o intervalo morto.
ospf timer dead seconds
O intervalo morto padrão nas interfaces P2P e de broadcast é de 40 segundos. O intervalo morto padrão nas interfaces P2MP e NBMA é de 120 segundos.
O intervalo morto deve ser, no mínimo, quatro vezes maior do que o intervalo de espera em uma interface.
- Defina o intervalo de retransmissão.
ospf timer retransmit interval
O intervalo de retransmissão padrão é de 5 segundos.
Uma configuração de intervalo de retransmissão muito pequena pode causar retransmissões desnecessárias de LSA. Normalmente, defina um intervalo maior do que o tempo de ida e volta de um pacote entre dois vizinhos.
Configuração do atraso de transmissão de LSA
Sobre a configuração do atraso de transmissão de LSA
Para evitar que os LSAs envelheçam durante a transmissão, defina um atraso de retransmissão de LSA, especialmente para links de baixa velocidade.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o atraso de transmissão do LSA.
ospf trans-delay seconds
O atraso padrão da transmissão de LSA é de 1 segundo.
Definição do intervalo de cálculo do SPF
Sobre a configuração do intervalo de cálculo do SPF
As alterações no LSDB resultam em cálculos de SPF. Quando a topologia muda com frequência, uma grande quantidade de recursos da rede e do roteador é ocupada pelo cálculo do SPF. Você pode ajustar o intervalo de cálculo do SPF para reduzir o impacto.
Em uma rede estável, é usado o intervalo mínimo. Se as alterações na rede se tornarem frequentes, o intervalo de cálculo do SPF aumentará de acordo com o intervalo incremental × 2n-2 para cada cálculo até que o intervalo máximo seja atingido. O valor n é o número de vezes de cálculo.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Defina o intervalo de cálculo do SPF.
spf-schedule-interval maximum-interval [ minimum-interval
[ incremental-interval ] ]
Por padrão, o intervalo máximo é de 5 segundos, o intervalo mínimo é de 50 milissegundos e o intervalo incremental é de 200 milissegundos.
Configuração do intervalo mínimo de chegada de LSA
Sobre a configuração do intervalo mínimo de chegada de LSA
O OSPF descarta todos os LSAs duplicados (com o mesmo tipo de LSA, ID de LS e ID de roteador) dentro do intervalo mínimo de chegada de LSA. Isso ajuda a evitar o uso excessivo da largura de banda e dos recursos do roteador devido a mudanças frequentes na rede.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Defina o intervalo mínimo de chegada de LSA.
lsa-arrival-interval interval
Por padrão, o intervalo mínimo de chegada de LSA é de 1.000 milissegundos.
Configuração do intervalo de geração de LSA
Sobre a configuração do intervalo de geração de LSA
Ajuste o intervalo de geração de LSA para evitar que os recursos da rede e os roteadores sejam sobrecarregados por LSAs no momento de mudanças frequentes na rede.
Em uma rede estável, é usado o intervalo mínimo. Se as alterações na rede se tornarem frequentes, o intervalo de geração de LSA será incrementado pelo intervalo incremental × 2n-2 para cada geração até que o intervalo máximo seja atingido. O valor n é o número de tempos de geração.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Defina o intervalo de geração de LSA.
lsa-generation-interval maximum-interval [ minimum-interval
[ incremental-interval ] ]
Por padrão, o intervalo máximo é de 5 segundos, o intervalo mínimo é de 50 milissegundos e o intervalo incremental é de 200 milissegundos.
Configuração do intervalo de estouro de saída do OSPF
Sobre a configuração do intervalo de estouro de saída do OSPF
Quando o número de LSAs no LSDB excede o limite superior, o LSDB está em um estado de estouro. Nesse estado, o OSPF não recebe nenhum LSA externo e exclui os LSAs externos gerados por ele mesmo para economizar recursos do sistema.
Essa tarefa permite que você configure o intervalo em que o OSPF sai do estado de estouro.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Defina o intervalo em que o OSPF sai do estado de estouro.
lsdb-overflow-interval interval
Por padrão, o intervalo de estouro de saída do OSPF é de 300 segundos. Um intervalo de 0 significa que o OSPF não sai do estado de estouro.
Configuração dos parâmetros de pacotes OSPF
Desativar o recebimento e o envio de pacotes OSPF pelas interfaces
Sobre a desativação de interfaces para recebimento e envio de pacotes OSPF
Para aumentar a adaptabilidade do OSPF e reduzir o consumo de recursos, você pode definir uma interface OSPF como "silenciosa". Uma interface OSPF silenciosa bloqueia os pacotes OSPF e não pode estabelecer nenhum vizinho OSPF
relacionamento. No entanto, outras interfaces no roteador ainda podem anunciar rotas diretas da interface em LSAs de roteador.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Desabilite as interfaces para que não recebam e enviem pacotes OSPF.
silent-interface { interface-type interface-number | all }Por padrão, uma interface OSPF pode receber e enviar pacotes OSPF.
Esse comando desativa apenas as interfaces associadas ao processo atual e não a outros processos. Vários processos OSPF podem desativar a mesma interface para que não receba e envie pacotes OSPF.
Adição do MTU da interface aos pacotes DD
Sobre como adicionar o MTU da interface aos pacotes DD
Por padrão, uma interface OSPF adiciona um valor de 0 ao campo MTU da interface de um pacote DD, em vez do MTU real da interface. Você pode permitir que uma interface adicione seu MTU aos pacotes DD.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Permitir que a interface adicione seu MTU aos pacotes DD.
ospf mtu-enable
Por padrão, a interface adiciona um valor de MTU de 0 aos pacotes DD.
Configuração do valor DSCP para pacotes OSPF de saída
Sobre o valor DSCP
O valor DSCP especifica a precedência dos pacotes de saída.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Defina o valor DSCP para pacotes OSPF de saída.
dscp dscp-valuePor padrão, o valor DSCP para pacotes OSPF de saída é 48.
Configuração do comprimento máximo dos pacotes OSPF que podem ser enviados por uma interface
Sobre a configuração do comprimento máximo dos pacotes OSPF que podem ser enviados por uma interface
Essa tarefa permite limitar o tamanho dos pacotes OSPF enviados por uma interface.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o comprimento máximo dos pacotes OSPF que podem ser enviados por uma interface.
ospf packet-size valuePor padrão, o comprimento máximo dos pacotes OSPF que uma interface pode enviar é igual à MTU da interface.
Configuração da taxa de transmissão da LSU
Sobre a configuração da taxa de transmissão da LSU
Durante a sincronização do LSDB, se o roteador local tiver vários vizinhos, ele deverá enviar muitas LSUs para cada vizinho. Quando um vizinho recebe LSUs em excesso em um curto período de tempo, podem ocorrer os seguintes eventos:
- O vizinho tem seu desempenho prejudicado porque usa muitos recursos do sistema para processar os pacotes LSU recebidos.
- O vizinho descarta os pacotes hello usados para manter o relacionamento de vizinhança porque está ocupado lidando com as LSUs. Como resultado, o relacionamento de vizinhança é interrompido. Para restabelecer o relacionamento com o vizinho, o roteador local deve enviar mais LSUs para o vizinho. Isso agrava a degradação do desempenho.
Essa tarefa permite que você limite a taxa de transmissão da LSU definindo o intervalo de transmissão da LSU e o número máximo de LSUs que podem ser enviadas em cada intervalo.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o OSPF para limitar a taxa de transmissão da LSU.
ospf lsu-flood-control [ interval count ]
Por padrão, o OSPF não limita a taxa de transmissão da LSU.
O uso inadequado desse comando pode causar roteamento anormal. Como prática recomendada, execute esse comando com os valores padrão.
- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- (Opcional.) Defina o intervalo de transmissão da LSU e o número máximo de LSUs que podem ser enviadas em cada intervalo.
transmit-pacing interval interval count count
Por padrão, uma interface OSPF envia um máximo de três pacotes LSU a cada 20 milissegundos.
Controle da geração, do anúncio e da recepção de LSA
Configuração do número máximo de LSAs externos no LSDB
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Defina o número máximo de LSAs externos no LSDB.
lsdb-overflow-limit number
Por padrão, o número máximo de LSAs externos no LSDB não é limitado.
Filtragem de LSAs de saída em uma interface
Sobre a filtragem de LSAs de saída em uma interface
Para reduzir o tamanho do LSDB do vizinho e economizar largura de banda, você pode executar essa tarefa em uma interface para filtrar os LSAs a serem enviados ao vizinho.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Filtrar LSAs de saída na interface.
ospf database-filter { all | { ase [ acl ipv4-acl-number ] | nssa [ acl
ipv4-acl-number ] | summary [ acl ipv4-acl-number ] } * }
Por padrão, os LSAs de saída não são filtrados na interface.
Filtragem de LSAs para o vizinho especificado
Sobre a filtragem de LSAs para o vizinho especificado
Em uma rede P2MP, um roteador pode ter vários vizinhos OSPF do tipo P2MP. Execute esta tarefa para impedir que o roteador envie LSAs para o vizinho P2MP especificado.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Filtrar LSAs para o vizinho P2MP especificado.
database-filter peer ip-address { all | { ase [ acl ipv4-acl-number ] |
nssa [ acl ipv4-acl-number ] | summary [ acl ipv4-acl-number ] } * }
Por padrão, os LSAs do vizinho P2MP especificado não são filtrados.
Aceleração da velocidade de convergência do OSPF
Ativação do OSPF ISPF
Sobre o ISPF
Quando a topologia muda, o Incremental Shortest Path First (ISPF) calcula apenas a parte afetada do SPT, em vez de todo o SPT.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Habilitar OSPF ISPF.
ispf enable
Por padrão, o OSPF ISPF está ativado.
Configuração da supressão de prefixo
Sobre a supressão de prefixo
Por padrão, uma interface OSPF anuncia todos os seus prefixos em LSAs. Para acelerar a convergência do OSPF, você pode impedir que as interfaces anunciem todos os seus prefixos. Esse recurso ajuda a aumentar a segurança da rede, impedindo o roteamento IP para as redes suprimidas.
Quando a supressão de prefixo está ativada:
- Em redes P2P e P2MP, o OSPF não anuncia links do Tipo 3 em LSAs do Tipo 1. Outras informações de roteamento ainda podem ser anunciadas para garantir o encaminhamento do tráfego.
- Em redes broadcast e NBMA, o DR gera LSAs do Tipo 2 com um comprimento de máscara de 32 para suprimir rotas de rede. Outras informações de roteamento ainda podem ser anunciadas para garantir o encaminhamento do tráfego. Se não houver vizinhos, o DR não anunciará links do Tipo 3 nos LSAs do Tipo 1.
Restrições e diretrizes para supressão de prefixos
Como prática recomendada, configure a supressão de prefixo em todos os roteadores OSPF se quiser usar a supressão de prefixo .
Configuração da supressão de prefixo para um processo OSPF
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Ativar a supressão de prefixo para o processo OSPF.
prefix-suppression
Por padrão, a supressão de prefixo é desativada para um processo OSPF.
Esse recurso não suprime os prefixos de endereços IP secundários, interfaces de loopback e interfaces passivas.
Configuração da supressão de prefixo para uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar a supressão de prefixo para a interface.
ospf prefix-suppression [ disable ]
Por padrão, a supressão de prefixo é desativada em uma interface.
Esse recurso não suprime os prefixos de endereços IP secundários.
Configuração da priorização de prefixos
Sobre a priorização de prefixos
Esse recurso permite que o dispositivo instale prefixos em ordem decrescente de prioridade: crítica, alta, média e baixa. As prioridades dos prefixos são atribuídas por meio de políticas de roteamento. Quando uma rota é atribuída a várias prioridades de prefixo, a rota usa a prioridade mais alta.
Por padrão, as rotas de host OSPF de 32 bits têm prioridade média e as outras rotas têm prioridade baixa.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Ativar a priorização de prefixo.
prefix-priority route-policy route-policy-name
Por padrão, a priorização de prefixo está desativada.
Configuração do OSPF PIC
Sobre o PIC
A Convergência Independente de Prefixo (PIC) permite que o dispositivo acelere a convergência da rede ao ignorar o número de prefixos.
Restrições e diretrizes para o OSPF PIC
Quando tanto o OSPF PIC quanto o OSPF FRR estão configurados, o OSPF FRR entra em vigor. O OSPF PIC aplica-se somente a rotas entre áreas e rotas externas.
Ativação do OSPF PIC
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Habilitar o PIC para OSPF.
pic [ additional-path-always ]
Por padrão, o OSPF PIC está ativado.
Configuração do modo de pacote de controle BFD para PIC OSPF
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilite o modo de pacote de controle BFD para o PIC OSPF.
ospf primary-path-detect bfd ctrl
Por padrão, o modo de pacote de controle BFD está desativado para o OSPF PIC.
Esse modo requer a configuração do BFD nos dois roteadores OSPF do link.
Configuração do modo de pacote de eco BFD para PIC OSPF
- Entre na visualização do sistema.
system-view- Configure o endereço IP de origem dos pacotes de eco BFD.
bfd echo-source-ip ip-addressPor padrão, o endereço IP de origem dos pacotes de eco do BFD não é configurado.
O endereço IP de origem não pode estar no mesmo segmento de rede que qualquer interface local. Para obter mais informações sobre esse comando, consulte Referência de comandos de alta disponibilidade.
- Entre na visualização da interface.
interface interface-type interface-number- Ativar o modo de pacote de eco BFD para PIC OSPF.
ospf primary-path-detect bfd echo
Por padrão, o modo de pacote de eco BFD está desativado para o OSPF PIC.
Esse modo requer a configuração do BFD em um roteador OSPF no link.
Configuração de recursos avançados do OSPF
Configuração de roteadores stub
Sobre roteadores stub
Um roteador stub é usado para controle de tráfego. Ele informa seu status como roteador stub aos roteadores OSPF vizinhos. Os roteadores vizinhos podem ter uma rota para o roteador stub, mas não usam o roteador stub para encaminhar dados.
Os LSAs de roteador do roteador stub podem conter valores diferentes de tipo de link. Um valor de 3 significa um link para uma rede stub, e o custo do link não será alterado por padrão. Para definir o custo do link como 65535, especifique a palavra-chave include-stub no comando stub-router. Um valor de 1, 2 ou 4 significa um link ponto a ponto, um link para uma rede de trânsito ou um link virtual. Nesses links, é usado um valor de custo máximo de 65535. Os vizinhos não enviam pacotes para o roteador stub desde que tenham uma rota com custo menor.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Configure o roteador como um roteador stub.
stub-router [ external-lsa [ max-metric-value ] | include-stub |
on-startup seconds | summary-lsa [ max-metric-value ] ] *
Por padrão, o roteador não está configurado como um roteador stub. Um roteador stub não está relacionado a uma área stub.
Compatibilidade com a RFC 1583
Sobre a compatibilidade com a RFC 1583
A RFC 1583 especifica um método diferente da RFC 2328 para selecionar a rota ideal para um destino em outro AS. Quando várias rotas estão disponíveis para o ASBR, o OSPF seleciona a rota ideal pelo site usando o seguinte procedimento:
- Seleciona a rota com a maior preferência.
- Se a RFC 2328 for compatível com a RFC 1583, todas essas rotas terão a mesma preferência.
- Se a RFC 2328 não for compatível com a RFC 1583, a rota intra-área em uma área não-backbone terá preferência para reduzir a carga da área de backbone. A rota interárea e a rota intraárea na área de backbone têm a mesma preferência.
- Seleciona a rota com o menor custo se duas rotas tiverem a mesma preferência.
- Seleciona a rota com o ID de área de origem maior se duas rotas tiverem o mesmo custo.
Restrições e diretrizes
Para evitar loops de roteamento, defina a compatibilidade RFC 1583 idêntica em todos os roteadores em um domínio de roteamento.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Habilite a compatibilidade com a RFC 1583.
rfc1583 compatible
Por padrão, a compatibilidade com a RFC 1583 está ativada.
Configuração do OSPF GR
Sobre o OSPF GR
O GR garante a continuidade do encaminhamento quando um protocolo de roteamento é reiniciado ou quando ocorre uma alternância ativo/em espera.
São necessários dois roteadores para concluir um processo de GR. Veja a seguir as funções do roteador em um processo de GR:
- GR restarter - Roteador de reinicialização gradual. Ele deve ter capacidade de GR.
- Ajudante de GR - Um vizinho do reiniciador de GR. Ele ajuda o reiniciador de GR a concluir o processo de GR.
O OSPF GR tem os seguintes tipos:
- IETF GR - Usa LSAs opacos para implementar o GR.
- GR não IETF - Usa sinalização local de link (LLS) para anunciar a capacidade de GR e usa sincronização fora da banda para sincronizar o LSDB.
Um dispositivo pode atuar como reiniciador de GR e auxiliar de GR ao mesmo tempo.
Restrições e diretrizes para OSPF GR
Não é possível ativar o OSPF NSR em um dispositivo que atua como reiniciador de GR.
Configuração do reiniciador OSPF GR
Configuração do reiniciador IETF OSPF GR
- Entre na visualização do sistema.
system-view- Habilite o OSPF e entre em sua visualização.
ospf [ process-id | router-id router-id ] *- Ativar o recurso de recepção e anúncio de LSA opaco.
opaque-capability enable
Por padrão, o recurso de recepção e anúncio de LSA opaco está ativado.
- Ativar o IETF GR.
graceful-restart ietf [ global | planned-only ] *
Por padrão, o recurso IETF GR está desativado.
- (Opcional.) Defina o intervalo de GR.
graceful-restart interval intervalPor padrão, o intervalo de GR é de 120 segundos.
Configuração do reiniciador GR OSPF não IETF
- Entre na visualização do sistema.
system-view- Habilite o OSPF e entre em sua visualização.
ospf [ process-id | router-id router-id ] *- Habilite o recurso de sinalização link-local.
enable link-local-signaling
Por padrão, o recurso de sinalização link-local está desativado.
- Ative o recurso de ressincronização fora da banda.
enable out-of-band-resynchronization
Por padrão, o recurso de ressincronização fora de banda está desativado.
- Habilitar GR não IETF.
graceful-restart [ nonstandard ] [ global | planned-only ] *
Por padrão, o recurso GR não IETF está desativado.
- (Opcional.) Defina o intervalo de GR.
graceful-restart interval intervalPor padrão, o intervalo de GR é de 120 segundos.
Configuração do OSPF GR helper
Configuração do auxiliar IETF OSPF GR
- Entre na visualização do sistema.
system-view- Habilite o OSPF e entre em sua visualização.
ospf [ process-id | router-id router-id ] *- Ativar o recurso de recepção e anúncio de LSA opaco.
opaque-capability enable
Por padrão, o recurso de recepção e anúncio de LSA opaco está ativado.
- Ativar o recurso auxiliar de GR.
graceful-restart helper enable [ planned-only ]
Por padrão, o recurso auxiliar de GR está ativado.
- (Opcional.) Ative a verificação rigorosa de LSA para o auxiliar de GR.
graceful-restart helper strict-lsa-checking
Por padrão, a verificação rigorosa de LSA para o auxiliar de GR está desativada.
Quando uma alteração de LSA no auxiliar de GR é detectada, o dispositivo auxiliar de GR sai do modo auxiliar de GR.
Configuração do auxiliar OSPF GR não IETF
- Entre na visualização do sistema.
system-view- Habilite o OSPF e entre em sua visualização.
ospf [ process-id | router-id router-id ] *- Habilite o recurso de sinalização link-local.
enable link-local-signaling
Por padrão, o recurso de sinalização link-local está desativado.
- Ative o recurso de ressincronização fora da banda.
enable out-of-band-resynchronization
Por padrão, o recurso de ressincronização fora de banda está desativado.
- Ativar o auxiliar de GR.
graceful-restart helper strict-lsa-checking
Por padrão, o GR helper está ativado.
- (Opcional.) Ative a verificação rigorosa de LSA para o auxiliar de GR.
graceful-restart helper strict-lsa-checking
Por padrão, a verificação rigorosa de LSA para o auxiliar de GR está desativada.
Quando uma alteração de LSA no auxiliar de GR é detectada, o dispositivo auxiliar de GR sai do modo auxiliar de GR.
Acionamento do OSPF GR
Sobre o acionamento do OSPF GR
Você pode acionar o OSPF GR executando uma alternância entre ativo/em espera ou usando o comando reset ospf process.
Procedimento
Para acionar o OSPF GR, execute o comando reset ospf [ process-id ] process graceful-restart
na visualização do usuário.
Configuração do OSPF NSR
Sobre o OSPF NSR
O roteamento ininterrupto (NSR) faz o backup das informações de estado do link OSPF do processo ativo para o processo em espera. Após uma alternância entre ativo e em espera, o NSR pode concluir a recuperação do estado do link e a regeneração de rotas sem derrubar as adjacências ou afetar os serviços de encaminhamento.
O NSR não exige a cooperação de dispositivos vizinhos para recuperar informações de roteamento e, normalmente, é usado com mais frequência do que o GR.
Restrições e diretrizes
Um dispositivo que tenha o OSPF NSR ativado não pode atuar como reiniciador de GR.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Ativar o NSR do OSPF.
non-stop-routingPor padrão, o NSR do OSPF está desativado.
Esse comando entra em vigor somente para o processo atual. Como prática recomendada, ative o NSR do OSPF para cada processo se houver vários processos OSPF.
Configuração de BFD para OSPF
Sobre o BFD para OSPF
O BFD fornece um mecanismo único para detectar e monitorar rapidamente a conectividade dos links entre os vizinhos do OSPF, o que melhora a velocidade de convergência da rede. Para obter mais informações sobre o BFD, consulte o Guia de configuração de alta disponibilidade.
O OSPF oferece suporte aos seguintes modos de detecção de BFD:
- Detecção de controle bidirecional - Exige que a configuração do BFD seja feita nos dois roteadores OSPF do link.
- Detecção de eco de salto único - Requer que a configuração do BFD seja feita em um roteador OSPF em o link.
Configuração da detecção de controle bidirecional
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilita a detecção de controle bidirecional BFD.
ospf bfd enable
Por padrão, a detecção de controle bidirecional do BFD está desativada.
As duas extremidades de uma sessão BFD devem estar no mesmo segmento de rede e na mesma área.
Configuração da detecção de eco de salto único
- Entre na visualização do sistema.
system-view- Configure o endereço de origem dos pacotes de eco.
bfd echo-source-ip ip-addressPor padrão, o endereço de origem dos pacotes de eco não é configurado.
O endereço IP de origem não pode estar no mesmo segmento de rede que qualquer interface local. Para obter mais informações sobre esse comando, consulte Referência de comandos de alta disponibilidade.
- Entre na visualização da interface.
interface interface-type interface-number- Ativar a detecção de eco de salto único BFD.
ospf bfd enable echo
Por padrão, a detecção de eco de salto único do BFD está desativada.
Configuração de OSPF FRR
Sobre o OSPF FRR
Uma falha de link ou de roteador em um caminho pode causar perda de pacotes até que o OSPF conclua a convergência de roteamento com base na nova topologia de rede. O FRR permite o roteamento rápido para minimizar o impacto de falhas de links ou nós.
Figura 7 Diagrama de rede para OSPF FRR
Conforme mostrado na Figura 7, configure o FRR no Roteador B usando uma política de roteamento para especificar um próximo salto de backup. Quando o link principal falha, o OSPF direciona os pacotes para o próximo salto de backup. Ao mesmo tempo, o OSPF calcula o caminho mais curto com base na nova topologia da rede. Ele encaminha os pacotes pelo caminho após a convergência da rede.
Você pode configurar o OSPF FRR para calcular um próximo salto de backup usando o algoritmo loop free alternate (LFA) ou especificar um próximo salto de backup usando uma política de roteamento.
Restrições e diretrizes para OSPF FRR
Quando tanto o OSPF PIC quanto o OSPF FRR estão configurados, o OSPF FRR entra em vigor.
Configuração do OSPF FRR para usar o algoritmo LFA para calcular um próximo salto de backup
Restrições e diretrizes
Não use o comando fast-reroute lfa junto com o comando vlink-peer.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- (Opcional.) Habilite o LFA em uma interface.
ospf fast-reroute lfa-backup
Por padrão, a interface é ativada com LFA e pode ser selecionada como uma interface de backup.
- Retornar à visualização do sistema.
quit- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Habilite o OSPF FRR para usar o algoritmo LFA para calcular um próximo salto de backup.
fast-reroute lfa [ abr-only ]
Por padrão, o OSPF FRR está desativado.
Se abr-only for especificado, a rota para o ABR será selecionada como o caminho de backup.
Configuração do OSPF FRR para usar um próximo salto de backup especificado em uma política de roteamento
Sobre a especificação de um próximo salto de backup em uma política de roteamento
Antes de executar esta tarefa, use o comando apply fast-reroute backup-interface para especificar um próximo salto de backup em uma política de roteamento para OSPF FRR. Para obter mais informações sobre o comando apply fast-reroute backup-interface e a configuração da política de roteamento, consulte "Configuração de políticas de roteamento".
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Habilite o OSPF FRR para usar um próximo salto de backup especificado em uma política de roteamento.
fast-reroute route-policy route-policy-namePor padrão, o OSPF FRR está desativado.
Configuração do modo de pacote de controle BFD para OSPF FRR
Sobre o modo de pacote de controle BFD para OSPF FRR
Por padrão, o OSPF FRR não usa o BFD para detectar falhas no link primário. Para acelerar a convergência do OSPF, ative o modo de pacote de controle BFD para que o OSPF FRR detecte falhas no link primário. Esse modo requer a configuração do BFD em ambos os roteadores OSPF no link.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilita o modo de pacote de controle BFD para FRR OSPF.
ospf primary-path-detect bfd ctrl
Por padrão, o modo de pacote de controle BFD está desativado para OSPF FRR.
Configuração do modo de pacote de eco BFD para FRR OSPF
Sobre o modo de pacote de eco BFD para OSPF FRR
Por padrão, o OSPF FRR não usa o BFD para detectar falhas no link primário. Para acelerar a convergência do OSPF, ative o modo de pacote de eco do BFD para que o FRR do OSPF detecte falhas no link primário. Esse modo requer a configuração do BFD em um roteador OSPF no link.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o endereço IP de origem dos pacotes de eco BFD.
bfd echo-source-ip ip-addressPor padrão, o endereço IP de origem dos pacotes de eco do BFD não é configurado.
O endereço IP de origem não pode estar no mesmo segmento de rede que o endereço IP de qualquer interface local.
Para obter mais informações sobre esse comando, consulte Referência de comandos de alta disponibilidade.
- Entre na visualização da interface.
interface interface-type interface-number- Ativar o modo de pacote de eco BFD para FRR OSPF.
ospf primary-path-detect bfd echo
Por padrão, o modo de pacote de eco BFD está desativado para FRR OSPF.
Configuração da autenticação OSPF
Sobre a autenticação de área e interface OSPF
Execute esta tarefa para configurar a autenticação de interface e área OSPF.
O OSPF adiciona a chave configurada aos pacotes enviados e usa a chave para autenticar os pacotes recebidos. Somente os pacotes que passam pela autenticação podem ser recebidos. Se um pacote falhar na autenticação, a relação de vizinhança do OSPF não poderá ser estabelecida.
Se você configurar a autenticação OSPF para uma área e uma interface nessa área, a interface usará a autenticação OSPF configurada nela.
Restrições e diretrizes para configurar a autenticação OSPF
O OSPF é compatível com os algoritmos de autenticação MD5 e HMAC-MD5.
A ID das chaves usadas para autenticação só pode estar no intervalo de 0 a 255.
Configuração da autenticação de área OSPF
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Entre na visualização de área.
area area-id- Configurar o modo de autenticação de área.
- Configure a autenticação HMAC-MD5/MD5.
authentication-mode { hmac-md5 | md5 } key-id { cipher | plain }
string
- Configure a autenticação simples.
authentication-mode simple { cipher | plain } string
Por padrão, nenhuma autenticação é configurada.
É necessário configurar o mesmo modo de autenticação e a mesma chave em todos os roteadores de uma área.
Configuração da autenticação da interface OSPF
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configurar o modo de autenticação da interface.
- Configure a autenticação simples.
ospf authentication-mode simple { cipher | plain } string
- Configure a autenticação HMAC-MD5/MD5.
ospf authentication-mode { hmac-md5 | md5 } key-id { cipher | plain }
string
Por padrão, nenhuma autenticação é configurada.
Você deve configurar o mesmo modo de autenticação e a mesma chave na interface local e na interface de par.
Configuração do GTSM para OSPF
Sobre o GTSM
O mecanismo de segurança TTL generalizado (GTSM) protege o dispositivo comparando o valor TTL no cabeçalho IP dos pacotes OSPF de entrada com um intervalo TTL válido. Se o valor TTL estiver dentro do intervalo TTL válido, o pacote será aceito. Caso contrário, o pacote será descartado.
O intervalo TTL válido é de 255 - a contagem de saltos configurada + 1 a 255.
Quando o GTSM está configurado, os pacotes OSPF enviados pelo dispositivo têm um TTL de 255.
O GTSM verifica os pacotes OSPF de vizinhos comuns e vizinhos de links virtuais. Ele não verifica os pacotes OSPF de vizinhos de links fictícios. Para obter informações sobre o GTSM para links fictícios OSPF, consulte o MPLS Configuration Guide.
Você pode configurar o GTSM na visualização de área OSPF ou na visualização de interface.
- A configuração na visualização de área OSPF se aplica a todas as interfaces OSPF na área.
- A configuração na visualização da interface tem precedência sobre a visualização da área OSPF.
Restrições e diretrizes para o GTSM
Para usar o GTSM, você deve configurá-lo nos dispositivos local e de pares. Você pode especificar valores diferentes de hop-count para eles.
Configuração do GTSM na visualização de área OSPF
Restrições e diretrizes
O GTSM na visualização de área OSPF aplica-se a todas as interfaces OSPF na área. O GTSM verifica os pacotes OSPF de vizinhos comuns e vizinhos de links virtuais.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Entre na visualização de área OSPF.
area area-id- Habilite o GTSM para a área OSPF.
ttl-security [ hops hop-count ]
Por padrão, o GTSM está desativado para a área OSPF.
Configuração do GTSM na visualização da interface
Restrições e diretrizes
O GTSM na visualização da interface aplica-se somente à interface atual. O GTSM verifica os pacotes OSPF de vizinhos comuns e vizinhos de links virtuais.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilita o GTSM para a interface.
ospf ttl-security [ hops hop-count | disable ]
Por padrão, o GTSM está desativado para a interface.
Configuração do registro de OSPF e das notificações SNMP
Registro de alterações no estado do vizinho
Sobre o registro de alterações no estado do vizinho
Execute esta tarefa para habilitar a saída de registros de alteração de estado de vizinhança para o centro de informações. O centro de informações processa os logs de acordo com as regras de saída definidas pelo usuário (se e onde enviar os logs). Para obter mais informações sobre o centro de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Habilite o registro em log das alterações de estado do vizinho.
log-peer-change
Por padrão, esse recurso de registro de alterações no estado do vizinho está ativado.
Configuração do recurso de registro do OSPF
Sobre os registros do OSPF
Os logs do OSPF incluem logs de pacotes hello, logs de cálculo de rota, logs de vizinhos, logs de rotas OSPF e logs de LSA auto-originados e recebidos.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Defina o número de registros OSPF.
event-log { hello { received [ abnormal | dropped ] | sent [ abnormal |
failed ] } | lsa-flush | peer | spf } size count
Por padrão, o dispositivo pode gerar um máximo de 100 registros OSPF para cada tipo.
Configuração do gerenciamento de rede OSPF
Sobre o gerenciamento de rede OSPF
Essa tarefa envolve as seguintes configurações:
- Vincule um processo OSPF ao MIB para que você possa usar o software de gerenciamento de rede para gerenciar o processo OSPF especificado.
- Ative as notificações SNMP para que o OSPF informe eventos importantes.
- Configure o intervalo de saída da notificação SNMP e o número máximo de notificações SNMP que podem ser emitidas em cada intervalo.
Para relatar eventos críticos de OSPF a um NMS, ative as notificações de SNMP para OSPF. Para que as notificações de SNMP sejam enviadas corretamente, você também deve configurar o SNMP no dispositivo. Para obter mais informações sobre a configuração de SNMP, consulte o guia de configuração de monitoramento e gerenciamento de rede do dispositivo.
Procedimento
- Entre na visualização do sistema.
system-view- Vincular o MIB a um processo OSPF.
ospf mib-binding process-id
Por padrão, o MIB é vinculado ao processo com a menor ID de processo.
- Ativar as notificações SNMP para OSPF.
snmp-agent trap enable ospf [ authentication-failure | bad-packet |
config-error | grhelper-status-change | grrestarter-status-change |
if-state-change | lsa-maxage | lsa-originate |
lsdb-approaching-overflow | lsdb-overflow | neighbor-state-change |
nssatranslator-status-change | retransmit |
virt-authentication-failure | virt-bad-packet | virt-config-error |
virt-retransmit | virtgrhelper-status-change | virtif-state-change |
virtneighbor-state-change ] *
Por padrão, as notificações SNMP para OSPF estão ativadas.
- Entre no modo de exibição OSPF.
ospf [ process-id | router-id router-id ] *- Configure o intervalo de saída da notificação SNMP e o número máximo de notificações SNMP que podem ser emitidas em cada intervalo.
snmp trap rate-limit interval trap-interval count trap-number
Por padrão, o OSPF emite no máximo sete notificações SNMP em um intervalo de 10 segundos.
Configuração do número máximo de entradas de solução de problemas de relacionamento com vizinhos OSPF
Sobre esta tarefa
Execute esta tarefa para definir o número máximo de entradas de solução de problemas de relacionamento com vizinhos que o OSPF pode registrar.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6342 e posteriores.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o número máximo de entradas de solução de problemas de relacionamento com vizinhos que o OSPF pode registrar.
ospf troubleshooting max-number number
Por padrão, o OSPF pode registrar um máximo de 100 entradas de solução de problemas de relacionamento com vizinhos.
Comandos de exibição e manutenção para OSPF
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações de registro do OSPF sobre pacotes hello recebidos ou enviados. | display ospf [ process-id ] event-log hello { received [ abnormal | dropped ] | sent } [ neighbor-id ] display ospf [ process-id ] event-log hello sent { abnormal | failed } [ neighbor-address ] |
| Exibir informações resumidas de rota no ABR OSPF. | display ospf [ process-id ] [ area area-id ] abr-summary [ ip-address { mask-length | mask } ] [ verbose ] |
| Exibir informações do próximo salto de backup do OSPF FRR. | display ospf [ process-id ] [ area-id ] fast-reroute lfa-candidate |
| Exibir informações de topologia OSPF. | display ospf [ process-id ] [ area-id ] spf-tree [ verbose ] |
| Exibir informações do processo OSPF. | display ospf [ process-id ] [ verbose ] |
| Exibir informações do OSPF ABR e ASBR. | display ospf [ process-id ] abr-asbr [ verbose ] |
| Exibir informações de sumarização de rotas OSPF ASBR. | display ospf [ process-id ] asbr-summary [ ip-address { mask-length | mask } ] |
| Exibir informações de registro do OSPF. | display ospf [ process-id ] event-log { lsa-flush | peer | spf } |
| Exibir informações do OSPF GR. | display ospf [ process-id ] graceful-restart [ verbose ] |
| Exibir informações da interface OSPF. | display ospf [ process-id ] interface [ interface-type interface-number | verbose ] |
| Exibir informações sobre os pacotes hello enviados pelas interfaces OSPF. | display ospf [ process-id ] interface [ interface-type interface-number ] hello |
| Exibir informações do OSPF LSDB. | display ospf [ process-id ] [ area area-id ] lsdb { asbr | network | nssa | opaque-area | opaque-link | router | summary } [ link-state-id ] [ originate-router advertising-router-id | self-originate ] display ospf [ process-id ] lsdb [ brief | originate-router advertising-router-id | self-originate ] display ospf [ process-id ] lsdb { ase | opaque-as ase } [ link-state-id ] [ originate-router advertising-router-id auto-originar ] |
| Exibir informações do próximo salto do OSPF. | display ospf [ process-id ] nexthop |
| Exibir informações de NSR do OSPF. | display ospf [ process-id ] non-stop-routing status |
| Exibir informações de vizinhos OSPF. | display ospf [ process-id ] peer [ hello | verbose ] [ interface-type interface-number ] [ neighbor-id ] |
| Exibir estatísticas de vizinhos para áreas OSPF. | display ospf [ process-id ] peer statistics |
| Exibir informações da fila de solicitações do OSPF. | display ospf [ process-id ] request-queue [ interface-type interface-number ] [ neighbor-id ] |
| Exibir informações da fila de retransmissão do OSPF. | display ospf [ process-id ] retrans-queue [ interface-type interface-number ] [ neighbor-id ] |
| Exibir informações da tabela de roteamento OSPF. | display ospf [ process-id ] routing [ ip-address { mask-length | mask } ] [ interface interface-type interface-number ] [ nexthop nexthop-address ] [ verbose ] |
| Exibir estatísticas do OSPF. | display ospf [ process-id ] statistics [ error | packet hello | [ interface-type interface-number ] ] ] |
| Exibir informações de solução de problemas de relacionamento com vizinhos OSPF. | display ospf troubleshooting |
| Exibir informações do link virtual OSPF. | display ospf [ process-id ] vlink |
| Exibir a ID da rota global. | display router id |
| Limpar informações de registro do OSPF. | reset ospf [ process-id ] event-log [ lsa-flush | peer | spf ] |
| Limpar informações de registro do OSPF sobre pacotes hello recebidos ou enviados. | reset ospf [ process-id ] event-log hello { received [ abnormal | dropped ] | sent [ anormal | falhou ] } |
| Reinicie um processo OSPF. | reset ospf [ process-id ] process [ graceful-restart ] |
| Reative a redistribuição de rotas OSPF. | reset ospf [ process-id ] redistribution |
| Limpar estatísticas do OSPF. | reset ospf [ process-id ] statistics |
| Limpar as informações de solução de problemas de relacionamento com vizinhos do OSPF. | redefinir a solução de problemas do ospf |
Exemplos de configuração do OSPF
Exemplo: Configuração do OSPF básico
Configuração de rede
Conforme mostrado na Figura 8:
- Habilite o OSPF em todos os switches e divida o AS em três áreas.
- Configure o Switch A e o Switch B como ABRs.
Figura 8 Diagrama de rede
Procedimento
- Configurar endereços IP para interfaces. (Detalhes não mostrados).
- Ativar OSPF:
# Configure o switch A.
<SwitchA> system-view
[SwitchA] router id 10.2.1.1
[SwitchA] ospf
[SwitchA-ospf-1] area 0
[SwitchA-ospf-1-area-0.0.0.0] network 10.1.1.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.0] quit
[SwitchA-ospf-1] area 1
[SwitchA-ospf-1-area-0.0.0.1] network 10.2.1.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.1] quit
[SwitchA-ospf-1] quit
<SwitchB> system-view
[SwitchB] router id 10.3.1.1
[SwitchB] ospf
[SwitchB-ospf-1] area 0
[SwitchB-ospf-1-area-0.0.0.0] network 10.1.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] quit
[SwitchB-ospf-1] area 2
[SwitchB-ospf-1-area-0.0.0.2] network 10.3.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.2] quit
[SwitchB-ospf-1] quit
<SwitchC> system-view
[SwitchC] router id 10.4.1.1
[SwitchC] ospf
[SwitchC-ospf-1] area 1
[SwitchC-ospf-1-area-0.0.0.1] network 10.2.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.1] network 10.4.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.1] quit
[SwitchC-ospf-1] quit
<SwitchD> system-view
[SwitchD] router id 10.5.1.1
[SwitchD] ospf
[SwitchD-ospf-1] area 2
[SwitchD-ospf-1-area-0.0.0.2] network 10.3.1.0 0.0.0.255
[SwitchD-ospf-1-area-0.0.0.2] network 10.5.1.0 0.0.0.255
[SwitchD-ospf-1-area-0.0.0.2] quit
[SwitchD-ospf-1] quit
Verificação da configuração
# Exibir informações sobre vizinhos no Switch A.
[SwitchA] display ospf peer verbose
OSPF Process 1 with Router ID 10.2.1.1
Neighbors
Area 0.0.0.0 interface 10.1.1.1(Vlan-interface100)'s neighbors
Router ID: 10.3.1.1 Address: 10.1.1.2 GR State: Normal
State: Full Mode: Nbr is master Priority: 1
DR: 10.1.1.1 BDR: 10.1.1.2 MTU: 0
Options is 0x02 (-|-|-|-|-|-|E|-)
Dead timer due in 37 sec
Neighbor is up for 06:03:59
Authentication Sequence: [ 0 ]
Neighbor state change count: 5
BFD status: Disabled
Area 0.0.0.1 interface 10.2.1.1(Vlan-interface200)'s neighbors
Router ID: 10.4.1.1 Address: 10.2.1.2 GR State: Normal
State: Full Mode: Nbr is master Priority: 1
DR: 10.2.1.1 BDR: 10.2.1.2 MTU: 0
Options is 0x02 (-|-|-|-|-|-|E|-)
Dead timer due in 32 sec
Neighbor is up for 06:03:12
Authentication Sequence: [ 0 ]
Neighbor state change count: 5
BFD status: Disabled
# Exibir informações de roteamento OSPF no Switch A.
[SwitchA] display ospf routing
OSPF Process 1 with Router ID 10.2.1.1
Routing Table
Topology base (MTID 0)
Routing for network
Destination Cost Type NextHop AdvRouter Area
10.2.1.0/24 1 Transit 10.2.1.1 10.2.1.1 0.0.0.1
10.3.1.0/24 2 Inter 10.1.1.2 10.3.1.1 0.0.0.0
10.4.1.0/24 2 Stub 10.2.1.2 10.4.1.1 0.0.0.1
10.5.1.0/24 3 Inter 10.1.1.2 10.3.1.1 0.0.0.0
10.1.1.0/24 1 Transit 10.1.1.1 10.2.1.1 0.0.0.0
Total nets: 5
Intra area: 3 Inter area: 2 ASE: 0 NSSA: 0
# Exibir informações de roteamento OSPF no Switch D.
[SwitchD] display ospf routing
OSPF Process 1 with Router ID 10.5.1.1
Routing Table
Topology base (MTID 0)
Routing for network
Destination Cost Type NextHop AdvRouter Area
10.2.1.0/24 3 Inter 10.3.1.1 10.3.1.1 0.0.0.2
45
10.3.1.0/24 1 Transit 10.3.1.2 10.3.1.1 0.0.0.2
10.4.1.0/24 4 Inter 10.3.1.1 10.3.1.1 0.0.0.2
10.5.1.0/24 1 Stub 10.5.1.1 10.5.1.1 0.0.0.2
10.1.1.0/24 2 Inter 10.3.1.1 10.3.1.1 0.0.0.2
Total nets: 5
Intra area: 2 Inter area: 3 ASE: 0 NSSA: 0
# No Switch D, faça ping no endereço IP 10.4.1.1 para testar a capacidade de alcance.
[SwitchD] ping 10.4.1.1
Ping 10.4.1.1 (10.4.1.1): 56 data bytes, press CTRL_C to break
56 bytes from 10.4.1.1: icmp_seq=0 ttl=253 time=1.549 ms
56 bytes from 10.4.1.1: icmp_seq=1 ttl=253 time=1.539 ms
56 bytes from 10.4.1.1: icmp_seq=2 ttl=253 time=0.779 ms
56 bytes from 10.4.1.1: icmp_seq=3 ttl=253 time=1.702 ms
56 bytes from 10.4.1.1: icmp_seq=4 ttl=253 time=1.471 ms
--- Ping statistics for 10.4.1.1 ---
5 packet(s) transmitted, 5 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 0.779/1.408/1.702/0.323 ms
Exemplo: Configuração da redistribuição de rotas OSPF
Configuração de rede
Conforme mostrado na Figura 9:
- Habilite o OSPF em todos os switches.
- Dividir o AS em três áreas.
- Configure o Switch A e o Switch B como ABRs.
- Configure o Switch C como um ASBR para redistribuir rotas externas (rotas estáticas).
Figura 9 Diagrama de rede
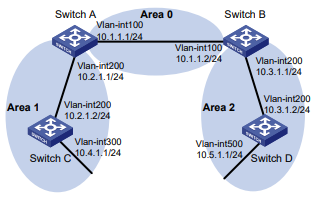
Procedimento
- Configurar endereços IP para interfaces. (Detalhes não mostrados).
- Habilite o OSPF (consulte "Exemplo: Configuração do OSPF básico").
- Configure o OSPF para redistribuir rotas:
# No Switch C, configure uma rota estática destinada à rede 3.1.2.0/24.
<SwitchC> system-view
[SwitchC] ip route-static 3.1.2.1 24 10.4.1.2
# No Switch C, configure o OSPF para redistribuir rotas estáticas.
[SwitchC] ospf 1
[SwitchC-ospf-1] import-route static
Verificação da configuração
# Exibir as informações de ABR/ASBR no Switch D.
<SwitchD> display ospf abr-asbr
OSPF Process 1 with Router ID 10.5.1.1
Routing Table to ABR and ASBR
Topology base (MTID 0)
Type Destination Area Cost Nexthop RtType
Intra 10.3.1.1 0.0.0.2 10 10.3.1.1 ABR
Inter 10.4.1.1 0.0.0.2 22 10.3.1.1 ASBR
# Exibir a tabela de roteamento OSPF no Switch D.
display ospf routing
OSPF Process 1 with Router ID 10.5.1.1
Routing Table
Topology base (MTID 0)
Routing for network
Destination Cost Type NextHop AdvRouter Area
10.2.1.0/24 22 Inter 10.3.1.1 10.3.1.1 0.0.0.2
10.3.1.0/24 10 Transit 10.3.1.2 10.3.1.1 0.0.0.2
10.4.1.0/24 25 Inter 10.3.1.1 10.3.1.1 0.0.0.2
10.5.1.0/24 10 Stub 10.5.1.1 10.5.1.1 0.0.0.2
10.1.1.0/24 12 Inter 10.3.1.1 10.3.1.1 0.0.0.2
Routing for ASEs
Destination Cost Type Tag NextHop AdvRouter
3.1.2.0/24 1 Type2 1 10.3.1.1 10.4.1.1
Total nets: 6
Intra area: 2 Inter area: 3 ASE: 1 NSSA: 0
Exemplo: Configuração da sumarização de rotas OSPF em um ASBR
Configuração de rede
Conforme mostrado na Figura 10:
- Configure o OSPF no Switch A, Switch B e Switch C na Área 2.
- Habilite o processo 1 e o processo 2 do OSPF no Switch B. O Switch B usa o processo 1 do OSPF para trocar informações de roteamento com o Switch A e usa o processo 2 do OSPF para trocar informações de roteamento com o Switch C.
- Atribua os endereços IP 2.1.2.1/24, 2.1.3.1/24 e 2.1.4.1/24 à interface VLAN 200 do Switch A. Para permitir que o Switch C aprenda rotas destinadas a 2.1.2.0/24, 2.1.3.0/24 e 2.1.4.0/24, configure o processo OSPF 2 no Switch B para redistribuir rotas do processo 1 e rotas diretas.
- Para minimizar o tamanho da tabela de roteamento no Switch C, configure a sumarização de rotas ASBR no Switch B. O Switch B anuncia apenas a rota de resumo 2.0.0.0/8.
Figura 10 Diagrama de rede

Procedimento
- Configurar endereços IP para interfaces. (Detalhes não mostrados).
- Configurar o OSPF:
# Habilite o processo 1 do OSPF no Switch A.
<SwitchA> system-view
[SwitchA] router id 11.2.1.1
[SwitchA] interface vlan-interface 200
[SwitchA-Vlan-interface200] ip address 2.1.2.1 24
[SwitchA-Vlan-interface200] ip address 2.1.3.1 24 sub
[SwitchA-Vlan-interface200] ip address 2.1.4.1 24 sub
[SwitchA-Vlan-interface200] quit
[SwitchA] ospf 1
[SwitchA-ospf-1] area 2
[SwitchA-ospf-1-area-0.0.0.2] network 1.1.1.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.2] network 2.1.0.0 0.0.255.255
[SwitchA-ospf-1-area-0.0.0.2] quit
[SwitchA-ospf-1] quit
# Habilite o processo 1 e o processo 2 do OSPF no Switch B.
<SwitchB> system-view
[SwitchB] router id 11.2.1.2
[SwitchB] ospf 1
[SwitchB-ospf-1] area 2
[SwitchB-ospf-1-area-0.0.0.2] network 1.1.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.2] quit
[SwitchB-ospf-1] quit
[SwitchB] ospf 2
[SwitchB-ospf-2] area 2
[SwitchB-ospf-2-area-0.0.0.2] network 3.1.1.0 0.0.0.255
[SwitchB-ospf-2-area-0.0.0.2] quit
[SwitchB-ospf-2] quit
# Habilite o processo 2 do OSPF no Switch C.
<SwitchC> system-view
[SwitchC] router id 11.1.1.2
[SwitchC] ospf 2
[SwitchC-ospf-2] area 2
[SwitchC-ospf-2-area-0.0.0.2] network 3.1.1.0 0.0.0.255
[SwitchC-ospf-2-area-0.0.0.2] network 4.1.0.0 0.0.255.255
[SwitchC-ospf-2-area-0.0.0.2] quit
[SwitchC-ospf-2] quit
- Configure o OSPF para redistribuir rotas:
# Configure o processo OSPF 2 no Switch B para redistribuir rotas do processo OSPF 1 e rotas diretas.
[SwitchB] ospf 2
[SwitchB-ospf-2]import-route direct
[SwitchB-ospf-2]import-route ospf 1
# Exibir informações da tabela de roteamento no Switch C.
[SwitchC] display ip routing-table
Destinations : 28 Routes : 28
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
1.1.1.0/24 O_ASE2 150 1 3.1.1.1 Vlan300
2.1.2.0/24 O_ASE2 150 1 3.1.1.1 Vlan300
2.1.3.0/24 O_ASE2 150 1 3.1.1.1 Vlan300
2.1.4.0/24 O_ASE2 150 1 3.1.1.1 Vlan300
3.1.1.0/24 Direct 0 0 3.1.1.2 Vlan300
3.1.1.0/32 Direct 0 0 3.1.1.2 Vlan300
3.1.1.2/32 Direct 0 0 127.0.0.1 InLoop0
3.1.1.255/32 Direct 0 0 3.1.1.2 Vlan300
4.1.1.0/24 Direct 0 0 4.1.1.1 Loop101
4.1.1.0/32 Direct 0 0 4.1.1.1 Loop101
4.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
4.1.1.255/32 Direct 0 0 4.1.1.1 Loop101
4.1.2.0/24 Direct 0 0 4.1.2.1 Loop102
4.1.2.0/32 Direct 0 0 4.1.2.1 Loop102
4.1.2.1/32 Direct 0 0 127.0.0.1 InLoop0
4.1.2.255/32 Direct 0 0 4.1.2.1 Loop102
4.1.3.0/24 Direct 0 0 4.1.3.1 Loop103
4.1.3.0/32 Direct 0 0 4.1.3.1 Loop103
4.1.3.1/32 Direct 0 0 127.0.0.1 InLoop0
4.1.3.255/32 Direct 0 0 4.1.3.1 Loop103
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
127.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
224.0.0.0/4 Direct 0 0 0.0.0.0 NULL0
224.0.0.0/24 Direct 0 0 0.0.0.0 NULL0
255.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
- Configure o OSPF para resumir as rotas no ASBR:
# Configure o processo 2 do OSPF no Switch B para anunciar a rota resumida 2.0.0.0/8.
[SwitchB] ospf 2
[SwitchB-ospf-2] asbr-summary 2.0.0.0 8
[SwitchB-ospf-2] quit
# Exibir informações da tabela de roteamento no Switch C.
[SwitchC]display ip routing-table
Destinations : 26 Routes : 26
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
1.1.1.0/24 O ASE2 150 1 3.1.1.1 Vlan300
2.0.0.0/8 O_ASE2 150 1 3.1.1.1 Vlan300
3.1.1.0/24 Direct 0 0 3.1.1.2 Vlan300
3.1.1.0/32 Direct 0 0 3.1.1.2 Vlan300
3.1.1.2/32 Direct 0 0 127.0.0.1 InLoop0
3.1.1.255/32 Direct 0 0 3.1.1.2 Vlan300
4.1.1.0/24 Direct 0 0 4.1.1.1 Loop101
4.1.1.0/32 Direct 0 0 4.1.1.1 Loop101
4.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
4.1.1.255/32 Direct 0 0 4.1.1.1 Loop101
4.1.2.0/24 Direct 0 0 4.1.2.1 Loop102
4.1.2.0/32 Direct 0 0 4.1.2.1 Loop102
4.1.2.1/32 Direct 0 0 127.0.0.1 InLoop0
4.1.2.255/32 Direct 0 0 4.1.2.1 Loop102
4.1.3.0/24 Direct 0 0 4.1.3.1 Loop103
4.1.3.0/32 Direct 0 0 4.1.3.1 Loop103
4.1.3.1/32 Direct 0 0 127.0.0.1 InLoop0
4.1.3.255/32 Direct 0 0 4.1.3.1 Loop103
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
127.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
224.0.0.0/4 Direct 0 0 0.0.0.0 NULL0
224.0.0.0/24 Direct 0 0 0.0.0.0 NULL0
255.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
Exemplo: Configuração da área de stub OSPF
Configuração de rede
Conforme mostrado na Figura 11:
- Habilite o OSPF em todos os switches e divida o AS em três áreas.
- Configure o Switch A e o Switch B como ABRs para encaminhar informações de roteamento entre áreas.
- Configure o Switch D como ASBR para redistribuir rotas estáticas.
- Configure a Área 1 como uma área de stub para reduzir os LSAs anunciados sem influenciar a capacidade de alcance.
Figura 11 Diagrama de rede
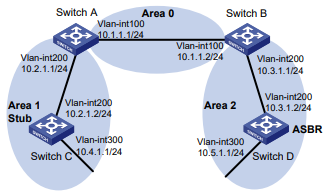
Procedimento
- Configurar endereços IP para interfaces. (Detalhes não mostrados).
- Habilite o OSPF (consulte "Exemplo: Configuração do OSPF básico").
- Configurar a redistribuição de rotas:
# Configure o Switch D para redistribuir rotas estáticas.
<SwitchD> system-view
[SwitchD] ip route-static 3.1.2.1 24 10.5.1.2
[SwitchD] ospf
[SwitchD-ospf-1] import-route static
[SwitchD-ospf-1] quit
# Exibir informações de ABR/ASBR no Switch C.
<SwitchC> display ospf abr-asbr
OSPF Process 1 with Router ID 10.4.1.1
Routing Table to ABR and ASBR
Topology base (MTID 0)
Type Destination Area Cost Nexthop RtType
Intra 10.2.1.1 0.0.0.1 3 10.2.1.1 ABR
Inter 10.5.1.1 0.0.0.1 7 10.2.1.1 ASBR
# Exibir a tabela de roteamento OSPF no Switch C.
<SwitchC> display ospf routing
OSPF Process 1 with Router ID 10.4.1.1
Routing Table
Topology base (MTID 0)
Routing for network
Destination Cost Type NextHop AdvRouter Area
10.2.1.0/24 3 Transit 0.0.0.0 10.2.1.1 0.0.0.1
10.3.1.0/24 7 Inter 10.2.1.1 10.2.1.1 0.0.0.1
10.4.1.0/24 3 Stub 10.4.1.1 10.4.1.1 0.0.0.1
10.5.1.0/24 17 Inter 10.2.1.1 10.2.1.1 0.0.0.1
10.1.1.0/24 5 Inter 10.2.1.1 10.2.1.1 0.0.0.1
Routing for ASEs
Destination Cost Type Tag NextHop AdvRouter
3.1.2.0/24 1 Type2 1 10.2.1.1 10.5.1.1
Total nets: 6
Intra area: 2 Inter area: 3 ASE: 1 NSSA: 0
- Configure a Área 1 como uma área de stub: # Configurar o switch A.
<SwitchA> system-view
[SwitchA] ospf
[SwitchA-ospf-1] area 1
[SwitchA-ospf-1-area-0.0.0.1] stub
[SwitchA-ospf-1-area-0.0.0.1] quit
[SwitchA-ospf-1] quit
# Configurar o switch C.
<SwitchC> system-view
[SwitchC] ospf
[SwitchC-ospf-1] area 1
[SwitchC-ospf-1-area-0.0.0.1] stub
[SwitchC-ospf-1-area-0.0.0.1] quit
[SwitchC-ospf-1] quit
# Exibir informações de roteamento OSPF no Switch C
[SwitchC] display ospf routing
OSPF Process 1 with Router ID 10.4.1.1
Routing Table
Topology base (MTID 0)
Routing for network
Destination Cost Type NextHop AdvRouter Area
0.0.0.0/0 4 Inter 10.2.1.1 10.2.1.1 0.0.0.1
10.2.1.0/24 3 Transit 0.0.0.0 10.2.1.1 0.0.0.1
10.3.1.0/24 7 Inter 10.2.1.1 10.2.1.1 0.0.0.1
10.4.1.0/24 3 Stub 10.4.1.1 10.4.1.1 0.0.0.1
10.5.1.0/24 17 Inter 10.2.1.1 10.2.1.1 0.0.0.1
10.1.1.0/24 5 Inter 10.2.1.1 10.2.1.1 0.0.0.1
Total nets: 6
Intra area: 2 Inter area: 4 ASE: 0 NSSA: 0
A saída mostra que uma rota padrão substitui a rota externa do AS.
# Configure a Área 1 como uma área totalmente stub.
[SwitchA] ospf
[SwitchA-ospf-1] area 1
[SwitchA-ospf-1-area-0.0.0.1] stub no-summary
[SwitchA-ospf-1-area-0.0.0.1] quit
[SwitchA-ospf-1] quit
# Exibir informações de roteamento OSPF no Switch C.
[SwitchC] display ospf routing
OSPF Process 1 with Router ID 10.4.1.1
Routing Table
Topology base (MTID 0)
Routing for network
Destination Cost Type NextHop AdvRouter Area
0.0.0.0/0 4 Inter 10.2.1.1 10.2.1.1 0.0.0.1
10.2.1.0/24 3 Transit 0.0.0.0 10.4.1.1 0.0.0.1
10.4.1.0/24 3 Stub 10.4.1.1 10.4.1.1 0.0.0.1
Total nets: 3
Intra area: 2 Inter area: 1 ASE: 0 NSSA: 0
A saída mostra que as rotas entre áreas foram removidas e que existe apenas uma rota externa (uma rota padrão) no Switch C.
Exemplo: Configuração da área NSSA do OSPF
Configuração de rede
Conforme mostrado na Figura 12:
- Configure o OSPF em todos os switches e divida o AS em três áreas.
- Configure o Switch A e o Switch B como ABRs para encaminhar informações de roteamento entre áreas.
- Configure a Área 1 como uma área NSSA e configure o Switch C como um ASBR para redistribuir rotas estáticas para o AS.
Figura 12 Diagrama de rede
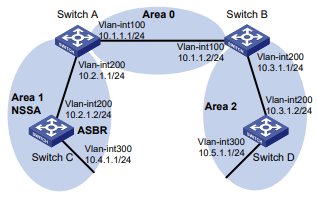
Procedimento
- Configurar endereços IP para interfaces.
- Habilite o OSPF (consulte "Exemplo: Configuração do OSPF básico").
- Configure a Área 1 como uma área NSSA: # Configurar o Switch A.
<SwitchA> system-view
[SwitchA] ospf
[SwitchA-ospf-1] area 1
[SwitchA-ospf-1-area-0.0.0.1] nssa
[SwitchA-ospf-1-area-0.0.0.1] quit
[SwitchA-ospf-1] quit
# Configure o switch C.
<SwitchC> system-view
[SwitchC] ospf
[SwitchC-ospf-1] area 1
[SwitchC-ospf-1-area-0.0.0.1] nssa
[SwitchC-ospf-1-area-0.0.0.1] quit
[SwitchC-ospf-1] quit
# Exibir informações de roteamento OSPF no Switch C.
[SwitchC] display ospf routing
OSPF Process 1 with Router ID 10.4.1.1
Routing Table
Topology base (MTID 0)
Routing for network
Destination Cost Type NextHop AdvRouter Area
10.2.1.0/24 3 Transit 10.2.1.2 10.4.1.1 0.0.0.1
10.3.1.0/24 7 Inter 10.2.1.1 10.2.1.1 0.0.0.1
10.4.1.0/24 3 Stub 10.4.1.1 10.4.1.1 0.0.0.1
10.5.1.0/24 17 Inter 10.2.1.1 10.2.1.1 0.0.0.1
10.1.1.0/24 5 Inter 10.2.1.1 10.2.1.1 0.0.0.1
Total nets: 5
Intra area: 2 Inter area: 3 ASE: 0 NSSA: 0
- Configurar a redistribuição de rotas:
# Configure o Switch C para redistribuir rotas estáticas.
[[SwitchC] ip route-static 3.1.3.1 24 10.4.1.2
[SwitchC] ospf
[SwitchC-ospf-1] import-route static
[SwitchC-ospf-1] quit
# Exibir informações de roteamento OSPF no Switch D.
display ospf routing
OSPF Process 1 with Router ID 10.5.1.1
Routing Table
Topology base (MTID 0)
Routing for network
Destination Cost Type NextHop AdvRouter Area
10.2.1.0/24 22 Inter 10.3.1.1 10.3.1.1 0.0.0.2
10.3.1.0/24 10 Transit 10.3.1.2 10.3.1.1 0.0.0.2
10.4.1.0/24 25 Inter 10.3.1.1 10.3.1.1 0.0.0.2
10.5.1.0/24 10 Stub 10.5.1.1 10.5.1.1 0.0.0.2
10.1.1.0/24 12 Inter 10.3.1.1 10.3.1.1 0.0.0.2
Routing for ASEs
Destination Cost Type Tag NextHop AdvRouter
3.1.3.0/24 1 Type2 1 10.3.1.1 10.2.1.1
Total nets: 6
Intra area: 2 Inter area: 3 ASE: 1 NSSA: 0
A saída mostra que existe uma rota externa importada da área NSSA no Switch D.
Exemplo: Configuração da eleição de DR do OSPF
Configuração de rede
Conforme mostrado na Figura 13:
- Habilite o OSPF nos Switches A, B, C e D na mesma rede.
- Configure o Switch D como DR e configure o Switch C como BDR.
- Altere as prioridades do roteador nas interfaces para configurar o Switch A como DR e o Switch C como BDR.
Figura 13 Diagrama de rede
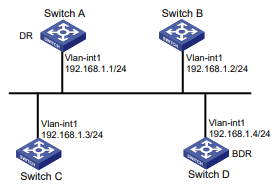
Procedimento
- Configurar endereços IP para interfaces. (Detalhes não mostrados).
- Configure as definições básicas do OSPF em todos os switches. (Detalhes não mostrados.) Para obter mais informações, consulte "Exemplo: Configuração do OSPF básico".
- Exibir informações de vizinhos OSPF no Switch A.
[SwitchA] display ospf peer verbose
OSPF Process 1 with Router ID 1.1.1.1
Neighbors
Area 0.0.0.0 interface 192.168.1.1(Vlan-interface1)'s neighbors
Router ID: 2.2.2.2 Address: 192.168.1.2 GR State: Normal
Switch A Switch B
Switch C Switch D
Vlan-int1
192.168.1.1/24
Vlan-int1
192.168.1.2/24
Vlan-int1
192.168.1.3/24
Vlan-int1
192.168.1.4/24
DR
BDR
State: 2-Way Mode: None Priority: 1
DR: 192.168.1.4 BDR: 192.168.1.3 MTU: 0
Options is 0x02 (-|-|-|-|-|-|E|-)
Dead timer due in 38 sec
Neighbor is up for 00:01:31
Authentication Sequence: [ 0 ]
Neighbor state change count: 6
BFD status: Disabled
Router ID: 3.3.3.3 Address: 192.168.1.3 GR State: Normal
State: Full Mode: Nbr is master Priority: 1
DR: 192.168.1.4 BDR: 192.168.1.3 MTU: 0
Options is 0x02 (-|-|-|-|-|-|E|-)
Dead timer due in 31 sec
Neighbor is up for 00:01:28
Authentication Sequence: [ 0 ]
Neighbor state change count: 6
BFD status: Disabled
Router ID: 4.4.4.4 Address: 192.168.1.4 GR State: Normal
State: Full Mode: Nbr is master Priority: 1
DR: 192.168.1.4 BDR: 192.168.1.3 MTU: 0
Options is 0x02 (-|-|-|-|-|-|E|-)
Dead timer due in 31 sec
Neighbor is up for 00:01:28
Authentication Sequence: [ 0 ]
Neighbor state change count: 6
BFD status: Disabled
A saída mostra que o comutador D é o DR e o comutador C é o BDR.
- Configure as prioridades do roteador nas interfaces: # Configurar o Switch A.
[SwitchA] interface vlan-interface 1
[SwitchA-Vlan-interface1] ospf dr-priority 100
[SwitchA-Vlan-interface1] quit
# Configure o Switch B.
[SwitchB] interface vlan-interface 1
[SwitchB-Vlan-interface1] ospf dr-priority 0
[SwitchB-Vlan-interface1] quit
# Configurar o switch C.
[SwitchC] interface vlan-interface 1
[SwitchC-Vlan-interface1] ospf dr-priority 2
[SwitchC-Vlan-interface1] quit
# Exibir informações sobre vizinhos no Switch D.
display ospf peer verbose
OSPF Process 1 with Router ID 4.4.4.4
Neighbors
Area 0.0.0.0 interface 192.168.1.4(Vlan-interface1)'s neighbors
Router ID: 1.1.1.1 Address: 192.168.1.1 GR State: Normal
State: Full Mode:Nbr is slave Priority: 100
DR: 192.168.1.4 BDR: 192.168.1.3 MTU: 0
Options is 0x02 (-|-|-|-|-|-|E|-)
Dead timer due in 31 sec
Neighbor is up for 00:11:17
Authentication Sequence: [ 0 ]
Neighbor state change count: 6
BFD status: Disabled
Router ID: 2.2.2.2 Address: 192.168.1.2 GR State: Normal
State: Full Mode:Nbr is slave Priority: 0
DR: 192.168.1.4 BDR: 192.168.1.3 MTU: 0
Options is 0x02 (-|-|-|-|-|-|E|-)
Dead timer due in 35 sec
Neighbor is up for 00:11:19
Authentication Sequence: [ 0 ]
Neighbor state change count: 6
BFD status: Disabled
Router ID: 3.3.3.3 Address: 192.168.1.3 GR State: Normal
State: Full Mode:Nbr is slave Priority: 2
DR: 192.168.1.4 BDR: 192.168.1.3 MTU: 0
Options is 0x02 (-|-|-|-|-|-|E|-)
Dead timer due in 33 sec
Neighbor is up for 00:11:15
Authentication Sequence: [ 0 ]
Neighbor state change count: 6
BFD status: Disabled
A saída mostra que o DR e o BDR não são alterados, pois as configurações de prioridade não entram em vigor imediatamente.
- Reinicie os processos OSPF:
# Reinicie o processo OSPF do Switch A.
<SwitchA> reset ospf 1 process
Reset OSPF process? [Y/N]:y
# Reinicie o processo OSPF do Switch B.
<SwitchB> reset ospf 1 process
Reset OSPF process? [Y/N]:y
# Reinicie o processo OSPF do Switch C.
<SwitchC> reset ospf 1 process
Reset OSPF process? [Y/N]:y
# Reinicie o processo OSPF do Switch D.
<SwitchD> reset ospf 1 process
Reset OSPF process? [Y/N]:y
# Exibir informações sobre vizinhos no Switch D.
<SwitchD> display ospf peer verbose
OSPF Process 1 with Router ID 4.4.4.4
Neighbors
Area 0.0.0.0 interface 192.168.1.4(Vlan-interface1)'s neighbors
Router ID: 1.1.1.1 Address: 192.168.1.1 GR State: Normal
State: Full Mode: Nbr is slave Priority: 100
DR: 192.168.1.1 BDR: 192.168.1.3 MTU: 0
Options is 0x02 (-|-|-|-|-|-|E|-)
Dead timer due in 39 sec
Neighbor is up for 00:01:40
Authentication Sequence: [ 0 ]
Neighbor state change count: 6
BFD status: Disabled
Router ID: 2.2.2.2 Address: 192.168.1.2 GR State: Normal
State: 2-Way Mode: None Priority: 0
DR: 192.168.1.1 BDR: 192.168.1.3 MTU: 0
Options is 0x02 (-|-|-|-|-|-|E|-)
Dead timer due in 35 sec
Neighbor is up for 00:01:44
Authentication Sequence: [ 0 ]
Neighbor state change count: 6
BFD status: Disabled
Router ID: 3.3.3.3 Address: 192.168.1.3 GR State: Normal
State: Full Mode: Nbr is slave Priority: 2
DR: 192.168.1.1 BDR: 192.168.1.3 MTU: 0
Options is 0x02 (-|-|-|-|-|-|E|-)
Dead timer due in 39 sec
Neighbor is up for 00:01:41
Authentication Sequence: [ 0 ]
Neighbor state change count: 6
BFD status: Disabled
A saída mostra que o comutador A se torna o DR e o comutador C se torna o BDR.
Se o estado de vizinhança estiver completo, o Switch D estabeleceu uma adjacência com o vizinho. Se o estado de vizinhança for bidirecional, os dois comutadores não são o DR ou o BDR e não trocam LSAs.
# Exibir informações da interface OSPF.
<SwitchA> display ospf interface
OSPF Process 1 with Router ID 1.1.1.1
Interfaces
Area: 0.0.0.0
IP Address Type State Cost Pri DR BDR
192.168.1.1 Broadcast DR 1 100 192.168.1.1 192.168.1.3
<SwitchB> display ospf interface
OSPF Process 1 with Router ID 2.2.2.2
Interfaces
Area: 0.0.0.0
IP Address Type State Cost Pri DR BDR
192.168.1.2 Broadcast DROther 1 0 192.168.1.1 192.168.1.3
O estado da interface DROther significa que a interface não é DR ou BDR.
Exemplo: Configuração do link virtual OSPF
Configuração de rede
Conforme mostrado na Figura 14, configure um link virtual entre o Switch B e o Switch C para conectar a Área 2 a a área de backbone. Após a configuração, o Switch B pode aprender rotas para a Área 2.
Figura 14 Diagrama de rede
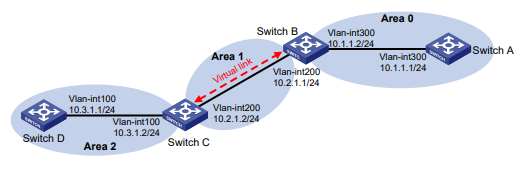
Procedimento
- Configurar endereços IP para interfaces. (Detalhes não mostrados).
- Ativar OSPF:
# Configure o switch A.
<SwitchA> system-view
[SwitchA] ospf 1 router-id 1.1.1.1
[SwitchA-ospf-1] area 0
[SwitchA-ospf-1-area-0.0.0.0] network 10.1.1.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.0] quit
[SwitchA-ospf-1] quit
<SwitchB> system-view
[SwitchB] ospf 1 router-id 2.2.2.2
[SwitchB-ospf-1] area 0
[SwitchB-ospf-1-area-0.0.0.0] network 10.1.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] quit
[SwitchB-ospf-1] area 1
[SwitchB–ospf-1-area-0.0.0.1] network 10.2.1.0 0.0.0.255
[SwitchB–ospf-1-area-0.0.0.1] quit
[SwitchB-ospf-1] quit
system-view
[SwitchC] ospf 1 router-id 3.3.3.3
[SwitchC-ospf-1] area 1
[SwitchC-ospf-1-area-0.0.0.1] network 10.2.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.1] quit
[SwitchC-ospf-1] area 2
[SwitchC–ospf-1-area-0.0.0.2] network 10.3.1.0 0.0.0.255
[SwitchC–ospf-1-area-0.0.0.2] quit
[SwitchC-ospf-1] quit
<SwitchD> system-view
[SwitchD] ospf 1 router-id 4.4.4.4
[SwitchD-ospf-1] area 2
[SwitchD-ospf-1-area-0.0.0.2] network 10.3.1.0 0.0.0.255
[SwitchD-ospf-1-area-0.0.0.2] quit
[SwitchD-ospf-1] quit
# Exibir a tabela de roteamento OSPF no Switch B.
[SwitchB] display ospf routing
OSPF Process 1 with Router ID 2.2.2.2
Routing Table
Topology base (MTID 0)
Routing for network
Destination Cost Type NextHop AdvRouter Area
10.2.1.0/24 2 Transit 10.2.1.1 3.3.3.3 0.0.0.1
10.1.1.0/24 2 Transit 10.1.1.2 2.2.2.2 0.0.0.0
Total nets: 2
Intra area: 2 Inter area: 0 ASE: 0 NSSA: 0
A saída mostra que o Switch B não tem rotas para a Área 2 porque a Área 0 não está diretamente conectada à Área 2.
- Configure um link virtual: # Configure o Switch B.
[SwitchB] ospf
[SwitchB-ospf-1] area 1
[SwitchB-ospf-1-area-0.0.0.1] vlink-peer 3.3.3.3
[SwitchB-ospf-1-area-0.0.0.1] quit
[SwitchB-ospf-1] quit
# Configurar o switch C.
[SwitchC] ospf 1
[SwitchC-ospf-1] area 1
[SwitchC-ospf-1-area-0.0.0.1] vlink-peer 2.2.2.2
[SwitchC-ospf-1-area-0.0.0.1] quit
[SwitchC-ospf-1] quit
# Exibir a tabela de roteamento OSPF no Switch B.
[SwitchB] display ospf routing
OSPF Process 1 with Router ID 2.2.2.2
Routing Table
Topology base (MTID 0)
Routing for network
Destination Cost Type NextHop AdvRouter Area
10.2.1.0/24 2 Transit 10.2.1.1 3.3.3.3 0.0.0.1
10.3.1.0/24 5 Inter 10.2.1.2 3.3.3.3 0.0.0.0
10.1.1.0/24 2 Transit 10.1.1.2 2.2.2.2 0.0.0.0
Total nets: 3
Intra area: 2 Inter area: 1 ASE: 0 NSSA: 0
A saída mostra que o Switch B aprendeu a rota 10.3.1.0/24 para a Área 2.
Exemplo: Configuração do OSPF GR
Configuração de rede
Conforme mostrado na Figura 15:
- O Switch A, o Switch B e o Switch C que pertencem ao mesmo AS e ao mesmo domínio de roteamento OSPF são compatíveis com GR.
- O comutador A atua como reiniciador de GR não IETF. Os comutadores B e C são os auxiliares de GR e sincronizam seus LSDBs com o comutador A por meio de comunicação OOB de GR.
Figura 15 Diagrama de rede
Procedimento
- Configurar endereços IP para interfaces. (Detalhes não mostrados).
- Ativar OSPF:
# Configure o Switch A.
SwitchA> system-view
[SwitchA] router id 1.1.1.1
[SwitchA] ospf 100
[SwitchA-ospf-100] area 0
[SwitchA-ospf-100-area-0.0.0.0] network 192.1.1.0 0.0.0.255
[SwitchA-ospf-100-area-0.0.0.0] quit
[SwitchA-ospf-1] quit
# Configure o Switch B.
<SwitchB> system-view
[SwitchB] router id 2.2.2.2
[SwitchB] ospf 100
[SwitchB-ospf-100] area 0
[SwitchB-ospf-100-area-0.0.0.0] network 192.1.1.0 0.0.0.255
[SwitchB-ospf-100-area-0.0.0.0] quit
[SwitchB-ospf-1] quit
# Configurar o switch C.
<SwitchC> system-view
[SwitchC] router id 3.3.3.3
[SwitchC] ospf 100
[SwitchC-ospf-100] area 0
[SwitchC-ospf-100-area-0.0.0.0] network 192.1.1.0 0.0.0.255
[SwitchC-ospf-100-area-0.0.0.0] quit
[SwitchC-ospf-1] quit
- Configurar o OSPF GR:
# Configure o Switch A como reiniciador OSPF GR não IETF: habilite a capacidade de sinalização local do link, a capacidade de ressincronização fora da banda e a capacidade GR não IETF para o processo OSPF 100.
[SwitchA-ospf-100] enable link-local-signaling
[SwitchA-ospf-100] enable out-of-band-resynchronization
[SwitchA-ospf-100] graceful-restart
[SwitchA-ospf-100] quit
# Configure o Switch B como auxiliar de GR: habilite o recurso de sinalização local de link e o recurso de ressincronização fora de banda para o processo 100 do OSPF.
[SwitchB-ospf-100] enable link-local-signaling
[SwitchB-ospf-100] enable out-of-band-resynchronization
# Configure o Switch C como auxiliar de GR: habilite o recurso de sinalização local de link e o
capacidade de ressincronização fora da banda para o processo 100 do OSPF.
[SwitchC-ospf-100] enable link-local-signaling
[SwitchC-ospf-100] enable out-of-band-resynchronization
Verificação da configuração
<SwitchA> debugging ospf event graceful-restart
<SwitchA> terminal monitor
<SwitchA> terminal logging level 7
<SwitchA> reset ospf 100 process graceful-restart
Reset OSPF process? [Y/N]:y
%Oct 21 15:29:28:727 2011 SwitchA OSPF/5/OSPF_NBR_CHG: OSPF 100 Neighbor
192.1.1.2(Vlan-interface100) from Full to Down.
%Oct 21 15:29:28:729 2011 SwitchA OSPF/5/OSPF_NBR_CHG: OSPF 100 Neighbor
192.1.1.3(Vlan-interface100) from Full to Down.
*Oct 21 15:29:28:735 2011 SwitchA OSPF/7/DEBUG:
OSPF 100 nonstandard GR Started for OSPF Router
*Oct 21 15:29:28:735 2011 SwitchA OSPF/7/DEBUG:
OSPF 100 created GR wait timer,timeout interval is 40(s).
*Oct 21 15:29:28:735 2011 SwitchA OSPF/7/DEBUG:
OSPF 100 created GR Interval timer,timeout interval is 120(s).
*Oct 21 15:29:28:758 2011 SwitchA OSPF/7/DEBUG:
OSPF 100 created OOB Progress timer for neighbor 192.1.1.3.
*Oct 21 15:29:28:766 2011 SwitchA OSPF/7/DEBUG:
OSPF 100 created OOB Progress timer for neighbor 192.1.1.2.
%Oct 21 15:29:29:902 2011 SwitchA OSPF/5/OSPF_NBR_CHG: OSPF 100 Neighbor
192.1.1.2(Vlan-interface100) from Loading to Full.
*Oct 21 15:29:29:902 2011 SwitchA OSPF/7/DEBUG:
OSPF 100 deleted OOB Progress timer for neighbor 192.1.1.2.
%Oct 21 15:29:30:897 2011 SwitchA OSPF/5/OSPF_NBR_CHG: OSPF 100 Neighbor
192.1.1.3(Vlan-interface100) from Loading to Full.
*Oct 21 15:29:30:897 2011 SwitchA OSPF/7/DEBUG:
OSPF 100 deleted OOB Progress timer for neighbor 192.1.1.3.
*Oct 21 15:29:30:911 2011 SwitchA OSPF/7/DEBUG:
OSPF GR: Process 100 Exit Restart,Reason : DR or BDR change,for neighbor : 192.1.1.3.
*Oct 21 15:29:30:911 2011 SwitchA OSPF/7/DEBUG:
OSPF 100 deleted GR Interval timer.
*Oct 21 15:29:30:912 2011 SwitchA OSPF/7/DEBUG:
OSPF 100 deleted GR wait timer.
%Oct 21 15:29:30:920 2011 SwitchA OSPF/5/OSPF_NBR_CHG: OSPF 100 Neighbor
192.1.1.2(Vlan-interface100) from Full to Down.
%Oct 21 15:29:30:921 2011 SwitchA OSPF/5/OSPF_NBR_CHG: OSPF 100 Neighbor
192.1.1.3(Vlan-interface100) from Full to Down.
%Oct 21 15:29:33:815 2011 SwitchA OSPF/5/OSPF_NBR_CHG: OSPF 100 Neighbor
192.1.1.3(Vlan-interface100) from Loading to Full.
%Oct 21 15:29:35:578 2011 SwitchA OSPF/5/OSPF_NBR_CHG: OSPF 100 Neighbor
192.1.1.2(Vlan-interface100) from Loading to Full.
A saída mostra que o comutador A completa o GR.
Exemplo: Configuração do NSR do OSPF
Configuração de rede
Conforme mostrado na Figura 16, o Comutador S, o Comutador A e o Comutador B pertencem ao mesmo domínio de roteamento OSPF. Habilite o NSR do OSPF no Switch S para garantir o roteamento correto quando ocorrer um chaveamento ativo/em espera no Switch S.
Figura 16 Diagrama de rede

Procedimento
- Configure os endereços IP e as máscaras de sub-rede para as interfaces nos switches. (Detalhes não mostrados).
- Configure o OSPF nos switches para garantir o seguinte: (Detalhes não mostrados).
- O Switch S, o Switch A e o Switch B podem se comunicar entre si na Camada 3.
- A atualização dinâmica de rotas pode ser implementada entre eles com o OSPF.
- Habilite o OSPF NSR no Switch S.
<SwitchS> system-view
[SwitchS] ospf 100
[SwitchS-ospf-100] non-stop-routing
[SwitchS-ospf-100] quit
Verificação da configuração
# Executar uma alternância entre ativo e em espera no Switch S.
[SwitchS] placement reoptimize
Predicted changes to the placement
Program Current location New location
---------------------------------------------------------------------
rib 0/0 0/0
staticroute 0/0 0/0
ospf 0/0 1/0
Continue? [y/n]:y
Re-optimization of the placement start. You will be notified on completion.
Re-optimization of the placement complete. Use 'display placement' to view the new
placement.
# Durante o período de transição, exiba os vizinhos OSPF no Switch A para verificar a relação de vizinhança entre o Switch A e o Switch S.
<SwitchA> display ospf peer
OSPF Process 1 with Router ID 2.2.2.1
Neighbor Brief Information
Area: 0.0.0.0
Router ID Address Pri Dead-Time State Interface
3.3.3.1 12.12.12.2 1 37 Full/BDR Vlan100
# Exibir rotas OSPF no Switch A para verificar se o Switch A tem uma rota para a interface de loopback no Switch B.
<SwitchA> display ospf routing
OSPF Process 1 with Router ID 2.2.2.1
Routing Table
Topology base (MTID 0)
Routing for network
Destination Cost Type NextHop AdvRouter Area
44.44.44.44/32 2 Stub 12.12.12.2 4.4.4.1 0.0.0.0
14.14.14.0/24 2 Transit 12.12.12.2 4.4.4.1 0.0.0.0
22.22.22.22/32 0 Stub 22.22.22.22 2.2.2.1 0.0.0.0
12.12.12.0/24 1 Transit 12.12.12.1 2.2.2.1 0.0.0.0
Total nets: 4
Intra area: 4 Inter area: 0 ASE: 0 NSSA: 0
# Exibir os vizinhos OSPF no Switch B para verificar a relação de vizinhança entre o Switch B e o Switch S.
<SwitchB> display ospf peer
OSPF Process 1 with Router ID 4.4.4.1
Neighbor Brief Information
Area: 0.0.0.0
Router ID Address Pri Dead-Time State Interface
3.3.3.1 14.14.14.2 1 39 Full/BDR Vlan200
# Exibir rotas OSPF no Switch B para verificar se o Switch B tem uma rota para a interface de loopback no Switch A.
<SwitchB> display ospf routing
OSPF Process 1 with Router ID 4.4.4.1
Routing Table
Topology base (MTID 0)
Routing for network
Destination Cost Type NextHop AdvRouter Area
44.44.44.44/32 0 Stub 44.44.44.44 4.4.4.1 0.0.0.0
14.14.14.0/24 1 Transit 14.14.14.1 4.4.4.1 0.0.0.0
22.22.22.22/32 2 Stub 14.14.14.2 2.2.2.1 0.0.0.0
12.12.12.0/24 2 Transit 14.14.14.2 2.2.2.1 0.0.0.0
Total nets: 4
Intra area: 4 Inter area: 0 ASE: 0 NSSA: 0A saída mostra o seguinte quando ocorre uma alternância entre ativo e em espera no Switch S:
Exemplo: Configuração de BFD para OSPF
Configuração de rede
Conforme mostrado na Figura 17, execute o OSPF no Switch A, no Switch B e no Switch C para que eles sejam acessíveis uns aos outros na camada de rede.
- Quando o link pelo qual o Switch A e o Switch B se comunicam por meio de um switch de camada 2 falha, o BFD pode detectar rapidamente a falha e notificar o OSPF sobre ela.
- O switch A e o switch B se comunicam por meio do switch C.
Figura 17 Diagrama de rede
Tabela 1 Atribuição de interface e endereço IP
| Dispositivo | Interface | Endereço IP |
| Chave A | Vlan-int10 | 192.168.0.102/24 |
| Chave A | Vlan-int11 | 10.1.1.102/24 |
| Chave A | Loop0 | 121.1.1.1/32 |
| Chave B | Vlan-int10 | 192.168.0.100/24 |
| Chave B | Vlan-int13 | 13.1.1.1/24 |
| Chave B | Loop0 | 120.1.1.1/32 |
| Chave C | Vlan-int11 | 10.1.1.100/24 |
| Chave C | Vlan-int13 | 13.1.1.2/24 |
Procedimento
- Configurar endereços IP para interfaces. (Detalhes não mostrados).
- Ativar OSPF:
# Configure o switch A.
<SwitchA> system-view
[SwitchA] ospf
[SwitchA-ospf-1] area 0
[SwitchA-ospf-1-area-0.0.0.0] network 192.168.0.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.0] network 10.1.1.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.0] network 121.1.1.1 0.0.0.0
[SwitchA-ospf-1-area-0.0.0.0] quit
[SwitchA-ospf-1] quit# Configure o Switch B.
<SwitchB> system-view
[SwitchB] ospf
[SwitchB-ospf-1] area 0
[SwitchB-ospf-1-area-0.0.0.0] network 192.168.0.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] network 13.1.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] network 120.1.1.1 0.0.0.0
[SwitchB-ospf-1-area-0.0.0.0] quit# Configurar o switch C.
<SwitchC> system-view
[SwitchC] ospf
[SwitchC-ospf-1] area 0
[SwitchC-ospf-1-area-0.0.0.0] network 10.1.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.0] network 13.1.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.0] quit
[SwitchC-ospf-1] quit- Configurar o BFD:
# Habilite o BFD no Switch A e configure os parâmetros do BFD.
[SwitchA] bfd session init-mode active
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ospf bfd enable
[SwitchA-Vlan-interface10] bfd min-transmit-interval 500
[SwitchA-Vlan-interface10] bfd min-receive-interval 500
[SwitchA-Vlan-interface10] bfd detect-multiplier 7
[SwitchA-Vlan-interface10] quit# Habilite o BFD no Switch B e configure os parâmetros do BFD.
[SwitchB] bfd session init-mode active
[SwitchB] interface vlan-interface 10
[SwitchB-Vlan-interface10] ospf bfd enable
[SwitchB-Vlan-interface10] bfd min-transmit-interval 500
[SwitchB-Vlan-interface10] bfd min-receive-interval 500
[SwitchB-Vlan-interface10] bfd detect-multiplier 6
[SwitchB-Vlan-interface10] quitVerificação da configuração
# Exibir as informações do BFD no Switch A.
<SwitchA> display bfd session
Total Session Num: 1 Up Session Num: 1 Init Mode: Active
IPv4 session working in control packet mode:
LD/RD SourceAddr DestAddr State Holdtime Interface
3/1 192.168.0.102 192.168.0.100 Up 1700ms Vlan10
# Exibir rotas destinadas a 120.1.1.1/32 no Switch A.
display ip routing-table 120.1.1.1 verbose
Summary Count : 1
Destination: 120.1.1.1/32
Protocol: O_INTRA
Process ID: 1
SubProtID: 0x1 Age: 04h20m37s
Cost: 1 Preference: 10
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 0
NibID: 0x26000002 LastAs: 0
AttrID: 0xffffffff Neighbor: 0.0.0.0
Flags: 0x1008c OrigNextHop: 192.168.0.100
Label: NULL RealNextHop: 192.168.0.100
BkLabel: NULL BkNextHop: N/A
SRLabel: NULL BkSRLabel: NULL
Tunnel ID: Invalid Interface: Vlan-interface10
BkTunnel ID: Invalid BkInterface: N/A
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0
A saída mostra que o Switch A se comunica com o Switch B por meio da interface de VLAN 10. Em seguida, o link na interface VLAN 10 falha.
# Exibir rotas destinadas a 120.1.1.1/32 no Switch A.
<SwitchA> display ip routing-table 120.1.1.1 verbose
Summary Count : 1
Destination: 120.1.1.1/32
Protocol: O_INTRA
Process ID: 1
SubProtID: 0x1 Age: 04h20m37s
Cost: 2 Preference: 10
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 0
NibID: 0x26000002 LastAs: 0
AttrID: 0xffffffff Neighbor: 0.0.0.0
Flags: 0x1008c OrigNextHop: 10.1.1.100
Label: NULL RealNextHop: 10.1.1.100
BkLabel: NULL BkNextHop: N/A
SRLabel: NULL BkSRLabel: NULL
Tunnel ID: Invalid Interface: Vlan-interface11
BkTunnel ID: Invalid BkInterface: N/A
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0
A saída mostra que o Switch A se comunica com o Switch B por meio da interface VLAN 11.
Exemplo: Configuração de OSPF FRR
Configuração de rede
Conforme mostrado na Figura 18, o Switch A, o Switch B e o Switch C residem no mesmo domínio OSPF. Configure o OSPF FRR para que, quando o link entre o Switch A e o Switch B falhar, o tráfego seja imediatamente transferido para o Link B.
Figura 18 Diagrama de rede
Tabela 2 Atribuição de interface e endereço IP
| Dispositivo | Interface | Endereço IP |
| Chave A | Vlan-int100 | 12.12.12.1/24 |
| Chave A | Vlan-int200 | 13.13.13.1/24 |
| Chave A | Loop0 | 1.1.1.1/32 |
| Chave B | Vlan-int101 | 24.24.24.4/24 |
| Chave B | Vlan-int200 | 13.13.13.2/24 |
| Chave B | Loop0 | 4.4.4.4/32 |
| Chave C | Vlan-int100 | 12.12.12.2/24 |
| Chave C | Vlan-int101 | 24.24.24.2/24 |
Procedimento
- Configure os endereços IP e as máscaras de sub-rede para as interfaces nos switches. (Detalhes não mostrados).
- Configure o OSPF nos switches para garantir que o Switch A, o Switch B e o Switch C possam se comunicar entre si na camada de rede. (Detalhes não mostrados).
- Configure o OSPF FRR para calcular automaticamente o próximo salto de backup:
Você pode ativar o OSPF FRR para calcular um próximo salto de backup usando o algoritmo LFA ou especificar um próximo salto de backup usando uma política de roteamento.
- (Método 1.) Habilite o OSPF FRR para calcular o próximo salto de backup usando o algoritmo LFA: # Configure o Switch A.
<SwitchA> system-view
[SwitchA] ospf 1
[SwitchA-ospf-1] fast-reroute lfa
[SwitchA-ospf-1] quit
# Configure o Switch B.
<SwitchB> system-view
[SwitchB] ospf 1
[SwitchB-ospf-1] fast-reroute lfa
[SwitchB-ospf-1] quit
- (Método 2.) Habilite o OSPF FRR para designar um próximo salto de backup usando uma política de roteamento.
# Configure o switch A.
<SwitchA> system-view
[SwitchA] ip prefix-list abc index 10 permit 4.4.4.4 32
[SwitchA] route-policy frr permit node 10
[SwitchA-route-policy-frr-10] if-match ip address prefix-list abc
[SwitchA-route-policy-frr-10] apply fast-reroute backup-interface vlan-interface
100 backup-nexthop 12.12.12.2
[SwitchA-route-policy-frr-10] quit
[SwitchA] ospf 1
[SwitchA-ospf-1] fast-reroute route-policy frr
[SwitchA-ospf-1] quit
# Configure o Switch B.
<SwitchB> system-view
[SwitchB] ip prefix-list abc index 10 permit 1.1.1.1 32
[SwitchB] route-policy frr permit node 10
[SwitchB-route-policy-frr-10] if-match ip address prefix-list abc
[SwitchB-route-policy-frr-10] apply fast-reroute backup-interface vlan-interface
101 backup-nexthop 24.24.24.2
[SwitchB-route-policy-frr-10] quit
[SwitchB] ospf 1
[SwitchB-ospf-1] fast-reroute route-policy frr
[SwitchB-ospf-1] quit
Verificação da configuração
# Exibir a rota 4.4.4.4/32 no Switch A para ver as informações do próximo salto de backup.
[SwitchA] display ip routing-table 4.4.4.4 verbose
Summary Count : 1
Destination: 4.4.4.4/32
Protocol: O_INTRA
Process ID: 1
SubProtID: 0x1 Age: 04h20m37s
Cost: 1 Preference: 10
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 0
NibID: 0x26000002 LastAs: 0
AttrID: 0xffffffff Neighbor: 0.0.0.0
Flags: 0x1008c OrigNextHop: 13.13.13.2
Label: NULL RealNextHop: 13.13.13.2
BkLabel: NULL BkNextHop: 12.12.12.2
SRLabel: NULL BkSRLabel: NULL
Tunnel ID: Invalid Interface: Vlan-interface200
BkTunnel ID: Invalid BkInterface: Vlan-interface100
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0
# Exibir a rota 1.1.1.1/32 no Switch B para ver as informações do próximo salto de backup.
[SwitchB] display ip routing-table 1.1.1.1 verbose
Summary Count : 1
Destination: 1.1.1.1/32
Protocol: O_INTRA
Process ID: 1
SubProtID: 0x1 Age: 04h20m37s
Cost: 1 Preference: 10
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 0
NibID: 0x26000002 LastAs: 0
AttrID: 0xffffffff Neighbor: 0.0.0.0
Flags: 0x1008c OrigNextHop: 13.13.13.1
Label: NULL RealNextHop: 13.13.13.1
BkLabel: NULL BkNextHop: 24.24.24.2
SRLabel: NULL BkSRLabel: NULL
Tunnel ID: Invalid Interface: Vlan-interface200
BkTunnel ID: Invalid BkInterface: Vlan-interface101
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0
Solução de problemas de configuração do OSPF
Nenhuma relação de vizinhança OSPF estabelecida
Sintoma
Nenhuma relação de vizinhança OSPF pode ser estabelecida.
Análise
Se o link físico e os protocolos da camada inferior funcionarem corretamente, verifique os parâmetros do OSPF configurados nas interfaces. Dois vizinhos devem ter os mesmos parâmetros, como o ID da área, o segmento de rede e a máscara. (Um link P2P ou virtual pode ter segmentos de rede e máscaras diferentes).
Solução
Para resolver o problema:
- Use o comando display ospf peer para verificar as informações de vizinhança do OSPF.
- Use o comando display ospf interface para verificar as informações da interface OSPF.
- Faça ping no endereço IP do roteador vizinho para verificar se a conectividade está normal.
- Verifique os cronômetros do OSPF. O intervalo morto em uma interface deve ser, no mínimo, quatro vezes o intervalo hello.
- Em uma rede NBMA, use o comando peer ip-address para especificar manualmente o vizinho.
- Pelo menos uma interface deve ter uma prioridade de roteador maior que 0 em uma rede NBMA ou de broadcast.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Informações de roteamento incorretas
Sintoma
O OSPF não consegue encontrar rotas para outras áreas.
Análise
A área de backbone deve manter a conectividade com todas as outras áreas. Se um roteador se conectar a mais de uma área, no mínimo uma área deve estar conectada ao backbone. O backbone não pode ser configurado como uma área stub.
Em uma área de stub, todos os roteadores não podem receber rotas externas, e todas as interfaces conectadas à área de stub devem pertencer a ela.
Solução
Para resolver o problema:
- Use o comando display ospf peer para verificar as informações de vizinhança.
- Use o comando display ospf interface para verificar as informações da interface OSPF.
- Use o comando display ospf lsdb para verificar o LSDB.
- Use o comando display current-configuration configuration ospf para verificar a configuração da área. Se mais de duas áreas estiverem configuradas, no mínimo uma área estará conectada ao backbone.
- Em uma área de stub, todos os roteadores conectados são configurados com o comando stub. Em uma área NSSA, todos os roteadores conectados são configurados com o comando nssa.
- Se um link virtual estiver configurado, use o comando display ospf vlink para verificar o estado do link virtual.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Configuração de PBR
Sobre a PBR
O roteamento baseado em políticas (PBR) usa políticas definidas pelo usuário para rotear pacotes. Uma política pode especificar parâmetros para pacotes que correspondem a critérios específicos, como ACLs. Os parâmetros incluem o próximo salto.
Processo de encaminhamento de pacotes
O dispositivo encaminha os pacotes recebidos usando o seguinte processo:
- O dispositivo usa o PBR para encaminhar os pacotes correspondentes.
- Se um dos eventos a seguir ocorrer, o dispositivo procurará uma rota (exceto a rota padrão) na tabela de roteamento para encaminhar os pacotes:
- Os pacotes não correspondem à política de PBR.
- O encaminhamento baseado em PBR falha.
- Se o encaminhamento falhar, o dispositivo usará a rota padrão para encaminhar os pacotes.
Tipos de PBR
O PBR inclui os seguintes tipos:
Política
Uma política inclui critérios de correspondência e ações a serem executadas nos pacotes correspondentes. Uma política pode ter um ou vários nós, como segue:
- Cada nó é identificado por um número de nó. Um número de nó menor tem uma prioridade mais alta.
- Um nó contém cláusulas if-match e apply. Uma cláusula if-match especifica um critério de correspondência e uma cláusula apply especifica uma ação.
- Um nó tem um modo de correspondência de permissão ou negação.
Uma política compara os pacotes com os nós em ordem de prioridade. Se um pacote corresponder aos critérios em um nó, ele será processado pela ação no nó. Se o pacote não corresponder a nenhum critério no nó, ele irá para o próximo nó em busca de uma correspondência. Se o pacote não corresponder aos critérios em nenhum nó, o dispositivo executará uma pesquisa na tabela de roteamento.
Relação entre cláusulas if-match
O PBR suporta apenas a cláusula if-match acl para definir um critério de correspondência de ACL. Em um nó, é possível especificar apenas uma cláusula if-match.
Relacionamento entre cláusulas apply
O PBR suporta apenas a cláusula apply next-hop para definir os próximos hops.
Relação entre o modo de correspondência e as cláusulas no nó
| Um pacote corresponde a todas as cláusulas if-match no nó? | Modo de correspondência | |
| Permissão | Negar | |
| Se o nó contiver cláusulas de aplicação, o PBR executará as cláusulas de aplicação no nó. | ||
| Sim. | Se o encaminhamento baseado em PBR for bem-sucedido, o PBR não comparar o pacote com o próximo nó. | O dispositivo executa uma pesquisa na tabela de roteamento para o pacote. |
| Se o nó não contiver cláusulas de aplicação, o dispositivo executará uma pesquisa na tabela de roteamento para o pacote. | ||
| Não. | O PBR compara o pacote com o próximo nó. | O PBR compara o pacote com o próximo nó. |
OBSERVAÇÃO:
Um nó que não tenha cláusulas if-match corresponde a qualquer pacote.
PBR e trilha
O PBR pode trabalhar com o recurso Track para adaptar dinamicamente o status de disponibilidade de uma cláusula de aplicação ao status do link de um objeto rastreado. O objeto rastreado pode ser um próximo salto.
- Quando a entrada de trilha associada a um objeto muda para Negativo, a cláusula apply é inválida.
- Quando a entrada da trilha muda para Positive ou NotReady, a cláusula apply é válida.
Para obter mais informações sobre a colaboração Track e PBR, consulte o Guia de configuração de alta disponibilidade.
Restrições e diretrizes: Configuração de PBR
Se o dispositivo realizar o encaminhamento no software, o PBR não processará os pacotes IP destinados ao dispositivo local.
Se o dispositivo realizar o encaminhamento em hardware e um pacote destinado a ele corresponder a uma política de PBR, a PBR executará as cláusulas de aplicação na política, inclusive a cláusula de encaminhamento. Quando você configurar uma política de PBR, tenha cuidado para evitar essa situação.
Visão geral das tarefas do PBR
Para configurar o PBR, execute as seguintes tarefas:
- Configuração de uma política
- Criação de um nó
- Definição de critérios de correspondência para um nó
- Configuração de ações para um nó
- Especificação de uma política para PBR
- Especificação de uma política para PBR local
- Especificação de uma política para PBR de interface
Escolha as seguintes tarefas, conforme necessário:
Configuração de uma política
Criação de um nó
- Entre na visualização do sistema.
system-view- Crie um nó para uma política e entre em sua visualização.
policy-based-route policy-name [ deny | permit ] node node-number- (Opcional.) Configure uma descrição para o nó de política.
description textPor padrão, nenhuma descrição é configurada para um nó de política.
Definição de critérios de correspondência para um nó
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do nó de política.
policy-based-route policy-name [ deny | permit ] node node-number- Definir critérios de correspondência.
- Definir um critério de correspondência de ACL.
if-match acl { acl-number | name acl-name }Por padrão, nenhum critério de correspondência de ACL é definido.
O critério de correspondência da ACL não pode corresponder às informações da Camada 2.
Ao usar a ACL para fazer a correspondência de pacotes, o PBR ignora a ação (permitir ou negar) e o tempo configurações de intervalo na ACL.
Configuração de ações para um nó
Sobre cláusulas apply
Você pode usar a cláusula apply next-hop para definir os próximos hops para pacotes correspondentes em um nó.
Restrições e diretrizes
Se você especificar um next hop ou um next hop padrão, o PBR fará periodicamente uma pesquisa na tabela FIB para determinar sua disponibilidade. Poderá ocorrer uma interrupção temporária do serviço se a PBR não atualizar a rota imediatamente após a alteração de seu status de disponibilidade.
Configuração de ações para direcionar o encaminhamento de pacotes
- Entre na visualização do sistema.
system-view- Entre na visualização do nó de política.
policy-based-route policy-name [ deny | permit ] node node-number- Configurar ações.
- Definir os próximos saltos.
apply next-hop { ip-address [ direct ] [ track
track-entry-number ] }&<1-2>
Por padrão, nenhum próximo salto é especificado.
Em um nó, é possível especificar um máximo de dois próximos saltos para backup em uma linha de comando ou executando esse comando várias vezes.
Especificação de uma política para PBR
Especificação de uma política para PBR local
Sobre a PBR local
Execute esta tarefa para especificar uma política de PBR local para orientar o encaminhamento de pacotes gerados localmente.
Restrições e diretrizes
Você pode especificar apenas uma política para o PBR local e deve se certificar de que a política especificada já existe. Antes de aplicar uma nova política, você deve primeiro remover a política atual.
O PBR local pode afetar os serviços locais, como ping e Telnet. Quando você usar o PBR local, certifique-se de compreender totalmente seu impacto nos serviços locais do dispositivo.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique uma política para PBR local.
ip local policy-based-route policy-name
Por padrão, o PBR local não está ativado.
Especificação de uma política para PBR de interface
Sobre a interface PBR
Execute esta tarefa para aplicar uma política a uma interface para orientar o encaminhamento de pacotes recebidos na interface.
Restrições e diretrizes
Você pode aplicar somente uma política a uma interface e deve certificar-se de que a política especificada já existe. Antes de aplicar uma nova política de PBR de interface a uma interface, você deve primeiro remover a política atual da interface.
Você pode aplicar uma política a várias interfaces.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique uma política para a interface PBR.
ip policy-based-route policy-name
Por padrão, nenhuma política de interface é aplicada a uma interface.
Comandos de exibição e manutenção para PBR
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações sobre a política de PBR. | display ip policy-based-route [ policy policy-name ] |
| Exibir a configuração e as estatísticas do PBR da interface. | display ip policy-based-route interface interface-type número da interface [ número do slot do slot ] |
| Exibir a configuração e as estatísticas do PBR local. | display ip policy-based-route local [ slot slot-number ] |
| Exibir a configuração do PBR. | display ip policy-based-route setup |
| Limpar estatísticas de PBR. | reset ip policy-based-route statistics [ policy policy-name ] |
Exemplos de configuração de PBR
Exemplo: Configuração de PBR local baseado em tipo de pacote
Configuração de rede
Conforme mostrado na Figura 1, o Switch B e o Switch C não têm uma rota para chegar um ao outro. Configure o PBR no Switch A para encaminhar todos os pacotes TCP para o próximo salto 1.1.2.2 (Switch B).
Figura 1 Diagrama de rede

Procedimento
- Configure o Switch A:
# Crie a VLAN 10 e a VLAN 20.
<SwitchA> system-view
[SwitchA] vlan 10
[SwitchA-vlan10] quit
[SwitchA] vlan 20
[SwitchA-vlan20] quit
# Configure os endereços IP da interface de VLAN 10 e da interface de VLAN 20.
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ip address 1.1.2.1 24
[SwitchA-Vlan-interface10] quit
[SwitchA] interface vlan-interface 20
[SwitchA-Vlan-interface20] ip address 1.1.3.1 24
[SwitchA-Vlan-interface20] quit
# Configure a ACL 3101 para corresponder aos pacotes TCP.
[SwitchA] acl advanced 3101
[SwitchA-acl-ipv4-adv-3101] rule permit tcp
[SwitchA-acl-ipv4-adv-3101] quit
# Configure o nó 5 para que a política aaa encaminhe os pacotes TCP para o próximo salto 1.1.2.2.
[SwitchA] policy-based-route aaa permit node 5
[SwitchA-pbr-aaa-5] if-match acl 3101
[SwitchA-pbr-aaa-5] apply next-hop 1.1.2.2
[SwitchA-pbr-aaa-5] quit
# Configure o PBR local aplicando a política aaa ao Switch A.
[SwitchA] ip local policy-based-route aaa
- Configure o Switch B: # Criar VLAN 10.
<SwitchB> system-view
[SwitchB] vlan 10
[SwitchB-vlan10] quit
# Configure o endereço IP da interface VLAN 10.
[SwitchB] interface vlan-interface 10
[SwitchB-Vlan-interface10] ip address 1.1.2.2 24
- Configure o Switch C: # Crie a VLAN 20.
<SwitchC> system-view
[SwitchC] vlan 20
[SwitchC-vlan20] quit
# Configure o endereço IP da interface VLAN 20.
[SwitchC] interface vlan-interface 20
[SwitchC-Vlan-interface20] ip address 1.1.3.2 24
Verificação da configuração
- Realize operações de telnet para verificar se o PBR local no Switch A funciona conforme configurado para encaminhar os pacotes TCP correspondentes para o próximo salto 1.1.2.2 (Switch B), como segue:
# Verifique se você pode fazer telnet no Switch B a partir do Switch A com sucesso. (Detalhes não mostrados).
# Verifique se não é possível fazer telnet no Switch C a partir do Switch A. (Detalhes não mostrados).
- Verifique se o Switch A encaminha pacotes que não sejam TCP por meio da interface VLAN 20. Por exemplo, verifique se você pode fazer ping no Switch C a partir do Switch A. (Detalhes não mostrados).
Exemplo: Configuração da interface PBR baseada em tipo de pacote
Configuração de rede
Conforme mostrado na Figura 2, o Switch B e o Switch C não têm uma rota para chegar um ao outro.
Configure o PBR no Switch A para encaminhar todos os pacotes TCP recebidos na interface VLAN 11 para o próximo salto 1.1.2.2 (Switch B).
Figura 2 Diagrama de rede
Procedimento
- Certifique-se de que o Switch B e o Switch C possam acessar o Host A. (Detalhes não mostrados.)
- Configure o Switch A:
# Crie a VLAN 10 e a VLAN 20.
<SwitchA> system-view
[SwitchA] vlan 10
[SwitchA-vlan10] quit
[SwitchA] vlan 20
[SwitchA-vlan20] quit
# Configure os endereços IP da interface de VLAN 10 e da interface de VLAN 20.
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ip address 1.1.2.1 24
[SwitchA-Vlan-interface10] quit
[SwitchA] interface vlan-interface 20
[SwitchA-Vlan-interface20] ip address 1.1.3.1 24
[SwitchA-Vlan-interface20] quit
# Configure a ACL 3101 para corresponder aos pacotes TCP.
[SwitchA] acl advanced 3101
[SwitchA-acl-ipv4-adv-3101] rule permit tcp
[SwitchA-acl-ipv4-adv-3101] quit
# Configure o nó 5 para que a política aaa encaminhe os pacotes TCP para o próximo salto 1.1.2.2.
[SwitchA] policy-based-route aaa permit node 5
[SwitchA-pbr-aaa-5] if-match acl 3101
[SwitchA-pbr-aaa-5] apply next-hop 1.1.2.2
[SwitchA-pbr-aaa-5] quit
# Configure a interface PBR aplicando a política aaa à interface VLAN 11.
[SwitchA] interface vlan-interface 11
[SwitchA-Vlan-interface11] ip address 10.110.0.10 24
[SwitchA-Vlan-interface11] ip policy-based-route aaa
[SwitchA-Vlan-interface11] quit
Verificação da configuração
- Realize operações de telnet para verificar se a interface PBR no Switch A funciona conforme configurado para encaminhar os pacotes TCP correspondentes para o próximo salto 1.1.2.2 (Switch B), como segue:
# Verifique se você pode fazer telnet para o Switch B a partir do Host A com sucesso. (Detalhes não mostrados.) # Verifique se não é possível fazer telnet para o Switch C a partir do Host A. (Detalhes não mostrados.)
- Verifique se o Switch A encaminha outros pacotes além dos pacotes TCP por meio da interface VLAN 20. Por exemplo, verifique se você pode fazer ping no Switch C a partir do Host A. (Detalhes não mostrados).
Exemplo: Configuração de PBR global baseado em tipo de pacote
Configuração de rede
Conforme mostrado na Figura 3, o Switch E e o Switch F não têm uma rota para chegar um ao outro. Configure o PBR global no Switch D para encaminhar pacotes TCP para o próximo salto 1.1.4.2 (Switch E).
Figura 3 Diagrama de rede
Procedimento
- Configure os endereços IP para as interfaces. Certifique-se de que os Comutadores A, B e C possam se comunicar com o Comutador E e o Comutador F, respectivamente. (Detalhes não mostrados).
- Configurar o Switch D:
# Configure a ACL 3101 para corresponder aos pacotes TCP provenientes das redes 1.1.1.0/24, 1.1.2.0/24 e 1.1.3.0/24.
<SwitchD> system-view
[SwitchD] acl advanced 3101
[SwitchD-acl-ipv4-adv-3101] rule permit tcp source 1.1.1.0 0.0.0.0.255
[SwitchD-acl-ipv4-adv-3101] rule permit tcp source 1.1.2.0 0.0.0.0.255
[SwitchD-acl-ipv4-adv-3101] rule permit tcp source 1.1.3.0 0.0.0.0.255
[SwitchD-acl-ipv4-adv-3101] quit# Configure o nó 5 na política de PBR aaa para encaminhar os pacotes TCP que correspondem à ACL 3101 para o próximo salto 1.1.4.2.
[SwitchD] policy-based-route aaa permit node 5
[SwitchD-pbr-aaa-5] if-match acl 3101
[SwitchD-pbr-aaa-5] apply next-hop 1.1.4.2
[SwitchD-pbr-aaa-5] quit
# Especifique a política de PBR aaa como a política global de PBR.
[SwitchD] ip global policy-based-route aaa
Verificação da configuração
- Execute operações de telnet para verificar se o PBR global no Switch D funciona conforme configurado para encaminhar os pacotes TCP correspondentes para o próximo salto 1.1.4.2 (Switch E), como segue:
# Verifique se você pode fazer telnet no Switch E a partir do Switch A, Switch B e Switch C com sucesso. (Detalhes não mostrados).
# Verifique se você não pode fazer telnet para o Switch F a partir do Switch A, Switch B ou Switch C. (Detalhes não mostrados).
- Verifique se o Switch D encaminha outros pacotes além dos pacotes TCP, desde que haja uma rota disponível. Por exemplo, verifique se você pode fazer ping no Switch F a partir do Switch A, Switch B e Switch C. (Detalhes não mostrados).
Configuração do roteamento estático IPv6
Sobre o roteamento estático IPv6
As rotas estáticas são configuradas manualmente e não podem se adaptar às mudanças na topologia da rede. Se ocorrer uma falha ou uma alteração topológica na rede, o administrador da rede deverá modificar as rotas estáticas manualmente. O roteamento estático IPv6 funciona bem em uma rede IPv6 simples.
Configuração de uma rota estática IPv6
- Entre na visualização do sistema.
system-view- Configurar uma rota estática IPv6.
ipv6 route-static ipv6-address prefix-length { interface-type
interface-number [ next-hop-address ] | next-hop-address } [ permanent ]
[ preference preference ] [ tag tag-value ] [ description text ]
Por padrão, nenhuma rota estática IPv6 é configurada.
- (Opcional.) Defina a preferência padrão para rotas estáticas IPv6.
ipv6 route-static default-preference default-preference
A configuração padrão é 60.
Exclusão de rotas estáticas IPv6
Sobre a exclusão de rotas estáticas IPv6
Para excluir uma rota estática IPv6, use o comando undo ipv6 route-static. Para excluir todas as rotas estáticas IPv6, inclusive a rota padrão, use o comando delete ipv6 static-routes all.
Procedimento
- Entre na visualização do sistema.
system-view- Excluir todas as rotas estáticas IPv6, inclusive a rota padrão.
delete ipv6 static-routes all
Esse comando pode interromper a comunicação da rede e causar falha no encaminhamento de pacotes. Antes de executar o comando, certifique-se de compreender totalmente o possível impacto na rede.
Configuração de BFD para rotas estáticas IPv6
Sobre o BFD para rotas estáticas IPv6
O BFD oferece um mecanismo de detecção rápida de falhas de propósito geral, padrão e independente de meio e protocolo. Ele pode detectar de maneira uniforme e rápida as falhas dos caminhos de encaminhamento bidirecional entre dois roteadores para protocolos, como protocolos de roteamento. Testes de BFD para rotas estáticas IPv6
a acessibilidade do próximo salto para cada rota estática IPv6. Se um próximo salto for inacessível, o BFD excluirá a rota estática IPv6 associada.
Para obter mais informações sobre o BFD, consulte o Guia de configuração de alta disponibilidade.
Restrições e diretrizes para BFD
Quando você configurar o BFD para rotas estáticas IPv6, siga estas restrições e diretrizes:
- Se você especificar um endereço IPv6 de origem para os pacotes BFD no dispositivo local, deverá especificar esse endereço IPv6 como o endereço IPv6 do próximo salto no dispositivo par.
- Se você especificar uma interface de saída não-P2P e um próximo salto direto, especifique a opção bfd-source ipv6-address como prática recomendada. Certifique-se de que o endereço IPv6 de origem dos pacotes BFD atenda aos seguintes requisitos:
- O endereço é o mesmo que o endereço IPv6 da interface de saída.
- O endereço está no mesmo segmento de rede que o endereço IPv6 do próximo salto do mesmo tipo.
Por exemplo, se o endereço IPv6 do próximo salto for um endereço local do link, o endereço IPv6 de origem dos pacotes BFD também deverá ser um endereço local do link.
- A ativação do BFD para uma rota com flapping pode piorar a situação.
Configuração do modo de pacote de controle BFD
Sobre o modo de pacote de controle BFD
Esse modo usa pacotes de controle BFD para detectar o status de um link bidirecionalmente em um nível de milissegundos.
O modo de pacote de controle BFD pode ser aplicado a rotas estáticas IPv6 com um próximo salto direto ou com um próximo salto indireto.
Restrições e diretrizes para o modo de pacote de controle BFD
Se você configurar o modo de pacote de controle BFD na extremidade local, também deverá configurar esse modo na extremidade do par.
Configuração do modo de pacote de controle BFD para uma rota estática IPv6 (próximo salto direto)
- Entre na visualização do sistema.
system-view- Configure o modo de pacote de controle BFD para uma rota estática IPv6.
ipv6 route-static ipv6-address prefix-length interface-type
interface-number next-hop-address bfd control-packet [ bfd-source
ipv6-address ] [ preference preference ] [ tag tag-value ] [ description
text ]
Por padrão, o modo de pacote de controle BFD para uma rota estática IPv6 não está configurado.
Configuração do modo de pacote de controle BFD para uma rota estática IPv6 (próximo salto indireto)
- Entre na visualização do sistema.
system-view- Configure o modo de pacote de controle BFD para uma rota estática IPv6.
ipv6 route-static ipv6-address prefix-length { next-hop-address bfd
control-packet bfd-source ipv6-address } [ preference preference ]
[ tag tag-value ] [ description text ]
Por padrão, o modo de pacote de controle BFD para uma rota estática IPv6 não está configurado.
Configuração do modo de pacote de eco BFD
Sobre o modo de pacote de eco de salto único
Com o modo de pacote de eco BFD ativado para uma rota estática, a interface de saída envia pacotes de eco BFD para o dispositivo de destino, que retorna os pacotes em loop para testar a capacidade de alcance do link.
Restrições e diretrizes
Não é necessário configurar o modo de pacote de eco BFD na extremidade do par.
Não use o BFD para uma rota estática com a interface de saída em estado de spoofing.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o endereço de origem dos pacotes de eco.
bfd echo-source-ipv6 ipv6-address
Por padrão, o endereço de origem dos pacotes de eco não é configurado.
O endereço de origem dos pacotes de eco deve ser um endereço unicast global.
Para obter mais informações sobre esse comando, consulte Referência de comandos de alta disponibilidade.
- Configurar o modo de pacote de eco BFD para uma rota estática IPv6.
ipv6 route-static ipv6-address prefix-length interface-type
interface-number next-hop-address bfd echo-packet [ bfd-source
ipv6-address ] [ preference preference ] [ tag tag-value ] [ description
text ]
Por padrão, o modo de pacote de eco BFD para uma rota estática IPv6 não está configurado. O endereço IPv6 do próximo salto deve ser um endereço unicast global.
Comandos de exibição e manutenção para roteamento estático IPv6
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações do próximo salto da rota estática IPv6. | display ipv6 route-static nib [ nib-id ] [ verbose ] |
| Exibir informações da tabela de roteamento estático IPv6. | display ipv6 route-static routing-table [ ipv6-address prefix-length ] |
| Exibir informações de rota estática IPv6. | display ipv6 routing-table protocol static [ inactive | verbose ] |
Exemplos de configuração de roteamento estático IPv6
Exemplo: Configuração de rota estática IPv6 básica
Configuração de rede
Conforme mostrado na Figura 1, configure rotas estáticas IPv6 para que os hosts possam se comunicar entre si.
Figura 1 Diagrama de rede
Procedimento
- Configure os endereços IPv6 para todas as interfaces de VLAN. (Detalhes não mostrados.)
- Configurar rotas estáticas IPv6:
# Configure uma rota estática IPv6 padrão no Switch A.
<SwitchA> system-view
[SwitchA] ipv6 route-static :: 0 4::2
# Configure duas rotas estáticas IPv6 no Switch B.
<SwitchB> system-view
[SwitchB] ipv6 route-static 1:: 64 4::1
[SwitchB] ipv6 route-static 3:: 64 5::1
# Configure uma rota estática IPv6 padrão no Switch C.
Gustavo aqui<SwitchC> system-view
[SwitchC] ipv6 route-static :: 0 5::2
- Configure os endereços IPv6 para todos os hosts e configure o gateway padrão do Host A, Host B e Host C como 1::1, 2::1 e 3::1.
Verificação da configuração
# Exibir as informações da rota estática IPv6 no Switch A.
[SwitchA] display ipv6 routing-table protocol static
Summary count : 1
Static Routing table status :
Summary count : 1
Destination: ::/0 Protocol : Static
NextHop : 4::2 Preference: 60
Interface : Vlan200 Cost : 0
Static Routing table status :
Summary count : 0
[SwitchB] display ipv6 routing-table protocol static
Summary count : 2
Static Routing table status :
Summary count : 2
Destination: 1::/64 Protocol : Static
NextHop : 4::1 Preference: 60
Interface : Vlan200 Cost : 0
Destination: 3::/64 Protocol : Static
NextHop : 5::1 Preference: 60
Interface : Vlan300 Cost : 0
Static Routing table status :
Summary count : 0
# Use o comando ping para testar a capacidade de alcance.
[SwitchA] ping ipv6 3::1
Ping6(56 data bytes) 4::1 --> 3::1, press CTRL_C to break
56 bytes from 3::1, icmp_seq=0 hlim=62 time=0.700 ms
56 bytes from 3::1, icmp_seq=1 hlim=62 time=0.351 ms
56 bytes from 3::1, icmp_seq=2 hlim=62 time=0.338 ms
56 bytes from 3::1, icmp_seq=3 hlim=62 time=0.373 ms
56 bytes from 3::1, icmp_seq=4 hlim=62 time=0.316 ms
--- Ping6 statistics for 3::1 ---
5 packet(s) transmitted, 5 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 0.316/0.416/0.700/0.143 ms
Exemplo: Configuração de BFD para rotas estáticas IPv6 (próximo salto direto)
Configuração de rede
Conforme mostrado na Figura 2:
- Configure uma rota estática IPv6 para a sub-rede 120::/64 no Switch A.
- Configure uma rota estática IPv6 para a sub-rede 121::/64 no Switch B.
- Habilite o BFD para ambas as rotas.
- Configure uma rota estática IPv6 para a sub-rede 120::/64 e uma rota estática IPv6 para a sub-rede 121::/64 no Switch C.
Quando o link entre o Switch A e o Switch B através do switch da Camada 2 falha, o BFD pode detectar a falha imediatamente, e o Switch A e o Switch B podem se comunicar através do Switch C.
Figura 2 Diagrama de rede
Tabela 1 Atribuição de interface e endereço IP
| Dispositivo | Interface | Endereço IPv6 |
| Chave A | Vlan-int10 | 12::1/64 |
| Chave A | Vlan-int11 | 10::102/64 |
| Chave B | Vlan-int10 | 12::2/64 |
| Chave B | Vlan-int13 | 13::1/64 |
| Chave C | Vlan-int11 | 10::100/64 |
| Chave C | Vlan-int13 | 13::2/64 |
Procedimento
- Configurar endereços IPv6 para interfaces. (Detalhes não mostrados).
- Configurar rotas estáticas IPv6 e BFD:
# Configure rotas estáticas IPv6 no Switch A e ative o modo de pacote de controle BFD para a rota estática que atravessa o switch de Camada 2.
<SwitchA> system-view
[SwitchA] interface vlan-interface 10
[SwitchA-vlan-interface10] bfd min-transmit-interval 500
[SwitchA-vlan-interface10] bfd min-receive-interval 500
[SwitchA-vlan-interface10] bfd detect-multiplier 9
[SwitchA-vlan-interface10] quit
[SwitchA] ipv6 route-static 120:: 64 vlan-interface 10 12::2 bfd control-packet
[SwitchA] ipv6 route-static 120:: 64 10::100 preference 65
[SwitchA] quit
# Configure rotas estáticas IPv6 no Switch B e ative o modo de pacote de controle BFD para a rota estática que atravessa o switch de Camada 2.
<SwitchB> system-view
[SwitchB] interface vlan-interface 10
[SwitchB-vlan-interface10] bfd min-transmit-interval 500
[SwitchB-vlan-interface10] bfd min-receive-interval 500
[SwitchB-vlan-interface10] bfd detect-multiplier 9
[SwitchB-vlan-interface10] quit
[SwitchB] ipv6 route-static 121:: 64 vlan-interface 10 12::1 bfd control-packet
[SwitchB] ipv6 route-static 121:: 64 vlan-interface 13 13::2 preference 65
[SwitchB] quit
# Configurar rotas estáticas IPv6 no Switch C.
<SwitchC> system-view
[SwitchC] ipv6 route-static 120:: 64 13::1
[SwitchC] ipv6 route-static 121:: 64 10::102
Verificação da configuração
# Exibir as sessões BFD no Switch A.
<SwitchA> display bfd session
Total Session Num: 1 Up Session Num: 1 Init Mode: Active
IPv6 Session Working Under Ctrl Mode:
Local Discr: 513 Remote Discr: 33
Source IP: 12::1
Destination IP: 12::2
Session State: Up Interface: Vlan10
Hold Time: 2012ms
A saída mostra que a sessão BFD foi criada.
# Exibir rotas estáticas IPv6 no Switch A.
<SwitchA> display ipv6 routing-table protocol static
Summary count : 1
Static Routing table status : <Active>
Summary count : 1
Destination: 120::/64 Protocol : Static
NextHop : 12::2 Preference: 60
Interface : Vlan10 Cost : 0
Direct Routing table status : <Inativo>
Summary count : 0
A saída mostra que o Switch A se comunica com o Switch B por meio da interface de VLAN 10. O link na interface VLAN 10 falha.
# Exibir novamente as rotas estáticas IPv6 no Switch A.
<SwitchA> display ipv6 routing-table protocol static
Summary count : 1
Static Routing table status : <Active>
Summary count : 1
Destination: 120::/64 Protocol : Static
NextHop : 10::100 Preference: 65
Interface : Vlan11 Cost : 0
Static Routing table status : <Inativo>
Summary count : 0
A saída mostra que o Switch A se comunica com o Switch B por meio da interface VLAN 11.
Exemplo: Configuração de BFD para rotas estáticas IPv6 (próximo salto indireto)
Configuração de rede
Conforme mostrado na Figura 3:
- O switch A tem uma rota para a interface Loopback 1 (2::9/128) no switch B, e a interface de saída é a interface VLAN 10.
- O Switch B tem uma rota para a interface Loopback 1 (1::9/128) no Switch A, e a interface de saída é a interface VLAN 12.
- O switch D tem uma rota para 1::9/128 e a interface de saída é a interface de VLAN 10. Ele também tem uma rota para 2::9/128, e a interface de saída é a interface de VLAN 12.
Configure o seguinte:
- Configure uma rota estática IPv6 para a sub-rede 120::/64 no Switch A.
- Configure uma rota estática IPv6 para a sub-rede 121::/64 no Switch B.
- Habilite o BFD para ambas as rotas.
- Configure uma rota estática IPv6 para a sub-rede 120::/64 e uma rota estática IPv6 para a sub-rede 121::/64 no Switch C e no Switch D.
Quando o link entre o Switch A e o Switch B através do Switch D falha, o BFD pode detectar a falha imediatamente e o Switch A e o Switch B podem se comunicar através do Switch C.
Figura 3 Diagrama de rede
Tabela 2 Atribuição de interface e endereço IP
| Dispositivo | Interface | Endereço IPv6 |
| Chave A | Vlan-int10 | 12::1/64 |
| Chave A | Vlan-int11 | 10::102/64 |
| Chave A | Loop1 | 1::9/128 |
| Chave B | Vlan-int12 | 11::2/64 |
| Chave B | Vlan-int13 | 13::1/64 |
| Chave B | Loop1 | 2::9/128 |
| Chave C | Vlan-int11 | 10::100/64 |
| Chave C | Vlan-int13 | 13::2/64 |
| Dispositivo | Interface | Endereço IPv6 |
| Chave D | Vlan-int10 | 12::2/64 |
| Chave D | Vlan-int12 | 11::1/64 |
Procedimento
- Configurar endereços IPv6 para interfaces. (Detalhes não mostrados).
- Configurar rotas estáticas IPv6 e BFD:
# Configure rotas estáticas IPv6 no Switch A e ative o modo de pacote de controle BFD para a rota estática IPv6 que atravessa o Switch D.
<SwitchA> system-view
[SwitchA] bfd multi-hop min-transmit-interval 500
[SwitchA] bfd multi-hop min-receive-interval 500
[SwitchA] bfd multi-hop detect-multiplier 9
[SwitchA] ipv6 route-static 120:: 64 2::9 bfd control-packet bfd-source 1::9
[SwitchA] ipv6 route-static 120:: 64 10::100 preference 65
[SwitchA] ipv6 route-static 2::9 128 12::2
[SwitchA] quit
# Configure rotas estáticas IPv6 no Switch B e ative o modo de pacote de controle BFD para a rota estática que atravessa o Switch D.
<SwitchB> system-view
[SwitchB] bfd multi-hop min-transmit-interval 500
[SwitchB] bfd multi-hop min-receive-interval 500
[SwitchB] bfd multi-hop detect-multiplier 9
[SwitchB] ipv6 route-static 121:: 64 1::9 bfd control-packet bfd-source 2::9
[SwitchB] ipv6 route-static 121:: 64 13::2 preference 65
[SwitchB] ipv6 route-static 1::9 128 11::1
[SwitchB] quit
# Configurar rotas estáticas IPv6 no Switch C.
<SwitchC> system-view
[SwitchC] ipv6 route-static 120:: 64 13::1
[SwitchC] ipv6 route-static 121:: 64 10::102
# Configurar rotas estáticas IPv6 no Switch D.
<SwitchD> system-view
[SwitchD] ipv6 route-static 120:: 64 11::2
[SwitchD] ipv6 route-static 121:: 64 12::1
[SwitchD] ipv6 route-static 2::9 128 11::2
[SwitchD] ipv6 route-static 1::9 128 12::1
Verificação da configuração
# Exibir as sessões BFD no Switch A.
<SwitchA> display bfd session
Total Session Num: 1 Up Session Num: 1 Init Mode: Active
IPv6 Session Working Under Ctrl Mode:
Local Discr: 513 Remote Discr: 33
Source IP: 1::9
Destination IP: 2::9
Session State: Up Interface: N/A
Hold Time: 2012msA saída mostra que a sessão BFD foi criada.
# Exibir as rotas estáticas IPv6 no Switch A.
<SwitchA> display ipv6 routing-table protocol static
Summary count : 1
Static Routing table status : <Active>
Summary count : 1
Destination: 120::/64 Protocol : Static
NextHop : 2::9 Preference: 60
Interface : Vlan10 Cost : 0
Static Routing table status : <Inativo>
Summary count : 0A saída mostra que o Switch A se comunica com o Switch B por meio da interface de VLAN 10. O link na interface VLAN 10 falha.
# Exibir novamente as rotas estáticas IPv6 no Switch A.
<SwitchA> display ipv6 routing-table protocol static
Summary count : 1
Static Routing table status : <Active>
Summary count : 1
Destination: 120::/64 Protocol : Static
NextHop : 10::100 Preference: 65
Interface : Vlan11 Cost : 0
Static Routing table status : <Inativo>
Summary count : 0A saída mostra que o Switch A se comunica com o Switch B por meio da interface VLAN 11.
Configuração de uma rota padrão IPv6
Sobre a rota padrão IPv6
Uma rota IPv6 padrão é usada para encaminhar pacotes que não correspondem a nenhuma entrada na tabela de roteamento. Uma rota IPv6 padrão pode ser configurada de uma das seguintes maneiras:
- O administrador de rede pode configurar uma rota padrão com um prefixo de destino de ::/0. Para
Para obter mais informações, consulte "Configuração do roteamento estático IPv6".
- Alguns protocolos de roteamento dinâmico (como OSPFv3 e RIPng) podem gerar uma rota IPv6 padrão. Por exemplo, um roteador upstream que esteja executando o OSPFv3 pode gerar uma rota IPv6 padrão e anunciá-la a outros roteadores. Esses roteadores instalam a rota IPv6 padrão com o próximo salto sendo o roteador upstream. Para obter mais informações, consulte os respectivos capítulos sobre esses protocolos de roteamento neste guia de configuração.
Configuração do RIPng
Sobre a RIPng
O RIP next generation (RIPng), como uma extensão do RIP-2 para suporte do IPv6, é um protocolo de roteamento de vetor de distância. Ele emprega UDP para trocar informações de rota por meio da porta 521. A maioria dos conceitos do RIP é aplicável ao RIPng.
Métricas de roteamento RIPng
O RIPng usa uma contagem de saltos para medir a distância até um destino. A contagem de saltos é a métrica ou o custo. A contagem de saltos de um roteador para uma rede diretamente conectada é 0. A contagem de saltos entre dois roteadores diretamente conectados é 1. Quando a contagem de saltos é maior ou igual a 16, a rede ou o host de destino é inacessível.
Entradas de rota RIPng
O RIPng armazena entradas de rota em um banco de dados. Cada entrada de rota contém os seguintes elementos:
- Endereço de destino - endereço IPv6 de um host de destino ou de uma rede.
- Endereço do próximo salto - endereço IPv6 do próximo salto.
- Interface de saída - Interface de saída da rota.
- Métrica - custo do roteador local até o destino.
- Route time-Tempo decorrido desde a atualização mais recente. O tempo é redefinido para 0 toda vez que a entrada de rota é atualizada.
- Route tag - Usada para controle de rota. Para obter mais informações, consulte "Configuração de políticas de roteamento".
Pacotes e anúncios RIPng
O RIPng faz multicasts de pacotes de solicitação e resposta para trocar informações de roteamento. Ele usa FF02::9 como endereço de destino e o endereço local do link FE80::/10 como endereço de origem. O RIPng troca informações de roteamento da seguinte forma:
- Quando o RIPng inicia ou precisa atualizar algumas entradas de rota, ele envia um pacote de solicitação multicast para os vizinhos.
- Quando um vizinho RIPng recebe o pacote de solicitação, ele envia de volta um pacote de resposta que contém a tabela de roteamento local. O RIPng também pode anunciar atualizações de rota em pacotes de resposta periodicamente ou anunciar uma atualização acionada causada por uma alteração de rota.
- Depois que o RIPng recebe a resposta, ele verifica a validade da resposta antes de adicionar rotas à sua tabela de roteamento, incluindo os seguintes detalhes:
- Se o endereço IPv6 de origem é o endereço local do link.
- Se o número da porta está correto.
- Um pacote de resposta que não passa na verificação é descartado.
Protocolos e padrões
Visão geral das tarefas de RIPng
Para configurar o RIPng, execute as seguintes tarefas:
- Configuração do RIPng básico
- (Opcional.) Configuração do controle de rota RIPng
- Configuração de uma métrica de roteamento adicional
- Configuração da compactação de rotas RIPng
- Anunciar uma rota padrão
- Configuração da filtragem de rotas recebidas/redistribuídas
- Definição de uma preferência para RIPng
- Configuração da redistribuição de rotas RIPng
- (Opcional.) Ajuste e otimização da rede RIPng
- Configuração de temporizadores RIPng
- Configuração de split horizon e poison reverse
- Configuração da taxa de envio de pacotes RIPng
- Definição do intervalo para envio de atualizações acionadas
- (Opcional.) Aumentar a disponibilidade do RIPng
- Configuração do RIPng GR
- Configuração do RIPng NSR
- Configuração de RIPng FRR
- (Opcional.) Aprimoramento da segurança do RIPng
- Configuração da verificação de campo zero para pacotes RIPng
- Aplicação de um perfil IPsec
Configuração do RIPng básico
- Entre na visualização do sistema.
system-view- Habilite o RIPng e entre em sua visualização.
ripng [ process-id ]Por padrão, o RIPng está desativado.
- Retornar à visualização do sistema.
quit- Entre na visualização da interface.
interface interface-type interface-number- Habilite o RIPng na interface.
ripng process-id enablePor padrão, o RIPng está desativado na interface.
Se o RIPng não estiver ativado em uma interface, ela não enviará nem receberá nenhuma rota RIPng.
Configuração do controle de rotas RIPng
Configuração de uma métrica de roteamento adicional
Sobre métricas de roteamento adicionais
Uma métrica de roteamento adicional (contagem de saltos) pode ser adicionada à métrica de uma rota RIPng de entrada ou saída.
- Uma métrica adicional de saída é adicionada à métrica de uma rota enviada e não altera a métrica da rota na tabela de roteamento.
- Uma métrica adicional de entrada é adicionada à métrica de uma rota recebida antes de a rota ser adicionada à tabela de roteamento, e a métrica da rota é alterada.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique uma métrica de roteamento adicional de entrada.
ripng metricin valueA métrica adicional padrão de uma rota de entrada é 0.
- Especifique uma métrica de roteamento adicional de saída.
ripng metricout valueA métrica adicional padrão de uma rota de saída é 1.
Configuração da compactação de rotas RIPng
Sobre a compactação de rotas RIPng
A sumarização de rotas do RIPng é baseada na interface. O RIPng anuncia uma rota resumida com base na correspondência mais longa.
A sumarização de rotas RIPng melhora a escalabilidade da rede, reduz o tamanho da tabela de roteamento e aumenta a eficiência da pesquisa na tabela de roteamento.
O RIPng anuncia uma rota resumida com a menor métrica de todas as rotas específicas.
Por exemplo, o RIPng tem duas rotas específicas a serem anunciadas por meio de uma interface: 1:11:11::24 com uma métrica de 2 e 1:11:12::34 com uma métrica de 3. Configure a sumarização de rotas na interface, para que o RIPng anuncie uma única rota 11::0/16 com uma métrica de 2.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Anunciar um prefixo IPv6 resumido.
ripng summary-address ipv6-address prefix-lengthPor padrão, nenhum prefixo IPv6 resumido é configurado na interface.
Anunciar uma rota padrão
Sobre o anúncio de rota padrão
Você pode configurar o RIPng para anunciar uma rota padrão com o custo especificado para seus vizinhos.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o RIPng para anunciar uma rota padrão.
ripng default-route { only | originate } [ cost cost-value |
route-policy route-policy-name ] *Por padrão, o RIPng não anuncia uma rota padrão.
Esse comando anuncia uma rota padrão na interface atual, independentemente de a rota padrão existir ou não na tabela de roteamento IPv6 local.
Configuração da filtragem de rotas recebidas/redistribuídas
Sobre a filtragem de rotas recebidas/redistribuídas
Execute esta tarefa para filtrar rotas recebidas ou redistribuídas usando uma ACL IPv6 ou uma lista de prefixos IPv6. Você também pode configurar o RIPng para filtrar rotas redistribuídas de outros protocolos de roteamento e rotas de um vizinho especificado .
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIPng.
ripng [ process-id ]- Configure uma política de filtro para filtrar as rotas recebidas.
filter-policy { ipv6-acl-number | prefix-list prefix-list-name }
importPor padrão, o RIPng não filtra as rotas recebidas.
- Configure uma política de filtro para filtrar rotas redistribuídas.
filter-policy { ipv6-acl-number | prefix-list prefix-list-name }
export [ protocol [ process-id ] ]
Por padrão, o RIPng não filtra as rotas redistribuídas.
Definição de uma preferência para RIPng
Sobre a preferência por RIPng
Cada protocolo de roteamento tem uma preferência. Quando eles encontram rotas para o mesmo destino, a rota encontrada pelo protocolo de roteamento com a preferência mais alta é selecionada como a rota ideal. Você pode definir manualmente uma preferência para o RIPng. Quanto menor o valor, maior a preferência.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIPng.
ripng [ process-id ]- Definir uma preferência para RIPng.
preference { preference | route-policy route-policy-name } *Por padrão, a preferência do RIPng é 100.
Configuração da redistribuição de rotas RIPng
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIPng.
ripng [ process-id ]- Redistribuir rotas de outros protocolos de roteamento.
- Redistribuir rotas diretas ou estáticas.
import-route { direct | static } [ cost cost-value | route-policy
route-policy-name ] *
- Redistribuir rotas do OSPFv3 ou de outros processos RIPng.
import-route { ospfv3 | ripng } [ process-id ] [ allow-direct | cost
cost-value | route-policy route-policy-name ] *
Por padrão, o RIPng não redistribui rotas de outros protocolos de roteamento.
- (Opcional.) Defina uma métrica de roteamento padrão para rotas redistribuídas.
default cost cost-valueA métrica padrão das rotas redistribuídas é 0.
Ajuste e otimização da rede RIPng
Configuração de temporizadores RIPng
Sobre os temporizadores RIPng
Você pode ajustar os temporizadores RIPng para otimizar o desempenho da rede RIPng.
Restrições e diretrizes
Ao ajustar os timers do RIPng, considere o desempenho da rede e realize configurações unificadas nos roteadores que executam o RIPng para evitar tráfego de rede desnecessário ou oscilação de rota.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIPng.
ripng [ process-id ]- Definir temporizadores RIPng.
timers { garbage-collect garbage-collect-value | suppress
suppress-value | timeout timeout-value | update update-value } *
As configurações padrão são as seguintes:
- O cronômetro de atualização é de 30 segundos.
- O cronômetro de tempo limite é de 180 segundos.
- O cronômetro de supressão é de 120 segundos.
- O cronômetro de coleta de lixo é de 120 segundos.
Configuração de split horizon e poison reverse
Restrições e diretrizes para split horizon e poison reverse
Ao configurar o split horizon e o poison reverse, siga estas restrições e diretrizes:
- Se tanto o split horizon quanto o poison reverse estiverem configurados, somente o recurso poison reverse terá efeito.
- O horizonte dividido desabilita o RIPng de enviar rotas pela interface em que as rotas foram aprendidas para evitar loops de roteamento entre vizinhos. Como prática recomendada, ative o split horizon para evitar loops de roteamento em casos normais.
- O Poison reverse permite que uma rota aprendida de uma interface seja anunciada por meio da interface. No entanto, a métrica da rota é definida como 16, o que significa que a rota não pode ser acessada.
Configuração do horizonte dividido
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar horizonte dividido.
ripng split-horizon
Por padrão, o horizonte dividido está ativado.
Configuração de poison reverse
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Habilitar o poison reverse.
ripng poison-reverse
Por padrão, o poison reverse está desativado.
Configuração da taxa de envio de pacotes RIPng
Sobre a configuração da taxa de envio de pacotes RIPng
Execute esta tarefa para especificar o intervalo de envio de pacotes RIPng e o número máximo de pacotes RIPng que podem ser enviados em cada intervalo. Esse recurso pode evitar que o excesso de pacotes RIPng afete o desempenho do sistema e consuma muita largura de banda.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIPng.
ripng [ process-id ]- Configuração da taxa de envio de pacotes RIPng.
- Execute os seguintes comandos em sequência para configurar a taxa de envio de pacotes RIPng na visualização RIPng:
ripng [ process-id ]output-delay time count countPor padrão, uma interface que executa o processo RIPng envia um máximo de três pacotes RIPng a cada 20 milissegundos.
- Execute os seguintes comandos em sequência para configurar a taxa de envio de pacotes RIPng na visualização da interface:
interface interface-type interface-numberripng output-delay time count count
Por padrão, uma interface usa a taxa de envio de pacotes RIPng do processo RIPng que ela executa.
Definição do intervalo para envio de atualizações acionadas
Sobre a configuração do intervalo para o envio de atualizações acionadas
Execute essa tarefa para evitar a sobrecarga da rede e reduzir o consumo de recursos do sistema causado por atualizações frequentes acionadas pelo RIPng.
Você pode usar o comando timer triggered para definir o intervalo máximo, o intervalo mínimo e o intervalo incremental para o envio de atualizações acionadas pelo RIPng.
Em uma rede estável, é usado o intervalo mínimo. Se as alterações na rede se tornarem frequentes, o intervalo de envio da atualização acionada será incrementado pelo intervalo incremental × 2n-2 para cada atualização acionada até que o intervalo máximo seja atingido. O valor n é o número de vezes de atualização acionada.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIPng.
ripng [ process-id ]- Defina o intervalo para o envio de atualizações acionadas.
timer triggered maximum-interval [ minimum-interval
[ incremental-interval ] ]
O intervalo máximo padrão é de 5 segundos, o intervalo mínimo padrão é de 50 milissegundos e o intervalo incremental padrão é de 200 milissegundos.
Configuração do RIPng GR
Sobre a RIPng GR
O GR garante a continuidade do encaminhamento quando um protocolo de roteamento é reiniciado ou quando ocorre uma alternância ativo/em espera.
São necessários dois roteadores para concluir um processo de GR. Veja a seguir as funções do roteador em um processo de GR:
- GR restarter - Roteador de reinicialização gradual. Ele deve ter capacidade de GR.
- Ajudante de GR - Um vizinho do reiniciador de GR. Ele ajuda o reiniciador de GR a concluir o processo de GR.
Depois que o RIPng é reiniciado em um roteador, ele precisa aprender novamente as rotas RIPng e atualizar sua tabela FIB, o que causa desconexões de rede e reconvergência de rotas.
Com o recurso de GR, o roteador que está reiniciando (conhecido como GR restarter) pode notificar o evento aos seus vizinhos com capacidade de GR. Os vizinhos com capacidade de GR (conhecidos como GR helpers) mantêm suas adjacências com
o roteador em um intervalo GR configurável. Durante esse processo, a tabela FIB do roteador não é alterada. Após a reinicialização, o roteador entra em contato com seus vizinhos para recuperar sua FIB.
Por padrão, um dispositivo habilitado para RIPng atua como auxiliar de GR. Execute esta tarefa no restarter GR.
Restrições e diretrizes
Não é possível ativar o RIPng NSR em um dispositivo que atua como reiniciador GR.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o RIPng e entre no modo de exibição RIPng.
ripng [ process-id ]- Habilite o recurso GR para RIPng.
graceful-restartPor padrão, o RIPng GR está desativado.
- (Opcional.) Defina o intervalo de GR.
graceful-restart interval intervalO intervalo padrão de GR é de 60 segundos.
Configuração do RIPng NSR
Sobre a RIPng NSR
O roteamento ininterrupto (NSR) faz o backup das informações de roteamento RIPng do processo ativo para o processo em espera. Após uma alternância entre ativo e em espera, o NSR pode concluir a regeneração de rotas sem derrubar adjacências ou afetar os serviços de encaminhamento.
O NSR não exige a cooperação de dispositivos vizinhos para recuperar informações de roteamento e, normalmente, é usado com mais frequência do que o GR.
Restrições e diretrizes
O RIPng NSR ativado para um processo RIPng tem efeito apenas nesse processo. Se houver vários processos RIPng, ative o RIPng NSR para cada processo como prática recomendada.
Um dispositivo que tenha o RIPng NSR ativado não pode atuar como reiniciador de GR.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIPng.
ripng [ process-id ]- Habilitar RIPng NSR.
non-stop-routingPor padrão, o RIPng NSR está desativado.
Configuração de RIPng FRR
Sobre a RIPng FRR
Uma falha de link ou de roteador em um caminho pode causar perda de pacotes e até mesmo loop de roteamento até que o RIPng conclua a convergência de roteamento com base na nova topologia de rede. O FRR permite o redirecionamento rápido para minimizar o impacto das falhas de links ou nós.
Figura 1 Diagrama de rede para RIPng FRR
Conforme mostrado na Figura 1, configure o FRR no Roteador B usando uma política de roteamento para especificar um próximo salto de backup. Quando o link primário falha, o RIPng direciona os pacotes para o próximo salto de backup. Ao mesmo tempo, o RIPng calcula o caminho mais curto com base na nova topologia de rede. Em seguida, o dispositivo encaminha os pacotes por esse caminho após a convergência da rede.
Restrições e diretrizes para RIPng FRR
O RIPng FRR está disponível somente quando o estado do link primário (com as interfaces da Camada 3 permanecendo ativas) muda de bidirecional para unidirecional ou para baixo.
O RIPng FRR só é eficaz para rotas RIPng que são aprendidas de vizinhos diretamente conectados.
Ativação do RIPng FRR
- Entre na visualização do sistema.
system-view- Configure uma política de roteamento.
Você deve especificar um próximo salto usando o comando apply ipv6 fast-reroute
em uma política de roteamento e especifique a política de roteamento para FRR. Para obter mais informações sobre a configuração da política de roteamento, consulte "Configuração de políticas de roteamento".
- Entre no modo de exibição RIPng.
ripng [ process-id ]- Habilitar RIPng FRR.
fast-reroute route-policy route-policy-namePor padrão, o RIPng FRR está desativado.
Habilitação de BFD para RIPng FRR
Sobre o BFD para RIPng FRR
Por padrão, o RIPng FRR não usa o BFD para detectar falhas no link primário. Para o RIPng FRR mais rápido, use a detecção de eco de salto único BFD no link primário de links redundantes para detectar falhas de link.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o endereço IP de origem dos pacotes de eco BFD.
bfd echo-source-ipv6 ipv6-address
Por padrão, o endereço IP de origem dos pacotes de eco do BFD não é configurado.
Como prática recomendada, não configure o endereço IP de origem no mesmo segmento de rede que qualquer interface local.
Para obter mais informações sobre esse comando, consulte Referência de comandos de alta disponibilidade.
- Entre na visualização da interface.
interface interface-type interface-number- Habilitar a detecção de eco de salto único BFD para RIPng FRR.
ripng primary-path-detect bfd echo
Por padrão, a detecção de eco de salto único BFD está desativada para RIPng FRR.
Aprimoramento da segurança RIPng
Configuração da verificação de campo zero para pacotes RIPng
Sobre a verificação de campo zero para pacotes RIPng
Alguns campos no cabeçalho do pacote RIPng devem ser zero. Esses campos são chamados de campos zero. Você pode ativar a verificação de campo zero para pacotes RIPng de entrada. Se um campo zero de um pacote contiver um valor diferente de zero, o RIPng não processará os pacotes. Se você tiver certeza de que todos os pacotes são confiáveis, desative a verificação de campo zero para economizar recursos da CPU.
Procedimento
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIPng.
ripng [ process-id ]- Ative a verificação de campo zero para pacotes RIPng de entrada.
checkzeroPor padrão, a verificação de campo zero para pacotes RIPng de entrada está ativada.
Aplicação de um perfil IPsec
Sobre os perfis IPsec
Para proteger as informações de roteamento e evitar ataques, você pode configurar o RIPng para autenticar os pacotes de protocolo usando um perfil IPsec.
Um perfil IPsec contém índices de parâmetros de segurança (SPIs) de entrada e saída. O RIPng compara o SPI de entrada definido no perfil IPsec com o SPI de saída nos pacotes recebidos. Dois dispositivos RIPng aceitam os pacotes um do outro e estabelecem um relacionamento de vizinhança somente se os SPIs forem os mesmos e os perfis IPsec relevantes corresponderem.
Para obter mais informações sobre perfis IPsec, consulte o Guia de configuração de segurança.
Restrições e diretrizes
Você pode aplicar um perfil IPsec a um processo RIPng ou a uma interface. Se uma interface e seu processo tiverem um perfil IPsec, o perfil IPsec aplicado à interface terá efeito.
Aplicação de um perfil IPsec a um processo
- Entre na visualização do sistema.
system-view- Entre no modo de exibição RIPng.
ripng [ process-id ]- Aplicar um perfil IPsec ao processo.
enable ipsec-profile profile-name
Por padrão, nenhum perfil IPsec é aplicado.
Aplicação de um perfil IPsec a uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Aplique um perfil IPsec à interface.
ripng ipsec-profile profile-namePor padrão, nenhum perfil IPsec é aplicado.
Comandos de exibição e manutenção para RIPng
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações de configuração de um processo RIPng. | display ripng [ process-id ] |
| Exibir informações do RIPng GR. | display ripng [ process-id ] reinício gracioso |
| Exibir informações de NSR do RIPng. | display ripng [ process-id ] roteamento ininterrupto |
| Exibir rotas no banco de dados RIPng. | display ripng process-id database [ ipv6-address prefix-length ] |
| Exibir informações de interface para um processo RIPng. | display ripng process-id interface [ número da interface do tipo interface ] |
| Exibir informações de vizinhos para um processo RIPng. | display ripng process-id neighbor [ número da interface do tipo interface ] |
| Exibir as informações de roteamento de um processo RIPng. | display ripng process-id route [ ipv6-endereço prefixo-comprimento [ verbose ] | peer ipv6-address | statistics ] |
| Reiniciar um processo RIPng. | reset ripng process-id process |
| Limpar estatísticas de um processo RIPng. | reset ripng process-id statistics |
Exemplos de configuração do RIPng
Exemplo: Configuração do RIPng básico
Configuração de rede
Conforme mostrado na Figura 2, o Switch A, o Switch B e o Switch C executam o RIPng. Configure a filtragem de rotas no Switch B para aceitar todas as rotas recebidas, exceto a rota 2::/64, e para anunciar somente a rota 4::/64.
Figura 2 Diagrama de rede
Procedimento
- Configure os endereços IPv6 para as interfaces. (Detalhes não mostrados).
- Configure as definições básicas do RIPng: # Configure o Switch A.
<SwitchA> system-view
[SwitchA] ripng 1
[SwitchA-ripng-1] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] ripng 1 enable
[SwitchA-Vlan-interface100] quit
[SwitchA] interface vlan-interface 400
[SwitchA-Vlan-interface400] ripng 1 enable
[SwitchA-Vlan-interface400] quit# Configure o Switch B.
<SwitchB> system-view
[SwitchB] ripng 1
[SwitchB-ripng-1] quit
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ripng 1 enable
[SwitchB-Vlan-interface100] quit
[SwitchB] interface vlan-interface 400
[SwitchB-Vlan-interface400] ripng 1 enable
[SwitchB-Vlan-interface400] quit# Configurar o switch C.
<SwitchC> system-view
[SwitchC] ripng 1
[SwitchC-ripng-1] quit
[SwitchC] interface vlan-interface 200
[SwitchC-Vlan-interface200] ripng 1 enable
[SwitchC-Vlan-interface200] quit
[SwitchC] interface vlan-interface 500
[SwitchC-Vlan-interface500] ripng 1 enable
[SwitchC-Vlan-interface500] quit
[SwitchC] interface vlan-interface 600
[SwitchC-Vlan-interface600] ripng 1 enable
[SwitchC-Vlan-interface600] quit# Exibir a tabela de roteamento RIPng no Switch B.
[SwitchB] display ripng 1 route
Route Flags: A - Aging, S - Suppressed, G - Garbage-collect, D – Direct
O - Optimal, F - Flush to RIB
----------------------------------------------------------------
Peer FE80::20F:E2FF:FE23:82F5 on Vlan-interface100
Destination 2::/64,
via FE80::20F:E2FF:FE23:82F5, cost 1, tag 0, AOF, 6 secs
Peer FE80::20F:E2FF:FE00:100 on Vlan-interface200
Destination 4::/64,
via FE80::20F:E2FF:FE00:100, cost 1, tag 0, AOF, 11 secs
Destination 5::/64,
via FE80::20F:E2FF:FE00:100, cost 1, tag 0, AOF, 11
Local route
Destination 1::/64,
via ::, cost 0, tag 0, DOF
Destination 3::/64,
via ::, cost 0, tag 0, DOF# Exibir a tabela de roteamento RIPng no Switch A.
[SwitchA] display ripng 1 route
Route Flags: A - Aging, S - Suppressed, G - Garbage-collect, D – Direct
O - Optimal, F - Flush to RIB
----------------------------------------------------------------
Peer FE80::200:2FF:FE64:8904 on Vlan-interface100
Destination 3::/64,
via FE80::200:2FF:FE64:8904, cost 1, tag 0, AOF, 31 secs
Destination 4::/64,
via FE80::200:2FF:FE64:8904, cost 2, tag 0, AOF, 31 secs
Destination 5::/64,
via FE80::200:2FF:FE64:8904, cost 2, tag 0, AOF, 31 secs
Local route
Destination 2::/64,
via ::, cost 0, tag 0, DOF
Destination 1::/64,
via ::, cost 0, tag 0, DOF- Configurar a filtragem de rotas:
# Use listas de prefixos IPv6 no Switch B para filtrar as rotas recebidas e redistribuídas.
[SwitchB] ipv6 prefix-list aaa permit 4:: 64
[SwitchB] ipv6 prefix-list bbb deny 2:: 64
[SwitchB] ipv6 prefix-list bbb permit :: 0 less-equal 128
[SwitchB] ripng 1
[SwitchB-ripng-1] filter-policy prefix-list aaa export
[SwitchB-ripng-1] filter-policy prefix-list bbb import
[SwitchB-ripng-1] quit# Exibir tabelas de roteamento RIPng no Switch B e no Switch A.
[SwitchB] display ripng 1 route
Route Flags: A - Aging, S - Suppressed, G - Garbage-collect, D – Direct
O - Optimal, F - Flush to RIB
----------------------------------------------------------------
Peer FE80::1:100 on Vlan-interface100
Peer FE80::3:200 on Vlan-interface200
Destination 4::/64,
via FE80::2:200, cost 1, tag 0, AOF, 11 secs
Destination 5::/64,
via FE80::2:200, cost 1, tag 0, AOF, 11 secs
Local route
Destination 1::/64,
via ::, cost 0, tag 0, DOF
Destination 3::/64,
via ::, cost 0, tag 0, DOF
[SwitchA] display ripng 1 route
Route Flags: A - Aging, S - Suppressed, G - Garbage-collect, D – Direct
O - Optimal, F - Flush to RIB
----------------------------------------------------------------
Peer FE80::2:100 on Vlan-interface100
Destination 4::/64,
via FE80::1:100, cost 2, tag 0, AOF, 2 secs
Local route
Destination 1::/64,
via ::, cost 0, tag 0, DOF
Destination 2::/64,
via ::, cost 0, tag 0, DOFExemplo: Configuração da redistribuição de rotas RIPng
Configuração de rede
Conforme mostrado na Figura 3, o Switch B se comunica com o Switch A por meio do RIPng 100 e com o Switch C por meio do RIPng 200.
Configure a redistribuição de rotas no Switch B, para que os dois processos RIPng possam redistribuir rotas um do outro.
Figura 3 Diagrama de rede
Procedimento
- Configure os endereços IPv6 para as interfaces. (Detalhes não mostrados).
- Configure as definições básicas do RIPng: # Habilite o RIPng 100 no Switch A.
<SwitchA> system-view
[SwitchA] ripng 100
[SwitchA-ripng-100] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] ripng 100 enable
[SwitchA-Vlan-interface100] quit
[SwitchA] interface vlan-interface 200
[SwitchA-Vlan-interface200] ripng 100 enable
[SwitchA-Vlan-interface200] quit# Habilite o RIPng 100 e o RIPng 200 no Switch B.
<SwitchB> system-view
[SwitchB] ripng 100
[SwitchB-ripng-100] quit
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ripng 100 enable
[SwitchB-Vlan-interface100] quit
[SwitchB] ripng 200
[SwitchB-ripng-200] quit
[SwitchB] interface vlan-interface 300
[SwitchB-Vlan-interface300] ripng 200 enable
[SwitchB-Vlan-interface300] quit# Habilite o RIPng 200 no Switch C.
<SwitchC> system-view
[SwitchC] ripng 200
[SwitchC] interface vlan-interface 300
[SwitchC-Vlan-interface300] ripng 200 enable
[SwitchC-Vlan-interface300] quit
[SwitchC] interface vlan-interface 400
[SwitchC-Vlan-interface400] ripng 200 enable
[SwitchC-Vlan-interface400] quit# Exibir a tabela de roteamento no Switch A.
[SwitchA] display ipv6 routing-table
Destination: ::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: 1::/64 Protocol : Direct
NextHop : :: Preference: 0
Interface : Vlan100 Cost : 0
Destination: 1::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: 2::/64 Protocol : Direct
NextHop : :: Preference: 0
Interface : Vlan200 Cost : 0
Destination: 2::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: FE80::/10 Protocol : Direct
NextHop : :: Preference: 0
Interface : NULL0 Cost : 0
Destination: FF00::/8 Protocol : Direct
NextHop : :: Preference: 0
Interface : NULL0 Cost : 0- Configurar a redistribuição de rotas RIPng:
# Configure a redistribuição de rotas entre os dois processos RIPng no Switch B.
[SwitchB] ripng 100
[SwitchB-ripng-100] import-route ripng 200
[SwitchB-ripng-100] quit
[SwitchB] ripng 200
[SwitchB-ripng-200] import-route ripng 100
[SwitchB-ripng-200] quit# Exibir a tabela de roteamento no Switch A.
[SwitchA] display ipv6 routing-table
Destinations : 8 Routes : 8
Destination: ::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: 1::/64 Protocol : Direct
NextHop : :: Preference: 0
Interface : Vlan100 Cost : 0
Destination: 1::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: 2::/64 Protocol : Direct
NextHop : :: Preference: 0
Interface : Vlan200 Cost : 0
Destination: 2::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: 4::/64 Protocol : RIPng
NextHop : FE80::200:BFF:FE01:1C02 Preference: 100
Interface : Vlan100 Cost : 1
Destination: FE80::/10 Protocol : Direct
NextHop : :: Preference: 0
Interface : NULL0 Cost : 0
Destination: FF00::/8 Protocol : Direct
NextHop : :: Preference: 0
Interface : NULL0 Cost : 0Exemplo: Configuração do RIPng GR
Configuração de rede
Conforme mostrado na Figura 4, o Switch A, o Switch B e o Switch C obtêm informações de roteamento IPv6 por meio do RIPng.
Configure o Switch A como o reiniciador de GR. Configure o Switch B e o Switch C como auxiliares de GR para sincronizar suas tabelas de roteamento com o Switch A usando GR.
Figura 4 Diagrama de rede
Procedimento
- Configure os endereços IPv6 para as interfaces. (Detalhes não mostrados).
- Configure o RIPng nos switches para garantir o seguinte: (Detalhes não mostrados).
- O Switch A, o Switch B e o Switch C podem se comunicar entre si na Camada 3.
- A atualização dinâmica de rotas pode ser implementada entre eles com o RIPng.
- Habilite o RIPng GR no Switch A.
<SwitchA> system-view
[SwitchA] ripng 1
[SwitchA-ripng-1] graceful-restartVerificação da configuração
# Reinicie o RIPng ou acione uma alternância ativo/em espera e, em seguida, exiba o status do GR no Switch A.
<SwitchA> display ripng 1 graceful-restart
RIPng process: 1
Graceful Restart capability : Enabled
Current GR state : Normal
Graceful Restart period : 60 seconds
Graceful Restart remaining time: 0 secondsExemplo: Configuração do RIPng NSR
Configuração de rede
Conforme mostrado na Figura 5, o Switch S, o Switch A e o Switch B obtêm informações de roteamento IPv6 por meio do RIPng.
Habilite o RIPng NSR no Switch S para garantir o roteamento correto quando ocorrer uma alternância ativo/em espera no Switch S.
Figura 5 Diagrama de rede

Procedimento
- O Switch S, o Switch A e o Switch B podem se comunicar entre si na Camada 3.
- A atualização dinâmica de rotas pode ser implementada entre eles com o RIPng.
- Habilite o RIPng NSR no Switch S.
<SwitchS> system-view
[SwitchS] ripng 1
[SwitchS-ripng-1] non-stop-routing
[SwitchS-ripng-1] quitVerificação da configuração
# Executar uma alternância entre ativo e em espera no Switch S.
[SwitchS] placement reoptimize
Predicted changes to the placement
Program Current location New location
---------------------------------------------------------------------
lb 0/0 0/0
lsm 0/0 0/0
Loop 0
2002::2/128 Vlan-int100
1200:1::1/64
Vlan-int100
1200:1::2/64
Vlan-int200
1400:1::2/64
Vlan-int200
1400:1::1/64
Loop 0
Switch S 4004::4/128
Switch A Switch B
slsp 0/0 0/0
rib6 0/0 0/0
routepolicy 0/0 0/0
rib 0/0 0/0
staticroute6 0/0 0/0
staticroute 0/0 0/0
ripng 0/0 1/0
Continue? [y/n]:y
Re-optimization of the placement start. You will be notified on completion
Re-optimization of the placement complete. Use 'display placement' to view the new
placement# Durante o período de transição, exiba os vizinhos RIPng no Switch A para verificar a relação de vizinhança entre o Switch A e o Switch S.
[SwitchA] display ripng 1 neighbor
Neighbor Address: FE80::AE45:5CE7:422E:2867
Interface : Vlan-interface100
Version : RIPng version 1 Last update: 00h00m23s
Bad packets: 0 Bad routes : 0# Exibir rotas RIPng no Switch A para verificar se o Switch A tem uma rota para a interface de loopback no Switch B.
[SwitchA] display ripng 1 route
Route Flags: A - Aging, S - Suppressed, G - Garbage-collect, D - Direct
O - Optimal, F - Flush to RIB
----------------------------------------------------------------
Peer FE80::AE45:5CE7:422E:2867 on Vlan-interface100
Destination 1400:1::/64,
via FE80::AE45:5CE7:422E:2867, cost 1, tag 0, AOF, 1 secs
Destination 4004::4/128,
via FE80::AE45:5CE7:422E:2867, cost 2, tag 0, AOF, 1 secs
Local route
Destination 2002::2/128,
via ::, cost 0, tag 0, DOF
Destination 1200:1::/64,
via ::, cost 0, tag 0, DOF# Exibir os vizinhos RIPng no Switch B para verificar a relação de vizinhança entre o Switch B e o Switch S.
[SwitchB] display ripng 1 neighbor
Neighbor Address: FE80::20C:29FF:FECE:6277
Interface : Vlan-interface200
Version : RIPng version 1 Last update: 00h00m18s
Bad packets: 0 Bad routes : 0# Exibir rotas RIPng no Switch B para verificar se o Switch B tem uma rota para a interface de loopback no Switch A.
[SwitchB] display ripng 1 route
Route Flags: A - Aging, S - Suppressed, G - Garbage-collect, D - Direct
O - Optimal, F - Flush to RIB
----------------------------------------------------------------
Peer FE80::20C:29FF:FECE:6277 on Vlan-interface200
Destination 2002::2/128,
via FE80::20C:29FF:FECE:6277, cost 2, tag 0, AOF, 24 secs
Destination 1200:1::/64,
via FE80::20C:29FF:FECE:6277, cost 1, tag 0, AOF, 24 secs
Local route
Destination 4004::4/128,
via ::, cost 0, tag 0, DOF
Destination 1400:1::/64,
via ::, cost 0, tag 0, DOFA saída mostra o seguinte quando ocorre uma alternância entre ativo e em espera no Switch S:
Exemplo: Configuração de RIPng FRR
Configuração de rede
Conforme mostrado na Figura 6, o Switch A, o Switch B e o Switch C executam RIPng. Configure o RIPng FRR para que quando o Link A se tornar unidirecional, o tráfego possa ser alternado para o Link B imediatamente.
Figura 6 Diagrama de rede
| Dispositivo | Interface | Endereço IP |
| Chave A | Interface VLAN 100 | 1::1/64 |
| Chave A | Interface VLAN 200 | 2::1/64 |
| Chave A | Loopback 0 | 10::1/128 |
| Chave B | Interface VLAN 101 | 3::1/64 |
| Chave B | Interface VLAN 200 | 2::2/64 |
| Chave B | Loopback 0 | 20::1/128 |
| Chave C | Interface VLAN 100 | 1::2/64 |
| Chave C | Interface VLAN 101 | 3::2/64 |
Procedimento
- Configure os endereços IPv6 para as interfaces nos switches. (Detalhes não mostrados).
- Configure o RIPng nos switches para garantir que o Switch A, o Switch B e o Switch C possam se comunicar entre si na Camada 3. (Detalhes não mostrados.)
- Configurar o RIPng FRR: # Configurar o Switch A.
<SwitchA> system-view
[SwitchA] ipv6 prefix-list abc index 10 permit 20::1 128
[SwitchA] route-policy frr permit node 10
[SwitchA-route-policy-frr-10] if-match ipv6 address prefix-list abc
[SwitchA-route-policy-frr-10] apply ipv6 fast-reroute backup-interface
vlan-interface 100 backup-nexthop 1::2
[SwitchA-route-policy-frr-10] quit
[SwitchA] ripng 1
[SwitchA-ripng-1] fast-reroute route-policy frr
[SwitchA-ripng-1] quit# Configure o Switch B.
<SwitchB> system-view
[SwitchB] ipv6 prefix-list abc index 10 permit 10::1 128
[SwitchB] route-policy frr permit node 10
[SwitchB-route-policy-frr-10] if-match ipv6 address prefix-list abc
[SwitchB-route-policy-frr-10] apply ipv6 fast-reroute backup-interface
vlan-interface 101 backup-nexthop 3::2
[SwitchB-route-policy-frr-10] quit
[SwitchB] ripng 1
[SwitchB-ripng-1] fast-reroute route-policy frr
[SwitchB-ripng-1] quitVerificação da configuração
# Exiba a rota 20::1/128 no Switch A para ver as informações do próximo salto de backup.
[SwitchA] display ipv6 routing-table 20::1 128 verbose
Summary count : 1
Destination: 20::1/128
Protocol: RIPng
Process ID: 1
SubProtID: 0x0 Age: 00h17m42s
Cost: 1 Preference: 100
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Inactive Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0xa OrigAs: 0
NibID: 0x22000003 LastAs: 0
AttrID: 0xffffffff Neighbor: FE80::34CD:9FF:FE2F:D02
Flags: 0x41 OrigNextHop: FE80::34CD:9FF:FE2F:D02
Label: NULL RealNextHop: FE80::34CD:9FF:FE2F:D02
BkLabel: NULL BkNextHop: FE80::7685:45FF:FEAD:102
SRLabel: NULL BkSRLabel: NULL
Tunnel ID: Invalid Interface: Vlan-interface200
BkTunnel ID: Invalid BkInterface: Vlan-interface100
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0# Exiba a rota 10::1/128 no Switch B para ver as informações do próximo salto de backup.
[SwitchB] display ipv6 routing-table 10::1 128 verbose
Summary count : 1
Destination: 10::1/128
Protocol: RIPng
Process ID: 1
SubProtID: 0x0 Age: 00h22m34s
Cost: 1 Preference: 100
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Inactive Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0xa OrigAs: 0
NibID: 0x22000001 LastAs: 0
AttrID: 0xffffffff Neighbor: FE80::34CC:E8FF:FE5B:C02
Flags: 0x41 OrigNextHop: FE80::34CC:E8FF:FE5B:C02
Label: NULL RealNextHop: FE80::34CC:E8FF:FE5B:C02
BkLabel: NULL BkNextHop: FE80::7685:45FF:FEAD:102
SRLabel: NULL BkSRLabel: NULL
Tunnel ID: Invalid Interface: Vlan-interface200
BkTunnel ID: Invalid BkInterface: Vlan-interface101
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0Exemplo: Configuração do perfil IPsec do RIPng
Configuração de rede
Conforme mostrado na Figura 7, configure o RIPng nos switches e configure os perfis IPsec nos switches para autenticar e criptografar os pacotes de protocolo.
Figura 7 Diagrama de rede
Procedimento
- Configure os endereços IPv6 para as interfaces. (Detalhes não mostrados).
- Configure as definições básicas do RIPng: # Configure o Switch A.
<SwitchA> system-view
[SwitchA] ripng 1
[SwitchA-ripng-1] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] ripng 1 enable
[SwitchA-Vlan-interface100] quit# Configure o Switch B.
<SwitchB> system-view
[SwitchB] ripng 1
[SwitchB-ripng-1] quit
[SwitchB] interface vlan-interface 200
[SwitchB-Vlan-interface200] ripng 1 enable
[SwitchB-Vlan-interface200] quit
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ripng 1 enable
[SwitchB-Vlan-interface100] quit# Configurar o switch C.
lt;SwitchC> system-view
[SwitchC] ripng 1
[SwitchC-ripng-1] quit
[SwitchC] interface vlan-interface 200
[SwitchC-Vlan-interface200] ripng 1 enable
[SwitchC-Vlan-interface200] quit- Configurar perfis IPsec do RIPng:
- No interruptor A:
# Crie um conjunto de transformação IPsec chamado protrf1.
[SwitchA] ipsec transform-set protrf1
# Especifique os algoritmos de criptografia e autenticação ESP.
[SwitchA-ipsec-transform-set-protrf1] esp encryption-algorithm 3des-cbc
[SwitchA-ipsec-transform-set-protrf1] esp authentication-algorithm md5
# Especifique o modo de transporte para encapsulamento.
[SwitchA-ipsec-transform-set-protrf1] encapsulation-mode transport
[SwitchA-ipsec-transform-set-protrf1] quit
# Criar um perfil IPsec manual chamado profile001.
[SwitchA] ipsec profile profile001 manual
# Referência do conjunto de transformação IPsec protrf1.
[SwitchA-ipsec-profile-profile001-manual] transform-set protrf1
# Configure os SPIs de entrada e saída para ESP.
[SwitchA-ipsec-profile-profile001-manual] sa spi inbound esp 256
[SwitchA-ipsec-profile-profile001-manual] sa spi outbound esp 256
# Configure as chaves SA de entrada e saída para ESP.
[SwitchA-ipsec-profile-profile001-manual] sa string-key inbound esp simple abc
[SwitchA-ipsec-profile-profile001-manual] sa string-key outbound esp simple abc
[SwitchA-ipsec-profile-profile001-manual] quit
- No interruptor B:
# Crie um conjunto de transformação IPsec chamado protrf1.
[SwitchB] ipsec transform-set protrf1
# Especifique os algoritmos de criptografia e autenticação ESP.
[SwitchB-ipsec-transform-set-protrf1] esp encryption-algorithm 3des-cbc
[SwitchB-ipsec-transform-set-protrf1] esp authentication-algorithm md5
# Especifique o modo de transporte para encapsulamento.
[SwitchB-ipsec-transform-set-protrf1] encapsulation-mode transport
[SwitchB-ipsec-transform-set-protrf1] quit
# Criar um perfil IPsec manual chamado profile001.
[SwitchB] ipsec profile profile001 manual
# Referência do conjunto de transformação IPsec protrf1.
[SwitchB-ipsec-profile-profile001-manual] transform-set protrf1
# Configure os SPIs de entrada e saída para ESP.
[SwitchB-ipsec-profile-profile001-manual] sa spi inbound esp 256
[SwitchB-ipsec-profile-profile001-manual] sa spi outbound esp 256
# Configure as chaves SA de entrada e saída para ESP.
[SwitchB-ipsec-profile-profile001-manual] sa string-key inbound esp simple abc
[SwitchB-ipsec-profile-profile001-manual] sa string-key outbound esp simple abc
[SwitchB-ipsec-profile-profile001-manual] quit
- No interruptor C:
# Crie um conjunto de transformação IPsec chamado protrf1.
[SwitchC] ipsec transform-set protrf1
# Especifique os algoritmos de criptografia e autenticação ESP.
[SwitchC-ipsec-transform-set-protrf1] esp encryption-algorithm 3des-cbc
[SwitchC-ipsec-transform-set-protrf1] esp authentication-algorithm md5
# Especifique o modo de transporte para encapsulamento.
[SwitchC-ipsec-transform-set-protrf1] encapsulation-mode transport
[SwitchC-ipsec-transform-set-protrf1] quit
# Criar um perfil IPsec manual chamado profile001.
[SwitchC] ipsec profile profile001 manual
# Referência do conjunto de transformação IPsec protrf1.
[SwitchC-ipsec-profile-profile001-manual] transform-set protrf1
# Configure os SPIs de entrada e saída para ESP.
[SwitchC-ipsec-profile-profile001-manual] sa spi inbound esp 256
[SwitchC-ipsec-profile-profile001-manual] sa spi outbound esp 256
# Configure as chaves SA de entrada e saída para ESP.
[SwitchC-ipsec-profile-profile001-manual] sa string-key inbound esp simple abc
[SwitchC-ipsec-profile-profile001-manual] sa string-key outbound esp simple abc
[SwitchC-ipsec-profile-profile001-manual] quit
- Aplique os perfis IPsec ao processo RIPng em cada dispositivo:
- No interruptor A:
[SwitchA] ripng 1
[SwitchA-ripng-1] enable ipsec-profile profile001
[SwitchA-ripng-1] quit
- No interruptor B:
[SwitchB] ripng 1
[SwitchB-ripng-1] enable ipsec-profile profile001
[SwitchB-ripng-1] quit
- No interruptor C:
[SwitchC] ripng 1
[SwitchC-ripng-1] enable ipsec-profile profile001
[SwitchC-ripng-1] quit
Verificação da configuração
# Verifique se os pacotes RIPng entre os Switches A, B e C estão protegidos por IPsec. (Detalhes não mostrados).
Configuração do OSPFv3
Sobre o OSPFv3
Este capítulo descreve como configurar o Open Shortest Path First versão 3 em conformidade com a RFC 2740 (OSPFv3) para uma rede IPv6.
Aplicavel somente a Serie S3300G
Comparação do OSPFv3 com o OSPFv2
O OSPFv3 e o OSPFv2 têm o seguinte em comum:
- ID do roteador e ID da área de 32 bits.
- Hello, Descrição do banco de dados (DD), Solicitação de estado do link (LSR), Atualização do estado do link (LSU), Confirmação do estado do link (LSAck).
- Mecanismos para encontrar vizinhos e estabelecer adjacências.
- Mecanismos para anunciar e envelhecer LSAs. O OSPFv3 e o OSPFv2 têm as seguintes diferenças:
- O OSPFv3 é executado em uma base por link. O OSPFv2 é executado em uma base por sub-rede IP.
- O OSPFv3 suporta a execução de vários processos em uma interface, mas o OSPFv2 não suporta.
- O OSPFv3 identifica os vizinhos pelo ID do roteador. O OSPFv2 identifica os vizinhos pelo endereço IP. Para obter mais informações sobre o OSPFv2, consulte "Configuração do OSPF".
Pacotes OSPFv3
O OSPFv3 usa os seguintes tipos de pacotes:
- Hello-Enviado periodicamente para localizar e manter vizinhos, contendo valores de timer, informações sobre o DR, o BDR e os vizinhos conhecidos.
- DD - Descreve o resumo de cada LSA no LSDB, trocado entre dois roteadores para sincronização de dados.
- LSR - Solicita os LSAs necessários do vizinho. Depois de trocar os pacotes DD, os dois roteadores sabem quais LSAs do vizinho estão faltando em seus LSDBs. Em seguida, eles enviam um pacote LSR um para o outro, solicitando os LSAs ausentes. O pacote LSA contém o resumo dos LSAs ausentes.
- LSU-Transmite os LSAs solicitados para o vizinho.
- LSAck - confirma o recebimento de pacotes LSU.
Tipos de LSA do OSPFv3
O OSPFv3 envia informações de roteamento em LSAs. Os seguintes LSAs são comumente usados:
- LSA de roteador - LSA do tipo 1, originado por todos os roteadores. Esse LSA descreve os estados coletados das interfaces do roteador em uma área e é inundado somente em uma única área.
- LSA de rede - LSA do tipo 2, originado para redes de broadcast e NBMA pelo DR. Esse LSA contém a lista de roteadores conectados à rede e é inundado somente em uma única área.
- LSA de prefixo entre áreas - LSA do tipo 3, originado por ABRs e inundado em toda a área associada ao LSA. Cada Inter-Area-Prefix LSA descreve uma rota com prefixo de endereço IPv6 para um destino fora da área, mas ainda dentro do AS.
- Inter-Area-Router LSA - LSA do tipo 4, originado por ABRs e transmitido por toda a área associada ao LSA. Cada LSA Inter-Area-Router descreve uma rota para o ASBR.
- AS External LSA - LSA do tipo 5, originado por ASBRs e inundado em todo o AS, exceto em áreas stub e Not-So-Stubby Areas (NSSAs). Cada LSA externo do AS descreve uma rota para outro AS. Uma rota padrão pode ser descrita por um AS External LSA.
- NSSA LSA - LSA do tipo 7, originado por ASBRs em NSSAs e inundado em uma única NSSA. Os LSAs da NSSA descrevem rotas para outros ASs.
- Link LSA - LSA do tipo 8. Um roteador origina um Link LSA separado para cada link anexado. Os LSAs de link têm escopo de inundação link-local. Cada Link LSA descreve o prefixo de endereço IPv6 do link e o endereço local do link do roteador.
- LSA de prefixo intra-área - LSA tipo 9. Cada LSA de prefixo intra-área contém informações de prefixo IPv6 em um roteador, área de stub ou informações de área de trânsito e tem escopo de inundação de área. Ele foi introduzido porque os LSAs de roteador e os LSAs de rede não contêm informações de endereço.
- Grace LSA - Tipo 11 de LSA, gerado por um reiniciador de GR na reinicialização e transmitido no link local. O reiniciador GR descreve a causa e o intervalo da reinicialização no Grace LSA para notificar seus vizinhos de que está realizando uma operação GR.
Protocolos e padrões
- RFC 2328, OSPF Versão 2
- RFC 3101, opção NSSA (Not-So-Stubby Area) do OSPF
- RFC 4552, Autenticação/Confidencialidade para OSPFv3
- RFC 5187, Reinício gracioso do OSPFv3
- RFC 5286, Especificação básica para redirecionamento rápido de IP: Alternativas sem loop
- RFC 5329, Extensões de engenharia de tráfego para OSPF versão 3
- RFC 5340, OSPF para IPv6
- RFC 5643, Base de informações de gerenciamento para OSPFv3
- RFC 6506, Suporte ao Trailer de Autenticação para OSPFv3
- RFC 6969, Atualização do registro de ID de instância do OSPFv3
- RFC 7166, Suporte ao Trailer de Autenticação para OSPFv3
Visão geral das tarefas do OSPFv3
Para configurar o OSPFv3, execute as seguintes tarefas:
- Ativação do OSPFv3
- (Opcional.) Configuração dos parâmetros de área do OSPFv3
- Configuração de uma área de stub
- Configuração de uma área NSSA
- Configuração de um link virtual OSPFv3
Execute esta tarefa em um ABR para criar um link virtual quando não for possível manter a conectividade entre uma área não-backbone e o backbone, ou dentro do backbone.
- (Opcional.) Configuração dos tipos de rede OSPFv3
- Configuração do tipo de rede de broadcast para uma interface OSPFv3
- Configuração do tipo de rede NBMA para uma interface OSPFv3
- Configuração do tipo de rede P2MP para uma interface OSPFv3
- Configuração do tipo de rede P2P para uma interface OSPFv3
- (Opcional.) Configuração do controle de rota OSPFv3
- Configuração da compactação de rotas entre áreas do OSPFv3
- Configuração da filtragem de rotas recebidas do OSPFv3
- Configuração da filtragem de LSA entre prefixos de área
- Definição de um custo OSPFv3 para uma interface
- Definição de uma preferência para OSPFv3
- Configuração da redistribuição de rotas OSPFv3
- (Opcional.) Configuração dos temporizadores do OSPFv3
- Configuração dos temporizadores de pacotes OSPFv3
- Configuração do atraso de transmissão de LSA
- Definição do intervalo de cálculo do SPF
- Configuração do intervalo de geração de LSA
- Configuração da taxa de transmissão da LSU
- (Opcional.) Definição de uma prioridade de DR para uma interface
- Ignorando a verificação de MTU para pacotes DD
- Desativar o recebimento e o envio de pacotes OSPFv3 pelas interfaces
- (Opcional.) Configuração da supressão de prefixo
- Configuração do OSPFv3 GR
- Configuração do NSR do OSPFv3
- Configuração de BFD para OSPFv3
- Configuração do OSPFv3 FRR
- (Opcional.) Aprimoramento da segurança do OSPFv3
- Configuração da autenticação OSPFv3
- Aplicação de um perfil IPsec para autenticar pacotes OSPFv3
- (Opcional.) Configuração do registro OSPFv3 e das notificações SNMP
- Ativação do registro de alterações no estado do vizinho
- Definição do número máximo de registros do OSPFv3
- Configuração do gerenciamento de rede OSPFv3
Ativação do OSPFv3
Sobre a ativação do OSPFv3
Para ativar um processo OSPFv3 em um roteador:
- Habilite o processo OSPFv3 globalmente.
- Atribua ao processo OSPFv3 um ID de roteador.
- Habilite o processo OSPFv3 nas interfaces relacionadas.
Um ID de processo OSPFv3 tem importância apenas local. O processo 1 em um roteador pode trocar pacotes com o processo 2 em outro roteador.
O OSPFv3 exige que você especifique manualmente um ID de roteador para cada roteador em um AS. Certifique-se de que todos os IDs de roteador atribuídos no AS sejam exclusivos.
Restrições e diretrizes
Se um roteador executar vários processos OSPFv3, você deverá especificar um ID de roteador exclusivo para cada processo.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite um processo OSPFv3 e entre em sua visualização.
ospfv3 [ process-id ]
Por padrão, nenhum processo OSPFv3 está ativado.
- Especifique uma ID de roteador.
router-id router-id
Por padrão, nenhum ID de roteador é configurado.
- Entre na visualização da interface.
interface interface-type interface-number- Habilite um processo OSPFv3 na interface.
ospfv3 process-id area area-id [ instance instance-id ]
Por padrão, nenhum processo OSPFv3 é ativado em uma interface.
Configuração dos parâmetros de área do OSPFv3
Sobre as áreas OSPFv3
O OSPFv3 tem os mesmos recursos de área stub, área NSSA e link virtual que o OSPFv2.
Depois que você divide um AS OSPFv3 em várias áreas, o número de LSAs é reduzido e os aplicativos OSPFv3 são ampliados. Para reduzir ainda mais o tamanho das tabelas de roteamento e o número de LSAs, configure as áreas não-backbone em uma borda de AS como áreas stub.
Uma área de stub não pode importar rotas externas, mas uma área NSSA pode importar rotas externas para o domínio de roteamento OSPFv3, mantendo outras características da área de stub.
As áreas não-backbone trocam informações de roteamento por meio da área de backbone, portanto, as áreas de backbone e não-backbone (inclusive o próprio backbone) devem ser totalmente interligadas. Se não for possível obter conectividade , configure links virtuais.
Configuração de uma área de stub
Restrições e diretrizes
Para configurar uma área de stub, você deve executar essa tarefa em todos os roteadores anexados à área.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Entre na visualização de área OSPFv3.
area area-id- Configure a área como uma área de stub.
stub [ default-route-advertise-always | no-summary ] *Por padrão, nenhuma área é configurada como área de stub.
A palavra-chave no-summary só está disponível no ABR de uma área de stub. Se você especificar a palavra-chave no-summary, o ABR só anunciará uma rota padrão em um LSA de prefixo entre áreas na área de stub.
- (Opcional.) Defina um custo para a rota padrão anunciada para a área de stub.
default cost cost-valuePor padrão, o custo da rota padrão anunciada para a área de stub é 1.
Configuração de uma área NSSA
Restrições e diretrizes
Para configurar uma área NSSA, você deve executar essa tarefa em todos os roteadores anexados à área.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Entre na visualização de área OSPFv3.
area area-id- Configure a área como uma área NSSA.
nssa [ default-route-advertise [ cost cost-value | nssa-only |
route-policy route-policy-name | tag tag | type type ] * |
no-import-route | no-summary | [ translate-always | translate-never ] |
suppress-fa | translator-stability-interval value ] *
Por padrão, nenhuma área é configurada como uma área NSSA.
Para configurar uma área totalmente NSSA, execute o comando nssa no-summary no ABR. O ABR de uma área totalmente NSSA não anuncia rotas entre áreas para a área.
- (Opcional.) Defina um custo para a rota padrão anunciada para a área NSSA.
default cost cost-valuePor padrão, o custo da rota padrão anunciada para a área NSSA é 1.
Esse comando só tem efeito na ABR/ASBR de uma área NSSA ou totalmente NSSA.
Configuração de um link virtual OSPFv3
Sobre os links virtuais do OSPFv3
Você pode configurar um link virtual para manter a conectividade entre uma área não-backbone e o backbone, ou no próprio backbone.
Restrições e diretrizes
As duas extremidades de um link virtual são ABRs que devem ser configurados com o comando vlink-peer.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Entre na visualização de área OSPFv3.
area area-id- Configurar um link virtual.
vlink-peer router-id [ dead seconds | hello seconds | instance
instance-id | ipsec-profile profile-name | retransmit seconds |
trans-delay seconds ] *
Configuração dos tipos de rede OSPFv3
Restrições e diretrizes para a configuração do tipo de rede OSPFv3
Com base no protocolo da camada de link, o OSPFv3 classifica as redes em diferentes tipos, incluindo broadcast, NBMA, P2MP e P2P.
- Se algum roteador em uma rede de broadcast não for compatível com multicasting, você poderá alterar o tipo de rede para NBMA.
- Se houver apenas dois roteadores executando o OSPFv3 em um segmento de rede, você poderá alterar o tipo de rede para P2P para economizar custos.
Configuração do tipo de rede de broadcast para uma interface OSPFv3
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o tipo de rede como broadcast para a interface OSPFv3.
ospfv3 network-type broadcast [ instance instance-id ]
Por padrão, o tipo de rede de uma interface é broadcast.
Configuração do tipo de rede NBMA para uma interface OSPFv3
Restrições e diretrizes
Para as interfaces NBMA, você deve especificar os endereços IP locais do link e as prioridades DR para seus vizinhos , pois essas interfaces não podem encontrar vizinhos por meio da transmissão de pacotes hello.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o tipo de rede como NBMA para a interface OSPFv3.
ospfv3 network-type nbma [ instance instance-id ]
Por padrão, o tipo de rede de uma interface é broadcast.
- (Opcional.) Defina a prioridade do roteador para a interface
ospfv3 dr-priority priorityPor padrão, uma interface tem uma prioridade de roteador de 1.
A prioridade do roteador de uma interface determina seu privilégio na seleção de DR/BDR.
- Especifique um vizinho NBMA.
ospfv3 peer ipv6-address [ cost cost-value | dr-priority priority ] [ instance instance-id ]Por padrão, nenhum endereço local de link é especificado para a interface vizinha.
Configuração do tipo de rede P2MP para uma interface OSPFv3
Restrições e diretrizes
Para interfaces P2MP (somente no modo unicast), você deve especificar os endereços IP locais de link dos vizinhos, pois essas interfaces não podem encontrar vizinhos por meio da transmissão de pacotes hello.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o tipo de rede como P2MP para a interface OSPFv3.
ospfv3 network-type p2mp [ unicast ] [ instance instance-id ]Por padrão, o tipo de rede de uma interface é broadcast.
- Especifique um vizinho unicast P2MP.
ospfv3 peer ipv6-address [ cost cost-value | dr-priority priority ] [ instance instance-id ]Por padrão, nenhum endereço local de link é especificado para a interface vizinha.
Configuração do tipo de rede P2P para uma interface OSPFv3
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o tipo de rede como P2P para a interface OSPFv3.
ospfv3 network-type p2p [ instance instance-id ]Por padrão, o tipo de rede de uma interface é broadcast.
Configuração do controle de rota OSPFv3
Configuração da compactação de rotas entre áreas do OSPFv3
Sobre a compactação de rotas entre áreas do OSPFv3
Se houver segmentos de rede contíguos em uma área, é possível resumi-los em um único segmento de rede no ABR. O ABR anunciará somente a rota resumida. Qualquer LSA no segmento de rede especificado não será anunciado, reduzindo o tamanho do LSDB em outras áreas.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Entre na visualização de área OSPFv3.
area area-id- Configure a sumarização de rotas no ABR.
abr-summary ipv6-address prefix-length [ not-advertise ] [ cost custo-valor ]Por padrão, a compactação de rotas não é configurada em um ABR.
Configuração da compactação de rotas redistribuídas
Sobre a compactação de rotas redistribuídas
Execute esta tarefa para permitir que um ASBR sumarize rotas externas dentro do intervalo de endereços especificado em uma única rota.
Um ASBR pode resumir rotas nos seguintes LSAs:
- LSAs do tipo 5.
- LSAs do tipo 7 em uma área NSSA.
- LSAs do tipo 5 traduzidos de LSAs do tipo 7 em uma área NSSA se o ASBR (também um ABR) for um tradutor. Se o ASBR não for um tradutor, ele não poderá resumir rotas em LSAs do tipo 5 traduzidos de LSAs do tipo 7.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Configurar a sumarização de rotas em um ASBR.
asbr-summary ipv6-address prefix-length [ cost cost-value |not-advertise | nssa-only | tag tag ] *Por padrão, a compactação de rotas não é configurada em um ASBR.
Configuração da filtragem de rotas recebidas do OSPFv3
Sobre a filtragem de rotas recebidas pelo OSPFv3
Essa tarefa permite que você filtre as rotas calculadas usando LSAs recebidos.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Configure o OSPFv3 para filtrar rotas calculadas usando LSAs recebidos.
filter-policy { ipv6-acl-number [ gateway prefix-list-name ] | prefix-list prefix-list-name [ gateway prefix-list-name ] | gateway prefix-list-name | route-policy route-policy-name } importPor padrão, o OSPFv3 aceita todas as rotas calculadas usando LSAs recebidos.
Esse comando só pode filtrar rotas computadas pelo OSPFv3. Somente as rotas não filtradas podem ser adicionadas à tabela de roteamento local.
Configuração da filtragem de LSA entre prefixos de área
Restrições e diretrizes
O comando filter tem efeito apenas nos ABRs.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Entre na visualização de área OSPFv3.
area area-id- Configure o OSPFv3 para filtrar LSAs de prefixo entre áreas.
filter { ipv6-acl-number | prefix-list prefix-list-name | route-policy route-policy-name } { export | import }Por padrão, o OSPFv3 aceita todos os LSAs de prefixo entre áreas.
Definição de um custo OSPFv3 para uma interface
Sobre a configuração de um custo OSPFv3 para uma interface
Você pode definir um custo OSPFv3 para uma interface com um dos métodos a seguir:
- Defina o valor do custo na visualização da interface.
- Defina um valor de referência de largura de banda para a interface, e o OSPFv3 calcula o custo automaticamente com base no valor de referência de largura de banda usando a seguinte fórmula:
Custo OSPFv3 da interface = valor de referência da largura de banda (100 Mbps) / largura de banda da interface (Mbps)
- Se o custo calculado for maior que 65535, o valor de 65535 será usado.
- Se o custo calculado for menor que 1, o valor de 1 será usado.
- Se nenhum custo for definido para uma interface, o OSPFv3 calculará automaticamente o custo da interface.
Definição de um custo na visualização da interface
system-view- Entre na visualização da interface.
interface interface-type interface-number- Definir um custo OSPFv3 para a interface.
ospfv3 cost cost-value [ instance instance-id ]Por padrão, o custo do OSPFv3 é 1 para uma interface VLAN e 0 para uma interface de loopback. O custo do OSPFv3 é calculado automaticamente de acordo com a largura de banda da interface para outras interfaces .
Definição de um valor de referência de largura de banda
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Defina um valor de referência de largura de banda.
valor de referência da largura de banda
O valor padrão de referência da largura de banda é 100 Mbps.
Definição de uma preferência para OSPFv3
Sobre a preferência de protocolo de roteamento
Um roteador pode executar vários protocolos de roteamento. O sistema atribui uma prioridade a cada protocolo. Quando esses protocolos de roteamento encontram a mesma rota, a rota encontrada pelo protocolo com a prioridade mais alta é selecionada.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Defina uma preferência para OSPFv3.
preference [ ase ] { preference | route-policy route-policy-name } *Por padrão, a preferência das rotas internas do OSPFv3 é 10, e a preferência das rotas externas do OSPFv3 é 150.
Configuração da redistribuição de rotas OSPFv3
Restrições e diretrizes
Como o OSPFv3 é um protocolo de roteamento de estado de link, ele não pode filtrar diretamente os LSAs a serem anunciados. O OSPFv3 filtra apenas as rotas redistribuídas. Somente as rotas que não são filtradas podem ser anunciadas em LSAs.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Configure o OSPFv3 para redistribuir rotas de outros protocolos de roteamento.
import-route { direct | static } [ cost cost-value | nssa-only | route-policy route-policy-name | tag tag | type type ] * import-route { ospfv3 | ripng } [ process-id | all-processes ] [ allow-direct | cost cost-value | nssa-only | route-policy route-policy-name | tag tag | type type ] *Por padrão, a redistribuição de rotas está desativada.
- (Opcional.) Configure o OSPFv3 para filtrar as rotas redistribuídas.
filter-policy { ipv6-acl-number | prefix-list prefix-list-name }
exportar [ direct | { ospfv3 | ripng } [ process-id ] | static ]
Por padrão, o OSPFv3 aceita todas as rotas redistribuídas.
Esse comando filtra apenas as rotas redistribuídas pelo comando import-route. Se nenhuma rota for redistribuída pelo comando import-route, esse comando não terá efeito.
- Definir uma tag para rotas redistribuídas.
tag padrão tag
Por padrão, a tag das rotas redistribuídas é 1.
Configuração da redistribuição de rotas padrão
Sobre a redistribuição de rotas padrão
O comando import-route não pode redistribuir uma rota externa padrão. Para redistribuir uma rota padrão , execute esta tarefa.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Redistribuir uma rota padrão.
default-route-advertise [ [ always | permit-calculate-other ] | cost
cost-value | route-policy route-policy-name | tag tag | type type ] *
Por padrão, nenhuma rota padrão é redistribuída.
- Definir uma tag para rotas redistribuídas.
tag padrão tag
Por padrão, a tag das rotas redistribuídas é 1.
Configuração dos temporizadores do OSPFv3
Configuração dos temporizadores de pacotes OSPFv3
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o intervalo de espera.
ospfv3 timer hello seconds [ instance instance-id ]
O intervalo hello padrão nas interfaces P2P e de broadcast é de 10 segundos. O intervalo hello padrão nas interfaces P2MP e NBMA é de 30 segundos.
- Defina o intervalo morto.
ospfv3 timer dead seconds [ instance instance-id ]
O intervalo morto padrão nas interfaces P2P e de broadcast é de 40 segundos. O intervalo morto padrão nas interfaces P2MP e NBMA é de 120 segundos.
O intervalo morto definido nas interfaces vizinhas não pode ser muito curto. Se o intervalo for muito curto, um vizinho do poderá ficar inativo facilmente.
- Defina o intervalo de sondagem.
ospfv3 timer poll seconds [ instance instance-id ]
Por padrão, o intervalo de sondagem é de 120 segundos.
- Defina o intervalo de retransmissão de LSA.
intervalo de retransmissão do temporizador ospfv3 [ instance instance-id ]
O intervalo padrão de retransmissão de LSA é de 5 segundos.
O intervalo de retransmissão de LSA não pode ser muito curto. Se o intervalo for muito curto, ocorrerão retransmissões desnecessárias.
Configuração do atraso de transmissão de LSA
Sobre a configuração do atraso de transmissão de LSA
Cada LSA no LSDB tem uma idade que é incrementada em 1 a cada segundo, mas a idade não muda durante a transmissão. Portanto, é necessário adicionar um atraso de transmissão ao tempo de idade, especialmente para links de baixa velocidade.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina o atraso de transmissão do LSA.
ospfv3 trans-delay seconds [ instance instance-id ]
Por padrão, o atraso de transmissão do LSA é de 1 segundo.
Definição do intervalo de cálculo do SPF
Sobre a configuração do intervalo de cálculo do SPF
As alterações no LSDB resultam em cálculos de SPF. Quando a topologia muda com frequência, uma grande quantidade de recursos da rede e do roteador é ocupada pelo cálculo do SPF. Você pode ajustar o intervalo de cálculo do SPF para reduzir o impacto.
Em uma rede estável, é usado o intervalo mínimo. Se as alterações na rede se tornarem frequentes, o intervalo de cálculo do SPF será incrementado pelo intervalo incremental × 2n-2 para cada cálculo até que o intervalo máximo seja atingido. O valor n é o número de vezes de cálculo.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Defina o intervalo de cálculo do SPF.
spf-schedule-interval maximum-interval [ minimum-interval
[ incremental-interval ] ]
Por padrão, o intervalo máximo é de 5 segundos, o intervalo mínimo é de 50 milissegundos e o intervalo incremental do é de 200 milissegundos.
Configuração do intervalo de geração de LSA
Sobre a configuração do intervalo de geração de LSA
Você pode ajustar o intervalo de geração de LSA para evitar que os recursos de rede e os roteadores sejam consumidos em excesso por alterações frequentes na rede.
Em uma rede estável, é usado o intervalo mínimo. Se as alterações na rede se tornarem frequentes, o intervalo de geração de LSA será incrementado pelo intervalo incremental × 2n-2 para cada geração até que o intervalo máximo seja atingido. O valor n é o número de tempos de geração.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Defina o intervalo de geração de LSA.
lsa-generation-interval maximum-interval [ minimum-interval
[ incremental-interval ] ]
Por padrão, o intervalo máximo é de 5 segundos, o intervalo mínimo é de 0 milissegundos e o intervalo incremental é de 0 milissegundos.
Configuração da taxa de transmissão da LSU
Sobre a configuração da taxa de transmissão da LSU
O envio de um grande número de pacotes LSU afeta o desempenho do roteador e consome uma grande quantidade de largura de banda da rede. Você pode configurar o roteador para enviar pacotes LSU em um intervalo e limitar o número máximo de pacotes LSU enviados de uma interface OSPFv3 em cada intervalo.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Defina a taxa de transmissão da LSU.
transmit-pacing interval interval count count
Por padrão, uma interface OSPFv3 envia um máximo de três pacotes LSU a cada 20 milissegundos.
Definição de uma prioridade de DR para uma interface
Sobre a prioridade de DR
A prioridade do roteador é usada para a eleição do DR. As interfaces com prioridade 0 não podem se tornar um DR ou BDR.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Defina uma prioridade de roteador.
ospfv3 dr-priority priority [ instance instance-id ]
A prioridade padrão do roteador é 1.
Configuração dos parâmetros de pacote do OSPFv3
Ignorando a verificação de MTU para pacotes DD
Sobre ignorar a verificação de MTU para pacotes DD
Quando os LSAs são poucos nos pacotes DD, não é necessário verificar o MTU nos pacotes DD para melhorar a eficiência do .
Restrições e diretrizes
Uma relação de vizinhança só pode ser estabelecida se o MTU da interface for igual ao do par.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ignorar a verificação de MTU para pacotes DD.
ospfv3 mtu-ignore [ instance instance-id ]
Por padrão, o OSPFv3 não ignora a verificação de MTU para pacotes DD.
Desativar o recebimento e o envio de pacotes OSPFv3 pelas interfaces
Sobre a desativação de interfaces para recebimento e envio de pacotes OSPFv3
Depois que uma interface OSPFv3 é definida como silenciosa, as rotas diretas da interface ainda podem ser anunciadas em LSAs de prefixo intra-área por meio de outras interfaces, mas outros pacotes OSPFv3 não podem ser anunciados. Nenhuma relação de vizinhança pode ser estabelecida na interface. Esse recurso pode aumentar a adaptabilidade da rede OSPFv3.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Desative as interfaces para que não recebam e enviem pacotes OSPFv3.
silent-interface { interface-type interface-number | all }Por padrão, as interfaces podem receber e enviar pacotes OSPFv3.
Esse comando desativa somente as interfaces que executam o processo atual. Entretanto, vários processos OSPFv3 podem desativar a mesma interface para que não receba nem envie pacotes OSPFv3 .
Configuração da supressão de prefixo
Sobre a supressão de prefixo
Por padrão, uma interface OSPFv3 anuncia todos os seus prefixos em LSAs. Para acelerar a convergência do OSPFv3, você pode impedir que as interfaces anunciem todos os seus prefixos. Esse recurso ajuda a aumentar a segurança da rede, impedindo o roteamento IP para as redes suprimidas.
Quando a supressão de prefixo está ativada:
- O OSPFv3 não anuncia os prefixos das interfaces suprimidas nos LSAs do tipo 8.
- Em redes broadcast e NBMA, o DR não anuncia os prefixos de interfaces suprimidas em LSAs do tipo 9 que fazem referência a LSAs do tipo 2.
- Nas redes P2P e P2MP, o OSPFv3 não anuncia os prefixos das interfaces suprimidas nos LSAs do Tipo 9 que fazem referência aos LSAs do Tipo 1.
Restrições e diretrizes para supressão de prefixos
Como prática recomendada, configure a supressão de prefixo em todos os roteadores OSPFv3 se quiser usar o prefixo supressão.
Configuração da supressão de prefixo para um processo OSPFv3
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Ativar a supressão de prefixo para o processo OSPFv3.
prefix-suppression
Por padrão, a supressão de prefixo é desativada para um processo OSPFv3.
A ativação da supressão de prefixo para um processo OSPFv3 não suprime os prefixos das interfaces de loopback e das interfaces passivas.
Configuração da supressão de prefixo para uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar a supressão de prefixo para a interface.
ospfv3 prefix-suppression [ disable ] [ instance instance-id ]
Por padrão, a supressão de prefixo é desativada em uma interface.
Configuração de um roteador stub
Sobre roteadores stub
Um roteador stub é usado para controle de tráfego. Ele informa seu status de roteador stub aos roteadores OSPFv3 vizinhos. Os roteadores vizinhos podem ter uma rota para o roteador stub, mas não usam o roteador stub para encaminhar dados.
Use um dos métodos a seguir para configurar um roteador como um roteador stub:
- Limpar o R-bit do campo Option nos LSAs de Tipo 1. Quando o bit R está limpo, o roteador OSPFv3 pode participar da distribuição da topologia OSPFv3 sem encaminhar tráfego.
- Use o recurso OSPFv3 max-metric router LSA. Esse recurso permite que o OSPFv3 anuncie seus LSAs Tipo 1 gerados localmente com um custo máximo de 65535. Os vizinhos não enviam pacotes para o roteador stub desde que tenham uma rota com custo menor.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Configure o roteador como um roteador stub.
- Configure o roteador como um roteador stub e limpe o bit R do campo Option nos LSAs do tipo 1.
stub-router r-bit [ include-stub | on-startup seconds ] *
- Configure o roteador como um roteador stub e anuncie os LSAs de tipo 1 gerados localmente com o custo máximo de 65535.
stub-router max-metric [ external-lsa [ max-metric-value ] |
summary-lsa [ max-metric-value ] | include-stub | on-startup seconds ]
*
Por padrão, o roteador não está configurado como um roteador stub. Um roteador stub não está relacionado a uma área stub.
Configuração do OSPFv3 GR
Sobre o OSPFv3 GR
O GR garante a continuidade do encaminhamento quando um protocolo de roteamento é reiniciado ou quando ocorre uma alternância ativo/em espera.
São necessários dois roteadores para concluir um processo de GR. Veja a seguir as funções do roteador em um processo de GR:
- GR restarter - Roteador de reinício gradual. Ele deve ser compatível com o Graceful Restart.
- Auxiliar de GR - O vizinho do reiniciador de GR. Ele ajuda o reiniciador de GR a concluir o processo de GR.
Para evitar a interrupção do serviço após uma alternância entre mestre e backup, um restarter GR que esteja executando o OSPFv3 deve executar as seguintes tarefas:
- Mantenha as entradas de encaminhamento do restarter GR estáveis durante a reinicialização.
- Estabelecer todas as adjacências e obter informações completas sobre a topologia após a reinicialização.
Após a alternância entre ativo e em espera, o reiniciador de GR envia um Grace LSA para informar aos vizinhos que está realizando um GR. Ao receber o Grace LSA, os vizinhos com a capacidade de auxiliar de GR entram no modo auxiliar (e são chamados de auxiliares de GR). Em seguida, o reiniciador de GR recupera suas adjacências e o LSDB com a ajuda dos ajudantes de GR.
Restrições e diretrizes para OSPFv3 GR
Não é possível ativar o NSR do OSPFv3 em um dispositivo que atue como reiniciador de GR.
Configuração do reiniciador de GR
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Habilite o recurso de GR.
graceful-restart enable [ global | planned-only ] *
Por padrão, o recurso de reinicialização do OSPFv3 GR está desativado.
- (Opcional.) Defina o intervalo de GR.
graceful-restart interval intervalPor padrão, o intervalo de GR é de 120 segundos.
Configuração do GR helper
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Ativar o recurso auxiliar de GR.
graceful-restart helper enable [ planned-only ]
Por padrão, o recurso auxiliar de GR está ativado.
- Ativar a verificação rigorosa de LSA.
graceful-restart helper strict-lsa-checking
Por padrão, a verificação rigorosa de LSA está desativada.
Acionamento do OSPFv3 GR
Sobre o acionamento do OSPFv3 GR
O OSPFv3 GR é acionado por uma alternância entre ativo e em espera ou quando essa tarefa é executada.
Procedimento
Para acionar o OSPFv3 GR, execute o comando reset ospfv3 [ process-id ] process graceful-restart na visualização do usuário.
Configuração do NSR do OSPFv3
Sobre o OSPFv3 NSR
O roteamento ininterrupto (NSR) faz o backup das informações de estado do link do OSPFv3 do processo ativo para o processo em espera. Após uma alternância entre ativo e em espera, o NSR pode concluir a recuperação do estado do link e a regeneração de rotas sem derrubar as adjacências ou afetar os serviços de encaminhamento.
O NSR não exige a cooperação de dispositivos vizinhos para recuperar informações de roteamento e, normalmente, é usado com mais frequência do que o GR.
Restrições e diretrizes
Um dispositivo que tenha o NSR do OSPFv3 ativado não pode atuar como reiniciador de GR.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Ativar NSR do OSPFv3.
non-stop-routingPor padrão, o NSR do OSPFv3 está desativado.
Esse comando entra em vigor somente para o processo atual. Como prática recomendada, ative o OSPFv3 NSR para cada processo se houver vários processos OSPFv3.
Configuração de BFD para OSPFv3
Sobre o BFD para OSPFv3
A detecção de encaminhamento bidirecional (BFD) fornece um mecanismo para detectar rapidamente a conectividade dos links entre os vizinhos do OSPFv3, melhorando a velocidade de convergência do OSPFv3. Para obter mais informações sobre o BFD, consulte o Guia de configuração de alta disponibilidade.
Depois de descobrir os vizinhos enviando pacotes hello, o OSPFv3 notifica o BFD sobre os endereços dos vizinhos, e o BFD usa esses endereços para estabelecer sessões. Antes de uma sessão BFD ser estabelecida, ela está no estado down. Nesse estado, os pacotes de controle do BFD são enviados em um intervalo não inferior a 1 segundo para reduzir o tráfego de pacotes de controle do BFD. Depois que a sessão BFD é estabelecida, os pacotes de controle BFD são enviados no intervalo negociado, implementando assim a detecção rápida de falhas.
Para configurar o BFD para OSPFv3, você precisa primeiro configurar o OSPFv3.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Especifique uma ID de roteador.
router-id router-id
- Sair da visualização OSPFv3.
quit- Entre na visualização da interface.
interface interface-type interface-number- Habilite um processo OSPFv3 na interface.
ospfv3 process-id area area-id [ instance instance-id ]
- Habilite o BFD na interface.
ospfv3 bfd enable [ instance instance-id ]
Por padrão, o BFD está desativado na interface OSPFv3.
Configuração do OSPFv3 FRR
Sobre o OSPFv3 FRR
Uma falha no link primário pode causar perda de pacotes e até mesmo um loop de roteamento até que o OSPFv3 conclua a convergência do roteamento com base na nova topologia da rede. O FRR do OSPFv3 permite o redirecionamento rápido para minimizar o tempo de failover.
Figura 1 Diagrama de rede para OSPFv3 FRR
Conforme mostrado na Figura 1, configure a FRR no Roteador B. A FRR do OSPFv3 calcula automaticamente um próximo salto de backup ou especifica um próximo salto de backup usando uma política de roteamento. Quando o link principal falha, o OSPFv3 direciona os pacotes para o próximo salto de backup. Ao mesmo tempo, o OSPFv3 calcula o caminho mais curto com base na nova topologia da rede. Ele encaminha os pacotes pelo caminho após a convergência da rede.
Você pode configurar o OSPFv3 FRR para calcular um próximo salto de backup usando o algoritmo loop free alternate (LFA) ou especificar um próximo salto de backup usando uma política de roteamento.
Configuração do OSPFv3 FRR para usar o algoritmo LFA para calcular um próximo salto de backup
Restrições e diretrizes
Não use o comando fast-reroute lfa junto com o comando vlink-peer.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- (Opcional.) Desative o LFA em uma interface.
ospfv3 fast-reroute lfa-backup exclude
Por padrão, a interface na qual o LFA está ativado pode ser selecionada como uma interface de backup.
- Retornar à visualização do sistema.
quit- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Habilite o OSPFv3 FRR para usar o algoritmo LFA para calcular um próximo salto de backup.
fast-reroute lfa [ abr-only ]
Por padrão, o FRR do OSPFv3 está desativado.
Se abr-only for especificado, a rota para o ABR será selecionada como o caminho de backup.
Configuração do OSPFv3 FRR para usar um próximo salto de backup em uma política de roteamento
Sobre a configuração de um próximo salto de backup em uma política de roteamento
Antes de executar essa tarefa, use o comando apply ipv6 fast-reroute backup-interface para especificar um próximo salto de backup na política de roteamento a ser usada. Para obter mais informações sobre o comando apply ipv6 fast-reroute backup-interface e a configuração da política de roteamento , consulte "Configuração de políticas de roteamento".
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- (Opcional.) Desative o LFA em uma interface.
ospfv3 fast-reroute lfa-backup exclude
Por padrão, a interface é ativada com LFA e pode ser selecionada como uma interface de backup.
- Retornar à visualização do sistema.
quit- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Configure o OSPFv3 FRR para usar um próximo salto de backup em uma política de roteamento.
fast-reroute route-policy route-policy-namePor padrão, o FRR do OSPFv3 está desativado.
Configuração do modo de pacote de controle BFD para OSPFv3 FRR
Sobre o modo de pacote de controle BFD para OSPFv3 FRR
Por padrão, o OSPFv3 FRR não usa o BFD para detectar falhas no link primário. Para acelerar a convergência do OSPFv3, ative o modo de pacote de controle BFD para que o OSPFv3 FRR detecte falhas no link primário. Esse modo requer a configuração do BFD nos dois roteadores OSPFv3 do link.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Ativar o modo de pacote de controle BFD para FRR OSPFv3.
ospfv3 primary-path-detect bfd ctrl [ instance instance-id ]
Por padrão, o modo de pacote de controle BFD está desativado para FRR OSPFv3.
Configuração do modo de pacote de eco BFD para FRR OSPFv3
Sobre o modo de pacote de eco BFD para FRR OSPFv3
Por padrão, o OSPFv3 FRR não usa o BFD para detectar falhas no link primário. Para acelerar a convergência do OSPFv3, ative o modo de pacote de eco do BFD para que o FRR do OSPFv3 detecte falhas no link primário. Esse modo requer a configuração do BFD em um roteador OSPFv3 no link.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o endereço IPv6 de origem dos pacotes de eco BFD.
bfd echo-source-ipv6 ipv6-address
Por padrão, o endereço IPv6 de origem dos pacotes de eco BFD não é configurado.
O endereço IPv6 de origem não pode estar no mesmo segmento de rede que o endereço IP de qualquer interface local.
Para obter mais informações sobre esse comando, consulte Referência de comandos de alta disponibilidade.
- Entre na visualização da interface.
interface interface-type interface-number- Habilitar o modo de pacote de eco BFD para FRR OSPFv3.
ospfv3 primary-path-detect bfd echo [ instance instance-id ]
Por padrão, o modo de pacote de eco BFD está desativado para FRR OSPFv3.
Aprimoramento da segurança do OSPFv3
Configuração da autenticação OSPFv3
Sobre a autenticação do OSPFv3
O OSPFv3 usa autenticação de chaveiro para evitar que as informações de roteamento vazem e que os roteadores sejam atacados.
O OSPFv3 adiciona a opção Authentication Trailer aos pacotes de saída e usa as informações de autenticação na opção para autenticar os pacotes de entrada. Somente os pacotes que passam pela autenticação podem ser recebidos. Se um pacote falhar na autenticação, a relação de vizinhança do OSPFv3 não poderá ser estabelecida.
Restrições e diretrizes
O modo de autenticação especificado para uma interface OSPFv3 tem prioridade mais alta do que o modo especificado para uma área OSPFv3.
O OSPFv3 é compatível apenas com os algoritmos de autenticação HMAC-SHA-256 e HMAC-SM3. A ID das chaves usadas para autenticação só pode estar no intervalo de 0 a 65535.
Configuração da autenticação de área OSPFv3
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Entre na visualização de área OSPFv3.
area area-id- Especifique um modo de autenticação para a área. authentication-mode keychain keychain-name Por padrão, nenhuma autenticação é executada para a área.
Para obter mais informações sobre chaveiros, consulte o Guia de configuração de segurança.
Configuração da autenticação da interface OSPFv3
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique um modo de autenticação para a interface.
ospfv3 authentication-mode keychain keychain-name [ instance
instance-id ]
Por padrão, nenhuma autenticação é executada para a interface.
Para obter mais informações sobre chaveiros, consulte o Guia de configuração de segurança.
Aplicação de um perfil IPsec para autenticar pacotes OSPFv3
Sobre o perfil IPsec para autenticar pacotes OSPFv3
Para proteger as informações de roteamento e evitar ataques, o OSPFv3 pode autenticar os pacotes de protocolo usando um perfil IPsec. Para obter mais informações sobre perfis IPsec, consulte o Guia de configuração de segurança.
Os pacotes OSPFv3 de saída contêm o índice de parâmetro de segurança (SPI) definido no perfil IPsec relevante. Um dispositivo compara o SPI contido em um pacote recebido com o perfil IPsec configurado. Se eles corresponderem, o dispositivo aceita o pacote. Caso contrário, o dispositivo descarta o pacote e não estabelece uma relação de vizinhança com o dispositivo remetente.
Restrições e diretrizes para aplicar um perfil IPsec
Você pode configurar um perfil IPsec para uma área, uma interface ou um link virtual.
- Para implementar a proteção IPsec baseada em área, configure o mesmo perfil IPsec nos roteadores da área de destino.
- Para implementar a proteção IPsec baseada em interface, configure o mesmo perfil IPsec nas interfaces entre dois roteadores vizinhos.
- Para implementar a proteção IPsec baseada em link virtual, configure o mesmo perfil IPsec nos dois roteadores conectados pelo link virtual.
- Se uma interface e sua área tiverem um perfil IPsec configurado, a interface usará seu próprio perfil IPsec.
- Se um link virtual e a área 0 tiverem um perfil IPsec configurado, o link virtual usará seu próprio perfil IPsec.
Aplicação de um perfil IPsec a uma área
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Entre na visualização de área OSPFv3.
area area-id- Aplicar um perfil IPsec à área.
enable ipsec-profile profile-name
Por padrão, nenhum perfil IPsec é aplicado.
Aplicação de um perfil IPsec a uma interface
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Aplicar um perfil IPsec à interface.
ospfv3 ipsec-profile profile-name [ instance instance-id ]
Por padrão, nenhum perfil IPsec é aplicado.
Aplicação de um perfil IPsec a um link virtual
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Entre na visualização de área OSPFv3.
area area-id- Aplicar um perfil IPsec a um link virtual.
vlink-peer router-id [ dead seconds | hello seconds | instance
instance-id | ipsec-profile profile-name | retransmit seconds |
trans-delay seconds ] *
Por padrão, nenhum perfil IPsec é aplicado.
Configuração do registro OSPFv3 e das notificações SNMP
Ativação do registro de alterações no estado do vizinho
Sobre o registro de alterações de estado de vizinhança
Com esse recurso ativado, o roteador fornece registros sobre as alterações de estado do vizinho para o centro de informações. O centro de informações processa os logs de acordo com as regras de saída definidas pelo usuário (se os logs devem ser enviados e onde devem ser enviados). Para obter mais informações sobre o centro de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Habilite o registro de alterações no estado do vizinho.
log-peer-change
Por padrão, esse recurso está ativado.
Configuração do número máximo de registros do OSPFv3
Sobre os registros do OSPFv3
Os logs do OSPFv3 incluem logs de cálculo de rota, logs de vizinhos e logs de envelhecimento de LSA.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Defina o número máximo de registros do OSPFv3.
event-log { lsa-flush | peer | spf } size count
Por padrão, o número máximo de registros de envelhecimento de LSA, registros de vizinhos ou registros de cálculo de rota é 10.
Configuração do gerenciamento de rede OSPFv3
Sobre o gerenciamento de rede OSPFv3
Essa tarefa envolve as seguintes configurações:
- Vincule um processo OSPFv3 ao MIB para que você possa usar o software de gerenciamento de rede para gerenciar o processo OSPFv3 especificado.
- Ative as notificações SNMP para que o OSPFv3 informe eventos importantes.
- Defina o intervalo de saída da notificação SNMP e o número máximo de notificações SNMP que podem ser emitidas em cada intervalo.
Para relatar eventos críticos do OSPFv3 a um NMS, ative as notificações de SNMP para o OSPFv3. Para que as notificações de SNMP sejam enviadas corretamente, você também deve configurar o SNMP no dispositivo. Para obter mais informações sobre a configuração de SNMP, consulte o guia de configuração de monitoramento e gerenciamento de rede do dispositivo.
O MIB padrão do OSPFv3 fornece apenas objetos MIB de instância única. Para identificar vários processos OSPFv3 no MIB padrão do OSPFv3, você deve atribuir um nome de contexto exclusivo a cada processo OSPFv3.
O contexto é um método introduzido no SNMPv3 para gerenciamento de várias instâncias. Para SNMPv1/v2c, você deve especificar um nome de comunidade como um nome de contexto para identificação de protocolo.
Procedimento
- Entre na visualização do sistema.
system-view- Vincular o MIB a um processo OSPFv3.
ospfv3 mib-binding process-id
Por padrão, o MIB é vinculado ao processo com a menor ID de processo.
- Ativar notificações SNMP para OSPFv3.
snmp-agent trap enable ospfv3 [ grrestarter-status-change |
grhelper-status-change | if-state-change | if-cfg-error | if-bad-pkt |
neighbor-state-change | nssatranslator-status-change |
virtif-bad-pkt | virtif-cfg-error | virtif-state-change |
virtgrhelper-status-change | virtneighbor-state-change ]*
Por padrão, as notificações SNMP para OSPFv3 estão ativadas.
- Entre na visualização OSPFv3.
ospfv3 [ process-id ]
- Configure um contexto SNMP para o processo OSPFv3.
snmp context-name context-name
Por padrão, nenhum contexto SNMP é configurado para o processo OSPFv3.
- (Opcional.) Defina o intervalo de saída da notificação SNMP e o número máximo de notificações SNMP que podem ser emitidas em cada intervalo.
snmp trap rate-limit interval trap-interval count trap-number
Por padrão, o OSPFv3 emite um máximo de sete notificações SNMP em 10 segundos.
Comandos de exibição e manutenção para OSPFv3
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações resumidas de rota no ABR OSPFv3. | display ospfv3 [ process-id ] [ area area-id ] abr-summary [ ipv6-address prefix-length ] [ verbose ] |
| Exibir informações de vizinhos do OSPFv3. | display ospfv3 [ process-id ] [ area-id ] peer [ [ interface-type interface-number ] [ verbose ] | peer-router-id | statistics ] |
| Exibir informações da lista de solicitações do OSPFv3. | display ospfv3 [ process-id ] [ area area-id ] request-queue [ interface-type interface-number ] [ neighbor-id ] |
| Exibir informações da lista de retransmissão do OSPFv3. | display ospfv3 [ process-id ] [ area area-id ] fila de retransmissões [ número da interface do tipo interface ] [ neighbor-id ] |
| Exibir informações de topologia do OSPFv3. | display ospfv3 [ process-id ] [ area area-id ] spf-tree [ verbose ] |
| Exibir informações do processo OSPFv3. | display ospfv3 [ process-id ] [ verbose ] |
| Exibir informações sobre as rotas para OSPFv3 ABR e ASBR. | display ospfv3 [ process-id ] abr-asbr |
| Exibir informações resumidas de rota no ASBR OSPFv3. | display ospfv3 [ process-id ] asbr-summary [ ipv6-address prefix-length ] [ verbose ] |
| Exibir informações de registro do OSPFv3. | display ospfv3 [ process-id ] event-log { lsa-flush | peer | spf } |
| Exibir informações do OSPFv3 GR. | display ospfv3 [ process-id ] graceful-restart [ verbose ] |
| Exibir informações da interface OSPFv3. | display ospfv3 [ process-id ] interface [ interface-type interface-number | verbose ] |
| Exibir informações do LSDB do OSPFv3. | display ospfv3 [ process-id ] lsdb [ { external | grace | inter-prefix | inter-router | intra-prefix | link | network | nssa | router | unknown [ type ] } [ link-state-id ] [ originate-router router-id | self-originate ] | statistics | total | verbose ] |
| Exibir informações do próximo salto do OSPFv3. | display ospfv3 [ process-id ] nexthop |
| Exibir informações de NSR do OSPFv3. | display ospfv3 [ process-id ] non-stop-routing |
| Exibir informações de roteamento OSPFv3. | display ospfv3 [ process-id ] routing [ ipv6-address prefix-length ] |
| Exibir estatísticas do OSPFv3. | display ospfv3 [ process-id ] statistics [ error ] |
| Exibir informações do link virtual OSPFv3. | display ospfv3 [ process-id ] vlink |
| Limpar informações de registro do OSPFv3. | reset ospfv3 [ process-id ] event-log [ lsa-flush | peer | spf ] |
| Reinicie um processo OSPFv3. | reset ospfv3 [ process-id ] process [ graceful-restart ] |
| Reinicie a redistribuição de rotas OSPFv3. | reset ospfv3 [ process-id ] redistribution |
| Limpar estatísticas do OSPFv3. | reset ospfv3 [ process-id ] statistics |
Exemplos de configuração do OSPFv3
Exemplo: Configuração da área de stub OSPFv3
Configuração de rede
Conforme mostrado na Figura 2:
- Habilite o OSPFv3 em todos os switches.
- Dividir o AS em três áreas.
- Configure o Switch B e o Switch C como ABRs para encaminhar informações de roteamento entre áreas.
- Configure a Área 2 como uma área de stub para reduzir os LSAs na área sem afetar a capacidade de alcance da rota.
Figura 2 Diagrama de rede
Procedimento
- Configurar endereços IPv6 para interfaces. (Detalhes não mostrados).
- Configurar o OSPFv3 básico:
# No Switch A, habilite o OSPFv3 e especifique o ID do roteador como 1.1.1.1.
<SwitchA> system-view
[SwitchA] ospfv3
[SwitchA-ospfv3-1] router-id 1.1.1.1
[SwitchA-ospfv3-1] quit
[SwitchA] interface vlan-interface 300
[SwitchA-Vlan-interface300] ospfv3 1 area 1
[SwitchA-Vlan-interface300] quit
[SwitchA] interface vlan-interface 200
[SwitchA-Vlan-interface200] ospfv3 1 area 1
[SwitchA-Vlan-interface200] quit
# No Switch B, ative o OSPFv3 e especifique o ID do roteador como 2.2.2.2.
<SwitchB> system-view
[SwitchB] ospfv3
[SwitchB-ospfv3-1] router-id 2.2.2.2
[SwitchB-ospfv3-1] quit
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ospfv3 1 area 0
[SwitchB-Vlan-interface100] quit
[SwitchB] interface vlan-interface 200
[SwitchB-Vlan-interface200] ospfv3 1 area 1
[SwitchB-Vlan-interface200] quit# No Switch C, ative o OSPFv3 e especifique o ID do roteador como 3.3.3.3.
<SwitchC> system-view
[SwitchC] ospfv3
[SwitchC-ospfv3-1] router-id 3.3.3.3
[SwitchC-ospfv3-1] quit
[SwitchC] interface vlan-interface 100
[SwitchC-Vlan-interface100] ospfv3 1 area 0
[SwitchC-Vlan-interface100] quit
[SwitchC] interface vlan-interface 400
[SwitchC-Vlan-interface400] ospfv3 1 area 2
[SwitchC-Vlan-interface400] quit
# No Switch D, habilite o OSPFv3 e especifique o ID do roteador como 4.4.4.4.
<SwitchD> system-view
[SwitchD] ospfv3
[SwitchD-ospfv3-1] router-id 4.4.4.4
[SwitchD-ospfv3-1] quit
[SwitchD] interface vlan-interface 400
[SwitchD-Vlan-interface400] ospfv3 1 area 2
[SwitchD-Vlan-interface400] quit
# Exibir os vizinhos OSPFv3 no Switch B.
[SwitchB] display ospfv3 peer
OSPFv3 Process 1 with Router ID 2.2.2.2
Area: 0.0.0.0
-------------------------------------------------------------------------
Router ID Pri State Dead-Time InstID Interface
3.3.3.3 1 Full/BDR 00:00:40 0 Vlan100
Area: 0.0.0.1
-------------------------------------------------------------------------
Router ID Pri State Dead-Time InstID Interface
1.1.1.1 1 Full/DR 00:00:40 0 Vlan200
# Exibir os vizinhos OSPFv3 no Switch C.
[SwitchC] display ospfv3 peer
OSPFv3 Process 1 with Router ID 3.3.3.3
Area: 0.0.0.0
-------------------------------------------------------------------------
Router ID Pri State Dead-Time InstID Interface
2.2.2.2 1 Full/DR 00:00:40 0 Vlan100
Area: 0.0.0.2
-------------------------------------------------------------------------
Router ID Pri State Dead-Time InstID Interface
4.4.4.4 1 Full/BDR 00:00:40 0 Vlan400
# Exibir informações da tabela de roteamento OSPFv3 no Switch D.
[SwitchD] display ospfv3 routing
OSPFv3 Process 1 with Router ID 4.4.4.4
-------------------------------------------------------------------------
I - Intra area route, E1 - Type 1 external route, N1 - Type 1 NSSA route
IA - Inter area route, E2 - Type 2 external route, N2 - Type 2 NSSA route
* - Selected route
*Destination: 2001::/64
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000004 Cost : 2
Interface : Vlan400 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
*Destination: 2001:1::/64
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000004 Cost : 3
Interface : Vlan400 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
*Destination: 2001:2::/64
Type : I Area : 0.0.0.2
AdvRouter : 4.4.4.4 Preference : 10
NibID : 0x23000002 Cost : 1
Interface : Vlan400 BkInterface: N/A
Nexthop : ::
BkNexthop : N/A
*Destination: 2001:3::1/128
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000004 Cost : 3
Interface : Vlan400 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
Total: 4
Intra area: 1 Inter area: 3 ASE: 0 NSSA: 0
- Configure a Área 2 como uma área de stub:
# Configure o Switch D.
[SwitchD] ospfv3
[SwitchD-ospfv3-1] area 2
[SwitchD-ospfv3-1-area-0.0.0.2] stub
# Configure o Switch C e especifique o custo da rota padrão enviada para a área de stub como 10.
[SwitchC] ospfv3
[SwitchC-ospfv3-1] area 2
[SwitchC-ospfv3-1-area-0.0.0.2] stub
[SwitchC-ospfv3-1-area-0.0.0.2] default-cost 10
# Exibir informações da tabela de roteamento OSPFv3 no Switch D.
[SwitchD] display ospfv3 routing
OSPFv3 Process 1 with Router ID 4.4.4.4
-------------------------------------------------------------------------
I - Intra area route, E1 - Type 1 external route, N1 - Type 1 NSSA route
IA - Inter area route, E2 - Type 2 external route, N2 - Type 2 NSSA route
* - Selected route
*Destination: ::/0
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000003 Cost : 11
Interface : Vlan400 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
*Destination: 2001::/64
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000003 Cost : 2
Interface : Vlan400 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
*Destination: 2001:1::/64
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000003 Cost : 3
Interface : Vlan400 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
*Destination: 2001:2::/64
Type : I Area : 0.0.0.2
AdvRouter : 4.4.4.4 Preference : 10
NibID : 0x23000001 Cost : 1
Interface : Vlan400 BkInterface: N/A
Nexthop : ::
BkNexthop : N/A
*Destination: 2001:3::1/128
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000003 Cost : 3
Interface : Vlan400 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
Total: 5
Intra area: 1 Inter area: 4 ASE: 0 NSSA: 0
A saída mostra que uma rota padrão foi adicionada e seu custo é o custo de uma rota direta mais o custo configurado.
- Configure a Área 2 como uma área totalmente stub:
# Configure a Área 2 como uma área totalmente restrita no Switch C.
[SwitchC-ospfv3-1-area-0.0.0.2] stub no-summary
# Exibir informações da tabela de roteamento OSPFv3 no Switch D.
[SwitchD] display ospfv3 routing
OSPFv3 Process 1 with Router ID 4.4.4.4
-------------------------------------------------------------------------
I - Intra area route, E1 - Type 1 external route, N1 - Type 1 NSSA route
IA - Inter area route, E2 - Type 2 external route, N2 - Type 2 NSSA route
* - Selected route
*Destination: ::/0
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000003 Cost : 11
Interface : Vlan400 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
*Destination: 2001:2::/64
Type : I Area : 0.0.0.2
AdvRouter : 4.4.4.4 Preference : 10
NibID : 0x23000001 Cost : 1
Interface : Vlan400 BkInterface: N/A
Nexthop : ::
BkNexthop : N/A
Total: 2
Intra area: 1 Inter area: 1 ASE: 0 NSSA: 0
A saída mostra que as entradas de rota são reduzidas. Todas as rotas indiretas são removidas, exceto a rota padrão.
Exemplo: Configuração da área NSSA do OSPFv3
Configuração de rede
Conforme mostrado na Figura 3:
- Configure o OSPFv3 em todos os switches e divida o AS em três áreas.
- Configure o Switch B e o Switch C como ABRs para encaminhar informações de roteamento entre áreas.
- Configure a Área 1 como uma área NSSA e configure o Switch A como um ASBR para redistribuir rotas estáticas para o AS.
Figura 3 Diagrama de rede
Procedimento
- Configurar endereços IPv6 para interfaces. (Detalhes não mostrados).
- Configure o OSPFv3 básico (consulte "Exemplo: Configuração da área de stub do OSPFv3").
- Configure a Área 1 como uma área NSSA: # Configurar o Switch A.
[SwitchA] ospfv3
[SwitchA-ospfv3-1] area 1
[SwitchA-ospfv3-1-area-0.0.0.1] nssa
[SwitchA-ospfv3-1-area-0.0.0.1] quit
[SwitchA-ospfv3-1] quit#Configure o Switch B.
[SwitchB] ospfv3
[SwitchB-ospfv3-1] area 1
[SwitchB-ospfv3-1-area-0.0.0.1] nssa
[SwitchB-ospfv3-1-area-0.0.0.1] quit
[SwitchB-ospfv3-1] quit# Exibir informações de roteamento OSPFv3 no Switch D.
[SwitchD] display ospfv3 1 routing
OSPFv3 Process 1 with Router ID 4.4.4.4
-------------------------------------------------------------------------
I - Intra area route, E1 - Type 1 external route, N1 - Type 1 NSSA route
IA - Inter area route, E2 - Type 2 external route, N2 - Type 2 NSSA route
* - Selected route
*Destination: 2001::/64
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000003 Cost : 2
Interface : Vlan200 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
*Destination: 2001:1::/64
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000003 Cost : 3
Interface : Vlan200 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
*Destination: 2001:2::/64
Type : I Area : 0.0.0.2
AdvRouter : 4.4.4.4 Preference : 10
NibID : 0x23000001 Cost : 1
Interface : Vlan200 BkInterface: N/A
Nexthop : ::
BkNexthop : N/A
*Destination: 2001:3::/64
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000003 Cost : 4
Interface : Vlan200 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
Total: 4
Intra area: 1 Inter area: 3 ASE: 0 NSSA: 0
- Configurar a redistribuição de rotas:
# Configure uma rota estática IPv6 e configure o OSPFv3 para redistribuir a rota estática no Switch A.
[SwitchA] ipv6 route-static 1234:: 64 null 0
[SwitchA] ospfv3 1
[SwitchA-ospfv3-1] import-route static
[SwitchA-ospfv3-1] quit
# Exibir informações de roteamento OSPFv3 no Switch D.
[SwitchD] display ospfv3 1 routing
OSPFv3 Process 1 with Router ID 4.4.4.4
-------------------------------------------------------------------------
I - Intra area route, E1 - Type 1 external route, N1 - Type 1 NSSA route
IA - Inter area route, E2 - Type 2 external route, N2 - Type 2 NSSA route
* - Selected route
*Destination: 2001::/64
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000002 Cost : 2
Interface : Vlan400 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
*Destination: 2001:1::/64
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000002 Cost : 3
Interface : Vlan400 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
*Destination: 2001:2::/64
Type : I Area : 0.0.0.2
AdvRouter : 4.4.4.4 Preference : 10
NibID : 0x23000004 Cost : 1
Interface : Vlan400 BkInterface: N/A
Nexthop : ::
BkNexthop : N/A
*Destination: 2001:3::/64
Type : IA Area : 0.0.0.2
AdvRouter : 3.3.3.3 Preference : 10
NibID : 0x23000002 Cost : 4
Interface : Vlan400 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
*Destination: 1234::/64
Type : E2 Tag : 1
AdvRouter : 2.2.2.2 Preference : 150
NibID : 0x23000001 Cost : 1
Interface : Vlan400 BkInterface: N/A
Nexthop : FE80::48C0:26FF:FEDA:305
BkNexthop : N/A
Total: 5
Intra area: 1 Inter area: 3 ASE: 1 NSSA: 0
A saída mostra que existe uma rota externa AS importada da área NSSA no Switch D.
Exemplo: Configuração da eleição de DR do OSPFv3
Configuração de rede
Conforme mostrado na Figura 4:
- Configure a prioridade do roteador 100 para o Switch A, a prioridade mais alta da rede, para que ele se torne o DR.
- Configure a prioridade de roteador 2 para o Switch C, a segunda prioridade mais alta da rede, para que ele se torne o BDR.
- Configure a prioridade de roteador 0 para o Switch B, para que ele não possa se tornar um DR ou BDR.
- O switch D usa a prioridade de roteador padrão 1.
Figura 4 Diagrama de rede
Procedimento
- Configurar endereços IPv6 para interfaces. (Detalhes não mostrados).
- Configurar o OSPFv3 básico:
# No Switch A, habilite o OSPFv3 e especifique o ID do roteador como 1.1.1.1.
<SwitchA> system-view
[SwitchA] ospfv3
[SwitchA-ospfv3-1] router-id 1.1.1.1
[SwitchA-ospfv3-1] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] ospfv3 1 area 0
[SwitchA-Vlan-interface100] quit
# No Switch B, ative o OSPFv3 e especifique o ID do roteador como 2.2.2.2.
<SwitchB> system-view
[SwitchB] ospfv3
[SwitchB-ospfv3-1] router-id 2.2.2.2
[SwitchB-ospfv3-1] quit
[SwitchB] interface vlan-interface 200
[SwitchB-Vlan-interface200] ospfv3 1 area 0
[SwitchB-Vlan-interface200] quit
# No Switch C, ative o OSPFv3 e especifique o ID do roteador como 3.3.3.3.
<SwitchC> system-view
[SwitchC] ospfv3
[SwitchC-ospfv3-1] router-id 3.3.3.3
[SwitchC-ospfv3-1] quit
[SwitchC] interface vlan-interface 100
[SwitchC-Vlan-interface100] ospfv3 1 area 0
[SwitchC-Vlan-interface100] quit
# No Switch D, habilite o OSPFv3 e especifique o ID do roteador como 4.4.4.4.
<SwitchC> system-view
[SwitchD] ospfv3
[SwitchD-ospfv3-1] router-id 4.4.4.4
[SwitchD-ospfv3-1] quit
[SwitchD] interface vlan-interface 200
[SwitchD-Vlan-interface200] ospfv3 1 area 0
[SwitchD-Vlan-interface200] quit
# Exibir informações sobre vizinhos no Switch A. Os switches têm a mesma prioridade DR padrão 1,
portanto, o switch D (o switch com o ID de roteador mais alto) é eleito o DR e o switch C é o BDR.
[SwitchA] display ospfv3 peer
OSPFv3 Process 1 with Router ID 1.1.1.1
Area: 0.0.0.0
-------------------------------------------------------------------------
Router ID Pri State Dead-Time InstID Interface
2.2.2.2 1 2-Way/DROther 00:00:36 0 Vlan200
3.3.3.3 1 Full/BDR 00:00:35 0 Vlan100
4.4.4.4 1 Full/DR 00:00:33 0 Vlan200
# Exibir informações de vizinhança no Switch D. Os estados de vizinhança estão todos completos.
[SwitchD] display ospfv3 peer
OSPFv3 Process 1 with Router ID 4.4.4.4
Area: 0.0.0.0
-------------------------------------------------------------------------
Router ID Pri State Dead-Time InstID Interface
1.1.1.1 1 Full/DROther 00:00:30 0 Vlan100
2.2.2.2 1 Full/DROther 00:00:37 0 Vlan200
3.3.3.3 1 Full/BDR 00:00:31 0 Vlan100
- Configure as prioridades do roteador para as interfaces:
# Defina a prioridade do roteador da interface VLAN 100 como 100 no Switch A.
[SwitchA] interface Vlan-interface 100
[SwitchA-Vlan-interface100] ospfv3 dr-priority 100
[SwitchA-Vlan-interface100] quit
# Defina a prioridade do roteador da interface VLAN 200 como 0 no Switch B.
[SwitchB] interface vlan-interface 200
[SwitchB-Vlan-interface200] ospfv3 dr-priority 0
[SwitchB-Vlan-interface200] quit
# Defina a prioridade do roteador da interface VLAN 100 como 2 no Switch C.
[SwitchC] interface Vlan-interface 100
[SwitchC-Vlan-interface100] ospfv3 dr-priority 2
[SwitchC-Vlan-interface100] quit
# Exibir informações sobre vizinhos no Switch A. As prioridades do roteador foram atualizadas, mas o DR e o BDR não foram alterados.
[SwitchA] display ospfv3 peer
OSPFv3 Process 1 with Router ID 1.1.1.1
Area: 0.0.0.0
-------------------------------------------------------------------------
Router ID Pri State Dead-Time InstID Interface
2.2.2.2 0 2-Way/DROther 00:00:36 0 Vlan200
3.3.3.3 2 Full/BDR 00:00:35 0 Vlan200
4.4.4.4 1 Full/DR 00:00:33 0 Vlan200
# Exibir informações de vizinhança no Switch D. O Switch D ainda é o DR.
[SwitchD] display ospfv3 peer
OSPFv3 Process 1 with Router ID 4.4.4.4
Area: 0.0.0.0
-------------------------------------------------------------------------
Router ID Pri State Dead-Time InstID Interface
1.1.1.1 100 Full/DROther 00:00:30 0 Vlan100
2.2.2.2 0 Full/DROther 00:00:37 0 Vlan200
3.3.3.3 2 Full/BDR 00:00:31 0 Vlan100
# Use os comandos shutdown e undo shutdown nas interfaces para reiniciar a eleição de DR e BDR. (Detalhes não mostrados.)
# Exibir informações de vizinhança no Switch A. A saída mostra que o Switch C se torna o BDR.
[SwitchA] display ospfv3 peer
OSPFv3 Process 1 with Router ID 1.1.1.1
Area: 0.0.0.0
-------------------------------------------------------------------------
Router ID Pri State Dead-Time InstID Interface
2.2.2.2 0 Full/DROther 00:00:36 0 Vlan200
3.3.3.3 2 Full/BDR 00:00:35 0 Vlan100
4.4.4.4 1 Full/DROther 00:00:33 0 Vlan200
# Exibir informações sobre vizinhos no Switch D.
[SwitchD] display ospfv3 peer
OSPFv3 Process 1 with Router ID 4.4.4.4
Area: 0.0.0.0
-------------------------------------------------------------------------
Router ID Pri State Dead-Time InstID Interface
1.1.1.1 100 Full/DR 00:00:30 0 Vlan100
2.2.2.2 0 2-Way/DROther 00:00:37 0 Vlan200
3.3.3.3 2 Full/BDR 00:00:31 0 Vlan100
A saída mostra que o Switch A se torna o DR.
Exemplo: Configuração da redistribuição de rotas OSPFv3
Configuração de rede
Conforme mostrado na Figura 5:
- O interruptor A, o interruptor B e o interruptor C estão na Área 2.
- O processo 1 do OSPFv3 e o processo 2 do OSPFv3 são executados no Switch B. O Switch B se comunica com o Switch A e o Switch C por meio do processo 1 do OSPFv3 e do processo 2 do OSPFv3.
- Configure o processo 2 do OSPFv3 para redistribuir as rotas diretas e as rotas do processo 1 do OSPFv3 no Switch B e defina a métrica das rotas redistribuídas como 3. O Switch C pode, então, aprender as rotas destinadas a 1::0/64 e 2::0/64, e o Switch A não pode aprender as rotas destinadas a 3::0/64 ou 4::0/64.
Figura 5 Diagrama de rede
Procedimento
- Configurar endereços IPv6 para interfaces. (Detalhes não mostrados).
- Configurar o OSPFv3 básico:
# Habilite o processo 1 do OSPFv3 no Switch A.
<SwitchA> system-view
[SwitchA] ospfv3 1
[SwitchA-ospfv3-1] router-id 1.1.1.1
[SwitchA-ospfv3-1] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] ospfv3 1 area 2
[SwitchA-Vlan-interface100] quit
[SwitchA] interface vlan-interface 200
[SwitchA-Vlan-interface200] ospfv3 1 area 2
[SwitchA-Vlan-interface200] quit
# Habilite o processo 1 do OSPFv3 e o processo 2 do OSPFv3 no Switch B.
<SwitchB> system-view
[SwitchB] ospfv3 1
[SwitchB-ospfv3-1] router-id 2.2.2.2
[SwitchB-ospfv3-1] quit
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ospfv3 1 area 2
[SwitchB-Vlan-interface100] quit
[SwitchB] ospfv3 2
[SwitchB-ospfv3-2] router-id 3.3.3.3
[SwitchB-ospfv3-2] quit
[SwitchB] interface vlan-interface 300
[SwitchB-Vlan-interface300] ospfv3 2 area 2
[SwitchB-Vlan-interface300] quit
# Habilite o processo 2 do OSPFv3 no Switch C.
<SwitchC> system-view
[SwitchC] ospfv3 2
[SwitchC-ospfv3-2] router-id 4.4.4.4
[SwitchC-ospfv3-2] quit
[SwitchC] interface vlan-interface 300
[SwitchC-Vlan-interface300] ospfv3 2 area 2
[SwitchC-Vlan-interface300] quit
[SwitchC] interface vlan-interface 400
[SwitchC-Vlan-interface400] ospfv3 2 area 2
[SwitchC-Vlan-interface400] quit
# Exibir a tabela de roteamento no Switch C.
[SwitchC] display ipv6 routing-table
Destinations : 7 Routes : 7
Destination: ::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: 3::/64 Protocol : Direct
NextHop : :: Preference: 0
Interface : Vlan300 Cost : 0
Destination: 3::2/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: 4::/64 Protocol : Direct
NextHop : :: Preference: 0
Interface : Vlan400 Cost : 0
Destination: 4::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: FE80::/10 Protocol : Direct
NextHop : :: Preference: 0
Interface : NULL0 Cost : 0
Destination: FF00::/8 Protocol : Direct
NextHop : :: Preference: 0
Interface : NULL0 Cost : 0
- Configurar a redistribuição de rotas OSPFv3:
# Configure o processo 2 do OSPFv3 para redistribuir as rotas diretas e as rotas do processo 1 do OSPFv3 no Switch B e defina a métrica das rotas redistribuídas como 3.
[SwitchB] ospfv3 2
[SwitchB-ospfv3-2] import-route ospfv3 1 cost 3
[SwitchB-ospfv3-2] import-route direct cost 3
[SwitchB-ospfv3-2] quit
# Exibir a tabela de roteamento no Switch C.
[SwitchC] display ipv6 routing-table
Destinations : 9 Routes : 9
Destination: ::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: 1::/64 Protocol : O_ASE2
NextHop : FE80::200:CFF:FE01:1C03 Preference: 150
Interface : Vlan300 Cost : 3
Destination: 2::/64 Protocol : O_ASE2
NextHop : FE80::200:CFF:FE01:1C03 Preference: 150
Interface : Vlan300 Cost : 3
Destination: 3::/64 Protocol : Direct
NextHop : :: Preference: 0
Interface : Vlan300 Cost : 0
Destination: 3::2/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: 4::/64 Protocol : Direct
NextHop : :: Preference: 0
Interface : Vlan400 Cost : 0
Destination: 4::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: FE80::/10 Protocol : Direct
NextHop : :: Preference: 0
Interface : NULL0 Cost : 0
Destination: FF00::/8 Protocol : Direct
NextHop : :: Preference: 0
Interface : NULL0 Cost : 0
Exemplo: Configuração da sumarização de rotas OSPFv3
Configuração de rede
Conforme mostrado na Figura 6:
- Os interruptores A, B e C estão na Área 2.
- O processo 1 do OSPFv3 e o processo 2 do OSPFv3 são executados no Switch B. O Switch B se comunica com o Switch A e o Switch C por meio do processo 1 do OSPFv3 e do processo 2 do OSPFv3, respectivamente.
- No Switch A, configure os endereços IPv6 2:1:1::1/64, 2:1:2::1/64 e 2:1:3::1/64 para a interface de VLAN 200.
- No Switch B, configure o processo 2 do OSPFv3 para redistribuir rotas diretas e as rotas do processo 1 do OSPFv3. O switch C pode então aprender as rotas destinadas a 2::/64, 2:1:1::/64, 2:1:2::/64 e 2:1:3::/64.
- No Switch B, configure a sumarização de rotas para anunciar apenas a rota de resumo 2::/16 para o Switch C.
Figura 6 Diagrama de rede
Procedimento
- Configurar endereços IPv6 para interfaces. (Detalhes não mostrados).
- Configurar o OSPFv3:
# Habilite o processo 1 do OSPFv3 no Switch A.
<SwitchA> system-view
[SwitchA] ospfv3 1
[SwitchA-ospfv3-1] router-id 1.1.1.1
[SwitchA-ospfv3-1] quit
[SwitchA] interface vlan-interface 100
witchA-Vlan-interface100] quit
[SwitchA] interface vlan-interface 200
[SwitchA-Vlan-interface200] ipv6 address 2:1:1::1 64
[SwitchA-Vlan-interface200] ipv6 address 2:1:2::1 64
[SwitchA-Vlan-interface200] ipv6 address 2:1:3::1 64
[SwitchA-Vlan-interface200] ospfv3 1 area 2
[SwitchA-Vlan-interface200] quit
# Habilite o processo 1 do OSPFv3 e o processo 2 do OSPFv3 no Switch B.
<SwitchB> system-view
[SwitchB] ospfv3 1
[SwitchB-ospfv3-1] router-id 2.2.2.2
[SwitchB-ospfv3-1] quit
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ospfv3 1 area 2
[SwitchB-Vlan-interface100] quit
[SwitchB] ospfv3 2
[SwitchB-ospfv3-2] router-id 3.3.3.3
[SwitchB-ospfv3-2] quit
[SwitchB] interface vlan-interface 300
[SwitchB-Vlan-interface300] ospfv3 2 area 2
[SwitchB-Vlan-interface300] quit
# Habilite o processo 2 do OSPFv3 no Switch C.
<SwitchC> system-view
[SwitchC] ospfv3 2
[SwitchC-ospfv3-2] router-id 4.4.4.4
[SwitchC-ospfv3-2] quit
[SwitchC] interface vlan-interface 300
[SwitchC-Vlan-interface300] ospfv3 2 area 2
[SwitchC-Vlan-interface300] quit
[SwitchC] interface vlan-interface 400
[SwitchC-Vlan-interface400] ospfv3 2 area 2
[SwitchC-Vlan-interface400] quit
- Configurar a redistribuição de rotas OSPFv3:
# Configure o processo 2 do OSPFv3 para redistribuir rotas diretas e as rotas do processo 1 do OSPFv3 no Switch B.
[SwitchB] ospfv3 2
[SwitchB-ospfv3-2] import-route ospfv3 1
[SwitchB-ospfv3-2] import-route direct
[SwitchB-ospfv3-2] quit
# Exibir a tabela de roteamento no Switch C.
[SwitchC] display ipv6 routing-table
Destinations : 12 Routes : 12
Destination: ::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
42
Destination: 1::/64 Protocol : O_ASE2
NextHop : FE80::200:CFF:FE01:1C03 Preference: 150
Interface : Vlan300 Cost : 1
Destination: 2::/64 Protocol : O_ASE2
NextHop : FE80::200:CFF:FE01:1C03 Preference: 150
Interface : Vlan300 Cost : 1
Destination: 2:1:1::/64 Protocol : O_ASE2
NextHop : FE80::200:CFF:FE01:1C03 Preference: 150
Interface : Vlan300 Cost : 1
Destination: 2:1:2::/64 Protocol : O_ASE2
NextHop : FE80::200:CFF:FE01:1C03 Preference: 150
Interface : Vlan300 Cost : 1
Destination: 2:1:3::/64 Protocol : O_ASE2
NextHop : FE80::200:CFF:FE01:1C03 Preference: 150
Interface : Vlan300 Cost : 1
Destination: 3::/64 Protocol : Direct
NextHop : 3::2 Preference: 0
Interface : Vlan300 Cost : 0
Destination: 3::2/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: 4::/64 Protocol : Direct
NextHop : 4::1 Preference: 0
Interface : Vlan400 Cost : 0
Destination: 4::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: FE80::/10 Protocol : Direct
NextHop : :: Preference: 0
Interface : NULL0 Cost : 0
Destination: FF00::/8 Protocol : Direct
NextHop : :: Preference: 0
Interface : NULL0 Cost : 0
- Configurar a sumarização de rotas ASBR:
# No Switch B, configure o processo 2 do OSPFv3 para anunciar uma única rota 2::/16.
[SwitchB] ospfv3 2
[SwitchB-ospfv3-2] asbr-summary 2:: 16
[SwitchB-ospfv3-2] quit
# Exibir a tabela de roteamento no Switch C.
[SwitchC] display ipv6 routing-table
Destinations : 9 Routes : 9
Destination: ::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: 1::/64 Protocol : O_ASE2
NextHop : FE80::200:CFF:FE01:1C03 Preference: 150
Interface : Vlan300 Cost : 1
Destination: 2::/16 Protocol : O_ASE2
NextHop : FE80::200:CFF:FE01:1C03 Preference: 150
Interface : Vlan300 Cost : 1
Destination: 3::/64 Protocol : Direct
NextHop : 3::2 Preference: 0
Interface : Vlan300 Cost : 0
Destination: 3::2/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: 4::/64 Protocol : Direct
NextHop : 4::1 Preference: 0
Interface : Vlan400 Cost : 0
Destination: 4::1/128 Protocol : Direct
NextHop : ::1 Preference: 0
Interface : InLoop0 Cost : 0
Destination: FE80::/10 Protocol : Direct
NextHop : :: Preference: 0
Interface : NULL0 Cost : 0
Destination: FF00::/8 Protocol : Direct
NextHop : :: Preference: 0
Interface : NULL0 Cost : 0
Exemplo: Configuração do OSPFv3 GR
Configuração de rede
Conforme mostrado na Figura 7:
- O Switch A, o Switch B e o Switch C que residem no mesmo AS e no mesmo domínio de roteamento OSPFv3 são compatíveis com GR.
- O comutador A atua como reiniciador de GR. Os comutadores B e C atuam como auxiliares de GR e sincronizam seus LSDBs com o comutador A por meio de GR.
Figura 7 Diagrama de rede
Procedimento
- Configurar endereços IPv6 para interfaces. (Detalhes não mostrados).
- Configurar o OSPFv3 básico:
# No Switch A, habilite o processo 1 do OSPFv3, habilite o GR e defina o ID do roteador como 1.1.1.1.
<SwitchA> system-view
[SwitchA] ospfv3 1
[SwitchA-ospfv3-1] router-id 1.1.1.1
[SwitchA-ospfv3-1] graceful-restart enable
[SwitchA-ospfv3-1] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] ospfv3 1 area 1
[SwitchA-Vlan-interface100] quit
# No Switch B, habilite o OSPFv3 e defina o ID do roteador como 2.2.2.2. (Por padrão, o GR helper é
habilitado no Switch B).
<SwitchB> system-view
[SwitchB] ospfv3 1
[SwitchB-ospfv3-1] router-id 2.2.2.2
[SwitchB-ospfv3-1] quit
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ospfv3 1 area 1
[SwitchB-Vlan-interface100] quit
# No Switch C, habilite o OSPFv3 e defina o ID do roteador como 3.3.3.3. (Por padrão, o GR helper está habilitado no Switch C).
<SwitchC> system-view
[SwitchC] ospfv3 1
[SwitchC-ospfv3-1] router-id 3.3.3.3
[SwitchC-ospfv3-1] quit
[SwitchC] interface vlan-interface 100
[SwitchC-Vlan-interface100] ospfv3 1 area 1
[SwitchC-Vlan-interface100] quit
Verificação da configuração
# Realize uma alternância mestre/backup no Switch A para acionar uma operação OSPFv3 GR. (Detalhes não mostrados.)
Exemplo: Configuração do NSR do OSPFv3
Configuração de rede
Conforme mostrado na Figura 8, o Switch S, o Switch A e o Switch B pertencem ao mesmo domínio de roteamento OSPFv3. Habilite o NSR do OSPFv3 no Switch S para garantir o roteamento correto quando ocorrer um switchover ativo/em espera no Switch S.
Figura 8 Diagrama de rede

Procedimento
- Configure os endereços IP e as máscaras de sub-rede para as interfaces nos switches. (Detalhes não mostrados).
- Configure o OSPFv3 nos switches para garantir que o Switch S, o Switch A e o Switch B possam se comunicar entre si na Camada 3. (Detalhes não mostrados.)
- Configurar o OSPFv3:
# No Switch A, habilite o OSPFv3 e defina o ID do roteador como 1.1.1.1.
<SwitchA> system-view
[SwitchA] ospfv3 1
[SwitchA-ospfv3-1] router-id 1.1.1.1
[SwitchA-ospfv3-1] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] ospfv3 1 area 1
[SwitchA-Vlan-interface100] quit
# No Switch B, habilite o OSPFv3 e defina o ID do roteador como 2.2.2.2.
<SwitchB> system-view
[SwitchB] ospfv3 1
[SwitchB-ospfv3-1] router-id 2.2.2.2
[SwitchB-ospfv3-1] quit
[SwitchB] interface vlan-interface 200
[SwitchB-Vlan-interface200] ospfv3 1 area 1
[SwitchB-Vlan-interface200] quit
# No Switch S, habilite o OSPFv3, defina o ID do roteador como 3.3.3.3 e habilite o NSR.
<SwitchS> system-view
[SwitchS] ospfv3 1
[SwitchS-ospfv3-1] router-id 3.3.3.3
[SwitchS-ospfv3-1] non-stop-routing
[SwitchS-ospfv3-1] quit
[SwitchS] interface vlan-interface 100
[SwitchS-Vlan-interface100] ospfv3 1 area 1
[SwitchS-Vlan-interface100] quit
[SwitchS] interface vlan-interface 200
[SwitchS-Vlan-interface200] ospfv3 1 area 1
[SwitchS-Vlan-interface200] quit
Verificação da configuração
# Verifique o seguinte:
- Quando ocorre uma alternância entre ativo e em espera no Switch S, as relações de vizinhança e as informações de roteamento no Switch A e no Switch B não são alteradas. (Detalhes não mostrados.)
- O tráfego do Switch A para o Switch B não foi afetado. (Detalhes não mostrados).
Exemplo: Configuração de BFD para OSPFv3
Configuração de rede
Conforme mostrado na Figura 9:
- Configure o OSPFv3 no Switch A, Switch B e Switch C e configure o BFD no link Switch A<->L2 Switch<->Switch B.
- Depois que o link Switch A<->L2 Switch<->Switch B falha, o BFD pode detectar rapidamente a falha e notificar o OSPFv3 sobre a falha. Em seguida, o switch A e o switch B se comunicam por meio do switch C.
Figura 9 Diagrama de rede
Tabela 1 Atribuição de interface e endereço IP
| Dispositivo | Interface | Endereço IPv6 |
| Chave A | Vlan-int10 | 2001::1/64 |
| Chave A | Vlan-int11 | 2001:2::1/64 |
| Chave B | Vlan-int10 | 2001::2/64 |
| Chave B | Vlan-int13 | 2001:3::2/64 |
| Chave C | Vlan-int11 | 2001:2::2/64 |
| Chave C | Vlan-int13 | 2001:3::1/64 |
Procedimento
- Configure os endereços IPv6 para as interfaces. (Detalhes não mostrados).
- Configurar o OSPFv3 básico:
# No Switch A, habilite o OSPFv3 e especifique o ID do roteador como 1.1.1.1.
<SwitchA> system-view
[SwitchA] ospfv3
[SwitchA-ospfv3-1] router-id 1.1.1.1
[SwitchA-ospfv3-1] quit
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ospfv3 1 area 0
[SwitchA-Vlan-interface10] quit
[SwitchA] interface vlan-interface 11
[SwitchA-Vlan-interface11] ospfv3 1 area 0
[SwitchA-Vlan-interface11] quit
# No Switch B, ative o OSPFv3 e especifique o ID do roteador como 2.2.2.2.
<SwitchB> system-view
[SwitchB] ospfv3
[SwitchB-ospfv3-1] router-id 2.2.2.2
[SwitchB-ospfv3-1] quit
[SwitchB] interface vlan-interface 10
[SwitchB-Vlan-interface10] ospfv3 1 area 0
[SwitchB-Vlan-interface10] quit
[SwitchB] interface vlan-interface 13
[SwitchB-Vlan-interface13] ospfv3 1 area 0
[SwitchB-Vlan-interface13] quit
# No Switch C, ative o OSPFv3 e especifique o ID do roteador como 3.3.3.3.
<SwitchC> system-view
[SwitchC] ospfv3
[SwitchC-ospfv3-1] router-id 3.3.3.3
[SwitchC-ospfv3-1] quit
[SwitchC] interface vlan-interface 11
[SwitchC-Vlan-interface11] ospfv3 1 area 0
[SwitchC-Vlan-interface11] quit
[SwitchC] interface vlan-interface 13
[SwitchC-Vlan-interface13] ospfv3 1 area 0
[SwitchC-Vlan-interface13] quit
- Configurar o BFD:
# Habilite o BFD e configure os parâmetros do BFD no Switch A.
[SwitchA] bfd session init-mode active
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ospfv3 bfd enable
[SwitchA-Vlan-interface10] bfd min-transmit-interval 500
[SwitchA-Vlan-interface10] bfd min-receive-interval 500
[SwitchA-Vlan-interface10] bfd detect-multiplier 7
[SwitchA-Vlan-interface10] return
# Habilite o BFD e configure os parâmetros do BFD no Switch B.
[SwitchB] bfd session init-mode active
[SwitchB] interface vlan-interface 10
[SwitchB-Vlan-interface10] ospfv3 bfd enable
[SwitchB-Vlan-interface10] bfd min-transmit-interval 500
[SwitchB-Vlan-interface10] bfd min-receive-interval 500
[SwitchB-Vlan-interface10] bfd detect-multiplier 6
Verificação da configuração
# Exibir as informações do BFD no Switch A.
<SwitchA> display bfd session
Total Session Num: 1 Init Mode: Active
IPv6 session working in control packet mode:
Local Discr: 1441 Remote Discr: 1450
Source IP: FE80::20F:FF:FE00:1202 (link-local address of VLAN-interface 10 on
Switch A)
Destination IP: FE80::20F:FF:FE00:1200 (link-local address of VLAN-interface 10 on
Switch B)
Session State: Up Interface: Vlan10
Hold Time: 2319ms
# Exibir rotas destinadas a 2001:4::0/64 no Switch A.
<SwitchA> display ipv6 routing-table 2001:4::0 64
Summary Count : 1
Destination: 2001:4::/64 Protocol : O_INTRA
NextHop : FE80::20F:FF:FE00:1200 Preference: 10
Interface : Vlan10
As informações de saída mostram que o Switch A se comunica com o Switch B por meio da interface de VLAN 10. O link na interface VLAN 10 falha.
# Exibir rotas para 2001:4::0/64 no Switch A.
<SwitchA> display ipv6 routing-table 2001:4::0 64
Summary Count : 1
Destination: 2001:4::/64 Protocol : O_INTRA
NextHop : FE80::BAAF:67FF:FE27:DCD0 Preference: 10
Interface : Vlan11 Cost : 2
A saída mostra que o Switch A se comunica com o Switch B por meio da interface VLAN 11.
Exemplo: Configuração do OSPFv3 FRR
Configuração de rede
Conforme mostrado na Figura 10, o Switch A, o Switch B e o Switch C residem no mesmo domínio OSPFv3. Configure o FRR do OSPFv3 para que, quando o Link A falhar, o tráfego seja imediatamente transferido para o Link B.
Figura 10 Diagrama de rede
Tabela 2 Atribuição de interface e endereço IP
| Dispositivo | Interface | Endereço IP | Dispositivo | Interface | Endereço IP |
| Chave A | Vlan-int100 | 1::1/64 | Chave B | Vlan-int101 | 3::1/64 |
| Vlan-int200 | 2::1/64 | Vlan-int200 | 2::2/64 | ||
| Loop0 | 10::1/128 | Loop0 | 20::1/128 | ||
| Chave C | Vlan-int100 | 1::2/64 | |||
| Vlan-int101 | 3::2/64 |
Procedimento
- Configure os endereços IPv6 e as máscaras de sub-rede para as interfaces nos switches. (Detalhes não mostrados).
- Configure o OSPFv3 nos switches para garantir que o Switch A, o Switch B e o Switch C possam se comunicar entre si na camada de rede. (Detalhes não mostrados).
- Configure o FRR do OSPFv3 para calcular automaticamente o próximo salto de backup:
Você pode ativar o FRR do OSPFv3 para calcular um próximo salto de backup usando o algoritmo LFA ou especificar um próximo salto de backup usando uma política de roteamento.
- (Método 1.) Ative o FRR do OSPFv3 para calcular o próximo salto de backup usando o algoritmo LFA:
# Configure o switch A.
<SwitchA> system-view
[SwitchA] ospfv3 1
[SwitchA-ospfv3-1] fast-reroute lfa
[SwitchA-ospfv3-1] quit
# Configure o Switch B.
<SwitchB> system-view
[SwitchB] ospfv3 1
[SwitchB-ospfv3-1] fast-reroute lfa
[SwitchB-ospfv3-1] quit
- (Método 2.) Habilite o OSPFv3 FRR para designar um próximo salto de backup usando uma política de roteamento:
# Configure o switch A.
<SwitchA> system-view
[SwitchA] ipv6 prefix-list abc index 10 permit 20::1 128
[SwitchA] route-policy frr permit node 10
[SwitchA-route-policy-frr-10] if-match ipv6 address prefix-list abc
[SwitchA-route-policy-frr-10] apply ipv6 fast-reroute backup-interface
vlan-interface 100 backup-nexthop 1::2
[SwitchA-route-policy-frr-10] quit
[SwitchA] ospfv3 1
[SwitchA-ospfv3-1] fast-reroute route-policy frr
[SwitchA-ospfv3-1] quit
# Configure o Switch B.
<SwitchB> system-view
[SwitchB] ipv6 prefix-list abc index 10 permit 10::1 128
[SwitchB] route-policy frr permit node 10
[SwitchB-route-policy-frr-10] if-match ipv6 address prefix-list abc
[SwitchB-route-policy-frr-10] apply ipv6 fast-reroute backup-interface
vlan-interface 101 backup-nexthop 3::2
[SwitchB-route-policy-frr-10] quit
[SwitchB] ospfv3 1
[SwitchB-ospfv3-1] fast-reroute route-policy frr
[SwitchB-ospfv3-1] quit
Verificação da configuração
# Exiba a rota 20::1/128 no Switch A para ver as informações do próximo salto de backup.
[SwitchA] display ipv6 routing-table 20::1 128 verbose
Summary count : 1
Destination: 20::1/128
Protocol: O_INTRA
Process ID: 1
SubProtID: 0x1 Age: 00h03m45s
Cost: 6 Preference: 10
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0xa OrigAs: 0
NibID: 0x23000005 LastAs: 0
AttrID: 0xffffffff Neighbor: ::
Flags: 0x10041 OrigNextHop: FE80::7685:45FF:FEAD:102
Label: NULL RealNextHop: FE80::7685:45FF:FEAD:102
BkLabel: NULL BkNextHop: FE80::34CD:9FF:FE2F:D02
SRLabel: NULL BkSRLabel: NULL
Tunnel ID: Invalid Interface: Vlan-interface200
BkTunnel ID: Invalid BkInterface: Vlan-interface100
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0
# Exiba a rota 10::1/128 no Switch B para ver as informações do próximo salto de backup.
[SwitchB] display ipv6 routing-table 10::1 128 verbose
Summary count : 1
Destination: 10::1/128
Protocol: O_INTRA
Process ID: 1
SubProtID: 0x1 Age: 00h03m10s
Cost: 1 Preference: 10
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0xa OrigAs: 0
NibID: 0x23000006 LastAs: 0
AttrID: 0xffffffff Neighbor: ::
Flags: 0x10041 OrigNextHop: FE80::34CC:E8FF:FE5B:C02
51
Label: NULL RealNextHop: FE80::34CC:E8FF:FE5B:C02
BkLabel: NULL BkNextHop: FE80::7685:45FF:FEAD:102
SRLabel: NULL BkSRLabel: NULL
Tunnel ID: Invalid Interface: Vlan-interface200
BkTunnel ID: Invalid BkInterface: Vlan-interface101
FtnIndex: 0x0 TrafficIndex: N/A
Connector: N/A PathID: 0x0
Exemplo: Configuração do perfil IPsec do OSPFv3
Configuração de rede
Conforme mostrado na Figura 11, todos os switches executam o OSPFv3 e o AS é dividido em duas áreas. Configure os perfis IPsec nos switches para autenticar e criptografar os pacotes de protocolo.
Figura 11 Diagrama de rede
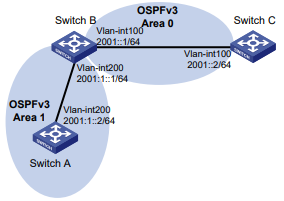
Procedimento
- Configurar endereços IPv6 para interfaces. (Detalhes não mostrados).
- Configurar os recursos básicos do OSPFv3:
# No Switch A, habilite o OSPFv3 e especifique o ID do roteador como 1.1.1.1.
<SwitchA> system-view
[SwitchA] ospfv3 1
[SwitchA-ospfv3-1] router-id 1.1.1.1
[SwitchA-ospfv3-1] quit
[SwitchA] interface vlan-interface 200
[SwitchA-Vlan-interface200] ospfv3 1 area 1
[SwitchA-Vlan-interface200] quit
# No Switch B, habilite o OSPFv3 e especifique o ID do roteador como 2.2.2.2.
<SwitchB> system-view
[SwitchB] ospfv3 1
[SwitchB-ospfv3-1] router-id 2.2.2.2
[SwitchB-ospfv3-1] quit
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ospfv3 1 area 0
[SwitchB-Vlan-interface100] quit
[SwitchB] interface vlan-interface 200
[SwitchB-Vlan-interface200] ospfv3 1 area 1
[SwitchB-Vlan-interface200] quit
# No Switch C, ative o OSPFv3 e especifique o ID do roteador como 3.3.3.3.
<SwitchC> system-view
[SwitchC] ospfv3 1
[SwitchC-ospfv3-1] router-id 3.3.3.3
[SwitchC-ospfv3-1] quit
[SwitchC] interface vlan-interface 100
[SwitchC-Vlan-interface100] ospfv3 1 area 0
[SwitchC-Vlan-interface100] quit
- Configurar perfis IPsec do OSPFv3:
- No interruptor A:
# Crie um conjunto de transformação IPsec chamado trans.
[SwitchA] ipsec transform-set trans
# Especifique o modo de encapsulamento como transporte.
[SwitchA-ipsec-transform-set-trans] encapsulation-mode transport
# Especifique os algoritmos de criptografia e autenticação ESP.
[SwitchA-ipsec-transform-set-trans] protocol esp
[SwitchA-ipsec-transform-set-trans] esp encryption-algorithm aes-cbc-128
[SwitchA-ipsec-transform-set-trans] esp authentication-algorithm sha1
[SwitchA-ipsec-transform-set-trans] quit
# Criar um perfil IPsec manual chamado profile001.
[SwitchA] ipsec profile profile001 manual
# Use o conjunto de transformação IPsec trans.
[SwitchA-ipsec-profile-manual-profile001] transform-set trans# Configure os SPIs de entrada e saída para ESP.
[SwitchA-ipsec-profile-manual-profile001] sa spi outbound esp 123456
[SwitchA-ipsec-profile-manual-profile001] sa spi inbound esp 123456# Configure as chaves SA de entrada e saída para ESP.
[SwitchA-ipsec-profile-manual-profile001] sa string-key outbound esp simple
abcdefg
[SwitchA-ipsec-profile-manual-profile001] sa string-key inbound esp simple
abcdefg
[SwitchA-ipsec-profile-manual-profile001] quit
- No interruptor B:
# Crie um conjunto de transformação IPsec chamado trans.
[SwitchB] ipsec transform-set trans
# Especifique o modo de encapsulamento como transporte.
[SwitchB-ipsec-transform-set-trans] encapsulation-mode transport
# Especifique os algoritmos de criptografia e autenticação ESP.
[SwitchB-ipsec-transform-set-trans] protocol esp
[SwitchB-ipsec-transform-set-trans] esp encryption-algorithm aes-cbc-128
[SwitchB-ipsec-transform-set-trans] esp authentication-algorithm sha1
[SwitchB-ipsec-transform-set-trans] quit
# Criar um perfil IPsec manual chamado profile001.
[SwitchB] ipsec profile profile001 manual
# Use o conjunto de transformação IPsec trans.
[SwitchB-ipsec-profile-manual-profile001] transform-set trans
# Configure os SPIs de entrada e saída para ESP.
[SwitchB-ipsec-profile-manual-profile001] sa spi outbound esp 123456
[SwitchB-ipsec-profile-manual-profile001] sa spi inbound esp 123456
# Configure as chaves SA de entrada e saída para ESP.
[SwitchB-ipsec-profile-manual-profile001] sa string-key outbound esp simple
abcdefg
[SwitchB-ipsec-profile-manual-profile001] sa string-key inbound esp simple
abcdefg
[SwitchB-ipsec-profile-manual-profile001] quit
Criar um perfil IPsec manual chamado profile002.
[SwitchB] ipsec profile profile002 manual
# Use o conjunto de transformação IPsec trans.
[SwitchB-ipsec-profile-manual-profile002] transform-set trans
# Configure os SPIs de entrada e saída para ESP.
[SwitchB-ipsec-profile-manual-profile002] sa spi outbound esp 256
[SwitchB-ipsec-profile-manual-profile002] sa spi inbound esp 256
# Configure as chaves SA de entrada e saída para ESP.
[SwitchB-ipsec-profile-manual-profile002] sa string-key outbound esp simple
byebye
[SwitchB-ipsec-profile-manual-profile001] sa string-key inbound esp simple byebye
[SwitchB-ipsec-profile-manual-profile001] quit
- No interruptor C:
# Crie um conjunto de transformação IPsec chamado trans.
[SwitchC] ipsec transform-set trans
# Especifique o modo de encapsulamento como transporte.
[SwitchC-ipsec-transform-set-trans] encapsulation-mode transport
# Especifique os algoritmos de criptografia e autenticação ESP.
[SwitchC-ipsec-transform-set-trans] protocol esp
[SwitchC-ipsec-transform-set-trans] esp encryption-algorithm aes-cbc-128
[SwitchC-ipsec-transform-set-trans] esp authentication-algorithm sha1
[SwitchC-ipsec-transform-set-trans] quit
# Criar um perfil IPsec manual chamado profile002.
[SwitchC] ipsec profile profile002 manual
# Use o conjunto de transformação IPsec trans.
[SwitchC-ipsec-profile-manual-profile002] transform-set trans
# Configure os SPIs de entrada e saída para ESP.
[SwitchC-ipsec-profile-manual-profile002] sa spi outbound esp 256
[SwitchC-ipsec-profile-manual-profile002] sa spi inbound esp 256
# Configure as chaves SA de entrada e saída para ESP.
[SwitchC-ipsec-profile-manual-profile002] sa string-key outbound esp simple
byebye
[SwitchC-ipsec-profile-manual-profile001] sa string-key inbound esp simple byebye
[SwitchC-ipsec-profile-manual-profile001] quit
- Aplique os perfis IPsec às áreas: # Configure o Switch A.
[SwitchA] ospfv3 1
[SwitchA-ospfv3-1] area 1
[SwitchA-ospfv3-1-area-0.0.0.1] enable ipsec-profile profile001
[SwitchA-ospfv3-1-area-0.0.0.1] quit
[SwitchA-ospfv3-1] quit
#Configure o Switch B.
[SwitchB] ospfv3 1
[SwitchB-ospfv3-1] area 0
[SwitchB-ospfv3-1-area-0.0.0.0] enable ipsec-profile profile002
[SwitchB-ospfv3-1-area-0.0.0.0] quit
[SwitchB-ospfv3-1] area 1
[SwitchB-ospfv3-1-area-0.0.0.1] enable ipsec-profile profile001
[SwitchB-ospfv3-1-area-0.0.0.1] quit
[SwitchB-ospfv3-1] quit
Configurar o switch C.
[SwitchC] ospfv3 1
[SwitchC-ospfv3-1] area 0
[SwitchC-ospfv3-1-area-0.0.0.0] enable ipsec-profile profile002
[SwitchC-ospfv3-1-area-0.0.0.0] quit
[SwitchC-ospfv3-1] quit
Verificação da configuração
# Verifique se os pacotes OSPFv3 entre os Switches A, B e C estão protegidos pelo IPsec. (Detalhes não mostrados).
Configuração do IPv6 PBR
Sobre o IPv6 PBR
O roteamento baseado em políticas IPv6 (PBR) usa políticas definidas pelo usuário para rotear pacotes IPv6. Uma política pode especificar parâmetros para pacotes que correspondem a critérios específicos, como ACLs. Os parâmetros incluem o próximo salto.
Processo de encaminhamento de pacotes IPv6
Um dispositivo encaminha os pacotes IPv6 recebidos usando o seguinte processo:
- O dispositivo usa o PBR para encaminhar os pacotes correspondentes.
- Se um dos eventos a seguir ocorrer, o dispositivo procurará uma rota (exceto a rota padrão) na tabela de roteamento para encaminhar os pacotes:
- Os pacotes não correspondem à política de PBR.
- O encaminhamento baseado em PBR falha.
- Se o encaminhamento falhar, o dispositivo usará a rota padrão para encaminhar os pacotes.
Tipos de PBR IPv6
O IPv6 PBR inclui os seguintes tipos:
Política
Uma política IPv6 inclui critérios de correspondência e ações a serem executadas nos pacotes correspondentes. Uma política pode ter um ou vários nós, como segue:
- Cada nó é identificado por um número de nó. Um número de nó menor tem uma prioridade mais alta.
- Um nó contém cláusulas if-match e apply. Uma cláusula if-match especifica um critério de correspondência e uma cláusula apply especifica uma ação.
- Um nó tem um modo de correspondência de permissão ou negação.
Uma política IPv6 compara pacotes com nós em ordem de prioridade. Se um pacote corresponder aos critérios em um nó, ele será processado pela ação no nó. Se o pacote não corresponder a nenhum critério no nó, ele irá para o próximo nó em busca de uma correspondência. Se o pacote não corresponder aos critérios em nenhum nó, o dispositivo executará uma pesquisa na tabela de roteamento para o pacote.
Relacionamento entre cláusulas if-match
O IPv6 PBR suporta apenas a cláusula if-match acl para definir um critério de correspondência de ACL. Em um nó, é possível especificar apenas uma cláusula if-match.
Relacionamento entre cláusulas apply
O IPv6 PBR suporta apenas a cláusula apply next-hop para definir os próximos hops.
Relação entre o modo de correspondência e as cláusulas no nó
| Um pacote corresponde a todas as cláusulas if-match no nó? | Modo de correspondência | |
| No modo de permissão | No modo de negação | |
| Se o nó contiver cláusulas de aplicação, o IPv6 PBR executará as cláusulas de aplicação no nó. | ||
| Sim | Se o encaminhamento baseado em IPv6 PBR for bem-sucedido, o IPv6 PBR não comparará o pacote com o próximo nó. | O dispositivo executa uma pesquisa na tabela de roteamento para o pacote. |
| Se o nó não contiver cláusulas de aplicação, o dispositivo executará uma pesquisa na tabela de roteamento para o pacote. | ||
| Não | O IPv6 PBR compara o pacote com o próximo nó. | O IPv6 PBR compara o pacote com o próximo nó. |
OBSERVAÇÃO:
Um nó que não tenha cláusulas if-match corresponde a qualquer pacote.
IPv6 PBR e Track
O IPv6 PBR pode trabalhar com o recurso Track para adaptar dinamicamente o status de disponibilidade de uma aplicação
para o status do link de um objeto rastreado. O objeto rastreado pode ser um próximo salto.
- Quando a entrada de trilha associada a um objeto muda para Negativo, a cláusula apply é inválida.
- Quando a entrada da trilha muda para Positive ou NotReady, a cláusula apply é válida.
Para obter mais informações sobre a colaboração Track e IPv6 PBR, consulte o Guia de configuração de alta disponibilidade.
Restrições e diretrizes: Configuração do IPv6 PBR
Se o dispositivo realizar o encaminhamento no software, o IPv6 PBR não processará os pacotes IP destinados ao dispositivo local.
Se o dispositivo realizar o encaminhamento em hardware e um pacote destinado a ele corresponder a uma política IPv6 PBR, o IPv6 PBR executará as cláusulas de aplicação na política, inclusive a cláusula de encaminhamento. Quando você configurar uma política de PBR IPv6, tenha cuidado para evitar essa situação.
Visão geral das tarefas do IPv6 PBR
Para configurar o IPv6 PBR, execute as seguintes tarefas:
- Configuração de uma política IPv6
- Criação de um nó IPv6
- Definição de critérios de correspondência para um nó IPv6
- Configuração de ações para um nó IPv6
- Especificação de uma política para IPv6 PBR Escolha as seguintes tarefas, conforme necessário:
Configuração de uma política IPv6
Criação de um nó IPv6
- Entre na visualização do sistema.
system-view- Crie uma política ou um nó de política IPv6 e entre em sua visualização.
ipv6 policy-based-route policy-name [ deny | permit ] node node-number- (Opcional.) Configure uma descrição para o nó de política IPv6.
description textPor padrão, nenhuma descrição é configurada para um nó de política IPv6.
Definição de critérios de correspondência para um nó IPv6
- Entre na visualização do sistema.
system-view- Entre na visualização do nó de política IPv6.
ipv6 policy-based-route policy-name [ deny | permit ] node node-number- Definir critérios de correspondência.
- Definir um critério de correspondência de ACL.
if-match acl { ipv6-acl-number | name ipv6-acl-name }Por padrão, nenhum critério de correspondência de ACL é definido.
O critério de correspondência da ACL não pode corresponder às informações da Camada 2.
Ao usar a ACL para fazer a correspondência de pacotes, o IPv6 PBR ignora a ação (permitir ou negar) e as configurações de intervalo de tempo na ACL.
Configuração de ações para um nó IPv6
Sobre cláusulas apply
O IPv6 PBR suporta apenas a cláusula apply next-hop para definir os próximos hops para pacotes correspondentes.
Restrições e diretrizes para a configuração de ações
Se você especificar um próximo salto ou um próximo salto padrão, o IPv6 PBR realizará periodicamente uma pesquisa na tabela FIB para determinar sua disponibilidade. Poderá ocorrer uma interrupção temporária do serviço se o IPv6 PBR não atualizar a rota imediatamente após a alteração de seu status de disponibilidade.
Configuração de ações para um nó
- Entre na visualização do sistema.
system-view- Entre na visualização do nó de política IPv6.
ipv6 policy-based-route policy-name [ deny | permit ] node node-number- Configurar ações para um nó.
- Defina os próximos saltos para pacotes IPv6 permitidos.
apply next-hop { ipv6-address [ direct ] [ track
track-entry-number ] }&<1-2>Por padrão, nenhum próximo salto é especificado.
É possível especificar vários next hops para backup em uma linha de comando ou executando esse comando várias vezes. É possível especificar um máximo de dois próximos hops para um nó.
Especificação de uma política para IPv6 PBR
Especificação de uma política IPv6 para PBR local IPv6
Sobre o PBR local IPv6
Execute esta tarefa para especificar uma política de IPv6 para PBR local de IPv6 para orientar o encaminhamento de pacotes gerados localmente .
Restrições e diretrizes
Você pode especificar apenas uma política para o PBR local IPv6 e deve se certificar de que a política especificada já existe. Antes de aplicar uma nova política, você deve primeiro remover a política atual.
O IPv6 local PBR pode afetar os serviços locais, como ping e Telnet. Quando você usar o IPv6 local PBR, certifique-se de compreender totalmente o impacto nos serviços locais do dispositivo.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique uma política IPv6 para PBR local IPv6.
ipv6 local policy-based-route policy-name
Por padrão, o PBR local IPv6 não está ativado.
Especificação de uma política IPv6 para PBR de interface IPv6
Sobre a interface PBR
Execute esta tarefa para aplicar uma política de IPv6 a uma interface para orientar o encaminhamento de pacotes recebidos somente na interface.
Restrições e diretrizes
É possível aplicar apenas uma política a uma interface e é necessário verificar se a política especificada já existe. Antes de aplicar uma nova política, você deve primeiro remover a política atual da interface.
Você pode aplicar uma política a várias interfaces.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Especifique uma política de IPv6 para PBR de interface IPv6.
ipv6 policy-based-route policy-name
Por padrão, nenhuma política de IPv6 é aplicada à interface.
Comandos de exibição e manutenção para IPv6 PBR
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações sobre a política de PBR IPv6. | display ipv6 policy-based-route [ policy policy-name ] |
| Exibir a configuração e as estatísticas do PBR da interface IPv6. | display ipv6 policy-based-route interface interface-type número da interface [ número do slot do slot ] |
| Exibir a configuração e as estatísticas do PBR local IPv6. | display ipv6 policy-based-route local [ slot slot-number ] |
| Exibir a configuração do IPv6 PBR. | display ipv6 policy-based-route setup |
| Limpar as estatísticas do IPv6 PBR. | reset ipv6 policy-based-route statistics [ policy policy-name ] |
Exemplos de configuração do IPv6 PBR
Exemplo: Configuração de PBR local IPv6 baseado em tipo de pacote
Configuração de rede
Conforme mostrado na Figura 1, os Comutadores B e C estão conectados por meio do Comutador A. Os Comutadores B e C não têm uma rota para chegar um ao outro.
Configure o IPv6 PBR no Switch A para encaminhar todos os pacotes TCP para o próximo salto 1::2 (Switch B).
Figura 1 Diagrama de rede
Procedimento
- Configure o Switch A:
# Crie a VLAN 10 e a VLAN 20.
<SwitchA> system-view
[SwitchA] vlan 10
[SwitchA-vlan10] quit
[SwitchA] vlan 20
[SwitchA-vlan20] quit
# Configure os endereços IPv6 da interface de VLAN 10 e da interface de VLAN 20.
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ipv6 address 1::1 64
[SwitchA-Vlan-interface10] quit
[SwitchA] interface vlan-interface 20
[SwitchA-Vlan-interface20] ipv6 address 2::1 64
[SwitchA-Vlan-interface20] quit
# Configure a ACL 3001 para corresponder aos pacotes TCP.
[SwitchA] acl ipv6 advanced 3001
[SwitchA-acl-ipv6-adv-3001] rule permit tcp
[SwitchA-acl-ipv6-adv-3001] quit
# Configure o nó 5 para que a política aaa encaminhe os pacotes TCP para o próximo salto 1::2.
[SwitchA] ipv6 policy-based-route aaa permit node 5
[SwitchA-pbr6-aaa-5] if-match acl 3001
[SwitchA-pbr6-aaa-5] apply next-hop 1::2
[SwitchA-pbr6-aaa-5] quit
# Configure o PBR local IPv6 aplicando a política aaa ao Switch A.
[SwitchA] ipv6 local policy-based-route aaa- Configure o Switch B: # Criar VLAN 10.
<SwitchB> system-view
[SwitchB] vlan 10
[SwitchB-vlan10] quit
# Configure o endereço IPv6 da interface VLAN 10.
<SwitchB> system-view
[SwitchB] vlan 10
[SwitchB-vlan10] quit- Configure o Switch C: # Crie a VLAN 20.
<SwitchC> system-view
[SwitchC] vlan 20
[SwitchC-vlan20] quit
# Configure o endereço IPv6 da interface VLAN 20.
[SwitchC] interface vlan-interface 20
[SwitchC-Vlan-interface20] ipv6 address 2::2 64
Verificação da configuração
- Realize operações de telnet para verificar se o PBR local IPv6 no Switch A funciona conforme configurado para encaminhar os pacotes TCP correspondentes para o próximo salto 1::2 (Switch B), como segue:
# Verifique se você pode fazer telnet para o Switch B a partir do Switch A com sucesso. (Detalhes não mostrados.) # Verifique se não é possível fazer telnet para o Switch C a partir do Switch A. (Detalhes não mostrados.)
- Verifique se o Switch A encaminha pacotes que não sejam TCP por meio da interface VLAN 20. Por exemplo, verifique se você pode fazer ping no Switch C a partir do Switch A. (Detalhes não mostrados).
Exemplo: Configuração da interface IPv6 PBR baseada em tipo de pacote
Configuração de rede
Conforme mostrado na Figura 2, o Switch B e o Switch C não têm uma rota para chegar um ao outro.
Configure o IPv6 PBR no Switch A para encaminhar todos os pacotes TCP recebidos na interface VLAN 11 para o próximo salto 1::2 (Switch B).
Figura 2 Diagrama de rede
Procedimento
- Configure o Switch A:
# Crie a VLAN 10 e a VLAN 20.
<SwitchA> system-view
[SwitchA] vlan 10
[SwitchA-vlan10] quit
[SwitchA] vlan 20
[SwitchA-vlan20] quit
[SwitchA] ripng 1
[SwitchA-ripng-1] quit
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ipv6 address 1::1 64
[SwitchA-Vlan-interface10] ripng 1 enable
[SwitchA-Vlan-interface10] quit
[SwitchA] interface vlan-interface 20
[SwitchA-Vlan-interface20] ipv6 address 2::1 64
[SwitchA-Vlan-interface20] ripng 1 enable
[SwitchA-Vlan-interface20] quit
# Configure a ACL 3001 para corresponder aos pacotes TCP.
[SwitchA] acl ipv6 advanced 3001
[SwitchA-acl-ipv6-adv-3001] rule permit tcp
[SwitchA-acl-ipv6-adv-3001] quit
# Configure o nó 5 para que a política aaa encaminhe os pacotes TCP para o próximo salto 1::2.
[SwitchA] ipv6 policy-based-route aaa permit node 5
[SwitchA-pbr6-aaa-5] if-match acl 3001
[SwitchA-pbr6-aaa-5] apply next-hop 1::2
[SwitchA-pbr6-aaa-5] quit
# Configure a interface IPv6 PBR aplicando a política aaa à interface VLAN 11.
[SwitchA] interface vlan-interface 11
[SwitchA-Vlan-interface11] ipv6 address 10::2 64
[SwitchA-Vlan-interface11] undo ipv6 nd ra halt
[SwitchA-Vlan-interface11] ripng 1 enable
[SwitchA-Vlan-interface11] ipv6 policy-based-route aaa
- Configure o Switch B: # Criar VLAN 10.
system-view
[SwitchB] vlan 10
[SwitchB-vlan10] quit
# Configure o RIPng. [SwitchB] ripng 1 [SwitchB-ripng-1] quit
[SwitchB] ripng 1
[SwitchB-ripng-1] quit
[SwitchB] interface vlan-interface 10
[SwitchB-Vlan-interface10] ipv6 address 1::2 64
[SwitchB-Vlan-interface10] ripng 1 enable
[SwitchB-Vlan-interface10] quit
- Configurar o switch C:
# Criar VLAN 20.
<SwitchC> system-view
[SwitchC] vlan 20
[SwitchC-vlan20] quit
# Configure o RIPng.
[SwitchC] ripng 1
[SwitchC-ripng-1] quit
[SwitchC] interface vlan-interface 20
[SwitchC-Vlan-interface20] ipv6 address 2::2 64
[SwitchC-Vlan-interface20] ripng 1 enable
[SwitchC-Vlan-interface20] quit
Verificação da configuração
- Habilite o IPv6 e configure o endereço IPv6 10::3 para o Host A.
C:\>ipv6 install
Installing...
Succeeded.
C:\>ipv6 adu 4/10::3
- Realize operações de telnet para verificar se a interface IPv6 PBR no Switch A funciona conforme configurado para encaminhar os pacotes TCP correspondentes para o próximo salto 1::2 (Switch B), como segue:
# Verifique se você pode fazer telnet para o Switch B a partir do Host A com sucesso. (Detalhes não mostrados.) # Verifique se não é possível fazer telnet para o Switch C a partir do Host A. (Detalhes não mostrados.)
- Verifique se o Switch A encaminha pacotes que não sejam TCP por meio da interface VLAN 20. Por exemplo, verifique se você pode fazer ping no Switch C a partir do Host A. (Detalhes não mostrados).
Exemplo: Configuração do PBR global IPv6 baseado em tipo de pacote
Configuração de rede
Conforme mostrado na Figura 3, o Switch E e o Switch F não têm uma rota para chegar um ao outro. Configure o PBR global IPv6 no Switch D para encaminhar pacotes TCP para o próximo salto 4::2 (Switch E).
Figura 3 Diagrama de rede
Procedimento
- Configure endereços IPv6 para as interfaces. Certifique-se de que os Comutadores A, B e C possam se comunicar com o Comutador E e o Comutador F, respectivamente. (Detalhes não mostrados).
- Configurar o Switch D:
# Configure a ACL 3101 do IPv6 para corresponder aos pacotes TCP provenientes das redes 1::0/64, 2::0/64 e 3::0/64.
<SwitchD> system-view
[SwitchD] acl ipv6 advanced 3101
[SwitchD-acl-ipv6-adv-3101] rule permit tcp source 1::0 64
[SwitchD-acl-ipv4-adv-3101] rule permit tcp source 2::0 64
[SwitchD-acl-ipv4-adv-3101] rule permit tcp source 3::0 64
[SwitchD-acl-ipv4-adv-3101] quit
# Configure o nó 5 na política de PBR IPv6 aaa para encaminhar os pacotes TCP que correspondem à ACL 3101 para o próximo salto 4::2.
[SwitchD] ipv6 policy-based-route aaa permit node 5
[SwitchD-pbr6-aaa-5] if-match acl 3101
[SwitchD-pbr6-aaa-5] apply next-hop 4::2
[SwitchD-pbr6-aaa-5] quit
# Especifique a política de PBR IPv6 aaa como a política de PBR global IPv6.
[SwitchD] ipv6 global policy-based-route aaa
Verificação da configuração
- Realize operações de telnet para verificar se o PBR global IPv6 no Switch D funciona conforme configurado para encaminhar os pacotes TCP correspondentes para o próximo salto 4::2 (Switch E), como segue:
# Verifique se você pode fazer telnet no Switch E a partir do Switch A, Switch B e Switch C com sucesso. (Detalhes não mostrados).
# Verifique se você não pode fazer telnet para o Switch F a partir do Switch A, Switch B ou Switch C. (Detalhes não mostrados).
- Verifique se o Switch D encaminha outros pacotes além dos pacotes TCP, desde que haja uma rota disponível. Por exemplo, verifique se você pode fazer ping no Switch F a partir do Switch A, Switch B e Switch C. (Detalhes não mostrados).
Configuração de políticas de roteamento
Sobre políticas de roteamento
As políticas de roteamento controlam os caminhos de roteamento filtrando e modificando as informações de roteamento.
As políticas de roteamento podem filtrar rotas anunciadas, recebidas e redistribuídas e modificar atributos de rotas específicas.
Implementação de uma política de roteamento
Para configurar uma política de roteamento:
- Configurar filtros com base em atributos de rota.
- Crie uma política de roteamento e aplique filtros à política de roteamento.
Filtros
ACL
As políticas de roteamento podem usar os seguintes filtros para corresponder às rotas.
Uma ACL pode corresponder ao destino ou ao próximo salto das rotas.
Para obter mais informações sobre ACLs, consulte o Guia de configuração de ACL e QoS.
Lista de prefixos IP
Uma lista de prefixos IP corresponde ao endereço de destino das rotas.
Uma lista de prefixos IP pode conter vários itens que especificam intervalos de prefixos. Cada prefixo de endereço IP de destino de uma rota é comparado com esses itens em ordem crescente de seus números de índice. Um prefixo corresponde à lista de prefixos IP se corresponder a um item da lista.
Política de roteamento
Uma política de roteamento pode conter vários nós, que estão em uma relação lógica OU. Um nó com um número menor é correspondido primeiro. Uma rota corresponde à política de roteamento se corresponder a um nó (exceto o nó configurado com a cláusula continue) na política de roteamento.
Cada nó tem um modo de correspondência de permissão ou negação.
- permit-Especifica o modo de correspondência de permissão para um nó de política de roteamento. Se uma rota atender a todos os requisitos
Se a rota não for comparada com as cláusulas if-match do nó, ela será tratada pelas cláusulas apply do nó. A rota não é comparada com o próximo nó, a menos que a cláusula continue esteja configurada. Se uma rota não atender a todas as cláusulas if-match do nó, ela será comparada com o próximo nó.
- deny - Especifica o modo de correspondência de negação para um nó de política de roteamento. As cláusulas apply e continue de um nó deny nunca são executadas. Se uma rota atender a todas as cláusulas de correspondência do nó, ela será negada sem ser comparada com o próximo nó. Se uma rota não atender a todas as cláusulas de correspondência do nó, ela será comparada com o próximo nó.
Um nó pode conter um conjunto de cláusulas if-match, apply e continue.
- cláusulas if-match - Especificam os critérios de correspondência que correspondem aos atributos das rotas. As cláusulas if-match estão em uma relação lógica AND. Uma rota deve atender a todas as cláusulas if-match para corresponder ao nó.
- cláusulas apply - Especificam as ações a serem executadas nas rotas permitidas, como a modificação de um atributo de rota.
- cláusula de continuação - Especifica o próximo nó. Uma rota que corresponda ao nó atual (nó de permissão) deve corresponder ao próximo nó especificado na mesma política de roteamento. A cláusula continue combina as cláusulas if-match e apply dos dois nós para aumentar a flexibilidade da política de roteamento. Depois que você configurar uma cláusula continue, uma rota poderá ser aprovada na política de roteamento mesmo que não corresponda ao próximo nó especificado. Para rejeitar essa rota, adicione um nó deny sem cláusulas.
Siga estas diretrizes ao configurar as cláusulas if-match, apply e continue:
- Se você quiser apenas filtrar rotas, não configure cláusulas de aplicação.
- Se você não configurar nenhuma cláusula if-match para um nó de permissão, o nó permitirá todas as rotas.
- Configure um nó de permissão que não contenha cláusulas if-match ou apply após vários nós de negação para permitir a passagem de rotas não correspondentes.
Visão geral das tarefas da política de roteamento
Para configurar uma política de roteamento, execute as seguintes tarefas:
- (Opcional.) Configure os filtros:
- Configuração de uma lista de prefixos IPv4
- Configuração de uma lista de prefixos IPv6
- Configuração de uma política de roteamento:
- Criação de uma política de roteamento
- Configuração de cláusulas if-match
- Configuração de cláusulas de aplicação
- Configuração da cláusula continue
Configuração de uma lista de prefixos IPv4
Restrições e diretrizes
Se todos os itens estiverem definidos para o modo negar, nenhuma rota poderá passar pela lista de prefixos IPv4. Para permitir rotas IPv4 não correspondentes, você deve configurar o item permit 0.0.0.0 0 less-equal 32 após vários itens deny .
Procedimento
- Entre na visualização do sistema.
system-view- Configurar uma lista de prefixos IPv4.
ip prefix-list prefix-list-name [ index index-number ] { deny | permit }
ip-address mask-length [ greater-equal min-mask-length ] [ less-equal
max-mask-length ]
Configuração de uma lista de prefixos IPv6
Restrições e diretrizes
Se todos os itens estiverem definidos para o modo negar, nenhuma rota poderá passar pela lista de prefixos IPv6. Para permitir rotas IPv6 não correspondentes, você deve configurar o item permit :: 0 less-equal 128 após vários itens deny.
Procedimento
- Entre na visualização do sistema.
system-view- Configurar uma lista de prefixos IPv6.
ipv6 prefix-list prefix-list-name [ index index-number ] { deny |
permit } ipv6-address { inverse inverse-prefix-length | prefix-length
[ greater-equal min-prefix-length ] [ less-equal max-prefix-length ] }
Configuração de uma política de roteamento
Criação de uma política de roteamento
Uma política de roteamento deve ter no mínimo um nó de permissão. Se todos os nós estiverem no modo de negação, nenhuma rota poderá passar pela política de roteamento.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma política de roteamento e um nó e entre na visualização do nó da política de roteamento.
route-policy route-policy-name { deny | permit } node node-numberConfiguração de cláusulas if-match
Sobre a configuração da cláusula if-match
Você pode especificar nenhuma cláusula if-match ou várias cláusulas if-match para um nó de política de roteamento. Se nenhuma cláusula if-match for especificada para um nó de permissão, todas as rotas poderão passar pelo nó. Se nenhuma cláusula if-match for especificada para um nó deny, nenhuma rota poderá passar pelo nó.
Restrições e diretrizes
Quando você configurar cláusulas if-match, siga estas restrições e diretrizes:
- As cláusulas if-match de um nó de política de roteamento têm uma relação lógica AND. Uma rota deve atender a todas as cláusulas if-match antes de poder ser executada pelas cláusulas apply do nó. Se uma rota
se o comando if-match exceder o comprimento máximo, serão geradas várias cláusulas if-match do mesmo tipo. Essas cláusulas têm uma relação OR lógica. Uma rota só precisa atender a uma delas.
- Todas as rotas IPv4 correspondem a um nó se as cláusulas if-match do nó usarem somente ACLs IPv6. Todas as rotas IPv6 correspondem a um nó se as cláusulas if-match do nó usarem somente ACLs IPv4.
- Se a ACL usada por uma cláusula if-match não existir, a cláusula será sempre correspondida. Se nenhuma regra da ACL especificada for correspondida ou se as regras de correspondência estiverem inativas, a cláusula não será correspondida.
- Se a lista de prefixos, a lista de comunidades ou a lista de comunidades estendida usada por uma cláusula if-match não existir, a cláusula será sempre correspondida. Se nenhuma regra da lista de prefixos, da lista de comunidades ou da lista de comunidades estendidas especificada for correspondida, a cláusula não será correspondida.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do nó da política de roteamento.
route-policy route-policy-name { deny | permit } node node-number
- Corresponde a rotas cujo destino, próximo salto ou endereço de origem corresponde a uma ACL ou lista de prefixos. IPv4:
if-match ip { address | next-hop | route-source } { acl ipv4-acl-number
| prefix-list prefix-list-name }
IPv6:
if-match ipv6 { address | next-hop | route-source } { acl
ipv6-acl-number | prefix-list prefix-list-name }
Por padrão, nenhum critério de correspondência de ACL ou de lista de prefixos é configurado.
- Configurar critérios de correspondência de rota.
- Corresponde a rotas com o custo especificado.
if-match cost cost-value
- Corresponde às rotas que têm a interface de saída especificada.
if-match interface { interface-type interface-number }&<1-16>
- Corresponde a rotas com o tipo de rota especificado.
if-match route-type { external-type1 | external-type1or2 |
external-type2 | internal | nssa-external-type1 |
nssa-external-type1or2 | nssa-external-type2 } *
- Corresponde a rotas IGP com o valor de tag especificado.
if-match tag tag-value
Por padrão, nenhum critério de correspondência de rota é configurado.
Configuração de cláusulas de aplicação
- Entre na visualização do sistema.
system-view- Entre na visualização do nó da política de roteamento.
route-policy route-policy-name { deny | permit } node node-number
- Configure o custo da rota e o tipo de custo.
- Definir um custo para as rotas.
apply cost [ + | - ] cost-value
Por padrão, nenhum custo é definido para as rotas.
- Definir um tipo de custo para as rotas.
apply cost-type { type-1 | type-2 }
Por padrão, nenhum tipo de custo é definido para as rotas.
- Defina o próximo salto para as rotas. IPv4:
apply ip-address next-hop ip-address [ public ]
IPv6:
apply ipv6 next-hop ipv6-address
Por padrão, nenhum próximo salto é definido para as rotas.
A configuração não se aplica a rotas redistribuídas.
- Configurar prioridades de rota.
- Definir uma precedência de IP para rotas correspondentes.
apply ip-precedence { value | clear }Por padrão, nenhuma precedência de IP é definida.
- Defina uma preferência.
apply preference preferencePor padrão, nenhuma preferência é definida.
- Definir uma prioridade de prefixo.
apply prefix-priority { critical | high | medium }Por padrão, a prioridade do prefixo é baixa.
- Definir um valor de tag para rotas IGP.
apply tag tag-valuePor padrão, nenhum valor de tag é definido para rotas IGP.
- Definir um link de backup para o redirecionamento rápido (FRR). IPv4:
apply fast-reroute { backup-interface interface-type interface-number
[ backup-nexthop ip-address ] | backup-nexthop ip-address }
IPv6:
apply ipv6 fast-reroute { backup-interface interface-type
interface-number [ backup-nexthop ipv6-address ] | backup-nexthop
ipv6-address }
Por padrão, nenhum link de backup é definido para FRR.
Configuração da cláusula continue
Restrições e diretrizes
Quando você configurar a cláusula continue para combinar vários nós, siga estas restrições e diretrizes:
- Se você configurar uma cláusula apply que defina valores de atributos diferentes em todos os nós, a cláusula apply
do nó configurado mais recentemente entra em vigor.
- Se você configurar as seguintes cláusulas de aplicação em todos os nós, a cláusula de aplicação de cada nó terá efeito:
- aplicar as-path sem a palavra-chave replace.
- aplicar o custo com a palavra-chave + ou -.
- aplicar a comunidade com a palavra-chave aditiva.
- aplique extcommunity com a palavra-chave additive.
- A cláusula apply comm-list delete configurada no nó atual não pode excluir os atributos da comunidade definidos pelas cláusulas apply community dos nós anteriores.
- Entre na visualização do sistema.
Procedimento
system-view- Entre na visualização do nó da política de roteamento.
route-policy route-policy-name { deny | permit } node node-number
- Especifique o próximo nó a ser correspondido.
continue [ node-number ]
Por padrão, nenhuma cláusula continue é configurada.
O próximo nó especificado deve ter um número maior do que o nó atual.
Configuração do temporizador de atraso de alteração da política de roteamento
Sobre o temporizador de atraso de alteração da política de roteamento
Esse recurso faz com que uma política de roteamento entre em vigor após um intervalo de tempo atrasado, o que evita que a configuração incompleta da política de roteamento seja emitida para causar anúncio de rota incorreto. O sistema inicia automaticamente o cronômetro quando uma política de roteamento é alterada. As alterações não entrarão em vigor na política até que o cronômetro de atraso de alteração expire.
Uma política de roteamento é alterada quando ocorre um dos seguintes eventos:
- É criada uma política de roteamento.
- Um nó de política de roteamento, cláusula if-match ou cláusula apply é adicionado, modificado ou excluído de uma política de roteamento.
- Uma lista de prefixos IPv4, uma lista de prefixos IPv6, uma lista de caminhos AS, uma lista de comunidades, uma lista de comunidades estendidas ou uma lista de MACs é adicionada, modificada ou excluída.
- A ACL usada por uma cláusula if-match é alterada.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o cronômetro de atraso de alteração da política de roteamento.
route-policy-change delay-time { time-value | unlimited }
Por padrão, as alterações na política de roteamento entram em vigor imediatamente, mas o protocolo de roteamento aguarda cinco segundos antes de processar as rotas da nova política de roteamento.
Quando o cronômetro de atraso expira, o protocolo de roteamento aguarda cinco segundos antes de processar as rotas da nova política de roteamento.
Comandos de exibição e manutenção de políticas de roteamento
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir estatísticas da lista de prefixos IPv4. | display ip prefix-list [ nome prefix-list-name ] |
| Exibir estatísticas da lista de prefixos IPv6. | display ipv6 prefix-list [ name prefix-list-name ] |
| Exibir informações sobre a política de roteamento. | display route-policy [ name route-policy-name ] |
| Limpar as estatísticas da lista de prefixos IPv4. | reset ip prefix-list [ prefix-list-name ] |
| Limpar as estatísticas da lista de prefixos IPv6. | reset ipv6 prefix-list [ prefix-list-name ] |
Exemplos de configuração de políticas de roteamento
Exemplo: Configuração de uma política de roteamento para redistribuição de rotas estáticas para o RIP
Configuração de rede
Conforme mostrado na Figura 1, o Switch A troca informações de roteamento com o Switch B usando RIP.
No Switch A, configure três rotas estáticas. Use uma política de roteamento para configurar o Switch B para redistribuir as redes 20.1.1.1/32 e 40.1.1.1/32 e bloquear a rede 30.1.1.1/32.
Figura 1 Diagrama de rede
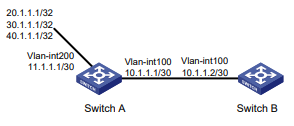
Procedimento
- Configure o Switch A:
# Configure endereços IP para as interfaces VLAN-interface 100 e VLAN-interface 200.
<SwitchA> system-view
[SwitchA] interface vlan-interface 100
[SwitchA-vlan-interface100] ip address 10.1.1.1 30
[SwitchA-vlan-interface100] quit
[SwitchA] interface vlan-interface 200
[SwitchA-vlan-interface200] ip address 11.1.1.1 30
[SwitchA-vlan-interface200] quit
# Habilite o RIP na interface VLAN-interface 100.
[SwitchA] interface vlan-interface 100
[SwitchA-vlan-interface100] rip 1 enable
[SwitchA-vlan-interface100] quit
# Configure três rotas estáticas e defina o próximo salto das três rotas como 11.1.1.2.
[SwitchA] ip route-static 20.1.1.1 32 11.1.1.2
[SwitchA] ip route-static 30.1.1.1 32 11.1.1.2
[SwitchA] ip route-static 40.1.1.1 32 11.1.1.2
# Configure uma política de roteamento.
[SwitchA] ip prefix-list a index 10 permit 30.1.1.1 32
[SwitchA] route-policy static2rip deny node 0
[SwitchA-route-policy-static2rip-0] if-match ip address prefix-list a
[SwitchA-route-policy-static2rip-0] quit
[SwitchA] route-policy static2rip permit node 10
[SwitchA-route-policy-static2rip-10] quit
# Habilite o RIP e aplique a política de roteamento static2rip para filtrar as rotas estáticas redistribuídas.
[SwitchA] rip
[SwitchA-rip-1] import-route static route-policy static2rip
- Configurar o Switch B:
# Configure um endereço IP para a interface VLAN-interface 100.
<SwitchB> system-view
[SwitchB] interface vlan-interface 100
[SwitchB-vlan-interface100] ip address 10.1.1.2 30
# Habilite o RIP.
[SwitchB] rip
[SwitchB-rip-1] quit
# Habilite o RIP na interface.
[SwitchB] interface vlan-interface 100
[SwitchB-vlan-interface100] rip 1 enable
[SwitchB-vlan-interface100] quit
Verificação da configuração
# Exibir as informações da tabela de roteamento no Switch B.
<SwitchB> display ip routing-table
Destinations : 14 Routes : 14
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
10.1.1.0/30 Direct 0 0 10.1.1.2 Vlan100
10.1.1.0/32 Direct 0 0 10.1.1.2 Vlan100
10.1.1.2/32 Direct 0 0 127.0.0.1 InLoop0
10.1.1.3/32 Direct 0 0 10.1.1.2 Vlan100
20.0.0.0/8 RIP 100 1 10.1.1.1 Vlan100
40.0.0.0/8 RIP 100 1 10.1.1.1 Vlan100
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
127.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
224.0.0.0/4 Direct 0 0 0.0.0.0 NULL0
224.0.0.0/24 Direct 0 0 0.0.0.0 NULL0
255.255.255.255/32 Direct 0 0 127.0.0.1 InLoop
Exemplo: Configuração de uma política de roteamento para redistribuição de rotas IPv6
Configuração de rede
Conforme mostrado na Figura 2:
- Execute o RIPng no Switch A e no Switch B.
- Configure três rotas estáticas no Switch A.
- No Switch A, aplique uma política de roteamento para redistribuir as rotas estáticas 20::/32 e 40::/32 e negar a rota 30::/32.
Figura 2 Diagrama de rede
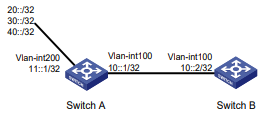
Procedimento
- Configure o Switch A:
# Configure endereços IPv6 para a interface de VLAN 100 e a interface de VLAN 200.
<SwitchA> system-view
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] ipv6 address 10::1 32
[SwitchA-Vlan-interface100] quit
[SwitchA] interface vlan-interface 200
[SwitchA-Vlan-interface200] ipv6 address 11::1 32
[SwitchA-Vlan-interface200] quit
# Habilite o RIPng na interface VLAN 100.
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] ripng 1 enable
[SwitchA-Vlan-interface100] quit
# Configure três rotas estáticas com o próximo salto 11::2 e verifique se as rotas estáticas estão ativas.
[SwitchA] ipv6 route-static 20:: 32 11::2
[SwitchA] ipv6 route-static 30:: 32 11::2
[SwitchA] ipv6 route-static 40:: 32 11::2
# Configure uma política de roteamento.
[SwitchA] ipv6 prefix-list a index 10 permit 30:: 32
[SwitchA] route-policy static2ripng deny node 0
[SwitchA-route-policy-static2ripng-0] if-match ipv6 address prefix-list a
[SwitchA-route-policy-static2ripng-0] quit
[SwitchA] route-policy static2ripng permit node 10
[SwitchA-route-policy-static2ripng-10] quit
# Habilite o RIPng e aplique a política de roteamento à redistribuição de rotas estáticas.
[SwitchA] ripng
[SwitchA-ripng-1] import-route static route-policy static2ripng
- Configure o Switch B:
# Configure o endereço IPv6 para a interface VLAN 100.
<SwitchB> system-view
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ipv6 address 10::2 32
# Habilite o RIPng.
[SwitchB] ripng
[SwitchB-ripng-1] quit# Habilite o RIPng na interface VLAN 100.
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ripng 1 enable
[SwitchB-Vlan-interface100] quit
Verificação da configuração
# Exibir a tabela de roteamento RIPng no Switch B.
[SwitchB] display ripng 1 route
Route Flags: A - Aging, S - Suppressed, G - Garbage-collect
----------------------------------------------------------------
Peer FE80::7D58:0:CA03:1 on Vlan-interface 100
Destination 20::/32,
via FE80::7D58:0:CA03:1, cost 1, tag 0, A, 8 secs
Destination 40::/32,
via FE80::7D58:0:CA03:1, cost 1, tag 0, A, 3 secs
Local route
Destination 10::/32,
via ::, cost 0, tag 0, DOF
06 - IP Multicast Configuration Guide
Visão geral do multicast
Introdução ao multicast
Como uma técnica que coexiste com unicast e broadcast, a técnica multicast aborda com eficácia o problema da transmissão de dados ponto a multiponto. Ao permitir a transmissão de dados ponto a multiponto de alta eficiência em uma rede, o multicast economiza muito a largura de banda da rede e reduz a carga da rede.
Com o uso da tecnologia multicast, uma operadora de rede pode fornecer facilmente serviços de informação com largura de banda e tempo críticos. Esses serviços incluem webcasting ao vivo, TV na Web, ensino à distância, telemedicina, rádio na Web e videoconferência em tempo real.
Técnicas de transmissão de informações
Unicast
As técnicas de transmissão de informações incluem unicast, broadcast e multicast.
Na transmissão unicast, a fonte de informações deve enviar uma cópia separada das informações para cada host que precisar delas.
Figura 1 Transmissão unicast
Na Figura 1, o host B, o host D e o host E precisam das informações. Um canal de transmissão separado deve ser estabelecido da fonte de informações para cada um desses hosts.
Na transmissão unicast, o tráfego transmitido pela rede é proporcional ao número de hosts que precisam das informações. Se um grande número de hosts precisar das informações, a fonte de informações deverá enviar uma cópia separada das mesmas informações para cada um desses hosts. O envio de muitas cópias pode exercer uma enorme pressão sobre a fonte de informações e a largura de banda da rede.
O unicast não é adequado para a transmissão de informações em lote.
Transmissão
Na transmissão de broadcast, a fonte de informações envia informações a todos os hosts da sub-rede, mesmo se alguns hosts não precisarem das informações.
Figura 2 Transmissão de broadcast
Na Figura 2, somente o Host B, o Host D e o Host E precisam das informações. Se as informações forem transmitidas para a sub-rede, o Host A e o Host C também as receberão. Além dos problemas de segurança das informações, a transmissão para hosts que não precisam das informações também causa inundação de tráfego na mesma sub-rede.
A difusão é desvantajosa na transmissão de dados para hosts específicos. Além disso, a transmissão por difusão representa um desperdício significativo de recursos de rede.
Multicast
O multicast proporciona transmissões de dados ponto a multiponto com o mínimo de consumo de rede. Quando alguns hosts da rede precisam de informações de multicast, o remetente das informações, ou fonte de multicast, envia apenas uma cópia das informações. As árvores de distribuição multicast são criadas por meio de protocolos de roteamento multicast, e os pacotes são replicados somente nos nós em que as árvores se ramificam.
Figura 3 Transmissão multicast
Na Figura 3, a fonte de multicast envia apenas uma cópia das informações para um grupo de multicast. O host B, o host D e o host E, que são receptores de informações, devem participar do grupo multicast. Os roteadores da rede duplicam e encaminham as informações com base na distribuição dos membros do grupo. Por fim, as informações são entregues corretamente ao Host B, Host D e Host E.
Em resumo, o multicast tem as seguintes vantagens:
- Vantagens em relação ao unicast - Os dados multicast são replicados e distribuídos até chegarem ao nó mais distante possível da origem. O aumento do número de hosts receptores não aumentará significativamente a carga da origem nem o uso dos recursos da rede.
- Vantagens em relação à transmissão - Os dados multicast são enviados somente para os receptores que precisam deles. Isso economiza a largura de banda da rede e aumenta a segurança da rede. Além disso, os dados multicast não são confinados à mesma sub-rede.
Recursos de multicast
- Um grupo multicast é um conjunto de receptores multicast identificado por um endereço IP multicast. Os hosts devem se associar a um grupo multicast para se tornarem membros do grupo multicast antes de receberem os dados multicast endereçados a esse grupo multicast. Normalmente, uma fonte multicast não precisa se associar a um grupo multicast.
- Uma fonte multicast é um remetente de informações. Ela pode enviar dados para vários grupos multicast ao mesmo tempo. Várias fontes multicast podem enviar dados para o mesmo grupo multicast ao mesmo tempo.
- As associações de grupos são dinâmicas. Os hosts podem entrar ou sair de grupos multicast a qualquer momento. Os grupos multicast não estão sujeitos a restrições geográficas.
- Os roteadores multicast ou dispositivos multicast de Camada 3 são roteadores ou switches de Camada 3 que oferecem suporte a multicast de Camada 3. Eles fornecem roteamento multicast e gerenciam associações de grupos multicast em sub-redes stub com membros de grupos anexados. O próprio roteador multicast pode ser um membro de grupo multicast.
Para entender melhor o conceito de multicast, você pode comparar a transmissão multicast com a transmissão de programas de TV.
Tabela 1 Comparação entre a transmissão de programas de TV e a transmissão multicast
| Transmissão de programas de TV | Transmissão multicast |
| Uma estação de TV transmite um programa de TV por meio de um canal. | Uma fonte multicast envia dados multicast para um grupo multicast. |
| Um usuário sintoniza o aparelho de TV no canal. | Um receptor entra no grupo multicast. |
| O usuário começa a assistir ao programa de TV transmitido pela estação de TV no canal. | O receptor começa a receber os dados multicast enviados pela fonte para o grupo multicast. |
| O usuário desliga o aparelho de TV ou sintoniza outro canal. | O receptor sai do grupo multicast ou entra em outro grupo. |
Benefícios e aplicativos de multicast
Benefícios do multicast
- Eficiência aprimorada: reduz a carga do processador dos servidores de origem das informações e dos dispositivos de rede.
- Desempenho ideal - reduz o tráfego redundante.
- Aplicativo distribuído - permite aplicativos ponto a multiponto ao preço de recursos mínimos de rede.
Aplicativos multicast
- Aplicativos multimídia e de streaming, como Web TV, rádio na Web e conferência de vídeo/áudio em tempo real
- Comunicação para treinamento e operações cooperativas, como ensino à distância e telemedicina
- Armazenamento de dados e aplicativos financeiros (cotações de ações)
- Qualquer outro aplicativo ponto a multiponto para distribuição de dados
Modelos multicast
Com base em como os receptores tratam as fontes de multicast, os modelos de multicast incluem multicast (ASM) de qualquer fonte, multicast filtrado pela fonte (SFM) e multicast específico da fonte (SSM).
Modelo ASM
No modelo ASM, qualquer fonte multicast pode enviar informações para um grupo multicast. Os receptores podem entrar em um grupo multicast e obter informações multicast endereçadas a esse grupo multicast de qualquer fonte multicast. Nesse modelo, os receptores não conhecem as posições das fontes de multicast com antecedência.
Modelo SFM
O modelo SFM é derivado do modelo ASM. Para uma fonte multicast, os dois modelos parecem ter a mesma arquitetura de associação multicast.
O modelo SFM amplia funcionalmente o modelo ASM. O software da camada superior verifica o endereço de origem dos pacotes multicast recebidos e permite ou nega o tráfego multicast de origens específicas.
Os receptores obtêm os dados multicast de apenas parte das fontes multicast. Para um receptor, as fontes multicast não são todas válidas, mas são filtradas.
Modelo SSM
O modelo SSM fornece um serviço de transmissão que permite que os receptores de multicast especifiquem as fontes de multicast nas quais estão interessados.
No modelo SSM, os receptores já determinaram os locais das fontes de multicast. Essa é a principal diferença entre o modelo SSM e o modelo ASM. Além disso, o modelo SSM usa um intervalo de endereços multicast diferente do modelo ASM/SFM. Caminhos dedicados de encaminhamento de multicast são estabelecidos entre os receptores e as fontes de multicast especificadas.
Endereços multicast
Endereços multicast IPv4
A IANA atribuiu o bloco de endereços da Classe D (224.0.0.0 a 239.255.255.255) ao multicast IPv4.
Tabela 2 Blocos e descrição de endereços IP de classe D
| Bloco de endereços | Descrição |
| 224.0.0.0 a 224.0.0.255 | Endereços de grupo permanentes reservados. O endereço IP 224.0.0.0 é reservado. Outros endereços IP podem ser usados por protocolos de roteamento e para pesquisa de topologia, manutenção de protocolos e assim por diante. A Tabela 3 lista os endereços de grupos permanentes comuns. Um pacote destinado a um endereço desse bloco não será encaminhado para além da sub-rede local, independentemente do valor TTL no cabeçalho IP. |
| 224.0.1.0 a 238.255.255.255 | Endereços de grupo com escopo global. Esse bloco inclui os seguintes tipos de endereços de grupo designados: 232.0.0.0/8-SSM endereços de grupo. 233.0.0.0/8-Endereços do grupo Glop. |
| 239.0.0.0 a 239.255.255.255 | Endereços multicast com escopo administrativo. Esses endereços são considerados exclusivos localmente em vez de globalmente exclusivos. Você pode reutilizá-los em domínios administrados por diferentes organizações sem causar conflitos. Para obter mais informações, consulte a RFC 2365. |
OBSERVAÇÃO:
Glop é um mecanismo de atribuição de endereços multicast entre diferentes ASs. Ao preencher um número de AS nos dois bytes do meio de 233.0.0.0, você obtém 255 endereços multicast para esse AS. Para obter mais informações, consulte a RFC 2770.
Tabela 3 Endereços comuns de grupos multicast permanentes
| Endereço | Descrição |
| 224.0.0.1 | Todos os sistemas nessa sub-rede, incluindo hosts e roteadores. |
| 224.0.0.2 | Todos os roteadores multicast nessa sub-rede. |
| 224.0.0.3 | Não atribuído. |
| 224.0.0.4 | Roteadores DVMRP. |
| 224.0.0.5 | Roteadores OSPF. |
| Endereço | Descrição |
| 224.0.0.6 | Roteadores designados OSPF e roteadores designados de backup. |
| 224.0.0.7 | Roteadores de árvore compartilhada (ST). |
| 224.0.0.8 | ST hosts. |
| 224.0.0.9 | Roteadores RIPv2. |
| 224.0.0.11 | Agentes móveis. |
| 224.0.0.12 | Servidor DHCP/agente de retransmissão. |
| 224.0.0.13 | Todos os roteadores PIM (Protocol Independent Multicast). |
| 224.0.0.14 | Encapsulamento RSVP. |
| 224.0.0.15 | Todos os roteadores CBT (Core-Based Tree). |
| 224.0.0.16 | SBM designada. |
| 224.0.0.17 | Todas as SBMs. |
| 224.0.0.18 | VRRP. |
Endereços multicast IPv6
Figura 4 Formato multicast do IPv6
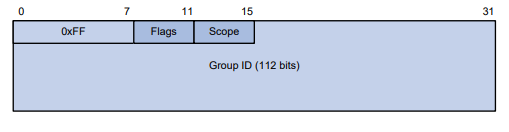
A seguir, descrevemos os campos de um endereço multicast IPv6:
- 0xFF-Os oito bits mais significativos são 11111111.
- Flags - O campo Flags contém quatro bits.
Figura 5 Formato do campo Flags
Tabela 4 Descrição do campo Flags
| Bit | Descrição |
| 0 | Reservado, definido como 0. |
| R | Quando definido como 0, esse endereço é um endereço multicast IPv6 sem um endereço RP incorporado. Quando definido como 1, esse endereço é um endereço multicast IPv6 com um endereço RP incorporado. (Os bits P e T também devem ser definidos como 1). |
| P | Quando definido como 0, esse endereço é um endereço multicast IPv6 não baseado em um prefixo unicast. Quando definido como 1, esse endereço é um endereço IPv6 multicast baseado em um prefixo unicast. (O bit T também deve ser definido como 1). |
| T | Quando definido como 0, esse endereço é um endereço IPv6 multicast atribuído permanentemente pela IANA. Quando definido como 1, esse endereço é um endereço multicast IPv6 transitório ou atribuído dinamicamente. |
- Escopo - O campo Escopo contém quatro bits, que representam o escopo da rede de Internet IPv6 à qual o tráfego multicast se destina.
Tabela 5 Valores do campo Escopo
| Valor | Significado |
| 0, F | Reservado. |
| 1 | Escopo local da interface. |
| 2 | Escopo do link-local. |
| 3 | Escopo local da sub-rede. |
| 4 | Escopo local do administrador. |
| 5 | Escopo local do site. |
| 6, 7, 9 até D | Não atribuído. |
| 8 | Escopo local da organização. |
| E | Escopo global. |
- ID do grupo - O campo ID do grupo contém 112 bits. Ele identifica de forma exclusiva um grupo multicast IPv6 no escopo definido pelo campo Escopo.
Endereços MAC multicast Ethernet
Um endereço MAC multicast Ethernet identifica os receptores que pertencem ao mesmo grupo multicast na camada de link de dados.
Endereços MAC de multicast IPv4
Conforme definido pela IANA, os 24 bits mais significativos de um endereço MAC multicast IPv4 são 0x01005E. O bit 25 é 0, e os outros 23 bits são os 23 bits menos significativos de um endereço multicast IPv4.
Figura 6 Mapeamento de endereços IPv4 para MAC
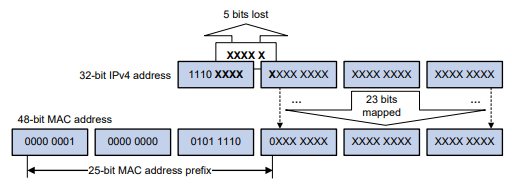
Os quatro bits mais significativos de um endereço multicast IPv4 são fixados em 1110. Em um mapeamento de endereço IPv4 para MAC, cinco bits do endereço multicast IPv4 são perdidos. Como resultado, 32 endereços multicast IPv4 são mapeados para o mesmo endereço MAC multicast IPv4. Um dispositivo pode receber dados multicast indesejados no processamento da camada 2, que precisam ser filtrados pela camada superior.
Endereços MAC multicast IPv6
Conforme definido pela IANA, os 16 bits mais significativos de um endereço MAC multicast IPv6 são 0x3333. Os 32 bits menos significativos são mapeados a partir dos 32 bits menos significativos de um endereço multicast IPv6. Portanto, o problema do mapeamento duplicado de endereços IPv6 para MAC também surge como o mapeamento de endereços IPv4 para MAC.
Figura 7 Mapeamento de endereços IPv6 para MAC
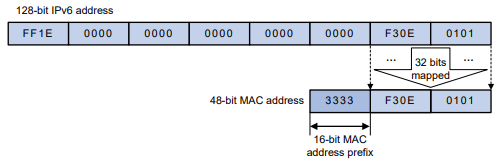
Protocolos multicast
Os protocolos multicast incluem as seguintes categorias:
- Protocolos multicast de Camada 3 e Camada 2:
- O multicast da camada 3 refere-se ao multicast IP que opera na camada de rede.
Protocolos multicast de camada 3 - IGMP, MLD, PIM, IPv6 PIM, MSDP, MBGP e IPv6 MBGP.
- O multicast de camada 2 refere-se ao multicast IP que opera na camada de enlace de dados.
Protocolos multicast da camada 2: snooping IGMP, snooping MLD, snooping PIM, snooping PIM IPv6, VLAN multicast e VLAN multicast IPv6.
- Protocolos multicast IPv4 e IPv6:
- Para redes IPv4 - snooping IGMP, snooping PIM, VLAN multicast, IGMP, PIM, MSDP e MBGP.
- Para redes IPv6: snooping MLD, snooping PIM IPv6, VLAN multicast IPv6, MLD, PIM IPv6 e MBGP IPv6.
Esta seção fornece apenas descrições gerais sobre aplicativos e funções dos protocolos multicast de Camada 2 e Camada 3 em uma rede. Para obter mais informações sobre esses protocolos, consulte os capítulos relacionados em .
Protocolos multicast de camada 3
Na Figura 8, os protocolos multicast da Camada 3 incluem protocolos de gerenciamento de grupos multicast e protocolos de roteamento multicast.
Figura 8 Posições dos protocolos multicast da Camada 3
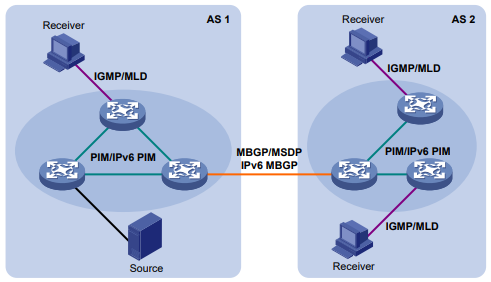
- Protocolos de gerenciamento de grupos multicast:
O Internet Group Management Protocol (IGMP) e o protocolo Multicast Listener Discovery (MLD) são protocolos de gerenciamento de grupos multicast. Normalmente, eles são executados entre hosts e dispositivos multicast de camada 3 que se conectam diretamente aos hosts para estabelecer e manter associações de grupos multicast.
- Protocolos de roteamento multicast:
Um protocolo de roteamento multicast é executado em dispositivos multicast da Camada 3 para estabelecer e manter rotas multicast e encaminhar pacotes multicast de forma correta e eficiente. As rotas multicast constituem caminhos de transmissão de dados sem loop (também conhecidos como árvores de distribuição multicast) de uma fonte de dados para vários receptores.
No modelo ASM, as rotas multicast incluem rotas intra-domínio e rotas inter-domínio.
- Um protocolo de roteamento multicast intra-domínio descobre fontes multicast e cria árvores de distribuição multicast em um AS para fornecer dados multicast aos receptores. Entre uma variedade de protocolos maduros de roteamento multicast intra-domínio, o PIM é o mais usado. Com base no mecanismo de encaminhamento, o PIM tem o modo denso (geralmente chamado de PIM-DM) e o modo esparso (geralmente chamado de PIM-SM).
- Um protocolo de roteamento multicast entre domínios é usado para fornecer informações multicast entre dois ASs. Até o momento, as soluções maduras incluem o MSDP (Multicast Source Discovery Protocol) e o MBGP. O MSDP propaga informações de origem multicast entre diferentes ASs. O MBGP é uma extensão do MP-BGP para troca de informações de roteamento multicast entre diferentes ASs.
No modelo SSM, as rotas multicast não são divididas em rotas intra-domínio e rotas inter-domínio. Como os receptores conhecem as posições das origens de multicast, os canais estabelecidos por meio do PIM-SM são suficientes para o transporte de informações de multicast.
Protocolos multicast de camada 2
Na Figura 9, os protocolos multicast da camada 2 incluem snooping IGMP, snooping MLD, snooping PIM, snooping PIM IPv6, VLAN multicast e VLAN multicast IPv6.
Figura 9 Posições dos protocolos multicast da Camada 2
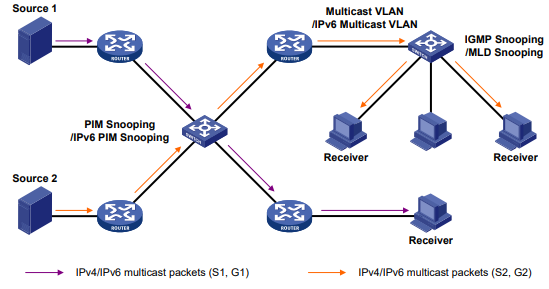
Receptor
Pacotes multicast IPv4/IPv6 (S1,G1) Pacotes multicast IPv4/IPv6(S2, G2)
- IGMP snooping e MLD snooping:
O IGMP snooping e o MLD snooping são mecanismos de restrição de multicast executados em dispositivos da Camada 2. Eles gerenciam e controlam grupos multicast monitorando e analisando mensagens IGMP ou MLD trocadas entre os hosts e os dispositivos multicast da Camada 3. Isso controla efetivamente a inundação de dados multicast nas redes da camada 2.
- snooping PIM e snooping PIM IPv6:
O snooping PIM e o snooping PIM IPv6 são executados em dispositivos da Camada 2. Eles trabalham com IGMP snooping ou MLD snooping para analisar as mensagens PIM recebidas. Em seguida, adicionam as portas interessadas em dados multicast específicos a uma entrada de roteamento de snooping PIM ou a uma entrada de roteamento de snooping PIM IPv6. Dessa forma, os dados multicast podem ser encaminhados somente para as portas interessadas nos dados.
- Multicast VLAN e IPv6 multicast VLAN:
A VLAN multicast ou a VLAN multicast IPv6 é executada em um dispositivo de camada 2 em uma rede multicast em que os receptores multicast do mesmo grupo existem em VLANs diferentes. Com esses protocolos, o dispositivo multicast da Camada 3 envia apenas uma cópia do multicast para a VLAN multicast ou a VLAN multicast IPv6 no dispositivo da Camada 2. Esse método evita o desperdício de largura de banda da rede e a sobrecarga do dispositivo da camada 3.
Mecanismo de encaminhamento de pacotes multicast
Em um modelo multicast, os hosts receptores de um grupo multicast geralmente estão localizados em diferentes áreas da rede. Eles são identificados pelo mesmo endereço de grupo multicast. Para entregar pacotes multicast a esses receptores, uma fonte multicast encapsula os dados multicast em um pacote IP com o endereço do grupo multicast como endereço de destino. Os roteadores multicast nos caminhos de encaminhamento encaminham os pacotes multicast que uma interface de entrada recebe por meio de várias interfaces de saída. Comparado a um modelo unicast, o modelo multicast é mais complexo nos seguintes aspectos:
- Para garantir a transmissão de pacotes multicast na rede, diferentes tabelas de roteamento são usadas para orientar o encaminhamento multicast. Essas tabelas de roteamento incluem tabelas de roteamento unicast, tabelas de roteamento para multicast (por exemplo, a tabela de roteamento MBGP) e tabelas de roteamento multicast estático.
- Para processar as mesmas informações multicast de diferentes pares recebidas em diferentes interfaces, o dispositivo multicast executa uma verificação de RPF em cada pacote multicast. O resultado da verificação de RPF determina se o pacote será encaminhado ou descartado. O mecanismo de verificação RPF é a base da maioria dos protocolos de roteamento multicast para implementar o encaminhamento multicast.
Para obter mais informações sobre o mecanismo RPF, consulte "Configuração de roteamento e encaminhamento multicast" e "Configuração de roteamento e encaminhamento multicast IPv6".
Arquitetura de multicast IP
O multicast IP aborda os seguintes problemas:
- Para onde a fonte multicast deve transmitir informações? (Endereçamento multicast.)
- Quais receptores existem na rede? (Registro de host).
- Onde está a fonte multicast que fornecerá dados aos receptores? (Descoberta da fonte multicast).
- Como as informações são transmitidas aos receptores? (Roteamento multicast.)
O multicast IP é um serviço de ponta a ponta. A arquitetura multicast envolve as seguintes partes:
- Mecanismo de endereçamento - Uma fonte multicast envia informações a um grupo de receptores por meio de um endereço multicast.
- Registro de host - Os hosts receptores podem entrar e sair de grupos multicast dinamicamente. Esse mecanismo é a base para o gerenciamento de associações de grupos.
- Roteamento multicast - Uma árvore de distribuição multicast (uma árvore de caminho de encaminhamento para dados multicast na rede) é construída para fornecer dados multicast de uma fonte multicast para os receptores.
- Aplicativos multicast - Um sistema de software compatível com aplicativos multicast, como videoconferência, deve ser instalado em hosts receptores e fontes multicast. A pilha TCP/IP deve suportar a recepção e a transmissão de dados multicast.
Notações comuns em multicast
As notações a seguir são comumente usadas na transmissão multicast:
- (*, G) - Árvore de ponto de encontro (RPT) ou um pacote multicast que qualquer fonte multicast envia para o grupo multicast G. O asterisco (*) representa qualquer fonte multicast e "G" representa um grupo multicast específico.
- (S, G) - Árvore de caminho mais curto (SPT) ou um pacote multicast que a fonte multicast "S" envia ao grupo multicast "G". "S" representa uma origem multicast específica e "G" representa um grupo multicast específico.
Configuração do IGMP snooping
Sobre o IGMP snooping
O IGMP snooping é executado em um dispositivo de camada 2 como um mecanismo de restrição de multicast para melhorar a eficiência do encaminhamento de multicast. Ele cria entradas de encaminhamento de multicast da Camada 2 a partir de pacotes IGMP trocados entre os hosts e o dispositivo da Camada 3.
Fundamentos do IGMP snooping
Conforme mostrado na Figura 1, quando o IGMP snooping não está ativado, o switch da Camada 2 inunda pacotes multicast para todos os hosts em uma VLAN. Quando o IGMP snooping está ativado, o switch da Camada 2 encaminha pacotes multicast de grupos multicast conhecidos somente para os receptores.
Figura 1 Transmissão de pacotes multicast sem e com IGMP snooping
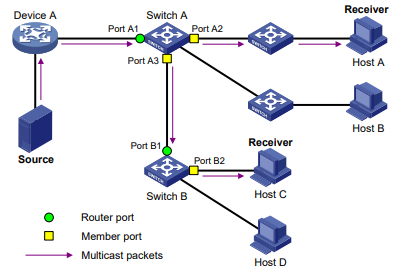
Portas de snooping IGMP
Conforme mostrado na Figura 2, o IGMP snooping é executado no Switch A e no Switch B, e o Host A e o Host C são receptores em um grupo multicast. As portas de snooping IGMP são divididas em portas de membro e portas de roteador.
Figura 2 Portas de snooping IGMP
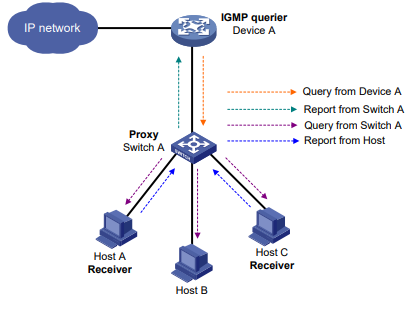
Portas do roteador
Em um dispositivo de Camada 2 com snooping IGMP, as portas para dispositivos multicast de Camada 3 são chamadas de portas de roteador. Na Figura 2, a porta A1 do switch A e a porta B1 do switch B são portas de roteador.
As portas do roteador contêm os seguintes tipos:
- Porta de roteador dinâmico - Quando uma porta recebe uma consulta geral IGMP cujo endereço de origem não é 0.0.0.0 ou recebe uma mensagem PIM hello, a porta é adicionada à lista de portas de roteador dinâmico. Ao mesmo tempo, um cronômetro de envelhecimento é iniciado para a porta. Se a porta receber qualquer uma das mensagens antes que o cronômetro expire, o cronômetro será reiniciado. Se a porta não receber nenhuma das mensagens quando o cronômetro expirar, a porta será removida da lista de portas do roteador dinâmico.
- Porta de roteador estático - Quando uma porta é configurada estaticamente como uma porta de roteador, ela é adicionada à lista de portas de roteador estático. A porta do roteador estático não envelhece e só pode ser excluída manualmente.
Não confunda a "porta do roteador" no IGMP snooping com a "interface roteada", comumente conhecida como "interface de camada 3". A porta do roteador no IGMP snooping é uma interface de camada 2.
Portas de membros
Em um dispositivo de camada 2 do IGMP snooping, as portas voltadas para os hosts receptores são chamadas de portas de membro. Na Figura 2, a Porta A2 e a Porta A3 do Switch A e a Porta B2 do Switch B são portas de membro.
As portas membros contêm os seguintes tipos:
- Porta de membro dinâmico - Quando uma porta recebe um relatório IGMP, ela é adicionada à entrada de encaminhamento do IGMP snooping dinâmico associado como uma interface de saída. Ao mesmo tempo, um cronômetro de envelhecimento é iniciado para a porta. Se a porta receber um relatório IGMP antes que o cronômetro expire, o cronômetro será reiniciado. Se a porta não receber um relatório IGMP quando o cronômetro expirar, a porta será removida da entrada de encaminhamento dinâmico associada.
- Porta membro estática - Quando uma porta é configurada estaticamente como porta membro, ela é adicionada à entrada de encaminhamento do IGMP snooping estático associado como uma interface de saída. A porta membro estática não envelhece e só pode ser excluída manualmente.
A menos que especificado de outra forma, as portas do roteador e as portas-membro neste documento incluem portas do roteador e portas-membro estáticas e dinâmicas.
Como funciona o IGMP snooping
As portas desta seção são portas dinâmicas. Para obter informações sobre como configurar e remover portas estáticas, consulte "Configuração de uma porta membro estática" e "Configuração de uma porta de roteador estática".
Os tipos de mensagens IGMP incluem consulta geral, relatório IGMP e mensagem de saída. Um dispositivo de camada 2 habilitado para snooping IGMP tem desempenho diferente, dependendo dos tipos de mensagem.
Consulta geral
O consultador IGMP envia periodicamente consultas gerais IGMP a todos os hosts e dispositivos na sub-rede local para verificar a existência de membros do grupo multicast.
Depois de receber uma consulta geral IGMP, o dispositivo de camada 2 encaminha a consulta para todas as portas da VLAN, exceto a porta receptora. O dispositivo de camada 2 também executa uma das seguintes ações:
- Se a porta receptora for uma porta de roteador dinâmico na lista de portas de roteador dinâmico, o dispositivo de Camada 2 reiniciará o cronômetro de envelhecimento da porta.
- Se a porta receptora não existir na lista de portas do roteador dinâmico, o dispositivo de camada 2 adicionará a porta à lista de portas do roteador dinâmico. Ele também inicia um cronômetro de envelhecimento para a porta.
Relatório IGMP
Um host envia um relatório IGMP para o consultador IGMP com as seguintes finalidades:
- Responde a consultas se o host for membro de um grupo multicast.
- Aplica-se a uma associação de grupo multicast.
Depois de receber um relatório IGMP de um host, o dispositivo de camada 2 encaminha o relatório por todas as portas do roteador na VLAN. Ele também resolve o endereço do grupo multicast relatado e procura na tabela de encaminhamento uma entrada correspondente da seguinte forma:
- Se não for encontrada nenhuma correspondência, o dispositivo de Camada 2 criará uma entrada de encaminhamento com a porta de recepção como uma interface de saída. Ele também marca a porta receptora como uma porta membro dinâmica e inicia um cronômetro de envelhecimento para a porta.
- Se for encontrada uma correspondência, mas a entrada de encaminhamento correspondente não contiver a porta de recepção, o dispositivo de Camada 2 adicionará a porta de recepção à lista de interfaces de saída. Ele também marca a porta receptora como uma porta membro dinâmica e inicia um cronômetro de envelhecimento para a porta.
- Se for encontrada uma correspondência e a entrada de encaminhamento correspondente contiver a porta receptora, o dispositivo de camada 2 reiniciará o cronômetro de envelhecimento da porta.
OBSERVAÇÃO:
Um dispositivo de camada 2 não encaminha um relatório IGMP por meio de uma porta não roteadora devido ao mecanismo de supressão de relatório IGMP do host. Se uma porta não roteadora tiver um host membro conectado, os hosts membros suprimirão seus relatórios IGMP ao receberem relatórios IGMP encaminhados pela porta não roteadora. O dispositivo de camada 2 não pode saber da existência dos hosts membros conectados à porta não roteadora.
Deixar mensagem
Um host receptor IGMPv1 não envia nenhuma mensagem de saída quando sai de um grupo multicast. O dispositivo de camada 2 não pode atualizar imediatamente o status da porta que se conecta ao host receptor. O dispositivo de camada 2 não remove a porta da lista de interfaces de saída na entrada de encaminhamento associada até que o tempo de envelhecimento do grupo expire.
Um host IGMPv2 ou IGMPv3 envia uma mensagem IGMP leave quando sai de um grupo multicast.
Quando o dispositivo de camada 2 recebe uma mensagem IGMP leave em uma porta de membro dinâmico, o dispositivo de camada 2 primeiro examina se uma entrada de encaminhamento corresponde ao endereço de grupo na mensagem.
- Se não for encontrada nenhuma correspondência, o dispositivo da Camada 2 descartará a mensagem IGMP leave.
- Se for encontrada uma correspondência, mas a porta receptora não for uma interface de saída na entrada de encaminhamento, o dispositivo de camada 2 descartará a mensagem IGMP leave.
- Se for encontrada uma correspondência e a porta receptora não for a única interface de saída na entrada de encaminhamento, o dispositivo de camada 2 executará as seguintes ações:
- Descarta a mensagem IGMP leave.
- Envia uma consulta específica de grupo IGMP para identificar se o grupo tem receptores ativos conectados à porta receptora.
- Define o cronômetro de envelhecimento da porta receptora para o dobro do intervalo de consulta do último membro do IGMP.
- Se for encontrada uma correspondência e a porta receptora for a única interface de saída na entrada de encaminhamento, o dispositivo de camada 2 executará as seguintes ações:
- Encaminha a mensagem IGMP leave para todas as portas do roteador na VLAN.
- Envia uma consulta específica de grupo IGMP para identificar se o grupo tem receptores ativos conectados à porta receptora.
- Define o cronômetro de envelhecimento da porta receptora para o dobro do intervalo de consulta do último membro do IGMP.
Depois de receber a mensagem IGMP leave em uma porta, o IGMP querier resolve o endereço do grupo multicast na mensagem. Em seguida, ele envia uma consulta específica de grupo IGMP para o grupo multicast por meio da porta receptora.
Depois de receber a consulta específica do grupo IGMP, o dispositivo de camada 2 encaminha a consulta por todas as portas do roteador e portas-membro do grupo na VLAN. Em seguida, ele aguarda o relatório IGMP de resposta dos hosts diretamente conectados. Para a porta membro dinâmica que recebeu a mensagem de saída, o dispositivo de camada 2 também executa uma das seguintes ações:
- Se a porta receber um relatório IGMP antes que o cronômetro de envelhecimento expire, o dispositivo de Camada 2 redefinirá o cronômetro de envelhecimento.
- Se a porta não receber um relatório IGMP quando o cronômetro de envelhecimento expirar, o dispositivo de Camada 2 removerá a porta da entrada de encaminhamento para o grupo multicast.
Proxy de snooping IGMP
Conforme mostrado na Figura 3, para reduzir o número de mensagens de relatório e de saída IGMP recebidas pelo dispositivo upstream, você pode ativar o proxy de snooping IGMP no dispositivo de borda. Com o proxy de snooping IGMP ativado, o dispositivo de borda atua como um host para que o consultador de snooping IGMP upstream envie mensagens de relatório e de saída IGMP para o Dispositivo A. O mecanismo de supressão de relatório IGMP do host no dispositivo de borda não tem efeito.
Figura 3 Proxy de snooping IGMP
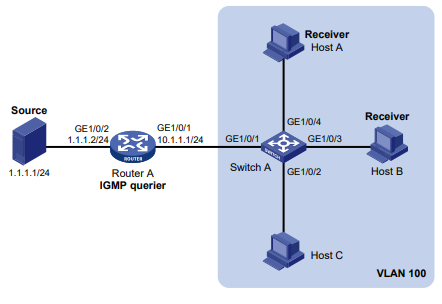
O dispositivo proxy IGMP snooping processa diferentes mensagens IGMP da seguinte forma:
- Consulta geral.
Depois de receber uma consulta geral IGMP, o dispositivo encaminha a consulta para todas as portas da VLAN, exceto a porta receptora. O dispositivo também gera um relatório IGMP com base nas informações de associação local e envia o relatório a todas as portas do roteador.
- Consulta específica de grupo ou consulta específica de grupo e fonte.
Depois de receber uma consulta específica de grupo IGMP ou uma consulta específica de grupo e fonte, o dispositivo encaminha a consulta para todas as portas da VLAN, exceto a porta receptora. Se a entrada de encaminhamento tiver uma porta membro, o dispositivo enviará um relatório a todas as portas do roteador na VLAN.
- Relatório.
Após receber um relatório IGMP de um host, o dispositivo procura uma entrada correspondente na tabela de encaminhamento da seguinte forma:
- Se for encontrada uma correspondência e a entrada de encaminhamento correspondente contiver a porta receptora, o dispositivo redefinirá o cronômetro de envelhecimento da porta.
- Se for encontrada uma correspondência, mas a entrada de encaminhamento correspondente não contiver a porta de recepção, o dispositivo adicionará a porta de recepção à lista de interfaces de saída. Ele também marca a porta receptora como uma porta membro dinâmica e inicia um cronômetro de envelhecimento para a porta.
- Se não for encontrada nenhuma correspondência, o dispositivo criará uma entrada de encaminhamento com a porta receptora como uma interface de saída. Ele também marca a porta receptora como uma porta membro dinâmica e inicia um cronômetro de envelhecimento para a porta. Em seguida, ele envia o relatório a todas as portas do roteador.
- Deixe sua mensagem.
Depois de receber a mensagem IGMP leave em uma porta, o dispositivo envia uma consulta específica do grupo IGMP pela porta receptora. O dispositivo envia a mensagem IGMP leave para todas as portas do roteador somente quando a última porta membro é removida da entrada de encaminhamento.
Protocolos e padrões
RFC 4541, Considerações sobre switches de protocolo de gerenciamento de grupos da Internet (IGMP) e descoberta de ouvinte multicast (MLD) Snooping
Restrições e diretrizes: Configuração do IGMP snooping
Para relatórios IGMP recebidos de VLANs secundárias, as entradas de encaminhamento de snooping IGMP associadas são mantidas pela VLAN primária. Portanto, você precisa ativar o IGMP snooping somente para a VLAN primária. A configuração do IGMP snooping feita nas VLANs secundárias não tem efeito. Para obter mais informações sobre VLANs primárias e VLANs secundárias, consulte o Layer 2-LAN Switching Configuration Guide.
As configurações do IGMP snooping feitas nas interfaces agregadas da Camada 2 não interferem nas configurações feitas nas portas-membro. Além disso, as configurações feitas nas interfaces agregadas da Camada 2 não participam dos cálculos de agregação. A configuração feita em uma porta membro do grupo agregado entra em vigor depois que a porta deixa o grupo agregado.
Alguns recursos podem ser configurados para uma VLAN na visualização VLAN ou para várias VLANs na visualização IGMP-snooping. A configuração feita na visualização de VLAN e a configuração feita na visualização de IGMP-snooping têm a mesma prioridade, e a configuração mais recente entra em vigor.
Alguns recursos podem ser configurados para uma VLAN na visualização VLAN ou globalmente para todas as VLANs na visualização IGMP-snooping. A configuração específica da VLAN tem prioridade sobre a configuração global.
Alguns recursos podem ser configurados para uma interface na visualização da interface ou para todas as interfaces das VLANs especificadas na visualização do IGMP-snooping. A configuração específica da interface tem prioridade sobre a configuração feita na visualização IGMP-snooping.
Visão geral das tarefas de IGMP snooping baseadas em VLAN
Para configurar o IGMP snooping para VLANs, execute as seguintes tarefas:
- Ativação do recurso IGMP snooping
- Ativação do IGMP snooping
Escolha as seguintes tarefas, conforme necessário:
- Ativação do IGMP snooping globalmente
- Ativação do IGMP snooping para VLANs
- (Opcional.) Configuração dos recursos básicos do IGMP snooping
- Especificação de uma versão do IGMP snooping
- Definição do número máximo de entradas de encaminhamento do IGMP snooping
- Configuração de entradas de endereço MAC multicast estático
- Configuração do intervalo de consulta do último membro do IGMP
- (Opcional.) Configuração dos recursos de porta do IGMP snooping
- Configuração de temporizadores de envelhecimento para portas dinâmicas
- Configuração de uma porta membro estática
- Configuração de uma porta de roteador estático
- Configuração de uma porta como um host membro simulado
- Ativação do processamento rápido de licenças
- Desativar a possibilidade de uma porta se tornar uma porta de roteador dinâmico
- (Opcional.) Configuração do consultador do IGMP snooping
- Ativação do consultador de snooping IGMP
- Ativação da eleição de consultores do IGMP snooping
- Configuração de parâmetros para consultas e respostas gerais do IGMP
- (Opcional.) Ativação do proxy de IGMP snooping
- (Opcional.) Configuração de parâmetros para mensagens IGMP
- Configuração de endereços IP de origem para mensagens IGMP
- Configuração da prioridade 802.1p para mensagens IGMP
- (Opcional.) Configuração de políticas de snooping IGMP
- Configuração de uma política de grupo multicast
- Ativação da filtragem de porta de origem multicast
- Ativação do descarte de dados multicast desconhecidos
- Ativação da supressão de relatórios IGMP
- Configuração do número máximo de grupos multicast em uma porta
- Ativação da substituição de grupos multicast
- Ativação do rastreamento de host
- Configuração de uma política de controle de acesso do IGMP snooping
- (Opcional.) Configuração do valor DSCP para pacotes de protocolo IGMP de saída
Ativação do recurso IGMP snooping
Sobre a ativação do recurso IGMP snooping
Você deve ativar o recurso de snooping IGMP antes de configurar outros recursos de snooping IGMP.
Procedimento
System View- Ative o recurso IGMP snooping e entre na visualização IGMP-snooping.
igmp-snoopingPor padrão, o recurso IGMP snooping está desativado.
Ativação do IGMP snooping
Ativação do IGMP snooping globalmente
Sobre como ativar o IGMP snooping globalmente
Depois que você ativa o IGMP snooping globalmente, o IGMP snooping é ativado para todas as VLANs. Você pode desativar o snooping IGMP para uma VLAN quando o snooping IGMP estiver ativado globalmente.
Restrições e diretrizes
Para configurar outros recursos do IGMP snooping para VLANs, você deve ativar o IGMP snooping para as VLANs específicas, mesmo que o IGMP snooping esteja ativado globalmente.
A configuração de snooping IGMP específica da VLAN tem prioridade sobre a configuração global de snooping IGMP. Por exemplo, se você ativar o snooping IGMP globalmente e depois usar o comando igmp-snooping disable para desativar o snooping IGMP para uma VLAN, o snooping IGMP será desativado na VLAN.
Procedimento
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Ativar o IGMP snooping globalmente.
global-enablePor padrão, o IGMP snooping é desativado globalmente.
- (Opcional.) Desative o IGMP snooping para uma VLAN.
- Retornar à visualização do sistema.
quit- Entre na visualização de VLAN.
vlan vlan-id- Desative o IGMP snooping para a VLAN.
igmp-snooping disablePor padrão, o status do IGMP snooping em uma VLAN é consistente com o status global do IGMP snooping.
Ativação do IGMP snooping para VLANs
Restrições e diretrizes
Você pode ativar o snooping IGMP para várias VLANs usando o comando enable vlan na visualização IGMP-snooping ou para uma VLAN usando o comando igmp-snooping enable na visualização VLAN. A configuração na visualização de VLAN tem a mesma prioridade que a configuração na visualização de IGMP-snooping.
A configuração do IGMP snooping em uma VLAN tem efeito apenas nas portas membros da VLAN.
Ativação do IGMP snooping para várias VLANs
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Ativar o IGMP snooping para as VLANs especificadas.
enable vlan vlan-listPor padrão, o status do IGMP snooping em uma VLAN é consistente com o status global do IGMP snooping .
Ativação do IGMP snooping para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Ativar o IGMP snooping para a VLAN.
igmp-snooping disablePor padrão, o status do IGMP snooping em uma VLAN é consistente com o status global do IGMP snooping.
Configuração dos recursos básicos do IGMP snooping
Especificação de uma versão do IGMP snooping
Sobre as versões do IGMP snooping
Diferentes versões do IGMP snooping processam diferentes versões de mensagens IGMP.
- O snooping IGMPv2 processa mensagens IGMPv1, mensagens IGMPv2 e consultas IGMPv3, mas inunda os relatórios IGMPv3 na VLAN em vez de processá-los.
- O snooping IGMPv3 processa mensagens IGMPv1, IGMPv2 e IGMPv3.
Restrições e diretrizes
Se você alterar a versão do IGMP snooping de 2 para 3, o dispositivo executará as seguintes ações:
- Limpa todas as entradas de encaminhamento do IGMP snooping que são criadas dinamicamente.
- Mantém entradas estáticas de encaminhamento de snooping IGMPv3 (*, G).
- Limpa as entradas estáticas de encaminhamento de snooping IGMPv3 (S, G), que serão restauradas quando a versão de snooping IGMP voltar a ser 3.
Para obter mais informações sobre entradas de encaminhamento de IGMP snooping estático, consulte "Configuração de uma porta membro estática".
Especificação de uma versão do IGMP snooping para várias VLANs
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Especifique uma versão do IGMP snooping para várias VLANs.
version version-number vlan vlan-listPor padrão, a versão do IGMP snooping para uma VLAN é 2.
Especificação de uma versão do IGMP snooping para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Especifique uma versão do IGMP snooping para a VLAN.
igmp-snooping version version-numberPor padrão, a versão do IGMP snooping para uma VLAN é 2.
Definição do número máximo de entradas de encaminhamento do IGMP snooping
Sobre a configuração do número máximo de entradas de encaminhamento do IGMP snooping
Você pode modificar o número máximo de entradas de encaminhamento do IGMP snooping, incluindo entradas dinâmicas e estáticas. Quando o número de entradas de encaminhamento no dispositivo atinge o limite superior, o dispositivo não remove automaticamente nenhuma entrada existente. Para permitir que novas entradas sejam criadas, remova algumas entradas manualmente.
Procedimento
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Defina o número máximo de entradas de encaminhamento do IGMP snooping.
entry-limit limitPor padrão, o número máximo de entradas de encaminhamento do IGMP snooping é 4294967295.
Configuração de entradas de endereço MAC multicast estático
Sobre as entradas de endereço MAC multicast estático
No multicast da Camada 2, as entradas de endereço MAC multicast podem ser criadas dinamicamente por meio de protocolos multicast da Camada 2 (como o IGMP snooping). Também é possível configurar manualmente entradas de endereço MAC multicast estático vinculando endereços MAC multicast e portas para controlar as portas de destino dos dados multicast.
Restrições e diretrizes
Você deve especificar um endereço MAC multicast não utilizado ao configurar uma entrada de endereço MAC multicast estático. Um endereço MAC multicast é o endereço MAC no qual o bit menos significativo do octeto mais significativo é 1.
Configuração de uma entrada de endereço MAC multicast estático na visualização do sistema
- Entre na visualização do sistema.
System View- Configurar uma entrada de endereço MAC multicast estático.
mac-address multicast mac-address interface interface-list vlan
vlan-idConfiguração de uma entrada de endereço MAC multicast estático na visualização de interface
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Configurar uma entrada de endereço MAC multicast estático.
mac-address multicast mac-address vlan vlan-idConfiguração do intervalo de consulta do último membro do IGMP
Sobre o intervalo de consulta do último membro do IGMP
Um host receptor inicia um cronômetro de atraso de relatório para um grupo multicast quando recebe uma consulta específica de grupo IGMP para o grupo. Esse temporizador é definido como um valor aleatório no intervalo de 0 ao tempo máximo de resposta anunciado na consulta. Quando o valor do cronômetro diminui para 0, o host envia um relatório IGMP para o grupo.
O intervalo de consulta do último membro do IGMP define o tempo máximo de resposta anunciado nas consultas específicas do grupo IGMP. Defina um valor adequado para o intervalo de consulta do último membro do IGMP para acelerar as respostas dos hosts às consultas específicas do grupo IGMP e evitar explosões de tráfego de relatórios IGMP.
Configuração global do intervalo de consulta do último membro do IGMP
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Defina globalmente o intervalo de consulta do último membro do IGMP.
last-member-query-interval intervalPor padrão, o intervalo global de consulta do último membro do IGMP é de 1 segundo.
Configuração do intervalo de consulta do último membro do IGMP para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Defina o intervalo de consulta do último membro do IGMP para a VLAN.
igmp-snooping last-member-query-interval intervalPor padrão, o intervalo de consulta do último membro do IGMP é de 1 segundo para uma VLAN.
Configuração dos recursos de porta do IGMP snooping
Configuração de temporizadores de envelhecimento para portas dinâmicas
Sobre temporizadores de envelhecimento para portas dinâmicas
Uma porta de roteador dinâmico é removida da lista de portas de roteador dinâmico se não receber uma consulta geral IGMP ou uma mensagem de alô PIM quando seu cronômetro de envelhecimento expirar.
Uma porta membro dinâmica é removida da porta membro dinâmica se não receber um relatório IGMP quando seu cronômetro de envelhecimento expirar.
Restrições e diretrizes
Defina um valor apropriado para os cronômetros de envelhecimento das portas dinâmicas. Por exemplo, se as associações de grupos multicast mudarem com frequência, defina um valor relativamente pequeno para o cronômetro de envelhecimento das portas de membros dinâmicos. Se as associações de grupos multicast raramente mudam, defina um valor relativamente grande.
Se uma porta de roteador dinâmico receber uma mensagem hello do PIMv2, o timer de envelhecimento da porta será especificado pela mensagem hello. Nesse caso, o comando router-aging-time ou igmp-snooping router-aging-time não tem efeito na porta.
As consultas específicas de grupos IGMP originadas pelo dispositivo de camada 2 acionam o ajuste dos timers de envelhecimento para portas de membros dinâmicos. Se uma porta de membro dinâmica receber uma consulta desse tipo, seu timer de envelhecimento será definido para o dobro do intervalo de consulta do último membro IGMP. Para obter mais informações sobre a configuração do intervalo de consulta do último membro IGMP no dispositivo de camada 2, consulte "Configuração do intervalo de consulta do último membro IGMP".
Configuração global dos timers de envelhecimento para portas dinâmicas
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Defina globalmente o cronômetro de envelhecimento para portas de roteador dinâmico.
router-aging-time secondsPor padrão, o timer de envelhecimento das portas dinâmicas do roteador é de 260 segundos.
- Defina o cronômetro de envelhecimento global para portas de membros dinâmicos globalmente.
host-aging-time secondsPor padrão, o cronômetro de envelhecimento das portas de membros dinâmicos é de 260 segundos.
Configuração dos timers de envelhecimento para portas dinâmicas em uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Defina o cronômetro de envelhecimento para portas de roteador dinâmico na VLAN.
igmp-snooping router-aging-time secondsPor padrão, o timer de envelhecimento das portas dinâmicas do roteador é de 260 segundos.
- Defina o cronômetro de envelhecimento para portas de membros dinâmicos na VLAN.
igmp-snooping host-aging-time secondsPor padrão, o cronômetro de envelhecimento das portas de membros dinâmicos é de 260 segundos.
Configuração de uma porta membro estática
Sobre portas-membro estáticas
Você pode configurar uma porta como porta membro estática de um grupo multicast para que os hosts conectados à porta possam sempre receber multicast do grupo. A porta de membro estático não responde a consultas IGMP. Quando você conclui ou cancela essa configuração em uma porta, ela não envia um relatório IGMP não solicitado ou uma mensagem de saída .
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-number- Configure a porta como uma porta membro estática.
igmp-snooping static-group group-address [ source-ip source-address ]
vlan vlan-idPor padrão, uma porta não é uma porta membro estática.
Configuração de uma porta de roteador estático
Sobre as portas estáticas do roteador
Você pode configurar uma porta como uma porta de roteador estático para um grupo multicast, de modo que todos os dados multicast do grupo recebidos na porta sejam encaminhados.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Configure a porta como uma porta de roteador estático.
igmp-snooping static-router-port vlan vlan-idPor padrão, uma porta não é uma porta de roteador estático.
Configuração de uma porta como um host membro simulado
Sobre hosts membros simulados
Quando uma porta é configurada como um host membro simulado, ela é equivalente a um host independente das seguintes maneiras:
- Ele envia um relatório IGMP não solicitado quando você conclui a configuração.
- Ele responde às consultas gerais do IGMP com relatórios IGMP.
- Ele envia uma mensagem IGMP leave quando você cancela a configuração.
A versão do IGMP em execução no host membro simulado é a mesma que a versão do IGMP snooping em execução na porta. A porta envelhece da mesma forma que uma porta membro dinâmica.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Configure a porta como um host membro simulado.
igmp-snooping host-join group-address [ source-ip source-address ] vlan vlan-idPor padrão, a porta não é um host membro simulado.
Ativação do processamento rápido de licenças
Sobre o processamento de licenças rápidas
Esse recurso permite que o dispositivo da Camada 2 remova imediatamente uma porta da entrada de encaminhamento de um grupo multicast quando a porta recebe uma mensagem de saída. O dispositivo de camada 2 não envia nem encaminha mais para a porta consultas específicas de grupo IGMP para o grupo.
Restrições e diretrizes
Não ative o processamento de saída rápida em uma porta que tenha vários hosts receptores em uma VLAN. Se você fizer isso, os receptores restantes não poderão receber dados multicast de um grupo depois que um receptor deixar o grupo.
Habilitação do processamento de licenças rápidas em nível global
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Ativar o processamento de saída rápida globalmente.
fast-leave [ vlan vlan-list ]Por padrão, o processamento de saída rápida é desativado globalmente.
Ativação do processamento de saída rápida em uma porta
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Ativar o processamento de saída rápida na porta.
igmp-snooping fast-leave [ vlan vlan-list ]Por padrão, o processamento de saída rápida é desativado em uma porta.
Desativar a possibilidade de uma porta se tornar uma porta de roteador dinâmico
Sobre como impedir que uma porta se torne uma porta de roteador dinâmico
Um host receptor pode enviar consultas gerais IGMP ou mensagens hello PIM para fins de teste. No dispositivo de camada 2, a porta que recebe uma das mensagens torna-se uma porta de roteador dinâmico. Antes que o cronômetro de envelhecimento da porta expire, podem ocorrer os seguintes problemas:
- Todos os dados multicast da VLAN à qual a porta pertence fluem para a porta. Em seguida, a porta encaminha os dados para os hosts receptores conectados. Os hosts receptores receberão dados multicast que não desejam receber.
- A porta encaminha as consultas gerais IGMP ou as mensagens hello PIM para seus dispositivos de Camada 3 upstream. Essas mensagens podem afetar o estado do protocolo de roteamento multicast (como o IGMP querier ou a eleição de DR) nos dispositivos da camada 3. Isso pode causar ainda mais interrupções na rede.
Para resolver esses problemas, você pode impedir que uma porta se torne uma porta de roteador dinâmico. Isso também melhora a segurança da rede e o controle sobre os hosts receptores.
Restrições e diretrizes
Essa configuração e a configuração da porta do roteador estático não interferem uma na outra.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Desative a porta para que ela não se torne uma porta de roteador dinâmico.
igmp-snooping router-port-deny [ vlan vlan-list ]Por padrão, uma porta tem permissão para se tornar uma porta de roteador dinâmico.
Configuração do consultador do IGMP snooping
Ativação do consultador de snooping IGMP
Sobre o consultador de snooping IGMP
Esse recurso permite que o dispositivo da camada 2 envie periodicamente consultas gerais de IGMP para estabelecer e manter entradas de encaminhamento de multicast na camada de enlace de dados. É possível configurar um consultador de snooping IGMP em uma rede sem dispositivos de multicast da Camada 3.
Restrições e diretrizes
Não ative o IGMP snooping querier em uma rede multicast que execute IGMP. Um consultador de snooping IGMP não participa de eleições de consultores IGMP. No entanto, ele pode afetar as eleições de consultores IGMP se enviar consultas gerais IGMP com um endereço IP de origem baixo.
Ativação do IGMP snooping querier para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Ativar o consultador IGMP snooping para a VLAN.
igmp-snooping querierPor padrão, o IGMP snooping querier está desativado para uma VLAN.
Ativação da eleição de consultores do IGMP snooping
Sobre a eleição de consultores do IGMP snooping
Para evitar a interrupção do tráfego causada pela falha de um único querier em uma VLAN, configure vários queriers na VLAN e ative a eleição de querier. Quando o querier eleito falha, o dispositivo inicia uma nova eleição de querier para garantir o encaminhamento de multicast. O mecanismo de eleição de consultores do IGMP snooping é o mesmo da eleição de consultores do IGMP.
Pré-requisitos para ativar a eleição de consultores do IGMP snooping
Antes de ativar a seleção de consultores do IGMP snooping, você deve concluir as seguintes tarefas:
- Ativar o consultador de snooping IGMP para uma VLAN. Para obter mais informações sobre como ativar o consultador de snooping IGMP, consulte "Ativação do consultador de snooping IGMP".
- Configure o endereço IP de origem para consultas gerais de IGMP como um endereço IP diferente de 0.0.0.0 e o endereço IP do querier local. Um querier IGMP snooping realiza a eleição de querier somente se o endereço IP de origem de uma consulta geral IGMP recebida não for 0.0.0.0 ou seu próprio endereço IP.
Certifique-se de que os consultores de snooping IGMP candidatos executem a mesma versão de snooping IGMP. Para especificar a versão do IGMP snooping, use o comando igmp-snooping version.
Ativação da seleção de consultores do IGMP snooping para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Ativar a seleção de consultores do IGMP snooping para a VLAN.
igmp-snooping querier-electionPor padrão, a seleção de consultores do IGMP snooping está desativada para uma VLAN.
Configuração de parâmetros para consultas e respostas gerais do IGMP
Sobre os parâmetros para consultas e respostas gerais do IGMP
Você pode modificar o intervalo de consulta geral do IGMP com base na condição real da rede.
Um host receptor inicia um cronômetro de atraso de relatório para cada grupo multicast ao qual se juntou quando recebe uma consulta geral IGMP. Esse cronômetro é definido com um valor aleatório no intervalo de 0 até o tempo máximo de resposta anunciado na consulta. Quando o valor do cronômetro chega a 0, o host envia um relatório IGMP para o grupo de multicast correspondente.
Defina um valor adequado para o tempo máximo de resposta para consultas gerais de IGMP para acelerar as respostas dos hosts às consultas gerais de IGMP e evitar explosões de tráfego de relatórios de IGMP.
Restrições e diretrizes
Para evitar a exclusão equivocada de membros de grupos multicast, certifique-se de que o intervalo de consulta geral IGMP seja maior do que o tempo máximo de resposta para consultas gerais IGMP.
Configuração de parâmetros para consultas e respostas gerais do IGMP em nível global
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Defina o tempo máximo de resposta para consultas gerais de IGMP.
max-response-time secondsPor padrão, o tempo máximo de resposta para consultas gerais de IGMP é de 10 segundos.
Configuração de parâmetros para consultas e respostas gerais do IGMP em uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Defina o intervalo de consulta geral do IGMP na VLAN.
igmp-snooping query-interval intervalPor padrão, o intervalo de consulta geral do IGMP é de 125 segundos para uma VLAN.
- Defina o tempo máximo de resposta para consultas gerais de IGMP na VLAN.
igmp-snooping max-response-time secondsPor padrão, o tempo máximo de resposta para consultas gerais de IGMP é de 10 segundos para uma VLAN.
Ativação do proxy de snooping IGMP
Sobre a ativação do proxy de IGMP snooping
O dispositivo habilitado com proxy de snooping IGMP é chamado de proxy de snooping IGMP. O proxy de snooping IGMP atua como um host para o dispositivo upstream. Ativado com o IGMP snooping querier, o proxy de snooping IGMP atua como roteador para dispositivos downstream e recebe mensagens de relatório e de saída em nome do dispositivo upstream. Como prática recomendada, ative o proxy de snooping IGMP no dispositivo de borda para aliviar o efeito causado pelo excesso de pacotes.
Restrições e diretrizes para ativar o proxy de IGMP snooping
Antes de ativar o proxy de snooping IGMP para uma VLAN, você deve primeiro ativar o snooping IGMP globalmente e ativar o snooping IGMP para a VLAN. O proxy de snooping IGMP não tem efeito em sub VLANs de uma VLAN multicast.
Use esse recurso com o IGMP snooping querier. Para obter mais informações sobre a ativação do IGMP snooping querier, consulte "Ativação do IGMP snooping querier".
Ativação do proxy de IGMP snooping para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Habilite o proxy de snooping IGMP para a VLAN.
igmp-snooping proxy enablePor padrão, o proxy de IGMP snooping está desativado para uma VLAN.
Configuração de parâmetros para mensagens IGMP
Configuração de endereços IP de origem para mensagens IGMP
Sobre a configuração de endereços IP de origem para mensagens IGMP
O IGMP snooping querier pode enviar consultas gerais IGMP com o endereço IP de origem 0.0.0.0. A porta que receber essas consultas não será mantida como porta de roteador dinâmico. Isso pode impedir que a entrada de encaminhamento do IGMP snooping dinâmico associado seja criada corretamente na camada de enlace de dados e, por fim, causar falhas no encaminhamento do tráfego multicast. Para evitar esse problema, você pode configurar um endereço IP diferente de zero como o endereço IP de origem das consultas IGMP no IGMP snooping querier. Essa configuração pode afetar a eleição do consultador IGMP dentro da sub-rede.
Você também pode alterar o endereço IP de origem dos relatórios IGMP ou deixar mensagens enviadas por um host membro simulado ou por um proxy IGMP snooping.
Configuração dos endereços IP de origem para mensagens IGMP em uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Configure o endereço IP de origem para consultas gerais de IGMP.
igmp-snooping general-query source-ip ip-addressPor padrão, o endereço IP de origem das consultas gerais do IGMP é o endereço IP da interface da VLAN atual. Se a interface VLAN atual não tiver um endereço IP, o endereço IP de origem será 0.0.0.0.
- Configure o endereço IP de origem para consultas específicas de grupos IGMP.
igmp-snooping special-query source-ip ip-addressPor padrão, o endereço IP de origem das consultas específicas de grupos IGMP é um dos seguintes:
- O endereço de origem das consultas específicas de grupos IGMP se o consultador IGMP snooping da VLAN tiver recebido consultas gerais IGMP.
- O endereço IP da interface VLAN atual se o consultador do IGMP snooping não receber uma consulta geral do IGMP.
- 0.0.0.0 se o consultador do IGMP snooping não receber uma consulta geral do IGMP e a interface da VLAN atual não tiver um endereço IP.
- Configure o endereço IP de origem para relatórios IGMP.
igmp-snooping report source-ip ip-addressPor padrão, o endereço IP de origem dos relatórios IGMP é o endereço IP da interface VLAN atual. Se a interface VLAN atual não tiver um endereço IP, o endereço IP de origem será 0.0.0.0.
igmp-snooping leave source-ip ip-addressPor padrão, o endereço IP de origem das mensagens IGMP leave é o endereço IP da interface VLAN atual. Se a interface VLAN atual não tiver um endereço IP, o endereço IP de origem será 0.0.0.0.
Configuração da prioridade 802.1p para mensagens IGMP
Sobre a prioridade 802.1p para mensagens IGMP
Quando ocorre congestionamento nas portas de saída do dispositivo de camada 2, ele encaminha as mensagens IGMP em sua ordem de prioridade 802.1p, da mais alta para a mais baixa. Você pode atribuir uma prioridade 802.1p mais alta às mensagens IGMP que são criadas ou encaminhadas pelo dispositivo.
Definição da prioridade 802.1p para mensagens IGMP globalmente
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Definir a prioridade 802.1p para mensagens IGMP.
dot1p-priority priorityPor padrão, a prioridade 802.1p global é 6 para mensagens IGMP.
Configuração da prioridade 802.1p para mensagens IGMP em uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Defina a prioridade 802.1p para mensagens IGMP na VLAN.
igmp-snooping dot1p-priority priorityPor padrão, a prioridade 802.1p é 6 para mensagens IGMP em uma VLAN.
Configuração de políticas de snooping IGMP
Configuração de uma política de grupo multicast
Sobre políticas de grupos multicast
Esse recurso permite que o dispositivo de camada 2 filtre relatórios IGMP usando uma ACL que especifica os grupos multicast e as origens opcionais. Ele é usado para controlar os grupos multicast aos quais os hosts podem se associar. Essa configuração tem efeito apenas nos grupos multicast aos quais as portas se unem dinamicamente.
Em um aplicativo multicast, um host envia um relatório IGMP não solicitado quando um usuário solicita um programa multicast. O dispositivo de camada 2 usa a política de grupo multicast para filtrar o relatório IGMP. O host pode ingressar no grupo multicast somente se o relatório IGMP for permitido pela política de grupo multicast.
Configuração de uma política de grupo multicast globalmente
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Configure uma política de grupo multicast globalmente.
group-policy ipv4-acl-number [ vlan vlan-list ]Por padrão, nenhuma política de grupo multicast é configurada, e os hosts podem participar de qualquer grupo multicast.
Configuração de uma política de grupo multicast em uma porta
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-number- Configure uma política de grupo multicast na porta.
igmp-snooping group-policy ipv4-acl-number [ vlan vlan-list ]Por padrão, nenhuma política de grupo multicast é configurada em uma porta, e os hosts conectados à porta podem participar de qualquer grupo multicast.
Ativação da filtragem de porta de origem multicast
Sobre a filtragem de portas de origem multicast
Esse recurso permite que o dispositivo de camada 2 descarte todos os pacotes de dados multicast e aceite os pacotes de protocolo multicast. Você pode ativar esse recurso em portas que se conectam somente a receptores multicast.
Restrições e diretrizes
Quando a filtragem de porta de origem multicast está ativada, o sistema ativa automaticamente a filtragem de porta de origem multicast.
A configuração feita para várias interfaces na visualização IGMP-snooping tem a mesma prioridade que a configuração específica da interface, e a configuração mais recente entra em vigor.
Ativação da filtragem de porta de origem multicast na visualização IGMP-snooping
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Ativar a filtragem de portas de origem multicast.
source-deny port interface-listPor padrão, a filtragem de porta de origem multicast está desativada.
Ativação da filtragem de porta de origem multicast na visualização da interface
- Entre na visualização do sistema.
System View- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Ativar a filtragem de portas de origem multicast.
igmp-snooping source-denyPor padrão, a filtragem de porta de origem multicast está desativada.
Ativação do descarte de dados multicast desconhecidos
Sobre o descarte de dados multicast desconhecidos
Dados multicast desconhecidos referem-se a dados multicast para os quais não existem entradas de encaminhamento na tabela de encaminhamento do IGMP snooping. Esse recurso permite que o dispositivo encaminhe dados multicast desconhecidos somente para a porta do roteador. Se o dispositivo não tiver uma porta de roteador, os dados multicast desconhecidos serão descartados.
Se você não ativar esse recurso, os dados multicast desconhecidos serão inundados na VLAN à qual os dados pertencem.
Restrições e diretrizes
Quando a eliminação de dados multicast IPv4 desconhecidos está ativada, o dispositivo também elimina dados multicast IPv6 desconhecidos.
Quando esse recurso está ativado em uma VLAN, o dispositivo ainda encaminha dados multicast desconhecidos para fora das portas do roteador, exceto para a porta do roteador receptor nessa VLAN.
Ativação da eliminação de dados multicast desconhecidos para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Ativar a eliminação de dados multicast desconhecidos para a VLAN.
igmp-snooping drop-unknownPor padrão, a eliminação de dados multicast desconhecidos está desativada para uma VLAN. Os dados multicast desconhecidos são inundados na VLAN.
Ativação da supressão de relatórios IGMP
Sobre a supressão de relatórios IGMP
Esse recurso permite que o dispositivo de camada 2 encaminhe apenas o primeiro relatório IGMP de um grupo multicast para o dispositivo de camada 3 diretamente conectado. Outros relatórios para o mesmo grupo no mesmo intervalo de consulta são descartados. Use esse recurso para reduzir o tráfego de multicast.
Procedimento
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Ativar a supressão de relatórios IGMP.
report-aggregationPor padrão, a supressão de relatório IGMP está ativada.
Configuração do número máximo de grupos multicast em uma porta
Sobre a configuração do número máximo de grupos multicast em uma porta
Você pode definir o número máximo de grupos multicast em uma porta para regular o tráfego da porta. Esse recurso tem efeito apenas nos grupos multicast aos quais uma porta se junta dinamicamente.
Se o número de grupos multicast em uma porta exceder o limite, o sistema removerá todas as entradas de encaminhamento associadas à porta. Os hosts receptores conectados a essa porta podem participar de grupos multicast
novamente antes que o número de grupos multicast na porta atinja o limite. Quando o número de grupos multicast na porta atinge o limite, a porta descarta automaticamente os relatórios IGMP para novos grupos.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Defina o número máximo de grupos multicast na porta.
igmp-snooping group-limit limit [ vlan vlan-list ]Por padrão, nenhum limite é colocado no número máximo de grupos multicast em uma porta.
Ativação da substituição de grupos multicast
Sobre a substituição de grupos multicast
Quando a substituição de grupos multicast está ativada, a porta não descarta relatórios IGMP para novos grupos se o número de grupos multicast na porta atingir o limite superior. Em vez disso, a porta deixa o grupo multicast que tem o endereço IP mais baixo e se junta ao novo grupo contido no relatório IGMP. O recurso de substituição de grupo multicast é normalmente usado no aplicativo de comutação de canal.
Restrições e diretrizes
Esse recurso entra em vigor somente nos grupos multicast aos quais uma porta se junta dinamicamente. Esse recurso não terá efeito se houver as seguintes condições:
O número de entradas de encaminhamento do IGMP snooping no dispositivo atinge o limite superior.
O grupo multicast ao qual a porta se juntou recentemente não está incluído na lista de grupos multicast mantida pelo dispositivo.
Ativação da substituição de grupos multicast globalmente
- Entre na visualização do sistema.
System View- Entre na visualização do IGMP-snooping.
igmp-snooping- Ativar a substituição de grupos multicast globalmente.
overflow-replace [ vlan vlan-list ]Por padrão, a substituição de grupos multicast é desativada globalmente.
Ativação da substituição de grupos multicast em uma porta
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Ativar a substituição de grupos multicast na porta.
igmp-snooping overflow-replace [ vlan vlan-list ]Por padrão, a substituição de grupos multicast é desativada em uma porta.
Ativação do rastreamento de host
Sobre o rastreamento do host
Esse recurso permite que o dispositivo de Camada 2 registre informações sobre os hosts membros que estão recebendo dados multicast. As informações incluem os endereços IP dos hosts, o tempo decorrido desde que os hosts ingressaram em grupos multicast e o tempo limite restante para os hosts. Esse recurso facilita o monitoramento e o gerenciamento dos hosts membros.
Ativação do rastreamento de host globalmente
- Entre na visualização do sistema.
System View- Entre no modo de exibição IGMP-snooping.
igmp-snooping- Ativar o rastreamento de host globalmente.
host-trackingPor padrão, o rastreamento de host é desativado globalmente.
Ativação do rastreamento de host para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Ativar o rastreamento de host para a VLAN.
igmp-snooping host-trackingPor padrão, o rastreamento de host está desativado para uma VLAN.
Configuração de uma política de controle de acesso do IGMP snooping
Sobre as políticas de controle de acesso do IGMP snooping
Esse recurso permite que o dispositivo use ACLs para filtrar relatórios IGMP e deixar mensagens de usuários de multicast. Os usuários de multicast podem ingressar ou sair somente de grupos de multicast permitidos pelas políticas de controle de acesso de snooping IGMP .
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização do perfil do usuário.
user-profile profile-namePara obter mais informações sobre esse comando, consulte comandos de perfil de usuário na Referência de comandos de segurança.
- Configure uma política de controle de acesso ao IGMP snooping.
igmp-snooping access-policy ipv4-acl-numberPor padrão, nenhuma política de controle de acesso ao IGMP snooping é configurada. Os usuários de multicast podem entrar ou sair de qualquer grupo de multicast.
Configuração do valor DSCP para pacotes de protocolo IGMP de saída
Sobre o valor DSCP para pacotes de protocolo IGMP de saída
O valor DSCP determina a prioridade de transmissão do pacote. Um valor DSCP maior representa uma prioridade mais alta.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização do IGMP snooping.
igmp-snooping- Defina o valor DSCP para pacotes de protocolo IGMP de saída.
dscp dscp-valuePor padrão, o valor DSCP é 48 para pacotes de protocolo IGMP de saída.
Comandos de exibição e manutenção para IGMP snooping
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir o status do IGMP snooping. | display igmp-snooping [ global | vlan vlan-id ] |
| Exibir entradas de grupos dinâmicos do IGMP snooping. | display igmp-snooping group [ group-address | source-address ] * [ vlan vlan-id ] [ interface interface-type interface-number | [ verbose ] [ slot slot-number ] ] |
| Exibir informações de rastreamento do host. | display igmp-snooping host-tracking vlan vlan-id group group-address [ source source-address ] [ slot slot slot-number ] |
| Exibir informações da porta dinâmica do roteador. | display igmp-snooping router-port [ vlan vlan-id [ verbose ] [ slot slot-número ] |
| Exibir entradas de grupos estáticos do IGMP snooping. | display igmp-snooping static-group [ group-address | source-address ] * [ vlan vlan-id ] [ verbose ] [ slot slot-número ] |
| Exibir informações sobre a porta estática do roteador. | display igmp-snooping static-router-port [ vlan vlan-id ] [ verbose ] [ slot slot-number ] |
| Exibir estatísticas das mensagens IGMP e das mensagens hello PIMv2 aprendidas pelo IGMP snooping. | display igmp-snooping statistics |
| Exibir entradas de encaminhamento rápido de multicast da Camada 2. | display l2-multicast fast-forwarding cache [ vlan vlan-id ] [ source-address | |
| group-address ] * [ slot slot-número ] | |
| Exibir informações sobre grupos multicast de IP de camada 2. | display l2-multicast ip [ group group-address | source source-address ] * [ vlan vlan-id ] [ slot slot-número ] |
| Exibir entradas de grupos multicast IP de camada 2. | display l2-multicast ip forwarding [ group group-address | source source-address ] * [ vlan vlan-id ] [ slot slot-number ] |
| Exibir informações sobre grupos multicast MAC de camada 2. | display l2-multicast mac [ mac-address ] [ vlan vlan-id ] [ slot slot-number ] |
| Exibir entradas de grupos multicast MAC de camada 2. | display l2-multicast mac forwarding [ mac-address ] [ vlan vlan-id ] [ slot slot-number ] |
| Exibir entradas de endereço MAC multicast estático. | display mac-address [ mac-address [ vlan vlan-id ] | [ multicast ] [ vlan vlan-id ] [ count ] ] |
| Limpar entradas de grupos dinâmicos do IGMP snooping. | reset igmp-snooping group { group-address [ source-address ] | all } [ vlan vlan-id ] |
| Limpar as informações da porta do roteador dinâmico. | reset igmp-snooping router-port { all | vlan vlan-id } |
| Limpar estatísticas de mensagens IGMP e mensagens hello PIMv2 obtidas por meio do IGMP snooping. | reset igmp-snooping statistics |
| Limpar entradas de encaminhamento rápido de multicast da Camada 2. | reset l2-multicast fast-forwarding cache [ vlan vlan-id ] { { source-address | group-address } * | all } [ slot slot-number ] |
Exemplos de configuração do IGMP snooping
Exemplo: Configuração de políticas de grupo do IGMP snooping baseadas em VLAN e ingresso simulado
Configuração de rede
Conforme mostrado na Figura 4, o Roteador A executa o IGMPv2 e atua como consultor IGMP. O switch A executa o snooping IGMPv2.
Configure uma política de grupo multicast e uma associação simulada para atender aos seguintes requisitos:
O host A e o host B recebem apenas os dados multicast endereçados ao grupo multicast 224.1.1.1. Os dados multicast podem ser encaminhados por meio da GigabitEthernet 1/0/3 e da GigabitEthernet 1/0/4 do Switch A ininterruptamente, mesmo que o Host A e o Host B não consigam receber os dados multicast.
O switch A descartará dados multicast desconhecidos em vez de inundá-los na VLAN 100.
Figura 4 Diagrama de rede
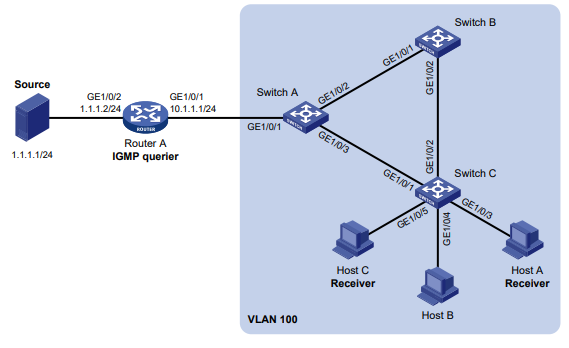
Procedimento
- Atribua um endereço IP e uma máscara de sub-rede a cada interface, conforme mostrado na Figura 4. (Detalhes não mostrados.)
- Configurar o Roteador A:
# Habilitar o roteamento multicast de IP.
<RouterA> system-view
[RouterA] multicast routing
[RouterA-mrib] quit
# Habilite o IGMP na GigabitEthernet 1/0/1.
[RouterA] interface gigabitethernet 1/0/1
[RouterA-GigabitEthernet1/0/1] igmp enable
[RouterA-GigabitEthernet1/0/1] quit
# Habilite o PIM-DM na GigabitEthernet 1/0/2.
[RouterA] interface gigabitethernet 1/0/2
[RouterA-GigabitEthernet1/0/2] pim dm
[RouterA-GigabitEthernet1/0/2] quit
- Configure o Switch A:
# Habilite o recurso de snooping IGMP.
<SwitchA> system-view
[SwitchA] igmp-snooping
[SwitchA-igmp-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/4 à VLAN.
[SwitchA] vlan 100
[SwitchA-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/4
# Habilite o IGMP snooping e habilite o descarte de dados multicast desconhecidos para a VLAN 100.
[SwitchA-vlan100] igmp-snooping enable
[SwitchA-vlan100] igmp-snooping drop-unknown
[SwitchA-vlan100] quit
# Configure uma política de grupo multicast para que os hosts na VLAN 100 possam participar apenas do grupo multicast 224.1.1.1.
[SwitchA] acl basic 2001
[SwitchA-acl-ipv4-basic-2001] rule permit source 224.1.1.1 0
[SwitchA-acl-ipv4-basic-2001] quit
[SwitchA] igmp-snooping
[SwitchA-igmp-snooping] group-policy 2001 vlan 100
[SwitchA-igmp-snooping] quit
# Configure a GigabitEthernet 1/0/3 e a GigabitEthernet 1/0/4 como hosts membros simulados do grupo multicast 224.1.1.1.
[SwitchA] interface gigabitethernet 1/0/3
[SwitchA-GigabitEthernet1/0/3] igmp-snooping host-join 224.1.1.1 vlan 100
[SwitchA-GigabitEthernet1/0/3] quit
[SwitchA] interface gigabitethernet 1/0/4
[SwitchA-GigabitEthernet1/0/4] igmp-snooping host-join 224.1.1.1 vlan 100
[SwitchA-GigabitEthernet1/0/4] quit
Verificação da configuração
# Envie relatórios IGMP do Host A e do Host B para participar dos grupos multicast 224.1.1.1 e 224.2.2.2. (Os detalhes não são mostrados).
# Exibir entradas dinâmicas do grupo IGMP snooping para a VLAN 100 no Switch A.
[SwitchA] display igmp-snooping group vlan 100
Total 1 entries.
VLAN 100: Total 1 entries.
(0.0.0.0, 224.1.1.1)
Host ports (2 in total):
GE1/0/3 (00:03:23)
GE1/0/4 (00:04:10)
O resultado mostra as seguintes informações:
O host A e o host B ingressaram no grupo multicast 224.1.1.1 por meio das portas membro GigabitEthernet 1/0/4 e GigabitEthernet 1/0/3 no switch A, respectivamente.
O host A e o host B não conseguiram entrar no grupo multicast 224.2.2.2.
Exemplo: Configuração de portas estáticas de snooping IGMP baseadas em VLAN
Configuração de rede
Conforme mostrado na Figura 5:
O Roteador A executa o IGMPv2 e atua como consultador IGMP. O Switch A, o Switch B e o Switch C executam o IGMPv2 snooping.
O host A e o host C são receptores permanentes do grupo multicast 224.1.1.1. Configure portas estáticas para atender aos seguintes requisitos:
Para aumentar a confiabilidade da transmissão do tráfego multicast, configure a GigabitEthernet 1/0/3 e a
GigabitEthernet 1/0/5 no Switch C como portas de membro estático para o grupo multicast 224.1.1.1.
Suponha que o STP seja executado na rede. Para evitar loops de dados, o caminho de encaminhamento do Switch A para o Switch C é bloqueado. Os dados multicast fluem para os receptores conectados ao Switch C somente ao longo do caminho do Switch A-Switch B-Switch C. Quando esse caminho é bloqueado, um mínimo de um IGMP
O ciclo de consulta-resposta deve ser concluído antes que os dados multicast fluam para os receptores ao longo do caminho do Switch A-Switch C. Nesse caso, o fornecimento de multicast é interrompido durante o processo. Para obter mais informações sobre o STP, consulte o Layer 2-LAN Switching Configuration Guide.
Configure a GigabitEthernet 1/0/3 no Switch A como uma porta de roteador estático. Assim, os dados multicast podem fluir para os receptores quase ininterruptamente ao longo do caminho do Switch A-Switch C quando o caminho do Switch A-Switch B-Switch C estiver bloqueado.
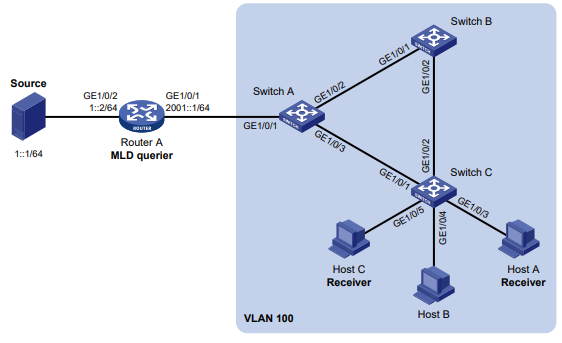
Figura 5 Diagrama de rede
Procedimento
- Atribua um endereço IP e uma máscara de sub-rede a cada interface, conforme mostrado na Figura 5. (Detalhes não mostrados.)
- Configurar o Roteador A:
# Habilitar o roteamento multicast de IP.
<RouterA> system-view
[RouterA] multicast routing
[RouterA-mrib] quit
# Habilite o IGMP na GigabitEthernet 1/0/1.
[RouterA] interface gigabitethernet 1/0/1
[RouterA-GigabitEthernet1/0/1] igmp enable
[RouterA-GigabitEthernet1/0/1] quit
# Habilite o PIM-DM na GigabitEthernet 1/0/2.
[RouterA] interface gigabitethernet 1/0/2
[RouterA-GigabitEthernet1/0/2] pim dm
[RouterA-GigabitEthernet1/0/2] quit
- Configure o Switch A:
# Habilite o recurso de snooping IGMP.
<SwitchA> system-view
[SwitchA] igmp-snooping
[SwitchA-igmp-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 à VLAN.
[SwitchA] vlan 100
[SwitchA-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/3
# Habilite o snooping IGMP para a VLAN 100.
[SwitchA-vlan100] igmp-snooping enable
[SwitchA-vlan100] quit
# Configure a GigabitEthernet 1/0/3 como uma porta de roteador estático.
[SwitchA] interface gigabitethernet 1/0/3
[SwitchA-GigabitEthernet1/0/3] igmp-snooping static-router-port vlan 100
[SwitchA-GigabitEthernet1/0/3] quit
- Configurar o Switch B:
# Habilite o recurso de snooping IGMP.
<SwitchB> system-view
[SwitchB] igmp-snooping
[SwitchB-igmp-snooping] quit
# Crie a VLAN 100 e atribua a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 à VLAN.
[SwitchB] vlan 100
[SwitchB-vlan100] port gigabitethernet 1/0/1 gigabitethernet 1/0/2
# Habilite o IGMP snooping para a VLAN 100.
[SwitchB-vlan100] igmp-snooping enable
[SwitchB-vlan100] quit
- Configurar o switch C:
# Habilite o recurso de snooping IGMP.
<SwitchC> system-view
[SwitchC] igmp-snooping
[SwitchC-igmp-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/5 à VLAN.
[SwitchC] vlan 100
[SwitchC-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/5
# Habilite o IGMP snooping para a VLAN 100.
[SwitchC-vlan100] igmp-snooping enable
[SwitchC-vlan100] quit
# Configure a GigabitEthernet 1/0/3 e a GigabitEthernet 1/0/5 como portas de membro estático para o grupo multicast 224.1.1.1.
[SwitchC] interface gigabitethernet 1/0/3
[SwitchC-GigabitEthernet1/0/3] igmp-snooping static-group 224.1.1.1 vlan 100
[SwitchC-GigabitEthernet1/0/3] quit
[SwitchC] interface gigabitethernet 1/0/5
[SwitchC-GigabitEthernet1/0/5] igmp-snooping static-group 224.1.1.1 vlan 100
[SwitchC-GigabitEthernet1/0/5] quit
Verificação da configuração
# Exibir informações da porta do roteador estático para a VLAN 100 no Switch A.
[SwitchA] display igmp-snooping static-router-port vlan 100
VLAN 100:
Router ports (1 in total):
GE1/0/3
A saída mostra que a GigabitEthernet 1/0/3 no Switch A se tornou uma porta de roteador estático.
# Exibir entradas de grupo IGMP snooping estáticas para a VLAN 100 no Switch C.
[SwitchC] display igmp-snooping static-group vlan 100
Total 1 entries.
VLAN 100: Total 1 entries.
(0.0.0.0, 224.1.1.1)
Host ports (2 in total):
GE1/0/3
GE1/0/5
A saída mostra que a GigabitEthernet 1/0/3 e a GigabitEthernet 1/0/5 no Switch C se tornaram portas de membro estático do grupo multicast 224.1.1.1.
Exemplo: Configuração do consultador de snooping IGMP baseado em VLAN
Configuração de rede
Conforme mostrado na Figura 6:
A rede é uma rede somente de camada 2.
A Fonte 1 e a Fonte 2 enviam dados multicast para os grupos multicast 224.1.1.1 e 225.1.1.1, respectivamente.
O host A e o host C são receptores do grupo multicast 224.1.1.1, e o host B e o host D são receptores do grupo multicast 225.1.1.1.
Todos os receptores de host executam IGMPv2 e todos os switches executam IGMPv2 snooping. O switch A (que está próximo às fontes de multicast) atua como consultor de snooping IGMP.
Configure os switches para atender aos seguintes requisitos:
Para evitar que os switches inundem dados desconhecidos na VLAN, habilite todos os switches para descartar dados multicast desconhecidos.
Um switch não marca uma porta que recebe uma consulta IGMP com endereço IP de origem 0.0.0.0 como uma porta de roteador dinâmico. Isso afeta negativamente o estabelecimento de entradas de encaminhamento da Camada 2 e o encaminhamento de tráfego multicast. Para evitar isso, configure o endereço IP de origem das consultas IGMP como um endereço IP diferente de zero.
Figura 6 Diagrama de rede
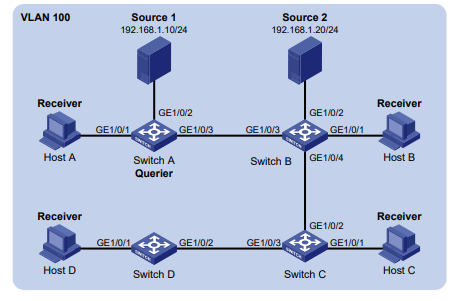
Procedimento
- Configure o Switch A:
# Habilite o recurso de snooping IGMP.
<SwitchA> system-view
[SwitchA] igmp-snooping
[SwitchA-igmp-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 à VLAN.
[SwitchA] vlan 100
[SwitchA-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/3
# Habilite o IGMP snooping e habilite o descarte de dados multicast desconhecidos para a VLAN 100.
Configure o Switch A como o consultador de snooping IGMP.
[SwitchA-vlan100] igmp-snooping querier
[SwitchA-vlan100] quit
# Na VLAN 100, especifique 192.168.1.1 como o endereço IP de origem das consultas gerais do IGMP.
[SwitchA-vlan100] igmp-snooping general-query source-ip 192.168.1.1# Na VLAN 100, especifique 192.168.1.1 como o endereço IP de origem das consultas específicas do grupo IGMP.
[SwitchA-vlan100] igmp-snooping special-query source-ip 192.168.1.1
[SwitchA-vlan100] quit
- Configurar o Switch B:
# Habilite o recurso de snooping IGMP.
<SwitchB> system-view
[SwitchB] igmp-snooping
[SwitchB-igmp-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/4 à VLAN.
[SwitchB] vlan 100
[SwitchB-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/4
# Habilite o IGMP snooping e habilite o descarte de dados multicast desconhecidos para a VLAN 100.
[SwitchB-vlan100] igmp-snooping enable
[SwitchB-vlan100] igmp-snooping drop-unknown
[SwitchB-vlan100] quit
- Configurar o switch C:
# Habilite o recurso de snooping IGMP.
<SwitchC> system-view
[SwitchC] igmp-snooping
[SwitchC-igmp-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 à VLAN.
[SwitchC] vlan 100
[SwitchC-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/3
# Habilite o IGMP snooping e habilite o descarte de dados multicast desconhecidos para a VLAN 100.
[SwitchC-vlan100] igmp-snooping enable
[SwitchC-vlan100] igmp-snooping drop-unknown
[SwitchC-vlan100] quit
- Configurar o Switch D:
# Habilite o recurso de snooping IGMP.
<SwitchD> system-view
[SwitchD] igmp-snooping
[SwitchD-igmp-snooping] quit
# Crie a VLAN 100 e atribua a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 à VLAN.
[SwitchD] vlan 100
[SwitchD-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/2
# Habilite o IGMP snooping e habilite o descarte de dados multicast desconhecidos para a VLAN 100.
[SwitchD-vlan100] igmp-snooping enable
[SwitchD-vlan100] igmp-snooping drop-unknown
[SwitchD-vlan100] quit
Verificação da configuração
# Exibir estatísticas de mensagens IGMP e mensagens hello PIMv2 aprendidas por meio do IGMP snooping no Switch B.
[SwitchB] display igmp-snooping statistics
Received IGMP general queries: 3
Received IGMPv1 reports: 0
Received IGMPv2 reports: 12
Received IGMP leaves: 0
Received IGMPv2 specific queries: 0
Sent IGMPv2 specific queries: 0
Received IGMPv3 reports: 0
Received IGMPv3 reports with right and wrong records: 0
Received IGMPv3 specific queries: 0
Received IGMPv3 specific sg queries: 0
Sent IGMPv3 specific queries: 0
Sent IGMPv3 specific sg queries: 0
Received PIMv2 hello: 0
Received error IGMP messages: 0
A saída mostra que todos os comutadores, exceto o Comutador A, podem receber as consultas gerais do IGMP depois que o Comutador A atua como o consultador do IGMP snooping.
Exemplo: Configuração de proxy de IGMP snooping baseado em VLAN
Configuração de rede
Conforme mostrado na Figura 7, o Roteador A executa o IGMPv2 e atua como consultor IGMP. O Switch A executa o snooping IGMPv2. Configure o proxy de snooping IGMP para que o Switch A possa executar as seguintes ações:
Encaminhar relatório IGMP e deixar mensagens para o Roteador A.
Responder às consultas IGMP enviadas pelo Roteador A e encaminhar as consultas aos hosts downstream.
Figura 7 Diagrama de rede
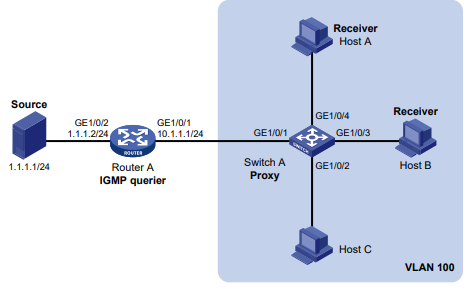
Procedimento
- Atribua um endereço IP e uma máscara de sub-rede a cada interface, conforme mostrado na Figura 7. (Detalhes não mostrados.)
- Configurar o Roteador A:
# Habilitar o roteamento multicast de IP.
<RouterA> system-view
[RouterA] multicast routing
[RouterA-mrib] quit
# Habilite o IGMP e o PIM-DM na GigabitEthernet 1/0/1.
[RouterA] interface gigabitethernet 1/0/1
[RouterA-GigabitEthernet1/0/1] igmp enable
[RouterA-GigabitEthernet1/0/1] pim dm
[RouterA-GigabitEthernet1/0/1] quit
# Habilite o PIM-DM na GigabitEthernet 1/0/2.
[RouterA] interface gigabitethernet 1/0/2
[RouterA-GigabitEthernet1/0/2] pim dm
[RouterA-GigabitEthernet1/0/2] quit
- Configure o Switch A:
# Habilite o recurso de snooping IGMP.
<SwitchA> system-view
[SwitchA] igmp-snooping
[SwitchA-igmp-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/4 à VLAN.
[SwitchA] vlan 100
[SwitchA-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/4
# Habilite o proxy de snooping e snooping IGMP para a VLAN.
[RouterA] interface gigabitethernet 1/0/2
[RouterA-GigabitEthernet1/0/2] pim dm
[RouterA-GigabitEthernet1/0/2] quit
Verificação da configuração
# Envie relatórios IGMP do Host A e do Host B para participar dos grupos multicast 224.1.1.1 e 224.1.1.1. (Detalhes não mostrados.)
# Exibir informações breves sobre as entradas de grupo do IGMP snooping no Switch A.
[SwitchA] display igmp-snooping group
Total 1 entries.
VLAN 100: Total 1 entries.
(0.0.0.0, 224.1.1.1)
Host ports (2 in total):
GE1/0/3 (00:04:00)
GE1/0/4 (00:04:04)
A saída mostra que a GigabitEthernet 1/0/3 e a GigabitEthernet 1/0/4 são portas membros do grupo multicast 224.1.1.1. O host A e o host B tornam-se receptores do grupo.
# Exibir informações de associação de grupo IGMP no Roteador A.
[RouterA] display igmp group
IGMP groups in total: 1
GigabitEthernet1/0/1(10.1.1.1):
IGMP groups reported in total: 1
Group address Last reporter Uptime Expires
224.1.1.1 0.0.0.0 00:00:31 00:02:03
# Enviar uma mensagem IGMP leave do Host A para sair do grupo multicast 224.1.1.1. (Detalhes não mostrados.)
# Exibir informações breves sobre as entradas de grupo do IGMP snooping no Switch A.[SwitchA] display igmp-snooping group
Total 1 entries.
VLAN 100: Total 1 entries.
(0.0.0.0, 224.1.1.1)
Host ports (1 in total):
GE1/0/3 ( 00:01:23 )
A saída mostra que a GigabitEthernet 1/0/3 é a única porta membro do grupo multicast 224.1.1.1. Somente o Host B permanece como receptor do grupo.
Solução de problemas do IGMP snooping
O encaminhamento de multicast da camada 2 não pode funcionar
Sintoma
O encaminhamento de multicast de camada 2 não pode funcionar no dispositivo de camada 2.
Solução
Para resolver o problema:
- Use o comando display igmp-snooping para exibir o status do IGMP snooping.
- Se o snooping IGMP não estiver ativado, use o comando igmp-snooping na visualização do sistema para ativar o recurso de snooping IGMP. Em seguida, use o comando igmp-snooping enable na visualização de VLAN para ativar o IGMP snooping para a VLAN.
- Se o snooping IGMP estiver ativado globalmente, mas não estiver ativado para a VLAN, use o comando igmp-snooping enable no modo de exibição VLAN para ativar o snooping IGMP para a VLAN.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
A política de grupo multicast não funciona
Sintoma
Os hosts podem receber dados multicast de grupos multicast que não são permitidos pela política de grupos multicast.
Solução
Para resolver o problema:
- Use o comando display acl para verificar se a ACL configurada atende aos requisitos da política de grupo multicast.
- Use o comando display this na visualização IGMP-snooping ou em uma visualização de interface correspondente para verificar se a política de grupo multicast correta foi aplicada. Se a política aplicada não estiver correta, use o comando group-policy ou igmp-snooping group-policy para aplicar a política de grupo multicast correta.
- Use o comando display igmp-snooping para verificar se o descarte de dados multicast desconhecidos está ativado. Se não estiver, use o comando igmp-snooping drop-unknown para ativar o descarte de dados multicast desconhecidos.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Configuração do snooping PIM
Sobre o snooping PIM
O snooping PIM é executado em dispositivos de camada 2. Ele trabalha com o IGMP snooping para analisar as mensagens PIM recebidas e adiciona as portas interessadas em dados multicast específicos a uma entrada de roteamento do PIM snooping. Dessa forma, os dados multicast podem ser encaminhados somente para as portas interessadas nos dados.
Figura 1 Transmissão de pacotes multicast sem ou com snooping PIM
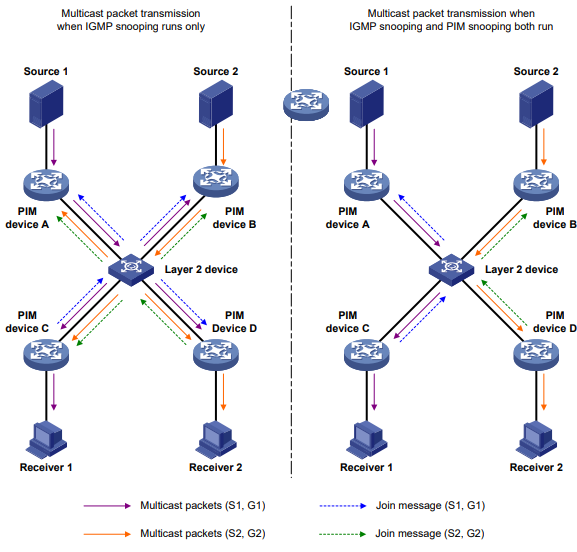
Conforme mostrado na Figura 1, a Fonte 1 envia dados multicast para o grupo multicast G1 e a Fonte 2 envia dados multicast para o grupo multicast G2. O receptor 1 pertence ao G1 e o receptor 2 pertence ao G2. As interfaces do switch de camada 2 que se conectam aos roteadores PIM estão na mesma VLAN.
Quando o switch de camada 2 executa somente o IGMP snooping, ele realiza as seguintes ações:
- Mantém as portas do roteador de acordo com as mensagens hello do PIM recebidas que os roteadores PIM enviam.
- Inunda todos os outros tipos de mensagens PIM recebidas, exceto as mensagens PIM hello na VLAN.
- Encaminha todos os dados multicast para todas as portas do roteador na VLAN.
Cada roteador PIM na VLAN, esteja ele interessado nos dados multicast ou não, pode receber todos os dados multicast e todas as mensagens PIM, exceto as mensagens PIM hello.
Quando o switch de camada 2 executa tanto o snooping IGMP quanto o snooping PIM, ele realiza as seguintes ações :
- Examina se um roteador PIM está interessado nos dados multicast endereçados a um grupo multicast de acordo com as mensagens PIM recebidas que o roteador envia.
- Adiciona apenas as portas que se conectam ao roteador e estão interessadas nos dados a uma entrada de roteamento do PIM snooping.
- Encaminha mensagens PIM e dados multicast apenas para os roteadores interessados nos dados, o que economiza a largura de banda da rede.
Para obter mais informações sobre o IGMP snooping e a porta do roteador, consulte "Configuração do IGMP snooping".
Restrições e diretrizes: Configuração do PIM snooping
O snooping PIM não entra em vigor nas VLANs secundárias. Como prática recomendada, não configure o snooping PIM para VLANs secundárias. Para obter mais informações sobre VLANs secundárias, consulte o Layer 2-LAN Switching Configuration Guide.
Depois que você configura o snooping PIM para uma VLAN, o snooping PIM entra em vigor somente nas portas que pertencem à VLAN.
Visão geral das tarefas de snooping do PIM
Para configurar o snooping PIM, execute as seguintes tarefas:
- Ativação do snooping PIM
- (Opcional.) Configuração do tempo de envelhecimento para portas globais após uma alternância mestre/subordinado
- Configuração do tempo de envelhecimento para portas vizinhas globais
- Configuração do tempo de envelhecimento das portas downstream globais e das portas do roteador global
Ativação do snooping PIM
- Entre na visualização do sistema.
System View- Ative o recurso IGMP snooping e entre na visualização IGMP-snooping.
igmp-snoopingPor padrão, o IGMP snooping está desativado.
Para obter mais informações sobre esse comando, consulte Comandos IGMP snooping em IP Multicast Command Reference.
- Retornar à visualização do sistema.
quit- Entre na visualização de VLAN.
vlan vlan-id- Ativar o IGMP snooping para a VLAN.
igmp-snooping disablePor padrão, o IGMP snooping está desativado em uma VLAN.
Para obter mais informações sobre esse comando, consulte Referência do comando IP Multicast.
- Ativar o snooping PIM para a VLAN.
pim-snooping enablePor padrão, o snooping PIM está desativado em uma VLAN.
Configuração do tempo de envelhecimento das portas globais após uma alternância entre mestre e subordinado
Sobre os portos globais
Uma porta global é uma porta virtual no dispositivo mestre, como uma interface agregada de camada 2. Uma porta global que atua como porta vizinha, porta de downstream ou porta de roteador é chamada de porta vizinha global, porta de downstream global e porta de roteador global, respectivamente.
Execute esta tarefa para reduzir a interrupção de dados multicast da Camada 2 causada pelo envelhecimento das entradas de snooping PIM após uma alternância entre mestre e subordinado.
Restrições e diretrizes
No caso de uma porta vizinha global, o tempo de envelhecimento definido não entra em vigor quando a porta recebe uma mensagem de olá do PIM após uma troca de mestre/subordinado. O tempo de envelhecimento da porta é determinado pelo tempo de envelhecimento na mensagem hello do PIM.
Para uma porta de roteador global ou uma porta de downstream global, o tempo de envelhecimento definido não entra em vigor quando a porta recebe uma mensagem de ingresso no PIM após uma alternância de mestre/subordinado. O tempo de envelhecimento da porta é determinado pelo tempo de envelhecimento da mensagem de ingresso no PIM.
Configuração do tempo de envelhecimento para portas vizinhas globais
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Defina o tempo de envelhecimento das portas vizinhas globais após uma troca de mestre/subordinado.
pim-snooping graceful-restart neighbor-aging-time secondsPor padrão, o tempo de envelhecimento das portas vizinhas globais após uma troca de mestre/subordinado é de 105 segundos.
Configuração do tempo de envelhecimento das portas downstream globais e das portas do roteador global
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Defina o tempo de envelhecimento das portas downstream globais e das portas do roteador global após uma troca de mestre/subordinado.
pim-snooping graceful-restart join-aging-time secondsPor padrão, o tempo de envelhecimento das portas downstream e das portas do roteador global após uma alternância mestre/subordinado é de 210 segundos.
Comandos de exibição e manutenção do PIM snooping
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações de vizinhos do PIM snooping. | display pim-snooping neighbor [ vlan vlan-id ] [ slot slot-número ] [ verbose ] |
| Exibir informações da porta do roteador PIM snooping. | display pim-snooping router-port [ vlan vlan-id ] [ slot slot-número ] [ verbose ] |
| Exibir entradas de roteamento de snooping PIM. | display pim-snooping routing-table [ vlan vlan-id ] [ slot slot-number ] [ verbose ] |
| Exibir estatísticas das mensagens PIM aprendidas por meio do snooping PIM. | display pim-snooping statistics |
| Limpar as estatísticas das mensagens PIM aprendidas por meio do PIM snooping. | reset pim-snooping statistics |
Exemplos de configuração do PIM snooping
Exemplo: Configuração do snooping PIM
Configuração de rede
Conforme mostrado na Figura 2:
O OSPF é executado na rede.
- A Fonte 1 e a Fonte 2 enviam dados multicast para os grupos multicast 224.1.1.1 e 225.1.1.1, respectivamente.
- O receptor 1 e o receptor 2 pertencem aos grupos multicast 224.1.1.1 e 225.1.1.1, respectivamente.
- O Roteador C e o Roteador D executam IGMP na GigabitEthernet 1/0/1. O Roteador A, o Roteador B, o Roteador C e o Roteador D executam o PIM-SM.
- A GigabitEthernet 1/0/2 no Roteador A atua como um C-BSR e um C-RP.
Configure o snooping IGMP e o snooping PIM no Switch A. Em seguida, o Switch A encaminha pacotes de protocolo PIM e pacotes de dados multicast somente para os roteadores que estão conectados aos receptores.
Figura 2 Diagrama de rede
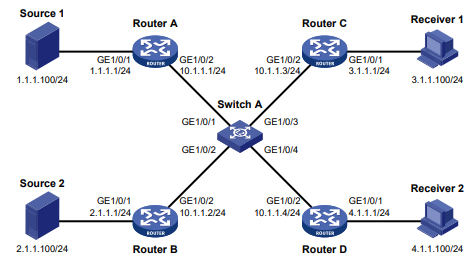
Procedimento
- Atribua um endereço IP e uma máscara de sub-rede a cada interface, conforme mostrado na Figura 2. (Detalhes não mostrados.)
- Configure o OSPF nos roteadores. (Detalhes não mostrados.)
- Configurar o Roteador A:
# Habilitar o roteamento multicast de IP.
<RouterA> system-view
[RouterA] multicast routing
[RouterA-mrib] quit
# Habilite o PIM-SM em cada interface.
[RouterA] interface gigabitethernet 1/0/1
[RouterA-GigabitEthernet1/0/1] pim sm
[RouterA-GigabitEthernet1/0/1] quit
[RouterA] interface gigabitethernet 1/0/2
[RouterA-GigabitEthernet1/0/2] pim sm
[RouterA-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/2 como um C-BSR e um C-RP.
[RouterA] pim
[RouterA-pim] c-bsr 10.1.1.1
[RouterA-pim] c-rp 10.1.1.1
[RouterA-pim] quit- Configurar o Roteador B:
# Habilitar o roteamento multicast de IP.
<RouterB> system-view
[RouterB] multicast routing
[RouterB-mrib] quit# Habilite o PIM-SM em cada interface.
[RouterB] interface gigabitethernet 1/0/1
[RouterB-GigabitEthernet1/0/1] pim sm
[RouterB-GigabitEthernet1/0/1] quit
[RouterB] interface gigabitethernet 1/0/2
[RouterB-GigabitEthernet1/0/2] pim sm
[RouterB-GigabitEthernet1/0/2] quit
- Configurar o Roteador C:
# Habilitar o roteamento multicast de IP.
<RouterC> system-view
[RouterC] multicast routing
[RouterC-mrib] quit
# Habilite o IGMP na GigabitEthernet 1/0/1.
[RouterC] interface gigabitethernet 1/0/1
[RouterC-GigabitEthernet1/0/1] igmp enable
[RouterC-GigabitEthernet1/0/1] quit
# Habilite o PIM-SM na GigabitEthernet 1/0/2.
[RouterC] interface gigabitethernet 1/0/2
[RouterC-GigabitEthernet1/0/2] pim sm
[RouterC-GigabitEthernet1/0/2] quit
- Configurar o Roteador D:
# Habilitar o roteamento multicast de IP.
<RouterD> system-view
[RouterD] multicast routing
[RouterD-mrib] quit
# Habilite o IGMP na GigabitEthernet 1/0/1.
[RouterD] interface gigabitethernet 1/0/1
[RouterD-GigabitEthernet1/0/1] igmp enable
[RouterD-GigabitEthernet1/0/1] quit
# Habilite o PIM-SM na GigabitEthernet 1/0/2.
[RouterD] interface gigabitethernet 1/0/2
[RouterD-GigabitEthernet1/0/2] pim sm
[RouterD-GigabitEthernet1/0/2] quit
- Configure o Switch A:
# Habilite o recurso de snooping IGMP.
<SwitchA> system-view
[SwitchA] igmp-snooping
[SwitchA-igmp-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/4 à VLAN.
[SwitchA] vlan 100
[SwitchA-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/4
# Habilite o snooping IGMP e o snooping PIM para a VLAN 100.
[SwitchA-vlan100] igmp-snooping enable
[SwitchA-vlan100] pim-snooping enable
[SwitchA-vlan100] quit
Verificação da configuração
# No Switch A, exiba as informações de vizinhos do PIM snooping para a VLAN 100.
[SwitchA] display pim-snooping neighbor vlan 100
Total 4 neighbors.
VLAN 100: Total 4 neighbors.
10.1.1.1
Ports (1 in total):
GE1/0/1 (00:32:43)
10.1.1.2
Ports (1 in total):
GE1/0/2 (00:32:43)
10.1.1.3
Ports (1 in total):
GE1/0/3 (00:32:43)
10.1.1.4
Ports (1 in total):
GE1/0/4 (00:32:43)
A saída mostra que o Roteador A, o Roteador B, o Roteador C e o Roteador D são vizinhos de snooping PIM.
# No Switch A, exiba as entradas de roteamento de snooping PIM para a VLAN 100.
[SwitchA] display pim-snooping routing-table vlan 100
Total 2 entries.
FSM Flag: NI-no info, J-join, PP-prune pending
VLAN 100: Total 2 entries.
(*, 224.1.1.1)
Upstream neighbor: 10.1.1.1
Upstream Ports (1 in total):
GE1/0/1
Downstream Ports (1 in total):
GE1/0/3
Expires: 00:03:01, FSM: J
(*, 225.1.1.1)
Upstream neighbor: 10.1.1.2
Upstream Ports (1 in total):
GE1/0/2
Downstream Ports (1 in total):
GE1/0/4
Expires: 00:03:11, FSM: J
O resultado mostra as seguintes informações:
- O Switch A encaminhará os dados multicast destinados ao grupo multicast 224.1.1.1 somente para o Roteador C.
- O switch A encaminhará os dados multicast destinados ao grupo multicast 225.1.1.1 somente para o roteador D.
Solução de problemas de snooping PIM
O snooping PIM não funciona em um dispositivo de camada 2
Sintoma
O snooping PIM não funciona em um dispositivo de camada 2.
Solução
Para resolver o problema:
- Use o comando display current-configuration para exibir informações sobre o snooping IGMP e o snooping PIM.
- Se o snooping IGMP não estiver ativado, ative o recurso de snooping IGMP e, em seguida, ative o snooping IGMP e o snooping PIM para a VLAN.
- Se o snooping PIM não estiver ativado, ative o snooping PIM para a VLAN.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Configuração de VLANs multicast
Recurso de VLAN multicast
Conforme mostrado na Figura 1, o Host A, o Host B e o Host C estão em três VLANs diferentes e no mesmo grupo multicast. Quando o Switch A (dispositivo de camada 3) recebe dados multicast para esse grupo, ele envia três cópias dos dados multicast para o Switch B (dispositivo de camada 2). Isso ocupa uma grande quantidade de largura de banda e aumenta a carga sobre o dispositivo de camada 3.
Figura 1 Transmissão multicast sem o recurso de VLAN multicast
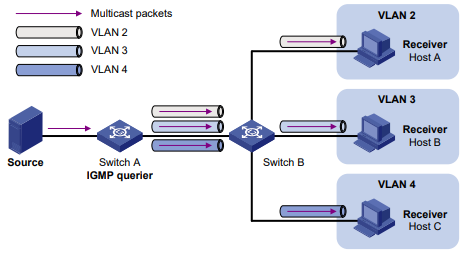
Depois que uma VLAN multicast é configurada no Switch B, o Switch A envia apenas uma cópia dos dados multicast para a VLAN multicast no Switch B. Esse método economiza largura de banda da rede e diminui a carga no dispositivo de Camada 3.
Implementações de VLAN multicast
As VLANs multicast incluem VLANs multicast baseadas em sub-VLANs e VLANs multicast baseadas em portas.
VLAN multicast baseada em sub-VLAN
Conforme mostrado na Figura 2:
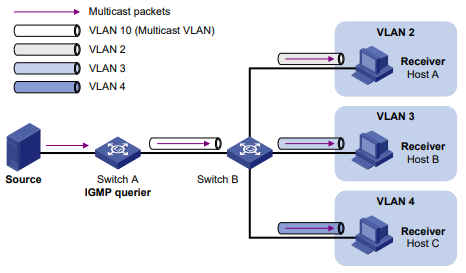
- O host A, o host B e o host C estão na VLAN 2 até a VLAN 4, respectivamente.
- No Switch B, a VLAN 10 é uma VLAN multicast. As VLAN 2 a VLAN 4 são sub-VLANs da VLAN 10.
- O IGMP snooping está ativado para a VLAN multicast e suas sub-VLANs.
Figura 2 VLAN multicast baseada em sub-VLAN
Pacotes multicast
O IGMP snooping gerencia as portas de roteador na VLAN de multicast e as portas de membro em cada sub-VLAN. Quando o Switch A recebe dados multicast da fonte multicast, ele envia apenas uma cópia dos dados multicast para a VLAN multicast no Switch B. Em seguida, o Switch B envia uma cópia separada para cada sub-VLAN na VLAN multicast.
VLAN multicast baseada em porta
Conforme mostrado na Figura 3:
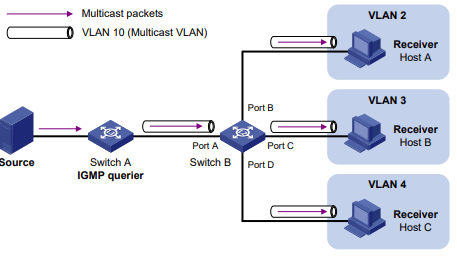
- O host A, o host B e o host C estão na VLAN 2 até a VLAN 4, respectivamente.
- No Switch B, a VLAN 10 é uma VLAN multicast. Todas as portas de usuário são portas híbridas e são atribuídas à VLAN 10.
- O IGMP snooping está ativado para a VLAN multicast e para a VLAN 2 até a VLAN 4.
Figura 3 VLAN multicast baseada em porta
O IGMP snooping gerencia as portas de roteador e as portas de membro na VLAN multicast. Quando o Switch A recebe dados multicast da fonte multicast, ele envia apenas uma cópia dos dados multicast para a VLAN multicast no Switch B. O Switch B envia uma cópia separada para cada porta de usuário na VLAN multicast.
Restrições e diretrizes: Configuração de VLAN multicast
A VLAN a ser configurada como uma VLAN multicast deve existir.
Se você tiver configurado uma VLAN multicast baseada em sub-VLAN e uma VLAN multicast baseada em porta em um dispositivo, a configuração da VLAN multicast baseada em porta entrará em vigor.
O recurso de VLAN multicast não entra em vigor nas VLANs secundárias. Como prática recomendada, não configure o recurso de VLAN multicast para VLANs secundárias. Para obter mais informações sobre VLANs secundárias, consulte o Layer 2-LAN Switching Configuration Guide.
Configuração de uma VLAN multicast baseada em sub-VLAN
Restrições e diretrizes
As VLANs a serem configuradas como sub-VLANs de uma VLAN multicast devem existir e não podem ser VLANs multicast ou sub-VLANs de qualquer outra VLAN multicast.
Pré-requisitos
Antes de configurar uma VLAN multicast baseada em sub-VLAN, você deve concluir as seguintes tarefas:
- Crie VLANs conforme necessário.
- Habilite o IGMP snooping para a VLAN a ser configurada como VLAN multicast e para as VLANs a serem configuradas como sub-VLANs.
Procedimento
- Entre na visualização do sistema.
System View- Configure uma VLAN como uma VLAN multicast e entre na visualização de VLAN multicast.
multicast-vlan vlan-idPor padrão, uma VLAN não é uma VLAN multicast.
- Atribua VLANs à VLAN multicast como sub-VLANs.
subvlan vlan-listConfiguração de uma VLAN multicast baseada em porta
Restrições e diretrizes
É possível atribuir portas de usuário a uma VLAN multicast na visualização de VLAN multicast ou atribuir uma porta de usuário a uma VLAN multicast na visualização de interface. Essas configurações têm a mesma prioridade.
Uma porta de usuário pode pertencer a apenas uma VLAN multicast.
Pré-requisitos
Antes de configurar uma VLAN multicast baseada em porta, você deve concluir as seguintes tarefas:
- Crie VLANs conforme necessário.
- Habilite o IGMP snooping para a VLAN a ser configurada como a VLAN multicast.
- Habilite o IGMP snooping para todas as VLANs que contêm receptores multicast.
- Configure os atributos das portas de usuário. Certifique-se de que as portas possam encaminhar pacotes da VLAN a ser configurada como a VLAN multicast e enviar os pacotes com a tag de VLAN removida. Para
Para obter mais informações sobre a configuração de atributos de porta, consulte Configuração de VLAN no Guia de Configuração de Switching de Camada 2-LAN.
Atribuição de portas de usuário a uma VLAN multicast na visualização de VLAN multicast
- Entre na visualização do sistema.
System View- Configure uma VLAN como uma VLAN multicast e entre na visualização de VLAN multicast.
multicast-vlan vlan-idPor padrão, uma VLAN não é uma VLAN multicast.
- Atribuir portas à VLAN multicast.
port interface-listAtribuição de portas de usuário a uma VLAN multicast na visualização de interface
- Entre na visualização do sistema.
System View- Configure uma VLAN como uma VLAN multicast e entre na visualização de VLAN multicast.
multicast-vlan vlan-idPor padrão, uma VLAN não é uma VLAN multicast.
- Retornar à visualização do sistema.
quit- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Atribuir a porta à VLAN multicast.
port multicast-vlan vlan-idPor padrão, uma porta não pertence a nenhuma VLAN multicast.
Definição do número máximo de entradas de encaminhamento de VLAN multicast
Sobre a configuração do número máximo de entradas de encaminhamento de VLAN multicast
Você pode definir o número máximo de entradas de encaminhamento de VLAN multicast no dispositivo. Quando o limite superior é atingido, o dispositivo não cria entradas de encaminhamento de VLAN multicast até que algumas entradas se esgotem ou sejam removidas manualmente.
Procedimento
- Entre na visualização do sistema.
System View- Defina o número máximo de entradas de encaminhamento de VLAN multicast.
multicast-vlan entry-limit limitA configuração padrão varia de acordo com o modelo do dispositivo. Para obter mais informações, consulte a referência do comando.
Comandos de exibição e manutenção para VLAN multicast
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações sobre VLANs multicast. | display multicast-vlan [ vlan-id ] |
| Exibir informações sobre entradas de encaminhamento de VLAN multicast. | display multicast-vlan forwarding-table [ group-address [ mask { mask-length | mask } ] | source-address [ mask { mask-length | mask } ] | slot slot-número | subvlan vlan-id | vlan vlan-id ] * |
| Exibir informações sobre grupos multicast em VLANs multicast. | display multicast-vlan group [ source-address | Endereço do grupo | Número do slot | Verbose vlan vlan-id ] * |
| Limpar grupos multicast em VLANs multicast. | reset multicast-vlan group [ source-address [ mask { mask-length | mask } ] | group-address [ mask { mask-length | mask } ] | vlan vlan-id ] * |
Exemplos de configuração de VLAN multicast
Exemplo: Configuração de VLAN multicast baseada em sub-VLAN
Configuração de rede
Conforme mostrado na Figura 4:
Figura 4 Diagrama de rede
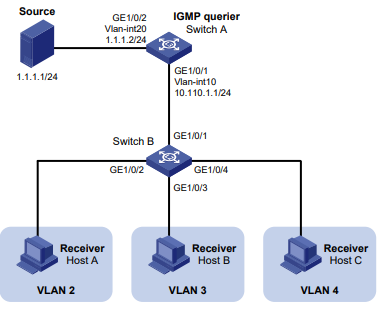
- O dispositivo de camada 3, Switch A, executa o IGMPv2 e atua como consultador IGMP. O dispositivo de camada 2, Switch B, executa o IGMPv2 snooping.
- A origem multicast envia dados multicast para o grupo multicast 224.1.1.1. Os receptores Host A, Host B e Host C pertencem à VLAN 2, VLAN 3 e VLAN 4, respectivamente.
Configure uma VLAN multicast baseada em sub-VLAN no Switch B para atender aos seguintes requisitos:
- O switch A envia os dados multicast para o switch B por meio da VLAN multicast.
- O switch B encaminha os dados multicast para os receptores em diferentes VLANs de usuário.
Procedimento
- Configure o Switch A:
# Habilitar o roteamento multicast de IP.
<SwitchA> system-view
[SwitchA] multicast routing
[SwitchA-mrib] quit# Crie a VLAN 20 e atribua a GigabitEthernet 1/0/2 à VLAN.
[SwitchA] vlan 20
[SwitchA-vlan20] port gigabitethernet 1/0/2
[SwitchA-vlan20] quit# Atribua um endereço IP à interface VLAN 20 e ative o PIM-DM na interface.
[SwitchA] interface vlan-interface 20
[SwitchA-Vlan-interface20] ip address 1.1.1.2 24
[SwitchA-Vlan-interface20] pim dm
[SwitchA-Vlan-interface20] quit# Criar a VLAN 10.
[SwitchA] vlan 10
[SwitchA-vlan10] quit# Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua a porta à VLAN 10 como um membro de VLAN marcada.
[SwitchA] interface gigabitethernet 1/0/1
[SwitchA-GigabitEthernet1/0/1] port link-type hybrid
[SwitchA-GigabitEthernet1/0/1] port hybrid vlan 10 tagged
[SwitchA-GigabitEthernet1/0/1] quit# Atribua um endereço IP à interface VLAN 10 e ative o IGMP na interface.
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ip address 10.110.1.1 24
[SwitchA-Vlan-interface10] igmp enable
[SwitchA-Vlan-interface10] quit- Configurar o Switch B:
# Habilite o recurso de snooping IGMP.
<SwitchB> system-view
[SwitchB] igmp-snooping
[SwitchB-igmp-snooping] quit
# Crie a VLAN 2, atribua a GigabitEthernet 1/0/2 à VLAN e ative o IGMP snooping para a VLAN.
[SwitchB] vlan 2
[SwitchB-vlan2] port gigabitethernet 1/0/2
[SwitchB-vlan2] igmp-snooping enable
[SwitchB-vlan2] quit# Crie a VLAN 3, atribua a GigabitEthernet 1/0/3 à VLAN e ative o IGMP snooping na VLAN.
[SwitchB] vlan 3
[SwitchB-vlan3] port gigabitethernet 1/0/3
[SwitchB-vlan3] igmp-snooping enable
[SwitchB-vlan3] quit# Crie a VLAN 4, atribua a GigabitEthernet 1/0/4 à VLAN e ative o IGMP snooping na VLAN.
[SwitchB] vlan 4
[SwitchB-vlan4] port gigabitethernet 1/0/4
[SwitchB-vlan4] igmp-snooping enable
[SwitchB-vlan4] quit# Crie a VLAN 10 e ative o IGMP snooping para a VLAN.
[SwitchB] vlan 10
[SwitchB-vlan10] igmp-snooping enable
[SwitchB-vlan10] quit
# Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua a porta à VLAN 10 como uma porta marcada Membro da VLAN.
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] port link-type hybrid
[SwitchB-GigabitEthernet1/0/1] port hybrid vlan 10 tagged
[SwitchB-GigabitEthernet1/0/1] quit
# Configure a VLAN 10 como uma VLAN multicast e atribua as VLANs 2 a 4 como sub-VLANs para a VLAN 10 multicast.
[SwitchB] multicast-vlan 10
[SwitchB-mvlan-10] subvlan 2 to 4
[SwitchB-mvlan-10] quit
Verificação da configuração
# Exibir informações sobre todas as VLANs multicast no Switch B.
[SwitchB] display multicast-vlan
Total 1 multicast VLANs.
Multicast VLAN 10:
Sub-VLAN list(3 in total):
2-4
Port list(0 in total):
# Exibir informações sobre grupos multicast em VLANs multicast no Switch B.
[SwitchB] display multicast-vlan group
Total 1 entries.
Multicast VLAN 10: Total 1 entries.
(0.0.0.0, 224.1.1.1)
Sub-VLANs (3 in total):
VLAN 2
VLAN 3
VLAN 4
A saída mostra que o grupo multicast 224.1.1.1 pertence à VLAN 10 multicast. A VLAN 10 de multicast contém as sub-VLANs VLAN 2 a VLAN 4. O switch B replicará os dados multicast da VLAN 10 para a VLAN 2 até a VLAN 4.
Exemplo: Configuração de VLAN multicast baseada em porta
Configuração de rede
Conforme mostrado na Figura 5:
Figura 5 Diagrama de rede
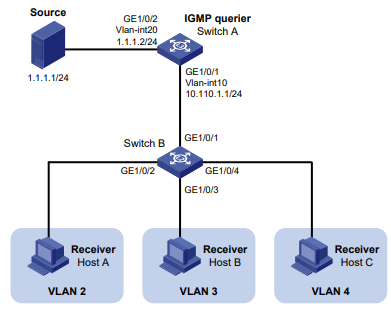
- O dispositivo de camada 3, Switch A, executa o IGMPv2 e atua como consultador IGMP. O dispositivo de camada 2, Switch B, executa o IGMPv2 snooping.
- A origem multicast envia dados multicast para o grupo multicast 224.1.1.1. Os receptores Host A, Host B e Host C pertencem à VLAN 2, VLAN 3 e VLAN 4, respectivamente.
Configure uma VLAN multicast baseada em porta no Switch B para atender aos seguintes requisitos:
- O Switch A envia dados multicast para o Switch B por meio da VLAN multicast.
- O switch B encaminha os dados multicast para os receptores em diferentes VLANs de usuário.
Procedimento
- Configure o Switch A:
# Habilitar o roteamento multicast de IP.
<SwitchA> system-view
[SwitchA] multicast routing [SwitchA-mrib] quit
# Crie a VLAN 20 e atribua a GigabitEthernet 1/0/2 à VLAN.
[SwitchA] vlan 20
[SwitchA-vlan20] port gigabitethernet 1/0/2
[SwitchA-vlan20] quit# Atribua um endereço IP à interface VLAN 20 e ative o PIM-DM na interface.
[SwitchA] interface vlan-interface 20
[SwitchA-Vlan-interface20] ip address 1.1.1.2 24
[SwitchA-Vlan-interface20] pim dm
[SwitchA-Vlan-interface20] quit# Crie a VLAN 10 e atribua a GigabitEthernet 1/0/1 à VLAN.
[SwitchA] vlan 10
[SwitchA-vlan10] port gigabitethernet 1/0/1
[SwitchA-vlan10] quit
# Atribua um endereço IP à interface VLAN 10 e ative o IGMP na interface.
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ip address 10.110.1.1 24
[SwitchA-Vlan-interface10] igmp enable
[SwitchA-Vlan-interface10] quit- Configurar o Switch B:
# Habilite o recurso de snooping IGMP.
<SwitchB> system-view
[SwitchB] igmp-snooping
[SwitchB-igmp-snooping] quit
# Crie a VLAN 10, atribua a GigabitEthernet 1/0/1 à VLAN e ative o IGMP snooping para a VLAN.
[SwitchB] vlan 10
[SwitchB-vlan10] port gigabitethernet 1/0/1
[SwitchB-vlan10] igmp-snooping enable
[SwitchB-vlan10] quit
# Crie a VLAN 2 e ative o IGMP snooping para a VLAN.
[SwitchB] vlan 2
[SwitchB-vlan2] igmp-snooping enable
[SwitchB-vlan2] quit
# Crie a VLAN 3 e ative o IGMP snooping para a VLAN.
[SwitchB] vlan 3
[SwitchB-vlan3] igmp-snooping enable
[SwitchB-vlan3] quit
# Crie a VLAN 4 e ative o IGMP snooping para a VLAN.
[SwitchB] vlan 4
[SwitchB-vlan4] igmp-snooping enable
[SwitchB-vlan4] quit
# Configure a GigabitEthernet 1/0/2 como uma porta híbrida e configure a VLAN 2 como o PVID da porta híbrida.
[SwitchB] interface gigabitethernet 1/0/2
[SwitchB-GigabitEthernet1/0/2] port link-type hybrid
[SwitchB-GigabitEthernet1/0/2] port hybrid pvid vlan 2
# Atribua a GigabitEthernet 1/0/2 à VLAN 2 e à VLAN 10 como um membro de VLAN sem marcação.
[SwitchB-GigabitEthernet1/0/2] port hybrid vlan 2 untagged
[SwitchB-GigabitEthernet1/0/2] port hybrid vlan 10 untagged
[SwitchB-GigabitEthernet1/0/2] quit
# Configure a GigabitEthernet 1/0/3 como uma porta híbrida e configure a VLAN 3 como o PVID da porta híbrida.
[SwitchB] interface gigabitethernet 1/0/3
[SwitchB-GigabitEthernet1/0/3] port link-type hybrid
[SwitchB-GigabitEthernet1/0/3] port hybrid pvid vlan 3
# Atribua a GigabitEthernet 1/0/3 à VLAN 3 e à VLAN 10 como um membro de VLAN sem marcação.
[SwitchB-GigabitEthernet1/0/3] port hybrid vlan 3 untagged
[SwitchB-GigabitEthernet1/0/3] port hybrid vlan 10 untagged
[SwitchB-GigabitEthernet1/0/3] quit
# Configure a GigabitEthernet 1/0/4 como uma porta híbrida e configure a VLAN 4 como o PVID da porta híbrida.
[SwitchB] interface gigabitethernet 1/0/4
[SwitchB-GigabitEthernet1/0/4] port link-type hybrid
[SwitchB-GigabitEthernet1/0/4] port hybrid pvid vlan 4
# Atribua a GigabitEthernet 1/0/4 à VLAN 4 e à VLAN 10 como um membro de VLAN sem marcação.
[SwitchB-GigabitEthernet1/0/4] port hybrid vlan 4 untagged
[SwitchB-GigabitEthernet1/0/4] port hybrid vlan 10 untagged
[SwitchB-GigabitEthernet1/0/4] quit
# Configure a VLAN 10 como uma VLAN multicast.
[SwitchB] multicast-vlan 10# Atribua a GigabitEthernet 1/0/2 e a GigabitEthernet 1/0/3 à VLAN 10.
[SwitchB-mvlan-10] port gigabitethernet 1/0/2 to gigabitethernet 1/0/3
[SwitchB-mvlan-10] quit# Atribua a GigabitEthernet 1/0/4 à VLAN 10.
[SwitchB] interface gigabitethernet 1/0/4
[SwitchB-GigabitEthernet1/0/4] port multicast-vlan 10
[SwitchB-GigabitEthernet1/0/4] quitVerificação da configuração
# Exibir informações sobre VLANs multicast no Switch B.
[SwitchB] display multicast-vlan
Total 1 multicast VLANs.
Multicast VLAN 10:
Sub-VLAN list(0 in total):
Port list(3 in total):
GE1/0/2
GE1/0/3
GE1/0/4# Exibir entradas dinâmicas de encaminhamento do IGMP snooping no Switch B.
[SwitchB] display igmp-snooping group
Total 1 entries.
VLAN 10: Total 1 entries.
11
(0.0.0.0, 224.1.1.1)
Host slots (0 in total):
Host ports (3 in total):
GE1/0/2 (00:03:23)
GE1/0/3 (00:04:07)
GE1/0/4 (00:04:16)A saída mostra que o IGMP snooping mantém as portas de usuário na VLAN multicast (VLAN 10). O switch B encaminhará os dados multicast da VLAN 10 por meio dessas portas de usuário.
Configuração do MLD snooping
Sobre o MLD snooping
O MLD snooping é executado em um dispositivo de camada 2 como um mecanismo de restrição de multicast IPv6 para melhorar a eficiência do encaminhamento de multicast. Ele cria entradas de encaminhamento de multicast da Camada 2 a partir de mensagens MLD trocadas entre os hosts e o dispositivo da Camada 3.
Fundamentos do MLD snooping
Conforme mostrado na Figura 1, quando o MLD snooping não está ativado, o switch da Camada 2 inunda todos os hosts em uma VLAN com pacotes multicast IPv6. Quando o MLD snooping está ativado, o switch da Camada 2 encaminha pacotes multicast de grupos multicast IPv6 conhecidos somente para os receptores.
Figura 1 Processos de transmissão de pacotes multicast sem e com MLD snooping
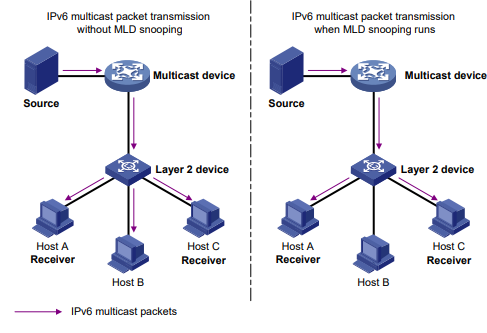
Portas do MLD snooping
Conforme mostrado na Figura 2, o MLD snooping é executado no Switch A e no Switch B, e o Host A e o Host C são hosts receptores em um grupo multicast IPv6. As portas do MLD snooping são divididas em portas de membro e portas de roteador.
Figura 2 Portas do MLD snooping
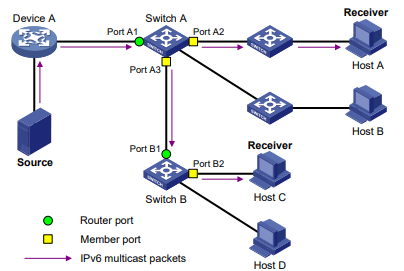
Portas do roteador
Em um dispositivo de Camada 2 com MLD snooping, as portas para dispositivos multicast de Camada 3 são chamadas de portas de roteador. Na Figura 2, a porta A1 do switch A e a porta B1 do switch B são portas de roteador.
As portas do roteador contêm os seguintes tipos:
- Porta de roteador dinâmico - Quando uma porta recebe uma consulta geral de MLD cujo endereço de origem não é 0::0 ou recebe uma mensagem de olá IPv6 PIM, a porta é adicionada à lista de portas de roteador dinâmico. Ao mesmo tempo, um cronômetro de envelhecimento é iniciado para a porta. Se a porta receber qualquer uma das mensagens antes que o cronômetro expire, o cronômetro será reiniciado. Se a porta não receber nenhuma das mensagens quando o cronômetro expirar, a porta será removida da lista de portas do roteador dinâmico.
- Porta de roteador estático - Quando uma porta é configurada estaticamente como uma porta de roteador, ela é adicionada à lista de portas de roteador estático. A porta do roteador estático não envelhece e só pode ser excluída manualmente.
Não confunda a "porta do roteador" no MLD snooping com a "interface roteada", comumente conhecida como "interface de camada 3". A porta do roteador no MLD snooping é uma interface de camada 2.
Portas de membros
Em um dispositivo de camada 2 do MLD snooping, as portas voltadas para os hosts receptores são chamadas de portas-membro. Na Figura 2, a Porta A2 e a Porta A3 do Switch A e a Porta B2 do Switch B são portas membros.
As portas membros contêm os seguintes tipos:
- Porta de membro dinâmico - Quando uma porta recebe um relatório MLD, ela é adicionada à entrada de encaminhamento de MLD snooping dinâmico associada como uma interface de saída. Ao mesmo tempo, um cronômetro de envelhecimento é iniciado para a porta. Se a porta receber um relatório MLD antes que o cronômetro expire, ele será reiniciado. Se a porta não receber um relatório MLD quando o cronômetro expirar, a porta será removida da entrada de encaminhamento dinâmico associada.
- Porta membro estática - Quando uma porta é configurada estaticamente como porta membro, ela é adicionada à entrada de encaminhamento do MLD snooping estático associado como uma interface de saída. A porta membro estática não envelhece e só pode ser excluída manualmente.
A menos que especificado de outra forma, as portas do roteador e as portas-membro neste documento incluem portas do roteador e portas-membro estáticas e dinâmicas.
Como funciona o MLD snooping
As portas desta seção são portas dinâmicas. Para obter informações sobre como configurar e remover portas estáticas, consulte "Configuração de uma porta membro estática" e "Configuração de uma porta de roteador estática".
As mensagens MLD incluem consulta geral, relatório MLD e mensagem concluída. Um dispositivo de camada 2 habilitado para MLD snooping tem um desempenho diferente, dependendo dos tipos de mensagens MLD.
Consulta geral
O MLD querier envia periodicamente consultas gerais de MLD a todos os hosts e dispositivos na sub-rede local para verificar a existência de membros do grupo multicast IPv6.
Depois de receber uma consulta geral MLD, o dispositivo da Camada 2 encaminha a consulta para todas as portas da VLAN, exceto a porta receptora. O dispositivo de camada 2 também executa uma das seguintes ações:
- Se a porta receptora for uma porta de roteador dinâmico na lista de portas de roteador dinâmico, o dispositivo de Camada 2 reiniciará o cronômetro de envelhecimento da porta do roteador.
- Se a porta receptora não existir na lista de portas do roteador dinâmico, o dispositivo de camada 2 adicionará a porta à lista de portas do roteador dinâmico. Ele também inicia um cronômetro de envelhecimento para a porta.
Relatório MLD
Um host envia um relatório MLD ao MLD querier para as seguintes finalidades:
- Responde a consultas se o host for membro de um grupo multicast IPv6.
- Aplica-se a uma associação de grupo multicast IPv6.
Depois de receber um relatório MLD de um host, o dispositivo de camada 2 encaminha o relatório por todas as portas do roteador na VLAN. Ele também resolve o endereço IPv6 do grupo multicast IPv6 relatado e procura na tabela de encaminhamento uma entrada correspondente da seguinte forma:
- Se não houver correspondência, o dispositivo de camada 2 cria uma entrada de encaminhamento para o grupo com a porta receptora como interface de saída. Ele também marca a porta receptora como uma porta membro dinâmica e inicia um cronômetro de envelhecimento para a porta.
- Se for encontrada uma correspondência, mas a entrada de encaminhamento correspondente não contiver a porta de recepção, o dispositivo de Camada 2 adicionará a porta de recepção à lista de interfaces de saída. Ele também marca a porta como uma porta membro dinâmica para a entrada de encaminhamento e inicia um cronômetro de envelhecimento para a porta.
- Se for encontrada uma correspondência e a entrada de encaminhamento correspondente contiver a porta receptora, o dispositivo da Camada 2 reiniciará o cronômetro de envelhecimento da porta.
OBSERVAÇÃO:
Um dispositivo de camada 2 não encaminha um relatório MLD por meio de uma porta não roteadora devido ao mecanismo de supressão de relatórios MLD do host. Se uma porta não roteadora tiver um host membro conectado, os hosts membros suprimirão seus relatórios MLD ao receberem relatórios MLD encaminhados pela porta não roteadora. O dispositivo de camada 2 não pode saber da existência dos hosts membros conectados à porta que não é de roteador.
Mensagem concluída
Quando um host sai de um grupo multicast IPv6, ele envia uma mensagem MLD done para os dispositivos da Camada 3. Quando o dispositivo da camada 2 recebe a mensagem MLD done em uma porta de membro dinâmico, ele primeiro examina se uma entrada de encaminhamento corresponde ao endereço do grupo multicast IPv6 na mensagem.
- Se não for encontrada nenhuma correspondência, o dispositivo de camada 2 descartará a mensagem MLD done.
- Se for encontrada uma correspondência, mas a porta receptora não for uma interface de saída na entrada de encaminhamento, o dispositivo de camada 2 descartará a mensagem MLD done.
- Se for encontrada uma correspondência e a porta receptora não for a única interface de saída na entrada de encaminhamento, o dispositivo de camada 2 executará as seguintes ações:
- Descarta a mensagem MLD done.
- Envia uma consulta específica de endereço multicast MLD para identificar se o grupo tem ouvintes ativos conectados à porta receptora.
- Define o cronômetro de envelhecimento da porta receptora para o dobro do intervalo de consulta do último ouvinte do MLD.
- Se for encontrada uma correspondência e a porta receptora for a única interface de saída na entrada de encaminhamento, o dispositivo de camada 2 executará as seguintes ações:
- Encaminha a mensagem MLD done para todas as portas do roteador na VLAN.
- Envia uma consulta específica de endereço multicast MLD para identificar se o grupo tem ouvintes ativos conectados à porta receptora.
- Define o cronômetro de envelhecimento da porta receptora para o dobro do intervalo de consulta do último ouvinte do MLD.
Depois de receber a mensagem MLD done em uma porta, o MLD querier resolve o endereço do grupo multicast IPv6 na mensagem. Em seguida, ele envia uma consulta específica de endereço multicast MLD para o grupo multicast IPv6 por meio da porta receptora.
Depois de receber a consulta específica de endereço multicast MLD, o dispositivo de camada 2 encaminha a consulta por todas as portas do roteador e portas-membro do grupo na VLAN. Em seguida, ele aguarda o relatório MLD de resposta dos hosts diretamente conectados. Para a porta membro dinâmica que recebeu a mensagem done, o dispositivo de camada 2 também executa uma das seguintes ações:
- Se a porta receber um relatório MLD antes que o cronômetro de envelhecimento expire, o dispositivo de Camada 2 redefinirá o cronômetro de envelhecimento da porta.
- Se a porta não receber nenhuma mensagem de relatório MLD quando o cronômetro de envelhecimento expirar, o dispositivo de Camada 2 removerá a porta da entrada de encaminhamento para o grupo multicast IPv6.
Proxy de MLD snooping
Conforme mostrado na Figura 3, para reduzir o número de mensagens MLD report e done recebidas pelo dispositivo upstream, você pode ativar o proxy de MLD snooping no dispositivo de borda. Com o proxy de MLD snooping ativado, o dispositivo de borda atua como um host para que o querier de MLD snooping upstream envie mensagens de relatório MLD e done para o Dispositivo A. O mecanismo de supressão de relatório MLD do host no dispositivo de borda não tem efeito.
Figura 3 Proxy de MLD snooping
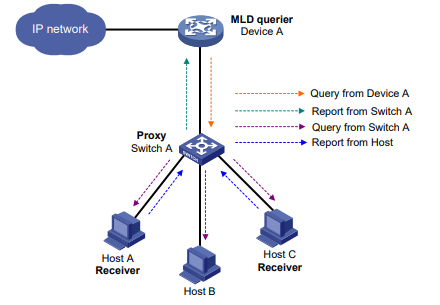
O dispositivo proxy MLD snooping processa diferentes mensagens MLD da seguinte forma:
- Consulta geral.
Depois de receber uma consulta geral MLD, o dispositivo encaminha a consulta para todas as portas da VLAN, exceto a porta receptora. O dispositivo também gera um relatório MLD com base nas informações de associação local e envia o relatório a todas as portas do roteador.
- Consulta específica de endereço multicast ou consulta específica de endereço e origem multicast.
Após o recebimento de uma consulta específica de endereço multicast MLD ou
Se o dispositivo estiver enviando uma consulta específica de endereço e fonte multicast, o dispositivo encaminhará a consulta a todas as portas da VLAN, exceto à porta receptora. Se a entrada de encaminhamento tiver uma porta membro, o dispositivo enviará uma resposta a todas as portas do roteador na VLAN.
- Relatório.
Depois de receber um relatório MLD de um host, o dispositivo procura uma entrada correspondente na tabela de encaminhamento da seguinte forma:
- Se for encontrada uma correspondência e a entrada de encaminhamento correspondente contiver a porta receptora, o dispositivo redefinirá o cronômetro de envelhecimento da porta.
- Se for encontrada uma correspondência, mas a entrada de encaminhamento correspondente não contiver a porta de recepção, o dispositivo adicionará a porta de recepção à lista de interfaces de saída. Ele também marca a porta receptora como uma porta membro dinâmica e inicia um cronômetro de envelhecimento para a porta.
- Se não for encontrada nenhuma correspondência, o dispositivo criará uma entrada de encaminhamento com a porta receptora como uma interface de saída. Ele também marca a porta receptora como uma porta membro dinâmica e inicia um cronômetro de envelhecimento para a porta. Em seguida, ele envia o relatório a todas as portas do roteador.
- Mensagem concluída.
Após receber a mensagem MLD done em uma porta, o dispositivo envia uma mensagem MLD
consulta específica de endereço multicast por meio da porta receptora. O dispositivo envia a mensagem MLD done a todas as portas do roteador somente quando a última porta membro é removida da entrada de encaminhamento.
Protocolos e padrões
RFC 4541, Considerações sobre switches de protocolo de gerenciamento de grupos da Internet (IGMP) e descoberta de ouvinte multicast (MLD) Snooping
Restrições e diretrizes: Configuração do MLD snooping
Para relatórios MLD recebidos de VLANs secundárias, as entradas de encaminhamento de MLD snooping relevantes são mantidas pela VLAN primária. Portanto, você precisa ativar o MLD snooping somente para a VLAN primária. A configuração feita nas VLANs secundárias não terá efeito. Para obter mais informações sobre VLANs primárias e secundárias, consulte o Layer 2-LAN Switching Configuration Guide.
As configurações do MLD snooping feitas nas interfaces agregadas da Camada 2 não interferem nas configurações feitas nas portas-membro. Além disso, as configurações feitas nas interfaces agregadas da Camada 2 não participam dos cálculos de agregação. A configuração feita em uma porta membro do grupo agregado entra em vigor depois que a porta deixa o grupo agregado.
Alguns recursos podem ser configurados para uma VLAN na visualização de VLAN ou para várias VLANs na visualização de MLD-snooping. A configuração específica da VLAN e a configuração feita na visualização MLD-snooping têm a mesma prioridade, e a configuração mais recente entra em vigor.
Alguns recursos podem ser configurados para uma VLAN na visualização VLAN ou globalmente para todas as VLANs na visualização MLD-snooping. A configuração específica da VLAN tem prioridade sobre a configuração global.
Alguns recursos podem ser configurados para uma interface na visualização de interface ou para todas as interfaces das VLANs especificadas na visualização MLD-snooping. A configuração específica da interface tem prioridade sobre a configuração feita na visualização MLD-snooping.
Visão geral das tarefas do MLD snooping baseado em VLAN
Para configurar o MLD snooping para VLANs, execute as seguintes tarefas:
Escolha as seguintes tarefas, conforme necessário:
- Ativação do MLD snooping globalmente
- Ativação do MLD snooping para VLANs
- (Opcional.) Configuração dos recursos básicos do MLD snooping
- Especificação de uma versão do MLD snooping
- Definição do número máximo de entradas de encaminhamento do MLD snooping
- Configuração de entradas de endereço MAC multicast IPv6 estático
- Configuração do intervalo de consulta do último ouvinte do MLD
- (Opcional.) Configuração dos recursos de porta do MLD snooping
- Configuração de temporizadores de envelhecimento para portas dinâmicas
- Configuração de uma porta membro estática
- Configuração de uma porta de roteador estático
- Configuração de uma porta como um host membro simulado
- Ativação do processamento rápido de licenças
- Desativar a possibilidade de uma porta se tornar uma porta de roteador dinâmico
- (Opcional.) Configuração do querier de MLD snooping
- Ativação do consultador de MLD snooping
- Ativação da eleição do querier do MLD snooping
- Configuração de parâmetros para consultas e respostas gerais de MLD
- (Opcional.) Ativação do proxy de MLD snooping
- Configuração de endereços IPv6 de origem para mensagens MLD
- Definição da prioridade 802.1p para mensagens MLD
- (Opcional.) Configuração de políticas de MLD snooping
- Configuração de uma política de grupo multicast IPv6
- Ativação da filtragem de portas de origem multicast IPv6
- Ativação da eliminação de dados multicast IPv6 desconhecidos
- Ativação da supressão de relatórios MLD
- Configuração do número máximo de grupos multicast IPv6 em uma porta
- Ativação da substituição de grupos multicast IPv6
- Ativação do rastreamento do host
- (Opcional.) Configuração do valor DSCP para pacotes de saída do protocolo MLD
Ativação do recurso MLD snooping
Sobre a ativação do recurso MLD snooping
Você deve ativar o recurso de MLD snooping antes de configurar outros recursos de MLD snooping.
Procedimento
System View- Ative o recurso MLD snooping e entre na visualização MLD-snooping.
mld-snoopingPor padrão, o recurso MLD snooping está desativado.
Ativação do MLD snooping
Ativação do MLD snooping globalmente
Sobre como ativar o MLD snooping globalmente
Depois que você ativa o MLD snooping globalmente, o MLD snooping é ativado para todas as VLANs. Você pode desativar o snooping MLD para uma VLAN quando o snooping MLD estiver ativado globalmente.
Restrições e diretrizes
Para configurar outros recursos do MLD snooping para VLANs, você deve ativar o MLD snooping para as VLANs específicas, mesmo que o MLD snooping esteja ativado globalmente.
A configuração de MLD snooping específica da VLAN tem prioridade sobre a configuração global de MLD snooping. Por exemplo, se você ativar o MLD snooping globalmente e depois usar o comando mld-snooping disable para desativar o MLD snooping para uma VLAN, o MLD snooping será desativado na VLAN.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Ativar o MLD snooping globalmente.
global-enablePor padrão, o MLD snooping é desativado globalmente.
- (Opcional.) Desative o MLD snooping para uma VLAN.
- Retornar à visualização do sistema.
quit- Entre na visualização de VLAN.
vlan vlan-id- Desativar o MLD snooping para a VLAN.
mld-snooping disablePor padrão, o status do MLD snooping em uma VLAN é consistente com o status global do MLD snooping .
Ativação do MLD snooping para VLANs
Restrições e diretrizes
Você pode ativar o MLD snooping para várias VLANs usando o comando enable vlan na visualização MLD-snooping ou para uma VLAN usando o comando mld-snooping enable na visualização VLAN. A configuração na visualização de VLAN tem a mesma prioridade que a configuração na visualização de MLD-snooping.
A configuração do MLD snooping em uma VLAN entra em vigor somente nas portas membros da VLAN.
Ativação do MLD snooping para várias VLANs
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Ativar o MLD snooping para várias VLANs.
enable vlan vlan-listPor padrão, o status do MLD snooping em uma VLAN é consistente com o status global do MLD snooping.
Ativação do MLD snooping para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Ativar o MLD snooping para a VLAN.
mld-snooping enablePor padrão, o status do MLD snooping em uma VLAN é consistente com o status global do MLD snooping.
Configuração dos recursos básicos do MLD snooping
Especificação de uma versão do MLD snooping
Sobre as versões do MLD snooping
Diferentes versões do MLD snooping podem processar diferentes versões de mensagens MLD:
- O snooping MLDv1 pode processar mensagens MLDv1 e consultas MLDv2, mas inunda os relatórios MLDv2 na VLAN em vez de processá-los.
- O snooping MLDv2 pode processar mensagens MLDv1 e MLDv2.
Restrições e diretrizes
Se você alterar a versão do MLD snooping de 2 para 1, o sistema executará as seguintes ações:
- Limpa todos os registros de encaminhamento do MLD snooping criados dinamicamente.
- Mantém entradas estáticas de encaminhamento de snooping MLDv2 (*, G).
- Limpa entradas estáticas de encaminhamento do snooping MLDv2 (S, G), que serão restauradas quando o snooping MLD for alternado novamente para o snooping MLDv2.
Para obter mais informações sobre entradas de encaminhamento de MLD snooping estático, consulte "Configuração de uma porta membro estática".
Especificação de uma versão do MLD snooping para várias VLANs
- Entre na visualização do sistema.
System View- Entre na visualização de MLD-snooping.
mld-snooping- Especifique uma versão do MLD snooping para várias VLANs.
version version-number vlan vlan-listPor padrão, a versão do MLD snooping para uma VLAN é 1.
Especificação de uma versão do MLD snooping para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Especifique uma versão do MLD snooping para a VLAN.
mld-snooping version version-numberPor padrão, a versão do MLD snooping para uma VLAN é 1.
Definição do número máximo de entradas de encaminhamento do MLD snooping
Sobre a configuração do número máximo de entradas de encaminhamento do MLD snooping
Você pode modificar o número máximo de entradas de encaminhamento de MLD snooping, incluindo entradas dinâmicas e estáticas. Quando o número de entradas de encaminhamento no dispositivo atinge o limite superior, o dispositivo não remove automaticamente nenhuma entrada existente. Para permitir que novas entradas sejam criadas, remova algumas entradas manualmente.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Defina o número máximo de entradas de encaminhamento de MLD snooping.
entry-limit limitPor padrão, o número máximo de entradas de encaminhamento do MLD snooping é 4294967295.
Configuração de entradas de endereço MAC multicast IPv6 estático
Sobre as entradas de endereço MAC multicast IPv6 estático
No multicast IPv6 da Camada 2, as entradas de endereço MAC multicast IPv6 podem ser criadas dinamicamente por meio de protocolos multicast da Camada 2 (como o MLD snooping). Também é possível configurar manualmente entradas de endereço MAC multicast IPv6 estáticas vinculando endereços MAC multicast IPv6 e portas para controlar as portas de destino dos dados multicast IPv6.
Restrições e diretrizes
Você deve especificar um endereço MAC multicast não utilizado ao configurar uma entrada de endereço MAC multicast IPv6 estático. Um endereço MAC multicast é o endereço MAC em que o bit menos significativo do octeto mais significativo é 1.
Configuração de uma entrada de endereço MAC multicast IPv6 estático na visualização do sistema
- Entre na visualização do sistema.
System View- Configurar uma entrada de endereço MAC multicast IPv6 estático.
mac-address multicast mac-address interface interface-list vlan
vlan-idConfiguração de uma entrada de endereço MAC multicast IPv6 estático na visualização da interface
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Configurar uma entrada de endereço MAC multicast IPv6 estático.
mac-address multicast mac-address vlan vlan-idConfiguração do intervalo de consulta do último ouvinte do MLD
Sobre o intervalo de consulta do último ouvinte do MLD
Um host receptor inicia um cronômetro de atraso de relatório para um grupo multicast IPv6 quando recebe uma consulta específica de endereço multicast MLD para o grupo. Esse cronômetro é definido com um valor aleatório no intervalo de 0 até o tempo máximo de resposta anunciado na consulta. Quando o valor do cronômetro diminui para 0, o host envia um relatório MLD para o grupo.
O intervalo da última consulta do ouvinte de MLD define o tempo máximo de resposta anunciado nas consultas específicas de endereço múltiplo de MLD. Defina um valor adequado para o intervalo de última consulta do ouvinte de MLD para acelerar as respostas dos hosts às consultas específicas de endereço múltiplo de MLD e evitar explosões de tráfego de relatório de MLD.
Definição do intervalo de consulta do último ouvinte do MLD em nível global
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Defina globalmente o intervalo de consulta do último ouvinte do MLD.
last-listener-query-interval intervalPor padrão, o intervalo de consulta do último ouvinte do MLD é de 1 segundo.
Definição do intervalo de consulta do último ouvinte de MLD para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Definir o intervalo de consulta do último ouvinte de MLD para a VLAN
mld-snooping last-listener-query-interval intervalPor padrão, o intervalo de consulta do último ouvinte do MLD é de 1 segundo para uma VLAN.
Configuração dos recursos de porta do MLD snooping
Configuração de temporizadores de envelhecimento para portas dinâmicas
Sobre temporizadores de envelhecimento para portas dinâmicas
Uma porta de roteador dinâmico será removida da lista de portas de roteador dinâmico se não receber uma consulta geral MLD ou uma mensagem de alô IPv6 PIM quando seu cronômetro de envelhecimento expirar.
Uma porta membro dinâmica é removida da porta membro dinâmica se não receber um relatório MLD quando seu cronômetro de envelhecimento expirar.
Restrições e diretrizes
Defina um valor adequado para os cronômetros de envelhecimento das portas dinâmicas com base nos requisitos reais da rede. Por exemplo, se os membros dos grupos multicast IPv6 mudarem com frequência, defina um valor relativamente pequeno para o cronômetro de envelhecimento das portas de membros dinâmicos.
Se uma porta de roteador dinâmico receber uma mensagem hello do IPv6 PIMv2, o timer de envelhecimento da porta será especificado pela mensagem hello. Nesse caso, o comando mld-snooping router-aging-time não tem efeito sobre a porta.
As consultas específicas de endereço multicast MLD originadas pelo dispositivo de Camada 2 acionam o ajuste dos timers de envelhecimento das portas membros dinâmicas. Se uma porta membro dinâmica receber essa consulta, seu cronômetro de envelhecimento será definido para o dobro do intervalo da última consulta do ouvinte MLD. Para obter mais informações sobre a configuração do intervalo de consulta do último ouvinte do MLD no dispositivo da Camada 2, consulte "Configuração do intervalo de consulta do último ouvinte do MLD".
Configuração global dos timers de envelhecimento para portas dinâmicas
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Defina globalmente o cronômetro de envelhecimento para portas de roteador dinâmico.
router-aging-time secondsPor padrão, o timer de envelhecimento das portas dinâmicas do roteador é de 260 segundos.
- Defina globalmente o cronômetro de envelhecimento para portas de membros dinâmicos.
host-aging-time secondsPor padrão, o cronômetro de envelhecimento das portas de membros dinâmicos é de 260 segundos.
Configuração dos timers de envelhecimento para portas dinâmicas em uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Defina o cronômetro de envelhecimento para portas de roteador dinâmico na VLAN.
mld-snooping router-aging-time secondsPor padrão, o timer de envelhecimento das portas dinâmicas do roteador é de 260 segundos para uma VLAN.
- Defina o cronômetro de envelhecimento para portas de membros dinâmicos na VLAN.
mld-snooping host-aging-time secondsPor padrão, o cronômetro de envelhecimento das portas de membros dinâmicos é de 260 segundos para uma VLAN.
Configuração de uma porta membro estática
Sobre portas-membro estáticas
Você pode configurar uma porta como porta membro estática de um grupo multicast IPv6 para que todos os hosts conectados à porta possam sempre receber dados multicast IPv6 do grupo. A porta de membro estático não responde a consultas MLD. Quando você conclui ou cancela essa configuração, a porta não envia um relatório não solicitado ou uma mensagem de conclusão.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Configure a porta como uma porta membro estática.
mld-snooping static-group ipv6-group-address [ source-ip
ipv6-source-address ] vlan vlan-idPor padrão, uma porta não é uma porta membro estática.
Configuração de uma porta de roteador estático
Sobre as portas estáticas do roteador
Você pode configurar uma porta como uma porta de roteador estático para um grupo multicast IPv6, de modo que todos os dados multicast IPv6 do grupo recebidos na porta sejam encaminhados.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Configure a porta como uma porta de roteador estático.
mld-snooping static-router-port vlan vlan-id
Por padrão, uma porta não é uma porta de roteador estático.
Configuração de uma porta como um host membro simulado
Sobre hosts membros simulados
Quando uma porta é configurada como um host membro simulado, ela é equivalente a um host independente das seguintes maneiras:
- Ele envia um relatório MLD não solicitado quando você conclui a configuração.
- Ele responde a consultas gerais de MLD com relatórios de MLD.
- Ele envia uma mensagem MLD done quando você remove a configuração.
A versão do MLD em execução no host membro simulado é a mesma que a versão do MLD snooping em execução na porta. A porta envelhece da mesma forma que uma porta membro dinâmica.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Configure a porta como um host membro simulado.
mld-snooping host-join ipv6-group-address [ source-ip
ipv6-source-address ] vlan vlan-idPor padrão, a porta não é um host membro simulado.
Ativação do processamento rápido de licenças
Sobre o processamento de licenças rápidas
Esse recurso permite que o dispositivo de camada 2 remova imediatamente uma porta da entrada de encaminhamento de um grupo multicast IPv6 quando a porta recebe uma mensagem de conclusão. O dispositivo não envia nem encaminha mais para a porta as consultas específicas de endereço multicast MLD para o grupo.
Restrições e diretrizes
Não ative o processamento de saída rápida em uma porta que tenha vários hosts receptores conectados em uma VLAN. Se você fizer isso, os receptores restantes não poderão receber dados multicast IPv6 de um grupo depois que um receptor deixar o grupo.
Habilitação do processamento de licenças rápidas em nível global
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Habilitar o processamento de saída rápida globalmente.
fast-leave [ vlan vlan-list ]Por padrão, o processamento de saída rápida é desativado globalmente.
Ativação do processamento de saída rápida em uma porta
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Ativar o processamento de saída rápida na porta.
mld-snooping fast-leave [ vlan vlan-list ]Por padrão, o processamento de saída rápida é desativado em uma porta.
Desativar a possibilidade de uma porta se tornar uma porta de roteador dinâmico
Sobre como impedir que uma porta se torne uma porta de roteador dinâmico
Um host receptor pode enviar consultas gerais MLD ou mensagens hello IPv6 PIM para fins de teste. No dispositivo de camada 2, a porta que recebe uma das mensagens se torna uma porta de roteador dinâmico. Antes que o cronômetro de envelhecimento da porta expire, podem ocorrer os seguintes problemas:
- Todos os dados multicast IPv6 da VLAN à qual a porta pertence fluem para a porta. Em seguida, a porta encaminha os dados para os hosts receptores conectados. Os hosts receptores receberão dados multicast IPv6 que não estão sendo esperados.
- A porta encaminha as consultas gerais MLD ou as mensagens hello IPv6 PIM para seus dispositivos de Camada 3 upstream. Essas mensagens podem afetar o estado do protocolo de roteamento multicast (como o MLD querier ou a eleição de DR) nos dispositivos da camada 3. Isso pode causar ainda mais interrupções na rede.
Para resolver esses problemas, você pode desativar a porta para que ela não se torne uma porta de roteador dinâmico ao receber qualquer uma das mensagens. Isso também melhora a segurança da rede e o controle sobre os hosts receptores.
Restrições e diretrizes
Essa configuração e a configuração da porta do roteador estático não interferem uma na outra.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-number- Desative a porta para que ela não se torne uma porta de roteador dinâmico.
mld-snooping router-port-deny [ vlan vlan-list ]Por padrão, uma porta tem permissão para se tornar uma porta de roteador dinâmico.
Configuração do consultador do MLD snooping
Ativação do consultador de MLD snooping
Sobre o consultador de MLD snooping
Esse recurso permite que o dispositivo de camada 2 envie periodicamente consultas gerais de MLD para estabelecer e manter entradas de encaminhamento de multicast na camada de enlace de dados. Você pode configurar um MLD snooping querier em uma rede sem dispositivos multicast de Camada 3.
Restrições e diretrizes
Não habilite o MLD snooping querier em uma rede multicast IPv6 que executa MLD. Um consultador MLD snooping não participa de eleições de consultores MLD. No entanto, ele pode afetar as eleições de consultores MLD se enviar consultas gerais MLD com um endereço IPv6 de origem baixo.
Ativação do consultador MLD snooping para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Ativar o consultador de MLD snooping para a VLAN.
mld-snooping querierPor padrão, o MLD snooping querier está desativado para uma VLAN.
Ativação da eleição do querier do MLD snooping
Sobre a eleição do querier do MLD snooping
Para evitar a interrupção do tráfego causada pela falha de um único querier em uma VLAN, configure vários queriers na VLAN e ative a eleição de querier. Quando o querier eleito falha, o dispositivo inicia uma nova eleição de querier para garantir o encaminhamento de multicast. O mecanismo para a eleição do querier do MLD snooping é o mesmo da eleição do querier do MLD.
Pré-requisitos
Antes de ativar a seleção do querier do MLD snooping, você deve concluir as seguintes tarefas:
- Ativar o MLD snooping querier para uma VLAN. Para obter mais informações sobre como ativar o MLD snooping querier, consulte "Como ativar o MLD snooping querier".
- Configure o endereço IPv6 de origem para consultas gerais de MLD como um endereço IPv6 diferente de :: e do endereço IPv6 do querier local. Um querier MLD snooping realiza a eleição de querier somente se o endereço IPv6 de origem de uma consulta geral MLD recebida não for :: ou seu próprio endereço IPv6.
- Certifique-se de que os consultores de MLD snooping candidatos executem a mesma versão de MLD snooping. Para especificar a versão do MLD snooping, use o comando mld-snooping version.
Ativação da seleção do querier do MLD snooping para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Ativar a seleção de consultores do MLD snooping para a VLAN.
mld-snooping querier-electionPor padrão, a eleição do querier do MLD snooping é desativada para uma VLAN.
Configuração de parâmetros para consultas e respostas gerais de MLD
Sobre os parâmetros para consultas e respostas gerais de MLD
Você pode modificar o intervalo de consulta geral do MLD com base nas condições reais da rede.
Um host receptor inicia um cronômetro de atraso de relatório para cada grupo multicast IPv6 ao qual se juntou quando recebe uma consulta geral MLD. Esse cronômetro é definido com um valor aleatório no intervalo de 0 até o tempo máximo de resposta anunciado na consulta. Quando o valor do cronômetro chega a 0, o host envia um relatório MLD para o grupo multicast IPv6 correspondente.
Defina um valor adequado para o tempo máximo de resposta das consultas gerais de MLD para acelerar as respostas dos hosts às consultas gerais de MLD e evitar picos de tráfego de relatórios de MLD.
Restrições e diretrizes
Para evitar a exclusão equivocada de membros de grupos multicast IPv6, certifique-se de que o intervalo da consulta geral de MLD seja maior do que o tempo máximo de resposta para consultas gerais de MLD.
Configuração de parâmetros para consultas e respostas gerais de MLD em nível global
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Defina o tempo máximo de resposta para consultas gerais de MLD.
max-response-time secondsPor padrão, o tempo máximo de resposta para as consultas gerais do MLD é de 10 segundos.
Configuração de parâmetros para consultas e respostas gerais de MLD para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Defina o intervalo de consulta geral de MLD na VLAN.
mld-snooping query-interval intervalPor padrão, o intervalo de consulta geral de MLD para uma VLAN é de 125 segundos.
- Defina o tempo máximo de resposta para consultas gerais de MLD na VLAN.
mld-snooping max-response-time secondsPor padrão, o tempo máximo de resposta para consultas gerais de MLD para uma VLAN é de 10 segundos.
Ativação do proxy de MLD snooping
Sobre o proxy de MLD snooping
O dispositivo habilitado com proxy de MLD snooping é chamado de proxy de MLD snooping. O proxy de MLD snooping atua como um host para o dispositivo upstream. Habilitado com o MLD snooping querier, o proxy de MLD snooping atua como roteador para dispositivos downstream e recebe mensagens de relatório e de conclusão em nome do dispositivo upstream. Como prática recomendada, ative o proxy de MLD snooping no dispositivo de borda para aliviar o efeito causado pelo excesso de pacotes.
Restrições e diretrizes para ativar o proxy de MLD snooping
Antes de ativar o proxy de MLD snooping para uma VLAN, você deve primeiro ativar o MLD snooping globalmente e ativar o MLD snooping para a VLAN. O proxy de MLD snooping não tem efeito em sub VLANs de uma VLAN multicast.
Use esse recurso com o MLD snooping querier. Para obter mais informações sobre a ativação do MLD snooping querier, consulte "Ativação do MLD snooping querier".
Ativação do proxy de MLD snooping para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Ativar o proxy de MLD snooping para a VLAN.
mld-snooping proxy enablePor padrão, o proxy de MLD snooping é desativado para uma VLAN.
Configuração de parâmetros para mensagens MLD
Configuração de endereços IPv6 de origem para mensagens MLD
Sobre a configuração de endereços IPv6 de origem para mensagens MLD
Você pode alterar o endereço IPv6 de origem das consultas MLD enviadas por um consultador MLD snooping. Essa configuração pode afetar a escolha do consultador MLD dentro da sub-rede.
Você também pode alterar o endereço IPv6 de origem dos relatórios MLD ou das mensagens concluídas enviadas por um host membro simulado ou por um proxy de MLD snooping.
Configuração dos endereços IPv6 de origem das mensagens MLD para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Configurar o endereço IPv6 de origem para consultas gerais de MLD.
mld-snooping general-query source-ip ipv6-addressPor padrão, o endereço IPv6 de origem das consultas gerais do MLD é o endereço IPv6 local do link da interface da VLAN atual. Se a interface VLAN atual não tiver um endereço IPv6 link-local, o endereço IPv6 de origem será FE80::02FF:FFFF:FE00:0001.
- Configurar o endereço IPv6 de origem para consultas específicas de endereço multicast MLD.
mld-snooping special-query source-ip ipv6-addressPor padrão, o endereço IPv6 de origem das consultas específicas de endereço multicast do MLD é um dos seguintes:
- O endereço de origem das consultas gerais de MLD se o MLD snooping querier da VLAN tiver recebido consultas gerais de MLD.
- O endereço IPv6 local do link da interface VLAN atual se o consultador do MLD snooping não receber uma consulta geral do MLD.
- FE80::02FF:FFFF:FE00:0001 se o consultador MLD snooping não receber uma consulta geral MLD e a interface VLAN atual não tiver um endereço IPv6 local de link.
- Configure o endereço IPv6 de origem para relatórios MLD.
mld-snooping report source-ip ipv6-addressPor padrão, o endereço IPv6 de origem dos relatórios MLD é o endereço IPv6 local do link da interface VLAN atual. Se a interface VLAN atual não tiver um endereço IPv6 link-local, o endereço IPv6 de origem será FE80::02FF:FFFF:FE00:0001.
mld-snooping done source-ip ipv6-addressPor padrão, o endereço IPv6 de origem das mensagens MLD done é o endereço IPv6 local do link da interface VLAN atual. Se a interface VLAN atual não tiver um endereço IPv6 link-local, o endereço IPv6 de origem será FE80::02FF:FFFF:FE00:0001.
Configuração da prioridade 802.1p para mensagens MLD
Sobre a prioridade 802.1p para mensagens MLD
Quando ocorre congestionamento nas portas de saída do dispositivo de camada 2, ele encaminha as mensagens MLD em sua ordem de prioridade 802.1p, da mais alta para a mais baixa. Você pode atribuir uma prioridade 802.1p mais alta às mensagens MLD que são criadas ou encaminhadas pelo dispositivo.
Definição da prioridade 802.1p para mensagens MLD em nível global
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Defina a prioridade 802.1p para mensagens MLD globalmente.
dot1p-priority priorityPor padrão, a prioridade 802.1p global é 6 para mensagens MLD.
Definição da prioridade 802.1p para mensagens MLD em uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Definir a prioridade 802.1p para mensagens MLD na VLAN.
mld-snooping dot1p-priority priorityPor padrão, a prioridade 802.1p é 6 para mensagens MLD em uma VLAN.
Configuração de políticas de MLD snooping
Configuração de uma política de grupo multicast IPv6
Sobre as políticas de grupo multicast IPv6
Esse recurso permite que o dispositivo de camada 2 filtre os relatórios MLD usando uma ACL que especifica os grupos multicast IPv6 e as origens opcionais. Ele é usado para controlar os grupos multicast IPv6 aos quais os hosts receptores podem se associar. Essa configuração tem efeito sobre os grupos multicast IPv6 aos quais as portas aderem dinamicamente.
Em um aplicativo multicast IPv6, um host envia um relatório MLD não solicitado quando um usuário solicita um programa multicast IPv6. O dispositivo de camada 2 usa a política de grupo multicast IPv6 para filtrar o relatório MLD. O host pode ingressar no grupo multicast IPv6 somente se o relatório MLD for permitido pela política de grupo multicast IPv6.
Configuração de uma política de grupo multicast IPv6 globalmente
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Configure uma política de grupo multicast IPv6 globalmente.
group-policy ipv6-acl-number [ vlan vlan-list ]Por padrão, não existem políticas de grupo multicast IPv6. Os hosts podem participar de qualquer grupo multicast IPv6.
Configuração de uma política de grupo multicast IPv6 em uma porta
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-number- Configure uma política de grupo multicast IPv6 na porta.
mld-snooping group-policy ipv6-acl-number [ vlan vlan-list ]
Por padrão, não existem políticas de grupo multicast IPv6 em uma porta. Os hosts conectados à porta podem ingressar em qualquer grupo multicast IPv6.
Ativação da filtragem de portas de origem multicast IPv6
Sobre a filtragem de portas de origem multicast IPv6
Esse recurso permite que o dispositivo de camada 2 descarte todos os pacotes de dados multicast IPv6 e aceite os pacotes de protocolo multicast IPv6. Você pode ativar esse recurso em portas que se conectam apenas a receptores de multicast IPv6.
A configuração feita na visualização MLD-snooping tem a mesma prioridade que a configuração específica da interface.
Restrições e diretrizes
Quando a filtragem de porta de origem multicast IPv6 está ativada, o dispositivo ativa automaticamente a filtragem de porta de origem multicast IPv4.
A configuração feita na visualização MLD-snooping tem a mesma prioridade que a configuração específica da interface, e a configuração mais recente entra em vigor.
Ativação da filtragem de porta de origem multicast IPv6 na visualização MLD-snooping
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Habilite a filtragem de portas de origem multicast IPv6 globalmente.
source-deny port interface-listPor padrão, a filtragem de portas de origem multicast IPv6 é desativada globalmente.
Ativação da filtragem de porta de origem multicast IPv6 na visualização da interface
- Entre na visualização do sistema.
System View- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Ativar a filtragem de porta de origem multicast IPv6 na porta.
mld-snooping source-denyPor padrão, a filtragem de porta de origem multicast IPv6 está desativada em uma porta.
Ativação da eliminação de dados multicast IPv6 desconhecidos
Sobre a eliminação de dados multicast IPv6 desconhecidos
Dados multicast IPv6 desconhecidos referem-se a dados multicast IPv6 para os quais não existem entradas de encaminhamento na tabela de encaminhamento do MLD snooping. Esse recurso permite que o dispositivo encaminhe dados multicast IPv6 desconhecidos somente para a porta do roteador. Se o dispositivo não tiver uma porta de roteador, os dados multicast IPv6 desconhecidos serão descartados.
Se você não ativar esse recurso, os dados multicast IPv6 desconhecidos serão inundados na VLAN à qual os dados pertencem.
Restrições e diretrizes
Quando a eliminação de dados multicast IPv6 desconhecidos está ativada, o dispositivo também elimina dados multicast IPv4 desconhecidos.
Quando esse recurso está ativado para uma VLAN, o dispositivo ainda encaminha dados multicast IPv6 desconhecidos para fora das portas do roteador (exceto a porta do roteador receptor) nessa VLAN.
Ativação da eliminação de dados multicast IPv6 desconhecidos para uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Ativar a eliminação de dados multicast IPv6 desconhecidos para a VLAN.
mld-snooping drop-unknownPor padrão, a eliminação de dados multicast IPv6 desconhecidos está desativada. Os dados multicast IPv6 desconhecidos são inundados.
Ativação da supressão de relatórios MLD
Sobre a supressão de relatórios MLD
Esse recurso permite que o dispositivo da Camada 2 encaminhe apenas o primeiro relatório MLD de um grupo multicast IPv6 para o dispositivo da Camada 3 diretamente conectado. Outros relatórios para o mesmo grupo no mesmo intervalo de consulta são descartados. Use esse recurso para reduzir o tráfego multicast.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Ativar a supressão de relatórios MLD.
report-aggregationPor padrão, a supressão de relatórios MLD está ativada.
Configuração do número máximo de grupos multicast IPv6 em uma porta
Sobre a configuração do número máximo de grupos multicast IPv6 em uma porta
Você pode definir o número máximo de grupos multicast IPv6 em uma porta para regular o tráfego da porta. Esse recurso tem efeito apenas nos grupos multicast IPv6 aos quais a porta se junta dinamicamente.
Se o número de grupos multicast IPv6 em uma porta exceder o limite, o sistema removerá todas as entradas de encaminhamento relacionadas a essa porta. Nesse caso, os hosts receptores conectados a essa porta podem se unir a grupos multicast IPv6 novamente antes que o número de grupos multicast IPv6 na porta atinja o limite. Quando o número de grupos multicast IPv6 na porta atinge o limite, a porta descarta automaticamente os relatórios MLD para novos grupos multicast IPv6.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-number- Defina o número máximo de grupos multicast IPv6 na porta.
mld-snooping group-limit limit [ vlan vlan-list ]Por padrão, nenhum limite é colocado no número máximo de grupos multicast IPv6 em uma porta.
Ativação da substituição de grupos multicast IPv6
Sobre a substituição de grupos multicast IPv6
Quando a substituição de grupos multicast IPv6 está ativada, a porta não descarta relatórios MLD para novos grupos se o número de grupos multicast na porta atingir o limite superior. Em vez disso, a porta sai de um grupo multicast IPv6 que tenha o endereço IPv6 mais baixo e entra no novo grupo contido no relatório MLD. O recurso de substituição de grupo multicast IPv6 é normalmente usado no aplicativo de comutação de canal.
Restrições e diretrizes
Esse recurso entra em vigor somente nos grupos multicast aos quais a porta se une dinamicamente. Esse recurso não terá efeito se houver as seguintes condições:
- O número de entradas de encaminhamento do MLD snooping no dispositivo atinge o limite superior.
- O grupo multicast IPv6 ao qual a porta se juntou recentemente não está incluído na lista de grupos multicast mantida pelo dispositivo.
Ativação da substituição de grupos multicast IPv6 globalmente
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Ativar a substituição de grupos multicast IPv6 globalmente.
overflow-replace [ vlan vlan-list ]Por padrão, a substituição de grupos multicast IPv6 é desativada globalmente.
Ativação da substituição de grupos multicast IPv6 em uma porta
- Entre na visualização do sistema.
System View- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Ativar a substituição de grupos multicast IPv6 na porta.
mld-snooping overflow-replace [ vlan vlan-list ]Por padrão, a substituição de grupos multicast IPv6 está desativada em uma porta.
Ativação do rastreamento de host
Sobre o rastreamento do host
Esse recurso permite que o dispositivo de Camada 2 registre informações sobre os hosts membros que estão recebendo dados multicast IPv6. As informações incluem os endereços IPv6 dos hosts, o tempo decorrido desde que os hosts ingressaram nos grupos multicast IPv6 e o tempo limite restante para os hosts. Esse recurso facilita o monitoramento e o gerenciamento dos hosts membros.
Ativação do rastreamento de host globalmente
- Entre na visualização do sistema.
System View- Entre na visualização do MLD-snooping.
mld-snooping- Ativar o rastreamento de host globalmente.
host-trackingPor padrão, o rastreamento de host é desativado globalmente.
Ativação do rastreamento de host em uma VLAN
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Ativar o rastreamento de host para a VLAN.
mld-snooping host-trackingPor padrão, o rastreamento de host está desativado em uma VLAN.
Configuração do valor DSCP para pacotes de saída do protocolo MLD
Sobre o valor DSCP para pacotes de saída do protocolo MLD
O valor DSCP determina a prioridade de transmissão do pacote. Um valor DSCP maior representa uma prioridade mais alta.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização do MLD snooping.
mld-snooping- Defina o valor DSCP para os pacotes de saída do protocolo MLD.
dscp dscp-valuePor padrão, o valor DSCP é 48 para pacotes de saída do protocolo MLD.
Comandos de exibição e manutenção do MLD snooping
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir entradas de encaminhamento rápido de multicast IPv6 de camada 2. | display ipv6 l2-multicast fast-forwarding cache [ vlan vlan-id ] [ ipv6-source-address | ipv6-group-address ] * [ slot slot-number ] |
| Exibir informações sobre grupos multicast IPv6 de camada 2. | display ipv6 l2-multicast ip [ group ipv6-group-address | source ipv6-source-address ] * [ vlan vlan-id ] [ slot slot-number ] |
| Exibir entradas de grupos multicast IPv6 de camada 2. | display ipv6 l2-multicast ip forwarding [ group ipv6-group-address | source ipv6-source-address ] * [ vlan vlan-id ] [ slot slot-number ] |
| Exibir informações sobre grupos multicast MAC IPv6 de camada 2. | display ipv6 l2-multicast mac [ mac-address ] [ vlan vlan-id ] [ slot slot-number ] |
| Exibir entradas de grupo multicast MAC IPv6 de camada 2. | display ipv6 l2-multicast mac forwarding [ mac-address ] [ vlan vlan-id ] [ slot slot-number ] |
| Exibir entradas de endereço MAC multicast IPv6 estático. | display mac-address [ mac-address [ vlan vlan-id ] | [ multicast ] [ vlan vlan-id ] [ count ] ] |
| Exibir o status do MLD snooping. | display mld-snooping [ global | vlan vlan-id ] |
| Exibir entradas de grupos dinâmicos de MLD snooping. | exibir grupo mld-snooping [ ipv6-group-address | ipv6-source-address ] * [ vlan vlan-id ] [ interface interface-type interface-number | [ verbose ] [ slot slot-number ] ] |
| Exibir informações de rastreamento do host. | display mld-snooping host-tracking vlan vlan-id group ipv6-group-address [ source ipv6-source-address ] [ slot slot-number ] |
| Exibir informações da porta dinâmica do roteador. | display mld-snooping router-port [ vlan vlan-id ] [ verbose ] [ slot slot-número ] |
| Exibir entradas de grupo de MLD snooping estático. | display mld-snooping static-group [ ipv6-group-address | ipv6-source-address ] * [ vlan vlan-id ] [ verbose ] [ slot slot-number ] |
| Exibir informações sobre a porta estática do roteador. | display mld-snooping static-router-port [ vlan vlan-id ] [ verbose ] [ slot slot-número ] |
| Exibir estatísticas das mensagens MLD e do hello do IPv6 PIM | exibir estatísticas de mld-snooping |
| mensagens aprendidas por meio do MLD snooping. | |
| Limpar entradas de encaminhamento rápido de multicast IPv6 de camada 2. | reset ipv6 l2-multicast fast-forwarding cache [ vlan vlan-id ] { { ipv6-source-address | ipv6-group-address } * | all } [ slot slot-number ] |
| Limpar entradas de grupos dinâmicos do MLD snooping. | reset mld-snooping group { ipv6-group-address [ ipv6-source-address ] | todos } [ vlan vlan-id ] |
| Limpar as informações da porta do roteador dinâmico. | reset mld-snooping router-port { all | vlan vlan-id } |
| Limpar as estatísticas das mensagens MLD e das mensagens hello do IPv6 PIM obtidas por meio do MLD snooping. | reset mld-snooping statistics |
Exemplos de configuração do MLD snooping
Exemplo: Configuração da política de grupo IPv6 baseada em VLAN e ingresso simulado
Configuração de rede
Conforme mostrado na Figura 4, o Roteador A executa o MLDv1 e atua como consultador de MLD, e o Switch A executa o MLDv1 snooping.
Configure a política de grupo e simule a associação para atender aos seguintes requisitos:
- O host A e o host B recebem apenas os dados multicast IPv6 endereçados ao grupo multicast IPv6 FF1E::101. Os dados multicast IPv6 podem ser encaminhados através da GigabitEthernet 1/0/3 e GigabitEthernet 1/0/4 do Switch A ininterruptamente, mesmo que o Host A e o Host B não consigam receber os dados multicast.
- O switch A descartará dados multicast IPv6 desconhecidos em vez de inundá-los na VLAN 100.
Figura 4 Diagrama de rede
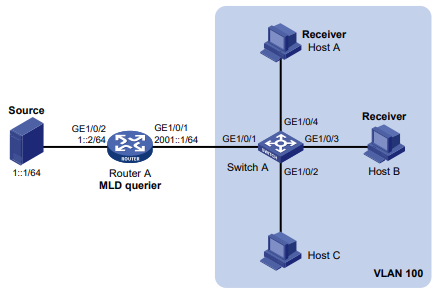
Procedimento
- Atribua um endereço IPv6 e um comprimento de prefixo a cada interface, conforme mostrado na Figura 4. (Detalhes não mostrados.)
- Configurar o Roteador A:
# Habilite o roteamento multicast IPv6.
<RouterA> system-view
[RouterA] ipv6 multicast routing
[RouterA-mrib6] quit# Habilite o MLD na GigabitEthernet 1/0/1.
[RouterA] interface gigabitethernet 1/0/1
[RouterA-GigabitEthernet1/0/1] mld enable
[RouterA-GigabitEthernet1/0/1] quit# Habilite o IPv6 PIM-DM na GigabitEthernet 1/0/2.
[RouterA] interface gigabitethernet 1/0/2
[RouterA-GigabitEthernet1/0/2] ipv6 pim dm
[RouterA-GigabitEthernet1/0/2] quit- Configure o Switch A:
# Habilite o recurso de espionagem MLD.
<SwitchA> system-view
[SwitchA] mld-snooping
[SwitchA-mld-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/4 à VLAN.
[SwitchA] vlan 100
[SwitchA-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/4
# Habilite o MLD snooping e habilite o descarte de dados multicast desconhecidos de IPv6 para a VLAN 100.
[SwitchA-vlan100] mld-snooping enable
[SwitchA-vlan100] mld-snooping drop-unknown
[SwitchA-vlan100] quit
# Configure uma política de grupo multicast IPv6 para que os hosts na VLAN 100 possam participar somente do grupo multicast IPv6 FF1E::101.
[SwitchA] acl ipv6 basic 2001
[SwitchA-acl-ipv6-basic-2001] rule permit source ff1e::101 128
[SwitchA-acl-ipv6-basic-2001] quit
[SwitchA] mld-snooping
[SwitchA–mld-snooping] group-policy 2001 vlan 100
[SwitchA–mld-snooping] quit
# Configure a GigabitEthernet 1/0/3 e a GigabitEthernet 1/0/4 como hosts membros simulados para ingressar no grupo multicast IPv6 FF1E::101.
[SwitchA] interface gigabitethernet 1/0/3
[SwitchA-GigabitEthernet1/0/3] mld-snooping host-join ff1e::101 vlan 100
[SwitchA-GigabitEthernet1/0/3] quit
[SwitchA] interface gigabitethernet 1/0/4
[SwitchA-GigabitEthernet1/0/4] mld-snooping host-join ff1e::101 vlan 100
[SwitchA-GigabitEthernet1/0/4] quit
Verificação da configuração
# Envie relatórios MLD do Host A e do Host B para ingressar nos grupos multicast IPv6 FF1E::101 e FF1E::202. (Detalhes não mostrados.)
# Exibir entradas dinâmicas do grupo MLD snooping para a VLAN 100 no Switch A.
[SwitchA] display mld-snooping group vlan 100
Total 1 entries.
VLAN 100: Total 1 entries.
(::, FF1E::101)
Host ports (2 in total):
GE1/0/3 (00:03:23)
GE1/0/4 (00:04:10)
O resultado mostra as seguintes informações:
- O Host A e o Host B ingressaram no grupo multicast IPv6 FF1E::101 por meio das portas membros GigabitEthernet 1/0/4 e GigabitEthernet 1/0/3 no Switch A, respectivamente.
- O host A e o host B não conseguiram entrar no grupo multicast FF1E::202.
Exemplo: Configuração de portas estáticas baseadas em VLAN
Configuração de rede
Conforme mostrado na Figura 5:
- O Roteador A executa o MLDv1 e atua como consultador de MLD. O switch A, o switch B e o switch C executam o MLDv1 snooping.
- O host A e o host C são receptores permanentes do grupo multicast IPv6 FF1E::101. Configure as portas estáticas para atender aos seguintes requisitos:
- Para aumentar a confiabilidade da transmissão do tráfego multicast IPv6, configure a GigabitEthernet 1/0/3
e GigabitEthernet 1/0/5 no Switch C como portas de membro estático para o grupo multicast IPv6 FF1E::101.
- Suponha que o STP seja executado na rede. Para evitar loops de dados, o caminho de encaminhamento do Switch A para o Switch C é bloqueado. Os dados multicast IPv6 fluem para os receptores conectados ao Switch C somente ao longo do caminho do Switch A-Switch B-Switch C. Quando esse caminho é bloqueado, é necessário concluir no mínimo um ciclo de resposta a consultas MLD antes que os dados multicast IPv6 fluam para os receptores
ao longo do caminho do Switch A-Switch C. Nesse caso, o fornecimento de multicast é interrompido durante o processo. Para obter mais informações sobre o STP, consulte o Layer 2-LAN Switching Configuration Guide.
Configure a GigabitEthernet 1/0/3 no Switch A como uma porta de roteador estático. Assim, os dados multicast IPv6 podem fluir para os receptores quase sem interrupções ao longo do caminho do Switch A-Switch C quando o caminho do Switch A-Switch B-Switch C estiver bloqueado.
Figura 5 Diagrama de rede
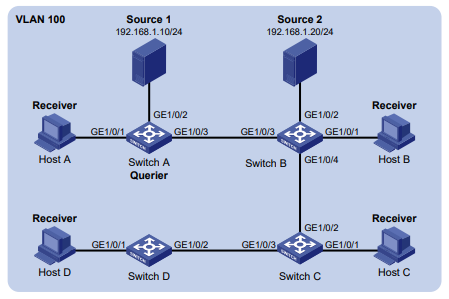
Procedimento
- Atribua um endereço IPv6 e um comprimento de prefixo a cada interface, conforme mostrado na Figura 5. (Detalhes não mostrados.)
- Configurar o Roteador A:
# Habilite o roteamento multicast IPv6.
<RouterA> system-view
[RouterA] ipv6 multicast routing
[RouterA-mrib6] quit# Habilite o MLD na GigabitEthernet 1/0/1.
[RouterA] interface gigabitethernet 1/0/1
[RouterA-GigabitEthernet1/0/1] mld enable
[RouterA-GigabitEthernet1/0/1] quit# Habilite o IPv6 PIM-DM na GigabitEthernet 1/0/2.
[RouterA] interface gigabitethernet 1/0/2
[RouterA-GigabitEthernet1/0/2] ipv6 pim dm
[RouterA-GigabitEthernet1/0/2] quit- Configure o Switch A:
# Habilite o recurso de espionagem MLD.
<SwitchA> system-view
[SwitchA] mld-snooping
[SwitchA-mld-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 à VLAN.
[SwitchA] vlan 100
[SwitchA-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/3
# Habilite o MLD snooping para a VLAN 100.
[SwitchA-vlan100] mld-snooping enable
[SwitchA-vlan100] quit
# Configure a GigabitEthernet 1/0/3 como uma porta de roteador estático.
[SwitchA] interface gigabitethernet 1/0/3
[SwitchA-GigabitEthernet1/0/3] mld-snooping static-router-port vlan 100
[SwitchA-GigabitEthernet1/0/3] quit
- Configurar o Switch B:
# Habilite o recurso de espionagem MLD.
<SwitchB> system-view
[SwitchB] mld-snooping
[SwitchB-mld-snooping] quit
# Crie a VLAN 100 e atribua a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 à VLAN.
[SwitchB] vlan 100
[SwitchB-vlan100] port gigabitethernet 1/0/1 gigabitethernet 1/0/2
# Habilite o MLD snooping para a VLAN 100. [SwitchB-vlan100] mld-snooping enable [SwitchB-vlan100] quit
- Configurar o switch C:
# Habilite o recurso de espionagem MLD.
<SwitchC> system-view
[SwitchC] mld-snooping
[SwitchC-mld-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/5 à VLAN.
[SwitchC] vlan 100
[SwitchC-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/5
# Habilite o MLD snooping para a VLAN 100.
[SwitchC] vlan 100
[SwitchC-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/5
# Configure a GigabitEthernet 1/0/3 e a GigabitEthernet 1/0/5 como portas de membro estático para o grupo multicast IPv6 FF1E::101.
[SwitchC] interface gigabitethernet 1/0/3
[SwitchC-GigabitEthernet1/0/3] mld-snooping static-group ff1e::101 vlan 100
[SwitchC-GigabitEthernet1/0/3] quit
[SwitchC] interface gigabitethernet 1/0/5
[SwitchC-GigabitEthernet1/0/5] mld-snooping static-group ff1e::101 vlan 100
[SwitchC-GigabitEthernet1/0/5] quit
Verificação da configuração
# Exibir informações da porta do roteador estático para a VLAN 100 no Switch A.
[SwitchA] display mld-snooping static-router-port vlan 100
VLAN 100:
Router ports (1 in total):
GE1/0/3
#A saída mostra que a GigabitEthernet 1/0/3 no Switch A se tornou uma porta de roteador estático.
# Exibir entradas de grupo MLD snooping estático na VLAN 100 no Switch C.
[SwitchC] display mld-snooping static-group vlan 100
Total 1 entries).
VLAN 100: Total 1 entries).
(::, FF1E::101)
Host ports (2 in total):
GE1/0/3
GE1/0/5
A saída mostra que a GigabitEthernet 1/0/3 e a GigabitEthernet 1/0/5 no Switch C se tornaram portas de membro estático do grupo multicast IPv6 FF1E::101.
Exemplo: Configuração do consultador de MLD snooping baseado em VLAN
Configuração de rede
Conforme mostrado na Figura 6:
- A rede é uma rede somente de camada 2.
- A origem 1 e a origem 2 enviam dados multicast para os grupos multicast IPv6 FF1E::101 e FF1E::102, respectivamente.
- O host A e o host C são receptores do grupo multicast IPv6 FF1E::101, e o host B e o host D são receptores do grupo multicast IPv6 FF1E::102.
- Todos os receptores de host executam MLDv1 e todos os switches executam MLDv1 snooping. O comutador A (que está próximo às fontes de multicast) atua como consultador de MLD snooping.
Para evitar que os switches inundem pacotes IPv6 desconhecidos na VLAN, habilite todos os switches para descartar pacotes multicast IPv6 desconhecidos.
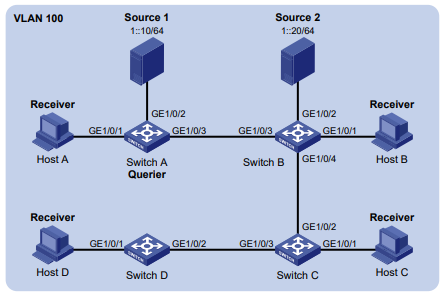
Figura 6 Diagrama de rede
Procedimento
- Configure o Switch A:
# Habilite o recurso de espionagem MLD.
<SwitchA> system-view
[SwitchA] mld-snooping
[SwitchA-mld-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 à VLAN.
[SwitchA] vlan 100
[SwitchA-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/3
# Habilite o MLD snooping e habilite o descarte de dados multicast IPv6 desconhecidos para a VLAN 100.
Configure o Switch A como o consultador de snooping MLD.
[SwitchA-vlan100] MLD-snooping querier
[SwitchA-vlan100] quit
- Configurar o Switch B:
# Habilite o recurso de espionagem MLD.
<SwitchB> system-view
[SwitchB] mld-snooping
[SwitchB-mld-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/4 à VLAN.
[SwitchB] vlan 100
[SwitchB-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/4
# Habilite o MLD snooping e habilite o descarte de dados multicast IPv6 desconhecidos para a VLAN 100.
[SwitchB-vlan100] mld-snooping enable [SwitchB-vlan100] mld-snooping drop-unknown [SwitchB-vlan100] quit
- Configurar o switch C:
# Habilite o recurso de espionagem MLD.
<SwitchC> system-view
[SwitchC] mld-snooping
[SwitchC-mld-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 à VLAN.
[SwitchC] vlan 100
[SwitchC-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/3
# Habilite o MLD snooping e habilite o descarte de dados multicast IPv6 desconhecidos para a VLAN 100.
[SwitchC-vlan100] mld-snooping enable
[SwitchC-vlan100] mld-snooping drop-unknown
[SwitchC-vlan100] quit
- Configurar o Switch D:
# Habilite o recurso de espionagem MLD.
<SwitchD> system-view
[SwitchD] mld-snooping
[SwitchD-mld-snooping] quit
# Crie a VLAN 100 e atribua a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 à VLAN.
[SwitchD] vlan 100
[SwitchD-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/2
# Habilite o MLD snooping e habilite o descarte de dados multicast IPv6 desconhecidos para a VLAN 100.
[SwitchD-vlan100] mld-snooping enable
[SwitchD-vlan100] mld-snooping drop-unknown
[SwitchD-vlan100] quit
Verificação da configuração
# Exibir estatísticas de mensagens MLD e mensagens hello de IPv6 PIM aprendidas por meio do MLD snooping no Switch B.
[SwitchB] display mld-snooping statistics
Received MLD general queries: 3
Received MLDv1 specific queries: 0
Received MLDv1 reports: 12
Received MLD dones: 0
Sent MLDv1 specific queries: 0
Received MLDv2 reports: 0
Received MLDv2 reports with right and wrong records: 0
Received MLDv2 specific queries: 0
Received MLDv2 specific sg queries: 0
Sent MLDv2 specific queries: 0
Sent MLDv2 specific sg queries: 0
Received IPv6 PIM hello: 0
Received error MLD messages: 0
O resultado mostra que todos os comutadores, exceto o Comutador A, podem receber as consultas gerais de MLD depois que o Comutador A atua como consultador de MLD snooping.
Exemplo: Configuração de proxy de MLD snooping baseado em VLAN
Configuração de rede
Conforme mostrado na Figura 7, o Roteador A executa o MLDv1 e atua como consultador de MLD. O switch A executa o snooping MLDv1. Configure o proxy de snooping MLD para que o Switch A possa executar as seguintes ações:
- Encaminhar relatório MLD e mensagens concluídas para o Roteador A.
- Responder às consultas MLD enviadas pelo Roteador A e encaminhar as consultas aos hosts downstream.
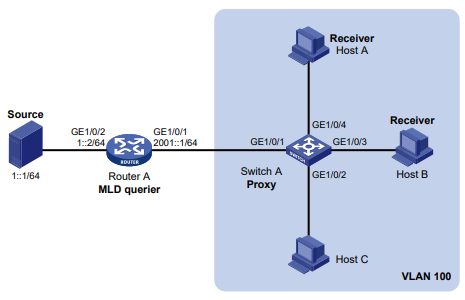
Figura 7 Diagrama de rede
Procedimento
- Atribua um endereço IPv6 e uma máscara de sub-rede a cada interface, conforme mostrado na Figura 7. (Detalhes não mostrados.)
- Configurar o Roteador A:
# Habilitar o roteamento multicast IPv6.
<RouterA> system-view
[RouterA] ipv6 multicast routing
[RouterA-mrib6] quit# Habilite o MLD e o IPv6 PIM-DM na GigabitEthernet 1/0/1.
[RouterA] interface gigabitethernet 1/0/1
[RouterA-GigabitEthernet1/0/1] mld enable
[RouterA-GigabitEthernet1/0/1] ipv6 pim dm
[RouterA-GigabitEthernet1/0/1] quit
# Habilite o IPv6 PIM-DM na GigabitEthernet 1/0/2.
[RouterA] interface gigabitethernet 1/0/2
[RouterA-GigabitEthernet1/0/2] ipv6 pim dm
[RouterA-GigabitEthernet1/0/2] quit- Configure o Switch A:
# Habilite o recurso de espionagem MLD.
<SwitchA> system-view
[SwitchA] mld-snooping
[SwitchA-mld-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/4 à VLAN.
[SwitchA] vlan 100
[SwitchA-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/4
# Habilite o proxy de MLD snooping e MLD snooping para a VLAN.
[SwitchA-vlan100] mld-snooping enable
[SwitchA-vlan100] mld-snooping proxy enable
[SwitchA-vlan100] quit
Verificação da configuração
# Envie relatórios MLD do Host A e do Host B para ingressar no grupo multicast IPv6 FF1E::101. (Detalhes não mostrados).
# Exibir entradas de grupo de MLD snooping no Switch A.
[SwitchA] display mld-snooping group
Total 1 entries.
VLAN 100: Total 1 entries.
(::, FF1E::101)
Host ports (2 in total):
GE1/0/3 (00:04:09)
GE1/0/4 (00:03:06)
A saída mostra que a GigabitEthernet 1/0/3 e a GigabitEthernet 1/0/4 são portas membros do grupo multicast IPv6 FF1E::101. O host A e o host B receberão dados multicast IPv6 para o grupo.
# Exibir informações de associação de grupo MLD no Roteador A.
[RouterA] display mld group
MLD groups in total: 1
GigabitEthernet1/0/1(2001::1):
MLD groups reported in total: 1
Group address: FF1E::101
Last reporter: FE80::2FF:FFFF:FE00:1
Uptime: 00:00:31
Expires: 00:03:48
# Enviar uma mensagem MLD done do Host A para sair do grupo multicast IPv6 FF1E::101. (Detalhes não mostrados).
# Exibir entradas de grupo de MLD snooping no Switch A.
[SwitchA] display mld-snooping group
Total 1 entries.
VLAN 100: Total 1 entries.
(::, FF1E::101)
Host ports (1 in total):
GE1/0/3 ( 00:01:23 )
A saída mostra que a GigabitEthernet 1/0/3 é a única porta membro do grupo multicast IPv6 FF1E::101. Somente o Host B receberá dados multicast IPv6 para o grupo.
Solução de problemas de MLD snooping
O encaminhamento multicast da camada 2 não pode funcionar
Sintoma
O encaminhamento de multicast da camada 2 não pode funcionar por meio do MLD snooping.
Solução
Para resolver o problema:
- Use o comando display mld-snooping para exibir o status do MLD snooping.
- Se o MLD snooping não estiver ativado, use o comando mld-snooping na visualização do sistema para ativar o recurso MLD snooping. Em seguida, use o comando mld-snooping enable na visualização de VLAN para ativar o MLD snooping para a VLAN.
- Se o MLD snooping estiver habilitado globalmente, mas não estiver habilitado para a VLAN, use o comando mld-snooping enable na visualização de VLAN para habilitar o MLD snooping para a VLAN.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
A política de grupo multicast IPv6 não funciona
Sintoma
Os hosts podem receber dados multicast IPv6 de grupos multicast IPv6 que não são permitidos pela política de grupos multicast IPv6.
Solução
Para resolver o problema:
- Use o comando display acl ipv6 para verificar se a ACL IPv6 configurada atende aos requisitos da política de grupo multicast IPv6.
- Use o comando display this na visualização MLD-snooping ou na visualização de interface para verificar se a política de grupo multicast IPv6 correta foi aplicada. Se a política aplicada não estiver correta, use o comando group-policy ou mld-snooping group-policy para aplicar a política de grupo multicast IPv6 correta.
- Use o comando display mld-snooping para verificar se o descarte de dados multicast IPv6 desconhecidos está ativado. Se não estiver, use o comando mld-snooping drop-unknown para ativar o descarte de dados multicast IPv6 desconhecidos.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Configuração do IPv6 PIM snooping
Sobre o IPv6 PIM snooping
O IPv6 PIM snooping é executado em dispositivos de camada 2. Ele funciona com o MLD snooping para analisar as mensagens IPv6 PIM recebidas e adiciona as portas interessadas em dados multicast específicos a uma entrada de roteamento do IPv6 PIM snooping. Dessa forma, os dados multicast podem ser encaminhados somente para as portas que estejam interessadas nos dados.
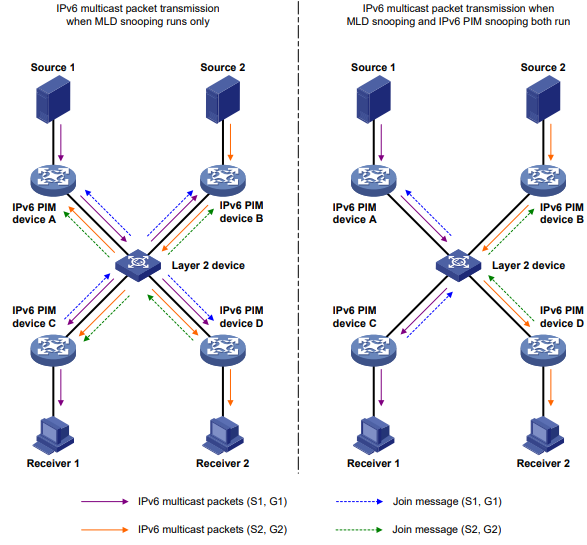
Figura 1 Transmissão de pacotes multicast sem ou com IPv6 PIM snooping
Conforme mostrado na Figura 1, a Fonte 1 envia dados multicast para o grupo multicast G1 e a Fonte 2 envia dados multicast para o grupo multicast G2. O receptor 1 pertence ao G1 e o receptor 2 pertence ao G2. As interfaces do switch de camada 2 que se conectam aos roteadores IPv6 compatíveis com PIM estão na mesma VLAN.
- Quando o switch de camada 2 executa somente o MLD snooping, ele realiza as seguintes ações:
- Mantém as portas do roteador de acordo com as mensagens hello do IPv6 PIM recebidas que os roteadores compatíveis com o IPv6 PIM enviam.
- Inunda todos os outros tipos de mensagens IPv6 PIM recebidas, exceto as mensagens PIM hello na VLAN.
- Encaminha todos os dados multicast para todas as portas do roteador na VLAN.
Cada roteador compatível com IPv6 PIM na VLAN, esteja ele interessado nos dados multicast ou não, pode receber todos os dados multicast e todas as mensagens IPv6 PIM, exceto as mensagens hello do IPv6 PIM.
- Quando o switch de camada 2 executa o snooping MLD e o snooping IPv6 PIM, ele realiza as seguintes ações:
- Examina se um roteador IPv6 PIM está interessado nos dados multicast destinados a um grupo multicast de acordo com as mensagens IPv6 PIM recebidas que o roteador envia.
- Adiciona somente as portas que se conectam ao roteador e estão interessadas nos dados a uma entrada de roteamento IPv6 PIM snooping.
- Encaminha mensagens IPv6 PIM e os dados multicast somente para o roteador de acordo com a entrada de encaminhamento multicast, o que economiza a largura de banda da rede.
Para obter mais informações sobre o MLD snooping e a porta do roteador, consulte "Configuração do MLD snooping".
Restrições e diretrizes: Configuração do IPv6 PIM snooping
Como prática recomendada, não configure o IPv6 PIM snooping para VLANs secundárias porque o IPv6 PIM snooping não entra em vigor em VLANs secundárias. Para obter mais informações sobre VLANs secundárias, consulte o Layer 2-LAN Switching Configuration Guide.
Depois que você ativa o snooping IPv6 PIM para uma VLAN, o snooping IPv6 PIM entra em vigor somente nas portas que pertencem à VLAN.
Visão geral das tarefas de snooping do IPv6 PIM
Para configurar o IPv6 PIM snooping, execute as seguintes tarefas:
- Ativação do snooping IPv6 PIM
- (Opcional.) Configuração do tempo de envelhecimento para portas globais após uma alternância mestre/subordinado
- Configuração do tempo de envelhecimento para portas vizinhas globais
- Configuração do tempo de envelhecimento das portas downstream globais e das portas do roteador global
Ativação do snooping IPv6 PIM
- Entre na visualização do sistema.
System View- Ative o recurso MLD snooping e entre na visualização MLD -snooping.
mld-snoopingPor padrão, o MLD snooping está desativado.
Para obter mais informações sobre esse comando, consulte Referência do comando IP Multicast.
- Retornar à visualização do sistema.
quit- Entre na visualização de VLAN.
vlan vlan-id- Ativar o MLD snooping para a VLAN.
mld-snooping enablePor padrão, o MLD snooping está desativado em uma VLAN.
Para obter mais informações sobre esse comando, consulte Referência do comando IP Multicast.
- Ativar o snooping IPv6 PIM para a VLAN.
ipv6 pim-snooping enablePor padrão, o IPv6 PIM snooping está desativado em uma VLAN.
Configuração do tempo de envelhecimento das portas globais após uma alternância entre mestre e subordinado
Sobre os portos globais
Uma porta global é uma porta virtual no dispositivo mestre, como uma interface agregada de camada 2. Uma porta global que atua como porta vizinha, porta de downstream ou porta de roteador é chamada de porta vizinha global, porta de downstream global e porta de roteador global, respectivamente.
Execute esta tarefa para reduzir a interrupção de dados multicast IPv6 da Camada 2 causada pelo envelhecimento das entradas de snooping PIM IPv6 após uma alternância entre mestre e subordinado.
Restrições e diretrizes
Para uma porta vizinha global, o tempo de envelhecimento definido não entra em vigor quando a porta recebe uma mensagem de alô do IPv6 PIM após uma troca de mestre/subordinado. O tempo de envelhecimento da porta é determinado pelo tempo de envelhecimento na mensagem hello do IPv6 PIM.
Para uma porta de roteador global ou uma porta de downstream global, o tempo de envelhecimento definido não entra em vigor quando a porta recebe uma mensagem de ingresso no IPv6 PIM após uma alternância de mestre/subordinado. O tempo de envelhecimento da porta é determinado pelo tempo de envelhecimento da mensagem de ingresso no IPv6 PIM.
Configuração do tempo de envelhecimento para portas vizinhas globais
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Defina o tempo de envelhecimento das portas vizinhas globais após uma troca de mestre/subordinado.
pim-snooping graceful-restart neighbor-aging-time secondsPor padrão, o tempo de envelhecimento das portas vizinhas globais após uma troca de mestre/subordinado é de 105 segundos.
Configuração do tempo de envelhecimento das portas downstream globais e das portas do roteador global
- Entre na visualização do sistema.
System View- Entre na visualização de VLAN.
vlan vlan-id- Defina o tempo de envelhecimento das portas downstream globais e das portas do roteador global após uma troca de mestre/subordinado.
pim-snooping graceful-restart join-aging-time secondsPor padrão, o tempo de envelhecimento das portas downstream e das portas do roteador global após uma alternância entre mestre/subordinado em é de 210 segundos.
Comandos de exibição e manutenção do IPv6 PIM snooping
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações de vizinhos do snooping IPv6 PIM. | display ipv6 pim-snooping neighbor [ vlan vlan-id ] [ slot slot-number ] [ verbose ] |
| Exibir informações da porta do roteador IPv6 PIM snooping. | display ipv6 pim-snooping router-port [ vlan vlan-id ] [ slot slot-number ] [ verbose ] |
| Exibir entradas de roteamento de snooping IPv6 PIM. | display ipv6 pim-snooping routing-table [ vlan vlan-id ] [ slot slot-número ] [ verbose ] |
| Exibir estatísticas das mensagens IPv6 PIM aprendidas por meio do IPv6 PIM snooping. | display ipv6 pim-snooping statistics |
| Limpar as estatísticas das mensagens IPv6 PIM aprendidas por meio do IPv6 PIM snooping. | reset ipv6 pim-snooping statistics |
Exemplos de configuração do IPv6 PIM snooping
Exemplo: Configuração do IPv6 PIM snooping
Configuração de rede
Conforme mostrado na Figura 2:
- O OSPFv3 é executado na rede.
- A Origem 1 e a Origem 2 enviam dados multicast IPv6 para os grupos multicast IPv6 FF1E::101 e FF2E::101, respectivamente.
- O receptor 1 e o receptor 2 pertencem aos grupos multicast IPv6 FF1E::101 e FF2E::101, respectivamente.
- O Roteador C e o Roteador D executam MLD na GigabitEthernet 1/0/1.
- O Roteador A, o Roteador B, o Roteador C e o Roteador D executam o IPv6 PIM-SM. A GigabitEthernet 1/0/2 no Roteador A atua como um C-BSR e um C-RP.
Configure o snooping MLD e o snooping IPv6 PIM no Switch A. Em seguida, o Switch A encaminha pacotes de protocolo IPv6 PIM e pacotes de dados multicast IPv6 somente para roteadores conectados a receptores.
Figura 2 Diagrama de rede
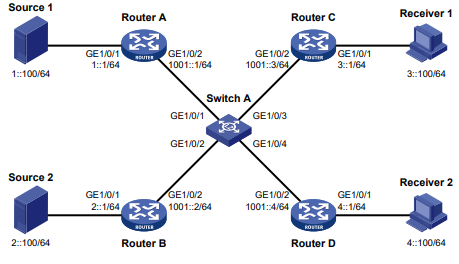
Procedimento
- Atribua um endereço IPv6 e um comprimento de prefixo a cada interface, conforme mostrado na Figura 2. (Detalhes não mostrados.)
- Configure o OSPFv3 nos roteadores. (Detalhes não mostrados.)
- Configurar o Roteador A:
# Habilite o roteamento multicast IPv6.
<RouterA> system-view
[RouterA] ipv6 multicast routing
[RouterA-mrib6] quit# Habilite o IPv6 PIM-SM em cada interface.
[RouterA] interface gigabitethernet 1/0/1
[RouterA-GigabitEthernet1/0/1] ipv6 pim sm
[RouterA-GigabitEthernet1/0/1] quit
[RouterA] interface gigabitethernet 1/0/2
[RouterA-GigabitEthernet1/0/2] ipv6 pim sm
[RouterA-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/2 como um C-BSR e um C-RP.
[RouterA] ipv6 pim
[RouterA-pim6] c-bsr 1001::1
[RouterA-pim6] c-rp 1001::1
[RouterA-pim6] quit- Configurar o Roteador B:
# Habilite o roteamento multicast IPv6.
<RouterB> system-view
[RouterB] ipv6 multicast routing
[RouterB-mrib6] quit# Habilite o IPv6 PIM-SM em cada interface.
[RouterB] interface gigabitethernet 1/0/1
[RouterB-GigabitEthernet1/0/1] ipv6 pim sm
[RouterB-GigabitEthernet1/0/1] quit
[RouterB] interface gigabitethernet 1/0/2
[RouterB-GigabitEthernet1/0/2] ipv6 pim sm
[RouterB-GigabitEthernet1/0/2] quit- Configurar o Roteador C:
# Habilite o roteamento multicast IPv6.
<RouterC> system-view
[RouterC] ipv6 multicast routing
[RouterC-mrib6] quit# Habilite o MLD na GigabitEthernet 1/0/1.
[RouterC] interface gigabitethernet 1/0/1
[RouterC-GigabitEthernet1/0/1] mld enable
[RouterC-GigabitEthernet1/0/1] quit# Habilite o IPv6 PIM-SM na GigabitEthernet 1/0/2.
[RouterC] interface gigabitethernet 1/0/2
[RouterC-GigabitEthernet1/0/2] ipv6 pim sm
[RouterC-GigabitEthernet1/0/2] quit
- Configurar o Roteador D:
# Habilite o roteamento multicast IPv6.
<RouterD> system-view
[RouterD] ipv6 multicast routing
[RouterD-mrib6] quit
# Habilite o MLD na GigabitEthernet 1/0/1.
[RouterD] interface gigabitethernet 1/0/1
[RouterD-GigabitEthernet1/0/1] mld enable
[RouterD-GigabitEthernet1/0/1] quit
# Habilite o IPv6 PIM-SM na GigabitEthernet 1/0/2.
[RouterD] interface gigabitethernet 1/0/2
[RouterD-GigabitEthernet1/0/2] ipv6 pim sm
[RouterD-GigabitEthernet1/0/2] quit
- Configure o Switch A:
# Habilite o recurso de espionagem MLD.
<SwitchA> system-view
[SwitchA] mld-snooping
[SwitchA-mld-snooping] quit
# Crie a VLAN 100 e atribua as GigabitEthernet 1/0/1 a GigabitEthernet 1/0/4 à VLAN.
[SwitchA] vlan 100
[SwitchA-vlan100] port gigabitethernet 1/0/1 to gigabitethernet 1/0/4
# Habilite o snooping MLD e o snooping IPv6 PIM para a VLAN 100.
[SwitchA-vlan100] mld-snooping enable
[SwitchA-vlan100] ipv6 pim-snooping enable
[SwitchA-vlan100] quit
Verificação da configuração
# No Switch A, exiba as informações de vizinho do IPv6 PIM snooping para a VLAN 100.
[SwitchA] display ipv6 pim-snooping neighbor vlan 100 Total de 4 vizinhos.
[SwitchA] display ipv6 pim-snooping neighbor vlan 100
Total 4 neighbors.
VLAN 100: Total 4 neighbors.
FE80::1
Ports (1 in total):
GE1/0/1 (00:32:43)
FE80::2
Ports (1 in total):
GE1/0/2 (00:32:43)
FE80::3
Ports (1 in total):
GE1/0/3 (00:32:43)
FE80::4
Ports (1 in total):
GE1/0/4 (00:32:43)
A saída mostra que o Roteador A, o Roteador B, o Roteador C e o Roteador D são vizinhos IPv6 PIM snooping.
# No Switch A, exiba as entradas de roteamento do IPv6 PIM snooping para a VLAN 100. [SwitchA] display ipv6 pim-snooping routing-table vlan 100 Total de 2 entradas.
[SwitchA] display ipv6 pim-snooping routing-table vlan 100
Total 2 entries.
FSM flag: NI-no info, J-join, PP-prune pending
VLAN 100: Total 2 entries.
(*, FF1E::101)
Upstream neighbor: FE80::1
Upstream ports (1 in total):
GE1/0/1
Downstream ports (1 in total):
GE1/0/3
Expires: 00:03:01, FSM: J
(*, FF2E::101)
Upstream neighbor: FE80::2
Upstream ports (1 in total):
GE1/0/2
Downstream ports (1 in total):
GE1/0/4
Expires: 00:03:01, FSM: J
O resultado mostra as seguintes informações:
- O Switch A encaminhará os dados multicast destinados ao grupo multicast IPv6 FF1E::101 somente para o Roteador C.
- O Switch A encaminhará os dados multicast destinados ao grupo multicast IPv6 FF2E::101 somente para o Roteador D.
Solução de problemas de snooping IPv6 PIM
Esta seção descreve problemas comuns de snooping IPv6 PIM e como solucioná-los.
O IPv6 PIM snooping não funciona em um dispositivo de camada 2
Sintoma
O IPv6 PIM snooping não funciona em um dispositivo de camada 2.
Solução
Para resolver o problema:
- Use o comando display current-configuration para exibir informações sobre o snooping MLD e o snooping IPv6 PIM.
- Se o snooping MLD não estiver ativado, ative o recurso de snooping MLD e, em seguida, ative o snooping MLD e o snooping IPv6 PIM para a VLAN.
- Se o snooping do IPv6 PIM não estiver ativado, ative o snooping do IPv6 PIM para a VLAN.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Configuração de VLANs multicast IPv6
Recurso de VLAN multicast IPv6
Conforme mostrado na Figura 1, o Host A, o Host B e o Host C estão em VLANs diferentes e no mesmo grupo multicast IPv6. Quando o Switch A (dispositivo de camada 3) recebe dados multicast IPv6 para esse grupo, ele encaminha três cópias dos dados para o Switch B (dispositivo de camada 2). Isso ocupa uma grande quantidade de largura de banda e aumenta a carga sobre o dispositivo de camada 3.
Figura 1 Transmissão multicast sem o recurso de VLAN multicast IPv6
Depois que uma VLAN multicast IPv6 é configurada no Switch B, o Switch A envia uma cópia dos dados multicast IPv6 para a VLAN multicast IPv6 no Switch B. Isso economiza largura de banda da rede e diminui a carga sobre o dispositivo de Camada 3.
Métodos de VLAN multicast IPv6
As VLANs de multicast IPv6 suportam VLANs de multicast IPv6 baseadas em sub-VLANs e VLANs de multicast IPv6 baseadas em portas.
VLAN multicast IPv6 baseada em sub-VLAN
Conforme mostrado na Figura 2:
- O host A, o host B e o host C estão na VLAN 2 até a VLAN 4, respectivamente.
- No Switch B, a VLAN 10 é uma VLAN multicast IPv6. As VLAN 2 a VLAN 4 são sub-VLANs da VLAN 10.
- O MLD snooping está ativado para a VLAN multicast e suas sub-VLANs.
Figura 2 VLAN multicast baseada em sub-VLAN
O MLD snooping gerencia as portas do roteador na VLAN multicast IPv6 e as portas-membro em cada sub-VLAN. Quando o Switch A recebe dados multicast IPv6 da fonte multicast IPv6, ele envia apenas uma cópia dos dados multicast IPv6 para a VLAN multicast IPv6 no Switch B. Em seguida, o Switch B envia uma cópia separada para cada sub-VLAN da VLAN multicast IPv6.
VLAN multicast IPv6 baseada em porta
Conforme mostrado na Figura 3:
- O host A, o host B e o host C estão na VLAN 2 até a VLAN 4, respectivamente. Todas as portas de usuário (portas com hosts conectados) no Switch B são portas híbridas.
- No Switch B, a VLAN 10 é uma VLAN multicast IPv6. Todas as portas de usuário são atribuídas à VLAN 10.
- O MLD snooping está ativado para a VLAN multicast IPv6 e suas sub-VLANs.
Figura 3 VLAN multicast IPv6 baseada em porta
O MLD snooping gerencia as portas do roteador e as portas-membro na VLAN multicast IPv6. Quando o Switch A recebe dados multicast IPv6 da fonte multicast IPv6, ele envia apenas uma cópia dos dados multicast IPv6 para a VLAN multicast IPv6 no Switch B. Em seguida, o Switch B envia uma cópia separada para cada porta de usuário na VLAN multicast IPv6.
Restrições e diretrizes: Configuração de VLAN multicast IPv6
A VLAN a ser configurada como uma VLAN multicast IPv6 deve existir.
Se você tiver configurado uma VLAN multicast IPv6 baseada em sub-VLAN e uma VLAN multicast IPv6 baseada em porta em um dispositivo, a configuração da VLAN multicast IPv6 baseada em porta entrará em vigor.
O recurso de VLAN multicast IPv6 não entra em vigor nas VLANs secundárias. Como prática recomendada, não configure o recurso IPv6 multicast VLAN para VLANs secundárias. Para obter mais informações sobre a VLAN secundária, consulte o Guia de configuração de comutação de Layer 2-LAN.
Configuração de uma VLAN multicast IPv6 baseada em sub-VLAN
Restrições e diretrizes
As VLANs a serem configuradas como sub-VLANs de uma VLAN multicast IPv6 devem existir e não podem ser VLANs multicast IPv6 ou sub-VLANs de quaisquer outras VLANs multicast IPv6.
Pré-requisitos
Antes de configurar uma VLAN multicast IPv6 baseada em sub-VLAN, você deve concluir as seguintes tarefas:
- Crie VLANs conforme necessário.
- Habilite o MLD snooping para a VLAN a ser configurada como a VLAN multicast IPv6 e para as VLANs a serem configuradas como sub-VLANs.
Procedimento
- Entre na visualização do sistema.
System View- Configure uma VLAN como uma VLAN de multicast IPv6 e entre na visualização de VLAN de multicast IPv6.
ipv6 multicast-vlan vlan-idPor padrão, uma VLAN não é uma VLAN de multicast IPv6.
- Atribua VLANs à VLAN multicast IPv6 como sub-VLANs.
subvlan vlan-listPor padrão, uma VLAN multicast IPv6 não tem sub-VLANs.
Configuração de uma VLAN multicast IPv6 baseada em porta
Restrições e diretrizes
É possível atribuir portas de usuário a uma VLAN multicast IPv6 na visualização de VLAN multicast IPv6 ou atribuir uma porta de usuário a uma VLAN multicast IPv6 na visualização de interface.
Uma porta de usuário pode pertencer a apenas uma VLAN multicast IPv6.
Pré-requisitos
Antes de configurar uma VLAN multicast IPv6 baseada em porta, você deve concluir as seguintes tarefas:
- Crie VLANs conforme necessário.
- Habilite o MLD snooping para a VLAN a ser configurada como a VLAN de multicast IPv6.
- Habilite o MLD snooping para todas as VLANs que contêm os receptores multicast.
- Configure os atributos das portas de usuário. Certifique-se de que as portas possam encaminhar pacotes da VLAN a ser configurada como a VLAN multicast IPv6 e enviar os pacotes com a tag de VLAN removida. Para obter mais informações sobre a configuração de atributos de porta, consulte Configuração de VLAN no Layer 2-LAN Switching Configuration Guide.
Atribuição de portas de usuário a uma VLAN multicast IPv6 na visualização de VLAN multicast IPv6
- Entre na visualização do sistema.
System View- Configure uma VLAN IPv6 como uma VLAN multicast IPv6 e entre no modo de exibição VLAN multicast IPv6.
ipv6 multicast-vlan vlan-idPor padrão, uma VLAN não é uma VLAN de multicast IPv6.
- Atribua portas à VLAN multicast IPv6 como portas de usuário.
port interface-listAtribuição de portas de usuário a uma VLAN multicast IPv6 na visualização da interface
- Entre na visualização do sistema.
System View- Configure uma VLAN IPv6 como uma VLAN multicast IPv6 e entre no modo de exibição VLAN multicast IPv6.
ipv6 multicast-vlan vlan-idPor padrão, uma VLAN não é uma VLAN de multicast IPv6.
- Retornar à visualização do sistema.
quit- Entre na visualização da interface da Camada 2.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-number- Atribua a porta à VLAN multicast IPv6 como uma porta de usuário.
porta ipv6 multicast-vlan vlan-id
Por padrão, uma porta não pertence a nenhuma VLAN multicast IPv6.
Definição do número máximo de entradas de encaminhamento de VLAN multicast IPv6
Sobre a configuração do número máximo de entradas de encaminhamento de VLAN multicast IPv6
Você pode definir o número máximo de entradas de encaminhamento de VLAN multicast IPv6 no dispositivo. Quando o limite superior é atingido, o dispositivo não cria entradas de encaminhamento de VLAN multicast IPv6 até que algumas entradas se esgotem ou sejam removidas manualmente.
Procedimento
- Entre na visualização do sistema.
System View- Defina o número máximo de entradas de encaminhamento de VLAN multicast IPv6.
ipv6 multicast-vlan entry-limit limitA configuração padrão varia de acordo com o modelo do dispositivo. Para obter mais informações, consulte a referência do comando.
Comandos de exibição e manutenção para VLANs multicast IPv6
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações sobre VLANs multicast IPv6. | exibir ipv6 multicast-vlan [ vlan-id ] |
| Exibir entradas de encaminhamento de VLAN multicast IPv6. | display ipv6 multicast-vlan forwarding-table [ ipv6-source-address [ prefix-length ] | ipv6-group-address [ prefix-length ] | slot slot-number | subvlan vlan-id | vlan vlan-id ] * |
| Exibir informações sobre entradas de grupos multicast IPv6 em VLANs multicast IPv6. | exibir grupo ipv6 multicast-vlan [ ipv6-source-address | ipv6-group-address | slot slot-number | verbose | vlan vlan-id ] * |
| Limpar entradas de grupos multicast IPv6 em VLANs multicast IPv6. | reset ipv6 multicast-vlan group [ ipv6-group-address [ prefix-length ] | ipv6-source-address [ prefix-length ] | vlan vlan-id ] * |
Exemplos de configuração de VLAN multicast IPv6
Exemplo: Configuração de VLAN multicast IPv6 baseada em sub-VLAN
Configuração de rede
Conforme mostrado na Figura 4:
- O dispositivo de camada 3, Switch A, executa o MLD e atua como consultador de MLD. O dispositivo de camada 2, Switch B, executa o MLDv1 snooping.
- A origem multicast IPv6 envia dados multicast IPv6 para o grupo multicast IPv6 FF1E::101. Os receptores Host A, Host B e Host C pertencem à VLAN 2, VLAN 3 e VLAN 4, respectivamente.
Configure uma VLAN multicast IPv6 baseada em sub-VLAN no Switch B para atender aos seguintes requisitos:
- O Switch A envia os dados multicast IPv6 para o Switch B por meio da VLAN multicast IPv6.
- O switch B encaminha os dados multicast IPv6 para os receptores em diferentes VLANs de usuário.
Figura 4 Diagrama de rede
Procedimento
- Configure o Switch A:
# Habilite o roteamento multicast IPv6.
<SwitchA> system-view
[SwitchA] ipv6 multicast routing
[SwitchA-mrib6] quit# Crie a VLAN 20 e atribua a GigabitEthernet 1/0/2 à VLAN.
[SwitchA] vlan 20
[SwitchA-vlan20] port gigabitethernet 1/0/2
[SwitchA-vlan20] quit# Atribua um endereço IPv6 à interface VLAN 20 e ative o IPv6 PIM-DM na interface.
[SwitchA] interface vlan-interface 20
[SwitchA-Vlan-interface20] ipv6 address 1::2 64
[SwitchA-Vlan-interface20] ipv6 pim dm
[SwitchA-Vlan-interface20] quit# Criar a VLAN 10.
[SwitchA] vlan 10
[SwitchA-vlan10] quit# Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua a porta à VLAN 10 como um membro de VLAN marcada.
[SwitchA] interface gigabitethernet 1/0/1
[SwitchA-GigabitEthernet1/0/1] port link-type hybrid
[SwitchA-GigabitEthernet1/0/1] port hybrid vlan 10 tagged
[SwitchA-GigabitEthernet1/0/1] quit# Atribua um endereço IPv6 à interface VLAN 10 e ative o MLD na interface.
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ipv6 address 2001::1 64
[SwitchA-Vlan-interface10] mld enable
[SwitchA-Vlan-interface10] quit- Configure o Switch B:
# Habilite o recurso de espionagem MLD.
<SwitchB> system-view
[SwitchB] mld-snooping
[SwitchB-mld-snooping] quit
# Crie a VLAN 2, atribua a GigabitEthernet 1/0/2 à VLAN e ative o MLD snooping para a VLAN.
[SwitchB] vlan 2
[SwitchB-vlan2] port gigabitethernet 1/0/2
[SwitchB-vlan2] mld-snooping enable
[SwitchB-vlan2] quit# Crie a VLAN 3, atribua a GigabitEthernet 1/0/3 à VLAN e ative o MLD snooping para a VLAN.
[SwitchB] vlan 3
[SwitchB-vlan3] port gigabitethernet 1/0/3
[SwitchB-vlan3] mld-snooping enable
[SwitchB-vlan3] quit# Crie a VLAN 4, atribua a GigabitEthernet 1/0/4 à VLAN e ative o MLD snooping para a VLAN.
[SwitchB] vlan 4
[SwitchB-vlan4] port gigabitethernet 1/0/4
[SwitchB-vlan4] mld-snooping enable
[SwitchB-vlan4] quit# Crie a VLAN 10 e ative o MLD snooping para a VLAN.
[SwitchB] vlan 10
[SwitchB-vlan10] mld-snooping enable
[SwitchB-vlan10] quit# Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua a porta à VLAN 10 como uma porta Membro da VLAN.
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] port link-type hybrid
[SwitchB-GigabitEthernet1/0/1] port hybrid vlan 10 tagged
[SwitchB-GigabitEthernet1/0/1] quit
# Configure a VLAN 10 como uma VLAN multicast IPv6 e atribua a VLAN 2 a VLAN 4 como sub-VLANs para a VLAN 10 multicast.
[SwitchB] ipv6 multicast-vlan 10
[SwitchB-ipv6-mvlan-10] subvlan 2 to 4
[SwitchB-ipv6-mvlan-10] quitVerificação da configuração
# Exibir informações sobre todas as VLANs multicast IPv6 no Switch B.
[SwitchB] display ipv6 multicast-vlan
Total 1 IPv6 multicast VLANs.
IPv6 multicast VLAN 10:
Sub-VLAN list(3 in total):
2-4
Port list(0 in total):# Exibir informações sobre grupos multicast IPv6 em VLANs multicast IPv6 no Switch B.
[SwitchB] display ipv6 multicast-vlan group
Total 1 entries.
IPv6 multicast VLAN 10: Total 1 entries.
(::, FF1E::101)
Sub-VLANs (3 in total):
VLAN 2
VLAN 3
VLAN 4A saída mostra que o grupo multicast IPv6 FF1E::101 pertence à VLAN 10 de multicast IPv6. A VLAN 10 de multicast IPv6 contém as sub-VLANs VLAN 2 a VLAN 4. O switch B replicará os dados multicast IPv6 da VLAN 10 para a VLAN 2 até a VLAN 4.
Exemplo: Configuração de VLAN multicast IPv6 baseada em porta
Configuração de rede
Conforme mostrado na Figura 5:
- O dispositivo de camada 3, Switch A, executa o MLDv1 e atua como consultador de MLD. O dispositivo de camada 2, Switch B, executa o MLDv1 snooping.
- A origem multicast IPv6 envia dados multicast IPv6 para o grupo multicast IPv6 FF1E::101. Os receptores Host A, Host B e Host C pertencem à VLAN 2, VLAN 3 e VLAN 4, respectivamente.
Configure uma VLAN multicast IPv6 baseada em porta no Switch B para atender aos seguintes requisitos:
- O Switch A envia dados multicast IPv6 para o Switch B por meio da VLAN multicast IPv6.
- O switch B encaminha os dados multicast IPv6 para os receptores em diferentes VLANs de usuário.
Figura 5 Diagrama de rede
Procedimento
- Configure o Switch A:
# Habilitar o roteamento multicast IPv6.
<SwitchA> system-view
[SwitchA] ipv6 multicast routing
[SwitchA-mrib6] quit# Crie a VLAN 20 e atribua a GigabitEthernet 1/0/2 à VLAN.
[SwitchA] vlan 20
[SwitchA-vlan20] port gigabitethernet 1/0/2
[SwitchA-vlan20] quit# Atribua um endereço IPv6 à interface VLAN 20 e ative o IPv6 PIM-DM na interface.
[SwitchA] interface vlan-interface 20
[SwitchA-Vlan-interface20] ipv6 address 1::2 64
[SwitchA-Vlan-interface20] ipv6 pim dm
[SwitchA-Vlan-interface20] quit# Crie a VLAN 10 e atribua a GigabitEthernet 1/0/1 à VLAN.
[SwitchA] vlan 10
[SwitchA-vlan10] port gigabitethernet 1/0/1
[SwitchA-vlan10] quit
# Atribua um endereço IPv6 à interface VLAN 10 e ative o MLD na interface.
[SwitchA] interface vlan-interface 10
[SwitchA-Vlan-interface10] ipv6 address 2001::1 64
[SwitchA-Vlan-interface10] mld enable
[SwitchA-Vlan-interface10] quit- Configure o Switch B:
# Habilite o recurso de espionagem MLD.
<SwitchB> system-view
[SwitchB] mld-snooping
[SwitchB-mld-snooping] quit
# Crie a VLAN 10, atribua a GigabitEthernet 1/0/1 à VLAN e ative o MLD snooping para a VLAN.
[SwitchB] vlan 10
[SwitchB-vlan10] port gigabitethernet 1/0/1
[SwitchB-vlan10] mld-snooping enable
[SwitchB-vlan10] quit# Crie a VLAN 2 e ative o MLD snooping para a VLAN.
[SwitchB] vlan 2
[SwitchB-vlan2] mld-snooping enable
[SwitchB-vlan2] quit# Crie a VLAN 3 e ative o MLD snooping para a VLAN.
[SwitchB] vlan 3
[SwitchB-vlan3] mld-snooping enable
[SwitchB-vlan3] quit
# Crie a VLAN 4 e ative o MLD snooping para a VLAN.
[SwitchB] vlan 4
[SwitchB-vlan4] mld-snooping enable
[SwitchB-vlan4] quit
# Configure a GigabitEthernet 1/0/2 como uma porta híbrida e configure a VLAN 2 como o PVID da porta híbrida.
[SwitchB] interface gigabitethernet 1/0/2
[SwitchB-GigabitEthernet1/0/2] port link-type hybrid
[SwitchB-GigabitEthernet1/0/2] port hybrid pvid vlan 2
# Atribua a GigabitEthernet 1/0/2 à VLAN 2 e à VLAN 10 como um membro de VLAN sem marcação.
[SwitchB-GigabitEthernet1/0/2] port hybrid vlan 2 untagged
[SwitchB-GigabitEthernet1/0/2] port hybrid vlan 10 untagged
[SwitchB-GigabitEthernet1/0/2] quit
# Configure a GigabitEthernet 1/0/3 como uma porta híbrida e configure a VLAN 3 como o PVID da porta híbrida.
[SwitchB] interface gigabitethernet 1/0/3
[SwitchB-GigabitEthernet1/0/3] port link-type hybrid
[SwitchB-GigabitEthernet1/0/3] port hybrid pvid vlan 3
# Atribua a GigabitEthernet 1/0/3 à VLAN 3 e à VLAN 10 como um membro de VLAN sem marcação.
[SwitchB-GigabitEthernet1/0/3] port hybrid vlan 3 untagged
[SwitchB-GigabitEthernet1/0/3] port hybrid vlan 10 untagged
[SwitchB-GigabitEthernet1/0/3] quit
# Configure a GigabitEthernet 1/0/4 como uma porta híbrida e configure a VLAN 4 como o PVID da porta híbrida.
[SwitchB] interface gigabitethernet 1/0/4
[SwitchB-GigabitEthernet1/0/4] port link-type hybrid
[SwitchB-GigabitEthernet1/0/4] port hybrid pvid vlan 4
# Atribua a GigabitEthernet 1/0/4 à VLAN 4 e à VLAN 10 como um membro de VLAN sem marcação.
[SwitchB-GigabitEthernet1/0/4] port hybrid vlan 4 untagged
[SwitchB-GigabitEthernet1/0/4] port hybrid vlan 10 untagged
[SwitchB-GigabitEthernet1/0/4] quit
# Configure a VLAN 10 como uma VLAN de multicast IPv6.
[SwitchB] ipv6 multicast-vlan 10# Atribua a GigabitEthernet 1/0/2 e a GigabitEthernet 1/0/3 à VLAN 10.
[SwitchB-ipv6-mvlan-10] port gigabitethernet 1/0/2 to gigabitethernet 1/0/3
[SwitchB-ipv6-mvlan-10] quit# Atribua a GigabitEthernet 1/0/4 à VLAN 10.
[SwitchB] interface gigabitethernet 1/0/4
[SwitchB-GigabitEthernet1/0/4] ipv6 port multicast-vlan 10
[SwitchB-GigabitEthernet1/0/4] quitVerificação da configuração
# Exibir informações sobre VLANs multicast IPv6 no Switch B.
[SwitchB] display ipv6 multicast-vlan
Total 1 IPv6 multicast VLANs.
IPv6 multicast VLAN 10:
Sub-VLAN list(0 in total):
Port list(3 in total):
GE1/0/2
GE1/0/3
GE1/0/4# Exibir entradas de encaminhamento dinâmico de MLD snooping no Switch B.
[SwitchB] display mld-snooping group
Total 1 entries.
VLAN 10: Total 1 entries.
11
(::, FF1E::101)
Host slots (0 in total):
Host ports (3 in total):
GE1/0/2 (00:03:23)
GE1/0/3 (00:04:07)
GE1/0/4 (00:04:16)
A saída mostra que o MLD snooping mantém as portas de usuário na VLAN multicast (VLAN 10). O switch B encaminhará os dados multicast IPv6 da VLAN 10 por meio dessas portas de usuário.
07 - ACL e QoS
Configuração de ACLs
Sobre ACLs
Uma lista de controle de acesso (ACL) é um conjunto de regras para identificar o tráfego com base em critérios como endereço IP de origem, endereço IP de destino e número da porta. As regras também são chamadas de instruções de permissão ou negação.
As ACLs são usadas principalmente para filtragem de pacotes. Você também pode usar ACLs em QoS, segurança, roteamento e outros módulos para identificar o tráfego. As decisões de descarte ou encaminhamento de pacotes dependem dos módulos que usam ACLs.
Numeração e nomeação de ACLs
Ao criar uma ACL, você deve atribuir a ela um número ou nome para identificação. Você pode especificar uma ACL existente por seu número ou nome. Cada tipo de ACL tem um intervalo exclusivo de números de ACL.
Para ACLs básicas ou avançadas com o mesmo número, você deve usar a palavra-chave ipv6 para diferenciá-las. Para ACLs com o mesmo nome, você deve usar as palavras-chave ipv6 ou mac para distingui-las.
Tipos de ACL
| Tipo | Número ACL | Versão IP | Critérios de correspondência |
| ACLs básicas | 2000 a 2999 | IPv4 | Endereço IPv4 de origem. |
| IPv6 | Endereço IPv6 de origem. | ||
| ACLs avançadas | 3000 a 3999 | IPv4 | Endereço IPv4 de origem, endereço IPv4 de destino, prioridade do pacote, número de protocolo e outros campos de cabeçalho de Camada 3 e Camada 4. |
| IPv6 | Endereço IPv6 de origem, endereço IPv6 de destino, prioridade do pacote, número de protocolo e outros campos de cabeçalho das Camadas 3 e 4. | ||
| ACLs de camada 2 | 4000 a 4999 | IPv4 e IPv6 | Campos de cabeçalho da camada 2, como endereços MAC de origem e destino, prioridade 802.1p e tipo de protocolo da camada de link. |
Ordem de partida
As regras em uma ACL são classificadas em uma ordem específica. Quando um pacote corresponde a uma regra, o dispositivo interrompe o processo de correspondência e executa a ação definida na regra. Se uma ACL contiver regras sobrepostas ou conflitantes, o resultado da correspondência e a ação a ser tomada dependerão da ordem das regras.
Os seguintes pedidos de correspondência ACL estão disponíveis:
- config - Classifica as regras ACL em ordem crescente de ID de regra. Uma regra com um ID mais baixo é correspondida antes de uma regra com um ID mais alto. Se você usar esse método, verifique cuidadosamente as regras e sua ordem.
- classifica automaticamente as regras ACL em ordem de profundidade. A ordenação em profundidade assegura que qualquer subconjunto de uma regra seja sempre correspondido antes da regra. A Tabela 1 lista a sequência de desempates que a ordenação em profundidade usa para classificar as regras de cada tipo de ACL.
Tabela 1 Classificar regras ACL em ordem de profundidade
| Tipo de ACL | Sequência de desempates |
| ACL básica IPv4 | Mais 0s no curinga do endereço IPv4 de origem (mais 0s significa um intervalo de endereços IPv4 mais restrito). Regra configurada anteriormente. |
| ACL avançada IPv4 | Número de protocolo específico. Mais 0s na máscara curinga do endereço IPv4 de origem. Mais 0s no curinga do endereço IPv4 de destino. Intervalo de números de porta de serviço TCP/UDP mais restrito. Regra configurada anteriormente. |
| ACL básica IPv6 | Prefixo mais longo para o endereço IPv6 de origem (um prefixo mais longo significa um intervalo de endereços IPv6 mais restrito). Regra configurada anteriormente. |
| ACL avançada IPv6 | Número de protocolo específico. Prefixo mais longo para o endereço IPv6 de origem. Prefixo mais longo para o endereço IPv6 de destino. Intervalo de números de porta de serviço TCP/UDP mais restrito. Regra configurada anteriormente. |
| Layer 2 ACL | Mais 1s na máscara do endereço MAC de origem (mais 1s significa um endereço MAC menor). Mais 1s na máscara de endereço MAC de destino. Regra configurada anteriormente. |
Uma máscara curinga, também chamada de máscara inversa, é um número binário de 32 bits representado em notação decimal pontilhada. Em contraste com uma máscara de rede, os bits 0 em uma máscara curinga representam bits "importantes" e os bits 1 representam bits "indiferentes". Se os bits "do care" em um endereço IP forem idênticos aos bits "do care" em um critério de endereço IP, o endereço IP corresponderá ao critério. Todos os bits "indiferentes" são ignorados. Os 0s e 1s em uma máscara curinga podem ser não contíguos. Por exemplo, 0.255.0.255 é uma máscara curinga válida .
Numeração de regras
As regras da ACL podem ser numeradas manualmente ou automaticamente. Esta seção descreve como funciona a numeração automática de regras ACL.
Etapa de numeração da regra
Se você não atribuir um ID à regra que está criando, o sistema atribuirá automaticamente um ID de regra a ela. A etapa de numeração da regra define o incremento pelo qual o sistema numera automaticamente as regras. Por exemplo, a etapa padrão de numeração de regras ACL é 5. Se você não atribuir IDs às regras que estiver criando, elas serão automaticamente numeradas como 0, 5, 10, 15 e assim por diante. Quanto maior for a etapa de numeração, mais regras você poderá inserir entre duas regras.
Ao introduzir um intervalo entre as regras em vez de numerá-las de forma contígua, você tem a flexibilidade de inserir regras em uma ACL. Esse recurso é importante para uma ACL de ordem configurada, em que as regras da ACL são correspondidas em ordem crescente de ID de regra.
A etapa de numeração de regras define o incremento pelo qual o sistema numera as regras automaticamente. Se você não especificar um ID de regra ao criar uma regra de ACL, o sistema atribuirá automaticamente um ID de regra a ela. Essa ID de regra é o múltiplo superior mais próximo da etapa de numeração da ID de regra mais alta atual, a partir da ID de regra inicial. Por exemplo, se a etapa de numeração da regra for 5 e a ID de regra mais alta atual for 12, a regra será numerada como 15.
Quanto maior for a etapa de numeração, mais regras você poderá inserir entre duas regras. Sempre que a ID da etapa ou da regra inicial for alterada, as regras serão renumeradas, começando pela ID da regra inicial. Por exemplo, se houver cinco regras numeradas como 0, 5, 9, 10 e 15, a alteração da etapa de 5 para 2 fará com que as regras sejam renumerados 0, 2, 4, 6 e 8.
Numeração e renumeração automática de regras
A ID atribuída automaticamente a uma regra ACL é o múltiplo mais alto mais próximo da etapa de numeração da ID de regra mais alta atual, começando com 0.
Por exemplo, se a etapa for 5 e houver cinco regras numeradas como 0, 5, 9, 10 e 12, a regra recém-definida será numerada como 15. Se a ACL não contiver uma regra, a primeira regra será numerada como 0.
Sempre que a etapa muda, as regras são renumeradas, começando em 0. Por exemplo, mudar a etapa de 5 para 2 renumera as regras 5, 10, 13 e 15 como regras 0, 2, 4 e 6.
Para uma ACL da ordem de correspondência automática, as regras são classificadas em ordem de profundidade primeiro e são renumeradas com base na ordem de correspondência. Por exemplo, as regras estão na ordem de correspondência de 0, 10 e 5. Alterar a etapa de numeração para 2 renumera as regras 0, 10 e 5 (e não 0, 5 e 10) como regras 0, 2, 4.
Filtragem de fragmentos com ACLs
A filtragem de pacotes tradicional corresponde apenas aos primeiros fragmentos dos pacotes e permite a passagem de todos os fragmentos subsequentes que não sejam os primeiros. Os invasores podem fabricar fragmentos que não sejam os primeiros para atacar as redes.
Para evitar riscos, o recurso ACL foi projetado da seguinte forma:
- Filtra todos os fragmentos por padrão, inclusive os fragmentos que não são os primeiros.
- Permite a modificação dos critérios de correspondência para fins de eficiência. Por exemplo, você pode configurar a ACL para filtrar apenas fragmentos que não sejam os primeiros.
Restrições e diretrizes: Configuração de ACL
- Se você criar uma ACL numerada, poderá entrar na visualização da ACL usando um dos seguintes comandos:
acl [ ipv6 ] number acl-number.acl { [ ipv6 ] { advanced | basic } | mac } acl-number.você pode acessar a exibição da ACL usando um dos seguintes comandos:
acl [ ipv6 ] name acl-name (for only basic ACLs and advanced ACLs) acl [ ipv6 ] number acl-number [ name acl-name ].acl { [ ipv6 ] { advanced | basic } | mac ] } name acl-name.acl [ ipv6 ] name acl-name (for only basic ACLs and advanced ACLs)acl { [ ipv6 ] { advanced | basic } | mac } name acl-name.- Endereços IP de origem e destino.
- Portas de origem e destino.
- Protocolo de camada de transporte.
- Tipo de mensagem ICMP ou ICMPv6, código de mensagem e nome da mensagem.
- Registro em log.
- Intervalo de tempo.
O encaminhamento lento exige que os pacotes sejam enviados ao plano de controle para o cálculo da entrada de encaminhamento, o que afeta o desempenho do encaminhamento do dispositivo.
Tarefas ACL em um relance
Para configurar uma ACL, execute as seguintes tarefas:
- Configure as ACLs de acordo com as características dos pacotes a serem correspondidos
- Configuração de uma ACL básica
- Configuração de uma ACL avançada
- Configuração de uma ACL de camada 2
- (Opcional.) Cópia de uma ACL
- (Opcional.) Configuração da filtragem de pacotes com ACLs
Configuração de uma ACL básica
Sobre ACLs básicas
As ACLs básicas correspondem aos pacotes com base apenas nos endereços IP de origem.
Configuração de uma ACL básica IPv4
- Entre na visualização do sistema.
System View- Crie uma ACL básica IPv4 e insira sua visualização. Escolha uma opção conforme necessário:
- Crie uma ACL básica IPv4 especificando um número de ACL.
acl number acl-number [ name acl-name ] [ match-order { auto | config } ]- Crie uma ACL básica IPv4 especificando a palavra-chave basic.
acl basic { acl-number | name acl-name } [ match-order { auto | config } ]- (Opcional.) Configure uma descrição para a ACL básica IPv4.
description textPor padrão, uma ACL básica IPv4 não tem uma descrição.
- (Opcional.) Defina a etapa de numeração da regra.
step step-value [ start start-value ]Por padrão, a etapa de numeração da regra é 5 e a ID da regra inicial é 0.
- Criar ou editar uma regra.
rule [ rule-id ] { deny | permit } [ counting | fragment | logging| source { source-address source-wildcard | any } | time-range time-range-name ]*A palavra-chave logging tem efeito somente quando o módulo (por exemplo, filtragem de pacotes) que usa a ACL suporta o registro.
- (Opcional.) Adicione ou edite um comentário de regra.
rule rule-id comment textPor padrão, nenhum comentário de regra é configurado.
Configuração de uma ACL básica IPv6
Restrições e diretrizes
Se uma ACL básica IPv6 for usada para classificação de tráfego QoS ou filtragem de pacotes:
- Não especifique a palavra-chave fragment.
- Não especifique a palavra-chave routing se a ACL for para aplicativo de saída.
Procedimento
- Entre na visualização do sistema.
System View- Crie uma visualização de ACL básica IPv6 e entre em sua visualização. Escolha uma opção conforme necessário:
- Crie uma ACL básica IPv6 especificando um número de ACL.
acl ipv6 number acl-number [ name acl-name ] [ match-order { auto | config } ]- Crie uma ACL básica IPv6 especificando a palavra-chave basic.
acl ipv6 basic { acl-number | name acl-name } [ match-order { auto | config } ]- (Opcional.) Configure uma descrição para a ACL básica IPv6.
description textPor padrão, uma ACL básica IPv6 não tem uma descrição.
- (Opcional.) Defina a etapa de numeração da regra.
step step-value [ start start-value ]Por padrão, a etapa de numeração da regra é 5 e a ID da regra inicial é 0.
- Criar ou editar uma regra.
rule [ rule-id ] { deny | permit } [ counting | fragment | logging| routing [ type routing-type ] | source { source-address source-prefix | source-address/source-prefix | any } | time-range time-range-name ] *A palavra-chave logging só tem efeito quando o módulo (por exemplo, filtragem de pacotes) que usa a ACL suporta o registro.
- (Opcional.) Adicione ou edite um comentário de regra.
rule rule-id comment textPor padrão, nenhum comentário de regra é configurado.
Configuração de uma ACL avançada
Sobre ACLs avançadas
As ACLs avançadas correspondem aos pacotes com base nos seguintes critérios:
- Endereços IP de origem.
- Endereços IP de destino.
- Prioridades de pacote.
- Tipos de protocolo.
- Outras informações de cabeçalho de protocolo, como números de porta TCP/UDP de origem e destino, sinalizadores TCP, tipos de mensagens ICMP e códigos de mensagens ICMP.
Em comparação com as ACLs básicas, as ACLs avançadas permitem uma filtragem mais flexível e precisa.
Configuração de uma ACL avançada de IPv4
- Entre na visualização do sistema.
System View- Crie uma ACL avançada IPv4 e insira sua visualização. Escolha uma opção conforme necessário:
- Crie uma ACL avançada IPv4 numerada especificando um número de ACL.
acl number acl-number [ name acl-name ] [ match-order { auto | config } ]- Crie uma ACL avançada IPv4 especificando a palavra-chave advanced.
acl advanced { acl-number | name acl-name } [ match-order { auto | config } ]- (Opcional.) Configure uma descrição para a ACL avançada de IPv4.
description textPor padrão, uma ACL avançada IPv4 não tem uma descrição.
- (Opcional.) Defina a etapa de numeração da regra.
step step-value [ start start-value ]Por padrão, a etapa de numeração da regra é 5 e a ID da regra inicial é 0.
- Criar ou editar uma regra.
rule [ rule-id ] { deny | permit } protocol [ { { ack ack-value | fin
fin-value | psh psh-value | rst rst-value | syn syn-value | urg
urg-value } * | established } | counting | destination { dest-address
dest-wildcard | any } | destination-port operator port | { dscp dscp
| { precedence precedence | tos tos } * } | fragment | icmp-type
{ icmp-type [ icmp-code ] | icmp-message } | logging | source
{ source-address source-wildcard | any } | source-port operator port
| time-range time-range-name ] *
A palavra-chave logging só tem efeito quando o módulo (por exemplo, filtragem de pacotes) que usa a ACL suporta o registro.
- (Opcional.) Adicione ou edite um comentário de regra.
rule rule-id comment textPor padrão, nenhum comentário de regra é configurado.
Configuração de uma ACL avançada de IPv6
Restrições e diretrizes
Se uma ACL avançada de IPv6 for para classificação de tráfego de QoS ou filtragem de pacotes:
- Não especifique a palavra-chave fragment.
- Não especifique a palavra-chave routing (roteamento), hop-by-hop (salto a salto) ou flow-label (rótulo de fluxo) se a ACL for para aplicativo de saída.
Procedimento
- Entre na visualização do sistema.
System View- Crie uma ACL avançada de IPv6 e insira sua visualização. Escolha uma opção conforme necessário:
- Crie uma ACL avançada IPv6 numerada especificando um número de ACL.
acl ipv6 number acl-number [ name acl-name ] [ match-order { auto |config } ]- Crie uma ACL avançada de IPv6 especificando a palavra-chave advanced.
acl ipv6 advanced { acl-number | name acl-name } [ match-order { auto | config } ]- (Opcional.) Configure uma descrição para a ACL avançada de IPv6.
description textPor padrão, uma ACL avançada de IPv6 não tem uma descrição.
- (Opcional.) Defina a etapa de numeração da regra.
step step-value [ start start-value ]Por padrão, a etapa de numeração da regra é 5 e a ID da regra inicial é 0.
- Criar ou editar uma regra.
fin-value | psh psh-value | rst rst-value | syn syn-value | urg urg-value }
* | established } | counting | destination { dest-address dest-prefix |
dest-address/dest-prefix | any } | destination-port operator port | |
dscp dscp | flow-label flow-label-value | fragment | icmp6-type
{ icmp6-type icmp6-code | icmp6-message } | logging | routing [ type
routing-type ] | hop-by-hop [ type hop-type ] | source { source-address
source-prefix | source-address/source-prefix | any } | source-port
operator port | time-range time-range-name ] *
A palavra-chave logging tem efeito somente quando o módulo (por exemplo, filtragem de pacotes) que usa a ACL suporta o registro.
- (Opcional.) Adicione ou edite um comentário de regra.
rule rule-id comment textPor padrão, nenhum comentário de regra é configurado.
Configuração de uma ACL de camada 2
Sobre as ACLs de camada 2
As ACLs de camada 2, também chamadas de ACLs de cabeçalho de quadro Ethernet, correspondem a pacotes com base nos campos de cabeçalho Ethernet de camada 2, como:
- Endereço MAC de origem.
- Endereço MAC de destino.
- Prioridade 802.1p (prioridade de VLAN).
- Tipo de protocolo da camada de enlace.
- Tipo de encapsulamento.
Procedimento
- Entre na visualização do sistema.
System View- Crie uma ACL de camada 2 e entre em sua visualização. Escolha uma opção conforme necessário:
- Crie uma ACL de camada 2 especificando um número de ACL.
acl number acl-number [ name acl-name ] [ match-order { auto |config } ]- Crie uma ACL de camada 2 especificando a palavra-chave mac.
acl mac { acl-number | name acl-name } [ match-order { auto | config } ]- (Opcional.) Configure uma descrição para a ACL de camada 2.
description textPor padrão, uma ACL de camada 2 não tem uma descrição.
- (Opcional.) Defina a etapa de numeração da regra.
step step-value [ start start-value ]Por padrão, a etapa de numeração da regra é 5 e a ID da regra inicial é 0.
- Criar ou editar uma regra.
rule [ rule-id ] { deny | permit } [ cos dot1p | counting | dest-mac
dest-address dest-mask | { lsap lsap-type lsap-type-mask | type
protocol-type protocol-type-mask } | source-mac source-address
source-mask | time-range time-range-name ] *- (Opcional.) Adicione ou edite um comentário de regra.
rule rule-id comment textPor padrão, nenhum comentário de regra é configurado.
Cópia de uma ACL
Sobre a cópia de uma ACL
Você pode criar uma ACL copiando uma ACL existente (ACL de origem). A nova ACL (ACL de destino) tem as mesmas propriedades e o mesmo conteúdo da ACL de origem, mas usa um número ou nome diferente do da ACL de origem.
Restrições e diretrizes
Para copiar uma ACL com êxito, certifique-se de que:
- A ACL de destino é do mesmo tipo que a ACL de origem.
- A ACL de origem já existe, mas a ACL de destino não.
Procedimento
- Entre na visualização do sistema.
System View- Copie uma ACL existente para criar uma nova ACL.
acl [ ipv6 | mac ] copy { source-acl-number | name source-acl-name } to { dest-acl-number | name dest-acl-name }Configuração da filtragem de pacotes com ACLs
Sobre a filtragem de pacotes com ACLs
Esta seção descreve os procedimentos para usar uma ACL na filtragem de pacotes. Por exemplo, você pode aplicar uma ACL a uma interface para filtrar pacotes de entrada ou de saída.
Aplicação de uma ACL a uma interface para filtragem de pacotes
Restrições e diretrizes
Na mesma direção de uma interface, você pode aplicar no máximo três ACLs: uma ACL IPv4, uma ACL IPv6 e uma ACL de camada 2.
O termo "interface" nesta seção refere-se coletivamente a interfaces Ethernet de camada 2 e interfaces VLAN.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface.
interface interface-type interface-number- Aplique uma ACL à interface para filtrar os pacotes.
packet-filter [ ipv6 | mac ] { acl-number | name acl-name } { inbound | outbound } [ hardware-count ]Por padrão, uma interface não filtra pacotes.
Configuração de registro e notificações SNMP para filtragem de pacotes
Sobre a configuração de registro em log e notificações SNMP para filtragem de pacotes
É possível configurar o módulo ACL para gerar entradas de registro ou notificações SNMP para filtragem de pacotes e enviá-las ao centro de informações ou ao módulo SNMP no intervalo de saída. A entrada de log ou a notificação registra o número de pacotes correspondentes e as regras de ACL correspondentes. Quando o primeiro pacote de um fluxo corresponde a uma regra de ACL, o intervalo de saída é iniciado e o dispositivo emite imediatamente uma entrada de registro ou notificação para esse pacote. Quando o intervalo de saída termina, o dispositivo emite uma entrada de registro ou notificação para os pacotes correspondentes subsequentes do fluxo.
Para obter mais informações sobre o centro de informações e o SNMP, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
System View- Defina o intervalo para a saída de logs ou notificações de filtragem de pacotes.
acl { logging | trap } interval intervalA configuração padrão é 0 minutos. Por padrão, o dispositivo não gera entradas de registro ou notificações SNMP para filtragem de pacotes.
Configuração da ação padrão de filtragem de pacotes
- Entre na visualização do sistema.
System View- Defina a ação padrão de filtragem de pacotes como negar.
filtro de pacotes padrão deny
Por padrão, o filtro de pacotes permite a passagem de pacotes que não correspondem a nenhuma regra de ACL.
Comandos de exibição e manutenção para ACL
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir estatísticas de configuração e correspondência de ACL. | display acl [ ipv6 | mac ] { acl-number | all | name acl-name } |
| Exibir informações do aplicativo ACL para filtragem de pacotes. | display packet-filter interface [ interface-type interface-number ] [ inbound | outbound ] [ slot slot-number ] |
| Exibir estatísticas de correspondência para ACLs de filtragem de pacotes. | display packet-filter statistics interface interface-type interface-number { inbound | outbound } [ [ ipv6 | mac ] { acl-number | name acl-name } ] [ brief ] |
| Exibir as estatísticas acumuladas para ACLs de filtragem de pacotes. | display packet-filter statistics sum { inbound | outbound } [ ipv6 | mac ] { acl-number | name acl-name } [ brief ] |
| Exibir informações detalhadas de filtragem de pacotes ACL. | display packet-filter verbose interface interface-type interface-number { inbound | outbound } [ [ ipv6 | mac ] { acl-number | name acl-name } ] [ slot slot-número ] |
| Exibir o uso de recursos de QoS e ACL. | display qos-acl resource [ slot slot-number ] |
| Limpar estatísticas de correspondência para ACLs de filtragem de pacotes. | reset packet-filter statistics interface [ interface-type interface-number ] { inbound | outbound } [ [ ipv6 | mac ] { acl-number | name acl-name } ] |
Exemplos de configuração de ACL
Exemplo: Configuração do filtro de pacotes baseado na interface
Configuração de rede
Uma empresa interconecta seus departamentos por meio do dispositivo. Configure um filtro de pacotes para:
- Permitir o acesso do escritório do Presidente a qualquer momento ao servidor do banco de dados financeiro.
- Permitir o acesso do departamento financeiro ao servidor do banco de dados somente durante o horário de trabalho (das 8:00 às 18:00) nos dias úteis.
- Negar o acesso de qualquer outro departamento ao servidor de banco de dados.
Figura 1 Diagrama de rede
Procedimento
# Criar um intervalo de tempo periódico das 8:00 às 18:00 em dias úteis.
<Device> system-view
[Device] time-range work 08:0 to 18:00 working-day# Crie uma ACL avançada IPv4 numerada como 3000.
[Device] acl advanced 3000# Configure uma regra para permitir o acesso do escritório do presidente ao servidor do banco de dados financeiro.
[Device-acl-ipv4-adv-3000] rule permit ip source 192.168.1.0 0.0.0.255 destination 192.168.0.100 0# Configure uma regra para permitir o acesso do departamento financeiro ao servidor de banco de dados durante o horário de trabalho.
[Device-acl-ipv4-adv-3000] rule permit ip source 192.168.2.0 0.0.0.255 destination 192.168.0.100 0 time-range work# Configure uma regra para negar acesso ao servidor do banco de dados financeiro.
[Device-acl-ipv4-adv-3000] rule deny ip source any destination 192.168.0.100 0
[Device-acl-ipv4-adv-3000] quit# Aplique a ACL 3000 avançada IPv4 para filtrar os pacotes de saída na interface GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] packet-filter 3000 outbound
[Device-GigabitEthernet1/0/1] quitVerificação da configuração
# Verifique se um computador do departamento financeiro pode fazer ping no servidor de banco de dados durante o horário de trabalho. (Todos os PCs deste exemplo usam o Windows XP).
C:\> ping 192.168.0.100
Pinging 192.168.0.100 with 32 bytes of data:
Reply from 192.168.0.100: bytes=32 time=1ms TTL=255
Reply from 192.168.0.100: bytes=32 time<1ms TTL=255
Reply from 192.168.0.100: bytes=32 time<1ms TTL=255
Reply from 192.168.0.100: bytes=32 time<1ms TTL=255
Ping statistics for 192.168.0.100:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 0ms, Maximum = 1ms, Average = 0ms# Verifique se um PC no departamento de Marketing não consegue fazer ping no servidor de banco de dados durante o horário de trabalho.
C:\> ping 192.168.0.100
Pinging 192.168.0.100 with 32 bytes of data:
Request timed out.
Request timed out.
Request timed out.
Request timed out.
Ping statistics for 192.168.0.100:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),# Exibir estatísticas de configuração e correspondência para a ACL 3000 avançada IPv4 no dispositivo durante o horário de trabalho.
[Device] display acl 3000
Advanced IPv4 ACL 3000, 3 rules,
ACL's step is 5
rule 0 permit ip source 192.168.1.0 0.0.0.255 destination 192.168.0.100 0
rule 5 permit ip source 192.168.2.0 0.0.0.255 destination 192.168.0.100 0 time-range work
(Active)
rule 10 deny ip destination 192.168.0.100 0Visão geral da QoS
Nas comunicações de dados, a Qualidade de Serviço (QoS) oferece garantias de serviço diferenciadas para tráfego diversificado em termos de largura de banda, atraso, jitter e taxa de queda, e tudo isso pode afetar a QoS.
A QoS gerencia os recursos da rede e prioriza o tráfego para equilibrar os recursos do sistema.
A seção a seguir descreve modelos típicos de serviços de QoS e técnicas de QoS amplamente usadas.
Modelos de serviço de QoS
Esta seção descreve vários modelos típicos de serviços de QoS.
Modelo de serviço de melhor esforço
O modelo de melhor esforço é um modelo de serviço único. O modelo de melhor esforço não é tão confiável quanto os outros modelos e não garante uma entrega sem atrasos.
O modelo de serviço de melhor esforço é o modelo padrão da Internet e se aplica à maioria dos aplicativos da rede . Ele usa o mecanismo de enfileiramento First In First Out (FIFO).
Modelo IntServ
O modelo de serviço integrado (IntServ) é um modelo de vários serviços que pode acomodar diversos requisitos de QoS. Esse modelo de serviço fornece a QoS diferenciada de forma mais granular, identificando e garantindo a QoS definida para cada fluxo de dados.
No modelo IntServ, um aplicativo deve solicitar o serviço da rede antes de enviar dados. O IntServ sinaliza a solicitação de serviço com o RSVP. Todos os nós que recebem a solicitação reservam recursos conforme solicitado e mantêm informações de estado para o fluxo do aplicativo.
O modelo IntServ exige altos recursos de armazenamento e processamento porque requer que todos os nós ao longo do caminho de transmissão mantenham informações sobre o estado do recurso para cada fluxo. Esse modelo é adequado para redes de pequeno porte ou de borda. Entretanto, não é adequado para redes de grande porte, por exemplo, para a camada central da Internet, onde há bilhões de fluxos.
Modelo DiffServ
O modelo de serviço diferenciado (DiffServ) é um modelo de vários serviços que pode atender a diversos requisitos de QoS. É fácil de implementar e ampliar. O DiffServ não sinaliza a rede para reservar recursos antes de enviar dados, como faz o IntServ.
Técnicas de QoS em uma rede
As técnicas de QoS incluem os seguintes recursos:
- Classificação do tráfego.
- Policiamento de tráfego.
- Modelagem de tráfego.
- Limite de taxa.
- Gerenciamento de congestionamento.
- Prevenção de congestionamento.
A seção a seguir apresenta brevemente essas técnicas de QoS.
Todas as técnicas de QoS deste documento são baseadas no modelo DiffServ.
Figura 2 Posição das técnicas de QoS em uma rede
Conforme mostrado na Figura 2, a classificação de tráfego, a modelagem de tráfego, o policiamento de tráfego, o gerenciamento de congestionamento e a prevenção de congestionamento implementam principalmente as seguintes funções:
- Classificação de tráfego - Utiliza critérios de correspondência para atribuir pacotes com as mesmas características a uma classe de tráfego. Com base nas classes de tráfego, você pode fornecer serviços diferenciados.
- Policiamento de tráfego - policia os fluxos e impõe penalidades para evitar o uso agressivo dos recursos da rede. Você pode aplicar o policiamento de tráfego ao tráfego de entrada e de saída de uma porta.
- Traffic shaping - Adapta a taxa de saída do tráfego aos recursos de rede disponíveis no dispositivo downstream para eliminar quedas de pacotes. O traffic shaping geralmente se aplica ao tráfego de saída de uma porta.
- Gerenciamento de congestionamento - Fornece uma política de agendamento de recursos para determinar a sequência de encaminhamento de pacotes quando ocorre congestionamento. O gerenciamento de congestionamento geralmente se aplica ao tráfego de saída de uma porta.
- Prevenção de congestionamento - Monitora o uso de recursos da rede. Geralmente é aplicado ao tráfego de saída de uma porta. Quando o congestionamento piora, a prevenção de congestionamento reduz o comprimento da fila descartando os pacotes.
Fluxo de processamento de QoS em um dispositivo
A Figura 3 descreve resumidamente como o módulo QoS processa o tráfego.
- O classificador de tráfego identifica e classifica o tráfego para ações subsequentes de QoS.
- O módulo de QoS executa várias ações de QoS no tráfego classificado, conforme configurado, dependendo da fase de processamento do tráfego e do status da rede. Por exemplo, você pode configurar o módulo de QoS para executar as seguintes operações:
- Policiamento de tráfego para o tráfego de entrada.
- Modelagem de tráfego para o tráfego de saída.
- Evitar o congestionamento antes que ele ocorra.
- Gerenciamento de congestionamento quando ocorre congestionamento.
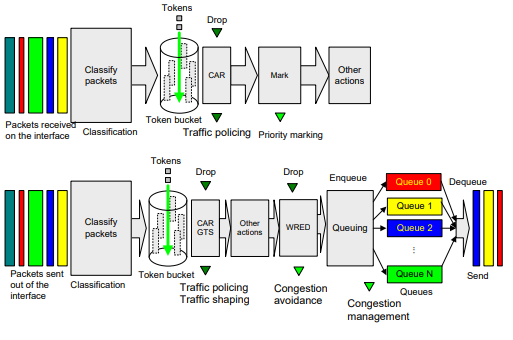
Figura 3 Fluxo de processamento de QoS
Abordagens de configuração de QoS
Você pode configurar a QoS usando a abordagem MQC ou a abordagem não-MQC.
Na abordagem de configuração modular de QoS (MQC), você configura os parâmetros de serviço de QoS usando políticas de QoS. Uma política de QoS define as ações de QoS a serem tomadas em diferentes classes de tráfego e pode ser aplicada a um objeto (como uma interface) para controlar o tráfego.
Na abordagem não-MQC, você configura os parâmetros de serviço de QoS sem usar uma política de QoS. Por exemplo, você pode usar o recurso de limite de taxa para definir um limite de taxa em uma interface sem usar uma política de QoS.
Configuração de uma política de QoS
Sobre as políticas de QoS
Uma política de QoS tem os seguintes componentes:
- Classe de tráfego - define os critérios de correspondência de pacotes.
- Comportamento do tráfego - define as ações de QoS a serem tomadas nos pacotes correspondentes.
Ao associar uma classe de tráfego a um comportamento de tráfego, uma política de QoS pode executar as ações de QoS nos pacotes correspondentes.
Uma política de QoS pode ter várias associações de classe e comportamento.
Definição de uma classe de tráfego
- Entre na visualização do sistema.
System View- Crie uma classe de tráfego e entre na visualização da classe de tráfego.
traffic classifier classifier-name [ operator { and | or } ]- (Opcional.) Configure uma descrição para a classe de tráfego.
description textPor padrão, nenhuma descrição é configurada para uma classe de tráfego.
- Configure um critério de correspondência.
if-match match-criteriaPor padrão, nenhum critério de correspondência é configurado.
Para obter mais informações, consulte o comando if-match na Referência de comandos ACL e QoS.
Definição de um comportamento de tráfego
- Entre na visualização do sistema.
System View- Crie um comportamento de tráfego e entre na visualização de comportamento de tráfego.
traffic behavior behavior-name- Configure uma ação no comportamento do tráfego.
Por padrão, nenhuma ação é configurada para um comportamento de tráfego.
Para obter mais informações sobre a configuração de uma ação, consulte os capítulos subsequentes sobre o tráfego policiamento, filtragem de tráfego, marcação de prioridade, contabilidade baseada em classe e assim por diante.
Definição de uma política de QoS
- Entre na visualização do sistema.
System View- Crie uma política de QoS e entre na visualização da política de QoS.
qos policy policy-name- Associe uma classe de tráfego a um comportamento de tráfego para criar uma associação entre classe e comportamento na política de QoS.
classifier classifier-name behavior behavior-name [ insert-before before-classifier-name ]Por padrão, uma classe de tráfego não está associada a um comportamento de tráfego. Repita esta etapa para criar mais associações entre classe e comportamento.
Destinos dos aplicativos
Você pode aplicar uma política de QoS aos seguintes destinos:
- Interface - A política de QoS entra em vigor no tráfego enviado ou recebido na interface.
- VLAN - A política de QoS entra em vigor no tráfego enviado ou recebido em todas as portas da VLAN.
- Globalmente - A política de QoS entra em vigor no tráfego enviado ou recebido em todas as portas.
- Perfil do usuário - A política de QoS entra em vigor no tráfego enviado ou recebido pelos usuários on-line do perfil do usuário.
Restrições e diretrizes para aplicar uma política de QoS
É possível modificar as classes de tráfego, os comportamentos de tráfego e as associações classe-comportamento em uma política de QoS mesmo depois de ela ser aplicada (exceto se for aplicada a um perfil de usuário). Se uma classe de tráfego usar uma ACL para classificação de tráfego, você poderá excluir ou modificar a ACL.
Quando uma política de QoS que contém uma ação CAR é aplicada em uma malha IRF, o tráfego que corresponde à política de QoS pode entrar na malha IRF por meio de interfaces em diferentes dispositivos membros da IRF. Nesse caso, o limite de taxa real que entra em vigor é a soma do CIR e do PIR na ação CAR multiplicada pelo número de grupos de portas envolvidos por padrão. As interfaces em diferentes dispositivos membros da IRF pertencem a diferentes grupos de portas. As interfaces no mesmo dispositivo membro da IRF podem pertencer ao mesmo grupo de portas ou a grupos de portas diferentes. Para identificar as informações do grupo de portas, execute o comando debug port mapping na visualização de sonda. As interfaces com o mesmo valor de Unidade pertencem ao mesmo grupo de portas.
Quando uma política de QoS que contém uma ação CAR é aplicada em uma malha IRF, o tráfego que corresponde à política de QoS pode deixar a malha IRF por meio de interfaces em diferentes dispositivos membros da IRF. Nesse caso, o limite de taxa real que entra em vigor é a soma do CIR e do PIR na ação CAR multiplicada pelo número de dispositivos membros da IRF que hospedam as interfaces por padrão.
Aplicação da política de QoS a uma interface
Restrições e diretrizes
Uma política de QoS pode ser aplicada a várias interfaces. Entretanto, somente uma política de QoS pode ser aplicada a uma direção (entrada ou saída) de uma interface.
A política de QoS aplicada ao tráfego de saída em uma interface não regula os pacotes locais. Os pacotes locais referem-se a pacotes de protocolos críticos enviados pelo sistema local para manutenção da operação. Os pacotes locais mais comuns incluem pacotes de manutenção de links, RIP, LDP e SSH.
O termo "interface" nesta seção refere-se às interfaces Ethernet de camada 2.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface.
interface interface-type interface-number- Aplique a política de QoS à interface.
qos vlan-policy policy-name vlan vlan-id-list { inbound | outbound }Por padrão, nenhuma política de QoS é aplicada a uma interface.
Aplicação da política de QoS às VLANs
Sobre a aplicação de políticas de QoS a VLANs
Você pode aplicar uma política de QoS às VLANs para regular o tráfego em todas as portas das VLANs.
Restrições e diretrizes
As políticas de QoS não podem ser aplicadas a VLANs dinâmicas, incluindo VLANs criadas pelo GVRP.
Quando você aplica uma política de QoS a VLANs, a política de QoS é aplicada às VLANs especificadas em todos os dispositivos membros da IRF. Se os recursos de hardware de um dispositivo membro da IRF forem insuficientes, a aplicação de uma política de QoS a VLANs poderá falhar no dispositivo membro da IRF. O sistema não reverte automaticamente a configuração da política de QoS já aplicada a outros dispositivos membros da IRF. Para garantir a consistência, use o comando undo qos vlan-policy para remover manualmente a configuração da política de QoS aplicada a eles.
Procedimento
- Entre na visualização do sistema.
System View- Aplique a política de QoS às VLANs.
qos apply policy policy-name global { inbound | outbound }Por padrão, nenhuma política de QoS é aplicada a uma VLAN.
Aplicar a política de QoS globalmente
Sobre o aplicativo de política de QoS global
Você pode aplicar uma política de QoS globalmente à direção de entrada ou saída de todas as portas.
Restrições e diretrizes
Se os recursos de hardware de um dispositivo membro da IRF forem insuficientes, a aplicação de uma política de QoS globalmente poderá falhar no dispositivo membro da IRF. O sistema não reverte automaticamente a configuração da política de QoS já aplicada a outros dispositivos membros da IRF. Para garantir a consistência, você deve usar
o comando global undo qos apply policy para remover manualmente a configuração da política de QoS aplicada a eles.
Procedimento
- Entre na visualização do sistema.
System View- Aplique a política de QoS globalmente.
qos apply policy policy-name { inbound | outbound }Por padrão, nenhuma política de QoS é aplicada globalmente.
Aplicação da política de QoS a um perfil de usuário
Sobre a aplicação da política de QoS a um perfil de usuário
Quando um perfil de usuário é configurado, é possível executar o policiamento de tráfego com base nos usuários. Depois que um usuário passa pela autenticação, o servidor de autenticação envia o nome do perfil de usuário associado ao usuário para o dispositivo. A política de QoS configurada na visualização do perfil de usuário entra em vigor somente quando os usuários ficam on-line.
Restrições e diretrizes
É possível aplicar uma política de QoS a vários perfis de usuário. Em uma direção de cada perfil de usuário, somente uma política pode ser aplicada. Para modificar uma política de QoS já aplicada a uma direção, primeiro remova a política de QoS aplicada.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização do perfil do usuário.
user-profile profile-name- Aplique a política de QoS ao perfil do usuário.
qos apply policy policy-name { inbound | outbound }Por padrão, nenhuma política de QoS é aplicada a um perfil de usuário.
| Parâmetro | Descrição |
| de entrada | Aplica uma política de QoS ao tráfego recebido pelo dispositivo a partir do perfil de usuário. |
| de saída | Aplica uma política de QoS ao tráfego enviado pelo dispositivo para o perfil de usuário. |
Comandos de exibição e manutenção de políticas de QoS
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir a configuração da política de QoS. | exibir política qos definida pelo usuário [ nome da política [ classifier classifier-name ] ] [ slot slot-número ] |
| Exibir informações sobre as políticas de QoS aplicadas globalmente. | display qos policy global [ slot slot-number ] [ inbound | outbound ] |
| Exibir informações sobre as políticas de QoS aplicadas às interfaces. | display qos policy interface [ interface-type interface-number ] [ inbound | outbound ] |
| Exibir informações sobre as políticas de QoS aplicadas aos perfis de usuário. | display qos policy user-profile [ name profile-name ] [ user-id user-id ] [ slot slot-number ] [ inbound | outbound ] |
| Exibir informações sobre as políticas de QoS aplicadas às VLANs. | display qos vlan-policy { name policy-name | vlan [ vlan-id ] } [ slot slot-number ] [ inbound | outbound ] |
| Exibir o uso de recursos de QoS e ACL. | display qos-acl resource [ slot slot-number ] |
| Exibir a configuração do comportamento do tráfego. | exibir comportamento de tráfego definido pelo usuário [ nome do comportamento ] [ número do slot do slot ] |
| Exibir a configuração da classe de tráfego. | exibir classificador de tráfego definido pelo usuário [ classifier-name ] [ slot slot-number ] |
| Limpar as estatísticas da política de QoS aplicada em uma determinada direção de uma VLAN. | reset qos vlan-policy [ vlan vlan-id ] [ inbound | de saída]. |
| Limpar as estatísticas de uma política de QoS aplicada globalmente. | reset qos policy global [ inbound | outbound ] |
| Limpar as estatísticas de uma política de QoS aplicada globalmente. | reset qos policy global [ inbound | outbound ] |
| Limpar as estatísticas da política de QoS aplicada em uma determinada direção de uma VLAN. | reset qos vlan-policy [ vlan vlan-id ] [ inbound | de saída]. |
Configuração do mapeamento de prioridades
Sobre o mapeamento de prioridades
Quando um pacote chega, um dispositivo atribui um conjunto de parâmetros de prioridade de QoS ao pacote com base em uma das seguintes opções:
- Um campo de prioridade transportado no pacote.
- A prioridade da porta de entrada.
Esse processo é chamado de mapeamento de prioridade. Durante esse processo, o dispositivo pode modificar a prioridade do pacote de acordo com as regras de mapeamento de prioridade. O conjunto de parâmetros de prioridade de QoS decide a prioridade de agendamento e a prioridade de encaminhamento do pacote.
O mapeamento de prioridades é implementado com mapas de prioridades e envolve as seguintes prioridades:
- Prioridade 802.1p.
- DSCP.
- EXP.
- Precedência de IP.
- Precedência local.
- Prioridade de queda.
Sobre as prioridades
As prioridades incluem os seguintes tipos: prioridades transportadas em pacotes e prioridades atribuídas localmente apenas para agendamento.
As prioridades transportadas por pacotes incluem a prioridade 802.1p, a precedência DSCP, a precedência IP e a EXP. Essas prioridades têm importância global e afetam a prioridade de encaminhamento dos pacotes na rede. Para obter mais informações sobre essas prioridades, consulte "Apêndices".
As prioridades atribuídas localmente têm importância apenas local. Elas são atribuídas pelo dispositivo apenas para agendamento. Essas prioridades incluem a precedência local, a prioridade de queda e a prioridade do usuário, como segue:
- Precedência local - Usado para enfileiramento. Um valor de precedência local corresponde a uma fila de saída. Um pacote com precedência local mais alta é atribuído a uma fila de saída de prioridade mais alta para ser agendado preferencialmente.
- Prioridade de descarte - Usado para tomar decisões de descarte de pacotes. Os pacotes com a maior prioridade de descarte são descartados preferencialmente.
- Prioridade do usuário-Precedência que o dispositivo extrai automaticamente de um campo de prioridade do pacote de acordo com seu caminho de encaminhamento. É um parâmetro para determinar a prioridade de agendamento e a prioridade de encaminhamento do pacote. A prioridade do usuário representa os seguintes itens:
- A prioridade 802.1p para pacotes da Camada 2.
- A precedência de IP para pacotes da Camada 3.
- A EXP para pacotes MPLS.
O dispositivo suporta apenas a precedência local para agendamento.
Mapas de prioridade
O dispositivo oferece vários tipos de mapas de prioridade. Ao examinar um mapa de prioridade, o dispositivo decide qual valor de prioridade atribuir a um pacote para o processamento subsequente do pacote.
Os mapas de prioridade padrão (conforme mostrado no Apêndice B Mapas de prioridade padrão) estão disponíveis para mapeamento de prioridade. Eles são adequados na maioria dos casos. Se um mapa de prioridade padrão não atender aos seus requisitos, você poderá modificar o mapa de prioridade conforme necessário.
Métodos de configuração de mapeamento de prioridade
Você pode configurar o mapeamento de prioridade usando qualquer um dos seguintes métodos:
- Configuração do modo de confiança de prioridade - Nesse método, você pode configurar uma porta para procurar um tipo de prioridade confiável (802.1p, por exemplo) em pacotes de entrada nos mapas de prioridade. Em seguida, o sistema mapeia a prioridade confiável para os tipos e valores de prioridade de destino.
- Alteração da prioridade da porta - Se nenhuma prioridade de pacote for confiável, será usada a prioridade da porta de entrada. Ao alterar a prioridade de uma porta, você altera a prioridade dos pacotes de entrada em a porta.
Processo de mapeamento de prioridades
Ao receber um pacote Ethernet em uma porta, o switch marca as prioridades de agendamento (precedência local e precedência de descarte) para o pacote Ethernet. Esse procedimento é feito de acordo com o modo de confiança de prioridade da porta receptora e o status de marcação 802.1Q do pacote, conforme mostrado na Figura 3.
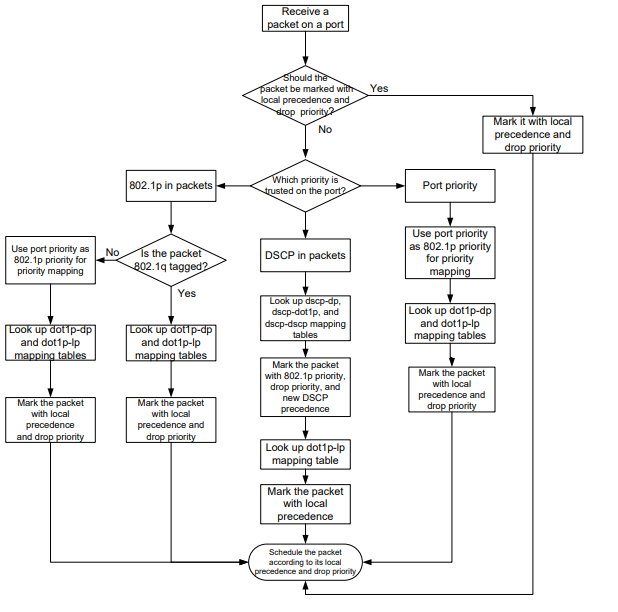
Figura 3 Processo de mapeamento de prioridades para um pacote Ethernet
Para obter informações sobre a marcação de prioridade, consulte "Configuração da marcação de prioridade".
Configuração de um mapa de prioridade
- Entre na visualização do sistema.
System View- Entrar na visualização do mapa de prioridade.
qos map-table{ dot1p-lp | dscp-dot1p | dscp-dscp }- Configurar mapeamentos para o mapa de prioridade.
import import-value-list export export-valuePor padrão, são usados os mapas de prioridade padrão. Para obter mais informações, consulte "Apêndice B Mapas de prioridade padrão".
Se você executar esse comando várias vezes, a configuração mais recente entrará em vigor.
Configuração de uma porta para confiar na prioridade do pacote para mapeamento de prioridade
Sobre a configuração de uma porta para confiar na prioridade do pacote
Você pode configurar o dispositivo para confiar em um determinado campo de prioridade transportado em pacotes para mapeamento de prioridade em portas ou globalmente. Ao configurar o tipo de prioridade de pacote confiável em uma interface, use as seguintes palavras-chave disponíveis:
- dot1p-Usa a prioridade 802.1p dos pacotes recebidos para mapeamento.
- dscp - Usa a precedência DSCP dos pacotes IP recebidos para mapeamento.
Restrições e diretrizes
O termo "interface" nesta seção refere-se às interfaces Ethernet de camada 2.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface.
interface interface-type interface-number- Configure o tipo de prioridade do pacote confiável.
qos trust { dot1p | dscp }Por padrão, uma interface não confia em nenhuma prioridade de pacote e usa a prioridade da porta como a prioridade 802.1p para mapeamento.
Alteração da prioridade da porta de uma interface
Sobre a prioridade da porta
Se uma interface não confiar em nenhuma prioridade de pacote, o dispositivo usará sua prioridade de porta para procurar parâmetros de prioridade para os pacotes de entrada. Ao alterar a prioridade da porta, você pode priorizar o tráfego recebido em diferentes interfaces.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface.
interface interface-type interface-number- Definir a prioridade da porta da interface.
qos priority [ dscp ] priority-valueA configuração padrão é 0.
Comandos de exibição e manutenção para mapeamento de prioridades
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir a configuração do mapa de prioridade. | display qos map-table [ dot1p-lp | dscp-dot1p | dscp-dscp ] |
| Exibe o tipo de prioridade de pacote confiável em uma porta. | display qos trust interface [ interface-type interface-number ] |
Exemplos de configuração de mapeamento de prioridade
Exemplo: Configuração de um modo de confiança prioritário
Configuração de rede
Conforme mostrado na Figura 4:
- A prioridade 802.1p do tráfego do Dispositivo A para o Dispositivo C é 3.
- A prioridade 802.1p do tráfego do Dispositivo B para o Dispositivo C é 1.
Configure o Dispositivo C para processar preferencialmente os pacotes do Dispositivo A para o servidor quando a GigabitEthernet 1/0/3 do Dispositivo C estiver congestionada.
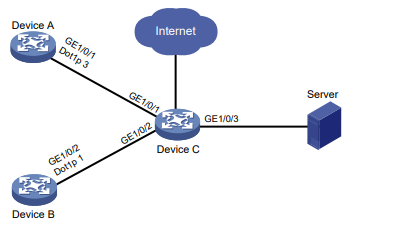
Figura 4 Diagrama de rede
Procedimento
(Método 1) Configure o dispositivo C para confiar na prioridade do pacote
# Configure a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 para confiar na prioridade 802.1p para mapeamento de prioridade.
<DeviceC> system-view
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] qos trust dot1p
[DeviceC-GigabitEthernet1/0/1] quit
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] qos trust dot1p
[DeviceC-GigabitEthernet1/0/2] quit(Método 2) Configure o dispositivo C para confiar na prioridade da porta
# Atribua prioridade de porta à GigabitEthernet 1/0/1 e à GigabitEthernet 1/0/2. Certifique-se de que os seguintes requisitos sejam atendidos:
- A prioridade da GigabitEthernet 1/0/1 é maior do que a da GigabitEthernet 1/0/2.
- Nenhum tipo de prioridade de pacote confiável está configurado na GigabitEthernet 1/0/1 ou na GigabitEthernet 1/0/2.
><DeviceC> system-view
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] qos priority 3
[DeviceC-GigabitEthernet1/0/1] quit
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] qos priority 1
[DeviceC-GigabitEthernet1/0/2] quitExemplo: Configurando tabelas de mapeamento de prioridade e marcação de prioridade
Configuração de rede
Conforme mostrado na Figura 5:
- O departamento de marketing se conecta à GigabitEthernet 1/0/1 do dispositivo, que define a prioridade 802.1p do tráfego do departamento de marketing como 3.
- O departamento de P&D se conecta à GigabitEthernet 1/0/2 do Device, que define a prioridade 802.1p do tráfego do departamento de P&D como 4.
- O departamento de gerenciamento se conecta à GigabitEthernet 1/0/3 do dispositivo, que define a prioridade 802.1p do tráfego do departamento de gerenciamento como 5.
Configure a prioridade da porta, a tabela de mapeamento 802.1p-para-local e a marcação de prioridade para implementar o plano conforme descrito na Tabela 1.
Tabela 1 Plano de configuração
| Destino do tráfego | Ordem de prioridade de tráfego | Plano de filas | ||
| Fonte de tráfego | Fila de saída | Prioridade da fila | ||
| Servidores públicos | Departamento de P&D > Departamento de gerenciamento > Departamento de marketing | Departamento de P&D | 6 | Alta |
| Departamento de gerenciamento | 4 | Médio | ||
| Departamento de marketing | 2 | Baixa | ||
| Internet | Departamento de gerenciamento > Departamento de marketing > Departamento de P&D | Departamento de P&D | 2 | Baixa |
| Departamento de gerenciamento | 6 | Alta | ||
| Departamento de marketing | 4 | Médio | ||
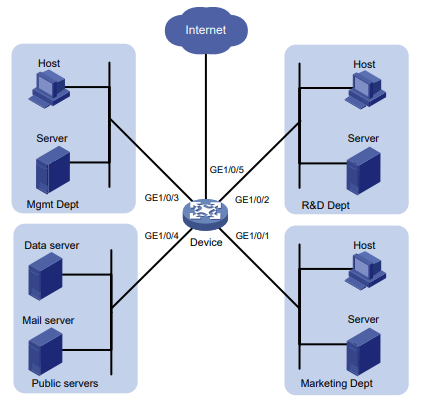
Figura 5 Diagrama de rede
Procedimento
- Configurar a prioridade da porta de confiança:
# Defina a prioridade da porta da GigabitEthernet 1/0/1 como 3.
>Device> system-view
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] qos priority 3
[Device-GigabitEthernet1/0/1] quit# Defina a prioridade da porta da GigabitEthernet 1/0/2 como 4.
[Device] interface gigabitethernet 1/0/2
[Device-GigabitEthernet1/0/2] qos priority 4
[Device-GigabitEthernet1/0/2] quit# Defina a prioridade da porta da GigabitEthernet 1/0/3 como 5.
[Device] interface gigabitethernet 1/0/3
[Device-GigabitEthernet1/0/3] qos priority 5
[Device-GigabitEthernet1/0/3] quit- Configure a tabela de mapeamento 802.1p-to-local para mapear os valores de prioridade 802.1p 3, 4 e 5 para os valores de precedência local 2, 6 e 4.
Isso garante que o departamento de P&D, o departamento de gerenciamento e o departamento de marketing tenham menos prioridades para acessar os servidores públicos.
[Device] qos map-table dot1p-lp
[Device-maptbl-dot1p-lp] import 3 export 2
[Device-maptbl-dot1p-lp] import 4 export 6
[Device-maptbl-dot1p-lp] import 5 export 4
[Device-maptbl-dot1p-lp] quit- Configure a marcação de prioridade para marcar os pacotes do departamento de gerenciamento, do departamento de marketing e do departamento de P&D para a Internet com os valores de prioridade 802.1p 4, 5 e 3.
Isso garante que o departamento de gerenciamento, o departamento de marketing e o departamento de P&D tenham menos prioridades para acessar a Internet.
# Crie a ACL 3000 e configure uma regra para corresponder aos pacotes HTTP.
[Device] acl advanced 3000
[Device-acl-adv-3000] rule permit tcp destination-port eq 80
[Device-acl-adv-3000] quit# Crie uma classe de tráfego chamada http e use a ACL 3000 como critério de correspondência.
[Device] traffic classifier http
[Device-classifier-http] if-match acl 3000
[Device-classifier-http] quit# Crie um comportamento de tráfego chamado admin e configure uma ação de marcação para o Gerenciamento
departamento.
[Device] traffic behavior admin
[Device-behavior-admin] remark dot1p 4
[Device-behavior-admin] quit# Criar uma política de QoS chamada admin e associar a classe de tráfego http ao comportamento do tráfego no administrador da política de QoS.
[Device] qos policy admin
[Device-qospolicy-admin] classifier http behavior admin
[Device-qospolicy-admin] quit# Aplique a política de QoS admin à direção de entrada da GigabitEthernet 1/0/3.
[Device] interface gigabitethernet 1/0/3
[Device-GigabitEthernet1/0/3] qos apply policy admin inbound# Crie um comportamento de tráfego chamado market e configure uma ação de marcação para o departamento de Marketing.
[Device] traffic behavior market
[Device-behavior-market] remark dot1p 5
[Device-behavior-market] quit# Criar uma política de QoS chamada market e associar a classe de tráfego http ao comportamento do tráfego no mercado de políticas de QoS.
[Device] qos policy market
[Device-qospolicy-market] classifier http behavior market
[Device-qospolicy-market] quit# Aplique o mercado de políticas de QoS à direção de entrada da GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] qos apply policy market inbound# Crie um comportamento de tráfego chamado rd e configure uma ação de marcação para o departamento de P&D.
[Device] traffic behavior rd
[Device-behavior-rd] remark dot1p 3
[Device-behavior-rd] quit# Criar uma política de QoS chamada rd e associar a classe de tráfego http ao comportamento de tráfego rd na QoS estrada da política.
[Device] interface gigabitethernet 1/0/2
[Device-GigabitEthernet1/0/2] qos apply policy rd inbound
Configuração de policiamento de tráfego, GTS e limite de taxa
Sobre policiamento de tráfego, GTS e limite de taxa
O limite de tráfego ajuda a atribuir recursos de rede (inclusive largura de banda) e a aumentar o desempenho da rede. Por exemplo, você pode configurar um fluxo para usar somente os recursos atribuídos a ele em um determinado intervalo de tempo. Isso evita o congestionamento da rede causado pela explosão de tráfego.
O policiamento de tráfego, o Generic Traffic Shaping (GTS) e o limite de taxa controlam a taxa de tráfego e o uso de recursos de acordo com as especificações de tráfego. Você pode usar token buckets para avaliar as especificações de tráfego.
Avaliação de tráfego e token buckets
Recursos do balde de token
Um bucket de token é análogo a um contêiner que contém um determinado número de tokens. Cada token representa uma determinada capacidade de encaminhamento. O sistema coloca tokens no balde em uma taxa constante. Quando o balde de tokens está cheio, os tokens extras fazem com que o balde transborde.
Avaliação do tráfego com o token bucket
Um mecanismo de token bucket avalia o tráfego observando o número de tokens no bucket. Se o número de tokens no compartimento for suficiente para encaminhar os pacotes:
- O tráfego está em conformidade com a especificação (chamado de tráfego em conformidade).
- Os tokens correspondentes são retirados do balde.
Caso contrário, o tráfego não estará em conformidade com a especificação (chamado de excesso de tráfego). Um bucket de token tem os seguintes parâmetros configuráveis:
- Taxa média na qual os tokens são colocados no bucket, que é a taxa média permitida de tráfego.
Normalmente, ela é definida como a taxa de informações comprometidas (CIR).
- Tamanho do burst ou a capacidade do bucket de token. É o tamanho máximo de tráfego permitido em cada burst. Geralmente é definido como o tamanho do burst comprometido (CBS). O tamanho do burst definido deve ser maior que o tamanho máximo do pacote.
Cada pacote que chega é avaliado.
Avaliação complicada
Você pode definir dois compartimentos de token, o compartimento C e o compartimento E, para avaliar o tráfego em um ambiente mais complicado e obter mais flexibilidade de policiamento. A seguir, os principais mecanismos usados para avaliação complexa:
- Taxa única e duas cores - Usa um compartimento de tokens e os seguintes parâmetros:
- CIR - Taxa na qual os tokens são colocados no bucket C. Define a taxa média de transmissão ou encaminhamento de pacotes permitida pelo bucket C.
- CBS - Tamanho do compartimento C, que especifica a explosão transitória de tráfego que o compartimento C pode encaminhar.
Quando um pacote chega, as seguintes regras se aplicam:
- Se o bucket C tiver tokens suficientes para encaminhar o pacote, o pacote será colorido de verde.
- Caso contrário, o pacote é colorido de vermelho.
- Taxa única de três cores - Usa dois compartimentos de tokens e os seguintes parâmetros:
- CIR - Taxa na qual os tokens são colocados no bucket C. Define a taxa média de transmissão ou encaminhamento de pacotes permitida pelo bucket C.
- CBS - Tamanho do compartimento C, que especifica a explosão transitória de tráfego que o compartimento C pode encaminhar.
- EBS - Tamanho do compartimento E menos o tamanho do compartimento C, que especifica a explosão transitória de tráfego que o compartimento E pode encaminhar. O EBS não pode ser 0. O tamanho do compartimento E é a soma do CBS e do EBS.
Quando um pacote chega, as seguintes regras se aplicam:
- Se o balde C tiver fichas suficientes, o pacote será colorido de verde.
- Se o balde C não tiver fichas suficientes, mas o balde E tiver fichas suficientes, o pacote será colorido de amarelo.
- Se nem o balde C nem o balde E tiverem tokens suficientes, o pacote será colorido de vermelho.
- Duas taxas e três cores - Usa dois compartimentos de tokens e os seguintes parâmetros:
- CIR - Taxa na qual os tokens são colocados no bucket C. Define a taxa média de transmissão ou encaminhamento de pacotes permitida pelo bucket C.
- CBS - Tamanho do compartimento C, que especifica a explosão transitória de tráfego que o compartimento C pode encaminhar.
- PIR - Taxa na qual os tokens são colocados no bucket E, que especifica a taxa média de transmissão ou encaminhamento de pacotes permitida pelo bucket E.
- EBS - Tamanho do bucket E, que especifica a explosão transitória de tráfego que o bucket E pode encaminhar.
Quando um pacote chega, as seguintes regras se aplicam:
- Se o balde C tiver fichas suficientes, o pacote será colorido de verde.
- Se o balde C não tiver fichas suficientes, mas o balde E tiver fichas suficientes, o pacote será colorido de amarelo.
- Se nem o balde C nem o balde E tiverem tokens suficientes, o pacote será colorido de vermelho.
Policiamento de tráfego
O policiamento de tráfego suporta o policiamento do tráfego de entrada e do tráfego de saída.
Uma aplicação típica do policiamento de tráfego é supervisionar a especificação do tráfego que entra em uma rede e limitá-lo dentro de uma faixa razoável. Outra aplicação é "disciplinar" o tráfego extra para evitar o uso agressivo dos recursos da rede por um aplicativo. Por exemplo, você pode limitar a largura de banda dos pacotes HTTP a menos de 50% do total. Se o tráfego de uma sessão exceder o limite, o policiamento de tráfego poderá descartar os pacotes ou redefinir a precedência de IP dos pacotes. A Figura 6 mostra um exemplo de policiamento de tráfego de saída em uma interface.
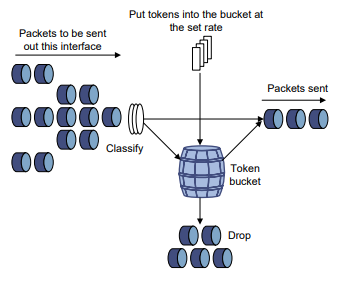
Figura 6 Policiamento de tráfego
O policiamento de tráfego é amplamente usado no policiamento do tráfego que entra nas redes ISP. Ele pode classificar o tráfego policiado e executar ações de policiamento predefinidas em cada pacote, dependendo do resultado da avaliação:
- Encaminhar o pacote se o resultado da avaliação for "conforme".
- Descartar o pacote se o resultado da avaliação for "excesso".
- Encaminhar o pacote com sua precedência remarcada se o resultado da avaliação for "conforme".
GTS
O GTS suporta a modelagem do tráfego de saída. O GTS limita a taxa de tráfego de saída armazenando em buffer o tráfego excedente. Você pode usar o GTS para adaptar a taxa de saída de tráfego em um dispositivo à taxa de tráfego de entrada do dispositivo conectado para evitar a perda de pacotes.
As diferenças entre o policiamento de tráfego e o GTS são as seguintes:
- Os pacotes a serem descartados com o policiamento de tráfego são mantidos em um buffer ou fila com o GTS, conforme mostrado na Figura 7. Quando há tokens suficientes no balde de tokens, os pacotes armazenados em buffer são enviados em uma taxa uniforme.
- O GTS pode resultar em atraso adicional e o policiamento de tráfego não.
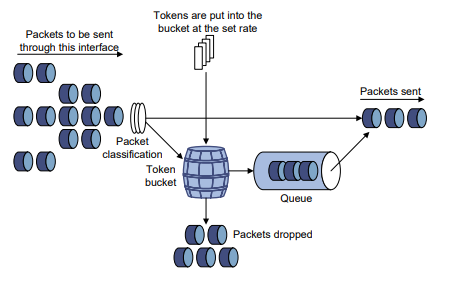
Figura 7 GTS
Por exemplo, na Figura 8, o Dispositivo B executa o policiamento de tráfego nos pacotes do Dispositivo A e descarta os pacotes que excedem o limite. Para evitar a perda de pacotes, você pode executar o GTS na interface de saída do Dispositivo A para que os pacotes que excedam o limite sejam armazenados em cache no Dispositivo A. Assim que os recursos forem liberados, o GTS retira os pacotes armazenados em cache e os envia.
Figura 8 Aplicativo GTS
Limite de taxa
O limite de taxa controla a taxa de tráfego de entrada e de saída. O tráfego de saída é tomado como exemplo.
O limite de taxa de uma interface especifica a taxa máxima de encaminhamento de pacotes (excluindo pacotes críticos).
O limite de taxa também usa token buckets para controle de tráfego. Quando o limite de taxa é configurado em uma interface, um compartimento de tokens manipula todos os pacotes a serem enviados pela interface para limitação de taxa. Se houver tokens suficientes no compartimento de tokens, os pacotes poderão ser encaminhados. Caso contrário, os pacotes serão colocados em filas de QoS para gerenciamento de congestionamento. Dessa forma, o tráfego que passa pela interface é controlado.
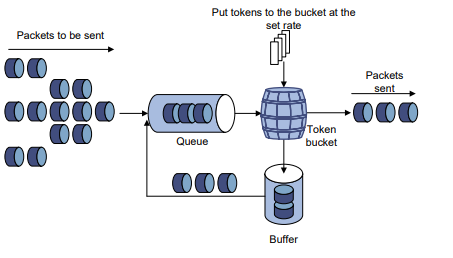
Figura 9 Implementação do limite de taxa
O mecanismo de token bucket limita a taxa de tráfego ao acomodar rajadas. Ele permite que o tráfego de rajadas seja transmitido se houver tokens suficientes disponíveis. Se os tokens forem escassos, os pacotes não poderão ser transmitidos até que tokens eficientes sejam gerados no token bucket. Ele restringe a taxa de tráfego à taxa de geração de tokens.
O limite de taxa controla a taxa total de todos os pacotes em uma interface. É mais fácil de usar do que o policiamento de tráfego para controlar a taxa de tráfego total.
Restrições e diretrizes: Configuração de policiamento de tráfego, GTS e limite de taxa
O CIR especificado não leva em conta o tráfego transmitido em intervalos entre quadros, e a taxa realmente permitida em uma interface é maior do que o CIR especificado.
Um intervalo entre quadros é um intervalo de tempo para a transmissão de 12 bits entre quadros. Esse intervalo tem as seguintes funções:
- Permite que o dispositivo diferencie um quadro de outro.
- Dá tempo para que o dispositivo processe o quadro atual e se prepare para receber o próximo quadro.
Configuração do policiamento de tráfego
Restrições e diretrizes
O dispositivo suporta os seguintes destinos de aplicativos para policiamento de tráfego:
- Interface.
- VLANs.
- Globalmente.
- Perfil do usuário.
Procedimento
- Entre na visualização do sistema.
System View- Definir uma classe de tráfego.
- Crie uma classe de tráfego e entre na visualização da classe de tráfego.
traffic classifier classifier-name [ operator { and | or } ]- Configure um critério de correspondência.
if-match match-criteriaPor padrão, nenhum critério de correspondência é configurado.
Para obter mais informações sobre o comando if-match, consulte Referência de comandos ACL e QoS.
- Retornar à visualização do sistema.
quit- Definir um comportamento de tráfego.
- Crie um comportamento de tráfego e entre na visualização de comportamento de tráfego.
traffic behavior behavior-name- Configure uma ação de policiamento de tráfego.
car cir committed-information-rate [ cbs committed-burst-size [ ebs excess-burst-size ] ] [ green action | red action | yellow action ] *car cir committed-information-rate [ cbs committed-burst-size ] pirpeak-information-rate [ ebs excess-burst-size ] [ green action | redaction | yellow action ] *Por padrão, nenhuma ação de policiamento de tráfego é configurada.
- Retornar à visualização do sistema.
quitqos policy policy-nameclassifier classifier-name behavior behavior-name Por padrão, uma classe de tráfego não é associada a um comportamento de tráfego.
quitPara obter mais informações, consulte "Aplicação da política de QoS". Por padrão, nenhuma política de QoS é aplicada.
Configuração do GTS
Restrições e diretrizes
O termo "interface" nesta seção refere-se às interfaces Ethernet de camada 2.
Procedimento
- Entre na visualização do sistema.
System Viewinterface interface-type interface-numberqos gts queue queue-id cir committed-information-rate [ cbs committed-burst-size ] undo qos gts queue queue-idPor padrão, o GTS não é configurado em uma interface.
Configuração do limite de taxa
Restrições e diretrizes
O termo "interface" nesta seção refere-se às interfaces Ethernet de camada 2.
Procedimento
- Entre na visualização do sistema.
System View- Entre na visualização da interface.
interface interface-type interface-number- Configure o limite de taxa para a interface.
qos lr { inbound | outbound } cir committed-information-rate [ cbs committed-burst-size ]Por padrão, nenhum limite de taxa é configurado em uma interface.
Comandos de exibição e manutenção para policiamento de tráfego, GTS e limite de taxa
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir a configuração e as estatísticas do GTS para interfaces. | display qos gts interface [ interface-type interface-number ] |
| Exibir configuração e estatísticas de limite de taxa. | display qos lr interface [ interface-type interface-number ] |
| Exibir o uso de recursos de QoS e ACL. | display qos-acl resource [ slot slot-number ] |
| Exibir a configuração do comportamento do tráfego. | exibir o comportamento do tráfego definido pelo usuário [ nome-do-comportamento ] |
Exemplos de configuração de policiamento de tráfego, GTS e limite de taxa
Exemplo: Configuração do policiamento de tráfego e do GTS
Requisitos de rede
Conforme mostrado na Figura 10:
- O servidor, o Host A e o Host B podem acessar a Internet por meio do Dispositivo A e do Dispositivo B.
- O servidor, Host A, e GigabitEthernet 1/0/1 do Dispositivo A estão no mesmo segmento de rede.
- O host B e a GigabitEthernet 1/0/2 do dispositivo A estão no mesmo segmento de rede.
Realize o controle de tráfego dos pacotes que a GigabitEthernet 1/0/1 do Dispositivo A recebe do servidor e do Host A usando as seguintes diretrizes:
- Limite a taxa de pacotes do servidor a 10240 kbps. Quando a taxa de tráfego está abaixo de 10240 kbps, o tráfego é encaminhado. Quando a taxa de tráfego excede 10240 kbps, os pacotes excedentes são marcados com o valor DSCP 0 e, em seguida, encaminhados.
- Limite a taxa de pacotes do Host A a 2560 kbps. Quando a taxa de tráfego está abaixo de 2560 kbps, o tráfego é encaminhado. Quando a taxa de tráfego excede 2560 kbps, os pacotes em excesso são descartados.
Realize o controle de tráfego na GigabitEthernet 1/0/1 e na GigabitEthernet 1/0/2 do Dispositivo B usando as seguintes diretrizes:
- Limite a taxa de tráfego de entrada na GigabitEthernet 1/0/1 a 20480 kbps, e os pacotes excedentes são descartados.
- Limite a taxa de tráfego de saída na GigabitEthernet 1/0/2 a 10240 kbps, e os pacotes em excesso são descartados.
Figura 10 Diagrama de rede
Procedimento de configuração
- Configurar o dispositivo A:
# Configure a ACL 2001 e a ACL 2002 para permitir os pacotes do servidor e do Host A, respectivamente.
[DeviceA] acl basic 2001
[DeviceA-acl-ipv4-basic-2001] rule permit source 1.1.1.1 0
[DeviceA-acl-ipv4-basic-2001] quit
[DeviceA] acl basic 2002
[DeviceA-acl-ipv4-basic-2002] rule permit source 1.1.1.2 0
[DeviceA-acl-ipv4-basic-2002] quit# Crie uma classe de tráfego chamada servidor e use a ACL 2001 como critério de correspondência.
[DeviceA] traffic classifier server
[DeviceA-classifier-server] if-match acl 2001
[DeviceA-classifier-server] quit# Crie uma classe de tráfego chamada host e use a ACL 2002 como critério de correspondência.
[DeviceA] traffic classifier host
[DeviceA-classifier-host] if-match acl 2002
[DeviceA-classifier-host] quit# Crie um comportamento de tráfego denominado servidor e configure uma ação de policiamento de tráfego (CIR 10240 kbps).
[DeviceA] traffic behavior server
[DeviceA-behavior-server] car cir 10240 red remark-dscp-pass 0
[DeviceA-behavior-server] quit# Crie um comportamento de tráfego chamado host e configure uma ação de policiamento de tráfego (CIR 2560 kbps).
[DeviceA] traffic behavior host
[DeviceA-behavior-host] car cir 2560
[DeviceA-behavior-host] quit# Crie uma política de QoS chamada car e associe as classes de tráfego server e host aos comportamentos de tráfego server e host na política de QoS car, respectivamente.
[DeviceA] qos policy car
[DeviceA-qospolicy-car] classifier server behavior server
[DeviceA-qospolicy-car] classifier host behavior host
[DeviceA-qospolicy-car] quit# Aplique a política de QoS car na direção de entrada da GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] qos apply policy car inbound- Configurar o dispositivo B:
# Crie a ACL 3001 e configure uma regra para corresponder aos pacotes HTTP.
<DeviceB> system-view
[DeviceB] acl advanced 3001
[DeviceB-acl-adv-3001] rule permit tcp destination-port eq 80
[DeviceB-acl-adv-3001] quit# Crie uma classe de tráfego chamada http e use a ACL 3001 como critério de correspondência.
[DeviceB] traffic classifier http
[DeviceB-classifier-http] if-match acl 3001
[DeviceB-classifier-http] quit# Criar uma classe de tráfego chamada class e configurar a classe de tráfego para corresponder a todos os pacotes.
[DeviceB] traffic classifier class
[DeviceB-classifier-class] if-match any
[DeviceB-classifier-class] quit# Crie um comportamento de tráfego chamado car_inbound e configure uma ação de policiamento de tráfego (CIR 20480 kbps).
[DeviceB] traffic behavior car_inbound
[DeviceB-behavior-car_inbound] car cir 20480
[DeviceB-behavior-car_inbound] quit# Crie um comportamento de tráfego chamado car_outbound e configure uma ação de policiamento de tráfego (CIR 10240 kbps).
[DeviceB] traffic behavior car_outbound
[DeviceB-behavior-car_outbound] car cir 10240
[DeviceB-behavior-car_outbound] quit# Criar uma política de QoS chamada car_inbound e associar a classe de tráfego ao tráfego comportamento car_inbound na política de QoS car_inbound.
[DeviceB] qos policy car_inbound
[DeviceB-qospolicy-car_inbound] classifier class behavior car_inbound
[DeviceB-qospolicy-car_inbound] quit# Criar uma política de QoS chamada car_outbound e associar a classe de tráfego http ao tráfego comportamento car_outbound na política de QoS car_outbound.
[DeviceB] qos policy car_outbound
[DeviceB-qospolicy-car_outbound] classifier http behavior car_outbound
[DeviceB-qospolicy-car_outbound] quit# Aplique a política de QoS car_inbound à direção de entrada da GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] qos apply policy car_inbound inbound# Aplique a política de QoS car_outbound à direção de saída da GigabitEthernet 1/0/2.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] qos apply policy car_outbound outbound
Configuração do gerenciamento de congestionamento
Sobre o gerenciamento de congestionamento
Causa, resultados negativos e contramedida do congestionamento
O congestionamento ocorre em um link ou nó quando o tamanho do tráfego excede a capacidade de processamento do link ou nó. É típico de uma rede de multiplexação estatística e pode ser causado por falhas no link, recursos insuficientes e várias outras causas.
A Figura 11 mostra dois cenários típicos de congestionamento.
Figura 11 Cenários de congestionamento de tráfego
O congestionamento produz os seguintes resultados negativos:
- Aumento do atraso e do jitter durante a transmissão de pacotes.
- Diminuição do rendimento da rede e da eficiência do uso de recursos.
- Exaustão de recursos de rede (memória, em particular) e até mesmo falha do sistema.
O congestionamento é inevitável em redes comutadas e ambientes de aplicativos multiusuários. Para melhorar o desempenho do serviço de sua rede, tome medidas para gerenciá-lo e controlá-lo.
A chave para o gerenciamento de congestionamento é definir uma política de envio de recursos para priorizar pacotes para encaminhamento quando ocorrer congestionamento.
Métodos de gerenciamento de congestionamento
O gerenciamento de congestionamento usa algoritmos de enfileiramento e agendamento para classificar e ordenar o tráfego que sai de uma porta.
O dispositivo é compatível com os seguintes mecanismos de enfileiramento:
- SP.
- WRR.
Enfileiramento de SP
O enfileiramento SP foi projetado para aplicativos de missão crítica que exigem serviço preferencial para reduzir o atraso de resposta quando ocorre congestionamento.
Figura 12 Enfileiramento de SP
Na Figura 12, o enfileiramento SP classifica oito filas em uma porta em oito classes, numeradas de 7 a 0 em ordem decrescente de prioridade.
O enfileiramento SP programa as oito filas em ordem decrescente de prioridade. O enfileiramento SP envia primeiro os pacotes da fila com a prioridade mais alta. Quando a fila com a prioridade mais alta está vazia, ela envia pacotes para a fila com a segunda prioridade mais alta e assim por diante. Você pode atribuir pacotes de missão crítica a uma fila de alta prioridade para garantir que eles sejam sempre atendidos primeiro. Os pacotes de serviços comuns podem ser atribuídos a filas de baixa prioridade para serem transmitidos quando as filas de alta prioridade estiverem vazias.
A desvantagem do enfileiramento SP é que os pacotes nas filas de prioridade mais baixa não podem ser transmitidos se houver pacotes nas filas de prioridade mais alta. Na pior das hipóteses, o tráfego de prioridade mais baixa pode nunca ser atendido.
Enfileiramento WRR
O enfileiramento WRR programa todas as filas sucessivamente para garantir que cada fila seja atendida por um determinado tempo, conforme mostrado na Figura 13.
Figura 13 Enfileiramento WRR
Suponha que uma porta forneça oito filas de saída. O WRR atribui a cada fila um valor de peso (representado por w7, w6, w5, w4, w3, w2, w1 ou w0). O valor do peso de uma fila decide a proporção de recursos atribuídos a ela. Em uma porta de 100 Mbps, você pode definir os valores de peso como 50, 30, 10, 10, 50, 30, 10 e 10 para w7 a w0. Dessa forma, a fila com a prioridade mais baixa pode obter um mínimo de 5 Mbps de largura de banda. O WRR resolve o problema de que o enfileiramento SP pode deixar de atender aos pacotes nas filas de baixa prioridade por um longo período.
Outra vantagem do enfileiramento WRR é que, quando as filas são agendadas sucessivamente, o tempo de serviço de cada fila não é fixo. Se uma fila estiver vazia, a próxima fila será agendada imediatamente. Isso melhora a eficiência do uso dos recursos de largura de banda.
O enfileiramento WRR inclui os seguintes tipos:
- Enfileiramento WRR básico - Contém várias filas. É possível definir o peso de cada fila, e o WRR programa essas filas com base nos parâmetros definidos pelo usuário de forma round robin.
- Enfileiramento WRR baseado em grupo - Todas as filas são programadas por WRR. Você pode dividir as filas de saída no grupo de filas de prioridade WRR 1 e no grupo de filas de prioridade WRR 2. A programação de filas round robin é realizada primeiro para o grupo 1. Se o grupo 1 estiver vazio, a programação de filas round robin será executada para o grupo 2. Somente o grupo 1 de filas de prioridade WRR é compatível com a versão atual do software.
Em uma interface habilitada com enfileiramento WRR baseado em grupo, é possível atribuir filas ao grupo SP. As filas do grupo SP são agendadas com SP. O grupo SP tem prioridade de agendamento mais alta do que os grupos WRR.
Visão geral das tarefas de gerenciamento de congestionamento
Para configurar o gerenciamento de congestionamento, execute as seguintes tarefas:
- Configuração de enfileiramento em uma interface
- Configuração de enfileiramento SP
- Configuração do enfileiramento WRR
- Configuração de enfileiramento SP+WRR
- Configuração de um perfil de agendamento de fila
Configuração de enfileiramento em uma interface
Restrições e diretrizes para a configuração de filas
O termo "interface" nesta seção refere-se às interfaces Ethernet de camada 2.
A ID da fila, o nome da fila, o grupo e o peso na saída do comando display qos queue interface formam um modelo de agendamento de fila. Um modelo de programação de fila corresponde a uma combinação exclusiva de configurações de parâmetros de fila em uma interface.
O dispositivo suporta no máximo oito modelos de agendamento de filas, incluindo o modelo de agendamento de filas padrão, o modelo de agendamento de filas para interfaces físicas IRF e o modelo de agendamento de filas predefinido para a CPU. Se várias interfaces usarem o mesmo modelo de agendamento de fila criado pelo usuário, certifique-se de que pelo menos um outro modelo de agendamento de fila não tenha sido usado em nenhuma interface.
Se todos os modelos de programação de filas forem usados, você poderá configurar o gerenciamento de congestionamento por meio de um perfil de programação de filas (consulte "Configuração de um perfil de programação de filas").
Configuração de enfileiramento SP
- Entre na visualização do sistema.
System Viewinterface interface-type interface-numberqos spPor padrão, uma interface usa o enfileiramento WRR de contagem de bytes.
Configuração do enfileiramento WRR
- Entre na visualização do sistema.
System Viewinterface interface-type interface-numberqos wrr weightPor padrão, uma interface usa o enfileiramento WRR de contagem de pacotes.
qos wrr queue-id group 1 weight schedule-valuePor padrão, todas as filas em uma interface habilitada para WRR estão no grupo WRR 1, e as filas 0 a 7 têm um peso de 1, 2, 3, 4, 5, 9, 13 e 15, respectivamente.
Configuração de enfileiramento SP+WRR
Restrições e diretrizes
Para configurar o peso do agendamento, você deve especificar a mesma unidade de agendamento especificada ao ativar o enfileiramento WRR.
Procedimento
- Entre na visualização do sistema.
System Viewinterface interface-type interface-numberqos wrr weightPor padrão, uma interface usa o enfileiramento WRR de contagem de pacotes.
qos wrr queue-id group spPor padrão, todas as filas em uma interface habilitada para WRR estão no grupo 1 de WRR.
qos wrr queue-id group 1 weight schedule-valuePor padrão, todas as filas em uma interface habilitada para WRR estão no grupo WRR 1, e as filas de 0 a 7 têm um peso de 1, 2, 3, 4, 5, 9, 13 e 15, respectivamente.
Configuração de um perfil de agendamento de fila
Sobre perfis de programação de filas
Em um perfil de programação de filas, é possível configurar parâmetros de programação para cada fila. Ao aplicar o perfil de programação de filas a uma interface, você pode implementar o gerenciamento de congestionamento na interface.
Os perfis de programação de filas suportam dois algoritmos de programação de filas: SP e WRR. Em um perfil de programação de filas, também é possível configurar SP+WRR. Para obter informações sobre cada algoritmo de agendamento, consulte "Sobre o gerenciamento de congestionamento". Quando os grupos SP e WRR são configurados em um perfil de programação de filas, a Figura 14 mostra a ordem de programação.
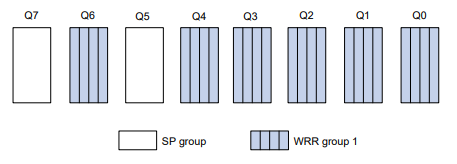
Figura 14 Perfil de agendamento de filas configurado com SP e WRR
- A fila 7 tem a prioridade mais alta no grupo SP. Seus pacotes são enviados preferencialmente.
- A fila 5 tem a segunda maior prioridade no grupo SP. Os pacotes na fila 5 são enviados quando a fila 7 está vazia.
- Todas as filas do grupo WRR 1 são programadas de acordo com seus pesos. Quando a fila 7 e a fila 5 estão vazias, o grupo WRR 1 é programado.
Restrições e diretrizes para a configuração do perfil de programação de filas
Quando você configurar um perfil de agendamento de fila, siga estas restrições e diretrizes:
- O termo "interface" nesta seção refere-se às interfaces Ethernet de camada 2.
- Somente um perfil de agendamento de fila pode ser aplicado a uma interface.
- É possível modificar os parâmetros de agendamento em um perfil de agendamento de fila já aplicado a uma interface.
Configuração de um perfil de agendamento de fila
- Entre na visualização do sistema.
System Viewqos qmprofile profile-namequeue queue-id spqueue queue-id wrr group group-id { weight | byte-count } schedule-valuePor padrão, todas as filas em um perfil de agendamento de filas usam o enfileiramento SP.
Aplicação de um perfil de programação de filas
- Entre na visualização do sistema.
System Viewinterface interface-type interface-numberqos apply qmprofile profile-namePor padrão, nenhum perfil de agendamento de fila é aplicado a uma interface.
Exemplo: Configuração de um perfil de programação de filas
Configuração de rede
Configure um perfil de agendamento de fila para atender aos seguintes requisitos na GigabitEthernet 1/0/1:
- A fila 7 tem a prioridade mais alta e seus pacotes são enviados preferencialmente.
- As filas de 0 a 6 estão no grupo WRR e são programadas de acordo com suas
pesos de contagem de pacotes, que são 2, 1, 2, 4, 6, 8 e 10, respectivamente. Quando a fila 7 está vazia, o grupo WRR é programado.
Procedimento
# Entre na visualização do sistema.
<Sysname> system-view# Criar um perfil de agendamento de fila chamado qm1.
[Sysname] qos qmprofile qm1
[Sysname-qmprofile-qm1]
# Configure a fila 7 para usar o enfileiramento SP.
[Sysname-qmprofile-qm1] queue 7 sp# Atribua as filas 0 a 6 ao grupo WRR 1, com seus pesos de contagem de pacotes como 2, 1, 2, 4, 6, 8 e 10, respectivamente.
[Sysname-qmprofile-qm1] queue 0 wrr group 1 weight 2
[Sysname-qmprofile-qm1] queue 1 wrr group 1 weight 1
[Sysname-qmprofile-qm1] queue 2 wrr group 1 weight 2
[Sysname-qmprofile-qm1] queue 3 wrr group 1 weight 4
[Sysname-qmprofile-qm1] queue 4 wrr group 1 weight 6
[Sysname-qmprofile-qm1] queue 5 wrr group 1 weight 8
[Sysname-qmprofile-qm1] queue 6 wrr group 1 weight 10
[Sysname-qmprofile-qm1] quit# Aplique o perfil de agendamento de filas qm1 à GigabitEthernet 1/0/1.
[Sysname] interface gigabitethernet 1/0/1
[Sysname-GigabitEthernet1/0/1] qos apply qmprofile qm1Após a conclusão da configuração, a GigabitEthernet 1/0/1 executa a programação de filas conforme especificado no perfil de programação de filas qm1.
Comandos de exibição e manutenção para gerenciamento de congestionamento
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir a configuração dos perfis de agendamento de filas. | exibir configuração do qos qmprofile [ nome-do-perfil ] [ número-do-slot do slot ] |
| Exibir os perfis de agendamento de filas aplicados às interfaces. | display qos qmprofile interface [ interface-type interface-number ] |
| Exibir saída estatísticas de tráfego baseadas em filas para interfaces. | display qos queue-statistics interface outbound |
| Exibir a configuração de enfileiramento de SP. | display qos queue sp interface [ interface-type interface-number ] |
| Exibir a configuração de enfileiramento WRR. | display qos queue wrr interface [ interface-type interface-number ] |
Configuração da filtragem de tráfego
Sobre a filtragem de tráfego
Você pode filtrar ou excluir o tráfego de uma classe associando a classe a uma ação de filtragem de tráfego. Para exemplo, você pode filtrar os pacotes provenientes de um endereço IP de acordo com o status da rede.
Restrições e diretrizes: Configuração de filtragem de tráfego
O dispositivo suporta os seguintes destinos de aplicativos para filtragem de tráfego:
- Interface.
- VLANs.
- Globalmente.
- Perfil do usuário.
Procedimento
- Entre na visualização do sistema.
System Viewtraffic classifier classifier-name [ operator { and | or } ]if-match match-criteriaPor padrão, nenhum critério de correspondência é configurado.
Para obter mais informações sobre a configuração de critérios de correspondência, consulte Referência de comandos ACL e QoS.
quittraffic behavior behavior-namefilter { deny | permit }Por padrão, nenhuma ação de filtragem de tráfego é configurada.
Se um comportamento de tráfego tiver a ação de negar filtro, todas as outras ações no comportamento de tráfego, exceto a contabilidade baseada em classe, não terão efeito.
quitqos policy policy-namequitPara obter mais informações, consulte "Aplicação da política de QoS". Por padrão, nenhuma política de QoS é aplicada.
display traffic behavior user-defined [ behavior-name ]Esse comando está disponível em qualquer visualização.
Exemplos de configuração de filtragem de tráfego
Exemplo: Configuração da filtragem de tráfego
Configuração de rede
Conforme mostrado na Figura 15, configure a filtragem de tráfego na GigabitEthernet 1/0/1 para negar os pacotes de entrada com um número de porta de origem diferente de 21.
Figura 15 Diagrama de rede
Procedimento
# Crie a ACL 3000 avançada e configure uma regra para corresponder aos pacotes cujo número da porta de origem não seja 21.
<Device> system-view
[Device] acl advanced 3000
[Device-acl-ipv4-adv-3000] rule 0 permit tcp source-port neq 21
[Device-acl-ipv4-adv-3000] quit# Crie uma classe de tráfego chamada classifier_1 e use a ACL 3000 como critério de correspondência na classe de tráfego.
[Device] traffic classifier classifier_1
[Device-classifier-classifier_1] if-match acl 3000
[Device-classifier-classifier_1] quit# Crie um comportamento de tráfego chamado behavior_1 e configure a ação de filtragem de tráfego para descartar pacotes.
[Device] traffic behavior behavior_1
[Device-behavior-behavior_1] filter deny
[Device-behavior-behavior_1] quit# Criar uma política de QoS denominada policy e associar a classe de tráfego classifier_1 ao comportamento do tráfego
comportamento_1 na política de QoS.
[Device] qos policy policy
[Device-qospolicy-policy] classifier classifier_1 behavior behavior_1
[Device-qospolicy-policy] quit# Aplique a política de QoS ao tráfego de entrada da GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] qos apply policy policy inboundConfiguração da marcação de prioridade
Sobre a marcação de prioridade
A marcação de prioridade define os campos de prioridade ou os bits de sinalização dos pacotes para modificar a prioridade dos pacotes. Por exemplo, você pode usar a marcação de prioridade para definir a precedência de IP ou DSCP para uma classe de pacotes IP para controlar o encaminhamento desses pacotes.
Para configurar a marcação de prioridade para definir os campos de prioridade ou os bits de sinalização de uma classe de pacotes, execute as seguintes tarefas:
- Configure um comportamento de tráfego com uma ação de marcação de prioridade.
- Associe a classe de tráfego ao comportamento do tráfego.
A marcação de prioridade pode ser usada junto com o mapeamento de prioridade. Para obter mais informações, consulte "Configuração do mapeamento de prioridade".
Configuração da marcação de prioridade
Restrições e diretrizes
O dispositivo suporta a aplicação de uma política de QoS que contenha uma ação de marcação de prioridade somente na direção de entrada.
Procedimento
- Entre na visualização do sistema.
System Viewtraffic classifier classifier-name [ operator { and | or } ]if-match match-criteriaPor padrão, nenhum critério de correspondência é configurado.
Para obter mais informações sobre o comando if-match, consulte Referência de comandos ACL e QoS.
- Retornar à visualização do sistema.
quittraffic behavior behavior-namePara ver as ações de marcação de prioridade configuráveis, consulte os comandos de observação em ACL e QoS Command Reference.
quitqos policy policy-namequitPara obter mais informações, consulte "Aplicação da política de QoS". Por padrão, nenhuma política de QoS é aplicada.
display traffic behavior user-defined [ behavior-name ]Esse comando está disponível em qualquer visualização.
Exemplos de configuração de marcação de prioridade
Exemplo: Configuração da marcação de prioridade
Configuração de rede
Conforme mostrado na Figura 16, configure a marcação de prioridade no dispositivo para atender aos seguintes requisitos:
| Fonte de tráfego | Destino | Prioridade de processamento |
| Host A, B | Servidor de dados | Alta |
| Host A, B | Servidor de correio eletrônico | Médio |
| Host A, B | Servidor de arquivos | Baixa |
Figura 16 Diagrama de rede
Procedimento
# Crie a ACL 3000 avançada e configure uma regra para corresponder aos pacotes com o endereço IP de destino 192.168.0.1.
<Device> system-view
[Device] acl advanced 3000
[Device-acl-ipv4-adv-3000] rule permit ip destination 192.168.0.1 0
[Device-acl-ipv4-adv-3000] quit# Crie a ACL 3001 avançada e configure uma regra para corresponder aos pacotes com o endereço IP de destino 192.168.0.2.
[Device] acl advanced 3001
[Device-acl-ipv4-adv-3001] rule permit ip destination 192.168.0.2 0
[Device-acl-ipv4-adv-3001] quit# Crie a ACL 3002 avançada e configure uma regra para corresponder aos pacotes com o endereço IP de destino 192.168.0.3.
[Device] acl advanced 3002
[Device-acl-ipv4-adv-3002] rule permit ip destination 192.168.0.3 0
[Device-acl-ipv4-adv-3002] quit# Crie uma classe de tráfego chamada classifier_dbserver e use a ACL 3000 como critério de correspondência na classe de tráfego.
[Device] traffic classifier classifier_dbserver
[Device-classifier-classifier_dbserver] if-match acl 3000
[Device-classifier-classifier_dbserver] quit# Crie uma classe de tráfego chamada classifier_mserver e use a ACL 3001 como critério de correspondência na classe de tráfego.
[Device] traffic classifier classifier_mserver
[Device-classifier-classifier_mserver] if-match acl 3001
[Device-classifier-classifier_mserver] quit
# Crie uma classe de tráfego chamada classifier_fserver e use a ACL 3002 como critério de correspondência na classe de tráfego.
[Device] traffic classifier classifier_fserver
[Device-classifier-classifier_fserver] if-match acl 3002
[Device-classifier-classifier_fserver] quit
# Crie um comportamento de tráfego chamado behavior_dbserver e configure a ação de definir o valor de precedência local como 4.
[Device] traffic behavior behavior_dbserver
[Device-behavior-behavior_dbserver] remark local-precedence 4
[Device-behavior-behavior_dbserver] quit
# Crie um comportamento de tráfego chamado behavior_mserver e configure a ação de definir o valor de precedência local como 3.
[Device] traffic behavior behavior_mserver
[Device-behavior-behavior_mserver] remark local-precedence 3
[Device-behavior-behavior_mserver] quit
# Crie um comportamento de tráfego chamado behavior_fserver e configure a ação de definir o valor de precedência local como 2.
[Device] traffic behavior behavior_fserver
[Device-behavior-behavior_fserver] remark local-precedence 2
[Device-behavior-behavior_fserver] quit
# Crie uma política de QoS chamada policy_server e associe classes de tráfego a comportamentos de tráfego na política de QoS.
[Device] qos policy policy_server
[Device-qospolicy-policy_server] classifier classifier_dbserver behavior
behavior_dbserver
[Device-qospolicy-policy_server] classifier classifier_mserver behavior
behavior_mserver
[Device-qospolicy-policy_server] classifier classifier_fserver behavior
behavior_fserver
[Device-qospolicy-policy_server] quit
# Aplique a política de QoS policy_server ao tráfego de entrada da GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] qos apply policy policy_server inbound
[Device-GigabitEthernet1/0/1] quit
Configuração de aninhamento
Sobre o aninhamento
O aninhamento adiciona uma tag de VLAN aos pacotes correspondentes para permitir que os pacotes com tag de VLAN passem pela VLAN correspondente. Por exemplo, você pode adicionar uma tag de VLAN externa aos pacotes de uma rede de cliente para uma rede de provedor de serviços. Isso permite que os pacotes passem pela rede do provedor de serviços carregando uma tag de VLAN atribuída pelo provedor de serviços.
Restrições e diretrizes: Configuração de aninhamento
O dispositivo suporta a aplicação de uma política de QoS que contém uma ação de aninhamento somente na direção de entrada:
Não ative o QinQ e aplique uma política de QoS que contenha uma ação de aninhamento na mesma interface. Caso contrário, o QinQ ou a política de QoS não entrará em vigor.
Para usar a ação de aninhamento para adicionar uma etiqueta de VLAN externa aos pacotes com a VLAN ID especificada, você deve usar o comando if-match customer-vlan-id vlan-id-list para corresponder aos pacotes com etiqueta única.
Procedimento
- Entre na visualização do sistema.
System Viewtraffic classifier classifier-name [ operator { and | or } ]if-match match-criteriaPor padrão, nenhum critério de correspondência é configurado para uma classe de tráfego.
Para obter mais informações sobre os critérios de correspondência, consulte o comando if-match na Referência de comandos ACL e QoS.
quittraffic behavior behavior-namenest top-most vlan vlan-idPor padrão, nenhuma ação de adição de tag de VLAN externa é configurada para um comportamento de tráfego.
quitqos policy policy-nameclassifier classifier-name behavior behavior-namePor padrão, uma classe de tráfego não está associada a um comportamento de tráfego.
quitPara obter mais informações, consulte "Aplicação da política de QoS". Por padrão, nenhuma política de QoS é aplicada.
display traffic behavior user-defined [ behavior-name ]Esse comando está disponível em qualquer visualização.
Exemplos de configuração de aninhamento
Exemplo: Configuração de aninhamento
Configuração de rede
Conforme mostrado na Figura 17:
- O Site 1 e o Site 2 na VPN A são duas filiais de uma empresa. Elas usam a VLAN 5 para transmitir o tráfego.
- Como o Site 1 e o Site 2 estão localizados em áreas diferentes, os dois sites usam o serviço de acesso VPN de um provedor de serviços. O provedor de serviços atribui a VLAN 100 aos dois sites.
Configure o aninhamento, para que as duas filiais possam se comunicar por meio da rede do provedor de serviços.
Figura 17 Diagrama de rede
Procedimento
- Configuração do PE 1:
# Crie uma classe de tráfego chamada teste para corresponder ao tráfego com VLAN ID 5.
<PE1> system-view
[PE1] traffic classifier test
[PE1-classifier-test] if-match customer-vlan-id 5
[PE1-classifier-test] quit# Configure uma ação para adicionar a tag 100 da VLAN externa no teste de comportamento do tráfego.
[PE1] traffic behavior test
[PE1-behavior-test] nest top-most vlan 100
[PE1-behavior-test] quit# Criar uma política de QoS chamada teste e associar a classe teste ao comportamento teste na política de QoS
[PE1] qos policy test
[PE1-qospolicy-test] classifier test behavior test
[PE1-qospolicy-test] quit# Configure a porta de downlink (GigabitEthernet 1/0/1) como uma porta híbrida e atribua a porta à VLAN 100 como um membro sem marcação.
[PE1] interface gigabitethernet 1/0/1
[PE1-GigabitEthernet1/0/1] port link-type hybrid
[PE1-GigabitEthernet1/0/1] port hybrid vlan 100 untagged# Aplique o teste de política de QoS ao tráfego de entrada da GigabitEthernet 1/0/1.
[PE1-GigabitEthernet1/0/1] qos apply policy test inbound
[PE1-GigabitEthernet1/0/1] quit
# Configure a porta de uplink (GigabitEthernet 1/0/2) como uma porta tronco e atribua-a à VLAN 100.
[PE1] interface gigabitethernet 1/0/2
[PE1-GigabitEthernet1/0/2] port link-type trunk
[PE1-GigabitEthernet1/0/2] port trunk permit vlan 100
[PE1-GigabitEthernet1/0/2] quit
- Configuração do PE 2:
Configure o PE 2 da mesma forma que o PE 1 está configurado.
Configuração do redirecionamento de tráfego
Sobre o redirecionamento de tráfego
O redirecionamento de tráfego redireciona os pacotes que correspondem aos critérios de correspondência especificados para um local para processamento.
Você pode redirecionar os pacotes para os seguintes destinos:
- CPU.
- Interface.
Restrições e diretrizes: Configuração de redirecionamento de tráfego
- O dispositivo suporta a aplicação de uma política de QoS que contenha uma ação de redirecionamento de tráfego somente na direção de entrada de uma interface.
- Se você executar o comando redirect várias vezes, a configuração mais recente entrará em vigor.
Procedimento
- Entre na visualização do sistema.
System Viewtraffic classifier classifier-name [ operator { and | or } ]if-match match-criteriaPor padrão, nenhum critério de correspondência é configurado para uma classe de tráfego.
Para obter mais informações sobre os critérios de correspondência, consulte o comando if-match na Referência de comandos ACL e QoS.
quittraffic behavior behavior-nameredirect { cpu | interface interface-type interface-number }Por padrão, nenhuma ação de redirecionamento de tráfego é configurada para um comportamento de tráfego.
quitqos policy policy-namequitPara obter mais informações, consulte "Aplicação da política de QoS". Por padrão, nenhuma política de QoS é aplicada.
display traffic behavior user-defined [ behavior-name ]Esse comando está disponível em qualquer visualização.
Exemplos de configuração de redirecionamento de tráfego
Exemplo: Configuração do redirecionamento de tráfego
Configuração de rede
Conforme mostrado na Figura 18:
- O dispositivo A está conectado ao dispositivo B por meio de dois links. O dispositivo A e o dispositivo B estão conectados a outros dispositivos.
- A GigabitEthernet 1/0/1 do Dispositivo A é uma porta tronco e pertence à VLAN 200 e à VLAN 201.
- A GigabitEthernet 1/0/2 do Dispositivo A e a GigabitEthernet 1/0/2 do Dispositivo B pertencem à VLAN 200.
- A GigabitEthernet 1/0/3 do Dispositivo A e a GigabitEthernet 1/0/3 do Dispositivo B pertencem à VLAN 201.
- No dispositivo A, o endereço IP da interface de VLAN 200 é 200.1.1.1/24 e o da interface de VLAN 201 é 201.1.1.1/24.
- No dispositivo B, o endereço IP da interface de VLAN 200 é 200.1.1.2/24 e o da interface de VLAN 201 é 201.1.1.2/24.
Configure as ações de redirecionamento do tráfego para uma interface para atender aos seguintes requisitos:
- Os pacotes com endereço IP de origem 2.1.1.1 recebidos na GigabitEthernet 1/0/1 do Dispositivo A são encaminhados para a GigabitEthernet 1/0/2.
- Os pacotes com endereço IP de origem 2.1.1.2 recebidos na GigabitEthernet 1/0/1 do Dispositivo A são encaminhados para a GigabitEthernet 1/0/3.
- Outros pacotes recebidos na GigabitEthernet 1/0/1 do Dispositivo A são encaminhados de acordo com a tabela de roteamento .

Figura 18 Diagrama de rede
Procedimento
# Crie a ACL 2000 básica e configure uma regra para corresponder aos pacotes com o endereço IP de origem 2.1.1.1.
<DeviceA> system-view
[DeviceA] acl basic 2000
[DeviceA-acl-ipv4-basic-2000] rule permit source 2.1.1.1 0
[DeviceA-acl-ipv4-basic-2000] quit# Crie a ACL 2001 básica e configure uma regra para corresponder aos pacotes com o endereço IP de origem 2.1.1.2.
[DeviceA] acl basic 2001
[DeviceA-acl-ipv4-basic-2001] rule permit source 2.1.1.2 0
[DeviceA-acl-ipv4-basic-2001] quit# Crie uma classe de tráfego chamada classifier_1 e use a ACL 2000 como critério de correspondência na classe de tráfego.
[DeviceA] traffic classifier classifier_1
[DeviceA-classifier-classifier_1] if-match acl 2000
[DeviceA-classifier-classifier_1] quit# Crie uma classe de tráfego chamada classifier_2 e use a ACL 2001 como critério de correspondência na classe de tráfego.
[DeviceA] traffic classifier classifier_2
[DeviceA-classifier-classifier_2] if-match acl 2001
[DeviceA-classifier-classifier_2] quit# Crie um comportamento de tráfego chamado behavior_1 e configure a ação de redirecionar o tráfego para a GigabitEthernet 1/0/2.
[DeviceA] traffic behavior behavior_1
[DeviceA-behavior-behavior_1] redirect interface gigabitethernet 1/0/2
[DeviceA-behavior-behavior_1] quit
# Crie um comportamento de tráfego chamado behavior_2 e configure a ação de redirecionar o tráfego para a GigabitEthernet 1/0/3.
[DeviceA] traffic behavior behavior_2
[DeviceA-behavior-behavior_2] redirect interface gigabitethernet 1/0/3
[DeviceA-behavior-behavior_2] quit
# Criar uma política de QoS chamada policy.
[DeviceA] qos policy policy# Associe o classificador de classe de tráfego classifier_1 ao comportamento de tráfego behavior_1 na política de QoS.
[DeviceA-qospolicy-policy] classifier classifier_1 behavior behavior_1# Associe a classe de tráfego classifier_2 com o comportamento de tráfego behavior_2 na política de QoS.
[DeviceA-qospolicy-policy] classifier classifier_2 behavior behavior_2
[DeviceA-qospolicy-policy] quit# Aplique a política de QoS ao tráfego de entrada da GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] qos apply policy policy inboundConfiguração do CAR global
Sobre a CAR global
A taxa de acesso comprometida global (CAR) é uma abordagem para policiar os fluxos de tráfego globalmente. Ela acrescenta flexibilidade ao CAR comum, em que o policiamento do tráfego é realizado somente por classe de tráfego ou por interface. Nessa abordagem, as ações de CAR são criadas na visualização do sistema e cada uma pode ser usada para policiar vários fluxos de tráfego como um todo.
A Global CAR fornece as seguintes ações de CAR: CAR agregada e CAR hierárquica.
CAR agregado
Uma ação CAR agregada é criada globalmente. Ela pode ser aplicada diretamente às interfaces ou usada nos comportamentos de tráfego associados a diferentes classes de tráfego para policiar vários fluxos de tráfego como um todo. A taxa total dos fluxos de tráfego deve estar em conformidade com as especificações de policiamento de tráfego definidas na ação CAR agregada .
CAR hierárquico
Uma ação CAR hierárquica é criada globalmente. Ela deve ser usada em conjunto com uma ação CAR comum ou CAR agregada. Com uma ação CAR hierárquica, você pode limitar o tráfego total de várias classes de tráfego.
Uma ação CAR hierárquica pode ser usada na ação CAR comum ou agregada para uma classe de tráfego no modo AND ou no modo OR.
- No modo AND, a taxa da classe de tráfego é estritamente limitada sob o CAR comum ou agregado. Esse modo se aplica a fluxos que devem ser estritamente limitados por taxa.
- No modo OR, a classe de tráfego pode usar a largura de banda ociosa de outras classes de tráfego associadas ao CAR hierárquico. Esse modo se aplica a tráfego de alta prioridade e com rajadas, como vídeo.
- Configure ações comuns do CAR para definir a taxa de tráfego para 2048 kbps para os dois fluxos.
- Configure uma ação CAR hierárquica para limitar sua taxa de tráfego total a 4096 kbps.
- Use a ação no modo AND na ação CAR comum para o fluxo de dados.
- Use a ação no modo OR na ação CAR comum para o fluxo de vídeo.
- Limite a taxa total de tráfego da porta de downlink.
- Permitir que cada porta de downlink encaminhe o tráfego à taxa máxima quando as outras portas estiverem ociosas. Por exemplo, você pode executar as seguintes tarefas:
- Use as ações comuns do CAR para limitar as taxas do fluxo de acesso à Internet 1 e do fluxo 2 a 128 kbps.
- Use uma ação CAR hierárquica para limitar sua taxa de tráfego total a 192 kbps.
- Use a ação CAR hierárquica para o fluxo 1 e o fluxo 2 no modo AND.
Ao usar os dois modos adequadamente, você pode aumentar a eficiência da largura de banda.
Por exemplo, suponha que existam dois fluxos: um fluxo de dados de baixa prioridade e um fluxo de vídeo de alta prioridade e com rajadas. Sua taxa de tráfego total não pode exceder 4096 kbps e o fluxo de vídeo deve ter a garantia de pelo menos 2048 kbps de largura de banda. Você pode executar as seguintes tarefas:
O fluxo de vídeo tem garantia de largura de banda de 2048 kbps e pode usar a largura de banda ociosa do fluxo de dados.
Em um cenário de superatribuição de largura de banda, a largura de banda da porta de uplink é menor do que a taxa de tráfego total da porta de downlink. Você pode usar o CAR hierárquico para atender aos seguintes requisitos:
Quando o fluxo 1 não está presente, o fluxo 2 é transmitido na taxa máxima, 128 kbps. Quando ambos os fluxos estão presentes, a taxa total dos dois fluxos não pode exceder 192 kbps. Como resultado, a taxa de tráfego do fluxo 2 pode cair abaixo de 128 kbps.
Restrições e diretrizes: Configuração global do CAR
- Somente o CAR agregado é compatível com a versão atual do software.
- O dispositivo suporta a aplicação de uma política de QoS que contém uma ação CAR agregada somente na direção de entrada.
- Quando uma política de QoS que contém uma ação CAR agregada é aplicada em uma malha IRF, o tráfego que corresponde à política de QoS pode entrar na malha IRF por meio de interfaces em diferentes dispositivos membros da IRF. Nesse caso, o limite de taxa real que entra em vigor é a soma do CIR e do PIR na ação CAR agregada multiplicada pelo número de grupos de portas envolvidos. As interfaces em diferentes dispositivos membros da IRF pertencem a diferentes grupos de portas. As interfaces no mesmo dispositivo membro da IRF podem pertencer ao mesmo grupo de portas ou a grupos de portas diferentes. Para identificar as informações do grupo de portas, execute o comando debug port mapping na visualização de sonda. As interfaces com o mesmo valor Unit pertencem ao mesmo grupo de portas.
Configuração do CAR agregado
- Entre na visualização do sistema.
System View- Definir uma classe de tráfego.
- Crie uma classe de tráfego e entre na visualização da classe de tráfego.
traffic classifier classifier-name [ operator { and | or } ]- Configure um critério de correspondência.
if-match match-criteriaPor padrão, nenhum critério de correspondência é configurado.
Para obter os critérios de correspondência configuráveis, consulte o comando if-match na Referência de comandos ACL e QoS.
- Retornar à visualização do sistema.
quit- Configurar uma ação CAR agregada.
qos car car-name aggregative cir committed-information-rate [ cbs
committed-burst-size [ ebs excess-burst-size ] ] [ green action | red
action | yellow action ] *qos car car-name aggregative cir committed-information-rate [ cbs
committed-burst-size ] pir peak-information-rate [ ebs
excess-burst-size ] [ green action | red action | yellow action ] *Por padrão, nenhuma ação CAR agregada é configurada.
- Definir um comportamento de tráfego.
- Entrar na visualização do comportamento do tráfego.
traffic behavior behavior-name- Use o CAR agregado no comportamento do tráfego.
car name car-namePor padrão, nenhuma ação CAR agregada é usada em um comportamento de tráfego.
- Aplique a política de QoS.
Para obter mais informações, consulte "Aplicação da política de QoS". Por padrão, nenhuma política de QoS é aplicada.
Comandos de exibição e manutenção para o CAR global
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir estatísticas das ações globais do CAR. | display qos car name [ car-name ] |
| Estatísticas claras para ações globais da CAR. | reset qos car name [ car-name ] |
Configuração da contabilidade baseada em classes
Sobre a contabilidade baseada em classes
A contabilidade baseada em classe coleta estatísticas por classe de tráfego. Por exemplo, você pode definir a ação para coletar estatísticas para o tráfego originado de um determinado endereço IP. Ao analisar as estatísticas, você pode determinar se ocorreram anomalias e que medidas tomar.
Restrições e diretrizes: Configuração de contabilidade baseada em classe
O dispositivo suporta os seguintes destinos de aplicativos para contabilidade baseada em classe:
- Interface.
- VLANs.
- Globalmente.
- Perfil do usuário.
Procedimento
- Entre na visualização do sistema.
System Viewtraffic classifier classifier-name [ operator { and | or } ]if-match match-criteriaPor padrão, nenhum critério de correspondência é configurado.
Para obter mais informações sobre o comando if-match, consulte Referência de comandos ACL e QoS.
quittraffic behavior behavior-nameaccounting { byte | packet }Por padrão, nenhuma ação de contabilização de tráfego é configurada.
quitqos policy policy-namequitPara obter mais informações, consulte "Aplicação da política de QoS". Por padrão, nenhuma política de QoS é aplicada.
display traffic behavior user-defined [ behavior-name ]Exemplos de configuração de contabilidade baseada em classe
Exemplo: Configurando contabilidade baseada em classes
Configuração de rede
Conforme mostrado na Figura 19, configure a contabilidade baseada em classe na GigabitEthernet 1/0/1 para coletar estatísticas para o tráfego de entrada de 1.1.1.1/24.
Figura 19 Diagrama de rede
Procedimento
# Crie a ACL 2000 básica e configure uma regra para corresponder aos pacotes com o endereço IP de origem 1.1.1.1.
<Device> system-view
[Device] acl basic 2000
[Device-acl-ipv4-basic-2000] rule permit source 1.1.1.1 0
[Device-acl-ipv4-basic-2000] quit# Crie uma classe de tráfego chamada classifier_1 e use a ACL 2000 como critério de correspondência na classe de tráfego.
[Device] traffic classifier classifier_1
[Device-classifier-classifier_1] if-match acl 2000
[Device-classifier-classifier_1] quit# Crie um comportamento de tráfego chamado behavior_1 e configure a ação de contabilidade baseada em classe.
[Device] traffic behavior behavior_1
[Device-behavior-behavior_1] accounting packet
[Device-behavior-behavior_1] quit# Criar uma política de QoS denominada policy e associar a classe de tráfego classifier_1 ao comportamento do tráfego
comportamento_1 na política de QoS.
[Device] qos policy policy
[Device-qospolicy-policy] classifier classifier_1 behavior behavior_1
[Device-qospolicy-policy] quit# Aplique a política de QoS ao tráfego de entrada da GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] qos apply policy policy inbound
[Device-GigabitEthernet1/0/1] quit# Exibir estatísticas de tráfego para verificar a configuração.
[Device] display qos policy interface gigabitethernet 1/0/1
Interface: GigabitEthernet1/0/1
Direction: Inbound
Policy: policy
Classifier: classifier_1
Operator: AND
Rule(s) :
If-match acl 2000
Behavior: behavior_1
Accounting enable:
28529 (Packets)Prioridade 802.1p
802.1p
A prioridade do 802.1p está no cabeçalho da camada 2. Ela se aplica a ocasiões em que a análise do cabeçalho da Camada 3 não é necessária e a QoS deve ser garantida na Camada 2.
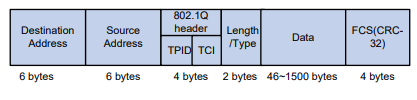
Figura 21 Um quadro Ethernet com um cabeçalho de tag 802.1Q
| Endereço de destino | Endereço de origem | 802.1Q cabeçalho | Comprimento /Tipo | Dados | FCS (CRC- 32) | |
| TPID | TCI |
Conforme mostrado na Figura 21, o cabeçalho da etiqueta 802.1Q de 4 bytes contém o identificador de protocolo de etiqueta (TPID) de 2 bytes e as informações de controle de etiqueta (TCI) de 2 bytes. O valor do TPID é 0x8100. A Figura 22 mostra o formato do cabeçalho da etiqueta 802.1Q. O campo Prioridade no cabeçalho da tag 802.1Q é chamado de prioridade 802.1p, porque seu uso está definido no IEEE 802.1p. A Tabela 8 mostra os valores da prioridade 802.1p.
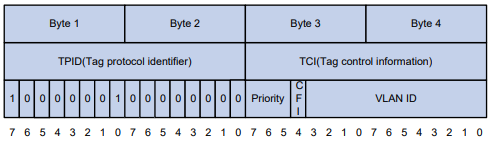
Figura 22 Cabeçalho da etiqueta 802.1Q
Tabela 8 Descrição da prioridade 802.1p
| Prioridade 802.1p (decimal) | Prioridade 802.1p (binária) | Descrição |
| 0 | 000 | melhor esforço |
| 1 | 001 | fundo |
| Prioridade 802.1p (decimal) | Prioridade 802.1p (binária) | Descrição |
| 2 | 010 | sobressalente |
| 3 | 011 | excelente esforço |
| 4 | 100 | carga controlada |
| 5 | 101 | vídeo |
| 6 | 110 | voz |
| 7 | 111 | gerenciamento de rede |
Configuração de buffers de dados
Sobre buffers de dados
Tipos de buffers de dados
Os buffers de dados armazenam temporariamente os pacotes para evitar a perda de pacotes. Os seguintes buffers de dados estão disponíveis:
- Buffer de entrada - Armazena os pacotes de entrada quando a CPU está ocupada.
- Buffer de saída - armazena pacotes de saída quando ocorre congestionamento na rede. A Figura 23 mostra a estrutura dos buffers de entrada e saída.
Figura 23 Estrutura do buffer de dados
Recursos de células e recursos de pacotes
Um buffer usa os seguintes tipos de recursos:
- Recursos de célula - Armazenar pacotes. O buffer usa recursos de célula com base no tamanho dos pacotes. Suponha que um recurso de célula forneça 208 bytes. O buffer aloca um recurso de célula para um pacote de 128 bytes e dois recursos de célula para um pacote de 300 bytes.
- Recursos de pacotes - Armazene ponteiros de pacotes. Um ponteiro de pacote indica onde o pacote está localizado nos recursos da célula. O buffer usa um recurso de pacote para cada pacote de entrada ou de saída.
Área fixa e área compartilhada
- Área fixa - Particionada em filas, cada uma delas dividida igualmente por todas as interfaces do switch, conforme mostrado na Figura. Quando ocorre um congestionamento ou a CPU está ocupada, aplicam-se as seguintes regras :
- Uma interface usa primeiro as filas relevantes da área fixa para armazenar pacotes.
- Quando uma fila está cheia, a interface usa a fila correspondente da área compartilhada.
- Quando a fila na área compartilhada também está cheia, a interface descarta os pacotes subsequentes.
O sistema aloca a área fixa entre as filas, conforme especificado pelo usuário. Mesmo que uma fila não esteja cheia, outras filas não podem ocupar seu espaço. Da mesma forma, o compartilhamento de uma fila para uma interface não pode ser preterido por outras interfaces, mesmo que ela não esteja cheia.
- Área compartilhada - Particionada em filas, cada uma das quais não é dividida igualmente pelas interfaces, conforme mostrado na Figura 24. O sistema determina o espaço real da área compartilhada para cada fila de acordo com a configuração do usuário e o número de pacotes realmente recebidos e enviados. Se uma fila não estiver cheia, outras filas poderão ocupar seu espaço.
O sistema coloca os pacotes recebidos ou enviados em todas as interfaces em uma fila, na ordem em que chegam. Quando a fila está cheia, os pacotes subsequentes são descartados.

Figura 24 Área fixa e área compartilhada
Restrições e diretrizes: Configuração do buffer de dados
Você pode configurar os buffers de dados manual ou automaticamente, ativando o recurso Burst. Se você tiver configurado os buffers de dados de uma forma, exclua a configuração antes de usar a outra forma. Caso contrário, a nova configuração não terá efeito.
Alterações inadequadas no buffer de dados podem causar problemas no sistema. Antes de alterar manualmente as configurações do buffer de dados, certifique-se de compreender o impacto dessas alterações no dispositivo. Como prática recomendada, use o comando burst-mode enable se o sistema exigir grandes espaços de buffer.
Visão geral das tarefas do buffer de dados
Para configurar o buffer de dados, execute as seguintes tarefas:
- Ativação do recurso Burst
- Configuração manual dos buffers de dados
Ativação do recurso Burst
Sobre o recurso Burst
O recurso Burst permite que o dispositivo aloque automaticamente recursos de células e pacotes. Ele é adequado para os seguintes cenários:
- O tráfego de broadcast ou multicast é intenso, resultando em rajadas de tráfego.
- O tráfego entra e sai de uma das seguintes maneiras:
- Entra em um dispositivo a partir de uma interface de alta velocidade e sai de uma interface de baixa velocidade.
- Entra por várias interfaces de mesma taxa ao mesmo tempo e sai por uma interface com a mesma taxa.
As configurações padrão do buffer de dados são alteradas depois que o recurso Burst é ativado. Você pode exibir as configurações do buffer de dados usando o comando display buffer.
Procedimento
- Entre na visualização do sistema.
System View- Ative o recurso Burst.
burst-mode enablePor padrão, o recurso Burst está desativado.
Configuração manual dos buffers de dados
Sobre a configuração manual do buffer de dados
Cada tipo de recurso de um buffer, pacote ou célula tem um tamanho fixo. Depois que você definir o tamanho da área compartilhada para um tipo de recurso, o restante será automaticamente atribuído à área fixa.
Por padrão, todas as filas têm uma parcela igual da área compartilhada e da área fixa. Você pode alterar o espaço máximo da área compartilhada e da área fixa de uma fila. As filas não configuradas usam as configurações padrão.
Restrições e diretrizes
É possível definir os seguintes parâmetros como 100% em um cenário de vídeo multicast para aliviar o problema de imagens travadas:
- A proporção máxima de área compartilhada de recursos de célula para uma fila.
- A proporção total de área compartilhada dos recursos da célula.
- A proporção máxima de área compartilhada de recursos de pacotes para uma fila.
- A proporção total de área compartilhada dos recursos de pacotes.
As configurações anteriores são mutuamente exclusivas da função Burst. Desative a função Burst antes de definir essas configurações.
Procedimento
- Entre na visualização do sistema.
System Viewbuffer egress [ slot slot-number ] { cell | packet } total-shared ratioratioSe esse comando não estiver configurado, você poderá exibir o valor padrão usando o comando display buffer.
buffer egress [ slot slot-number ] { cell | packet } [ queue queue-id ] shared ratio ratioA configuração padrão é 10% para recursos de célula e recursos de pacote.
O espaço máximo real da área compartilhada para cada fila é determinado com base na sua configuração e no número de pacotes a serem recebidos e enviados.
buffer egress [ slot slot-number ] { cell | packet } queue queue-id guaranteed ratio ratioA configuração padrão é 12% para recursos de célula e recursos de pacote.
A soma das proporções de área fixa configuradas para todas as filas não pode exceder a proporção total de área fixa. Caso contrário, a configuração falhará.
aplicação de bufferNão é possível modificar diretamente a configuração aplicada. Para modificar a configuração, você deve cancelar o aplicativo, reconfigurar os buffers de dados e reaplicar a configuração.
Comandos de exibição e manutenção para buffers de dados
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir configurações de tamanho do buffer. | display buffer [ slot slot-number ] [ queue [ queue-id ] ] |
| Exibir o uso do buffer de dados. | exibir o uso do buffer [ número do slot do slot ] |
Configuração de intervalos de tempo
Sobre intervalos de tempo
Você pode implementar um serviço com base na hora do dia aplicando um intervalo de tempo a ele. Um serviço baseado em tempo entra em vigor somente nos períodos de tempo especificados pelo intervalo de tempo. Por exemplo, você pode implementar regras de ACL baseadas em tempo aplicando a elas um intervalo de tempo.
Os seguintes tipos básicos de intervalos de tempo estão disponíveis:
- Intervalo de tempo periódico-Recorre periodicamente em um dia ou dias da semana.
- Intervalo de tempo absoluto - Representa apenas um período de tempo e não se repete. O período ativo de um intervalo de tempo é calculado da seguinte forma:
- Combinação de todos os demonstrativos periódicos.
- Combinação de todas as declarações absolutas.
- Tomando a interseção dos dois conjuntos de declarações como o período ativo do intervalo de tempo.
Restrições e diretrizes: Configuração do intervalo de tempo
Quando você configurar o modo de hardware ACL, siga estas restrições e diretrizes:
- Se não houver um intervalo de tempo, o serviço baseado no intervalo de tempo não entrará em vigor.
- Você pode criar um máximo de 1.024 intervalos de tempo, cada um com um máximo de 32 declarações periódicas e 12 declarações absolutas.
Procedimento
- Entre na visualização do sistema.
System View- Crie ou edite um intervalo de tempo.
time-range time-range-name { start-time to end-time days [ from time1 date1 ] [ to time2 date2 ] | from time1 date1 [ to time2 date2 ] | to time2 date2 }Se for fornecido um nome de intervalo de tempo existente, esse comando adicionará uma instrução ao intervalo de tempo.
Comandos de exibição e manutenção para intervalos de tempo
Execute o comando display em qualquer visualização.
| Tarefa | Comando |
| Exibir a configuração e o status do intervalo de tempo. | exibir intervalo de tempo { time-range-name | all } |
Exemplos de configuração de intervalo de tempo
Exemplo: Configuração de um intervalo de tempo
Configuração de rede
Conforme mostrado na Figura 1, configure uma ACL no dispositivo para permitir que o Host A acesse o servidor somente durante as 8:00 e 18:00 horas nos dias úteis de junho de 2015 até o final do ano.
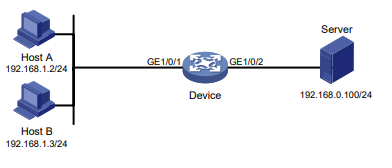
Figura 25 Diagrama de rede
Procedimento
# Crie um intervalo de tempo periódico entre 8:00 e 18:00 nos dias úteis de junho de 2015 até o final do ano.
<Device> system-view
[Device] time-range work 8:0 to 18:0 working-day from 0:0 6/1/2015 to 24:00 12/31/2015
# Crie uma ACL básica IPv4 com o número 2001 e configure uma regra na ACL para permitir pacotes somente de 192.168.1.2/32 durante o intervalo de tempo de trabalho.
[Device] acl basic 2001
[Device-acl-ipv4-basic-2001] rule permit source 192.168.1.2 0 time-range work
[Device-acl-ipv4-basic-2001] rule deny source any time-range work
[Device-acl-ipv4-basic-2001] quit
# Aplique a ACL básica IPv4 2001 para filtrar os pacotes de saída na GigabitEthernet 1/0/2.
[Device] interface gigabitethernet 1/0/2
[Device-GigabitEthernet1/0/2] packet-filter 2001 outbound
[Device-GigabitEthernet1/0/2] quit
Verificação da configuração
# Verifique se o trabalho de intervalo de tempo está ativo no dispositivo.
[Device] display time-range all
Current time is 13:58:35 6/19/2015 Friday
Time-range : work (Active)
08:00 to 18:00 working-day
from 00:00 6/1/2015 to 00:00 1/1/2016 08 - Security Configuration Guide
Configuração de AAA
Sobre a AAA
Implementação do AAA
A autenticação, a autorização e a contabilidade (AAA) fornecem uma estrutura uniforme para a implementação do gerenciamento de acesso à rede. Esse recurso especifica as seguintes funções de segurança:
- Autenticação - identifica os usuários e verifica sua validade.
- Autorização - Concede direitos diferentes a usuários diferentes e controla o acesso dos usuários a recursos e serviços. Por exemplo, você pode permitir que os usuários do escritório leiam e imprimam arquivos e impedir que os convidados acessem arquivos no dispositivo.
- Accounting (Contabilidade) - Registra os detalhes de uso da rede dos usuários, incluindo o tipo de serviço, a hora de início e o tráfego. Essa função permite a cobrança com base no tempo e no tráfego e a auditoria do comportamento do usuário.
Diagrama de rede AAA
O AAA usa um modelo cliente/servidor. O cliente é executado no dispositivo de acesso ou no servidor de acesso à rede (NAS), que autentica as identidades do usuário e controla o acesso do usuário. O servidor mantém as informações do usuário de forma centralizada. Veja a Figura 1.
Figura 1 Diagrama de rede AAA
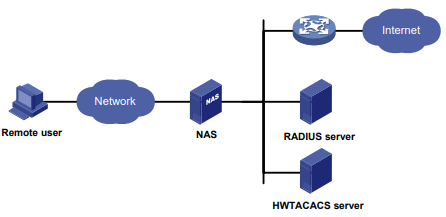
Para acessar redes ou recursos além do NAS, um usuário envia suas informações de identidade para o NAS. O NAS passa de forma transparente as informações do usuário para os servidores AAA e aguarda o resultado da autenticação, autorização e contabilidade. Com base no resultado, o NAS determina se deve permitir ou negar a solicitação de acesso.
O AAA tem várias implementações, incluindo HWTACACS, LDAP e RADIUS. O RADIUS é usado com mais frequência.
Você pode usar servidores diferentes para implementar funções de segurança diferentes. Por exemplo, você pode usar um servidor HWTACACS para autenticação e autorização e usar um servidor RADIUS para contabilidade.
Você pode escolher as funções de segurança fornecidas pelo AAA conforme necessário. Por exemplo, se a sua empresa quiser que os funcionários sejam autenticados antes de acessarem recursos específicos, você implantará um servidor de autenticação. Se forem necessárias informações sobre o uso da rede, você também configurará um servidor de contabilidade.
O dispositivo executa a autenticação dinâmica de senha.
RADIUS
O Remote Authentication Dial-In User Service (RADIUS) é um protocolo de interação de informações distribuídas que usa um modelo cliente/servidor. O protocolo pode proteger as redes contra acesso não autorizado e é frequentemente usado em ambientes de rede que exigem alta segurança e acesso remoto do usuário.
O processo de autorização do RADIUS é combinado com o processo de autenticação do RADIUS, e as informações de autorização do usuário são incluídas nas respostas de autenticação. O RADIUS usa a porta UDP 1812 para autenticação e a porta UDP 1813 para contabilidade.
O RADIUS foi originalmente projetado para acesso discado de usuários e foi estendido para suportar métodos de acesso adicionais, como Ethernet e ADSL.
Modelo cliente/servidor
O cliente RADIUS é executado nos NASs localizados em toda a rede. Ele passa informações do usuário para os servidores RADIUS e age de acordo com as respostas para, por exemplo, rejeitar ou aceitar solicitações de acesso do usuário.
O servidor RADIUS é executado no computador ou na estação de trabalho no centro da rede e mantém informações relacionadas à autenticação do usuário e ao acesso ao serviço de rede.
O servidor RADIUS opera usando o seguinte processo:
- Recebe solicitações de autenticação, autorização e contabilidade de clientes RADIUS.
- Realiza a autenticação, a autorização ou a contabilidade do usuário.
- Retorna informações de controle de acesso do usuário (por exemplo, rejeitando ou aceitando a solicitação de acesso do usuário) para os clientes.
O servidor RADIUS também pode atuar como cliente de outro servidor RADIUS para fornecer serviços de proxy de autenticação.
O servidor RADIUS mantém os seguintes bancos de dados:
- Usuários - Armazena informações do usuário, como nomes de usuário, senhas, protocolos aplicados e endereços IP.
- Clients - Armazena informações sobre clientes RADIUS, como chaves compartilhadas e endereços IP.
- Dictionary - Armazena atributos do protocolo RADIUS e seus valores.
Figura 2 Bancos de dados do servidor RADIUS
Mecanismo de segurança de troca de informações
O cliente e o servidor RADIUS trocam informações entre si com a ajuda de chaves compartilhadas, que são pré-configuradas no cliente e no servidor. Um pacote RADIUS tem um campo de 16 bytes chamado Authenticator. Esse campo inclui uma assinatura gerada pelo uso do algoritmo MD5, a chave compartilhada e algumas outras informações. O receptor do pacote verifica a assinatura e aceita o pacote somente se a assinatura estiver correta. Esse mecanismo garante a segurança das informações trocadas entre o cliente e o servidor RADIUS.
As chaves compartilhadas também são usadas para criptografar as senhas de usuário incluídas nos pacotes RADIUS.
Métodos de autenticação do usuário
O servidor RADIUS oferece suporte a vários métodos de autenticação de usuário, como PAP, CHAP e EAP.
Processo básico de troca de pacotes RADIUS
A Figura 3 ilustra as interações entre um host de usuário, o cliente RADIUS e o servidor RADIUS.
Figura 3 Processo básico de troca de pacotes RADIUS
O RADIUS é usado no fluxo de trabalho a seguir:
- O host envia uma solicitação de conexão que inclui o nome de usuário e a senha do usuário para o cliente RADIUS .
- O cliente RADIUS envia uma solicitação de autenticação (Access-Request) para o servidor RADIUS. A solicitação inclui a senha do usuário, que foi processada pelo algoritmo MD5 e pela chave compartilhada.
- O servidor RADIUS autentica o nome de usuário e a senha. Se a autenticação for bem-sucedida, o servidor enviará de volta um pacote Access-Accept que contém as informações de autorização do usuário . Se a autenticação falhar, o servidor retornará um pacote Access-Reject.
- O cliente RADIUS permite ou nega o usuário de acordo com o resultado da autenticação. Se o resultado permitir o usuário, o cliente RADIUS enviará um pacote de solicitação de início de contabilização (Accounting-Request) para o servidor RADIUS.
- O servidor RADIUS retorna um pacote de confirmação (Accounting-Response) e inicia a contabilidade.
- O usuário acessa os recursos da rede.
- O host solicita que o cliente RADIUS encerre a conexão.
- O cliente RADIUS envia um pacote de solicitação de interrupção de contabilização (Accounting-Request) para o servidor RADIUS.
- O servidor RADIUS retorna uma confirmação (Accounting-Response) e interrompe a contabilização do usuário.
- O cliente RADIUS notifica o usuário sobre o encerramento.
Formato do pacote RADIUS
O RADIUS usa UDP para transmitir pacotes. O protocolo também usa uma série de mecanismos para garantir a troca suave de pacotes entre o servidor RADIUS e o cliente. Esses mecanismos incluem o mecanismo de cronômetro, o mecanismo de retransmissão e o mecanismo de servidor de backup.
Figura 4 Formato do pacote RADIUS
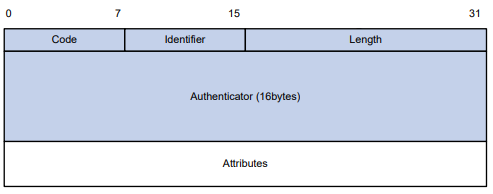
As descrições dos campos são as seguintes:
- O campo Code (1 byte de comprimento) indica o tipo do pacote RADIUS. A Tabela 1 apresenta os principais valores de e seus significados.
Tabela 1 Principais valores do campo Código
| Código | Tipo de pacote | Descrição |
| 1 | Solicitação de acesso | Do cliente para o servidor. Um pacote desse tipo inclui informações do usuário para o servidor autenticar o usuário. Ele deve conter o atributo User-Name e, opcionalmente, pode conter os atributos de Endereço IP do NAS, Senha do usuário e Porta do NAS. |
| 2 | Acessar-Aceitar | Do servidor para o cliente. Se todos os valores de atributos incluídos na Access-Request forem aceitáveis, a autenticação será bem-sucedida e o servidor enviará uma resposta Access-Accept. |
| 3 | Acesso-Rejeição | Do servidor para o cliente. Se qualquer valor de atributo incluído na Access-Request for inaceitável, a autenticação falhará e o servidor enviará uma resposta Access-Reject. |
| 4 | Contabilidade-Solicitação | Do cliente para o servidor. Um pacote desse tipo inclui informações do usuário para que o servidor inicie ou interrompa a contabilização para o usuário. O atributo Acct-Status-Type no pacote indica se a contabilidade deve ser iniciada ou interrompida. |
| 5 | Contabilidade-Resposta | Do servidor para o cliente. O servidor envia um pacote desse tipo para notificar o cliente de que recebeu o Accounting-Request e registrou com êxito as informações contábeis. |
- O campo Identifier (1 byte de comprimento) é usado para combinar pacotes de resposta com pacotes de solicitação e para detectar pacotes de solicitação duplicados. Os pacotes de solicitação e resposta do mesmo processo de troca para a mesma finalidade (como autenticação ou contabilidade) têm o mesmo identificador.
- O campo Length (comprimento de 2 bytes) indica o comprimento de todo o pacote (em bytes), incluindo os campos Code (Código), Identifier (Identificador), Length (Comprimento), Authenticator (Autenticador) e Attributes (Atributos). Os bytes além desse comprimento são considerados preenchimento e são ignorados pelo receptor. Se o comprimento de um pacote recebido for menor que esse comprimento, o pacote será descartado.
- O campo Authenticator (16 bytes de comprimento) é usado para autenticar as respostas do servidor RADIUS e para criptografar as senhas dos usuários. Há dois tipos de autenticadores: autenticador de solicitação e autenticador de resposta.
- O campo Attributes (variável em comprimento) inclui informações de autenticação, autorização e contabilidade. Esse campo pode conter vários atributos, cada um com os seguintes subcampos:
- Tipo - Tipo do atributo.
- Comprimento - Comprimento do atributo em bytes, incluindo os subcampos Tipo, Comprimento e Valor.
- Value-Valor do atributo. Seu formato e conteúdo dependem do subcampo Type.
Atributos RADIUS estendidos
O protocolo RADIUS apresenta excelente extensibilidade. O atributo Vendor-Specific (atributo 26) permite que um fornecedor defina atributos estendidos. Os atributos estendidos podem implementar funções que o protocolo RADIUS padrão não oferece.
Um fornecedor pode encapsular vários subatributos no formato TLV no atributo 26 para fornecer funções estendidas. Conforme mostrado na Figura 5, um subatributo encapsulado no atributo 26 consiste nas seguintes partes:
- Vendor-ID-ID do fornecedor. O byte mais significativo é 0. Os outros três bytes contêm um código em conformidade com a RFC 1700.
- Vendor-Type-Tipo do subatributo.
- Vendor-Length-Comprimento do subatributo.
- Dados do fornecedor - Conteúdo do subatributo.
O dispositivo oferece suporte a subatributos RADIUS com ID de fornecedor 25506. Para obter mais informações, consulte "Apêndice C Subatributos RADIUS (ID de fornecedor 25506)".
Figura 5 Formato do atributo 26
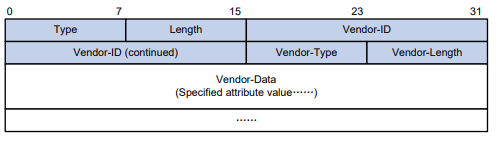
HWTACACS
O HWTACACS (HW Terminal Access Controller Access Control System) é um protocolo de segurança aprimorado baseado no TACACS (RFC 1492). O HWTACACS é semelhante ao RADIUS e usa um modelo cliente/servidor para a troca de informações entre o NAS e o servidor HWTACACS.
O HWTACACS normalmente fornece serviços AAA para PPP, VPDN e usuários de terminal. Em um cenário típico de HWTACACS, os usuários de terminal precisam fazer login no NAS. Trabalhando como o cliente HWTACACS, o NAS envia os nomes de usuário e as senhas dos usuários ao servidor HWTACACS para autenticação. Depois de passar pela autenticação e obter direitos autorizados, um usuário faz login no dispositivo e executa as operações do . O servidor HWTACACS registra as operações que cada usuário realiza.
Diferenças entre HWTACACS e RADIUS
O HWTACACS e o RADIUS têm muitos recursos em comum, como o uso de um modelo cliente/servidor, o uso de chaves compartilhadas para criptografia de dados e o fornecimento de flexibilidade e escalabilidade. A Tabela 2 lista as principais diferenças entre o HWTACACS e o RADIUS.
Tabela 2 Principais diferenças entre o HWTACACS e o RADIUS
| HWTACACS | RADIUS |
| Usa TCP, que fornece uma rede de transmissão confiável | Usa UDP, que oferece alta eficiência de transporte. |
| Criptografa o pacote inteiro, exceto o cabeçalho HWTACACS. | Criptografa apenas o campo de senha do usuário em um pacote de autenticação. |
| Os pacotes de protocolo são complicados e a autorização é independente da autenticação. A autenticação e a autorização podem ser implantadas em diferentes servidores HWTACACS. | Os pacotes de protocolo são simples e o processo de autorização é combinado com o processo de autenticação. |
| Oferece suporte à autorização de comandos de configuração. O acesso aos comandos depende das funções e da autorização do usuário. Um usuário pode usar somente os comandos permitidos pelas funções do usuário e autorizados pelo servidor HWTACACS. | Não oferece suporte à autorização de comandos de configuração. O acesso aos comandos depende exclusivamente das funções do usuário. Para obter mais informações sobre as funções do usuário, consulte o Fundamentals Configuration Guide. |
Processo básico de troca de pacotes HWTACACS
A Figura 6 descreve como o HWTACACS executa a autenticação, a autorização e a contabilidade do usuário para um usuário Telnet.
Figura 6 Processo básico de troca de pacotes HWTACACS para um usuário Telnet

O HWTACACS opera usando o seguinte fluxo de trabalho:
- Um usuário de Telnet envia uma solicitação de acesso ao cliente HWTACACS.
- O cliente HWTACACS envia um pacote de autenticação inicial para o servidor HWTACACS quando recebe a solicitação.
- O servidor HWTACACS envia de volta uma resposta de autenticação para solicitar o nome de usuário.
- Ao receber a resposta, o cliente HWTACACS pergunta ao usuário o nome de usuário.
- O usuário digita o nome de usuário.
- Depois de receber o nome de usuário do usuário, o cliente HWTACACS envia ao servidor um pacote de autenticação contínua que inclui o nome de usuário.
- O servidor HWTACACS envia de volta uma resposta de autenticação para solicitar a senha de login.
- Após o recebimento da resposta, o cliente HWTACACS solicita ao usuário a senha de login.
- O usuário digita a senha.
- Depois de receber a senha de login, o cliente HWTACACS envia ao servidor HWTACACS um pacote de autenticação contínua que inclui a senha de login.
- Se a autenticação for bem-sucedida, o servidor HWTACACS enviará de volta uma resposta de autenticação para indicar que o usuário foi aprovado na autenticação.
- O cliente HWTACACS envia um pacote de solicitação de autorização de usuário para o servidor HWTACACS.
- Se a autorização for bem-sucedida, o servidor HWTACACS enviará de volta uma resposta de autorização, indicando que o usuário agora está autorizado.
- Sabendo que o usuário agora está autorizado, o cliente HWTACACS envia sua CLI para o usuário e permite que ele faça login.
- O cliente HWTACACS envia uma solicitação de início de contabilização para o servidor HWTACACS.
- O servidor HWTACACS envia de volta uma resposta de contabilização, indicando que recebeu a solicitação start-accounting.
- O usuário faz logoff.
- O cliente HWTACACS envia uma solicitação de interrupção de contabilização para o servidor HWTACACS.
- O servidor HWTACACS envia de volta uma resposta stop-accounting, indicando que a solicitação stop-accounting foi recebida.
LDAP
O LDAP (Lightweight Directory Access Protocol) fornece um serviço de diretório padrão multiplataforma. O LDAP foi desenvolvido com base no protocolo X.500. Ele aprimora as seguintes funções do X.500:
- Acesso interativo de leitura/gravação.
- Navegue.
- Pesquisar.
O LDAP é adequado para armazenar dados que não mudam com frequência. O protocolo é usado para armazenar informações do usuário. Por exemplo, o software de servidor LDAP Active Directory Server é usado nos sistemas operacionais Microsoft Windows. O software armazena as informações do usuário e as informações do grupo de usuários para autenticação e autorização de login do usuário.
Serviço de diretório LDAP
O LDAP usa diretórios para manter as informações da organização, as informações de pessoal e as informações de recursos. Os diretórios são organizados em uma estrutura de árvore e incluem entradas. Uma entrada é um conjunto de atributos com nomes distintos (DNs). Os atributos são usados para armazenar informações como nomes de usuário, senhas, e-mails, nomes de computadores e números de telefone.
O LDAP usa um modelo cliente/servidor, e todas as informações de diretório são armazenadas no servidor LDAP. Os produtos de servidor LDAP comumente usados incluem o Microsoft Active Directory Server, o IBM Tivoli Directory Server e o Sun ONE Directory Server.
Autenticação e autorização LDAP
O AAA pode usar o LDAP para fornecer serviços de autenticação e autorização para os usuários. O LDAP define um conjunto de operações para implementar suas funções. As principais operações de autenticação e autorização são a operação de associação e a operação de pesquisa.
- A operação bind permite que um cliente LDAP execute as seguintes operações:
- Estabeleça uma conexão com o servidor LDAP.
- Obter os direitos de acesso ao servidor LDAP.
- Verifique a validade das informações do usuário.
- A operação de pesquisa cria condições de pesquisa e obtém as informações de recursos de diretório do servidor LDAP.
- Usa o DN do administrador do servidor LDAP para vincular-se ao servidor LDAP. Depois que a associação é criada, o cliente estabelece uma conexão com o servidor e obtém o direito de pesquisar.
Na autenticação LDAP, o cliente executa as seguintes tarefas:
Na autorização LDAP, o cliente executa as mesmas tarefas que na autenticação LDAP. Quando o cliente constrói condições de pesquisa, ele obtém informações de autorização e a lista de DNs do usuário.
Processo básico de autenticação LDAP
O exemplo a seguir ilustra o processo básico de autenticação LDAP para um usuário Telnet.
Figura 7 Processo básico de autenticação LDAP para um usuário Telnet
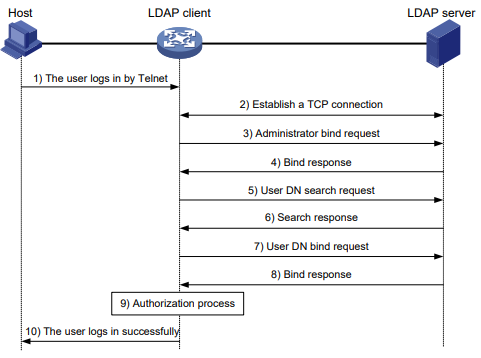
A seguir, mostramos o processo básico de autenticação LDAP:
- Um usuário Telnet inicia uma solicitação de conexão e envia o nome de usuário e a senha para o cliente LDAP.
- Após receber a solicitação, o cliente LDAP estabelece uma conexão TCP com o servidor LDAP.
- Para obter o direito de pesquisar, o cliente LDAP usa o DN e a senha do administrador para enviar uma solicitação de associação de administrador ao servidor LDAP.
- O servidor LDAP processa a solicitação. Se a operação de associação for bem-sucedida, o servidor LDAP enviará uma confirmação ao cliente LDAP.
- O cliente LDAP envia uma solicitação de pesquisa de DN de usuário com o nome de usuário do usuário Telnet para o servidor LDAP.
- Após receber a solicitação, o servidor LDAP procura o DN do usuário pelo DN de base, escopo de pesquisa e condições de filtragem. Se for encontrada uma correspondência, o servidor LDAP enviará uma resposta para notificar o cliente LDAP sobre a pesquisa bem-sucedida. Pode haver um ou mais DNs de usuário encontrados.
- O cliente LDAP usa o DN de usuário obtido e a senha de usuário inserida como parâmetros para enviar uma solicitação de associação de DN de usuário ao servidor LDAP. O servidor verificará se a senha do usuário está correta.
- O servidor LDAP processa a solicitação e envia uma resposta para notificar o cliente LDAP sobre o resultado da operação de associação. Se a operação de associação falhar, o cliente LDAP usará outro DN de usuário obtido como parâmetro para enviar uma solicitação de associação de DN de usuário ao servidor LDAP. Esse processo continua até que um DN seja vinculado com êxito ou até que todos os DNs não sejam vinculados. Se todos os DNs de usuário não forem vinculados, o cliente LDAP notificará o usuário sobre a falha no login e negará a solicitação de acesso do usuário.
- O cliente LDAP salva o DN do usuário que foi vinculado e troca pacotes de autorização com o servidor de autorização.
- Se a autorização LDAP for usada, consulte o processo de autorização mostrado na Figura 8.
- Se outro método for esperado para autorização, o processo de autorização desse método será aplicado.
- Após a autorização bem-sucedida, o cliente LDAP notifica o usuário sobre o login bem-sucedido.
Processo básico de autorização LDAP
O exemplo a seguir ilustra o processo básico de autorização LDAP para um usuário Telnet.
Figura 8 Processo básico de autorização LDAP para um usuário Telnet
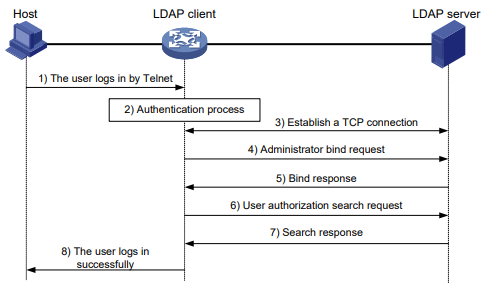
A seguir, mostramos o processo básico de autorização LDAP:
- Um usuário de Telnet inicia uma solicitação de conexão e envia o nome de usuário e a senha para o dispositivo. O dispositivo atuará como cliente LDAP durante a autorização.
- Após receber a solicitação, o dispositivo troca pacotes de autenticação com o servidor de autenticação do usuário:
- Se a autenticação LDAP for usada, veja o processo de autenticação mostrado na Figura 7.
- - Se o dispositivo (o cliente LDAP) usar o mesmo servidor LDAP para autenticação e autorização, pule para a etapa 6.
- - Se o dispositivo (o cliente LDAP) usar servidores LDAP diferentes para autenticação e autorização, pule para a etapa 4.
- Se outro método de autenticação for usado, o processo de autenticação desse método será aplicado. O dispositivo atua como cliente LDAP. Pule para a etapa 3.
- O cliente LDAP estabelece uma conexão TCP com o servidor de autorização LDAP.
- Para obter o direito de pesquisar, o cliente LDAP usa o DN e a senha do administrador para enviar uma solicitação de associação de administrador ao servidor LDAP.
- O servidor LDAP processa a solicitação. Se a operação de associação for bem-sucedida, o servidor LDAP enviará uma confirmação ao cliente LDAP.
- O cliente LDAP envia uma solicitação de pesquisa de autorização com o nome de usuário do usuário Telnet para o servidor LDAP. Se o usuário usar o mesmo servidor LDAP para autenticação e autorização, o cliente enviará a solicitação com o DN de usuário salvo do usuário Telnet para o servidor LDAP.
- Após receber a solicitação, o servidor LDAP procura as informações do usuário pelo DN base, escopo de pesquisa, condições de filtragem e atributos LDAP. Se for encontrada uma correspondência, o servidor LDAP enviará uma resposta para notificar o cliente LDAP sobre a pesquisa bem-sucedida.
- Após a autorização bem-sucedida, o cliente LDAP notifica o usuário sobre o login bem-sucedido.
Gerenciamento de usuários com base em domínios ISP e tipos de acesso de usuário
O AAA gerencia os usuários com base nos domínios ISP e nos tipos de acesso dos usuários.
Em um NAS, cada usuário pertence a um domínio ISP. O NAS determina o domínio ISP ao qual um usuário pertence com base no nome de usuário inserido pelo usuário no login.
Figura 9 Determinação do domínio do ISP para um usuário por nome de usuário
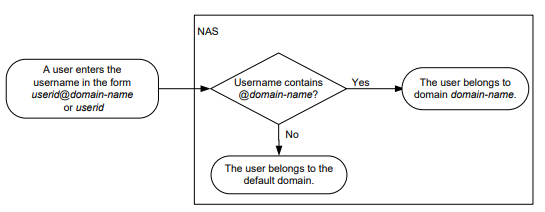
O AAA gerencia os usuários no mesmo domínio ISP com base nos tipos de acesso dos usuários. O dispositivo suporta os seguintes tipos de acesso de usuário:
- LAN - Os usuários da LAN devem passar pela autenticação 802.1X ou MAC para ficar on-line.
- Login - Os usuários de login incluem usuários de SSH, Telnet, FTP e terminal que fazem login no dispositivo. Os usuários de terminal podem acessar por meio de uma porta de console.
- Portal - Os usuários do portal devem passar pela autenticação do portal para acessar a rede.
- HTTP/HTTPS - Os usuários fazem login no dispositivo por meio de HTTP ou HTTPS.
O dispositivo também fornece módulos de autenticação (como o 802.1X) para a implementação de políticas de gerenciamento de autenticação de usuários. Se você configurar esses módulos de autenticação, os domínios ISP para os usuários dos tipos de acesso dependerão da configuração dos módulos de autenticação.
Métodos de autenticação, autorização e contabilidade
O AAA suporta a configuração de diferentes métodos de autenticação, autorização e contabilidade para diferentes tipos de usuários em um domínio ISP. O NAS determina o domínio ISP e o tipo de acesso de um usuário. O NAS também usa os métodos configurados para o tipo de acesso no domínio para controlar o acesso do usuário.
O AAA também suporta a configuração de um conjunto de métodos padrão para um domínio ISP. Esses métodos padrão são aplicados aos usuários para os quais não há métodos AAA configurados.
Métodos de autenticação
O dispositivo é compatível com os seguintes métodos de autenticação:
- Sem autenticação - Esse método confia em todos os usuários e não executa a autenticação. Para fins de segurança, não use esse método.
- Autenticação local - O NAS autentica os usuários por si só, com base nas informações de usuário configuradas localmente, incluindo nomes de usuário, senhas e atributos. A autenticação local permite alta velocidade e baixo custo, mas a quantidade de informações que podem ser armazenadas é limitada pelo tamanho do espaço de armazenamento.
- Autenticação remota - O NAS trabalha com um servidor remoto para autenticar os usuários. O NAS se comunica com o servidor remoto por meio do protocolo RADIUS, LDAP ou HWTACACS. O servidor gerencia as informações do usuário de forma centralizada. A autenticação remota fornece serviços de autenticação de alta capacidade, confiáveis e centralizados para vários NASs. Você pode configurar métodos de backup a serem usados quando o servidor remoto não estiver disponível.
Métodos de autorização
O dispositivo é compatível com os seguintes métodos de autorização:
- Sem autorização - O NAS não realiza nenhuma troca de autorização. As informações de autorização padrão a seguir são aplicadas depois que os usuários passam pela autenticação:
- Os usuários de login obtêm a função de usuário de nível 0. Para obter mais informações sobre a função de usuário de nível 0, consulte Configuração do RBAC no Guia de Configuração dos Fundamentos.
- O diretório de trabalho dos usuários de login FTP, SFTP e SCP é o diretório raiz do NAS. No entanto, os usuários não têm permissão para acessar o diretório raiz.
- Usuários sem login podem acessar a rede.
- Autorização local - O NAS realiza a autorização de acordo com os atributos de usuário configurados localmente para os usuários.
- Autorização remota - O NAS trabalha com um servidor remoto para autorizar os usuários. A autorização RADIUS está vinculada à autenticação RADIUS. A autorização RADIUS pode funcionar somente depois que a autenticação RADIUS for bem-sucedida e as informações de autorização forem incluídas no pacote Access-Accept. A autorização HWTACACS ou LDAP é separada da autenticação, e as informações de autorização são incluídas na resposta de autorização após a autenticação bem-sucedida. Você pode configurar métodos de backup a serem usados quando o servidor remoto não estiver disponível.
Métodos contábeis
O dispositivo suporta os seguintes métodos de contabilidade:
- Sem contabilidade - O NAS não realiza contabilidade para os usuários.
- Contabilidade local - A contabilidade local é implementada no NAS. Ela conta e controla o número de usuários simultâneos que usam a mesma conta de usuário local, mas não fornece estatísticas para cobrança.
- Contabilidade remota - O NAS funciona com um servidor RADIUS ou HWTACACS para contabilidade. Você pode configurar métodos de backup a serem usados quando o servidor remoto não estiver disponível.
Funções estendidas AAA
O dispositivo fornece os seguintes serviços de login para aumentar a segurança do dispositivo:
- Autorização de comando - Permite que o NAS deixe o servidor de autorização determinar se um comando inserido por um usuário de login é permitido. Os usuários de login podem executar somente os comandos permitidos pelo servidor de autorização. Para obter mais informações sobre a autorização de comando, consulte o Guia de configuração de fundamentos.
- Contabilização de comandos - Quando a autorização de comandos está desativada, a contabilização de comandos permite que o servidor de contabilização registre todos os comandos válidos executados no dispositivo. Quando a autorização de comando está ativada, a contabilidade de comando permite que o servidor de contabilidade registre todos os comandos autorizados. Para obter mais informações sobre a contabilidade de comandos, consulte o Fundamentals Configuration Guide.
- Autenticação de função de usuário - Autentica cada usuário que deseja obter outra função de usuário sem fazer logout ou ser desconectado. Para obter mais informações sobre autenticação de função de usuário, consulte o Fundamentals Configuration Guide.
Recurso de servidor RADIUS do dispositivo
Ative o recurso de servidor RADIUS do dispositivo para trabalhar com clientes RADIUS para autenticação e autorização de usuários. O dispositivo pode atuar como um servidor RADIUS dedicado ou como um servidor RADIUS e um cliente RADIUS ao mesmo tempo.
O recurso do servidor RADIUS oferece redes flexíveis com menos custos. Conforme mostrado na Figura 10, o Dispositivo A fornece funções de servidor RADIUS na camada de distribuição; o Dispositivo B e o Dispositivo C são configurados com esquemas RADIUS para implementar a autenticação e a autorização do usuário na camada de acesso.
Figura 10 Diagrama de rede
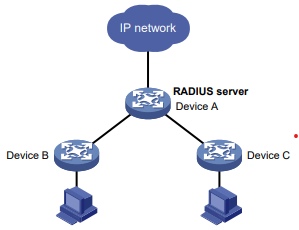
O recurso de servidor RADIUS oferece suporte às seguintes operações:
- Gerencia os dados do usuário RADIUS, que são gerados a partir de informações do usuário local e incluem nome de usuário, senha, descrição, ACL de autorização, VLAN de autorização e tempo de expiração.
- Gerencia clientes RADIUS. Você pode adicionar, modificar e excluir clientes RADIUS. Um cliente RADIUS é identificado pelo endereço IP e inclui informações de atributo, como a chave compartilhada. O recurso de servidor RADIUS processa as solicitações de autenticação somente dos clientes RADIUS gerenciados e ignora as solicitações de clientes desconhecidos.
- Autentica e autoriza os usuários do tipo de acesso à rede. O servidor não fornece contabilidade.
Quando o servidor RADIUS recebe um pacote RADIUS, ele executa as seguintes ações:
- Verifica se o pacote é enviado de um cliente RADIUS gerenciado.
- Verifica o pacote com a chave compartilhada.
- Verifica se a conta de usuário existe, se a senha está correta e se outros atributos atendem aos requisitos (por exemplo, se a conta está dentro do período de validade).
- Determina o resultado da autenticação e autoriza privilégios específicos para o usuário autenticado.
O recurso de servidor RADIUS do dispositivo tem as seguintes restrições:
- A porta de autenticação é fixada em UDP 1812 e não pode ser modificada.
- O recurso é suportado em redes IPv4, mas não em redes IPv6.
- O servidor fornece apenas os métodos de autenticação PAP e CHAP.
- Os nomes de usuário enviados ao servidor RADIUS não podem incluir um nome de domínio.
Protocolos e padrões
- RFC 2865, Serviço de Discagem de Usuário para Autenticação Remota (RADIUS)
- RFC 2866, Contabilidade RADIUS
- RFC 2867, Modificações de contabilidade RADIUS para suporte ao protocolo de túnel
- RFC 2868, Atributos RADIUS para suporte ao protocolo de túnel
- RFC 2869, Extensões RADIUS
- RFC 3576, Extensões de autorização dinâmica para o RADIUS (Remote Authentication Dial In User Service)
- RFC 4818, Atributo RADIUS Delegated-IPv6-Prefix
- RFC 5176, Extensões de autorização dinâmica para o RADIUS (Remote Authentication Dial In User Service)
- RFC 1492, Um protocolo de controle de acesso, às vezes chamado de TACACS
- RFC 1777, Protocolo de acesso a diretórios leves
- RFC 2251, Lightweight Directory Access Protocol (v3)
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS (consulte "Configuração de FIPS") e no modo não-FIPS.
Visão geral das tarefas AAA
Para configurar o AAA, execute as seguintes tarefas:
- Configuração de esquemas AAA
- Configuração de usuários locais
- Configuração do RADIUS
- Configuração do HWTACACS
- Configuração do LDAP
- Configuração de um domínio ISP
- Criação de um domínio ISP
- Configuração dos atributos de domínio do ISP
- Configuração de métodos AAA para um domínio ISP
- Configuração de métodos de autenticação para um domínio ISP
- Configuração de métodos de autorização para um domínio ISP
- Configuração de métodos de contabilidade para um domínio ISP
- (Opcional.) Configuração de recursos avançados de AAA
- Definição do número máximo de usuários de login simultâneos
- Configuração de um NAS-ID
- Configuração da ID do dispositivo
- Ativação do registro de solicitação de alteração de senha
- Configuração do recurso do servidor RADIUS
- Configuração da política de registro de conexão
- Configuração do recurso de teste AAA
Se a autenticação local for usada, configure os usuários locais e os atributos relacionados. Se a autenticação remota for usada, configure os esquemas RADIUS, LDAP ou HWTACACS necessários.
Configure métodos de autenticação, autorização e contabilidade para um domínio ISP, conforme necessário. Esses métodos usam esquemas AAA existentes.
Configuração de usuários locais
Sobre os usuários locais
Para implementar a autenticação, a autorização e a contabilidade locais, crie usuários locais e configure os atributos do usuário no dispositivo. Os usuários e atributos locais são armazenados no banco de dados de usuários locais do dispositivo. Um usuário local é identificado exclusivamente pela combinação de um nome de usuário e um tipo de usuário.
Os usuários locais são classificados nos seguintes tipos:
- Usuário de gerenciamento do dispositivo - Usuário que faz login no dispositivo para gerenciamento do dispositivo.
- Usuário de acesso à rede - Usuário que acessa recursos de rede por meio do dispositivo.
- Descrição - Informações descritivas do usuário.
- Tipo de serviço - Serviços que o usuário pode usar. A autenticação local verifica os tipos de serviço de um usuário local. Se nenhum dos tipos de serviço estiver disponível, o usuário não poderá passar na autenticação.
- Estado do usuário - Se um usuário local pode ou não solicitar serviços de rede. Há dois estados de usuário: ativo e bloqueado. Um usuário no estado ativo pode solicitar serviços de rede, mas um usuário no estado bloqueado não pode.
- Limite superior de logins simultâneos usando o mesmo nome de usuário - Número máximo de usuários que podem acessar o dispositivo simultaneamente usando o mesmo nome de usuário. Quando o número atinge o limite superior, nenhum outro usuário local pode acessar o dispositivo usando o nome de usuário.
- Grupo de usuários - Cada usuário local pertence a um grupo de usuários local e tem todos os atributos do grupo. Os atributos incluem os atributos de controle de senha e os atributos de autorização. Para obter mais informações sobre o grupo de usuários locais, consulte "Configuração dos atributos do grupo de usuários".
- Atributos de vinculação - Os atributos de vinculação controlam o escopo dos usuários e são verificados durante a autenticação local de um usuário. Se os atributos de um usuário não corresponderem aos atributos de associação configurados para a conta de usuário local, o usuário não poderá ser aprovado na autenticação.
- Atributos de autorização - Os atributos de autorização indicam os direitos do usuário depois que ele passa pela autenticação local.
- Atributos de controle de senha - Os atributos de controle de senha ajudam a controlar a segurança da senha para usuários locais. Os atributos de controle de senha incluem tempo de envelhecimento da senha, comprimento mínimo da senha, verificação da composição da senha, verificação da complexidade da senha e limite de tentativas de login.
- Período de validade - Período de tempo em que um usuário de acesso à rede é considerado válido para autenticação.
A seguir, são mostrados os atributos configuráveis do usuário local:
Configure os atributos de autorização com base no tipo de serviço dos usuários locais.
É possível configurar um atributo de autorização na visualização de grupo de usuários ou na visualização de usuário local. A configuração de um atributo de autorização na visualização do usuário local tem precedência sobre a configuração do atributo na visualização do grupo de usuários.
O atributo configurado na visualização do grupo de usuários tem efeito sobre todos os usuários locais do grupo de usuários. O atributo configurado na visualização do usuário local tem efeito apenas sobre o usuário local.
É possível configurar um atributo de controle de senha na visualização do sistema, na visualização do grupo de usuários ou na visualização do usuário local. Um atributo de controle de senha com um intervalo efetivo menor tem uma prioridade mais alta. Para obter mais informações sobre gerenciamento de senhas e configuração de senhas globais, consulte "Configuração do controle de senhas".
Visão geral das tarefas de configuração do usuário local
Para configurar usuários locais, execute as seguintes tarefas:
- Configuração dos atributos do usuário local
- Configuração de atributos para usuários de gerenciamento de dispositivos
- Configuração de atributos para usuários de acesso à rede
- (Opcional.) Configuração dos atributos do grupo de usuários
- (Opcional.) Configuração do recurso de exclusão automática de usuário local
Restrições e diretrizes para a configuração do usuário local
A partir da versão 6348P01, os padrões de fábrica do dispositivo fornecem um usuário local padrão chamado clouduser do tipo HTTP. A senha do usuário é admin e a função do usuário é network-admin. Nas versões do anteriores à 6348P01, nenhum usuário local padrão é fornecido.
Configuração de atributos para usuários de gerenciamento de dispositivos
Restrições e diretrizes
Ao configurar o atributo de vinculação de interface para um usuário de gerenciamento de dispositivo, siga estas restrições e diretrizes para evitar falhas de autenticação:
- Especifique a interface de acesso real do usuário como a interface de vinculação para o usuário.
- Certifique-se de que os pacotes de autenticação do usuário incluam a interface de acesso do usuário.
Se o controle de senhas for ativado globalmente para usuários de gerenciamento de dispositivos usando o comando password-control enable, o dispositivo não exibirá as senhas de usuários locais nem as manterá na configuração em execução. Quando você desativa globalmente o controle de senha para usuários de gerenciamento de dispositivos, as senhas de usuários locais são automaticamente restauradas na configuração em execução. Para exibir a configuração em execução, use o comando display current-configuration.
É possível configurar atributos de autorização e atributos de controle de senha na visualização de usuário local ou de grupo de usuários. A configuração na visualização do usuário local tem precedência sobre a configuração na visualização do grupo de usuários.
Procedimento
- Entre na visualização do sistema.
system viewlocal-user user-name class manageNo modo não-FIPS:
password [ { hash | simple } string ]Um usuário não protegido por senha passa na autenticação se fornecer o nome de usuário correto e passar nas verificações de atributos. Para aumentar a segurança, configure uma senha para cada usuário de gerenciamento de dispositivos.
No modo FIPS:
passwordSomente usuários protegidos por senha podem passar pela autenticação. Você deve definir a senha no modo interativo para um usuário de gerenciamento de dispositivos.
No modo não-FIPS:
service-type { ftp | { http | https | ssh | telnet | terminal } * }No modo FIPS:
service-type { https | ssh | terminal } *Por padrão, nenhum serviço é autorizado a um usuário de gerenciamento de dispositivos.
state { active | block }Por padrão, um usuário de gerenciamento de dispositivos está no estado ativo e pode solicitar serviços de rede.
access-limit max-user-numberPor padrão, o número de logins simultâneos não é limitado para um usuário de gerenciamento de dispositivos.
Esse comando entra em vigor somente quando a contabilidade local está configurada para usuários de gerenciamento de dispositivos. Esse comando não se aplica aos usuários de FTP, SFTP ou SCP que não oferecem suporte à contabilidade.
bind-attribute location interface interface-type interface-numberPor padrão, nenhum atributo de vinculação de interface é configurado para um usuário de gerenciamento de dispositivos.
authorization-attribute { idle-cut minutes | user-role role-name | work-directory directory-name } *As seguintes configurações padrão se aplicam:
- O diretório de trabalho dos usuários de FTP, SFTP e SCP é o diretório raiz do NAS. No entanto, os usuários não têm permissão para acessar o diretório raiz.
- A função de usuário network-operator é atribuída a usuários locais criados por um usuário network-admin ou de nível 15.
- Defina o tempo de envelhecimento da senha.
password-control aging aging-timepassword-control length lengthpassword-control composition type-number type-number [ type-length type-length ]password-control complexity { same-character | user-name } checkpassword-control login-attempt login-times [ exceed { lock | lock-time time | unlock } ]Por padrão, um usuário de gerenciamento de dispositivos usa os atributos de controle de senha do grupo de usuários ao qual o usuário pertence.
group group-namePor padrão, um usuário de gerenciamento de dispositivos pertence ao grupo de usuários system.
Configuração de atributos para usuários de acesso à rede
Restrições e diretrizes
Se o controle de senha for ativado globalmente para usuários de acesso à rede usando o comando password-control enable network-class, o dispositivo não exibirá as senhas de usuários locais nem as manterá na configuração em execução. Quando você desativa globalmente o controle de senha para usuários de acesso à rede, as senhas de usuários locais são automaticamente restauradas na configuração em execução. Para exibir a configuração em execução, use o comando display current-configuration.
É possível configurar atributos de autorização e atributos de controle de senha na visualização de usuário local ou de grupo de usuários. A configuração na visualização do usuário local tem precedência sobre a configuração na visualização do grupo de usuários.
Configure o atributo de vinculação de local com base nos tipos de serviço dos usuários.
- Para usuários 802.1X, especifique as interfaces Ethernet de camada 2 habilitadas para 802.1X por meio das quais os usuários acessam o dispositivo.
- Para usuários de autenticação MAC, especifique as interfaces Ethernet de camada 2 habilitadas para autenticação MAC por meio das quais os usuários acessam o dispositivo.
- Para usuários de autenticação da Web, especifique as interfaces Ethernet de camada 2 habilitadas para autenticação da Web por meio das quais os usuários acessam o dispositivo.
- Para usuários do portal, especifique as interfaces habilitadas para portal por meio das quais os usuários acessam o dispositivo. Especifique as interfaces Ethernet de camada 2 se o portal estiver ativado em interfaces VLAN e o comando portal roaming enable não for usado.
Procedimento
- Entre na visualização do sistema.
system viewlocal-user user-name class networkpassword { cipher | simple } stringdescription textPor padrão, nenhuma descrição é configurada para um usuário local.
service-type { lan-access | portal }Por padrão, nenhum serviço é autorizado a um usuário de acesso à rede.
state { active | block }Por padrão, um usuário de acesso à rede está no estado ativo e pode solicitar serviços de rede.
access-limit max-user-numberPor padrão, o número de logins simultâneos não é limitado para um usuário de acesso à rede.
bind-attribute { ip ip-address | location interface interface-type interface-number | mac mac-address | vlan vlan-id } *Por padrão, nenhum atributo de vinculação é configurado para um usuário de acesso à rede.
authorization-attribute { acl acl-number | idle-cut minutes | ip-pool ipv4-pool-name | ipv6-pool ipv6-pool-name | session-timeout minutes | user-profile profile-name | vlan vlan-id } *Por padrão, um usuário de acesso à rede não tem atributos de autorização.
- Defina o comprimento mínimo da senha.
password-control length lengthpassword-control composition type-number type-number [ type-length type-length ]password-control complexity { same-character | user-name } checkPor padrão, um usuário de acesso à rede usa os atributos de controle de senha do grupo de usuários ao qual o usuário pertence.
group group-namePor padrão, um usuário de acesso à rede pertence ao grupo de usuários system.
validity-datetime { from start-date start-time to expiration-date expiration-time | from start-date start-time | to expiration-date expiration-time }Por padrão, o período de validade de um usuário de acesso à rede não expira.
Configuração de atributos de grupos de usuários
Sobre os atributos do grupo de usuários
Os grupos de usuários simplificam a configuração e o gerenciamento de usuários locais. Um grupo de usuários contém um grupo de usuários locais e tem um conjunto de atributos de usuários locais. É possível configurar atributos de usuário local para um grupo de usuários a fim de implementar o gerenciamento centralizado de atributos de usuário para os usuários locais do grupo. Os atributos locais do usuário que podem ser gerenciados incluem atributos de autorização.
Procedimento
- Entre na visualização do sistema.
system viewuser-group group-namePor padrão, existe um grupo de usuários definido pelo sistema. O nome do grupo é system.
authorization-attribute { acl acl-number | idle-cut minutes | ip-pool ipv4-pool-name | ipv6-pool ipv6-pool-name | session-timeout minutes | user-profile profile-name | vlan vlan-id | work-directory directory-name } *Por padrão, nenhum atributo de autorização é configurado para um grupo de usuários.
- Defina o tempo de envelhecimento da senha.
password-control aging aging-timepassword-control length lengthpassword-control composition type-number type-number [ type-length type-length ]password-control login-attempt login-times [ exceed { lock | lock-time time | unlock } ]password-control login-attempt login-times [ exceed { lock | lock-time time | unlock } ]Por padrão, um grupo de usuários usa as configurações globais de controle de senha. Para obter mais informações, consulte "Configuração do controle de senhas".
Configuração do recurso de exclusão automática de usuário local
Sobre o recurso de exclusão automática de usuário local
Esse recurso permite que o dispositivo examine a validade dos usuários locais em períodos de tempo fixos de 10 minutos e exclua automaticamente os usuários locais expirados.
Procedimento
- Entrar na visualização do sistema
system viewlocal-user auto-delete enablePor padrão, o recurso de exclusão automática de usuário local está desativado.
Comandos de exibição e manutenção para usuários locais e grupos de usuários locais
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir a configuração do usuário local e as estatísticas do usuário on-line. | display local-user [ class { manage | network } | idle-cut { disable | enable } | service-type { ftp | http | https | lan-access | portal | ssh | telnet | terminal } | state { active | block } | user-name user-name class { manage | network } | vlan vlan-id ] |
| Exibir a configuração do grupo de usuários. | display user-group { all | name group-name } |
Configuração do RADIUS
Visão geral das tarefas RADIUS
Para configurar o RADIUS, execute as seguintes tarefas:
- Configuração de um perfil EAP
- Configuração de um perfil de teste para detecção do status do servidor RADIUS
- Criação de um esquema RADIUS
- Especificação de servidores de autenticação RADIUS
- Especificação dos servidores de contabilidade RADIUS
- Especificação das chaves compartilhadas para comunicação RADIUS segura
- (Opcional.) Definição do status dos servidores RADIUS
- (Opcional.) Configuração dos temporizadores RADIUS
- (Opcional.) Configuração de parâmetros para pacotes RADIUS
- Especificação do endereço IP de origem para pacotes RADIUS de saída
- Configuração do formato do nome de usuário e das unidades de estatísticas de tráfego
- Definição do número máximo de tentativas de transmissão de solicitações RADIUS
- Definição do número máximo de tentativas de contabilização em tempo real
- Configuração da prioridade DSCP para pacotes RADIUS
- (Opcional.) Configuração de parâmetros para atributos RADIUS
- Especificação do formato do atributo NAS-Port
- Configuração do método de verificação do atributo Login-Service para usuários de SSH, FTP e terminal
- Interpretação do atributo de classe RADIUS como parâmetros CAR
- Configuração do formato do endereço MAC para o atributo 31 do RADIUS
- Especificação do formato do atributo NAS-Port-ID
- Definição da unidade de medição de dados para o atributo Remanent_Volume
- Configuração do recurso de conversão de atributos RADIUS
- (Opcional.) Configuração de recursos estendidos do RADIUS
- Configuração do buffer de pacotes de interrupção de contabilização do RADIUS
- Ativação do envio forçado de pacotes de parada de contabilização
- Ativação do recurso de compartilhamento de carga do servidor RADIUS
- Configuração do recurso de contabilização RADIUS
- Configuração do recurso de controle de sessão RADIUS
- Configuração do recurso RADIUS DAS
- Ativação de notificações SNMP para RADIUS
- Desativação do serviço RADIUS
Para executar a detecção de status do servidor RADIUS com base em EAP, você deve configurar um perfil EAP e especificar o perfil EAP em um perfil de teste.
Para detectar o status de um servidor RADIUS, você deve configurar um perfil de teste e configurar o servidor RADIUS para usar o perfil de teste em um esquema RADIUS.
Execute esta tarefa se nenhuma chave compartilhada for especificada ao configurar a autenticação RADIUS ou os servidores de contabilidade .
Restrições e diretrizes para a configuração do RADIUS
Se o servidor de autenticação em um esquema RADIUS for fornecido pelo recurso de servidor RADIUS no dispositivo, você precisará configurar apenas os seguintes itens para o esquema RADIUS:
- Servidor de autenticação RADIUS.
- Chave compartilhada para comunicação RADIUS.
- Formato do nome de usuário para interação com o servidor RADIUS.
Configuração de um perfil EAP
Sobre os perfis do EAP
Um perfil EAP é um conjunto de configurações de autenticação EAP, incluindo o método de autenticação EAP e o arquivo de certificado CA a ser usado para alguns métodos de autenticação EAP.
Restrições e diretrizes
Você pode especificar um perfil EAP em vários perfis de teste. Você pode configurar um máximo de 16 perfis EAP.
Pré-requisitos
Antes de especificar um arquivo de certificado da CA, use FTP ou TFTP para transferir o arquivo de certificado da CA para o diretório raiz da mídia de armazenamento padrão no dispositivo.
Em uma malha IRF, certifique-se de que um arquivo de certificado CA já exista no diretório raiz da mídia de armazenamento padrão no dispositivo mestre antes de especificar o arquivo.
Procedimento
- Entre na visualização do sistema.
system vieweap-profile eap-profile-namemethod { md5 | peap-gtc | peap-mschapv2 | ttls-gtc | ttls-mschapv2 }Por padrão, o método de autenticação EAP é MD5-challenge.
ca-file file-namePor padrão, nenhum arquivo de certificado CA é especificado para a autenticação EAP.
Você deve especificar um arquivo de certificado de CA para verificar o certificado do servidor RADIUS se o método de autenticação EAP for PEAP-GTC, PEAP-MSCHAPv2, TTLS-GTC ou TTLS-MSCHAPv2.
Configuração de um perfil de teste para detecção do status do servidor RADIUS
Sobre os perfis de teste para detecção do status do servidor RADIUS
Para detectar a acessibilidade ou a disponibilidade de um servidor de autenticação RADIUS, especifique um perfil de teste para o servidor RADIUS ao especificar o servidor em um esquema RADIUS. Com o perfil de teste, o dispositivo atualiza o status do servidor RADIUS a cada intervalo de detecção, de acordo com o resultado da detecção. Se o servidor estiver inacessível ou indisponível, o dispositivo definirá o status do servidor como bloqueado. Se o servidor estiver acessível ou disponível, o dispositivo definirá o status do servidor como ativo.
O dispositivo suporta os seguintes métodos de detecção de status do servidor RADIUS:
- Detecção simples - Para um servidor RADIUS, o dispositivo simula uma solicitação de autenticação com o nome de usuário e a senha especificados no perfil de teste usado pelo servidor. A solicitação de autenticação é enviada ao servidor RADIUS em cada intervalo de detecção. O dispositivo determina que o servidor RADIUS está acessível se receber uma resposta do servidor dentro do intervalo.
- Detecção baseada em EAP - Para um servidor RADIUS, o dispositivo simula uma autenticação EAP com o nome de usuário e a senha especificados no perfil de teste usado pelo servidor. A autenticação EAP simulada começa no início de cada intervalo de detecção. Se a autenticação EAP for concluída em um intervalo de detecção, o dispositivo determinará que o servidor RADIUS está disponível.
Simulando um processo completo de autenticação EAP, a detecção baseada em EAP fornece resultados de detecção mais confiáveis do que a detecção simples. Como prática recomendada, configure a detecção baseada em EAP em um ambiente de rede em que a autenticação EAP esteja configurada.
Restrições e diretrizes
Você pode configurar vários perfis de teste no sistema.
O dispositivo começa a detectar o status de um servidor de autenticação RADIUS somente se um perfil de teste existente for especificado para o servidor.
Se você especificar um perfil EAP inexistente em um perfil de teste, o dispositivo executará uma detecção simples para os servidores RADIUS que usam o perfil de teste. Depois que o perfil EAP for configurado, o dispositivo iniciará a detecção baseada em EAP no próximo intervalo de detecção.
O dispositivo para de detectar o status de um servidor RADIUS quando uma das seguintes operações é realizada:
- O servidor RADIUS é removido do esquema RADIUS.
- A configuração do perfil de teste para o servidor RADIUS é removida na visualização do esquema RADIUS.
- O perfil de teste especificado para o servidor RADIUS é excluído.
- O servidor RADIUS é definido manualmente para o estado bloqueado.
- O esquema RADIUS que contém o servidor RADIUS é excluído.
Procedimento
- Entre na visualização do sistema.
system viewradius-server test-profile profile-name username name [ password { cipher | simple } string ] [ interval interval ] [ eap-profile eap-profile-name ]Criação de um esquema RADIUS
Restrições e diretrizes
Você pode configurar um máximo de 16 esquemas RADIUS. Um esquema RADIUS pode ser usado por vários domínios ISP.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameEspecificação de servidores de autenticação RADIUS
Sobre os servidores de autenticação RADIUS
Um servidor de autenticação RADIUS conclui a autenticação e a autorização em conjunto, pois as informações de autorização são incluídas nas respostas de autenticação enviadas aos clientes RADIUS.
Você pode especificar um servidor de autenticação primário e um máximo de 16 servidores de autenticação secundários para um esquema RADIUS. Os servidores secundários fornecem serviços AAA quando o servidor primário fica inacessível. O dispositivo procura um servidor ativo na ordem em que os servidores secundários são configurados.
Quando o compartilhamento de carga do servidor RADIUS está ativado, o dispositivo distribui a carga de trabalho entre todos os servidores sem considerar as funções de servidor primário e secundário. O dispositivo verifica o valor do peso e o número de usuários atendidos atualmente para cada servidor ativo e, em seguida, determina o servidor mais adequado em termos de desempenho para receber uma solicitação de autenticação.
Restrições e diretrizes
Se a redundância não for necessária, especifique apenas o servidor primário.
Um servidor de autenticação RADIUS pode funcionar como servidor de autenticação primário para um esquema e como servidor de autenticação secundário para outro esquema ao mesmo tempo.
Dois servidores de autenticação em um esquema, primário ou secundário, não podem ter a mesma combinação de nome de host, endereço IP e número de porta.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameprimary authentication { host-name | ipv4-address | ipv6 ipv6-address } [ port-number | key { cipher | simple } string | test-profile profile-name | weight weight-value ] *Por padrão, nenhum servidor de autenticação RADIUS primário é especificado.
A palavra-chave weight só tem efeito quando o recurso de compartilhamento de carga do servidor RADIUS está ativado para o esquema RADIUS.
secondary authentication { host-name | ipv4-address | ipv6 ipv6-address } [ port-number | key { cipher | simple } string | test-profile profile-name | weight weight-value ] *Por padrão, nenhum servidor de autenticação RADIUS secundário é especificado.
A palavra-chave weight só tem efeito quando o recurso de compartilhamento de carga do servidor RADIUS está ativado para o esquema RADIUS.
Especificação dos servidores de contabilidade RADIUS
Sobre os servidores de contabilidade RADIUS
Você pode especificar um servidor de contabilidade primário e um máximo de 16 servidores de contabilidade secundários para um esquema RADIUS. Os servidores secundários fornecem serviços AAA quando o servidor primário fica indisponível. O dispositivo procura um servidor ativo na ordem em que os servidores secundários são configurados.
Quando o compartilhamento de carga do servidor RADIUS está ativado, o dispositivo distribui a carga de trabalho entre todos os servidores sem considerar as funções de servidor primário e secundário. O dispositivo verifica o valor do peso e o número de usuários atendidos atualmente para cada servidor ativo e, em seguida, determina o servidor mais adequado em termos de desempenho para receber uma solicitação de contabilidade.
Restrições e diretrizes
Se a redundância não for necessária, especifique apenas o servidor primário.
Um servidor de contabilidade RADIUS pode funcionar como servidor de contabilidade primário para um esquema e como servidor de contabilidade secundário para outro esquema ao mesmo tempo.
Dois servidores de contabilidade em um esquema, primário ou secundário, não podem ter a mesma combinação de nome de host, endereço IP e número de porta.
O RADIUS não oferece suporte à contabilidade para usuários de FTP, SFTP e SCP.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameprimary accounting { host-name | ipv4-address | ipv6 ipv6-address } [ port-number | key { cipher | simple } string | weight weight-value ] *Por padrão, nenhum servidor de contabilidade RADIUS primário é especificado.
A palavra-chave weight só tem efeito quando o recurso de compartilhamento de carga do servidor RADIUS está ativado para o esquema RADIUS.
secondary accounting { host-name | ipv4-address | ipv6 ipv6-address } [ port-number | key { cipher | simple } string | weight weight-value ] *Por padrão, nenhum servidor de contabilidade RADIUS secundário é especificado.
A palavra-chave weight só tem efeito quando o recurso de compartilhamento de carga do servidor RADIUS está ativado para o esquema RADIUS.
Especificação das chaves compartilhadas para comunicação RADIUS segura
Sobre as chaves compartilhadas para a comunicação segura do RADIUS
O cliente e o servidor RADIUS usam o algoritmo MD5 e chaves compartilhadas para gerar o valor do Authenticator para autenticação de pacotes e criptografia de senhas de usuários. O cliente e o servidor devem usar a mesma chave para cada tipo de comunicação.
Uma chave configurada nessa tarefa é para todos os servidores do mesmo tipo (contabilidade ou autenticação) no esquema. A chave tem prioridade mais baixa do que uma chave configurada individualmente para um servidor RADIUS.
Restrições e diretrizes
A chave compartilhada configurada no dispositivo deve ser a mesma que a chave compartilhada configurada no servidor RADIUS .
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-namekey { accounting | authentication } { cipher | simple } stringPor padrão, nenhuma chave compartilhada é especificada para a comunicação segura do RADIUS.
Definição do status dos servidores RADIUS
Sobre o status do servidor RADIUS
Para controlar os servidores RADIUS com os quais o dispositivo se comunica quando os servidores atuais não estão mais disponíveis, defina o status dos servidores RADIUS como bloqueado ou ativo. Você pode especificar um servidor primário
servidor RADIUS e vários servidores RADIUS secundários. Os servidores secundários funcionam como backup do servidor primário. Quando o recurso de compartilhamento de carga do servidor RADIUS está desativado, o dispositivo escolhe os servidores com base nas seguintes regras:
- Quando o servidor primário está no estado ativo, o dispositivo tenta primeiro se comunicar com o servidor primário. Se o servidor primário não puder ser acessado, o dispositivo procurará um servidor secundário ativo na ordem em que os servidores estiverem configurados.
- Quando um ou mais servidores estão no estado ativo, o dispositivo tenta se comunicar apenas com esses servidores ativos, mesmo que os servidores não estejam disponíveis.
- Quando todos os servidores estão em estado bloqueado, o dispositivo tenta se comunicar apenas com o servidor principal.
- Se um servidor não puder ser acessado, o dispositivo executará as seguintes operações:
- Altera o status do servidor para bloqueado.
- Inicia um cronômetro de silêncio para o servidor.
- Tenta se comunicar com o próximo servidor secundário em estado ativo que tem a prioridade mais alta.
- Quando o timer de silêncio de um servidor expira ou quando você define manualmente o servidor para o estado ativo, o status do servidor volta a ser ativo. O dispositivo não verifica o servidor novamente durante o processo de autenticação ou contabilidade.
- O processo de pesquisa continua até que o dispositivo encontre um servidor secundário disponível ou tenha verificado todos os servidores secundários em estado ativo. Se nenhum servidor estiver acessível, o dispositivo considerará a tentativa de autenticação ou contabilização uma falha.
- Quando você remove um servidor em uso, a comunicação com o servidor é interrompida. O dispositivo procura um servidor em estado ativo verificando primeiro o servidor primário e, em seguida, os servidores secundários na ordem em que foram configurados.
- Quando o status de um servidor RADIUS é alterado automaticamente, o dispositivo altera o status desse servidor de forma correspondente em todos os esquemas RADIUS nos quais esse servidor é especificado.
- Quando um servidor RADIUS é definido manualmente como bloqueado, a detecção de servidor é desativada para o servidor, independentemente de ter sido especificado um perfil de teste para o servidor. Quando o servidor RADIUS é definido para o estado ativo, a detecção do servidor é ativada para o servidor no qual um perfil de teste existente é especificado.
Por padrão, o dispositivo define o status de todos os servidores RADIUS como ativo. Entretanto, em algumas situações, você deve alterar o status de um servidor. Por exemplo, se um servidor falhar, você poderá alterar o status do servidor para bloqueado para evitar tentativas de comunicação com o servidor.
Restrições e diretrizes
O status do servidor configurado não pode ser salvo em nenhum arquivo de configuração e só pode ser visualizado com o comando display radius scheme.
Depois que o dispositivo for reiniciado, todos os servidores serão restaurados para o estado ativo.
O dispositivo seleciona um servidor acessível para a autenticação ou contabilização de um novo usuário de acordo com as regras de seleção de servidor desta seção se o recurso de compartilhamento de carga do servidor RADIUS estiver desativado. No entanto, essas regras não se aplicam à reautenticação de usuários on-line se o modo de seleção do servidor RADIUS para reautenticação estiver definido como herdar usando o comando reauthentication server-select inherit.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-name- Definir o status do servidor de autenticação RADIUS primário.
state primary authentication { active | block }state primary accounting { active | block }state secondary authentication [ { host-name | ipv4-address | ipv6 ipv6-address } [ port-number ] ] { active | block }state secondary accounting [ { host-name | ipv4-address | ipv6 ipv6-address } [ port-number ] ] { active | block }Por padrão, um servidor RADIUS está no estado ativo.
Configuração de temporizadores RADIUS
Sobre os temporizadores RADIUS
O dispositivo usa os seguintes tipos de temporizadores para controlar a comunicação com um servidor RADIUS:
- Temporizador de tempo limite de resposta do servidor (response-timeout) - Define o intervalo de retransmissão da solicitação RADIUS. O cronômetro começa imediatamente após o envio de uma solicitação RADIUS. Se o dispositivo não receber uma resposta do servidor RADIUS antes que o cronômetro expire, ele reenviará a solicitação.
- Temporizador de silêncio do servidor (quiet) - Define a duração para manter um servidor inacessível no estado bloqueado. Se um servidor não estiver acessível, o dispositivo alterará o status do servidor para bloqueado, iniciará esse cronômetro para o servidor e tentará se comunicar com outro servidor no estado ativo. Após a expiração do cronômetro de silêncio do servidor, o dispositivo altera o status do servidor de volta para ativo.
- Timer de contabilidade em tempo real (realtime-accounting) - Define o intervalo em que o dispositivo envia pacotes de contabilidade em tempo real para o servidor de contabilidade RADIUS para usuários on-line.
Restrições e diretrizes
Considere o número de servidores secundários ao configurar o número máximo de tentativas de transmissão de pacotes RADIUS e o cronômetro de tempo limite de resposta do servidor RADIUS. Se o esquema RADIUS incluir muitos servidores secundários, o processo de retransmissão poderá ser muito longo e a conexão do cliente no módulo de acesso, como a Telnet, poderá atingir o tempo limite.
Quando as conexões do cliente têm um curto período de tempo limite, um grande número de servidores secundários pode fazer com que a tentativa inicial de autenticação ou contabilização falhe. Nesse caso, reconecte o cliente em vez de ajustar as tentativas de transmissão de pacotes RADIUS e o cronômetro de tempo limite de resposta do servidor. Normalmente, a próxima tentativa será bem-sucedida, pois o dispositivo bloqueou os servidores inacessíveis para reduzir o tempo de localização de um servidor acessível.
Verifique se o temporizador de silêncio do servidor está definido corretamente. Um timer muito curto pode resultar em falhas frequentes de autenticação ou contabilidade. Isso ocorre porque o dispositivo continuará a tentar se comunicar com um servidor inacessível que esteja em estado ativo. Um timer muito longo pode bloquear temporariamente um servidor acessível que tenha se recuperado de uma falha. Isso ocorre porque o servidor permanecerá no estado bloqueado até que o temporizador expire.
Um intervalo curto de contabilização em tempo real ajuda a melhorar a precisão da contabilização, mas exige muitos recursos do sistema. Quando houver 1.000 ou mais usuários, defina o intervalo para 15 minutos ou mais.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-name- Defina o timer de tempo limite de resposta do servidor RADIUS.
timer response-timeout secondsA configuração padrão é 3 segundos.
timer quiet minutesA configuração padrão é de 5 minutos.
timer realtime-accounting interval [ second ]A configuração padrão é 12 minutos.
Especificação do endereço IP de origem para pacotes RADIUS de saída
Sobre o endereço IP de origem para pacotes RADIUS de saída
O endereço IP de origem dos pacotes RADIUS que um NAS envia deve corresponder ao endereço IP do NAS configurado no servidor RADIUS. Um servidor RADIUS identifica um NAS por seu endereço IP. Ao receber um pacote RADIUS, o servidor RADIUS verifica o endereço IP de origem do pacote.
- Se for o endereço IP de um NAS gerenciado, o servidor processará o pacote.
- Se não for o endereço IP de um NAS gerenciado, o servidor descartará o pacote.
Antes de enviar um pacote RADIUS, o NAS seleciona um endereço IP de origem na seguinte ordem:
- O endereço IP de origem especificado para o esquema RADIUS.
- O endereço IP de origem especificado na visualização do sistema.
- O endereço IP da interface de saída especificada pela rota.
Restrições e diretrizes para a configuração do endereço IP de origem
Você pode especificar um endereço IP de origem para pacotes RADIUS de saída na visualização do esquema RADIUS ou na visualização do sistema.
- O endereço IP especificado na visualização do esquema RADIUS aplica-se somente a um esquema RADIUS.
- O endereço IP especificado na visualização do sistema se aplica a todos os esquemas RADIUS.
O endereço IP de origem dos pacotes RADIUS que um NAS envia deve corresponder ao endereço IP do NAS que está configurado no servidor RADIUS.
Como prática recomendada, especifique um endereço de interface de loopback como o endereço IP de origem dos pacotes RADIUS de saída para evitar a perda de pacotes RADIUS causada por erros de porta física.
O endereço de origem dos pacotes RADIUS de saída é normalmente o endereço IP de uma interface de saída no NAS para se comunicar com o servidor RADIUS. Entretanto, em algumas situações, você deve alterar o endereço IP de origem. Por exemplo, quando o VRRP estiver configurado para failover com estado, configure o IP virtual do grupo VRRP de uplink como o endereço de origem.
Você pode especificar diretamente um endereço IP de origem para os pacotes RADIUS de saída ou especificar uma interface de origem para fornecer o endereço IP de origem para os pacotes RADIUS de saída. A configuração da interface de origem e a configuração do endereço IP de origem substituem uma à outra.
Especificação de uma interface de origem ou endereço IP de origem para todos os esquemas RADIUS
- Entre na visualização do sistema.
system viewradius nas-ip { interface interface-type interface-number | { ipv4-address | ipv6 ipv6-address } }Por padrão, o endereço IP de origem de um pacote RADIUS de saída é o endereço IPv4 primário ou o endereço IPv6 da interface de saída.
Especificação de uma interface de origem ou endereço IP de origem para um esquema RADIUS
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-namenas-ip { ipv4-address | interface interface-type interface-number | ipv6 ipv6-address }Por padrão, o endereço IP de origem de um pacote RADIUS de saída é aquele especificado pelo uso do comando radius nas-ip na visualização do sistema. Se o comando radius nas-ip não for usado, o endereço IP de origem será o endereço IP primário da interface de saída.
Configuração do formato do nome de usuário e das unidades de estatísticas de tráfego
Sobre o formato do nome de usuário e as unidades de estatísticas de tráfego
Um nome de usuário está no formato userid@isp-name, em que a parte isp-name representa o nome de domínio ISP do usuário. Por padrão, o nome de domínio do ISP é incluído em um nome de usuário. Entretanto, os servidores RADIUS mais antigos podem não reconhecer nomes de usuário que contenham os nomes de domínio do ISP. Nesse caso, você pode configurar o dispositivo para remover o nome de domínio de cada nome de usuário a ser enviado.
O dispositivo relata estatísticas de tráfego de usuários on-line em pacotes de contabilidade. As unidades de medição de tráfego são configuráveis.
Restrições e diretrizes
Se dois ou mais domínios ISP usarem o mesmo esquema RADIUS, configure o esquema RADIUS para manter o nome do domínio ISP nos nomes de usuário para identificação do domínio.
Para obter precisão na contabilidade, certifique-se de que as unidades de estatísticas de tráfego configuradas no dispositivo e nos servidores de contabilidade RADIUS sejam as mesmas.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameuser-name-format { keep-original | with-domain | without-domain }Por padrão, o nome de domínio do ISP é incluído em um nome de usuário.
Se o dispositivo for especificado como servidor RADIUS no esquema, o formato do nome de usuário deverá ser definido como without-domain (sem domínio).
data-flow-format { data { byte | giga-byte | kilo-byte | mega-byte } | packet { giga-packet | kilo-packet | mega-packet | one-packet } }*Por padrão, o tráfego é contado em bytes e pacotes.
Configuração do número máximo de tentativas de transmissão de solicitações RADIUS
Sobre a configuração do número máximo de tentativas de transmissão de solicitações RADIUS
O RADIUS usa pacotes UDP para transferir dados. Como a comunicação UDP não é confiável, o RADIUS usa um mecanismo de retransmissão para aumentar a confiabilidade. Uma solicitação RADIUS será retransmitida se o NAS não receber uma resposta do servidor para a solicitação dentro do cronômetro de tempo limite de resposta. Para obter mais informações sobre o cronômetro de tempo limite de resposta do servidor RADIUS, consulte "Definição do status dos servidores RADIUS".
Você pode definir o número máximo para o NAS retransmitir uma solicitação RADIUS para o mesmo servidor. Quando o número máximo é atingido, o NAS tenta se comunicar com outros servidores RADIUS no estado ativo. Se nenhum outro servidor estiver em estado ativo no momento, o NAS considerará a tentativa de autenticação ou contabilidade uma falha.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameretry retriesPor padrão, o número máximo é 3 para tentativas de transmissão de solicitações RADIUS.
Definição do número máximo de tentativas de contabilização em tempo real
Sobre a configuração do número máximo de tentativas de contabilização em tempo real
Se você definir o número máximo de tentativas de contabilização em tempo real, o dispositivo desconectará os usuários dos quais não forem recebidas respostas de contabilização dentro das tentativas permitidas.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameretry realtime-accounting retriesPor padrão, o número máximo é 5 para tentativas de contabilização em tempo real.
Configuração da prioridade DSCP para pacotes RADIUS
Sobre a prioridade DSCP para pacotes RADIUS
A prioridade DSCP no campo ToS determina a prioridade de transmissão dos pacotes RADIUS. Um valor maior representa uma prioridade mais alta.
Procedimento
- Entre na visualização do sistema.
system viewradius [ ipv6 ] dscp dscp-valuePor padrão, a prioridade DSCP é 0 para pacotes RADIUS.
Especificação do formato do atributo NAS-Port
Sobre esta tarefa
Execute esta tarefa para especificar o formato do atributo NAS-Port (atributo 5) enviado pelo dispositivo ao servidor RADIUS. Os seguintes formatos estão disponíveis:
- Formato padrão - Contém as seguintes partes:
- ID de membro IRF de 8 bits.
- Número do slot de 4 bits.
- Índice de porta de 8 bits.
- VLAN ID de 12 bits.
- Formato da porta - Contém o valor no último segmento da interface de acesso do usuário. Por exemplo, se um usuário ficar on-line a partir da GigabitEthernet 1/0/2, o valor do atributo NAS-Port será 2.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6342 e posteriores.
Restrições e diretrizes
Para trocar pacotes RADIUS corretamente com um servidor RADIUS, configure o dispositivo com o mesmo formato de atributo NAS-Port que o servidor RADIUS.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameattribute 5 format portPor padrão, o atributo NAS-Port usa o formato padrão.
Configuração do método de verificação do atributo Login-Service para usuários de SSH, FTP e terminal
Sobre os métodos de verificação do atributo Login-Service
O dispositivo suporta os seguintes métodos de verificação do atributo Login-Service (atributo 15 do RADIUS) de usuários de SSH, FTP e terminal:
- Strict - Matches Login-Service valores de atributo 50, 51 e 52 para SSH, FTP e serviços de terminal, respectivamente.
- Loose - Corresponde ao valor 0 do atributo padrão Login-Service para SSH, FTP e serviços de terminal.
Um pacote Access-Accept recebido para um usuário deve conter o valor de atributo correspondente. Caso contrário, o usuário não poderá fazer login no dispositivo.
Restrições e diretrizes
Use o método de verificação solta somente quando o servidor não emitir os valores de atributo Login-Service 50, 51 e 52 para usuários de SSH, FTP e terminal.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameattribute 15 check-mode { loose | strict }O método de verificação padrão é rigoroso.
Interpretação do atributo de classe RADIUS como parâmetros CAR
Sobre a interpretação do atributo de classe RADIUS como parâmetros CAR
Um servidor RADIUS pode fornecer parâmetros CAR para monitoramento e controle de tráfego com base no usuário usando o atributo de classe RADIUS (atributo 25) nos pacotes RADIUS. Você pode configurar o dispositivo para interpretar o atributo class como parâmetros CAR.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameattribute 25 carPor padrão, o atributo de classe RADIUS não é interpretado como parâmetros CAR.
Configuração do formato do endereço MAC para o atributo 31 do RADIUS
Restrições e diretrizes
Servidores RADIUS de tipos diferentes podem ter requisitos diferentes para o formato de endereço MAC no atributo 31 do RADIUS. Configure o formato do endereço MAC do atributo 31 do RADIUS para atender aos requisitos dos servidores RADIUS.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameattribute 31 mac-format section { one |{ six | three } separator separator-character } { lowercase | uppercase }Por padrão, um endereço MAC está no formato HH-HH-HH-HH-HH-HH-HH-HH. O endereço MAC é separado por hífen (-) em seis seções com letras em caixa alta.
A palavra-chave one está disponível somente na versão 6312 e posteriores.
Especificação do formato do atributo NAS-Port-ID
Sobre esta tarefa
Execute esta tarefa para especificar o formato do atributo NAS-Port-ID (atributo 87) enviado pelo dispositivo ao servidor RADIUS. Os seguintes formatos estão disponíveis:
- Formato padrão - O formato padrão varia de acordo com o tipo de acesso do usuário.
- Para usuários do portal, o atributo NAS-Port-Id está no formato SlotID00IfNOVlanID:
- Para usuários de autenticação 802.1X e MAC, o atributo NAS-Port-Id está no
- Para usuários de login, o dispositivo não inclui o atributo NAS-Port-Id nos pacotes RADIUS.
- Formato Interface-name - Contém o nome da interface de acesso do usuário. Por exemplo, se um usuário acessar a rede a partir da GigabitEthernet 1/0/1, o atributo NAS-Port-ID será definido como GigabitEthernet1/0/1.
- SlotID - Representa um ID de membro IRF de 2 bytes.
- 00 - Representa uma cadeia de 2 bytes de 0s.
- SeNO- Representa um índice de porta de 3 bytes.
- VLANID - Representa uma VLAN ID de 9 bytes.
slot=xx;subslot=xx;port=xx;vlanid=xx formato.
- slot - ID do membro do IRF.
- subslot - número do slot.
- port - índice da porta.
- vlanid - VLAN ID
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6342 e posteriores.
Restrições e diretrizes
Para trocar pacotes RADIUS corretamente com um servidor RADIUS, configure o dispositivo com o mesmo formato de atributo NAS-Port-ID que o servidor RADIUS.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameattribute 87 format interface-namePor padrão, o atributo NAS-Port usa o formato padrão.
Definição da unidade de medição de dados para o atributo Remanent_Volume
Sobre a unidade de medição de dados para o atributo Remanent_Volume
O servidor RADIUS usa o atributo Remanent_Volume em respostas de autenticação ou de contabilidade em tempo real para notificar o dispositivo sobre a quantidade atual de dados disponíveis para usuários on-line.
Restrições e diretrizes
Certifique-se de que a unidade de medida configurada seja igual à unidade de medida de dados do usuário no servidor RADIUS .
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameattribute remanent-volume unit { byte | giga-byte | kilo-byte | mega-byte }Por padrão, a unidade de medida de dados é o kilobyte.
Configuração do recurso de conversão de atributos RADIUS
Sobre a tradução de atributos RADIUS
O recurso de tradução de atributos RADIUS permite que o dispositivo funcione corretamente com os servidores RADIUS de diferentes fornecedores que oferecem suporte a atributos RADIUS incompatíveis com o dispositivo.
A tradução de atributos do RADIUS tem as seguintes implementações:
- Conversão de atributos - Converte atributos RADIUS de origem em atributos RADIUS de destino com base nas regras de conversão de atributos RADIUS.
- Rejeição de atributos - Rejeita atributos RADIUS com base nas regras de rejeição de atributos RADIUS.
- Para os pacotes RADIUS enviados:
- Exclui os atributos rejeitados dos pacotes.
- Usa os atributos RADIUS de destino para substituir os atributos que correspondem às regras de conversão de atributos RADIUS nos pacotes.
- Para os pacotes RADIUS recebidos:
- Ignora os atributos rejeitados nos pacotes.
- Interpreta os atributos que correspondem às regras de conversão de atributos RADIUS como os atributos RADIUS de destino.
Quando o recurso de conversão de atributos RADIUS está ativado, o dispositivo processa os pacotes RADIUS da seguinte forma:
Para identificar atributos proprietários do RADIUS, você pode definir os atributos como atributos estendidos do RADIUS e, em seguida, converter os atributos estendidos do RADIUS em atributos compatíveis com o dispositivo.
Restrições e diretrizes para a configuração da conversão de atributos RADIUS
Configure regras de conversão ou regras de rejeição para um atributo RADIUS.
Configure regras baseadas em direção ou em tipo de pacote para um atributo RADIUS.
Para a tradução baseada em direção de um atributo RADIUS, você pode configurar uma regra para cada direção (entrada ou saída). Para a tradução baseada em tipo de pacote de um atributo RADIUS, você pode configurar uma regra para cada tipo de pacote RADIUS (RADIUS Access-Accept, RADIUS Access-Request ou RADIUS accounting).
Configuração do recurso de conversão de atributos RADIUS para um esquema RADIUS
- Entre na visualização do sistema.
system viewradius attribute extended attribute-name [ vendor vendor-id ] code attribute-code type { binary | date | integer | interface-id | ip | ipv6 | ipv6-prefix | octets | string }radius scheme radius-scheme-nameattribute translatePor padrão, esse recurso está desativado.
- Configure uma regra de conversão de atributo RADIUS.
attribute convert src-attr-name to dest-attr-name { { access-accept | access-request | accounting } * | { received | sent } * }Por padrão, nenhuma regra de conversão de atributo RADIUS é configurada.
attribute reject attr-name { { access-accept | access-request | accounting } * | { received | sent } * }Por padrão, nenhuma regra de rejeição de atributo RADIUS é configurada.
Configuração do recurso de conversão de atributos RADIUS para um DAS RADIUS
- Entre na visualização do sistema.
system viewradius attribute extended attribute-name [ vendor vendor-id ] code attribute-code type { binary | date | integer | interface-id | ip | ipv6 | ipv6-prefix | octets | string }radius dynamic-author serverattribute translatePor padrão, esse recurso está desativado.
- Configure uma regra de conversão de atributo RADIUS.
attribute convert src-attr-name to dest-attr-name { { coa-ack | coa-request } * | { received | sent } * }Por padrão, nenhuma regra de conversão de atributo RADIUS é configurada.
attribute reject attr-name { { coa-ack | coa-request } * | { received | sent } * }Por padrão, nenhuma regra de rejeição de atributo RADIUS é configurada.
Configuração do buffer de pacotes de interrupção de contabilização do RADIUS
Sobre o buffer de pacotes RADIUS stop-accounting
O dispositivo envia solicitações de interrupção de contabilização RADIUS quando recebe solicitações de interrupção de conexão de hosts ou comandos de interrupção de conexão de um administrador. No entanto, o dispositivo pode falhar
para receber uma resposta para uma solicitação de interrupção de contabilização em uma única transmissão. Ative o dispositivo para armazenar em buffer as solicitações de interrupção de contabilização do RADIUS que não receberam respostas do servidor de contabilização. O dispositivo reenviará as solicitações até que as respostas sejam recebidas.
Para limitar os tempos de transmissão, defina um número máximo de tentativas de transmissão que podem ser feitas para solicitações individuais de interrupção de contabilização do RADIUS. Quando são feitas as tentativas máximas para uma solicitação, o dispositivo descarta a solicitação armazenada em buffer.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-namestop-accounting-buffer enablePor padrão, o recurso de buffer está ativado.
retry stop-accounting retriesA configuração padrão é 500.
Ativação do envio forçado de pacotes de parada de contabilização
Sobre o envio forçado de pacotes stop-accounting
Normalmente, se o dispositivo não enviar um pacote de contabilização inicial ao servidor RADIUS para um usuário autenticado, ele não enviará um pacote de contabilização final quando o usuário ficar off-line. Se o servidor tiver gerado uma entrada de usuário para o usuário sem pacotes start-accounting, ele não liberará a entrada de usuário quando o usuário ficar off-line. Esse recurso força o dispositivo a enviar pacotes stop-accounting para o servidor RADIUS quando o usuário fica off-line para liberar a entrada de usuário no servidor em tempo hábil.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-namestop-accounting-packet send-forcePor padrão, o envio forçado de pacotes de parada de contabilização está desativado. O dispositivo não envia pacotes de interrupção de contabilização quando os usuários para os quais não são enviados pacotes de início de contabilização ficam off-line.
Ativação do recurso de compartilhamento de carga do servidor RADIUS
Sobre o compartilhamento de carga do servidor RADIUS
Por padrão, o dispositivo se comunica com os servidores RADIUS com base nas funções do servidor. Primeiro, ele tenta se comunicar com o servidor primário e, se o servidor primário não puder ser acessado, ele procura os servidores secundários na ordem em que foram configurados. O primeiro servidor secundário em estado ativo é usado para comunicação. Nesse processo, a carga de trabalho é sempre colocada no servidor ativo.
Use o recurso de compartilhamento de carga do servidor RADIUS para distribuir dinamicamente a carga de trabalho entre vários servidores, independentemente de suas funções. O dispositivo encaminha uma solicitação AAA para o servidor mais adequado de todos os servidores ativos no esquema depois de comparar os valores de peso e os números de usuários atendidos atualmente. Especifique um valor de peso para cada servidor RADIUS com base na capacidade AAA do servidor. Um valor de peso maior indica uma capacidade AAA maior.
No compartilhamento de carga do servidor RADIUS, quando o dispositivo envia uma solicitação de início de contabilização a um servidor para um usuário, ele encaminha todas as solicitações de contabilização subsequentes do usuário para o mesmo servidor. Se o servidor de contabilidade não puder ser acessado, o dispositivo retornará uma mensagem de falha de contabilidade em vez de procurar outro servidor de contabilidade ativo.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameserver-load-sharing enablePor padrão, esse recurso está desativado.
Configuração do recurso de contabilização RADIUS
Sobre a contabilização RADIUS
Quando o recurso de contabilização está ativado, o dispositivo envia automaticamente um pacote de contabilização para o servidor RADIUS após a reinicialização de todo o dispositivo. Ao receber o pacote de contabilização, o servidor RADIUS faz o logout de todos os usuários on-line para que eles possam fazer login novamente pelo dispositivo. Sem esse recurso, os usuários não podem fazer login novamente após a reinicialização, pois o servidor RADIUS considera que eles estão on-line.
Você pode configurar o intervalo pelo qual o dispositivo espera para reenviar o pacote de contabilização e o número máximo de tentativas.
O recurso de contabilização estendido aprimora o recurso de contabilização em uma arquitetura distribuída.
O recurso de contabilização estendida é aplicável aos usuários da LAN. Os dados do usuário são salvos nos dispositivos membros da IRF por meio dos quais os usuários acessam o sistema. Quando o recurso de contabilização estendida está ativado, o sistema envia automaticamente um pacote de contabilização para o servidor RADIUS após a reinicialização de um dispositivo membro. O pacote contém o identificador do dispositivo membro. Ao receber o pacote de contabilização, o servidor RADIUS faz o logout de todos os usuários on-line que acessam o sistema por meio do dispositivo membro. Se nenhum usuário estiver on-line por meio do dispositivo membro, a malha IRF não enviará um pacote de contabilização após a reinicialização do dispositivo membro.
Restrições e diretrizes
Para que o recurso de contabilização estendida tenha efeito, o servidor RADIUS deve ser executado no IMC e o recurso de contabilização deve estar ativado.
Procedimento
- Entre na visualização do sistema.
system viewradius scheme radius-scheme-nameaccounting-on enable [ interval interval | send send-times ] *Por padrão, o recurso de contabilização está desativado.
accounting-on extendedPor padrão, a contabilização estendida está desativada.
Configuração do recurso de controle de sessão RADIUS
Sobre o controle de sessão RADIUS
Habilite esse recurso para que o servidor RADIUS altere dinamicamente as informações de autorização do usuário (como ACL de autorização, VLAN e grupo de usuários) ou desconecte usuários à força usando pacotes de controle de sessão. Essa tarefa permite que o dispositivo receba pacotes de controle de sessão RADIUS na porta UDP 1812.
Para verificar os pacotes de controle de sessão enviados de um servidor RADIUS, especifique o servidor RADIUS como um cliente de controle de sessão para o dispositivo.
Restrições e diretrizes
O recurso de controle de sessão RADIUS só pode funcionar com servidores RADIUS em execução no IMC. A configuração do cliente de controle de sessão entra em vigor somente quando o recurso de controle de sessão está ativado.
Se o dispositivo atuar como NAS e o servidor IMC implantado com o EAD atribuir ACLs de autorização ao dispositivo, você deverá ativar o recurso de controle de sessão no dispositivo. Isso garante que as ACLs de autorização possam entrar em vigor.
Procedimento
- Entre na visualização do sistema.
system viewradius session-control enablePor padrão, o recurso de controle de sessão está desativado.
radius session-control client { ip ipv4-address | ipv6 ipv6-address } [ key { cipher | simple } string ]Por padrão, nenhum cliente de controle de sessão é especificado.
Configuração do recurso RADIUS DAS
Sobre o recurso RADIUS DAS
As Extensões de Autorização Dinâmica (DAE) para RADIUS, definidas na RFC 5176, podem fazer logoff de usuários on-line e alterar as informações de autorização de usuários on-line.
Em uma rede RADIUS, o servidor RADIUS normalmente atua como o cliente DAE (DAC) e o NAS atua como o servidor DAE (DAS).
Quando o recurso RADIUS DAS está ativado, o NAS executa as seguintes operações:
- Escuta a porta UDP padrão ou especificada para receber solicitações de DAE.
- Faz o logoff dos usuários on-line que correspondem aos critérios das solicitações, altera suas informações de autorização, desliga ou reinicia suas portas de acesso ou reautentica os usuários.
- Envia respostas DAE para o DAC. O DAE define os seguintes tipos de pacotes:
- Mensagens de desconexão (DMs) - O DAC envia solicitações de DM para o DAS para fazer logoff de mensagens específicas.
usuários on-line.
- Mensagens de alteração de autorização (mensagens CoA) - O DAC envia solicitações CoA para o DAS para alterar as informações de autorização de usuários on-line específicos.
Procedimento
- Entre na visualização do sistema.
system viewradius dynamic-author serverPor padrão, o recurso RADIUS DAS está desativado.
client { ip ipv4-address | ipv6 ipv6-address } [ key { cipher | simple } string ]Por padrão, não são especificados DACs RADIUS.
port port-numberPor padrão, a porta RADIUS DAS é 3799.
Ativação de notificações SNMP para RADIUS
Sobre as notificações SNMP para RADIUS
Quando as notificações SNMP estão ativadas para o RADIUS, o agente SNMP é compatível com as seguintes notificações geradas pelo RADIUS:
- Notificação de servidor RADIUS inacessível - O servidor RADIUS não pode ser acessado. O RADIUS gera essa notificação se não receber uma resposta a uma solicitação de contabilidade ou autenticação dentro do número especificado de tentativas de transmissão de solicitações do RADIUS.
- Notificação de servidor RADIUS acessível - O servidor RADIUS pode ser acessado. O RADIUS gera essa notificação para um servidor RADIUS bloqueado anteriormente após a expiração do cronômetro de silêncio.
- Notificação de falhas de autenticação excessivas - O número de falhas de autenticação em comparação com o número total de tentativas de autenticação excede o limite especificado.
Para que as notificações RADIUS SNMP sejam enviadas corretamente, você também deve configurar o SNMP no dispositivo. Para obter mais informações sobre a configuração de SNMP, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
system viewsnmp-agent trap enable radius [ accounting-server-down | accounting-server-up | authentication-error-threshold | authentication-server-down | authentication-server-up ] *Por padrão, todas as notificações SNMP são desativadas para o RADIUS.
Desativação do serviço RADIUS
Sobre a desativação do serviço RADIUS
Por padrão, o serviço RADIUS está ativado. O dispositivo pode enviar e receber pacotes RADIUS. Os invasores podem usar o controle de sessão RADIUS e as portas DAE para atacar o dispositivo. Para proteger o dispositivo quando ocorrer um ataque desse tipo, desative temporariamente o serviço RADIUS no dispositivo. Depois que a rede estiver segura, reative o serviço RADIUS.
Se as configurações nos servidores RADIUS exigirem modificações ou se os servidores RADIUS não puderem fornecer serviços temporariamente, você poderá desativar temporariamente o serviço RADIUS no dispositivo.
Quando o serviço RADIUS é desativado, o dispositivo para de enviar e receber pacotes RADIUS. Se um novo usuário ficar on-line, o dispositivo usará o método de autenticação, autorização ou contabilização de backup para processar esse usuário. Se o dispositivo não tiver concluído a solicitação de autenticação ou contabilização para um usuário antes de o serviço RADIUS ser desativado, ele usará as seguintes regras para processar esse usuário:
- Se o dispositivo tiver enviado solicitações de autenticação RADIUS para esse usuário a um servidor RADIUS, o dispositivo processará esse usuário dependendo do recebimento de uma resposta do servidor RADIUS.
- Se o dispositivo receber uma resposta do servidor RADIUS, ele usará a resposta para determinar se o usuário foi aprovado na autenticação. Se o usuário tiver sido aprovado na autenticação, o dispositivo atribuirá informações de autorização a esse usuário de acordo com a resposta.
- Se o dispositivo não receber nenhuma resposta do servidor RADIUS, ele tentará usar o método de autenticação de backup para autenticar esse usuário.
- Se o dispositivo tiver enviado solicitações de início de contabilização RADIUS para esse usuário a um servidor RADIUS, o dispositivo processará esse usuário dependendo do recebimento de uma resposta do servidor RADIUS.
- Se o dispositivo receber uma resposta do servidor RADIUS, ele permitirá que o usuário fique on-line. No entanto, o dispositivo não pode enviar solicitações de atualização de contabilidade ou de interrupção de contabilidade para o servidor RADIUS. Ele também não pode armazenar em buffer as solicitações de contabilidade. Quando o usuário fica off-line, o servidor RADIUS não consegue fazer o logoff desse usuário a tempo. O resultado da contabilização pode ser impreciso.
- Se o dispositivo não receber nenhuma resposta do servidor RADIUS, ele tentará usar o método de contabilidade de backup .
Restrições e diretrizes
A desativação do serviço RADIUS não afeta o recurso de servidor RADIUS do dispositivo.
Os processos de autenticação, autorização e contabilidade realizados por outros métodos não são alternados para o RADIUS quando você reativa o serviço RADIUS.
Procedimento
- Entre na visualização do sistema.
system viewundo radius enablePor padrão, o serviço RADIUS está ativado.
Para reativar o serviço RADIUS, use o comando radius enable.
Comandos de exibição e manutenção para RADIUS
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir a configuração do esquema RADIUS. | display radius scheme [ radius-scheme-name ] |
| Exibir estatísticas de carga de autenticação e contabilidade para todos os servidores RADIUS. | exibir estatísticas de carga do servidor radius |
| Exibir estatísticas de pacotes RADIUS. | exibir estatísticas de raio |
| Exibir informações sobre o buffer | exibir stop-accounting-buffer |
| Solicitações RADIUS de interrupção de contabilização para as quais nenhuma resposta foi recebida. | { radius-scheme radius-scheme-name | session-id session-id | time-range start-time end-time | user-name user-name } |
| Limpar o histórico de estatísticas de carga de autenticação e contabilidade de todos os servidores RADIUS. | reset radius server-load statistics |
| Limpar estatísticas do RADIUS. | reset radius statistics |
| Limpar o RADIUS armazenado em buffer solicitações de interrupção de prestação de contas para as quais não foram recebidas respostas. | reset stop-accounting-buffer { radius-scheme radius-scheme-name | session-id session-id | time-range start-time end-time | user-name user-name } |
Configuração do HWTACACS
Visão geral das tarefas do HWTACACS
Para configurar o HWTACACS, execute as seguintes tarefas:
- Criação de um esquema HWTACACS
- Especificação dos servidores de autenticação HWTACACS
- Especificação dos servidores de autorização HWTACACS
- Especificação dos servidores de contabilidade HWTACACS
- Especificação das chaves compartilhadas para a comunicação segura do HWTACACS
- (Opcional.) Configuração dos temporizadores do HWTACACS
- (Opcional.) Configuração de parâmetros para pacotes HWTACACS
- (Opcional.) Configuração do buffer de pacotes HWTACACS stop-accounting
Execute essa tarefa se nenhuma chave compartilhada for especificada durante a configuração dos servidores HWTACACS.
Especificação do endereço IP de origem para pacotes HWTACACS de saída
Definição do formato do nome de usuário e das unidades de estatísticas de tráfego
Criação de um esquema HWTACACS
Restrições e diretrizes
É possível configurar um máximo de 16 esquemas HWTACACS. Um esquema HWTACACS pode ser usado por vários domínios ISP.
Procedimento
- Entre na visualização do sistema.
system viewhwtacacs scheme hwtacacs-scheme-nameEspecificação dos servidores de autenticação HWTACACS
Sobre os servidores de autenticação HWTACACS
Você pode especificar um servidor de autenticação primário e um máximo de 16 servidores de autenticação secundários para um esquema HWTACACS. Quando o servidor primário não pode ser acessado, o dispositivo procura os servidores secundários na ordem em que foram configurados. O primeiro servidor secundário em estado ativo é usado para comunicação.
Restrições e diretrizes
Se a redundância não for necessária, especifique apenas o servidor primário.
Um servidor HWTACACS pode funcionar como servidor de autenticação primário em um esquema e como servidor de autenticação secundário em outro esquema ao mesmo tempo.
Dois servidores de autenticação HWTACACS em um esquema, primário ou secundário, não podem ter a mesma combinação de nome de host, endereço IP e número de porta.
Procedimento
- Entre na visualização do sistema.
system viewhwtacacs scheme hwtacacs-scheme-nameprimary authentication { host-name | ipv4-address | ipv6 ipv6-address } [ port-number | key { cipher | simple } string | single-connection ] *Por padrão, nenhum servidor de autenticação HWTACACS primário é especificado.
secondary authentication { host-name | ipv4-address | ipv6 ipv6-address } [ port-number | key { cipher | simple } string | single-connection ] *Por padrão, nenhum servidor de autenticação HWTACACS secundário é especificado.
Especificação dos servidores de autorização HWTACACS
Sobre os servidores de autorização HWTACACS
Você pode especificar um servidor de autorização primário e um máximo de 16 servidores de autorização secundários para um esquema HWTACACS. Quando o servidor primário não está disponível, o dispositivo procura os servidores secundários na ordem em que foram configurados. O primeiro servidor secundário no estado ativo é usado para comunicação.
Restrições e diretrizes
Se a redundância não for necessária, especifique apenas o servidor primário.
Um servidor HWTACACS pode funcionar como servidor de autorização primário de um esquema e como servidor de autorização secundário de outro esquema ao mesmo tempo.
Dois servidores de autorização HWTACACS em um esquema, primário ou secundário, não podem ter a mesma combinação de nome de host, endereço IP e número de porta.
Procedimento
- Entre na visualização do sistema.
system viewhwtacacs scheme hwtacacs-scheme-nameprimary authorization { host-name | ipv4-address | ipv6 ipv6-address } [ port-number | key { cipher | simple } string | single-connection ] *Por padrão, nenhum servidor de autorização HWTACACS primário é especificado.
secondary authorization { host-name | ipv4-address | ipv6 ipv6-address } [ port-number | key { cipher | simple } string | single-connection ] *Por padrão, nenhum servidor de autorização HWTACACS secundário é especificado.
Especificação dos servidores de contabilidade HWTACACS
Sobre os servidores de contabilidade HWTACACS
Você pode especificar um servidor de contabilidade primário e um máximo de 16 servidores de contabilidade secundários para um esquema HWTACACS. Quando o servidor primário não está disponível, o dispositivo procura os servidores secundários na ordem em que foram configurados. O primeiro servidor secundário em estado ativo é usado para comunicação.
Restrições e diretrizes
Se a redundância não for necessária, especifique apenas o servidor primário.
Um servidor HWTACACS pode funcionar como servidor de contabilidade primário de um esquema e como servidor de contabilidade secundário de outro esquema ao mesmo tempo.
Dois servidores de contabilidade HWTACACS em um esquema, primário ou secundário, não podem ter a mesma combinação de nome de host, endereço IP e número de porta.
O HWTACACS não oferece suporte à contabilidade para usuários de FTP, SFTP e SCP.
Procedimento
- Entre na visualização do sistema.
system viewhwtacacs scheme hwtacacs-scheme-nameprimary accounting { host-name | ipv4-address | ipv6 ipv6-address } [ port-number | key { cipher | simple } string | single-connection ] *Por padrão, nenhum servidor de contabilidade HWTACACS primário é especificado.
secondary accounting { host-name | ipv4-address | ipv6 ipv6-address } [ port-number | key { cipher | simple } string | single-connection ] *Por padrão, nenhum servidor de contabilidade HWTACACS secundário é especificado.
Especificação das chaves compartilhadas para a comunicação segura do HWTACACS
Sobre chaves compartilhadas para comunicação HWTACACS segura
O cliente e o servidor HWTACACS usam o algoritmo MD5 e chaves compartilhadas para gerar o valor do Authenticator para autenticação de pacotes e criptografia de senhas de usuários. O cliente e o servidor devem usar a mesma chave para cada tipo de comunicação.
Execute esta tarefa para configurar chaves compartilhadas para servidores em um esquema HWTACACS. As chaves entram em vigor em todos os servidores para os quais uma chave compartilhada não foi configurada individualmente.
Restrições e diretrizes
Certifique-se de que a chave compartilhada configurada no dispositivo seja a mesma que a chave compartilhada configurada no servidor HWTACACS.
Procedimento
- Entre na visualização do sistema.
system viewhwtacacs scheme hwtacacs-scheme-namekey { accounting | authentication | authorization } { cipher | simple } stringPor padrão, nenhuma chave compartilhada é especificada para a comunicação segura do HWTACACS.
Configuração de temporizadores HWTACACS
Sobre os temporizadores HWTACACS e o status do servidor
O dispositivo usa os seguintes temporizadores para controlar a comunicação com um servidor HWTACACS:
- Temporizador de tempo limite de resposta do servidor (response-timeout) - Define o temporizador de tempo limite de resposta do servidor HWTACACS. O dispositivo inicia esse cronômetro imediatamente após o envio de uma solicitação de autenticação, autorização ou contabilidade HWTACACS. Se o dispositivo não receber uma resposta do servidor dentro do cronômetro, ele definirá o servidor como bloqueado. Em seguida, o dispositivo envia a solicitação a outro servidor HWTACACS.
- Timer de contabilidade em tempo real (realtime-accounting) - Define o intervalo em que o dispositivo envia pacotes de contabilidade em tempo real para o servidor de contabilidade HWTACACS para usuários on-line.
- Temporizador de silêncio do servidor (quiet) - Define a duração para manter um servidor inacessível no estado bloqueado. Se um servidor não puder ser acessado, o dispositivo alterará o status do servidor para bloqueado, iniciará esse cronômetro para o servidor e tentará se comunicar com outro servidor no estado ativo. Após a expiração do cronômetro de silêncio do servidor, o dispositivo altera o status do servidor de volta para ativo.
A configuração do temporizador de silêncio do servidor afeta o status dos servidores HWTACACS. Se o esquema incluir um servidor HWTACACS primário e vários servidores HWTACACS secundários, o dispositivo se comunicará com os servidores HWTACACS com base nas seguintes regras:
- Quando o servidor primário está em estado ativo, o dispositivo se comunica com o servidor primário. Quando o servidor primário estiver inacessível, o dispositivo pesquisará um servidor secundário em estado ativo na ordem em que foram configurados.
- Quando um ou mais servidores estão no estado ativo, o dispositivo tenta se comunicar apenas com esses servidores, mesmo que eles não estejam acessíveis.
- Quando todos os servidores estão em estado bloqueado, o dispositivo tenta se comunicar apenas com o servidor principal.
- Se o servidor primário estiver inacessível, o dispositivo alterará o status do servidor para bloqueado e iniciará um cronômetro de silêncio para o servidor. Quando o cronômetro de silêncio do servidor expira, o status do servidor volta a ser ativo. O dispositivo não verifica o servidor novamente durante o processo de autenticação, autorização ou contabilidade.
- O processo de pesquisa continua até que o dispositivo encontre um servidor secundário disponível ou verifique todos os servidores secundários em estado ativo. Se nenhum servidor estiver disponível, o dispositivo considerará a tentativa de autenticação, autorização ou contabilidade uma falha.
- Quando você remove um servidor em uso, a comunicação com o servidor é interrompida. O dispositivo procura um servidor em estado ativo verificando primeiro o servidor primário e, em seguida, os servidores secundários na ordem em que foram configurados.
- Quando o status de um servidor HWTACACS é alterado automaticamente, o dispositivo altera o status desse servidor de forma correspondente em todos os esquemas HWTACACS nos quais esse servidor é especificado.
Restrições e diretrizes
Um intervalo curto de contabilização em tempo real ajuda a melhorar a precisão da contabilização, mas exige muitos recursos do sistema. Quando houver 1.000 ou mais usuários, defina um intervalo de contabilização em tempo real maior que 15 minutos.
Procedimento
- Entre na visualização do sistema.
system viewhwtacacs scheme hwtacacs-scheme-name- Defina o cronômetro de tempo limite de resposta do servidor HWTACACS.
timer response-timeout secondsPor padrão, o temporizador de tempo limite de resposta do servidor HWTACACS é de 5 segundos.
timer realtime-accounting minutesPor padrão, o intervalo de contabilização em tempo real é de 12 minutos.
timer quiet minutesPor padrão, o timer de silêncio do servidor é de 5 minutos.
Especificação do endereço IP de origem para pacotes HWTACACS de saída
Sobre o endereço IP de origem para pacotes HWTACACS de saída
O endereço IP de origem dos pacotes HWTACACS que um NAS envia deve corresponder ao endereço IP do NAS configurado no servidor HWTACACS. Um servidor HWTACACS identifica um NAS pelo endereço IP. Quando o servidor HWTACACS recebe um pacote, ele verifica o endereço IP de origem do pacote.
- Se for o endereço IP de um NAS gerenciado, o servidor processará o pacote.
- Se não for o endereço IP de um NAS gerenciado, o servidor descartará o pacote.
Antes de enviar um pacote HWTACACS, o NAS seleciona um endereço IP de origem na seguinte ordem:
- O endereço IP de origem especificado para o esquema HWTACACS.
- O endereço IP de origem especificado na visualização do sistema.
- O endereço IP da interface de saída especificada pela rota.
Restrições e diretrizes para a configuração do endereço IP de origem
Você pode especificar o endereço IP de origem dos pacotes HWTACACS de saída na visualização do esquema HWTACACS ou na visualização do sistema.
- O endereço IP especificado na visualização do esquema HWTACACS se aplica a um esquema HWTACACS.
- O endereço IP especificado na visualização do sistema se aplica a todos os esquemas HWTACACS.
O endereço IP de origem dos pacotes HWTACACS que um NAS envia deve corresponder ao endereço IP do NAS que está configurado no servidor HWTACACS.
Como prática recomendada, especifique um endereço de interface de loopback como endereço IP de origem para pacotes HWTACACS de saída para evitar a perda de pacotes HWTACACS causada por erros de porta física.
Para se comunicar com o servidor HWTACACS, o endereço de origem dos pacotes HWTACACS de saída é normalmente o endereço IP de uma interface de saída no NAS. Entretanto, em algumas situações, você deve alterar o endereço IP de origem. Por exemplo, quando o VRRP estiver configurado para failover com estado, configure o IP virtual do grupo VRRP de uplink como o endereço de origem.
Você pode especificar diretamente um endereço IP de origem para os pacotes HWTACACS de saída ou especificar uma interface de origem para fornecer o endereço IP de origem para os pacotes HWTACACS de saída. A configuração da interface de origem e a configuração do endereço IP de origem substituem uma à outra.
Especificação de uma interface de origem ou endereço IP de origem para todos os esquemas HWTACACS
- Entre na visualização do sistema.
system viewhwtacacs nas-ip { interface interface-type interface-number | { ipv4-address | ipv6 ipv6-address } }Por padrão, o endereço IP de origem de um pacote HWTACACS enviado ao servidor é o endereço IPv4 primário ou o endereço IPv6 da interface de saída.
Especificação de uma interface de origem ou endereço IP de origem para um esquema HWTACACS
- Entre na visualização do sistema.
system viewhwtacacs scheme hwtacacs-scheme-namenas-ip { ipv4-address | interface interface-type interface-number | ipv6 ipv6-address }Por padrão, o endereço IP de origem de um pacote HWTACACS de saída é aquele configurado com o comando hwtacacs nas-ip na visualização do sistema. Se o comando hwtacacs nas-ip não for usado, o endereço IP de origem será o endereço IP primário da interface de saída.
Configuração do formato do nome de usuário e das unidades de estatísticas de tráfego
Sobre o formato do nome de usuário e as unidades de estatísticas de tráfego
Um nome de usuário geralmente está no formato userid@isp-name, em que a parte isp-name representa o nome de domínio do ISP do usuário. Por padrão, o nome de domínio do ISP é incluído em um nome de usuário. Se os servidores HWTACACS não reconhecerem nomes de usuário que contenham nomes de domínio ISP, você poderá configurar o dispositivo para enviar nomes de usuário sem nomes de domínio para os servidores.
O dispositivo relata estatísticas de tráfego de usuários on-line em pacotes de contabilidade.
Restrições e diretrizes
Se dois ou mais domínios ISP usarem o mesmo esquema HWTACACS, configure o esquema HWTACACS para manter o nome do domínio ISP nos nomes de usuário para identificação do domínio.
Para obter precisão na contabilidade, certifique-se de que as unidades de medição de tráfego configuradas no dispositivo sejam as mesmas que as unidades de medição de tráfego configuradas nos servidores de contabilidade HWTACACS.
Procedimento
- Entre na visualização do sistema.
system viewhwtacacs scheme hwtacacs-scheme-nameuser-name-format { keep-original | with-domain | without-domain }Por padrão, o nome de domínio do ISP é incluído em um nome de usuário.
data-flow-format { data { byte | giga-byte | kilo-byte | mega-byte } | packet { giga-packet | kilo-packet | mega-packet | one-packet } }*Por padrão, o tráfego é contado em bytes e pacotes.
Configuração do buffer de pacotes HWTACACS stop-accounting
Sobre o buffer de pacotes HWTACACS stop-accounting
O dispositivo envia solicitações de interrupção de contabilização HWTACACS quando recebe solicitações de interrupção de conexão de hosts ou comandos de interrupção de conexão de um administrador. No entanto, o dispositivo pode não receber uma resposta para uma solicitação de interrupção de contabilização em uma única transmissão. Ative o dispositivo para armazenar em buffer as solicitações de interrupção de contabilização do HWTACACS que não receberam respostas do servidor de contabilização. O dispositivo reenviará as solicitações até que as respostas sejam recebidas.
Para limitar os tempos de transmissão, defina um número máximo de tentativas que podem ser feitas para a transmissão de solicitações individuais de interrupção de contabilização do HWTACACS. Quando são feitas as tentativas máximas para uma solicitação, o dispositivo descarta a solicitação armazenada em buffer.
Procedimento
- Entre na visualização do sistema.
system viewhwtacacs scheme hwtacacs-scheme-namestop-accounting-buffer enablePor padrão, o recurso de buffer está ativado.
retry stop-accounting retriesA configuração padrão é 100.
Comandos de exibição e manutenção do HWTACACS
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir a configuração ou as estatísticas do servidor dos esquemas HWTACACS. | exibir esquema hwtacacs [ hwtacacs-scheme-name [ statistics ] ] |
| Exibir informações sobre as solicitações de interrupção de contabilização do HWTACACS em buffer para as quais não foram recebidas respostas. | display stop-accounting-buffer hwtacacs-scheme hwtacacs-scheme-name |
| Limpar estatísticas do HWTACACS. | reset hwtacacs statistics { accounting | all | autenticação | autorização } |
| Limpar o HWTACACS armazenado em buffer solicitações de interrupção de prestação de contas para as quais não foram recebidas respostas. | reset stop-accounting-buffer hwtacacs-scheme hwtacacs-scheme-name |
Configuração do LDAP
Visão geral das tarefas LDAP
Para configurar o LDAP, execute as seguintes tarefas:
- Configuração de um servidor LDAP
- Criação de um servidor LDAP
- Configuração do endereço IP do servidor LDAP
- (Opcional.) Especificar a versão do LDAP
- (Opcional.) Configuração do período de tempo limite do servidor LDAP
- Configuração dos atributos do administrador
- Configuração de atributos de usuário LDAP
- (Opcional.) Configuração de um mapa de atributos LDAP
- Criação de um esquema LDAP
- Especificação do servidor de autenticação LDAP
- (Opcional.) Especificar o servidor de autorização LDAP
- (Opcional.) Especificação de um mapa de atributos LDAP para autorização LDAP
Criação de um servidor LDAP
- Entre na visualização do sistema.
system viewldap server server-nameConfiguração do endereço IP do servidor LDAP
Restrições e diretrizes
Você pode configurar um endereço IPv4 ou um endereço IPv6 para um servidor LDAP. Se você configurar o endereço IP para um servidor LDAP várias vezes, a configuração mais recente entrará em vigor.
Procedimento
- Entre na visualização do sistema.
system viewldap server server-name{ ip ipv4-address | ipv6 ipv6-address } [ port port-number ]Por padrão, um servidor LDAP não tem um endereço IP.
Especificação da versão do LDAP
Restrições e diretrizes
O dispositivo é compatível com LDAPv2 e LDAPv3.
Um servidor Microsoft LDAP suporta apenas LDAPv3.
A versão LDAP especificada no dispositivo deve ser consistente com a versão especificada no servidor LDAP .
Procedimento
- Entre na visualização do sistema.
system viewldap server server-nameprotocol-version { v2 | v3 }Por padrão, o LDAPv3 é usado.
Definição do período de tempo limite do servidor LDAP
Sobre o período de tempo limite do servidor LDAP
Se o dispositivo enviar uma solicitação de associação ou pesquisa a um servidor LDAP sem receber a resposta do servidor dentro do período de tempo limite do servidor, o tempo limite da solicitação de autenticação ou autorização será atingido. Em seguida, o dispositivo tenta o método de autenticação ou autorização de backup. Se nenhum método de backup estiver configurado no domínio ISP, o dispositivo considerará a tentativa de autenticação ou autorização uma falha .
Procedimento
- Entre na visualização do sistema.
system viewldap server server-nameserver-timeout time-intervalPor padrão, o período de tempo limite do servidor LDAP é de 10 segundos.
Configuração dos atributos do administrador
Sobre os atributos do administrador
Para configurar o DN e a senha do administrador para vinculação com o servidor LDAP durante a autenticação LDAP:
Procedimento
- Entre na visualização do sistema.
system viewldap server server-namelogin-dn dn-stringPor padrão, nenhum DN de administrador é especificado.
O DN do administrador especificado no dispositivo deve ser o mesmo que o DN do administrador configurado no servidor LDAP.
login-password { cipher | simple } stringPor padrão, nenhuma senha de administrador é especificada.
Configuração de atributos de usuário LDAP
Sobre os atributos de usuário LDAP
Para autenticar um usuário, um cliente LDAP deve concluir as seguintes operações:
- Estabeleça uma conexão com o servidor LDAP.
- Obtenha o DN do usuário no servidor LDAP.
- Use o DN do usuário e a senha do usuário para se associar ao servidor LDAP.
O LDAP fornece um mecanismo de pesquisa de DN para obter o DN do usuário. De acordo com o mecanismo, um cliente LDAP envia solicitações de pesquisa ao servidor com base na política de pesquisa determinada pelos atributos de usuário LDAP do cliente LDAP.
Os atributos do usuário LDAP incluem:
- Base de pesquisa DN.
- Escopo da pesquisa.
- Atributo de nome de usuário.
- Formato do nome de usuário.
- Classe de objeto do usuário.
Restrições e diretrizes
Se o servidor LDAP contiver muitos níveis de diretório, uma pesquisa de DN de usuário a partir do diretório raiz poderá levar muito tempo. Para aumentar a eficiência, você pode alterar o ponto de partida especificando o DN de base da pesquisa.
Procedimento
- Entre na visualização do sistema.
system viewldap server server-namesearch-base-dn base-dnPor padrão, nenhum DN de base de pesquisa de usuário é especificado.
search-scope { all-level | single-level }Por padrão, o escopo de pesquisa do usuário é all-level.
user-parameters user-name-attribute { name-attribute | cn | uid }Por padrão, o atributo de nome de usuário é cn.
user-parameters user-name-format { with-domain | without-domain }Por padrão, o formato do nome de usuário é without-domain (sem domínio).
user-parameters user-object-class object-class-namePor padrão, nenhuma classe de objeto de usuário é especificada, e a classe de objeto de usuário padrão no servidor LDAP é usada. A classe de objeto de usuário padrão para esse comando varia de acordo com o modelo do servidor.
Configuração de um mapa de atributos LDAP
Sobre os mapas de atributos LDAP
Configure um mapa de atributos LDAP para definir uma lista de entradas de mapeamento de atributos LDAP-AAA. Para aplicar o mapa de atributos LDAP, especifique o nome do mapa de atributos LDAP no esquema LDAP usado para autorização.
O recurso de mapa de atributos LDAP permite que o dispositivo converta atributos LDAP obtidos de um servidor de autorização LDAP em atributos AAA reconhecíveis pelo dispositivo com base nas entradas de mapeamento. Como o dispositivo ignora atributos LDAP não reconhecidos, configure as entradas de mapeamento para incluir atributos LDAP importantes que não devem ser ignorados.
Um atributo LDAP pode ser mapeado somente para um atributo AAA. Diferentes atributos LDAP podem ser mapeados para o mesmo atributo AAA.
Procedimento
- Entre na visualização do sistema.
system viewldap attribute-map map-namemap ldap-attribute ldap-attribute-name [ prefix prefix-value delimiter delimiter-value ] aaa-attribute { user-group | user-profile }Criação de um esquema LDAP
Restrições e diretrizes
Você pode configurar um máximo de 16 esquemas LDAP. Um esquema LDAP pode ser usado por vários domínios do ISP .
Procedimento
- Entre na visualização do sistema.
system viewldap scheme ldap-scheme-nameEspecificação do servidor de autenticação LDAP
- Entre na visualização do sistema.
system viewldap scheme ldap-scheme-nameauthentication-server server-namePor padrão, nenhum servidor de autenticação LDAP é especificado.
Especificação do servidor de autorização LDAP
- Entre na visualização do sistema.
system viewldap scheme ldap-scheme-nameauthorization-server server-namePor padrão, nenhum servidor de autorização LDAP é especificado.
Especificação de um mapa de atributos LDAP para autorização LDAP
Sobre o mapa de atributos LDAP para autorização LDAP
Especifique um mapa de atributos LDAP para autorização LDAP para converter atributos LDAP obtidos do servidor de autorização LDAP em atributos AAA reconhecíveis pelo dispositivo.
Restrições e diretrizes
Você pode especificar apenas um mapa de atributos LDAP em um esquema LDAP.
Procedimento
- Entre na visualização do sistema.
system viewldap scheme ldap-scheme-nameattribute-map map-namePor padrão, nenhum mapa de atributos LDAP é especificado.
Comandos de exibição e manutenção para LDAP
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir a configuração dos esquemas LDAP. | exibir esquema ldap [ ldap-scheme-name ] |
Criação de um domínio ISP
Sobre os domínios ISP
Em um cenário de rede com vários ISPs, o dispositivo pode se conectar a usuários de diferentes ISPs. Esses usuários podem ter diferentes atributos de usuário, como diferentes estruturas de nome de usuário e senha, diferentes tipos de serviço e diferentes direitos. Para gerenciar usuários de diferentes ISPs, configure métodos de autenticação, autorização e contabilidade e atributos de domínio para cada domínio ISP, conforme necessário.
O dispositivo suporta um máximo de 16 domínios ISP, incluindo o domínio ISP definido pelo sistema
sistema. Você pode especificar um dos domínios do ISP como o domínio padrão.
No dispositivo, cada usuário pertence a um domínio ISP. Se um usuário não fornecer um nome de domínio ISP no login, o dispositivo considerará que o usuário pertence ao domínio ISP padrão.
Cada domínio ISP tem um conjunto de métodos AAA definidos pelo sistema, que são autenticação local, autorização local e contabilidade local. Se você não configurar nenhum método AAA para um domínio ISP, o dispositivo usará os métodos AAA definidos pelo sistema para os usuários do domínio.
O dispositivo escolhe um domínio de autenticação para cada usuário na seguinte ordem:
- O domínio de autenticação especificado para o módulo de acesso.
- O domínio do ISP no nome de usuário.
- O domínio ISP padrão do dispositivo.
Se o domínio escolhido não existir no dispositivo, ele procurará o domínio ISP que acomoda os usuários atribuídos a domínios inexistentes. (O suporte para a configuração do domínio de autenticação depende do módulo de acesso). Se esse domínio ISP não estiver configurado, a autenticação do usuário falhará.
Restrições e diretrizes para a configuração do domínio ISP
Um domínio ISP não pode ser excluído se for o domínio ISP padrão. Antes de usar o comando undo domain, altere o domínio para um domínio ISP não padrão usando o comando undo domain default enable.
Você pode modificar as configurações do sistema de domínio ISP definido pelo sistema, mas não pode excluir o domínio.
Para evitar falhas de autenticação, autorização ou contabilidade do RADIUS, use nomes de domínio curtos para garantir que os nomes de usuário que contenham um nome de domínio não excedam 253 caracteres.
Criação de um domínio ISP
- Entre na visualização do sistema.
system viewdomain isp-namePor padrão, existe um domínio ISP definido pelo sistema. O nome do domínio é system.
Especificação do domínio padrão do ISP
- Entre na visualização do sistema.
system viewdomain default enable isp-namePor padrão, o domínio ISP padrão é o sistema de domínio ISP definido pelo sistema.
Especificação de um domínio ISP para usuários atribuídos a domínios inexistentes
- Entre na visualização do sistema.
system viewdomain if-unknown isp-namePor padrão, nenhum domínio ISP é especificado para acomodar os usuários que são atribuídos a domínios inexistentes.
Configuração dos atributos de domínio do ISP
Definição do status do domínio ISP
Sobre o status do domínio ISP
Ao colocar o domínio ISP em estado ativo ou bloqueado, você permite ou nega solicitações de serviço de rede de usuários no domínio.
Procedimento
- Entre na visualização do sistema.
system viewdomain isp-namestate { active | block }Por padrão, um domínio ISP está em estado ativo, e os usuários do domínio podem solicitar serviços de rede.
Configuração de atributos de autorização para um domínio ISP
Sobre os atributos de autorização
O dispositivo é compatível com os seguintes atributos de autorização:
- ACL - O dispositivo restringe o acesso dos usuários autenticados apenas aos recursos de rede permitidos pela ACL.
- Ação CAR - O atributo controla o fluxo de tráfego de usuários autenticados.
- Número máximo de grupos multicast - O atributo restringe o número máximo de grupos multicast aos quais um usuário autenticado pode se associar simultaneamente.
- Pool de endereços IPv4 - O dispositivo atribui endereços IPv4 do pool a usuários autenticados no domínio.
- Pool de endereços IPv6 - O dispositivo atribui endereços IPv6 do pool a usuários autenticados no domínio.
- URL de redirecionamento - O dispositivo redireciona os usuários do domínio para o URL depois que eles passam pela autenticação.
- Grupo de usuários - Os usuários autenticados no domínio obtêm todos os atributos do grupo de usuários.
- Perfil do usuário - O dispositivo restringe o comportamento do usuário com base no perfil do usuário.
O dispositivo atribui os atributos de autorização no domínio ISP aos usuários autenticados que não recebem esses atributos do servidor.
Procedimento
- Entre na visualização do sistema.
system viewdomain isp-nameauthorization-attribute { acl acl-number | car inbound cir committed-information-rate [ pir peak-information-rate ] outbound cir committed-information-rate [ pir peak-information-rate ] | igmp max-access-number max-access-number | ip-pool ipv4-pool-name | ipv6-pool ipv6-pool-name | mld max-access-number max-access-number | url url-string | user-group user-group-name | user-profile profile-name }As configurações padrão são as seguintes:
- Um usuário IPv4 pode participar simultaneamente de um máximo de quatro grupos multicast IGMP.
- Um usuário IPv6 pode participar simultaneamente de um máximo de quatro grupos multicast MLD.
- Não existem outros atributos de autorização.
Inclusão do período de tempo ocioso na duração on-line do usuário a ser enviada ao servidor
Sobre a inclusão do período de tempo ocioso na duração on-line do usuário a ser enviada ao servidor
Se um usuário ficar off-line devido a falha ou mau funcionamento da conexão, a duração on-line do usuário enviada ao servidor inclui o período de tempo limite de inatividade atribuído pelo servidor de autorização. A duração on-line gerada no servidor é maior do que a duração on-line real do usuário.
Para os usuários do portal, o dispositivo inclui o período de tempo ocioso definido para o recurso de detecção de usuário do portal on-line na duração on-line do usuário. Para obter mais informações sobre a detecção on-line de usuários do portal, consulte "Configuração da autenticação do portal".
Procedimento
- Entre na visualização do sistema.
system viewdomain isp-namesession-time include-idle-timePor padrão, a duração on-line do usuário enviada ao servidor não inclui o período de tempo limite de inatividade.
Configuração de métodos AAA para um domínio ISP
Configuração de métodos de autenticação para um domínio ISP
Restrições e diretrizes
Quando você configurar a autenticação remota, siga estas restrições e diretrizes:
- Se o método de autenticação usar um esquema RADIUS e o método de autorização não usar um esquema RADIUS, o AAA aceitará somente o resultado da autenticação do servidor RADIUS. A mensagem Access-Accept do servidor RADIUS também inclui as informações de autorização, mas o dispositivo ignora essas informações.
- Se for especificado um esquema HWTACACS, o dispositivo usará o nome de usuário inserido para autenticação de função. Se for especificado um esquema RADIUS, o dispositivo usará o nome de usuário $enabn$ no servidor RADIUS para autenticação de função. A variável n representa um nível de função do usuário. Para obter mais informações sobre a autenticação de função de usuário, consulte o Guia de Configuração dos Fundamentos.
A palavra-chave none não é compatível com o modo FIPS.
Pré-requisitos
Antes de configurar os métodos de autenticação, conclua as seguintes tarefas:
- Determine o tipo de acesso ou o tipo de serviço a ser configurado. Com o AAA, você pode configurar um método de autenticação para cada tipo de acesso e tipo de serviço.
- Determine se deseja configurar o método de autenticação padrão para todos os tipos de acesso ou tipos de serviço. O método de autenticação padrão se aplica a todos os usuários de acesso. No entanto, o método tem uma prioridade mais baixa do que o método de autenticação especificado para um tipo de acesso ou tipo de serviço.
Procedimento
- Entre na visualização do sistema.
system viewdomain isp-nameauthentication default { hwtacacs-scheme hwtacacs-scheme-name [ radius-scheme radius-scheme-name ] [ local ] [ none ] | ldap-scheme ldap-scheme-name [ local ] [ none ] | local [ none ] | none | radius-scheme radius-scheme-name [ hwtacacs-scheme hwtacacs-scheme-name ] [ local ] [ none ] }Por padrão, o método de autenticação padrão é o local.
- Especifique os métodos de autenticação para usuários da LAN.
authentication lan-access { ldap-scheme ldap-scheme-name [ local ] [ none ] | local [ none ] | none | radius-scheme radius-scheme-name [ local ] [ none ] }Por padrão, os métodos de autenticação padrão são usados para usuários da LAN.
authentication login { hwtacacs-scheme hwtacacs-scheme-name [ radius-scheme radius-scheme-name ] [ local ] [ none ] | ldap-scheme ldap-scheme-name [ local ] [ none ] | local [ none ] | none | radius-scheme radius-scheme-name [ hwtacacs-scheme hwtacacs-scheme-name ] [ local ] [ none ] } Por padrão, os métodos de autenticação padrão são usados para usuários de login.
authentication portal { ldap-scheme ldap-scheme-name [ local ] [ none ] | local [ none ] | none | radius-scheme radius-scheme-name [ local ] [ none ] }Por padrão, os métodos de autenticação padrão são usados para os usuários do portal.
authentication super { hwtacacs-scheme hwtacacs-scheme-name | radius-scheme radius-scheme-name } *Por padrão, os métodos de autenticação padrão são usados para obter uma função de usuário temporária.
Configuração de métodos de autorização para um domínio ISP
Restrições e diretrizes
O dispositivo não é compatível com a autorização LDAP na versão atual do software.
Para usar um esquema RADIUS como método de autorização, especifique o nome do esquema RADIUS que está configurado como método de autenticação para o domínio ISP. Se um esquema RADIUS inválido for especificado como método de autorização, a autenticação e a autorização RADIUS falharão.
A palavra-chave none não é compatível com o modo FIPS.
Pré-requisitos
Antes de configurar os métodos de autorização, conclua as seguintes tarefas:
- Determine o tipo de acesso ou o tipo de serviço a ser configurado. Com o AAA, você pode configurar um esquema de autorização para cada tipo de acesso e tipo de serviço.
- Determine se deseja configurar o método de autorização padrão para todos os tipos de acesso ou tipos de serviço. O método de autorização padrão se aplica a todos os usuários de acesso. No entanto, o método tem uma prioridade mais baixa do que o método de autorização especificado para um tipo de acesso ou tipo de serviço.
Procedimento
- Entre na visualização do sistema.
system viewdomain isp-nameauthorization default { hwtacacs-scheme hwtacacs-scheme-name [ radius-scheme radius-scheme-name ] [ local ] [ none ] | local [ none ] | none | radius-scheme radius-scheme-name [ hwtacacs-scheme hwtacacs-scheme-name ] [ local ] [ none ] }Por padrão, o método de autorização é local.
- Especifique os métodos de autorização de comando.
authorization command { hwtacacs-scheme hwtacacs-scheme-name [ local ] [ none ] | local [ none ] | none }Por padrão, os métodos de autorização padrão são usados para autorização de comando.
authorization lan-access { local [ none ] | none | radius-scheme radius-scheme-name [ local ] [ none ] }Por padrão, os métodos de autorização padrão são usados para usuários da LAN.
authorization login { hwtacacs-scheme hwtacacs-scheme-name [ radius-scheme radius-scheme-name ] [ local ] [ none ] | local [ none ] | none | radius-scheme radius-scheme-name [ hwtacacs-schemehwtacacs-scheme-name ] [ local ] [ none ] }Por padrão, os métodos de autorização padrão são usados para usuários de login.
authorization portal { local [ none ] | none | radius-scheme radius-scheme-name [ local ] [ none ] }Por padrão, os métodos de autorização padrão são usados para os usuários do portal.
Configuração de métodos de contabilidade para um domínio ISP
Restrições e diretrizes
Os usuários de FTP, SFTP e SCP não são compatíveis com a contabilidade.
A contabilidade local não fornece estatísticas para cobrança. Ela apenas conta e controla o número de usuários simultâneos que usam a mesma conta de usuário local. O limite é configurado com o comando access-limit.
A palavra-chave none não é compatível com o modo FIPS.
Pré-requisitos
Antes de configurar os métodos de contabilidade, conclua as seguintes tarefas:
- Determine o tipo de acesso ou o tipo de serviço a ser configurado. Com o AAA, você pode configurar um método de contabilização para cada tipo de acesso e tipo de serviço.
- Determine se deseja configurar o método de contabilização padrão para todos os tipos de acesso ou tipos de serviço. O método de contabilização padrão se aplica a todos os usuários de acesso. No entanto, o método tem uma prioridade mais baixa do que o método de contabilização especificado para um tipo de acesso ou tipo de serviço.
Procedimento
- Entre na visualização do sistema.
system viewdomain isp-nameaccounting default { hwtacacs-scheme hwtacacs-scheme-name [ radius-scheme radius-scheme-name ] [ local ] [ none ] | local [ none ] | none | radius-scheme radius-scheme-name [ hwtacacs-scheme hwtacacs-scheme-name ] [ local ] [ none ] }Por padrão, o método de contabilidade é local.
- Especifique o método de contabilização do comando.
accounting command hwtacacs-scheme hwtacacs-scheme-namePor padrão, os métodos de contabilidade padrão são usados para a contabilidade de comandos.
accounting lan-access { broadcast radius-scheme radius-scheme-name1 radius-scheme radius-scheme-name2 [ local ] [ none ] | local [ none ] | none | radius-scheme radius-scheme-name [ local ] [ none ] }Por padrão, os métodos de contabilidade padrão são usados para usuários da LAN.
accounting login { hwtacacs-scheme hwtacacs-scheme-name [ radius-scheme radius-scheme-name ] [ local ] [ none ] | local [ none ] | none | radius-scheme radius-scheme-name [ hwtacacs-scheme hwtacacs-scheme-name ] [ local ] [ none ] }Por padrão, os métodos de contabilidade padrão são usados para usuários de login.
accounting portal { broadcast radius-scheme radius-scheme-name1 radius-scheme radius-scheme-name2 [ local ] [ none ] | local [ none ] | none | radius-scheme radius-scheme-name [ local ] [ none ] }Por padrão, os métodos de contabilidade padrão são usados para os usuários do portal.
- Configure o controle de acesso para usuários que enfrentam falhas no início da contabilidade.
accounting start-fail { offline | online }Por padrão, o dispositivo permite que os usuários que enfrentam falhas no início da contabilidade permaneçam on-line.
accounting update-fail { [ max-times max-times ] offline | online }Por padrão, o dispositivo permite que os usuários que falharam em todas as tentativas de atualização de contas permaneçam on-line.
accounting quota-out { offline | online }Por padrão, o dispositivo faz logoff de usuários que tenham usado suas cotas de contabilidade.
Comandos de exibição e manutenção para domínios ISP
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações de configuração sobre um domínio ISP ou todos os domínios ISP. | exibir domínio [ nome-isp ] |
Definição do número máximo de usuários de login simultâneos
Sobre a configuração do número máximo de usuários de login simultâneos
Execute esta tarefa para definir o número máximo de usuários simultâneos que podem fazer logon no dispositivo por meio de um protocolo específico, independentemente de seus métodos de autenticação. Os métodos de autenticação incluem nenhuma autenticação, autenticação local e autenticação remota.
Procedimento
- Entre na visualização do sistema.
system viewNo modo não-FIPS:
aaa session-limit { ftp | http | https | ssh | telnet } max-sessionsNo modo FIPS:
aaa session-limit { https | ssh } max-sessionsPor padrão, o número máximo de usuários de login simultâneos é 32 para cada tipo de usuário.
Configuração de um NAS-ID
Sobre os NAS-IDs
Durante a autenticação RADIUS, o dispositivo usa um NAS-ID para definir o atributo NAS-Identifier dos pacotes RADIUS para que o servidor RADIUS possa identificar o local de acesso dos usuários.
Configure um perfil NAS-ID para manter as associações de NAS-ID e VLAN no dispositivo, de modo que o dispositivo possa enviar diferentes cadeias de atributo NAS-Identifier em solicitações RADIUS de diferentes VLANs.
Restrições e diretrizes
Você pode aplicar um perfil NAS-ID a interfaces habilitadas para segurança de porta ou portal. Para obter mais informações, consulte "Configuração da autenticação do portal" e "Configuração da segurança da porta".
É possível configurar várias vinculações de NAS-ID e VLAN em um perfil de NAS-ID.
Um NAS-ID pode ser vinculado a mais de uma VLAN, mas uma VLAN pode ser vinculada a apenas um NAS-ID. Se você configurar vários vínculos para a mesma VLAN, a configuração mais recente entrará em vigor.
Procedimento
- Entre na visualização do sistema.
system viewaaa nas-id profile profile-namenas-id nas-identifier bind vlan vlan-idConfiguração da ID do dispositivo
Sobre o ID do dispositivo
O RADIUS usa o valor do atributo Acct-Session-ID como ID de contabilidade de um usuário. O dispositivo gera um valor Acct-Session-ID para cada usuário on-line com base na hora do sistema, nos dígitos aleatórios e na ID do dispositivo.
Procedimento
- Entre na visualização do sistema.
system viewaaa device-id device-idPor padrão, a ID do dispositivo é 0.
Ativação do registro de solicitação de alteração de senha
Sobre esta tarefa
Use esse recurso para aumentar a proteção das senhas dos usuários de Telnet, SSH, HTTP, HTTPS, NETCONF sobre SSH e NETCONF sobre SOAP e melhorar a segurança do sistema.
Esse recurso permite que o dispositivo gere logs para solicitar aos usuários que alterem suas senhas fracas em um intervalo de 24 horas e no login dos usuários.
Uma senha é uma senha fraca se não atender aos seguintes requisitos:
- Restrição de composição de senha configurada usando o comando password-control composition.
- Restrição de comprimento mínimo de senha definida usando o comprimento de controle de senha comando.
- Ele não pode conter o nome de usuário ou as letras invertidas do nome de usuário.
Para um usuário NETCONF sobre SSH ou NETCONF sobre SOAP, o dispositivo também gera um registro de solicitação de alteração de senha se houver uma das seguintes condições:
- A senha atual do usuário é a senha padrão ou expirou.
- O usuário faz login no dispositivo pela primeira vez ou usa uma nova senha para fazer login depois que o controle de senha global é ativado.
O dispositivo não gerará mais registros de solicitação de alteração de senha para um usuário quando houver uma das seguintes condições:
- O recurso de registro do prompt de alteração de senha está desativado.
- O usuário alterou a senha e a nova senha atende aos requisitos de controle de senha.
- O status de ativação de um recurso de controle de senha relacionado foi alterado para que a senha atual do usuário atenda aos requisitos de controle de senha.
- A política de composição de senhas ou o comprimento mínimo da senha foi alterado.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6318P01 e posteriores.
Restrições e diretrizes
Você pode usar o comando display password-control para exibir a configuração do controle de senha. Para obter mais informações sobre os comandos de controle de senha, consulte comandos de controle de senha em Referência de comandos de segurança.
Procedimento
- Entre na visualização do sistema.
system viewlocal-server log change-password-promptPor padrão, o registro do prompt de alteração de senha está ativado.
Configuração do recurso do servidor RADIUS
Visão geral das tarefas dos recursos do servidor RADIUS
Para configurar o recurso do servidor RADIUS, execute as seguintes tarefas:
- Configuração de usuários RADIUS
- Especificação de clientes RADIUS
- Ativação da configuração do servidor RADIUS
Restrições e diretrizes para o recurso de servidor RADIUS
Para usar esse recurso, instale o pacote de recursos do FreeRadius compatível com a versão do software do dispositivo. Para obter mais informações sobre a instalação de um pacote de recursos, consulte atualização de software no Guia de Configuração Básica.
Para garantir a operação correta do recurso de servidor RADIUS, desative o controle de sessão RADIUS no dispositivo.
Configuração de usuários RADIUS
Para configurar os usuários do RADIUS, é necessário configurar os usuários de acesso à rede, que são a base dos dados do usuário do RADIUS.
Um usuário RADIUS tem os seguintes atributos: nome de usuário, senha, descrição, ACL de autorização, VLAN de autorização e tempo de expiração. Para obter mais informações, consulte "Configuração de atributos para usuários de acesso à rede".
Especificação de clientes RADIUS
Sobre a especificação de clientes RADIUS
Execute esta tarefa para especificar clientes RADIUS e chaves compartilhadas para gerenciamento centralizado. O recurso de servidor RADIUS não aceita solicitações de clientes RADIUS que não são gerenciados pelo sistema.
Restrições e diretrizes
O endereço IP de um cliente RADIUS deve ser o mesmo que o endereço IP de origem dos pacotes RADIUS de saída especificados no cliente RADIUS.
A chave compartilhada de um cliente RADIUS especificada no servidor RADIUS deve ser a mesma que a configuração no cliente RADIUS.
Procedimento
- Entre na visualização do sistema.
system viewradius-server client ip ipv4-address key { cipher | simple } stringAtivação da configuração do servidor RADIUS
Sobre a ativação da configuração do servidor RADIUS
Na inicialização do dispositivo, a configuração do servidor RADIUS é ativada automaticamente, incluindo usuários e clientes RADIUS. É possível ativar imediatamente a configuração mais recente do servidor RADIUS se você tiver adicionado, modificado ou excluído clientes RADIUS e usuários de acesso à rede de onde os dados do usuário RADIUS são gerados.
Procedimento
- Entre na visualização do sistema.
system viewradius-server activateA execução desse comando reinicia o processo do servidor RADIUS e ocorrerá uma interrupção do serviço de autenticação durante a reinicialização.
Comandos de exibição e manutenção para usuários e clientes RADIUS
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações sobre usuários RADIUS ativados. | exibir radius-server active-user [ nome do usuário ] |
| Exibir informações sobre clientes RADIUS ativados. | exibir radius-server active-client |
Configuração da política de registro de conexão
Sobre a política de registro de conexões
Use esse recurso em cenários em que o dispositivo atua como um cliente de login FTP, SSH, SFTP ou Telnet para estabelecer uma conexão com um servidor de login. Esse recurso permite que o dispositivo forneça a um servidor de contabilidade as informações de início e término da conexão. Quando o cliente de login estabelece uma conexão com o servidor de login, o sistema envia uma solicitação de início de contabilização para o servidor de contabilização. Quando a conexão é encerrada, o sistema envia uma solicitação de interrupção de contabilidade ao servidor de contabilidade.
Restrições e diretrizes
O dispositivo inclui o nome de usuário inserido por um usuário nos pacotes de contabilização a serem enviados ao servidor AAA para registro de conexão. O formato do nome de usuário configurado com o uso do comando user-name-format no esquema de contabilização não tem efeito.
Procedimento
- Entre na visualização do sistema.
system viewaaa connection-recording policyaccounting hwtacacs-scheme hwtacacs-scheme-nameComandos de exibição e manutenção da política de registro de conexão
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir a configuração da política de registro de conexão. | exibir política de registro de conexão aaa |
Configuração do recurso de teste AAA
Sobre o recurso de teste AAA
Esse recurso permite que o dispositivo envie solicitações de autenticação ou contabilidade aos servidores AAA especificados para simular um processo de autenticação ou contabilidade de um usuário. Use esse recurso para identificar os motivos da falha na interação entre o dispositivo e os servidores AAA. Esse recurso é aplicável somente ao RADIUS.
Ao executar um teste AAA, o dispositivo ignora o status dos servidores AAA especificados e o recurso de compartilhamento de carga do servidor RADIUS. O processo de um teste AAA é o seguinte:
- O dispositivo envia solicitações de autenticação que contêm o nome de usuário e a senha especificados para o servidor de autenticação especificado ou para os servidores de autenticação no esquema RADIUS especificado. O dispositivo tenta se comunicar com os servidores de autenticação no esquema especificado em sequência.
- O dispositivo recebe uma resposta de autenticação (independentemente de a autenticação ser bem-sucedida ou não).
- O dispositivo não recebe nenhuma resposta de autenticação depois de fazer todas as tentativas de solicitação de autenticação.
- O dispositivo envia solicitações de início de contabilização para o servidor de contabilização especificado ou para os servidores de contabilização no esquema RADIUS especificado. O dispositivo tenta se comunicar com os servidores de contabilidade no esquema especificado em sequência.
- O dispositivo recebe uma resposta de início de contabilização (independentemente de a contabilização ser bem-sucedida ou não).
- O dispositivo não recebe nenhuma resposta de início de contabilização depois de fazer todas as tentativas de solicitação de início de contabilização.
- O dispositivo envia solicitações de interrupção de contabilização aos servidores de contabilização para os quais enviou uma solicitação de início de contabilização.
- O dispositivo recebe uma resposta de parada de contabilização.
- O dispositivo não recebe nenhuma resposta de parada de contabilização depois de fazer todas as tentativas de solicitação de parada de contabilização.
O processo vai para a próxima etapa nas seguintes situações:
Essa etapa será ignorada se nenhum servidor de autenticação correto for especificado para o teste AAA ou se nenhum servidor de autenticação estiver configurado no esquema RADIUS especificado.
O processo vai para a próxima etapa nas seguintes situações:
Esta etapa e a próxima serão ignoradas se nenhum servidor de contabilidade correto for especificado para o teste AAA ou se nenhum servidor de contabilidade estiver configurado no esquema RADIUS especificado.
O processo é concluído nas seguintes situações:
Para identificar os atributos que causam falhas na autenticação ou na contabilização, você pode configurar o dispositivo para incluir atributos específicos nas solicitações RADIUS ou definir valores para atributos específicos nas solicitações. A Tabela 3 mostra os atributos que as solicitações RADIUS contêm por padrão.
Tabela 3 Atributos que as solicitações RADIUS contêm por padrão
| Tipo de pacote | Atributos que o tipo de pacotes carrega por padrão |
| Solicitação de autenticação RADIUS | Nome de usuário CHAP-Password (ou User-Password) CHAP-Challenge Endereço NAS-IP (ou endereço NAS-IPv6) Service-Type Protocolo emoldurado Identificador NAS Tipo de porta NAS Acct-Session-Id |
| Solicitação de contabilidade RADIUS | Nome de usuário Tipo de status da conta Endereço NAS-IP (ou endereço NAS-IPv6) Identificador NAS Acct-Session-Id Acct-Delay-Time Acct-Terminate-Cause |
Restrições e diretrizes
Quando você realizar um teste AAA, siga estas restrições e diretrizes:
- O dispositivo pode se comunicar incorretamente com os servidores AAA durante um teste AAA. Certifique-se de que nenhum usuário fique on-line ou off-line durante um texto AAA.
- Se a configuração do esquema RADIUS especificado for alterada, a nova configuração não afetará o teste AAA atual. A modificação entrará em vigor no próximo teste.
- O sistema pode ter apenas um teste AAA por vez. Outro teste AAA só pode ser realizado após o término do teste atual.
Quando você configurar atributos a serem incluídos ou excluídos das solicitações do RADIUS, siga estas restrições e diretrizes:
- Antes de incluir um atributo que já esteja configurado para ser excluído das solicitações RADIUS, você deve cancelar a configuração de exclusão usando o comando undo exclude.
- Antes de excluir um atributo que já esteja configurado para ser incluído nas solicitações RADIUS, você deve cancelar a configuração de inclusão usando o comando undo include.
Pré-requisitos
Antes de executar um teste AAA, você deve configurar um esquema RADIUS que contenha os servidores RADIUS a serem testados.
Planeje os atributos RADIUS a serem incluídos nas solicitações RADIUS. Além dos atributos carregados por padrão, o dispositivo adiciona os atributos especificados aos pacotes RADIUS na ordem em que são especificados usando o comando include. Não será possível adicionar atributos adicionais a uma solicitação RADIUS se o comprimento da solicitação RADIUS atingir 4096 bytes.
Procedimento
- (Opcional.) Configure um grupo de teste de atributos RADIUS:
- Entre na visualização do sistema.
system viewradius attribute-test-group attr-test-group-nameVocê pode criar vários grupos de teste de atributos RADIUS.
[ vendor vendor-id ] code attribute-code } type { binary | date | integer | interface-id | ip | ipv6 | ipv6-prefix | octets | string } value attribute-valueUse esse comando para adicionar atributos que as solicitações RADIUS não carregam por padrão às solicitações RADIUS.
Para um atributo que as solicitações do RADIUS carregam por padrão, você pode usar esse comando para alterar o valor do atributo.
exclude { accounting | authentication } name attribute-nameUse esse comando para excluir um atributo que as solicitações RADIUS carregam por padrão das solicitações RADIUS enviadas durante um teste AAA para ajudar a solucionar problemas de autenticação ou contabilidade falhas.
quitquittest-aaa user user-name password password radius-scheme radius-scheme-name [ radius-server { ipv4-address | ipv6 ipv6-address } port-number ] [ chap | pap ] [ attribute-test-group attr-test-group-name ] [ trace ]Exemplos de configuração de AAA
Exemplo: Configuração de AAA para usuários SSH por um servidor HWTACACS
Configuração de rede
Conforme mostrado na Figura 11, configure o switch para atender aos seguintes requisitos:
- Use o servidor HWTACACS para autenticação, autorização e contabilidade do usuário SSH.
- Atribua a função de usuário padrão network-operator aos usuários de SSH depois que eles passarem pela autenticação.
- Exclua os nomes de domínio dos nomes de usuário enviados ao servidor HWTACACS.
- Use expert como chaves compartilhadas para comunicação HWTACACS segura.
Figura 11 Diagrama de rede
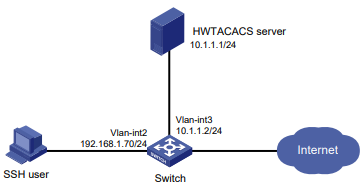
Configuração do servidor HWTACACS
# Defina as chaves compartilhadas como expert para comunicação segura com o switch, adicione uma conta para o usuário SSH e especifique a senha. (Os detalhes não são mostrados).
Configuração do switch
# Configure endereços IP para as interfaces. (Detalhes não mostrados.)
# Crie um esquema HWTACACS.
<Switch> system-view
[Switch] hwtacacs scheme hwtac# Especifique o servidor de autenticação primário.
[Switch-hwtacacs-hwtac] primary authentication 10.1.1.1 49# Especifique o servidor de autorização principal.
[Switch-hwtacacs-hwtac] primary authorization 10.1.1.1 49# Especifique o servidor de contabilidade principal.
[Switch-hwtacacs-hwtac] primary accounting 10.1.1.1 49[Switch-hwtacacs-hwtac] primary accounting 10.1.1.1 49
# Defina as chaves compartilhadas para expert em formato de texto simples para uma comunicação HWTACACS segura.
[Switch-hwtacacs-hwtac] key authentication simple expert
[Switch-hwtacacs-hwtac] key authorization simple expert
[Switch-hwtacacs-hwtac] key accounting simple expert# Exclua os nomes de domínio dos nomes de usuário enviados ao servidor HWTACACS.
[Switch-hwtacacs-hwtac] user-name-format without-domain
[Switch-hwtacacs-hwtac] quit# Crie um domínio ISP chamado bbb e configure o domínio para usar o esquema HWTACACS para autenticação, autorização e contabilidade de usuários de login.
[Switch-isp-bbb] authentication login hwtacacs-scheme hwtac
[Switch-isp-bbb] authorization login hwtacacs-scheme hwtac
[Switch-isp-bbb] accounting login hwtacacs-scheme hwtac
[Switch-isp-bbb] quit# Crie pares de chaves RSA e DSA locais.
[Switch] public-key local create rsa
[Switch] public-key local create dsa# Habilite o serviço Stelnet.
[Switch] ssh server enable# Habilite a autenticação de esquema para as linhas de usuário VTY 0 a VTY 63.
[Switch] line vty 0 63
[Switch-line-vty0-63] authentication-mode scheme
[Switch-line-vty0-63] quit# Habilite o recurso de função de usuário padrão para atribuir aos usuários autenticados de SSH a função de usuário padrão operador de rede.
[Switch] role default-role enableVerificação da configuração
# Inicie uma conexão SSH com o switch e digite o nome de usuário e a senha corretos. O usuário faz o login no switch. (Detalhes não mostrados).
# Verifique se o usuário pode usar os comandos permitidos pela função de usuário network-operator. (Detalhes não mostrados).
Exemplo: Configuração de autenticação local, autorização HWTACACS e contabilidade RADIUS para usuários SSH
Configuração de rede
Conforme mostrado na Figura 12, configure o switch para atender aos seguintes requisitos:
- Execute a autenticação local para usuários de SSH.
- Use o servidor HWTACACS e o servidor RADIUS para autorização e contabilidade do usuário SSH, respectivamente.
- Exclua os nomes de domínio dos nomes de usuário enviados aos servidores.
- Atribua a função de usuário padrão network-operator aos usuários de SSH depois que eles passarem pela autenticação.
Configure uma conta chamada hello para o usuário SSH. Configure as chaves compartilhadas para a comunicação segura com o servidor HWTACACS e o servidor RADIUS.
Figura 12 Diagrama de rede
Configuração do servidor HWTACACS
# Defina as chaves compartilhadas como expert para comunicação segura com o switch, adicione uma conta para o usuário SSH e especifique a senha. (Os detalhes não são mostrados).
Configuração do servidor RADIUS
# Defina as chaves compartilhadas como expert para comunicação segura com o switch, adicione uma conta para o usuário SSH e especifique a senha. (Os detalhes não são mostrados).
Configuração do switch
# Configure os endereços IP para as interfaces. (Detalhes não mostrados.)
# Crie pares de chaves RSA e DSA locais.
<Switch> system-view
[Switch] public-key local create rsa
[Switch] public-key local create dsa# Habilite o serviço Stelnet.
[Switch] ssh server enable# Habilite a autenticação de esquema para as linhas de usuário VTY 0 a VTY 63.
[Switch] line vty 0 63
[Switch-line-vty0-63] authentication-mode scheme
[Switch-line-vty0-63] quit# Configure um esquema HWTACACS.
[Switch] hwtacacs scheme hwtac
[Switch-hwtacacs-hwtac] primary authorization 10.1.1.2 49
[Switch-hwtacacs-hwtac] key authorization simple expert
[Switch-hwtacacs-hwtac] user-name-format without-domain
[Switch-hwtacacs-hwtac] quit# Configure um esquema RADIUS.
[Switch] radius scheme rd
[Switch-radius-rd] primary accounting 10.1.1.1 1813
[Switch-radius-rd] key accounting simple expert
[Switch-radius-rd] user-name-format without-domain
[Switch-radius-rd] quit# Crie um usuário de gerenciamento de dispositivos.
[Switch] local-user hello class manage# Atribua o serviço SSH ao usuário local.
[Switch-luser-manage-hello] service-type ssh# Defina a senha como 123456TESTplat&! em formato de texto simples para o usuário local. No modo FIPS, você deve definir a senha no modo interativo.
[Switch-luser-manage-hello] password simple 123456TESTplat&!
[Switch-luser-manage-hello] quit# Crie um domínio ISP chamado bbb e configure os usuários de login para usar autenticação local, autorização HWTACACS e contabilidade RADIUS.
[Switch] domain bbb
[Switch-isp-bbb] authentication login local
[Switch-isp-bbb] authorization login hwtacacs-scheme hwtac
[Switch-isp-bbb] accounting login radius-scheme rd
[Switch-isp-bbb] quit# Habilite o recurso de função de usuário padrão para atribuir aos usuários autenticados de SSH a função de usuário padrão
[Switch] role default-role enableVerificação da configuração
# Inicie uma conexão SSH com o switch e digite o nome de usuário hello@bbb e a senha correta. O usuário faz o login no switch. (Os detalhes não são mostrados).
# Verifique se o usuário pode usar os comandos permitidos pela função de usuário network-operator. (Detalhes não mostrados).
Exemplo: Configuração de autenticação e autorização para usuários SSH por um servidor RADIUS
Configuração de rede
Conforme mostrado na Figura 13, configure o switch para atender aos seguintes requisitos:
- Use o servidor RADIUS para autenticação e autorização de usuário SSH.
- Inclua nomes de domínio nos nomes de usuário enviados ao servidor RADIUS.
- Atribua a função de usuário padrão network-operator aos usuários de SSH depois que eles passarem pela autenticação.
O servidor RADIUS é executado no IMC PLAT 5.0 (E0101) e no IMC UAM 5.0 (E0101). Adicione uma conta com o nome de usuário hello@bbb no servidor RADIUS.
O servidor RADIUS e o switch usam expert como a chave compartilhada para a comunicação segura do RADIUS. As portas para autenticação e contabilidade são 1812 e 1813, respectivamente.
Figura 13 Diagrama de rede
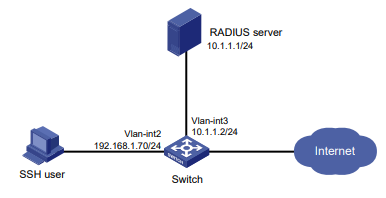
Configuração do servidor RADIUS
- Adicione o switch à plataforma IMC como um dispositivo de acesso:
- Defina a chave compartilhada como expert para uma comunicação RADIUS segura.
- Defina as portas para autenticação e contabilidade como 1812 e 1813, respectivamente.
- Selecione Device Management Service na lista Service Type (Tipo de serviço).
- Selecione Intelbras na lista Access Device Type (Tipo de dispositivo de acesso).
- Selecione um dispositivo de acesso na lista de dispositivos ou adicione manualmente um dispositivo de acesso. Neste exemplo de , o endereço IP do dispositivo é 10.1.1.2.
- Use os valores padrão para outros parâmetros e clique em OK.
- Endereço IP especificado com o uso do comando nas-ip.
- Endereço IP especificado com o uso do comando radius nas-ip.
- Endereço IP da interface de saída (o padrão).
- Adicione uma conta para gerenciamento de dispositivos:
- Digite o nome da conta hello@bbb e especifique a senha.
- Selecione SSH na lista Service Type (Tipo de serviço).
- Especifique 10.1.1.0 a 10.1.1.255 como o intervalo de endereços IP dos hosts a serem gerenciados.
- Clique em OK.
Faça login no IMC, clique na guia Service e selecione User Access Manager > Access Device Management > Access Device na árvore de navegação. Em seguida, clique em Add (Adicionar) para configurar um dispositivo de acesso da seguinte forma:
O endereço IP do dispositivo de acesso especificado aqui deve ser o mesmo que o endereço IP de origem dos pacotes RADIUS enviados pelo switch. O endereço IP de origem é escolhido na seguinte ordem no switch:
Figura 14: Adição do switch como um dispositivo de acesso
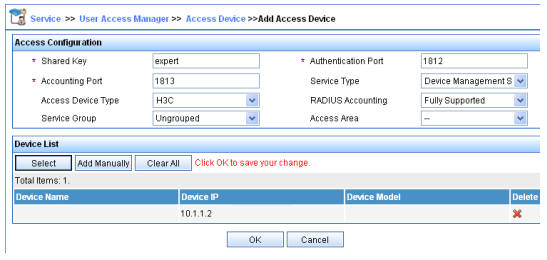
Clique na guia User e selecione Access User View > Device Mgmt User na árvore de navegação. Em seguida, clique em Add (Adicionar) para configurar uma conta de gerenciamento de dispositivos da seguinte forma:
OBSERVAÇÃO:
O intervalo de endereços IP deve conter o endereço IP do switch.
Figura 15: Adição de uma conta para gerenciamento de dispositivos
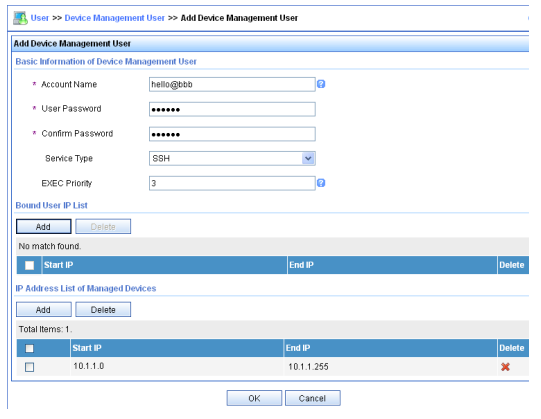
Configuração do switch
# Configure os endereços IP para as interfaces. (Detalhes não mostrados.)
# Crie pares de chaves RSA e DSA locais.
<Switch> system-view
[Switch] public-key local create rsa
[Switch] public-key local create dsa# Habilite o serviço Stelnet.
[Switch] ssh server enable# Habilite a autenticação de esquema para as linhas de usuário VTY 0 a VTY 63.
[Switch] line vty 0 63
[Switch-line-vty0-63] authentication-mode scheme
[Switch-line-vty0-63] quit# Ative o recurso de função de usuário padrão para atribuir aos usuários SSH autenticados a função de usuário padrão
[Switch] role default-role enable# Criar um esquema RADIUS.
[Switch] radius scheme rad# Especifique o servidor de autenticação primário.
[Switch-radius-rad] primary authentication 10.1.1.1 1812# Defina a chave compartilhada como expert em formato de texto simples para comunicação segura com o servidor.
[Switch-radius-rad] key authentication simple expert# Incluir nomes de domínio nos nomes de usuário enviados ao servidor RADIUS.
[Switch-radius-rad] user-name-format with-domain
[Switch-radius-rad] quit# Crie um domínio ISP chamado bbb e configure métodos de autenticação, autorização e contabilidade para usuários de login.
[Switch] domain bbb
[Switch-isp-bbb] authentication login radius-scheme rad
[Switch-isp-bbb] authorization login radius-scheme rad
[Switch-isp-bbb] accounting login none
[Switch-isp-bbb] quitVerificação da configuração
# Inicie uma conexão SSH com o switch e digite o nome de usuário hello@bbb e a senha correta. O usuário faz o login no switch. (Os detalhes não são mostrados).
# Verifique se o usuário pode usar os comandos permitidos pela função de usuário network-operator. (Detalhes não mostrados).
Exemplo: Configuração da autenticação para usuários SSH por um servidor LDAP
Configuração de rede
Conforme mostrado na Figura 16, o servidor LDAP usa o domínio ldap.com e executa o Microsoft Windows 2003 Server Active Directory.
Configure o switch para atender aos seguintes requisitos:
- Use o servidor LDAP para autenticar os usuários de SSH.
- Atribua a função de usuário de nível 0 aos usuários de SSH depois que eles passarem pela autenticação.
No servidor LDAP, defina a senha do administrador como admin!123456, adicione um usuário chamado aaa e defina a senha do usuário como ldap!123456.
Figura 16 Diagrama de rede
Configuração do servidor LDAP
- Adicione um usuário chamado aaa e defina a senha como ldap!123456:
- No servidor LDAP, selecione Iniciar > Painel de controle > Ferramentas administrativas.
- Clique duas vezes em Usuários e computadores do Active Directory.
- Na árvore de navegação, clique em Usuários sob o nó ldap.com.
- Selecione Ação > Novo > Usuário no menu para exibir a caixa de diálogo para adicionar um usuário.
- Digite o nome de logon aaa e clique em Next.
- Na caixa de diálogo, digite a senha ldap!123456, selecione as opções conforme necessário e clique em Next.
- Clique em OK.
- Adicionar o usuário aaa ao grupo Usuários:
- Na árvore de navegação, clique em Usuários sob o nó ldap.com.
- No painel direito, clique com o botão direito do mouse no usuário aaa e selecione Propriedades.
- Na caixa de diálogo, clique na guia Member Of (Membro de) e clique em Add (Adicionar).
- Na caixa de diálogo Select Groups (Selecionar grupos), digite Users (Usuários) no campo Enter the object names to select (Digite os nomes dos objetos a serem selecionados) e clique em OK.
- Defina a senha do administrador como admin!123456:
- No painel direito, clique com o botão direito do mouse no usuário Administrator e selecione Set Password (Definir senha).
- Na caixa de diálogo, digite a senha do administrador. (Detalhes não mostrados.)
A janela Usuários e computadores do Active Directory é exibida.
Figura 17: Adição do usuário aaa
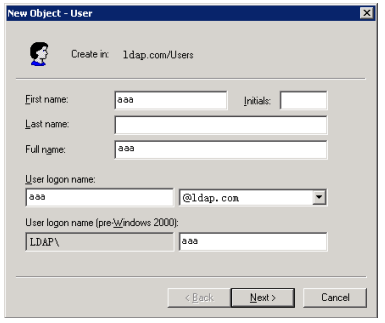
Figura 18 Configuração da senha do usuário
Figura 19 Modificação das propriedades do usuário
O usuário aaa é adicionado ao grupo Usuários.
Figura 20: Adição do usuário aaa ao grupo Users
Configuração do switch
# Configurar endereços IP para interfaces. (Os detalhes não são mostrados).
# Crie pares de chaves RSA e DSA locais.
<Switch> system-view
[Switch] public-key local create rsa
[Switch] public-key local create dsa# Habilite o serviço Stelnet.
[Switch] ssh server enable# Habilite a autenticação de esquema para as linhas de usuário VTY 0 a VTY 63.
[Switch] line vty 0 63
[Switch-line-vty0-63] authentication-mode scheme
[Switch-line-vty0-63] quit# Configure um servidor LDAP.
[Switch] ldap server ldap1# Especifique o endereço IP do servidor de autenticação LDAP.
[Switch-ldap-server-ldap1] ip 10.1.1.1# Especifique o DN do administrador.
[Switch-ldap-server-ldap1] login-dn cn=administrator,cn=users,dc=ldap,dc=com# Especifique a senha do administrador.
[Switch-ldap-server-ldap1] login-password simple admin!123456# Configure o DN base para a pesquisa de usuários.
[Switch-ldap-server-ldap1] search-base-dn dc=ldap,dc=com
[Switch-ldap-server-ldap1] quit# Criar um esquema LDAP.
[Switch] ldap scheme ldap-shm1# Especifique o servidor de autenticação LDAP.
[Switch-ldap-ldap-shm1] authentication-server ldap1
[Switch-ldap-ldap-shm1] quit# Crie um domínio ISP chamado bbb e configure métodos de autenticação, autorização e contabilidade para usuários de login.
[Switch] domain bbb
[Switch-isp-bbb] authentication login ldap-scheme ldap-shm1
[Switch-isp-bbb] authorization login none
[Switch-isp-bbb] accounting login none
[Switch-isp-bbb] quitVerificação da configuração
# Inicie uma conexão SSH com o switch e digite o nome de usuário aaa@bbb e a senha ldap!123456. O usuário faz login no switch. (Detalhes não mostrados).
# Verifique se o usuário pode usar os comandos permitidos pela função de usuário de nível 0. (Detalhes não mostrados).
Exemplo: Configuração de AAA para usuários 802.1X por um servidor RADIUS
Configuração de rede
Conforme mostrado na Figura 21, configure o switch para atender aos seguintes requisitos:
- Use o servidor RADIUS para autenticação, autorização e contabilidade de usuários 802.1X.
- Use o controle de acesso baseado em MAC na GigabitEthernet 1/0/1 para autenticar todos os usuários 802.1X na porta separadamente.
- Inclua nomes de domínio nos nomes de usuário enviados ao servidor RADIUS.
Neste exemplo, o servidor RADIUS é executado no IMC PLAT 5.0 (E0101) e no IMC UAM 5.0 (E0101). No servidor RADIUS, execute as seguintes tarefas:
- Adicione um serviço que cobra 120 dólares por até 120 horas por mês e atribui usuários autenticados à VLAN 4.
- Configure um usuário com o nome dot1x@bbb e atribua o serviço a esse usuário.
Defina as chaves compartilhadas como expert para comunicação RADIUS segura. Defina as portas para autenticação e contabilidade como 1812 e 1813, respectivamente.
Figura 21 Diagrama de rede
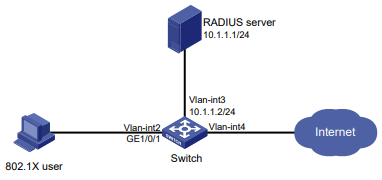
Configuração do servidor RADIUS
- Adicione o switch à plataforma IMC como um dispositivo de acesso:
- Defina a chave compartilhada como expert para autenticação segura e comunicação contábil.
- Defina as portas para autenticação e contabilidade como 1812 e 1813, respectivamente.
- Selecione LAN Access Service na lista Service Type (Tipo de serviço).
- Selecione Intelbras(General) na lista Access Device Type (Tipo de dispositivo de acesso).
- Selecione um dispositivo de acesso na lista de dispositivos ou adicione manualmente um dispositivo de acesso. Neste exemplo , o endereço IP do dispositivo é 10.1.1.2.
- Use os valores padrão para outros parâmetros e clique em OK.
- Endereço IP especificado com o uso do comando nas-ip.
- Endereço IP especificado com o uso do comando radius nas-ip.
- Endereço IP da interface de saída (o padrão).
- Adicione um plano de cobrança:
- Adicione um plano chamado UserAcct.
- Selecione Flat rate (Taxa fixa) na lista Charging Template (Modelo de cobrança).
- Selecione time para Charge Based on, selecione Monthly para Billing Term e digite 120 no campo Campo de taxa fixa.
- Digite 120 no campo Limite de uso e selecione hr (horas) para o campo em. A configuração permite que o usuário acesse a Internet por até 120 horas por mês.
- Use os valores padrão para outros parâmetros e clique em OK.
- Adicionar um serviço:
- Adicione um serviço chamado Dot1x auth e defina o sufixo do serviço como bbb, o domínio de autenticação do usuário 802.1X. Com o sufixo de serviço configurado, você deve configurar o dispositivo de acesso para enviar nomes de usuário que incluam nomes de domínio para o servidor RADIUS.
- Selecione UserAcct na lista Charging Plan (Plano de cobrança).
- Selecione Deploy VLAN e defina o ID da VLAN a ser atribuída a 4.
- Configure outros parâmetros conforme necessário.
- Clique em OK.
- Adicionar um usuário:
- Selecione o usuário ou adicione um usuário chamado hello.
- Especifique o nome da conta como dot1x e configure a senha.
- Selecione Dot1x auth na área Access Service (Serviço de acesso).
- Configure outros parâmetros conforme necessário e clique em OK.
Faça login no IMC, clique na guia Service e selecione User Access Manager > Access Device Management > Access Device na árvore de navegação. Em seguida, clique em Add (Adicionar) para configurar um dispositivo de acesso da seguinte forma:
O endereço IP do dispositivo de acesso especificado aqui deve ser o mesmo que o endereço IP de origem dos pacotes RADIUS enviados pelo switch. O endereço IP de origem é escolhido na seguinte ordem no switch:
Figura 22: Adição do switch como um dispositivo de acesso
Clique na guia Service e selecione Accounting Manager > Charging Plans na árvore de navegação para acessar a página de configuração do plano de cobrança. Em seguida, clique em Add (Adicionar) para configurar um plano de cobrança da seguinte forma:
Figura 23: Adição de um plano de cobrança
Clique na guia Service e selecione User Access Manager > Service Configuration na árvore de navegação. Em seguida, clique em Adicionar para configurar um serviço da seguinte forma:
Figura 24: Adição de um serviço
Clique na guia Usuário e selecione Visualização do usuário de acesso > Todos os usuários de acesso na árvore de navegação para acessar a página Todos os usuários de acesso. Em seguida, clique em Adicionar para configurar um usuário da seguinte forma:
Figura 25: Adição de uma conta de usuário de acesso
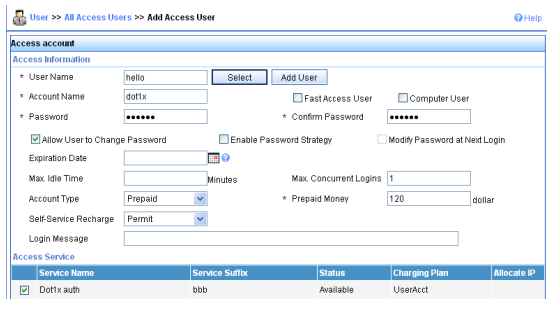
Configuração do switch
- Configurar um esquema RADIUS:
# Crie um esquema RADIUS chamado rad e entre na visualização do esquema RADIUS.
<Switch> system-view
[Switch] radius scheme rad# Especifique o servidor de autenticação primário e o servidor de contabilidade primário e configure as chaves para comunicação com os servidores.
[Switch-radius-rad] primary authentication 10.1.1.1
[Switch-radius-rad] primary accounting 10.1.1.1
[Switch-radius-rad] key authentication simple expert
[Switch-radius-rad] key accounting simple expert# Inclua nomes de domínio nos nomes de usuário enviados ao servidor RADIUS.
[Switch-radius-rad] user-name-format with-domain
[Switch-radius-rad] quit# Crie um domínio ISP chamado bbb e entre no modo de exibição de domínio ISP.
[Switch] domain bbb# Configure o domínio ISP para usar o esquema RADIUS rad para autenticação, autorização e contabilidade dos usuários da LAN.
[Switch-isp-bbb] authentication lan-access radius-scheme rad
[Switch-isp-bbb] authorization lan-access radius-scheme rad
[Switch-isp-bbb] accounting lan-access radius-scheme rad
[Switch-isp-bbb] quit[Switch] dot1x# Habilite o 802.1X para a GigabitEthernet 1/0/1.
[Switch] interface gigabitethernet 1/0/1
[Switch-GigabitEthernet1/0/1] dot1x# Configure o método de controle de acesso. Por padrão, uma porta habilitada para 802.1X usa o controle de acesso baseado em MAC.
[Switch-GigabitEthernet1/0/1] dot1x port-method macbasedVerificação da configuração
- No host, use a conta dot1x@bbb para passar a autenticação 802.1X:
- Clique na guia Authentication (Autenticação) da janela de propriedades.
- Selecione a opção Ativar autenticação IEEE 802.1X para esta rede.
- Selecione o desafio MD5 como o tipo de EAP.
- Clique em OK.
- No switch, verifique se o servidor atribui a porta que conecta o cliente à VLAN 4 depois que o usuário passa pela autenticação. (Detalhes não mostrados).
- Exibir informações de conexão 802.1X no switch.
# Se o host executar o cliente Windows XP 802.1X, configure as propriedades da conexão de rede da seguinte forma:
O usuário passa na autenticação depois de inserir o nome de usuário e a senha corretos na página de autenticação.
# Se o host executar o cliente iNode, não serão necessárias opções avançadas de autenticação. O usuário pode passar na autenticação depois de inserir o nome de usuário dot1x@bbb e a senha correta na página de propriedades do cliente.
IMPORTANTE:
Certifique-se de que o cliente possa atualizar seu endereço IP para acessar os recursos na VLAN autorizada depois de passar pela autenticação.
[Switch] display dot1x connectionExemplo: Configuração de autenticação e autorização para Usuários 802.1X pelo dispositivo como um servidor RADIUS
Configuração de rede
Conforme mostrado na Figura 26, o Switch B atua como servidor RADIUS para autenticação e autorização de usuários 802.1X conectados ao NAS (Switch A).
Configure os switches para atender aos seguintes requisitos:
- Execute a autenticação de usuário 802.1X na GigabitEthernet 1/0/1 do NAS.
- A chave compartilhada é expert e a porta de autenticação é 1812.
- Exclua os nomes de domínio dos nomes de usuário enviados ao servidor RADIUS.
- O nome de usuário para autenticação 802.1X é dot1x.
- Depois que o usuário passa pela autenticação, o servidor RADIUS autoriza a VLAN 4 para a porta do NAS à qual o usuário está se conectando.
Figura 26 Diagrama de rede
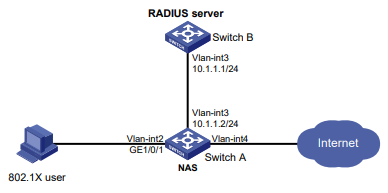
Procedimento
- Configure o NAS:
- Configurar um esquema RADIUS:
# Configure um esquema RADIUS chamado rad e entre na visualização do esquema RADIUS.
<SwitchA> system-view
[SwitchA] radius scheme rad# Especifique o servidor de autenticação principal com o endereço IP 10.1.1.1 e defina a chave compartilhada como expert em formato de texto simples.
[SwitchA-radius-rad] primary authentication 10.1.1.1 key simple expert# Exclua os nomes de domínio dos nomes de usuário enviados ao servidor RADIUS. [SwitchA-radius-rad] user-name-format without-domain
[SwitchA-radius-rad] user-name-format without-domain
[SwitchA-radius-rad] quit# Crie um domínio ISP chamado bbb e entre no modo de exibição de domínio ISP.
[SwitchA] domain bbb# Configure o domínio ISP para usar o esquema RADIUS rad para autenticação e autorização de usuários da LAN e não para realizar a contabilidade dos usuários da LAN.
[SwitchA-isp-bbb] authentication lan-access radius-scheme rad
[SwitchA-isp-bbb] authorization lan-access radius-scheme rad
[SwitchA-isp-bbb] accounting lan-access none
[SwitchA-isp-bbb] quit# Habilite o 802.1X para a GigabitEthernet 1/0/1. [SwitchA] interface gigabitethernet 1/0/1
[SwitchA] interface gigabitethernet 1/0/1
[SwitchA-GigabitEthernet1/0/1] dot1x# Especifique bbb como o domínio de autenticação obrigatório para usuários 802.1X na interface.
[SwitchA-GigabitEthernet1/0/1] dot1x mandatory-domain bbb
[SwitchA-GigabitEthernet1/0/1] quit# Habilite o 802.1X globalmente.
[SwitchA] dot1x# Crie um usuário de acesso à rede chamado dot1x.
<SwitchB> system-view
[SwitchB] local-user dot1x class network# Configure a senha como 123456 em formato de texto simples.
[SwitchB-luser-network-dot1x] password simple 123456# Configure a VLAN 4 como a VLAN de autorização.
[SwitchB-luser-network-dot1x] authorization-attribute vlan 4
[SwitchB-luser-network-dot1x] quit# Configure o endereço IP do cliente RADIUS como 10.1.1.2 e a chave compartilhada como expert em formato de texto simples.
[SwitchB] radius-server client ip 10.1.1.2 key simple expert# Ativar a configuração do servidor RADIUS.
[SwitchB] radius-server activateVerificação da configuração
- No servidor RADIUS, exiba os clientes e usuários RADIUS ativados.
[SwitchB] display radius-server active-client
Total 1 RADIUS clients.
Client IP: 10.1.1.2
[SwitchB] display radius-server active-user dot1x
Total 1 RADIUS users matched.
Username: dot1x
Description: Not configured
Authorization attributes:
VLAN ID: 4
ACL number: Not configured
Validity period:
Expiration time: Not configuredSe o host executar o cliente 802.1X integrado do Windows, configure as propriedades da conexão de rede da seguinte forma:
- Clique na guia Authentication (Autenticação) da janela de propriedades.
- Selecione a opção Ativar autenticação IEEE 802.1X para esta rede.
- Selecione o desafio MD5 como o tipo de EAP.
- Clique em OK.
Se o host executar o cliente iNode, não serão necessárias opções avançadas de autenticação. O usuário passa na autenticação depois de inserir o nome de usuário e a senha corretos na página de autenticação ou no cliente iNode.
IMPORTANTE:
Certifique-se de que o cliente possa atualizar seu endereço IP para acessar os recursos na VLAN autorizada depois de passar pela autenticação.
[SwitchA] display dot1x connectionSolução de problemas de AAA
Falha na autenticação RADIUS
Sintoma
A autenticação do usuário sempre falha.
Análise
Os possíveis motivos incluem:
- Existe uma falha de comunicação entre o NAS e o servidor RADIUS.
- O nome de usuário não está no formato userid@isp-name ou o domínio ISP não está configurado corretamente no NAS.
- O usuário não está configurado no servidor RADIUS.
- A senha inserida pelo usuário está incorreta.
- O servidor RADIUS e o NAS estão configurados com chaves compartilhadas diferentes.
Solução
Para resolver o problema:
- Verifique os seguintes itens:
- O NAS e o servidor RADIUS podem fazer ping entre si.
- O nome de usuário está no formato userid@isp-name e o domínio ISP está configurado corretamente no NAS.
- O usuário está configurado no servidor RADIUS.
- A senha correta é inserida.
- A mesma chave compartilhada é configurada no servidor RADIUS e no NAS.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Falha na entrega do pacote RADIUS
Sintoma
Os pacotes RADIUS não conseguem acessar o servidor RADIUS.
Análise
Os possíveis motivos incluem:
Solução
Para resolver o problema:
- Verifique os seguintes itens:
- O link entre o NAS e o servidor RADIUS funciona bem nas camadas física e de link de dados.
- O endereço IP do servidor RADIUS está configurado corretamente no NAS.
- Os números de porta UDP de autenticação e contabilidade configurados no NAS são os mesmos do servidor RADIUS.
- Os números das portas de autenticação e contabilidade do servidor RADIUS estão disponíveis.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Erro de contabilidade RADIUS
Sintoma
Um usuário é autenticado e autorizado, mas a contabilidade do usuário não é normal.
Análise
A configuração do servidor de contabilidade no NAS não está correta. Os possíveis motivos incluem:
Solução
Para resolver o problema:
- Verifique os seguintes itens:
- O número da porta de contabilidade está configurado corretamente.
- O endereço IP do servidor de contabilidade está configurado corretamente no NAS.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Solução de problemas do HWTACACS
Semelhante à solução de problemas do RADIUS. Consulte "Falha na autenticação RADIUS", "Falha na entrega de pacotes RADIUS" e "Erro de contabilidade RADIUS".
Falha na autenticação LDAP
Sintoma
A autenticação do usuário falha.
Análise
Os possíveis motivos incluem:
Solução
Para resolver o problema:
- Verifique os seguintes itens:
- O NAS e o servidor LDAP podem fazer ping entre si.
- O endereço IP e o número da porta do servidor LDAP configurado no NAS correspondem aos do servidor.
- O nome de usuário está no formato correto e o domínio do ISP para a autenticação do usuário está configurado corretamente no NAS.
- O usuário está configurado no servidor LDAP.
- A senha correta é inserida.
- O DN do administrador e a senha do administrador estão configurados corretamente.
- Os atributos de usuário (por exemplo, o atributo de nome de usuário) configurados no NAS são consistentes com aqueles configurados no servidor LDAP.
- O DN da base de pesquisa do usuário para autenticação é especificado.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Apêndices
Apêndice A Atributos RADIUS comumente usados
Os atributos RADIUS comumente usados são definidos na RFC 2865, RFC 2866, RFC 2867 e RFC 2868.
Tabela 4 Atributos RADIUS comumente usados
| Não. | Atributo | Não. | Atributo |
| 1 | Nome de usuário | 45 | Conta autêntica |
| 2 | Senha de usuário | 46 | Hora da sessão de contas |
| 3 | Senha CHAP | 47 | Pacotes de entrada de contas |
| 4 | Endereço IP do NAS | 48 | Pacotes de saída de contas |
| 5 | Porta NAS | 49 | Acct-Terminate-Cause |
| 6 | Tipo de serviço | 50 | Acct-Multi-Session-Id |
| 7 | Protocolo emoldurado | 51 | Contagem de links de contas |
| 8 | Endereço IP emoldurado | 52 | Entrada de conta-Gigawords |
| 9 | Máscara de rede-IP emoldurada | 53 | Saída de contas-Gigawords |
| 10 | Roteamento emoldurado | 54 | (não atribuído) |
| 11 | ID do filtro | 55 | Event-Timestamp |
| 12 | Emoldurado-MTU | 56-59 | (não atribuído) |
| 13 | Compressão emoldurada | 60 | CHAP-Challenge |
| 14 | Login-IP-Host | 61 | NAS-Port-Type |
| 15 | Serviço de login | 62 | Limite de porta |
| 16 | Login-TCP-Port | 63 | Login-LAT-Port |
| 17 | (não atribuído) | 64 | Tipo túnel |
| 18 | Mensagem de resposta | 65 | Tipo túnel-médio |
| 19 | Número de retorno de chamada | 66 | Ponto de extremidade do cliente do túnel |
| 20 | ID de retorno de chamada | 67 | Ponto de extremidade do servidor de túnel |
| 21 | (não atribuído) | 68 | Conexão de túnel de contas |
| 22 | Rota emoldurada | 69 | Senha do túnel |
| 23 | Rede IPX emoldurada | 70 | Senha ARAP |
| 24 | Estado | 71 | Recursos ARAP |
| 25 | Classe | 72 | Acesso à zona ARAP |
| 26 | Específico do fornecedor | 73 | ARAP-Segurança |
| 27 | Tempo limite da sessão | 74 | ARAP-Dados de segurança |
| 28 | Tempo limite de inatividade | 75 | Senha-Retenção |
| 29 | Rescisão - Ação | 76 | Prompt |
| 30 | Called-Station-Id | 77 | Informações de conexão |
| 31 | Calling-Station-Id | 78 | Token de configuração |
| 32 | Identificador NAS | 79 | Mensagem EAP |
| 33 | Estado do proxy | 80 | Autenticador de mensagens |
| 34 | Login-LAT-Service | 81 | ID do grupo privado do túnel |
| 35 | Login-LAT-Node | 82 | ID de atribuição de túnel |
| 36 | Login-LAT-Group | 83 | Preferência de túnel |
| 37 | Framed-AppleTalk-Link | 84 | ARAP-Challenge-Response (Resposta ao desafio ARAP) |
| 38 | Rede Framed-AppleTalk | 85 | Intervalo contábil-interino |
| 39 | Framed-AppleTalk-Zone | 86 | Acct-Tunnel-Packets-Lost |
| 40 | Tipo de status da conta | 87 | NAS-Port-Id |
| 41 | Tempo de atraso da conta | 88 | Piscina emoldurada |
| 42 | Octetos de entrada de conta | 89 | (não atribuído) |
| 43 | Octetos de saída de contas | 90 | Identificador de autenticação de cliente de túnel |
| 44 | Acct-Session-Id | 91 | ID de autenticação do servidor de túnel |
Apêndice B Descrições dos atributos RADIUS padrão comumente usados
| Não. | Atributo | Descrição |
| 1 | Nome de usuário | Nome do usuário a ser autenticado. |
| 2 | Senha de usuário | Senha do usuário para autenticação PAP, presente apenas nos pacotes Access-Request quando a autenticação PAP é usada. |
| 3 | Senha CHAP | Resumo da senha do usuário para autenticação CHAP, presente apenas nos pacotes Access-Request quando a autenticação CHAP é usada. |
| 4 | Endereço IP do NAS | Endereço IP que o servidor usará para identificar o cliente. Normalmente, um cliente |
| Não. | Atributo | Descrição |
| é identificado pelo endereço IP de sua interface de acesso. Esse atributo está presente apenas nos pacotes Access-Request. | ||
| 5 | Porta NAS | Porta física do NAS que o usuário acessa. |
| 6 | Tipo de serviço | Tipo de serviço que o usuário solicitou ou tipo de serviço a ser fornecido. |
| 7 | Protocolo emoldurado | Protocolo de encapsulamento para acesso em estrutura. |
| 8 | Endereço IP emoldurado | Endereço IP atribuído ao usuário. |
| 11 | ID do filtro | Nome da lista de filtros. Esse atributo é analisado da seguinte forma:
|
| 12 | Emoldurado-MTU | MTU para o link de dados entre o usuário e o NAS. Por exemplo, esse atributo pode ser usado para definir o tamanho máximo dos pacotes EAP que podem ser processados na autenticação EAP 802.1X. |
| 14 | Login-IP-Host | Endereço IP da interface NAS que o usuário acessa. |
| 15 | Serviço de login | Tipo de serviço que o usuário usa para fazer login. |
| 18 | Mensagem de resposta | Texto a ser exibido para o usuário, que pode ser usado pelo servidor para comunicar informações, por exemplo, a causa da falha de autenticação. |
| 26 | Específico do fornecedor | Atributo proprietário específico do fornecedor. Um pacote pode conter um ou mais atributos proprietários, cada um dos quais pode conter um ou mais subatributos. |
| 27 | Tempo limite da sessão | Duração máxima do serviço para o usuário antes do encerramento da sessão. |
| 28 | Tempo limite de inatividade | Tempo ocioso máximo permitido para o usuário antes do encerramento da sessão. |
| 31 | Calling-Station-Id | Identificação do usuário que o NAS envia ao servidor. Para o serviço de acesso à LAN fornecido por um dispositivo Intelbras, esse atributo inclui o endereço MAC do usuário. |
| 32 | Identificador NAS | Identificação que o NAS usa para se identificar para o servidor RADIUS. |
| 40 | Tipo de status da conta | Tipo do pacote Accounting-Request. Os valores possíveis incluem:
|
| 45 | Conta autêntica | Método de autenticação usado pelo usuário. Os valores possíveis incluem:
|
| 60 | CHAP-Challenge | Desafio CHAP gerado pelo NAS para o cálculo MD5 durante a autenticação CHAP. |
| 61 | NAS-Port-Type | Tipo da porta física do NAS que está autenticando o usuário. Os valores possíveis incluem:
|
| 64 | Tipo túnel | Protocolos de tunelamento usados. O valor 13 representa VLAN. Se o valor for 13, o dispositivo interpretará os atributos Tunnel-Type, Tunnel-Medium-Type e Tunnel-Private-Group-ID como atributos para atribuir VLANs. |
| 65 | Tipo túnel-médio | Tipo de meio de transporte a ser usado para criar um túnel. Para atribuição de VLAN, o valor deve ser 6 para indicar a mídia 802 mais Ethernet. |
| 79 | Mensagem EAP | Usado para encapsular pacotes EAP para permitir que o RADIUS ofereça suporte à autenticação EAP. |
| 80 | Autenticador de mensagens | Usado para autenticação e verificação de pacotes de autenticação para evitar falsificação de Access-Requests. Esse atributo está presente quando a autenticação EAP é usada. |
| 81 | ID do grupo privado do túnel | ID do grupo para uma sessão de túnel. Para atribuir VLANs, o NAS transmite VLAN IDs usando esse atributo. |
| 87 | NAS-Port-Id | Cadeia de caracteres para descrever a porta do NAS que está autenticando o usuário. |
| 168 | Endereço IPv6 emoldurado | Endereço IPv6 atribuído pelo servidor para o NAS atribuir ao host. O endereço deve ser exclusivo. |
Apêndice C Subatributos RADIUS (ID de fornecedor 25506)
A Tabela 5 lista todos os subatributos RADIUS com ID de fornecedor 25506. O suporte a esses subatributos depende do modelo do dispositivo.
Tabela 5 Subatributos RADIUS (ID de fornecedor 25506)
| Não. | Subatributo | Descrição |
| 1 | Taxa de pico de entrada | Taxa de pico na direção do usuário para o NAS, em bps. |
| 2 | Taxa média de entrada | Taxa média na direção do usuário para o NAS, em bps. |
| 3 | Taxa básica de entrada | Taxa básica na direção do usuário para o NAS, em bps. |
| 4 | Taxa de pico de saída | Taxa de pico na direção do NAS para o usuário, em bps. |
| 5 | Taxa média de saída | Taxa média na direção do NAS para o usuário, em bps. |
| 6 | Taxa básica de saída | Taxa básica na direção do NAS para o usuário, em bps. |
| 15 | Remanent_Volume | Quantidade total de dados disponíveis para a conexão, em diferentes unidades para diferentes tipos de servidor. |
| 17 | ISP-ID | Domínio do ISP em que o usuário obtém informações de autorização. |
| 20 | Comando | Operação para a sessão, usada para o controle da sessão. Os valores possíveis incluem:
|
| 25 | Código de resultado | Resultado da operação Trigger-Request ou SetPolicy, zero para sucesso e qualquer outro valor para falha. |
| 26 | Connect_ID | Índice da conexão do usuário. |
| 27 | PortalURL | URL de redirecionamento do PADM atribuído a usuários PPPoE. |
| 28 | Ftp_Directory | Diretório de trabalho do usuário de FTP, SFTP ou SCP. Quando o cliente RADIUS atua como servidor FTP, SFTP ou SCP, esse atributo é usado para definir o diretório de trabalho de um usuário FTP, SFTP ou SCP no cliente RADIUS. |
| 29 | Exec_Privilege | Prioridade do usuário EXEC. |
| 32 | Endereço IP NAT | Endereço IP público atribuído ao usuário quando o endereço IP e a porta de origem são traduzidos. |
| 33 | NAT-Start-Port | Número da porta inicial do intervalo de portas atribuído ao usuário quando o endereço IP de origem e a porta são traduzidos. |
| 34 | Porta final NAT | Número da porta final do intervalo de portas atribuído ao usuário quando o endereço IP de origem e a porta são traduzidos. |
| 59 | NAS_Startup_Timestamp | Tempo de inicialização do NAS em segundos, representado pelo tempo decorrido após 00:00:00 em 1º de janeiro de 1970 (UTC). |
| 60 | Ip_Host_Addr | Endereço IP do usuário e endereço MAC incluídos nas solicitações de autenticação e contabilidade, no formato A.B.C.D hh:hh:hh:hh:hh:hh:hh. É necessário um espaço entre o endereço IP e o endereço MAC. |
| 61 | User_Notify | Informações que devem ser enviadas do servidor para o cliente de forma transparente. |
| 62 | Usuário_HeartBeat | Valor de hash atribuído depois que um usuário 802.1X passa pela autenticação, que é uma cadeia de 32 bytes. Esse atributo é armazenado na lista de usuários do NAS e verifica os pacotes de handshake do usuário 802.1X. Esse atributo só existe em Access-Accept e Pacotes Accounting-Request. |
| 98 | Grupo_de_recepção_multicast | Endereço IP do grupo multicast ao qual o host do usuário se junta como receptor. Esse subatributo pode aparecer várias vezes em um pacote multicast para indicar que o usuário pertence a vários grupos multicast. |
| 100 | IP6_Multicast_Receive_Group | Endereço IPv6 do grupo multicast ao qual o host do usuário se junta como receptor. Esse subatributo pode aparecer várias vezes em um pacote multicast para indicar que o usuário pertence a vários grupos multicast. |
| 101 | Limite de acesso MLD | Número máximo de grupos multicast MLD aos quais o usuário pode se associar simultaneamente. |
| 102 | nome local | Nome do túnel local L2TP. |
| 103 | Limite de acesso IGMP | Número máximo de grupos multicast IGMP aos quais o usuário pode se associar simultaneamente. |
| 104 | Instância VPN | Instância MPLS L3VPN à qual um usuário pertence. |
| 105 | Perfil da ANCP | Nome do perfil ANCP. |
| 135 | Cliente-Primário-DNS | Endereço IP do servidor DNS primário. |
| 136 | Cliente-Secundário-DNS | Endereço IP do servidor DNS secundário. |
| 140 | Grupo de usuários | Grupos de usuários atribuídos depois que o usuário passa pela autenticação. Normalmente, um usuário pode pertencer a apenas um grupo de usuários. |
| 144 | Acct_IPv6_Input_Octets | Bytes de pacotes IPv6 na direção de entrada. A unidade de medida depende da configuração do dispositivo. |
| 145 | Acct_IPv6_Output_Octets | Bytes de pacotes IPv6 na direção de saída. A unidade de medida depende da configuração do dispositivo. |
| 146 | Acct_IPv6_Input_Packets | Número de pacotes IPv6 na direção de entrada. A unidade de medida depende da configuração do dispositivo. |
| 147 | Acct_IPv6_Output_Packets | Número de pacotes IPv6 na direção de saída. A unidade de medida depende da configuração do dispositivo. |
| 148 | Acct_IPv6_Input_Gigawords | Bytes de pacotes IPv6 na direção de entrada. A unidade de medida é 4G bytes. |
| 149 | Acct_IPv6_Output_Gigawords | Bytes de pacotes IPv6 na direção de saída. A unidade de medida é 4G bytes. |
| 155 | Funções de usuário | Lista de funções de usuário separadas por espaço. |
| 210 | Av-Pair | Par de atributos definido pelo usuário. Os pares de atributos disponíveis incluem:
|
| outra ACL para o usuário. | ||
| 230 | Nome da porta NAS | Interface por meio da qual o usuário se conecta ao NAS. |
| 246 | Auth_Detail_Result | Detalhes da contabilidade. O servidor envia pacotes Access-Accept com os subatributos 246 e 250 nas seguintes situações:
|
| 247 | Tamanho da rajada de entrada comprometida | Tamanho da rajada comprometida do usuário para o NAS, em bits. O comprimento total não pode exceder 4 bytes para esse campo. Esse subatributo deve ser atribuído juntamente com o atributo Input-Average-Rate. |
| 248 | Tamanho da rajada de saída comprometida | Tamanho da rajada comprometida do NAS para o usuário, em bits. O comprimento total não pode exceder 4 bytes para esse campo. Esse subatributo deve ser atribuído juntamente com o atributo Output-Average-Rate. |
| 249 | tipo de autenticação | Tipo de autenticação. O valor pode ser:
|
| 250 | WEB-URL | URL de redirecionamento para usuários. |
| 251 | ID do assinante | ID do plano familiar. |
| 252 | Perfil do assinante | Nome da política de QoS para o plano familiar do assinante. |
| 255 | ID do produto | Nome do produto. |
Apêndice D Formato das ACLs de autorização dinâmica
O servidor pode atribuir uma ACL de autorização dinâmica que contenha várias regras a um usuário de diferentes maneiras:
O formato de uma regra de ACL dinâmica é o seguinte:
aclrule?same?acl-name?acl-type?ver-type?rule-id?protocol=protocol-type?counting?dst-ip=ip-addr
?src-ip=ip-addr?dst-port=port-value?src-port=port-value?action=action-type
Os campos da regra estão descritos na Tabela 6. A seguir, um exemplo de regra de ACL dinâmica: aclrule?same?test?1?1?1?protocol=3?counting?dst-ip=1.1.1.1/1.1.1.1?src-ip=1.1.1.1/0?dst-port=1
.2000?src-port=5.2000-3000?action=1
Tabela 6 Campos em uma regra de ACL dinâmica
| Campo | Descrição | Observações |
| aclrule | Indica que a parte a seguir contém informações sobre uma regra de ACL dinâmica. | Necessário. |
| mesmo | Indica que o usuário atual herdará as regras dinâmicas de ACL que foram atribuídas com êxito a outro usuário autenticado. Se o servidor atribuir a um usuário a mesma ACL dinâmica que outro usuário, mas as regras forem diferentes para os dois usuários, o dispositivo aplicará ao outro usuário as regras da ACL dinâmica do usuário que ficar on-line primeiro. | Necessário. |
| nome da acl | Nome da ACL, uma cadeia de caracteres sem distinção entre maiúsculas e minúsculas de 1 a 63 caracteres. O nome da ACL deve começar com uma letra e não pode ser todo ou igual a uma ACL estática existente no dispositivo. | Necessário. |
| tipo acl | Tipo de ACL. 1 indica uma ACL avançada. Na versão atual do software, somente as ACLs avançadas são compatíveis. | Necessário. |
| tipo ver | Tipo de protocolo IP:
|
Necessário. |
| ID da regra | Número da regra ACL, no intervalo de 0 a 65534. | Necessário. |
| tipo de protocolo | Tipo de protocolo:
|
Opcional. |
| contagem | Indica que as estatísticas de correspondência de regras estão ativadas. Se uma regra não incluir esse campo, as estatísticas de correspondência de regras estarão desativadas para a regra. | Opcional. |
| ip-addr | Informações de endereço IP. Por exemplo, 1.1.1.1/1.1.1.1, 1.1.1.1/0 ou 3::3/128. Se o valor for any, a regra corresponderá a qualquer endereço IP. | Opcional. |
| valor da porta | Informações da porta TCP ou UDP, no formato X.YYY.
|
Opcional. |
| tipo de ação | Tipo de ação:
|
Opcional. |
As restrições a seguir se aplicam às ACLs de autorização dinâmica:
- Para os seis primeiros campos (aclrule?same?acl-name?acl-type?ver-type?rule-id) de uma regra de ACL dinâmica, suas posições são fixas. O dispositivo não poderá interpretar uma regra de ACL dinâmica se as posições dos seis campos forem alteradas. Para os outros campos, são permitidas alterações de posição.
- As configurações de todos os campos nas regras devem atender à lógica de configuração das regras ACL no dispositivo para que o dispositivo possa interpretá-las corretamente.
- Todas as regras de ACL dinâmicas em uma autorização devem pertencer ao mesmo nome de ACL.
- Uma ACL dinâmica deve ter regras e o formato das regras deve ser válido.
Visão geral do 802.1X
Sobre o protocolo 802.1X
O 802.1X é um protocolo de controle de acesso à rede baseado em portas, amplamente utilizado em redes Ethernet. O protocolo controla o acesso à rede autenticando os dispositivos conectados às portas LAN habilitadas para 802.1X.
Arquitetura 802.1X
802.1X opera no modelo cliente/servidor. Conforme mostrado na Figura 1, a autenticação 802.1X inclui as seguintes entidades:
- Cliente (suplicante) - Um terminal de usuário que busca acesso à LAN. O terminal deve ter o software 802.1X para se autenticar no dispositivo de acesso.
- Dispositivo de acesso (autenticador) - Autentica o cliente para controlar o acesso à LAN. Em um ambiente 802.1X típico, o dispositivo de acesso usa um servidor de autenticação para realizar a autenticação.
- Servidor de autenticação - Fornece serviços de autenticação para o dispositivo de acesso. O servidor de autenticação primeiro autentica os clientes 802.1X usando os dados enviados pelo dispositivo de acesso. Em seguida, o servidor retorna os resultados da autenticação ao dispositivo de acesso para tomar decisões de acesso. Normalmente, o servidor de autenticação é um servidor RADIUS. Em uma LAN pequena, é possível usar o dispositivo de acesso como servidor de autenticação.
Figura 1 Arquitetura 802.1X
Porta controlada/não controlada e status de autorização da porta
802.1X define duas portas lógicas para a porta de acesso à rede: porta controlada e porta não controlada. Qualquer pacote que chegue à porta de acesso à rede é visível para ambas as portas lógicas.
- Porta não controlada - Está sempre aberta para receber e transmitir pacotes de autenticação.
- Porta controlada - filtra os pacotes dependendo do estado da porta.
- Estado autorizado - A porta controlada está no estado autorizado quando o cliente passa pela autenticação. A porta permite a passagem do tráfego.
- Estado não autorizado - A porta está em estado não autorizado quando o cliente falha na autenticação. A porta controla o tráfego usando um dos seguintes métodos:
- Executa o controle de tráfego bidirecional para negar o tráfego de e para o cliente.
- Executa o controle de tráfego unidirecional para negar o tráfego do cliente. O dispositivo suporta apenas o controle de tráfego unidirecional.
Figura 2 Estado de autorização de uma porta controlada
Métodos de troca de pacotes
O 802.1X usa o Extensible Authentication Protocol (EAP) para transportar informações de autenticação para o cliente, o dispositivo de acesso e o servidor de autenticação. O EAP é uma estrutura de autenticação que usa o modelo cliente/servidor. A estrutura oferece suporte a vários métodos de autenticação, incluindo MD5-Challenge, EAP-Transport Layer Security (EAP-TLS) e EAP protegido (PEAP).
O 802.1X define o EAP over LAN (EAPOL) para transmitir pacotes EAP entre o cliente e o dispositivo de acesso em uma LAN com ou sem fio. Entre o dispositivo de acesso e o servidor de autenticação, o 802.1X fornece informações de autenticação por meio de retransmissão EAP ou terminação EAP.
Retransmissão EAP
A retransmissão EAP é definida no IEEE 802.1X. Nesse modo, o dispositivo de rede usa pacotes EAP over RADIUS (EAPOR) para enviar informações de autenticação ao servidor RADIUS, conforme mostrado na Figura 3.
Figura 3 Retransmissão EAP
No modo de retransmissão EAP, o cliente deve usar o mesmo método de autenticação que o servidor RADIUS. No dispositivo de acesso, você só precisa usar o comando dot1x authentication-method eap para ativar a retransmissão EAP.
Encerramento do EAP
Conforme mostrado na Figura 4, o dispositivo de acesso executa as seguintes operações no modo de terminação EAP:
- Termina os pacotes EAP recebidos do cliente.
- Encapsula as informações de autenticação do cliente em pacotes RADIUS padrão.
- Usa PAP ou CHAP para autenticação no servidor RADIUS.
Figura 4 Encerramento do EAP
Comparação entre retransmissão e terminação de EAP
| Método de troca de pacotes | Benefícios | Limitações |
| Retransmissão EAP |
|
O servidor RADIUS deve ser compatível com o EAP-Message e o Atributos Message-Authenticator e o método de autenticação EAP usado pelo cliente. |
| Encerramento do EAP | Funciona com qualquer servidor RADIUS que ofereça suporte à autenticação PAP ou CHAP. |
|
Formatos de pacotes
Formato do pacote EAP
A Figura 5 mostra o formato do pacote EAP.
Figura 5 Formato do pacote EAP
Formato do pacote EAPOL
A Figura 6 mostra o formato do pacote EAPOL.
Figura 6 Formato do pacote EAPOL
Tabela 1 Tipos de pacotes EAPOL
| Valor | Tipo | Descrição |
| 0x00 | Pacote EAP | O cliente e o dispositivo de acesso usam pacotes EAP para transportar informações de autenticação. |
| 0x01 | EAPOL-Start | O cliente envia uma mensagem EAPOL-Start para iniciar a autenticação 802.1X no dispositivo de acesso. |
| 0x02 | EAPOL-Logoff | O cliente envia uma mensagem EAPOL-Logoff para informar ao dispositivo de acesso que o cliente está se desconectando. |
- Length - Comprimento dos dados em bytes ou comprimento do corpo do pacote. Se o tipo de pacote for EAPOL-Start ou EAPOL-Logoff, esse campo será definido como 0 e nenhum campo de corpo de pacote será seguido.
- Packet body (Corpo do pacote) - Conteúdo do pacote. Quando o tipo de pacote EAPOL é EAP-Packet, o campo Packet body (Corpo do pacote) contém um pacote EAP.
EAP sobre RADIUS
O RADIUS adiciona dois atributos, EAP-Message e Message-Authenticator, para dar suporte à autenticação EAP. Para conhecer o formato do pacote RADIUS, consulte "Configuração de AAA".
- Mensagem EAP.
O RADIUS encapsula os pacotes EAP no atributo EAP-Message, conforme mostrado na Figura 7. O campo Type tem 79 bytes e o campo Value pode ter até 253 bytes. Se um pacote EAP for maior que 253 bytes, o RADIUS o encapsula em vários atributos EAP-Message.
Figura 7 Formato do atributo EAP-Message
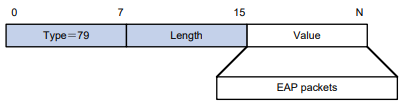
Conforme mostrado na Figura 8, o RADIUS inclui o atributo Message-Authenticator em todos os pacotes que têm um atributo EAP-Message para verificar sua integridade. O receptor do pacote descarta o pacote se a soma de verificação da integridade do pacote calculada for diferente do valor do atributo Message-Authenticator. O Message-Authenticator impede que os pacotes de autenticação EAP sejam adulterados durante a autenticação EAP.
Figura 8 Formato do atributo Message-Authenticator

Procedimentos de autenticação 802.1X
A autenticação 802.1X tem dois métodos: Retransmissão EAP e terminação EAP. Você escolhe um dos modos dependendo do suporte do servidor RADIUS para pacotes EAP e métodos de autenticação EAP.
Retransmissão EAP
A Figura 9 mostra o procedimento básico de autenticação 802.1X no modo de retransmissão EAP, supondo que a autenticação EAP MD5-Challenge seja usada.
Figura 9 Procedimento de autenticação 802.1X no modo de retransmissão EAP
As etapas a seguir descrevem o procedimento de autenticação 802.1X:
- Quando um usuário inicia o cliente 802.1X e digita um nome de usuário e uma senha registrados, o cliente 802.1X envia um pacote EAPOL-Start para o dispositivo de acesso.
- O dispositivo de acesso responde com um pacote EAP-Request/Identity para solicitar o nome de usuário do cliente .
- Em resposta ao pacote EAP-Request/Identity, o cliente envia o nome de usuário em um pacote EAP-Response/Identity para o dispositivo de acesso.
- O dispositivo de acesso retransmite o pacote EAP-Response/Identity em um pacote RADIUS Access-Request para o servidor de autenticação.
- O servidor de autenticação usa as informações de identidade no RADIUS Access-Request para pesquisar seu banco de dados de usuários. Se for encontrada uma entrada correspondente, o servidor usará um desafio gerado aleatoriamente (EAP-Request/MD5-Challenge) para criptografar a senha na entrada. Em seguida, o servidor envia o desafio em um pacote RADIUS Access-Challenge para o dispositivo de acesso.
- O dispositivo de acesso transmite o pacote EAP-Request/MD5-Challenge para o cliente.
- O cliente usa o desafio recebido para criptografar a senha e envia a senha criptografada em um pacote EAP-Response/MD5-Challenge para o dispositivo de acesso.
- O dispositivo de acesso retransmite o pacote EAP-Response/MD5-Challenge em um pacote RADIUS Access-Request para o servidor de autenticação.
- O servidor de autenticação compara a senha criptografada recebida com a senha criptografada gerada na etapa 5. Se as duas senhas forem idênticas, o servidor considerará o cliente válido e enviará um pacote RADIUS Access-Accept ao dispositivo de acesso.
- Ao receber o pacote RADIUS Access-Accept, o dispositivo de acesso executa as seguintes operações :
- Envia um pacote EAP-Success para o cliente.
- Define a porta controlada no estado autorizado.
- Depois que o cliente fica on-line, o dispositivo de acesso envia periodicamente solicitações de handshake para verificar se o cliente ainda está on-line. Por padrão, se duas tentativas consecutivas de handshake falharem, o dispositivo faz o logoff do cliente.
- Ao receber uma solicitação de handshake, o cliente retorna uma resposta. Se o cliente não retornar uma resposta após um número de tentativas consecutivas de handshake (duas por padrão), o dispositivo de acesso fará o logoff do cliente. Esse mecanismo de handshake permite a liberação oportuna dos recursos de rede usados pelos usuários do 802.1X que ficaram off-line de forma anormal.
- O cliente também pode enviar um pacote EAPOL-Logoff para solicitar um logoff ao dispositivo de acesso.
- Em resposta ao pacote EAPOL-Logoff, o dispositivo de acesso altera o status da porta controlada de autorizada para não autorizada. Em seguida, o dispositivo de acesso envia um pacote EAP-Failure para o cliente.
O cliente pode acessar a rede.
Encerramento do EAP
A Figura 10 mostra o procedimento básico de autenticação 802.1X no modo de terminação EAP, supondo que a autenticação CHAP seja usada.
Figura 10 Procedimento de autenticação 802.1X no modo de terminação EAP
No modo de terminação EAP, o dispositivo de acesso, e não o servidor de autenticação, gera um desafio MD5 para criptografia de senha. Em seguida, o dispositivo de acesso envia o desafio MD5 juntamente com o nome de usuário e a senha criptografada em um pacote RADIUS padrão para o servidor RADIUS.
Início da autenticação 802.1X
Tanto o cliente 802.1X quanto o dispositivo de acesso podem iniciar a autenticação 802.1X.
801.2X cliente como iniciador
O cliente envia um pacote EAPOL-Start para o dispositivo de acesso para iniciar a autenticação 802.1X. O endereço MAC de destino do pacote é o endereço multicast especificado pelo IEEE 802.1X 01-80-C2-00-00-03 ou o endereço MAC de difusão. Se qualquer dispositivo intermediário entre o cliente e o servidor de autenticação não for compatível com o endereço multicast, você deverá usar um cliente 802.1X que possa enviar pacotes EAPOL-Start de difusão. Por exemplo, você pode usar o cliente iNode 802.1X.
Dispositivo de acesso como iniciador
Se o cliente não puder enviar pacotes EAPOL-Start, configure o dispositivo de acesso para iniciar a autenticação. Um exemplo é o cliente 802.1X disponível no Windows XP.
O dispositivo de acesso é compatível com os seguintes modos:
- Modo de acionamento de multicast - O dispositivo de acesso envia pacotes EAP-Request/Identity por multicast para iniciar a autenticação 802.1X no intervalo de solicitação de identidade.
- Modo de disparo unicast - Ao receber um quadro de um endereço MAC desconhecido, o dispositivo de acesso envia um pacote EAP-Request/Identity da porta de recepção para o endereço MAC. O dispositivo retransmite o pacote se nenhuma resposta for recebida dentro do intervalo de tempo limite da solicitação de identidade. Esse processo continua até que seja atingido o número máximo de tentativas de solicitação definido com o uso do comando dot1x retry.
O temporizador de tempo limite de solicitação de nome de usuário define o intervalo de solicitação de identidade para o acionador multicast e o intervalo de tempo limite de solicitação de identidade para o acionador unicast.
Métodos de controle de acesso
A Intelbras implementa o controle de acesso baseado em portas, conforme definido no protocolo 802.1X, e amplia o protocolo para oferecer suporte ao controle de acesso baseado em MAC.
- Controle de acesso baseado em porta - Quando um usuário 802.1X passa pela autenticação em uma porta, qualquer usuário subsequente pode acessar a rede pela porta sem autenticação. Quando o usuário autenticado faz logoff, todos os outros usuários são desconectados.
- Controle de acesso baseado em MAC - Cada usuário é autenticado separadamente em uma porta. Quando um usuário faz logoff, nenhum outro usuário on-line é afetado.
801.2X Manipulação de VLAN
VLAN de autorização
A VLAN de autorização controla o acesso de um usuário 802.1X a recursos de rede autorizados. O dispositivo é compatível com VLANs de autorização atribuídas localmente ou por um servidor remoto.
IMPORTANTE:
Somente servidores remotos podem atribuir VLANs de autorização marcadas.
Autorização de VLAN remota
Na autorização de VLAN remota, é necessário configurar uma VLAN de autorização para um usuário no servidor remoto. Depois que o usuário se autentica no servidor, o servidor atribui informações de VLAN de autorização ao dispositivo. Em seguida, o dispositivo atribui a porta de acesso do usuário à VLAN de autorização como um membro marcado ou não marcado.
O dispositivo suporta a atribuição das seguintes informações de VLAN de autorização pelo servidor remoto:
- VLAN ID.
- Nome da VLAN, que deve ser o mesmo que a descrição da VLAN no dispositivo de acesso.
- Uma cadeia de VLAN IDs e nomes de VLAN.
Na cadeia de caracteres, algumas VLANs são representadas por seus IDs e algumas VLANs são representadas por seus nomes.
- Nome do grupo de VLAN.
Para obter mais informações sobre grupos de VLAN, consulte o Layer 2-LAN Switching Configuration Guide.
- VLAN ID com um sufixo de t ou u.
Os sufixos t e u exigem que o dispositivo atribua a porta de acesso à VLAN como um membro marcado ou não marcado, respectivamente. Por exemplo, 2u indica a atribuição da porta à VLAN 2 como um membro sem marcação.
Se um nome de VLAN ou um nome de grupo de VLAN for atribuído, o dispositivo converterá as informações em uma VLAN ID antes da atribuição da VLAN.
IMPORTANTE:
Para que uma VLAN representada por seu nome de VLAN seja atribuída com êxito, você deve se certificar de que a VLAN foi criada no dispositivo.
Para atribuir VLAN IDs com sufixos, certifique-se de que a porta de acesso do usuário seja uma porta híbrida ou tronco que execute o controle de acesso baseado em porta.
Para garantir uma atribuição bem-sucedida, as VLANs de autorização atribuídas pelo servidor remoto não podem ser de nenhum dos tipos a seguir:
- VLANs aprendidas dinamicamente.
- VLANs reservadas.
- VLANs privadas.
Se o servidor atribuir um grupo de VLANs, o dispositivo de acesso selecionará uma VLAN conforme descrito na Tabela 2.
Tabela 2 Seleção de VLAN de autorização em um grupo de VLANs
| Informações sobre VLAN | Seleção de VLAN de autorização |
|
IDs de VLAN Nomes de VLAN Nome do grupo de VLAN IDs de VLAN e nomes de VLAN |
Se a porta habilitada para 802.1X executar o controle de acesso baseado em MAC, o dispositivo selecionará uma VLAN de autorização do grupo de VLANs para um usuário de acordo com as regras a seguir:
|
| VLAN IDs com sufixos |
|
Na versão 6318P01 e posteriores, o dispositivo inclui o atributo User-VLAN-ID nas solicitações de contabilidade RADIUS para informar o servidor RADIUS sobre a VLAN de autorização atribuída aos usuários 802.1X. O servidor RADIUS pode então incluir informações sobre a VLAN de autorização do usuário em seus registros sobre usuários 802.1X.
- Se o servidor RADIUS atribuir uma VLAN ID ou um nome de VLAN como a VLAN de autorização para um usuário, o dispositivo incluirá a VLAN de autorização atribuída pelo servidor no atributo User-VLAN-ID.
- Se o servidor RADIUS atribuir um grupo de VLANs nas informações da VLAN de autorização a um usuário, o dispositivo incluirá uma VLAN no atributo User-VLAN-ID, conforme descrito na Tabela 3.
Tabela 3 Inclusão de uma VLAN no atributo User-VLAN-ID dos pacotes de contabilidade RADIUS
| Informações sobre VLAN | VLAN no atributo User-VLAN-ID |
|
IDs de VLAN Nomes de VLAN Nome do grupo de VLAN IDs de VLAN e nomes de VLAN |
|
| VLAN IDs com sufixos | O dispositivo inclui a VLAN de autorização sem marcação no atributo User-VLAN-ID nos pacotes de solicitação de contabilidade RADIUS. Se não houver nenhuma VLAN de autorização untagged disponível, o dispositivo incluirá a VLAN inicial do usuário no atributo User-VLAN-ID nos pacotes de solicitação de contabilidade RADIUS. |
Autorização de VLAN local
Para executar a autorização de VLAN local para um usuário, especifique a VLAN ID na lista de atributos de autorização da conta de usuário local para esse usuário. Para cada usuário local, é possível especificar apenas um ID de VLAN de autorização. A porta de acesso do usuário é atribuída à VLAN como um membro não marcado.
IMPORTANTE:
A autorização de VLAN local não é compatível com a atribuição de VLANs marcadas.
Para obter mais informações sobre a configuração do usuário local, consulte "Configuração de AAA".
Manipulação de VLAN de autorização em uma porta habilitada para 802.1X
A Tabela 4 descreve como o dispositivo de acesso lida com as VLANs (exceto as VLANs especificadas com sufixos) em uma porta habilitada para 802.1X.
Tabela 4 Manipulação de VLAN
| Método de controle de acesso à porta | Manipulação de VLAN |
| Baseado em portas | O dispositivo atribui a porta à VLAN de autorização do primeiro usuário autenticado. Todos os usuários 802.1X subsequentes podem acessar a VLAN sem autenticação. Se a VLAN de autorização tiver o atributo untagged, o dispositivo atribuirá a porta à VLAN de autorização como um membro untagged e definirá a VLAN como o PVID. Se a VLAN de autorização tiver o atributo marcado, o dispositivo atribuirá a porta à VLAN como um membro marcado sem alterar o PVID. OBSERVAÇÃO: O atributo tagged é compatível apenas com portas tronco e híbridas. |
| Baseado em MAC | Em uma porta híbrida com a VLAN baseada em MAC ativada, o dispositivo mapeia o endereço MAC de cada usuário para sua própria VLAN de autorização. O PVID da porta não é alterado. Em uma porta híbrida de acesso, tronco ou VLAN baseada em MAC desativada:
|
IMPORTANTE:
- Se os usuários estiverem conectados a uma porta cujo tipo de link seja de acesso, certifique-se de que a VLAN de autorização atribuída pelo servidor tenha o atributo untagged. A atribuição de VLAN falhará se o servidor emitir uma VLAN que tenha o atributo tagged.
- Ao atribuir VLANs a usuários conectados a uma porta trunk ou a uma porta híbrida desativada por VLAN baseada em MAC, certifique-se de que haja apenas uma VLAN sem marcação. Se uma VLAN untagged diferente for atribuída a um usuário subsequente, o usuário não poderá passar na autenticação.
- Como prática recomendada para aumentar a segurança da rede, não use o comando port hybrid vlan para atribuir uma porta híbrida a uma VLAN de autorização como um membro marcado.
A VLAN atribuída pelo servidor a um usuário como uma VLAN de autorização pode ter sido configurada na porta de acesso do usuário, mas com um modo de marcação diferente. Por exemplo, o servidor atribui uma VLAN de autorização com o atributo tagged, mas a mesma VLAN configurada na porta tem o atributo untagged. Nessa situação, as configurações de VLAN que entram em vigor para o usuário dependem do tipo de link da porta.
- Se o tipo de link da porta for acesso ou tronco, as configurações de VLAN de autorização atribuídas pelo servidor sempre terão efeito sobre o usuário enquanto ele estiver on-line. Depois que o usuário fica off-line, as configurações de VLAN na porta entram em vigor.
- Se o tipo de link da porta for híbrido, as configurações de VLAN definidas na porta terão efeito. Por exemplo, o servidor atribui a VLAN 30 com o atributo untagged a um usuário na porta híbrida. No entanto, a VLAN 30 foi configurada na porta com o atributo tagged usando o comando port hybrid vlan tagged. Finalmente, a VLAN tem o atributo marcado na porta.
Para que um usuário autenticado pelo 802.1X acesse a rede em uma porta híbrida quando nenhuma VLAN de autorização estiver configurada para o usuário, execute uma das seguintes tarefas:
- Se a porta receber pacotes de autenticação com tags do usuário em uma VLAN, use o comando port hybrid vlan para configurar a porta como um membro com tags na VLAN.
- Se a porta receber pacotes de autenticação untagged do usuário em uma VLAN, use o comando port hybrid vlan para configurar a porta como um membro untagged na VLAN.
Em uma porta com a reautenticação periódica de usuário on-line ativada, o recurso de VLAN baseada em MAC não entra em vigor para um usuário que esteja on-line desde antes da ativação desse recurso. O dispositivo de acesso cria um mapeamento de MAC para VLAN para o usuário quando os seguintes requisitos são atendidos:
- O usuário é aprovado na reautenticação.
- A VLAN de autorização do usuário é alterada.
Para obter mais informações sobre a configuração de VLAN e VLANs baseadas em MAC, consulte o Layer 2-LAN Switching Configuration Guide.
VLAN de convidado
A VLAN de convidado 802.1X em uma porta acomoda usuários que não realizaram a autenticação 802.1X. Os usuários da VLAN guest podem acessar um conjunto limitado de recursos de rede, como um servidor de software, para fazer download de software antivírus e patches do sistema. Quando um usuário na VLAN de convidado passa pela autenticação 802.1X, ele é removido da VLAN de convidado e pode acessar recursos de rede autorizados.
O dispositivo de acesso lida com VLANs em uma porta habilitada para 802.1X com base em seu método de controle de acesso 802.1X.
Controle de acesso baseado em portas
| Status de autenticação | Manipulação de VLAN |
| Um usuário acessa a porta habilitada para 802.1X quando a porta está no estado automático. | O dispositivo atribui a porta à VLAN de convidado 802.1X. Todos os usuários 802.1X nessa porta podem acessar apenas os recursos da VLAN de convidados. A atribuição da VLAN de convidado varia de acordo com o modo de link de porta. Para obter mais informações, consulte a Tabela 4 em "VLAN de autorização". |
| Um usuário na VLAN de convidado 802.1X falha na autenticação 802.1X. | Se uma VLAN 802.1X Auth-Fail estiver disponível, o dispositivo atribuirá a porta à VLAN Auth-Fail. Todos os usuários dessa porta podem acessar apenas os recursos da VLAN Auth-Fail. Se nenhuma VLAN Auth-Fail estiver configurada, a porta ainda estará na VLAN de convidado 802.1X. Todos os usuários da porta estão na VLAN de convidado. Para obter informações sobre a VLAN 802.1X Auth-Fail, consulte "VLAN Auth-Fail". |
| Um usuário na VLAN de convidado 802.1X passa pela autenticação 802.1X. | O dispositivo remove a porta da VLAN de convidado 802.1X e atribui a porta à VLAN de autorização do usuário. Se o servidor de autenticação não atribuir uma VLAN de autorização, aplica-se o PVID inicial da porta. O usuário e todos os usuários 802.1X subsequentes são atribuídos à VLAN inicial da porta. Depois que o usuário faz logoff, a porta é atribuída novamente à VLAN de convidado. OBSERVAÇÃO: O PVID inicial de uma porta habilitada para 802.1X refere-se ao PVID usado pela porta antes de ela ser atribuída a qualquer VLAN 802.1X. |
IMPORTANTE:
Quando a porta recebe um pacote com uma tag de VLAN, o pacote será encaminhado dentro da VLAN marcada se a VLAN não for a VLAN de convidado.
Controle de acesso baseado em MAC
| Status de autenticação | Manipulação de VLAN |
| Um usuário acessa a porta habilitada para 802.1X e não realizou a autenticação 802.1X. | O dispositivo cria um mapeamento entre o endereço MAC do usuário e a VLAN de convidado 802.1X. O usuário pode acessar apenas os recursos da VLAN de convidado. |
| Um usuário na VLAN de convidado 802.1X falha na autenticação 802.1X. | Se uma VLAN 802.1X Auth-Fail estiver disponível, o dispositivo remapeará o endereço MAC do usuário para a VLAN Auth-Fail. O usuário pode acessar apenas os recursos da VLAN Auth-Fail. Se nenhuma VLAN 802.1X Auth-Fail estiver configurada, o usuário será removido da VLAN guest e adicionado ao PVID inicial. |
| Um usuário na VLAN de convidado 802.1X passa pela autenticação 802.1X. | O dispositivo remapeia o endereço MAC do usuário para a VLAN de autorização. Se o servidor de autenticação não atribuir uma VLAN de autorização, o dispositivo remapeia o endereço MAC do usuário para o PVID inicial na porta. |
Auth-Fail VLAN
A VLAN 802.1X Auth-Fail em uma porta acomoda os usuários que falharam na autenticação 802.1X por não estarem em conformidade com a estratégia de segurança da organização. Por exemplo, a VLAN acomoda usuários que digitaram uma senha incorreta. Os usuários da VLAN Auth-Fail podem acessar um conjunto limitado de recursos de rede, como um servidor de software, para fazer download de software antivírus e patches de sistema.
O dispositivo de acesso lida com VLANs em uma porta habilitada para 802.1X com base em seu método de controle de acesso 802.1X.
Controle de acesso baseado em portas
| Status de autenticação | Manipulação de VLAN |
| Um usuário acessa a porta e falha na autenticação 802.1X. | O dispositivo atribui a porta à VLAN Auth-Fail. Todos os usuários 802.1X nessa porta podem acessar apenas os recursos da VLAN Auth-Fail. A atribuição da VLAN Auth-Fail varia de acordo com o modo de link da porta. Para obter mais informações, consulte a Tabela 4 em "VLAN de autorização". |
| Um usuário na rede 802.1X Auth-Fail A VLAN falha na autenticação 802.1X. | A porta ainda está na VLAN Auth-Fail, e todos os usuários 802.1X dessa porta estão nessa VLAN. |
| Um usuário na VLAN 802.1X Auth-Fail passa na autenticação 802.1X. | O dispositivo atribui a porta à VLAN de autorização do usuário e remove a porta da VLAN Auth-Fail. Se o servidor de autenticação não atribuir uma VLAN de autorização, será aplicado o PVID inicial da porta. O usuário e todos os usuários 802.1X subsequentes são atribuídos ao PVID inicial. Depois que o usuário faz logoff, a porta é atribuída à VLAN de convidado. Se nenhuma VLAN de convidado estiver configurada, a porta será atribuída ao PVID inicial da porta. |
Controle de acesso baseado em MAC
| Status de autenticação | Manipulação de VLAN |
| Um usuário acessa a porta e falha na autenticação 802.1X. | O dispositivo mapeia o endereço MAC do usuário para a VLAN 802.1X Auth-Fail. O usuário pode acessar apenas os recursos da VLAN Auth-Fail. |
| Um usuário na rede 802.1X Auth-Fail A VLAN falha na autenticação 802.1X. | O usuário ainda está na VLAN Auth-Fail. |
| Um usuário na VLAN 802.1X Auth-Fail passa na autenticação 802.1X. | O dispositivo remapeia o endereço MAC do usuário para a VLAN de autorização. Se o servidor de autenticação não atribuir uma VLAN de autorização, o dispositivo remapeia o endereço MAC do usuário para o PVID inicial na porta. |
VLAN crítica
A VLAN crítica 802.1X em uma porta acomoda usuários 802.1X que falharam na autenticação porque nenhum dos servidores RADIUS em seu domínio ISP está acessível. Os usuários da VLAN crítica podem acessar um conjunto limitado de recursos de rede, dependendo da configuração.
O recurso de VLAN crítica entra em vigor quando a autenticação 802.1X é realizada somente por meio de servidores RADIUS. Se um usuário 802.1X falhar na autenticação local após a autenticação RADIUS, o usuário não será atribuído à VLAN crítica. Para obter mais informações sobre os métodos de autenticação, consulte "Configuração de AAA".
O dispositivo de acesso lida com VLANs em uma porta habilitada para 802.1X com base em seu método de controle de acesso 802.1X.
Controle de acesso baseado em portas
| Status de autenticação | Manipulação de VLAN |
| Um usuário acessa a porta e falha na autenticação 802.1X porque todos os servidores RADIUS estão inacessíveis. | O dispositivo atribui a porta à VLAN crítica. O usuário 802.1X e todos os usuários 802.1X subsequentes nessa porta podem acessar apenas os recursos da VLAN crítica 802.1X. A atribuição da VLAN crítica varia de acordo com o modo de link da porta. Para obter mais informações, consulte a Tabela 4 em "VLAN de autorização". |
| Um usuário na VLAN crítica 802.1X falha na autenticação porque todos os servidores RADIUS estão inacessíveis. | A porta ainda está na VLAN crítica. |
| Um usuário na VLAN crítica 802.1X falha na autenticação por qualquer motivo que não seja servidores inacessíveis. | Se uma VLAN 802.1X Auth-Fail tiver sido configurada, a porta será atribuída à VLAN Auth-Fail. Se nenhuma VLAN 802.1X Auth-Fail estiver configurada, a porta será atribuída ao PVID inicial da porta. |
| Um usuário na VLAN crítica 802.1X passa na autenticação 802.1X. | O dispositivo atribui a porta à VLAN de autorização do usuário e remove a porta da VLAN crítica 802.1X. Se o servidor de autenticação não atribuir uma VLAN de autorização, aplica-se o PVID inicial da porta. O usuário e todos os usuários 802.1X subsequentes são atribuídos a essa VLAN da porta. Depois que o usuário faz logoff, a porta é atribuída à VLAN de convidado. Se nenhuma VLAN de convidado 802.1X estiver configurada, o PVID inicial da porta será restaurado. |
| Um usuário na VLAN de convidado 802.1X falha na autenticação porque todos os servidores RADIUS estão inacessíveis. | O dispositivo atribui a porta à VLAN crítica 802.1X, e todos os usuários 802.1X dessa porta estão nessa VLAN. |
| Um usuário na VLAN 802.1X Auth-Fail falha na autenticação porque todos os servidores RADIUS estão inacessíveis. | A porta ainda está na VLAN 802.1X Auth-Fail. Todos os usuários do 802.1X nessa porta podem acessar apenas os recursos da VLAN 802.1X Auth-Fail. |
| Um usuário que passou na autenticação falha na reautenticação porque todos os servidores RADIUS estão inacessíveis, e o usuário é desconectado do dispositivo. | O dispositivo atribui a porta à VLAN crítica 802.1X. |
Se a porta for adicionada à VLAN crítica porque não há servidores RADIUS acessíveis, o dispositivo executará as seguintes operações depois de detectar um servidor RADIUS acessível:
- Remove a porta da VLAN crítica.
- Envia uma mensagem multicast EAP-Request/Identity da porta para acionar a autenticação.
Controle de acesso baseado em MAC
| Status de autenticação | Manipulação de VLAN |
| Um usuário acessa a porta e falha na autenticação 802.1X porque todos os servidores RADIUS estão inacessíveis. | O dispositivo mapeia o endereço MAC do usuário para a VLAN crítica 802.1X. O usuário pode acessar apenas os recursos da VLAN crítica 802.1X. |
| Um usuário na VLAN crítica 802.1X falha na autenticação porque todos os servidores RADIUS estão inacessíveis. | O usuário ainda está na VLAN crítica. |
| Um usuário na VLAN crítica 802.1X falha na autenticação 802.1X por qualquer motivo que não seja servidores inacessíveis. | Se uma VLAN 802.1X Auth-Fail tiver sido configurada, o dispositivo remapeará o endereço MAC do usuário para a ID da VLAN Auth-Fail. Se nenhuma VLAN 802.1X Auth-Fail tiver sido configurada, o dispositivo remapeia o endereço MAC do usuário para o PVID inicial. |
| Um usuário na VLAN crítica 802.1X passa na autenticação 802.1X. | O dispositivo remapeia o endereço MAC do usuário para a VLAN de autorização. Se o servidor de autenticação não atribuir uma VLAN de autorização ao usuário, o dispositivo remapeia o endereço MAC do usuário para o PVID inicial na porta. |
| Um usuário na VLAN de convidado 802.1X falha na autenticação porque todos os servidores RADIUS estão inacessíveis. | O dispositivo remapeia o endereço MAC do usuário para a VLAN crítica 802.1X. O usuário pode acessar apenas os recursos da VLAN crítica 802.1X. |
| Um usuário na VLAN 802.1X Auth-Fail falha na autenticação porque todos os servidores RADIUS estão inacessíveis. | O usuário permanece na VLAN 802.1X Auth-Fail. |
Se um usuário for adicionado à VLAN crítica porque não há servidores RADIUS acessíveis, o dispositivo executará as seguintes operações depois de detectar um servidor RADIUS acessível:
- Remove o usuário da VLAN crítica.
- Envia uma mensagem unicast EAP-Request/Identity da porta para o usuário para reautenticação.
VLAN de voz crítica
A VLAN de voz crítica 802.1X em uma porta acomoda usuários de voz 802.1X que falharam na autenticação porque nenhum dos servidores RADIUS em seu domínio ISP está acessível.
O recurso de VLAN de voz crítica entra em vigor quando a autenticação 802.1X é realizada somente por meio de servidores RADIUS. Se um usuário de voz 802.1X falhar na autenticação local após a autenticação RADIUS, o usuário de voz não será atribuído à VLAN de voz crítica. Para obter mais informações sobre os métodos de autenticação, consulte "Configuração de AAA".
Quando um servidor RADIUS acessível é detectado, o dispositivo executa operações em uma porta com base em seu método de controle de acesso 802.1X.
Controle de acesso baseado em portas
Quando um servidor RADIUS acessível é detectado, o dispositivo remove a porta da VLAN de voz crítica. A porta envia um pacote multicast EAP-Request/Identity a todos os usuários de voz 802.1X na porta para acionar a autenticação.
Controle de acesso baseado em MAC
Quando um servidor RADIUS acessível é detectado, o dispositivo remove os usuários de voz 802.1X da VLAN de voz crítica. A porta envia um pacote unicast EAP-Request/Identity para cada usuário de voz 802.1X que foi atribuído à VLAN de voz crítica para acionar a autenticação.
Atribuição de ACL
É possível especificar uma ACL para um usuário 802.1X no servidor de autenticação para controlar o acesso do usuário aos recursos da rede. Depois que o usuário passa pela autenticação 802.1X, o servidor de autenticação atribui a ACL à porta de acesso do usuário. Em seguida, a porta permite ou rejeita o tráfego correspondente para o usuário, dependendo das regras configuradas na ACL. Essa ACL é chamada de ACL de autorização.
O dispositivo suporta a atribuição de ACLs estáticas e dinâmicas como ACLs de autorização.
- ACLs estáticas - As ACLs estáticas podem ser atribuídas por um servidor RADIUS ou pelo dispositivo de acesso. Quando o servidor ou o dispositivo de acesso atribui uma ACL estática a um usuário, ele atribui apenas o número da ACL. Você deve criar manualmente a ACL e configurar suas regras no dispositivo de acesso.
- Modificar as regras de ACL na ACL de autorização no dispositivo de acesso.
- Atribua outra ACL ao usuário a partir do servidor RADIUS ou do dispositivo de acesso.
- ACLs dinâmicas - As ACLs dinâmicas e suas regras são implantadas automaticamente por um servidor RADIUS e não podem ser configuradas no dispositivo de acesso. As ACLs dinâmicas só podem ser ACLs nomeadas. Depois que o dispositivo recebe uma ACL dinâmica implantada pelo servidor e suas regras, ele cria automaticamente a ACL e configura suas regras.
Para alterar as permissões de acesso de um usuário, você pode usar um dos métodos a seguir:
As ACLs estáticas e suas regras podem ser excluídas manualmente do dispositivo de acesso.
Se a ACL dinâmica atribuída pelo servidor a um usuário tiver o mesmo nome de uma ACL estática, a ACL dinâmica não poderá ser emitida e o usuário não poderá ficar on-line.
Uma ACL dinâmica e suas regras são automaticamente excluídas do dispositivo de acesso depois que todos os seus usuários ficam off-line.
As ACLs dinâmicas e suas regras não podem ser modificadas ou excluídas manualmente no dispositivo de acesso. Para exibir informações sobre as ACLs dinâmicas e suas regras, use o comando display dot1x connection ou display acl.
IMPORTANTE:
A atribuição de ACLs dinâmicas é compatível apenas com a versão 6309P01 ou posterior.
As ACLs de autorização compatíveis incluem os seguintes tipos:
- ACLs básicas, que são numeradas no intervalo de 2000 a 2999.
- ACLs avançadas, que são numeradas no intervalo de 3000 a 3999.
- ACLs de camada 2, que são numeradas no intervalo de 4000 a 4999.
IMPORTANTE:
Para que uma ACL de autorização tenha efeito, certifique-se de que a ACL exista com regras e que nenhuma das regras contenha a palavra-chave counting, established, fragment, source-mac ou logging.
Para obter mais informações sobre ACLs, consulte o Guia de configuração de ACL e QoS.
Atribuição de perfil de usuário
É possível especificar um perfil de usuário para um usuário 802.1X no servidor de autenticação para controlar o acesso do usuário aos recursos da rede. Depois que o usuário passa pela autenticação 802.1X, o servidor de autenticação atribui o perfil de usuário ao usuário para filtrar o tráfego.
O servidor de autenticação pode ser o dispositivo de acesso local ou um servidor RADIUS. Em ambos os casos, o servidor especifica apenas o nome do perfil de usuário. Você deve configurar o perfil de usuário no dispositivo de acesso.
Para alterar as permissões de acesso do usuário, você pode usar um dos métodos a seguir:
- Modifique a configuração do perfil de usuário no dispositivo de acesso.
- Especifique outro perfil de usuário para o usuário no servidor de autenticação. Para obter mais informações sobre perfis de usuário, consulte "Configuração de perfis de usuário".
Atribuição de URL de redirecionamento
O dispositivo é compatível com o atributo de URL atribuído por um servidor RADIUS quando a porta habilitada para 802.1X executa o controle de acesso baseado em MAC e o estado de autorização da porta é automático. Durante a autenticação, as solicitações HTTP ou HTTPS de um usuário 802.1X são redirecionadas para a interface da Web especificada pelo atributo de URL atribuído pelo servidor. Depois que o usuário passa pela autenticação na Web, o servidor RADIUS registra o endereço MAC do usuário e usa uma DM (Disconnect Message) para fazer logoff do usuário. Quando o usuário iniciar a autenticação 802.1X novamente, ele será aprovado na autenticação e ficará on-line com êxito.
Esse recurso é mutuamente exclusivo do recurso de assistente de EAD.
Por padrão, o dispositivo escuta a porta 6654 para solicitações HTTPS a serem redirecionadas. Para alterar o número da porta de escuta do redirecionamento, consulte Configuração do redirecionamento de HTTP no Guia de configuração de serviços de camada 3 IP.
Reautenticação 802.1X periódica
A reautenticação periódica do 802.1X rastreia o status da conexão dos usuários on-line e atualiza os atributos de autorização (como ACL e VLAN) atribuídos pelo servidor.
O dispositivo reautentica os usuários 802.1X on-line no intervalo de reautenticação periódica quando o recurso de reautenticação periódica on-line do usuário está ativado. O intervalo é controlado por um timer, que pode ser configurado pelo usuário. Uma alteração no temporizador de reautenticação periódica aplica-se aos usuários on-line somente depois que o temporizador antigo expirar e os usuários forem aprovados na autenticação.
O temporizador de tempo limite da sessão atribuído pelo servidor (atributo Session-Timeout) e a ação de encerramento (atributo Termination-Action) juntos podem afetar o recurso de reautenticação periódica do usuário on-line. Para exibir os atributos Session-Timeout e Termination-Action atribuídos pelo servidor, use o comando display dot1x connection (consulte Referência de comandos de segurança).
- Se a ação de encerramento for Padrão (logoff), a reautenticação periódica on-line do usuário no dispositivo entrará em vigor somente quando o temporizador de reautenticação periódica for menor do que o temporizador de tempo limite da sessão.
- Se a ação de encerramento for Radius-request, as configurações de reautenticação periódica do usuário on-line no dispositivo não terão efeito. O dispositivo reautentica os usuários 802.1X on-line após a expiração do temporizador de tempo limite da sessão.
Se nenhum temporizador de tempo limite de sessão for atribuído pelo servidor, o fato de o dispositivo executar ou não a reautenticação periódica do 802.1X dependerá da configuração de reautenticação periódica no dispositivo. O suporte para a atribuição dos atributos Session-Timeout e Termination-Action depende do modelo do servidor.
Com o recurso RADIUS DAS ativado, o dispositivo reautentica imediatamente um usuário ao receber uma mensagem CoA que contém o atributo de reautenticação de um servidor de autenticação RADIUS. Nesse caso, a reautenticação será executada independentemente do fato de a reautenticação periódica 802.1X estar ativada no dispositivo. Para obter mais informações sobre a configuração do RADIUS DAS, consulte "Configuração de AAA".
Por padrão, o dispositivo faz logoff dos usuários 802.1X on-line se nenhum servidor estiver acessível para a reautenticação 802.1X. O recurso keep-online mantém os usuários 802.1X autenticados on-line quando nenhum servidor está acessível para a reautenticação 802.1X.
As VLANs atribuídas a um usuário on-line antes e depois da reautenticação podem ser iguais ou diferentes.
Assistente de EAD
O Endpoint Admission Defense (EAD) é uma solução integrada de controle de acesso a endpoints da Intelbras para melhorar a capacidade de defesa contra ameaças de uma rede. A solução permite que o cliente de segurança, o servidor de política de segurança, o dispositivo de acesso e o servidor de terceiros operem juntos. Se um dispositivo terminal quiser acessar uma rede EAD, ele deverá ter um cliente EAD, que executa a autenticação 802.1X.
O recurso de assistente de EAD permite que o dispositivo de acesso redirecione as solicitações HTTP ou HTTPS de um usuário para um URL de redirecionamento para download e instalação de um cliente EAD. Esse recurso elimina a tarefa administrativa de implantar clientes EAD.
Aplicavel somente a Serie S3300G
O assistente de EAD é implementado pela seguinte funcionalidade:
- IP gratuito.
Um IP gratuito é um segmento de rede de acesso livre, que tem um conjunto limitado de recursos de rede, como software e servidores DHCP. Para garantir a conformidade com a estratégia de segurança, um usuário não autenticado pode acessar somente esse segmento para realizar operações. Por exemplo, o usuário pode fazer download do cliente EAD de um servidor de software ou obter um endereço IP dinâmico de um servidor DHCP.
- URL de redirecionamento.
Se um usuário 802.1X não autenticado estiver usando um navegador da Web para acessar a rede, o assistente de EAD redirecionará as solicitações de acesso à rede do usuário para um URL específico. Por exemplo, você pode usar esse recurso para redirecionar o usuário para a página de download do software do cliente EAD.
O recurso de assistente de EAD cria automaticamente uma regra de EAD baseada em ACL para abrir o acesso ao URL de redirecionamento para cada usuário redirecionado.
As regras de EAD são implementadas usando recursos de ACL. Quando o cronômetro da regra de EAD expira ou o usuário passa na autenticação, a regra é removida. Se os usuários não fizerem o download do cliente EAD ou não passarem na autenticação antes que o tempo expire, eles deverão se reconectar à rede para acessar o IP livre.
Configuração do 802.1X
Restrições e diretrizes: Configuração do 802.1X
Você pode configurar o recurso de segurança de porta para executar o 802.1X. A segurança da porta combina e amplia a autenticação 802.1X e MAC. Aplica-se a uma rede (uma WLAN, por exemplo) que requer diferentes métodos de autenticação para diferentes usuários em uma porta. Para obter mais informações sobre o recurso de segurança da porta, consulte "Configuração da segurança da porta".
Ao definir as configurações 802.1X em uma interface, siga estas restrições e diretrizes:
- O 802.1X é compatível apenas com interfaces Ethernet de camada 2 que não pertencem a um grupo de agregação.
- Não altere o tipo de link de uma porta quando a VLAN de convidado 802.1X, a VLAN de falha de autenticação ou a VLAN crítica da porta tiver usuários.
- Se vários métodos de autenticação estiverem configurados para o domínio de autenticação e a autenticação remota RADIUS for o método principal, o dispositivo não adicionará usuários à VLAN crítica quando o RADIUS estiver inacessível. Em vez disso, ele usa um método de autenticação de backup para autenticar os usuários. O dispositivo adiciona um usuário à VLAN crítica somente quando a autenticação remota RADIUS é o método de autenticação final usado para o usuário e o servidor RADIUS está inacessível.
Para configurar vários métodos de autenticação para um domínio de autenticação, use a opção
comando padrão de autenticação.
Para garantir um redirecionamento HTTPS bem-sucedido para os usuários em qualquer uma das situações a seguir, certifique-se de que existam interfaces de VLAN para as VLANs que transportam seus pacotes:
- Os usuários recebem um URL de redirecionamento.
- O assistente EAD está ativado.
Pré-requisitos para o 802.1X
Antes de configurar o 802.1X, conclua as seguintes tarefas:
- Configure um domínio ISP e um esquema AAA (autenticação local ou RADIUS) para usuários 802.1X.
- Se a autenticação RADIUS for usada, crie contas de usuário no servidor RADIUS.
- Se a autenticação local for usada, crie contas de usuário locais no dispositivo de acesso e defina o tipo de serviço como lan-access.
Ativação do 802.1X
Restrições e diretrizes
Para que o 802.1X entre em vigor em uma porta, você deve habilitá-lo globalmente e na porta.
Se o PVID for uma VLAN de voz, o recurso 802.1X não poderá entrar em vigor na porta. Para obter mais informações sobre VLANs de voz, consulte o Layer 2-LAN Switching Configuration Guide.
Procedimento
- Entre na visualização do sistema.
system viewdot1xPor padrão, o 802.1X é desativado globalmente.
interface interface-type interface-numberdot1xPor padrão, o 802.1X está desativado em uma porta.
Ativação do relé EAP ou da terminação EAP
Sobre a seleção do modo EAP
Considere os seguintes fatores para selecionar um modo EAP adequado:
- Suporte do servidor RADIUS para pacotes EAP.
- Métodos de autenticação compatíveis com o cliente 802.1X e o servidor RADIUS.
Restrições e diretrizes
- Se o modo de retransmissão EAP for usado, o comando user-name-format configurado na visualização do esquema RADIUS não terá efeito. O dispositivo de acesso envia os dados de autenticação do cliente para o servidor sem nenhuma modificação. Para obter mais informações sobre o comando user-name-format, consulte Referência de comandos de segurança.
- Você pode usar a terminação EAP e a retransmissão EAP em qualquer uma das seguintes situações:
- O cliente está usando apenas a autenticação EAP MD5-Challenge. Se a terminação EAP for usada, você deverá ativar a autenticação CHAP no dispositivo de acesso.
- O cliente é um cliente iNode 802.1X e inicia somente a autenticação EAP de nome de usuário e senha. Se a terminação EAP for usada, você poderá ativar a autenticação PAP ou CHAP no dispositivo de acesso. Entretanto, para fins de segurança, você deve usar a autenticação CHAP no dispositivo de acesso.
- Para usar o EAP-TLS, o PEAP ou qualquer outro método de autenticação EAP, você deve usar a retransmissão EAP. Ao tomar sua decisão, consulte "Comparação entre retransmissão EAP e terminação EAP" para obter ajuda.
Procedimento
- Entre na visualização do sistema.
system viewdot1x authentication-method { chap | eap | pap }Por padrão, o dispositivo de acesso executa a terminação EAP e usa CHAP para se comunicar com o servidor RADIUS.
Configuração do estado de autorização da porta
Sobre os estados de autorização de porta
O estado de autorização da porta determina se o cliente tem acesso à rede. É possível controlar os seguintes estados de autorização de uma porta:
- Authorized - Coloca a porta no estado autorizado, permitindo que os usuários da porta acessem a rede sem autenticação.
- Unauthorized - Coloca a porta no estado não autorizado, negando quaisquer solicitações de acesso de usuários na porta.
- Auto - coloca a porta inicialmente em estado não autorizado para permitir a passagem apenas de pacotes EAPOL. Depois que um usuário passa pela autenticação, define a porta no estado autorizado para permitir o acesso à rede. Você pode usar essa opção na maioria dos cenários.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x port-control { authorized-force | auto | unauthorized-force }Por padrão, o estado automático se aplica.
Especificação de um método de controle de acesso
Sobre os métodos de controle de acesso
O dispositivo é compatível com métodos de controle de acesso baseados em portas e em MAC.
Restrições e diretrizes
Se houver usuários 802.1X on-line em uma porta, a alteração do método de controle de acesso fará com que os usuários on-line fiquem off-line.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x port-method { macbased | portbased }Por padrão, aplica-se o controle de acesso baseado em MAC.
Especificação de um domínio de autenticação obrigatório em uma porta
Sobre o domínio de autenticação obrigatório
É possível colocar todos os usuários 802.1X em um domínio de autenticação obrigatório para autenticação, autorização e contabilidade em uma porta. Nenhum usuário pode usar uma conta em qualquer outro domínio para acessar a rede por meio da porta. A implementação de um domínio de autenticação obrigatório aumenta a flexibilidade da implementação do controle de acesso 802.1X.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x mandatory-domain domain-namePor padrão, nenhum domínio de autenticação 802.1X obrigatório é especificado.
Configuração dos timers de tempo limite de autenticação 802.1X
Sobre os timers de tempo limite de autenticação 802.1X
O dispositivo de rede usa os seguintes temporizadores de tempo limite de autenticação 802.1X:
- Timer de tempo limite do cliente - É iniciado quando o dispositivo de acesso envia um pacote EAP-Request/MD5-Challenge a um cliente. Se nenhuma resposta for recebida quando esse cronômetro expirar, o dispositivo de acesso retransmitirá a solicitação ao cliente.
- Temporizador de tempo limite do servidor - Começa quando o dispositivo de acesso envia um pacote RADIUS Access-Request para o servidor de autenticação. Se nenhuma resposta for recebida quando esse cronômetro expirar, a autenticação 802.1X falhará.
Restrições e diretrizes
Na maioria dos casos, as configurações padrão são suficientes. Você pode editar os temporizadores, dependendo das condições da rede.
- Em uma rede de baixa velocidade, aumente o cronômetro de tempo limite do cliente.
- Em uma rede com servidores de autenticação de desempenho diferente, ajuste o cronômetro de tempo limite do servidor.
Para evitar o logoff forçado antes que o cronômetro de tempo limite do servidor expire, defina o cronômetro de tempo limite do servidor com um valor menor ou igual ao produto dos valores a seguir:
- O número máximo de tentativas de transmissão de pacotes RADIUS definido pelo uso do parâmetro retry na visualização do esquema RADIUS.
- O timer de tempo limite de resposta do servidor RADIUS definido usando o timer response-timeout na visualização do esquema RADIUS.
Para obter informações sobre como definir o número máximo de tentativas de transmissão de pacotes RADIUS e o cronômetro de tempo limite de resposta do servidor RADIUS, consulte "Configuração do AAA".
Procedimento
- Entre na visualização do sistema.
system viewdot1x timer supp-timeout supp-timeout-valueO padrão é 30 segundos.
dot1x timer server-timeout server-timeout-valueeO padrão é 100 segundos.
Configuração da reautenticação 802.1X
Restrições e diretrizes
O dispositivo seleciona um temporizador de reautenticação periódica para a reautenticação 802.1X na seguinte ordem :
- Temporizador de reautenticação atribuído pelo servidor.
- Temporizador de reautenticação específico da porta.
- Temporizador de reautenticação global.
- Temporizador de reautenticação padrão.
Depois de executar uma reautenticação manual, o dispositivo reautentica todos os usuários 802.1X on-line em uma porta, independentemente do atributo de reautenticação atribuído pelo servidor e do recurso de reautenticação periódica na porta.
A modificação da configuração do domínio de autenticação obrigatório ou do método de tratamento de mensagens EAP não afeta a reautenticação de usuários 802.1X on-line. A configuração modificada entra em vigor somente nos usuários 802.1X que ficarem on-line após a modificação.
Se a reautenticação periódica for acionada para um usuário enquanto ele estiver aguardando a sincronização on-line, o sistema executará a sincronização on-line e não executará a reautenticação para o usuário.
Procedimento
- Entre na visualização do sistema.
system view- Defina um cronômetro de reautenticação periódica global.
dot1x timer reauth-period reauth-period-valueeA configuração padrão é 3600 segundos.
interface interface-type interface-numberedot1x timer reauth-period reauth-period-valuequitPor padrão, nenhum temporizador de reautenticação periódica é definido em uma porta. A porta usa o temporizador de reautenticação periódica 802.1X global.
interface interface-type interface-numberdot1x re-authenticatePor padrão, o recurso está desativado.
dot1x re-authenticate manualdot1x re-authenticate server-unreachable keep-onlinePor padrão, esse recurso está desativado. O dispositivo faz logoff dos usuários 802.1X on-line se nenhum servidor de autenticação estiver acessível para a reautenticação 802.1X.
Use o recurso keep-online de acordo com a condição real da rede. Em uma rede de recuperação rápida, é possível usar o recurso keep-online para evitar que os usuários do 802.1X fiquem on-line e que o fique off-line com frequência.
Configuração do timer de silêncio
Sobre o timer silencioso
O temporizador de silêncio permite que o dispositivo de acesso aguarde um período de tempo antes de processar qualquer solicitação de autenticação de um cliente que tenha falhado em uma autenticação 802.1X.
Restrições e diretrizes
Você pode editar o timer de silêncio, dependendo das condições da rede.
- Em uma rede vulnerável, defina o timer de silêncio para um valor alto.
- Em uma rede de alto desempenho com resposta rápida de autenticação, defina o timer de silêncio para um valor baixo .
Procedimento
- Entre na visualização do sistema.
system viewdot1x quiet-periodPor padrão, o cronômetro está desativado.
dot1x timer quiet-period quiet-period-valueO padrão é 60 segundos.
Configuração de uma VLAN de convidado 802.1X
Restrições e diretrizes
- Você pode configurar apenas uma VLAN de convidado 802.1X em uma porta. As VLANs de convidado 802.1X em portas diferentes podem ser diferentes.
- Atribua IDs diferentes para a VLAN da porta, a VLAN de voz e a VLAN de convidado 802.1X em uma porta. A atribuição garante que a porta possa processar corretamente o tráfego de entrada com marcação de VLAN.
- Para que o recurso 802.1X guest VLAN funcione corretamente, não configure esse recurso junto com o assistente EAD.
- Em uma porta híbrida, a VLAN de convidado só pode ser uma VLAN sem marcação.
- Se uma VLAN de voz e uma VLAN de convidado 802.1X estiverem configuradas em uma porta híbrida, a VLAN de voz terá prioridade mais alta do que a VLAN de convidado 802.1X. Um pacote é encaminhado para fora da VLAN de voz se corresponder às configurações da VLAN de voz. Se não corresponder às configurações da VLAN de voz, seu endereço MAC de origem poderá ser adicionado à VLAN de convidado 802.1X.
- Quando você configurar vários recursos de segurança em uma porta, siga as diretrizes da Tabela 5.
Tabela 5 Relações entre a VLAN de convidado 802.1X e outros recursos de segurança
| Recurso | Descrição do relacionamento | Referência |
| 802.1X Auth-Fail VLAN em uma porta que executa o controle de acesso baseado em MAC | A VLAN 802.1X Auth-Fail tem uma prioridade mais alta do que a VLAN 802.1X guest. | Consulte "802.1X VLAN manipulação". |
| Ações de proteção contra intrusão de porta em uma porta que executa o controle de acesso baseado em MAC | O recurso 802.1X guest VLAN tem prioridade mais alta do que a ação de bloqueio de MAC. O recurso 802.1X guest VLAN tem prioridade mais baixa do que a ação de desligamento da porta do recurso de proteção contra intrusão de porta. |
Consulte "Configuração da segurança da porta". |
Pré-requisitos
Antes de configurar uma VLAN de convidado 802.1X, conclua as seguintes tarefas:
- Crie a VLAN a ser especificada como a VLAN de convidado 802.1X.
- Se a porta habilitada para 802.1X executar o controle de acesso baseado em MAC, execute as seguintes operações para a porta:
- Configure a porta como uma porta híbrida.
- Ativar a VLAN baseada em MAC na porta. Para obter mais informações sobre VLANs baseadas em MAC, consulte Guia de configuração de switching de LAN de camada 2
- Se o tipo de porta for híbrido, verifique se a VLAN a ser especificada como VLAN de convidado não está na lista de VLANs marcadas da porta.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x guest-vlan guest-vlan-idPor padrão, não existe nenhuma VLAN de convidado 802.1X em uma porta.
Ativação do atraso na atribuição de VLAN de convidado 802.1X
Sobre o atraso na atribuição da VLAN de convidado 802.1X
Esse recurso atrasa a atribuição de uma porta habilitada para 802.1X à VLAN de convidado 802.1X quando a autenticação 802.1X é acionada na porta.
Esse recurso se aplica somente a situações em que a autenticação 802.1X é acionada por pacotes EAPOL-Start de clientes 802.1X ou pacotes de endereços MAC desconhecidos.
Para usar esse recurso, a porta habilitada para 802.1X deve executar o controle de acesso baseado em MAC. Para usar o novo atraso de atribuição de VLAN de convidado 802.1X acionado por MAC, você também deve configurar o acionador unicast 802.1X na porta.
Quando a autenticação 802.1X é acionada em uma porta, o dispositivo executa as seguintes operações:
- Envia um pacote unicast EAP-Request/Identity para o endereço MAC que aciona a autenticação .
- Retransmite o pacote se nenhuma resposta for recebida dentro do intervalo de tempo limite de solicitação de nome de usuário definido com o uso do comando dot1x timer tx-period.
- Atribui a porta à VLAN de convidado 802.1X depois que o número máximo de tentativas de solicitação definido com o uso do comando dot1x retry for atingido.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x guest-vlan-delay { eapol | new-mac }Por padrão, o atraso na atribuição de VLAN de convidado 802.1X é desativado em uma porta.
Configuração de uma VLAN 802.1X Auth-Fail
Restrições e diretrizes
- Atribua IDs diferentes para a VLAN da porta, a VLAN de voz e a VLAN 802.1X Auth-Fail em uma porta. A atribuição garante que a porta possa processar corretamente o tráfego de entrada com marcação de VLAN.
- Você pode configurar apenas uma VLAN 802.1X Auth-Fail em uma porta. As VLANs 802.1X Auth-Fail em portas diferentes podem ser diferentes.
- Em uma porta híbrida, a VLAN Auth-Fail só pode ser uma VLAN sem marcação.
- Quando você configurar vários recursos de segurança em uma porta, siga as diretrizes da Tabela 6.
Tabela 6 Relações da VLAN 802.1X Auth-Fail com outros recursos
| Recurso | Descrição do relacionamento | Referência |
| VLAN convidada de autenticação MAC em uma porta que executa Controle de acesso baseado em MAC | A VLAN 802.1X Auth-Fail tem alta prioridade. | Consulte "Configuração da autenticação MAC". |
| Ações de proteção contra intrusão de porta em uma porta que executa Controle de acesso baseado em MAC | O recurso 802.1X Auth-Fail VLAN tem prioridade mais alta do que a ação de bloqueio de MAC. O recurso 802.1X Auth-Fail VLAN tem prioridade mais baixa do que a ação de desligamento da porta do recurso de proteção contra intrusão de porta. |
Consulte "Configuração da segurança da porta". |
Pré-requisitos
Antes de configurar uma VLAN 802.1X Auth-Fail, conclua as seguintes tarefas:
- Crie a VLAN a ser especificada como a VLAN 802.1X Auth-Fail.
- Se a porta habilitada para 802.1X executar o controle de acesso baseado em MAC, execute as seguintes operações para a porta:
- Configure a porta como uma porta híbrida.
- Ativar a VLAN baseada em MAC na porta. Para obter mais informações sobre VLANs baseadas em MAC, consulte Guia de configuração de switching de LAN de camada 2
- Se o tipo de porta for híbrido, verifique se a VLAN a ser especificada como a VLAN de falha de autenticação não está na lista de VLANs marcadas na porta.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x auth-fail vlan authfail-vlan-idPor padrão, não existe nenhuma VLAN 802.1X Auth-Fail em uma porta.
Configuração de uma VLAN crítica 802.1X
Restrições e diretrizes para a configuração da VLAN crítica 802.1X
- Atribua IDs diferentes ao PVID, à VLAN de voz e à VLAN crítica 802.1X em uma porta. A atribuição garante que a porta possa processar corretamente o tráfego de entrada com marcação de VLAN.
- Você pode configurar apenas uma VLAN crítica 802.1X em uma porta. As VLANs críticas 802.1X em portas diferentes podem ser diferentes.
- Em uma porta híbrida, a VLAN crítica só pode ser uma VLAN sem marcação.
Pré-requisitos
Antes de configurar uma VLAN crítica 802.1X, conclua as seguintes tarefas:
- Crie a VLAN a ser especificada como uma VLAN crítica.
- Se a porta habilitada para 802.1X executar o controle de acesso baseado em MAC, execute as seguintes operações para a porta:
- Configure a porta como uma porta híbrida.
- Habilite a VLAN baseada em MAC na porta. Para obter mais informações sobre VLANs baseadas em MAC, consulte Guia de configuração de switching de LAN de camada 2
- Se o tipo de porta for híbrido, verifique se a VLAN a ser especificada como a VLAN crítica não está na lista de VLANs marcadas na porta.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x critical vlan critical-vlan-idPor padrão, não existe nenhuma VLAN crítica 802.1X em uma porta.
Ativação do recurso de VLAN de voz crítica 802.1X
Restrições e diretrizes
O recurso não entrará em vigor se o usuário de voz estiver na VLAN 802.1X Auth-Fail.
Pré-requisitos
Antes de ativar o recurso de VLAN de voz crítica 802.1X em uma porta, conclua as seguintes tarefas:
- Habilite o LLDP globalmente e na porta.
O dispositivo usa LLDP para identificar usuários de voz. Para obter informações sobre o LLDP, consulte o Layer 2-LAN Switching Configuration Guide.
- Ativar a VLAN de voz na porta.
Para obter informações sobre VLANs de voz, consulte o Layer 2-LAN Switching Configuration Guide.
- Especifique uma VLAN crítica 802.1X na porta. Essa configuração garante que um usuário de voz seja atribuído à VLAN crítica se houver falha na autenticação por inacessibilidade dos servidores RADIUS antes que o dispositivo o reconheça como um usuário de voz. Se uma VLAN crítica 802.1X não estiver disponível, o usuário de voz poderá ser desconectado.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x critical-voice-vlanPor padrão, o recurso 802.1X critical voice VLAN está desativado em uma porta.
Configuração do envelhecimento de usuários não autenticados 802.1X
Sobre o envelhecimento de usuários não autenticados 802.1X
- O envelhecimento de usuários não autenticados X se aplica a usuários adicionados a uma VLAN 802.1X guest, critical ou Auth-Fail porque não foram autenticados ou falharam na autenticação.
Quando um usuário em uma dessas VLANs envelhece, o dispositivo remove o usuário da VLAN e exclui a entrada do endereço MAC do usuário da porta de acesso.
Para que os usuários de uma dessas VLANs em uma porta sejam autenticados com êxito e fiquem on-line em outra porta, ative esse recurso. Em qualquer outro cenário, desative esse recurso como prática recomendada.
O mecanismo de envelhecimento do usuário 802.1X em uma porta depende do seu modo de controle de acesso.
- Se a porta usar o controle de acesso baseado em porta, um temporizador de envelhecimento do usuário será iniciado quando a porta for atribuída à VLAN crítica ou Auth-Fail. Quando o temporizador de envelhecimento expira, a porta é removida da VLAN e todas as entradas de endereço MAC dos usuários na VLAN também são removidas.
- Se a porta usar o controle de acesso baseado em MAC, um timer de envelhecimento do usuário será iniciado para cada usuário 802.1X quando ele for atribuído à VLAN Auth-Fail, crítica ou guest. Quando o temporizador de envelhecimento de um usuário expira, o dispositivo remove esse usuário da VLAN.
Os usuários removidos não poderão acessar nenhum recurso da rede até que outra autenticação seja acionada.
Restrições e diretrizes
Como prática recomendada, use esse recurso em uma porta somente se quiser que seus usuários não autenticados sejam autenticados em e fiquem on-line em uma porta diferente.
Procedimento
- Entre na visualização do sistema.
system viewdot1x timer user-aging { auth-fail-vlan | critical-vlan | guest-vlan } aging-time-valuePor padrão, os temporizadores de envelhecimento do usuário para todos os tipos aplicáveis de VLANs 802.1X são de 1.000 segundos.
interface interface-type interface-numberdot1x unauthenticated-user aging enablePor padrão, o envelhecimento do usuário não autenticado 802.1X está ativado.
Envio de pacotes EAP-Success na atribuição de usuários à VLAN crítica 802.1X
Sobre esta tarefa
Por padrão, o dispositivo envia pacotes EAP-Failure para clientes 802.1X quando os usuários do cliente são atribuídos à VLAN crítica 802.1X. Alguns clientes 802.1X, como os clientes 802.1X integrados ao Windows, não podem responder ao pacote EAP-Request/Identity do dispositivo para reautenticação se tiverem recebido um pacote EAP-Failure. Como resultado, a reautenticação para esses clientes falhará depois que o servidor de autenticação se tornar acessível.
Para evitar essa situação, habilite o dispositivo para enviar pacotes EAP-Success em vez de pacotes EAP-Failure para clientes 802.1X quando os usuários clientes forem atribuídos à VLAN crítica 802.1X.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x critical eapolPor padrão, o dispositivo envia um pacote EAP-Failure a um cliente 802.1X quando seu usuário cliente é atribuído à VLAN crítica.
Ativação da sincronização on-line de usuários 802.1X
Sobre a sincronização on-line de usuários 802.1X
IMPORTANTE:
Esse recurso entra em vigor somente quando o dispositivo usa um servidor IMC RADIUS para autenticar usuários 802.1X.
Para garantir que o servidor RADIUS mantenha as mesmas informações de usuário 802.1X on-line que o dispositivo depois que o estado do servidor mudar de inacessível para acessível, use esse recurso.
Esse recurso sincroniza as informações do usuário 802.1X on-line entre o dispositivo e o servidor RADIUS quando é detectado que o estado do servidor RADIUS mudou de inacessível para acessível.
Ao sincronizar as informações do usuário 802.1X on-line em uma porta com o servidor RADIUS, o dispositivo inicia a autenticação 802.1X sucessivamente para cada usuário 802.1X on-line autenticado no servidor RADIUS.
Se a sincronização falhar para um usuário on-line, o dispositivo fará o logoff desse usuário, a menos que a falha ocorra porque o servidor se tornou inacessível novamente.
Restrições e diretrizes
O tempo necessário para concluir a sincronização de usuários on-line aumenta à medida que o número de usuários on-line cresce. Isso pode resultar em um atraso maior para que novos usuários 802.1X e usuários na VLAN crítica se autentiquem ou reautentiquem no servidor RADIUS e fiquem on-line.
Para que esse recurso tenha efeito, você deve usá-lo em conjunto com o recurso de detecção de status do servidor RADIUS, que pode ser configurado com o comando radius-server test-profile. Quando você configurar esse recurso, certifique-se de que o intervalo de detecção seja menor do que o timer de silêncio do servidor RADIUS configurado com o comando timer quiet na visualização do esquema RADIUS. O servidor
O estado do servidor RADIUS muda para ativo após a expiração do timer de silêncio, independentemente de sua acessibilidade real. A definição de um intervalo de detecção mais curto do que o timer de silêncio impede que o recurso de detecção de status do servidor RADIUS informe falsamente a acessibilidade do servidor.
Para obter mais informações sobre o recurso de detecção de status do servidor RADIUS, consulte "Configuração de AAA".
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x server-recovery online-user-syncPor padrão, a sincronização on-line de usuários 802.1X está desativada.
Configuração do recurso de disparo de autenticação
Sobre os acionadores de autenticação
O recurso de disparo de autenticação permite que o dispositivo de acesso inicie a autenticação 802.1X quando os clientes 802.1X não puderem iniciar a autenticação.
Esse recurso fornece o acionador multicast e o acionador unicast (consulte Iniciação da autenticação 802.1X em "Visão geral do 802.1X").
Restrições e diretrizes
- Ative o acionador multicast em uma porta quando os clientes conectados à porta não puderem enviar pacotes EAPOL-Start para iniciar a autenticação 802.1X.
- Ative o acionador unicast em uma porta se apenas alguns clientes 802.1X estiverem conectados à porta e esses clientes não puderem iniciar a autenticação.
- Para evitar a duplicação de pacotes de autenticação, não ative os dois acionadores em uma porta.
- Como prática recomendada, não use o acionador unicast em uma porta que executa o controle de acesso baseado em porta. Se fizer isso, os usuários da porta poderão não ficar on-line corretamente.
Procedimento
- Entre na visualização do sistema.
system viewdot1x timer tx-period tx-period-valueO padrão é 30 segundos.
interface interface-type interface-numberdot1x { multicast-trigger | unicast-trigger }Por padrão, o acionador multicast está ativado e o acionador unicast está desativado.
Descarte de solicitações duplicadas de EAPOL-Start 802.1X
Sobre esta tarefa
Durante a autenticação 802.1X, o dispositivo pode receber solicitações EAPOL-Start duplicadas de um usuário 802.1X. Por padrão, o dispositivo entrega as solicitações EAPOL-Start duplicadas ao servidor de autenticação, desde que sejam legais. No entanto, esse mecanismo pode resultar em falha de autenticação se o servidor de autenticação não puder responder a solicitações EAPOL-Start duplicadas. Para resolver esse problema, execute esta tarefa na interface de acesso do usuário para descartar solicitações EAPOL-Start duplicadas.
Restrições e diretrizes
Esse recurso é compatível apenas com a versão 6309P01 ou posterior.
Como prática recomendada, execute essa tarefa somente se o servidor não puder responder a solicitações duplicadas de EAPOL-Start. Não execute essa tarefa em outras situações.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x duplicate-eapol-start discardPor padrão, o dispositivo não descarta solicitações duplicadas de EAPOL-Start em uma interface se as solicitações forem legais.
Definição do número máximo de usuários 802.1X simultâneos em uma porta
Sobre a configuração do número máximo de usuários 802.1X simultâneos em uma porta
Execute essa tarefa para evitar que os recursos do sistema sejam usados em excesso.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x max-user max-numberO padrão é 4294967295.
Definição do número máximo de tentativas de solicitação de autenticação
Sobre a retransmissão da solicitação de autenticação
O dispositivo de acesso retransmite uma solicitação de autenticação se não receber nenhuma resposta à solicitação do cliente em um determinado período de tempo. Para definir o tempo, use o comando
dot1x timer tx-period tx-period-valueProcedimento
- Entre na visualização do sistema.
system viewdot1x retry retriesA configuração padrão é 2.
Configuração do handshake do usuário on-line
Sobre o handshake do usuário on-line
O recurso de handshake de usuário on-line verifica o status de conectividade dos usuários 802.1X on-line. O dispositivo de acesso envia solicitações de handshake (EAP-Request/Identity) aos usuários on-line no intervalo especificado pelo comando dot1x timer handshake-period. Se o dispositivo não receber nenhum pacote EAP-Response/Identity de um usuário on-line depois de ter feito o máximo de tentativas de handshake, o dispositivo colocará o usuário no estado off-line. Para definir o máximo de tentativas de handshake, use o comando dot1x retry.
Normalmente, o dispositivo não responde aos pacotes EAP-Response/Identity dos clientes 802.1X com pacotes EAP-Success. Alguns clientes 802.1X ficarão off-line se não receberem os pacotes EAP-Success para handshake. Para evitar esse problema, ative o recurso de resposta de handshake do usuário on-line.
Se forem implantados clientes iNode, você também poderá ativar o recurso de segurança de handshake do usuário on-line para verificar as informações de autenticação nos pacotes de handshake dos clientes. Esse recurso pode impedir que os usuários 802.1X que usam software de cliente ilegal contornem a verificação de segurança do iNode, como a detecção de placas de interface de rede (NICs) duplas. Se um usuário falhar na verificação de segurança do handshake, o dispositivo colocará o usuário no estado off-line.
Restrições e diretrizes
- Se a rede tiver clientes 802.1X que não podem trocar pacotes de handshake com o dispositivo de acesso, desative o recurso de handshake de usuário on-line. Essa operação evita que as conexões 802.1X sejam incorretamente interrompidas.
- Para usar o recurso de segurança de handshake de usuário on-line, certifique-se de que o recurso de handshake de usuário on-line esteja ativado.
- O recurso de segurança de handshake de usuário on-line entra em vigor somente na rede em que o cliente iNode e o servidor IMC são usados.
- Ative o recurso de resposta de handshake do usuário on-line somente se os clientes 802.1X ficarem off-line sem receber pacotes EAP-Success do dispositivo.
Procedimento
- Entre na visualização do sistema.
system viewdot1x timer handshake-period handshake-period-valueO padrão é 15 segundos.
interface interface-type interface-numberdot1x handshakePor padrão, o recurso está ativado.
dot1x handshake securePor padrão, o recurso está desativado.
dot1x handshake reply enablePor padrão, o dispositivo não responde aos pacotes EAP-Response/Identity dos clientes 802.1X durante o processo de handshake on-line.
Configuração da detecção de pacotes para autenticação 802.1X
Sobre esta tarefa
Quando a detecção de pacotes para autenticação 802.1X está ativada em uma porta, o dispositivo envia pacotes de detecção para os usuários 802.1X conectados a essa porta em intervalos de detecção off-line definidos pelo uso do timer de detecção off-line. Se o dispositivo não receber uma resposta de um usuário depois de ter feito o máximo de tentativas de transmissão de pacotes dentro de um intervalo de detecção off-line, ele fará o logoff desse usuário e solicitará que o servidor RADIUS pare de contabilizar o usuário.
Quando a detecção de pacotes para autenticação 802.1X e a detecção off-line 802.1X estão ativadas, o dispositivo processa um usuário 802.1X da seguinte forma:
- Se a detecção off-line 802.1X determinar que um usuário está on-line, o dispositivo não enviará pacotes de detecção para esse usuário.
- Se a detecção off-line do 802.1X determinar que um usuário está off-line, o dispositivo não fará imediatamente o logoff desse usuário. Em vez disso, o dispositivo envia um pacote de detecção para esse usuário. Ele fará o logoff do usuário se não receber uma resposta do mesmo após ter feito o máximo de tentativas de transmissão de pacotes dentro de um intervalo de detecção off-line.
O 802.1X usa pacotes de solicitação ARP para detectar o status on-line de usuários IPv4 e usa pacotes NS para detectar o status on-line de usuários IPv6.
A detecção de pacotes adota o princípio de contagem antes de julgar. O dispositivo diminui as tentativas de detecção (tentativas de transmissão de pacotes) em 1 somente depois de determinar que não recebeu uma resposta de um usuário. O dispositivo interrompe o processo de detecção quando o número de tentativas de detecção chega a 0. A duração desde o momento em que o usuário envia o último pacote até o momento em que o usuário é desconectado é calculada usando a seguinte fórmula: duração = (tentativas + 1) * T + X. A Figura 11 mostra o processo de detecção de pacotes. Nesse exemplo, o dispositivo envia um pacote de detecção para um usuário 802.1X no máximo duas vezes.
Figura 11 Diagrama de rede para o processo de detecção de pacotes
Compatibilidade de recursos e versões de software
Esse recurso é compatível apenas com a versão 6348P01 e posteriores.
Restrições e diretrizes
Para garantir que o dispositivo esteja ciente das alterações de endereço IP do usuário, ative o snooping ARP e o snooping ND em conjunto com a detecção de pacotes para autenticação 802.1X. Se você não ativar o ARP snooping ou o ND snooping, o dispositivo não saberá das alterações de endereço IP do usuário. Como resultado, o dispositivo ainda enviará pacotes de detecção para os endereços IP originais dos usuários e fará o logout falso desses usuários.
Procedimento
- Entre na visualização do sistema.
system viewdot1x timer offline-detect offline-detect-valuePor padrão, o cronômetro de detecção off-line expira em 300 segundos.
interface interface-type interface-numberdot1x packet-detect enablePor padrão, a detecção de pacotes para autenticação 802.1X está desativada.
dot1x packet-detect retry retriesPor padrão, o dispositivo envia um pacote de detecção para um usuário 802.1X no máximo duas vezes.
Especificação de delimitadores de nomes de domínio compatíveis
Sobre os delimitadores de nome de domínio suportados
Por padrão, o dispositivo de acesso aceita o sinal de arroba (@) como delimitador. Também é possível configurar o dispositivo de acesso para acomodar usuários 802.1X que usam outros delimitadores de nome de domínio. O sinal
Os delimitadores configuráveis incluem o sinal de arroba (@), a barra invertida (\), o ponto (.) e a barra invertida (/). Os nomes de usuário que incluem nomes de domínio podem usar o formato nome de usuário@nome de domínio, nome de domínio\nome de usuário, nome de usuário.nome de domínio ou nome de usuário/nome de domínio.
Se uma cadeia de caracteres de nome de usuário 802.1X contiver vários delimitadores configurados, o delimitador mais à direita será o delimitador de nome de domínio. Por exemplo, se você configurar a barra invertida (\), o ponto (.) e a barra invertida (/) como delimitadores, o delimitador de nome de domínio para a cadeia de caracteres de nome de usuário 121.123/22\@abc será a barra invertida (\). O nome de usuário é @abc e o nome de domínio é 121.123/22.
Restrições e diretrizes
Se uma cadeia de caracteres de nome de usuário não contiver nenhum dos delimitadores, o dispositivo de acesso autenticará o usuário no domínio ISP obrigatório ou padrão.
Se você configurar o dispositivo de acesso para enviar nomes de usuário com nomes de domínio para o servidor RADIUS, certifique-se de que o delimitador de domínio possa ser reconhecido pelo servidor RADIUS. Para a configuração do formato do nome de usuário, consulte o comando user-name-format na Referência de comandos de segurança.
Procedimento
- Entre na visualização do sistema.
system viewdot1x domain-delimiter stringPor padrão, somente o delimitador de sinal de arroba (@) é suportado.
Remoção das tags de VLAN dos pacotes do protocolo 802.1X enviados por uma porta
Sobre a remoção das tags de VLAN dos pacotes do protocolo 802.1X enviados por uma porta
Esse recurso opera em uma porta híbrida para que ela envie pacotes do protocolo 802.1X com suas tags de VLAN removidas, independentemente de a porta ser um membro com ou sem tags de uma VLAN.
Use esse recurso se a porta híbrida habilitada para 802.1X for um membro marcado de seu PVID e os clientes 802.1X conectados não puderem reconhecer pacotes de protocolo 802.1X marcados com VLAN.
Restrições e diretrizes
Esse recurso remove as tags de VLAN de todos os pacotes de protocolo 802.1X enviados da porta para clientes 802.1X. Não use esse recurso se houver clientes 802.1X com reconhecimento de VLAN conectados à porta. Como prática recomendada, execute essa tarefa somente no cenário aplicável descrito.
Pré-requisitos
Defina o tipo de link da porta habilitada para 802.1X como híbrido. Para obter mais informações, consulte Configuração de VLAN no Guia de configuração de comutação de LAN de camada 2.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x eapol untagPor padrão, o fato de o dispositivo remover as tags de VLAN de todos os pacotes do protocolo 802.1X enviados de uma porta para clientes 802.1X depende da configuração no módulo VLAN.
CUIDADO:
Esse comando remove as tags de VLAN de todos os pacotes do protocolo 802.1X enviados da porta para os clientes 802.1X. Não use esse comando se os clientes 802.1X com reconhecimento de VLAN estiverem conectados à porta. Como prática recomendada, use esse comando somente no cenário aplicável descrito.
Configuração do número máximo de tentativas de autenticação 802.1X para usuários autenticados por MAC
Sobre tentativas de autenticação para usuários autenticados por MAC
Quando uma porta usa tanto a autenticação 802.1X quanto a autenticação MAC, o dispositivo aceita solicitações de autenticação 802.1X de usuários autenticados por MAC. Se um usuário autenticado por MAC for aprovado na autenticação 802.1X, ele ficará on-line como um usuário 802.1X. Se o usuário falhar na autenticação 802.1X, ele continuará a fazer tentativas de autenticação 802.1X, dependendo da configuração do cliente.
Execute esta tarefa para limitar o número de tentativas de autenticação 802.1X feitas por um usuário autenticado por MAC.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x after-mac-auth max-attempt max-attemptsPor padrão, o número de tentativas de autenticação 802.1X para usuários autenticados por MAC não é limitado em uma porta.
Ativação do congelamento de IP do usuário 802.1X
Sobre o congelamento de IP do usuário 802.1X
Esse recurso funciona com o recurso de proteção de origem de IP. A proteção de origem de IP baseada em 802.1X exige que os clientes 802.1X suportem o envio de endereços IP do usuário para o dispositivo de acesso. O dispositivo usa informações como endereços MAC de usuário e endereços IP obtidos por meio do 802.1X para gerar associações IPSG e filtrar pacotes IPv4 de usuários 802.1X não autenticados. Para obter informações sobre a proteção de origem de IP, consulte "Configuração da proteção de origem de IP".
Esse recurso impede que qualquer usuário 802.1X autenticado em uma porta altere seus endereços IP. Depois que você ativar esse recurso, a porta não atualizará os endereços IP em associações dinâmicas de IPSG para usuários 802.1X. Se um usuário 802.1X usar um endereço IP diferente do endereço IP em sua entrada de associação IPSG, a porta negará o acesso do usuário.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x user-ip freezePor padrão, o congelamento de IP do usuário 802.1X está desativado.
Ativação da geração de entradas dinâmicas de ligação IPSG para usuários autenticados 802.1X
Sobre esta tarefa
IMPORTANTE:
Esse recurso deve funcionar em conjunto com o recurso IPSG (IP source guard).
Por padrão, o dispositivo gera uma entrada de associação IPv4SG ou IPv6SG dinâmica para um usuário autenticado 802.1X depois que o usuário obtém um endereço IP estático ou atribuído por DHCP.
Para aumentar a segurança, permitindo que apenas os usuários 802.1X com endereços IP atribuídos por DHCP acessem a rede, execute as seguintes operações:
- Ativar IPSG.
- Desative a geração de entradas dinâmicas de ligação IPv4SG ou IPv6SG para usuários autenticados 802.1X.
- Habilite o snooping DHCP. O dispositivo gerará entradas de associação IPv4SG ou IPv6SG para os usuários com base no DHCP snooping.
Para obter mais informações sobre o IPSG, consulte IP source guard no Security Configuration Guide.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6340 e posteriores.
Restrições e diretrizes
Esse recurso entra em vigor somente nos usuários 802.1X que ficam on-line depois que o recurso é ativado. Se o endereço IP de um usuário 802.1X on-line for alterado, o dispositivo atualizará a entrada de associação dinâmica IPv4SG ou IPv6SG para esse usuário.
A desativação desse recurso não exclui as entradas de associação IPv4SG ou IPv6SG dinâmicas existentes para usuários 802.1X on-line. Se o endereço IP de um usuário 802.1X on-line mudar depois que o recurso for desativado, o dispositivo excluirá a entrada de associação dinâmica de IPv4SG ou IPv6SG desse usuário.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x { ip-verify-source | ipv6-verify-source } enablePor padrão, a geração de entradas dinâmicas de associação IPv4SG ou IPv6SG para usuários autenticados 802.1X está ativada.
Configuração da vinculação de endereços MAC 802.1X
Sobre a vinculação de endereços MAC 802.1X
Esse recurso pode vincular automaticamente endereços MAC de usuários 802.1X autenticados à porta de acesso dos usuários e gerar entradas de vinculação de endereços MAC 802.1X. Você também pode usar o comando dot1x mac-binding mac-address para adicionar manualmente entradas de associação de endereços MAC 802.1X.
802.1X As entradas de vinculação de endereço MAC nunca envelhecem. Elas podem sobreviver a um logoff de usuário ou a uma reinicialização do dispositivo. Se os usuários nas entradas de associação de endereços MAC 802.1X executarem a autenticação 802.1X em outra porta, eles não poderão passar a autenticação.
Restrições e diretrizes
O recurso de vinculação de endereço MAC 802.1X entra em vigor somente quando a porta executa o controle de acesso baseado em MAC.
Para excluir uma entrada de associação de endereço MAC 802.1X, use o comando undo dot1x mac-binding mac-address. Uma entrada de associação de endereço MAC 802.1X não pode ser excluída quando o usuário da entrada estiver on-line.
Depois que o número de entradas de associação de endereços MAC 802.1X atingir o limite superior de usuários 802.1X simultâneos (definido com o comando dot1x max-user), haverá as seguintes restrições:
- Os usuários que não estiverem nas entradas de associação falharão na autenticação mesmo depois que os usuários nas entradas de associação ficarem off-line.
- Não são permitidas novas entradas de vinculação de endereço MAC 802.1X.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberdot1x mac-binding enablePor padrão, o recurso está desativado.
dot1x mac-binding mac-addressPor padrão, não existem entradas de vinculação de endereço MAC 802.1X em uma porta.
Configuração do recurso de assistente de EAD
Restrições e diretrizes
Quando você configurar o assistente de EAD, siga estas restrições e diretrizes:
- Você deve desativar a autenticação MAC e a segurança da porta globalmente antes de ativar o recurso de assistente EAD.
- Para que o recurso de assistente de EAD entre em vigor em uma porta habilitada para 802.1X, é necessário definir o modo de autorização da porta como automático.
- Quando a autenticação MAC global ou a segurança da porta está ativada, o IP livre não entra em vigor.
- Para que o recurso 802.1X guest VLAN funcione corretamente, não ative o assistente EAD junto com o recurso 802.1X guest VLAN.
- A partir da versão 6331, o comando dot1x ead-assistant permit authentication-escape foi adicionado para remover o problema de mau funcionamento da VLAN 802.1X Auth-Fail e da VLAN crítica quando o assistente de EAD está ativado. Esse comando permite que o dispositivo remova as entradas de EAD dos usuários antes de atribuí-los à 802.1X Auth-Fail e às VLANs críticas.
- Se você usar os recursos de IP livre e Auth-Fail VLAN juntos, certifique-se de que os recursos na Auth-Fail VLAN estejam nos segmentos de IP livre.
- O servidor que fornece o URL de redirecionamento deve estar no IP livre acessível a usuários não autenticados.
A partir da versão 6328, você pode usar o assistente de EAD em conjunto com a autenticação MAC. Quando você usar o assistente de EAD e a autenticação MAC no dispositivo, siga estas restrições e diretrizes:
- Se o assistente de EAD e a autenticação MAC estiverem configurados, o dispositivo não marcará o endereço MAC de um usuário que falhou na autenticação MAC como um endereço MAC silencioso. Se o usuário nunca tiver sido aprovado na autenticação MAC, os pacotes do usuário poderão acionar a autenticação MAC novamente somente depois que a entrada do EAD do usuário se esgotar.
- Como prática recomendada, não configure VLANs convidadas ou VLANs críticas com autenticação MAC. As VLANs podem não funcionar corretamente quando o assistente EAD e a autenticação MAC estiverem configurados no dispositivo.
- Como prática recomendada, não configure o recurso de autenticação da Web ou de proteção de origem IP. Esses recursos podem não funcionar corretamente quando o assistente EAD e a autenticação MAC estiverem configurados no dispositivo.
- Se o endereço MAC de um usuário tiver sido marcado como endereço MAC silencioso antes de você ativar o assistente EAD, os pacotes do usuário poderão acionar a autenticação 802.1X ou MAC somente depois que o timer de silêncio expirar.
- A partir da versão 6331, o comando dot1x ead-assistant permit authentication-escape foi adicionado para remover o problema de mau funcionamento da VLAN crítica de autenticação MAC quando o assistente de EAD está ativado. Esse comando permite que o dispositivo remova as entradas do EAD dos usuários do antes de atribuir os usuários às VLANs críticas de autenticação MAC.
Procedimento
- Entre na visualização do sistema.
system viewdot1x ead-assistant enabledot1x ead-assistant free-ip ip-address { mask-length | mask-address }Repita esse comando para configurar vários IPs livres.
dot1x ead-assistant url url-stringPor padrão, não existe URL de redirecionamento.
Por padrão, o dispositivo escuta a porta 6654 para solicitações HTTPS a serem redirecionadas. Para alterar o número da porta de escuta do redirecionamento, consulte Configuração do redirecionamento de HTTP no Guia de configuração de serviços de camada 3 IP.
dot1x timer ead-timeout ead-timeout-valueA configuração padrão é 30 minutos.
Para evitar o uso de recursos de ACL quando houver um grande número de usuários EAD, é possível reduzir o timer da regra EAD.
dot1x ead-assistant permit authentication-escapePor padrão, o 802.1X Auth-Fail e as VLANs críticas e as VLANs críticas de autenticação MAC não podem entrar em vigor quando o assistente 802.1X EAD está ativado.
Esse comando é compatível apenas com a versão 6331 e posteriores.
Definição do tamanho máximo dos fragmentos de EAP-TLS enviados ao servidor
Sobre a fragmentação 802.1X EAP-TLS
Quando o dispositivo usa o método de autenticação EAP-TLS no modo de retransmissão EAP, os pacotes RADIUS podem exceder o tamanho máximo de pacote suportado pelo servidor RADIUS. Essa situação geralmente ocorre porque as mensagens EAP-TLS longas são encapsuladas no atributo EAP-Message do pacote RADIUS enviado ao servidor RADIUS.
Para evitar falhas de autenticação causadas por pacotes muito grandes, fragmente as mensagens EAP-TLS de acordo com o tamanho máximo de pacote RADIUS suportado pelo servidor RADIUS remoto.
Por exemplo, o comprimento máximo do pacote permitido pelo servidor é de 1.200 bytes e o comprimento de um pacote RADIUS (excluindo o atributo EAP-Message) é de 800 bytes. Para garantir que o comprimento máximo de um pacote RADIUS não exceda 1.200 bytes, você deve definir o comprimento máximo de um fragmento EAP-TLS como um valor inferior a 400 bytes.
Restrições e diretrizes
A fragmentação 802.1X EAP-TLS só tem efeito quando o modo de retransmissão EAP é usado. Para obter mais informações sobre a ativação do relé EAP, consulte "Ativação do relé EAP ou da terminação EAP".
Procedimento
- Entre na visualização do sistema.
system viewdot1x eap-tls-fragment to-server eap-tls-max-lengthPor padrão, as mensagens EAP-TLS não são fragmentadas.
Encerrar a sessão de usuários 802.1X
Sobre esta tarefa
Execute esta tarefa para fazer logoff dos usuários 802.1X especificados e limpar as informações sobre esses usuários do dispositivo. Esses usuários devem executar a autenticação 802.1X para ficarem on-line novamente.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6318P01 e posteriores.
Procedimento
Para fazer logoff de usuários 802.1X, execute o seguinte comando na visualização do usuário:
reset dot1x access-user [ interface interface-type interface-number | mac mac-address | username username | vlan vlan-id ]Ativação do registro de usuários 802.1X
Sobre o registro de usuários 802.1X
Esse recurso permite que o dispositivo gere logs sobre os usuários do 802.1X e envie os logs para o centro de informações. Para que os logs sejam gerados corretamente, é necessário configurar também o centro de informações no dispositivo. Para obter mais informações sobre a configuração da central de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Restrições e diretrizes
Para evitar entradas excessivas de registro de usuários 802.1X, use esse recurso somente se precisar analisar logins ou logouts anormais de usuários 802.1X.
Procedimento
- Entre na visualização do sistema.
system viewdot1x access-user log enable [ abnormal-logoff | failed-login | normal-logoff | successful-login ] *Por padrão, o registro de usuários 802.1X está desativado.
Se você não especificar nenhum parâmetro, esse comando habilitará todos os tipos de registros de usuários 802.1X.
Comandos de exibição e manutenção para 802.1X
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações de sessão 802.1X, estatísticas ou informações de configuração de portas especificadas ou de todas as portas. | display dot1x [ sessions | statistics ] [ interface interface-type interface-número ] |
| Exibir informações de usuário 802.1X on-line. | display dot1x connection [ open ] [ interface interface-type interface-number | slot slot-number | user-mac mac-address | nome de usuário name-string ] |
| Exibir informações de endereço MAC de usuários 802.1X em VLANs 802.1X de um tipo específico. | display dot1x mac-address { auth-fail-vlan | critical-vlan | guest-vlan } [ interface interface-type interface-number ] |
| Remover usuários da VLAN de convidado 802.1X em uma porta. | reset dot1x guest-vlan interface interface-type interface-number [ mac-address mac-address ] |
| Limpar estatísticas 802.1X. | reset dot1x statistics [ interface interface-type interface-number ] |
802.1X Exemplos de configuração de autenticação
Exemplo: Configuração da autenticação 802.1X básica
Configuração de rede
Conforme mostrado na Figura 12, o dispositivo de acesso executa a autenticação 802.1X para os usuários que se conectam à GigabitEthernet 1/0/1. Implemente o controle de acesso baseado em MAC na porta, para que o logoff de um usuário não afete outros usuários 802.1X on-line.
Use servidores RADIUS para realizar a autenticação, a autorização e a contabilidade dos usuários 802.1X. Se a autenticação RADIUS falhar, execute a autenticação local no dispositivo de acesso.
Configure o servidor RADIUS em 10.1.1.1/24 como o servidor primário de autenticação e contabilidade e o servidor RADIUS em 10.1.1.2/24 como o servidor secundário de autenticação e contabilidade. Atribua todos os usuários ao domínio bbb do ISP.
Defina a chave compartilhada como nome para os pacotes entre o dispositivo de acesso e o servidor de autenticação. Defina a chave compartilhada como dinheiro para os pacotes entre o dispositivo de acesso e o servidor de contabilidade.
Figura 12 Diagrama de rede
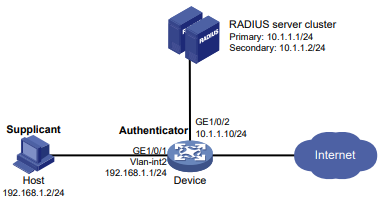
Procedimento
Para obter informações sobre os comandos RADIUS usados no dispositivo de acesso neste exemplo, consulte
Referência de comandos de segurança.
- Configure os servidores RADIUS e adicione contas de usuário para os usuários 802.1X. Certifique-se de que os servidores RADIUS possam fornecer serviços de autenticação, autorização e contabilidade. (Detalhes não mostrados.)
- Atribua um endereço IP a cada interface. (Detalhes não mostrados).
- Configure as contas de usuário para os usuários 802.1X no dispositivo de acesso:
# Adicione um usuário de acesso à rede local com nome de usuário localuser e senha localpass em texto simples. (Certifique-se de que o nome de usuário e a senha sejam os mesmos que os configurados nos servidores RADIUS).
<Device> system-view
[Device] local-user localuser class network
[Device-luser-network-localuser] password simple localpass# Defina o tipo de serviço como lan-access.
[Device-luser-network-localuser] service-type lan-access
[Device-luser-network-localuser] quit# Crie um esquema RADIUS chamado radius1 e entre na visualização do esquema RADIUS.
[Device] radius scheme radius1# Especifique os endereços IP dos servidores RADIUS primários de autenticação e contabilidade.
[Device-radius-radius1] primary authentication 10.1.1.1
[Device-radius-radius1] primary accounting 10.1.1.1# Configure os endereços IP dos servidores RADIUS secundários de autenticação e contabilidade.
[Device-radius-radius1] secondary authentication 10.1.1.2
[Device-radius-radius1] secondary accounting 10.1.1.2# Especifique a chave compartilhada entre o dispositivo de acesso e o servidor de autenticação.
[Device-radius-radius1] key authentication simple name# Especifique a chave compartilhada entre o dispositivo de acesso e o servidor de contabilidade.
[Device-radius-radius1] key accounting simple money# Excluir os nomes de domínio do ISP dos nomes de usuário enviados aos servidores RADIUS.
[Device-radius-radius1] user-name-format without-domain
[Device-radius-radius1] quitOBSERVAÇÃO:
O dispositivo de acesso deve usar o mesmo formato de nome de usuário que o servidor RADIUS. Se o servidor RADIUS incluir o nome de domínio do ISP no nome de usuário, o dispositivo de acesso também deverá fazê-lo.
# Crie um domínio ISP chamado bbb e entre no modo de exibição de domínio ISP.
[Device] domain bbb# Aplique o esquema RADIUS radius1 ao domínio ISP e especifique a autenticação local como o método de autenticação secundário.
[Device-isp-bbb] authentication lan-access radius-scheme radius1 local
[Device-isp-bbb] authorization lan-access radius-scheme radius1 local
[Device-isp-bbb] accounting lan-access radius-scheme radius1 local
[Device-isp-bbb] quit# Habilite o 802.1X na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] dot1x# Habilite o controle de acesso baseado em MAC na porta. Por padrão, a porta usa o controle de acesso baseado em MAC.
[Device-GigabitEthernet1/0/1] dot1x port-method macbased# Especifique o domínio ISP bbb como o domínio obrigatório.
[Device-GigabitEthernet1/0/1] dot1x mandatory-domain bbb
[Device-GigabitEthernet1/0/1] quit# Habilite o 802.1X globalmente.
[Device-GigabitEthernet1/0/1] dot1x mandatory-domain bbb
[Device-GigabitEthernet1/0/1] quitVerificação da configuração
# Verifique a configuração 802.1X na GigabitEthernet 1/0/1.
[Device] display dot1x interface gigabitethernet 1/0/1# Exibir as informações de conexão do usuário depois que um usuário 802.1X for aprovado na autenticação.
[Device] display dot1x connectionExemplo: Configuração da VLAN de convidado 802.1X e da VLAN de autorização
Configuração de rede
Conforme mostrado na Figura 13:
- Use servidores RADIUS para realizar autenticação, autorização e contabilidade para usuários 802.1X que se conectam à GigabitEthernet 1/0/2. Implemente o controle de acesso baseado em porta na porta.
- Configure a VLAN 10 como a VLAN de convidado 802.1X na GigabitEthernet 1/0/2. O host e o servidor de atualização estão na VLAN 10, e o host pode acessar o servidor de atualização e fazer download do software cliente 802.1X.
- Configure uma política de QoS para negar pacotes destinados à Internet (5.1.1.1) e aplique a política de QoS à direção de saída da VLAN 10. A configuração impede que os usuários da VLAN de convidados 802.1X acessem a Internet antes de passarem pela autenticação 802.1X.
- Depois que o host passa pela autenticação 802.1X, o dispositivo de acesso atribui o host à VLAN 5 , onde está a GigabitEthernet 1/0/3. O host pode acessar a Internet.
Figura 13 Diagrama de rede
Procedimento
Para obter informações sobre os comandos RADIUS usados no dispositivo de acesso neste exemplo, consulte Referência de comandos de segurança.
- Configure o servidor RADIUS para fornecer serviços de autenticação, autorização e contabilidade. Configure as contas de usuário e a VLAN de autorização (VLAN 5, neste exemplo) para os usuários. (Detalhes não mostrados.)
- Crie VLANs e atribua portas às VLANs no dispositivo de acesso.
OBSERVAÇÃO:
Por padrão, a VLAN 1 existe e todas as portas pertencem à VLAN. Não é necessário criar a VLAN ou atribuir a GigabitEthernet 1/0/2 à VLAN.
<Device> system-view
[Device] vlan 10
[Device-vlan10] port gigabitethernet 1/0/1
[Device-vlan10] quit
[Device] vlan 2
[Device-vlan2] port gigabitethernet 1/0/4
[Device-vlan2] quit
[Device] vlan 5
[Device-vlan5] port gigabitethernet 1/0/3
[Device-vlan5] quit# Configure a ACL 3000 avançada para corresponder aos pacotes destinados a 5.1.1.1.
[Device] acl advanced 3000
[Device-acl-ipv4-adv-3000] rule permit ip destination 5.1.1.1 0.0.0.255
[Device-acl-ipv4-adv-3000] quit# Especifique a ACL 3000 avançada na classe de tráfego classifier_1 para corresponder ao tráfego.
[Device] traffic classifier classifier_1
[Device-classifier-classifier_1] if-match acl 3000
[Device-classifier-classifier_1] quit# Configure o comportamento de tráfego behavior_1 para negar os pacotes correspondentes.
[Device] traffic behavior behavior_1
[Device-behavior-behavior_1] filter deny
[Device-behavior-behavior_1] quit# Configurar a política de QoS policy_1 para associar a classe de tráfego classifier_1 ao comportamento do tráfego behavior_1.
[Device] traffic behavior behavior_1
[Device-behavior-behavior_1] filter deny
[Device-behavior-behavior_1] quit# Aplique a política de QoS policy_1 à direção de saída da VLAN 10.
[Device] qos vlan-policy policy_1 vlan 10 outbound# Crie o esquema RADIUS 2000 e entre na visualização do esquema RADIUS.
[Device] radius scheme 2000# Especifique o servidor em 10.11.1.1 como o servidor de autenticação principal e defina a porta de autenticação como 1812.
[Device-radius-2000] primary authentication 10.11.1.1 1812# Especifique o servidor em 10.11.1.1 como o servidor de contabilidade principal e defina a porta de contabilidade como 1813.
[Device-radius-2000] primary accounting 10.11.1.1 1813# Defina a chave compartilhada como abc em texto simples para uma comunicação segura entre o servidor de autenticação e o dispositivo.
[Device-radius-2000] key authentication simple abc# Defina a chave compartilhada como abc em texto simples para comunicação segura entre o servidor de contabilidade e o dispositivo.
[Device-radius-2000] key accounting simple abc# Excluir os nomes de domínio do ISP dos nomes de usuário enviados ao servidor RADIUS.
[Device-radius-2000] user-name-format without-domain
[Device-radius-2000] quit# Crie o domínio ISP bbb e entre na visualização do domínio ISP.
[Device] domain bbb# Aplique o esquema RADIUS 2000 ao domínio ISP para autenticação, autorização e contabilidade.
[Device-isp-bbb] authentication lan-access radius-scheme 2000
[Device-isp-bbb] authorization lan-access radius-scheme 2000
[Device-isp-bbb] accounting lan-access radius-scheme 2000
[Device-isp-bbb] quit# Habilite o 802.1X na GigabitEthernet 1/0/2.
[Device] interface gigabitethernet 1/0/2
[Device-GigabitEthernet1/0/2] dot1x# Implemente o controle de acesso baseado em porta na porta.
[Device-GigabitEthernet1/0/2] dot1x port-method portbased# Defina o modo de autorização da porta como automático. Por padrão, a porta usa o modo automático.
[Device-GigabitEthernet1/0/2] dot1x port-control auto# Especifique a VLAN 10 como a VLAN de convidado 802.1X na GigabitEthernet 1/0/2.
[Device-GigabitEthernet1/0/2] dot1x guest-vlan 10
[Device-GigabitEthernet1/0/2] quit# Habilite o 802.1X globalmente.
[Device] dot1xVerificação da configuração
# Verifique a configuração da VLAN de convidado 802.1X na GigabitEthernet 1/0/2.
[Device] display dot1x interface gigabitethernet 1/0/2# Verifique se a GigabitEthernet 1/0/2 está atribuída à VLAN 10 antes que qualquer usuário passe pela autenticação na porta.
[Device] display vlan 10# Depois que um usuário passar pela autenticação, exiba informações sobre a GigabitEthernet 1/0/2. Verifique se a GigabitEthernet 1/0/2 está atribuída à VLAN 5.
[Device] display interface gigabitethernet 1/0/2Exemplo: Configuração do 802.1X com atribuição de ACL
Configuração de rede
Conforme mostrado na Figura 14, o host que se conecta à GigabitEthernet 1/0/1 deve passar pela autenticação 802.1X para acessar a Internet.
Execute a autenticação 802.1X na GigabitEthernet 1/0/1. Use o servidor RADIUS em 10.1.1.1 como servidor de autenticação e autorização, e o servidor RADIUS em 10.1.1.2 como servidor de contabilidade.
Configure a atribuição de ACL na GigabitEthernet 1/0/1 para negar o acesso de usuários 802.1X ao servidor FTP das 8:00 às 18:00 nos dias úteis.
Figura 14 Diagrama de rede
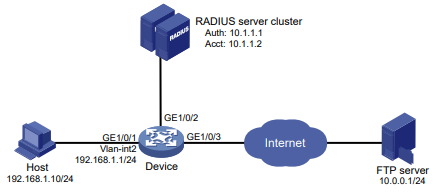
Procedimento
Para obter informações sobre os comandos RADIUS usados no dispositivo de acesso neste exemplo, consulte
Referência de comandos de segurança.
- Configure os servidores RADIUS para fornecer serviços de autenticação, autorização e contabilidade. Adicione contas de usuário e especifique a ACL (ACL 3000, neste exemplo) para os usuários. (Os detalhes não são mostrados).
- Atribua um endereço IP a cada interface, conforme mostrado na Figura 14. (Detalhes não mostrados).
- Configure um esquema RADIUS no dispositivo de acesso:
# Crie o esquema RADIUS 2000 e entre na visualização do esquema RADIUS.
<Device> system-view
[Device] radius scheme 2000# Especifique o servidor em 10.1.1.1 como o servidor de autenticação principal e defina a autenticação porto até 1812.
[Device-radius-2000] primary authentication 10.1.1.1 1812# Especifique o servidor em 10.1.1.2 como o servidor de contabilidade principal e defina a porta de contabilidade como 1813.
[Device-radius-2000] primary accounting 10.1.1.2 1813# Defina a chave compartilhada como abc em texto simples para uma comunicação segura entre o servidor de autenticação e o dispositivo.
[Device-radius-2000] key authentication simple abc# Defina a chave compartilhada como abc em texto simples para comunicação segura entre o servidor de contabilidade e o dispositivo.
[Device-radius-2000] key accounting simple abc# Excluir os nomes de domínio do ISP dos nomes de usuário enviados ao servidor RADIUS.
[Device-radius-2000] user-name-format without-domain
[Device-radius-2000] quit# Crie o domínio ISP bbb e entre na visualização do domínio ISP.
[Device] domain bbb# Aplique o esquema RADIUS 2000 ao domínio ISP para autenticação, autorização e contabilidade.
[Device-isp-bbb] authentication lan-access radius-scheme 2000
[Device-isp-bbb] authorization lan-access radius-scheme 2000
[Device-isp-bbb] accounting lan-access radius-scheme 2000
[Device-isp-bbb] quit[Device] time-range ftp 8:00 to 18:00 working-day[Device] acl advanced 3000
[Device-acl-ipv4-adv-3000] rule 0 deny ip destination 10.0.0.1 0 time-range ftp
[Device-acl-ipv4-adv-3000] quit# Habilite o 802.1X na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] dot1x
[Device-GigabitEthernet1/0/1] quit# Habilite o 802.1X globalmente.
[Device] dot1xVerificação da configuração
# Use a conta de usuário para passar a autenticação. (Detalhes não mostrados).
# Verifique se o usuário não pode fazer ping no servidor FTP a qualquer momento das 8:00 às 18:00 em qualquer dia da semana.
C:\>ping 10.0.0.1
Pinging 10.0.0.1 with 32 bytes of data:
Request timed out.
Request timed out.
Request timed out.
Request timed out.
Ping statistics for 10.0.0.1:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),A saída mostra que a ACL 3000 está ativa no usuário, e o usuário não pode acessar o servidor FTP.
Exemplo: Configuração do 802.1X com assistente EAD (com agente de retransmissão DHCP)
Configuração de rede
Conforme mostrado na Figura 15:
- A intranet 192.168.1.0/24 está conectada à GigabitEthernet 1/0/1 do dispositivo de acesso.
- Os hosts usam DHCP para obter endereços IP.
- Um servidor DHCP e um servidor Web são implantados na sub-rede 192.168.2.0/24 para que os usuários obtenham endereços IP e façam download do software cliente.
Implante uma solução de EAD para a intranet para atender aos seguintes requisitos:
- Permita que usuários não autenticados e usuários que falharam na autenticação 802.1X acessem 192.168.2.0/24. Os usuários podem obter endereços IP e fazer download de software.
- Se esses usuários usarem um navegador da Web para acessar uma rede diferente de 192.168.2.0/24, redirecione-os para o servidor da Web para fazer o download do cliente 802.1X.
- Permitir que usuários 802.1X autenticados acessem a rede.
Figura 15 Diagrama de rede
Procedimento
- Certifique-se de que o servidor DHCP, o servidor Web e os servidores de autenticação tenham sido configurados corretamente. (Detalhes não mostrados.)
- Configure um endereço IP para cada interface. (Detalhes não mostrados).
- Configurar a retransmissão de DHCP: # Habilite o DHCP.
<Device> system-view
[Device] dhcp enable# Habilite o agente de retransmissão DHCP na interface VLAN 2.
[Device] interface vlan-interface 2
[Device-Vlan-interface2] dhcp select relay# Especifique o servidor DHCP 192.168.2.2 na interface do agente de retransmissão VLAN-interface 2.
[Device-Vlan-interface2] dhcp relay server-address 192.168.2.2
[Device-Vlan-interface2] quit# Crie o esquema RADIUS 2000 e entre na visualização do esquema RADIUS.
[Device] radius scheme 2000# Especifique o servidor em 10.1.1.1 como o servidor de autenticação principal e defina a porta de autenticação como 1812.
[Device-radius-2000] primary authentication 10.1.1.1 1812# Especifique o servidor em 10.1.1.2 como o servidor de contabilidade principal e defina a porta de contabilidade como 1813.
[Device-radius-2000] primary accounting 10.1.1.2 1813# Defina a chave compartilhada como abc em texto simples para uma comunicação segura entre o servidor de autenticação e o dispositivo.
[Device-radius-2000] key authentication simple abc# Defina a chave compartilhada como abc em texto simples para comunicação segura entre o servidor de contabilidade e o dispositivo.
[Device-radius-2000] key accounting simple abc# Excluir os nomes de domínio do ISP dos nomes de usuário enviados ao servidor RADIUS.
[Device-radius-2000] user-name-format without-domain
[Device-radius-2000] quit# Crie o domínio ISP bbb e entre na visualização do domínio ISP.
[Device] domain bbb# Aplique o esquema RADIUS 2000 ao domínio ISP para autenticação, autorização e contabilidade.
[Device-isp-bbb] authentication lan-access radius-scheme 2000
[Device-isp-bbb] authorization lan-access radius-scheme 2000
[Device-isp-bbb] accounting lan-access radius-scheme 2000
[Device-isp-bbb] quit# Configure o IP livre.
[Device] dot1x ead-assistant free-ip 192.168.2.0 24# Configure o URL de redirecionamento para download do software do cliente.
[Device] dot1x ead-assistant url http://192.168.2.3# Habilite o recurso de assistente de EAD.
[Device] dot1x ead-assistant enable# Habilite o 802.1X na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] dot1x
[Device-GigabitEthernet1/0/1] quit# Habilite o 802.1X globalmente.
[Device] dot1xVerificação da configuração
# Verificar a configuração do 802.1X.
[Device] display dot1x# Verifique se você pode fazer ping em um endereço IP na sub-rede IP livre a partir de um host.
C:\>ping 192.168.2.3
C:\>ping 192.168.2.3
Pinging 192.168.2.3 with 32 bytes of data:
Reply from 192.168.2.3: bytes=32 time< TTL=128
Reply from 192.168.2.3: bytes=32 time< TTL=128
Reply from 192.168.2.3: bytes=32 time< TTL=128
Reply from 192.168.2.3: bytes=32 time< TTL=128
Ping statistics for 192.168.2.3:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 0ms, Maximum = 0ms, Average = 0msA saída mostra que você pode acessar a sub-rede IP livre antes de passar pela autenticação 802.1X.
# Verifique se você é redirecionado para o servidor da Web quando digita no navegador da Web um endereço IP que não está no IP livre. (Detalhes não mostrados.)
Exemplo: Configuração do 802.1X com assistente EAD (com servidor DHCP)
Configuração de rede
Conforme mostrado na Figura 16:
- A intranet 192.168.1.0/24 está conectada à GigabitEthernet 1/0/1 do dispositivo de acesso.
- Os hosts usam DHCP para obter endereços IP.
- Um servidor Web é implementado na sub-rede 192.168.2.0/24 para que os usuários façam download do software cliente. Implemente uma solução de EAD para a intranet para atender aos seguintes requisitos:
- Permita que usuários não autenticados e usuários que falharam na autenticação 802.1X acessem 192.168.2.0/24. Os usuários podem fazer download de software.
- Se esses usuários usarem um navegador da Web para acessar uma rede diferente de 192.168.2.0/24, redirecione-os para o servidor da Web para fazer download do cliente 802.1X.
- Permitir que usuários 802.1X autenticados acessem a rede.
Figura 16 Diagrama de rede
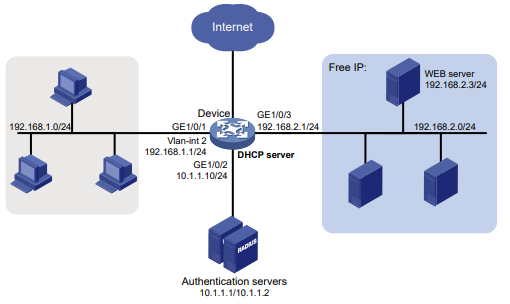
Procedimento
- Certifique-se de que o servidor da Web e os servidores de autenticação tenham sido configurados corretamente. (Detalhes não mostrados.)
- Configure um endereço IP para cada interface. (Detalhes não mostrados).
- Configure o servidor DHCP:
# Habilite o DHCP.
<Device> system-view
[Device] dhcp enable# Habilite o servidor DHCP na interface VLAN 2.
[Device] interface vlan-interface 2
[Device-Vlan-interface2] dhcp select server
[Device-Vlan-interface2] quit# Criar o pool de endereços DHCP 0.
[Device] dhcp server ip-pool 0# Especifique a sub-rede 192.168.1.0/24 no pool de endereços DHCP 0.
[Device-dhcp-pool-0] network 192.168.1.0 mask 255.255.255.0# Especifique o endereço de gateway 192.168.1.1 no pool de endereços DHCP 0.
[Device-dhcp-pool-0] gateway-list 192.168.1.1
[Device-dhcp-pool-0] quit# Crie o esquema RADIUS 2000 e entre na visualização do esquema RADIUS.
[Device] radius scheme 2000# Especifique o servidor em 10.1.1.1 como o servidor de autenticação principal e defina a porta de autenticação como 1812.
[Device-radius-2000] primary authentication 10.1.1.1 1812# Especifique o servidor em 10.1.1.2 como o servidor de contabilidade principal e defina a porta de contabilidade como 1813.
[Device-radius-2000] primary accounting 10.1.1.2 1813# Defina a chave compartilhada como abc em texto simples para uma comunicação segura entre o servidor de autenticação e o dispositivo.
[Device-radius-2000] key authentication simple abc# Defina a chave compartilhada como abc em texto simples para comunicação segura entre o servidor de contabilidade e o dispositivo.
[Device-radius-2000] key accounting simple abc# Excluir os nomes de domínio do ISP dos nomes de usuário enviados ao servidor RADIUS.
[Device-radius-2000] user-name-format without-domain
[Device-radius-2000] quit# Crie o domínio ISP bbb e entre na visualização do domínio ISP.
[Device] domain bbb# Aplique o esquema RADIUS 2000 ao domínio ISP para autenticação, autorização e contabilidade.
[Device-isp-bbb] authentication lan-access radius-scheme 2000
[Device-isp-bbb] authorization lan-access radius-scheme 2000
[Device-isp-bbb] accounting lan-access radius-scheme 2000
[Device-isp-bbb] quit# Configure o IP livre.
[Device] dot1x ead-assistant free-ip 192.168.2.0 24# Configure o URL de redirecionamento para download do software do cliente.
[Device] dot1x ead-assistant url http://192.168.2.3# Habilite o recurso de assistente de EAD.
[Device] dot1x ead-assistant enable# Habilite o 802.1X na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] dot1x
[Device-GigabitEthernet1/0/1] quit# Habilite o 802.1X globalmente.
[Device] dot1xVerificação da configuração
# Verificar a configuração do 802.1X.
[Device] display dot1x# Verifique se você pode fazer ping em um endereço IP na sub-rede IP livre a partir de um host.
C:\>ping 192.168.2.3
Pinging 192.168.2.3 with 32 bytes of data:
Reply from 192.168.2.3: bytes=32 time< TTL=128
Reply from 192.168.2.3: bytes=32 time< TTL=128
Reply from 192.168.2.3: bytes=32 time< TTL=128
Reply from 192.168.2.3: bytes=32 time< TTL=128
Ping statistics for 192.168.2.3:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 0ms, Maximum = 0ms, Average = 0msA saída mostra que você pode acessar a sub-rede IP livre antes de passar pela autenticação 802.1X.
# Verifique se você é redirecionado para o servidor da Web quando digita no navegador da Web um endereço IP que não está no IP livre. (Detalhes não mostrados.)
Solução de problemas do 802.1X
Falha no redirecionamento do URL do assistente de EAD
Sintoma
Os usuários não autenticados não são redirecionados para o URL de redirecionamento especificado depois que inserem endereços de sites externos em seus navegadores da Web.
Análise
O redirecionamento não ocorrerá por um dos seguintes motivos:
- O endereço está no formato de string. O sistema operacional do host considera a cadeia como um nome de site e tenta resolver a cadeia. Se a resolução falhar, o sistema operacional envia uma solicitação ARP, mas o endereço de destino não está na notação decimal com pontos. O recurso de redirecionamento redireciona esse tipo de solicitação ARP.
- O endereço está em um segmento IP livre. Nenhum redirecionamento ocorrerá, mesmo que nenhum host esteja presente com o endereço.
- O URL de redirecionamento não está em um segmento de IP livre.
- Nenhum servidor está usando o URL de redirecionamento ou o servidor com o URL não fornece serviços da Web.
Solução
Para resolver o problema:
- Digite um endereço IP decimal com pontos que não esteja em nenhum segmento de IP livre.
- Verifique se o dispositivo de acesso e o servidor estão configurados corretamente.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Configuração da autenticação MAC
Sobre a autenticação MAC
A autenticação MAC controla o acesso à rede autenticando os endereços MAC de origem em uma porta. O recurso não requer software cliente, e os usuários não precisam digitar um nome de usuário e uma senha para acessar a rede. O dispositivo inicia um processo de autenticação MAC quando detecta um endereço MAC de origem desconhecida em uma porta habilitada para autenticação MAC. Se o endereço MAC for aprovado na autenticação, o usuário poderá acessar os recursos de rede autorizados. Se a autenticação falhar, o dispositivo marcará o endereço MAC como um endereço MAC silencioso, descartará o pacote e iniciará um cronômetro de silêncio. O dispositivo descarta todos os pacotes subsequentes do endereço MAC dentro do tempo de silêncio. O mecanismo de quiet evita a autenticação repetida em um curto período de tempo.
Políticas de conta de usuário
A autenticação MAC é compatível com as seguintes políticas de conta de usuário:
- Política global de conta de usuário - Pode ser uma das seguintes opções:
- Política de conta de usuário baseada em MAC - Uma conta de usuário baseada em MAC para cada usuário. Conforme mostrado na Figura 1, o dispositivo de acesso usa os endereços MAC de origem nos pacotes como nomes de usuário e senhas de usuários para autenticação MAC. Essa política é adequada para um ambiente inseguro.
OBSERVAÇÃO:
A política de conta de usuário baseada em MAC também suporta a configuração de uma senha compartilhada por todos os usuários.
Contas de usuário baseadas em MAC.
- Política de conta de usuário compartilhada - Uma conta de usuário compartilhada para todos os usuários. Você especifica um nome de usuário e uma senha, que não são necessariamente um endereço MAC, para todos os usuários de autenticação MAC no dispositivo de acesso, conforme mostrado na Figura 2. Essa política é adequada para um ambiente seguro.
- Política de conta de usuário específica de intervalo de MAC - Uma conta de usuário compartilhada para usuários em um intervalo de endereços MAC específico. Você especifica um nome de usuário e uma senha (que não são necessariamente um endereço MAC) para usuários em um intervalo específico de endereços MAC no dispositivo de acesso, conforme mostrado na Figura 3. Por exemplo, é possível especificar um nome de usuário e uma senha para usuários com uma OUI específica para autenticação MAC.
IMPORTANTE:
Figura 1 Política de conta de usuário baseada em MAC
Figura 2 Política de conta de usuário compartilhada (global)
Figura 3 Política de conta de usuário compartilhada (específica para intervalos de endereços MAC)
Métodos de autenticação
Você pode executar a autenticação MAC no dispositivo de acesso (autenticação local) ou por meio de um servidor RADIUS.
Para obter mais informações sobre como configurar a autenticação local e a autenticação RADIUS, consulte "Configuração de AAA".
Autenticação RADIUS
Se forem usadas contas baseadas em MAC, o dispositivo de acesso enviará, por padrão, o endereço MAC de origem de um pacote como nome de usuário e senha para o servidor RADIUS para autenticação. Se uma senha for
configurado para contas baseadas em MAC, o dispositivo de acesso envia a senha configurada como a senha para o servidor RADIUS.
Se for usada uma conta compartilhada, o dispositivo de acesso enviará o nome de usuário e a senha da conta compartilhada ao servidor RADIUS para autenticação.
O dispositivo de acesso e o servidor RADIUS usam o Password Authentication Protocol (PAP) ou o Challenge Handshake Authentication Protocol (CHAP) para comunicação.
Autenticação local
Se forem usadas contas baseadas em MAC, o dispositivo de acesso usará, por padrão, o endereço MAC de origem de um pacote como nome de usuário e senha para procurar uma correspondência no banco de dados de contas local. Se uma senha for configurada para contas baseadas em MAC, o dispositivo usará a senha configurada para procurar uma correspondência no banco de dados de contas local.
Se for usada uma conta compartilhada, o dispositivo de acesso usará o nome de usuário e a senha da conta compartilhada para procurar uma correspondência no banco de dados de contas local.
Atribuição de VLAN
VLAN de autorização
A VLAN de autorização controla o acesso de um usuário de autenticação MAC a recursos de rede autorizados. O dispositivo suporta VLANs de autorização atribuídas localmente ou por um servidor remoto.
IMPORTANTE:
Somente servidores remotos podem atribuir VLANs de autorização marcadas.
Autorização de VLAN remota
Na autorização de VLAN remota, é necessário configurar uma VLAN de autorização para um usuário no servidor remoto. Depois que o usuário se autentica no servidor, o servidor atribui informações de VLAN de autorização ao dispositivo. Em seguida, o dispositivo atribui a porta de acesso do usuário à VLAN de autorização como um membro marcado ou não marcado.
O dispositivo suporta a atribuição das seguintes informações de VLAN de autorização pelo servidor remoto:
- VLAN ID.
- Nome da VLAN, que deve ser o mesmo que a descrição da VLAN no dispositivo de acesso.
- Uma cadeia de VLAN IDs e nomes de VLAN.
Na cadeia de caracteres, algumas VLANs são representadas por seus IDs e algumas VLANs são representadas por seus nomes.
- Nome do grupo de VLAN.
Para obter mais informações sobre grupos de VLAN, consulte o Layer 2-LAN Switching Configuration Guide.
- VLAN ID com um sufixo de t ou u.
Os sufixos t e u exigem que o dispositivo atribua a porta de acesso à VLAN como um membro marcado ou não marcado, respectivamente. Por exemplo, 2u indica a atribuição da porta à VLAN 2 como um membro sem marcação.
Se um nome de VLAN ou um nome de grupo de VLAN for atribuído, o dispositivo converterá as informações em uma VLAN ID antes da atribuição da VLAN.
IMPORTANTE:
Para que uma VLAN representada por seu nome de VLAN seja atribuída com êxito, você deve se certificar de que a VLAN foi criada no dispositivo.
Para atribuir VLAN IDs com sufixos, certifique-se de que a porta de acesso do usuário seja uma porta híbrida ou de tronco.
IMPORTANTE:
Para garantir uma atribuição bem-sucedida, as VLANs de autorização atribuídas pelo servidor remoto não podem ser de nenhum dos tipos a seguir:
- VLANs aprendidas dinamicamente.
- VLANs reservadas.
- VLANs privadas.
Se o servidor atribuir um grupo de VLANs, o dispositivo de acesso selecionará uma VLAN conforme descrito na Tabela 1.
Tabela 1 Seleção de VLAN de autorização em um grupo de VLANs
| Informações sobre VLAN | Seleção de VLAN de autorização |
|
IDs de VLAN Nomes de VLAN Nome do grupo de VLAN IDs de VLAN e nomes de VLAN |
O dispositivo seleciona uma VLAN de autorização do grupo de VLANs para um usuário de acordo com as seguintes regras:
|
| VLAN IDs com sufixos |
Por exemplo, o servidor de autenticação envia a string 1u 2t 3 para o dispositivo de acesso de um usuário. O dispositivo atribui a VLAN 1 como uma VLAN não marcada e todas as VLANs restantes (inclusive a VLAN 3) como VLANs marcadas. A VLAN 1 se torna o PVID. |
Na versão 6318P01 e posteriores, o dispositivo inclui o atributo User-VLAN-ID nas solicitações de contabilidade RADIUS para informar ao servidor RADIUS a VLAN de autorização atribuída aos usuários de autenticação MAC. O servidor RADIUS pode então incluir informações de VLAN de autorização do usuário em seus registros sobre usuários de autenticação MAC.
- Se o servidor RADIUS atribuir uma VLAN ID ou um nome de VLAN como a VLAN de autorização para um usuário, o dispositivo incluirá a VLAN de autorização atribuída pelo servidor no atributo User-VLAN-ID.
- Se o servidor RADIUS atribuir um grupo de VLANs nas informações de VLAN de autorização a um usuário, o dispositivo incluirá uma VLAN no atributo User-VLAN-ID, conforme descrito na Tabela 2.
Tabela 2 Inclusão de uma VLAN no atributo User-VLAN-ID dos pacotes de contabilidade RADIUS
| Informações sobre VLAN | VLAN no atributo User-VLAN-ID |
|
IDs de VLAN Nomes de VLAN Nome do grupo de VLAN IDs de VLAN e nomes de VLAN |
|
| VLAN IDs com sufixos | O dispositivo inclui a VLAN de autorização sem marcação no atributo User-VLAN-ID nos pacotes de solicitação de contabilidade RADIUS. Se não houver nenhuma VLAN de autorização untagged disponível, o dispositivo incluirá a VLAN inicial do usuário no atributo User-VLAN-ID nos pacotes de solicitação de contabilidade RADIUS. |
Autorização de VLAN local
Para executar a autorização de VLAN local para um usuário, especifique a VLAN ID na lista de atributos de autorização da conta de usuário local para esse usuário. Para cada usuário local, é possível especificar apenas um ID de VLAN de autorização. A porta de acesso do usuário é atribuída à VLAN como um membro não marcado.
IMPORTANTE:
A autorização de VLAN local não é compatível com a atribuição de VLANs marcadas.
Para obter mais informações sobre a configuração do usuário local, consulte "Configuração de AAA".
Manipulação de VLAN de autorização em uma porta habilitada para autenticação MAC
A Tabela 3 descreve a maneira como o dispositivo de acesso à rede lida com as VLANs de autorização (exceto as VLANs especificadas com sufixos) para usuários autenticados por MAC em uma porta.
Tabela 3 Manipulação de VLAN
| Tipo de porta | Manipulação de VLAN |
|
OBSERVAÇÃO: O atributo tagged é compatível apenas com portas tronco e híbridas. |
| Porta híbrida com VLAN baseada em MAC ativada | O dispositivo mapeia o endereço MAC de cada usuário para sua própria VLAN de autorização, independentemente de a porta ser um membro marcado. O PVID da porta não é alterado. |
IMPORTANTE:
- Se os usuários estiverem conectados a uma porta cujo tipo de link seja de acesso, certifique-se de que a VLAN de autorização atribuída pelo servidor tenha o atributo untagged. A atribuição de VLAN falhará se o servidor emitir uma VLAN que tenha o atributo tagged.
- Ao atribuir VLANs a usuários conectados a uma porta trunk ou a uma porta híbrida desativada por VLAN baseada em MAC, certifique-se de que haja apenas uma VLAN sem marcação. Se uma VLAN untagged diferente for atribuída a um usuário subsequente, o usuário não poderá passar na autenticação.
- Como prática recomendada para aumentar a segurança da rede, não use o comando port hybrid vlan para atribuir uma porta híbrida a uma VLAN de autorização como um membro marcado.
A VLAN atribuída pelo servidor a um usuário como uma VLAN de autorização pode ter sido configurada na porta de acesso do usuário, mas com um modo de marcação diferente. Por exemplo, o servidor atribui uma VLAN de autorização com o atributo tagged, mas a mesma VLAN configurada na porta tem o atributo untagged. Nessa situação, as configurações de VLAN que entram em vigor para o usuário dependem do tipo de link da porta.
- Se o tipo de link da porta for acesso ou tronco, as configurações de VLAN de autorização atribuídas pelo servidor sempre terão efeito sobre o usuário enquanto ele estiver on-line. Depois que o usuário fica off-line, as configurações de VLAN na porta entram em vigor.
- Se o tipo de link da porta for híbrido, as configurações de VLAN definidas na porta terão efeito. Por exemplo, o servidor atribui a VLAN 30 com o atributo untagged a um usuário na porta híbrida. No entanto, a VLAN 30 foi configurada na porta com o atributo tagged usando o comando port hybrid vlan tagged. Finalmente, a VLAN tem o atributo marcado na porta.
Para que um usuário autenticado por MAC acesse a rede em uma porta híbrida quando nenhuma VLAN de autorização estiver configurada para o usuário, execute uma das seguintes tarefas:
- Se a porta receber pacotes de autenticação com tags do usuário em uma VLAN, use o comando port hybrid vlan para configurar a porta como um membro com tags na VLAN.
- Se a porta receber pacotes de autenticação untagged do usuário em uma VLAN, use o comando port hybrid vlan para configurar a porta como um membro untagged na VLAN.
VLAN de convidado
A VLAN de convidado de autenticação MAC em uma porta acomoda usuários que falharam na autenticação MAC por qualquer motivo que não seja o servidor inacessível. Por exemplo, a VLAN acomoda usuários com senhas inválidas inseridas.
Você pode implementar um conjunto limitado de recursos de rede na VLAN de convidado de autenticação MAC. Por exemplo, um servidor de software para fazer download de software e patches de sistema.
Uma porta híbrida é sempre atribuída a uma VLAN de convidado de autenticação MAC como um membro não marcado. Após a atribuição, não reconfigure a porta como um membro marcado na VLAN.
O dispositivo reautentica os usuários na VLAN de convidado de autenticação MAC em um intervalo específico. A Tabela 4 mostra a maneira como o dispositivo de acesso à rede lida com as VLANs de convidados para usuários de autenticação MAC.
Tabela 4 Manipulação de VLAN
| Status de autenticação | Manipulação de VLAN |
| Um usuário na VLAN de convidado de autenticação MAC falha na autenticação MAC. | O usuário ainda está na VLAN de convidado da autenticação MAC. |
| Um usuário na VLAN de convidado de autenticação MAC passa na autenticação MAC. | O dispositivo remapeia o endereço MAC do usuário para a VLAN de autorização atribuída pelo servidor de autenticação. Se nenhuma VLAN de autorização estiver configurada para o usuário no servidor de autenticação, o dispositivo remapeia o endereço MAC do usuário para o PVID da porta. |
VLAN crítica
A VLAN crítica de autenticação MAC em uma porta acomoda usuários que falharam na autenticação MAC porque não há servidores de autenticação RADIUS acessíveis. Os usuários em uma VLAN crítica de autenticação MAC podem acessar apenas os recursos de rede na VLAN crítica.
O recurso de VLAN crítica entra em vigor quando a autenticação MAC é realizada somente por meio de servidores RADIUS. Se um usuário de autenticação MAC falhar na autenticação local após a autenticação RADIUS, o usuário não será atribuído à VLAN crítica. Para obter mais informações sobre os métodos de autenticação, consulte "Configuração de AAA".
A Tabela 5 mostra a maneira como o dispositivo de acesso à rede lida com VLANs críticas para usuários de autenticação MAC.
Tabela 5 Manipulação de VLAN
| Status de autenticação | Manipulação de VLAN |
| Um usuário falha na autenticação MAC porque todos os servidores RADIUS estão inacessíveis. | O dispositivo mapeia o endereço MAC do usuário para a VLAN crítica de autenticação MAC. O usuário ainda está na VLAN crítica de autenticação MAC se o usuário falhar na reautenticação MAC porque todos os servidores RADIUS estão inacessíveis. Se nenhuma VLAN crítica de autenticação MAC estiver configurada, o dispositivo mapeará o endereço MAC do usuário para o PVID da porta. |
| Um usuário na VLAN guest de autenticação MAC falha na autenticação porque todos os servidores RADIUS estão inacessíveis. | O usuário permanece na VLAN de convidado da autenticação MAC. |
| Um usuário na VLAN crítica de autenticação MAC falha na autenticação MAC por qualquer motivo que não seja o servidor inacessível. | Se uma VLAN de convidado tiver sido configurada, o dispositivo mapeará o endereço MAC do usuário para a VLAN de convidado. Se nenhuma VLAN de convidado estiver configurada, o dispositivo mapeará o endereço MAC do usuário para o PVID da porta. |
| Um usuário na VLAN crítica de autenticação MAC passa na autenticação MAC. | O dispositivo remapeia o endereço MAC do usuário para a VLAN de autorização atribuída pelo servidor de autenticação. Se nenhuma VLAN de autorização estiver configurada para o usuário no servidor de autenticação, o dispositivo remapeia o endereço MAC do usuário para o PVID da porta de acesso. |
VLAN de voz crítica
A VLAN de voz crítica de autenticação MAC em uma porta acomoda usuários de voz com autenticação MAC que falharam na autenticação porque nenhum dos servidores RADIUS em seu domínio ISP está acessível.
O recurso de VLAN de voz crítica entra em vigor quando a autenticação MAC é realizada somente por meio de servidores RADIUS. Se um usuário de voz com autenticação MAC falhar na autenticação local após a autenticação RADIUS, o usuário não será atribuído à VLAN de voz crítica. Para obter mais informações sobre os métodos de autenticação, consulte "Configuração de AAA".
A Tabela 6 mostra a maneira como o dispositivo de acesso à rede lida com VLANs de voz críticas para usuários de voz com autenticação MAC.
Tabela 6 Manipulação de VLAN
| Status de autenticação | Manipulação de VLAN |
| Um usuário de voz falha na autenticação MAC porque todos os servidores RADIUS estão inacessíveis. | O dispositivo mapeia o endereço MAC do usuário de voz para a VLAN de voz crítica de autenticação MAC. O usuário de voz ainda está na VLAN de voz crítica de autenticação MAC se o usuário de voz falhar na reautenticação MAC porque todos os servidores RADIUS estão inacessíveis. Se nenhuma VLAN de voz crítica de autenticação MAC estiver configurada, o dispositivo mapeará o endereço MAC do usuário de voz para o PVID da porta. |
| Um usuário de voz na VLAN de voz crítica de autenticação MAC falha na autenticação MAC por qualquer motivo que não seja o servidor inacessível. | Se uma VLAN de convidado tiver sido configurada, o dispositivo mapeará o endereço MAC do usuário de voz para a VLAN de convidado. Se nenhuma VLAN de convidado estiver configurada, o dispositivo mapeará o endereço MAC do usuário de voz para o PVID da porta. |
| Um usuário de voz na VLAN de voz crítica de autenticação MAC passa na autenticação MAC. | O dispositivo remapeia o endereço MAC do usuário de voz para a VLAN de autorização atribuída pelo servidor de autenticação. Se nenhuma VLAN de autorização estiver configurada para o usuário de voz no servidor de autenticação, o dispositivo remapeia o endereço MAC do usuário de voz para o PVID da porta de acesso. |
Atribuição de ACL
É possível especificar uma ACL de autorização na conta de usuário para um usuário de autenticação MAC no servidor de autenticação para controlar o acesso do usuário aos recursos da rede. Depois que o usuário passa pela autenticação MAC, o servidor de autenticação atribui a ACL de autorização à porta de acesso do usuário. Em seguida, a porta permite ou descarta o tráfego correspondente para o usuário, dependendo das regras configuradas na ACL. Essa ACL é chamada de ACL de autorização.
O dispositivo suporta a atribuição de ACLs estáticas e dinâmicas como ACLs de autorização.
- ACLs estáticas - As ACLs estáticas podem ser atribuídas por um servidor RADIUS ou pelo dispositivo de acesso. Quando o servidor ou o dispositivo de acesso atribui uma ACL estática a um usuário, ele atribui apenas o número da ACL. Você deve criar manualmente a ACL e configurar suas regras no dispositivo de acesso.
- Modificar as regras de ACL na ACL de autorização no dispositivo de acesso.
- Atribua outra ACL ao usuário a partir do servidor RADIUS ou do dispositivo de acesso. As ACLs estáticas e suas regras podem ser excluídas manualmente do dispositivo de acesso.
- ACLs dinâmicas - As ACLs dinâmicas e suas regras são implantadas automaticamente por um servidor RADIUS e não podem ser configuradas no dispositivo de acesso. As ACLs dinâmicas só podem ser ACLs nomeadas. Depois que o dispositivo recebe uma ACL dinâmica implantada pelo servidor e suas regras, ele cria automaticamente a ACL e configura suas regras.
Para alterar as permissões de acesso de um usuário, você pode usar um dos métodos a seguir:
Se a ACL dinâmica atribuída pelo servidor a um usuário tiver o mesmo nome de uma ACL estática, a ACL dinâmica não poderá ser emitida e o usuário não poderá ficar on-line.
Uma ACL dinâmica e suas regras são automaticamente excluídas do dispositivo de acesso depois que todos os seus usuários ficam off-line.
As ACLs dinâmicas e suas regras não podem ser modificadas ou excluídas manualmente no dispositivo de acesso. Para exibir informações sobre as ACLs dinâmicas e suas regras, use o comando display
conexão mac-authentication ou comando display acl.
IMPORTANTE:
A atribuição de ACLs dinâmicas é compatível apenas com a versão 6309P01 ou posterior.
As ACLs de autorização compatíveis incluem os seguintes tipos:
IMPORTANTE:
Para que uma ACL de autorização tenha efeito, certifique-se de que a ACL exista com regras e que nenhuma das regras contenha a palavra-chave counting, established, fragment, source-mac, cos, dest-mac, lsap, vxlan ou logging.
Para obter mais informações sobre ACLs, consulte o Guia de configuração de ACL e QoS.
Atribuição de perfil de usuário
É possível especificar um perfil de usuário na conta de usuário para um usuário de autenticação MAC no servidor de autenticação para controlar o acesso do usuário aos recursos da rede. Depois que o usuário passa pela autenticação MAC, o servidor de autenticação atribui o perfil de usuário ao usuário para filtrar o tráfego para esse usuário.
O servidor de autenticação pode ser o dispositivo de acesso local ou um servidor RADIUS. Em ambos os casos, o servidor especifica apenas o nome do perfil do usuário. Você deve configurar o perfil de usuário no dispositivo de acesso.
Para alterar as permissões de acesso do usuário, você pode usar um dos métodos a seguir:
- Modifique a configuração do perfil de usuário no dispositivo de acesso.
- Especifique outro perfil de usuário para o usuário no servidor de autenticação. Para obter mais informações sobre perfis de usuário, consulte "Configuração de perfis de usuário".
Atribuição de URL de redirecionamento
O dispositivo é compatível com o atributo de URL atribuído por um servidor RADIUS. Durante a autenticação MAC, as solicitações HTTP ou HTTPS de um usuário são redirecionadas para a interface da Web especificada pelo atributo de URL atribuído pelo servidor. Depois que o usuário passa pela autenticação na Web, o servidor RADIUS registra o endereço MAC do usuário e usa uma DM (Disconnect Message) para fazer logoff do usuário. Quando o usuário iniciar a autenticação MAC novamente, ele será aprovado na autenticação e ficará on-line com êxito.
Por padrão, o dispositivo escuta a porta 6654 para solicitações HTTPS a serem redirecionadas. Para alterar o número da porta de escuta do redirecionamento, consulte Configuração do redirecionamento de HTTP no Guia de configuração de serviços de camada 3 IP.
Reautenticação periódica de MAC
A reautenticação periódica do MAC rastreia o status da conexão dos usuários on-line e atualiza os atributos de autorização atribuídos pelo servidor RADIUS. Os atributos incluem a ACL e a VLAN.
O dispositivo reautentica os usuários de autenticação MAC on-line no intervalo de reautenticação periódica quando o recurso de reautenticação MAC periódica está ativado. O intervalo é controlado por um timer, que pode ser configurado pelo usuário. Uma alteração no timer de reautenticação periódica se aplica aos usuários de autenticação MAC on-line somente depois que o timer antigo expira e os usuários de autenticação MAC são aprovados na autenticação.
Os atributos RADIUS Session-Timeout (atributo 27) e Termination-Action (atributo 29) atribuídos pelo servidor podem afetar o recurso de reautenticação periódica de MAC. Para exibir os atributos Session-Timeout e Termination-Action atribuídos pelo servidor, use o comando display mac-authentication connection.
- Se a ação de encerramento for fazer o logoff dos usuários, a reautenticação periódica do MAC entrará em vigor somente quando o timer de reautenticação periódica for menor que o timer de tempo limite da sessão. Se o temporizador de tempo limite da sessão for mais curto, o dispositivo fará logoff dos usuários autenticados on-line quando o temporizador de tempo limite da sessão expirar.
- Se a ação de encerramento for reautenticar os usuários, a configuração de reautenticação periódica de MAC no dispositivo não poderá entrar em vigor. O dispositivo reautentica os usuários de autenticação MAC on-line depois que o temporizador de tempo limite da sessão atribuído pelo servidor expira.
Se nenhum temporizador de tempo limite da sessão for atribuído pelo servidor, o fato de o dispositivo executar ou não a reautenticação periódica do MAC dependerá da configuração de reautenticação periódica do MAC no dispositivo. O suporte para a atribuição dos atributos Session-Timeout e Termination-Action depende do modelo do servidor.
Com o recurso RADIUS DAS ativado, o dispositivo reautentica imediatamente um usuário ao receber uma mensagem CoA que contém o atributo de reautenticação de um servidor de autenticação RADIUS. Nesse caso, a reautenticação será executada independentemente de a reautenticação MAC periódica estar ativada no dispositivo. Para obter mais informações sobre a configuração do RADIUS DAS, consulte "Configuração de AAA".
Por padrão, o dispositivo faz logoff de usuários de autenticação MAC on-line se nenhum servidor estiver acessível para reautenticação MAC. O recurso keep-online mantém os usuários autenticados da autenticação MAC on-line quando nenhum servidor está acessível para a reautenticação MAC.
As VLANs atribuídas a um usuário on-line antes e depois da reautenticação podem ser iguais ou diferentes.
Restrições e diretrizes: Configuração da autenticação MAC
Ao configurar a autenticação MAC em uma interface, siga estas restrições e diretrizes:
- A autenticação MAC é compatível apenas com as interfaces Ethernet de camada 2 que não pertencem a um grupo de agregação.
- Não altere o tipo de link de uma porta quando a VLAN de convidado de autenticação MAC ou a VLAN crítica da porta tiver usuários.
Se o endereço MAC que falhou na autenticação for um endereço MAC estático ou um endereço MAC que tenha sido aprovado em qualquer autenticação de segurança, o dispositivo não marcará o endereço MAC como um endereço silencioso.
Para garantir um redirecionamento HTTPS bem-sucedido para os usuários aos quais foi atribuído um URL de redirecionamento, certifique-se de que existam interfaces de VLAN para as VLANs que transportam seus pacotes.
Visão geral das tarefas de autenticação MAC
Para configurar a autenticação MAC, execute as seguintes tarefas:
- Ativação da autenticação MAC
- Configurar os recursos básicos de autenticação MAC
- Especificação de um método de autenticação MAC
- Especificação de um domínio de autenticação MAC
- Configuração da política de conta de usuário
- (Opcional.) Configuração dos temporizadores de autenticação MAC
- (Opcional.) Configuração da reautenticação periódica de MAC
- (Opcional.) Configuração da atribuição de VLAN de autenticação MAC
- Configuração de uma VLAN de convidado com autenticação MAC
- Configuração de uma VLAN crítica de autenticação MAC
- Ativação do recurso de VLAN de voz crítica de autenticação MAC
- (Opcional.) Configuração de outros recursos de autenticação MAC
- Configuração do envelhecimento do usuário de autenticação MAC não autenticada
- Configuração da detecção off-line da autenticação MAC
- Configuração da detecção de pacotes para autenticação MAC
- Ativação da sincronização on-line de usuários para autenticação MAC
- Configuração do número máximo de usuários simultâneos de autenticação MAC em uma porta
- Ativação do modo multi-VLAN de autenticação MAC em uma porta
- Configuração do atraso da autenticação MAC
- Inclusão de endereços IP de usuários em solicitações de autenticação MAC
- Permitir o processamento paralelo da autenticação MAC e da autenticação 802.1X
- Fazer logoff de usuários de autenticação MAC
- Ativação do registro de usuário de autenticação MAC
Execute esta tarefa para não autenticar novamente os usuários on-line quando ocorrerem alterações de VLAN em uma porta.
Pré-requisitos para a autenticação MAC
Antes de configurar a autenticação MAC, conclua as seguintes tarefas:
- Certifique-se de que o recurso de segurança da porta esteja desativado. Para obter mais informações sobre a segurança da porta, consulte "Configuração da segurança da porta".
- Configure um domínio ISP e especifique um método AAA. Para obter mais informações, consulte "Configuração de AAA".
- Para a autenticação local, também é necessário criar contas de usuário locais (incluindo nomes de usuário e senhas) e especificar o serviço de acesso à LAN para usuários locais.
- Para a autenticação RADIUS, certifique-se de que o dispositivo e o servidor RADIUS possam se comunicar e crie contas de usuário no servidor RADIUS. Se estiver usando contas baseadas em MAC, verifique se o nome de usuário e a senha de cada conta são iguais ao endereço MAC de cada usuário de autenticação MAC.
Ativação da autenticação MAC
Restrições e diretrizes
Para que a autenticação MAC entre em vigor em uma porta, você deve ativar esse recurso globalmente e na porta.
A autenticação MAC não poderá entrar em vigor em uma porta se o dispositivo estiver sem recursos de ACL quando você executar uma das seguintes operações:
- Ativar a autenticação MAC na porta enquanto a autenticação MAC tiver sido ativada globalmente.
- Habilite a autenticação MAC globalmente no sistema enquanto a autenticação MAC estiver habilitada na porta.
Procedimento
- Entre na visualização do sistema.
system viewmac-authenticationPor padrão, a autenticação MAC é desativada globalmente.
interface interface-type interface-numbermac-authenticationPor padrão, a autenticação MAC está desativada em uma porta.
Especificação de um método de autenticação MAC
Sobre os métodos de autenticação MAC
A autenticação MAC baseada em RADIUS é compatível com os seguintes métodos de autenticação:
- PAP-Transporta nomes de usuário e senhas em texto simples. O método de autenticação se aplica a cenários que não exigem alta segurança.
- CHAP - Transporta nomes de usuário em texto simples e senhas em formato criptografado pela rede. O CHAP é mais seguro que o PAP.
Restrições e diretrizes
O dispositivo deve usar o mesmo método de autenticação que o servidor RADIUS.
Procedimento
- Entre na visualização do sistema.
system viewmac-authentication authentication-method { chap | pap }Por padrão, o dispositivo usa PAP para autenticação de MAC.
Especificação de um domínio de autenticação MAC
Sobre domínios de autenticação para autenticação MAC
Por padrão, os usuários da autenticação MAC estão no domínio de autenticação padrão do sistema. Para implementar diferentes políticas de acesso para os usuários, é possível usar um dos seguintes métodos para especificar domínios de autenticação para usuários de autenticação MAC:
- Especifique um domínio de autenticação global na visualização do sistema. Essa configuração de domínio se aplica a todas as portas ativadas com autenticação MAC.
- Especifique um domínio de autenticação para uma porta individual na visualização da interface.
A autenticação MAC escolhe um domínio de autenticação para os usuários em uma porta nesta ordem: o domínio específico da porta, o domínio global e o domínio padrão. Para obter mais informações sobre domínios de autenticação, consulte "Configuração de AAA".
Procedimento
- Entre na visualização do sistema.
system view- Na visualização do sistema:
mac-authentication domain domain-nameinterface interface-type interface-numbermac-authentication domain domain-namePor padrão, o domínio de autenticação padrão do sistema é usado para usuários de autenticação MAC.
Configuração da política de conta de usuário
Restrições e diretrizes
IMPORTANTE:
As contas de usuário específicas do intervalo MAC são compatíveis apenas com a versão 6310 ou posterior.
Para usuários em um intervalo de endereços MAC, a conta de usuário específica do intervalo de endereços MAC tem prioridade mais alta do que as configurações globais da conta de usuário.
Você pode configurar um máximo de 16 intervalos de endereços MAC e deve se certificar de que os intervalos de endereços MAC não se sobreponham.
Se você definir as configurações da conta de usuário várias vezes para o mesmo intervalo de endereços MAC, a configuração mais recente substituirá a anterior.
As contas específicas de intervalo MAC se aplicam somente a endereços MAC unicast.
- Se você especificar um intervalo de endereços MAC que contenha apenas endereços MAC multicast, a execução desse comando falhará.
- Se você especificar um intervalo de endereços MAC que contenha endereços MAC unicast e multicast, o comando terá efeito somente nos endereços MAC unicast.
O endereço MAC totalmente zero é inválido para a autenticação MAC. Os usuários com o endereço MAC totalmente zero não podem passar na autenticação MAC.
Procedimento
- Entre na visualização do sistema.
system view- Use uma conta de usuário baseada em MAC para cada usuário.
mac-authentication user-name-format mac-address [ { with-hyphen [ separator colon ] | without-hyphen } [ lowercase | uppercase ] ] [ password { cipher | simple } string ]As palavras-chave separador de dois pontos estão disponíveis somente na versão 6340 e posteriores.
mac-authentication user-name-format fixed [ account name ] [ password { cipher | simple } string ]Por padrão, o dispositivo usa o endereço MAC de cada usuário como nome de usuário e senha para autenticação MAC. Os endereços MAC estão em notação hexadecimal, sem hífens, e as letras estão em minúsculas.
mac-authentication mac-range-account mac-address mac-address mask { mask | mask-length } account name password { cipher | simple } stringPor padrão, nenhum nome de usuário ou senha é configurado especificamente para um intervalo de endereços MAC. A política global de conta de usuário se aplica aos usuários.
Configuração de temporizadores de autenticação MAC
Sobre os temporizadores de autenticação MAC
A autenticação MAC usa os seguintes temporizadores:
- Timer de detecção off-line - Define o intervalo em que o dispositivo deve aguardar o tráfego de um usuário antes que o dispositivo determine que o usuário está ocioso. Se o dispositivo não tiver recebido tráfego de um usuário antes de o temporizador expirar, o dispositivo fará logoff desse usuário e solicitará que o servidor de contabilidade pare de contabilizar o usuário. Esse cronômetro entra em vigor somente quando o recurso de detecção off-line de autenticação MAC está ativado.
- Temporizador de silêncio - Define o intervalo que o dispositivo deve aguardar antes de executar a autenticação MAC para um usuário que falhou na autenticação MAC. Todos os pacotes do endereço MAC são descartados durante o período de silêncio. Esse mecanismo de silêncio evita que a autenticação repetida afete o desempenho do sistema.
- Temporizador de tempo limite do servidor - Define o intervalo em que o dispositivo aguarda uma resposta de um servidor RADIUS antes que o dispositivo determine que o servidor RADIUS não está disponível. Se o temporizador expirar durante a autenticação MAC, o usuário falhará na autenticação MAC.
Como prática recomendada, defina o cronômetro de envelhecimento do endereço MAC com o mesmo valor do cronômetro de detecção off-line. Essa operação evita que um usuário autenticado por MAC seja desconectado dentro do intervalo de detecção off-line devido à expiração da entrada do endereço MAC.
Restrições e diretrizes
Para evitar o logoff forçado antes que o cronômetro de tempo limite do servidor expire, defina o cronômetro de tempo limite do servidor com um valor menor ou igual ao produto dos valores a seguir:
- O número máximo de tentativas de transmissão de pacotes RADIUS definido pelo uso do parâmetro retry
na visualização do esquema RADIUS.
- O timer de tempo limite de resposta do servidor RADIUS definido usando o timer response-timeout
na visualização do esquema RADIUS.
Para obter informações sobre como definir o número máximo de tentativas de transmissão de pacotes RADIUS e o cronômetro de tempo limite de resposta do servidor RADIUS, consulte "Configuração do AAA".
Procedimento
- Entre na visualização do sistema.
system viewmac-authentication timer { offline-detect offline-detect-value | quiet quiet-value | server-timeout server-timeout-value }Por padrão, o cronômetro de detecção off-line é de 300 segundos, o cronômetro de silêncio é de 60 segundos e o cronômetro de tempo limite do servidor é de 100 segundos.
Configuração da reautenticação periódica de MAC
Restrições e diretrizes
O dispositivo seleciona um temporizador de reautenticação periódica para a reautenticação de MAC na seguinte ordem:
- Temporizador de reautenticação atribuído pelo servidor.
- Temporizador de reautenticação específico da porta.
- Temporizador de reautenticação global.
- Temporizador de reautenticação padrão.
A modificação do domínio de autenticação MAC, do método de autenticação MAC ou da configuração do formato da conta de usuário não afeta a reautenticação dos usuários de autenticação MAC on-line. A configuração modificada entra em vigor somente nos usuários de autenticação MAC que ficam on-line após a modificação.
Se a reautenticação periódica for acionada para um usuário enquanto ele estiver aguardando a sincronização on-line, o sistema executará a sincronização on-line e não executará a reautenticação para o usuário.
Procedimento
- Entre na visualização do sistema.
system view- Defina um cronômetro de reautenticação periódica global.
mac-authentication timer reauth-period reauth-period-valueA configuração padrão é 3600 segundos.
interface interface-type interface-numbermac-authentication timer reauth-period reauth-period-valuequitPor padrão, nenhum temporizador periódico de reautenticação de MAC é definido em uma porta. A porta usa o cronômetro de reautenticação periódica de MAC global .
interface interface-type interface-numbermac-authentication re-authenticatePor padrão, a reautenticação periódica de MAC está desativada em uma porta.
mac-authentication re-authenticate server-unreachable keep-onlinePor padrão, o recurso keep-online está desativado. O dispositivo faz logoff dos usuários de autenticação MAC on-line se nenhum servidor estiver acessível para reautenticação MAC.
Em uma rede de recuperação rápida, é possível usar o recurso keep-online para evitar que os usuários de autenticação MAC fiquem on-line e off-line com frequência.
Configuração de uma VLAN de convidado com autenticação MAC
Restrições e diretrizes
Ao configurar a VLAN de convidado de autenticação MAC em uma porta, siga as diretrizes da Tabela 7.
Tabela 7 Relações da VLAN de convidado de autenticação MAC com outros recursos de segurança
| Recurso | Descrição do relacionamento | Referência |
| Recurso silencioso de autenticação MAC | O recurso de VLAN de convidado de autenticação MAC tem prioridade mais alta. Quando um usuário falha na autenticação MAC, ele pode acessar os recursos na VLAN de convidado. O endereço MAC do usuário não é marcado como um endereço MAC silencioso. |
Consulte "Configuração dos temporizadores de autenticação MAC". |
| Proteção contra intrusão de portas | O recurso de VLAN de convidado tem prioridade mais alta do que a ação de bloqueio de MAC, mas prioridade mais baixa do que a ação de desligamento de porta do recurso de proteção contra intrusão de porta. | Consulte "Configuração da segurança da porta". |
Pré-requisitos
Antes de configurar a VLAN de convidado de autenticação MAC em uma porta, conclua as seguintes tarefas:
- Crie a VLAN a ser especificada como a VLAN de convidado de autenticação MAC.
- Configure a porta como uma porta híbrida e configure a VLAN como um membro sem marcação na porta.
- Habilite a VLAN baseada em MAC na porta.
Para obter informações sobre a configuração de VLAN, consulte o Layer 2-LAN Switching Configuration Guide.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numbermac-authentication guest-vlan guest-vlan-idPor padrão, nenhuma VLAN de convidado de autenticação MAC é especificada em uma porta.
É possível configurar apenas uma VLAN de convidado de autenticação MAC em uma porta. As VLANs convidadas de autenticação MAC em portas diferentes podem ser diferentes.
mac-authentication guest-vlan auth-period period-valueA configuração padrão é 30 segundos.
Configuração de uma VLAN crítica de autenticação MAC
Restrições e diretrizes
Ao configurar a VLAN crítica de autenticação MAC em uma porta, siga as diretrizes da Tabela 8.
Tabela 8 Relações da VLAN crítica de autenticação MAC com outros recursos de segurança
| Recurso | Descrição do relacionamento | Referência |
| Recurso silencioso de autenticação de MAC | O recurso de VLAN crítica de autenticação MAC tem prioridade mais alta. Quando um usuário falha na autenticação MAC porque nenhum servidor de autenticação RADIUS está acessível, o usuário pode acessar os recursos na VLAN crítica. O endereço MAC do usuário não é marcado como um endereço MAC silencioso. |
Consulte "Configuração dos temporizadores de autenticação MAC". |
| Proteção contra intrusão de portas | O recurso de VLAN crítica tem prioridade mais alta do que a ação de bloqueio de MAC, mas prioridade mais baixa do que a ação de desligamento de porta do recurso de proteção contra intrusão de porta. | Consulte "Configuração da segurança da porta". |
Pré-requisitos
Antes de configurar a VLAN crítica de autenticação MAC em uma porta, conclua as seguintes tarefas:
- Crie a VLAN a ser especificada como a VLAN crítica de autenticação MAC.
- Configure a porta como uma porta híbrida e configure a VLAN como um membro sem marcação na porta.
- Habilite a VLAN baseada em MAC na porta.
Para obter informações sobre a configuração de VLAN, consulte o Layer 2-LAN Switching Configuration Guide.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numbermac-authentication critical vlan critical-vlan-idPor padrão, nenhuma VLAN crítica de autenticação MAC é especificada em uma porta.
É possível configurar apenas uma VLAN crítica de autenticação MAC em uma porta. As VLANs críticas de autenticação MAC em portas diferentes podem ser diferentes.
Ativação do recurso de VLAN de voz crítica de autenticação MAC
Pré-requisitos
Antes de ativar o recurso VLAN de voz crítica de autenticação MAC em uma porta, conclua as seguintes tarefas:
- Habilite o LLDP globalmente e na porta.
O dispositivo usa LLDP para identificar usuários de voz. Para obter informações sobre o LLDP, consulte o Layer 2-LAN Switching Configuration Guide.
- Ativar a VLAN de voz na porta.
Para obter informações sobre VLANs de voz, consulte o Layer 2-LAN Switching Configuration Guide.
- Especifique uma VLAN crítica de autenticação MAC na porta. Essa configuração garante que um usuário de voz seja atribuído à VLAN crítica se houver falha na autenticação por inacessibilidade dos servidores RADIUS antes que o dispositivo o reconheça como um usuário de voz. Se uma VLAN crítica de autenticação MAC não estiver disponível, o usuário de voz poderá ser desconectado.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numbermac-authentication critical-voice-vlanPor padrão, o recurso de VLAN de voz crítica de autenticação MAC está desativado em uma porta.
Configuração do envelhecimento do usuário de autenticação MAC não autenticada
Sobre o envelhecimento do usuário de autenticação MAC não autenticado
O envelhecimento do usuário de autenticação MAC não autenticado aplica-se aos usuários adicionados a uma VLAN crítica ou convidada de autenticação MAC porque não foram autenticados ou falharam na autenticação.
Quando um usuário de uma dessas VLANs envelhece, o dispositivo remove o usuário da VLAN e exclui a entrada do endereço MAC do usuário da porta de acesso.
Para que os usuários de uma dessas VLANs em uma porta sejam autenticados com êxito e fiquem on-line em outra porta, ative esse recurso. Em qualquer outro cenário, desative esse recurso como prática recomendada.
Restrições e diretrizes
Como prática recomendada, use esse recurso em uma porta somente se quiser que seus usuários não autenticados sejam autenticados em e fiquem on-line em uma porta diferente.
Procedimento
- Entre na visualização do sistema.
system viewmac-authentication timer user-aging { critical-vlan | guest-vlan } aging-time-valuePor padrão, o temporizador de envelhecimento do usuário é de 1.000 segundos para todos os tipos aplicáveis de autenticação MAC VLANs.
interface interface-type interface-numbermac-authentication unauthenticated-user aging enablePor padrão, o envelhecimento do usuário da autenticação MAC não autenticada está ativado.
Configuração da detecção off-line da autenticação MAC
Sobre a detecção off-line da autenticação MAC
Ative a detecção off-line da autenticação MAC para detectar usuários ociosos em uma porta. Se a porta não tiver recebido tráfego de um usuário quando o timer de detecção off-line expirar, o dispositivo fará o logoff desse usuário e solicitará que o servidor de contabilidade pare de contabilizar os usuários. Para obter informações sobre a configuração do temporizador de detecção off-line na visualização do sistema, consulte "Configuração dos temporizadores de autenticação MAC".
A desativação desse recurso impede que o dispositivo inspecione o status do usuário on-line.
Além da detecção off-line da autenticação MAC baseada em porta, é possível configurar os parâmetros de detecção off-line por usuário, como segue:
- Defina um timer de detecção off-line específico para um usuário e controle se deve usar a tabela de snooping ARP ou ND para determinar o estado off-line do usuário.
- Se a tabela ARP snooping ou ND snooping for usada, o dispositivo pesquisará a tabela ARP snooping ou ND snooping antes de verificar se há tráfego do usuário dentro do intervalo de detecção. Se for encontrada uma entrada correspondente de ARP snooping ou ND snooping, o dispositivo redefinirá o timer de detecção off-line e o usuário permanecerá on-line. Se o timer de detecção off-line expirar porque o usuário
- Se a tabela de snooping ARP ou ND não for usada, o dispositivo desconectará o usuário se não tiver recebido tráfego desse usuário antes que o temporizador de detecção off-line expire.
- Ignora a detecção off-line para o usuário. Você pode escolher essa opção se o usuário for um terminal burro. Um terminal burro pode não conseguir ficar on-line novamente depois de ser desconectado pelo recurso de detecção off-line.
o dispositivo não tiver encontrado uma entrada de snooping correspondente para o usuário ou não tiver recebido tráfego do usuário, o dispositivo desconectará o usuário.
Ao desconectar o usuário, o dispositivo também notifica o servidor RADIUS (se houver) para interromper a contabilidade do usuário.
O dispositivo usa as configurações de detecção off-line para um usuário na seguinte sequência:
- Configurações de detecção off-line específicas do usuário.
- Configurações de detecção off-line atribuídas ao usuário pelo servidor RADIUS. As configurações incluem o cronômetro de detecção off-line, o uso da tabela de snooping ARP ou ND na detecção off-line e a possibilidade de ignorar a detecção off-line.
- Configurações de detecção off-line baseadas em portas.
Restrições e diretrizes
Quando a detecção off-line da autenticação MAC for usada, certifique-se de que o valor do timer de envelhecimento para entradas dinâmicas de endereço MAC seja menor ou igual ao valor padrão do timer de detecção off-line (300 segundos) para usuários de autenticação MAC. O cronômetro de envelhecimento das entradas dinâmicas de endereço MAC pode ser configurado com o comando mac-address timer aging seconds.
Para que o recurso de detecção off-line específico do usuário entre em vigor para um usuário, certifique-se de que o recurso de detecção off-line de autenticação MAC esteja ativado na porta de acesso do usuário.
As configurações de detecção off-line específicas do usuário entram em vigor para os usuários on-line imediatamente após serem configuradas.
Procedimento
- Entre na visualização do sistema.
system viewmac-authentication offline-detect mac-address mac-address { ignore | timer offline-detect-value [ check-arp-or-nd-snooping ] }Por padrão, as configurações de detecção off-line definidas nas portas de acesso entram em vigor e o cronômetro de detecção off-line definido na visualização do sistema é usado.
interface interface-type interface-numbermac-authentication offline-detect enablePor padrão, a detecção off-line da autenticação MAC está ativada em uma porta.
Configuração da detecção de pacotes para autenticação MAC
Sobre esta tarefa
Quando a detecção de pacotes para autenticação MAC está ativada em uma porta, o dispositivo envia pacotes de detecção para os usuários de autenticação MAC conectados a essa porta em intervalos de detecção off-line definidos usando o timer de detecção off-line. Se o dispositivo não receber uma resposta de um usuário depois de ter feito o máximo de tentativas de transmissão de pacotes dentro de um intervalo de detecção off-line, ele fará o logoff desse usuário e solicitará que o servidor RADIUS pare de contabilizar o usuário.
Quando a detecção de pacotes para autenticação MAC e a detecção off-line de autenticação MAC estão ambas ativadas, o dispositivo processa um usuário de autenticação MAC da seguinte forma:
- Se a detecção off-line da autenticação MAC determinar que um usuário está on-line, o dispositivo não enviará pacotes de detecção para esse usuário.
- Se a detecção off-line da autenticação MAC determinar que um usuário está off-line, o dispositivo não fará imediatamente o logoff desse usuário. Em vez disso, o dispositivo envia um pacote de detecção para esse usuário. Ele fará o logoff do usuário se não receber uma resposta do mesmo após ter feito o máximo de tentativas de transmissão de pacotes dentro de um intervalo de detecção off-line.
A autenticação MAC usa pacotes de solicitação ARP para detectar o status on-line de usuários IPv4 e usa pacotes NS para detectar o status on-line de usuários IPv6.
A detecção de pacotes adota o princípio de contagem antes de julgar. O dispositivo diminui as tentativas de detecção (tentativas de transmissão de pacotes) em 1 somente depois de determinar que não recebeu uma resposta de um usuário. O dispositivo interrompe o processo de detecção quando o número de tentativas de detecção chega a 0. A duração desde o momento em que o usuário envia o último pacote para o
O tempo em que o usuário é desconectado é calculado com a seguinte fórmula: duração = (tentativas + 1) * T + X. A Figura 4 mostra o processo de detecção de pacotes. Nesse exemplo, o dispositivo envia um pacote de detecção para um usuário de autenticação MAC no máximo duas vezes.
Figura 4 Diagrama de rede para o processo de detecção de pacotes
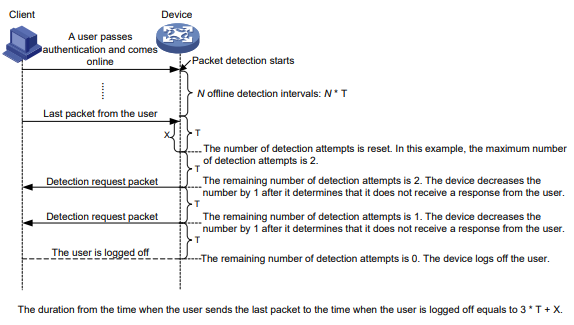
Compatibilidade de recursos e versões de software
Esse recurso é compatível apenas com a versão 6348P01 e posteriores.
Restrições e diretrizes
Para garantir que o dispositivo esteja ciente das alterações de endereço IP do usuário, ative o snooping ARP e o snooping ND em conjunto com a detecção de pacotes para autenticação MAC. Se você não ativar o ARP snooping ou o ND snooping, o dispositivo não saberá das alterações de endereço IP do usuário. Como resultado, o dispositivo ainda enviará pacotes de detecção para os endereços IP originais dos usuários e fará o logout falso desses usuários.
Procedimento
- Entre na visualização do sistema.
system viewmac-authentication timer offline-detect offline-detect-valuePor padrão, o cronômetro de detecção off-line expira em 300 segundos.
interface interface-type interface-numbermac-authentication packet-detect enablePor padrão, a detecção de pacotes para autenticação MAC está desativada.
mac-authentication packet-detect retry retriesPor padrão, o dispositivo envia um pacote de detecção para um usuário de autenticação MAC no máximo duas vezes.
Ativação da sincronização on-line de usuários para autenticação MAC
Sobre a sincronização on-line de usuários para autenticação MAC
IMPORTANTE:
Esse recurso entra em vigor somente quando o dispositivo usa um servidor IMC RADIUS para autenticar usuários de autenticação MAC.
Para garantir que o servidor RADIUS mantenha as mesmas informações de usuário de autenticação MAC on-line que o dispositivo depois que o estado do servidor mudar de inacessível para acessível, use esse recurso.
Esse recurso sincroniza as informações do usuário de autenticação MAC on-line entre o dispositivo e o servidor RADIUS quando é detectado que o estado do servidor RADIUS mudou de inacessível para acessível.
Ao sincronizar as informações do usuário de autenticação MAC on-line em uma porta com o servidor RADIUS, o dispositivo inicia a autenticação MAC sucessivamente para cada usuário de autenticação MAC on-line autenticado para o servidor RADIUS.
Se a sincronização falhar para um usuário on-line, o dispositivo fará o logoff desse usuário, a menos que a falha ocorra porque o servidor se tornou inacessível novamente.
Restrições e diretrizes
O tempo necessário para concluir a sincronização de usuários on-line aumenta à medida que o número de usuários on-line cresce. Isso pode resultar em um atraso maior para que novos usuários de autenticação MAC e usuários na VLAN crítica se autentiquem ou reautentiquem no servidor RADIUS e fiquem on-line.
Para que esse recurso tenha efeito, você deve usá-lo em conjunto com o recurso de detecção de status do servidor RADIUS, que pode ser configurado com o comando radius-server test-profile. Para obter mais informações sobre o recurso de detecção de status do servidor RADIUS, consulte "Configuração de AAA".
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numbermac-authentication server-recovery online-user-syncPor padrão, a sincronização on-line de usuários para autenticação MAC está desativada.
Configuração do número máximo de usuários simultâneos de autenticação MAC em uma porta
Sobre a limitação do número de usuários simultâneos de autenticação MAC em uma porta
Execute essa tarefa para evitar que os recursos do sistema sejam usados em excesso.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numbermac-authentication max-user max-numberA configuração padrão é 4294967295.
Ativação do modo multi-VLAN de autenticação MAC em uma porta
Sobre os modos VLAN de autenticação MAC
Por padrão, o modo de VLAN única de autenticação MAC é aplicado em uma porta. Nesse modo, o tráfego de um usuário on-line não pode ser enviado em VLANs diferentes em uma porta sem interrupção do serviço. Para acomodar aplicativos sensíveis a atrasos ou interrupções de serviço em um ambiente de várias VLANs, por exemplo, telefones IP, ative o modo de autenticação MAC de várias VLANs.
No modo multi-VLAN, a porta encaminha o tráfego de um usuário em diferentes VLANs sem reautenticação se o usuário tiver sido autenticado e estiver on-line em qualquer VLAN da porta. Sem a necessidade de reautenticação, o tráfego de um usuário on-line pode ser enviado para diferentes VLANs sem atraso ou interrupção do serviço.
No modo de VLAN única, a porta reautentica um usuário on-line quando o tráfego recebido desse usuário contém uma tag de VLAN diferente da VLAN na qual o usuário foi autenticado. O processo de autenticação difere dependendo da configuração de movimentação de MAC na segurança da porta e do status de atribuição da VLAN de autorização, como segue:
- Se nenhuma VLAN de autorização tiver sido atribuída ao usuário on-line, o dispositivo primeiro fará o logoff do usuário e, em seguida, reautenticará o usuário na nova VLAN.
- Se o usuário on-line tiver sido atribuído a uma VLAN de autorização, o dispositivo tratará o usuário de acordo com a configuração de movimentação de MAC na segurança da porta.
- Se a movimentação de MAC estiver desativada na segurança da porta, o usuário não poderá passar pela autenticação e ficar on-line a partir da nova VLAN até que fique off-line na porta.
- Se a movimentação de MAC estiver ativada na segurança da porta, o usuário poderá passar pela autenticação na nova VLAN e ficar on-line sem precisar primeiro ficar off-line na porta. Depois que o usuário passa pela autenticação na nova VLAN, a sessão de autenticação original do usuário é excluída da porta.
Para ativar o recurso de movimentação de MAC de segurança de porta, use o comando port-security mac-move permit.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numbermac-authentication host-mode multi-vlanPor padrão, a autenticação MAC opera no modo de VLAN única em uma porta.
Configuração do atraso da autenticação MAC
Sobre o atraso da autenticação MAC
Quando a autenticação 802.1X e a autenticação MAC estiverem ativadas em uma porta, você poderá atrasar a autenticação MAC para que a autenticação 802.1X seja preferencialmente acionada.
Se nenhuma autenticação 802.1X for acionada ou se a autenticação 802.1X falhar dentro do período de atraso, a porta continuará a processar a autenticação MAC.
Restrições e diretrizes
Não defina o modo de segurança da porta como mac-else-userlogin-secure ou mac-else-userlogin-secure-ext ao usar o atraso de autenticação MAC. O atraso não entra em vigor em uma porta em qualquer um dos dois modos. Para obter mais informações sobre os modos de segurança da porta, consulte "Configurando a segurança da porta".
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numbermac-authentication timer auth-delay timePor padrão, o atraso da autenticação MAC está desativado.
Inclusão de endereços IP de usuários em solicitações de autenticação MAC
Sobre o recurso de inclusão de endereços IP de usuários em solicitações de autenticação MAC
IMPORTANTE:
Esse recurso só pode funcionar em conjunto com um servidor IMC.
Para evitar conflitos de IP resultantes de alterações nos endereços IP estáticos, use esse recurso em uma porta que tenha usuários de autenticação MAC com endereços IP estáticos.
Esse recurso adiciona endereços IP de usuários às solicitações de autenticação MAC enviadas ao servidor de autenticação. Quando a autenticação MAC é acionada para um usuário, o dispositivo verifica se o endereço IP do usuário é inválido.
- Se o endereço IP for válido, o dispositivo enviará uma solicitação de autenticação MAC com o endereço IP incluído.
- Se o endereço IP não for um endereço IP de host válido ou se o pacote de disparo não contiver um endereço IP, o dispositivo não iniciará a autenticação MAC.
- Se o pacote for um pacote DHCP com um endereço IP de origem 0.0.0.0, o dispositivo enviará uma solicitação de autenticação MAC sem incluir o endereço IP. Nesse caso, o servidor IMC não examina o endereço IP do usuário quando realiza a autenticação.
Após o recebimento da solicitação de autenticação que inclui o endereço IP do usuário, o servidor IMC compara os endereços IP e MAC do usuário com seus mapeamentos IP-MAC locais.
- Se for encontrada uma correspondência exata ou se não for encontrada nenhuma correspondência, o usuário será aprovado na autenticação MAC. No último caso, o servidor cria um mapeamento IP-MAC para o usuário.
- Se for encontrado um mapeamento para o endereço MAC, mas os endereços IP não corresponderem, o usuário falhará na autenticação MAC.
Restrições e diretrizes
Não use esse recurso em conjunto com a VLAN de convidado de autenticação MAC em uma porta. Se ambos os recursos forem usados, o dispositivo não poderá executar a autenticação MAC para um usuário depois que esse usuário for adicionado à VLAN de convidado de autenticação MAC.
Você pode especificar uma ACL para identificar endereços IP de origem que podem ou não acionar a autenticação MAC. Ao configurar a ACL, siga estas diretrizes:
- O número da ACL especificado representa uma ACL IPv4 e uma ACL IPv6 com o mesmo número. Por exemplo, se o número da ACL for 2000, você especificará tanto a ACL IPv4 2000 quanto a ACL IPv6 2000. A ACL IPv4 e a ACL IPv6 serão usadas para processar pacotes IPv4 e pacotes IPv6, respectivamente.
- Use regras de permissão para identificar endereços IP de origem válidos para a autenticação MAC. Use regras de negação para identificar endereços IP de origem que não podem acionar a autenticação MAC.
- Nas regras, somente a palavra-chave de ação (permitir ou negar) e o critério de correspondência do IP de origem podem ter efeito.
- Como prática recomendada, configure uma regra de negação para excluir os endereços IPv6 que começam com fe80 do acionamento da autenticação MAC.
- Se você configurar regras de permissão, adicione uma regra de negar tudo na parte inferior da ACL.
IMPORTANTE:
Se o host do usuário estiver configurado com IPv6, o dispositivo poderá receber pacotes que contenham um IPv6
endereço local do link, que começa com fe80. Ocorrerá falha na autenticação MAC ou vinculação MAC-IP incorreta se esse endereço for usado na autenticação MAC. Para evitar esses problemas, configure uma ACL básica para excluir os endereços IPv6 que começam com fe80.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numbermac-authentication carry user-ip [ exclude-ip acl acl-number ]Por padrão, uma solicitação de autenticação MAC não inclui o endereço IP do usuário.
Permitir o processamento paralelo da autenticação MAC e da autenticação 802.1X
Sobre o processamento paralelo da autenticação MAC e da autenticação 802.1X
Esse recurso permite que uma porta que processa a autenticação MAC após a conclusão da autenticação 802.1X processe a autenticação MAC em paralelo com a autenticação 802.1X.
Certifique-se de que a porta atenda aos seguintes requisitos:
- A porta é configurada com autenticação 802.1X e autenticação MAC e executa o controle de acesso baseado em MAC para autenticação 802.1X.
- A porta está ativada com o acionador unicast 802.1X.
Quando a porta recebe um pacote de um endereço MAC desconhecido, ela envia um pacote EAP-Request/Identity unicast para o endereço MAC. Depois disso, a porta processa imediatamente a autenticação MAC sem aguardar o resultado da autenticação 802.1X.
Depois que a autenticação MAC for bem-sucedida, a porta será atribuída à VLAN de autorização de autenticação MAC.
- Se a autenticação 802.1X falhar, o resultado da autenticação MAC entrará em vigor.
- Se a autenticação 802.1X for bem-sucedida, o dispositivo tratará a porta e o endereço MAC com base no resultado da autenticação 802.1X.
A sequência de processos da autenticação 802.1X e da autenticação MAC pode ser configurada de outras maneiras. Para que a porta execute a autenticação MAC antes de ser atribuída à VLAN de convidado 802.1X, ative o atraso na atribuição de nova VLAN de convidado 802.1X acionada por MAC. Para obter informações sobre o novo atraso na atribuição de VLAN de convidado 802.1X acionado por MAC, consulte "Configuração do 802.1X".
Restrições e diretrizes
Para configurar a autenticação 802.1X e a autenticação MAC na porta, use um dos métodos a seguir:
- Habilite os recursos de autenticação 802.1X e MAC separadamente na porta.
- Ativar a segurança da porta na porta. O modo de segurança da porta deve ser userlogin-secure-or-mac ou
userlogin-secure-or-mac-ext.
Para obter informações sobre a configuração do modo de segurança da porta, consulte "Configuração da segurança da porta".
Para que o recurso de processamento paralelo funcione corretamente, não ative o atraso da autenticação MAC na porta . Essa operação atrasará a autenticação MAC depois que a autenticação 802.1X for acionada.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numbermac-authentication parallel-with-dot1xPor padrão, esse recurso está desativado.
Fazer logoff de usuários de autenticação MAC
Sobre esta tarefa
Execute esta tarefa para fazer logoff dos usuários de autenticação MAC especificados e limpar as informações sobre esses usuários no dispositivo. Esses usuários devem executar a autenticação MAC para ficarem on-line novamente.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6318P01 e posteriores.
Procedimento
Para fazer logoff de usuários de autenticação MAC, execute o seguinte comando na visualização do usuário:
reset mac-authentication access-user [ interface interface-type interface-number | mac mac-address | username username | vlan vlan-id ]Ativação do registro de usuário de autenticação MAC
Sobre o registro de usuário de autenticação MAC
Esse recurso permite que o dispositivo gere logs sobre os usuários de autenticação MAC e envie os logs para o centro de informações. Para que os logs sejam gerados corretamente, também é necessário configurar o centro de informações no dispositivo. Para obter mais informações sobre a configuração da central de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Restrições e diretrizes
Para evitar o excesso de entradas de registro de usuários de autenticação MAC, use esse recurso somente se precisar analisar logins ou logouts anormais de usuários de autenticação MAC.
Procedimento
- Entre na visualização do sistema.
system viewmac-authentication access-user log enable [ failed-login | logoff | successful-login ] *Por padrão, o registro de usuários de autenticação MAC está desativado.
Se você não especificar nenhum parâmetro, esse comando habilitará todos os tipos de autenticação MAC logs de usuários.
Comandos de exibição e manutenção para autenticação MAC
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações de autenticação MAC. | display mac-authentication [ interface interface-type interface-number ] |
| Exibir conexões de autenticação MAC. | display mac-authentication connection [ open ] [ interface interface-type interface-number | slot slot-number | user-mac mac-address | user-name nome de usuário ] |
| Exibir os endereços MAC dos usuários de autenticação MAC em um tipo de VLAN de autenticação MAC. | display mac-authentication mac-address { critical-vlan | guest-vlan } [ interface-type interface-number ] |
| Limpar estatísticas de autenticação MAC. | reset mac-authentication statistics [ interface interface-type interface-number ] |
| Remover usuários da VLAN crítica de autenticação MAC em uma porta. | reset mac-authentication critical vlan interface interface-type interface-number [ mac-address mac-address ] |
| Remover usuários da VLAN de voz crítica de autenticação MAC em uma porta. | reset mac-authentication critical-voice-vlan interface interface-type interface-number [ mac-address mac-address ] |
| Remover usuários da VLAN de convidados de autenticação MAC em uma porta. | reset mac-authentication guest-vlan interface interface-type número da interface [ endereço mac mac-address ] |
Exemplos de configuração de autenticação MAC
Exemplo: Configuração da autenticação MAC local
Configuração de rede
Conforme mostrado na Figura 5, o dispositivo executa a autenticação MAC local na GigabitEthernet 1/0/1 para controlar o acesso dos usuários à Internet.
Configure o dispositivo para atender aos seguintes requisitos:
- Detectar se um usuário ficou off-line a cada 180 segundos.
- Negar um usuário por 180 segundos se o usuário falhar na autenticação MAC.
- Autenticar todos os usuários no domínio bbb do ISP.
- Use o endereço MAC de cada usuário como nome de usuário e senha para autenticação. Os endereços MAC estão em notação hexadecimal com hífens e as letras estão em minúsculas.
Figura 5 Diagrama de rede
Procedimento
# Adicione um usuário local de acesso à rede. Neste exemplo, configure o nome de usuário e a senha como o endereço MAC do Host A 00-e0-fc-12-34-56.
<Device> system-view
[Device] local-user 00-e0-fc-12-34-56 class network
[Device-luser-network-00-e0-fc-12-34-56] password simple 00-e0-fc-12-34-56# Especifique o serviço de acesso à LAN para o usuário.
[Device-luser-network-00-e0-fc-12-34-56] service-type lan-access
[Device-luser-network-00-e0-fc-12-34-56] quit# Configure o domínio bbb do ISP para executar a autenticação local para usuários da LAN.
[Device] domain bbb
[Device-isp-bbb] authentication lan-access local
[Device-isp-bbb] quit# Habilite a autenticação MAC na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] mac-authentication
[Device-GigabitEthernet1/0/1] quit# Especifique o domínio ISP bbb como o domínio de autenticação MAC.
[Device] mac-authentication domain bbb# Configure os temporizadores de autenticação MAC.
[Device] mac-authentication timer offline-detect 180
[Device] mac-authentication timer quiet 180# Use o endereço MAC de cada usuário como nome de usuário e senha para a autenticação MAC. Os endereços MAC estão em notação hexadecimal com hífens e as letras estão em minúsculas.
[Device] mac-authentication user-name-format mac-address with-hyphen lowercase# Habilite a autenticação MAC globalmente.
[Device] mac-authenticationVerificação da configuração
# Exibir configurações e estatísticas de autenticação MAC para verificar sua configuração.
[Device] display mac-authentication
Global MAC authentication parameters:
MAC authentication : Enabled
Authentication method : PAP
User name format : MAC address in lowercase(xx-xx-xx-xx-xx-xx)
Username : mac
Password : Not configured
Offline detect period : 180 s
Quiet period : 180 s
Server timeout : 100 s
Reauth period : 3600 s
User aging period for critical VLAN : 1000 s
User aging period for guest VLAN : 1000 s
Authentication domain : bbb
Online MAC-auth wired users : 1
Silent MAC users:
MAC address VLAN ID From port Port index
00e0-fc11-1111 8 GE1/0/1 1
GigabitEthernet1/0/1 is link-up
MAC authentication : Enabled
Carry User-IP : Disabled
Authentication domain : Not configured
Auth-delay timer : Disabled
Periodic reauth : Disabled
Re-auth server-unreachable : Logoff
Guest VLAN : Not configured
Guest VLAN reauthentication : Enabled
Guest VLAN auth-period : 30 s
Critical VLAN : Not configured
Critical voice VLAN : Disabled
Host mode : Single VLAN
Offline detection : Enabled
Authentication order : Default
User aging : Enabled
Server-recovery online-user-sync : Enabled
Auto-tag feature : Disabled
VLAN tag configuration ignoring : Disabled
Max online users : 4294967295
Authentication attempts : successful 1, failed 0
Current online users : 1
MAC address Auth state
00e0-fc12-3456 AuthenticatedA saída mostra que o host A foi aprovado na autenticação MAC e ficou on-line. O host B falhou na autenticação MAC e seu endereço MAC está marcado como um endereço MAC silencioso.
Exemplo: Configuração da autenticação MAC baseada em RADIUS
Configuração de rede
Conforme mostrado na Figura 6, o dispositivo usa servidores RADIUS para realizar a autenticação, a autorização e a contabilidade dos usuários. Os servidores RADIUS usam o método de autenticação CHAP.
Para controlar o acesso do usuário à Internet por autenticação MAC, execute as seguintes tarefas:
- Habilite a autenticação MAC globalmente e na GigabitEthernet 1/0/1.
- Configure o dispositivo para usar CHAP para autenticação de MAC.
- Configure o dispositivo para detectar se um usuário ficou off-line a cada 180 segundos.
- Configure o dispositivo para negar um usuário por 180 segundos se o usuário falhar na autenticação MAC.
- Configure todos os usuários para pertencerem ao domínio bbb do ISP.
- Use uma conta de usuário compartilhada para todos os usuários, com nome de usuário aaa e senha 123456.
Figura 6 Diagrama de rede
Procedimento
Certifique-se de que os servidores RADIUS e o dispositivo de acesso possam se comunicar entre si.
- Configure os servidores RADIUS para fornecer serviços de autenticação, autorização e contabilidade. Crie uma conta compartilhada com o nome de usuário aaa e a senha 123456 para os usuários de autenticação MAC. (Detalhes não mostrados.)
- Configure a autenticação MAC baseada em RADIUS no dispositivo:
# Configure um esquema RADIUS.
<Device> system-view
[Device] radius scheme 2000
[Device-radius-2000] primary authentication 10.1.1.1 1812
[Device-radius-2000] primary accounting 10.1.1.2 1813
[Device-radius-2000] key authentication simple abc
[Device-radius-2000] key accounting simple abc
[Device-radius-2000] user-name-format without-domain
[Device-radius-2000] quit# Especifique CHAP como o método de autenticação para autenticação MAC.
[Device] mac-authentication authentication-method chap# Aplique o esquema RADIUS ao domínio bbb do ISP para autenticação, autorização e contabilidade.
[Device] domain bbb
[Device-isp-bbb] authentication default radius-scheme 2000
[Device-isp-bbb] authorization default radius-scheme 2000
[Device-isp-bbb] accounting default radius-scheme 2000
[Device-isp-bbb] quit# Habilite a autenticação MAC na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] mac-authentication
[Device-GigabitEthernet1/0/1] quit# Especifique o domínio de autenticação MAC como domínio ISP bbb.
[Device] mac-authentication domain bbb# Defina os temporizadores de autenticação MAC.
[Device] mac-authentication timer offline-detect 180
[Device] mac-authentication timer quiet 180# Especifique o nome de usuário aaa e a senha 123456 em texto simples para a conta compartilhada pelos usuários de autenticação MAC.
[Device] mac-authentication user-name-format fixed account aaa password simple 123456# Habilite a autenticação MAC globalmente.
[Device] mac-authenticationVerificação da configuração
# Verificar a configuração da autenticação MAC.
[Device] display mac-authentication
Global MAC authentication parameters:
MAC authentication : Enabled
Authentication method : CHAP
Username format : Fixed account
Username : aaa
Password : ******
Offline detect period : 180 s
Quiet period : 180 s
Server timeout : 100 s
Reauth period : 3600 s
User aging period for critical VLAN : 1000 s
User aging period for guest VLAN : 1000 s
Authentication domain : bbb
Online MAC-auth wired users : 1
Silent MAC users:
MAC address VLAN ID From port Port index
GigabitEthernet1/0/1 is link-up
MAC authentication : Enabled
Carry User-IP : Disabled
Authentication domain : Not configured
Auth-delay timer : Disabled
Periodic reauth : Disabled
Re-auth server-unreachable : Logoff
Guest VLAN : Not configured
Guest VLAN reauthentication : Enabled
Guest VLAN auth-period : 30 s
Critical VLAN : Not configured
Critical voice VLAN : Disabled
Host mode : Single VLAN
Offline detection : Enabled
Authentication order : Default
User aging : Enabled
Server-recovery online-user-sync : Enabled
Auto-tag feature : Disabled
VLAN tag configuration ignoring : Disabled
Max online users : 4294967295
Authentication attempts : successful 1, failed 0
Current online users : 1
MAC address Auth state
00e0-fc12-3456 AuthenticatedExemplo: Configuração da atribuição de ACL para autenticação MAC
Configuração de rede
Conforme mostrado na Figura 7, configure o dispositivo para atender aos seguintes requisitos:
- Use servidores RADIUS para realizar a autenticação, a autorização e a contabilidade dos usuários.
- Execute a autenticação MAC na GigabitEthernet 1/0/1 para controlar o acesso à Internet.
- Use o endereço MAC de cada usuário como nome de usuário e senha para a autenticação MAC. Os endereços MAC estão em notação hexadecimal com hífens e as letras estão em minúsculas.
- Use uma ACL para negar que usuários autenticados acessem o servidor FTP em 10.0.0.1.
Figura 7 Diagrama de rede
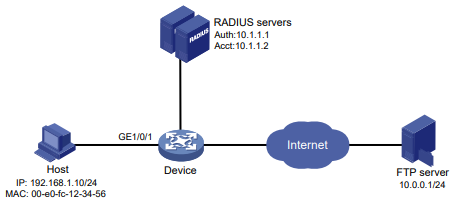
Procedimento
Certifique-se de que os servidores RADIUS e o dispositivo de acesso possam se comunicar entre si.
- Configure os servidores RADIUS:
- Configure a ACL 3000 para negar pacotes destinados a 10.0.0.1 no dispositivo.
# Configure os servidores RADIUS para fornecer serviços de autenticação, autorização e contabilidade. (Detalhes não mostrados).
# Adicione uma conta de usuário com 00-e0-fc-12-34-56 como nome de usuário e senha em cada servidor RADIUS. (Detalhes não mostrados.)
# Especifique a ACL 3000 como a ACL de autorização para a conta de usuário. (Detalhes não mostrados).
<Device> system-view
[Device] acl advanced 3000
[Device-acl-ipv4-adv-3000] rule 0 deny ip destination 10.0.0.1 0
[Device-acl-ipv4-adv-3000] quit# Configure um esquema RADIUS.
[Device] radius scheme 2000
[Device-radius-2000] primary authentication 10.1.1.1 1812
[Device-radius-2000] primary accounting 10.1.1.2 1813
[Device-radius-2000] key authentication simple abc
[Device-radius-2000] key accounting simple abc
[Device-radius-2000] user-name-format without-domain
[Device-radius-2000] quit# Aplicar o esquema RADIUS a um domínio ISP para autenticação, autorização e contabilidade.
[Device] domain bbb
[Device-isp-bbb] authentication default radius-scheme 2000
[Device-isp-bbb] authorization default radius-scheme 2000
[Device-isp-bbb] accounting default radius-scheme 2000
[Device-isp-bbb] quit# Especifique o domínio ISP para autenticação MAC.
[Device] mac-authentication domain bbb# Use o endereço MAC de cada usuário como nome de usuário e senha para autenticação MAC. Os endereços MAC estão em notação hexadecimal com hífens e as letras estão em minúsculas.
[Device] mac-authentication user-name-format mac-address with-hyphen lowercase# Habilite a autenticação MAC na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] mac-authentication
[Device-GigabitEthernet1/0/1] quit# Habilite a autenticação MAC globalmente.
[Device] mac-authenticationVerificação da configuração
# Verificar a configuração da autenticação MAC.
[Device] display mac-authentication
Global MAC authentication parameters:
MAC authentication : Enable
Authentication method : PAP
Username format : MAC address in lowercase(xx-xx-xx-xx-xx-xx)
Username : mac
Password : Not configured
Offline detect period : 300 s
Quiet period : 60 s
Server timeout : 100 s
Reauth period : 3600 s
User aging period for critical VLAN : 1000 s
User aging period for guest VLAN : 1000 s
Authentication domain : bbb
Online MAC-auth wired users : 1
Silent MAC users:
MAC address VLAN ID From port Port index
GigabitEthernet1/0/1 is link-up
MAC authentication : Enabled
Carry User-IP : Disabled
Authentication domain : Not configured
Auth-delay timer : Disabled
Periodic reauth : Disabled
Re-auth server-unreachable : Logoff
Guest VLAN : Not configured
Guest VLAN reauthentication : Enabled
Guest VLAN auth-period : 30 s
Critical VLAN : Not configured
Critical voice VLAN : Disabled
Host mode : Single VLAN
Offline detection : Enabled
Authentication order : Default
User aging : Enabled
Server-recovery online-user-sync : Enabled
Auto-tag feature : Disabled
VLAN tag configuration ignoring : Disabled
Max online users : 4294967295
Authentication attempts : successful 1, failed 0
Current online users : 1
MAC address Auth state
00e0-fc12-3456 Authenticated# Verifique se não é possível fazer ping no servidor FTP a partir do host.
C:\>ping 10.0.0.1
Pinging 10.0.0.1 with 32 bytes of data:
Request timed out.
Request timed out.
Request timed out.
Request timed out.
Ping statistics for 10.0.0.1:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),A saída mostra que a ACL 3000 foi atribuída à GigabitEthernet 1/0/1 para negar o acesso ao servidor FTP.
Configuração da autenticação do portal
Sobre a autenticação do portal
A autenticação do portal controla o acesso do usuário às redes. O portal autentica um usuário pelo nome de usuário e pela senha que ele digita em uma página de autenticação do portal. Normalmente, a autenticação do portal é implementada na camada de acesso e nas entradas de dados vitais.
Em uma rede habilitada para portal, os usuários podem iniciar ativamente a autenticação do portal visitando o site de autenticação fornecido pelo servidor da Web do portal. Ou então, eles são redirecionados para a página de autenticação do portal para autenticação quando visitam outros sites.
O dispositivo é compatível com o Portal 1.0, Portal 2.0 e Portal 3.0.
Vantagens da autenticação de portal
A autenticação de portal tem as seguintes vantagens:
- Permite que os usuários realizem a autenticação por meio de um navegador da Web sem instalar software cliente.
- Oferece aos ISPs opções de gerenciamento diversificadas e funções ampliadas. Por exemplo, os ISPs podem colocar anúncios, fornecer serviços comunitários e publicar informações na página de autenticação.
- Oferece suporte a vários modos de autenticação. Por exemplo, a autenticação re-DHCP implementa um esquema flexível de atribuição de endereços e salva endereços IP públicos. A autenticação entre sub-redes pode autenticar usuários que residem em uma sub-rede diferente da do dispositivo de acesso.
Funções ampliadas do portal
Ao forçar a aplicação de patches e políticas antivírus, as funções estendidas do portal ajudam os hosts a se defenderem contra vírus. O Portal suporta as seguintes funções estendidas:
- Verificação de segurança - Detecta, após a autenticação, se um host de usuário instala ou não software antivírus, arquivo de definição de vírus, software não autorizado e patches de sistema operacional.
- Restrição de acesso a recursos - Permite que um usuário autenticado acesse determinados recursos de rede, como o servidor de vírus e o servidor de patches. Os usuários podem acessar mais recursos de rede depois de passar pela verificação de segurança.
A verificação de segurança deve cooperar com o servidor de política de segurança do Intelbras IMC e com o cliente iNode.
Sistema de portal
Um sistema de portal típico consiste nos seguintes componentes básicos: cliente de autenticação, dispositivo de acesso, servidor de autenticação do portal, servidor da Web do portal, servidor AAA e servidor de política de segurança.
Figura 1 Sistema de portal
Cliente de autenticação
Um cliente de autenticação é um navegador da Web que executa HTTP/HTTPS ou um host de usuário que executa um cliente de portal. A verificação de segurança para o host do usuário é implementada por meio da interação entre o cliente do portal e o servidor de política de segurança. Somente o cliente Intelbras iNode é suportado.
Dispositivo de acesso
Um dispositivo de acesso fornece serviços de acesso. Ele tem as seguintes funções:
- Redireciona todas as solicitações HTTP ou HTTPS de usuários não autenticados para o servidor da Web do portal.
- Interage com o servidor de autenticação do portal e com o servidor AAA para concluir a autenticação, a autorização e a contabilidade.
- Permite que os usuários que passam pela autenticação do portal acessem recursos de rede autorizados.
Servidor de portal
Um servidor de portal refere-se coletivamente a um servidor de autenticação de portal e a um servidor da Web de portal.
O servidor da Web do portal envia a página de autenticação da Web para os clientes de autenticação e encaminha as informações de autenticação do usuário (nome de usuário e senha) para o servidor de autenticação do portal. O servidor de autenticação do portal recebe solicitações de autenticação dos clientes de autenticação e interage com o dispositivo de acesso para autenticar os usuários. O servidor da Web do portal geralmente é integrado ao servidor de autenticação do portal e também pode ser um servidor independente.
Servidor AAA
O servidor AAA interage com o dispositivo de acesso para implementar a autenticação, a autorização e a contabilidade dos usuários do portal. Em um sistema de portal, um servidor RADIUS pode realizar a autenticação, a autorização e a contabilização dos usuários do portal, e um servidor LDAP pode realizar a autenticação dos usuários do portal .
Servidor de política de segurança
O servidor de política de segurança interage com o cliente do portal e o dispositivo de acesso para verificação de segurança e autorização de usuários. Somente os hosts que executam clientes de portal podem interagir com o servidor de política de segurança.
Autenticação de portal usando um servidor de portal remoto
Os componentes de um sistema de portal interagem da seguinte forma:
- Um usuário não autenticado inicia a autenticação acessando um site da Internet por meio de um navegador da Web. Ao receber a solicitação HTTP ou HTTPS, o dispositivo de acesso a redireciona para o
- O usuário insere as informações de autenticação na página/caixa de diálogo de autenticação e envia as informações. O servidor da Web do portal encaminha as informações para o servidor de autenticação do portal. O servidor de autenticação do portal processa as informações e as encaminha para o dispositivo de acesso.
- O dispositivo de acesso interage com o servidor AAA para implementar autenticação, autorização e contabilidade para o usuário.
- Se as políticas de segurança não forem impostas ao usuário, o dispositivo de acesso permitirá que o usuário autenticado acesse as redes.
Página de autenticação da Web fornecida pelo servidor da Web do portal. O usuário também pode visitar o site de autenticação para fazer login. O usuário deve fazer login por meio do cliente Intelbras iNode para funções estendidas do portal.
Se forem impostas políticas de segurança ao usuário, o cliente do portal, o dispositivo de acesso e o servidor de políticas de segurança interagem para verificar o host do usuário. Se o usuário passar na verificação de segurança, o servidor de políticas de segurança autoriza o usuário a acessar recursos com base no resultado da verificação.
Serviço de portal local
Componentes do sistema
Conforme mostrado na Figura 2, um sistema de portal local consiste em um cliente de autenticação, um dispositivo de acesso e um servidor AAA. O dispositivo de acesso atua como servidor da Web do portal e como servidor de autenticação do portal para fornecer o serviço da Web do portal local para o cliente de autenticação. O cliente de autenticação só pode ser um navegador da Web e não pode ser um host de usuário que executa um cliente de portal. Portanto, não há suporte para as funções estendidas do portal e não é necessário um servidor de política de segurança.
Figura 2 Componentes do sistema

Personalização da página do portal
Para fornecer o serviço da Web do portal local, é necessário personalizar um conjunto de páginas de autenticação que o dispositivo enviará aos usuários. Você pode personalizar vários conjuntos de páginas de autenticação, compactar cada conjunto de páginas em um arquivo .zip e carregar os arquivos compactados na mídia de armazenamento do dispositivo. No dispositivo, você deve especificar um dos arquivos como o arquivo de página de autenticação padrão usando o comando default-logon-page.
Para obter mais informações sobre a personalização da página de autenticação, consulte "Personalização das páginas de autenticação".
Modos de autenticação do portal
A autenticação de portal tem três modos: autenticação direta, autenticação re-DHCP e autenticação entre sub-redes. Na autenticação direta e na autenticação re-DHCP, não existem dispositivos de encaminhamento da Camada 3 entre o cliente de autenticação e o dispositivo de acesso. Na autenticação entre sub-redes, os dispositivos de encaminhamento da Camada 3 podem existir entre o cliente de autenticação e o dispositivo de acesso .
Autenticação direta
Um usuário configura manualmente um endereço IP público ou obtém um endereço IP público por meio de DHCP. Antes da autenticação, o usuário pode acessar apenas o servidor da Web do portal e o servidor livre de autenticação predefinido.
sites. Depois de passar pela autenticação, o usuário pode acessar outros recursos da rede. O processo de autenticação direta é mais simples do que o de autenticação re-DHCP.
Autenticação de novo DHCP
Antes de um usuário passar pela autenticação, o DHCP aloca um endereço IP (um endereço IP privado) para o usuário. O usuário pode acessar apenas o servidor da Web do portal e sites predefinidos sem autenticação. Depois que o usuário passa pela autenticação, o DHCP realoca um endereço IP (um endereço IP público) para o usuário. O usuário pode então acessar outros recursos da rede. Nenhum endereço IP público é alocado para usuários que falham na autenticação. A autenticação do re-DHCP salva os endereços IP públicos. Por exemplo, um ISP pode alocar endereços IP públicos para usuários de banda larga somente quando eles acessam redes além da rede da comunidade residencial.
Somente o cliente Intelbras iNode suporta a autenticação re-DHCP. A autenticação do portal IPv6 não é compatível com o modo de autenticação re-DHCP.
Autenticação entre sub-redes
A autenticação entre sub-redes é semelhante à autenticação direta, exceto pelo fato de permitir a existência de dispositivos de encaminhamento da Camada 3 entre o cliente de autenticação e o dispositivo de acesso.
Na autenticação direta, na autenticação re-DHCP e na autenticação entre sub-redes, o endereço IP de um usuário o identifica exclusivamente. Depois que um usuário passa pela autenticação, o dispositivo de acesso gera uma ACL para o usuário com base no endereço IP do usuário para controlar o encaminhamento dos pacotes do usuário. Como não existe nenhum dispositivo de encaminhamento da Camada 3 entre os clientes de autenticação e o dispositivo de acesso na autenticação direta e na autenticação re-DHCP, o dispositivo de acesso pode aprender os endereços MAC do usuário. O dispositivo de acesso pode aumentar sua capacidade de controlar o encaminhamento de pacotes usando os endereços MAC aprendidos.
Processo de autenticação do portal
A autenticação direta e a autenticação entre sub-redes compartilham o mesmo processo de autenticação. A autenticação Re-DHCP tem um processo diferente, pois tem dois procedimentos de alocação de endereços.
Autenticação direta/processo de autenticação entre sub-redes (com autenticação CHAP/PAP)
Figura 3 Processo de autenticação direta/autenticação entre sub-redes
O processo de autenticação direta/entre sub-redes é o seguinte:
- Um usuário do portal acessa a Internet por meio de HTTP ou HTTPS, e o pacote HTTP ou HTTPS chega ao dispositivo de acesso.
- Se o pacote corresponder a uma regra de portal livre, o dispositivo de acesso permitirá a passagem do pacote.
- Se o pacote não corresponder a nenhuma regra sem portal, o dispositivo de acesso redirecionará o pacote para o servidor Web do portal. O servidor Web do portal envia a página de autenticação da Web ao usuário para que ele digite seu nome de usuário e senha.
- O servidor da Web do portal envia as informações de autenticação do usuário para o servidor de autenticação do portal.
- O servidor de autenticação do portal e o dispositivo de acesso trocam mensagens CHAP. Essa etapa é ignorada para a autenticação PAP. O servidor de autenticação do portal decide o método (CHAP ou PAP) a ser usado.
- O servidor de autenticação do portal adiciona o nome de usuário e a senha em um pacote de solicitação de autenticação e o envia ao dispositivo de acesso. Enquanto isso, o servidor de autenticação do portal inicia um cronômetro para aguardar um pacote de resposta de autenticação.
- O dispositivo de acesso e o servidor RADIUS trocam pacotes RADIUS.
- O dispositivo de acesso envia um pacote de resposta de autenticação ao servidor de autenticação do portal para notificar o sucesso ou a falha da autenticação.
- O servidor de autenticação do portal envia um pacote de sucesso ou falha de autenticação para o cliente.
- Se a autenticação for bem-sucedida, o servidor de autenticação do portal enviará um pacote de confirmação de resposta de autenticação para o dispositivo de acesso.
- O cliente e o servidor de política de segurança trocam informações de verificação de segurança. O servidor de política de segurança detecta se o host do usuário instala ou não software antivírus, arquivos de definição de vírus, software não autorizado e patches do sistema operacional.
- O servidor de política de segurança autoriza o usuário a acessar determinados recursos da rede com base no resultado da verificação. O dispositivo de acesso salva as informações de autorização e as utiliza para controlar o acesso do usuário.
Se o cliente for um cliente iNode, o processo de autenticação inclui a etapa 9 e a etapa 10 para funções de portal estendidas. Caso contrário, o processo de autenticação estará concluído.
Processo de autenticação de novo DHCP (com autenticação CHAP/PAP)
Figura 4 Processo de autenticação do Re-DHCP
O processo de autenticação do re-DHCP é o seguinte:
As etapas de 1 a 7 são as mesmas do processo de autenticação direta/autenticação entre sub-redes.
- Após receber o pacote de sucesso da autenticação, o cliente obtém um endereço IP público por meio do DHCP. Em seguida, o cliente notifica o servidor de autenticação do portal de que possui um endereço IP público.
- O servidor de autenticação do portal notifica o dispositivo de acesso de que o cliente obteve um endereço IP público.
- O dispositivo de acesso detecta a alteração do IP do cliente por meio do DHCP e, em seguida, notifica o servidor de autenticação do portal de que detectou uma alteração do IP do cliente.
- Após receber os pacotes de notificação de alteração de IP enviados pelo cliente e pelo dispositivo de acesso, o servidor de autenticação do portal notifica o cliente sobre o sucesso do login.
- O servidor de autenticação do portal envia um pacote de confirmação de alteração de IP para o dispositivo de acesso.
- O cliente e o servidor de política de segurança trocam informações de verificação de segurança. O servidor de política de segurança detecta se o host do usuário instala ou não software antivírus, arquivos de definição de vírus, software não autorizado e patches do sistema operacional.
- O servidor de política de segurança autoriza o usuário a acessar determinados recursos da rede com base no resultado da verificação. O dispositivo de acesso salva as informações de autorização e as utiliza para controlar o acesso do usuário.
As etapas 13 e 14 são para funções de portal estendidas.
Suporte do portal para EAP
Para usar a autenticação do portal que suporta EAP, o servidor e o cliente de autenticação do portal devem ser o servidor do portal Intelbras IMC e o cliente do portal Intelbras iNode. A autenticação do portal local não é compatível com a autenticação EAP.
Em comparação com a autenticação baseada em nome de usuário e senha, a autenticação baseada em certificado digital garante maior segurança.
O EAP (Extensible Authentication Protocol) oferece suporte a vários métodos de autenticação baseados em certificados digitais, por exemplo, o EAP-TLS. Trabalhando em conjunto com o EAP, a autenticação de portal pode implementar a autenticação de usuário baseada em certificado digital.
Figura 5 Diagrama de fluxo de trabalho do suporte do portal para EAP

Conforme mostrado na Figura 5, o cliente de autenticação e o servidor de autenticação de portal trocam pacotes de autenticação EAP. O servidor de autenticação de portal e o dispositivo de acesso trocam pacotes de autenticação de portal que contêm os atributos EAP-Message. O dispositivo de acesso e o servidor RADIUS trocam pacotes RADIUS que contêm os atributos EAP-Message. O servidor RADIUS compatível com a função de servidor EAP processa os pacotes EAP encapsulados nos atributos de mensagem EAP e fornece o resultado da autenticação EAP.
O dispositivo de acesso não processa, mas apenas transporta atributos de mensagem EAP entre o servidor de autenticação do portal e o servidor RADIUS. Portanto, o dispositivo de acesso não requer nenhuma configuração adicional para dar suporte à autenticação EAP.
Regras de filtragem do portal
O dispositivo de acesso usa regras de filtragem de portal para controlar o encaminhamento do tráfego do usuário.
Com base na configuração e no status de autenticação dos usuários do portal, o dispositivo gera as seguintes categorias de regras de filtragem do portal:
- Categoria 1 - A regra permite a passagem de pacotes de usuários destinados ao servidor Web do portal e de pacotes que correspondem às regras sem portal.
- Categoria 2 - Para um usuário autenticado sem ACL autorizada, a regra permite que o usuário acesse qualquer recurso de rede de destino. Para um usuário autenticado com uma ACL autorizada, a regra permite que os usuários acessem os recursos permitidos pela ACL. O dispositivo adiciona a regra quando um usuário fica on-line e exclui a regra quando o usuário fica off-line.
- ACLs básicas (ACL 2000 a ACL 2999).
- ACLs avançadas (ACL 3000 a ACL 3999).
- ACLs de camada 2 (ACL 4000 a ACL 4999).
- Categoria 3 - A regra redireciona todas as solicitações HTTP ou HTTPS de usuários não autenticados para o servidor da Web do portal.
- Categoria 4 - Para autenticação direta e autenticação entre sub-redes, a regra proíbe a passagem de qualquer pacote de usuário. Para a autenticação re-DHCP, o dispositivo proíbe a passagem de pacotes de usuários com endereços de origem privados.
O dispositivo suporta os seguintes tipos de ACLs de autorização:
Para que uma ACL de autorização tenha efeito, certifique-se de que a ACL exista e tenha regras de ACL, excluindo as regras configuradas com a palavra-chave counting, established, fragment, source-mac ou logging. Para obter mais informações sobre regras de ACL, consulte os comandos de ACL em Referência de comandos de ACL e QoS.
Depois de receber um pacote de usuário, o dispositivo compara o pacote com as regras de filtragem da categoria 1 à categoria 4. Quando o pacote corresponde a uma regra, o processo de correspondência é concluído.
Restrições e diretrizes: Configuração do portal
A autenticação do portal pela Web não suporta a verificação de segurança para os usuários. Para implementar a verificação de segurança, o cliente deve ser o cliente Intelbras iNode.
A autenticação do portal suporta a passagem de NAT, seja ela iniciada por um cliente da Web ou por um cliente Intelbras iNode. O NAT traversal deve ser configurado quando o cliente do portal estiver em uma rede privada e o servidor do portal estiver em uma rede pública.
Visão geral das tarefas de autenticação do portal
Para configurar a autenticação do portal, execute as seguintes tarefas:
- Configuração de um serviço de portal remoto
- Configuração de um servidor de autenticação de portal remoto
- Configuração de um servidor Web de portal
- Configuração de um serviço de portal local
- Configuração dos recursos do serviço de portal local
- Configuração de um servidor Web de portal
- Ativação da autenticação do portal e especificação de um servidor da Web do portal
- Ativação da autenticação do portal em uma interface
- Especificação de um servidor Web de portal em uma interface
- (Opcional.) Especificação de um pool de endereços IP de pré-autenticação
- (Opcional.) Especificação de um domínio de autenticação de portal
- (Opcional.) Controle do acesso do usuário ao portal
- Configuração de uma regra sem portal
- Configuração de uma sub-rede de origem de autenticação
- Configuração de uma sub-rede de destino de autenticação
- Configuração do suporte do proxy da Web para autenticação do portal
- Verificação da emissão de regras de filtragem de portal de categoria 2
- Definição do número máximo de usuários do portal
- Ativação da verificação rigorosa das informações de autorização do portal
- Permitir que apenas usuários com endereços IP atribuídos por DHCP passem pela autenticação do portal
- Ativação do roaming do portal
- Configuração do recurso de permissão de falha do portal
- (Opcional.) Configuração dos recursos de detecção de portal
- Configuração da detecção on-line de usuários do portal
- Configuração da detecção do servidor de autenticação do portal
- Configuração da detecção do servidor Web do portal
- Configuração da sincronização de usuários do portal
- (Opcional.) Configuração de atributos para pacotes de portal e pacotes RADIUS
- Configuração de atributos de pacotes de portal
- Configuração de atributos para pacotes RADIUS
- (Opcional.) Configuração de recursos relacionados on-line e off-line para usuários do portal
- Fazer logout de usuários do portal on-line
- Ativação do registro de login/logout do usuário do portal
- (Opcional.) Configuração dos recursos de autenticação do portal estendido
- Desativar o recurso de entrada Rule ARP ou ND para clientes do portal
- Configuração do redirecionamento da Web
Execute essa tarefa se for usado um servidor de portal remoto.
Execute esta tarefa se o dispositivo de acesso atuar como servidor de autenticação de portal e servidor da Web de portal.
Você pode configurar o atributo BAS-IP ou BAS-IPv6 para pacotes de portal e especificar a ID do dispositivo.
Você pode configurar os atributos NAS-Port-Id e NAS-Port-Type e aplicar um perfil NAS-ID a uma interface.
Pré-requisitos para a autenticação do portal
O recurso do portal oferece uma solução para autenticação da identidade do usuário e verificação de segurança. Para concluir a autenticação da identidade do usuário, o portal deve cooperar com o RADIUS.
Antes de configurar o portal, você deve concluir as seguintes tarefas:
- O servidor de autenticação do portal, o servidor da Web do portal e o servidor RADIUS foram instalados e configurados corretamente.
- Para usar o modo de autenticação do portal re-DHCP, verifique se o agente de retransmissão DHCP está ativado no dispositivo de acesso e se o servidor DHCP está instalado e configurado corretamente.
- O cliente do portal, o dispositivo de acesso e os servidores podem se comunicar entre si.
- Para usar o servidor RADIUS remoto, configure nomes de usuário e senhas no servidor RADIUS e configure o cliente RADIUS no dispositivo de acesso. Para obter informações sobre a configuração do cliente RADIUS, consulte "Configuração de AAA".
- Para implementar funções de portal estendido, instale e configure o CAMS EAD ou o IMC EAD. Certifique-se de que as ACLs configuradas no dispositivo de acesso correspondam à ACL de isolamento e à ACL de segurança no servidor de política de segurança. Para a instalação e a configuração do servidor de políticas de segurança consulte o Manual do usuário do componente de política de segurança do CAMS EAD ou a Ajuda da política de segurança do IMC EAD.
Configuração de um servidor de autenticação de portal remoto
Sobre a configuração do servidor de autenticação do portal remoto
Com a autenticação de portal ativada, o dispositivo procura um servidor de autenticação de portal para um pacote de solicitação de portal recebido de acordo com o endereço IP de origem do pacote.
- Se for encontrado um servidor de autenticação de portal correspondente, o dispositivo considerará o pacote válido e enviará um pacote de resposta de autenticação para o servidor de autenticação de portal. Depois que um usuário faz login no dispositivo, ele interage com o servidor de autenticação do portal conforme necessário.
- Se não for encontrado nenhum servidor de autenticação de portal correspondente, o dispositivo descartará o pacote.
Restrições e diretrizes
Não exclua um servidor de autenticação de portal em uso. Caso contrário, os usuários autenticados por esse servidor não poderão fazer o logout corretamente.
Procedimento
- Entre na visualização do sistema.
system viewportal server server-nameVocê pode criar vários servidores de autenticação de portal.
IPv4:
ip ipv4-address [ key { cipher | simple } string ]IPv6:
ipv6 ipv6-address [ key { cipher | simple } string ]port port-numberPor padrão, o número da porta UDP é 50100.
Esse número de porta deve ser o mesmo que o número da porta de escuta especificado no servidor de autenticação do portal.
server-type { cmcc | imc }Por padrão, o tipo de servidor de autenticação do portal é IMC.
O tipo de servidor especificado deve ser o mesmo que o tipo de servidor de autenticação do portal realmente usado.
server-register [ interval interval-value ]Por padrão, o dispositivo não se registra em um servidor de autenticação de portal.
Configuração de um servidor Web de portal
Visão geral das tarefas do servidor Web do Portal
Para configurar um servidor Web de portal, execute as seguintes tarefas:
- Configurar parâmetros básicos para um servidor Web de portal
- (Opcional.) Ativação do recurso captive-bypass
- (Opcional.) Configuração de uma regra de correspondência para redirecionamento de URL
Configurar parâmetros básicos para um servidor Web de portal
- Entre na visualização do sistema.
system viewportal web-server server-nameVocê pode criar vários servidores da Web de portal.
url url-stringPor padrão, nenhuma URL é especificada para um servidor da Web do portal.
url-parameter param-name { original-url | source-address | source-mac [ encryption { aes | des } key { cipher | simple } string ] | value expression }Por padrão, nenhum parâmetro de URL de redirecionamento é configurado.
server-type { cmcc | imc }Por padrão, o tipo de servidor da Web do portal é IMC.
Essa configuração é aplicável somente ao serviço de portal remoto.
O tipo de servidor especificado deve ser o mesmo que o tipo de servidor da Web do portal realmente usado.
Ativação do recurso captive-bypass
Sobre o recurso captive-bypass
Por padrão, o dispositivo envia automaticamente a página de autenticação do portal para os dispositivos iOS e alguns dispositivos Android quando eles estão conectados à rede. O recurso captive-bypass permite que o dispositivo envie a página de autenticação do portal para os dispositivos iOS e alguns dispositivos Android somente quando eles acessarem a Internet usando navegadores.
Procedimento
- Entre na visualização do sistema.
system viewportal web-server server-namecaptive-bypass enablePor padrão, o recurso de desvio cativo está desativado.
Configuração de uma regra de correspondência para redirecionamento de URL
Sobre as regras de correspondência para redirecionamento de URL
Uma regra de correspondência de redirecionamento de URL corresponde a solicitações HTTP ou HTTPS por informações de URL ou User-Agent solicitadas pelo usuário e redireciona as solicitações correspondentes para o URL de redirecionamento especificado. Portanto, as regras de correspondência de redirecionamento de URL permitem um redirecionamento de URL mais flexível do que o comando url. O comando url é usado somente para redirecionar solicitações HTTP ou HTTPS de usuários não autenticados do para o servidor da Web do portal para autenticação.
Restrições e diretrizes
Para que um usuário acesse com êxito um URL de redirecionamento, configure uma regra portal-free para permitir a aprovação de solicitações HTTP ou HTTPS destinadas ao URL de redirecionamento. Para obter informações sobre como configurar regras de portal-free, consulte o comando portal free-rule.
Se os comandos url e if-match forem executados, o comando if-match terá prioridade para executar o redirecionamento de URL.
Procedimento
- Entre na visualização do sistema.
system viewportal web-server server-nameif-match { original-url url-string redirect-url url-string [ url-param-encryption { aes | des } key { cipher | simple } string ] | user-agent string redirect-url url-string }Configuração dos recursos do serviço de portal local
Sobre o serviço do portal local
Depois que um serviço de portal local é configurado, o dispositivo atua como servidor da Web do portal e servidor de autenticação do portal para executar a autenticação do portal nos usuários. O arquivo da página de autenticação do portal é salvo no diretório raiz do dispositivo.
Restrições e diretrizes para a configuração dos recursos do serviço de portal local
Para que uma interface use o serviço de portal local, o URL do servidor da Web do portal especificado para a interface deve atender aos seguintes requisitos:
- O endereço IP na URL deve ser o endereço IP de uma interface de camada 3 (exceto 127.0.0.1) no dispositivo, e o endereço IP deve ser acessível aos clientes do portal.
- O URL deve terminar com /portal/. Por exemplo: http://1.1.1.1/portal/.
Como prática recomendada para a operação correta do serviço da Web do portal local, use o arquivo de página de autenticação padrão no diretório raiz da mídia de armazenamento do dispositivo. Para usar páginas de autenticação personalizadas, você deve seguir rigorosamente as restrições e diretrizes relacionadas ao personalizar suas próprias páginas de autenticação. Para obter mais informações sobre as restrições e diretrizes, consulte "Personalização de páginas de autenticação".
Personalização de páginas de autenticação
Sobre a personalização das páginas de autenticação
As páginas de autenticação são arquivos HTML. A autenticação do portal local requer as seguintes páginas de autenticação:
- Página de logon
- Página de sucesso do logon
- Página de falha de logon
- Página on-line
- Página de sistema ocupado
- Página de sucesso do logoff
Você deve personalizar as páginas de autenticação, incluindo os elementos de página que as páginas de autenticação usarão, por exemplo, back.jpg para a página de autenticação Logon.htm.
Siga as regras de personalização da página de autenticação ao editar os arquivos da página de autenticação.
Regras de nome de arquivo
Os nomes dos arquivos da página principal de autenticação são fixos (consulte a Tabela 1). Você pode definir os nomes dos arquivos que não sejam os arquivos da página principal de autenticação. Os nomes de arquivos e de diretórios não diferenciam maiúsculas de minúsculas.
Tabela 1 Nomes de arquivos da página principal de autenticação
| Página principal de autenticação | Nome do arquivo |
| Página de logon | logon.htm |
| Página de sucesso do logon | logonSuccess.htm |
| Página de falha de logon | logonFail.htm |
Página on-line Enviado após o usuário ficar on-line para notificação on-line |
online.htm |
Página de sistema ocupado Enviado quando o sistema está ocupado ou o usuário está no processo de logon |
ocupado.htm |
| Página de sucesso do logoff | logoffSuccess.htm |
Regras de solicitação de página
O servidor da Web do portal local suporta apenas solicitações Get e Post.
- Solicitações Get - Usadas para obter os arquivos estáticos nas páginas de autenticação e não permitem recursão. Por exemplo, se o arquivo Logon.htm incluir conteúdo que execute a ação Get no arquivo ca.htm, o arquivo ca.htm não poderá incluir nenhuma referência ao arquivo Logon.htm.
- Post requests - Usado quando os usuários enviam pares de nome de usuário e senha, fazem login e logout.
Regras de atributo de solicitação de postagem
- Observe os seguintes requisitos ao editar um formulário de uma página de autenticação:
- Uma página de autenticação pode ter vários formulários, mas deve haver um e somente um formulário cuja ação seja logon.cgi. Caso contrário, as informações do usuário não poderão ser enviadas para o dispositivo de acesso.
- O atributo de nome de usuário é fixado como PtUser. O atributo de senha é fixado como PtPwd.
- O valor do atributo PtButton é Logon ou Logoff, o que indica a ação que o usuário solicita.
- Uma solicitação de logon Post deve conter os atributos PtUser, PtPwd e PtButton.
- Uma solicitação de logoff Post deve conter o atributo PtButton.
- As páginas de autenticação logon.htm e logonFail.htm devem conter a solicitação logon Post. O exemplo a seguir mostra parte do script na página logon.htm.
<form action=logon.cgi method = post >
<p>User name:<input type="text" name = "PtUser" style="width:160px;height:22px"
maxlength=64>
<p>Password :<input type="password" name = "PtPwd" style="width:160px;height:22px"
maxlength=32>
<p><input type=SUBMIT value="Logon" name = "PtButton" style="width:60px;"
onclick="form.action=form.action+location.search;">
</form>O exemplo a seguir mostra parte do script na página online.htm.
<form action=logon.cgi method = post >
<p><input type=SUBMIT value="Logoff" name="PtButton" style="width:60px;">
</form>Regras de compactação e salvamento de arquivos de página
Você deve compactar as páginas de autenticação e seus elementos de página em um arquivo zip padrão.
- O nome de um arquivo zip pode conter apenas letras, números e sublinhados.
- As páginas de autenticação devem ser colocadas no diretório raiz do arquivo zip.
- Os arquivos Zip podem ser transferidos para o dispositivo por meio de FTP ou TFTP e devem ser salvos no diretório raiz do dispositivo.
Exemplos de arquivos zip no dispositivo:
<Sysname> dir
Directory of flash:
1 -rw- 1405 Feb 28 2008 15:53:20 ssid1.zip
0 -rw- 1405 Feb 28 2008 15:53:31 ssid2.zip
2 -rw- 1405 Feb 28 2008 15:53:39 ssid3.zip
3 -rw- 1405 Feb 28 2008 15:53:44 ssid4.zip
2540 KB total (1319 KB free)Redirecionamento de usuários autenticados para uma página da Web específica
Para fazer com que o dispositivo redirecione automaticamente os usuários autenticados para uma página da Web específica, faça o seguinte em logon.htm e logonSuccess.htm:
- Em logon.htm, defina o atributo target do Form como _blank. Veja o conteúdo em cinza:
<form method=post action=logon.cgi target="_blank"> <html>
<head>
<title>>LogonSuccess</title>
<script type="text/javascript" language="javascript"
src="pt_private.js"></script>
</head>
<body> onload="pt_init();" onbeforeunload="return pt_unload();">
... ...
</body>
</html>Configuração de um serviço da Web do portal local
Pré-requisitos
Antes de configurar um serviço da Web de portal local baseado em HTTPS, você deve concluir as seguintes tarefas:
- Configure uma política de PKI, obtenha o certificado da CA e solicite um certificado local. Para obter mais informações, consulte "Configuração de PKI".
- Configure uma política de servidor SSL e especifique o domínio PKI configurado na política PKI.
Durante o estabelecimento da conexão SSL, o navegador do usuário pode exibir uma mensagem informando que não é possível verificar a identidade do servidor por meio de um certificado. Para que os usuários realizem a autenticação do portal sem verificar essa mensagem, configure uma política de servidor SSL para solicitar um certificado confiável para o cliente no dispositivo. O nome da política deve ser https_redirect. Para obter mais informações sobre a configuração da política do servidor SSL , consulte "Configuração de SSL".
Procedimento
- Entre na visualização do sistema.
system viewportal local-web-server { http | https ssl-server-policy policy-name [ tcp-port port-number ] }default-logon-page filenamePor padrão, o arquivo de página de autenticação padrão para um serviço da Web do portal local é o arquivo defaultfile.zip.
tcp-port port-numberPor padrão, o número da porta de escuta do serviço HTTP é 80 e o número da porta de escuta do serviço HTTPS é o número da porta TCP definido pelo comando portal local-web-server.
Ativação da autenticação do portal em uma interface
Restrições e diretrizes
Ao ativar a autenticação de portal em uma interface, siga estas restrições e diretrizes:
- O modo de autenticação entre sub-redes (camada 3) não requer dispositivos de encaminhamento da camada 3 entre o dispositivo de acesso e os clientes de autenticação do portal. Entretanto, se houver um dispositivo de encaminhamento de camada 3 entre o cliente de autenticação e o dispositivo de acesso, você deverá usar o modo de autenticação de portal entre sub-redes.
- É possível ativar a autenticação do portal IPv4 e a autenticação do portal IPv6 em uma interface.
Ao configurar a autenticação do portal re-DHCP em uma interface, siga estas restrições e diretrizes:
- Certifique-se de que a interface tenha um endereço IP válido antes de ativar a autenticação do portal re-DHCP na interface.
- Com a autenticação do portal re-DHCP, configure o ARP autorizado na interface como uma prática recomendada para garantir que somente usuários válidos possam acessar a rede. Com o ARP autorizado configurado na interface, a interface aprende entradas ARP somente dos usuários que obtiveram um endereço público do DHCP.
- Para que a autenticação do portal re-DHCP seja bem-sucedida, certifique-se de que o valor do atributo BAS-IP ou BAS-IPv6 seja o mesmo que o endereço IP do dispositivo especificado no servidor de autenticação do portal. Para configurar o atributo, use o comando portal { bas-ip | bas-ipv6 }.
- Um servidor de portal IPv6 não é compatível com a autenticação de portal re-DHCP.
A autenticação do portal é compatível com o redirecionamento de HTTP e HTTPS. Para redirecionar os pacotes HTTPS dos usuários do portal, verifique se o número da porta de escuta de redirecionamento de HTTPS especificado (o padrão é 6654) está disponível. Para obter mais informações sobre como alterar o número da porta de escuta do redirecionamento de HTTPS, consulte Configuração do redirecionamento de HTTPS no Guia de configuração de serviços da camada 3-IP.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberIPv4:
portal enable method { direct | layer3 | redhcp }IPv6:
portal ipv6 enable method { direct | layer3 }Por padrão, a autenticação do portal está desativada.
Especificação de um servidor Web de portal em uma interface
Sobre a especificação de um servidor Web de portal em uma interface
Com um servidor da Web do portal especificado em uma interface, o dispositivo redireciona as solicitações HTTP dos usuários do portal na interface para o servidor da Web do portal.
É possível especificar um servidor Web de portal IPv4 e um servidor Web de portal IPv6 em uma interface.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberportal [ ipv6 ] apply web-server server-name [ fail-permit | secondary ]Por padrão, nenhum servidor Web de portal é especificado em uma interface.
A palavra-chave secondary é compatível apenas com a versão 6348P01 e posteriores.
Especificação de um pool de endereços IP de pré-autenticação
Sobre os pools de endereços IP de pré-autenticação
Você deve especificar um pool de endereços IP de pré-autenticação em uma interface habilitada para portal na seguinte situação:
- Os usuários do portal acessam a rede por meio de uma subinterface da interface habilitada para o portal.
- A subinterface não tem um endereço IP.
- Os usuários do portal precisam obter endereços IP por meio de DHCP.
- Se a interface estiver configurada com um pool de endereços IP de pré-autenticação, o usuário usará o seguinte endereço IP:
- Se o cliente estiver configurado para obter um endereço IP automaticamente por meio de DHCP, o usuário obterá um endereço do pool de endereços IP especificado.
- Se o cliente estiver configurado com um endereço IP estático, o usuário usará o endereço IP estático.
- Se a interface tiver um endereço IP, mas não houver um pool de IPs de pré-autenticação especificado, o usuário usará o endereço IP estático ou o endereço IP obtido de um servidor DHCP.
- Se a interface não tiver um endereço IP ou um pool de IPs de pré-autenticação especificado, o usuário não poderá executar a autenticação do portal.
Depois que um usuário se conecta a uma interface habilitada para portal, ele usa um endereço IP para autenticação de portal de acordo com as seguintes regras:
Depois que o usuário passa pela autenticação do portal, o servidor AAA autoriza um pool de endereços IP para reatribuir um endereço IP ao usuário. Se nenhum pool de endereços IP autorizado for implementado, o usuário continuará usando o endereço IP anterior.
Restrições e diretrizes
Essa configuração só tem efeito quando a autenticação direta do portal IPv4 está ativada na interface.
Certifique-se de que o pool de endereços IP especificado exista e esteja completo. Caso contrário, o usuário não poderá obter o endereço IP e não poderá executar a autenticação do portal.
Se o usuário do portal não realizar a autenticação ou não passar na autenticação, o endereço IP atribuído ainda será mantido.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberportal [ ipv6 ] pre-auth ip-pool pool-namePor padrão, nenhum pool de endereços IP de pré-autenticação é especificado em uma interface.
Especificação de um domínio de autenticação de portal
Sobre os domínios de autenticação do portal
Um domínio de autenticação define um conjunto de políticas de autenticação, autorização e contabilidade. Cada usuário do portal pertence a um domínio de autenticação e é autenticado, autorizado e contabilizado no domínio.
Com um domínio de autenticação especificado em uma interface, o dispositivo usa o domínio de autenticação para AAA de usuários do portal. Isso permite um controle flexível do acesso ao portal.
Restrições e diretrizes para a especificação de um domínio de autenticação de portal
O dispositivo seleciona o domínio de autenticação para um usuário do portal nesta ordem:
- Domínio ISP especificado para a interface.
- Domínio do ISP incluído no nome de usuário.
- Domínio ISP padrão do sistema.
Se o domínio escolhido não existir no dispositivo, o dispositivo procurará o domínio ISP configurado para acomodar usuários atribuídos a domínios inexistentes. Se esse domínio ISP não estiver configurado, a autenticação do usuário falhará. Para obter informações sobre domínios ISP, consulte "Configuração de AAA".
Para a ACL de autorização no domínio de autenticação, aplicam-se as seguintes regras:
- Se o tráfego do usuário corresponder a uma regra na ACL, o dispositivo processará o tráfego com base na declaração de permissão ou negação da regra.
- Se o tráfego do usuário não corresponder a nenhuma regra da ACL, o dispositivo permitirá o tráfego. Para negar esse tráfego, configure a última regra da ACL para negar todos os pacotes usando o comando rule deny ip.
- Se a ACL contiver regras que especifiquem um endereço de origem, os usuários talvez não consigam ficar on-line. Não especifique um endereço IPv4, IPv6 ou MAC de origem quando você configurar uma regra na ACL.
Especificação de um domínio de autenticação de portal em uma interface
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberportal [ ipv6 ] domain domain-namePor padrão, nenhum domínio de autenticação de portal é especificado em uma interface.
É possível especificar um domínio de autenticação de portal IPv4 e um domínio de autenticação de portal IPv6 em uma interface.
Controle do acesso do usuário ao portal
Configuração de uma regra sem portal
Sobre as regras de isenção de portal
Uma regra sem portal permite que usuários específicos acessem sites externos específicos sem autenticação no portal.
Os itens correspondentes para uma regra sem portal incluem o nome do host, o endereço IP de origem/destino, o número da porta TCP/UDP, o endereço MAC de origem, a interface de acesso e a VLAN. Os pacotes que corresponderem a uma regra portal-free não acionarão a autenticação do portal, de modo que os usuários que enviarem os pacotes poderão acessar diretamente os sites externos especificados.
Restrições e diretrizes para a configuração de uma regra sem portal
Se você especificar uma VLAN e uma interface, a interface deverá pertencer à VLAN. Se a interface não pertencer à VLAN, a regra sem portal não terá efeito.
Você não pode configurar duas ou mais regras livres de portal com os mesmos critérios de filtragem. Caso contrário, o sistema avisa que a regra já existe.
Independentemente de a autenticação do portal estar ativada ou não, você só pode adicionar ou remover uma regra sem portal. Não é possível modificá-la.
Configuração de uma regra livre de portal baseada em IP
- Entre na visualização do sistema.
system viewIPv4:
portal free-rule rule-number { destination ip { ipv4-address { mask-length | mask } | any } [ tcp tcp-port-number | udp udp-port-number ] | source ip { ipv4-address { mask-length | mask } | any } [ tcp tcp-port-number | udp udp-port-number ] } * [ interface interface-type interface-number ]IPv6:
portal free-rule rule-number { destination ipv6 { ipv6-address prefix-length | any } [ tcp tcp-port-number | udp udp-port-number ] | source ipv6 { ipv6-address prefix-length | any } [ tcp tcp-port-number | udp udp-port-number ] } * [ interface interface-type interface-number ]Configuração de uma regra livre de portal com base na origem
- Entre na visualização do sistema.
system viewportal free-rule rule-number source { interface interface-type interface-number | mac mac-address | vlan vlan-id } *A opção vlan vlan-id tem efeito apenas nos usuários do portal que acessam a rede por meio de interfaces VLAN.
Configuração de uma regra livre de portal baseada em destino
- Entre na visualização do sistema.
system viewportal free-rule rule-number destination host-nameAntes de configurar regras livres de portal baseadas em destino, certifique-se de que um servidor DNS esteja implantado na rede.
Configuração de uma sub-rede de origem de autenticação
Sobre sub-redes de origem de autenticação
Ao configurar as sub-redes de origem da autenticação, você especifica que somente os pacotes HTTP ou HTTPS de usuários nas sub-redes de origem da autenticação podem acionar a autenticação do portal. Se um usuário não autenticado não estiver em nenhuma sub-rede de origem da autenticação, o dispositivo de acesso descartará todos os pacotes HTTP ou HTTPS do usuário que não corresponderem a nenhuma regra sem portal.
Restrições e diretrizes
As sub-redes de origem de autenticação se aplicam somente à autenticação de portal entre sub-redes.
No modo de autenticação de portal direto ou re-DHCP, um usuário do portal e sua interface de acesso (habilitada para portal) estão na mesma sub-rede. Não é necessário especificar a sub-rede como a sub-rede de origem da autenticação.
- No modo direto, o dispositivo de acesso considera a sub-rede de origem da autenticação como qualquer endereço IP de origem.
- No modo re-DHCP, o dispositivo de acesso considera a sub-rede de origem da autenticação em uma interface como a sub-rede à qual pertence o endereço IP privado da interface.
Se as sub-redes de origem e de destino da autenticação estiverem configuradas em uma interface, somente as sub-redes de destino da autenticação terão efeito.
Você pode configurar várias sub-redes de origem de autenticação. Se as sub-redes de origem se sobrepuserem, a sub-rede com o maior escopo de endereço (com a menor máscara ou prefixo) entrará em vigor.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberIPv4:
portal layer3 source ipv4-network-address { mask-length | mask }Por padrão, os usuários de qualquer sub-rede devem passar pela autenticação do portal.
IPv6:
portal ipv6 layer3 source ipv6-network-address prefix-lengthPor padrão, os usuários de qualquer sub-rede devem passar pela autenticação do portal.
Configuração de uma sub-rede de destino de autenticação
Sobre sub-redes de destino de autenticação
Ao configurar as sub-redes de destino da autenticação, você especifica que os usuários acionam a autenticação do portal somente quando acessam as sub-redes especificadas (excluindo os endereços IP de destino e as sub-redes especificadas nas regras sem portal). Os usuários podem acessar outras sub-redes sem autenticação de portal.
Restrições e diretrizes
Se as sub-redes de origem e de destino da autenticação estiverem configuradas em uma interface, somente as sub-redes de destino da autenticação terão efeito.
Você pode configurar várias sub-redes de destino de autenticação. Se as sub-redes de destino se sobrepuserem, a sub-rede com o maior escopo de endereço (com a menor máscara ou prefixo) entrará em vigor.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberIPv4:
portal free-all except destination ipv4-network-address { mask-length | mask }IPv6:
portal ipv6 free-all except destination ipv6-network-address prefix-lengthPor padrão, os usuários que acessam quaisquer sub-redes devem passar pela autenticação do portal.
Configuração do suporte do proxy da Web para autenticação do portal
Sobre o suporte do proxy da Web para autenticação do portal
Para permitir que as solicitações de HTTP com proxy de um servidor proxy da Web acionem a autenticação do portal, especifique o número da porta do servidor proxy da Web no dispositivo. Se uma porta do servidor proxy da Web não for especificada no dispositivo, as solicitações de HTTP com proxy do servidor proxy da Web serão descartadas e a autenticação do portal não poderá ser acionada.
Restrições e diretrizes
Se o navegador de um usuário usar o protocolo Web Proxy Auto-Discovery (WPAD) para descobrir servidores proxy da Web, será necessário executar as seguintes tarefas no dispositivo:
- Especifique os números das portas dos servidores proxy da Web.
- Configure regras de portal-free para permitir que os pacotes de usuários destinados ao servidor WPAD passem sem autenticação.
Se os usuários do portal ativarem o proxy da Web em seus navegadores, eles deverão adicionar o endereço IP do servidor de autenticação do portal como uma exceção de proxy em seus navegadores. Assim, os pacotes HTTP que os usuários enviam ao servidor de autenticação do portal não serão enviados aos servidores proxy da Web.
Você não pode especificar a porta 443 do servidor proxy da Web no dispositivo.
Você pode executar esse comando várias vezes para especificar vários números de porta de servidores proxy da Web.
Procedimento
- Entre na visualização do sistema.
system viewportal web-proxy port port-numberPor padrão, nenhum número de porta de servidores proxy da Web é especificado. As solicitações HTTP com proxy são descartadas.
Verificação da emissão de regras de filtragem de portal de categoria 2
Sobre a verificação da emissão de regras de filtragem de portal de categoria 2
As regras de filtragem de portal de categoria 2 permitem que usuários autenticados acessem recursos de rede autorizados. Por padrão, o dispositivo permite que um usuário autenticado fique on-line, desde que um dispositivo membro tenha emitido uma regra de filtragem de portal de categoria 2 para o usuário. Os usuários que ficam on-line a partir de interfaces globais podem não conseguir acessar os recursos da rede porque algumas portas membros podem não ter regras de categoria 2 para os usuários. Para resolver esse problema, habilite o dispositivo para verificar a emissão de regras de filtragem de portal de categoria 2. Em seguida, o dispositivo permite que os usuários fiquem on-line somente quando todos os dispositivos membros tiverem emitido regras de filtragem de portal de categoria 2 para os usuários.
Como prática recomendada, execute essa tarefa quando a autenticação do portal estiver ativada em uma interface global.
Procedimento
- Entre na visualização do sistema.
system viewportal user-rule assign-check enablePor padrão, o dispositivo não verifica a emissão de regras de filtragem de portal de categoria 2.
Definição do número máximo de usuários do portal
Sobre a configuração do número máximo de usuários do portal
Execute esta tarefa para controlar o número total de usuários do portal no sistema e o número máximo de usuários do portal IPv4 ou IPv6 em uma interface.
Restrições e diretrizes para definir o número máximo de usuários do portal
Certifique-se de que o número máximo combinado de usuários do portal IPv4 e IPv6 especificado em todas as interfaces não exceda o número máximo permitido pelo sistema. Caso contrário, o número excedente de usuários do portal não conseguirá fazer login no dispositivo.
Definição do número máximo global de usuários do portal
- Entre na visualização do sistema.
system viewportal max-user max-numberPor padrão, nenhum limite é definido para o número global de usuários do portal.
Se você definir o número máximo global menor do que o número de usuários atuais do portal on-line no dispositivo, essa configuração ainda terá efeito. Os usuários on-line não são afetados, mas o sistema proíbe o login de novos usuários do portal.
Definição do número máximo de usuários do portal em uma interface
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberportal { ipv4-max-user | ipv6-max-user } max-numberPor padrão, nenhum limite é definido para o número de usuários do portal em uma interface.
Se você definir o número máximo menor do que o número atual de usuários do portal em uma interface, essa configuração ainda terá efeito. Os usuários on-line não são afetados, mas o sistema proíbe que novos usuários do portal façam login a partir da interface.
Ativação da verificação rigorosa das informações de autorização do portal
Sobre a verificação rigorosa das informações de autorização do portal
O recurso de verificação rigorosa permite que um usuário do portal permaneça on-line somente quando as informações de autorização do usuário forem implantadas com êxito.
Ativação da verificação rigorosa das informações de autenticação do portal em uma interface
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberportal authorization { acl | user-profile } strict-checkingCUIDADO:
- A verificação rigorosa falhará se a ACL ou o perfil de usuário autorizado não existir no dispositivo ou se o dispositivo não conseguir implantar o perfil de usuário.
- É possível ativar a verificação rigorosa da ACL autorizada, do perfil de usuário autorizado ou de ambos. Se você ativar a verificação da ACL e do perfil do usuário, o usuário será desconectado se uma das verificações falhar.
Por padrão, a verificação rigorosa das informações de autorização do portal está desativada em uma interface. Os usuários do portal permanecem on-line mesmo quando a ACL ou o perfil de usuário autorizado não existe ou quando o dispositivo não consegue implantar o perfil de usuário.
Permitir que apenas usuários com endereços IP atribuídos por DHCP passem pela autenticação do portal
Sobre permitir que apenas usuários com endereços IP atribuídos por DHCP passem pela autenticação do portal
Esse recurso permite que apenas os usuários com endereços IP atribuídos por DHCP passem pela autenticação do portal. Use esse recurso para garantir que somente os usuários com endereços IP válidos possam acessar a rede.
Restrições e diretrizes
Esse recurso entra em vigor somente quando o dispositivo atua como dispositivo de acesso e servidor DHCP. A configuração desse recurso não afeta os usuários do portal on-line.
Permitir que apenas usuários com endereços IP atribuídos por DHCP passem pela autenticação do portal em uma interface
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberportal [ ipv6 ] user-dhcp-only CUIDADO:
- Depois que esse recurso for configurado, os usuários com endereços IP estáticos não poderão passar pela autenticação do portal para ficar on-line.
- Quando esse recurso for configurado em uma rede IPv6, desative o recurso de endereço IPv6 temporário. Caso contrário, os usuários de IPv6 usarão endereços IPv6 temporários para acessar a rede IPv6 e falharão na autenticação do portal.
Por padrão, tanto os usuários com endereços IP obtidos por DHCP quanto os usuários com endereços IP estáticos podem passar pela autenticação para ficar on-line.
Ativação do roaming do portal
Sobre o roaming do portal
Se o roaming do portal estiver ativado em uma interface de VLAN, um usuário do portal on-line poderá acessar recursos de qualquer porta da Camada 2 na VLAN sem reautenticação.
Se o roaming de portal estiver desativado, para acessar recursos de rede externa de uma porta de Camada 2 diferente da porta de acesso atual na VLAN, o usuário deverá fazer o seguinte
- Efetua o logout da porta atual.
- Reautentica na nova porta da Camada 2.
Restrições e diretrizes
O roaming do portal tem efeito apenas nos usuários do portal que fazem login a partir de interfaces VLAN. Ele não tem efeito sobre os usuários do portal que fazem login a partir da interface comum da Camada 3.
Não é possível ativar o roaming do portal quando houver usuários do portal on-line no dispositivo.
Para que o roaming do portal entre em vigor, você deve desativar o recurso de entrada Rule ARP ou ND usando o comando
undo portal refresh { arp | nd } enableProcedimento
- Entre na visualização do sistema.
system viewportal roaming enablePor padrão, o roaming de portal está desativado.
Configuração do recurso de permissão de falha do portal
Sobre o recurso portal fail-permit
Execute esta tarefa para configurar o recurso de permissão de falha do portal em uma interface. Quando o dispositivo de acesso detecta que o servidor de autenticação do portal ou o servidor da Web do portal não pode ser acessado, ele permite que os usuários da interface tenham acesso à rede sem autenticação do portal.
Se você ativar a permissão de falha para um servidor de autenticação de portal e um servidor da Web de portal em uma interface, a interface fará o seguinte:
- Desativa a autenticação do portal quando um dos servidores não pode ser acessado.
- Retoma a autenticação do portal quando ambos os servidores estiverem acessíveis.
Depois que a autenticação do portal for retomada, os usuários não autenticados deverão ser aprovados na autenticação do portal para acessar a rede. Os usuários que foram aprovados na autenticação do portal antes do evento de falha de permissão podem continuar acessando a rede.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberportal [ ipv6 ] fail-permit server server-namePor padrão, o portal fail-permit está desativado para um servidor de autenticação de portal.
portal [ ipv6 ] fail-permit web-serverPor padrão, a permissão de falha do portal está desativada para um servidor da Web do portal. Esse recurso é compatível apenas com a versão 6348P01 e posteriores.
Configuração dos recursos de detecção de portal
Configuração da detecção on-line de usuários do portal
Sobre a detecção on-line para usuários do portal
Use o recurso de detecção on-line para detectar rapidamente logouts anormais de usuários do portal. Configure a detecção de ARP ou ICMP para usuários do portal IPv4. Configure a detecção de ND ou ICMPv6 para os usuários do portal IPv6.
Se o dispositivo não receber nenhum pacote de um usuário do portal dentro do tempo ocioso, o dispositivo detectará o status on-line do usuário da seguinte forma:
- Detecção de ICMP ou ICMPv6 - Envia solicitações de ICMP ou ICMPv6 ao usuário em intervalos configuráveis para detectar o status do usuário.
- Se o dispositivo receber uma resposta dentro do número máximo de tentativas de detecção, ele considerará que o usuário está on-line e interromperá o envio de pacotes de detecção. Em seguida, o dispositivo redefine o cronômetro de inatividade e repete o processo de detecção quando o cronômetro expira.
- Se o dispositivo não receber nenhuma resposta após o número máximo de tentativas de detecção, o dispositivo fará o logout do usuário.
- Detecção de ARP ou ND - Envia solicitações de ARP ou ND ao usuário e detecta o status de entrada de ARP ou ND do usuário em intervalos configuráveis.
- Se a entrada ARP ou ND do usuário for atualizada dentro do número máximo de tentativas de detecção, o dispositivo considerará que o usuário está on-line e interromperá a detecção. Em seguida, o dispositivo redefine o cronômetro de inatividade e repete o processo de detecção quando o cronômetro expirar.
- Se a entrada ARP ou ND do usuário não for atualizada após o número máximo de tentativas de detecção , o dispositivo fará o logout do usuário.
Restrições e diretrizes
A detecção de ARP e a detecção de ND aplicam-se somente à autenticação direta e à autenticação do portal re-DHCP. A detecção de ICMP aplica-se a todos os modos de autenticação de portal.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberIPv4:
portal user-detect type { arp | icmp } [ retry retries ] [ interval interval ] [ idle time ]IPv6:
portal ipv6 user-detect type { icmpv6 | nd } [ retry retries ] [ interval interval ] [ idle time ]Por padrão, a detecção on-line é desativada para usuários do portal em uma interface.
Configuração da detecção do servidor de autenticação do portal
Sobre a detecção do servidor de autenticação do portal
Durante a autenticação do portal, se a comunicação entre o dispositivo de acesso e o servidor de autenticação do portal for interrompida, os novos usuários do portal não poderão fazer login. Os usuários do portal on-line não poderão fazer logout normalmente.
Para resolver esse problema, o dispositivo de acesso precisa ser capaz de detectar rapidamente as alterações de acessibilidade do servidor do portal e tomar as medidas correspondentes para lidar com as alterações.
O recurso de detecção do servidor de autenticação de portal permite que o dispositivo detecte periodicamente os pacotes de portal enviados por um servidor de autenticação de portal para determinar a acessibilidade do servidor. Se o dispositivo receber um pacote de portal dentro de um tempo limite de detecção (tempo limite de tempo limite) e o pacote de portal for válido, o dispositivo considerará o servidor de autenticação de portal acessível. Caso contrário, o dispositivo considerará o servidor de autenticação de portal inacessível.
Os pacotes de portal incluem pacotes de login de usuário, pacotes de logout de usuário e pacotes de heartbeat. Os pacotes de heartbeat são enviados periodicamente por um servidor. Ao detectar os pacotes heartbeat, o dispositivo pode detectar o status real do servidor mais rapidamente do que ao detectar outros pacotes de portal.
Restrições e diretrizes
O recurso de detecção de servidor de autenticação de portal entra em vigor somente quando o dispositivo tem uma interface habilitada para portal.
Somente o servidor de autenticação do portal IMC suporta o envio de pacotes de pulsação. Para testar a acessibilidade do servidor por meio da detecção de pacotes de heartbeat, você deve ativar o recurso de heartbeat do servidor no servidor de autenticação do portal IMC.
Você pode configurar o dispositivo para executar uma ou mais das seguintes ações quando o status de acessibilidade do servidor for alterado:
- Envio de uma mensagem de registro, que contém o nome, o estado atual e o estado original do servidor de autenticação do portal.
- Ativação da permissão de falha do portal. Quando o servidor de autenticação do portal não pode ser acessado, o recurso de permissão de falha do portal em uma interface permite que os usuários da interface tenham acesso à rede. Quando o servidor se recupera, ele retoma a autenticação do portal na interface. Para obter mais informações, consulte "Configuração do recurso de permissão de falha do portal".
- Certifique-se de que o tempo limite de detecção configurado no dispositivo seja maior do que o intervalo de pulsação do servidor configurado no servidor de autenticação do portal.
Procedimento
- Entre na visualização do sistema.
system viewportal server server-nameserver-detect [ timeout timeout ] logPor padrão, a detecção do servidor de autenticação do portal está desativada.
Configuração da detecção do servidor Web do portal
Sobre a detecção do servidor Web do portal
Um processo de autenticação de portal não poderá ser concluído se a comunicação entre o dispositivo de acesso e o servidor da Web do portal for interrompida. Para resolver esse problema, você pode ativar a detecção do servidor da Web do portal no dispositivo de acesso.
Com o recurso de detecção do servidor da Web do portal, o dispositivo de acesso simula um processo de acesso à Web para iniciar uma conexão TCP com o servidor da Web do portal. Se a conexão TCP puder ser estabelecida com êxito, o dispositivo de acesso considerará a detecção bem-sucedida e o servidor da Web do portal estará acessível. Caso contrário, ele considera que a detecção falhou. O status de autenticação do portal nas interfaces do dispositivo de acesso não afeta o recurso de detecção do servidor da Web do portal.
Você pode configurar os seguintes parâmetros de detecção:
- Intervalo de detecção - Intervalo no qual o dispositivo detecta a capacidade de alcance do servidor.
- Número máximo de falhas consecutivas - Se o número de falhas de detecção consecutivas atingir esse valor, o dispositivo de acesso considerará que o servidor Web do portal está inacessível.
Você pode configurar o dispositivo para executar uma ou mais das seguintes ações quando o status de acessibilidade do servidor for alterado:
- Envio de uma mensagem de registro, que contém o nome, o estado atual e o estado original do servidor Web do portal.
- Ativação da permissão de falha do portal. Quando o servidor da Web do portal não pode ser acessado, o recurso de permissão de falha do portal em uma interface permite que os usuários da interface tenham acesso à rede. Quando o servidor se recupera, ele retoma a autenticação do portal na interface. Para obter mais informações, consulte "Configuração do recurso de permissão de falha do portal".
Restrições e diretrizes
O recurso de detecção do servidor da Web do portal entra em vigor somente quando a URL do servidor da Web do portal é especificada em e o dispositivo tem uma interface habilitada para portal.
Procedimento
- Entre na visualização do sistema.
system viewportal web-server server-nameserver-detect [ interval interval ] [ retry retries ] logPor padrão, a detecção do servidor Web do portal está desativada.
Configuração da sincronização de usuários do portal
Sobre a sincronização de usuários do portal
Quando o dispositivo de acesso perde a comunicação com um servidor de autenticação do portal, as informações do usuário do portal no dispositivo de acesso e no servidor de autenticação do portal podem ser inconsistentes após o restabelecimento da comunicação. Para resolver esse problema, o dispositivo fornece o recurso de sincronização de usuário do portal. Esse recurso é implementado com o envio e a detecção de pacotes de sincronização do portal , como segue:
- O servidor de autenticação do portal envia as informações do usuário on-line para o dispositivo de acesso em um pacote de sincronização no intervalo de pulsação do usuário.
- Ao receber o pacote de sincronização, o dispositivo de acesso compara os usuários contidos no pacote com sua própria lista de usuários e executa as seguintes operações:
- Se um usuário contido no pacote não existir no dispositivo de acesso, o dispositivo de acesso informará ao servidor de autenticação do portal para excluir o usuário. O dispositivo de acesso inicia o timer de detecção de sincronização (timeout timeout) imediatamente quando um usuário faz login.
- Se o usuário não aparecer em nenhum pacote de sincronização dentro de um intervalo de detecção de sincronização, o dispositivo de acesso considerará que o usuário não existe no servidor de autenticação do portal e fará o logout do usuário.
O intervalo de pulsação do usuário é definido no servidor de autenticação do portal.
Restrições e diretrizes
A sincronização do usuário do portal requer um servidor de autenticação do portal para suportar a função de pulsação do usuário do portal. Somente o servidor de autenticação do portal IMC suporta a função de pulsação do usuário do portal. Para implementar o recurso de sincronização de usuários do portal, também é necessário configurar a função de pulsação do usuário no servidor de autenticação do portal. Certifique-se de que o intervalo de pulsação do usuário configurado no servidor de autenticação do portal não seja maior do que o tempo limite de detecção de sincronização configurado no dispositivo de acesso.
A exclusão de um servidor de autenticação de portal no dispositivo de acesso também exclui a configuração de sincronização do usuário para o servidor de autenticação de portal.
Procedimento
- Entre na visualização do sistema.
system viewportal server server-nameuser-sync timeout timeoutPor padrão, a sincronização de usuários do portal está desativada.
Configuração dos atributos do pacote do portal
Configuração do atributo BAS-IP ou BAS-IPv6
Sobre esta tarefa
Se o dispositivo executar o Portal 2.0, os pacotes não solicitados enviados ao servidor de autenticação do portal deverão conter o atributo BAS-IP. Se o dispositivo executar o Portal 3.0, os pacotes não solicitados enviados ao servidor de autenticação do portal deverão conter o atributo BAS-IP ou BAS-IPv6.
Depois que esse atributo é configurado, o endereço IP de origem dos pacotes do portal de notificação não solicitados que o dispositivo envia ao servidor de autenticação do portal é o endereço BAS-IP ou BAS-IPv6 configurado. Se o atributo não estiver configurado, o endereço IP de origem dos pacotes do portal será o endereço IP da interface de saída do pacote.
Restrições e diretrizes
Durante um processo de autenticação do portal re-DHCP ou de logout obrigatório do usuário, o dispositivo envia pacotes de notificação do portal para o servidor de autenticação do portal. Para que o processo de autenticação ou de logout seja concluído, certifique-se de que o atributo BAS-IP/BAS-IPv6 seja o mesmo que o endereço IP do dispositivo especificado no servidor de autenticação do portal.
Você deve configurar o atributo BAS-IP ou BAS-IPv6 em uma interface habilitada para autenticação de portal se as seguintes condições forem atendidas:
- O servidor de autenticação do portal é um servidor Intelbras IMC.
- O endereço IP do dispositivo do portal especificado no servidor de autenticação do portal não é o endereço IP da interface de saída do pacote do portal.
Configuração do atributo BAS-IP ou BAS-IPv6 em uma interface
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberIPv4:
portal bas-ip ipv4-addressPor padrão, o atributo BAS-IP de um pacote de resposta do portal IPv4 é o endereço IPv4 de origem do pacote. O atributo BAS-IP de um pacote de notificação do portal IPv4 é o endereço IPv4 da interface de saída do pacote.
IPv6:
portal bas-ipv6 ipv6-addressPor padrão, o atributo BAS-IPv6 de um pacote de resposta do portal IPv6 é o endereço IPv6 de origem do pacote. O atributo BAS-IPv6 de um pacote de notificação do portal IPv6 é o endereço IPv6 da interface de saída do pacote.
Especificação da ID do dispositivo
Sobre a especificação do ID do dispositivo
O servidor de autenticação do portal usa IDs de dispositivos para identificar os dispositivos que enviam pacotes de protocolo para o servidor do portal.
Restrições e diretrizes
Certifique-se de que o ID do dispositivo configurado seja diferente de qualquer outro dispositivo de acesso que esteja se comunicando com o mesmo servidor de autenticação do portal.
Procedimento
- Entre na visualização do sistema.
system viewportal device-id device-idPor padrão, um dispositivo não é configurado com um ID de dispositivo.
Configuração de atributos para pacotes RADIUS
Especificação de um formato para o atributo NAS-Port-Id
Sobre a especificação de um formato para o atributo NAS-Port-Id
Os servidores RADIUS de diferentes fornecedores podem exigir formatos diferentes do atributo NAS-Port-Id nos pacotes RADIUS. Você pode especificar o formato do atributo NAS-Port-Id conforme necessário.
O dispositivo é compatível com formatos predefinidos (formatos 1, 2, 3 e 4). Para obter mais informações sobre os formatos , consulte os comandos do portal na Referência de comandos de segurança.
Procedimento
- Entre na visualização do sistema.
system viewportal nas-port-id format { 1 | 2 | 3 | 4 }Por padrão, o formato do atributo NAS-Port-Id é o formato 2.
Configuração do atributo NAS-Port-Type
Sobre o atributo NAS-Port-Type
O atributo NAS-Port-Type em uma solicitação RADIUS representa o tipo de interface de acesso de um usuário.
O dispositivo de acesso talvez não consiga obter corretamente o tipo de interface de acesso dos usuários quando houver vários dispositivos de rede entre o dispositivo de acesso e o cliente do portal. Para que o dispositivo de acesso envie o tipo correto de interface de acesso para o servidor RADIUS, execute esta tarefa para configurar o atributo NAS-Port-Type.
Restrições e diretrizes
Essa configuração entra em vigor apenas para os usuários do portal que estiverem on-line recentemente.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberportal nas-port-type { 802.11 | adsl-cap | adsl-dmt | async | cable | ethernet | g.3-fax | hdlc | idsl | isdn-async-v110 | isdn-async-v120 | isdn-sync | piafs | sdsl | sync | virtual | wireless-other | x.25 | x.75 | xdsl }Por padrão, o NAS-Port-Type transportado nas solicitações RADIUS de saída é Ethernet (valor de atributo 15).
Aplicação de um perfil NAS-ID a uma interface
Sobre a aplicação de um perfil NAS-ID a uma interface
Por padrão, o dispositivo envia o nome do dispositivo no atributo NAS-Identifier de todas as solicitações RADIUS.
Um perfil NAS-ID permite que você envie diferentes cadeias de atributos NAS-Identifier em solicitações RADIUS de diferentes VLANs. As cadeias de caracteres podem ser nomes de organizações, nomes de serviços ou qualquer critério de categorização de usuários, dependendo dos requisitos administrativos.
Por exemplo, mapeie o NAS-ID companyA para todas as VLANs da empresa A. O dispositivo enviará companyA no atributo NAS-Identifier para que o servidor RADIUS identifique as solicitações de qualquer usuário da empresa A.
Restrições e diretrizes
Você pode aplicar um perfil NAS-ID a uma interface habilitada para portal. Se nenhum perfil NAS-ID for especificado na interface ou se não for encontrado um NAS-ID correspondente no perfil especificado, o dispositivo usará o nome do dispositivo como o NAS-ID da interface.
Procedimento
- Entre na visualização do sistema.
system viewaaa nas-id profile profile-namePara obter mais informações sobre esse comando, consulte Referência de comandos de segurança.
nas-id nas-identifier bind vlan vlan-idPara obter mais informações sobre esse comando, consulte Comandos AAA em Referência de comandos de segurança. O acesso ao portal corresponde somente à VLAN ID interna dos pacotes QinQ. Para obter mais informações sobre QinQ, consulte o Guia de Configuração de Comutação de Camada 2-LAN.
- Retornar à visualização do sistema.
quitinterface interface-type interface-numberportal nas-id-profile profile-nameFazer logout de usuários do portal on-line
Sobre o logout de usuários do portal on-line
Esse recurso exclui os usuários que passaram pela autenticação do portal e encerra as autenticações do portal em andamento.
Restrições e diretrizes
Quando o número de usuários on-line ultrapassa 2.000, a execução do comando portal delete-user leva alguns minutos.
Para garantir o logout bem-sucedido dos usuários on-line, não desative a autenticação do portal nem execute a alternância de dispositivo mestre/subordinado na interface habilitada para o portal durante a execução do comando.
Procedimento
- Entre na visualização do sistema.
system viewportal delete-user { ipv4-address | all | interface interface-type interface-number | ipv6 ipv6-address }Ativação do registro de login/logout do usuário do portal
Sobre como ativar o registro de login/logout do usuário do portal
Esse recurso registra informações sobre eventos de login e logout de usuários. As informações incluem o nome de usuário, o endereço IP e o endereço MAC do usuário, a interface de acesso do usuário, a VLAN e o resultado do login. Os registros são enviados para o centro de informações do dispositivo. Para que os logs sejam enviados corretamente, você também deve configurar o centro de informações no dispositivo. Para obter mais informações sobre a configuração do centro de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
system viewportal log enablePor padrão, o registro de login/logout do usuário do portal está desativado.
Desativar o recurso de entrada Rule ARP ou ND para clientes do portal
Sobre esta tarefa
Quando o recurso de entrada Rule ARP ou ND está ativado para clientes do portal, as entradas ARP ou ND para clientes do portal são entradas Rule depois que os clientes ficam on-line. As entradas de regra não envelhecerão e serão excluídas imediatamente após os clientes do portal ficarem off-line. Se um cliente do portal ficar off-line e tentar ficar on-line antes que a entrada ARP ou ND seja reaprendida para o cliente, ele falhará na autenticação.
Para evitar essa falha de autenticação, desative esse recurso. Em seguida, as entradas ARP ou ND para os clientes do portal são entradas dinâmicas depois que os clientes ficam on-line e são excluídas somente quando se esgotam.
Restrições e diretrizes
A ativação ou desativação desse recurso não afeta as entradas de regra/dinâmica de ARP ou ND existentes.
Procedimento
- Entre na visualização do sistema.
system viewundo portal refresh { arp | nd } enablePor padrão, o recurso de entrada Rule ARP ou ND está ativado para clientes do portal.
Configuração do redirecionamento da Web
Sobre o redirecionamento da Web
O redirecionamento da Web é um recurso simplificado do portal. Com o redirecionamento da Web, um usuário não executa a autenticação do portal, mas é redirecionado diretamente para o URL especificado na primeira tentativa de acesso à Web em um navegador. Após o intervalo de redirecionamento especificado, o usuário é redirecionado do site visitante para o URL especificado novamente.
O redirecionamento da Web pode fornecer serviços ampliados aos ISPs. Por exemplo, os ISPs podem colocar anúncios e publicar informações na página da Web redirecionada.
Restrições e diretrizes
O recurso de redirecionamento da Web entra em vigor somente em pacotes HTTP que usam o número de porta padrão 80. O redirecionamento da Web não funciona quando o redirecionamento da Web e a autenticação do portal estão ativados.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberweb-redirect [ ipv6 ] url url-string [ interval interval ]Por padrão, o redirecionamento da Web está desativado.
Comandos de exibição e manutenção do portal
Execute comandos de exibição em qualquer visualização e o comando reset na visualização do usuário.
| Tarefa | Comando |
| Exibir a configuração do portal e o estado de execução do portal. | display portal interface interface-type interface-number |
| Exibir estatísticas de pacotes para servidores de autenticação de portal. | exibir estatísticas de pacotes do portal [ server server-name ] |
| Exibir regras do portal. | display portal rule { all | dynamic | static } interface interface-type interface-number [ slot slot-number ] |
| Exibir informações do servidor de autenticação do portal. | exibir servidor de portal [ nome do servidor ] |
| Exibir informações do usuário do portal. | display portal user { all | interface-type interface-number | ip ipv4-address | ipv6 ipv6-address } [ verbose ] |
| Exibir informações do servidor da Web do portal. | servidor web do portal de exibição [ nome do servidor ] |
| Exibir informações da regra de redirecionamento da Web. | display web-redirect rule interface interface-type interface-number [ slot slot-number ] |
| Limpar estatísticas de pacotes para servidores de autenticação de portal. | reset portal packet statistics [ server nome-do-servidor ] |
Exemplos de configuração do portal
Exemplo: Configuração da autenticação direta do portal
Configuração de rede
Conforme mostrado na Figura 6, o host está diretamente conectado ao switch (o dispositivo de acesso). O host recebe um endereço IP público manualmente ou por meio de DHCP. Um servidor de portal atua como um servidor de autenticação de portal e um servidor da Web de portal. Um servidor RADIUS atua como servidor de autenticação/contabilidade.
Configure a autenticação direta do portal, para que o host possa acessar somente o servidor do portal antes de passar pela autenticação e acessar outros recursos da rede depois de passar pela autenticação.
Figura 6 Diagrama de rede
Pré-requisitos
- Configure os endereços IP do host, do switch e dos servidores, conforme mostrado na Figura 6, e certifique-se de que eles possam se comunicar entre si.
- Configure o servidor RADIUS corretamente para fornecer funções de autenticação e contabilidade.
Configuração do servidor de autenticação do portal no IMC PLAT 5.0
Neste exemplo, o servidor do portal é executado no IMC PLAT 5.0(E0101) e no IMC UAM 5.0(E0101).
- Configure o servidor de autenticação do portal:
- Faça login no IMC e clique na guia Service (Serviço).
- Selecione User Access Manager > Portal Service Management > Server na árvore de navegação para abrir a página de configuração do servidor do portal, conforme mostrado na Figura 7.
- Configure os parâmetros do servidor do portal conforme necessário. Este exemplo usa as configurações padrão.
- Clique em OK.
- Configure o grupo de endereços IP:
- Selecione User Access Manager > Portal Service Management > IP Group na árvore de navegação para abrir a página de configuração do grupo de endereços IP do portal.
- Clique em Add para abrir a página, conforme mostrado na Figura 8.
- Digite o nome do grupo IP.
- Digite o endereço IP inicial e o endereço IP final do grupo de IP. Certifique-se de que o endereço IP do host esteja no grupo de IPs.
- Selecione um grupo de serviços.
- Selecione a ação Normal.
- Clique em OK.
- Adicionar um dispositivo de portal:
- Selecione User Access Manager > Portal Service Management > Device na árvore de navegação para abrir a página de configuração do dispositivo do portal.
- Clique em Add para abrir a página, conforme mostrado na Figura 9.
- Digite o nome do dispositivo NAS.
- Digite o endereço IP da interface do switch conectada ao host.
- Digite a chave, que deve ser a mesma configurada no switch.
- Defina se deseja ativar a realocação de endereços IP.
- Selecione se deseja oferecer suporte às funções de heartbeat do servidor e heartbeat do usuário.
- Clique em OK.
- Associe o dispositivo do portal ao grupo de endereços IP:
- Conforme mostrado na Figura 10, clique no ícone na coluna Port Group Information Management do dispositivo NAS para abrir a página de configuração do grupo de portas.
- Clique em Add para abrir a página, conforme mostrado na Figura 11.
- Digite o nome do grupo de portas.
- Selecione o grupo de endereços IP configurado.
- Use as configurações padrão para outros parâmetros.
- Clique em OK.
- Selecione User Access Manager > Service Parameters > Validate System Configuration > Validar configuração do sistema em na árvore de navegação para que as configurações entrem em vigor.
Figura 7 Configuração do servidor do portal
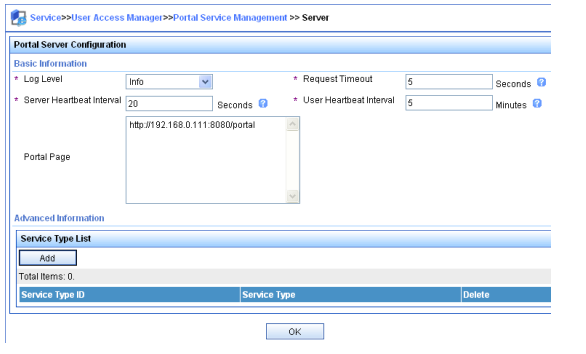
Este exemplo usa o grupo padrão Ungrouped.
Figura 8: Adição de um grupo de endereços IP
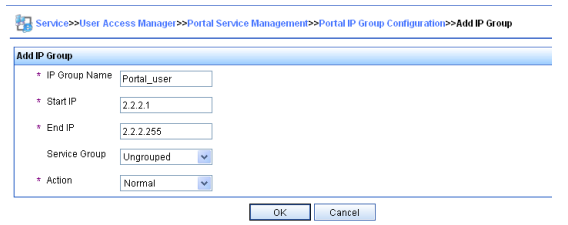
Este exemplo usa a autenticação direta do portal e, portanto, selecione No na lista Reallocate IP (Realocar IP).
Neste exemplo, selecione No para Support Server Heartbeat e Support User Heartbeat.
Figura 9 Adição de um dispositivo de portal
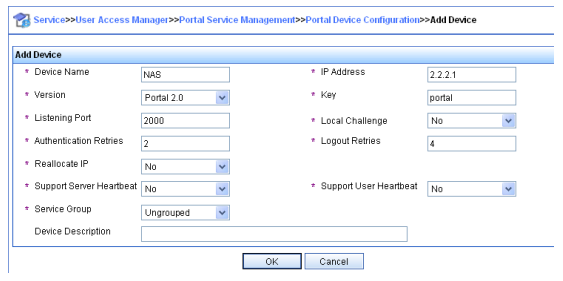
O endereço IP usado pelo usuário para acessar a rede deve estar dentro desse grupo de endereços IP.
Figura 10 Lista de dispositivos

Figura 11 Adição de um grupo de portas
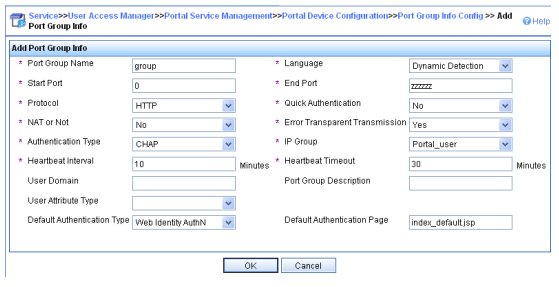
Configuração do switch
- Configurar um esquema RADIUS:
# Crie um esquema RADIUS chamado rs1 e entre em sua visualização.
<Switch> system-view
[Switch] radius scheme rs1# Especifique o servidor de autenticação principal e o servidor de contabilidade principal e configure as chaves para comunicação com os servidores.
[Switch-radius-rs1] primary authentication 192.168.0.112
[Switch-radius-rs1] primary accounting 192.168.0.112
[Switch-radius-rs1] key authentication simple radius
[Switch-radius-rs1] key accounting simple radius# Excluir o nome de domínio do ISP do nome de usuário enviado ao servidor RADIUS.
[Switch-radius-rs1] user-name-format without-domain
[Switch-radius-rs1] quit# Habilite o controle de sessão RADIUS.
[Switch] radius session-control enable# Crie um domínio ISP chamado dm1 e entre em sua visualização.
[Switch] domain dm1# Configurar métodos AAA para o domínio ISP.
[Switch-isp-dm1] authentication portal radius-scheme rs1
[Switch-isp-dm1] authorization portal radius-scheme rs1
[Switch-isp-dm1] accounting portal radius-scheme rs1
[Switch-isp-dm1] quit# Configure o domínio dm1 como o domínio padrão do ISP. Se um usuário digitar o nome de usuário sem o nome do domínio ISP no login, os métodos de autenticação e contabilidade do domínio padrão serão usados para o usuário.
[Switch] domain default enable dm1# Configure um servidor de autenticação de portal.
[Switch] portal server newpt
[Switch-portal-server-newpt] ip 192.168.0.111 key simple portal
[Switch-portal-server-newpt] port 50100
[Switch-portal-server-newpt] quit# Configure um servidor Web de portal.
[Switch] portal web-server newpt
[Switch-portal-websvr-newpt] url http://192.168.0.111:8080/portal
[Switch-portal-websvr-newpt] quit# Habilite a autenticação direta do portal na interface VLAN 100.
[Switch] interface vlan-interface 100
[Switch–Vlan-interface100] portal enable method direct# Especifique o servidor Web do portal newpt na interface VLAN 100.
[Switch–Vlan-interface100] portal apply web-server newpt# Configure o BAS-IP como 2.2.2.1 para pacotes de portal enviados da interface VLAN 100 para o servidor de autenticação de portal.
[Switch–Vlan-interface100] portal bas-ip 2.2.2.1
[Switch–Vlan-interface100] quitVerificação da configuração
# Verificar se a configuração do portal entrou em vigor.
[Switch] display portal interface vlan-interface 100
Portal information of Vlan-interface100
NAS-ID profile : Not configured
Authorization : Strict checking
ACL : Disabled
User profile : Disabled
IPv4:
Portal status: Enabled
Portal authentication method: Direct
Portal web server: newpt
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ip: 2.2.2.1
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Mask
Destination authenticate subnet:
IP address Mask
IPv6:
Portal status: Disabled
Portal authentication method: Disabled
Portal web server: Not configured
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ipv6: Not configured
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Prefix length
Destination authenticate subnet:
IP address Prefix lengthUm usuário pode realizar a autenticação do portal usando o cliente Intelbras iNode ou por meio de um navegador da Web. Antes de passar pela autenticação, o usuário pode acessar somente a página de autenticação http://192.168.0.111:8080/portal. Todas as solicitações da Web do usuário serão redirecionadas para a página de autenticação. Depois de passar pela autenticação, o usuário pode acessar outros recursos da rede.
# Depois que o usuário passar pela autenticação, use o seguinte comando para exibir informações sobre o usuário do portal.
[Switch] display portal user interface vlan-interface 100
Total portal users: 1
Username: abc
Portal server: newpt
State: Online
VPN instance: N/A
MAC IP VLAN Interface
0015-e9a6-7cfe 2.2.2.2 100 Vlan-interface100
Authorization information:
DHCP IP pool: N/A
User profile: N/A
Session group profile: N/A
ACL number: N/A
Inbound CAR: N/A
Outbound CAR: N/AExemplo: Configuração da autenticação do portal re-DHCP
Configuração de rede
Conforme mostrado na Figura 12, o host está diretamente conectado ao switch (o dispositivo de acesso). O host obtém um endereço IP por meio do servidor DHCP. Um servidor de portal atua como um servidor de autenticação de portal e um servidor da Web de portal. Um servidor RADIUS atua como servidor de autenticação/contabilidade.
Configure a autenticação do portal re-DHCP. Antes de passar pela autenticação, o host recebe um endereço IP privado. Depois de passar pela autenticação, o host recebe um endereço IP público e pode acessar os recursos da rede.
Figura 12 Diagrama de rede
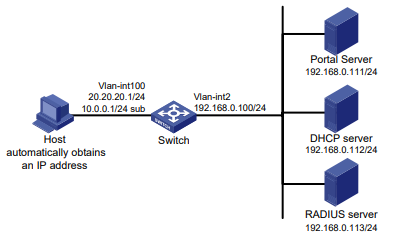
Restrições e diretrizes
- Para autenticação do portal re-DHCP, configure um pool de endereços públicos (20.20.20.0/24) e um pool de endereços privados (10.0.0.0/24) no servidor DHCP. (Detalhes não mostrados.)
- Para autenticação do portal re-DHCP:
- O switch deve ser configurado como um agente de retransmissão DHCP.
- A interface habilitada para portal deve ser configurada com um endereço IP primário (um endereço IP público) e um endereço IP secundário (um endereço IP privado).
- Certifique-se de que o endereço IP do dispositivo do portal adicionado ao servidor do portal seja o endereço IP público (20.20.20.1) da interface do switch que conecta o host. O intervalo de endereços IP privados para o grupo de endereços IP associado ao dispositivo do portal é a sub-rede privada 10.0.0.0/24 onde o host reside. O intervalo de endereços IP públicos para o grupo de endereços IP é a sub-rede pública 20.20.20.0/24.
Para obter informações sobre a configuração do agente de retransmissão DHCP, consulte o Guia de Configuração de Serviços de Camada 3 IP.
Pré-requisitos
- Configure os endereços IP para o switch e os servidores, conforme mostrado na Figura 12, e certifique-se de que o host, o switch e os servidores possam se comunicar entre si.
- Configure o servidor RADIUS corretamente para fornecer funções de autenticação e contabilidade.
Procedimento
- Configurar um esquema RADIUS:
# Crie um esquema RADIUS chamado rs1 e entre em sua visualização.
<Switch> system-view
[Switch] radius scheme rs1# Especifique o servidor de autenticação principal e o servidor de contabilidade principal e configure o chaves para comunicação com os servidores.
[Switch-radius-rs1] primary authentication 192.168.0.113
[Switch-radius-rs1] primary accounting 192.168.0.113
[Switch-radius-rs1] key authentication simple radius
[Switch-radius-rs1] key accounting simple radius# Excluir o nome de domínio do ISP do nome de usuário enviado ao servidor RADIUS.
[Switch-radius-rs1] user-name-format without-domain
[Switch-radius-rs1] quit# Habilite o controle de sessão RADIUS.
[Switch] radius session-control enable# Crie um domínio ISP chamado dm1 e entre em sua visualização.
[Switch] domain dm1# Configure os métodos AAA para o domínio ISP.
[Switch-isp-dm1] authentication portal radius-scheme rs1
[Switch-isp-dm1] authorization portal radius-scheme rs1
[Switch-isp-dm1] accounting portal radius-scheme rs1
[Switch-isp-dm1] quit# Configure o domínio dm1 como o domínio padrão do ISP. Se um usuário digitar o nome de usuário sem o nome do domínio ISP no login, os métodos de autenticação e contabilidade do domínio padrão serão usados para o usuário.
[Switch] domain default enable dm1# Configurar o relé DHCP.
[Switch] dhcp enable
[Switch] dhcp relay client-information record
[Switch] interface vlan-interface 100
[Switch–Vlan-interface100] ip address 20.20.20.1 255.255.255.0
[Switch–Vlan-interface100] ip address 10.0.0.1 255.255.255.0 sub
[Switch-Vlan-interface100] dhcp select relay
[Switch-Vlan-interface100] dhcp relay server-address 192.168.0.112# Habilite o ARP autorizado.
[Switch-Vlan-interface100] arp authorized enable
[Switch-Vlan-interface100] quit# Configure um servidor de autenticação de portal.
[Switch] portal server newpt
[Switch-portal-server-newpt] ip 192.168.0.111 key simple portal
[Switch-portal-server-newpt] port 50100
[Switch-portal-server-newpt] quit# Configure um servidor da Web do portal.
[Switch] portal web-server newpt
[Switch-portal-websvr-newpt] url http://192.168.0.111:8080/portal
[Switch-portal-websvr-newpt] quit# Habilite a autenticação do portal re-DHCP na interface VLAN 100.
[Switch] interface vlan-interface 100
[Switch–Vlan-interface100] portal enable method redhcp# Especifique o newpt do servidor Web do portal na interface VLAN 100.
[Switch–Vlan-interface100] portal apply web-server newpt# Configure o BAS-IP como 20.20.20.1 para pacotes de portal enviados da interface VLAN 100 para o servidor de autenticação de portal.
[Switch–Vlan-interface100] portal bas-ip 20.20.20.1
[Switch–Vlan-interface100] quitVerificação da configuração
# Verifique se a configuração do portal entrou em vigor.
[Switch] display portal interface vlan-interface 100
Portal information of Vlan-interface100
NAS-ID profile : Not configured
Authorization : Strict checking
ACL : Disabled
User profile : Disabled
IPv4:
Portal status: Enabled
Portal authentication method: Redhcp
Portal web server: newpt
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ip: 20.20.20.1
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Mask
Destination authenticate subnet:
IP address Mask
IPv6:
Portal status: Disabled
Portal authentication method: Disabled
Portal web server: Not configured
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ipv6: Not configured
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Prefix length
Destination authenticate subnet:
IP address Prefix lengthAntes de passar pela autenticação, um usuário que usa o cliente Intelbras iNode pode acessar apenas a página de autenticação http://192.168.0.111:8080/portal. Todas as solicitações da Web do usuário serão redirecionadas para a página de autenticação. Depois de passar pela autenticação, o usuário pode acessar outros recursos da rede.
# Depois que o usuário passar pela autenticação, use o seguinte comando para exibir informações sobre o usuário do portal.
[Switch] display portal user interface vlan-interface 100
Total portal users: 1
Username: abc
Portal server: newpt
State: Online
VPN instance: N/A
MAC IP VLAN Interface
0015-e9a6-7cfe 20.20.20.2 100 Vlan-interface100
Authorization information:
DHCP IP pool: N/A
User profile: N/A
Session group profile: N/A
ACL number: N/A
Inbound CAR: N/A
Outbound CAR: N/AExemplo: Configuração da autenticação do portal entre sub-redes
Configuração de rede
Conforme mostrado na Figura 13, o Switch A é compatível com a autenticação de portal. O host acessa o Switch A por meio do Switch B. Um servidor de portal atua como servidor de autenticação de portal e como servidor Web de portal. Um servidor RADIUS atua como servidor de autenticação/contabilidade.
Configure o Switch A para autenticação de portal entre sub-redes. Antes de passar pela autenticação, o host pode acessar apenas o servidor Web do portal. Depois de passar pela autenticação, o usuário pode acessar outros recursos da rede.
Figura 13 Diagrama de rede
Restrições e diretrizes
Certifique-se de que o endereço IP do dispositivo do portal adicionado no servidor de autenticação do portal seja o endereço IP (20.20.20.1) da interface do switch que conecta o host. O grupo de endereços IP associado ao dispositivo do portal é a sub-rede do host (8.8.8.0/24).
Pré-requisitos
- Configure os endereços IP para o switch e os servidores, conforme mostrado na Figura 13, e certifique-se de que o host, o switch e os servidores possam se comunicar entre si.
- Configure o servidor RADIUS corretamente para fornecer funções de autenticação e contabilidade.
Procedimento
- Configure um esquema RADIUS:
# Crie um esquema RADIUS chamado rs1 e entre em sua visualização.
<SwitchA> system-view
[SwitchA] radius scheme rs# Especifique o servidor de autenticação principal e o servidor de contabilidade principal e configure as chaves para comunicação com os servidores.
[SwitchA-radius-rs1] primary authentication 192.168.0.112
[SwitchA-radius-rs1] primary accounting 192.168.0.112
[SwitchA-radius-rs1] key authentication simple radius
[SwitchA-radius-rs1] key accounting simple radius# Excluir o nome de domínio do ISP do nome de usuário enviado ao servidor RADIUS.
[SwitchA-radius-rs1] user-name-format without-domain
[SwitchA-radius-rs1] quit# Habilite o controle de sessão RADIUS.
[SwitchA] radius session-control enable# Crie um domínio ISP chamado dm1 e entre em sua visualização.
[SwitchA] domain dm1# Configurar métodos AAA para o domínio ISP.
[SwitchA-isp-dm1] authentication portal radius-scheme rs1
[SwitchA-isp-dm1] authorization portal radius-scheme rs1
[SwitchA-isp-dm1] accounting portal radius-scheme rs1
[SwitchA-isp-dm1] quit# Configure o domínio dm1 como o domínio padrão do ISP. Se um usuário digitar o nome de usuário sem o nome do domínio ISP no login, os métodos de autenticação e contabilidade do domínio padrão serão usados para o usuário.
[SwitchA] domain default enable dm1# Configure um servidor de autenticação de portal.
[SwitchA] portal server newpt
[SwitchA-portal-server-newpt] ip 192.168.0.111 key simple portal
[SwitchA-portal-server-newpt] port 50100
[SwitchA-portal-server-newpt] quit# Configure um servidor Web de portal.
[SwitchA] portal web-server newpt
[SwitchA-portal-websvr-newpt] url http://192.168.0.111:8080/portal
[SwitchA-portal-websvr-newpt] quit# Habilite a autenticação de portal entre sub-redes na interface VLAN 4.
[SwitchA] interface vlan-interface 4
[SwitchA–Vlan-interface4] portal enable method layer3# Especifique o newpt do servidor da Web do portal na interface VLAN 4.
[SwitchA–Vlan-interface4] portal apply web-server newpt# Configure o BAS-IP como 20.20.20.1 para pacotes de portal enviados da interface VLAN 4 para o servidor de autenticação de portal.
[SwitchA–Vlan-interface4] portal bas-ip 20.20.20.1
[SwitchA–Vlan-interface4] quitVerificação da configuração
# Verifique se a configuração do portal entrou em vigor.
[SwitchA] display portal interface vlan-interface 4
Portal information of Vlan-interface4
NAS-ID profile : Not configured
Authorization : Strict checking
ACL : Disabled
User profile : Disabled
IPv4:
Portal status: Enabled
Portal authentication method: Layer3
Portal web server: newpt
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ip: 20.20.20.1
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Mask
Destination authenticate subnet:
IP address Mask
IPv6:
Portal status: Disabled
Portal authentication method: Disabled
Portal web server: Not configured
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ipv6: Not configured
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Prefix length
Destination authenticate subnet:
IP address Prefix lengthUm usuário pode realizar a autenticação do portal usando o cliente Intelbras iNode ou por meio de um navegador da Web. Antes de passar pela autenticação, o usuário pode acessar apenas a página de autenticação http://192.168.0.111:8080/portal. Todas as solicitações da Web do usuário serão redirecionadas para a página de autenticação. Depois de passar pela autenticação, o usuário pode acessar outros recursos da rede.
# Depois que o usuário passar pela autenticação, use o seguinte comando para exibir informações sobre o usuário do portal.
[SwitchA] display portal user interface vlan-interface 4
Total portal users: 1
Username: abc
Portal server: newpt
State: Online
VPN instance: N/A
MAC IP VLAN Interface
0000-0000-0000 8.8.8.2 4 Vlan-interface4
Authorization information:
DHCP IP pool: N/A
User profile: N/A
Session group profile: N/A
ACL number: N/A
Inbound CAR: N/A
Outbound CAR: N/AExemplo: Configuração da autenticação de portal direto estendido
Configuração de rede
Conforme mostrado na Figura 14, o host está diretamente conectado ao switch (o dispositivo de acesso). O host recebe um endereço IP público manualmente ou por meio de DHCP. Um servidor de portal atua como um servidor de autenticação de portal e um servidor da Web de portal. Um servidor RADIUS atua como servidor de autenticação/contabilidade.
Configure a autenticação de portal direto estendido. Se o host falhar na verificação de segurança após passar pela autenticação de identidade, ele poderá acessar apenas a sub-rede 192.168.0.0/24. Depois de passar pela verificação de segurança, o host poderá acessar outros recursos da rede.
Figura 14 Diagrama de rede
Pré-requisitos
- Configure os endereços IP do host, do switch e dos servidores, conforme mostrado na Figura 14, e certifique-se de que eles possam se comunicar entre si.
- Configure o servidor RADIUS corretamente para fornecer funções de autenticação e contabilidade.
Procedimento
- Configurar um esquema RADIUS:
# Crie um esquema RADIUS chamado rs1 e entre em sua visualização.
<Switch> system-view
[Switch] radius scheme rs1# Especifique o servidor de autenticação principal e o servidor de contabilidade principal e configure o chaves para comunicação com os servidores.
[Switch-radius-rs1] primary authentication 192.168.0.112
[Switch-radius-rs1] primary accounting 192.168.0.112
[Switch-radius-rs1] key accounting simple radius
[Switch-radius-rs1] key authentication simple radius
[Switch-radius-rs1] user-name-format without-domain# Habilite o controle de sessão RADIUS.
[Switch] radius session-control enable# Especifique um cliente de controle de sessão com endereço IP 192.168.0.112 e chave compartilhada 12345 em formato de texto simples.
[Switch] radius session-control client ip 192.168.0.112 key simple 12345# Crie um domínio ISP chamado dm1 e entre em sua visualização.
[Switch] domain dm1# Configurar métodos AAA para o domínio ISP.
[Switch-isp-dm1] authentication portal radius-scheme rs1
[Switch-isp-dm1] authorization portal radius-scheme rs1
[Switch-isp-dm1] accounting portal radius-scheme rs1
[Switch-isp-dm1] quit# Configure o domínio dm1 como o domínio padrão do ISP. Se um usuário digitar o nome de usuário sem o nome do domínio ISP no login, os métodos de autenticação e contabilidade do domínio padrão serão usados para o usuário.
[Switch] domain default enable dm1[Switch] acl advanced 3000
[Switch-acl-ipv4-adv-3000] rule permit ip destination 192.168.0.0 0.0.0.255
[Switch-acl-ipv4-adv-3000] rule deny ip
[Switch-acl-ipv4-adv-3000] quit
[Switch] acl advanced 3001
[Switch-acl-ipv4-adv-3001] rule permit ip
[Switch-acl-ipv4-adv-3001] quitOBSERVAÇÃO:
Certifique-se de especificar a ACL 3000 como a ACL de isolamento e a ACL 3001 como a ACL de segurança no servidor de política de segurança.
# Configure um servidor de autenticação de portal.
[Switch] portal server newpt
[Switch-portal-server-newpt] ip 192.168.0.111 key simple portal
[Switch-portal-server-newpt] port 50100
[Switch-portal-server-newpt] quit# Configurar um servidor Web de portal.
[Switch] portal web-server newpt
[Switch-portal-websvr-newpt] url http://192.168.0.111:8080/portal
[Switch-portal-websvr-newpt] quit# Habilite a autenticação direta do portal na interface VLAN 100.
[Switch] interface vlan-interface 100
[Switch–Vlan-interface100] portal enable method direct# Especifique o servidor Web do portal newpt na interface VLAN 100.
[Switch–Vlan-interface100] portal apply web-server newpt# Configure o BAS-IP como 2.2.2.1 para pacotes de portal enviados da interface VLAN 100 para o servidor de autenticação de portal.
[Switch–Vlan-interface100] portal bas-ip 2.2.2.1
[Switch–Vlan-interface100] quitVerificação da configuração
# Verifique se a configuração do portal entrou em vigor.
[Switch] display portal interface vlan-interface 100
Portal information of Vlan-interface100
NAS-ID profile : Not configured
Authorization : Strict checking
ACL : Disabled
User profile : Disabled
IPv4:
Portal status: Enabled
Portal authentication method: Direct
Portal web server: newpt
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ip: 2.2.2.1
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Mask
Destination authenticate subnet:
IP address Mask
IPv6:
Portal status: Disabled
Portal authentication method: Disabled
Portal web server: Not configured
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ipv6: Not configured
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Prefix length
Destination authenticate subnet:
IP address Prefix lengthAntes de passar pela autenticação do portal, um usuário que usa o cliente Intelbras iNode pode acessar apenas a página de autenticação http://192.168.0.111:8080/portal. Todas as solicitações da Web do usuário serão redirecionadas para a página de autenticação.
- O usuário pode acessar os recursos permitidos pela ACL 3000 depois de passar apenas pela autenticação de identidade.
- O usuário pode acessar os recursos de rede permitidos pela ACL 3001 depois de passar pela autenticação de identidade e pela verificação de segurança.
# Depois que o usuário for aprovado na autenticação de identidade e na verificação de segurança, use o seguinte comando para exibir informações sobre o usuário do portal.
[Switch] display portal user interface vlan-interface 100
Total portal users: 1
Username: abc
Portal server: newpt
State: Online
VPN instance: N/A
MAC IP VLAN Interface
0015-e9a6-7cfe 2.2.2.2 100 Vlan-interface100
Authorization information:
DHCP IP pool: N/A
User profile: N/A
Session group profile: N/A
ACL number: 3001 (active)
Inbound CAR: N/A
Outbound CAR: N/AExemplo: Configuração da autenticação estendida do portal re-DHCP
Configuração de rede
Conforme mostrado na Figura 15, o host está diretamente conectado ao switch (o dispositivo de acesso). O host obtém um endereço IP por meio do servidor DHCP. Um servidor de portal atua como um servidor de autenticação de portal e um servidor da Web de portal. Um servidor RADIUS atua como servidor de autenticação/contabilidade.
Configure a autenticação estendida do portal re-DHCP. Antes de passar pela autenticação do portal, o host recebe um endereço IP privado. Depois de passar pela autenticação de identidade do portal, o host obtém um endereço IP público e aceita a verificação de segurança. Se o host falhar na verificação de segurança, ele poderá acessar apenas a sub-rede 192.168.0.0/24. Depois de passar pela verificação de segurança, o host poderá acessar outros recursos da rede.
Figura 15 Diagrama de rede
Restrições e diretrizes
- Para autenticação do portal re-DHCP, configure um pool de endereços públicos (20.20.20.0/24) e um pool de endereços privados (10.0.0.0/24) no servidor DHCP. (Detalhes não mostrados.)
- Para autenticação do portal re-DHCP:
- O switch deve ser configurado como um agente de retransmissão DHCP.
- A interface habilitada para portal deve ser configurada com um endereço IP primário (um endereço IP público) e um endereço IP secundário (um endereço IP privado).
- Certifique-se de que o endereço IP do dispositivo do portal adicionado ao servidor do portal seja o endereço IP público (20.20.20.1) da interface do switch que conecta o host. O intervalo de endereços IP privados para o grupo de endereços IP associado ao dispositivo do portal é a sub-rede privada 10.0.0.0/24 onde o host reside. O intervalo de endereços IP públicos para o grupo de endereços IP é a sub-rede pública 20.20.20.0/24.
Para obter informações sobre a configuração do agente de retransmissão DHCP, consulte o Guia de Configuração de Serviços de Camada 3 IP.
Pré-requisitos
- Configure os endereços IP para o switch e os servidores, conforme mostrado na Figura 15, e certifique-se de que o host, o switch e os servidores possam se comunicar entre si.
- Configure o servidor RADIUS corretamente para fornecer funções de autenticação e contabilidade.
Procedimento
- Configure um esquema RADIUS:
# Crie um esquema RADIUS chamado rs1 e entre em sua visualização.
<Switch> system-view
[Switch] radius scheme rs1# Especifique o servidor de autenticação primário e o servidor de contabilidade primário e configure as chaves para comunicação com os servidores.
[Switch-radius-rs1] primary authentication 192.168.0.113
[Switch-radius-rs1] primary accounting 192.168.0.113
[Switch-radius-rs1] key accounting simple radius
[Switch-radius-rs1] key authentication simple radius
[Switch-radius-rs1] user-name-format without-domain# Habilite o controle de sessão RADIUS.
[Switch] radius session-control enable# Especifique um cliente de controle de sessão com endereço IP 192.168.0.113 e chave compartilhada 12345 em formato de texto simples.
[Switch] radius session-control client ip 192.168.0.113 key simple 12345# Crie um domínio ISP chamado dm1 e entre em sua visualização.
[Switch] domain dm1# Configurar métodos AAA para o domínio ISP.
[Switch-isp-dm1] authentication portal radius-scheme rs1
[Switch-isp-dm1] authorization portal radius-scheme rs1
[Switch-isp-dm1] accounting portal radius-scheme rs1
[Switch-isp-dm1] quit# Configure o domínio dm1 como o domínio padrão do ISP. Se um usuário digitar o nome de usuário sem o nome do domínio ISP no login, os métodos de autenticação e contabilidade do domínio padrão serão usados para o usuário.
[Switch] domain default enable dm1[Switch] acl advanced 3000
[Switch-acl-ipv4-adv-3000] rule permit ip destination 192.168.0.0 0.0.0.255
[Switch-acl-ipv4-adv-3000] rule deny ip
[Switch-acl-ipv4-adv-3000] quit
[Switch] acl advanced 3001
[Switch-acl-ipv4-adv-3001] rule permit ip
[Switch-acl-ipv4-adv-3001] quitOBSERVAÇÃO:
Certifique-se de especificar a ACL 3000 como a ACL de isolamento e a ACL 3001 como a ACL de segurança no servidor de política de segurança.
[Switch] dhcp enable
[Switch] dhcp relay client-information record
[Switch] interface vlan-interface 100
[Switch–Vlan-interface100] ip address 20.20.20.1 255.255.255.0
[Switch–Vlan-interface100] ip address 10.0.0.1 255.255.255.0 sub
[Switch-Vlan-interface100] dhcp select relay
[Switch-Vlan-interface100] dhcp relay server-address 192.168.0.112# Habilite o ARP autorizado.
[Switch-Vlan-interface100] arp authorized enable
[Switch-Vlan-interface100] quit# Configure um servidor de autenticação de portal.
[Switch] portal server newpt
[Switch-portal-server-newpt] ip 192.168.0.111 key simple portal
[Switch-portal-server-newpt] port 50100
[Switch-portal-server-newpt] quit# Configurar um servidor Web de portal.
[Switch] portal web-server newpt
[Switch-portal-websvr-newpt] url http://192.168.0.111:8080/portal
[Switch-portal-websvr-newpt] quit# Habilite a autenticação do portal re-DHCP na interface VLAN 100.
[Switch] interface vlan-interface 100
[Switch–Vlan-interface100] portal enable method redhcp# Especifique o newpt do servidor Web do portal na interface VLAN 100.
[Switch–Vlan-interface100] portal apply web-server newpt# Configure o BAS-IP como 20.20.20.1 para pacotes de portal enviados da interface VLAN 100 para o servidor de autenticação de portal.
[Switch–Vlan-interface100] portal bas-ip 20.20.20.1
[Switch–Vlan-interface100] quitVerificação da configuração
# Verifique se a configuração do portal entrou em vigor.
[Switch] display portal interface vlan-interface 100
Portal information of Vlan-interface100
NAS-ID profile : Not configured
Authorization : Strict checking
ACL : Disabled
User profile : Disabled
IPv4:
Portal status: Enabled
Portal authentication method: Redhcp
Portal web server: newpt
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ip: 20.20.20.1
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Mask
Destination authenticate subnet:
IP address Mask
IPv6:
Portal status: Disabled
Portal authentication method: Disabled
Portal web server: Not configured
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ipv6: Not configured
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Prefix length
Destination authenticate subnet:
IP address Prefix lengthAntes de passar pela autenticação do portal, um usuário que usa o cliente Intelbras iNode pode acessar apenas a página de autenticação http://192.168.0.111:8080/portal. Todas as solicitações da Web do usuário serão redirecionadas para a página de autenticação.
- O usuário pode acessar os recursos permitidos pela ACL 3000 depois de passar apenas pela autenticação de identidade.
- O usuário pode acessar os recursos de rede permitidos pela ACL 3001 depois de passar pela autenticação de identidade e pela verificação de segurança.
# Depois que o usuário for aprovado na autenticação de identidade e na verificação de segurança, use o seguinte comando para exibir informações sobre o usuário do portal.
[Switch] display portal user interface vlan-interface 100
Total portal users: 1
Username: abc
Portal server: newpt
State: Online
VPN instance: N/A
MAC IP VLAN Interface
0015-e9a6-7cfe 20.20.20.2 100 Vlan-interface100
Authorization information:
DHCP IP pool: N/A
User profile: N/A
Session group profile: N/A
ACL number: 3001 (active)
Inbound CAR: N/A
Outbound CAR: N/AExemplo: Configuração da autenticação estendida do portal entre sub-redes
Configuração de rede
Conforme mostrado na Figura 16, o Switch A é compatível com a autenticação de portal. O host acessa o Switch A por meio do Switch B. Um servidor de portal atua como servidor de autenticação de portal e como servidor Web de portal. Um servidor RADIUS atua como servidor de autenticação/contabilidade.
Configure o Switch A para autenticação estendida de portal entre sub-redes. Antes de passar pela autenticação do portal, o host pode acessar apenas o servidor do portal. Depois de passar pela autenticação de identidade do portal, o host aceita a verificação de segurança. Se o host falhar na verificação de segurança, ele poderá acessar apenas a sub-rede 192.168.0.0/24. Depois de passar na verificação de segurança, o host pode acessar outros recursos da rede.
Figura 16 Diagrama de rede
Restrições e diretrizes
Certifique-se de que o endereço IP do dispositivo do portal adicionado no servidor do portal seja o endereço IP (20.20.20.1) da interface do switch que conecta o host. O grupo de endereços IP associado ao dispositivo do portal é a sub-rede do host (8.8.8.0/24).
Pré-requisitos
- Configure os endereços IP para o switch e os servidores, conforme mostrado na Figura 16, e certifique-se de que o host, o switch e os servidores possam se comunicar entre si.
- Configure o servidor RADIUS corretamente para fornecer funções de autenticação e contabilidade.
Procedimento
- Configurar um esquema RADIUS:
# Crie um esquema RADIUS chamado rs1 e entre em sua visualização.
<SwitchA> system-view
[SwitchA] radius scheme rs1# Especifique o servidor de autenticação principal e o servidor de contabilidade principal e configure o chaves para comunicação com os servidores.
[SwitchA-radius-rs1] primary authentication 192.168.0.112
[SwitchA-radius-rs1] primary accounting 192.168.0.112
[SwitchA-radius-rs1] key accounting simple radius
[SwitchA-radius-rs1] key authentication simple radius
[SwitchA-radius-rs1] user-name-format without-domain# Habilite o controle de sessão RADIUS.
[SwitchA] radius session-control enable# Especifique um cliente de controle de sessão com endereço IP 192.168.0.112 e chave compartilhada 12345 em formato de texto simples.
witchA] radius session-control client ip 192.168.0.112 key simple 12345# Crie um domínio ISP chamado dm1 e entre em sua visualização.
[SwitchA] domain dm1# Configurar métodos AAA para o domínio ISP.
[SwitchA-isp-dm1] authentication portal radius-scheme rs1
[SwitchA-isp-dm1] authorization portal radius-scheme rs1
[SwitchA-isp-dm1] accounting portal radius-scheme rs1
[SwitchA-isp-dm1] quit# Configure o domínio dm1 como o domínio padrão do ISP. Se um usuário digitar o nome de usuário sem o nome do domínio ISP no login, os métodos de autenticação e contabilidade do domínio padrão serão usados para o usuário.
[SwitchA] domain default enable dm1[SwitchA] acl advanced 3000
[SwitchA-acl-ipv4-adv-3000] rule permit ip destination 192.168.0.0 0.0.0.255
[SwitchA-acl-ipv4-adv-3000] rule deny ip
[SwitchA-acl-ipv4-adv-3000] quit
[SwitchA] acl advanced 3001
[SwitchA-acl-ipv4-adv-3001] rule permit ip
[SwitchA-acl-ipv4-adv-3001] quitOBSERVAÇÃO:
Certifique-se de especificar a ACL 3000 como a ACL de isolamento e a ACL 3001 como a ACL de segurança no servidor de política de segurança.
# Configure um servidor de autenticação de portal.
[SwitchA] portal server newpt
[SwitchA-portal-server-newpt] ip 192.168.0.111 key simple portal
[SwitchA-portal-server-newpt] port 50100
[SwitchA-portal-server-newpt] quit#Configurar um servidor Web de portal.
[SwitchA] portal web-server newpt
[SwitchA-portal-websvr-newpt] url http://192.168.0.111:8080/portal
[SwitchA-portal-websvr-newpt] quit# Habilite a autenticação de portal entre sub-redes na interface VLAN 4.
[SwitchA] interface vlan-interface 4
[SwitchA–Vlan-interface4] portal enable method layer3# Especifique o newpt do servidor da Web do portal na interface VLAN 4.
[SwitchA–Vlan-interface4] portal apply web-server newpt# Configure o BAS-IP como 20.20.20.1 para pacotes de portal enviados da interface VLAN 4 para o servidor de autenticação de portal.
[SwitchA–Vlan-interface4] portal bas-ip 20.20.20.1
[SwitchA–Vlan-interface4] quitVerificação da configuração
# Verifique se a configuração do portal entrou em vigor.
[SwitchA] display portal interface vlan-interface 4
Portal information of Vlan-interface4
NAS-ID profile : Not configured
Authorization : Strict checking
ACL : Disabled
User profile : Disabled
IPv4:
Portal status: Enabled
Portal authentication method: Layer3
Portal web server: newpt
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ip: 20.20.20.1
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Mask
Destination authenticate subnet:
IP address Mask
IPv6:
Portal status: Disabled
Portal authentication method: Disabled
Portal web server: Not configured
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ip: Not configured
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Prefix length
Destination authenticate subnet:
IP address Prefix lengthAntes de passar pela autenticação do portal, um usuário que usa o cliente Intelbras iNode pode acessar apenas a página de autenticação http://192.168.0.111:8080/portal. Todas as solicitações da Web do usuário serão redirecionadas para a página de autenticação.
- O usuário pode acessar os recursos permitidos pela ACL 3000 depois de passar apenas pela autenticação de identidade.
- O usuário pode acessar os recursos de rede permitidos pela ACL 3001 depois de passar pela autenticação de identidade e pela verificação de segurança.
# Depois que o usuário for aprovado na autenticação de identidade e na verificação de segurança, use o seguinte comando para exibir informações sobre o usuário do portal.
[SwitchA] display portal user interface vlan-interface 4
Total portal users: 1
Username: abc
Portal server: newpt
State: Online
VPN instance: N/A
MAC IP VLAN Interface
0015-e9a6-7cfe 8.8.8.2 4 Vlan-interface4
Authorization information:
DHCP IP pool: N/A
User profile: N/A
Session group profile: N/A
ACL number: 3001 (active)
Inbound CAR: N/A
Outbound CAR: N/AExemplo: Configuração da detecção do servidor do portal e da sincronização do usuário do portal
Configuração de rede
Conforme mostrado na Figura 17, o host está diretamente conectado ao switch (o dispositivo de acesso). O host recebe um endereço IP público manualmente ou por meio de DHCP. Um servidor de portal atua como um servidor de autenticação de portal e um servidor da Web de portal. Um servidor RADIUS atua como servidor de autenticação/contabilidade.
- Configure a autenticação direta do portal no switch, para que o host possa acessar somente o servidor do portal antes de passar pela autenticação e acessar outros recursos da rede depois de passar pela autenticação.
- Configure o switch para detectar o estado de acessibilidade do servidor de autenticação do portal, enviar mensagens de registro quando houver mudanças de estado e desativar a autenticação do portal quando o servidor de autenticação estiver inacessível.
- Configure o switch para sincronizar periodicamente as informações do usuário do portal com o servidor do portal.
Figura 17 Diagrama de rede
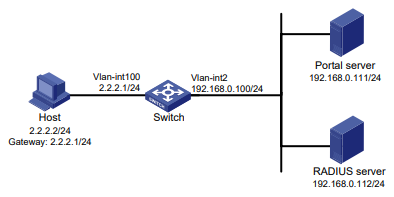
Pré-requisitos
- Configure os endereços IP para o switch e os servidores, conforme mostrado na Figura 17, e certifique-se de que o host, o switch e os servidores possam se comunicar entre si.
- Configure o servidor RADIUS corretamente para fornecer funções de autenticação e contabilidade.
Configuração do servidor de autenticação do portal no IMC PLAT 5.0
Neste exemplo, o servidor do portal é executado no IMC PLAT 5.0(E0101) e no IMC UAM 5.0(E0101).
- Configure o servidor de autenticação do portal:
- Faça login no IMC e clique na guia Service (Serviço).
- Selecione User Access Manager > Portal Service Management > Server na árvore de navegação para abrir a página de configuração do servidor do portal, conforme mostrado na Figura 18.
- Configure o intervalo de heartbeat do servidor do portal e o intervalo de heartbeat do usuário.
- Use as configurações padrão para outros parâmetros.
- Clique em OK.
- Configure o grupo de endereços IP:
- Selecione User Access Manager > Portal Service Management > IP Group na árvore de navegação para abrir a página de configuração do grupo de endereços IP do portal.
- Clique em Add para abrir a página, conforme mostrado na Figura 19.
- Digite o nome do grupo IP.
- Digite o endereço IP inicial e o endereço IP final do grupo de IP. Certifique-se de que o endereço IP do host esteja no grupo de IPs.
- Selecione um grupo de serviços.
- Selecione a ação Normal.
- Clique em OK.
- Adicionar um dispositivo de portal:
- Selecione User Access Manager > Portal Service Management > Device na árvore de navegação para abrir a página de configuração do dispositivo do portal.
- Clique em Add para abrir a página, conforme mostrado na Figura 20.
- Digite o nome do dispositivo NAS.
- Digite o endereço IP da interface do switch conectada ao host.
- Digite a chave, que deve ser a mesma configurada no switch.
- Defina se deseja ativar a realocação de endereços IP.
- Selecione se deseja oferecer suporte às funções de heartbeat do servidor e heartbeat do usuário.
- Clique em OK.
- Associe o dispositivo do portal ao grupo de endereços IP:
- Conforme mostrado na Figura 21, clique no ícone na coluna Port Group Information Management (Gerenciamento de informações do grupo de portas) do dispositivo NAS para abrir a página de configuração do grupo de portas.
- Clique em Add para abrir a página, conforme mostrado na Figura 22.
- Digite o nome do grupo de portas.
- Selecione o grupo de endereços IP configurado.
- Use as configurações padrão para outros parâmetros.
- Clique em OK.
- Selecione User Access Manager > Service Parameters > Validate System Configuration na árvore de navegação para que as configurações entrem em vigor.
Figura 18 Configuração do servidor de autenticação do portal
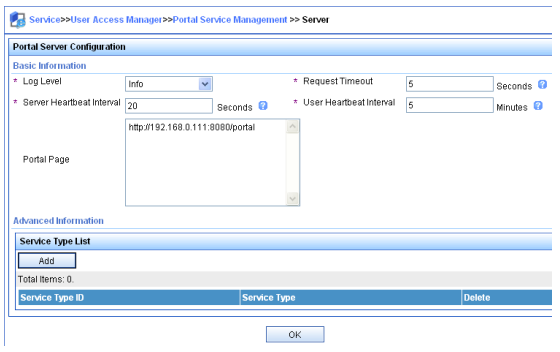
Este exemplo usa o grupo padrão Ungrouped.
Figura 19: Adição de um grupo de endereços IP
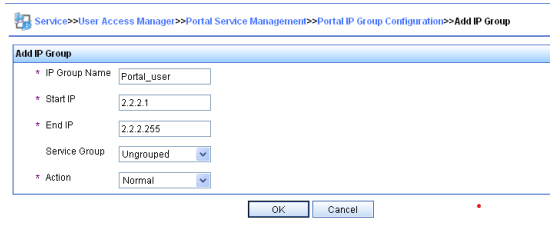
Este exemplo usa a autenticação direta do portal e, portanto, selecione No (Não) na lista Reallocate IP (Realocar IP).
Neste exemplo, selecione Yes para Support Server Heartbeat e Support User Heartbeat.
Figura 20: Adição de um dispositivo de portal
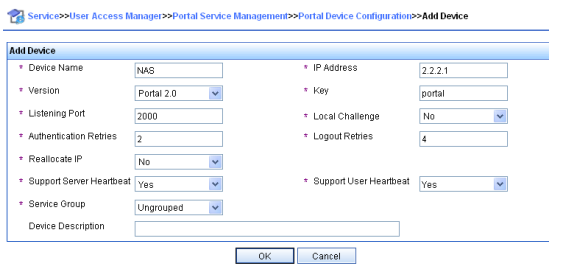
O endereço IP usado pelo usuário para acessar a rede deve estar dentro desse grupo de endereços IP.
Figura 21 Lista de dispositivos

Figura 22: Adição de um grupo de portas
Configuração do switch
- Configurar um esquema RADIUS:
# Crie um esquema RADIUS chamado rs1 e entre em sua visualização.
<Switch> system-view
[Switch] radius scheme rs1# Especifique o servidor de autenticação principal e o servidor de contabilidade principal e configure o chaves para comunicação com os servidores.
[Switch-radius-rs1] primary authentication 192.168.0.112
[Switch-radius-rs1] primary accounting 192.168.0.112
[Switch-radius-rs1] key authentication simple radius
[Switch-radius-rs1] key accounting simple radius# Excluir o nome de domínio do ISP do nome de usuário enviado ao servidor RADIUS.
[Switch-radius-rs1] user-name-format without-domain
[Switch-radius-rs1] quit# Habilite o controle de sessão RADIUS.
[Switch] radius session-control enable# Crie um domínio ISP chamado dm1 e entre em sua visualização.
[Switch] domain dm1# Configurar métodos AAA para o domínio ISP.
[Switch-isp-dm1] authentication portal radius-scheme rs1
[Switch-isp-dm1] authorization portal radius-scheme rs1
[Switch-isp-dm1] accounting portal radius-scheme rs1
[Switch-isp-dm1] quit# Configure o domínio dm1 como o domínio padrão do ISP. Se um usuário digitar o nome de usuário sem o nome do domínio ISP no login, os métodos de autenticação e contabilidade do domínio padrão serão usados para o usuário.
[Switch] domain default enable dm1# Configure um servidor de autenticação de portal.
[Switch] portal server newpt
[Switch-portal-server-newpt] ip 192.168.0.111 key simple portal
[Switch-portal-server-newpt] port 50100# Configure a detecção de acessibilidade do servidor de autenticação do portal: defina o intervalo de detecção do servidor para 40 segundos e envie mensagens de registro quando houver alterações no status de acessibilidade.
[Switch-portal-server-newpt] server-detect timeout 40 logOBSERVAÇÃO:
O valor do tempo limite deve ser maior ou igual ao intervalo de heartbeat do servidor do portal.
# Configure a sincronização do usuário do portal com o servidor de autenticação do portal e defina o intervalo de detecção de sincronização como 600 segundos.
[Switch-portal-server-newpt] user-sync timeout 600
[Switch-portal-server-newpt] quitOBSERVAÇÃO:
O valor do tempo limite deve ser maior ou igual ao intervalo de heartbeat do usuário do portal.
# Configure um servidor da Web do portal.
[Switch] portal web-server newpt
[Switch-portal-websvr-newpt] url http://192.168.0.111:8080/portal
[Switch-portal-websvr-newpt] quit# Habilite a autenticação direta do portal na interface VLAN 100.
[Switch] interface vlan-interface 100
[Switch–Vlan-interface100] portal enable method direct# Habilite o portal fail-permit para o servidor de autenticação de portal newpt.
[Switch–Vlan-interface100] portal fail-permit server newpt# Especifique o servidor Web do portal newpt na interface VLAN 100.
[Switch–Vlan-interface100] portal apply web-server newpt# Configure o BAS-IP como 2.2.2.1 para pacotes de portal enviados da interface VLAN 100 para o servidor de autenticação de portal.
[Switch–Vlan-interface100] portal bas-ip 2.2.2.1
[Switch–Vlan-interface100] quitVerificação da configuração
# Use o comando a seguir para exibir informações sobre o servidor de autenticação do portal.
[Switch] display portal server newpt
Portal server: newpt
Type : IMC
IP : 192.168.0.111
VPN instance : Not configured
Port : 50100
Server Detection : Timeout 40s Action: log
User synchronization : Timeout 600s
Status : UpO status Up do servidor de autenticação de portal indica que o servidor de autenticação de portal pode ser acessado. Se o dispositivo de acesso detectar que o servidor de autenticação do portal não pode ser acessado, o campo Status na saída do comando exibirá Down. O dispositivo de acesso gera um servidor
unreachable log "Portal server newpt turns down from up." e desativa a autenticação do portal na interface de acesso, para que o host possa acessar a rede externa sem autenticação.
Exemplo: Configuração da autenticação direta do portal usando um serviço da Web do portal local
Configuração de rede
Conforme mostrado na Figura 23, o host está diretamente conectado ao switch (o dispositivo de acesso). O host recebe um endereço IP público manualmente ou por meio de DHCP. O switch atua como um servidor de autenticação de portal e um servidor Web de portal. Um servidor RADIUS atua como servidor de autenticação/contabilidade.
Configure a autenticação direta do portal no switch. Antes de um usuário passar pela autenticação do portal, ele pode acessar apenas o servidor Web do portal. Depois de passar pela autenticação do portal, o usuário pode acessar outros recursos da rede.
Figura 23 Diagrama de rede
Pré-requisitos
- Configure os endereços IP do host, do switch e do servidor, conforme mostrado na Figura 23, e certifique-se de que eles possam se comunicar entre si.
- Configure o servidor RADIUS corretamente para fornecer funções de autenticação e contabilidade.
Procedimento
- Configurar um esquema RADIUS:
# Crie um esquema RADIUS chamado rs1 e entre em sua visualização.
<Switch> system-view
[Switch] radius scheme rs1# Especifique o servidor de autenticação principal e o servidor de contabilidade principal e configure as chaves para comunicação com os servidores.
[Switch-radius-rs1] primary authentication 192.168.0.112
[Switch-radius-rs1] primary accounting 192.168.0.112
[Switch-radius-rs1] key authentication simple radius
[Switch-radius-rs1] key accounting simple radius# Excluir o nome de domínio do ISP do nome de usuário enviado ao servidor RADIUS.
[Switch-radius-rs1] user-name-format without-domain
[Switch-radius-rs1] quit# Habilite o controle de sessão RADIUS.
[Switch] radius session-control enable# Crie um domínio ISP chamado dm1 e entre em sua visualização.
[Switch] domain dm1# Configurar métodos AAA para o domínio ISP.
[Switch-isp-dm1] authentication portal radius-scheme rs1
[Switch-isp-dm1] authorization portal radius-scheme rs1
[Switch-isp-dm1] accounting portal radius-scheme rs1
[Switch-isp-dm1] quit# Configure o domínio dm1 como o domínio padrão do ISP. Se um usuário digitar o nome de usuário sem o nome do domínio ISP no login, os métodos de autenticação e contabilidade do domínio padrão serão usados para o usuário.
[Switch] domain default enable dm1# Configure um servidor da Web do portal chamado newpt e especifique http://2.2.2.1:2331/portal como o URL do servidor da Web do portal. O endereço IP no URL deve ser o endereço IP de uma interface de camada 3 acessível aos clientes do portal ou uma interface de loopback (exceto 127.0.0.1) no dispositivo.
[Switch] portal web-server newpt
[Switch-portal-websvr-newpt] url http://2.2.2.1:2331/portal
[Switch-portal-websvr-newpt] quit# Habilite a autenticação direta do portal na interface VLAN 100.
[Switch] interface vlan-interface 100
[Switch–Vlan-interface100] portal enable method direct# Especifica o servidor Web do portal newpt na interface VLAN 100.
[Switch–Vlan-interface100] portal apply web-server newpt
[Switch–Vlan-interface100] quit# Crie um serviço da Web de portal local baseado em HTTP e insira sua visualização.
[Switch] portal local-web-server http# Especifique o arquivo defaultfile.zip como o arquivo de página de autenticação padrão para o serviço da Web do portal local. (Certifique-se de que o arquivo exista no diretório raiz do switch).
[Switch–portal-local-websvr-http] default-logon-page defaultfile.zip# Defina o número da porta de escuta HTTP como 2331 para o serviço Web do portal local.
[Switch–portal-local-webserver-http] tcp-port 2331
[Switch–portal-local-websvr-http] quitVerificação da configuração
# Verificar se a configuração do portal entrou em vigor.
[Switch] display portal interface vlan-interface 100
Portal information of Vlan-interface 100
Authorization Strict checking
ACL Disabled
User profile Disabled
IPv4:
Portal status: Enabled
Portal authentication method: Direct
Portal web server: newpt
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ip: Not configured
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Mask
Destination authenticate subnet:
IP address Mask
IPv6:
Portal status: Disabled
Portal authentication method: Disabled
Portal web server: Not configured
Secondary portal Web server: Not configured
Portal mac-trigger-server: Not configured
Authentication domain: Not configured
User-dhcp-only: Disabled
Pre-auth IP pool: Not configured
Max Portal users: Not configured
Bas-ipv6: Not configured
User detection: Not configured
Action for server detection:
Server type Server name Action
-- -- --
Layer3 source network:
IP address Prefix length
Destination authenticate subnet:
IP address Prefix lengthUm usuário pode realizar a autenticação do portal por meio de uma página da Web. Antes de passar pela autenticação, o usuário pode acessar somente a página de autenticação http://2.2.2.1:2331/portal e todas as solicitações da Web serão redirecionadas para a página de autenticação. Depois de passar pela autenticação, o usuário pode acessar outros recursos da rede.
# Depois que o usuário passar pela autenticação, use o seguinte comando para exibir informações sobre o usuário do portal.
[Switch] display portal user interface vlan-interface 100
Total portal users: 1
Username: abc
Portal server: newpt
State: Online
VPN instance: N/A
MAC IP VLAN Interface
0015-e9a6-7cfe 2.2.2.2 100 Vlan-interface100
Authorization information:
DHCP IP pool: N/A
User profile: N/A
Session group profile: N/A
ACL number: N/A
Inbound CAR: N/A
Outbound CAR: N/APortal de solução de problemas
Nenhuma página de autenticação do portal é enviada para os usuários
Sintoma
Quando um usuário é redirecionado para o servidor de autenticação do portal IMC, nenhuma página de autenticação do portal ou mensagem de erro é solicitada ao usuário. A página de login está em branco.
Análise
A chave configurada no dispositivo de acesso ao portal e a configurada no servidor de autenticação do portal são inconsistentes. Como resultado, a verificação do pacote falha e o servidor de autenticação do portal se recusa a enviar a página de autenticação.
Solução
Use o comando display this na visualização do servidor de autenticação do portal no dispositivo de acesso para verificar se uma chave está configurada para o servidor de autenticação do portal.
- Se nenhuma chave estiver configurada, configure a chave correta.
- Se uma chave estiver configurada, use o comando ip ou ipv6 na visualização do servidor de autenticação do portal para corrigir a chave ou corrija a chave configurada para o dispositivo de acesso no servidor de autenticação do portal .
Não é possível fazer logout de usuários do portal no dispositivo de acesso
Sintoma
Não é possível usar o comando portal delete-user no dispositivo de acesso para fazer logout de um usuário do portal, mas o usuário do portal pode fazer logout clicando no botão Disconnect (Desconectar) no cliente de autenticação do portal.
Análise
Quando você executa o comando portal delete-user no dispositivo de acesso para fazer logout de um usuário, o dispositivo de acesso envia uma mensagem de notificação de logout não solicitada para o servidor de autenticação do portal. O número da porta de destino na notificação de logout é o número da porta de escuta do servidor de autenticação do portal configurado no dispositivo de acesso. Se esse número de porta de escuta não for o número de porta de escuta real configurado no servidor, o servidor não poderá receber a notificação. Como resultado, o servidor não fará o logout do usuário.
Quando um usuário usa o botão Desconectar no cliente de autenticação para fazer logout, o servidor de autenticação do portal envia uma mensagem de solicitação de logout não solicitada para o dispositivo de acesso. O dispositivo de acesso usa a porta de origem na solicitação de logout como a porta de destino na mensagem ACK de logout. Como resultado, o servidor de autenticação do portal pode definitivamente receber a mensagem ACK de logout e fazer o logout do usuário.
Solução
- Use o comando display portal server para exibir a porta de escuta do servidor de autenticação do portal configurado no dispositivo de acesso.
- Use o comando portal server na visualização do sistema para alterar o número da porta de escuta para a porta de escuta real do servidor de autenticação do portal.
Não é possível fazer logout de usuários do portal no servidor RADIUS
Sintoma
O dispositivo de acesso usa o servidor Intelbras IMC como servidor RADIUS para realizar a autenticação de identidade dos usuários do portal. Não é possível fazer logout dos usuários do portal no servidor RADIUS.
Análise
O servidor Intelbras IMC usa pacotes de controle de sessão para enviar solicitações de desconexão ao dispositivo de acesso. No dispositivo de acesso, a porta UDP de escuta para pacotes de controle de sessão está desativada por padrão. Portanto, o dispositivo de acesso não pode receber as solicitações de logout do usuário do portal do servidor RADIUS.
Solução
No dispositivo de acesso, execute o comando radius session-control enable no sistema view para habilitar a função de controle de sessão RADIUS.
Os usuários desconectados pelo dispositivo de acesso ainda existem no servidor de autenticação do portal
Sintoma
Após o logout de um usuário do portal no dispositivo de acesso, o usuário ainda existe no servidor de autenticação do portal .
Análise
Quando você executa o comando portal delete-user no dispositivo de acesso para fazer logout de um usuário, o dispositivo de acesso envia uma notificação de logout não solicitada para o servidor de autenticação do portal. Se o endereço BAS-IP ou BAS-IPv6 contido na notificação de logout for diferente do endereço IP do dispositivo do portal especificado no servidor de autenticação do portal, o servidor de autenticação do portal descartará a notificação de logout. Quando o envio das notificações de logout se esgota, o dispositivo de acesso faz o logout do usuário. No entanto, o servidor de autenticação do portal não recebe a notificação de logout com êxito, e, portanto, considera que o usuário ainda está on-line.
Solução
Configure o atributo BAS-IP ou BAS-IPv6 na interface ativada com a autenticação do portal. Certifique-se de que o valor do atributo seja o mesmo do endereço IP do dispositivo do portal especificado no servidor de autenticação do portal.
Os usuários autenticados no portal Re-DHCP não conseguem fazer login com êxito
Sintoma
O dispositivo executa a autenticação do portal re-DHCP para os usuários. Um usuário digita o nome de usuário e a senha corretos, e o cliente obtém com êxito os endereços IP privados e públicos. No entanto, o resultado da autenticação para o usuário é uma falha.
Análise
Quando o dispositivo de acesso detecta que o endereço IP do cliente foi alterado, ele envia um pacote de portal não solicitado para notificar a alteração de IP ao servidor de autenticação do portal. O servidor de autenticação do portal notifica o sucesso da autenticação somente depois de receber a notificação de alteração de IP do dispositivo de acesso e do cliente.
Se o endereço BAS-IP ou BAS-IPv6 contido no pacote de notificação do portal for diferente do endereço IP do dispositivo do portal especificado no servidor de autenticação do portal, o servidor de autenticação do portal descartará o pacote de notificação do portal. Como resultado, o servidor de autenticação do portal considera que o usuário falhou na autenticação.
Solução
Configure o atributo BAS-IP ou BAS-IPv6 na interface ativada com a autenticação do portal. Certifique-se de que o valor do atributo seja o mesmo do endereço IP do dispositivo do portal especificado no servidor de autenticação do portal.
Configuração da autenticação da Web
Sobre a autenticação na Web
A autenticação da Web é implementada nas interfaces Ethernet de camada 2 do dispositivo de acesso para controlar o acesso do usuário às redes. O dispositivo de acesso redireciona os usuários não autenticados para o site especificado. Os usuários podem acessar os recursos do site sem autenticação. Se os usuários quiserem acessar outros recursos da rede, eles deverão passar pela autenticação.
Vantagens da autenticação na Web
A autenticação na Web tem as seguintes vantagens:
- Permite que os usuários realizem a autenticação por meio de páginas da Web sem instalar software cliente.
- Oferece aos ISPs opções de gerenciamento diversificadas e funções ampliadas. Por exemplo, os ISPs podem colocar anúncios, fornecer serviços comunitários e publicar informações na página de autenticação.
Sistema de autenticação da Web
Um sistema típico de autenticação na Web consiste em quatro componentes básicos: cliente de autenticação, dispositivo de acesso, servidor da Web do portal local e servidor AAA.
Figura 1 Sistema de autenticação na Web usando o servidor de portal local
Cliente de autenticação
Um cliente de autenticação é um navegador da Web que executa HTTP ou HTTPS.
Dispositivo de acesso
Um dispositivo de acesso tem as seguintes funções:
- Redireciona todas as solicitações HTTP ou HTTPS do usuário que não correspondem às regras sem autenticação para a página de autenticação da Web antes da autenticação.
- Interage com o servidor AAA para concluir a autenticação, a autorização e a contabilidade. Para obter mais informações sobre o AAA, consulte "Configuração do AAA".
- Permite que os usuários aprovados na autenticação acessem recursos de rede autorizados.
Portal local Servidor da Web
O dispositivo de acesso atua como o servidor da Web do portal local. O servidor da Web do portal local envia a página de autenticação da Web para os clientes de autenticação e obtém as informações de autenticação do usuário (nome de usuário e senha).
Servidor AAA
Um servidor AAA interage com o dispositivo de acesso para implementar a autenticação, a autorização e a contabilidade do usuário. Um servidor RADIUS pode executar autenticação, autorização e contabilidade para usuários de autenticação na Web. Um servidor LDAP pode executar a autenticação para usuários de autenticação da Web.
Processo de autenticação na Web
Figura 2 Processo de autenticação na Web
O processo de autenticação na Web é o seguinte:
- Um usuário não autenticado envia uma solicitação HTTP ou HTTPS. Quando o dispositivo de acesso recebe a solicitação HTTP ou HTTPS em uma interface Ethernet de camada 2 habilitada com autenticação da Web, ele redireciona a solicitação para a página de autenticação da Web. O usuário digita o nome de usuário e a senha na página de autenticação da Web.
- O dispositivo de acesso e o servidor AAA trocam pacotes RADIUS para autenticar o usuário.
- Se o usuário for aprovado na autenticação RADIUS, o servidor da Web do portal local enviará uma página de sucesso de login para o cliente de autenticação.
Se o usuário solicitar a página de autenticação da Web ou recursos gratuitos da Web, o dispositivo de acesso permitirá a solicitação. Nenhuma autenticação na Web é executada.
Se o usuário falhar na autenticação RADIUS, o servidor da Web do portal local enviará uma página de falha de login para o cliente de autenticação.
Suporte à autenticação da Web para atribuição de VLAN
VLAN de autorização
A autenticação na Web usa VLANs autorizadas pelo servidor AAA ou pelo dispositivo de acesso para controlar o acesso a recursos de rede de usuários autenticados.
Depois que um usuário passa pela autenticação da Web, o servidor AAA ou o dispositivo de acesso autoriza o usuário a acessar uma VLAN. Se a VLAN de autorização não existir, o dispositivo de acesso primeiro criará a VLAN e, em seguida, atribuirá a interface de acesso do usuário como um membro sem marcação à VLAN. Se a VLAN de autorização já existir, o dispositivo de acesso atribuirá diretamente a interface de acesso do usuário como um membro sem marcação à VLAN. Em seguida, o usuário pode acessar os recursos na VLAN de autorização.
A Tabela 1 descreve a maneira como o dispositivo de acesso lida com as VLANs de autorização para usuários autenticados na Web .
Tabela 1 Manipulação de VLAN
| Tipo de porta | Manipulação de VLAN |
|
O dispositivo atribui a porta à VLAN de autorização do primeiro usuário autenticado. A VLAN de autorização torna-se o PVID. Todos os usuários de autenticação da Web na porta devem receber a mesma VLAN de autorização. Se uma VLAN de autorização diferente for atribuída a um usuário subsequente, o usuário não poderá passar na autenticação da Web. |
| Porta híbrida com VLAN baseada em MAC ativada | O dispositivo mapeia o endereço MAC de cada usuário para sua própria VLAN de autorização, independentemente de a porta ser um membro marcado. O PVID da porta não é alterado. |
Auth-Fail VLAN
Uma VLAN de falha de autenticação é uma VLAN atribuída a usuários que falham na autenticação. A VLAN Auth-Fail fornece aos usuários recursos de rede, como o servidor de patches, o servidor de definições de vírus, o servidor de software cliente e o servidor de software antivírus. Os usuários podem usar esses recursos para atualizar seu software cliente ou outros programas.
A autenticação da Web oferece suporte à VLAN Auth-Fail em uma interface que executa o controle de acesso baseado em MAC. Se um usuário na interface falhar na autenticação, os dispositivos de acesso criarão uma entrada de VLAN MAC com base no endereço MAC do usuário e adicionarão o usuário à VLAN Auth-Fail. Em seguida, o usuário pode acessar os recursos de IP sem portal na VLAN Auth-Fail. Todas as solicitações HTTP ou HTTPS para recursos IP sem portal serão redirecionadas para a página de autenticação. Se o usuário ainda falhar na autenticação, a interface permanecerá na VLAN Auth-Fail. Se o usuário for aprovado na autenticação, o dispositivo de acesso removerá a interface da VLAN Auth-Fail e atribuirá a interface a uma VLAN da seguinte forma:
- Se o servidor de autenticação atribuir uma VLAN de autorização ao usuário, o dispositivo de acesso atribuirá a interface à VLAN de autorização.
- Se o servidor de autenticação não atribuir uma VLAN de autorização ao usuário, o dispositivo de acesso atribuirá a interface à VLAN padrão.
Suporte à autenticação da Web para ACLs de autorização
A autenticação na Web usa ACLs autorizadas pelo servidor AAA ou pelo dispositivo de acesso para controlar o acesso do usuário aos recursos da rede e limitar os direitos de acesso do usuário. Quando um usuário passa na autenticação, o servidor AAA e o dispositivo de acesso atribuem uma ACL de autorização à interface de acesso do usuário. O dispositivo de acesso filtra o tráfego do usuário na interface de acesso de acordo com a ACL autorizada.
Você deve configurar as ACLs de autorização no dispositivo de acesso se especificar ACLs de autorização no servidor de autenticação.
Para alterar os critérios de controle de acesso do usuário, é possível especificar uma ACL de autorização diferente no servidor de autenticação ou alterar as regras na ACL de autorização no dispositivo de acesso.
O dispositivo é compatível com os seguintes tipos de ACLs de autorização:
- ACLs básicas (ACL 2000 a ACL 2999).
- ACLs avançadas (ACL 3000 a ACL 3999).
- ACLs de camada 2 (ACL 4000 a ACL 4999).
Para que uma ACL de autorização tenha efeito, certifique-se de que a ACL exista e tenha regras de ACL, excluindo as regras configuradas com a palavra-chave counting, established, fragment, source-mac ou logging. Para obter mais informações sobre regras de ACL, consulte Comandos de ACL em Referência de comandos de ACL e QoS.
Restrições e diretrizes: Configuração da autenticação da Web
Para redirecionar corretamente as solicitações de HTTPS para usuários não autenticados, certifique-se de que as VLANs de entrada de pacotes tenham interfaces de camada 3 (interfaces de VLAN) configuradas.
Para acessar os recursos na VLAN de autorização ou de falha de autenticação, um usuário deve atualizar o endereço IP do cliente após ser atribuído à VLAN de autorização ou de falha de autenticação.
Como prática recomendada, execute a autenticação da Web em usuários diretamente conectados ao dispositivo. Conforme mostrado na Figura 3, se você ativar a autenticação da Web na Porta B para autenticar usuários não conectados diretamente (os hosts), deverá seguir estas restrições e diretrizes:
- Se o servidor RADIUS atribuir uma VLAN de autorização aos usuários, verifique se as seguintes condições foram atendidas:
- O link entre o Dispositivo A e o Dispositivo B é um link de tronco.
- Os PVIDs da Porta A1 e da Porta B são os mesmos da VLAN ID de autorização.
- Se o servidor RADIUS não atribuir uma VLAN de autorização aos usuários, verifique se os PVIDs da Porta A1 e da Porta B são os mesmos.
Figura 3 Autenticação na Web para usuários não conectados diretamente
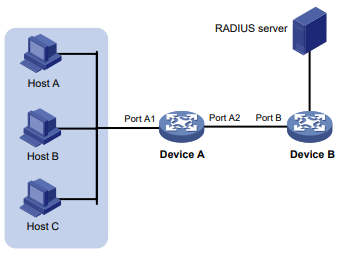
Visão geral das tarefas de autenticação na Web
Para configurar a autenticação da Web, execute as seguintes tarefas:
- Configuração de um servidor de autenticação da Web
- Configuração de um serviço de portal local
- Ativação da autenticação da Web
- (Opcional.) Especificação de um domínio de autenticação da Web
- (Opcional.) Configuração do tempo de espera do redirecionamento
- (Opcional.) Configuração do cronômetro de envelhecimento para entradas temporárias de endereço MAC para autenticação na Web
- (Opcional.) Configuração de uma sub-rede sem autenticação da Web
- (Opcional.) Definição do número máximo de usuários de autenticação da Web
- (Opcional.) Configuração da detecção de usuário de autenticação da Web on-line
- (Opcional.) Configuração de uma VLAN de falha de autenticação
- (Opcional.) Configuração da autenticação da Web para oferecer suporte ao proxy da Web
Pré-requisitos para autenticação na Web
O dispositivo oferece suporte a dois métodos de autenticação na Web, que são a autenticação local e a autenticação RADIUS.
Para usar o método de autenticação RADIUS, você deve concluir as seguintes tarefas:
- Instale um servidor RADIUS e configure-o adequadamente.
- Certifique-se de que o cliente de autenticação, o dispositivo de acesso e o servidor RADIUS possam se comunicar entre si.
- Configure as contas de usuário no servidor RADIUS e configure as informações do cliente RADIUS no dispositivo de acesso.
Para usar o método de autenticação local, é necessário configurar os usuários locais no dispositivo de acesso. Para obter mais informações sobre clientes RADIUS e usuários locais, consulte "Configuração de AAA".
Configuração de um servidor de autenticação da Web
Restrições e diretrizes
Especifique o endereço IP de uma interface de Camada 3 no dispositivo que possa ser roteada para o cliente Web como o endereço IP de escuta do servidor de autenticação da Web. Como prática recomendada, use o endereço IP de uma interface de loopback em vez do endereço IP de uma interface de Camada 3. Uma interface de loopback tem as seguintes vantagens:
- O status de uma interface de loopback é estável. Não haverá falhas de acesso à página de autenticação causadas por falhas na interface.
- Uma interface de loopback não encaminha os pacotes recebidos para nenhuma rede, evitando o impacto no desempenho do sistema quando há muitas solicitações de acesso à rede.
Procedimento
- Entre na visualização do sistema.
system viewweb-auth server server-nameip ipv4-address port port-numberO número da porta do servidor de autenticação da Web deve ser o mesmo da porta de escuta do serviço da Web do portal local .
url url-stringO endereço IP e o número da porta no URL de redirecionamento especificado devem ser iguais aos do servidor de autenticação da Web.
url-parameter parameter-name { original-url | source-address | source-mac | value expression }Por padrão, nenhum parâmetro é adicionado ao URL de redirecionamento de um servidor de autenticação da Web.
Configuração de um serviço de portal local
Para obter informações sobre a configuração do serviço de portal local, consulte "Configuração da autenticação do portal".
Ativação da autenticação da Web
Restrições e diretrizes
Para que a autenticação da Web funcione corretamente, não ative a segurança da porta nem configure o modo de segurança da porta na interface Ethernet de camada 2 ativada com a autenticação da Web. Para obter mais informações sobre a segurança da porta, consulte "Configuração da segurança da porta".
Para redirecionar os pacotes HTTPS dos usuários de autenticação da Web, verifique se o número da porta de escuta de redirecionamento de HTTPS especificado (o padrão é 6654) está disponível. Para obter mais informações sobre como alterar
o número da porta de escuta do redirecionamento de HTTPS, consulte Configuração do redirecionamento de HTTPS no Guia de configuração de serviços da camada 3IP.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberweb-auth enable apply server server-namePor padrão, a autenticação da Web está desativada.
Especificação de um domínio de autenticação da Web
Sobre o domínio de autenticação da Web
É possível especificar diferentes domínios de autenticação para usuários de autenticação da Web em diferentes interfaces. Depois de especificar um domínio de autenticação da Web em uma interface, o dispositivo usa o domínio de autenticação para AAA de todos os usuários de autenticação da Web na interface, ignorando os nomes de domínio contidos nos nomes de usuário.
O dispositivo seleciona o domínio de autenticação para um usuário de autenticação da Web em uma interface nesta ordem:
- O domínio de autenticação especificado para a interface.
- O domínio de autenticação contido no nome de usuário.
- O domínio de autenticação padrão do sistema.
- O domínio do ISP configurado para acomodar usuários atribuídos a domínios inexistentes.
Se o domínio selecionado não existir no dispositivo, a autenticação do usuário falhará. Para obter informações sobre domínios ISP, consulte "Configuração de AAA".
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberweb-auth domain domain-namePor padrão, nenhum domínio de autenticação é especificado para usuários de autenticação da Web.
Configuração do tempo de espera do redirecionamento
Sobre o tempo de espera do redirecionamento
O tempo de espera de redirecionamento determina o período de tempo que o dispositivo espera para redirecionar um usuário para a página da Web especificada depois que o usuário passa pela autenticação na Web.
É necessário alterar o tempo de espera do redirecionamento em alguns cenários, por exemplo, quando um usuário precisa atualizar o endereço IP do cliente depois de passar pela autenticação na Web. Para garantir que a página da Web especificada possa ser aberta com êxito, defina o tempo de espera de redirecionamento como sendo maior do que o tempo que o usuário leva para atualizar o endereço IP do cliente.
Procedimento
- Entre na visualização do sistema.
system viewweb-auth server server-nameredirect-wait-time periodPor padrão, o tempo de espera do redirecionamento para usuários autenticados é de 5 segundos.
Configuração do temporizador de envelhecimento para entradas temporárias de endereço MAC para autenticação na Web
Sobre o cronômetro de envelhecimento
Se a autenticação na Web estiver ativada, o dispositivo gerará uma entrada temporária de endereço MAC quando detectar o tráfego de um usuário pela primeira vez. A entrada registra o endereço MAC, a interface de acesso e a ID da VLAN do usuário, bem como o tempo de envelhecimento da entrada.
O cronômetro de envelhecimento funciona da seguinte forma:
- Se o usuário não iniciar a autenticação quando o timer de envelhecimento expirar, o dispositivo excluirá a entrada temporária.
- Se o usuário for aprovado na autenticação antes que o timer de envelhecimento expire, o dispositivo excluirá o timer de envelhecimento e registrará as informações on-line do usuário de autenticação da Web.
- Se o usuário falhar na autenticação antes que o timer de envelhecimento expire e uma VLAN de falha de autenticação for especificada para a autenticação da Web, o dispositivo associará o endereço MAC do usuário à
VLAN Auth-Fail e redefinir o cronômetro de envelhecimento. Se o usuário ainda falhar na autenticação quando o temporizador de envelhecimento expirar, o dispositivo excluirá a entrada temporária do usuário.
Compatibilidade de recursos e versões de software
Esse recurso é compatível apenas com a versão 6343P08 e posteriores.
Restrições e diretrizes
Como prática recomendada, altere o cronômetro de envelhecimento para um valor maior nos seguintes casos:
- Os usuários de autenticação da Web sem direitos de acesso enviam tráfego com frequência em um curto espaço de tempo. Como resultado, o dispositivo de acesso inicia continuamente o processo de autenticação na Web, aumentando a carga no dispositivo.
- Quando um usuário falha na autenticação, ele não tem tempo suficiente para obter recursos da VLAN Auth-Fail, por exemplo, ele não conseguiu fazer o download dos patches de vírus.
Procedimento
- Entre na visualização do sistema.
system viewweb-auth timer temp-entry-aging aging-time-valuePor padrão, o cronômetro de envelhecimento para entradas temporárias de endereço MAC é de 60 segundos.
Configuração de uma sub-rede sem autenticação da Web
Sobre sub-redes sem autenticação da Web
É possível configurar uma sub-rede sem autenticação da Web para que os usuários possam acessar livremente os recursos da rede na sub-rede sem serem autenticados.
Restrições e diretrizes
Como prática recomendada, não configure o mesmo valor de endereço para uma sub-rede livre de autenticação da Web e um IP livre de 802.1X. Caso contrário, quando você cancelar uma das configurações, a outra configuração também não terá efeito.
Procedimento
- Entre na visualização do sistema.
system viewweb-auth free-ip ip-address { mask-length | mask }Definição do número máximo de usuários de autenticação da Web
Restrições e diretrizes
Se o número máximo de usuários de autenticação on-line na Web definido for menor do que o número de usuários atuais de autenticação on-line na Web, o limite poderá ser definido com êxito e não afetará os usuários de autenticação on-line na Web. No entanto, o sistema não permite que novos usuários de autenticação na Web façam login até que o número caia abaixo do limite.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberweb-auth max-user max-numberPor padrão, o número máximo de usuários de autenticação da Web é 1024.
Configuração da detecção de usuário de autenticação on-line na Web
Sobre a detecção de usuário de autenticação on-line na Web
Esse recurso permite que o dispositivo detecte pacotes de um usuário on-line no intervalo de detecção especificado. Se nenhum pacote do usuário for recebido dentro do intervalo, o dispositivo fará o logout do usuário e notificará o servidor RADIUS para interromper a contabilização do usuário.
Restrições e diretrizes
Para evitar que o dispositivo faça o logout de usuários por engano, defina o intervalo de detecção como sendo o mesmo que o tempo de envelhecimento das entradas de endereço MAC.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberweb-auth offline-detect interval intervalPor padrão, a detecção de usuários com autenticação on-line na Web está desativada.
Configuração de uma VLAN de falha de autenticação
Restrições e diretrizes
Para que a VLAN Auth-Fail tenha efeito, você também deve ativar a VLAN baseada em MAC na interface e definir a sub-rede da VLAN Auth-Fail como a sub-rede livre de autenticação da Web.
Como a VLAN baseada em MAC entra em vigor somente nas portas híbridas, a VLAN Auth-Fail também entra em vigor somente nas portas híbridas.
Não exclua a VLAN que foi configurada como uma VLAN de falha de autenticação. Para excluir essa VLAN, primeiro cancele a configuração da VLAN de falha de autenticação usando o comando undo web-auth auth-fail vlan.
Procedimento
- Entre na visualização do sistema.
system viewinterface interface-type interface-numberweb-auth auth-fail vlan authfail-vlan-idPor padrão, nenhuma VLAN Auth-Fail é configurada em uma interface.
Configuração da autenticação da Web para oferecer suporte ao proxy da Web
Sobre o suporte do proxy da Web para autenticação na Web
Por padrão, as solicitações HTTP com proxy não podem acionar a autenticação na Web, mas são silenciosamente descartadas. Para permitir que essas solicitações HTTP acionem a autenticação na Web, especifique os números das portas dos servidores proxy da Web no dispositivo.
Restrições e diretrizes
Se o navegador de um usuário usar o protocolo WPAD (Web Proxy Auto-Discovery) para descobrir servidores proxy da Web, você deverá executar as seguintes tarefas:
- Adicione os números de porta dos servidores proxy da Web no dispositivo.
- Configure regras sem autenticação para permitir que os pacotes de usuários destinados ao endereço IP do servidor WPAD passem sem autenticação.
- Você deve adicionar os números de porta dos servidores proxy da Web no dispositivo.
- Os usuários devem certificar-se de que seus navegadores que usam um servidor proxy da Web não usem o servidor proxy para o endereço IP de escuta do servidor da Web do portal local. Assim, os pacotes HTTP que o usuário da autenticação da Web envia para o servidor da Web do portal local não são enviados para o servidor proxy da Web.
Para que a autenticação da Web seja compatível com o proxy da Web:
Procedimento
- Entre na visualização do sistema.
system viewweb-auth proxy port port-numberVocê pode executar esse comando várias vezes para especificar vários números de porta de servidores proxy da Web.
Comandos de exibição e manutenção para autenticação na Web
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações de configuração de autenticação da Web nas interfaces. | display web-auth [ interface interface-type interface-number ] |
| Exibir sub-redes sem autenticação da Web. | display web-auth free-ip |
| Exibir informações do servidor de autenticação da Web. | display web-auth server [ server-name ] |
| Exibir informações do usuário de autenticação da Web. | display web-auth user [ interface interface-type interface-number | slot slot-number ] |
Exemplos de configuração de autenticação da Web
Exemplo: Configuração da autenticação da Web usando o método de autenticação local
Configuração de rede
Conforme mostrado na Figura 4, o host está diretamente conectado ao dispositivo por meio da GigabitEthernet 1/0/1.
Configure a autenticação da Web na GigabitEthernet 1/0/1 e use autenticação e autorização locais para os usuários.
Configure o dispositivo para enviar páginas personalizadas de autenticação da Web aos usuários e usar HTTP para transferir os dados de autenticação.
Figura 4 Diagrama de rede
Procedimento
- Personalize as páginas de autenticação, compacte-as em um arquivo e carregue o arquivo no diretório raiz da mídia de armazenamento do dispositivo. Neste exemplo, o arquivo é abc.zip. (Detalhes não mostrados).
- Atribua endereços IP ao host e ao dispositivo, conforme mostrado na Figura 4, e certifique-se de que o host e o dispositivo possam se comunicar.
- Configure um usuário local:
# Crie um usuário de acesso à rede local chamado localuser.
<Dispositivo>system-view
[Device] local-user localuser class network# Defina a senha como localpass em formato de texto simples para o usuário localuser. [Device-luser-network-localuser] password simple localpass
[Device-luser-network-localuser] password simple localpass# Autorize o usuário a usar os serviços de acesso à LAN.
[Device-luser-network-localuser] service-type lan-access
[Device-luser-network-localuser] quit# Crie um domínio ISP chamado local.
[Device] domain local# Configure o domínio ISP para executar autenticação, autorização e contabilidade locais para usuários de acesso à LAN.
[Device-isp-local] authentication lan-access local
[Device-isp-local] authorization lan-access local
[Device-isp-local] accounting lan-access local
[Device-isp-local] quit# Crie um serviço da Web de portal local baseado em HTTP e insira sua visualização.
[Device] portal local-web-server http# Especifique o arquivo abc.zip como o arquivo de página de autenticação padrão para o serviço da Web do portal local. (Esse arquivo deve existir no diretório raiz do dispositivo).
[Device-portal-local-websvr-http] default-logon-page abc.zip# Especifique o número da porta de escuta HTTP como 80 para o serviço da Web do portal.
[Device–portal-local-websvr-http] tcp-port 80
[Device-portal-local-websvr-http] quit# Crie um servidor de autenticação da Web chamado usuário.
[Device] web-auth server user# Configure o URL de redirecionamento para o servidor de autenticação da Web como http://20.20.0.1/portal/.
[Device-web-auth-server-user] url http://20.20.0.1/portal/# Especifique 20.20.0.1 como o endereço IP e 80 como o número da porta do servidor de autenticação da Web.
[Device-web-auth-server-user] ip 20.20.0.1 port 80
[Device-web-auth-server-user] quit# Especifique o domínio local do ISP como o domínio de autenticação da Web.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] web-auth domain local# Habilite a autenticação da Web usando o usuário do servidor de autenticação da Web.
[Device-GigabitEthernet1/0/1] web-auth enable apply server user
[Device-GigabitEthernet1/0/1] quitVerificação da configuração
# Exibir informações de usuário de autenticação on-line da Web depois que o usuário localuser for aprovado na autenticação da Web.
<Device> display web-auth user
Total online web-auth users: 1
User Name: localuser
MAC address: acf1-df6c-f9ad
Access interface: GigabitEthernet1/0/1
Initial VLAN: 100
Authorization VLAN: N/A
Authorization ACL ID: N/A
Authorization user profile: N/AExemplo: Configuração da autenticação na Web usando o método de autenticação RADIUS
Configuração de rede
Conforme mostrado na Figura 5, o host está diretamente conectado ao dispositivo por meio da GigabitEthernet 1/0/1.
Configure a autenticação da Web na GigabitEthernet 1/0/1 e use um servidor RADIUS para realizar a autenticação e a autorização dos usuários.
Configure o dispositivo para enviar páginas personalizadas de autenticação da Web aos usuários e usar HTTP para transferir os dados de autenticação.
Figura 5 Diagrama de rede
Procedimento
- Configure o servidor RADIUS adequadamente para fornecer funções de autenticação e contabilidade para os usuários. Neste exemplo, o nome de usuário é configurado como user1 no servidor RADIUS. (Detalhes não mostrados.)
- Personalize as páginas de autenticação, compacte-as em um arquivo e carregue o arquivo no diretório raiz da mídia de armazenamento do switch. Neste exemplo, o arquivo é abc.zip.
- Crie VLANs, atribua endereços IP às interfaces de VLAN e atribua interfaces às VLANs. Certifique-se de que o host, o servidor RADIUS e o dispositivo possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar um esquema RADIUS:
# Crie um esquema RADIUS chamado rs1.
<Device> system-view
[Device] radius scheme rs1# Especifique o servidor de autenticação principal e o servidor de contabilidade principal e configure o chaves para comunicação com os servidores.
[Device-radius-rs1] primary authentication 192.168.0.112
[Device-radius-rs1] primary accounting 192.168.0.112
[Device-radius-rs1] key authentication simple radius
[Device-radius-rs1] key accounting simple radius# Excluir o nome de domínio do ISP do nome de usuário enviado ao servidor RADIUS.
[Device-radius-rs1] user-name-format without-domain
[Device-radius-rs1] quit# Crie um domínio ISP chamado dm1.
[Device] domain dm1# Configurar métodos AAA para o domínio ISP
[Device-isp-dm1] authentication lan-access radius-scheme rs1
[Device-isp-dm1] authorization lan-access radius-scheme rs1
[Device-isp-dm1] accounting lan-access radius-scheme rs1
[Device-isp-dm1] quit# Criar um serviço da Web de portal local baseado em HTTP.
[Device] portal local-web-server http# Especifique o arquivo abc.zip como o arquivo de página de autenticação padrão para o serviço da Web do portal local. (Esse arquivo deve existir diretamente no diretório raiz da mídia de armazenamento).
[Device-portal-local-websvr-http] default-logon-page abc.zip# Especifique 80 como o número da porta ouvida pelo serviço da Web do portal local.
[Device–portal-local-websvr-http] tcp-port 80
[Device-portal-local-websvr-http] quit# Crie um servidor de autenticação da Web chamado usuário.
[Device] web-auth server user# Especifique http://20.20.0.1/portal/ como o URL de redirecionamento para o servidor de autenticação da Web.
[Device-web-auth-server-user] url http://20.20.0.1/portal/# Especifique o endereço IP do servidor de autenticação da Web como 20.20.0.1 (o endereço IP do Loopback 0) e o número da porta como 80.
[Device-web-auth-server-user] ip 20.20.0.1 port 80
[Device-web-auth-server-user] quit# Especifique o domínio dml como o domínio de autenticação da Web.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] web-auth domain dm1# Habilite a autenticação da Web usando o usuário do servidor de autenticação da Web.
[Device-GigabitEthernet1/0/1] web-auth enable apply server user
[Device-GigabitEthernet1/0/1] quitVerificação da configuração
# Exibir informações do usuário de autenticação da Web depois que o usuário user1 for aprovado na autenticação da Web.
<Device> display web-auth user
Total online web-auth users: 1
User Name: user1
MAC address: acf1-df6c-f9ad
Access interface: GigabitEthernet1/0/1
Initial VLAN: 100
Authorization VLAN: N/A
Authorization ACL ID: N/A
Authorization user profile: N/ASolução de problemas de autenticação da Web
Falha ao ficar on-line (interface de autenticação local usando o domínio padrão do ISP)
Sintoma
Nenhum domínio de autenticação foi especificado para a interface de autenticação local. Um usuário não consegue passar na autenticação da Web para ficar on-line.
Análise
Se nenhum domínio de autenticação da Web for especificado, o domínio ISP padrão do sistema (sistema de domínio) será usado para autenticação da Web. O domínio padrão do sistema usa o método de autenticação local por
padrão. Usando essas configurações de domínio padrão, a autenticação local deve ter funcionado corretamente.
A falha na autenticação local pode ocorrer porque o método de autenticação do domínio padrão do sistema foi alterado ou porque o domínio padrão do sistema foi alterado.
Solução
Para resolver o problema, execute as seguintes tarefas:
- Use o comando display domain para identificar se os métodos AAA para usuários da Web no domínio padrão do sistema são locais.
- Se os métodos AAA para usuários da Web no domínio padrão do sistema não forem locais, reconfigure os métodos AAA como locais.
Configuração da autenticação tripla
Sobre a autenticação tripla
A autenticação tripla permite que uma porta de acesso execute a autenticação Web, MAC e 802.1X. Um terminal pode acessar a rede se for aprovado em um tipo de autenticação. Para obter mais informações sobre autenticação 802.1X, autenticação MAC e autenticação Web, consulte "Configuração da autenticação 802.1X ", "Configuração da autenticação MAC" e "Configuração da autenticação Web".
Rede típica de autenticação tripla
A autenticação tripla é adequada para uma LAN que inclui terminais que exigem diferentes serviços de autenticação, conforme mostrado na Figura 1. A porta de acesso habilitada para autenticação tripla pode executar a autenticação MAC para a impressora, a autenticação 802.1X para o PC instalado com o cliente 802.1X e a autenticação Web para o usuário da Web.
Figura 1 Diagrama de rede de autenticação tripla
Mecanismo de autenticação tripla
Os três tipos de autenticação são acionados por pacotes diferentes:
- A porta de acesso executa a autenticação MAC para um terminal quando recebe um pacote de difusão ARP ou DHCP do terminal pela primeira vez. Se o terminal for aprovado na autenticação MAC, ele poderá acessar a rede. Se a autenticação MAC falhar, a porta de acesso executará a autenticação 802.1X ou Web.
- A porta de acesso executa a autenticação 802.1X quando recebe um pacote EAP de um cliente 802.1X ou de um cliente de terceiros. Se o recurso de acionamento unicast do 802.1X estiver ativado na porta de acesso, qualquer pacote do cliente poderá acionar uma autenticação 802.1X.
- A porta de acesso realiza a autenticação da Web quando recebe um pacote HTTP de um terminal.
- Se o terminal passar primeiro na autenticação MAC, a autenticação Web será encerrada imediatamente, mas a autenticação 802.1X continuará. Se o terminal também passar na autenticação 802.1X, as informações de autenticação 802.1X substituirão as informações de autenticação MAC para o terminal.
- Se o terminal passar primeiro pela autenticação 802.1X ou Web, os outros tipos de autenticação serão encerrados imediatamente e não poderão ser acionados novamente.
Se um terminal acionar diferentes tipos de autenticação, as autenticações serão processadas ao mesmo tempo. A falha de um tipo de autenticação não afeta os outros. Quando um terminal passa em um tipo de autenticação, os outros tipos de autenticação são processados da seguinte forma:
terminal. Se o terminal falhar na autenticação 802.1X, o usuário permanecerá on-line como um usuário de autenticação MAC e somente a autenticação 802.1X poderá ser acionada novamente.
Suporte à autenticação tripla para atribuição de VLAN
VLAN de autorização
Depois que um usuário passa pela autenticação, o servidor de autenticação atribui uma VLAN de autorização à porta de acesso do usuário. O usuário pode então acessar os recursos de rede na VLAN autorizada.
Falha de autenticação VLAN
A porta de acesso adiciona um usuário a uma VLAN de falha de autenticação configurada na porta depois que o usuário falha na autenticação.
- Para um usuário de autenticação 802.1X - Adiciona o usuário à VLAN Auth-Fail configurada para autenticação 802.1X.
- Para um usuário de autenticação da Web - Adiciona o usuário à VLAN Auth-Fail configurada para autenticação da Web.
- Para um usuário de autenticação MAC - Adiciona o usuário à VLAN de convidado configurada para autenticação MAC.
- Se um usuário na VLAN Web Auth-Fail falhar na autenticação MAC, o usuário será movido para a VLAN guest de autenticação MAC.
- Se um usuário na VLAN Web Auth-Fail ou na VLAN guest de autenticação MAC falhar na autenticação 802.1X, o usuário será movido para a VLAN 802.1X Auth-Fail.
- Se um usuário na VLAN 802.1X Auth-Fail falhar na autenticação MAC ou na autenticação Web, o usuário ainda estará na VLAN 802.1X Auth-Fail.
A porta de acesso suporta a configuração de todos os tipos de VLANs de falha de autenticação ao mesmo tempo. Se um usuário falhar em mais de um tipo de autenticação, a VLAN de falha de autenticação do usuário será alterada da seguinte forma:
VLAN sem acesso ao servidor
Se um usuário falhar na autenticação devido a um servidor inacessível, a porta de acesso adicionará o usuário a uma VLAN de servidor inacessível.
- Para um usuário de autenticação 802.1X - Adiciona o usuário à VLAN crítica configurada para autenticação 802.1X.
- Para um usuário de autenticação da Web - Adiciona o usuário à VLAN Auth-Fail configurada para autenticação da Web.
- Para um usuário de autenticação MAC - Adiciona o usuário à VLAN crítica configurada para autenticação MAC.
- Se o usuário não for submetido à autenticação 802.1X, ele será adicionado à VLAN inacessível ao servidor configurada para a última autenticação.
- Se o usuário na VLAN Web Auth-Fail ou na VLAN crítica de autenticação MAC também falhar na autenticação 802.1X, o usuário será adicionado à VLAN crítica de autenticação 802.1X.
A porta de acesso suporta a configuração de todos os tipos de VLANs inacessíveis ao servidor ao mesmo tempo. Um usuário é adicionado à VLAN de servidor inalcançável da seguinte forma:
Suporte à autenticação tripla para autorização de ACL
Depois que um usuário passa pela autenticação, o servidor de autenticação atribui uma ACL de autorização à porta de acesso do usuário. A porta de acesso usa a ACL para filtrar o tráfego do usuário.
Para usar a autorização ACL, você deve especificar ACLs de autorização no servidor de autenticação e configurar as ACLs no dispositivo de acesso. É possível alterar a autorização de acesso do usuário alterando a ACL de autorização no servidor de autenticação ou alterando as regras da ACL de autorização no dispositivo de acesso.
Suporte à autenticação tripla para detecção de usuários on-line
É possível configurar os seguintes recursos para detectar o status on-line dos usuários:
- Habilite a detecção de usuários on-line para usuários de autenticação da Web.
- Habilite o handshake de usuário on-line ou o recurso de reautenticação periódica de usuário on-line para usuários 802.1X.
- Habilite a detecção off-line para usuários de autenticação MAC.
Restrições e diretrizes: Autenticação tripla
Na autenticação tripla, a autenticação 802.1X deve usar o método de controle de acesso baseado em MAC.
Se a autenticação na Web estiver ativada em uma porta, configure as sub-redes das VLANs de falha de autenticação e das VLANs inacessíveis ao servidor da porta como sub-redes livres de autenticação na Web. Isso garante que um usuário com falha de autenticação possa acessar a VLAN de falha de autenticação ou a VLAN inacessível ao servidor.
Não configure IPs livres de autenticação da Web e IPs livres de 802.1X. Se você fizer isso, somente os IPs livres do 802.1X terão efeito.
Visão geral das tarefas de autenticação tripla
Escolha as seguintes tarefas, conforme necessário:
- Configurar a autenticação 802.1X
- Configurar a autenticação MAC
- Configurar a autenticação da Web
Para obter mais informações, consulte "Configuração do 802.1X".
Para obter mais informações, consulte "Configuração da autenticação MAC".
Para obter mais informações, consulte "Configuração da autenticação da Web".
Exemplos de configuração de autenticação tripla
Exemplo: Configuração da autenticação tripla básica
Configuração de rede
Conforme mostrado na Figura 2, os terminais estão conectados ao dispositivo para acessar a rede IP. Configure a autenticação tripla na interface de camada 2 do dispositivo que se conecta aos terminais. Um terminal que passa por um dos três métodos de autenticação, autenticação 802.1X, autenticação Web e autenticação MAC, pode acessar a rede IP.
- Atribua endereços IP na sub-rede 192.168.1.0/24 aos terminais.
- Use o servidor RADIUS remoto para realizar autenticação, autorização e contabilidade. Configure o dispositivo para enviar nomes de usuário que não contenham nomes de domínio do ISP para o servidor RADIUS.
- Configure o servidor local de autenticação da Web no dispositivo para usar o endereço IP de escuta 4.4.4.4. Configure o dispositivo para enviar uma página de autenticação padrão para o usuário da Web e encaminhar os dados de autenticação usando HTTP.
Figura 2 Diagrama de rede
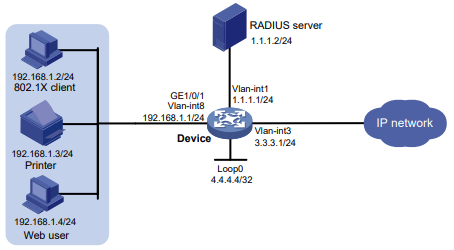
Procedimento
- Certifique-se de que os terminais, o servidor e o dispositivo possam se comunicar entre si. (Detalhes não mostrados).
- Configure o servidor RADIUS para fornecer autenticação, autorização e contabilidade normais para os usuários. Neste exemplo, configure o seguinte no servidor RADIUS:
- Um usuário 802.1X com nome de usuário userdot.
- Um usuário de autenticação da Web com nome de usuário userpt.
- Um usuário de autenticação MAC com nome de usuário e senha, sendo ambos o endereço MAC de a impressora f07d6870725f.
- Configurar a autenticação da Web:
# Configure VLANs e endereços IP para as interfaces de VLAN e adicione portas a VLANs específicas. (Detalhes não mostrados).
# Edite as páginas de autenticação, comprima as páginas em um arquivo .zip chamado abc e carregue o arquivo .zip no dispositivo por FTP. (Detalhes não mostrados.)
# Crie um serviço da Web de portal local baseado em HTTP e especifique o arquivo abc.zip como o arquivo de página de autenticação padrão do serviço da Web de portal local.
<Device> system-view
[Device] portal local-web-server http
[Device-portal-local-websvr-http] default-logon-page abc.zip
[Device-portal-local-websvr-http] quit# Atribua o endereço IP 4.4.4.4 ao Loopback 0.
[Device] interface loopback 0
[Device-LoopBack0] ip address 4.4.4.4 32
[Device-LoopBack0] quit# Crie um servidor de autenticação da Web chamado webserver e entre em sua exibição.
[Device] web-auth server webserver# Configure o URL de redirecionamento para o servidor de autenticação da Web como http://4.4.4.4/portal/.
[Device-web-auth-server-webserver] url http://4.4.4.4/portal/# Especifique 4.4.4.4 como o endereço IP e 80 como o número da porta do servidor de autenticação da Web.
[Device-web-auth-server-webserver] ip 4.4.4.4 port 80
[Device-web-auth-server-webserver] quit# Habilite a autenticação da Web na GigabitEthernet 1/0/1 e especifique o servidor de autenticação da Web servidor da Web na interface.
[Device] interface gigabitethernet 1/0/1
[Device–GigabitEthernet1/0/1] web-auth enable apply server webserver
[Device–GigabitEthernet1/0/1] quit# Habilite a autenticação 802.1X globalmente.
[Device] dot1x# Habilite a autenticação 802.1X (é necessário o controle de acesso baseado em MAC) na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device–GigabitEthernet1/0/1] dot1x port-method macbased
[Device–GigabitEthernet1/0/1] dot1x
[Device–GigabitEthernet1/0/1] quit# Habilite a autenticação MAC globalmente.
[Device] mac-authentication# Habilite a autenticação MAC na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device–GigabitEthernet1/0/1] mac-authentication
[Device–GigabitEthernet1/0/1] quit# Crie um esquema RADIUS chamado rs1.
[Device] radius scheme rs1# Especifique os servidores e chaves de autenticação e contabilidade primários.
[Device-radius-rs1] primary authentication 1.1.1.2
[Device-radius-rs1] primary accounting 1.1.1.2
[Device-radius-rs1] key authentication simple radius
[Device-radius-rs1] key accounting simple radius# Especifique os nomes de usuário enviados ao servidor RADIUS para que não contenham nomes de domínio.
[Device-radius-rs1] user-name-format without-domain
[Device-radius-rs1] quit# Criar um domínio ISP chamado triplo.
[Device] domain triple# Configure o domínio para usar o esquema RADIUS rs1 para autenticação, autorização e contabilidade de usuários de acesso à LAN.
[Device-isp-triple] authentication lan-access radius-scheme rs1
[Device-isp-triple] authorization lan-access radius-scheme rs1
[Device-isp-triple] accounting lan-access radius-scheme rs1
[Device-isp-triple] quit# Configure o domínio triplo como o domínio padrão. Se um nome de usuário inserido por um usuário não incluir um nome de domínio ISP, será usado o método AAA do domínio padrão.
[Device] domain default enable tripleVerificação da configuração
- Verifique se o usuário da Web pode ser aprovado na autenticação da Web.
# No terminal do usuário da Web, use um navegador da Web para acessar uma rede externa e, em seguida, digite o nome de usuário e a senha corretos na página de autenticação http://4.4.4.4/portal/logon.html. (Detalhes não mostrados.)
# Exibir informações sobre usuários de autenticação on-line na Web.
[Device] display web-auth user
Total online web-auth users: 1
User Name: localuser
MAC address: acf1-df6c-f9ad
Access interface: GigabitEthernet1/0/1
Initial VLAN: 8
Authorization VLAN: N/A
Authorization ACL ID: N/A
Authorization user profile: N/A# Conecte a impressora à rede. (Detalhes não mostrados.)
# Exibir informações sobre usuários de autenticação MAC on-line.
[Device] display mac-authentication connection
Total connections: 1
Slot ID: 1
User MAC address: f07d-6870-725f
Access interface: GigabitEthernet1/0/1
Username: f07d6870725f
User access state: Successful
Authentication domain: triple
Initial VLAN: 8
Authorization untagged VLAN: N/A
Authorization tagged VLAN: N/A
Authorization VSI: N/A
Authorization ACL ID: N/A
Authorization user profile: N/A
Authorization CAR: N/A
Authorization URL: N/A
Termination action: Default
Session timeout period: N/A
Online from: 2015/01/04 18:01:43
Online duration: 0h 0m 2s# No cliente 802.1X, inicie a autenticação 802.1X e, em seguida, digite o nome de usuário e a senha corretos. (Os detalhes não são mostrados.)
# Exibir informações sobre usuários 802.1X on-line.
[Device] display dot1x connection
Total connections: 1
Slot ID: 1
User MAC address: 7446-a091-84fe
Access interface: GigabitEthernet1/0/1
Username: userdot
User access state: Successful
Authentication domain: triple
IPv4 address: 192.168.1.2
Authentication method: CHAP
Initial VLAN: 8
Authorization untagged VLAN: N/A
Authorization tagged VLAN list: N/A
Authorization VSI: N/A
Authorization ACL ID: N/A
Authorization user profile: N/A
Authorization CAR: N/A
Authorization URL: N/A
Termination action: Default
Session timeout period: N/A
Online from: 2015/01/04 18:13:01
Online duration: 0h 0m 14sExemplo: Configuração da autenticação tripla para suportar a VLAN de autorização e a VLAN de falha de autenticação
Configuração de rede
Conforme mostrado na Figura 3, os terminais estão conectados ao dispositivo para acessar a rede IP. Configure a autenticação tripla na interface de camada 2 do dispositivo conectada aos terminais. Um terminal que passa por um dos três métodos de autenticação, autenticação 802.1X, autenticação Web e autenticação MAC, pode acessar a rede IP.
- O terminal de autenticação da Web usa o DHCP para obter um endereço IP em 192.168.1.0/24 antes da autenticação e em 3.3.3.0/24 depois de passar na autenticação. Se o terminal falhar na autenticação, ele solicitará endereços IP em 2.2.2.0/24 por meio do DHCP.
- O terminal 802.1X usa o DHCP para obter um endereço IP em 192.168.1.0/24 antes da autenticação e em 3.3.3.0/24 depois de passar pela autenticação. Se o terminal falhar na autenticação, ele solicitará endereços IP em 2.2.2.0/24 por meio do DHCP.
- Depois de passar pela autenticação, a impressora obtém o endereço IP 3.3.3.111/24, que é vinculado ao seu endereço MAC por meio do DHCP.
- Use o servidor RADIUS remoto para realizar autenticação, autorização e contabilidade. Configure o dispositivo para remover os nomes de domínio do ISP dos nomes de usuário enviados ao servidor RADIUS.
- Configure o servidor local de autenticação da Web no dispositivo para usar o endereço IP de escuta 4.4.4.4. Configure o dispositivo para enviar uma página de autenticação padrão para o usuário da Web e encaminhar os dados de autenticação usando HTTP.
- Configure a VLAN 3 como a VLAN de autorização. Os usuários que passam pela autenticação são adicionados a essa VLAN.
- Configure a VLAN 2 como a VLAN de falha de autenticação. Os usuários que falham na autenticação são adicionados a essa VLAN.
Você pode usar o dispositivo de acesso ou um dispositivo conectado como servidor DHCP. Neste exemplo, o dispositivo de acesso (o dispositivo) fornece o serviço DHCP.
Figura 3 Diagrama de rede
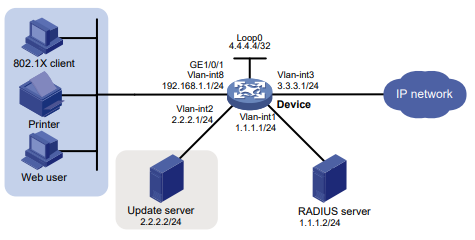
Procedimento
- Certifique-se de que os terminais, os servidores e o dispositivo possam se comunicar entre si. (Detalhes não mostrados.)
- Configure o servidor RADIUS para fornecer autenticação, autorização e contabilidade normais para os usuários. Neste exemplo, configure o seguinte no servidor RADIUS:
- Um usuário 802.1X com nome de usuário userdot.
- Um usuário de autenticação da Web com nome de usuário userpt.
- Um usuário de autenticação MAC com nome de usuário e senha, sendo ambos o endereço MAC da impressora f07d6870725f.
- Uma VLAN de autorização (VLAN 3).
- Configure o endereço IP do servidor de atualização como um endereço IP sem autenticação.
<Device> system-view
[web-auth free-ip 2.2.2.2.2 24# Configure VLANs e endereços IP para as interfaces de VLAN e adicione portas a VLANs específicas. (Detalhes não mostrados).
# Habilite o DHCP.
[Device] dhcp enable# Excluir o endereço IP do servidor de atualização da atribuição dinâmica de endereços.
[dhcp server forbidden-ip 2.2.2.2
# Configure o pool de endereços DHCP 1 para atribuir endereços IP e outros parâmetros de configuração a clientes na sub-rede 192.168.1.0.
[Device] dhcp server ip-pool 1
[Device-dhcp-pool-1] network 192.168.1.0 mask 255.255.255.0
[Device-dhcp-pool-1] expired day 0 hour 0 minute 1
[Device-dhcp-pool-1] gateway-list 192.168.1.1
[Device-dhcp-pool-1] quit# Configure o pool de endereços DHCP 2 para atribuir o endereço IP e outros parâmetros de configuração aos clientes na sub-rede 2.2.2.0.
[Device] dhcp server ip-pool 2
[Device-dhcp-pool-2] network 2.2.2.0 mask 255.255.255.0
[Device-dhcp-pool-2] expired day 0 hour 0 minute 1
[Device-dhcp-pool-2] gateway-list 2.2.2.1
[Device-dhcp-pool-2] quit# Configure o pool de endereços DHCP 3 para atribuir o endereço IP e outros parâmetros de configuração aos clientes na sub-rede 3.3.3.0.
[Device] dhcp server ip-pool 3
[Device-dhcp-pool-3] network 3.3.3.0 mask 255.255.255.0
[Device-dhcp-pool-3] expired day 0 hour 0 minute 1
[Device-dhcp-pool-3] gateway-list 3.3.3.1
[Device-dhcp-pool-3] quit# Configure o pool de endereços DHCP 4 e associe o endereço MAC da impressora f07d-6870-725f ao IP
endereço 3.3.3.111/24 nesse pool de endereços.
[Device] dhcp server ip-pool 4
[Device-dhcp-pool-4] static-bind ip-address 3.3.3.111 mask 255.255.255.0
client-identifier f07d-6870-725f
[Device-dhcp-pool-4] quit- Configurar a autenticação da Web:
# Crie um serviço da Web de portal local baseado em HTTP e especifique o arquivo defaultfile.zip como o arquivo de página de autenticação padrão do serviço da Web de portal local.
[Device] portal local-web-server http
[Device-portal-local-websvr-http] default-logon-page defaultfile.zip
[Device-portal-local-websvr-http] quit# Atribua o endereço IP 4.4.4.4 ao Loopback 0.
[Device] interface loopback 0
[Device-LoopBack0] ip address 4.4.4.4 32
[Device-LoopBack0] quit# Crie um servidor de autenticação da Web chamado webserver.
[Device] web-auth server webserver# Configure o URL de redirecionamento do servidor de autenticação da Web como http://4.4.4.4/portal/.
[Device-web-auth-server-webserver] url http://4.4.4.4/portal/# Especifique 4.4.4.4 como o endereço IP e 80 como o número da porta do servidor de autenticação da Web.
[Device-web-auth-server-webserver] ip 4.4.4.4 port 80
[Device-web-auth-server-webserver] quit# Configure o endereço IP do servidor de atualização como um endereço IP sem autenticação.
[Device] web-auth free-ip 2.2.2.2 24# Habilite a autenticação da Web na GigabitEthernet 1/0/1 e especifique a VLAN 2 como a VLAN Auth-Fail.
[Device] interface gigabitethernet 1/0/1
[Device–GigabitEthernet1/0/1] port link-type hybrid
[Device–GigabitEthernet1/0/1] mac-vlan enable
[Device–GigabitEthernet1/0/1] web-auth enable apply server webserver
[Device–GigabitEthernet1/0/1] web-auth auth-fail vlan 2
[Device–GigabitEthernet1/0/1] quit- Configurar a autenticação 802.1X:
# Habilite a autenticação 802.1X globalmente.
[Device] dot1x# Habilite a autenticação 802.1X (requer controle de acesso baseado em MAC) na GigabitEthernet 1/0/1 e especifique a VLAN 2 como a VLAN Auth-Fail.
[Device] interface gigabitethernet 1/0/1
[Device–GigabitEthernet1/0/1] dot1x port-method macbased
[Device–GigabitEthernet1/0/1] dot1x
[Device–GigabitEthernet1/0/1] dot1x auth-fail vlan 2
[Device–GigabitEthernet1/0/1] quit- Configurar a autenticação MAC:
# Habilite a autenticação MAC globalmente.
[Device] mac-authentication# Habilite a autenticação MAC na GigabitEthernet 1/0/1 e especifique a VLAN 2 como a VLAN de convidado.
[Device] interface gigabitethernet 1/0/1
[Device–GigabitEthernet1/0/1] mac-authentication
[Device–GigabitEthernet1/0/1] mac-authentication guest-vlan 2
[Device–GigabitEthernet1/0/1] quit- Configurar um esquema RADIUS:
# Crie um esquema RADIUS chamado rs1.
[Device] radius scheme rs1# Especifique os servidores e chaves de autenticação e contabilidade primários.
[Device-radius-rs1] primary authentication 1.1.1.2
[Device-radius-rs1] primary accounting 1.1.1.2
[Device-radius-rs1] key authentication simple radius
[Device-radius-rs1] key accounting simple radius# Especifique os nomes de usuário enviados ao servidor RADIUS para que não contenham nomes de domínio.
[Device-radius-rs1] user-name-format without-domain
[Device-radius-rs1] quit- Configurar um domínio ISP:
# Criar um domínio ISP chamado triplo.
[Device] domain triple# Configure o domínio para usar o esquema RADIUS rs1 para autenticação, autorização e contabilidade de usuários de acesso à LAN.
[Device-isp-triple] authentication lan-access radius-scheme rs1
[Device-isp-triple] authorization lan-access radius-scheme rs1
[Device-isp-triple] accounting lan-access radius-scheme rs1
[Device-isp-triple] quit# Configure o domínio triplo como o domínio padrão. Se um nome de usuário inserido por um usuário não incluir um nome de domínio ISP, serão usados os métodos AAA do domínio padrão.
[Device] domain default enable tripleVerificação da configuração
- Verifique se o usuário da Web pode ser aprovado na autenticação da Web.
# No terminal do usuário da Web, use um navegador da Web para acessar uma rede externa e, em seguida, digite o nome de usuário e a senha corretos na página de autenticação http://4.4.4.4/portal/logon.html. (Detalhes não mostrados.)
# Use o comando display web-auth user para exibir informações sobre os usuários on-line.
[Device] display web-auth user
Total online web-auth users: 1
User Name: userpt
MAC address: 6805-ca17-4a0b
Access interface: GigabitEthernet1/0/1
Initial VLAN: 8
Authorization VLAN: 3
Authorization ACL ID: N/A
Authorization user profile: N/A- Verifique se a impressora pode passar pela autenticação MAC.
# Conecte a impressora à rede. (Detalhes não mostrados.)
# Exibir informações sobre usuários de autenticação MAC on-line.
[Device] display mac-authentication connection
Total connections: 1
Slot ID: 1
User MAC address: f07d-6870-725f
Access interface: GigabitEthernet1/0/1
Username: f07d6870725f
User access state: Successful
Authentication domain: triple
Initial VLAN: 8
Authorization untagged VLAN: 3
Authorization tagged VLAN: N/A
Authorization VSI: N/A
Authorization ACL ID: N/A
Authorization user profile: N/A
Authorization CAR: N/A
Authorization URL: N/A
Termination action: Default
Session timeout period: N/A
Online from: 2015/01/04 18:01:43
Online duration: 0h 0m 2s- Verifique se o usuário 802.1X pode passar pela autenticação 802.1X.
# No cliente 802.1X, inicie a autenticação 802.1X e digite o nome de usuário e a senha corretos. (Os detalhes não são mostrados.)
# Exibir informações sobre usuários 802.1X on-line.
[Device] display dot1x connection
Total connections: 1
Slot ID: 1
User MAC address: 7446-a091-84fe
Access interface: GigabitEthernet1/0/1
Username: userdot
User access state: Successful
Authentication domain: triple
IPv4 address: 3.3.3.3
Authentication method: CHAP
Initial VLAN: 8
Authorization untagged VLAN: 3
Authorization tagged VLAN list: N/A
Authorization VSI: N/A
Authorization ACL ID: N/A
Authorization user profile: N/A
Authorization CAR: N/A
Authorization URL: N/A
Termination action: Default
Session timeout period: N/A
Online from: 2015/01/04 18:13:01
Online duration: 0h 0m 14s- Verifique se os usuários que passaram na autenticação receberam VLANs de autorização. # Exibir entradas de MAC-VLAN de usuários on-line.
[Device] display mac-vlan all
The following MAC VLAN addresses exist:
S:Static D:Dynamic
MAC ADDR MASK VLAN ID PRIO STATE
--------------------------------------------------------
6805-ca17-4a0b ffff-ffff-ffff 3 0 D
f07d-6870-725f ffff-ffff-ffff 3 0 D
7446-a091-84fe ffff-ffff-ffff 3 0 D
Total MAC VLAN address count:3- Verifique se foram atribuídos endereços IP aos usuários on-line.
[Device] display dhcp server ip-in-use
IP address Client-identifier/ Lease expiration Type
Hardware address
3.3.3.111 01f0-7d68-7072-5f Jan 4 18:14:17 2015 Auto:(C)
3.3.3.2 0168-05ca-174a-0b Jan 4 18:15:01 2015 Auto:(C)
3.3.3.3 0174-46a0-9184-fe Jan 4 18:15:03 2015 Auto:(C)- Quando um terminal falha na autenticação, ele é adicionado à VLAN 2. Você pode usar os comandos de exibição anteriores para exibir a entrada MAC-VLAN e o endereço IP do terminal. (Detalhes não mostrados).
Configuração da segurança da porta
Sobre a segurança das portas
A segurança da porta combina e estende a autenticação 802.1X e MAC para fornecer controle de acesso à rede baseado em MAC . O recurso se aplica a portas que usam métodos de autenticação diferentes para os usuários.
Principais funções
A segurança da porta oferece as seguintes funções:
- Evita o acesso não autorizado a uma rede verificando o endereço MAC de origem do tráfego de entrada.
- Impede o acesso a dispositivos ou hosts não autorizados, verificando o endereço MAC de destino do tráfego de saída.
- Controla o aprendizado e a autenticação de endereços MAC em uma porta para garantir que a porta aprenda apenas endereços MAC confiáveis de origem.
Recursos de segurança da porta
NTK
O recurso need to know (NTK) impede a interceptação de tráfego verificando o endereço MAC de destino nos quadros de saída. O recurso garante que os quadros sejam enviados somente para os seguintes hosts:
- Hosts que foram aprovados na autenticação.
- Hosts cujos endereços MAC foram aprendidos ou configurados no dispositivo de acesso.
Proteção contra intrusões
O recurso de proteção contra intrusão verifica se há quadros ilegais no endereço MAC de origem nos quadros de entrada e executa uma ação predefinida em cada quadro ilegal detectado. A ação pode ser desativar a porta temporariamente, desativar a porta permanentemente ou bloquear os quadros do endereço MAC ilegal por 3 minutos (não configurável pelo usuário).
Um quadro é ilegal se o endereço MAC de origem não puder ser aprendido em um modo de segurança de porta ou se for de um cliente que falhou na autenticação 802.1X ou MAC.
Modos de segurança da porta
A segurança da porta é compatível com as seguintes categorias de modos de segurança:
- Controle de aprendizagem de MAC - Inclui dois modos: autoLearn e seguro. O aprendizado de endereço MAC é permitido em uma porta no modo autoLearn e desativado no modo seguro.
- Autenticação - Os modos de segurança dessa categoria implementam a autenticação MAC, a autenticação 802.1X ou uma combinação desses dois métodos de autenticação.
Ao receber um quadro, a porta em um modo de segurança procura o endereço MAC de origem na tabela de endereços MAC. Se for encontrada uma correspondência, a porta encaminha o quadro. Se não houver correspondência, a porta aprende o endereço MAC ou executa a autenticação, dependendo do modo de segurança. Se o quadro for ilegal, a porta tomará a ação predefinida de NTK ou de proteção contra intrusão ou enviará notificações de SNMP. Os quadros de saída não são restringidos pela ação NTK da segurança da porta, a menos que acionem o recurso NTK.
A Tabela 1 descreve os modos de segurança da porta e os recursos de segurança.
Tabela 1 Modos de segurança da porta
| Finalidade | Modo de segurança | Recursos que podem ser acionados | |
| Desativação do recurso de segurança da porta | noRestrictions (o modo padrão) Nesse modo, a segurança da porta é desativada na porta e o acesso a ela não é restrito. | N/A | |
| Controle do aprendizado de endereço MAC | autoLearn | NTK/proteção contra intrusão | |
| seguro | |||
| Execução da autenticação 802.1X | userLogin | N/A | |
| userLoginSecure | NTK/proteção contra intrusão | ||
| userLoginSecureExt | |||
| userLoginWithOUI | |||
| Realização de autenticação MAC | macAddressWithRadius | NTK/proteção contra intrusão | |
| Realização de uma combinação de autenticação MAC e autenticação 802.1X | Ou | macAddressOrUserLoginSecure | NTK/proteção contra intrusão |
| macAddressOrUserLoginSecureExt | |||
| Além disso | macAddressElseUserLoginSecure | ||
| macAddressElseUserLoginSecureE xt |
Os nomes dos modos são ilustrados a seguir:
- userLogin especifica a autenticação 802.1X e o controle de acesso baseado em porta. userLogin with Secure especifica a autenticação 802.1X e o controle de acesso baseado em MAC. Ext indica que permite que vários usuários 802.1X sejam autenticados e atendidos ao mesmo tempo. Um modo de segurança sem Ext permite que apenas um usuário passe pela autenticação 802.1X.
- macAddress especifica a autenticação MAC.
- Else especifica que o método de autenticação anterior a Else é aplicado primeiro. Se a autenticação falhar, o fato de passar ou não para o método de autenticação após Else depende do tipo de protocolo da solicitação de autenticação.
- Or especifica que o método de autenticação que segue Or é aplicado primeiro. Se a autenticação falhar, o método de autenticação anterior a Or será aplicado.
Controle do aprendizado de endereço MAC
- autoLearn.
Uma porta nesse modo pode aprender endereços MAC. Os endereços MAC aprendidos automaticamente não são adicionados à tabela de endereços MAC como endereço MAC dinâmico. Em vez disso, esses endereços MAC são adicionados à tabela de endereços MAC seguros como endereços MAC seguros. Você também pode configurar endereços MAC seguros usando o comando port-security mac-address security.
Uma porta no modo autoLearn permite a passagem de quadros originados dos seguintes endereços MAC:
- Endereços MAC seguros.
- Endereços MAC configurados usando os comandos mac-address dynamic e mac-address static.
Quando o número de endereços MAC seguros atinge o limite superior, a porta passa para o modo seguro.
- seguro.
O aprendizado de endereço MAC é desativado em uma porta no modo seguro. Você configura os endereços MAC usando os comandos mac-address static e mac-address dynamic. Para obter mais informações sobre a configuração das entradas da tabela de endereços MAC, consulte o Guia de configuração de switching de camada 2-LAN.
Uma porta em modo seguro permite a passagem apenas de quadros originados dos seguintes endereços MAC:
- Endereços MAC seguros.
- Endereços MAC configurados usando os comandos mac-address dynamic e mac-address static.
Execução da autenticação 802.1X
- userLogin.
Uma porta nesse modo executa a autenticação 802.1X e implementa o controle de acesso baseado em porta. A porta pode atender a vários usuários 802.1X. Quando um usuário 802.1X passa pela autenticação na porta, qualquer usuário 802.1X subsequente pode acessar a rede pela porta sem autenticação.
- userLoginSecure.
Uma porta nesse modo executa a autenticação 802.1X e implementa o controle de acesso baseado em MAC. A porta atende a apenas um usuário que passa pela autenticação 802.1X.
- userLoginSecureExt.
Esse modo é semelhante ao modo userLoginSecure, exceto pelo fato de que esse modo é compatível com vários usuários 802.1X on-line.
- userLoginWithOUI.
Esse modo é semelhante ao modo userLoginSecure. A diferença é que uma porta nesse modo também permite quadros de um usuário cujo endereço MAC contém uma OUI específica.
Nesse modo, a porta executa primeiro a verificação da OUI. Se a verificação da OUI falhar, a porta executará a autenticação 802.1X. A porta permite quadros que passam pela verificação OUI ou pela autenticação 802.1X.
OBSERVAÇÃO:
Um OUI é um número de 24 bits que identifica de forma exclusiva um fornecedor, fabricante ou organização. Nos endereços MAC, os três primeiros octetos são o OUI.
Realização de autenticação MAC
macAddressWithRadius: Uma porta nesse modo executa a autenticação MAC e atende a vários usuários.
Realização de uma combinação de autenticação MAC e autenticação 802.1X
- macAddressOrUserLoginSecure.
Esse modo é a combinação dos modos macAddressWithRadius e userLoginSecure. O modo permite que um usuário de autenticação 802.1X e vários usuários de autenticação MAC façam login.
Nesse modo, a porta executa primeiro a autenticação 802.1X. Por padrão, se a autenticação 802.1X falhar, a autenticação MAC será executada.
No entanto, a porta nesse modo processa a autenticação de forma diferente quando existem as seguintes condições:
- A porta está habilitada com processamento paralelo de autenticação MAC e autenticação 802.1X.
- A porta está ativada com o acionador unicast 802.1X.
- A porta recebe um pacote de um endereço MAC desconhecido.
Nessas condições, a porta envia um pacote unicast EAP-Request/Identity para o endereço MAC para iniciar a autenticação 802.1X. Depois disso, a porta processa imediatamente a autenticação MAC sem aguardar o resultado da autenticação 802.1X.
- macAddressOrUserLoginSecureExt.
Esse modo é semelhante ao modo macAddressOrUserLoginSecure, exceto pelo fato de que esse modo é compatível com vários usuários de autenticação 802.1X e MAC.
- macAddressElseUserLoginSecure.
Esse modo é a combinação dos modos macAddressWithRadius e userLoginSecure, sendo que a autenticação MAC tem uma prioridade mais alta, como indica a palavra-chave Else. O modo permite que um usuário de autenticação 802.1X e vários usuários de autenticação MAC façam login.
Nesse modo, a porta executa a autenticação MAC ao receber quadros não 802.1X. Ao receber quadros 802.1X, a porta executa a autenticação MAC e, em seguida, se a autenticação falhar, a autenticação 802.1X.
- macAddressElseUserLoginSecureExt.
Esse modo é semelhante ao modo macAddressElseUserLoginSecure, exceto pelo fato de que esse modo é compatível com vários usuários de autenticação 802.1X e MAC, como a palavra-chave Ext indica.
Restrições e diretrizes: Configuração da segurança da porta
Esse recurso se aplica a redes, como uma WLAN, que exigem diferentes métodos de autenticação para diferentes usuários em uma porta.
Como prática recomendada, use o recurso de autenticação 802.1X ou autenticação MAC em vez de segurança de porta para cenários que exigem apenas autenticação 802.1X ou autenticação MAC. Para obter mais informações sobre a autenticação 802.1X e MAC, consulte "Configuração do 802.1X" e "Configuração da autenticação MAC".
As configurações de segurança da porta são compatíveis apenas com as interfaces Ethernet de camada 2 que não pertencem a um grupo de agregação de camada 2.
Para garantir um redirecionamento de HTTPS bem-sucedido para os usuários aos quais foi atribuído um URL de redirecionamento, certifique-se de que existam interfaces de VLAN para as VLANs que transportam seus pacotes.
Visão geral das tarefas de segurança da porta
Para configurar a segurança da porta, execute as seguintes tarefas:
- Configuração de recursos básicos de segurança de porta
- Ativação da segurança da porta
- Configuração do modo de segurança da porta
- Definição do limite de segurança da porta para o número de endereços MAC seguros em uma porta
- Configuração de endereços MAC seguros
- (Opcional.) Configuração do NTK
- (Opcional.) Configuração da proteção contra intrusão
- (Opcional.) Configuração de recursos estendidos de segurança de porta
- Ignorar informações de autorização do servidor
- Configuração da movimentação de MAC
- Ativação do recurso authorization-fail-offline
- Definição do limite de segurança da porta quanto ao número de endereços MAC para VLANs específicas em uma porta
- Ativação do modo de autenticação aberta
- Configuração de VLANs livres para segurança da porta
- Aplicação de um perfil NAS-ID à segurança da porta
- Ativação de estatísticas de tráfego para autenticação MAC e usuários 802.1X
- Especificar um endereço IP e uma máscara para calcular o IP de origem dos pacotes de detecção de ARP Os recursos de segurança estendida da porta também podem entrar em vigor quando a segurança da porta está desativada, mas a autenticação 802.1X ou MAC está ativada.
- (Opcional.) Ativação de notificações SNMP para segurança de porta
Ativação da segurança da porta
Restrições e diretrizes
Quando você configurar a segurança da porta, siga estas restrições e diretrizes:
- Quando a segurança da porta está ativada, não é possível ativar a autenticação 802.1X ou MAC, nem alterar o modo de controle de acesso ou o estado de autorização da porta. A segurança da porta modifica automaticamente essas configurações em diferentes modos de segurança.
- Você pode usar o comando undo port-security enable para desativar a segurança da porta. Como o comando faz logoff de usuários on-line, certifique-se de que nenhum usuário on-line esteja presente.
- A ativação ou desativação da segurança da porta redefine as seguintes configurações de segurança para o padrão:
- Modo de controle de acesso 802.1X, que é baseado em MAC.
- Estado de autorização da porta, que é automático.
Para obter mais informações sobre a autenticação 802.1X e a configuração da autenticação MAC, consulte "Configuração do 802.1X" e "Configuração da autenticação MAC".
Pré-requisitos
Antes de ativar a segurança da porta, desative a autenticação 802.1X e MAC globalmente.
Procedimento
- Entre na visualização do sistema.
system view- Ativar a segurança da porta.
port-security enable
Por padrão, a segurança da porta está desativada.
Configuração do modo de segurança da porta
Restrições e diretrizes
Você pode especificar um modo de segurança de porta quando a segurança de porta estiver desativada, mas sua configuração não poderá ter efeito.
A alteração do modo de segurança de uma porta faz o logoff dos usuários on-line da porta.
Não habilite a autenticação 802.1X ou a autenticação MAC em uma porta em que a segurança da porta esteja habilitada.
Depois de ativar a segurança da porta, você pode alterar o modo de segurança de uma porta somente quando ela estiver operando no modo noRestrictions (padrão). Para alterar o modo de segurança da porta de uma porta em qualquer outro modo, primeiro use o comando undo port-security port-mode para restaurar o modo de segurança da porta padrão.
O dispositivo suporta o atributo de URL atribuído por um servidor RADIUS nos seguintes modos de segurança de porta:
- mac-authentication.
- mac-else-userlogin-secure.
- mac-else-userlogin-secure-ext.
- login de usuário seguro.
- userlogin-secure-ext.
- userlogin-secure-or-mac.
- userlogin-secure-or-mac-ext.
- login de usuário sem.
Durante a autenticação, as solicitações HTTP ou HTTPS de um usuário são redirecionadas para a interface da Web especificada pelo atributo URL atribuído pelo servidor. Depois que o usuário passa pela autenticação na Web, o servidor RADIUS registra o endereço MAC do usuário e usa uma DM (Disconnect Message) para fazer logoff do usuário. Quando o usuário iniciar novamente a autenticação 802.1X ou MAC, ele será aprovado na autenticação e ficará on-line com êxito.
Para redirecionar as solicitações de HTTPS dos usuários de segurança de porta, especifique a porta de escuta de redirecionamento de HTTPS em o dispositivo. Para obter mais informações, consulte Redirecionamento de HTTP no Guia de Configuração de Serviços de Camada 3 IP.
Pré-requisitos
Antes de definir um modo de segurança de porta para uma porta, conclua as seguintes tarefas:
- Desativar a autenticação 802.1X e MAC.
- Se você estiver configurando o modo autoLearn, defina o limite da segurança da porta para o número de endereços MAC seguros. Não é possível alterar a configuração quando a porta estiver operando no modo autoLearn.
Procedimento
- Entre na visualização do sistema.
system view- Defina um valor OUI para autenticação de usuário.
port-security oui index index-value mac-address oui-value
Por padrão, nenhum valor OUI é configurado para autenticação de usuário. Esse comando é necessário apenas para o modo userlogin-withoui.
É possível definir várias OUIs, mas quando o modo de segurança da porta é userlogin-withoui, a porta permite um usuário 802.1X e somente um usuário que corresponda a uma das OUIs especificadas.
- Entre na visualização da interface.
interface interface-type interface-number- Definir o modo de segurança da porta.
port-security port-mode { autolearn | mac-authentication |
mac-else-userlogin-secure | mac-else-userlogin-secure-ext | secure
| userlogin | userlogin-secure | userlogin-secure-ext |
userlogin-secure-or-mac | userlogin-secure-or-mac-ext |
userlogin-withoui }Por padrão, uma porta opera no modo noRestrictions.
Definição do limite de segurança da porta para o número de endereços MAC seguros em uma porta
Sobre o limite da segurança da porta quanto ao número de endereços MAC seguros em uma porta
Você pode definir o número máximo de endereços MAC seguros que a segurança de porta permite em uma porta para as seguintes finalidades:
- Controle do número de usuários simultâneos na porta.
Para uma porta operando em um modo de segurança (exceto para autoLearn e secure), o limite superior é igual ao menor dos seguintes valores:
- O limite de endereços MAC seguros que a segurança da porta permite.
- O limite de usuários simultâneos permitido pelo modo de autenticação em uso.
- Controle do número de endereços MAC seguros na porta no modo autoLearn.
Você também pode definir o número máximo de endereços MAC seguros que a segurança da porta permite para VLANs específicas ou para cada VLAN em uma porta.
O limite do Port Security para o número de endereços MAC seguros em uma porta é independente do limite de aprendizagem de MAC descrito na configuração da tabela de endereços MAC. Para obter mais informações sobre a configuração da tabela de endereços MAC, consulte o Layer 2-LAN Switching Configuration Guide.
Procedimento
system view- Entre na visualização da interface.
interface interface-type interface-number- Defina o número máximo de endereços MAC seguros permitidos em uma porta.
port-security max-mac-count max-count[ vlan [ vlan-id-list ] ]
Por padrão, a segurança da porta não limita o número de endereços MAC seguros em uma porta.
Configuração de endereços MAC seguros
Sobre endereços MAC seguros
Os endereços MAC seguros são configurados ou aprendidos no modo autoLearn. Se os endereços MAC seguros forem salvos, eles podem sobreviver a uma reinicialização do dispositivo. É possível associar um endereço MAC seguro somente a uma porta em uma VLAN.
Os endereços MAC seguros incluem endereços MAC seguros estáticos, fixos e dinâmicos.
Tabela 2 Comparação de endereços MAC seguros estáticos, fixos e dinâmicos
| Tipo | Fontes de endereço | Mecanismo de envelhecimento | Pode ser salvo e sobreviver a uma reinicialização do dispositivo? |
| Estático | Adicionado manualmente (usando o comando port-security mac-address security sem a palavra-chave sticky). | Não disponível. Os endereços MAC estáticos seguros nunca envelhecem, a menos que você execute uma das seguintes tarefas: Remova manualmente esses endereços MAC. Alterar o modo de segurança da porta. Desative o recurso de segurança da porta. | Sim. |
| Adesivo | Adicionado manualmente (usando o comando de segurança port-security mac-address com a palavra-chave sticky). Convertido de MAC seguro dinâmico | Por padrão, os endereços MAC fixos não envelhecem. No entanto, você pode configurar um timer de envelhecimento ou usar o timer de envelhecimento junto com o recurso de envelhecimento por inatividade para remover endereços MAC fixos antigos. Se apenas o temporizador de envelhecimento estiver configurado, o temporizador de envelhecimento contará independentemente do fato de os dados de tráfego terem sido enviados do sticky | Sim. O temporizador de envelhecimento seguro do MAC é reiniciado em uma reinicialização. |
| Tipo | Fontes de endereço | Mecanismo de envelhecimento | Pode ser salvo e sobreviver a uma reinicialização do dispositivo? |
| endereços. | Endereços MAC. | ||
| Aprendido automaticamente quando o recurso de MAC seguro dinâmico está desativado. | Se o timer de envelhecimento e o recurso de envelhecimento por inatividade estiverem configurados, o timer de envelhecimento será reiniciado assim que os dados de tráfego forem detectados nos endereços MAC fixos. | ||
| Convertido de endereços MAC fixos. | Não. | ||
| Dinâmico | Aprendido automaticamente depois que o recurso de MAC seguro dinâmico é ativado. | Igual aos endereços MAC fixos. | Todos os endereços MAC dinâmicos seguros são perdidos na reinicialização. |
Quando o número máximo de entradas de endereço MAC seguro é atingido, a porta muda para o modo seguro. No modo seguro, a porta não pode adicionar ou aprender mais endereços MAC seguros. A porta permite apenas a passagem de quadros originados de endereços MAC seguros ou de endereços MAC configurados com o uso do comando mac-address dynamic ou mac-address static.
Pré-requisitos
Antes de configurar endereços MAC seguros, conclua as seguintes tarefas:
- Definir o limite da segurança da porta para o número de endereços MAC na porta. Execute essa tarefa antes de ativar o modo autoLearn.
- Defina o modo de segurança da porta como autoLearn.
- Configure a porta para permitir a passagem de pacotes da VLAN especificada ou adicione a porta à VLAN. Certifique-se de que a VLAN já exista.
Adição de endereços MAC seguros
- Entre na visualização do sistema.
system view- Defina o cronômetro de envelhecimento do MAC seguro.
port-security timer autolearn aging [ second ] time-valuePor padrão, os endereços MAC seguros não envelhecem.
- Configure um endereço MAC seguro.
- Configure um endereço MAC seguro na visualização do sistema.
port-security mac-address security [ sticky ] mac-address interface
interface-type interface-number vlan vlan-id- Execute os seguintes comandos em sequência para configurar um endereço MAC seguro na visualização da interface:
interface interface-type interface-numberinterface interface-type interface-number
port-security mac-address security [ sticky ] mac-address vlan
vlan-idPor padrão, não existem endereços MAC seguros configurados manualmente.
Em uma VLAN, um endereço MAC não pode ser especificado como um endereço MAC estático seguro e como um endereço MAC fixo.
Ativação do envelhecimento por inatividade para endereços MAC seguros
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-number- Habilite o envelhecimento por inatividade para endereços MAC seguros.
port-security mac-address aging-type inactivityPor padrão, o recurso de envelhecimento por inatividade é desativado para endereços MAC seguros.
Ativação do recurso MAC seguro dinâmico
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-number- Habilite o recurso de MAC seguro dinâmico.
port-security mac-address dynamicPor padrão, o recurso de MAC seguro dinâmico está desativado. Os endereços MAC fixos podem ser salvos no arquivo de configuração. Uma vez salvos, eles podem sobreviver a uma reinicialização do dispositivo.
Configuração do NTK
Sobre o recurso NTK
O recurso NTK verifica o endereço MAC de destino nos quadros de saída para garantir que os quadros sejam encaminhados somente para dispositivos confiáveis.
O recurso NTK é compatível com os seguintes modos:
- ntkonly - encaminha somente quadros unicast com um endereço MAC de destino autenticado.
- ntk-withbroadcasts - Encaminha somente quadros de broadcast e unicast com um endereço MAC de destino autenticado.
- ntk-withmulticasts - Encaminha somente quadros de broadcast, multicast e unicast com um endereço MAC de destino autenticado.
- ntkauto - Encaminha somente quadros de broadcast, multicast e unicast com um endereço MAC de destino autenticado e somente quando a porta tem usuários on-line.
Restrições e diretrizes
O recurso NTK descarta qualquer quadro unicast com um endereço MAC de destino desconhecido.
Nem todos os modos de segurança de porta suportam o acionamento do recurso NTK. Para obter mais informações, consulte a Tabela 1.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-number- Configurar o recurso NTK.
port-security ntk-mode { ntk-withbroadcasts | ntk-withmulticasts |
ntkauto | ntkonly }Por padrão, o NTK está desativado em uma porta e todos os quadros podem ser enviados.
Configuração da proteção contra intrusão
Sobre a proteção contra intrusão
A proteção contra intrusões executa uma das seguintes ações em uma porta em resposta a quadros ilegais:
- blockmac - Adiciona os endereços MAC de origem de quadros ilegais à lista de endereços MAC bloqueados e descarta os quadros. Um endereço MAC bloqueado será desbloqueado em 3 minutos. Esse intervalo não pode ser configurado pelo usuário.
- disableport - desativa a porta até que você a abra manualmente.
- disableport-temporarily-Desabilita a porta por um período de tempo. O período pode ser configurado com o comando port-security timer disableport.
Restrições e diretrizes
Em uma porta operando no modo macAddressElseUserLoginSecure ou no modo macAddressElseUserLoginSecureExt, a proteção contra intrusão é acionada somente depois que a autenticação MAC e a autenticação 802.1X falharem no mesmo quadro.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-number- Configure o recurso de proteção contra intrusão.
port-security intrusion-mode { blockmac | disableport |
disableport-temporarily }Por padrão, a proteção contra intrusão está desativada.
- (Opcional.) Defina o período de tempo limite de silêncio durante o qual uma porta permanece desativada.
- quit
- port-security timer disableport time-value
Por padrão, o período de tempo limite de silêncio da porta é de 20 segundos.
Ignorar informações de autorização do servidor
Sobre ignorar informações de autorização do servidor
É possível configurar uma porta para ignorar as informações de autorização recebidas do servidor (local ou remoto) depois que um usuário de autenticação 802.1X ou MAC for aprovado na autenticação.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-number- Ignorar as informações de autorização recebidas do servidor de autenticação.
port-security authorization ignorePor padrão, uma porta usa as informações de autorização recebidas do servidor de autenticação.
Configuração da movimentação de MAC
Sobre a mudança da MAC
O movimento MAC de segurança de porta entra em vigor nos seguintes cenários:
- Movimentação entre portas em um dispositivo - Um usuário on-line autenticado por meio da autenticação 802.1X ou MAC se movimenta entre as portas do dispositivo. A VLAN do usuário ou o método de autenticação pode mudar ou permanecer inalterado após a mudança.
- Movimentação inter-VLAN em uma porta - Um usuário on-line autenticado por meio da autenticação 802.1X ou MAC se movimenta entre VLANs em uma porta híbrida ou tronco. Além disso, os pacotes que acionam a autenticação têm tags de VLAN.
O Port Security MAC move permite que um usuário on-line autenticado por meio da autenticação 802.1X ou MAC em uma porta ou VLAN seja reautenticado e fique on-line em outra porta ou VLAN sem ficar off-line primeiro. Depois que o usuário passa pela autenticação na nova porta ou VLAN, o sistema remove a sessão de autenticação do usuário na porta ou VLAN original.
OBSERVAÇÃO:
Para a autenticação MAC, o recurso de movimentação de MAC aplica-se somente quando o modo de autenticação MAC de VLAN única é usado. O recurso de movimentação de MAC não se aplica a usuários de autenticação de MAC que se movimentam entre VLANs em uma porta com o modo multi-VLAN de autenticação de MAC ativado.
Se esse recurso estiver desativado, os usuários autenticados por 802.1X ou MAC deverão ficar off-line antes de poderem ser reautenticados com êxito em uma nova porta ou VLAN para ficar on-line.
Para um usuário que se desloca entre portas, a porta da qual o usuário se desloca é chamada de porta de origem e a porta para a qual o usuário se desloca é chamada de porta de destino.
Na porta de destino, um usuário de autenticação 802.1X ou MAC será reautenticado na VLAN autorizada na porta de origem se a porta de origem estiver habilitada com VLAN baseada em MAC. Se essa VLAN não tiver permissão para passar pela porta de destino, a reautenticação falhará. Para evitar essa situação, ative o desvio de verificação de VLAN na porta de destino. Esse recurso ignora a verificação das informações de VLAN em os pacotes que acionam a autenticação 802.1X ou a autenticação MAC para os usuários que se deslocam para a porta.
Restrições e diretrizes
Como prática recomendada para minimizar os riscos de segurança, ative o MAC move somente se for necessário o roaming do usuário entre as portas.
- Os usuários autenticados por X ou MAC não podem se mover entre portas em um dispositivo ou entre VLANs em uma porta se o número máximo de usuários on-line no servidor de autenticação tiver sido atingido.
O modo multi-VLAN de autenticação MAC tem prioridade mais alta do que o MAC move para usuários que se deslocam entre VLANs em uma porta. Se o modo multi-VLAN de autenticação MAC estiver ativado, esses usuários poderão ficar on-line na nova VLAN sem serem reautenticados. Para ativar o modo multi-VLAN de autenticação MAC, use o comando mac-authentication host-mode multi-vlan. Para obter mais informações sobre o modo multi-VLAN de autenticação MAC, consulte "Configuração da autenticação MAC".
Ao configurar o desvio de verificação de VLAN para usuários que se deslocam entre portas, siga estas diretrizes:
- Para garantir uma reautenticação bem-sucedida, ative o desvio de verificação de VLAN em uma porta de destino se a porta de origem estiver ativada com VLAN baseada em MAC.
- Se a porta de destino for uma porta tronco habilitada para 802.1X, você deverá configurá-la para enviar pacotes do protocolo 802.1X sem tags de VLAN. Para obter mais informações, consulte "Configuração do 802.1X".
Procedimento
- Entre na visualização do sistema.
system view- Habilitar a movimentação de MAC.
port-security mac-move permitPor padrão, a movimentação de MAC está desativada.
- (Opcional.) Ative o bypass de verificação de VLAN na porta para os usuários que se deslocam para ela.
- Entre na visualização da interface.
interface interface-type interface-number- Ativar o desvio de verificação de VLAN.
port-security mac-move bypass-vlan-checkPor padrão, o recurso de desvio de verificação de VLAN está desativado.
Esse comando é compatível apenas com a versão 6318P01 e posteriores.
Ativação do recurso authorization-fail-offline
Sobre o recurso authorization-fail-offline
IMPORTANTE:
O recurso authorization-fail-offline entra em vigor somente nos usuários de segurança de porta que falharam na autorização de ACL ou de perfil de usuário.
O recurso authorization-fail-offline faz o logoff dos usuários do port security que não obtiveram autorização. Um usuário falha na autorização nas seguintes situações:
- O dispositivo ou servidor não consegue atribuir o atributo de autorização especificado ao usuário.
- O dispositivo ou servidor atribui ao usuário informações de autorização que não existem no dispositivo.
Esse recurso não se aplica a usuários que não obtiveram autorização de VLAN. O dispositivo faz o logoff desses usuários diretamente.
Você também pode ativar o recurso de quiet timer para usuários de autenticação 802.1X ou MAC que foram desconectados pelo recurso authorization-fail-offline. O dispositivo adiciona esses usuários à fila de silêncio da autenticação 802.1X ou MAC. Dentro do quiet timer, o dispositivo não processa os pacotes desses usuários nem os autentica. Se você não ativar o recurso quiet timer, o dispositivo imediatamente autenticará esses usuários ao receber pacotes deles.
Pré-requisitos
Para que o recurso do timer de silêncio entre em vigor, conclua as seguintes tarefas:
- Para usuários 802.1X, use o comando dot1x quiet-period para ativar o timer de silêncio e use o comando dot1x timer quiet-period para definir o timer.
- Para usuários de autenticação MAC, use o comando mac-authentication timer quiet para definir o timer de silêncio para a autenticação MAC.
Procedimento
- Entre na visualização do sistema.
system view- Habilite o recurso authorization-fail-offline.
port-security authorization-fail offline [ quiet-period ]Por padrão, esse recurso está desativado e o dispositivo não faz logoff dos usuários que não obtiveram autorização.
Definição do limite de segurança da porta quanto ao número de endereços MAC para VLANs específicas em uma porta
Sobre o limite do port security no número de endereços MAC para VLANs específicas em uma porta
Normalmente, a segurança da porta permite o acesso dos seguintes tipos de endereços MAC em uma porta:
- Endereços MAC que passam pela autenticação 802.1X ou MAC.
- Endereços MAC na VLAN de convidado de autenticação MAC ou na VLAN crítica de autenticação MAC.
- Endereços MAC na VLAN de convidado 802.1X, na VLAN 802.1X Auth-Fail ou na VLAN crítica 802.1X.
Esse recurso limita o número de endereços MAC que a segurança da porta permite acessar em uma porta por meio de VLANs específicas. Use esse recurso para evitar disputas de recursos entre endereços MAC e garantir um desempenho confiável para cada usuário de acesso na porta. Quando o número de endereços MAC em uma VLAN na porta atinge o limite superior, o dispositivo nega qualquer endereço MAC subsequente em a VLAN na porta.
Restrições e diretrizes
Em uma porta, o número máximo de endereços MAC em uma VLAN não pode ser menor do que o número de endereços MAC existentes na VLAN. Se o número máximo especificado for menor, a configuração não terá efeito.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-number- Definir o limite de segurança da porta para o número de endereços MAC para VLANs específicas na porta.
port-security mac-limit max-number per-vlan vlan-id-list
A configuração padrão é 2147483647.
Ativação do modo de autenticação aberta
Sobre o modo de autenticação aberta
Esse recurso permite que os usuários de acesso (usuários de autenticação 802.1X ou MAC) de uma porta fiquem on-line e acessem a rede, mesmo que usem nomes de usuário inexistentes ou senhas incorretas.
Os usuários de acesso que ficam on-line no modo de autenticação aberta são chamados de usuários abertos. A autorização e a contabilidade não estão disponíveis para usuários abertos. Para exibir informações sobre usuários abertos, use os seguintes comandos:
- exibir conexão dot1x aberta.
- exibir conexão de autenticação mac aberta.
Esse recurso não afeta o acesso de usuários que usam informações de usuário corretas.
Restrições e diretrizes
Quando você configurar o modo de autenticação aberta, siga estas restrições e diretrizes:
- Se o modo de autenticação aberta global estiver ativado, todas as portas serão ativadas com o modo de autenticação aberta, independentemente da configuração do modo de autenticação aberta específica da porta. Se o modo de autenticação aberta global estiver desativado, o fato de uma porta estar ativada com o modo de autenticação aberta depende da configuração do modo de autenticação aberta específica da porta.
- A configuração do modo de autenticação aberta tem prioridade mais baixa do que a VLAN 802.1X Auth-Fail e a VLAN de convidado de autenticação MAC. O modo de autenticação aberta não entrará em vigor em uma porta se ela também estiver configurada com a VLAN 802.1X Auth-Fail ou com a VLAN guest de autenticação MAC. Para obter informações sobre a autenticação 802.1X e a autenticação MAC, consulte "Visão geral do 802.1X", "Configuração do 802.1X" e "Configuração da autenticação MAC".
Procedimento
- Entre na visualização do sistema.
system view- Ativar o modo de autenticação aberta global.
display dot1x connection openPor padrão, o modo de autenticação aberta global está desativado.
- Entre na visualização da interface.
interface interface-type interface-number- Ativar o modo de autenticação aberta na porta.
display mac-authentication connection openPor padrão, o modo de autenticação aberta está desativado em uma porta.
Configuração de VLANs livres para segurança da porta
Sobre esta tarefa
Esse recurso permite que os pacotes das VLANs especificadas não acionem a autenticação 802.1X ou MAC em uma porta configurada com qualquer um dos seguintes recursos:
- Autenticação 802.1X.
- Autenticação MAC.
- Um dos seguintes modos de segurança de porta:
- userLogin.
- userLoginSecure.
- userLoginWithOUI.
- userLoginSecureExt.
- macAddressWithRadius.
- macAddressOrUserLoginSecure.
- macAddressElseUserLoginSecure.
- macAddressOrUserLoginSecureExt.
- macAddressElseUserLoginSecureExt.
Compatibilidade de software e recursos
Esse recurso é compatível apenas com a versão 6328 e posteriores.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-number- Configure VLANs livres para a segurança da porta.
port-security free-vlan vlan-id-listPor padrão, não há VLANs livres para segurança de porta em uma porta.
Aplicação de um perfil NAS-ID à segurança da porta
Sobre os perfis NAS-ID
Por padrão, o dispositivo envia o nome do dispositivo no atributo NAS-Identifier de todas as solicitações RADIUS.
Um perfil NAS-ID permite que você envie diferentes cadeias de atributos NAS-Identifier em solicitações RADIUS de diferentes VLANs. As cadeias de caracteres podem ser nomes de organizações, nomes de serviços ou qualquer critério de categorização de usuários, dependendo dos requisitos administrativos.
Por exemplo, mapeie o NAS-ID companyA para todas as VLANs da empresa A. O dispositivo enviará companyA no atributo NAS-Identifier para que o servidor RADIUS identifique as solicitações de qualquer usuário da empresa A.
Restrições e diretrizes
Você pode aplicar um perfil NAS-ID à segurança da porta globalmente ou em uma porta. Em uma porta, o dispositivo seleciona um perfil NAS-ID na seguinte ordem:
- O perfil NAS-ID específico da porta.
- O perfil NAS-ID aplicado globalmente.
Se nenhum perfil de NAS-ID for aplicado ou se nenhuma associação correspondente for encontrada no perfil selecionado, o dispositivo usará o nome do dispositivo como NAS-ID.
Para obter mais informações sobre a configuração do perfil NAS-ID, consulte "Configuração de AAA".
Procedimento
- Entre na visualização do sistema.
system view- Aplicar um perfil NAS-ID.
- Aplique um perfil NAS-ID globalmente.
port-security nas-id-profile profile-name- Execute os seguintes comandos em sequência para aplicar um perfil NAS-ID a uma interface:
interface interface-type interface-numberport-security nas-id-profile profile-namePor padrão, nenhum perfil NAS-ID é aplicado na visualização do sistema ou na visualização da interface.
Ativação de estatísticas de tráfego para autenticação MAC e usuários 802.1X
Sobre esta tarefa
Por padrão, as estatísticas de usuários de autenticação 802.1X e MAC coletadas e enviadas ao servidor de contabilidade incluem apenas a duração on-line dos usuários. Para coletar e enviar suas estatísticas de tráfego para o servidor de contabilidade, além da duração on-line, execute esta tarefa.
Esse recurso entra em vigor para os usuários de autenticação 802.1X e MAC quando a segurança da porta está ativada ou quando a autenticação 802.1X e MAC estão ativadas separadamente no dispositivo.
Se uma porta executar a autenticação MAC ou a autenticação 802.1X no modo de controle de acesso baseado em MAC, esse recurso coletará estatísticas de tráfego de usuários por MAC na porta.
Se uma porta executar a autenticação 802.1X no modo de controle de acesso baseado em porta, esse recurso coletará estatísticas de tráfego de usuários por porta.
Com esse recurso ativado, o dispositivo requer mais recursos de ACL para novos usuários de autenticação 802.1X ou MAC. Se o dispositivo ficar sem recursos de ACL, a autenticação falhará para novos usuários de autenticação 802.1X ou MAC.
Restrições e diretrizes
Esse recurso está disponível na versão 6312 e posteriores.
Esse recurso entra em vigor apenas para os usuários que ficam on-line depois que o recurso é ativado.
Ative esse recurso somente se a contabilização do tráfego for necessária e somente se houver recursos suficientes de ACL. Se a rede tiver um grande número de usuários de autenticação 802.1X e MAC on-line quando esse recurso estiver ativado, os recursos de ACL poderão se tornar insuficientes. Esse problema causa falha na autenticação de novos usuários de autenticação 802.1X e MAC. Para obter mais informações sobre a autenticação 802.1X e MAC, consulte "Configuração do 802.1X" e "Configuração da autenticação MAC".
Procedimento
- Entre na visualização do sistema.
system view- Habilite as estatísticas de tráfego para usuários de autenticação 802.1X e MAC.
port-security traffic-statistics enablePor padrão, o dispositivo não coleta estatísticas de tráfego para usuários de autenticação 802.1X e MAC.
Especificar um endereço IP e uma máscara para calcular o IP de origem dos pacotes de detecção de ARP
Sobre esta tarefa
Por padrão, o dispositivo usa 0.0.0.0 como endereço IP de origem dos pacotes de detecção de ARP. A rede pode ter usuários que não conseguem responder aos pacotes de detecção de ARP com o endereço IP de origem 0.0.0.0. Como resultado, o dispositivo determina inadequadamente que esses usuários ficaram off-line. Para resolver o problema, use esse recurso para especificar um endereço IP e uma máscara para calcular o IP de origem dos pacotes de detecção de ARP enviados a um usuário em conjunto com o endereço IP do usuário.
O dispositivo usa a seguinte fórmula para calcular o endereço IP de origem dos pacotes de detecção de ARP: IP de origem = (IP do usuário e máscara especificada) | (IP especificado e ~máscara especificada). O parâmetro ~máscara representa o inverso de uma máscara. Por exemplo, a máscara inversa de 255.255.255.0 é 0.0.0.255. Se o endereço IP de um usuário for 192.168.8.1/24 e o endereço IP e a máscara especificados pelo uso desse recurso forem 1.1.1.11/255.255.255.0, o endereço IP de origem dos pacotes de detecção de ARP será 192.168.8.11/24.
Compatibilidade de recursos e versões de software
Esse recurso é compatível apenas com a versão 6348P01 e posteriores.
Restrições e diretrizes
Esse recurso entra em vigor apenas para os usuários que ficam on-line depois que ele é configurado.
Procedimento
- Entre na visualização do sistema.
system view- Especifique um endereço IP e uma máscara para calcular o IP de origem dos pacotes de detecção de ARP.
port-security packet-detect arp-source-ip factor ip-address { mask
| mask-length }Por padrão, nenhum endereço IP ou máscara é especificado para calcular o IP de origem dos pacotes de detecção de ARP. O IP de origem dos pacotes de detecção de ARP é 0.0.0.0.
Ativação de notificações SNMP para segurança da porta
Sobre as notificações SNMP para segurança de porta
Use esse recurso para relatar eventos críticos de segurança de porta a um NMS. Para que as notificações de eventos de segurança de porta sejam enviadas corretamente, você também deve configurar o SNMP no dispositivo. Para obter mais informações sobre a configuração de SNMP, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
system view- Habilite as notificações SNMP para segurança da porta.
snmp-agent trap enable port-security [ address-learned | dot1x-failure | dot1x-logoff | dot1x-logon | intrusion | mac-auth-failure | mac-auth-logoff | mac-auth-logon ] *Por padrão, as notificações de SNMP são desativadas para a segurança da porta.
Ativação do registro de usuário de segurança de porta
Sobre o registro de usuários de segurança de porta
Esse recurso permite que o dispositivo gere logs sobre os usuários de segurança de porta e envie os logs para o centro de informações. Para que os logs sejam gerados corretamente, você também deve configurar o centro de informações no dispositivo. Para obter mais informações sobre a configuração da central de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Restrições e diretrizes
Para evitar entradas excessivas de registro de usuário de segurança de porta, use esse recurso somente se precisar analisar eventos anormais de usuário de segurança de porta.
Procedimento
- Entre na visualização do sistema.
system view- Habilite o registro de usuário de segurança da porta.
port-security access-user log enable [ failed-authorization | mac-learning | violation | vlan-mac-limit ] *Por padrão, o registro de usuário de segurança de porta está desativado.
Se você não especificar nenhum parâmetro, esse comando habilitará todos os tipos de logs de usuário de segurança de porta.
Comandos de exibição e manutenção para segurança de porta
Executar comandos de exibição em qualquer visualização:
| Tarefa | Comando |
| Exibir a configuração de segurança da porta, as informações de operação e as estatísticas. | exibir port-security [ interface interface-type interface-number ] |
| Exibir informações sobre endereços MAC bloqueados. | display port-security mac-address block [ tipo de interface |
| Tarefa | Comando |
| interface-número ] [ vlan vlan-id ] [ count ] | |
| Exibir informações sobre endereços MAC seguros. | display port-security mac-address security [ tipo de interface interface-número ] [ vlan vlan-id ] [ count ] |
Exemplos de configuração de segurança de porta
Exemplo: Configuração da segurança da porta no modo autoLearn
Configuração de rede
Conforme mostrado na Figura 1, configure a GigabitEthernet 1/0/1 no dispositivo para atender aos seguintes requisitos:
- Aceite até 64 usuários sem autenticação.
- Ter permissão para aprender e adicionar endereços MAC como endereços MAC fixos e definir o cronômetro de envelhecimento seguro do MAC para 30 minutos.
- Pare de aprender os endereços MAC quando o número de endereços MAC seguros chegar a 64. Se chegar algum quadro com um endereço MAC desconhecido, a proteção contra intrusão será iniciada e a porta será desligada e permanecerá em silêncio por 30 segundos.
Figura 1 Diagrama de rede
Procedimento
# Ativar a segurança da porta.
<Device> system-view
[Device] port-security enable# Defina o cronômetro de envelhecimento do MAC seguro para 30 minutos.
[Device] port-security timer autolearn aging 30# Defina o limite da segurança da porta para o número de endereços MAC seguros como 64 na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] port-security max-mac-count 64# Defina o modo de segurança da porta como autoLearn.
[Device-GigabitEthernet1/0/1] port-security port-mode autolearn
# Configure a porta para ficar em silêncio por 30 segundos depois que o recurso de proteção contra intrusão for acionado.
[Device-GigabitEthernet1/0/1] port-security intrusion-mode disableport-temporarily
[Device-GigabitEthernet1/0/1] quit
[Device] port-security timer disableport 30
Verificação da configuração
# Verificar a configuração de segurança da porta.
[Device] display port-security interface gigabitethernet 1/0/1
Global port security parameters:
Port security : Enabled
AutoLearn aging time : 30 min
Disableport timeout : 30 s
Blockmac timeout : 180 s
MAC move : Denied
Authorization fail : Online
NAS-ID profile : Not configured
Dot1x-failure trap : Disabled
Dot1x-logon trap : Disabled
Dot1x-logoff trap : Disabled
Intrusion trap : Disabled
Address-learned trap : Disabled
Mac-auth-failure trap : Disabled
Mac-auth-logon trap : Disabled
Mac-auth-logoff trap : Disabled
Open authentication : Disabled
OUI value list :
Index : 1 Value : 123401
GigabitEthernet1/0/1 is link-up
Port mode : autoLearn
NeedToKnow mode : Disabled
Intrusion protection mode : DisablePortTemporarily
Security MAC address attribute
Learning mode : Sticky
Aging type : Periodical
Max secure MAC addresses : 64
Current secure MAC addresses : 0
Authorization : Permitted
NAS-ID profile : Not configured
Free VLANs : Not configured
Open authentication : Disabled
MAC-move VLAN check bypass : Disabled
A porta permite o aprendizado de endereços MAC, e você pode visualizar o número de endereços MAC aprendidos no campo Current secure MAC addresses (Endereços MAC seguros atuais).
# Exibir informações adicionais sobre os endereços MAC aprendidos.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] display this
#
interface GigabitEthernet1/0/1
port-security max-mac-count 64
port-security port-mode autolearn
port-security mac-address security sticky 0002-0000-0015 vlan 1
port-security mac-address security sticky 0002-0000-0014 vlan 1
20
port-security mac-address security sticky 0002-0000-0013 vlan 1
port-security mac-address security sticky 0002-0000-0012 vlan 1
port-security mac-address security sticky 0002-0000-0011 vlan 1
#
[Device-GigabitEthernet1/0/1] quit
# Verifique se o modo de segurança da porta muda para seguro depois que o número de endereços MAC aprendidos pela porta chega a 64.
[Device] display port-security interface gigabitethernet 1/0/1# Verifique se a porta será desativada por 30 segundos após receber um quadro com um endereço MAC desconhecido. (Detalhes não mostrados.)
# Depois que a porta for reativada, exclua vários endereços MAC seguros.
[Device] undo port-security mac-address security sticky 0002-0000-0015 vlan 1
[Device] undo port-security mac-address security sticky 0002-0000-0014 vlan 1
...# Verifique se o modo de segurança da porta muda para autoLearn e se a porta pode aprender os endereços MAC novamente. (Detalhes não mostrados.)
Exemplo: Configuração da segurança da porta no modo userLoginWithOUI
Configuração de rede
Conforme mostrado na Figura 2, um cliente está conectado ao dispositivo por meio da GigabitEthernet 1/0/1. O dispositivo autentica o cliente com um servidor RADIUS no domínio sun do ISP. Se a autenticação for bem-sucedida, o cliente estará autorizado a acessar a Internet.
- O servidor RADIUS em 192.168.1.2 atua como o servidor de autenticação primário e o servidor de contabilidade secundário. O servidor RADIUS em 192.168.1.3 atua como servidor de autenticação secundário e servidor de contabilidade primário. A chave compartilhada para autenticação é name, e a chave compartilhada para contabilidade é money.
- Todos os usuários usam os métodos de autenticação, autorização e contabilidade do domínio sun do ISP.
- O tempo limite de resposta do servidor RADIUS é de 5 segundos. O número máximo de tentativas de retransmissão de pacotes RADIUS é 5. O dispositivo envia pacotes de contabilidade em tempo real para o servidor RADIUS em intervalos de 15 minutos e envia nomes de usuário sem nomes de domínio para o servidor RADIUS.
Configure a GigabitEthernet 1/0/1 para permitir a autenticação de apenas um usuário 802.1X e de um usuário que use um dos valores OUI especificados.
Figura 2 Diagrama de rede
Procedimento
As etapas de configuração a seguir abrangem alguns comandos de configuração AAA/RADIUS. Para obter mais informações sobre os comandos, consulte Referência de comandos de segurança.
Certifique-se de que o host e o servidor RADIUS possam se comunicar.
- Configurar AAA:
# Configure um esquema RADIUS chamado radsun.
<Device> system-view
[Device] radius scheme radsun
[Device-radius-radsun] primary authentication 192.168.1.2
[Device-radius-radsun] primary accounting 192.168.1.3
[Device-radius-radsun] secondary authentication 192.168.1.3
[Device-radius-radsun] secondary accounting 192.168.1.2
[Device-radius-radsun] key authentication simple name
[Device-radius-radsun] key accounting simple money
[Device-radius-radsun] timer response-timeout 5
[Device-radius-radsun] retry 5
[Device-radius-radsun] timer realtime-accounting 15
[Device-radius-radsun] user-name-format without-domain
[Device-radius-radsun] quit# Configurar o domínio sun do ISP.
[Device] domain sun
[Device-isp-sun] authentication lan-access radius-scheme radsun
[Device-isp-sun] authorization lan-access radius-scheme radsun
[Device-isp-sun] accounting lan-access radius-scheme radsun
[Device-isp-sun] quit- Configurar o 802.1X:
# Defina o método de autenticação 802.1X como CHAP. Por padrão, o método de autenticação para 802.1X é CHAP.
[Device] dot1x authentication-method chap# Especifique o domínio sun do ISP como o domínio de autenticação obrigatório para usuários 802.1X na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] dot1x mandatory-domain sun
[Device-GigabitEthernet1/0/1] quit- Configurar a segurança da porta:
# Ativar a segurança da porta.
[Device] port-security enable# Adicione cinco valores de OUI. (Você pode adicionar até 16 valores de OUI. A porta permite que apenas um usuário correspondente a uma das OUIs passe pela autenticação).
[Device] port-security oui index 1 mac-address 1234-0100-1111
[Device] port-security oui index 2 mac-address 1234-0200-1111
[Device] port-security oui index 3 mac-address 1234-0300-1111
[Device] port-security oui index 4 mac-address 1234-0400-1111
[Device] port-security oui index 5 mac-address 1234-0500-1111Verificação da configuração
# Verifique se a GigabitEthernet 1/0/1 permite que apenas um usuário 802.1X seja autenticado.
[Device] display port-security interface gigabitethernet 1/0/1
Global port security parameters:
Port security : Enabled
AutoLearn aging time : 30 min
Disableport timeout : 30 s
Blockmac timeout : 180 s
MAC move : Denied
Authorization fail : Online
NAS-ID profile : Not configured
Dot1x-failure trap : Disabled
Dot1x-logon trap : Disabled
Dot1x-logoff trap : Disabled
Intrusion trap : Disabled
Address-learned trap : Disabled
Mac-auth-failure trap : Disabled
Mac-auth-logon trap : Disabled
Mac-auth-logoff trap : Disabled
Open authentication : Disabled
OUI value list :
Index : 1 Value : 123401
Index : 2 Value : 123402
Index : 3 Value : 123403
Index : 4 Value : 123404
Index : 5 Value : 123405
GigabitEthernet1/0/1 is link-up
Port mode : userLoginWithOUI
NeedToKnow mode : Disabled
Intrusion protection mode : NoAction
Security MAC address attribute
Learning mode : Sticky
Aging type : Periodical
Max secure MAC addresses : Not configured
Current secure MAC addresses : 1
Authorization :Permitted
NAS-ID profile : Not configured
Free VLANs : Not configured
Open authentication : Disabled
MAC-move VLAN check bypass : Disabled# Exibir informações sobre o usuário 802.1X on-line para verificar a configuração 802.1X.
[Device] display dot1x# Verifique se a porta também permite que um usuário cujo endereço MAC tenha uma OUI entre as OUIs especificadas passe na autenticação.
[Device] display mac-address interface gigabitethernet 1/0/1
MAC Address VLAN ID State Port/NickName Aging
1234-0300-0011 1 Learned GE1/0/1 Y
Exemplo: Configuração da segurança da porta no modo macAddressElseUserLoginSecure
Configuração de rede
Conforme mostrado na Figura 3, um cliente está conectado ao dispositivo por meio da GigabitEthernet 1/0/1. O dispositivo autentica o cliente por um servidor RADIUS no domínio sun do ISP. Se a autenticação for bem-sucedida, o cliente estará autorizado a acessar a Internet.
Configure a GigabitEthernet 1/0/1 do dispositivo para atender aos seguintes requisitos:
- Permitir que mais de um usuário autenticado por MAC faça logon.
- Para usuários 802.1X, execute primeiro a autenticação MAC e, em seguida, se a autenticação MAC falhar,
Autenticação 802.1X. Permitir que apenas um usuário 802.1X faça logon.
- Use o endereço MAC de cada usuário como nome de usuário e senha para autenticação MAC. Os endereços MAC estão em notação hexadecimal com hífens e as letras estão em maiúsculas.
- Defina o número total de usuários autenticados por MAC e usuários autenticados por 802.1X como 64.
- Habilite o NTK (modo ntkonly) para evitar o envio de quadros para endereços MAC desconhecidos.
Figura 3 Diagrama de rede
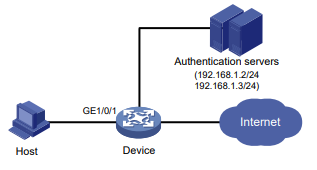
Procedimento
Certifique-se de que o host e o servidor RADIUS possam se comunicar.
- Configure a autenticação/contabilidade RADIUS e as configurações de domínio do ISP. (Consulte "Exemplo: Configuração da segurança da porta no modo userLoginWithOUI").
- Configurar a segurança da porta: # Habilitar a segurança da porta.
<Device> system-view
[Device] port-security enable# Use o endereço MAC de cada usuário como nome de usuário e senha para autenticação MAC. Os endereços MAC estão em notação hexadecimal com hífens e as letras estão em maiúsculas.
[Device] mac-authentication user-name-format mac-address with-hyphen uppercase# Especifique o domínio de autenticação MAC.
[Device] mac-authentication domain sun# Defina o método de autenticação 802.1X como CHAP. Por padrão, o método de autenticação para 802.1X é CHAP.
[Device] dot1x authentication-method chap# Defina o limite da segurança da porta para o número de endereços MAC para 64 na porta.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] port-security max-mac-count 64# Defina o modo de segurança da porta como macAddressElseUserLoginSecure.
[Device-GigabitEthernet1/0/1] port-security port-mode mac-else-userlogin-secure# Defina o modo NTK da porta como ntkonly.
[Device-GigabitEthernet1/0/1] port-security ntk-mode ntkonly
[Device-GigabitEthernet1/0/1] quitVerificação da configuração
# Verificar a configuração de segurança da porta.
[Device] display port-security interface gigabitethernet 1/0/1
Global port security parameters:
Port security : Enabled
AutoLearn aging time : 30 min
Disableport timeout : 30 s
Blockmac timeout : 180 s
MAC move : Denied
Authorization fail : Online
NAS-ID profile : Not configured
Dot1x-failure trap : Disabled
Dot1x-logon trap : Disabled
Dot1x-logoff trap : Disabled
Intrusion trap : Disabled
Address-learned trap : Disabled
Mac-auth-failure trap : Disabled
Mac-auth-logon trap : Disabled
Mac-auth-logoff trap : Disabled
Open authentication : Disabled
OUI value list
GigabitEthernet1/0/1 is link-up
Port mode : macAddressElseUserLoginSecure
NeedToKnow mode : NeedToKnowOnly
Intrusion protection mode : NoAction
Security MAC address attribute
Learning mode : Sticky
Aging type : Periodical
Max secure MAC addresses : 64
Current secure MAC addresses : 0
Authorization : Permitted
NAS-ID profile : Not configured
Free VLANs : Not configured
Open authentication : Disabled
MAC-move VLAN check bypass : Disabled# Depois que os usuários passarem pela autenticação, exiba as informações de autenticação MAC. Verifique se a GigabitEthernet 1/0/1 permite que vários usuários de autenticação MAC sejam autenticados.
[Device] display mac-authentication interface gigabitethernet 1/0/1
Global MAC authentication parameters:
MAC authentication : Enabled
Authentication method : PAP
User name format : MAC address in uppercase(XX-XX-XX-XX-XX-XX)
Username : mac
Password : Not configured
Offline detect period : 300 s
Quiet period : 180 s
Server timeout : 100 s
Reauth period : 3600 s
User aging period for critical VLAN : 1000 s
User aging period for guest VLAN : 1000 s
Authentication domain : sun
Online MAC-auth wired users : 3
Silent MAC users:
MAC address VLAN ID From port Port index
GigabitEthernet1/0/1 is link-up
MAC authentication : Enabled
Carry User-IP : Disabled
Authentication domain : Not configured
Auth-delay timer : Disabled
Periodic reauth : Disabled
Re-auth server-unreachable : Logoff
Guest VLAN : Not configured
Guest VLAN auth-period : 30 s
Critical VLAN : Not configured
Critical voice VLAN : Disabled
Host mode : Single VLAN
Offline detection : Enabled
Authentication order : Default
User aging : Enabled
Server-recovery online-user-sync : Enabled
Auto-tag feature : Disabled
VLAN tag configuration ignoring : Disabled
Max online users : 4294967295
Authentication attempts : successful 3, failed 7
Current online users : 3
MAC address Auth state
1234-0300-0011 Authenticated
1234-0300-0012 Authenticated
1234-0300-0013 Authenticated# Exibir informações de autenticação 802.1X. Verifique se a GigabitEthernet 1/0/1 permite apenas um
[Device] display dot1x interface gigabitethernet 1/0/1
Global 802.1X parameters:
802.1X authentication : Enabled
CHAP authentication : Enabled
26
Max-tx period : 30 s
Handshake period : 15 s
Quiet timer : Disabled
Quiet period : 60 s
Supp timeout : 30 s
Server timeout : 100 s
Reauth period : 3600 s
Max auth requests : 2
User aging period for Auth-Fail VLAN : 1000 s
User aging period for critical VLAN : 1000 s
User aging period for guest VLAN : 1000 s
EAD assistant function : Disabled
EAD timeout : 30 min
Domain delimiter : @
Online 802.1X wired users : 1
GigabitEthernet1/0/1 is link-up
802.1X authentication : Enabled
Handshake : Enabled
Handshake reply : Disabled
Handshake security : Disabled
Unicast trigger : Disabled
Periodic reauth : Disabled
Port role : Authenticator
Authorization mode : Auto
Port access control : MAC-based
Multicast trigger : Enabled
Mandatory auth domain : sun
Guest VLAN : Not configured
Auth-Fail VLAN : Not configured
Critical VLAN : Not configured
Critical voice VLAN : Disabled
Add Guest VLAN delay : Disabled
Re-auth server-unreachable : Logoff
Max online users : 4294967295
User IP freezing : Disabled
Reauth period : 60 s
Send Packets Without Tag : Disabled
Max Attempts Fail Number : 0
User aging : Enabled
Server-recovery online-user-sync : Enabled
EAPOL packets: Tx 16331, Rx 102
Sent EAP Request/Identity packets : 16316
EAP Request/Challenge packets: 6
EAP Success packets: 4
EAP Failure packets: 5
Received EAPOL Start packets : 6
27
EAPOL LogOff packets: 2
EAP Response/Identity packets : 80
EAP Response/Challenge packets: 6
Error packets: 0
Online 802.1X users: 1
MAC address Auth state
0002-0000-0011 Authenticated# Verifique se os quadros com endereço MAC de destino desconhecido, endereço multicast ou endereço de broadcast são descartados. (Detalhes não mostrados.)
Solução de problemas de segurança da porta
Não é possível definir o modo de segurança da porta
Sintoma
Não é possível definir o modo de segurança da porta para uma porta.
Análise
Para uma porta que esteja operando em um modo de segurança de porta diferente de noRestrictions, não é possível alterar o modo de segurança da porta usando o comando port-security port-mode.
Solução
Para resolver o problema:
- Defina o modo de segurança da porta como noRestrictions.
[Device-GigabitEthernet1/0/1] undo port-security port-mode- Defina um novo modo de segurança de porta para a porta, por exemplo, autoLearn.
[Device-GigabitEthernet1/0/1] port-security port-mode autolearn- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Não é possível configurar endereços MAC seguros
Sintoma
Não é possível configurar endereços MAC seguros.
Análise
Nenhum endereço MAC seguro pode ser configurado em uma porta que esteja operando em um modo de segurança de porta diferente de autoLearn.
Solução
Para resolver o problema:
- Defina o modo de segurança da porta como autoLearn.
[Device-GigabitEthernet1/0/1] undo port-security port-mode
[Device-GigabitEthernet1/0/1] port-security max-mac-count 64
[Device-GigabitEthernet1/0/1] port-security port-mode autolearn
[Device-GigabitEthernet1/0/1] port-security mac-address security 1-1-2 vlan 1- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Configuração de perfis de usuário
Sobre perfis de usuário
Um perfil de usuário define um conjunto de parâmetros, como uma política de QoS, para um usuário ou uma classe de usuários. Um perfil de usuário pode ser reutilizado quando um usuário se conecta à rede em uma interface diferente.
O aplicativo de perfil de usuário permite o policiamento flexível do tráfego por usuário. Sempre que um usuário passa pela autenticação, o servidor envia ao dispositivo o nome do perfil de usuário especificado para o usuário. O dispositivo aplica os parâmetros do perfil de usuário ao usuário.
Os perfis de usuário são normalmente usados para alocação de recursos por usuário. Por exemplo, o policiamento de tráfego baseado em interface limita a quantidade total de largura de banda disponível para um grupo de usuários. No entanto, o policiamento de tráfego baseado no perfil do usuário pode limitar a quantidade de largura de banda disponível para um único usuário.
Pré-requisitos para o perfil de usuário
Um perfil de usuário funciona com métodos de autenticação. Você deve configurar a autenticação para um perfil de usuário. Para obter informações sobre os métodos de autenticação compatíveis, consulte os guias de configuração dos módulos de autenticação relacionados em .
Configuração de um perfil de usuário
- Entre na visualização do sistema.
system view- Crie um perfil de usuário e entre na visualização do perfil de usuário.
user-profile profile-name- Aplique uma política de QoS existente ao perfil do usuário.
qos apply policy policy-name { inbound | outbound }Por padrão, nenhuma política de QoS é aplicada a um perfil de usuário.
Para obter informações sobre políticas de QoS, consulte o Guia de configuração de ACL e QoS.
Comandos de exibição e manutenção de perfis de usuário
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações de configuração e de usuário on-line para o perfil de usuário especificado ou para todos os perfis de usuário. | display user-profile [ name profile-name ] [ slot slot-number ] |
Exemplos de configuração de perfil de usuário
Exemplo: Configuração de perfis de usuário e políticas de QoS
Requisitos de rede
Conforme mostrado na Figura 1, o dispositivo executa a autenticação 802.1X local nos usuários do domínio user
para eficiência de autenticação e autorização.
Configure perfis de usuário e políticas de QoS no dispositivo para atender aos seguintes requisitos:
- O usuário A não pode acessar a Internet entre 8:30 e 12:00 todos os dias, mesmo que o usuário A seja aprovado na autenticação 802.1X.
- O usuário B tem uma velocidade de upload de 2 Mbps depois de passar pela autenticação 802.1X.
- O usuário C tem uma velocidade de download de 4 Mbps depois de passar pela autenticação 802.1X.
Figura 1 Diagrama de rede
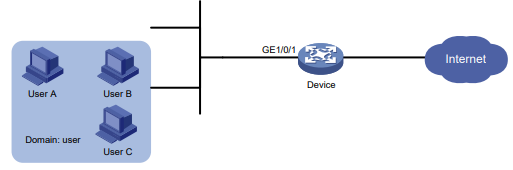
Procedimento de configuração
- Configure uma política de QoS para o usuário A:
# Crie um intervalo de tempo periódico das 8:30 às 12:00 todos os dias.
<Device> system-view
[Device] time-range for_usera 8:30 to 12:00 daily# Crie a ACL 2000 básica IPv4 e configure uma regra para corresponder a todos os pacotes durante o intervalo de tempo
para_usar.
[Device] acl basic 2000
[Device-acl-basic-2000] rule permit time-range for_usera
[Device-acl-basic-2000] quit# Crie uma classe de tráfego chamada for_usera e use a ACL 2000 como critério de correspondência.
[Device] traffic classifier for_usera
[Device-classifier-for_usera] if-match acl 2000
[Device-classifier-for_usera] quit# Crie um comportamento de tráfego chamado for_usera e configure a ação de negação.
[Device] traffic behavior for_usera
[Device-behavior-for_usera] filter deny
[Device-behavior-for_usera] quit# Crie uma política de QoS chamada for_usera e associe a classe de tráfego for_usera e o comportamento de tráfego for_usera na política de QoS.
[Device] qos policy for_usera
[Device-qospolicy-for_usera] classifier for_usera behavior for_usera
[Device-qospolicy-for_usera] quit- Crie um perfil de usuário para o usuário A e aplique a política de QoS ao perfil de usuário:
# Crie um perfil de usuário chamadousera
.[Device] user-profile usera# Aplique a política de QoS for_usera à direção de entrada do perfil de usuário usera.
[[Device-user-profile-usera] qos apply policy for_usera inbound
[Device-user-profile-usera] quit- Configure uma política de QoS para limitar a taxa de tráfego do usuário B: # Crie uma classe de tráfego chamada class para corresponder a todos os pacotes.
[Device] traffic classifier class
[Device-classifier-class] if-match any
[Device-classifier-class] quit# Crie um comportamento de tráfego chamado for_userb e configure uma ação de policiamento de tráfego (CIR 2000
kbps).
[Device] traffic behavior for_userb
[Device-behavior-for_userb] car cir 2000
[Device-behavior-for_userb] quit# Criar uma política de QoS chamada for_userb e associar a classe de tráfego e o comportamento do tráfego
for_userb na política de QoS.
[Device] qos policy for_userb
[Device-qospolicy-for_userb] classifier class behavior for_userb
[Device-qospolicy-for_userb] quit- Crie um perfil de usuário para o Usuário B e aplique a política de QoS ao perfil de usuário: # Crie um perfil de usuário chamado userb.
[Device] user-profile userb# Aplicar a política de QoS for_userb à direção de entrada do perfil de usuário userb. [Device-user-profile-userb] qos apply policy for_userb inbound [Device-user-profile-userb] quit
- Configure uma política de QoS para limitar a taxa de tráfego do usuário C:
# Crie um comportamento de tráfego chamado for_userc e configure uma ação de policiamento de tráfego (CIR 4000 kbps).
[Device-user-profile-userb] qos apply policy for_userb inbound
[Device-user-profile-userb] quit# Criar uma política de QoS chamada for_userc e associar a classe de tráfego e o comportamento do tráfego
for_userc na política de QoS.
[Device] traffic behavior for_userc
[Device-behavior-for_userc] car cir 4000
[Device-behavior-for_userc] quit- Crie um perfil de usuário para o Usuário C e aplique a política de QoS ao perfil de usuário:
# Crie um perfil de usuário chamado userc.
[Device] user-profile userc# Aplique a política de QoS for_userc à direção de saída do perfil de usuário userc.
[Device-user-profile-userc] qos apply policy for_userc outbound
[Device-user-profile-userc] quit- Configure os usuários locais:
# Crie um usuário local chamado usera.
[Device] local-user usera class networkNovo usuário local adicionado.
# Defina a senha como a12345 para o usuário usera.
[Device-luser-network-usera] password simple a12345# Autorize o usuário usera a usar o serviço de acesso à LAN.
[Device-luser-network-usera] service-type lan-access# Especifique o perfil de usuário usera como o perfil de usuário de autorização para o usuário usera.
[Device-luser-network-usera] authorization-attribute user-profile usera
[Device-luser-network-usera] quit# Crie um usuário local chamado userb.
[Device] local-user userb class network
New local user added.# Defina a senha como b12345 para o usuário userb.
[Device-luser-network-userb] password simple b12345# Autorize o usuário userb a usar o serviço de acesso à LAN.
[Device-luser-network-userb] service-type lan-access# Especifique o perfil de usuário userb como o perfil de usuário de autorização para o usuário userb.
[Device-luser-network-userb] authorization-attribute user-profile userb
[Device-luser-network-userb] quit# Crie um usuário local chamado userc.
[Device] local-user userc class network
New local user added.# Defina a senha como c12345 para o usuário userc.
[Device-luser-network-userc] password simple c12345# Autorize o usuário userc a usar o serviço de acesso à LAN.
[Device-luser-network-userc] service-type lan-access# Especifique o perfil de usuário userc como o perfil de usuário de autorização para o usuário userc.
[Device-luser-network-userc] authorization-attribute user-profile userc
[Device-luser-network-userc] quit- Configure os métodos de autenticação, autorização e contabilidade para usuários locais:
[Device] domain user
[Device-isp-user] authentication lan-access local
[Device-isp-user] authorization lan-access local
[Device-isp-user] accounting login none
[Device-isp-user] quit- Configurar o 802.1X:
# Habilite o 802.1X na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] dot1x# Habilite o controle de acesso baseado em MAC na porta. Por padrão, uma porta usa o controle de acesso baseado em MAC.
[Device-GigabitEthernet1/0/1] dot1x port-method macbased
[Device-GigabitEthernet1/0/1] quit# Habilite o 802.1X globalmente.
[Device] dot1xVerificação da configuração
# Verifique se os três usuários podem passar pela autenticação 802.1X e se as políticas de QoS têm efeito sobre esses usuários. (Detalhes não mostrados).
# Exibir informações do perfil do usuário.
<Device> display user-profile
User-Profile: usera
Inbound:
Policy: for_usera
slot 1:
User -:
Authentication type: 802.1X
Network attributes:
Interface : GigabitEthernet1/0/1
MAC address : 6805-ca06-557b
Service VLAN : 1
User-Profile: userb
Inbound:
Policy: for_userb
slot 1:
User -:
Authentication type: 802.1X
Network attributes:
Interface : GigabitEthernet1/0/1
MAC address : 80c1-6ee0-2664
Service VLAN : 1
User-Profile: userc
Outbound:
Policy: for_userc
slot 1:
User -:
Authentication type: 802.1X
Network attributes:
Interface : GigabitEthernet1/0/1
MAC address : 6805-ca05-3efa
Service VLAN : 1
Configuração do controle de senhas
Sobre o controle de senhas
O controle de senha permite implementar os seguintes recursos:
- Gerencie a configuração de login e super senha, expirações e atualizações para usuários locais.
- Controle o status de login do usuário com base em políticas predefinidas.
Para obter mais informações sobre usuários locais, consulte "Configuração de AAA". Para obter informações sobre super senhas, consulte RBAC no Fundamentals Configuration Guide.
Configuração de senha
Comprimento mínimo da senha
É possível definir o tamanho mínimo das senhas de usuário. O sistema rejeita a configuração de uma senha que seja menor do que o tamanho mínimo configurado.
Política de composição de senhas
Uma senha pode ser uma combinação de caracteres dos seguintes tipos:
- Letras maiúsculas de A a Z.
- Letras minúsculas de a a z.
- Dígitos de 0 a 9.
- Caracteres especiais na Tabela 1. Para obter mais informações sobre caracteres especiais, consulte CLI em
Guia de configuração de fundamentos.
Tabela 1 Caracteres especiais
| Nome do personagem | Símbolo | Nome do personagem | Símbolo |
| Sinal de E comercial | & | Apóstrofe | ' |
| Asterisco | * | No sinal | @ |
| Citação anterior | ` | Corte traseiro | \ |
| Espaço em branco | N/A | Caret | ^ |
| Cólon | : | Vírgula | , |
| Sinal de dólar | $ | Ponto | . |
| Sinal de igual | = | Ponto de exclamação | ! |
| Suporte de ângulo esquerdo | < | Braçadeira esquerda | { |
| Suporte esquerdo | [ | Parêntese esquerdo | ( |
| Sinal de menos | - | Sinal de porcentagem | % |
| Sinal de mais | + | Sinal de libra | # |
| Aspas | " | Suporte de ângulo reto | > |
| Braçadeira direita | } | Suporte direito | ] |
| Parêntese direito | ) | Ponto e vírgula | ; |
| Nome do personagem | Símbolo | Nome do personagem | Símbolo |
| Faixa | / | Tilde | ~ |
| Underscore | _ | Barra vertical | | |
Dependendo dos requisitos de segurança do sistema, você pode definir o número mínimo de tipos de caracteres que uma senha deve conter e o número mínimo de caracteres para cada tipo, conforme mostrado na Tabela 2.
Tabela 2 Política de composição de senhas
| Nível de combinação de senha | Número mínimo de tipos de caracteres | Número mínimo de caracteres para cada tipo |
| Nível 1 | Um | Um |
| Nível 2 | Dois | Um |
| Nível 3 | Três | Um |
| Nível 4 | Quatro | Um |
Quando um usuário define ou altera uma senha, o sistema verifica se a senha atende ao requisito de combinação. Se não atender, a operação falhará.
Política de verificação da complexidade da senha
Uma senha menos complicada tem maior probabilidade de ser quebrada, como uma senha que contenha o nome de usuário ou caracteres repetidos. Para aumentar a segurança, você pode configurar uma política de verificação da complexidade da senha para garantir que todas as senhas de usuários sejam relativamente complicadas. Quando um usuário configura uma senha, o sistema verifica a complexidade da senha. Se a senha for incompatível com a complexidade, a configuração falhará.
Você pode aplicar os seguintes requisitos de complexidade de senha:
- Uma senha não pode conter o nome de usuário ou o inverso do nome de usuário. Por exemplo, se o nome de usuário for abc, uma senha como abc982 ou 2cba não é suficientemente complexa.
- Não é permitido um mínimo de três caracteres consecutivos idênticos. Por exemplo, senha
a111 não é suficientemente complexo.
Atualização e expiração de senhas
Atualização de senha
Esse recurso permite definir o intervalo mínimo em que os usuários podem alterar suas senhas. Um usuário só pode alterar a senha uma vez dentro do intervalo especificado.
O intervalo mínimo não se aplica às seguintes situações:
- Um usuário é solicitado a alterar a senha no primeiro login.
- O tempo de envelhecimento da senha expira.
Expiração da senha
A expiração da senha impõe um ciclo de vida a uma senha de usuário. Após a expiração da senha, o usuário precisa alterá-la.
O sistema exibe uma mensagem de erro para uma tentativa de login com uma senha expirada. O usuário é solicitado a fornecer uma nova senha. A nova senha deve ser válida e o usuário deve digitar exatamente a mesma senha ao confirmá-la.
Os usuários da Web, usuários de Telnet, usuários de SSH e usuários de console podem alterar suas próprias senhas. Os usuários de FTP devem ter suas senhas alteradas pelo administrador.
Aviso antecipado sobre a expiração pendente da senha
Quando um usuário faz login, o sistema verifica se a senha expirará em um tempo igual ou inferior ao período de notificação especificado. Em caso afirmativo, o sistema notifica o usuário quando a senha expirará e oferece uma opção para o usuário alterar a senha.
- Se o usuário definir uma nova senha válida, o sistema registrará a nova senha e o tempo de configuração.
- Se o usuário não alterar a senha ou não conseguir alterá-la, o sistema permitirá que o usuário faça login usando a senha atual até que ela expire.
Usuários da Web, usuários de Telnet, usuários de SSH e usuários de console podem alterar suas próprias senhas. Os usuários de FTP devem ter suas senhas alteradas pelo administrador.
Login com uma senha expirada
Você pode permitir que um usuário faça login um determinado número de vezes dentro de um período de tempo após a expiração da senha. Por exemplo, se você definir o número máximo de logins com uma senha expirada como 3 e o período de tempo como 15 dias, um usuário poderá fazer logon três vezes dentro de 15 dias após a expiração da senha.
Histórico de senhas
Esse recurso permite que o sistema armazene as senhas que um usuário usou.
Quando um usuário de acesso à rede altera a senha, o sistema compara a nova senha com a senha atual e com as armazenadas nos registros do histórico de senhas. A nova senha deve ser diferente da atual e das armazenadas nos registros do histórico em, no mínimo, quatro caracteres diferentes. Caso contrário, o sistema exibirá uma mensagem de erro e a nova senha não será definida com êxito.
As senhas locais e as super senhas dos usuários de gerenciamento de dispositivos são armazenadas em forma de hash e não podem ser convertidas em textos simples. Quando um usuário de gerenciamento de dispositivos alterar uma senha local ou uma super senha, siga estas regras:
- Se a nova senha for definida usando o método hash, o sistema não comparará a nova senha com a atual e com as armazenadas nos registros de histórico de senhas.
- Se a nova senha for definida em texto simples, o sistema comparará a nova senha com a senha atual e com as armazenadas nos registros do histórico de senhas. Uma nova senha deve ser diferente das armazenadas nos registros de histórico de senhas. Se a senha atual for necessária, a nova senha também deverá ser diferente da atual em um mínimo de quatro caracteres diferentes. Caso contrário, o sistema exibirá uma mensagem de erro e a nova senha não será definida com êxito.
É possível definir o número máximo de registros de histórico de senhas que o sistema manterá para cada usuário. Quando o número de registros de histórico de senhas exceder a configuração, o registro mais recente substituirá o mais antigo.
As senhas de login atuais não são armazenadas no histórico de senhas dos usuários de gerenciamento de dispositivos. Os usuários de gerenciamento de dispositivos têm suas senhas salvas em texto cifrado, que não pode ser recuperado para senhas de texto simples.
Controle de login do usuário
Primeiro login
Por padrão, se o recurso de controle de senha global estiver ativado, os usuários deverão alterar a senha no primeiro login antes de poderem acessar o sistema. Nessa situação, as alterações de senha não estão sujeitas ao intervalo mínimo de atualização de senha. Se não for necessário que os usuários alterem a senha no primeiro login, desative o recurso de alteração de senha no primeiro login.
Limite de tentativas de login
Limitar o número de falhas de login consecutivas pode impedir efetivamente a adivinhação de senhas.
O limite de tentativas de login entra em vigor para usuários de FTP, Web e VTY. Ele não tem efeito sobre os seguintes tipos de usuários:
- Usuários inexistentes (usuários não configurados no dispositivo).
- Usuários que fazem login no dispositivo por meio de portas de console.
Se um usuário não conseguir fazer login, o sistema adicionará a conta de usuário e o endereço IP do usuário à lista negra de controle de senhas. Quando o usuário não consegue fazer login depois de fazer o número máximo de tentativas consecutivas, o limite de tentativas de login limita o usuário e a conta de usuário de uma das seguintes maneiras:
- Desativa a conta de usuário até que a conta seja removida manualmente da lista negra de controle de senhas.
- Permite que o usuário continue usando a conta de usuário. O endereço IP e a conta de usuário do usuário são removidos da lista negra de controle de senhas quando o usuário usa essa conta para fazer login com êxito no dispositivo.
- Desativa a conta de usuário por um período de tempo.
O usuário pode usar a conta para fazer login quando houver uma das seguintes condições:
- O cronômetro de bloqueio expira.
- A conta é removida manualmente da lista negra de controle de senhas antes que o tempo de bloqueio expire.
OBSERVAÇÃO:
Essa conta é bloqueada somente para esse usuário. Outros usuários ainda podem usar essa conta, e o usuário na lista negra pode usar outras contas de usuário.
Tempo máximo de inatividade da conta
É possível definir o tempo máximo de inatividade da conta para as contas de usuário. Quando uma conta fica inativa por esse período de tempo desde o último login bem-sucedido, a conta se torna inválida.
Controle de login com uma senha fraca
Esse recurso está disponível somente na versão 6318P01 e posteriores.
O sistema verifica se há senhas fracas para usuários de gerenciamento de dispositivos Telnet, SSH, HTTP ou HTTPS. Uma senha é fraca se não atender aos seguintes requisitos:
- Restrição de composição de senha.
- Restrição de comprimento mínimo da senha.
- Política de verificação da complexidade da senha.
Por padrão, o sistema exibe uma mensagem sobre uma senha fraca, mas não força o usuário a alterá-la. Para aumentar a segurança do dispositivo, você pode ativar o recurso de alteração obrigatória de senha fraca, que força os usuários a alterar as senhas fracas identificadas. Os usuários podem fazer login no dispositivo somente depois que suas senhas atenderem aos requisitos de senha.
A senha não é exibida em nenhum formato
Por motivos de segurança, nada é exibido quando um usuário digita uma senha.
Registro em log
O sistema gera um log sempre que um usuário altera sua senha com êxito ou é adicionado à lista negra de controle de senhas devido a falhas de login.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS (consulte "Configuração de FIPS") e no modo não-FIPS.
Restrições e diretrizes: Configuração do controle de senhas
IMPORTANTE:
Para ativar com êxito o recurso de controle de senha global e permitir que os usuários de gerenciamento de dispositivos façam login no dispositivo, certifique-se de que o dispositivo tenha espaço de armazenamento suficiente.
Os recursos de controle de senha podem ser configurados em várias exibições diferentes, e diferentes exibições suportam diferentes recursos. As configurações definidas em diferentes visualizações ou para diferentes objetos têm os seguintes intervalos de aplicação:
- As configurações para super senhas se aplicam somente a super senhas.
- As configurações na visualização do usuário local se aplicam apenas à senha do usuário local.
- As configurações na visualização de grupo de usuários se aplicam às senhas dos usuários locais no grupo de usuários se você não configurar políticas de senha para esses usuários na visualização de usuário local.
- As configurações globais na visualização do sistema se aplicam às senhas dos usuários locais em todos os grupos de usuários se você não configurar políticas de senha para esses usuários na visualização do usuário local e na visualização do grupo de usuários.
Para senhas de usuários locais, as configurações com um escopo de aplicativo menor têm prioridade mais alta.
Visão geral das tarefas de controle de senhas
Para configurar o controle de senha, execute as seguintes tarefas:
- Ativação do controle de senha
- (Opcional.) Configuração dos parâmetros globais de controle de senha
- (Opcional.) Configuração dos parâmetros de controle de senha do grupo de usuários
- (Opcional.) Configuração dos parâmetros de controle da senha do usuário local
- (Opcional.) Configuração dos parâmetros de controle da super senha
Ativação do controle de senha
Sobre o controle de senhas
Em versões anteriores à versão 6318P01:
Ative o controle de senha global para que todas as configurações de controle de senha entrem em vigor. Para que um recurso específico de controle de senha entre em vigor, ative seu próprio recurso de controle de senha.
Na versão 6318P01 e versões posteriores:
O recurso de expiração de senha e o recurso de gerenciamento do histórico de senhas entram em vigor somente depois que o recurso de controle de senha global também estiver ativado.
Restrições e diretrizes
Depois que o controle de senha global for ativado, siga estas restrições e diretrizes:
- Não é possível exibir as configurações de senha e super senha para usuários de gerenciamento de dispositivos usando os comandos de exibição correspondentes.
- Não é possível exibir a configuração de senha para usuários de acesso à rede usando o comando display correspondente.
- As senhas configuradas para usuários locais devem conter no mínimo quatro caracteres diferentes.
- No modo FIPS, o recurso de controle de senha global é ativado para usuários de gerenciamento de dispositivos e não pode ser desativado para eles.
- Para garantir o funcionamento correto do controle de senha, configure o dispositivo para usar o NTP para obter a hora UTC. Depois que o controle de senha global for ativado, o controle de senha registrará a hora UTC quando a senha for definida. A hora UTC registrada pode não ser consistente com a hora UTC real devido a uma falha de energia ou reinicialização do dispositivo. A inconsistência fará com que o recurso de expiração de senha não funcione corretamente. Para obter informações sobre NTP, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
- O dispositivo gera automaticamente um arquivo .dat e o salva na mídia de armazenamento. O arquivo é usado para registrar as informações de autenticação e login dos usuários locais. Não exclua ou modifique manualmente o arquivo.
- O recurso de controle de senha global permite que o sistema registre as senhas do histórico. Quando o número de registros de senhas do histórico de um usuário atinge o número máximo, o registro mais recente do histórico substitui o mais antigo. Para excluir os registros de histórico de senhas existentes, use um dos métodos a seguir:
- Use o comando undo password-control enable para desativar o recurso de controle de senha globalmente.
- Use o comando reset password-control history-record para limpar manualmente as senhas do site .
Procedimento
- Entre na visualização do sistema.
system view- Ative o recurso de controle de senha global. No modo não-FIPS:
password-control enable [ network-class ]Por padrão, o recurso de controle de senha global está desativado para usuários de gerenciamento de dispositivos e acesso à rede.
No modo FIPS:
password-control enable [ network-class ]Por padrão, o recurso de controle de senha global é ativado para usuários de gerenciamento de dispositivos e não pode ser desativado. O recurso de controle de senha global é desativado para usuários de acesso à rede.
- (Opcional.) Habilite um recurso específico de controle de senha.
password-control { aging | composition | history | length } enablePor padrão, todos os quatro recursos de controle de senha estão ativados.
Configuração dos parâmetros globais de controle de senha
Restrições e diretrizes
Os parâmetros globais de controle de senha na visualização do sistema se aplicam a todos os usuários locais de gerenciamento de dispositivos e acesso à rede.
É possível configurar todos os recursos de controle de senha para usuários de gerenciamento de dispositivos. O tempo de envelhecimento da senha, o comprimento mínimo da senha, a política de complexidade da senha, a política de composição da senha e o limite de tentativas de login do usuário podem ser configurados na visualização do sistema, na visualização do grupo de usuários e na visualização do usuário local.
É possível configurar apenas os seguintes recursos de controle de senha para usuários de acesso à rede:
- Comprimento mínimo da senha.
- Política de complexidade de senha.
- Política de composição de senhas.
- Intervalo mínimo de atualização de senha.
- Número máximo de registros de histórico de senhas para cada usuário.
O comprimento mínimo da senha, a política de complexidade da senha e a política de composição da senha podem ser configurados na visualização do sistema, na visualização do grupo de usuários e na visualização do usuário local.
As configurações de senha com um escopo de aplicativo menor têm prioridade mais alta. Para usuários locais, as configurações de senha definidas na visualização do usuário local têm a prioridade mais alta e as configurações globais na visualização do sistema têm a prioridade mais baixa.
O comando password-control login-attempt entra em vigor imediatamente e pode afetar os usuários que já estão na lista negra de controle de senhas. Outras configurações de controle de senha não têm efeito sobre os usuários que efetuaram login ou sobre as senhas que foram configuradas.
Procedimento
- Entre na visualização do sistema.
system view- Configurar as definições de senha.
- Defina o comprimento mínimo da senha. No modo não-FIPS:
password-control length lengthA configuração padrão é de 10 caracteres. No modo FIPS:
password-control length lengthO comprimento padrão é de 15 caracteres.
- Configure a política de composição de senhas. No modo não-FIPS:
password-control composition type-number type-number [ type-length type-length ]Por padrão:
- Em versões anteriores à Versão 6318P01, uma senha deve conter no mínimo um tipo de caractere e no mínimo um caractere para cada tipo.
- Na versão 6318P01 e posteriores, a senha deve conter no mínimo dois tipos de caracteres e um mínimo de um caractere para cada tipo.
No modo FIPS:
password-control composition type-number type-number [ type-length type-length ]Por padrão, uma senha deve conter um mínimo de quatro tipos de caracteres e um mínimo de um caractere para cada tipo.
- Configure a política de verificação da complexidade da senha.
password-control complexity { same-character | user-name } checkNas versões anteriores à Versão 6318P01, o sistema não executa a verificação da complexidade da senha por padrão.
Na versão 6318P01 e posteriores, as configurações padrão são as seguintes:
- No modo não-FIPS, a verificação de nome de usuário está ativada e a verificação de caracteres repetidos está desativada.
- No modo FIPS, o sistema não executa a verificação da complexidade da senha.
- Defina o número máximo de registros de histórico de senhas para cada usuário.
histórico de controle de senha número máximo de registros
A configuração padrão é 4.
- Configure a atualização e a expiração da senha.
- Defina o intervalo mínimo de atualização da senha.
password-control aging aging-timeA configuração padrão é 24 horas.
- Defina o tempo de envelhecimento da senha.
password-control aging aging-timeA configuração padrão é 90 dias.
- Defina o número de dias durante os quais um usuário é notificado sobre a expiração pendente da senha.
password-control alert-before-expire alert-timeA configuração padrão é 7 dias.
- Defina o número máximo de dias e o número máximo de vezes que um usuário pode fazer login após a expiração da senha.
password-control expired-user-login delay delay times timesPor padrão, um usuário pode fazer login três vezes dentro de 30 dias após a expiração da senha.
- Configure o controle de login do usuário.
- Configure o limite de tentativas de login.
password-control login-attempt login-times [ exceed { lock | lock-time time | unlock } ]Por padrão, o número máximo de tentativas de login é 3 e um usuário que não conseguir fazer login após o número especificado de tentativas deverá aguardar 1 minuto antes de tentar novamente.
- Defina o tempo máximo de inatividade da conta.
password-control login idle-time idle-timeA configuração padrão é 90 dias.
Se uma conta de usuário ficar inativa por esse período de tempo, ela se tornará inválida e não poderá mais ser usada para fazer login no dispositivo. Para desativar a restrição do tempo de inatividade da conta, defina o valor do tempo de inatividade como 0.
- Defina o tempo limite de autenticação do usuário.
password-control authentication-timeout timeoutA configuração padrão é 600 segundos.
Esse comando tem efeito apenas em usuários de Telnet e terminais.
- Desative a alteração de senha no primeiro login.
undo password-control change-password first-login enablePor padrão, o recurso de alteração de senha no primeiro login está ativado.
No modo FIPS, o recurso de alteração de senha no primeiro login não pode ser desativado.
- Ativar a alteração obrigatória de senha fraca.
password-control change-password weak-password enablePor padrão, o recurso de alteração obrigatória de senha fraca está desativado. Esse recurso está disponível somente na versão 6318P01 e posteriores.
Configuração dos parâmetros de controle de senha do grupo de usuários
- Entre na visualização do sistema.
system view- Crie um grupo de usuários e insira sua visualização.
user-group group-namePara obter informações sobre como configurar um grupo de usuários, consulte "Configuração de AAA".
- Configure o tempo de envelhecimento da senha para o grupo de usuários.
password-control aging aging-timePor padrão, o tempo de envelhecimento da senha do grupo de usuários é igual ao tempo de envelhecimento da senha global.
- Configure o tamanho mínimo da senha para o grupo de usuários.
password-control length lengthPor padrão, o comprimento mínimo da senha do grupo de usuários é igual ao comprimento mínimo global da senha .
- Configure a política de composição de senhas para o grupo de usuários.
password-control composition type-number type-number [ type-length type-length ]Por padrão, a política de composição de senha do grupo de usuários é igual à política de composição de senha global.
- Configure a política de verificação da complexidade da senha para o grupo de usuários.
password-control login-attempt login-times [ exceed { lock | lock-time time | unlock } ]Por padrão, a política de verificação de complexidade de senha do grupo de usuários é igual à política de verificação de complexidade de senha global.
- Configure o limite de tentativas de login.
password-control login-attempt login-times [ exceed { lock | lock-time time | unlock } ]Por padrão, a política de tentativa de login do grupo de usuários é igual à política global de tentativa de login.
Configuração dos parâmetros de controle de senha do usuário local
- Entre na visualização do sistema.
system view- Crie um usuário de gerenciamento de dispositivos ou de acesso à rede e insira sua visualização.
- Crie um usuário de gerenciamento de dispositivos e insira sua visualização.
local-user user-name class manage- Crie um usuário de acesso à rede e insira sua visualização.
local-user user-name class networkPara obter informações sobre a configuração do usuário local, consulte "Configuração de AAA".
- Configure o tempo de envelhecimento da senha para o usuário local.
password-control aging aging-timePor padrão, a configuração é igual à do grupo de usuários ao qual o usuário local pertence. Se nenhum tempo de envelhecimento for configurado para o grupo de usuários, a configuração global se aplicará ao usuário local.
Esse comando está disponível apenas para usuários de gerenciamento de dispositivos.
- Configure o tamanho mínimo da senha para o usuário local.
password-control length lengthPor padrão, a configuração é igual à do grupo de usuários ao qual o usuário local pertence. Se não houver comprimento mínimo de senha configurado para o grupo de usuários, a configuração global será aplicada ao usuário local.
- Configure a política de composição de senhas para o usuário local.
password-control composition type-number type-number [ type-length type-length ]Por padrão, as configurações são iguais às do grupo de usuários ao qual o usuário local pertence. Se nenhuma política de composição de senhas estiver configurada para o grupo de usuários, as configurações globais serão aplicadas ao usuário local.
- Configure a política de verificação da complexidade da senha para o usuário local.
password-control login-attempt login-times [ exceed { lock | lock-time time | unlock } ]Por padrão, as configurações são iguais às do grupo de usuários ao qual o usuário local pertence. Se nenhuma política de verificação de complexidade de senha estiver configurada para o grupo de usuários, as configurações globais serão aplicadas ao usuário local.
- Configure o limite de tentativas de login.
password-control login-attempt login-times [ exceed { lock | lock-time time | unlock } ]Por padrão, as configurações são iguais às do grupo de usuários ao qual o usuário local pertence. Se nenhuma política de tentativa de login estiver configurada para o grupo de usuários, as configurações globais serão aplicadas ao usuário local.
Esse comando está disponível apenas para usuários de gerenciamento de dispositivos.
Configuração dos parâmetros de controle da super senha
- Entre na visualização do sistema.
system view- Defina o tempo de envelhecimento da senha para as super senhas.
password-control super aging aging-timeA configuração padrão é 90 dias.
password-control super length lengthA configuração padrão é de 10 caracteres. No modo FIPS:
password-control super length lengthA configuração padrão é de 15 caracteres.
- Configure a política de composição de senhas para super senhas. No modo não-FIPS:
password-control super composition type-number type-number
[ type-length type-length ]Por padrão:
- Em versões anteriores à Versão 6318P01, uma super senha deve conter no mínimo um tipo de caractere e um mínimo de um caractere para cada tipo.
- Na versão 6318P01 e posteriores, uma super senha deve conter no mínimo dois tipos de caracteres e no mínimo um caractere para cada tipo.
No modo FIPS:
password-control super composition type-number type-number
[ type-length type-length ]Por padrão, uma super senha deve conter um mínimo de quatro tipos de caracteres e um mínimo de um caractere para cada tipo.
Comandos de exibição e manutenção para controle de senha
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir a configuração do controle de senha. | exibir controle de senha [ super ] |
| Exibir informações sobre usuários na lista negra de controle de senhas. | exibir lista negra de controle de senhas [ user-name user-name | ip ipv4-address | ipv6 ipv6-address] |
| Exclua usuários da lista negra de controle de senhas. | redefinir lista negra de controle de senha [ nome do usuário nome do usuário ] |
| Limpar registros de senha do histórico. | reset password-control history-record [ user-name user-name | super [ role role-name ] | network-class [ user-name user-name ] ] ] |
OBSERVAÇÃO:
O comando reset password-control history-record pode excluir os registros de histórico de senhas de um ou de todos os usuários, mesmo quando o recurso de gerenciamento de histórico de senhas estiver desativado.
Exemplos de configuração de controle de senha
Exemplo: Configuração do controle de senhas
Configuração de rede
Configure uma política global de controle de senhas para atender aos seguintes requisitos:
- A senha deve conter um mínimo de 16 caracteres.
- Uma senha deve conter um mínimo de quatro tipos de caracteres e um mínimo de quatro caracteres para cada tipo.
- Um usuário de FTP ou VTY que não fornecer a senha correta em duas tentativas sucessivas de login será permanentemente proibido de fazer login.
- Um usuário pode fazer login cinco vezes dentro de 60 dias após a expiração da senha.
- Uma senha expira após 30 dias.
- O intervalo mínimo de atualização da senha é de 36 horas.
- O tempo máximo de inatividade da conta é de 30 dias.
- Uma senha não pode conter o nome de usuário ou o inverso do nome de usuário.
- Não é permitido um mínimo de três caracteres consecutivos idênticos em uma senha.
Configure uma política de controle de super senha para a função de usuário network-operator para atender aos seguintes requisitos:
- Uma super senha deve conter um mínimo de 24 caracteres.
- Uma super senha deve conter um mínimo de quatro tipos de caracteres e um mínimo de cinco caracteres para cada tipo.
Configure uma política de controle de senha para o teste de usuário Telnet local para atender aos seguintes requisitos:
- A senha deve conter um mínimo de 24 caracteres.
- A senha deve conter um mínimo de quatro tipos de caracteres e um mínimo de cinco caracteres para cada tipo.
- A senha do usuário local expira após 20 dias.
Procedimento
# Habilite o recurso de controle de senha globalmente.
<Sysname> system-view
[Sysname] password-control enable# Desative uma conta de usuário permanentemente se um usuário falhar em duas tentativas consecutivas de login na conta de usuário.
[Sysname] password-control login-attempt 2 exceed lock# Defina todas as senhas para expirar após 30 dias.
[Sysname] password-control login-attempt 2 exceed lock# Defina globalmente o comprimento mínimo da senha para 16 caracteres.
[Sysname] password-control length 16# Defina o intervalo mínimo de atualização da senha para 36 horas.
[Sysname] password-control update-interval 36# Especifique que um usuário pode fazer login cinco vezes dentro de 60 dias após a expiração da senha.
[Sysname] password-control expired-user-login delay 60 times 5# Defina o tempo máximo de inatividade da conta como 30 dias.
[Sysname] password-control login idle-time 30# Recusar qualquer senha que contenha o nome de usuário ou o inverso do nome de usuário.
[Sysname] password-control complexity user-name check# Recuse uma senha que contenha um mínimo de três caracteres consecutivos idênticos.
[Sysname] password-control complexity same-character check# Especifique globalmente que todas as senhas devem conter um mínimo de quatro tipos de caracteres e um mínimo de quatro caracteres para cada tipo.
[Sysname] password-control composition type-number 4 type-length 4# Defina o comprimento mínimo da super senha para 24 caracteres.
[Sysname] password-control super length 24# Especifique que uma super senha deve conter um mínimo de quatro tipos de caracteres e um mínimo de cinco caracteres para cada tipo.
[Sysname] password-control super composition type-number 4 type-length 5# Configure uma super senha usada para mudar para a função de usuário network-operator como
123456789ABGFTweuix@#$%! em texto simples.
[Sysname] super password role network-operator simple 123456789ABGFTweuix@#$%!# Crie um usuário de gerenciamento de dispositivos chamado test.
[Sysname] local-user test class manage# Defina o tipo de serviço do usuário como Telnet.
[Sysname-luser-manage-test] service-type telnet# Defina o comprimento mínimo da senha como 24 para o usuário local.
[Sysname-luser-manage-test] password-control length 24# Especifique que a senha do usuário local deve conter um mínimo de quatro tipos de caracteres e um mínimo de cinco caracteres para cada tipo.
[Sysname-luser-manage-test] password-control composition type-number 4 type-length 5# Defina a senha do usuário local para expirar após 20 dias.
[Sysname-luser-manage-test] password-control aging 20# Configure a senha do usuário local no modo interativo.
[Sysname-luser-manage-test] password
Password:
Confirm :
Updating user information. Please wait ... ...
[Sysname-luser-manage-test] quitVerificação da configuração
# Exibir a configuração do controle de senha global.
<Sysname> display password-control
Global password control configurations:
Password control: Enabled(device management users)
Disabled (network access users)
Password aging: Enabled (30 days)
Password length: Enabled (16 characters)
Password composition: Enabled (4 types, 4 characters per type)
Password history: Enabled (max history record:4)
Early notice on password expiration: 7 days
Maximum login attempts: 2
User authentication timeout: 600 seconds
Action for exceeding login attempts: Lock
Minimum interval between two updates: 36 hours
User account idle time: 30 days
Logins with aged password: 5 times in 60 days
Password complexity: Enabled (username checking)
Enabled (repeated characters checking)
Password change: Enabled (first login)
Disabled (mandatory weak password change)# Exibir a configuração de controle de senha para super senhas.
<Sysname> display password-control super
Super password control configurations:
Password aging: Enabled (90 days)
Password length: Enabled (24 characters)
Password composition: Enabled (4 types, 5 characters per type)# Exibir a configuração de controle de senha para o teste de usuário local.
<Sysname> display local-user user-name test class manage
Total 1 local users matched.
Device management user test:
State: Active
Service type: Telnet
User group: system
Bind attributes:
Authorization attributes:
Work directory: flash:
User role list: network-operator
Password control configurations:
Password aging: 20 days
Password length: 24 characters
Password composition: 4 types, 5 characters per type
Gerenciamento de chaves públicas
Sobre o gerenciamento de chaves públicas
Este capítulo descreve o gerenciamento de chaves públicas para os seguintes algoritmos de chaves assimétricas:
- Algoritmo Revest-Shamir-Adleman (RSA).
- Algoritmo de assinatura digital (DSA).
- Algoritmo de assinatura digital de curva elíptica (ECDSA).
Visão geral do algoritmo de chave assimétrica
Os algoritmos de chave assimétrica são usados por aplicativos de segurança para proteger as comunicações entre duas partes, conforme mostrado na Figura 1. Os algoritmos de chave assimétrica usam duas chaves separadas (uma pública e uma privada) para criptografia e descriptografia. Os algoritmos de chave simétrica usam apenas uma chave.
Figura 1 Criptografia e descriptografia
O proprietário da chave pode distribuir a chave pública em texto simples na rede, mas deve manter a chave privada em privacidade. É matematicamente inviável calcular a chave privada, mesmo que um invasor conheça o algoritmo e a chave pública.
Uso de algoritmos de chave assimétrica
Os aplicativos de segurança (como SSH, SSL e PKI) usam os algoritmos de chave assimétrica para as seguintes finalidades:
- Criptografia e descriptografia - Qualquer receptor de chave pública pode usar a chave pública para criptografar informações, mas somente o proprietário da chave privada pode descriptografar as informações.
- Assinatura digital - O proprietário da chave usa a chave privada para assinar digitalmente as informações a serem enviadas. O receptor descriptografa as informações com a chave pública do remetente para verificar a autenticidade das informações.
RSA, DSA e ECDSA podem realizar assinatura digital, mas somente o RSA pode realizar criptografia e descriptografia.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS (consulte "Configuração de FIPS") e no modo não-FIPS.
Visão geral das tarefas de gerenciamento de chaves públicas
Para gerenciar chaves públicas, execute as seguintes tarefas:
- Criação de um par de chaves local
- Distribuir uma chave pública de host local Escolha uma das tarefas a seguir:
- Exportação de uma chave pública de host
- Exibição de uma chave pública de host
Para permitir que o dispositivo par autentique o dispositivo local, você deve distribuir a chave pública do dispositivo local para o dispositivo par.
- Configuração de uma chave pública de host de par Escolha uma das tarefas a seguir:
- Importação de uma chave pública de host de par a partir de um arquivo de chave pública
- Inserção de uma chave pública de host de par
Para criptografar informações enviadas a um dispositivo par ou autenticar a assinatura digital do dispositivo par, você deve configurar a chave pública do dispositivo par no dispositivo local.
- (Opcional.) Destruição de um par de chaves local
Criação de um par de chaves local
Restrições e diretrizes
Quando você criar um par de chaves locais, siga estas diretrizes:
- O algoritmo de chave deve ser o mesmo exigido pelo aplicativo de segurança.
- Quando você criar um par de chaves RSA ou DSA, insira um comprimento de módulo de chave apropriado no prompt. Quanto maior for o comprimento do módulo da chave, maior será a segurança e maior será o tempo de geração da chave.
Quando você criar um par de chaves ECDSA, escolha a curva elíptica apropriada. A curva elíptica determina o comprimento da chave ECDSA. Quanto maior for o comprimento da chave, maior será a segurança e maior será o tempo de geração da chave.
Consulte a Tabela 1 para obter mais informações sobre comprimentos de módulo de chave e comprimentos de chave.
- Se você não atribuir um nome ao par de chaves, o sistema atribuirá o nome padrão ao par de chaves e marcará o par de chaves como padrão. Você também pode atribuir o nome padrão a outro par de chaves, mas o sistema não marcará o par de chaves como padrão. O nome do par de chaves deve ser exclusivo entre todos os pares de chaves nomeados manualmente que usam o mesmo algoritmo de chaves. Se ocorrer um conflito de nomes, o sistema perguntará se você deseja substituir o par de chaves existente.
- Os pares de chaves são salvos automaticamente e podem sobreviver às reinicializações do sistema.
Tabela 1 Uma comparação de diferentes tipos de algoritmos de chave assimétrica
| Tipo | Pares de chaves gerados | Comprimento do módulo/chave |
| RSA | No modo não-FIPS: Um par de chaves de host, se você especificar um nome de par de chaves. Um par de chaves de servidor e um par de chaves de host, se você não especificar um nome de par de chaves. Ambos os pares de chaves usam seus nomes padrão. No modo FIPS: Um par de chaves do host. OBSERVAÇÃO: Somente o SSH 1.5 usa o par de chaves do servidor RSA. | Comprimento do módulo da chave RSA: No modo não-FIPS: 512 a 4096 bits, 1024 bits por padrão. Para garantir a segurança, use um mínimo de 768 bits. No modo FIPS: Um múltiplo de 256 bits no intervalo de 2048 a 4096 bits, 2048 bits por padrão. |
| Tipo | Pares de chaves gerados | Comprimento do módulo/chave |
| DSA | Um par de chaves de host. | Comprimento do módulo da chave DSA: No modo não-FIPS: 512 a 2048 bits, 1024 bits por padrão. Para garantir a segurança, use um mínimo de 768 bits. No modo FIPS: 2048 bits. |
| ECDSA | Um par de chaves de host. | Comprimento da chave ECDSA: No modo não-FIPS: 192, 256, 384 ou 521 bits. No modo FIPS: 256, 384 ou 521 bits. |
Procedimento
- Entre na visualização do sistema.
system view- Crie um par de chaves local. No modo não-FIPS:
public-key local create { dsa | ecdsa [ secp192r1 | secp256r1 | secp384r1
| secp521r1 ] | rsa } [ name key-name ]No modo FIPS:
public-key local create { dsa | ecdsa [ secp256r1 | secp384r1 |
secp521r1 ] | rsa } [ name key-name ]Distribuição de uma chave pública de host local
Sobre a distribuição de chaves públicas do host local
Você deve distribuir uma chave pública de host local a um dispositivo par para que ele possa realizar as seguintes operações:
- Use a chave pública para criptografar as informações enviadas ao dispositivo local.
- Autenticar a assinatura digital assinada pelo dispositivo local.
Para distribuir uma chave pública de host local, você deve primeiro exportar ou exibir a chave.
- Exportar uma chave pública do host:
- Exportar uma chave pública de host para um arquivo.
- Exporte uma chave pública de host para a tela do monitor e salve-a em um arquivo.
Depois que a chave for exportada para um arquivo, transfira o arquivo para o dispositivo par. No dispositivo par, importe a chave do arquivo.
- Exibir uma chave pública de host.
Depois que a chave for exibida, registre-a; por exemplo, copie-a em um arquivo não formatado. No dispositivo par , você deve digitar literalmente a chave.
Exportação de uma chave pública de host
Restrições e diretrizes
Quando você exportar uma chave pública de host, siga estas restrições e diretrizes:
- Se você especificar um nome de arquivo no comando, o comando exportará a chave para o arquivo especificado.
- Se você não especificar um nome de arquivo, o comando exportará a chave para a tela do monitor. Você deve salvar manualmente a chave exportada em um arquivo.
Procedimento
- Entre na visualização do sistema.
system view- Exportar uma chave pública de host local.
- Exportar uma chave pública de host RSA: No modo não-FIPS:
public-key local export rsa [ name key-name ] { openssh | ssh1 | ssh2 }
[ filename ]No modo FIPS:
public-key local export rsa [ name key-name ] { openssh | ssh2 }
[ filename ]- Exportar uma chave pública de host ECDSA.
public-key local export ecdsa [ name key-name ] { openssh | ssh2 }
[ filename ]- Exportar uma chave pública de host DSA.
public-key local export dsa [ name key-name ] { openssh | ssh2 }
[ filename ]Exibição de uma chave pública de host
Execute as seguintes tarefas em qualquer visualização:
- Exibir chaves públicas RSA locais.
display public-key local rsa public [ name key-name ]
Não distribua a chave pública do servidor RSA serverkey (padrão) para um dispositivo par.
- Exibir chaves públicas ECDSA locais.
display public-key local ecdsa public [ name key-name ]- Exibir chaves públicas DSA locais.
display public-key local dsa public [ name key-name ]Configuração de uma chave pública de host de par
Sobre a configuração da chave pública do host par
Para criptografar informações enviadas a um dispositivo par ou autenticar a assinatura digital do dispositivo par, você deve configurar a chave pública do dispositivo par no dispositivo local.
Você pode configurar a chave pública do host par usando os seguintes métodos:
- Importe a chave pública do host do par de um arquivo de chave pública (recomendado).
- Insira manualmente (digite ou copie) a chave pública do host do par.
Para obter informações sobre como obter a chave pública do host de um dispositivo, consulte "Distribuição de uma chave pública do host local".
Restrições e diretrizes para a configuração da chave pública do host par
Quando você configurar uma chave pública de host par, siga estas restrições e diretrizes:
- Quando você inserir manualmente a chave pública do host par, verifique se a chave inserida está no formato correto. Para obter a chave pública do host par no formato correto, use a tela
public-key local public para exibir a chave pública no dispositivo par e registrar a chave. O formato da chave pública exibida de qualquer outra forma pode estar incorreto. Se a chave não estiver no formato correto, o sistema descartará a chave e exibirá uma mensagem de erro.
- Sempre importe em vez de inserir a chave pública do host par se não tiver certeza de que o dispositivo é compatível com o formato da chave pública do host par gravada.
Importação de uma chave pública de host de par a partir de um arquivo de chave pública
Sobre a importação de uma chave pública de host par
Antes de executar essa tarefa, certifique-se de ter exportado a chave pública do host para um arquivo no dispositivo par e de ter obtido o arquivo do dispositivo par. Para obter informações sobre a exportação de uma chave pública de host, consulte "Exportação de uma chave pública de host".
Depois que você importar a chave, o sistema converterá automaticamente a chave pública importada em uma cadeia de caracteres no formato PKCS (Public Key Cryptography Standards).
Procedimento
- Entre na visualização do sistema.
system view- Importar uma chave pública de host de par a partir de um arquivo de chave pública.
public-key peer keyname import sshkey filenamePor padrão, não existem chaves públicas de host de pares.
Inserção de uma chave pública de host de par
Sobre a inserção de uma chave pública de host de par
Antes de executar essa tarefa, certifique-se de ter exibido a chave no dispositivo par e gravado a chave. Para obter informações sobre a exibição de uma chave pública de host, consulte "Exibição de uma chave pública de host".
Procedimento
- Entre na visualização do sistema.
system view- Especifique um nome para a chave pública do host par e entre no modo de exibição de chave pública.
public-key peer keyname- Digite ou copie a chave.
Você pode usar espaços e retornos de carro, mas o sistema não os salva.
- Sair da visualização da chave pública.
peer-public-key endQuando você sai da visualização da chave pública, o sistema salva automaticamente a chave pública do host par.
Destruição de um par de chaves local
Sobre a destruição de um par de chaves local
Para garantir a segurança, destrua o par de chaves local e gere um novo par de chaves em qualquer uma das seguintes situações:
- Houve vazamento da chave local. Pode ocorrer um evento de intrusão.
- A mídia de armazenamento do dispositivo é substituída.
- O certificado local expirou. Para obter mais informações sobre certificados locais, consulte "Configuração da PKI do site ".
Procedimento
- Entre na visualização do sistema.
system view- Destruir um par de chaves local.
public-key local destroy { dsa | ecdsa | rsa } [ name key-name ]Comandos de exibição e manutenção de chaves públicas
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir chaves públicas locais. | display public-key local { dsa | ecdsa | rsa } public [ name key-name ] |
| Exibir chaves públicas do host par. | display public-key peer [ brief | name publickey-name ] |
Exemplos de gerenciamento de chaves públicas
Exemplo: Inserção de uma chave pública de host de par
Configuração de rede
Conforme mostrado na Figura 2, para evitar acesso ilegal, o Dispositivo B autentica o Dispositivo A por meio de uma assinatura digital. Antes de configurar os parâmetros de autenticação no Dispositivo B, use o procedimento a seguir para configurar a chave pública do Dispositivo A no Dispositivo B:
- Crie pares de chaves RSA no Dispositivo A e exiba as chaves públicas dos pares de chaves RSA.
- Especifique manualmente a chave pública do host RSA do Dispositivo A no Dispositivo B.
Figura 2 Diagrama de rede

Procedimento
- Configurar o dispositivo A:
# Crie pares de chaves RSA locais com os nomes padrão no Dispositivo A e use o comprimento do módulo de chave padrão (1024 bits).
[DeviceA] display public-key local rsa public
=============================================
Key name: hostkey (default)
Key type: RSA
Time when key pair created: 16:48:31 2011/05/12
Key code:
30819F300D06092A864886F70D010101050003818D0030818902818100DA3B90F59237347B
8D41B58F8143512880139EC9111BFD31EB84B6B7C7A1470027AC8F04A827B30C2CAF79242E
45FDFF51A9C7E917DB818D54CB7AEF538AB261557524A7441D288EC54A5D31EFAE4F681257
6D7796490AF87A8C78F4A7E31F0793D8BA06FB95D54EBB9F94EB1F2D561BF66EA27DFD4788
CB47440AF6BB25ACA50203010001
=============================================
Key name: serverkey (default)
Key type: RSA
Time when key pair created: 16:48:31 2011/05/12
Key code:
307C300D06092A864886F70D0101010500036B003068026100C9451A80F7F0A9BA1A90C7BC
1C02522D194A2B19F19A75D9EF02219068BD7FD90FCC2AF3634EEB9FA060478DD0A1A49ACE
E1362A4371549ECD85BA04DEE4D6BB8BE53B6AED7F1401EE88733CA3C4CED391BAE633028A
AC41C80A15953FB22AA30203010001- Configurar o dispositivo B:
# Digite a chave pública do host do Dispositivo A na exibição de chave pública. A chave deve ser literalmente a mesma exibida no Dispositivo A.
<DeviceB> system-view
[DeviceB] public-key peer devicea
Enter public key view. Return to system view with "peer-public-key end" command.
[DeviceB-pkey-public-key-devicea]30819F300D06092A864886F70D010101050003818D003081
8902818100DA3B90F59237347B
[DeviceB-pkey-public-key-devicea]8D41B58F8143512880139EC9111BFD31EB84B6B7C7A14700
27AC8F04A827B30C2CAF79242E
[DeviceB-pkey-public-key-devicea]45FDFF51A9C7E917DB818D54CB7AEF538AB261557524A744
1D288EC54A5D31EFAE4F681257
[DeviceB-pkey-public-key-devicea]6D7796490AF87A8C78F4A7E31F0793D8BA06FB95D54EBB9F
94EB1F2D561BF66EA27DFD4788
[DeviceB-pkey-public-key-devicea]CB47440AF6BB25ACA50203010001
Verificação da configuração
# Verifique se a chave pública do host par configurada no Dispositivo B é a mesma que a chave exibida no Dispositivo A.
[DeviceB] display public-key peer name devicea
=============================================
Key name: devicea
Key type: RSA
Key modulus: 1024
Key code:
30819F300D06092A864886F70D010101050003818D0030818902818100DA3B90F59237347B
8D41B58F8143512880139EC9111BFD31EB84B6B7C7A1470027AC8F04A827B30C2CAF79242E
45FDFF51A9C7E917DB818D54CB7AEF538AB261557524A7441D288EC54A5D31EFAE4F681257
6D7796490AF87A8C78F4A7E31F0793D8BA06FB95D54EBB9F94EB1F2D561BF66EA27DFD4788
CB47440AF6BB25ACA50203010001
Exemplo: Importação de uma chave pública de um arquivo de chave pública
Configuração de rede
Conforme mostrado na Figura 3, o Dispositivo B autentica o Dispositivo A por meio de uma assinatura digital. Antes de configurar os parâmetros de autenticação no Dispositivo B, use o procedimento a seguir para configurar a chave pública do Dispositivo A no Dispositivo B:
- Crie pares de chaves RSA no Dispositivo A e exporte a chave pública do host RSA para um arquivo.
- Importe a chave pública do host RSA do Dispositivo A do arquivo de chave pública para o Dispositivo B.
Figura 3 Diagrama de rede

Procedimento
- Configurar o dispositivo A:
# Crie pares de chaves RSA locais com os nomes padrão no Dispositivo A e use o comprimento do módulo de chave padrão (1024 bits).
<DeviceA> system-view
[DeviceA] public-key local create rsa
The range of public key modulus is (512 ~ 4096).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
...
Create the key pair successfully.# Exibir todas as chaves públicas RSA locais.
[DeviceA] display public-key local rsa public
=============================================
Device A Device B
10.1.1.1/24 10.1.1.2/24
9
Key name: hostkey (default)
Key type: RSA
Time when key pair created: 16:48:31 2011/05/12
Key code:
30819F300D06092A864886F70D010101050003818D0030818902818100DA3B90F59237347B
8D41B58F8143512880139EC9111BFD31EB84B6B7C7A1470027AC8F04A827B30C2CAF79242E
45FDFF51A9C7E917DB818D54CB7AEF538AB261557524A7441D288EC54A5D31EFAE4F681257
6D7796490AF87A8C78F4A7E31F0793D8BA06FB95D54EBB9F94EB1F2D561BF66EA27DFD4788
CB47440AF6BB25ACA50203010001
=============================================
Key name: serverkey (default)
Key type: RSA
Time when key pair created: 16:48:31 2011/05/12
Key code:
307C300D06092A864886F70D0101010500036B003068026100C9451A80F7F0A9BA1A90C7BC
1C02522D194A2B19F19A75D9EF02219068BD7FD90FCC2AF3634EEB9FA060478DD0A1A49ACE
E1362A4371549ECD85BA04DEE4D6BB8BE53B6AED7F1401EE88733CA3C4CED391BAE633028A
AC41C80A15953FB22AA30203010001# Exporte a chave pública do host RSA para o arquivo devicea.pub.
[DeviceA] public-key local export rsa ssh2 devicea.pub# Habilite o servidor FTP, crie um usuário FTP com nome de usuário ftp e senha hello12345 e configure a função do usuário FTP como network-admin.
[DeviceA] ftp server enable
[DeviceA] local-user ftp
[DeviceA-luser-manage-ftp] password simple hello12345
[DeviceA-luser-manage-ftp] service-type ftp
[DeviceA-luser-manage-ftp] authorization-attribute user-role network-admin
[DeviceA-luser-manage-ftp] quit- Configurar o dispositivo B:
# Use o FTP no modo binário para obter o arquivo de chave pública devicea.pub do dispositivo A.
<DeviceB> ftp 10.1.1.1
Connected to 10.1.1.1 (10.1.1.1).
220 FTP service ready.
User(10.1.1.1:(none)):ftp
331 Password required for ftp.
Password:
230 User logged in.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> binary
200 TYPE is now 8-bit binary
ftp> get devicea.pub
227 Entering Passive Mode (10,1,1,1,118,252)
150 Accepted data connection
226 File successfully transferred
301 bytes received in 0.003 seconds (98.0 kbyte/s)
ftp> quit
221-Goodbye. You uploaded 0 and downloaded 1 kbytes.
10
221 Logout# Importe a chave pública do host do arquivo de chaves devicea.pub.
<DeviceB> system-view
[DeviceB] public-key peer devicea import sshkey devicea.pubVerificação da configuração
# Verifique se a chave pública do host par configurada no Dispositivo B é a mesma que a chave exibida no Dispositivo A.
[DeviceB] display public-key peer name devicea
=============================================
Key name: devicea
Key type: RSA
Key modulus: 1024
Key code:
30819F300D06092A864886F70D010101050003818D0030818902818100DA3B90F59237347B
8D41B58F8143512880139EC9111BFD31EB84B6B7C7A1470027AC8F04A827B30C2CAF79242E
45FDFF51A9C7E917DB818D54CB7AEF538AB261557524A7441D288EC54A5D31EFAE4F681257
6D7796490AF87A8C78F4A7E31F0793D8BA06FB95D54EBB9F94EB1F2D561BF66EA27DFD4788
CB47440AF6BB25ACA50203010001
Configuração de PKI
Sobre a PKI
A infraestrutura de chave pública (PKI) é uma infraestrutura de chave assimétrica para criptografar e descriptografar dados para proteger os serviços de rede.
A PKI usa certificados digitais para distribuir e empregar chaves públicas e fornece comunicação de rede e comércio eletrônico com serviços de segurança, como autenticação de usuário, confidencialidade de dados e integridade de dados. Para obter mais informações sobre chaves públicas, consulte "Gerenciamento de chaves públicas ".
Terminologia da PKI
Certificado digital
Um certificado digital é um documento eletrônico assinado por uma CA que vincula uma chave pública à identidade de seu proprietário.
Um certificado digital inclui as seguintes informações:
- Nome do emissor (nome da CA que emitiu o certificado).
- Nome do titular (nome do indivíduo ou grupo para o qual o certificado é emitido).
- Informações de identidade do sujeito.
- Chave pública do sujeito.
- Assinatura do CA.
- Período de validade.
Um certificado digital deve estar em conformidade com os padrões internacionais do ITU-T X.509, dos quais o X.509 v3 é o mais comumente usado.
Este capítulo aborda os seguintes tipos de certificados:
- Certificado de CA - Certificado de uma CA. Várias CAs em um sistema de PKI formam uma árvore de CAs, com a CA raiz no topo. A CA raiz gera um certificado autoassinado, e cada CA de nível inferior possui um certificado de CA emitido pela CA imediatamente acima dela. A cadeia desses certificados forma uma cadeia de confiança.
- Certificado de autoridade de registro (RA) - Certificado emitido por uma AC para uma RA. As RAs atuam como proxies das CAs para processar solicitações de registro em um sistema PKI.
- Certificado local - certificado digital emitido por uma CA para uma entidade de PKI local, que contém a chave pública da entidade.
- Certificado de par - certificado digital assinado por CA de um par, que contém a chave pública do par.
Impressão digital do certificado da CA raiz
Cada certificado de CA raiz tem uma impressão digital exclusiva, que é o valor de hash do conteúdo do certificado. A impressão digital de um certificado de CA raiz pode ser usada para autenticar a validade da CA raiz.
Lista de revogação de certificados
Uma lista de revogação de certificados (LCR) é uma lista de números de série de certificados que foram revogados. Uma LCR é criada e assinada pela CA que originalmente emitiu os certificados.
A CA publica CRLs periodicamente para revogar certificados. As entidades associadas aos certificados revogados não devem ser confiáveis.
A CA deve revogar um certificado quando ocorrer uma das seguintes condições:
- O nome do assunto do certificado é alterado.
- A chave privada está comprometida.
- A associação entre o sujeito e o CA é alterada. Por exemplo, quando um funcionário deixa de trabalhar em uma organização.
Política da CA
Uma política de AC é um conjunto de critérios que uma AC segue para processar solicitações de certificados, emitir e revogar certificados e publicar LCRs. Normalmente, uma AC anuncia sua política em uma declaração de prática de certificação (CPS). Você pode obter uma política de AC por meios externos, como telefone, disco e e-mail. Certifique-se de entender a política da CA antes de selecionar uma CA confiável para solicitação de certificado, pois diferentes CAs podem usar políticas diferentes.
Arquitetura de PKI
Um sistema de PKI consiste em entidades de PKI, ACs, RAs e um repositório de certificados/CRLs, conforme mostrado na Figura 1.
Figura 1 Arquitetura de PKI
Entidade PKI
Uma entidade de PKI é um usuário final que usa certificados de PKI. A entidade de PKI pode ser um operador, uma organização, um dispositivo como um roteador ou um switch, ou um processo em execução em um computador. As entidades de PKI usam o SCEP para se comunicar com a CA ou RA.
CA
Autoridade de certificação que concede e gerencia certificados. Uma CA emite certificados, define os períodos de validade do certificado e revoga certificados publicando LCRs.
RA
Autoridade de registro, que descarrega a CA ao processar solicitações de inscrição de certificados. A RA aceita solicitações de certificados, verifica a identidade do usuário e determina se deve solicitar à CA a emissão de certificados.
O RA é opcional em um sistema de PKI. Nos casos em que houver preocupação com a segurança de expor a CA ao acesso direto à rede, é aconselhável delegar algumas das tarefas a um RA. Assim, a AC pode se concentrar em suas tarefas principais de assinar certificados e LCRs.
Repositório de certificados/CRLs
Um ponto de distribuição de certificados que armazena certificados e LCRs e distribui esses certificados e LCRs para entidades de PKI. Ele também fornece a função de consulta. Um repositório de PKI pode ser um servidor de diretório que usa o protocolo LDAP ou HTTP, sendo que o LDAP é comumente usado.
Recuperação, uso e manutenção de um certificado digital
O fluxo de trabalho a seguir descreve a recuperação, o uso e a manutenção de um certificado digital. Este exemplo de usa uma CA que tem uma RA para processar solicitações de registro de certificados.
- Uma entidade de PKI gera um par de chaves assimétricas e envia uma solicitação de certificado à RA. A solicitação de certificado contém a chave pública e suas informações de identidade.
- A RA verifica a identidade da entidade e envia uma assinatura digital contendo as informações de identidade e a chave pública para a CA.
- A CA verifica a assinatura digital, aprova a solicitação e emite um certificado.
- Após receber o certificado da CA, a RA envia o certificado para o repositório de certificados e notifica a entidade PKI de que o certificado foi emitido.
- A entidade PKI obtém o certificado do repositório de certificados.
- Para estabelecer uma conexão segura para comunicação, duas entidades de PKI trocam certificados locais para autenticar uma à outra. A conexão só pode ser estabelecida se ambas as entidades verificarem que o certificado do par é válido.
- Você pode remover o certificado local de uma entidade PKI e solicitar um novo quando ocorrer uma das seguintes condições:
- O certificado local está prestes a expirar.
- A chave privada do certificado está comprometida.
Aplicativos de PKI
VPN
A tecnologia PKI pode atender aos requisitos de segurança das transações on-line. Como uma infraestrutura, a PKI tem uma ampla gama de aplicações. O sistema de PKI da Intelbras pode fornecer gerenciamento de certificados para IPsec e SSL.
Veja a seguir alguns exemplos de aplicativos.
Uma VPN é uma rede privada de comunicação de dados construída sobre a infraestrutura de comunicação pública. Uma VPN pode usar protocolos de segurança de camada de rede (por exemplo, IPsec) em conjunto com criptografia baseada em PKI e tecnologias de assinatura digital para confidencialidade.
E-mails seguros
A PKI pode atender aos requisitos de confidencialidade, integridade, autenticação e não repúdio do e-mail. Um protocolo de e-mail seguro comum é o Secure/Multipurpose Internet Mail Extensions (S/MIME), que se baseia na PKI e permite a transferência de e-mails criptografados com assinatura.
Segurança na Web
A PKI pode ser usada na fase de handshake do SSL para verificar as identidades das partes comunicantes por meio de certificados digitais.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS (consulte "Configuração de FIPS") e no modo não-FIPS.
Visão geral das tarefas de PKI
Para configurar a PKI, execute as seguintes tarefas:
- Configuração de uma entidade PKI
- Configuração de um domínio PKI
- (Opcional.) Especificar o caminho de armazenamento para certificados e LCRs
- Solicitação de um certificado
Escolha uma das seguintes tarefas:
- Ativação do modo de solicitação automática de certificado on-line
- Envio manual de uma solicitação de certificado on-line
- Envio manual de uma solicitação de certificado no modo off-line
- (Opcional.) Abortar uma solicitação de certificado
Você pode obter o certificado da CA, os certificados locais e os certificados de pares relacionados a um domínio PKI de uma CA e salvá-los localmente para aumentar a eficiência da pesquisa.
- (Opcional.) Verificação de certificados PKI
- (Opcional.) Exportação de certificados
- (Opcional.) Remoção de um certificado
- (Opcional.) Configuração de uma política de controle de acesso baseada em certificado
As políticas de controle de acesso baseadas em certificados permitem autorizar o acesso a um dispositivo (por exemplo, um servidor HTTPS) com base nos atributos do certificado de um cliente autenticado.
Configuração de uma entidade PKI
Sobre as entidades de PKI
Um solicitante de certificado usa uma entidade para fornecer suas informações de identidade a uma AC. Uma entidade PKI válida deve incluir uma ou mais das seguintes categorias de identidade:
- Nome distinto (DN) da entidade, que inclui ainda o nome comum, o código do país, a localidade, a organização, a unidade na organização e o estado. Se você configurar o DN para uma entidade, será necessário um nome comum.
- FQDN da entidade.
- Endereço IP da entidade.
Restrições e diretrizes
Siga estas restrições e diretrizes ao configurar uma entidade de PKI:
- O fato de as categorias de identidade serem obrigatórias ou opcionais depende da política da CA. Siga a política da CA para definir as configurações da entidade. Por exemplo, se a política da CA exigir o DN da entidade, mas você configurar apenas o endereço IP, a CA rejeitará a solicitação de certificado da entidade.
- O complemento SCEP no servidor CA do Windows 2000 tem restrições quanto ao comprimento dos dados de uma solicitação de certificado. Se uma solicitação de uma entidade PKI exceder o limite de comprimento de dados, o servidor CA não responderá à solicitação de certificado. Nesse caso, você pode usar um meio fora de banda para enviar a solicitação. Outros tipos de servidores de CA, como servidores RSA e servidores OpenCA, não têm essas restrições.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma entidade PKI e insira sua visualização.
pki entity entity-name- Definir um nome comum para a entidade.
common-name common-name-stingPor padrão, o nome comum não é definido.
- Definir o código do país da entidade.
country country-code-stringPor padrão, o código do país não é definido.
locality locality-namePor padrão, a localidade não é definida.
organization org-namePor padrão, a organização não é definida.
- Defina a unidade da entidade na organização.
organization-unit org-unit-namePor padrão, a unidade não é definida.
state state-namePor padrão, o estado não é definido.
- Define o FQDN da entidade.
fqdn fqdn-name-stringPor padrão, o FQDN não é definido.
ip { ip-address | interface interface-type interface-number }Por padrão, o endereço IP não está configurado.
Configuração de um domínio PKI
Sobre o domínio PKI
Um domínio de PKI contém informações de registro para uma entidade de PKI. Ele é localmente significativo e destina-se apenas ao uso por outros aplicativos, como IKE e SSL.
Visão geral das tarefas do domínio PKI
Para configurar um domínio PKI, execute as seguintes tarefas:
- Criação de um domínio PKI
- Especificando a CA confiável
- Especificando o nome da entidade PKI
- Especificação da autoridade de recepção da solicitação de certificado
- Especificação do URL de solicitação de certificado
- (Opcional.) Configuração do intervalo de sondagem SCEP e do número máximo de tentativas de sondagem
- Especificação do servidor LDAP
Essa tarefa é necessária quando uma das seguintes condições for atendida:
- O dispositivo deve obter certificados da CA usando o protocolo LDAP.
- Um URL LDAP que não contém o nome do host do servidor LDAP é especificado como o URL do repositório de LCR.
- Especificação da impressão digital para verificação do certificado da CA raiz
Essa etapa é necessária se o modo de solicitação automática de certificado estiver configurado no domínio da PKI.
Se o modo de solicitação manual de certificado estiver configurado, você poderá ignorar essa etapa e verificar manualmente a impressão digital exibida durante a verificação do certificado da CA raiz.
Criação de um domínio PKI
- Entre na visualização do sistema.
system-view- Crie um domínio PKI e insira sua visualização.
pki domain domain-nameEspecificando a CA confiável
Sobre a especificação da CA confiável
O domínio PKI deve ter um certificado de CA antes que você possa solicitar um certificado local. Para obter um certificado de CA, o nome da CA confiável deve ser especificado. O nome da CA confiável identifica exclusivamente a CA a ser usada se houver várias CAs no servidor de CA.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Especifique o nome da CA confiável.
ca identifier namePor padrão, nenhum nome de CA confiável é especificado.
Especificando o nome da entidade PKI
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Especifique o nome da entidade PKI.
certificate request entity entity-namePor padrão, nenhum nome de entidade PKI é especificado.
Especificação da autoridade de recepção da solicitação de certificado
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Especifique a autoridade de recepção da solicitação de certificado.
certificate request from { ca | ra }Por padrão, nenhuma autoridade de recepção de solicitação de certificado é especificada.
Especificação do URL de solicitação de certificado
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Especifique o URL da autoridade de recepção de solicitação de certificado para a qual o dispositivo envia solicitações de certificado.
certificate request url url-stringPor padrão, o URL de solicitação de certificado não é especificado.
Configuração do intervalo de sondagem SCEP e do número máximo de tentativas de sondagem
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Defina o intervalo de sondagem SCEP e o número máximo de tentativas de sondagem.
certificate request polling { count count | interval interval }Por padrão, o dispositivo pesquisa o servidor CA para obter o status da solicitação de certificado a cada 20 minutos. O número máximo de tentativas de sondagem é 50.
Especificação do servidor LDAP
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Especifique o servidor LDAP.
ldap-server host hostname [ port port-number ]Por padrão, nenhum servidor LDAP é especificado.
Especificação da impressão digital para verificação do certificado da CA raiz
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Configure a impressão digital para verificar o certificado de CA raiz. No modo não-FIPS:
root-certificate fingerprint { md5 | sha1 } stringNo modo FIPS:
root-certificate fingerprint sha1 stringPor padrão, nenhuma impressão digital é configurada.
Especificação do par de chaves para solicitação de certificado
Restrições e diretrizes
Você pode especificar um par de chaves inexistente para a solicitação de certificado. A entidade PKI cria automaticamente o par de chaves antes de enviar uma solicitação de certificado.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Especifique o par de chaves para a solicitação de certificado.
- Especifique um par de chaves RSA.
public-key rsa { { encryption name encryption-key-name [ length
key-length ] | signature name signature-key-name [ length key-length ] }
* | general name key-name [ length key-length ] }- Especifique um par de chaves ECDSA. No modo não-FIPS:
public-key ecdsa name key-name [ secp192r1 | secp256r1 | secp384r1 |
secp521r1 ]No modo FIPS:
public-key ecdsa name key-name [ secp256r1 | secp384r1 | secp521r1 ]
- Especifique um par de chaves DSA.
public-key dsa name key-name [ length key-length ]Por padrão, nenhum par de chaves é especificado.
Especificar a finalidade pretendida para o certificado
Sobre a especificação da finalidade pretendida para um certificado
Um certificado emitido contém as extensões que restringem o uso do certificado a finalidades específicas. Você pode especificar as finalidades pretendidas para um certificado, que serão incluídas na solicitação de certificado enviada à autoridade certificadora. Entretanto, as extensões reais contidas em um certificado emitido dependem da política da CA e podem ser diferentes das especificadas no domínio da PKI. O fato de um aplicativo usar o certificado durante a autenticação depende da política do aplicativo.
As extensões de certificado compatíveis incluem:
- ike-Certificates com essa extensão podem ser usados por pares IKE.
- ssl-client - Certificados com essa extensão podem ser usados por clientes SSL.
- ssl-server - Certificados com essa extensão podem ser usados por servidores SSL.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Especifique o uso pretendido para o certificado.
usage { ike | ssl-client | ssl-server } *Por padrão, o certificado pode ser usado por todos os aplicativos compatíveis, incluindo IKE, cliente SSL, e servidor SSL.
Especificação do endereço IP de origem para pacotes do protocolo PKI
Sobre a especificação do endereço IP de origem para pacotes do protocolo PKI
Essa tarefa é necessária se a política da CA exigir que o servidor da CA aceite solicitações de certificado de um endereço IP ou de uma sub-rede específica.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Especifique um endereço IP de origem para os pacotes do protocolo PKI. IPv4:
source ip { ip-address | interface interface-type interface-number }IPv6:
source ipv6 { ipv6-address | interface interface-type interface-number }Por padrão, o endereço IP de origem dos pacotes do protocolo PKI é o endereço IP da interface de saída .
Especificação do caminho de armazenamento para certificados e LCRs
Sobre a especificação do caminho de armazenamento para certificados e LCRs
O dispositivo tem um caminho de armazenamento padrão para certificados e CRLs. Você pode alterar o caminho de armazenamento e especificar caminhos diferentes para os certificados e as CRLs.
Depois de alterar o caminho de armazenamento de certificados ou LCRs, os arquivos de certificado e os arquivos de LCR no caminho original são movidos para o novo caminho. Os arquivos de certificado usam a extensão de arquivo .cer ou .p12 e os arquivos de CRL usam a extensão de arquivo .crl.
Restrições e diretrizes
Se você alterar o caminho de armazenamento, salve a configuração antes de reiniciar ou desligar o dispositivo para evitar a perda de certificados ou CRLs.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique o caminho de armazenamento para certificados e CRLs.
pki storage { certificates | crls } dir-pathPor padrão, o dispositivo armazena certificados e CRLs no diretório PKI na mídia de armazenamento do dispositivo.
Solicitação de um certificado
Sobre a configuração da solicitação de certificado
Para solicitar um certificado, uma entidade de PKI deve fornecer suas informações de identidade e sua chave pública a uma AC. Uma solicitação de certificado pode ser enviada a uma CA no modo off-line ou on-line.
- Modo off-line - Uma solicitação de certificado é enviada por meio de um método fora de banda, como
telefone, disco ou e-mail.
- Modo on-line - Uma solicitação de certificado pode ser enviada automática ou manualmente a uma AC por meio do protocolo SCEP (Simple Certificate Enrollment Protocol).
Restrições e diretrizes para a configuração da solicitação de certificado
Ao solicitar um certificado local em um domínio PKI, siga estas restrições e diretrizes:
- Para evitar que um certificado local existente se torne inválido, não execute as seguintes tarefas:
- Crie um par de chaves com o mesmo nome do par de chaves contido no certificado. Para criar um par de chaves, use o comando public-key local create.
- Destrua o par de chaves contido no certificado.
Para destruir um par de chaves, use o comando public-key local destroy.
- Para solicitar manualmente um novo certificado em um domínio PKI que já tenha um certificado local, use o procedimento a seguir:
- Use o comando pki delete-certificate para excluir o certificado local existente.
- Um domínio de PKI pode ter certificados locais usando apenas um tipo de algoritmo criptográfico (DSA, ECDSA ou RSA). Se DSA ou ECDSA for usado, um domínio de PKI poderá ter apenas um certificado local. Se for usado RSA, um domínio PKI poderá ter um certificado local para assinatura e um certificado local para criptografia.
Pré-requisitos para a configuração da solicitação de certificado
Certifique-se de que o dispositivo esteja sincronizado com o servidor CA. Se o dispositivo não estiver sincronizado com a hora do servidor CA, a solicitação de certificado poderá falhar porque o certificado poderá ser considerado fora do período de validade. Para obter informações sobre como configurar a hora do sistema, consulte Fundamentals Configuration Guide.
Ativação do modo de solicitação automática de certificado on-line
Sobre o modo de solicitação automática de certificado on-line
No modo de solicitação automática, uma entidade PKI sem certificados locais envia automaticamente uma solicitação de certificado à CA quando um aplicativo trabalha com a entidade PKI. Por exemplo, quando a negociação IKE usa uma assinatura digital para autenticação de identidade, mas nenhum certificado local está disponível, a entidade envia automaticamente uma solicitação de certificado. Ela salva o certificado localmente após obter o certificado da CA.
Um certificado de CA deve estar presente antes de você solicitar um certificado local. Se não houver nenhum certificado de CA no domínio da PKI, a entidade PKI obterá automaticamente um certificado de CA antes de enviar uma solicitação de certificado.
Restrições e diretrizes
No modo de solicitação automática, o dispositivo não solicita automaticamente um novo certificado se o certificado atual estiver prestes a expirar ou tiver expirado, o que pode causar interrupções no serviço.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Ative o modo de solicitação automática de certificado on-line.
certificate request mode auto [ password { cipher | simple } string ]Por padrão, aplica-se o modo de solicitação manual.
Se a política da CA exigir uma senha para a revogação do certificado, especifique a senha neste comando .
Envio manual de uma solicitação de certificado on-line
Sobre o modo de solicitação manual de certificado on-line
No modo de solicitação manual, você deve executar o comando pki request-certificate domain para solicitar um certificado local em um domínio de PKI. O certificado será salvo no domínio após ser obtido da CA.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Defina o modo de solicitação de certificado como manual. modo de solicitação de certificado manual Por padrão, aplica-se o modo de solicitação manual.
- Retornar à visualização do sistema.
quit- Obter um certificado CA.
Consulte "Obtenção de certificados".
Essa etapa é necessária se o domínio PKI não tiver um certificado de CA. O certificado da CA é usado para verificar a autenticidade e a validade do certificado local obtido.
- Enviar manualmente uma solicitação de certificado SCEP.
pki request-certificate domain domain-name [ password password ]Esse comando não é salvo no arquivo de configuração.
Se a política da CA exigir uma senha para a revogação do certificado, especifique a senha nesse comando.
Envio manual de uma solicitação de certificado no modo off-line
Sobre o envio de solicitação de certificado no modo off-line
Use esse método se a CA não for compatível com o SCEP ou se não for possível estabelecer uma conexão de rede entre o dispositivo e a CA.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Defina o modo de solicitação de certificado como manual. modo de solicitação de certificado manual Por padrão, aplica-se o modo de solicitação manual.
- Retornar à visualização do sistema.
quit- Obtenha o certificado da CA. Consulte "Obtenção de certificados".
Essa etapa é necessária se o domínio PKI não tiver um certificado de CA. O certificado da CA é usado para verificar a autenticidade e a validade do certificado local obtido.
- Imprima a solicitação de certificado no formato PKCS10 no terminal ou salve a solicitação de certificado em um arquivo PKCS10.
pki request-certificate domain domain-name pkcs10 [ filename filename ]Esse comando não é salvo no arquivo de configuração.
- Transferir informações de solicitação de certificado para a CA usando um método fora de banda.
- Transfira o certificado local emitido da CA para o dispositivo local usando um método fora de banda.
- Importar o certificado local para o domínio PKI.
pki import domain domain-name { der local filename filename | p12 local
filename filename | pem local } [ filename filename ]Abortar uma solicitação de certificado
Sobre como abortar uma solicitação de certificado
Antes de a CA emitir um certificado, você pode abortar uma solicitação de certificado e alterar seus parâmetros, como o nome comum, o código do país ou o FQDN. Você pode usar o comando display pki certificate request-status para exibir o status de uma solicitação de certificado.
Como alternativa, você também pode remover um domínio PKI para abortar a solicitação de certificado associada.
Procedimento
- Entre na visualização do sistema.
system-view- Abortar uma solicitação de certificado.
pki abort-certificate-request domain domain-name
Esse comando não é salvo no arquivo de configuração.
Obtenção de certificados
Sobre a obtenção de certificados
Você pode obter o certificado da CA, os certificados locais e os certificados de pares relacionados a um domínio PKI de uma CA e salvá-los localmente para aumentar a eficiência da pesquisa. Para isso, use o modo off-line ou o modo on-line:
- No modo off-line, obtenha os certificados por um meio fora de banda, como FTP, disco ou e-mail, e importe-os localmente. Use esse modo quando o repositório de CRL não for especificado, o servidor CA não for compatível com o SCEP ou o servidor CA gerar o par de chaves para os certificados.
- No modo on-line, você pode obter o certificado CA por meio do SCEP e obter certificados locais ou certificados de pares por meio do LDAP.
Restrições e diretrizes
Siga estas restrições e diretrizes ao obter certificados de uma AC
- Se um certificado de CA já existir localmente, você não poderá obtê-lo novamente no modo on-line. Se você quiser obter um novo certificado CA, use o comando pki delete-certificate para excluir primeiro o certificado CA existente e os certificados locais.
- Se já existirem certificados locais ou de pares, você poderá obter novos certificados locais ou de pares para substituir os existentes. Se for usado RSA, um domínio PKI poderá ter dois certificados locais, um para assinatura e outro para criptografia.
- Se a verificação da LCR estiver ativada, a obtenção de um certificado aciona a verificação da LCR. Se o certificado a ser obtido tiver sido revogado, o certificado não poderá ser obtido.
- O dispositivo compara o período de validade de um certificado com a hora do sistema local para determinar se o certificado é válido. Certifique-se de que a hora do sistema do dispositivo esteja sincronizada com o servidor CA.
Pré-requisitos
- Antes de obter certificados locais ou de pares no modo on-line, certifique-se de que um servidor LDAP esteja configurado corretamente no domínio da PKI.
- Antes de importar certificados no modo off-line, conclua as seguintes tarefas:
- Use FTP ou TFTP para carregar os arquivos de certificado na mídia de armazenamento do dispositivo.
Se o FTP ou TFTP não estiver disponível, exiba e copie o conteúdo de um certificado em um arquivo no dispositivo. Certifique-se de que o certificado esteja no formato PEM, pois somente certificados no formato PEM podem ser importados.
- Antes de importar um certificado local ou um certificado de par, obtenha a cadeia de certificados da CA que assina o certificado.
Essa etapa é necessária somente se a cadeia de certificados da CA não estiver disponível no domínio da PKI nem contida no certificado a ser importado.
- Antes de importar um certificado local que contenha um par de chaves criptografadas, entre em contato com o administrador da CA para obter a senha necessária para importar o certificado.
Procedimento
- Entre na visualização do sistema.
system-view- Obter certificados.
- Importar certificados no modo off-line.
pki import domain domain-name { der { ca | local | peer } filename
filename | p12 local filename filename | pem { ca | local | peer }
[ filename filename ] }
- Obter certificados no modo on-line.
pki retrieve-certificate domain domain-name { ca | local | peer
entity-name }
Esse comando não é salvo no arquivo de configuração.
Verificação de certificados de PKI
Sobre a verificação da certificação
Um certificado é verificado automaticamente quando é solicitado, obtido ou usado por um aplicativo. Se o certificado expirar, se não for emitido por uma CA confiável ou se for revogado, o certificado não poderá ser usado.
Você pode ativar ou desativar a verificação da CRL em um domínio de PKI. A verificação da CRL verifica se um certificado está na CRL. Se estiver, o certificado foi revogado e sua entidade de origem não é confiável.
Para usar a verificação de CRL, uma CRL deve ser obtida de um repositório de CRL. O dispositivo seleciona um repositório de LCR na seguinte ordem:
- Repositório de CRL especificado no domínio PKI usando o comando crl url.
- repositório de CRL no certificado que está sendo verificado.
- Repositório de LCR no certificado de CA ou repositório de LCR no certificado de CA de nível superior se o certificado que estiver sendo verificado for um certificado de CA
Se nenhum repositório de CRL for encontrado após o processo de seleção, o dispositivo obterá a CRL por meio do SCEP. Nesse cenário, o certificado da CA e os certificados locais devem ter sido obtidos.
Um certificado falha na verificação da LCR nas seguintes situações:
- Uma LCR não pode ser obtida durante a verificação da LCR do certificado.
- A verificação da CRL verifica se o certificado foi revogado.
Restrições e diretrizes para verificação de certificados
Ao verificar o certificado de CA de um domínio de PKI, o sistema precisa verificar todos os certificados na cadeia de certificados de CA. Para garantir um processo bem-sucedido de verificação de certificado, o dispositivo deve ter todos os domínios de PKI aos quais pertencem os certificados de CA na cadeia de certificados.
O sistema verifica os certificados da CA na cadeia de certificados da CA da seguinte forma:
- Identifica o certificado pai do certificado de nível mais baixo.
Cada certificado CA contém um campo de emissor que identifica a CA principal que emitiu o certificado .
- Localiza o domínio PKI ao qual pertence o certificado pai.
- Executa a verificação de CRL no domínio PKI para verificar se o certificado pai foi revogado. Se ele tiver sido revogado, o certificado não poderá ser usado.
Essa etapa não será executada quando a verificação da CRL estiver desativada no domínio da PKI.
- Repete as etapas anteriores para os certificados de nível superior na cadeia de certificados CA até chegar ao certificado CA raiz .
- Verifica se cada certificado de CA na cadeia de certificados é emitido pela CA pai nomeada, começando pela CA raiz.
Verificação de certificados com verificação de CRL
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- (Opcional.) Especifique o URL do repositório de LCR.
crl url url-stringPor padrão, o URL do repositório de CRL não é especificado.
- Ativar a verificação de CRL.
crl check enablePor padrão, a verificação de CRL está ativada.
- Retornar à visualização do sistema.
quit- Obtenha o certificado da CA. Consulte "Obtenção de certificados".
O domínio PKI deve ter um certificado CA antes que você possa verificar os certificados nele.
- (Opcional.) Obtenha a CRL e salve-a localmente.
pki retrieve-crl domain domain-namePara verificar um certificado de CA não raiz e certificados locais, o dispositivo recupera automaticamente a CRL se o domínio PKI não tiver CRL.
A nova CRL obtida substitui a antiga, se houver.
A LCR obtida é emitida por uma AC na cadeia de certificados da AC armazenada no domínio da PKI.
- Verificar manualmente a validade dos certificados.
pki validate-certificate domain domain-name { ca | local }Verificação de certificados sem verificação de CRL
- Entre na visualização do sistema.
system-view- Entre na visualização do domínio PKI.
pki domain domain-name- Desativar a verificação de CRL.
undo crl check enable
Por padrão, a verificação de CRL está ativada.
- Retornar à visualização do sistema.
quit- Obtenha um certificado de CA para o domínio PKI. Consulte "Obtenção de certificados".
O domínio PKI deve ter um certificado CA antes que você possa verificar os certificados nele.
- Verificar manualmente a validade do certificado.
pki validate-certificate domain domain-name { ca | local }Esse comando não é salvo no arquivo de configuração.
Exportação de certificados
Sobre certificados de exportação
É possível exportar o certificado CA e os certificados locais em um domínio PKI para arquivos de certificado. Os arquivos de certificado exportados podem então ser importados de volta para o dispositivo ou para outros aplicativos PKI.
Restrições e diretrizes
Para exportar todos os certificados no formato PKCS12, o domínio PKI deve ter no mínimo um certificado local. Se o domínio PKI não tiver nenhum certificado local, os certificados no domínio PKI não poderão ser exportados.
Se você não especificar um nome de arquivo ao exportar um certificado no formato PEM, esse comando exibirá o conteúdo do certificado no terminal.
Quando você exporta um certificado local com pares de chaves RSA para um arquivo, o nome do arquivo do certificado pode ser diferente do nome do arquivo especificado no comando. O nome real do arquivo de certificado depende da finalidade do par de chaves contido no certificado. Para obter mais informações sobre a regra de nomeação de arquivo, consulte o comando pki export na Referência de comandos de segurança.
Procedimento
- Entre na visualização do sistema.
system-view- Certificados de exportação.
- Exportar certificados no formato DER.
pki export domain domain-name der { all | ca | local } filename filename- Exportar certificados no formato PKCS12.
pki export domain domain-name p12 { all | local } passphrase p12-key
filename filename- Exportar certificados no formato PEM.
pki export domain domain-name pem { { all | local } [ { 3des-cbc |
aes-128-cbc | aes-192-cbc | aes-256-cbc | des-cbc } pem-key ] | ca }
[ filename filename ]Remoção de um certificado
Sobre a remoção de certificados
Você pode remover certificados de um domínio PKI nas seguintes situações:
- Remova um certificado CA, um certificado local ou um certificado de par se o certificado tiver expirado ou estiver prestes a expirar.
- Remova um certificado local se a chave privada do certificado estiver comprometida ou se você quiser solicitar um novo certificado local para substituir o existente.
Restrições e diretrizes
Depois que você remover o certificado CA, o sistema removerá automaticamente os certificados locais, os certificados de pares e as LCRs do domínio.
Para remover um certificado local e solicitar um novo certificado, execute as seguintes tarefas:
- Remova o certificado local.
- Use o comando public-key local destroy para destruir o par de chaves local existente.
- Use o comando public-key local create para gerar um novo par de chaves.
- Solicitar um novo certificado.
Para obter mais informações sobre as opções public-key local destroy e public-key local create
consulte Referência de comandos de segurança.
Procedimento
- Entre na visualização do sistema.
system-view- Remover um certificado.
pki delete-certificate domain domain-name { ca | local | peer [ serial
serial-num ] }Se você usar a palavra-chave peer sem especificar um número de série, esse comando removerá todos os certificados peer .
Configuração de uma política de controle de acesso baseada em certificado
Sobre políticas de controle de acesso baseadas em certificados
As políticas de controle de acesso baseadas em certificados permitem autorizar o acesso a um dispositivo (por exemplo, um servidor HTTPS) com base nos atributos do certificado de um cliente autenticado.
Regras de controle de acesso e grupos de atributos de certificados
Uma política de controle de acesso baseada em certificado é um conjunto de regras de controle de acesso (instruções de permissão ou negação), cada uma associada a um grupo de atributos de certificado. Um grupo de atributos de certificado contém várias regras de atributos, cada uma definindo um critério de correspondência para um atributo no campo de nome do emissor do certificado, nome do assunto ou nome do assunto alternativo.
Mecanismo de correspondência de certificados
Se um certificado corresponder a todas as regras de atributo em um grupo de atributos de certificado associado a uma regra de controle de acesso, o sistema determinará que o certificado corresponde à regra de controle de acesso. Nesse cenário, o processo de correspondência é interrompido e o sistema executa a ação de controle de acesso definida na regra de controle de acesso.
As condições a seguir descrevem como uma política de controle de acesso baseada em certificado verifica a validade de um certificado:
- Se um certificado corresponder a uma declaração de permissão, o certificado será aprovado na verificação.
- Se um certificado corresponder a uma declaração de negação ou não corresponder a nenhuma declaração na política, o certificado será considerado inválido.
- Se uma declaração estiver associada a um grupo de atributos inexistente, ou se o grupo de atributos não tiver regras de atributos, o certificado corresponderá à declaração.
- Se a política de controle de acesso baseada em certificado especificada para um aplicativo de segurança (por exemplo, HTTPS) não existir, todos os certificados do aplicativo serão aprovados na verificação.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um grupo de atributos de certificado e insira sua visualização.
pki certificate attribute-group group-name- Configure uma regra de atributo para o nome do emissor, nome do assunto ou nome alternativo do assunto.
attribute id { alt-subject-name { fqdn | ip } | { issuer-name | subject-name }
{ dn | fqdn | ip } } { ctn | equ | nctn | nequ} attribute-valuePor padrão, nenhuma regra de atributo é configurada.
- Retornar à visualização do sistema.
quit- Crie uma política de controle de acesso baseada em certificado e insira sua visualização.
pki certificate access-control-policy policy-namePor padrão, não existem políticas de controle de acesso baseadas em certificados.
- Crie uma regra de controle de acesso a certificados.
rule [ id ] { deny | permit } group-namePor padrão, nenhuma regra de controle de acesso a certificados é configurada, e todos os certificados podem passar na verificação.
É possível criar várias regras de controle de acesso a certificados para uma política de controle de acesso baseada em certificados.
Comandos de exibição e manutenção para PKI
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações sobre a política de controle de acesso baseada em certificados. | exibir pki certificate access-control-policy [ policy-name ] |
| Exibição certificado atributo informações do grupo de certificados. | tela pki grupo de atributos de certificado [ nome-do-grupo ] |
| Exibir o conteúdo de um certificado. | exibir domínio do certificado pki nome do domínio { ca | local | peer [ serial serial-num ] } |
| Exibir o status da solicitação de certificado. | exibir pki certificate request-status [ domínio nome-do-domínio ] |
| Exibir CRLs armazenadas localmente em um domínio PKI. | exibir pki crl domain nome do domínio |
Exemplos de configuração de PKI
Você pode usar diferentes aplicativos de software, como o Windows Server, o RSA Keon e o OpenCA, para atuar como servidor de CA.
Se você usar o Windows Server ou o OpenCA, deverá instalar o complemento SCEP para o Windows Server ou ativar o SCEP para o OpenCA. Em ambos os casos, quando você configurar um domínio PKI, deverá usar o comando certificate request from ra para especificar o RA para aceitar solicitações de certificado.
Se você usar o RSA Keon, o complemento SCEP não será necessário. Ao configurar um domínio PKI, você deve usar o comando certificate request from ca para especificar a CA que aceitará solicitações de certificado .
Exemplo: Solicitação de um certificado de um servidor RSA Keon CA
Configuração de rede
Configure a entidade PKI (o dispositivo) para solicitar um certificado local do servidor CA.
Figura 2 Diagrama de rede
Configuração do servidor RSA Keon CA
- Crie um servidor CA chamado myca:
Neste exemplo, você deve configurar esses atributos básicos no servidor CA:
- Apelido-Nome da CA confiável.
- Atributos DN-DN do sujeito da AC, incluindo o nome comum (CN), a unidade organizacional (OU), a organização (O) e o país (C).
Você pode usar os valores padrão para outros atributos.
- Configurar atributos estendidos:
Configure os parâmetros na seção Jurisdiction Configuration (Configuração de jurisdição) na página de gerenciamento do servidor CA:
- Selecione os perfis de extensão corretos.
- Ative a função de autovetting do SCEP para permitir que o servidor CA aprove automaticamente as solicitações de certificado sem intervenção manual.
- Especifique a lista de endereços IP para autovetting do SCEP.
Configuração do dispositivo
- Sincronize a hora do sistema do dispositivo com o servidor CA para que o dispositivo solicite corretamente certificados ou obtenha LCRs. (Detalhes não mostrados.)
- Crie uma entidade chamada aaa e defina o nome comum como Device.
<Device> system-view
[Device] pki entity aaa
[Device-pki-entity-aaa] common-name Device
[Device-pki-entity-aaa] quit- Configure um domínio PKI:
# Crie um domínio PKI chamado torsa e insira sua visualização.
[Device] pki domain torsa# Especifique o nome da CA confiável. A configuração deve ser a mesma do nome da CA configurada no servidor CA. Este exemplo usa myca.
[Device-pki-domain-torsa] ca identifier myca# Configure o URL do servidor CA. O formato do URL é http://host:port/Issuing Jurisdiction ID, em que Issuing Jurisdiction ID é uma cadeia hexadecimal gerada no servidor da CA.
[Device-pki-domain-torsa] certificate request url
http://1.1.2.22:446/80f6214aa8865301d07929ae481c7ceed99f95bd# Configure o dispositivo para enviar solicitações de certificado para ca.
[Device-pki-domain-torsa] certificate request from ca# Defina o nome da entidade PKI como aaa.
[Device-pki-domain-torsa] certificate request entity aaa
# Especifique o URL do repositório de CRL.
[Device-pki-domain-torsa] crl url ldap://1.1.2.22:389/CN=myca
# Especifique um par de chaves RSA de uso geral de 1024 bits chamado abc para solicitação de certificado.
[Device-pki-domain-torsa] public-key rsa general name abc length 1024
[Device-pki-domain-torsa] quit
- Gerar o par de chaves RSA.
[Device] public-key local create rsa name abc
The range of public key modulus is (512 ~ 4096).
If the key modulus is greater than 512,it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
..........................++++++
.....................................++++++
Create the key pair successfully.
- Solicitar um certificado local:
# Obtenha o certificado CA e salve-o localmente.
[Device] pki retrieve-certificate domain torsa ca
The trusted CA's finger print is:
MD5 fingerprint:EDE9 0394 A273 B61A F1B3 0072 A0B1 F9AB
SHA1 fingerprint: 77F9 A077 2FB8 088C 550B A33C 2410 D354 23B2 73A8
Is the finger print correct?(Y/N):y
Retrieved the certificates successfully.# Envie uma solicitação de certificado manualmente e defina a senha de revogação do certificado como 1111.
A senha de revogação de certificado é necessária quando um servidor RSA Keon CA é usado.
[Device] pki request-certificate domain torsa password 1111
Start to request general certificate ...
……
Request certificate of domain torsa successfullyVerificação da configuração
# Exibir informações sobre o certificado local no domínio PKI torsa.
[Device] display pki certificate domain torsa local
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
15:79:75:ec:d2:33:af:5e:46:35:83:bc:bd:6e:e3:b8
Signature Algorithm: sha1WithRSAEncryption
Issuer: CN=myca
Validity
Not Before: Jan 6 03:10:58 2013 GMT
Not After : Jan 6 03:10:58 2014 GMT
Subject: CN=Device
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (1024 bit)
Modulus:
00:ab:45:64:a8:6c:10:70:3b:b9:46:34:8d:eb:1a:
a1:b3:64:b2:37:27:37:9d:15:bd:1a:69:1d:22:0f:
3a:5a:64:0c:8f:93:e5:f0:70:67:dc:cd:c1:6f:7a:
0c:b1:57:48:55:81:35:d7:36:d5:3c:37:1f:ce:16:
7e:f8:18:30:f6:6b:00:d6:50:48:23:5c:8c:05:30:
6f:35:04:37:1a:95:56:96:21:95:85:53:6f:f2:5a:
dc:f8:ec:42:4a:6d:5c:c8:43:08:bb:f1:f7:46:d5:
f1:9c:22:be:f3:1b:37:73:44:f5:2d:2c:5e:8f:40:
3e:36:36:0d:c8:33:90:f3:9b
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 CRL Distribution Points:
Full Name:
DirName: CN = myca
Signature Algorithm: sha1WithRSAEncryption
b0:9d:d9:ac:a0:9b:83:99:bf:9d:0a:ca:12:99:58:60:d8:aa:
73:54:61:4b:a2:4c:09:bb:9f:f9:70:c7:f8:81:82:f5:6c:af:
25:64:a5:99:d1:f6:ec:4f:22:e8:6a:96:58:6c:c9:47:46:8c:
f1:ba:89:b8:af:fa:63:c6:c9:77:10:45:0d:8f:a6:7f:b9:e8:
25:90:4a:8e:c6:cc:b8:1a:f8:e0:bc:17:e0:6a:11:ae:e7:36:
87:c4:b0:49:83:1c:79:ce:e2:a3:4b:15:40:dd:fe:e0:35:52:
ed:6d:83:31:2c:c2:de:7c:e0:a7:92:61:bc:03:ab:40:bd:69:
1b:f5Para exibir informações detalhadas sobre o certificado CA, use o comando display pki certificate domain.
Exemplo: Solicitação de um certificado de um servidor CA do Windows Server 2003
Configuração de rede
Configure a entidade PKI (o dispositivo) para solicitar um certificado local de um servidor CA do Windows Server 2003.
Figura 3 Diagrama de rede
Configuração do servidor CA do Windows Server 2003
- Instale o componente de serviço de certificado:
- Selecione Painel de controle > Adicionar ou remover programas no menu Iniciar.
- Selecione Adicionar/Remover componentes do Windows > Serviços de certificado.
- Clique em Next para iniciar a instalação.
- Defina o nome da CA. Neste exemplo, defina o nome da CA como myca.
- Instale o complemento SCEP:
- Modifique os atributos do serviço de certificado:
- Selecione Painel de controle > Ferramentas administrativas > Autoridade de certificação no menu Iniciar.
Por padrão, o Windows Server 2003 não oferece suporte ao SCEP. É necessário instalar o complemento SCEP no servidor para que uma entidade de PKI registre e obtenha um certificado do servidor. Depois que o SCEP
Quando a instalação do add-on estiver concluída, você verá um URL. Especifique esse URL como o URL de solicitação de certificado no dispositivo.
Se o componente de serviço de certificado e o complemento SCEP tiverem sido instalados com êxito, deverá haver dois certificados emitidos pela CA para o RA.
- Clique com o botão direito do mouse no servidor CA na árvore de navegação e selecione Propriedades > Módulo de política.
- Clique em Propriedades e selecione Seguir as configurações no modelo de certificado, se aplicável. Caso contrário, emita o certificado automaticamente.
- Modificar os atributos dos serviços de informações da Internet:
- Selecione Painel de Controle > Ferramentas Administrativas > Serviços de Informações da Internet (IIS) Manager no menu Iniciar.
- Selecione Web Sites na árvore de navegação.
- Clique com o botão direito do mouse em Default Web Site e selecione Properties > Home Directory.
- Especifique o caminho para o serviço de certificado no campo Caminho local.
- Especifique um número de porta TCP exclusivo para o site padrão para evitar conflitos com os serviços existentes. Este exemplo usa a porta 8080.
Configuração do dispositivo
- Sincronize a hora do sistema do dispositivo com o servidor CA para que o dispositivo solicite certificados corretamente. (Detalhes não mostrados.)
- Crie uma entidade chamada aaa e defina o nome comum como teste.
<Device> system-view
[Device] pki entity aaa
[Device-pki-entity-aaa] common-name test
[Device-pki-entity-aaa] quit- Configure um domínio PKI:
# Crie um domínio PKI chamado winserver e insira sua visualização.
[Device] pki domain winserver# Defina o nome da CA confiável como myca.
[Device-pki-domain-winserver] ca identifier myca# Configure o URL de solicitação de certificado. O formato do URL é http://host:port/certsrv/mscep/mscep.dll, em que host:port é o endereço IP do host e o número da porta do servidor CA.
[Device-pki-domain-winserver] certificate request url
http://4.4.4.1:8080/certsrv/mscep/mscep.dll# Configure o dispositivo para enviar solicitações de certificado para ra.
[Device-pki-domain-winserver] certificate request from ra# Defina o nome da entidade PKI como aaa.
[Device-pki-domain-winserver] certificate request entity aaa# Configure um par de chaves RSA de uso geral de 1024 bits chamado abc para solicitação de certificado. [Device-pki-domain-winserver] public-key rsa general name abc length 1024 [Device-pki-domain-winserver] quit
- Gerar o par de chaves RSA abc.
[Device] public-key local create rsa name abc
The range of public key modulus is (512 ~ 4096).
If the key modulus is greater than 512,it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
..........................++++++
.....................................++++++
Create the key pair successfully.
- Solicitar um certificado local:
# Obtenha o certificado CA e salve-o localmente.
[Device] pki retrieve-certificate domain winserver ca
The trusted CA's finger print is:
MD5 fingerprint:766C D2C8 9E46 845B 4DCE 439C 1C1F 83AB
SHA1 fingerprint:97E5 DDED AB39 3141 75FB DB5C E7F8 D7D7 7C9B 97B4
Is the finger print correct?(Y/N):y
Retrieved the certificates successfully# Envie uma solicitação de certificado manualmente.
[Device] pki request-certificate domain winserver
Start to request general certificate ...
…
Request certificate of domain winserver successfullyVerificação da configuração
# Exibir informações sobre o certificado local no winserver do domínio PKI.
[Device] display pki certificate domain winserver local
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
(Negative)01:03:99:ff:ff:ff:ff:fd:11
Signature Algorithm: sha1WithRSAEncryption
Issuer: CN=sec
Validity
Not Before: Dec 24 07:09:42 2012 GMT
Not After : Dec 24 07:19:42 2013 GMT
Subject: CN=test
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:c3:b5:23:a0:2d:46:0b:68:2f:71:d2:14:e1:5a:
55:6e:c5:5e:26:86:c1:5a:d6:24:68:02:bf:29:ac:
dc:31:41:3f:5d:5b:36:9e:53:dc:3a:bc:0d:11:fb:
d6:7d:4f:94:3c:c1:90:4a:50:ce:db:54:e0:b3:27:
a9:6a:8e:97:fb:20:c7:44:70:8f:f0:b9:ca:5b:94:
f0:56:a5:2b:87:ac:80:c5:cc:04:07:65:02:39:fc:
db:61:f7:07:c6:65:4c:e4:5c:57:30:35:b4:2e:ed:
9c:ca:0b:c1:5e:8d:2e:91:89:2f:11:e3:1e:12:8a:
f8:dd:f8:a7:2a:94:58:d9:c7:f8:1a:78:bd:f5:42:
51:3b:31:5d:ac:3e:c3:af:fa:33:2c:fc:c2:ed:b9:
ee:60:83:b3:d3:e5:8e:e5:02:cf:b0:c8:f0:3a:a4:
b7:ac:a0:2c:4d:47:5f:39:4b:2c:87:f2:ee:ea:d0:
c3:d0:8e:2c:80:83:6f:39:86:92:98:1f:d2:56:3b:
d7:94:d2:22:f4:df:e3:f8:d1:b8:92:27:9c:50:57:
f3:a1:18:8b:1c:41:ba:db:69:07:52:c1:9a:3d:b1:
2d:78:ab:e3:97:47:e2:70:14:30:88:af:f8:8e:cb:
68:f9:6f:07:6e:34:b6:38:6a:a2:a8:29:47:91:0e:
25:39
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Key Usage:
Digital Signature, Non Repudiation, Key Encipherment, Data Encipherment
X509v3 Subject Key Identifier:
C9:BB:D5:8B:02:1D:20:5B:40:94:15:EC:9C:16:E8:9D:6D:FD:9F:34
X509v3 Authority Key Identifier:
keyid:32:F1:40:BA:9E:F1:09:81:BD:A8:49:66:FF:F8:AB:99:4A:30:21:9B
X509v3 CRL Distribution Points:
Full Name:
URI:file://\\g07904c\CertEnroll\sec.crl
Authority Information Access:
CA Issuers - URI:http://gc/CertEnroll/gc_sec.crt
CA Issuers - URI:file://\\gc\CertEnroll\gc_sec.crt
1.3.6.1.4.1.311.20.2:
.0.I.P.S.E.C.I.n.t.e.r.m.e.d.i.a.t.e.O.f.f.l.i.n.e
Signature Algorithm: sha1WithRSAEncryption
76:f0:6c:2c:4d:bc:22:59:a7:39:88:0b:5c:50:2e:7a:5c:9d:
6c:28:3c:c0:32:07:5a:9c:4c:b6:31:32:62:a9:45:51:d5:f5:
36:8f:47:3d:47:ae:74:6c:54:92:f2:54:9f:1a:80:8a:3f:b2:
14:47:fa:dc:1e:4d:03:d5:d3:f5:9d:ad:9b:8d:03:7f:be:1e:
29:28:87:f7:ad:88:1c:8f:98:41:9a:db:59:ba:0a:eb:33:ec:
cf:aa:9b:fc:0f:69:3a:70:f2:fa:73:ab:c1:3e:4d:12:fb:99:
31:51:ab:c2:84:c0:2f:e5:f6:a7:c3:20:3c:9a:b0:ce:5a:bc:
0f:d9:34:56:bc:1e:6f:ee:11:3f:7c:b2:52:f9:45:77:52:fb:
46:8a:ca:b7:9d:02:0d:4e:c3:19:8f:81:46:4e:03:1f:58:03:
bf:53:c6:c4:85:95:fb:32:70:e6:1b:f3:e4:10:ed:7f:93:27:
90:6b:30:e7:81:36:bb:e2:ec:f2:dd:2b:bb:b9:03:1c:54:0a:
00:3f:14:88:de:b8:92:63:1e:f5:b3:c2:cf:0a:d5:f4:80:47:
6f:fa:7e:2d:e3:a7:38:46:f6:9e:c7:57:9d:7f:82:c7:46:06:
7d:7c:39:c4:94:41:bd:9e:5c:97:86:c8:48:de:35:1e:80:14:
02:09:ad:08Para exibir informações detalhadas sobre o certificado CA, use o comando display pki certificate domain.
Exemplo: Solicitação de um certificado de um servidor OpenCA
Configuração de rede
Configure a entidade PKI (o dispositivo) para solicitar um certificado local do servidor CA.
Figura 4 Diagrama de rede
Configuração do servidor OpenCA
Configure o servidor OpenCA conforme as instruções dos manuais relacionados. (Detalhes não mostrados.)
Certifique-se de que a versão do servidor OpenCA seja posterior à versão 0.9.2, pois as versões anteriores não são compatíveis com o SCEP.
Configuração do dispositivo
- Sincronize a hora do sistema do dispositivo com o servidor CA para que o dispositivo solicite certificados corretamente. (Detalhes não mostrados.)
- Crie uma entidade PKI chamada aaa e configure o nome comum, o código do país, o nome da organização e a UO para a entidade.
<Device> system-view
[Device] pki entity aaa
[Device-pki-entity-aaa] common-name rnd
[Device-pki-entity-aaa] country CN
[Device-pki-entity-aaa] organization test
[Device-pki-entity-aaa] organization-unit software
[Device-pki-entity-aaa] quit- Configure um domínio PKI:
# Crie um domínio PKI chamado openca e entre em sua exibição.
[Device] pki domain openca# Defina o nome da CA confiável como myca.
[Device-pki-domain-openca] ca identifier myca# Configure o URL de solicitação de certificado. O URL está no formato http://host/cgi-bin/pki/scep, em que host é o endereço IP do host do servidor OpenCA.
[Device-pki-domain-openca] certificate request url
http://192.168.222.218/cgi-bin/pki/scep# Configure o dispositivo para enviar solicitações de certificado para a RA.
[Device-pki-domain-openca] certificate request from raEspecifique a entidade PKI aaa para a solicitação de certificado.
[Device-pki-domain-openca] certificate request entity aaa# Configure um par de chaves RSA de uso geral de 1024 bits chamado abc para solicitação de certificado.
[Device-pki-domain-openca] public-key rsa general name abc length 1024
[Device-pki-domain-openca] quit- Gerar o par de chaves RSA abc.
[Device] public-key local create rsa name abc
The range of public key modulus is (512 ~ 4096).
If the key modulus is greater than 512,it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
..........................++++++
.....................................++++++
Create the key pair successfully.
- Solicitar um certificado local:
# Obtenha o certificado CA e salve-o localmente.
[Device] pki retrieve-certificate domain openca ca
The trusted CA's finger print is:
MD5 fingerprint:5AA3 DEFD 7B23 2A25 16A3 14F4 C81C C0FA
SHA1 fingerprint:9668 4E63 D742 4B09 90E0 4C78 E213 F15F DC8E 9122
Is the finger print correct?(Y/N):y
Retrieved the certificates successfully# Envie uma solicitação de certificado manualmente.
[Device] pki request-certificate domain openca
Start to request general certificate ...
…
Request certificate of domain openca successfullyVerificação da configuração
# Exibir informações sobre o certificado local no domínio PKI openca.
[Device] display pki certificate domain openca local
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
21:1d:b8:d2:e4:a9:21:28:e4:de
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=CN, L=shangdi, ST=pukras, O=OpenCA Labs, OU=mysubUnit, CN=sub-ca,
DC=pki-subdomain, DC=mydomain-sub, DC=com
Validity
Not Before: Jun 30 09:09:09 2011 GMT
Not After : May 1 09:09:09 2012 GMT
Subject: CN=rnd, O=test, OU=software, C=CN
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (1024 bit)
Modulus:
00:b8:7a:9a:b8:59:eb:fc:70:3e:bf:19:54:0c:7e:
c3:90:a5:d3:fd:ee:ff:c6:28:c6:32:fb:04:6e:9c:
d6:5a:4f:aa:bb:50:c4:10:5c:eb:97:1d:a7:9e:7d:
53:d5:31:ff:99:ab:b6:41:f7:6d:71:61:58:97:84:
37:98:c7:7c:79:02:ac:a6:85:f3:21:4d:3c:8e:63:
8d:f8:71:7d:28:a1:15:23:99:ed:f9:a1:c3:be:74:
0d:f7:64:cf:0a:dd:39:49:d7:3f:25:35:18:f4:1c:
59:46:2b:ec:0d:21:1d:00:05:8a:bf:ee:ac:61:03:
6c:1f:35:b5:b4:cd:86:9f:45
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Cert Type:
SSL Client, S/MIME
X509v3 Key Usage:
Digital Signature, Non Repudiation, Key Encipherment
X509v3 Extended Key Usage:
TLS Web Client Authentication, E-mail Protection, Microsoft
Smartcardlogin
Netscape Comment:
User Certificate of OpenCA Labs
X509v3 Subject Key Identifier:
24:71:C9:B8:AD:E1:FE:54:9A:EA:E9:14:1B:CD:D9:45:F4:B2:7A:1B
X509v3 Authority Key Identifier:
keyid:85:EB:D5:F7:C9:97:2F:4B:7A:6D:DD:1B:4D:DD:00:EE:53:CF:FD:5B
X509v3 Issuer Alternative Name:
DNS:root@docm.com, DNS:, IP Address:192.168.154.145, IP
Address:192.168.154.138
Authority Information Access:
CA Issuers - URI:http://192.168.222.218/pki/pub/cacert/cacert.crt
OCSP - URI:http://192.168.222.218:2560/
1.3.6.1.5.5.7.48.12 - URI:http://192.168.222.218:830/
X509v3 CRL Distribution Points:
Full Name:
URI:http://192.168.222.218/pki/pub/crl/cacrl.crl
Signature Algorithm: sha256WithRSAEncryption
5c:4c:ba:d0:a1:35:79:e6:e5:98:69:91:f6:66:2a:4f:7f:8b:
0e:80:de:79:45:b9:d9:12:5e:13:28:17:36:42:d5:ae:fc:4e:
ba:b9:61:f1:0a:76:42:e7:a6:34:43:3e:2d:02:5e:c7:32:f7:
6b:64:bb:2d:f5:10:6c:68:4d:e7:69:f7:47:25:f5:dc:97:af:
ae:33:40:44:f3:ab:e4:5a:a0:06:8f:af:22:a9:05:74:43:b6:
e4:96:a5:d4:52:32:c2:a8:53:37:58:c7:2f:75:cf:3e:8e:ed:
46:c9:5a:24:b1:f5:51:1d:0f:5a:07:e6:15:7a:02:31:05:8c:
03:72:52:7c:ff:28:37:1e:7e:14:97:80:0b:4e:b9:51:2d:50:
98:f2:e4:5a:60:be:25:06:f6:ea:7c:aa:df:7b:8d:59:79:57:
8f:d4:3e:4f:51:c1:34:e6:c1:1e:71:b5:0d:85:86:a5:ed:63:
1e:08:7f:d2:50:ac:a0:a3:9e:88:48:10:0b:4a:7d:ed:c1:03:
9f:87:97:a3:5e:7d:75:1d:ac:7b:6f:bb:43:4d:12:17:9a:76:
b0:bf:2f:6a:cc:4b:cd:3d:a1:dd:e0:dc:5a:f3:7c:fb:c3:29:
b0:12:49:5c:12:4c:51:6e:62:43:8b:73:b9:26:2a:f9:3d:a4:
81:99:31:89Para exibir informações detalhadas sobre o certificado CA, use o comando display pki certificate domain.
Exemplo: Configuração da negociação IKE com assinatura digital RSA de um servidor CA do Windows Server 2003
Configuração de rede
Conforme mostrado na Figura 5, é necessário estabelecer um túnel IPsec entre o Dispositivo A e o Dispositivo B. O túnel IPsec protege o tráfego entre o Host A na sub-rede 10.1.1.0/24 e o Host B na sub-rede 1.1.1.0/24.
O dispositivo A e o dispositivo B usam o IKE para configurar SAs, e a proposta do IKE usa assinatura digital RSA para autenticação de identidade.
O dispositivo A e o dispositivo B usam a mesma CA.
Figura 5 Diagrama de rede
Configuração do servidor CA do Windows Server 2003
Consulte "Exemplo: Solicitação de um certificado de um servidor CA do Windows Server 2003".
Configuração do dispositivo A
# Configurar uma entidade PKI.
<DeviceA> system-view
[DeviceA] pki entity en
[DeviceA-pki-entity-en] ip 2.2.2.1
[DeviceA-pki-entity-en] common-name devicea
[DeviceA-pki-entity-en] quit# Configure um domínio PKI.
[DeviceA] pki domain 1
[DeviceA-pki-domain-1] ca identifier CA1
[DeviceA-pki-domain-1] certificate request url http://1.1.1.100/certsrv/mscep/mscep.dll
[DeviceA-pki-domain-1] certificate request entity en
[DeviceA-pki-domain-1] ldap-server host 1.1.1.102# Configure o dispositivo para enviar solicitações de certificado para ra.
[DeviceA-pki-domain-1] certificate request from ra# Configure um par de chaves RSA de uso geral de 1024 bits chamado abc para solicitação de certificado.
[DeviceA-pki-domain-1] public-key rsa general name abc length 1024
[DeviceA-pki-domain-1] quit# Gerar o par de chaves RSA.
[DeviceA] public-key local create rsa name abc
The range of public key modulus is (512 ~ 4096).
If the key modulus is greater than 512,it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
..........................++++++
.....................................++++++
Create the key pair successfully.# Obtenha o certificado CA e salve-o localmente.
[DeviceA] pki retrieve-certificate domain 1 ca# Envie uma solicitação de certificado manualmente.
[DeviceA] pki request-certificate domain 1# Crie a proposta 1 do IKE e configure o método de autenticação como assinatura digital RSA.
[DeviceA] ike proposal 1
[DeviceA-ike-proposal-1] authentication-method rsa-signature
[DeviceA-ike-proposal-1] quit# Especifique o domínio PKI usado na negociação IKE para o par de perfis IKE.
[DeviceA] ike profile peer
[DeviceA-ike-profile-peer] certificate domain 1Configuração do dispositivo B
# Configurar uma entidade PKI.
<DeviceB> system-view
[DeviceB] pki entity en
[DeviceB-pki-entity-en] ip 3.3.3.1
[DeviceB-pki-entity-en] common-name deviceb
[DeviceB-pki-entity-en] quit# Configure um domínio PKI.
[DeviceB] pki domain 1
[DeviceB-pki-domain-1] ca identifier CA1
[DeviceB-pki-domain-1] certificate request url http://1.1.1.100/certsrv/mscep/mscep.dll
[DeviceB-pki-domain-1] certificate request entity en
[DeviceB-pki-domain-1] ldap-server host 1.1.1.102# Configure o dispositivo para enviar solicitações de certificado para ra.
[DeviceB-pki-domain-1] certificate request from ra# Configure um par de chaves RSA de uso geral de 1024 bits chamado abc para solicitação de certificado.
[DeviceB-pki-domain-1] public-key rsa general name abc length 1024
[DeviceB-pki-domain-1] quit# Gerar o par de chaves RSA.
[DeviceB] public-key local create rsa name abc
The range of public key modulus is (512 ~ 4096).
If the key modulus is greater than 512,it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
..........................++++++
.....................................++++++
Create the key pair successfully.# Obtenha o certificado da CA e salve-o localmente.
[DeviceB] pki retrieve-certificate domain 1 ca
The trusted CA's finger print is:
MD5 fingerprint:5C41 E657 A0D6 ECB4 6BD6 1823 7473 AABC
SHA1 fingerprint:1616 E7A5 D89A 2A99 9419 1C12 D696 8228 87BC C266
Is the finger print correct?(Y/N):y
Retrieved the certificates successfully.# Envie uma solicitação de certificado manualmente.
[DeviceB] pki request-certificate domain 1
Start to request general certificate ...
...
Certificate requested successfully.# Crie a proposta 1 do IKE e configure o método de autenticação como assinatura digital RSA.
[DeviceB] ike proposal 1
[DeviceB-ike-proposal-1] authentication-method rsa-signature
[DeviceB-ike-proposal-1] quit# Especifique o domínio PKI usado na negociação IKE para o par de perfis IKE.
[DeviceB] ike profile peer
[DeviceB-ike-profile-peer] certificate domain 1As configurações são para negociação IKE com assinatura digital RSA. Para obter informações sobre como configurar as SAs do IPsec, consulte "Configuração do IPsec".
Exemplo: Configuração de uma política de controle de acesso baseada em certificado
Configuração de rede
Conforme mostrado na Figura 6, o host acessa o dispositivo por meio de HTTPS.
Configure uma política de controle de acesso baseada em certificado no dispositivo para autenticar o host e verificar a validade do certificado do host.
Figura 6 Diagrama de rede
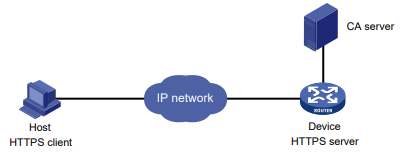
Procedimento
- Crie o domínio PKI domain1 para ser usado pelo SSL. (Detalhes não mostrados).
- Solicite um certificado de servidor SSL para o dispositivo do servidor CA. (Detalhes não mostrados).
- Configure o servidor HTTPS:
# Configure uma política de servidor SSL chamada abc.
<Device> system-view
[Device] ssl server-policy abc
[Device-ssl-server-policy-abc] pki-domain domain1
[Device-ssl-server-policy-abc] client-verify enable
[Device-ssl-server-policy-abc] quit# Aplique a política de servidor SSL abc ao servidor HTTPS.
[Device] ip https ssl-server-policy abc# Habilite o servidor HTTPS.
[Device] ip https enable- Configurar grupos de atributos de certificados:
# Crie um grupo de atributos de certificado chamado mygroup1 e adicione duas regras de atributos. A primeira regra define que o DN no DN do assunto contém a cadeia de caracteres aabbcc. A segunda regra define que o endereço IP do emissor do certificado é 10.0.0.1.
[Device] pki certificate attribute-group mygroup1
[Device-pki-cert-attribute-group-mygroup1] attribute 1 subject-name dn ctn aabbcc
[Device-pki-cert-attribute-group-mygroup1] attribute 2 issuer-name ip equ 10.0.0.1
[Device-pki-cert-attribute-group-mygroup1] quit# Crie um grupo de atributos de certificado chamado mygroup2 e adicione duas regras de atributos. A primeira regra define que o FQDN no nome do assunto alternativo não contém a cadeia de caracteres apple. A segunda regra define que o DN do nome do emissor do certificado contém a cadeia de caracteres aabbcc.
[Device] pki certificate attribute-group mygroup2
[Device-pki-cert-attribute-group-mygroup2] attribute 1 alt-subject-name fqdn nctn
apple
[Device-pki-cert-attribute-group-mygroup2] attribute 2 issuer-name dn ctn aabbcc
[Device-pki-cert-attribute-group-mygroup2] quit- Configure uma política de controle de acesso baseada em certificado:
# Crie uma política de controle de acesso baseada em certificado chamada myacp.
[Device] pki certificate access-control-policy myacp# Defina uma declaração para negar os certificados que correspondem às regras de atributo no grupo de atributo de certificado mygroup1.
[Device-pki-cert-acp-myacp] rule 1 deny mygroup1# Defina uma instrução para permitir os certificados que correspondem às regras de atributo no grupo de atributo de certificado mygroup2.
[Device-pki-cert-acp-myacp] rule 2 permit mygroup2
[Device-pki-cert-acp-myacp] quit# Aplique a política de controle de acesso baseada em certificado myacp ao servidor HTTPS.
[Device] ip https certificate access-control-policy myacpVerificação da configuração
# No host, acesse o servidor HTTPS por meio de um navegador da Web.
O servidor primeiro verifica a validade do certificado do host de acordo com a política de controle de acesso baseada em certificado configurada. No certificado do host, o DN do assunto é aabbcc, o endereço IP do emissor do certificado é 1.1.1.1 e o FQDN do nome alternativo do assunto é banaba.
O certificado do host não corresponde ao grupo de atributos de certificado mygroup1 especificado na regra 1 da política de controle de acesso baseada em certificado. O certificado continua a corresponder à regra 2.
O certificado do host corresponde ao grupo de atributos de certificado mygroup2 especificado na regra 2. Como a regra 2 é uma instrução de permissão, o certificado passa na verificação e o host pode acessar o servidor HTTPS.
Exemplo: Importação e exportação de certificados
Configuração de rede
Conforme mostrado na Figura 7, o Dispositivo B substituirá o Dispositivo A na rede. O domínio PKI exportdomain no Dispositivo A tem dois certificados locais que contêm a chave privada e um certificado de CA. Para garantir que os certificados ainda sejam válidos depois que o Dispositivo B substituir o Dispositivo A, copie os certificados do Dispositivo A para o Dispositivo B da seguinte forma:
- Exporte os certificados no domínio PKI exportdomain no Dispositivo A para arquivos de certificado .pem.
Durante a exportação, criptografe a chave privada nos certificados locais usando 3DES_CBC com a senha 11111.
- Transfira os arquivos de certificado do Dispositivo A para o Dispositivo B por meio do host FTP.
- Importe os arquivos de certificado para o domínio PKI importdomain no Dispositivo B.
Figura 7 Diagrama de rede
Procedimento
- Exportar os certificados no Dispositivo A:
# Exportar o certificado da CA para um arquivo .pem.
<DeviceA> system-view
[DeviceA] pki export domain exportdomain pem ca filename pkicachain.pem# Exporte o certificado local para um arquivo chamado pkilocal.pem no formato PEM e use 3DES_CBC para criptografar a chave privada com a senha 111111.
[DeviceA] pki export domain exportdomain pem local 3des-cbc 111111 filename
pkilocal.pemAgora, o Dispositivo A tem três arquivos de certificado no formato PEM:
- Um arquivo de certificado de CA chamado pkicachain.pem.
- Um arquivo de certificado local chamado pkilocal.pem-signature, que contém a chave privada para assinatura.
- Um arquivo de certificado local chamado pkilocal.pem-encryption, que contém a chave privada para criptografia.
# Exibir o arquivo de certificado local pkilocal.pem-signature.
[DeviceA] quit
<DeviceA> more pkilocal.pem-signature
Bag Attributes
friendlyName:
localKeyID: 90 C6 DC 1D 20 49 4F 24 70 F5 17 17 20 2B 9E AC 20 F3 99 89
subject=/C=CN/O=OpenCA Labs/OU=Users/CN=subsign 11
issuer=/C=CN/L=shangdi/ST=pukras/O=OpenCA Labs/OU=docm/CN=subca1
-----BEGIN CERTIFICATE-----
MIIEgjCCA2qgAwIBAgILAJgsebpejZc5UwAwDQYJKoZIhvcNAQELBQAwZjELMAkG
…
-----END CERTIFICATE-----
Bag Attributes
friendlyName:
localKeyID: 90 C6 DC 1D 20 49 4F 24 70 F5 17 17 20 2B 9E AC 20 F3 99 89
Key Attributes: <No Attributes>
-----BEGIN ENCRYPTED PRIVATE KEY-----
MIICxjBABgkqhkiG9w0BBQ0wMzAbBgkqhkiG9w0BBQwwDgQIZtjSjfslJCoCAggA
…
-----END ENCRYPTED PRIVATE KEY-----
<DeviceA> more pkilocal.pem-encryption
Bag Attributes
friendlyName:
localKeyID: D5 DF 29 28 C8 B9 D9 49 6C B5 44 4B C2 BC 66 75 FE D6 6C C8
subject=/C=CN/O=OpenCA Labs/OU=Users/CN=subencr 11
issuer=/C=CN/L=shangdi/ST=pukras/O=OpenCA Labs/OU=docm/CN=subca1
-----BEGIN CERTIFICATE-----
MIIEUDCCAzigAwIBAgIKCHxnAVyzWhIPLzANBgkqhkiG9w0BAQsFADBmMQswCQYD
…
-----END CERTIFICATE-----
Bag Attributes
friendlyName:
localKeyID: D5 DF 29 28 C8 B9 D9 49 6C B5 44 4B C2 BC 66 75 FE D6 6C C8
Key Attributes: <No Attributes>
-----BEGIN ENCRYPTED PRIVATE KEY-----
MIICxjBABgkqhkiG9w0BBQ0wMzAbBgkqhkiG9w0BBQwwDgQI7H0mb4O7/GACAggA
…
-----END ENCRYPTED PRIVATE KEY-----
- Faça o download dos arquivos de certificado pkicachain.pem, pkilocal.pem-signature e
pkilocal.pem-encryption do Dispositivo A para o host por meio de FTP. (Detalhes não mostrados.)
- Faça upload dos arquivos de certificado pkicachain.pem, pkilocal.pem-signature e
pkilocal.pem-encryption do host para o Dispositivo B por meio de FTP. (Detalhes não mostrados.)
- Importe os arquivos de certificado para o Dispositivo B:
# Desativar a verificação de CRL. (Você pode configurar a verificação de CRL conforme necessário. Este exemplo pressupõe que a verificação de CRL não é necessária).
<DeviceB> system-view
[DeviceB] pki domain importdomain
[DeviceB-pki-domain-importdomain] undo crl check enable# Especifique o sinal do par de chaves RSA para assinatura e o par de chaves RSA encr para criptografia.
[DeviceB-pki-domain-importdomain] public-key rsa signature name sign encryption name
encr
[DeviceB-pki-domain-importdomain] quit# Importar o arquivo de certificado da CA pkicachain.pem no formato PEM para o domínio PKI.
[DeviceB] pki import domain importdomain pem ca filename pkicachain.pem# Importar o arquivo de certificado local pkilocal.pem-signature no formato PEM para o domínio PKI. O arquivo de certificado contém um par de chaves.
[DeviceB] pki import domain importdomain pem local filename pkilocal.pem-signature
Please input the password:******# Importar o arquivo de certificado local pkilocal.pem-encryption no formato PEM para o domínio PKI. O arquivo de certificado contém um par de chaves.
[DeviceB] pki import domain importdomain pem local filename pkilocal.pem-encryption
Please input the password:******# Exibir as informações do certificado local importado no Dispositivo B.
[DeviceB] display pki certificate domain importdomain local
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
98:2c:79:ba:5e:8d:97:39:53:00
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=CN, L=shangdi, ST=pukras, O=OpenCA Labs, OU=docm, CN=subca1
Validity
Not Before: May 26 05:56:49 2011 GMT
Not After : Nov 22 05:56:49 2012 GMT
Subject: C=CN, O=OpenCA Labs, OU=Users, CN=subsign 11
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (1024 bit)
Modulus:
00:9f:6e:2f:f6:cb:3d:08:19:9a:4a:ac:b4:ac:63:
ce:8d:6a:4c:3a:30:19:3c:14:ff:a9:50:04:f5:00:
ee:a3:aa:03:cb:b3:49:c4:f8:ae:55:ee:43:93:69:
6c:bf:0d:8c:f4:4e:ca:69:e5:3f:37:5c:83:ea:83:
ad:16:b8:99:37:cb:86:10:6b:a0:4d:03:95:06:42:
ef:ef:0d:4e:53:08:0a:c9:29:dd:94:28:02:6e:e2:
9b:87:c1:38:2d:a4:90:a2:13:5f:a4:e3:24:d3:2c:
bf:98:db:a7:c2:36:e2:86:90:55:c7:8c:c5:ea:12:
01:31:69:bf:e3:91:71:ec:21
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Cert Type:
SSL Client, S/MIME
X509v3 Key Usage:
Digital Signature, Non Repudiation
X509v3 Extended Key Usage:
TLS Web Client Authentication, E-mail Protection, Microsoft
Smartcardlogin
Netscape Comment:
User Certificate of OpenCA Labs
X509v3 Subject Key Identifier:
AA:45:54:29:5A:50:2B:89:AB:06:E5:BD:0D:07:8C:D9:79:35:B1:F5
X509v3 Authority Key Identifier:
keyid:70:54:40:61:71:31:02:06:8C:62:11:0A:CC:A5:DB:0E:7E:74:DE:DD
X509v3 Subject Alternative Name:
email:subsign@docm.com
X509v3 Issuer Alternative Name:
DNS:subca1@docm.com, DNS:, IP Address:1.1.2.2, IP Address:2.2.1.1
Authority Information Access:
CA Issuers - URI:http://titan/pki/pub/cacert/cacert.crt
OCSP - URI:http://titan:2560/
1.3.6.1.5.5.7.48.12 - URI:http://titan:830/
X509v3 CRL Distribution Points:
Full Name:
URI:http://192.168.40.130/pki/pub/crl/cacrl.crl
Signature Algorithm: sha256WithRSAEncryption
18:e7:39:9a:ad:84:64:7b:a3:85:62:49:e5:c9:12:56:a6:d2:
46:91:53:8e:84:ba:4a:0a:6f:28:b9:43:bc:e7:b0:ca:9e:d4:
1f:d2:6f:48:c4:b9:ba:c5:69:4d:90:f3:15:c4:4e:4b:1e:ef:
2b:1b:2d:cb:47:1e:60:a9:0f:81:dc:f2:65:6b:5f:7a:e2:36:
29:5d:d4:52:32:ef:87:50:7c:9f:30:4a:83:de:98:8b:6a:c9:
3e:9d:54:ee:61:a4:26:f3:9a:40:8f:a6:6b:2b:06:53:df:b6:
5f:67:5e:34:c8:c3:b5:9b:30:ee:01:b5:a9:51:f9:b1:29:37:
02:1a:05:02:e7:cc:1c:fe:73:d3:3e:fa:7e:91:63:da:1d:f1:
db:28:6b:6c:94:84:ad:fc:63:1b:ba:53:af:b3:5d:eb:08:b3:
5b:d7:22:3a:86:c3:97:ef:ac:25:eb:4a:60:f8:2b:a3:3b:da:
5d:6f:a5:cf:cb:5a:0b:c5:2b:45:b7:3e:6e:39:e9:d9:66:6d:
ef:d3:a0:f6:2a:2d:86:a3:01:c4:94:09:c0:99:ce:22:19:84:
2b:f0:db:3e:1e:18:fb:df:56:cb:6f:a2:56:35:0d:39:94:34:
6d:19:1d:46:d7:bf:1a:86:22:78:87:3e:67:fe:4b:ed:37:3d:
d6:0a:1c:0b
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
08:7c:67:01:5c:b3:5a:12:0f:2f
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=CN, L=shangdi, ST=pukras, O=OpenCA Labs, OU=docm, CN=subca1
Validity
Not Before: May 26 05:58:26 2011 GMT
Not After : Nov 22 05:58:26 2012 GMT
Subject: C=CN, O=OpenCA Labs, OU=Users, CN=subencr 11
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (1024 bit)
Modulus:
00:db:26:13:d3:d1:a4:af:11:f3:6d:37:cf:d0:d4:
48:50:4e:0f:7d:54:76:ed:50:28:c6:71:d4:48:ae:
4d:e7:3d:23:78:70:63:18:33:f6:94:98:aa:fa:f6:
62:ed:8a:50:c6:fd:2e:f4:20:0c:14:f7:54:88:36:
2f:e6:e2:88:3f:c2:88:1d:bf:8d:9f:45:6c:5a:f5:
94:71:f3:10:e9:ec:81:00:28:60:a9:02:bb:35:8b:
bf:85:75:6f:24:ab:26:de:47:6c:ba:1d:ee:0d:35:
75:58:10:e5:e8:55:d1:43:ae:85:f8:ff:75:81:03:
8c:2e:00:d1:e9:a4:5b:18:39
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Cert Type:
SSL Server
X509v3 Key Usage:
Key Encipherment, Data Encipherment
Netscape Comment:
VPN Server of OpenCA Labs
X509v3 Subject Key Identifier:
CC:96:03:2F:FC:74:74:45:61:38:1F:48:C0:E8:AA:18:24:F0:2B:AB
X509v3 Authority Key Identifier:
keyid:70:54:40:61:71:31:02:06:8C:62:11:0A:CC:A5:DB:0E:7E:74:DE:DD
X509v3 Subject Alternative Name:
email:subencr@docm.com
X509v3 Issuer Alternative Name:
DNS:subca1@docm.com, DNS:, IP Address:1.1.2.2, IP Address:2.2.1.1
Authority Information Access:
CA Issuers - URI:http://titan/pki/pub/cacert/cacert.crt
OCSP - URI:http://titan:2560/
1.3.6.1.5.5.7.48.12 - URI:http://titan:830/
X509v3 CRL Distribution Points:
Full Name:
URI:http://192.168.40.130/pki/pub/crl/cacrl.crl
Signature Algorithm: sha256WithRSAEncryption
53:69:66:5f:93:f0:2f:8c:54:24:8f:a2:f2:f1:29:fa:15:16:
90:71:e2:98:e3:5c:c6:e3:d4:5f:7a:f6:a9:4f:a2:7f:ca:af:
c4:c8:c7:2c:c0:51:0a:45:d4:56:e2:81:30:41:be:9f:67:a1:
23:a6:09:50:99:a1:40:5f:44:6f:be:ff:00:67:9d:64:98:fb:
72:77:9e:fd:f2:4c:3a:b2:43:d8:50:5c:48:08:e7:77:df:fb:
25:9f:4a:ea:de:37:1e:fb:bc:42:12:0a:98:11:f2:d9:5b:60:
bc:59:72:04:48:59:cc:50:39:a5:40:12:ff:9d:d0:69:3a:5e:
3a:09:5a:79:e0:54:67:a0:32:df:bf:72:a0:74:63:f9:05:6f:
5e:28:d2:e8:65:49:e6:c7:b5:48:7d:95:47:46:c1:61:5a:29:
90:65:45:4a:88:96:e4:88:bd:59:25:44:3f:61:c6:b1:08:5b:
86:d2:4f:61:4c:20:38:1c:f4:a1:0b:ea:65:87:7d:1c:22:be:
b6:17:17:8a:5a:0f:35:4c:b8:b3:73:03:03:63:b1:fc:c4:f5:
e9:6e:7c:11:e8:17:5a:fb:39:e7:33:93:5b:2b:54:72:57:72:
5e:78:d6:97:ef:b8:d8:6d:0c:05:28:ea:81:3a:06:a0:2e:c3:
79:05:cd:c3Para exibir informações detalhadas sobre o certificado CA, use o comando display pki certificate domain.
Solução de problemas de configuração de PKI
Esta seção fornece informações de solução de problemas comuns com a PKI.
Falha ao obter o certificado CA
Sintoma
O certificado CA não pode ser obtido.
Análise
- A conexão de rede está inoperante, por exemplo, porque o cabo de rede está danificado ou os conectores estão com mau contato.
- Nenhuma CA confiável foi especificada.
- O URL de solicitação de certificado está incorreto ou não foi especificado.
- A hora do sistema do dispositivo não está sincronizada com o servidor CA.
- O servidor CA não aceita o endereço IP de origem especificado no domínio PKI ou nenhum endereço IP de origem foi especificado.
- A impressão digital do certificado da CA raiz é ilegal.
Solução
- Corrija os problemas de conexão de rede, se houver.
- Configure a CA confiável e todos os outros parâmetros necessários no domínio da PKI.
- Use o comando ping para verificar se o servidor CA pode ser acessado.
- Sincronize a hora do sistema do dispositivo com o servidor CA.
- Especifique o endereço IP de origem correto que o servidor da CA pode aceitar. Para obter as configurações corretas, entre em contato com o administrador da CA.
- Verifique a impressão digital do certificado CA no servidor CA.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Falha ao obter certificados locais
Sintoma
Os certificados locais podem ser obtidos.
Análise
- A conexão de rede está inoperante.
- O domínio PKI não tem um certificado de CA antes de você enviar a solicitação de certificado local.
- O servidor LDAP não está configurado ou está configurado incorretamente.
- Nenhum par de chaves é especificado para a solicitação de certificado no domínio PKI, ou o par de chaves especificado não corresponde ao contido nos certificados locais obtidos.
- Nenhuma entidade PKI está configurada no domínio PKI ou a configuração da entidade PKI está incorreta.
- A verificação da CRL está ativada, mas o domínio PKI não tem uma CRL e não pode obter uma.
- O servidor CA não aceita o endereço IP de origem especificado no domínio PKI ou nenhum endereço IP de origem foi especificado.
- A hora do sistema do dispositivo não está sincronizada com o servidor CA.
Solução
- Corrija os problemas de conexão de rede, se houver.
- Obter ou importar o certificado CA.
- Configure os parâmetros corretos do servidor LDAP.
- Especifique o par de chaves para a solicitação de certificado ou remova o par de chaves existente, especifique um novo par de chaves e envie novamente uma solicitação de certificado local.
- Verifique a política de registro na CA ou RA e certifique-se de que os atributos da entidade PKI atendam aos requisitos da política.
- Obtenha a LCR no repositório de LCR.
- Especifique o endereço IP de origem correto que o servidor da CA pode aceitar. Para obter as configurações corretas, entre em contato com o administrador da CA.
- Sincronize a hora do sistema do dispositivo com o servidor CA.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Falha ao solicitar certificados locais
Sintoma
Não é possível enviar solicitações de certificados locais.
Análise
- A conexão de rede está inoperante, por exemplo, porque o cabo de rede está danificado ou os conectores estão com mau contato.
- O domínio PKI não tem um certificado de CA antes do envio da solicitação de certificado local.
- O URL de solicitação de certificado está incorreto ou não foi especificado.
- A autoridade de recepção da solicitação de certificado está incorreta ou não foi especificada.
- Os parâmetros necessários da entidade PKI não estão configurados ou estão configurados incorretamente.
- Nenhum par de chaves é especificado no domínio PKI para solicitação de certificado ou o par de chaves é alterado durante um processo de solicitação de certificado.
- Aplicativos exclusivos de solicitação de certificado estão sendo executados no domínio da PKI.
- O servidor CA não aceita o endereço IP de origem especificado no domínio PKI ou nenhum endereço IP de origem foi especificado.
- A hora do sistema do dispositivo não está sincronizada com o servidor CA.
Solução
- Corrija os problemas de conexão de rede, se houver.
- Obter ou importar o certificado CA.
- Use o comando ping para verificar se o servidor de registro pode ser acessado.
- Use o comando certificate request from para especificar a autoridade de recepção correta da solicitação de certificado .
- Configure os parâmetros da entidade PKI conforme exigido pela política de registro na CA ou RA.
- Especifique o par de chaves para a solicitação de certificado ou remova o par de chaves existente, especifique um novo par de chaves e envie novamente uma solicitação de certificado local.
- Use o comando pki abort-certificate-request domain para abortar a solicitação de certificado.
- Especifique o endereço IP de origem correto que o servidor da CA pode aceitar. Para obter as configurações corretas, entre em contato com o administrador da CA.
- Sincronize a hora do sistema do dispositivo com o servidor CA.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Falha na obtenção de CRLs
Sintoma
As CRLs não podem ser obtidas.
Análise
- A conexão de rede está inoperante, por exemplo, porque o cabo de rede está danificado ou os conectores estão com mau contato.
- O domínio da PKI não tem um certificado de CA antes de você tentar obter as LCRs.
- A URL do repositório de CRL não está configurada e não pode ser obtida do certificado da CA ou dos certificados locais no domínio da PKI.
- O URL especificado do repositório de LCR está incorreto.
- O dispositivo tenta obter CRLs por meio do SCEP, mas apresenta os seguintes problemas:
- O domínio PKI não possui certificados locais.
- Os pares de chaves nos certificados foram alterados.
- O domínio PKI tem URL incorreto para solicitação de certificado.
- O repositório de CRLs usa LDAP para a distribuição de CRLs. No entanto, o endereço IP ou o nome do host do servidor LDAP não está contido no URL do repositório de LCR nem configurado no domínio da PKI.
- A CA não emite CRLs.
- O servidor CA não aceita o endereço IP de origem especificado no domínio PKI ou nenhum endereço IP de origem foi especificado.
Solução
- Corrija os problemas de conexão de rede, se houver.
- Obter ou importar o certificado CA.
- Se o URL do repositório de LCR não puder ser obtido, verifique se as seguintes condições existem:
- O URL da solicitação de certificado é válido.
- Um certificado local foi obtido com sucesso.
- O certificado local contém uma chave pública que corresponde ao par de chaves armazenado localmente.
- Verifique se o endereço do servidor LDAP está contido no URL do repositório de LCR ou se está configurado em no domínio da PKI.
- Verifique se o servidor CA suporta a publicação de CRLs.
- Especifique um endereço IP de origem correto que o servidor da CA possa aceitar. Para obter as configurações corretas, entre em contato com o administrador da CA.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Falha ao importar o certificado CA
Sintoma
O certificado CA não pode ser importado.
Análise
- A verificação da CRL está ativada, mas o dispositivo não tem uma CRL no domínio da PKI e não pode obter uma.
- O formato especificado no qual o arquivo de certificado da CA deve ser importado não corresponde ao formato real do arquivo de certificado.
Solução
- Use o comando undo crl check enable para desativar a verificação de CRL no domínio PKI.
- Verifique se o formato do arquivo importado está correto.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Falha ao importar o certificado local
Sintoma
O certificado local não pode ser importado.
Análise
- O domínio PKI não tem um certificado CA e o arquivo de certificado local a ser importado não contém a cadeia de certificados CA.
- A verificação da CRL está ativada, mas o dispositivo não tem uma CRL no domínio da PKI e não pode obter uma.
- O formato especificado no qual o arquivo de certificado local deve ser importado não corresponde ao formato real do arquivo de certificado.
- O dispositivo e o certificado não têm o par de chaves local.
- O certificado foi revogado.
- O certificado está fora do período de validade.
- A hora do sistema está incorreta.
Solução
- Obter ou importar o certificado CA.
- Use o comando undo crl check enable para desativar a verificação de CRL ou obtenha a CRL correta antes de importar certificados.
- Certifique-se de que o formato do arquivo a ser importado esteja correto.
- Certifique-se de que o arquivo de certificado contenha a chave privada.
- Certifique-se de que o certificado não tenha sido revogado.
- Verifique se o certificado é válido.
- Configure a hora correta do sistema para o dispositivo.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Falha ao exportar certificados
Sintoma
Os certificados não podem ser exportados.
Análise
- O domínio PKI não tem certificados locais quando você exporta todos os certificados no formato PKCS12.
- O caminho de exportação especificado não existe.
- O caminho de exportação especificado é ilegal.
- A chave pública do certificado local a ser exportado não corresponde à chave pública do par de chaves configurado no domínio PKI.
- O espaço de armazenamento do dispositivo está cheio.
Solução
- Obtenha ou solicite certificados locais primeiro.
- Use o comando mkdir para criar o caminho necessário.
- Especifique um caminho de exportação correto.
- Configure o par de chaves correto no domínio da PKI.
- Limpe o espaço de armazenamento do dispositivo.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Falha ao definir o caminho de armazenamento
Sintoma
O caminho de armazenamento de certificados ou LCRs não pode ser definido.
Análise
- O caminho de armazenamento especificado não existe.
- O caminho de armazenamento especificado é ilegal.
- O espaço de armazenamento do dispositivo está cheio.
Solução
- Use o comando mkdir para criar o caminho.
- Especifique um caminho de armazenamento válido para certificados ou CRLs.
- Limpe o espaço de armazenamento do dispositivo.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
A negociação IKEv2 falhou porque não foram encontradas propostas IKEv2 correspondentes 72
A negociação do IPsec SA falhou porque não foram encontrados conjuntos de transformação IPsec correspondentes 72
Falha no estabelecimento do túnel IPsec 73
Configuração do IPsec
Sobre o IPsec
A segurança IP (IPsec) é definida pela IETF para fornecer segurança interoperável, de alta qualidade e baseada em criptografia para comunicações IP. É uma tecnologia de VPN de camada 3 que transmite dados em um canal seguro estabelecido entre dois pontos finais (como dois gateways de segurança). Esse canal seguro é normalmente chamado de túnel IPsec.
Estrutura IPsec
O IPsec é uma estrutura de segurança que possui os seguintes protocolos e algoritmos:
- Cabeçalho de autenticação (AH).
- Encapsulating Security Payload (ESP).
- Internet Key Exchange (IKE).
- Algoritmos para autenticação e criptografia.
AH e ESP são protocolos de segurança que fornecem serviços de segurança. O IKE executa a troca automática de chaves . Para obter mais informações sobre o IKE, consulte "Configuração do IKE".
Serviços de segurança IPsec
O IPsec fornece os seguintes serviços de segurança para pacotes de dados na camada IP:
- Confidencialidade: o remetente criptografa os pacotes antes de transmiti-los pela Internet, protegendo-os contra interceptação durante o trajeto.
- Integridade dos dados: o receptor verifica os pacotes recebidos do remetente para garantir que não tenham sido adulterados durante a transmissão.
- Autenticação da origem dos dados - O receptor verifica a autenticidade do remetente.
- Anti-repetição - O receptor examina os pacotes e descarta pacotes desatualizados e duplicados.
Benefícios do IPsec
O IPsec oferece os seguintes benefícios:
- Redução da sobrecarga de negociação de chaves e manutenção simplificada com o suporte do protocolo IKE. O IKE oferece negociação automática de chaves e configuração e manutenção automáticas de associações de segurança (SA) IPsec.
- Boa compatibilidade. Você pode aplicar o IPsec a todos os sistemas e serviços de aplicativos baseados em IP sem modificá-los.
- Criptografia por pacote em vez de por fluxo. A criptografia por pacote permite flexibilidade e aumenta muito a segurança do IP.
Protocolos de segurança
O IPsec vem com dois protocolos de segurança, AH e ESP. Eles definem como encapsular os pacotes IP e os serviços de segurança que podem oferecer.
- O AH (protocolo 51) define o encapsulamento do cabeçalho AH em um pacote IP, conforme mostrado na Figura 3. O AH pode fornecer serviços de autenticação de origem de dados, integridade de dados e anti-repetição para
impede a adulteração de dados, mas não pode impedir a espionagem. Portanto, ele é adequado para a transmissão de dados não confidenciais. Os algoritmos de autenticação suportados pelo AH incluem HMAC-MD5 e HMAC-SHA1.
- O ESP (protocolo 50) define o encapsulamento do cabeçalho e do trailer do ESP em um pacote IP, conforme mostrado na Figura 3. O ESP pode fornecer serviços de criptografia de dados, autenticação de origem de dados, integridade de dados e anti-repetição. Diferentemente do AH, o ESP pode garantir a confidencialidade dos dados porque pode criptografá-los antes de encapsulá-los em pacotes IP. Os algoritmos de criptografia compatíveis com o ESP incluem DES, 3DES e AES, e os algoritmos de autenticação incluem HMAC-MD5 e HMAC-SHA1.
Tanto o AH quanto o ESP fornecem serviços de autenticação, mas o serviço de autenticação fornecido pelo AH é mais forte. Na prática, você pode escolher um ou ambos os protocolos de segurança. Quando o AH e o ESP são usados, um pacote IP é encapsulado primeiro pelo ESP e depois pelo AH.
Modos de encapsulamento
O IPsec oferece suporte aos seguintes modos de encapsulamento: modo de transporte e modo de túnel.
Modo de transporte
Os protocolos de segurança protegem os dados da camada superior de um pacote IP. Somente os dados da camada de transporte são usados para calcular os cabeçalhos do protocolo de segurança. Os cabeçalhos de protocolo de segurança calculados e os dados criptografados (somente para encapsulamento ESP) são colocados após o cabeçalho IP original. Você pode usar o modo de transporte quando a proteção de segurança de ponta a ponta for necessária (os pontos de início e fim da transmissão segura são os pontos de início e fim reais dos dados). O modo de transporte é normalmente usado para proteger as comunicações entre hosts, conforme mostrado na Figura 1.
Figura 1 Proteção IPsec no modo de transporte
Modo túnel
Os protocolos de segurança protegem todo o pacote IP. O pacote IP inteiro é usado para calcular os cabeçalhos do protocolo de segurança. Os cabeçalhos de protocolo de segurança calculados e os dados criptografados (somente para encapsulamento ESP) são encapsulados em um novo pacote IP. Nesse modo, o pacote encapsulado tem dois cabeçalhos IP. O cabeçalho IP interno é o cabeçalho IP original. O cabeçalho IP externo é adicionado pelo dispositivo de rede que fornece o serviço IPsec. Você deve usar o modo de túnel quando os pontos de início e fim da transmissão protegida não forem os pontos de início e fim reais dos pacotes de dados (por exemplo, quando dois gateways fornecem IPsec, mas os pontos de início e fim dos dados são dois hosts atrás dos gateways). O modo de túnel é normalmente usado para proteger as comunicações de gateway para gateway, conforme mostrado na Figura 2.
Figura 2 Proteção IPsec no modo túnel
A Figura 3 mostra como os protocolos de segurança encapsulam um pacote IP em diferentes modos de encapsulamento.
Figura 3 Encapsulamentos do protocolo de segurança em diferentes modos
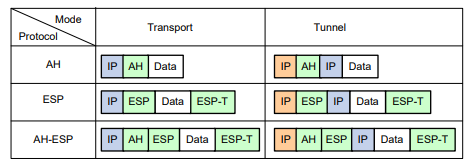
Associação de segurança
Uma associação de segurança (SA) é um acordo negociado entre duas partes comunicantes chamadas pares IPsec. Uma SA inclui os seguintes parâmetros para proteção de dados:
- Protocolos de segurança (AH, ESP ou ambos).
- Modo de encapsulamento (modo de transporte ou modo de túnel).
- Algoritmo de autenticação (HMAC-MD5 ou HMAC-SHA1).
- Algoritmo de criptografia (DES, 3DES ou AES).
- Chaves compartilhadas e suas vidas úteis.
Uma SA é unidirecional. São necessárias pelo menos duas SAs para proteger os fluxos de dados em uma comunicação bidirecional. Se dois pares quiserem usar AH e ESP para proteger os fluxos de dados entre eles, eles constroem uma SA independente para cada protocolo em cada direção.
Uma SA é identificada exclusivamente por um tripleto, que consiste no índice do parâmetro de segurança (SPI), no endereço IP de destino e no identificador do protocolo de segurança. Um SPI é um número de 32 bits. Ele é transmitido no cabeçalho AH/ESP.
Uma SA pode ser configurada manualmente ou por meio do IKE.
- Modo manual - Configure todos os parâmetros da SA por meio de comandos. Esse modo de configuração é complexo e não oferece suporte a alguns recursos avançados (como atualização periódica de chaves), mas pode implementar o IPsec sem o IKE. Esse modo é usado principalmente em redes pequenas e estáticas ou quando o número de pares IPsec na rede é pequeno.
- Modo de negociação IKE - Os pares negociam e mantêm a SA por meio do IKE. Esse modo de configuração é simples e tem boa capacidade de expansão. Como prática recomendada, configure SAs por meio de negociações IKE em redes dinâmicas de médio e grande porte.
Uma SA configurada manualmente nunca se esgota. Uma SA criada pelo IKE tem um tempo de vida útil, que pode ser de dois tipos:
- Tempo de vida baseado em tempo - Define por quanto tempo a SA pode ser válida após ser criada.
- Vida útil baseada em tráfego - Define o tráfego máximo que a SA pode processar.
Se ambos os cronômetros de tempo de vida forem configurados para uma SA, ela se tornará inválida quando um dos cronômetros de tempo de vida expirar. Antes que a SA expire, o IKE negocia uma nova SA, que assume o controle imediatamente após sua criação.
Autenticação e criptografia
Algoritmos de autenticação
O IPsec usa algoritmos de hash para realizar a autenticação. Um algoritmo de hash produz um resumo de comprimento fixo para uma mensagem de comprimento arbitrário. Os pares IPsec calculam respectivamente os resumos de mensagens para cada pacote. O receptor compara o resumo local com o resumo recebido do remetente. Se os resumos forem
idênticos, o receptor considera o pacote intacto e a identidade do remetente válida. O IPsec usa os algoritmos de autenticação baseados em HMAC (Hash-based Message Authentication Code), incluindo o HMAC-MD5 e o HMAC-SHA1. Em comparação com o HMAC-SHA1, o HMAC-MD5 é mais rápido, mas menos seguro.
Algoritmos de criptografia
O IPsec usa algoritmos de criptografia simétrica, que criptografam e descriptografam dados usando as mesmas chaves. Os seguintes algoritmos de criptografia estão disponíveis para o IPsec no dispositivo:
- DES - criptografa um bloco de texto simples de 64 bits com uma chave de 56 bits. O DES é o algoritmo menos seguro, mas o mais rápido.
- 3DES - criptografa dados de texto simples com três chaves DES de 56 bits. O comprimento da chave totaliza até 168 bits. Ele oferece força de segurança moderada e é mais lento que o DES.
- AES - criptografa dados de texto simples com uma chave de 128 bits, 192 bits ou 256 bits. O AES oferece a maior força de segurança e é mais lento que o 3DES.
Tráfego protegido por IPsec
Os túneis IPsec podem proteger os seguintes tipos de tráfego:
- Pacotes que correspondem a ACLs específicas.
- Pacotes roteados para uma interface de túnel.
- Pacotes de protocolos de roteamento IPv6.
Dois pares usam políticas de segurança (políticas IPsec ou perfis IPsec) para proteger os pacotes entre eles. Uma política de segurança define o intervalo de pacotes a serem protegidos pelo IPsec e os parâmetros de segurança usados para a proteção. Para obter mais informações sobre políticas IPsec e perfis IPsec, consulte "Política IPsec e perfil IPsec".
As informações a seguir descrevem como o IPsec protege os pacotes:
- Quando um par IPsec identifica os pacotes a serem protegidos de acordo com a política de segurança, ele configura um túnel IPsec e envia o pacote para o par remoto por meio do túnel. O túnel IPsec pode ser configurado manualmente com antecedência ou pode ser configurado por meio da negociação IKE acionada pelo pacote. Os túneis IPsec são, na verdade, as SAs IPsec. Os pacotes de entrada são protegidos pela SA de entrada e os pacotes de saída são protegidos pela SA de saída.
- Quando o par IPsec remoto recebe o pacote, ele descarta, desencapsula ou encaminha diretamente o pacote de acordo com a política de segurança configurada.
IPsec baseado em ACL
Para implementar o IPsec baseado em ACL, configure uma ACL para definir os fluxos de dados a serem protegidos, especifique a ACL em uma política de IPsec e, em seguida, aplique a política de IPsec a uma interface. Você pode aplicar uma política IPsec a interfaces físicas, como interfaces seriais e interfaces Ethernet, ou a interfaces virtuais, como interfaces de túnel e interfaces de modelo virtual.
O IPsec baseado em ACL funciona da seguinte forma:
- Quando os pacotes enviados pela interface correspondem a uma regra de permissão da ACL, os pacotes são protegidos pela SA IPsec de saída e encapsulados com IPsec.
- Quando a interface recebe um pacote IPsec destinado ao dispositivo local, ela procura o SA IPsec de entrada de acordo com o SPI no cabeçalho do pacote IPsec para desencapsulamento. Se o pacote desencapsulado corresponder a uma regra de permissão da ACL, o dispositivo processará o pacote. Se o pacote desencapsulado não corresponder a nenhuma regra de permissão da ACL, o dispositivo descartará o pacote.
O dispositivo suporta os seguintes modos de proteção de fluxo de dados:
- Modo padrão - Um túnel IPsec protege um fluxo de dados. O fluxo de dados permitido por uma regra de ACL é protegido por um túnel IPsec estabelecido exclusivamente para ele.
- Modo de agregação - Um túnel IPsec protege todos os fluxos de dados permitidos por todas as regras de uma ACL. Esse modo só é usado para se comunicar com dispositivos de versões antigas.
- Modo por host - Um túnel IPsec protege um fluxo de dados de host para host. Um fluxo de dados de host para host é identificado por uma regra de ACL e protegido por um túnel IPsec estabelecido exclusivamente para ele. Esse modo consome mais recursos do sistema quando existem vários fluxos de dados entre duas sub-redes a serem protegidas.
IPsec baseado em protocolo de roteamento IPv6
Você pode implementar o IPsec baseado em protocolo de roteamento IPv6 vinculando um perfil IPsec a um protocolo de roteamento IPv6. Todos os pacotes do protocolo são encapsulados com IPsec. Os protocolos de roteamento IPv6 compatíveis incluem OSPFv3 e RIPng.
Todos os pacotes dos aplicativos que não estão vinculados ao IPsec e os pacotes IPsec que não conseguiram ser desencapsulados são descartados.
Em cenários de comunicação um-para-muitos, você deve configurar as SAs IPsec para um protocolo de roteamento IPv6 no modo manual devido aos seguintes motivos:
- O mecanismo de troca automática de chaves protege as comunicações entre dois pontos. Em cenários de comunicação de um para muitos, a troca automática de chaves não pode ser implementada.
- Os cenários de comunicação de um para muitos exigem que todos os dispositivos usem os mesmos parâmetros de SA (SPI e chave) para receber e enviar pacotes. As SAs negociadas pelo IKE não podem atender a esse requisito.
Política IPsec e perfil IPsec
As políticas e os perfis IPsec definem os parâmetros usados para estabelecer túneis IPsec entre dois pares e o intervalo de pacotes a serem protegidos.
Política de IPsec
Uma política IPsec é um conjunto de entradas de política IPsec que têm o mesmo nome, mas números de sequência diferentes.
Uma política IPsec contém as seguintes configurações:
- Uma ACL que define o intervalo de fluxos de dados a serem protegidos.
- Um conjunto de transformação IPsec que define os parâmetros de segurança usados para a proteção IPsec.
- Modo de estabelecimento de SA IPsec.
Os modos de estabelecimento de SA IPsec compatíveis são a configuração manual e a negociação IKE.
- Endereços IP locais e remotos que definem os pontos inicial e final do túnel IPsec.
Na mesma política IPsec, uma entrada de política IPsec com um número de sequência menor tem uma prioridade mais alta. Ao enviar um pacote, a interface aplicada com uma política IPsec examina as entradas da política IPsec em ordem crescente de números de sequência. Se o pacote corresponder à ACL de uma entrada de política IPsec, a interface encapsulará o pacote de acordo com a entrada de política IPsec. Se nenhuma correspondência for encontrada, a interface enviará o pacote sem a proteção IPsec.
Quando a interface recebe um pacote IPsec destinado ao dispositivo local, ela procura o SA IPsec de entrada de acordo com o SPI no cabeçalho do pacote IPsec para desencapsulamento. Se o pacote desencapsulado corresponder a uma regra de permissão da ACL, o dispositivo processará o pacote. Se o pacote desencapsulado não corresponder a uma regra de permissão da ACL, o dispositivo descartará o pacote.
Perfil IPsec
Um perfil IPsec tem configurações semelhantes às de uma política IPsec. Ele é identificado exclusivamente por um nome e não oferece suporte à configuração de ACL.
Os perfis IPsec podem ser classificados nos seguintes tipos:
- Perfil IPsec manual - Um perfil IPsec manual é usado para proteger os protocolos de roteamento IPv6. Ele especifica o conjunto de transformação IPsec usado para proteger os fluxos de dados e os SPIs e chaves usados pelas SAs.
- Perfil IPsec baseado em IKE - Um perfil IPsec baseado em IKE é aplicado a interfaces de túnel para proteger o tráfego em túnel. Ele especifica os conjuntos de transformação IPsec usados para proteger os fluxos de dados e o perfil IKE usado para a negociação IKE.
IPsec RRI
O IPsec Reverse Route Injection (RRI) permite que um gateway de túnel IPsec adicione e exclua automaticamente rotas estáticas destinadas às redes privadas protegidas. Ele adiciona automaticamente as rotas estáticas quando as SAs IPsec são estabelecidas e exclui as rotas estáticas quando as SAs IPsec são excluídas. Isso reduz bastante a carga de trabalho de configuração de rota estática no gateway e aumenta a escalabilidade da VPN IPsec.
O IPsec RRI é aplicável a gateways que precisam fornecer muitos túneis IPsec (por exemplo, um gateway de sede).
Conforme mostrado na Figura 4, o tráfego entre o centro da empresa e as filiais é protegido pelo IPsec. O gateway no centro da empresa é configurado com rotas estáticas para rotear o tráfego para as interfaces protegidas por IPsec. É difícil adicionar ou modificar rotas estáticas no gateway do centro da empresa se a VPN IPsec tiver um grande número de filiais ou se a estrutura da rede mudar.
Figura 4 VPN IPsec
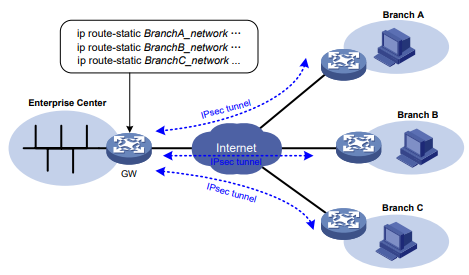
Depois que você ativar o IPsec RRI no gateway, ele adicionará automaticamente uma rota estática à tabela de roteamento sempre que um túnel IPsec for estabelecido. O endereço IP de destino é a rede privada protegida e o próximo salto é o endereço IP remoto do túnel IPsec. O tráfego destinado à extremidade do par é roteado para a interface do túnel IPsec e, portanto, protegido pelo IPsec.
Você pode anunciar as rotas estáticas criadas pelo IPsec RRI na rede interna, e o dispositivo de rede interna pode usá-las para encaminhar o tráfego na VPN IPsec.
Você pode definir preferências para as rotas estáticas criadas pelo IPsec RRI para implementar um gerenciamento flexível de rotas. Por exemplo, você pode definir a mesma preferência para várias rotas para o mesmo destino para implementar o compartilhamento de carga ou pode definir preferências diferentes para implementar o backup de rotas.
Também é possível definir tags para as rotas estáticas criadas pelo IPsec RRI para implementar o controle flexível de rotas por meio de políticas de roteamento.
Protocolos e padrões
- RFC 2401, Arquitetura de segurança para o protocolo da Internet
- RFC 2402, Cabeçalho de autenticação IP
- RFC 2406, IP Encapsulating Security Payload
- RFC 4552, Autenticação/Confidencialidade para OSPFv3
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS (consulte "Configuração de FIPS") e no modo não-FIPS.
Restrições e diretrizes: Configuração do IPsec
Normalmente, o IKE usa a porta UDP 500 para comunicação, e o AH e o ESP usam os números de protocolo 51 e 50, respectivamente. Certifique-se de que o tráfego desses protocolos não seja negado nas interfaces com IKE ou IPsec configurados.
Implementação do IPsec baseado em ACL
As ACLs para IPsec têm efeito apenas no tráfego gerado pelo dispositivo e no tráfego destinado ao dispositivo. Elas não têm efeito sobre o tráfego encaminhado pelo dispositivo. Por exemplo, um túnel IPsec baseado em ACL pode proteger as mensagens de registro que o dispositivo envia a um servidor de registro, mas não protege os fluxos de dados e os fluxos de voz que são encaminhados pelo dispositivo.
Visão geral das tarefas IPsec baseadas em ACL
Para configurar o IPsec baseado em ACL, execute as seguintes tarefas:
- Configuração de uma ACL
- Configuração de um conjunto de transformação IPsec
- Configuração de uma política IPsec Escolha uma das tarefas a seguir:
- Configuração de uma política IPsec manual
- Configuração de uma política IPsec baseada em IKE
- Aplicação de uma política IPsec a uma interface
- (Opcional.) Configuração de recursos de acessibilidade para IPsec baseado em ACL
- Ativação da verificação de ACL para pacotes não encapsulados
- Configuração do IPsec anti-replay
- Configuração da redundância anti-repetição do IPsec
- Vinculação de uma interface de origem a uma política IPsec
- Ativação da pré-classificação de QoS
- Configuração do bit DF dos pacotes IPsec
- Configuração do IPsec RRI
- Configuração do tempo de vida e do tempo limite de inatividade da SA IPsec global
- Configuração da fragmentação do IPsec
- Definição do número máximo de túneis IPsec
- (Opcional.) Configuração de registro e notificação SNMP para IPsec.
- Ativação de registro para pacotes IPsec
- Configuração de notificações SNMP para IPsec
Configuração de uma ACL
O IPsec usa ACLs para identificar o tráfego a ser protegido.
Palavras-chave nas regras de ACL
Uma ACL é uma coleção de regras de ACL. Cada regra de ACL é uma instrução de negação ou permissão. Uma instrução de permissão identifica um fluxo de dados protegido pelo IPsec, e uma instrução de negação identifica um fluxo de dados que não é protegido pelo IPsec. O IPsec compara um pacote com as regras da ACL e processa o pacote de acordo com a primeira regra correspondente.
- Cada regra ACL corresponde tanto ao tráfego de saída quanto ao tráfego de entrada retornado. Suponha que haja uma regra 0 que permita a origem ip 1.1.1.0 0.0.0.255 e o destino 2.2.2.0 0.0.0.0.255. Essa regra corresponde tanto ao tráfego de 1.1.1.0 para 2.2.2.0 quanto ao tráfego de 2.2.2.0 para 1.1.1.0.
- Na direção de saída, se uma instrução de permissão for correspondida, o IPsec considerará que o pacote requer proteção e continuará a processá-lo. Se uma instrução deny for correspondida ou se não for encontrada nenhuma correspondência, o IPsec considerará que o pacote não requer proteção e o entregará ao próximo módulo.
- Na direção de entrada:
- Os pacotes não IPsec que correspondem a uma instrução de permissão são descartados.
- Os pacotes IPsec destinados ao próprio dispositivo são desencapsulados. Por padrão, o
Os pacotes desencapsulados são comparados com as regras da ACL. Somente aqueles que correspondem a uma
são processados. Os outros pacotes são descartados. Se a verificação de ACL para
se estiver desativado, os pacotes IPsec desencapsulados não serão comparados com as regras da ACL e serão processados diretamente por outros módulos.
Ao definir regras de ACL para IPsec, siga estas diretrizes:
- Permita apenas os fluxos de dados que precisam ser protegidos e use a palavra-chave any com cautela. Com a palavra-chave any especificada em uma instrução de permissão, todo o tráfego de saída que corresponder à instrução de permissão será protegido pelo IPsec. Todos os pacotes IPsec de entrada que corresponderem à instrução de permissão serão recebidos e processados, mas todos os pacotes não IPsec de entrada serão descartados. Isso fará com que todo o tráfego de entrada que não precisa de proteção IPsec seja descartado.
- Evite conflitos de instruções no escopo das entradas de política IPsec. Ao criar uma instrução deny, tenha cuidado com seu escopo e ordem de correspondência em relação às instruções permit. As entradas de política em uma política IPsec têm diferentes prioridades de correspondência. Os conflitos de regras de ACL entre elas podem causar mau tratamento dos pacotes. Por exemplo, ao configurar uma instrução de permissão para uma entrada de política IPsec para proteger um fluxo de tráfego de saída, é preciso evitar que o fluxo de tráfego corresponda a uma instrução de negação em uma entrada de política IPsec de prioridade mais alta. Caso contrário, os pacotes serão enviados como pacotes normais. Se corresponderem a uma instrução de permissão na extremidade receptora, serão descartados pelo IPsec.
O exemplo a seguir mostra como uma declaração incorreta causa o descarte inesperado de pacotes. Somente a configuração relacionada à ACL é apresentada.
Suponha que o Roteador A esteja conectado à sub-rede 1.1.2.0/24 e que o Roteador B esteja conectado à sub-rede 3.3.3.0/24, e que a configuração da política IPsec no Roteador A e no Roteador B seja a seguinte:
- Configuração do IPsec no Roteador A:
acl advanced 3000
rule 0 permit ip source 1.1.1.0 0.0.0.255 destination 2.2.2.0 0.0.0.255
rule 1 deny ip
acl advanced 3001
9
rule 0 permit ip source 1.1.2.0 0.0.0.255 destination 3.3.3.0 0.0.0.255
rule 1 deny ip
#
ipsec policy testa 1 isakmp <---IPsec policy entry with a higher priority
security acl 3000
ike-profile aa
transform-set 1
#
ipsec policy testa 2 isakmp <---IPsec policy entry with a lower priority
security acl 3001
ike-profile bb
transform-set 1- Configuração do IPsec no Roteador B:
acl advanced 3001
rule 0 permit ip source 3.3.3.0 0.0.0.255 destination 1.1.2.0 0.0.0.255
rule 1 deny ip
#
ipsec policy testb 1 isakmp
security acl 3001
ike-profile aa
transform-set 1No Roteador A, aplique a política IPsec testa à interface de saída do Roteador A. A política IPsec contém duas entradas de política, testa 1 e testa 2. As ACLs usadas pelas duas entradas de política contêm, cada uma, uma regra que corresponde ao tráfego de 1.1.2.0/24 a 3.3.3.0/24. A regra usada na entrada de política testa 1 é uma instrução deny e a usada na entrada de política testa 2 é uma instrução permit. Como a testa 1 é correspondida antes da testa 2, o tráfego de 1.1.2.0/24 para 3.3.3.0/24 corresponderá à instrução deny e será enviado como tráfego normal. Quando o tráfego chega ao Roteador B, ele corresponde à regra 0 (uma instrução de permissão) na ACL 3001 usada no teste da política IPsec aplicada. Como o tráfego não IPsec que corresponde a uma instrução de permissão deve ser descartado na interface de entrada, o Roteador B descarta o tráfego.
Para garantir que a sub-rede 1.1.2.0/24 possa acessar a sub-rede 3.3.3.0/24, você pode excluir a regra de negação na ACL 3000 no Roteador A.
ACLs de imagem espelhada
Para garantir que as SAs possam ser configuradas e que o tráfego protegido pelo IPsec possa ser processado corretamente entre dois pares IPsec, crie ACLs de imagem espelhada nos pares IPsec. Conforme mostrado na Figura 5, as regras de ACL no Roteador B são imagens espelhadas das regras no Roteador A. Dessa forma, as SAs podem ser criadas com êxito para o tráfego entre o Host A e o Host C e para o tráfego entre a Rede 1 e a Rede 2.
Figura 5 ACLs de imagem espelhada
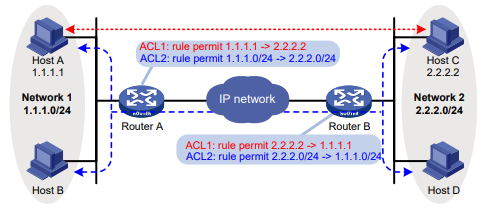
Se as regras de ACL nos pares IPsec não formarem imagens espelhadas umas das outras, as SAs poderão ser configuradas somente quando os dois requisitos a seguir forem atendidos:
- O intervalo especificado por uma regra ACL em um par é coberto por sua regra ACL equivalente no outro par. Conforme mostrado na Figura 6, o intervalo especificado pela regra ACL configurada no Roteador A é coberto por sua contraparte no Roteador B.
- O par com a regra mais restrita inicia a negociação da SA. Se uma regra de ACL mais ampla for usada pelo iniciador da SA, a solicitação de negociação poderá ser rejeitada porque o tráfego correspondente está além do escopo do respondente. Conforme mostrado na Figura 6, a negociação SA iniciada pelo Host A para o Host C é aceita, mas as negociações SA do Host C para o Host A, do Host C para o Host B e do Host D para o Host A são rejeitadas.
Figura 6 ACLs de imagens não espelhadas
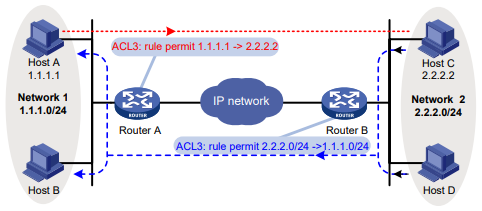
Configuração de um conjunto de transformação IPsec
Sobre o conjunto de transformação IPsec
Um conjunto de transformação IPsec, parte de uma política IPsec, define os parâmetros de segurança para a negociação de SA IPsec, incluindo o protocolo de segurança, os algoritmos de criptografia e os algoritmos de autenticação.
Restrições e diretrizes
As alterações em um conjunto de transformação IPsec afetam somente as SAs negociadas após as alterações. Para aplicar as alterações às SAs existentes, execute o comando reset ipsec sa para limpar as SAs, de modo que elas possam ser configuradas usando os parâmetros atualizados.
No modo FIPS, você deve especificar o algoritmo de criptografia ESP e o algoritmo de autenticação ESP para um conjunto de transformação IPsec que usa o protocolo de segurança ESP.
Quando você definir o modo de encapsulamento de pacotes (túnel ou transporte) para um conjunto de transformação IPsec, siga estas diretrizes:
- O modo de transporte se aplica somente quando os endereços IP de origem e destino dos fluxos de dados correspondem aos do túnel IPsec.
- O IPsec para protocolos de roteamento IPv6 suporta apenas o modo de transporte.
Quando você configurar o recurso Perfect Forward Secrecy (PFS) em um conjunto de transformação IPsec, siga estas diretrizes:
- No IKEv1, o nível de segurança do grupo DH do iniciador deve ser maior ou igual ao do respondente. Essa restrição não se aplica ao IKEv2.
- A extremidade sem o recurso PFS realiza a negociação de SA de acordo com os requisitos de PFS da extremidade do par.
É possível especificar vários algoritmos de autenticação ou criptografia para o mesmo protocolo de segurança. O algoritmo especificado anteriormente tem prioridade mais alta.
Alguns algoritmos estão disponíveis somente para o IKEv2. Consulte a Tabela 1.
Tabela 1 Algoritmos disponíveis somente para o IKEv2
| Tipo | Algoritmos |
| Algoritmo de criptografia | aes-ctr-128 aes-ctr-192 aes-ctr-256 camellia-cbc-128 camellia-cbc-192 camellia-cbc-256 gmac-128 gmac-192 gmac-256 gcm-128 gcm-192 gcm-256 |
| Algoritmo de autenticação | aes-xcbc-mac |
| Algoritmo PFS | dh-group19 dh-group20 |
Procedimento
- Entre na visualização do sistema.
system view- Crie um conjunto de transformação IPsec e entre em sua visualização.
ipsec transform-set transform-set-name- Especifique o protocolo de segurança para o conjunto de transformação IPsec.
protocol { ah | ah-esp | esp }Por padrão, o protocolo de segurança ESP é usado.
- Especifique os algoritmos de criptografia para ESP. Ignore esta etapa se o comando protocol ah estiver configurado.
No modo não-FIPS:
esp encryption-algorithm { 3des-cbc | aes-cbc-128 | aes-cbc-192 |
aes-cbc-256 | aes-ctr-128 | aes-ctr-192 | aes-ctr-256 | camellia-cbc-128 | camellia-cbc-192 | camellia-cbc-256 | des-cbc |
gmac-128 | gmac-192 | gmac-256 | gcm-128 | gcm-192 | gcm-256 | null } *Por padrão, nenhum algoritmo de criptografia é especificado para o ESP. No modo FIPS:
esp encryption-algorithm { aes-cbc-128 | aes-cbc-192 | aes-cbc-256 |
aes-ctr-128 | aes-ctr-192 | aes-ctr-256 | gmac-128 | gmac-192 | gmac-256
| gcm-128 | gcm-192 | gcm-256 } *Por padrão, nenhum algoritmo de criptografia é especificado para o ESP.
- Especifique os algoritmos de autenticação para ESP. Ignore esta etapa se o comando protocol ah estiver configurado.
No modo não-FIPS:
esp authentication-algorithm { aes-xcbc-mac | md5 | sha1 | sha256 |
sha384 | sha512 } *Por padrão, nenhum algoritmo de autenticação é especificado para o ESP. O algoritmo aes-xcbc-mac está disponível somente para o IKEv2. No modo FIPS:
esp authentication-algorithm { sha1 | sha256 | sha384 | sha512 } *Por padrão, nenhum algoritmo de autenticação é especificado para o ESP.
- Especifique os algoritmos de autenticação para AH. Ignore esta etapa se o comando protocol esp estiver configurado.
No modo não-FIPS:
ah authentication-algorithm { aes-xcbc-mac | md5 | sha1 | sha256 |
sha384 | sha512 } *Por padrão, nenhum algoritmo de autenticação é especificado para o AH. O algoritmo aes-xcbc-mac está disponível somente para o IKEv2. No modo FIPS:
ah authentication-algorithm { aes-xcbc-mac | md5 | sha1 | sha256 |
sha384 | sha512 } *Por padrão, nenhum algoritmo de autenticação é especificado para o AH.
- Especifique o modo de encapsulamento de pacotes.
encapsulation-mode { transport | tunnel }Por padrão, o protocolo de segurança encapsula os pacotes IP no modo túnel.
- (Opcional.) Habilite o recurso PFS. No modo não-FIPS:
pfs { dh-group1 | dh-group2 | dh-group5 | dh-group14 | dh-group24 |
dh-group19 | dh-group20 }No modo FIPS:
pfs { dh-group14 | dh-group19 | dh-group20 }Por padrão, o recurso PFS está desativado.
Para obter mais informações sobre o PFS, consulte "Configuração do IKE".
- (Opcional.) Ative o recurso ESN (Extended Sequence Number, número de sequência estendido).
esn enable [ both ]Por padrão, o recurso ESN está desativado.
Configuração de uma política IPsec manual
Em uma política IPsec manual, os parâmetros são configurados manualmente, como as chaves, os SPIs e os endereços IP das duas extremidades no modo túnel.
Restrições e diretrizes
Quando você configurar uma política IPsec manual, certifique-se de que a configuração IPsec em ambas as extremidades do túnel IPsec atenda aos seguintes requisitos:
- As políticas IPsec nas duas extremidades devem ter conjuntos de transformação IPsec que usem os mesmos protocolos de segurança, algoritmos de segurança e modo de encapsulamento.
- O endereço IPv4 remoto configurado na extremidade local deve ser o mesmo que o endereço IPv4 primário da interface aplicada com a política IPsec na extremidade remota. O endereço IPv6 remoto configurado na extremidade local deve ser o mesmo que o primeiro endereço IPv6 da interface aplicada com a política IPsec na extremidade remota.
- Em cada extremidade, configure os parâmetros para a SA de entrada e a SA de saída e certifique-se de que as SAs em cada direção sejam exclusivas: Para uma SA de saída, certifique-se de que seu tripleto (endereço IP remoto, protocolo de segurança e SPI) seja exclusivo. Para uma SA de entrada, certifique-se de que seu SPI seja exclusivo.
- A SA de entrada local deve usar o mesmo SPI e as mesmas chaves que a SA de saída remota. O mesmo se aplica à SA de saída local e à SA de entrada remota.
- As chaves para as SAs IPsec nas duas extremidades do túnel devem ser configuradas no mesmo formato. Por exemplo, se a extremidade local usar uma chave no formato hexadecimal, a extremidade remota também deverá usar uma chave no formato hexadecimal. Se você configurar uma chave nos formatos de caractere e hexadecimal, somente a configuração mais recente terá efeito.
- Se você configurar uma chave em formato de caractere para ESP, o dispositivo gerará automaticamente uma chave de autenticação e uma chave de criptografia para ESP.
Procedimento
- Entre na visualização do sistema.
system view- Crie uma entrada de política IPsec manual e insira sua visualização.
ipsec { ipv6-policy | policy } policy-name seq-number manual- (Opcional.) Configure uma descrição para a política IPsec.
description textPor padrão, nenhuma descrição é configurada.
- Especifique uma ACL para a política IPsec.
security acl [ ipv6 ] { acl-number | name acl-name }Por padrão, nenhuma ACL é especificada para uma política IPsec. Você pode especificar apenas uma ACL para uma política IPsec.
- Especifique um conjunto de transformação IPsec para a política IPsec.
transform-set transform-set-namePor padrão, nenhum conjunto de transformação IPsec é especificado para uma política IPsec.
Você pode especificar apenas um conjunto de transformação IPsec para uma política IPsec manual.
- Especifique o endereço IP remoto do túnel IPsec.
remote-address { ipv4-address | ipv6 ipv6-address }Por padrão, o endereço IP remoto do túnel IPsec não é especificado.
- Configure um SPI para a SA IPsec de entrada.
sa spi inbound { ah | esp } spi-numberPor padrão, nenhum SPI é configurado para a SA IPsec de entrada.
- Configure um SPI para a SA IPsec de saída.
sa spi outbound { ah | esp } spi-numberPor padrão, nenhum SPI é configurado para a SA IPsec de saída.
- Configurar chaves para a SA IPsec.
- Configure uma chave de autenticação em formato hexadecimal para AH.
sa hex-key authentication { inbound | outbound } ah { cipher | simple }
string- Configure uma chave de autenticação em formato de caractere para AH.
sa string-key { inbound | outbound } ah { cipher | simple } string- Configure uma chave em formato de caractere para o ESP.
sa string-key { inbound | outbound } esp { cipher | simple } string- Configure uma chave de autenticação em formato hexadecimal para ESP.
sa hex-key authentication { inbound | outbound } esp { cipher |
simple }- Configure uma chave de criptografia em formato hexadecimal para ESP.
sa hex-key encryption { inbound | outbound } esp { cipher | simple }
stringPor padrão, nenhuma chave é configurada para a SA IPsec.
Configure as chaves corretamente para o protocolo de segurança (AH, ESP ou ambos) que você especificou no conjunto de transformação IPsec usado pela política IPsec.
Configuração de uma política IPsec baseada em IKE
Sobre a configuração da política IPsec baseada em IKE
Em uma política de IPsec baseada em IKE, os parâmetros são negociados automaticamente por meio de IKE. Para configurar uma política IPsec baseada em IKE, use um dos métodos a seguir:
- Configure-o diretamente, configurando os parâmetros na visualização da política IPsec.
- Configure-o usando um modelo de política IPsec existente com os parâmetros a serem negociados configurados.
Um dispositivo que usa uma política IPsec configurada dessa forma não pode iniciar uma negociação SA, mas pode responder a uma solicitação de negociação. Os parâmetros não definidos no modelo são determinados pelo iniciador. Por exemplo, em um modelo de política IPsec, a ACL é opcional. Se você não especificar uma ACL, o intervalo de proteção IPsec não terá limite. Portanto, o dispositivo aceita todas as configurações de ACL do iniciador da negociação.
Quando as informações da extremidade remota (como o endereço IP) são desconhecidas, esse método permite que a extremidade remota inicie negociações com a extremidade local.
Os parâmetros configuráveis para um modelo de política IPsec são os mesmos de quando você configura diretamente uma política IPsec baseada em IKE. A diferença é que mais parâmetros são opcionais para um modelo de política IPsec. Exceto os conjuntos de transformação IPsec e o perfil IKE, todos os outros parâmetros são opcionais.
Restrições e diretrizes para a configuração da política IPsec baseada em IKE
As políticas IPsec nas duas extremidades do túnel devem ter conjuntos de transformação IPsec que usem os mesmos protocolos de segurança, algoritmos de segurança e modo de encapsulamento.
As políticas IPsec nas duas extremidades do túnel devem ter os mesmos parâmetros de perfil IKE.
Uma política IPsec baseada em IKE pode usar no máximo seis conjuntos de transformação IPsec. Durante uma negociação IKE, a IKE procura um conjunto de transformação IPsec totalmente compatível nas duas extremidades do túnel IPsec. Se nenhuma correspondência for encontrada, nenhuma SA poderá ser configurada e os pacotes que esperam ser protegidos serão descartados.
O endereço IP remoto do túnel IPsec é obrigatório em um iniciador de negociação IKE e é opcional no respondente. O endereço IP remoto especificado na extremidade local deve ser o mesmo que o endereço IP local especificado na extremidade remota.
A SA IPsec usa as configurações locais de tempo de vida ou as propostas pelo par, o que for menor.
A SA IPsec pode ter um tempo de vida baseado em tempo e um tempo de vida baseado em tráfego. A SA IPsec expira quando o tempo de vida expira.
Se você especificar um perfil IKEv1 e um perfil IKEv2 para uma política IPsec, o perfil IKEv2 será usado preferencialmente. Para obter mais informações sobre os perfis IKEv1 e IKEv2, consulte "Configuração do IKE" e "Configuração do IKEv2".
Configuração direta de uma política IPsec baseada em IKE
- Entre na visualização do sistema.
system view- Crie uma entrada de política IPsec baseada em IKE e entre em sua visualização.
ipsec { ipv6-policy | policy } policy-name seq-number isakmp- (Opcional.) Configure uma descrição para a política IPsec.
description textPor padrão, nenhuma descrição é configurada.
- Especifique uma ACL para a política IPsec.
security acl [ ipv6 ] { acl-number | name acl-name } [ aggregation |
per-host ]Por padrão, nenhuma ACL é especificada para uma política IPsec. Você pode especificar apenas uma ACL para uma política IPsec.
- Especifique os conjuntos de transformação IPsec para a política IPsec.
transform-set transform-set-name&<1-6>Por padrão, nenhum conjunto de transformação IPsec é especificado para uma política IPsec.
- Especifique um perfil IKE ou IKEv2 para a política IPsec.
- Especifique um perfil IKE.
ike-profile profile-namePor padrão, nenhum perfil IKE é especificado para uma política IPsec.
- Especifique um perfil IKEv2.
ikev2-profile profile-namePor padrão, nenhum perfil IKEv2 é especificado para uma política IPsec.
- Especifique o endereço IP local do túnel IPsec.
local-address { ipv4-address | ipv6 ipv6-address }Por padrão, o endereço IPv4 local do túnel IPsec é o endereço IPv4 primário da interface à qual a política IPsec é aplicada. O endereço IPv6 local do túnel IPsec é o primeiro endereço IPv6 da interface à qual a política IPsec é aplicada.
O endereço IP local especificado por esse comando deve ser o mesmo que o endereço IP usado como identidade IKE local.
Em uma rede VRRP, o endereço IP local deve ser o endereço IP virtual do grupo VRRP ao qual pertence a interface aplicada ao IPsec.
- Especifique o endereço IP remoto do túnel IPsec.
remote-address { [ ipv6 ] host-name | ipv4-address | ipv6 ipv6-address }Por padrão, o endereço IP remoto do túnel IPsec não é especificado.
- (Opcional.) Defina o tempo de vida ou o tempo limite de inatividade para a SA IPsec.
- Definir o tempo de vida da SA IPsec.
sa duration { time-based seconds | traffic-based kilobytes }Por padrão, o tempo de vida da SA global é usado.
- Defina o tempo limite de inatividade da SA IPsec.
sa idle-time secondsPor padrão, é usado o tempo limite ocioso da SA IPsec global.
- (Opcional.) Ative o recurso de preenchimento de confidencialidade do fluxo de tráfego (TFC).
tfc enablePor padrão, o recurso de preenchimento de TFC está desativado.
Configuração de uma política IPsec baseada em IKE usando um modelo de política IPsec
- Entre na visualização do sistema.
system view- Crie um modelo de política IPsec e entre em sua visualização.
ipsec { ipv6-policy-template | policy-template } template-name
seq-number- (Opcional.) Configure uma descrição para o modelo de política IPsec.
description textPor padrão, nenhuma descrição é configurada.
- (Opcional.) Especifique uma ACL para o modelo de política IPsec.
security acl [ ipv6 ] { acl-number | name acl-name } [ aggregation |
per-host ]Por padrão, nenhuma ACL é especificada para um modelo de política IPsec. Você pode especificar apenas uma ACL para um modelo de política IPsec.
- Especifique os conjuntos de transformação IPsec para o modelo de política IPsec.
transform-set transform-set-name&<1-6>Por padrão, nenhum conjunto de transformação IPsec é especificado para um modelo de política IPsec.
- Especifique um perfil IKE ou IKEv2 para o modelo de política IPsec.
- Especifique um perfil IKE.
ike-profile profile-namePor padrão, nenhum perfil IKE é especificado para um modelo de política IPsec.
Certifique-se de que o perfil IKE especificado não seja usado por outra política IPsec ou modelo de política IPsec.
- Especifique um perfil IKEv2.
ikev2-profile profile-namePor padrão, nenhum perfil IKEv2 é especificado para um modelo de política IPsec.
- Especifique o endereço IP local do túnel IPsec.
local-address { ipv4-address | ipv6 ipv6-address }O endereço IPv4 e o endereço IPv6 locais padrão são o endereço IPv4 primário e o primeiro endereço IPv6 da interface em que a política IPsec é aplicada.
O endereço IP local especificado por esse comando deve ser o mesmo que o endereço IP usado como identidade IKE local.
Em uma rede VRRP, o endereço IP local deve ser o endereço IP virtual do grupo VRRP ao qual pertence a interface aplicada ao IPsec.
- Especifique o endereço IP remoto do túnel IPsec.
remote-address { [ ipv6 ] host-name | ipv4-address | ipv6 ipv6-address }Por padrão, o endereço IP remoto do túnel IPsec não é especificado.
- (Opcional.) Defina o tempo de vida e o tempo limite de inatividade para a SA IPsec.
- Definir o tempo de vida da SA IPsec.
sa duration { time-based seconds | traffic-based kilobytes }Por padrão, o tempo de vida da SA global é usado.
- Defina o tempo limite de inatividade da SA IPsec.
sa duration { time-based seconds | traffic-based kilobytes }Por padrão, é usado o tempo limite ocioso da SA IPsec global.
- (Opcional.) Ative o recurso de preenchimento de confidencialidade do fluxo de tráfego (TFC).
tfc enablePor padrão, o recurso de preenchimento de TFC está desativado.
- Retornar à visualização do sistema.
quit- Crie uma política IPsec usando o modelo de política IPsec.
ipsec { ipv6-policy | policy } policy-name seq-number isakmp template
template-nameAplicação de uma política IPsec a uma interface
Restrições e diretrizes
Você pode aplicar uma política IPsec às interfaces para proteger os fluxos de dados.
- Uma política de IPsec baseada em IKE pode ser aplicada a várias interfaces. Como prática recomendada, aplique uma política IPsec baseada em IKE a apenas uma interface.
- Uma política IPsec manual pode ser aplicada a apenas uma interface.
Para cancelar a proteção IPsec, remova a aplicação da política IPsec.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-number- Aplicar uma política IPsec à interface.
ipsec apply { ipv6-policy | policy } policy-namePor padrão, nenhuma política IPsec é aplicada a uma interface.
Em uma interface, você pode aplicar apenas uma política IPv4 IPsec e uma política IPv6 IPsec.
Ativação da verificação de ACL para pacotes não encapsulados
Sobre a verificação de ACL para pacotes não encapsulados
Esse recurso compara os pacotes IPsec de entrada não encapsulados com a ACL na política IPsec e descarta aqueles que não correspondem a nenhuma regra de permissão da ACL. Esse recurso pode proteger as redes contra ataques que usam pacotes IPsec falsificados.
Esse recurso se aplica somente ao IPsec no modo túnel.
Procedimento
- Entre na visualização do sistema.
system view- Ativar a verificação de ACL para pacotes desencapsulados.
ipsec decrypt-check enable Por padrão, a verificação de ACL para pacotes não encapsulados está ativada.
Configuração do IPsec anti-replay
Sobre o IPsec anti-replay
O IPsec anti-replay protege as redes contra ataques anti-replay usando um mecanismo de janela deslizante chamado janela anti-replay. Esse recurso verifica o número de sequência de cada pacote IPsec recebido em relação ao intervalo atual de números de sequência de pacotes IPsec da janela deslizante. Se o número de sequência não estiver no intervalo de números de sequência atual, o pacote será considerado um pacote de repetição e será descartado.
O desencapsulamento de pacotes IPsec envolve cálculos complicados. O desencapsulamento de pacotes reproduzidos não é necessário, e o processo de desencapsulamento consome grandes quantidades de recursos e prejudica o desempenho, resultando em DoS. O anti-reprodução do IPsec pode verificar e descartar os pacotes reproduzidos antes do desencapsulamento.
Em algumas situações, os pacotes de dados de serviço são recebidos em uma ordem diferente da ordem original. O recurso anti-repetição do IPsec os descarta como pacotes repetidos, o que afeta as comunicações. Se isso acontecer, desative a verificação anti-reprodução do IPsec ou ajuste o tamanho da janela anti-reprodução conforme necessário.
Restrições e diretrizes
O anti-reprodução do IPsec não afeta as SAs do IPsec criadas manualmente. De acordo com o protocolo IPsec, somente as SAs IPsec baseadas em IKE suportam o anti-replay.
Defina o tamanho da janela anti-reprodução como o menor possível para reduzir o impacto no desempenho do sistema.
A não detecção de ataques anti-repetição pode resultar em negação de serviços. Se você quiser desativar o anti-repetição do IPsec, certifique-se de compreender o impacto da operação na segurança da rede.
Procedimento
- Entre na visualização do sistema.
system view- Ativar o anti-repetição IPsec.
ipsec anti-replay checkPor padrão, o anti-repetição do IPsec está ativado.
- Defina o tamanho da janela anti-repetição do IPsec.
ipsec anti-replay window widthO tamanho padrão é 64.
Configuração da redundância anti-repetição do IPsec
Sobre a redundância anti-repetição do IPsec
Esse recurso sincroniza as seguintes informações do dispositivo ativo para o dispositivo em espera em intervalos configuráveis baseados em pacotes:
- Valores de limite inferior da janela anti-repetição do IPsec para pacotes de entrada.
- Números de sequência anti-repetição do IPsec para pacotes de saída.
Esse recurso, usado junto com a redundância IPsec, garante o encaminhamento ininterrupto do tráfego IPsec e a proteção anti-repetição quando o dispositivo ativo falha.
Procedimento
- Entre na visualização do sistema.
system view- Ativar a redundância do IPsec.
ipsec redundancy enablePor padrão, a redundância do IPsec está desativada.
- Entre na visualização de política IPsec ou na visualização de modelo de política IPsec.
- Entre no modo de exibição da política IPsec.
ipsec { ipv6-policy | policy } policy-name seq-number [ isakmp |
manual ]- Entre na visualização do modelo de política IPsec.
ipsec { ipv6-policy-template | policy-template } template-name
seq-number- Defina o intervalo de sincronização da janela anti-repetição para pacotes de entrada e o intervalo de sincronização do número de sequência para pacotes de saída.
redundancy replay-interval inbound inbound-interval outbound
outbound-intervalPor padrão, o dispositivo ativo sincroniza a janela anti-repetição toda vez que recebe 1.000 pacotes e sincroniza o número de sequência toda vez que envia 100.000 pacotes.
Vinculação de uma interface de origem a uma política IPsec
Sobre a interface de origem e a vinculação de políticas IPsec
Para alta disponibilidade, um dispositivo central geralmente é conectado a um ISP por meio de dois links, que operam em modo de backup ou compartilhamento de carga. As duas interfaces negociam com seus pares para estabelecer SAs IPsec, respectivamente. Quando uma interface falha e ocorre um failover de link, a outra interface precisa levar algum tempo para renegociar SAs, o que resulta em interrupção do serviço.
Para resolver esses problemas, vincule uma interface de origem a uma política IPsec e aplique a política a ambas as interfaces. Isso permite que as duas interfaces físicas usem a mesma interface de origem para negociar SAs IPsec. Enquanto a interface de origem estiver ativa, as SAs IPsec negociadas não serão removidas e continuarão funcionando, independentemente do failover do link.
Restrições e diretrizes
Somente as políticas IPsec baseadas em IKE podem ser vinculadas a uma interface de origem. Uma política IPsec pode ser vinculada a apenas uma interface de origem.
Uma interface de origem pode ser vinculada a várias políticas IPsec.
Se a interface de origem vinculada a uma política IPsec for removida, a política IPsec se tornará uma política IPsec comum.
Se nenhum endereço local for especificado para uma política IPsec que tenha sido vinculada a uma interface de origem, a política IPsec usará o endereço IP da interface de origem vinculada para realizar a negociação IKE. Se for especificado um endereço local, a política IPsec usará o endereço local para realizar a negociação IKE.
Procedimento
- Entre na visualização do sistema.
system view- Vincular uma interface de origem a uma política IPsec.
ipsec { ipv6-policy | policy } policy-name local-address
interface-type interface-number
Por padrão, nenhuma interface de origem está vinculada a uma política IPsec.
Ativação da pré-classificação de QoS
Sobre a pré-classificação de QoS
Quando uma política de IPsec e uma política de QoS são aplicadas a uma interface, a QoS classifica os pacotes usando os novos cabeçalhos adicionados pelo IPsec. Se você quiser que a QoS classifique os pacotes usando os cabeçalhos dos pacotes IP originais, ative o recurso de pré-classificação da QoS.
Restrições e diretrizes
Se você configurar o IPsec e o QoS em uma interface, verifique se as regras de classificação de tráfego do IPsec correspondem às regras de classificação de tráfego do QoS. Se as regras não corresponderem, a QoS poderá classificar os pacotes de uma SA IPsec em filas diferentes, fazendo com que os pacotes sejam enviados fora de ordem. Quando o IPsec anti-replay estiver ativado, o IPsec descartará os pacotes de entrada que estiverem fora da janela anti-replay, resultando em perda de pacotes.
As regras de classificação do tráfego IPsec são determinadas pelas regras da ACL especificada. Para obter mais informações sobre política e classificação de QoS, consulte o Guia de configuração de ACL e QoS.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da política IPsec ou na visualização do modelo de política IPsec.
- Entre no modo de exibição da política IPsec.
ipsec { ipv6-policy | policy } policy-name seq-number [ isakmp |
manual ]- Entre na visualização do modelo de política IPsec.
ipsec { ipv6-policy-template | policy-template } template-name
seq-number- Habilitar a pré-classificação de QoS.
qos pre-classifyPor padrão, a pré-classificação de QoS está desativada.
Configuração do bit DF dos pacotes IPsec
Sobre a configuração de bits DF para pacotes IPsec
Execute esta tarefa para configurar o bit Don't Fragment (DF) no novo cabeçalho IP dos pacotes IPsec de uma das seguintes maneiras:
- clear - Limpa o bit DF no novo cabeçalho.
- set - Define o bit DF no novo cabeçalho.
- copy-Copia o bit DF no cabeçalho IP original para o novo cabeçalho IP.
Você pode configurar o bit DF na visualização do sistema e na visualização da interface. A configuração do bit DF na visualização da interface tem precedência sobre a configuração do bit DF na visualização do sistema. Se a configuração de bit DF na visualização da interface não estiver configurada, a interface usará a configuração de bit DF na visualização do sistema.
Restrições e diretrizes para a configuração de bits DF para pacotes IPsec
A configuração do bit DF tem efeito somente no modo túnel e altera o bit DF no novo cabeçalho IP em vez do cabeçalho IP original.
Configure a mesma definição de bit DF nas interfaces em que a mesma política IPsec vinculada a uma interface de origem é aplicada.
Se o bit DF estiver definido, os dispositivos no caminho não poderão fragmentar os pacotes IPsec. Para evitar que os pacotes IPsec sejam descartados, certifique-se de que o MTU do caminho seja maior que o tamanho do pacote IPsec. Como prática recomendada, limpe o bit DF se você não puder se certificar de que o MTU do caminho seja maior que o tamanho do pacote IPsec.
Configuração do bit DF dos pacotes IPsec em uma interface
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-number- Configure o bit DF dos pacotes IPsec na interface.
ipsec global-df-bit { clear | copy | set }Por padrão, a interface usa a configuração global de bits DF.
Configuração do bit DF dos pacotes IPsec globalmente
- Entre na visualização do sistema.
system view- Configure o bit DF dos pacotes IPsec globalmente.
ipsec global-df-bit { clear | copy | set }Por padrão, o IPsec copia o bit DF do cabeçalho IP original para o novo cabeçalho IP.
Configuração do IPsec RRI
Restrições e diretrizes
A ativação do IPsec RRI para uma política IPsec exclui todas as SAs IPsec existentes criadas por essa política IPsec. O IPsec RRI cria rotas estáticas de acordo com as novas SAs IPsec.
A desativação do IPsec RRI para uma política IPsec exclui todos os SAs IPsec existentes criados por essa política IPsec e as rotas estáticas associadas.
O IPsec RRI é compatível com o modo túnel e o modo transporte.
Se você alterar o valor de preferência ou o valor de tag de uma política IPsec, o dispositivo excluirá todos os SAs IPsec criados por essa política IPsec e as rotas estáticas associadas. A alteração entra em vigor para futuras rotas estáticas criadas pelo IPsec RRI.
O IPsec RRI não gera uma rota estática para um endereço de destino a ser protegido se o endereço de destino não estiver definido na ACL usada por uma política IPsec ou por um modelo de política IPsec. Você deve configurar manualmente uma rota estática para o endereço de destino.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização de política IPsec ou na visualização de modelo de política IPsec.
- Entre no modo de exibição da política IPsec.
ipsec { policy | ipv6-policy } policy-name seq-number isakmp
- Entre na visualização do modelo de política IPsec.
ipsec { ipv6-policy-template | policy-template } template-name
seq-number- Ativar IPsec RRI.
reverse-route dynamicPor padrão, o IPsec RRI está desativado.
- (Opcional.) Defina o valor de preferência para as rotas estáticas criadas pelo IPsec RRI.
reverse-route preference numberO valor padrão é 60.
- (Opcional.) Defina o valor da tag para as rotas estáticas criadas pelo IPsec RRI.
reverse-route tag tag-valueO valor padrão é 0.
Configuração do IPsec para protocolos de roteamento IPv6
Visão geral das tarefas de proteção IPsec para protocolos de roteamento IPv6
Para configurar a proteção IPsec para protocolos de roteamento IPv6, execute as seguintes tarefas:
- Configuração de um conjunto de transformação IPsec
- Configuração de um perfil IPsec manual
- Aplicação do perfil IPsec a um protocolo de roteamento IPv6
- (Opcional.) Configuração da fragmentação do IPsec
- (Opcional.) Configuração do número máximo de túneis IPsec
- (Opcional.) Ativação de registro para pacotes IPsec
- (Opcional.) Configuração de notificações SNMP para IPsec
Configuração de um perfil IPsec manual
Sobre o perfil IPsec manual
Um perfil IPsec manual especifica o conjunto de transformação IPsec usado para proteger os fluxos de dados e os SPIs e chaves usados pelas SAs.
Restrições e diretrizes
Quando você configurar um perfil IPsec manual, verifique se a configuração do perfil IPsec em ambas as extremidades do túnel atende aos seguintes requisitos:
- O conjunto de transformação IPsec especificado no perfil IPsec nas duas extremidades do túnel deve ter o mesmo protocolo de segurança, algoritmos de criptografia e autenticação e modo de encapsulamento de pacotes.
- As SAs IPsec de entrada e saída locais devem ter o mesmo SPI e a mesma chave.
- As SAs IPsec nos dispositivos no mesmo escopo devem ter a mesma chave. O escopo é definido por protocolos. Para o OSPFv3, o escopo consiste em vizinhos do OSPFv3 ou em uma área do OSPFv3. Para o RIPng, o escopo consiste em vizinhos diretamente conectados ou em um processo RIPng.
- As chaves para as SAs IPsec nas duas extremidades do túnel devem ser configuradas no mesmo formato. Por exemplo, se a extremidade local usar uma chave no formato hexadecimal, a extremidade remota também deverá usar uma chave no formato hexadecimal. Se você configurar uma chave nos formatos de caractere e hexadecimal, somente a configuração mais recente terá efeito.
- Se você configurar uma chave em formato de caractere para ESP, o dispositivo gerará automaticamente uma chave de autenticação e uma chave de criptografia para ESP.
Procedimento
- Entre na visualização do sistema.
system view- Crie um perfil IPsec manual e insira sua visualização.
ipsec profile profile-name manualA palavra-chave manual não é necessária se você inserir a visualização de um perfil IPsec existente.
- (Opcional.) Configure uma descrição para o perfil IPsec.
description textPor padrão, nenhuma descrição é configurada.
- Especifique um conjunto de transformação IPsec.
transform-set transform-set-namePor padrão, nenhum conjunto de transformação IPsec é especificado em um perfil IPsec. O conjunto de transformação IPsec especificado deve usar o modo de transporte.
- Configurar um SPI para uma SA.
sa spi { inbound | outbound } { ah | esp } spi-number
Por padrão, nenhum SPI é configurado para uma SA.
- Configure as chaves para a SA IPsec.
- Configure uma chave de autenticação em formato hexadecimal para AH.
sa hex-key authentication { inbound | outbound } ah { cipher | simple }
string- Configure uma chave de autenticação em formato de caractere para AH.
sa string-key { inbound | outbound } ah { cipher | simple } string- Configure uma chave em formato de caractere para o ESP.
sa string-key { inbound | outbound } esp { cipher | simple } string- Configure uma chave de autenticação em formato hexadecimal para ESP.
sa hex-key authentication { inbound | outbound } esp { cipher |
simple }- Configure uma chave de criptografia em formato hexadecimal para ESP.
sa hex-key encryption { inbound | outbound } esp { cipher | simple }
stringPor padrão, nenhuma chave é configurada para a SA IPsec.
Configure uma chave para o protocolo de segurança (AH, ESP ou ambos) que você especificou.
Aplicação do perfil IPsec a um protocolo de roteamento IPv6
Para obter informações sobre o procedimento de configuração, consulte Configuração de OSPFv3 e RIPng no Guia de configuração de roteamento de camada 3 IP.
Configuração do tempo de vida e do tempo limite de inatividade da SA IPsec global
Sobre a duração da SA IPsec global e o tempo limite de inatividade
Se o tempo de vida da SA IPsec e o tempo limite de inatividade não estiverem configurados em uma política IPsec, modelo de política IPsec ou perfil IPsec, serão usadas as configurações globais.
Quando o IKE negocia SAs IPsec, ele usa as configurações locais de tempo de vida ou as propostas pelo par, o que for menor.
Uma SA IPsec pode ter um tempo de vida baseado em tempo e um tempo de vida baseado em tráfego. A SA IPsec expira quando o tempo de vida expira.
Procedimento
- Entre na visualização do sistema.
system view- Defina o tempo de vida ou o tempo limite de inatividade da SA IPsec global.
- Definir o tempo de vida da SA IPsec global.
ipsec sa global-duration { time-based seconds | traffic-based
kilobytes }Por padrão, o tempo de vida da SA baseada em tempo é de 3600 segundos e o tempo de vida da SA baseada em tráfego é de 1843200 kilobytes.
- Definir o tempo limite de inatividade da SA global.
ipsec sa idle-time secondsPor padrão, o recurso de tempo limite ocioso do IPsec SA global está desativado.
Configuração da fragmentação do IPsec
Sobre a fragmentação do IPsec
Execute esta tarefa para configurar o dispositivo para fragmentar os pacotes antes ou depois do encapsulamento IPsec.
Se você configurar o dispositivo para fragmentar os pacotes antes do encapsulamento IPsec, o dispositivo predeterminará o tamanho do pacote encapsulado antes do encapsulamento real. Se o tamanho do pacote encapsulado exceder o MTU da interface de saída, o dispositivo fragmentará os pacotes antes do encapsulamento. Se o bit DF de um pacote for definido, o dispositivo descartará o pacote e enviará uma mensagem de erro ICMP.
Se você configurar o dispositivo para fragmentar os pacotes após o encapsulamento IPsec, o dispositivo encapsulará diretamente os pacotes e fragmentará os pacotes encapsulados nos módulos de serviço subsequentes.
Restrições e diretrizes
Esse recurso entra em vigor em pacotes IPv4 protegidos por IPsec.
Procedimento
- Entre na visualização do sistema.
system view- Configurar a fragmentação do IPsec.
ipsec fragmentation { after-encryption | before-encryption }Por padrão, o dispositivo fragmenta os pacotes antes do encapsulamento IPsec.
Definição do número máximo de túneis IPsec
Restrições e diretrizes
Para maximizar o desempenho simultâneo do IPsec quando a memória for suficiente, aumente o número máximo de túneis IPsec. Para garantir a disponibilidade do serviço quando a memória for insuficiente, diminua o número máximo de túneis IPsec.
Procedimento
- Entre na visualização do sistema.
system view- Defina o número máximo de túneis IPsec.
ipsec limit max-tunnel tunnel-limitO número de túneis IPsec não é limitado.
Ativação de registro para pacotes IPsec
Sobre o registro de pacotes IPsec
Execute esta tarefa para ativar o registro em log de pacotes IPsec que são descartados por motivos como falha na pesquisa de SA IPsec, falha na autenticação AH-ESP e falha na criptografia ESP. As informações de registro incluem os endereços IP de origem e destino, o valor SPI e o número de sequência de um pacote IPsec descartado, além do motivo do descarte.
Procedimento
- Entre na visualização do sistema.
system view- Ativar o registro de pacotes IPsec.
ipsec logging packet enabletPor padrão, o registro de pacotes IPsec está desativado.
Configuração de notificações SNMP para IPsec
Sobre as notificações SNMP para IPsec
Depois que você ativar as notificações SNMP para IPsec, o módulo IPsec notificará o NMS sobre eventos importantes do módulo. As notificações são enviadas ao módulo SNMP do dispositivo. Para que as notificações sejam enviadas corretamente, você também deve configurar o SNMP no dispositivo. Para obter mais informações sobre as notificações de SNMP, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Para gerar e emitir notificações SNMP para um tipo específico de evento ou falha do IPsec, execute as seguintes tarefas:
- Ative as notificações SNMP para IPsec globalmente.
- Ative as notificações SNMP para o tipo de falha ou evento.
Procedimento
- Entre na visualização do sistema.
system view- Ative as notificações SNMP para IPsec globalmente.
snmp-agent trap enable ipsec globalPor padrão, as notificações SNMP para IPsec estão desativadas.
- Ative as notificações SNMP para os tipos de falha ou evento especificados.
snmp-agent trap enable ipsec [ auth-failure | decrypt-failure |
encrypt-failure | invalid-sa-failure | no-sa-failure | policy-add |
policy-attach | policy-delete | policy-detach | tunnel-start |
tunnel-stop ] *Por padrão, as notificações SNMP para todos os tipos de falhas e eventos estão desativadas.
Comandos de exibição e manutenção para IPsec
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações sobre a política IPsec. | exibir ipsec { ipv6-policy | policy } [ policy-name [ seq-number ] ] |
| Exibir informações do modelo de política IPsec. | display ipsec { ipv6-policy-template | policy-template } [ nome-do-modelo [ seq-número ] ] |
| Exibir informações do perfil IPsec. | exibir perfil ipsec [ nome-do-perfil ] |
| Exibir informações de SA IPsec. | display ipsec sa [ brief | count | interface interface-type interface-number | { ipv6-policy | policy } policy-name [ seq-number ] | profile profile-name | remote [ ipv6 ] ip-address ] |
| Exibir estatísticas de IPsec. | display ipsec statistics [ tunnel-id tunnel-id ] |
| Exibir informações do conjunto de transformação IPsec. | exibir ipsec transform-set [ transform-set-name ] |
| Exibir informações sobre o túnel IPsec. | display ipsec tunnel { brief | count | tunnel-id tunnel-id } |
| Limpar SAs IPsec. | reset ipsec sa [ { ipv6-policy | policy } policy-name [ seq-number ] | profile policy-name | remote { ipv4-address | ipv6 ipv6-address } | spi { ipv4-address | ipv6 ipv6-address } { ah | esp } spi-num ] |
| Limpar estatísticas do IPsec. | reset ipsec statistics [ tunnel-id tunnel-id ] |
Exemplos de configuração do IPsec
Exemplo: Configuração de um túnel IPsec em modo manual para pacotes IPv4
Configuração de rede
Conforme mostrado na Figura 7, estabeleça um túnel IPsec entre o Switch A e o Switch B para proteger os fluxos de dados entre os switches. Configure o túnel da seguinte forma:
- Especifique o modo de encapsulamento como túnel, o protocolo de segurança como ESP, o algoritmo de criptografia como AES-CBC-192 e o algoritmo de autenticação como HMAC-SHA1.
- Configurar manualmente SAs IPsec.
Figura 7 Diagrama de rede

Procedimento
- Configure o Switch A:
# Configure um endereço IP para a interface VLAN 1.
<SwitchA> system-view
[SwitchA] interface vlan-interface 1
[SwitchA-Vlan-interface1] ip address 2.2.2.1 255.255.255.0
[SwitchA-Vlan-interface1] quit# Configure uma ACL avançada de IPv4 para identificar os fluxos de dados entre o Switch A e o Switch B.
[SwitchA] acl advanced 3101
[SwitchA-acl-ipv4-adv-3101] rule 0 permit ip source 2.2.2.1 0 destination 2.2.3.1 0
[SwitchA-acl-ipv4-adv-3101] quit# Crie um conjunto de transformação IPsec chamado tran1.
[SwitchA] ipsec transform-set tran1# Especifique o modo de encapsulamento como túnel.
[SwitchA-ipsec-transform-set-tran1] encapsulation-mode tunnel# Especifique o protocolo de segurança como ESP.
[RouterA-ipsec-transform-set-tran1] protocol esp# Especifique os algoritmos de criptografia e autenticação ESP.
[SwitchA-ipsec-transform-set-tran1] esp encryption-algorithm aes-cbc-192
[SwitchA-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchA-ipsec-transform-set-tran1] quit# Crie uma entrada de política IPsec manual. Especifique o nome da política como map1 e defina o número de sequência como 10.
[SwitchA] ipsec policy map1 10 manual# Especifique a ACL 3101.
[SwitchA-ipsec-policy-manual-map1-10] security acl 3101# Especifique o conjunto de transformação IPsec tran1.
[SwitchA-ipsec-policy-manual-map1-10] transform-set tran1# Especifique o endereço IP remoto do túnel IPsec como 2.2.3.1.
[SwitchA-ipsec-policy-manual-map1-10] remote-address 2.2.3.1 # Configure SPIs de entrada e saída para ESP.
<[SwitchA-ipsec-policy-manual-map1-10] sa spi outbound esp 12345
[SwitchA-ipsec-policy-manual-map1-10] sa spi inbound esp 54321 # Configure as chaves SA de entrada e saída para ESP.
[SwitchA-ipsec-policy-manual-map1-10] sa string-key outbound esp simple abcdefg
[SwitchA-ipsec-policy-manual-map1-10] sa string-key inbound esp simple gfedcba
[SwitchA-ipsec-policy-manual-map1-10] quit# Aplique o mapa de política IPsec1 à interface VLAN 1.
[SwitchA] interface vlan-interface 1
[SwitchA-Vlan-interface1] ipsec apply policy map1- Configurar o Switch B:
# Configure um endereço IP para a interface VLAN 1.
<SwitchB> system-view
[SwitchB] interface vlan-interface 1
[SwitchB-Vlan-interface1] ip address 2.2.3.1 255.255.255.0
[SwitchB-Vlan-interface1] quit# Configure uma ACL avançada de IPv4 para identificar os fluxos de dados entre o Switch B e o Switch A.
[SwitchB] acl advanced 3101
[SwitchB-acl-ipv4-adv-3101] rule 0 permit ip source 2.2.3.1 0 destination 2.2.2.1 0
[SwitchB-acl-ipv4-adv-3101] quit# Crie um conjunto de transformação IPsec chamado tran1.
[SwitchB] ipsec transform-set tran1# Especifique o modo de encapsulamento como túnel.
[SwitchB-ipsec-transform-set-tran1] encapsulation-mode tunnel# Especifique o protocolo de segurança como ESP.
[SwitchB-ipsec-transform-set-tran1] protocol esp# Especifique os algoritmos de criptografia e autenticação ESP.
[SwitchB-ipsec-transform-set-tran1] esp encryption-algorithm aes-cbc-192
[SwitchB-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchB-ipsec-transform-set-tran1] quit# Criar uma entrada de política IPsec manual. Especifique o nome da política como use1 e defina a sequência
número para 10.
[SwitchB] ipsec policy use1 10 manual# Especifique a ACL 3101.
[SwitchB-ipsec-policy-manual-use1-10] security acl 3101# Especifique o conjunto de transformação IPsec tran1.
[SwitchB-ipsec-policy-manual-use1-10] transform-set tran1# Especifique o endereço IP remoto do túnel IPsec como 2.2.2.1.
[SwitchB-ipsec-policy-manual-use1-10] remote-address 2.2.2.1# Configure os SPIs de entrada e saída para ESP.
[SwitchB-ipsec-policy-manual-use1-10] sa spi outbound esp 54321
[SwitchB-ipsec-policy-manual-use1-10] sa spi inbound esp 12345# Configure as chaves SA de entrada e saída para ESP.
[SwitchB-ipsec-policy-manual-use1-10] sa string-key outbound esp simple gfedcba
[SwitchB-ipsec-policy-manual-use1-10] sa string-key inbound esp simple abcdefg
[SwitchB-ipsec-policy-manual-use1-10] quit# Aplique a política IPsec use1 à interface VLAN 1.
[SwitchB] interface vlan-interface 1
[SwitchB-Vlan-interface1] ipsec apply policy use1Verificação da configuração
Após a conclusão da configuração, é estabelecido um túnel IPsec entre o Switch A e o Switch B, e o tráfego entre os switches é protegido por IPsec. Este exemplo usa o Switch A para verificar a configuração.
# Use o comando display ipsec sa para exibir os SAs IPsec no Switch A.
[SwitchA] display ipsec sa
-------------------------------
Interface: Vlan-interface 1
-------------------------------
-----------------------------
IPsec policy: map1
Sequence number: 10
Mode: manual
-----------------------------
Tunnel id: 549
Encapsulation mode: tunnel
Path MTU: 1443
Tunnel:
local address: 2.2.2.1
remote address: 2.2.3.1
Flow:
as defined in ACL 3101
[Inbound ESP SA]
SPI: 54321 (0x0000d431)
Transform set: ESP-ENCRYPT-AES-CBC-192 ESP-AUTH-SHA1
No duration limit for this SA
[Outbound ESP SA]
SPI: 12345 (0x00003039)
Transform set: ESP-ENCRYPT-AES-CBC-192 ESP-AUTH-SHA1
No duration limit for this SAExemplo: Configuração de um túnel IPsec baseado em IKE para pacotes IPv4
Configuração de rede
Conforme mostrado na Figura 8, estabeleça um túnel IPsec entre o Switch A e o Switch B para proteger os fluxos de dados entre eles. Configure o túnel IPsec da seguinte forma:
- Especifique o modo de encapsulamento como túnel, o protocolo de segurança como ESP, o algoritmo de criptografia como AES-CBC-192 e o algoritmo de autenticação como HMAC-SHA1.
- Configurar SAs por meio de negociação IKE.
Figura 8 Diagrama de rede

Procedimento
- Configure o Switch A:
# Configure um endereço IP para a interface VLAN 1.
<SwitchA> system-view
[SwitchA] interface vlan-interface 1
[SwitchA-Vlan-interface1] ip address 2.2.2.1 255.255.255.0
[SwitchA-Vlan-interface1] quit# Configure uma ACL avançada IPv4 para identificar fluxos de dados do Switch A para o Switch B.
[SwitchA] acl number 3101
[SwitchA-acl-adv-3101] rule 0 permit ip source 2.2.2.1 0 destination 2.2.3.1 0
[SwitchA-acl-adv-3101] quit# Crie um conjunto de transformação IPsec chamado tran1.
[SwitchA] ipsec transform-set tran1# Especifique o modo de encapsulamento como túnel.
[SwitchA-ipsec-transform-set-tran1] encapsulation-mode tunnel# Especifique o protocolo de segurança como ESP.
[SwitchA-ipsec-transform-set-tran1] protocol esp# Especifique os algoritmos de criptografia e autenticação ESP.
[SwitchA-ipsec-transform-set-tran1] esp encryption-algorithm aes-cbc-192
[SwitchA-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchA-ipsec-transform-set-tran1] quit# Crie um keychain IKE chamado keychain1.
[SwitchA] ike keychain keychain1# Especifique 12345zxcvb!@#$%ZXCVB em texto simples como a chave pré-compartilhada a ser usada com o par remoto em 2.2.3.1.
[SwitchA-ike-keychain-keychain1] pre-shared-key address 2.2.3.1 255.255.255.0 key
simple 12345zxcvb!@#$%ZXCVB
[SwitchA-ike-keychain-keychain1] quit# Criar e configurar o perfil IKE chamado profile1.
[SwitchA] ike profile profile1
[SwitchA-ike-profile-profile1] keychain keychain1
[SwitchA-ike-profile-profile1] match remote identity address 2.2.3.1 255.255.255.0
[SwitchA-ike-profile-profile1] quit# Criar uma entrada de política IPsec baseada em IKE. Especifique o nome da política como map1 e defina o parâmetro
número de sequência para 10.
[SwitchA] ipsec policy map1 10 isakmp# Aplique a ACL 3101.
[SwitchA-ipsec-policy-isakmp-map1-10] security acl 3101# Aplicar o conjunto de transformação IPsec tran1.
[SwitchA-ipsec-policy-isakmp-map1-10] transform-set tran1# Especifique os endereços IP locais e remotos do túnel IPsec como 2.2.2.1 e 2.2.3.1.
[SwitchA-ipsec-policy-isakmp-map1-10] local-address 2.2.2.1
[SwitchA-ipsec-policy-isakmp-map1-10] remote-address 2.2.3.1# Aplicar o perfil IKE profile1.
[SwitchA-ipsec-policy-isakmp-map1-10] ike-profile profile1
[SwitchA-ipsec-policy-isakmp-map1-10] quit# Aplique o mapa de política IPsec1 à interface VLAN 1.
[SwitchA] interface vlan-interface 1
[SwitchA-Vlan-interface1] ipsec apply policy map1- Configurar o Switch B:
# Configure um endereço IP para a interface VLAN 1.
<SwitchB> system-view
[SwitchB] interface vlan-interface 1
[SwitchB-Vlan-interface1] ip address 2.2.3.1 255.255.255.0
[SwitchB-Vlan-interface1] quit# Configure uma ACL avançada IPv4 para identificar fluxos de dados do Switch B para o Switch A.
[SwitchB] acl number 3101
[SwitchB-acl-adv-3101] rule 0 permit ip source 2.2.3.1 0 destination 2.2.2.1 0
[SwitchB-acl-adv-3101] quit# Crie um conjunto de transformação IPsec chamado tran1.
[SwitchB] ipsec transform-set tran1# Especifique o modo de encapsulamento como túnel.
[SwitchB-ipsec-transform-set-tran1] encapsulation-mode tunnel# Especifique o protocolo de segurança como ESP.
[SwitchB-ipsec-transform-set-tran1] protocol esp# Especifique os algoritmos de criptografia e autenticação ESP.
[SwitchB-ipsec-transform-set-tran1] esp encryption-algorithm aes-cbc-192
[SwitchB-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchB-ipsec-transform-set-tran1] quit# Crie um keychain IKE chamado keychain1.
[SwitchB] ike keychain keychain1# Especifique 12345zxcvb!@#$%ZXCVB em texto simples como a chave pré-compartilhada a ser usada com o par remoto em 2.2.2.1.
[SwitchB-ike-keychain-keychain1] pre-shared-key address 2.2.2.1 255.255.255.0 key
simple 12345zxcvb!@#$%ZXCVB
[SwitchB-ike-keychain-keychain1] quit# Criar e configurar o perfil IKE chamado profile1.
[SwitchB] ike profile profile1
[SwitchB-ike-profile-profile1] keychain keychain1
[SwitchB-ike-profile-profile1] match remote identity address 2.2.2.1 255.255.255.0
[SwitchB-ike-profile-profile1] quit# Crie uma entrada de política IPsec baseada em IKE. Especifique o nome da política como use1 e defina o parâmetro
número de sequência para 10.
[SwitchB] ipsec policy use1 10 isakmp# Aplique a ACL 3101.
[SwitchB-ipsec-policy-isakmp-use1-10] security acl 3101# Aplicar o conjunto de transformação IPsec tran1.
[SwitchB-ipsec-policy-isakmp-use1-10] transform-set tran1# Especifique os endereços IP locais e remotos do túnel IPsec como 2.2.3.1 e 2.2.2.1.
[SwitchB-ipsec-policy-isakmp-use1-10] local-address 2.2.3.1
[SwitchB-ipsec-policy-isakmp-use1-10] remote-address 2.2.2.1# Aplicar o perfil IKE profile1.
[SwitchB-ipsec-policy-isakmp-use1-10] ike-profile profile1
[SwitchB-ipsec-policy-isakmp-use1-10] quit# Aplique a política IPsec use1 à interface VLAN 1.
[SwitchB] interface vlan-interface 1
[SwitchB-Vlan-interface1] ipsec apply policy use1Verificação da configuração
# Iniciar uma conexão entre o Switch A e o Switch B para acionar a negociação IKE. Depois que as SAs do IPsec são negociadas com sucesso pelo IKE, o tráfego entre os dois switches é protegido pelo IPsec.
Exemplo: Configuração de IPsec para RIPng
Configuração de rede
Conforme mostrado na Figura 9, o Switch A, o Switch B e o Switch C aprendem rotas IPv6 por meio do RIPng.
Estabeleça um túnel IPsec entre os switches para proteger os pacotes RIPng transmitidos entre eles. Especifique o protocolo de segurança como ESP, o algoritmo de criptografia como AES de 128 bits e o algoritmo de autenticação como HMAC-SHA1 para o túnel IPsec.
Figura 9 Diagrama de rede

Análise de requisitos
Para atender aos requisitos de configuração de rede, execute as seguintes tarefas:
- Configurar o RIPng básico.
Para obter mais informações sobre as configurações de RIPng, consulte o Guia de Configuração de Roteamento de Camada 3 IP.
- Configurar um perfil IPsec.
- Os perfis IPsec em todos os switches devem ter conjuntos de transformação IPsec que usem o mesmo protocolo de segurança, algoritmos de autenticação e criptografia e modo de encapsulamento.
- O SPI e a chave configurados para a SA de entrada e para a SA de saída devem ser os mesmos em cada switch.
- O SPI e a chave configurados para as SAs em todos os switches devem ser os mesmos.
- Aplique o perfil IPsec a um processo RIPng ou a uma interface.
- Configure o Switch A:
Procedimento
# Configurar endereços IPv6 para interfaces. (Detalhes não mostrados.)
# Configurar o RIPng básico.
<SwitchA> system-view
[SwitchA] ripng 1
[SwitchA-ripng-1] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] ripng 1 enable
[SwitchA-Vlan-interface100] quit# Crie e configure o conjunto de transformação IPsec chamado tran1.
[SwitchA] ipsec transform-set tran1
[SwitchA-ipsec-transform-set-tran1] encapsulation-mode transport
[SwitchA-ipsec-transform-set-tran1] protocol esp
[SwitchA-ipsec-transform-set-tran1] esp encryption-algorithm aes-cbc-128
[SwitchA-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchA-ipsec-transform-set-tran1] quit# Criar e configurar o perfil IPsec chamado profile001.
[SwitchA] ipsec profile profile001 manual
[SwitchA-ipsec-profile-manual-profile001] transform-set tran1
[SwitchA-ipsec-profile-manual-profile001] sa spi outbound esp 123456
[SwitchA-ipsec-profile-manual-profile001] sa spi inbound esp 123456
[SwitchA-ipsec-profile-manual-profile001] sa string-key outbound esp simple abcdefg
[SwitchA-ipsec-profile-manual-profile001] sa string-key inbound esp simple abcdefg
[SwitchA-ipsec-profile-manual-profile001] quit# Aplique o perfil IPsec ao processo 1 do RIPng.
[SwitchA] ripng 1
[SwitchA-ripng-1] enable ipsec-profile profile001
[SwitchA-ripng-1] quit- Configurar o Switch B:
# Configurar endereços IPv6 para interfaces. (Detalhes não mostrados.)
# Configurar o RIPng básico.
<SwitchB> system-view
[SwitchB] ripng 1
[SwitchB-ripng-1] quit
[SwitchB] interface vlan-interface 200
[SwitchB-Vlan-interface200] ripng 1 enable
[SwitchB-Vlan-interface200] quit
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ripng 1 enable
[SwitchB-Vlan-interface100] quit# Crie e configure o conjunto de transformação IPsec chamado tran1.
[SwitchB] ipsec transform-set tran1
[SwitchB-ipsec-transform-set-tran1] encapsulation-mode transport
[SwitchB-ipsec-transform-set-tran1] protocol esp
[SwitchB-ipsec-transform-set-tran1] esp encryption-algorithm aes-cbc-128
[SwitchB-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchB-ipsec-transform-set-tran1] quit# Criar e configurar o perfil IPsec chamado profile001.
[SwitchB] ipsec profile profile001 manual
[SwitchB-ipsec-profile-manual-profile001] transform-set tran1
[SwitchB-ipsec-profile-manual-profile001] sa spi outbound esp 123456
[SwitchB-ipsec-profile-manual-profile001] sa spi inbound esp 123456
[SwitchB-ipsec-profile-manual-profile001] sa string-key outbound esp simple abcdefg
[SwitchB-ipsec-profile-manual-profile001] sa string-key inbound esp simple abcdefg
[SwitchB-ipsec-profile-manual-profile001] quit# Aplique o perfil IPsec ao processo 1 do RIPng.
[SwitchB] ripng 1
[SwitchB-ripng-1] enable ipsec-profile profile001
[SwitchB-ripng-1] quit- Configurar o switch C:
# Configurar endereços IPv6 para interfaces. (Detalhes não mostrados.)
# Configurar o RIPng básico.
<SwitchC> system-view
[SwitchC] ripng 1
[SwitchC-ripng-1] quit
[SwitchC] interface vlan-interface 200
[SwitchC-Vlan-interface200] ripng 1 enable
[SwitchC-Vlan-interface200] quit# Crie e configure o conjunto de transformação IPsec chamado tran1.
[SwitchC] ipsec transform-set tran1
[SwitchC-ipsec-transform-set-tran1] encapsulation-mode transport
[SwitchC-ipsec-transform-set-tran1] protocol esp
[SwitchC-ipsec-transform-set-tran1] esp encryption-algorithm aes-cbc-128
[SwitchC-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchC-ipsec-transform-set-tran1] quit
# Criar e configurar o perfil IPsec chamado profile001.
[SwitchC] ipsec profile profile001 manual
[SwitchC-ipsec-profile-manual-profile001] transform-set tran1
[SwitchC-ipsec-profile-manual-profile001] sa spi outbound esp 123456
[SwitchC-ipsec-profile-manual-profile001] sa spi inbound esp 123456
[SwitchC-ipsec-profile-manual-profile001] sa string-key outbound esp simple abcdefg
[SwitchC-ipsec-profile-manual-profile001] sa string-key inbound esp simple abcdefg
[SwitchC-ipsec-profile-manual-profile001] quit# Aplique o perfil IPsec ao processo 1 do RIPng.
[SwitchC] ripng 1
[SwitchC-ripng-1] enable ipsec-profile profile001
[SwitchC-ripng-1] quitVerificação da configuração
Após a conclusão da configuração, o Switch A, o Switch B e o Switch C obtêm informações de roteamento IPv6 por meio do RIPng. As SAs IPsec são configuradas com sucesso nos switches para proteger os pacotes RIPng. Este exemplo usa o Switch A para verificar a configuração.
# Exibir a configuração do RIPng. A saída mostra que o perfil IPsec profile001 foi aplicado ao processo 1 do RIPng.
[SwitchA] display ripng 1
RIPng process : 1
Preference : 100
Checkzero : Enabled
Default Cost : 0
Maximum number of load balanced routes : 8
Update time : 30 secs Timeout time : 180 secs
Suppress time : 120 secs Garbage-Collect time : 120 secs
Update output delay: 20(ms) Output count: 3
Graceful-restart interval: 60 secs
Triggered Interval : 5 50 200
Number of periodic updates sent : 186
Number of triggered updates sent : 1
IPsec profile name: profile001# Exibir as SAs IPsec estabelecidas.
[SwitchA] display ipsec sa
-------------------------------
Global IPsec SA
-------------------------------
-----------------------------
IPsec profile: profile001
Mode: Manual
-----------------------------
Encapsulation mode: transport
[Inbound ESP SA]
SPI: 123456 (0x3039)
Connection ID: 90194313219
Transform set: ESP-ENCRYPT-AES-CBC-128 ESP-AUTH-SHA1
No duration limit for this SA
[Outbound ESP SA]
SPI: 123456 (0x3039)
Connection ID: 64424509441
Transform set: ESP-ENCRYPT-AES-CBC-128ESP-AUTH-SHA1
No duration limit for this SAExemplo: Configuração do IPsec RRI
Configuração de rede
Conforme mostrado na Figura 10, as filiais acessam o centro corporativo por meio de uma VPN IPsec. Configure a VPN IPsec da seguinte forma:
- Configure um túnel IPsec entre o Switch A e cada gateway de filial (Switch B, Switch C e Switch D) para proteger o tráfego entre as sub-redes 4.4.4.0/24 e 5.5.5.0/24.
- Configure os túneis para usar o protocolo de segurança ESP, o algoritmo de criptografia DES e o algoritmo de autenticação SHA1-HMAC-96. Use IKE para negociação de SA IPsec.
- Configure a proposta IKE para usar o método de autenticação de chave pré-compartilhada, o algoritmo de criptografia 3DES e o algoritmo de autenticação HMAC-SHA1.
- Configure o IPsec RRI no Switch A para criar automaticamente rotas estáticas para as filiais com base nas SAs IPsec estabelecidas.
- Atribua endereços IPv4 às interfaces nos switches de acordo com a Figura 10. (Os detalhes não são mostrados).
- Configure o Switch A:
Figura 10 Diagrama de rede
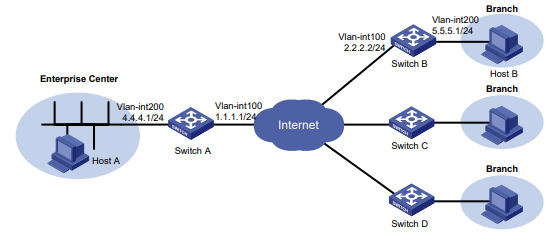
Procedimento
# Crie um conjunto de transformação IPsec chamado tran1 e especifique ESP como o protocolo de segurança, DES
como o algoritmo de criptografia e HMAC-SHA-1-96 como o algoritmo de autenticação.
<SwitchA> system-view
[SwitchA] ipsec transform-set tran1
[SwitchA-ipsec-transform-set-tran1] encapsulation-mode tunnel
[SwitchA-ipsec-transform-set-tran1] protocol esp
[SwitchA-ipsec-transform-set-tran1] esp encryption-algorithm des
[SwitchA-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchA-ipsec-transform-set-tran1] quit# Criar e configurar o perfil IKE chamado profile1.
[SwitchA] ike profile profile1
[SwitchA-ike-profile-profile1] keychain key1
[SwitchA-ike-profile-profile1] match remote identity address 2.2.2.2 255.255.255.0
[SwitchA-ike-profile-profile1] quit# Crie um modelo de política IPsec chamado temp1. Especifique o conjunto de transformação IPsec tran1 e o perfil IKE profile1 para o modelo de política IPsec.
[SwitchA] ipsec policy-template temp1 1
[SwitchA-ipsec-policy-template-temp1-1] transform-set tran1
[SwitchA-ipsec-policy-template-temp1-1] ike-profile profile1# Habilite o IPsec RRI, defina a preferência como 100 e a tag como 1000 para as rotas estáticas criadas pelo IPsec RRI.
[SwitchA-ipsec-policy-template-temp1-1] reverse-route dynamic
[SwitchA-ipsec-policy-template-temp1-1] reverse-route preference 100
[SwitchA-ipsec-policy-template-temp1-1] reverse-route tag 1000
[SwitchA-ipsec-policy-template-temp1-1] quit# Crie uma entrada de política IPsec baseada em IKE usando o modelo de política IPsec temp1. Especifique o nome da política como map1 e defina o número de sequência como 10.
[SwitchA] ipsec policy map1 10 isakmp template temp1# Crie uma proposta IKE chamada 1 e especifique 3DES como o algoritmo de criptografia,
HMAC-SHA1 como algoritmo de autenticação e pré-compartilhamento como método de autenticação.
[SwitchA] ike proposal 1
[SwitchA-ike-proposal-1] encryption-algorithm 3des-cbc
[SwitchA-ike-proposal-1] authentication-algorithm sha
[SwitchA-ike-proposal-1] authentication-method pre-share
[SwitchA-ike-proposal-1] quit# Crie um chaveiro IKE chamado key1 e especifique 123 em texto simples como a chave pré-compartilhada a ser usada com o par remoto em 2.2.2.2.
[SwitchA] ike keychain key1
[SwitchA-ike-keychain-key1] pre-shared-key address 2.2.2.2 key simple 123
[SwitchA-ike-keychain-key1] quit# Aplique o mapa de política IPsec1 à interface VLAN 100.
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] ipsec apply policy map1
[SwitchA-Vlan-interface100] quit- Configurar o Switch B:
# Crie um conjunto de transformação IPsec chamado tran1 e especifique ESP como o protocolo de segurança, DES
como o algoritmo de criptografia e HMAC-SHA-1-96 como o algoritmo de autenticação.
[SwitchB] ipsec transform-set tran1
[SwitchB-ipsec-transform-set-tran1] encapsulation-mode tunnel
[SwitchB-ipsec-transform-set-tran1] protocol esp
[SwitchB-ipsec-transform-set-tran1] esp encryption-algorithm des
[SwitchB-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchB-ipsec-transform-set-tran1] quit# Configure a ACL 3000 avançada IPv4 para identificar o tráfego da sub-rede 5.5.5.0/24 para a sub-rede 4.4.4.0/24.
<[SwitchB] acl advanced 3000
[SwitchB-acl-ipv4-adv-3000] rule permit ip source 5.5.5.0 0.0.0.255 destination
4.4.4.0 0.0.0.255
[SwitchB-acl-ipv4-adv-3000] quit# Criar e configurar o perfil IKE chamado profile1.
[SwitchB] ike profile profile1
[SwitchB-ike-profile-profile1] keychain key1
[SwitchB-ike-profile-profile1] match remote identity address 1.1.1.1 255.255.255.0
[SwitchB-ike-profile-profile1] quit# Crie uma entrada de política IPsec baseada em IKE chamada map1 e defina as seguintes configurações para a entrada de política:
- Defina o número de sequência como 10.
- Especifique o conjunto de transformação tran1 e a ACL 3000.
- Especifique o endereço IP remoto do túnel como 1.1.1.1.
- Especifique o perfil IKE profile1.
[SwitchB] ipsec policy map1 10 isakmp
[SwitchB-ipsec-policy-isakmp-map1-10] transform-set tran1
[SwitchB-ipsec-policy-isakmp-map1-10] security acl 3000
[SwitchB-ipsec-policy-isakmp-map1-10] remote-address 1.1.1.1
[SwitchB-ipsec-policy-isakmp-map1-10] ike-profile profile1
[SwitchB-ipsec-policy-isakmp-map1-10] quit# Crie uma proposta IKE chamada 1 e especifique 3DES como o algoritmo de criptografia,
HMAC-SHA1 como algoritmo de autenticação e pré-compartilhamento como método de autenticação.
[SwitchB] ike proposal 1
[SwitchB-ike-proposal-1] encryption-algorithm 3des-cbc
[SwitchB-ike-proposal-1] authentication-algorithm sha
[SwitchB-ike-proposal-1] authentication-method pre-share
[SwitchB-ike-proposal-1] quit# Crie um chaveiro IKE chamado key1 e especifique 123 em texto simples como a chave pré-compartilhada a ser usada com o par remoto em 1.1.1.1.
[SwitchB] ike keychain key1
[SwitchB-ike-keychain-key1] pre-shared-key address 1.1.1.1 key simple 123
[SwitchB-ike-keychain-key1] quit# Aplique o mapa de política IPsec1 à interface VLAN 100.
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ipsec apply policy map1
[SwitchB-Vlan-interface100] quitCertifique-se de que o Switch B tenha uma rota para a rede privada do par, com a interface de saída como VLAN-interface 100.
- Configure o Switch C e o Switch D da mesma forma que o Switch B está configurado.
Verificação da configuração
- Verifique se o IPsec RRI pode criar automaticamente uma rota estática do Switch A para o Switch B:
# Iniciar uma conexão da sub-rede 5.5.5.0/24 com a sub-rede 4.4.4.0/24. A negociação IKE é acionada para estabelecer SAs IPsec entre o Switch A e o Switch B. (Detalhes não mostrados).
# Verifique se as SAs IPsec estão estabelecidas no Switch A.
[SwitchA] display ipsec sa
-------------------------------
Interface: Vlan-interface100
-------------------------------
-----------------------------
IPsec policy: map1
Sequence number: 10
Mode: Template
-----------------------------
Tunnel id: 0
Encapsulation mode: tunnel
Perfect Forward Secrecy:
Inside VPN:
Extended Sequence Numbers enable: N
Traffic Flow Confidentiality enable: N
Path MTU: 1463
Tunnel:
local address: 1.1.1.1
remote address: 2.2.2.2
Flow:
sour addr: 4.4.4.0/255.255.255.0 port: 0 protocol: ip
dest addr: 5.5.5.0/255.255.255.0 port: 0 protocol: ip
[Inbound ESP SAs]
SPI: 1014286405 (0x3c74c845)
Connection ID: 90194313219
Transform set: ESP-ENCRYPT-DES-CBC ESP-AUTH-SHA1
SA duration (kilobytes/sec): 1843200/3600
SA remaining duration (kilobytes/sec): 1843199/3590
Max received sequence-number: 4
Anti-replay check enable: Y
Anti-replay window size: 64
UDP encapsulation used for NAT traversal: N
Status: Active
[Outbound ESP SAs]
SPI: 4011716027 (0xef1dedbb)
Connection ID: 64424509441
Transform set: ESP-ENCRYPT-DES-CBC ESP-AUTH-SHA1
SA duration (kilobytes/sec): 1843200/3600
SA remaining duration (kilobytes/sec): 1843199/3590
Max sent sequence-number: 4
UDP encapsulation used for NAT traversal: N
Status: Active# Verifique se o IPsec RRI criou uma rota estática para chegar ao Switch B.
[SwitchA] display ip routing-table verbose- Verifique se o Switch A pode criar automaticamente rotas estáticas para o Switch C e o Switch D da mesma forma que você verifica o recurso IPsec RRI usando o Switch A e o Switch B. (Detalhes não mostrados).
Configuração do IKE
Sobre a IKE
Criado com base em uma estrutura definida pelo ISAKMP, o Internet Key Exchange (IKE) fornece negociação automática de chaves e serviços de estabelecimento de SA para o IPsec.
Benefícios do IKE
O IKE oferece os seguintes benefícios para o IPsec:
- Negocia automaticamente os parâmetros do IPsec.
- Realiza trocas de DH para calcular chaves compartilhadas, garantindo que cada SA tenha uma chave independente de outras chaves.
- Negocia automaticamente as SAs quando o número de sequência no cabeçalho AH ou ESP transborda, garantindo que o IPsec possa fornecer o serviço anti-repetição usando o número de sequência.
Relação entre IPsec e IKE
Conforme mostrado na Figura 11, o IKE negocia SAs para o IPsec e transfere as SAs para o IPsec, e o IPsec usa as SAs para proteger os pacotes IP.
Figura 11 Relação entre IKE e IPsec
Processo de negociação IKE
O IKE negocia chaves e SAs para IPsec em duas fases:
- Fase 1 - Os dois pares estabelecem uma SA IKE, um canal seguro e autenticado para comunicação.
- Fase 2 - Usando a SA IKE estabelecida na fase 1, os dois pares negociam para estabelecer SAs IPsec.
A negociação da fase 1 pode usar o modo principal ou o modo agressivo.
Processo de troca IKE no modo principal
Conforme mostrado na Figura 12, o modo principal de negociação do IKE na fase 1 envolve três pares de mensagens:
- Troca de SA - Usada para negociar a política de segurança do IKE.
- Troca de chaves - Usada para trocar o valor público do DH e outros valores, como o número aleatório. Os dois pares usam os dados trocados para gerar dados-chave e usam a chave de criptografia e a chave de autenticação para garantir a segurança dos pacotes IP.
- Intercâmbio de dados de ID e autenticação - Usado para autenticação de identidade.
Figura 12 Processo de troca IKE no modo principal
Processo de troca IKE em modo agressivo
Conforme mostrado na Figura 13, o processo de negociação da fase 1 do IKE no modo agressivo é o seguinte:
- O iniciador (par 1) envia uma mensagem contendo as informações locais do IKE para o par 2. A mensagem inclui parâmetros usados para o estabelecimento de SA IKE, dados de chaveamento e informações de identidade do par 1.
- O par 2 escolhe os parâmetros de estabelecimento do IKE a serem usados, gera a chave e autentica a identidade do par 1. Em seguida, ele envia os dados do IKE para o par 1.
- O par 1 gera a chave, autentica a identidade do par 2 e envia os resultados para o par 1. Após o processo anterior, uma IKE SA é estabelecida entre o par 1 e o par 2.
O modo agressivo é mais rápido que o modo principal, mas não oferece proteção de informações de identidade. O modo principal oferece proteção de informações de identidade, mas é mais lento. Escolha o modo de negociação apropriado de acordo com seus requisitos.
Figura 13 Processo de troca IKE em modo agressivo
Mecanismo de segurança IKE
O IKE tem uma série de mecanismos de autoproteção e oferece suporte à autenticação segura de identidade, à distribuição de chaves e ao estabelecimento de SAs IPsec em redes inseguras.
Autenticação de identidade
O mecanismo de autenticação de identidade IKE é usado para autenticar a identidade dos pares em comunicação. O dispositivo é compatível com os seguintes métodos de autenticação de identidade:
- Autenticação de chave pré-compartilhada - Dois pares em comunicação usam a chave compartilhada pré-configurada para autenticação de identidade.
- Autenticação de assinatura RSA e autenticação de assinatura DSA - Dois pares em comunicação usam os certificados digitais emitidos pela CA para autenticação de identidade.
O método de autenticação de chave pré-compartilhada não requer certificados e é fácil de configurar. Geralmente, ele é implantado em redes pequenas.
Os métodos de autenticação de assinatura oferecem maior segurança e geralmente são implementados em redes com a sede e algumas filiais. Quando implantado em uma rede com muitas filiais, um método de autenticação de assinatura pode simplificar a configuração, pois é necessário apenas um domínio de PKI. Se você usar o método de autenticação de chave pré-compartilhada, deverá configurar uma chave pré-compartilhada para cada filial no nó da sede.
Algoritmo DH
O algoritmo DH é um algoritmo de chave pública. Com esse algoritmo, dois pares podem trocar material de chaveamento e, em seguida, usar o material para calcular as chaves compartilhadas. Devido à complexidade da descriptografia, um terceiro não pode descriptografar as chaves mesmo depois de interceptar todos os materiais de chaveamento.
PFS
O recurso Perfect Forward Secrecy (PFS) é um recurso de segurança baseado no algoritmo DH. Depois que o PFS é ativado, uma troca adicional de DH é realizada na fase 2 do IKE para garantir que as chaves IPsec não tenham relações derivadas com as chaves IKE e que uma chave quebrada não traga ameaças a outras chaves.
Protocolos e padrões
- RFC 2408, Associação de Segurança da Internet e Protocolo de Gerenciamento de Chaves (ISAKMP)
- RFC 2409, Troca de chaves da Internet (IKE)
- RFC 2412, O protocolo de determinação de chaves OAKLEY
- Rascunho da Internet, draft-ietf-ipsec-isakmp-xauth-06
- Rascunho da Internet, draft-dukes-ike-mode-cfg-02
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS (consulte "Configuração de FIPS") e no modo não-FIPS.
Visão geral das tarefas IKE
Para configurar o IKE, execute as seguintes tarefas:
- (Opcional.) Configuração de um perfil IKE
- Criação de um perfil IKE
- Configuração de IDs de pares para o perfil IKE
- Especificação do conjunto de chaves IKE ou do domínio PKI
- Configuração do modo de negociação da fase 1 do IKE
- Especificação de propostas IKE para o perfil IKE
- Configuração da ID local para o perfil IKE
- Configuração de recursos opcionais para o perfil IKE
- Configuração de uma proposta IKE
- Configuração de um chaveiro IKE
- (Opcional.)Configuração das informações de identidade global
- (Opcional.)Configuração do recurso IKE keepalive
- (Opcional.)Configuração do recurso IKE NAT keepalive
- (Opcional.)Configuração do IKE DPD global
- (Opcional.)Ativação da recuperação de SPI inválido
- (Opcional.)Configuração do número máximo de SAs IKE
- (Opcional.)Configuração de notificações SNMP para IKE
Pré-requisitos para a configuração do IKE
Determine os seguintes parâmetros antes da configuração do IKE:
- Os algoritmos a serem usados durante a negociação IKE, incluindo o método de autenticação de identidade, o algoritmo de criptografia, o algoritmo de autenticação e o grupo DH.
- Algoritmos diferentes oferecem níveis diferentes de proteção. Um algoritmo mais forte oferece mais resistência à descriptografia, mas usa mais recursos.
- Um grupo DH que usa mais bits oferece maior segurança, mas precisa de mais tempo para o processamento.
- A chave pré-compartilhada ou o domínio de PKI para negociação IKE. Para obter mais informações sobre PKI, consulte "Configuração de PKI".
- As políticas de IPsec baseadas em IKE para os pares em comunicação. Se você não especificar um perfil IKE em uma política IPsec, o dispositivo selecionará um perfil IKE para a política IPsec. Se nenhum perfil IKE estiver configurado, serão usadas as configurações IKE definidas globalmente. Para obter mais informações sobre o IPsec, consulte "Configuração do IPsec".
Configuração de um perfil IKE
Criação de um perfil IKE
Sobre o perfil IKE
Execute esta tarefa para criar um perfil IKE.
O objetivo de um perfil IKE é fornecer um conjunto de parâmetros para a negociação IKE.
Procedimento
- Entre na visualização do sistema.
system view- Crie um perfil IKE e entre em sua visualização.
ike profile profile-nameConfiguração de IDs de pares para o perfil IKE
Sobre a configuração do ID de par
Execute esta tarefa para configurar os IDs de pares para correspondência de perfis IKE. Quando o dispositivo precisa selecionar um perfil IKE para a negociação IKE com um par, ele compara o ID de par recebido com os IDs de par de seus perfis IKE locais. Se for encontrada uma correspondência, ele usará o perfil IKE com a ID de par correspondente para a negociação IKE.
Restrições e diretrizes
Para um perfil IKE, você pode configurar várias IDs de pares. Uma ID de par configurada anteriormente tem uma prioridade mais alta.
Dois pares IKE devem ter ou não IDs de pares configurados.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização do perfil IKE.
ike profile profile-name- Configure uma ID de par para o perfil IKE.
match remote { certificate policy-name | identity { address
{ { ipv4-address [ mask | mask-length ] | range low-ipv4-address
high-ipv4-address } | ipv6 { ipv6-address [ prefix-length ] | range
low-ipv6-address high-ipv6-address } } | fqdn fqdn-name | user-fqdn
user-fqdn-name } }Especificação do conjunto de chaves IKE ou do domínio PKI
Restrições e diretrizes
Configure o chaveiro IKE ou o domínio PKI para as propostas IKE a serem usadas. Para usar a autenticação de assinatura digital, configure um domínio de PKI. Para usar a autenticação de chave pré-compartilhada, configure um chaveiro IKE .
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização do perfil IKE.
ike profile profile-name- Especifique o keychain para autenticação de chave pré-compartilhada ou o domínio PKI usado para solicitar um certificado para autenticação de assinatura digital.
- Especifique o chaveiro.
keychain keychain-name- Especifique o domínio PKI.
certificate domain domain-namePor padrão, nenhum conjunto de chaves IKE ou domínio PKI é especificado em um perfil IKE.
Configuração do modo de negociação da fase 1 do IKE
Restrições e diretrizes
Especifique o modo de negociação da fase 1 do IKE (principal ou agressivo) que o dispositivo usa como iniciador. Quando o dispositivo atua como respondedor, ele usa o modo de negociação IKE do iniciador.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização do perfil IKE.
ike profile profile-name- Especifique o modo de negociação IKE para a fase 1. No modo não-FIPS:
exchange-mode { aggressive | main }No modo FIPS:
exchange-mode mainPor padrão, a negociação IKE na fase 1 usa o modo principal.
Especificação de propostas IKE para o perfil IKE
Restrições e diretrizes
Especifique as propostas de IKE que o dispositivo pode usar como iniciador. Uma proposta IKE especificada anteriormente tem uma prioridade mais alta. Quando o dispositivo atua como respondedor, ele usa as propostas IKE configuradas na visualização do sistema para corresponder às propostas IKE recebidas do iniciador. Se nenhuma proposta correspondente for encontrada, a negociação falhará.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização do perfil IKE.
ike profile profile-name- Especificar propostas IKE para o perfil IKE.
proposal proposal-number&<1-6>Por padrão, nenhuma proposta IKE é especificada para um perfil IKE e as propostas IKE configuradas na visualização do sistema são usadas para a negociação IKE.
Configuração da ID local para o perfil IKE
Restrições e diretrizes
Para autenticação de assinatura digital, o dispositivo pode usar um ID de qualquer tipo. Se a ID local for um endereço IP diferente do endereço IP no certificado local, o dispositivo usará o FQDN (o nome do dispositivo configurado com o comando sysname).
Para autenticação de chave pré-compartilhada, o dispositivo pode usar uma ID de qualquer tipo que não seja o DN.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização do perfil IKE.
ike profile profile-name- Configure a ID local.
local-identity { address { ipv4-address | ipv6 ipv6-address } | dn |
fqdn [ fqdn-name ] | user-fqdn [ user-fqdn-name ] }Por padrão, nenhuma ID local é configurada para um perfil IKE, e um perfil IKE usa a ID local configurada na visualização do sistema. Se a ID local não estiver configurada na visualização do sistema, o perfil IKE usará o endereço IP da interface à qual a política IPsec ou o modelo de política IPsec é aplicado como ID local.
Configuração de recursos opcionais para o perfil IKE
- Entre na visualização do sistema.
system view- Entre na visualização do perfil IKE.
ike profile profile-name- Configure os recursos opcionais conforme necessário.
- Configurar o IKE DPD.
dpd interval interval [ retry seconds ] { on-demand | periodic }Por padrão, o IKE DPD não está configurado para um perfil IKE e um perfil IKE usa as configurações de DPD definidas na visualização do sistema. Se o IKE DPD também não estiver configurado na visualização do sistema, o dispositivo não realizará a detecção de pares IKE mortos.
As configurações do IKE DPD definidas na visualização do perfil IKE têm precedência sobre as definidas na visualização do sistema.
- Especifique a interface local ou o endereço IP ao qual o perfil IKE pode ser aplicado.
match local address { interface-type interface-number |
{ ipv4-address | ipv6 ipv6-address } }Por padrão, um perfil IKE pode ser aplicado a qualquer interface local ou endereço IP.
Um perfil IKE configurado com esse comando tem prioridade mais alta do que aqueles não configurados com esse comando.
- Especifique uma prioridade para o perfil IKE.
priority priorityPor padrão, a prioridade de um perfil IKE é 100.
O dispositivo seleciona um perfil IKE local para negociação IKE da seguinte forma:
- Primeiro, ele seleciona um perfil IKE com o comando match local address configurado.
- Se houver empate, ele seleciona o perfil IKE com um número de prioridade menor.
- Se ainda houver empate, ele seleciona o perfil IKE configurado anteriormente.
Configuração de uma proposta IKE
Sobre a proposta IKE
Uma proposta IKE define um conjunto de atributos que descrevem como deve ocorrer a negociação IKE na fase 1. Você pode criar várias propostas IKE com prioridades diferentes. A prioridade de uma proposta IKE é representada por seu número de sequência. Quanto menor o número de sequência, maior a prioridade.
Dois pares devem ter pelo menos uma proposta IKE correspondente para que a negociação IKE seja bem-sucedida. Durante a negociação IKE:
- O iniciador envia suas propostas IKE para o par.
- Se o iniciador estiver usando uma política IPsec com um perfil IKE, o iniciador enviará todas as propostas IKE especificadas no perfil IKE para o par. Uma proposta IKE especificada anteriormente para o perfil IKE tem uma prioridade mais alta.
- Se o iniciador estiver usando uma política IPsec sem perfil IKE, o iniciador enviará todas as suas propostas IKE para o par. Uma proposta IKE com um número menor tem uma prioridade mais alta.
- O par pesquisa suas próprias propostas IKE em busca de uma correspondência. A pesquisa começa na proposta IKE com a prioridade mais alta e prossegue em ordem decrescente de prioridade até que uma correspondência seja encontrada. As propostas IKE correspondentes são usadas para estabelecer a SA IKE. Se todas as propostas IKE definidas pelo usuário não corresponderem, os dois pares usarão suas propostas IKE padrão para estabelecer a SA IKE.
- Entre na visualização do sistema.
Duas propostas IKE correspondentes têm o mesmo algoritmo de criptografia, método de autenticação, algoritmo de autenticação e grupo DH. O tempo de vida da SA assume a menor das configurações de tempo de vida da SA das duas propostas.
Procedimento
system view- Crie uma proposta IKE e insira sua visualização.
ike proposal proposal-numberPor padrão, existe uma proposta IKE padrão.
- Configure uma descrição para a proposta IKE.
descriptionPor padrão, uma proposta IKE não tem uma descrição.
- Especifique um algoritmo de criptografia para a proposta IKE.
No modo não-FIPS:
encryption-algorithm { 3des-cbc | aes-cbc-128 | aes-cbc-192 |
aes-cbc-256 | des-cbc }Por padrão, é usado o algoritmo de criptografia DES de 56 bits no modo CBC.
No modo FIPS:
encryption-algorithm { aes-cbc-128 | aes-cbc-192 | aes-cbc-256 }Por padrão, é usado o algoritmo de criptografia AES de 128 bits no modo CBC.
- Especifique um método de autenticação para a proposta IKE.
authentication-method{ dsa-signature | ecdsa-signature | pre-share |
rsa-signature }Por padrão, é usado o método de autenticação de chave pré-compartilhada.
- Especifique um algoritmo de autenticação para a proposta IKE.
No modo não-FIPS:
authentication-algorithm { md5 | sha | sha256 | sha384 | sha512 }Por padrão, é usado o algoritmo de autenticação HMAC-SHA1.
No modo FIPS:
authentication-algorithm { sha | sha256 | sha384 | sha512 }Por padrão, é usado o algoritmo de autenticação HMAC-SHA256.
- Especifique um grupo DH para negociação de chaves na fase 1.
No modo não-FIPS:
dh{ group1 | group14 | group19 | group2 | group20 | group24 | group5 }O grupo DH 1 (o grupo DH de 768 bits) é usado por padrão.
No modo FIPS:
dh{ group14 | group19 | group20 | group24 }O grupo DH 14 (o grupo DH de 2048 bits) é usado por padrão.
- (Opcional.) Defina o tempo de vida da SA IKE para a proposta IKE.
sa duration secondsPor padrão, o tempo de vida da IKE SA é de 86400 segundos.
Configuração de um chaveiro IKE
Sobre o chaveiro IKE
Execute essa tarefa quando você configurar o IKE para usar a chave pré-compartilhada para autenticação. Siga estas diretrizes ao configurar um conjunto de chaves IKE:
- Dois pares devem ser configurados com a mesma chave pré-compartilhada para passar a chave pré-compartilhada
autenticação.
- Você pode especificar o endereço local configurado na visualização da política IPsec ou do modelo de política IPsec (usando o comando local-address) para que o chaveiro IKE seja aplicado. Se nenhum endereço local estiver configurado, especifique o endereço IP da interface que usa a política IPsec.
- O dispositivo determina a prioridade de um chaveiro IKE da seguinte forma:
- O dispositivo examina a existência do comando match local address. Um chaveiro IKE com o comando match local address configurado tem uma prioridade mais alta.
- Se houver empate, o dispositivo compara os números de prioridade. Um chaveiro IKE com um número de prioridade menor tem uma prioridade mais alta.
- Se ainda houver empate, o dispositivo preferirá um chaveiro IKE configurado anteriormente.
Procedimento
- Entre na visualização do sistema.
system view- Crie um chaveiro IKE e entre em sua visualização.
chaveiro ike nome do chaveiro
- Configure uma chave pré-compartilhada. No modo não-FIPS:
pre-shared-key { address { ipv4-address [ mask | mask-length ] | ipv6
ipv6-address [ prefix-length ] } | hostname host-name } key { cipher |
simple } stringNo modo FIPS:
pre-shared-key { address { ipv4-address [ mask | mask-length ] | ipv6
ipv6-address [ prefix-length ] } | hostname host-name } key [ cipher
string ]Por padrão, nenhuma chave pré-compartilhada é configurada.
- (Opcional.) Especifique uma interface local ou um endereço IP ao qual o chaveiro IKE pode ser aplicado.
match local address { interface-type interface-number | { ipv4-address
| ipv6 ipv6-address } }Por padrão, um chaveiro IKE pode ser aplicado a qualquer interface local ou endereço IP.
- (Opcional.) Especifique uma prioridade para o chaveiro IKE.
priority priorityA prioridade padrão é 100.
Configuração das informações de identidade global
Restrições e diretrizes
A identidade global pode ser usada pelo dispositivo para todas as negociações de SA IKE, e a identidade local (definida pelo comando local-identity) pode ser usada somente pelo dispositivo que usa o perfil IKE.
Quando a autenticação por assinatura é usada, você pode definir qualquer tipo de informação de identidade. Quando a autenticação de chave pré-compartilhada é usada, você não pode definir o DN como a identidade.
Procedimento
- Entre na visualização do sistema.
system view- Configure a identidade global a ser usada pela extremidade local.
ike identity { address { ipv4-address | ipv6 ipv6-address }| dn | fqdn
[ fqdn-name ] | user-fqdn [ user-fqdn-name ] }Por padrão, o endereço IP da interface à qual a política IPsec ou o modelo de política IPsec é aplicado é usado como a identidade IKE.
- (Opcional.) Configure o dispositivo local para sempre obter as informações de identidade do certificado local para autenticação de assinatura.
ike signature-identity from-certificatePor padrão, a extremidade local usa as informações de identidade especificadas por local-identity ou ike identity para autenticação de assinatura.
Configure esse comando quando o modo agressivo e a autenticação por assinatura forem usados e o dispositivo se interconectar com um dispositivo par baseado no Comware 5. O Comware 5 suporta apenas DN para autenticação de assinatura.
Configuração do recurso IKE keepalive
Sobre o recurso IKE keepalive
O IKE envia pacotes keepalive para consultar a vivacidade do par. Se o par estiver configurado com o tempo limite de comunicação contínua, você deverá configurar o intervalo de comunicação contínua no dispositivo local. Se o par não receber nenhum pacote keepalive durante o tempo limite, a SA do IKE será excluída junto com as SAs do IPsec negociadas.
Restrições e diretrizes
Configure o IKE DPD em vez do IKE keepalive, a menos que o IKE DPD não seja compatível com o par. O recurso IKE keepalive envia keepalives em intervalos regulares, o que consome largura de banda e recursos da rede.
O tempo limite do keepalive configurado no dispositivo local deve ser maior do que o intervalo do keepalive configurado no par. Como raramente ocorre a perda de mais de três pacotes consecutivos em uma rede , você pode definir o tempo limite de keepalive três vezes mais longo que o intervalo de keepalive.
Procedimento
- Entre na visualização do sistema.
system view- Defina o intervalo de manutenção da IKE SA.
ike keepalive interval intervalPor padrão, nenhum keepalives é enviado ao par.
- Defina o tempo limite do IKE SA keepalive.
ike keepalive timeout secondsPor padrão, o IKE SA keepalive nunca atinge o tempo limite.
Configuração do recurso IKE NAT keepalive
Sobre o recurso IKE NAT keepalive
Se o tráfego IPsec passar por um dispositivo NAT, você deverá configurar o recurso de passagem de NAT. Se nenhum pacote atravessar um túnel IPsec em um período de tempo, as sessões NAT serão envelhecidas e excluídas, impedindo que o túnel transmita dados para a extremidade pretendida. Para evitar que as sessões NAT sejam envelhecidas, configure o recurso NAT keepalive no gateway IKE atrás do dispositivo NAT para enviar pacotes NAT keepalive ao seu par periodicamente para manter a sessão NAT ativa.
Procedimento
- Entre na visualização do sistema.
system view- Defina o intervalo IKE NAT keepalive.
ike nat-keepalive secondsO intervalo padrão é de 20 segundos.
Configuração do IKE DPD global
Sobre o IKE DPD
O DPD detecta pares mortos. Ele pode operar no modo periódico ou no modo sob demanda.
- DPD periódico - Envia uma mensagem DPD em intervalos regulares. Ele permite a detecção antecipada de pares mortos, mas consome mais largura de banda e CPU.
- DPD sob demanda - Envia uma mensagem DPD com base no tráfego. Quando o dispositivo tem tráfego para enviar e não está ciente da vivacidade do par, ele envia uma mensagem DPD para consultar o status do par. Se o dispositivo não tiver tráfego para enviar, ele nunca enviará mensagens DPD. Como prática recomendada, use o modo on-demand.
O IKE DPD funciona da seguinte forma:
- O dispositivo local envia uma mensagem DPD para o par e aguarda uma resposta do par.
- Se o par não responder dentro do intervalo de repetição especificado pelo parâmetro retry seconds, o dispositivo local reenviará a mensagem.
- Se nenhuma resposta for recebida dentro do intervalo de nova tentativa, a extremidade local enviará a mensagem DPD novamente. O sistema permite um máximo de duas tentativas.
- Se o dispositivo local não receber resposta após duas tentativas, o dispositivo considerará o par como morto e excluirá a SA IKE juntamente com as SAs IPsec negociadas.
- Se o dispositivo local receber uma resposta do par durante o processo de detecção, o par será considerado vivo. O dispositivo local executa uma detecção DPD novamente quando o intervalo de acionamento é atingido ou quando tem tráfego para enviar, dependendo do modo DPD.
Restrições e diretrizes
Quando as configurações de DPD são definidas na visualização de perfil IKE e na visualização do sistema, aplicam-se as configurações de DPD na visualização de perfil IKE. Se o DPD não estiver configurado na visualização de perfil IKE, serão aplicadas as configurações de DPD na visualização do sistema.
É uma boa prática definir o intervalo de acionamento maior que o intervalo de repetição para que uma detecção de DPD não seja acionada durante uma nova tentativa de DPD.
Procedimento
- Entre na visualização do sistema.
system view- Ativar o envio de mensagens IKE DPD.
ike dpd interval interval [ retry seconds ] { on-demand | periodic }Por padrão, o IKE DPD está desativado.
Ativação da recuperação de SPI inválido
Sobre a recuperação de SPI inválido
Um "buraco negro" do IPsec ocorre quando um par do IPsec falha (por exemplo, um par pode falhar se ocorrer uma reinicialização). Um par falha e perde suas SAs com o outro par. Quando um par IPsec recebe um pacote de dados para o qual não consegue encontrar uma SA, é encontrado um SPI inválido. O par descarta o pacote de dados e tenta enviar uma notificação de SPI inválido para o originador dos dados. Essa notificação é enviada usando a SA IKE. Como nenhuma IKE SA está disponível, a notificação não é enviada. O par de origem continua enviando os dados usando a IPsec SA que tem o SPI inválido, e o par receptor continua descartando o tráfego.
O recurso de recuperação de SPI inválido permite que o par receptor configure uma IKE SA com o originador para que uma notificação de SPI inválido possa ser enviada. Ao receber a notificação, o par de origem exclui a SA IPsec que tem o SPI inválido. Se o originador tiver dados para enviar, novas SAs serão configuradas.
Restrições e diretrizes
Tenha cuidado ao ativar o recurso de recuperação de SPI inválido, pois o uso desse recurso pode resultar em um ataque de DoS. Os invasores podem fazer um grande número de notificações de SPI inválido para o mesmo par.
Procedimento
- Entre na visualização do sistema.
system view- Habilita a recuperação de SPI inválido.
ike invalid-spi-recovery enablePor padrão, a recuperação de SPI inválido está desativada.
Configuração do número máximo de SAs IKE
Sobre a configuração do número máximo de SAs IKE
Você pode definir o número máximo de SAs IKE semiabertas e o número máximo de SAs IKE estabelecidas.
- O número máximo suportado de SAs IKE semiabertas depende da capacidade de processamento do dispositivo. Ajuste o número máximo de SAs IKE entreabertas para utilizar totalmente a capacidade de processamento do dispositivo sem afetar a eficiência da negociação da SA IKE.
- O número máximo suportado de SAs IKE estabelecidas depende do espaço de memória do dispositivo. Ajuste o número máximo de SAs IKE estabelecidas para fazer uso total do espaço de memória do dispositivo sem afetar outros aplicativos do sistema.
Procedimento
- Entre na visualização do sistema.
system view- Defina o número máximo de SAs IKE semiabertas e o número máximo de SAs IKE estabelecidas.
ike limit { max-negotiating-sa negotiation-limit | max-sa sa-limit }Por padrão, não há limite para o número máximo de IKE SAs.
Configuração de notificações SNMP para IKE
Sobre a configuração de notificação SNMP para IKE
Depois que você ativar as notificações SNMP para o IKE, o módulo IKE notificará o NMS sobre eventos importantes do módulo. As notificações são enviadas ao módulo SNMP do dispositivo. Para que as notificações sejam enviadas corretamente, você também deve configurar o SNMP no dispositivo. Para obter mais informações sobre as notificações de SNMP, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Para gerar e emitir notificações SNMP para um tipo específico de evento ou falha IKE, execute as seguintes tarefas:
- Ative as notificações SNMP para IKE globalmente.
- Ative as notificações SNMP para o tipo de falha ou evento.
Procedimento
- Entrar na visualização do sistema
system view- Ative as notificações SNMP para IKE globalmente.
snmp-agent trap enable ike globalPor padrão, as notificações SNMP para IKE estão desativadas.
- Ative as notificações SNMP para os tipos de falha ou evento especificados.
snmp-agent trap enable ike [ attr-not-support | auth-failure |
cert-type-unsupport | cert-unavailable | decrypt-failure |
encrypt-failure | invalid-cert-auth | invalid-cookie | invalid-id |
invalid-proposal | invalid-protocol | invalid-sign | no-sa-failure |
proposal-add | proposal–delete | tunnel-start | tunnel-stop |
unsupport-exch-type ] *Por padrão, as notificações SNMP para todos os tipos de falhas e eventos estão desativadas.
Comandos de exibição e manutenção para IKE
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações de configuração sobre todas as propostas IKE. | proposta de exibição ike |
| Exibir informações sobre as SAs IKE atuais. | display ike sa [ verbose [ connection-id connection-id | endereço remoto [ ipv6 ] remote-address ] ] |
| Exibir estatísticas IKE. | exibir estatísticas ike |
| Excluir SAs IKE. | reset ike sa [ connection-id connection-id ] |
| Limpar estatísticas do IKE MIB. | reset ike statistics |
Exemplos de configuração do IKE
Exemplo: Configuração do IKE no modo principal com autenticação de chave pré-compartilhada
Configuração de rede
Conforme mostrado na Figura 14, configure um túnel IPsec baseado em IKE entre o Switch A e o Switch B para proteger a comunicação entre os switches.
- Configure os dois switches para usar a proposta IKE padrão para a negociação IKE.
- Configure os dois switches para usar o método de autenticação de chave pré-compartilhada para a negociação IKE.
Figura 14 Diagrama de rede

Procedimento
- Certifique-se de que o Switch A e o Switch B possam se comunicar.
- Configure o Switch A:
# Configure um endereço IP para a interface VLAN 1.
<SwitchA> system-view
[SwitchA] interface vlan-interface 1
[SwitchA-vlan-interface1] ip address 1.1.1.1 255.255.0.0
[SwitchA-vlan-interface1] quit# Configure o IPv4 advanced ACL 3101 para identificar o tráfego do Switch A para o Switch B.
[SwitchA] acl advanced 3101
[SwitchA-acl-ipv4-adv-3101] rule 0 permit ip source 1.1.1.1 0 destination 2.2.2.2 0
[SwitchA-acl-ipv4-adv-3101] quit# Crie um conjunto de transformação IPsec chamado tran1.
[SwitchA] ipsec transform-set tran1# Defina o modo de encapsulamento de pacotes como túnel.
[SwitchA-ipsec-transform-set-tran1] encapsulation-mode tunnel# Use o protocolo ESP para o conjunto de transformação IPsec. [Especifique os algoritmos de criptografia e autenticação.
[SwitchA-ipsec-transform-set-tran1] esp encryption-algorithm aes-cbc-192
[SwitchA-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchA-ipsec-transform-set-tran1] quit# Crie um keychain IKE chamado keychain1.
[SwitchA] ike keychain keychain1# Especifique 12345zxcvb!@#$%ZXCVB em texto simples como a chave pré-compartilhada a ser usada com o par remoto em 2.2.2.2.
[SwitchA-ike-keychain-keychain1] pre-shared-key address 2.2.2.2.2 255.255.0.0 key simple 12345zxcvb!@#$%ZXCVB
Criar um perfil IKE chamado profile1.
[SwitchA] ike profile profile1# Especifique o chaveiro IKE keychain keychain1.
[SwitchA-ike-profile-profile1] keychain keychain1
# Configure um ID de par com o tipo de identidade como endereço IP e o valor como 2.2.2.2/16. [SwitchA-ike-profile-profile1] match remote identity address 2.2.2.2 255.255.0.0 [SwitchA-ike-profile-profile1] quit
# Crie uma entrada de política IPsec baseada em IKE. Especifique o nome da política como map1 e defina o número de sequência como 10.
[SwitchA] ipsec policy map1 10 isakmp# Especifique o endereço IP remoto 2.2.2.2 para o túnel IPsec. [SwitchA-ipsec-policy-isakmp-map1-10] remote-address 2.2.2.2 # Especifique a ACL 3101 para identificar o tráfego a ser protegido.
[SwitchA-ipsec-policy-isakmp-map1-10] security acl 3101# Especifique o conjunto de transformação IPsec tran1 para a política IPsec.
[SwitchA-ipsec-policy-isakmp-map1-10] transform-set tran1# Especifique o perfil IKE profile1 para a política IPsec.
[SwitchA-ipsec-policy-isakmp-map1-10] ike-profile profile1
[SwitchA-ipsec-policy-isakmp-map1-10] quit# Aplique o mapa de política IPsec1 à interface VLAN 1.
[SwitchA] interface vlan-interface 1
[SwitchA-Vlan-interface1] ipsec apply policy map1- Configure o Switch B:
# Configure um endereço IP para a interface VLAN 1.
<SwitchB> system-view
[SwitchB] interface Vlan-interface1
[SwitchB-Vlan-interface1] ip address 2.2.2.2 255.255.0.0
[SwitchB-Vlan-interface1] quit
# Crie um conjunto de transformação IPsec chamado tran1.
[SwitchB] ipsec transform-set tran1# Defina o modo de encapsulamento de pacotes como túnel.
[SwitchB-ipsec-transform-set-tran1] encapsulation-mode tunnel# Use o protocolo ESP para o conjunto de transformação IPsec. [Especifique os algoritmos de criptografia e autenticação.
[SwitchB-ipsec-transform-set-tran1] esp encryption-algorithm aes-cbc-192
[SwitchB-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchB-ipsec-transform-set-tran1] quit# Crie um keychain IKE chamado keychain1.
[SwitchB]ike keychain keychain1
# Especifique 12345zxcvb!@#$%ZXCVB em texto simples como a chave pré-compartilhada a ser usada com o par remoto em 1.1.1.1.
[SwitchB-ike-keychain-keychain1] pre-shared-key address 2.2.2.2 255.255.0.0 key
simple 12345zxcvb!@#$%ZXCVB
[SwitchA-ike-keychain-keychain1] quitCriar um perfil IKE chamado profile1.
[SwitchB] ike profile profile1# Especificar o chaveiro IKE keychain keychain1
[SwitchB] ike keychain keychain1# Configure um ID de par com o tipo de identidade como endereço IP e o valor como 1.1.1.1/16. [SwitchB-ike-profile-profile1] match remote identity address 1.1.1.1 255.255.0.0 [SwitchB-ike-profile-profile1] quit
# Crie uma entrada de política IPsec baseada em IKE. Especifique o nome da política como use1 e defina o número de sequência como 10.
[SwitchB] ipsec policy use1 10 isakmp# Especifique o endereço IP remoto 1.1.1.1 para o túnel IPsec. [SwitchB-ipsec-policy-isakmp-use1-10] remote-address 1.1.1.1 # Especifique a ACL 3101 para identificar o tráfego a ser protegido.
[SwitchB-ipsec-policy-isakmp-use1-10] security acl 3101# Especifique o conjunto de transformação IPsec tran1 para a política IPsec.
[SwitchB-ipsec-policy-isakmp-use1-10] transform-set tran1# Especifique o perfil IKE profile1 para a política IPsec.
[SwitchB-ipsec-policy-isakmp-use1-10] ike-profile profile1
[SwitchB-ipsec-policy-isakmp-use1-10] quit# Aplique a política IPsec use1 à interface VLAN 1.
[SwitchB] interface vlan-interface 1
[SwitchB-Vlan-interface1] ipsec apply policy use1Verificação da configuração
# Iniciar uma conexão entre o Switch A e o Switch B para acionar a negociação IKE. Depois que as SAs do IPsec são negociadas com sucesso pelo IKE, o tráfego entre os dois switches é protegido pelo IPsec.
Exemplo: Configuração de um túnel IPsec baseado em IKE para pacotes IPv4
Configuração de rede
Conforme mostrado na Figura 15, estabeleça um túnel IPsec entre o Switch A e o Switch B para proteger os fluxos de dados entre os switches. Configure o túnel IPsec da seguinte forma:
- Especifique o modo de encapsulamento como túnel, o protocolo de segurança como ESP, o algoritmo de criptografia como AES-CBC-192 e o algoritmo de autenticação como HMAC-SHA1.
- Configurar SAs por meio de negociação IKE.
Figura 15 Diagrama de rede

Procedimento
- Configure o Switch A:
# Configure um endereço IP para a interface VLAN 1.
<SwitchA> system-view
[SwitchA] interface vlan-interface 1
[SwitchA-Vlan-interface1] ip address 2.2.2.1 255.255.255.0
[SwitchA-Vlan-interface1] quit# Configure uma ACL avançada de IPv4 para identificar os fluxos de dados do Switch A para o Switch B.
[SwitchA] acl advanced 3101
[SwitchA-acl-ipv4-adv-3101] rule 0 permit ip source 2.2.2.1 0 destination 2.2.3.1 0
[SwitchA-acl-ipv4-adv-3101] quit# Crie um conjunto de transformação IPsec chamado tran1.
[SwitchA] ipsec transform-set tran1# Especifique o modo de encapsulamento como túnel.
[SwitchA-ipsec-transform-set-tran1] encapsulation-mode tunnel# Especifique o protocolo de segurança como ESP.
[SwitchA-ipsec-transform-set-tran1] protocol esp# Especifique os algoritmos de criptografia e autenticação ESP.
[SwitchA-ipsec-transform-set-tran1] esp encryption-algorithm aes-cbc-192
[SwitchA-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchA-ipsec-transform-set-tran1] quit# Crie um keychain IKE chamado keychain1.
[SwitchA] ike keychain keychain1# Especifique 12345zxcvb!@#$%ZXCVB em texto simples como a chave pré-compartilhada a ser usada com o par remoto em 2.2.3.1.
[SwitchA-ike-keychain-keychain1] pre-shared-key address 2.2.3.1 255.255.255.0 key
simple 12345zxcvb!@#$%ZXCVB
[SwitchA-ike-keychain-keychain1] quit# Criar e configurar um perfil IKE chamado profile1.
[SwitchA] ike profile profile1
[SwitchA-ike-profile-profile1] keychain keychain1
[SwitchA-ike-profile-profile1] match remote identity address 2.2.3.1 255.255.255.0
[SwitchA-ike-profile-profile1] quit# Crie uma entrada de política IPsec baseada em IKE. Especifique o nome da política como map1 e defina o número de sequência como 10.
[SwitchA] ipsec policy map1 10 isakmp# Especifique a ACL 3101.
[SwitchA-ipsec-policy-isakmp-map1-10] security acl 3101# Especifique o conjunto de transformação IPsec tran1.
[SwitchA-ipsec-policy-isakmp-map1-10] transform-set tran1# Especifique os endereços IP locais e remotos do túnel IPsec como 2.2.2.1 e 2.2.3.1.
[SwitchA-ipsec-policy-isakmp-map1-10] local-address 2.2.2.1
[SwitchA-ipsec-policy-isakmp-map1-10] remote-address 2.2.3.1# Especifique o perfil IKE profile1.
[SwitchA-ipsec-policy-isakmp-map1-10] ike-profile profile1
[SwitchA-ipsec-policy-isakmp-map1-10] quit# Aplique o mapa de política IPsec1 à interface VLAN 1.
[SwitchA] interface vlan-interface 1
[SwitchA-Vlan-interface1] ipsec apply policy map1- Configurar o Switch B:
# Configure um endereço IP para a interface VLAN 1.
<SwitchB> system-view
[SwitchB] interface vlan-interface 1
[SwitchB-Vlan-interface1] ip address 2.2.3.1 255.255.255.0
[SwitchB-Vlan-interface1] quit# Configure uma ACL avançada de IPv4 para identificar os fluxos de dados do Switch B para o Switch A.
[SwitchB] acl advanced 3101
[SwitchB-acl-ipv4-adv-3101] rule 0 permit ip source 2.2.3.1 0 destination 2.2.2.1 0
[SwitchB-acl-ipv4-adv-3101] quit# Crie um conjunto de transformação IPsec chamado tran1.
[SwitchB] ipsec transform-set tran1# Especifique o modo de encapsulamento como túnel.
[SwitchB-ipsec-transform-set-tran1] encapsulation-mode tunnel# Especifique o protocolo de segurança como ESP.
[SwitchB-ipsec-transform-set-tran1] protocol esp# Especifique os algoritmos de criptografia e autenticação ESP.
[SwitchB-ipsec-transform-set-tran1] esp encryption-algorithm aes-cbc-192
[SwitchB-ipsec-transform-set-tran1] esp authentication-algorithm sha1
[SwitchB-ipsec-transform-set-tran1] quit# Crie um keychain IKE chamado keychain1.
[SwitchA] ike keychain keychain1# Especifique 12345zxcvb!@#$%ZXCVB em texto simples como a chave pré-compartilhada a ser usada com o par remoto em 2.2.2.1.
[SwitchB-ike-keychain-keychain1] pre-shared-key address 2.2.2.1 255.255.255.0 key
simple 12345zxcvb!@#$%ZXCVB
[SwitchB-ike-keychain-keychain1] quit# Criar e configurar um perfil IKE chamado profile1.
[SwitchB] ike profile profile1
[SwitchB-ike-profile-profile1] keychain keychain1
[SwitchB-ike-profile-profile1] match remote identity address 2.2.2.1 255.255.255.0
[SwitchB-ike-profile-profile1] quit# Crie uma entrada de política IPsec baseada em IKE. Especifique o nome da política como use1 e defina o parâmetro
número de sequência para 10.
[SwitchB] ipsec policy use1 10 isakmp# Especifique a ACL 3101.
[SwitchB-ipsec-policy-isakmp-use1-10] security acl 3101# Especifique o conjunto de transformação IPsec tran1.
[SwitchB-ipsec-policy-isakmp-use1-10] transform-set tran1# Especifique os endereços IP locais e remotos do túnel IPsec como 2.2.3.1 e 2.2.2.1.
[SwitchB-ipsec-policy-isakmp-use1-10] local-address 2.2.3.1
[SwitchB-ipsec-policy-isakmp-use1-10] remote-address 2.2.2.1# Especifique o perfil IKE profile1.
[SwitchB-ipsec-policy-isakmp-use1-10] ike-profile profile1
[SwitchB-ipsec-policy-isakmp-use1-10] quit# Aplique a política IPsec use1 à interface VLAN 1.
[SwitchB] interface vlan-interface 1
[SwitchB-Vlan-interface1] ipsec apply policy use1Verificação da configuração
# Iniciar uma conexão entre o Switch A e o Switch B para acionar a negociação IKE. Depois que as SAs do IPsec são negociadas com sucesso pelo IKE, o tráfego entre os dois switches é protegido pelo IPsec.
Solução de problemas do IKE
A negociação IKE falhou porque não foram encontradas propostas IKE correspondentes
Sintoma
<Sysname> display ike sa
Connection-ID Remote Flag DOI
------------------------------------------------------------------
1 192.168.222.5 Unknown IPsec
Flags:
RD--READY RL--REPLACED FD-FADING RK-REKEY
2. Quando a depuração de eventos IKE e a depuração de pacotes estão ativadas, as seguintes mensagens são exibidas:
Mensagem de depuração de evento IKE:
The attributes are unacceptable.Mensagem de depuração do pacote IKE:
Construct notification packet: NO_PROPOSAL_CHOSEN.Análise
Determinadas configurações de proposta IKE estão incorretas.
Solução
- Examine a configuração da proposta IKE para ver se as duas extremidades têm propostas IKE correspondentes.
- Modifique a configuração da proposta IKE para garantir que as duas extremidades tenham propostas IKE correspondentes.
A negociação IKE falhou porque nenhuma proposta IKE ou chaveiro IKE foi especificado corretamente
Sintoma
<Sysname> display ike sa
Connection-ID Remote Flag DOI
------------------------------------------------------------------
1 192.168.222.5 Unknown IPsec
Flags:
RD--READY RL--REPLACED FD-FADING RK-REKEY- A seguinte mensagem de depuração de evento IKE ou de depuração de pacote é exibida: Mensagem de depuração de evento IKE:
Notification PAYLOAD_MALFORMED is received.Mensagem de depuração do pacote IKE:
Construct notification packet: PAYLOAD_MALFORMED.Análise
- Se as seguintes informações de depuração forem exibidas, o perfil IKE correspondente não está usando a proposta IKE correspondente:
Failed to find proposal 1 in profile profile1.- Se as seguintes informações de depuração forem exibidas, o perfil IKE correspondente não está usando o chaveiro IKE correspondente:
Failed to find keychain keychain1 in profile profile1.Solução
- Verifique se a proposta IKE correspondente (proposta IKE 1 neste exemplo de mensagem de depuração) está especificada para o perfil IKE (perfil IKE 1 no exemplo).
- Verifique se o chaveiro IKE correspondente (chaveiro IKE 1 neste exemplo de mensagem de depuração) está especificado para o perfil IKE (perfil IKE 1 no exemplo).
A negociação da SA IPsec falhou porque não foram encontrados conjuntos de transformação IPsec correspondentes
Sintoma
- O comando display ike sa mostra que a negociação da IKE SA foi bem-sucedida e que a IKE SA está no estado RD, mas o comando display ipsec sa mostra que a IPsec SA esperada ainda não foi negociada.
- A seguinte mensagem de depuração do IKE é exibida:
The attributes are unacceptable.Ou:
Construct notification packet: NO_PROPOSAL_CHOSEN.Análise
Algumas configurações da política IPsec estão incorretas.
Solução
- Examine a configuração do IPsec para ver se as duas extremidades têm conjuntos correspondentes de transformação do IPsec .
- Modifique a configuração do IPsec para garantir que as duas extremidades tenham conjuntos de transformação IPsec correspondentes.
Falha na negociação de SA IPsec devido a informações de identidade inválidas
Sintoma
- O comando display ike sa mostra que a negociação da IKE SA foi bem-sucedida e que a IKE SA está no estado RD, mas o comando display ipsec sa mostra que a IPsec SA esperada ainda não foi negociada.
- A seguinte mensagem de depuração do IKE foi exibida:
Notification INVALID_ID_INFORMATION is received.Ou:
Failed to get IPsec policy when renegotiating IPsec SA. Delete IPsec SA.
Construct notification packet: INVALID_ID_INFORMATIONAnálise
Algumas configurações de política IPsec do respondedor estão incorretas. Verifique as configurações da seguinte forma:
- Use o comando display ike sa verbose para verificar se os perfis IKE correspondentes foram encontrados na fase 1 da negociação IKE. Se não forem encontrados perfis IKE correspondentes e a política IPsec estiver usando um perfil IKE, a negociação da SA IPsec falhará.
# Identificar se foram encontrados perfis IKE correspondentes na fase 1 da negociação IKE. A saída a seguir mostra que não foi encontrado nenhum perfil IKE correspondente:
display ike sa verbose
-----------------------------------------------
Connection ID: 3
Outside VPN:
Inside VPN:
Profile:
Transmitting entity: Responder
-----------------------------------------------
Local IP: 192.168.222.5
Local ID type: IPV4_ADDR
Local ID: 192.168.222.5
Remote IP: 192.168.222.71
Remote ID type: IPV4_ADDR
Remote ID: 192.168.222.71
Authentication-method: PRE-SHARED-KEY
Authentication-algorithm: MD5
Encryption-algorithm: 3DES-CBC
Life duration(sec): 86400
Remaining key duration(sec): 85847
Exchange-mode: Main
Diffie-Hellman group: Group 1
NAT traversal: Not detected # Identifique se a política IPsec está usando um perfil IKE. A saída a seguir mostra que um perfil IKE é usado pela política IPsec.
[Sysname] display ipsec policy
-------------------------------------------
IPsec Policy: policy1
Interface: GigabitEthernet1/0/1
-------------------------------------------
-----------------------------
Sequence number: 1
Mode: ISAKMP
-----------------------------
Description:
Security data flow: 3000
Selector mode: aggregation
Local address: 192.168.222.5
Remote address: 192.168.222.71
Transform set: transform1
IKE profile: profile1
SA duration(time based):
SA duration(traffic based):
SA idle time:- Verifique se a ACL especificada para a política IPsec está configurada corretamente. Se o intervalo de fluxo definido pela ACL do respondente for menor do que o definido pela ACL do iniciador, haverá falha na correspondência da proposta IPsec.
Por exemplo, se a ACL do iniciador definir um fluxo de um segmento de rede para outro, mas a ACL do respondente definir um fluxo de um host para outro host, a correspondência de propostas IPsec falhará.
# No iniciador:
[Sysname] display acl 3000
Advanced IPv4 ACL 3000, 1 rule,
ACL's step is 5
rule 0 permit ip source 192.168.222.0 0.0.0.255 destination 192.168.222.0 0.0.0.255# No respondedor:
[Sysname] display acl 3000
Advanced IPv4 ACL 3000, 1 rule,
ACL's step is 5
rule 0 permit ip source 192.168.222.71 0 destination 192.168.222.5 0- Verifique se a política IPsec tem um endereço remoto e um conjunto de transformação IPsec configurados e se o conjunto de transformação IPsec tem todas as configurações necessárias definidas.
Se, por exemplo, a política IPsec não tiver um endereço remoto configurado, a negociação da SA IPsec falhará:
[Sysname] display ipsec policy
-------------------------------------------
IPsec Policy: policy1
Interface: GigabitEthernet1/0/1
-------------------------------------------
-----------------------------
Sequence number: 1
Mode: ISAKMP
-----------------------------
Security data flow: 3000
Selector mode: aggregation
Local address: 192.168.222.5
Remote address:
Transform set: transform1
IKE profile: profile1
SA duration(time based):
SA duration(traffic based):
SA idle time:- Se a política IPsec especificar um perfil IKE, mas nenhum perfil IKE correspondente tiver sido encontrado na negociação IKE, execute uma das seguintes tarefas no respondente:
- Remover o perfil IKE especificado da política IPsec.
- Modificar o perfil IKE especificado para corresponder ao perfil IKE do iniciador.
- Se o intervalo de fluxo definido pela ACL do respondente for menor do que o definido pela ACL do iniciador, modifique a ACL do respondente para que ela defina um intervalo de fluxo igual ou maior do que o da ACL do iniciador.
Por exemplo:
[Sysname] display acl 3000
Advanced IPv4 ACL 3000, 2 rules,
ACL's step is 5
rule 0 permit ip source 192.168.222.0 0.0.0.255 destination 192.168.222.0 0.0.0.255Configuração do IKEv2
Sobre o IKEv2
O Internet Key Exchange versão 2 (IKEv2) é uma versão aprimorada do IKEv1. Da mesma forma que o IKEv1, o IKEv2 tem um conjunto de mecanismos de autoproteção e pode ser usado em redes inseguras para autenticação de identidade confiável, distribuição de chaves e negociação de SA IPsec. O IKEv2 oferece proteção mais forte contra ataques e maior capacidade de troca de chaves, além de precisar de menos trocas de mensagens do que o IKEv1.
Processo de negociação IKEv2
Em comparação com o IKEv1, o IKEv2 simplifica o processo de negociação e é muito mais eficiente.
O IKEv2 define três tipos de trocas: trocas iniciais, troca CREATE_CHILD_SA e troca INFORMATIONAL.
Conforme mostrado na Figura 16, o IKEv2 usa duas trocas durante o processo de troca inicial: IKE_SA_INIT e IKE_AUTH, cada uma com duas mensagens.
- IKE_SA_INIT exchange - Negocia os parâmetros do IKE SA e troca as chaves.
- Troca IKE_AUTH - Autentica a identidade do par e estabelece SAs IPsec.
Após as trocas iniciais de quatro mensagens, o IKEv2 configura uma IKE SA e um par de IPsec SAs. Para que o IKEv1 configure uma IKE SA e um par de IPsec SAs, ele deve passar por duas fases que usam um mínimo de seis mensagens.
Para configurar mais um par de IPsec SAs dentro da IKE SA, o IKEv2 executa uma troca adicional de duas mensagens - a troca CREATE_CHILD_SA. Uma troca CREATE_CHILD_SA cria um par de IPsec SAs. O IKEv2 também usa a troca CREATE_CHILD_SA para rechavear as IKE SAs e as Child SAs.
O IKEv2 usa a troca INFORMATIONAL para transmitir mensagens de controle sobre erros e notificações.
Figura 16 IKEv2 Processo de troca inicial
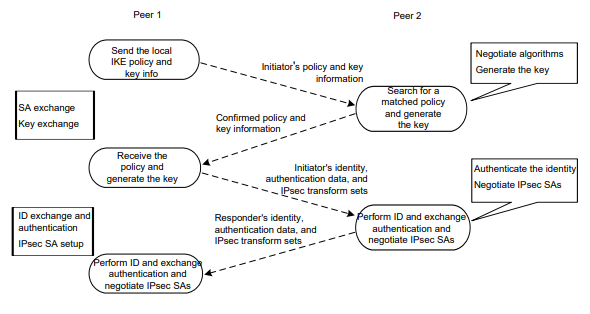
Novos recursos no IKEv2
DH adivinhando
Na troca IKE_SA_INIT, o iniciador adivinha o grupo DH que o respondente provavelmente usará e o envia em uma mensagem de solicitação IKE_SA_INIT. Se a estimativa do iniciador estiver correta, o respondente responde com uma mensagem de resposta IKE_SA_INIT e a troca IKE_SA_INIT é concluída. Se a suposição estiver errada, o respondente responde com uma mensagem INVALID_KE_PAYLOAD que contém o grupo DH que ele deseja usar. O iniciador usa então o grupo DH selecionado pelo respondente para reiniciar a troca IKE_SA_INIT. O mecanismo de adivinhação de DH permite uma configuração mais flexível do grupo DH e permite que o iniciador se adapte a diferentes respondentes.
Desafio de cookies
As mensagens para a troca IKE_SA_INIT estão em texto simples. Um respondedor IKEv1 não pode confirmar a validade dos iniciadores e deve manter SAs IKE semiabertas, o que torna o respondedor suscetível a ataques DoS. Um invasor pode enviar um grande número de solicitações IKE_SA_INIT com endereços IP de origem falsos para o respondedor, esgotando os recursos do sistema do respondedor.
O IKEv2 introduz o mecanismo de desafio de cookie para evitar esses ataques DoS. Quando um respondente IKEv2 mantém um número limite de SAs IKE semiabertas, ele inicia o mecanismo de desafio de cookie. O respondente gera um cookie e o inclui na resposta enviada ao iniciador. Se o iniciador iniciar uma nova solicitação IKE_SA_INIT que contenha o cookie correto, o respondedor considerará o iniciador válido e prosseguirá com a negociação. Se o cookie carregado estiver incorreto, o respondente encerrará a negociação.
O mecanismo de desafio de cookies para de funcionar automaticamente quando o número de IKE SAs entreabertas cai abaixo do limite.
Rekeying de SA IKEv2
Para fins de segurança, tanto as SAs IKE quanto as SAs IPsec têm um tempo de vida útil e devem ser rechaveadas quando esse tempo expirar. O tempo de vida de uma SA IKEv1 é negociado. O tempo de vida de uma SA IKEv2, por outro lado, é configurado. Se dois pares forem configurados com tempos de vida diferentes, o par com o tempo de vida mais curto sempre iniciará o rechaveamento da SA. Esse mecanismo reduz a possibilidade de dois pares iniciarem simultaneamente uma rechaveamento. O rekeying simultâneo resulta em SAs redundantes e inconsistência de status de SA nos dois pares.
Retransmissão de mensagens IKEv2
Diferentemente das mensagens IKEv1, as mensagens IKEv2 aparecem em pares de solicitação/resposta. O IKEv2 usa o campo Message ID no cabeçalho da mensagem para identificar o par solicitação/resposta. Se um iniciador enviar uma solicitação, mas não receber nenhuma resposta com o mesmo valor de ID de mensagem em um período específico, o iniciador retransmitirá a solicitação.
É sempre o iniciador do IKEv2 que inicia a retransmissão, e a mensagem retransmitida deve usar o mesmo valor de ID de mensagem.
Protocolos e padrões
- RFC 2408, Associação de Segurança da Internet e Protocolo de Gerenciamento de Chaves (ISAKMP)
- RFC 4306, Protocolo de troca de chaves da Internet (IKEv2)
- RFC 4718, Esclarecimentos e diretrizes de implementação do IKEv2
- RFC 2412, O protocolo de determinação de chaves OAKLEY
- RFC 5996, Protocolo de troca de chaves da Internet versão 2 (IKEv2)
Visão geral das tarefas do IKEv2
Para configurar o IKEv2, execute as seguintes tarefas:
- Configuração de um perfil IKEv2
- Criação de um perfil IKEv2
- Especificação dos métodos de autenticação de identidade local e remota
- Configuração do conjunto de chaves IKEv2 ou do domínio PKI
- Configuração da ID local para o perfil IKEv2
- Configuração de IDs de pares para o perfil IKEv2
- Configuração de recursos opcionais para o perfil IKEv2
- Configuração de uma política IKEv2
- Configuração de uma proposta IKEv2
Se você especificar uma proposta IKEv2 em uma política IKEv2, deverá configurar a proposta IKEv2.
- Configuração de um chaveiro IKEv2
Essa tarefa é necessária quando uma ou ambas as extremidades usam o método de autenticação de chave pré-compartilhada.
- (Opcional.) Ativação do recurso de desafio de cookies
O recurso de desafio de cookies tem efeito somente nos respondedores IKEv2.
- (Opcional.) Configuração do recurso IKEv2 DPD
- (Opcional.) Configuração do recurso IKEv2 NAT keepalive
Pré-requisitos para a configuração do IKEv2
Determine os seguintes parâmetros antes da configuração do IKEv2:
- A força dos algoritmos para negociação IKEv2, incluindo os algoritmos de criptografia, os algoritmos de proteção de integridade, os algoritmos PRF e os grupos DH. Algoritmos diferentes fornecem níveis diferentes de proteção. Um algoritmo mais forte significa melhor resistência à descriptografia de dados protegidos, mas exige mais recursos. Normalmente, quanto mais longa a chave, mais forte é o algoritmo.
- Os métodos de autenticação de identidade local e remota.
- Para usar o método de autenticação de chave pré-compartilhada, você deve determinar a chave pré-compartilhada.
- Para usar o método de autenticação de assinatura digital RSA, você deve determinar o domínio de PKI a ser usado pela extremidade local. Para obter informações sobre a PKI, consulte "Configuração da PKI".
Configuração de um perfil IKEv2
Criação de um perfil IKEv2
Sobre o perfil IKEv2
O objetivo de um perfil IKEv2 é fornecer um conjunto de parâmetros para a negociação IKEv2.
Procedimento
- Entre na visualização do sistema.
system view- Crie um perfil IKEv2 e entre em sua visualização.
ikev2 profile profile-nameEspecificação dos métodos de autenticação de identidade local e remota
Restrições e diretrizes
Os métodos de autenticação de identidade local e remota devem ser especificados e podem ser diferentes. Você pode especificar apenas um método de autenticação de identidade local e vários métodos de autenticação de identidade remota.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização do perfil IKEv2.
ikev2 profile profile-name- Especifique os métodos de autenticação de identidade local e remota.
authentication-method { local | remote } { dsa-signature |
ecdsa-signature | pre-share | rsa-signature }Por padrão, nenhum método de autenticação de identidade local ou remota é configurado.
Configuração do chaveiro IKEv2 ou do domínio PKI
Restrições e diretrizes
Configure o chaveiro IKEv2 ou o domínio PKI para o perfil IKEv2 a ser usado. Para usar a autenticação de assinatura digital, configure um domínio PKI. Para usar a autenticação de chave pré-compartilhada, configure um chaveiro IKEv2.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização do perfil IKEv2.
ikev2 profile profile-name- Especifique o keychain para autenticação de chave pré-compartilhada ou o domínio PKI usado para solicitar um certificado para autenticação de assinatura digital.
- Especifique o chaveiro.
keychain keychain-name- Especifique o domínio PKI.
certificate domain domain-namePor padrão, nenhum domínio de PKI ou chaveiro IKEv2 é especificado para um perfil IKEv2.
Configuração da ID local para o perfil IKEv2
Restrições e diretrizes
Para autenticação de assinatura digital, o dispositivo pode usar um ID de qualquer tipo. Se o ID local for um endereço IP diferente do endereço IP no certificado local, o dispositivo usará o FQDN como ID local. O FQDN é o nome do dispositivo configurado usando o comando sysname.
Para autenticação de chave pré-compartilhada, o dispositivo pode usar uma ID de qualquer tipo que não seja o DN.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização do perfil IKEv2.
ikev2 profile profile-name- Configure a ID local.
identity local { address { ipv4-address | ipv6 ipv6-address } | dn |
email email-string | fqdn fqdn-name | key-id key-id-string }Por padrão, nenhuma ID local é configurada, e o dispositivo usa o endereço IP da interface em que a política IPsec se aplica como ID local.
Configuração de IDs de pares para o perfil IKEv2
Sobre a configuração do ID de par
Execute esta tarefa para configurar o ID do par para correspondência de perfil IKEv2. Quando o dispositivo precisa selecionar um perfil IKEv2 para negociação IKEv2 com um par, ele compara o ID de par recebido com os IDs de par de seus perfis IKE locais. Se for encontrada uma correspondência, ele usará o perfil IKEv2 com a ID de par correspondente para negociação. Os perfis IKEv2 serão comparados em ordem decrescente de suas prioridades.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização do perfil IKEv2.
ikev2 profile profile-name- Configure uma ID de par.
match remote { certificate policy-name | identity { address
{ { ipv4-address [ mask | mask-length ] | range low-ipv4-address
high-ipv4-address } | ipv6 { ipv6-address [ prefix-length ] | range
low-ipv6-address high-ipv6-address } } | fqdn fqdn-name | email
email-string | key-id key-id-string } }Você deve configurar no mínimo uma ID de par em cada um dos dois pares.
Configuração de recursos opcionais para o perfil IKEv2
- Entre na visualização do sistema.
system view- Entre na visualização do perfil IKEv2.
ikev2 profile profile-name- Configure os recursos opcionais conforme necessário.
- Configurar o IKEv2 DPD.
dpd interval interval [ retry seconds ] { on-demand | periodic }Por padrão, o IKEv2 DPD não está configurado para um perfil IKEv2 e um perfil IKEv2 usa as configurações de DPD definidas na visualização do sistema. Se o IKEv2 DPD também não estiver configurado na visualização do sistema, o dispositivo não realizará a detecção de pares IKEv2 mortos.
- Especifique a interface local ou o endereço IP ao qual o perfil IKEv2 pode ser aplicado. match local address { interface-type interface-number | ipv4-address | ipv6 ipv6-address }
Por padrão, um perfil IKEv2 pode ser aplicado a qualquer interface local ou endereço IP local.
Use esse comando para especificar qual endereço ou interface pode usar o perfil IKEv2 para negociação IKEv2. Especifique o endereço local configurado na visualização da política IPsec ou do modelo de política IPsec (usando o comando local-address) para esse comando. Se nenhum endereço local estiver configurado, especifique o endereço IP da interface que usa a política IPsec.
- Especifique uma prioridade para o perfil IKEv2.
priority priorityPor padrão, a prioridade de um perfil IKEv2 é 100.
Quando o dispositivo precisa selecionar um perfil IKEv2 para negociação IKEv2 com um par, ele compara a ID do par recebida com a ID do par de seus perfis IKEv2 locais em ordem decrescente de prioridades
- Defina o tempo de vida da SA IKEv2 para o perfil IKEv2.
sa duration secondsPor padrão, o tempo de vida da SA do IKEv2 é de 86400 segundos.
As extremidades local e remota podem usar diferentes tempos de vida da SA IKEv2 e não negociam o tempo de vida. A extremidade com um tempo de vida de SA menor iniciará uma negociação de SA quando o tempo de vida expirar.
- Defina o intervalo IKEv2 NAT keepalive.
nat-keepalive secondsPor padrão, é usada a configuração global IKEv2 NAT keepalive.
Configure esse comando quando o dispositivo estiver atrás de um gateway NAT. O dispositivo envia pacotes NAT keepalive regularmente ao seu par para evitar que a sessão NAT seja envelhecida por não haver tráfego correspondente.
- Ative o recurso de troca de configuração.
config-exchange { request | set { accept | send } }Por padrão, todas as opções de troca de configuração estão desativadas.
Esse recurso se aplica a cenários em que a sede e as filiais se comunicam por meio de túneis virtuais. Ele permite a troca de mensagens de solicitação e definição de endereço IP entre o gateway IPsec em uma filial e o gateway IPsec na sede.
Tabela 2 Descrições dos parâmetros
| Parâmetro | Descrição |
| solicitação | Permite que o gateway IPsec em uma filial envie mensagens de solicitação de endereço IP para o gateway IPsec na sede. |
| definir aceitar | Permite que o gateway IPsec em uma filial aceite os endereços IP enviados pelo gateway IPsec na sede. |
| definir enviar | Permite que o gateway IPsec da sede envie endereços IP para os gateways IPsec das filiais. |
Configuração de uma política IKEv2
Sobre o mecanismo de seleção de políticas IKEv2
Durante a troca IKE_SA_INIT, cada extremidade tenta encontrar uma política IKEv2 correspondente, usando o endereço IP do gateway de segurança local como critério de correspondência.
- Se as políticas do IKEv2 estiverem configuradas, o IKEv2 procurará uma política do IKEv2 que use o endereço IP do gateway de segurança local. Se nenhuma política IKEv2 usar o endereço IP ou se a política estiver usando uma proposta incompleta, a troca IKE_SA_INIT falhará.
- Se nenhuma política IKEv2 estiver configurada, o IKEv2 usará a política IKEv2 padrão do sistema.
O dispositivo corresponde às políticas IKEv2 na ordem decrescente de suas prioridades. Para determinar a prioridade de uma política IKEv2:
- Primeiro, o dispositivo examina a existência do comando match local address. Uma política IKEv2 com o comando match local address configurado tem uma prioridade mais alta.
- Se houver empate, o dispositivo comparará os números de prioridade. Uma política IKEv2 com um número de prioridade menor tem uma prioridade mais alta.
- Se ainda houver empate, o dispositivo dará preferência a uma política IKEv2 configurada anteriormente.
Procedimento
- Entre na visualização do sistema.
system view- Crie uma política IKEv2 e entre em sua visualização.
ikev2 policy policy-namePor padrão, existe uma política IKEv2 denominada default.
- Especifique a interface ou o endereço local usado para a correspondência de políticas IKEv2.
match local address { interface-type interface-number | ipv4-address |
ipv6 ipv6-address }Por padrão, nenhuma interface ou endereço local é usado para correspondência de política IKEv2, e a política corresponde a qualquer interface ou endereço local.
- Especifique uma proposta IKEv2 para a política IKEv2.
proposal proposal-namePor padrão, nenhuma proposta IKEv2 é especificada para uma política IKEv2.
- Especifique uma prioridade para a política IKEv2.
priority priorityPor padrão, a prioridade de uma política IKEv2 é 100.
Configuração de uma proposta IKEv2
Sobre a proposta IKEv2
Uma proposta IKEv2 contém parâmetros de segurança usados nas trocas IKE_SA_INIT, incluindo os algoritmos de criptografia, os algoritmos de proteção de integridade, os algoritmos PRF e os grupos DH. Um algoritmo especificado anteriormente tem uma prioridade mais alta.
Restrições e diretrizes
Uma proposta IKEv2 completa deve ter pelo menos um conjunto de parâmetros de segurança, incluindo um algoritmo de criptografia, um algoritmo de proteção de integridade, um algoritmo PRF e um grupo DH.
Você pode especificar várias propostas IKEv2 para uma política IKEv2. Uma proposta especificada anteriormente tem uma prioridade mais alta.
Procedimento
- Entre na visualização do sistema.
system view- Crie uma proposta IKEv2 e entre em sua visualização.
ikev2 proposal proposal-namePor padrão, existe uma proposta IKEv2 denominada default.
No modo não-FIPS, a proposta padrão usa as seguintes configurações:
- Algoritmos de criptografia AES-CBC-128 e 3DES.
- Algoritmos de proteção de integridade HMAC-SHA1 e HMAC-MD5.
- Algoritmos PRF HMAC-SHA1 e HMAC-MD5.
- Grupos DH 2 e 5.
No modo FIPS, a proposta padrão usa as seguintes configurações:
- Algoritmos de criptografia AES-CBC-128 e AES-CTR-128.
- Algoritmos de proteção de integridade HMAC-SHA1 e HMAC-SHA256.
- Algoritmos PRF HMAC-SHA1 e HMAC-SHA256.
- Grupos DH 14 e 19.
- Especifique os algoritmos de criptografia.
No modo não-FIPS:
encryption { 3des-cbc | aes-cbc-128 | aes-cbc-192 | aes-cbc-256 |
aes-ctr-128 | aes-ctr-192 | aes-ctr-256 | camellia-cbc-128 |
camellia-cbc-192 | camellia-cbc-256 | des-cbc } *No modo FIPS:
encryption { aes-cbc-128 | aes-cbc-192 | aes-cbc-256 | aes-ctr-128 |
aes-ctr-192 | aes-ctr-256 } *Por padrão, uma proposta IKEv2 não tem nenhum algoritmo de criptografia.
No modo não-FIPS:
integrity { aes-xcbc-mac | md5 | sha1 | sha256 | sha384 | sha512 }*No modo FIPS:
integrity { sha1 | sha256 | sha384 | sha512 } *Por padrão, uma proposta IKEv2 não tem nenhum algoritmo de proteção de integridade.
- Especifique os grupos DH.
No modo não-FIPS:
dh { group1 | group14 | group2 | group24 | group5 | group19 | group20 } *No modo FIPS:
dh { group14 | group19 | group20 } *Por padrão, uma proposta IKEv2 não tem nenhum grupo DH.
- Especifique os algoritmos PRF.
No modo não-FIPS:
prf { aes-xcbc-mac | md5 | sha1 | sha256 | sha384 | sha512 } *No modo FIPS:
prf { sha1 | sha256 | sha384 | sha512 } *Por padrão, uma proposta IKEv2 usa os algoritmos de proteção de integridade como algoritmos PRF.
Configuração de um chaveiro IKEv2
Sobre o chaveiro IKEv2
Um keychain IKEv2 especifica as chaves pré-compartilhadas usadas para a negociação IKEv2.
Um chaveiro IKEv2 pode ter vários pares IKEv2. Cada par tem uma chave pré-compartilhada simétrica ou um par de chaves pré-compartilhadas assimétricas e informações para identificar o par (como o nome do host do par, o endereço IP ou o intervalo de endereços ou o ID).
Um iniciador de negociação IKEv2 usa o nome do host do par ou o endereço IP/intervalo de endereços como critério de correspondência para procurar um par. Um respondente usa o endereço IP/intervalo de endereços ou ID do host do par como critério de correspondência para procurar um par.
Procedimento
- Entre na visualização do sistema.
system view- Crie um chaveiro IKEv2 e entre em sua visualização.
ikev2 keychain keychain-name- Crie um par IKEv2 e entre em sua visualização.
peer name- Configure um nome de host para o par:
hostname namePor padrão, nenhum nome de host é configurado para um par IKEv2.
- Configure um endereço IP de host ou um intervalo de endereços para o par:
address { ipv4-address [ mask | mask-length ] | ipv6 ipv6-address
[ prefix-length ] }Por padrão, nenhum endereço IP de host ou intervalo de endereços é configurado para um par IKEv2. Você deve configurar diferentes endereços IP de host/intervalos de endereços para diferentes pares.
- Configure uma ID para o par:
identity { address { ipv4-address | ipv6 { ipv6-address } } | fqdn
fqdn-name | email email-string | key-id key-id-string }Por padrão, nenhuma informação de identidade é configurada para um par IKEv2.
- Configure uma chave pré-compartilhada para o par.
pre-shared-key [ local | remote ] { ciphertext | plaintext } stringPor padrão, um par IKEv2 não tem uma chave pré-compartilhada.
Configurar parâmetros globais do IKEv2
Ativação do recurso de desafio de cookies
Sobre o recurso de desafio de cookies
Habilite o desafio de cookies nos respondentes para protegê-los contra ataques de DoS que usam um grande número de endereços IP de origem para forjar solicitações IKE_SA_INIT.
Procedimento
- Entre na visualização do sistema.
system view- Ativar o desafio do cookie IKEv2.
ikev2 cookie-challenge numberPor padrão, o desafio de cookies IKEv2 está desativado.
Configuração do recurso IKEv2 DPD
Sobre o IKEv2 DPD
O IKEv2 DPD detecta pares IKEv2 mortos no modo periódico ou sob demanda.
- DPD IKEv2 periódico - Verifica a vivacidade de um par IKEv2 enviando mensagens DPD em intervalos regulares.
- IKEv2 DPD sob demanda - Verifica a vivacidade de um par IKEv2 enviando mensagens DPD antes de enviar dados.
- Antes de enviar dados, o dispositivo identifica o intervalo de tempo em que o último pacote IPsec foi recebido do par. Se o intervalo de tempo exceder o intervalo DPD, ele enviará uma mensagem DPD ao par para detectar sua vivacidade.
- Se o dispositivo não tiver dados para enviar, ele nunca enviará mensagens DPD.
Restrições e diretrizes
Se você configurar o IKEv2 DPD na visualização de perfil IKEv2 e na visualização do sistema, serão aplicadas as configurações do IKEv2 DPD na visualização de perfil IKEv2. Se você não configurar o IKEv2 DPD na visualização de perfil do IKEv2, serão aplicadas as configurações do IKEv2 DPD na visualização do sistema.
Procedimento
- Entre na visualização do sistema.
system view- Configurar o IKEv2 DPD global.
ikev2 dpd interval interval [ retry seconds ] { on-demand | periodic }Por padrão, o DPD global está desativado.
Configuração do recurso IKEv2 NAT keepalive
Sobre o recurso IKEv2 NAT keepalive
Configure esse recurso no gateway IKEv2 atrás do dispositivo NAT. O gateway envia pacotes NAT keepalive regularmente ao seu par para manter a sessão NAT ativa, de modo que o par possa acessar o dispositivo.
O intervalo NAT keepalive deve ser menor que o tempo de vida da sessão NAT. Esse recurso entra em vigor depois que o dispositivo detecta o dispositivo NAT.
Procedimento
- Entre na visualização do sistema.
system view- Defina o intervalo IKEv2 NAT keepalive.
ikev2 nat-keepalive secondsPor padrão, o intervalo IKEv2 NAT keepalive é de 10 segundos.
Comandos de exibição e manutenção para IKEv2
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir a configuração da política IKEv2. | exibir política ikev2 [ nome da política | padrão ] |
| Exibir a configuração do perfil IKEv2. | exibir perfil ikev2 [ nome-do-perfil ] |
| Tarefa | Comando |
| Exibir a configuração da proposta IKEv2. | exibir proposta ikev2 [ nome | padrão ] |
| Exibir as informações do IKEv2 SA. | display ikev2 sa [ count | [ { local | remoto } { ipv4-address | ipv6 ipv6-address } ] [ verbose [ tunnel tunnel-id ] ] ] |
| Exibir estatísticas do IKEv2. | exibir estatísticas ikev2 |
| Excluir SAs IKEv2 e as SAs secundárias negociadas por meio das SAs IKEv2. | reset ikev2 sa [ [ { local | remoto } { ipv4-address | ipv6 ipv6-address } ] | tunnel tunnel-id ] [ fast ] |
| Limpar estatísticas do IKEv2. | reset ikev2 statistics |
Solução de problemas do IKEv2
A negociação IKEv2 falhou porque não foram encontradas propostas IKEv2 correspondentes
Sintoma
A SA do IKEv2 está no status IN-NEGO.
<Sysname> display ikev2 sa
Tunnel ID Local Remote Status
---------------------------------------------------------------------------
5 123.234.234.124/500 123.234.234.123/500 IN-NEGO
Status:
IN-NEGO: Negotiating, EST: Established, DEL:DeletingAnálise
Determinadas configurações de proposta IKEv2 estão incorretas.
Solução
- Examine a configuração da proposta IKEv2 para ver se as duas extremidades têm propostas IKEv2 correspondentes.
- Modifique a configuração da proposta IKEv2 para garantir que as duas extremidades tenham propostas IKEv2 correspondentes.
A negociação da SA IPsec falhou porque não foram encontrados conjuntos de transformação IPsec correspondentes
Sintoma
O comando display ikev2 sa mostra que a negociação da SA IKEv2 foi bem-sucedida e que a SA IKEv2 está no status EST. O comando display ipsec sa mostra que as SAs IPsec esperadas ainda não foram negociadas.
Análise
Algumas configurações da política IPsec estão incorretas.
Solução
- Examine a configuração do IPsec para ver se as duas extremidades têm conjuntos correspondentes de transformação do IPsec .
- Modifique a configuração do IPsec para garantir que as duas extremidades tenham conjuntos de transformação IPsec correspondentes.
Falha no estabelecimento do túnel IPsec
Sintoma
As ACLs e as propostas IKEv2 estão configuradas corretamente em ambas as extremidades. As duas extremidades não podem estabelecer um túnel IPsec ou não podem se comunicar por meio do túnel IPsec estabelecido.
Análise
As SAs IKEv2 ou IPsec em ambas as extremidades são perdidas. O motivo pode ser o fato de a rede estar instável e o dispositivo ser reinicializado.
Solução
- Use o comando display ikev2 sa para examinar se existe uma SA IKEv2 em ambas as extremidades. Se a SA IKEv2 em uma extremidade for perdida, exclua a SA IKEv2 na outra extremidade usando o comando reset ikev2 sa e acione uma nova negociação. Se houver uma SA IKEv2 em ambas as extremidades, vá para a próxima etapa.
- Use o comando display ipsec sa para examinar se existem SAs IPsec em ambas as extremidades. Se as SAs de IPsec em uma extremidade forem perdidas, exclua as SAs de IPsec na outra extremidade usando o comando reset ipsec sa e acione uma nova negociação.
Configuração de SSH
Sobre o SSH
O Secure Shell (SSH) é um protocolo de segurança de rede. Usando criptografia e autenticação, o SSH pode implementar acesso remoto seguro e transferência de arquivos em uma rede insegura.
O SSH usa o modelo cliente-servidor típico para estabelecer um canal para transferência segura de dados com base no TCP.
O SSH inclui duas versões: SSH1.x e SSH2.0 (doravante denominadas SSH1 e SSH2), que não são compatíveis. O SSH2 é melhor que o SSH1 em termos de desempenho e segurança.
Aplicativos SSH
O dispositivo é compatível com os seguintes aplicativos SSH:
- Telnet seguro - O Stelnet fornece serviços de acesso a terminais de rede seguros e confiáveis. Por meio da Stelnet, um usuário pode fazer login com segurança em um servidor remoto. A Stelnet pode proteger os dispositivos contra ataques, como falsificação de IP e interceptação de senhas de texto simples. O dispositivo pode atuar como um servidor Stelnet ou um cliente Stelnet.
- Protocolo de transferência segura de arquivos - Baseado no SSH2, o SFTP usa conexões SSH para oferecer transferência segura de arquivos. O dispositivo pode atuar como um servidor SFTP, permitindo que um usuário remoto faça login no servidor SFTP para gerenciamento e transferência seguros de arquivos. O dispositivo também pode atuar como um cliente SFTP, permitindo que um usuário faça login do dispositivo em um dispositivo remoto para transferência segura de arquivos.
- Cópia segura - Baseado no SSH2, o SCP oferece um método seguro para copiar arquivos. O dispositivo pode atuar como um servidor SCP, permitindo que um usuário faça login no dispositivo para fazer upload e download de arquivos. O dispositivo também pode atuar como um cliente SCP, permitindo que um usuário faça login no dispositivo para um dispositivo remoto para transferência segura de arquivos.
- NETCONF sobre SSH - Baseado no SSH2, ele permite que os usuários façam login com segurança no dispositivo por meio do SSH e executem operações NETCONF no dispositivo por meio do
Conexões NETCONF-over-SSH. O dispositivo pode atuar apenas como um servidor NETCONF-over-SSH. Para obter mais informações sobre o NETCONF, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Ao atuar como um servidor ou cliente SSH, o dispositivo é compatível com as seguintes versões de SSH:
- Ao atuar como servidor Stelnet, SFTP ou SCP, o dispositivo suporta SSH2 e SSH1 no modo não-FIPS e somente SSH2 no modo FIPS.
- Ao atuar como um cliente SSH, o dispositivo suporta apenas SSH2.
- Ao atuar como um servidor NETCONF-over-SSH, o dispositivo suporta apenas SSH2.
Como o SSH funciona
Esta seção usa o SSH2 como exemplo para descrever as etapas para estabelecer uma sessão SSH.
Tabela 1 Etapas para estabelecer uma sessão SSH
| Estágios | Descrição |
| Estabelecimento de conexão | O servidor SSH escuta as solicitações de conexão na porta 22. Depois que um cliente inicia uma solicitação de conexão, o servidor e o cliente estabelecem uma conexão TCP. |
| Negociação de versão | As duas partes determinam uma versão a ser usada. |
| Estágios | Descrição |
| Negociação de algoritmos | O SSH é compatível com vários algoritmos. Com base nos algoritmos locais, as duas partes negociam os seguintes algoritmos: Algoritmo de troca de chaves para gerar chaves de sessão. Algoritmo de criptografia para criptografar dados. Algoritmo de chave pública para assinatura digital e autenticação. Algoritmo HMAC para proteger a integridade dos dados. |
| Troca de chaves | As duas partes usam o algoritmo de troca de DH para gerar dinamicamente as chaves de sessão e o ID da sessão. As chaves de sessão são usadas para proteger a transferência de dados. A ID da sessão é usada para identificar a conexão SSH. Nesse estágio, o cliente também autentica o servidor. |
| Autenticação | O servidor SSH autentica o cliente em resposta à solicitação de autenticação do cliente. |
| Solicitação de sessão | Depois de passar pela autenticação, o cliente envia uma solicitação de sessão ao servidor para solicitar o estabelecimento de uma sessão (ou solicitar o serviço Stelnet, SFTP, SCP ou NETCONF). |
| Interação | Depois que o servidor concede a solicitação, o cliente e o servidor começam a se comunicar um com o outro na sessão. Nesse estágio, você pode colar comandos em formato de texto e executá-los na CLI. O texto colado de uma só vez não deve ter mais de 2000 bytes. Como prática recomendada para garantir a execução correta dos comandos, cole comandos que estejam na mesma visualização. Para executar comandos com mais de 2000 bytes, salve os comandos em um arquivo de configuração, carregue o arquivo no servidor por meio de SFTP e use-o para reiniciar o servidor. |
Métodos de autenticação SSH
Esta seção descreve os métodos de autenticação que são compatíveis com o dispositivo quando ele atua como um servidor SSH.
Autenticação por senha
O servidor SSH autentica um cliente por meio do mecanismo AAA. O processo de autenticação de senha é o seguinte:
- O cliente envia ao servidor uma solicitação de autenticação que inclui o nome de usuário criptografado e a senha.
- O servidor executa as seguintes operações:
- Descriptografa a solicitação para obter o nome de usuário e a senha em texto simples.
- Verifica o nome de usuário e a senha localmente ou por meio de autenticação AAA remota.
- Informa o cliente sobre o resultado da autenticação.
Se o servidor AAA remoto exigir que o usuário digite uma senha para autenticação secundária, ele enviará ao servidor SSH uma resposta de autenticação com um prompt. O prompt é transmitido de forma transparente ao cliente para notificar o usuário a digitar uma senha específica. Quando o usuário digita a senha correta, o servidor AAA examina a validade da senha. Se a senha for válida, o servidor SSH retorna uma mensagem de sucesso de autenticação para o cliente.
Os clientes SSH1 não são compatíveis com a autenticação de senha secundária iniciada pelo servidor AAA. Para obter mais informações sobre o AAA, consulte "Configuração do AAA".
Autenticação interativa do teclado
Na autenticação interativa por teclado, o servidor de autenticação remota e o usuário trocam informações sobre para autenticação da seguinte forma:
- O servidor de autenticação remota envia um prompt para o servidor SSH em uma resposta de autenticação .
O prompt indica as informações que devem ser fornecidas pelo usuário.
- O servidor SSH transmite de forma transparente o prompt para o terminal do cliente.
- O usuário insere as informações necessárias conforme solicitado.
Esse processo se repete várias vezes se o servidor de autenticação remota exigir mais informações interativas. O servidor de autenticação remota retorna uma mensagem de sucesso de autenticação depois que o usuário fornece todas as informações interativas necessárias.
Se o servidor de autenticação remota não exigir informações interativas, o processo de autenticação interativa por teclado será igual ao da autenticação por senha.
Autenticação de chave pública
O servidor autentica um cliente verificando a assinatura digital do cliente. O processo de autenticação de chave pública é o seguinte:
- O cliente envia ao servidor uma solicitação de autenticação de chave pública que inclui o nome de usuário, a chave pública e o nome do algoritmo da chave pública.
Se o certificado digital do cliente for exigido na autenticação, o cliente também encapsulará o certificado digital na solicitação de autenticação. O certificado digital contém as informações da chave pública do cliente.
- O servidor verifica a chave pública do cliente.
- Se a chave pública for inválida, o servidor informará ao cliente sobre a falha na autenticação.
- Se a chave pública for válida, o servidor solicitará a assinatura digital do cliente. Após receber a assinatura, o servidor usa a chave pública para verificar a assinatura e informa ao cliente o resultado da autenticação.
Ao atuar como um servidor SSH, o dispositivo suporta o uso dos algoritmos de chave pública DSA, ECDSA e RSA para verificar assinaturas digitais.
Ao atuar como um cliente SSH, o dispositivo suporta o uso dos algoritmos de chave pública DSA, ECDSA e RSA para gerar assinaturas digitais.
Para obter mais informações sobre a configuração de chaves públicas, consulte "Gerenciamento de chaves públicas".
Autenticação por senha e chave pública
O servidor exige que os clientes SSH2 passem tanto pela autenticação de senha quanto pela autenticação de chave pública. No entanto, um cliente SSH1 só precisa passar por uma das autenticações.
Qualquer autenticação
O servidor exige que os clientes passem pela autenticação interativa de teclado, autenticação de senha ou autenticação de chave pública. O sucesso com qualquer um dos métodos de autenticação é suficiente para a conexão com o servidor.
Suporte SSH para a Suíte B
O Suite B contém um conjunto de algoritmos de criptografia e autenticação que atendem a requisitos de alta segurança. A Tabela 2 lista todos os algoritmos do Suite B.
O servidor e o cliente SSH suportam o uso do certificado X.509v3 para autenticação de identidade em conformidade com as especificações de algoritmo, negociação e autenticação definidas na RFC 6239.
Tabela 2 Algoritmos do conjunto B
| Nível de segurança | Algoritmo de troca de chaves | Algoritmo de criptografia e algoritmo HMAC | Algoritmo de chave pública |
| 128 bits | ecdh-sha2-nistp256 | AES128-GCM | x509v3-ecdsa-sha2-nistp256 |
| 192 bits | ecdh-sha2-nistp384 | AES256-GCM | x509v3-ecdsa-sha2-nistp384 |
| Ambos | ecdh-sha2-nistp256 ecdh-sha2-nistp384 | AES128-GCM AES256-GCM | x509v3-ecdsa-sha2-nistp256 x509v3-ecdsa-sha2-nistp384 |
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não-FIPS. Para obter mais informações sobre o modo FIPS, consulte "Configuração de FIPS".
Configuração do dispositivo como um servidor SSH
Visão geral das tarefas do servidor SSH
Para configurar um servidor SSH, execute as seguintes tarefas:
- Geração de pares de chaves locais
- (Opcional.) Especificação da porta de serviço SSH
- Ativação do servidor SSH
- Ativação do servidor Stelnet
- Ativação do servidor SFTP
- Ativação do servidor SCP
- Habilitação do NETCONF por SSH
- Configuração das linhas de usuário para login SSH
- Configuração da chave pública do host de um cliente
Necessário somente para servidores Stelnet e NETCONF-over-SSH.
Necessário para o método de autenticação publickey, password-publickey ou any.
- Configuração de um usuário SSH
- Necessário para o método de autenticação keyboard-interactive, publickey, password-publickey ou any.
- Opcional para o método de autenticação por senha.
- (Opcional.) Configuração dos parâmetros de gerenciamento de SSH
- (Opcional.) Especificação de um domínio PKI para o servidor SSH
- (Opcional.) Desconectar sessões SSH
As configurações de gerenciamento de SSH, como as de autenticação e controle de conexão, ajudam a melhorar a segurança das conexões SSH.
Geração de pares de chaves locais
Sobre pares de chaves locais
Os pares de chaves DSA, ECDSA ou RSA no servidor SSH são necessários para gerar as chaves de sessão e o ID da sessão no estágio de troca de chaves. Eles também podem ser usados por um cliente para autenticar o servidor. Quando um cliente autentica o servidor, ele compara a chave pública recebida do servidor com a chave pública do servidor que o cliente salvou localmente. Se as chaves forem consistentes, o cliente usará a chave pública do servidor salva localmente para descriptografar a assinatura digital recebida do servidor. Se a descriptografia for bem-sucedida, o servidor será aprovado na autenticação.
Para oferecer suporte a clientes SSH que usam diferentes tipos de pares de chaves, gere pares de chaves DSA, ECDSA e RSA no servidor SSH.
- Pares de chaves RSA - O servidor SSH gera um par de chaves de servidor e um par de chaves de host para RSA. O par de chaves do servidor RSA é usado somente no SSH1 para criptografar a chave de sessão para a transmissão segura da chave de sessão. Ele não é usado no SSH2, pois não é necessária nenhuma transmissão de chave de sessão no SSH2.
- Par de chaves DSA - O servidor SSH gera somente um par de chaves de host DSA. O SSH1 não é compatível com o algoritmo DSA.
- Par de chaves ECDSA - O servidor SSH gera apenas um par de chaves de host ECDSA.
Restrições e diretrizes
Os pares de chaves locais DSA, ECDSA e RSA para SSH usam nomes padrão. Não é possível atribuir nomes aos pares de chaves.
Se o dispositivo não tiver pares de chaves RSA com nomes padrão, ele gerará automaticamente um par de chaves de servidor RSA e um par de chaves de host RSA quando o SSH for iniciado. Os dois pares de chaves usam seus nomes padrão. O aplicativo SSH é iniciado quando você executa um comando de servidor SSH no dispositivo.
O comprimento do módulo da chave deve ser inferior a 2048 bits quando você gerar o par de chaves DSA no servidor SSH.
Ao gerar um par de chaves ECDSA, você pode gerar apenas um par de chaves ECDSA secp256r1 ou secp384r1.
O servidor SSH operando no modo FIPS suporta apenas pares de chaves ECDSA e RSA. Não gere um par de chaves DSA no servidor SSH no modo FIPS.
Procedimento
- Entre na visualização do sistema.
system view- Gerar pares de chaves locais.
public-key local create { dsa | ecdsa { secp256r1 | secp384r1 } | rsa }Especificação da porta de serviço SSH
Sobre a porta de serviço SSH
A porta padrão do serviço SSH é 22. Você pode especificar outra porta para o serviço SSH para melhorar a segurança das conexões SSH.
Procedimento
- Entre na visualização do sistema.
system view- Especifique a porta do serviço SSH.
ssh server port port-number CUIDADO:
- Se você modificar o número da porta SSH quando o servidor SSH estiver ativado, o serviço SSH será reiniciado e todas as conexões SSH serão encerradas após a modificação. Os usuários de SSH devem se reconectar ao servidor SSH para acessar o servidor.
- Se você definir a porta SSH como um número de porta conhecido, o serviço que usa o número de porta conhecido
pode não iniciar. Os números de porta bem conhecidos estão no intervalo de 1 a 1024.
Por padrão, a porta de serviço SSH é 22.
Ativação do servidor Stelnet
Sobre a ativação do servidor Stelnet
Depois que você ativar o servidor Stelnet no dispositivo, um cliente poderá fazer login no dispositivo por meio do Stelnet.
Procedimento
- Entre na visualização do sistema.
system view- Habilite o servidor Stelnet.
ssh server enablePor padrão, o servidor Stelnet está desativado.
Ativação do servidor SFTP
Sobre a ativação do servidor SFTP
Depois que você ativar o servidor SFTP no dispositivo, um cliente poderá fazer login no dispositivo por meio do SFTP.
Restrições e diretrizes
Ao atuar como um servidor SFTP, o dispositivo não oferece suporte a conexões SFTP iniciadas por clientes SSH1.
Procedimento
- Entre na visualização do sistema.
system view- Habilite o servidor SFTP.
sftp server enablePor padrão, o servidor SFTP está desativado.
Ativação do servidor SCP
Sobre a ativação do servidor SCP
Depois que você ativar o servidor SCP no dispositivo, um cliente poderá fazer login no dispositivo por meio do SCP.
Restrições e diretrizes
Ao atuar como um servidor SCP, o dispositivo não oferece suporte a conexões SCP iniciadas por clientes SSH1 .
Procedimento
- Entre na visualização do sistema.
system view- Habilite o servidor SCP.
scp server enablePor padrão, o servidor SCP está desativado.
Habilitação do NETCONF por SSH
Sobre a ativação do NETCONF por SSH
Depois que você ativar o NETCONF sobre SSH no dispositivo, um cliente poderá executar operações do NETCONF no dispositivo por meio de uma conexão NETCONF sobre SSH.
Restrições e diretrizes
Ao atuar como servidor na conexão NETCONF-over-SSH, o dispositivo não é compatível com as solicitações de conexão iniciadas por clientes SSH1.
Procedimento
- Entre na visualização do sistema.
system view- Habilite o NETCONF por SSH.
netconf ssh server enablePor padrão, o NETCONF sobre SSH está desativado.
Para obter mais informações sobre os comandos NETCONF sobre SSH, consulte Gerenciamento de rede e Referência de comandos de monitoramento.
Configuração das linhas de usuário para login SSH
Sobre a configuração da linha do usuário para login SSH
Dependendo do aplicativo SSH, um cliente SSH pode ser um cliente Stelnet, cliente SFTP, cliente SCP ou cliente NETCONF-over-SSH.
Somente os clientes Stelnet e NETCONF-over-SSH exigem a configuração da linha do usuário. A configuração da linha do usuário entra em vigor nos clientes no próximo login.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização de linha de usuário VTY.
line vty number [ ending-number ]- Defina o modo de autenticação de login como esquema.
authentication-mode schemePor padrão, o modo de autenticação é a senha.
Para obter mais informações sobre esse comando, consulte Referência de comandos dos fundamentos.
Configuração da chave pública do host de um cliente
Sobre a chave pública do host do cliente
Na autenticação de chave pública, o servidor compara o nome de usuário SSH e a chave pública do host do cliente recebidos do cliente com o nome de usuário SSH salvo localmente e a chave pública do host do cliente. Se forem iguais, o servidor verifica a assinatura digital que o cliente envia. O cliente gera a assinatura digital usando a chave privada que está emparelhada com a chave pública do host do cliente.
Para autenticação por chave pública, autenticação por senha e chave pública ou qualquer autenticação, você deve executar as seguintes tarefas:
- Configure a chave pública do host DSA, ECDSA ou RSA do cliente no servidor.
- Especifique a chave privada do host associada no cliente para gerar a assinatura digital.
Se o dispositivo atuar como um cliente SSH, especifique o algoritmo de chave pública no cliente. O algoritmo determina a chave privada do host associada para gerar a assinatura digital.
Métodos de configuração da chave pública do cliente
Você pode configurar a chave pública do host cliente usando os seguintes métodos:
- Insira manualmente o conteúdo da chave pública do host de um cliente no servidor.
- Exiba a chave pública do host no cliente e registre a chave.
- Digite a chave pública do host do cliente, caractere por caractere, no servidor, ou use o método de copiar e colar.
A chave inserida manualmente deve estar no formato DER sem ser convertida. Para que a chave exibida atenda ao requisito quando o cliente for um dispositivo Intelbras, use a opção de exibição
comando public-key local public. O formato da chave pública exibido de qualquer outra forma (por exemplo, usando o comando public-key local export) pode estar incorreto. Se a chave não estiver no formato correto, o sistema a descartará.
- Importar a chave pública do host do cliente de um arquivo de chave pública.
- Salve o arquivo de chave pública do cliente no servidor. Por exemplo, transfira o arquivo de chave pública do cliente para o servidor em modo binário por meio de FTP ou TFTP.
- Importe a chave pública do cliente do arquivo de chave pública salvo localmente.
Durante o processo de importação, o servidor converte automaticamente a chave pública do host em uma cadeia de caracteres no formato PKCS.
Restrições e diretrizes
Como prática recomendada, configure não mais do que 20 chaves públicas de host de clientes SSH em um servidor SSH. Importe a chave pública do host do cliente como prática recomendada.
Inserção da chave pública do host de um cliente
- Entre na visualização do sistema.
system view- Digite a visualização da chave pública.
public-key peer keyname- Configurar a chave pública do host de um cliente.
Digite o conteúdo da chave pública do host do cliente, caractere por caractere, ou use o método de copiar e colar.
Ao inserir o conteúdo da chave pública do host de um cliente, você pode usar espaços e retornos de carro entre os caracteres, mas o sistema não os salva. Para obter mais informações, consulte "Gerenciamento de chaves públicas".
- Saia da visualização da chave pública e salve a chave.
peer-public-key endImportar a chave pública do host de um cliente do arquivo de chave pública
- Entre na visualização do sistema.
system view- Importar a chave pública de um cliente do arquivo de chave pública.
public-key peer keyname import sshkey filenameConfiguração de um usuário SSH
Sobre o usuário SSH
Configure um usuário SSH e um usuário local, dependendo do método de autenticação.
- Se o método de autenticação for publickey, você deverá criar um usuário SSH e um usuário local no servidor SSH. Os dois usuários devem ter o mesmo nome de usuário, para que o usuário SSH possa receber o diretório de trabalho e a função de usuário corretos.
- Se o método de autenticação for a senha, você deverá executar uma das seguintes tarefas:
- Para autenticação local, configure um usuário local no servidor SSH.
- Para autenticação remota, configure um usuário SSH em um servidor de autenticação remota, por exemplo, um servidor RADIUS.
Não é necessário criar um usuário SSH usando o comando ssh user. No entanto, se quiser exibir todos os usuários SSH, inclusive os usuários SSH somente com senha, para gerenciamento centralizado, poderá usar esse comando para criá-los. Se esse usuário SSH tiver sido criado, certifique-se de ter especificado o tipo de serviço e o método de autenticação corretos.
- Se o método de autenticação for teclado-interativo, senha-chave pública ou qualquer outro, você deverá criar um usuário SSH no servidor SSH e executar uma das seguintes tarefas:
- Para autenticação local, configure um usuário local no servidor SSH.
- Para autenticação remota, configure um usuário SSH em um servidor de autenticação remota, por exemplo, um servidor RADIUS.
Em ambos os casos, o usuário local ou o usuário SSH configurado no servidor de autenticação remoto deve ter o mesmo nome de usuário que o usuário SSH.
Para obter informações sobre a configuração de usuários locais e autenticação remota, consulte "Configuração de AAA".
Restrições e diretrizes
Se você alterar os parâmetros de autenticação de um usuário SSH conectado, a alteração entrará em vigor para o usuário no próximo login.
Quando o dispositivo opera como um servidor SSH no modo FIPS, ele não oferece suporte ao método de autenticação any ou publickey.
Para um usuário SFTP ou SCP, o diretório de trabalho depende do método de autenticação.
- Se o método de autenticação for publickey ou password-publickey, a pasta de trabalho será especificada pelo comando authorization-attribute na visualização do usuário local associado.
- Se o método de autenticação for teclado-interativo ou senha, o diretório de trabalho será autorizado pelo AAA.
Para um usuário SSH, a função do usuário também depende do método de autenticação.
- Se o método de autenticação for publickey ou password-publickey, a função do usuário será especificada pelo comando authorization-attribute na visualização do usuário local associado.
- Se o método de autenticação for teclado-interativo ou senha, a função do usuário será autorizada pelo AAA.
Para todos os métodos de autenticação, exceto a autenticação interativa por teclado e a autenticação por senha, você deve especificar a chave pública ou o certificado digital do host do cliente.
- Para um cliente que envia as informações da chave pública do usuário diretamente para o servidor, especifique a chave pública do host do cliente no servidor. A chave pública especificada já deve existir. Para obter mais informações sobre chaves públicas, consulte "Configuração da chave pública do host de um cliente". Se você especificar várias chaves públicas de cliente, o dispositivo verificará a identidade do usuário usando as chaves públicas na ordem em que foram especificadas. O usuário é válido se for aprovado em uma verificação de chave pública.
- Para um cliente que envia as informações da chave pública do usuário para o servidor por meio de um certificado digital, especifique o domínio de PKI no servidor. Esse domínio de PKI verifica o certificado digital do cliente. Para que a verificação seja bem-sucedida, o domínio PKI especificado deve ter o certificado CA correto. Para
Procedimento
Especifique o domínio da PKI, use o comando ssh user ou ssh server pki-domain. Para obter mais informações sobre a configuração de um domínio de PKI, consulte "Configuração de PKI".
- Entre na visualização do sistema.
system view- Crie um usuário SSH e especifique o tipo de serviço e o método de autenticação. No modo não-FIPS:
ssh user username service-type { all | netconf | scp | sftp | stelnet }
authentication-type { keyboard-interactive | password | { any |
password-publickey | publickey } [ assign { pki-domain domain-name |
publickey keyname&<1-6> } ] }No modo FIPS:
ssh user username service-type { all | netconf | scp | sftp | stelnet }
ssh user username service-type { all | netconf | scp | sftp | stelnet }
authentication-type { keyboard-interactive | password |
password-publickey [ assign { pki-domain domain-name | publickey
keyname&<1-6> } ] }Um servidor SSH suporta até 1024 usuários SSH.
Configuração dos parâmetros de gerenciamento de SSH
Ativação do servidor SSH para dar suporte a clientes SSH1
- Entre na visualização do sistema.
system view- Habilite o servidor SSH para oferecer suporte a clientes SSH1.
ssh server compatible-ssh1x enablePor padrão, o servidor SSH não oferece suporte a clientes SSH1. Esse comando não está disponível no modo FIPS.
Ativação da renegociação do algoritmo SSH e da troca de chaves
- Entre na visualização do sistema.
system view- Habilite a renegociação do algoritmo SSH e a troca de chaves.
ssh server key-re-exchange enable [ interval interval ]Por padrão, a renegociação do algoritmo SSH e a troca de chaves estão desativadas. Esse comando não está disponível no modo FIPS.
O comando entra em vigor somente em novas conexões SSH estabelecidas depois que o comando é configurado e não afeta as conexões SSH existentes.
Definição do intervalo mínimo para atualização do par de chaves do servidor RSA
- Entre na visualização do sistema.
system view- Defina o intervalo mínimo para atualizar o par de chaves do servidor RSA.
ssh server rekey-interval intervalPor padrão, o dispositivo não atualiza o par de chaves do servidor RSA. Esse comando não está disponível no modo FIPS.
Essa configuração entra em vigor somente em clientes SSH1.
Configuração do timer de tempo limite de autenticação do usuário SSH
- Entre na visualização do sistema.
system view- Defina o temporizador de tempo limite de autenticação do usuário SSH.
ssh server authentication-timeout time-out-valueA configuração padrão é 60 segundos.
Execute essa tarefa para evitar a ocupação mal-intencionada de conexões TCP. Se um usuário não terminar a autenticação quando o timer de tempo limite expirar, a conexão não poderá ser estabelecida.
Definição do número máximo de tentativas de autenticação SSH
- Entre na visualização do sistema.
system view- Defina o número máximo de tentativas de autenticação SSH.
ssh server authentication-retries retriesA configuração padrão é 3.
Execute essa tarefa para evitar a invasão mal-intencionada de nomes de usuário e senhas. Se o método de autenticação for qualquer um, o número total de tentativas de autenticação de chave pública e de autenticação de senha não poderá exceder o limite superior.
Especificação de uma ACL de controle de login SSH
- Entre na visualização do sistema.
system view- Especifique uma ACL de controle de login SSH. IPv4:
ssh server acl { advanced-acl-number | basic-acl-number | mac
mac-acl-number }IPv6:
ssh server ipv6 acl { ipv6 { advanced-acl-number | basic-acl-number }
| mac mac-acl-number }Esse recurso usa uma ACL para filtrar clientes SSH que iniciam conexões SSH com o servidor. Por padrão, nenhuma ACL é especificada e todos os usuários de SSH podem iniciar conexões SSH com o servidor.
Ativação do registro de tentativas de login SSH que são negadas pela ACL de controle de login SSH
- Entre na visualização do sistema.
system view- Ative o registro de tentativas de login de SSH que são negadas pela ACL de controle de login de SSH.
ssh server acl-deny-log enablePor padrão, o registro é desativado para tentativas de login que são negadas pela ACL de controle de login do SSH.
Esse comando permite que o SSH gere mensagens de log para tentativas de login do SSH que são negadas pela ACL de controle de login do SSH e envie as mensagens para o centro de informações.
Configuração do valor DSCP nos pacotes que o servidor SSH envia aos clientes SSH
- Entre na visualização do sistema.
system view- Defina o valor DSCP nos pacotes que o servidor SSH envia para os clientes SSH. IPv4:
ssh server dscp dscp-valueIPv6:
ssh server ipv6 dscp dscp-valuePor padrão, o valor DSCP dos pacotes SSH é 48.
O valor DSCP de um pacote define a prioridade do pacote e afeta a prioridade de transmissão do pacote. Um valor DSCP maior representa uma prioridade mais alta.
Configuração do temporizador de tempo limite ocioso da conexão SFTP
- Entre na visualização do sistema.
system view- Defina o temporizador de tempo limite de inatividade da conexão SFTP.
sftp server idle-timeout time-out-valuePor padrão, o tempo limite de inatividade da conexão SFTP é de 10 minutos.
Quando o cronômetro de tempo limite de ociosidade da conexão SFTP expira, o sistema automaticamente interrompe a conexão e libera os recursos da conexão.
Definição do número máximo de usuários SSH on-line
- Entre na visualização do sistema.
system view- Defina o número máximo de usuários SSH on-line.
aaa session-limit ssh max-sessionsA configuração padrão é 32.
Quando o número de usuários de SSH on-line atinge o limite superior, o sistema nega novas solicitações de conexão SSH. A alteração do limite superior não afeta os usuários de SSH on-line.
Para obter mais informações sobre esse comando, consulte Comandos AAA em Referência de comandos de segurança.
Especificação de um domínio PKI para o servidor SSH
Sobre a especificação de um domínio PKI para o servidor SSH
O domínio PKI especificado para o servidor SSH tem as seguintes funções:
- O servidor SSH usa o domínio PKI para enviar seu certificado ao cliente no estágio de troca de chaves.
- O servidor SSH usa o domínio PKI para autenticar o certificado do cliente se nenhum domínio PKI for especificado para a autenticação do cliente usando o comando ssh user.
Procedimento
- Entre na visualização do sistema.
system view- Especifique um domínio PKI para o servidor SSH.
ssh server pki-domain domain-namePor padrão, nenhum domínio PKI é especificado para o servidor SSH.
Desconexão de sessões SSH
Sobre a desconexão de sessões SSH
O dispositivo suporta sessões de login simultâneas. Para evitar que um usuário de login SSH interfira na sua configuração, você pode desconectar esse usuário de login SSH.
Procedimento
Execute o seguinte comando na visualização do usuário para desconectar as sessões SSH:
free ssh { user-ip { ip-address | ipv6 ipv6-address } [ port port-number ] |
user-pid pid-number | username username }Configuração do dispositivo como um cliente Stelnet
Visão geral das tarefas do cliente Stelnet
Para configurar um cliente Stelnet, execute as seguintes tarefas:
- Geração de pares de chaves locais
Necessário somente para o método de autenticação publickey, password-publickey ou any.
- (Opcional.) Especificar o endereço IP de origem para pacotes SSH de saída
- Estabelecimento de uma conexão com um servidor Stelnet
- (Opcional.) Exclusão das chaves públicas do servidor salvas no arquivo de chaves públicas no cliente Stelnet
- (Opcional.) Estabelecimento de uma conexão com um servidor Stelnet baseado na Suíte B
Geração de pares de chaves locais
Sobre a geração de pares de chaves locais
Você deve gerar pares de chaves locais em clientes Stelnet quando o servidor Stelnet usar publickey, password-publickey ou qualquer outro método de autenticação.
Restrições e diretrizes
Os pares de chaves locais DSA, ECDSA e RSA para SSH usam nomes padrão. Não é possível atribuir nomes aos pares de chaves.
O comprimento do módulo da chave deve ser inferior a 2048 bits quando você gera um par de chaves DSA.
Ao gerar um par de chaves ECDSA, você pode gerar apenas um par de chaves ECDSA secp256r1 ou secp384r1.
O cliente Stelnet operando no modo FIPS suporta apenas pares de chaves ECDSA e RSA.
Procedimento
- Entre na visualização do sistema.
system view- Gerar pares de chaves locais.
public-key local create { dsa | ecdsa { secp256r1 | secp384r1 } | rsa }Especificação do endereço IP de origem para pacotes SSH de saída
Sobre a especificação do endereço IP de origem para pacotes SSH de saída
Depois que você especificar o endereço IP de origem para os pacotes SSH de saída em um cliente Stelnet, o cliente usará o endereço IP especificado para se comunicar com o servidor Stelnet.
Restrições e diretrizes
Como prática recomendada, especifique o endereço IP de uma interface de loopback como o endereço de origem dos pacotes SSH de saída para as seguintes finalidades:
- Garantir a comunicação entre o cliente Stelnet e o servidor Stelnet.
- Aprimoramento da capacidade de gerenciamento dos clientes Stelnet no serviço de autenticação.
Procedimento
- Entre na visualização do sistema.
system view- Especifique o endereço de origem dos pacotes SSH de saída. IPv4:
ssh client source { interface interface-type interface-number | ip
ip-address }Por padrão, um cliente Stelnet IPv4 usa o endereço IPv4 primário da interface de saída na rota correspondente como o endereço de origem dos pacotes SSH de saída.
IPv6:
ssh client ipv6 source { interface interface-type interface-number |
ipv6 ipv6-address }Por padrão, um cliente Stelnet IPv6 seleciona automaticamente um endereço IPv6 de origem para pacotes SSH de saída, em conformidade com a RFC 3484.
Estabelecimento de uma conexão com um servidor Stelnet
Sobre como estabelecer uma conexão com um servidor Stelnet
Execute esta tarefa para ativar o recurso de cliente Stelnet no dispositivo e estabelecer uma conexão com o servidor Stelnet. Você pode especificar o algoritmo de chave pública e os algoritmos preferenciais de criptografia, HMAC e troca de chaves a serem usados durante a conexão.
Para acessar o servidor, um cliente deve usar a chave pública do host do servidor para autenticar o servidor. Como prática recomendada, configure a chave pública do host do servidor no dispositivo em uma rede insegura. Se a chave pública do host do servidor não estiver configurada no cliente, o cliente o notificará para confirmar se deseja continuar com o acesso.
- Se você optar por continuar, o cliente acessará o servidor e fará o download da chave pública do host do servidor. A chave pública baixada será usada para autenticar o servidor nos acessos subsequentes.
Se a chave pública do servidor não for especificada, quando você se conectar ao servidor, o dispositivo salvará a chave pública do servidor no arquivo de chave pública. Ele não salva a chave pública do servidor no arquivo de configuração.
- Se você optar por não continuar, a conexão não poderá ser estabelecida.
Restrições e diretrizes para estabelecer uma conexão com um servidor Stelnet
Um cliente Stelnet não pode estabelecer conexões com servidores Stelnet IPv4 e IPv6.
Estabelecimento de uma conexão com um servidor Stelnet IPv4
Execute o seguinte comando na visualização do usuário para estabelecer uma conexão com um servidor Stelnet IPv4: No modo não-FIPS:
<ssh2 server [ port-number ] [ identity-key { dsa | ecdsa-sha2-nistp256 |
ecdsa-sha2-nistp384 | rsa | { x509v3-ecdsa-sha2-nistp256 |
x509v3-ecdsa-sha2-nistp384 } pki-domain domain-name } | prefer-compress
zlib | prefer-ctos-cipher { 3des-cbc | aes128-cbc | aes128-ctr | aes128-gcm
| aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm | des-cbc } |
prefer-ctos-hmac { md5 | md5-96 | sha1 | sha1-96 | sha2-256 | sha2-512 } |
prefer-kex { dh-group-exchange-sha1 | dh-group1-sha1 | dh-group14-sha1 |
ecdh-sha2-nistp256 | ecdh-sha2-nistp384 } | prefer-stoc-cipher { 3des-cbc
| aes128-cbc | aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc |
aes256-ctr | aes256-gcm | des-cbc } | prefer-stoc-hmac { md5 | md5-96 | sha1
| sha1-96 | sha2-256 | sha2-512 } ] * [ dscp dscp-value | escape character |
{ public-key keyname | server-pki-domain domain-name } | source { interface
interface-type interface-number | ip ip-address } ] *
No modo FIPS:
ssh2 server [ port-number ] [ identity-key { ecdsa-sha2-nistp256 |
ecdsa-sha2-nistp384 | rsa | { x509v3-ecdsa-sha2-nistp256 |
x509v3-ecdsa-sha2-nistp384 } pki-domain domain-name } | prefer-compress
zlib | prefer-ctos-cipher { aes128-cbc | aes128-ctr | aes128-gcm |
aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm } | prefer-ctos-hmac
{ sha1 | sha1-96 | sha2-256 | sha2-512 } | prefer-kex { dh-group14-sha1 |
ecdh-sha2-nistp256 | ecdh-sha2-nistp384 } | prefer-stoc-cipher
{ aes128-cbc | aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc |
aes256-ctr | aes256-gcm } | prefer-stoc-hmac { sha1 | sha1-96 | sha2-256 |
sha2-512 } ] * [ escape character | { public-key keyname | server-pki-domain
domain-name } | source { interface interface-type interface-number | ip
ip-address } ] *Estabelecimento de uma conexão com um servidor Stelnet IPv6
Execute o seguinte comando na visualização do usuário para estabelecer uma conexão com um servidor Stelnet IPv6: No modo não-FIPS:
ssh2 ipv6 server [ port-number ] [ -i interface-type interface-number ]
[ identity-key { dsa | ecdsa-sha2-nistp256 | ecdsa-sha2-nistp384 | rsa |
{ x509v3-ecdsa-sha2-nistp256 | x509v3-ecdsa-sha2-nistp384 } pki-domain
domain-name } | prefer-compress zlib | prefer-ctos-cipher { 3des-cbc |
aes128-cbc | aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc | aes256-ctr
| aes256-gcm | des-cbc } | prefer-ctos-hmac { md5 | md5-96 | sha1 | sha1-96 |
sha2-256 | sha2-512 } | prefer-kex { dh-group-exchange-sha1 |
dh-group1-sha1 | dh-group14-sha1 | ecdh-sha2-nistp256 |
ecdh-sha2-nistp384 } | prefer-stoc-cipher { 3des-cbc | aes128-cbc |
aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm
| des-cbc } | prefer-stoc-hmac { md5 | md5-96 | sha1 | sha1-96 | sha2-256 |
sha2-512 } ] * [ dscp dscp-value | escape character | { public-key keyname |
server-pki-domain domain-name } | source { interface interface-type
interface-number | ipv6 ipv6-address } ] *No modo FIPS:
ssh2 ipv6 server [ port-number ] [ -i interface-type interface-number ]
[ identity-key { ecdsa-sha2-nistp256 | ecdsa-sha2-nistp384 | rsa |
{ x509v3-ecdsa-sha2-nistp256 | x509v3-ecdsa-sha2-nistp384 } pki-domain
domain-name } | prefer-compress zlib | prefer-ctos-cipher { aes128-cbc |
aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm }
| prefer-ctos-hmac { sha1 | sha1-96 | sha2-256 | sha2-512 } | prefer-kex
{ dh-group14-sha1 | ecdh-sha2-nistp256 | ecdh-sha2-nistp384 } |
prefer-stoc-cipher { aes128-cbc | aes128-ctr | aes128-gcm | aes192-ctr |
aes256-cbc | aes256-ctr | aes256-gcm } | prefer-stoc-hmac { sha1 | sha1-96
| sha2-256 | sha2-512 } ] * [ escape character | { public-key keyname |
server-pki-domain domain-name } | source { interface interface-type
interface-number | ipv6 ipv6-address } ] *
Exclusão das chaves públicas do servidor salvas no arquivo de chaves públicas no cliente Stelnet
Sobre a exclusão de chaves públicas do servidor salvas no arquivo de chaves públicas no cliente Stelnet
Quando o cliente Stelnet alterna para o modo FIPS, mas a chave pública do servidor salva localmente não está em conformidade com o FIPS, o cliente não pode se conectar ao servidor. Para se conectar ao servidor, exclua a chave pública do servidor salva no cliente e certifique-se de que uma chave pública compatível com FIPS tenha sido gerada no servidor.
Procedimento
- Entre na visualização do sistema.
system view- Exclua as chaves públicas do servidor salvas no arquivo de chaves públicas no cliente Stelnet.
delete ssh client server-public-key [ server-ip ip-address ]Estabelecimento de uma conexão com um servidor Stelnet baseado no Suite B
Execute o seguinte comando na visualização do usuário para estabelecer uma conexão com um servidor Stelnet baseado no Suite B:
IPv4:
ssh2 server [ port-number ] suite-b [ 128-bit | 192-bit ] pki-domain
domain-name [ server-pki-domain domain-name ] [ prefer-compress zlib ]
[ dscp dscp-value | escape character | source { interface interface-type
interface-number | ip ip-address } ] *
IPv6:
ssh2 ipv6 server [ port-number ] [ -i interface-type interface-number ]
suite-b [ 128-bit | 192-bit ] pki-domain domain-name [ server-pki-domain
domain-name ] [ prefer-compress zlib ] [ dscp dscp-value | escape character |
source { interface interface-type interface-number | ipv6 ipv6-address } ] *
Configuração do dispositivo como um cliente SFTP
Visão geral das tarefas do cliente SFTP
Para configurar um cliente SFTP, execute as seguintes tarefas:
- Geração de pares de chaves locais
Necessário apenas para o método de autenticação publickey, password-publickey ou any.
- (Opcional.) Especificar o endereço IP de origem para pacotes SFTP de saída
- Estabelecimento de uma conexão com um servidor SFTP
- (Opcional.) Exclusão das chaves públicas do servidor salvas no arquivo de chaves públicas no cliente SFTP
- (Opcional.) Estabelecimento de uma conexão com um servidor SFTP baseado na Suíte B
- (Opcional.) Trabalho com diretórios SFTP
- (Opcional.) Trabalho com arquivos SFTP
- (Opcional.) Exibir informações de ajuda
- (Opcional.) Encerrar a conexão com o servidor SFTP
Geração de pares de chaves locais
Sobre a geração de pares de chaves locais
Você deve gerar pares de chaves locais nos clientes SFTP quando o servidor SFTP usar a chave pública, a senha-chave pública ou qualquer outro método de autenticação.
Restrições e diretrizes
Os pares de chaves locais DSA, ECDSA e RSA para SSH usam nomes padrão. Não é possível atribuir nomes aos pares de chaves.
O comprimento do módulo da chave deve ser inferior a 2048 bits quando você gera um par de chaves DSA.
Ao gerar um par de chaves ECDSA, você pode gerar apenas um secp256r1 ou secp384r1
Par de chaves ECDSA.
O cliente SFTP operando no modo FIPS suporta apenas pares de chaves ECDSA e RSA.
Procedimento
- Entre na visualização do sistema.
system view- Gerar pares de chaves locais.
public-key local create { dsa | ecdsa { secp256r1 | secp384r1 } | rsa }Especificação do endereço IP de origem para pacotes SFTP de saída
Sobre a especificação do endereço IP de origem para pacotes SFTP de saída
Depois que você especificar o endereço IP de origem para os pacotes SFTP de saída em um cliente SFTP, o cliente usará o endereço IP especificado para se comunicar com o servidor SFTP.
Restrições e diretrizes
Como prática recomendada, especifique o endereço IP de uma interface de loopback como o endereço de origem dos pacotes SFTP de saída para as seguintes finalidades:
- Garantir a comunicação entre o cliente SFTP e o servidor SFTP.
- Aprimoramento da capacidade de gerenciamento de clientes SFTP no serviço de autenticação.
Procedimento
- Entre na visualização do sistema.
system view- Especifique o endereço de origem dos pacotes SFTP de saída. IPv4:
sftp client source { ip ip-address | interface interface-type
interface-number }Por padrão, um cliente SFTP usa o endereço IPv4 primário da interface de saída na rota correspondente como o endereço de origem dos pacotes SFTP de saída.
IPv6:
sftp client ipv6 source { ipv6 ipv6-address | interface interface-type
interface-number }Por padrão, um cliente SFTP IPv6 seleciona automaticamente um endereço IPv6 de origem para os pacotes SFTP de saída, em conformidade com a RFC 3484.
Estabelecimento de uma conexão com um servidor SFTP
Sobre como estabelecer uma conexão com um servidor SFTP
Execute esta tarefa para ativar o recurso de cliente SFTP no dispositivo e estabelecer uma conexão com o servidor SFTP. Você pode especificar o algoritmo de chave pública e os algoritmos preferenciais de criptografia, HMAC e troca de chaves a serem usados durante a conexão.
Para acessar o servidor, um cliente deve usar a chave pública do host do servidor para autenticar o servidor. Como prática recomendada, configure a chave pública do host do servidor no dispositivo em uma rede insegura. Se a chave pública do host do servidor não estiver configurada no cliente, o cliente o notificará para confirmar se deseja continuar com o acesso.
- Se você optar por continuar, o cliente acessará o servidor e fará o download da chave pública do host do servidor. A chave pública baixada será usada para autenticar o servidor nos acessos subsequentes.
Se a chave pública do servidor não for especificada quando você se conectar ao servidor, o dispositivo salvará a chave pública do servidor no arquivo de chave pública. Ele não salva a chave pública do servidor no arquivo de configuração.
- Se você optar por não continuar, a conexão não poderá ser estabelecida.
Restrições e diretrizes para estabelecer uma conexão com um servidor SFTP
Um cliente SFTP não pode estabelecer conexões com servidores SFTP IPv4 e IPv6.
Estabelecimento de uma conexão com um servidor SFTP IPv4
Execute o seguinte comando na visualização do usuário para estabelecer uma conexão com um servidor SFTP IPv4: No modo não-FIPS:
sftp server [ port-number ] [ identity-key { dsa | ecdsa-sha2-nistp256 |
ecdsa-sha2-nistp384 | rsa | { x509v3-ecdsa-sha2-nistp256 |
x509v3-ecdsa-sha2-nistp384 } pki-domain domain-name } | prefer-compress
zlib | prefer-ctos-cipher { 3des-cbc | aes128-cbc | aes128-ctr | aes128-gcm
| aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm | des-cbc } |
prefer-ctos-hmac { md5 | md5-96 | sha1 | sha1-96 | sha2-256 | sha2-512 } |
prefer-kex { dh-group-exchange-sha1 | dh-group1-sha1 | dh-group14-sha1 |
ecdh-sha2-nistp256 | ecdh-sha2-nistp384 } | prefer-stoc-cipher { 3des-cbc
| aes128-cbc | aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc |
aes256-ctr | aes256-gcm | des-cbc } | prefer-stoc-hmac { md5 | md5-96 | sha1
| sha1-96 | sha2-256 | sha2-512 } ] * [ dscp dscp-value | { public-key keyname
| server-pki-domain domain-name } | source { interface interface-type
interface-number | ip ip-address } ] *}No modo FIPS:
sftp server [ port-number ] [ identity-key { ecdsa-sha2-nistp256 |
ecdsa-sha2-nistp384 | rsa | { x509v3-ecdsa-sha2-nistp256 |
x509v3-ecdsa-sha2-nistp384 } pki-domain domain-name } | prefer-compress
zlib | prefer-ctos-cipher { aes128-cbc | aes128-ctr | aes128-gcm |
aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm } | prefer-ctos-hmac
{ sha1 | sha1-96 | sha2-256 | sha2-512 } | prefer-kex { dh-group14-sha1 |
ecdh-sha2-nistp256 | ecdh-sha2-nistp384 } | prefer-stoc-cipher
{ aes128-cbc | aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc |
aes256-ctr | aes256-gcm } | prefer-stoc-hmac { sha1 | sha1-96 | sha2-256 |
sha2-512 } ] * [ { public-key keyname | server-pki-domain domain-name } |
source { interface interface-type interface-number | ip ip-address } ] *
Estabelecimento de uma conexão com um servidor SFTP IPv6
Execute o seguinte comando na visualização do usuário para estabelecer uma conexão com um servidor SFTP IPv6:
No modo não-FIPS:
sftp ipv6 server [ port-number ] [ -i interface-type interface-number ]
[ identity-key { dsa | ecdsa-sha2-nistp256 | ecdsa-sha2-nistp384 | rsa |
{ x509v3-ecdsa-sha2-nistp256 | x509v3-ecdsa-sha2-nistp384 } pki-domain
domain-name } | prefer-compress zlib | prefer-ctos-cipher { 3des-cbc |
aes128-cbc | aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc | aes256-ctr
| aes256-gcm | des-cbc } | prefer-ctos-hmac { md5 | md5-96 | sha1 | sha1-96 |
sha2-256 | sha2-512 } | prefer-kex { dh-group-exchange-sha1 |
dh-group1-sha1 | dh-group14-sha1 | ecdh-sha2-nistp256 |
ecdh-sha2-nistp384 } | prefer-stoc-cipher { 3des-cbc | aes128-cbc |
aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm
| des-cbc } | prefer-stoc-hmac { md5 | md5-96 | sha1 | sha1-96 | sha2-256 |
sha2-512 } ] * [ dscp dscp-value | { public-key keyname | server-pki-domain
domain-name } | source { interface interface-type interface-number | ipv6
ipv6-address } ] *No modo FIPS:
sftp ipv6 server [ port-number ] [ -i interface-type interface-number ]
[ identity-key { ecdsa-sha2-nistp256 | ecdsa-sha2-nistp384 | rsa |
{ x509v3-ecdsa-sha2-nistp256 | x509v3-ecdsa-sha2-nistp384 } pki-domain
domain-name } | prefer-compress zlib | prefer-ctos-cipher { aes128-cbc |
aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm }
| prefer-ctos-hmac { sha1 | sha1-96 | sha2-256 | sha2-512 } | prefer-kex
{ dh-group14-sha1 | ecdh-sha2-nistp256 | ecdh-sha2-nistp384 } |
prefer-stoc-cipher { aes128-cbc | aes128-ctr | aes128-gcm | aes192-ctr |
aes256-cbc | aes256-ctr | aes256-gcm } | prefer-stoc-hmac { sha1 | sha1-96 |
sha2-256 | sha2-512 } ] * [ { public-key keyname | server-pki-domain
domain-name } | source { interface interface-type interface-number | ipv6
ipv6-address } ] *Exclusão das chaves públicas do servidor salvas no arquivo de chaves públicas no cliente SFTP
Sobre a exclusão de chaves públicas do servidor salvas no arquivo de chaves públicas no cliente SFTP
Quando o cliente SFTP alterna para o modo FIPS, mas a chave pública do servidor salva localmente não está em conformidade com o FIPS, o cliente não pode se conectar ao servidor. Para se conectar ao servidor, exclua a chave pública do servidor salva no cliente e certifique-se de que uma chave pública compatível com FIPS tenha sido gerada no servidor.
Procedimento
- Entre na visualização do sistema.
system view- Exclua as chaves públicas do servidor salvas no arquivo de chaves públicas no cliente SFTP.
delete ssh client server-public-key [ server-ip ip-address ]Estabelecimento de uma conexão com um servidor SFTP baseado no Suite B
Execute o seguinte comando na visualização do usuário para estabelecer uma conexão com um servidor SFTP baseado no Suite B:
IPv4:
sftp server [ port-number ] suite-b [ 128-bit | 192-bit ] pki-domain
domain-name [ server-pki-domain domain-name ] [ prefer-compress zlib ]
[ dscp dscp-value | source { interface interface-type interface-number | ip
ip-address } ] *IPv6:
sftp ipv6 server [ port-number ] [ -i interface-type interface-number ]
suite-b [ 128-bit | 192-bit ] pki-domain domain-name [ server-pki-domain
domain-name ] [ prefer-compress zlib ] [ dscp dscp-value | escape character |
source { interface interface-type interface-number | ipv6 ipv6-address } ] *Trabalho com diretórios SFTP
Sobre as operações de diretório SFTP
Depois de estabelecer uma conexão com um servidor SFTP, você pode operar os diretórios do servidor SFTP.
Alteração do diretório de trabalho no servidor SFTP
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Altere o diretório de trabalho no servidor SFTP.
cd [ remote-path ]- (Opcional.) Retorne ao diretório de nível superior.
cdupExibição do diretório de trabalho atual no servidor SFTP
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Exibir o diretório de trabalho atual no servidor SFTP.
pwdExibição de arquivos em um diretório
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Exibir arquivos em um diretório.
- dir [ -a | -l ] [ caminho remoto ]
- ls [ -a | -l ] [ caminho remoto ]
O comando dir tem a mesma função que o comando ls.
Alteração do nome de um diretório no servidor SFTP
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Altere o nome de um diretório no servidor SFTP.
rename oldname newnameCriação de um novo diretório no servidor SFTP
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Crie um novo diretório no servidor SFTP.
mkdir remote-pathExclusão de diretórios no servidor SFTP
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Excluir um ou mais diretórios do servidor SFTP.
rmdir remote-pathTrabalho com arquivos SFTP
Sobre as operações de arquivos SFTP
Depois de estabelecer uma conexão com um servidor SFTP, você pode operar arquivos no servidor SFTP.
Alteração do nome de um arquivo no servidor SFTP
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Alterar o nome de um arquivo no servidor SFTP.
rename old-name new-nameFazer download de um arquivo do servidor SFTP e salvá-lo localmente
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Faça o download de um arquivo do servidor SFTP e salve-o localmente.
get remote-file [ local-file ]Carregamento de um arquivo local para o servidor SFTP
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Faça upload de um arquivo local para o servidor SFTP.
put local-file [ remote-file ]Exibir arquivos em um diretório
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Exibir arquivos em um diretório.
- dir [ -a | -l ] [ caminho remoto ]
- ls [ -a | -l ] [ caminho remoto ]
O comando dir tem a mesma função que o comando ls.
Exclusão de um arquivo do servidor SFTP
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Excluir um arquivo do servidor SFTP.
- delete remote-file
- remove remote-file
O comando delete tem a mesma função que o comando remove.
Exibição de informações de ajuda
Sobre a exibição de informações de ajuda
Depois de estabelecer uma conexão com o servidor SFTP, você pode exibir as informações de ajuda dos comandos do cliente SFTP, inclusive a sintaxe do comando e a configuração dos parâmetros.
Procedimento
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Exibir informações de ajuda do comando do cliente SFTP.
- help
- ?
O comando de ajuda tem a mesma função que o comando ?
Encerrar a conexão com o servidor SFTP
- Entre na visualização do cliente SFTP.
Para obter mais informações, consulte "Estabelecimento de uma conexão com um servidor SFTP".
- Encerre a conexão com o servidor SFTP e retorne à visualização do usuário.
- bye
- exit
- quit
Os três comandos têm a mesma função.
Configuração do dispositivo como um cliente SCP
Visão geral das tarefas do cliente SCP
Para configurar um cliente SCP, execute as seguintes tarefas:
- Geração de pares de chaves locais
Necessário somente para publickey, password-publickey ou qualquer método de autenticação.
- (Opcional.) Especificar o endereço IP de origem para pacotes SCP de saída
- Estabelecimento de uma conexão com um servidor SCP
- (Opcional.) Exclusão das chaves públicas do servidor salvas no arquivo de chaves públicas no cliente SCP
- (Opcional.) Estabelecimento de uma conexão com um servidor SCP com base na Suíte B
Geração de pares de chaves locais
Sobre a geração de pares de chaves locais
Você deve gerar pares de chaves locais nos clientes SCP quando o servidor SCP usar a chave pública, a senha-chave pública ou qualquer outro método de autenticação.
Restrições e diretrizes
Os pares de chaves locais DSA, ECDSA e RSA para SSH usam nomes padrão. Não é possível atribuir nomes aos pares de chaves.
O comprimento do módulo da chave deve ser inferior a 2048 bits quando você gera um par de chaves DSA.
Ao gerar um par de chaves ECDSA, você pode gerar apenas um secp256r1 ou secp384r1
Par de chaves ECDSA.
O cliente SCP operando no modo FIPS suporta apenas pares de chaves ECDSA e RSA.
Procedimento
- Entre na visualização do sistema.
system view- Gerar pares de chaves locais.
public-key local create { dsa | ecdsa { secp256r1 | secp384r1 } | rsa }Especificação do endereço IP de origem para pacotes SCP de saída
Sobre a especificação do endereço IP de origem para pacotes SCP de saída
Depois que você especificar o endereço IP de origem para os pacotes SCP de saída em um cliente SCP, o cliente usará o endereço IP especificado para se comunicar com o servidor SCP.
Restrições e diretrizes
Como prática recomendada, especifique o endereço IP de uma interface de loopback como o endereço de origem dos pacotes SCP de saída para as seguintes finalidades:
- Garantir a comunicação entre o cliente SCP e o servidor SCP.
- Aprimoramento da capacidade de gerenciamento de clientes SCP no serviço de autenticação.
Procedimento
- Entre na visualização do sistema.
system view- Especifique o endereço de origem dos pacotes SCP de saída. IPv4:
scp client source { interface interface-type interface-number | ip
ip-address }Por padrão, um cliente SCP usa o endereço IPv4 primário da interface de saída na rota correspondente como o endereço de origem dos pacotes SCP de saída.
IPv6:
scp client ipv6 source { interface interface-type interface-number
| ipv6 ipv6-address }Por padrão, um cliente SCP seleciona automaticamente um endereço IPv6 como o endereço de origem dos pacotes de saída, em conformidade com a RFC 3484.
Estabelecimento de uma conexão com um servidor SCP
Sobre como estabelecer uma conexão com um servidor SCP
Execute esta tarefa para ativar o recurso de cliente SCP no dispositivo, estabelecer uma conexão com o servidor SCP e transferir arquivos com o servidor. Você pode especificar o algoritmo de chave pública e os algoritmos preferenciais de criptografia, HMAC e troca de chaves a serem usados durante a conexão.
Para acessar o servidor, um cliente deve usar a chave pública do host do servidor para autenticar o servidor. Como prática recomendada, configure a chave pública do host do servidor no dispositivo em uma rede insegura. Se a chave pública do host do servidor não estiver configurada no cliente, o cliente o notificará para confirmar se deseja continuar com o acesso.
- Se você optar por continuar, o cliente acessará o servidor e fará o download da chave pública do host do servidor. A chave pública baixada será usada para autenticar o servidor nos acessos subsequentes.
Se a chave pública do servidor não for especificada quando você se conectar ao servidor, o dispositivo salvará a chave pública do servidor no arquivo de chave pública. Ele não salva a chave pública do servidor no arquivo de configuração.
- Se você optar por não continuar, a conexão não poderá ser estabelecida.
Restrições e diretrizes para estabelecer uma conexão com um servidor SCP
Um cliente SCP não pode estabelecer conexões com servidores SCP IPv4 e IPv6.
Estabelecimento de uma conexão com um servidor SCP IPv4
Execute o seguinte comando na visualização do usuário para se conectar a um servidor SCP IPv4 e transferir arquivos com o servidor:
No modo não-FIPS:
scp server [ port-number ] { put | get } source-file-name
[ destination-file-name ] [ identity-key { dsa | ecdsa-sha2-nistp256 |
ecdsa-sha2-nistp384 | rsa | { x509v3-ecdsa-sha2-nistp256 |
x509v3-ecdsa-sha2-nistp384 } pki-domain domain-name } | prefer-compress
zlib | prefer-ctos-cipher { 3des-cbc | aes128-cbc | aes128-ctr | aes128-gcm
| aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm | des-cbc } |
prefer-ctos-hmac { md5 | md5-96 | sha1 | sha1-96 | sha2-256 | sha2-512 } |
prefer-kex { dh-group-exchange-sha1 | dh-group1-sha1 | dh-group14-sha1 |
ecdh-sha2-nistp256 | ecdh-sha2-nistp384 } | prefer-stoc-cipher { 3des-cbc
| aes128-cbc | aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc |
aes256-ctr | aes256-gcm | des-cbc } | prefer-stoc-hmac { md5 | md5-96 | sha1
| sha1-96 | sha2-256 | sha2-512 } ] * [ { public-key keyname |
server-pki-domain domain-name } | source { interface interface-type
interface-number | ip ip-address } ] * [ user username [ password password ] ]No modo FIPS:
[ destination-file-name ] [ identity-key { ecdsa-sha2-nistp256 |
ecdsa-sha2-nistp384 | rsa | { x509v3-ecdsa-sha2-nistp256 |
x509v3-ecdsa-sha2-nistp384 } pki-domain domain-name } | prefer-compress
zlib | prefer-ctos-cipher { aes128-cbc | aes128-ctr | aes128-gcm |
aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm } | prefer-ctos-hmac
{ sha1 | sha1-96 | sha2-256 | sha2-512 } | prefer-kex { dh-group14-sha1 |
ecdh-sha2-nistp256 | ecdh-sha2-nistp384 } | prefer-stoc-cipher
{ aes128-cbc | aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc |
aes256-ctr | aes256-gcm } | prefer-stoc-hmac { sha1 | sha1-96 | sha2-256 |
sha2-512 } ] * [ { public-key keyname | server-pki-domain domain-name } |
source { interface interface-type interface-number | ip ip-address } ] *
[ user username [ password password ] ]Estabelecimento de uma conexão com um servidor SCP IPv6
Execute o seguinte comando na visualização do usuário para se conectar a um servidor SCP IPv6 e transferir arquivos com o servidor.
No modo não-FIPS:
scp ipv6 server [ port-number ] [ -i interface-type interface-number ] { put
| get } source-file-name [ destination-file-name ] [ identity-key { dsa |
ecdsa-sha2-nistp256 | ecdsa-sha2-nistp384 | rsa |
{ x509v3-ecdsa-sha2-nistp256 | x509v3-ecdsa-sha2-nistp384 } pki-domain
domain-name } | prefer-compress zlib | prefer-ctos-cipher { 3des-cbc |
aes128-cbc | aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc | aes256-ctr
| aes256-gcm | des-cbc } | prefer-ctos-hmac { md5 | md5-96 | sha1 | sha1-96 |
sha2-256 | sha2-512 } | prefer-kex { dh-group-exchange-sha1 |
dh-group1-sha1 | dh-group14-sha1 | ecdh-sha2-nistp256 |
ecdh-sha2-nistp384 } | prefer-stoc-cipher { 3des-cbc | aes128-cbc |
aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm
| des-cbc } | prefer-stoc-hmac { md5 | md5-96 | sha1 | sha1-96 | sha2-256 |
sha2-512 } ] * [ { public-key keyname | server-pki-domain domain-name } |
source { interface interface-type interface-number | ipv6 ipv6-address } ]
* [ user username [ password password ] ]No modo FIPS:
scp ipv6 server [ port-number ] [ -i interface-type interface-number ] { put
| get } source-file-name [ destination-file-name ] [ identity-key
{ ecdsa-sha2-nistp256 | ecdsa-sha2-nistp384 | rsa |
{ x509v3-ecdsa-sha2-nistp256 | x509v3-ecdsa-sha2-nistp384 } pki-domain
domain-name } | prefer-compress zlib | prefer-ctos-cipher { aes128-cbc |
aes128-ctr | aes128-gcm | aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm }
| prefer-ctos-hmac { sha1 | sha1-96 | sha2-256 | sha2-512 } | prefer-kex
{ dh-group14-sha1 | ecdh-sha2-nistp256 | ecdh-sha2-nistp384 } |
prefer-stoc-cipher { aes128-cbc | aes128-ctr | aes128-gcm | aes192-ctr |
aes256-cbc | aes256-ctr | aes256-gcm } | prefer-stoc-hmac { sha1 | sha1-96
| sha2-256 | sha2-512 } ] * [ { public-key keyname | server-pki-domain
domain-name } | source { interface interface-type interface-number | ipv6
ipv6-address } ] * [ user username [ password password ] ]Exclusão das chaves públicas do servidor salvas no arquivo de chaves públicas no cliente SCP
Sobre a exclusão de chaves públicas do servidor salvas no arquivo de chaves públicas no cliente SCP
Quando o cliente SCP alterna para o modo FIPS, mas a chave pública do servidor salva localmente não está em conformidade com o FIPS, o cliente não pode se conectar ao servidor. Para se conectar ao servidor, exclua a chave pública do servidor salva no cliente e certifique-se de que uma chave pública em conformidade com o FIPS tenha sido gerada no servidor.
Procedimento
- Entre na visualização do sistema.
system view- Exclua as chaves públicas do servidor salvas no arquivo de chaves públicas no cliente SCP.
delete ssh client server-public-key [ server-ip ip-address ]Estabelecimento de uma conexão com um servidor SCP baseado no Suite B
Execute o seguinte comando na visualização do usuário para estabelecer uma conexão com um servidor SCP baseado no Suite B:
IPv4:
scp server [ port-number ] { put | get } source-file-name
[ destination-file-name ] suite-b [ 128-bit | 192-bit ] pki-domain
domain-name [ server-pki-domain domain-name ] [ prefer-compress zlib ]
[ source { interface interface-type interface-number | ip ip-address } ] *
[ user username [ password password ] ]IPv6:
scp ipv6 server [ port-number ] [ -i interface-type interface-number ] { put
| get } source-file-name [ destination-file-name ] suite-b [ 128-bit |
192-bit ] pki-domain domain-name [ server-pki-domain domain-name ]
[ prefer-compress zlib ] [ source { interface interface-type
interface-number | ipv6 ipv6-address } ] * [ user username [ password
password ] ]Especificação de algoritmos para SSH2
Sobre algoritmos para SSH2
O cliente e o servidor SSH2 usam os seguintes tipos de algoritmos para negociação de algoritmos durante o estabelecimento da sessão Stelnet, SFTP ou SCP:
- Algoritmos de troca de chaves.
- Algoritmos de chave pública.
- Algoritmos de criptografia.
- Algoritmos MAC.
Se você especificar os algoritmos, o SSH2 usará somente os algoritmos especificados para a negociação de algoritmos. O cliente usa os algoritmos especificados para iniciar a negociação, e o servidor usa os algoritmos correspondentes para negociar com o cliente. Se forem especificados vários algoritmos do mesmo tipo, o algoritmo especificado anteriormente terá prioridade mais alta durante a negociação.
Especificação de algoritmos de troca de chaves para SSH2
- Entre na visualização do sistema.
system view- Especifique os algoritmos de troca de chaves para SSH2. No modo não-FIPS:
ssh2 algorithm key-exchange { dh-group-exchange-sha1 | dh-group1-sha1
| dh-group14-sha1 | ecdh-sha2-nistp256 | ecdh-sha2-nistp384 } *Por padrão, o SSH2 usa o ecdh-sha2-nistp256, ecdh-sha2-nistp384,
algoritmos de troca de chaves dh-group-exchange-sha1, dh-group14-sha1 e dh-group1-sha1 em ordem decrescente de prioridade para negociação de algoritmos.
No modo FIPS:
ssh2 algorithm key-exchange { dh-group14-sha1 | ecdh-sha2-nistp256 |
ecdh-sha2-nistp384 } **Por padrão, o SSH2 usa os protocolos ecdh-sha2-nistp256, ecdh-sha2-nistp384 e
algoritmos de troca de chaves dh-group14-sha1 em ordem decrescente de prioridade para negociação de algoritmos.
Especificação de algoritmos de chave pública para SSH2
- Entre na visualização do sistema.
system view- Especifique os algoritmos de chave pública para SSH2. No modo não-FIPS:
ssh2 algorithm public-key { dsa | ecdsa-sha2-nistp256 |
ecdsa-sha2-nistp384 | rsa | x509v3-ecdsa-sha2-nistp256 |
x509v3-ecdsa-sha2-nistp384 } *
Por padrão, o SSH2 usa o x509v3-ecdsa-sha2-nistp256,
Os algoritmos de chave pública x509v3-ecdsa-sha2-nistp384, ecdsa-sha2-nistp256, ecdsa-sha2-nistp384, rsa e dsa em ordem decrescente de prioridade para negociação de algoritmos.
No modo FIPS:
ssh2 algorithm public-key { ecdsa-sha2-nistp256 | ecdsa-sha2-nistp384
| rsa | x509v3-ecdsa-sha2-nistp256 | x509v3-ecdsa-sha2-nistp384 } *
Por padrão, o SSH2 usa o x509v3-ecdsa-sha2-nistp256,
x509v3-ecdsa-sha2-nistp384, ecdsa-sha2-nistp256, ecdsa-sha2-nistp384 e algoritmos de chave pública rsa em ordem decrescente de prioridade para negociação de algoritmos.
Especificação de algoritmos de criptografia para SSH2
- Entre na visualização do sistema.
system view- Especifique os algoritmos de criptografia para SSH2. No modo não-FIPS:
ssh2 algorithm cipher { 3des-cbc | aes128-cbc | aes128-ctr | aes128-gcm
| aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm | des-cbc } *
Por padrão, o SSH2 usa os algoritmos de criptografia aes128-ctr, aes192-ctr, aes256-ctr, aes128-gcm, aes256-gcm, aes128-cbc, 3des-cbc, aes256-cbc e des-cbc em ordem decrescente de prioridade para negociação de algoritmo.
No modo FIPS:
ssh2 algorithm cipher { aes128-cbc | aes128-ctr | aes128-gcm |
aes192-ctr | aes256-cbc | aes256-ctr | aes256-gcm } *
Por padrão, o SSH2 usa os algoritmos de criptografia aes128-ctr, aes192-ctr, aes256-ctr, aes128-gcm, aes256-gcm, aes128-cbc e aes256-cbc em ordem decrescente de prioridade para negociação de algoritmo.
Especificação de algoritmos MAC para SSH2
- Entre na visualização do sistema.
system view- Especifique os algoritmos MAC para SSH2. No modo não-FIPS:
ssh2 algorithm mac { md5 | md5-96 | sha1 | sha1-96 | sha2-256 | sha2-512 }
*
Por padrão, o SSH2 usa os padrões sha2-256, sha2-512, sha1, md5, sha1-96 e md5-96
Algoritmos MAC em ordem decrescente de prioridade para negociação de algoritmos. No modo FIPS:
ssh2 algorithm mac { sha1 | sha1-96 | sha2-256 | sha2-512 } *
Por padrão, o SSH2 usa os algoritmos MAC sha2-256, sha2-512, sha1 e sha1-96 em ordem decrescente de prioridade para negociação de algoritmo.
Comandos de exibição e manutenção para SSH
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibe as chaves públicas dos pares de chaves locais. | display public-key local { dsa | ecdsa | rsa } public [ name publickey-name ] |
| Exibir informações sobre chaves públicas de pares. | display public-key peer [ brief | name publickey-name ] |
| Exibir a configuração do endereço IP de origem do cliente SCP. | exibir fonte do cliente scp |
| Exibir a configuração do endereço IP de origem do cliente SFTP. | exibir a origem do cliente sftp |
| Exibir informações da chave pública do servidor salvas no arquivo de chave pública no cliente SSH. | exibir ssh client server-public-key [ server-ip ip-address ] |
| Exibir a configuração do endereço IP de origem do cliente Stelnet. | exibir a origem do cliente ssh |
| Exibir o status ou as sessões do servidor SSH. | display ssh server { session | status } |
| Exibir informações do usuário SSH no servidor SSH. | exibir informações de usuário ssh [ nome de usuário ] |
| Exibir algoritmos usados pelo SSH2 no estágio de negociação de algoritmos. | exibir algoritmo ssh2 |
Para obter mais informações sobre os comandos display public-key local e display public-key peer, consulte comandos de gerenciamento de chaves públicas em Referência de comandos de segurança.
Exemplos de configuração da Stelnet
Salvo indicação em contrário, os dispositivos nos exemplos de configuração operam no modo não-FIPS.
Quando o dispositivo atua como um servidor Stelnet operando no modo FIPS, somente os pares de chaves ECDSA e RSA são compatíveis. Não gere um par de chaves DSA no servidor Stelnet.
Exemplo: Configuração do dispositivo como um servidor Stelnet (autenticação por senha)
Configuração de rede
Conforme mostrado na Figura 1:
- O switch atua como servidor Stelnet e usa a autenticação por senha para autenticar o cliente Stelnet. O nome de usuário e a senha do cliente são salvos no switch.
- O host atua como cliente Stelnet, usando o software cliente Stelnet (SSH2). Depois que o usuário no host faz login no switch por meio do Stelnet, ele pode configurar e gerenciar o switch como administrador de rede.
Figura 1 Diagrama de rede
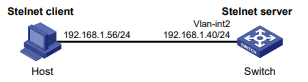
Procedimento
- Configure o servidor Stelnet: # Gerar pares de chaves RSA.
<Switch> system-view
[Switch] public-key local create rsa
The range of public key modulus is (512 ~ 4096).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
........................++++++
...................++++++
..++++++++
............++++++++
Create the key pair successfully.
# Gerar um par de chaves DSA.
[Switch] public-key local create dsa
The range of public key modulus is (512 ~ 2048).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
.++++++++++++++++++++++++++++++++++++++++++++++++++*
........+......+.....+......................................+
...+.................+..........+...+.
Create the key pair successfully.# Gerar um par de chaves ECDSA.
[Switch] public-key local create ecdsa secp256r1
Generating Keys...
.
Create the key pair successfully.# Habilite o servidor Stelnet.
[Switch] ssh server enable# Atribuir um endereço IP à interface VLAN 2. O cliente Stelnet usa esse endereço como destino da conexão SSH.
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ip address 192.168.1.40 255.255.255.0
[Switch-Vlan-interface2] quit# Defina o modo de autenticação como AAA para linhas de usuário.
[Switch] line vty 0 63
[Switch-line-vty0-63] authentication-mode scheme
[Switch-line-vty0-63] quit# Crie um usuário de gerenciamento de dispositivo local chamado client001.
[Switch] local-user client001 class manage# Defina a senha como hello12345 em texto simples para o usuário local client001.
[Switch-luser-manage-client001] password simple hello12345# Autorize o usuário local client001 a usar o serviço SSH.
[Switch-luser-manage-client001] service-type ssh# Atribua a função de usuário administrador de rede ao usuário local client001.
[Switch-luser-manage-client001] authorization-attribute user-role network-admin
[Switch-luser-manage-client001] quit# Crie um usuário SSH chamado client001. Especifique o tipo de serviço como stelnet e o
como senha para o usuário.
[Switch] ssh user client001 service-type stelnet authentication-type password- Estabeleça uma conexão com o servidor Stelnet:
Há diferentes tipos de software cliente Stelnet, como o PuTTY e o OpenSSH. Este exemplo usa um cliente Stelnet que executa o PuTTY versão 0.58.
Para estabelecer uma conexão com o servidor Stelnet:
- Inicie o PuTTY.exe para acessar a interface mostrada na Figura 2.
- No campo Nome do host (ou endereço IP), digite o endereço IP 192.168.1.40 do servidor Stelnet.
- Clique em Open.
Figura 2 Especificação do nome do host (ou endereço IP)
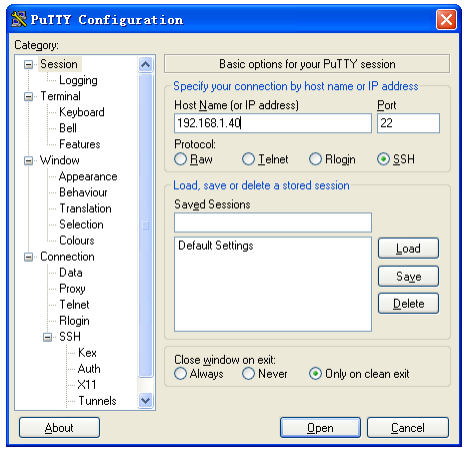
- Digite o nome de usuário client001 e a senha hello12345 para fazer login no servidor Stelnet.
Exemplo: Configuração do dispositivo como um servidor Stelnet (autenticação de chave pública)
Configuração de rede
Conforme mostrado na Figura 3:
- O switch atua como servidor Stelnet e usa autenticação de chave pública e o algoritmo de chave pública RSA.
- O host atua como cliente Stelnet, usando o software cliente Stelnet (SSH2). Depois que o usuário no host faz login no switch por meio da Stelnet, ele pode configurar e gerenciar o switch como um administrador de rede .
Figura 3 Diagrama de rede
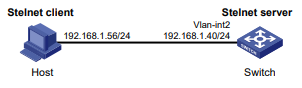
Procedimento
Na configuração do servidor, é necessária a chave pública do host do cliente. Use o software do cliente para gerar pares de chaves RSA no cliente antes de configurar o servidor Stelnet.
Há diferentes tipos de software cliente Stelnet, como o PuTTY e o OpenSSH. Este exemplo usa um cliente Stelnet que executa o PuTTY versão 0.58.
O procedimento de configuração é o seguinte:
- Gerar pares de chaves RSA no cliente Stelnet:
- Execute o PuTTYGen.exe no cliente, selecione SSH-2 RSA e clique em Generate (Gerar).
Figura 4 Geração de um par de chaves no cliente
- Continue movendo o mouse durante o processo de geração de chaves, mas não coloque o mouse sobre a barra de progresso verde mostrada na Figura 5. Caso contrário, a barra de progresso para de se mover e o progresso da geração do par de chaves é interrompido.
Figura 5 Processo de geração
- Depois que o par de chaves for gerado, clique em Save public key (Salvar chave pública) para salvar a chave pública. É exibida uma janela de salvamento de arquivo.
Figura 6 Salvando um par de chaves no cliente
- Digite um nome de arquivo (key.pub, neste exemplo) e clique em Salvar.
- Na página mostrada na Figura 6, clique em Save private key (Salvar chave privada) para salvar a chave privada. É exibida uma caixa de diálogo de confirmação.
- Clique em Yes.
É exibida uma janela de salvamento de arquivo.
- Digite um nome de arquivo (private.ppk, neste exemplo) e clique em Save (Salvar).
- Transmita o arquivo de chave pública para o servidor por meio de FTP ou TFTP. (Detalhes não mostrados.)
- Configure o servidor Stelnet:
# Gerar pares de chaves RSA.
<Switch> system-view
[Switch] public-key local create rsa
The range of public key modulus is (512 ~ 4096).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
........................++++++
...................++++++
..++++++++
............++++++++
Create the key pair successfully.# Gerar um par de chaves DSA.
[Switch] public-key local create dsa
The range of public key modulus is (512 ~ 2048).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
.++++++++++++++++++++++++++++++++++++++++++++++++++*
........+......+.....+......................................+
...+.................+..........+...+
Create the key pair successfully# Gerar um par de chaves ECDSA.
[Switch] public-key local create ecdsa secp256r1
Generating Keys...
.
Create the key pair successfully.# Habilite o servidor Stelnet.
[Switch] ssh server enable# Atribuir um endereço IP à interface VLAN 2. O cliente Stelnet usa esse endereço IP como destino da conexão SSH.
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ip address 192.168.1.40 255.255.255.0
[Switch-Vlan-interface2] quit# Defina o modo de autenticação como AAA para linhas de usuário.
[Switch] line vty 0 63
[Switch-line-vty0-63] authentication-mode scheme
[Switch-line-vty0-63] quit# Importe a chave pública do cliente do arquivo de chave pública key.pub e nomeie-a como switchkey.
[Switch] public-key peer switchkey import sshkey key.pub# Crie um usuário SSH chamado client002. Especifique o método de autenticação como publickey para o usuário e atribua a chave pública switchkey ao usuário.
[Switch] ssh user client002 service-type stelnet authentication-type publickey assign
publickey switchkey# Crie um usuário de gerenciamento de dispositivo local chamado client002.
[Switch] local-user client002 class manage# Autorize o usuário local client002 a usar o serviço SSH.
[Switch-luser-manage-client002] service-type ssh# Atribua a função de usuário administrador de rede ao usuário local client002.
[Switch-luser-manage-client002] authorization-attribute user-role network-admin
[Switch-luser-manage-client002] quit- Inicie o PuTTY.exe no cliente Stelnet para acessar a interface mostrada na Figura 7.
- No campo Nome do host (ou endereço IP), digite o endereço IP 192.168.1.40 do servidor Stelnet.
Figura 7 Especificação do nome do host (ou endereço IP)
- Na árvore de navegação, selecione Conexão > SSH. A janela mostrada na Figura 8 é exibida.
- Defina a versão preferencial do protocolo SSH como 2.
Figura 8 Configuração da versão preferencial do SSH
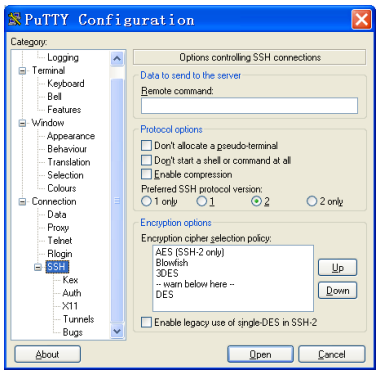
- Na árvore de navegação, selecione Conexão > SSH > Autenticação. A janela mostrada na Figura 9 é exibida.
- Clique em Browse... para abrir a janela de seleção de arquivos e selecione o arquivo de chave privada (private.ppk neste exemplo).
- Clique em Open.
Figura 9 Especificação do arquivo de chave privada
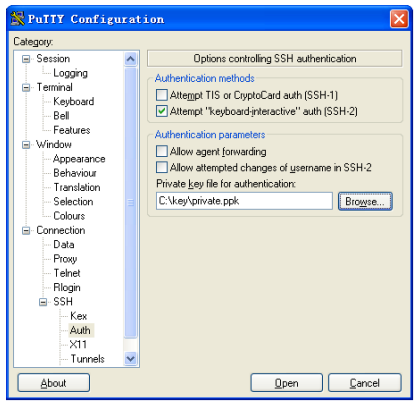
- Digite o nome de usuário client002 para fazer login no servidor Stelnet.
Exemplo: Configuração do dispositivo como um cliente Stelnet (autenticação por senha)
Configuração de rede
Conforme mostrado na Figura 10:
- O Switch B atua como servidor Stelnet e usa autenticação por senha para autenticar o cliente Stelnet. O nome de usuário e a senha do cliente são salvos no Switch B.
- O Switch A atua como cliente Stelnet. Depois que o usuário no Switch A fizer login no Switch B por meio da Stelnet, o usuário poderá configurar e gerenciar o Switch B como administrador de rede.
Figura 10 Diagrama de rede
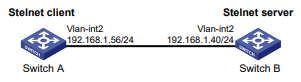
Procedimento
- Configure o servidor Stelnet: # Gerar pares de chaves RSA.
<SwitchB> system-view
[SwitchB] public-key local create rsa
The range of public key modulus is (512 ~ 4096).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
........................++++++
...................++++++
..++++++++
............++++++++
Create the key pair successfully.# Gerar um par de chaves DSA.
[SwitchB] public-key local create dsa
The range of public key modulus is (512 ~ 2048).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
.++++++++++++++++++++++++++++++++++++++++++++++++++*
........+......+.....+......................................+
...+.................+..........+...+
Create the key pair successfully.# Gerar um par de chaves ECDSA.
[SwitchB] public-key local create ecdsa secp256r1
Generating Keys...
.
Create the key pair successfully.# Habilite o servidor Stelnet.
[SwitchB] ssh server enable.# Atribuir um endereço IP à interface VLAN 2. O cliente Stelnet usa esse endereço como o endereço de destino da conexão SSH.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address 192.168.1.40 255.255.255.0
[SwitchB-Vlan-interface2] quit# Defina o modo de autenticação como AAA para linhas de usuário.
[SwitchB] line vty 0 63
[SwitchB-line-vty0-63] authentication-mode scheme
[SwitchB-line-vty0-63] quit# Crie um usuário de gerenciamento de dispositivo local chamado client001.
[SwitchB] local-user client001 class manage# Defina a senha como hello12345 em texto simples para o usuário local client001.
[SwitchB-luser-manage-client001] password simple hello12345# Autorize o usuário local client001 a usar o serviço SSH.
[SwitchB-luser-manage-client001] service-type ssh# Atribua a função de usuário administrador de rede ao usuário local client001.
[SwitchB-luser-manage-client001] authorization-attribute user-role network-admin
[SwitchB-luser-manage-client001] quit# Crie um usuário SSH chamado client001. Especifique o tipo de serviço como stelnet e o método de autenticação como senha para o usuário.
[SwitchB] ssh user client001 service-type stelnet authentication-type password- Estabeleça uma conexão com o servidor Stelnet: # Atribuir um endereço IP à interface VLAN 2.
<SwitchA> system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 192.168.1.56 255.255.255.0
[SwitchA-Vlan-interface2] quit
[SwitchA] quitAntes de estabelecer uma conexão com o servidor, você pode configurar a chave pública do host do servidor no cliente para autenticar o servidor.
- Para configurar a chave pública do host do servidor no cliente, execute as seguintes tarefas:
# Use o comando display public-key local dsa public no servidor para exibir a chave pública do host do servidor. (Os detalhes não são mostrados).
# Entre na visualização da chave pública do cliente e copie a chave pública do host do servidor para o cliente.
[SwitchA] public-key peer key1
Enter public key view. Return to system view with "peer-public-key end" command.
[SwitchA-pkey-public-key-key1]308201B73082012C06072A8648CE3804013082011F028181
0
0D757262C4584C44C211F18BD96E5F0
[SwitchA-pkey-public-key-key1]61C4F0A423F7FE6B6B85B34CEF72CE14A0D3A5222FE08CEC
E
65BE6C265854889DC1EDBD13EC8B274
[SwitchA-pkey-public-key-key1]DA9F75BA26CCB987723602787E922BA84421F22C3C89CB9B
0
6FD60FE01941DDD77FE6B12893DA76E
[SwitchA-pkey-public-key-key1]EBC1D128D97F0678D7722B5341C8506F358214B16A2FAC4B
3
68950387811C7DA33021500C773218C
[SwitchA-pkey-public-key-key1]737EC8EE993B4F2DED30F48EDACE915F0281810082269009
E
14EC474BAF2932E69D3B1F18517AD95
[SwitchA-pkey-public-key-key1]94184CCDFCEAE96EC4D5EF93133E84B47093C52B20CD35D0
2
492B3959EC6499625BC4FA5082E22C5
[SwitchA-pkey-public-key-key1]B374E16DD00132CE71B020217091AC717B612391C76C1FB2
E
88317C1BD8171D41ECB83E210C03CC9
[SwitchA-pkey-public-key-key1]B32E810561C21621C73D6DAAC028F4B1585DA7F42519718C
C
9B09EEF0381840002818000AF995917
[SwitchA-pkey-public-key-key1]E1E570A3F6B1C2411948B3B4FFA256699B3BF871221CC9C5
D
F257523777D033BEE77FC378145F2AD
[SwitchA-pkey-public-key-key1]D716D7DB9FCABB4ADBF6FB4FDB0CA25C761B308EF53009F7
1
01F7C62621216D5A572C379A32AC290
[SwitchA-pkey-public-key-key1]E55B394A217DA38B65B77F0185C8DB8095522D1EF044B465
E
8716261214A5A3B493E866991113B2D
[SwitchA-pkey-public-key-key1]485348
[SwitchA-pkey-public-key-key1] peer-public-key end
[SwitchA] quit# Estabeleça uma conexão SSH com o servidor e especifique a chave pública do host do servidor.
<SwitchA> ssh2 192.168.1.40 public-key key1
Username: client001
Press CTRL+C to abort.
Connecting to 192.168.1.40 port 22.
client001@192.168.1.40's password:
Enter a character ~ and a dot to abort.
******************************************************************************
* Copyright (c) 2004-2017 New Intelbras Technologies Co., Ltd. All rights reserved.*
* Without the owner's prior written consent, *
* no decompiling or reverse-engineering shall be allowed. *
******************************************************************************
<SwitchB> Depois de digitar o nome de usuário client001 e a senha hello12345, você poderá se conectar com sucesso ao Switch B.
- Se o cliente não tiver a chave pública do host do servidor, digite o nome de usuário client001 e, em seguida, digite y para acessar o servidor e fazer download da chave pública do host do servidor.
<SwitchA> ssh2 192.168.1.40
Username: client001
Press CTRL+C to abort.
Connecting to 192.168.1.40 port 22.
The server is not authenticated. Continue? [Y/N]:y
Do you want to save the server public key? [Y/N]:y
client001@192.168.1.40's password:
Enter a character ~ and a dot to abort.
******************************************************************************
* Copyright (c) 2004-2017 New Intelbras Technologies Co., Ltd. All rights reserved.*
* Without the owner's prior written consent, *
* no decompiling or reverse-engineering shall be allowed. *
******************************************************************************
<SwitchB>Depois de digitar a senha hello12345, você poderá acessar o Switch B com sucesso. Na próxima tentativa de conexão, o cliente autentica o servidor usando a chave pública do host do servidor salva no cliente.
Exemplo: Configuração do dispositivo como um cliente Stelnet (autenticação de chave pública)
Configuração de rede
Conforme mostrado na Figura 11:
- O switch B atua como servidor Stelnet e usa autenticação de chave pública e o algoritmo de chave pública DSA.
- O Switch A atua como cliente Stelnet. Depois que o usuário no Switch A fizer login no Switch B por meio da Stelnet, o usuário poderá configurar e gerenciar o Switch B como administrador de rede.
Figura 11 Diagrama de rede
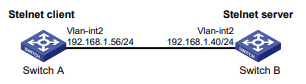
Procedimento
Na configuração do servidor, é necessária a chave pública do host do cliente. Gere um par de chaves DSA no cliente antes de configurar o servidor Stelnet.
- Configure o cliente Stelnet:
# Atribuir um endereço IP à interface VLAN 2.
<SwitchA> system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 192.168.1.56 255.255.255.0
[SwitchA-Vlan-interface2] quit# Gerar um par de chaves DSA.
[SwitchA] public-key local create dsa
The range of public key modulus is (512 ~ 2048).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
.++++++++++++++++++++++++++++++++++++++++++++++++++*
........+......+.....+......................................+
...+.................+..........+...+
Create the key pair successfully. # Exporte a chave pública do host DSA para um arquivo de chave pública chamado key.pub.
[SwitchA] public-key local export dsa ssh2 key.pub
[SwitchA] quit# Transmita o arquivo de chave pública key.pub para o servidor por meio de FTP ou TFTP. (Detalhes não mostrados.)
- Configure o servidor Stelnet: # Gerar pares de chaves RSA.
<SwitchB> system-view
[SwitchB] public-key local create rsa
The range of public key modulus is (512 ~ 4096)
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Switch A Switch B
Vlan-int2
192.168.1.56/24
Vlan-int2
192.168.1.40/24
Stelnet client Stelnet server
41
Input the modulus length [default = 1024]:
Generating Keys...
........................++++++
...................++++++
..++++++++
............++++++++
Create the key pair successfully.# Gerar um par de chaves DSA.
[SwitchB] public-key local create dsa
The range of public key modulus is (512 ~ 2048).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
.++++++++++++++++++++++++++++++++++++++++++++++++++*
........+......+.....+......................................+
...+.................+..........+...+
Create the key pair successfully.# Gerar um par de chaves ECDSA.
[SwitchB] public-key local create ecdsa secp256r1
Generating Keys...
.
Create the key pair successfully.# Habilite o servidor Stelnet.
[SwitchB] ssh server enable.# Atribuir um endereço IP à interface VLAN 2. O cliente Stelnet usa esse endereço como o endereço de destino para a conexão SSH.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address 192.168.1.40 255.255.255.0
[SwitchB-Vlan-interface2] quit# Defina o modo de autenticação como AAA para linhas de usuário.
[SwitchB] line vty 0 63
[SwitchB-line-vty0-63] authentication-mode scheme
[SwitchB-line-vty0-63] quit# Importe a chave pública do par do arquivo de chave pública key.pub e nomeie-a como switchkey.
[SwitchB] public-key peer switchkey import sshkey key.pub.# Crie um usuário SSH chamado client002. Especifique o método de autenticação como publickey para o usuário. Atribua a chave pública switchkey ao usuário.
[SwitchB] ssh user client002 service-type stelnet authentication-type publickey
assign publickey switchkey# Crie um usuário de gerenciamento de dispositivo local chamado client002.
[Switch] local-user client002 class manage# Autorize o usuário local client002 a usar o serviço SSH.
[SwitchB-luser-manage-client002] service-type ssh# Atribua a função de usuário administrador de rede ao usuário local client002.
[SwitchB-luser-manage-client002] authorization-attribute user-role network-admin
[SwitchB-luser-manage-client002] quit- Estabeleça uma conexão SSH com o servidor Stelnet.
<SwitchA> ssh2 192.168.1.40 identity-key dsa
Username: client002
Press CTRL+C to abort.
Connecting to 192.168.1.40 port 22.
The server is not authenticated. Continue? [Y/N]:y
Do you want to save the server public key? [Y/N]:n
Enter a character ~ and a dot to abort.
******************************************************************************
* Copyright (c) 2004-2017 New Intelbras Technologies Co., Ltd. All rights reserved.*
* Without the owner's prior written consent, *
* no decompiling or reverse-engineering shall be allowed. *
******************************************************************************
<SwitchB>Depois de digitar o nome de usuário client002 e, em seguida, digitar y para continuar acessando o servidor, você poderá fazer login no servidor com êxito.
Exemplo: Configuração de Stelnet com base em algoritmos Suite B de 128 bits
Configuração de rede
Conforme mostrado na Figura 12:
- O switch B atua como servidor Stelnet Suite B (SSH2) e usa autenticação de chave pública para autenticar o cliente Stelnet.
- O Switch A atua como um cliente do Stelnet Suite B (SSH2). Depois que o usuário do Switch A faz login no Switch B por meio do software cliente Stelnet Suite B, ele pode configurar e gerenciar o Switch B como administrador.
Figura 12 Diagrama de rede
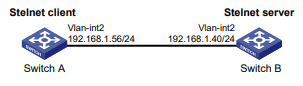
Procedimento
- Gerar o certificado do cliente e o certificado do servidor. (Detalhes não mostrados).
Primeiro, você deve configurar os certificados do servidor e do cliente, pois eles são necessários para a autenticação de identidade entre as duas partes.
Neste exemplo, o arquivo de certificado do servidor é ssh-server-ecdsa256.p12 e o arquivo de certificado do cliente é ssh-client-ecdsa256.p12.
- Configure o cliente Stelnet:
Você pode modificar a versão pkix do software cliente OpenSSH para oferecer suporte ao Suite B. Este exemplo usa um switch Intelbras como cliente Stelnet.
# Fazer upload do arquivo de certificado do servidor ssh-server-ecdsa256.p12 e do arquivo de certificado do cliente
ssh-client-ecdsa256.p12 para o cliente Stelnet por meio de FTP ou TFTP. (Detalhes não mostrados).
# Crie um domínio PKI chamado server256 para verificar o certificado do servidor e insira sua visualização.
<SwitchA> system-view
[SwitchA] pki domain server256# Desativar a verificação de CRL.
[SwitchA-pki-domain-server256] undo crl check enable
[SwitchA-pki-domain-server256] quit# Importar o arquivo de certificado local ssh-server-ecdsa256.p12 para o servidor de domínio PKI256.
[SwitchA] pki import domain server256 p12 local filename ssh-server-ecdsa256.p12
The system is going to save the key pair. You must specify a key pair name, which is
a case-insensitive string of 1 to 64 characters. Valid characters include a to z, A
to Z, 0 to 9, and hyphens (-).
Please enter the key pair name[default name: server256]:# Exibir informações sobre os certificados locais no servidor de domínio PKI256.
[SwitchA] display pki certificate domain server256 local
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 3 (0x3)
Signature Algorithm: ecdsa-with-SHA256
Issuer: C=CN, ST=Beijing, L=Beijing, O=Intelbras, OU=Software, CN=SuiteB CA
Validity
Not Before: Aug 21 08:39:51 2015 GMT
Not After : Aug 20 08:39:51 2016 GMT
Subject: C=CN, ST=Beijing, O=Intelbras, OU=Software, CN=SSH Server secp256
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (256 bit)
pub:
04:a2:b4:b4:66:1e:3b:d5:50:50:0e:55:19:8d:52:
6d:47:8c:3d:3d:96:75:88:2f:9a:ba:a2:a7:f9:ef:
0a:a9:20:b7:b6:6a:90:0e:f8:c6:de:15:a2:23:81:
3c:9e:a2:b7:83:87:b9:ad:28:c8:2a:5e:58:11:8e:
c7:61:4a:52:51
ASN1 OID: prime256v1
NIST CURVE: P-256
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
08:C1:F1:AA:97:45:19:6A:DA:4A:F2:87:A1:1A:E8:30:BD:31:30:D7
X509v3 Authority Key Identifier:
keyid:5A:BE:85:49:16:E5:EB:33:80:25:EB:D8:91:50:B4:E6:3E:4F:B8:22
Signature Algorithm: ecdsa-with-SHA256
30:65:02:31:00:a9:16:e9:c1:76:f0:32:fc:4b:f9:8f:b6:7f:
31:a0:9f:de:a7:cc:33:29:27:2c:71:2e:f9:0d:74:cb:25:c9:
00:d2:52:18:7f:58:3f:cc:7e:8b:d3:42:65:00:cb:63:f8:02:
30:01:a2:f6:a1:51:04:1c:61:78:f6:6b:7e:f9:f9:42:8d:7c:
a7:bb:47:7c:2a:85:67:0d:81:12:0b:02:98:bc:06:1f:c1:3c:
9b:c2:1b:4c:44:38:5a:14:b2:48:63:02:2b# Crie um domínio PKI chamado client256 para o certificado do cliente e insira sua visualização.
[SwitchA] pki domain client256# Desativar a verificação de CRL.
[SwitchA-pki-domain-client256] undo crl check enable
[SwitchA-pki-domain-client256] quit# Importar o arquivo de certificado local ssh-client-ecdsa256.p12 para o domínio PKI client256.
[SwitchA] pki import domain client256 p12 local filename ssh-client-ecdsa256.p12
The system is going to save the key pair. You must specify a key pair name, which is
a case-insensitive string of 1 to 64 characters. Valid characters include a to z, A
to Z, 0 to 9, and hyphens (-).
Please enter the key pair name[default name: client256]:# Exibir informações sobre certificados locais no domínio PKI client256.
[SwitchA] display pki certificate domain client256 local
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 4 (0x4)
Signature Algorithm: ecdsa-with-SHA256
Issuer: C=CN, ST=Beijing, L=Beijing, O=Intelbras, OU=Software, CN=SuiteB CA
Validity
Not Before: Aug 21 08:41:09 2015 GMT
Not After : Aug 20 08:41:09 2016 GMT
Subject: C=CN, ST=Beijing, O=Intelbras, OU=Software, CN=SSH Client secp256
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (256 bit)
pub:
04:da:e2:26:45:87:7a:63:20:e7:ca:7f:82:19:f5:
96:88:3e:25:46:f8:2f:9a:4c:70:61:35:db:e4:39:
b8:38:c4:60:4a:65:28:49:14:32:3c:cc:6d:cd:34:
29:83:84:74:a7:2d:0e:75:1c:c2:52:58:1e:22:16:
12:d0:b4:8a:92
ASN1 OID: prime256v1
NIST CURVE: P-256
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
1A:61:60:4D:76:40:B8:BA:5D:A1:3C:60:BC:57:98:35:20:79:80:FC
X509v3 Authority Key Identifier:
keyid:5A:BE:85:49:16:E5:EB:33:80:25:EB:D8:91:50:B4:E6:3E:4F:B8:22
Signature Algorithm: ecdsa-with-SHA256
30:66:02:31:00:9a:6d:fd:7d:ab:ae:54:9a:81:71:e6:bb:ad:
5a:2e:dc:1d:b3:8a:bf:ce:ee:71:4e:8f:d9:93:7f:a3:48:a1:
5c:17:cb:22:fa:8f:b3:e5:76:89:06:9f:96:47:dc:34:87:02:
31:00:e3:af:2a:8f:d6:8d:1f:3a:2b:ae:2f:97:b3:52:63:b6:
18:67:70:2c:93:2a:41:c0:e7:fa:93:20:09:4d:f4:bf:d0:11:
66:0f:48:56:01:1e:c3:be:37:4e:49:19:cf:c6# Atribuir um endereço IP à interface VLAN 2.
<SwitchA> system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 192.168.1.56 255.255.255.0
[SwitchA-Vlan-interface2] quit- Configure o servidor Stelnet:
# Fazer upload do arquivo de certificado do servidor ssh-server-ecdsa256.p12 e do arquivo de certificado do cliente
ssh-client-ecdsa256.p12 para o servidor Stelnet por meio de FTP ou TFTP. (Detalhes não mostrados.)
# Crie um domínio PKI chamado client256 para verificar o certificado do cliente e importe o arquivo do certificado do cliente para esse domínio. (Detalhes não mostrados.)
# Crie um domínio PKI chamado server256 para o certificado do servidor e importe o arquivo do certificado do servidor para esse domínio. (Detalhes não mostrados.)
# Especifique os algoritmos do Suite B para negociação de algoritmos.
system-view
[SwitchB] ssh2 algorithm key-exchange ecdh-sha2-nistp256
[SwitchB] ssh2 algorithm cipher aes128-gcm
[SwitchB] ssh2 algorithm public-key x509v3-ecdsa-sha2-nistp256
x509v3-ecdsa-sha2-nistp384 # Especifique server256 como o domínio PKI do certificado do servidor.
[SwitchB] ssh server pki-domain server256# Habilite o servidor Stelnet.
[SwitchB] ssh server enable.# Atribuir um endereço IP à interface VLAN 2.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address 192.168.1.40 255.255.255.0
[SwitchB-Vlan-interface2] quit# Defina o modo de autenticação como AAA para linhas de usuário.
[SwitchB] line vty 0 63
[SwitchB-line-vty0-63] authentication-mode scheme
[SwitchB-line-vty0-63] quit# Crie um usuário de gerenciamento de dispositivo local chamado client001. Autorize o usuário a usar o SSH
e atribua a função de usuário administrador de rede ao usuário.
[SwitchB] local-user client001 class manage [SwitchB-luser-manage-client001] service-type ssh
[SwitchB-luser-manage-client001] authorization-attribute user-role network-admin
[SwitchB-luser-manage-client001] quit# Crie um usuário SSH chamado client001. Especifique o método de autenticação de chave pública para o usuário
e especifique client256 como o domínio PKI para verificar o certificado do cliente.
[SwitchB] ssh user client001 service-type stelnet authentication-type publickey
assign pki-domain client256- Estabeleça uma conexão SSH com o servidor Stelnet com base nos algoritmos Suite B de 128 bits: # Estabeleça uma conexão SSH com o servidor em 192.168.1.40.
ssh2 192.168.1.40 suite-b 128-bit pki-domain client256 server-pki-domain
server256
Username: client001
Press CTRL+C to abort.
Connecting to 192.168.1.40 port 22.
Enter a character ~ and a dot to abort.
******************************************************************************
* Copyright (c) 2004-2017 New Intelbras Technologies Co., Ltd. All rights reserved.*
* Without the owner's prior written consent, *
* no decompiling or reverse-engineering shall be allowed. *
******************************************************************************
Exemplos de configuração de SFTP
Salvo indicação em contrário, os dispositivos nos exemplos de configuração operam no modo não-FIPS.
Quando o dispositivo atua como um servidor SFTP operando no modo FIPS, somente os pares de chaves ECDSA e RSA são compatíveis. Não gere um par de chaves DSA no servidor SFTP.
Exemplo: Configuração do dispositivo como um servidor SFTP (autenticação por senha)
Configuração de rede
Conforme mostrado na Figura 13:
- O switch atua como servidor SFTP e usa a autenticação por senha para autenticar o cliente SFTP. O nome de usuário e a senha do cliente são salvos no switch.
- O host atua como cliente SFTP. Depois que o usuário no cliente faz login no switch por meio do SFTP, ele pode executar operações de gerenciamento e transferência de arquivos no switch como administrador de rede.
Figura 13 Diagrama de rede
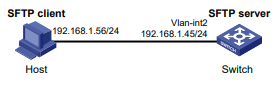
Procedimento
- Configure o servidor SFTP:
# Gerar pares de chaves RSA.
system-view
[Switch] public-key local create rsa
The range of public key modulus is (512 ~ 4096).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
SFTP client SFTP server
Generating Keys...
........................++++++
...................++++++
..++++++++
............++++++++
Create the key pair successfully. # Gerar um par de chaves DSA.
[Switch] public-key local create dsa
The range of public key modulus is (512 ~ 2048).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
.++++++++++++++++++++++++++++++++++++++++++++++++++*
........+......+.....+......................................+
...+.................+..........+...+
Create the key pair successfully.# Gerar um par de chaves ECDSA.
[Switch] public-key local create ecdsa secp256r1
Generating Keys...
.
Create the key pair successfully.# Habilite o servidor SFTP.
[Switch] sftp server enable# Atribua um endereço IP à interface VLAN 2. O cliente usa esse endereço como o destino da conexão SSH.
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ip address 192.168.1.45 255.255.255.0
[Switch-Vlan-interface2] quit# Crie um usuário de gerenciamento de dispositivo local chamado client002.
[Switch] local-user client002 class manage# Defina a senha como hello12345 em texto simples para o usuário local client002.
[Switch-luser-manage-client002] password simple hello12345# Autorize o usuário local client002 a usar o serviço SSH.
[Switch-luser-manage-client002] service-type ssh# Atribua a função de usuário network-admin e o diretório de trabalho flash:/ ao usuário local client002.
[Switch-luser-manage-client002] authorization-attribute user-role network-admin
work-directory flash:/
[Switch-luser-manage-client002] quit# Crie um usuário SSH chamado client002. Especifique o método de autenticação como senha e o tipo de serviço como sftp para o usuário.
[Switch] ssh user client002 service-type sftp authentication-type password- Estabeleça uma conexão entre o cliente SFTP e o servidor SFTP:
Este exemplo usa um cliente SFTP que executa o PSFTP do PuTTy versão 0.58. O PSFTP suporta apenas autenticação por senha.
Para estabelecer uma conexão com o servidor SFTP:
- Execute o psftp.exe para iniciar a interface do cliente mostrada na Figura 14 e digite o seguinte comando:
abrir 192.168.1.45
- Digite o nome de usuário client002 e a senha hello12345 para fazer login no servidor SFTP.
Figura 14 Interface do cliente SFTP
Exemplo: Configuração do dispositivo como um cliente SFTP (autenticação de chave pública)
Configuração de rede
Conforme mostrado na Figura 15:
- O switch B atua como servidor SFTP e usa autenticação de chave pública e o algoritmo de chave pública RSA.
- O Switch A atua como cliente SFTP. Depois que o usuário do Switch A fizer login no Switch B por meio do SFTP, ele poderá executar operações de gerenciamento e transferência de arquivos no Switch B como administrador da rede .
Figura 15 Diagrama de rede
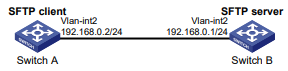
Procedimento
Na configuração do servidor, é necessária a chave pública do host do cliente. Gere pares de chaves RSA no cliente antes de configurar o servidor SFTP.
- Configure o cliente SFTP:
# Atribuir um endereço IP à interface VLAN 2.
system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 192.168.0.2 255.255.255.0
[SwitchA-Vlan-interface2] quit # Gerar pares de chaves RSA.
[SwitchA] public-key local create rsa
The range of public key size is (512 ~ 4096).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
........................++++++
...................++++++
..++++++++
............++++++++
Create the key pair successfully.# Exporte a chave pública do host para um arquivo de chave pública chamado pubkey.
[SwitchA] public-key local export rsa ssh2 pubkey
[SwitchA] quit# Transmita o arquivo de chave pública pubkey para o servidor por meio de FTP ou TFTP. (Detalhes não mostrados.)
- Configure o servidor SFTP: # Gerar pares de chaves RSA.
system-view
[SwitchB] public-key local create rsa
The range of public key size is (512 ~ 4096).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
........................++++++
...................++++++
..++++++++
............++++++++
Create the key pair successfully. # Gerar um par de chaves DSA.
[SwitchB] public-key local create dsa
The range of public key size is (512 ~ 2048).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
.++++++++++++++++++++++++++++++++++++++++++++++++++*
........+......+.....+......................................+
...+.................+..........+...+
Create the key pair successfully.# Gerar um par de chaves ECDSA.
[SwitchB] public-key local create ecdsa secp256r1
Generating Keys...
.
Create the key pair successfully.# Habilite o servidor SFTP.
[SwitchB] sftp server enable# Atribua um endereço IP à interface VLAN 2. O cliente SSH usa esse endereço como o destino da conexão SSH.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address 192.168.0.1 255.255.255.0
[SwitchB-Vlan-interface2] quit# Importe a chave pública do par do arquivo de chave pública pubkey e nomeie-a como switchkey.
[SwitchB] public-key peer switchkey import sshkey pubkey# Crie um usuário SSH chamado client001. Especifique o tipo de serviço como sftp e o método de autenticação como publickey para o usuário. Atribua a chave pública switchkey ao usuário.
[SwitchB] ssh user client001 service-type sftp authentication-type publickey assign
publickey switchkey# Crie um usuário de gerenciamento de dispositivo local chamado client001.
[SwitchB] local-user client001 class manage# Autorize o usuário local client001 a usar o serviço SSH.
[SwitchB-luser-manage-client001] service-type ssh# Atribua a função de usuário network-admin e o diretório de trabalho flash:/ ao usuário local client001.
[SwitchB-luser-manage-client001] authorization-attribute user-role network-admin
work-directory flash:/
[SwitchB-luser-manage-client001] quit- Estabeleça uma conexão com o servidor SFTP:
# Estabeleça uma conexão com o servidor SFTP e entre na exibição do cliente SFTP.
sftp 192.168.0.1 identity-key rsa
Username: client001
Press CTRL+C to abort.
Connecting to 192.168.0.1 port 22.
The server is not authenticated. Continue? [Y/N]:y
Do you want to save the server public key? [Y/N]:n
sftp> # Exibir arquivos no diretório atual do servidor, excluir o arquivo z e verificar o resultado.
sftp> dir -l
-rwxrwxrwx 1 noone nogroup 1759 Aug 23 06:52 config.cfg
-rwxrwxrwx 1 noone nogroup 225 Aug 24 08:01 pubkey2
-rwxrwxrwx 1 noone nogroup 283 Aug 24 07:39 pubkey
drwxrwxrwx 1 noone nogroup 0 Sep 01 06:22 new
-rwxrwxrwx 1 noone nogroup 225 Sep 01 06:55 pub
-rwxrwxrwx 1 noone nogroup 0 Sep 01 08:00 z
sftp> delete z
Removing /z
sftp> dir -l
-rwxrwxrwx 1 noone nogroup 1759 Aug 23 06:52 config.cfg
-rwxrwxrwx 1 noone nogroup 225 Aug 24 08:01 pubkey2
-rwxrwxrwx 1 noone nogroup 283 Aug 24 07:39 pubkey
drwxrwxrwx 1 noone nogroup 0 Sep 01 06:22 new
-rwxrwxrwx 1 noone nogroup 225 Sep 01 06:55 pub# Adicione um diretório chamado new1 e verifique o resultado.
sftp> mkdir new1
sftp> dir -l
51
-rwxrwxrwx 1 noone nogroup 1759 Aug 23 06:52 config.cfg
-rwxrwxrwx 1 noone nogroup 225 Aug 24 08:01 pubkey2
-rwxrwxrwx 1 noone nogroup 283 Aug 24 07:39 pubkey
drwxrwxrwx 1 noone nogroup 0 Sep 01 06:22 new
-rwxrwxrwx 1 noone nogroup 225 Sep 01 06:55 pub
drwxrwxrwx 1 noone nogroup 0 Sep 02 06:30 new1# Altere o nome do diretório new1 para new2 e verifique o resultado.
sftp> rename new1 new2
sftp> dir -l
-rwxrwxrwx 1 noone nogroup 1759 Aug 23 06:52 config.cfg
-rwxrwxrwx 1 noone nogroup 225 Aug 24 08:01 pubkey2
-rwxrwxrwx 1 noone nogroup 283 Aug 24 07:39 pubkey
drwxrwxrwx 1 noone nogroup 0 Sep 01 06:22 new
-rwxrwxrwx 1 noone nogroup 225 Sep 01 06:55 pub
drwxrwxrwx 1 noone nogroup 0 Sep 02 06:33 new2# Faça o download do arquivo pubkey2 do servidor e salve-o como um arquivo local chamado public.
sftp> sftp> get pubkey2 public
Fetching / pubkey2 to public
/pubkey2 100% 225 1.4KB/s 00:00Fazendo upload do pu para / puk sftp> dir -l
sftp> put pu puk
Uploading pu to / puk
sftp> dir -l
-rwxrwxrwx 1 noone nogroup 1759 Aug 23 06:52 config.cfg
-rwxrwxrwx 1 noone nogroup 225 Aug 24 08:01 pubkey2
-rwxrwxrwx 1 noone nogroup 283 Aug 24 07:39 pubkey
drwxrwxrwx 1 noone nogroup 0 Sep 01 06:22 new
drwxrwxrwx 1 noone nogroup 0 Sep 02 06:33 new2
-rwxrwxrwx 1 noone nogroup 283 Sep 02 06:35 pub
-rwxrwxrwx 1 noone nogroup 283 Sep 02 06:36 puk
sftp># Sair da exibição do cliente SFTP.
sftp> quit
Exemplo: Configuração de SFTP com base em algoritmos Suite B de 192 bits
Configuração de rede
Conforme mostrado na Figura 16:
- O switch B atua como servidor SFTP Suite B (SSH2) e usa autenticação de chave pública para autenticar o cliente SFTP.
- O Switch A atua como um cliente do SFTP Suite B (SSH2). Depois que o usuário do Switch A fizer login no Switch B com base no software cliente SFTP Suite B, ele poderá gerenciar e transferir arquivos no Switch B como administrador.
Figura 16 Diagrama de rede
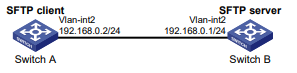
Procedimento
- Gerar o certificado do cliente e o certificado do servidor. (Detalhes não mostrados).
Primeiro, você deve configurar os certificados do servidor e do cliente, pois eles são necessários para a autenticação de identidade entre as duas partes.
Neste exemplo, o arquivo de certificado do servidor é ssh-server-ecdsa384.p12 e o arquivo de certificado do cliente é ssh-client-ecdsa384.p12.
- Configure o cliente SFTP:
Você pode modificar a versão pkix do software cliente OpenSSH para oferecer suporte ao Suite B. Este exemplo usa um switch Intelbras como cliente SFTP.
# Fazer upload do arquivo de certificado do servidor ssh-server-ecdsa384.p12 e do arquivo de certificado do cliente
ssh-client-ecdsa384.p12 para o cliente SFTP por meio de FTP ou TFTP. (Detalhes não mostrados.)
# Crie um domínio PKI chamado server384 para verificar o certificado do servidor e insira sua visualização.
<SwitchA> system-view
[SwitchA] pki domain server384# Desabilita a verificação de CRL.
[SwitchA-pki-domain-server384] undo crl check enable
[SwitchA-pki-domain-server384] quit# Importar o arquivo de certificado local ssh-server-ecdsa384.p12 para o servidor de domínio PKI384.
[SwitchA] pki import domain server384 p12 local filename ssh-server-ecdsa384.p12
The system is going to save the key pair. You must specify a key pair name, which is
a case-insensitive string of 1 to 64 characters. Valid characters include a to z, A
to Z, 0 to 9, and hyphens (-).
Please enter the key pair name[default name: server384]:# Exibir informações sobre os certificados locais no servidor de domínio PKI384.
[SwitchA] display pki certificate domain server384 local
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 1 (0x1)
Signature Algorithm: ecdsa-with-SHA384
Issuer: C=CN, ST=Beijing, L=Beijing, O=Intelbras, OU=Software, CN=SuiteB CA
Validity
Not Before: Aug 20 10:08:41 2015 GMT
Not After : Aug 19 10:08:41 2016 GMT
Subject: C=CN, ST=Beijing, O=Intelbras, OU=Software, CN=ssh server
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (384 bit)
pub:
04:4a:33:e5:99:8d:49:45:a7:a3:24:7b:32:6a:ed:
b6:36:e1:4d:cc:8c:05:22:f4:3a:7c:5d:b7:be:d1:
e6:9e:f0:ce:95:39:ca:fd:a0:86:cd:54:ab:49:60:
SFTP client SFTP server
Switch A Switch B
Vlan-int2
192.168.0.2/24
Vlan-int2
192.168.0.1/24
10:be:67:9f:90:3a:18:e2:7d:d9:5f:72:27:09:e7:
bf:7e:64:0a:59:bb:b3:7d:ae:88:14:94:45:b9:34:
d2:f3:93:e1:ba:b4:50:15:eb:e5:45:24:31:10:c7:
07:01:f9:dc:a5:6f:81
ASN1 OID: secp384r1
NIST CURVE: P-384
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
10:16:64:2C:DA:C1:D1:29:CD:C0:74:40:A9:70:BD:62:8A:BB:F4:D5
X509v3 Authority Key Identifier:
keyid:5A:BE:85:49:16:E5:EB:33:80:25:EB:D8:91:50:B4:E6:3E:4F:B8:22
Signature Algorithm: ecdsa-with-SHA384
30:65:02:31:00:80:50:7a:4f:c5:cd:6a:c3:57:13:7f:e9:da:
c1:72:7f:45:30:17:c2:a7:d3:ec:73:3d:5f:4d:e3:96:f6:a3:
33:fb:e4:b9:ff:47:f1:af:9d:e3:03:d2:24:53:40:09:5b:02:
30:45:d1:bf:51:fd:da:22:11:90:03:f9:d4:05:ec:d6:7c:41:
fc:9d:a1:fd:5b:8c:73:f8:b6:4c:c3:41:f7:c6:7f:2f:05:2d:
37:f8:52:52:26:99:28:97:ac:6e:f9:c7:01# Crie um domínio PKI chamado client384 para o certificado do cliente e insira sua visualização.
[SwitchA] pki domain client384# Desativar a verificação de CRL.
[SwitchA-pki-domain-client384] undo crl check enable
[SwitchA-pki-domain-client384] quit# Importar o arquivo de certificado local ssh-client-ecdsa384.p12 para o domínio PKI client384.
[SwitchA] pki import domain client384 p12 local filename ssh-client-ecdsa384.p12
The system is going to save the key pair. You must specify a key pair name, which is
a case-insensitive string of 1 to 64 characters. Valid characters include a to z, A
to Z, 0 to 9, and hyphens (-).
Please enter the key pair name[default name: client384]:# Exibir informações sobre certificados locais no domínio PKI client384.
[SwitchA]display pki certificate domain client384 local
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 2 (0x2)
Signature Algorithm: ecdsa-with-SHA384
Issuer: C=CN, ST=Beijing, L=Beijing, O=Intelbras, OU=Software, CN=SuiteB CA
Validity
Not Before: Aug 20 10:10:59 2015 GMT
Not After : Aug 19 10:10:59 2016 GMT
Subject: C=CN, ST=Beijing, O=Intelbras, OU=Software, CN=ssh client
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
54
Public-Key: (384 bit)
pub:
04:85:7c:8b:f4:7a:36:bf:74:f6:7c:72:f9:08:69:
d0:b9:ac:89:98:17:c9:fc:89:94:43:da:9a:a6:89:
41:d3:72:24:9b:9a:29:a8:d1:ba:b4:e5:77:ba:fc:
df:ae:c6:dd:46:72:ab:bc:d1:7f:18:7d:54:88:f6:
b4:06:54:7e:e7:4d:49:b4:07:dc:30:54:4b:b6:5b:
01:10:51:6b:0c:6d:a3:b1:4b:c9:d9:6c:d6:be:13:
91:70:31:2a:92:00:76
ASN1 OID: secp384r1
NIST CURVE: P-384
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
BD:5F:8E:4F:7B:FE:74:03:5A:D1:94:DB:CA:A7:82:D6:F7:78:A1:B0
X509v3 Authority Key Identifier:
keyid:5A:BE:85:49:16:E5:EB:33:80:25:EB:D8:91:50:B4:E6:3E:4F:B8:22
Signature Algorithm: ecdsa-with-SHA384
30:66:02:31:00:d2:06:fa:2c:0b:0d:f0:81:90:01:c3:3d:bf:
97:b3:79:d8:25:a0:e2:0e:ed:00:c9:48:3e:c9:71:43:c9:b4:
2a:a6:0a:27:80:9e:d4:0f:f2:db:db:5b:40:b1:a9:0a:e4:02:
31:00:ee:00:e1:07:c0:2f:12:3f:88:ea:fe:19:05:ef:56:ca:
33:71:75:5e:11:c9:a6:51:4b:3e:7c:eb:2a:4d:87:2b:71:7c:
30:64:fe:14:ce:06:d5:0a:e2:cf:9a:69:19:ff- Configure o servidor SFTP:
# Fazer upload do arquivo de certificado do servidor ssh-server-ecdsa384.p12 e do arquivo de certificado do cliente
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 192.168.0.2 255.255.255.0
[SwitchA-Vlan-interface2] quit
[SwitchA] quit# Crie um domínio PKI chamado client384 para verificar o certificado do cliente e importe o arquivo do certificado do cliente para esse domínio. (Detalhes não mostrados.)
# Crie um domínio PKI chamado server384 para o certificado do servidor e importe o arquivo do certificado do servidor para esse domínio. (Detalhes não mostrados.)
# Especifique os algoritmos da Suíte B para a negociação de algoritmos. [SwitchB] ssh2 algorithm key-exchange ecdh-sha2-nistp384 [SwitchB] ssh2 algorithm cipher aes256-gcm
[SwitchB] ssh2 algorithm public-key x509v3-ecdsa-sha2-nistp384 # Especifique server384 como o domínio PKI do certificado do servidor. [SwitchB] ssh server pki-domain server384
# Habilite o servidor SFTP.
[SwitchB] sftp server enable# Atribuir um endereço IP à interface VLAN 2.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address 192.168.0.1 255.255.255.0
[SwitchB-Vlan-interface2] quit# Defina o modo de autenticação como AAA para linhas de usuário.
[SwitchB] line vty 0 63
[SwitchB-line-vty0-63] authentication-mode scheme
[SwitchB-line-vty0-63] quit# Crie um usuário de gerenciamento de dispositivo local chamado client001. Autorize o usuário a usar o SSH
e atribua a função de usuário administrador de rede ao usuário.
[SwitchB] local-user client001 class manage
[SwitchB-luser-manage-client001] service-type ssh
[SwitchB-luser-manage-client001] authorization-attribute user-role network-admin
[SwitchB-luser-manage-client001] quit# Crie um usuário SSH chamado client001. Especifique o método de autenticação de chave pública para o usuário e especifique client384 como o domínio PKI para verificar o certificado do cliente.
[SwitchB] ssh user client001 service-type sftp authentication-type publickey assign
pki-domain client384- Estabeleça uma conexão SFTP com o servidor SFTP com base nos algoritmos 192-bit Suite B: # Estabeleça uma conexão SFTP com o servidor em 192.168.0.1.
sftp 192.168.0.1 suite-b 192-bit pki-domain client384 server-pki-domain
server384
Username: client001
Press CTRL+C to abort.
Connecting to 192.168.0.1 port 22.
sftp> Exemplos de configuração do SCP
Salvo indicação em contrário, os dispositivos nos exemplos de configuração operam no modo não-FIPS.
Quando o dispositivo atua como um servidor SCP operando no modo FIPS, somente os pares de chaves ECDSA e RSA são suportados. Não gere um par de chaves DSA no servidor SCP.
Exemplo: Configuração do SCP com autenticação por senha
Configuração de rede
Conforme mostrado na Figura 17:
- O Switch B atua como servidor SCP e usa autenticação por senha para autenticar o cliente SCP. O nome de usuário e a senha do cliente são salvos no Switch B.
- O switch A atua como cliente SCP. Depois que o usuário do Switch A fizer login no Switch B por meio do SCP, o usuário do poderá transferir arquivos entre os switches como administrador de rede.
Figura 17 Diagrama de rede
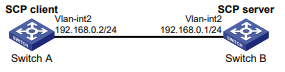
Procedimento
- Configure o servidor SCP: # Gerar pares de chaves RSA.
system-view
[SwitchB] public-key local create rsa
The range of public key modulus is (512 ~ 4096).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
........................++++++
...................++++++
..++++++++
............++++++++
Create the key pair successfully. # Gerar um par de chaves DSA.
[SwitchB] public-key local create dsa
The range of public key modulus is (512 ~ 2048).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
.++++++++++++++++++++++++++++++++++++++++++++++++++*
........+......+.....+......................................+
...+.................+..........+...+.
Create the key pair successfully.# Gerar um par de chaves ECDSA.
[SwitchB] public-key local create ecdsa secp256r1
Generating Keys...
.
Create the key pair successfully.# Habilite o servidor SCP.
[SwitchB] scp server enable# Configure um endereço IP para a interface VLAN 2. O cliente usa esse endereço como o destino da conexão SCP.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address 192.168.0.1 255.255.255.0
[SwitchB-Vlan-interface2] quit# Crie um usuário de gerenciamento de dispositivo local chamado client001.
[SwitchB] local-user client001 class manage# Defina a senha como hello12345 em texto simples para o usuário local client001.
[SwitchB-luser-manage-client001] password simple hello12345# Autorize o usuário local client001 a usar o serviço SSH.
[SwitchB-luser-manage-client001] service-type ssh# Atribua a função de usuário administrador de rede ao usuário local client001.
[SwitchB-luser-manage-client001] authorization-attribute user-role network-admin
[SwitchB-luser-manage-client001] quit# Crie um usuário SSH chamado client001. Especifique o tipo de serviço como scp e o método de autenticação como senha para o usuário.
[SwitchB] ssh user client001 service-type scp authentication-type password- Configure um endereço IP para a interface VLAN 2 no cliente SCP.
system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 192.168.0.2 255.255.255.0
[SwitchA-Vlan-interface2] quit
[SwitchA] quit - Conecte-se ao servidor SCP, faça o download do arquivo remote.bin do servidor e salve-o como um arquivo local chamado local.bin.
scp 192.168.0.1 get remote.bin local.bin
Username: client001
Press CTRL+C to abort.
Connecting to 192.168.0.1 port 22.
The server is not authenticated. Continue? [Y/N]:y
Do you want to save the server public key? [Y/N]:n
client001@192.168.0.1’s password:
remote.bin 100% 2875 2.8KB/s 00:00 Exemplo: Configuração do SCP com base nos algoritmos do Suite B
Configuração de rede
Conforme mostrado na Figura 18:
- O switch B atua como servidor SCP Suite B (SSH2) e usa autenticação de chave pública para autenticar o cliente SCP.
- O comutador A atua como um cliente do SCP Suite B (SSH2). Depois que o usuário do Switch A fizer login no Switch B por meio do software cliente SCP Suite B, ele poderá transferir arquivos entre os switches como administrador de rede.
Figura 18 Diagrama de rede
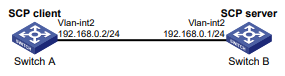
Procedimento
- Gerar os certificados do cliente e os certificados do servidor. (Detalhes não mostrados).
Primeiro, você deve configurar os certificados do servidor e do cliente, pois eles são necessários para a autenticação de identidade entre as duas partes.
Neste exemplo, os arquivos de certificado do servidor são ssh-server-ecdsa256.p12 e
ssh-server-ecdsa384.p12. Os arquivos de certificado do cliente são ssh-client-ecdsa256.p12 e
ssh-client-ecdsa384.p12.
- Configure o cliente SCP:
Você pode modificar a versão pkix do software cliente OpenSSH para oferecer suporte ao Suite B. Este exemplo usa um switch Intelbras como cliente SCP.
# Faça upload dos arquivos de certificado do servidor (ssh-server-ecdsa256.p12 e
ssh-server-ecdsa384.p12) e os arquivos de certificado do cliente (ssh-client-ecdsa256.p12 e
ssh-client-ecdsa384.p12) para o cliente SCP por meio de FTP ou TFTP. (Detalhes não mostrados.)
# Crie um domínio PKI chamado server256 para verificar o certificado ecdsa256 do servidor e insira sua visualização.
system-view
[SwitchA] pki domain server256 # Desabilita a verificação de CRL.
[SwitchA-pki-domain-server256] undo crl check enable
[SwitchA-pki-domain-server256] quit# Importar o arquivo de certificado local ssh-server-ecdsa256.p12 para o servidor de domínio PKI256.
[SwitchA] pki import domain server256 p12 local filename ssh-server-ecdsa256.p12
[SwitchA] pki import domain server256 p12 local filename ssh-server-ecdsa256.p12
The system is going to save the key pair. You must specify a key pair name, which is
a case-insensitive string of 1 to 64 characters. Valid characters include a to z, A
to Z, 0 to 9, and hyphens (-).
Please enter the key pair name[default name: server256]:# Exibir informações sobre certificados locais no servidor de domínio PKI256.
[SwitchA] display pki certificate domain server256 local
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 3 (0x3)
Signature Algorithm: ecdsa-with-SHA256
Issuer: C=CN, ST=Beijing, L=Beijing, O=Intelbras, OU=Software, CN=SuiteB CA
Validity
Not Before: Aug 21 08:39:51 2015 GMT
Not After : Aug 20 08:39:51 2016 GMT
Subject: C=CN, ST=Beijing, O=Intelbras, OU=Software, CN=SSH Server secp256
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (256 bit)
pub:
04:a2:b4:b4:66:1e:3b:d5:50:50:0e:55:19:8d:52:
6d:47:8c:3d:3d:96:75:88:2f:9a:ba:a2:a7:f9:ef:
0a:a9:20:b7:b6:6a:90:0e:f8:c6:de:15:a2:23:81:
3c:9e:a2:b7:83:87:b9:ad:28:c8:2a:5e:58:11:8e:
c7:61:4a:52:51
ASN1 OID: prime256v1
NIST CURVE: P-256
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
08:C1:F1:AA:97:45:19:6A:DA:4A:F2:87:A1:1A:E8:30:BD:31:30:D7
X509v3 Authority Key Identifier:
keyid:5A:BE:85:49:16:E5:EB:33:80:25:EB:D8:91:50:B4:E6:3E:4F:B8:22
Signature Algorithm: ecdsa-with-SHA256
30:65:02:31:00:a9:16:e9:c1:76:f0:32:fc:4b:f9:8f:b6:7f:
31:a0:9f:de:a7:cc:33:29:27:2c:71:2e:f9:0d:74:cb:25:c9:
00:d2:52:18:7f:58:3f:cc:7e:8b:d3:42:65:00:cb:63:f8:02:
30:01:a2:f6:a1:51:04:1c:61:78:f6:6b:7e:f9:f9:42:8d:7c:
a7:bb:47:7c:2a:85:67:0d:81:12:0b:02:98:bc:06:1f:c1:3c:
9b:c2:1b:4c:44:38:5a:14:b2:48:63:02:2b# Crie um domínio PKI chamado client256 para o certificado ecdsa256 do cliente e insira sua visualização.
[SwitchA] pki domain client256# Desativar a verificação de CRL.
[SwitchA-pki-domain-client256] undo crl check enable
[SwitchA-pki-domain-client256] quit# Importar o arquivo de certificado local ssh-client-ecdsa256.p12 para o domínio PKI client256.
[SwitchA] pki import domain client256 p12 local filename ssh-client-ecdsa256.p12
The system is going to save the key pair. You must specify a key pair name, which is
a case-insensitive string of 1 to 64 characters. Valid characters include a to z, A
to Z, 0 to 9, and hyphens (-).
Please enter the key pair name[default name: client256]:# Exibir informações sobre certificados locais no domínio PKI client256.
[SwitchA] display pki certificate domain client256 local
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 4 (0x4)
Signature Algorithm: ecdsa-with-SHA256
Issuer: C=CN, ST=Beijing, L=Beijing, O=Intelbras, OU=Software, CN=SuiteB CA
Validity
Not Before: Aug 21 08:41:09 2015 GMT
Not After : Aug 20 08:41:09 2016 GMT
Subject: C=CN, ST=Beijing, O=Intelbras, OU=Software, CN=SSH Client secp256
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (256 bit)
pub:
04:da:e2:26:45:87:7a:63:20:e7:ca:7f:82:19:f5:
96:88:3e:25:46:f8:2f:9a:4c:70:61:35:db:e4:39:
b8:38:c4:60:4a:65:28:49:14:32:3c:cc:6d:cd:34:
29:83:84:74:a7:2d:0e:75:1c:c2:52:58:1e:22:16:
12:d0:b4:8a:92
ASN1 OID: prime256v1
NIST CURVE: P-256
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
1A:61:60:4D:76:40:B8:BA:5D:A1:3C:60:BC:57:98:35:20:79:80:FC
X509v3 Authority Key Identifier:
keyid:5A:BE:85:49:16:E5:EB:33:80:25:EB:D8:91:50:B4:E6:3E:4F:B8:22
60
Signature Algorithm: ecdsa-with-SHA256
30:66:02:31:00:9a:6d:fd:7d:ab:ae:54:9a:81:71:e6:bb:ad:
5a:2e:dc:1d:b3:8a:bf:ce:ee:71:4e:8f:d9:93:7f:a3:48:a1:
5c:17:cb:22:fa:8f:b3:e5:76:89:06:9f:96:47:dc:34:87:02:
31:00:e3:af:2a:8f:d6:8d:1f:3a:2b:ae:2f:97:b3:52:63:b6:
18:67:70:2c:93:2a:41:c0:e7:fa:93:20:09:4d:f4:bf:d0:11:
66:0f:48:56:01:1e:c3:be:37:4e:49:19:cf:c6# Crie um domínio PKI chamado server384 para verificar o certificado ecdsa384 do servidor e insira sua visualização.
[SwitchA] pki domain server384# Desativar a verificação de CRL.
[SwitchA-pki-domain-server384] undo crl check enable
[SwitchA-pki-domain-server384] quit# Importar o arquivo de certificado local ssh-server-ecdsa384.p12 para o servidor de domínio PKI384.
[SwitchA] pki import domain server384 p12 local filename ssh-server-ecdsa384.p12
The system is going to save the key pair. You must specify a key pair name, which is
a case-insensitive string of 1 to 64 characters. Valid characters include a to z, A
to Z, 0 to 9, and hyphens (-).
Please enter the key pair name[default name: server384]:# Exibir informações sobre os certificados locais no servidor de domínio PKI384.
[SwitchA] display pki certificate domain server384 local
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 1 (0x1)
Signature Algorithm: ecdsa-with-SHA384
Issuer: C=CN, ST=Beijing, L=Beijing, O=Intelbras, OU=Software, CN=SuiteB CA
Validity
Not Before: Aug 20 10:08:41 2015 GMT
Not After : Aug 19 10:08:41 2016 GMT
Subject: C=CN, ST=Beijing, O=Intelbras, OU=Software, CN=ssh server
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (384 bit)
pub:
04:4a:33:e5:99:8d:49:45:a7:a3:24:7b:32:6a:ed:
b6:36:e1:4d:cc:8c:05:22:f4:3a:7c:5d:b7:be:d1:
e6:9e:f0:ce:95:39:ca:fd:a0:86:cd:54:ab:49:60:
10:be:67:9f:90:3a:18:e2:7d:d9:5f:72:27:09:e7:
bf:7e:64:0a:59:bb:b3:7d:ae:88:14:94:45:b9:34:
d2:f3:93:e1:ba:b4:50:15:eb:e5:45:24:31:10:c7:
07:01:f9:dc:a5:6f:81
ASN1 OID: secp384r1
NIST CURVE: P-384
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
10:16:64:2C:DA:C1:D1:29:CD:C0:74:40:A9:70:BD:62:8A:BB:F4:D5
X509v3 Authority Key Identifier:
keyid:5A:BE:85:49:16:E5:EB:33:80:25:EB:D8:91:50:B4:E6:3E:4F:B8:22
Signature Algorithm: ecdsa-with-SHA384
30:65:02:31:00:80:50:7a:4f:c5:cd:6a:c3:57:13:7f:e9:da:
c1:72:7f:45:30:17:c2:a7:d3:ec:73:3d:5f:4d:e3:96:f6:a3:
33:fb:e4:b9:ff:47:f1:af:9d:e3:03:d2:24:53:40:09:5b:02:
30:45:d1:bf:51:fd:da:22:11:90:03:f9:d4:05:ec:d6:7c:41:
fc:9d:a1:fd:5b:8c:73:f8:b6:4c:c3:41:f7:c6:7f:2f:05:2d:
37:f8:52:52:26:99:28:97:ac:6e:f9:c7:01# Crie um domínio PKI chamado client384 para o certificado ecdsa384 do cliente e insira sua visualização.
[SwitchA] pki domain client384# Desativar a verificação de CRL.
[SwitchA-pki-domain-client384] undo crl check enable
[SwitchA-pki-domain-client384] quit# Importar o arquivo de certificado local ssh-client-ecdsa384.p12 para o domínio PKI client384.
[SwitchA] pki import domain client384 p12 local filename ssh-client-ecdsa384.p12
The system is going to save the key pair. You must specify a key pair name, which is
a case-insensitive string of 1 to 64 characters. Valid characters include a to z, A
to Z, 0 to 9, and hyphens (-).
Please enter the key pair name[default name: client384]:# Exibir informações sobre certificados locais no domínio PKI client384.
[SwitchA] display pki certificate domain client384 local
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 2 (0x2)
Signature Algorithm: ecdsa-with-SHA384
Issuer: C=CN, ST=Beijing, L=Beijing, O=Intelbras, OU=Software, CN=SuiteB CA
Validity
Not Before: Aug 20 10:10:59 2015 GMT
Not After : Aug 19 10:10:59 2016 GMT
Subject: C=CN, ST=Beijing, O=Intelbras, OU=Software, CN=ssh client
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (384 bit)
pub:
04:85:7c:8b:f4:7a:36:bf:74:f6:7c:72:f9:08:69:
d0:b9:ac:89:98:17:c9:fc:89:94:43:da:9a:a6:89:
41:d3:72:24:9b:9a:29:a8:d1:ba:b4:e5:77:ba:fc:
df:ae:c6:dd:46:72:ab:bc:d1:7f:18:7d:54:88:f6:
b4:06:54:7e:e7:4d:49:b4:07:dc:30:54:4b:b6:5b:
01:10:51:6b:0c:6d:a3:b1:4b:c9:d9:6c:d6:be:13:
91:70:31:2a:92:00:76
ASN1 OID: secp384r1
62
NIST CURVE: P-384
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
BD:5F:8E:4F:7B:FE:74:03:5A:D1:94:DB:CA:A7:82:D6:F7:78:A1:B0
X509v3 Authority Key Identifier:
keyid:5A:BE:85:49:16:E5:EB:33:80:25:EB:D8:91:50:B4:E6:3E:4F:B8:22
Signature Algorithm: ecdsa-with-SHA384
30:66:02:31:00:d2:06:fa:2c:0b:0d:f0:81:90:01:c3:3d:bf:
97:b3:79:d8:25:a0:e2:0e:ed:00:c9:48:3e:c9:71:43:c9:b4:
2a:a6:0a:27:80:9e:d4:0f:f2:db:db:5b:40:b1:a9:0a:e4:02:
31:00:ee:00:e1:07:c0:2f:12:3f:88:ea:fe:19:05:ef:56:ca:
33:71:75:5e:11:c9:a6:51:4b:3e:7c:eb:2a:4d:87:2b:71:7c:
30:64:fe:14:ce:06:d5:0a:e2:cf:9a:69:19:ff# Atribuir um endereço IP à interface VLAN 2.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 192.168.0.2 255.255.255.0
[SwitchA-Vlan-interface2] quit- Configure o servidor SCP:
# Faça upload dos arquivos de certificado do servidor (ssh-server-ecdsa256.p12 e
ssh-server-ecdsa384.p12) e os arquivos de certificado do cliente (ssh-client-ecdsa256.p12 e
ssh-client-ecdsa384.p12) para o servidor SCP por meio de FTP ou TFTP. (Detalhes não mostrados.)
# Crie um domínio de PKI chamado client256 para verificar o certificado ecdsa256 do cliente e importe o arquivo desse certificado para esse domínio. Crie um domínio de PKI chamado server256 para o certificado ecdsa256 do servidor e importe o arquivo desse certificado para esse domínio. (Detalhes não mostrados.)
# Crie um domínio de PKI chamado client384 para verificar o certificado ecdsa384 do cliente e importe o arquivo desse certificado para esse domínio. Crie um domínio de PKI chamado server384 para o certificado ecdsa384 do servidor e importe o arquivo desse certificado para esse domínio. (Detalhes não mostrados.)
# Especifique os algoritmos do Suite B para negociação de algoritmos.
system-view
[SwitchB] ssh2 algorithm key-exchange ecdh-sha2-nistp256 ecdh-sha2-nistp384
[SwitchB] ssh2 algorithm cipher aes128-gcm aes256-gcm
[SwitchB] ssh2 algorithm public-key x509v3-ecdsa-sha2-nistp256
x509v3-ecdsa-sha2-nistp384 # Habilitar o servidor SCP.
[SwitchB] scp server enable# Atribuir um endereço IP à interface VLAN 2.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address 192.168.0.1 255.255.255.0
[SwitchB-Vlan-interface2] quit# Defina o modo de autenticação como AAA para linhas de usuário.
[SwitchB] line vty 0 63
[SwitchB-line-vty0-63] authentication-mode scheme
[SwitchB-line-vty0-63] quit# Crie um usuário de gerenciamento de dispositivo local chamado client001. Autorize o usuário a usar o SSH
e atribua a função de usuário administrador de rede ao usuário.
[SwitchB] local-user client001 class manage
[SwitchB-luser-manage-client001] service-type ssh
[SwitchB-luser-manage-client001] authorization-attribute user-role network-admin
[SwitchB-luser-manage-client001] quit# Crie um usuário de gerenciamento de dispositivo local chamado client002. Autorize o usuário a usar o SSH
e atribua a função de usuário administrador de rede ao usuário.
[SwitchB] local-user client001 class manage
[SwitchB-luser-manage-client001] service-type ssh
[SwitchB-luser-manage-client001] authorization-attribute user-role network-admin
[SwitchB-luser-manage-client001] quit- Estabeleça uma conexão SCP com o servidor SCP:
- Baseado nos algoritmos Suite B de 128 bits:
# Especifique server256 como o domínio PKI do certificado do servidor.
[SwitchB]ssh server pki-domain server256# Crie um usuário SSH client001. Especifique o método de autenticação de chave pública para o usuário e especifique client256 como o domínio PKI para verificar o certificado do cliente.
[SwitchB] ssh user client001 service-type scp authentication-type publickey assign
pki-domain client256# Estabeleça uma conexão SCP com o servidor SCP em 192.168.0.1 com base nos algoritmos de 128 bits do Suite B.
scp 192.168.0.1 get src.cfg suite-b 128-bit pki-domain client256
server-pki
-domain server256
Username: client001
Press CTRL+C to abort.
Connecting to 192.168.0.1 port 22.
src.cfg 100% 4814 4.7KB/s 00:00
- Com base nos algoritmos do Suite B de 192 bits:
# Especifique server384 como o domínio PKI do certificado do servidor.
[SwitchB] ssh server pki-domain server384# Crie um usuário SSH client002. Especifique o método de autenticação de chave pública para o usuário e especifique client384 como o domínio PKI para verificar o certificado do cliente.
[Switch] ssh user client002 service-type scp authentication-type publickey assign
pki-domain client384# Estabeleça uma conexão SCP com o servidor SCP em 192.168.0.1 com base nos algoritmos 192-bit Suite B.
scp 192.168.0.1 get src.cfg suite-b 192-bit pki-domain client384
server-pki
-domain server384
Username: client002
Press CTRL+C to abort.
Connecting to 192.168.0.1 port 22.
src.cfg 100% 4814 4.7KB/s 00:00
Exemplos de configuração do NETCONF sobre SSH
Salvo indicação em contrário, os dispositivos nos exemplos de configuração estão no modo não-FIPS.
Quando o dispositivo atua como um servidor NETCONF-over-SSH operando no modo FIPS, somente os pares de chaves ECDSA e RSA são compatíveis. Não gere um par de chaves DSA no servidor NETCONF-over-SSH.
Exemplo: Configuração do NETCONF por SSH com autenticação por senha
Configuração de rede
Conforme mostrado na Figura 19:
- O switch atua como servidor NETCONF-over-SSH e usa a autenticação por senha para autenticar o cliente. O nome de usuário e a senha do cliente são salvos no switch.
- O host atua como cliente NETCONF-over-SSH, usando o software cliente SSH2. Depois que o usuário no host faz login no switch por meio do NETCONF sobre SSH, ele pode executar operações do NETCONF no switch como administrador de rede.
Figura 19 Diagrama de rede
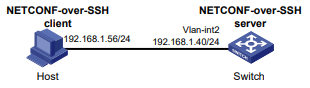
Procedimento
# Gerar pares de chaves RSA.
<Switch> system-view
[Switch] public-key local create rsa
The range of public key modulus is (512 ~ 4096).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
........................++++++
...................++++++
..++++++++
............++++++++
Create the key pair successfully.
# Gerar um par de chaves DSA.
[Switch] public-key local create dsa
The range of public key modulus is (512 ~ 2048).
If the key modulus is greater than 512, it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
.++++++++++++++++++++++++++++++++++++++++++++++++++*
........+......+.....+......................................+
...+.................+..........+...+.
Create the key pair successfully.# Gerar um par de chaves ECDSA.
[Switch] public-key local create ecdsa secp256r1
Generating Keys...
.
Create the key pair successfully.# Habilite o NETCONF por SSH.
[Switch] ssh server enable# Configure um endereço IP para a interface VLAN 2. O cliente usa esse endereço como destino da conexão NETCONF-over-SSH.
[Switch] interface vlan-interface 2
[Switch-Vlan-interface2] ip address 192.168.1.40 255.255.255.0
[Switch-Vlan-interface2] quit# Defina o modo de autenticação como AAA para linhas de usuário.
[Switch] line vty 0 63
[Switch-line-vty0-63] authentication-mode scheme
[Switch-line-vty0-63] quit# Crie um usuário de gerenciamento de dispositivo local chamado client001.
[Switch] local-user client001 class manage# Defina a senha como hello12345 em texto simples para o usuário local client001.
[Switch-luser-manage-client001] password simple hello12345# Autorize o usuário local client001 a usar o serviço SSH.
[Switch-luser-manage-client001] service-type ssh# Atribua a função de usuário administrador de rede ao usuário local client001.
[Switch-luser-manage-client001] authorization-attribute user-role network-admin
[Switch-luser-manage-client001] quit# Crie um usuário SSH chamado client001. Especifique o tipo de serviço como NETCONF e o método de autenticação como senha para o usuário.
[Switch] ssh user client001 service-type netconf authentication-type passwordVerificação da configuração
# Verifique se você pode realizar operações NETCONF após fazer login no switch. (Detalhes não mostrados).
Configuração de SSL
Sobre a SSL
O Secure Sockets Layer (SSL) é um protocolo criptográfico que oferece segurança de comunicação para protocolos de camada de aplicativos baseados em TCP, como o HTTP. O SSL tem sido amplamente usado em aplicativos como comércio eletrônico e serviços bancários on-line para fornecer transmissão segura de dados pela Internet.
Serviços de segurança SSL
O SSL fornece os seguintes serviços de segurança:
- A Privacy-SSL usa um algoritmo de criptografia simétrica para criptografar dados. Ele usa o algoritmo de chave assimétrica do RSA para criptografar a chave usada pelo algoritmo de criptografia simétrica. Para obter mais informações sobre o RSA, consulte "Gerenciamento de chaves públicas".
- Autenticação - o SSL usa assinaturas digitais baseadas em certificados para autenticar o servidor e o cliente SSL. O servidor e o cliente SSL obtêm certificados digitais por meio de PKI. Para obter mais informações sobre PKI e certificados digitais, consulte "Configuração de PKI".
- Integridade - a SSL usa o código de autenticação de mensagem (MAC) para verificar a integridade da mensagem. Ele usa um algoritmo MAC e uma chave para transformar uma mensagem de qualquer comprimento em uma mensagem de comprimento fixo. Qualquer alteração na mensagem original resultará em uma alteração na mensagem calculada
mensagem de comprimento fixo. Conforme mostrado na Figura 1, o processo de verificação da integridade da mensagem é o seguinte:
- O remetente usa um algoritmo MAC e uma chave para calcular um valor MAC para uma mensagem. Em seguida, ele anexa o valor MAC à mensagem e a envia ao receptor.
- O receptor usa a mesma chave e o mesmo algoritmo MAC para calcular um valor MAC para a mensagem recebida e o compara com o valor MAC anexado à mensagem.
- Se os dois valores MAC coincidirem, o receptor considera a mensagem intacta. Caso contrário, o receptor considera que a mensagem foi adulterada e a descarta.
Figura 1 Diagrama do algoritmo MAC
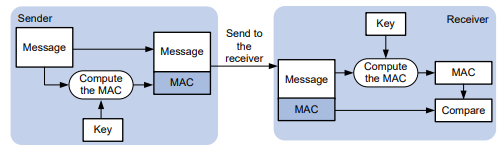
Pilha de protocolos SSL
A pilha de protocolos SSL inclui os seguintes protocolos:
- Protocolo de registro SSL na camada inferior.
- Protocolo de handshake SSL, protocolo de especificação de cifra de alteração SSL e protocolo de alerta SSL na camada superior.
Figura 2 Pilha de protocolos SSL
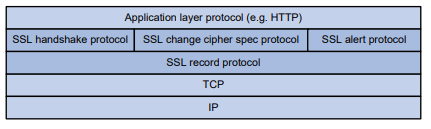
A seguir, descrevemos as principais funções dos protocolos SSL:
- Protocolo de registro SSL - fragmenta os dados recebidos da camada superior, calcula e adiciona MAC aos dados e criptografa os dados.
- Protocolo de handshake SSL - negocia o pacote de criptografia usado para comunicação segura, autentica o servidor e o cliente e troca com segurança as chaves entre o servidor e o cliente. O conjunto de cifras que precisa ser negociado inclui o algoritmo de criptografia simétrica, o algoritmo de troca de chaves e o algoritmo MAC.
- Protocolo SSL change cipher spec - Notifica o receptor de que os pacotes subsequentes devem ser protegidos com base no conjunto de cifras e na chave negociados.
- Protocolo de alerta SSL - Envia mensagens de alerta para a parte receptora. Uma mensagem de alerta contém o nível de gravidade do alerta e uma descrição.
Versões do protocolo SSL
As versões do protocolo SSL incluem SSL 2.0, SSL 3.0, TLS 1.0 (ou SSL 3.1), TLS 1.1 e TLS 1.2. Como o SSL 3.0 é conhecido por ser inseguro, você pode desativar o SSL 3.0 para o servidor SSL a fim de garantir a segurança.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS (consulte "Configuração de FIPS") e no modo não-FIPS.
Restrições e diretrizes: Configuração de SSL
Por padrão, o servidor SSL pode se comunicar com clientes que executam todas as versões do protocolo SSL. Quando o servidor recebe uma mensagem Client Hello do SSL 2.0 de um cliente, ele notifica o cliente para usar uma versão mais recente para comunicação.
Visão geral das tarefas de SSL
Configuração do servidor SSL
- Configuração de uma política de servidor SSL
- (Opcional.) Desativar versões do protocolo SSL para o servidor SSL
- (Opcional.) Desativar a renegociação da sessão SSL
Configuração do cliente SSL
Configuração de uma política de cliente SSL
Configuração de uma política de servidor SSL
Sobre as políticas de servidor SSL
Uma política de servidor SSL é um conjunto de parâmetros SSL usados pelo dispositivo quando ele atua como servidor SSL. Uma política de servidor SSL entra em vigor somente depois de ser associada a um aplicativo, como o HTTPS.
Procedimento
- Entre na visualização do sistema.
system view- Crie uma política de servidor SSL e insira sua visualização.
ssl server-policy policy-name- Especifique um domínio PKI para a política de servidor SSL.
pki-domain domain-namePor padrão, nenhum domínio PKI é especificado para uma política de servidor SSL.
Se a autenticação do servidor SSL for necessária, você deverá especificar um domínio PKI e solicitar um certificado local para o servidor SSL no domínio.
Para obter informações sobre a configuração de um domínio de PKI, consulte "Configuração de PKI".
- Especifique os conjuntos de códigos que a política do servidor SSL suporta. No modo não-FIPS:
ciphersuite { dhe_rsa_aes_128_cbc_sha | dhe_rsa_aes_128_cbc_sha256 |
dhe_rsa_aes_256_cbc_sha | dhe_rsa_aes_256_cbc_sha256 |
ecdhe_ecdsa_aes_128_cbc_sha256 | ecdhe_ecdsa_aes_128_gcm_sha256 |
ecdhe_ecdsa_aes_256_cbc_sha384 | ecdhe_ecdsa_aes_256_gcm_sha384 |
ecdhe_rsa_aes_128_cbc_sha256 | ecdhe_rsa_aes_128_gcm_sha256 |
ecdhe_rsa_aes_256_cbc_sha384 | ecdhe_rsa_aes_256_gcm_sha384 |
exp_rsa_des_cbc_sha | exp_rsa_rc2_md5 | exp_rsa_rc4_md5 |
rsa_3des_ede_cbc_sha | rsa_aes_128_cbc_sha | rsa_aes_128_cbc_sha256 |
rsa_aes_256_cbc_sha | rsa_aes_256_cbc_sha256 | rsa_des_cbc_sha |
rsa_rc4_128_md5 | rsa_rc4_128_sha } *No modo FIPS:
ciphersuite { ecdhe_ecdsa_aes_128_cbc_sha256 |
ecdhe_ecdsa_aes_256_cbc_sha384 | ecdhe_ecdsa_aes_128_gcm_sha256 |
ecdhe_ecdsa_aes_256_gcm_sha384 | ecdhe_rsa_aes_128_cbc_sha256 |
ecdhe_rsa_aes_128_gcm_sha256 | ecdhe_rsa_aes_256_cbc_sha384 |
ecdhe_rsa_aes_256_gcm_sha384 | rsa_aes_128_cbc_sha |
rsa_aes_128_cbc_sha256 | rsa_aes_256_cbc_sha |
rsa_aes_256_cbc_sha256 } *Por padrão, uma política de servidor SSL oferece suporte a todos os pacotes de cifras.
- (Opcional.) Defina o número máximo de sessões que o servidor SSL pode armazenar em cache e o tempo limite do cache de sessão.
session { cachesize size | timeout time } *Por padrão, o servidor SSL pode armazenar em cache um máximo de 500 sessões, e o tempo limite do cache de sessão é de 3600 segundos.
- Habilite a autenticação obrigatória ou opcional do cliente SSL.
client-verify { enable | optional }Por padrão, a autenticação do cliente SSL está desativada. O servidor SSL não executa autenticação baseada em certificado digital em clientes SSL.
Ao autenticar um cliente usando o certificado digital, o servidor SSL verifica a cadeia de certificados apresentada pelo cliente. Ele também verifica se os certificados da cadeia de certificados (exceto o certificado da CA raiz) não foram revogados.
- (Opcional.) Permita que o servidor SSL envie a cadeia completa de certificados para o cliente durante a negociação SSL.
certificate-chain-sending enablePor padrão, o servidor SSL envia o certificado do servidor em vez da cadeia completa de certificados para o cliente durante a negociação.
Configuração de uma política de cliente SSL
Sobre as políticas de cliente SSL
Uma política de cliente SSL é um conjunto de parâmetros SSL usados pelo dispositivo quando ele atua como cliente SSL. O cliente SSL usa as configurações da política de cliente para estabelecer uma conexão com o servidor. Uma política de cliente SSL entra em vigor somente depois de ser associada a um aplicativo.
Restrições e diretrizes
Como prática recomendada para aumentar a segurança do sistema, não especifique SSL 3.0 para a política de cliente SSL.
Procedimento
- Entre na visualização do sistema.
system view- Crie uma política de cliente SSL e insira sua visualização.
ssl client-policy policy-name- Especifique um domínio PKI para a política de cliente SSL.
pki-domain domain-namePor padrão, nenhum domínio PKI é especificado para uma política de cliente SSL.
Se a autenticação do cliente SSL for necessária, você deverá especificar um domínio de PKI e solicitar um certificado local para o cliente SSL no domínio de PKI.
Para obter informações sobre a configuração de um domínio de PKI, consulte "Configuração de PKI".
- Especifique o conjunto de cifras preferido para a política de cliente SSL. No modo não-FIPS:
prefer-cipher { dhe_rsa_aes_128_cbc_sha | dhe_rsa_aes_128_cbc_sha256
| dhe_rsa_aes_256_cbc_sha | dhe_rsa_aes_256_cbc_sha256 |
ecdhe_ecdsa_aes_128_cbc_sha256 | ecdhe_ecdsa_aes_128_gcm_sha256 |
ecdhe_ecdsa_aes_256_cbc_sha384 | ecdhe_ecdsa_aes_256_gcm_sha384 |
ecdhe_rsa_aes_128_cbc_sha256 | ecdhe_rsa_aes_128_gcm_sha256 |
ecdhe_rsa_aes_256_cbc_sha384 | ecdhe_rsa_aes_256_gcm_sha384 |
exp_rsa_des_cbc_sha | exp_rsa_rc2_md5 | exp_rsa_rc4_md5 |
rsa_3des_ede_cbc_sha | rsa_aes_128_cbc_sha | rsa_aes_128_cbc_sha256
| rsa_aes_256_cbc_sha | rsa_aes_256_cbc_sha256 | rsa_des_cbc_sha |
rsa_rc4_128_md5 | rsa_rc4_128_sha }O conjunto de cifras preferido padrão no modo não-FIPS é rsa_rc4_128_md5. No modo FIPS:
prefer-cipher { ecdhe_ecdsa_aes_128_cbc_sha256 |
ecdhe_ecdsa_aes_128_gcm_sha256 | ecdhe_ecdsa_aes_256_cbc_sha384 |
ecdhe_ecdsa_aes_256_gcm_sha384 | ecdhe_rsa_aes_128_cbc_sha256 |
ecdhe_rsa_aes_128_gcm_sha256 | ecdhe_rsa_aes_256_cbc_sha384 |
ecdhe_rsa_aes_256_gcm_sha384 | rsa_aes_128_cbc_sha |
rsa_aes_128_cbc_sha256 | rsa_aes_256_cbc_sha |
rsa_aes_256_cbc_sha256 }O conjunto de cifras preferido padrão no modo FIPS é rsa_aes_128_cbc_sha.
- Especifique a versão do protocolo SSL para a política de cliente SSL. No modo não-FIPS:
version { ssl3.0 | tls1.0 | tls1.1 | tls1.2 }No modo FIPS:
version { tls1.0 | tls1.1 | tls1.2 }Por padrão, uma política de cliente SSL usa TLS 1.0.
- Habilite o cliente SSL para autenticar servidores por meio de certificados digitais.
server-verify enablePor padrão, a autenticação do servidor SSL está ativada.
Desativação de versões do protocolo SSL para o servidor SSL
Sobre a desativação de versões do protocolo SSL para o servidor SSL
Para aumentar a segurança do sistema, você pode impedir que o servidor SSL use versões específicas do protocolo SSL (SSL 3.0, TLS 1.0 e TLS 1.1) para negociação de sessão.
Restrições e diretrizes
A desativação de uma versão do protocolo SSL não afeta a disponibilidade de versões anteriores do protocolo SSL. Por exemplo, se você executar o comando ssl version tls1.1 disable, o TLS 1.1 será desativado, mas o TLS 1.0 ainda estará disponível para o servidor SSL.
Procedimento
- Entre na visualização do sistema.
system view- Desative as versões do protocolo SSL para o servidor SSL. No modo não-FIPS:
ssl version { ssl3.0 | tls1.0 | tls1.1 } * disablePor padrão, o servidor SSL é compatível com SSL 3.0, TLS 1.0, TLS 1.1 e TLS 1.2. No modo FIPS:
ssl version { tls1.0 | tls1.1 } * disablePor padrão, o servidor SSL é compatível com TLS 1.0, TLS 1.1 e TLS 1.2.
Desativação da renegociação de sessão SSL
Sobre a desativação da renegociação de sessão SSL
O recurso de renegociação de sessão SSL permite que o cliente e o servidor SSL reutilizem uma sessão SSL negociada anteriormente para um handshake abreviado.
A desativação da renegociação de sessão causa mais sobrecarga computacional ao sistema, mas pode evitar possíveis riscos.
Restrições e diretrizes
Desative a renegociação de sessão SSL somente quando for explicitamente necessário.
Procedimento
- Entre na visualização do sistema.
system view- Desativar a renegociação de sessão SSL.
ssl renegotiation disablePor padrão, a renegociação de sessão SSL está ativada.
Comandos de exibição e manutenção para SSL
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações sobre a política do cliente SSL. | exibir política de cliente ssl [ policy-name ] |
| Exibir informações sobre a política do servidor SSL. | exibir ssl server-policy [ policy-name ] |
Exemplos de configuração da política do servidor SSL
Exemplo: Configuração de uma política de servidor SSL
Configuração de rede
Conforme mostrado na Figura 3, os usuários precisam acessar e gerenciar o dispositivo por meio da página da Web.
Para proteger o dispositivo e evitar que os dados sejam espionados ou adulterados, configure o dispositivo para ser acessado somente por HTTPS.
Neste exemplo, o servidor CA executa o Windows Server e tem o plug-in SCEP instalado. Para atender aos requisitos de rede, execute as seguintes tarefas:
- Configure o dispositivo como o servidor HTTPS e solicite um certificado de servidor para o dispositivo. Para
Mais informações sobre HTTPS, consulte o Fundamentals Configuration Guide.
- Solicite um certificado de cliente para o host para que o dispositivo possa autenticar a identidade do host .
Figura 3 Diagrama de rede
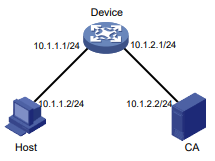
Procedimento
- Certifique-se de que o dispositivo, o host e o servidor CA possam se comunicar entre si. (Detalhes não mostrados.)
- Configure o servidor HTTPS no dispositivo:
# Crie uma entidade PKI chamada en. Defina o nome comum e o FQDN para a entidade.
system-view
[Device] pki entity en
[Device-pki-entity-en] common-name http-server1
[Device-pki-entity-en] fqdn ssl.security.com
[Device-pki-entity-en] quit # Crie o domínio PKI 1 e especifique o servidor CA como o nome da CA confiável. Defina o URL do servidor de registro como http://10.1.2.2/certsrv/mscep/mscep.dll, a autoridade para solicitação de certificado como RA e a entidade para solicitação de certificado como en. Defina o URL do repositório de CRL como http://10.1.2.2/CertEnroll/caserver.crl.
[Device] pki domain 1
[Device-pki-domain-1] ca identifier CA server
[Device-pki-domain-1] certificate request url
http://10.1.2.2/certsrv/mscep/mscep.dll
[Device-pki-domain-1] certificate request from ra
[Device-pki-domain-1] certificate request entity en
[Device-pki-domain-1] crl url http://10.1.2.2/CertEnroll/caserver.crl# Configure um par de chaves RSA de uso geral chamado abc e defina o comprimento do módulo da chave como 1024 bits.
[Device-pki-domain-1] public-key rsa general name abc length 1024
[Device-pki-domain-1] quit# Gerar par de chaves RSA abc.
[Device] public-key local create rsa name abc
The range of public key size is (512 ~ 4096).
If the key modulus is greater than 512,it will take a few minutes.
Press CTRL+C to abort.
Input the modulus length [default = 1024]:
Generating Keys...
..........................++++++
.....................................++++++
Create the key pair successfully.# Obter o certificado CA.
[Device] pki retrieve-certificate domain 1 ca
The trusted CA's finger print is:
MD5 fingerprint:7682 5865 ACC2 7B16 6F52 D60F D998 4484
SHA1 fingerprint:DF6B C53A E645 5C81 D6FC 09B0 3459 DFD1 94F6 3DDE
Is the finger print correct?(Y/N):y
Retrieved the certificates successfully.# Solicite um certificado de servidor para o dispositivo.
[Device] pki request-certificate domain 1
Start to request general certificate ...
Certificate requested successfully.# Crie uma política de servidor SSL chamada myssl.
[Device] ssl server-policy myssl# Especifique o domínio PKI 1 para a política do servidor SSL.
[Device-ssl-server-policy-myssl] pki-domain 1# Habilitar a autenticação do cliente.
[Device-ssl-server-policy-myssl] client-verify enable
[Device-ssl-server-policy-myssl] quit# Configure o serviço HTTPS para usar a política de servidor SSL myssl.
[Device] ip https ssl-server-policy myssl# Habilite o serviço HTTPS.
[Device] ip https enable# Crie um usuário local chamado usera. Defina a senha como hello12345, o tipo de serviço como https e a função do usuário como network-admin.
[Device] local-user usera
[Device-luser-usera] password simple hello12345
[Device-luser-usera] service-type https
[Device-luser-usera] authorization-attribute user-role network-admin- Solicitar um certificado de cliente para o host:
- Inicie o IE no host e digite http://10.1.2.2/certsrv na barra de endereços.
- Solicita um certificado de cliente para o host. (Detalhes não mostrados).
Verificação da configuração
Execute as seguintes tarefas no host:
- Inicie o IE e digite https://10.1.1.1 na barra de endereços.
- Selecione o certificado emitido pelo servidor CA para o host. A página de login do dispositivo deve ser exibida.
- Digite o nome de usuário usera e a senha 123.
Verifique se agora você pode fazer login na interface da Web para acessar e gerenciar o dispositivo.
Configuração da detecção e prevenção de ataques
Visão geral
A detecção e a prevenção de ataques permitem que um dispositivo detecte ataques inspecionando os pacotes que chegam e tome medidas de prevenção (como o descarte de pacotes) para proteger uma rede privada.
Ataques que o dispositivo pode evitar
Esta seção descreve os ataques que o dispositivo pode detectar e evitar.
Ataque de fragmento TCP
Um invasor lança ataques de fragmentos TCP enviando fragmentos TCP de ataque definidos na RFC 1858:
- Primeiros fragmentos nos quais o cabeçalho TCP é menor que 20 bytes.
- Fragmentos não-primeiro com um deslocamento de fragmento de 8 bytes (FO=1).
Normalmente, o filtro de pacotes detecta os endereços IP de origem e destino, as portas de origem e destino e o protocolo da camada de transporte do primeiro fragmento de um pacote TCP. Se o primeiro fragmento for aprovado na detecção, todos os fragmentos subsequentes do pacote TCP terão permissão para passar.
Como o primeiro fragmento de pacotes TCP de ataque não atinge nenhuma correspondência no filtro de pacotes, todos os fragmentos subsequentes podem passar. Depois que o host receptor remonta os fragmentos, ocorre um ataque de fragmento TCP.
Para evitar ataques de fragmentos TCP, ative a prevenção de ataques de fragmentos TCP para descartar fragmentos TCP de ataque .
Ataque de dicionário de login
O ataque de dicionário de login é um processo automatizado para tentar fazer login experimentando todas as senhas possíveis de uma lista pré-arranjada de valores (o dicionário). Várias tentativas de login podem ocorrer em um curto período de tempo.
Você pode configurar o recurso de atraso de login para reduzir a velocidade dos ataques de dicionário de login. Esse recurso permite que o dispositivo atrase a aceitação de outra solicitação de login depois de detectar uma tentativa de login fracassada de um usuário.
Configuração da prevenção de ataques de fragmentos TCP
Sobre a prevenção de ataques de fragmentos TCP
O recurso de prevenção de ataques de fragmentos TCP detecta o comprimento e o deslocamento de fragmentos dos fragmentos TCP recebidos e descarta os fragmentos TCP de ataque.
Restrições e diretrizes
A prevenção de ataques de fragmentos TCP tem precedência sobre a prevenção de ataques de pacote único. Quando ambos são usados, os pacotes TCP de entrada são processados primeiro pela prevenção contra ataques de fragmentos TCP e, em seguida, pela política de defesa contra ataques de pacote único.
Procedimento
- Entre na visualização do sistema.
system view- Ativar a prevenção de ataques de fragmentos TCP.
attack-defense tcp fragment enablePor padrão, a prevenção de ataques de fragmentos TCP está ativada.
Ativação do atraso de login
Sobre o atraso no login
O recurso de atraso de login faz com que o dispositivo deixe de aceitar uma solicitação de login de um usuário depois que ele falha em uma tentativa de login. Esse recurso pode retardar os ataques de dicionário de login.
O recurso de atraso de login é independente do recurso de prevenção de ataques de login.
Procedimento
- Entre na visualização do sistema.
system view- Ative o recurso de atraso de login.
attack-defense login reauthentication-delay secondsPor padrão, o recurso de atraso de login está desativado. O dispositivo não atrasa a aceitação de uma solicitação de login de um usuário que tenha falhado em uma tentativa de login.
Configuração da prevenção de ataques TCP
Sobre a prevenção de ataques TCP
A prevenção de ataques TCP pode detectar e impedir ataques que exploram o processo de estabelecimento de conexão TCP .
Configuração da prevenção de ataques Naptha
Sobre a prevenção de ataques de Naptha
O Naptha é um ataque DDoS que tem como alvo os sistemas operacionais. Ele explora a vulnerabilidade de consumo de recursos na pilha TCP/IP e no processo de aplicativos de rede. O invasor estabelece um grande número de conexões TCP em um curto período de tempo e as deixa em determinados estados sem solicitar nenhum dado. Essas conexões TCP deixam a vítima sem recursos do sistema, o que resulta em um colapso do sistema.
Depois que você ativar a prevenção de ataques Naptha, o dispositivo verificará periodicamente o número de conexões TCP em cada estado (CLOSING, ESTABLISHED, FIN_WAIT_1, FIN_WAIT_2 e LAST_ACK). Se o número de conexões TCP em um estado exceder o limite, o dispositivo acelerará o envelhecimento das conexões TCP nesse estado para atenuar o ataque Naptha.
Procedimento
- Entre na visualização do sistema.
system view- Habilite a prevenção de ataques Naptha.
tcp anti-naptha enablePor padrão, a prevenção de ataques Naptha está desativada.
- (Opcional.) Defina o número máximo de conexões TCP em um estado.
tcp state { closing | established | fin-wait-1 | fin-wait-2 | last-ack }
connection-limit numberPor padrão, o número máximo de conexões TCP em cada estado (CLOSING, ESTABLISHED, FIN_WAIT_1, FIN_WAIT_2 e LAST_ACK) é 50.
Para desativar o dispositivo de acelerar o envelhecimento das conexões TCP em um estado, defina o valor como 0.
- (Opcional.) Defina o intervalo para verificar o número de conexões TCP em cada estado.
tcp check-state interval intervalPor padrão, o intervalo para verificar o número de conexões TCP em cada estado é de 30 segundos.
Configuração da proteção de origem IP
Sobre o IPSG
O IPSG (IP source guard) evita ataques de spoofing usando uma tabela de vinculação IPSG para filtrar pacotes ilegítimos. Normalmente, esse recurso é configurado em interfaces do lado do usuário.
Mecanismo operacional do IPSG
A tabela de associação do IPSG contém associações que associam endereço IP, endereço MAC, VLAN ou qualquer combinação. O IPSG usa as associações para corresponder a um pacote de entrada. Se for encontrada uma correspondência, o pacote será encaminhado. Se não houver correspondência, o pacote será descartado.
Os vínculos IPSG podem ser estáticos ou dinâmicos.
Conforme mostrado na Figura 1, o IPSG encaminha apenas os pacotes que correspondem a uma associação do IPSG.
Figura 1 Aplicativo IPSG
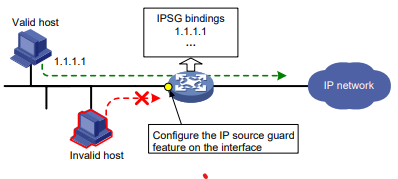
Vinculações IPSG estáticas
Os vínculos IPSG estáticos são configurados manualmente. Elas são adequadas para cenários em que existem poucos hosts em uma LAN e seus endereços IP são configurados manualmente. Por exemplo, você pode configurar uma associação IPSG estática em uma interface que se conecta a um servidor. Essa associação permite que a interface receba pacotes somente do servidor.
Os vínculos IPSG estáticos em uma interface implementam as seguintes funções:
- Filtre os pacotes IPv4 ou IPv6 recebidos na interface.
- Cooperar com a detecção de ataque ARP no IPv4 para verificação da validade do usuário. Para obter informações sobre a detecção de ataques ARP, consulte "Configuração da proteção contra ataques ARP".
- Cooperar com a detecção de ataque ND no IPv6 para verificação da validade do usuário. Para obter informações sobre a detecção de ataques ND, consulte "Configuração da defesa contra ataques ND".
As associações estáticas de IPSG podem ser globais ou específicas da interface.
- Vinculação estática global - Vincula o endereço IP e o endereço MAC na visualização do sistema. A associação entra em vigor em todas as interfaces para filtrar pacotes e evitar ataques de falsificação de usuário.
- Vinculação estática específica da interface - Vincula o endereço IP, o endereço MAC, a VLAN ou qualquer combinação dos itens na visualização da interface. A associação entra em vigor somente na interface para verificar a validade dos usuários que estão tentando acessar a interface.
Vinculações dinâmicas de IPSG
O IPSG obtém automaticamente informações do usuário de outros módulos para gerar associações dinâmicas. Uma associação dinâmica do IPSG pode conter endereço MAC, endereço IPv4 ou IPv6, etiqueta de VLAN, interface de entrada e tipo de associação. O tipo de associação identifica o módulo de origem da associação, como DHCP snooping, DHCPv6 snooping, agente de retransmissão DHCP ou agente de retransmissão DHCPv6.
Por exemplo, as associações de IPSG baseadas em DHCP são adequadas para cenários em que os hosts em uma LAN obtêm endereços IP por meio de DHCP. O IPSG é configurado no servidor DHCP, no dispositivo de snooping DHCP ou no agente de retransmissão DHCP. Ele gera associações dinâmicas com base nas associações de clientes no servidor DHCP, nas entradas de snooping DHCP ou nas entradas de retransmissão DHCP. O IPSG permite apenas a passagem de pacotes dos clientes DHCP.
IPv4SG dinâmico
Os vínculos dinâmicos gerados com base em diferentes módulos de origem destinam-se a diferentes usos:
| Tipos de interface | Módulos de origem | Uso de encadernação |
| Porta Ethernet de camada 2 | DHCP snooping 802.1X | Filtragem de pacotes. |
| ARP snooping | Para cooperação com módulos (como o módulo MFF) para fornecer serviços de segurança. | |
| Interface VLAN | Agente de retransmissão DHCP | Filtragem de pacotes. |
| Servidor DHCP | Para cooperação com módulos (como o módulo ARP autorizado) para fornecer serviços de segurança. |
Para obter mais informações sobre o 802.1X, consulte "Configuração do 802.1X". Para obter informações sobre snooping de ARP, snooping de DHCP, retransmissão de DHCP e servidor DHCP, consulte o Guia de configuração de serviços de IP de camada 3.
IPv6SG dinâmico
Os vínculos dinâmicos do IPv6SG gerados com base em diferentes módulos de origem destinam-se a diferentes usos:
| Tipos de interface | Módulos de origem | Uso de encadernação |
| Porta Ethernet de camada 2 | DHCPv6 snooping ND snooping 802.1X | Filtragem de pacotes. |
| Interface VLAN | Agente de retransmissão DHCPv6 | Filtragem de pacotes. |
Para obter mais informações sobre o snooping DHCPv6, consulte o Guia de Configuração de Serviços de Camada 3 IP. Para obter mais informações sobre o snooping ND, consulte Configuração básica de IPv6 no Guia de configuração de serviços de camada 3 IP. Para obter mais informações sobre o registro de entrada de prefixo ND RA, consulte Descoberta de vizinhos IPv6 no Guia de configuração de serviços da camada 3IP. Para obter mais informações sobre o agente de retransmissão DHCPv6, consulte o Guia de configuração de serviços da camada 3-IP. Para obter mais informações sobre o servidor DHCPv6, consulte o Guia de configuração de serviços da camada 3-IP.
Visão geral das tarefas do IPSG
Para configurar o IPv4SG, execute as seguintes tarefas:
- Ativação do IPv4SG
- (Opcional.) Configuração de uma ligação IPv4SG estática
- (Opcional.) Exclusão de pacotes IPv4 da filtragem IPSG
Para configurar o IPv6SG, execute as seguintes tarefas:
- Ativação do IPv6SG
- (Opcional.) Configuração de uma ligação IPv6SG estática
Configuração do recurso IPv4SG
Ativação do IPv4SG
Sobre o recurso IPv4SG em uma interface
Quando você ativa o IPSG em uma interface, o IPSG estático e o dinâmico são ativados.
- O IPv4SG estático usa associações estáticas configuradas com o comando ip source binding. Para obter mais informações, consulte "Configuração de uma associação IPv4SG estática".
- Dynamic O IPv4SG gera associações dinâmicas a partir de módulos de origem relacionados. O IPv4SG usa as associações para filtrar os pacotes IPv4 de entrada com base nos critérios de correspondência especificados no comando ip verify source.
Restrições e diretrizes
Para implementar o IPv4SG dinâmico, certifique-se de que o 802.1X, o ARP snooping, o DHCP snooping, o agente de retransmissão DHCP ou o servidor DHCP estejam funcionando corretamente na rede.
Ativação do IPv4SG em uma interface
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-numberOs seguintes tipos de interface são compatíveis:
- Interface Ethernet de camada 2.
- Interface VLAN.
- Habilite o IPv4SG na interface.
ip verify source { ip-address | ip-address mac-address | mac-address }Por padrão, o IPv4SG está desativado em uma interface.
ip verify source trustConfiguração de uma associação IPv4SG estática
Sobre os vínculos IPv4SG estáticos
Você pode configurar associações IPv4SG estáticas globais e estáticas específicas da interface. As associações estáticas globais têm prioridade sobre as associações estáticas e dinâmicas específicas da interface. Uma interface usa primeiro as associações estáticas globais para fazer a correspondência de pacotes. Se não for encontrada nenhuma correspondência, a interface usará as associações estáticas e dinâmicas da interface para fazer a correspondência dos pacotes.
Restrições e diretrizes
Os vínculos estáticos globais entram em vigor em todas as interfaces do dispositivo.
Para configurar uma associação IPv4SG estática para o recurso de detecção de ataque ARP, certifique-se de que as seguintes condições sejam atendidas:
A opção vlan vlan-id deve ser especificada.
- A detecção de ataques ARP deve estar ativada para a VLAN especificada.
Configuração de uma associação IPv4SG estática global
- Entre na visualização do sistema.
system view- Configure uma associação IPv4SG estática global.
ip source binding ip-address ip-address mac-address mac-addressConfiguração de uma associação IPv4SG estática em uma interface
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-numberOs seguintes tipos de interface são compatíveis:
- Interface Ethernet de camada 2.
- Interface VLAN.
- Configurar uma ligação IPv4SG estática.
ip source binding { ip-address ip-address | ip-address ip-address
mac-address mac-address | mac-address mac-address } [ vlan vlan-id ]Você pode configurar a mesma associação IPv4SG estática em diferentes interfaces.
Exclusão de pacotes IPv4 da filtragem IPSG
Sobre a exclusão de pacotes IPv4 da filtragem IPSG
Por padrão, o IPv4SG processa todos os pacotes IPv4 de entrada em uma interface e descarta os pacotes que não correspondem às associações do IPSG. Para permitir que pacotes IPv4 específicos que não correspondem a nenhuma associação do IPSG passem pela interface, você pode especificar os itens de origem dos pacotes para isenção de filtragem do IPSG. Todos os pacotes IPv4 com os itens de origem especificados são encaminhados sem serem processados pelo IPSG.
Procedimento
system view- Exclui da filtragem IPSG os pacotes IPv4 com os itens de origem especificados.
ip verify source exclude vlan start-vlan-id [ to end-vlan-id ]Por padrão, nenhum item de origem excluído é configurado.
Você pode executar esse comando várias vezes para especificar várias VLANs excluídas. As VLANs excluídas especificadas não podem se sobrepor.
Configuração do recurso IPv6SG
Ativação do IPv6SG
Sobre o recurso IPv6SG em uma interface
Quando você ativa o IPv6SG em uma interface, o IPv6SG estático e o dinâmico são ativados.
- O IPv6SG estático usa associações estáticas configuradas usando a associação de origem ipv6
comando. Para obter mais informações, consulte "Configuração de uma associação IPv6SG estática".
- Dinâmico O IPv6SG gera associações dinâmicas a partir de módulos de origem relacionados. O IPv6SG usa as associações para filtrar os pacotes IPv6 de entrada com base nos critérios de correspondência especificados no comando ipv6 verify source.
Restrições e diretrizes
Para implementar o IPv6SG dinâmico, certifique-se de que o snooping DHCPv6, o agente de retransmissão DHCPv6 ou o snooping ND estejam funcionando corretamente na rede.
Ativação do IPv6SG em uma interface
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-numberHá suporte para os seguintes tipos de interface:
- Interface Ethernet de camada 2.
- Interface VLAN.
- Habilite o IPv6SG na interface.
ipv6 verify source { ip-address | ip-address mac-address |
mac-address }Por padrão, o IPv6SG está desativado em uma interface.
Configuração de uma associação IPv6SG estática
Sobre as associações IPv6SG estáticas
Você pode configurar associações IPv6SG estáticas globais e estáticas específicas da interface. As associações estáticas globais têm prioridade sobre as associações estáticas e dinâmicas específicas da interface. Uma interface usa primeiro as associações estáticas globais para corresponder aos pacotes. Se não for encontrada nenhuma correspondência, a interface usará as associações estáticas e dinâmicas na interface para fazer a correspondência dos pacotes.
Restrições e diretrizes
Os vínculos estáticos globais entram em vigor em todas as interfaces do dispositivo.
Para configurar uma ligação IPv6SG estática para o recurso de detecção de ataque ND, a opção vlan vlan-id deve ser especificada e a detecção de ataque ND deve estar ativada para a VLAN especificada.
Configuração de uma associação IPv6SG estática global
system view- Configure uma associação IPv6SG estática global.
ipv6 source binding ip-address ipv6-address mac-address mac-addressConfiguração de uma associação IPv6SG estática em uma interface
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-numberOs seguintes tipos de interface são compatíveis:
- Interface Ethernet de camada 2.
- Interface VLAN.
- Configurar uma ligação IPv6SG estática.
ipv6 source binding { ip-address ipv6-address | ip-address ipv6-address
mac-address mac-address | mac-address mac-address } [ vlan vlan-id ]Você pode configurar a mesma associação IPv6SG estática em diferentes interfaces.
Comandos de exibição e manutenção para IPSG
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir vínculos IPv4SG. | display ip source binding [ static | [ arp-snooping-vlan | dhcp-relay | dhcp-server | dhcp-snooping | dot1x ] ] [ ip-address ip-address ] [ mac-address mac-address ] [ vlan vlan-id ] [ interface tipo interface-número da interface ] [ slot slot-number ] |
| Exibir itens de origem que foram configurados para serem excluídos da filtragem de IPSG. | display ip verify source excluded [ vlan start-vlan-id [ to end-vlan-id ] ] ] [ slot slot-número ] |
| Exibir associações de endereços IPv6SG. | display ipv6 source binding [ static | [ dhcpv6-server | dhcpv6-snooping | dot1x ] ] [ ip-address ipv6-address ] [ mac-address mac-address ] [ vlan vlan-id ] [ interface interface-type interface-number ] [ slot slot-number ] |
| Exibir as associações de prefixo IPv6SG. | display ipv6 source binding pd [ prefix prefix/prefix-length ] [ mac-address mac-address ] [ vlan vlan-id ] [ interface-type interface-number ] [ slot slot-number ] |
Exemplos de configuração do IPSG
Exemplo: Configuração de IPv4SG estático
Configuração de rede
Conforme mostrado na Figura 2, todos os hosts usam endereços IP estáticos.
Configure as associações IPv4SG estáticas no Dispositivo A e no Dispositivo B para atender aos seguintes requisitos:
Figura 2 Diagrama de rede
Procedimento
# Configure endereços IP para as interfaces. (Detalhes não mostrados.) # Habilite o IPv4SG na GigabitEthernet 1/0/2.
system-view
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] ip verify source ip-address mac-address
[DeviceA-GigabitEthernet1/0/2] quit # Configure uma associação IPv4SG estática para o Host A.
[DeviceA] ip source binding ip-address 192.168.0.1 mac-address 0001-0203-0406# Habilite o IPv4SG na GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] ip verify source ip-address mac-address# Na GigabitEthernet 1/0/1, configure uma associação IPv4SG estática para o Host B.
[DeviceA-GigabitEthernet1/0/1] ip source binding mac-address 0001-0203-0407
[DeviceA-GigabitEthernet1/0/1] quitVerificação da configuração
# Verifique se os vínculos IPv4SG estáticos foram configurados com êxito no Dispositivo A.
display ip source binding static
Total entries found: 2
IP Address MAC Address Interface VLAN Type
192.168.0.1 0001-0203-0406 N/A N/A Static
N/A 0001-0203-0407 GE1/0/1 N/A Static Exemplo: Configuração do IPv4SG dinâmico baseado em DHCP snooping
Configuração de rede
Conforme mostrado na Figura 3, o host (o cliente DHCP) obtém um endereço IP do servidor DHCP. Execute as seguintes tarefas:
- Ative o snooping de DHCP no dispositivo para garantir que o cliente DHCP obtenha um endereço IP do servidor DHCP autorizado. Para gerar uma entrada de snooping DHCP para o cliente DHCP, ative o registro das informações do cliente nas entradas de snooping DHCP.
- Habilite o IPv4SG dinâmico na GigabitEthernet 1/0/1 para filtrar os pacotes de entrada usando as associações IPv4SG geradas com base nas entradas do DHCP snooping. Somente os pacotes do cliente DHCP têm permissão para passar.
Figura 3 Diagrama de rede
Procedimento
- Configure o servidor DHCP.
Para obter informações sobre a configuração do servidor DHCP, consulte o Guia de Configuração de Serviços de Camada 3 IP .
- Configure o dispositivo:
# Configure endereços IP para as interfaces. (Detalhes não mostrados.) # Habilite o DHCP snooping.
system-view
[Device] dhcp snooping enable # Configure a GigabitEthernet 1/0/2 como uma interface confiável.
[Device] interface gigabitethernet 1/0/2
[Device-GigabitEthernet1/0/2] dhcp snooping trust
[Device-GigabitEthernet1/0/2] quit# Habilite o IPv4SG na GigabitEthernet 1/0/1 e verifique o endereço IP de origem e o endereço MAC para o IPSG dinâmico.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] ip verify source ip-address mac-address# Habilite o registro das informações do cliente nas entradas do DHCP snooping na GigabitEthernet 1/0/1.
[Device-GigabitEthernet1/0/1] dhcp snooping binding record
[Device-GigabitEthernet1/0/1] quitVerificação da configuração
# Exibir as associações dinâmicas de IPv4SG geradas com base nas entradas de DHCP snooping.
[Device] display ip source binding dhcp-snooping
Total entries found: 1
IP Address MAC Address Interface VLAN Type
192.168.0.1 0001-0203-0406 GE1/0/1 1 DHCP snoopingExemplo: Configuração do IPv4SG dinâmico baseado em agente de retransmissão DHCP
Configuração de rede
Conforme mostrado na Figura 4, o agente de retransmissão DHCP está ativado no switch. O host obtém um endereço IP do servidor DHCP por meio do agente de retransmissão DHCP.
Habilite o IPv4SG dinâmico na interface VLAN 100 para filtrar os pacotes de entrada usando as associações IPv4SG geradas com base nas entradas de retransmissão DHCP.
Figura 4 Diagrama de rede
Procedimento
- Configurar o IPv4SG dinâmico:
# Configure os endereços IP para as interfaces. (Detalhes não mostrados).
# Habilite o IPv4SG na interface VLAN 100 e verifique o endereço IP de origem e o endereço MAC para o IPSG dinâmico.
system-view
[Switch] interface vlan-interface 100
[Switch-Vlan-interface100] ip verify source ip-address mac-address
[Switch-Vlan-interface100] quit - Configure o agente de retransmissão DHCP:
# Habilite o serviço DHCP.
[Switch] dhcp enable# Habilite o registro de entradas de retransmissão DHCP.
[Switch] dhcp relay client-information record# Configure a interface VLAN 100 para operar no modo de retransmissão DHCP.
[Switch] interface vlan-interface 100
[Switch-Vlan-interface100] dhcp select relay# Especifique o endereço IP do servidor DHCP.
[Switch-Vlan-interface100] dhcp relay server-address 10.1.1.1
[Switch-Vlan-interface100] quitVerificação da configuração
# Exibir associações dinâmicas de IPv4SG geradas com base em entradas de retransmissão DHCP.
[Switch] display ip source binding dhcp-relay
Total entries found: 1
IP Address MAC Address Interface VLAN Type
192.168.0.1 0001-0203-0406 Vlan100 100 DHCP relayA interface VLAN 100 filtrará os pacotes com base na associação IPv4SG.
Exemplo: Configuração de IPv6SG estático
Configuração de rede
Conforme mostrado na Figura 5, configure uma associação IPv6SG estática na GigabitEthernet 1/0/1 do dispositivo para permitir a passagem apenas de pacotes IPv6 do host.
Figura 5 Diagrama de rede
Procedimento
# Habilite o IPv6SG na GigabitEthernet 1/0/1.
system-view
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] ipv6 verify source ip-address mac-address # Na GigabitEthernet 1/0/1, configure uma associação IPv6SG estática para o host.
[Device-GigabitEthernet1/0/1] ipv6 source binding ip-address 2001::1 mac-address
0001-0202-0202
[Device-GigabitEthernet1/0/1] quitVerificação da configuração
# Verifique se a associação IPv6SG estática foi configurada com êxito no dispositivo.
[Device] display ipv6 source binding static
Total entries found: 1
IPv6 Address MAC Address Interface VLAN Type
2001::1 0001-0202-0202 GE1/0/1 N/A StaticExemplo: Configuração de associações de endereços IPv6SG dinâmicos baseados em DHCPv6 snooping
Configuração de rede
Conforme mostrado na Figura 6, o host (o cliente DHCPv6) obtém um endereço IP do servidor DHCPv6. Execute as seguintes tarefas:
- Ative o snooping DHCPv6 no dispositivo para garantir que o cliente DHCPv6 obtenha um endereço IPv6 do servidor DHCPv6 autorizado. Para gerar uma entrada de snooping DHCPv6 para o cliente DHCPv6, ative o registro das informações do cliente nas entradas de snooping DHCPv6.
- Habilite o IPv6SG dinâmico na GigabitEthernet 1/0/1 para filtrar os pacotes de entrada usando as associações IPv6SG geradas com base nas entradas do DHCPv6 snooping. Somente os pacotes do cliente DHCPv6 têm permissão para passar.
Figura 6 Diagrama de rede
Procedimento
- Configurar o DHCPv6 snooping:
# Habilite o DHCPv6 snooping globalmente.
system-view
[Device] ipv6 dhcp snooping enable # Configure a GigabitEthernet 1/0/2 como uma interface confiável.
[Device] interface gigabitethernet 1/0/2
[Device-GigabitEthernet1/0/2] ipv6 dhcp snooping trust
[Device-GigabitEthernet1/0/2] quit- Ativar o IPv6SG:
# Habilite o IPv6SG na GigabitEthernet 1/0/1 e verifique o endereço IP de origem e o endereço MAC para o IPv6SG dinâmico.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] ipv6 verify source ip-address mac-address# Habilite o registro das informações do cliente nas entradas do DHCPv6 snooping na GigabitEthernet 1/0/1.
[Device-GigabitEthernet1/0/1] ipv6 dhcp snooping binding record
[Device-GigabitEthernet1/0/1] quitVerificação da configuração
# Exibir as associações dinâmicas de IPv6SG geradas com base nas entradas de DHCPv6 snooping.
[Device] display ipv6 source binding dhcpv6-snooping
Total entries found: 1
IPv6 Address MAC Address Interface VLAN Type
2001::1 040a-0000-0001 GE1/0/1 1 DHCPv6 snoopingA GigabitEthernet 1/0/1 filtrará os pacotes com base na associação IPv6SG.
Exemplo: Configuração de ligações dinâmicas de prefixo IPv6SG baseadas em DHCPv6 snooping
Configuração de rede
Conforme mostrado na Figura 7, o host (o cliente DHCPv6) obtém um prefixo IPv6 do servidor DHCPv6. Execute as seguintes tarefas:
- Ative o snooping DHCPv6 no dispositivo para garantir que o cliente DHCPv6 obtenha um prefixo IPv6 do servidor DHCPv6 autorizado. Para gerar uma entrada de prefixo de snooping DHCPv6 para o cliente DHCPv6, ative o registro de informações de prefixo IPv6 nas entradas de snooping DHCPv6.
- Habilite o IPv6SG dinâmico na GigabitEthernet 1/0/1 para filtrar os pacotes de entrada usando as associações IPv6SG geradas com base nas entradas de prefixo do DHCPv6 snooping. Somente os pacotes do cliente DHCPv6 têm permissão para passar.
Figura 7 Diagrama de rede
Procedimento
- Configurar o DHCPv6 snooping.
# Habilite o DHCPv6 snooping globalmente.
system-view
[Device] ipv6 dhcp snooping enable # Configure a GigabitEthernet 1/0/2 como uma interface confiável.
[Device] interface gigabitethernet 1/0/2
[Device-GigabitEthernet1/0/2] ipv6 dhcp snooping trust
[Device-GigabitEthernet1/0/2] quit# Habilite o registro de entradas de prefixo do DHCPv6 snooping na GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] ipv6 dhcp snooping pd binding record- Ativar o IPv6SG.
# Habilite o IPv6SG na GigabitEthernet 1/0/1 e verifique o endereço IP de origem e o endereço MAC para o IPv6SG dinâmico.
[Device-GigabitEthernet1/0/1] ipv6 verify source ip-address mac-address
[Device-GigabitEthernet1/0/1] quitVerificação da configuração
# Exibir as associações dinâmicas de IPv6SG geradas com base nas entradas de DHCPv6 snooping.
[Device] display ipv6 source binding pd
Total entries found: 1
IPv6 prefix MAC address Interface VLAN
2001:410:1::/48 0010-9400-0004 GE1/0/1 1A GigabitEthernet 1/0/1 filtrará os pacotes com base na associação IPv6SG.
Exemplo: Configuração do IPv6SG dinâmico baseado em agente de retransmissão DHCPv6
Configuração de rede
Conforme mostrado na Figura 8, o agente de retransmissão DHCPv6 está ativado no switch. Os clientes obtêm endereços IPv6 do servidor DHCPv6 por meio do agente de retransmissão DHCPv6.
Habilite o IPv6SG dinâmico na interface VLAN 3 para filtrar os pacotes de entrada usando as associações IPv6SG geradas com base nas entradas de retransmissão DHCPv6.
Figura 8 Diagrama de rede
Procedimento
- Configure o agente de retransmissão DHCPv6:
# Crie a VLAN 2 e a VLAN 3, atribua interfaces às VLANs e especifique endereços IP para a interface VLAN 2 e a interface VLAN 3. (Detalhes não mostrados.)
# Habilite o agente de retransmissão DHCPv6 na interface VLAN 3.
[Switch] interface vlan-interface 3
[Switch-Vlan-interface3] ipv6 dhcp select relay# Habilite o registro de entradas de retransmissão de DHCPv6 na interface.
[Switch-Vlan-interface3] ipv6 dhcp relay client-information record# Especifique o endereço do servidor DHCPv6 2::2 no agente de retransmissão.
[Switch-Vlan-interface3] ipv6 dhcp relay server-address 2::2
[Switch-Vlan-interface3] quit- Habilite o IPv6SG na interface VLAN 3 e verifique o endereço IP de origem e o endereço MAC do IPv6SG dinâmico.
system-view
[Switch] interface vlan-interface 3
[Switch-Vlan-interface3] ipv6 verify source ip-address mac-address
[Switch-Vlan-interface3] quit Verificação da configuração
# Exibir associações dinâmicas de IPv6SG geradas com base em entradas de retransmissão DHCPv6.
[Switch] display ipv6 source binding dhcpv6-relay
Total entries found: 1
IP Address MAC Address Interface VLAN Type
1::2 0001-0203-0406 Vlan3 3 DHCPv6 relayA interface VLAN 3 filtrará os pacotes com base na associação IPv6SG.
Configuração da proteção contra ataques ARP
Sobre a proteção contra ataques ARP
O dispositivo pode fornecer vários recursos para detectar e impedir ataques de ARP e vírus na LAN. Um invasor pode explorar as vulnerabilidades do ARP para atacar dispositivos de rede das seguintes maneiras:
- Envia um grande número de pacotes IP não resolvíveis para manter o dispositivo receptor ocupado com a resolução de endereços IP até que sua CPU fique sobrecarregada. Os pacotes IP não resolvíveis referem-se a pacotes IP para os quais o ARP não consegue encontrar os endereços MAC correspondentes.
- Envia um grande número de pacotes ARP para sobrecarregar a CPU do dispositivo receptor.
- Atua como um usuário ou gateway confiável para enviar pacotes ARP para que os dispositivos receptores obtenham entradas ARP incorretas.
Visão geral das tarefas de proteção contra ataques ARP
Todas as tarefas de proteção contra ataques ARP são opcionais.
- Prevenção de ataques de inundação
- Configuração da proteção contra ataques de IP não resolvíveis
- Configuração do limite de taxa de pacotes ARP
- Configuração da detecção de ataques ARP baseados em MAC de origem
- Prevenção de ataques de spoofing de usuários e gateways
- Configuração da verificação de consistência do MAC de origem do pacote ARP
- Configuração da confirmação ativa de ARP
- Configuração de ARP autorizado
- Configuração da detecção de ataques ARP
- Configuração da verificação de validade do pacote ARP
- Configuração do encaminhamento restrito de ARP
- Ignorando portas de entrada de pacotes ARP durante a verificação de validade do usuário
- Ativação do registro de detecção de ataques ARP
- Configuração da varredura de ARP e do ARP fixo
- Configuração da proteção de gateway ARP
- Exemplo: Configuração da proteção de gateway ARP
- Configuração da filtragem de ARP
Configuração da proteção contra ataques de IP não resolvíveis
Sobre a proteção contra ataques de IP sem solução
Se um dispositivo receber um grande número de pacotes IP não resolvíveis de um host, poderão ocorrer as seguintes situações:
- O dispositivo envia um grande número de solicitações ARP, sobrecarregando as sub-redes de destino.
- O dispositivo continua tentando resolver os endereços IP de destino, sobrecarregando sua CPU. Para proteger o dispositivo contra esses ataques de IP, você pode configurar os seguintes recursos:
- Supressão de fonte ARP - Interrompe a resolução de pacotes de um endereço IP se o número de pacotes IP não resolvíveis do endereço IP exceder o limite superior em 5 segundos. O dispositivo continua a resolução de ARP quando o intervalo termina. Esse recurso é aplicável se os pacotes de ataque tiverem os mesmos endereços de origem.
- Roteamento ARP blackhole - Cria uma rota blackhole destinada a um endereço IP não resolvido. O dispositivo descarta todos os pacotes correspondentes até que a rota blackhole seja excluída. Uma rota de blackhole é excluída quando seu cronômetro de envelhecimento é atingido ou quando a rota se torna acessível.
Depois que uma rota blackhole é criada para um endereço IP não resolvido, o dispositivo inicia imediatamente a primeira sondagem de rota blackhole ARP enviando uma solicitação ARP. Se a resolução falhar, o dispositivo continuará a sondagem de acordo com as configurações da sonda. Se a resolução do endereço IP for bem-sucedida em uma sondagem, o dispositivo converterá a rota de blackhole em uma rota normal. Se uma rota de blackhole ARP envelhecer antes de o dispositivo concluir todas as sondagens, o dispositivo excluirá a rota de blackhole e não executará as sondagens restantes.
Esse recurso é aplicável independentemente do fato de os pacotes de ataque terem os mesmos endereços de origem .
Configuração da supressão de fonte ARP
- Entre na visualização do sistema.
system view- Ativar a supressão da fonte ARP.
arp source-suppression enablePor padrão, a supressão de fonte ARP está desativada.
- Defina o número máximo de pacotes não resolvíveis que o dispositivo pode processar por endereço IP de origem em 5 segundos.
arp source-suppression limit limit-valuePor padrão, o número máximo é 10.
Configuração do roteamento de blackhole ARP
Restrições e diretrizes
Defina a contagem da sonda de rota de blackhole ARP para um valor alto, por exemplo, 25. Se o dispositivo não conseguir alcançar o endereço IP de destino temporariamente e a contagem de sondas for muito pequena, todas as sondas poderão ser concluídas antes que o problema seja resolvido. Como resultado, os pacotes que não forem de ataque serão descartados. Essa configuração pode evitar essa situação.
Procedimento
- Entre na visualização do sistema.
system view- Ativar o roteamento ARP blackhole.
arp resolving-route enablePor padrão, o roteamento ARP blackhole está ativado.
- (Opcional.) Defina o número de sondas de rota ARP blackhole para cada endereço IP não resolvido.
arp resolving-route probe-count countA configuração padrão é de três sondas.
- (Opcional.) Defina o intervalo em que o dispositivo sonda as rotas ARP blackhole.
arp resolving-route probe-interval intervalA configuração padrão é 1 segundo.
Comandos de exibição e manutenção para proteção contra ataques de IP não resolvíveis
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações de configuração de supressão de fonte ARP. | exibir arp source-suppression |
Exemplo: Configuração da proteção contra ataques de IP não resolvíveis
Configuração de rede
Conforme mostrado na Figura 1, uma LAN contém duas áreas: uma área de P&D na VLAN 10 e uma área de escritório na VLAN 20. Cada área se conecta ao gateway (Device) por meio de um switch de acesso.
Um grande número de solicitações ARP é detectado na área do escritório e é considerado um ataque causado por pacotes IP não solucionáveis. Para evitar o ataque, configure a supressão da origem do ARP ou o roteamento de blackhole do ARP .
Figura 1 Diagrama de rede
Procedimento
- Se os pacotes de ataque tiverem o mesmo endereço de origem, configure a supressão de origem ARP:
# Habilite a supressão de fonte ARP.
system-view
[Device] arp source-suppression enable # Configure o dispositivo para processar um máximo de 100 pacotes não resolvíveis por endereço IP de origem em 5 segundos.
[Device] arp source-suppression limit 100- Se os pacotes de ataque tiverem endereços de origem diferentes, configure o roteamento de blackhole ARP:
# Habilite o roteamento de blackhole ARP.
[Device] arp resolving-route enableConfiguração do limite de taxa de pacotes ARP
Sobre o limite de taxa de pacotes ARP
O recurso de limite de taxa de pacotes ARP permite que você limite a taxa de pacotes ARP entregues à CPU. Um dispositivo habilitado para detecção de ataque ARP enviará todos os pacotes ARP recebidos à CPU para inspeção. O processamento excessivo de pacotes ARP fará com que o dispositivo funcione mal ou até mesmo trave. Para resolver esse problema, configure o limite de taxa de pacotes ARP. Quando a taxa de recebimento de pacotes ARP na interface exceder o limite de taxa, esses pacotes serão descartados.
Você pode ativar o envio de notificações para o módulo SNMP ou ativar o registro para o limite de taxa de pacotes ARP.
- Se o envio de notificações estiver ativado, o dispositivo enviará a maior taxa de pacotes ARP cruzada no limite dentro do intervalo de envio em uma notificação para o módulo SNMP. Você deve usar a opção
comando snmp-agent target-host para definir o tipo de notificação e o host de destino. Para obter mais informações sobre notificações, consulte Referência de comandos de monitoramento e gerenciamento de rede.
- Se o registro em log para o limite de taxa de pacotes ARP estiver ativado, o dispositivo enviará a taxa de pacotes ARP mais alta cruzada pelo limite dentro do intervalo de envio em uma mensagem de registro para o centro de informações. Você pode configurar o módulo do centro de informações para definir as regras de saída de registro. Para obter mais informações sobre a central de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Restrições e diretrizes
Como prática recomendada, configure esse recurso quando a detecção de ataque ARP, o ARP snooping ou o MFF estiver ativado ou quando forem detectados ataques de inundação ARP.
Se forem enviadas notificações e mensagens de registro excessivas para o limite de taxa de pacotes ARP, é possível aumentar o intervalo de envio de notificações e mensagens de registro.
Se você ativar o envio e o registro de notificações para o limite de taxa de pacotes ARP em uma interface agregada de camada 2 , os recursos se aplicarão a todas as portas membros da agregação.
Procedimento
- Entre na visualização do sistema.
system view- (Opcional.) Habilite as notificações SNMP para o limite de taxa de pacotes ARP.
snmp-agent trap enable arp [ rate-limit ]Por padrão, as notificações SNMP para o limite de taxa de pacotes ARP estão desativadas.
- (Opcional.) Ative o registro para o limite de taxa de pacotes ARP.
arp rate-limit log enablePor padrão, o registro em log do limite de taxa de pacotes ARP está desativado.
- (Opcional.) Defina o intervalo de envio de mensagens de notificação e de registro.
arp rate-limit log interval intervalPor padrão, o dispositivo envia notificações e mensagens de registro a cada 60 segundos.
- Entre na visualização da interface.
interface interface-type interface-numberOs tipos de interface compatíveis incluem interface Ethernet de camada 2 e interface agregada de camada 2.
- Ativar o limite de taxa de pacotes ARP.
arp rate-limit [ pps ]Por padrão, o limite de taxa de pacotes ARP está ativado.
Configuração da detecção de ataques ARP baseados em MAC de origem
Sobre a detecção de ataques ARP baseados em MAC de origem
Esse recurso verifica o número de pacotes ARP entregues à CPU. Se o número de pacotes do mesmo endereço MAC dentro de 5 segundos exceder um limite, o dispositivo gerará uma entrada de ataque ARP para o endereço MAC. Se o recurso de registro de ARP estiver ativado, o dispositivo tratará o ataque usando um dos seguintes métodos antes que a entrada de ataque ARP se esgote:
- Monitor-Only gera mensagens de registro.
- Filter - Gera mensagens de registro e filtra os pacotes ARP subsequentes do endereço MAC e os pacotes de dados originados ou destinados ao endereço MAC.
Para ativar o recurso de registro de ARP, use o comando arp source-mac log enable. Para obter informações sobre o recurso de registro de ARP, consulte ARP no Guia de Configuração de Serviços de Camada 3 IP.
Quando uma entrada de ataque ARP se esgota, os pacotes ARP originados do endereço MAC na entrada podem ser processados corretamente.
Restrições e diretrizes
Quando você altera o método de tratamento de monitor para filtro, a configuração entra em vigor imediatamente. Quando você altera o método de tratamento de filtro para monitor, o dispositivo continua filtrando os pacotes que correspondem às entradas de ataque existentes.
Você pode excluir os endereços MAC de alguns gateways e servidores dessa detecção. Esse recurso não inspeciona os pacotes ARP desses dispositivos, mesmo que eles sejam atacantes.
Procedimento
- Entre na visualização do sistema.
system view- Habilite a detecção de ataques ARP baseados em MAC de origem e especifique o método de tratamento.
arp source-mac { filter | monitor }Por padrão, esse recurso está desativado.
- Defina o limite.
arp source-mac threshold threshold-valuePor padrão, o limite é 30.
- Defina o cronômetro de envelhecimento para entradas de ataque ARP.
arp source-mac aging-time timePor padrão, o tempo de vida é de 300 segundos.
arp source-mac exclude-mac mac-address&<1-10>Por padrão, nenhum endereço MAC é excluído.
arp source-mac log enablePor padrão, o registro em log da detecção de ataques ARP baseados em MAC de origem está desativado.
Comandos de exibição e manutenção para detecção de ataques ARP baseados em MAC de origem
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir entradas de ataque ARP detectadas pela detecção de ataque ARP baseado em MAC de origem. | display arp source-mac { interface interface-type interface-number [ slot slot-number ] | slot slot-number } |
Exemplo: Configuração da detecção de ataques ARP baseados em MAC de origem
Configuração de rede
Conforme mostrado na Figura 2, os hosts acessam a Internet por meio de um gateway (dispositivo). Se os usuários mal-intencionados enviarem um grande número de solicitações ARP ao gateway, este poderá falhar e não conseguirá processar as solicitações dos clientes. Para resolver esse problema, configure a detecção de ataques ARP com base no MAC de origem no gateway.
Figura 2 Diagrama de rede
Procedimento
# Habilite a detecção de ataques ARP baseados em MAC de origem e especifique o método de tratamento como filtro.
system-view
[Device] arp source-mac filter # Defina o limite como 30.
[Device] arp source-mac threshold 30# Defina o tempo de vida das entradas de ataque ARP como 60 segundos.
[Device] arp source-mac aging-time 60# Excluir o endereço MAC 0012-3f86-e94c dessa detecção.
[Device] arp source-mac exclude-mac 0012-3f86-e94cConfiguração da verificação de consistência do MAC de origem do pacote ARP
Sobre a verificação de consistência do MAC de origem do pacote ARP
Esse recurso permite que um gateway filtre os pacotes ARP cujo endereço MAC de origem no cabeçalho Ethernet seja diferente do endereço MAC do remetente no corpo da mensagem. Esse recurso permite que o gateway aprenda as entradas ARP corretas.
Procedimento
- Entre na visualização do sistema.
system view- Ativar a verificação de consistência do endereço MAC de origem do pacote ARP.
arp valid-check enablePor padrão, a verificação de consistência do endereço MAC de origem do pacote ARP está desativada.
Configuração da confirmação ativa de ARP
Sobre a confirmação ativa de ARP
Configure esse recurso nos gateways para evitar falsificação de usuário.
A confirmação ativa de ARP impede que um gateway gere entradas ARP incorretas. No modo estrito, um gateway executa verificações de validade mais rigorosas antes de criar uma entrada ARP:
- Ao receber uma solicitação ARP destinada ao gateway, o gateway envia uma resposta ARP, mas
não cria uma entrada ARP.
- Ao receber uma resposta ARP, o gateway determina se resolveu o endereço IP do remetente:
- Em caso afirmativo, o gateway executa a confirmação ativa. Quando a resposta ARP é verificada como válida, o gateway cria uma entrada ARP.
- Se não, o gateway descarta o pacote.
Procedimento
- Entre na visualização do sistema.
system view- Habilite o recurso de confirmação ativa de ARP.
arp active-ack [ strict ] enablePor padrão, esse recurso está desativado.
Para que a confirmação ativa do ARP tenha efeito no modo estrito, certifique-se de que o roteamento ARP blackhole esteja ativado.
Configuração de ARP autorizado
Sobre a ARP autorizada
As entradas ARP autorizadas são geradas com base nas concessões de endereço dos clientes DHCP no servidor DHCP ou nas entradas de cliente dinâmico no agente de retransmissão DHCP. Para obter mais informações sobre o servidor DHCP e o agente de retransmissão DHCP, consulte o Guia de Configuração de Serviços de Camada 3IP.
Use esse recurso para evitar a falsificação de usuários e permitir que apenas clientes autorizados acessem os recursos da rede.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-numberSomente interfaces VLAN são compatíveis.
- Habilite o ARP autorizado na interface.
arp authorized enablePor padrão, o ARP autorizado está desativado.
Configuração da detecção de ataques ARP
Sobre a detecção de ataques ARP
A detecção de ataques ARP permite que os dispositivos de acesso bloqueiem pacotes ARP de clientes não autorizados para evitar ataques de falsificação de usuário e de gateway.
A detecção de ataques ARP oferece os seguintes recursos:
- Verificação da validade do usuário.
- Verificação da validade do pacote ARP.
- Encaminhamento restrito por ARP.
- Ignoração da porta de entrada do pacote ARP durante a verificação de validade do usuário
- Registro de detecção de ataque ARP.
Se a verificação de validade do pacote ARP e a verificação de validade do usuário estiverem ativadas, a primeira será aplicada primeiro e, em seguida, a segunda.
Não configure a detecção de ataque ARP junto com o ARP snooping. Caso contrário, as entradas do ARP snooping não poderão ser geradas.
Configuração da verificação de validade do usuário
Sobre a verificação da validade do usuário
A verificação de validade do usuário não verifica os pacotes ARP recebidos em interfaces confiáveis de ARP. Esse recurso compara o IP do remetente e o MAC do remetente no pacote ARP recebido em uma interface ARP não confiável com os critérios de correspondência na seguinte ordem:
- Regras de verificação de validade do usuário.
- Se for encontrada uma correspondência, o dispositivo processará o pacote ARP de acordo com a regra.
- Se não for encontrada nenhuma correspondência ou se nenhuma regra de verificação de validade do usuário estiver configurada, prossiga para a etapa 2.
- Ligações IPSG estáticas, entradas de segurança 802.1X e entradas de DHCP snooping.
- Se for encontrada uma correspondência, o dispositivo determinará que o pacote ARP é válido. Em seguida, o dispositivo encaminha o pacote procurando uma entrada que contenha o endereço IP de destino.
- Se for encontrada uma correspondência e a interface de recebimento for igual à interface na entrada com um endereço IP de remetente correspondente, o dispositivo executará o encaminhamento da Camada 3.
- Se for encontrada uma correspondência, mas a interface de recebimento for diferente da interface na entrada com um endereço IP de remetente correspondente, o dispositivo executará o encaminhamento da Camada 2.
- Se nenhuma correspondência for encontrada, o dispositivo executará o encaminhamento da Camada 2.
- Se nenhuma correspondência for encontrada, o dispositivo descartará o pacote ARP.
As associações estáticas de proteção de origem de IP são criadas com o comando ip source binding. Para obter mais informações, consulte "Configuração da proteção de origem de IP".
As entradas do DHCP snooping são geradas automaticamente pelo DHCP snooping. Para obter mais informações, consulte
Guia de configuração de serviços de camada 3-IP.
- As entradas de segurança X registram os mapeamentos de IP para MAC dos clientes 802.1X. Depois que um cliente passa pela autenticação 802.1X e carrega seu endereço IP em um dispositivo habilitado para detecção de ataques ARP, o dispositivo gera automaticamente uma entrada de segurança 802.1X. O cliente 802.1X deve estar ativado para carregar seu endereço IP no dispositivo. Para obter mais informações, consulte "Configuração do 802.1X".
Restrições e diretrizes
Ao configurar a verificação de validade do usuário, certifique-se de que um ou mais dos itens a seguir estejam configurados:
- Regras de verificação de validade do usuário.
- Ligações de proteção de origem de IP estático.
- DHCP snooping.
- 802.1X.
Se nenhum dos itens estiver configurado, o dispositivo não realizará a verificação de validade do usuário e não poderá encaminhar corretamente todos os pacotes ARP de entrada em interfaces não confiáveis de ARP.
Especifique um endereço IP, um endereço MAC e uma VLAN em que a detecção de ataque ARP esteja ativada para uma ligação de proteção de origem de IP . Caso contrário, nenhum pacote ARP poderá corresponder à ligação de proteção de origem de IP.
Configuração das regras de verificação de validade do usuário
- Entre na visualização do sistema.
system view- Configure uma regra de verificação de validade do usuário.
arp detection rule rule-id { deny | permit } ip { ip-address [ mask ] | any }
mac { mac-address [ mask ] | any } [ vlan vlan-id ]Por padrão, nenhuma regra de verificação de validade do usuário é configurada.
Ativação da detecção de ataques ARP em uma VLAN
- Entre na visualização do sistema.
system view- Entre na visualização de VLAN.
vlan vlan-id- Ativar a detecção de ataques ARP.
arp detection enablePor padrão, a detecção de ataques ARP está desativada. O dispositivo não executa a verificação de validade do usuário.
- (Opcional.) Configure uma interface que não exija a verificação de validade do usuário ARP como uma interface confiável.
- Retornar à visualização do sistema.
quit- Entre na visualização da interface.
interface interface-type interface-numberOs tipos de interface compatíveis incluem a interface Ethernet de camada 2 e a interface agregada de camada 2.
- Configure a interface como uma interface confiável excluída da detecção de ataques ARP.
arp detection trustPor padrão, uma interface não é confiável.
Configuração da verificação de validade do pacote ARP
Sobre a verificação da validade do pacote ARP
A verificação da validade do pacote ARP não verifica os pacotes ARP recebidos em interfaces confiáveis de ARP. Para verificar os pacotes ARP recebidos em interfaces não confiáveis, você pode especificar os seguintes objetos a serem verificados:
- src-mac - Verifica se o endereço MAC do remetente no corpo da mensagem é idêntico ao endereço MAC de origem no cabeçalho Ethernet. Se forem idênticos, o pacote será encaminhado. Caso contrário, o pacote será descartado.
- dst-mac - Verifica o endereço MAC de destino das respostas ARP. Se o endereço MAC de destino for totalmente zero, totalmente um ou inconsistente com o endereço MAC de destino no cabeçalho da Ethernet, o pacote será considerado inválido e descartado.
- ip - Verifica os endereços IP do remetente e do destino das respostas ARP e o endereço IP do remetente das solicitações ARP. Os endereços IP all-one ou multicast são considerados inválidos e os pacotes correspondentes são descartados.
Pré-requisitos
Antes de configurar a verificação de validade do pacote ARP, é necessário configurar primeiro a verificação de validade do usuário. Para mais informações sobre a configuração da verificação de validade do usuário, consulte "Configuração da verificação de validade do usuário".
Ativação da verificação de validade do pacote ARP
- Entre na visualização do sistema.
system view- Habilite a verificação da validade do pacote ARP e especifique os objetos a serem verificados.
arp detection validate { dst-mac | ip | src-mac } *Por padrão, a verificação de validade do pacote ARP está desativada.
Ativação da detecção de ataques ARP em uma VLAN
- Entre na visualização do sistema.
system view- Entre na visualização de VLAN.
vlan vlan-id- Ativar a detecção de ataques ARP.
arp detection enablePor padrão, a detecção de ataques ARP está desativada. O dispositivo não executa a verificação de validade do pacote ARP.
- (Opcional.) Execute os seguintes comandos em sequência para configurar a interface que não exige a verificação de validade do pacote ARP como uma interface confiável:
- Retornar à visualização do sistema.
quit- Entre na visualização da interface.
interface interface-type interface-numberOs tipos de interface compatíveis incluem a interface Ethernet de camada 2 e a interface agregada de camada 2.
- Configure a interface como uma interface confiável excluída da detecção de ataques ARP.
arp detection trustPor padrão, uma interface não é confiável.
Configuração do encaminhamento restrito de ARP
Sobre o encaminhamento restrito de ARP
O encaminhamento restrito de ARP não tem efeito sobre os pacotes ARP recebidos em interfaces confiáveis de ARP e encaminha os pacotes ARP corretamente. Esse recurso controla o encaminhamento de pacotes ARP recebidos em interfaces não confiáveis e que passaram pela verificação de validade do usuário da seguinte forma:
- Se os pacotes forem solicitações ARP, eles serão encaminhados pela interface confiável.
- Se os pacotes forem respostas de ARP, eles serão encaminhados de acordo com o endereço MAC de destino. Se não for encontrada nenhuma correspondência na tabela de endereços MAC, eles serão encaminhados pela interface confiável.
Restrições e diretrizes
O encaminhamento restrito de ARP não se aplica a pacotes ARP que usam endereços MAC de destino multiportas.
Pré-requisitos
Configure a verificação de validade do usuário antes de configurar o encaminhamento restrito de ARP. Para obter informações sobre a configuração da verificação de validade do usuário, consulte "Configuração da verificação de validade do usuário".
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização de VLAN.
vlan vlan-id- Ativar o encaminhamento restrito de ARP.
arp restricted-forwarding enablePor padrão, o encaminhamento restrito de ARP está desativado.
Ignorando portas de entrada de pacotes ARP durante a verificação de validade do usuário
Sobre ignorar portas de entrada de pacotes ARP durante a verificação de validade do usuário
A detecção de ataques ARP executa a verificação da validade do usuário em pacotes ARP de interfaces não confiáveis ARP. O IP do remetente e o MAC do remetente no pacote ARP recebido são comparados com as entradas usadas para a verificação da validade do usuário. Além disso, a verificação da validade do usuário compara a porta de entrada do pacote ARP com a porta nas entradas. Se não for encontrada nenhuma porta correspondente, o pacote ARP será descartado. Para obter mais informações sobre a verificação de validade do usuário, consulte "Configuração da verificação de validade do usuário".
É possível configurar o dispositivo para ignorar as portas de entrada dos pacotes ARP durante a verificação de validade do usuário. Se um pacote ARP for aprovado na verificação de validade do usuário, o dispositivo executará diretamente o encaminhamento da Camada 2 para o pacote. Ele não procura mais uma ligação IPSG estática correspondente, uma entrada de segurança 802.1X ou uma entrada DHCP snooping pelo endereço IP de destino do pacote ARP.
Procedimento
- Entre na visualização do sistema.
system view- Ignorar portas de entrada de pacotes ARP durante a verificação de validade do usuário.
arp detection port-match-ignorePor padrão, as portas de entrada dos pacotes ARP são verificadas durante a invalidade do usuário.
Ativação do registro de detecção de ataques ARP
Sobre o registro de detecção de ataques ARP
O recurso de registro de detecção de ataque ARP permite que um dispositivo gere mensagens de registro de detecção de ataque ARP quando pacotes ARP ilegais são detectados. Uma mensagem de registro de detecção de ataque ARP contém as seguintes informações:
- Interface de recebimento dos pacotes ARP.
- Endereço IP do remetente.
- Número total de pacotes ARP descartados.
Procedimento
- Entre na visualização do sistema.
system view- Habilite o registro de detecção de ataques ARP.
arp detection log enable [ interval interval | number number ]Por padrão, o registro de detecção de ataques ARP está desativado.
Comandos de exibição e manutenção para detecção de ataques ARP
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir as VLANs ativadas com detecção de ataque ARP. | exibir detecção de arp |
| Exibir estatísticas de origem de ataque ARP. | display arp detection statistics attack-source slot slot-number |
| Exibir estatísticas de pacotes descartados pela detecção de ataques ARP. | exibir estatísticas de detecção de arp packet-drop [ interface tipo interface-número da interface ] |
| Limpar estatísticas de origem de ataque ARP. | reset arp detection statistics attack-source [ slot slot-número ] |
| Limpar estatísticas de pacotes descartados pela detecção de ataques ARP. | reset arp detection statistics packet-drop [ interface tipo interface-número da interface ] |
Exemplo: Configuração da verificação de validade do usuário
Configuração de rede
Conforme mostrado na Figura 3, configure o Dispositivo B para executar a verificação de validade do usuário com base nas entradas de segurança 802.1X dos hosts conectados.
Figura 3 Diagrama de rede
Procedimento
- Adicione todas as interfaces do Dispositivo B à VLAN 10 e especifique o endereço IP da interface VLAN 10 no Dispositivo A. (Os detalhes não são mostrados).
- Configure o servidor DHCP no Dispositivo A e configure o pool de endereços DHCP 0.
system-view
[DeviceA] dhcp enable
[DeviceA] dhcp server ip-pool 0
[DeviceA-dhcp-pool-0] network 10.1.1.0 mask 255.255.255.0 - Configure o Host A e o Host B como clientes 802.1X e configure-os para carregar endereços IP para detecção de ataque ARP . (Detalhes não mostrados.)
- Configure o dispositivo B:
# Habilite o 802.1X.
system-view
[DeviceB] dot1x
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] dot1x
[DeviceB-GigabitEthernet1/0/1] quit
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] dot1x
[DeviceB-GigabitEthernet1/0/2] quit # Adicione um teste de usuário local.
[DeviceB] local-user test
[DeviceB-luser-test] service-type lan-access
[DeviceB-luser-test] password simple test
[DeviceB-luser-test] quit# Habilite a detecção de ataque ARP para a VLAN 10 para verificar a validade do usuário com base nas entradas 802.1X.
[DeviceB] vlan 10
[DeviceB-vlan10] arp detection enable# Configure a interface upstream como uma interface ARP confiável. Por padrão, uma interface é uma interface não confiável.
[DeviceB-vlan10] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] arp detection trust
[DeviceB-GigabitEthernet1/0/3] quitVerificação da configuração
# Verifique se os pacotes ARP recebidos nas interfaces GigabitEthernet 1/0/1 e GigabitEthernet 1/0/2 são verificados em relação às entradas 802.1X.
Exemplo: Configuração da verificação de validade do usuário e da verificação de validade do pacote ARP
Configuração de rede
Conforme mostrado na Figura 4, configure o Dispositivo B para executar a verificação de validade do pacote ARP e a verificação de validade do usuário com base em associações de proteção de fonte IP estática e entradas de DHCP snooping para hosts conectados.
Figura 4 Diagrama de rede
Procedimento
- Adicione todas as interfaces do Dispositivo B à VLAN 10 e especifique o endereço IP da interface VLAN 10 no Dispositivo A. (Os detalhes não são mostrados.)
- Configure o servidor DHCP no Dispositivo A e configure o pool de endereços DHCP 0.
system-view
[DeviceA] dhcp enable
[DeviceA] dhcp server ip-pool 0
[DeviceA-dhcp-pool-0] network 10.1.1.0 mask 255.255.255.0 - Configure o Host A (cliente DHCP) e o Host B. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilite o DHCP snooping.
system-view
[DeviceB] dhcp snooping enable
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] dhcp snooping trust
[DeviceB-GigabitEthernet1/0/3] quit # Habilite o registro das informações do cliente nas entradas do DHCP snooping na GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] dhcp snooping binding record
[DeviceB-GigabitEthernet1/0/1] quit# Habilite a detecção de ataques ARP para a VLAN 10.
[DeviceB] vlan 10
[DeviceB-vlan10] arp detection enable# Configure a interface upstream como uma interface confiável. Por padrão, uma interface é uma interface não confiável.
[DeviceB-vlan10] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] arp detection trust
[DeviceB-GigabitEthernet1/0/3] quit# Configure uma entrada de ligação de proteção de fonte IP estática na interface GigabitEthernet 1/0/2 para verificação de validade do usuário.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] ip source binding ip-address 10.1.1.6 mac-address
0001-0203-0607 vlan 10
[DeviceB-GigabitEthernet1/0/2] quit# Habilite a verificação de validade do pacote ARP verificando os endereços MAC e IP dos pacotes ARP.
[DeviceB] arp detection validate dst-mac ip src-macVerificação da configuração
# Verifique se o Dispositivo B verifica primeiro a validade dos pacotes ARP recebidos na GigabitEthernet 1/0/1 e na GigabitEthernet 1/0/2. Se os pacotes ARP forem confirmados como válidos, o Dispositivo B executará a verificação de validade do usuário usando os vínculos estáticos de proteção da fonte IP e, finalmente, as entradas de DHCP snooping.
Exemplo: Configuração do encaminhamento restrito de ARP
Configuração de rede
Conforme mostrado na Figura 5, configure o encaminhamento restrito de ARP no Dispositivo B, onde a detecção de ataque ARP está configurada. O isolamento de portas configurado no Dispositivo B pode entrar em vigor para solicitações de ARP de difusão.
Figura 5 Diagrama de rede
Procedimento
- Configure a VLAN 10, adicione interfaces à VLAN 10 e especifique o endereço IP da interface VLAN 10 no Dispositivo A. (Os detalhes não são mostrados).
- Configure o servidor DHCP no Dispositivo A e configure o pool de endereços DHCP 0.
system-view
[DeviceA] dhcp enable
[DeviceA] dhcp server ip-pool 0
[DeviceA-dhcp-pool-0] network 10.1.1.0 mask 255.255.255.0 - Configure o Host A (cliente DHCP) e o Host B. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilite o DHCP snooping e configure a GigabitEthernet 1/0/3 como uma interface confiável de DHCP.
system-view
[DeviceB] dhcp snooping enable
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] dhcp snooping trust
[DeviceB-GigabitEthernet1/0/3] quit # Habilite a detecção de ataque ARP para verificação da validade do usuário.
[DeviceB] vlan 10
[DeviceB-vlan10] arp detection enable# Configure a GigabitEthernet 1/0/3 como uma interface confiável de ARP. [DeviceB-vlan10] interface gigabitethernet 1/0/3 [DeviceB-GigabitEthernet1/0/3] arp detection trust [DeviceB-GigabitEthernet1/0/3] quit
# Configure uma entrada de proteção de fonte IP estática na interface GigabitEthernet 1/0/2.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] ip source binding ip-address 10.1.1.6 mac-address
0001-0203-0607 vlan 10
[DeviceB-GigabitEthernet1/0/2] quit# Habilite a verificação de validade do pacote ARP verificando os endereços MAC e IP dos pacotes ARP.
[DeviceB] arp detection validate dst-mac ip src-mac# Configurar o isolamento da porta.
[DeviceB] port-isolate group 1
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port-isolate enable group 1
[DeviceB-GigabitEthernet1/0/1] quit
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port-isolate enable group 1
[DeviceB-GigabitEthernet1/0/2] quitDepois que as configurações são concluídas, o Dispositivo B primeiro verifica a validade dos pacotes ARP recebidos na GigabitEthernet 1/0/1 e na GigabitEthernet 1/0/2. Se os pacotes ARP forem confirmados como válidos, o Dispositivo B executará a verificação de validade do usuário usando os vínculos de proteção de origem de IP estático e, finalmente, as entradas de DHCP snooping. No entanto, as solicitações de difusão ARP enviadas do Host A podem passar pela verificação no Dispositivo B e chegar ao Host B. O isolamento da porta falha.
# Habilite o encaminhamento restrito de ARP.
[DeviceB] vlan 10
[DeviceB-vlan10] arp restricted-forwarding enable
[DeviceB-vlan10] quitVerificação da configuração
# Verifique se o dispositivo B encaminha solicitações de difusão ARP do host A para o dispositivo A por meio da interface confiável GigabitEthernet 1/0/3. O host B não pode receber esses pacotes. O isolamento da porta está funcionando corretamente.
Configuração da varredura de ARP e do ARP fixo
Sobre a varredura de ARP e o ARP fixo
A varredura ARP é normalmente usada junto com o recurso ARP fixo em redes estáveis e de pequena escala.
A varredura ARP cria automaticamente entradas ARP para dispositivos em um intervalo de endereços. O dispositivo executa a varredura de ARP nas etapas a seguir:
- Envia solicitações ARP para cada endereço IP no intervalo de endereços.
- Obtém seus endereços MAC por meio de respostas ARP recebidas.
- Cria entradas ARP dinâmicas.
O ARP fixo converte as entradas ARP dinâmicas existentes (inclusive as geradas pela varredura ARP) em entradas ARP estáticas. Essas entradas ARP estáticas têm os mesmos atributos das entradas ARP configuradas manualmente. Esse recurso impede que as entradas ARP sejam modificadas por invasores.
Você pode definir a taxa de envio de pacotes ARP se o intervalo de varredura tiver um grande número de endereços IP. Essa configuração pode evitar o alto uso da CPU e a carga pesada da rede causada por uma explosão de tráfego ARP.
Restrições e diretrizes
Os endereços IP em entradas ARP existentes não são verificados.
Devido ao limite do número total de entradas de ARP estático, algumas entradas de ARP dinâmico podem falhar na conversão.
O comando arp fixup é uma operação única. Você pode usar esse comando novamente para converter as entradas ARP dinâmicas aprendidas posteriormente em estáticas.
Para excluir uma entrada ARP estática convertida de uma dinâmica, use o comando undo arp ip-address. Você também pode usar o comando reset arp all para excluir todas as entradas ARP ou o comando reset arp static para excluir todas as entradas ARP estáticas.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-number- Acionar uma varredura ARP.
arp scan [ start-ip-address to end-ip-address ] [ send-rate pps ] CUIDADO:
A varredura de ARP levará algum tempo. Para interromper uma varredura em andamento, pressione Ctrl + C. As entradas ARP dinâmicas são criadas com base nas respostas ARP recebidas antes do término da varredura.
- Retornar à visualização do sistema.
quit- Converter entradas ARP dinâmicas existentes em entradas ARP estáticas.
arp fixupConfiguração da proteção de gateway ARP
Sobre a proteção de gateway ARP
Configure esse recurso em interfaces não conectadas a um gateway para evitar ataques de spoofing de gateway.
Quando uma interface desse tipo recebe um pacote ARP, ela verifica se o endereço IP do remetente no pacote é consistente com o de qualquer gateway protegido. Em caso afirmativo, ela descarta o pacote. Caso contrário, ela trata o pacote corretamente.
Restrições e diretrizes
É possível ativar a proteção de gateway ARP para um máximo de oito gateways em uma interface.
Não configure os comandos arp filter source e arp filter binding em uma interface.
Se a proteção de gateway ARP funcionar com detecção de ataque ARP, MFF e ARP snooping, a proteção de gateway ARP será aplicada primeiro.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-numberOs tipos de interface compatíveis incluem interface Ethernet de camada 2 e interface agregada de camada 2.
- Ativar a proteção de gateway ARP para o gateway especificado.
aarp filter source ip-addressPor padrão, a proteção de gateway ARP está desativada.
Exemplo: Configuração da proteção de gateway ARP
Configuração de rede
Conforme mostrado na Figura 6, o Host B lança ataques de falsificação de gateway ao Device B. Como resultado, o tráfego que o Device B pretende enviar ao Device A é enviado ao Host B.
Configure o Dispositivo B para bloquear esses ataques.
Figura 6 Diagrama de rede
Procedimento
# Configure a proteção de gateway ARP no dispositivo B.
system-view
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] arp filter source 10.1.1.1
[DeviceB-GigabitEthernet1/0/1] quit
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] arp filter source 10.1.1.1 Verificação da configuração
# Verifique se a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 descartam os pacotes ARP de entrada cujo endereço IP do remetente é o endereço IP do gateway.
Configuração da filtragem de ARP
Filtragem de ARP
O recurso de filtragem de ARP pode evitar ataques de falsificação de gateway e de usuário.
Uma interface ativada com esse recurso verifica os endereços IP e MAC do remetente em um pacote ARP recebido em relação às entradas permitidas. Se for encontrada uma correspondência, o pacote será tratado corretamente. Caso contrário, o pacote será descartado.
Restrições e diretrizes
É possível configurar um máximo de oito entradas permitidas em uma interface.
Não configure os comandos arp filter source e arp filter binding em uma interface.
Se a filtragem de ARP funcionar com a detecção de ataques ARP, MFF e ARP snooping, a filtragem de ARP será aplicada primeiro.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-numberOs tipos de interface compatíveis incluem interface Ethernet e interface agregada de camada 2.
- Habilite a filtragem de ARP e configure uma entrada permitida. arp filter binding ip-address mac-address Por padrão, a filtragem de ARP está desabilitada.
Exemplo: Configuração da filtragem de ARP
Configuração de rede
Conforme mostrado na Figura 7, os endereços IP e MAC do Host A são 10.1.1.2 e 000f-e349-1233, respectivamente. Os endereços IP e MAC do Host B são 10.1.1.3 e 000f-e349-1234, respectivamente.
Configure a filtragem de ARP na GigabitEthernet 1/0/1 e na GigabitEthernet 1/0/2 do Dispositivo B para permitir pacotes ARP somente do Host A e do Host B.
Figura 7 Diagrama de rede
Procedimento
# Configure a filtragem de ARP no dispositivo B.
system-view
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] arp filter binding 10.1.1.2 000f-e349-1233
[DeviceB-GigabitEthernet1/0/1] quit
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] arp filter binding 10.1.1.3 000f-e349-1234 Verificação da configuração
# Verifique se a GigabitEthernet 1/0/1 permite pacotes ARP do host A e descarta outros pacotes ARP.
# Verifique se a GigabitEthernet 1/0/2 permite pacotes ARP do Host B e descarta outros pacotes ARP.
Configuração da defesa contra ataques ND
Sobre a defesa de ataque do ND
A defesa contra ataques ND (Neighbor Discovery) do IPv6 é capaz de identificar mensagens ND forjadas para evitar ataques ND.
O protocolo IPv6 ND não oferece nenhum mecanismo de segurança e é vulnerável a ataques de rede. Conforme mostrado na Figura 1, um invasor pode enviar as seguintes mensagens ICMPv6 forjadas para realizar ataques ND:
- Mensagens NS/NA/RS forjadas com um endereço IPv6 de um host vítima. O gateway e outros hosts atualizam a entrada ND da vítima com informações de endereço incorretas. Como resultado, todos os pacotes destinados à vítima são enviados ao terminal atacante.
- Mensagens RA forjadas com o endereço IPv6 de um gateway vítima. Como resultado, todos os hosts conectados ao gateway vítima mantêm parâmetros de configuração IPv6 e entradas ND incorretos.
Figura 1 Diagrama de ataque ND
Visão geral das tarefas de ataque e defesa da ND
Todas as tarefas de defesa de ataque ND são opcionais.
- Ativação da verificação de consistência do MAC de origem para mensagens ND
- Configuração da detecção de ataques ND
- Configuração da proteção RA
Ativação da verificação de consistência do MAC de origem para mensagens ND
Sobre a verificação de consistência do MAC de origem
O recurso de verificação de consistência do MAC de origem é normalmente configurado nos gateways para evitar ataques ND.
Esse recurso verifica a consistência do endereço MAC de origem e do endereço da camada de link de origem para cada mensagem ND que chega.
- Se o endereço MAC de origem e o endereço da camada de link de origem não forem os mesmos, o dispositivo descartará o pacote.
- Se os endereços forem os mesmos, o dispositivo continuará aprendendo as entradas ND.
O recurso de registro de ND registra eventos de inconsistência de MAC de origem e envia as mensagens de registro para o centro de informações. O centro de informações pode então enviar mensagens de registro de diferentes módulos de origem para diferentes destinos. Para obter mais informações sobre o centro de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
system view- Ativar a verificação de consistência do MAC de origem para mensagens ND.
ipv6 nd mac-check enablePor padrão, a verificação de consistência do MAC de origem está desativada para mensagens ND.
- (Opcional.) Ative o recurso de registro de ND.
ipv6 nd check log enablePor padrão, o recurso de registro ND está desativado.
Como prática recomendada, desative o recurso de registro de ND para evitar o excesso de registros de ND.
Configuração da detecção de ataques ND
Sobre a detecção de ataques ND
A detecção de ataques ND verifica as mensagens ND recebidas quanto à validade do usuário para evitar ataques de falsificação. Normalmente, é configurada em dispositivos de acesso. É compatível com os seguintes recursos:
- Verificação da validade do usuário.
- Registro de detecção de ataques ND.
A detecção de ataques ND define os seguintes tipos de interfaces:
- Interface confiável ND - O dispositivo encaminha diretamente as mensagens ND ou os pacotes de dados recebidos pelas interfaces confiáveis ND. Ele não executa a verificação de validade do usuário.
- Interface ND não confiável - O dispositivo descarta as mensagens RA e de redirecionamento recebidas pelas interfaces ND não confiáveis. Para outros tipos de mensagens ND recebidas pelas interfaces ND não confiáveis, o dispositivo verifica a validade do usuário.
A detecção de ataques ND compara o endereço IPv6 de origem e o endereço MAC de origem em uma mensagem ND recebida com entradas de segurança de outros módulos.
- Se for encontrada uma correspondência, o dispositivo verificará se o usuário é legal na VLAN receptora e encaminhará o pacote.
- Se nenhuma correspondência for encontrada, o dispositivo verifica se o usuário é ilegal e descarta a mensagem ND.
A detecção de ataque ND usa entradas estáticas de vinculação de proteção de origem IPv6, entradas de snooping ND e entradas de snooping DHCPv6 para verificação da validade do usuário.
As entradas estáticas de vinculação de proteção de origem IPv6 são criadas usando o comando ipv6 source binding. Para obter informações sobre a proteção de origem IPv6, consulte "Configuração da proteção de origem IP". Para obter informações sobre o snooping DHCPv6, consulte o Guia de Configuração de Serviços de Camada 3 IP. Para obter informações sobre o snooping de ND, consulte o Guia de configuração de serviços da camada 3-IP.
Restrições e diretrizes
Quando você configurar a detecção de ataques ND, siga estas restrições e diretrizes:
- Para evitar que as interfaces não confiáveis de ND descartem todas as mensagens ND recebidas, certifique-se de que um ou mais desses recursos estejam configurados: IPv6 source guard static bindings, DHCPv6 snooping e ND snooping.
- Para tornar os vínculos estáticos de proteção de origem IPv6 eficazes para a detecção de ataques ND, você deve executar as seguintes operações:
- Especifique a opção vlan vlan-id no comando ipv6 source binding.
- Habilite a detecção de ataques ND para a mesma VLAN.
Ativação da detecção de ND em uma VLAN
- Entre na visualização do sistema.
system view- Entre na visualização de VLAN.
vlan vlan-id- Ativar a detecção de ataques ND.
ipv6 nd check log enablePor padrão, a detecção de ataques ND está desativada.
- (Opcional.) Configure a interface como interface confiável ND:
- Retornar à visualização do sistema.
quit- Entre na visualização da interface agregada ou Ethernet de camada 2.
interface interface-type interface-number- Configure a interface como interface confiável ND.
ipv6 nd detection trustPor padrão, todas as interfaces são interfaces não confiáveis ND.
Ativação do registro de detecção de ataques ND
Sobre o registro de detecção de ataques ND
Esse recurso permite que um dispositivo gere registros quando detecta pacotes ND inválidos. As informações de registro ajudam os administradores a localizar e resolver problemas. Cada log registra as seguintes informações:
- Números de porta da vítima em uma VLAN.
- Endereço IP de origem dos pacotes ND inválidos.
- Endereço MAC de origem dos pacotes ND inválidos.
- VLAN ID dos pacotes ND inválidos.
- Número total de pacotes ND descartados.
Procedimento
- Entre na visualização do sistema.
system view- Habilite o registro de detecção de ataques ND.
ipv6 nd detection log enablePor padrão, o registro de detecção de ataques ND está desativado.
Comandos de exibição e manutenção para detecção de ataques ND
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir estatísticas de mensagens ND descartadas pela detecção de ataques ND. | exibir estatísticas de detecção de ipv6 nd [ interface tipo interface-número da interface ] |
| Limpar as estatísticas de detecção de ataques ND. | reset ipv6 nd detection statistics [ interface interface-type interface-number ] |
Exemplo: Configuração da detecção de ataques ND
Configuração de rede
Conforme mostrado na Figura 2, configure a detecção de ataque ND no Dispositivo B para verificar a validade do usuário para mensagens ND do Host A e do Host B.
Figura 2 Diagrama de rede
Procedimento
- Configurar o dispositivo A:
# Criar a VLAN 10.
system-view
[DeviceA] vlan 10
[DeviceA-vlan10] quit # Configure a GigabitEthernet 1/0/3 para a VLAN 10 do tronco.
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port link-type trunk
[DeviceA-GigabitEthernet1/0/3] port trunk permit vlan 10
[DeviceA-GigabitEthernet1/0/3] quit# Atribuir o endereço IPv6 10::1/64 à interface VLAN 10.
[DeviceA] interface vlan-interface 10
[DeviceA-Vlan-interface10] ipv6 address 10::1/64
[DeviceA-Vlan-interface10] quit- Configure o dispositivo B:
# Criar VLAN 10.
system-view
[DeviceB] vlan 10
[DeviceB-vlan10] quit # Configure a GigabitEthernet 1/0/1, a GigabitEthernet 1/0/2 e a GigabitEthernet 1/0/3 para a VLAN 10 do tronco.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type access
[DeviceB-GigabitEthernet1/0/1] port access vlan 10
[DeviceB-GigabitEthernet1/0/1] quit
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type access
[DeviceB-GigabitEthernet1/0/2] port access vlan 10
[DeviceB-GigabitEthernet1/0/2] quit
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] port link-type trunk
[DeviceB-GigabitEthernet1/0/3] port trunk permit vlan 10
[DeviceB-GigabitEthernet1/0/3] quit# Ativar a detecção de ataque ND para a VLAN 10.
[DeviceB] vlan 10
[DeviceB-vlan10] ipv6 nd detection enable# Habilite o snooping ND para endereços unicast globais IPv6 e o snooping ND para endereços IPv6 link-local na VLAN 10.
[DeviceB-vlan10] ipv6 nd snooping enable global
[DeviceB-vlan10] ipv6 nd snooping enable link-local
[DeviceB-vlan10] quit# Configure a GigabitEthernet 1/0/3 como interface confiável ND.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] ipv6 nd detection trust
Verificação da configuração
Verifique se o Dispositivo B inspeciona todas as mensagens ND recebidas pela GigabitEthernet 1/0/1 e GigabitEthernet 1/0/2 com base nas entradas de snooping ND. (Detalhes não mostrados.)
Configuração do RA guard
Sobre o RA guard
O RA guard permite que os dispositivos de acesso da Camada 2 analisem e bloqueiem mensagens RA indesejadas e forjadas.
Ao receber uma mensagem RA, o dispositivo toma a decisão de encaminhamento ou descarte com base na função do dispositivo conectado ou na política de proteção RA.
- Se a função do dispositivo conectado à interface receptora for roteador, o dispositivo encaminhará a mensagem RA. Se a função for host, o dispositivo descartará a mensagem RA.
- Se nenhuma função de dispositivo anexado for definida, o dispositivo usará a política de proteção de RA aplicada à VLAN da interface receptora para corresponder à mensagem RA.
- Se a política não contiver critérios de correspondência, ela não entrará em vigor e o dispositivo encaminhará a mensagem RA.
- Se o conteúdo da mensagem RA corresponder a todos os critérios da política, o dispositivo encaminhará a mensagem. Caso contrário, o dispositivo descarta a mensagem.
Especificar a função do dispositivo conectado
Restrições e diretrizes
Certifique-se de que sua configuração seja consistente com o tipo do dispositivo conectado. Se você não tiver conhecimento do tipo de dispositivo, não especifique uma função para o dispositivo.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
- Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-number- Entre na visualização da interface agregada.
interface bridge-aggregation interface-number- Especifique a função do dispositivo conectado à interface.
ipv6 nd raguard role { host | router }Por padrão, a função do dispositivo conectado à interface não é especificada.
Configuração e aplicação de uma política de proteção RA
Sobre a configuração da política de proteção RA
Configure uma política de proteção RA se você não especificar uma função para o dispositivo conectado ou se quiser filtrar as mensagens RA enviadas por um roteador.
Procedimento
- Entre na visualização do sistema.
system view- Crie uma política de proteção RA e entre em sua visualização.
if-match acl { ipv6-acl-number | name ipv6-acl-name }- Configure a política de proteção RA. Escolha as seguintes tarefas, conforme necessário:
- Especifique um critério de correspondência de ACL.
if-match prefix acl { ipv6-acl-number | name ipv6-acl-name }- Especifique um critério de correspondência de prefixo.
if-match prefix acl { ipv6-acl-number | name ipv6-acl-name }- Especifique um critério de correspondência de preferência de roteador.
if-match router-preference maximum { high | low | medium }- Especifique um critério de correspondência de sinalizador M.
if-match autoconfig managed-address-flag { off | on }- Especifique um critério de correspondência de sinalizador O.
if-match autoconfig other-flag { off | on }- Especifique um critério de correspondência de limite de salto máximo ou mínimo.
if-match hop-limit { maximum | minimum } limitPor padrão, a política de proteção RA não está configurada.
- Sair da visualização da política de proteção RA.
quit- Entre na visualização de VLAN.
vlan vlan-number- Aplique uma política de proteção RA à VLAN.
ipv6 nd raguard apply policy [ policy-name ]Por padrão, nenhuma política de RA guard é aplicada à VLAN.
Ativação do recurso de registro de proteção RA
Sobre o registro de proteção RA
Esse recurso permite que um dispositivo gere registros quando detecta mensagens RA forjadas. As informações de registro ajudam os administradores a localizar e resolver problemas. Cada log registra as seguintes informações:
- Nome da interface que recebeu a mensagem RA forjada.
- Endereço IP de origem da mensagem RA forjada.
- Número de mensagens RA descartadas na interface.
O recurso de registro de proteção RA envia as mensagens de registro para o centro de informações. O centro de informações pode então enviar mensagens de registro de diferentes módulos de origem para diferentes destinos. Para obter mais informações sobre o centro de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
system view- Ative o recurso de registro de proteção RA.
ipv6 nd raguard log enablePor padrão, o recurso de registro de proteção RA está desativado.
Comandos de exibição e manutenção para a proteção RA
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir a configuração da política de proteção de RA. | exibir a política de proteção de dados ipv6 nd [ policy-name ] |
| Exibir estatísticas de proteção RA. | display ipv6 nd raguard statistics [ interface interface-type interface-number ] |
| Limpar estatísticas de proteção RA. | reset ipv6 nd raguard statistics [ interface interface-type interface-number ] |
Exemplo: Configuração do RA guard
Configuração de rede
Conforme mostrado na Figura 3, a GigabitEthernet 1/0/1, a GigabitEthernet 1/0/2 e a GigabitEthernet 1/0/3 do Dispositivo B estão na VLAN 10.
Configure o RA guard no Dispositivo B para filtrar mensagens RA forjadas e indesejadas.
- Configure uma política RA na VLAN 10 para a GigabitEthernet 1/0/2 para filtrar todas as mensagens RA recebidas do dispositivo desconhecido.
- Especifique host como a função do host. Todas as mensagens RA recebidas na GigabitEthernet 1/0/1 são descartadas.
- Especifique roteador como a função do Dispositivo A. Todas as mensagens RA recebidas na GigabitEthernet 1/0/3 são encaminhadas.
Figura 3 Diagrama de rede
Procedimento
# Criar uma política de proteção RA chamada policy1.
system-view
[DeviceB] ipv6 nd raguard policy policy1 # Defina a preferência máxima do roteador como alta para a política de proteção de RA.
[DeviceB-raguard-policy-policy1] if-match router-preference maximum high# Especifique on como o critério de correspondência do sinalizador M para a política de proteção RA.
[DeviceB-raguard-policy-policy1] if-match autoconfig managed-address-flag on# Especifique on como o critério de correspondência do sinalizador O para a política de proteção RA.
[DeviceB-raguard-policy-policy1] if-match autoconfig other-flag on# Defina o limite máximo de saltos anunciados como 120 para a política de proteção RA.
[DeviceB-raguard-policy-policy1] if-match hop-limit maximum 120# Defina o limite mínimo de salto anunciado como 100 para a política de proteção RA.
[DeviceB-raguard-policy-policy1] if-match hop-limit minimum 100
[DeviceB-raguard-policy-policy1] quit# Atribua a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 à VLAN 10.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type access
[DeviceB-GigabitEthernet1/0/1] port access vlan 10
[DeviceB-GigabitEthernet1/0/1] quit
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type access
[DeviceB-GigabitEthernet1/0/2] port access vlan 10
[DeviceB-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 para a VLAN 10 do tronco.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] port link-type trunk
[DeviceB-GigabitEthernet1/0/3] port trunk permit vlan 10
[DeviceB-GigabitEthernet1/0/3] quit# Aplique a política de proteção RA policy1 à VLAN 10.
[DeviceB] vlan 10
[DeviceB-vlan10] ipv6 nd raguard apply policy policy1
[DeviceB-vlan10] quit# Especifique host como a função do dispositivo conectado à GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] ipv6 nd raguard role host
[DeviceB-GigabitEthernet1/0/1] quit# Especifique roteador como a função do dispositivo conectado à GigabitEthernet 1/0/3.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] ipv6 nd raguard role router
[DeviceB-GigabitEthernet1/0/3] quitVerificação da configuração
# Verifique se o dispositivo encaminha ou descarta as mensagens RA recebidas na GigabitEthernet 1/0/2 com base na política de proteção RA. (Detalhes não mostrados.)
# Verifique se o dispositivo descarta as mensagens RA recebidas na GigabitEthernet 1/0/1. (Detalhes não mostrados.)
# Verifique se o dispositivo encaminha as mensagens RA recebidas na GigabitEthernet 1/0/3 para outras interfaces na VLAN 10. (Detalhes não mostrados.)
Configuração do SAVI
Sobre a SAVI
O SAVI (Source Address Validation Improvement) verifica a validade dos endereços de origem dos pacotes IPv6 unicast globais. Ele implementa a verificação de validade usando os recursos de snooping ND, snooping DHCPv6, detecção de ataque ND e proteção de origem IP. O SAVI verifica apenas os endereços unicast globais e encaminha os pacotes que passam pela verificação de validade. Os pacotes originados de um endereço inválido são descartados.
Cenários de aplicação do SAVI
Somente DHCPv6
Os hosts conectados ao dispositivo habilitado para SAVI obtêm endereços somente por meio de DHCPv6. As mensagens DHCPv6, as mensagens ND (excluindo as mensagens RA e RR) e os pacotes de dados IPv6 são verificados com base nas entradas de snooping do DHCPv6 e nas entradas de vinculação de proteção de origem IPv6 estática.
Somente SLAAC
Os hosts conectados ao dispositivo habilitado para SAVI obtêm endereços somente por meio do SLAAC (Stateless Address Autoconfiguration). Nesse cenário, o SAVI descarta todas as mensagens DHCPv6. Somente as mensagens ND e os pacotes de dados IPv6 são verificados com base nas entradas de snooping do DHCPv6 e nas entradas de vinculação de proteção de origem IPv6 estática.
DHCPv6+SLAAC
Os hosts conectados ao dispositivo habilitado para SAVI obtêm endereços por meio de DHCPv6 e SLAAC. Nesse cenário, o SAVI verifica todas as mensagens DHCPv6, mensagens ND e pacotes de dados IPv6 com base nas entradas de snooping DHCPv6, entradas de snooping ND e entradas de vinculação de proteção de origem IPv6 estática.
Visão geral das tarefas SAVI
Para configurar o SAVI, execute as seguintes tarefas:
- Habilitando a SAVI
- Configuração da proteção de origem IPv6
- Configuração do DHCPv6 snooping
- Configuração dos parâmetros de ND
- (Opcional.) Configuração do atraso na exclusão de entradas
- (Opcional.) Ativação do registro de falsificação de pacotes e do registro de entrada de filtragem
Habilitando a SAVI
- Entre na visualização do sistema.
system view- Ativar SAVI.
ipv6 savi strictPor padrão, o SAVI está desativado.
Configuração da proteção de origem IPv6
- Ativar a proteção de origem IPv6 em uma interface.
- (Opcional.) Configure as associações IPv6SG estáticas.
Para obter mais informações sobre a configuração da proteção de origem IPv6, consulte "Configuração da proteção de origem IP".
Configuração do DHCPv6 snooping
Restrições e diretrizes
Habilite somente o snooping DHCPv6 para o cenário somente SLAAC.
Procedimento
- Ativar o snooping DHCPv6.
- Especifique as portas confiáveis do DHCPv6 snooping.
- Habilite o registro de informações do cliente nas entradas do DHCPv6 snooping.
Para obter mais informações sobre a configuração do DHCPv6 snooping, consulte o Guia de Configuração de Serviços de Camada 3 IP.
Configuração dos parâmetros de ND
Restrições e diretrizes
Habilite somente a detecção de ataque ND para o cenário somente DHCPv6.
Procedimento
- Habilite o snooping ND para endereços unicast globais.
Para obter mais informações sobre o ND snooping, consulte Noções básicas de IPv6 no Layer 3-IP Services Configuration Guide.
- Ativar a detecção de ataques ND.
Para obter mais informações sobre a detecção de ataques ND, consulte "Configuração da defesa contra ataques ND".
- Especifique as portas confiáveis ND.
Para obter mais informações sobre portas confiáveis ND, consulte "Configuração da defesa contra ataques ND".
Configuração do atraso de exclusão de entrada
Sobre o atraso na exclusão de entradas
O atraso de exclusão de entrada é o período de tempo que o dispositivo aguarda antes de excluir as entradas de snooping DHCPv6 e as entradas de snooping ND de uma porta inativa.
Procedimento
- Entre na visualização do sistema.
system view- Definir o atraso de exclusão de entrada.
ipv6 savi down-delay delay-timePor padrão, o atraso na exclusão de entradas é de 30 segundos.
Ativação do registro de falsificação de pacotes e do registro de entradas de filtragem
Sobre esta tarefa
O registro de falsificação de pacotes permite que o dispositivo gere mensagens de registro para os pacotes falsificados detectados pelo SAVI.
As entradas de filtragem são associações efetivas usadas para filtrar pacotes IPv6 pelo endereço IPv6 de origem. O registro de entrada de filtragem permite que o dispositivo gere mensagens de registro para entradas de filtragem. Uma mensagem de registro contém o endereço IPv6, o endereço MAC, a VLAN e a interface de uma entrada de filtragem.
O dispositivo envia mensagens de registro de entrada de filtragem e falsificação de pacotes para o centro de informações. Com o centro de informações, é possível definir regras de filtragem e saída de mensagens de registro, inclusive destinos de saída. Para obter mais informações sobre como usar a central de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6328 e posteriores.
Procedimento
- Entre na visualização do sistema.
system view- Habilite o registro de falsificação de pacotes.
ipv6 savi log enable spoofing-packet [ interval interval |
total-number number ] *Por padrão, o registro de falsificação de pacotes está desativado.
- Ativar o registro de entrada de filtragem.
ipv6 savi log enable filter-entryPor padrão, o registro de entrada de filtragem está desativado.
Exemplos de configuração do SAVI
Exemplo: Configuração de SAVI somente DHCPv6
Configuração de rede
Conforme mostrado na Figura 1, configure o SAVI no switch para atender aos seguintes requisitos:
- Os clientes obtêm endereços IPv6 somente por meio do DHCPv6.
- O SAVI verifica os endereços de origem das mensagens DHCPv6, das mensagens ND (excluindo as mensagens RA e RR) e dos pacotes de dados IPv6 na GigabitEthernet 1/0/2 e na GigabitEthernet 1/0/3.
Figura 1 Diagrama de rede
Procedimento
# Habilite o SAVI.
system-view
[Switch] ipv6 savi strict # Atribuir GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 à VLAN 2.
[Switch] vlan 2
[Switch-vlan2] port gigabitethernet 1/0/1 gigabitethernet 1/0/2 gigabitethernet 1/0/3
[Switch-vlan2] quit# Habilite o DHCPv6 snooping.
[Switch] ipv6 dhcp snooping enable# Configure a GigabitEthernet 1/0/1 como uma porta confiável de DHCPv6 snooping.
[Switch] interface gigabitethernet 1/0/1
[Switch-GigabitEthernet1/0/1] ipv6 dhcp snooping trust
[Switch-GigabitEthernet1/0/1] quit# Habilite o registro de entradas de DHCPv6 snooping na GigabitEthernet 1/0/2 e na GigabitEthernet 1/0/3.
[Switch] interface gigabitethernet 1/0/2
[Switch-GigabitEthernet1/0/2] ipv6 dhcp snooping binding record
[Switch-GigabitEthernet1/0/2] quit
[Switch] interface gigabitethernet 1/0/3
[Switch-GigabitEthernet1/0/3] ipv6 dhcp snooping binding record
[Switch-GigabitEthernet1/0/3] quit# Ativar a detecção de ataques ND.
[Switch] vlan 2
[Switch-vlan2] ipv6 nd detection enable
[Switch-vlan2] quit# Habilite a proteção de origem IPv6 na GigabitEthernet 1/0/2 e na GigabitEthernet 1/0/3.
[Switch] interface gigabitethernet 1/0/2
[Switch-GigabitEthernet1/0/2] ipv6 verify source ip-address mac-address
[Switch-GigabitEthernet1/0/2] quit
[Switch] interface gigabitethernet 1/0/3
[Switch-GigabitEthernet1/0/3] ipv6 verify source ip-address mac-address
[Switch-GigabitEthernet1/0/3] quitExemplo: Configuração de SAVI somente com SLAAC
Configuração de rede
Conforme mostrado na Figura 2, configure o SAVI no Switch B para atender aos seguintes requisitos:
- Os hosts obtêm endereços IPv6 somente por meio do SLAAC.
- As mensagens DHCPv6 são descartadas na GigabitEthernet 1/0/1 até a GigabitEthernet 1/0/3 na VLAN 2.
- O SAVI verifica os endereços de origem das mensagens ND e dos pacotes de dados IPv6 na GigabitEthernet 1/0/1 e na GigabitEthernet 1/0/2.
Figura 2 Diagrama de rede
Procedimento
# Habilite o SAVI.
system-view
[SwitchB] ipv6 savi strict # Atribuir GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 à VLAN 2.
[SwitchB] vlan 2
[SwitchB-vlan2] port gigabitethernet 1/0/1 gigabitethernet 1/0/2 gigabitethernet 1/0/3
[SwitchB-vlan2] quit# Habilite o snooping ND para endereços unicast globais na VLAN 2.
[SwitchB] vlan 2
[SwitchB-vlan2] ipv6 nd snooping enable global# Habilite a detecção de ataques ND para a VLAN 2.
[SwitchB-vlan2] ipv6 nd detection enable
[SwitchB-vlan2] quit# Habilite o DHCPv6 snooping.
<[SwitchB] ipv6 dhcp snooping enable# Configure a GigabitEthernet 1/0/3 como uma porta confiável ND.
[SwitchB] interface gigabitethernet 1/0/3
[SwitchB-GigabitEthernet1/0/3] ipv6 nd detection trust
[SwitchB-GigabitEthernet1/0/3] quit# Habilite a proteção de origem IPv6 na GigabitEthernet 1/0/1 e na GigabitEthernet 1/0/2.
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] ipv6 verify source ip-address mac-address
[SwitchB-GigabitEthernet1/0/1] quit
[SwitchB] interface gigabitethernet 1/0/2
[SwitchB-GigabitEthernet1/0/2] ipv6 verify source ip-address mac-address
[SwitchB-GigabitEthernet1/0/2] quitExemplo: Configuração de DHCPv6+SLAAC SAVI
Configuração de rede
Conforme mostrado na Figura 3, configure o SAVI no Switch B para atender aos seguintes requisitos:
- Os hosts obtêm endereços IP por meio de DHCPv6 ou SLAAC.
- O SAVI verifica os endereços de origem das mensagens DHCPv6, das mensagens ND e dos pacotes de dados IPv6 na GigabitEthernet 1/0/3 até a GigabitEthernet 1/0/5.
Figura 3 Diagrama de rede
Procedimento
# Habilite o SAVI.
system-view
[SwitchB] ipv6 savi strict # Atribuir GigabitEthernet 1/0/1 a GigabitEthernet 1/0/5 à VLAN 2.
[SwitchB] vlan 2
[SwitchB-vlan2] port gigabitethernet 1/0/1 gigabitethernet 1/0/2 gigabitethernet 1/0/3
gigabitethernet 1/0/4 gigabitethernet 1/0/5# Habilite o DHCPv6 snooping.
[SwitchB] ipv6 dhcp snooping enable# Habilite o registro de entradas de DHCPv6 snooping na GigabitEthernet 1/0/3 até a GigabitEthernet 1/0/5.
[SwitchB] interface gigabitethernet 1/0/3
[SwitchB-GigabitEthernet1/0/3] ipv6 dhcp snooping binding record
[SwitchB-GigabitEthernet1/0/3] quit
[SwitchB] interface gigabitethernet 1/0/4
[SwitchB-GigabitEthernet1/0/4] ipv6 dhcp snooping binding record
[SwitchB-GigabitEthernet1/0/4] quit
[SwitchB] interface gigabitethernet 1/0/5
[SwitchB-GigabitEthernet1/0/5] ipv6 dhcp snooping binding record
[SwitchB-GigabitEthernet1/0/5] quit# Configure a GigabitEthernet 1/0/1 como uma porta confiável de DHCPv6 snooping.
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] ipv6 dhcp snooping trust
[SwitchB-GigabitEthernet1/0/1] quit# Habilite o snooping ND para endereços unicast globais na VLAN 2.
[SwitchB] vlan 2
[SwitchB-vlan2] ipv6 nd snooping enable global# Habilite a detecção de ataques ND para a VLAN 2.
[SwitchB-vlan2] ipv6 nd detection enable
[SwitchB-vlan2] quit# Configure a GigabitEthernet 1/0/2 como uma porta confiável ND.
[SwitchB] interface gigabitethernet 1/0/2
[SwitchB-GigabitEthernet1/0/2] ipv6 nd detection trust
[SwitchB-GigabitEthernet1/0/2] quit# Habilite a proteção de origem IPv6 na GigabitEthernet 1/0/3 até a GigabitEthernet 1/0/5.
[SwitchB] interface gigabitethernet 1/0/3
[SwitchB-GigabitEthernet1/0/3] ipv6 verify source ip-address mac-address
[SwitchB-GigabitEthernet1/0/3] quit
[SwitchB] interface gigabitethernet 1/0/4
[SwitchB-GigabitEthernet1/0/4] ipv6 verify source ip-address mac-address
[SwitchB-GigabitEthernet1/0/4] quit
[SwitchB] interface gigabitethernet 1/0/5
[SwitchB-GigabitEthernet1/0/5] ipv6 verify source ip-address mac-address
Configuração do MFF
Sobre a MFF
O encaminhamento forçado por MAC (MFF) implementa o isolamento da Camada 2 e a comunicação da Camada 3 entre hosts no mesmo domínio de broadcast.
Um dispositivo habilitado para MFF intercepta solicitações ARP e retorna o endereço MAC de um gateway (ou servidor) para os remetentes. Dessa forma, os remetentes são forçados a enviar pacotes para o gateway para monitoramento de tráfego e prevenção de ataques.
Modelo de rede MFF
Conforme mostrado na Figura 1, os hosts são conectados ao Switch C por meio do Switch A e do Switch B, que são chamados de nós de acesso Ethernet (EANs). Os EANs habilitados para MFF encaminham os pacotes dos hosts para o gateway para posterior encaminhamento. Os hosts estão isolados na Camada 2, mas podem se comunicar na Camada 3.
Figura 1 Diagrama de rede para MFF
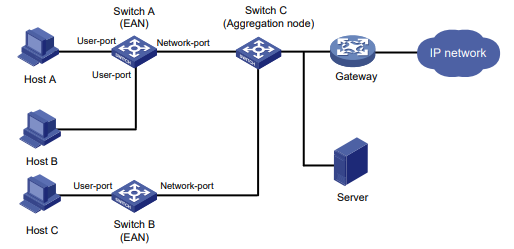
O MFF funciona com qualquer um dos seguintes recursos para implementar a filtragem de tráfego e o isolamento da Camada 2 nos EANs:
- ARP snooping (consulte o Guia de Configuração de Serviços de Camada 3 IP).
- Proteção da fonte de IP (consulte "Configuração da proteção da fonte de IP").
- Detecção de ARP (consulte "Configuração da proteção contra ataques ARP").
- Mapeamento de VLAN (consulte o Guia de configuração de comutação de LAN de camada 2).
Funções de porta
Existem dois tipos de portas, a porta do usuário e a porta da rede, em uma VLAN habilitada para MFF.
Porta do usuário
Uma porta de usuário MFF está diretamente conectada a um host e processa os seguintes pacotes de forma diferente:
- Permite a passagem de pacotes multicast.
- Entrega pacotes ARP à CPU.
- Processa os pacotes unicast da seguinte forma:
- Se os endereços MAC dos gateways tiverem sido aprendidos, a porta do usuário permitirá a passagem apenas dos pacotes unicast com os endereços MAC dos gateways como endereços MAC de destino.
- Se nenhum endereço MAC de gateways tiver sido aprendido, a porta do usuário descartará todos os pacotes unicast recebidos.
Porta de rede
Uma porta de rede MFF está conectada a qualquer um dos seguintes dispositivos de rede:
- Um switch de acesso.
- Um switch de distribuição.
- Uma porta de entrada.
- Um servidor.
Uma porta de rede processa os seguintes pacotes de forma diferente:
- Permite a passagem de pacotes multicast.
- Entrega pacotes ARP à CPU.
- Nega pacotes de difusão que não sejam pacotes DHCP e ARP.
Processamento de pacotes ARP no MFF
Um dispositivo habilitado para MFF implementa a comunicação da Camada 3 entre hosts interceptando solicitações ARP dos hosts e respondendo com o endereço MAC de um gateway. Esse mecanismo ajuda a reduzir o número de mensagens de difusão.
O dispositivo MFF processa os pacotes ARP da seguinte forma:
- Depois de receber uma solicitação ARP de um host, o dispositivo MFF envia o endereço MAC do gateway correspondente para o host. Dessa forma, os hosts da rede precisam se comunicar na Camada 3 por meio de um gateway.
- Após receber uma solicitação ARP de um gateway, o dispositivo MFF envia o endereço MAC do host solicitado para o gateway se a entrada correspondente estiver disponível. Se a entrada não estiver disponível, o dispositivo MFF encaminhará a solicitação ARP.
- O dispositivo MFF encaminha respostas ARP entre hosts e gateways.
- Se os endereços MAC de origem das solicitações ARP dos gateways forem diferentes dos registrados, o dispositivo MFF atualiza e transmite os endereços IP e MAC dos gateways.
Gateway padrão MFF
O MFF aplica-se somente a redes em que os endereços IP dos hosts são configurados manualmente. Como os hosts não podem obter as informações do gateway por meio do DHCP, o gateway padrão deve ser especificado pelo comando mac-forced-forwarding default-gateway. A MFF mantém apenas um gateway padrão para cada VLAN. A MFF atualiza o endereço MAC do gateway padrão ao receber um pacote ARP com um endereço MAC de remetente diferente do gateway padrão.
Protocolos e padrões
RFC 4562, Encaminhamento forçado por MAC
Visão geral das tarefas do MFF
Para configurar o MFF, execute as seguintes tarefas:
- Habilitação de MFF
- Configuração de uma porta de rede
- (Opcional.) Ativação da sonda periódica de gateway
- Especificação dos endereços IP dos servidores
Se houver servidores na rede, você deverá executar essa tarefa para garantir a comunicação entre os servidores e os hosts.
Habilitação de MFF
Restrições e diretrizes
- Um dispositivo habilitado para MFF e um host não podem fazer ping entre si.
- Quando a MFF trabalha com associações estáticas de proteção de origem de IP, você deve configurar IDs de VLAN nas associações estáticas. Caso contrário, os pacotes IP permitidos pela proteção de origem de IP serão permitidos mesmo que seus endereços MAC de destino não sejam o endereço MAC do gateway.
- O MFF não é suportado em uma rede em que o modo de balanceamento de carga VRRP esteja configurado.
Pré-requisitos
Para que o MFF entre em vigor, verifique se o ARP snooping está ativado na VLAN em que o MFF está ativado.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização de VLAN.
vlan vlan-id- Ativar MFF.
mac-forced-forwarding default-gateway gateway-ipPor padrão, o MFF está desativado.
Configuração de uma porta de rede
Restrições e diretrizes
Em uma VLAN com MFF ativado, é necessário configurar as seguintes portas como portas de rede:
- Portas upstream conectadas ao gateway.
- Portas conectadas a outros dispositivos MFF.
A agregação de links é suportada pelas portas de rede em uma VLAN habilitada para MFF, mas não é suportada pelas portas de usuário na VLAN. Você pode adicionar as portas de rede a grupos de agregação de links, mas não pode adicionar as portas de usuário a grupos de agregação de links. Para obter mais informações sobre agregação de links, consulte o Layer 2-LAN Switching Configuration Guide.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface.
interface interface-type interface-number- Configure a porta como uma porta de rede.
mac-forced-forwarding network-portPor padrão, a porta é uma porta de usuário.
Ativação da sonda periódica de gateway
Sobre a sonda periódica de gateway
Você pode configurar o dispositivo MFF para detectar gateways a cada 30 segundos quanto à alteração de endereços MAC enviando pacotes ARP forjados. Os pacotes ARP usam 0.0.0.0 como o endereço IP do remetente e o endereço MAC da ponte como o endereço MAC do remetente.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização de VLAN.
vlan vlan-id- Ativar a sonda periódica de gateway.
mac-forced-forwarding gateway probePor padrão, esse recurso está desativado.
Especificação dos endereços IP dos servidores
Sobre o endereço IP do servidor
Os endereços IP do servidor podem ser os das interfaces em um roteador em um grupo VRRP e os dos servidores que colaboram com a MFF, como um servidor RADIUS.
Quando o dispositivo MFF recebe uma solicitação ARP de um servidor, o dispositivo pesquisa as entradas de endereço IP para MAC que armazenou. Em seguida, o dispositivo responde ao servidor com o endereço MAC solicitado.
Como resultado, os pacotes de um host para um servidor são encaminhados pelo gateway. Entretanto, os pacotes de um servidor para um host não são encaminhados pelo gateway.
O MFF não verifica se o endereço IP de um servidor está no mesmo segmento de rede que o de um gateway. Em vez disso, ele verifica se o endereço IP de um servidor é totalmente zero ou totalmente um. Um endereço IP de servidor totalmente zero ou totalmente um é inválido.
Restrições e diretrizes
Se a interface do servidor que se conecta ao dispositivo MFF usar endereços IP secundários para enviar pacotes ARP , inclua todos esses endereços IP na lista de endereços IP do servidor.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização de VLAN.
vlan vlan-id- Especifique os endereços IP dos servidores.
mac-forced-forwarding server server-ip&<1-10>Por padrão, nenhum endereço IP do servidor é especificado.
Comandos de exibição e manutenção para MFF
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir a configuração da porta MFF. | exibir interface de encaminhamento forçado de mac |
| Exibir a configuração da MFF para uma VLAN. | display mac-forced-forwarding vlan vlan-id |
Exemplos de configuração de MFF
Exemplo: Configuração de MFF em uma rede em árvore
Configuração de rede
Conforme mostrado na Figura 2, todos os dispositivos estão na VLAN 100. Os hosts A, B e C recebem endereços IP manualmente.
Configure a MFF para isolar os hosts na Camada 2 e permitir que eles se comuniquem entre si por meio do gateway na Camada 3.
Figura 2 Diagrama de rede
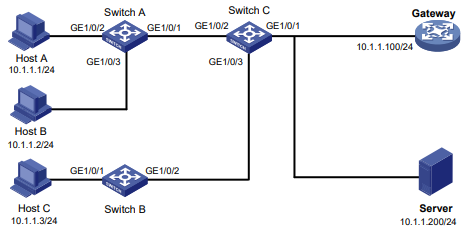
Procedimento
- Configure os endereços IP dos hosts e do gateway, conforme mostrado na Figura 2.
- Configure o Switch A:
# Configure o MFF na VLAN 100.
[SwitchA] vlan 100
[SwitchA-vlan100] mac-forced-forwarding default-gateway 10.1.1.100# Especifique o endereço IP do servidor.
[SwitchA-vlan100] mac-forced-forwarding server 10.1.1.200# Habilite o ARP snooping na VLAN 100.
[SwitchA-vlan100] arp snooping enable
[SwitchA-vlan100] quit# Configure a GigabitEthernet 1/0/1 como uma porta de rede.
[SwitchA-vlan100] arp snooping enable
[SwitchA-vlan100] quit- Configure o Switch B:
# Configure o MFF na VLAN 100.
[SwitchB] vlan 100
[SwitchB-vlan100] mac-forced-forwarding default-gateway 10.1.1.100# Especifique o endereço IP do servidor.
[SwitchB-vlan100] mac-forced-forwarding server 10.1.1.200# Habilite o ARP snooping na VLAN 100.
[SwitchB-vlan100] arp snooping enable
[SwitchB-vlan100] quit# Configure a GigabitEthernet 1/0/2 como uma porta de rede.
[SwitchB] interface gigabitethernet 1/0/2 1/0/6
[SwitchB-GigabitEthernet1/0/2] mac-forced-forwarding network-portExemplo: Configuração de MFF em uma rede em anel
Configuração de rede
Conforme mostrado na Figura 3, todos os dispositivos estão na VLAN 100 e os switches formam um anel. Os hosts A, B e C recebem endereços IP manualmente.
Configure a MFF para isolar os hosts na Camada 2 e permitir que eles se comuniquem entre si por meio do gateway na Camada 3.
Figura 3 Diagrama de rede
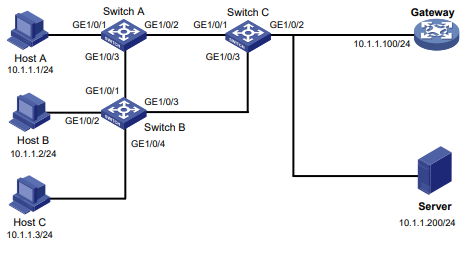
Procedimento
- Configure os endereços IP dos hosts e do gateway, conforme mostrado na Figura 3.
- Configure o Switch A:
# Habilite o STP globalmente para garantir que o STP esteja habilitado nas interfaces.
Configure o MFF na VLAN 100.
[SwitchA] vlan 100
[SwitchA-vlan100] mac-forced-forwarding default-gateway 10.1.1.100# Especifique o endereço IP do servidor.
[SwitchA-vlan100] mac-forced-forwarding server 10.1.1.200# Habilite o ARP snooping na VLAN 100.
[SwitchA-vlan100] arp snooping enable
[SwitchA-vlan100] quit# Configure a GigabitEthernet 1/0/2 e a GigabitEthernet 1/0/3 como portas de rede.
[SwitchA] interface gigabitethernet 1/0/2
[SwitchA-GigabitEthernet1/0/2] mac-forced-forwarding network-port
[SwitchA-GigabitEthernet1/0/2] quit
[SwitchA] interface gigabitethernet 1/0/3
[SwitchA-GigabitEthernet1/0/3] mac-forced-forwarding network-port- Configurar o Switch B:
# Habilite o STP globalmente para garantir que o STP esteja habilitado nas interfaces.
[SwitchB] stp global enableConfigure o MFF na VLAN 100.
[SwitchB] vlan 100
[SwitchB-vlan100] mac-forced-forwarding default-gateway 10.1.1.100# Especifique o endereço IP do servidor.
[SwitchB-vlan100] mac-forced-forwarding server 10.1.1.200# Habilite o ARP snooping na VLAN 100.
[SwitchB-vlan100] arp snooping enable
[SwitchB-vlan100] quit# Configure a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/3 como portas de rede.
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] mac-forced-forwarding network-port
[SwitchB-GigabitEthernet1/0/1] quit
[SwitchB] interface gigabitethernet 1/0/3
[SwitchB-GigabitEthernet1/0/3] mac-forced-forwarding network-port- Habilite o STP no Switch C globalmente para garantir que o STP esteja habilitado nas interfaces.
system-view
[SwitchC] stp global enable
Configuração de mecanismos de criptografia
Sobre mecanismos de criptografia
Os mecanismos de criptografia criptografam e descriptografam dados para módulos de serviço.
O dispositivo suporta apenas um mecanismo de criptografia de software, que é um conjunto de algoritmos de criptografia de software. O mecanismo de criptografia de software está sempre ativado.
Quando um módulo de serviço requer criptografia/descriptografia de dados, ele envia os dados desejados para o mecanismo de criptografia. Depois que o mecanismo de criptografia conclui a criptografia/descriptografia de dados, ele envia os dados de volta para o módulo de serviço .
Comandos de exibição e manutenção para mecanismos de criptografia
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações do mecanismo de criptografia. | exibir o mecanismo de criptografia |
| Exibir estatísticas do mecanismo de criptografia. | exibir estatísticas do mecanismo de criptografia [ slot de ID do motor ID do motor slot-number ] |
| Limpar estatísticas do mecanismo de criptografia. | reset crypto-engine statistics [ engine-id engine-id slot slot-number ] |
Configuração do FIPS
Sobre o FIPS
O Federal Information Processing Standards (FIPS) foi desenvolvido pelo National Institute of Standards and Technology (NIST) dos Estados Unidos. O FIPS especifica os requisitos para módulos criptográficos.
Níveis de segurança FIPS
O FIPS 140-2 define quatro níveis de segurança, denominados Nível 1 a Nível 4, de baixo a alto. O dispositivo é compatível com o Nível 2.
Salvo indicação em contrário, o termo "FIPS" refere-se ao Nível 2 FIPS 140-2 neste documento.
Funcionalidade FIPS
No modo FIPS, o dispositivo tem requisitos de segurança rigorosos. Ele executa autotestes nos módulos de criptografia para verificar se os módulos estão funcionando corretamente.
Um dispositivo FIPS também atende aos requisitos de funcionalidade definidos no Network Device Protection Profile (NDPP) do Common Criteria (CC).
Autotestes FIPS
Para garantir a operação correta dos módulos de criptografia, o FIPS fornece mecanismos de autoteste, incluindo autotestes de inicialização e autotestes condicionais.
Se um autoteste de inicialização falhar, o dispositivo em que existe o processo de autoteste será reinicializado. Se um autoteste condicional falhar, o sistema emitirá uma mensagem de falha de autoteste.
OBSERVAÇÃO:
Se o autoteste falhar, entre em contato com o Suporte da Intelbras.
Autotestes de inicialização
O autoteste de inicialização examina a disponibilidade dos algoritmos criptográficos permitidos pelo FIPS. O dispositivo suporta os seguintes tipos de autotestes de inicialização:
- Teste de conhecimento e resposta (KAT)
Um algoritmo criptográfico é executado em dados para os quais a saída correta já é conhecida. O resultado calculado é comparado com a resposta conhecida. Se elas não forem idênticas, o teste KAT falha.
- Teste condicional par a par (PWCT)
- Teste de assinatura e autenticação - O teste é executado quando um par de chaves assimétricas DSA, RSA ou ECDSA é gerado. O sistema usa a chave privada para assinar os dados específicos e, em seguida, usa a chave pública para autenticar os dados assinados. Se a autenticação for bem-sucedida, o teste será bem-sucedido.
- Teste de criptografia e descriptografia - O teste é executado quando um par de chaves assimétricas RSA é gerado. O sistema usa a chave pública para criptografar uma cadeia de texto simples e, em seguida, usa a chave privada para descriptografar o texto criptografado. Se o resultado da descriptografia for o mesmo da cadeia de texto simples original, o teste será bem-sucedido.
O autoteste de inicialização examina os algoritmos criptográficos listados na Tabela 1.
Tabela 1 Lista de autotestes de inicialização
| Tipo | Operações |
| KAT | Testa os seguintes algoritmos: SHA1, SHA224, SHA256, SHA384 e SHA512. HMAC-SHA1, HMAC-SHA224, HMAC-SHA256, HMAC-SHA384 e HMAC-SHA512. AES. RSA (assinatura e autenticação). ECDH. DRBG. GCM. GMAC. |
| PWCT | Testa os seguintes algoritmos: RSA (assinatura e autenticação). RSA (criptografia e descriptografia). DSA (assinatura e autenticação). ECDSA (assinatura e autenticação). |
Autotestes condicionais
Um autoteste condicional é executado quando um módulo criptográfico assimétrico ou um módulo gerador de números aleatórios é chamado. Os autotestes condicionais incluem os seguintes tipos:
- Assinatura e autenticação PWCT - Esse teste é executado quando um par de chaves assimétricas DSA ou RSA é gerado. O sistema usa a chave privada para assinar os dados específicos e, em seguida, usa a chave pública para autenticar os dados assinados. Se a autenticação for bem-sucedida, o teste será bem-sucedido.
- Teste do gerador de números aleatórios contínuos - É executado quando um número aleatório é gerado. O sistema compara o número aleatório gerado com o número aleatório gerado anteriormente. Se os dois números forem iguais, o teste falhará. Esse teste também é executado quando um par de chaves assimétricas DSA ou RSA é gerado.
Restrições e diretrizes: FIPS
Requisitos para pares de chaves e senhas
Antes de você reinicializar o dispositivo para entrar no modo FIPS, o sistema remove automaticamente todos os pares de chaves configurados no modo não-FIPS e todos os certificados digitais em conformidade com o FIPS. Os certificados digitais em conformidade com o FIPS são certificados baseados em MD5 com um comprimento de módulo de chave inferior a 2048 bits. Não é possível fazer login no dispositivo por meio de SSH depois que o dispositivo entra no modo FIPS. Para fazer login no dispositivo no modo FIPS por meio de SSH, faça login no dispositivo por meio de uma porta de console e crie um par de chaves para o servidor SSH.
A senha para entrar no dispositivo no modo FIPS deve estar em conformidade com as políticas de controle de senha, como comprimento, complexidade e política de envelhecimento da senha. Quando o cronômetro de envelhecimento de uma senha expira, o sistema solicita que você altere a senha. Se você ajustar a hora do sistema depois que o dispositivo entrar no modo FIPS, a senha de login poderá expirar antes do próximo login, pois a hora original do sistema normalmente é muito anterior à hora real.
Diretrizes de reversão de configuração
A reversão da configuração é suportada no modo FIPS e também durante uma alternância entre o modo FIPS e o modo não-FIPS. Após uma reversão da configuração entre o modo FIPS e o modo não-FIPS, execute as seguintes tarefas:
- Exclua o usuário local e configure um novo usuário local. Os atributos do usuário local incluem senha, função do usuário e tipo de serviço.
- Salvar o arquivo de configuração atual.
- Especifique o arquivo de configuração atual como o arquivo de configuração de inicialização.
- Reinicialize o dispositivo. A nova configuração entra em vigor após a reinicialização. Durante esse processo, não saia do sistema nem realize outras operações.
Se um dispositivo entrar no modo FIPS ou não-FIPS por meio de reinicialização automática, a reversão da configuração falhará. Para dar suporte à reversão da configuração, você deve executar o comando save depois que o dispositivo entrar no modo FIPS ou não-FIPS.
Compatibilidade com IRF
Todos os dispositivos em uma malha IRF devem estar operando no mesmo modo, seja no modo FIPS ou no modo não-FIPS.
Para ativar o modo FIPS em uma malha IRF, você deve reinicializar toda a malha IRF.
Alterações de recursos no modo FIPS
Depois que o sistema entra no modo FIPS, ocorrem as seguintes alterações de recursos:
- O modo de autenticação de login do usuário só pode ser um esquema.
- O servidor e o cliente FTP/TFTP estão desativados.
- O servidor e o cliente Telnet estão desativados.
- O servidor HTTP está desativado.
- SNMPv1 e SNMPv2c estão desativados. Somente o SNMPv3 está disponível.
- O servidor SSL é compatível apenas com TLS1.0, TLS1.1 e TLS1.2.
- O servidor SSH não é compatível com clientes SSHv1 ou pares de chaves DSA.
- Os pares de chaves RSA e DSA gerados devem ter um comprimento de módulo de 2048 bits.
Quando o dispositivo atua como um servidor para autenticar um cliente por meio da chave pública, o par de chaves do cliente também deve ter um comprimento de módulo de 2048 bits.
- Os pares de chaves ECDSA gerados devem ter um comprimento de módulo de mais de 256 bits.
Quando o dispositivo atua como um servidor para autenticar um cliente por meio da chave pública, o par de chaves do cliente também deve ter um comprimento de módulo superior a 256 bits.
- SSH, SNMPv3, IPsec e SSL não são compatíveis com DES, 3DES, RC4 ou MD5.
- O recurso de controle de senha não pode ser desativado globalmente. O comando undo password-control enable não tem efeito.
- Uma chave compartilhada AAA, uma chave pré-compartilhada IKE ou uma chave de autenticação SNMPv3 deve ter pelo menos 15 caracteres e conter letras maiúsculas e minúsculas, dígitos e caracteres especiais.
- A senha de um usuário local de gerenciamento de dispositivos e a senha para alternar funções de usuário devem estar em conformidade com as políticas de controle de senha. Por padrão, a senha deve ter pelo menos 15 caracteres e deve conter letras maiúsculas e minúsculas, dígitos e caracteres especiais.
Entrando no modo FIPS
Sobre como entrar no modo FIPS
Para que o dispositivo entre no modo FIPS, você pode usar um dos seguintes métodos:
- Reinicialização automática - O sistema executa automaticamente as seguintes operações:
- Solicita que você especifique o nome de usuário e a senha para o próximo login.
- Cria um arquivo de configuração padrão do FIPS chamado fips-startup.cfg.
- Especifica o arquivo de configuração padrão do FIPS como o arquivo de configuração de inicialização.
- Reinicializa e carrega o arquivo de configuração padrão do FIPS para entrar no modo FIPS.
- Reinicialização manual - Você deve concluir as tarefas de configuração necessárias e reinicializar o dispositivo manualmente.
Restrições e diretrizes
Depois de executar o comando fips mode enable, o sistema solicita que você escolha um método de reinicialização.
- Se você não fizer uma escolha dentro de 30 segundos ou pressionar Ctrl+C, o sistema ativará o modo FIPS e aguardará que você conclua manualmente as tarefas de configuração do modo FIPS.
- Se você selecionar o método de reinicialização automática, poderá pressionar Ctrl+C para cancelar o processo de configuração do modo FIPS interativo e o comando fips mode enable.
Uso do método de reinicialização automática para entrar no modo FIPS
Pré-requisitos
Para garantir a eficácia da senha de login de acordo com as políticas de controle de senha, defina a hora correta do sistema.
Procedimento
- Entre na visualização do sistema.
system view- Ativar o modo FIPS.
fips mode enablePor padrão, o modo FIPS está desativado.
- Depois que o prompt de escolha do método de reinicialização for exibido, digite Y dentro de 30 minutos. O sistema inicia o processo interativo de configuração do modo FIPS.
CUIDADO:
A reinicialização do sistema pode interromper os serviços em andamento. Execute as operações anteriores com cuidado.
- Digite o nome de usuário e a senha de login conforme solicitado.
A senha deve ter no mínimo 15 caracteres e deve conter letras maiúsculas e minúsculas, dígitos e caracteres especiais. Depois de inserir o nome de usuário e a senha, o dispositivo executa as seguintes operações:
- Cria um usuário local de gerenciamento de dispositivos que usa o nome de usuário e a senha inseridos.
- Atribui ao usuário o serviço de terminal e a função de usuário administrador de rede.
- Salva a configuração em execução e especifica o arquivo de configuração como o arquivo de configuração de inicialização.
- Reinicializa, carrega o arquivo de configuração de inicialização e entra no modo FIPS.
Para fazer login no dispositivo, é necessário inserir o nome de usuário e a senha configurados. Após o login, você será identificado como o oficial de criptografia do modo FIPS.
Uso do método de reinicialização manual para entrar no modo FIPS
Pré-requisitos
- Para garantir a eficácia da senha de login de acordo com as políticas de controle de senha, defina a hora correta do sistema.
- Configure o recurso de controle de senha.
- Habilite o recurso de controle de senha globalmente.
- Configure políticas de controle de senhas.
- Defina o número de tipos de caracteres que uma senha deve conter como 4.
- Defina o número mínimo de caracteres para cada tipo como um caractere.
- Defina o comprimento mínimo de uma senha de usuário para 15 caracteres.
Para obter mais informações sobre o recurso de controle de senha, consulte controle de senha no Security Configuration Guide.
- Configure um usuário local.
- Crie um usuário local de gerenciamento de dispositivos.
- Especifique uma senha que esteja em conformidade com as políticas de controle de senha.
- Atribua o serviço de terminal ao usuário.
- Atribua a função de usuário administrador de rede ao usuário.
Procedimento
- Entre na visualização do sistema.
system view- Ativar o modo FIPS.
fips mode enablePor padrão, o modo FIPS está desativado.
- Depois que o prompt de escolha do método de reinicialização for exibido, digite N.
O sistema ativa o modo FIPS e aguarda que você conclua as tarefas de configuração do modo FIPS. Antes de reinicializar o dispositivo para entrar no modo FIPS, não execute nenhum comando, exceto salvar e comandos usados para preparar a entrada no modo FIPS. Se você executar qualquer outro comando, os comandos poderão não ter efeito.
CUIDADO:
- A reinicialização do sistema pode interromper os serviços em andamento. Execute as operações anteriores com cuidado.
- Se você selecionar o método de reinicialização manual para entrar no modo FIPS, deverá concluir manualmente as configurações para entrar no modo FIPS. Se você não fizer isso, o dispositivo entrará no modo FIPS após a inicialização
mas não é possível fazer login no dispositivo.
- Salve a configuração em execução e especifique o arquivo de configuração como o arquivo de configuração de inicialização.
- Exclua o arquivo de configuração de inicialização .mdb.
Ao carregar um arquivo de configuração .mdb, o dispositivo carrega todas as configurações do arquivo. As configurações que não são compatíveis com o modo FIPS podem afetar a operação do dispositivo.
- Reinicie o dispositivo.
O dispositivo é reinicializado, carrega o arquivo de configuração de inicialização e entra no modo FIPS. Para fazer login no dispositivo, é necessário digitar o nome de usuário e a senha configurados. Após o login, você é identificado como o oficial de criptografia do modo FIPS.
Acionamento manual de autotestes
Sobre o acionamento de autotestes
Você pode acionar manualmente os autotestes FIPS para verificar a operação dos módulos de criptografia a qualquer momento, conforme necessário. Os autotestes acionados são os mesmos que os autotestes de inicialização.
Procedimento
- Entre na visualização do sistema.
system view- Autotestes de acionamento.
fips self-test CUIDADO:
Um autoteste bem-sucedido exige que todos os algoritmos criptográficos sejam aprovados no autoteste. Se o autoteste falhar, o dispositivo em que existe o processo de autoteste será reinicializado.
Sair do modo FIPS
Sobre como sair do modo FIPS
Depois que você desativar o modo FIPS e reiniciar o dispositivo, ele funcionará no modo não-FIPS. Para que o dispositivo saia do modo FIPS, você pode usar um dos seguintes métodos de reinicialização:
- Reinicialização automática - O sistema cria automaticamente um arquivo de configuração padrão não-FIPS
O arquivo de configuração de inicialização é chamado non-fips-startup.cfg, especifica o arquivo como o arquivo de configuração de inicialização e é reinicializado para entrar no modo não FIPS. Você pode fazer login no dispositivo sem fornecer nome de usuário ou senha.
- Reinicialização manual - Você deve concluir manualmente as tarefas de configuração para entrar no modo não-FIPS e, em seguida, reinicializar o dispositivo. Para fazer login no dispositivo após a reinicialização, é necessário inserir as informações do usuário conforme exigido pelas configurações do modo de autenticação.
A seguir estão as configurações padrão do modo de autenticação:
- Linha VTY - autenticação por senha.
- Linha AUX - A autenticação está desativada.
Você pode modificar as configurações de autenticação conforme necessário.
Uso do método de reinicialização automática para sair do modo FIPS
- Entre na visualização do sistema.
system view- Desativar o modo FIPS.
undo fips mode enablePor padrão, o modo FIPS está desativado.
- Selecione o método de reinicialização automática.
CUIDADO:
A reinicialização do sistema pode interromper os serviços em andamento. Execute as operações anteriores com cuidado.
Uso do método de reinicialização manual para sair do modo FIPS
- Entre na visualização do sistema.
system view- Desativar o modo FIPS.
undo fips mode enablePor padrão, o modo FIPS está desativado.
- Selecione o método de reinicialização manual.
CUIDADO:
A reinicialização do sistema pode interromper os serviços em andamento. Execute as operações anteriores com cuidado.
- Configurar as definições de autenticação de login.
- Se você fez login no dispositivo por meio de SSH, execute as seguintes tarefas sem desconectar a linha do usuário atual:
- Definir o modo de autenticação como esquema para linhas VTY.
- Especifique o nome de usuário e a senha. Se você não especificar o nome de usuário ou a senha, o dispositivo usará o nome de usuário e a senha atuais.
- Se tiver feito login no dispositivo por meio de uma porta de console, defina as configurações de autenticação de login para o tipo atual de linhas de usuário, conforme descrito na tabela a seguir:
| Método de login atual | Requisitos de autenticação de login |
| Esquema | Defina a autenticação como esquema e especifique o nome de usuário e a senha. Se você não especificar o nome de usuário ou a senha, o dispositivo usará o nome de usuário e a senha atuais. |
| Senha | Defina a autenticação como senha e especifique a senha. Se você não especificar a senha, o dispositivo usará a senha atual. |
| Nenhum | Defina a autenticação como nenhuma. |
- Salve a configuração em execução e especifique o arquivo como o arquivo de configuração de inicialização.
- Exclua o arquivo de configuração de inicialização .mdb.
- Reinicie o dispositivo.
Comandos de exibição e manutenção para FIPS
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibe o número da versão da base de algoritmos do dispositivo. | exibir versão de criptografia |
| Exibir o estado do modo FIPS. | exibir status fips |
Exemplos de configuração de FIPS
Exemplo: Entrada no modo FIPS por meio de reinicialização automática
Configuração de rede
Use o método de reinicialização automática para entrar no modo FIPS e use uma porta de console para fazer login no dispositivo no modo FIPS.
Procedimento
# Se você quiser salvar a configuração atual, execute o comando save antes de ativar o modo FIPS.
# Habilite o modo FIPS e escolha o método de reinicialização automática para entrar no modo FIPS. Defina o nome de usuário como root e a senha como 12345zxcvb!@#$%ZXCVB.
system-view
[Sysname] fips mode enable
FIPS mode change requires a device reboot. Continue? [Y/N]:y
Reboot the device automatically? [Y/N]:y
The system will create a new startup configuration file for FIPS mode. After you set the
login username and password for FIPS mode, the device will reboot automatically.
Enter username(1-55 characters):root
Enter password(15-63 characters):
Confirm password:
Waiting for reboot... After reboot, the device will enter FIPS mode. Verificação da configuração
Após a reinicialização do dispositivo, digite o nome de usuário root e a senha 12345zxcvb!@#$%ZXCVB. O sistema solicita que você configure uma nova senha. Depois que você configurar a nova senha, o dispositivo entrará no modo FIPS. A nova senha deve ser diferente da senha anterior. Ela deve ter pelo menos 15 caracteres e conter letras maiúsculas e minúsculas, dígitos e caracteres especiais. Para obter mais informações sobre os requisitos da senha, consulte a saída do sistema.
Press ENTER to get started.
login: root
Password:
First login or password reset. For security reason, you need to change your password. Please
enter your password.
old password:
new password:
confirm:
Updating user information. Please wait ... ...
…
<Sysname># Exibir o estado do modo FIPS.
display fips status
FIPS mode is enabled. # Exibir o arquivo de configuração padrão.
more fips-startup.cfg
#
password-control enable
#
local-user root class manage
service-type terminal
authorization-attribute user-role network-admin
#
fips mode enable
#
return
Exemplo: Entrada no modo FIPS por meio de reinicialização manual
Configuração de rede
Use o método de reinicialização manual para entrar no modo FIPS e use uma porta de console para fazer login no dispositivo no modo FIPS.
Procedimento
# Habilite o recurso de controle de senha globalmente.
<Sysname> system-view
[Sysname] password-control enable# Defina o número de tipos de caracteres que uma senha deve conter como 4 e defina o número mínimo de caracteres para cada tipo como um caractere.
[Sysname] password-control composition type-number 4 type-length 1
# Defina o tamanho mínimo das senhas de usuário para 15 caracteres.
[Sysname] password-control length 15# Adicione uma conta de usuário local para o gerenciamento do dispositivo, incluindo um nome de usuário de teste, uma senha de
[Sysname] local-user test class manage
[Sysname-luser-manage-test] password simple 12345zxcvb!@#$%ZXCVB
[Sysname-luser-manage-test] authorization-attribute user-role network-admin
[Sysname-luser-manage-test] service-type terminal
[Sysname-luser-manage-test] quit# Habilite o modo FIPS e escolha o método de reinicialização manual para entrar no modo FIPS.
[Sysname] fips mode enable
FIPS mode change requires a device reboot. Continue? [Y/N]:y
Reboot the device automatically? [Y/N]:n
Change the configuration to meet FIPS mode requirements, save the configuration to the
next-startup configuration file, and then reboot to enter FIPS mode.# Salve a configuração atual no diretório raiz da mídia de armazenamento e especifique-a como o arquivo de configuração de inicialização.
[Sysname] save
The current configuration will be written to the device. Are you sure? [Y/N]:y
Please input the file name(*.cfg)[flash:/startup.cfg]
(To leave the existing filename unchanged, press the enter key):
flash:/startup.cfg exists, overwrite? [Y/N]:y
Validating file. Please wait...
Saved the current configuration to mainboard device successfully.
[Sysname] quit# Exclua o arquivo de configuração de inicialização em formato binário.
delete flash:/startup.mdb
Delete flash:/startup.mdb?[Y/N]:y
Deleting file flash:/startup.mdb...Done. # Reinicie o dispositivo.
reboot Verificação da configuração
Depois que o dispositivo for reinicializado, digite um nome de usuário de teste e uma senha de 12345zxcvb!@#$%ZXCVB. O sistema solicita que você configure uma nova senha. Depois que você configurar a nova senha, o
O dispositivo entra no modo FIPS. A nova senha deve ser diferente da senha anterior. Ela deve ter pelo menos 15 caracteres e conter letras maiúsculas e minúsculas, dígitos e caracteres especiais. Para obter mais informações sobre os requisitos da senha, consulte a saída do sistema.
Press ENTER to get started.
login: test
Password:
First login or password reset. For security reason, you need to change your pass
word. Please enter your password.
old password:
new password:
confirm:
Updating user information. Please wait ... ...
…
# Exibir o estado do modo FIPS.
display fips status
FIPS mode is enabled. Exemplo: Saída do modo FIPS por meio de reinicialização automática
Configuração de rede
Depois de fazer login no dispositivo no modo FIPS por meio de uma porta de console, use o método de reinicialização automática para sair do modo FIPS.
Procedimento
# Desativar o modo FIPS.
[Sysname] undo fips mode enable
FIPS mode change requires a device reboot. Continue? [Y/N]:y
The system will create a new startup configuration file for non-FIPS mode and then reboot
automatically. Continue? [Y/N]:y
Waiting for reboot... After reboot, the device will enter non-FIPS mode.Verificação da configuração
Depois que o dispositivo for reinicializado, você poderá entrar no sistema.
# Exibir o estado do modo FIPS.
display fips status
FIPS mode is disabled. Exemplo: Saída do modo FIPS por meio de reinicialização manual
Configuração de rede
Depois de fazer login no dispositivo no modo FIPS pela porta do console com o nome de usuário test e a senha 12345zxcvb!@#$%ZXCVB, use o método de reinicialização manual para sair do modo FIPS.
Procedimento
# Desativar o modo FIPS.
[Sysname] undo fips mode enable
FIPS mode change requires a device reboot. Continue? [Y/N]:y
The system will create a new startup configuration file for non-FIPS mode, and then reboot
automatically. Continue? [Y/N]:n
Change the configuration to meet non-FIPS mode requirements, save the configuration to
the next-startup configuration file, and then reboot to enter non-FIPS mode.# Salve a configuração atual no diretório raiz da mídia de armazenamento e especifique-a como o arquivo de configuração de inicialização.
[Sysname] save
The current configuration will be written to the device. Are you sure? [Y/N]:y
Please input the file name(*.cfg)[flash:/startup.cfg]
(To leave the existing filename unchanged, press the enter key):
flash:/startup.cfg exists, overwrite? [Y/N]:y
Validating file. Please wait...
Saved the current configuration to mainboard device successfully.
[Sysname] quit# Exclua o arquivo de configuração de inicialização em formato binário.
delete flash:/startup.mdb
Delete flash:/startup.mdb?[Y/N]:y
Deleting file flash:/startup.mdb...Done. # Reinicie o dispositivo.
reboot Verificação da configuração
Após a reinicialização do dispositivo, a autenticação é desativada para o login do console por padrão.
Press ENTER to get started.
login: test
Password:
Last successfully login time:…
…
# Exibir o estado do modo FIPS.
display fips status
FIPS mode is disabled. Configuração de um cliente 802.1X
Sobre os clientes 802.1X
Conforme mostrado na Figura 1, o recurso de cliente 802.1X permite que o dispositivo de acesso atue como suplicante em a arquitetura 802.1X. Para obter informações sobre a arquitetura 802.1X, consulte "Visão geral do 802.1X".
Figura 1 Diagrama de rede do cliente 802.1X
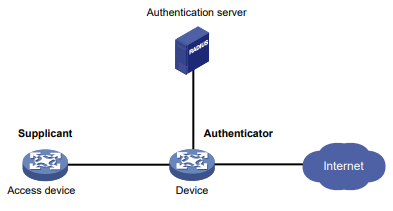
- Visão geral das tarefas do cliente X
Para configurar um cliente 802.1X, execute as seguintes tarefas:
- Ativação do recurso de cliente 802.1X
- Configuração de um nome de usuário e senha de cliente 802.1X
- Especificação de um método de autenticação EAP de cliente 802.1X
- (Opcional.) Configuração de um endereço MAC de cliente 802.1X
- (Opcional.) Especificação de um modo de cliente 802.1X para o envio de pacotes EAP-Response e EAPOL-Logoff
- (Opcional.) Configuração de um identificador anônimo de cliente 802.1X
- Especificação de uma política de cliente SSL
Essa tarefa é necessária quando você especifica a autenticação PEAP-MSCHAPv2, PEAP-GTC, TTLS-MSCHAPv2 ou TTLS-GTC como o método de autenticação EAP do cliente 802.1X.
Ativação do recurso de cliente 802.1X
- Entre na visualização do sistema.
system view- Entre na visualização da interface Ethernet.
interface interface-type interface-number- Ativar o recurso de cliente 802.1X.
dot1x supplicant enablePor padrão, o recurso de cliente 802.1X está desativado.
Configuração de um nome de usuário e senha de cliente 802.1X
Restrições e diretrizes
Para garantir que a autenticação seja bem-sucedida, certifique-se de que o nome de usuário e a senha configurados no dispositivo sejam consistentes com o nome de usuário e a senha configurados no servidor de autenticação.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface Ethernet.
interface interface-type interface-number- Configure um nome de usuário de cliente 802.1X.
dot1x supplicant username usernamePor padrão, nenhum nome de usuário de cliente 802.1X é configurado.
- Definir uma senha de cliente 802.1X.
dot1x supplicant password { cipher | simple } stringPor padrão, nenhuma senha de cliente 802.1X é configurada.
Especificação de um método de autenticação EAP de cliente 802.1X
Sobre os métodos de autenticação EAP do cliente 802.1X
Os clientes 802.1X no dispositivo são compatíveis com os seguintes métodos de autenticação EAP:
- MD5-Challenge.
- PEAP-MSCHAPv2.
- PEAP-GTC.
- TTLS-MSCHAPv2.
- TTLS-GTC.
Restrições e diretrizes
A matriz a seguir mostra as restrições para a seleção de métodos de autenticação no cliente 802.1X e no autenticador:
| Método de autenticação especificado no cliente 802.1X | Método de troca de pacotes especificado no autenticador |
| Desafio MD5 | Retransmissão EAP Encerramento do EAP |
| PEAP-MSCHAPv2 PEAP-GTC TTLS-MSCHAPv2 TTLS-GTC | Retransmissão EAP |
Para obter informações sobre os métodos de troca de pacotes 802.1X, consulte "Configuração do 802.1X".
Certifique-se de que o método de autenticação EAP do cliente 802.1X especificado seja compatível com o servidor de autenticação.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface Ethernet.
interface interface-type interface-number- Especifique um método de autenticação EAP de cliente 802.1X.
dot1x supplicant eap-method { md5 | peap-gtc | peap-mschapv2 |
ttls-gtc | ttls-mschapv2 }Por padrão, uma interface habilitada para cliente 802.1X usa a autenticação EAP MD5-Challenge.
Configuração de um endereço MAC de cliente 802.1X
Sobre os endereços MAC de clientes 802.1X
O autenticador adiciona o endereço MAC de um cliente 802.1X autenticado à tabela de endereços MAC e, em seguida, atribui direitos de acesso ao cliente.
Se várias interfaces Ethernet no dispositivo atuarem como clientes 802.1X, configure um endereço MAC exclusivo para cada interface a fim de garantir o sucesso da autenticação 802.1X.
Você pode usar um dos métodos a seguir para configurar um endereço MAC exclusivo para cada interface:
- Execute o comando mac-address na visualização da interface Ethernet. Para obter informações sobre esse comando, consulte Referência de comandos de comutação de Layer 2-LAN.
- Configurar um endereço MAC de cliente 802.1X.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface Ethernet.
interface interface-type interface-number- Configurar um endereço MAC de cliente 802.1X.
dot1x supplicant mac-address mac-addressPor padrão, o cliente 802.1X em uma interface Ethernet usa o endereço MAC da interface para a autenticação 802.1X. Se o endereço MAC da interface não estiver disponível, o cliente 802.1X usará o endereço MAC do dispositivo para a autenticação 802.1X.
Especificação de um modo de cliente 802.1X para o envio de pacotes EAP-Response e EAPOL-Logoff
Sobre a especificação de um modo de cliente 802.1X para o envio de pacotes EAP-Response e EAPOL-Logoff
A autenticação 802.1X suporta os modos unicast e multicast para enviar pacotes EAP-Response e EAPOL-Logoff. Como prática recomendada, use o modo multicast para evitar falhas de autenticação 802.1X se o dispositivo NAS na rede não suportar o recebimento de pacotes EAP-Response ou EAPOL-Logoff unicast.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface Ethernet.
interface interface-type interface-number- Especifique um modo de autenticação 802.1X para enviar pacotes EAP-Response e EAPOL-Logoff.
dot1x supplicant transmit-mode { multicast | unicast }Por padrão, a autenticação 802.1X usa o modo unicast para enviar pacotes EAP-Response e EAPOL-Logoff.
Configuração de um identificador anônimo de cliente 802.1X
Sobre os identificadores anônimos de clientes 802.1X
Na primeira fase de autenticação, os pacotes enviados ao autenticador não são criptografados. O uso de um identificador anônimo de cliente 802.1X impede que o nome de usuário do cliente 802.1X seja divulgado na primeira fase. O dispositivo habilitado para cliente 802.1X envia o identificador anônimo para o autenticador em vez do nome de usuário do cliente 802.1X. O nome de usuário do cliente 802.1X será enviado ao autenticador em pacotes criptografados na segunda fase.
Se nenhum identificador anônimo de cliente 802.1X estiver configurado, o dispositivo enviará o nome de usuário do cliente 802.1X na primeira fase de autenticação.
O identificador anônimo de cliente 802.1X configurado entra em vigor somente se um dos seguintes métodos de autenticação EAP for usado:
- PEAP-MSCHAPv2.
- PEAP-GTC.
- TTLS-MSCHAPv2.
- TTLS-GTC.
Se a autenticação EAP MD5-Challenge for usada, o identificador anônimo do cliente 802.1X configurado não terá efeito. O dispositivo usa o nome de usuário do cliente 802.1X na primeira fase de autenticação.
Restrições e diretrizes
Não configure o identificador anônimo do cliente 802.1X se o servidor de autenticação específico do fornecedor não puder identificar identificadores anônimos.
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface Ethernet.
interface interface-type interface-number- Configure um identificador anônimo de cliente 802.1X.
dot1x supplicant anonymous identify identifierPor padrão, nenhum identificador anônimo de cliente 802.1X é configurado.
Especificação de uma política de cliente SSL
Sobre as políticas de cliente SSL
Se a autenticação PEAP-MSCHAPv2, PEAP-GTC, TTLS-MSCHAPv2 ou TTLS-GTC for usada, o processo de autenticação 802.1X será o seguinte:
- A primeira fase - O dispositivo atua como um cliente SSL para negociar com o servidor SSL.
O cliente SSL usa os parâmetros SSL definidos na política de cliente SSL especificada para estabelecer uma conexão com o servidor SSL para negociação. Os parâmetros SSL incluem um domínio PKI, conjuntos de cifras compatíveis e a versão SSL. Para obter informações sobre a configuração da política do cliente SSL, consulte "Configuração de SSL".
- A segunda fase - O dispositivo usa o resultado negociado para criptografar e transmitir os pacotes de autenticação trocados.
Se a autenticação MD5-Challenge for usada, o dispositivo não usará uma política de cliente SSL durante o processo de autenticação .
Procedimento
- Entre na visualização do sistema.
system view- Entre na visualização da interface Ethernet.
interface interface-type interface-number- Especifique uma política de cliente SSL.
dot1x supplicant ssl-client-policy policy-namePor padrão, uma interface habilitada para cliente 802.1X usa a política de cliente SSL padrão.
Comandos de exibição e manutenção para o cliente 802.1X
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações do cliente 802.1X. | exibir dot1x supplicant [ interface interface-type interface-number ] |
09 - High Availability Configuration Guide
Configuração do Ethernet OAM
Sobre o Ethernet OAM
O OAM (Operation, Administration, and Maintenance) da Ethernet é uma ferramenta que monitora o status do link da Camada 2 e aborda problemas comuns relacionados ao link na "última milha". O Ethernet OAM aprimora o gerenciamento e a manutenção da Ethernet. Você pode usá-lo para monitorar o status do link ponto a ponto entre dois dispositivos conectados diretamente.
Principais funções do Ethernet OAM
O Ethernet OAM oferece as seguintes funções:
- Monitoramento do desempenho do link - monitora os índices de desempenho de um link, incluindo perda de pacotes, atraso e jitter, e coleta estatísticas de tráfego de vários tipos.
- Detecção de falhas e alarme - Verifica a conectividade de um link enviando unidades de dados do protocolo OAM (OAMPDUs) e informa aos administradores da rede quando ocorre um erro no link.
- Loopback remoto - Verifica a qualidade do link e localiza erros de link por meio de looping back de OAMPDUs.
Ethernet OAMPDUs
O Ethernet OAM opera na camada de link de dados. O Ethernet OAM informa o status do link por meio da troca periódica de OAMPDUs entre dispositivos, para que o administrador possa gerenciar a rede com eficiência.
Os OAMPDUs Ethernet incluem os seguintes tipos mostrados na Tabela 1.
Tabela 1 Funções de diferentes tipos de OAMPDUs
| Tipo de OAMPDU | Função |
| Informações OAMPDU | Usado para transmitir informações de estado de uma entidade Ethernet OAM, incluindo informações sobre o dispositivo local e dispositivos remotos e informações personalizadas, para a entidade Ethernet OAM remota e manter conexões OAM. |
| OAMPDU de notificação de evento | Usado pelo monitoramento de links para notificar a entidade OAM remota quando ela detecta problemas no link intermediário. |
| OAMPDU de controle de loopback | Usado para controle de loopback remoto. Ao inserir as informações usadas para ativar/desativar o loopback em uma OAMPDU de controle de loopback, é possível ativar/desativar o loopback em uma entidade OAM remota. |
OBSERVAÇÃO:
Ao longo deste documento, uma porta habilitada para Ethernet OAM é chamada de entidade Ethernet OAM ou entidade OAM.
Como funciona o Ethernet OAM
Esta seção descreve os procedimentos de trabalho do Ethernet OAM.
Estabelecimento de conexão Ethernet OAM
O estabelecimento da conexão OAM também é conhecido como fase de descoberta, em que uma entidade Ethernet OAM descobre a entidade OAM remota para estabelecer uma sessão.
Nessa fase, duas entidades OAM conectadas trocam OAMPDUs de informações para anunciar suas configurações e recursos de OAM uma à outra para comparação. Se as configurações de Loopback, detecção de link e evento de link forem iguais, as entidades OAM estabelecerão uma conexão OAM.
Uma entidade OAM opera no modo ativo ou no modo passivo. As entidades OAM no modo ativo iniciam as conexões OAM, e as entidades OAM no modo passivo aguardam e respondem às solicitações de conexão OAM. Para configurar uma conexão OAM entre duas entidades OAM, você deve definir pelo menos uma entidade para operar no modo ativo.
A Tabela 2 mostra as ações que um dispositivo pode executar em diferentes modos.
Tabela 2 Modo Ethernet OAM ativo e modo Ethernet OAM passivo
| Item | Modo Ethernet OAM ativo | Modo OAM de Ethernet passiva |
| Iniciando a descoberta de OAM | Disponível | Não disponível |
| Resposta à descoberta de OAM | Disponível | Disponível |
| Transmissão de informações OAMPDUs | Disponível | Disponível |
| Transmissão de OAMPDUs de notificação de eventos | Disponível | Disponível |
| Transmissão de OAMPDUs de informações sem nenhum TLV | Disponível | Disponível |
| Transmissão de OAMPDUs de controle de loopback | Disponível | Não disponível |
| Resposta a OAMPDUs de controle de loopback | Disponível | Disponível |
Depois que uma conexão Ethernet OAM é estabelecida, as entidades Ethernet OAM trocam OAMPDUs de informações no intervalo de transmissão do pacote de handshake para detectar a disponibilidade da conexão Ethernet OAM. Se uma entidade Ethernet OAM não receber nenhuma OAMPDU de informações dentro do tempo limite de conexão Ethernet OAM, a conexão Ethernet OAM será considerada desconectada.
Monitoramento de links
A detecção de erros em uma Ethernet é difícil, especialmente quando a conexão física na rede não está desconectada, mas o desempenho da rede está se degradando gradualmente.
O monitoramento de links detecta falhas de links em vários ambientes. As entidades Ethernet OAM monitoram o status do link por meio da troca de OAMPDUs de notificação de eventos. Ao detectar um dos eventos de erro de link listados na Tabela 3, uma entidade OAM envia um OAMPDU de notificação de evento para sua entidade OAM par. O administrador da rede pode acompanhar as alterações de status da rede recuperando o registro.
Tabela 3 Eventos de erro de link do Ethernet OAM
| Eventos de link Ethernet OAM | Descrição |
| Evento de quadro com erro | Um evento de quadro com erro ocorre quando o número de quadros com erro detectados na janela de detecção (intervalo de detecção especificado) excede o limite predefinido. |
| Evento de período de quadro com erro | Um evento de período de quadro com erro ocorre quando o número de erros de quadro na janela de detecção (número especificado de quadros recebidos) excede o limite predefinido. |
| Evento de segundos de quadros com erro | Um evento de segundos de quadro com erro ocorre quando o número de segundos de quadro com erro (o segundo em que um quadro com erro aparece é chamado de segundo de quadro com erro) detectado em uma porta na janela de detecção (intervalo de detecção especificado) atinge o limite predefinido. |
Detecção remota de falhas
As informações OAMPDUs são trocadas periodicamente entre as entidades Ethernet OAM em conexões OAM estabelecidas. Quando o tráfego é interrompido devido à falha ou indisponibilidade do dispositivo, a entidade Ethernet OAM na extremidade defeituosa envia informações de erro ao seu par. A entidade Ethernet OAM usa o campo de sinalização em Information OAMPDUs para indicar as informações de erro (qualquer tipo de evento de link crítico, conforme mostrado na Tabela 4). É possível usar as informações de registro para rastrear o status do link em andamento e solucionar prontamente os problemas .
Tabela 4 Eventos críticos do link
| Tipo | Descrição | Frequências de transmissão de OAMPDU |
| Falha no link | O sinal do link de par foi perdido. | Uma vez por segundo. |
| Suspiro de morte | Ocorreu uma falha inesperada, como falta de energia. | Sem parar. |
| Evento crítico | Ocorreu um evento crítico indeterminado. | Sem parar. |
Loopback remoto
O loopback remoto está disponível somente depois que a conexão Ethernet OAM é estabelecida. Com o loopback remoto ativado, a entidade Ethernet OAM no modo ativo envia OAMPDUs não-OAMP para seu par. Depois de receber esses quadros, o par não os encaminha de acordo com seus endereços de destino. Em vez disso, ele os devolve ao remetente pelo caminho original.
O loopback remoto permite que você verifique o status do link e localize falhas no link. A execução periódica do loopback remoto ajuda a detectar prontamente as falhas da rede. Além disso, a realização do loopback remoto por segmentos de rede ajuda a localizar falhas na rede.
Protocolos e padrões
IEEE 802.3ah, Carrier Sense Multiple Access with Collision Detection (CSMA/CD), Método de acesso e especificações da camada física
Restrições e diretrizes: Configuração do Ethernet OAM
O suporte do dispositivo para o envio e recebimento de OAMPDUs de informações com eventos de link críticos é o seguinte:
- Pode receber OAMPDUs de informações com os eventos de link críticos listados na Tabela 4.
- Pode enviar OAMPDUs de informação com eventos de falha de link.
- Pode enviar OAMPDUs de informações com eventos Dying Gasp quando o dispositivo é reinicializado ou quando as portas relevantes são desligadas manualmente. As portas IRF físicas, no entanto, não podem enviar esse tipo de OAMPDUs.
- Não é possível enviar OAMPDUs de informações com eventos críticos.
Visão geral das tarefas do Ethernet OAM
Para configurar o Ethernet OAM, execute as seguintes tarefas:
- Configuração das funções básicas do Ethernet OAM
- (Opcional.) Configuração dos temporizadores de detecção de conexão Ethernet OAM
- (Opcional.) Configuração da detecção de eventos de link
- Configuração da detecção de eventos de símbolos errados
- Configuração da detecção de eventos de quadros com erro
- Configuração da detecção de eventos de período de quadros com erro
- Configuração da detecção de eventos de segundos de quadros com erro
- (Opcional.) Configuração da ação que uma porta executa após receber um evento Ethernet OAM da extremidade remota
- (Opcional.) Configuração do loopback remoto do Ethernet OAM
- Ativação do loopback remoto do Ethernet OAM para uma porta
- Rejeição da solicitação de loopback remoto do Ethernet OAM de uma porta remota
Configuração das funções básicas do Ethernet OAM
Sobre os modos Ethernet OAM
Para configurar uma conexão Ethernet OAM entre duas entidades Ethernet OAM, você deve definir pelo menos uma entidade para operar no modo ativo. Uma entidade Ethernet OAM pode iniciar a conexão OAM somente no modo ativo.
Restrições e diretrizes
Para alterar o modo Ethernet OAM em uma porta habilitada para Ethernet OAM, primeiro desative o Ethernet OAM na porta.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberoam mode { active | passive }O padrão é o modo Ethernet OAM ativo.
oam enableO Ethernet OAM é desativado por padrão.
Configuração dos temporizadores de detecção de conexão Ethernet OAM
Sobre os temporizadores de detecção de conexão Ethernet OAM
Depois que uma conexão Ethernet OAM é estabelecida, as entidades Ethernet OAM trocam OAMPDUs de informações no intervalo de transmissão do pacote de handshake para detectar a disponibilidade da conexão Ethernet OAM. Se uma entidade Ethernet OAM não receber nenhuma OAMPDU de informações dentro do tempo limite de conexão Ethernet OAM, a conexão Ethernet OAM será considerada desconectada.
Ao ajustar o intervalo de transmissão do pacote de handshake e o timer de tempo limite da conexão, você pode alterar a resolução do tempo de detecção das conexões Ethernet OAM.
Restrições e diretrizes para a configuração de temporizadores de detecção de conexão Ethernet OAM
Quando você configurar o Ethernet OAM, siga estas restrições e diretrizes:
- Você pode configurar esse comando na visualização do sistema ou da porta. A configuração na visualização do sistema entra em vigor em todas as portas e a configuração na visualização da porta entra em vigor na porta especificada. Para uma porta, a configuração na visualização de porta tem precedência.
- Depois que o cronômetro de tempo limite de uma conexão Ethernet OAM expira, a entidade OAM local envelhece e encerra sua conexão com a entidade OAM par. Para manter as conexões Ethernet OAM estáveis, defina o temporizador de tempo limite da conexão como sendo, no mínimo, cinco vezes o intervalo de transmissão do pacote de handshake .
Configuração global dos temporizadores de detecção de conexão Ethernet OAM
- Entre na visualização do sistema.
System-viewoam global timer hello intervalO padrão é 1000 milissegundos.
oam global timer keepalive intervalO padrão é 5000 milissegundos.
Configuração dos temporizadores de detecção de conexão Ethernet OAM em uma porta
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberoam timer hello intervalPor padrão, uma interface usa o valor configurado globalmente.
oam timer keepalive intervalPor padrão, uma interface usa o valor configurado globalmente.
Configuração da detecção de eventos de símbolos errados
Restrições e diretrizes para configurar a detecção de eventos de símbolo com erro
Você pode configurar essa função na visualização do sistema ou da porta. A configuração na visualização do sistema entra em vigor em todas as portas, e a configuração na visualização da porta entra em vigor na porta especificada. Para uma porta, a configuração na visualização de porta tem precedência.
Configuração global da detecção de eventos de símbolos errados
- Entre na visualização do sistema.
System-viewoam global errored-symbol-period window window-valuePor padrão, a janela de detecção de eventos de símbolos com erro é 100000000.
oam global errored-symbol-period threshold threshold-valuePor padrão, o limite de acionamento do evento de símbolo com erro é 1.
Configuração da detecção de eventos de símbolos errados em uma porta
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberoam errored-symbol-period window window-valuePor padrão, uma interface usa o valor configurado globalmente.
oam errored-symbol-period threshold threshold-valuePor padrão, uma interface usa o valor configurado globalmente.
Configuração da detecção de eventos de quadros com erro
Restrições e diretrizes para configurar a detecção de eventos de quadros com erro
Você pode configurar essa função na visualização do sistema ou da porta. A configuração na visualização do sistema entra em vigor em todas as portas, e a configuração na visualização da porta entra em vigor na porta especificada. Para uma porta, a configuração na visualização de porta tem precedência.
Configuração global da detecção de eventos de quadros com erro
- Entre na visualização do sistema.
System-viewoam global errored-frame window window-valuePor padrão, a janela de detecção de eventos de quadro com erro é de 1.000 milissegundos.
oam global errored-frame threshold threshold-valuePor padrão, o limite de disparo do evento de quadro com erro é 1.
Configuração da detecção de eventos de quadros com erro em uma porta
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberoam errored-frame window window-valuePor padrão, uma interface usa o valor configurado globalmente.
oam errored-frame threshold threshold-valuePor padrão, uma interface usa o valor configurado globalmente.
Configuração da detecção de eventos de período de quadros com erro
Restrições e diretrizes para configurar a detecção de eventos de período de quadros com erro
Você pode configurar essa função na visualização do sistema ou da porta. A configuração na visualização do sistema entra em vigor em todas as portas, e a configuração na visualização da porta entra em vigor na porta especificada. Para uma porta, a configuração na visualização de porta tem precedência.
Configuração global da detecção de eventos de período de quadros com erro
- Entre na visualização do sistema.
System-viewoam global errored-frame-period window window-valuePor padrão, a janela de detecção de eventos de período de quadro com erro é 10000000.
oam global errored-frame-period threshold threshold-valuePor padrão, o limite de acionamento do evento de período de quadro com erro é 1.
Configuração da detecção de eventos de período de quadros com erro em uma porta
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberoam errored-frame-period window window-valuePor padrão, uma interface usa o valor configurado globalmente.
oam errored-frame-period threshold threshold-valuePor padrão, uma interface usa o valor configurado globalmente.
Configuração da detecção de eventos de segundos de quadros com erro
Restrições e diretrizes para configurar a detecção de eventos de segundos de quadros com erro
- Você pode configurar essa função na visualização do sistema ou da porta. A configuração na visualização do sistema entra em vigor em todas as portas, e a configuração na visualização da porta entra em vigor na porta especificada. Para uma porta, a configuração na visualização de porta tem precedência.
- Certifique-se de que o limite de disparo de segundos de quadro com erro seja menor do que a janela de detecção de segundos de quadro com erro. Caso contrário, nenhum evento de segundos de quadro com erro poderá ser gerado.
Configuração global da detecção de eventos de segundos de quadros com erro
- Entre na visualização do sistema.
System-viewoam global errored-frame-seconds window window-valuePor padrão, a janela de detecção de eventos de segundos de quadro com erro é de 60000 milissegundos.
oam global errored-frame-seconds threshold threshold-valuePor padrão, o limite de acionamento do evento de segundos de quadro com erro é 1.
Configuração da detecção de eventos de segundos de quadros com erro em uma porta
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberoam errored-frame-seconds window window-valuePor padrão, uma interface usa o valor configurado globalmente.
oam errored-frame-seconds threshold threshold-valuePor padrão, uma interface usa o valor configurado globalmente.
Configuração da ação que uma porta executa após receber um evento Ethernet OAM da extremidade remota
Sobre esse recurso
Esse recurso permite que uma porta registre eventos e encerre automaticamente a conexão OAM e defina o estado do link como inativo.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberoam remote-failure { connection-expired | critical-event | dying-gasp | link-fault } action error-link-downPor padrão, a porta registra apenas o evento Ethernet OAM que recebe da extremidade remota.
Ativação do loopback remoto do Ethernet OAM para uma porta
Use esse recurso com cautela, pois a ativação do loopback remoto do Ethernet OAM afeta outros serviços.
Sobre o loopback remoto do Ethernet OAM
Quando você ativa o loopback remoto do Ethernet OAM em uma porta, a porta envia OAMPDUs de controle de loopback para uma porta remota. Depois de receber os OAMPDUs de controle de loopback, a porta remota entra no estado de loopback. Em seguida, a porta remota retorna todos os pacotes enviados da porta local, exceto os OAMPDUs. Ao observar quantos desses pacotes retornam, você pode calcular a taxa de perda de pacotes no link e avaliar o desempenho do link.
Restrições e diretrizes para ativar o loopback remoto do Ethernet OAM
- O loopback remoto do Ethernet OAM está disponível somente após o estabelecimento da conexão Ethernet OAM. Ele pode ser executado somente por entidades Ethernet OAM que operam no modo Ethernet OAM ativo.
- O loopback remoto está disponível somente em links full-duplex que suportam loopback remoto em ambas as extremidades.
- O loopback remoto do Ethernet OAM deve ser suportado tanto pela porta remota quanto pela porta de envio.
- A ativação do loopback remoto do Ethernet OAM interrompe as comunicações de dados. Depois que o loopback remoto do Ethernet OAM for desativado, todas as portas envolvidas serão desativadas e, em seguida, ativadas. O loopback remoto do Ethernet OAM pode ser desativado por qualquer um dos seguintes eventos:
- Desativação do Ethernet OAM.
- Desativação do loopback remoto do Ethernet OAM.
- Tempo limite da conexão Ethernet OAM.
- A ativação do teste de loopback interno em uma porta no teste de loopback remoto pode encerrar o teste de loopback remoto. Para obter mais informações sobre o teste de loopback, consulte o Layer 2-LAN Switching Configuration Guide.
- É possível ativar o loopback remoto do Ethernet OAM em uma porta específica na visualização do usuário, na visualização do sistema ou na visualização da porta Ethernet. Os efeitos da configuração são os mesmos.
Ativação do loopback remoto do Ethernet OAM para uma porta na visualização do sistema
- (Opcional.) Entre na visualização do sistema.
System-viewTambém é possível executar essa tarefa na visualização do usuário.
oam remote-loopback start interface interface-type interface-numberPor padrão, o loopback remoto do Ethernet OAM está desativado.
Ativação do loopback remoto do Ethernet OAM para uma porta na visualização da interface
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberoam remote-loopback startPor padrão, o loopback remoto do Ethernet OAM está desativado.
Rejeição da solicitação de loopback remoto do Ethernet OAM de uma porta remota
Sobre esse recurso
O recurso de loopback remoto do Ethernet OAM afeta outros serviços. Para resolver esse problema, você pode desativar uma porta para que ela não seja controlada pelos OAMPDUs de controle de loopback enviados por uma porta remota. A porta local rejeita, então, a solicitação de loopback remoto do Ethernet OAM da porta remota.
Restrições e diretrizes
Esse recurso não afeta o teste de loopback remoto em andamento na porta. Ele entra em vigor quando o próximo loopback remoto é iniciado na porta.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberoam remote-loopback reject-requestPor padrão, uma porta não rejeita a solicitação de loopback remoto do Ethernet OAM de uma porta remota.
Comandos de exibição e manutenção para Ethernet OAM
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário:
| Tarefa | Comando |
| Exibir informações sobre uma conexão Ethernet OAM. | display oam { local | remoto } [ interface interface-type interface-number ] |
| Exibir a configuração do Ethernet OAM. | display oam configuration [ interface interface-type interface-number ] |
| Exibir as estatísticas de eventos críticos após o estabelecimento de uma conexão Ethernet OAM. | display oam critical-event [ interface interface-type interface-number ] |
| Exibir as estatísticas dos eventos de erro de link do Ethernet OAM após o estabelecimento de uma conexão Ethernet OAM. | display oam link-event { local | remote } [ interface interface-type interface-number ] |
| Limpar estatísticas de pacotes Ethernet OAM e eventos de erro de link Ethernet OAM. | reset oam [ interface interface-type interface-number ] |
Exemplos de configuração do Ethernet OAM
Exemplo: Configuração do Ethernet OAM
Configuração de rede
Na rede mostrada na Figura 1, execute as seguintes operações:
- Habilite o Ethernet OAM no Dispositivo A e no Dispositivo B para detectar automaticamente erros de link entre os dois dispositivos
- Determine o desempenho do link entre o Dispositivo A e o Dispositivo B coletando estatísticas sobre os quadros de erro recebidos pelo Dispositivo A
Figura 1 Diagrama de rede

Procedimento
- Configure o dispositivo A:
# Configure a GigabitEthernet 1/0/1 para operar no modo Ethernet OAM ativo e habilite o Ethernet OAM para ela.
<DeviceA> system-view
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] oam mode active
[DeviceA-GigabitEthernet1/0/1] oam enable# Defina a janela de detecção de eventos de quadros com erro para 20.000 milissegundos e defina o limite de disparo de eventos de quadros com erro para 10.
[DeviceA-GigabitEthernet1/0/1] oam errored-frame window 200
[DeviceA-GigabitEthernet1/0/1] oam errored-frame threshold 10
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/1 para operar no modo Ethernet OAM passivo (o padrão) e habilite o Ethernet OAM para ela.
<DeviceB> system-view
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] oam mode passive
[DeviceB-GigabitEthernet1/0/1] oam enable
[DeviceB-GigabitEthernet1/0/1] quitVerificação da configuração
Use o comando display oam critical-event para exibir as estatísticas dos eventos de link crítico do Ethernet OAM. Por exemplo:
# Exibir as estatísticas dos eventos de link crítico do Ethernet OAM em todas as portas do Dispositivo A.
[DeviceA] display oam critical-event
-----------[GigabitEthernet1/0/1] -----------
Local link status : UP
Event statistics
Link fault : Not occurred
Dying gasp : Not occurred
Critical event : Not occurredA saída mostra que não ocorreu nenhum evento de link crítico no link entre o Dispositivo A e o Dispositivo B.
Use o comando display oam link-event para exibir as estatísticas dos eventos de link Ethernet OAM. Por exemplo:
# Exibir estatísticas de eventos de link Ethernet OAM da extremidade local do Dispositivo A.
[DeviceA] display oam link-event local
------------ [GigabitEthernet1/0/1] -----------
Link status: UP
OAM local errored frame event
Event time stamp : 5789 x 100 milliseconds
Errored frame window : 200 x 100 milliseconds
Errored frame threshold : 10 error frames
Errored frame : 13 error frames
Error running total : 350 error frames
Event running total : 17 eventsO resultado mostra o seguinte:
- Ocorreram 350 erros depois que o Ethernet OAM foi ativado no Dispositivo A.
- 17 erros foram causados por quadros de erro.
- O link é instável.
Configuração de CFD
Sobre o CFD
O Connectivity Fault Detection (CFD), que está em conformidade com o IEEE 802.1ag Connectivity Fault Management (CFM) e o ITU-T Y.1731, é um mecanismo OAM de camada de link por VLAN de ponta a ponta. O CFD é usado para detecção de conectividade de link, verificação de falhas e localização de falhas.
Conceitos básicos de CFD
Domínio de manutenção
Um domínio de manutenção (MD) define a rede ou parte da rede em que o CFD desempenha sua função. Um MD é identificado por seu nome MD.
Associação de manutenção
Uma associação de manutenção (MA) é uma parte de um MD. É possível configurar várias MAs em um MD, conforme necessário. Uma AM é identificada pelo nome do MD + nome da AM.
Um MA atende à VLAN especificada ou a nenhuma VLAN. Uma MA que atende a uma VLAN é considerada portadora do atributo VLAN. Uma MA que não atende a nenhuma VLAN é considerada como não portadora de nenhum atributo de VLAN.
Ponto de manutenção
Um MP é configurado em uma porta e pertence a um MA. Os MPs incluem os seguintes tipos: pontos finais de associação de manutenção (MEPs) e pontos intermediários de associação de manutenção (MIPs).
Os MEPs definem o limite do MA. Cada MEP é identificado por uma ID de MEP. Os MEPs incluem MEPs voltados para o interior e MEPs voltados para o exterior:
- Um MEP voltado para o exterior envia pacotes para sua porta de host.
- Um MEP voltado para dentro não envia pacotes para sua porta de host. Em vez disso, ele envia pacotes para outras portas do dispositivo.
Um MIP é interno a um MA. Ele não pode enviar pacotes CFD ativamente, mas pode manipular e responder a pacotes CFD. Os MIPs são criados automaticamente pelo dispositivo. Ao cooperar com os MEPs, um MIP pode executar uma função semelhante ao ping e ao traceroute.
Lista MEP
Uma lista de MEPs é um conjunto de MEPs locais que podem ser configurados e os MEPs remotos a serem monitorados no mesmo MA. Ela lista todos os MEPs configurados em diferentes dispositivos no mesmo MA. Todos os MEPs têm IDs de MEP exclusivos. Quando um MEP recebe de um dispositivo remoto uma mensagem de verificação de continuidade (CCM) com uma ID de MEP que não está na lista de MEPs do MA, ele descarta a mensagem.
O dispositivo local deve enviar mensagens CCM com os bits de sinalização Remote Defect Indication (RDI). Caso contrário, o dispositivo par não poderá detectar determinadas falhas. Quando um MEP local não tiver aprendido todos os MEPs remotos na lista de MEPs, os MEPs no MA poderão não conter os bits de sinalização RDI nos CCMs.
Níveis de CFD
Níveis de MD
Para localizar as falhas com precisão, o CFD introduz oito níveis (de 0 a 7) nos MDs. Quanto maior o número, mais alto o nível e maior a área coberta. Os domínios podem se tocar ou se aninhar (se o domínio externo tiver um nível mais alto do que o aninhado), mas não podem se cruzar ou se sobrepor.
Os níveis de MD facilitam a localização da falha e a tornam mais precisa. Conforme mostrado na Figura 1, o MD_A em azul claro aninha o MD_B em azul escuro. Se uma falha de conectividade for detectada no limite do MD_A, qualquer um dos dispositivos no MD_A, incluindo o Dispositivo A até o Dispositivo E, poderá falhar. Se uma falha de conectividade também for detectada no limite do MD_B, os pontos de falha poderão ser qualquer um dos Dispositivos B até o Dispositivo D. Se os dispositivos no MD_B puderem operar corretamente, pelo menos o Dispositivo C estará operacional.
Figura 1 Dois MDs aninhados
O CFD troca mensagens e executa operações por domínio. Ao planejar corretamente os MDs em uma rede, é possível usar o CFD para localizar rapidamente os pontos de falha.
Níveis MA e MP
O nível de uma MA é igual ao nível do MD ao qual a MA pertence. O nível de um MEP é igual ao nível do MD ao qual o MEP pertence.
O nível de um MIP é definido por sua regra de geração e pelo MD ao qual o MIP pertence. Os MIPs são gerados em cada porta automaticamente de acordo com as seguintes regras de geração de MIPs:
- Regra padrão - Se não houver nenhum MIP de nível inferior em uma interface, será criado um MIP no nível atual. Um MIP pode ser criado mesmo que nenhum MEP esteja configurado na interface.
- Regra explícita - Se não houver nenhum MIP de nível inferior e houver uma MEP de nível inferior em uma interface, será criado um MIP no nível atual. Um MIP só poderá ser criado quando um MEP de nível inferior for criado na interface.
Se uma porta não tiver MIP, o sistema verificará os MAs em cada MD (dos níveis mais baixos aos mais altos) e seguirá o procedimento descrito na Figura 2 para criar ou não MIPs no nível atual.
Figura 2 Procedimento de criação de MIPs
Exemplo de classificação CFD
A Figura 3 demonstra um exemplo de classificação do módulo CFD. Foram projetados quatro níveis de MDs (0, 2, 3 e 5). Quanto maior o número, mais alto o nível e maior a área coberta. Os MPs são configurados nas portas do Dispositivo A até o Dispositivo F. A porta A do Dispositivo B é configurada com os seguintes MPs:
- Um MIP de nível 5.
- Um MEP de nível 3 voltado para o interior.
- Um MEP de nível 2 voltado para o interior.
- Um MEP de nível 0 voltado para o exterior.
Figura 3 Exemplo de classificação CFD
Processamento de pacotes de MPs
Para um MA com atributo de VLAN, os MPs do MA enviam pacotes somente na VLAN que o MA atende. O nível de pacotes enviados por um MP é igual ao nível do MD ao qual o MP pertence.
Para um MA que não carrega o atributo VLAN, os MPs do MA só podem ser MEPs voltados para o exterior. O nível dos pacotes enviados por um MEP voltado para o exterior é igual ao nível do MD ao qual o MEP pertence.
Um MEP encaminha pacotes em um nível superior sem nenhum processamento e só processa pacotes de seu nível ou inferior.
Um MIP encaminha pacotes de um nível diferente sem nenhum processamento e processa apenas os pacotes de seu nível .
Funções CFD
As funções do CFD, que são implementadas por meio dos MPs, incluem:
- Verificação de continuidade (CC).
- Loopback (LB).
- Linktrace (LT).
- Sinal de indicação de alarme (AIS).
- Medição de perdas (LM).
- Medição de atraso (DM).
- Test (TST).
Verificação de continuidade
As falhas de conectividade geralmente são causadas por falhas no dispositivo ou erros de configuração. A verificação de continuidade examina a conectividade entre os MEPs. Essa função é implementada por meio do envio periódico de CCMs pelos MEPs. Um CCM enviado por um MEP deve ser recebido por todos os outros MEPs no mesmo MA. Se um MEP não conseguir receber os CCMs dentro de 3,5 vezes o intervalo de envio, o link será considerado defeituoso e um registro será gerado. Quando vários MEPs enviam CCMs ao mesmo tempo, a verificação do link multiponto-para-multiponto é realizada. Os quadros CCM são quadros multicast.
Loopback
Semelhante ao ping na camada IP, o loopback verifica a conectividade entre um dispositivo de origem e um dispositivo de destino. Para implementar essa função, o MEP de origem envia mensagens de loopback (LBMs) para o MEP de destino. Dependendo do fato de o MEP de origem poder receber uma mensagem de resposta de loopback (LBR) do MEP de destino, o estado do link entre os dois pode ser verificado.
Os quadros LBM são quadros multicast e unicast. O dispositivo pode enviar e receber quadros LBM unicast e pode receber quadros LBM multicast, mas não pode enviar quadros LBM multicast. Os quadros LBR são quadros unicast.
Linktrace
O Linktrace é semelhante ao traceroute. Ele identifica o caminho entre o MEP de origem e o MP de destino. O MEP de origem envia as mensagens de linktrace (LTMs) para o MP de destino. Depois de receber as mensagens, o MP de destino e os MIPs pelos quais os quadros LTM passam enviam mensagens de resposta de linktrace (LTRs) para o MEP de origem. Com base nas mensagens de resposta, o MEP de origem pode identificar o caminho até o MP de destino. Os quadros LTM são quadros multicast e os LTRs são quadros unicast.
AIS
A função AIS suprime o número de alarmes de erro relatados pelos MEPs. Se um MEP local não receber nenhum quadro CCM de seu par MEP dentro de 3,5 vezes o intervalo de transmissão CCM, ele começará imediatamente a enviar quadros AIS. Os quadros AIS são enviados periodicamente na direção oposta à dos quadros CCM. Quando o MEP par recebe os quadros AIS, ele suprime os alarmes de erro localmente e continua a enviar os quadros AIS. Se o MEP local receber quadros CCM dentro de 3,5 vezes o tempo de intervalo de transmissão do CCM, ele interrompe o envio de quadros AIS e restaura a função de alarme de erro. Os quadros AIS são quadros multicast.
LM
A função LM mede a perda de quadros em uma determinada direção entre um par de MEPs. O MEP de origem envia mensagens de medição de perda (LMMs) para o MEP de destino. O MEP de destino responde com respostas de medição de perda (LMRs). O MEP de origem calcula o número de quadros perdidos de acordo com os valores do contador dos dois LMRs consecutivos (o LMR atual e o LMR anterior). Os LMMs e LMRs são quadros unicast.
DM
A função DM mede os atrasos de quadro entre dois MEPs, incluindo os seguintes tipos:
- Medição de atraso de quadro unidirecional
- Registra o tempo de recepção.
- Calcula e registra o atraso de transmissão do link e o jitter (variação de atraso) de acordo com o tempo de transmissão e o tempo de recepção.
- Medição de atraso de quadro bidirecional
- Registra o tempo de recepção de DMR.
- Calcula o atraso de transmissão do link e o jitter de acordo com o tempo de recepção do DMR e o tempo de transmissão do DMM.
O MEP de origem envia um quadro de medição de atraso unidirecional (1DM), que contém o tempo de transmissão, para o MEP de destino. Quando o MEP de destino recebe o quadro 1DM, ele faz o seguinte:
O MEP de origem envia uma mensagem de medição de atraso (DMM), que contém o tempo de transmissão, para o MEP de destino. Quando o MEP de destino recebe a DMM, ele responde com uma resposta de medição de atraso (DMR). A DMR contém o tempo de recepção e o tempo de transmissão da DMM e o tempo de transmissão da DMR. Quando o MEP de origem recebe o DMR, ele faz o seguinte:
Os quadros DMM e DMR são quadros unicast.
Os quadros 1DM são quadros unicast.
TST
A função TST testa os erros de bits entre dois MEPs. O MEP de origem envia um quadro TST, que carrega o padrão de teste, como uma sequência de bits pseudo-aleatória (PRBS) ou totalmente zero, para o MEP de destino. Quando o MEP de destino recebe o quadro TST, ele determina os erros de bits calculando e comparando o conteúdo do quadro TST. Os quadros TST são quadros unicast.
EAIS
O EAIS (Ethernet Alarm Indication Signal, sinal de indicação de alarme Ethernet) permite a colaboração entre o status da porta Ethernet e a função AIS. Quando uma porta do dispositivo (não necessariamente um MP) fica inativa, ela imediatamente começa a enviar quadros EAIS periodicamente para suprimir os alarmes de erro. Quando a porta volta a funcionar, ela para imediatamente de enviar quadros EAIS. Quando o MEP recebe os quadros EAIS, ele suprime os alarmes de erro localmente e continua a enviar os quadros EAIS. Se um MEP não receber nenhum quadro EAIS dentro de 3,5 vezes o intervalo de transmissão do quadro EAIS, a falha será considerada eliminada. A porta para de enviar quadros EAIS e restaura a função de alarme de erro. Os quadros EAIS são quadros multicast.
Protocolos e padrões
- IEEE 802.1ag, redes locais com ponte virtual Alteração 5: Gerenciamento de falhas de conectividade
- ITU-T Y.1731, funções e mecanismos OAM para redes baseadas em Ethernet
Restrições e diretrizes: Configuração de CFD
Quando você configurar o CFD, siga estas restrições e diretrizes:
- Configure o CC antes de usar a ID do MEP remoto para configurar outras funções de CFD. Essa restrição não se aplica quando você usa o endereço MAC do MEP remoto para configurar outras funções de CFD.
- Não configure uma interface agregada de camada 2 como IPP se houver as seguintes condições:
- A interface agregada da Camada 2 existe entre um MEP voltado para dentro e um MEP remoto.
- O endereço MAC do MEP remoto é usado para funções CFD.
- Normalmente, uma porta bloqueada pelo recurso spanning tree não pode receber ou enviar mensagens CFD, exceto nos seguintes casos:
- A porta está configurada como um MEP voltado para o exterior.
- A porta está configurada como um MIP ou MEP voltado para dentro, que ainda pode receber e enviar mensagens CFD, exceto mensagens CCM.
Para obter informações sobre IPPs, consulte Configuração de DRNI no Layer 2-LAN Switching Configuration Guide.
Para obter mais informações sobre o recurso spanning tree, consulte o Layer 2-LAN Switching Configuration Guide.
Visão geral das tarefas de CFD
Para configurar o CFD, execute as seguintes tarefas:
- Configuração das definições básicas de CFD
- Habilitação de CFD
- Configuração de instâncias de serviço
- Configuração de MEPs
- Configuração de regras de geração automática de MIPs
- Configuração das funções CFD
- Configuração da CC
- (Opcional.) Configuração de LB
- (Opcional.) Configuração do LT
- (Opcional.) Configuração do AIS
- (Opcional.) Configurando o LM
- (Opcional.) Configuração de DM unidirecional
- (Opcional.) Configuração de DM bidirecional
- (Opcional.) Configuração do TST
- (Opcional.) Configuração do EAIS
Pré-requisitos para CFD
Para que o CFD funcione corretamente, projete a rede executando as seguintes tarefas:
- Classifique os MDs em toda a rede e defina o limite de cada MD.
- Atribua um nome para cada MD. Certifique-se de que os dispositivos no mesmo MD usem o mesmo nome de MD.
- Defina o MA em cada MD de acordo com a VLAN que você deseja monitorar.
- Atribua um nome para cada MA. Certifique-se de que os dispositivos da mesma MA no mesmo MD usem o mesmo nome de MA.
- Determine a lista de MEP de cada MA em cada MD. Certifique-se de que os dispositivos no mesmo MA mantenham a mesma lista MEP.
- Nas bordas de MD e MA, os MEPs devem ser projetados na porta do dispositivo. Os MIPs podem ser projetados em dispositivos ou portas que não estejam nas bordas.
Configuração das definições básicas de CFD
Ativação de CFD
- Entre na visualização do sistema.
System-viewcfd enablePor padrão, o CFD está desativado.
Configuração de instâncias de serviço
Sobre instâncias de serviço
Antes de configurar os MEPs e MIPs, você deve primeiro configurar as instâncias de serviço. Uma instância de serviço é um conjunto de pontos de acesso de serviço (SAPs) e pertence a um MA em um MD.
O MD e o MA definem o atributo de nível e o atributo de VLAN das mensagens tratadas pelos MPs em uma instância de serviço. Os MPs do MA que não têm atributo de VLAN não pertencem a nenhuma VLAN.
Procedimento
- Entre na visualização do sistema.
System-viewcfd md md-name [ index index-value ] level level-value [ md-id { dns dns-name | mac mac-address subnumber | none } ]cfd service-instance instance-id ma-id { icc-based ma-name | integer ma-num | string ma-name | vlan-based [ vlan-id ] } [ ma-index index-value ] md md-name [ vlan vlan-id ]Configuração de MEPs
Sobre os MPEs
O CFD é implementado por meio de várias operações em MEPs. Quando um MEP é configurado em uma instância de serviço, o nível de MD e o atributo de VLAN da instância de serviço tornam-se o atributo do MEP.
Restrições e diretrizes
- Você pode especificar uma interface como MEP para apenas um dos MAs não específicos de VLAN no mesmo nível. Além disso, o MEP deve estar voltado para o exterior.
- Se um MEP em um MA não específico de VLAN não receber uma mensagem CCM dentro de 3,5 intervalos CCM de um MEP remoto, o MEP local colocará sua interface em estado de link down. Esse comportamento do MEP local facilita a troca rápida para RRPP ou Smart Link.
Pré-requisitos
Antes de configurar os MEPs, você deve configurar as instâncias de serviço.
Procedimento
- Entre na visualização do sistema.
System-viewcfd meplist mep-list service-instance instance-idO MEP criado deve ser incluído na lista de MEPs configurados.
interface interface-type interface-numbercfd mep mep-id service-instance instance-id { inbound | outbound }Configuração de regras de geração automática de MIPs
Sobre as regras de geração automática de MIPs
Como entidades funcionais em uma instância de serviço, os MIPs respondem a vários quadros CFD, como os quadros LTM e LBM. Você pode configurar regras de geração automática de MIPs para que o sistema crie MIPs automaticamente.
Qualquer um dos eventos a seguir pode fazer com que os MIPs sejam criados ou excluídos depois que você tiver configurado o
comando cfd mip-rule:
- Ativação ou desativação do CFD.
- Criação ou exclusão de MEPs em uma porta.
- Ocorrem alterações no atributo VLAN de uma porta.
- A regra especificada no comando cfd mip-rule é alterada.
Restrições e diretrizes
- Uma MA sem atributo de VLAN é normalmente usada para detectar o status do link direto. O sistema não pode gerar MIPs para essas MAs.
- Para um MA com atributo de VLAN, o sistema não gera MIPs se o mesmo MEP ou um MEP de nível superior existir na interface.
Procedimento
- Entre na visualização do sistema.
System-viewcfd mip-rule { default | explicit } service-instance instance-idPor padrão, nenhuma regra para gerar MIPs é configurada e o sistema não cria automaticamente nenhum MIP.
Configuração das funções CFD
Configuração da CC
Sobre a CC
Depois que a função CC é configurada, os MEPs em um MA podem enviar periodicamente quadros CCM para manter a conectividade.
Você deve configurar o CC antes de usar a ID do MEP remoto para configurar outras funções de CFD. Essa restrição não se aplica quando você usa o endereço MAC do MEP remoto para configurar outras funções de CFD.
Quando a vida útil de um quadro CCM expira, o link para o MEP remetente é considerado desconectado. Ao definir o intervalo de CCM, use as configurações descritas na Tabela 1.
Tabela 1 Codificação de campo de intervalo CCM
| Campo de intervalo CCM | Intervalo de transmissão | Vida útil máxima do CCM |
| 1 | 10/3 milissegundos | 35/3 milissegundos |
| 2 | 10 milissegundos | 35 milissegundos |
| 3 | 100 milissegundos | 350 milissegundos |
| 4 | 1 segundo | 3,5 segundos |
| 5 | 10 segundos | 35 segundos |
| 6 | 60 segundos | 210 segundos |
| 7 | 600 segundos | 2100 segundos |
OBSERVAÇÃO:
- O intervalo de valores do campo de intervalo é de 1 a 7. Se você definir o valor como 1 ou 2, a verificação de continuidade poderá funcionar incorretamente devido a restrições de hardware.
- As mensagens CCM com um valor de campo de intervalo de 1 a 3 são mensagens CCM de intervalo curto. As mensagens CCM
As mensagens com um valor de campo de intervalo de 4 a 7 são mensagens CCM de intervalo longo.
Restrições e diretrizes
Ao configurar o intervalo do CCM, siga estas restrições e diretrizes:
- Configure o mesmo valor de campo de intervalo CCM para todos os MEPs no mesmo MA.
- Depois que o campo de intervalo de CCMs for modificado, o MEP deverá aguardar outro intervalo de CCMs antes de enviar CCMs.
- Se o dispositivo não puder processar mensagens CCM de intervalo curto, a definição do valor do campo de intervalo CCM como menor que 4 pode fazer com que a função CC funcione de forma instável.
Procedimento
- Entre na visualização do sistema.
System-viewcfd cc interval interval-value service-instance instance-idPor padrão, o valor do campo de intervalo é 4.
interface interface-type interface-numbercfd cc service-instance instance-id mep mep-id enablePor padrão, o envio de CCM está desativado em um MEP.
Configuração de LB
Para verificar o estado do link entre o MEP local e o MEP remoto, execute o seguinte comando em qualquer visualização:
cfd loopback service-instance instance-id mep mep-id { target-mac mac-address | target-mep target-mep-id } [ number number ]Configuração do LT
Sobre a LT
O LT pode rastrear o caminho entre os MEPs de origem e de destino e pode localizar falhas de link enviando automaticamente mensagens LT. As duas funções são implementadas da seguinte forma:
- Caminho de rastreamento - O MEP de origem primeiro envia mensagens LTM para o MEP de destino. Com base nas mensagens LTR em resposta às mensagens LTM, o caminho entre os dois MEPs é identificado.
- Envio automático de mensagens LT - Se o MEP de origem não receber quadros CCM do MEP de destino dentro de 3,5 vezes o intervalo de transmissão, ele considerará o link defeituoso. Em seguida, o MEP de origem envia quadros LTM, com o campo TTL definido com o valor máximo de 255, para o MEP de destino. Com base nos LTRs retornados, a origem da falha é localizada.
Pré-requisitos
Antes de configurar o LT em um MEP em um MA com atributo de VLAN, crie a VLAN à qual o MA pertence.
Procedimento
- Identifique o caminho entre um MEP de origem e um MEP de destino.
cfd linktrace service-instance instance-id mep mep-id { target-mac mac-address | target-mep target-mep-id } [ ttl ttl-value ] [ hw-only ]Esse comando está disponível em qualquer visualização.
System-viewcfd linktrace auto-detection [ size size-value ]Por padrão, o envio automático de mensagens LT está desativado.
Configuração do AIS
Sobre a AIS
A função AIS suprime o número de alarmes de erro relatados pelos MEPs.
Restrições e diretrizes
Se você ativar o AIS, os MEPs em uma instância de serviço não poderão enviar quadros AIS nas seguintes condições:
- Nenhum nível de transmissão de quadro AIS está configurado.
- O nível de transmissão do quadro AIS é menor do que o nível MD da instância de serviço.
Se você habilitar o AIS e configurar um nível de transmissão de quadro AIS igual ao nível MD de uma instância de serviço, os MEPs na instância de serviço:
- Pode suprimir alarmes de erro.
- Não é possível enviar quadros AIS para MDs com nível mais alto.
Procedimento
- Entre na visualização do sistema.
System-viewcfd ais enablePor padrão, o AIS está desativado.
cfd ais level level-value service-instance instance-idPor padrão, o nível de transmissão do quadro AIS não é configurado.
O nível de transmissão do quadro AIS deve ser maior que o nível MD da instância de serviço.
cfd ais period period-value service-instance instance-idPor padrão, o intervalo de transmissão do quadro AIS é de 1 segundo.
Configuração da linha linear
Sobre a LM
A função LM mede a perda de quadros entre MEPs. As estatísticas de perda de quadros incluem o número de quadros perdidos, a taxa de perda de quadros e o número médio de quadros perdidos para os MEPs de origem e de destino.
Procedimento
Para configurar o LM, execute o seguinte comando em qualquer visualização:
cfd slm service-instance instance-id mep mep-id { target-mac mac-address | target-mep target-mep-id } [ dot1p dot1p-value ] [ number number ] [ interval interval ]Configuração de DM unidirecional
Sobre o DM unidirecional
A função DM unidirecional mede o atraso do quadro unidirecional entre dois MEPs e monitora e gerencia o desempenho da transmissão do link.
Restrições e diretrizes
Siga estas diretrizes ao configurar o DM unidirecional em um MEP:
- O DM unidirecional exige que a configuração de tempo no MEP transmissor e no MEP receptor seja a mesma. Para fins de medição da variação do atraso do quadro, essa exigência pode ser relaxada.
- Para visualizar o resultado do teste, use o comando display cfd dm one-way history no MEP de destino .
Procedimento
Para configurar o DM unidirecional, execute o seguinte comando em qualquer visualização:
cfd dm one-way service-instance instance-id mep mep-id { target-mac mac-address | target-mep target-mep-id } [ number number ]Configuração de DM bidirecional
Sobre o DM bidirecional
A função DM bidirecional mede o atraso do quadro bidirecional, o atraso médio do quadro bidirecional e a variação do atraso do quadro bidirecional entre dois MEPs. Ela também monitora e gerencia o desempenho de transmissão do link .
Procedimento
Para configurar o DM bidirecional, execute o seguinte comando em qualquer visualização:
cfd dm two-way service-instance instance-id mep mep-id { target-mac mac-address | target-mep target-mep-id } dot1p dot1p-value ] [ number number ] [ interval interval ]Configuração do TST
Sobre a TST
A função TST detecta erros de bits em um link e monitora e gerencia o desempenho da transmissão do link.
Restrições e diretrizes
Para visualizar o resultado do teste, use o comando display cfd tst no MEP de destino.
Procedimento
Para configurar o TST, execute o seguinte comando em qualquer visualização:
cfd tst service-instance instance-id mep mep-id { target-mac mac-address | target-mep target-mep-id } [ number number ] [ length-of-test length ] [ pattern-of-test { all-zero | prbs } [ with-crc ] ]Configuração do EAIS
Restrições e diretrizes
Siga estas diretrizes ao configurar o EAIS em um MEP:
- É possível configurar o EAIS em um dispositivo que não seja compatível ou não esteja configurado com CFD. No entanto, o EAIS deve colaborar com a função CFD na rede, portanto, você deve configurar o CFD na rede.
- Você pode configurar o EAIS na porta membro de um grupo de agregação, mas a configuração não entra em vigor. Se você configurar o EAIS na porta e depois adicioná-la a um grupo de agregação, a configuração do EAIS não entrará em vigor imediatamente. Depois que a porta deixa o grupo de agregação, a configuração do EAIS entra em vigor.
- Se a interseção das VLANs configuradas onde os quadros EAIS podem ser transmitidos e as VLANs às quais a porta pertence estiver vazia, nenhum quadro EAIS será enviado. Se a interseção contiver mais de 70 VLANs e o intervalo de transmissão do quadro EAIS for de 1 segundo, o uso da CPU será muito alto. Como prática recomendada, defina o intervalo de transmissão do quadro EAIS para 60 segundos nesse caso.
Procedimento
- Entre na visualização do sistema.
System-viewcfd ais-track link-status globalPor padrão, a colaboração entre o status da porta e o AIS está desativada.
interface interface-type interface-numbercfd ais-track link-status level level-valuePor padrão, o nível de transmissão do quadro EAIS não é configurado.
cfd ais-track link-status period period-valuePor padrão, o intervalo de transmissão do quadro EAIS não é configurado.
cfd ais-track link-status vlan vlan-listPor padrão, os quadros EAIS só podem ser transmitidos dentro da VLAN padrão da porta.
Os quadros EAIS são transmitidos dentro da interseção das VLANs especificadas com esse comando e as VLANs existentes no dispositivo.
Comandos de exibição e manutenção para CFD
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibe a configuração e as informações do AIS no MEP especificado. | exibir cfd ais [ service-instance instance-id [ mep mep-id ] ] ] |
| Exibe a configuração do AIS e as informações associadas ao status da porta especificada. | display cfd ais-track link-status [ interface-type interface-number ] |
| Exibe o resultado do DM unidirecional no MEP especificado. | display cfd dm one-way history [ service-instance instance-id [ mep mep-id ] ] |
| Exibir informações de LTR recebidas por um MEP. | exibir cfd linktrace-reply [ service-instance instance-id [ mep mep-id ] ] |
| Exibir o conteúdo das mensagens LTR recebidas como respostas aos LTMs enviados automaticamente. | exibir cfd linktrace-reply auto-detecção [ tamanho tamanho-valor ] |
| Exibir informações de configuração do MD. | display cfd md |
| Exibir o atributo e as informações de execução dos MEPs. | exibir cfd mep mep-id service-instance instance-id |
| Exibir listas MEP em uma instância de serviço. | exibir cfd meplist [ service-instance instance-id ] |
| Exibir informações de MP. | exibir cfd mp [ interface interface-type interface-number ] |
| Exibir informações sobre um MEP remoto. | exibir cfd remote-mep service-instance instance-id mep mep-id |
| Exibir a configuração da instância de serviço. | exibir cfd service-instance [ instance-id ] |
| Exibir o status do CFD. | exibir status do cfd |
| Exibe o resultado do TST no MEP especificado. | exibir cfd tst [ service-instance instance-id [ mep mep-id ] ] ] |
| Limpa o resultado do DM unidirecional no MEP especificado. | reset cfd dm one-way history [ service-instance instance-id [ mep mep-id ] ] |
| Limpa o resultado do TST no MEP especificado. | reset cfd tst [ service-instance instance-id [ mep mep-id ] ] ] |
Exemplos de configuração de CFD
Exemplo: Configuração de CFD
Configuração de rede
Conforme mostrado na Figura 4:
- A rede é composta por cinco dispositivos e é dividida em dois MDs: MD_A (nível 5) e MD_B (nível 3). Todas as portas pertencem à VLAN 100 e todas as MAs nos dois MDs atendem à VLAN 100. Suponha que os endereços MAC do Dispositivo A até o Dispositivo E sejam 0010-FC01-6511,
0010-FC02-6512, 0010-FC03-6513, 0010-FC04-6514 e 0010-FC05-6515, respectivamente.
- O MD_A tem três portas de borda: GigabitEthernet 1/0/1 no Dispositivo A, GigabitEthernet 1/0/3 no Dispositivo D e GigabitEthernet 1/0/4 no Dispositivo E. Todas elas são MEPs voltadas para dentro. O MD_B tem duas portas de borda: GigabitEthernet 1/0/3 no Dispositivo B e GigabitEthernet 1/0/1 no Dispositivo D. Ambas são MEPs voltadas para o exterior.
- No MD_A, o Dispositivo B é projetado para ter MIPs quando sua porta é configurada com MEPs de baixo nível. A porta GigabitEthernet 1/0/3 está configurada com MEPs do MD_B, e os MIPs do MD_A podem ser configurados nessa porta. Você deve configurar a regra de geração de MIP da MD_A como explícita.
- Os MIPs do MD_B são projetados no Dispositivo C e são configurados em todas as portas. Você deve configurar a regra de geração de MIP como padrão.
- Configure CC para monitorar a conectividade entre todos os MEPs em MD_A e MD_B. Configure LB para localizar falhas de link e use as funções AIS e EAIS para suprimir os alarmes de erro relatados.
- Depois que as informações de status de toda a rede forem obtidas, use LT, LM, DM unidirecional, DM bidirecional e TST para detectar falhas de link.
Figura 4 Diagrama de rede
Procedimento
- Configure uma VLAN e atribua portas a ela:
- Ativar CFD:
Em cada dispositivo mostrado na Figura 4, crie a VLAN 100 e atribua as portas GigabitEthernet 1/0/1 a GigabitEthernet 1/0/4 à VLAN 100.
# Habilite o CFD no dispositivo A.
<DeviceA> system-view
[DeviceA] cfd enable# Configure o dispositivo B até o dispositivo E da mesma forma que o dispositivo A está configurado. (Os detalhes não são mostrados).
# Criar MD_A (nível 5) no Dispositivo A e criar a instância de serviço 1 (na qual o MA é identificado por uma VLAN e atende à VLAN 100).
[DeviceA] cfd md MD_A level 5
[DeviceA] cfd service-instance 1 ma-id vlan-based md MD_A vlan 100# Configure o dispositivo E da mesma forma que o dispositivo A está configurado. (Os detalhes não são mostrados).
# Criar MD_A (nível 5) no Dispositivo B e criar a instância de serviço 1 (na qual o MA é identificado por uma VLAN e atende à VLAN 100).
[DeviceB] cfd md MD_A level 5
[DeviceB] cfd service-instance 1 ma-id vlan-based md MD_A vlan 100# Criar MD_B (nível 3) e criar a instância de serviço 2 (na qual o MA é identificado por uma VLAN e atende à VLAN 100).
[DeviceB] cfd md MD_B level 3
[DeviceB] cfd service-instance 2 ma-id vlan-based md MD_B vlan 100# Configure o dispositivo D da mesma forma que o dispositivo B está configurado. (Os detalhes não são mostrados).
# Crie MD_B (nível 3) no Dispositivo C e crie a instância de serviço 2 (na qual o MA é identificado por uma VLAN e atende à VLAN 100).
[DeviceC] cfd md MD_B level 3
[DeviceC] cfd service-instance 2 ma-id vlan-based md MD_B vlan 100# No dispositivo A, configure uma lista MEP na instância de serviço 1 e crie o MEP 1001 voltado para dentro na instância de serviço 1 na GigabitEthernet 1/0/1.
[DeviceA] cfd meplist 1001 4002 5001 service-instance 1
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] cfd mep 1001 service-instance 1 inbound
[DeviceA-GigabitEthernet1/0/1] quit# No dispositivo B, configure uma lista MEP nas instâncias de serviço 1 e 2.
[DeviceB] cfd meplist 1001 4002 5001 service-instance 1
[DeviceB] cfd meplist 2001 4001 service-instance 2# Crie o MEP 2001 voltado para o exterior na instância de serviço 2 na GigabitEthernet 1/0/3.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] cfd mep 2001 service-instance 2 outbound
[DeviceB-GigabitEthernet1/0/3] quit# No dispositivo D, configure uma lista MEP nas instâncias de serviço 1 e 2.
[DeviceD] cfd meplist 1001 4002 5001 service-instance 1
[DeviceD] cfd meplist 2001 4001 service-instance 2# Crie o MEP 4001 voltado para o exterior na instância de serviço 2 na GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] cfd mep 4001 service-instance 2 outbound
[DeviceD-GigabitEthernet1/0/1] quit# Crie o MEP 4002 voltado para a entrada na instância de serviço 1 na GigabitEthernet 1/0/3.
[DeviceD] interface gigabitethernet 1/0/3
[DeviceD-GigabitEthernet1/0/3] cfd mep 4002 service-instance 1 inbound
[DeviceD-GigabitEthernet1/0/3] quit# No dispositivo E, configure uma lista MEP na instância de serviço 1.
[DeviceE] cfd meplist 1001 4002 5001 service-instance 1# Crie o MEP 5001 voltado para a entrada na instância de serviço 1 na GigabitEthernet 1/0/4.
[DeviceE] interface gigabitethernet 1/0/4
[DeviceE-GigabitEthernet1/0/4] cfd mep 5001 service-instance 1 inbound
[DeviceE-GigabitEthernet1/0/4] quit# Configure a regra de geração de MIP na instância de serviço 1 no Dispositivo B como explícita.
[DeviceB] cfd mip-rule explicit service-instance 1# Configure a regra de geração de MIP na instância de serviço 2 no Dispositivo C como padrão.
[DeviceC] cfd mip-rule default service-instance 2# No dispositivo A, habilite o envio de quadros CCM para o MEP 1001 na instância de serviço 1 na GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] cfd cc service-instance 1 mep 1001 enable
[DeviceA-GigabitEthernet1/0/1] quit# No dispositivo B, habilite o envio de quadros CCM para o MEP 2001 na instância de serviço 2 em GigabitEthernet 1/0/3.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] cfd cc service-instance 2 mep 2001 enable
[DeviceB-GigabitEthernet1/0/3] quit# No dispositivo D, habilite o envio de quadros CCM para o MEP 4001 na instância de serviço 2 em GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] cfd cc service-instance 2 mep 4001 enable
[DeviceD-GigabitEthernet1/0/1] quit# Habilite o envio de quadros CCM para o MEP 4002 na instância de serviço 1 na GigabitEthernet 1/0/3.
[DeviceD] interface gigabitethernet 1/0/3
[DeviceD-GigabitEthernet1/0/3] cfd cc service-instance 1 mep 4002 enable
[DeviceD-GigabitEthernet1/0/3] quit# No Dispositivo E, habilite o envio de quadros CCM para o MEP 5001 na instância de serviço 1 na GigabitEthernet 1/0/4.
[DeviceE] interface gigabitethernet 1/0/4
[DeviceE-GigabitEthernet1/0/4] cfd cc service-instance 1 mep 5001 enable
[DeviceE-GigabitEthernet1/0/4] quit# Habilite o AIS no dispositivo B. Configure o nível de transmissão do quadro AIS como 5 e o intervalo de transmissão do quadro AIS como 1 segundo na instância de serviço 2.
[DeviceB] cfd ais enable
[DeviceB] cfd ais level 5 service-instance 2
[DeviceB] cfd ais period 1 service-instance 2# Habilitar a colaboração de status de porta-AIS no Dispositivo B.
[DeviceB] cfd ais-track link-status global# Na GigabitEthernet 1/0/3 do Dispositivo B, configure o nível de transmissão do quadro EAIS como 5 e o intervalo de transmissão do quadro EAIS como 60 segundos. Especifique as VLANs em que os quadros EAIS podem ser transmitidos como VLAN 100.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] cfd ais-track link-status level 5
[DeviceB-GigabitEthernet1/0/3] cfd ais-track link-status period 60
[DeviceB-GigabitEthernet1/0/3] cfd ais-track link-status vlan 100
[DeviceB-GigabitEthernet1/0/3] quitVerificação da configuração
# Habilite o LB no Dispositivo A para verificar o status do link entre o MEP 1001 e o MEP 5001 na instância de serviço 1.
[DeviceA] cfd loopback service-instance 1 mep 1001 target-mep 5001
Loopback to MEP 5001 with the sequence number start from 1001-43404:
Reply from 0010-fc05-6515: sequence number=1001-43404 time=5ms
Reply from 0010-fc05-6515: sequence number=1001-43405 time=5ms
Reply from 0010-fc05-6515: sequence number=1001-43406 time=5ms
Reply from 0010-fc05-6515: sequence number=1001-43407 time=5ms
Reply from 0010-fc05-6515: sequence number=1001-43408 time=5ms
Sent: 5 Received: 5 Lost: 0# Identifique o caminho entre o MEP 1001 e o MEP 5001 na instância de serviço 1 no Dispositivo A.
[DeviceA] cfd linktrace service-instance 1 mep 1001 target-mep 5001
Linktrace to MEP 5001 with the sequence number 1001-43462:
MAC address TTL Last MAC Relay action
0010-fc05-6515 63 0010-fc02-6512 Hit# Teste a perda de quadros do MEP 1001 para o MEP 4002 na instância de serviço 1 no Dispositivo A.
[DeviceA] cfd slm service-instance 1 mep 1001 target-mep 4002
Reply from 0010-fc04-6514
Far-end frame loss: 10 Near-end frame loss: 20
Reply from 0010-fc04-6514
Far-end frame loss: 40 Near-end frame loss: 40
Reply from 0010-fc04-6514
Far-end frame loss: 0 Near-end frame loss: 10
Reply from 0010-fc04-6514
Far-end frame loss: 30 Near-end frame loss: 30
Average
Far-end frame loss: 20 Near-end frame loss: 25
Far-end frame loss rate: 25.00% Near-end frame loss rate: 32.00%
Send LMMs: 5 Received: 5 Lost: 0# Teste o atraso do quadro unidirecional do MEP 1001 para o MEP 4002 na instância de serviço 1 no Dispositivo A.
[DeviceA] cfd dm one-way service-instance 1 mep 1001 target-mep 4002
5 1DMs have been sent. Please check the result on the remote device.# Exibir o resultado do DM unidirecional no MEP 4002 na instância de serviço 1 no Dispositivo D.
[DeviceD] display cfd dm one-way history service-instance 1 mep 4002
Service instance: 1
MEP ID: 4002
Sent 1DM total number: 0
Received 1DM total number: 5
Frame delay: 10ms 9ms 11ms 5ms 5ms
Delay average: 8ms
Delay variation: 5ms 4ms 6ms 0ms 0ms
Variation average: 3ms# Teste o atraso do quadro bidirecional do MEP 1001 para o MEP 4002 na instância de serviço 1 no Dispositivo A.
[DeviceA] cfd dm two-way service-instance 1 mep 1001 target-mep 4002
Frame delay:
Reply from 0010-fc04-6514: 2406us
Reply from 0010-fc04-6514: 2215us
Reply from 0010-fc04-6514: 2112us
Reply from 0010-fc04-6514: 1812us
Reply from 0010-fc04-6514: 2249us
Average: 2158us
Sent DMMs: 5 Received: 5 Lost: 0
Frame delay variation: 191us 103us 300us 437us
Average: 257us# Teste os erros de bits no link do MEP 1001 para o MEP 4002 na instância de serviço 1 no Dispositivo A.
[DeviceA] cfd tst service-instance 1 mep 1001 target-mep 4002
5 TSTs have been sent. Please check the result on the remote device.# Exibir o resultado do TST no MEP 4002 na instância de serviço 1 no Dispositivo D.
[DeviceD] display cfd tst service-instance 1 mep 4002
Service instance: 1
MEP ID: 4002
Sent TST total number: 0
Received TST total number: 5
Received from 0010-fc01-6511, Bit True, sequence number 0
Received from 0010-fc01-6511, Bit True, sequence number 1
Received from 0010-fc01-6511, Bit True, sequence number 2
Received from 0010-fc01-6511, Bit True, sequence number 3
Received from 0010-fc01-6511, Bit True, sequence number 4Configuração do DLDP
Sobre a DLDP
Os mecanismos de detecção da camada física, como a negociação automática, podem detectar sinais físicos e falhas. Entretanto, eles não podem detectar falhas de comunicação em links unidirecionais em que a camada física está em estado conectado.
Como um protocolo de camada de enlace de dados, o DLDP (Device Link Detection Protocol) pode fazer o seguinte:
- Monitore o status do link de fibra ou do link de par trançado na camada de link.
- Cooperar com os protocolos da camada física para detectar se o link está conectado corretamente e se as duas extremidades do link podem trocar pacotes corretamente.
Quando o DLDP detecta links unidirecionais, ele pode desligar automaticamente a porta defeituosa para evitar problemas de rede. Como alternativa, um usuário pode desligar manualmente a porta defeituosa.
Cenário de aplicação
Um link se torna unidirecional quando apenas uma extremidade do link pode receber pacotes da outra extremidade. Os links de fibra unidirecionais ocorrem nos seguintes casos:
- As fibras são conectadas de forma cruzada.
- Uma fibra não está conectada em uma extremidade ou uma fibra de um par de fibras está quebrada.
A Figura 1 mostra uma conexão de fibra correta e dois tipos de conexões de fibra unidirecionais.
Quando o DLDP detecta links unidirecionais, ele pode desligar automaticamente a porta defeituosa para evitar problemas na rede. Como alternativa, um usuário pode desligar manualmente a porta defeituosa.
Figura 1 Conexões de fibra corretas e incorretas
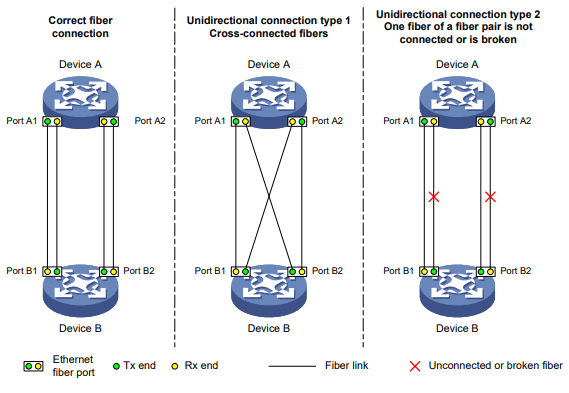
Conceitos básicos
Estados de vizinhos DLDP
Se a porta A puder receber pacotes da camada de enlace da porta B no mesmo enlace, a porta B será um vizinho DLDP da porta
A. Duas portas que podem trocar pacotes são vizinhas.
Tabela 1 Estados vizinhos do DLDP
| Temporizador DLDP | Descrição |
| Confirmado | O link para um vizinho DLDP é bidirecional. |
| Não confirmado | O estado do link para um vizinho recém-descoberto não é determinado. |
Estados da porta DLDP
Uma porta habilitada para DLDP é chamada de porta DLDP. Uma porta DLDP pode ter vários vizinhos, e seu estado varia de acordo com o estado do vizinho DLDP.
Tabela 2 Estados da porta DLDP
| Estado | Descrição |
| Inicial | O DLDP está ativado na porta, mas está desativado globalmente. |
| Inativo | O DLDP está ativado na porta e globalmente, e o link está fisicamente inoperante. |
| Bidirecional | O DLDP está ativado na porta e globalmente, e existe pelo menos um vizinho no estado Confirmado. |
| Unidirecional | O DLDP está ativado na porta e globalmente, e não existe nenhum vizinho no estado Confirmed. Nesse estado, uma porta não envia nem recebe mais pacotes que não sejam pacotes DLDP. |
Temporizadores DLDP
Tabela 3 Temporizadores DLDP
| Temporizador DLDP | Descrição |
| Temporizador de anúncios | Intervalo de envio de pacotes de anúncio (o padrão é 5 segundos e pode ser configurado). |
| Temporizador da sonda | Intervalo de envio do pacote de sonda. Esse cronômetro é definido como 1 segundo. |
| Temporizador de eco | O cronômetro Echo é acionado quando uma sonda é iniciada para um novo vizinho. As informações sobre o vizinho são excluídas quando o cronômetro expira. Esse cronômetro é definido como 10 segundos. |
| Temporizador de entrada | Quando um novo vizinho se une, é criada uma entrada de vizinho e o temporizador Entry correspondente é acionado se o vizinho estiver no estado Confirmed. Quando um anúncio é recebido, o dispositivo atualiza a entrada de vizinho correspondente e o cronômetro Entry. Quando o temporizador Entry expira, o temporizador Enhanced e o temporizador Echo são acionados para o vizinho. O valor de um cronômetro de entrada é três vezes maior que o do cronômetro de anúncio. |
| Temporizador aprimorado | Intervalo de envio de pacotes de sonda. Esse cronômetro é definido como 1 segundo. Quando o timer Entry expira, o timer Enhanced é acionado e os pacotes de sondagem são enviados. Ao mesmo tempo, o timer Echo é acionado. |
| Temporizador DelayDown | Se uma porta estiver fisicamente inativa, o dispositivo acionará o temporizador DelayDown, em vez de remover a entrada de vizinho correspondente. O timer padrão do DelayDown é de 1 segundo e pode ser configurado. Quando o temporizador DelayDown expira, o dispositivo remove as informações de vizinho DLDP correspondentes se a porta estiver inoperante e não executa nenhuma ação de controle se a porta estiver ativa. |
| Temporizador RecoverProbe | Esse cronômetro é definido como 2 segundos. Uma porta em estado unidirecional envia regularmente pacotes RecoverProbe para detectar se um link unidirecional foi restaurado para bidirecional. |
Modo de autenticação DLDP
Você pode usar a autenticação DLDP para evitar ataques à rede e detecção ilegal.
Tabela 4 Modo de autenticação DLDP
| Modo de autenticação | Processamento no lado de envio do pacote DLDP | Processamento no lado de recebimento do pacote DLDP |
| Não autenticação | O lado do envio define o campo Authentication (Autenticação) dos pacotes DLDP como 0. | O lado receptor examina as informações de autenticação dos pacotes DLDP recebidos e descarta os pacotes em que as informações de autenticação estão em conflito com a configuração local. |
| Autenticação de texto simples | O lado emissor define o campo Authentication (Autenticação) como a senha configurada em texto simples. | |
| MD5 autenticação | O lado do envio criptografa a senha configurada pelo usuário usando o algoritmo MD5 e atribui o resumo ao campo Authentication (Autenticação). |
Como funciona o DLDP
Detecção de um vizinho
Quando dois dispositivos estiverem conectados por meio de uma fibra óptica ou de um cabo de rede, habilite o DLDP para detectar links unidirecionais para o vizinho. A seguir, ilustramos o processo de detecção de links unidirecionais em dois casos:
- Os links unidirecionais ocorrem antes de você ativar o DLDP.
Figura 2 Fibras com conexão cruzada
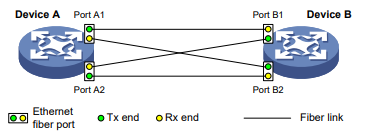
Conforme mostrado na Figura 2, antes de você ativar a DLDP, as fibras ópticas entre o Dispositivo A e o Dispositivo B estão conectadas de forma cruzada. Depois que você ativa o DLDP, as quatro portas estão todas ativas e em estado unidirecional e enviam pacotes RecoverProbe. Tome a porta A1 como exemplo para ilustrar o processo de detecção de link unidirecional .
- A porta A1 recebe o pacote RecoverProbe da porta B2 e retorna um pacote RecoverEcho .
- A porta B2 não pode receber nenhum pacote RecoverEcho da porta A1, portanto a porta B2 não pode se tornar vizinha da porta A1.
- A porta B1 pode receber o pacote RecoverEcho da porta A1, mas a porta B1 não é o destino pretendido, portanto, a porta B1 não pode se tornar vizinha da porta A1.
O mesmo processo ocorre nas outras três portas. As quatro portas estão todas em estado unidirecional.
- Os links unidirecionais ocorrem depois que você ativa o DLDP.
Figura 3 Fibra quebrada
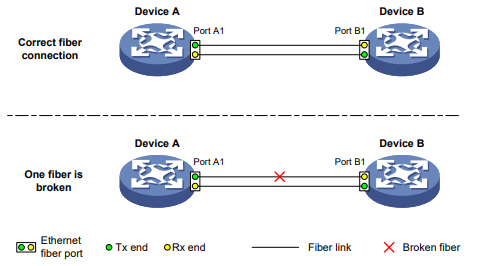
Conforme mostrado na Figura 3, o Dispositivo A e o Dispositivo B estão conectados por meio de uma fibra óptica. Depois que você ativar o DLDP, a Porta A1 e a Porta B1 estabelecerão a vizinhança bidirecional da seguinte forma:
- A porta A1, que está fisicamente ativa, entra no estado unidirecional e envia um pacote RecoverProbe .
- Depois de receber o pacote RecoverProbe, a porta B1 retorna um pacote RecoverEcho.
- Depois que a porta A1 recebe o pacote RecoverEcho, ela examina as informações de vizinhança no pacote. Se as informações de vizinhança corresponderem às informações locais, a porta A1 estabelece a vizinhança com a porta B1 e passa para o estado bidirecional. Em seguida, a porta A1 inicia o cronômetro Entry e envia periodicamente pacotes Advertisement.
- Depois que a porta B1 recebe o pacote Advertisement, ela estabelece a vizinhança Unconfirmed com a porta A1. Em seguida, a porta B1 inicia o timer Echo e o timer Probe, e o site envia periodicamente pacotes Probe.
- Depois de receber o pacote Probe, a porta A1 retorna um pacote Echo.
- Depois que a porta B1 recebe o pacote Echo, ela examina as informações de vizinhança no pacote. Se as informações de vizinhança corresponderem às informações locais, o estado de vizinhança da porta A1 se tornará Confirmed. Em seguida, a porta B1 passa para o estado bidirecional, inicia o cronômetro Entry e envia periodicamente pacotes Advertisement.
A vizinhança bidirecional entre a porta A1 e a porta B1 foi estabelecida.
Depois disso, quando a extremidade Rx da porta B1 deixa de receber sinais, a porta B1 fica fisicamente inativa e entra no estado Inativo. Como a extremidade Tx da porta B1 ainda pode enviar sinais para a porta A1, a porta A1 permanece ativa. Depois que o timer Entry da porta B1 expira, a porta A1 inicia o timer Enhanced e o timer Echo e envia um pacote de sonda para a porta B1. Como a linha Tx da porta A1 está interrompida, a porta A1 não pode receber o pacote Echo da porta B1 após a expiração do timer Echo. A porta A1 entra então no estado unidirecional e envia um pacote Disable à porta B1. Ao mesmo tempo, a porta A1 exclui a vizinhança com a porta B1 e inicia o cronômetro RecoverProbe. A porta B1 permanece no estado Inativo durante esse processo.
Quando uma interface está fisicamente inativa, mas a extremidade Tx da interface ainda está funcionando, o DLDP envia um pacote LinkDown para informar ao par que deve excluir a entrada de vizinho relevante.
Detecção de vários vizinhos
Quando vários dispositivos estiverem conectados por meio de um hub, ative o DLDP em todas as interfaces conectadas ao hub para detectar links unidirecionais entre os vizinhos. Quando não há nenhum vizinho confirmado, uma interface entra no estado unidirecional.
Figura 4 Diagrama de rede

Conforme mostrado na Figura 4, os dispositivos A e D estão conectados por meio de um hub e habilitados com DLDP. Quando a Porta A1, a Porta B1 e a Porta C1 detectam que o link para a Porta D1 falha, elas excluem a vizinhança com a Porta D1, mas permanecem no estado bidirecional.
Restrições e diretrizes: Configuração do DLDP
Quando você configurar o DLDP, siga estas restrições e diretrizes de configuração:
- Para que o DLDP funcione corretamente, ative o DLDP em ambos os lados e certifique-se de que as configurações a seguir sejam consistentes:
- Intervalo para enviar pacotes de anúncio.
- Modo de autenticação DLDP.
- Senha.
- Para que o DLDP funcione corretamente, configure o modo full duplex para as portas nas duas extremidades do link e configure a mesma velocidade para as duas portas.
Visão geral das tarefas DLDP
Para configurar o DLDP, execute as seguintes tarefas:
- Ativação do DLDP
- (Opcional.) Definir o intervalo para enviar pacotes de propaganda
- (Opcional.) Configuração do temporizador DelayDown
- (Opcional.) Configuração do modo de desligamento da porta
- (Opcional.) Configuração da autenticação DLDP
Ativação do DLDP
Sobre a ativação do DLDP
Depois que uma porta é ativada com o DLDP, ela entra no estado inicial e, em seguida, faz a transição para o estado unidirecional. Por padrão, o DLDP bloqueia uma porta imediatamente quando ela faz a transição para o estado Unidirecional. Esse comportamento causa uma interrupção no tráfego que dura até que a porta entre no estado Bidirecional ao estabelecer um vizinho Confirmado.
Você pode definir o tempo de atraso para o DLDP bloquear uma porta em uma transição de estado inicial para não unidirecional. O DLDP não bloqueia a porta até que o tempo de atraso expire.
Procedimento
- Entre na visualização do sistema.
System-viewdldp global enablePor padrão, o DLDP está globalmente desativado.
interface interface-type interface-numberdldp enable [ initial-unidirectional-delay time ]Por padrão, o DLDP está desativado em uma porta e, quando o DLDP está ativado, uma porta é bloqueada imediatamente após uma transição de estado inicial para não unidirecional.
Configuração do intervalo para envio de pacotes de propaganda
Sobre a configuração do intervalo para enviar pacotes de propaganda
Para garantir que o DLDP possa detectar links unidirecionais antes que o desempenho da rede se deteriore, defina o intervalo de anúncio adequado ao seu ambiente de rede. Como prática recomendada, use o intervalo padrão .
Procedimento
- Entre na visualização do sistema.
System-viewdldp interval intervalPor padrão, o intervalo é de 5 segundos.
Configuração do temporizador DelayDown
Sobre a configuração do temporizador DelayDown
Quando a linha Tx falha, algumas portas podem ficar inativas e depois voltar a funcionar, causando oscilações no sinal óptico na linha Rx. Para evitar que o dispositivo remova entradas vizinhas nesses casos, defina o temporizador DelayDown para o dispositivo. O dispositivo inicia o temporizador DelayDown quando uma porta fica inativa devido a uma falha na linha Tx. Se a porta permanecer inativa quando o cronômetro expirar, o dispositivo removerá as informações de vizinho DLDP. Se a porta voltar a funcionar, o dispositivo não tomará nenhuma medida.
Procedimento
- Entre na visualização do sistema.
System-viewdldp delaydown-timer timeO padrão é 1 segundo.
A configuração do temporizador DelayDown se aplica a todas as portas habilitadas para DLDP.
Configuração do modo de desligamento da porta
Sobre os modos de desligamento da porta
Ao detectar um link unidirecional, o DLDP desliga as portas em um dos seguintes modos:
- Modo automático - Quando o DLDP detecta um link unidirecional, ele desliga a porta unidirecional. Quando o link se torna bidirecional, o DLDP ativa a porta que foi desligada.
- Modo manual - Quando o DLDP detecta um link unidirecional, ele não desliga a porta. Você precisa desligá-la manualmente. Para verificar o status do link, use o comando undo shutdown para ativar a porta. Se o link se tornar bidirecional, a porta se tornará bidirecional. Use esse modo para evitar que links normais sejam desligados devido a relatórios falsos de links unidirecionais nos seguintes casos:
- O desempenho da rede é baixo.
- O dispositivo está ocupado.
- A utilização da CPU é alta.
- Modo híbrido - Quando o DLDP detecta um link unidirecional, ele desliga a porta unidirecional e interrompe a detecção do link. Para verificar o status do link, use o comando undo shutdown para ativar a porta. Se o link se tornar bidirecional, a porta se tornará bidirecional.
Restrições e diretrizes
Você pode definir o modo de desligamento da porta para todas as interfaces na visualização do sistema ou para uma única interface na visualização da interface. A configuração na visualização da interface tem precedência sobre a configuração na visualização do sistema.
Para ativar o loopback de OAM remoto em uma porta DLDP, defina o modo de desligamento da porta como manual. Caso contrário, o DLDP desligará automaticamente a porta quando receber um pacote enviado por ele mesmo. Isso causa falha no loopback de OAM remoto. Para obter mais informações sobre o Ethernet OAM, consulte "Configuração do Ethernet OAM".
Configuração do modo de desligamento da porta global
- Entre na visualização do sistema.
System-viewdldp unidirectional-shutdown { auto | hybrid | manual }O modo padrão é auto.
Configuração do modo de desligamento da porta para uma interface
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberdldp port unidirectional-shutdown { auto | hybrid | manual }Por padrão, a configuração global é usada.
Configuração da autenticação DLDP
Sobre a autenticação DLDP
Você pode proteger sua rede contra ataques e sondas mal-intencionadas configurando um modo de autenticação DLDP apropriado, que pode ser autenticação de texto simples ou autenticação MD5. Se sua rede for segura, você pode optar por não autenticar.
Procedimento
- Entre na visualização do sistema.
System-viewdldp authentication-mode { md5 | none | simple }O modo de autenticação padrão é none.
dldp authentication-password { cipher | simple } stringPor padrão, nenhuma senha é configurada para a autenticação DLDP.
Se você não configurar a senha de autenticação depois de configurar o modo de autenticação, o modo de autenticação será none, independentemente do modo de autenticação que você configurar.
Comandos de exibição e manutenção para DLDP
Execute comandos de exibição em qualquer visualização e o comando reset na visualização do usuário.
| Tarefa | Comando |
| Exibir a configuração DLDP globalmente e de uma porta. | exibir dldp [ interface interface-type interface-number ] |
| Exibe as estatísticas dos pacotes DLDP que passam por uma porta. | exibir estatísticas de dldp [ interface interface-type interface-number ] |
| Limpar as estatísticas dos pacotes DLDP que passam por uma porta. | reset dldp statistics [ interface interface-type interface-number ] |
Exemplos de configuração do DLDP
Exemplo: Configuração do modo de desligamento automático da porta
Configuração de rede
Conforme mostrado na Figura 5, o Dispositivo A e o Dispositivo B estão conectados por meio de dois pares de fibras.
Configure o DLDP para desligar automaticamente a porta defeituosa ao detectar um link unidirecional e automaticamente ativar a porta depois que você eliminar a falha.
Figura 5 Diagrama de rede

Procedimento
- Configure o dispositivo A:
# Habilite o DLDP globalmente.
<DeviceA> system-view
[DeviceA] dldp global enable# Configure a GigabitEthernet 1/0/1 para operar no modo full duplex e a 1000 Mbps, e habilite DLDP na porta.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] duplex full
[DeviceA-GigabitEthernet1/0/1] speed 1000
[DeviceA-GigabitEthernet1/0/1] dldp enable
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 para operar no modo full duplex e a 1000 Mbps, e habilite o DLDP na porta.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] duplex full
[DeviceA-GigabitEthernet1/0/2] speed 1000
[DeviceA-GigabitEthernet1/0/2] dldp enable
[DeviceA-GigabitEthernet1/0/2] quit# Defina o modo de desligamento da porta global como automático.
[DeviceA] dldp unidirectional-shutdown auto# Habilite o DLDP globalmente.
<DeviceA> system-view
[DeviceB] dldp global enable# Configure a GigabitEthernet 1/0/1 para operar no modo full duplex e a 1000 Mbps, e habilite o DLDP nela.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] duplex full
[DeviceB-GigabitEthernet1/0/1] speed 1000
[DeviceB-GigabitEthernet1/0/1] dldp enable
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 para operar no modo full duplex e a 1000 Mbps, e habilite o DLDP nela.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] duplex full
[DeviceB-GigabitEthernet1/0/2] speed 1000
[DeviceB-GigabitEthernet1/0/2] dldp enable
[DeviceB-GigabitEthernet1/0/2] quit# Defina o modo de desligamento da porta global como automático.
[DeviceB] dldp unidirectional-shutdown autoVerificação da configuração
# Exibir a configuração DLDP globalmente e em todas as portas habilitadas para DLDP do Dispositivo A.
[DeviceA] display dldp
DLDP global status: Enabled
DLDP advertisement interval: 5s
DLDP authentication-mode: None
DLDP unidirectional-shutdown mode: Auto
DLDP delaydown-timer value: 1s
Number of enabled ports: 2
Interface GigabitEthernet1/0/1
DLDP port state: Bidirectional
DLDP port unidirectional-shutdown mode: None
DLDP initial-unidirectional-delay: 0s
Number of the port’s neighbors: 1
Neighbor MAC address: 0023-8956-3600
Neighbor port index: 1
Neighbor state: Confirmed
Neighbor aged time: 11s
Neighbor echo time: -
Interface GigabitEthernet1/0/2
DLDP port state: Bidirectional
DLDP port unidirectional-shutdown mode: None
DLDP initial-unidirectional-delay: 0s
Number of the port’s neighbors: 1
Neighbor MAC address: 0023-8956-3600
Neighbor port index: 2
Neighbor state: Confirmed
Neighbor aged time: 12s
Neighbor echo time: -A saída mostra que tanto a GigabitEthernet 1/0/1 quanto a GigabitEthernet 1/0/2 são bidirecionais.
# Habilite o monitoramento de registros no terminal atual do dispositivo A. Defina o nível mais baixo dos registros que podem ser enviados ao terminal atual como 6.
[DeviceA] quit
<DeviceA> terminal monitor
The current terminal is enabled to display logs.
<DeviceA> terminal logging level 6As seguintes informações de registro são exibidas no Dispositivo A:
<DeviceA>%Jul 11 17:40:31:089 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the
interface Physical state on the interface GigabitEthernet1/0/1 changed to down.
%Jul 11 17:40:31:091 2012 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/1 changed to down.
%Jul 11 17:40:31:677 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the interface
Physical state on the interface GigabitEthernet1/0/2 changed to down.
%Jul 11 17:40:31:678 2012 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/2 changed to down.
%Jul 11 17:40:38:544 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the interface
Physical state on the interface GigabitEthernet1/0/1 l changed to up.
%Jul 11 17:40:38:836 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the interface
Physical state on the interface GigabitEthernet1/0/2 changed to up.O resultado mostra o seguinte:
- O status da porta da GigabitEthernet 1/0/1 e da GigabitEthernet 1/0/2 é down e depois up.
- O status do link da GigabitEthernet 1/0/1 e da GigabitEthernet 1/0/2 está sempre inativo.
# Exibir a configuração DLDP globalmente e de todas as portas habilitadas para DLDP.
<DeviceA> display dldp
DLDP global status: Enabled
DLDP advertisement interval: 5s
DLDP authentication-mode: None
DLDP unidirectional-shutdown mode: Auto
DLDP delaydown-timer value: 1s
Number of enabled ports: 2
Interface GigabitEthernet1/0/1
DLDP port state: Unidirectional
DLDP port unidirectional-shutdown mode: None
DLDP initial-unidirectional-delay: 0s
Number of the port’s neighbors: 0 (Maximum number ever detected: 1)
Interface GigabitEthernet1/0/2
DLDP port state: Unidirectional
DLDP port unidirectional-shutdown mode: None
DLDP initial-unidirectional-delay: 0s
Number of the port’s neighbors: 0 (Maximum number ever detected: 1)A saída mostra que o status da porta DLDP da GigabitEthernet 1/0/1 e da GigabitEthernet 1/0/2 é unidirecional. O DLDP detecta links unidirecionais nessas portas e as desliga automaticamente.
Os links unidirecionais são causados por fibras conectadas de forma cruzada. Corrija as conexões das fibras. Como resultado, as portas desligadas pelo DLDP se recuperam automaticamente, e o Dispositivo A exibe as seguintes informações de registro:
<DeviceA>%Jul 11 17:42:57:709 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the
interface GigabitEthernet1/0/1 changed to down.
%Jul 11 17:42:58:603 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the interface
GigabitEthernet1/0/2 changed to down.
%Jul 11 17:43:02:342 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the interface
GigabitEthernet1/0/1 changed to up.
%Jul 11 17:43:02:343 2012 DeviceA DLDP/6/DLDP_NEIGHBOR_CONFIRMED: A neighbor was confirmed
on interface GigabitEthernet1/0/1. The neighbor's system MAC is 0023-8956-3600, and the
port index is 1.
%Jul 11 17:43:02:344 2012 DeviceA DLDP/6/DLDP_LINK_BIDIRECTIONAL: DLDP detected a
bidirectional link on interface GigabitEthernet1/0/1.
%Jul 11 17:43:02:353 2012 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/1 changed to up.
%Jul 11 17:43:02:357 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the interface
GigabitEthernet1/0/2 changed to up.
%Jul 11 17:43:02:362 2012 DeviceA DLDP/6/DLDP_NEIGHBOR_CONFIRMED: A neighbor was confirmed
on interface GigabitEthernet1/0/2. The neighbor's system MAC is 0023-8956-3600, and the
port index is 2.
%Jul 11 17:43:02:362 2012 DeviceA DLDP/6/DLDP_LINK_BIDIRECTIONAL: DLDP detected a
bidirectional link on interface GigabitEthernet1/0/2.
%Jul 11 17:43:02:368 2012 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/2 changed to up.A saída mostra que o status da porta e o status do link da GigabitEthernet 1/0/1 e da GigabitEthernet 1/0/2 agora estão ativos e seus vizinhos DLDP estão determinados.
Exemplo: Configuração do modo de desligamento manual da porta
Configuração de rede
Conforme mostrado na Figura 6, o Dispositivo A e o Dispositivo B estão conectados por meio de dois pares de fibras.
Configure o DLDP para detectar links unidirecionais. Quando um link unidirecional é detectado, o administrador do deve desligar manualmente a porta.
Figura 6 Diagrama de rede
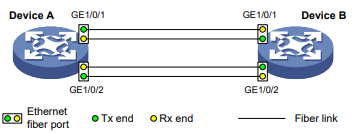
Procedimento
- Configurar o dispositivo A:
# Habilite o DLDP globalmente.
<DeviceA> system-view
[DeviceA] dldp enable# Configure a GigabitEthernet 1/0/1 para operar no modo full duplex e a 1000 Mbps, e habilite o DLDP na porta.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] duplex full
[DeviceA-GigabitEthernet1/0/1] speed 1000
[DeviceA-GigabitEthernet1/0/1] dldp enable
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 para operar no modo full duplex e a 1000 Mbps, e habilite o DLDP na porta.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] duplex full
[DeviceA-GigabitEthernet1/0/2] speed 1000
[DeviceA-GigabitEthernet1/0/2] dldp enable
[DeviceA-GigabitEthernet1/0/2] quit# Defina o modo de desligamento da porta global como manual.
[DeviceA] dldp unidirectional-shutdown manual# Habilite o DLDP globalmente.
<DeviceB> system-view
[DeviceB] dldp global enable# Configure a GigabitEthernet 1/0/1 para operar no modo full duplex e a 1000 Mbps, e habilite o DLDP nela.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] duplex full
[DeviceB-GigabitEthernet1/0/1] speed 1000
[DeviceB-GigabitEthernet1/0/1] dldp enable
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 para operar no modo full duplex e a 1000 Mbps, e habilite o DLDP nela.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] duplex full
[DeviceB-GigabitEthernet1/0/2] speed 1000
[DeviceB-GigabitEthernet1/0/2] dldp enable
[DeviceB-GigabitEthernet1/0/2] quit# Defina o modo de desligamento da porta global como manual.
[DeviceB] dldp unidirectional-shutdown manualVerificação da configuração
# Exibir a configuração DLDP globalmente e em todas as portas habilitadas para DLDP do Dispositivo A.
[DeviceA] display dldp
DLDP global status: Enabled
DLDP advertisement interval: 5s
DLDP authentication-mode: None
DLDP unidirectional-shutdown mode: Manual
DLDP delaydown-timer value: 1s
Number of enabled ports: 2
Interface GigabitEthernet1/0/1
DLDP port state: Bidirectional
DLDP port unidirectional-shutdown mode: None
DLDP initial-unidirectional-delay: 0s
Number of the port’s neighbors: 1
Neighbor MAC address: 0023-8956-3600
Neighbor port index: 1
Neighbor state: Confirmed
Neighbor aged time: 11s
Neighbor echo time: -
Interface GigabitEthernet1/0/2
DLDP port state: Bidirectional
DLDP port unidirectional-shutdown mode: None
DLDP initial-unidirectional-delay: 0s
Number of the port’s neighbors: 1
Neighbor MAC address: 0023-8956-3600
Neighbor port index: 2
Neighbor state: Confirmed
Neighbor aged time: 12s
Neighbor echo time: -A saída mostra que tanto a GigabitEthernet 1/0/1 quanto a GigabitEthernet 1/0/2 estão em estado bidirecional, o que significa que ambos os links são bidirecionais.
# Habilite o monitoramento de registros no terminal atual do dispositivo A. Defina o nível mais baixo dos registros que podem ser enviados ao terminal atual como 6.
[DeviceA] quit
<DeviceA> terminal monitor
The current terminal is enabled to display logs.
<DeviceA> terminal logging level 6As seguintes informações de registro são exibidas no Dispositivo A:
<DeviceA>%Jul 12 08:29:17:786 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the
interface GigabitEthernet1/0/1 changed to down.
%Jul 12 08:29:17:787 2012 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/1 changed to down.
%Jul 12 08:29:17:800 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the interface
GigabitEthernet1/0/2 changed to down.
%Jul 12 08:29:17:800 2012 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/2 changed to down.
%Jul 12 08:29:25:004 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the interface
GigabitEthernet1/0/1 changed to up.
%Jul 12 08:29:25:005 2012 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/1 changed to up.
%Jul 12 08:29:25:893 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the interface
GigabitEthernet1/0/2 changed to up.
%Jul 12 08:29:25:894 2012 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/2 changed to up.A saída mostra que o status da porta e o status do link da GigabitEthernet 1/0/1 e da GigabitEthernet 1/0/2 estão inativos e, em seguida, ativos.
# Exibir a configuração DLDP globalmente e de todas as portas habilitadas para DLDP.
<DeviceA> display dldp
DLDP global status: Enabled
DLDP advertisement interval: 5s
DLDP authentication-mode: None
DLDP unidirectional-shutdown mode: Manual
DLDP delaydown-timer value: 1s
Number of enabled ports: 2
Interface GigabitEthernet1/0/1
DLDP port state: Unidirectional
DLDP port unidirectional-shutdown mode: None
DLDP initial-unidirectional-delay: 0s
Number of the port’s neighbors: 0 (Maximum number ever detected: 1)
Interface GigabitEthernet1/0/2
DLDP port state: Unidirectional
DLDP port unidirectional-shutdown mode: None
DLDP initial-unidirectional-delay: 0s
Number of the port’s neighbors: 0 (Maximum number ever detected: 1)A saída mostra que o status da porta DLDP da GigabitEthernet 1/0/1 e da GigabitEthernet 1/0/2 é unidirecional. O DLDP detecta links unidirecionais nas duas portas, mas não os desliga.
Os links unidirecionais são causados por fibras conectadas de forma cruzada. Desligue manualmente as duas portas: # Desligue a GigabitEthernet 1/0/1.
<DeviceA> system-view
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] shutdownAs seguintes informações de registro são exibidas no Dispositivo A:
[DeviceA-GigabitEthernet1/0/1]%Jul 12 08:34:23:717 2012 DeviceA IFNET/3/PHY_UPDOWN:
Physical state on the interface GigabitEthernet1/0/1 changed to down.
%Jul 12 08:34:23:718 2012 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/1 changed to down.
%Jul 12 08:34:23:778 2012 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the interface
GigabitEthernet1/0/2 changed to down.
%Jul 12 08:34:23:779 2012 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/2 changed to down.A saída mostra que o status da porta e o status do link da GigabitEthernet 1/0/1 e da GigabitEthernet 1/0/2 agora estão inativos.
# Desligue a GigabitEthernet 1/0/2.
[DeviceA-GigabitEthernet1/0/1] quit
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] shutdownCorrija as conexões de fibra e ative as duas portas:
# Ativar a GigabitEthernet 1/0/2.
[DeviceA-GigabitEthernet1/0/2] undo shutdownAs seguintes informações de registro são exibidas no Dispositivo A:
[DeviceA-GigabitEthernet1/0/2]%Jul 12 08:46:17:677 2012 DeviceA IFNET/3/PHY_UPDOWN:
Physical state on the interface GigabitEthernet1/0/2 changed to up.
%Jul 12 08:46:17:678 2012 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/2 changed to up.
%Jul 12 08:46:17:959 2012 DeviceA DLDP/6/DLDP_NEIGHBOR_CONFIRMED: A neighbor was confirmed
on interface GigabitEthernet1/0/2. The neighbor's system MAC is 0023-8956-3600, and the
port index is 2.
%Jul 12 08:46:17:959 2012 DeviceA DLDP/6/DLDP_LINK_BIDIRECTIONAL: DLDP detected a
bidirectional link on interface GigabitEthernet1/0/2.A saída mostra que o status da porta e o status do link da GigabitEthernet 1/0/2 agora estão ativos e seus vizinhos DLDP estão determinados.
# Ativar a GigabitEthernet 1/0/1.
[DeviceA-GigabitEthernet1/0/2] quit
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] undo shutdownAs seguintes informações de registro são exibidas no Dispositivo A:
[DeviceA-GigabitEthernet1/0/1]%Jul 12 08:48:25:952 2012 DeviceA IFNET/3/PHY_UPDOWN:
Physical state on the interface GigabitEthernet1/0/1 changed to up.
%Jul 12 08:48:25:952 2012 DeviceA DLDP/6/DLDP_NEIGHBOR_CONFIRMED: A neighbor was confirmed
on interface GigabitEthernet1/0/1. The neighbor's system MAC is 0023-8956-3600, and the
port index is 1.
%Jul 12 08:48:25:953 2012 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/1 changed to up.
%Jul 12 08:48:25:953 2012 DeviceA DLDP/6/DLDP_LINK_BIDIRECTIONAL: DLDP detected a
bidirectional link on interface GigabitEthernet1/0/1.A saída mostra que o status da porta e o status do link da GigabitEthernet 1/0/1 agora estão ativos e seus vizinhos DLDP estão determinados.
Exemplo: Configuração do modo de desligamento da porta híbrida
Configuração de rede
Conforme mostrado na Figura 7, o Dispositivo A e o Dispositivo B estão conectados por meio de dois pares de fibras.
Configure o DLDP para detectar links unidirecionais. Quando um link unidirecional é detectado, o DLDP desliga automaticamente a porta unidirecional. O administrador precisa ativar a porta depois de eliminar a falha.
Figura 7 Diagrama de rede
Procedimento
- Configurar o dispositivo A:
# Habilite o DLDP globalmente.
<DeviceA> system-view
[DeviceA] dldp enable# Configure a GigabitEthernet 1/0/1 para operar no modo full duplex e a 1000 Mbps, e habilite o DLDP na porta.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] duplex full
[DeviceA-GigabitEthernet1/0/1] speed 1000
[DeviceA-GigabitEthernet1/0/1] dldp enable
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 para operar no modo full duplex e a 1000 Mbps, e habilite o DLDP na porta.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] duplex full
[DeviceA-GigabitEthernet1/0/2] speed 1000
[DeviceA-GigabitEthernet1/0/2] dldp enable
[DeviceA-GigabitEthernet1/0/2] quit# Defina o modo de desligamento da porta global como híbrido.
[DeviceA] dldp unidirectional-shutdown hybrid# Habilite o DLDP globalmente.
<DeviceB> system-view
[DeviceB] dldp global enable# Configure a GigabitEthernet 1/0/1 para operar no modo full duplex e a 1000 Mbps, e habilite o DLDP nela.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] duplex full
[DeviceB-GigabitEthernet1/0/1] speed 1000
[DeviceB-GigabitEthernet1/0/1] dldp enable
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 para operar no modo full duplex e a 1000 Mbps, e habilite o DLDP nela.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] duplex full
[DeviceB-GigabitEthernet1/0/2] speed 1000
[DeviceB-GigabitEthernet1/0/2] dldp enable
[DeviceB-GigabitEthernet1/0/2] quit# Defina o modo de desligamento da porta global como híbrido.
[DeviceB] dldp unidirectional-shutdown hybridVerificação da configuração
# Exibir a configuração DLDP globalmente e em todas as portas habilitadas para DLDP do Dispositivo A.
[DeviceA] display dldp
DLDP global status: Enabled
DLDP advertisement interval: 5s
DLDP authentication-mode: None
DLDP unidirectional-shutdown mode: Hybrid
DLDP delaydown-timer value: 1s
Number of enabled ports: 2
Interface GigabitEthernet1/0/1
DLDP port state: Bidirectional
DLDP port unidirectional-shutdown mode: None
DLDP initial-unidirectional-delay: 0s
Number of the port’s neighbors: 1
Neighbor MAC address: 0023-8956-3600
Neighbor port index: 1
Neighbor state: Confirmed
Neighbor aged time: 11s
Neighbor echo time: -
Interface GigabitEthernet1/0/2
DLDP port state: Bidirectional
DLDP port unidirectional-shutdown mode: None
DLDP initial-unidirectional-delay: 0s
Number of the port’s neighbors: 1
Neighbor MAC address: 0023-8956-3600
Neighbor port index: 2
Neighbor state: Confirmed
Neighbor aged time: 12s
Neighbor echo time: -A saída mostra que tanto a GigabitEthernet 1/0/1 quanto a GigabitEthernet 1/0/2 estão em estado bidirecional, o que significa que ambos os links são bidirecionais.
# Habilite o monitoramento de registros no terminal atual do dispositivo A. Defina o nível mais baixo dos registros que podem ser enviados ao terminal atual como 6.
[DeviceA] quit
<DeviceA> terminal monitor
The current terminal is enabled to display logs.
<DeviceA> terminal logging level 6As seguintes informações de registro são exibidas no Dispositivo A:
<DeviceA>%Jan 4 07:16:06:556 2011 DeviceA DLDP/5/DLDP_NEIGHBOR_AGED: A neighbor on
interface
GigabitEthernet1/0/1 was deleted because the neighbor was aged. The neighbor's system MAC
is 0023-8956-3600, and the port index is 162.
%Jan 4 07:16:06:560 2011 DeviceA DLDP/5/DLDP_NEIGHBOR_AGED: A neighbor on interface
GigabitEthernet1/0/2 was deleted because the neighbor was aged. The neighbor's system MAC
is 0023-8956-3600, and the port index is 165.
%Jan 4 07:16:06:724 2011 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the interface
GigabitEthernet1/0/1 changed to down.
%Jan 4 07:16:06:730 2011 DeviceA IFNET/3/PHY_UPDOWN: Physical state on the interface
GigabitEthernet1/0/2 changed to down.
%Jan 4 07:16:06:736 2011 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/1 changed to down.
%Jan 4 07:16:06:738 2011 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/2 changed to down.
%Jan 4 07:16:07:152 2011 DeviceA DLDP/3/DLDP_LINK_UNIDIRECTIONAL: DLDP detected a
unidirectional link on interface GigabitEthernet1/0/1. DLDP automatically shut down the
interface. Please manually bring up the interface.
%Jan 4 07:16:07:156 2011 DeviceA DLDP/3/DLDP_LINK_UNIDIRECTIONAL: DLDP detected a
unidirectional link on interface GigabitEthernet1/0/2. DLDP automatically shut down the
interface. Please manually bring up the interface.A saída mostra que o status da porta e o status do link da GigabitEthernet 1/0/1 e da GigabitEthernet 1/0/2 estão inativos.
# Exibir a configuração DLDP globalmente e de todas as portas habilitadas para DLDP.
<DeviceA> display dldp
DLDP global status: Enabled
DLDP advertisement interval: 5s
DLDP authentication-mode: None
DLDP unidirectional-shutdown mode: Hybrid
DLDP delaydown-timer value: 1s
Number of enabled ports: 2
Interface GigabitEthernet1/0/1
DLDP port state: Inactive
DLDP port unidirectional-shutdown mode: None
DLDP initial-unidirectional-delay: 0s
Number of the port's neighbors: 0 (Maximum number ever detected: 1)
Interface GigabitEthernet1/0/2
DLDP port state: Inactive
DLDP port unidirectional-shutdown mode: None
DLDP initial-unidirectional-delay: 0s
Number of the port's neighbors: 0 (Maximum number ever detected: 1)A saída mostra que o DLDP detecta um link unidirecional e desliga a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2.
Os links unidirecionais são causados por fibras conectadas de forma cruzada. Levante as duas portas depois de corrigir a conexão da fibra:
# Ativar a GigabitEthernet 1/0/1.
<DeviceA> system-view
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] undo shutdownAs seguintes informações de registro são exibidas no Dispositivo A:
[DeviceA-GigabitEthernet1/0/1]%Jan 4 07:33:26:574 2011 DeviceA IFNET/3/PHY_UPDOWN:
Physical state on the interface GigabitEthernet1/0/1 changed to up.
%Jan 4 07:33:57:562 2011 DeviceA DLDP/6/DLDP_NEIGHBOR_CONFIRMED: A neighbor was confirmed
on interface GigabitEthernet1/0/1. The neighbor's system MAC is 0023-8956-3600, and the
port index is 162.
%Jan 4 07:33:57:563 2011 DeviceA DLDP/6/DLDP_LINK_BIDIRECTIONAL: DLDP detected a
bidirectional link on interface GigabitEthernet1/0/1.
%Jan 4 07:33:57:590 2011 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/1 changed to up.
%Jan 4 07:33:57:609 2011 DeviceA STP/6/STP_DETECTED_TC: Instance 0's port
GigabitEthernet1/0/1 detected a topology change.A saída mostra que o status da porta e o status do link da GigabitEthernet 1/0/1 agora estão ativos e seus vizinhos DLDP estão determinados.
# Ativar a GigabitEthernet 1/0/2.
[DeviceA-GigabitEthernet1/0/1] quit
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] undo shutdownAs seguintes informações de registro são exibidas no Dispositivo A:
[DeviceA-GigabitEthernet1/0/2]%Jan 4 07:35:26:574 2011 DeviceA IFNET/3/PHY_UPDOWN:
Physical state on the interface GigabitEthernet1/0/2 changed to up.
%Jan 4 07:35:57:562 2011 DeviceA DLDP/6/DLDP_NEIGHBOR_CONFIRMED: A neighbor was confirmed
on interface GigabitEthernet1/0/2. The neighbor's system MAC is 0023-8956-3600, and the
port index is 162.
%Jan 4 07:35:57:563 2011 DeviceA DLDP/6/DLDP_LINK_BIDIRECTIONAL: DLDP detected a
bidirectional link on interface GigabitEthernet1/0/2.
%Jan 4 07:35:57:590 2011 DeviceA IFNET/5/LINK_UPDOWN: Line protocol state on the interface
GigabitEthernet1/0/2 changed to up.
%Jan 4 07:35:57:609 2011 DeviceA STP/6/STP_DETECTED_TC: Instance 0's port
GigabitEthernet1/0/2 detected a topology change.A saída mostra que o status da porta e o status do link da GigabitEthernet 1/0/2 agora estão ativos e seus vizinhos DLDP estão determinados.
Configuração do RRPP
Sobre a RRPP
O RRPP (Rapid Ring Protection Protocol) é um protocolo de camada de link projetado para anéis Ethernet. O RRPP pode evitar tempestades de transmissão causadas por loops de dados quando um anel Ethernet está íntegro. O RRPP também pode restaurar rapidamente os caminhos de comunicação entre os nós quando um link é desconectado no anel. Em comparação com o protocolo spanning tree, o tempo de convergência do RRPP é rápido e independente do número de nós no anel Ethernet. O RRPP é aplicável a redes de grande diâmetro.
Aplicavel somente a Serie S3300G
Rede RRPP
A Figura 1 mostra uma rede RRPP típica com dois anéis Ethernet e vários nós. O RRPP detecta o status do anel e envia informações de alteração de topologia por meio da troca de RRPPDUs (Rapid Ring Protection Protocol Data Units) entre os nós.
Figura 1 Diagrama de rede do RRPP
Domínio RRPP
Um domínio RRPP é identificado exclusivamente por um ID de domínio. Os dispositivos interconectados com a mesma ID de domínio e VLANs de controle constituem um domínio RRPP. Um domínio RRPP contém os seguintes elementos:
- Anel e subanel primários.
- VLAN de controle.
- Nó mestre, nó de trânsito, nó de borda e nó de borda assistente.
- Porta primária, porta secundária, porta comum e porta de borda.
Conforme mostrado na Figura 1, o domínio 1 é um domínio RRPP, contendo dois anéis RRPP: Anel 1 e Anel 2. Todos os nós nos dois anéis RRPP pertencem ao domínio RRPP.
Anel RRPP
Uma topologia Ethernet em forma de anel é chamada de anel RRPP. Os anéis RRPP incluem anéis primários e subanéis. É possível configurar um anel como anel primário ou subanel especificando seu nível de anel. O anel primário é de nível 0, e um subanel é de nível 1. Um domínio RRPP contém um ou vários
Anéis RRPP, um servindo como anel primário e os outros servindo como anéis secundários. Um anel pode estar em um dos seguintes estados:
- Estado de saúde - Todos os links físicos no anel Ethernet estão conectados.
- Estado de desconexão - Alguns links físicos no anel Ethernet não estão conectados.
Conforme mostrado na Figura 1, o Domínio 1 contém dois anéis RRPP: Anel 1 e Anel 2. O nível é definido como 0 para o Anel 1 e 1 para o Anel 2. O Anel 1 está configurado como o anel primário e o Anel 2 está configurado como um subanel .
VLAN de controle e VLAN protegida
- VLAN de controle
- Uma VLAN de controle primária, que é a VLAN de controle do anel primário.
- Uma VLAN de controle secundária, que é a VLAN de controle para subrings.
- VLAN protegida
Em um domínio RRPP, uma VLAN de controle é dedicada à transferência de RRPPDUs. Em um dispositivo, as portas que acessam um anel RRPP pertencem às VLANs de controle do anel, e somente essas portas podem ingressar nas VLANs de controle.
Um domínio RRPP é configurado com as seguintes VLANs de controle:
Depois de especificar uma VLAN como a VLAN de controle primária, o sistema configura automaticamente a VLAN de controle secundária. A VLAN ID é a VLAN ID de controle primário mais um. Todas as subrings no mesmo domínio RRPP compartilham a mesma VLAN de controle secundária. A configuração do endereço IP é proibida nas interfaces da VLAN de controle.
Uma VLAN protegida é dedicada à transferência de pacotes de dados. Tanto as portas RRPP quanto as não RRPP podem ser atribuídas a uma VLAN protegida.
Função do nó
Cada dispositivo em um anel RRPP é um nó. A função de um nó é configurável. O RRPP tem as seguintes funções de nó:
- Nó mestre - Cada anel tem apenas um nó mestre. O nó mestre inicia o mecanismo de sondagem e determina as operações a serem executadas após uma mudança de topologia.
- Nó de trânsito - No anel primário, os nós de trânsito referem-se a todos os nós, exceto o nó mestre. No subanel, os nós de trânsito referem-se a todos os nós, exceto o nó mestre e os nós em que o anel primário faz interseção com o subanel. Um nó de trânsito monitora o estado de seus links RRPP diretamente conectados e notifica o nó mestre sobre as alterações no estado do link, se houver. Com base nas alterações do estado do link, o nó mestre determina as operações a serem executadas.
- Nó de borda - Um nó especial que reside no anel primário e em um subanel ao mesmo tempo. Um nó de borda atua como um nó mestre ou nó de trânsito no anel primário e como um nó de borda no subanel.
- Nó de borda assistente - Um nó especial que reside no anel primário e em um subanel ao mesmo tempo. Um nó de borda assistente atua como um nó mestre ou nó de trânsito no anel primário e como um nó de borda assistente no subanel. Esse nó trabalha em conjunto com o nó de borda para detectar a integridade do anel primário e realizar a proteção de loop.
Conforme mostrado na Figura 1, o Anel 1 é o anel primário e o Anel 2 é um subanel. O dispositivo A é o nó mestre do anel 1. O dispositivo B, o dispositivo C e o dispositivo D são os nós de trânsito do anel 1. O dispositivo E é o nó mestre do anel 2, o dispositivo B é o nó de borda do anel 2 e o dispositivo C é o nó de borda assistente do anel 2.
Função da porta
- Porta primária e porta secundária
- A porta primária e a porta secundária são projetadas para desempenhar a função de enviar e receber pacotes Hello, respectivamente.
- Quando um anel RRPP está no estado Health, a porta secundária nega logicamente as VLANs protegidas e permite apenas os pacotes das VLANs de controle.
- Quando um anel RRPP está no estado Desconectado, a porta secundária encaminha pacotes de VLANs protegidas.
- Porta comum e porta de borda
Cada nó mestre ou nó de trânsito tem duas portas conectadas a um anel RRPP, uma porta primária e uma porta secundária. Você pode determinar a função de uma porta.
Em termos de funcionalidade, a porta primária e a porta secundária de um nó mestre têm as seguintes diferenças:
Em termos de funcionalidade, a porta primária e a porta secundária de um nó de trânsito são as mesmas. Ambas são projetadas para transferir pacotes de protocolo e pacotes de dados em um anel RRPP.
Conforme mostrado na Figura 1, o Dispositivo A é o nó mestre do Anel 1. A Porta 1 e a Porta 2 são a porta primária e a porta secundária do nó mestre no Anel 1, respectivamente. O Dispositivo B, o Dispositivo C e o Dispositivo D são os nós de trânsito do Anel 1. Sua Porta 1 e Porta 2 são a porta primária e a porta secundária no Anel 1, respectivamente.
As portas que conectam o nó de borda e o nó de borda assistente ao anel primário são portas comuns. As portas que conectam o nó de borda e o nó de borda assistente somente aos subanéis são portas de borda. Você pode determinar a função de uma porta.
Conforme mostrado na Figura 1, o Dispositivo B e o Dispositivo C residem no Anel 1 e no Anel 2. A Porta 1 e a Porta 2 do dispositivo B e a Porta 1 e a Porta 2 do dispositivo C acessam o anel primário, portanto, são portas comuns. A Porta 3 do Dispositivo B e a Porta 3 do Dispositivo C acessam apenas o subanel, portanto, são portas de borda.
Grupo de anéis RRPP
Para reduzir o tráfego de Edge-Hello, você pode configurar um grupo de subrings no nó de borda ou no nó de borda assistente. Você deve configurar um dispositivo como o nó de borda desses subrings e outro dispositivo como o nó de borda assistente desses subrings. Além disso, os subanéis do nó de borda e do nó de borda assistente devem se conectar aos mesmos túneis de pacotes de subanéis no anel principal (SRPTs). Os pacotes Edge-Hello do nó de borda desses subanéis viajam para o nó de borda assistente desses subanéis pelo mesmo link.
Um grupo de anéis RRPP configurado no nó de borda é um grupo de anéis RRPP de nó de borda. Um grupo de anéis RRPP configurado em um nó de borda assistente é um grupo de anéis RRPP de nó de borda assistente. Apenas um subanel em um grupo de anéis RRPP de nó de borda tem permissão para enviar pacotes Edge-Hello.
RRPPDUs
Os RRPPDUs de subanéis são transmitidos como pacotes de dados no anel primário, e os RRPPDUs do anel primário só podem ser transmitidos dentro do anel primário. No anel primário, os pacotes Common-Flush-FDB e os pacotes Complete-Flush-FDB dos subanéis são enviados à CPU de cada nó para processamento.
Tabela 1 Tipos de RRPPDU e suas funções
| Tipo | Descrição |
| Olá | O nó mestre envia pacotes Hello (também conhecidos como pacotes de saúde) para detectar a integridade de um anel em uma rede. |
| Link-Down | Quando uma porta no nó de trânsito, no nó de borda ou no nó de borda assistente falha, o nó inicia pacotes Link-Down para notificar o nó mestre sobre a desconexão do anel. |
| Common-Flush-FDB | Quando um anel RRPP passa para o estado de desconexão, o nó mestre inicia os pacotes Common-Flush-FDB (FDB significa Forwarding Database, banco de dados de encaminhamento). Ele usa os pacotes para instruir os nós de trânsito, os nós de borda e os nós de borda assistentes a atualizar suas próprias entradas de endereço MAC e entradas ARP/ND. |
| Complete-Flush-FDB | Quando um anel RRPP passa para o estado de saúde, o nó mestre envia pacotes Complete-Flush-FDB para as seguintes finalidades:
|
| Edge - Olá | O nó de borda envia pacotes Edge-Hello para examinar os SRPTs entre o nó de borda e o nó de borda assistente. |
| Falha grave | O nó de borda assistente envia pacotes Major-Fault para notificar o nó de borda sobre a falha do SRPT quando um SRPT entre o nó de borda assistente e o nó de borda é desconectado. |
Temporizadores RRPP
Quando o RRPP determina o estado do link de um anel Ethernet, ele usa os seguintes temporizadores:
Temporizador Hello
O temporizador Hello especifica o intervalo em que o nó mestre envia pacotes Hello da porta primária.
Temporizador de falha
O temporizador Fail especifica o atraso máximo dos pacotes Hello enviados da porta primária para a porta secundária do nó mestre. Se a porta secundária receber os pacotes Hello enviados pelo nó mestre local antes que o temporizador Fail expire, o anel estará no estado Health. Se a porta secundária não receber os pacotes Hello antes que o temporizador Fail expire, o anel passa para o estado Disconnect (Desconectar).
Em um domínio RRPP, um nó de trânsito aprende o valor do temporizador de falha no nó mestre por meio dos pacotes Hello recebidos. Isso garante que todos os nós da rede em anel tenham configurações consistentes do temporizador de falha .
Temporizador de atraso de conexão
Esse recurso evita a troca frequente de caminhos de encaminhamento de tráfego RRPP causada por estados instáveis da porta RRPP. Esse recurso se comporta de forma diferente dependendo de você especificar ou não a palavra-chave distribute no comando linkup-delay-timer.
- Se você não especificar a palavra-chave distribute, o nó mestre iniciará o timer de atraso de conexão quando uma porta defeituosa for ativada e o nó mestre receber pacotes Hello da porta secundária.
- Se o nó mestre ainda puder receber pacotes Hello da porta secundária após a expiração do temporizador de atraso de conexão, o nó mestre executará as seguintes operações:
- Altera o estado do anel RRPP de Disconnect para Health.
- Alterna o tráfego da porta secundária para a porta primária.
- Se o nó mestre não puder receber pacotes Hello da porta secundária após a expiração do temporizador de falha e antes da expiração do temporizador de atraso de conexão, o nó mestre executará as seguintes operações:
- Interrompe o cronômetro de atraso de conexão.
- Mantém o anel RRPP no estado de desconexão.
- Se você especificar a palavra-chave distribute, todos os nós no domínio RRPP poderão saber o valor do temporizador de atraso de conexão por meio dos pacotes Hello. Quando a porta defeituosa é ativada, o nó mestre executa as seguintes operações:
- O nó RRPP hospedeiro bloqueia a porta defeituosa (a porta defeituosa não pode enviar ou receber nenhum pacote).
- Inicia o cronômetro de atraso de conexão.
Se a porta não se tornar defeituosa depois que o temporizador de atraso de conexão expirar, o nó RRPP anfitrião definirá o estado da porta como ativo. O nó mestre pode receber novamente os pacotes Hello de sua porta secundária. Em seguida, o nó mestre altera o estado do anel RRPP de Disconnect para Health e alterna o tráfego da porta secundária para a porta primária.
Se a porta se tornar defeituosa novamente antes que o temporizador de atraso de link-up expire, o nó RRPP hospedeiro bloqueia a porta e interrompe o temporizador de atraso de link-up.
Como funciona o RRPP
Mecanismo de votação
O mecanismo de sondagem é usado pelo nó mestre de um anel RRPP para examinar o estado de integridade da rede em anel.
O nó mestre envia pacotes Hello de sua porta principal no intervalo Hello. Esses pacotes Hello passam por cada nó de trânsito no anel, um por vez.
- Se o anel estiver completo, a porta secundária do nó mestre receberá pacotes Hello antes que o cronômetro de falha expire. O nó mestre mantém a porta secundária bloqueada.
- Se o anel for desconectado, a porta secundária do nó mestre não receberá os pacotes Hello antes que o temporizador Fail expire. O nó mestre libera a porta secundária do bloqueio de VLANs protegidas. Ele envia pacotes Common-Flush-FDB para instruir todos os nós de trânsito a atualizar suas próprias entradas de endereço MAC e entradas ARP/ND.
Mecanismo de alarme de queda de link
Em um domínio RRPP, quando o nó de trânsito, o nó de borda ou o nó de borda assistente descobre que alguma de suas portas está inativa, ele envia imediatamente pacotes Link-Down para o nó mestre. Quando o nó mestre recebe um pacote de Link-Down, ele executa as seguintes ações:
- Libera a porta secundária do bloqueio de VLANs protegidas.
- Envia pacotes Common-Flush-FDB para instruir todos os nós de trânsito, nós de borda e nós de borda assistentes a atualizar suas entradas de endereço MAC e entradas ARP/ND.
Depois que cada nó atualiza suas próprias entradas, o tráfego é transferido para o link normal.
Recuperação de anéis
Quando as portas em um domínio RRPP nos nós de trânsito, nos nós de borda ou nos nós de borda auxiliares voltam a funcionar, o anel é recuperado. No entanto, o nó mestre pode detectar a recuperação do anel após um período de tempo. Um loop temporário pode surgir na VLAN protegida durante esse período. Como resultado, ocorre uma tempestade de broadcast.
Para evitar esses casos, os nós não mestres bloqueiam as portas imediatamente quando descobrem que as portas que acessam o anel foram ativadas novamente. Os nós bloqueiam apenas os pacotes da VLAN protegida e permitem a passagem apenas dos pacotes da VLAN de controle. As portas bloqueadas são ativadas somente quando os nós determinam que nenhum loop será gerado por essas portas.
Mecanismo de supressão de tempestades de transmissão em caso de falha do SRPT em uma subrings multi-homed
Conforme mostrado na Figura 5, o Anel 1 é o anel primário, e o Anel 2 e o Anel 3 são subanéis. Quando os dois SRPTs entre o nó de borda e o nó de borda assistente estiverem inativos, os nós mestres do Anel 2 e do Anel 3 abrirão suas portas secundárias. Um loop é gerado entre o Dispositivo B, o Dispositivo C, o Dispositivo E e o Dispositivo F, causando uma tempestade de broadcast.
Para evitar a geração de um loop, o nó de borda bloqueará temporariamente a porta de borda. A porta de borda bloqueada é ativada somente quando o nó de borda determina que nenhum loop será gerado quando a porta de borda for ativada.
Grupo de anéis RRPP
Em um grupo de anéis RRPP de nó de borda, somente a subanel ativada com o menor ID de domínio e ID de anel pode enviar pacotes Edge-Hello. Em um grupo de anéis RRPP de nó de borda assistente, qualquer subanel ativado que tenha recebido pacotes Edge-Hello encaminhará esses pacotes para os outros subanéis ativados. Quando um grupo de anéis RRPP de nó de borda e um grupo de anéis RRPP de nó de borda assistente são configurados, a carga de trabalho da CPU é reduzida pelos seguintes motivos:
- Apenas um subanel envia pacotes Edge-Hello para o nó de borda.
- Apenas um subanel recebe pacotes Edge-Hello no nó de borda assistente.
Conforme mostrado na Figura 5, o Dispositivo B é o nó de borda do Anel 2 e do Anel 3. O dispositivo C é o nó de borda assistente do Anel 2 e do Anel 3. O dispositivo B e o dispositivo C precisam enviar ou receber pacotes Edge-Hello com frequência. Se mais subanéis forem configurados, o Dispositivo B e o Dispositivo C enviarão ou receberão um grande número de pacotes Edge-Hello.
Para reduzir o tráfego do Edge-Hello, execute as seguintes tarefas:
- Atribua o Anel 2 e o Anel 3 a um grupo de anéis RRPP configurado no nó de borda Device B.
- Atribua o Anel 2 e o Anel 3 a um grupo de anéis RRPP configurado no dispositivo C do nó de borda assistente.
Se todos os anéis estiverem ativados, somente o anel 2 do dispositivo B enviará pacotes Edge-Hello.
Rede típica de RRPP
Anel único
Conforme mostrado na Figura 2, existe apenas um único anel na topologia da rede. Você só precisa definir um domínio RRPP.
Figura 2 Diagrama esquemático de uma rede de anel único
Anéis tangentes
Conforme mostrado na Figura 3, há dois ou mais anéis na topologia da rede e existe apenas um nó comum entre os anéis. Você deve definir um domínio RRPP para cada anel.
Figura 3 Diagrama esquemático de uma rede de anel tangente
Anéis de interseção
Conforme mostrado na Figura 4, existem dois ou mais anéis na topologia da rede e dois nós comuns entre os anéis. Você só precisa definir um domínio RRPP e configurar um anel como o anel primário e os outros anéis como subanéis.
Figura 4 Diagrama esquemático de uma rede de anéis de interseção
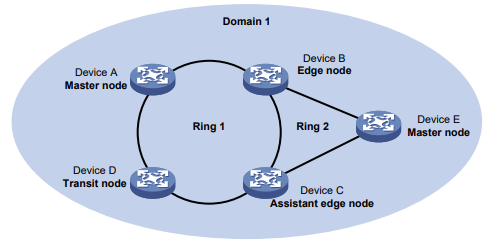
Anéis de conexão dupla
Conforme mostrado na Figura 5, existem dois ou mais anéis na topologia da rede e dois nós comuns semelhantes entre os anéis. Você só precisa definir um domínio RRPP e configurar um anel como o anel primário e os outros anéis como subanéis.
Figura 5 Diagrama esquemático de uma rede dual-homed-ring
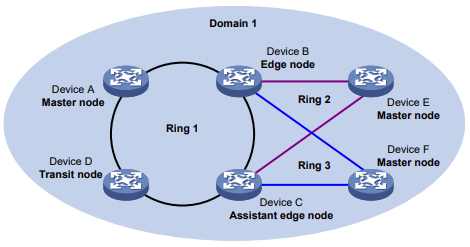
Protocolos e padrões
RFC 3619, comutação automática de proteção Ethernet (EAPS) versão 1 da Extreme Networks
Restrições e diretrizes: Configuração do RRPP
- O RRPP não tem um mecanismo de eleição automática. Você deve configurar cada nó da rede em anel corretamente para que o RRPP monitore e proteja a rede em anel.
- Você pode configurar o RRPP na seguinte ordem:
- Criar domínios de RRPP com base no planejamento de serviços.
- Especifique as VLANs de controle e as VLANs protegidas para cada domínio RRPP.
- Determine as funções de anel e as funções de nó com base nos caminhos de tráfego em cada domínio RRPP.
Visão geral das tarefas do RRPP
Para configurar o RRPP, execute as seguintes tarefas:
- Criação de um domínio RRPP
- Configuração de VLANs de controle
- Configuração de VLANs protegidas
- Configuração de anéis RRPP
- Configuração de portas RRPP
- Configuração de nós RRPP
- Ativação de um domínio RRPP
- (Opcional.) Configuração dos temporizadores RRPP
- Configuração do temporizador Hello e do temporizador de falha
- Configuração do temporizador de atraso de conexão
- (Opcional.) Configuração de um grupo de anel RRPP
- (Opcional.) Ativação de notificações SNMP para RRPP
Execute essa tarefa nos dispositivos que você deseja configurar como nós no domínio RRPP.
Execute essa tarefa em todos os nós do domínio RRPP.
Execute essa tarefa em todos os nós do domínio RRPP.
Execute essa tarefa nas portas de cada nó destinadas a acessar os anéis RRPP.
Execute essa tarefa em todos os nós do domínio RRPP.
Execute essa tarefa em todos os nós do domínio RRPP.
Execute essa tarefa no nó mestre do domínio RRPP.
Execute essa tarefa no nó de borda e no nó de borda assistente no domínio RRPP.
Pré-requisitos para o RRPP
Antes de configurar o RRPP, você deve construir fisicamente uma topologia Ethernet em forma de anel.
Criação de um domínio RRPP
Sobre a criação de um domínio RRPP
Quando você criar um domínio RRPP, especifique uma ID de domínio para identificar exclusivamente o domínio RRPP. Todos os dispositivos no mesmo domínio RRPP devem ser configurados com a mesma ID de domínio.
Restrições e diretrizes
Execute essa tarefa nos dispositivos que você deseja configurar como nós no domínio RRPP.
Procedimento
- Entre na visualização do sistema.
System-viewrrpp domain domain-idConfiguração de VLANs de controle
Restrições e diretrizes
- Execute essa tarefa em todos os nós do domínio RRPP.
- Antes de configurar os anéis RRPP em um domínio RRPP, configure primeiro as mesmas VLANs de controle para todos os nós no domínio RRPP. Você só precisa configurar a VLAN de controle primária para um domínio RRPP. O sistema configura automaticamente a VLAN de controle secundária. Ele usa a ID da VLAN de controle primária mais 1 como ID da VLAN de controle secundária. Para que a configuração da VLAN de controle seja bem-sucedida, certifique-se de que as IDs das duas VLANs de controle sejam consecutivas e não tenham sido atribuídas anteriormente.
- Não configure a VLAN padrão de uma porta que acessa um anel RRPP como a VLAN de controle.
- Para que as RRPPDUs sejam encaminhadas corretamente, não habilite o QinQ ou o mapeamento de VLAN nas VLANs de controle.
- Depois de configurar os anéis RRPP para um domínio RRPP, não é possível excluir ou modificar a VLAN de controle primário do domínio. Só é possível usar o comando undo control-vlan para excluir uma VLAN de controle primária.
- Para transmitir RRPPDUs de forma transparente em um dispositivo não configurado com RRPP, certifique-se de que apenas as duas portas que acessam o anel RRPP permitam pacotes das VLANs de controle. Caso contrário, os pacotes de outras VLANs poderão entrar nas VLANs de controle no modo de transmissão transparente e atingir o anel RRPP.
Procedimento
- Entre na visualização do sistema.
System-viewrrpp domain domain-idcontrol-vlan vlan-idConfiguração de VLANs protegidas
Restrições e diretrizes
- Execute essa tarefa em todos os nós do domínio RRPP.
- Antes de configurar os anéis RRPP em um domínio RRPP, configure as mesmas VLANs protegidas para todos os nós no domínio RRPP. Todas as VLANs às quais as portas RRPP são atribuídas devem ser protegidas pelos domínios RRPP.
Pré-requisitos
Antes de configurar VLANs protegidas, você deve configurar uma região MST e a tabela de mapeamento VLAN-para-instância. Para obter mais informações sobre regiões MST, consulte spanning tree configuration no Layer 2-LAN Switching Configuration Guide.
Procedimento
- Entre na visualização do sistema.
System-viewrrpp domain domain-idprotected-vlan reference-instance instance-id-listConfiguração de anéis RRPP
Ao configurar um anel RRPP, você deve configurar as portas que conectam cada nó ao anel RRPP antes de configurar os nós.
Pré-requisitos
Antes de configurar um anel RRPP, é necessário configurar as VLANs de controle e as VLANs protegidas.
Configuração de portas RRPP
Restrições e diretrizes
- Execute essa tarefa nas portas de cada nó destinadas a acessar os anéis RRPP.
- Não habilite a função de loopback remoto do OAM em uma porta RRPP. Caso contrário, poderão ocorrer tempestades de transmissão temporárias.
- Para acelerar a convergência da topologia, use o comando link-delay para ativar a função de relatório rápido do status do link em uma porta RRPP. Use esse comando para definir o intervalo de supressão de mudança de estado físico como 0 segundos. Para obter mais informações sobre o comando link-delay, consulte Layer 2-LAN Switching Command Reference.
- Não atribua uma porta a um grupo de agregação e a um anel RRPP. Se você fizer isso, a porta não entrará em vigor no anel RRPP.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberport link-type trunkPor padrão, o tipo de link de uma interface é acesso.
Para obter mais informações sobre o comando, consulte Layer 2-LAN Switching Command Reference.
port trunk permit vlan { vlan-id-list | all }Por padrão, uma porta tronco permite apenas a passagem de pacotes da VLAN 1. As portas RRPP sempre permitem a passagem de pacotes das VLANs de controle.
Para obter mais informações sobre o comando, consulte Layer 2-LAN Switching Command Reference.
undo stp enablePor padrão, o recurso de spanning tree está ativado.
Para obter mais informações sobre o comando, consulte Layer 2-LAN Switching Command Reference.
Configuração de nós RRPP
Restrições e diretrizes
- Execute essa tarefa em todos os nós do domínio RRPP.
- Se um dispositivo transportar vários anéis RRPP em um domínio RRPP, ele só poderá ser um nó de borda ou um nó de borda assistente em um subanel.
- Ao configurar um nó de borda ou um nó de borda assistente, você deve configurar o anel primário antes de configurar os subanéis.
Especificação de um nó mestre
- Entre na visualização do sistema.
System-viewrrpp domain domain-idring ring-id node-mode master [ primary-port interface-type interface-number ] [ secondary-port interface-type interface-number ] level level-valueEspecificação de um nó de trânsito
- Entre na visualização do sistema.
System-viewrrpp domain domain-idring ring-id node-mode transit [ primary-port interface-type interface-number ] [ secondary-port interface-type interface-number ] level level-valueEspecificação de um nó de borda
- Entre na visualização do sistema.
System-viewrrpp domain domain-idring ring-id node-mode { master | transit } [ primary-port interface-type interface-number ] [ secondary-port interface-type interface-number ] level level-valuering ring-id node-mode edge [ edge-port interface-type interface-number ]Especificação de um nó de borda auxiliar
- Entre na visualização do sistema.
System-viewrrpp domain domain-idring ring-id node-mode { master | transit } [ primary-port interface-type interface-number ] [ secondary-port interface-type interface-number ] level level-valuePor padrão, um dispositivo não é um nó do anel RRPP.
ring ring-id node-mode assistant-edge [ edge-port interface-type interface-number ]Ativação de um domínio RRPP
Restrições e diretrizes
- Execute essa tarefa em todos os nós do domínio RRPP.
- Antes de ativar um domínio RRPP no dispositivo atual, ative o protocolo RRPP e os anéis RRPP para o domínio RRPP no dispositivo atual.
- Antes de ativar os subanéis em um dispositivo, você deve ativar o anel primário. Antes de desativar o anel primário no dispositivo, você deve desativar todos os subanéis. Caso contrário, o sistema exibirá avisos de erro.
- Para evitar que os pacotes Hello dos subanéis fiquem em loop no anel primário, habilite primeiro o anel primário em seu nó mestre. Em seguida, habilite os subanéis em seus respectivos nós mestres.
Procedimento
- Entre na visualização do sistema.
System-viewrrpp enablePor padrão, o RRPP está desativado.
rrpp domain domain-idring ring-id enablePor padrão, um anel RRPP está desativado.
Configuração de temporizadores RRPP
Restrições e diretrizes para a configuração do temporizador RRPP
Execute essa tarefa no nó mestre de um domínio RRPP.
Configuração do temporizador Hello e do temporizador de falha
Restrições e diretrizes
- O temporizador de falha deve ser maior ou igual a três vezes o temporizador Hello.
- Em uma rede com anel duplo, para evitar loops temporários quando o anel primário falhar, certifique-se de que o valor de A seja maior que o valor de B, onde:
- A é a diferença entre os valores do temporizador de falha no nó mestre do subanel e no nó mestre do anel primário.
- B é o dobro do valor do temporizador Hello no nó mestre do subanel.
Procedimento
- Entre na visualização do sistema.
System-viewrrpp domain domain-idtimer hello-timer hello-value fail-timer fail-valuePor padrão, o valor do temporizador Hello é de 1 segundo e o valor do temporizador Fail é de 3 segundos.
Configuração do temporizador de atraso de conexão
Restrições e diretrizes
Se a palavra-chave distribute não for especificada, o valor do timer de atraso de conexão não poderá ser maior que o valor do timer Fail menos duas vezes o valor do timer Hello.
Se você especificar a palavra-chave distribute em uma rede RRPP que implementa o balanceamento de carga, deverá configurar o timer de atraso de link-up para cada domínio RRPP para que o timer tenha efeito. Se você definir valores de timer diferentes para domínios RRPP diferentes, o menor valor de timer entrará em vigor.
Procedimento
- Entre na visualização do sistema.
System-viewrrpp domain domain-idlinkup-delay-timer delay-time [ distribute ]Por padrão, o valor do temporizador de atraso de link-up é 0 segundos e a palavra-chave distribute não é especificada.
Configuração de um grupo de anel RRPP
Sobre a configuração de um grupo de anéis RRPP
Para reduzir o tráfego de Edge-Hello, atribua subanéis com o mesmo nó de borda e nó de borda assistente a um grupo de anéis RRPP. Um grupo de anéis RRPP deve ser configurado tanto no nó de borda quanto no nó de borda assistente . Ele só pode ser configurado nesses dois tipos de nós.
Restrições e diretrizes
- Execute essa tarefa no nó de borda e no nó de borda assistente no domínio RRPP.
- Você pode atribuir um subanel a apenas um grupo de anéis RRPP. Os grupos de anel RRPP configurados no nó de borda e no nó de borda assistente devem conter os mesmos subanéis. Caso contrário, o grupo de anéis RRPP não poderá funcionar corretamente.
- Os subanéis em um grupo de anéis RRPP devem compartilhar o mesmo nó de borda e nó de borda assistente. O nó de borda e o nó de borda assistente devem ter os mesmos SRPTs.
- Certifique-se de que um dispositivo seja o nó de borda ou o nó de borda assistente nos subanéis em um grupo de anéis RRPP.
- Certifique-se de que os grupos de anéis RRPP no nó de borda e no nó de borda assistente tenham as mesmas configurações e status de ativação.
- Certifique-se de que todos os subanéis em um grupo de anéis RRPP tenham os mesmos SRPTs. Se as SRPTs desses subanéis forem diferentes, o grupo de anéis RRPP não poderá funcionar corretamente.
Procedimento
- Entre na visualização do sistema.
System-viewrrpp ring-group ring-group-idPor padrão, não existem grupos de anel RRPP.
domain domain-id ring ring-id-listPor padrão, nenhum anel secundário é atribuído a um grupo de anéis RRPP.
Ativação de notificações SNMP para RRPP
Sobre como ativar as notificações SNMP para o RRPP
Para relatar eventos críticos de RRPP a um NMS, ative as notificações de SNMP para RRPP. Para que as notificações de eventos de RRPP sejam enviadas corretamente, você também deve configurar o SNMP no dispositivo. Para obter mais informações sobre a configuração de SNMP, consulte o guia de configuração de monitoramento e gerenciamento de rede do dispositivo.
Procedimento
- Entre na visualização do sistema.
System-viewsnmp-agent trap enable rrpp [ major-fault | multi-master | ring-fail | ring-recover ] *Por padrão, as notificações SNMP para RRPP estão desativadas.
Comandos de exibição e manutenção para RRPP
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações breves sobre o RRPP. | exibir resumo do rrpp |
| Exibir informações de configuração do grupo RRPP. | exibir rrpp ring-group [ ring-group-id ] |
| Exibir estatísticas de RRPPDU. | exibir domínio de estatísticas rrpp domain-id [ ring ring-id ] |
| Exibir informações detalhadas do RRPP. | exibir domínio rrpp verbose domain-id [ ring ring-id ] |
| Limpar estatísticas de RRPPDU. | reset rrpp statistics domain domain-id [ ring ring-id ] |
Exemplos de configuração do RRPP
Exemplo: Configuração de um único anel
Configuração de rede
Conforme mostrado na Figura 6:
- O dispositivo A, o dispositivo B, o dispositivo C e o dispositivo D formam o domínio RRPP 1. Especifique a VLAN de controle primário do domínio RRPP 1 como VLAN 4092. Especifique as VLANs protegidas do domínio 1 de RRPP como VLANs 1 a 30.
- O dispositivo A, o dispositivo B, o dispositivo C e o dispositivo D formam o anel primário 1.
- Especifique o Dispositivo A como o nó mestre do anel primário 1, a GigabitEthernet 1/0/1 como a porta primária e a GigabitEthernet 1/0/2 como a porta secundária.
- Especifique o Dispositivo B, o Dispositivo C e o Dispositivo D como os nós de trânsito do anel primário 1. Especifique GigabitEthernet 1/0/1 como a porta primária e GigabitEthernet 1/0/2 como a porta secundária no Dispositivo B, Dispositivo C e Dispositivo D.
Figura 6 Diagrama de rede
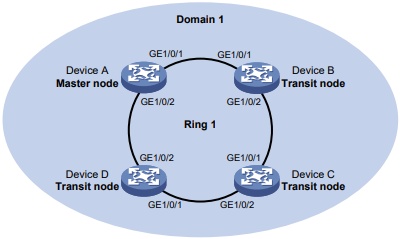
Procedimento
- Configure o dispositivo A:
# Criar VLANs de 1 a 30.
<DeviceA> system-view
[DeviceA] vlan 1 to 30# Mapeie essas VLANs para o MSTI 1.
[DeviceA] stp region-configuration
[DeviceA-mst-region] instance 1 vlan 1 to 30# Ativar a configuração da região MST.
[DeviceA-mst-region] active region-configuration
[DeviceA-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico para 0 segundos na GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] link-delay up 0
[DeviceA-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceA-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceA-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] link-delay up 0
[DeviceA-GigabitEthernet1/0/2] link-delay down 0
[DeviceA-GigabitEthernet1/0/2] undo stp enable
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceA-GigabitEthernet1/0/2] quit# Criar o domínio RRPP 1.
[DeviceA] rrpp domain 1# Configure a VLAN 4092 como a VLAN de controle primário do domínio 1 do RRPP.
[DeviceA-rrpp-domain1] control-vlan 4092# Configure as VLANs mapeadas para MSTI 1 como VLANs protegidas do domínio RRPP 1.
[DeviceA-rrpp-domain1] protected-vlan reference-instance 1# Configure o dispositivo A como o nó mestre do anel primário 1, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceA-rrpp-domain1] ring 1 node-mode master primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceA-rrpp-domain1] ring 1 enable
[DeviceA-rrpp-domain1] quit# Habilitar o RRPP.
[DeviceA] rrpp enable# Criar VLANs de 1 a 30.
<DeviceB> system-view
[DeviceB] vlan 1 to 30# Mapeie essas VLANs para o MSTI 1.
[DeviceB] stp region-configuration
[DeviceB-mst-region] instance 1 vlan 1 to 30# Ativar a configuração da região MST.
[DeviceB-mst-region] active region-configuration
[DeviceB-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico como 0 segundos na GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] link-delay up 0
[DeviceB-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceB-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceB-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] link-delay up 0
[DeviceB-GigabitEthernet1/0/2] link-delay down 0
[DeviceB-GigabitEthernet1/0/2] undo stp enable
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceB-GigabitEthernet1/0/2] quit# Criar o domínio RRPP 1.
[DeviceB] rrpp domain 1# Configure a VLAN 4092 como a VLAN de controle primário do domínio 1 do RRPP.
[DeviceB-rrpp-domain1] control-vlan 4092# Configure as VLANs mapeadas para MSTI 1 como VLANs protegidas do domínio RRPP 1.
[DeviceB-rrpp-domain1] protected-vlan reference-instance 1# Configure o dispositivo B como o nó de trânsito do anel primário 1, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceB-rrpp-domain1] ring 1 node-mode transit primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceB-rrpp-domain1] ring 1 enable
[DeviceB-rrpp-domain1] quit# Habilitar o RRPP.
[DeviceB] rrpp enableConfigure o Dispositivo C da mesma forma que o Dispositivo B está configurado.
Configure o Dispositivo D da mesma forma que o Dispositivo B está configurado.
Verificação da configuração
# Use os comandos de exibição para visualizar as informações operacionais e de configuração do RRPP em cada dispositivo .
Exemplo: Configuração de anéis de interseção
Configuração de rede
Conforme mostrado na Figura 7:
- O dispositivo A, o dispositivo B, o dispositivo C, o dispositivo D e o dispositivo E formam o domínio RRPP 1. A VLAN 4092 é a VLAN de controle primário do domínio RRPP 1. O domínio 1 do RRPP protege as VLANs 1 a 30.
- O dispositivo A, o dispositivo B, o dispositivo C e o dispositivo D formam o anel primário 1. O dispositivo B, o dispositivo C e o dispositivo E formam o subanel 2.
- O dispositivo A é o nó mestre do anel primário 1, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária.
- O dispositivo E é o nó mestre do subanel 2, com GigabitEthernet 1/0/1 como porta primária e GigabitEthernet 1/0/2 como porta secundária.
- O dispositivo B é o nó de trânsito do anel primário 1 e o nó de borda do subanel 2, com GigabitEthernet 1/0/3 como porta de borda.
- O dispositivo C é o nó de trânsito do anel primário 1 e o nó de borda assistente do subanel 1, com GigabitEthernet 1/0/3 como porta de borda.
- O dispositivo D é o nó de trânsito do anel primário 1, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária.
Figura 7 Diagrama de rede
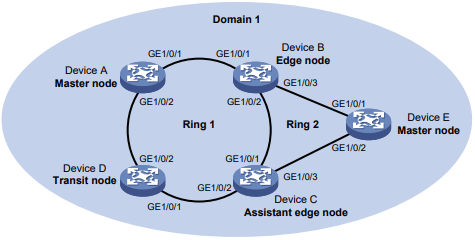
Procedimento
- Configurar o dispositivo A:
# Criar VLANs de 1 a 30.
<DeviceA> system-view
[DeviceA] vlan 1 to 30# Mapeie essas VLANs para o MSTI 1.
[DeviceA] stp region-configuration
[DeviceA-mst-region] instance 1 vlan 1 to 30# Ativar a configuração da região MST.
[DeviceA-mst-region] active region-configuration
[DeviceA-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico para 0 segundos na GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] link-delay up 0
[DeviceA-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceA-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceA-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] link-delay up 0
[DeviceA-GigabitEthernet1/0/2] link-delay down 0
[DeviceA-GigabitEthernet1/0/2] undo stp enable
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceA-GigabitEthernet1/0/2] quit# Criar o domínio RRPP 1.
[DeviceA] rrpp domain 1# Configure a VLAN 4092 como a VLAN de controle primário do domínio 1 do RRPP.
[DeviceA-rrpp-domain1] control-vlan 4092# Configure as VLANs mapeadas para MSTI 1 como as VLANs protegidas do domínio RRPP 1.
[DeviceA-rrpp-domain1] protected-vlan reference-instance 1# Configure o dispositivo A como o nó mestre do anel primário 1, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceA-rrpp-domain1] ring 1 node-mode master primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceA-rrpp-domain1] ring 1 enable
[DeviceA-rrpp-domain1] quit# Habilitar o RRPP.
[DeviceA] rrpp enable# Criar VLANs de 1 a 30.
<DeviceB> system-view
[DeviceB] vlan 1 to 30# Mapeie essas VLANs para o MSTI 1.
[DeviceB] stp region-configuration
[DeviceB-mst-region] instance 1 vlan 1 to 30# Ativar a configuração da região MST.
[DeviceB-mst-region] active region-configuration
[DeviceB-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico como 0 segundos na GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] link-delay up 0
[DeviceB-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceB-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceB-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] link-delay up 0
[DeviceB-GigabitEthernet1/0/2] link-delay down 0
[DeviceB-GigabitEthernet1/0/2] undo stp enable
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceB-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] link-delay up 0
[DeviceB-GigabitEthernet1/0/3] undo stp enable
[DeviceB-GigabitEthernet1/0/3] port link-type trunk
[DeviceB-GigabitEthernet1/0/3] port trunk permit vlan 1 to 30
[DeviceB-GigabitEthernet1/0/3] quit# Criar o domínio RRPP 1.
[DeviceB] rrpp domain 1# Configure a VLAN 4092 como a VLAN de controle primário do domínio 1 do RRPP.
[DeviceB-rrpp-domain1] control-vlan 4092# Configure as VLANs mapeadas para MSTI 1 como VLANs protegidas do domínio RRPP 1.
[DeviceB-rrpp-domain1] protected-vlan reference-instance 1# Configure o dispositivo B como um nó de trânsito do anel primário 1, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceB-rrpp-domain1] ring 1 node-mode transit primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceB-rrpp-domain1] ring 1 enable# Configure o Dispositivo B como o nó de borda do subanel 2, com GigabitEthernet 1/0/3 como a porta de borda. Habilite o anel 2.
[DeviceB-rrpp-domain1] ring 2 node-mode edge edge-port gigabitethernet 1/0/3
[DeviceB-rrpp-domain1] ring 2 enable
[DeviceB-rrpp-domain1] quit# Habilitar o RRPP.
[DeviceB] rrpp enable# Criar VLANs de 1 a 30.
<DeviceC> system-view
[DeviceC] vlan 1 to 30# Mapeie essas VLANs para o MSTI 1.
[DeviceC] stp region-configuration
[DeviceC-mst-region] instance 1 vlan 1 to 30# Ativar a configuração da região MST.
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico para 0 segundos na GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] link-delay up 0
[DeviceC-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceC-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceC-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceC-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] link-delay up 0
[DeviceC-GigabitEthernet1/0/2] link-delay down 0
[DeviceC-GigabitEthernet1/0/2] undo stp enable
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceC-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/3
[DeviceC-GigabitEthernet1/0/3] link-delay up 0
[DeviceC-GigabitEthernet1/0/3] link-delay down 0
[DeviceC-GigabitEthernet1/0/3] undo stp enable
[DeviceC-GigabitEthernet1/0/3] port link-type trunk
[DeviceC-GigabitEthernet1/0/3] port trunk permit vlan 1 to 30
[DeviceC-GigabitEthernet1/0/3] quit# Criar o domínio RRPP 1.
[DeviceC] rrpp domain 1# Configure a VLAN 4092 como a VLAN de controle primário do domínio 1 do RRPP.
[DeviceC-rrpp-domain1] control-vlan 4092# Configure as VLANs mapeadas para MSTI 1 como as VLANs protegidas do domínio RRPP 1.
[DeviceC-rrpp-domain1] protected-vlan reference-instance 1# Configure o dispositivo C como um nó de trânsito do anel primário 1, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceC-rrpp-domain1] ring 1 node-mode transit primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceC-rrpp-domain1] ring 1 enable# Configure o dispositivo C como o nó de borda assistente do subanel 2, com GigabitEthernet 1/0/3 como porta de borda. Habilite o anel 2.
[DeviceC-rrpp-domain1] ring 2 node-mode assistant-edge edge-port gigabitethernet
1/0/3
[DeviceC-rrpp-domain1] ring 2 enable
[DeviceC-rrpp-domain1] quit# Habilitar o RRPP.
[DeviceC] rrpp enable# Criar VLANs de 1 a 30.
<DeviceD> system-view
[DeviceD] vlan 1 to 30# Mapeie essas VLANs para o MSTI 1.
[DeviceD] stp region-configuration
[DeviceD-mst-region] instance 1 vlan 1 to 30# Ativar a configuração da região MST.
[DeviceD-mst-region] active region-configuration
[DeviceD-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico para 0 segundos na GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] link-delay up 0
[DeviceD-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceD-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceD-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceD-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceD-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] link-delay up 0
[DeviceD-GigabitEthernet1/0/2] link-delay down 0
[DeviceD-GigabitEthernet1/0/2] undo stp enable
[DeviceD-GigabitEthernet1/0/2] port link-type trunk
[DeviceD-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceD-GigabitEthernet1/0/2] quit# Criar o domínio RRPP 1.
[DeviceD] rrpp domain 1# Configure a VLAN 4092 como a VLAN de controle primário do domínio 1 do RRPP.
[DeviceD-rrpp-domain1] control-vlan 4092# Configure as VLANs mapeadas para MSTI 1 como as VLANs protegidas do domínio RRPP 1.
[DeviceD-rrpp-domain1] protected-vlan reference-instance 1# Configure o dispositivo D como o nó de trânsito do anel primário 1, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceD-rrpp-domain1] ring 1 node-mode transit primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceD-rrpp-domain1] ring 1 enable
[DeviceD-rrpp-domain1] quit# Habilitar o RRPP.
[DeviceD] rrpp enable# Criar VLANs de 1 a 30.
<DeviceE> system-view
[DeviceE] vlan 1 to 30# Mapeie essas VLANs para o MSTI 1.
[DeviceE] stp region-configuration
[DeviceE-mst-region] instance 1 vlan 1 to 30# Ativar a configuração da região MST.
[DeviceE-mst-region] active region-configuration
[DeviceE-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico para 0 segundos na GigabitEthernet 1/0/1.
[DeviceE] interface gigabitethernet 1/0/1
[DeviceE-GigabitEthernet1/0/1] link-delay up 0
[DeviceE-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceE-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceE-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceE-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceE-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceE] interface gigabitethernet 1/0/2
[DeviceE-GigabitEthernet1/0/2] link-delay up 0
[DeviceE-GigabitEthernet1/0/2] link-delay down 0
[DeviceE-GigabitEthernet1/0/2] undo stp enable
[DeviceE-GigabitEthernet1/0/2] port link-type trunk
[DeviceE-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceE-GigabitEthernet1/0/2] quit# Criar o domínio RRPP 1.
[DeviceE] rrpp domain 1# Configure a VLAN 4092 como a VLAN de controle primário do domínio 1 do RRPP.
[DeviceE-rrpp-domain1] control-vlan 4092# Configure as VLANs mapeadas para MSTI 1 como as VLANs protegidas do domínio RRPP 1.
[DeviceE-rrpp-domain1] protected-vlan reference-instance 1# Configure o dispositivo E como o nó mestre do subanel 2, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 2.
[DeviceE-rrpp-domain1] ring 2 node-mode master primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 1
[DeviceE-rrpp-domain1] ring 2 enable
[DeviceE-rrpp-domain1] quit# Habilitar o RRPP.
[DeviceE] rrpp enableVerificação da configuração
# Use os comandos de exibição para visualizar as informações operacionais e de configuração do RRPP em cada dispositivo.
Exemplo: Configuração de anéis de interseção com balanceamento de carga
Configuração de rede
Conforme mostrado na Figura 8:
- O dispositivo A, o dispositivo B, o dispositivo C, o dispositivo D e o dispositivo F formam o domínio RRPP 1. A VLAN 100 é a VLAN de controle primário do domínio RRPP. O dispositivo A é o nó mestre do anel primário, o anel 1. O dispositivo D é o nó de trânsito do anel 1. O dispositivo F é o nó mestre do anel secundário 3. O dispositivo C é o nó de borda do anel secundário 3. O dispositivo B é o nó de borda assistente do subanel Ring 3.
- O dispositivo A, o dispositivo B, o dispositivo C, o dispositivo D e o dispositivo E formam o domínio RRPP 2. A VLAN 105 é a VLAN de controle primário do domínio RRPP. O dispositivo A é o nó mestre do anel primário, Anel 1. O dispositivo D é o nó de trânsito do anel 1. O dispositivo E é o nó mestre do anel secundário 2. O dispositivo C é o nó de borda do anel secundário 2. O dispositivo B é o nó de borda assistente do subanel Ring 2.
- Especifique a VLAN 11 como a VLAN protegida do domínio 1 e a VLAN 12 como a VLAN protegida do domínio 2. Você pode implementar o balanceamento de carga baseado em VLAN no Ring 1.
- O anel 2 e o anel 3 têm o mesmo nó de borda e nó de borda assistente, e os dois subanéis têm os mesmos SRPTs. Você pode adicionar o Anel 2 e o Anel 3 a um grupo de anéis RRPP para reduzir o tráfego Edge-Hello.
Figura 8 Diagrama de rede
Procedimento
- Configurar o dispositivo A:
# Crie as VLANs 11 e 12.
<DeviceA> system-view
[DeviceA] vlan 11 to 12# Mapeie a VLAN 11 para MSTI 1 e a VLAN 12 para MSTI 2.
[DeviceA] stp region-configuration
[DeviceA-mst-region] instance 1 vlan 11
[DeviceA-mst-region] instance 2 vlan 12# Ativar a configuração da região MST.
[DeviceA-mst-region] active region-configuration
[DeviceA-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico para 0 segundos na GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] link-delay up 0
[DeviceA-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceA-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceA-GigabitEthernet1/0/1] port link-type trunk# Remova a porta da VLAN 1 e a atribua às VLANs 11 e 12.
[DeviceA-GigabitEthernet1/0/1] undo port trunk permit vlan 1
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan 11 12# Configure a VLAN 11 como a VLAN padrão.
[DeviceA-GigabitEthernet1/0/1] port trunk pvid vlan 11
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] link-delay up 0
[DeviceA-GigabitEthernet1/0/2] link-delay down 0
[DeviceA-GigabitEthernet1/0/2] undo stp enable
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] undo port trunk permit vlan 1
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 11 12
[DeviceA-GigabitEthernet1/0/2] port trunk pvid vlan 11
[DeviceA-GigabitEthernet1/0/2] quit# Criar o domínio RRPP 1.
[DeviceA] rrpp domain 1# Configure a VLAN 100 como a VLAN de controle primário do domínio 1 do RRPP.
[DeviceA-rrpp-domain1] control-vlan 100# Configure a VLAN mapeada para MSTI 1 como a VLAN protegida do domínio RRPP 1.
[DeviceA-rrpp-domain1] protected-vlan reference-instance 1# Configure o dispositivo A como o nó mestre do anel primário 1, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceA-rrpp-domain1] ring 1 node-mode master primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceA-rrpp-domain1] ring 1 enable
[DeviceA-rrpp-domain1] quit# Criar o domínio RRPP 2.
[DeviceA] rrpp domain 2# Configure a VLAN 105 como a VLAN de controle primário do domínio 2 do RRPP.
[DeviceA-rrpp-domain2] control-vlan 105# Configure a VLAN mapeada para MSTI 2 como a VLAN protegida do domínio RRPP 2.
[DeviceA-rrpp-domain2] protected-vlan reference-instance 2# Configure o dispositivo A como o nó mestre do anel primário 1, com a GigabitEthernet 1/0/2 como a porta mestre e a GigabitEthernet 1/0/1 como a porta secundária. Habilite o anel 1.
[DeviceA-rrpp-domain2] ring 1 node-mode master primary-port gigabitethernet 1/0/2
secondary-port gigabitethernet 1/0/1 level 0
[DeviceA-rrpp-domain2] ring 1 enable
[DeviceA-rrpp-domain2] quit# Habilitar o RRPP.
[DeviceA] rrpp enable# Crie as VLANs 11 e 12.
<DeviceB> system-view
[DeviceB] vlan 11 to 12# Mapeie a VLAN 11 para MSTI 1 e a VLAN 12 para MSTI 2.
[DeviceB] stp region-configuration
[DeviceB-mst-region] instance 1 vlan 11
[DeviceB-mst-region] instance 2 vlan 12# Ativar a configuração da região MST.
[DeviceB-mst-region] active region-configuration
[DeviceB-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico para 0 segundos na GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] link-delay up 0
[DeviceB-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceB-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceB-GigabitEthernet1/0/1] port link-type trunk# Remova a porta da VLAN 1 e a atribua às VLANs 11 e 12.
[DeviceB-GigabitEthernet1/0/1] undo port trunk permit vlan 1
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 11 12# Configure a VLAN 11 como a VLAN padrão.
[DeviceB-GigabitEthernet1/0/1] port trunk pvid vlan 11
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] link-delay up 0
[DeviceB-GigabitEthernet1/0/2] link-delay down 0
[DeviceB-GigabitEthernet1/0/2] undo stp enable
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] undo port trunk permit vlan 1
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 11 12
[DeviceB-GigabitEthernet1/0/2] port trunk pvid vlan 11
[DeviceB-GigabitEthernet1/0/2] quit# Defina o intervalo de supressão de alteração do estado físico como 0 segundos na GigabitEthernet 1/0/3.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] link-delay up 0
[DeviceB-GigabitEthernet1/0/3] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceB-GigabitEthernet1/0/3] undo stp enable# Configure a porta como uma porta tronco.
[DeviceB-GigabitEthernet1/0/3] port link-type trunk# Remova a porta da VLAN 1 e a atribua à VLAN 12.
[DeviceB-GigabitEthernet1/0/3] undo port trunk permit vlan 1
[DeviceB-GigabitEthernet1/0/3] port trunk permit vlan 12# Configure a VLAN 12 como a VLAN padrão.
[DeviceB-GigabitEthernet1/0/3] port trunk pvid vlan 12
[DeviceB-GigabitEthernet1/0/3] quit# Defina o intervalo de supressão de alteração do estado físico como 0 segundos na GigabitEthernet 1/0/4.
[DeviceB] interface gigabitethernet 1/0/4
[DeviceB-GigabitEthernet1/0/4] link-delay up 0
[DeviceB-GigabitEthernet1/0/4] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceB-GigabitEthernet1/0/4] undo stp enable# Configure a porta como uma porta tronco.
[DeviceB-GigabitEthernet1/0/4] port link-type trunk# Remova a porta da VLAN 1 e a atribua à VLAN 11.
[DeviceB-GigabitEthernet1/0/4] undo port trunk permit vlan 1
[DeviceB-GigabitEthernet1/0/4] port trunk permit vlan 11# Configure a VLAN 11 como a VLAN padrão.
[DeviceB-GigabitEthernet1/0/4] port trunk pvid vlan 11
[DeviceB-GigabitEthernet1/0/4] quit# Criar o domínio RRPP 1.
[DeviceB] rrpp domain 1# Configure a VLAN 100 como a VLAN de controle primário do domínio 1 do RRPP.
[DeviceB-rrpp-domain1] control-vlan 100# Configure a VLAN mapeada para MSTI 1 como a VLAN protegida do domínio RRPP 1.
[DeviceB-rrpp-domain1] protected-vlan reference-instance 1# Configure o Dispositivo B como um nó de trânsito do anel primário 1 no domínio 1 do RRPP, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceB-rrpp-domain1] ring 1 node-mode transit primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceB-rrpp-domain1] ring 1 enable# Configure o Dispositivo B como o nó de borda assistente da subcircunscrição 3 no domínio 1 do RRPP, com GigabitEthernet 1/0/4 como a porta de borda. Habilite a subcadeia 3.
[DeviceB-rrpp-domain1] ring 3 node-mode assistant-edge edge-port gigabitethernet
1/0/4
[DeviceB-rrpp-domain1] ring 3 enable
[DeviceB-rrpp-domain1] quit# Criar o domínio RRPP 2.
[DeviceB] rrpp domain 2# Configure a VLAN 105 como a VLAN de controle primário do domínio 2 do RRPP.
[DeviceB-rrpp-domain2] control-vlan 105# Configure a VLAN mapeada para MSTI 2 como a VLAN protegida do domínio RRPP 2.
[DeviceB-rrpp-domain2] protected-vlan reference-instance 2# Configure o dispositivo B como o nó de trânsito do anel primário 1, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceB-rrpp-domain2] ring 1 node-mode transit primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceB-rrpp-domain2] ring 1 enable# Configure o Dispositivo B como o nó de borda assistente da subcircunscrição 2 no domínio 2 do RRPP, com GigabitEthernet 1/0/3 como a porta de borda. Habilite a subcadeia 2.
[DeviceB-rrpp-domain2] ring 2 node-mode assistant-edge edge-port gigabitethernet
1/0/3
[DeviceB-rrpp-domain2] ring 2 enable
[DeviceC-rrpp-domain2] quit# Habilitar o RRPP.
[DeviceB] rrpp enable# Crie as VLANs 11 e 12.
<DeviceC> system-view
[DeviceC] vlan 11 to 12# Mapeie a VLAN 11 para MSTI 1 e a VLAN 12 para MSTI 2.
[DeviceC] stp region-configuration
[DeviceC-mst-region] instance 1 vlan 11
[DeviceC-mst-region] instance 2 vlan 12# Ativar a configuração da região MST.
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico para 0 segundos na GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] link-delay up 0
[DeviceC-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceC-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceC-GigabitEthernet1/0/1] port link-type trunk# Remova a porta da VLAN 1 e a atribua às VLANs 11 e 12.
[DeviceC-GigabitEthernet1/0/1] undo port trunk permit vlan 1
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 11 12# Configure a VLAN 11 como a VLAN padrão.
[DeviceC-GigabitEthernet1/0/1] port trunk pvid vlan 11
[DeviceC-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] link-delay up 0
[DeviceC-GigabitEthernet1/0/2] link-delay down 0
[DeviceC-GigabitEthernet1/0/2] undo stp enable
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] undo port trunk permit vlan 1
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan 11 12
[DeviceC-GigabitEthernet1/0/2] port trunk pvid vlan 11
[DeviceC-GigabitEthernet1/0/2] quit# Defina o intervalo de supressão de alteração do estado físico como 0 segundos na GigabitEthernet 1/0/3.
[DeviceC] interface gigabitethernet 1/0/3
[DeviceC-GigabitEthernet1/0/3] link-delay up 0
[DeviceC-GigabitEthernet1/0/3] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceC-GigabitEthernet1/0/3] undo stp enable# Configure a porta como uma porta tronco.
[DeviceC-GigabitEthernet1/0/3] port link-type trunk# Remova a porta da VLAN 1 e a atribua à VLAN 12.
[DeviceC-GigabitEthernet1/0/3] undo port trunk permit vlan 1
[DeviceC-GigabitEthernet1/0/3] port trunk permit vlan 12# Configure a VLAN 12 como a VLAN padrão.
[DeviceC-GigabitEthernet1/0/3] port trunk pvid vlan 12
[DeviceC-GigabitEthernet1/0/3] quit# Defina o intervalo de supressão de alteração do estado físico para 0 segundos na GigabitEthernet 1/0/4.
[DeviceC] interface gigabitethernet 1/0/4
[DeviceC-GigabitEthernet1/0/4] link-delay up 0
[DeviceC-GigabitEthernet1/0/4] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceC-GigabitEthernet1/0/4] undo stp enable# Configure a porta como uma porta tronco.
[DeviceC-GigabitEthernet1/0/4] port link-type trunk# Remova a porta da VLAN 1 e a atribua à VLAN 11.
[DeviceC-GigabitEthernet1/0/4] undo port trunk permit vlan 1
[DeviceC-GigabitEthernet1/0/4] port trunk permit vlan 11# Configure a VLAN 11 como a VLAN padrão.
[DeviceC-GigabitEthernet1/0/4] port trunk pvid vlan 11
[DeviceC-GigabitEthernet1/0/4] quit# Criar o domínio RRPP 1.
[DeviceC] rrpp domain 1# Configure a VLAN 100 como a VLAN de controle primário do domínio 1 do RRPP.
[DeviceC-rrpp-domain1] control-vlan 100# Configure a VLAN mapeada para MSTI 1 como a VLAN protegida do domínio RRPP 1.
[DeviceC-rrpp-domain1] protected-vlan reference-instance 1# Configure o dispositivo C como o nó de trânsito do anel primário 1 no domínio 1 do RRPP, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceC-rrpp-domain1] ring 1 node-mode transit primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceC-rrpp-domain1] ring 1 enable# Configure o Dispositivo C como o nó de borda da subcircunscrição 3 no domínio 1 do RRPP, com a GigabitEthernet 1/0/4 como porta de borda. Habilite a subcadeia 3.
[DeviceC-rrpp-domain1] ring 3 node-mode edge edge-port gigabitethernet 1/0/4
[DeviceC-rrpp-domain1] ring 3 enable
[DeviceC-rrpp-domain1] quit# Criar o domínio RRPP 2.
[DeviceC] rrpp domain 2# Configure a VLAN 105 como a VLAN de controle primário do domínio 2 do RRPP.
[DeviceC-rrpp-domain2] control-vlan 105# Configure a VLAN mapeada para MSTI 2 como a VLAN protegida do domínio RRPP 2.
[DeviceC-rrpp-domain2] protected-vlan reference-instance 2# Configure o dispositivo C como o nó de trânsito do anel primário 1 no domínio 2 do RRPP, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceC-rrpp-domain2] ring 1 node-mode transit primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceC-rrpp-domain2] ring 1 enable# Configure o Dispositivo C como o nó de borda da sub-rede 2 no domínio 2 do RRPP, com GigabitEthernet 1/0/3 como a porta de borda. Habilite a subcadeia 2.
[DeviceC-rrpp-domain2] ring 2 node-mode edge edge-port gigabitethernet 1/0/3
[DeviceC-rrpp-domain2] ring 2 enable
[DeviceC-rrpp-domain2] quit# Habilitar o RRPP.
[DeviceC] rrpp enable# Crie as VLANs 11 e 12.
<DeviceD> system-view
[DeviceD] vlan 11 to 12# Mapeie a VLAN 11 para MSTI 1 e a VLAN 12 para MSTI 2.
[DeviceD] stp region-configuration
[DeviceD-mst-region] instance 1 vlan 11
[DeviceD-mst-region] instance 2 vlan 12# Ativar a configuração da região MST.
[DeviceD-mst-region] active region-configuration
[DeviceD-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico para 0 segundos na GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] link-delay up 0
[DeviceD-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceD-GigabitEthernet1/0/1] undo stp enableConfigure a porta como uma porta tronco.
[DeviceD-GigabitEthernet1/0/1] port link-type trunk# Remova a porta da VLAN 1 e a atribua às VLANs 11 e 12.
[DeviceD-GigabitEthernet1/0/1] undo port trunk permit vlan 1
[DeviceD-GigabitEthernet1/0/1] port trunk permit vlan 11 12# Configure a VLAN 11 como a VLAN padrão.
[DeviceD-GigabitEthernet1/0/1] port trunk pvid vlan 11
[DeviceD-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] link-delay up 0
[DeviceD-GigabitEthernet1/0/2] link-delay down 0
[DeviceD-GigabitEthernet1/0/2] undo stp enable
[DeviceD-GigabitEthernet1/0/2] port link-type trunk
[DeviceD-GigabitEthernet1/0/2] undo port trunk permit vlan 1
[DeviceD-GigabitEthernet1/0/2] port trunk permit vlan 11 12
[DeviceD-GigabitEthernet1/0/2] port trunk pvid vlan 11
[DeviceD-GigabitEthernet1/0/2] quit# Criar o domínio RRPP 1.
[DeviceD] rrpp domain 1# Configure a VLAN 100 como a VLAN de controle primário do domínio 1 do RRPP.
[DeviceD-rrpp-domain1] control-vlan 100# Configure a VLAN mapeada para MSTI 1 como a VLAN protegida do domínio RRPP 1.
[DeviceD-rrpp-domain1] protected-vlan reference-instance 1# Configure o Dispositivo D como o nó de trânsito do anel primário 1 no domínio 1 do RRPP, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceD-rrpp-domain1] ring 1 node-mode transit primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceD-rrpp-domain1] ring 1 enable
[DeviceD-rrpp-domain1] quit# Criar o domínio RRPP 2.
[DeviceD] rrpp domain 2# Configure a VLAN 105 como a VLAN de controle primário do domínio 2 do RRPP.
[DeviceD-rrpp-domain2] control-vlan 105# Configure a VLAN mapeada para MSTI 2 como a VLAN protegida do domínio RRPP 2.
[DeviceD-rrpp-domain2] protected-vlan reference-instance 2# Configure o Dispositivo D como o nó de trânsito do anel primário 1 no domínio 2 do RRPP, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite o anel 1.
[DeviceD-rrpp-domain2] ring 1 node-mode transit primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 0
[DeviceD-rrpp-domain2] ring 1 enable
[DeviceD-rrpp-domain2] quit# Habilitar o RRPP.
[DeviceD] rrpp enable# Criar VLAN 12.
<DeviceE> system-view
[DeviceE] vlan 12# Mapeie a VLAN 12 para o MSTI 2.
[DeviceE-vlan12] quit
[DeviceE] stp region-configuration
[DeviceE-mst-region] instance 2 vlan 12# Ativar a configuração da região MST.
[DeviceE-mst-region] active region-configuration
[DeviceE-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico para 0 segundos na GigabitEthernet 1/0/1.
[DeviceE] interface gigabitethernet 1/0/1
[DeviceE-GigabitEthernet1/0/1] link-delay up 0
[DeviceE-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceE-GigabitEthernet1/0/1] undo stp enableConfigure a porta como uma porta tronco.
[DeviceE-GigabitEthernet1/0/1] port link-type trunk# Remova a porta da VLAN 1 e a atribua à VLAN 12.
[DeviceE-GigabitEthernet1/0/1] undo port trunk permit vlan 1
[DeviceE-GigabitEthernet1/0/1] port trunk permit vlan 12# Configure a VLAN 12 como a VLAN padrão.
[DeviceE-GigabitEthernet1/0/1] port trunk pvid vlan 12
[DeviceE-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceE] interface gigabitethernet 1/0/2
[DeviceE-GigabitEthernet1/0/2] link-delay up 0
[DeviceE-GigabitEthernet1/0/2] link-delay down 0
[DeviceE-GigabitEthernet1/0/2] undo stp enable
[DeviceE-GigabitEthernet1/0/2] port link-type trunk
[DeviceE-GigabitEthernet1/0/2] undo port trunk permit vlan 1
[DeviceE-GigabitEthernet1/0/2] port trunk permit vlan 12
[DeviceE-GigabitEthernet1/0/2] port trunk pvid vlan 12
[DeviceE-GigabitEthernet1/0/2] quit# Criar o domínio RRPP 2.
[DeviceE] rrpp domain 2# Configure a VLAN 105 como a VLAN de controle primário do domínio 2 do RRPP.
[DeviceE-rrpp-domain2] control-vlan 105# Configure a VLAN mapeada para MSTI 2 como a VLAN protegida do domínio RRPP 2.
[DeviceE-rrpp-domain2] protected-vlan reference-instance 2# Configure o Dispositivo E como o modo mestre do subanel 2 no domínio 2 do RRPP, com a GigabitEthernet 1/0/2 como porta primária e a GigabitEthernet 1/0/1 como porta secundária. Habilite o anel 2.
[DeviceE-rrpp-domain2] ring 2 node-mode master primary-port gigabitethernet 1/0/2
secondary-port gigabitethernet 1/0/1 level 1
[DeviceE-rrpp-domain2] ring 2 enable
[DeviceE-rrpp-domain2] quit# Habilitar o RRPP.
[DeviceE] rrpp enable# Criar VLAN 11.
<DeviceF> system-view
[DeviceF] vlan 11
[DeviceF-vlan11] quit# Mapear a VLAN 11 para o MSTI 1.
[DeviceF] stp region-configuration
[DeviceF-mst-region] instance 1 vlan 11# Ative a configuração da região MST.
[DeviceF-mst-region] active region-configuration
[DeviceF-mst-region] quit# Defina o intervalo de supressão de alteração do estado físico para 0 segundos na GigabitEthernet 1/0/1.
[DeviceF] interface gigabitethernet 1/0/1
[DeviceF-GigabitEthernet1/0/1] link-delay up 0
[DeviceF-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceF-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceF-GigabitEthernet1/0/1] port link-type trunk# Remova a porta da VLAN 1 e a atribua à VLAN 11.
[DeviceF-GigabitEthernet1/0/1] undo port trunk permit vlan 1
[DeviceF-GigabitEthernet1/0/1] port trunk permit vlan 11# Configure a VLAN 11 como a VLAN padrão.
[DeviceF-GigabitEthernet1/0/1] port trunk pvid vlan 11
[DeviceF-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceF] interface gigabitethernet 1/0/2
[DeviceF-GigabitEthernet1/0/2] link-delay up 0
[DeviceF-GigabitEthernet1/0/2] link-delay down 0
[DeviceF-GigabitEthernet1/0/2] undo stp enable
[DeviceF-GigabitEthernet1/0/2] port link-type trunk
[DeviceF-GigabitEthernet1/0/2] undo port trunk permit vlan 1
[DeviceF-GigabitEthernet1/0/2] port trunk permit vlan 11
[DeviceF-GigabitEthernet1/0/2] port trunk pvid vlan 11
[DeviceF-GigabitEthernet1/0/2] quit# Criar o domínio RRPP 1.
[DeviceF] rrpp domain 1# Configure a VLAN 100 como a VLAN de controle primário do domínio 1 do RRPP.
[DeviceF-rrpp-domain1] control-vlan 100# Configure a VLAN mapeada para MSTI 1 como a VLAN protegida do domínio RRPP 1.
[DeviceF-rrpp-domain1] protected-vlan reference-instance 1# Configure o Dispositivo F como o nó mestre da subcircunscrição 3 no domínio 1 do RRPP, com a GigabitEthernet 1/0/1 como porta primária e a GigabitEthernet 1/0/2 como porta secundária. Habilite a sub-rede 3.
[DeviceF-rrpp-domain1] ring 3 node-mode master primary-port gigabitethernet 1/0/1
secondary-port gigabitethernet 1/0/2 level 1
[DeviceF-rrpp-domain1] ring 3 enable
[DeviceF-rrpp-domain1] quit# Habilitar o RRPP.
[DeviceF] rrpp enable# Crie o grupo de anéis RRPP 1 no Dispositivo B e adicione os subanéis 2 e 3 ao grupo de anéis RRPP.
[DeviceB] rrpp ring-group 1
[DeviceB-rrpp-ring-group1] domain 2 ring 2
[DeviceB-rrpp-ring-group1] domain 1 ring 3# Crie o grupo de anéis RRPP 1 no dispositivo C e adicione os subanéis 2 e 3 ao grupo de anéis RRPP.
[DeviceC] rrpp ring-group 1
[DeviceC-rrpp-ring-group1] domain 2 ring 2
[DeviceC-rrpp-ring-group1] domain 1 ring 3Verificação da configuração
# Use os comandos de exibição para visualizar as informações operacionais e de configuração do RRPP em cada dispositivo.
Solução de problemas de RRPP
O nó primário não pode receber pacotes Hello quando o estado do link está normal
Sintoma
Quando o estado do link está normal, o nó mestre não pode receber pacotes Hello e desbloqueia a porta secundária.
Análise
As causas possíveis são as seguintes:
- Um ou mais nós no anel RRPP não estão habilitados com o RRPP.
- As IDs de domínio ou VLANs de controle não são as mesmas para todos os nós no anel RRPP.
- A porta no anel RRPP não está funcionando corretamente.
Solução
Para resolver o problema:
- Use o comando display rrpp brief para determinar se o RRPP está ativado para todos os nós. Se não estiver, use o comando rrpp enable e o comando ring enable para habilitar o RRPP e os anéis RRPP para todos os nós.
- Use o comando display rrpp brief para determinar se a ID do domínio e a ID da VLAN de controle primário são as mesmas para todos os nós. Se não forem, defina a mesma ID de domínio e ID de VLAN de controle primário para os nós.
- Use o comando display rrpp verbose para examinar o estado do link de cada porta em cada anel.
- Use o comando debugging rrpp em cada nó para determinar se uma porta recebe ou transmite pacotes Hello. Se isso não ocorrer, os pacotes Hello serão perdidos.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Configuração do ERPS
Sobre o ERPS
O Ethernet Ring Protection Switching (ERPS) é um protocolo de camada de link robusto que garante uma topologia livre de loop e implementa uma rápida recuperação de link.
Aplicavel somente a Serie S3300G
Estrutura do ERPS
Figura 1 Estrutura do anel do ERPS
Anéis
Os anéis ERPS podem ser divididos em anéis principais e subanéis. Uma rede ERPS consiste em um anel principal ou vários anéis principais e vários subanéis. Por padrão, um anel é um anel principal. Você pode configurar um anel como um subanel manualmente.
Conforme mostrado na Figura 1, um anel principal é um anel fechado formado pelo Dispositivo A, Dispositivo B, Dispositivo C e Dispositivo D. Um subanel é um anel aberto formado pelo link Dispositivo C<->Dispositivo E<->Dispositivo F<->Dispositivo D.
RPL
Um anel ERPS é composto de muitos nós. Alguns nós usam links de proteção de anel (RPLs) para evitar loops no anel ERPS. Conforme mostrado na Figura 1, o link entre o Dispositivo A e o Dispositivo B e o link entre o Dispositivo E e o Dispositivo F são RPLs.
Nós
Os nós do ERPS incluem nós proprietários, nós vizinhos, nós de interconexão e nós normais.
- O nó proprietário e o nó vizinho bloqueiam e desbloqueiam portas na RPL para evitar loops e tráfego de switch. Uma RPL conecta um nó proprietário e um nó vizinho.
- Os nós de interconexão conectam anéis diferentes. Os nós de interconexão residem em subanéis e encaminham pacotes de serviço, mas não pacotes de protocolo.
- Os nós normais encaminham os pacotes de serviço e os pacotes de protocolo.
Conforme mostrado na Figura 1, no anel principal, o dispositivo A é o nó proprietário e o dispositivo B é o nó vizinho. No anel secundário, o dispositivo E é o nó proprietário e o dispositivo F é o nó vizinho. Os dispositivos C e D são nós de interconexão.
Portas
Cada nó consiste em duas portas de membro do anel ERPS: Porta 0 e porta 1. As portas de membro do anel ERPS têm os seguintes tipos:
- Porta RPL - Porta em um link RPL.
- Porta de interconexão - Porta que conecta um subanel a um anel principal.
- Porta normal - Tipo padrão de uma porta que encaminha pacotes de serviço e pacotes de protocolo.
Conforme mostrado na Figura 1, as portas A1, B1, E1 e F1 são portas RPL. As portas C3 e D3 são portas de interconexão. As outras portas são portas normais.
Instâncias
Um anel ERPS suporta várias instâncias ERPS. Uma instância de ERPS é um anel lógico para processar pacotes de serviços e protocolos. Cada instância de ERPS tem seu próprio nó proprietário e mantém seu próprio estado e dados. Uma instância de ERPS é identificada exclusivamente pelo ID do anel e pelo ID da VLAN dos pacotes ERPS. O ID do anel indica o anel dos pacotes ERPS. Ele pode ser representado pelo último byte no endereço MAC de destino dos pacotes . O VLAN ID indica a instância ERPS dos pacotes.
Pacotes do protocolo ERPS
Os pacotes do protocolo ERPS são pacotes R-APS (Ring Automatic Protection Switching). Você pode configurar o nível do pacote R-APS. Um nó não processa pacotes R-APS cujos níveis sejam maiores que o nível dos pacotes enviados pelo nó. Em um anel, os níveis dos pacotes R-APS devem ser os mesmos para todos os nós em uma instância do ERPS.
Tabela 1 Tipos e funções de pacotes R-APS
| Tipo de pacote | Função |
| Nenhuma solicitação, bloqueio de RPL (NR-RB) | Quando o link está estável, um nó proprietário em estado ocioso envia periodicamente pacotes NR-RB para informar a outros nós que as portas RPL estão bloqueadas. Os nós que recebem os pacotes NR-RB desbloqueiam as portas disponíveis e atualizam as entradas de endereço MAC. |
| Sem solicitação (NR) | Depois que a falha do link é eliminada, o nó que detecta a recuperação envia periodicamente pacotes NR. Quando o nó proprietário recebe os pacotes NR, ele inicia o cronômetro WTR. O nó para de enviar pacotes NR depois de receber pacotes NR-RB do nó proprietário. |
| Falha de sinal (SF) | Quando um link deixa de enviar ou receber sinais, o nó que detecta a falha envia periodicamente pacotes SF. Quando o nó proprietário e o nó vizinho recebem os pacotes FS, eles desbloqueiam as portas RPL. O nó para de enviar pacotes SF depois que a falha é eliminada. |
| Interruptor manual (MS) | Uma porta configurada com o modo MS é bloqueada e envia periodicamente pacotes MS. Quando outros nós recebem os pacotes MS, eles desbloqueiam as portas disponíveis e atualizam as entradas de endereço MAC. |
| Chave forçada (FS) | Uma porta configurada com o modo FS é bloqueada e envia periodicamente pacotes FS. Quando os outros nós recebem os pacotes FS, eles desbloqueiam todas as portas e atualizam as entradas de endereço MAC. |
| Flush | Se a topologia de um subanel mudar, as portas de interconexão no subanel transmitem pacotes de descarga. Todos os nós que recebem os pacotes de descarga atualizam as entradas de endereço MAC. |
OBSERVAÇÃO:
- Normalmente, os pacotes R-APS são transmitidos em um anel. Os pacotes de descarga originados do subanel podem ser encaminhados para o anel principal.
- Os pacotes de serviço podem ser transmitidos entre diferentes anéis.
Estados do nó ERPS
Tabela 2 Estados do ERPS
| Estado | Descrição |
| Init | Estado para um nó de não interconexão que tenha menos de duas portas de membro de anel ERPS ou para um nó de interconexão que não tenha portas de membro de anel ERPS. |
| Inativo | Estado estável quando todos os links não RPL estão disponíveis. Nesse estado, o nó proprietário bloqueia a porta RPL e envia periodicamente pacotes NR-RB. O nó vizinho bloqueia a porta RPL. Todos os nós entram no estado ocioso depois que o nó proprietário entra no estado ocioso. |
| Proteção | Estado em que um link não RPL está com defeito. Nesse estado, o link RPL é desbloqueado para encaminhar o tráfego. Todos os nós entram no estado de proteção depois que um nó entra no estado de proteção. |
| MS | Estado em que os caminhos de tráfego são comutados manualmente. Todos os nós entram no estado MS depois que um nó é configurado com o modo MS. |
| FS | Estado em que os caminhos de tráfego são comutados à força. Todos os nós entram no estado FS depois que um nó é configurado com o modo FS. |
| Pendente | Estado transitório entre os estados anteriores. |
Temporizadores ERPS
Temporizador de espera
O temporizador de espera começa quando a porta detecta uma falha de link. A porta informa a falha de link se a falha persistir quando o cronômetro expirar.
Esse temporizador atrasa o tempo de relatório de falhas e afeta o desempenho de comutação do link.
Temporizador de guarda
O timer de guarda começa quando a porta detecta uma recuperação de link. A porta não processa os pacotes R-APS antes que o cronômetro expire.
Esse temporizador impede que os pacotes R-APS afetem a rede e afeta o desempenho da comutação de links quando existem vários pontos de falhas.
Temporizador WTR
No modo revertivo, o cronômetro WTR é iniciado quando o nó proprietário no estado de proteção recebe pacotes NR. O RPL é desbloqueado e o nó recuperado é bloqueado antes que o cronômetro expire. O nó proprietário bloqueia a RPL e envia pacotes NR-RB quando o cronômetro expira. Se a porta receber pacotes SF antes que o cronômetro expire, o cronômetro será interrompido e a RPL permanecerá desbloqueada.
Esse temporizador evita que falhas intermitentes de link afetem a rede.
Temporizador WTB
No modo revertivo, o cronômetro WTB é iniciado quando o nó proprietário no estado MS ou FS recebe pacotes NR. A RPL é desbloqueada e o nó recuperado envia pacotes NR antes que o cronômetro expire. O nó proprietário bloqueia a RPL e envia pacotes NR-RB quando o cronômetro expira. Se a porta receber pacotes SF antes que o cronômetro expire, o cronômetro será interrompido e a RPL permanecerá desbloqueada.
Esse cronômetro evita que as portas RPL sejam bloqueadas e desbloqueadas com frequência.
Mecanismo de operação do ERPS
O ERPS usa o mecanismo de detecção definido na ITU-T G.8032/Y.1344 para localizar o ponto de falha e identificar falhas unidirecionais ou bidirecionais.
O ERPS usa os pacotes SF para relatar falhas de sinal em um link e os pacotes NR para relatar a recuperação do link. Quando um nó detecta uma alteração no status do link, ele envia três pacotes primeiro e, em seguida, envia os pacotes subsequentes a cada cinco segundos.
Mecanismo de relatório de ligação descendente
Figura 2 Mecanismo de relatório de ligação descendente
Conforme mostrado na Figura 2, o mecanismo de relatório de link-down usa o seguinte processo:
- O dispositivo C e o dispositivo D detectam a falha no link e executam as seguintes operações:
- Bloqueie as portas em ambos os lados do link defeituoso.
- Enviar periodicamente pacotes SF para outros nós.
- O dispositivo A e o dispositivo B recebem os pacotes SF e realizam as seguintes operações:
- Desbloquear portas RPL.
- Atualize as entradas de endereço MAC. Os pacotes de serviço são transferidos para o link RPL.
Mecanismo de recuperação de links
Figura 3 Mecanismo de recuperação de links
Conforme mostrado na Figura 3, o mecanismo de recuperação de link usa o seguinte processo:
- O dispositivo C e o dispositivo D detectam a recuperação do link e executam as seguintes operações:
- Bloquear as portas recuperadas.
- Inicie o cronômetro de guarda.
- Enviar pacotes NR.
- Quando o dispositivo A (nó proprietário) recebe os pacotes NR, ele não realiza nenhuma operação se estiver no modo não revertivo. Se o dispositivo A estiver no modo revertivo, ele executará as seguintes operações:
- Inicia o cronômetro WTR.
- Bloqueia a porta RPL e envia periodicamente pacotes NR-RB quando o cronômetro WTR expira.
- Quando os outros nós recebem os pacotes NR-RB, eles realizam as seguintes operações:
- O dispositivo B (porta vizinha) bloqueia a porta RPL.
- O dispositivo C e o dispositivo D desbloqueiam as portas recuperadas. Os pacotes de serviço são comutados para o link recuperado.
Mecanismo de balanceamento de carga de várias instâncias
Figura 4 Mecanismo de balanceamento de carga de várias instâncias
Uma topologia em anel do ERPS pode transportar tráfego de várias VLANs. O tráfego de diferentes VLANs pode ser balanceado entre diferentes instâncias de ERPS.
O ERPS usa os seguintes tipos de VLANs:
- VLAN de controle - Transporta pacotes de protocolo ERPS. Cada instância do ERPS tem sua própria VLAN de controle.
- VLAN protegida - Transporta pacotes de dados. Cada instância do ERPS tem sua própria VLAN protegida. As VLANs protegidas são configuradas usando os mapeamentos entre VLANs e MSTIs.
Conforme mostrado na Figura 4, o anel ERPS é configurado com a instância 1 e a instância 2. Para a instância 1, o nó proprietário é o Dispositivo A e o RPL é o link entre o Dispositivo A e o Dispositivo B. Para a instância 2, o nó proprietário é o Dispositivo C e o RPL é o link entre o Dispositivo C e o Dispositivo D. O tráfego de diferentes VLANs pode ser balanceado entre diferentes links.
Mecanismo de configuração manual
O ERPS é compatível com os seguintes modos de configuração manual:
- MS - Use o comando erps switch manual para bloquear uma porta membro do anel ERPS. Uma porta no modo MS é bloqueada e envia pacotes MS. Os nós que recebem os pacotes MS desbloqueiam as portas disponíveis. Se os nós no modo MS receberem um pacote SF, eles desbloquearão as portas bloqueadas.
- FS - Use o comando erps switch force ring para bloquear uma porta membro do anel ERPS. Uma porta no modo FS é bloqueada e envia pacotes FS. Os nós que recebem os pacotes FS desbloqueiam as portas disponíveis. Se os nós no modo FS receberem um pacote SF, eles não desbloquearão as portas bloqueadas.
Mecanismo de colaboração
Para detectar e eliminar falhas de link, normalmente em um link de fibra, use o ERPS com CFD e Track. Você pode associar as portas de membro de anel do ERPS à função de verificação de continuidade do CFD por meio de entradas de rastreamento. Para obter mais informações sobre CFD e Track, consulte "Configuração de CFD" e "Configuração de Track".
Diagramas de rede do ERPS
Um anel principal
A rede tem um anel principal.
Figura 5 Diagrama de rede
Um anel principal conectando um subanel
A rede tem um anel principal e um subanel.
Figura 6 Diagrama de rede
Um anel principal conectando vários subanéis
A rede tem três ou mais anéis. Cada subanel é conectado ao anel principal por dois nós de interconexão.
Figura 7 Diagrama de rede
Um subanel que conecta vários subanéis
A rede tem três ou mais anéis. Conforme mostrado na Figura 8, o subanel 1 está conectado ao anel principal. Outros subanéis são conectados ao subanel 1 por dois nós de interconexão.
Figura 8 Diagrama de rede
Um subanel conectando vários anéis
A rede tem três ou mais anéis. No mínimo um subanel está conectado a dois anéis. Conforme mostrado na Figura 9, um nó de interconexão no subanel 2 está conectado ao anel principal e outro nó de interconexão está conectado ao subanel 1. Conforme mostrado na Figura 10, o subanel 3 está conectado ao subanel 1 e ao subanel 2.
Figura 9 Diagrama de rede 1
Figura 10 Diagrama de rede 2
Protocolos e padrões
- ITU-T G.8032, Recomendação ITU-T G.8032/Y.1344, Comutação de proteção de anel Ethernet
- IEEE 802.1D, IEEE Std 802.1D™-2004, Padrão IEEE para redes de área local e metropolitana - pontes de controle de acesso de mídia (MAC)
- IEEE 802.3, IEEE Std 802.3-2008, Padrão IEEE para tecnologia da informação
Restrições e diretrizes: Configuração do ERPS
O ERPS não oferece um mecanismo de eleição. Para implementar a detecção e a proteção de anel, configure todos os nós corretamente.
Visão geral das tarefas do ERPS
Para configurar o ERPS, execute as seguintes tarefas:
- Habilitando o ERPS globalmente
- Configuração de um anel ERPS
- Criação de um anel ERPS
- Configuração de portas de membro do anel ERPS
- Configuração de VLANs de controle
- Configuração de VLANs protegidas
- Configuração da função de nó
- Ativação do ERPS para uma instância
- (Opcional.) Ativação de pacotes R-APS para conter o ID do anel no endereço MAC de destino.
- (Opcional.) Configuração dos níveis de pacotes R-APS
- (Opcional.) Configuração de temporizadores ERPS
- (Opcional.) Configuração do modo não revertivo
- (Opcional.) Definição de um modo de comutação
- (Opcional.) Associar um anel a um subanel
- (Opcional.) Ativação da transmissão transparente de pacotes de descarga.
- (Opcional.) Associação de uma porta de membro de anel ERPS a uma entrada de trilha
- (Opcional.) Remoção das configurações do modo MS e do modo FS para um anel ERPS
Execute essa tarefa nos dispositivos que você deseja configurar como nós de ERPS.
Execute essa tarefa em todos os nós de um anel ERPS.
Execute essa tarefa em todos os nós de um anel ERPS.
Execute essa tarefa em todos os nós de um anel ERPS.
Execute essa tarefa no nó proprietário em um anel ERPS.
Execute essa tarefa no nó proprietário em um anel ERPS.
Execute essa tarefa nos nós que você deseja bloquear suas portas.
Execute essa tarefa no nó de interconexão em um anel ERPS.
Execute essa tarefa no nó de interconexão em um anel ERPS.
Pré-requisitos
Antes de configurar o ERPS, conclua as seguintes tarefas:
- Estabelecer a topologia de anel Ethernet.
- Determine os anéis de ERPS, as instâncias de ERPS, as VLANs de controle, as VLANs protegidas e as funções de nó.
Habilitando o ERPS globalmente
Restrições e diretrizes
- Execute essa tarefa nos dispositivos que você deseja configurar como nós de ERPS.
- Para que o ERPS entre em vigor em uma instância, ative-o globalmente primeiro.
Procedimento
- Entre na visualização do sistema.
System-viewerps enablePor padrão, o ERPS é desativado globalmente.
Configuração de um anel ERPS
Criação de um anel ERPS
Restrições e diretrizes
- Execute essa tarefa em todos os nós de um anel ERPS.
- Uma ID de anel identifica de forma exclusiva um anel ERPS. Todos os nós em um anel ERPS devem ser configurados com a mesma ID de anel.
Procedimento
- Entre na visualização do sistema.
System-viewerps ring ring-idring-type sub-ringPor padrão, um anel ERPS é um anel principal.
Configuração de portas de membro do anel ERPS
Restrições e diretrizes
- Execute essa tarefa nas portas de cada nó destinadas a acessar os anéis do ERPS.
- As portas de membro do anel ERPS permitem automaticamente a passagem de pacotes da VLAN de controle.
- Não habilite o loopback remoto do Ethernet OAM para portas de membros do anel ERPS. Esse recurso pode causar uma tempestade de broadcast. Para obter mais informações sobre o Ethernet OAM, consulte "Configuração do Ethernet OAM".
- Para uma convergência mais rápida da topologia, use o comando link-delay nas portas de membro do anel ERPS para definir o intervalo de supressão de mudança de estado físico como 0 segundos. Para obter mais informações sobre o comando link-delay, consulte Layer 2-LAN Switching Command Reference.
- Você deve configurar as portas de membro do anel ERPS como portas tronco.
- Não atribua uma interface a um grupo de agregação e a um anel ERPS. Se você fizer isso, a interface não entrará em vigor no anel ERPS e não poderá ser exibida com o comando display erps detail.
Configuração dos atributos da porta de membro do anel ERPS
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberport link-type trunkPor padrão, uma porta é uma porta de acesso.
Para obter mais informações sobre esse comando, consulte Referência de comandos de comutação de Layer 2-LAN.
port trunk permit vlan { vlan-id-list | all }Por padrão, uma porta tronco é atribuída apenas à VLAN 1.
Para obter mais informações sobre esse comando, consulte Referência de comandos de comutação de Layer 2-LAN.
undo stp enablePor padrão, o recurso de spanning tree está ativado.
Para obter mais informações sobre esse comando, consulte Referência de comandos de comutação de Layer 2-LAN.
Configuração de uma porta de membro do anel ERPS
- Entre na visualização do sistema.
System-viewerps ring ring-id{ port0 | port1 } interface interface-type interface-numberPor padrão, um anel ERPS não tem portas de membro do anel ERPS.
Configuração de VLANs de controle
Restrições e diretrizes
- Execute essa tarefa em todos os nós de um anel ERPS.
- A VLAN de controle deve ser uma VLAN que não tenha sido criada no dispositivo.
- Configure a mesma VLAN de controle para todos os nós em uma instância do ERPS.
- Não configure a VLAN padrão de uma porta membro do anel ERPS como a VLAN de controle.
- Não habilite o QinQ ou o mapeamento de VLAN nas VLANs de controle. Se você fizer isso, os pacotes ERPS não poderão ser encaminhados e recebidos corretamente.
- Certifique-se de que a instância do ERPS tenha sido configurada. Depois que a instância do ERPS for ativada, a VLAN de controle não poderá ser alterada.
- Para que um dispositivo não configurado com ERPS transmita pacotes ERPS de forma transparente, certifique-se de que apenas as duas portas que acessam o anel ERPS permitam pacotes da VLAN de controle. Se outras portas do dispositivo permitirem pacotes da VLAN de controle, os pacotes de outras VLANs poderão entrar na VLAN de controle e atingir o anel ERPS.
Procedimento
- Entre na visualização do sistema.
System-viewerps ring ring-idinstance instance-idcontrol-vlan vlan-idConfiguração de VLANs protegidas
Restrições e diretrizes
- Execute essa tarefa em todos os nós de um anel ERPS.
- Configure a mesma VLAN protegida para todos os nós de uma instância do ERPS. Para implementar o balanceamento de carga, configure diferentes VLANs protegidas para diferentes instâncias de ERPS.
Pré-requisitos
Antes de configurar VLANs protegidas, você deve configurar uma região MST e a tabela de mapeamento VLAN-para-instância. Para obter mais informações sobre as regiões MST, consulte Configuração da árvore de abrangência no Guia de configuração de comutação de camada 2-LAN.
Procedimento
- Entre na visualização do sistema.
System-viewerps ring ring-idinstance instance-idprotected-vlan reference-instance instance-id-listConfiguração da função de nó
Restrições e diretrizes
- Execute essa tarefa em todos os nós de um anel ERPS.
- Para que o nó proprietário funcione corretamente, você deve configurar apenas um nó proprietário para um anel ERPS.
- Você só pode configurar o nó de interconexão para subrings.
Procedimento
- Entre na visualização do sistema.
System-viewerps ring ring-idinstance instance-idnode-role { { owner | neighbor } rpl | interconnection } { port0 | port1 }Por padrão, um nó é um nó normal.
Ativação do ERPS para uma instância
Restrições e diretrizes
- Execute essa tarefa em todos os nós de um anel ERPS.
- Você pode ativar o ERPS para uma instância somente quando ela estiver configurada com uma VLAN de controle e uma VLAN protegida.
Procedimento
- Entre na visualização do sistema.
System-viewerps ring ring-idinstance instance-idinstance enablePor padrão, o ERPS está desativado para uma instância.
Habilitação de pacotes R-APS para conter o ID do anel no endereço MAC de destino
Sobre esse recurso
Execute esta tarefa para configurar o ID do anel como o último byte do endereço MAC de destino para pacotes R-APS. O anel de pacotes R-APS pode ser identificado por seus endereços MAC de destino.
Restrições e diretrizes
Execute essa tarefa em todos os nós de um anel ERPS.
Procedimento
- Entre na visualização do sistema.
System-viewerps ring ring-idr-aps ring-macPor padrão, os pacotes R-APS não contêm IDs de anel em seus endereços MAC de destino. O último byte do endereço MAC de destino é 1.
Configuração dos níveis de pacotes R-APS
Restrições e diretrizes
Execute essa tarefa em todos os nós de um anel ERPS.
Em um anel, os níveis dos pacotes R-APS devem ser os mesmos para todos os nós em uma instância do ERPS.
Um nó não processa pacotes R-APS cujos níveis são maiores do que o nível dos pacotes R-APS enviados pelo nó.
Procedimento
- Entre na visualização do sistema.
System-viewerps ring ring-idinstance instance-idr-aps level level-valuePor padrão, o nível dos pacotes R-APS é 7.
Configuração de temporizadores ERPS
Restrições e diretrizes
Execute essa tarefa no nó proprietário em um anel ERPS.
Procedimento
- Entre na visualização do sistema.
System-viewerps ring ring-idinstance instance-idtimer guard guard-valuePor padrão, o temporizador de guarda é de 500 milissegundos.
timer hold-off hold-off-valuePor padrão, o temporizador de espera é de 0 milissegundos.
timer wtr wtr-valuePor padrão, o temporizador WTR é de 5 minutos.
Configuração do modo não revertivo
Sobre a configuração do modo não revertivo
Execute esta tarefa se você não quiser voltar ao link recuperado depois que a falha do link for eliminada.
Restrições e diretrizes
Execute essa tarefa no nó proprietário em um anel ERPS.
Procedimento
- Entre na visualização do sistema.
System-viewerps ring ring-idinstance instance-idrevertive-operation non-revertivePor padrão, o modo revertivo é usado.
Configuração de um modo de comutação
Restrições e diretrizes
Execute essa tarefa nos nós que você deseja bloquear suas portas.
Procedimento
- Entre na visualização do sistema.
System-viewerps switch { force | manual } ring ring-id instance instance-id { port0 | port1 }Por padrão, nenhum modo de comutação é definido.
Associação de um anel a um sub-anel
Sobre a associação de um anel a um sub-anel
Em uma rede com vários anéis, execute esta tarefa se quiser anunciar alterações de topologia em um subanel para um anel .
Restrições e diretrizes
Execute essa tarefa no nó de interconexão em um anel ERPS.
Procedimento
- Entre na visualização do sistema.
System-viewerps ring ring-idring-type sub-ringPor padrão, um anel ERPS é um anel principal.
instance instance-idsub-ring connect ring ring-id instance instance-idPor padrão, um subanel não está associado a nenhum anel.
Ativação da transmissão transparente do pacote de descarga
Sobre a ativação da transmissão transparente de pacotes flush
Esse recurso permite que os nós de interconexão encaminhem pacotes de descarga para alterações de topologia no subanel para o anel associado ao subanel. O anel associado pode liberar a tabela de endereços MAC rapidamente para acelerar a convergência.
Restrições e diretrizes
Execute essa tarefa no nó de interconexão em um anel ERPS.
Para usar esse recurso, você também deve associar um subanel no nó de interconexão com o anel.
Procedimento
- Entre na visualização do sistema.
System-viewerps tcn-propagationPor padrão, a transmissão transparente do pacote de descarga está desativada.
Associação de uma porta de membro de anel ERPS a uma entrada de trilha
Restrições e diretrizes
Antes de associar uma porta a uma entrada de trilha, certifique-se de que a porta tenha ingressado em uma instância de ERPS.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberport erps ring ring-id instance instance-id track track-entry-indexPor padrão, uma porta membro do anel ERPS não está associada a nenhuma entrada de trilha.
Remoção das configurações do modo MS e do modo FS para um anel ERPS
Sobre a remoção das configurações do modo MS e do modo FS
Depois que você configurar essa tarefa, o nó proprietário poderá ignorar o cronômetro WTR e alternar imediatamente o tráfego para o link recuperado após a recuperação do link.
Essa tarefa também alterna um anel ERPS no modo não revertivo para o modo revertivo.
Procedimento
- Entre na visualização do sistema.
System-viewerps clear ring ring-id instance instance-idExibição e atualização de ERPS
Execute comandos de exibição em qualquer visualização e redefina comandos na visualização do usuário.
| Tarefa | Comando |
| Exibir informações breves sobre o ERPS. | exibir erps |
| Exibir informações detalhadas sobre o ERPS. | display erps detail ring ring-id [ instance instance-id ] |
| Exibir estatísticas de pacotes ERPS. | exibir estatísticas erps [ ring ring-id [ instance instance-id ] ] |
| Limpar estatísticas de pacotes ERPS. | reset erps statistics ring ring-id [ instance instance-id ] |
Exemplos de configuração do ERPS
Exemplo: Configuração de um anel
Configuração de rede
Conforme mostrado na Figura 11, execute as seguintes tarefas para eliminar os loops na rede:
- Configure o anel como anel ERPS 1.
- Configure a VLAN 100 como a VLAN de controle para o anel 1 do ERPS.
- Configure as VLANs 1 a 30 como VLANs protegidas para o anel 1 do ERPS.
- Configure o Dispositivo A como o nó proprietário, a GigabitEthernet 1/0/1 como porta 0 de membro do anel ERPS e a porta RPL, e a GigabitEthernet 1/0/2 como porta 1 de membro do anel ERPS.
- Configure o Dispositivo B como o nó vizinho, a GigabitEthernet 1/0/1 como porta 0 de membro do anel ERPS e a porta RPL, e a GigabitEthernet 1/0/2 como porta 1 de membro do anel ERPS.
- Configure o Dispositivo C e o Dispositivo D como nós normais, a GigabitEthernet 1/0/1 como porta 0 de membro do anel ERPS e a GigabitEthernet 1/0/2 como porta 1 de membro do anel ERPS.
Figura 11 Diagrama de rede
Procedimento
- Configurar o dispositivo A.
# Crie VLANs de 1 a 30, mapeie essas VLANs para MSTI 1 e ative a configuração da região MST.
<DeviceA> system-view
[DeviceA] vlan 1 to 30
[DeviceA] stp region-configuration
[DeviceA-mst-region] instance 1 vlan 1 to 30
[DeviceA-mst-region] active region-configuration
[DeviceA-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] link-delay up 0
[DeviceA-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceA-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 30.
[DeviceA-GigabitEthernet1/0/1] port link-type trunk
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] link-delay up 0
[DeviceA-GigabitEthernet1/0/2] link-delay down 0
[DeviceA-GigabitEthernet1/0/2] undo stp enable
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceA-GigabitEthernet1/0/2] quit# Criar anel ERPS 1.
[DeviceA] erps ring 1# Configure as portas de membro do anel ERPS.
[DeviceA-erps-ring1] port0 interface gigabitethernet 1/0/1
[DeviceA-erps-ring1] port1 interface gigabitethernet 1/0/2# Habilite os pacotes R-APS para conter o ID do anel no endereço MAC de destino.
[DeviceA-erps-ring1] r-aps ring-mac# Criar a instância 1 do ERPS.
[DeviceA-erps-ring1] instance 1# Configure a função de nó.
[DeviceA-erps-ring1-inst1] node-role owner rpl port0# Configure a VLAN de controle.
[DeviceA-erps-ring1-inst1] control-vlan 100# Configure as VLANs protegidas.
[DeviceA-erps-ring1-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceA-erps-ring1-inst1] instance enable
[DeviceA-erps-ring1-inst1] quit
[DeviceA-erps-ring1] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceA] cfd enable
[DeviceA] cfd md MD_A level 5# Criar a instância de serviço 1, na qual o MA é identificado por uma VLAN e atende à VLAN 1.
[DeviceA] cfd service-instance 1 ma-id vlan-based md MD_A vlan 1# Configure uma lista MEP na instância de serviço 1, crie o MEP 1001 voltado para o exterior na instância de serviço 1 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceA] cfd meplist 1001 1002 service-instance 1
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] cfd mep 1001 service-instance 1 outbound
[DeviceA-GigabitEthernet1/0/1] cfd cc service-instance 1 mep 1001 enable
[DeviceA-GigabitEthernet1/0/1] quit# Criar a instância de serviço 2, na qual o MA é identificado por uma VLAN e atende à VLAN 2.
[DeviceA] cfd service-instance 2 ma-id vlan-based md MD_A vlan 2# Configure uma lista MEP na instância de serviço 2, crie o MEP 2001 voltado para o exterior na instância de serviço 1 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceA] cfd meplist 2001 2002 service-instance 2
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] cfd mep 2001 service-instance 2 outbound
[DeviceA-GigabitEthernet1/0/2] cfd cc service-instance 2 mep 2001 enable
[DeviceA-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 1001 na instância de serviço 1.
[DeviceA] track 1 cfd cc service-instance 1 mep 1001# Associe a GigabitEthernet 1/0/1 à entrada de trilha 1 e abra a porta.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port erps ring 1 instance 1 track 1
[DeviceA-GigabitEthernet1/0/1] undo shutdown
[DeviceA-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 2 e associe-a à função CC do CFD para o MEP 2001 na instância de serviço 2.
[DeviceA] track 2 cfd cc service-instance 2 mep 2001# Associe a GigabitEthernet 1/0/2 à entrada de trilha 2 e abra a porta.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port erps ring 1 instance 1 track 2
[DeviceA-GigabitEthernet1/0/2] undo shutdown
[DeviceA-GigabitEthernet1/0/2] quit# Ativar o ERPS.
[DeviceA] erps enable# Crie VLANs de 1 a 30, mapeie essas VLANs para MSTI 1 e ative a configuração da região MST.
<DeviceB> system-view
[DeviceB] vlan 1 to 30
[DeviceB] stp region-configuration
[DeviceB-mst-region] instance 1 vlan 1 to 30
[DeviceB-mst-region] active region-configuration
[DeviceB-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] link-delay up 0
[DeviceB-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceB-GigabitEthernet1/0/1] undo stp enable
[DeviceB-GigabitEthernet1/0/1] port link-type trunk# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 30.
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] link-delay up 0
[DeviceB-GigabitEthernet1/0/2] link-delay down 0
[DeviceB-GigabitEthernet1/0/2] undo stp enable
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceB-GigabitEthernet1/0/2] quit# Criar anel ERPS 1.
[DeviceB] erps ring 1# Configure as portas de membro do anel ERPS.
[DeviceB-erps-ring1] port0 interface gigabitethernet 1/0/1
[DeviceB-erps-ring1] port1 interface gigabitethernet 1/0/2# Habilite os pacotes R-APS para conter o ID do anel no endereço MAC de destino.
[DeviceB-erps-ring1] r-aps ring-mac# Criar a instância 1 do ERPS.
[DeviceB-erps-ring1] instance 1# Configure a função de nó.
[DeviceB-erps-ring1-inst1] node-role neighbor rpl port0# Configure a VLAN de controle.
[DeviceB-erps-ring1-inst1] control-vlan 100# Configure as VLANs protegidas.
[DeviceB-erps-ring1-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceB-erps-ring1-inst1] instance enable
[DeviceB-erps-ring1-inst1] quit
[DeviceB-erps-ring1] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceB] cfd enable
[DeviceB] cfd md MD_A level 5# Criar a instância de serviço 1, na qual o MA é identificado por uma VLAN e atende à VLAN 1.
[DeviceB] cfd service-instance 1 ma-id vlan-based md MD_A vlan 1# Configure uma lista de MEP na instância de serviço 1, crie o MEP 1002 voltado para o exterior na instância de serviço 1 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceB] cfd meplist 1001 1002 service-instance 1
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] cfd mep 1002 service-instance 1 outbound
[DeviceB-GigabitEthernet1/0/1] cfd cc service-instance 1 mep 1002 enable
[DeviceB-GigabitEthernet1/0/1] quit# Criar a instância de serviço 3, na qual o MA é identificado por uma VLAN e atende à VLAN 3.
[DeviceB] cfd service-instance 3 ma-id vlan-based md MD_A vlan 3# Configure uma lista MEP na instância de serviço 3, crie o MEP 3002 voltado para o exterior na instância de serviço 1 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceB] cfd meplist 3001 3002 service-instance 3
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] cfd mep 3002 service-instance 3 outbound
[DeviceB-GigabitEthernet1/0/2] cfd cc service-instance 3 mep 3002 enable
[DeviceB-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 1002 na instância de serviço 1.
[DeviceB] track 1 cfd cc service-instance 1 mep 1002# Associe a GigabitEthernet 1/0/1 à entrada de trilha 1 e abra a porta.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port erps ring 1 instance 1 track 1
[DeviceB-GigabitEthernet1/0/1] undo shutdown
[DeviceB-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 3 e associe-a à função CC do CFD para o MEP 3002 na instância de serviço 3.
[DeviceB] track 3 cfd cc service-instance 3 mep 3002# Associe a GigabitEthernet 1/0/2 à entrada de trilha 3 e abra a porta.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port erps ring 1 instance 1 track 2
[DeviceB-GigabitEthernet1/0/2] undo shutdown
[DeviceB-GigabitEthernet1/0/2] quit# Ativar o ERPS.
[DeviceB] erps enable# Crie VLANs de 1 a 30, mapeie essas VLANs para MSTI 1 e ative a configuração da região MST.
<DeviceC> system-view
[DeviceC] vlan 1 to 30
[DeviceC] stp region-configuration
[DeviceC-mst-region] instance 1 vlan 1 to 30
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] link-delay up 0
[DeviceC-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceC-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 30.
[DeviceC-GigabitEthernet1/0/1] port link-type trunk
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceC-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] link-delay up 0
[DeviceC-GigabitEthernet1/0/2] link-delay down 0
[DeviceC-GigabitEthernet1/0/2] undo stp enable
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceC-GigabitEthernet1/0/2] quit# Criar anel ERPS 1.
[DeviceC] erps ring 1# Configure as portas de membro do anel ERPS.
[DeviceC-erps-ring1] port0 interface gigabitethernet 1/0/1
[DeviceC-erps-ring1] port1 interface gigabitethernet 1/0/2# Habilite os pacotes R-APS para conter o ID do anel no endereço MAC de destino.
[DeviceC-erps-ring1] r-aps ring-mac# Criar a instância 1 do ERPS.
[DeviceC-erps-ring1] instance 1# Configure a VLAN de controle.
[DeviceC-erps-ring1-inst1] control-vlan 100# Configure as VLANs protegidas.
[DeviceC-erps-ring1-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceC-erps-ring1-inst1] instance enable
[DeviceC-erps-ring1-inst1] quit
[DeviceC-erps-ring1] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceC] cfd enable
[DeviceC] cfd md MD_A level 5# Criar a instância de serviço 3, na qual o MA é identificado por uma VLAN e atende à VLAN 3.
[DeviceC] cfd service-instance 3 ma-id vlan-based md MD_A vlan 3# Configure uma lista MEP na instância de serviço 3, crie o MEP 3001 voltado para o exterior na instância de serviço 3 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceC] cfd meplist 3001 3002 service-instance 3
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] cfd mep 3001 service-instance 3 outbound
[DeviceC-GigabitEthernet1/0/2] cfd cc service-instance 3 mep 3001 enable
[DeviceC-GigabitEthernet1/0/2] quit# Criar a instância de serviço 4, na qual o MA é identificado por uma VLAN e atende à VLAN 4.
[DeviceC] cfd service-instance 4 ma-id vlan-based md MD_A vlan 4# Configure uma lista MEP na instância de serviço 4, crie o MEP 4001 voltado para o exterior na instância de serviço 4 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceC] cfd meplist 4001 4002 service-instance 4
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] cfd mep 4001 service-instance 4 outbound
[DeviceC-GigabitEthernet1/0/1] cfd cc service-instance 4 mep 4001 enable
[DeviceC-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 3001 na instância de serviço 3.
[DeviceC] track 1 cfd cc service-instance 3 mep 3001# Associe a GigabitEthernet 1/0/2 à entrada de trilha 1 e abra a porta.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] port erps ring 1 instance 1 track 1
[DeviceC-GigabitEthernet1/0/2] undo shutdown
[DeviceC-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 2 e associe-a à função CC do CFD para MEP 4001 na instância de serviço 4.
[DeviceC] track 2 cfd cc service-instance 4 mep 4001# Associe a GigabitEthernet 1/0/1 à entrada de trilha 3 e abra a porta.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] port erps ring 1 instance 1 track 2
[DeviceC-GigabitEthernet1/0/1] undo shutdown
[DeviceC-GigabitEthernet1/0/1] quit# Ativar o ERPS.
[DeviceC] erps enable# Crie VLANs de 1 a 30, mapeie essas VLANs para MSTI 1 e ative a configuração da região MST.
<DeviceD> system-view
[DeviceD] vlan 1 to 30
[DeviceD] stp region-configuration
[DeviceD-mst-region] instance 1 vlan 1 to 30
[DeviceD-mst-region] active region-configuration
[DeviceD-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link como 0 segundos na GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] link-delay up 0
[DeviceD-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceD-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 30.
[DeviceD-GigabitEthernet1/0/1] port link-type trunk
[DeviceD-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceD-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] link-delay up 0
[DeviceD-GigabitEthernet1/0/2] link-delay down 0
[DeviceD-GigabitEthernet1/0/2] undo stp enable
[DeviceD-GigabitEthernet1/0/2] port link-type trunk
[DeviceD-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceD-GigabitEthernet1/0/2] quit# Criar anel ERPS 1.
[DeviceD] erps ring 1# Configure as portas de membro do anel ERPS.
[DeviceD-erps-ring1] port0 interface gigabitethernet 1/0/1
[DeviceD-erps-ring1] port1 interface gigabitethernet 1/0/2# Habilite os pacotes R-APS para conter o ID do anel no endereço MAC de destino.
[DeviceD-erps-ring1] r-aps ring-mac# Criar a instância 1 do ERPS.
[DeviceD-erps-ring1] instance 1# Configure a VLAN de controle.
[DeviceD-erps-ring1-inst1] control-vlan 100# Configure as VLANs protegidas.
[DeviceD-erps-ring1-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceD-erps-ring1-inst1] instance enable
[DeviceD-erps-ring1-inst1] quit
[DeviceD-erps-ring1] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceD] cfd enable
[DeviceD] cfd md MD_A level 5# Crie a instância de serviço 2, na qual o MA é identificado por uma VLAN e atende à VLAN 2.
[DeviceD] cfd service-instance 2 ma-id vlan-based md MD_A vlan 2# Configure uma lista MEP na instância de serviço 2, crie o MEP 2002 voltado para o exterior na instância de serviço 2 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceD] cfd meplist 2001 2002 service-instance 2
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] cfd mep 2002 service-instance 2 outbound
[DeviceD-GigabitEthernet1/0/2] cfd cc service-instance 2 mep 2002 enable
[DeviceD-GigabitEthernet1/0/2] quit# Criar a instância de serviço 4, na qual o MA é identificado por uma VLAN e atende à VLAN 4.
[DeviceD] cfd service-instance 4 ma-id vlan-based md MD_A vlan 4# Configure uma lista MEP na instância de serviço 4, crie o MEP 4002 voltado para o exterior na instância de serviço 4 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceD] cfd meplist 4001 4002 service-instance 4
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] cfd mep 4002 service-instance 4 outbound
[DeviceD-GigabitEthernet1/0/1] cfd cc service-instance 4 mep 4002 enable
[DeviceD-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 2002 na instância de serviço 2.
[DeviceD] track 1 cfd cc service-instance 2 mep 2002# Associe a GigabitEthernet 1/0/2 à entrada de trilha 1 e abra a porta.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] port erps ring 1 instance 1 track 1
[DeviceD-GigabitEthernet1/0/2] undo shutdown
[DeviceD-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 2 e associe-a à função CC do CFD para o MEP 4002 na instância de serviço 4.
[DeviceD] track 2 cfd cc service-instance 4 mep 4002# Associe a GigabitEthernet 1/0/1 à entrada de trilha 2 e abra a porta.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] port erps ring 1 instance 1 track 2
[DeviceD-GigabitEthernet1/0/1] undo shutdown
[DeviceD-GigabitEthernet1/0/1] quit# Ativar o ERPS.
[DeviceD] erps enableVerificação da configuração
# Exibir informações sobre a instância 1 do ERPS para o dispositivo A.
[DeviceA] display erps detail ring 1
Ring ID : 1
Port0 : GigabitEthernet1/0/1
Port1 : GigabitEthernet1/0/2
Subring : No
Default MAC : No
Instance ID : 1
Node role : Owner
Node state : Idle
Connect(ring/instance) : -
Control VLAN : 100
Protected VLAN : Reference-instance 1
Guard timer : 500 ms
Hold-off timer : 0 ms
WTR timer : 5 min
Revertive operation : Revertive
Enable status : Yes, Active status : Yes
R-APS level : 7
Port PortRole PortStatus
----------------------------------------------------------------------------
Port0 RPL Block
Port1 Non-RPL UpO resultado mostra as seguintes informações:
- O dispositivo A é o nó proprietário.
- O anel ERPS está em estado ocioso.
- A porta RPL está bloqueada.
- A porta não RPL está desbloqueada.
Exemplo: Configuração de um subanel
Configuração de rede
Conforme mostrado na Figura 12, execute as seguintes tarefas para eliminar os loops na rede:
- Configure a VLAN 100 e a VLAN 200 como VLANs de controle para o anel principal e o sub-anel, respectivamente.
- Configure as VLANs 1 a 30 como as VLANs protegidas para o anel principal e o sub-anel.
- Configure o Dispositivo A como o nó proprietário do anel principal, a GigabitEthernet 1/0/1 como porta 0 de membro do anel ERPS e a porta RPL, e a GigabitEthernet 1/0/2 como porta 1 de membro do anel ERPS.
- Configure o Dispositivo B como o nó vizinho do anel principal, a GigabitEthernet 1/0/1 como porta 0 de membro do anel ERPS e a porta RPL, e a GigabitEthernet 1/0/2 como porta 1 de membro do anel ERPS.
- Configure os dispositivos C e D como nós de interconexão, GigabitEthernet 1/0/1 como porta de membro do anel ERPS 0, GigabitEthernet 1/0/2 como porta de membro do anel ERPS 1 e GigabitEthernet 1/0/3 como porta de interconexão.
- Configure o Dispositivo E como o nó proprietário do sub-anel, a GigabitEthernet 1/0/1 como porta 0 de membro do anel ERPS e a porta RPL, e a GigabitEthernet 1/0/2 como porta 1 de membro do anel ERPS.
- Configure o Dispositivo F como o nó vizinho do sub-anel, a GigabitEthernet 1/0/1 como a porta 0 de membro do anel ERPS e a porta RPL, e a GigabitEthernet 1/0/2 como a porta 1 de membro do anel ERPS.
Figura 12 Diagrama de rede
Procedimento
- Configure o dispositivo A.
# Crie VLANs de 1 a 30, mapeie essas VLANs para MSTI 1 e ative a configuração da região MST.
<DeviceA> system-view
[DeviceA] vlan 1 to 30
[DeviceA] stp region-configuration
[DeviceA-mst-region] instance 1 vlan 1 to 30
[DeviceA-mst-region] active region-configuration
[DeviceA-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] link-delay up 0
[DeviceA-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceA-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 30.
[DeviceA-GigabitEthernet1/0/1] port link-type trunk
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] link-delay up 0
[DeviceA-GigabitEthernet1/0/2] link-delay down 0
[DeviceA-GigabitEthernet1/0/2] undo stp enable
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceA-GigabitEthernet1/0/2] quit# Criar anel ERPS 1.
[DeviceA] erps ring 1# Configure as portas de membro do anel ERPS.
[DeviceA-erps-ring1] port0 interface gigabitethernet 1/0/1
[DeviceA-erps-ring1] port1 interface gigabitethernet 1/0/2# Criar instância 1 do ERPS.
[DeviceA-erps-ring1] instance 1# Configure a função do nó.
[DeviceA-erps-ring1-inst1] node-role owner rpl port0# Configure a VLAN de controle.
[DeviceA-erps-ring1-inst1] control-vlan 100# Configure as VLANs protegidas.
[DeviceA-erps-ring1-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceA-erps-ring1-inst1] instance enable
[DeviceA-erps-ring1-inst1] quit
[DeviceA-erps-ring1] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceA] cfd enable
[DeviceA] cfd md MD_A level 5# Criar a instância de serviço 1, na qual o MA é identificado por uma VLAN e atende à VLAN 1.
[DeviceA] cfd service-instance 1 ma-id vlan-based md MD_A vlan 1# Configure uma lista MEP na instância de serviço 1, crie o MEP 1001 voltado para o exterior na instância de serviço 1 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceA] cfd meplist 1001 1002 service-instance 1
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] cfd mep 1001 service-instance 1 outbound
[DeviceA-GigabitEthernet1/0/1] cfd cc service-instance 1 mep 1001 enable
[DeviceA-GigabitEthernet1/0/1] quit# Criar a instância de serviço 2, na qual o MA é identificado por uma VLAN e atende à VLAN 2.
[DeviceA] cfd service-instance 2 ma-id vlan-based md MD_A vlan 2# Configure uma lista MEP na instância de serviço 2, crie o MEP 2001 voltado para o exterior na instância de serviço 1 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceA] cfd meplist 2001 2002 service-instance 2
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] cfd mep 2001 service-instance 2 outbound
[DeviceA-GigabitEthernet1/0/2] cfd cc service-instance 2 mep 2001 enable
[DeviceA-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 1001 na instância de serviço 1.
[DeviceA] track 1 cfd cc service-instance 1 mep 1001# Associe a GigabitEthernet 1/0/1 à entrada de trilha 1 e abra a porta.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port erps ring 1 instance 1 track 1
[DeviceA-GigabitEthernet1/0/1] undo shutdown
[DeviceA-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 2 e associe-a à função CC do CFD para o MEP 2001 na instância de serviço 2.
[DeviceA] track 2 cfd cc service-instance 2 mep 2001# Associe a GigabitEthernet 1/0/2 à entrada de trilha 2 e abra a porta.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port erps ring 1 instance 1 track 2
[DeviceA-GigabitEthernet1/0/2] undo shutdown
[DeviceA-GigabitEthernet1/0/2] quit# Ativar o ERPS.
[DeviceA] erps enable# Crie VLANs de 1 a 30, mapeie essas VLANs para MSTI 1 e ative a configuração da região MST.
<DeviceB> system-view
[DeviceB] vlan 1 to 30
[DeviceB] stp region-configuration
[DeviceB-mst-region] instance 1 vlan 1 to 30
[DeviceB-mst-region] active region-configuration
[DeviceB-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] link-delay up 0
[DeviceB-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceB-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 30.
[DeviceB-GigabitEthernet1/0/1] port link-type trunk
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] link-delay up 0
[DeviceB-GigabitEthernet1/0/2] link-delay down 0
[DeviceB-GigabitEthernet1/0/2] undo stp enable
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceB-GigabitEthernet1/0/2] quit# Criar anel ERPS 1.
[DeviceB] erps ring 1# Configure as portas de membro do anel ERPS.
[DeviceB-erps-ring1] port0 interface gigabitethernet 1/0/1
[DeviceB-erps-ring1] port1 interface gigabitethernet 1/0/2# Criar instância 1 do ERPS.
[DeviceB-erps-ring1] instance 1# Configure a função do nó.
[DeviceB-erps-ring1-inst1] node-role neighbor rpl port0# Configure a VLAN de controle.
[DeviceB-erps-ring1-inst1] control-vlan 100# Configure as VLANs protegidas.
[DeviceB-erps-ring1-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceB-erps-ring1-inst1] instance enable
[DeviceB-erps-ring1-inst1] quit
[DeviceB-erps-ring1] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceB] cfd enable
[DeviceB] cfd md MD_A level 5# Criar a instância de serviço 1, na qual o MA é identificado por uma VLAN e atende à VLAN 1.
[DeviceB] cfd service-instance 1 ma-id vlan-based md MD_A vlan 1# Configure uma lista MEP na instância de serviço 1, crie o MEP 1002 voltado para o exterior na instância de serviço 1 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceB] cfd meplist 1001 1002 service-instance 1
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] cfd mep 1002 service-instance 1 outbound
[DeviceB-GigabitEthernet1/0/1] cfd cc service-instance 1 mep 1002 enable
[DeviceB-GigabitEthernet1/0/1] quit# Criar a instância de serviço 3, na qual o MA é identificado por uma VLAN e atende à VLAN 3.
[DeviceB] cfd service-instance 3 ma-id vlan-based md MD_A vlan 3# Configure uma lista MEP na instância de serviço 3, crie o MEP 3002 voltado para o exterior na instância de serviço 2 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceB] cfd meplist 3001 3002 service-instance 3
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] cfd mep 3002 service-instance 3 outbound
[DeviceB-GigabitEthernet1/0/2] cfd cc service-instance 3 mep 3002 enable
[DeviceB-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 1002 na instância de serviço 1.
[DeviceB] track 1 cfd cc service-instance 1 mep 1002# Associe a GigabitEthernet 1/0/1 à entrada de trilha 1 e abra a porta.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port erps ring 1 instance 1 track 1
[DeviceB-GigabitEthernet1/0/1] undo shutdown
[DeviceB-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 3 e associe-a à função CC do CFD para o MEP 3002 na instância de serviço 3.
[DeviceB] track 3 cfd cc service-instance 3 mep 3002# Associe a GigabitEthernet 1/0/2 à entrada de trilha 3 e abra a porta.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port erps ring 1 instance 1 track 2
[DeviceB-GigabitEthernet1/0/2] undo shutdown
[DeviceB-GigabitEthernet1/0/2] quit# Ativar o ERPS.
[DeviceB] erps enable# Crie VLANs de 1 a 30, mapeie essas VLANs para MSTI 1 e ative a configuração da região MST.
<DeviceC> system-view
[DeviceC] vlan 1 to 30
[DeviceC] stp region-configuration
[DeviceC-mst-region] instance 1 vlan 1 to 30
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] link-delay up 0
[DeviceC-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceC-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 30.
[DeviceC-GigabitEthernet1/0/1] port link-type trunk
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceC-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] link-delay up 0
[DeviceC-GigabitEthernet1/0/2] link-delay down 0
[DeviceC-GigabitEthernet1/0/2] undo stp enable
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceC-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/3
[DeviceC-GigabitEthernet1/0/3] link-delay up 0
[DeviceC-GigabitEthernet1/0/3] link-delay down 0
[DeviceC-GigabitEthernet1/0/3] undo stp enable
[DeviceC-GigabitEthernet1/0/3] port link-type trunk
[DeviceC-GigabitEthernet1/0/3] port trunk permit vlan 1 to 30
[DeviceC-GigabitEthernet1/0/3] quit# Criar anel ERPS 1.
[DeviceC] erps ring 1# Configure as portas de membro do anel ERPS.
[DeviceC-erps-ring1] port0 interface gigabitethernet 1/0/1
[DeviceC-erps-ring1] port1 interface gigabitethernet 1/0/2# Criar instância 1 do ERPS.
[DeviceC-erps-ring1] instance 1# Configure a VLAN de controle.
[DeviceC-erps-ring1-inst1] control-vlan 100# Configure as VLANs protegidas.
[DeviceC-erps-ring1-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceC-erps-ring1-inst1] instance enable
[DeviceC-erps-ring1-inst1] quit
[DeviceC-erps-ring1] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceC] cfd enable
[DeviceC] cfd md MD_A level 5# Criar a instância de serviço 3, na qual o MA é identificado por uma VLAN e atende à VLAN 3.
[DeviceC] cfd service-instance 3 ma-id vlan-based md MD_A vlan 3# Configure uma lista MEP na instância de serviço 3, crie o MEP 3001 voltado para o exterior na instância de serviço 3 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceC] cfd meplist 3001 3002 service-instance 3
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] cfd mep 3001 service-instance 3 outbound
[DeviceC-GigabitEthernet1/0/2] cfd cc service-instance 3 mep 3001 enable
[DeviceC-GigabitEthernet1/0/2] quit# Criar a instância de serviço 4, na qual o MA é identificado por uma VLAN e atende à VLAN 4.
[DeviceC] cfd service-instance 4 ma-id vlan-based md MD_A vlan 4# Configure uma lista MEP na instância de serviço 4, crie o MEP 4001 voltado para o exterior na instância de serviço 4 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceC] cfd meplist 4001 4002 service-instance 4
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] cfd mep 4001 service-instance 4 outbound
[DeviceC-GigabitEthernet1/0/1] cfd cc service-instance 4 mep 4001 enable
[DeviceC-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 3001 na instância de serviço 3.
[DeviceC] track 1 cfd cc service-instance 3 mep 3001# Associe a GigabitEthernet 1/0/2 à entrada de trilha 1 e abra a porta.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] port erps ring 1 instance 1 track 1
[DeviceC-GigabitEthernet1/0/2] undo shutdown
[DeviceC-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 2 e associe-a à função CC do CFD para MEP 4001 na instância de serviço 4.
[DeviceC] track 2 cfd cc service-instance 4 mep 4001# Associe a GigabitEthernet 1/0/1 à entrada de trilha 2 e abra a porta.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] port erps ring 1 instance 1 track 2
[DeviceC-GigabitEthernet1/0/1] undo shutdown
[DeviceC-GigabitEthernet1/0/1] quit# Criar o anel 2 do ERPS.
[DeviceC] erps ring 2# Configure as portas de membro do anel ERPS.
[DeviceC-erps-ring2] port0 interface gigabitethernet 1/0/3# Configure o anel 2 do ERPS como subanel.
[DeviceC-erps-ring2] ring-type sub-ring# Crie a instância 1 do ERPS.
[DeviceC-erps-ring2] instance 1# Configure a função do nó.
[DeviceC-erps-ring2-inst1] node-role interconnection port0# Configure a VLAN de controle.
[DeviceC-erps-ring2-inst1] control-vlan 110# Configure as VLANs protegidas.
[DeviceC-erps-ring2-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceC-erps-ring2-inst1] instance enable
[DeviceC-erps-ring2-inst1] quit
[DeviceC-erps-ring2] quit# Criar a instância de serviço 5, na qual o MA é identificado por uma VLAN e atende à VLAN 5.
[DeviceC] cfd service-instance 5 ma-id vlan-based md MD_A vlan 5# Configure uma lista MEP na instância de serviço 5, crie o MEP 5001 voltado para o exterior na instância de serviço 3 e ative o envio de CCM na GigabitEthernet 1/0/3.
[DeviceC] cfd meplist 5001 5002 service-instance 5
[DeviceC] interface gigabitethernet 1/0/3
[DeviceC-GigabitEthernet1/0/3] cfd mep 5001 service-instance 5 outbound
[DeviceC-GigabitEthernet1/0/3] cfd cc service-instance 5 mep 5001 enable
[DeviceC-GigabitEthernet1/0/3] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 5001 na instância de serviço 3.
[DeviceC] track 1 cfd cc service-instance 5 mep 5001# Associe a GigabitEthernet 1/0/3 à entrada de trilha 1 e abra a porta.
[DeviceC] interface gigabitethernet 1/0/3
[DeviceC-GigabitEthernet1/0/3] port erps ring 2 instance 1 track 1
[DeviceC-GigabitEthernet1/0/3] undo shutdown
[DeviceC-GigabitEthernet1/0/3] quit# Ativar o ERPS.
[DeviceC] erps enable# Crie VLANs de 1 a 30, mapeie essas VLANs para MSTI 1 e ative a configuração da região MST.
<DeviceD> system-view
[DeviceD] vlan 1 to 30
[DeviceD] stp region-configuration
[DeviceD-mst-region] instance 1 vlan 1 to 30
[DeviceD-mst-region] active region-configuration
[DeviceD-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] link-delay up 0
[DeviceD-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceD-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 30.
[DeviceD-GigabitEthernet1/0/1] port link-type trunk
[DeviceD-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceD-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] link-delay up 0
[DeviceD-GigabitEthernet1/0/2] link-delay down 0
[DeviceD-GigabitEthernet1/0/2] undo stp enable
[DeviceD-GigabitEthernet1/0/2] port link-type trunk
[DeviceD-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceD-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/3
[DeviceD-GigabitEthernet1/0/3] link-delay up 0
[DeviceD-GigabitEthernet1/0/3] link-delay down 0
[DeviceD-GigabitEthernet1/0/3] undo stp enable
[DeviceD-GigabitEthernet1/0/3] port link-type trunk
[DeviceD-GigabitEthernet1/0/3] port trunk permit vlan 1 to 30
[DeviceD-GigabitEthernet1/0/3] quit# Criar anel ERPS 1.
[DeviceD] erps ring 1# Configure as portas de membro do anel ERPS.
[DeviceD-erps-ring1] port0 interface gigabitethernet 1/0/1
[DeviceD-erps-ring1] port1 interface gigabitethernet 1/0/2# Criar instância 1 do ERPS.
[DeviceD-erps-ring1] instance 1# Configure a VLAN de controle.
[DeviceD-erps-ring1-inst1] control-vlan 100# Configure as VLANs protegidas.
[DeviceD-erps-ring1-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceD-erps-ring1-inst1] instance enable
[DeviceD-erps-ring1-inst1] quit
[DeviceD-erps-ring1] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceD] cfd enable
[DeviceD] cfd md MD_A level 5# Criar a instância de serviço 2, na qual o MA é identificado por uma VLAN e atende à VLAN 2.
[DeviceD] cfd service-instance 2 ma-id vlan-based md MD_A vlan 2# Configure uma lista MEP na instância de serviço 2, crie o MEP 2002 voltado para o exterior na instância de serviço 2 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceD] cfd meplist 2001 2002 service-instance 2
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] cfd mep 2002 service-instance 2 outbound
[DeviceD-GigabitEthernet1/0/2] cfd cc service-instance 2 mep 2002 enable
[DeviceD-GigabitEthernet1/0/2] quit# Criar a instância de serviço 4, na qual o MA é identificado por uma VLAN e atende à VLAN 4.
[DeviceD] cfd service-instance 4 ma-id vlan-based md MD_A vlan 4# Configure uma lista MEP na instância de serviço 4, crie o MEP 4002 voltado para o exterior na instância de serviço 4 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceD] cfd meplist 4001 4002 service-instance 4
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] cfd mep 4002 service-instance 4 outbound
[DeviceD-GigabitEthernet1/0/1] cfd cc service-instance 4 mep 4002 enable
[DeviceD-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 2002 na instância de serviço 2.
[DeviceD] track 1 cfd cc service-instance 2 mep 2002# Associe a GigabitEthernet 1/0/2 à entrada de trilha 1 e abra a porta.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] port erps ring 1 instance 1 track 1
[DeviceD-GigabitEthernet1/0/2] undo shutdown
[DeviceD-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 2 e associe-a à função CC do CFD para o MEP 4002 na instância de serviço 4.
[DeviceD] track 2 cfd cc service-instance 4 mep 4002# Associe a GigabitEthernet 1/0/1 à entrada de trilha 2 e abra a porta.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] port erps ring 1 instance 1 track 2
[DeviceD-GigabitEthernet1/0/1] undo shutdown
[DeviceD-GigabitEthernet1/0/1] quit# Criar anel ERPS 2.
[DeviceD] erps ring 2# Configure as portas de membro do anel ERPS.
[DeviceD-erps-ring2] port0 interface gigabitethernet 1/0/3# Configure o anel 2 do ERPS como subanel.
[DeviceD-erps-ring2] ring-type sub-ring# Crie a instância 1 do ERPS.
[DeviceD-erps-ring2] instance 1# Configure a função do nó.
[DeviceD-erps-ring2-inst1] node-role interconnection port0# Configure a VLAN de controle.
[DeviceD-erps-ring2-inst1] control-vlan 110# Configure as VLANs protegidas.
[DeviceD-erps-ring2-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceD-erps-ring2-inst1] instance enable
[DeviceD-erps-ring2-inst1] quit
[DeviceD-erps-ring2] quit# Crie a instância de serviço 6, na qual o MA é identificado por uma VLAN e atende à VLAN 6.
[DeviceD] cfd service-instance 6 ma-id vlan-based md MD_A vlan 6# Configure uma lista de MEP na instância de serviço 6, crie o MEP 6002 voltado para o exterior na instância de serviço 3 e ative o envio de CCM na GigabitEthernet 1/0/3.
[DeviceD] cfd meplist 6001 6002 service-instance 6
[DeviceD] interface gigabitethernet 1/0/3
[DeviceD-GigabitEthernet1/0/3] cfd mep 6002 service-instance 6 outbound
[DeviceD-GigabitEthernet1/0/3] cfd cc service-instance 6 mep 6002 enable
[DeviceD-GigabitEthernet1/0/3] quit# Crie a entrada de trilha 3 e associe-a à função CC do CFD para o MEP 6002 em serviço instância 6.
[DeviceD] track 3 cfd cc service-instance 6 mep 6002# Associe a GigabitEthernet 1/0/3 à entrada de trilha 3 e abra a porta.
[DeviceD] interface gigabitethernet 1/0/3
[DeviceD-GigabitEthernet1/0/3] port erps ring 2 instance 1 track 3
[DeviceD-GigabitEthernet1/0/3] undo shutdown
[DeviceD-GigabitEthernet1/0/3] quit# Ativar o ERPS.
[DeviceD] erps enable# Crie VLANs de 1 a 30, mapeie essas VLANs para MSTI 1 e ative a configuração da região MST.
<DeviceE> system-view
[DeviceE] vlan 1 to 30
[DeviceE] stp region-configuration
[DeviceE-mst-region] instance 1 vlan 1 to 30
[DeviceE-mst-region] active region-configuration
[DeviceE-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceE] interface gigabitethernet 1/0/1
[DeviceE-GigabitEthernet1/0/1] link-delay up 0
[DeviceE-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceE-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 30.
[DeviceE-GigabitEthernet1/0/1] port link-type trunk
[DeviceE-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceE-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceE] interface gigabitethernet 1/0/2
[DeviceE-GigabitEthernet1/0/2] link-delay up 0
[DeviceE-GigabitEthernet1/0/2] link-delay down 0
[DeviceE-GigabitEthernet1/0/2] undo stp enable
[DeviceE-GigabitEthernet1/0/2] port link-type trunk
[DeviceE-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceE-GigabitEthernet1/0/2] quit# Criar anel ERPS 2.
[DeviceE] erps ring 2# Configure as portas de membro do anel ERPS.
[DeviceE-erps-ring2] port0 interface gigabitethernet 1/0/1
[DeviceE-erps-ring2] port1 interface gigabitethernet 1/0/2# Configure o anel 2 do ERPS como o sub-anel.
[DeviceE-erps-ring2] ring-type sub-ring# Criar a instância 1 do ERPS.
[DeviceE-erps-ring2] instance 1# Configure a função de nó.
[DeviceE-erps-ring2] node-role owner rpl port0# Configure a VLAN de controle.
[DeviceE-erps-ring2-inst1] control-vlan 110# Configure as VLANs protegidas.
[DeviceE-erps-ring2-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceE-erps-ring2-inst1] instance enable
[DeviceE-erps-ring2-inst1] quit
[DeviceE-erps-ring2] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceE] cfd enable
[DeviceE] cfd md MD_A level 5# Crie a instância de serviço 6, na qual o MA é identificado por uma VLAN e atende à VLAN 6.
[DeviceE] cfd service-instance 6 ma-id vlan-based md MD_A vlan 6# Configure uma lista MEP na instância de serviço 6, crie o MEP 6001 voltado para o exterior na instância de serviço 6 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceE] cfd meplist 6001 6002 service-instance 6
[DeviceE] interface gigabitethernet 1/0/2
[DeviceE-GigabitEthernet1/0/2] cfd mep 6001 service-instance 6 outbound
[DeviceE-GigabitEthernet1/0/2] cfd cc service-instance 6 mep 6001 enable
[DeviceE-GigabitEthernet1/0/2] quit# Criar a instância de serviço 7, na qual o MA é identificado por uma VLAN e atende à VLAN 7.
[DeviceE] cfd service-instance 7 ma-id vlan-based md MD_A vlan 7# Configure uma lista MEP na instância de serviço 7, crie o MEP 7001 voltado para o exterior na instância de serviço 7 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceE] cfd meplist 7001 7002 service-instance 7
[DeviceE] interface gigabitethernet 1/0/1
[DeviceE-GigabitEthernet1/0/1] cfd mep 7001 service-instance 7 outbound
[DeviceE-GigabitEthernet1/0/1] cfd cc service-instance 7 mep 7001 enable
[DeviceE-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para MEP 6001 na instância de serviço 6.
[DeviceE] track 1 cfd cc service-instance 6 mep 6001# Associe a GigabitEthernet 1/0/2 à entrada de trilha 1 e abra a porta.
[DeviceE] interface gigabitethernet 1/0/2
[DeviceE-GigabitEthernet1/0/2] port erps ring 2 instance 1 track 1
[DeviceE-GigabitEthernet1/0/2] undo shutdown
[DeviceE-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 2 e associe-a à função CC do CFD para MEP 7001 na instância de serviço 7.
[DeviceE] track 2 cfd cc service-instance 7 mep 7001# Associe a GigabitEthernet 1/0/1 à entrada de trilha 2 e abra a porta.
[DeviceE] interface gigabitethernet 1/0/1
[DeviceE-GigabitEthernet1/0/1] port erps ring 2 instance 1 track 2
[DeviceE-GigabitEthernet1/0/1] undo shutdown
[DeviceE-GigabitEthernet1/0/1] quit# Ativar o ERPS.
[DeviceE] erps enable# Crie VLANs de 1 a 30, mapeie essas VLANs para MSTI 1 e ative a configuração da região MST.
<DeviceF> system-view
[DeviceF] vlan 1 to 30
[DeviceF] stp region-configuration
[DeviceF-mst-region] instance 1 vlan 1 to 30
[DeviceF-mst-region] active region-configuration
[DeviceF-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceF] interface gigabitethernet 1/0/1
[DeviceF-GigabitEthernet1/0/1] link-delay up 0
[DeviceF-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceF-GigabitEthernet1/0/1] undo stp enable
[DeviceF-GigabitEthernet1/0/1] port link-type trunk# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 30.
[DeviceF-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceF-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceF] interface gigabitethernet 1/0/2
[DeviceF-GigabitEthernet1/0/2] link-delay up 0
[DeviceF-GigabitEthernet1/0/2] link-delay down 0
[DeviceF-GigabitEthernet1/0/2] undo stp enable
[DeviceF-GigabitEthernet1/0/2] port link-type trunk
[DeviceF-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceF-GigabitEthernet1/0/2] quit# Criar anel ERPS 2.
[DeviceF] erps ring 2# Configure as portas de membro do anel ERPS.
[DeviceF-erps-ring2] port0 interface gigabitethernet 1/0/1
[DeviceF-erps-ring2] port1 interface gigabitethernet 1/0/2# Configure o anel 2 do ERPS como o sub-anel.
[DeviceF-erps-ring2] ring-type sub-ring# Criar a instância 1 do ERPS.
[DeviceF-erps-ring2] instance 1# Configure a função de nó.
[DeviceF-erps-ring2] node-role neighbor rpl port0# Configure a VLAN de controle.
[DeviceF-erps-ring2-inst1] control-vlan 110# Configure as VLANs protegidas.
[DeviceF-erps-ring2-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceF-erps-ring2-inst1] instance enable
[DeviceF-erps-ring2-inst1] quit
[DeviceF-erps-ring2] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceF] cfd enable
[DeviceF] cfd md MD_A level 5# Criar a instância de serviço 5, na qual o MA é identificado por uma VLAN e atende à VLAN 5.
[DeviceF] cfd service-instance 5 ma-id vlan-based md MD_A vlan 5# Configure uma lista MEP na instância de serviço 5, crie o MEP 5002 voltado para o exterior na instância de serviço 5 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceF] cfd meplist 5001 5002 service-instance 5
[DeviceF] interface gigabitethernet 1/0/2
[DeviceF-GigabitEthernet1/0/2] cfd mep 5002 service-instance 5 outbound
[DeviceF-GigabitEthernet1/0/2] cfd cc service-instance 5 mep 5002 enable
[DeviceF-GigabitEthernet1/0/2] quit# Criar a instância de serviço 7, na qual o MA é identificado por uma VLAN e atende à VLAN 7.
[DeviceF] cfd service-instance 7 ma-id vlan-based md MD_A vlan 7# Configure uma lista MEP na instância de serviço 7, crie o MEP 7002 voltado para o exterior na instância de serviço 7 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceF] cfd meplist 7001 7002 service-instance 7
[DeviceF] interface gigabitethernet 1/0/1
[DeviceF-GigabitEthernet1/0/1] cfd mep 7002 service-instance 7 outbound
[DeviceF-GigabitEthernet1/0/1] cfd cc service-instance 7 mep 7002 enable
[DeviceF-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 5001 na instância de serviço 5.
[DeviceF] track 1 cfd cc service-instance 5 mep 5002# Associe a GigabitEthernet 1/0/2 à entrada de trilha 1 e abra a porta.
[DeviceF] interface gigabitethernet 1/0/2
[DeviceF-GigabitEthernet1/0/2] port erps ring 2 instance 1 track 1
[DeviceF-GigabitEthernet1/0/2] undo shutdown
[DeviceF-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 2 e associe-a à função CC do CFD para o MEP 7002 na instância de serviço 7.
[DeviceF] track 2 cfd cc service-instance 7 mep 7002# Associe a GigabitEthernet 1/0/1 à entrada de trilha 2 e abra a porta.
[DeviceF] interface gigabitethernet 1/0/1
[DeviceF-GigabitEthernet1/0/1] port erps ring 2 instance 1 track 2
[DeviceF-GigabitEthernet1/0/1] undo shutdown
[DeviceF-GigabitEthernet1/0/1] quit# Ativar o ERPS.
[DeviceF] erps enableVerificação da configuração
# Exibir informações sobre a instância 1 do ERPS para o dispositivo A.
[Device A] display erps detail ring 1
Ring ID : 1
Port0 : GigabitEthernet1/0/1
Port1 : GigabitEthernet1/0/2
Subring : Yes
Default MAC : No
Instance ID : 1
Node role : Owner
Node state : Idle
Connect(ring/instance) : -
Control VLAN : 100
Protected VLAN : Reference-instance 1
Guard timer : 500 ms
Hold-off timer : 0 ms
WTR timer : 5 min
Revertive operation : Revertive
Enable status : Yes, Active status : Yes
R-APS level : 7
Port PortRole PortStatus
----------------------------------------------------------------------------
Port0 RPL Block
Port1 Non-RPL UpO resultado mostra as seguintes informações:
- O dispositivo A é o nó proprietário.
- O anel ERPS está em estado ocioso.
- A porta RPL está bloqueada.
- A porta não RPL está desbloqueada.
Exemplo: Configuração do balanceamento de carga multi-instância de um anel
Configuração de rede
Conforme mostrado na Figura 13, execute as seguintes tarefas para melhorar a utilização dos recursos da rede e implementar o balanceamento de carga entre os links:
- Configure as instâncias 1 e 2 do ERPS no anel do ERPS.
- Para a instância 1 do ERPS, configure os itens a seguir:
- Configure o dispositivo A como o nó proprietário.
- Configure o link entre os Dispositivos A e B como o RPL.
- Configure a VLAN 100 como a VLAN de controle.
- Configure as VLANs 1 a 30 como VLANs protegidas.
- Para a instância 2 do ERPS, configure os itens a seguir:
- Configure o dispositivo A como o nó proprietário.
- Configure o link entre os Dispositivos C e D como o RPL.
- Configure a VLAN 100 como a VLAN de controle.
- Configure as VLANs 31 a 60 como VLANs protegidas.
Figura 13 Diagrama de rede
Procedimento
- Configurar o dispositivo A.
# Crie VLANs de 1 a 60, mapeie as VLANs de 1 a 30 para MSTI 1, mapeie as VLANs de 31 a 60 para MSTI 2 e ative a configuração da região MST.
<DeviceA> system-view
[DeviceA] vlan 1 to 60
[DeviceA] stp region-configuration
[DeviceA-mst-region] instance 1 vlan 1 to 30
[DeviceA-mst-region] instance 2 vlan 31 to 60
[DeviceA-mst-region] active region-configuration
[DeviceA-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] link-delay up 0
[DeviceA-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceA-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 60.
[DeviceA-GigabitEthernet1/0/1] port link-type trunk
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan 1 to 60
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] link-delay up 0
[DeviceA-GigabitEthernet1/0/2] link-delay down 0
[DeviceA-GigabitEthernet1/0/2] undo stp enable
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 1 to 60
[DeviceA-GigabitEthernet1/0/2] quit# Criar anel ERPS 1.
[DeviceA] erps ring 1# Configure as portas de membro do anel ERPS.
[DeviceA-erps-ring1] port0 interface gigabitethernet 1/0/1
[DeviceA-erps-ring1] port1 interface gigabitethernet 1/0/2# Criar instância 1 do ERPS.
[DeviceA-erps-ring1] instance 1# Configure a função do nó.
[DeviceA-erps-ring1-inst1] node-role owner rpl port0# Configure a VLAN de controle.
[DeviceA-erps-ring1-inst1] control-vlan 100# Configure as VLANs protegidas.
[DeviceA-erps-ring1-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceA-erps-ring1-inst1] instance enable
[DeviceA-erps-ring1-inst1] quit
[DeviceA-erps-ring1] quit# Criar a instância 2 do ERPS.
[DeviceA-erps-ring1] instance 2# Configure a VLAN de controle.
[DeviceA-erps-ring1-inst2] control-vlan 110# Configure as VLANs protegidas.
[DeviceA-erps-ring1-inst2] protected-vlan reference-instance 2# Habilite o ERPS para a instância 2.
[DeviceA-erps-ring1-inst2] instance enable
[DeviceA-erps-ring1-inst2] quit
[DeviceA-erps-ring1] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceA] cfd enable
[DeviceA] cfd md MD_A level 5# Criar a instância de serviço 1, na qual o MA é identificado por uma VLAN e atende à VLAN 1.
[DeviceA] cfd service-instance 1 ma-id vlan-based md MD_A vlan 1# Configure uma lista MEP na instância de serviço 1, crie o MEP 1001 voltado para o exterior na instância de serviço 1 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceA] cfd meplist 1001 1002 service-instance 1
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] cfd mep 1001 service-instance 1 outbound
[DeviceA-GigabitEthernet1/0/1] cfd cc service-instance 1 mep 1001 enable
[DeviceA-GigabitEthernet1/0/1] quit# Criar a instância de serviço 2, na qual o MA é identificado por uma VLAN e atende à VLAN 2.
[DeviceA] cfd service-instance 2 ma-id vlan-based md MD_A vlan 2# Configure uma lista de MEP na instância de serviço 2, crie o MEP 2001 voltado para o exterior na instância de serviço 1 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceA] cfd meplist 2001 2002 service-instance 2
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] cfd mep 2001 service-instance 2 outbound
[DeviceA-GigabitEthernet1/0/2] cfd cc service-instance 2 mep 2001 enable
[DeviceA-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 1001 na instância de serviço 1.
[DeviceA] track 1 cfd cc service-instance 1 mep 1001# Associe a GigabitEthernet 1/0/1 à entrada de trilha 1 e abra a porta para as instâncias 1 e 2 do ERPS.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port erps ring 1 instance 1 track 1
[DeviceA-GigabitEthernet1/0/1] port erps ring 1 instance 2 track 1
[DeviceA-GigabitEthernet1/0/1] undo shutdown
[DeviceA-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 2 e associe-a à função CC do CFD para o MEP 2001 na instância de serviço 2.
[DeviceA] track 2 cfd cc service-instance 2 mep 2001# Associe a GigabitEthernet 1/0/2 à entrada de trilha 2 e abra a porta para as instâncias 1 e 2 do ERPS.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port erps ring 1 instance 1 track 2
[DeviceA-GigabitEthernet1/0/2] port erps ring 1 instance 2 track 2
[DeviceA-GigabitEthernet1/0/2] undo shutdown
[DeviceA-GigabitEthernet1/0/2] quit# Ativar o ERPS.
[DeviceA] erps enable# Crie VLANs de 1 a 60, mapeie as VLANs de 1 a 30 para MSTI 1, mapeie as VLANs de 31 a 60 para MSTI 2 e ative a configuração da região MST.
<DeviceB> system-view
[DeviceB] vlan 1 to 60
[DeviceB] stp region-configuration
[DeviceB-mst-region] instance 1 vlan 1 to 30
[DeviceB-mst-region] instance 2 vlan 31 to 60
[DeviceB-mst-region] active region-configuration
[DeviceB-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] link-delay up 0
[DeviceB-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceB-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 60.
[DeviceB-GigabitEthernet1/0/1] port link-type trunk
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 1 to 60
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] link-delay up 0
[DeviceB-GigabitEthernet1/0/2] link-delay down 0
[DeviceB-GigabitEthernet1/0/2] undo stp enable
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 1 to 60
[DeviceB-GigabitEthernet1/0/2] quit# Criar anel ERPS 1.
[DeviceB] erps ring 1# Configure as portas de membro do anel ERPS.
[DeviceB-erps-ring1] port0 interface gigabitethernet 1/0/1
[DeviceB-erps-ring1] port1 interface gigabitethernet 1/0/2# Criar instância 1 do ERPS.
[DeviceB-erps-ring1] instance 1# Configure a função do nó.
[DeviceB-erps-ring1-inst1] node-role neighbor rpl port0# Configure a VLAN de controle.
[DeviceB-erps-ring1-inst1] control-vlan 100# Configure as VLANs protegidas.
[DeviceB-erps-ring1-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceB-erps-ring1-inst1] instance enable
[DeviceB-erps-ring1-inst1] quit
[DeviceB-erps-ring1] quit# Criar a instância 2 do ERPS.
[DeviceB-erps-ring1] instance 2# Configure a VLAN de controle.
[DeviceB-erps-ring1-inst2] control-vlan 110# Configure as VLANs protegidas.
[DeviceB-erps-ring1-inst2] protected-vlan reference-instance 2# Habilite o ERPS para a instância 2.
[DeviceB-erps-ring1-inst2] instance enable
[DeviceB-erps-ring1-inst2] quit
[DeviceB-erps-ring1] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceB] cfd enable
[DeviceB] cfd md MD_A level 5# Criar a instância de serviço 1, na qual o MA é identificado por uma VLAN e atende à VLAN 1.
[DeviceB] cfd service-instance 1 ma-id vlan-based md MD_A vlan 1# Configure uma lista MEP na instância de serviço 1, crie o MEP 1002 voltado para o exterior na instância de serviço 1 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceB] cfd meplist 1001 1002 service-instance 1
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] cfd mep 1002 service-instance 1 outbound
[DeviceB-GigabitEthernet1/0/1] cfd cc service-instance 1 mep 1002 enable
[DeviceB-GigabitEthernet1/0/1] quit# Criar a instância de serviço 3, na qual o MA é identificado por uma VLAN e atende à VLAN 3.
[DeviceB] cfd service-instance 3 ma-id vlan-based md MD_A vlan 3# Configure uma lista MEP na instância de serviço 3, crie o MEP 3002 voltado para o exterior na instância de serviço 3 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceB] cfd meplist 3001 3002 service-instance 3
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] cfd mep 3002 service-instance 3 outbound
[DeviceB-GigabitEthernet1/0/2] cfd cc service-instance 3 mep 3002 enable
[DeviceB-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 1002 em serviço instância 1.
[DeviceB] track 1 cfd cc service-instance 1 mep 1002# Associe a GigabitEthernet 1/0/1 à entrada de trilha 1 e abra a porta para as instâncias 1 e 2 do ERPS.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port erps ring 1 instance 1 track 1
[DeviceB-GigabitEthernet1/0/1] port erps ring 1 instance 2 track 1
[DeviceB-GigabitEthernet1/0/1] undo shutdown
[DeviceB-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 2 e associe-a à função CC do CFD para o MEP 3002 na instância de serviço 3.
[DeviceB] track 2 cfd cc service-instance 3 mep 3002# Associe a GigabitEthernet 1/0/2 à entrada de trilha 2 e abra a porta para as instâncias 1 e 2 do ERPS.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port erps ring 1 instance 1 track 2
[DeviceB-GigabitEthernet1/0/2] port erps ring 1 instance 2 track 2
[DeviceB-GigabitEthernet1/0/2] undo shutdown
[DeviceB-GigabitEthernet1/0/2] quit# Ativar o ERPS.
[DeviceB] erps enable# Crie VLANs de 1 a 60, mapeie as VLANs de 1 a 30 para MSTI 1, mapeie as VLANs de 31 a 60 para MSTI 2 e ative a configuração da região MST.
<DeviceC> system-view
[DeviceC] vlan 1 to 60
[DeviceC] stp region-configuration
[DeviceC-mst-region] instance 1 vlan 1 to 30
[DeviceC-mst-region] instance 2 vlan 31 to 60
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] link-delay up 0
[DeviceC-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceC-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 60.
[DeviceC-GigabitEthernet1/0/1] port link-type trunk
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 1 to 60
[DeviceC-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] link-delay up 0
[DeviceC-GigabitEthernet1/0/2] link-delay down 0
[DeviceC-GigabitEthernet1/0/2] undo stp enable
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan 1 to 60
[DeviceC-GigabitEthernet1/0/2] quit# Criar anel ERPS 1.
[DeviceC] erps ring 1# Configure as portas de membro do anel ERPS.
[DeviceC-erps-ring1] port0 interface gigabitethernet 1/0/1
[DeviceC-erps-ring1] port1 interface gigabitethernet 1/0/2# Criar instância 1 do ERPS.
[DeviceC-erps-ring1] instance 1# Configure a VLAN de controle.
[DeviceC-erps-ring1-inst1] control-vlan 100# Configure as VLANs protegidas.
[DeviceC-erps-ring1-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceC-erps-ring1-inst1] instance enable
[DeviceC-erps-ring1-inst1] quit
[DeviceC-erps-ring1] quit# Criar a instância 2 do ERPS.
[DeviceC-erps-ring1] instance 2# Configure a função de nó.
[DeviceC-erps-ring1-inst2] node-role owner rpl port0# Configure a VLAN de controle.
[DeviceC-erps-ring1-inst2] control-vlan 110# Configure as VLANs protegidas.
[DeviceC-erps-ring1-inst2] protected-vlan reference-instance 2# Habilite o ERPS para a instância 2.
[DeviceC-erps-ring1-inst2] instance enable
[DeviceC-erps-ring1-inst2] quit
[DeviceC-erps-ring1] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceC] cfd enable
[DeviceC] cfd md MD_A level 5# Criar a instância de serviço 3, na qual o MA é identificado por uma VLAN e atende à VLAN 3.
[DeviceC] cfd service-instance 3 ma-id vlan-based md MD_A vlan 3# Configure uma lista MEP na instância de serviço 3, crie o MEP 3001 voltado para o exterior na instância de serviço 3 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceC] cfd meplist 3001 3002 service-instance 3
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] cfd mep 3001 service-instance 3 outbound
[DeviceC-GigabitEthernet1/0/2] cfd cc service-instance 3 mep 3001 enable
[DeviceC-GigabitEthernet1/0/2] quit# Criar a instância de serviço 4, na qual o MA é identificado por uma VLAN e atende à VLAN 4.
[DeviceC] cfd service-instance 4 ma-id vlan-based md MD_A vlan 4# Configure uma lista MEP na instância de serviço 4, crie o MEP 4001 voltado para o exterior na instância de serviço 4 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceC] cfd meplist 4001 4002 service-instance 4
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] cfd mep 4001 service-instance 4 outbound
[DeviceC-GigabitEthernet1/0/1] cfd cc service-instance 4 mep 4001 enable
[DeviceC-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 3001 em serviço instância 3.
[DeviceC] track 1 cfd cc service-instance 3 mep 3001# Associe a GigabitEthernet 1/0/2 à entrada de trilha 1 e abra a porta para as instâncias 1 e 2 do ERPS.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] port erps ring 1 instance 1 track 1
[DeviceC-GigabitEthernet1/0/2] port erps ring 1 instance 2 track 1
[DeviceC-GigabitEthernet1/0/2] undo shutdown
[DeviceC-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 2 e associe-a à função CC do CFD para MEP 4001 na instância de serviço 4.
[DeviceC] track 2 cfd cc service-instance 4 mep 4001# Associe a GigabitEthernet 1/0/1 à entrada de trilha 2 e abra a porta para as instâncias 1 e 2 do ERPS.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] port erps ring 1 instance 1 track 2
[DeviceC-GigabitEthernet1/0/1] port erps ring 1 instance 2 track 2
[DeviceC-GigabitEthernet1/0/1] undo shutdown
[DeviceC-GigabitEthernet1/0/1] quit# Ativar o ERPS.
[DeviceC] erps enable# Crie VLANs de 1 a 60, mapeie as VLANs de 1 a 30 para MSTI 1, mapeie as VLANs de 31 a 60 para MSTI 2 e ative a configuração da região MST.
<DeviceD> system-view
[DeviceD] vlan 1 to 60
[DeviceD] stp region-configuration
[DeviceD-mst-region] instance 1 vlan 1 to 30
[DeviceD-mst-region] instance 2 vlan 31 to 60
[DeviceD-mst-region] active region-configuration
[DeviceD-mst-region] quit# Defina o intervalo de supressão de alteração do estado do link para 0 segundos na GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] link-delay up 0
[DeviceD-GigabitEthernet1/0/1] link-delay down 0# Desative o recurso spanning tree na porta.
[DeviceD-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco e atribua a ela as VLANs 1 a 60.
[DeviceD-GigabitEthernet1/0/1] port link-type trunk
[DeviceD-GigabitEthernet1/0/1] port trunk permit vlan 1 to 60
[DeviceD-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] link-delay up 0
[DeviceD-GigabitEthernet1/0/2] link-delay down 0
[DeviceD-GigabitEthernet1/0/2] undo stp enable
[DeviceD-GigabitEthernet1/0/2] port link-type trunk
[DeviceD-GigabitEthernet1/0/2] port trunk permit vlan 1 to 60
[DeviceD-GigabitEthernet1/0/2] quit# Criar anel ERPS 1.
[DeviceD] erps ring 1# Configure as portas de membro do anel ERPS.
[DeviceD-erps-ring1] port0 interface gigabitethernet 1/0/1
[DeviceD-erps-ring1] port1 interface gigabitethernet 1/0/2# Criar instância 1 do ERPS.
[DeviceD-erps-ring1] instance 1# Configure a VLAN de controle.
[DeviceD-erps-ring1-inst1] control-vlan 100# Configure as VLANs protegidas.
[DeviceD-erps-ring1-inst1] protected-vlan reference-instance 1# Habilite o ERPS para a instância 1.
[DeviceD-erps-ring1-inst1] instance enable
[DeviceD-erps-ring1-inst1] quit# Criar instância do ERPS 2.
[DeviceD-erps-ring1] instance 2# Configure a função do nó.
[DeviceD-erps-ring1-inst2] node-role neighbor rpl port0# Configure a VLAN de controle.
[DeviceD-erps-ring1-inst2] control-vlan 110# Configure as VLANs protegidas.
[DeviceD-erps-ring1-inst2] protected-vlan reference-instance 2# Habilite o ERPS para a instância 2.
[DeviceD-erps-ring1-inst2] instance enable
[DeviceD-erps-ring1-inst2] quit
[DeviceD-erps-ring1] quit# Habilite o CFD e crie um MD de nível 5 chamado MD_A.
[DeviceD] cfd enable
[DeviceD] cfd md MD_A level 5# Criar a instância de serviço 2, na qual o MA é identificado por uma VLAN e atende à VLAN 2.
[DeviceD] cfd service-instance 2 ma-id vlan-based md MD_A vlan 2# Configure uma lista MEP na instância de serviço 2, crie o MEP 2002 voltado para o exterior na instância de serviço 2 e ative o envio de CCM na GigabitEthernet 1/0/2.
[DeviceD] cfd meplist 2001 2002 service-instance 2
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] cfd mep 2002 service-instance 2 outbound
[DeviceD-GigabitEthernet1/0/2] cfd cc service-instance 2 mep 2002 enable
[DeviceD-GigabitEthernet1/0/2] quit# Criar a instância de serviço 4, na qual o MA é identificado por uma VLAN e atende à VLAN 4.
[DeviceD] cfd service-instance 4 ma-id vlan-based md MD_A vlan 4# Configure uma lista MEP na instância de serviço 4, crie o MEP 4002 voltado para o exterior na instância de serviço 4 e ative o envio de CCM na GigabitEthernet 1/0/1.
[DeviceD] cfd meplist 4001 4002 service-instance 4
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] cfd mep 4002 service-instance 4 outbound
[DeviceD-GigabitEthernet1/0/1] cfd cc service-instance 4 mep 4002 enable
[DeviceD-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 1 e associe-a à função CC do CFD para o MEP 2002 na instância de serviço 2.
[DeviceD] track 1 cfd cc service-instance 2 mep 2002# Associe a GigabitEthernet 1/0/2 à entrada de trilha 1 e abra a porta para as instâncias 1 e 2 do ERPS.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] port erps ring 1 instance 1 track 1
[DeviceD-GigabitEthernet1/0/2] port erps ring 1 instance 2 track 1
[DeviceD-GigabitEthernet1/0/2] undo shutdown
[DeviceD-GigabitEthernet1/0/2] quit# Crie a entrada de trilha 2 e associe-a à função CC do CFD para o MEP 4002 na instância de serviço 4.
[DeviceD] track 2 cfd cc service-instance 4 mep 4002# Associe a GigabitEthernet 1/0/1 à entrada de trilha 2 e abra a porta para as instâncias 1 e 2 do ERPS.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] port erps ring 1 instance 1 track 2
[DeviceD-GigabitEthernet1/0/1] port erps ring 1 instance 2 track 2
[DeviceD-GigabitEthernet1/0/1] undo shutdown
[DeviceD-GigabitEthernet1/0/1] quit# Ativar o ERPS.
[DeviceD] erps enableVerificação da configuração
# Exibir informações sobre a instância 1 do ERPS para o dispositivo A.
[Device A] display erps detail ring 1
Ring ID : 1
Port0 : GigabitEthernet1/0/1
Port1 : GigabitEthernet1/0/2
Subring : No
Default MAC : No
Instance ID : 1
Node role : Owner
Node state : Idle
Connect(ring/instance) : -
Control VLAN : 100
Protected VLAN : Reference-instance 1
Guard timer : 500 ms
Hold-off timer : 0 ms
WTR timer : 5 min
Revertive operation : Revertive
Enable status : Yes, Active status : Yes
R-APS level : 7
Port PortRole PortStatus
----------------------------------------------------------------------------
Port0 RPL Block
Port1 Non-RPL Up
Instance ID : 2
Node role : Normal
Node state : Idle
Connect(ring/instance) : -
Control VLAN : 100
Protected VLAN : Reference-instance 2
Guard timer : 500 ms
Hold-off timer : 0 ms
WTR timer : 5 min
Revertive operation : Revertive
Enable status : Yes, Active status : Yes
R-APS level : 7
Port PortRole PortStatus
----------------------------------------------------------------------------
Port0 Non-RPL Up
Port1 Non-RPL UpO resultado mostra as seguintes informações:
- Para a instância 1 do ERPS:
- O dispositivo A é o nó proprietário.
- O anel ERPS está em estado ocioso.
- A porta RPL está bloqueada.
- A porta não RPL está desbloqueada.
- Para a instância 2 do ERPS:
- O dispositivo A é um nó normal.
- O anel ERPS está em estado ocioso.
- A porta não RPL está desbloqueada.
Solução de problemas do ERPS
O nó proprietário não pode receber pacotes SF de um nó defeituoso quando o estado do link está normal
Sintoma
O link entre o nó proprietário e o nó com defeito está disponível, mas o nó proprietário não pode receber pacotes SF enviados pelo nó com defeito. A porta RPL está bloqueada.
Análise
Os possíveis motivos incluem:
- O ERPS não está ativado para alguns nós no anel ERPS.
- As IDs de anel são diferentes para os nós no mesmo anel ERPS.
- As IDs de VLAN de controle são diferentes para os nós na mesma instância do ERPS.
- Uma porta no anel ERPS está com defeito.
Soluções
Para resolver o problema:
- Use o comando display erps para verificar se o ERPS está ativado para todos os nós do anel ERPS. Se o ERPS estiver desativado para alguns nós, use o comando erps enable para ativar o ERPS para os nós.
- Defina a mesma ID de anel para todos os nós em um anel ERPS e configure a mesma VLAN de controle para todos os nós em uma instância ERPS.
- Use o comando display erps detail para examinar o status da porta em todos os nós. Ative as portas em estado inativo.
- Use o comando debugging erps em todos os nós para exibir informações de depuração sobre pacotes e status do nó.
Configuração do Smart Link
Sobre o Smart Link
Cenário de aplicação
O Smart Link oferece redundância de link e tempo de convergência de menos de um segundo em uma rede de uplink duplo. Conforme mostrado na Figura 1, o Smart Link está configurado no Dispositivo C e no Dispositivo D. O link secundário assume o controle rapidamente quando o link primário falha.
Aplicavel somente a Serie S3300G
Figura 1 Diagrama de rede de uplink duplo
Uma rede Smart Link tem os seguintes dispositivos:
- Dispositivos Smart Link - Um dispositivo Smart Link tem dois uplinks. Um dispositivo Smart Link deve ser configurado com um grupo de links inteligentes e uma VLAN de controle de transmissão para transmitir mensagens de flush. Os dispositivos C e D na Figura 1 são dispositivos Smart Link.
- Dispositivos associados - Um dispositivo associado é um dispositivo de uplink ao qual os dispositivos Smart Link estão conectados. Um dispositivo associado é compatível com o Smart Link e recebe mensagens de flush enviadas da VLAN de controle especificada. Quando ocorre uma troca de link primário/secundário, o dispositivo associado atualiza as entradas de endereço MAC e as entradas ARP/ND de acordo com as mensagens flush recebidas. O dispositivo A, o dispositivo B e o dispositivo E na Figura 1 são dispositivos associados.
Terminologia
Grupo de links inteligentes
Um grupo de links inteligentes consiste em apenas duas portas membros: a primária e a secundária. Apenas uma porta está ativa para encaminhamento de cada vez, e a outra porta está bloqueada e em estado de espera. Quando ocorre uma falha de link na porta ativa devido ao desligamento da porta ou à presença de um link unidirecional, a porta em espera se torna ativa e assume o controle. A porta ativa original passa para o estado bloqueado.
Conforme mostrado na Figura 1, a porta C1 e a porta C2 do dispositivo C formam um grupo de links inteligentes. A porta C1 está ativa e a porta C2 está em espera. A porta D1 e a porta D2 do dispositivo D formam outro grupo de links inteligentes. A porta D1 está ativa, e a porta D2 está em espera.
Porta primária/secundária
A porta primária e a porta secundária são dois tipos de porta em um grupo de links inteligentes. Quando ambas as portas em um grupo de links inteligentes estão ativas, a porta primária passa preferencialmente para o estado de encaminhamento. A porta secundária permanece em estado de espera. Quando a porta primária falha, a porta secundária assume o controle para encaminhar o tráfego.
Conforme mostrado na Figura 1, a porta C1 do dispositivo C e a porta D1 do dispositivo D são portas primárias. A porta C2 do dispositivo C e a porta D2 do dispositivo D são portas secundárias.
Link primário/secundário
O link que conecta a porta primária em um grupo de links inteligentes é o link primário. O link que conecta a porta secundária é o link secundário.
Mensagem de descarga
Quando ocorre a troca de link, o grupo de links inteligentes usa mensagens flush para notificar outros dispositivos para que atualizem suas entradas de endereço MAC e entradas ARP/ND. As mensagens flush são pacotes comuns de dados multicast e serão descartadas por uma porta receptora bloqueada.
VLAN protegida
Um grupo de links inteligentes controla o estado de encaminhamento de VLANs protegidas. Cada grupo de links inteligentes em uma porta controla uma VLAN protegida diferente. O estado da porta em uma VLAN protegida é determinado pelo estado da porta no grupo de links inteligentes.
VLAN de controle de transmissão
A VLAN de controle de transmissão é usada para transmitir mensagens de flush. Quando ocorre a troca de link, os dispositivos (como o Dispositivo C e o Dispositivo D na Figura 1) enviam mensagens de flush dentro da VLAN de controle de transmissão.
VLAN de controle de recepção
A VLAN de controle de recebimento é usada para receber e processar mensagens de descarga. Quando ocorre a troca de link, os dispositivos (como o Dispositivo A, o Dispositivo B e o Dispositivo E na Figura 1) recebem e processam mensagens de flush na VLAN de controle de recebimento. Além disso, eles atualizam o endereço MAC e as entradas ARP/ND.
Como o Smart Link funciona
Backup de links
Conforme mostrado na Figura 1, o link na porta C1 do dispositivo C é o link primário. O link na porta C2 do dispositivo C é o link secundário. A porta C1 está em estado de encaminhamento e a porta C2 está em estado de espera. Quando o link primário falha, a porta C2 assume o encaminhamento do tráfego e a porta C1 é bloqueada e colocada em estado de espera.
Quando uma porta muda para o estado de encaminhamento, o sistema emite informações de registro para notificar o usuário sobre a mudança de estado da porta.
Mudança de topologia
A troca de link pode desatualizar as entradas de endereço MAC e as entradas ARP/ND em todos os dispositivos. Um mecanismo de atualização de flush é fornecido para garantir a transmissão correta dos pacotes. Com esse mecanismo, um dispositivo habilitado para Smart Link atualiza suas informações transmitindo mensagens de flush pelo link de backup para seus dispositivos upstream. Esse mecanismo exige que os dispositivos upstream sejam capazes de reconhecer as mensagens de flush do Smart Link para atualizar suas entradas de encaminhamento de endereço MAC e entradas ARP/ND.
Modo de preempção
Conforme mostrado na Figura 1, o link na porta C1 do dispositivo C é o link primário. O link na porta C2 do dispositivo C é o link secundário. Quando o link primário falha, a porta C1 é automaticamente bloqueada e colocada em estado de espera, e a porta C2 assume o controle para encaminhar o tráfego. Quando o link primário se recupera, ocorre uma das seguintes ações:
- Se o grupo de links inteligentes não estiver configurado com um modo de preempção, a porta C1 permanecerá bloqueada para manter o encaminhamento do tráfego estável. A porta C1 não assume o encaminhamento do tráfego até a próxima troca de link.
- Se o grupo de links inteligentes estiver configurado com um modo de preempção e as condições de preempção forem atendidas, a porta C1 assumirá o encaminhamento do tráfego assim que seu link for recuperado. A porta C2 é automaticamente bloqueada e colocada em estado de espera.
Compartilhamento de carga
Uma rede em anel pode transportar o tráfego de várias VLANs. O Smart Link pode encaminhar o tráfego de diferentes VLANs em diferentes grupos de smart links para compartilhamento de carga.
Para implementar o compartilhamento de carga, você pode atribuir uma porta a vários grupos de links inteligentes. Configure cada grupo com uma VLAN protegida diferente. Certifique-se de que o estado da porta seja diferente nesses grupos de links inteligentes, para que o tráfego de VLANs diferentes possa ser encaminhado por caminhos diferentes.
Você pode configurar VLANs protegidas para um grupo de links inteligentes fazendo referência a Multiple Spanning Tree Instances (MSTIs). Para obter mais informações sobre MSTIs, consulte Layer 2-LAN Switching Configuration Guide.
Colaboração entre o Smart Link e o Monitor Link para detecção do status da porta
O Smart Link não pode detectar quando ocorrem falhas no uplink dos dispositivos upstream ou quando as falhas são eliminadas. Você pode configurar a função Monitor Link para monitorar o status das portas de uplink dos dispositivos upstream. O Monitor Link adapta o estado up/down das portas de downlink às portas de uplink e aciona o Smart Link para executar a alternância de link no dispositivo downstream. Para obter mais informações sobre o Monitor Link, consulte "Configuração do Monitor Link".
Colaboração entre o Smart Link e o Track para detecção do status do link
O Smart Link não pode detectar links unidirecionais, fibras mal conectadas ou perda de pacotes em dispositivos intermediários ou caminhos de rede do uplink. Ele também não pode detectar quando as falhas são eliminadas. Para detectar o status do link, as portas membros do grupo de links inteligentes devem usar protocolos de detecção de links. Quando uma falha é detectada ou eliminada, os protocolos de detecção de link informam ao Smart Link para alternar os links.
O Smart Link colabora com os protocolos de detecção de links por meio de entradas de trilha. Ele suporta apenas a função de verificação de continuidade (CC) da detecção de falhas de conectividade (CFD) para implementar a detecção de links. O CFD notifica as portas membros do grupo de links inteligentes sobre eventos de detecção de falhas usando VLANs de detecção e portas de detecção. Uma porta responde a um evento de verificação de continuidade somente quando a VLAN de controle do grupo de links inteligentes ao qual ela pertence corresponde à VLAN de detecção. Para obter mais informações sobre entradas de trilha e a função CC do CFD, consulte "Configuração de trilha" e "Configuração de CFD".
Restrições e diretrizes: Configuração do Smart Link
Se você configurar uma porta como membro de um grupo de agregação e como membro de um grupo de links inteligentes, somente a configuração do grupo de agregação terá efeito. A porta não é mostrada na saída do comando display smart-link group. A configuração do grupo de links inteligentes entra em vigor depois que a porta deixa o grupo de agregação.
Visão geral das tarefas do Smart Link
Para configurar o Smart Link, execute as seguintes tarefas:
- Configuração de um dispositivo Smart Link
- Configuração de VLANs protegidas para um grupo de links inteligentes
- Configuração de portas membros para um grupo de links inteligentes
- (Opcional.) Configuração de um modo de preempção para um grupo de links inteligentes
- (Opcional.) Ativação do envio de mensagens de descarga
- (Opcional.) Configuração da colaboração entre o Smart Link e o Track
- Ativação de um dispositivo associado para receber mensagens de descarga
Configuração de um dispositivo Smart Link
Pré-requisitos para a configuração do dispositivo Smart Link
Antes de configurar um dispositivo Smart Link, conclua as seguintes tarefas:
- Para evitar loops, desligue uma porta antes de configurá-la como membro de um grupo de links inteligentes. Você pode ativar a porta somente depois de concluir a configuração do grupo de links inteligentes.
- Desative o recurso spanning tree, RRPP e ERPS nas portas que você deseja adicionar ao grupo de links inteligentes.
Configuração de VLANs protegidas para um grupo de links inteligentes
Pré-requisitos
Antes de configurar VLANs protegidas, você deve configurar uma região MST e a tabela de mapeamento VLAN-para-instância. Para obter mais informações sobre regiões MST, consulte spanning tree configuration no Layer 2-LAN Switching Configration Guide.
Procedimento
- Entre na visualização do sistema.
System-viewsmart-link group group-idprotected-vlan reference-instance instance-id-listConfiguração de portas membros para um grupo de links inteligentes
Restrições e diretrizes
Você pode configurar as portas membros de um grupo de links inteligentes na visualização do grupo de links inteligentes ou na visualização da interface. As configurações feitas nessas duas visualizações têm o mesmo efeito.
Na visualização do grupo de links inteligentes
- Entre na visualização do sistema.
System-viewsmart-link group group-idport interface-type interface-number { primary | secondary }Por padrão, nenhuma porta membro é configurada para um grupo de links inteligentes.
Na visualização da interface
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberport smart-link group group-id { primary | secondary }Por padrão, uma interface não é membro de um grupo de links inteligentes.
Configuração de um modo de preempção para um grupo de links inteligentes
- Entre na visualização do sistema.
System-viewsmart-link group group-idpreemption mode { role | speed [ threshold threshold-value ] }Por padrão, a preempção está desativada.
preemption delay delayPor padrão, o atraso de preempção é de 1 segundo.
A configuração do atraso de preempção entra em vigor somente depois que um modo de preempção é configurado.
Ativação do envio de mensagens de descarga
Restrições e diretrizes
- A VLAN de controle configurada para um grupo de links inteligentes deve ser diferente da VLAN de controle configurada para qualquer outro grupo de links inteligentes.
- Certifique-se de que a VLAN de controle configurada já exista e atribua as portas membros do grupo de links inteligentes à VLAN de controle.
- A VLAN de controle de um grupo de links inteligentes também deve ser uma de suas VLANs protegidas. Não remova a VLAN de controle. Caso contrário, as mensagens de flush não poderão ser enviadas corretamente.
Procedimento
- Entre na visualização do sistema.
System-viewsmart-link group group-idflush enable [ control-vlan vlan-id ]Por padrão, a atualização de descarga está ativada e a VLAN 1 é a VLAN de controle.
Configuração da colaboração entre o Smart Link e o Track
Sobre a colaboração entre a Smart Link e a Track
O Smart Link colabora com a função CC do CFD por meio de entradas de trilha para implementar a detecção do link .
Pré-requisitos
Antes de configurar a colaboração entre o Smart Link e o Track em uma porta, você deve atribuir a porta ao grupo de links inteligentes.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberport smart-link group group-id track track-entry-numberPor padrão, as portas membros do grupo de links inteligentes não colaboram com entradas de trilha.
Habilitação de um dispositivo associado para receber mensagens de descarga
Restrições e diretrizes
- Não é necessário habilitar todas as portas dos dispositivos associados para receber mensagens de descarga. Ative o recurso somente em todas as VLANs de controle das portas nos links primário e secundário entre o dispositivo Smart Link e o dispositivo de destino.
- Se nenhuma VLAN de controle for especificada para o processamento de mensagens de descarga, o dispositivo encaminhará as mensagens de descarga recebidas sem nenhum processamento.
- Certifique-se de que a VLAN de controle de recepção seja a mesma que a VLAN de controle de transmissão configurada no dispositivo Smart Link. Se elas não forem iguais, o dispositivo associado encaminhará as mensagens de descarga recebidas diretamente, sem nenhum processamento.
- Não remova as VLANs de controle. Caso contrário, as mensagens de descarga não poderão ser enviadas corretamente.
- Certifique-se de que as VLANs de controle sejam VLANs existentes e atribua as portas capazes de receber mensagens de flush às VLANs de controle.
Pré-requisitos
Desative o recurso de spanning tree nas portas do dispositivo associado que se conectam às portas membro do grupo de links inteligentes. Caso contrário, as portas descartarão as mensagens de descarga quando não estiverem em estado de encaminhamento, se ocorrer uma alteração na topologia.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbersmart-link flush enable [ control-vlan vlan-id-list ]Por padrão, nenhuma VLAN de controle recebe mensagens de descarga.
Comandos de exibição e manutenção do Smart Link
Execute comandos de exibição em qualquer visualização e o comando reset na visualização do usuário:
| Tarefa | Comando |
| Exibir informações sobre as mensagens de descarga recebidas. | display smart-link flush |
| Exibir informações do grupo de links inteligentes. | display smart-link group { group-id | todos } |
| Limpar as estatísticas sobre mensagens de descarga. | reset smart-link statistics |
Exemplos de configuração do Smart Link
Exemplo: Configuração de um único grupo de links inteligentes
Configuração de rede
Conforme mostrado na Figura 2:
- O dispositivo C e o dispositivo D são dispositivos Smart Link. O dispositivo A, o dispositivo B e o dispositivo E são dispositivos associados. O tráfego das VLANs 1 a 30 no Dispositivo C e no Dispositivo D é duplamente uplinkado para o Dispositivo A.
- Configure o Smart Link no dispositivo C e no dispositivo D para backup de uplink duplo.
Figura 2 Diagrama de rede
Procedimento
- Configurar o dispositivo C:
# Criar VLANs de 1 a 30.
<DeviceC> system-view
[DeviceC] vlan 1 to 30# Mapeie essas VLANs para o MSTI 1.
[DeviceC] stp region-configuration
[DeviceC-mst-region] instance 1 vlan 1 to 30# Ativar a configuração da região MST.
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit# Desligue a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] shutdown# Desative o recurso de spanning tree na porta.
[DeviceC-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceC-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceC-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] shutdown
[DeviceC-GigabitEthernet1/0/2] undo stp enable
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceC-GigabitEthernet1/0/2] quit# Crie o grupo de links inteligentes 1 e configure todas as VLANs mapeadas para MSTI 1 como VLANs protegidas.
[DeviceC] smart-link group 1
[DeviceC-smlk-group1] protected-vlan reference-instance 1# Configure a GigabitEthernet 1/0/1 como a porta primária e a GigabitEthernet 1/0/2 como a porta secundária do grupo de links inteligentes 1.
[DeviceC-smlk-group1] port gigabitethernet 1/0/1 primary
[DeviceC-smlk-group1] port gigabitethernet 1/0/2 secondary# Habilite o envio de mensagens flush no grupo de links inteligentes 1 e configure a VLAN 10 como a VLAN de controle de transmissão.
[DeviceC-smlk-group1] flush enable control-vlan 10
[DeviceC-smlk-group1] quit# Ativar novamente a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] undo shutdown
[DeviceC-GigabitEthernet1/0/1] quit
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] undo shutdown
[DeviceC-GigabitEthernet1/0/2] quit# Criar VLANs de 1 a 30.
<DeviceD> system-view
[DeviceD] vlan 1 to 30# Mapeie essas VLANs para o MSTI 1.
[DeviceD] stp region-configuration
[DeviceD-mst-region] instance 1 vlan 1 to 30# Ativar a configuração da região MST.
[DeviceD-mst-region] active region-configuration
[DeviceD-mst-region] quit# Desligue a GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] shutdown# Desative o recurso de spanning tree na porta.
[DeviceD-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceD-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceD-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceD-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] shutdown
[DeviceD-GigabitEthernet1/0/2] undo stp enable
[DeviceD-GigabitEthernet1/0/2] port link-type trunk
[DeviceD-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceD-GigabitEthernet1/0/2] quit# Crie o grupo de links inteligentes 1 e configure todas as VLANs mapeadas para MSTI 1 como VLANs protegidas.
[DeviceD] smart-link group 1
[DeviceD-smlk-group1] protected-vlan reference-instance 1# Configure a GigabitEthernet 1/0/1 como a porta primária e a GigabitEthernet 1/0/2 como a porta secundária do grupo de links inteligentes 1.
[DeviceD-smlk-group1] port gigabitethernet 1/0/1 primary
[DeviceD-smlk-group1] port gigabitethernet 1/0/2 secondary# Habilite o envio de mensagens flush no grupo de links inteligentes 1 e configure a VLAN 20 como a VLAN de controle de transmissão.
[DeviceD-smlk-group1] flush enable control-vlan 20
[DeviceD-smlk-group1] quit# Ativar novamente a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] undo shutdown
[DeviceD-GigabitEthernet1/0/1] quit
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] undo shutdown
[DeviceD-GigabitEthernet1/0/2] quit# Criar VLANs de 1 a 30.
<DeviceB> system-view
[DeviceB] vlan 1 to 30# Configure a GigabitEthernet 1/0/1 como uma porta tronco.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30# Habilite o recebimento de mensagens de flush e configure a VLAN 10 e a VLAN 20 como as VLANs de controle de recebimento na porta.
[DeviceB-GigabitEthernet1/0/1] smart-link flush enable control-vlan 10 20
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30# Desativar o recurso de spanning tree na porta.
[DeviceB-GigabitEthernet1/0/2] undo stp enable# Habilite o recebimento de mensagens flush e configure a VLAN 20 como a VLAN de controle de recebimento na porta.
[DeviceB-GigabitEthernet1/0/2] smart-link flush enable control-vlan 20
[DeviceB-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 como uma porta tronco.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceB-GigabitEthernet1/0/3] port trunk permit vlan 1 to 30# Desativar o recurso de spanning tree na porta.
[DeviceB-GigabitEthernet1/0/3] undo stp enable# Habilite o recebimento de mensagens flush e configure a VLAN 10 como a VLAN de controle de recebimento na porta.
[DeviceB-GigabitEthernet1/0/3] smart-link flush enable control-vlan 10
[DeviceB-GigabitEthernet1/0/3] quit# Criar VLANs de 1 a 30.
<DeviceE> system-view
[DeviceE] vlan 1 to 30# Configure a GigabitEthernet 1/0/1 como uma porta tronco.
[DeviceE] interface gigabitethernet 1/0/1
[DeviceE-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceE-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30# Habilite o recebimento de mensagens flush e configure a VLAN 10 e a VLAN 20 como as VLANs de controle de recebimento na porta.
[DeviceE-GigabitEthernet1/0/1] smart-link flush enable control-vlan 10 20
[DeviceE-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco.
[DeviceE] interface gigabitethernet 1/0/2
[DeviceE-GigabitEthernet1/0/2] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceE-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30# Desativar o recurso de spanning tree na porta.
[DeviceE-GigabitEthernet1/0/2] undo stp enable# Habilite o recebimento de mensagens flush e configure a VLAN 10 como a VLAN de controle de recebimento na porta.
[DeviceE-GigabitEthernet1/0/2] smart-link flush enable control-vlan 10
[DeviceE-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 como uma porta tronco.
[DeviceE] interface gigabitethernet 1/0/3
[DeviceE-GigabitEthernet1/0/3] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceE-GigabitEthernet1/0/3] port trunk permit vlan 1 to 30# Desativar o recurso de spanning tree na porta.
[DeviceE-GigabitEthernet1/0/3] undo stp enable# Habilite o recebimento de mensagens flush e configure a VLAN 20 como a VLAN de controle de recebimento na porta.
[DeviceE-GigabitEthernet1/0/3] smart-link flush enable control-vlan 20
[DeviceE-GigabitEthernet1/0/3] quit# Criar VLANs de 1 a 30.
<DeviceA> system-view
[DeviceA] vlan 1 to 30# Configure a GigabitEthernet 1/0/1 como uma porta tronco.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs de 1 a 30.
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30# Habilite o recebimento de mensagens flush e configure a VLAN 10 e a VLAN 20 como as VLANs de controle de recebimento na porta.
[DeviceA-GigabitEthernet1/0/1] smart-link flush enable control-vlan 10 20
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceA-GigabitEthernet1/0/2] smart-link flush enable control-vlan 10 20
[DeviceA-GigabitEthernet1/0/2] quitVerificação da configuração
# Exibir a configuração do grupo de links inteligentes no dispositivo C.
[DeviceC] display smart-link group 1
Smart link group 1 information:
Device ID : 000f-e23d-5af0
Preemption mode : None
Preemption delay : 1(s)
Control VLAN : 10
Protected VLAN : Reference Instance 1
Member Role State Flush-count Last-flush-time
-----------------------------------------------------------------------------
GE1/0/1 PRIMARY ACTIVE 5 16:45:20 2012/04/21
GE1/0/2 SECONDARY STANDBY 1 16:37:20 2012/04/21# Exibir as mensagens de descarga recebidas no Dispositivo B.
[DeviceB] display smart-link flush
Received flush packets : 5
Receiving interface of the last flush packet : GigabitEthernet1/0/3
Receiving time of the last flush packet : 16:50:21 2012/04/21
Device ID of the last flush packet : 000f-e23d-5af0
Control VLAN of the last flush packet : 10Exemplo: Configuração do compartilhamento de carga de vários grupos de links inteligentes
Configuração de rede
Conforme mostrado na Figura 3:
- O dispositivo C é um dispositivo Smart Link. O dispositivo A, o dispositivo B e o dispositivo D são dispositivos associados. O tráfego das VLANs 1 a 200 no dispositivo C é duplamente uplinkado para o dispositivo A pelo dispositivo B e pelo dispositivo D.
- Implemente backup de uplink duplo e compartilhamento de carga no Dispositivo C. O tráfego das VLANs 1 a 100 é transferido para o Dispositivo A pelo Dispositivo B. O tráfego das VLANs 101 a 200 é transferido para o Dispositivo A pelo Dispositivo D.
Figura 3 Diagrama de rede
Procedimento
- Configurar o dispositivo C:
# Crie a VLAN 1 até a VLAN 200.
<DeviceC> system-view
[DeviceC] vlan 1 to 200# Mapeie as VLANs 1 a 100 para o MSTI 1 e as VLANs 101 a 200 para o MSTI 2.
[DeviceC] stp region-configuration
[DeviceC-mst-region] instance 1 vlan 1 to 100
[DeviceC-mst-region] instance 2 vlan 101 to 200# Ativar a configuração da região MST.
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit# Desligue a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] shutdown# Desative o recurso de spanning tree na porta.
[DeviceC-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceC-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta à VLAN 1 até a VLAN 200.
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 1 to 200
[DeviceC-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] shutdown
[DeviceC-GigabitEthernet1/0/2] undo stp enable
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan 1 to 200
[DeviceC-GigabitEthernet1/0/2] quit# Crie o grupo de links inteligentes 1 e configure todas as VLANs mapeadas para MSTI 1 como VLANs protegidas para o grupo de links inteligentes 1.
[DeviceC] smart-link group 1
[DeviceC-smlk-group1] protected-vlan reference-instance 1# Configure a GigabitEthernet 1/0/1 como a porta primária e a GigabitEthernet 1/0/2 como a porta secundária do grupo de links inteligentes 1.
[DeviceC-smlk-group1] port gigabitethernet 1/0/1 primary
[DeviceC-smlk-group1] port gigabitethernet 1/0/2 secondary# Habilite a preempção de função no grupo de links inteligentes 1, habilite o envio de mensagens de flush e configure a VLAN 10 como a VLAN de controle de transmissão.
[DeviceC-smlk-group1] preemption mode role
[DeviceC-smlk-group1] flush enable control-vlan 10
[DeviceC-smlk-group1] quit# Crie o grupo de links inteligentes 2 e configure todas as VLANs mapeadas para MSTI 2 como VLANs protegidas para o grupo de links inteligentes 2.
[DeviceC] smart-link group 2
[DeviceC-smlk-group2] protected-vlan reference-instance 2# Configure a GigabitEthernet 1/0/1 como a porta secundária e a GigabitEthernet 1/0/2 como a porta primária do grupo de links inteligentes 2.
[DeviceC-smlk-group2] port gigabitethernet 1/0/2 primary
[DeviceC-smlk-group2] port gigabitethernet 1/0/1 secondary# Habilite a preempção de função no grupo de links inteligentes 2, habilite o envio de mensagens de flush e configure a VLAN 110 como a VLAN de controle de transmissão.
[DeviceC-smlk-group2] preemption mode role
[DeviceC-smlk-group2] flush enable control-vlan 110
[DeviceC-smlk-group2] quit# Ativar a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] undo shutdown
[DeviceC-GigabitEthernet1/0/1] quit
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] undo shutdown
[DeviceC-GigabitEthernet1/0/2] quit# Crie a VLAN 1 até a VLAN 200.
<DeviceB> system-view
[DeviceB] vlan 1 to 200# Configure a GigabitEthernet 1/0/1 como uma porta tronco.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs 1 a 200.
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 1 to 200# Habilite o recebimento de mensagens flush e configure a VLAN 10 e a VLAN 110 como as VLANs de controle de recebimento na porta.
[DeviceB-GigabitEthernet1/0/1] smart-link flush enable control-vlan 10 110
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type trunk# Atribuir a porta às VLANs 1 a 200.
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 1 to 200# Desativar o recurso de spanning tree na porta.
[DeviceB-GigabitEthernet1/0/2] undo stp enable# Habilite o recebimento de mensagens flush e configure a VLAN 10 e a VLAN 110 como as VLANs de controle de recebimento na porta.
[DeviceB-GigabitEthernet1/0/2] smart-link flush enable control-vlan 10 110
[DeviceB-GigabitEthernet1/0/2] quit# Crie a VLAN 1 até a VLAN 200.
<DeviceD> system-view
[DeviceD] vlan 1 to 200# Configure a GigabitEthernet 1/0/1 como uma porta tronco.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs 1 a 200.
[DeviceD-GigabitEthernet1/0/1] port trunk permit vlan 1 to 200# Habilite o recebimento de mensagens flush e configure a VLAN 10 e a VLAN 110 como as VLANs de controle de recebimento na porta.
[DeviceD-GigabitEthernet1/0/1] smart-link flush enable control-vlan 10 110
[DeviceD-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] port link-type trunk# Atribuir a porta às VLANs 1 a 200.
[DeviceD-GigabitEthernet1/0/2] port trunk permit vlan 1 to 200# Desativar o recurso de spanning tree na porta.
[DeviceD-GigabitEthernet1/0/2] undo stp enable# Habilite o recebimento de mensagens flush e configure a VLAN 10 e a VLAN 110 como as VLANs de controle de recebimento na porta.
[DeviceD-GigabitEthernet1/0/2] smart-link flush enable control-vlan 10 110
[DeviceD-GigabitEthernet1/0/2] quit# Crie a VLAN 1 até a VLAN 200.
<DeviceA> system-view
[DeviceA] vlan 1 to 200# Configure a GigabitEthernet 1/0/1 como uma porta tronco.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs 1 a 200.
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan 1 to 200# Habilite o recebimento de mensagens flush e configure a VLAN 10 e a VLAN 110 como as VLANs de controle de recebimento na porta.
[DeviceA-GigabitEthernet1/0/1] smart-link flush enable control-vlan 10 110
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 1 to 200
[DeviceA-GigabitEthernet1/0/2] smart-link flush enable control-vlan 10 110
[DeviceA-GigabitEthernet1/0/2] quitVerificação da configuração
# Exibir a configuração do grupo de links inteligentes no dispositivo C.
[DeviceC] display smart-link group all
Smart link group 1 information:
Device ID : 000f-e23d-5af0
Preemption mode : Role
Preemption delay : 1(s)
Control VLAN : 10
Protected VLAN : Reference Instance 1
Member Role State Flush-count Last-flush-time
-----------------------------------------------------------------------------
GE1/0/1 PRIMARY ACTIVE 5 16:45:20 2012/04/21
GE1/0/2 SECONDARY STANDBY 1 16:37:20 2012/04/21
Smart link group 2 information:
Device ID : 000f-e23d-5af0
Preemption mode : Role
Preemption delay : 1(s)
Control VLAN : 110
Protected VLAN : Reference Instance 2
Member Role State Flush-count Last-flush-time
-----------------------------------------------------------------------------
GE1/0/2 PRIMARY ACTIVE 5 16:45:20 2012/04/21
GE1/0/1 SECONDARY STANDBY 1 16:37:20 2012/04/21# Exibir as mensagens de descarga recebidas no Dispositivo B.
[DeviceB] display smart-link flush
Received flush packets : 5
Receiving interface of the last flush packet : GigabitEthernet1/0/2
Receiving time of the last flush packet : 16:25:21 2012/04/21
Device ID of the last flush packet : 000f-e23d-5af0
Control VLAN of the last flush packet : 10Exemplo: Configuração da colaboração do Smart Link e do Track
Configuração de rede
Conforme mostrado na Figura 4:
- O dispositivo A, o dispositivo B, o dispositivo C e o dispositivo D formam o domínio de manutenção (MD) MD_A de nível 5. O dispositivo C é um dispositivo Smart Link e o dispositivo A, o dispositivo B e o dispositivo D são dispositivos associados. O tráfego das VLANs 1 a 200 no Dispositivo C é duplamente uplinkado para o Dispositivo A pelo Dispositivo B e pelo Dispositivo D.
- Configure a colaboração entre o Smart Link e a função CC do CFD por meio de entradas de trilha para atender aos seguintes requisitos:
- O tráfego das VLANs 1 a 100 é transferido para o dispositivo A pelo dispositivo C por meio da GigabitEthernet 1/0/1 (porta primária do grupo de links inteligentes 1).
- O tráfego das VLANs 101 a 200 é transferido para o dispositivo A pelo dispositivo C por meio da GigabitEthernet 1/0/2 (porta primária do grupo de links inteligentes 2).
- Quando o link entre o Dispositivo C e o Dispositivo A falha, o tráfego é rapidamente alternado para a porta secundária de cada grupo de links inteligentes. Depois que a falha é eliminada, o tráfego é alternado de volta para as portas primárias.
Para obter mais informações sobre o CFD, consulte "Configuração do CFD".
Figura 4 Diagrama de rede
Procedimento
- Configurar o dispositivo A:
# Crie a VLAN 1 até a VLAN 200.
<DeviceA> system-view
[DeviceA] vlan 1 to 200# Configure a GigabitEthernet 1/0/1 como uma porta tronco.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs 1 a 200.
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan 1 to 200# Habilite o recebimento de mensagens flush e configure a VLAN 10 e a VLAN 110 como as VLANs de controle de recebimento na porta.
[DeviceA-GigabitEthernet1/0/1] smart-link flush enable control-vlan 10 110
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 1 to 200
[DeviceA-GigabitEthernet1/0/2] smart-link flush enable control-vlan 10 110
[DeviceA-GigabitEthernet1/0/2] quit# Habilite o CFD e crie o MD MD_A de nível 5.
[DeviceA] cfd enable
[DeviceA] cfd md MD_A level 5# Crie a instância de serviço 1 na qual o nome do MA é baseado no ID da VLAN em MD_A e configure o MA para atender à VLAN 10.
[DeviceA] cfd service-instance 1 ma-id vlan-based md MD_A vlan 10# Crie uma lista de MEP na instância de serviço 1, crie o MEP 1002 voltado para o exterior e habilite o envio de CCM na instância de serviço 1 na GigabitEthernet 1/0/1.
[DeviceA] cfd meplist 1001 1002 service-instance 1
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] cfd mep 1002 service-instance 1 outbound
[DeviceA-GigabitEthernet1/0/1] cfd cc service-instance 1 mep 1002 enable
[DeviceA-GigabitEthernet1/0/1] quit# Crie a instância de serviço 2 na qual o nome do MA é baseado no ID da VLAN em MD_A e configure o MA para atender à VLAN 110.
[DeviceA] cfd service-instance 2 ma-id vlan-based md MD_A vlan 110# Crie uma lista de MEP na instância de serviço 2, crie o MEP 1002 voltado para o exterior e habilite o envio de CCM na instância de serviço 2 na GigabitEthernet 1/0/2.
[DeviceA] cfd meplist 2001 2002 service-instance 2
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] cfd mep 2002 service-instance 2 outbound
[DeviceA-GigabitEthernet1/0/2] cfd cc service-instance 2 mep 2002 enable
[DeviceA-GigabitEthernet1/0/2] quit# Crie a VLAN 1 até a VLAN 200.
<DeviceB> system-view
[DeviceB] vlan 1 to 200# Configure a GigabitEthernet 1/0/1 como uma porta tronco.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs 1 a 200.
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 1 to 200# Habilite o recebimento de mensagens flush e configure a VLAN 10 e a VLAN 110 como as VLANs de controle de recebimento na porta.
[DeviceB-GigabitEthernet1/0/1] smart-link flush enable control-vlan 10 110
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type trunk# Atribuir a porta às VLANs 1 a 200.
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 1 to 200# Desativar o recurso de spanning tree na porta.
[DeviceB-GigabitEthernet1/0/2] undo stp enable# Habilite o recebimento de mensagens flush e configure a VLAN 10 e a VLAN 110 como as VLANs de controle de recebimento na porta.
[DeviceB-GigabitEthernet1/0/2] smart-link flush enable control-vlan 10 110
[DeviceB-GigabitEthernet1/0/2] quit# Crie a VLAN 1 até a VLAN 200.
<DeviceC> system-view
[DeviceC] vlan 1 to 200# Mapeie as VLANs de 1 a 100 para o MSTI 1 e as VLANs de 101 a 200 para o MSTI 2.
[DeviceC] stp region-configuration
[DeviceC-mst-region] instance 1 vlan 1 to 100
[DeviceC-mst-region] instance 2 vlan 101 to 200# Ativar a configuração da região MST.
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit# Desligue a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] shutdown# Desative o recurso de spanning tree na porta.
[DeviceC-GigabitEthernet1/0/1] undo stp enable# Configure a porta como uma porta tronco.
[DeviceC-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs 1 a 200.
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 1 to 200
[DeviceC-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] shutdown
[DeviceC-GigabitEthernet1/0/2] undo stp enable
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan 1 to 200
[DeviceC-GigabitEthernet1/0/2] quit# Crie o grupo de links inteligentes 1 e configure todas as VLANs mapeadas para MSTI 1 como VLANs protegidas para o grupo de links inteligentes 1.
[DeviceC] smart-link group 1
[DeviceC-smlk-group1] protected-vlan reference-instance 1# Configure a GigabitEthernet 1/0/1 como a porta primária e a GigabitEthernet 1/0/2 como a porta secundária do grupo de links inteligentes 1.
[DeviceC-smlk-group1] port gigabitethernet 1/0/1 primary
[DeviceC-smlk-group1] port gigabitethernet 1/0/2 secondary# Habilitar a preempção de função no grupo de links inteligentes 1, habilitar o envio de mensagens de descarga e configurar VLAN 10 como a VLAN de controle de transmissão.
[DeviceC-smlk-group1] preemption mode role
[DeviceC-smlk-group1] flush enable control-vlan 10
[DeviceC-smlk-group1] quit# Crie o grupo de links inteligentes 2 e configure todas as VLANs mapeadas para MSTI 2 como VLANs protegidas para o grupo de links inteligentes 2.
[DeviceC] smart-link group 2
[DeviceC-smlk-group2] protected-vlan reference-instance 2# Configure a GigabitEthernet 1/0/1 como a porta secundária e a GigabitEthernet 1/0/2 como a porta primária do grupo de links inteligentes 2.
[DeviceC-smlk-group2] port gigabitethernet 1/0/2 primary
[DeviceC-smlk-group2] port gigabitethernet 1/0/1 secondary# Habilite a preempção de função no grupo de links inteligentes 2, habilite o envio de mensagens de flush e configure a VLAN 110 como a VLAN de controle de transmissão.
[DeviceC-smlk-group2] preemption mode role
[DeviceC-smlk-group2] flush enable control-vlan 110
[DeviceC-smlk-group2] quit# Habilite o CFD e crie o MD MD_A de nível 5.
[DeviceC] cfd enable
[DeviceC] cfd md MD_A level 5# Crie a instância de serviço 1 na qual o nome do MA é baseado no ID da VLAN em MD_A e configure o MA para atender à VLAN 10.
[DeviceC] cfd service-instance 1 ma-id vlan-based md MD_A vlan 10# Crie uma lista de MEP na instância de serviço 1. Crie o MEP 1001 voltado para o exterior e habilite o envio de CCM na instância de serviço 1 na GigabitEthernet 1/0/1.
[DeviceC] cfd meplist 1001 1002 service-instance 1
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] cfd mep 1001 service-instance 1 outbound
[DeviceC-GigabitEthernet1/0/1] cfd cc service-instance 1 mep 1001 enable
[DeviceC-GigabitEthernet1/0/1] quit# Crie a instância de serviço 2 na qual o nome do MA é baseado no ID da VLAN em MD_A e configure o MA para atender à VLAN 110.
[DeviceC] cfd service-instance 2 ma-id vlan-based md MD_A vlan 110# Crie uma lista MEP na instância de serviço 2. Crie o MEP 2001 voltado para o exterior. Habilite o envio de CCM na instância de serviço 2 na GigabitEthernet 1/0/2.
[DeviceC] cfd meplist 2001 2002 service-instance 2
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] cfd mep 2001 service-instance 2 outbound
[DeviceC-GigabitEthernet1/0/2] cfd cc service-instance 2 mep 2001 enable
[DeviceC-GigabitEthernet1/0/2] quit# Criar a entrada de trilha 1 que está associada à função CFD CC do MEP 1001 em serviço instância 1.
[DeviceC] track 1 cfd cc service-instance 1 mep 1001# Configure a colaboração entre a porta primária GigabitEthernet 1/0/1 do grupo de links inteligentes 1 e a função CC do CFD por meio da entrada de trilha 1 e abra a porta.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] port smart-link group 1 track 1
[DeviceC-GigabitEthernet1/0/1] undo shutdown
[DeviceC-GigabitEthernet1/0/1] quit# Crie a entrada de trilha 1 que está associada à função CFD CC do MEP 1001 na instância de serviço 1.
[DeviceC] track 2 cfd cc service-instance 2 mep 2001# Configure a colaboração entre a porta primária GigabitEthernet 1/0/2 do grupo de links inteligentes 2 e a função CC do CFD por meio da entrada de trilha 2 e abra a porta.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] port smart-link group 2 track 2
[DeviceC-GigabitEthernet1/0/2] undo shutdown
[DeviceC-GigabitEthernet1/0/2] quit# Crie a VLAN 1 até a VLAN 200.
<DeviceD> system-view
[DeviceD] vlan 1 to 200# Configure a GigabitEthernet 1/0/1 como uma porta tronco.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] port link-type trunk# Atribuir a porta às VLANs 1 a 200.
[DeviceD-GigabitEthernet1/0/1] port trunk permit vlan 1 to 200# Habilite o recebimento de mensagens flush e configure a VLAN 10 e a VLAN 110 como as VLANs de controle de recebimento na porta.
[DeviceD-GigabitEthernet1/0/1] smart-link flush enable control-vlan 10 110
[DeviceD-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] port link-type trunk# Atribuir a porta às VLANs 1 a 200.
[DeviceD-GigabitEthernet1/0/2] port trunk permit vlan 1 to 200# Desativar o recurso de spanning tree na porta.
[DeviceD-GigabitEthernet1/0/2] undo stp enable# Habilite o recebimento de mensagens flush e configure a VLAN 10 e a VLAN 110 como as VLANs de controle de recebimento na porta.
[DeviceD-GigabitEthernet1/0/2] smart-link flush enable control-vlan 10 110
[DeviceD-GigabitEthernet1/0/2] quitVerificação da configuração
# Quando a fibra óptica entre o Dispositivo A e o Dispositivo B falhar, exiba a configuração do grupo de links inteligentes no Dispositivo C.
[DeviceC] display smart-link group all
Smart link group 1 information:
Device ID : 000f-e23d-5af0
Preemption mode : Role
Preemption delay : 1(s)
Control VLAN : 10
Protected VLAN : Reference Instance 1
Member Role State Flush-count Last-flush-time
-----------------------------------------------------------------------------
GE1/0/1 PRIMARY DOWN 5 16:45:20 2012/04/21
GE1/0/2 SECONDARY ACTIVE 1 16:37:20 2012/04/21
Smart link group 2 information:
Device ID : 000f-e23d-5af0
Preemption mode : Role
Preemption delay : 1(s)
Control VLAN : 110
Protected VLAN : Reference Instance 2
Member Role State Flush-count Last-flush-time
-----------------------------------------------------------------------------
GE1/0/2 PRIMARY ACTIVE 5 16:45:20 2012/04/21
GE1/0/1 SECONDARY STANDBY 1 16:37:20 2012/04/21A saída mostra que a porta primária GigabitEthernet 1/0/1 do grupo de links inteligentes 1 falha e a porta secundária GigabitEthernet 1/0/2 está em estado de encaminhamento.
Configuração do Monitor Link
Sobre o Monitor Link
O Monitor Link associa o estado das interfaces de downlink ao estado das interfaces de uplink em um grupo de links de monitoramento. Quando o Monitor Link desliga as interfaces de downlink devido a uma falha no uplink, o dispositivo downstream muda a conectividade para outro link.
Figura 1 Cenário do aplicativo Monitor Link
Um grupo de links de monitoração contém interfaces de uplink e downlink. Uma interface pode pertencer a apenas um grupo de links de monitor.
- As interfaces de uplink são as interfaces monitoradas.
- As interfaces de downlink são as interfaces de monitoramento.
- A porta B1 e a porta B2 do dispositivo B formam um grupo de links de monitor. A porta B1 é uma interface de uplink e a porta B2 é uma interface de downlink.
- A porta D1 e a porta D2 do dispositivo D formam outro grupo de links de monitor. A porta D1 é uma interface de uplink e a porta D2 é uma interface de downlink.
Conforme mostrado na Figura 1:
Um grupo de links de monitoramento funciona independentemente de outros grupos de links de monitoramento. Quando um grupo de links de monitoramento não contém nenhuma interface de uplink ou todas as suas interfaces de uplink estão inativas, o grupo de links de monitoramento é desativado. Isso força a desativação de todas as interfaces de downlink ao mesmo tempo. Quando qualquer interface de uplink é ativada, o grupo de links de monitoramento é ativado e ativa todas as interfaces de downlink.
Restrições e diretrizes: Configuração do Monitor Link
Siga estas restrições e diretrizes ao configurar o Monitor Link:
- Não desligue ou ative manualmente as interfaces de downlink em um grupo de links de monitoramento.
- Para evitar mudanças frequentes de estado das interfaces de downlink caso as interfaces de uplink no grupo de links do monitor se desloquem, você pode configurar um atraso de comutação. O atraso de comutação é o tempo que as interfaces de downlink aguardam antes de serem ativadas após uma interface de uplink.
Monitore as tarefas do Link em um relance
Para configurar o Monitor Link, execute as seguintes tarefas:
- Ativação do Monitor Link globalmente
- Criação de um grupo de links de monitor
- Configuração das interfaces de membros do grupo de links do monitor
- (Opcional.) Configuração do limite da interface de uplink para acionar a troca de estado do grupo de links do monitor
- (Opcional.) Configuração do atraso de comutação para as interfaces de downlink em um grupo de links de monitoramento
Ativação do Monitor Link globalmente
Sobre como ativar o Monitor Link globalmente
Todos os grupos de links de monitoramento podem operar somente depois que você ativar o Monitor Link globalmente. Quando você desativa o Monitor Link globalmente, todos os grupos de links de monitoramento não podem operar e as interfaces de downlink derrubadas pelos grupos de links de monitoramento retomam seus estados originais.
Procedimento
- Entre na visualização do sistema.
System-viewundo monitor-link disablePor padrão, o Monitor Link é ativado globalmente.
Criação de um grupo de links de monitor
- Entre na visualização do sistema.
System-viewmonitor-link group group-idConfiguração das interfaces de membros do grupo de links do monitor
Restrições e diretrizes
- Uma interface pode ser atribuída a apenas um grupo de links de monitor.
- Para evitar mudanças indesejadas de estado down/up nas interfaces de downlink, configure as interfaces de uplink antes de configurar as interfaces de downlink.
- Se você tiver configurado uma porta selecionada de um grupo de agregação como interface de downlink de um grupo de links de monitoramento, não configure uma porta não selecionada do grupo de agregação como interface de uplink do grupo de links de monitoramento.
- Não adicione uma interface agregada e suas portas membros ao mesmo grupo de links de monitoramento.
- Você pode configurar as interfaces de membro de um grupo de links de monitor na visualização do grupo de links de monitor ou na visualização da interface. As configurações feitas nessas visualizações têm o mesmo efeito. A configuração é compatível com as seguintes interfaces:
- Interfaces Ethernet de camada 2.
- Interfaces agregadas de camada 2.
Configuração de interfaces de membros do grupo de links de monitor na visualização do grupo de links de monitor
- Entre na visualização do sistema.
System-viewmonitor-link group group-idport interface-type interface-number { downlink | uplink }Por padrão, não existem interfaces de membro em um grupo de links de monitoramento.
Configuração de interfaces de membros do grupo de links de monitoramento na visualização de interface
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numberport monitor-link group group-id { downlink | uplink }Por padrão, a interface não é um membro do grupo de links de monitoramento.
Configuração do limite da interface de uplink para acionar a troca de estado do grupo de links do monitor
- Entre na visualização do sistema.
System-viewmonitor-link group group-iduplink up-port-threshold number-of-portPor padrão, o limite da interface de uplink para acionar a troca de estado do grupo de links do monitor é 1.
Configuração do atraso de comutação para as interfaces de downlink em um grupo de links de monitoramento
- Entre na visualização do sistema.
System-viewmonitor-link group group-iddownlink up-delay delayPor padrão, o atraso de comutação é de 0 segundos. As interfaces de downlink são ativadas assim que uma interface de uplink é ativada.
Comandos de exibição e manutenção do Monitor Link
Execute o comando display em qualquer visualização:
| Tarefa | Comando |
| Exibir informações do grupo de links do monitor. | grupo de links de monitor de exibição { group-id | all } |
Exemplos de configuração do Monitor Link
Exemplo: Configuração do Monitor Link
Configuração de rede
Conforme mostrado na Figura 2:
- O dispositivo C é um dispositivo Smart Link e o dispositivo A, o dispositivo B e o dispositivo D são dispositivos associados. O tráfego das VLANs 1 a 30 no Dispositivo C é duplamente conectado ao Dispositivo A por meio de um grupo de links inteligentes.
- Implemente backup de uplink duplo no Dispositivo C. Quando o link entre o Dispositivo A e o Dispositivo B (ou Dispositivo D) falhar, o Dispositivo C poderá detectar a falha no link. Em seguida, ele executa a alternância de uplink no grupo de links inteligentes.
Para obter mais informações sobre o Smart Link, consulte "Configuração do Smart Link".
Figura 2 Diagrama de rede
Procedimento
- Configurar o dispositivo C:
# Criar VLANs de 1 a 30.
<DeviceC> system-view
[DeviceC] vlan 1 to 30# Mapeie essas VLANs para o MSTI 1.
[DeviceC] stp region-configuration
[DeviceC-mst-region] instance 1 vlan 1 to 30# Ativar a configuração da região MST.
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit# Desligue a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] shutdown# Desative o recurso de spanning tree na interface.
[DeviceC-GigabitEthernet1/0/1] undo stp enable# Configure a interface como uma porta tronco.
[DeviceC-GigabitEthernet1/0/1] port link-type trunk# Atribuir a interface às VLANs 1 a 30.
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30
[DeviceC-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] shutdown
[DeviceC-GigabitEthernet1/0/2] undo stp enable
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceC-GigabitEthernet1/0/2] quit# Crie o grupo de links inteligentes 1 e configure todas as VLANs mapeadas para MSTI 1 como VLANs protegidas para o grupo de links inteligentes 1.
[DeviceC] smart-link group 1
[DeviceC-smlk-group1] protected-vlan reference-instance 1# Configure a GigabitEthernet 1/0/1 como a porta primária e a GigabitEthernet 1/0/2 como a porta secundária do grupo de links inteligentes 1.
[DeviceC-smlk-group1] port gigabitethernet 1/0/1 primary
[DeviceC-smlk-group1] port gigabitethernet 1/0/2 secondary# Habilite o grupo de links inteligentes para transmitir mensagens de descarga.
[DeviceC-smlk-group1] flush enable
[DeviceC-smlk-group1] quit# Ativar a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] undo shutdown
[DeviceC-GigabitEthernet1/0/1] quit
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] undo shutdown
[DeviceC-GigabitEthernet1/0/2] quit# Criar VLANs de 1 a 30.
<DeviceA> system-view
[DeviceA] vlan 1 to 30# Configure a GigabitEthernet 1/0/1 como uma porta tronco.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type trunk# Atribuir a interface às VLANs 1 a 30.
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30# Habilite o recebimento de mensagens de descarga na interface.
[DeviceA-GigabitEthernet1/0/1] smart-link flush enable
[DeviceA-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 da mesma forma que a GigabitEthernet 1/0/1.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30
[DeviceA-GigabitEthernet1/0/2] smart-link flush enable
[DeviceA-GigabitEthernet1/0/2] quit# Criar VLANs de 1 a 30.
<DeviceB> system-view
[DeviceB] vlan 1 to 30# Configure a GigabitEthernet 1/0/1 como uma porta tronco.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type trunk# Atribuir a interface às VLANs 1 a 30.
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30# Habilite o recebimento de mensagens de descarga na interface.
[DeviceB-GigabitEthernet1/0/1] smart-link flush enable
[DeviceB-GigabitEthernet1/0/1] quit# Desative o recurso de spanning tree na GigabitEthernet 1/0/2.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] undo stp enable# Configure a interface como uma porta tronco.
[DeviceB-GigabitEthernet1/0/2] port link-type trunk# Atribuir a interface às VLANs 1 a 30.
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30# Habilite o recebimento de mensagens de descarga na interface.
[DeviceB-GigabitEthernet1/0/2] smart-link flush enable
[DeviceB-GigabitEthernet1/0/2] quit# Criar o grupo de links de monitor 1.
[DeviceB] monitor-link group 1# Configure a GigabitEthernet 1/0/1 como uma interface de uplink para o grupo de links de monitoramento 1.
[DeviceB-mtlk-group1] port gigabitethernet 1/0/1 uplink# Configure a GigabitEthernet 1/0/2 como uma interface de downlink para o grupo de links de monitoramento 1.
[DeviceB-mtlk-group1] port gigabitethernet 1/0/2 downlink
[DeviceB-mtlk-group1] quit# Criar VLANs de 1 a 30.
<DeviceD> system-view
[DeviceD] vlan 1 to 30# Configure a GigabitEthernet 1/0/1 como uma porta tronco.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] port link-type trunk# Atribuir a interface às VLANs 1 a 30.
[DeviceD-GigabitEthernet1/0/1] port trunk permit vlan 1 to 30# Habilite o recebimento de mensagens de descarga na interface.
[DeviceD-GigabitEthernet1/0/1] smart-link flush enable
[DeviceD-GigabitEthernet1/0/1] quit# Desative o recurso de spanning tree na GigabitEthernet 1/0/2.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] undo stp enable# Configure a interface como uma porta tronco.
[DeviceD-GigabitEthernet1/0/2] port link-type trunk# Atribuir a interface às VLANs 1 a 30.
[DeviceD-GigabitEthernet1/0/2] port trunk permit vlan 1 to 30# Habilite o recebimento de mensagens de descarga na interface.
[DeviceD-GigabitEthernet1/0/2] smart-link flush enable
[DeviceD-GigabitEthernet1/0/2] quit# Criar o grupo de links de monitor 1.
[DeviceD] monitor-link group 1# Configure a GigabitEthernet 1/0/1 como uma interface de uplink para o grupo de links de monitoramento 1.
[DeviceD-mtlk-group1] port gigabitethernet 1/0/1 uplink# Configure a GigabitEthernet 1/0/2 como uma interface de downlink para o grupo de links de monitoramento 1.
[DeviceD-mtlk-group1] port gigabitethernet 1/0/2 downlink
[DeviceD-mtlk-group1] quitVerificação da configuração
# Quando a GigabitEthernet 1/0/2 no Dispositivo A cair devido a uma falha de link, verifique as informações sobre o grupo de links de monitoramento 1 no Dispositivo B.
[DeviceB] display monitor-link group 1
Monitor link group 1 information:
Group status : UP
Downlink up-delay : 0(s)
Last-up-time : 16:38:26 2012/4/21
Last-down-time : 16:37:20 2012/4/21
Up-port-threshold : 1
Member Role Status
------------------------------------------------
GE1/0/1 UPLINK UP
GE1/0/2 DOWNLINK UP# Verificar informações sobre o grupo de links de monitor 1 no Dispositivo D.
[DeviceD] display monitor-link group 1
Monitor link group 1 information:
Group status : DOWN
Downlink up-delay : 0(s)
Last-up-time : 16:37:20 2012/4/21
Last-down-time : 16:38:26 2012/4/21
Up-port-threshold : 1
Member Role Status
------------------------------------------------
GE1/0/1 UPLINK DOWN
GE1/0/2 DOWNLINK DOWNConfiguração de VRRP
Sobre o VRRP
Normalmente, é possível configurar um gateway padrão para cada host em uma LAN. Todos os pacotes destinados a outras redes são enviados por meio do gateway padrão. Conforme mostrado na Figura 1, quando o gateway padrão falha, nenhum host pode se comunicar com redes externas.
Figura 1 Rede LAN
O uso de um gateway padrão facilita a configuração, mas exige alta disponibilidade. O uso de mais gateways de saída melhora a disponibilidade do link, mas introduz o problema de roteamento entre os egressos.
O Virtual Router Redundancy Protocol (VRRP) foi projetado para resolver esse problema. O VRRP adiciona um grupo de gateways de rede a um grupo VRRP chamado roteador virtual. O grupo VRRP tem um mestre e vários backups, e fornece um endereço IP virtual. Os hosts da sub-rede usam o endereço IP virtual como gateway de rede padrão para se comunicar com redes externas.
O VRRP evita pontos únicos de falha e simplifica a configuração nos hosts. Quando o mestre do grupo VRRP em uma LAN multicast ou broadcast (por exemplo, uma rede Ethernet) falha, outro roteador do grupo VRRP assume o controle. A troca é concluída sem causar recálculo dinâmico de rota, redescoberta de rota, reconfiguração de gateway nos hosts ou interrupção de tráfego.
O VRRP opera em um dos seguintes modos:
- Modo padrão - Implementado com base em RFCs. Para obter mais informações, consulte "Modo padrão VRRP".
- Modo de balanceamento de carga - Estende o modo padrão do VRRP para distribuir a carga entre os membros do grupo VRRP. Para obter mais informações, consulte "Modo de balanceamento de carga VRRP".
O VRRP tem duas versões: VRRPv2 e VRRPv3. O VRRPv2 é compatível com o VRRP IPv4. O VRRPv3 é compatível com IPv4 VRRP e IPv6 VRRP.
Grupo VRRP
O VRRP adiciona um grupo de gateways de rede a um grupo VRRP chamado roteador virtual. O grupo VRRP tem um mestre e vários backups e fornece um endereço IP virtual. Os hosts da sub-rede usam o endereço IP virtual como gateway de rede padrão para se comunicar com redes externas.
O administrador pode adicionar um roteador a um grupo VRRP criando o grupo VRRP em uma interface de Camada 3 no roteador.
OBSERVAÇÃO:
Em um dispositivo, as interfaces adicionadas aos grupos VRRP com o mesmo número de grupo VRRP pertencem a grupos VRRP diferentes.
Modo padrão VRRP
Rede VRRP
Conforme mostrado na Figura 2, o Roteador A, o Roteador B e o Roteador C formam um roteador virtual, que tem um endereço IP virtual configurado manualmente. Os hosts da sub-rede usam o roteador virtual como gateway padrão.
O roteador com a prioridade mais alta entre os três roteadores é eleito como mestre, e os outros dois são backups. Somente o mestre no grupo VRRP pode fornecer serviço de gateway. Quando o mestre falha, os roteadores de backup elegem um novo mestre para assumir o serviço de gateway ininterrupto.
Figura 2 Rede VRRP
Endereço IP virtual e proprietário do endereço IP
O endereço IP virtual do roteador virtual pode ser um dos seguintes endereços IP:
- Endereço IP não utilizado na sub-rede em que o grupo VRRP reside.
- Endereço IP de uma interface em um roteador do grupo VRRP.
No último caso, o roteador é chamado de proprietário do endereço IP. Um grupo VRRP pode ter apenas um proprietário de endereço IP.
Prioridade do roteador em um grupo VRRP
O VRRP determina a função (mestre ou backup) de cada roteador em um grupo VRRP por prioridade. Um roteador com prioridade mais alta tem maior probabilidade de se tornar o mestre.
Uma prioridade VRRP pode estar no intervalo de 0 a 255, e um número maior representa uma prioridade mais alta. As prioridades de 1 a 254 são configuráveis. A prioridade 0 é reservada para usos especiais, e a prioridade 255 é para o
Proprietário do endereço IP. O proprietário do endereço IP em um grupo VRRP sempre tem uma prioridade de execução de 255 e atua como mestre, desde que funcione corretamente.
Preempção
Um roteador em um grupo VRRP opera no modo não preemptivo ou no modo preemptivo.
- Modo não preemptivo - O roteador mestre atua como mestre desde que funcione corretamente, mesmo que um roteador de backup receba posteriormente uma prioridade mais alta. O modo não preemptivo ajuda a evitar a alternância frequente entre os roteadores mestre e de backup.
- Modo preemptivo - Um backup inicia uma nova eleição de mestre e assume o papel de mestre quando detecta que tem uma prioridade mais alta do que o mestre atual. O modo preemptivo garante que o roteador com a prioridade mais alta em um grupo VRRP sempre atue como mestre.
Método de autenticação
Para evitar ataques de usuários não autorizados, os roteadores membros do VRRP adicionam chaves de autenticação nos pacotes VRRP para autenticar uns aos outros. O VRRP oferece os seguintes métodos de autenticação:
- Autenticação simples
O remetente preenche uma chave de autenticação no pacote VRRP, e o receptor compara a chave de autenticação recebida com sua chave de autenticação local. Se as duas chaves de autenticação forem iguais, o pacote VRRP recebido é legítimo. Caso contrário, o pacote recebido é ilegítimo e é descartado.
- Autenticação MD5
O remetente calcula um resumo para o pacote VRRP usando a chave de autenticação e o algoritmo MD5 e salva o resultado no pacote. O receptor executa a mesma operação com a chave de autenticação e o algoritmo MD5 e compara o resultado com o conteúdo do cabeçalho de autenticação. Se os resultados forem iguais, o pacote VRRP recebido é legítimo. Caso contrário, o pacote recebido é ilegítimo e é descartado.
Em uma rede segura, você pode optar por não autenticar os pacotes VRRP.
OBSERVAÇÃO:
O IPv4 VRRPv3 e o IPv6 VRRPv3 não oferecem suporte à autenticação de pacotes VRRP.
Temporizadores VRRP
Skew_Time
O Skew_Time ajuda a evitar a situação em que vários backups em um grupo VRRP se tornam o mestre quando o mestre no grupo VRRP falha.
O Skew_Time não é configurável; seu valor depende da versão do VRRP.
- No VRRPv2 (descrito na RFC 3768), Skew_Time é (256 - Prioridade do roteador)/256.
- No VRRPv3 (descrito na RFC 5798), Skew_Time é ((256 - prioridade do roteador) × intervalo de anúncio do VRRP)/256.
Intervalo de anúncio de VRRP
O mestre em um grupo VRRP envia periodicamente anúncios VRRP para declarar sua presença.
Você pode configurar o intervalo em que o mestre envia anúncios VRRP. Se um backup não receber nenhum anúncio de VRRP quando o cronômetro (3 × intervalo de anúncio de VRRP + Skew_Time) expirar, ele assumirá o papel de mestre.
Temporizador de atraso de preempção VRRP
Você pode configurar o temporizador de atraso de preempção do VRRP para as seguintes finalidades:
- Evite mudanças frequentes de estado entre os membros de um grupo VRRP.
- Forneça aos backups tempo suficiente para coletar informações (como informações de roteamento).
No modo de preempção, um backup não se torna imediatamente o mestre depois de receber um anúncio com prioridade mais baixa do que a prioridade local. Em vez disso, ele aguarda um período de tempo (tempo de atraso de preempção + Skew_Time) antes de assumir o controle como mestre.
Eleição de mestre
Os roteadores em um grupo VRRP determinam suas funções por prioridade. Quando um roteador entra em um grupo VRRP, ele tem uma função de backup. A função do roteador muda de acordo com as seguintes situações:
- Se o backup não receber nenhum anúncio de VRRP quando o cronômetro (3 × intervalo de anúncio + Skew_Time) expirar, ele se tornará o mestre.
- Se o backup receber um anúncio VRRP com prioridade igual ou superior dentro do cronômetro (3 × intervalo do anúncio + Skew_Time), ele continuará sendo um backup.
- Se o backup receber um anúncio VRRP com uma prioridade menor dentro do cronômetro (3 × intervalo do anúncio + Skew_Time), os seguintes resultados se aplicarão:
- Ele continua sendo um backup quando está operando em modo não preemptivo.
- Ele se torna o mestre ao operar no modo preemptivo.
O mestre eleito inicia um intervalo de anúncio de VRRP para enviar periodicamente anúncios de VRRP para notificar os backups de que está operando corretamente. Cada um dos backups inicia um cronômetro para aguardar os anúncios do mestre.
Quando vários roteadores em um grupo VRRP declaram que são os mestres devido a problemas de rede, aquele com a prioridade mais alta se torna o mestre. Se dois roteadores tiverem a mesma prioridade, o que tiver o endereço IP mais alto se tornará o mestre.
Rastreamento de VRRP
A função de rastreamento do VRRP usa o analisador de qualidade de rede (NQA) ou a detecção de encaminhamento bidirecional (BFD) para monitorar o estado do mestre ou do link upstream. A colaboração entre o VRRP e o NQA ou o BFD por meio de uma entrada de rastreamento implementa as seguintes funções:
- Monitora o link upstream e altera a prioridade do roteador de acordo com o estado do link. Se o link upstream falhar, os hosts da sub-rede não poderão acessar redes externas por meio do roteador e o estado da entrada de trilha se tornará negativo. A prioridade do mestre diminui em um valor especificado, e um roteador com prioridade mais alta no grupo VRRP se torna o mestre. A alternância garante a comunicação ininterrupta entre os hosts da sub-rede e as redes externas.
- Monitora o estado do mestre nos backups. Quando o mestre falha, um backup assume imediatamente o controle para garantir uma comunicação ininterrupta.
Quando a entrada de rastreamento muda de Negativa para Positiva ou Não pronta, o roteador restaura automaticamente sua prioridade. Para obter mais informações sobre entradas de trilha, consulte "Configuração de trilha".
Para ativar o rastreamento VRRP, configure os roteadores no grupo VRRP para operar primeiro no modo preemptivo. Essa configuração garante que somente o roteador com a prioridade mais alta opere como mestre.
Aplicativo VRRP
Mestre/backup
No modo mestre/backup, somente o mestre encaminha os pacotes, conforme mostrado na Figura 3. Quando o mestre falha, um novo mestre é eleito entre os backups. Esse modo requer apenas um grupo VRRP, e cada roteador do grupo tem uma prioridade diferente. Aquele com a prioridade mais alta se torna o mestre.
Figura 3 VRRP no modo mestre/backup
Suponha que o Roteador A esteja atuando como mestre para encaminhar pacotes para redes externas, e que o Roteador B e o Roteador C sejam backups em estado de escuta. Quando o Roteador A falha, o Roteador B e o Roteador C elegem um novo mestre para encaminhar pacotes para hosts na sub-rede.
Compartilhamento de carga
Um roteador pode participar de vários grupos VRRP. Com prioridades diferentes em grupos VRRP diferentes, o roteador pode atuar como mestre em um grupo VRRP e como backup em outro.
No modo de compartilhamento de carga, vários grupos VRRP fornecem serviços de gateway. Esse modo requer um mínimo de dois grupos VRRP, e cada grupo tem um mestre e vários backups. As funções de mestre nos grupos VRRP são assumidas por roteadores diferentes, conforme mostrado na Figura 4.
Figura 4 Compartilhamento de carga do VRRP
Um roteador pode estar em vários grupos VRRP e ter uma prioridade diferente em cada grupo. Conforme mostrado na Figura 4, existem os seguintes grupos VRRP:
- Grupo VRRP 1 - O roteador A é o mestre. O Roteador B e o Roteador C são os backups.
- Grupo VRRP 2 - O Roteador B é o mestre. O Roteador A e o Roteador C são os backups.
- Grupo VRRP 3 - O roteador C é o mestre. O Roteador A e o Roteador B são os backups.
Para implementar o compartilhamento de carga entre o Roteador A, o Roteador B e o Roteador C, execute as seguintes tarefas:
- Configure os endereços IP virtuais do grupo VRRP 1, 2 e 3 como endereços IP de gateway padrão para hosts na sub-rede.
- Atribua a prioridade mais alta ao Roteador A, B e C no grupo VRRP 1, 2 e 3, respectivamente.
Modo de balanceamento de carga VRRP
Em um grupo VRRP de modo padrão, somente o mestre pode encaminhar pacotes e os backups estão em estado de escuta. É possível criar vários grupos VRRP para compartilhar o tráfego, mas é necessário configurar gateways diferentes para os hosts na sub-rede.
No modo de balanceamento de carga, um grupo VRRP mapeia seu endereço IP virtual para vários endereços MAC virtuais, atribuindo um endereço MAC virtual a cada roteador membro. Cada roteador desse grupo VRRP pode encaminhar o tráfego e responder a solicitações ARP IPv4 ou solicitações ND IPv6 de hosts. Como seus endereços MAC virtuais são diferentes, o tráfego dos hosts é distribuído entre os membros do grupo VRRP. O modo de balanceamento de carga simplifica a configuração e melhora a eficiência do encaminhamento.
O modo de balanceamento de carga VRRP usa os mesmos mecanismos de eleição de mestre, preempção e rastreamento que o modo padrão. Novos mecanismos foram introduzidos no modo de balanceamento de carga VRRP, conforme descrito nas seções a seguir.
Atribuição de endereço MAC virtual
No modo de balanceamento de carga, o mestre atribui endereços MAC virtuais aos roteadores no grupo VRRP. O mestre usa endereços MAC diferentes para responder a solicitações ARP ou solicitações ND de hosts diferentes. Os roteadores de backup, no entanto, não respondem a solicitações ARP ou ND de hosts.
Em uma rede IPv4, um grupo VRRP com balanceamento de carga funciona da seguinte forma:
- O mestre atribui endereços MAC virtuais a todos os roteadores membros, inclusive a si mesmo. Este exemplo pressupõe que o endereço IP virtual do grupo VRRP seja 10.1.1.1/24, que o Roteador A seja o mestre e que o Roteador B seja o backup. O Roteador A atribui 000f-e2ff-0011 para si mesmo e 000f-e2ff-0012 para o Roteador B. Veja a Figura 5.
- Quando chega uma solicitação de ARP, o mestre (Roteador A) seleciona um endereço MAC virtual com base no algoritmo de balanceamento de carga para responder à solicitação de ARP. Neste exemplo, o Roteador A retorna o endereço MAC virtual dele mesmo em resposta à solicitação ARP do Host A. O Roteador A retorna o endereço MAC virtual do Roteador B em resposta à solicitação ARP do Host B. Veja a Figura 6.
- Cada host envia pacotes para o endereço MAC retornado. Conforme mostrado na Figura 7, o host A envia pacotes para o roteador A e o host B envia pacotes para o roteador B.
Figura 5 Atribuição de endereço MAC virtual
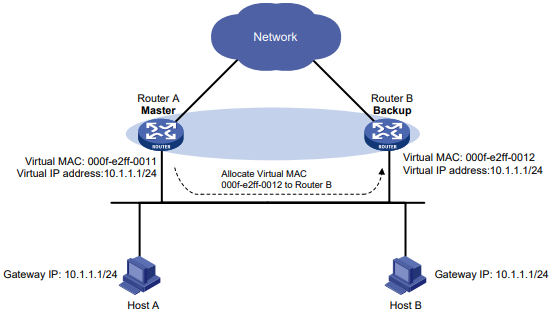
Figura 6 Resposta a solicitações ARP
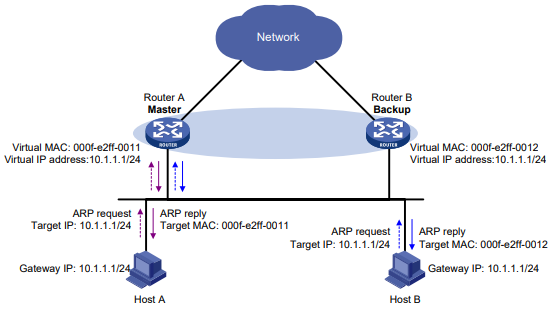
Figura 7 Envio de pacotes a diferentes roteadores para encaminhamento
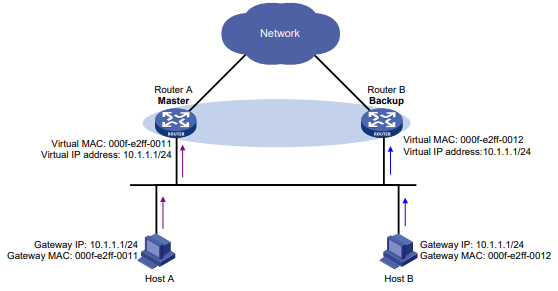
Na resposta ARP enviada pelo mestre, o endereço MAC de origem no cabeçalho Ethernet é diferente do endereço MAC do remetente no corpo da mensagem. Para que o dispositivo de camada 2 encaminhe o pacote ARP, siga estas diretrizes de configuração no dispositivo de camada 2:
- Não ative a verificação de consistência do endereço MAC de origem do pacote ARP.
- Não especifique a palavra-chave src-mac quando você ativar a verificação de validade do pacote ARP para detecção de ARP.
Para obter mais informações sobre a verificação de consistência do endereço MAC de origem do pacote ARP e a detecção de ARP, consulte o Guia de configuração de segurança.
Encaminhador virtual
Criação de forwarder virtual
Os endereços MAC virtuais permitem a distribuição do tráfego entre os roteadores em um grupo VRRP. Para permitir que os roteadores do grupo VRRP encaminhem pacotes, os VFs devem ser criados neles. Cada VF está associado a um endereço MAC virtual no grupo VRRP e encaminha os pacotes que são enviados para esse endereço MAC virtual.
Os VFs são criados em roteadores em um grupo VRRP, da seguinte forma:
- O mestre atribui endereços MAC virtuais a todos os roteadores do grupo VRRP. Cada roteador membro cria um VF para esse endereço MAC e se torna o proprietário desse VF.
- Cada proprietário de VF anuncia suas informações de VF para os outros roteadores membros.
- Depois de receber o anúncio do VF, cada um dos outros roteadores cria o VF anunciado. Por fim, cada roteador membro mantém um VF para cada endereço MAC virtual no grupo VRRP.
Peso e prioridade do VF
O peso de um VF indica a capacidade de encaminhamento de um VF. Um peso maior significa maior capacidade de encaminhamento. Quando o peso é menor que o limite inferior de falha, o VF não pode encaminhar pacotes.
A prioridade de uma VF determina o estado da VF. Entre os VFs criados em diferentes roteadores membros para o mesmo endereço MAC virtual, o VF com a prioridade mais alta está no estado ativo. Essa VF, conhecida como AVF (active virtual forwarder), encaminha os pacotes. Todos os outros VFs escutam o estado do AVF e são conhecidos como encaminhadores virtuais de escuta (LVFs). A prioridade do VF está no intervalo de 0 a 255, sendo 255
é reservado para o proprietário da VF. Quando o peso de um proprietário de VF é maior ou igual ao limite inferior de falha, a prioridade do proprietário de VF é 255.
A prioridade de um VF é calculada com base em seu peso.
- Se o peso VF for maior ou igual ao limite inferior de falha, aplicam-se as seguintes prioridades VF:
- Em um proprietário VF, a prioridade VF é 255.
- Em um proprietário não VF, a prioridade VF é calculada como peso/(número de AVFs locais + 1).
- Se o peso do VF for menor do que o limite inferior de falha, a prioridade do VF será 0.
Backup VF
Os VFs correspondentes a um endereço MAC virtual em diferentes roteadores do grupo VRRP fazem backup de um outro.
Figura 8 Informações sobre o VF
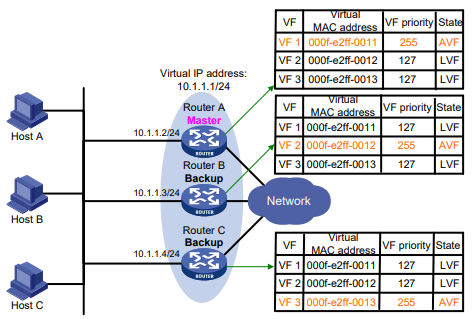
A Figura 8 mostra a tabela de VFs em cada roteador do grupo VRRP e como as VFs fazem backup umas das outras. O mestre, o Roteador A, atribui os endereços MAC virtuais 000f-e2ff-0011, 000f-e2ff-0012 e 000f-e2ff-0013 a ele mesmo, ao Roteador B e ao Roteador C, respectivamente. Cada roteador cria VF 1, VF 2 e VF 3 para os endereços MAC virtuais 000f-e2ff-0011, 000f-e2ff-0012 e 000f-e2ff-0013, respectivamente. Os VFs para o mesmo endereço MAC virtual em roteadores diferentes fazem backup um do outro. Por exemplo, as instâncias de VF 1 no Roteador A, no Roteador B e no Roteador C fazem backup umas das outras.
- A instância da VF 1 no Roteador A (o proprietário da VF 1) tem prioridade 255. Ela atua como AVF para encaminhar pacotes enviados para o endereço MAC virtual 000f-e2ff-0011.
- As instâncias da VF 1 no Roteador B e no Roteador C têm uma prioridade de 255/(1 + 1), ou 127. Como suas prioridades são menores do que a prioridade da instância VF 1 no Roteador A, elas atuam como LVFs. Esses LVFs escutam o estado da instância VF 1 no Roteador A.
- Quando a instância VF 1 no Roteador A falha, as instâncias VF 1 no Roteador B e no Roteador C elegem aquela com prioridade mais alta como o novo AVF. Esse AVF encaminha os pacotes destinados ao endereço MAC virtual 000f-e2ff-0011. Se as prioridades dos dois LVFs forem as mesmas, o LVF com um endereço MAC de dispositivo maior se tornará o novo AVF.
Um VF sempre opera no modo preemptivo. Quando um LVF encontra seu valor de prioridade mais alto do que o anunciado pelo AVF, o LVF se declara como AVF.
Temporizadores VF
Quando o AVF em um roteador falha, o novo AVF em outro roteador cria os seguintes temporizadores para o AVF com falha:
- Temporizador de redirecionamento - Antes que esse temporizador expire, o mestre ainda usa o endereço MAC virtual correspondente ao AVF com falha para responder às solicitações ARP/ND dos hosts. O proprietário do AVF pode compartilhar a carga de tráfego se o proprietário do AVF retomar a operação normal dentro desse período. Quando esse temporizador expirar, o mestre deixará de usar o endereço MAC virtual correspondente ao AVF com falha para responder às solicitações ARP/ND dos hosts.
- Temporizador de tempo limite - A duração após a qual o novo AVF assume as responsabilidades do proprietário do VF com falha. Antes que esse cronômetro expire, todos os roteadores do grupo VRRP mantêm os VFs que correspondem ao AVF com falha. O novo AVF encaminha os pacotes destinados ao endereço MAC virtual do AVF com falha. Quando esse cronômetro expira, todos os roteadores do grupo VRRP removem os VFs que correspondem ao AVF com falha, inclusive o novo AVF. Os pacotes destinados ao endereço MAC virtual do AVF com falha não são mais encaminhados.
Rastreamento VF
Um AVF encaminha pacotes destinados ao endereço MAC do AVF. Se o link upstream do AVF falhar, mas nenhum LVF assumir o controle, os hosts que usam o endereço MAC do AVF como endereço MAC de gateway não poderão acessar a rede externa.
A função de rastreamento de VF pode resolver esse problema. Você pode usar o NQA ou o BFD para monitorar o estado do link upstream do proprietário do VF e associar os VFs ao NQA ou ao BFD por meio da função de rastreamento. Isso permite a colaboração entre o VRRP e o NQA ou o BFD por meio do módulo Track. Quando o link upstream falha, o estado da entrada de rastreamento muda para Negativo. Os pesos dos VFs (incluindo o AVF) no roteador diminuem em um valor específico. O LVF correspondente com uma prioridade mais alta em outro roteador torna-se o AVF e encaminha os pacotes.
Protocolos e padrões
- RFC 3768, Protocolo de Redundância de Roteador Virtual (VRRP)
- RFC 5798, Virtual Router Redundancy Protocol (VRRP) Versão 3 para IPv4 e IPv6
Configuração do VRRP IPv4
Restrições e diretrizes: Configuração do VRRP IPv4
O IPv4 VRRP não entra em vigor nas portas membros dos grupos de agregação. A configuração nos roteadores em um grupo IPv4 VRRP deve ser consistente.
Cada grupo IPv4 VRRP corresponde a um endereço MAC virtual. O número máximo de grupos IPv4 VRRP suportados em uma interface depende do número máximo de endereços MAC virtuais suportados na interface.
Visão geral das tarefas do IPv4 VRRP
Para configurar o IPv4 VRRP, execute as seguintes tarefas:
- Especificação de um modo de operação IPv4 VRRP
- (Opcional.) Especificação da versão IPv4 VRRP
- Configuração de um grupo VRRP IPv4
- (Opcional.) Configuração dos atributos do pacote IPv4 VRRP
- (Opcional.) Configuração do rastreamento de FV
- (Opcional.) Configuração do modo de envio de pacotes para IPv4 VRRPv3
- (Opcional.) Ativação do envio periódico de pacotes ARP gratuitos para o IPv4 VRRP
- (Opcional.) Configuração de um grupo VRRP IPv4 subordinado para seguir um grupo VRRP IPv4 mestre
- (Opcional.) Ativação de notificações SNMP para VRRP
Essa configuração só tem efeito no modo de balanceamento de carga VRRP.
Especificação de um modo de operação IPv4 VRRP
Restrições e diretrizes
Depois que um modo operacional IPv4 VRRP é configurado em um roteador, todos os grupos IPv4 VRRP no roteador operam no modo operacional especificado.
Procedimento
- Entre na visualização do sistema.
System-view- Especifique o modo padrão.
undo vrrp modevrrp mode load-balance [ version-8 ]Por padrão, o VRRP opera no modo padrão.
Especificação da versão IPv4 VRRP
Sobre as versões IPv4 do VRRP
O VRRP IPv4 pode usar o VRRPv2 e o VRRPv3.
Restrições e diretrizes
Para que um grupo VRRP IPv4 funcione corretamente, certifique-se de que a mesma versão do VRRP seja usada em todos os roteadores do grupo VRRP IPv4.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp version version-numberPor padrão, o VRRPv3 é usado.
Configuração de um grupo VRRP IPv4
Sobre o grupo VRRP IPv4
Um grupo VRRP pode funcionar corretamente depois que você o cria e atribui a ele um mínimo de um endereço IP virtual. É possível configurar vários endereços IP virtuais para o grupo VRRP em uma interface que se conecta a várias sub-redes para backup do roteador em diferentes sub-redes.
Se você desativar um grupo VRRP IPv4, o grupo VRRP entrará no estado Inicializar e a configuração existente no grupo VRRP permanecerá inalterada. Você pode modificar a configuração do grupo VRRP. A modificação entra em vigor quando você ativa o grupo VRRP novamente.
Restrições e diretrizes
| Item | Observações |
| Número máximo de grupos VRRP e endereços IP virtuais | No modo de balanceamento de carga VRRP, o dispositivo suporta um máximo de grupos VRRP MaxVRNum/N. MaxVRNum refere-se ao número máximo de grupos VRRP suportados pelo dispositivo no modo padrão VRRP. N refere-se ao número de dispositivos no grupo VRRP. |
| Endereço IP virtual | Quando o VRRP está operando no modo padrão, o endereço IP virtual de um grupo VRRP pode ser um dos seguintes endereços: Endereço IP não utilizado na sub-rede em que o grupo VRRP reside. Endereço IP de uma interface em um roteador do grupo VRRP. No modo de balanceamento de carga, o endereço IP virtual de um grupo VRRP pode ser qualquer endereço IP não atribuído da sub-rede em que o grupo VRRP reside. Ele não pode ser o endereço IP de nenhuma interface no grupo VRRP. Nenhum proprietário de endereço IP pode existir em um grupo VRRP. Um grupo VRRP IPv4 sem endereços IP virtuais configurados pode existir em um dispositivo, desde que outras configurações (por exemplo, prioridade e modo de preempção) estejam disponíveis. Esse grupo VRRP permanece em estado inativo e não funciona. Para que os hosts da sub-rede acessem redes externas, como prática recomendada, configure os seguintes endereços na mesma sub-rede: Endereço IP virtual de um grupo VRRP IPv4. Endereços IP da interface de downlink dos membros do grupo VRRP. |
| Proprietário do endereço IP | Em um proprietário de endereço IP, como prática recomendada, não use o comando network para ativar o OSPF na interface que possui o endereço IP virtual do grupo VRRP. Para obter mais informações sobre o comando network, consulte Referência de comandos de roteamento de IP de camada 3. A remoção do grupo VRRP no proprietário do endereço IP causa colisão de endereços IP. Para evitar a colisão, altere o endereço IP da interface no proprietário do endereço IP antes de remover o grupo VRRP da interface. A prioridade de execução de um proprietário de endereço IP é sempre 255, e você não precisa configurá-la. Um proprietário de endereço IP sempre opera no modo preemptivo. Se você configurar o comando vrrp vrid track priority reduced ou vrrp vrid track switchover em um proprietário de endereço IP, a configuração não terá efeito até que o roteador se torne um proprietário de endereço não IP. |
| Associação de VRRP com uma entrada de trilha | Quando a entrada da trilha muda de Negativa para Positiva ou Não pronta, o roteador restaura automaticamente sua prioridade ou o roteador mestre com falha se torna o mestre novamente. |
Criação de um grupo VRRP e atribuição de um endereço IP virtual
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp vrid virtual-router-id virtual-ip virtual-addressConfiguração de um grupo VRRP IPv4
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp vrid virtual-router-id priority priority-valueA configuração padrão é 100.
vrrp vrid virtual-router-id preempt-mode [ delay delay-value ]Por padrão, o roteador em um grupo VRRP opera no modo preemptivo e o tempo de atraso de preempção é de 0 centissegundos, o que significa uma preempção imediata.
vrrp vrid virtual-router-id track track-entry-number { forwarder-switchover member-ip ip-address | priority reduced [ priority-reduced ] | switchover | weight reduced [ weight-reduced ] }Por padrão, um grupo VRRP não está associado a nenhuma entrada de trilha.
Desativação de um grupo VRRP IPv4
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp vrid virtual-router-id shutdownConfiguração de atributos de pacotes IPv4 VRRP
Restrições e diretrizes
- É possível configurar diferentes modos de autenticação e chaves de autenticação para grupos VRRP em uma interface. Entretanto, os membros do mesmo grupo VRRP devem usar o mesmo modo de autenticação e a mesma chave de autenticação.
- No VRRPv2, todos os roteadores em um grupo VRRP devem ter o mesmo intervalo de anúncio do VRRP.
- No VRRPv3, as configurações do modo de autenticação e da chave de autenticação não têm efeito.
- No VRRPv3, os roteadores em um grupo VRRP IPv4 podem ter intervalos diferentes para enviar anúncios VRRP. O mestre no grupo VRRP envia anúncios VRRP em intervalos especificados e registra o intervalo nos anúncios. Depois que um backup recebe o anúncio, ele registra o intervalo no anúncio. Se o backup não receber um anúncio VRRP antes que o timer (3 x intervalo registrado + Skew_Time) expire, ele considerará o mestre como falho e assumirá o controle.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp vrid virtual-router-id authentication-mode { md5 | simple } { cipher | plain } stringPor padrão, a autenticação está desativada.
vrrp vrid virtual-router-id timer advertise adver-intervalA configuração padrão é 100 centissegundos.
Como prática recomendada para manter a estabilidade do sistema, defina o intervalo de anúncio do VRRP para ser maior que 100 centissegundos.
vrrp vrid virtual-router-id source-interface interface-type interface-numberPor padrão, a interface de origem para receber e enviar pacotes VRRP não é especificada. A interface em que o grupo VRRP reside envia e recebe pacotes VRRP.
vrrp check-ttl enablePor padrão, a verificação de TTL para pacotes IPv4 VRRP está ativada.
quitvrrp dscp dscp-valuePor padrão, o valor DSCP para pacotes VRRP é 48.
O valor DSCP identifica a prioridade do pacote durante a transmissão.
Configuração do rastreamento de FV
Sobre o rastreamento da VF
Você pode configurar o rastreamento de VF tanto no modo padrão quanto no modo de balanceamento de carga, mas a função só tem efeito no modo de balanceamento de carga.
No modo de balanceamento de carga, você pode estabelecer a colaboração entre os VFs e o NQA ou o BFD por meio da função de rastreamento. Quando o estado da entrada de rastreamento passa para Negativo, os pesos de todos os VFs no grupo VRRP no roteador diminuem em um valor específico. Quando o estado da entrada de rastreamento passa para Positivo ou Não pronto, os valores de peso originais dos VFs são restaurados.
Restrições e diretrizes
- Por padrão, o peso de um VF é 255, e seu limite inferior de falha é 10.
- Quando o peso de um proprietário de VF é maior ou igual ao limite inferior de falha, sua prioridade é sempre 255. A prioridade não muda com o peso. Quando o link upstream do proprietário da VF falha, um LVF deve assumir o controle como AVF. A troca ocorre quando o peso do proprietário da VF cai abaixo do limite inferior de falha. Isso exige que o peso reduzido do proprietário da VF seja maior que 245.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp vrid virtual-router-id track track-entry-number { forwarder-switchover member-ip ip-address | priority reduced [ priority-reduced ] | switchover | weight reduced [ weight-reduced ] }Por padrão, nenhuma entrada de trilha é especificada.
Configuração do modo de envio de pacotes para IPv4 VRRPv3
Sobre o modo de envio de pacotes para IPv4 VRRPv3
Um roteador configurado com VRRPv3 pode processar pacotes VRRPv2 de entrada, mas um roteador configurado com VRRPv2 não pode processar pacotes VRRPv3 de entrada. Quando a versão VRRP dos roteadores em um grupo VRRP é alterada de VRRPv2 para VRRPv3, vários mestres podem ser eleitos no grupo VRRP. Para resolver o problema, você pode definir o modo de envio de pacotes para o IPv4 VRRPv3. Essa tarefa permite que um roteador configurado com VRRPv3 envie pacotes VRRPv2 e se comunique com roteadores configurados com VRRPv2.
Restrições e diretrizes
- O modo de envio de pacotes para IPv4 VRRPv3 tem efeito apenas nos pacotes VRRP de saída. Um roteador configurado com VRRPv3 pode processar pacotes VRRPv2 e VRRPv3 de entrada.
- Se você definir o modo de envio de pacotes para IPv4 VRRPv3 e configurar a autenticação de pacotes VRRP, as informações de autenticação serão transportadas nos pacotes VRRPv2 de saída, mas não nos pacotes VRRPv3 de saída.
- O intervalo de anúncio do VRRP é definido em centissegundos usando o comando vrrp vrid timer advertise. O intervalo de anúncio do VRRP contido nos pacotes VRRPv2 enviados pelos roteadores configurados com o VRRPv3 pode ser diferente do valor configurado. Para obter informações sobre o intervalo de anúncio do VRRP, consulte o comando vrrp vrid timer advertise na Referência de comandos de alta disponibilidade.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp vrid virtual-router-id vrrpv3-send-packet { v2-only | v2v3-both }Por padrão, um roteador configurado com VRRPv3 envia somente pacotes VRRPv3.
Ativação do envio periódico de pacotes ARP gratuitos para o IPv4 VRRP
Sobre o envio periódico de pacotes ARP gratuitos para o IPv4 VRRP
Esse recurso permite que o roteador mestre em um grupo VRRP envie periodicamente pacotes ARP gratuitos. Em seguida, os dispositivos downstream podem atualizar a entrada de endereço MAC para o endereço MAC virtual do grupo VRRP em tempo hábil.
Restrições e diretrizes
- Esse recurso entra em vigor somente no modo padrão VRRP.
- Se você alterar o intervalo de envio de pacotes ARP gratuitos, a configuração entrará em vigor no próximo intervalo de envio.
- O mestre envia o primeiro pacote ARP gratuito em um momento aleatório na segunda metade do intervalo definido depois que você executa o comando vrrp send-gratuitous-arp. Isso evita que muitos pacotes ARP gratuitos sejam enviados ao mesmo tempo.
- O intervalo de envio de pacotes ARP gratuitos pode ser muito maior do que o intervalo definido quando as seguintes condições forem atendidas:
- Existem vários grupos VRRP no dispositivo.
- Um intervalo de envio curto é definido.
Procedimento
- Entre na visualização do sistema.
System-viewvrrp send-gratuitous-arp [ interval interval ]Por padrão, o envio periódico de pacotes ARP gratuitos é desativado para o IPv4 VRRP.
Configuração de um grupo VRRP IPv4 subordinado para seguir um grupo VRRP IPv4 mestre
Sobre grupos IPv4 VRRP mestre e subordinados
Cada grupo VRRP determina a função do dispositivo (mestre ou backup) por meio da troca de pacotes VRRP entre os dispositivos membros, o que pode consumir largura de banda e recursos de CPU excessivos. Para reduzir o número de pacotes VRRP na rede, você pode configurar um grupo VRRP subordinado para seguir um grupo VRRP mestre.
Um grupo VRRP mestre determina a função do dispositivo por meio da troca de pacotes VRRP entre os dispositivos membros. Um grupo VRRP que segue um grupo mestre, chamado de grupo VRRP subordinado, não troca pacotes VRRP entre seus dispositivos membros. O estado do grupo VRRP subordinado segue o estado do grupo mestre.
Restrições e diretrizes
- Para garantir a eleição do roteador mestre, defina as configurações, como a prioridade do roteador, o modo preemptivo e a função de rastreamento para o grupo VRRP IPv4 mestre. As configurações não são necessárias para os grupos IPv4 VRRP subordinados.
- Você pode configurar um grupo VRRP subordinado para seguir um grupo VRRP mestre nos modos VRRP padrão e de balanceamento de carga. A configuração entra em vigor somente no modo padrão VRRP.
- Um grupo VRRP IPv4 não pode ser tanto um grupo mestre quanto um grupo subordinado.
- Um grupo VRRP IPv4 permanece no estado Inativo se estiver configurado para seguir um grupo mestre inexistente.
- Se um grupo VRRP IPv4 no estado Inativo ou Inicializar seguir um grupo mestre que não esteja no estado inativo, o estado do grupo VRRP não é alterado.
- Um grupo VRRP IPv4 subordinado não troca pacotes VRRP, o que pode fazer com que a entrada de endereço MAC para seu endereço MAC virtual não seja atualizada nos dispositivos downstream. Como prática recomendada, ative o envio periódico de pacotes ARP gratuitos para o VRRP IPv4 usando o comando vrrp send-gratuitous-arp.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp vrid virtual-router-id name namePor padrão, um grupo VRRP IPv4 não atua como um grupo mestre.
quitinterface interface-type interface-numbervrrp vrid virtual-router-id follow namePor padrão, um grupo VRRP IPv4 não segue um grupo VRRP mestre.
Ativação de notificações SNMP para VRRP
Sobre as notificações SNMP para VRRP
Para relatar eventos críticos de VRRP a um NMS, ative as notificações de SNMP para VRRP. Para que as notificações de eventos VRRP sejam enviadas corretamente, você também deve configurar o SNMP no dispositivo. Para obter mais informações sobre a configuração de SNMP, consulte o guia de configuração de monitoramento e gerenciamento de rede do dispositivo.
Procedimento
- Entre na visualização do sistema.
System-viewsnmp-agent trap enable vrrp [ auth-failure | new-master ]Por padrão, as notificações SNMP para VRRP estão ativadas.
Comandos de exibição e manutenção para IPv4 VRRP
Execute comandos de exibição em qualquer visualização e o comando reset na visualização do usuário.
| Tarefa | Comando |
| Exibir estados de grupos VRRP IPv4. | display vrrp [ interface interface-type interface-number [ vrid virtual-router-id ] ] [ verbose ] |
| Exibir as associações de grupos IPv4 VRRP mestre-subordinado. | display vrrp binding [ interface interface-type interface-number [ vrid virtual-router-id ] | name name ] |
| Exibir estatísticas de grupos VRRP IPv4. | display vrrp statistics [ interface interface-type interface-number [ vrid virtual-router-id ] ] |
| Limpar estatísticas do IPv4 VRRP grupos. | reset vrrp statistics [ interface interface-type interface-number [ vrid virtual-router-id ] ] |
Configuração do IPv6 VRRP
Restrições e diretrizes: Configuração do VRRP IPv6
O IPv6 VRRP não entra em vigor nas portas membros dos grupos de agregação. A configuração nos roteadores em um grupo IPv6 VRRP deve ser consistente.
Cada grupo IPv6 VRRP corresponde a um endereço MAC virtual. O número máximo de grupos IPv6 VRRP suportados em uma interface depende do número máximo de endereços MAC virtuais suportados na interface.
Visão geral das tarefas do IPv6 VRRP
Para configurar o IPv6 VRRP, execute as seguintes tarefas:
- Especificação de um modo de operação IPv6 VRRP
- Configuração de um grupo VRRP IPv6
- (Opcional.) Configuração do rastreamento de FV
- (Opcional.) Configuração dos atributos do pacote IPv6 VRRP
- (Opcional.) Ativação do envio periódico de pacotes ND para o IPv6 VRRP
- (Opcional.) Configuração de um grupo IPv6 VRRP subordinado para seguir um grupo IPv6 VRRP mestre
Essa configuração só tem efeito no modo de balanceamento de carga VRRP.
Especificação de um modo de operação IPv6 VRRP
Restrições e diretrizes
Depois que o modo operacional do IPv6 VRRP é especificado em um roteador, todos os grupos IPv6 VRRP no roteador operam no modo operacional especificado.
Procedimento
- Entre na visualização do sistema.
System-view- Especifique o modo padrão.
undo vrrp ipv6 modevrrp ipv6 mode load-balancePor padrão, o VRRP opera no modo padrão.
Configuração de um grupo VRRP IPv6
Sobre o grupo IPv6 VRRP
Um grupo VRRP pode funcionar corretamente depois que você o cria e atribui a ele um mínimo de um endereço IPv6 virtual. É possível configurar vários endereços IPv6 virtuais para o grupo VRRP em uma interface que se conecta a várias sub-redes para backup do roteador.
Se você desativar um grupo VRRP IPv6, o grupo VRRP entrará no estado Inicializar e a configuração existente no grupo VRRP permanecerá inalterada. Você pode modificar a configuração do grupo VRRP. A modificação entra em vigor quando você ativa o grupo VRRP novamente.
Restrições e diretrizes
| Item | Observações |
| Número máximo de grupos VRRP e endereços IPv6 virtuais | No modo de balanceamento de carga VRRP, o dispositivo suporta um máximo de grupos VRRP MaxVRNum/N. MaxVRNum refere-se ao número máximo de grupos VRRP suportados pelo dispositivo no modo padrão VRRP. N refere-se ao número de dispositivos no grupo VRRP. |
| Endereço IPv6 virtual | No modo de balanceamento de carga, o endereço IPv6 virtual de um grupo VRRP não pode ser o mesmo que o endereço IPv6 de nenhuma interface do grupo VRRP. Nenhum proprietário de endereço IP pode existir em um grupo VRRP. Um grupo VRRP IPv6 sem endereços IPv6 virtuais configurados pode existir em um dispositivo, desde que outras configurações (por exemplo, prioridade e modo de preempção) estejam disponíveis. Esse grupo VRRP permanece em estado inativo e não funciona. Para que os hosts da sub-rede acessem redes externas, como prática recomendada, configure os seguintes endereços na mesma sub-rede: Endereço IPv6 virtual de um grupo VRRP IPv6. Endereços IPv6 da interface de downlink dos membros do grupo VRRP. |
| Proprietário do endereço IP | Em um proprietário de endereço IP, como prática recomendada, não use o comando ospfv3 area para ativar o OSPF na interface que possui o endereço IPv6 virtual do grupo VRRP. Para obter mais informações sobre o comando ospfv3 area, consulte Referência de comandos de roteamento da camada 3IP. A remoção do grupo VRRP no proprietário do endereço IP causa colisão de endereços IP. Para evitar a colisão, altere o endereço IPv6 da interface no proprietário do endereço IP antes de remover o grupo VRRP da interface. A prioridade de execução de um proprietário de endereço IP é sempre 255, e você não precisa configurá-la. Um proprietário de endereço IP sempre opera no modo preemptivo. Se você configurar o comando vrrp ipv6 vrid track priority reduced ou vrrp ipv6 vrid track switchover em um proprietário de endereço IP, a configuração não entrará em vigor até que o roteador se torne um proprietário de endereço não IP. Em um proprietário de endereço IP, desative a detecção de endereços duplicados (DAD) na interface configurada com o VRRP. Para desativar a DAD, defina o argumento de intervalo como 0 para o comando ipv6 nd dad attempts. Para obter mais informações sobre o comando, consulte Comandos básicos de IPv6 na Referência de comandos de serviços IP de camada 3. |
| Associação de VRRP com uma entrada de trilha | Quando a entrada da trilha muda de Negativa para Positiva ou Não pronta, o roteador restaura automaticamente sua prioridade ou o roteador mestre com falha se torna o mestre novamente. |
Criação de um grupo VRRP e atribuição de um endereço IPv6 virtual
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp ipv6 vrid virtual-router-id virtual-ip virtual-address link-localO primeiro endereço IPv6 virtual que você atribuir a um grupo VRRP IPv6 deve ser um endereço local de link. Ele deve ser o último endereço removido. Somente um endereço local de link é permitido em um grupo VRRP.
Configuração de um grupo VRRP IPv6
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp ipv6 vrid virtual-router-id virtual-ip virtual-address link-localPor padrão, nenhum endereço unicast global é atribuído a um grupo VRRP IPv6.
vrrp ipv6 vrid virtual-router-id priority priority-valueA configuração padrão é 100.
vrrp ipv6 vrid virtual-router-id preempt-mode [ delay delay-value ]Por padrão, o roteador em um grupo VRRP opera no modo preemptivo e o tempo de atraso de preempção é de 0 centissegundos, o que significa uma preempção imediata.
vrrp ipv6 vrid virtual-router-id track track-entry-number { forwarder-switchover member-ip ipv6-address | priority reduced [ priority-reduced ] | switchover | weight reduced [ weight-reduced ] }Por padrão, um grupo VRRP não está associado a nenhuma entrada de trilha.
Desativação de um grupo VRRP IPv6
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp ipv6 vrid virtual-router-id shutdownPor padrão, um grupo VRRP IPv6 está ativado.
Configuração do rastreamento de FV
Sobre o rastreamento da VF
Você pode configurar o rastreamento de VF tanto no modo padrão quanto no modo de balanceamento de carga, mas a função só tem efeito no modo de balanceamento de carga.
No modo de balanceamento de carga, você pode configurar os VFs em um grupo VRRP para monitorar uma entrada de trilha. Quando o estado da entrada de trilha passa para Negativo, os pesos de todos os VFs do grupo VRRP no roteador diminuem em um valor específico. Quando o estado da entrada de trilha passa para Positivo ou Não pronto, os pesos originais dos VFs são restaurados.
Restrições e diretrizes
- Por padrão, o peso de um VF é 255, e seu limite inferior de falha é 10.
- Quando o peso de um proprietário de VF é maior ou igual ao limite inferior de falha, sua prioridade é sempre 255. A prioridade não muda com o peso. Quando o link upstream do proprietário da VF falha, um LVF deve assumir o controle como AVF. A troca ocorre quando o peso do proprietário da VF cai abaixo do limite inferior de falha. Isso exige que o peso reduzido para o proprietário da VF seja maior que 245.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp ipv6 vrid virtual-router-id track track-entry-number { forwarder-switchover member-ip ipv6-address | priority reduced [ priority-reduced ] | switchover | weight reduced [ weight-reduced ] }Por padrão, nenhuma entrada de trilha é especificada.
Configuração de atributos de pacotes IPv6 VRRP
Restrições e diretrizes
- Os roteadores em um grupo IPv6 VRRP podem ter intervalos diferentes para enviar anúncios VRRP. O mestre no grupo VRRP envia anúncios VRRP no intervalo especificado e carrega o atributo de intervalo nos anúncios. Depois que um backup recebe o anúncio, ele registra o intervalo no anúncio. Se o backup não receber um anúncio VRRP antes que o timer (3 x intervalo registrado + Skew_Time) expire, ele considerará o mestre como falho e assumirá o controle.
- Um alto volume de tráfego de rede pode fazer com que um backup não receba anúncios VRRP do mestre dentro do tempo especificado. Como resultado, ocorre uma troca inesperada de mestre. Para resolver esse problema, configure um intervalo maior.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp ipv6 vrid virtual-router-id timer advertise adver-intervalA configuração padrão é 100 centissegundos.
Como prática recomendada para manter a estabilidade do sistema, defina o intervalo de anúncio do VRRP como superior a 100 centissegundos.
quitvrrp ipv6 dscp dscp-valuePor padrão, o valor DSCP para pacotes IPv6 VRRP é 56.
O valor DSCP identifica a prioridade do pacote durante a transmissão.
Ativação do envio periódico de pacotes ND para o IPv6 VRRP
Sobre o envio periódico de pacotes ND para o IPv6 VRRP
Esse recurso permite que o roteador mestre em um grupo VRRP IPv6 envie periodicamente pacotes ND. Assim, os dispositivos downstream podem atualizar a entrada de endereço MAC para o endereço MAC virtual do grupo VRRP IPv6 em tempo hábil.
Restrições e diretrizes
- Esse recurso entra em vigor somente no modo padrão VRRP.
- Se você alterar o intervalo de envio dos pacotes ND, a configuração entrará em vigor no próximo intervalo de envio.
- O mestre envia o primeiro pacote ND em um momento aleatório na segunda metade do intervalo definido depois que você executa o comando vrrp ipv6 send-nd. Isso evita que muitos pacotes ND sejam enviados ao mesmo tempo.
- O intervalo de envio dos pacotes ND pode ser muito maior do que o intervalo definido quando as seguintes condições forem atendidas:
- Existem vários grupos VRRP IPv6 no dispositivo.
- Um intervalo de envio curto é definido.
Procedimento
- Entre na visualização do sistema.
System-viewvrrp ipv6 send-nd [ interval interval ]Por padrão, o envio periódico de pacotes ND está desativado para o IPv6 VRRP.
Configuração de um grupo IPv6 VRRP subordinado para seguir um grupo IPv6 VRRP mestre
Sobre grupos IPv6 VRRP mestre e subordinados
Cada grupo IPv6 VRRP determina a função do dispositivo (mestre ou backup) trocando pacotes VRRP entre os dispositivos membros, o que pode consumir largura de banda e recursos de CPU excessivos. Para reduzir o número de pacotes VRRP na rede, você pode configurar um grupo IPv6 VRRP subordinado para seguir um grupo IPv6 VRRP mestre.
Um grupo IPv6 VRRP mestre determina a função do dispositivo por meio da troca de pacotes VRRP entre os dispositivos membros. Um grupo IPv6 VRRP que segue um grupo mestre, chamado de grupo VRRP subordinado, não troca pacotes VRRP entre seus dispositivos membros. O estado do grupo VRRP subordinado segue o estado do grupo mestre.
Restrições e diretrizes
- Para garantir a eleição do roteador mestre, defina as configurações, como a prioridade do roteador, o modo preemptivo e a função de rastreamento para o grupo VRRP IPv6 mestre. As configurações não são necessárias para os grupos IPv6 VRRP subordinados.
- Você pode configurar um grupo VRRP IPv6 subordinado para seguir um grupo VRRP IPv6 mestre nos modos VRRP padrão e de balanceamento de carga. A configuração entra em vigor somente no modo padrão VRRP.
- Um grupo VRRP IPv6 não pode ser tanto um grupo mestre quanto um grupo subordinado.
- Um grupo IPv6 VRRP permanecerá no estado Inativo se estiver configurado para seguir um grupo IPv6 VRRP mestre inexistente.
- Se um grupo IPv6 VRRP no estado Inativo ou Inicializar seguir um grupo mestre que não esteja no estado
Estado inativo, o estado do grupo VRRP não é alterado.
- Um grupo VRRP IPv6 subordinado não troca pacotes VRRP, o que pode fazer com que a entrada de endereço MAC para seu endereço MAC virtual não seja atualizada nos dispositivos downstream. Como prática recomendada, ative o envio periódico de pacotes ND para o IPv6 VRRP usando o comando vrrp ipv6 send-nd.
Procedimento
- Entre na visualização do sistema.
System-viewinterface interface-type interface-numbervrrp ipv6 vrid virtual-router-id name namePor padrão, um grupo VRRP IPv6 não atua como um grupo mestre.
quitinterface interface-type interface-numbervrrp ipv6 vrid virtual-router-id follow namePor padrão, um grupo VRRP IPv6 não segue um grupo VRRP mestre.
Comandos de exibição e manutenção para IPv6 VRRP
Execute comandos de exibição em qualquer visualização e o comando reset na visualização do usuário.
| Tarefa | Comando |
| Exibir os estados dos grupos IPv6 VRRP. | display vrrp ipv6 [ interface interface-type interface-number [ vrid virtual-router-id ] ] [ verbose ] |
| Exibir as associações de grupos IPv6 VRRP mestre-subordinado. | display vrrp ipv6 binding [ interface interface-type interface-number [ vrid virtual-router-id ] | name name ] |
| Exibir estatísticas de grupos VRRP IPv6. | display vrrp ipv6 statistics [ interface interface-type interface-number [ vrid virtual-router-id ] ] |
| Limpar estatísticas de grupos VRRP IPv6. | reset vrrp ipv6 statistics [ interface interface-type interface-number [ vrid virtual-router-id ] ] |
Exemplos de configuração do VRRP IPv4
Exemplo: Configuração de um único grupo VRRP
Configuração de rede
Conforme mostrado na Figura 9, o Switch A e o Switch B formam um grupo VRRP. Eles usam o endereço IP virtual 10.1.1.111/24 para fornecer serviço de gateway para a sub-rede onde reside o Host A.
O switch A opera como mestre para encaminhar pacotes do host A para o host B. Quando o switch A falha, o switch B assume o controle para encaminhar pacotes para o host A.
Figura 9 Diagrama de rede
Procedimento
- Configure o Switch A: # Configurar a VLAN 2.
<SwitchA> system-view
[SwitchA] vlan 2
[SwitchA-vlan2] port gigabitethernet 1/0/5
[SwitchA-vlan2] quit
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 10.1.1.1 255.255.255.0# Crie o grupo VRRP 1 na interface VLAN 2 e defina seu endereço IP virtual como 10.1.1.111.
[SwitchA-Vlan-interface2] vrrp vrid 1 virtual-ip 10.1.1.111# Atribua ao Switch A uma prioridade mais alta que a do Switch B no grupo 1 do VRRP, para que o Switch A possa se tornar o mestre.
[SwitchA-Vlan-interface2] vrrp vrid 1 priority 110# Configure o Switch A para operar no modo preemptivo, de modo que ele possa se tornar o mestre sempre que funcionar corretamente. Defina o atraso de preempção para 5.000 centissegundos para evitar a troca frequente de status.
[SwitchA-Vlan-interface2] vrrp vrid 1 preempt-mode delay 5000<SwitchB> system-view
[SwitchB] vlan 2
[SwitchB-Vlan2] port gigabitethernet 1/0/5
[SwitchB-vlan2] quit
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address 10.1.1.2 255.255.255.0# Crie o grupo VRRP 1 na interface VLAN 2 e defina seu endereço IP virtual como 10.1.1.111.
[SwitchB-Vlan-interface2] vrrp vrid 1 virtual-ip 10.1.1.111# Defina a prioridade do Roteador B como 100 no grupo 1 do VRRP.
[SwitchB-Vlan-interface2] vrrp vrid 1 priority 100# Configure o Switch B para operar no modo preemptivo e defina o atraso de preempção para 5.000 centissegundos.
[SwitchB-Vlan-interface2] vrrp vrid 1 preempt-mode delay 5000Verificação da configuração
# Ping do Host B a partir do Host A. (Detalhes não mostrados).
# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch A.
[SwitchA-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 5000
Auth Type : None
Virtual IP : 10.1.1.111
Virtual MAC : 0000-5e00-0101
Master IP : 10.1.1.1# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch B.
[SwitchB-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 5000
Become Master : 401ms left
Auth Type : None
Virtual IP : 10.1.1.111
Virtual MAC : 0000-5e00-0101
Master IP : 10.1.1.1A saída mostra que o Switch A está operando como mestre no grupo VRRP 1 para encaminhar pacotes do Host A para o Host B.
# Desconecte o link entre o Host A e o Switch A e verifique se o Host A ainda pode fazer o ping do Host B. (Detalhes não mostrados).
# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch B.
[SwitchB-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 5000
Auth Type : None
Virtual IP : 10.1.1.111
Virtual MAC : 0000-5e00-0101
Master IP : 10.1.1.2A saída mostra que, quando o Switch A falha, o Switch B assume o controle para encaminhar os pacotes do Host A para o Host B.
# Recupere o link entre o host A e o switch A e exiba informações detalhadas sobre o grupo VRRP 1 no switch A.
[SwitchA-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 5000
Auth Type : None
Virtual IP : 10.1.1.111
Virtual MAC : 0000-5e00-0101
Master IP : 10.1.1.1A saída mostra que, depois que o Switch A retoma a operação normal, ele se torna o mestre para encaminhar pacotes do Host A para o Host B.
Exemplo: Configuração de vários grupos VRRP
Configuração de rede
Conforme mostrado na Figura 10, o Switch A e o Switch B formam dois grupos VRRP. O grupo VRRP 1 usa o endereço IP virtual 10.1.1.100/25 para fornecer serviço de gateway para hosts na VLAN 2, e o grupo VRRP 2 usa o endereço IP virtual 10.1.1.200/25 para fornecer serviço de gateway para hosts na VLAN 3.
Atribua uma prioridade mais alta ao Switch A do que ao Switch B no grupo VRRP 1, mas uma prioridade mais baixa no grupo VRRP 2. O tráfego da VLAN 2 e da VLAN 3 pode então ser distribuído entre os dois switches. Quando um dos switches falha, o switch íntegro fornece o serviço de gateway para ambas as VLANs.
Figura 10 Diagrama de rede
Procedimento
- Configure o Switch A: # Configurar a VLAN 2.
<SwitchA> system-view [SwitchA] vlan 2
[SwitchA-vlan2] port gigabitethernet 1/0/5 [SwitchA-vlan2] quit
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 10.1.1.1 255.255.255.128
# Crie o grupo VRRP 1 e defina seu endereço IP virtual como 10.1.1.100.
[SwitchA-Vlan-interface2] vrrp vrid 1 virtual-ip 10.1.1.100# Atribua ao Switch A uma prioridade mais alta que a do Switch B no grupo VRRP 1, para que o Switch A possa se tornar o mestre do grupo.
[SwitchA-Vlan-interface2] vrrp vrid 1 priority 110 [SwitchA-Vlan-interface2] quit
# Configure a VLAN 3.
[SwitchA] vlan 3
[SwitchA-vlan3] port gigabitethernet 1/0/6
[SwitchA-vlan3] quit
[SwitchA] interface vlan-interface 3
[SwitchA-Vlan-interface3] ip address 10.1.1.130 255.255.255.128# Crie o grupo VRRP 2 e defina seu endereço IP virtual como 10.1.1.200.
[SwitchA-Vlan-interface3] vrrp vrid 2 virtual-ip 10.1.1.200- Configure o Switch B: # Configurar a VLAN 2.
<SwitchB> system-view
[SwitchB] vlan 2
[SwitchB-vlan2] port gigabitethernet 1/0/5
[SwitchB-vlan2] quit
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address 10.1.1.2 255.255.255.128# Crie o grupo VRRP 1 e defina seu endereço IP virtual como 10.1.1.100.
[SwitchB-Vlan-interface2] vrrp vrid 1 virtual-ip 10.1.1.100 [SwitchB-Vlan-interface2] quit# Configure a VLAN 3.
[SwitchB] vlan 3
[SwitchB-vlan3] port gigabitethernet 1/0/6
[SwitchB-vlan3] quit
[SwitchB] interface vlan-interface 3
[SwitchB-Vlan-interface3] ip address 10.1.1.131 255.255.255.128# Crie o grupo VRRP 2 e defina seu endereço IP virtual como 10.1.1.200.
[SwitchB-Vlan-interface3] vrrp vrid 2 virtual-ip 10.1.1.200# Atribua ao Switch B uma prioridade mais alta que a do Switch A no grupo VRRP 2, para que o Switch B possa se tornar o mestre do grupo.
[SwitchB-Vlan-interface3] vrrp vrid 2 priority 110Verificação da configuração
# Exibir informações detalhadas sobre os grupos VRRP no Switch A.
[SwitchA-Vlan-interface3] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 2
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : 10.1.1.100
Virtual MAC : 0000-5e00-0101
Master IP : 10.1.1.1
Interface Vlan-interface3
VRID : 2 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Become Master : 203ms left
Auth Type : None
Virtual IP : 10.1.1.200
Virtual MAC : 0000-5e00-0102
Master IP : 10.1.1.131# Exibir informações detalhadas sobre os grupos VRRP no Switch B.
[SwitchB-Vlan-interface3] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 2
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Become Master : 211ms left
Auth Type : None
Virtual IP : 10.1.1.100
Virtual MAC : 0000-5e00-0101
Master IP : 10.1.1.1
Interface Vlan-interface3
VRID : 2 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : 10.1.1.200
Virtual MAC : 0000-5e00-0102
Master IP : 10.1.1.131O resultado mostra as seguintes informações:
- O switch A está operando como mestre no grupo VRRP 1 para encaminhar o tráfego da Internet para hosts que usam o gateway padrão 10.1.1.100/25.
- O switch B está operando como mestre no grupo VRRP 2 para encaminhar o tráfego da Internet para hosts que usam o gateway padrão 10.1.1.200/25.
Exemplo: Configuração do balanceamento de carga VRRP
Configuração de rede
Conforme mostrado na Figura 11, o Switch A, o Switch B e o Switch C formam um grupo VRRP com balanceamento de carga. Eles usam o endereço IP virtual 10.1.1.1/24 para fornecer serviço de gateway para a sub-rede 10.1.1.0/24.
Configure os VFs no Switch A, Switch B e Switch C para monitorar suas respectivas interfaces de VLAN 3. Quando a interface de qualquer um deles falha, os pesos dos VFs no switch problemático diminuem para que outro AVF possa assumir o controle.
Figura 11 Diagrama de rede
Procedimento
- Configure o Switch A: # Configurar a VLAN 2.
<SwitchA> system-view
[SwitchA] vlan 2
[SwitchA-vlan2] port gigabitethernet 1/0/5
[SwitchA-vlan2] quit# Configure o VRRP para operar no modo de balanceamento de carga.
[SwitchA] vrrp mode load-balance# Crie o grupo VRRP 1 e defina seu endereço IP virtual como 10.1.1.1.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ip address 10.1.1.2 24
[SwitchA-Vlan-interface2] vrrp vrid 1 virtual-ip 10.1.1.1# Atribua ao Switch A a prioridade mais alta no grupo VRRP 1, para que o Switch A possa se tornar o mestre.
[SwitchA-Vlan-interface2] vrrp vrid 1 priority 120# Configure o Switch A para operar no modo preemptivo, de modo que ele possa se tornar o mestre sempre que funcionar corretamente. Defina o atraso de preempção para 5.000 centissegundos para evitar a troca frequente de status.
[SwitchA-Vlan-interface2] vrrp vrid 1 preempt-mode delay 5000
[SwitchA-Vlan-interface2] quit# Crie a entrada de trilha 1 para monitorar o status do link upstream da interface VLAN 3. Quando o link upstream falha, a entrada de trilha passa para Negativo.
[SwitchA] track 1 interface vlan-interface 3# Configure os VFs no grupo VRRP 1 para monitorar a entrada de trilha 1 e diminua seus pesos em 250 quando a entrada de trilha passar para Negativo.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] vrrp vrid 1 track 1 weight reduced 250- Configure o Switch B:
# Configurar a VLAN 2.
<SwitchB> system-view
[SwitchB] vlan 2
[SwitchB-vlan2] port gigabitethernet 1/0/5
[SwitchB-vlan2] quit# Configure o VRRP para operar no modo de balanceamento de carga.
[SwitchB] vrrp mode load-balance# Crie o grupo VRRP 1 e defina seu endereço IP virtual como 10.1.1.1.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ip address 10.1.1.3 24
[SwitchB-Vlan-interface2] vrrp vrid 1 virtual-ip 10.1.1.1# Atribua ao Switch B uma prioridade mais alta que a do Switch C no grupo 1 do VRRP, para que o Switch B possa se tornar o mestre quando o Switch A falhar.
[SwitchB-Vlan-interface2] vrrp vrid 1 priority 110# Configure o Switch B para operar no modo preemptivo e defina o atraso de preempção para 5.000 centissegundos.
[SwitchB-Vlan-interface2] vrrp vrid 1 preempt-mode delay 5000
[SwitchB-Vlan-interface2] quit# Crie a entrada de trilha 1 para monitorar o status do link upstream da interface VLAN 3. Quando o link upstream falha, a entrada de trilha passa para Negativo.
[SwitchB] track 1 interface vlan-interface 3# Configure os VFs no grupo VRRP 1 para monitorar a entrada de trilha 1 e diminua seus pesos em 250 quando a entrada de trilha passar para Negativo.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] vrrp vrid 1 track 1 weight reduced 250- Configurar o Switch C: # Configurar a VLAN 2.
<SwitchC> system-view
[SwitchC] vlan 2
[SwitchC-vlan2] port gigabitethernet 1/0/5
[SwitchC-vlan2] quit# Configure o VRRP para operar no modo de balanceamento de carga.
[SwitchC] vrrp mode load-balance# Crie o grupo VRRP 1 e defina seu endereço IP virtual como 10.1.1.1.
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] ip address 10.1.1.4 24
[SwitchC-Vlan-interface2] vrrp vrid 1 virtual-ip 10.1.1.1# Configure o Switch C para operar no modo preemptivo e defina o atraso de preempção para 5.000 centissegundos.
[SwitchC-Vlan-interface2] vrrp vrid 1 preempt-mode delay 5000
[SwitchC-Vlan-interface2] quit# Crie a entrada de trilha 1 para monitorar o status do link upstream da interface VLAN 3. Quando o link upstream falha, a entrada de trilha passa para Negativo.
[SwitchC] track 1 interface vlan-interface 3# Configure os VFs no grupo VRRP 1 para monitorar a entrada de trilha 1 e diminua seus pesos em 250 quando a entrada de trilha passar para Negativo.
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] vrrp vrid 1 track 1 weight reduced 250Verificação da configuração
# Verifique se o host A pode fazer ping na rede externa. (Detalhes não mostrados.)
# Exibir informações detalhadas sobre o grupo 1 de VRRP no Switch A.
[SwitchA-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 120 Running Pri : 120
Preempt Mode : Yes Delay Time : 5000
Auth Type : None
Virtual IP : 10.1.1.1
Member IP List : 10.1.1.2 (Local, Master)
10.1.1.3 (Backup)
10.1.1.4 (Backup)
Forwarder Information: 3 Forwarders 1 Active
Config Weight : 255
Running Weight : 255
Forwarder 01
State : Active
Virtual MAC : 000f-e2ff-0011 (Owner)
Owner ID : 0000-5e01-1101
Priority : 255
Active : local
Forwarder 02
State : Listening
Virtual MAC : 000f-e2ff-0012 (Learnt)
Owner ID : 0000-5e01-1103
Priority : 127
Active : 10.1.1.3
Forwarder 03
State : Listening
Virtual MAC : 000f-e2ff-0013 (Learnt)
Owner ID : 0000-5e01-1105
Priority : 127
Active : 10.1.1.4
Forwarder Weight Track Information:
Track Object : 1 State : Positive Weight Reduced : 250# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch B.
[SwitchB-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 5000
Become Master : 410ms left
Auth Type : None
Virtual IP : 10.1.1.1
Member IP List : 10.1.1.3 (Local, Backup)
10.1.1.2 (Master)
10.1.1.4 (Backup)
Forwarder Information: 3 Forwarders 1 Active
Config Weight : 255
Running Weight : 255
Forwarder 01
State : Listening
Virtual MAC : 000f-e2ff-0011 (Learnt)
Owner ID : 0000-5e01-1101
Priority : 127
Active : 10.1.1.2
Forwarder 02
State : Active
Virtual MAC : 000f-e2ff-0012 (Owner)
Owner ID : 0000-5e01-1103
Priority : 255
Active : local
Forwarder 03
State : Listening
Virtual MAC : 000f-e2ff-0013 (Learnt)
Owner ID : 0000-5e01-1105
Priority : 127
Active : 10.1.1.4
Forwarder Weight Track Information:
Track Object : 1 State : Positive Weight Reduced : 250# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch C.
[SwitchC-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 5000
Become Master : 401ms left
Auth Type : None
Virtual IP : 10.1.1.1
Member IP List : 10.1.1.4 (Local, Backup)
10.1.1.2 (Master)
10.1.1.3 (Backup)
Forwarder Information: 3 Forwarders 1 Active
Config Weight : 255
Running Weight : 255
Forwarder 01
State : Listening
Virtual MAC : 000f-e2ff-0011 (Learnt)
Owner ID : 0000-5e01-1101
Priority : 127
Active : 10.1.1.2
Forwarder 02
State : Listening
Virtual MAC : 000f-e2ff-0012 (Learnt)
Owner ID : 0000-5e01-1103
Priority : 127
Active : 10.1.1.3
Forwarder 03
State : Active
Virtual MAC : 000f-e2ff-0013 (Owner)
Owner ID : 0000-5e01-1105
Priority : 255
Active : local
Forwarder Weight Track Information:
Track Object : 1 State : Positive Weight Reduced : 250A saída mostra que o switch A é o mestre no grupo 1 do VRRP e cada um dos três switches tem um AVF e dois LVFs.
# Desconecte o link da interface VLAN 3 no Switch A e exiba informações detalhadas sobre o grupo VRRP 1 no Switch A.
[SwitchA-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 120 Running Pri : 120
Preempt Mode : Yes Delay Time : 5000
Auth Type : None
Virtual IP : 10.1.1.1
Member IP List : 10.1.1.2 (Local, Master)
10.1.1.3 (Backup)
10.1.1.4 (Backup)
Forwarder Information: 3 Forwarders 0 Active
Config Weight : 255
Running Weight : 5
Forwarder 01
State : Initialize
Virtual MAC : 000f-e2ff-0011 (Owner)
Owner ID : 0000-5e01-1101
Priority : 0
Active : 10.1.1.4
Forwarder 02
State : Initialize
Virtual MAC : 000f-e2ff-0012 (Learnt)
Owner ID : 0000-5e01-1103
Priority : 0
Active : 10.1.1.3
Forwarder 03
State : Initialize
Virtual MAC : 000f-e2ff-0013 (Learnt)
Owner ID : 0000-5e01-1105
Priority : 0
Active : 10.1.1.4
Forwarder Weight Track Information:
Track Object : 1 State : Negative Weight Reduced : 250# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch C.
[SwitchC-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 5000
Become Master : 401ms left
Auth Type : None
Virtual IP : 10.1.1.1
Member IP List : 10.1.1.4 (Local, Backup)
10.1.1.2 (Master)
10.1.1.3 (Backup)
Forwarder Information: 3 Forwarders 2 Active
Config Weight : 255
Running Weight : 255
Forwarder 01
State : Active
Virtual MAC : 000f-e2ff-0011 (Take Over)
Owner ID : 0000-5e01-1101
Priority : 85
Active : local
Forwarder 02
State : Listening
Virtual MAC : 000f-e2ff-0012 (Learnt)
Owner ID : 0000-5e01-1103
Priority : 85
Active : 10.1.1.3
Forwarder 03
State : Active
Virtual MAC : 000f-e2ff-0013 (Owner)
Owner ID : 0000-5e01-1105
Priority : 255
Active : local
Forwarder Weight Track Information:
Track Object : 1 State : Positive Weight Reduced : 250A saída mostra que, quando a interface VLAN 3 no Switch A falha, os pesos das VFs no Switch A caem abaixo do limite inferior de falha. Todas as VFs no Switch A passam para o estado Initialize e não podem encaminhar tráfego. O VF para o endereço MAC 000f-e2ff-0011 no Switch C se torna o AVF para encaminhar o tráfego.
# Quando o cronômetro de tempo limite (cerca de 1800 segundos) expirar, exiba informações detalhadas sobre o grupo VRRP 1 no Switch C.
[SwitchC-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 5000
Become Master : 402ms left
Auth Type : None
Virtual IP : 10.1.1.1
Member IP List : 10.1.1.4 (Local, Backup)
10.1.1.2 (Master)
10.1.1.3 (Backup)
Forwarder Information: 2 Forwarders 1 Active
Config Weight : 255
Running Weight : 255
Forwarder 02
State : Listening
Virtual MAC : 000f-e2ff-0012 (Learnt)
Owner ID : 0000-5e01-1103
Priority : 127
Active : 10.1.1.3
Forwarder 03
State : Active
Virtual MAC : 000f-e2ff-0013 (Owner)
Owner ID : 0000-5e01-1105
Priority : 255
Active : local
Forwarder Weight Track Information:
Track Object : 1 State : Positive Weight Reduced : 250
A saída mostra que, quando o cronômetro de tempo limite expira, o VF para o endereço MAC virtual 000f-e2ff-0011 é removido. A VF não encaminha mais os pacotes destinados ao endereço MAC.
# Quando o Switch A falhar, exiba informações detalhadas sobre o grupo VRRP 1 no Switch B.
[SwitchB-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 5000
Auth Type : None
Virtual IP : 10.1.1.1
Member IP List : 10.1.1.3 (Local, Master)
10.1.1.4 (Backup)
Forwarder Information: 2 Forwarders 1 Active
Config Weight : 255
Running Weight : 255
Forwarder 02
State : Active
Virtual MAC : 000f-e2ff-0012 (Owner)
Owner ID : 0000-5e01-1103
Priority : 255
Active : local
Forwarder 03
State : Listening
Virtual MAC : 000f-e2ff-0013 (Learnt)
Owner ID : 0000-5e01-1105
Priority : 127
Active : 10.1.1.4
Forwarder Weight Track Information:
Track Object : 1 State : Positive Weight Reduced : 250O resultado mostra as seguintes informações:
- Quando o Switch A falha, o Switch B se torna o mestre porque tem prioridade mais alta que o Switch C.
- O VF do endereço MAC virtual 000f-e2ff-0011 foi removido.
Exemplos de configuração do IPv6 VRRP
Exemplo: Configuração de um único grupo VRRP
Configuração de rede
Conforme mostrado na Figura 12, o Switch A e o Switch B formam um grupo VRRP. Eles usam os endereços IP virtuais 1::10/64 e FE80::10 para fornecer serviço de gateway para a sub-rede onde reside o Host A.
O host A aprende 1::10/64 como seu gateway padrão a partir das mensagens RA enviadas pelos switches.
O switch A opera como mestre para encaminhar pacotes do host A para o host B. Quando o switch A falha, o switch B assume o controle para encaminhar pacotes para o host A.
Figura 12 Diagrama de rede
Procedimento
- Configure o Switch A: # Configurar a VLAN 2.
<SwitchA> system-view
[SwitchA] vlan 2
[SwitchA-vlan2] port gigabitethernet 1/0/5
[SwitchA-vlan2] quit
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ipv6 address fe80::1 link-local
[SwitchA-Vlan-interface2] ipv6 address 1::1 64# Crie o grupo VRRP 1 e defina seus endereços IPv6 virtuais como FE80::10 e 1::10.
[SwitchA-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip fe80::10 link-local
[SwitchA-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip 1::10# Atribua ao Switch A uma prioridade mais alta que a do Switch B no grupo 1 do VRRP, para que o Switch A possa se tornar o mestre.
[SwitchA-Vlan-interface2] vrrp ipv6 vrid 1 priority 110# Configure o Switch A para operar no modo preemptivo, de modo que ele possa se tornar o mestre sempre que funcionar corretamente. Defina o atraso de preempção para 5.000 centissegundos para evitar a troca frequente de status.
[SwitchA-Vlan-interface2] vrrp ipv6 vrid 1 preempt-mode delay 5000# Habilite o Switch A a enviar mensagens RA, para que o Host A possa saber o endereço do gateway padrão.
[SwitchA-Vlan-interface2] undo ipv6 nd ra halt- Configure o Switch B: # Configurar a VLAN 2.
<SwitchB> system-view
[SwitchB] vlan 2
[SwitchB-vlan2] port gigabitethernet 1/0/5
[SwitchB-vlan2] quit
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ipv6 address fe80::2 link-local
[SwitchB-Vlan-interface2] ipv6 address 1::2 64# Crie o grupo VRRP 1 e defina seus endereços IPv6 virtuais como FE80::10 e 1::10.
[SwitchB-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip fe80::10 link-local
[SwitchB-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip 1::10# Configure o Switch B para operar no modo preemptivo e defina o atraso de preempção para 5.000 centissegundos.
[SwitchB-Vlan-interface2] vrrp ipv6 vrid 1 preempt-mode delay 5000# Habilite o Switch B a enviar mensagens RA, para que o Host A possa saber o endereço do gateway padrão.
[SwitchB-Vlan-interface2] undo ipv6 nd ra haltVerificação da configuração
# Ping do Host B a partir do Host A. (Detalhes não mostrados).
# Exibir informações detalhadas sobre o grupo 1 de VRRP no Switch A.
[SwitchA-Vlan-interface2] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 5000
Auth Type : None
Virtual IP : FE80::10
1::10
Virtual MAC : 0000-5e00-0201
Master IP : FE80::1# Exibir informações detalhadas sobre o grupo 1 do VRRP no Switch B.
[SwitchB-Vlan-interface2] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 5000
Become Master : 403ms left
Auth Type : None
Virtual IP : FE80::10
1::10
Virtual MAC : 0000-5e00-0201
Master IP : FE80::1A saída mostra que o Switch A está operando como mestre no grupo VRRP 1 para encaminhar pacotes do Host A para o Host B.
# Desconecte o link entre o Host A e o Switch A e verifique se o Host A ainda pode fazer o ping do Host B. (Detalhes não mostrados).
# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch B.
[SwitchB-Vlan-interface2] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 5000
Auth Type : None
Virtual IP : FE80::10
1::10
Virtual MAC : 0000-5e00-0201
Master IP : FE80::2A saída mostra que, quando o Switch A falha, o Switch B assume o controle para encaminhar os pacotes do Host A para o Host B.
# Recupere o link entre o host A e o switch A e exiba informações detalhadas sobre o grupo VRRP 1 no switch A.
[SwitchA-Vlan-interface2] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 5000
Auth Type : None
Virtual IP : FE80::10
1::10
Virtual MAC : 0000-5e00-0201
Master IP : FE80::1A saída mostra que, depois que o Switch A retoma a operação normal, ele se torna o mestre para encaminhar pacotes do Host A para o Host B.
Exemplo: Configuração de vários grupos VRRP
Configuração de rede
Conforme mostrado na Figura 13, o Switch A e o Switch B formam dois grupos VRRP. O grupo VRRP 1 usa os endereços IPv6 virtuais 1::10/64 e FE80::10 para fornecer serviço de gateway para hosts na VLAN 2. O grupo VRRP 2 usa os endereços IPv6 virtuais 2::10/64 e FE90::10 para fornecer o serviço de gateway para os hosts da VLAN 3.
A partir das mensagens RA enviadas pelos switches, os hosts da VLAN 2 aprendem 1::10/64 como gateway padrão. Os hosts da VLAN 3 aprendem 2::10/64 como gateway padrão.
Atribua ao switch A uma prioridade mais alta do que a do switch B no grupo VRRP 1, mas uma prioridade mais baixa no grupo VRRP 2. O tráfego da VLAN 2 e da VLAN 3 pode então ser distribuído entre os dois switches. Quando um dos switches falha, o switch saudável fornece o serviço de gateway para ambas as VLANs.
Figura 13 Diagrama de rede
Procedimento
- Configure o Switch A: # Configurar a VLAN 2.
<SwitchA> system-view
[SwitchA] vlan 2
[SwitchA-vlan2] port gigabitethernet 1/0/5
[SwitchA-vlan2] quit
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ipv6 address fe80::1 link-local
[SwitchA-Vlan-interface2] ipv6 address 1::1 64# Crie o grupo VRRP 1 e defina seus endereços IPv6 virtuais como FE80::10 a 1::10.
[SwitchA-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip fe80::10 link-local
[SwitchA-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip 1::10# Atribua ao Switch A uma prioridade mais alta que a do Switch B no grupo VRRP 1, para que o Switch A possa se tornar o mestre do grupo.
[SwitchA-Vlan-interface2] vrrp ipv6 vrid 1 priority 110# Habilite o Switch A a enviar mensagens RA, para que os hosts da VLAN 2 possam saber o endereço do gateway padrão.
[SwitchA-Vlan-interface2] undo ipv6 nd ra halt
[SwitchA-Vlan-interface2] quit# Configure a VLAN 3.
[SwitchA] vlan 3
[SwitchA-vlan3] port gigabitethernet 1/0/6
[SwitchA-vlan3] quit
[SwitchA] interface vlan-interface 3
[SwitchA-Vlan-interface3] ipv6 address fe90::1 link-local
[SwitchA-Vlan-interface3] ipv6 address 2::1 64# Crie o grupo VRRP 2 e defina seus endereços IPv6 virtuais como FE90::10 e 2::10.
[SwitchA-Vlan-interface3] vrrp ipv6 vrid 2 virtual-ip fe90::10 link-local
[SwitchA-Vlan-interface3] vrrp ipv6 vrid 2 virtual-ip 2::10# Habilite o Switch A a enviar mensagens RA, para que os hosts da VLAN 3 possam saber o endereço do gateway padrão.
[SwitchA-Vlan-interface3] undo ipv6 nd ra halt- Configure o Switch B: # Configurar a VLAN 2.
<SwitchB> system-view
[SwitchB-vlan2] port gigabitethernet 1/0/5
[SwitchB-vlan2] quit
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ipv6 address fe80::2 link-local
[SwitchB-Vlan-interface2] ipv6 address 1::2 64# Crie o grupo VRRP 1 e defina seus endereços IPv6 virtuais como FE80::10 e 1::10.
[SwitchB-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip fe80::10 link-local
[SwitchB-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip 1::10# Habilite o Switch B a enviar mensagens RA, para que os hosts da VLAN 2 possam saber o endereço do gateway padrão.
[SwitchB-Vlan-interface2] undo ipv6 nd ra halt
[SwitchB-Vlan-interface2] quit# Configure a VLAN 3.
[SwitchB] vlan 3
[SwitchB-vlan3] port gigabitethernet 1/0/6
[SwitchB-vlan3] quit
[SwitchB] interface vlan-interface 3
[SwitchB-Vlan-interface3] ipv6 address fe90::2 link-local
[SwitchB-Vlan-interface3] ipv6 address 2::2 64# Crie o grupo VRRP 2 e defina seus endereços IPv6 virtuais como FE90::10 e 2::10.
[SwitchB-Vlan-interface3] vrrp ipv6 vrid 2 virtual-ip fe90::10 link-local
[SwitchB-Vlan-interface3] vrrp ipv6 vrid 2 virtual-ip 2::10# Atribua ao Switch B uma prioridade mais alta que a do Switch A no grupo VRRP 2, para que o Switch B possa se tornar o mestre do grupo.
[SwitchB-Vlan-interface3] vrrp ipv6 vrid 2 priority 110# Habilite o Switch B a enviar mensagens RA, para que os hosts da VLAN 3 possam saber o endereço do gateway padrão.
[SwitchB-Vlan-interface3] undo ipv6 nd ra haltVerificação da configuração
# Exibir informações detalhadas sobre os grupos VRRP no Switch A.
[SwitchA-Vlan-interface3] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 2
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : FE80::10
1::10
Virtual MAC : 0000-5e00-0201
Master IP : FE80::1
Interface Vlan-interface3
VRID : 2 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Become Master : 402ms left
Auth Type : None
Virtual IP : FE90::10
2::10
Virtual MAC : 0000-5e00-0202
Master IP : FE90::2# Exibir informações detalhadas sobre os grupos VRRP no Switch B.
[SwitchB-Vlan-interface3] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 2
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Become Master : 401ms left
Auth Type : None
Virtual IP : FE80::10
1::10
Virtual MAC : 0000-5e00-0201
Master IP : FE80::1
Interface Vlan-interface3
VRID : 2 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : FE90::10
2::10
Virtual MAC : 0000-5e00-0202
Master IP : FE90::2O resultado mostra as seguintes informações:
- O switch A está operando como mestre no grupo VRRP 1 para encaminhar o tráfego da Internet para hosts que usam o gateway padrão 1::10/64.
- O switch B está operando como mestre no grupo VRRP 2 para encaminhar o tráfego da Internet para hosts que usam o gateway padrão 2::10/64.
Exemplo: Configuração do balanceamento de carga VRRP
Configuração de rede
Conforme mostrado na Figura 14, o Switch A, o Switch B e o Switch C formam um grupo VRRP com balanceamento de carga. Eles usam os endereços IPv6 virtuais FE80::10 e 1::10 para fornecer serviço de gateway para a sub-rede 1::/64.
Os hosts na sub-rede 1::/64 aprendem 1::10 como seu gateway padrão a partir de mensagens RA enviadas pelos switches.
Configure os VFs no Switch A, Switch B ou Switch C para monitorar suas respectivas interfaces de VLAN 3. Quando a interface de qualquer um deles falha, os pesos dos VFs no switch problemático diminuem para que outro AVF possa assumir o controle.
Figura 14 Diagrama de rede
Procedimento
- Configure o Switch A: # Configurar a VLAN 2.
<SwitchA> system-view
[SwitchA] vlan 2
[SwitchA-vlan2] port gigabitethernet 1/0/5
[SwitchA-vlan2] quit# Configure o VRRP para operar no modo de balanceamento de carga.
[SwitchA] vrrp ipv6 mode load-balance# Crie o grupo VRRP 1 e defina seus endereços IPv6 virtuais como FE80::10 e 1::10.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ipv6 address fe80::1 link-local
[SwitchA-Vlan-interface2] ipv6 address 1::1 64
[SwitchA-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip fe80::10 link-local
[SwitchA-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip 1::10# Atribua ao Switch A a prioridade mais alta no grupo VRRP 1, para que o Switch A possa se tornar o mestre.
[SwitchA-Vlan-interface2] vrrp ipv6 vrid 1 priority 120# Configure o Switch A para operar no modo preemptivo, de modo que ele possa se tornar o mestre sempre que funcionar corretamente. Defina o atraso de preempção para 5.000 centissegundos para evitar a troca frequente de status.
[SwitchA-Vlan-interface2] vrrp ipv6 vrid 1 preempt-mode delay 5000# Habilite o Switch A a enviar mensagens RA, para que os hosts da sub-rede 1::/64 possam saber o endereço do gateway padrão.
[SwitchA-Vlan-interface2] undo ipv6 nd ra halt
[SwitchA-Vlan-interface2] quit# Crie a entrada de trilha 1 para monitorar o status do link upstream da interface VLAN 3. Quando o link upstream falha, a entrada de trilha passa para Negativo.
[SwitchA] track 1 interface vlan-interface 3# Configure os VFs no grupo VRRP 1 para monitorar a entrada de trilha 1 e diminua seus pesos em 250 quando a entrada de trilha passar para Negativo.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] vrrp ipv6 vrid 1 track 1 weight reduced 250- Configure o Switch B: # Configurar a VLAN 2.
<SwitchB> system-view
[SwitchB] vlan 2
[SwitchB-vlan2] port gigabitethernet 1/0/5
[SwitchB-vlan2] quit# Configure o VRRP para operar no modo de balanceamento de carga.
[SwitchB] vrrp ipv6 mode load-balance# Crie o grupo VRRP 1 e defina seus endereços IPv6 virtuais como FE80::10 e 1::10.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ipv6 address fe80::2 link-local
[SwitchB-Vlan-interface2] ipv6 address 1::2 64
[SwitchB-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip fe80::10 link-local
[SwitchB-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip 1::10# Atribua ao Switch B uma prioridade mais alta que a do Switch C no grupo 1 do VRRP, para que o Switch B possa se tornar o mestre quando o Switch A falhar.
[SwitchB-Vlan-interface2] vrrp ipv6 vrid 1 priority 110# Configure o Switch B para operar no modo preemptivo e defina o atraso de preempção para 5.000 centissegundos.
[SwitchB-Vlan-interface2] vrrp ipv6 vrid 1 preempt-mode delay 5000# Habilite o Switch B a enviar mensagens RA para que os hosts na sub-rede 1::/64 possam saber o endereço do gateway padrão.
[SwitchB-Vlan-interface2] undo ipv6 nd ra halt
[SwitchB-Vlan-interface2] quit# Crie a entrada de trilha 1 para monitorar o status do link upstream da interface VLAN 3. Quando o
se o link upstream falhar, a entrada da trilha será transferida para Negativo.
[SwitchB] track 1 interface vlan-interface 3# Configure os VFs no grupo VRRP 1 para monitorar a entrada de trilha 1 e diminua seus pesos em 250 quando a entrada de trilha passar para Negativo.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] vrrp ipv6 vrid 1 track 1 weight reduced 250- Configurar o switch C:
# Configure a VLAN 2.
<SwitchC> system-view
[SwitchC] vlan 2
[SwitchC-vlan2] port gigabitethernet 1/0/5
[SwitchC-vlan2] quit# Configure o VRRP para operar no modo de balanceamento de carga.
[SwitchC] vrrp ipv6 mode load-balance# Crie o grupo VRRP 1 e defina seus endereços IPv6 virtuais como FE80::10 e 1::10.
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] ipv6 address fe80::3 link-local
[SwitchC-Vlan-interface2] ipv6 address 1::3 64
[SwitchC-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip fe80::10 link-local
[SwitchC-Vlan-interface2] vrrp ipv6 vrid 1 virtual-ip 1::10# Configure o Switch C para operar no modo preemptivo e defina o atraso de preempção para 5.000 centissegundos.
[SwitchC-Vlan-interface2] vrrp ipv6 vrid 1 preempt-mode delay 5000# Habilite o Switch C a enviar mensagens RA, para que os hosts da sub-rede 1::/64 possam saber o endereço do gateway padrão.
[SwitchC-Vlan-interface2] undo ipv6 nd ra halt
[SwitchC-Vlan-interface2] quit# Crie a entrada de trilha 1 para monitorar o status do link upstream da interface VLAN 3. Quando o link upstream falha, a entrada de trilha passa para Negativo.
[SwitchC] track 1 interface vlan-interface 3# Configure os VFs no grupo VRRP 1 para monitorar a entrada de trilha 1 e diminua seus pesos em 250 quando a entrada de trilha passar para Negativo.
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] vrrp ipv6 vrid 1 track 1 weight reduced 250Verificação da configuração
# Verifique se o host A pode fazer ping na rede externa. (Detalhes não mostrados.)
# Exiba informações detalhadas sobre o grupo 1 do VRRP no Switch A.
[SwitchA-Vlan-interface2] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 120 Running Pri : 120
Preempt Mode : Yes Delay Time : 5000
Auth Type : None
Virtual IP : FE80::10
1::10
Member IP List : FE80::1 (Local, Master)
FE80::2 (Backup)
FE80::3 (Backup)
Forwarder Information: 3 Forwarders 1 Active
Config Weight : 255
Running Weight : 255
Forwarder 01
State : Active
Virtual MAC : 000f-e2ff-4011 (Owner)
Owner ID : 0000-5e01-1101
Priority : 255
Active : local
Forwarder 02
State : Listening
Virtual MAC : 000f-e2ff-4012 (Learnt)
Owner ID : 0000-5e01-1103
Priority : 127
Active : FE80::2
Forwarder 03
State : Listening
Virtual MAC : 000f-e2ff-4013 (Learnt)
Owner ID : 0000-5e01-1105
Priority : 127
Active : FE80::3
Forwarder Weight Track Information:
Track Object : 1 State : Positive Weight Reduced : 250# Exibir informações detalhadas sobre o grupo 1 do VRRP no Switch B.
[SwitchB-Vlan-interface2] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 5000
Become Master : 401ms left
Auth Type : None
Virtual IP : FE80::10
1::10
Member IP List : FE80::2 (Local, Backup)
FE80::1 (Master)
FE80::3 (Backup)
Forwarder Information: 3 Forwarders 1 Active
Config Weight : 255
Running Weight : 255
Forwarder 01
State : Listening
Virtual MAC : 000f-e2ff-4011 (Learnt)
Owner ID : 0000-5e01-1101
Priority : 127
Active : FE80::1
Forwarder 02
State : Active
Virtual MAC : 000f-e2ff-4012 (Owner)
Owner ID : 0000-5e01-1103
Priority : 255
Active : local
Forwarder 03
State : Listening
Virtual MAC : 000f-e2ff-4013 (Learnt)
Owner ID : 0000-5e01-1105
Priority : 127
Active : FE80::3
Forwarder Weight Track Information:
Track Object : 1 State : Positive Weight Reduced : 250# Exibir informações detalhadas sobre o grupo 1 do VRRP no Switch C.
[SwitchC-Vlan-interface2] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 5000
Become Master : 402ms left
Auth Type : None
Virtual IP : FE80::10
1::10
Member IP List : FE80::3 (Local, Backup)
FE80::1 (Master)
FE80::2 (Backup)
Forwarder Information: 3 Forwarders 1 Active
Config Weight : 255
Running Weight : 255
Forwarder 01
State : Listening
Virtual MAC : 000f-e2ff-4011 (Learnt)
Owner ID : 0000-5e01-1101
Priority : 127
Active : FE80::1
Forwarder 02
State : Listening
Virtual MAC : 000f-e2ff-4012 (Learnt)
Owner ID : 0000-5e01-1103
Priority : 127
Active : FE80::2
Forwarder 03
State : Active
Virtual MAC : 000f-e2ff-4013 (Owner)
Owner ID : 0000-5e01-1105
Priority : 255
Active : local
Forwarder Weight Track Information:
Track Object : 1 State : Positive Weight Reduced : 250A saída mostra que o switch A é o mestre no grupo 1 do VRRP e cada um dos três switches tem um AVF e dois LVFs.
# Desconecte o link da interface VLAN 3 no Switch A e exiba informações detalhadas sobre o grupo VRRP 1 no Switch A.
[SwitchA-Vlan-interface2] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 120 Running Pri : 120
Preempt Mode : Yes Delay Time : 5000
Auth Type : None
Virtual IP : FE80::10
1::10
Member IP List : FE80::1 (Local, Master)
FE80::2 (Backup)
FE80::3 (Backup)
Forwarder Information: 3 Forwarders 0 Active
Config Weight : 255
Running Weight : 5
Forwarder 01
State : Initialize
Virtual MAC : 000f-e2ff-4011 (Owner)
Owner ID : 0000-5e01-1101
Priority : 0
Active : FE80::3
Forwarder 02
State : Initialize
Virtual MAC : 000f-e2ff-4012 (Learnt)
Owner ID : 0000-5e01-1103
Priority : 0
Active : FE80::2
Forwarder 03
State : Initialize
Virtual MAC : 000f-e2ff-4013 (Learnt)
Owner ID : 0000-5e01-1105
Priority : 0
Active : FE80::3
Forwarder Weight Track Information:
Track Object : 1 State : Negative Weight Reduced : 250
# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch C.
[SwitchC-Vlan-interface2] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 5000
Become Master : 410ms left
Auth Type : None
Virtual IP : FE80::10
1::10
Member IP List : FE80::3 (Local, Backup)
FE80::1 (Master)
FE80::2 (Backup)
Forwarder Information: 3 Forwarders 2 Active
Config Weight : 255
Running Weight : 255
Forwarder 01
State : Active
Virtual MAC : 000f-e2ff-4011 (Take Over)
Owner ID : 0000-5e01-1101
Priority : 85
Active : local
Forwarder 02
State : Listening
Virtual MAC : 000f-e2ff-4012 (Learnt)
Owner ID : 0000-5e01-1103
Priority : 85
Active : FE80::2
Forwarder 03
State : Active
Virtual MAC : 000f-e2ff-4013 (Owner)
Owner ID : 0000-5e01-1105
Priority : 255
Active : local
Forwarder Weight Track Information:
Track Object : 1 State : Positive Weight Reduced : 250A saída mostra que, quando a interface VLAN 3 no Switch A falha, os pesos das VFs no Switch A caem abaixo do limite inferior de falha. Todas as VFs no Switch A passam para o estado Initialize e não podem encaminhar tráfego. O VF para o endereço MAC 000f-e2ff-4011 no Switch C torna-se o AVF para encaminhar o tráfego.
# Quando o cronômetro de tempo limite (cerca de 1800 segundos) expirar, exiba informações detalhadas sobre o grupo VRRP 1 no Switch C.
[SwitchC-Vlan-interface2] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 5000
Become Master : 400ms left
Auth Type : None
Virtual IP : FE80::10
1::10
Member IP List : FE80::3 (Local, Backup)
FE80::1 (Master)
FE80::2 (Backup)
Forwarder Information: 2 Forwarders 1 Active
Config Weight : 255
Running Weight : 255
Forwarder 02
State : Listening
Virtual MAC : 000f-e2ff-4012 (Learnt)
Owner ID : 0000-5e01-1103
Priority : 127
Active : FE80::2
Forwarder 03
State : Active
Virtual MAC : 000f-e2ff-4013 (Owner)
Owner ID : 0000-5e01-1105
Priority : 255
Active : local
Forwarder Weight Track Information:
Track Object : 1 State : Positive Weight Reduced : 250A saída mostra que, quando o cronômetro de tempo limite expira, o VF para o endereço MAC virtual 000f-e2ff-4011 é removido. A VF não encaminha mais os pacotes destinados ao endereço MAC.
# Quando o Switch A falhar, exiba informações detalhadas sobre o grupo VRRP 1 no Switch B.
[SwitchB-Vlan-interface2] display vrrp ipv6 verbose
IPv6 Virtual Router Information:
Running Mode : Load Balance
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 5000
Auth Type : None
Virtual IP : FE80::10
1::10
Member IP List : FE80::2 (Local, Master)
FE80::3 (Backup)
Forwarder Information: 2 Forwarders 1 Active
Config Weight : 255
Running Weight : 255
Forwarder 02
State : Active
Virtual MAC : 000f-e2ff-4012 (Owner)
Owner ID : 0000-5e01-1103
Priority : 255
Active : local
Forwarder 03
State : Listening
Virtual MAC : 000f-e2ff-4013 (Learnt)
Owner ID : 0000-5e01-1105
Priority : 127
Active : FE80::3
Forwarder Weight Track Information:
Track Object : 1 State : Positive Weight Reduced : 250O resultado mostra as seguintes informações:
- Quando o Switch A falha, o Switch B se torna o mestre porque tem prioridade mais alta que o Switch C.
- O VF do endereço MAC virtual 000f-e2ff-4011 foi removido.
Solução de problemas de VRRP
É exibido um prompt de erro
Sintoma
Um prompt de erro "O roteador virtual detectou um erro de configuração de VRRP." é exibido durante a configuração do .
Análise
Esse sintoma provavelmente é causado pelos seguintes motivos:
- O intervalo de anúncio do VRRP no pacote não é o mesmo do grupo VRRP atual (somente no VRRPv2).
- O número de endereços IP virtuais no pacote não é o mesmo que o do grupo VRRP atual.
- A lista de endereços IP virtuais não é a mesma do grupo VRRP atual.
- Um dispositivo no grupo VRRP recebe pacotes VRRP ilegítimos. Por exemplo, o proprietário do endereço IP recebe um pacote VRRP com a prioridade 255.
Solução
Para resolver o problema:
- Modifique a configuração nos roteadores dos grupos VRRP para garantir uma configuração consistente.
- Tome medidas de localização de falhas e antiataque para eliminar possíveis ameaças.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Vários mestres aparecem em um grupo VRRP
Sintoma
Vários mestres aparecem em um grupo VRRP.
Análise
É normal que um grupo VRRP tenha vários mestres por um curto período, e essa situação não requer intervenção manual.
Se vários mestres coexistirem por um período mais longo, verifique as seguintes condições:
- Os mestres não podem receber anúncios uns dos outros.
- Os anúncios recebidos são ilegítimos.
Solução
Para resolver o problema:
- Ping entre esses mestres:
- Se a operação de ping falhar, examine a conectividade da rede.
- Se a operação de ping for bem-sucedida, verifique se há inconsistências de configuração no número de endereços IP virtuais, endereços IP virtuais e autenticação. Para o VRRP IPv4, certifique-se também de que a mesma versão do VRRP esteja configurada em todos os roteadores do grupo VRRP. Para o VRRPv2, verifique se o mesmo intervalo de anúncio do VRRP está configurado nos roteadores do grupo VRRP.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Flapping rápido do estado do VRRP
Sintoma
Ocorre uma oscilação rápida do estado do VRRP.
Análise
O intervalo de anúncio do VRRP está definido como muito curto.
Solução
Para resolver o problema:
Configuração do BFD
Sobre a BFD
O BFD (Bidirectional Forwarding Detection, detecção de encaminhamento bidirecional) oferece um mecanismo de detecção rápida de falhas de uso geral, padrão, independente de meio e protocolo. Ele pode detectar e monitorar a conectividade de links em IP para detectar falhas de comunicação rapidamente, de modo que medidas possam ser tomadas para garantir a continuidade do serviço e aumentar a disponibilidade da rede.
O BFD pode detectar de maneira uniforme e rápida as falhas dos caminhos de encaminhamento bidirecional entre dois dispositivos para protocolos de camada superior, como protocolos de roteamento. O mecanismo hello usado pelos protocolos de camada superior precisa de segundos para detectar uma falha de link, enquanto o BFD pode fornecer detecção medida em milissegundos.
Estabelecimento e encerramento da sessão BFD
O BFD não fornece nenhum mecanismo de descoberta de vizinhos. O protocolo superior notifica o BFD sobre os roteadores para os quais ele precisa estabelecer sessões. Depois de estabelecer uma vizinhança, o protocolo superior notifica o BFD sobre as informações do vizinho, incluindo os endereços de destino e de origem. O BFD usa as informações para estabelecer uma sessão BFD.
Quando o BFD detecta uma falha de link, ele executa as seguintes tarefas:
- O BFD limpa a sessão vizinha e notifica o protocolo sobre a falha.
- O protocolo encerra a vizinhança no link.
- Se houver um link de backup disponível, o protocolo o usará para comunicação.
Detecção de salto único e detecção de vários saltos
O BFD pode ser usado para detecções de salto único e de vários saltos.
- Detecção de salto único - detecta a conectividade IP entre dois sistemas conectados diretamente.
- Detecção multihop - detecta qualquer um dos caminhos entre dois sistemas. Esses caminhos têm vários saltos e podem se sobrepor.
Modos de sessão BFD
As sessões BFD usam pacotes de eco e pacotes de controle.
Modo de pacote de eco
Os pacotes de eco são encapsulados em pacotes UDP com o número de porta 3785.
A extremidade local do link envia pacotes de eco para estabelecer sessões BFD e monitorar o status do link. A extremidade do par não estabelece sessões BFD e apenas encaminha os pacotes de volta à extremidade de origem. Se a extremidade local não receber pacotes de eco da extremidade do par dentro do tempo de detecção, ela considerará que a sessão está inativa.
No modo de pacote de eco, o BFD suporta apenas a detecção de um único salto e as sessões de BFD são independentes do modo de operação.
Modo de pacote de controle
Os pacotes de controle são encapsulados em pacotes UDP com número de porta 3784 para detecção de um único salto ou número de porta 4784 para detecção de vários saltos.
Ambas as extremidades do link trocam pacotes de controle BFD para monitorar o status do link.
Antes de uma sessão BFD ser estabelecida, o BFD tem dois modos de operação: ativo e passivo.
- Modo ativo - o BFD envia ativamente pacotes de controle BFD, independentemente do recebimento de qualquer pacote de controle BFD do par.
- Modo passivo - o BFD não envia pacotes de controle até que um pacote de controle BFD seja recebido do par.
Pelo menos uma extremidade deve operar no modo ativo para que uma sessão BFD seja estabelecida.
Depois que uma sessão BFD é estabelecida, as duas extremidades podem operar nos seguintes modos de operação BFD:
- Modo assíncrono - O dispositivo envia periodicamente pacotes de controle BFD. O dispositivo considera que a sessão está inativa se não receber nenhum pacote de controle BFD dentro de um intervalo específico.
- Modo de demanda - O dispositivo envia periodicamente pacotes de controle BFD. Se a extremidade do par estiver operando no modo Assíncrono (padrão), a extremidade do par para de enviar pacotes de controle BFD. Se a extremidade do par estiver operando no modo Demand (demanda), ambas as extremidades param de enviar pacotes de controle BFD. Quando a conectividade com outro sistema precisa ser verificada explicitamente, um sistema envia vários pacotes de controle BFD com o bit Poll (P) definido no intervalo de transmissão negociado. Se nenhuma resposta for recebida dentro do intervalo de detecção, a sessão será considerada inativa. Se for constatado que a conectividade está ativa, nenhum outro pacote de controle BFD será enviado até que o próximo comando seja emitido.
Recursos suportados
| Recursos | Referência |
| Roteamento estático OSPF RIP Redirecionamento rápido de IP (FRR) | Guia de configuração de roteamento de IP de camada 3 |
| Roteamento estático IPv6 OSPFv3 | Guia de configuração de roteamento de IP de camada 3 |
| PIM | Guia de configuração do IP Multicast |
| Faixa | "Configurando a trilha" |
| Agregação de links Ethernet | Guia de configuração de switching de LAN de camada 2 |
Protocolos e padrões
- RFC 5880, Detecção de encaminhamento bidirecional (BFD)
- RFC 5881, BFD (Bidirectional Forwarding Detection, detecção de encaminhamento bidirecional) para IPv4 e IPv6 (salto único)
- RFC 5882, Aplicação genérica de detecção de encaminhamento bidirecional (BFD)
- RFC 5883, Bidirectional Forwarding Detection (BFD) para caminhos de múltiplos saltos
- RFC 7130, Bidirectional Forwarding Detection (BFD) em interfaces de grupo de agregação de links (LAG)
Restrições e diretrizes: Configuração do BFD
- Por padrão, o dispositivo executa o BFD versão 1 e é compatível com o BFD versão 0. Não é possível alterar a versão do BFD para 0 por meio de comandos. Quando o dispositivo par executa a versão 0 do BFD, o dispositivo local muda automaticamente para a versão 0 do BFD.
- Depois que uma sessão BFD é estabelecida, as duas extremidades negociam os parâmetros BFD, incluindo o intervalo mínimo de envio, o intervalo mínimo de recebimento, o modo de inicialização e a autenticação de pacotes, por meio da troca de pacotes de negociação. Elas usam os parâmetros negociados sem afetar o status da sessão.
- A oscilação da sessão BFD pode ocorrer em uma interface agregada com portas de membros em diferentes dispositivos membros da IRF. Quando o dispositivo mestre, que recebe e envia pacotes BFD, é removido ou reiniciado, um dispositivo subordinado pode não assumir imediatamente o controle. Por exemplo, um dispositivo subordinado não assumirá o controle quando o dispositivo subordinado tiver um tempo de detecção curto ou um grande número de sessões BFD.
- Em uma malha IRF, se o tempo de detecção for menor do que o atraso do relatório de queda do link IRF, a sessão BFD poderá ser interrompida. Para evitar esse problema, configure o atraso do relatório de queda de link IRF para ser menor que o tempo de detecção. Para obter informações sobre a configuração do atraso do relatório de queda de link da IRF, consulte IRF configuration no Virtual Technologies Configuration Guide.
Configuração do modo de pacote de eco
Procedimento
- Entre na visualização do sistema.
System-view- Configure o endereço IP de origem dos pacotes de eco.
- Configure o endereço IP de origem dos pacotes de eco.
bfd echo-source-ip ip-addressPor padrão, nenhum endereço IPv4 de origem é configurado para pacotes de eco.
Como prática recomendada, não configure o endereço IPv4 de origem para estar no mesmo segmento de rede que o endereço IPv4 de qualquer interface local. Se você configurar esse endereço IPv4 de origem, um grande número de pacotes de redirecionamento ICMP poderá ser enviado pelo par, resultando em congestionamento do link.
- Configure o endereço IPv6 de origem dos pacotes de eco.
bfd echo-source-ipv6 ipv6-addressPor padrão, nenhum endereço IPv6 de origem é configurado para pacotes de eco.
O endereço IPv6 de origem dos pacotes de eco só pode ser um endereço unicast global.
- (Opcional.) Defina os parâmetros do modo de pacote de eco.
- Entre na visualização da interface.
interface interface-type interface-number- Defina o intervalo mínimo para receber pacotes de eco BFD.
bfd min-echo-receive-interval intervalA configuração padrão é 400 milissegundos.
- Defina o multiplicador do tempo de detecção.
bfd detect-multiplier valuesA configuração padrão é 5.
Configuração do modo de pacote de controle
Restrições e diretrizes
Depois que um protocolo de camada superior é configurado para suportar o BFD, o dispositivo cria automaticamente sessões de BFD no modo de pacote de controle. Não é necessário executar essa tarefa.
O BFD versão 0 não é compatível com os seguintes comandos:
- Modo de inicialização da sessão bfd.
- bfd authentication-mode.
- habilitação de demanda bfd.
- bfd echo enable.
Configuração do modo de pacote de controle para detecção de salto único
- Entre na visualização do sistema.
System-view- Especifique o modo para estabelecer uma sessão BFD.
bfd session init-mode { active | passive }Por padrão, ativo é especificado.
- Entre na visualização da interface.
interface interface-type interface-number- (Opcional.) Configure o modo de autenticação para pacotes de controle de salto único.
bfd authentication-mode { hmac-md5 | hmac-mmd5 | hmac-msha1 |
hmac-sha1 | m-md5 | m-sha1 | md5 | sha1 | simple } key-id { cipher
cipher-string | plain plain-string }Por padrão, os pacotes BFD de salto único não são autenticados.
- Habilite o modo de sessão do BFD de demanda.
bfd demand enablePor padrão, a sessão BFD está no modo Assíncrono.
- (Opcional.) Habilite o modo de pacote de eco. Por padrão,
bfd echo [ receive | send ] enableo modo de pacote de eco está desabilitado.
Configure esse comando para sessões BFD nas quais os pacotes de controle são enviados. Quando você ativa o modo de pacote de eco para essa sessão em estado ativo, o BFD envia periodicamente pacotes de eco para detectar a conectividade do link e diminuir a taxa de recebimento de pacotes de controle.
- Defina o intervalo mínimo para transmissão e recebimento de pacotes de controle BFD de salto único.
- Defina o intervalo mínimo para a transmissão de pacotes de controle BFD de salto único.
bfd min-transmit-interval intervalA configuração padrão é 400 milissegundos.
- Defina o intervalo mínimo para receber pacotes de controle BFD de salto único.
bfd min-receive-interval intervaA configuração padrão é 400 milissegundos.
- Defina o multiplicador de tempo de detecção de salto único.
bfd detect-multiplier valuesA configuração padrão é 5.
- (Opcional.) Crie uma sessão BFD para detectar o estado da interface local.
bfd detect-interface source-ip ip-address [ discriminator local
local-value remote remote-value ] [ template template-name ]Por padrão, nenhuma sessão BFD é criada para detectar o estado da interface local.
Esse comando implementa a colaboração rápida entre o estado da interface e o estado da sessão BFD. Quando o BFD detecta uma falha de link, ele define o estado do protocolo da camada de link como DOWN(BFD). Esse comportamento ajuda os aplicativos que dependem do estado do protocolo da camada de link a obter uma convergência rápida.
- (Opcional.) Configure o cronômetro que atrasa a comunicação da primeira falha no estabelecimento da sessão BFD à camada de enlace de dados.
bfd detect-interface first-fail-timer secondsPor padrão, a primeira falha no estabelecimento da sessão BFD não é informada à camada de enlace de dados.
- (Opcional.) Habilite o processamento especial para sessões BFD.
bfd detect-interface special-processing [ admin-down |
authentication-change | session-up ] *Por padrão, todos os tipos de processamento especial para sessões BFD estão desativados.
Configuração do modo de pacote de controle para detecção de múltiplos saltos
- Entre na visualização do sistema.
System-view- Especifique o modo para estabelecer uma sessão BFD.
bfd session init-mode { active | passive }Por padrão, active é especificado.
- (Opcional.) Configure o modo de autenticação para pacotes de controle BFD multihop.
bfd multi-hop authentication-mode { hmac-md5 | hmac-mmd5 | hmac-msha1
| hmac-sha1 | m-md5 | m-sha1 | md5 | sha1 | simple } key-id { cipher
cipher-string | plain plain-string }Por padrão, nenhuma autenticação é realizada.
- Configure o número da porta de destino para pacotes de controle BFD multihop.
bfd multi-hop destination-port port-numberA configuração padrão é 4784.
- Defina o multiplicador de tempo de detecção multihop.
bfd multi-hop detect-multiplier valueA configuração padrão é 5.
- Defina o intervalo mínimo para transmissão e recebimento de pacotes de controle BFD multihop.
- Defina o intervalo mínimo para a transmissão de pacotes de controle BFD multihop.
bfd multi-hop min-transmit-interval intervalA configuração padrão é 400 milissegundos.
- Defina o intervalo mínimo para receber pacotes de controle BFD multihop.
bfd multi-hop min-receive-interval intervalA configuração padrão é 400 milissegundos.
Configuração de um modelo BFD
Sobre a configuração de um modelo BFD
Execute esta tarefa para especificar os parâmetros de BFD em um modelo para sessões sem próximos hops. Você pode configurar os parâmetros de BFD para LSPs e PWs por meio de um modelo de BFD.
Você pode usar um modelo BFD para ajustar os parâmetros de sessão das sessões BFD usadas para detectar os estados da interface .
Procedimento
- Entre na visualização do sistema.
System-view- Crie um modelo BFD e entre na visualização do modelo BFD.
bfd template template-name- (Opcional.) Configure o modo de autenticação para pacotes de controle BFD.
bfd authentication-mode { hmac-md5 | hmac-mmd5 | hmac-msha1 |
hmac-sha1 | m-md5 | m-sha1 | md5 | sha1 | simple } key-id { cipher
cipher-string | plain plain-string }Por padrão, nenhuma autenticação é realizada.
- Defina o multiplicador do tempo de detecção.
bfd detect-multiplier valuesA configuração padrão é 5.
- Defina o intervalo mínimo para transmissão e recebimento de pacotes de controle BFD.
- Defina o intervalo mínimo para a transmissão de pacotes de controle BFD.
bfd min-transmit-interval intervalA configuração padrão é 400 milissegundos.
- Defina o intervalo mínimo para receber pacotes de controle BFD.
bfd min-receive-interval intervaA configuração padrão é 400 milissegundos.
Ativação de notificações SNMP para BFD
Sobre as notificações SNMP para BFD
Para relatar eventos críticos de BFD a um NMS, ative as notificações de SNMP para BFD. Para que as notificações de eventos do BFD sejam enviadas corretamente, você também deve configurar o SNMP conforme descrito no Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
System-view- Ativar notificações SNMP para BFD.
snmp-agent trap enable bfdPor padrão, as notificações SNMP são ativadas para o BFD.
Comandos de exibição e manutenção para BFD
Execute o comando display em qualquer visualização e o comando reset na visualização do usuário.
| Tarefa | Comando |
| Exibir informações da sessão BFD. | exibir sessão bfd [ discriminador value | verbose ] |
| Limpar estatísticas da sessão BFD. | redefinir as estatísticas da sessão bfd |
Configuração de trilha
Sobre a trilha
O módulo Track funciona entre os módulos de aplicativos e os módulos de detecção. Ele protege as diferenças entre os vários módulos de detecção dos módulos de aplicativos.
Mecanismo de colaboração
O módulo Track colabora com módulos de detecção e módulos de aplicativos.
Conforme mostrado na Figura 1, a colaboração é ativada quando você associa o módulo Track a um módulo de detecção e a um módulo de aplicativo, e funciona da seguinte forma:
- O módulo de detecção examina objetos específicos, como status da interface, status do link, capacidade de alcance da rede e desempenho da rede, e informa ao módulo Track os resultados da detecção.
- O módulo Track envia os resultados da detecção para o módulo do aplicativo.
- Quando notificados sobre alterações no objeto rastreado, os módulos do aplicativo podem reagir para evitar a interrupção da comunicação e a degradação do desempenho da rede.
Figura 1 Colaboração por meio do módulo Track
Colaboração entre o módulo Track e um módulo de detecção
O módulo de detecção envia o resultado da detecção do objeto rastreado para o módulo Track. O módulo Track altera o status da entrada de rastreamento da seguinte forma:
- Se o objeto rastreado funcionar corretamente, o estado da entrada do rastreamento será Positivo. Por exemplo, o estado da entrada da trilha é Positivo em uma das seguintes condições:
- A interface de destino está ativa.
- A rede de destino pode ser acessada.
- Se o objeto rastreado não funcionar corretamente, o estado da entrada do rastreamento será Negativo. Por exemplo, o estado da entrada de trilha é Negativo em uma das seguintes condições:
- A interface de destino está inativa.
- A rede de destino não pode ser acessada.
- Se o resultado da detecção for inválido, o estado do registro da trilha será NotReady. Por exemplo, o estado do registro de trilha será NotReady se a operação NQA associada não existir.
Colaboração entre o módulo Track e um módulo de aplicativo
O módulo de rastreamento informa as alterações de status da entrada de rastreamento ao módulo do aplicativo. O módulo do aplicativo pode então tomar as medidas corretas para evitar a interrupção da comunicação e a degradação do desempenho da rede.
Módulos de detecção compatíveis
Os seguintes módulos de detecção podem ser associados ao módulo Track:
Módulos de aplicativos suportados
Os seguintes módulos de aplicativos podem ser associados ao módulo Track:
- VRRP.
- Roteamento estático.
- PBR
- Smart Link.
- EAA.
- ERPS.
Restrições e diretrizes: Configuração da pista
Ao configurar uma entrada de trilha para um módulo de aplicativo, você pode definir um atraso de notificação para evitar a notificação imediata de alterações de status.
Quando o atraso não é configurado e a convergência da rota é mais lenta do que a notificação de alteração do estado do link, ocorrem falhas de comunicação. Por exemplo, quando o mestre em um grupo VRRP detecta uma falha na interface de uplink por meio do Track, o Track notifica imediatamente o mestre para diminuir sua prioridade. Em seguida, um backup com prioridade mais alta se apresenta como o novo mestre. Quando a interface de uplink com falha se recupera, o módulo Track notifica imediatamente o mestre original para restaurar sua prioridade. Se a rota do uplink não tiver se recuperado, ocorrerá uma falha de encaminhamento.
Exemplo de aplicativo de colaboração
A seguir, um exemplo de colaboração entre NQA, Track e roteamento estático.
Configure uma rota estática com o próximo salto 192.168.0.88 no dispositivo. Se o próximo salto for alcançável, a rota estática será válida. Se o próximo salto se tornar inacessível, a rota estática será inválida. Para essa finalidade, configure a colaboração de roteamento estático do NQA-Track da seguinte forma:
- Crie uma operação NQA para monitorar a acessibilidade do endereço IP 192.168.0.88.
- Crie uma entrada de trilha e associe-a à operação NQA.
- Quando o próximo salto 192.168.0.88 é alcançável, o NQA envia o resultado para o módulo Track. O módulo Track define a entrada da trilha como estado Positivo.
- Quando o próximo salto se torna inalcançável, o NQA envia o resultado para o módulo Track. O módulo Track define a entrada da trilha para o estado Negativo.
- Associe a entrada de trilha à rota estática.
- Quando a entrada de trilha está em estado Positivo, o módulo de roteamento estático considera a rota estática como válida.
- Quando a entrada de trilha está em estado Negativo, o módulo de roteamento estático considera a rota estática inválida.
Acompanhe as tarefas em um relance
Para implementar a função de colaboração, estabeleça associações entre o módulo Track e os módulos de detecção, e entre o módulo Track e os módulos de aplicativos.
Para configurar o módulo Track, execute as seguintes tarefas:
- Associar o módulo Track a um módulo de detecção
- Como associar o rastreamento ao NQA
- Associação de trilha com BFD
- Como associar a trilha ao CFD
- Associando o Track ao gerenciamento de interface
- Associação do Track ao gerenciamento de rotas
- Associação da trilha ao LLDP
- Associar o módulo Track a um módulo de aplicativo
- Associação da trilha ao VRRP
- Associação da trilha ao roteamento estático
- Associação de trilha com PBR
- Associação de trilha com Smart Link
- Associação da trilha ao EAA
- Associação do rastro ao ERPS
Associar o módulo Track a um módulo de detecção
Como associar o rastreamento ao NQA
Sobre a associação da Track com o NQA
O NQA oferece suporte a vários tipos de operação para analisar o desempenho da rede e a qualidade do serviço. Por exemplo, uma operação do NQA pode detectar periodicamente se um destino é alcançável ou se uma conexão TCP pode ser estabelecida.
Uma operação NQA funciona da seguinte forma quando associada a uma entrada de trilha:
- Se as falhas consecutivas da sonda atingirem o limite especificado, o módulo NQA notificará o módulo Track de que o objeto rastreado apresentou mau funcionamento. Em seguida, o módulo Track define a entrada do rastreamento como estado Negativo.
- Se o limite especificado não for atingido, o módulo NQA notificará o módulo Track de que o objeto rastreado está funcionando corretamente. Em seguida, o módulo Track define a entrada do rastreamento como estado Positivo.
Para obter mais informações sobre o NQA, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Restrições e diretrizes
Se você associar uma entrada de trilha a uma operação NQA inexistente ou a uma entrada de reação, o estado da entrada de trilha será NotReady.
Procedimento
- Entre na visualização do sistema.
System-view- Crie uma entrada de trilha associada a uma entrada de reação NQA e entre na visualização de trilha.
track track-entry-number nqa entry admin-name operation-tag reaction
item-number- Defina o atraso para notificar o módulo do aplicativo sobre alterações no estado da entrada de trilha.
delay { negative negative-time | positive positive-time } *Por padrão, o módulo Track notifica o módulo de aplicativo imediatamente quando a entrada de trilha muda de estado.
Associação de trilha com BFD
Sobre a associação da Track com a BFD
É possível associar uma entrada de trilha a uma sessão de BFD no modo eco ou a uma sessão de BFD no modo controle. Para obter mais informações sobre o BFD, consulte "Configuração do BFD".
O Track e o BFD associados funcionam da seguinte forma:
- Se o BFD detectar que o link falhou, ele informará o módulo Track sobre a falha do link. O módulo Track define a entrada do track para o estado Negativo.
- Se o BFD detectar que o link está operando corretamente, o módulo Track define a entrada do track para o estado Positive.
Restrições e diretrizes
Quando você associar uma entrada de trilha ao BFD, não configure o endereço IP virtual de um grupo VRRP como o endereço local ou remoto da sessão BFD.
Pré-requisitos
Antes de associar o Track a uma sessão de BFD em modo eco, configure o endereço IP de origem dos pacotes de eco do BFD. Para obter mais informações, consulte "Configuração do BFD".
Procedimento
- Entre na visualização do sistema.
System-view- Crie uma entrada de trilha e associe-a a uma sessão BFD. Escolha as opções para configurar conforme necessário:
- Crie uma entrada de trilha associada a uma sessão BFD no modo eco e entre no modo de exibição de trilha.
track track-entry-number bfd echo interface interface-type interface-number remote ip remote-ip-address local ip local-ip-address- Crie uma entrada de trilha associada a uma sessão BFD no modo de controle e entre na visualização de trilha.
track track-entry-number bfd ctrl [ interface interface-type interface-number ] remote ip remote-ip-address local ip local-ip-address- Defina o atraso para notificar o módulo do aplicativo sobre alterações no estado da entrada de trilha.
delay { negative negative-time | positive positive-time } *Por padrão, o módulo Track notifica o módulo de aplicativo imediatamente quando o estado de entrada da trilha é alterado.
Como associar a trilha ao CFD
Sobre a associação da trilha com o CFD
O Track e o CFD associados funcionam da seguinte forma:
- Se o CFD detectar que o link falhou, ele informará o módulo Track sobre a falha do link. O módulo de rastreamento define a entrada de rastreamento como estado Negativo.
- Se o CFD detectar que o link está funcionando corretamente, o módulo Track define a entrada da trilha para o estado Positivo.
Para obter mais informações sobre o CFD, consulte "Configuração do CFD".
Pré-requisitos
Antes de associar o Track ao CFD, ative o CFD e crie um MEP. Para obter mais informações, consulte "Configuração do CFD".
Procedimento
- Entre na visualização do sistema.
System-view- Crie um registro de trilha associado ao CFD e entre na visualização de trilha.
track track-entry-number cfd cc service-instance instance-id mep mep-id- Defina o atraso para notificar o módulo do aplicativo sobre alterações no estado da entrada de trilha.
delay { negative negative-time | positive positive-time } *Por padrão, o módulo Track notifica o módulo de aplicativo imediatamente quando o estado de entrada da trilha é alterado.
Associando o Track ao gerenciamento de interface
Sobre a associação da trilha com o gerenciamento de interface
O módulo de gerenciamento de interface monitora o status do link ou o status do protocolo da camada de rede das interfaces. A trilha associada e o gerenciamento de interface funcionam da seguinte forma:
- Quando o status do protocolo da camada de rede ou do link da interface muda para up, o módulo de gerenciamento de interface informa o módulo Track sobre a mudança. O módulo de rastreamento define a entrada de rastreamento para o estado Positivo.
- Quando o status do link ou do protocolo da camada de rede da interface muda para down, o módulo de gerenciamento de interface informa o módulo Track sobre a alteração. O módulo Track define a entrada track para o estado Negative.
Procedimento
- Entre na visualização do sistema.
System-view- Crie um registro de trilha associado ao gerenciamento de interface e entre na visualização de trilha.
- Crie uma entrada de trilha para monitorar o status do link de uma interface e entre na visualização de trilha.
track track-entry-number interface interface-type interface-number- Crie uma entrada de trilha para monitorar o status físico de uma interface e entre na visualização de trilha.
track track-entry-number interface interface-type interface-number physical- Crie uma entrada de trilha para monitorar o status do protocolo da camada de rede de uma interface e entre na visualização de trilha.
track track-entry-number interface interface-type interface-number protocol { ipv4 | ipv6 }- Defina o atraso para notificar o módulo do aplicativo sobre alterações no estado da entrada de trilha.
delay { negative negative-time | positive positive-time } *Por padrão, o módulo Track notifica o módulo de aplicativo imediatamente quando o estado de entrada da trilha é alterado.
Associação do Track ao gerenciamento de rotas
Sobre a associação da trilha com o gerenciamento de rotas
O módulo de gerenciamento de rota monitora as alterações de entrada de rota na tabela de roteamento. O rastreamento associado e o gerenciamento de rotas operam da seguinte forma:
- Quando uma entrada de rota monitorada é encontrada na tabela de roteamento, o módulo de gerenciamento de rotas informa o módulo Track. O módulo Track define a entrada de rota como estado Positivo.
- Quando uma entrada de rota monitorada é removida da tabela de roteamento, o módulo de gerenciamento de rotas informa o módulo Track sobre a alteração. O módulo Track define a entrada de rota como estado Negativo.
Procedimento
- Entre na visualização do sistema.
System-view- Crie um registro de trilha associado a um registro de rota e entre na visualização de trilha.
track track-entry-number ip route ip-address { mask-length | mask } reachability- Defina o atraso para notificar o módulo do aplicativo sobre alterações no estado da entrada de trilha.
delay { negative negative-time | positive positive-time } *Por padrão, o módulo Track notifica o módulo de aplicativo imediatamente quando o estado de entrada da trilha é alterado.
Associação da trilha ao LLDP
Sobre a associação da trilha com o LLDP
O módulo LLDP monitora a disponibilidade de vizinhos das interfaces LLDP. A trilha associada e o LLDP funcionam da seguinte forma:
- Quando o vizinho da interface LLDP monitorada estiver disponível, o módulo LLDP informará o módulo Track. O módulo Track define a entrada do track para o estado Positivo.
- Quando o vizinho da interface LLDP monitorada não está disponível, o módulo LLDP informa o módulo Track. O módulo Track define a entrada de rastreamento como estado Negativo.
Para obter mais informações sobre LLDP, consulte o Layer 2-LAN Switching Configuration Guide.
Procedimento
- Entre na visualização do sistema.
System-view- Crie uma entrada de trilha associada a uma interface LLDP e entre na visualização de trilha.
track track-entry-number lldp neighbor interface interface-type
interface-number- Defina o atraso para notificar o módulo do aplicativo sobre alterações no estado da entrada de trilha.
delay { negative negative-time | positive positive-time } *Por padrão, o módulo Track notifica o módulo de aplicativo imediatamente quando o estado de entrada da trilha é alterado.
Associar o módulo Track a um módulo de aplicativo
Antes de associar o módulo Track a um módulo de aplicativo, certifique-se de que o registro de trilha associado tenha sido criado.
Pré-requisitos para associar o módulo Track a um módulo de aplicativo
Crie um registro de trilha antes de associá-lo a um módulo de aplicativo.
Um módulo de aplicativo pode obter informações incorretas sobre o status do track entry se o track entry associado não existir.
Associação da trilha ao VRRP
Sobre a associação da trilha com o VRRP
Quando o VRRP estiver operando no modo padrão ou no modo de balanceamento de carga, associe o módulo Track ao grupo VRRP para implementar as seguintes ações:
- Altere a prioridade de um roteador de acordo com o status do uplink. Se ocorrer uma falha no uplink do roteador, o grupo VRRP não estará ciente da falha do uplink. Se o roteador for o mestre, os hosts da LAN não poderão acessar a rede externa. Para resolver esse problema, configure um módulo de detecção - colaboração entre roteador e VRRP. O módulo de detecção monitora o status do uplink do roteador e notifica o módulo Track sobre o resultado da detecção.
Quando o uplink falha, o módulo de detecção notifica o módulo Track para alterar o status da entrada da trilha monitorada para Negativo. A prioridade do mestre diminui em um valor especificado pelo usuário. Um roteador com prioridade mais alta no grupo VRRP torna-se o mestre.
- Monitore o mestre em um backup. Se ocorrer uma falha no mestre, o backup operando no modo de comutação mudará para o mestre imediatamente para manter a comunicação normal.
Quando o VRRP estiver operando no modo de balanceamento de carga, associe o módulo Track ao VRRP VF para implementar as seguintes funções:
- Alterar a prioridade do AVF de acordo com seu estado de uplink. Quando o uplink do AVF falha, a entrada da trilha muda para o estado Negativo. O peso do AVF diminui em um valor especificado pelo usuário. O VF com uma prioridade mais alta torna-se o novo AVF para encaminhar pacotes.
- Monitore o status do AVF a partir do LVF. Quando o AVF falha, o LVF que está operando no modo de comutação se torna o novo AVF para garantir o encaminhamento contínuo.
Para obter mais informações sobre a configuração do VRRP, consulte "Configuração do VRRP".
Restrições e diretrizes para a associação da trilha com o VRRP
- O rastreamento de VRRP não tem efeito em um proprietário de endereço IP. A configuração entra em vigor quando o roteador não atua como proprietário do endereço IP.
Um proprietário de endereço IP é o roteador com seu endereço IP de interface usado como endereço IP virtual do grupo VRRP.
- Quando o status da entrada de trilha muda de Negativo para Positivo ou Não Pronto, o roteador ou VF associado restaura sua prioridade automaticamente.
Associação do Track a um grupo VRRP
- Entre na visualização do sistema.
System-view- Entre na visualização da interface.
interface interface-type interface-number- Associar uma entrada de trilha a um grupo VRRP.
vrrp [ ipv6 ] vrid virtual-router-id track track-entry-number { forwarder-switchover member-ip ip-address | priority reduced [ priority-reduced ] switchover | weight reduced [ weight-reduced ] }Por padrão, nenhuma entrada de trilha está associada a um grupo VRRP.
Esse comando é suportado quando o VRRP está operando no modo padrão e no modo de balanceamento de carga.
Associação de trilha a um VRRP VF
- Entre na visualização do sistema.
System-view- Entre na visualização da interface.
interface interface-type interface-number- Associe a trilha a um VRRP VF.
vrrp [ ipv6 ] vrid virtual-router-id track track-entry-number { forwarder-switchover member-ip ip-address | priority reduced [ priority-reduced ] switchover | weight reduced [ weight-reduced ] }Por padrão, nenhuma entrada de trilha está associada a um VRRP VF.
Esse comando pode ser configurado quando o VRRP estiver operando no modo padrão ou no modo de balanceamento de carga. No entanto, a configuração só tem efeito quando o VRRP está operando no modo de balanceamento de carga .
Associação da trilha ao roteamento estático
Sobre a associação de trilhas com roteamento estático
Uma rota estática é uma rota configurada manualmente para rotear pacotes. Para obter mais informações sobre a configuração de rotas estáticas, consulte o Guia de Configuração de Roteamento de IP de Camada 3.
As rotas estáticas não podem se adaptar às mudanças na topologia da rede. Falhas nos links ou alterações na topologia da rede podem tornar as rotas inacessíveis e causar interrupções na comunicação.
Para resolver esse problema, configure outra rota para fazer backup da rota estática. Quando a rota estática está acessível, os pacotes são encaminhados pela rota estática. Quando a rota estática não pode ser acessada, os pacotes são encaminhados pela rota de backup.
Para verificar a acessibilidade de uma rota estática em tempo real, associe o módulo Track à rota estática.
Se você especificar o próximo salto, mas não a interface de saída ao configurar uma rota estática, poderá configurar a colaboração entre o módulo de roteamento estático e detecção de trilha. Essa colaboração permite que você verifique a acessibilidade da rota estática com base no estado de entrada da trilha.
- Se a entrada da trilha estiver no estado Positivo, as seguintes condições existirão:
- O próximo salto da rota estática pode ser acessado.
- A rota estática configurada é válida.
- Se a entrada da trilha estiver no estado Negativo, existem as seguintes condições:
- O próximo salto da rota estática não pode ser acessado.
- A rota estática configurada é inválida.
- Se a entrada da trilha estiver no estado NotReady, existem as seguintes condições:
- A acessibilidade do próximo salto da rota estática é desconhecida.
- A rota estática é válida.
Restrições e diretrizes
Se uma rota estática precisar de recursão de rota, a entrada de trilha associada deverá monitorar o próximo salto da rota recursiva. O próximo salto da rota estática não pode ser monitorado. Caso contrário, uma rota válida poderá ser considerada inválida.
Procedimento
- Entre na visualização do sistema.
System-view- Associe uma rota estática a uma entrada de trilha para verificar a acessibilidade do próximo salto.
ip route-static { dest-address { mask-length | mask } | group group-name } { interface-type interface-number [ next-hop-address ] [ backup-interface interface-type interface-number [ backup-nexthop backup-nexthop-address ] [ permanent ] | bfd { control-packet | echo-packet } | permanent | track track-entry-number ] | next-hop-address [ recursive-lookup host-route ] [ bfd control-packet bfd-source ip-address | permanent | track track-entry-number ] } [ preference preference ] [ tag tag-value ] [ description text ]Por padrão, o Track não está associado ao roteamento estático.
Associação de trilha com PBR
Sobre a associação da Track com a PBR
O PBR usa políticas definidas pelo usuário para encaminhar pacotes. Você pode especificar parâmetros em uma política de PBR para orientar o encaminhamento dos pacotes que correspondem a critérios específicos. Para obter mais informações sobre PBR, consulte o Guia de configuração de roteamento de IP de camada 3.
O PBR não pode detectar a disponibilidade de nenhuma ação tomada sobre os pacotes. Quando uma ação não está disponível, os pacotes processados por ela podem ser descartados. Por exemplo, se a interface de saída especificada para o PBR falhar, o PBR não poderá detectar a falha e continuará a encaminhar os pacotes correspondentes para fora da interface.
Para permitir que o PBR detecte alterações na topologia e melhore a flexibilidade do aplicativo PBR, configure a colaboração do módulo de detecção de Track-PBR.
Depois que você associar uma entrada de rastreamento a uma cláusula apply, o módulo de detecção associado à entrada de rastreamento enviará ao Track o resultado da detecção da disponibilidade do objeto rastreado.
- O estado Positive da entrada da trilha indica que o objeto está disponível e que a cláusula apply é válida.
- O estado Negativo da entrada da trilha indica que o objeto não está disponível e que a cláusula apply é inválida.
- O estado NotReady da entrada de trilha indica que a cláusula apply é válida. Você pode associar uma entrada de trilha somente aos próximos saltos.
Pré-requisitos para a associação da trilha com a PBR
Antes de associar o Track ao PBR, crie um nó de política e defina os critérios de correspondência.
Associação de trilha com PBR
- Entre na visualização do sistema.
System-view- Crie um nó de política e entre em sua visualização.
policy-based-route policy-name [ deny | permit ] node node-number- Definir um critério de correspondência de ACL.
if-match acl { acl-number | name acl-name }Por padrão, nenhum critério de correspondência de ACL é definido.
O critério de correspondência da ACL não pode corresponder às informações da Camada 2.
Ao usar a ACL para fazer a correspondência de pacotes, o PBR ignora a ação (permitir ou negar) e as configurações de intervalo de tempo na ACL.
- Definir os próximos saltos e associar os próximos saltos a uma entrada de trilha.
apply next-hop { ip-address [ direct ] [ track track-entry-number ] }&<1-n>Por padrão, nenhum próximo salto é definido.
Associação de trilha com IPv6 PBR
- Entre na visualização do sistema.
System-view- Crie um nó de política IPv6 e entre em sua visualização.
ipv6 policy-based-route policy-name [ deny | permit ] node node-number- Definir um critério de correspondência de ACL.
if-match acl { ipv6-acl-number | name ipv6-acl-name }Por padrão, nenhum critério de correspondência de ACL é definido.
O critério de correspondência da ACL não pode corresponder às informações da Camada 2.
Ao usar a ACL para fazer a correspondência de pacotes, o IPv6 PBR ignora a ação (permitir ou negar) e as configurações de intervalo de tempo na ACL.
- Definir os próximos saltos e associar os próximos saltos a uma entrada de trilha.
apply next-hop { ipv6-address [ direct ] [ track track-entry-number ] } &<1-n>Por padrão, nenhum próximo salto é definido.
Como associar a trilha ao Smart Link
Sobre a associação da Track com o Smart Link
O Smart Link não pode detectar links unidirecionais, fibras mal conectadas ou perda de pacotes em dispositivos intermediários ou caminhos de rede do uplink. Ele também não pode detectar quando as falhas são eliminadas. Para verificar o status do link, as portas Smart Link devem usar protocolos de detecção de link. Quando uma falha é detectada ou eliminada, os protocolos de detecção de link informam ao Smart Link para alternar os links.
Você pode configurar a colaboração entre o Smart Link e o Track em uma porta membro do grupo de links inteligentes. O Smart Link colabora com o recurso CC do CFD por meio da entrada de rastreamento para detectar o status do link na porta.
- Quando a entrada da trilha está em estado Positivo, o link está em estado normal. O Smart Link não realiza a troca de link para o grupo de links inteligentes.
- Quando a entrada da trilha está em estado Negativo, o link falhou. O Smart Link determina se deve realizar a troca de link de acordo com o modo de preempção de link e a função da porta configurada no grupo de smart link.
- Quando a entrada da trilha está no estado NotReady, o estado da porta não é alterado. Para obter mais informações sobre o Smart Link, consulte "Configuração do Smart Link".
Restrições e diretrizes
A entrada da trilha a ser usada para colaboração com o Smart Link deve ter sido associada ao recurso CC do CFD.
Procedimento
- Entre na visualização do sistema.
System-view- Entre na visualização da interface Ethernet de camada 2 ou na visualização da interface agregada de camada 2.
interface interface-type interface-number- Configurar a colaboração entre o Smart Link e o Track na porta.
port smart-link group group-id track track-entry-numberPor padrão, a colaboração entre o Smart Link e o Track não está configurada.
Associação da trilha ao EAA
Sobre a associação da Track com a EAA
Você pode configurar as políticas de monitoramento de eventos de trilha do EAA para monitorar as alterações de estado de positivo para negativo ou de negativo para positivo das entradas de trilha.
- Se você especificar apenas uma entrada de trilha para uma política, o EAA acionará a política quando detectar a alteração de estado especificada na entrada de trilha.
- Se você especificar várias entradas de trilha para uma política, o EAA acionará a política quando detectar a alteração de estado especificada na última entrada de trilha monitorada. Por exemplo, se você configurar uma política para monitorar a alteração de estado de positivo para negativo de várias entradas de faixa, o EAA acionará a política quando a última entrada de faixa positiva monitorada pela política for alterada para o estado Negativo.
Você pode definir um tempo de supressão para uma política de monitor de eventos de rastreamento. O cronômetro começa quando a política é acionada. O sistema não processa as mensagens que relatam o evento de faixa monitorado até que o tempo do cronômetro se esgote.
Para obter mais informações sobre o EAA, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
- Entre na visualização do sistema.
System-view- Crie uma política de monitor definida pela CLI e insira sua visualização ou insira a visualização de uma política de monitor definida pela CLI existente.
rtm cli-policy policy-name- Configure um evento de trilha.
event track track-entry-number-list state { negative | positive } [ suppress-time suppress-time ]Por padrão, uma política de monitoramento não monitora nenhum evento de trilha.
Associação do rastro ao ERPS
Sobre a associação da Track com o ERPS
Para detectar e eliminar falhas de link, normalmente em um link de fibra, use o ERPS com CFD e Track. Você pode associar as portas de membro de anel do ERPS à função de verificação de continuidade do CFD por meio de entradas de rastreamento.
O CFD relata eventos de link somente quando a VLAN monitorada é a VLAN de controle da instância do ERPS para a porta.
A trilha altera o estado de entrada da trilha com base no resultado do monitoramento do CFD e notifica a alteração do estado de entrada da trilha ao anel EPRS associado.
- Quando a entrada da trilha está em estado Positivo, o link da porta monitorada do membro do anel ERPS está em estado normal. O anel ERPS não transfere o tráfego para outros links.
- Quando a entrada da trilha está em estado Negativo, o link da porta monitorada do membro do anel ERPS está com defeito. O anel ERPS transfere o tráfego para outros links.
- Quando a entrada da trilha está no estado NotReady, o estado da porta membro do anel ERPS não é alterado.
Para obter mais informações sobre o ERPS, consulte "Configuração do ERPS".
Restrições e diretrizes
Antes de associar uma porta a uma entrada de trilha, certifique-se de que a porta tenha ingressado em uma instância de ERPS.
Procedimento
- Entre na visualização do sistema.
System-view- Entre na visualização da interface Ethernet da Camada 2 ou na visualização da interface agregada da Camada 2.
interface interface-type interface-number- Associar uma porta de membro de anel ERPS a uma entrada de trilha.
port erps ring ring-id instance instance-id track track-entry-indexPor padrão, uma porta membro do anel ERPS não está associada a nenhuma entrada de trilha.
Comandos de exibição e manutenção do Track
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações sobre entradas de trilha. | display track { track-entry-number | todos [ negativo | positivo ] } [ brief ] |
Exemplos de configuração de trilha
Exemplo: Configuração da colaboração VRRP-Track-NQA
Configuração de rede
Conforme mostrado na Figura 2:
- O host A precisa acessar o host B. O gateway padrão do host A é 10.1.1.10/24.
- O Switch A e o Switch B pertencem ao grupo VRRP 1. O endereço IP virtual do grupo VRRP 1 é 10.1.1.10.
Configure a colaboração VRRP-Track-NQA para monitorar o uplink no mestre e atender aos seguintes requisitos:
- Quando o Switch A funciona corretamente, ele encaminha os pacotes do Host A para o Host B.
- Quando o NQA detecta uma falha no uplink do Switch A, o Switch B encaminha os pacotes do Host A para o Host B.
Figura 2 Diagrama de rede
Procedimento
- Crie VLANs e atribua portas a elas. Configure o endereço IP de cada interface de VLAN, conforme mostrado na Figura 2. (Detalhes não mostrados.)
- Configure uma operação NQA no Switch A:
# Criar uma operação NQA com o nome de administrador admin e a tag de operação test.
<SwitchA> system-view
[SwitchA] nqa entry admin test# Especifique o tipo de operação de eco ICMP.
[SwitchA-nqa-admin-test] type icmp-echo# Especifique 10.1.2.2 como o endereço de destino das solicitações de eco ICMP.
[SwitchA-nqa-admin-test-icmp-echo] destination ip 10.1.2.2# Configure a operação de eco do ICMP para ser repetida a cada 100 milissegundos.
[SwitchA-nqa-admin-test-icmp-echo] frequency 100# Configure a entrada de reação 1, especificando que cinco falhas consecutivas da sonda acionam o módulo Track.
[SwitchA-nqa-admin-test-icmp-echo] reaction 1 checked-element probe-fail
threshold-type consecutive 5 action-type trigger-only
[SwitchA-nqa-admin-test-icmp-echo] quit# Iniciar a operação de NQA.
[SwitchA] nqa schedule admin test start-time now lifetime forever- No Switch A, configure a entrada de trilha 1 e associe-a à entrada de reação 1 da operação NQA.
[SwitchA] track 1 nqa entry admin test reaction 1
[SwitchA-track-1] quit- Configure o VRRP no Switch A:
# Especifique o VRRPv2 para ser executado na interface VLAN 2.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] vrrp version 2# Crie o grupo VRRP 1 e configure o endereço IP virtual 10.1.1.10 para o grupo.
[SwitchA-Vlan-interface2] vrrp vrid 1 virtual-ip 10.1.1.10# Defina a prioridade do Switch A como 110 no grupo 1 do VRRP.
[SwitchA-Vlan-interface2] vrrp vrid 1 priority 110# Defina o modo de autenticação do grupo VRRP 1 como simples e a chave de autenticação como hello.
[SwitchA-Vlan-interface2] vrrp vrid 1 authentication-mode simple hello# Configure o mestre para enviar pacotes VRRP a cada 500 centissegundos.
[SwitchA-Vlan-interface2] vrrp vrid 1 timer advertise 500# Configure o Switch A para operar no modo preemptivo e defina o atraso de preempção para 5.000 centissegundos.
[SwitchA-Vlan-interface2] vrrp vrid 1 preempt-mode timer delay 5000# Associe o grupo VRRP 1 à entrada de trilha 1 e diminua a prioridade do roteador em 30 quando o estado da entrada de trilha 1 mudar para Negativo.
[SwitchA-Vlan-interface2] vrrp vrid 1 track 1 priority reduced 30- Configure o VRRP no Switch B:
# Especifique o VRRPv2 para ser executado na interface VLAN 2.
<SwitchB> system-view
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] vrrp version 2# Crie o grupo VRRP 1 e configure o endereço IP virtual 10.1.1.10 para o grupo.
[SwitchB-Vlan-interface2] vrrp vrid 1 virtual-ip 10.1.1.10# Defina o modo de autenticação do grupo VRRP 1 como simples e a chave de autenticação como hello.
Configure o mestre para enviar pacotes VRRP a cada 500 centissegundos.
[SwitchB-Vlan-interface2] vrrp vrid 1 timer advertise 500# Configure o Switch B para operar no modo preemptivo e defina o atraso de preempção para 5.000 centissegundos.
[SwitchB-Vlan-interface2] vrrp vrid 1 preempt-mode timer delay 5000Verificação da configuração
# Faça ping no host B a partir do host A para verificar se o host B pode ser acessado. (Detalhes não mostrados.)
# Exibir informações detalhadas sobre o grupo 1 de VRRP no Switch A.
[SwitchA-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 500
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 5000
Auth Type : Simple Key : ******
Virtual IP : 10.1.1.10
Virtual MAC : 0000-5e00-0101
Master IP : 10.1.1.1
VRRP Track Information:
Track Object : 1 State : Positive Pri Reduced : 30# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch B.
[SwitchB-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 500
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 5000
Become Master : 2200ms left
Auth Type : Simple Key : ******
Virtual IP : 10.1.1.10
Master IP : 10.1.1.1A saída mostra que, no grupo VRRP 1, o Switch A é o mestre e o Switch B é um backup. O switch A encaminha pacotes do host A para o host B.
# Desconecte o link entre o Switch A e o Switch C e verifique se o Host A ainda pode fazer o ping do Host B. (Detalhes não mostrados).
# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch A.
[SwitchA-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 500
Admin Status : Up State : Backup
Config Pri : 110 Running Pri : 80
Preempt Mode : Yes Delay Time : 5000
Become Master : 2200ms left
Auth Type : Simple Key : ******
Virtual IP : 10.1.1.10
Master IP : 10.1.1.2
VRRP Track Information:
Track Object : 1 State : Negative Pri Reduced : 301# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch B.
[SwitchB-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 500
Admin Status : Up State : Master
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 5000
Auth Type : Simple Key : ******
Virtual IP : 10.1.1.10
Virtual MAC : 0000-5e00-0101
Master IP : 10.1.1.2A saída mostra que o Switch A se torna o backup e o Switch B se torna o mestre. O switch B encaminha os pacotes do host A para o host B.
Exemplo: Configuração de uma sessão BFD em modo eco para um backup VRRP para monitorar o mestre
Configuração de rede
Conforme mostrado na Figura 3:
- O Switch A e o Switch B pertencem ao grupo VRRP 1. O endereço IP virtual do grupo VRRP 1 é 192.168.0.10.
- O gateway padrão dos hosts na LAN é 192.168.0.10.
Configure a colaboração VRRP-Track-BFD (modo eco) para monitorar o mestre no backup e atender aos seguintes requisitos:
- Quando o Switch A funciona corretamente, os hosts da LAN acessam a Internet por meio do Switch A.
- Quando o Switch A falha, o backup (Switch B) pode detectar a mudança de estado do mestre por meio da sessão BFD no modo eco e se tornar o novo mestre. Os hosts da LAN acessam a Internet por meio do Switch B.
Figura 3 Diagrama de rede
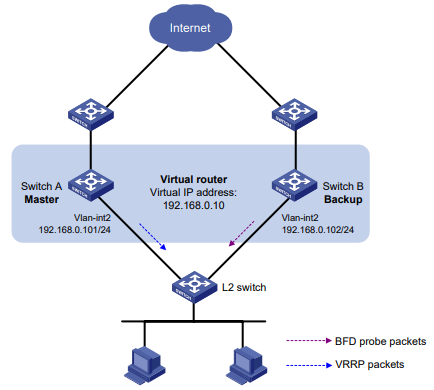
Procedimento
- Crie VLANs e atribua portas a elas. Configure o endereço IP de cada interface de VLAN, conforme mostrado na Figura 3. (Detalhes não mostrados.)
- Configure o Switch A:
# Crie o grupo VRRP 1 e configure o endereço IP virtual 192.168.0.10 para o grupo.
<SwitchA> system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] vrrp vrid 1 virtual-ip 192.168.0.10# Defina a prioridade do Switch A como 110 no grupo 1 do VRRP.
[SwitchA-Vlan-interface2] vrrp vrid 1 priority 110
[SwitchA-Vlan-interface2] return- Configure o Switch B:
# Especifique 10.10.10.10 como o endereço de origem dos pacotes de eco BFD.
<SwitchB> system-view
[SwitchB] bfd echo-source-ip 10.10.10.10# Crie a entrada de trilha 1 e associe-a à sessão BFD em modo eco para verificar a acessibilidade do Switch A.
[SwitchB] track 1 bfd echo interface vlan-interface 2 remote ip 192.168.0.101 local
ip 192.168.0.102
[SwitchB-track-1] quit# Crie o grupo VRRP 1 e configure o endereço IP virtual 192.168.0.10 para o grupo.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] vrrp vrid 1 virtual-ip 192.168.0.10# Configure o grupo VRRP 1 para monitorar o status da entrada de trilha 1.
[SwitchB-Vlan-interface2] vrrp vrid 1 track 1 switchover
[SwitchB-Vlan-interface2] return
Verificação da configuração
# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch A.
<SwitchA> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : 192.168.0.10
Virtual MAC : 0000-5e00-0101
Master IP : 192.168.0.101
# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch B.
<SwitchB> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Become Master : 2200ms left
Auth Type : None
Virtual IP : 192.168.0.10
Master IP : 192.168.0.101
VRRP Track Information:
Track Object : 1 State : Positive Switchover
# Exibir informações sobre a entrada de trilha 1 no Switch B.
<SwitchB> display track 1
Track ID: 1
State: Positive
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: BFD echo
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
BFD session mode: Echo
Outgoing interface: Vlan-interface2
VPN instance name: --
Remote IP: 192.168.0.101
Local IP: 192.168.0.102A saída mostra que, quando o status da entrada da trilha se torna positivo, o interruptor A é o principal e o interruptor B é o reserva.
# Habilite a depuração do estado do VRRP e a depuração da notificação de eventos BFD no Switch B.
<SwitchB> terminal debugging
<SwitchB> terminal monitor
<SwitchB> debugging vrrp fsm
<SwitchB> debugging bfd ntfy# Quando o Switch A falha, a seguinte saída é exibida no Switch B.
*Dec 17 14:44:34:142 2008 SwitchB BFD/7/DEBUG: Notify application:TRACK State:DOWN
*Dec 17 14:44:34:144 2008 SwitchB VRRP4/7/FSM:
IPv4 Vlan-interface2 | Virtual Router 1 : Backup --> Master reason: The status of the
tracked object changed# Exibir informações detalhadas sobre o grupo VRRP no Switch B.
<SwitchB> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : 192.168.0.10
Virtual MAC : 0000-5e00-0101
Master IP : 192.168.0.102
VRRP Track Information:
Track Object : 1 State : Negative SwitchoverA saída mostra que, quando a sessão BFD em modo eco detecta que o Switch A está falhando, o módulo Track notifica o VRRP para alterar o status do Switch B para mestre. O backup pode rapidamente se antecipar como mestre sem esperar por um período três vezes maior que o intervalo de anúncio mais o Skew_Time.
Exemplo: Configuração de uma sessão BFD no modo de controle para um backup VRRP para monitorar o mestre
Configuração de rede
Conforme mostrado na Figura 4:
- O Switch A e o Switch B pertencem ao grupo VRRP 1. O endereço IP virtual do grupo VRRP 1 é 192.168.0.10.
- O gateway padrão dos hosts na LAN é 192.168.0.10.
Configure a colaboração VRRP-Track-BFD (modo de controle) para monitorar o mestre no backup e atender aos seguintes requisitos:
- Quando o Switch A funciona corretamente, os hosts da LAN acessam a Internet por meio do Switch A.
- Quando o Switch A falha, o backup (Switch B) pode detectar a mudança de estado do mestre por meio da sessão BFD no modo de controle e se tornar o novo mestre. Os hosts da LAN acessam a Internet por meio do Switch B.
Figura 4 Diagrama de rede
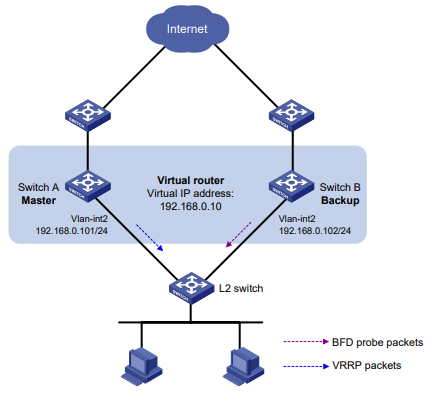
Procedimento
- Crie VLANs e atribua portas a elas. Configure o endereço IP de cada interface de VLAN, conforme mostrado na Figura 4. (Detalhes não mostrados.)
- Configure o Switch A:
# Crie o grupo VRRP 1 e configure o endereço IP virtual 192.168.0.10 para o grupo.
<SwitchA> system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] vrrp vrid 1 virtual-ip 192.168.0.10# Defina a prioridade do Switch A como 110 no grupo 1 do VRRP.
[SwitchA-Vlan-interface2] vrrp vrid 1 priority 110
[SwitchA-Vlan-interface2] return# Crie a entrada de trilha 1 e associe-a à sessão BFD no modo de controle para verificar a acessibilidade do Switch B.
[SwitchA] track 1 bfd ctrl interface vlan-interface 2 remote ip 192.168.0.102 local
ip 192.168.0.101
[SwitchA-track-1] quit- Configurar o Switch B:
# Crie o grupo VRRP 1 e configure o endereço IP virtual 192.168.0.10 para o grupo.
<SwitchB> system-view
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] vrrp vrid 1 virtual-ip 192.168.0.10# Configure o grupo VRRP 1 para monitorar a entrada de trilha 1, de modo que o Switch B possa assumir o controle como mestre quando a entrada de trilha mudar para o estado Negativo.
[SwitchB-Vlan-interface2] vrrp vrid 1 track 1 switchover
[SwitchB-Vlan-interface2] return
# Crie a entrada de trilha 1 e associe-a à sessão BFD no modo de controle para verificar a acessibilidade do Switch A.
[SwitchB] track 1 bfd ctrl interface vlan-interface 2 remote ip 192.168.0.101 local
ip 192.168.0.102
[SwitchB-track-1] quitVerificação da configuração
# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch A.
<SwitchA> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : 192.168.0.10
Virtual MAC : 0000-5e00-0101
Master IP : 192.168.0.101# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch B.
display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Become Master : 2200ms left
Auth Type : None
Virtual IP : 192.168.0.10
Master IP : 192.168.0.101
VRRP Track Information:
Track Object : 1 State : Positive Switchover # Exibir informações sobre a entrada de trilha 1 no Switch B.
<SwitchB> exibir faixa 1 ID da faixa: 1
Estado: Positivo
Duração: 0 dias 0 horas 0 minutos 32 segundos Tipo de objeto rastreado: BFD ctrl
Atraso de notificação: Positivo 0, Negativo 0 (em segundos) Objeto rastreado:
Modo de sessão BFD: Ctrl
Interface de saída: Vlan-interface2 Nome da instância VPN: --
IP remoto: 192.168.0.101
IP local: 192.168.0.102
A saída mostra que, quando o status da entrada da trilha se torna positivo, o interruptor A é o principal e o interruptor B é o reserva.
# Habilite a depuração do estado do VRRP e a depuração da notificação de eventos BFD no Switch B.
<SwitchB> terminal debugging
<SwitchB> terminal monitor
<SwitchB> debugging vrrp fsm
<SwitchB> debugging bfd ntfy# Quando o Switch A falha, a seguinte saída é exibida no Switch B.
*Dec 17 14:44:34:142 2008 SwitchB BFD/7/DEBUG: Notify application:TRACK State:DOWN
*Dec 17 14:44:34:144 2008 SwitchB VRRP4/7/FSM:
IPv4 Vlan-interface2 | Virtual Router 1 : Backup --> Master reason: The status of the
tracked object changed# Exibir informações detalhadas sobre o grupo VRRP no Switch B.
<SwitchB> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : 192.168.0.10
Virtual MAC : 0000-5e00-0101
Master IP : 192.168.0.102
VRRP Track Information:
Track Object : 1 State : Negative SwitchoverA saída mostra que, quando a sessão BFD no modo de controle detecta que o Switch A falhou, o módulo Track notifica o VRRP para alterar o status do Switch B para mestre. O backup pode rapidamente antecipar
como mestre sem esperar por um período três vezes maior que o intervalo de anúncio mais o Skew_Time.
Exemplo: Configuração de uma sessão BFD em modo eco para o VRRP master monitorar o uplink
Configuração de rede
Conforme mostrado na Figura 5:
- O Switch A e o Switch B pertencem ao grupo VRRP 1. O endereço IP virtual do grupo VRRP 1 é 192.168.0.10.
- O gateway padrão dos hosts na LAN é 192.168.0.10.
Configure a colaboração VRRP-Track-BFD (modo eco) para monitorar o uplink no mestre e atender aos seguintes requisitos:
- Quando o Switch A funciona corretamente, os hosts da LAN acessam a Internet por meio do Switch A.
- Quando o Switch A detecta que o uplink está inoperante por meio da sessão BFD no modo eco, o Switch B pode se antecipar como mestre. Os hosts da LAN podem acessar a Internet por meio do Switch B.
Figura 5 Diagrama de rede
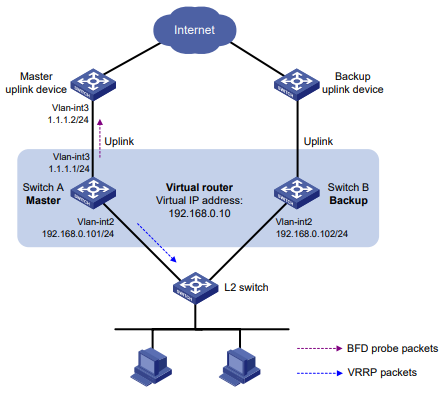
Procedimento
- Crie VLANs e atribua portas a elas. Configure o endereço IP de cada interface de VLAN, conforme mostrado na Figura 5. (Detalhes não mostrados.)
- Configure o Switch A:
# Especifique 10.10.10.10 como o endereço de origem dos pacotes de eco BFD.
<SwitchA> system-view
[SwitchA] bfd echo-source-ip 10.10.10.10
# Crie a entrada de trilha 1 para a sessão BFD no modo eco para verificar a acessibilidade do dispositivo de uplink (1.1.1.2).
[SwitchA] track 1 bfd echo interface vlan-interface 3 remote ip 1.1.1.2 local ip
1.1.1.1
[SwitchA-track-1] quit# Crie o grupo VRRP 1 e especifique 192.168.0.10 como o endereço IP virtual do grupo.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] vrrp vrid 1 virtual-ip 192.168.0.10# Defina a prioridade do Switch A como 110 no grupo 1 do VRRP.
[SwitchA-Vlan-interface2] vrrp vrid 1 priority 110# Associe o grupo VRRP 1 à entrada de trilha 1 e diminua a prioridade do roteador em 20 quando o estado da entrada de trilha 1 mudar para Negativo.
[SwitchA-Vlan-interface2] vrrp vrid 1 track 1 priority reduced 20
[SwitchA-Vlan-interface2] return- No Switch B, crie o grupo VRRP 1 e especifique 192.168.0.10 como o endereço IP virtual do grupo.
<SwitchB> system-view
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] vrrp vrid 1 virtual-ip 192.168.0.10
[SwitchB-Vlan-interface2] returnVerificação da configuração
# Exibir informações detalhadas sobre o grupo VRRP no Switch A.
<SwitchA> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : 192.168.0.10
Virtual MAC : 0000-5e00-0101
Master IP : 192.168.0.101
VRRP Track Information:
Track Object : 1 State : Positive Pri Reduced : 20# Exibir informações sobre a entrada de trilha 1 no Switch A.
<SwitchA> display track 1
Track ID: 1
State: Positive
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: BFD echo
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
BFD session mode: Echo
Outgoing interface: Vlan-interface2
VPN instance name: --
Remote IP: 1.1.1.2
Local IP: 1.1.1.1# Exibir informações detalhadas sobre o grupo VRRP no Switch B.
<SwitchB> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Become Master : 2200ms left
Auth Type : None
Virtual IP : 192.168.0.10
Master IP : 192.168.0.101A saída mostra que, quando o status da entrada de trilha 1 se torna positivo, o interruptor A é o principal e o interruptor B é o reserva.
# Exibir informações sobre a entrada de trilha 1 quando o uplink do Switch A cair.
<SwitchA> display track 1
Track ID: 1
State: Negative
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: BFD echo
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
BFD session mode: Echo
Outgoing interface: Vlan-interface2
VPN instance name: --
Remote IP: 1.1.1.2
Local IP: 1.1.1.1# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch A.
<SwitchA> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 110 Running Pri : 90
Preempt Mode : Yes Delay Time : 0
Become Master : 2200ms left
Auth Type : None
Virtual IP : 192.168.0.10
Master IP : 192.168.0.102
VRRP Track Information:
Track Object : 1 State : Negative Pri Reduced : 20
# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch B.
<SwitchB> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : 192.168.0.10
Virtual MAC : 0000-5e00-0101
Master IP : 192.168.0.102
A saída mostra que, quando o Switch A detecta que o uplink falha por meio da sessão BFD no modo eco, ele diminui sua prioridade em 20. Em seguida, o switch B faz a preempção como mestre.
Exemplo: Configuração de uma sessão BFD no modo de controle para que o VRRP master monitore o uplink
Configuração de rede
Conforme mostrado na Figura 6:
- O Switch A e o Switch B pertencem ao grupo VRRP 1. O endereço IP virtual do grupo VRRP 1 é 192.168.0.10.
- O gateway padrão dos hosts na LAN é 192.168.0.10.
Configure a colaboração VRRP-Track-BFD (modo de controle) para monitorar o uplink no mestre e atender aos seguintes requisitos:
- Quando o Switch A funciona corretamente, os hosts da LAN acessam a Internet por meio do Switch A.
- Quando o Switch A detecta que o uplink está inoperante por meio da sessão BFD no modo de controle, o Switch B pode assumir o papel de mestre. Os hosts da LAN podem acessar a Internet por meio do Switch B.
Figura 6 Diagrama de rede
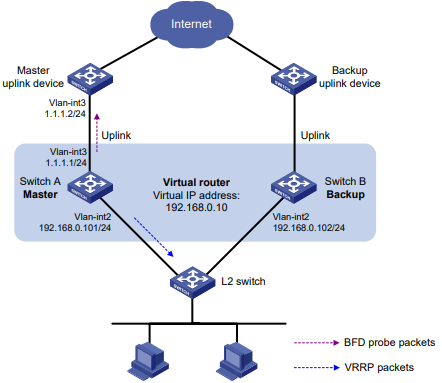
Procedimento
- Crie VLANs e atribua portas a elas. Configure o endereço IP de cada interface de VLAN, conforme mostrado na Figura 6. (Detalhes não mostrados.)
- Configure o Switch A:
# Crie o grupo VRRP 1 e especifique 192.168.0.10 como o endereço IP virtual do grupo.
<SwitchA> system-view
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] vrrp vrid 1 virtual-ip 192.168.0.10# Defina a prioridade do Switch A como 110 no grupo 1 do VRRP.
[SwitchA-Vlan-interface2] vrrp vrid 1 priority 110# Associe o grupo VRRP 1 à entrada de trilha 1 e diminua a prioridade do roteador em 20 quando o estado da entrada de trilha 1 mudar para Negativo.
[SwitchA-Vlan-interface2] vrrp vrid 1 track 1 priority reduced 20
[SwitchA-Vlan-interface2] quit# Crie a entrada de trilha 1 para a sessão BFD no modo de controle para monitorar a acessibilidade do dispositivo de uplink (1.1.1.2).
[SwitchA] track 1 bfd ctrl interface vlan-interface 3 remote ip 1.1.1.2 local ip
1.1.1.1
[SwitchA-track-1] quit- No dispositivo de uplink do Switch A, crie a entrada de trilha 1 e associe-a à sessão BFD no modo de controle para verificar a acessibilidade do Switch A.
<Master> system-view
[Master] track 1 bfd ctrl interface vlan-interface 3 remote ip 1.1.1.1 local ip 1.1.1.2
[Master-track-1] quit- No Switch B, crie o grupo VRRP 1 e especifique 192.168.0.10 como o endereço IP virtual do grupo.
<SwitchB> system-view
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] vrrp vrid 1 virtual-ip 192.168.0.10
[SwitchB-Vlan-interface2] returnVerificação da configuração
# Exibir informações detalhadas sobre o grupo VRRP no Switch A.
<SwitchA> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : 192.168.0.10
Virtual MAC : 0000-5e00-0101
Master IP : 192.168.0.101
VRRP Track Information:
Track Object : 1 State : Positive Pri Reduced : 20# Exibir informações sobre a entrada de trilha 1 no Switch A.
<SwitchA> display track 1
Track ID: 1
State: Positive
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: BFD ctrl
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
BFD session mode: Ctrl
Outgoing interface: Vlan-interface2
VPN instance name: --
Remote IP: 1.1.1.2
Local IP: 1.1.1.1# Exibir informações detalhadas sobre o grupo VRRP no Switch B.
<SwitchB> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Become Master : 2200ms left
Auth Type : None
Virtual IP : 192.168.0.10
Master IP : 192.168.0.101A saída mostra que, quando o status da entrada de trilha 1 se torna positivo, o interruptor A é o principal e o interruptor B é o reserva.
# Exibir informações sobre a entrada de trilha 1 quando o uplink do Switch A cair.
<SwitchA> display track 1
Track ID: 1
State: Negative
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: BFD ctrl
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
BFD session mode: Ctrl
Outgoing interface: Vlan-interface2
VPN instance name: --
Remote IP: 1.1.1.2
Local IP: 1.1.1.1# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch A.
<SwitchA> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 110 Running Pri : 90
Preempt Mode : Yes Delay Time : 0
Become Master : 2200ms left
Auth Type : None
Virtual IP : 192.168.0.10
Master IP : 192.168.0.102
VRRP Track Information:
Track Object : 1 State : Negative Pri Reduced : 20# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch B.
<SwitchB> display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : 192.168.0.10
Virtual MAC : 0000-5e00-0101
Master IP : 192.168.0.102
A saída mostra que quando o Switch A detecta que o uplink falha por meio da sessão BFD no modo de controle, ele diminui sua prioridade em 20. Em seguida, o switch B faz a preempção como mestre.
Exemplo: Configuração do roteamento estático - Colaboração entre trilha e NQA
Configuração de rede
Conforme mostrado na Figura 7:
- O switch A é o gateway padrão dos hosts da rede 20.1.1.0/24.
- O switch D é o gateway padrão dos hosts da rede 30.1.1.0/24.
- Os hosts das duas redes se comunicam entre si por meio de rotas estáticas.
Para garantir a disponibilidade da rede, configure o backup de rotas e o roteamento estático - colaboração Track-NQA no Switch A e no Switch D da seguinte forma:
- No Switch A, atribua uma prioridade mais alta à rota estática para 30.1.1.0/24 com o próximo salto do Switch B. Essa rota é a rota principal. A rota estática para 30.1.1.0/24 com o próximo salto do Switch C atua como rota de backup. Quando a rota principal não está disponível, a rota de backup entra em vigor. O switch A encaminha pacotes para 30.1.1.0/24 por meio do switch C.
- No Switch D, atribua uma prioridade mais alta à rota estática para 20.1.1.0/24 com o próximo salto do Switch B. Essa rota é a rota principal. A rota estática para 20.1.1.0/24 com o próximo salto do Switch C atua como rota de backup. Quando a rota principal não está disponível, a rota de backup entra em vigor. O switch D encaminha pacotes para 20.1.1.0/24 por meio do switch C.
Figura 7 Diagrama de rede
Procedimento
- Crie VLANs e atribua portas a elas. Configure o endereço IP de cada interface de VLAN, conforme mostrado na Figura 7. (Detalhes não mostrados.)
- Configure o Switch A:
# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.1.1.2 e a prioridade padrão (60). Associe essa rota estática à entrada de trilha 1.
<SwitchA> system-view
[SwitchA] ip route-static 30.1.1.0 24 10.1.1.2 track 1# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.3.1.3 e prioridade 80.
[SwitchA] ip route-static 30.1.1.0 24 10.3.1.3 preference 80# Configure uma rota estática para 10.2.1.4 com o próximo salto 10.1.1.2.
[SwitchA] ip route-static 10.2.1.4 24 10.1.1.2# Criar uma operação NQA com o nome de administrador admin e a tag de operação test.
[SwitchA] nqa entry admin test# Especifique o tipo de operação de eco ICMP.
[SwitchA-nqa-admin-test] type icmp-echo# Especifique 10.2.1.4 como o endereço de destino da operação. [Especifique 10.1.1.2 como o próximo salto da operação.
[SwitchA-nqa-admin-test-icmp-echo] next-hop ip 10.1.1.2# Configure a operação de eco do ICMP para ser repetida a cada 100 milissegundos.
[SwitchA-nqa-admin-test-icmp-echo] frequency 100# Configure a entrada de reação 1, especificando que cinco falhas consecutivas da sonda acionam o módulo Track.
[SwitchA-nqa-admin-test-icmp-echo] reaction 1 checked-element probe-fail
threshold-type consecutive 5 action-type trigger-only
[SwitchA-nqa-admin-test-icmp-echo] quit# Iniciar a operação de NQA.
[SwitchA] nqa schedule admin test start-time now lifetime forever# Configure a entrada de trilha 1 e associe-a à entrada de reação 1 da operação NQA.
[SwitchA] track 1 nqa entry admin test reaction 1
[SwitchA-track-1] quit- Configurar o Switch B:
# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.2.1.4.
<SwitchB> system-view
[SwitchB] ip route-static 30.1.1.0 24 10.2.1.4# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.1.1.1.
[SwitchB] ip route-static 20.1.1.0 24 10.1.1.1- Configurar o switch C:
# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.4.1.4.
<SwitchC> system-view
[SwitchC] ip route-static 30.1.1.0 24 10.4.1.4# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.3.1.1.
[SwitchC] ip route-static 20.1.1.0 24 10.3.1.1- Configurar o Switch D:
# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.2.1.2 e a prioridade padrão (60). Associe essa rota estática à entrada de trilha 1.
<SwitchD> system-view
[SwitchD] ip route-static 20.1.1.0 24 10.2.1.2 track 1# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.4.1.3 e prioridade 80.
[SwitchD] ip route-static 20.1.1.0 24 10.4.1.3 preference 80# Configure uma rota estática para 10.1.1.1 com o próximo salto 10.2.1.2.
[SwitchD] ip route-static 10.1.1.1 24 10.2.1.2# Criar uma operação NQA com o nome de administrador admin e a tag de operação test.
[SwitchA] nqa entry admin test# Especifique o tipo de operação de eco ICMP.
[SwitchD-nqa-admin-test] type icmp-echo# Especifique 10.1.1.1 como o endereço de destino da operação.
[SwitchD-nqa-admin-test-icmp-echo] destination ip 10.1.1.1Especifique 10.2.1.2 como o próximo salto da operação.
[SwitchD-nqa-admin-test-icmp-echo] next-hop ip 10.2.1.2# Configure a operação de eco ICMP para se repetir a cada 100 milissegundos.
[SwitchD-nqa-admin-test-icmp-echo] frequency 100# Configure a entrada de reação 1, especificando que cinco falhas consecutivas da sonda acionam o módulo Track.
[SwitchD-nqa-admin-test-icmp-echo] reaction 1 checked-element probe-fail
threshold-type consecutive 5 action-type trigger-only
[SwitchD-nqa-admin-test-icmp-echo] quit# Iniciar a operação de NQA.
[SwitchD] nqa schedule admin test start-time now lifetime forever# Configure a entrada de trilha 1 e associe-a à entrada de reação 1 da operação NQA.
[SwitchD] track 1 nqa entry admin test reaction 1
[SwitchD-track-1] quitVerificação da configuração
# Exibir informações sobre a entrada da trilha no Switch A.
[SwitchA] display track all
Track ID: 1
State: Positive
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: NQA
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
NQA entry: admin test
Reaction: 1
Remote IP/URL:--
Local IP:--
Interface:--A saída mostra que o status da entrada da trilha é Positivo, indicando que a operação NQA foi bem-sucedida e a rota principal está disponível.
# Exibir a tabela de roteamento do Switch A.
[SwitchA] display ip routing-table
Destinations : 10 Routes : 10
Destination/Mask Proto Pre Cost NextHop Interface
10.1.1.0/24 Direct 0 0 10.1.1.1 Vlan2
10.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
10.2.1.0/24 Static 60 0 10.1.1.2 Vlan2
10.3.1.0/24 Direct 0 0 10.3.1.1 Vlan3
10.3.1.1/32 Direct 0 0 127.0.0.1 InLoop0
20.1.1.0/24 Direct 0 0 20.1.1.1 Vlan6
20.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
30.1.1.0/24 Static 60 0 10.1.1.2 Vlan2
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0A saída mostra que o Switch A encaminha pacotes para 30.1.1.0/24 por meio do Switch B.
# Remova o endereço IP da interface VLAN-interface 2 no Switch B.
<SwitchB> system-view
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] undo ip address# Exibir informações sobre a entrada da trilha no Switch A.
[SwitchA] display track all
Track ID: 1
State: Negative
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: NQA
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
NQA entry: admin test
Reaction: 1
Remote IP/URL:--
Local IP:--
Interface:--A saída mostra que o status da entrada da trilha é Negativo, indicando que a operação NQA falhou e que a rota principal não está disponível.
# Exibir a tabela de roteamento do Switch A.
[SwitchA] display ip routing-table
Destinations : 10 Routes : 10
Destination/Mask Proto Pre Cost NextHop Interface
10.1.1.0/24 Direct 0 0 10.1.1.1 Vlan2
10.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
10.2.1.0/24 Static 60 0 10.1.1.2 Vlan2
10.3.1.0/24 Direct 0 0 10.3.1.1 Vlan3
10.3.1.1/32 Direct 0 0 127.0.0.1 InLoop0
20.1.1.0/24 Direct 0 0 20.1.1.1 Vlan6
20.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
30.1.1.0/24 Static 80 0 10.3.1.3 Vlan3
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0A saída mostra que o Switch A encaminha pacotes para 30.1.1.0/24 por meio do Switch C. A rota estática de backup entrou em vigor.
# Verifique se os hosts em 20.1.1.0/24 podem se comunicar com os hosts em 30.1.1.0/24 quando a rota principal falhar.
[SwitchA] ping -a 20.1.1.1 30.1.1.1
Ping 30.1.1.1: 56 data bytes, press CTRL_C to break
Reply from 30.1.1.1: bytes=56 Sequence=1 ttl=254 time=2 ms
Reply from 30.1.1.1: bytes=56 Sequence=2 ttl=254 time=1 ms
Reply from 30.1.1.1: bytes=56 Sequence=3 ttl=254 time=1 ms
Reply from 30.1.1.1: bytes=56 Sequence=4 ttl=254 time=2 ms
33
Reply from 30.1.1.1: bytes=56 Sequence=5 ttl=254 time=1 ms
--- Ping statistics for 30.1.1.1 ---
5 packet(s) transmitted, 5 packet(s) received, 0.00% packet loss
round-trip min/avg/max/std-dev = 1/1/2/1 ms# Verifique se os hosts em 30.1.1.0/24 podem se comunicar com os hosts em 20.1.1.0/24 quando a rota principal falhar.
[SwitchB] ping -a 30.1.1.1 20.1.1.1
Ping 20.1.1.1: 56 data bytes, press CTRL_C to break
Reply from 20.1.1.1: bytes=56 Sequence=1 ttl=254 time=2 ms
Reply from 20.1.1.1: bytes=56 Sequence=2 ttl=254 time=1 ms
Reply from 20.1.1.1: bytes=56 Sequence=3 ttl=254 time=1 ms
Reply from 20.1.1.1: bytes=56 Sequence=4 ttl=254 time=1 ms
Reply from 20.1.1.1: bytes=56 Sequence=5 ttl=254 time=1 ms
--- Ping statistics for 20.1.1.1 ---
5 packet(s) transmitted, 5 packet(s) received, 0.00% packet loss
round-trip min/avg/max/std-dev = 1/1/2/1 msExemplo: Configuração de colaboração de roteamento estático-Track-BFD (modo eco)
Configuração de rede
Conforme mostrado na Figura 8:
- O switch A é o gateway padrão dos hosts da rede 20.1.1.0/24.
- O switch B é o gateway padrão dos hosts da rede 30.1.1.0/24.
- Os hosts das duas redes se comunicam entre si por meio de rotas estáticas.
Para garantir a disponibilidade da rede, configure a colaboração de backup de rota e roteamento estático-Track-BFD (modo eco) no Switch A e no Switch B da seguinte forma:
- No Switch A, atribua uma prioridade mais alta à rota estática para 30.1.1.0/24 com o próximo salto do Switch B. Essa rota é a rota principal. A rota estática para 30.1.1.0/24 com o próximo salto do Switch C atua como rota de backup. Quando a rota principal não está disponível, a sessão BFD no modo eco pode detectar rapidamente a falha na rota para que a rota de backup entre em vigor.
- No Switch B, atribua uma prioridade mais alta à rota estática para 20.1.1.0/24 com o próximo salto do Switch A. Essa rota é a rota principal. A rota estática para 20.1.1.0/24 com o próximo salto do Switch C atua como rota de backup. Quando a rota principal não está disponível, a sessão BFD no modo eco pode detectar rapidamente a falha na rota para que a rota de backup entre em vigor.
Figura 8 Diagrama de rede
Procedimento
- Crie VLANs e atribua portas a elas. Configure o endereço IP de cada interface de VLAN, conforme mostrado na Figura 8. (Detalhes não mostrados.)
- Configure o Switch A:
# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.2.1.2 e a prioridade padrão (60). Associe essa rota estática à entrada de trilha 1.
<SwitchA> system-view
[SwitchA] ip route-static 30.1.1.0 24 10.2.1.2 track 1# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.3.1.3 e prioridade 80.
[SwitchA] ip route-static 30.1.1.0 24 10.3.1.3 preference 80# Especifique 10.10.10.10 como o endereço de origem dos pacotes de eco BFD.
[SwitchA] bfd echo-source-ip 10.10.10.10# Configure a entrada de trilha 1 e associe-a à sessão BFD no modo eco para verificar a conectividade entre o Switch A e o Switch B.
[SwitchA] track 1 bfd echo interface vlan-interface 2 remote ip 10.2.1.2 local ip
10.2.1.1
[SwitchA-track-1] quit- Configurar o Switch B:
# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.2.1.1 e a prioridade padrão (60). Associe essa rota estática à entrada de trilha 1.
<SwitchB> system-view
[SwitchB] ip route-static 20.1.1.0 24 10.2.1.1 track 1# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.4.1.3 e prioridade 80.
[SwitchB] ip route-static 20.1.1.0 24 10.4.1.3 preference 80# Especifique 1.1.1.1 como o endereço de origem dos pacotes de eco BFD.
[SwitchB] bfd echo-source-ip 1.1.1.1# Configure a entrada de trilha 1 e associe-a à sessão BFD em modo eco para verificar a conectividade entre o Switch B e o Switch A.
[SwitchB] track 1 bfd echo interface vlan-interface 2 remote ip 10.2.1.1 local ip
10.2.1.2
[SwitchB-track-1] quit- Configurar o switch C:
# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.4.1.2.
<SwitchC> system-view
[SwitchC] ip route-static 30.1.1.0 24 10.4.1.2# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.3.1.1.
[SwitchC] ip route-static 20.1.1.0 24 10.3.1.1Verificação da configuração
# Exibir informações sobre a entrada da trilha no Switch A.
[SwitchA] display track all
Track ID: 1
State: Positive
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: BFD echo
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
BFD session mode: Echo
Outgoing interface: Vlan-interface2
VPN instance name: --
Remote IP: 10.2.1.2
Local IP: 10.2.1.1O resultado mostra que o status da entrada de trilha é Positivo, indicando que o próximo salto 10.2.1.2 pode ser alcançado.
# Exibir a tabela de roteamento do Switch A.
[SwitchA] display ip routing-table
Destinations : 9 Routes : 9
Destination/Mask Proto Pre Cost NextHop Interface
10.2.1.0/24 Direct 0 0 10.2.1.1 Vlan2
10.2.1.1/32 Direct 0 0 127.0.0.1 InLoop0
10.3.1.0/24 Direct 0 0 10.3.1.1 Vlan3
10.3.1.1/32 Direct 0 0 127.0.0.1 InLoop0
20.1.1.0/24 Direct 0 0 20.1.1.1 Vlan5
20.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
30.1.1.0/24 Static 60 0 10.2.1.2 Vlan2
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0A saída mostra que o Switch A encaminha pacotes para 30.1.1.0/24 por meio do Switch B. A rota estática principal entrou em vigor.
# Remova o endereço IP da interface VLAN 2 no Switch B.
<SwitchB> system-view
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] undo ip address# Exibir informações sobre a entrada da trilha no Switch A.
[SwitchA] display track all
Track ID: 1
State: Negative
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: BFD echo
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
BFD session mode: Echo
Outgoing interface: Vlan-interface2
VPN instance name: --
Remote IP: 10.2.1.2
Local IP: 10.2.1.1A saída mostra que o status da entrada de trilha é Negativo, indicando que o próximo salto 10.2.1.2 não pode ser alcançado.
# Exibir a tabela de roteamento do Switch A.
[SwitchA] display ip routing-table
Destinations : 9 Routes : 9
Destination/Mask Proto Pre Cost NextHop Interface
10.2.1.0/24 Direct 0 0 10.2.1.1 Vlan2
10.2.1.1/32 Direct 0 0 127.0.0.1 InLoop0
10.3.1.0/24 Direct 0 0 10.3.1.1 Vlan3
10.3.1.1/32 Direct 0 0 127.0.0.1 InLoop0
20.1.1.0/24 Direct 0 0 20.1.1.1 Vlan5
20.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
30.1.1.0/24 Static 80 0 10.3.1.3 Vlan3
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0A saída mostra que o Switch A encaminha pacotes para 30.1.1.0/24 por meio do Switch C. A rota estática de backup entrou em vigor.
# Verifique se os hosts em 20.1.1.0/24 podem se comunicar com os hosts em 30.1.1.0/24 quando a rota principal falhar.
[SwitchA] ping -a 20.1.1.1 30.1.1.1
Ping 30.1.1.1: 56 data bytes, press CTRL_C to break
Reply from 30.1.1.1: bytes=56 Sequence=1 ttl=254 time=2 ms
Reply from 30.1.1.1: bytes=56 Sequence=2 ttl=254 time=1 ms
Reply from 30.1.1.1: bytes=56 Sequence=3 ttl=254 time=1 ms
Reply from 30.1.1.1: bytes=56 Sequence=4 ttl=254 time=2 ms
Reply from 30.1.1.1: bytes=56 Sequence=5 ttl=254 time=1 ms
--- Ping statistics for 30.1.1.1 ---
5 packet(s) transmitted, 5 packet(s) received, 0.00% packet loss
round-trip min/avg/max/std-dev = 1/1/2/1 ms# Verifique se os hosts em 30.1.1.0/24 ainda podem se comunicar com os hosts em 20.1.1.0/24 quando a rota principal falhar.
[SwitchB] ping -a 30.1.1.1 20.1.1.1
Ping 20.1.1.1: 56 data bytes, press CTRL_C to break
Reply from 20.1.1.1: bytes=56 Sequence=1 ttl=254 time=2 ms
Reply from 20.1.1.1: bytes=56 Sequence=2 ttl=254 time=1 ms
Reply from 20.1.1.1: bytes=56 Sequence=3 ttl=254 time=1 ms
Reply from 20.1.1.1: bytes=56 Sequence=4 ttl=254 time=1 ms
Reply from 20.1.1.1: bytes=56 Sequence=5 ttl=254 time=1 ms
--- Ping statistics for 20.1.1.1 ---
5 packet(s) transmitted, 5 packet(s) received, 0.00% packet loss
round-trip min/avg/max/std-dev = 1/1/2/1 msExemplo: Configuração de colaboração de roteamento estático-Track-BFD (modo de controle)
Configuração de rede
Conforme mostrado na Figura 9:
- O switch A é o gateway padrão dos hosts da rede 20.1.1.0/24.
- O switch B é o gateway padrão dos hosts da rede 30.1.1.0/24.
- Os hosts das duas redes se comunicam entre si por meio de rotas estáticas.
Para garantir a disponibilidade da rede, configure a colaboração de backup de rota e roteamento estático-Track-BFD (modo de controle) no Switch A e no Switch B da seguinte forma:
- No Switch A, atribua uma prioridade mais alta à rota estática para 30.1.1.0/24 com o próximo salto do Switch B. Essa rota é a rota principal. A rota estática para 30.1.1.0/24 com o próximo salto do Switch C atua como rota de backup. Quando a rota principal não está disponível, a sessão BFD no modo de controle pode detectar rapidamente a falha na rota para que a rota de backup entre em vigor.
- No Switch B, atribua uma prioridade mais alta à rota estática para 20.1.1.0/24 com o próximo salto do Switch A. Essa rota é a rota principal. A rota estática para 20.1.1.0/24 com o próximo salto do Switch C atua como rota de backup. Quando a rota principal não está disponível, a sessão BFD no modo de controle pode detectar rapidamente a falha na rota para que a rota de backup entre em vigor.
Figura 9 Diagrama de rede
Procedimento
- Crie VLANs e atribua portas a elas. Configure o endereço IP de cada interface de VLAN, conforme mostrado na Figura 9. (Detalhes não mostrados.)
- Configure o Switch A:
# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.2.1.2 e a prioridade padrão (60). Associe essa rota estática à entrada de trilha 1.
<SwitchA> system-view
[SwitchA] ip route-static 30.1.1.0 24 10.2.1.2 track 1# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.3.1.3 e prioridade 80.
[SwitchA] ip route-static 30.1.1.0 24 10.3.1.3 preference 80# Configure a entrada de trilha 1 e associe-a à sessão BFD no modo de controle para verificar a conectividade entre o Switch A e o Switch B.
[SwitchA] track 1 bfd ctrl interface vlan-interface 2 remote ip 10.2.1.2 local ip
10.2.1.1
[SwitchA-track-1] quit- Configurar o Switch B:
# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.2.1.1 e a prioridade padrão (60). Associe essa rota estática à entrada de trilha 1.
<SwitchB> system-view
[SwitchB] ip route-static 20.1.1.0 24 10.2.1.1 track 1# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.4.1.3 e prioridade 80.
[SwitchB] ip route-static 20.1.1.0 24 10.4.1.3 preference 80# Configure a entrada de trilha 1 e associe-a à sessão BFD no modo de controle para verificar a conectividade entre o Switch B e o Switch A.
[SwitchB] track 1 bfd ctrl interface vlan-interface 2 remote ip 10.2.1.1 local ip
10.2.1.2
[SwitchB-track-1] quit- Configurar o switch C:
# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.4.1.2.
<SwitchC> system-view
[SwitchC] ip route-static 30.1.1.0 24 10.4.1.2# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.3.1.1.
[SwitchC] ip route-static 20.1.1.0 24 10.3.1.1Verificação da configuração
# Exibir informações sobre a entrada da trilha no Switch A.
[SwitchA] display track all
Track ID: 1
State: Positive
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: BFD ctrl
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
BFD session mode: Echo
Outgoing interface: Vlan-interface2
VPN instance name: --
Remote IP: 10.2.1.2
Local IP: 10.2.1.1O resultado mostra que o status da entrada da trilha é Positivo, indicando que o próximo salto 10.2.1.2 pode ser alcançado.
# Exibir a tabela de roteamento do Switch A.
[SwitchA] display ip routing-table
Destinations : 9 Routes : 9
Destination/Mask Proto Pre Cost NextHop Interface
10.2.1.0/24 Direct 0 0 10.2.1.1 Vlan2
10.2.1.1/32 Direct 0 0 127.0.0.1 InLoop0
10.3.1.0/24 Direct 0 0 10.3.1.1 Vlan3
10.3.1.1/32 Direct 0 0 127.0.0.1 InLoop0
20.1.1.0/24 Direct 0 0 20.1.1.1 Vlan5
20.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
30.1.1.0/24 Static 60 0 10.2.1.2 Vlan2
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0A saída mostra que o Switch A encaminha pacotes para 30.1.1.0/24 por meio do Switch B. A rota estática principal entrou em vigor.
# Remova o endereço IP da interface VLAN 2 no Switch B.
<SwitchB> system-view
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] undo ip address# Exibir informações sobre a entrada da trilha no Switch A.
[SwitchA] display track all
Track ID: 1
State: Negative
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: BFD ctrl
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
BFD session mode: Echo
Outgoing interface: Vlan-interface2
VPN instance name: --
Remote IP: 10.2.1.2
Local IP: 10.2.1.1A saída mostra que o status da entrada de trilha é Negativo, indicando que o próximo salto 10.2.1.2 não pode ser alcançado.
# Exibir a tabela de roteamento do Switch A.
[SwitchA] display ip routing-table
Destinations : 9 Routes : 9
Destination/Mask Proto Pre Cost NextHop Interface
10.2.1.0/24 Direct 0 0 10.2.1.1 Vlan2
10.2.1.1/32 Direct 0 0 127.0.0.1 InLoop0
10.3.1.0/24 Direct 0 0 10.3.1.1 Vlan3
10.3.1.1/32 Direct 0 0 127.0.0.1 InLoop0
20.1.1.0/24 Direct 0 0 20.1.1.1 Vlan5
20.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
30.1.1.0/24 Static 80 0 10.3.1.3 Vlan3
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0A saída mostra que o Switch A encaminha pacotes para 30.1.1.0/24 por meio do Switch C. A rota estática de backup entrou em vigor.
# Verifique se os hosts em 20.1.1.0/24 podem se comunicar com os hosts em 30.1.1.0/24 quando a rota principal falhar.
[SwitchA] ping -a 20.1.1.1 30.1.1.1
Ping 30.1.1.1: 56 data bytes, press CTRL_C to break
Reply from 30.1.1.1: bytes=56 Sequence=1 ttl=254 time=2 ms
Reply from 30.1.1.1: bytes=56 Sequence=2 ttl=254 time=1 ms
Reply from 30.1.1.1: bytes=56 Sequence=3 ttl=254 time=1 ms
Reply from 30.1.1.1: bytes=56 Sequence=4 ttl=254 time=2 ms
Reply from 30.1.1.1: bytes=56 Sequence=5 ttl=254 time=1 ms
--- Ping statistics for 30.1.1.1 ---
5 packet(s) transmitted, 5 packet(s) received, 0.00% packet loss
round-trip min/avg/max/std-dev = 1/1/2/1 ms# Verifique se os hosts em 30.1.1.0/24 ainda podem se comunicar com os hosts em 20.1.1.0/24 quando a rota principal falhar.
[SwitchB] ping -a 30.1.1.1 20.1.1.1
Ping 20.1.1.1: 56 data bytes, press CTRL_C to break
Reply from 20.1.1.1: bytes=56 Sequence=1 ttl=254 time=2 ms
Reply from 20.1.1.1: bytes=56 Sequence=2 ttl=254 time=1 ms
Reply from 20.1.1.1: bytes=56 Sequence=3 ttl=254 time=1 ms
Reply from 20.1.1.1: bytes=56 Sequence=4 ttl=254 time=1 ms
Reply from 20.1.1.1: bytes=56 Sequence=5 ttl=254 time=1 ms
--- Ping statistics for 20.1.1.1 ---
5 packet(s) transmitted, 5 packet(s) received, 0.00% packet loss
round-trip min/avg/max/std-dev = 1/1/2/1 msExemplo: Configuração da colaboração de gerenciamento da interface VRRP-Track
Configuração de rede
Conforme mostrado na Figura 10:
- O host A precisa acessar o host B. O gateway padrão do host A é 10.1.1.10/24.
- O Switch A e o Switch B pertencem ao grupo VRRP 1. O endereço IP virtual do grupo VRRP 1 é 10.1.1.10.
Configure a colaboração de gerenciamento de interface VRRP-Track para monitorar a interface de uplink no mestre e atender aos seguintes requisitos:
- Quando o Switch A funciona corretamente, ele encaminha os pacotes do Host A para o Host B.
- Quando o VRRP detecta uma falha na interface de uplink do Switch A por meio do módulo de gerenciamento de interface, o Switch B encaminha os pacotes do Host A para o Host B.
Figura 10 Diagrama de rede
Procedimento
- Crie VLANs e atribua portas a elas. Configure o endereço IP de cada interface de VLAN, conforme mostrado na Figura 10. (Detalhes não mostrados).
- Configure o Switch A:
# Configure a entrada de trilha 1 e associe-a ao status do link da interface de uplink VLAN-interface 3.
[SwitchA] track 1 interface vlan-interface 3
[SwitchA-track-1] quit# Crie o grupo VRRP 1 e configure o endereço IP virtual 10.1.1.10 para o grupo.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] vrrp vrid 1 virtual-ip 10.1.1.10# Defina a prioridade do Switch A como 110 no grupo 1 do VRRP.
[SwitchA-Vlan-interface2] vrrp vrid 1 priority 110# Associe o grupo VRRP 1 à entrada de trilha 1 e diminua a prioridade do roteador em 30 quando o estado da entrada de trilha 1 mudar para Negativo.
[SwitchA-Vlan-interface2] vrrp vrid 1 track 1 priority reduced 30- No Switch B, crie o grupo VRRP 1 e configure o endereço IP virtual 10.1.1.10 para o grupo.
<SwitchB> system-view
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] vrrp vrid 1 virtual-ip 10.1.1.10Verificação da configuração
# Faça ping no host B a partir do host A para verificar se o host B pode ser acessado. (Detalhes não mostrados.) # Exibir informações detalhadas sobre o grupo 1 do VRRP no Switch A.
[SwitchA-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 110 Running Pri : 110
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : 10.1.1.10
Virtual MAC : 0000-5e00-0101
Master IP : 10.1.1.1
VRRP Track Information:
Track Object : 1 State : Positive Pri Reduced : 30# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch B.
[SwitchB-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Become Master : 2200ms left
Auth Type : None
Virtual IP : 10.1.1.10
Master IP : 10.1.1.1A saída mostra que, no grupo VRRP 1, o Switch A é o mestre e o Switch B é um backup. O switch A encaminha pacotes do host A para o host B.
# Desligue a interface de uplink VLAN-interface 3 no Switch A.
[SwitchA-Vlan-interface2] interface vlan-interface 3
[SwitchA-Vlan-interface3] shutdown# Faça ping no host B a partir do host A para verificar se o host B pode ser acessado. (Detalhes não mostrados.) # Exibir informações detalhadas sobre o grupo 1 do VRRP no Switch A.
[SwitchA-Vlan-interface3] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Backup
Config Pri : 110 Running Pri : 80
Preempt Mode : Yes Delay Time : 0
Become Master : 2200ms left
Auth Type : None
Virtual IP : 10.1.1.10
Master IP : 10.1.1.2
VRRP Track Information:
Track Object : 1 State : Negative Pri Reduced : 30# Exibir informações detalhadas sobre o grupo VRRP 1 no Switch B.
[SwitchB-Vlan-interface2] display vrrp verbose
IPv4 Virtual Router Information:
Running Mode : Standard
Total number of virtual routers : 1
Interface Vlan-interface2
VRID : 1 Adver Timer : 100
Admin Status : Up State : Master
Config Pri : 100 Running Pri : 100
Preempt Mode : Yes Delay Time : 0
Auth Type : None
Virtual IP : 10.1.1.10
Virtual MAC : 0000-5e00-0101
Master IP : 10.1.1.2A saída mostra que o Switch A se torna o backup e o Switch B se torna o mestre. O switch B encaminha os pacotes do host A para o host B.
Exemplo: Configuração do roteamento estático - colaboração Track-LLDP
Requisitos de rede
Conforme mostrado na Figura 11:
- O dispositivo A é o gateway padrão dos hosts da rede 20.1.1.0/24.
- O dispositivo B é o gateway padrão dos hosts da rede 30.1.1.0/24.
- Os hosts das duas redes se comunicam entre si por meio de rotas estáticas.
Para garantir a disponibilidade da rede, configure o backup de rotas e o roteamento estático - colaboração Track-LLDP no Dispositivo A e no Dispositivo B da seguinte forma:
- No dispositivo A, atribua uma prioridade mais alta à rota estática para 30.1.1.0/24 com o próximo salto do dispositivo B. Essa rota é a rota principal. A rota estática para 30.1.1.0/24 com o próximo salto do dispositivo C atua como rota de backup. Quando a rota principal não está disponível, a rota de backup entra em vigor. O dispositivo A encaminha os pacotes destinados a 30.1.1.0/24 para o dispositivo C.
- No Dispositivo B, atribua uma prioridade mais alta à rota estática para 20.1.1.0/24 com o próximo salto do Dispositivo A. Essa rota é a rota principal. A rota estática para 20.1.1.0/24 com o próximo salto do dispositivo C atua como rota de backup. Quando a rota principal não está disponível, a rota de backup entra em vigor. O dispositivo B encaminha os pacotes destinados a 20.1.1.0/24 para o dispositivo C.
Figura 11 Diagrama de rede
Procedimento
- Configure o endereço IP de cada interface, conforme mostrado na Figura 11. (Detalhes não mostrados).
- Configure o dispositivo A:
# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.1.1.2 e a prioridade padrão (60). Associe essa rota estática à entrada de trilha 1.
<DeviceA> system-view
[DeviceA] ip route-static 30.1.1.0 24 10.2.1.2 track 1# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.3.1.3 e prioridade 80.
[DeviceA] ip route-static 30.1.1.0 24 10.3.1.3 preference 80# Habilite o LLDP globalmente.
[DeviceA] lldp global enable# Habilite o LLDP na GigabitEthernet 1/0/1. (Essa etapa é opcional porque o LLDP está habilitado na porta por padrão).
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] lldp enable# Configure a entrada de trilha 1 e associe-a à disponibilidade do vizinho para a interface LLDP GigabitEthernet 1/0/1.
[DeviceA] track 1 lldp neighbor interface gigabitethernet 1/0/1
[DeviceA-track-1] quit- Configurar o dispositivo B:
# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.2.1.1 e a prioridade padrão (60). Associe essa rota estática à entrada de trilha 1.
<DeviceB> system-view
[DeviceB] ip route-static 20.1.1.0 24 10.2.1.1 track 1# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.4.1.3 e prioridade 80.
[DeviceB] ip route-static 20.1.1.0 24 10.4.1.3 preference 80# Habilite o LLDP globalmente.
[DeviceB] lldp global enable# Habilite o LLDP na GigabitEthernet 1/0/1. (Essa etapa é opcional porque o LLDP está habilitado na porta por padrão).
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] lldp enable# Configure a entrada de trilha 1 e associe-a à disponibilidade do vizinho para a interface LLDP
[DeviceB] track 1 lldp neighbor interface gigabitethernet 1/0/1
[DeviceB-track-1] quit- Configurar o dispositivo C:
# Configure uma rota estática para 30.1.1.0/24 com o próximo salto 10.4.1.2.
<DeviceC> system-view
[DeviceC] ip route-static 30.1.1.0 24 10.4.1.2# Configure uma rota estática para 20.1.1.0/24 com o próximo salto 10.3.1.1.
[DeviceC] ip route-static 20.1.1.0 24 10.3.1.1Verificação da configuração
# Exibir informações de entrada de trilha no dispositivo A.
[DeviceA] display track all
Track ID: 1
State: Positive
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: LLDP
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
LLDP interface: GigabitEthernet1/0/1A saída mostra que o status da entrada de trilha 1 é Positivo, indicando que o vizinho da interface LLDP GigabitEthernet 1/0/1 está disponível. A rota principal entra em vigor.
# Exibir a tabela de roteamento do Dispositivo A.
[DeviceA] display ip routing-table
Destinations : 9 Routes : 9
Destination/Mask Proto Pre Cost NextHop Interface
10.2.1.0/24 Direct 0 0 10.2.1.1 GE1/0/1
10.2.1.1/32 Direct 0 0 127.0.0.1 InLoop0
10.3.1.0/24 Direct 0 0 10.3.1.1 GE1/0/2
10.3.1.1/32 Direct 0 0 127.0.0.1 InLoop0
20.1.1.0/24 Direct 0 0 20.1.1.1 GE1/0/3
20.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
30.1.1.0/24 Static 60 0 10.2.1.2 GE1/0/1
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0A saída mostra que o Dispositivo A encaminha pacotes para 30.1.1.0/24 por meio do Dispositivo B. # No dispositivo B, desative o LLDP na GigabitEthernet 1/0/1.
<DeviceB> system-view
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] undo lldp enable# Exibir informações de entrada de trilha no Dispositivo A.
[DeviceA] display track all
Track ID: 1
State: Negative
Duration: 0 days 0 hours 0 minutes 32 seconds
Tracked object type: LLDP
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
LLDP interface: GigabitEthernet1/0/1A saída mostra que o status da entrada de trilha 1 é Negativo, indicando que o vizinho da interface LLDP GigabitEthernet 1/0/1 não está disponível. A rota principal falha.
# Exibir a tabela de roteamento do Dispositivo A.
[DeviceA] display ip routing-table
Destinations : 9 Routes : 9
Destination/Mask Proto Pre Cost NextHop Interface
10.2.1.0/24 Direct 0 0 10.2.1.1 GE1/0/1
10.2.1.1/32 Direct 0 0 127.0.0.1 InLoop0
10.3.1.0/24 Direct 0 0 10.3.1.1 GE1/0/2
10.3.1.1/32 Direct 0 0 127.0.0.1 InLoop0
20.1.1.0/24 Direct 0 0 20.1.1.1 GE1/0/3
20.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
30.1.1.0/24 Static 80 0 10.3.1.3 GE1/0/2
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0A saída mostra que o Dispositivo A encaminha os pacotes destinados a 30.1.1.0/24 para o Dispositivo C. A rota estática de backup entrou em vigor.
# Verifique se os hosts em 20.1.1.0/24 podem se comunicar com os hosts em 30.1.1.0/24 quando a rota principal falhar.
[DeviceA] ping -a 20.1.1.1 30.1.1.1
Ping 30.1.1.1: 56 data bytes, press CTRL_C to break
Reply from 30.1.1.1: bytes=56 Sequence=1 ttl=254 time=2 ms
Reply from 30.1.1.1: bytes=56 Sequence=2 ttl=254 time=1 ms
Reply from 30.1.1.1: bytes=56 Sequence=3 ttl=254 time=1 ms
Reply from 30.1.1.1: bytes=56 Sequence=4 ttl=254 time=2 ms
Reply from 30.1.1.1: bytes=56 Sequence=5 ttl=254 time=1 ms
--- Ping statistics for 30.1.1.1 ---
5 packet(s) transmitted, 5 packet(s) received, 0.00% packet loss
round-trip min/avg/max/std-dev = 1/1/2/1 ms# Verifique se os hosts em 30.1.1.0/24 podem se comunicar com os hosts em 20.1.1.0/24 quando a rota principal falhar.
[DeviceB] ping -a 30.1.1.1 20.1.1.1
Ping 20.1.1.1: 56 data bytes, press CTRL_C to break
Reply from 20.1.1.1: bytes=56 Sequence=1 ttl=254 time=2 ms
Reply from 20.1.1.1: bytes=56 Sequence=2 ttl=254 time=1 ms
Reply from 20.1.1.1: bytes=56 Sequence=3 ttl=254 time=1 ms
Reply from 20.1.1.1: bytes=56 Sequence=4 ttl=254 time=1 ms
Reply from 20.1.1.1: bytes=56 Sequence=5 ttl=254 time=1 ms
--- Ping statistics for 20.1.1.1 ---
5 packet(s) transmitted, 5 packet(s) received, 0.00% packet loss
round-trip min/avg/max/std-dev = 1/1/2/1 msExemplo: Configuração da colaboração Smart Link-Track-CFD
Para obter informações sobre o exemplo de configuração da colaboração Smart Link-Track-CFD, consulte "Configuração do Smart Link".
Configuração de loopback MAC swap
Sobre a troca de MAC de loopback
A troca de MAC de loopback é uma técnica que testa o desempenho da rede da Camada 2. Normalmente, ela é usada para medir a conectividade Ethernet e o desempenho da rede.
A troca de MAC de loopback permite que um testador envie pacotes de teste (de acordo com os parâmetros especificados) para uma interface do dispositivo testado. Ao receber os pacotes de teste, a interface troca os endereços MAC de origem e destino dos pacotes de teste e, em seguida, retorna os pacotes de teste para o testador. Dessa forma, o testador obtém a conectividade da rede e analisa o desempenho da rede.
A troca de Loopback MAC é compatível apenas com quadros Ethernet com pacotes IP como carga útil. A troca de Loopback MAC tem os dois tipos a seguir:
- Troca de MAC de loopback local
- Troca de MAC de loopback remoto
Mecanismo operacional de troca de MAC de loopback
Troca de MAC de loopback local
O escopo do teste para a troca de MAC de loopback local é a rede do testador até a interface de downlink no dispositivo testado (incluindo o dispositivo testado).
Conforme mostrado na Figura 1, o testador envia pacotes de teste para a interface de downlink no Dispositivo B. Ao receber os pacotes, o dispositivo testado troca os endereços MAC de origem e destino nos pacotes de teste na interface de downlink e, em seguida, retorna os pacotes de teste para o testador por meio da interface especificada.
Figura 1 Troca de MAC de loopback local
Troca de MAC de loopback remoto
O escopo do teste para a troca de MAC de loopback local é a rede do testador até a interface de uplink no dispositivo testado (excluindo o dispositivo testado).
Conforme mostrado na Figura 2, o testador envia pacotes de teste para a interface de uplink no Dispositivo B. Ao receber os pacotes, o dispositivo testado troca os endereços MAC de origem e destino nos pacotes de teste na interface de uplink e, em seguida, retorna os pacotes de teste para o testador por meio da interface de uplink.
Figura 2 Troca de MAC de loopback remoto
Restrições: Compatibilidade de versão de software com troca de MAC de loopback
A troca de Loopback MAC é compatível apenas com a versão R6348P01 e posteriores.
Restrições e diretrizes: configuração de loopback MAC swap
A troca de MAC de loopback interromperá os serviços na interface testada, mas não afetará os serviços em outras interfaces.
Visão geral das tarefas de troca de MAC de loopback
Para configurar a troca de MAC de loopback, execute as seguintes tarefas:
- Configuração da troca de MAC de loopback local
- Configuração da troca de MAC de loopback remoto
Configuração da troca de MAC de loopback local
Sobre esta tarefa
O escopo do teste para a troca de MAC de loopback local é a rede do testador até a interface de downlink no dispositivo testado (incluindo o dispositivo testado).
Depois de iniciar o teste de troca de MAC de loopback local, o testador envia pacotes de teste para a interface de downlink no dispositivo testado. O dispositivo testado troca os endereços MAC de origem e de destino nos pacotes de teste na interface de downlink e, em seguida, faz um loopback dos pacotes de teste para o testador por meio da interface especificada. Dessa forma, são obtidas informações sobre a conectividade e a qualidade da rede.
Restrições e diretrizes
Depois de configurar os parâmetros de troca de MAC de loopback local, você precisa executar o comando loopback swap-mac start para iniciar o teste.
Execute o comando loopback swap-mac start novamente para iniciar um novo teste se o teste anterior for interrompido automaticamente após a expiração do cronômetro de tempo limite ou se for interrompido manualmente com o comando loopback swap-mac stop.
Os testes de troca de MAC de loopback local afetarão a operação normal da rede. Como prática recomendada para minimizar o impacto na rede, execute o comando loopback swap-mac stop imediatamente para interromper o teste depois de concluído.
Procedimento
- Entre na visualização do sistema.
System-view- Entre na visualização da interface.
interface interface-type interface-number- Configure os parâmetros de troca de MAC de loopback local.
loopback local swap-mac source-mac source-mac-address dest-mac dest-mac-address vlan vlan-id [ inner-vlan inner-vlan-id ] interface interface-type interface-number [ timeout { time-value | none } ]- Inicie o teste de loopback MAC swap.
loopback swap-mac start- (Opcional.) Interrompa o teste de troca de MAC de loopback.
loopback swap-mac startConfiguração da troca de MAC de loopback remoto
Sobre esta tarefa
O escopo do teste para a troca de MAC de loopback local é a rede do testador até a interface de uplink no dispositivo testado (excluindo o dispositivo testado).
Depois de iniciar o teste de troca de MAC de loopback remoto, o testador envia pacotes de teste para a interface de uplink no dispositivo testado. O dispositivo testado troca os endereços MAC de origem e de destino nos pacotes de teste na interface de uplink e, em seguida, faz o loopback dos pacotes de teste para o testador por meio da interface de uplink. Dessa forma, são obtidas informações sobre a conectividade e a qualidade da rede.
Restrições e diretrizes
Depois de configurar os parâmetros de troca de MAC de loopback remoto, você precisa executar o comando loopback swap-mac start para iniciar o teste.
Execute o comando loopback swap-mac start novamente para iniciar um novo teste se o teste anterior for interrompido automaticamente após a expiração do cronômetro de tempo limite ou se for interrompido manualmente com o comando loopback swap-mac stop.
Os testes de troca de MAC de loopback remoto afetarão a operação normal da rede. Como prática recomendada para minimizar o impacto na rede, execute o comando loopback swap-mac stop imediatamente para interromper o teste depois de concluído.
Procedimento
- Entre na visualização do sistema.
System-view- Entre na visualização da interface.
interface interface-type interface-number- Configurar parâmetros de troca de MAC de loopback remoto.
loopback remote swap-mac source-mac source-mac-address dest-mac
dest-mac-address vlan vlan-id [ inner-vlan inner-vlan-id ] [ timeout
{ time-value | none } ]- Inicie o teste de loopback MAC swap.
loopback swap-mac start- (Opcional.) Interrompa o teste de troca de MAC de loopback.
loopback swap-mac startComandos de exibição e manutenção para loopback MAC swap
Execute o comando display em qualquer visualização.
| Tarefa | Comando |
| Exibir informações de teste de loopback MAC swap. | exibir informações de loopback swap-mac |
Exemplos de configuração de Loopback MAC swap
Exemplo: Configuração da troca de MAC de loopback local
Configuração de rede
Conforme mostrado na Figura 3, o Dispositivo B está conectado à rede Ethernet por meio do GE 1/0/1 e está conectado ao usuário por meio do GE 1/0/2.
Configure a troca de MAC de loopback local para testar a conectividade Ethernet e o desempenho da rede. O escopo do teste inclui o Dispositivo B.
Figura 3 Diagrama de rede
Procedimento
- Crie a VLAN 100 no Dispositivo B. Configure a GigabitEthernet 1/0/1 como uma porta tronco e atribua a porta à VLAN 100. Configure a GigabitEthernet 1/0/2 como uma porta híbrida, defina seu PVID como VLAN 100 e atribua-o à VLAN 100 como um membro untagged.
<Device B> system-view
[Device B] vlan 100
[Device B] interface gigabitethernet 1/0/1
[Device B-GigabitEthernet1/0/1] port link-type trunk
[Device B-GigabitEthernet1/0/1] port trunk permit vlan 100
[Device B-GigabitEthernet1/0/1] quit
[Device B] interface gigabitethernet 1/0/2
[Device B-GigabitEthernet1/0/2] port link-type hybrid
[Device B-GigabitEthernet1/0/2] port hybrid pvid vlan 100
[Device B-GigabitEthernet1/0/2] port hybrid vlan 100 untagged- Configure a troca de MAC de loopback local na GigabitEthernet 1/0/2 e especifique a GigabitEthernet 1/0/1 para fazer o looping de volta dos pacotes de teste.
[Device B-GigabitEthernet1/0/2] loopback local swap-mac source-mac 0001-0001-0001
dest-mac 0002-0002-0002 vlan 100 interface gigabitethernet 1/0/1 timeout 80- Inicie o teste de loopback MAC swap.
[Device B-GigabitEthernet1/0/2] loopback swap-mac start
[Device B-GigabitEthernet1/0/2] quit
[Device B] quitVerificação da configuração
# Use o comando display loopback swap-mac information para exibir as informações do teste de loopback MAC swap.
<Device B > display loopback swap-mac information
Loopback type : local
Loopback state : running
Loopback test times(s) : 80
Loopback interface : GigabitEthernet1/0/1
Loopback output interface : GigabitEthernet1/0/2
Loopback source MAC : 0001-0001-0001
Loopback destination MAC : 0002-0002-0002
Loopback vlan : 100
Loopback inner vlan : 0
Loopback packets : 0
Drop packets : 0Exemplo: Configuração da troca de MAC de loopback remoto
Configuração de rede
Conforme mostrado na Figura 3, o Dispositivo B está conectado à rede Ethernet por meio do GE 1/0/1.
Configure a troca de MAC de loopback remoto para testar a conectividade Ethernet e o desempenho da rede. O escopo do teste não inclui o Dispositivo B.
Figura 4 Diagrama de rede
Procedimento
- Crie a VLAN 100 no Dispositivo B. Configure a GigabitEthernet 1/0/1 como uma porta tronco e atribua a porta à VLAN 100.
<Device B> system-view
[Device B] vlan 100
[Device B] interface gigabitethernet 1/0/1
[Device B-GigabitEthernet1/0/1] port link-type trunk
[Device B-GigabitEthernet1/0/1] port trunk permit vlan 100- Configure a troca de MAC de loopback remoto na GigabitEthernet 1/0/1.
[Device B-GigabitEthernet1/0/1] loopback remote swap-mac source-mac 0001-0001-0001
dest-mac 0002-0002-0002 vlan 100 timeout 80- Inicie o teste de loopback MAC swap.
[Device B-GigabitEthernet1/0/1] loopback swap-mac start
[Device B-GigabitEthernet1/0/1] quit
[Device B] quitVerificação da configuração
# Use o comando display loopback swap-mac information para exibir as informações do teste de loopback MAC swap.
<Device B> display loopback swap-mac information
Loopback type : remote
Loopback state : running
Loopback test time(s) : 80
Loopback interface : GigabitEthernet1/0/1
Loopback source MAC : 0001-0001-0001
Loopback destination MAC : 0002-0002-0002
Loopback vlan : 100
Loopback inner vlan : 0
Loopback packets : 010 - Guia de configuração da gestão e monitorização da rede
Uso de ping, tracert e depuração do sistema
Ping
Sobre o ping
Utilize a ferramenta ping para determinar se um endereço é alcançável.
O ping envia solicitações de eco ICMP (ECHO-REQUEST) para o dispositivo de destino. Ao receber as solicitações, o dispositivo de destino responde com respostas de eco ICMP (ECHO-REPLY) para o dispositivo de origem. O dispositivo de origem exibe estatísticas sobre a operação do ping, incluindo o número de pacotes enviados, número de respostas de eco recebidas e o tempo de ida e volta. Você pode medir o desempenho da rede analisando essas estatísticas.
Você pode usar o comando ping –r para exibir os roteadores pelos quais as solicitações de eco ICMP passaram. O procedimento de teste do ping –r é mostrado na Figura 1:
- O dispositivo de origem (Dispositivo A) envia uma solicitação de eco ICMP para o dispositivo de destino (Dispositivo C) com a opção RR vazia.
- O dispositivo intermediário (Dispositivo B) adiciona o endereço IP de sua interface de saída (1.1.2.1) à opção RR da solicitação de eco ICMP e encaminha o pacote.
- Ao receber a solicitação, o dispositivo de destino copia a opção RR na solicitação e adiciona o endereço IP de sua interface de saída (1.1.2.2) à opção RR. Então, o dispositivo de destino envia uma resposta de eco ICMP.
- O dispositivo intermediário adiciona o endereço IP de sua interface de saída (1.1.1.2) à opção RR na resposta de eco ICMP e, em seguida, encaminha a resposta.
- Ao receber a resposta, o dispositivo de origem adiciona o endereço IP de sua interface de entrada (1.1.1.1) à opção RR. As informações detalhadas das rotas do Dispositivo A para o Dispositivo C são formatadas como: 1.1.1.1 <-> {1.1.1.2; 1.1.2.1} <-> 1.1.2.2.
Figura 1 Operação de ping
Uso de um comando ping para testar a conectividade da rede
Execute as seguintes tarefas em qualquer visualização:
- Determinar se um endereço IPv4 é alcançável.
ping [ ip ] [ -a source-ip | -c count | -f | -h ttl | -i interface-type
interface-number | -m interval | -n | -p pad | -q | -r | -s packet-size | -t
timeout | -tos tos | -v ] * hostAumente o tempo limite (indicado pela palavra-chave -t) em uma rede de baixa velocidade.
- Determinar se um endereço IPv6 pode ser acessado.
ping ipv6 [ -a source-ipv6 | -c count | -i interface-type
interface-number | -m interval | -q | -s packet-size | -t timeout | -tc
traffic-class | -v ] * host hostAumente o tempo de timeout (indicado pela palavra-chave -t) em uma rede de baixa velocidade.
Exemplo: Usando o utilitário ping
Configuração de rede
Conforme mostrado na Figura 2, determine se o Dispositivo A e o Dispositivo C podem se comunicar.
Figura 2 Diagrama de rede

Dispositivo Dispositivo DispositivoC
Procedimento
# Teste a conectividade entre o dispositivo A e o dispositivo C.
<DeviceA> ping 1.1.2.2
Ping 1.1.2.2 (1.1.2.2): 56 data bytes, press CTRL_C to break
56 bytes from 1.1.2.2: icmp_seq=0 ttl=254 time=2.137 ms
56 bytes from 1.1.2.2: icmp_seq=1 ttl=254 time=2.051 ms
56 bytes from 1.1.2.2: icmp_seq=2 ttl=254 time=1.996 ms
56 bytes from 1.1.2.2: icmp_seq=3 ttl=254 time=1.963 ms
56 bytes from 1.1.2.2: icmp_seq=4 ttl=254 time=1.991 ms
--- Ping statistics for 1.1.2.2 ---
5 packet(s) transmitted, 5 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 1.963/2.028/2.137/0.062 ms
A saída mostra as seguintes informações:
- O dispositivo A envia cinco pacotes ICMP para o dispositivo C e o dispositivo A recebe cinco pacotes ICMP.
- Nenhum pacote ICMP é perdido.
- A rota pode ser acessada.
Tracert
Sobre o tracert
O Tracert (também chamado de Traceroute) permite a recuperação dos endereços IP dos dispositivos da Camada 3 no caminho para um destino. Em caso de falha na rede, use o tracert para testar a conectividade da rede e identificar os nós com falha.
Figura 3 Operação do Tracert
O Tracert usa mensagens de erro ICMP recebidas para obter os endereços IP dos dispositivos. O Tracert funciona como mostrado na Figura 3:
- O dispositivo de origem envia um pacote UDP com um valor TTL de 1 para o dispositivo de destino. A porta UDP de destino não é usada por nenhum aplicativo no dispositivo de destino.
- O primeiro salto (Dispositivo B, o primeiro dispositivo da Camada 3 que recebe o pacote) responde enviando uma mensagem de erro ICMP com TTL expirado para a origem, com seu endereço IP (1.1.1.2) encapsulado. Dessa forma, o dispositivo de origem pode obter o endereço do primeiro dispositivo da Camada 3 (1.1.1.2).
- O dispositivo de origem envia um pacote com um valor TTL de 2 para o dispositivo de destino.
- O segundo salto (Dispositivo C) responde com uma mensagem de erro ICMP expirada por TTL, que fornece ao dispositivo de origem o endereço do segundo dispositivo da Camada 3 (1.1.2.2).
- Esse processo continua até que um pacote enviado pelo dispositivo de origem chegue ao dispositivo de destino final. Como nenhum aplicativo usa a porta de destino especificada no pacote, o dispositivo de destino responde com uma mensagem ICMP de porta inalcançável para o dispositivo de origem, com seu endereço IP encapsulado. Dessa forma, o dispositivo de origem obtém o endereço IP do dispositivo de destino (1.1.3.2).
- O dispositivo de origem determina isso:
- O pacote chegou ao dispositivo de destino depois de receber a mensagem ICMP de porta inalcançável.
- O caminho para o dispositivo de destino é de 1.1.1.2 a 1.1.2.2 a 1.1.3.2.
Uso de um comando tracert para identificar falhas ou todos os nós em um caminho
Execute as seguintes tarefas em qualquer visualização:
- Rastrear a rota para um destino IPv4.
tracert [ -a source-ip | -f first-ttl | -m max-ttl | -p port | -q
packet-number | -t tos | -w timeout ] * host
- Rastrear a rota para um destino IPv6.
tracert ipv6 [ -f first-hop | -m max-hops | -p port | -q packet-number | -t
traffic-class | -w timeout ] * host
Exemplo: Usando o utilitário tracert
Configuração de rede
Conforme mostrado na Figura 4, o Dispositivo A não conseguiu fazer Telnet no Dispositivo C.
Teste a conectividade de rede entre o Dispositivo A e o Dispositivo C. Se eles não conseguirem se comunicar, localize os nós com falha na rede.
Figura 4 Diagrama de rede

Dispositivo Dispositivo DispositivoC
Procedimento
- Configure endereços IP para os dispositivos, conforme mostrado na Figura 4.
- Configure uma rota estática no Dispositivo A.
<DeviceA> system-view
[DeviceA] ip route-static 0.0.0.0 0.0.0.0 1.1.1.2
- Teste a conectividade entre o dispositivo A e o dispositivo C.
[DeviceA] ping 1.1.2.2
Ping 1.1.2.2(1.1.2.2): 56 -data bytes, press CTRL_C to break
Request time out
Request time out
Request time out
Request time out
Request time out
--- Ping statistics for 1.1.2.2 ---
5 packet(s) transmitted,0 packet(s) received,100.0% packet loss
A saída mostra que o Dispositivo A e o Dispositivo C não conseguem se comunicar.
- Identificar nós com falha:
# Habilite o envio de pacotes de tempo limite ICMP no Dispositivo B.
<DeviceB> system-view
[DeviceB] ip ttl-expires enable# Habilite o envio de pacotes ICMP de destino inalcançável no Dispositivo C.
<DeviceC> system-view
[DeviceC] ip unreachables enable
# Identificar os nós com falha.
[DeviceA] tracert 1.1.2.2
traceroute to 1.1.2.2 (1.1.2.2) 30 hops at most,40 bytes each packet, press CTRL_C
to break
1 1.1.1.2 (1.1.1.2) 1 ms 2 ms 1 ms
2 * * *
3 * * *
4 * * *
5
[DeviceA]
A saída mostra que o Dispositivo A pode alcançar o Dispositivo B, mas não pode alcançar o Dispositivo C. Ocorreu um erro na conexão entre o Dispositivo B e o Dispositivo C.
- Para identificar a causa do problema, execute os seguintes comandos no Dispositivo A e no Dispositivo C:
- Execute o comando debugging ip icmp e verifique se o Dispositivo A e o Dispositivo C podem enviar e receber os pacotes ICMP corretos.
- Execute o comando display ip routing-table para verificar se o Dispositivo A e o Dispositivo C têm uma rota entre si.
Depuração do sistema
Sobre a depuração do sistema
O dispositivo suporta depuração para a maioria dos protocolos e recursos e fornece informações de depuração para ajudar os usuários a diagnosticar erros.
Os seguintes switches controlam a exibição das informações de depuração:
Chave de depuração de módulo - Controla se as informações de depuração específicas do módulo devem ser geradas.
Chave de saída de tela - Controla se as informações de depuração devem ser exibidas em uma determinada tela. Use os comandos terminal monitor e terminal logging level para ativar a chave de saída de tela. Para obter mais informações sobre esses dois comandos, consulte Referência de comandos de gerenciamento e monitoramento de rede.
Conforme mostrado na Figura 5, o dispositivo pode fornecer depuração para os três módulos 1, 2 e 3. As informações de depuração podem ser exibidas em um terminal somente quando a chave de depuração do módulo e a chave de saída da tela estiverem ativadas.
Normalmente, as informações de depuração são exibidas em um console. Você também pode enviar informações de depuração para outros destinos. Para obter mais informações, consulte "Configuração do centro de informações".
Figura 5 Relação entre o módulo e a chave de saída da tela
Depuração de um módulo de recurso
Restrições e diretrizes
CUIDADO:
A saída de mensagens de depuração excessivas aumenta o uso da CPU e reduz o desempenho do sistema. Para garantir o desempenho do sistema, ative a depuração somente para módulos que estejam em uma condição excepcional.
Habilite a depuração de módulos para fins de solução de problemas. Quando a depuração estiver concluída, use o comando
comando undo debugging all para desativar todas as funções de depuração.
Procedimento
- Ativar a depuração de um módulo.
debugging module-name [ option ]Por padrão, a depuração é desativada para todos os módulos. Esse comando está disponível na visualização do usuário.
- (Opcional.) Exibir os recursos de depuração ativados.
display debugging [ module-name ]Configuração do NQA
Sobre o NQA
O analisador de qualidade de rede (NQA) permite medir o desempenho da rede, verificar os níveis de serviço para serviços e aplicativos IP e solucionar problemas de rede.
Mecanismo operacional do NQA
Uma operação de NQA contém um conjunto de parâmetros, como o tipo de operação, o endereço IP de destino e o número da porta, para definir como a operação é executada. Cada operação do NQA é identificada pela combinação do nome do administrador e da tag da operação. Você pode configurar o cliente NQA para executar as operações em períodos de tempo programados.
Conforme mostrado na Figura 1, o dispositivo de origem do NQA (cliente NQA) envia dados para o dispositivo de destino do NQA simulando serviços e aplicativos IP para medir o desempenho da rede.
Todos os tipos de operações de NQA requerem o cliente NQA, mas somente as operações de TCP, eco UDP, jitter UDP e voz requerem o servidor NQA. As operações de NQA para serviços que já são fornecidos pelo dispositivo de destino, como FTP, não precisam do servidor NQA. Você pode configurar o servidor NQA para escutar e responder a endereços IP e portas específicos para atender a várias necessidades de teste.
Figura 1 Diagrama de rede
Depois de iniciar uma operação de NQA, o cliente NQA executa periodicamente a operação no intervalo especificado usando o comando frequency.
Você pode definir o número de sondas que o cliente NQA executa em uma operação usando o comando probe count. Para as operações de voz e de jitter de caminho, o cliente NQA executa apenas uma sonda por operação e o comando de contagem de sondas não está disponível.
Colaboração com a trilha
O NQA pode colaborar com o módulo Track para notificar os módulos de aplicativos sobre alterações de estado ou desempenho, de modo que os módulos de aplicativos possam tomar ações predefinidas.
A colaboração NQA + Track está disponível para os seguintes módulos de aplicativos:
- VRRP
- Roteamento estático.
- Roteamento baseado em políticas.
- Redirecionamento de tráfego
- Link inteligente
A seguir, descrevemos como uma rota estática destinada a 192.168.0.88 é monitorada por meio de colaboração:
- O NQA monitora a capacidade de alcance do 192.168.0.88.
- Quando o 192.168.0.88 se torna inacessível, o NQA notifica o módulo Track sobre a alteração.
- O módulo Track notifica o módulo de roteamento estático sobre a mudança de estado.
- O módulo de roteamento estático define a rota estática como inválida de acordo com uma ação predefinida. Para obter mais informações sobre colaboração, consulte o Guia de configuração de alta disponibilidade.
Monitoramento de limites
O monitoramento de limites permite que o cliente NQA tome uma ação predefinida quando as métricas de desempenho da operação do NQA violam os limites especificados.
A Tabela 1 descreve as relações entre as métricas de desempenho e os tipos de operação do NQA.
Tabela 1 Métricas de desempenho e tipos de operação do NQA
| Métrica de desempenho | Tipos de operação NQA que podem coletar a métrica | ||
| Duração da sonda | Todos os tipos de operação NQA, exceto jitter UDP, tracert UDP, jitter de caminho e voz | ||
| Número de falhas na sonda | Todos os tipos de operação NQA, exceto jitter UDP, tracert UDP, jitter de caminho e voz | ||
| Tempo de ida e volta | Jitter ICMP, jitter UDP e voz | ||
| Número de pacotes descartados | Jitter ICMP, jitter UDP e voz | ||
| Jitter unidirecional (origem para destino ou destino para origem) | Jitter ICMP, jitter UDP e voz | ||
| Atraso unidirecional (origem para destino ou destino para origem) | Jitter ICMP, jitter UDP e voz | ||
| Fator de comprometimento do planejamento calculado (ICPIF) (consulte "Configuração da operação de voz") | Voz | ||
| Mean Opinion Scores (MOS) (consulte "Configuração da operação de voz") | Voz |
Modelos NQA
Um modelo de NQA é um conjunto de parâmetros (como endereço de destino e número de porta) que define como uma operação de NQA é executada. Os recursos podem usar o modelo de NQA para coletar estatísticas.
Você pode criar vários modelos de NQA no cliente NQA. Cada modelo deve ser identificado por um nome de modelo exclusivo.
Visão geral das tarefas do NQA
Para configurar o NQA, execute as seguintes tarefas:
- Configuração do servidor NQA
Execute essa tarefa no dispositivo de destino antes de configurar as operações de TCP, eco UDP, jitter UDP, e voz.
- Ativação do cliente NQA
- Configuração de operações de NQA ou modelos de NQA Selecione as seguintes tarefas, conforme necessário:
- Configuração de operações de NQA no cliente NQA
- Configuração de modelos de NQA no cliente NQA
Depois de configurar uma operação de NQA, você pode programar o cliente NQA para executar a operação de NQA.
Um modelo de NQA não é executado imediatamente após ser configurado. O modelo cria e executa a operação NQA somente quando ela é exigida pelo recurso (como balanceamento de carga) ao qual o modelo é aplicado.
Configuração do servidor NQA
Restrições e diretrizes
Para executar operações de TCP, eco UDP, jitter UDP e voz, você deve configurar o servidor NQA no dispositivo de destino. O servidor NQA escuta e responde a solicitações nos endereços IP e portas especificados.
É possível configurar vários serviços de escuta TCP ou UDP em um servidor NQA, sendo que cada um corresponde a um endereço IP e a um número de porta específicos.
O endereço IP e o número da porta de um serviço de escuta devem ser exclusivos no servidor NQA e corresponder à configuração no cliente NQA.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o servidor NQA.
nqa server enablePor padrão, o servidor NQA está desativado.
- Configure um serviço de escuta TCP.
nqa server tcp-connect ip-address port-number [ tos tos ]Essa tarefa é necessária apenas para operações TCP.
- Configure um serviço de escuta UDP.
nqa server udp-echo ip-address port-number [ tos tos ]Essa tarefa é necessária apenas para operações de eco UDP, jitter UDP e voz.
Ativação do cliente NQA
- Entre na visualização do sistema.
system-view- Ativar o cliente NQA.
nqa agent enablePor padrão, o cliente NQA está ativado.
A configuração do cliente NQA entra em vigor depois que você ativa o cliente NQA.
Configuração de operações de NQA no cliente NQA
Visão geral das tarefas de operações do NQA
Para configurar as operações de NQA, execute as seguintes tarefas:
- Configuração de uma operação de NQA
- Configuração da operação de eco ICMP
- Configuração da operação de jitter ICMP
- Configuração da operação DHCP
- Configuração da operação de DNS
- Configuração da operação de FTP
- Configuração da operação HTTP
- Configuração da operação de jitter UDP
- Configuração da operação de SNMP
- Configuração da operação TCP
- Configuração da operação de eco UDP
- Configuração da operação UDP tracert
- Configuração da operação de voz
- Configuração da operação DLSw
- Configuração da operação de jitter de caminho
- (Opcional.) Configuração de parâmetros opcionais para a operação de NQA
- (Opcional.) Configuração do recurso de colaboração
- (Opcional.) Configuração do monitoramento de limites
- (Opcional.) Configuração do recurso de coleta de estatísticas NQA
- (Opcional.) Configuração do salvamento dos registros do histórico de NQA
- Agendamento da operação de NQA no cliente NQA
Configuração da operação de eco ICMP
Sobre a operação de eco ICMP
A operação ICMP echo mede a capacidade de alcance de um dispositivo de destino. Ela tem a mesma função que o comando ping, mas fornece mais informações de saída. Além disso, se houver vários caminhos entre os dispositivos de origem e de destino, você poderá especificar o próximo salto para a operação de eco ICMP.
A operação de eco ICMP envia uma solicitação de eco ICMP para o dispositivo de destino por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de eco ICMP e entre em sua visualização.
type icmp-echo- Especifique o endereço IP de destino para solicitações de eco ICMP. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o endereço IP de origem para solicitações de eco ICMP. Escolha uma das tarefas a seguir:
- Use o endereço IP da interface especificada como o endereço IP de origem.
source interface interface-type interface-numberPor padrão, o endereço IP de origem das solicitações de eco ICMP é o endereço IP principal da interface de saída.
A interface de origem especificada deve estar ativa.
- Especifique o endereço IPv4 de origem.
source ip ip-addressPor padrão, o endereço IPv4 de origem das solicitações de eco ICMP é o endereço IPv4 primário da interface de saída.
O endereço IPv4 de origem especificado deve ser o endereço IPv4 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique o endereço IPv6 de origem.
source ipv6 ipv6-addressPor padrão, o endereço IPv6 de origem das solicitações de eco ICMP é o endereço IPv6 primário da interface de saída.
O endereço IPv6 de origem especificado deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique a interface de saída ou o endereço IP do próximo salto para solicitações de eco ICMP. Escolha uma das tarefas a seguir:
- Especifique a interface de saída para solicitações de eco ICMP.
out interface interface-type interface-numberPor padrão, a interface de saída para solicitações de eco ICMP não é especificada. O cliente NQA determina a interface de saída com base na pesquisa da tabela de roteamento.
- Especifique o endereço IPv4 do próximo salto.
next-hop ip ip-addressPor padrão, nenhum endereço IPv4 de próximo salto é especificado.
- Especifique o endereço IPv6 do próximo salto.
next-hop ipv6 ipv6-addressPor padrão, nenhum endereço IPv6 de próximo salto é especificado.
- (Opcional.) Defina o tamanho da carga útil para cada solicitação de eco ICMP.
data-size sizeO tamanho padrão da carga útil é de 100 bytes.
- (Opcional.) Especifique a cadeia de caracteres de preenchimento de carga útil para solicitações de eco ICMP.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
Configuração da operação de jitter ICMP
Sobre a operação de jitter ICMP
A operação de jitter ICMP mede jitters unidirecionais e bidirecionais. O resultado da operação o ajuda a determinar se a rede pode transportar serviços sensíveis a jitter, como serviços de voz e vídeo em tempo real.
A operação de jitter do ICMP funciona da seguinte forma:
- O cliente NQA envia pacotes ICMP para o dispositivo de destino.
- O dispositivo de destino marca a hora de cada pacote que recebe e, em seguida, envia o pacote de volta ao cliente NQA.
- Ao receber as respostas, o cliente NQA calcula o jitter de acordo com os registros de data e hora.
A operação de jitter ICMP envia um número de pacotes ICMP para o dispositivo de destino por sonda. O número de pacotes a serem enviados é determinado pelo uso do comando probe packet-number.
Restrições e diretrizes
O comando display nqa history não exibe os resultados ou as estatísticas da operação de jitter ICMP. Para exibir os resultados ou as estatísticas da operação, use o comando display nqa result ou display nqa statistics.
Antes de iniciar a operação, certifique-se de que os dispositivos de rede estejam sincronizados com a hora usando NTP. Para obter mais informações sobre o NTP, consulte "Configuração do NTP".
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de jitter ICMP e entre em sua visualização.
type icmp-jitter- Especifique o endereço IP de destino para pacotes ICMP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Defina o número de pacotes ICMP enviados por sonda.
probe packet-number packet-numberA configuração padrão é 10.
probe packet-interval intervalA configuração padrão é 20 milissegundos.
probe packet-timeout timeoutA configuração padrão é 3000 milissegundos.
- Especifique o endereço IP de origem para pacotes ICMP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes ICMP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote ICMP poderá ser enviado.
Configuração da operação DHCP
Sobre a operação do DHCP
A operação DHCP mede se o servidor DHCP pode ou não responder às solicitações do cliente. O DHCP também mede a quantidade de tempo que o cliente NQA leva para obter um endereço IP de um servidor DHCP.
O cliente NQA simula o agente de retransmissão DHCP para encaminhar solicitações DHCP para aquisição de endereço IP do servidor DHCP. A interface que executa a operação DHCP não altera seu endereço IP. Quando a operação de DHCP é concluída, o cliente NQA envia um pacote para liberar o endereço IP obtido.
A operação DHCP adquire um endereço IP do servidor DHCP por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de DHCP e entre em sua visualização.
type dhcp- Especifique o endereço IP do servidor DHCP como o endereço IP de destino dos pacotes DHCP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique a interface de saída para os pacotes de solicitação de DHCP.
out interface interface-type interface-numberPor padrão, o cliente NQA determina a interface de saída com base na pesquisa da tabela de roteamento.
- Especifique o endereço IP de origem dos pacotes de solicitação de DHCP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes de solicitação de DHCP é o endereço IP primário de sua interface de saída.
O endereço IP de origem especificado deve ser o endereço IP de uma interface local, e a interface local deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
Configuração da operação de DNS
Sobre a operação do DNS
A operação de DNS simula a resolução de nomes de domínio e mede o tempo que o cliente NQA leva para resolver um nome de domínio em um endereço IP por meio de um servidor DNS. A entrada de DNS obtida não é salva.
A operação de DNS resolve um nome de domínio em um endereço IP por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de DNS e entre em sua visualização.
type dns- Especifique o endereço IP do servidor DNS como o endereço IP de destino dos pacotes DNS.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o nome de domínio a ser traduzido.
resolve-target domain-namePor padrão, nenhum nome de domínio é especificado.
Configuração da operação de FTP
Sobre a operação de FTP
A operação FTP mede o tempo para o cliente NQA transferir um arquivo para um servidor FTP ou fazer download de um arquivo a partir dele.
A operação FTP faz upload ou download de um arquivo de um servidor FTP por sonda.
Restrições e diretrizes
Para carregar (colocar) um arquivo no servidor FTP, use o comando filename para especificar o nome do arquivo que deseja carregar. O arquivo deve existir no cliente NQA.
Para fazer download (obter) de um arquivo do servidor FTP, inclua o nome do arquivo que deseja fazer download no comando url. O arquivo deve existir no servidor FTP. O cliente NQA não salva o arquivo obtido do servidor FTP.
Use um arquivo pequeno para a operação de FTP. Um arquivo grande pode resultar em falha na transferência devido ao tempo limite ou pode afetar outros serviços devido à quantidade de largura de banda da rede que ele ocupa.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de FTP e entre em sua visualização.
type ftp- Especifique um nome de usuário de login de FTP.
username usernamePor padrão, nenhum nome de usuário de login de FTP é especificado.
- Especifique uma senha de login de FTP.
password { cipher | simple } stringPor padrão, nenhuma senha de login de FTP é especificada.
- Especifique o endereço IP de origem dos pacotes de solicitação de FTP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes de solicitação de FTP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhuma solicitação de FTP poderá ser enviada.
- Defina o modo de transmissão de dados.
mode { active | passive }O modo padrão é active.
operation { get | put }O tipo de operação FTP padrão é get.
- Especifique o URL de destino para a operação de FTP.
url urlPor padrão, nenhum URL de destino é especificado para uma operação de FTP. Digite o URL em um dos seguintes formatos:
ftp://host/filename.ftp://host:port/filename.O argumento filename é necessário apenas para a operação get.
- Especifique o nome do arquivo a ser carregado.
filename file-namePor padrão, nenhum arquivo é especificado.
Essa tarefa é necessária apenas para a operação de colocação.
A configuração não entra em vigor para a operação get.
Configuração da operação HTTP
Sobre a operação HTTP
A operação HTTP mede o tempo que o cliente NQA leva para obter respostas de um servidor HTTP. A operação HTTP é compatível com os seguintes tipos de operação:
Get - Recupera dados, como uma página da Web, do servidor HTTP.
Post - Envia dados para o servidor HTTP para processamento.
Raw - Envia uma solicitação HTTP definida pelo usuário para o servidor HTTP. Você deve configurar manualmente o conteúdo da solicitação HTTP a ser enviada.
A operação HTTP conclui a operação do tipo especificado por probe.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de HTTP e insira sua visualização.
type http- Especifique o URL de destino para a operação HTTP.
url urlPor padrão, nenhum URL de destino é especificado para uma operação HTTP. Digite o URL em um dos seguintes formatos:
http://host/resourcehttp://host:port/resource- Especifique um nome de usuário de login HTTP.
username usernamePor padrão, nenhum nome de usuário de login HTTP é especificado.
password { cipher | simple } stringPor padrão, nenhuma senha de login HTTP é especificada.
- Especifique a versão do HTTP.
version { v1.0 | v1.1 }Por padrão, o HTTP 1.0 é usado.
operation { get | post | raw }O tipo de operação HTTP padrão é get.
Se você definir o tipo de operação como bruto, o cliente adicionará o conteúdo configurado na exibição de solicitação bruta à solicitação HTTP a ser enviada ao servidor HTTP.
- Configure a solicitação bruta de HTTP.
- Entrar na visualização de solicitação bruta.
raw-requestToda vez que você entra na visualização de solicitação bruta, o conteúdo da solicitação bruta configurada anteriormente é apagado.
- Digite ou cole o conteúdo da solicitação.
Por padrão, nenhum conteúdo de solicitação é configurado.
Para garantir operações bem-sucedidas, certifique-se de que o conteúdo da solicitação não contenha aliases de comando configurados usando o comando alias. Para obter mais informações sobre o comando alias, consulte Comandos da CLI em Referência de comandos básicos.
- Salve a entrada e retorne à visualização da operação HTTP:
quitEssa etapa é necessária somente quando o tipo de operação é definido como bruto.
- Especifique o endereço IP de origem para os pacotes HTTP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes HTTP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de solicitação poderá ser enviado.
Configuração da operação de jitter UDP
Sobre a operação de jitter UDP
A operação de jitter UDP mede jitters unidirecionais e bidirecionais. O resultado da operação o ajuda a determinar se a rede pode transportar serviços sensíveis a jitter, como serviços de voz e vídeo em tempo real.
A operação de jitter UDP funciona da seguinte forma:
- O cliente NQA envia pacotes UDP para a porta de destino.
- O dispositivo de destino marca a hora de cada pacote que recebe e, em seguida, envia o pacote de volta ao cliente NQA.
- Ao receber as respostas, o cliente NQA calcula o jitter de acordo com os registros de data e hora.
A operação de jitter UDP envia um número de pacotes UDP para o dispositivo de destino por sonda. O número de pacotes a serem enviados é determinado pelo uso do comando probe packet-number.
A operação de jitter UDP requer tanto o servidor NQA quanto o cliente NQA. Antes de executar a operação de jitter UDP, configure o serviço de escuta UDP no servidor NQA. Para obter mais informações sobre a configuração do serviço de escuta UDP, consulte "Configuração do servidor NQA".
Restrições e diretrizes
Para garantir o sucesso das operações de jitter UDP e evitar afetar os serviços existentes, não execute as operações em portas conhecidas de 1 a 1023.
O comando display nqa history não exibe os resultados ou as estatísticas da operação de jitter UDP. Para exibir os resultados ou as estatísticas da operação de jitter UDP, use o comando display nqa result ou display nqa statistics.
Antes de iniciar a operação, certifique-se de que os dispositivos de rede estejam sincronizados com a hora usando NTP. Para obter mais informações sobre o NTP, consulte "Configuração do NTP".
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de jitter UDP e entre em sua visualização.
type udp-jitter- Especifique o endereço IP de destino para pacotes UDP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
O endereço IP de destino deve ser o mesmo que o endereço IP do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o número da porta de destino para pacotes UDP.
destination ip ip-addressPor padrão, nenhum número de porta de destino é especificado.
O número da porta de destino deve ser o mesmo que o número da porta do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o endereço IP de origem para pacotes UDP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes UDP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote UDP poderá ser enviado.
- Especifique o número da porta de origem para pacotes UDP.
destination port port-numberPor padrão, o cliente NQA escolhe aleatoriamente uma porta não utilizada como a porta de origem quando a operação é iniciada.
- Defina o número de pacotes UDP enviados por sonda. sonda número de pacotes número de pacotes A configuração padrão é 10.
- Defina o intervalo para o envio de pacotes UDP.
probe packet-interval intervalA configuração padrão é 20 milissegundos.
probe packet-timeout timeoutA configuração padrão é 3000 milissegundos.
- (Opcional.) Defina o tamanho da carga útil de cada pacote UDP.
data-size sizeO tamanho padrão da carga útil é de 100 bytes.
- (Opcional.) Especifique a cadeia de caracteres de preenchimento de carga útil para pacotes UDP.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
Configuração da operação de SNMP
Sobre a operação SNMP
A operação SNMP testa se o serviço SNMP está disponível em um agente SNMP.
A operação SNMP envia um pacote SNMPv1, um pacote SNMPv2c e um pacote SNMPv3 para o agente SNMP por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de SNMP e entre em sua visualização.
type snmp- Especifique o endereço de destino dos pacotes SNMP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o endereço IP de origem dos pacotes SNMP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes SNMP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote SNMP poderá ser enviado.
- Especifique o número da porta de origem dos pacotes SNMP.
destination port port-numberPor padrão, o cliente NQA escolhe aleatoriamente uma porta não utilizada como a porta de origem quando a operação é iniciada.
- Especifique o nome da comunidade transportado nos pacotes SNMPv1 e SNMPv2c.
community read { cipher | simple } community-namePor padrão, os pacotes SNMPv1 e SNMPv2c contêm o nome de comunidade public.
Certifique-se de que o nome da comunidade especificado seja o mesmo que o nome da comunidade configurado no agente SNMP.
Configuração da operação TCP
Sobre a operação do TCP
A operação TCP mede o tempo que o cliente NQA leva para estabelecer uma conexão TCP com uma porta no servidor NQA.
A operação TCP requer tanto o servidor NQA quanto o cliente NQA. Antes de executar uma operação TCP, configure um serviço de escuta TCP no servidor NQA. Para obter mais informações sobre a configuração do serviço de escuta TCP, consulte "Configuração do servidor NQA".
A operação TCP configura uma conexão TCP por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de TCP e entre em sua visualização.
type tcp- Especifique o endereço de destino dos pacotes TCP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
O endereço de destino deve ser o mesmo que o endereço IP do serviço de escuta TCP configurado no servidor NQA. Para configurar um serviço de escuta TCP no servidor, use o comando nqa server tcp-connect.
- Especifique a porta de destino para pacotes TCP.
destination ip ip-addressPor padrão, nenhum número de porta de destino é configurado.
O número da porta de destino deve ser o mesmo que o número da porta do serviço de escuta TCP configurado no servidor NQA. Para configurar um serviço de escuta TCP no servidor, use o comando nqa server tcp-connect.
- Especifique o endereço IP de origem para pacotes TCP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes TCP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote TCP poderá ser enviado.
Configuração da operação de eco UDP
Sobre a operação de eco UDP
A operação de eco UDP mede o tempo de ida e volta entre o cliente e uma porta UDP no servidor NQA.
A operação de eco UDP requer tanto o servidor NQA quanto o cliente NQA. Antes de executar uma operação de eco UDP, configure um serviço de escuta UDP no servidor NQA. Para obter mais informações sobre a configuração do serviço de escuta UDP, consulte "Configuração do servidor NQA".
A operação de eco UDP envia um pacote UDP para o dispositivo de destino por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de eco UDP e entre em sua visualização.
type udp-echo- Especifique o endereço de destino para pacotes UDP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
O endereço de destino deve ser o mesmo que o endereço IP do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o número da porta de destino para pacotes UDP.
destination ip ip-addressPor padrão, nenhum número de porta de destino é especificado.
O número da porta de destino deve ser o mesmo que o número da porta do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o endereço IP de origem para pacotes UDP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes UDP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote UDP poderá ser enviado.
- Especifique o número da porta de origem para pacotes UDP.
destination port port-numberPor padrão, o cliente NQA escolhe aleatoriamente uma porta não utilizada como a porta de origem quando a operação é iniciada.
- (Opcional.) Defina o tamanho da carga útil para cada pacote UDP.
data-size sizeA configuração padrão é 100 bytes.
- (Opcional.) Especifique a cadeia de caracteres de preenchimento de carga útil para pacotes UDP.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
Configuração da operação UDP tracert
Sobre a operação de tracert UDP
A operação UDP tracert determina o caminho de roteamento do dispositivo de origem para o dispositivo de destino.
A operação UDP tracert envia um pacote UDP para um salto ao longo do caminho por sonda.
Restrições e diretrizes
A operação de tracert UDP não é compatível com redes IPv6. Para determinar o caminho de roteamento que os pacotes IPv6 percorrem da origem até o destino, use o comando tracert ipv6. Para obter mais informações sobre o comando, consulte Referência de comandos de gerenciamento e monitoramento de rede.
Pré-requisitos
Antes de configurar a operação UDP tracert, você deve executar as seguintes tarefas:
Habilite o envio de mensagens ICMP de tempo excedido nos dispositivos intermediários entre os dispositivos de origem e de destino. Se os dispositivos intermediários forem dispositivos Intelbras, use o comando ip ttl-expires enable.
Habilite o envio de mensagens ICMP de destino inalcançável no dispositivo de destino. Se o dispositivo de destino for um dispositivo Intelbras, use o comando ip unreachables enable.
Para obter mais informações sobre os comandos ip ttl-expires enable e ip unreachables enable, consulte Referência de comandos de serviços da camada 3IP.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de operação UDP tracert e entre em sua visualização.
type udp-tracert- Especifique o dispositivo de destino para a operação. Escolha uma das tarefas a seguir:
- Especifique o dispositivo de destino por seu nome de host.
destination host host-namePor padrão, nenhum nome de host de destino é especificado.
- Especifique o dispositivo de destino por seu endereço IP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o número da porta de destino para pacotes UDP.
destination ip ip-addressPor padrão, o número da porta de destino é 33434.
Esse número de porta deve ser um número não utilizado no dispositivo de destino, para que o dispositivo de destino possa responder com mensagens ICMP de porta inalcançável.
- Especifique uma interface de saída para pacotes UDP.
out interface interface-type interface-numberPor padrão, o cliente NQA determina a interface de saída com base na pesquisa da tabela de roteamento.
- Especifique o endereço IP de origem para pacotes UDP.
- Especifique o endereço IP da interface especificada como o endereço IP de origem.
source interface interface-type interface-numberPor padrão, o endereço IP de origem dos pacotes UDP é o endereço IP primário de sua interface de saída.
- Especifique o endereço IP de origem.
source ip ip-addressA interface de origem especificada deve estar ativa. O endereço IP de origem deve ser o endereço IP de uma interface local, e a interface local deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique o número da porta de origem para pacotes UDP.
destination port port-numberPor padrão, o cliente NQA escolhe aleatoriamente uma porta não utilizada como a porta de origem quando a operação é iniciada.
- Defina o número máximo de falhas consecutivas da sonda.
max-failure timesA configuração padrão é 5.
- Definir o valor TTL inicial para pacotes UDP.
init-ttl valueA configuração padrão é 1.
- (Opcional.) Defina o tamanho da carga útil para cada pacote UDP.
data-size sizeA configuração padrão é 100 bytes.
- (Opcional.) Habilite o recurso de não fragmentação.
no-fragment enablePor padrão, o recurso de não fragmentação está desativado.
Configuração da operação de Voice
Sobre a operação de Voice
A operação de voz mede o desempenho da rede VoIP. A operação de voz funciona da seguinte forma:
- O cliente NQA envia pacotes de voz em intervalos de envio para o dispositivo de destino (NQA servidor).
Os pacotes de voz são de um dos seguintes tipos de codec:
- G.711 A-law.
- G.711 µ-law.
- G.729 A-law.
- O dispositivo de destino registra a hora de cada pacote de voz que recebe e o envia de volta à origem.
A operação de voz envia um número de pacotes de voz para o dispositivo de destino por sonda. O número de pacotes a serem enviados por sonda é determinado pelo uso do comando probe packet-number.
Os seguintes parâmetros que refletem o desempenho da rede VoIP podem ser calculados usando as métricas coletadas pela operação de voz:
Calculated Planning Impairment Factor (ICPIF) - Mede o comprometimento da qualidade da voz em uma rede VoIP. É determinado pela perda de pacotes e pelo atraso. Um valor mais alto representa uma qualidade de serviço inferior.
Mean Opinion Scores (MOS) - Um valor MOS pode ser avaliado usando o valor ICPIF, no intervalo de 1 a 5. Um valor mais alto representa uma qualidade de serviço superior.
A avaliação da qualidade de voz depende da tolerância dos usuários à qualidade de voz. Para usuários com maior tolerância à qualidade de voz, use o comando advantage-factor para definir um fator de vantagem. Quando o sistema calcula o valor ICPIF, ele subtrai o fator de vantagem para modificar os valores ICPIF e MOS para avaliação da qualidade de voz.
A operação de voz requer tanto o servidor NQA quanto o cliente NQA. Antes de executar uma operação de voz, configure um serviço de escuta UDP no servidor NQA. Para obter mais informações sobre a configuração do serviço de escuta UDP, consulte "Configuração do servidor NQA".
Restrições e diretrizes
Para garantir o sucesso das operações de voz e evitar afetar os serviços existentes, não execute as operações em portas conhecidas de 1 a 1023.
O comando display nqa history não exibe os resultados ou as estatísticas da operação de voz. Para exibir os resultados ou as estatísticas da operação de voz, use o comando display nqa result ou display nqa statistics.
Antes de iniciar a operação, certifique-se de que os dispositivos de rede estejam sincronizados com a hora usando NTP. Para obter mais informações sobre o NTP, consulte "Configuração do NTP".
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de voz e entre em sua visualização.
type voice- Especifique o endereço IP de destino para pacotes de voz.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é configurado.
O endereço IP de destino deve ser o mesmo que o endereço IP do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o número da porta de destino dos pacotes de voz.
destination ip ip-addressPor padrão, nenhum número de porta de destino é configurado.
O número da porta de destino deve ser o mesmo que o número da porta do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o endereço IP de origem dos pacotes de voz.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes de voz é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de voz poderá ser enviado.
- Especifique o número da porta de origem dos pacotes de voz.
destination port port-numberPor padrão, o cliente NQA escolhe aleatoriamente uma porta não utilizada como a porta de origem quando a operação é iniciada.
- Configure os parâmetros básicos de operação de voz.
- Especifique o tipo de codec.
codec-type { g711a | g711u | g729a }Por padrão, o tipo de codec é G.711 A-law.
- Defina o fator de vantagem para calcular os valores de MOS e ICPIF.
advantage-factor factorPor padrão, o fator de vantagem é 0.
- Configure os parâmetros da sonda para a operação de voz.
- Defina o número de pacotes de voz a serem enviados por sonda.
probe packet-number packet-numberA configuração padrão é 1000.
- Defina o intervalo para o envio de pacotes de voz.
A configuração padrão é 20 milissegundos.probe packet-interval interval - Especifique por quanto tempo o cliente NQA aguarda uma resposta do servidor antes de considerar que a resposta expirou.
probe packet-timeout timeoutA configuração padrão é 5000 milissegundos.
- Configure os parâmetros de carga útil.
- Defina o tamanho da carga útil dos pacotes de voz.
data-size sizePor padrão, o tamanho do pacote de voz varia de acordo com o tipo de codec. O tamanho padrão do pacote é 172 bytes para o tipo de codec G.711A-law e G.711 µ-law, e 32 bytes para o tipo de codec G.729 A-law.
- (Opcional.) Especifique a cadeia de caracteres de preenchimento de carga útil para pacotes de voz.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
Configuração da operação DLSw
Sobre a operação do DLSw
A operação DLSw mede o tempo de resposta de um dispositivo DLSw. Ela configura uma conexão DLSw com o dispositivo DLSw por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de DLSw e entre em sua visualização.
type dlsw- Especifique o endereço IP de destino para os pacotes de sondagem.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o endereço IP de origem para os pacotes de sondagem.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes de sondagem é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
Configuração da operação de jitter de caminho
Sobre a operação de jitter de caminho
A operação de jitter de caminho mede o jitter, os jitters negativos e os jitters positivos do cliente NQA para cada salto no caminho para o destino.
A operação de jitter de caminho executa as seguintes etapas por sonda:
- Obtém o caminho do cliente NQA até o destino por meio do tracert. Um máximo de 64 saltos pode ser detectado.
- Envia um número de solicitações de eco ICMP para cada salto ao longo do caminho. O número de solicitações de eco ICMP a serem enviadas é definido com o uso do comando probe packet-number.
Pré-requisitos
Antes de configurar a operação de jitter de caminho, você deve executar as seguintes tarefas:
Habilite o envio de mensagens ICMP de tempo excedido nos dispositivos intermediários entre os dispositivos de origem e de destino. Se os dispositivos intermediários forem dispositivos Intelbras, use o comando ip ttl-expires enable.
Habilite o envio de mensagens ICMP de destino inalcançável no dispositivo de destino. Se o dispositivo de destino for um dispositivo Intelbras, use o comando ip unreachables enable.
Para obter mais informações sobre os comandos ip ttl-expires enable e ip unreachables enable, consulte Referência de comandos de serviços de IP de camada 3.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de jitter de caminho e entre em sua visualização.
type path-jitter- Especifique o endereço IP de destino para solicitações de eco ICMP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o endereço IP de origem para solicitações de eco ICMP.
source ip ip-addressPor padrão, o endereço IP de origem das solicitações de eco ICMP é o endereço IP principal da interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhuma solicitação de eco ICMP poderá ser enviada.
- Configure os parâmetros da sonda para a operação de jitter de caminho.
- Defina o número de solicitações de eco ICMP a serem enviadas por sonda.
probe packet-number packet-numberA configuração padrão é 10.
- Defina o intervalo para o envio de solicitações de eco ICMP.
probe packet-interval intervalA configuração padrão é 20 milissegundos.
- Especifique por quanto tempo o cliente NQA aguarda uma resposta do servidor antes de considerar que a resposta expirou.
probe packet-timeout timeoutA configuração padrão é 3000 milissegundos.
- (Opcional.) Especifique um caminho LSR.
lsr-path ip-address&<1-8>lPor padrão, nenhum caminho LSR é especificado.
A operação de jitter de caminho usa o tracert para detectar o caminho LSR até o destino e envia solicitações de eco ICMP para cada salto no caminho LSR.
- Execute a operação de jitter de caminho somente no endereço de destino.
target-onlyPor padrão, a operação de jitter de caminho é executada em cada salto do caminho até o destino.
- (Opcional.) Defina o tamanho da carga útil para cada solicitação de eco ICMP.
data-size sizeA configuração padrão é 100 bytes.
- (Opcional.) Especifique a cadeia de caracteres de preenchimento de carga útil para solicitações de eco ICMP.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
Configuração de parâmetros opcionais para a operação do NQA
Restrições e diretrizes
A menos que especificado de outra forma, os seguintes parâmetros opcionais se aplicam a todos os tipos de operações de NQA. As configurações dos parâmetros entram em vigor somente na operação atual.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização de uma operação NQA existente.
nqa entry admin-name operation-tag- Configure uma descrição para a operação.
description textPor padrão, nenhuma descrição é configurada.
- Defina o intervalo em que a operação NQA se repete.
frequency intervalPara uma operação de jitter de voz ou de caminho, a configuração padrão é 60000 milissegundos.
Para outros tipos de operações, a configuração padrão é 0 milissegundos, e apenas uma operação é executada.
Quando o intervalo expirar, mas a operação não for concluída ou não tiver atingido o tempo limite, a próxima operação não será iniciada.
- Especifique os tempos da sonda.
probe count timesEm uma operação de tracert UDP, o cliente NQA executa três sondas para cada salto até o destino por padrão.
Em outros tipos de operações, o cliente NQA executa uma sonda para o destino por operação por padrão.
Esse comando não está disponível para as operações de voz e de jitter de caminho. Cada uma dessas operações executa apenas uma sonda.
- Defina o tempo limite da sonda.
probe timeout timeoutA configuração padrão é 3000 milissegundos.
Esse comando não está disponível para as operações de jitter ICMP, jitter UDP, voz ou jitter de caminho.
- Defina o número máximo de saltos que os pacotes de sonda podem percorrer.
ttl valueA configuração padrão é 30 para pacotes de sondagem da operação UDP tracert e 20 para pacotes de sondagem de outros tipos de operações.
Esse comando não está disponível para as operações de DHCP ou de jitter de caminho.
- Defina o valor ToS no cabeçalho IP dos pacotes de sondagem.
tos valueA configuração padrão é 0.
- Ativar o recurso de desvio da tabela de roteamento.
opção de rota bypass-route
Por padrão, o recurso de desvio da tabela de roteamento está desativado.
Esse comando não está disponível para as operações de DHCP ou de jitter de caminho.
Esse comando não terá efeito se o endereço de destino da operação NQA for um endereço IPv6.
Configuração do recurso de colaboração
Sobre o recurso de colaboração
A colaboração é implementada pela associação de uma entrada de reação de uma operação de NQA a uma entrada de trilha. A entrada de reação monitora a operação de NQA. Se o número de falhas na operação atingir o limite especificado em , a ação configurada será acionada.
Restrições e diretrizes
O recurso de colaboração não está disponível para os seguintes tipos de operações:
Operação de jitter ICMP.
Operação de jitter UDP.
Operação de tracert UDP.
Operação de voz.
Operação de jitter de caminho.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização de uma operação NQA existente.
nqa entry admin-name operation-tag- Configurar uma entrada de reação.
reaction item-number checked-element probe-fail threshold-type consecutive consecutive-occurrences action-type trigger-onlyNão é possível modificar o conteúdo de uma entrada de reação existente.
- Retornar à visualização do sistema.
quit- Trilha de associado com NQA.
Para obter informações sobre a configuração, consulte o Guia de configuração de alta disponibilidade.
- Associe o Track a um módulo de aplicativo.
Para obter informações sobre a configuração, consulte o Guia de configuração de alta disponibilidade.
Configuração do monitoramento de limites
Sobre o monitoramento de limites
Esse recurso permite monitorar o status de execução da operação de NQA. Uma operação de NQA suporta os seguintes tipos de limite:
média-Se o valor médio da métrica de desempenho monitorada exceder o limite superior de ou ficar abaixo do limite inferior, ocorre uma violação do limite.
acumular-Se o número total de vezes que o índice de desempenho monitorado estiver fora do intervalo de valores especificado atingir ou exceder o limite especificado, ocorrerá uma violação do limite.
consecutivo-Se o número de vezes consecutivas em que o índice de desempenho monitorado estiver fora do intervalo de valores especificado atingir ou exceder o limite especificado, ocorrerá uma violação do limite.
As violações de limite para o tipo de limite médio ou acumulado são determinadas em uma base por operação NQA. As violações de limite para o tipo consecutivo são determinadas a partir do momento em que a operação de NQA é iniciada.
As seguintes ações podem ser acionadas:
none-O NQA exibe os resultados apenas na tela do terminal. Ele não envia traps para o NMS.
trap-only-NQA exibe os resultados na tela do terminal e, enquanto isso, envia traps para o NMS.
Para enviar traps para o NMS, o endereço do NMS deve ser especificado usando o comando snmp-agent target-host. Para obter mais informações sobre o comando, consulte Referência de comandos de gerenciamento e monitoramento de rede.
O NQA somente de acionamento exibe os resultados na tela do terminal e, enquanto isso, aciona outros módulos para colaboração.
Em uma entrada de reação, configure um elemento monitorado, um tipo de limite e uma ação a ser acionada para implementar o monitoramento de limite.
O estado de uma entrada de reação pode ser inválido, acima do limite ou abaixo do limite.
Antes do início de uma operação de NQA, a entrada de reação está em um estado inválido.
Se o limite for violado, o estado da entrada será definido como acima do limite. Caso contrário, o estado da entrada será definido como abaixo do limite.
Restrições e diretrizes
O recurso de monitoramento de limite não está disponível para as operações de jitter de caminho.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização de uma operação NQA existente.
nqa entry admin-name operation-tag- Habilite o envio de traps para o NMS quando condições específicas forem atendidas.
reaction trap { path-change | probe-failure
consecutive-probe-failures | test-complete | test-failure
[ accumulate-probe-failures ] }
Por padrão, nenhuma armadilha é enviada ao NMS.
As operações ICMP jitter, UDP jitter e voz suportam apenas a palavra-chave test-complete. Os parâmetros a seguir não estão disponíveis para a operação UDP tracert:
- A opção probe-failure consecutive-probe-failures.
- O argumento accumulate-probe-failures.
- Configure o monitoramento de limites. Escolha as opções para configurar conforme necessário:
- Monitore a duração da operação.
reaction item-number checked-element probe-duration
threshold-type { accumulate accumulate-occurrences | average |
consecutive consecutive-occurrences } threshold-value
upper-threshold lower-threshold [ action-type { none | trap-only } ]
Essa entrada de reação não é compatível com as operações de jitter ICMP, jitter UDP, tracert UDP ou voz
- Monitore os tempos de falha.
reaction item-number checked-element probe-fail threshold-type
{ accumulate accumulate-occurrences | consecutive
consecutive-occurrences } [ action-type { none | trap-only } ]
Essa entrada de reação não é compatível com as operações de jitter ICMP, jitter UDP, tracert UDP ou voz.
- Monitore o tempo de ida e volta.
reaction item-number checked-element rtt threshold-type
{ accumulate accumulate-occurrences | average } threshold-value
upper-threshold lower-threshold [ action-type { none | trap-only } ]
Somente as operações de jitter ICMP, jitter UDP e voz suportam essa entrada de reação.
- Monitore a perda de pacotes.
reaction item-number checked-element packet-loss threshold-type
accumulate accumulate-occurrences [ action-type { none |
trap-only } ]
Somente as operações de jitter ICMP, jitter UDP e voz suportam essa entrada de reação.
- Monitore o jitter unidirecional.
reaction item-number checked-element { jitter-ds | jitter-sd }
threshold-type { accumulate accumulate-occurrences | average }
threshold-value upper-threshold lower-threshold [ action-type
{ none | trap-only } ]
Somente as operações de jitter ICMP, jitter UDP e voz suportam essa entrada de reação.
- Monitore o atraso unidirecional.
reaction item-number checked-element { owd-ds | owd-sd }
threshold-value upper-threshold lower-threshold
Somente as operações de jitter ICMP, jitter UDP e voz suportam essa entrada de reação.
- Monitore o valor ICPIF.
reaction item-number checked-element icpif threshold-value
upper-threshold lower-threshold [ action-type { none | trap-only } ]
Somente a operação de voz suporta essa entrada de reação.
- Monitore o valor de MOS.
reaction item-number checked-element mos threshold-value
upper-threshold lower-threshold [ action-type { none | trap-only } ]
Somente a operação de voz suporta essa entrada de reação.
A operação DNS não oferece suporte à ação de enviar mensagens de interceptação. Para a operação de DNS, o tipo de ação só pode ser nenhum.
Configuração do recurso de coleta de estatísticas do NQA
Sobre a coleta de estatísticas do NQA
O NQA forma estatísticas dentro do mesmo intervalo de coleta como um grupo de estatísticas. Para exibir informações sobre os grupos de estatísticas, use o comando display nqa statistics.
Quando o número máximo de grupos de estatísticas é atingido, o cliente NQA exclui o grupo de estatísticas mais antigo para salvar um novo.
Um grupo de estatísticas é automaticamente excluído quando seu tempo de espera expira.
Restrições e diretrizes
O recurso de coleta de estatísticas do NQA não está disponível para as operações de tracert UDP.
Se você usar o comando frequency para definir o intervalo como 0 milissegundos para uma operação de NQA, o NQA não gerará nenhum grupo de estatísticas para a operação.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização de uma operação NQA existente.
nqa entry admin-name operation-tag- Defina o intervalo de coleta de estatísticas. intervalo de intervalo de estatísticas A configuração padrão é 60 minutos.
- Defina o número máximo de grupos de estatísticas que podem ser salvos.
statistics max-group number
Por padrão, o cliente NQA pode salvar no máximo dois grupos de estatísticas para uma operação. Para desativar o recurso de coleta de estatísticas do NQA, defina o argumento number como 0.
- Defina o tempo de espera dos grupos de estatísticas. statistics hold-time hold-time A configuração padrão é 120 minutos.
Configuração do salvamento de registros de histórico de NQA
Sobre o salvamento do registro do histórico do NQA
Essa tarefa permite que o cliente NQA salve os registros do histórico do NQA. É possível usar o comando display nqa history para exibir os registros de histórico do NQA.
Restrições e diretrizes
O recurso de salvamento do registro do histórico do NQA não está disponível para os seguintes tipos de operações:
Operação de jitter ICMP.
Operação de jitter UDP.
Operação de voz.
Operação de jitter de caminho.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização de uma operação NQA existente.
nqa entry admin-name operation-tag- Habilite o salvamento de registros de histórico para a operação NQA.
history-record enablePor padrão, esse recurso é ativado somente para a operação UDP tracert.
- Defina o tempo de vida dos registros do histórico.
history-record keep-time keep-timeA configuração padrão é 120 minutos.
Um registro é excluído quando sua vida útil é atingida.
- Defina o número máximo de registros de histórico que podem ser salvos.
history-record number numberA configuração padrão é 50.
Quando o número máximo de registros de histórico for atingido, o sistema excluirá o registro mais antigo para salvar um novo.
Agendamento da operação de NQA no cliente NQA
Sobre a programação de operações do NQA
A operação NQA é executada entre a hora de início e a hora de término especificadas (a hora de início mais a duração da operação). Se a hora de início especificada estiver adiantada em relação à hora do sistema, a operação será iniciada imediatamente. Se tanto a hora de início quanto a hora de término especificadas estiverem adiantadas em relação à hora do sistema, a operação não será iniciada. Para exibir a hora atual do sistema, use o comando display clock.
Restrições e diretrizes
Não é possível entrar na visualização do tipo de operação ou na visualização de uma operação NQA programada.
Um ajuste de hora do sistema não afeta as operações de NQA iniciadas ou concluídas. Ele afeta apenas as operações de NQA que não foram iniciadas.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique os parâmetros de agendamento para uma operação de NQA.
nqa schedule admin-name operation-tag start-time { hh:mm:ss
[ yyyy/mm/dd | mm/dd/yyyy ] | now } lifetime { lifetime | forever }
[ recurring ]
Configuração de modelos de NQA no cliente NQA
Restrições e diretrizes
Alguns parâmetros de operação de um modelo NQA podem ser especificados pela configuração do modelo ou pelo recurso que usa o modelo. Quando ambos são especificados, os parâmetros na configuração do modelo entram em vigor.
Visão geral das tarefas do modelo NQA
Para configurar modelos de NQA, execute as seguintes tarefas:
- Execute pelo menos uma das seguintes tarefas:
- Configuração do modelo ICMP
- Configuração do modelo de DNS
- Configuração do modelo TCP
- Configuração do modelo TCP semiaberto
- Configuração do modelo UDP
- Configuração do modelo HTTP
- Configuração do modelo HTTPS
- Configuração do modelo de FTP
- Configuração do modelo RADIUS
- Configuração do modelo SSL
- (Opcional.) Configuração de parâmetros opcionais para o modelo NQA
Configuração do modelo ICMP
Sobre o modelo ICMP
Um recurso que usa o modelo ICMP executa a operação ICMP para medir a capacidade de alcance de um dispositivo de destino. O modelo ICMP é compatível com redes IPv4 e IPv6.
Procedimento
system-view- Crie um modelo ICMP e entre em sua visualização.
nqa template icmp name- Especifique o endereço IP de destino para a operação. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é configurado.
- Especifique o endereço IP de origem para solicitações de eco ICMP. Escolha uma das tarefas a seguir:
- Use o endereço IP da interface especificada como o endereço IP de origem.
source interface interface-type interface-numberPor padrão, o endereço IP primário da interface de saída é usado como endereço IP de origem das solicitações de eco ICMP.
A interface de origem especificada deve estar ativa.
- Especifique o endereço IPv4 de origem.
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como endereço IPv4 de origem das solicitações de eco ICMP.
O endereço IPv4 de origem especificado deve ser o endereço IPv4 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique o endereço IPv6 de origem.
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como endereço IPv6 de origem das solicitações de eco ICMP.
O endereço IPv6 de origem especificado deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique o endereço IP do próximo salto para solicitações de eco ICMP. IPv4:
next-hop ip ip-addressIPv6:
next-hop ipv6 ipv6-addressPor padrão, nenhum endereço IP do próximo salto é configurado.
- Configure o envio do resultado da sonda por sonda.
reaction trigger per-probePor padrão, o resultado da sonda é enviado ao recurso que usa o modelo após três sondas consecutivas com falha ou sucesso.
Se você executar os comandos reaction trigger per-probe e reaction trigger probe-pass várias vezes, a configuração mais recente entrará em vigor.
Se você executar os comandos reaction trigger per-probe e reaction trigger probe-fail várias vezes, a configuração mais recente entrará em vigor.
- (Opcional.) Defina o tamanho da carga útil para cada solicitação ICMP.
data-size sizeA configuração padrão é 100 bytes.
- (Opcional.) Especifique a cadeia de caracteres de preenchimento de carga útil para solicitações de eco ICMP.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
Configuração do modelo de DNS
Sobre o modelo de DNS
Um recurso que usa o modelo de DNS executa a operação de DNS para determinar o status do servidor. O modelo de DNS é compatível com redes IPv4 e IPv6.
Na visualização do modelo de DNS, você pode especificar o endereço que se espera que seja retornado. Se os endereços IP retornados incluírem o endereço esperado, o servidor DNS é válido e a operação é bem-sucedida. Caso contrário, a operação falhará.
Pré-requisitos
Crie um mapeamento entre o nome de domínio e um endereço antes de executar a operação de DNS. Para obter informações sobre a configuração do servidor DNS, consulte os documentos sobre a configuração do servidor DNS .
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo de DNS e entre na visualização do modelo de DNS.
nqa template icmp name- Especifique o endereço IP de destino para os pacotes de sondagem. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço de destino é especificado.
- Especifique o número da porta de destino para os pacotes de sondagem.
destination ip ip-addressPor padrão, o número da porta de destino é 53.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 de origem dos pacotes de sondagem é o endereço IPv4 primário de sua interface de saída.
O endereço IPv4 de origem deve ser o endereço IPv4 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 de origem dos pacotes de sondagem é o endereço IPv6 primário de sua interface de saída.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique o número da porta de origem para os pacotes de sondagem.
destination port port-numberPor padrão, nenhum número de porta de origem é especificado.
- Especifique o nome de domínio a ser traduzido.
resolve-target domain-namePor padrão, nenhum nome de domínio é especificado.
- Especifique o tipo de resolução de nome de domínio.
resolve-type { A | AAAA }Por padrão, o tipo é o tipo A.
Uma consulta do tipo A resolve um nome de domínio para um endereço IPv4 mapeado, e uma consulta do tipo AAAA para um endereço IPv6 mapeado.
- (Opcional.) Especifique o endereço IP que se espera que seja retornado. IPv4:
expect ip ip-addressIPv6:
expect ipv6 ipv6-addressPor padrão, nenhum endereço IP esperado é especificado.
Configuração do modelo TCP
Sobre o modelo TCP
Um recurso que usa o modelo TCP executa a operação TCP para testar se o cliente NQA pode estabelecer uma conexão TCP com uma porta específica no servidor.
Na visualização do modelo TCP, você pode especificar os dados esperados a serem retornados. Se você não especificar os dados esperados, a operação TCP testará apenas se o cliente pode estabelecer uma conexão TCP com o servidor.
A operação TCP requer tanto o servidor NQA quanto o cliente NQA. Antes de executar uma operação TCP, configure um serviço de escuta TCP no servidor NQA. Para obter mais informações sobre a configuração do serviço de escuta TCP , consulte "Configuração do servidor NQA".
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo TCP e insira sua visualização.
nqa template tcp name- Especifique o endereço IP de destino para os pacotes de sondagem. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é especificado.
O endereço de destino deve ser o mesmo que o endereço IP do serviço de escuta TCP configurado no servidor NQA. Para configurar um serviço de escuta TCP no servidor, use o comando nqa server tcp-connect.
- Especifique o número da porta de destino para a operação.
destination ip ip-addressPor padrão, nenhum número de porta de destino é especificado.
O número da porta de destino deve ser o mesmo que o número da porta do serviço de escuta TCP configurado no servidor NQA. Para configurar um serviço de escuta TCP no servidor, use o comando nqa server tcp-connect.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IP de origem deve ser o endereço IPv4 de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- (Opcional.) Especifique a string de preenchimento de carga útil para os pacotes de sonda.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
- (Opcional.) Configure os dados esperados.
expect data expression [ offset number ]Por padrão, nenhum dado esperado é configurado.
O cliente NQA executa a verificação de dados esperados somente quando você configura o preenchimento de dados e a verificação de dados esperados, comandos expect-data.
Configuração do modelo TCP semiaberto
Sobre o modelo TCP meio aberto
Um recurso que usa o modelo TCP semiaberto executa a operação TCP semiaberto para testar se o serviço TCP está disponível no servidor. A operação de TCP semiaberto é usada quando o recurso não consegue obter uma resposta do servidor TCP por meio de uma conexão TCP existente.
Na operação TCP semiaberta, o cliente NQA envia um pacote TCP ACK para o servidor. Se o cliente receber um pacote RST, ele considerará que o serviço TCP está disponível no servidor.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo TCP semiaberto e entre em sua visualização.
nqa template tcphalfopen name- Especifique o endereço IP de destino da operação. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é especificado.
O endereço de destino deve ser o mesmo que o endereço IP do serviço de escuta TCP configurado no servidor NQA. Para configurar um serviço de escuta TCP no servidor, use o comando nqa server tcp-connect.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IPv4 de origem deve ser o endereço IPv4 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique o endereço IP do próximo salto para os pacotes de sondagem. IPv4:
next-hop ip ip-addressIPv6:
next-hop ipv6 ipv6-addressPor padrão, o endereço IP do próximo salto é configurado.
- Configure o envio do resultado da sonda por sonda.
reaction trigger per-probePor padrão, o resultado da sonda é enviado ao recurso que usa o modelo após três sondas consecutivas com falha ou sucesso.
Se você executar os comandos reaction trigger per-probe e reaction trigger probe-pass várias vezes, a configuração mais recente entrará em vigor.
Se você executar os comandos reaction trigger per-probe e reaction trigger probe-fail várias vezes, a configuração mais recente entrará em vigor.
Configuração do modelo UDP
Sobre o modelo UDP
Um recurso que usa o modelo UDP executa a operação UDP para testar os seguintes itens:
Alcançabilidade de uma porta específica no servidor NQA.
Disponibilidade do serviço solicitado no servidor do NQA.
Na visualização do modelo UDP, você pode especificar os dados esperados a serem retornados. Se você não especificar os dados esperados, a operação UDP testará apenas se o cliente pode receber o pacote de resposta do servidor.
A operação UDP requer tanto o servidor NQA quanto o cliente NQA. Antes de executar uma operação UDP, configure um serviço de escuta UDP no servidor NQA. Para obter mais informações sobre a configuração do serviço de escuta UDP, consulte "Configuração do servidor NQA".
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo UDP e insira sua visualização.
nqa template udp name- Especifique o endereço IP de destino da operação. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é especificado.
O endereço de destino deve ser o mesmo que o endereço IP do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o número da porta de destino para a operação.
destination ip ip-addressPor padrão, nenhum número de porta de destino é especificado.
O número da porta de destino deve ser o mesmo que o número da porta do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IP de origem deve ser o endereço IPv4 de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique a cadeia de caracteres de preenchimento de carga útil para os pacotes de sondagem.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
- (Opcional.) Defina o tamanho da carga útil para os pacotes de sondagem.
data-size sizeA configuração padrão é 100 bytes.
- (Opcional.) Configure os dados esperados.
expect data expression [ offset number ]Por padrão, nenhum dado esperado é configurado.
A verificação de dados esperados é realizada somente quando o comando de preenchimento de dados e o comando de dados esperados estão configurados.
Configuração do modelo HTTP
Sobre o modelo HTTP
Um recurso que usa o modelo HTTP executa a operação HTTP para medir o tempo que o cliente NQA leva para obter dados de um servidor HTTP.
Os dados esperados são verificados somente quando os dados são configurados e a resposta HTTP contém o campo Content-Length no cabeçalho HTTP.
O código de status do pacote HTTP é um campo de três dígitos em notação decimal e inclui as informações de status do servidor HTTP. O primeiro dígito define a classe da resposta.
Pré-requisitos
Antes de executar a operação HTTP, você deve configurar o servidor HTTP.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo HTTP e insira sua visualização.
nqa template http name- Especifique o URL de destino para o modelo HTTP.
url urlPor padrão, nenhum URL de destino é especificado para um modelo HTTP. Digite o URL em um dos seguintes formatos:
http://host/resourcehttp://host:port/resource- Especifique um nome de usuário de login HTTP.
username usernamePor padrão, nenhum nome de usuário de login HTTP é especificado.
password { cipher | simple } stringPor padrão, nenhuma senha de login HTTP é especificada.
- Especifique a versão do HTTP.
version { v1.0 | v1.1 }Por padrão, o HTTP 1.0 é usado.
operation { get | post | raw }Por padrão, o tipo de operação HTTP é get.
Se você definir o tipo de operação como bruto, o cliente adicionará o conteúdo configurado na exibição de solicitação bruta à solicitação HTTP a ser enviada ao servidor HTTP.
- Configure o conteúdo da solicitação bruta HTTP.
- Entrar na visualização de solicitação bruta.
raw-requestToda vez que você entra na visualização de solicitação bruta, o conteúdo da solicitação bruta configurado anteriormente é apagado.
- Digite ou cole o conteúdo da solicitação.
Por padrão, nenhum conteúdo de solicitação é configurado.
Para garantir operações bem-sucedidas, certifique-se de que o conteúdo da solicitação não contenha aliases de comando configurados usando o comando alias. Para obter mais informações sobre o comando alias, consulte Comandos da CLI em Referência de comandos básicos.
- Retornar à visualização do modelo HTTP.
quitO sistema salva automaticamente a configuração na visualização de solicitação bruta antes de retornar à visualização de modelo HTTP.
Essa etapa é necessária somente quando o tipo de operação é definido como bruto.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IPv4 de origem deve ser o endereço IPv4 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- (Opcional.) Configure os códigos de status esperados.
expect status status-listPor padrão, nenhum código de status esperado é configurado.
- (Opcional.) Configure os dados esperados.
expect data expression [ offset number ]Por padrão, nenhum dado esperado é configurado.
Configuração do modelo HTTPS
Sobre o modelo HTTPS
Um recurso que usa o modelo HTTPS executa a operação HTTPS para medir o tempo que o cliente NQA leva para obter dados de um servidor HTTPS.
Os dados esperados são verificados somente quando os dados esperados são configurados e a resposta HTTPS contém o campo Content-Length no cabeçalho HTTPS.
O código de status do pacote HTTPS é um campo de três dígitos em notação decimal e inclui as informações de status do servidor HTTPS. O primeiro dígito define a classe da resposta.
Pré-requisitos
Antes de executar a operação HTTPS, configure o servidor HTTPS e a política de cliente SSL para o cliente SSL. Para obter informações sobre a configuração de políticas de cliente SSL, consulte o Guia de Configuração de Segurança.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo HTTPS e insira sua visualização.
nqa template https name- Especifique o URL de destino para o modelo HTTPS.
url urlPor padrão, nenhum URL de destino é especificado para um modelo HTTPS. Digite o URL em um dos seguintes formatos:
:
https://host/resource
https://host:port/resourceusername usernamePor padrão, nenhum nome de usuário de login HTTPS é especificado.
password { cipher | simple } stringPor padrão, nenhuma senha de login HTTPS é especificada.
- Especifique uma política de cliente SSL.
ssl-client-policy policy-namePor padrão, nenhuma política de cliente SSL é especificada.
- Especifique a versão do HTTPS.
version { v1.0 | v1.1 }Por padrão, é usado o HTTPS 1.0.
operation { get | post | raw }Por padrão, o tipo de operação HTTPS é get.
Se você definir o tipo de operação como bruto, o cliente adicionará o conteúdo configurado na exibição de solicitação bruta à solicitação HTTPS a ser enviada ao servidor HTTPS.
- Configure o conteúdo da solicitação bruta HTTPS.
- Entrar na visualização de solicitação bruta.
raw-requestToda vez que você entra na visualização de solicitação bruta, o conteúdo da solicitação bruta configurado anteriormente é apagado.
- Digite ou cole o conteúdo da solicitação.
Por padrão, nenhum conteúdo de solicitação é configurado.
Para garantir operações bem-sucedidas, certifique-se de que o conteúdo da solicitação não contenha aliases de comando configurados usando o comando alias. Para obter mais informações sobre o comando alias, consulte Comandos da CLI em Referência de comandos básicos.
- Retornar à visualização do modelo HTTPS.
quitO sistema salva automaticamente a configuração na visualização de solicitação bruta antes de retornar à visualização do modelo HTTPS.
Essa etapa é necessária somente quando o tipo de operação é definido como bruto.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IP de origem deve ser o endereço IPv4 de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- (Opcional.) Configure os dados esperados.
expect data expression [ offset number ]Por padrão, nenhum dado esperado é configurado.
- (Opcional.) Configure os códigos de status esperados.
expect status status-listPor padrão, nenhum código de status esperado é configurado.
Configuração do modelo de FTP
Sobre o modelo FTP
Um recurso que usa o modelo FTP executa a operação FTP. A operação mede o tempo que o cliente NQA leva para transferir um arquivo para um servidor FTP ou fazer download de um arquivo a partir dele.
Configure o nome de usuário e a senha para que o cliente FTP faça login no servidor FTP antes de executar uma operação de FTP. Para obter informações sobre como configurar o servidor FTP, consulte o Fundamentals Configuration Guide.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo de FTP e insira sua visualização.
nqa template ftp name- Especifique um nome de usuário de login de FTP.
username usernamePor padrão, nenhum nome de usuário de login de FTP é especificado.
- Especifique uma senha de login de FTP.
password { cipher | simple } stingPor padrão, nenhuma senha de login de FTP é especificada.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IP de origem deve ser o endereço IPv4 de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Defina o modo de transmissão de dados.
mode { active | passive }O modo padrão é active.
operation { get | put }Por padrão, o tipo de operação FTP é get, o que significa obter arquivos do servidor FTP.
- Especifique o URL de destino para o modelo de FTP.
url urlPor padrão, nenhum URL de destino é especificado para um modelo de FTP. Digite o URL em um dos seguintes formatos:
ftp://host/filename.
ftp://host:port/filename.
Quando você executa a operação get, o nome do arquivo é obrigatório.
Quando você executa a operação put, o argumento filename não tem efeito, mesmo que esteja especificado. O nome do arquivo para a operação put é determinado com o uso do comando filename.
- Especifique o nome de um arquivo a ser transferido.
filename filenamePor padrão, nenhum arquivo é especificado.
Essa tarefa é necessária apenas para a operação de colocação.
A configuração não entra em vigor para a operação get.
Configuração do modelo RADIUS
Sobre a operação de autenticação RADIUS baseada em modelo
Um recurso que usa o modelo RADIUS executa a operação de autenticação RADIUS para verificar a disponibilidade do serviço de autenticação no servidor RADIUS.
O fluxo de trabalho da operação de autenticação RADIUS é o seguinte:
- O cliente NQA envia uma solicitação de autenticação (Access-Request) para o servidor RADIUS. A solicitação inclui o nome de usuário e a senha. A senha é criptografada usando o algoritmo MD5 e a chave compartilhada.
- O servidor RADIUS autentica o nome de usuário e a senha.
- Se a autenticação for bem-sucedida, o servidor enviará um pacote Access-Accept para o cliente NQA.
- Se a autenticação falhar, o servidor enviará um pacote Access-Reject para o cliente NQA.
- O cliente NQA determina a disponibilidade do serviço de autenticação no servidor RADIUS com base no pacote de resposta recebido:
- Se um pacote Access-Accept for recebido, o serviço de autenticação estará disponível no servidor RADIUS.
- Se um pacote Access-Reject for recebido, o serviço de autenticação não estará disponível no servidor RADIUS.
Pré-requisitos
Antes de configurar o modelo RADIUS, especifique um nome de usuário, uma senha e uma chave compartilhada no servidor RADIUS. Para obter mais informações sobre a configuração do servidor RADIUS, consulte AAA no Security Configuration Guide.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo RADIUS e entre em sua visualização.
nqa template radius name- Especifique o endereço IP de destino da operação. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o número da porta de destino para a operação.
destination ip ip-addressPor padrão, o número da porta de destino é 1812.
- Especifique um nome de usuário.
username usernamePor padrão, nenhum nome de usuário é especificado.
- Especifique uma senha.
password { cipher | simple } stringPor padrão, nenhuma senha é especificada.
- Especifique uma chave compartilhada para autenticação RADIUS segura.
key { cipher | simple } string
Por padrão, nenhuma chave compartilhada é especificada para a autenticação RADIUS.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IP de origem deve ser o endereço IPv4 de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
Configuração do modelo SSL
Sobre o modelo SSL
Um recurso que usa o modelo SSL executa a operação SSL para medir o tempo necessário para estabelecer uma conexão SSL com um servidor SSL.
Pré-requisitos
Antes de configurar o modelo SSL, você deve configurar a política de cliente SSL. Para obter informações sobre a configuração de políticas de cliente SSL, consulte o Guia de Configuração de Segurança.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo SSL e insira sua visualização.
nqa template ssl name- Especifique o endereço IP de destino da operação. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o número da porta de destino para a operação.
destination ip ip-addressPor padrão, o número da porta de destino não é especificado.
- Especifique uma política de cliente SSL.
ssl-client-policy policy-namePor padrão, nenhuma política de cliente SSL é especificada.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IP de origem deve ser o endereço IPv4 de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
Configuração de parâmetros opcionais para o modelo NQA
Restrições e diretrizes
A menos que especificado de outra forma, os seguintes parâmetros opcionais se aplicam a todos os tipos de modelos de NQA. As configurações dos parâmetros têm efeito somente no modelo NQA atual.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização de um modelo de NQA existente.
nqa template { dns | ftp | http | https | icmp | radius | ssl | tcp |
tcphalfopen | udp } name- Configure uma descrição.
description textPor padrão, nenhuma descrição é configurada.
- Defina o intervalo em que a operação NQA se repete.
frequency intervalA configuração padrão é 5000 milissegundos.
Quando o intervalo expirar, mas a operação não for concluída ou não tiver atingido o tempo limite, a próxima operação não será iniciada.
- Defina o tempo limite da sonda.
probe timeout timeoutA configuração padrão é 3000 milissegundos.
- Defina o TTL para os pacotes de sonda.
ttl valueA configuração padrão é 20.
Esse comando não está disponível para o modelo ARP.
- Defina o valor ToS no cabeçalho IP dos pacotes de sondagem.
tos valueA configuração padrão é 0.
Esse comando não está disponível para o modelo ARP.
- Defina o número de sondas consecutivas bem-sucedidas para determinar um evento de operação bem-sucedida.
reaction trigger probe-pass countA configuração padrão é 3.
Se o número de sondas consecutivas bem-sucedidas para uma operação de NQA for atingido, o cliente do NQA notificará o recurso que usa o modelo do evento de operação bem-sucedida.
- Defina o número de falhas consecutivas da sonda para determinar uma falha de operação.
reaction trigger probe-fail countA configuração padrão é 3.
Se o número de falhas consecutivas da sonda para uma operação de NQA for atingido, o cliente de NQA notificará o recurso que usa o modelo de NQA sobre a falha na operação.
Comandos de exibição e manutenção para NQA
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir registros de histórico das operações do NQA. | display nqa history [ nome-do-administrador-tag-da-operação ] | ||
| Exibir os resultados atuais de monitoramento das entradas de reação. | display nqa reaction counters [ admin-name operation-tag [ item-number ] ] | ||
| Exibe o resultado mais recente da operação de NQA. | display nqa result [ admin-name operation-tag ] | ||
| Exibir o status do servidor NQA. | display nqa server status | ||
| Exibir estatísticas de NQA. | display nqa statistics [ admin-name operation-tag ] |
Exemplos de configuração do NQA
Exemplo: Configuração da operação de eco ICMP
Configuração de rede
Conforme mostrado na Figura 2, configure uma operação de eco ICMP no cliente NQA (Dispositivo A) para testar o tempo de ida e volta até o Dispositivo B. O próximo salto do Dispositivo A é o Dispositivo C.
Figura 2 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 2. (Detalhes não mostrados.)
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar uma operação de eco ICMP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type icmp-echo# Especifique 10.2.2.2 como o endereço IP de destino das solicitações de eco ICMP.
[DeviceA-nqa-admin-test1-icmp-echo] destination ip 10.2.2.2# Especifique 10.1.1.2 como o próximo salto. As solicitações de eco ICMP são enviadas pelo Dispositivo C para o Dispositivo B.
[DeviceA-nqa-admin-test1-icmp-echo] next-hop ip 10.1.1.2# Configure a operação de eco ICMP para realizar 10 sondagens.
[DeviceA-nqa-admin-test1-icmp-echo] probe count 10# Defina o tempo limite da sonda como 500 milissegundos para a operação de eco ICMP.
[DeviceA-nqa-admin-test1-icmp-echo] probe timeout 500# Configure a operação de eco ICMP para se repetir a cada 5000 milissegundos.
[DeviceA-nqa-admin-test1-icmp-echo] frequency 5000# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-icmp-echo] history-record enable# Defina o número máximo de registros de histórico como 10.
[DeviceA-nqa-admin-test1-icmp-echo] history-record number 10
[DeviceA-nqa-admin-test1-icmp-echo] quit# Iniciar a operação de eco ICMP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever
# Depois que a operação de eco ICMP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de eco ICMP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 10 Receive response times: 10
Min/Max/Average round trip time: 2/5/3
Square-Sum of round trip time: 96
Last succeeded probe time: 2011-08-23 15:00:01.2
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação de eco ICMP.
[DeviceA] display nqa history admin test1
Registros de histórico de entrada de NQA (admin admin, tag test):
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test) history records:
Index Response Status Time
370 3 Succeeded 2007-08-23 15:00:01.2
369 3 Succeeded 2007-08-23 15:00:01.2
368 3 Succeeded 2007-08-23 15:00:01.2
367 5 Succeeded 2007-08-23 15:00:01.2
366 3 Succeeded 2007-08-23 15:00:01.2
365 3 Succeeded 2007-08-23 15:00:01.2
364 3 Succeeded 2007-08-23 15:00:01.1
363 2 Succeeded 2007-08-23 15:00:01.1
362 3 Succeeded 2007-08-23 15:00:01.1
361 2 Succeeded 2007-08-23 15:00:01.1A saída mostra que os pacotes enviados pelo Dispositivo A podem chegar ao Dispositivo B por meio do Dispositivo C. Não há perda de pacotes durante a operação. Os tempos mínimo, máximo e médio de ida e volta são 2, 5 e 3 milissegundos, respectivamente.
Exemplo: Configuração da operação de jitter ICMP
Configuração de rede
Conforme mostrado na Figura 3, configure uma operação de jitter ICMP para testar o jitter entre o Dispositivo A e o Dispositivo B.
Figura 3 Diagrama de rede
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 3. (Detalhes não mostrados.)
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo A:
# Criar uma operação de jitter ICMP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type icmp-jitter# Especifique 10.2.2.2 como o endereço de destino da operação.
[DeviceA-nqa-admin-test1-icmp-jitter] destination ip 10.2.2.2# Configure a operação para ser repetida a cada 1000 milissegundos.
[DeviceA-nqa-admin-test1-icmp-jitter] frequency 1000
[DeviceA-nqa-admin-test1-icmp-jitter] quit# Iniciar a operação de jitter ICMP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação de jitter ICMP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de jitter ICMP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 10 Receive response times: 10
Min/Max/Average round trip time: 1/2/1
Square-Sum of round trip time: 13
Last packet received time: 2015-03-09 17:40:29.8
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
ICMP-jitter results:
RTT number: 10
Min positive SD: 0 Min positive DS: 0
Max positive SD: 0 Max positive DS: 0
Positive SD number: 0 Positive DS number: 0
Positive SD sum: 0 Positive DS sum: 0
Positive SD average: 0 Positive DS average: 0
Positive SD square-sum: 0 Positive DS square-sum: 0
IP network
NQA server
Min negative SD: 1 Min negative DS: 2
Max negative SD: 1 Max negative DS: 2
Negative SD number: 1 Negative DS number: 1
Negative SD sum: 1 Negative DS sum: 2
Negative SD average: 1 Negative DS average: 2
Negative SD square-sum: 1 Negative DS square-sum: 4
SD average: 1 DS average: 2
One way results:
Max SD delay: 1 Max DS delay: 2
Min SD delay: 1 Min DS delay: 2
Number of SD delay: 1 Number of DS delay: 1
Sum of SD delay: 1 Sum of DS delay: 2
Square-Sum of SD delay: 1 Square-Sum of DS delay: 4
Lost packets for unknown reason: 0# Exibir as estatísticas da operação de jitter ICMP.
[DeviceA] display nqa statistics admin test1
NQA entry (admin admin, tag test1) test statistics:
NO. : 1
Start time: 2015-03-09 17:42:10.7
Life time: 156 seconds
Send operation times: 1560 Receive response times: 1560
Min/Max/Average round trip time: 1/2/1
Square-Sum of round trip time: 1563
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
ICMP-jitter results:
RTT number: 1560
Min positive SD: 1 Min positive DS: 1
Max positive SD: 1 Max positive DS: 2
Positive SD number: 18 Positive DS number: 46
Positive SD sum: 18 Positive DS sum: 49
Positive SD average: 1 Positive DS average: 1
Positive SD square-sum: 18 Positive DS square-sum: 55
Min negative SD: 1 Min negative DS: 1
Max negative SD: 1 Max negative DS: 2
Negative SD number: 24 Negative DS number: 57
Negative SD sum: 24 Negative DS sum: 58
Negative SD average: 1 Negative DS average: 1
Negative SD square-sum: 24 Negative DS square-sum: 60
SD average: 16 DS average: 2
One way results:
Max SD delay: 1 Max DS delay: 2
Min SD delay: 1 Min DS delay: 1
Number of SD delay: 4 Number of DS delay: 4
Sum of SD delay: 4 Sum of DS delay: 5
Square-Sum of SD delay: 4 Square-Sum of DS delay: 7
Lost packets for unknown reason: 0Exemplo: Configuração da operação DHCP
Configuração de rede
Conforme mostrado na Figura 4, configure uma operação de DHCP para testar o tempo necessário para que o Switch A obtenha um endereço IP do servidor DHCP (Switch B).
Figura 4 Diagrama de rede
Interruptor InterruptorB
Procedimento
# Criar uma operação DHCP.
<SwitchA> system-view
[SwitchA] nqa entry admin test1
[SwitchA-nqa-admin-test1] type dhcp# Especifique o endereço do servidor DHCP (10.1.1.2) como o endereço de destino.
[SwitchA-nqa-admin-test1-dhcp] destination ip 10.1.1.2# Habilite o salvamento de registros de histórico.
[SwitchA-nqa-admin-test1-dhcp] history-record enable
[SwitchA-nqa-admin-test1-dhcp] quit# Iniciar a operação DHCP.
[SwitchA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação DHCP for executada por um período de tempo, interrompa a operação.
[SwitchA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação DHCP.
[SwitchA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 512/512/512
Square-Sum of round trip time: 262144
Last succeeded probe time: 2011-11-22 09:56:03.2
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
# Exibir os registros de histórico da operação DHCP.
[SwitchA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 512 Succeeded 2011-11-22 09:56:03.2
A saída mostra que o Switch A levou 512 milissegundos para obter um endereço IP do servidor DHCP.
Exemplo: Configuração da operação de DNS
Configuração de rede
Conforme mostrado na Figura 5, configure uma operação de DNS para testar se o Dispositivo A pode realizar a resolução de endereços por meio do servidor DNS e testar o tempo de resolução.
Figura 5 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 5. (Detalhes não mostrados.)
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar uma operação de DNS.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type dns
# Especifique o endereço IP do servidor DNS (10.2.2.2) como o endereço de destino.
[DeviceA-nqa-admin-test1-dns] destination ip 10.2.2.2# Especifique host.com como o nome de domínio a ser traduzido.
[DeviceA-nqa-admin-test1-dns] resolve-target host.com# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-dns] history-record enable
[DeviceA-nqa-admin-test1-dns] quit# Iniciar a operação de DNS.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever
# Depois que a operação do DNS for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de DNS.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 62/62/62
Square-Sum of round trip time: 3844
Last succeeded probe time: 2011-11-10 10:49:37.3
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação de DNS.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test) history records:
Index Response Status Time
1 62 Succeeded 2011-11-10 10:49:37.3A saída mostra que o Dispositivo A levou 62 milissegundos para traduzir o nome de domínio host.com em um endereço IP.
Exemplo: Configuração da operação de FTP
Configuração de rede
Conforme mostrado na Figura 6, configure uma operação de FTP para testar o tempo necessário para o Dispositivo A carregar um arquivo no servidor FTP. O nome de usuário e a senha de login são admin e systemtest, respectivamente. O arquivo a ser transferido para o servidor FTP é config.txt.
Figura 6 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 6. (Detalhes não mostrados.)
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar uma operação de FTP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type ftp# Especifique o URL do servidor FTP.
[DeviceA-nqa-admin-test-ftp] url ftp://10.2.2.2# Especifique 10.1.1.1 como o endereço IP de origem.
[DeviceA-nqa-admin-test1-ftp] source ip 10.1.1.1# Configure o dispositivo para fazer upload do arquivo config.txt para o servidor FTP.
[DeviceA-nqa-admin-test1-ftp] operation put
[DeviceA-nqa-admin-test1-ftp] filename config.txt# Defina a senha para systemtest para a operação de FTP.
[DeviceA-nqa-admin-test1-ftp] password simple systemtest# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-ftp] history-record enable
[DeviceA-nqa-admin-test1-ftp] quit# Iniciar a operação de FTP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação de FTP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de FTP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 173/173/173
Square-Sum of round trip time: 29929
Last succeeded probe time: 2011-11-22 10:07:28.6
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to disconnect: 0
Failures due to no connection: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação de FTP.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 173 Succeeded 2011-11-22 10:07:28.6A saída mostra que o Dispositivo A levou 173 milissegundos para carregar um arquivo no servidor FTP.
Exemplo: Configuração da operação HTTP
Configuração de rede
Conforme mostrado na Figura 7, configure uma operação HTTP no cliente NQA para testar o tempo necessário para obter dados do servidor HTTP.
Figura 7 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 7. (Detalhes não mostrados.)
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Crie uma operação HTTP.
system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type http
# Especifique o URL do servidor HTTP.
[DeviceA-nqa-admin-test1-http] url http://10.2.2.2/index.htm# Configure a operação HTTP para obter dados do servidor HTTP.
[DeviceA-nqa-admin-test1-http] operation get# Configure a operação para usar a versão 1.0 do HTTP.
[DeviceA-nqa-admin-test1-http] version v1.0# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-http] history-record enable
[DeviceA-nqa-admin-test1-http] quit# Iniciar a operação HTTP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação HTTP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação HTTP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 64/64/64
Square-Sum of round trip time: 4096
Last succeeded probe time: 2011-11-22 10:12:47.9
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to disconnect: 0
Failures due to no connection: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação HTTP.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 64 Succeeded 2011-11-22 10:12:47.9A saída mostra que o Dispositivo A levou 64 milissegundos para obter dados do servidor HTTP.
Exemplo: Configuração da operação de jitter UDP
Configuração de rede
Conforme mostrado na Figura 8, configure uma operação de jitter UDP para testar o jitter, o atraso e o tempo de ida e volta entre o Dispositivo A e o Dispositivo B.
Figura 8 Diagrama de rede
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 8. (Detalhes não mostrados.)
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilitar o servidor NQA.
system-view
[DeviceB] nqa server enable
# Configure um serviço de escuta para escutar a porta UDP 9000 no endereço IP 10.2.2.2.
[DeviceB] nqa server udp-echo 10.2.2.2 9000- Configurar o dispositivo A:
# Criar uma operação de jitter UDP.
system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type udp-jitter
# Especifique 10.2.2.2 como o endereço de destino da operação.
[DeviceA-nqa-admin-test1-udp-jitter] destination ip 10.2.2.2# Defina o número da porta de destino como 9000.
[DeviceA-nqa-admin-test1-udp-jitter] destination port 9000Configure a operação para se repetir a cada 1000 milissegundos.
[DeviceA-nqa-admin-test1-udp-jitter] frequency 1000
[DeviceA-nqa-admin-test1-udp-jitter] quit# Iniciar a operação de jitter UDP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação de jitter UDP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de jitter UDP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 10 Receive response times: 10
Min/Max/Average round trip time: 15/32/17
Square-Sum of round trip time: 3235
Last packet received time: 2011-05-29 13:56:17.6
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
UDP-jitter results:
RTT number: 10
Min positive SD: 4 Min positive DS: 1
Max positive SD: 21 Max positive DS: 28
Positive SD number: 5 Positive DS number: 4
Positive SD sum: 52 Positive DS sum: 38
Positive SD average: 10 Positive DS average: 10
Positive SD square-sum: 754 Positive DS square-sum: 460
Min negative SD: 1 Min negative DS: 6
Max negative SD: 13 Max negative DS: 22
Negative SD number: 4 Negative DS number: 5
Negative SD sum: 38 Negative DS sum: 52
Negative SD average: 10 Negative DS average: 10
Negative SD square-sum: 460 Negative DS square-sum: 754
SD average: 10 DS average: 10
One way results:
Max SD delay: 15 Max DS delay: 16
Min SD delay: 7 Min DS delay: 7
Number of SD delay: 10 Number of DS delay: 10
Sum of SD delay: 78 Sum of DS delay: 85
Square-Sum of SD delay: 666 Square-Sum of DS delay: 787
SD lost packets: 0 DS lost packets: 0
Lost packets for unknown reason: 0# Exibir as estatísticas da operação de jitter UDP.
[DeviceA] display nqa statistics admin test1
NQA entry (admin admin, tag test1) test statistics:
NO. : 1
Start time: 2011-05-29 13:56:14.0
Life time: 47 seconds
Send operation times: 410 Receive response times: 410
Min/Max/Average round trip time: 1/93/19
Square-Sum of round trip time: 206176
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
UDP-jitter results:
RTT number: 410
Min positive SD: 3 Min positive DS: 1
Max positive SD: 30 Max positive DS: 79
Positive SD number: 186 Positive DS number: 158
Positive SD sum: 2602 Positive DS sum: 1928
Positive SD average: 13 Positive DS average: 12
Positive SD square-sum: 45304 Positive DS square-sum: 31682
Min negative SD: 1 Min negative DS: 1
Max negative SD: 30 Max negative DS: 78
Negative SD number: 181 Negative DS number: 209
Negative SD sum: 181 Negative DS sum: 209
Negative SD average: 13 Negative DS average: 14
Negative SD square-sum: 46994 Negative DS square-sum: 3030
SD average: 9 DS average: 1
One way results:
Max SD delay: 46 Max DS delay: 46
Min SD delay: 7 Min DS delay: 7
Number of SD delay: 410 Number of DS delay: 410
Sum of SD delay: 3705 Sum of DS delay: 3891
Square-Sum of SD delay: 45987 Square-Sum of DS delay: 49393
SD lost packets: 0 DS lost packets: 0
Lost packets for unknown reason: 0
Exemplo: Configuração da operação SNMP
Configuração de rede
Conforme mostrado na Figura 9, configure uma operação SNMP para testar o tempo que o cliente NQA usa para obter uma resposta do agente SNMP.
Figura 9 Diagrama de rede

Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 9. (Detalhes não mostrados.)
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configure o agente SNMP (Dispositivo B): # Defina a versão do SNMP como all.
<DeviceB> system-view
[DeviceB] snmp-agent sys-info version all# Defina a comunidade de leitura como pública.
[DeviceB] snmp-agent community read public# Defina a comunidade de gravação como privada.
[DeviceB] snmp-agent community write private- Configurar o dispositivo A:
# Criar uma operação SNMP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type snmp# Especifique 10.2.2.2 como o endereço IP de destino da operação SNMP.
[DeviceA-nqa-admin-test1-snmp] destination ip 10.2.2.2# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-snmp] history-record enable
[DeviceA-nqa-admin-test1-snmp] quit# Iniciar a operação SNMP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação SNMP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação SNMP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 50/50/50
Square-Sum of round trip time: 2500
Last succeeded probe time: 2011-11-22 10:24:41.1
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação SNMP.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 50 Succeeded 2011-11-22 10:24:41.1
A saída mostra que o Dispositivo A levou 50 milissegundos para receber uma resposta do agente SNMP.
Exemplo: Configuração da operação TCP
Configuração de rede
Conforme mostrado na Figura 10, configure uma operação TCP para testar o tempo necessário para que o Dispositivo A estabeleça uma conexão TCP com o Dispositivo B.
Figura 10 Diagrama de rede

Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 10. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilitar o servidor NQA.
system-view
[DeviceB] nqa server enable
# Configure um serviço de escuta para escutar a porta TCP 9000 no endereço IP 10.2.2.2.
[DeviceB] nqa server tcp-connect 10.2.2.2 9000
- Configurar o dispositivo A:
# Crie uma operação TCP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type tcp
# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqa-admin-test1-tcp] destination ip 10.2.2.2# Defina o número da porta de destino como 9000.
[DeviceA-nqa-admin-test1-tcp] destination port 9000# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-tcp] history-record enable
[DeviceA-nqa-admin-test1-tcp] quit# Iniciar a operação TCP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação TCP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação TCP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 13/13/13
Square-Sum of round trip time: 169
Last succeeded probe time: 2011-11-22 10:27:25.1
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to disconnect: 0
Failures due to no connection: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação TCP.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 13 Succeeded 2011-11-22 10:27:25.1A saída mostra que o Dispositivo A levou 13 milissegundos para estabelecer uma conexão TCP com a porta 9000 no servidor NQA.
Exemplo: Configuração da operação de echo UDP
Configuração de rede
Conforme mostrado na Figura 11, configure uma operação de eco UDP no cliente NQA para testar o tempo de ida e volta para o Dispositivo B. O número da porta de destino é 8000.
Figura 11 Diagrama de rede
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 11. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilitar o servidor NQA.
system-view
[DeviceB] nqa server enable
# Configure um serviço de escuta para escutar a porta UDP 8000 no endereço IP 10.2.2.2.
[DeviceB] nqa server udp-echo 10.2.2.2 8000- Configurar o dispositivo A:
# Criar uma operação de eco UDP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type udp-echo# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqa-admin-test1-udp-echo] destination ip 10.2.2.2# Defina o número da porta de destino como 8000.
[DeviceA-nqa-admin-test1-udp-echo] destination port 8000# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-udp-echo] history-record enable
[DeviceA-nqa-admin-test1-udp-echo] quit# Iniciar a operação de eco UDP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação de eco UDP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de eco UDP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 25/25/25
Square-Sum of round trip time: 625
Last succeeded probe time: 2011-11-22 10:36:17.9
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação de eco UDP.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 25 Succeeded 2011-11-22 10:36:17.9A saída mostra que o tempo de ida e volta entre o Dispositivo A e a porta 8000 no Dispositivo B é de 25 milissegundos.
Exemplo: Configuração da operação UDP tracert
Configuração de rede
Conforme mostrado na Figura 12, configure uma operação de tracert UDP para determinar o caminho de roteamento do Dispositivo A para o Dispositivo B.
Figura 12 Diagrama de rede
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 12. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Execute o comando ip ttl-expires enable nos dispositivos intermediários e execute o comando ip unreachables enable no Dispositivo B.
- Configurar o dispositivo A:
# Criar uma operação de tracert UDP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type udp-tracert# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqa-admin-test1-udp-tracert] destination ip 10.2.2.2# Defina o número da porta de destino como 33434.
[DeviceA-nqa-admin-test1-udp-tracert] destination port 33434# Configure o dispositivo A para executar três sondas em cada salto.
[DeviceA-nqa-admin-test1-udp-tracert] probe count 3Defina o tempo limite da sonda como 500 milissegundos.
[DeviceA-nqa-admin-test1-udp-tracert] probe timeout 500# Configure a operação de tracert UDP para ser repetida a cada 5000 milissegundos.
[DeviceA-nqa-admin-test1-udp-tracert] frequency 5000# Especifique GigabitEthernet 1/0/1 como a interface de saída para pacotes UDP.
[DeviceA-nqa-admin-test1-udp-tracert] out interface gigabitethernet 1/0/1# Habilite o recurso de não fragmentação.
[DeviceA-nqa-admin-test1-udp-tracert] no-fragment enableDefina o número máximo de falhas consecutivas da sonda como 6.
[DeviceA-nqa-admin-test1-udp-tracert] max-failure 6# Defina o valor TTL como 1 para pacotes UDP na rodada inicial da operação de tracert UDP.
[DeviceA-nqa-admin-test1-udp-tracert] init-ttl 1# Iniciar a operação de tracert UDP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação UDP tracert for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de tracert UDP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 6 Receive response times: 6
Min/Max/Average round trip time: 1/1/1
Square-Sum of round trip time: 1
Last succeeded probe time: 2013-09-09 14:46:06.2
Extended results:
Packet loss in test: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
UDP-tracert results:
TTL Hop IP Time
1 3.1.1.1 2013-09-09 14:46:03.2
2 10.2.2.2 2013-09-09 14:46:06.2
# Exibir os registros de histórico da operação UDP tracert.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index TTL Response Hop IP Status Time
1 2 2 10.2.2.2 Succeeded 2013-09-09 14:46:06.2
1 2 1 10.2.2.2 Succeeded 2013-09-09 14:46:05.2
1 2 2 10.2.2.2 Succeeded 2013-09-09 14:46:04.2
1 1 1 3.1.1.1 Succeeded 2013-09-09 14:46:03.2
1 1 2 3.1.1.1 Succeeded 2013-09-09 14:46:02.2
1 1 1 3.1.1.1 Succeeded 2013-09-09 14:46:01.2
Exemplo: Configuração da operação de voz
Configuração de rede
Conforme mostrado na Figura 13, configure uma operação de voz para testar jitters, atraso, MOS e ICPIF entre o Dispositivo A e o Dispositivo B.
Figura 13 Diagrama de rede
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 13. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilitar o servidor NQA.
system-view
[DeviceB] nqa server enable
# Configure um serviço de escuta para escutar a porta UDP 9000 no endereço IP 10.2.2.2.
[DeviceB] nqa server udp-echo 10.2.2.2 9000
- Configure o dispositivo A:
# Criar uma operação de voz.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type voice
# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqa-admin-test1-voice] destination ip 10.2.2.2# Defina o número da porta de destino como 9000.
[DeviceA-nqa-admin-test1-voice] destination port 9000
[DeviceA-nqa-admin-test1-voice] quit# Iniciar a operação de voz.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação de voz for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de voz.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1000 Receive response times: 1000
Min/Max/Average round trip time: 31/1328/33
Square-Sum of round trip time: 2844813
Last packet received time: 2011-06-13 09:49:31.1
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
Voice results:
RTT number: 1000
Min positive SD: 1 Min positive DS: 1
Max positive SD: 204 Max positive DS: 1297
Positive SD number: 257 Positive DS number: 259
Positive SD sum: 759 Positive DS sum: 1797
Positive SD average: 2 Positive DS average: 6
Positive SD square-sum: 54127 Positive DS square-sum: 1691967
Min negative SD: 1 Min negative DS: 1
Max negative SD: 203 Max negative DS: 1297
Negative SD number: 255 Negative DS number: 259
Negative SD sum: 759 Negative DS sum: 1796
Negative SD average: 2 Negative DS average: 6
Negative SD square-sum: 53655 Negative DS square-sum: 1691776
SD average: 2 DS average: 6
One way results:
Max SD delay: 343 Max DS delay: 985
Min SD delay: 343 Min DS delay: 985
Number of SD delay: 1 Number of DS delay: 1
Sum of SD delay: 343 Sum of DS delay: 985
Square-Sum of SD delay: 117649 Square-Sum of DS delay: 970225
SD lost packets: 0 DS lost packets: 0
Lost packets for unknown reason: 0
Voice scores:
MOS value: 4.38 ICPIF value: 0# Exibir as estatísticas da operação de voz.
[DeviceA] display nqa statistics admin test1
NQA entry (admin admin, tag test1) test statistics:
NO. : 1
Start time: 2011-06-13 09:45:37.8
Life time: 331 seconds
Send operation times: 4000 Receive response times: 4000
Min/Max/Average round trip time: 15/1328/32
Square-Sum of round trip time: 7160528
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
Voice results:
RTT number: 4000
Min positive SD: 1 Min positive DS: 1
Max positive SD: 360 Max positive DS: 1297
Positive SD number: 1030 Positive DS number: 1024
Positive SD sum: 4363 Positive DS sum: 5423
Positive SD average: 4 Positive DS average: 5
Positive SD square-sum: 497725 Positive DS square-sum: 2254957
Min negative SD: 1 Min negative DS: 1
Max negative SD: 360 Max negative DS: 1297
Negative SD number: 1028 Negative DS number: 1022
Negative SD sum: 1028 Negative DS sum: 1022
Negative SD average: 4 Negative DS average: 5
Negative SD square-sum: 495901 Negative DS square-sum: 5419
SD average: 16 DS average: 2
One way results:
Max SD delay: 359 Max DS delay: 985
Min SD delay: 0 Min DS delay: 0
Number of SD delay: 4 Number of DS delay: 4
Sum of SD delay: 1390 Sum of DS delay: 1079
Square-Sum of SD delay: 483202 Square-Sum of DS delay: 973651
SD lost packets: 0 DS lost packets: 0
Lost packets for unknown reason: 0
Voice scores:
Max MOS value: 4.38 Min MOS value: 4.38
Max ICPIF value: 0 Min ICPIF value: 0Exemplo: Configuração da operação DLSw
Configuração de rede
Conforme mostrado na Figura 14, configure uma operação DLSw para testar o tempo de resposta do dispositivo DLSw.
Figura 14 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 14. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar uma operação DLSw.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type dlsw# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqa-admin-test1-dlsw] destination ip 10.2.2.2# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-dlsw] history-record enable
[DeviceA-nqa-admin-test1-dlsw] quit# Iniciar a operação DLSw.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever
# Depois que a operação DLSw for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação DLSw.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 19/19/19
Square-Sum of round trip time: 361
Last succeeded probe time: 2011-11-22 10:40:27.7
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to disconnect: 0
Failures due to no connection: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação DLSw.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 19 Succeeded 2011-11-22 10:40:27.7A saída mostra que o tempo de resposta do dispositivo DLSw é de 19 milissegundos.
Exemplo: Configuração da operação de jitter de caminho
Configuração de rede
Conforme mostrado na Figura 15, configure uma operação de jitter de caminho para testar o tempo de ida e volta e os jitters do Dispositivo A para o Dispositivo B e o Dispositivo C.
Figura 15 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 15. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Execute o comando ip ttl-expires enable no Dispositivo B e execute o comando ip unreachables enable no Dispositivo C.
# Criar uma operação de jitter de caminho.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type path-jitter
# Especifique 10.2.2.2 como o endereço IP de destino das solicitações de eco ICMP.
[DeviceA-nqa-admin-test1-path-jitter] destination ip 10.2.2.2# Configure a operação de jitter de caminho para ser repetida a cada 10.000 milissegundos.
[DeviceA-nqa-admin-test1-path-jitter] frequency 10000
[DeviceA-nqa-admin-test1-path-jitter] quit# Iniciar a operação de jitter de caminho.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação de jitter de caminho for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de jitter de caminho.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Hop IP 10.1.1.2
Basic Results
Send operation times: 10 Receive response times: 10
Min/Max/Average round trip time: 9/21/14
Square-Sum of round trip time: 2419
Extended Results
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
Path-Jitter Results
Jitter number: 9
Min/Max/Average jitter: 1/10/4
Positive jitter number: 6
Min/Max/Average positive jitter: 1/9/4
Sum/Square-Sum positive jitter: 25/173
Negative jitter number: 3
Min/Max/Average negative jitter: 2/10/6
Sum/Square-Sum positive jitter: 19/153
Hop IP 10.2.2.2
Basic Results
Send operation times: 10 Receive response times: 10
Min/Max/Average round trip time: 15/40/28
Square-Sum of round trip time: 4493
Extended Results
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
Path-Jitter Results
Jitter number: 9
Min/Max/Average jitter: 1/10/4
Positive jitter number: 6
Min/Max/Average positive jitter: 1/9/4
Sum/Square-Sum positive jitter: 25/173
Negative jitter number: 3
Min/Max/Average negative jitter: 2/10/6
Sum/Square-Sum positive jitter: 19/153Exemplo: Configuração da colaboração NQA
Configuração de rede
Conforme mostrado na Figura 16, configure uma rota estática para o Switch C com o Switch B como o próximo salto no Switch
A. Associe a rota estática, uma entrada de trilha e uma operação de eco ICMP para monitorar o estado da rota estática .
Figura 16 Diagrama de rede
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 16. (Detalhes não mostrados).
- No Switch A, configure uma rota estática e associe a rota estática à entrada de trilha 1.
<SwitchA> system-view
[SwitchA] ip route-static 10.1.1.2 24 10.2.1.1 track 1- No Switch A, configure uma operação de eco ICMP:
# Criar uma operação NQA com o nome de administrador admin e a tag de operação test1.
[SwitchA] nqa entry admin test1# Configure o tipo de operação do NQA como eco ICMP.
[SwitchA-nqa-admin-test1] type icmp-echo# Especifique 10.2.1.1 como o endereço IP de destino.
[SwitchA-nqa-admin-test1-icmp-echo] destination ip 10.2.1.1[Configure a operação para se repetir a cada 100 milissegundos.
[SwitchA-nqa-admin-test1-icmp-echo] frequency 100# Criar entrada de reação 1. Se o número de falhas consecutivas da sonda chegar a 5, a colaboração será acionada.
[SwitchA-nqa-admin-test1-icmp-echo] reaction 1 checked-element probe-fail
threshold-type consecutive 5 action-type trigger-only
[SwitchA-nqa-admin-test1-icmp-echo] quit# Iniciar a operação ICMP.
[SwitchA] nqa schedule admin test1 start-time now lifetime forever- No Switch A, crie a entrada de trilha 1 e associe-a à entrada de reação 1 da operação NQA.
[SwitchA] track 1 nqa entry admin test1 reaction 1Verificação da configuração
# Exibir informações sobre todas as entradas de trilha no Switch A.
[SwitchA] display track all
Track ID: 1
State: Positive
Duration: 0 days 0 hours 0 minutes 0 seconds
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
NQA entry: admin test1
Reaction: 1# Exibir informações breves sobre as rotas ativas na tabela de roteamento do Switch A.
[SwitchA] display ip routing-table
Destinations : 13 Routes : 13
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
10.1.1.0/24 Static 60 0 10.2.1.1 Vlan3
10.2.1.0/24 Direct 0 0 10.2.1.2 Vlan3
10.2.1.0/32 Direct 0 0 10.2.1.2 Vlan3
10.2.1.2/32 Direct 0 0 127.0.0.1 InLoop0
10.2.1.255/32 Direct 0 0 10.2.1.2 Vlan3
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
127.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
224.0.0.0/4 Direct 0 0 0.0.0.0 NULL0
224.0.0.0/24 Direct 0 0 0.0.0.0 NULL0
255.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0A saída mostra que a rota estática com o próximo salto 10.2.1.1 está ativa e o status da entrada da trilha é positivo.
# Remova o endereço IP da interface VLAN 3 no Switch B.
<SwitchB> system-view
[SwitchB] interface vlan-interface 3
[SwitchB-Vlan-interface3] undo ip address# Exibir informações sobre todas as entradas de trilha no Switch A.
[SwitchA] display track all
Track ID: 1
State: Negative
Duration: 0 days 0 hours 0 minutes 0 seconds
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
NQA entry: admin test1
Reaction: 1# Exibir informações breves sobre as rotas ativas na tabela de roteamento do Switch A.
[SwitchA] display ip routing-table
Destinations : 12 Routes : 12
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
10.2.1.0/24 Direct 0 0 10.2.1.2 Vlan3
10.2.1.0/32 Direct 0 0 10.2.1.2 Vlan3
10.2.1.2/32 Direct 0 0 127.0.0.1 InLoop0
10.2.1.255/32 Direct 0 0 10.2.1.2 Vlan3
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
127.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
224.0.0.0/4 Direct 0 0 0.0.0.0 NULL0
224.0.0.0/24 Direct 0 0 0.0.0.0 NULL0
255.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0A saída mostra que a rota estática não existe e o status da entrada de trilha é negativo.
Exemplo: Configuração do modelo ICMP
Configuração de rede
Conforme mostrado na Figura 17, configure um modelo ICMP para que um recurso execute a operação de eco ICMP do Dispositivo A para o Dispositivo B.
Figura 17 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 17. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar modelo ICMP icmp.
<DeviceA> system-view
[DeviceA] nqa template icmp icmp# Especifique 10.2.2.2 como o endereço IP de destino das solicitações de eco ICMP.
[DeviceA-nqatplt-icmp-icmp] destination ip 10.2.2.2# Defina o tempo limite da sonda como 500 milissegundos para a operação de eco ICMP.
[DeviceA-nqatplt-icmp-icmp] probe timeout 500# Configure a operação de eco ICMP para se repetir a cada 3000 milissegundos.
[DeviceA-nqatplt-icmp-icmp] frequency 3000# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-icmp-icmp] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-icmp-icmp] reaction trigger probe-fail 2Exemplo: Configuração do modelo de DNS
Configuração de rede
Conforme mostrado na Figura 18, configure um modelo de DNS para que um recurso execute a operação de DNS. A operação testa se o Dispositivo A pode executar a resolução de endereços por meio do servidor DNS.
Figura 18 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 18. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar modelo de DNS dns.
<DeviceA> system-view
[DeviceA] nqa template dns dns# Especifique o endereço IP do servidor DNS (10.2.2.2) como o endereço IP de destino.
[DeviceA-nqatplt-dns-dns] destination ip 10.2.2.2# Especifique host.com como o nome de domínio a ser traduzido.
[DeviceA-nqatplt-dns-dns] resolve-target host.com# Defina o tipo de resolução de nome de domínio como tipo A.
[DeviceA-nqatplt-dns-dns] resolve-type A# Especifique 3.3.3.3 como o endereço IP esperado.
[DeviceA-nqatplt-dns-dns] expect ip 3.3.3.3# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-dns-dns] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-dns-dns] reaction trigger probe-fail 2Exemplo: Configuração do modelo TCP
Configuração de rede
Conforme mostrado na Figura 19, configure um modelo TCP para que um recurso execute a operação TCP. A operação testa se o Dispositivo A pode estabelecer uma conexão TCP com o Dispositivo B.
Figura 19 Diagrama de rede
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 19. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilitar o servidor NQA.
system-view
[DeviceB] nqa server enable
# Configure um serviço de escuta para escutar a porta TCP 9000 no endereço IP 10.2.2.2.
[DeviceB] nqa server tcp-connect 10.2.2.2 9000
- Configurar o dispositivo A:
# Criar modelo TCP tcp.
<DeviceA> system-view
[DeviceA] nqa template tcp tcp# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqatplt-tcp-tcp] destination ip 10.2.2.2# Defina o número da porta de destino como 9000.
[DeviceA-nqatplt-tcp-tcp] destination port 9000# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-tcp-tcp] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-tcp-tcp] reaction trigger probe-fail 2Exemplo: Configuração do modelo TCP semiaberto
Configuração de rede
Conforme mostrado na Figura 20, configure um modelo TCP semiaberto para um recurso para testar se o Dispositivo B pode fornecer o serviço TCP para o Dispositivo A.
Figura 20 Diagrama de rede

Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 20. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo A:
# Criar teste de modelo TCP semiaberto.
<DeviceA> system-view
[DeviceA] nqa template tcphalfopen test# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqatplt-tcphalfopen-test] destination ip 10.2.2.2# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-tcphalfopen-test] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-tcphalfopen-test] reaction trigger probe-fail 2Exemplo: Configuração do modelo UDP
Configuração de rede
Conforme mostrado na Figura 21, configure um modelo UDP para que um recurso execute a operação UDP. A operação testa se o Dispositivo A pode receber uma resposta do Dispositivo B.
Figura 21 Diagrama de rede
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 21. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilitar o servidor NQA.
<DeviceB> system-view
[DeviceB] nqa server enable
# Configure um serviço de escuta para escutar a porta UDP 9000 no endereço IP 10.2.2.2.
[DeviceB] nqa server udp-echo 10.2.2.2 9000
- Configurar o dispositivo A:
# Criar modelo UDP udp.
<DeviceA> system-view
[DeviceB] nqa server enableExemplo: Configuração do modelo HTTP
Configuração de rede
Conforme mostrado na Figura 22, configure um modelo HTTP para que um recurso execute a operação HTTP. A operação testa se o cliente NQA pode obter dados do servidor HTTP.
Figura 22 Diagrama de rede

Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 22. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar modelo HTTP http.
<DeviceA> system-view
[DeviceA] nqa template http http# Especifique http://10.2.2.2/index.htm como o URL do servidor HTTP.
[DeviceA-nqatplt-http-http] url http://10.2.2.2/index.htm# Defina o tipo de operação HTTP como get.
[DeviceA-nqatplt-http-http] operation get# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-http-http] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-http-http] reaction trigger probe-fail 2Exemplo: Configuração do modelo HTTPS
Configuração de rede
Conforme mostrado na Figura 23, configure um modelo HTTPS para um recurso para testar se o cliente NQA pode obter dados do servidor HTTPS (Dispositivo B).
Figura 23 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 23. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Configure uma política de cliente SSL chamada abc no Dispositivo A e certifique-se de que o Dispositivo A possa usar a política para se conectar ao servidor HTTPS. (Detalhes não mostrados.)
# Criar teste de modelo HTTPS.
system-view
[DeviceA] nqa template https https
# Especifique http://10.2.2.2/index.htm como o URL do servidor HTTPS.
[DeviceA-nqatplt-https-https] url https://10.2.2.2/index.htm# Especifique a política de cliente SSL abc para o modelo HTTPS.
[DeviceA-nqatplt-https- https] ssl-client-policy abc# Defina o tipo de operação HTTPS como get (o tipo de operação HTTPS padrão).
[DeviceA-nqatplt-https-https] operation get# Defina a versão do HTTPS como 1.0 (a versão padrão do HTTPS).
[DeviceA-nqatplt-https-https] version v1.0# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-https-https] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-https-https] reaction trigger probe-fail 2Exemplo: Configuração do modelo de FTP
Configuração de rede
Conforme mostrado na Figura 24, configure um modelo de FTP para que um recurso execute a operação de FTP. A operação testa se o Dispositivo A pode carregar um arquivo no servidor FTP. O nome de usuário e a senha de login são admin e systemtest, respectivamente. O arquivo a ser transferido para o servidor FTP é config.txt.
Figura 24 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 24. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar modelo de FTP ftp.
<DeviceA> system-view
[DeviceA] nqa template ftp ftp# Especifique o URL do servidor FTP.
[DeviceA-nqatplt-ftp-ftp] url ftp://10.2.2.2# Especifique 10.1.1.1 como o endereço IP de origem.
[DeviceA-nqatplt-ftp-ftp] source ip 10.1.1.1# Configure o dispositivo para fazer upload do arquivo config.txt para o servidor FTP.
[DeviceA-nqatplt-ftp-ftp] operation put
[DeviceA-nqatplt-ftp-ftp] filename config.txt# Defina o nome de usuário como admin para o login no servidor FTP.
[DeviceA-nqatplt-ftp-ftp] password simple systemtest# Defina a senha como systemtest para o login do servidor FTP.
[DeviceA-nqatplt-ftp-ftp] password simple systemtest
# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-ftp-ftp] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-ftp-ftp] reaction trigger probe-fail 2Exemplo: Configuração do modelo RADIUS
Configuração de rede
Conforme mostrado na Figura 25, configure um modelo RADIUS para um recurso para testar se o servidor RADIUS (Dispositivo B) pode fornecer serviço de autenticação para o Dispositivo A. O nome de usuário e a senha são admin e systemtest, respectivamente. A chave compartilhada é 123456 para autenticação RADIUS segura.
Figura 25 Diagrama de rede

Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 25. (Os detalhes não são mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Configurar o servidor RADIUS. (Detalhes não mostrados.) # Criar modelo RADIUS radius.
<DeviceA> system-view
[DeviceA] nqa template radius radius# Especifique 10.2.2.2 como o endereço IP de destino da operação.
[DeviceA-nqatplt-radius-radius] destination ip 10.2.2.2# Defina o nome de usuário como admin.
[DeviceA-nqatplt-radius-radius] username admin# Defina a senha como systemtest.
[DeviceA-nqatplt-radius-radius] password simple systemtest# Defina a chave compartilhada como 123456 em texto simples para autenticação RADIUS segura.
[DeviceA-nqatplt-radius-radius] key simple 123456# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-radius-radius] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-radius-radius] reaction trigger probe-fail 2Exemplo: Configuração do modelo SSL
Configuração de rede
Conforme mostrado na Figura 26, configure um modelo SSL para um recurso para testar se o Dispositivo A pode estabelecer uma conexão SSL com o servidor SSL no Dispositivo B.
Figura 26 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 26. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Configure uma política de cliente SSL chamada abc no Dispositivo A e certifique-se de que o Dispositivo A possa usar a política para se conectar ao servidor SSL no Dispositivo B. (Detalhes não mostrados).
# Criar modelo SSL ssl.
system-view
[DeviceA] nqa template ssl ssl # Defina o endereço IP de destino e o número da porta como 10.2.2.2 e 9000, respectivamente.
[DeviceA-nqatplt-ssl-ssl] destination ip 10.2.2.2
[DeviceA-nqatplt-ssl-ssl] destination port 9000# Especifique a política de cliente SSL abc para o modelo SSL.
[DeviceA-nqatplt-ssl-ssl] ssl-client-policy abc# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-ssl-ssl] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-ssl-ssl] reaction trigger probe-fail 2Configuração do NTP
Sobre a NTP
O NTP é usado para sincronizar os relógios do sistema entre servidores de horário distribuídos e clientes em uma rede. O NTP é executado por UDP e usa a porta UDP 123.
Cenários de aplicativos NTP
Várias tarefas, inclusive gerenciamento de rede, cobrança, auditoria e computação distribuída, dependem da configuração precisa e sincronizada da hora do sistema nos dispositivos de rede. Normalmente, o NTP é usado em grandes redes para sincronizar dinamicamente a hora entre os dispositivos de rede.
O NTP garante maior precisão do relógio do que a configuração manual do relógio do sistema. Em uma rede pequena que não exige alta precisão do relógio, é possível manter o tempo sincronizado entre os dispositivos alterando os relógios do sistema um a um.
Mecanismo de funcionamento do NTP
A Figura 1 mostra como o NTP sincroniza a hora do sistema entre dois dispositivos (Dispositivo A e Dispositivo B, neste exemplo). Suponha que:
Antes da sincronização de horário, o horário é definido como 10:00:00 am para o Dispositivo A e 11:00:00 am para o Dispositivo B.
O dispositivo B é usado como servidor NTP. O dispositivo A deve ser sincronizado com o dispositivo B.
Uma mensagem NTP leva 1 segundo para ir do Dispositivo A ao Dispositivo B e do Dispositivo B ao Dispositivo A.
O Dispositivo B leva 1 segundo para processar a mensagem NTP.
Figura 1 Fluxo de trabalho básico
O processo de sincronização é o seguinte:
- O Dispositivo A envia ao Dispositivo B uma mensagem NTP, que recebe um registro de data e hora quando sai do Dispositivo A. O registro de data e hora é 10:00:00 am (T1).
- Quando essa mensagem NTP chega ao Dispositivo B, o Dispositivo B adiciona um registro de data e hora mostrando a hora em que a mensagem chegou ao Dispositivo B. O registro de data e hora é 11:00:01 am (T2).
- Quando a mensagem NTP sai do Dispositivo B, o Dispositivo B adiciona um registro de data e hora mostrando a hora em que a mensagem saiu do Dispositivo B. O registro de data e hora é 11:00:02 am (T3).
- Quando o Dispositivo A recebe a mensagem NTP, a hora local do Dispositivo A é 10:00:03 am (T4). Até o momento, o Dispositivo A pode calcular os seguintes parâmetros com base nos registros de data e hora:
O atraso de ida e volta da mensagem NTP: Atraso = (T4 - T1) - (T3 - T2) = 2 segundos.
Diferença de tempo entre o Dispositivo A e o Dispositivo B: Deslocamento = [ (T2 - T1) + (T3 - T4) ] /2 = 1 hora. Com base nesses parâmetros, o Dispositivo A pode ser sincronizado com o Dispositivo B.
Esta é apenas uma descrição aproximada do mecanismo de trabalho do NTP. Para obter mais informações, consulte os protocolos e padrões relacionados em .
Arquitetura NTP
O NTP usa estratos de 1 a 16 para definir a precisão do relógio, conforme mostrado na Figura 2. Um valor de estrato mais baixo representa maior precisão. Os relógios nos estratos 1 a 15 estão em estado sincronizado, e os relógios no estrato 16 não estão sincronizados.
Figura 2 Arquitetura do NTP
Um servidor NTP de estrato 1 obtém sua hora de uma fonte de hora autorizada, como um relógio atômico. Ele fornece a hora para outros dispositivos como o servidor NTP principal. Um servidor de horário de estrato 2 recebe seu horário de um servidor de horário de estrato 1, e assim por diante.
Para garantir a precisão e a disponibilidade do tempo, você pode especificar vários servidores NTP para um dispositivo. O dispositivo seleciona um servidor NTP ideal como a fonte do relógio com base em parâmetros como estrato. O relógio que o dispositivo seleciona é chamado de fonte de referência. Para obter mais informações sobre a seleção do relógio, consulte os protocolos e padrões relacionados.
Se os dispositivos em uma rede não puderem ser sincronizados com uma fonte de hora autorizada, você poderá executar as seguintes tarefas:
Selecione um dispositivo que tenha um relógio relativamente preciso na rede.
Use o relógio local do dispositivo como relógio de referência para sincronizar outros dispositivos na rede .
Modos de associação NTP
O NTP é compatível com os seguintes modos de associação:
Modo cliente/servidor
Modo ativo/passivo simétrico
Modo de transmissão
Modo multicast
Você pode selecionar um ou mais modos de associação para sincronização de horário. A Tabela 1 fornece uma descrição detalhada dos quatro modos de associação.
Neste documento, um "servidor NTP" ou um "servidor" refere-se a um dispositivo que opera como um servidor NTP no modo cliente/servidor. Servidores de horário referem-se a todos os dispositivos que podem fornecer sincronização de horário, incluindo servidores NTP, pares simétricos NTP, servidores de broadcast e servidores multicast.
Tabela 1 Modos de associação NTP
| Modo | Processo de trabalho | Princípio | Cenário de aplicação | ||||
| No cliente, especifique o endereço IP do servidor NTP. | |||||||
| Cliente/servidor | Um cliente envia uma mensagem de sincronização de relógio para os servidores NTP. Ao receber a mensagem, os servidores operam automaticamente no modo de servidor e enviam uma resposta. Se o cliente puder ser sincronizado com vários servidores de horário, ele selecionará um relógio ideal e sincronizará seu relógio local com a fonte de referência ideal após receber as respostas dos servidores. | Um cliente pode sincronizar com um servidor, mas um servidor não pode sincronizar com um cliente. | Como mostra a Figura 2, esse modo é destinado a configurações em que os dispositivos de um estrato mais alto sincronizam com dispositivos de um estrato mais baixo. | ||||
| No par ativo simétrico, especifique o endereço IP do par passivo simétrico. | |||||||
| Ativo/passivo simétrico | Um par ativo simétrico envia periodicamente mensagens de sincronização de relógio para um par passivo simétrico. O par passivo simétrico opera automaticamente no modo passivo simétrico e envia uma resposta. Se o par ativo simétrico puder ser sincronizado com vários servidores de horário, ele selecionará um relógio ideal e sincronizará seu relógio local com a fonte de referência ideal após receber as respostas dos servidores. | Um par ativo simétrico e um par passivo simétrico podem ser sincronizados um com o outro. Se ambos estiverem sincronizados, o par com um estrato mais alto será sincronizado com o par com um estrato mais baixo. | Como mostra a Figura 2, esse modo é usado com mais frequência entre servidores com o mesmo estrato para operar como backup um para o outro. Se um servidor não conseguir se comunicar com todos os servidores de um estrato inferior, ele ainda poderá se sincronizar com os servidores do mesmo estrato. | ||||
| Transmissão | Um servidor envia periodicamente mensagens de sincronização de relógio para o endereço de transmissão | Um cliente de transmissão pode sincronizar com um servidor de transmissão, mas um | Um servidor de transmissão envia sincronização de relógio mensagens para sincronizar | ||||
| 255.255.255.255. Os clientes ouvem as mensagens de broadcast dos servidores para sincronizar com o servidor de acordo com as mensagens de broadcast. Quando um cliente recebe a primeira mensagem de broadcast, o cliente e o servidor começam a trocar mensagens para calcular o atraso da rede entre eles. Então, somente o servidor de transmissão envia mensagens de sincronização de relógio. | O servidor de transmissão não pode sincronizar com um cliente de transmissão. | clientes na mesma sub-rede. Como mostra a Figura 2, o modo de broadcast é destinado a configurações que envolvem um ou poucos servidores e uma população de clientes potencialmente grande. O modo de broadcast tem menor precisão de tempo do que os modos cliente/servidor e ativo/passivo simétrico porque somente os servidores de broadcast enviam mensagens de sincronização de relógio. | |||||
| Multicast | Um servidor multicast envia periodicamente mensagens de sincronização de relógio para o endereço multicast configurado pelo usuário. Os clientes ouvem as mensagens multicast dos servidores e sincronizam com o servidor de acordo com as mensagens recebidas. | Um cliente multicast pode sincronizar-se com um servidor multicast, mas um servidor multicast não pode sincronizar-se com um cliente multicast. | Um servidor multicast pode fornecer sincronização de horário para clientes na mesma sub-rede ou em sub-redes diferentes. O modo multicast tem menor precisão de tempo do que os modos cliente/servidor e ativo/passivo simétrico. |
Segurança NTP
Para aumentar a segurança da sincronização de horário, o NTP fornece as funções de controle de acesso e autenticação.
Controle de acesso ao NTP
Você pode controlar o acesso ao NTP usando uma ACL. Os direitos de acesso estão na seguinte ordem, do menos restritivo para o mais restritivo:
Peer - Permite solicitações de horário e consultas de controle NTP (como alarmes, status de autenticação e informações do servidor de horário) e permite que o dispositivo local se sincronize com um dispositivo par.
Server - Permite solicitações de horário e consultas de controle NTP, mas não permite que o dispositivo local se sincronize com um dispositivo par.
Sincronização - Permite apenas solicitações de tempo de um sistema cujo endereço atenda aos critérios da lista de acesso.
Query (Consulta) - Permite apenas consultas de controle NTP de um dispositivo par para o dispositivo local.
Quando o dispositivo recebe uma solicitação NTP, ele compara a solicitação com os direitos de acesso na ordem do menos restritivo para o mais restritivo: par, servidor, sincronização e consulta.
Se nenhum controle de acesso ao NTP estiver configurado, aplica-se o direito de acesso de pares.
Se o endereço IP do dispositivo par corresponder a uma instrução de permissão em uma ACL, o direito de acesso será concedido ao dispositivo par. Se uma instrução deny ou nenhuma ACL corresponder, nenhum direito de acesso será concedido.
Se nenhuma ACL for especificada para um direito de acesso ou se a ACL especificada para o direito de acesso não for criada, o direito de acesso não será concedido.
Se nenhuma das ACLs especificadas para os direitos de acesso for criada, será aplicado o direito de acesso do par.
Se nenhuma das ACLs especificadas para os direitos de acesso contiver regras, nenhum direito de acesso será concedido.
Esse recurso oferece segurança mínima para um sistema que executa NTP. Um método mais seguro é a autenticação NTP.
Autenticação NTP
Use esse recurso para autenticar as mensagens NTP para fins de segurança. Se uma mensagem NTP for aprovada na autenticação, o dispositivo poderá recebê-la e obter informações de sincronização de horário. Caso contrário, o dispositivo descartará a mensagem. Essa função garante que o dispositivo não sincronize com um servidor de horário não autorizado .
Figura 3 Autenticação NTP
Conforme mostrado na Figura 3, a autenticação NTP é realizada da seguinte forma:
- O remetente usa a chave identificada pelo ID da chave para calcular um resumo da mensagem NTP por meio do algoritmo de autenticação MD5/HMAC. Em seguida, ele envia o resumo calculado juntamente com a mensagem NTP e o ID da chave para o receptor.
- Ao receber a mensagem, o receptor executa as seguintes ações:
- Encontra a chave de acordo com o ID da chave na mensagem.
- Usa a chave e o algoritmo de autenticação MD5/HMAC para calcular o resumo da mensagem .
- Compara o digest com o digest contido na mensagem NTP.
- Se forem diferentes, o receptor descartará a mensagem.
- Se forem iguais e não for necessário estabelecer uma associação NTP, o receptor fornecerá um pacote de resposta. Para obter informações sobre associações NTP, consulte "Configuração do número máximo de associações dinâmicas".
- Se forem iguais e for necessário estabelecer ou já existir uma associação NTP, o dispositivo local determinará se o remetente tem permissão para usar o ID de autenticação. Se o remetente tiver permissão para usar o ID de autenticação, o receptor aceitará a mensagem. Se o remetente não tiver permissão para usar a ID de autenticação, o receptor descartará a mensagem .
Protocolos e padrões
RFC 1305, Especificação, implementação e análise do Network Time Protocol (versão 3)
RFC 5905, Network Time Protocol Version 4: Especificação de protocolo e algoritmos
Restrições e diretrizes: Configuração do NTP
Não é possível configurar o NTP e o SNTP no mesmo dispositivo.
O NTP é compatível apenas com as interfaces da Camada 3.
Não configure o NTP em uma porta de membro agregado.
O serviço NTP e o serviço SNTP são mutuamente exclusivos. Você só pode ativar o serviço NTP ou o serviço SNTP de cada vez.
Para evitar mudanças frequentes de horário ou até mesmo falhas de sincronização, não especifique mais de uma fonte de referência em uma rede.
∙ Para usar o NTP para sincronização de horário, você deve usar o comando clock protocol para especificar o NTP para obter o horário. Para obter mais informações sobre o comando clock protocol, consulte os comandos de gerenciamento de dispositivos na Referência de comandos básicos.
Visão geral das tarefas NTP
Para configurar o NTP, execute as seguintes tarefas:
- Ativação do serviço NTP
- Configuração do modo de associação NTP
- Configuração do NTP no modo cliente/servidor
- Configuração do NTP no modo ativo/passivo simétrico
- Configuração do NTP no modo de broadcast
- Configuração do NTP no modo multicast
- (Opcional.) Configurar o relógio local como a fonte de referência
- (Opcional.) Configuração dos direitos de controle de acesso
- (Opcional.) Configuração da autenticação NTP
- Configuração da autenticação NTP no modo cliente/servidor
- Configuração da autenticação NTP no modo ativo/passivo simétrico
- Configuração da autenticação NTP no modo de broadcast
- Configuração da autenticação NTP no modo multicast
- (Opcional.) Controle do envio e recebimento de pacotes NTP
- Especificação de um endereço de origem para mensagens NTP
- Desativar o recebimento de mensagens NTP por uma interface
- Configuração do número máximo de associações dinâmicas
- Definição de um valor DSCP para pacotes NTP
- (Opcional.) Especificação dos limites de deslocamento de tempo do NTP para saídas de registro e de interceptação
- Entre na visualização do sistema.
Ativação do serviço NTP
Restrições e diretrizes
O NTP e o SNTP são mutuamente exclusivos. Antes de ativar o NTP, certifique-se de que o SNTP esteja desativado.
Procedimento
system-view- Habilite o serviço NTP.
ntp-service enablePor padrão, o serviço NTP está desativado.
Configuração do modo de associação NTP
Configuração do NTP no modo cliente/servidor
Restrições e diretrizes
Para configurar o NTP no modo cliente/servidor, especifique um servidor NTP para o cliente.
Para que um cliente sincronize com um servidor NTP, certifique-se de que o servidor esteja sincronizado por outros dispositivos ou use seu relógio local como fonte de referência.
Se o nível de estrato de um servidor for maior ou igual ao de um cliente, o cliente não sincronizará com esse servidor.
Você pode especificar vários servidores para um cliente executando o comando ntp-service unicast-server ou
comando ntp-service ipv6 unicast-server várias vezes.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique um servidor NTP para o dispositivo. IPv4:
ntp-service unicast-server { server-name | ip-address }
[ authentication-keyid keyid | maxpoll maxpoll-interval | minpoll
minpoll-interval | priority | source interface-type interface-number |
version number ] *IPv6:
ntp-service ipv6 unicast-server { server-name | ipv6-address }
[ authentication-keyid keyid | maxpoll maxpoll-interval | minpoll
minpoll-interval | priority | source interface-type interface-number ]
*Por padrão, nenhum servidor NTP é especificado.
Configuração do NTP no modo ativo/passivo simétrico
Restrições e diretrizes
Para configurar o NTP no modo ativo/passivo simétrico, especifique um par passivo simétrico para o par ativo.
Para que um par passivo simétrico processe mensagens NTP de um par ativo simétrico, execute o comando
comando ntp-service enable no par passivo simétrico para ativar o NTP.
Para sincronização de horário entre o par ativo simétrico e o par passivo simétrico, certifique-se de que um ou ambos estejam em estado sincronizado.
Você pode especificar vários pares passivos simétricos executando o comando ntp-service unicast-peer ou ntp-service ipv6 unicast-peer várias vezes.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique um par passivo simétrico para o dispositivo. IPv4:
ntp-service unicast-peer { peer-name | ip-address }
[ authentication-keyid keyid | maxpoll maxpoll-interval | minpoll
minpoll-interval | priority | source interface-type interface-number |
version number ] *IPv6:
ntp-service ipv6 unicast-peer { peer-name | ipv6-address }
[ authentication-keyid keyid | maxpoll maxpoll-interval | minpoll
minpoll-interval | priority | source interface-type interface-number ]
*Por padrão, nenhum par passivo simétrico é especificado.
Configuração do NTP no modo de broadcast
Restrições e diretrizes
Para configurar o NTP no modo de broadcast, você deve configurar um cliente de broadcast NTP e um servidor de broadcast NTP.
Para que um cliente de transmissão sincronize com um servidor de transmissão, certifique-se de que o servidor de transmissão esteja sincronizado por outros dispositivos ou use seu relógio local como fonte de referência.
Configuração do cliente de transmissão
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o dispositivo para operar no modo de cliente de broadcast.
ntp-service broadcast-clientPor padrão, o dispositivo não opera em nenhum modo de associação NTP.
Depois que você executar o comando, o dispositivo receberá mensagens de broadcast NTP da interface especificada .
Configuração do servidor de transmissão
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o dispositivo para operar no modo de servidor de transmissão NTP.
ntp-service broadcast-server [ authentication-keyid keyid | version number ] *Por padrão, o dispositivo não opera em nenhum modo de associação NTP.
Depois que você executar o comando, o dispositivo enviará mensagens de broadcast NTP a partir da interface especificada.
Configuração do NTP no modo multicast
Restrições e diretrizes
Para configurar o NTP no modo multicast, você deve configurar um cliente NTP multicast e um servidor NTP multicast.
Para que um cliente multicast sincronize com um servidor multicast, certifique-se de que o servidor multicast esteja sincronizado por outros dispositivos ou use seu relógio local como fonte de referência.
Configuração de um cliente multicast
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o dispositivo para operar no modo de cliente multicast. IPv4:
ntp-service multicast-client [ ip-address ]IPv6:
ntp-service ipv6 multicast-client ipv6-address
Por padrão, o dispositivo não opera em nenhum modo de associação NTP.
Depois que você executar o comando, o dispositivo receberá mensagens multicast NTP da interface especificada .
Configuração do servidor multicast
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o dispositivo para operar no modo de servidor multicast. IPv4:
ntp-service multicast-server [ ip-address ] [ authentication-keyid
keyid | ttl ttl-number | version number ] *
IPv6:
ntp-service ipv6 multicast-server ipv6-address [ authentication-keyid
keyid | ttl ttl-number ] *Por padrão, o dispositivo não opera em nenhum modo de associação NTP.
Depois que você executar o comando, o dispositivo enviará mensagens multicast de NTP a partir da interface especificada.
Configuração do relógio local como fonte de referência
Sobre como configurar o relógio local como a fonte de referência
Essa tarefa permite que o dispositivo use o relógio local como referência para que o dispositivo seja sincronizado.
Restrições e diretrizes
Certifique-se de que o relógio local possa fornecer a precisão de tempo necessária para a rede. Depois de configurar o relógio local como fonte de referência, o relógio local é sincronizado e pode funcionar como um servidor de horário para sincronizar outros dispositivos na rede. Se o relógio local estiver incorreto, ocorrerão erros de sincronização.
A hora do sistema é revertida para o padrão inicial do BIOS após uma reinicialização a frio. Como prática recomendada, não configure o relógio local como a fonte de referência nem configure o dispositivo como um servidor de horário.
Os dispositivos diferem em termos de precisão do relógio. Como prática recomendada para evitar oscilações na rede e falhas na sincronização do relógio, configure apenas um relógio de referência no mesmo segmento de rede e certifique-se de que o relógio tenha alta precisão.
Pré-requisitos
Antes de configurar esse recurso, ajuste a hora do sistema local para garantir que ela seja precisa.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o relógio local como a fonte de referência.
ntp-service refclock-master [ ip-address ] [ stratum ]Por padrão, o dispositivo não usa o relógio local como fonte de referência.
Configuração dos direitos de controle de acesso
Pré-requisitos
Antes de configurar o direito de os dispositivos pares acessarem os serviços NTP no dispositivo local, crie e configure as ACLs associadas ao direito de acesso. Para obter informações sobre a configuração de uma ACL, consulte o Guia de configuração de ACL e QoS.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o direito dos dispositivos pares de acessar os serviços NTP no dispositivo local. IPv4:
ntp-service access { peer | query | server | synchronization } acl
ipv4-acl-number
IPv6:
ntp-service ipv6 { peer | query | server | synchronization } acl
ipv6-acl-numberPor padrão, o direito dos dispositivos pares de acessar os serviços NTP no dispositivo local é peer.
Configuração da autenticação NTP
Configuração da autenticação NTP no modo cliente/servidor
Restrições e diretrizes
Para garantir uma autenticação NTP bem-sucedida no modo cliente/servidor, configure o mesmo ID de chave de autenticação, algoritmo e chave no servidor e no cliente. Certifique-se de que o dispositivo par tenha permissão para usar o ID da chave para autenticação no dispositivo local.
Os resultados da autenticação NTP diferem quando são realizadas configurações diferentes no cliente e no servidor. Para obter mais informações, consulte a Tabela 2. (N/A na tabela significa que o fato de a configuração ser ou não realizada não faz diferença).
Tabela 2 Resultados da autenticação NTP
| Cliente | Servidor | ||||||||||
| Ativar a autenticação NTP | Especifique o servidor e a chave | Chave confiável | Ativar a autenticação NTP | Chave confiável | |||||||
| Autenticação bem-sucedida | |||||||||||
| Sim | Sim | Sim | Sim | Sim | |||||||
| Falha na autenticação | |||||||||||
| Sim | Sim | Sim | Sim | Não | |||||||
| Sim | Sim | Sim | Não | N/A | |||||||
| Sim | Sim | Não | N/A | N/A | |||||||
| Autenticação não realizada | |||||||||||
| Sim | Não | N/A | N/A | N/A | |||||||
| Não | N/A | N/A | N/A | N/A |
Configuração da autenticação NTP para um cliente
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configure uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
- Associar a chave especificada a um servidor NTP. IPv4:
ntp-service unicast-server { server-name | ip-address }
keyid de autenticação keyid
IPv6:
ntp-service ipv6 unicast-server { server-name | ipv6-address }
keyid de autenticação keyid
Configuração da autenticação NTP para um servidor
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configurar uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
Configuração da autenticação NTP no modo ativo/passivo simétrico
Restrições e diretrizes
Para garantir uma autenticação NTP bem-sucedida no modo ativo/passivo simétrico, configure o mesmo ID de chave de autenticação, algoritmo e chave no par ativo e no par passivo. Certifique-se de que o dispositivo par tenha permissão para usar o ID da chave para autenticação no dispositivo local.
Os resultados da autenticação NTP diferem quando configurações diferentes são realizadas no par ativo e no par passivo. Para obter mais informações, consulte a Tabela 3. (N/A na tabela significa que o fato de a configuração ser ou não realizada não faz diferença).
Tabela 3 Resultados da autenticação NTP
| Par ativo | Par passivo | ||||||||||
| Ativar a autenticação NTP | Especifique o par e a chave | Chave confiável | Nível de estrato | Ativar a autenticação NTP | Chave confiável | ||||||
| Autenticação bem-sucedida | |||||||||||
| Sim | Sim | Sim | N/A | Sim | Sim | ||||||
| Falha na autenticação | |||||||||||
| Sim | Sim | Sim | N/A | Sim | Não | ||||||
| Sim | Sim | Sim | N/A | Não | N/A | ||||||
| Sim | Não | N/A | N/A | Sim | N/A | ||||||
| Não | N/A | N/A | N/A | Sim | N/A | ||||||
| Sim | Sim | Não | Maior do que o par passivo | N/A | N/A | ||||||
| Sim | Sim | Não | Menor que o par passivo | Sim | N/A | ||||||
| Autenticação não realizada | |||||||||||
| Sim | Não | N/A | N/A | Não | N/A | ||||||
| Não | N/A | N/A | N/A | Não | N/A | ||||||
| Sim | Sim | Não | Menor que o par passivo | Não | N/A |
Configuração da autenticação NTP para um par ativo
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configure uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
- Associar a chave especificada a um par passivo. IPv4:
ntp-service unicast-peer { ip-address | peer-name }
authentication-keyid keyidIPv6:
ntp-service ipv6 unicast-peer { ipv6-address | peer-name }
authentication-keyid keyidConfiguração da autenticação NTP para um par passivo
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configurar uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
Configuração da autenticação NTP no modo de broadcast
Restrições e diretrizes
Para garantir uma autenticação NTP bem-sucedida no modo de transmissão, configure o mesmo ID de chave de autenticação, algoritmo e chave no servidor e no cliente de transmissão. Certifique-se de que o dispositivo par tenha permissão para usar o ID da chave para autenticação no dispositivo local.
Os resultados da autenticação NTP diferem quando são realizadas configurações diferentes no cliente e no servidor de transmissão. Para obter mais informações, consulte a Tabela 4. (N/A na tabela significa que o fato de a configuração ser ou não realizada não faz diferença).
Tabela 4 Resultados da autenticação NTP
| Servidor de transmissão | Cliente de transmissão | ||||||||
| Ativar a autenticação NTP | Especifique o servidor e a chave | Chave confiável | Ativar a autenticação NTP | Chave confiável | |||||
| Autenticação bem-sucedida | |||||||||
| Sim | Sim | Sim | Sim | Sim | |||||
| Falha na autenticação | |||||||||
| Sim | Sim | Sim | Sim | Não | |||||
| Sim | Sim | Sim | Não | N/A | |||||
| Sim | Sim | Não | Sim | N/A | |||||
| Sim | Não | N/A | Sim | N/A | |||||
| Não | N/A | N/A | Sim | N/A | |||||
| Autenticação não realizada | |||||||||
| Sim | Sim | Não | Não | N/A | |||||
| Sim | Não | N/A | Não | N/A | |||||
| Não | N/A | N/A | Não | N/A |
Configuração da autenticação NTP para um cliente de broadcast
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configurar uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
Configuração da autenticação NTP para um servidor de transmissão
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configurar uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
- Entre na visualização da interface.
interface interface-type interface-number- Associar a chave especificada ao servidor de transmissão.
ntp-service broadcast-server authentication-keyid keyidPor padrão, o servidor de transmissão não está associado a uma chave.
Configuração da autenticação NTP no modo multicast
Restrições e diretrizes
Para garantir uma autenticação NTP bem-sucedida no modo multicast, configure o mesmo ID de chave de autenticação, algoritmo e chave no servidor e no cliente multicast. Certifique-se de que o dispositivo par tenha permissão para usar o ID da chave para autenticação no dispositivo local.
Os resultados da autenticação NTP diferem quando são realizadas configurações diferentes no cliente e no servidor de transmissão. Para obter mais informações, consulte a Tabela 5. (N/A na tabela significa que o fato de a configuração ser ou não realizada não faz diferença).
Tabela 5 Resultados da autenticação NTP
| Servidor multicast | Cliente multicast | ||||||||
| Ativar a autenticação NTP | Especifique o servidor e a chave | Chave confiável | Ativar a autenticação NTP | Chave confiável | |||||
| Autenticação bem-sucedida | |||||||||
| Sim | Sim | Sim | Sim | Sim | |||||
| Falha na autenticação | |||||||||
| Sim | Sim | Sim | Sim | Não | |||||
| Sim | Sim | Sim | Não | N/A | |||||
| Sim | Sim | Não | Sim | N/A | |||||
| Sim | Não | N/A | Sim | N/A | |||||
| Não | N/A | N/A | Sim | N/A | |||||
| Autenticação não realizada | |||||||||
| Sim | Sim | Não | Não | N/A | |||||
| Sim | Não | N/A | Não | N/A | |||||
| Não | N/A | N/A | Não | N/A |
Configuração da autenticação NTP para um cliente multicast
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configure uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
Configuração da autenticação NTP para um servidor multicast
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configure uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
- Entre na visualização da interface.
interface interface-type interface-number- Associar a chave especificada a um servidor multicast. IPv4:
ntp-service multicast-server [ ip-address ] authentication-keyid keyidIPv6:
ntp-service ipv6 multicast-server ipv6-multicast-address
authentication-keyid keyidPor padrão, nenhum servidor multicast é associado à chave especificada.
Controle do envio e recebimento de pacotes NTP
Especificação de um endereço de origem para mensagens NTP
Sobre a especificação de um endereço de origem para mensagens NTP
Você pode especificar um endereço de origem ou uma interface de origem para as mensagens NTP. Se você especificar uma interface de origem para as mensagens NTP, o dispositivo usará o endereço IP da interface especificada como endereço de origem para enviar mensagens NTP.
Restrições e diretrizes
Para evitar que as alterações de status da interface causem falhas na comunicação NTP, especifique uma interface que esteja sempre ativa como a interface de origem, uma interface de loopback, por exemplo.
Quando o dispositivo responde a uma solicitação NTP, o endereço IP de origem da resposta NTP é sempre o endereço IP da interface que recebeu a solicitação NTP.
Se você tiver especificado a interface de origem das mensagens NTP no comando ntp-service unicast-server/ntp-service ipv6 unicast-server ou ntp-service unicast-peer/ntp-service ipv6 unicast-peer, o endereço IP da interface especificada será usado como endereço IP de origem das mensagens NTP.
Se você tiver configurado o comando ntp-service broadcast-server ou ntp-service multicast-server/ntp-service ipv6 multicast-server em uma visualização de interface, o endereço IP da interface será usado como endereço IP de origem para mensagens NTP de broadcast ou multicast.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique o endereço de origem das mensagens NTP. IPv4:
ntp-service source { interface-type interface-number | ip-address }IPv6:
ntp-service ipv6 source interface-type interface-numberPor padrão, nenhum endereço de origem é especificado para mensagens NTP.
Desativar o recebimento de mensagens NTP por uma interface
Sobre a desativação do recebimento de mensagens NTP por uma interface
Quando o NTP está ativado, todas as interfaces, por padrão, podem receber mensagens NTP. Para fins de segurança, você pode desativar o recebimento de mensagens NTP em algumas interfaces.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Desative o recebimento de pacotes NTP pela interface. IPv4:
undo ntp-service inbound enableIPv6:
undo ntp-service ipv6 inbound enablePor padrão, uma interface recebe mensagens NTP.
Configuração do número máximo de associações dinâmicas
Sobre a configuração do número máximo de associações dinâmicas
Execute esta tarefa para restringir o número de associações dinâmicas e evitar que elas ocupem muitos recursos do sistema.
O NTP tem os seguintes tipos de associações:
Associação estática - Uma associação criada manualmente.
Associação dinâmica - Associação temporária criada pelo sistema durante a operação do NTP. Uma associação dinâmica é removida se nenhuma mensagem for trocada em cerca de 12 minutos.
A seguir, descrevemos como uma associação é estabelecida em diferentes modos de associação:
Modo cliente/servidor - Depois que você especifica um servidor NTP, o sistema cria uma associação estática no cliente. O servidor simplesmente responde passivamente após o recebimento de uma mensagem, em vez de criar uma associação (estática ou dinâmica).
Modo ativo/passivo simétrico - Depois que você especificar um par passivo simétrico em um par ativo simétrico, as associações estáticas serão criadas no par ativo simétrico e as associações dinâmicas serão criadas no par passivo simétrico.
Modo de broadcast ou multicast - As associações estáticas são criadas no servidor e as associações dinâmicas são criadas no cliente.
Restrições e diretrizes
Um único dispositivo pode ter um máximo de 128 associações simultâneas, incluindo associações estáticas e dinâmicas.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o número máximo de sessões dinâmicas.
ntp-service max-dynamic-sessions numberPor padrão, o número máximo de sessões dinâmicas é 100.
Definição de um valor DSCP para pacotes NTP
Sobre os valores DSCP para pacotes NTP
O valor DSCP determina a precedência de envio de um pacote NTP.
Procedimento
- Entre na visualização do sistema.
system-view- Defina um valor DSCP para os pacotes NTP. IPv4:
ntp-service dscp dscp-valueIPv6:
ntp-service ipv6 dscp dscp-valueO valor DSCP padrão é 48 para pacotes IPv4 e 56 para pacotes IPv6.
Especificação dos limites de deslocamento de tempo do NTP para saídas de log e trap
Sobre os limites de deslocamento de tempo do NTP para saídas de log e trap
Por padrão, o sistema sincroniza o horário do cliente NTP com o servidor e emite um registro e uma interceptação quando a diferença de horário excede 128 ms por várias vezes.
Depois de definir os limites de deslocamento de tempo do NTP para saídas de logs e traps, o sistema sincroniza a hora do cliente com o servidor quando o deslocamento de tempo excede 128 ms por várias vezes, mas emite logs e traps somente quando o deslocamento de tempo excede os limites especificados, respectivamente.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique os limites de deslocamento de tempo do NTP para saídas de registro e de interceptação.
ntp-service time-offset-threshold { log log-threshold | trap trap-threshold } *Por padrão, nenhum limite de deslocamento de tempo NTP é definido para saídas de registro e de interceptação.
Comandos de exibição e manutenção para NTP
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir informações sobre associações NTP IPv6. | display ntp-service ipv6 sessions [ verbose ] | ||
| Exibir informações sobre associações NTP IPv4. | display ntp-service sessions [ verbose ] | ||
| Exibir informações sobre o status do serviço NTP. | display ntp-service status | ||
| Exibir informações breves sobre os servidores NTP, desde o dispositivo local até o servidor NTP primário. | display ntp-service trace [ source interface-type interface-number ] |
Exemplos de configuração de NTP
Exemplo: Configuração do modo de associação cliente/servidor NTP
Configuração de rede
Conforme mostrado na Figura 4, execute as seguintes tarefas:
Configure o relógio local do Dispositivo A como sua fonte de referência, com nível de estrato 2.
Configure o Dispositivo B para operar no modo cliente e especifique o Dispositivo A como o servidor NTP do Dispositivo B.
Figura 4 Diagrama de rede

Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Dispositivo A e o Dispositivo B possam se comunicar, conforme mostrado na Figura 4. (Detalhes não mostrados.)
- Configurar o dispositivo A:
# Habilite o serviço NTP.
<DeviceA> system-view
[DeviceA] ntp-service enable
# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[DeviceA] ntp-service refclock-master 2- Configurar o dispositivo B:
# Habilite o serviço NTP.
<DeviceB> system-view
[DeviceB] ntp-service enable# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Especifique o dispositivo A como o servidor NTP do dispositivo B.
[DeviceB] ntp-service unicast-server 1.0.1.11Verificação da configuração
# Verifique se o Dispositivo B sincronizou sua hora com o Dispositivo A e se o nível de estrato do relógio do Dispositivo B é 3.
[DeviceB] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 1.0.1.11
Local mode: client
Reference clock ID: 1.0.1.11
Leap indicator: 00
Clock jitter: 0.000977 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00383 ms
Root dispersion: 16.26572 ms
Reference time: d0c6033f.b9923965 Wed, Dec 29 2010 18:58:07.724
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Dispositivo B e o Dispositivo A.
[DeviceB] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[12345]1.0.1.11 127.127.1.0 2 1 64 15 -4.0 0.0038 16.262
Notes: 1 source(master), 2 source(peer), 3 selected, 4 candidate, 5 configured.
Total sessions: 1Exemplo: Configuração do modo de associação cliente/servidor NTP IPv6
Configuração de rede
Conforme mostrado na Figura 5, execute as seguintes tarefas:
Configure o relógio local do Dispositivo A como sua fonte de referência, com nível de estrato 2.
Configure o Dispositivo B para operar no modo cliente e especifique o Dispositivo A como o servidor NTP IPv6 do Dispositivo B.
Figura 5 Diagrama de rede
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Dispositivo A e o Dispositivo B possam se comunicar, conforme mostrado na Figura 5. (Detalhes não mostrados.)
- Configurar o dispositivo A:
# Habilite o serviço NTP.
<DeviceA> system-view
[DeviceA] ntp-service enable
# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[DeviceA] ntp-service refclock-master 2- Configurar o dispositivo B:
# Habilite o serviço NTP.
<DeviceB> system-view
[DeviceB] ntp-service enable# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Especifique o dispositivo A como o servidor NTP IPv6 do dispositivo B.
[DeviceB] ntp-service ipv6 unicast-server 3000::34Verificação da configuração
# Verifique se o Dispositivo B sincronizou sua hora com o Dispositivo A e se o nível de estrato do relógio do Dispositivo B é 3.
[DeviceB] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3000::34
Local mode: client
Reference clock ID: 163.29.247.19
Leap indicator: 00
Clock jitter: 0.000977 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.02649 ms
Root dispersion: 12.24641 ms
Reference time: d0c60419.9952fb3e Wed, Dec 29 2010 19:01:45.598
System poll interval: 64 s# Verifique se uma associação NTP IPv6 foi estabelecida entre o Dispositivo B e o Dispositivo A.
[DeviceB] display ntp-service ipv6 sessions
Notes: 1 source(master), 2 source(peer), 3 selected, 4 candidate, 5 configured.
Source: [12345]3000::34
Reference: 127.127.1.0 Clock stratum: 2
Reachabilities: 15 Poll interval: 64
Last receive time: 19 Offset: 0.0
Roundtrip delay: 0.0 Dispersion: 0.0
Total sessions: 1Exemplo: Configuração do modo de associação ativo/passivo simétrico do NTP
Configuração de rede
Conforme mostrado na Figura 6, execute as seguintes tarefas:
Configure o relógio local do Dispositivo A como sua fonte de referência, com nível de estrato 2.
Configure o Dispositivo A para operar no modo ativo simétrico e especifique o Dispositivo B como o par passivo do Dispositivo A.
Figura 6 Diagrama de rede
Dispositivo DispositivoB
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Dispositivo A e o Dispositivo B possam se comunicar, conforme mostrado na Figura 6. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilite o serviço NTP.
<DeviceB> system-view
[DeviceB] ntp-service enable# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp- Configurar o dispositivo A:
# Habilite o serviço NTP.
<DeviceA> system-view
[DeviceA] ntp-service enable
# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[DeviceA] ntp-service refclock-master 2# Configure o dispositivo B como o par passivo simétrico.
[DeviceA] ntp-service unicast-peer 3.0.1.32Verificação da configuração
# Verifique se o dispositivo B sincronizou sua hora com o dispositivo A.
[DeviceB] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3.0.1.31
Local mode: sym_passive
Reference clock ID: 3.0.1.31
Leap indicator: 00
Clock jitter: 0.000916 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00609 ms
Root dispersion: 1.95859 ms
Reference time: 83aec681.deb6d3e5 Wed, Jan 8 2014 14:33:11.081
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Dispositivo B e o Dispositivo A.
[DeviceB] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[12]3.0.1.31 127.127.1.0 2 62 64 34 0.4251 6.0882 1392.1
Notes: 1 source(master), 2 source(peer), 3 selected, 4 candidate, 5 configured.
Total sessions: 1
Exemplo: Configuração do modo de associação ativo/passivo simétrico do NTP IPv6
Configuração de rede
Conforme mostrado na Figura 7, execute as seguintes tarefas:
Configure o relógio local do Dispositivo A como sua fonte de referência, com nível de estrato 2.
Configure o Dispositivo A para operar no modo ativo simétrico e especifique o Dispositivo B como o par passivo do IPv6 do Dispositivo A.
Figura 7 Diagrama de rede
Dispositivo DispositivoB
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Dispositivo A e o Dispositivo B possam se comunicar, conforme mostrado na Figura 7. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilite o serviço NTP.
<DeviceB> system-view
[DeviceB] ntp-service enable# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp- Configurar o dispositivo A:
# Habilite o serviço NTP.
<DeviceA> system-view
[DeviceA] ntp-service enable
# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[DeviceA] ntp-service refclock-master 2# Configure o dispositivo B como o par passivo simétrico IPv6.
[DeviceA] ntp-service ipv6 unicast-peer 3000::36Verificação da configuração
# Verifique se o dispositivo B sincronizou sua hora com o dispositivo A.
[DeviceB] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3000::35
Local mode: sym_passive
Reference clock ID: 251.73.79.32
Leap indicator: 11
Clock jitter: 0.000977 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.01855 ms
Root dispersion: 9.23483 ms
Reference time: d0c6047c.97199f9f Wed, Dec 29 2010 19:03:24.590
System poll interval: 64 s# Verifique se uma associação NTP IPv6 foi estabelecida entre o Dispositivo B e o Dispositivo A.
[DeviceB] display ntp-service ipv6 sessions
Notes: 1 source(master), 2 source(peer), 3 selected, 4 candidate, 5 configured.
Source: [1234]3000::35
Reference: 127.127.1.0 Clock stratum: 2
Reachabilities: 15 Poll interval: 64
Last receive time: 19 Offset: 0.0
Roundtrip delay: 0.0 Dispersion: 0.0
Total sessions: 1Exemplo: Configuração do modo de associação de transmissão NTP
Configuração de rede
Conforme mostrado na Figura 8, configure o Switch C como servidor NTP para vários dispositivos em um segmento de rede para sincronizar a hora dos dispositivos.
Configure o relógio local do Switch C como sua fonte de referência, com nível de estrato 2.
Configure o Switch C para operar no modo de servidor de broadcast e enviar mensagens de broadcast da interface VLAN 2.
Configure o Switch A e o Switch B para operar no modo de cliente de broadcast e ouvir mensagens de broadcast na interface VLAN 2.
Figura 8 Diagrama de rede
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Comutador A, o Comutador B e o Comutador C possam se comunicar entre si, conforme mostrado na Figura 8. (Detalhes não mostrados.)
- Configurar o switch C:
# Habilite o serviço NTP.
<SwitchC> system-view
[SwitchC] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchC] clock protocol ntp# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[SwitchC] ntp-service refclock-master 2# Configure o Switch C para operar no modo de servidor de broadcast e enviar mensagens de broadcast da interface VLAN 2.
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] ntp-service broadcast-server- Configure o Switch A:
# Habilite o serviço NTP.
<SwitchA> system-view
[SwitchA] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchA] clock protocol ntp# Configure o Switch A para operar no modo de cliente de broadcast e receber mensagens de broadcast na interface VLAN 2.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ntp-service broadcast-client- Configure o Switch B:
# Habilite o serviço NTP.
<SwitchB> system-view
[SwitchB] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchB] clock protocol ntp# Configure o Switch B para operar no modo de cliente de broadcast e receber mensagens de broadcast na interface VLAN 2.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ntp-service broadcast-clientVerificação da configuração
O procedimento a seguir usa o Switch A como exemplo para verificar a configuração.
# Verifique se o Switch A está sincronizado com o Switch C e se o nível de estrato do relógio é 3 no Switch A e 2 no Switch C.
[SwitchA-Vlan-interface2] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3.0.1.31
Local mode: bclient
Reference clock ID: 3.0.1.31
Leap indicator: 00
Clock jitter: 0.044281 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00229 ms
Root dispersion: 4.12572 ms
Reference time: d0d289fe.ec43c720 Sat, Jan 8 2011 7:00:14.922
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Switch A e o Switch C.
[SwitchA-Vlan-interface2] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[1245]3.0.1.31 127.127.1.0 2 1 64 519 -0.0 0.0022 4.1257
Notes: 1 source(master),2 source(peer),3 selected,4 candidate,5 configured.
Total sessions: 1Exemplo: Configuração do modo de associação multicast do NTP
Configuração de rede
Conforme mostrado na Figura 9, configure o Switch C como servidor NTP para vários dispositivos em diferentes segmentos de rede para sincronizar a hora dos dispositivos.
Configure o relógio local do Switch C como sua fonte de referência, com nível de estrato 2.
Configure o Switch C para operar no modo de servidor multicast e enviar mensagens multicast da interface VLAN 2.
Configure o Switch A e o Switch D para operar no modo de cliente multicast e receber mensagens multicast na interface VLAN 3 e na interface VLAN 2, respectivamente.
Figura 9 Diagrama de rede
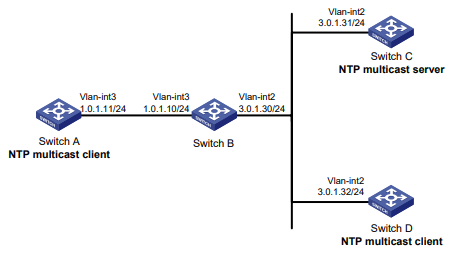
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que os switches possam alcançar um ao outro, conforme mostrado na Figura 9. (Detalhes não mostrados.)
- Configurar o switch C:
# Habilite o serviço NTP.
<SwitchC> system-view
[SwitchC] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchC] clock protocol ntp# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[SwitchC] ntp-service refclock-master 2# Configure o Switch C para operar no modo de servidor multicast e enviar mensagens multicast da interface VLAN 2.
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] ntp-service multicast-server
- Configurar o Switch D:
# Habilite o serviço NTP.
<SwitchD> system-view
[SwitchD] ntp-service enable
# Especifique o NTP para obter a hora.
[SwitchD] clock protocol ntp# Configure o Switch D para operar no modo de cliente multicast e receber mensagens multicast na interface VLAN 2.
[SwitchD] interface vlan-interface 2
[SwitchD-Vlan-interface2] ntp-service multicast-client- Verifique a configuração:
# Verifique se o Switch D está sincronizado com o Switch C e se o nível de estrato do relógio é 3 no Switch D e 2 no Switch C.
O Switch D e o Switch C estão na mesma sub-rede, portanto o Switch D pode receber as mensagens multicast do Switch C sem estar habilitado com as funções multicast.
[SwitchD-Vlan-interface2] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3.0.1.31
Local mode: bclient
Reference clock ID: 3.0.1.31
Leap indicator: 00
Clock jitter: 0.044281 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00229 ms
Root dispersion: 4.12572 ms
Reference time: d0d289fe.ec43c720 Sat, Jan 8 2011 7:00:14.922
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Switch D e o Switch C.
[SwitchD-Vlan-interface2] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[1245]3.0.1.31 127.127.1.0 2 1 64 519 -0.0 0.0022 4.1257
Notes: 1 source(master),2 source(peer),3 selected,4 candidate,5 configured.
Total sessions: 1- Configurar o Switch B:
Como o Switch A e o Switch C estão em sub-redes diferentes, você deve ativar as funções multicast no Switch B antes que o Switch A possa receber mensagens multicast do Switch C.
# Habilite as funções de multicast de IP.
<SwitchB> system-view
[SwitchB] multicast routing
[SwitchB-mrib] quit
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] pim dm
[SwitchB-Vlan-interface2] quit
[SwitchB] vlan 3
[SwitchB-vlan3] port gigabitethernet 1/0/1
[SwitchB-vlan3] quit
[SwitchB] interface vlan-interface 3
[SwitchB-Vlan-interface3] igmp enable
[SwitchB-Vlan-interface3] igmp static-group 224.0.1.1
[SwitchB-Vlan-interface3] quit
[SwitchB] igmp-snooping
[SwitchB-igmp-snooping] quit
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] igmp-snooping static-group 224.0.1.1 vlan 3- Configure o Switch A:
# Habilite o serviço NTP.
<SwitchA> system-view
[SwitchA] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchA] clock protocol ntp# Configure o Switch A para operar no modo de cliente multicast e receber mensagens multicast na interface VLAN 3.
[SwitchA] interface vlan-interface 3
[SwitchA-Vlan-interface3] ntp-service multicast-clientVerificação da configuração
# Verifique se o Switch A sincronizou sua hora com o Switch C e se o nível de estrato do relógio do Switch A é 3.
[SwitchA-Vlan-interface3] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3.0.1.31
Local mode: bclient
Reference clock ID: 3.0.1.31
Leap indicator: 00
Clock jitter: 0.165741 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00534 ms
Root dispersion: 4.51282 ms
Reference time: d0c61289.10b1193f Wed, Dec 29 2010 20:03:21.065
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Switch A e o Switch C.
[SwitchA-Vlan-interface3] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[1234]3.0.1.31 127.127.1.0 2 247 64 381 -0.0 0.0053 4.5128
Notes: 1 source(master),2 source(peer),3 selected,4 candidate,5 configured.
Total sessions: 1Exemplo: Configuração do modo de associação multicast do NTP IPv6
Configuração de rede
Conforme mostrado na Figura 10, configure o Switch C como servidor NTP para vários dispositivos em diferentes segmentos de rede para sincronizar a hora dos dispositivos.
Configure o relógio local do Switch C como sua fonte de referência, com nível de estrato 2.
Configure o Switch C para operar no modo de servidor multicast IPv6 e enviar mensagens multicast IPv6 da interface VLAN 2.
Configure o Switch A e o Switch D para operar no modo de cliente multicast IPv6 e receber mensagens multicast IPv6 na interface VLAN 3 e na interface VLAN 2, respectivamente.
Figura 10 Diagrama de rede
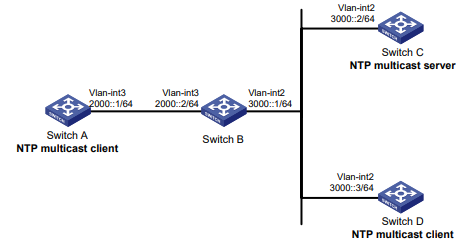
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que os switches possam se comunicar entre si, conforme mostrado na Figura 10. (Detalhes não mostrados.)
- Configurar o switch C:
# Habilite o serviço NTP.
<SwitchC> system-view
[SwitchC] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchC] clock protocol ntp# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[SwitchC] ntp-service refclock-master 2# Configure o Switch C para operar no modo de servidor multicast IPv6 e enviar mensagens multicast da interface VLAN 2.
[SwitchD] interface vlan-interface 2
[SwitchD-Vlan-interface2] ntp-service ipv6 multicast-client ff24::1
- Configurar o Switch D:
# Habilite o serviço NTP.
<SwitchD> system-view
[SwitchD] ntp-service enable
# Especifique o NTP para obter a hora.
[SwitchD] clock protocol ntp# Configure o Switch D para operar no modo de cliente multicast IPv6 e receber mensagens multicast na interface VLAN 2.
[SwitchD] interface vlan-interface 2
[SwitchD-Vlan-interface2] ntp-service ipv6 multicast-client ff24::1
- Verifique a configuração:
# Verifique se o Switch D sincronizou sua hora com o Switch C e se o nível de estrato do relógio do Switch D é 3.
O Switch D e o Switch C estão na mesma sub-rede, portanto o Switch D pode receber as mensagens multicast IPv6 do Switch C sem estar habilitado com as funções multicast IPv6.
[SwitchD-Vlan-interface2] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3000::2
Local mode: bclient
Reference clock ID: 165.84.121.65
Leap indicator: 00
Clock jitter: 0.000977 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00000 ms
Root dispersion: 8.00578 ms
Reference time: d0c60680.9754fb17 Wed, Dec 29 2010 19:12:00.591
System poll interval: 64 s- Configurar o Switch B:
Como o Switch A e o Switch C estão em sub-redes diferentes, você deve ativar as funções de multicast IPv6 no Switch B antes que o Switch A possa receber mensagens de multicast IPv6 do Switch C.
# Habilite as funções de multicast IPv6.
<SwitchB> system-view
[SwitchB] ipv6 multicast routing
[SwitchB-mrib6] quit
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ipv6 pim dm
[SwitchB-Vlan-interface2] quit
[SwitchB] vlan 3
[SwitchB-vlan3] port gigabitethernet 1/0/1
[SwitchB-vlan3] quit
[SwitchB] interface vlan-interface 3
[SwitchB-Vlan-interface3] mld enable
[SwitchB-Vlan-interface3] mld static-group ff24::1
[SwitchB-Vlan-interface3] quit
[SwitchB] mld-snooping
[SwitchB-mld-snooping] quit
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] mld-snooping static-group ff24::1 vlan 3- Configure o Switch A:
# Habilite o serviço NTP.
<SwitchA> system-view
[SwitchA] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchA] clock protocol ntp# Configure o Switch A para operar no modo de cliente multicast IPv6 e receber mensagens multicast IPv6 na interface VLAN 3.
[SwitchA] interface vlan-interface 3
[SwitchA-Vlan-interface3] ntp-service ipv6 multicast-client ff24::1Verificação da configuração
# Verifique se o Switch A está sincronizado com o Switch C e se o nível de estrato do relógio é 3 no Switch A e 2 no Switch C.
[SwitchA-Vlan-interface3] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3000::2
Local mode: bclient
Reference clock ID: 165.84.121.65
Leap indicator: 00
Clock jitter: 0.165741 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00534 ms
Root dispersion: 4.51282 ms
Reference time: d0c61289.10b1193f Wed, Dec 29 2010 20:03:21.065
System poll interval: 64 sExemplo: Configuração do modo de associação cliente/servidor NTP com autenticação
Configuração de rede
Conforme mostrado na Figura 11, execute as seguintes tarefas:
Configure o relógio local do Dispositivo A como sua fonte de referência, com nível de estrato 2.
Configure o Dispositivo B para operar no modo cliente e especifique o Dispositivo A como o servidor NTP do Dispositivo B.
Configure a autenticação NTP no Dispositivo A e no Dispositivo B.
Figura 11 Diagrama de rede
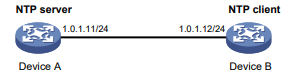
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Dispositivo A e o Dispositivo B possam se comunicar, conforme mostrado na Figura 11. (Detalhes não mostrados.)
- Configurar o dispositivo A:
# Habilite o serviço NTP.
<DeviceA> system-view
[DeviceA] ntp-service enable
# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[DeviceA] ntp-service refclock-master 2- Configurar o dispositivo B:
# Habilite o serviço NTP.
<DeviceB> system-view
[DeviceB] ntp-service enable# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Habilite a autenticação NTP no Dispositivo B.
[DeviceB] ntp-service authentication enable# Crie uma chave de autenticação de texto simples, com ID de chave 42 e valor de chave aNiceKey.
[DeviceB] ntp-service authentication-keyid 42 authentication-mode md5 simple aNiceKey# Especifique a chave como uma chave confiável.
[DeviceB] ntp-service reliable authentication-keyid 42# Especifique o Dispositivo A como o servidor NTP do Dispositivo B e associe o servidor à chave 42.
[DeviceB] ntp-service unicast-server 1.0.1.11 authentication-keyid 42Para permitir que o Dispositivo B sincronize seu relógio com o Dispositivo A, ative a autenticação NTP no Dispositivo A.
- Configure a autenticação NTP no Dispositivo A: # Habilite a autenticação NTP.
[DeviceA] ntp-service authentication enable# Crie uma chave de autenticação de texto simples, com ID de chave 42 e valor de chave aNiceKey.
[DeviceA] ntp-service authentication-keyid 42 authentication-mode md5 simple aNiceKey# Especifique a chave como uma chave confiável.
[[DeviceA] ntp-service reliable authentication-keyid 42Verificação da configuração
# Verifique se o Dispositivo B sincronizou sua hora com o Dispositivo A e se o nível de estrato do relógio do Dispositivo B é 3.
[DeviceB] display ntp-service status
Clock status: synchronized
Clock stratum: 3
1.0.1.11/24 1.0.1.12/24
Device A Device B
NTP server NTP client
34
System peer: 1.0.1.11
Local mode: client
Reference clock ID: 1.0.1.11
Leap indicator: 00
Clock jitter: 0.005096 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00655 ms
Root dispersion: 1.15869 ms
Reference time: d0c62687.ab1bba7d Wed, Dec 29 2010 21:28:39.668
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Dispositivo B e o Dispositivo A.
[DeviceB] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[1245]1.0.1.11 127.127.1.0 2 1 64 519 -0.0 0.0065 0.0
Notes: 1 source(master),2 source(peer),3 selected,4 candidate,5 configured.
Total sessions: 1Exemplo: Configuração do modo de associação de transmissão NTP com autenticação
Configuração de rede
Conforme mostrado na Figura 12, configure o Switch C como servidor NTP para vários dispositivos no mesmo segmento de rede para sincronizar a hora dos dispositivos. Configure o Switch A e o Switch B para autenticar o servidor NTP.
Configure o relógio local do Switch C como sua fonte de referência, com nível de estrato 3.
Configure o Switch C para operar no modo de servidor de broadcast e enviar mensagens de broadcast da interface VLAN 2.
Configure o Switch A e o Switch B para operar no modo de cliente de broadcast e receber mensagens de broadcast na interface VLAN 2.
Habilite a autenticação NTP no Switch A, Switch B e Switch C.
Figura 12 Diagrama de rede
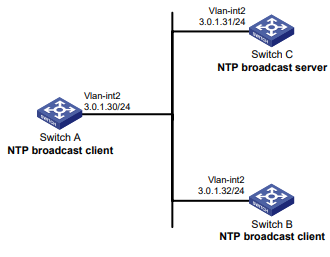
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Switch A, o Switch B e o Switch C possam se comunicar entre si, conforme mostrado na Figura 12. (Detalhes não mostrados).
- Configure o Switch A:
# Habilite o serviço NTP.
<SwitchA> system-view
[SwitchA] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchA] clock protocol ntp# Habilite a autenticação NTP no Switch A. Crie uma chave de autenticação NTP de texto simples, com ID de chave 88 e valor de chave 123456. Especifique-a como uma chave confiável.
[SwitchA] ntp-service authentication enable
[SwitchA] ntp-service authentication-keyid 88 authentication-mode md5 simple 123456
[SwitchA] ntp-service reliable authentication-keyid 88
# Configure o Switch A para operar no modo de cliente de broadcast NTP e receber mensagens de broadcast NTP na interface VLAN 2.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ntp-service broadcast-client- Configure o Switch B:
# Habilite o serviço NTP.
<SwitchB> system-view
[SwitchB] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchB] clock protocol ntp# Habilite a autenticação NTP no Switch B. Crie uma chave de autenticação NTP de texto simples, com ID de chave 88 e valor de chave 123456. Especifique-a como uma chave confiável.
[SwitchB] ntp-service authentication enable
[SwitchB] ntp-service authentication-keyid 88 authentication-mode md5 simple 123456
[SwitchB] ntp-service reliable authentication-keyid 88# Configure o Switch B para operar no modo de cliente de broadcast e receber mensagens de broadcast NTP na interface VLAN 2.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ntp-service broadcast-client- Configurar o switch C:
# Habilite o serviço NTP.
<SwitchC> system-view
[SwitchC] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchC] clock protocol ntp# Especifique o relógio local como a fonte de referência, com nível de estrato 3.
[SwitchC] ntp-service refclock-master 3# Configure o Switch C para operar no modo de servidor de transmissão NTP e use a interface VLAN 2 para enviar pacotes de transmissão NTP.
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] ntp-service broadcast-server
[SwitchC-Vlan-interface2] quit- Verifique a configuração:
A autenticação NTP está ativada no Switch A e no Switch B, mas não no Switch C, portanto o Switch A e o Switch B não podem sincronizar seus relógios locais com o Switch C.
[SwitchB-Vlan-interface2] display ntp-service status
Clock status: unsynchronized
Clock stratum: 16
Reference clock ID: none- Habilite a autenticação NTP no Switch C:
# Habilite a autenticação NTP no Switch C. Crie uma chave de autenticação NTP de texto simples, com ID de chave 88 e valor de chave 123456. Especifique-a como uma chave confiável.
[SwitchC] ntp-service authentication enable
[SwitchC] ntp-service authentication-keyid 88 authentication-mode md5 simple 123456
[SwitchC] ntp-service reliable authentication-keyid 88# Especifique o Switch C como um servidor de transmissão NTP e associe a chave 88 ao Switch C.
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] ntp-service broadcast-server authentication-keyid 88Verificação da configuração
# Verifique se o Switch B sincronizou sua hora com o Switch C e se o nível de estrato do relógio do Switch B é 4.
[SwitchB-Vlan-interface2] display ntp-service status
Clock status: synchronized
Clock stratum: 4
System peer: 3.0.1.31
Local mode: bclient
Reference clock ID: 3.0.1.31
Leap indicator: 00
Clock jitter: 0.006683 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00127 ms
Root dispersion: 2.89877 ms
Reference time: d0d287a7.3119666f Sat, Jan 8 2011 6:50:15.191
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Switch B e o Switch C.
[SwitchB-Vlan-interface2] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[1245]3.0.1.31 127.127.1.0 3 3 64 68 -0.0 0.0000 0.0
Notes: 1 source(master),2 source(peer),3 selected,4 candidate,5 configured.
Total sessions: 1Configuração do SNTP
Sobre o SNTP
O SNTP é uma versão simplificada do NTP, somente para clientes, especificada na RFC 4330. Ele usa o mesmo formato de pacote e procedimento de troca de pacotes que o NTP, mas oferece sincronização mais rápida ao preço da precisão do tempo.
Modo de trabalho SNTP
O SNTP suporta apenas o modo cliente/servidor. Um dispositivo habilitado para SNTP pode receber a hora dos servidores NTP, mas não pode fornecer serviços de hora a outros dispositivos.
Se você especificar vários servidores NTP para um cliente SNTP, será selecionado o servidor com o melhor estrato. Se vários servidores estiverem no mesmo estrato, será selecionado o servidor NTP cujo pacote de hora for recebido primeiro.
Protocolos e padrões
RFC 4330, Simple Network Time Protocol (SNTP) Versão 4 para IPv4, IPv6 e OSI
Restrições e diretrizes: Configuração do SNTP
Ao configurar o SNTP, siga estas restrições e diretrizes:
Não é possível configurar o NTP e o SNTP no mesmo dispositivo.
∙ Para usar o NTP para sincronização de horário, você deve usar o comando clock protocol para especificar o NTP para obter o horário. Para obter mais informações sobre o comando clock protocol, consulte os comandos de gerenciamento de dispositivos no Fundamentals Configuration Guide.
Visão geral das tarefas do SNTP
Para configurar o SNTP, execute as seguintes tarefas:
- Ativação do serviço SNTP
- Especificação de um servidor NTP para o dispositivo
- (Opcional.) Configuração da autenticação SNTP
- (Opcional.) Especificação dos limites de intervalo de tempo do SNTP para saídas de registro e de interceptação
Ativação do serviço SNTP
Restrições e diretrizes
O serviço NTP e o serviço SNTP são mutuamente exclusivos. Antes de ativar o SNTP, certifique-se de que o NTP esteja desativado.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o serviço SNTP.
sntp enablePor padrão, o serviço SNTP está desativado.
Especificação de um servidor NTP para o dispositivo
Restrições e diretrizes
Para usar um servidor NTP como fonte de horário, certifique-se de que seu relógio tenha sido sincronizado. Se o nível de estrato do servidor NTP for maior ou igual ao do cliente, o cliente não sincronizará com o servidor NTP.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique um servidor NTP para o dispositivo. IPv4:
sntp unicast-server { server-name | ip-address }
[ authentication-keyid keyid | source interface-type interface-number
| version number ] *
IPv6:
sntp ipv6 unicast-server { server-name | ipv6-address }
[ authentication-keyid keyid | source interface-type interface-number ]
*Por padrão, nenhum servidor NTP é especificado para o dispositivo.
Você pode especificar vários servidores NTP para o cliente repetindo essa etapa.
Para executar a autenticação, você precisa especificar a opção authentication-keyid keyid.
Configuração da autenticação SNTP
Sobre a autenticação SNTP
A autenticação SNTP garante que um cliente SNTP seja sincronizado somente com um servidor NTP autenticado e confiável.
Restrições e diretrizes
Ative a autenticação no servidor NTP e no cliente SNTP.
Use o mesmo ID de chave de autenticação, algoritmo e chave no servidor NTP e no cliente SNTP. Especifique a chave como uma chave confiável tanto no servidor NTP quanto no cliente SNTP. Para obter informações sobre como configurar a autenticação NTP em um servidor NTP, consulte "Configuração do NTP".
No cliente SNTP, associe a chave especificada ao servidor NTP. Certifique-se de que o servidor tenha permissão para usar o ID da chave para autenticação no cliente.
Com a autenticação desativada, o cliente SNTP pode sincronizar com o servidor NTP, independentemente de o servidor NTP estar habilitado com autenticação.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a autenticação SNTP.
sntp authentication enablePor padrão, a autenticação SNTP está desativada.
- Configurar uma chave de autenticação SNTP.
sntp authentication-keyid keyid authentication-mode { hmac-sha-1 |
hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 } { cipher | simple } string
[ acl ipv4-acl-number | ipv6 acl ipv6-acl-number ] *Por padrão, não existe nenhuma chave de autenticação SNTP.
- Especifique a chave como uma chave confiável.
sntp reliable authentication-keyid keyidPor padrão, nenhuma chave confiável é especificada.
- Associe a chave de autenticação SNTP a um servidor NTP. IPv4:
sntp unicast-server { server-name | ip-address } authentication-keyid
keyidkeyidIPv6:
sntp ipv6 unicast-server { server-name | ipv6-address }
authentication-keyid keyidPor padrão, nenhum servidor NTP é especificado.
Especificação dos limites de deslocamento de tempo do SNTP para saídas de log e trap
Sobre os limites de intervalo de tempo do SNTP para saídas de log e trap
Por padrão, o sistema sincroniza o horário do cliente SNTP com o servidor e emite um registro e uma interceptação quando a diferença de horário excede 128 ms por várias vezes.
Depois de definir os limites de desvio de tempo do SNTP para saídas de logs e traps, o sistema sincroniza a hora do cliente com o servidor quando o desvio de tempo excede 128 ms por várias vezes, mas emite logs e traps somente quando o desvio de tempo excede os limites especificados, respectivamente.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique os limites de deslocamento de tempo do SNTP para saídas de registro e de interceptação.
sntp time-offset-threshold { log log-threshold | trap trap-threshold }*Por padrão, nenhum limite de deslocamento de tempo SNTP é definido para saídas de registro e trap.
Comandos de exibição e manutenção para SNTP
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir informações sobre todas as associações SNTP IPv6. | display sntp ipv6 sessions | ||
| Exibir informações sobre todas as associações SNTP IPv4. | display sntp sessions |
Exemplos de configuração de SNTP
Exemplo: Configurando SNTP
Configuração de rede
Conforme mostrado na Figura 13, execute as seguintes tarefas:
Configure o relógio local do Dispositivo A como sua fonte de referência, com nível de estrato 2.
Configure o Dispositivo B para operar no modo de cliente SNTP e especifique o Dispositivo A como o servidor NTP.
Configure a autenticação NTP no Dispositivo A e a autenticação SNTP no Dispositivo B.
Figura 13 Diagrama de rede
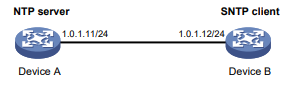
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Dispositivo A e o Dispositivo B possam se comunicar, conforme mostrado na Figura 13. (Detalhes não mostrados.)
- Configurar o dispositivo A:
# Habilite o serviço NTP.
<DeviceA> system-view
[DeviceA] ntp-service enable
# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Configure o relógio local como a fonte de referência, com nível de estrato 2.
[DeviceA] ntp-service refclock-master 2# Habilite a autenticação NTP no dispositivo A.
[DeviceA] ntp-service authentication enable# Configure uma chave de autenticação NTP de texto simples, com ID de chave 10 e valor de chave aNiceKey.
[DeviceA] ntp-service authentication-keyid 10 authentication-mode md5 simple
aNiceKey# Especifique a chave como uma chave confiável.
[DeviceA] ntp-service reliable authentication-keyid 10- Configurar o dispositivo B:
# Habilite o serviço SNTP.
<DeviceB> system-view
[DeviceB] sntp enable
# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Habilite a autenticação SNTP no Dispositivo B.
[DeviceB] clock protocol ntp# Configure uma chave de autenticação de texto simples, com ID de chave 10 e valor de chave aNiceKey.
[DeviceB] sntp authentication-keyid 10 authentication-mode md5 simple aNiceKey# Especifique a chave como uma chave confiável.
[DeviceB] sntp authentication enable# Especifique o Dispositivo A como o servidor NTP do Dispositivo B e associe o servidor à chave 10.
[DeviceB] sntp reliable authentication-keyid 10Verificação da configuração
# Verifique se uma associação SNTP foi estabelecida entre o Dispositivo B e o Dispositivo A, e se o Dispositivo B sincronizou sua hora com o Dispositivo A.
[DeviceB] display sntp sessions
NTP server Stratum Version Last receive time
1.0.1.11 2 4 Tue, May 17 2011 9:11:20.833 (Synced)Configuração de PoE
Sobre o PoE
O Power over Ethernet (PoE) permite que um dispositivo de rede forneça energia aos terminais por meio de cabos de par trançado .
Sistema PoE
Conforme mostrado na Figura 1, um sistema PoE inclui os seguintes elementos:
Fonte de alimentação PoE - Uma fonte de alimentação PoE fornece energia para todo o sistema PoE.
PSE - Um equipamento de fornecimento de energia (PSE) fornece energia aos PDs. Os dispositivos PSE são classificados em dispositivos PSE únicos e dispositivos PSE múltiplos.
Um dispositivo de PSE único tem apenas um firmware PSE.
Um dispositivo com vários PSEs tem vários PSEs. Um dispositivo com vários PSEs usa IDs de PSE para identificar diferentes PSEs. Para visualizar o mapeamento entre a ID e o número do slot de um PSE, execute o comando display poe device.
PI - Uma interface de energia (PI) é uma interface Ethernet compatível com PoE em um PSE.
PD - Um dispositivo alimentado (PD) recebe energia de um PSE. Os PDs incluem telefones IP, APs, carregadores portáteis, terminais POS e câmeras Web. Você também pode conectar um PD a uma fonte de alimentação redundante para obter confiabilidade.
Figura 1 Diagrama do sistema PoE
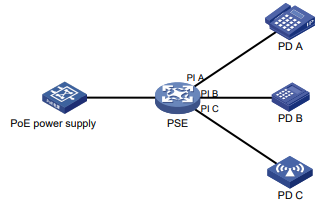
AI-driven PoE
O PoE orientado por IA integra de forma inovadora as tecnologias de IA aos switches PoE e oferece os seguintes benefícios:
Gerenciamento adaptativo da fonte de alimentação
O PoE orientado por IA pode ajustar de forma adaptativa os parâmetros da fonte de alimentação para atender às necessidades de energia em vários cenários, como vários tipos de PDs, e resolver problemas como falta de fonte de alimentação para um PD e falha de energia, minimizando a intervenção humana.
Gerenciamento de energia baseado em prioridades
Quando a energia exigida pelos PDs excede a energia que pode ser fornecida pelo switch PoE, o sistema fornece energia aos PDs com base nas prioridades do PI para garantir o fornecimento de energia aos negócios críticos e reduzir o fornecimento de energia aos PIs de prioridades mais baixas.
Gerenciamento inteligente do módulo de energia
Para um switch PoE com arquitetura de módulo de alimentação duplo, o PoE orientado por IA pode calcular e regular automaticamente a saída de energia de cada módulo de alimentação com base no tipo e na quantidade dos módulos de alimentação, maximizando o uso de energia de cada módulo de alimentação. Quando um módulo de energia é removido, o AI-driven PoE recalcula para garantir preferencialmente o fornecimento de energia aos PDs que estão sendo alimentados.
Alta segurança PoE
Quando ocorre uma exceção, como curto-circuito ou interrupção do circuito, o PoE orientado por IA inicia imediatamente a autoproteção para proteger o switch PoE contra danos ou queimaduras.
PoE perpétuo
Durante uma reinicialização a quente do switch PoE a partir do comando de reinicialização, o PoE orientado por IA monitora continuamente os estados dos PDs e garante o fornecimento contínuo de energia aos PDs, mantendo a estabilidade do serviço do terminal.
PoE remoto
O PoE orientado por IA ajusta de forma adaptativa a largura de banda da rede com base na distância de transmissão entre um PSE e um PD. Quando a distância de transmissão ultrapassa 100 m (328,08 pés), o sistema diminui automaticamente a taxa da porta para reduzir a perda de linha e garantir a qualidade da transmissão de sinal e energia. Com o PoE orientado por IA ativado, um PSE pode transmitir energia para um PD de 200 a 250 m (656,17 a 820,21 pés) de distância.
Protocolos e padrões
802.3af-2003, IEEE Standard for Information Technology - Telecommunications and Information Exchange Between Systems - Local and Metropolitan Area Networks - Specific Requirements - Part 3: Carrier Sense Multiple Access with Collision Detection (CSMA/CD) Access Method and Physical Layer Specifications - Data Terminal Equipment (DTE) Power Via Media Dependent Interface (MDI)
802.3at-2009, Padrão IEEE para tecnologia da informação - Redes de área local e metropolitana - Requisitos específicos - Parte 3: Método de acesso CSMA/CD e especificações da camada física - Alteração 3: Alimentação do equipamento terminal de dados (DTE) por meio de melhorias na interface dependente de mídia (MDI)
Restrições: Compatibilidade de hardware com PoE
Somente os modelos PoE suportam o recurso PoE.
Restrições e diretrizes: Configuração de PoE
Você pode configurar um PI por meio de uma das seguintes maneiras:
Configure as definições diretamente no PI.
Configure um perfil PoE e aplique-o ao PI. Se você aplicar um perfil PoE a vários PIs, esses PIs terão os mesmos recursos PoE. Se você conectar um PD a outro PI, poderá aplicar o perfil PoE do PI original ao novo PI. Esse método alivia a tarefa de configurar o PoE no novo PI.
Você só pode usar uma maneira de configurar um parâmetro para um PI. Para usar a outra maneira de reconfigurar um parâmetro, você deve primeiro remover a configuração original.
Você deve usar o mesmo método de configuração para os comandos poe max-power max-power e poe priority { critical | high | low }.
Visão geral das tarefas de configuração do PoE
Para configurar o PoE, execute as seguintes tarefas:
- Ativação de PoE em um PI
- (Opcional.) Ativação do PoE orientado por IA
- (Opcional.) Ativação de PoE rápido para um PSE
- (Opcional) Permitir correntes de inrush consumidas por PDs
- (Opcional.) Ativação do ciclo de energia do PI em uma reinicialização a quente do sistema
- (Opcional.) Configuração da detecção de PD
- Ativação da detecção de PD não padrão
- Configuração de um modo de detecção de PD
- (Opcional.) Configuração da energia PoE
- Configuração da potência máxima de PI
- (Opcional.) Configuração da política de prioridade PI
- (Opcional.) Configuração do monitoramento de PoE
- Configuração do monitoramento de energia do PSE
- Associação de PoE com trilha
- (Opcional.) Atualização do firmware do PSE em serviço
- (Opcional.) Ativação da fonte de alimentação PoE forçada
- (Opcional.) Configuração do TMPDO para o MPS
Para usar um perfil PoE para ativar o PoE e configurar a prioridade e a potência máxima para um PI, consulte "Configuração de um PI usando um perfil PoE".
Pré-requisitos para configurar o PoE
Antes de configurar o PoE, verifique se a fonte de alimentação PoE e os PSEs estão funcionando corretamente.
Ativação de PoE em um PI
Sobre a ativação do PoE em um PI
Depois que você ativar o PoE em um PI, o PI fornecerá energia ao PD conectado se o PI não resultar em sobrecarga de energia do PSE. A sobrecarga do PSE ocorre quando a soma do consumo de energia de todos os PIs excede a potência máxima do PSE.
Se o PI resultar em sobrecarga de energia PSE, as seguintes restrições se aplicam:
Se a política de prioridade do PI não estiver ativada, o PI não fornecerá energia ao PD conectado.
Se a política de prioridade do PI estiver ativada, o fato de os PDs poderem ser alimentados depende da prioridade do PI.
Para obter mais informações sobre a política de prioridade do PI, consulte "Configuração da política de prioridade do PI".
Restrições e diretrizes
A energia pode ser transmitida por um cabo de par trançado em um dos seguintes modos:
Modo de par de sinais - Os pares de sinais 1, 2, 3 e 6 do cabo de par trançado são usados para transmissão de energia.
Modo de par sobressalente - Os pares sobressalentes 4, 5, 7 e 8 do cabo de par trançado são usados para transmissão de energia.
Um PI pode fornecer energia a um PD somente quando o PI e o PD usam o mesmo modo de transmissão de energia. Se o PI e o PD usarem modos de transmissão de energia diferentes, será necessária uma reconexão.
O dispositivo suporta a transmissão de energia somente em pares de sinais.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar na visualização PI.
interface interface-type interface-number- (Opcional.) Configure uma descrição para o PD conectado ao PI.
poe pd-description textPor padrão, nenhuma descrição é configurada para o PD conectado ao PI.
O PoE é ativado nos PIs se o dispositivo for iniciado com os padrões de fábrica e é desativado nos PIs quando o dispositivo é iniciado com a configuração inicial.
Para obter mais informações sobre a configuração inicial do dispositivo e os padrões de fábrica, consulte o gerenciamento de arquivos de configuração.
Habilitando o PoE orientado por IA
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o PoE orientado por IA.
poe ai enablePor padrão, o PoE orientado por IA está desativado.
O AI-driven PoE ajusta automaticamente os parâmetros da fonte de alimentação para atender às necessidades de energia. Se você desativar o AI-driven PoE, o sistema reverterá os parâmetros para as configurações anteriores ao ajuste.
Habilitação de PoE rápido para um PSE
Sobre o PoE rápido para um PSE
Esse recurso permite que um PI em um PSE forneça energia aos PDs imediatamente após o PSE ser ligado.
Restrições e diretrizes
Você deve reconfigurar esse recurso se tiver modificado outras configurações de PoE após a configuração desse recurso.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o PoE rápido para um PSE.
poe fast-on enable pse pse-idPor padrão, o PoE rápido está desativado em um PSE.
Esse comando é compatível apenas com a versão 6328 e posteriores.
Permitir correntes de inrush consumidas por PDs
Sobre a permissão de correntes de inrush consumidas por PDs
A corrente de irrupção pode ocorrer na inicialização do PD e acionar a autoproteção do PSE. Como resultado, o PSE para de fornecer energia aos PDs. Para continuar o fornecimento de energia aos PDs, configure esse recurso para permitir correntes de pico consumidas pelos PDs.
O IEEE 802.3af e o IEEE 802.3at definem especificações para a corrente de irrupção. O suporte para as especificações definidas pelo IEEE 802.3af e/ou IEEE 802.3at depende do modelo do dispositivo.
Restrições e diretrizes
CUIDADO:
As correntes de irrupção podem danificar os componentes do dispositivo. Use esse recurso com cuidado.
Esse recurso está disponível somente para um PSE que tenha um nome de modelo terminado com um caractere B, LSPPSE48B, por exemplo. Para obter o nome do modelo do PSE, execute o comando display poe pse .
Procedimento
- Entre na visualização do sistema.
system-view- Permitir correntes de inrush consumidas pelos PDs.
poe high-inrush enable pse pse-idPor padrão, as correntes de irrupção consumidas pelos PDs não são permitidas.
Ativação do ciclo de energia do PI em uma reinicialização a quente do sistema
Sobre a ativação do ciclo de energia do PI em uma reinicialização a quente do sistema
Durante o processo de reinicialização a quente do sistema (após a execução do comando de reinicialização), os PIs continuam fornecendo energia aos PDs, mas as conexões de dados entre os PDs e o dispositivo são interrompidas. Após a reinicialização do sistema, os PDs podem não reiniciar as conexões de dados com o dispositivo. O ciclo de energia dos PIs em uma reinicialização a quente do sistema permite que os PDs restabeleçam as conexões de dados com o dispositivo após uma reinicialização a quente.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar no ciclo de energia do PI em uma reinicialização a quente do sistema.
poe reset enablePor padrão, o ciclo de energia do PI em uma reinicialização a quente do sistema está desativado.
Configuração da detecção de PD
Ativação da detecção de PD não padrão
Sobre a ativação da detecção de PD não padrão
Os PDs são classificados em PDs padrão e PDs não padrão. Os PDs padrão estão em conformidade com o IEEE 802.3af e o IEEE 802.3at. Um PSE fornece energia a um PD não padrão somente depois que a detecção de PD não padrão é ativada.
O dispositivo suporta a detecção de PD não padrão baseada em PSE e PI. A ativação da detecção de DP não padrão para um PSE habilita esse recurso para todos os PIs no PSE. Como prática recomendada para desativar a detecção de DP não padrão para todos os PIs com êxito em uma única operação, desative esse recurso na visualização do sistema e na visualização da interface.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite a detecção de PD não padrão. Escolha uma opção conforme necessário.
- Ativar a detecção de PD não padrão para o PSE.
poe legacy enable pse pse-idPor padrão, a detecção de PD não padrão está desativada para um PSE.
- Execute os seguintes comandos em sequência para ativar a detecção de PD não padrão para um PI:
interface interface-type interface-numberpoe legacy enablePor padrão, a detecção de PD fora do padrão é desativada para um PI.
Configuração de um modo de detecção de PD
Sobre os modos de detecção de PD
O dispositivo detecta PDs em um dos seguintes modos:
Nenhum - O dispositivo fornece energia aos PDs que estão conectados corretamente ao dispositivo sem causar curto-circuito.
Simples - O dispositivo fornece energia a PDs que atendem aos requisitos básicos do 802.3af ou 802.3at.
Rigoroso - O dispositivo fornece energia a PDs que atendem a todos os requisitos da norma 802.3af ou 802.3at.
Restrições e diretrizes
CUIDADO:
Um dispositivo não-PD pode ser danificado quando a energia é fornecida a ele. Para evitar danos ao dispositivo, não use o modo nenhum quando o PI se conectar a um dispositivo não-PD.
Essa tarefa está disponível somente para um PSE que tenha um nome de modelo terminado com um caractere B, LSPPSE48B, por exemplo. Para obter o nome do modelo do PSE, execute o comando display poe pse.
Para que essa tarefa tenha efeito em PDs não padrão, você deve ativar a detecção para PDs não padrão usando o comando poe legacy enable.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar na visualização PI.
interface interface-type interface-number- Configure o modo de detecção de PD.
poe detection-mode { none | simple | strict }O padrão varia de acordo com a versão do software
Configuração de energia PoE
Configuração da potência máxima de PI
Sobre a potência máxima de PI
A potência máxima do PI é a potência máxima que um PI pode fornecer ao PD conectado. Se o PD exigir mais energia do que a energia máxima do PI, o PI não fornecerá energia ao PD.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar na visualização PI.
interface interface-type interface-number- Configure a potência máxima para o PI.
poe max-power max-powerO padrão varia de acordo com a versão do software
Configuração da política de prioridade PI
Sobre a política de prioridade PI
A política de prioridade de PI permite que o PSE realize a alocação de energia com base em prioridade para PIs quando ocorrer sobrecarga de energia do PSE. Os níveis de prioridade para PIs são crítico, alto e baixo em ordem decrescente.
Quando ocorre uma sobrecarga de energia do PSE, o PSE fornece energia aos PDs da seguinte forma:
Se a política de prioridade PI estiver desativada, o PSE fornecerá energia aos PDs, dependendo de você ter configurado a energia máxima do PSE.
Se você tiver configurado a potência máxima do PSE, o PSE não fornecerá energia ao PD recém-adicionado ou existente que cause sobrecarga de energia do PSE.
Se você não tiver configurado a potência máxima do PSE, o mecanismo de autoproteção do PoE será acionado. O PSE interrompe o fornecimento de energia a todos os PDs.
Se a política de prioridade PI estiver ativada, o PSE fornecerá energia aos PDs da seguinte forma:
Se um PD que estiver sendo alimentado causar sobrecarga de energia ao PSE, o PSE deixará de fornecer energia ao PD.
Se um PD recém-adicionado causar sobrecarga de energia do PSE, o PSE fornecerá energia aos PDs em ordem decrescente de prioridade dos PIs aos quais estão conectados. Se o PD recém-adicionado e um PD que está sendo alimentado tiverem a mesma prioridade, o PD que está sendo alimentado terá precedência. Se vários PIs que estão sendo alimentados tiverem a mesma prioridade, os PIs com IDs menores terão precedência.
Restrições e diretrizes
Antes de configurar um PI com prioridade crítica, verifique se a potência restante da potência máxima do PSE menos as potências máximas dos PIs existentes com prioridade crítica é maior do que a potência máxima do PI.
A configuração de um PI cuja energia é antecipada permanece inalterada.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a política de prioridade PI.
poe pd-policy priorityPor padrão, a política de prioridade PI está desativada.
- Entrar na visualização PI.
interface interface-type interface-number- (Opcional.) Configure uma prioridade para o PI.
poe priority { critical | high | low }Por padrão, a prioridade de um PI é baixa.
Configuração do monitoramento de PoE
Configuração do monitoramento de energia do PSE
Sobre o monitoramento de energia PSE
O sistema monitora a utilização de energia PSE e envia mensagens de notificação quando a utilização de energia PSE excede ou cai abaixo do limite. Se a utilização da energia PSE ultrapassar o limite várias vezes seguidas, o sistema enviará mensagens de notificação somente para o primeiro cruzamento. Para mais informações sobre a mensagem de notificação, consulte "Configuração de SNMP".
Procedimento
- Entre na visualização do sistema.
system-view- Configure um limite de alarme de energia para um PSE.
poe utilization-threshold value pse pse-idPor padrão, o limite de alarme de energia para um PSE é de 80%.
Associação de PoE com trilha
Sobre esta tarefa
O módulo PoE pode colaborar com o módulo Track para monitorar o status do link entre o dispositivo e um PD. Por exemplo, se o PD suportar o teste de eco ICMP NQA, você poderá especificar uma entrada de rastreamento associada ao NQA para testar a acessibilidade do PD. O teste de eco NQA ICMP deve ser configurado em uma interface de camada 3. O PI é uma interface de camada 2. É necessário criar uma interface VLAN para o teste de eco ICMP e atribuir o PI à VLAN.
O módulo Track notifica o módulo PoE sobre os seguintes resultados de monitoramento:
Positivo - O objeto monitorado pode ser acessado.
Negativo - O objeto monitorado não pode ser acessado.
NotReady - O resultado do monitoramento não está pronto por motivos como a inexistência do grupo NQA associado à entrada da trilha.
Quando o módulo Track detecta uma falha no link, ele altera o estado da entrada do track de positivo para negativo, o que faz com que o módulo PoE execute as seguintes ações:
somente alarme: Emite uma notificação e um registro SNMP.
alarm-reboot-pd: Emite uma notificação e um registro SNMP e reinicializa o PD conectado ao PI.
Para obter informações sobre as notificações de SNMP, consulte Configuração de SNMP no Guia de configuração de monitoramento e gerenciamento de rede.
Para obter informações sobre registros, consulte a configuração do centro de informações no Guia de configuração de monitoramento e gerenciamento de rede.
Para obter informações sobre o módulo Track, consulte a configuração do track no Guia de configuração de alta disponibilidade.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6348P01 e posteriores.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar na visualização PI.
interface interface-type interface-number- Associe o PI a uma entrada de trilha.
poe track track-entry-number action { alarm | alarm-reboot-pd }Por padrão, um PI não está associado a uma entrada de trilha.
Configuração de um PI usando um perfil PoE
Restrições e diretrizes
Para modificar um perfil PoE aplicado em um PI, primeiro remova o perfil PoE do PI.
Você pode configurar um PI no PI ou usando um perfil PoE. Os comandos poe max-power max-power e poe priority { critical | high | low } devem ser configurados usando o mesmo método.
Configuração de um perfil PoE
- Entre na visualização do sistema.
system-view- Crie um perfil PoE e entre em sua visualização.
poe-profile profile-name [ index ]Por padrão, não existem perfis PoE.
- Ativar PoE.
poe enablePor padrão, o PoE está desativado.
- (Opcional.) Configure a potência máxima de PI.
poe max-power max-powerO padrão varia de acordo com a versão do software
- (Opcional.) Configure uma prioridade PI.
poe priority { critical | high | low }A prioridade padrão é baixa.
Esse comando entra em vigor somente depois que a política de prioridade PI é ativada.
Aplicação de um perfil PoE
Restrições e diretrizes
Você pode aplicar um perfil PoE a vários PIs na visualização do sistema ou a um único PI na visualização do PI. Se você executar a operação em ambas as visualizações para o mesmo PI, a operação mais recente terá efeito.
Você pode aplicar apenas um perfil PoE a um PI.
Aplicação de um perfil PoE na visualização do sistema
- Entre na visualização do sistema.
system-view- Aplicar um perfil PoE aos PIs.
apply poe-profile { index index | name profile-name } interface
interface-rangePor padrão, um perfil PoE não é aplicado a um PI.
Aplicação de um perfil PoE na visualização PI
- Entre na visualização do sistema.
system-view- Entrar na visualização PI.
interface interface-type interface-number- Aplicar o perfil PoE à interface.
apply poe-profile { index index | name profile-name }
Por padrão, um perfil PoE não é aplicado a um PI.
Atualização do firmware do PSE em serviço
Sobre a atualização do firmware do PSE em serviço
Você pode atualizar o firmware do PSE em serviço nos seguintes modos:
Refresh mode (Modo de atualização) - Atualiza o firmware do PSE sem excluí-lo. Você pode usar o modo de atualização na maioria dos casos.
Full mode (Modo completo) - Exclui o firmware atual do PSE e recarrega um novo. Use o modo completo se o firmware do PSE estiver danificado e você não puder executar nenhum comando PoE.
Restrições e diretrizes
Se a atualização do firmware do PSE falhar devido a uma interrupção, como a reinicialização do dispositivo, você poderá reiniciar o dispositivo e atualizá-lo novamente no modo completo. Após a atualização, reinicie o dispositivo manualmente para que o novo firmware do PSE entre em vigor.
Procedimento
- Entre na visualização do sistema.
system-view- Atualize o firmware do PSE em serviço.
poe update { full | refresh } filename [ pse pse-id ]Ativação da fonte de alimentação PoE forçada
Sobre esta tarefa
Antes de fornecer energia a um PD, o dispositivo realiza uma detecção do PD. Ele fornece energia ao PD somente depois que o PD passa na detecção. Se o PD falhar na detecção, mas a energia fornecida pelo dispositivo atender às especificações do PD, você poderá configurar essa tarefa para ativar a fonte de alimentação forçada para o PD.
Restrições e diretrizes
CUIDADO:
Essa tarefa permite que o dispositivo forneça energia a um PD diretamente sem realizar uma detecção do PD. Para evitar danos ao PD, certifique-se de que a energia fornecida pelo dispositivo atenda às especificações do PD antes de configurar esse comando.
Essa tarefa é compatível apenas com a versão 6340 e posteriores.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar na visualização PI.
interface interface-type interface-number- Ativar a fonte de alimentação PoE forçada.
poe force-powerPor padrão, a fonte de alimentação PoE forçada está desativada.
Configuração do TMPDO para o MPS
Sobre esta tarefa
A MPS (Maintain Power Signature, assinatura de manutenção de energia) é uma assinatura elétrica fornecida por um PD. O PD usa essa assinatura para manter a conexão com o PSE no modo de suspensão. O PD envia periodicamente uma corrente de pulso compatível com PoE para o PSE. Se o PSE detectar a corrente de pulso compatível com PoE do PD dentro do TMPDO, ele fornecerá energia ao PD. Se o PSE não detectar a corrente de pulso compatível com PoE do PD dentro do TMPDO, ele não fornecerá energia ao PD.
Para enviar correntes de pulso em intervalos maiores para reduzir a energia de espera, você pode usar esse comando para alterar o TMPDO para que seja mais longo.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com o R6350 e versões posteriores.
Restrições e diretrizes
Somente os módulos PSE que têm um nome de modelo LSPPSE**A são compatíveis com esse recurso. Para visualizar os modelos PSE, execute o comando display poe pse.
Se você executar o comando várias vezes, a configuração mais recente entrará em vigor.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o TMPDO para o MPS.
poe mps pse pse-id tmpdo { timer | long |normal }Por padrão, o modo TMPDO normal é usado para o MPS. O TMPDO para o MPS é de 324 milissegundos.
Comandos de exibição e manutenção para PoE
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir informações gerais do PSE. | display poe device [ slot slot-number ] | ||
| Exibe as informações de fornecimento de energia para o PI especificado. | display poe interface [ interface-type interface-number ] | ||
| Exibir informações de energia para PIs. | display poe interface power [ interface-type interface-number ] | ||
| Exibir informações detalhadas do PSE. | display poe pse [ pse-id ] | ||
| Exibe as informações de fornecimento de energia para todos os PIs em um PSE. | display poe pse pse-id interface | ||
| Exibir informações de energia para todos os PIs em um PSE. | display poe pse pse-id interface power | ||
| Exibir todas as informações sobre o perfil PoE. | display poe-profile [ index index | name profile-name ] | ||
| Exibe todas as informações sobre o perfil PoE aplicado ao PI especificado. | display poe-profile interface interface-type interface-number |
Exemplos de configuração de PoE
Exemplo: Configurando PoE
Configuração de rede
Conforme mostrado na Figura 2, configure o PoE da seguinte forma:
Habilite o dispositivo para fornecer energia a telefones IP e APs.
Permita que o dispositivo forneça energia aos telefones IP primeiro quando houver sobrecarga.
Forneça ao AP B uma potência máxima de 9000 miliwatts.
Figura 2 Diagrama de rede
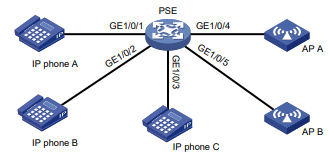
Procedimento
# Habilitar a política de prioridade PI.
<PSE> system-view
[PSE] poe pd-policy priority
# Habilite o PoE na GigabitEthernet 1/0/1, GigabitEthernet 1/0/2 e GigabitEthernet 1/0/3 e configure a prioridade da fonte de alimentação como crítica.
[PSE] interface gigabitethernet 1/0/1
[PSE-GigabitEthernet1/0/1] poe enable
[PSE-GigabitEthernet1/0/1] poe priority critical
[PSE-GigabitEthernet1/0/1] quit
[PSE] interface gigabitethernet 1/0/2
[PSE-GigabitEthernet1/0/2] poe enable
[PSE-GigabitEthernet1/0/2] poe priority critical
[PSE-GigabitEthernet1/0/2] quit
[PSE] interface gigabitethernet 1/0/3
[PSE-GigabitEthernet1/0/3] poe enable
[PSE-GigabitEthernet1/0/3] poe priority critical
[PSE-GigabitEthernet1/0/3] quit# Habilite o PoE na GigabitEthernet 1/0/4 e na GigabitEthernet 1/0/5 e defina a potência máxima da GigabitEthernet 1/0/5 como 9000 miliwatts.
[PSE] interface gigabitethernet 1/0/4
[PSE-GigabitEthernet1/0/4] poe enable
[PSE-GigabitEthernet1/0/4] quit
[PSE] interface gigabitethernet 1/0/5
[PSE-GigabitEthernet1/0/5] poe enable
[PSE-GigabitEthernet1/0/5] poe max-power 9000
Verificação da configuração
# Conecte os telefones IP e os APs ao PSE para verificar se eles podem obter energia e operar o corretamente. (Detalhes não mostrados.)
Solução de problemas de PoE
Falha ao definir a prioridade de um PI como crítica
Sintoma
Falha na configuração da prioridade da fonte de alimentação para um PI.
Solução
Para resolver o problema:
- Identifique se a potência garantida restante do PSE é menor do que a potência máxima do PI. Se for, aumente a potência máxima do PSE ou reduza a potência máxima do PI.
- Identifique se a prioridade foi configurada por meio de outros métodos. Se a prioridade tiver sido configurada, remova a configuração.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Falha ao aplicar um perfil PoE a um PI
Sintoma
Falha na aplicação do perfil PoE para um PI.
Solução
Para resolver o problema:
- Identifique se algumas configurações no perfil PoE foram configuradas. Se tiverem sido configuradas, remova a configuração.
- Identifique se as configurações do perfil PoE atendem aos requisitos do PI. Se não atenderem, modifique as configurações no perfil PoE.
- Identifique se outro perfil PoE já está aplicado ao PI. Se estiver, remova o aplicativo.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Configuração de SNMP
Sobre o SNMP
O Simple Network Management Protocol (SNMP) é usado para que uma estação de gerenciamento acesse e opere os dispositivos em uma rede, independentemente de seus fornecedores, características físicas e tecnologias de interconexão.
O SNMP permite que os administradores de rede leiam e definam as variáveis nos dispositivos gerenciados para monitoramento de estado, solução de problemas, coleta de estatísticas e outros fins de gerenciamento.
Estrutura SNMP
A estrutura do SNMP contém os seguintes elementos:
Gerenciador de SNMP - Funciona em um NMS para monitorar e gerenciar os dispositivos compatíveis com SNMP na rede. Ele pode obter e definir valores de objetos MIB no agente.
Agente SNMP - Funciona em um dispositivo gerenciado para receber e tratar solicitações do NMS e envia notificações ao NMS quando ocorrem eventos, como uma alteração no estado da interface.
Management Information Base (MIB) - Especifica as variáveis (por exemplo, status da interface e uso da CPU) mantidas pelo agente SNMP para que o gerente SNMP leia e defina.
Figura 1 Relação entre NMS, agente e MIB
Controle de acesso ao MIB e ao MIB baseado em visualização
Um MIB armazena variáveis chamadas "nós" ou "objetos" em uma hierarquia de árvore e identifica cada nó com um OID exclusivo. Um OID é uma cadeia numérica pontilhada que identifica exclusivamente o caminho do nó raiz para um nó folha. Por exemplo, o objeto B na Figura 2 é identificado exclusivamente pelo OID {1.2.1.1}.
Figura 2 Árvore MIB
Uma visualização MIB representa um conjunto de objetos MIB (ou hierarquias de objetos MIB) com determinados privilégios de acesso e é identificada por um nome de visualização. Os objetos MIB incluídos na visualização MIB são acessíveis, enquanto os excluídos da visualização MIB são inacessíveis.
Uma visualização MIB pode ter vários registros de visualização, cada um identificado por um par de árvore oid view-name. Você controla o acesso ao MIB atribuindo visualizações do MIB a grupos ou comunidades SNMP.
Operações SNMP
O SNMP oferece as seguintes operações básicas:
Get-NMS recupera o valor de um nó de objeto em um MIB de agente.
O Set-NMS modifica o valor de um nó de objeto em um MIB de agente.
Notificação - As notificações de SNMP incluem traps e informs. O agente SNMP envia traps ou informs para relatar eventos ao NMS. A diferença entre esses dois tipos de notificação é que as informações exigem confirmação, mas as armadilhas não. As informações são mais confiáveis, mas também consomem muitos recursos. As traps estão disponíveis em SNMPv1, SNMPv2c e SNMPv3. Os informes são disponíveis somente em SNMPv2c e SNMPv3.
Versões de protocolo
O dispositivo suporta SNMPv1, SNMPv2c e SNMPv3 no modo não-FIPS e suporta apenas SNMPv3 no modo FIPS. Um NMS e um agente SNMP devem usar a mesma versão SNMP para se comunicarem entre si.
SNMPv1 - Usa nomes de comunidade para autenticação. Para acessar um agente SNMP, um NMS deve usar o mesmo nome de comunidade definido no agente SNMP. Se o nome da comunidade usado pelo NMS for diferente do nome da comunidade definido no agente, o NMS não poderá estabelecer uma sessão SNMP para acessar o agente ou receber traps do agente.
SNMPv2c - Usa nomes de comunidade para autenticação. O SNMPv2c é compatível com o SNMPv1, mas oferece suporte a mais tipos de operação, tipos de dados e códigos de erro.
SNMPv3 - Usa um modelo de segurança baseado no usuário (USM) para proteger a comunicação SNMP. Você pode configurar mecanismos de autenticação e privacidade para autenticar e criptografar pacotes SNMP para integridade, autenticidade e confidencialidade.
Modos de controle de acesso
O SNMP usa os seguintes modos para controlar o acesso aos objetos MIB:
O modo View-based Access Control Model-VACM controla o acesso a objetos MIB atribuindo visualizações MIB a comunidades ou usuários de SNMP.
Controle de acesso baseado em função - o modo RBAC controla o acesso a objetos MIB atribuindo funções de usuário a comunidades ou usuários de SNMP.
⚪ As comunidades SNMP ou os usuários com função de usuário predefinida network-admin ou level-15 têm acesso de leitura e gravação a todos os objetos MIB.
⚪ As comunidades SNMP ou os usuários com função de usuário predefinida network-operator têm acesso somente de leitura a todos os objetos MIB.
⚪ As comunidades SNMP ou os usuários com uma função de usuário definida pelo usuário têm direitos de acesso aos objetos MIB, conforme especificado pelo comando rule.
O modo RBAC controla o acesso por objeto MIB e o modo VACM controla o acesso por visualização MIB. Como prática recomendada para aumentar a segurança do MIB, use o modo RBAC.
Se você criar a mesma comunidade ou usuário SNMP com ambos os modos várias vezes, a configuração mais recente terá efeito. Para obter mais informações sobre RBAC, consulte Referência de comandos básicos.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não-FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de configuração de segurança.
Visão geral das tarefas de SNMP
Para configurar o SNMP, execute as seguintes tarefas:
- Ativação do agente SNMP
- Ativação de versões SNMP
- Configuração dos parâmetros básicos do SNMP
- (Opcional.) Configuração dos parâmetros comuns do SNMP
- Configuração de uma comunidade SNMPv1 ou SNMPv2c
- Configuração de um grupo e usuário SNMPv3
- (Opcional.) Configuração de notificações SNMP
- (Opcional.) Examinar a configuração do sistema em busca de alterações
- (Opcional.) Examinar a configuração do sistema em busca de alterações
Sobre esta tarefa
O módulo SNMP examina periodicamente a configuração de execução do sistema, a configuração de inicialização e o arquivo de configuração da próxima inicialização em busca de alterações e gera um registro se for encontrada alguma alteração. Se a notificação SNMP para alterações de configuração tiver sido ativada, o sistema também gerará uma notificação SNMP .
Procedimento
- Entre na visualização do sistema.
system-view- Defina o intervalo em que o módulo SNMP examina a configuração do sistema em busca de alterações.
snmp-agent configuration-examine interval intervalPor padrão, o módulo SNMP examina a configuração do sistema em busca de alterações em intervalos de 600 segundos.
- Ativar a notificação SNMP para alterações na configuração do sistema.
snmp-agent trap enable configurationPor padrão, a notificação SNMP é ativada para alterações na configuração do sistema.
- Configuração do registro de SNMP
Ativação do agente SNMP
Restrições e diretrizes
O agente SNMP é ativado quando você usa qualquer comando que comece com snmp-agent, exceto o comando snmp-agent calculate-password.
O agente SNMP não será ativado quando a porta na qual o agente escutará for usada por outro serviço. Você pode usar o comando snmp-agent port para especificar uma porta de escuta. Para exibir as informações de uso da porta UDP, execute o comando display udp verbose. Para obter mais informações sobre o comando display udp verbose, consulte Comandos de otimização de desempenho de IP no Guia de Configuração de Serviços de Camada 3 IP.
Se você desativar o agente SNMP, as configurações de SNMP não terão efeito. O comando display current-configuration não exibe as configurações de SNMP. As definições de SNMP não serão salvas no arquivo de configuração. Para que as configurações de SNMP tenham efeito, ative o agente SNMP.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o agente SNMP.
snmp-agentPor padrão, o status de ativação do agente SNMP é o seguinte:
- Nos seguintes switches, o agente SNMP está desativado.
- Série de switches S3300G e S2300G
Ativação de versões SNMP
Restrições e diretrizes
O dispositivo suporta SNMPv1, SNMPv2c e SNMPv3 no modo não-FIPS e suporta apenas SNMPv3 no modo FIPS. Um NMS e um agente SNMP devem usar a mesma versão de SNMP para se comunicarem entre si.
Para usar as notificações SNMP no IPv6, ative o SNMPv2c ou o SNMPv3.
Procedimento
- Entre na visualização do sistema.
system-view- Habilitar versões SNMP. No modo não-FIPS:
snmp-agent sys-info version { all | { v1 | v2c | v3 } * }No modo FIPS:
snmp-agent sys-info version { all | v3 }Por padrão, o SNMPv3 está ativado.
Se você executar o comando várias vezes com opções diferentes, todas as configurações terão efeito , mas somente uma versão de SNMP será usada pelo agente e pelo NMS para comunicação.
Configuração dos parâmetros comuns do SNMP
Restrições e diretrizes
Uma ID de mecanismo SNMP identifica exclusivamente um dispositivo em uma rede gerenciada por SNMP. Certifique-se de que a ID do mecanismo SNMP local seja exclusiva em sua rede gerenciada por SNMP para evitar problemas de comunicação. Por padrão, o dispositivo recebe uma ID de mecanismo SNMP exclusiva.
Se você tiver configurado usuários SNMPv3, altere a ID do mecanismo SNMP local somente quando necessário. A alteração pode anular os nomes de usuário SNMPv3 e as chaves criptografadas que você configurou.
O agente SNMP não será ativado quando a porta na qual o agente escutará for usada por outro serviço. Você pode usar o comando snmp-agent port para alterar a porta de escuta do SNMP. Como prática recomendada, execute o comando display udp verbose para visualizar as informações de uso da porta UDP antes de especificar uma nova porta de escuta do SNMP. Para obter mais informações sobre o comando display udp verbose, consulte Comandos de otimização de desempenho de IP no Guia de configuração de serviços de IP de camada 3.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique uma porta de escuta SNMP.
snmp-agent port port-numberPor padrão, a porta de escuta do SNMP é a porta UDP 161.
- Definir uma ID de mecanismo SNMP local.
snmp-agent local-engineid engineidPor padrão, o ID do mecanismo SNMP local é o ID da empresa mais o ID do dispositivo. Cada dispositivo tem uma ID de dispositivo exclusiva.
- Definir uma ID de mecanismo para uma entidade SNMP remota.
snmp-agent remote { ipv4-address | ipv6 ipv6-address } engineid engineidPor padrão, não existem IDs de mecanismo de entidade remota.
Essa etapa é necessária para que o dispositivo envie notificações SNMPv3 a um host, normalmente o NMS.
- Criar ou atualizar uma visualização MIB.
snmp-agent mib-view { excluded | included } view-name oid-tree [ mask mask-value ]Por padrão, a visualização MIB ViewDefault é predefinida. Nessa visualização, todos os objetos MIB na subárvore iso, exceto as subárvores snmpUsmMIB, snmpVacmMIB e snmpModules.18, são acessíveis.
Cada par oid-árvore view-name representa um registro de visualização. Se você especificar o mesmo registro com diferentes máscaras de sub-árvore MIB várias vezes, a configuração mais recente terá efeito.
- Configurar as informações de gerenciamento do sistema.
- Configure o contato do sistema.
snmp-agent sys-info contact sys-contact- Configure o local do sistema.
snmp-agent sys-info location sys-locationPor padrão, o local do sistema é Brasil.
- Criar um contexto SNMP.
snmp-agent context context-namePor padrão, não existem contextos SNMP.
- Configure o tamanho máximo do pacote SNMP (em bytes) que o agente SNMP pode manipular.
snmp-agent packet max-size byte-countPor padrão, um agente SNMP pode processar pacotes SNMP com um tamanho máximo de 1500 bytes.
- Definir o valor DSCP para respostas SNMP.
snmp-agent packet response dscp dscp-valuePor padrão, o valor DSCP para respostas SNMP é 0.
Configuração de uma comunidade SNMPv1 ou SNMPv2c
Sobre a configuração de uma comunidade SNMPv1 ou SNMPv2c
É possível criar uma comunidade SNMPv1 ou SNMPv2c usando um nome de comunidade ou criando um usuário SNMPv1 ou SNMPv2c. Depois de criar um usuário SNMPv1 ou SNMPv2c, o sistema cria automaticamente uma comunidade usando o nome de usuário como o nome da comunidade.
Restrições e diretrizes para a configuração de uma comunidade SNMPv1 ou SNMPv2c
As configurações SNMPv1 e SNMPv2c não são compatíveis com o modo FIPS. Certifique-se de que o NMS e o agente usem o mesmo nome de comunidade SNMP.
Somente usuários com a função de usuário network-admin ou nível 15 podem criar comunidades, usuários ou grupos SNMPv1 ou SNMPv2c. Os usuários com outras funções de usuário não podem criar comunidades, usuários ou grupos SNMPv1 ou SNMPv2c, mesmo que essas funções tenham acesso a comandos relacionados ou comandos do recurso SNMPv1 ou SNMPv2c.
Configuração de uma comunidade SNMPv1/v2c por um nome de comunidade
- Entre na visualização do sistema.
system-view- Crie uma comunidade SNMPv1/v2c. Escolha uma opção conforme necessário.
- No modo VACM:
snmp-agent community { read | write } [ simple | cipher ]
community-name [ mib-view view-name ] [ acl { ipv4-acl-number | name
ipv4-acl-name } | acl ipv6 { ipv6-acl-number | name ipv6-acl-name } ]
*- No modo RBAC:
snmp-agent community [ simple | cipher ] community-name user-role
role-name [ acl { ipv4-acl-number | name ipv4-acl-name } | acl ipv6
{ ipv6-acl-number | name ipv6-acl-name } ] *- (Opcional.) Mapeie o nome da comunidade SNMP para um contexto SNMP.
snmp-agent community-map community-name context context-nameConfiguração de uma comunidade SNMPv1/v2c por meio da criação de um usuário SNMPv1/v2c
- Entre na visualização do sistema.
system-view- Criar um grupo SNMPv1/v2c.
snmp-agent group { v1 | v2c } group-name [ notify-view view-name |
read-view view-name | write-view view-name ] * [ acl { ipv4-acl-number |
name ipv4-acl-name } | acl ipv6 { ipv6-acl-number | name
ipv6-acl-name } ] *- Adicione um usuário SNMPv1/v2c ao grupo.
snmp-agent usm-user { v1 | v2c } user-name group-name [ acl
{ ipv4-acl-number | name ipv4-acl-name } | acl ipv6 { ipv6-acl-number
| name ipv6-acl-name } ] *
O sistema cria automaticamente uma comunidade SNMP usando o nome de usuário como o nome da comunidade.
- (Opcional.) Mapeie o nome da comunidade SNMP para um contexto SNMP.
snmp-agent community-map community-name context context-nameConfiguração de um grupo e usuário SNMPv3
Restrições e diretrizes para a configuração de um grupo e usuário SNMPv3
Somente usuários com a função de usuário network-admin ou nível 15 podem criar usuários ou grupos SNMPv3. Usuários com outras funções de usuário não podem criar usuários ou grupos SNMPv3, mesmo que essas funções tenham acesso a comandos relacionados ou comandos do recurso SNMPv3.
Os usuários de SNMPv3 são gerenciados em grupos. Todos os usuários de SNMPv3 em um grupo compartilham o mesmo modelo de segurança, mas podem usar chaves e algoritmos de autenticação e criptografia diferentes. A Tabela 1 descreve os requisitos básicos de configuração para diferentes modelos de segurança.
Tabela 1 Requisitos básicos de configuração para diferentes modelos de segurança
| Modelo de segurança | Palavra-chave para o grupo | Parâmetros para o usuário | Observações | ||||
| Autenticação com privacidade | privacidade | Algoritmos e chaves de autenticação e criptografia | Para que um NMS acesse o agente, certifique-se de que o NMS e o agente usem as mesmas chaves de autenticação e criptografia. | ||||
| Autenticação sem privacidade | autenticação | Algoritmo e chave de autenticação | Para que um NMS acesse o agente, certifique-se de que o NMS e o agente usem a mesma chave de autenticação. | ||||
| Sem autenticação, sem privacidade | N/A | N/A | As chaves de autenticação e criptografia, se configuradas, não entram em vigor. |
Configuração de um grupo e usuário SNMPv3 no modo não-FIPS
- Entre na visualização do sistema.
system-view- Criar um grupo SNMPv3.
snmp-agent group v3 group-name [ authentication | privacy ]
[ notify-view view-name | read-view view-name | write-view view-name ] *
[ acl { ipv4-acl-number | name ipv4-acl-name } | acl ipv6
{ ipv6-acl-number | name ipv6-acl-name } ] *
- (Opcional.) Calcule a forma criptografada para a chave em forma de texto simples.
snmp-agent calculate-password plain-password mode { 3desmd5 | 3dessha |
aes192md5 | aes192sha | aes256md5 | aes256sha | md5 | sha }
{ local-engineid | specified-engineid engineid }
- Crie um usuário SNMPv3. Escolha uma opção conforme necessário.
- No modo VACM:
snmp-agent usm-user v3 user-name group-name [ remote { ipv4-address |
ipv6 ipv6-address } ] [ { cipher | simple } authentication-mode { md5 |
sha } auth-password [ privacy-mode { 3des | aes128 | aes192 | aes256 |
des56 } priv-password ] ] [ acl { ipv4-acl-number | name
ipv4-acl-name } | acl ipv6 { ipv6-acl-number | name ipv6-acl-name } ]
*- No modo RBAC:
snmp-agent usm-user v3 user-name user-role role-name [ remote
{ ipv4-address | ipv6 ipv6-address } ] [ { cipher | simple }
authentication-mode { md5 | sha } auth-password [ privacy-mode { 3des
| aes128 | aes192 | aes256 | des56 } priv-password ] ] [ acl
{ ipv4-acl-number | name ipv4-acl-name } | acl ipv6 { ipv6-acl-number
| name ipv6-acl-name } ] *Para enviar notificações a um NMS SNMPv3, você deve especificar a palavra-chave remote.
- (Opcional.) Atribua uma função de usuário ao usuário SNMPv3 criado no modo RBAC.
snmp-agent usm-user v3 user-name user-role role-namePor padrão, um usuário SNMPv3 tem a função de usuário atribuída a ele em sua criação.
Configuração de um grupo e usuário SNMPv3 no modo FIPS
- Entre na visualização do sistema.
system-view- Criar um grupo SNMPv3.
snmp-agent group v3 group-name { authentication | privacy }
[ notify-view view-name | read-view view-name | write-view view-name ]
* [ acl { ipv4-acl-number | name ipv4-acl-name } | acl ipv6
{ ipv6-acl-number | name ipv6-acl-name } ] *- (Opcional.) Calcule a forma criptografada para a chave em forma de texto simples.
snmp-agent calculate-password plain-password mode { aes192sha |
aes256sha | sha } { local-engineid | specified-engineid engineid }
- Crie um usuário SNMPv3. Escolha uma opção conforme necessário.
- No modo VACM:
snmp-agent usm-user v3 user-name group-name [ remote { ipv4-address |
ipv6 ipv6-address } ] { cipher | simple } authentication-mode sha
auth-password [ privacy-mode { aes128 | aes192 | aes256 }
priv-password ] [ acl { ipv4-acl-number | name ipv4-acl-name } | acl
ipv6 { ipv6-acl-number | name ipv6-acl-name } ] *
- No modo RBAC:
snmp-agent usm-user v3 user-name user-role role-name [ remote
{ ipv4-address | ipv6 ipv6-address } ] { cipher | simple }
authentication-mode sha auth-password [ privacy-mode { aes128 |
aes192 | aes256 } priv-password ] [ acl { ipv4-acl-number | name
ipv4-acl-name } | acl ipv6 { ipv6-acl-number | name ipv6-acl-name } ]
*Para enviar notificações a um NMS SNMPv3, você deve especificar a palavra-chave remote.
- (Opcional.) Atribua uma função de usuário ao usuário SNMPv3 criado no modo RBAC.
snmp-agent usm-user v3 user-name user-role role-namePor padrão, um usuário SNMPv3 tem a função de usuário atribuída a ele em sua criação.
Configuração de notificações SNMP
Sobre as notificações SNMP
O agente SNMP envia notificações (traps e informs) para informar o NMS sobre eventos significativos, como alterações no estado do link e logins ou logouts de usuários. Depois que você ativa as notificações para um módulo, o módulo envia as notificações geradas para o agente SNMP. O agente SNMP envia as notificações recebidas como traps ou informs com base na configuração atual. Salvo indicação em contrário, a palavra-chave trap na linha de comando inclui tanto traps quanto informs.
Ativação de notificações SNMP
Restrições e diretrizes
Ative uma notificação de SNMP somente se necessário. As notificações de SNMP consomem muita memória e podem afetar o desempenho do dispositivo.
Para gerar notificações de linkUp ou linkDown quando o estado do link de uma interface for alterado, você deve executar as seguintes tarefas:
Habilite a notificação de linkUp ou linkDown globalmente usando o comando snmp-agent trap enable standard [ linkdown | linkup ] *.
Habilite a notificação de linkUp ou linkDown na interface usando o comando enable snmp trap updown.
Depois que você ativar as notificações para um módulo, o fato de o módulo gerar ou não notificações também depende da configuração do módulo. Para obter mais informações, consulte o guia de configuração de cada módulo.
Para usar as notificações SNMP no IPv6, ative o SNMPv2c ou o SNMPv3.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar notificações SNMP.
snmp-agent trap enable [ configuration | protocol | standard
[ authentication | coldstart | linkdown | linkup | warmstart ] * |
system ]
Por padrão, as notificações de configuração SNMP, as notificações padrão e as notificações do sistema estão ativadas. A ativação de outras notificações SNMP varia de acordo com os módulos.
Para que o dispositivo envie notificações SNMP para um protocolo, primeiro ative o protocolo.
- Entre na visualização da interface.
interface interface-type interface-number- Ativar notificações de estado do link.
enable snmp trap updownPor padrão, as notificações de estado do link estão ativadas.
Configuração de parâmetros para o envio de notificações SNMP
Sobre os parâmetros para o envio de notificações SNMP
Você pode configurar o agente SNMP para enviar notificações como traps ou informs a um host, normalmente um NMS, para análise e gerenciamento. As traps são menos confiáveis e usam menos recursos do que as informs, pois um NMS não envia uma confirmação quando recebe uma trap.
Quando ocorre congestionamento na rede ou o destino não pode ser alcançado, o agente SNMP armazena as notificações em uma fila. Você pode definir o tamanho da fila e o tempo de vida da notificação (o tempo máximo que uma notificação pode permanecer na fila). Quando o tamanho da fila é atingido, o sistema descarta a nova notificação recebida. Se a modificação do tamanho da fila fizer com que o número de notificações na fila ultrapasse o tamanho da fila, as notificações mais antigas serão descartadas para receber novas notificações. Uma notificação é excluída quando sua vida útil expira.
Você pode estender as notificações padrão de linkUp/linkDown para incluir a descrição da interface e o tipo de interface , mas deve se certificar de que o NMS seja compatível com as mensagens SNMP estendidas.
Configuração dos parâmetros para envio de traps de SNMP
- Entre na visualização do sistema.
System View
- Configure um host de destino. No modo não-FIPS:
snmp-agent target-host trap address udp-domain { ipv4-target-host |
ipv6 ipv6-target-host } [ udp-port port-number ] [ dscp dscp-value ]
params securityname security-string [ v1 | v2c | v3 [ authentication |
privacy ] ]No modo FIPS:
snmp-agent target-host trap address udp-domain { ipv4-target-host |
ipv6 ipv6-target-host } [ udp-port port-number ] [ dscp dscp-value ]
params securityname security-string v3 { authentication | privacy }Por padrão, nenhum host de destino é configurado.
- (Opcional.) Configure um endereço de origem para o envio de traps.
snmp-agent trap source interface-type interface-numberPor padrão, o SNMP usa o endereço IP da interface roteada de saída como o endereço IP de origem .
Configuração dos parâmetros para envio de informações SNMP
- Entre na visualização do sistema.
system-view- Configure um host de destino. No modo não-FIPS:
snmp-agent target-host inform address udp-domain { ipv4-target-host |
ipv6 ipv6-target-host } [ udp-port port-number ] params securityname
security-string { v2c | v3 [ authentication | privacy ] }
No modo FIPS:
snmp-agent target-host inform address udp-domain { ipv4-target-host |
ipv6 ipv6-target-host } [ udp-port port-number ] params securityname
security-string v3 { authentication | privacy }Por padrão, nenhum host de destino é configurado.
Somente o SNMPv2c e o SNMPv3 suportam pacotes de informações.
- (Opcional.) Configure um endereço de origem para o envio de informações.
snmp-agent inform source interface-type interface-numberPor padrão, o SNMP usa o endereço IP da interface roteada de saída como o endereço IP de origem.
Configuração de parâmetros comuns para o envio de notificações
- Entre na visualização do sistema.
system-view- (Opcional.) Habilite notificações estendidas de linkUp/linkDown.
snmp-agent trap if-mib link extendedPor padrão, o agente SNMP envia notificações padrão de linkUp/linkDown.
Se o NMS não for compatível com notificações estendidas de linkUp/linkDown, não use esse comando.
- (Opcional.) Defina o tamanho da fila de notificação.
snmp-agent trap queue-size sizePor padrão, a fila de notificação pode conter 100 mensagens de notificação.
- (Opcional.) Defina o tempo de vida da notificação.
snmp-agent trap life secondsA duração padrão da notificação é de 120 segundos.
Examinar a configuração do sistema em busca de alterações
Sobre esta tarefa
O módulo SNMP examina periodicamente a configuração de execução do sistema, a configuração de inicialização e o arquivo de configuração da próxima inicialização em busca de alterações e gera um registro se for encontrada alguma alteração. Se a notificação SNMP para alterações de configuração tiver sido ativada, o sistema também gerará uma notificação SNMP.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o intervalo em que o módulo SNMP examina a configuração do sistema em busca de alterações.
snmp-agent configuration-examine interval intervalPor padrão, o módulo SNMP examina a configuração do sistema em busca de alterações em intervalos de 600 segundos.
Esse comando é compatível apenas com a versão 6340 e posteriores.
- Ativar a notificação SNMP para alterações na configuração do sistema.
snmp-agent trap enable configurationPor padrão, a notificação SNMP é ativada para alterações na configuração do sistema.
Configuração do registro de SNMP
Sobre o registro de SNMP
O agente SNMP registra solicitações Get, solicitações Set, respostas Set, notificações SNMP e falhas de autenticação SNMP, mas não registra respostas Get.
Operação Get - O agente registra o endereço IP do NMS, o nome do nó acessado e o OID do nó.
Operação Set - O agente registra o endereço IP do NMS, o nome do nó acessado, o OID do nó, o valor da variável, o código de erro e o índice da operação Set.
Rastreamento de notificações - O agente registra as notificações de SNMP depois de enviá-las ao NMS.
Falha de autenticação de SNMP - O agente registra informações relacionadas quando um NMS não consegue ser autenticado pelo agente.
O módulo SNMP envia esses registros para o centro de informações. É possível configurar o centro de informações para enviar essas mensagens a determinados destinos, como o console e o buffer de log. O tamanho total de saída para o campo do nó (nome do nó MIB) e o campo do valor (valor do nó MIB) em cada entrada de registro é de 1024 bytes. Se esse limite for excedido, o centro de informações truncará os dados nos campos. Para obter mais informações sobre o centro de informações, consulte "Configuração do centro de informações".
Restrições e diretrizes
Ative o registro de SNMP somente se necessário. O registro em log de SNMP consome muita memória e pode afetar o desempenho do dispositivo.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o registro de SNMP.
snmp-agent log { all | authfail | get-operation | set-operation }Por padrão, o registro de SNMP está desativado.
- Ativar o registro de notificações SNMP.
snmp-agent trap logPor padrão, o registro de notificações SNMP está desativado.
Comandos de exibição e manutenção para SNMP
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir informações da comunidade SNMPv1 ou SNMPv2c. (Esse comando não é compatível com o modo FIPS). | display snmp-agent community [ read | write ] | ||
| Exibir contextos SNMP. | display snmp-agent context [ context-name ] | ||
| Exibir informações do grupo SNMP. | display snmp-agent group [ group-name ] | ||
| Exibe a ID do mecanismo local. | display snmp-agent local-engineid | ||
| Exibir informações do nó SNMP MIB. | display snmp-agent mib-node [ details | index-node | trap-node | verbose ] | ||
| Exibir informações de visualização do MIB. | display snmp-agent mib-view [ exclude | include | viewwname view-name ] | ||
| Exibir IDs de motores remotos. | display snmp-agent remote [ { ipv4-address | ipv6 ipv6-address } ] | ||
| Exibir estatísticas do agente SNMP. | display snmp-agent statistics | ||
| Exibir informações do sistema do agente SNMP. | display snmp-agent sys-info [ contact | location | version ] * | ||
| Exibir informações básicas sobre a fila de notificação. | display snmp-agent trap queue | ||
| Exibir o status de habilitação de notificações SNMP para módulos. | display snmp-agent trap-list | ||
| Exibir informações do usuário SNMPv3. | display snmp-agent usm-user [ engineid engineid | username user-name | group group-name ] * |
Exemplos de configuração de SNMP
Exemplo: Configuração de SNMPv1/SNMPv2c
O dispositivo não é compatível com esse exemplo de configuração no modo FIPS.
O procedimento de configuração é o mesmo para SNMPv1 e SNMPv2c. Este exemplo usa o SNMPv1.
Configuração de rede
Conforme mostrado na Figura 3, o NMS (1.1.1.2/24) usa o SNMPv1 para gerenciar o agente SNMP (1.1.1.1/24), e o agente envia automaticamente notificações para informar eventos ao NMS.
Figura 3 Diagrama de rede
center>
Procedimento
- Configurar o agente SNMP:
# Atribua o endereço IP 1.1.1.1/24 ao agente e certifique-se de que o agente e o NMS possam se comunicar. (Detalhes não mostrados.)
# Especifique o SNMPv1 e crie uma comunidade somente de leitura pública e uma comunidade de leitura e gravação privado.
<Agent> system-view
[Agent] snmp-agent sys-info version v1
[Agent] snmp-agent community read public
[Agent] snmp-agent community write private# Configure as informações de contato e localização física do agente.
[Agent] snmp-agent sys-info contact Mr.Wang-Tel:3306
[Agent] snmp-agent sys-info location telephone-closet,3rd-floor# Habilite as notificações de SNMP, especifique o NMS em 1.1.1.2 como um destino de trap de SNMP e use public como o nome da comunidade. (Para garantir que o NMS possa receber traps, especifique a mesma versão de SNMP no comando snmp-agent target-host que está configurado no NMS).
[Agent] snmp-agent trap enable
[Agent] snmp-agent target-host trap address udp-domain 1.1.1.2 params securityname
public v1- Configure o SNMP NMS:
- Especifique SNMPv1.
- Crie uma comunidade somente de leitura pública e uma comunidade de leitura e gravação privada.
- Defina o cronômetro de tempo limite e o número máximo de novas tentativas, conforme necessário. Para obter informações sobre como configurar o NMS, consulte o manual do NMS.
OBSERVAÇÃO:
As configurações de SNMP do agente e do NMS devem corresponder.
Verificação da configuração
# Tentativa de obter o valor MTU da interface NULL0 do agente. A tentativa foi bem-sucedida.
Send request to 1.1.1.1/161 ...
Protocol version: SNMPv1
Operation: Get
Request binding:
1: 1.3.6.1.2.1.2.2.1.4.135471
Response binding:
1: Oid=ifMtu.135471 Syntax=INT Value=1500
Get finished
# Use um nome de comunidade incorreto para obter o valor de um nó MIB no agente. Você pode ver uma interceptação de falha de autenticação no NMS.
1.1.1.1/2934 V1 Trap = authenticationFailure
SNMP Version = V1
Community = public
Command = Trap
Enterprise = 1.3.6.1.4.1.43.1.16.4.3.50
GenericID = 4
SpecificID = 0
Time Stamp = 8:35:25.68Exemplo: Configuração do SNMPv3
Configuração de rede
Conforme mostrado na Figura 4, o NMS (1.1.1.2/24) usa o SNMPv3 para monitorar e gerenciar o agente (1.1.1.1/24). O agente envia automaticamente notificações para informar eventos ao NMS. A porta UDP 162 padrão é usada para notificações de SNMP.
O NMS e o agente realizam a autenticação quando estabelecem uma sessão SNMP. O algoritmo de autenticação é SHA-1 e a chave de autenticação é 123456TESTauth&!. O NMS e o agente também criptografam os pacotes SNMP entre eles usando o algoritmo AES e a chave de criptografia 123456TESTencr&!.
Figura 4 Diagrama de rede
center>
Configuração do SNMPv3 no modo RBAC
- Configurar o agente:
# Atribua o endereço IP 1.1.1.1/24 ao agente e certifique-se de que o agente e o NMS possam se comunicar. (Detalhes não mostrados.)
#Crie a função de usuário test e atribua a test acesso somente leitura aos objetos no snmpMIB
(OID:1.3.6.1.6.3.1), incluindo os objetos linkUp e linkDown.
<Agent> system-view
[Agent] role name test
[Agent-role-test] rule 1 permit read oid 1.3.6.1.6.3.1# Atribua ao usuário teste de função acesso somente de leitura ao nó do sistema (OID:1.3.6.1.2.1.1) e acesso de leitura e gravação ao nó das interfaces (OID:1.3.6.1.2.1.2).
[Agent-role-test] rule 2 permit read oid 1.3.6.1.2.1.1
[Agent-role-test] rule 3 permit read write oid 1.3.6.1.2.1.2
[Agent-role-test] quit# Criar usuário SNMPv3 RBACtest. Atribua a função de usuário test ao RBACtest. Definir a autenticação
algoritmo para SHA-1, chave de autenticação para 123456TESTauth&!, algoritmo de criptografia para AES e chave de criptografia para 123456TESTencr&!
[Agent] snmp-agent usm-user v3 RBACtest user-role test simple authentication-mode sha
123456TESTauth&! privacy-mode aes128 123456TESTencr&!#Configure as informações de contato e localização física do agente.
[Agent] snmp-agent sys-info contact Mr.Wang-Tel:3306
[Agent] snmp-agent sys-info location telephone-closet,3rd-floor#Habilite as notificações no agente. Especifique o NMS em 1.1.1.2 como o destino da notificação e RBACtest como o nome de usuário.
[Agent] snmp-agent trap enable
[Agent] snmp-agent target-host trap address udp-domain 1.1.1.2 params
securitynameRBACtest v3 privacy- Configure o NMS:
- Especifique SNMPv3.
- Criar o usuário SNMPv3 RBACtest.
- Habilite a autenticação e a criptografia. Defina o algoritmo de autenticação como SHA-1, a chave de autenticação como 123456TESTauth&!, o algoritmo de criptografia como AES e a chave de criptografia como 123456TESTencr&!
- Defina o cronômetro de tempo limite e o número máximo de novas tentativas.
Para obter informações sobre como configurar o NMS, consulte o manual do NMS.
OBSERVAÇÃO:
As configurações de SNMP no agente e no NMS devem corresponder.
Configuração do SNMPv3 no modo VACM
- Configure o agente:
# Atribua o endereço IP 1.1.1.1/24 ao agente e certifique-se de que o agente e o NMS possam se comunicar. (Detalhes não mostrados.)
# Crie o grupo SNMPv3 managev3group e atribua ao managev3group acesso somente leitura aos objetos sob o nó snmpMIB (OID: 1.3.6.1.2.1.2.2) na visualização de teste, incluindo os objetos linkUp e linkDown.
<Agent> system-view
[Agent] undo snmp-agent mib-view ViewDefault
[Agent] snmp-agent mib-view included test snmpMIB
[Agent] snmp-agent group v3 managev3group privacy read-view test#Atribuir ao grupo SNMPv3 managev3group acesso de leitura e gravação aos objetos do sistema
(OID: 1.3.6.1.2.1.1) e o nó de interfaces (OID: 1.3.6.1.2.1.2) na visualização de teste.
[Agent] snmp-agent mib-view included test 1.3.6.1.2.1.1
[Agent] snmp-agent mib-view included test 1.3.6.1.2.1.2
[Agent] snmp-agent group v3 managev3group privacy read-view test write-view test# Adicione o usuário VACMtest ao grupo SNMPv3 managev3group e defina o algoritmo de autenticação como SHA-1, a chave de autenticação como 123456TESTauth&!, o algoritmo de criptografia como AES e a chave de criptografia como 123456TESTencr&!
[Agent] snmp-agent usm-user v3 VACMtest managev3group simple authentication-mode sha
123456TESTauth&! privacy-mode aes128 123456TESTencr&!# Configure as informações de contato e localização física do agente.
[Agent] snmp-agent sys-info contact Mr.Wang-Tel:3306
[Agent] snmp-agent sys-info location telephone-closet,3rd-floor# Habilite as notificações no agente. Especifique o NMS em 1.1.1.2 como o destino do trap e VACMtest como o nome de usuário.
[Agent] snmp-agent sys-info contact Mr.Wang-Tel:3306
[Agent] snmp-agent sys-info location telephone-closet,3rd-floor- Configurar o SNMP NMS:
- Especifique SNMPv3.
- Criar o usuário VACMtest do SNMPv3.
- Habilite a autenticação e a criptografia. Defina o algoritmo de autenticação como SHA-1, a chave de autenticação como 123456TESTauth&!, o algoritmo de criptografia como AES e a chave de criptografia como 123456TESTencr&!
- Defina o cronômetro de tempo limite e o número máximo de novas tentativas.
Para obter informações sobre como configurar o NMS, consulte o manual do NMS.
OBSERVAÇÃO:
As configurações de SNMP no agente e no NMS devem corresponder.
Verificação da configuração
Use o nome de usuário RBACtest para acessar o agente.
# Recupere o valor do nó sysName. O valor Agent é retornado.
# Defina o valor do nó sysName como Sysname. A operação falha porque o NMS não tem acesso de gravação ao nó.
# Desligar ou ativar uma interface no agente. O NMS recebe notificações de linkUP (OID: 1.3.6.1.6.3.1.1.5.4) ou linkDown (OID: 1.3.6.1.6.3.1.1.5.3).
Use o nome de usuário VACMtest para acessar o agente.
# Recupere o valor do nó sysName. O valor Agent é retornado.
# Defina o valor do nó sysName como Sysname. A operação foi bem-sucedida.
# Desligar ou ativar uma interface no agente. O NMS recebe notificações de linkUP (OID: 1.3.6.1.6.3.1.1.5.4) ou linkDown (OID: 1.3.6.1.6.3.1.1.5.3).
Configuração do RMON
Sobre a RMON
O Remote Network Monitoring (RMON) é um protocolo de gerenciamento de rede baseado em SNMP. Ele permite o monitoramento e gerenciamento remoto proativo de dispositivos de rede.
Mecanismo de funcionamento do RMON
O RMON pode coletar periódica ou continuamente estatísticas de tráfego para uma porta Ethernet e monitorar os valores dos objetos MIB em um dispositivo. Quando um valor atinge o limite, o dispositivo registra automaticamente o evento ou envia uma notificação ao NMS. O NMS não precisa pesquisar constantemente as variáveis MIB e comparar os resultados.
O RMON usa notificações SNMP para notificar os NMSs sobre várias condições de alarme. O SNMP informa ao NMS as alterações de status operacional da função e da interface, como link up, link down e falha de módulo.
Grupos RMON
Entre os grupos RMON padrão, o dispositivo implementa o grupo de estatísticas, o grupo de histórico, o grupo de eventos, o grupo de alarmes, o grupo de configuração da sonda e o grupo de histórico do usuário. O sistema Comware também implementa um grupo de alarme privado, que aprimora o grupo de alarme padrão. O grupo de configuração da sonda e o grupo de histórico do usuário não são configuráveis na CLI. Para configurar esses dois grupos , é necessário acessar o MIB.
Grupo de estatísticas
O grupo de estatísticas coleta amostras de estatísticas de tráfego para interfaces Ethernet monitoradas e armazena as estatísticas na tabela de estatísticas Ethernet (ethernetStatsTable). As estatísticas incluem:
Número de colisões.
Erros de alinhamento de CRC.
Número de pacotes de tamanho menor ou maior que o normal.
Número de transmissões.
Número de multicasts.
Número de bytes recebidos.
Número de pacotes recebidos.
As estatísticas na tabela de estatísticas da Ethernet são somas cumulativas.
Grupo de história
O grupo de histórico coleta periodicamente amostras de estatísticas de tráfego em interfaces e salva as amostras de histórico na tabela de histórico (etherHistoryTable). As estatísticas incluem:
Utilização da largura de banda.
Número de pacotes de erro.
Número total de pacotes.
A tabela de histórico armazena as estatísticas de tráfego coletadas para cada intervalo de amostragem.
Grupo de eventos
O grupo de eventos controla a geração e as notificações de eventos acionados pelos alarmes definidos no grupo de alarmes e no grupo de alarmes privados. Os métodos de tratamento de eventos de alarme RMON são os seguintes:
Log - Registra informações de eventos (incluindo hora e descrição do evento) na tabela de registro de eventos para que o dispositivo de gerenciamento possa obter os registros por meio de SNMP.
Trap - Envia uma notificação SNMP quando o evento ocorre.
Log-Trap - Registra informações de eventos na tabela de registro de eventos e envia uma notificação SNMP quando o evento ocorre.
Nenhum - Não realiza nenhuma ação.
Grupo de alarmes
O grupo de alarmes RMON monitora variáveis de alarme, como a contagem de pacotes de entrada (etherStatsPkts) em uma interface. Depois que você cria uma entrada de alarme, o agente RMON coleta amostras do valor da variável de alarme monitorada regularmente. Se o valor da variável monitorada for maior ou igual ao limite crescente, um evento de alarme crescente será acionado. Se o valor da variável monitorada for menor ou igual ao limite de queda, será acionado um evento de alarme de queda. O grupo de eventos define a ação a ser tomada no evento de alarme.
Se uma entrada de alarme cruzar um limite várias vezes seguidas, o agente RMON gera um evento de alarme apenas para o primeiro cruzamento. Por exemplo, se o valor de uma variável de alarme amostrada cruzar o limite de subida várias vezes antes de cruzar o limite de descida, somente o primeiro cruzamento acionará um evento de alarme de subida, conforme mostrado na Figura 1.
Figura 1 Eventos de alarme ascendente e descendente
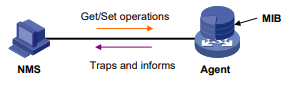
Grupo de alarme privado
O grupo de alarmes privados permite que você realize operações matemáticas básicas em várias variáveis e compare o resultado do cálculo com os limites de subida e descida.
O agente RMON faz uma amostragem das variáveis e executa uma ação de alarme com base em uma entrada de alarme particular, como segue:
- Amostrar as variáveis de alarme privadas na fórmula definida pelo usuário.
- Processa os valores amostrados com a fórmula.
- Compara o resultado do cálculo com os limites predefinidos e, em seguida, executa uma das seguintes ações:
- Aciona o evento associado ao evento de alarme crescente se o resultado for igual ou maior que o limite crescente.
- Aciona o evento associado ao evento de alarme de queda se o resultado for igual ou menor que o limite de queda.
Se uma entrada de alarme particular cruzar um limite várias vezes seguidas, o agente RMON gerará um evento de alarme apenas para o primeiro cruzamento. Por exemplo, se o valor de uma variável de alarme amostrada
cruzar o limite de subida várias vezes antes de cruzar o limite de descida, somente o primeiro cruzamento aciona um evento de alarme de subida.
Tipos de amostra para o grupo de alarme e o grupo de alarme privado
O agente RMON é compatível com os seguintes tipos de amostra:
absoluto - O RMON compara o valor da variável monitorada com os limites de subida e descida no final do intervalo de amostragem.
O delta-RMON subtrai o valor da variável monitorada na amostra anterior do valor atual e, em seguida, compara a diferença com os limites de subida e descida.
Protocolos e padrões
RFC 4502, Base de Informações de Gerenciamento de Monitoramento Remoto de Rede Versão 2
RFC 2819, Base de informações de gerenciamento de monitoramento remoto de rede Status deste memorando
Configuração da função de estatísticas RMON
Sobre a função de estatísticas RMON
O RMON implementa a função de estatísticas por meio do grupo de estatísticas Ethernet e do grupo de histórico.
O grupo de estatísticas Ethernet fornece a estatística cumulativa de uma variável desde o momento em que a entrada de estatísticas é criada até a hora atual.
O grupo de histórico fornece estatísticas que são amostradas para uma variável para cada intervalo de amostragem. O grupo de histórico usa a tabela de controle de histórico para controlar a amostragem e armazena amostras na tabela de histórico.
Criação de uma entrada de estatísticas RMON Ethernet
Restrições e diretrizes
O índice de uma entrada de estatísticas RMON deve ser globalmente exclusivo. Se o índice tiver sido usado por outra interface, a operação de criação falhará.
Você pode criar apenas uma entrada de estatísticas RMON para uma interface Ethernet.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface Ethernet.
interface interface-type interface-number- Criar uma entrada de estatísticas RMON Ethernet.
rmon statistics entry-number [ owner text ]Criação de uma entrada de controle de histórico RMON
Restrições e diretrizes
É possível configurar várias entradas de controle de histórico para uma interface, mas é preciso garantir que os números de entrada e os intervalos de amostragem sejam diferentes.
É possível criar uma entrada de controle de histórico com êxito, mesmo que o tamanho do compartimento especificado exceda o tamanho da tabela de histórico disponível. O RMON definirá o tamanho do compartimento o mais próximo possível do tamanho esperado do compartimento.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface Ethernet.
interface interface-type interface-number- Crie uma entrada de controle de histórico RMON.
rmon history entry-number buckets number interval interval [ owner text ]Por padrão, não existem entradas de controle de histórico do RMON.
É possível criar várias entradas de controle de histórico do RMON para uma interface Ethernet.
Configuração da função de alarme RMON
Restrições e diretrizes
Ao criar um novo evento, alarme ou entrada de alarme particular, siga estas restrições e diretrizes:
A entrada não deve ter o mesmo conjunto de parâmetros que uma entrada existente.
O número máximo de entradas não foi atingido.
A Tabela 1 mostra os parâmetros a serem comparados para duplicação e os limites de entrada.
Tabela 1 Restrições de configuração do RMON
| Entrada | Parâmetros a serem comparados | Número máximo de entradas | |||
| Evento | Descrição do evento (descrição string) Tipo de evento (log, trap, logtrap ou nenhum) Nome da comunidade (security-string) | 60 | |||
| Alarme | Variável de alarme (variável de alarme) Intervalo de amostragem (intervalo de amostragem) Tipo de amostra (absoluta ou delta) Limite crescente (valor limiar1) Limite de queda (valor limiar2) | 60 | |||
| Alarme privado | Fórmula de variável de alarme (prialarm-formula) Intervalo de amostragem (intervalo de amostragem) Tipo de amostra (absoluta ou delta) Limite crescente (valor limiar1) Limite de queda (valor limiar2) | 50 |
Pré-requisitos
Para enviar notificações ao NMS quando um alarme for acionado, configure o agente SNMP conforme descrito em em "Configuração de SNMP" antes de configurar a função de alarme RMON.
Procedimento
- Entre na visualização do sistema.
system-view- (Opcional.) Crie uma entrada de evento RMON.
rmon event entry-number [ description string ] { log | log-trap
security-string | none | trap security-string } [ owner text ]
Por padrão, não existem entradas de eventos RMON.
- Criar uma entrada de alarme RMON.
- Criar uma entrada de alarme RMON.
rmon alarm entry-number alarm-variable sampling-interval
{ absolute | delta } [ startup-alarm { falling | rising |
rising-falling } ] rising-threshold threshold-value1 event-entry1
falling-threshold threshold-value2 event-entry2 [ owner text ]- Criar uma entrada de alarme privado RMON.
rmon prialarm entry-number prialarm-formula prialarm-des
sampling-interval { absolute | delta } [ startup-alarm { falling |
rising | rising-falling } ] rising-threshold threshold-value1
event-entry1 falling-threshold threshold-value2 event-entry2
entrytype { forever | cycle cycle-period } [ owner text ]Por padrão, não existem entradas de alarme RMON ou entradas de alarme privado RMON.
Você pode associar um alarme a um evento que ainda não foi criado. O alarme acionará o evento somente depois que o evento for criado.
Comandos de exibição e manutenção para RMON
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir entradas de alarme RMON. | display rmon alarm [ entry-number ] | ||
| Exibir entradas de eventos RMON. | display rmon event [ entry-number ] | ||
| Exibir informações de registro para entradas de eventos. | display rmon eventlog [ entry-number ] | ||
| Exibir entradas de controle de histórico RMON e amostras de histórico. | display rmon history [ interface-type interface-number ] | ||
| Exibir entradas de alarme privado RMON. | display rmon prialarm [ entry-number ] | ||
| Exibir estatísticas RMON. | display rmon statistics [ interface-type interface-number] |
Exemplos de configuração RMON
Exemplo: Configuração da função de estatísticas de Ethernet
Configuração de rede
Conforme mostrado na Figura 2, crie uma entrada de estatísticas RMON Ethernet no dispositivo para coletar estatísticas de tráfego cumulativas para GigabitEthernet 1/0/1.
Figura 2 Diagrama de rede
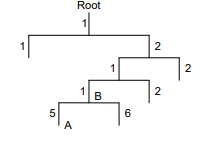
Procedimento
# Criar uma entrada de estatísticas RMON Ethernet para GigabitEthernet 1/0/1.
<Sysname> system-view
[Sysname] interface gigabitethernet 1/0/1
[Sysname-GigabitEthernet1/0/1] rmon statistics 1 owner user1Verificação da configuração
# Exibir estatísticas coletadas para a GigabitEthernet 1/0/1.
display rmon statistics gigabitethernet 1/0/1
EtherStatsEntry 1 owned by user1 is VALID.
Interface : GigabitEthernet1/0/1
etherStatsOctets : 21657 , etherStatsPkts : 307
etherStatsBroadcastPkts : 56 , etherStatsMulticastPkts : 34
etherStatsUndersizePkts : 0 , etherStatsOversizePkts : 0
etherStatsFragments : 0 , etherStatsJabbers : 0
etherStatsCRCAlignErrors : 0 , etherStatsCollisions : 0
etherStatsDropEvents (insufficient resources): 0
Incoming packets by size:
64 : 235 , 65-127 : 67 , 128-255 : 4
256-511: 1 , 512-1023: 0 , 1024-1518: 0 # Obtenha as estatísticas de tráfego do NMS por meio de SNMP. (Detalhes não mostrados.)
Exemplo: Configuração da função de estatísticas de histórico
Configuração de rede
Conforme mostrado na Figura 3, crie uma entrada de controle de histórico RMON no dispositivo para obter amostras das estatísticas de tráfego da GigabitEthernet 1/0/1 a cada minuto.
Figura 3 Diagrama de rede

Procedimento
# Crie uma entrada de controle de histórico RMON para obter amostras de estatísticas de tráfego a cada minuto para a GigabitEthernet 1/0/1. Mantenha um máximo de oito amostras para a interface na tabela de estatísticas do histórico.
<Sysname> system-view
[Sysname] interface gigabitethernet 1/0/1
[Sysname-GigabitEthernet1/0/1] rmon history 1 buckets 8 interval 60 owner user1Verificação da configuração
# Exibir as estatísticas de histórico coletadas para a GigabitEthernet 1/0/1. [Sysname-GigabitEthernet1/0/1] display rmon history HistoryControlEntry 1 owned by user1 is VALID
[Sysname-GigabitEthernet1/0/1] display rmon history
HistoryControlEntry 1 owned by user1 is VALID
Sampled interface : GigabitEthernet1/0/1
Sampling interval : 60(sec) with 8 buckets max
Sampling record 1 :
dropevents : 0 , octets : 834
packets : 8 , broadcast packets : 1
multicast packets : 6 , CRC alignment errors : 0
undersize packets : 0 , oversize packets : 0
fragments : 0 , jabbers : 0
collisions : 0 , utilization : 0
Sampling record 2 :
dropevents : 0 , octets : 962
packets : 10 , broadcast packets : 3
multicast packets : 6 , CRC alignment errors : 0
undersize packets : 0 , oversize packets : 0
fragments : 0 , jabbers : 0
collisions : 0 , utilization : 0 # Obtenha as estatísticas de tráfego do NMS por meio de SNMP. (Detalhes não mostrados).
Exemplo: Configuração da função de alarme
Configuração de rede
Conforme mostrado na Figura 4, configure o dispositivo para monitorar a estatística de tráfego de entrada na GigabitEthernet 1/0/1 e enviar alarmes RMON quando uma das condições a seguir for atendida:
A amostra delta de 5 segundos para a estatística de tráfego ultrapassa o limite de aumento (100).
A amostra delta de 5 segundos para a estatística de tráfego cai abaixo do limite de queda (50).
Figura 4 Diagrama de rede

Procedimento
# Configure o agente SNMP (o dispositivo) com as mesmas configurações de SNMP que o NMS em 1.1.1.2. Este exemplo usa SNMPv1, comunidade de leitura pública e comunidade de gravação privada.
<Sysname> system-view
[Sysname] snmp-agent
[Sysname] snmp-agent community read public
[Sysname] snmp-agent community write private
[Sysname] snmp-agent sys-info version v1
[Sysname] snmp-agent trap enable
[Sysname] snmp-agent trap log
[Sysname] snmp-agent target-host trap address udp-domain 1.1.1.2 params securityname
public# Criar uma entrada de estatísticas RMON Ethernet para GigabitEthernet 1/0/1.
[Sysname] interface gigabitethernet 1/0/1
[Sysname-GigabitEthernet1/0/1] rmon statistics 1 owner user1
[Sysname-GigabitEthernet1/0/1] quit# Crie uma entrada de evento RMON e uma entrada de alarme RMON para enviar notificações SNMP quando a amostra delta para 1.3.6.1.2.1.16.1.1.1.4.1 exceder 100 ou cair abaixo de 50.
[Sysname] rmon event 1 trap public owner user1
[Sysname] rmon alarm 1 1.3.6.1.2.1.16.1.1.1.4.1 5 delta rising-threshold 100 1
falling-threshold 50 1 owner user1OBSERVAÇÃO:
A string 1.3.6.1.2.1.16.1.1.1.4.1 é a instância do objeto para GigabitEthernet 1/0/1. Os dígitos antes do último dígito (1.3.6.1.2.1.16.1.1.1.4) representam o objeto para estatísticas de tráfego total de entrada. O último dígito (1) é o índice de entrada de estatísticas RMON Ethernet para GigabitEthernet 1/0/1.
Verificação da configuração
# Exibir a entrada de alarme RMON.
display rmon alarm 1
AlarmEntry 1 owned by user1 is VALID.
Sample type : delta
Sampled variable : 1.3.6.1.2.1.16.1.1.1.4.1
Sampling interval (in seconds) : 5
Rising threshold : 100(associated with event 1)
Falling threshold : 50(associated with event 1)
Alarm sent upon entry startup : risingOrFallingAlarm
Latest value : 0 # Exibir estatísticas da GigabitEthernet 1/0/1.
<Sysname> display rmon statistics gigabitethernet 1/0/1
Interface : GigabitEthernet1/0/1
etherStatsOctets : 57329 , etherStatsPkts : 455
etherStatsBroadcastPkts : 53 , etherStatsMulticastPkts : 353
etherStatsUndersizePkts : 0 , etherStatsOversizePkts : 0
etherStatsFragments : 0 , etherStatsJabbers : 0
etherStatsCRCAlignErrors : 0 , etherStatsCollisions : 0
etherStatsDropEvents (insufficient resources): 0
Incoming packets by size :
64 : 7 , 65-127 : 413 , 128-255 : 35
256-511: 0 , 512-1023: 0 , 1024-1518: 0 O NMS recebe a notificação quando o alarme é acionado.
Configuração do NETCONF
Sobre a NETCONF
O Network Configuration Protocol (NETCONF) é um protocolo de gerenciamento de rede baseado em XML. Ele fornece mecanismos programáveis para gerenciar e configurar dispositivos de rede. Por meio do NETCONF, você pode configurar parâmetros de dispositivos, recuperar valores de parâmetros e coletar estatísticas. Para uma rede que tenha dispositivos de fornecedores, você pode desenvolver um sistema NMS baseado em NETCONF para configurar e gerenciar dispositivos de forma simples e eficaz.
Estrutura do NETCONF
O NETCONF tem as seguintes camadas: camada de conteúdo, camada de operações, camada de RPC e camada de protocolo de transporte.
Formato da mensagem NETCONF
NETCONF
Todas as mensagens NETCONF são baseadas em XML e estão em conformidade com a RFC 4741. Uma mensagem NETCONF recebida deve passar pela verificação do esquema XML antes de ser processada. Se uma mensagem NETCONF não passar na verificação do esquema XML, o dispositivo enviará uma mensagem de erro ao cliente.
Para obter informações sobre as operações do NETCONF compatíveis com o dispositivo e os dados operáveis, consulte a referência da API XML do NETCONF para o dispositivo.
O exemplo a seguir mostra uma mensagem NETCONF para obter todos os parâmetros de todas as interfaces do dispositivo:
<?xml version="1.0" encoding="utf-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-bulk>
<filtro type="subtree">
<top xmlns="http://www.intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface/>
</Interfaces>
</Ifmgr>
</top>
</filtro>
</get-bulk>
</rpc>NETCONF sobre SOAP
Todas as mensagens NETCONF sobre SOAP são baseadas em XML e estão em conformidade com a RFC 4741. As mensagens NETCONF estão contidas no elemento <Body> das mensagens SOAP. As mensagens NETCONF sobre SOAP também estão em conformidade com as seguintes regras:
As mensagens SOAP devem usar os namespaces do Envelope SOAP.
As mensagens SOAP devem usar os namespaces SOAP Encoding.
As mensagens SOAP não podem conter as seguintes informações:
⚪ Referência de DTD.
⚪ Instruções de processamento de XML.
O exemplo a seguir mostra uma mensagem NETCONF sobre SOAP para obter todos os parâmetros de todas as interfaces do dispositivo:
<env:Envelope xmlns:env="http://www.w3.org/2003/05/soap-envelope">
<env:Header>
<auth:Authentication env:mustUnderstand="1"
xmlns:auth="http://www.Intelbras.com/netconf/base:1.0">
<auth:AuthInfo>800207F0120020C</auth:AuthInfo>
</auth:Authentication>
</env:Header>
<env:Body>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-bulk>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface/>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get-bulk>
</rpc>
</env:Body>
</env:Envelope>
Como usar o NETCONF
Você pode usar o NETCONF para gerenciar e configurar o dispositivo usando os métodos da Tabela 2.
Tabela 2 Métodos NETCONF para configurar o dispositivo
| Ferramenta de configuração | Método de login | Observações | |||
| CLI | Porta do console SSH Telnet | Para executar operações NETCONF, copie as mensagens NETCONF válidas para a CLI no modo de exibição XML. | |||
| Interface da Web padrão para o dispositivo | HTTP HTTPS | O sistema converte automaticamente as operações de configuração na interface da Web em mensagens NETCONF e as envia ao dispositivo para realizar operações NETCONF. | |||
| Interface de usuário personalizada | N/A | Para usar esse método, você deve ativar o NETCONF sobre SOAP. As mensagens NETCONF serão encapsuladas em SOAP para transmissão. |
Protocolos e padrões
RFC 3339, Data e hora na Internet: Timestamps
RFC 4741, Protocolo de Configuração NETCONF
RFC 4742, Usando o protocolo de configuração NETCONF sobre Secure SHell (SSH)
RFC 4743, Uso do NETCONF sobre o protocolo SOAP (Simple Object Access Protocol)
RFC 5277, Notificações de eventos NETCONF
RFC 5381, Experiência de implementação do NETCONF sobre SOAP
RFC 5539, NETCONF sobre segurança da camada de transporte (TLS)
RFC 6241, Protocolo de Configuração de Rede
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS (consulte o Guia de configuração de segurança) e no modo não-FIPS.
Visão geral das tarefas do NETCONF
Para configurar o NETCONF, execute as seguintes tarefas:
- Estabelecimento de uma sessão NETCONF
- (Opcional.) Configuração dos atributos da sessão NETCONF
- Estabelecimento de sessões NETCONF sobre SOAP
- Estabelecimento de sessões NETCONF sobre SSH
- Estabelecimento de sessões NETCONF sobre Telnet ou NETCONF sobre console
- Troca de recursos
- (Opcional.) Recuperação de informações de configuração do dispositivo
- Recuperação de informações de configuração e estado do dispositivo
- Recuperação de configurações não padrão
- Recuperação de informações do NETCONF
- Recuperação do conteúdo do arquivo YANG
- Recuperação de informações da sessão NETCONF
- (Opcional.) Filtragem de dados
Filtragem baseada em tabela
Filtragem baseada em colunas
- (Opcional.) Bloqueio ou desbloqueio da configuração em execução
- Bloqueio da configuração em execução
- Desbloqueio da configuração em execução
- (Opcional.) Modificação da configuração
- (Opcional.) Gerenciamento de arquivos de configuração
- Salvando a configuração em execução
- Carregando a configuração
- Reverter a configuração
- (Opcional.) Realização de operações da CLI por meio do NETCONF
- (Opcional.) Assinatura de eventos
- Assinatura de eventos syslog
- Assinatura de eventos monitorados pelo NETCONF
- Assinatura de eventos relatados por módulos
- (Opcional.) Encerramento de sessões NETCONF
- (Opcional.) Retornar à CLI
Estabelecimento de uma sessão NETCONF
Restrições e diretrizes para o estabelecimento de sessões NETCONF
Depois que uma sessão NETCONF é estabelecida, o dispositivo envia automaticamente seus recursos para o cliente. Você deve enviar os recursos do cliente para o dispositivo antes de poder executar qualquer outra operação NETCONF.
Antes de executar uma operação NETCONF, certifique-se de que nenhum outro usuário esteja configurando ou gerenciando o dispositivo. Se vários usuários configurarem ou gerenciarem o dispositivo simultaneamente, o resultado poderá ser diferente do esperado.
Você pode usar o comando aaa session-limit para definir o número máximo de sessões NETCONF que o dispositivo pode suportar. Se o limite superior for atingido, novos usuários do NETCONF não poderão acessar o dispositivo. Para obter informações sobre esse comando, consulte AAA no Guia de Configuração de Segurança.
Configuração dos atributos da sessão NETCONF
Sobre os namespaces específicos do módulo para NETCONF
O NETCONF oferece suporte aos seguintes tipos de namespaces:
Espaço de nomes comum - O espaço de nomes comum é compartilhado por todos os módulos. Em um pacote que usa o namespace comum, o namespace é indicado no elemento <top>, e os módulos são listados no elemento <top>.
Exemplo:
<rpc message-id="100" xmlns="urn:ietf:Params:xml:ns:netconf:base:1.0">
<get-bulk>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get-bulk>
</rpc>
Espaço de nomes específico do módulo - Cada módulo tem seu próprio espaço de nomes. Um pacote que usa um namespace específico de módulo não tem o elemento <top>. O namespace segue o nome do módulo.
Exemplo:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-bulk>
<filter type="subtree">
<Ifmgr xmlns="http://www.Intelbras.com/netconf/data:1.0-Ifmgr">
<Interfaces>
</Interfaces>
</Ifmgr>
</filter>
</get-bulk>
</rpc>
O espaço de nomes comum é incompatível com os espaços de nomes específicos do módulo. Para configurar uma sessão NETCONF, o dispositivo e o cliente devem usar o mesmo tipo de espaço de nomes. Por padrão, o espaço de nomes comum é usado. Se o cliente não for compatível com o espaço de nomes comum, use esse recurso para configurar o dispositivo para usar espaços de nomes específicos do módulo.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o tempo limite de inatividade da sessão NETCONF.
netconf { agent | soap } idle-timeout minute;| Palavra-chave | Descrição | ||
| agent | Especifica as seguintes sessões: NETCONF em sessões SSH. NETCONF em sessões Telnet. NETCONF em sessões de console. Por padrão, o tempo limite de inatividade é 0, e as sessões nunca atingem o tempo limite. | ||
| soap | Especifica as seguintes sessões: NETCONF sobre SOAP sobre sessões HTTP. NETCONF sobre SOAP sobre sessões HTTPS. A configuração padrão é 10 minutos. |
- Ativar o registro de NETCONF.
netconf log source { all | { agent | soap | web } * } { protocol-operation
{ all | { action | config | get | set | session | syntax | others } * }
| row-operation | verbose }
Por padrão, o registro em log do NETCONF está desativado.
- Configure o NETCONF para usar namespaces específicos do módulo.
netconf capability specific-namespacePor padrão, o namespace comum é usado.
Para que a configuração tenha efeito, você deve restabelecer a sessão NETCONF.
Estabelecimento de sessões NETCONF sobre SOAP
Sobre o NETCONF sobre SOAP
É possível usar uma interface de usuário personalizada para estabelecer uma sessão NETCONF sobre SOAP para o dispositivo e realizar operações NETCONF. O NETCONF sobre SOAP encapsula as mensagens NETCONF em mensagens SOAP e transmite as mensagens SOAP por HTTP ou HTTPS.
Restrições e diretrizes
Você pode adicionar um domínio de autenticação ao parâmetro <UserName> de uma solicitação SOAP. O domínio de autenticação entra em vigor somente na solicitação atual.
O domínio de autenticação obrigatório configurado usando o comando netconf soap domain tem precedência sobre o domínio de autenticação especificado no parâmetro <UserName> de uma solicitação SOAP.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o NETCONF por SOAP. No modo não-FIPS:
netconf soap { http | https } enableNo modo FIPS:
netconf soap https enablePor padrão, o recurso NETCONF over SOAP é desativado se o dispositivo for iniciado com a configuração inicial.
Se o dispositivo for iniciado com os padrões de fábrica, o estado de ativação do NETCONF over SOAP varia de acordo com a plataforma de hardware e a versão do software, conforme mostrado na Tabela 3.
Para obter mais informações sobre configuração inicial, padrões de fábrica e configuração de inicialização, consulte o gerenciamento de arquivos de configuração no Guia de Configuração Básica.
- Defina o valor DSCP para pacotes NETCONF sobre SOAP. No modo não-FIPS:
netconf soap { http | https } dscp dscp-valueNo modo FIPS:
netconf soap https dscp dscp-valuePor padrão, o valor DSCP é 0 para pacotes NETCONF sobre SOAP.
- Use uma ACL IPv4 para controlar o acesso ao NETCONF sobre SOAP. No modo não-FIPS:
netconf soap { http | https } acl { ipv4-acl-number | name ipv4-acl-name }No modo FIPS:
netconf soap https acl { ipv4-acl-number | name ipv4-acl-name }Por padrão, nenhuma ACL IPv4 é aplicada para controlar o acesso ao NETCONF sobre SOAP.
Somente os clientes permitidos pela ACL IPv4 podem estabelecer sessões NETCONF sobre SOAP.
- Especifique um domínio de autenticação obrigatório para usuários do NETCONF.
netconf soap domain domain-namePor padrão, nenhum domínio de autenticação obrigatório é especificado para os usuários do NETCONF. Para obter informações sobre domínios de autenticação, consulte o Guia de Configuração de Segurança.
- Use a interface de usuário personalizada para estabelecer uma sessão NETCONF sobre SOAP com o dispositivo. Para obter informações sobre a interface de usuário personalizada, consulte o guia do usuário da interface.
Estabelecimento de sessões NETCONF sobre SSH
Pré-requisitos
Antes de estabelecer uma sessão NETCONF sobre SSH, certifique-se de que a interface de usuário personalizada possa acessar o dispositivo por meio de SSH.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o NETCONF por SSH.
netconf ssh server enablePor padrão, o NETCONF sobre SSH está desativado.
- Especifique a porta de escuta para pacotes NETCONF sobre SSH.
netconf ssh server port port-numberPor padrão, o número da porta de escuta é 830.
- Use a interface de usuário personalizada para estabelecer uma sessão NETCONF sobre SSH com o dispositivo. Para obter informações sobre a interface de usuário personalizada, consulte o guia do usuário da interface.
Estabelecimento de sessões NETCONF sobre Telnet ou NETCONF sobre console
Restrições e diretrizes
Para garantir a correção do formato de uma mensagem NETCONF, não insira a mensagem manualmente. Copie e cole a mensagem.
Enquanto o dispositivo estiver executando uma operação NETCONF, não execute nenhuma outra operação, como colar uma mensagem NETCONF ou pressionar Enter.
Para que o dispositivo identifique as mensagens NETCONF, você deve adicionar a marca de fim ]]>]]> no final de cada mensagem NETCONF. Os exemplos deste documento não têm necessariamente essa marca de fim. Adicione a marca de fim em operações reais.
Pré-requisitos
Para estabelecer uma sessão NETCONF sobre Telnet ou uma sessão NETCONF sobre console, primeiro faça login no dispositivo por meio de Telnet ou da porta do console.
Procedimento
Para entrar na visualização XML, execute o seguinte comando na visualização do usuário:
xmlSe o prompt da visualização XML for exibido, a sessão NETCONF sobre Telnet ou NETCONF sobre console foi estabelecida com êxito.
Troca de recursos
Sobre o intercâmbio de capacidades
Depois que uma sessão NETCONF é estabelecida, o dispositivo envia seus recursos para o cliente. Você deve usar uma mensagem hello para enviar os recursos do cliente ao dispositivo antes de poder executar qualquer outra operação NETCONF.
Mensagem Hello do dispositivo para o cliente
<?xml version="1.0" encoding="UTF-8"?>
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>urn:ietf:params:netconf:base:1.1</capability>
<capability>urn:ietf:params:netconf:writable-running</capability>
<capability>urn:ietf:params:netconf:capability:notification:1.0</capability>
<capability>urn:ietf:params:netconf:capability:validate:1.1</capability>
<capability>urn:ietf:params:netconf:capability:interleave:1.0</capability>
<capability>urn:Intelbras:params:netconf:capability:Intelbras-netconf-ext:1.0</capability>
</capabilities>
<session-id>1</session-id>
</hello>
O elemento <capabilities> contém os recursos compatíveis com o dispositivo. Os recursos suportados variam de acordo com o modelo do dispositivo.
O elemento <session-id> contém a ID exclusiva atribuída à sessão NETCONF.
Mensagem Hello do cliente para o dispositivo
Depois de receber a mensagem hello do dispositivo, copie a seguinte mensagem hello para notificar o dispositivo sobre os recursos suportados pelo cliente:
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>conjunto de capacidades</capability>
</capabilities>
</hello>
| Item | Descrição | ||
| capability-set | Especifica um conjunto de recursos compatíveis com o cliente. Use as tags <capability> e </capability> para incluir cada conjunto de recursos definidos pelo usuário. |
Recuperação de informações de configuração do dispositivo
Restrições e diretrizes para a recuperação da configuração do dispositivo
Durante uma operação <get>, <get-bulk>, <get-config> ou <get-bulk-config>, o NETCONF substitui caracteres não identificáveis nos dados recuperados por pontos de interrogação (?) antes de enviar os dados ao cliente. Se o processo de um módulo relevante ainda não tiver sido iniciado, a operação retornará a seguinte mensagem:
<?xml version="1.0"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<data/>
</rpc-reply>
A operação <get><netconf-state/></get> não oferece suporte à filtragem de dados.
Para obter mais informações sobre as operações do NETCONF, consulte as referências da API XML do NETCONF para o dispositivo.
Recuperação de informações de configuração e estado do dispositivo
Você pode usar as seguintes operações NETCONF para recuperar informações de configuração e estado do dispositivo:
Operação <get> - Recupera todas as informações de configuração e estado do dispositivo que correspondem às condições especificadas.
Operação <get-bulk> - Recupera entradas de dados a partir da entrada de dados seguinte àquela com o índice especificado. Uma entrada de dados contém uma entrada de configuração do dispositivo e uma entrada de informações de estado. A saída retornada não inclui as informações do índice.
A mensagem <get> e a mensagem <get-bulk> compartilham o seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<getoperation>
<filter>
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
Specify the module, submodule, table name, and column name
</top>
</filter>
</getoperation>
</rpc>
| Item | Descrição | ||
| getoperation | Nome da operação, get ou get-bulk. | ||
| filter | Especifica as condições de filtragem, como o nome do módulo, o nome do submódulo, o nome da tabela e o nome da coluna. Se você especificar um nome de módulo, a operação recuperará os dados do módulo especificado. Se você não especificar um nome de módulo, a operação recuperará os dados de todos os módulos. Se você especificar um nome de submódulo, a operação recuperará os dados do submódulo especificado. Se você não especificar um nome de submódulo, a operação recuperará os dados de todos os submódulos. Se você especificar um nome de tabela, a operação recuperará os dados da tabela especificada. Se você não especificar um nome de tabela, a operação recuperará os dados de todas as tabelas. Se você especificar apenas a coluna de índice, a operação recuperará os dados de todas as colunas. Se você especificar a coluna de índice e quaisquer outras colunas, a operação recuperará os dados da coluna de índice e das colunas especificadas. |
Uma mensagem <get-bulk> pode conter os atributos de contagem e índice.
| Item | Descrição | ||
| índex | Especifica o índice. Se você não especificar esse item, o valor do índice começará com 1 por padrão. | ||
| count | Especifica a quantidade de entrada de dados. O atributo count está em conformidade com as seguintes regras: O atributo count pode ser colocado no nó do módulo e no nó da tabela. Em outros nós, ele não pode ser resolvido. Quando o atributo de contagem é colocado no nó do módulo, um nó descendente herda esse atributo de contagem se o nó descendente não contiver o atributo de contagem. A operação <get-bulk> recupera todas as entradas de dados restantes, começando pela entrada de dados próxima àquela com o índice especificado, se uma das seguintes condições ocorrer: Você não especifica o atributo count. O número de entradas de dados correspondentes é menor que o valor da contagem atributo. |
O exemplo de mensagem <get-bulk> a seguir especifica os atributos de contagem e índice:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:xc="http://www.Intelbras.com/netconf/base:1.0">
<get-bulk>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0"
xmlns:base="http://www.Intelbras.com/netconf/base:1.0">
<Syslog>
<Logs xc:count="5">
<Log>
<Index>10</Index>
</Log>
</Logs>
</Syslog>
</top>
</filter>
</get-bulk>
</rpc>
Ao recuperar as informações da interface, o dispositivo não consegue identificar se um valor inteiro para o
O elemento <IfIndex> representa um nome ou índice de interface. Para resolver o problema, você pode usar o elemento
atributo valuetype para especificar o tipo de valor. O atributo valuetype tem os seguintes valores:
| Valor | Descrição | ||
| name | O elemento está carregando um nome. | ||
| index | O elemento está carregando um índice. | ||
| auto | Valor padrão. O dispositivo usa o valor do elemento como um nome para correspondência de informações. Se nenhuma correspondência for encontrada, o dispositivo usará o valor como um índice para correspondência de interface ou de informações. |
O exemplo a seguir especifica um valor de tipo de índice para o elemento <IfIndex>:
<rpc xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<getoperation>
<filter>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0" xmlns:base="http://www.Intelbras.com/netconf/base:1.0">
<VLAN>
<TrunkInterfaces>
<Interface>
<IfIndex base:valuetype="index">1</IfIndex>
</Interface>
</TrunkInterfaces>
</VLAN>
</top>
</filter>
</getoperation>
</rpc>
Se a operação <get> ou < get-bulk> for bem-sucedida, o dispositivo retornará os dados recuperados no seguinte formato:
<?xml version="1.0"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<data>
Estado do dispositivo e dados de configuração
</data>
</rpc-reply>
Recuperação de configurações não padrão
As operações <get-config> e <get-bulk-config> são usadas para recuperar todas as configurações não padrão. As operações
As mensagens <get-config> e <get-bulk-config> podem conter o elemento <filter> para filtragem de dados.
As mensagens <get-config> e <get-bulk-config> são semelhantes. A seguir, um exemplo de mensagem <get-config>:
<?xml version="1.0"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-config>
<source>
<running/>
</source>
<filter>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
Especifique o nome do módulo, o nome do submódulo, o nome da tabela e o nome da coluna
</top>
</filter>
</get-config>
</rpc>
Se a operação <get-config> ou <get-bulk-config> for bem-sucedida, o dispositivo retornará os dados recuperados no seguinte formato:
<?xml version="1.0"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<data>
Dados que correspondem ao filtro especificado
</data>
</rpc-reply>
Recuperação de informações do NETCONF
Use a mensagem <get><netconf-state/></get> para recuperar informações do NETCONF. # Copie o texto a seguir para o cliente para recuperar informações do NETCONF:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="m-641" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get>
<filter type='subtree'>
<netconf-state xmlns='urn:ietf:params:xml:ns:yang:ietf-netconf-monitoring'>
<getType/>
</netconf-state>
</filter>
</get>
</rpc>
Se você não especificar um valor para getType, a operação de recuperação recuperará todas as informações do NETCONF. O valor de getType pode ser uma das seguintes operações:
| Operação | Descrição | ||
| capacidades | Recupera os recursos do dispositivo. | ||
| armazenamentos de dados | Recupera bancos de dados do dispositivo. | ||
| esquemas | Recupera a lista de nomes de arquivos YANG do dispositivo. | ||
| sessões | Recupera informações da sessão do dispositivo. | ||
| estatísticas | Recupera as estatísticas do NETCONF. |
Se a operação <get><netconf-state/></get> for bem-sucedida, o dispositivo retornará uma resposta no seguinte formato:
<?xml version="1.0"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<data>
Informações NETCONF recuperadas
</data>
</rpc-reply>
Recuperação do conteúdo do arquivo YANG
Os arquivos YANG salvam as operações NETCONF compatíveis com o dispositivo. Um usuário pode conhecer as operações compatíveis recuperando e analisando o conteúdo dos arquivos YANG.
Os arquivos YANG estão integrados no software do dispositivo e são nomeados no formato yang_identifier@yang_version.yang. Não é possível visualizar os nomes dos arquivos YANG executando o comando dir. Para obter informações sobre como recuperar os nomes dos arquivos YANG, consulte "Recuperação de informações NETCONF".
# Copie o texto a seguir para o cliente para recuperar o arquivo YANG chamado
<?xml version="1.0"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-schema xmlns='urn:ietf:params:xml:ns:yang:ietf-netconf-monitoring'>
<identifier>syslog-data</identifier>
<version>2017-01-01</version>
<format>yang</format>
</get-schema>
</rpc>
Se a operação <get-schema> for bem-sucedida, o dispositivo retornará uma resposta no seguinte formato:
<?xml version="1.0"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<data>
Conteúdo do arquivo YANG especificado
</data>
</rpc-reply>
Recuperação de informações da sessão NETCONF
Use a operação <get-sessions> para recuperar as informações da sessão NETCONF do dispositivo.
# Copie a seguinte mensagem para o cliente para recuperar as informações da sessão NETCONF do dispositivo:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-sessions/>
</rpc>
Se a operação <get-sessions> for bem-sucedida, o dispositivo retornará uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-sessions>
<Session>
<SessionID>ID da sessão de configuração</SessionID>
<Line>Informações da linha</Line>
<UserName>Nome do usuário que está criando a sessão</UserName>
<Since>Hora em que a sessão foi criada</Since>
<LockHeld>Se a sessão mantém um bloqueio</LockHeld>
</Session>
</get-sessions>
</rpc-reply>
Exemplo: Recuperação de uma entrada de dados para a tabela de interface
Configuração de rede
Recupera uma entrada de dados para a tabela de interface.
Procedimento
# Entre na exibição XML.
<Sysname> xml# Notificar o dispositivo sobre os recursos do NETCONF compatíveis com o cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>urn:ietf:params:netconf:base:1.0</capability>
</capabilities>
</hello>
# Recuperar uma entrada de dados para a tabela de interface.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:web="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-bulk>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0" xmlns:web="http://www.Intelbras.com/netconf/base:1.0">
<Ifmgr>
<Interfaces web:count="1">
</Interfaces>
</Ifmgr>
</top>
</filter>
</get-bulk>
</rpc>
Verificação da configuração
Se o cliente receber o texto a seguir, a operação <get-bulk> foi bem-sucedida:
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:web="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="100">
<data>
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<IfIndex>3</IfIndex>
<Name>GigabitEthernet1/0/2</Name>
<AbbreviatedName>GE1/0/2</AbbreviatedName>
<PortIndex>3</PortIndex>
<ifTypeExt>22</ifTypeExt>
<ifType>6</ifType>
<Description>Interface GigabitEthernet1/0/2</Description>
<AdminStatus>2</AdminStatus>
<OperStatus>2</OperStatus>
<ConfigSpeed>0</ConfigSpeed>
<ActualSpeed>100000</ActualSpeed>
<ConfigDuplex>3</ConfigDuplex>
<ActualDuplex>1</ActualDuplex>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</data>
</rpc-reply>
Exemplo: Recuperação de dados de configuração não padrão
Configuração de rede
Recupera todos os dados de configuração não padrão.
Procedimento
# Entre na exibição XML.
<Sysname> xml# Notificar o dispositivo sobre os recursos do NETCONF compatíveis com o cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello>
# Recuperar todos os dados de configuração não padrão.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-config>
<source>
<running/>
</source>
</get-config>
</rpc>
Verificação da configuração
Se o cliente receber o texto a seguir, a operação <get-config> foi bem-sucedida:
```html<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:web="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="100">
<data>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<IfIndex>1307</IfIndex>
<Shutdown>1</Shutdown>
</Interface>
<Interface>
<IfIndex>1308</IfIndex>
<Shutdown>1</Shutdown>
</Interface>
<Interface>
<IfIndex>1309</IfIndex>
<Shutdown>1</Shutdown>
</Interface>
<Interface>
<IfIndex>1311</IfIndex>
<VlanType>2</VlanType>
</Interface>
<Interface>
<IfIndex>1313</IfIndex>
<VlanType>2</VlanType>
</Interface>
</Interfaces>
</Ifmgr>
<Syslog>
<LogBuffer>
<BufferSize>120</BufferSize>
</LogBuffer>
</Syslog>
<System>
<Device>
<SysName>Sysname</SysName>
<TimeZone>
<Zone>+11:44</Zone>
<ZoneName>beijing</ZoneName>
</TimeZone>
</Device>
</System>
</top>
</data>
</rpc-reply>
Exemplo: Recuperação de dados de configuração do syslog
Configuração de rede
Recuperar dados de configuração do módulo Syslog.
Procedimento
# Entre na exibição XML.
<Sysname> xml# Notificar o dispositivo sobre os recursos do NETCONF compatíveis com o cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello>
# Recuperar dados de configuração para o módulo Syslog.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-config>
<source>
<running/>
</source>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Syslog/>
</top>
</filter>
</get-config>
</rpc>
Verificação da configuração
Se o cliente receber o texto a seguir, a operação <get-config> foi bem-sucedida:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="100">
<data>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Syslog>
<LogBuffer>
<BufferSize>120</BufferSize>
</LogBuffer>
</Syslog>
</top>
</data>
</rpc-reply>
Exemplo: Recuperação de informações da sessão NETCONF
Configuração de rede
Obter informações sobre a sessão NETCONF.
Procedimento
# Entre na visualização XML.
<Sysname> xml# Copie a seguinte mensagem para o cliente para trocar recursos com o dispositivo:
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello>
# Copie a seguinte mensagem para o cliente para obter as informações da sessão NETCONF atual no dispositivo:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-sessions/>
</rpc>
Verificação da configuração
Se o cliente receber uma mensagem como a seguinte, a operação será bem-sucedida:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="100">
<get-sessions>
<Session>
<SessionID>1</SessionID>
<Line>vty0</Line>
<UserName></UserName>
<Since>2017-01-07T00:24:57</Since>
<LockHeld>false</LockHeld>
</Session>
</get-sessions>
</rpc-reply>
O resultado mostra as seguintes informações:
A ID da sessão de uma sessão NETCONF existente é 1.
O tipo de usuário de login é vty0.
O horário de login é 2017-01-07T00:24:57.
O usuário não detém o bloqueio da configuração.
Filtragem de dados
Sobre a filtragem de dados
Você pode definir um filtro para filtrar as informações ao executar um comando <get>, <get-bulk>, <get-config> ou
operação <get-bulk-config>. A filtragem de dados inclui os seguintes tipos:
Filtragem baseada em tabela - filtra as informações da tabela.
Filtragem baseada em coluna - filtra informações de uma única coluna.
Restrições e diretrizes para filtragem de dados
Para que a filtragem baseada em tabela tenha efeito, você deve configurar a filtragem baseada em tabela antes da filtragem baseada em coluna.
Filtragem baseada em tabela
Sobre a filtragem baseada em tabelas
O namespace é http://www.Intelbras.com/netconf/base:1.0. O nome do atributo é filter (filtro). Para obter informações sobre o suporte à correspondência baseada em tabela, consulte as referências da API XML do NETCONF.
# Copie o texto a seguir para o cliente para recuperar os dados mais longos com o endereço IP 1.1.1.0 e o comprimento da máscara 24 da tabela de roteamento IPv4:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0">
<get>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Route>
<Ipv4Routes>
<RouteEntry Intelbras:filter="IP 1.1.1.0 MaskLen 24 longer"/>
</Ipv4Routes>
</Route>
</top>
</filter>
</get>
</rpc>
Restrições e diretrizes
Para usar a filtragem baseada em tabela, especifique um critério de correspondência para o atributo de linha de filtro.
Filtragem baseada em colunas
Sobre a filtragem baseada em colunas
A filtragem baseada em colunas inclui a filtragem de correspondência completa, a filtragem de correspondência de expressão regular e a filtragem de correspondência condicional. A filtragem de correspondência completa tem a prioridade mais alta e a filtragem de correspondência condicional tem a prioridade mais baixa. Quando mais de um critério de filtragem é especificado, o que tiver a prioridade mais alta entra em vigor.
Filtragem de correspondência completa
Você pode especificar um valor de elemento em uma mensagem XML para implementar a filtragem de correspondência completa. Se forem fornecidos vários valores de elemento, o sistema retornará os dados que correspondem a todos os valores especificados.
# Copie o texto a seguir para o cliente para recuperar os dados de configuração de todas as interfaces no estado UP:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<AdminStatus>1</AdminStatus>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get>
</rpc>
Você também pode especificar um nome de atributo que seja igual a um nome de coluna da tabela atual na linha para implementar a filtragem de correspondência completa. O sistema retorna apenas os dados de configuração que correspondem a esse nome de atributo. A mensagem XML equivalente à filtragem de correspondência completa baseada em valor de elemento acima é a seguinte:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0" xmlns:data="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface data:AdminStatus="1"/>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get>
</rpc>
Os exemplos acima mostram que tanto a filtragem de correspondência completa baseada em valor de elemento quanto a filtragem de correspondência completa baseada em nome de atributo podem recuperar as mesmas informações de índice e coluna para todas as interfaces em estado ativo.
Filtragem de correspondências de expressões regulares
Para implementar uma filtragem de dados complexa com caracteres, você pode adicionar um atributo regExp para um elemento específico.
Os tipos de dados compatíveis incluem inteiro, data e hora, cadeia de caracteres, endereço IPv4, máscara IPv4, endereço IPv6, endereço MAC, OID e fuso horário.
# Copie o texto a seguir para o cliente para recuperar as descrições das interfaces, sendo que todos os caracteres devem ser letras maiúsculas de A a Z:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0">
<get-config>
<source>
<running/>
</source>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<Description Intelbras:regExp="^[A-Z]*$"/>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get-config>
</rpc>
Filtragem de correspondência condicional
Para implementar uma filtragem de dados complexa com dígitos e cadeias de caracteres, você pode adicionar uma correspondência
para um elemento específico. A Tabela 4 lista os operadores de correspondência condicional.
Tabela 4 Operadores de correspondência condicional
| Operação | Operador | Observações | |||
| Mais de | match="more:value" | Mais do que o valor especificado. Os tipos de dados compatíveis incluem data, dígito e cadeia de caracteres. | |||
| Menos de | match="less:value" | Menor que o valor especificado. Os tipos de dados compatíveis incluem data, dígito e cadeia de caracteres. | |||
| Não menos que | match="notLess:value" | Não menor que o valor especificado. Os tipos de dados compatíveis incluem data, dígito e cadeia de caracteres. | |||
| Não mais do que | match="notMore:value" | Não mais do que o valor especificado. Os tipos de dados compatíveis incluem data, dígito e cadeia de caracteres. | |||
| Igual | match="equal:value" | Igual ao valor especificado. Os tipos de dados compatíveis incluem data, dígito, cadeia de caracteres, OID e BOOL. | |||
| Não igual | match="notEqual:value" | Não é igual ao valor especificado. Os tipos de dados compatíveis incluem data, dígito, cadeia de caracteres, OID e BOOL. | |||
| Incluir | match="include:string" | Inclui a string especificada. Os tipos de dados compatíveis incluem apenas a cadeia de caracteres. | |||
| Não inclui | match="exclude:string" | Exclui a string especificada. Os tipos de dados compatíveis incluem apenas a cadeia de caracteres. | |||
| Comece com | match="startWith:string" | Começa com a cadeia de caracteres especificada. Os tipos de dados compatíveis incluem cadeia de caracteres e OID. | |||
| Terminar com | match="endWith:string" | Termina com a cadeia de caracteres especificada. Os tipos de dados compatíveis incluem apenas cadeia de caracteres. |
# Copie o texto a seguir para o cliente para recuperar informações de extensão sobre a entidade cujo uso da CPU é superior a 50%:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0">
<get>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Device>
<ExtPhysicalEntities>
<Entity>
<CpuUsage Intelbras:match="more:50"/>
</Entity>
</ExtPhysicalEntities>
</Device>
</top>
</filter>
</get>
</rpc>
Exemplo: Filtragem de dados com correspondência de expressão regular
Configuração de rede
Recupere todos os dados, inclusive Gigabit, na coluna Description (Descrição) da tabela Interfaces no módulo Ifmgr.
Procedimento
# Entre na visualização XML.
<Sysname> xml# Notifique o dispositivo sobre os recursos do NETCONF compatíveis com o cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello>
# Recupere todos os dados, incluindo Gigabit, na coluna Description (Descrição) da tabela Interfaces no módulo Ifmgr.
<?xml version="1.0"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0">
<get>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<Description Intelbras:regExp="(Gigabit)+"/>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get>
</rpc>
Verificação da configuração
Se o cliente receber o texto a seguir, a operação foi bem-sucedida:
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<IfIndex>2681</IfIndex>
<Descrição>Interface GigabitEthernet1/0/1</Descrição>
</Interface>
<Interface>
<IfIndex>2685</IfIndex>
<Descrição>Interface GigabitEthernet1/0/2</Descrição>
</Interface>
<Interface>
<IfIndex>2689</IfIndex>
<Descrição>Interface GigabitEthernet1/0/3</Descrição>
</Interface>
</Interfaces>
</Ifmgr>
</top>
Exemplo: Filtragem de dados por correspondência condicional
Configuração de rede
Recupere dados na coluna Name com o valor ifindex não inferior a 5000 na tabela Interfaces do módulo Ifmgr.
Procedimento
# Entre na exibição XML.
<Sysname> xml# Notificar o dispositivo sobre os recursos do NETCONF compatíveis com o cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capacidade>urn:ietf:params:netconf:base:1.0</capacidade>
</capabilities>
</hello># Recupere dados na coluna Name com o valor ifindex não inferior a 5000 na tabela Interfaces do módulo Ifmgr.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0">
<get>
<filtro type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<IfIndex Intelbras:match="notLess:5000"/>
<Nome/>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</filtro>
</get>
</rpc>Verificação da configuração
Se o cliente receber o texto a seguir, a operação foi bem-sucedida:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0" message-id="100">
<data>
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<IfIndex>7241</IfIndex>
<Nome>NULL0</Nome>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</data>
</rpc-reply>Bloqueio ou desbloqueio da configuração em execução
Sobre o bloqueio e o desbloqueio da configuração
Há vários métodos disponíveis para configurar o dispositivo, como CLI, NETCONF e SNMP. Antes de configurar, gerenciar ou solucionar problemas do dispositivo, você pode bloquear a configuração para impedir que outros usuários alterem a configuração do dispositivo. Depois de bloquear a configuração, somente você poderá executar as operações <edit-config> para alterar a configuração ou desbloquear a configuração. Outros usuários podem apenas ler a configuração.
Sobre o bloqueio e o desbloqueio da configuração
Há vários métodos disponíveis para configurar o dispositivo, como CLI, NETCONF e SNMP. Antes
de configurar, gerenciar ou solucionar problemas do dispositivo, você pode bloquear a
configuração para impedir que outros usuários alterem a configuração do dispositivo. Depois de
bloquear a configuração, somente você poderá executar as operações
Restrições e diretrizes para bloqueio e desbloqueio de configurações
A operação
Bloqueio da configuração em execução
Copie o seguinte texto para o cliente para bloquear a configuração em execução:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<lock>
<target>
<running/>
</target>
</lock>
</rpc>Se a operação de <lock> for bem-sucedida, o dispositivo retorna uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Desbloqueio da configuração em execução
Copie o seguinte texto para o cliente para desbloquear a configuração em execução:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<unlock>
<target>
<running/>
</target>
</unlock>
</rpc>Se a operação de <unlock> for bem-sucedida, o dispositivo retorna uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Exemplo: Bloqueando a configuração em execução
Configuração de rede
Bloqueie a configuração do dispositivo para que outros usuários não possam alterá-la.
Procedimento
- Entre no modo XML.
<Sysname> xml<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello><?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<lock>
<target>
<running/>
</target>
</lock>
</rpc>Verificando a configuração
Se o cliente receber a seguinte resposta, a operação de <lock> é bem-sucedida:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Se outro cliente enviar uma solicitação de bloqueio, o dispositivo retornará a seguinte resposta:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rpc-error>
<error-type>protocol</error-type>
<error-tag>lock-denied</error-tag>
<error-severity>error</error-severity>
<error-message xml:lang="en">Lock failed because the NETCONF lock is held by another session.</error-message>
<error-info>
<session-id>1</session-id>
</error-info>
</rpc-error>
</rpc-reply>A saída mostra que a operação de <lock> falhou. O cliente com ID de sessão 1 está mantendo o bloqueio.
Modificando as configurações
Sobre a operação <edit-config>
A operação <edit-config> inclui as seguintes operações: merge, create, replace, remove, delete, default-operation, error-option, test-option e incremental. Para mais informações sobre as operações, consulte "Operações NETCONF suportadas".
Procedimento
Copie o seguinte texto para realizar a operação <edit-config>:
<?xml version="1.0"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target><running></running></target>
<error-option>
error-option
</error-option>
<config>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
Especifique o nome do módulo, nome do submódulo, nome da tabela e nome da coluna
</top>
</config>
</edit-config>
</rpc>O elemento <error-option> indica a ação a ser tomada em resposta a um erro que ocorre durante a operação. Ele tem os seguintes valores:
| Valor | Descrição | ||
| stop-on-error | Interrompe a operação <edit-config>. | ||
| continue-on-error | Continua a operação <edit-config>. | ||
| rollback-on-error | Reverte a configuração para a configuração anterior à operação <edit-config>. |
Por padrão, uma operação <edit-config> não pode ser realizada enquanto o dispositivo está revertendo a configuração. Se o tempo de reversão exceder o tempo máximo que o cliente pode esperar, o cliente determina que a operação <edit-config> falhou e executa a operação novamente. Como a reversão anterior não está concluída, a operação aciona outra reversão. Se esse processo se repetir, os recursos de CPU e memória serão esgotados e o dispositivo será reiniciado.
Para permitir que uma operação <edit-config> seja realizada durante uma reversão de configuração, execute uma operação <action> para alterar o valor do atributo DisableEditConfigWhenRollback para false.
Se a operação <edit-config> for bem-sucedida, o dispositivo retornará uma resposta no seguinte formato:
<?xml version="1.0"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Você também pode realizar a operação <get> para verificar se o valor do elemento atual é o mesmo que o valor especificado através da operação <edit-config>.
Exemplo: Modificando a Configuração
Configuração de Rede
Altere o tamanho do buffer de log para o módulo Syslog para 512.
Procedimento
Entre na visualização XML.
<Sysname> xmlInforme o dispositivo das capacidades NETCONF suportadas no cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>urn:ietf:params:netconf:base:1.0</capability>
</capabilities>
</hello>Altere o tamanho do buffer de log para o módulo Syslog para 512.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:web="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target>
<running/>
</target>
<config>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0" web:operation="merge">
<Syslog>
<LogBuffer>
<BufferSize>512</BufferSize>
</LogBuffer>
</Syslog>
</top>
</config>
</edit-config>
</rpc>Verificando a Configuração
Se o cliente receber o seguinte texto, a operação <edit-config> foi bem-sucedida:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Salvando a Configuração Atual
Sobre a operação <save>
A operação <save> salva a configuração atual para um arquivo de configuração e especifica o arquivo como o arquivo de configuração principal do próximo inicialização.
Restrições e diretrizes
A operação <save> é intensiva em recursos. Não execute esta operação quando os recursos do sistema estiverem fortemente ocupados.
Procedimento
Copie o seguinte texto para o cliente:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save OverWrite="false" Binary-only="false">
<file>Nome do arquivo de configuração</file>
</save>
</rpc>file
Especifica um arquivo de configuração .cfg pelo seu nome. O nome deve começar com o nome do meio de armazenamento. Se você especificar a coluna do arquivo, um nome de arquivo é necessário.
Se o atributo Binary-only for falso, o dispositivo salva a configuração em execução nos arquivos de configuração de texto e binário.
- Se o arquivo .cfg especificado não existir, o dispositivo cria os arquivos de configuração binária e de texto para salvar a configuração em execução.
- Se você não especificar a coluna do arquivo, o dispositivo salva a configuração em execução nos arquivos de configuração de texto e binário da próxima inicialização.
OverWrite
Determina se deve sobrescrever o arquivo especificado se o arquivo já existir. Os seguintes valores estão disponíveis:
- true - Sobrescreva o arquivo.
- false - Não sobrescreva o arquivo. A configuração em execução não pode ser salva, e o sistema exibe uma mensagem de erro. O valor padrão é verdadeiro.
Binary-only
Determina se deve salvar a configuração em execução apenas no arquivo de configuração binária. Os seguintes valores estão disponíveis:
- true - Salve a configuração em execução apenas no arquivo de configuração binária.
- false - Salve a configuração em execução nos arquivos de configuração de texto e binário. Para mais informações, consulte a descrição para a coluna do arquivo nesta tabela. O valor padrão é falso.
Salvando a Configuração em Execução em Ambos os Arquivos de Configuração de Texto e Binário
A operação <save> requer mais tempo.
Se a operação <save> for bem-sucedida, o dispositivo retorna uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Exemplo: Salvando a Configuração em Execução
Configuração de Rede
Salve a configuração em execução no arquivo config.cfg.
Procedimento
Entre na visualização XML.
<Sysname> xmlInforme o dispositivo das capacidades NETCONF suportadas no cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>urn:ietf:params:netconf:base:1.0</capability>
</capabilities>
</hello>Salve a configuração em execução do dispositivo no arquivo config.cfg.
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save>
<file>config.cfg</file>
</save>
</rpc>Verificando a Configuração
Se o cliente receber a seguinte resposta, a operação <save> foi bem-sucedida:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Carregando a Configuração
Sobre a operação <load>
A operação <load> mescla a configuração de um arquivo de configuração na configuração em execução da seguinte forma:
- Carrega as configurações que não existem na configuração em execução.
- Sobrescreve as configurações que já existem na configuração em execução.
Restrições e diretrizes
Ao realizar uma operação <load>, siga estas restrições e diretrizes:
- A operação <load> é intensiva em recursos. Não execute esta operação quando os recursos do sistema estiverem fortemente ocupados.
- Algumas configurações em um arquivo de configuração podem conflitar com as configurações existentes. Para que as configurações no arquivo tenham efeito, exclua as configurações conflitantes existentes e, em seguida, carregue o arquivo de configuração.
Procedimento
Copie o seguinte texto para o cliente para carregar um arquivo de configuração para o dispositivo:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<load>
<file>Nome do arquivo de configuração</file>
</load>
</rpc>O nome do arquivo de configuração deve começar com o nome do meio de armazenamento e terminar com a extensão .cfg.
Se a operação <load> for bem-sucedida, o dispositivo retorna uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Revertendo a configuração
Restrições e diretrizes
A operação <rollback> é intensiva em recursos. Não execute esta operação quando os recursos do sistema estiverem fortemente ocupados.
Por padrão, uma operação <edit-config> não pode ser realizada enquanto o dispositivo está revertendo a configuração. Para permitir que uma operação <edit-config> seja realizada durante uma reversão de configuração, execute uma operação <action> para alterar o valor do atributo DisableEditConfigWhenRollback para false.
Revertendo a configuração com base em um arquivo de configuração
Copie o seguinte texto para o cliente para reverter a configuração em execução para a configuração em um arquivo de configuração:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rollback>
<file>Especifique o nome do arquivo de configuração</file>
</rollback>
</rpc>Se a operação <rollback> for bem-sucedida, o dispositivo retorna uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Revertendo a configuração com base em um ponto de reversão
Sobre a reversão de configuração com base em um ponto de reversão
Você pode reverter a configuração em execução com base em um ponto de reversão quando uma das seguintes situações ocorrer:
- Um cliente NETCONF envia uma solicitação de reversão.
- O tempo ocioso da sessão NETCONF é maior que o tempo limite ocioso de reversão.
- Um cliente NETCONF é desconectado inesperadamente do dispositivo.
Restrições e diretrizes
Vários usuários podem configurar o dispositivo simultaneamente. Como melhor prática, bloqueie o sistema antes de reverter a configuração para evitar que outros usuários modifiquem a configuração em execução.
Procedimento
- Bloqueie a configuração em execução. Para mais informações, consulte "Bloqueando ou desbloqueando a configuração em execução".
- Habilitar a reversão de configuração com base em um ponto de reversão.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save-point>
<begin>
<confirm-timeout>100</confirm-timeout>
</begin>
</save-point>
</rpc><rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save-point>
<commit>
<label>SUPPORT VLAN</label>
<comment>VLAN 1 a 100 e interfaces.</comment>
</commit>
</save-point>
</rpc><rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save-point>
<get-commits>
<commit-label>SUPPORT VLAN</commit-label>
</get-commits>
</save-point>
</rpc><rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save-point>
<get-commit-information>
<commit-information>
<commit-label>SUPPORT VLAN</commit-label>
</commit-information>
</get-commit-information>
</save-point>
</rpc><rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save-point>
<rollback>
<commit-label>SUPPORT VLAN</commit-label>
</rollback>
</save-point>
</rpc><rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save-point>
<end/>
</save-point>
</rpc>Realizando Operações de CLI através do NETCONF
Sobre Operações de CLI através do NETCONF
Você pode inserir linhas de comando em mensagens XML para configurar o dispositivo.
Restrições e diretrizes
Realizar operações de CLI através do NETCONF consome recursos. Como melhor prática, não realize as seguintes tarefas:
- Inserir várias linhas de comando em uma única mensagem XML.
- Usar o NETCONF para realizar uma operação de CLI quando outros usuários estiverem realizando operações de CLI do NETCONF.
Procedimento
- Copie o seguinte texto para o cliente para executar os comandos:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<CLI>
<Execution>
Comandos
</Execution>
</CLI>
</rpc><Execution> pode conter múltiplos comandos, com um comando em cada linha.<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<CLI>
<Execution>
<![CDATA[Respostas aos comandos]]>
</Execution>
</CLI>
</rpc-reply>Exemplo: Realizando Operações de CLI
Configuração de Rede
Envie o comando de exibição de VLAN para o dispositivo.
Procedimento
- Entre na visualização XML.
<Sysname> xml<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello><?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<CLI>
<Execution>
display vlan
</Execution>
</CLI>
</rpc>Se o cliente receber o seguinte texto, a operação foi bem-sucedida:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<CLI>
<Execution><![CDATA[
<Sysname>display vlan
Total VLANs: 1
As VLANs incluem:
1 (padrão)
]]></Execution>
</CLI>
</rpc-reply>Assinatura de Eventos
Sobre Assinatura de Eventos
Quando um evento ocorre no dispositivo, o dispositivo envia informações sobre o evento para clientes NETCONF que se inscreveram no evento.
Restrições e diretrizes
- A assinatura de evento não é suportada para sessões NETCONF sobre SOAP.
- Uma assinatura entra em vigor apenas na sessão atual. É cancelada quando a sessão é terminada.
- Se você não especificar o fluxo de evento a ser inscrito, o dispositivo enviará notificações de eventos do syslog para o cliente NETCONF.
Inscrição em eventos de syslog
Copie a seguinte mensagem para o cliente para concluir a assinatura:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<create-subscription xmlns="urn:ietf:params:xml:ns:netconf:notification:1.0">
<stream>NETCONF</stream>
<filter>
<event xmlns="http://www.Intelbras.com/netconf/event:1.0">
<Code>code</Code>
<Group>group</Group>
<Severity>severity</Severity>
</event>
</filter>
<startTime>start-time</startTime>
<stopTime>stop-time</stopTime>
</create-subscription>
</rpc>Item Descrição
streamEspecifica o fluxo de evento. O nome para o fluxo de evento syslog é NETCONF.eventEspecifica o evento. Para obter informações sobre os eventos aos quais você pode se inscrever, consulte as referências de mensagem de log do sistema para o dispositivo.codeEspecifica o símbolo mnemônico da mensagem de log.groupEspecifica o nome do módulo da mensagem de log.severityEspecifica o nível de gravidade da mensagem de log.start-timeEspecifica o horário de início da assinatura.stop-timeEspecifica o horário de término da assinatura.
Se a inscrição for bem-sucedida, o dispositivo retornará uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns:netconf="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Se a inscrição falhar, o dispositivo retornará uma mensagem de erro no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rpc-error>
<error-type>error-type</error-type>
<error-tag>error-tag</error-tag>
<error-severity>error-severity</error-severity>
<error-message xml:lang="en">error-message</error-message>
</rpc-error>
</rpc-reply>Para obter mais informações sobre mensagens de erro, consulte o RFC 4741.
Inscrição em eventos monitorados pelo NETCONF
Depois que você se inscreve em eventos conforme descrito nesta seção, o NETCONF regularmente verifica os eventos inscritos e envia os eventos que correspondem à condição de inscrição para o cliente NETCONF.
# Copie a seguinte mensagem para o cliente para completar a inscrição:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<create-subscription xmlns='urn:ietf:params:xml:ns:netconf:notification:1.0'>
<stream>NETCONF_MONITOR_EXTENSION</stream>
<filter>
<NetconfMonitor xmlns='http://www.Intelbras.com/netconf/monitor:1.0'>
<XPath>XPath</XPath>
<Interval>interval</Interval>
<ColumnConditions>
<ColumnCondition>
<ColumnName>ColumnName</ColumnName>
<ColumnValue>ColumnValue</ColumnValue>
<ColumnCondition>ColumnCondition</ColumnCondition>
</ColumnCondition>
</ColumnConditions>
<MustIncludeResultColumns>
<ColumnName>columnName</ColumnName>
</MustIncludeResultColumns>
</NetconfMonitor>
</filter>
<startTime>start-time</startTime>
<stopTime>stop-time</stopTime>
</create-subscription>
</rpc>
Descrição do Item
stream Especifica o fluxo de eventos. O nome do fluxo de eventos é NETCONF_MONITOR_EXTENSION.
NetconfMonitor Especifica as informações de filtragem para o evento.
XPath Especifica o caminho do evento no formato de ModuleName[/SubmoduleName]/TableName.
interval Especifica o intervalo para o NETCONF obter eventos que correspondam à condição de inscrição. A faixa de valores é de 1 a 4294967 segundos. O valor padrão é 300 segundos.
ColumnName Especifica o nome de uma coluna no formato [GroupName.]ColumnName.
ColumnValue Especifica o valor de referência.
ColumnCondition Especifica o operador:
- more.
- less.
- notLess.
- notMore.
- equal.
- notEqual.
- include.
- exclude.
- startWith.
- endWith.
Escolha um operador de acordo com o tipo do valor de referência.
start-time Especifica o horário de início da inscrição.
stop-time Especifica o horário de término da inscrição.
Se a inscrição for bem-sucedida, o dispositivo retorna uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns:netconf="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>
Inscrevendo-se em eventos relatados por módulos
Após se inscrever em eventos conforme descrito nesta seção, os módulos especificados relatam eventos inscritos ao NETCONF. O NETCONF envia os eventos para o cliente NETCONF.
# Copie a seguinte mensagem para o cliente para completar a inscrição:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:xs="http://www.Intelbras.com/netconf/base:1.0">
<create-subscription xmlns="urn:ietf:params:xml:ns:netconf:notification:1.0">
<stream>XXX_STREAM</stream>
<filter type="subtree">
<event xmlns="http://www.Intelbras.com/netconf/event:1.0/xxx-features-list-name:1.0">
<ColumnName xs:condition="Condition">value</ColumnName>
</event>
</filter>
<startTime>start-time</startTime>
<stopTime>stop-time</stopTime>
</create-subscription>
</rpc>
Descrição do Item
| stream | Especifica o fluxo de eventos. Os fluxos de eventos suportados variam de acordo com o modelo do dispositivo. | ||
| event | Especifica o nome do evento. Um fluxo de eventos inclui múltiplos eventos. Os eventos usam os mesmos namespaces do fluxo de eventos. | ||
| ColumnName | Especifica o nome de uma coluna. | ||
| ColumnCondition | Especifica o operador:
| ||
| value | Especifica o valor de referência para a coluna. | ||
| start-time | Especifica o horário de início da inscrição. | ||
| stop-time | Especifica o horário de término da inscrição. |
Se a inscrição for bem-sucedida, o dispositivo retorna uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns:netconf="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>
Cancelando uma inscrição
Você pode cancelar uma inscrição que você configurou na sessão atual.
# Copie a seguinte mensagem para o cliente para cancelar uma inscrição:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<cancel-subscription xmlns="urn:ietf:params:xml:ns:netconf:notification:1.0">
<stream>XXX_STREAM</stream>
</cancel-subscription>
</rpc>
Descrição do Item
stream Especifica o fluxo de eventos.
Se a operação de cancelamento for bem-sucedida, o dispositivo retorna uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="100">
<ok/>
</rpc-reply>
Se a inscrição não existir, o dispositivo retorna uma mensagem de erro no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rpc-error>
<error-type>error-type</error-type>
<error-tag>error-tag</error-tag>
<error-severity>error-severity</error-severity>
<error-message xml:lang="en">A inscrição do fluxo a ser cancelado não existe: Nome do fluxo = XXX_STREAM.</error-message>
</rpc-error>
</rpc-reply>
Exemplo: Inscrevendo-se em eventos de syslog
Configuração de rede
Configure um cliente para se inscrever em eventos de syslog sem limite de tempo. Após a inscrição, todos os eventos no dispositivo são enviados para o cliente antes que a sessão entre o dispositivo e o cliente seja terminada.
Procedimento
# Entre na visualização XML.
<Sysname> xml# Notifique o dispositivo das capacidades NETCONF suportadas no cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello>
# Inscreva-se em eventos de syslog sem limite de tempo.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<create-subscription xmlns="urn:ietf:params:xml:ns:netconf:notification:1.0">
<stream>NETCONF</stream>
</create-subscription>
</rpc>
Verificando a configuração
# Se o cliente receber a seguinte resposta, a inscrição foi bem-sucedida:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="100">
<ok/>
</rpc-reply>
# Quando outro cliente (192.168.100.130) fizer login no dispositivo, o dispositivo enviará uma notificação para o cliente que se inscreveu em todos os eventos:
<?xml version="1.0" encoding="UTF-8"?>
<notification xmlns="urn:ietf:params:xml:ns:netconf:notification:1.0">
<eventTime>2011-01-04T12:30:52</eventTime>
<event xmlns="http://www.Intelbras.com/netconf/event:1.0">
<Group>SHELL</Group>
<Code>SHELL_LOGIN</Code>
<Slot>1</Slot>
<Severity>Notification</Severity>
<context>VTY logado de 192.168.100.130.</context>
</event>
</notification>
Término de sessões NETCONF
Sobre o término de sessões NETCONF
O NETCONF permite que um cliente termine as sessões NETCONF de outros clientes. Um cliente cuja sessão é terminada retorna à visualização do usuário.
Procedimento
# Copie a seguinte mensagem para o cliente para encerrar uma sessão NETCONF:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<kill-session>
<session-id>
Especificar session-ID
</session-id>
</kill-session>
</rpc>
Se a operação <kill-session> for bem-sucedida, o dispositivo retorna uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>
Exemplo: Terminando outra sessão NETCONF
Configuração de rede
O usuário cujo ID de sessão é 1 termina a sessão com o ID de sessão 2.
Procedimento
# Entre na visualização XML.
<Sysname> xml# Notifique o dispositivo das capacidades NETCONF suportadas no cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello>
# Termine a sessão com o ID de sessão 2.
<rpc message-id="100"xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<kill-session>
<session-id>2</session-id>
</kill-session>
</rpc>
Verificando a configuração
Se o cliente receber o seguinte texto, a sessão NETCONF com o ID de sessão 2 foi encerrada, e o cliente com o ID de sessão 2 retornou da visualização XML para a visualização do usuário:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>
Retornando para a CLI
Restrições e diretrizes
Antes de retornar da visualização XML para o CLI, você deve primeiro completar a troca de capacidade entre o dispositivo e o cliente.
Procedimento
# Copie o seguinte texto para o cliente para retornar da visualização XML para o CLI:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<close-session/>
</rpc>
Quando o dispositivo recebe a solicitação de fechar a sessão, ele envia a seguinte resposta e retorna para a visualização do usuário do CLI:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>
Operações NETCONF Suportadas
Este capítulo descreve as operações NETCONF disponíveis com o Comware 7.
action
Guia de uso
Esta operação emite ações para configurações não padrão, por exemplo, ação de reinicialização.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<action>
<top xmlns="http://www.Intelbras.com/netconf/action:1.0">
<Ifmgr>
<ClearAllIfStatistics>
<Clear>
</Clear>
</ClearAllIfStatistics>
</Ifmgr>
</top>
</action>
</rpc>
CLI
Recomendações de uso
Esta operação executa comandos da CLI.
Uma mensagem de solicitação envolve os comandos no elemento
Você pode usar os seguintes elementos para executar comandos:
- Execução - Executa comandos na visualização do usuário.
- Configuração - Executa comandos na visualização do sistema. Para executar comandos em uma visualização de nível inferior da visualização do sistema, use o elemento
para entrar na visualização primeiro. Para usar este elemento, inclua o atributo exec-use-channel e especifique um valor para o atributo: - false - Executa comandos sem usar um canal.
- true - Executa comandos usando um canal temporário. O canal é fechado automaticamente após a execução.
- persist - Executa comandos usando o canal persistente para a sessão.
Para usar o canal persistente, primeiro execute uma operação
para abrir o canal persistente. Se você não fizer isso, o sistema abrirá automaticamente o canal persistente. Após usar o canal persistente, execute uma operação para fechar o canal e retornar à visualização do sistema. Se você não executar uma operação , o sistema permanecerá na visualização e executará os comandos subsequentes na visualização.
Você também pode especificar o atributo error-when-rollback no elemento
- true - Rejeita solicitações de operação da CLI e retorna mensagens de erro.
- false (o padrão) - Permite operações da CLI.
Para que as operações da CLI sejam executadas corretamente, defina o valor do atributo error-when-rollback como true.
Uma sessão NETCONF suporta apenas um canal persistente, mas suporta vários canais temporários.
O NETCONF não suporta a execução de comandos interativos.
Você não pode executar o comando quit usando um canal para sair da visualização do usuário.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<CLI>
<Configuration exec-use-channel="false" error-when-rollback="true">vlan 3</Configuration>
</CLI>
</rpc>
close-session
Recomendações de uso
Esta operação termina a sessão NETCONF atual, desbloqueia a configuração e libera os recursos (por exemplo, memória) usados pela sessão. Após esta operação, você sai da visualização XML.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<close-session/>
</rpc>
edit-config: create
Recomendações de uso
Esta operação cria itens de configuração de destino.
Para usar o atributo create em uma operação
- Se a tabela suportar a criação de um item de configuração de destino e o item não existir, a operação criará o item e configurará o item.
- Se o item especificado já existir, uma mensagem de erro de data-exist será retornada.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:xc="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target>
<running/>
</target>
<config>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Syslog xmlns="http://www.Intelbras.com/netconf/config:1.0" xc:operation="create">
<LogBuffer>
<BufferSize>120</BufferSize>
</LogBuffer>
</Syslog>
</top>
</config>
</edit-config>
</rpc>
edit-config: delete
Recomendações de uso
Esta operação exclui a configuração especificada.
- Se o destino especificado tiver apenas o índice da tabela, a operação removerá toda a configuração do destino especificado e o próprio destino.
- Se o destino especificado tiver o índice da tabela e dados de configuração, a operação removerá os dados de configuração especificados deste destino.
- Se o destino especificado não existir, uma mensagem de erro será retornada, mostrando que o destino não existe.
Exemplo XML
A sintaxe é a mesma que a mensagem edit-config com o atributo create. Altere o atributo operation de create para delete.
edit-config: merge
Recomendações de uso
Esta operação confirma itens de configuração de destino para a configuração em execução.
Para usar o atributo merge em uma operação
- Se o item especificado existir, a operação atualiza diretamente a configuração do item.
- Se o item especificado não existir, a operação cria o item e configura o item.
- Se o item especificado não existir e não puder ser criado, uma mensagem de erro será retornada.
Exemplo XML
O formato de dados XML é o mesmo que a mensagem edit-config com o atributo create. Altere o atributo operation de create para merge.
edit-config: remove
Recomendações de uso
Esta operação remove a configuração especificada.
- Se o destino especificado tiver apenas o índice da tabela, a operação removerá toda a configuração do destino especificado e o próprio destino.
- Se o destino especificado tiver o índice da tabela e dados de configuração, a operação removerá os dados de configuração especificados deste destino.
- Se o destino especificado não existir, ou a mensagem XML não especificar quaisquer destinos, uma mensagem de sucesso será retornada.
Exemplo XML
A sintaxe é a mesma que a mensagem edit-config com o atributo create. Altere o atributo operation de create para remove.
edit-config: replace
Recomendações de uso
Esta operação substitui a configuração especificada.
- Se o destino especificado existir, a operação substitui a configuração do destino pela configuração carregada na mensagem.
- Se o destino especificado não existir, mas for permitido ser criado, a operação cria o destino e depois aplica a configuração.
- Se o destino especificado não existir e não for permitido ser criado, a operação não é realizada e uma mensagem de erro de valor inválido é retornada.
Exemplo XML
A sintaxe é a mesma da mensagem edit-config com o atributo create. Altere o atributo operation de create para replace.
edit-config: test-option
Recomendações de uso
Esta operação determina se deve ou não confirmar um item de configuração em uma operação
O elemento
- test-then-set—Realiza uma verificação de sintaxe e confirma um item se o item passar na verificação. Se o item falhar na verificação, o item não é confirmado. Este é o valor padrão de test-option.
- set—Confirma o item sem realizar uma verificação de sintaxe.
- test-only—Realiza apenas uma verificação de sintaxe. Se o item passar na verificação, uma mensagem de sucesso é retornada. Caso contrário, uma mensagem de erro é retornada.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target>
<running/>
</target>
<test-option>test-only</test-option>
<config xmlns:xc="urn:ietf:params:xml:ns:netconf:base:1.0">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr xc:operation="merge">
<Interfaces>
<Interface>
<IfIndex>262</IfIndex>
<Description>222</Description>
<ConfigSpeed>2</ConfigSpeed>
<ConfigDuplex>1</ConfigDuplex>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</config>
</edit-config>
</rpc>
edit-config: default-operation
Recomendações de uso
Esta operação modifica a configuração em execução do dispositivo usando o método de operação padrão.
O NETCONF usa um dos seguintes atributos de operação para modificar a configuração: merge, create, delete e replace. Se você não especificar um atributo de operação para uma mensagem
O elemento
- merge—Valor padrão para o elemento
. - replace—Valor usado quando o atributo de operação não é especificado e o método de operação padrão é especificado como replace.
- none—Valor usado quando o atributo de operação não é especificado e o método de operação padrão é especificado como none. Se este valor for especificado, a operação
é usada apenas para verificação de esquema em vez de emitir uma configuração. Se a verificação de esquema for aprovada, uma mensagem de sucesso é retornada. Caso contrário, uma mensagem de erro é retornada.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target>
<running/>
</target>
<default-operation>none</default-operation>
<config xmlns:xc="urn:ietf:params:xml:ns:netconf:base:1.0">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<IfIndex>262</IfIndex>
<Description>222222</Description>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</config>
</edit-config>
</rpc>
edit-config: error-option
Recomendações de uso
Esta operação determina a ação a ser tomada em caso de erro de configuração.
O elemento
- stop-on-error—Interrompe a operação e retorna uma mensagem de erro. Este é o valor padrão de error-option.
- continue-on-error—Continua a operação e retorna uma mensagem de erro.
- rollback-on-error—Reverte a configuração.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target>
<running/>
</target>
<error-option>continue-on-error</error-option>
<config xmlns:xc="urn:ietf:params:xml:ns:netconf:base:1.0">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr xc:operation="merge">
<Interfaces>
<Interface>
<IfIndex>262</IfIndex>
<Description>222</Description>
<ConfigSpeed>1024</ConfigSpeed>
<ConfigDuplex>1</ConfigDuplex>
</Interface>
<Interface>
<IfIndex>263</IfIndex>
<Description>333</Description>
<ConfigSpeed>1024</ConfigSpeed>
<ConfigDuplex>1</ConfigDuplex>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</config>
</edit-config>
</rpc>
edit-config: incremental
Guia de uso
Essa operação adiciona dados de configuração a uma coluna sem afetar os dados originais.
O atributo incremental se aplica a uma coluna de lista, como a coluna vlan permitlist.
Você pode usar o atributo incremental para operações
O suporte para o atributo incremental varia por módulo. Para mais informações, consulte os documentos XML da API NETCONF.
Exemplo XML
# Adicionar VLANs 1 a 10 a uma lista de VLANs não marcadas que tem VLANs não marcadas 12 a 15.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0">
<edit-config>
<target>
<running/>
</target>
<config xmlns:xc="urn:ietf:params:xml:ns:netconf:base:1.0">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<VLAN xc:operation="merge">
<HybridInterfaces>
<Interface>
<IfIndex>262</IfIndex>
<UntaggedVlanList Intelbras: incremental="true">1-10</UntaggedVlanList>
</Interface>
</HybridInterfaces>
</VLAN>
</top>
</config>
</edit-config>
</rpc>
get
Guia de uso
Essa operação recupera informações de configuração e estado do dispositivo.
Exemplo XML
# Recuperar informações de configuração e estado do dispositivo para o módulo Syslog.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:xc="http://www.Intelbras.com/netconf/base:1.0">
<get>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Syslog>
</Syslog>
</top>
</filter>
</get>
</rpc>
get-bulk
Guia de uso
Essa operação recupera um número de entradas de dados (incluindo informações de configuração e estado do dispositivo) começando pela entrada de dados seguinte àquela com o índice especificado.
Exemplo XML
# Recuperar informações de configuração e estado do dispositivo para todas as interfaces.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-bulk>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces xc:count="5" xmlns:xc="http://www.Intelbras.com/netconf/base:1.0">
<Interface/>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get-bulk>
</rpc>
get-bulk-config
Guia de uso
Essa operação recupera um número de entradas de dados de configuração não padrão começando pela entrada de dados seguinte àquela com o índice especificado.
Exemplo XML
# Recuperar configuração não padrão para todas as interfaces.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-bulk-config>
<source>
<running/>
</source>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr>
</Ifmgr>
</top>
</filter>
</get-bulk-config>
</rpc>
get-config
Guia de uso
Essa operação recupera dados de configuração não padrão. Se não houver dados de configuração não padrão, o dispositivo retorna uma resposta com dados vazios.
Exemplo XML
# Recuperar dados de configuração não padrão para a tabela de interfaces.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:xc="http://www.Intelbras.com/netconf/base:1.0">
<get-config>
<source>
<running/>
</source>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr>
<Interfaces>
<Interface/>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get-config>
</rpc>
get-sessions
Guia de uso
Essa operação recupera informações sobre todas as sessões NETCONF no sistema. Você não pode especificar um ID de sessão para recuperar informações sobre uma sessão NETCONF específica.
Exemplo XML# Recuperar informações sobre todas as sessões NETCONF no sistema.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-sessions/>
</rpc>
kill-session
Guia de uso
Essa operação termina a sessão NETCONF para outro usuário. Essa operação não pode terminar a sessão NETCONF para o usuário atual.
Exemplo XML
# Terminar a sessão NETCONF com o ID da sessão 1.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<kill-session>
<session-id>1</session-id>
</kill-session>
</rpc>
load
Guia de uso
Essa operação carrega a configuração. Após o dispositivo terminar uma operação
Exemplo XML
# Mesclar a configuração no arquivo a1.cfg na configuração em execução do dispositivo.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<load>
<file>a1.cfg</file>
</load>
</rpc>
lock
Guia de uso
Essa operação trava a configuração. Após a configuração ser bloqueada, você não pode executar operações
Depois que um usuário trava a configuração, outros usuários não podem usar o NETCONF ou quaisquer outros métodos de configuração, como CLI e SNMP, para configurar o dispositivo.
Exemplo XML
# Travar a configuração.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<lock>
<target>
<running/>
</target>
</lock>
</rpc>
rollback
Guia de uso
Essa operação reverte a configuração. Para fazer isso, você deve especificar o arquivo de configuração no elemento
Exemplo XML
# Reverter a configuração em execução para a configuração no arquivo 1A.cfg.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rollback>
<file>1A.cfg</file>
</rollback>
</rpc>
save
Guia de uso
Essa operação salva a configuração em execução. Você pode usar o elemento
O atributo OverWrite determina se a configuração em execução substitui o arquivo de configuração original quando o arquivo especificado já existe.
O atributo Binary-only determina se salvar a configuração em execução apenas para o arquivo de configuração binária.
Exemplo XML
# Salvar a configuração em execução no arquivo test.cfg.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save OverWrite="false" Binary-only="true">
<file>test.cfg</file>
</save>
</rpc>
unlock
Guia de uso
Essa operação desbloqueia a configuração para que outros usuários possam configurar o dispositivo.
Terminar uma sessão NETCONF automaticamente desbloqueia a configuração.
Exemplo XML
# Desbloquear a configuração.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<unlock>
<target>
<running/>
</target>
</unlock>
</rpc>
Configurando CWMP
Sobre CWMP
O Protocolo de Gerenciamento da WAN do Equipamento do Cliente (CWMP), também chamado de "TR-069", é uma especificação técnica do Fórum DSL para o gerenciamento remoto de dispositivos de rede.
O protocolo foi inicialmente projetado para fornecer autoconfiguração remota através de um servidor para um grande número de dispositivos de usuário final dispersos em uma rede. O CWMP pode ser usado em diferentes tipos de redes, incluindo Ethernet.
Estrutura da Rede CWMP
A Figura 1 mostra uma estrutura básica da rede CWMP.
Como o CWMP funciona
Método RPC
O CWMP usa métodos de chamada de procedimento remoto (RPC) para comunicação bidirecional entre CPE e ACS. Os métodos RPC são encapsulados em HTTP ou HTTPS.
| Método RPC | Descrição | ||
Get | O ACS obtém os valores dos parâmetros no CPE. | ||
Set | O ACS modifica os valores dos parâmetros no CPE. | ||
Inform | O CPE envia uma mensagem Inform para o ACS com os seguintes propósitos: | ||
| |||
Download | O ACS solicita que o CPE baixe um arquivo de imagem de configuração ou software de uma URL específica para atualização de software ou configuração. | ||
Upload | O ACS solicita que o CPE faça upload de um arquivo para uma URL específica. | ||
Reboot | O ACS reinicia o CPE remotamente para que o CPE conclua uma atualização ou se recupere de uma condição de erro. |
Autoconexão entre ACS e CPE
O CPE inicia automaticamente uma conexão com o ACS quando um dos seguintes eventos ocorre:
- Mudança na URL do ACS. O CPE inicia uma solicitação de conexão para a nova URL do ACS.
- Inicialização do CPE. O CPE inicia uma conexão com o ACS após a inicialização.
- Expiração do intervalo Inform periódico. O CPE reinicia uma conexão com o ACS no intervalo Inform.
- Expiração do tempo de inicialização da conexão agendada. O CPE inicia uma conexão com o ACS no horário agendado.
Estabelecimento de conexão CWMP
Os passos de 1 a 5 na Figura 2 mostram o procedimento de estabelecimento de conexão entre o CPE e o ACS.
- Após obter os parâmetros básicos do ACS, o CPE inicia uma conexão TCP com o ACS.
- Se o HTTPS for usado, o CPE e o ACS inicializam o SSL para uma conexão HTTP segura.
- O CPE envia uma mensagem Inform em HTTPS para iniciar uma sessão CWMP.
- Após o CPE passar pela autenticação, o ACS retorna uma resposta Inform para estabelecer a sessão.
- Após enviar todas as solicitações, o CPE envia uma mensagem de postagem HTTP vazia.
Troca de ACS principal/secundário
Típicamente, dois ACSs são usados em uma rede CWMP para monitorar consecutivamente os CPEs. Quando o ACS principal precisa reiniciar, ele aponta o CPE para o ACS secundário. Os passos 6 a 11 na Figura 3 mostram o procedimento de troca entre o ACS principal e secundário.
- Antes do ACS principal reiniciar, ele consulta a URL do ACS definida no CPE.
- O CPE responde com sua configuração de URL do ACS.
- O ACS principal envia uma solicitação de definição para alterar a URL do ACS no CPE para a URL do ACS secundário.
- Após a modificação da URL do ACS, o CPE envia uma resposta.
- O ACS principal envia uma mensagem HTTP vazia para notificar o CPE de que não possui outras solicitações.
- O CPE fecha a conexão e, em seguida, inicia uma nova conexão com a URL do ACS secundário.
Restrições e diretrizes: Configuração CWMP
Você pode configurar atributos do ACS e do CPE a partir da CLI do CPE, do servidor DHCP ou do ACS. Para um atributo, os valores atribuídos pela CLI e pelo ACS têm prioridade mais alta do que o valor atribuído pelo DHCP. Os valores atribuídos pela CLI e pelo ACS sobrescrevem um ao outro, o que for atribuído por último.
Este documento descreve apenas a configuração de atributos do ACS e do CPE a partir da CLI e do servidor DHCP. Para obter mais informações sobre a configuração e o uso do ACS, consulte a documentação do ACS.
Tarefas CWMP em uma visão geral
Para configurar CWMP, execute as seguintes tarefas:
- Habilitar CWMP pela CLI
- Você também pode habilitar CWMP a partir de um servidor DHCP.
- Configurar atributos do ACS
- Configurar os atributos preferidos do ACS
- (Opcional) Configurar os atributos padrão do ACS pela CLI
- Configurar atributos do CPE
- Especificar uma política de cliente SSL para conexão HTTPS ao ACS
- (Opcional) Configurar parâmetros de autenticação do ACS
- (Opcional) Configurar o código de provisionamento
- (Opcional) Configurar a interface de conexão CWMP
- (Opcional) Configurar parâmetros de autoconexão
- (Opcional) Definir o temporizador close-wait
- (Opcional) Habilitar travessia NAT para o CPE
Habilitando CWMP pela CLI
- Entrar no modo de visualização do sistema.
system-viewcwmpcwmp enablePor padrão, o CWMP está desabilitado.
Configurando atributos do ACS
Sobre os atributos do ACS
Você pode configurar dois conjuntos de atributos do ACS para o CPE: preferido e padrão.
- Os atributos do ACS preferidos são configuráveis a partir da CLI do CPE, do servidor DHCP e do ACS.
- Os atributos do ACS padrão são configuráveis apenas pela CLI.
Se os atributos do ACS preferidos não estiverem configurados, o CPE usará os atributos do ACS padrão para o estabelecimento de conexão.
Configurando os atributos do ACS preferidos
Atribuindo atributos do ACS a partir do servidor DHCP
O servidor DHCP em uma rede CWMP atribui as seguintes informações aos CPEs:
- Endereços IP para os CPEs.
- Endereço do servidor DNS.
- URL do ACS e informações de autenticação de login do ACS.
Esta seção apresenta como usar a opção DHCP 43 para atribuir a URL do ACS e o nome de usuário e senha de autenticação de login do ACS. Para obter mais informações sobre DHCP e DNS, consulte o Guia de Configuração de Serviços IP da Camada 3.
Se o servidor DHCP for um dispositivo Intelbras, você pode configurar a opção DHCP 43 usando o comando option 43 hex 01length URL username password.
- length - Um número hexadecimal que indica o comprimento total dos argumentos de comprimento, URL, nome de usuário e senha, incluindo os espaços entre esses argumentos. Nenhum espaço é permitido entre a palavra-chave 01 e o valor do comprimento.
- URL - URL do ACS.
- username - Nome de usuário para o CPE se autenticar no ACS.
- password - Senha para o CPE se autenticar no ACS.
NOTA: A URL do ACS, nome de usuário e senha devem usar o formato hexadecimal e ser separados por espaços.
O exemplo a seguir configura o endereço do ACS como http://169.254.76.31:7547/acs, nome de usuário como 1234 e senha como 5678:
Sysname> system-view
Sysname] dhcp server ip-pool 0
Sysname-dhcp-pool-0] option 43 hex
0127687474703A2F2F3136392E3235342E37362E33313A373534372F61637320313233342035363738
| Atributo | Valor do atributo | Forma hexadecimal | |||
| Comprimento | 39 caracteres | 27 | |||
| URL do ACS | http://169.254.76.31:7547/acs | 687474703A2F2F3136392E3235342E37362E33313A373534372F61637320 | |||
| Nome de usuário do ACS | 1234 | 3132333420 | |||
| Senha do ACS | 5678 | 35363738 |
Configurando Atributos ACS Preferidos pela CLI
- Entrar na visão do sistema.
system-viewcwmpcwmp acs preferred-url urlPor padrão, nenhuma URL ACS preferida foi configurada.
cwmp acs preferred-username usernamePor padrão, nenhum nome de usuário foi configurado para autenticação na URL ACS preferida.
cwmp acs preferred-password { cipher | simple } stringPor padrão, nenhuma senha foi configurada para autenticação na URL ACS preferida.
Configurando Atributos ACS Padrão pela CLI
- Entrar na visão do sistema.
system-viewcwmpcwmp acs default-url urlPor padrão, nenhuma URL ACS padrão foi configurada.
cwmp acs default-username usernamePor padrão, nenhum nome de usuário foi configurado para autenticação na URL ACS padrão.
cwmp acs default-password { cipher | simple } stringPor padrão, nenhuma senha foi configurada para autenticação na URL ACS padrão.
Configurando Atributos CPE
Especificando uma Política de Cliente SSL para Conexão HTTPS ao ACS
Sobre Especificar uma Política de Cliente SSL para Conexão HTTPS ao ACS
Esta tarefa é necessária quando o ACS usa HTTPS para acesso seguro. CWMP usa HTTP ou HTTPS para transmissão de dados. Quando HTTPS é usado, a URL ACS começa com https://. Você deve especificar uma política de cliente SSL para o CPE autenticar o ACS para o estabelecimento de conexão HTTPS.
Pré-requisitos
Antes de realizar esta tarefa, primeiro crie uma política de cliente SSL. Para obter mais informações sobre como configurar políticas de cliente SSL, consulte o Guia de Configuração de Segurança.
Procedimento
- Entrar na visão do sistema.
system-viewcwmpssl client-policy nome-politicaPor padrão, nenhuma política de cliente SSL é especificada.
Configurando Parâmetros de Autenticação ACS
Sobre os Parâmetros de Autenticação ACS
Para proteger o CPE contra acessos não autorizados, configure um nome de usuário e uma senha do CPE para autenticação ACS. Quando um ACS inicia uma conexão com o CPE, o ACS deve fornecer o nome de usuário e a senha corretos.
Procedimento
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe username usernamePor padrão, nenhum nome de usuário foi configurado para autenticação no CPE.
cwmp cpe password { cipher | simple } stringPor padrão, nenhuma senha foi configurada para autenticação no CPE.
A configuração de senha é opcional. Você pode especificar apenas um nome de usuário para autenticação.
Configurando o Código de Provisão
Sobre o Código de Provisão
O ACS pode usar o código de provisão para identificar serviços atribuídos a cada CPE. Para implantação correta da configuração, certifique-se de que o mesmo código de provisão seja configurado no CPE e no ACS. Para informações sobre o suporte do seu ACS para códigos de provisão, consulte a documentação do ACS.
Procedimento
- Entrar na visão do sistema.
system-view
system-viewcwmpcwmp cpe provision-code provision-codeO código de provisão padrão é PROVISIONINGCODE.
Configurando a Interface de Conexão CWMP
Sobre a Configuração da Interface de Conexão CWMP
A interface de conexão CWMP é a interface que o CPE usa para se comunicar com o ACS. Para estabelecer uma conexão CWMP, o CPE envia o endereço IP desta interface nos mensagens Inform, e o ACS responde a este endereço IP.
Tipicamente, o CPE seleciona a interface de conexão CWMP automaticamente. Se a interface de conexão CWMP não for a interface que conecta o CPE ao ACS, o CPE falhará em estabelecer uma conexão CWMP com o ACS. Nesse caso, você precisa configurar manualmente a interface de conexão CWMP.
Procedimento
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe connect interface interface-type interface-numberPor padrão, nenhuma interface de conexão CWMP é especificada.
Configurando Parâmetros de Autoconexão
Sobre os Parâmetros de Autoconexão
Você pode configurar o CPE para se conectar ao ACS periodicamente, ou em um horário agendado para configuração ou atualização de software.
O CPE tenta uma conexão automaticamente quando um dos seguintes eventos ocorre:
- O CPE falha em se conectar ao ACS. O CPE considera uma tentativa de conexão como falhada quando o temporizador close-wait expira. Este temporizador começa quando o CPE envia uma solicitação Inform. Se o CPE falhar em receber uma resposta antes do temporizador expirar, o CPE reenvia a solicitação Inform.
- A conexão é desconectada antes que a sessão na conexão seja concluída.
Para proteger os recursos do sistema, limite o número de tentativas que o CPE pode fazer para se conectar ao ACS.
Configurando o Recurso de Informe Periódico
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe inform interval enablePor padrão, esta função está desabilitada.
cwmp cpe inform interval intervalPor padrão, o CPE envia uma mensagem Inform para iniciar uma sessão a cada 600 segundos.
Agendando uma Inicialização de Conexão
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe inform time timePor padrão, nenhuma inicialização de conexão foi agendada.
Configurando o Número Máximo de Tentativas de Conexão
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe connect retry retriesPor padrão, o CPE tenta uma conexão falhada até que a conexão seja estabelecida.
Configurando o Temporizador de Espera de Fechamento
Sobre o Temporizador de Espera de Fechamento
O temporizador de espera de fechamento especifica o seguinte:
- O tempo máximo que o CPE espera pela resposta a uma solicitação de sessão. O CPE determina que sua tentativa de sessão falhou quando o temporizador expira.
- O tempo que a conexão com o ACS pode ficar ociosa antes de ser terminada. O CPE termina a conexão com o ACS se nenhum tráfego for enviado ou recebido antes que o temporizador expire.
Procedimento
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe wait timeout secondsPor padrão, o temporizador de espera de fechamento é 30 segundos.
Habilitando Traversal NAT para o CPE
Sobre Traversal NAT
Para que a solicitação de conexão iniciada do ACS alcance o CPE, é necessário habilitar o Traversal NAT no CPE quando um gateway NAT reside entre o CPE e o ACS.
O recurso de Traversal NAT está em conformidade com o RFC 3489 Simple Traversal of UDP Through NATs (STUN). O recurso permite que o CPE descubra o gateway NAT e obtenha um vínculo NAT aberto (um endereço IP público e vínculo de porta) pelo qual o ACS pode enviar pacotes não solicitados. O CPE envia o vínculo para o ACS quando inicia uma conexão com o ACS. Para que as solicitações de conexão enviadas pelo ACS a qualquer momento alcancem o CPE, o CPE mantém o vínculo NAT aberto. Para obter mais informações sobre NAT, consulte o Guia de Configuração de Serviços IP - Camada 3.
Procedimento
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe stun enablePor padrão, o Traversal NAT está desabilitado no CPE.
Comandos de Exibição e Manutenção para CWMP
Execute os comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir configuração CWMP. | display cwmp configuration | ||
| Exibir o status atual do CWMP. | display cwmp status |
Exemplos de Configuração CWMP
Exemplo: Configurando CWMP
Configuração de rede
Conforme mostrado na Figura 4, use Intelbras IMC BIMS como o ACS para configurar em massa os dispositivos (CPEs) e atribuir atributos ACS aos CPEs a partir do servidor DHCP.
Os arquivos de configuração para os CPEs nas salas de equipamentos A e B são configure1.cfg e configure2.cfg, respectivamente.
| Item | Setting | ||
| Preferred ACS URL | http://10.185.10.41:9090 | ||
| ACS username | admin | ||
| ACS password | 12345 |
| Room | Device | Serial number | |||
| A | CPE 1 | 210231A95YH10C000045 | |||
| CPE 2 | 210235AOLNH12000010 | ||||
| B | CPE 3 | 210235AOLNH12000015 | |||
| CPE 4 | 210235AOLNH12000017 | ||||
| CPE 5 | 210235AOLNH12000020 | ||||
| CPE 6 | 210235AOLNH12000022 |
Configurando o ACS:
- Conecte-se ao ACS:
- Inicie um navegador da Web no terminal de configuração do ACS.
- Na barra de endereço do navegador da Web, insira o URL e o número da porta do ACS. Neste exemplo, utilizaremos http://10.185.10.41:8080/imc.
- Na página de login, insira o nome de usuário e a senha de login do ACS e clique em "Login".
- Crie um grupo de CPE para cada sala de equipamentos:
- Selecione Serviço > BIMS > Grupo de CPE na barra de navegação superior.
- A página do Grupo de CPE será exibida.
- Clique em "Adicionar".
- Insira um nome de usuário e clique em "OK".
- Repita os passos anteriores para criar um grupo de CPE para as CPEs na Sala B.
- Adicione as CPEs ao grupo de CPE para cada sala de equipamentos:
- Selecione Serviço > BIMS > Gerenciamento de Recursos > Adicionar CPE na barra de navegação superior.
- Na página Adicionar CPE, configure os parâmetros a seguir:
- Tipo de Autenticação - Selecione Nome de Usuário ACS.
- Nome da CPE - Insira um nome para a CPE.
- Nome de Usuário ACS - Insira "admin".
- Senha ACS Gerada - Selecione Entrada Manual.
- Senha ACS - Insira uma senha para autenticação ACS.
- Confirmar Senha ACS - Reinsira a senha.
- Modelo de CPE - Selecione o modelo de CPE.
- Grupo de CPE - Selecione o grupo de CPE.
- Clique em "OK".
- Verifique se a CPE foi adicionada com sucesso na página Todas as CPEs. Figure 8 Viewing CPEs
- Repita as etapas anteriores para adicionar CPE 2 e CPE 3 ao grupo de CPE para a Sala A, e adicione as CPEs na Sala B ao grupo de CPE para a Sala B.
- Configure um modelo de configuração para cada sala de equipamentos:
- Selecione Serviço > BIMS > Gerenciamento de Configuração > Modelos de Configuração na barra de navegação superior. Figure 9 Configuration Templates page
- Clique em "Importar".
- Selecione um arquivo de configuração de origem, selecione Segmento de Configuração como tipo de modelo e clique em "OK".
- O modelo de configuração criado será exibido na lista de Modelos de Configuração após uma importação de arquivo bem-sucedida.
- IMPORTANTE: Se o primeiro comando no arquivo de modelo de configuração for system-view, verifique se não há caracteres na frente do comando.
Figura 10 Importando um modelo de configuração

Figura 11 Lista de Modelos de Configuração

Repita as etapas anteriores para configurar um modelo de configuração para a Sala B.
- Adicione entradas à biblioteca de software:
- Selecione Serviço > BIMS > Gerenciamento de Configuração > Biblioteca de Software na barra de navegação superior.
- Clique em "Importar".
- Selecione um arquivo de origem e clique em "OK".
- Repita as etapas anteriores para adicionar entradas de biblioteca de software para CPEs de diferentes modelos.
- Crie uma tarefa de implantação automática para cada sala de equipamentos:
- Selecione Serviço > BIMS > Gerenciamento de Configuração > Guia de Implantação na barra de navegação superior.
- Clique em Por Modelo de CPE no campo Configuração de Implantação Automática.
- Selecione um modelo de configuração, selecione Configuração de Inicialização na lista Tipo de Arquivo a ser Implantaodo e clique em Selecionar Modelo para selecionar as CPEs na Sala A. Em seguida, clique em "OK".
- Clique em "OK" na página Configuração de Implantação Automática.
- Repita as etapas anteriores para adicionar uma tarefa de implantação para as CPEs na Sala B.
Figura 12 Página da Biblioteca de Software

Figura 13 Importando Software para CPEs

Figura 14 Guia de Implantação

Você pode pesquisar as CPEs pelo grupo de CPEs.
Figura 15 Configuração de Implantação Automática

Figura 16 Resultado da Operação

Configurando o servidor DHCP
Neste exemplo, um dispositivo Intelbras está operando como servidor DHCP.
- Configure um pool de endereços IP para atribuir endereços IP e o endereço do servidor DNS aos CPEs.
Neste exemplo, é usada a sub-rede 10.185.10.0/24 para a atribuição de endereços IP.
Ativar DHCP.
<DHCP_server> system-view
[DHCP_server] dhcp enable
Ativar servidor DHCP na VLAN-interface 1.
interface vlan-interface 1
dhcp select server
quit
Excluir o endereço do servidor DNS 10.185.10.60 e o endereço IP ACS 10.185.10.41 da alocação dinâmica.
dhcp server forbidden-ip 10.185.10.41
dhcp server forbidden-ip 10.185.10.60
Criar pool de endereços DHCP 0.
dhcp server ip-pool 0
Atribuir a sub-rede 10.185.10.0/24 ao pool de endereços e especificar o endereço do servidor DNS 10.185.10.60 no pool de endereços.
network 10.185.10.0 mask 255.255.255.0
dns-list 10.185.10.60
2. Configure a opção DHCP 43 para conter a URL do ACS, nome de usuário e senha em formato hexadecimal.
option 43 hex
013B687474703A2F2F6163732E64617461626173653A393039302F616373207669636B792031323345
Configurando o servidor DNS
Mapear http://acs.database:9090 para http://10.185.1.41:9090 no servidor DNS. Para mais informações sobre a configuração do DNS, consulte a documentação do servidor DNS.
Conectando os CPEs à rede
# Conectar o CPE 1 à rede e, em seguida, ligar o CPE. (Detalhes não mostrados.)
# Fazer login no CPE 1 e configurar a VLAN-interface 2 para usar DHCP para a aquisição de endereço IP, e atribuir GigabitEthernet 1/0/1 à VLAN-interface 2. Na inicialização, o CPE obtém o endereço IP e as informações do ACS do servidor DHCP para iniciar uma conexão com o ACS. Após a conexão ser estabelecida, o CPE interage com o ACS para concluir a autoconfiguração.
<CPE1> system-view
[CPE1] vlan 2
[CPE1-vlan2] quit
[CPE1] interface gigabitethernet 1/0/1
[CPE1-GigabitEthernet1/0/1] port access vlan 2
[CPE1-GigabitEthernet1/0/1] quit
[CPE1] interface vlan-interface 2
[CPE1-Vlan-interface2] ip address dhcp-alloc
# Repetir as etapas anteriores para configurar os outros CPEs.
Verificando a configuração
# Execute o comando display current-configuration para verificar se as configurações em execução nos CPEs são as mesmas que as configurações emitidas pelo ACS.
Configurando EAA
Sobre EAA
A Arquitetura de Automação Incorporada (EAA) é uma estrutura de monitoramento que permite que você defina eventos monitorados e ações a serem tomadas em resposta a um evento. Ele permite que você crie políticas de monitoramento usando a CLI ou scripts Tcl.
Estrutura do EAA
A estrutura do EAA inclui:
- Um conjunto de fontes de eventos
- Um conjunto de monitores de eventos
- Um gerenciador de eventos em tempo real (RTM)
- Um conjunto de políticas de monitoramento definidas pelo usuário
Veja a Figura 1 para uma representação visual da estrutura do EAA.
Fontes de eventos
As fontes de eventos são módulos de software ou hardware que disparam eventos. Por exemplo:
- O módulo CLI dispara um evento quando você insere um comando.
- O módulo Syslog (o centro de informações) dispara um evento quando recebe uma mensagem de log.
Monitores de eventos
O EAA cria um monitor de evento para monitorar o sistema para o evento especificado em cada política de monitoramento. Um monitor de evento notifica o RTM para executar a política de monitoramento quando o evento monitorado ocorre.
RTM
O RTM gerencia a criação, a máquina de estados e a execução de políticas de monitoramento.
Políticas de monitoramento do EAA
Uma política de monitoramento especifica o evento a ser monitorado e as ações a serem tomadas quando o evento ocorre. Você pode configurar políticas de monitoramento do EAA usando a CLI ou Tcl.
Uma política de monitoramento contém os seguintes elementos:
- Um evento
- No mínimo, uma ação
- No mínimo, uma função de usuário
- Uma configuração de tempo de execução
Para obter mais informações sobre esses elementos, consulte "Elementos em uma política de monitoramento".
Elementos em uma política de monitoramento
Elementos em uma política de monitoramento do EAA incluem:
- Evento
- Ação
- Papel de usuário
- Tempo de execução
Evento
A Tabela 1 mostra os tipos de eventos que o EAA pode monitorar.
| Tipo de Evento | Descrição | ||
| CLI | O evento CLI ocorre em resposta a operações monitoradas realizadas na CLI. | ||
| Syslog | O evento Syslog ocorre quando o centro de informações recebe o log monitorado dentro de um período específico. | ||
| Processo | O evento de processo ocorre em resposta a uma alteração de estado do processo monitorado (como uma exceção, desligamento, início ou reinício). Mudanças de estado manuais e automáticas podem causar o evento. | ||
| Hotplug | O evento de hotplug ocorre quando o dispositivo membro monitorado entra ou sai da rede IRF. | ||
| Interface | Cada evento de interface está associado a dois limites definidos pelo usuário: início e reinício. Um evento de interface ocorre quando a estatística de tráfego da interface monitorada ultrapassa o limite de início nas seguintes situações: • A estatística ultrapassa o limite de início pela primeira vez. • A estatística ultrapassa o limite de início cada vez após ultrapassar o limite de reinício. | ||
| SNMP | Cada evento SNMP está associado a dois limites definidos pelo usuário: início e reinício. Um evento SNMP ocorre quando o valor da variável MIB monitorada ultrapassa o limite de início nas seguintes situações: • O valor da variável monitorada ultrapassa o limite de início pela primeira vez. • O valor da variável monitorada ultrapassa o limite de início cada vez após ultrapassar o limite de reinício. | ||
| SNMP-Notification | O evento de notificação SNMP ocorre quando o valor da variável MIB monitorada em uma notificação SNMP corresponde à condição especificada. | ||
| Rastreamento | O evento de rastreamento ocorre quando o estado da entrada de rastreamento muda de Positivo para Negativo ou de Negativo para Positivo. |
Ação
Você pode criar uma série de ações dependentes da ordem para responder ao evento especificado na política de monitoramento.
As seguintes ações estão disponíveis:
- Executar um comando.
- Enviar um log.
- Habilitar uma troca ativa/passiva.
- Executar um reinício sem salvar a configuração em execução.
Papel de usuário
Para que o EAA execute uma ação em uma política de monitoramento, você deve atribuir à política o papel de usuário que tem acesso aos comandos e recursos específicos da ação.
Para obter mais informações sobre papéis de usuário, consulte o RBAC no Guia de Configuração Fundamental.
Tempo de Execução
O tempo de execução limita a quantidade de tempo que a política de monitoramento executa suas ações a partir do momento em que é acionada.
Variáveis de Ambiente do EAA
As variáveis de ambiente do EAA desvinculam a configuração dos argumentos de ação da política de monitoramento para que você possa modificar uma política facilmente.
Variáveis definidas pelo sistema são fornecidas por padrão e não podem ser criadas, excluídas ou modificadas pelos usuários.
Tabela 2 Variáveis de ambiente do EAA definidas pelo sistema por tipo de evento
| Evento | Nome da Variável e Descrição | ||
| Qualquer evento |
| ||
| CLI |
| ||
| Syslog |
| ||
| Hotplug |
| ||
| Interface |
| ||
| SNMP |
| ||
| SNMP-Notification |
| ||
| Processo |
|
Variáveis definidas pelo usuário
Você pode usar variáveis definidas pelo usuário para todos os tipos de eventos.
Os nomes das variáveis definidas pelo usuário podem conter dígitos, caracteres e o sinal de sublinhado (_), exceto que o sinal de sublinhado não pode ser o caractere principal.
Configurando uma variável de ambiente do EAA definida pelo usuário
Sobre a configuração de uma variável de ambiente do EAA definida pelo usuário
Configure variáveis de ambiente do EAA definidas pelo usuário para que você possa usá-las ao criar políticas de monitoramento do EAA.
Procedimento
- Entre no modo de visualização do sistema.
system-viewrtm environment var-name var-valuePara as variáveis definidas pelo sistema, consulte a Tabela 2.
Configurando uma política de monitoramento
Restrições e diretrizes
Garanta que as ações em diferentes políticas não entrem em conflito. O resultado da execução da política será imprevisível se políticas que conflitam em ações estiverem sendo executadas simultaneamente.
Você pode atribuir o mesmo nome de política a uma política definida por CLI e a uma política definida por Tcl. No entanto, não pode atribuir o mesmo nome a políticas que são do mesmo tipo.
Uma política de monitoramento suporta apenas um evento e tempo de execução. Se você configurar vários eventos para uma política, o mais recente entrará em vigor.
Uma política de monitoramento suporta no máximo 64 papéis de usuário válidos. Os papéis de usuário adicionados após atingir esse limite não terão efeito.
Configurando uma política de monitoramento a partir da CLI
Restrições e diretrizes
Você pode configurar uma série de ações a serem executadas em resposta ao evento especificado em uma política de monitoramento. O EAA executa as ações em ordem crescente de IDs de ação. Ao adicionar ações a uma política, você deve garantir que a ordem de execução esteja correta. Se duas ações tiverem o mesmo ID, a mais recente entrará em vigor.
Procedimento
- Entre no modo de visualização do sistema.
system-viewrtm event syslog buffer-size buffer-sizePor padrão, o buffer de log monitorado pelo EAA armazena no máximo 50000 logs.
rtm cli-policy nome-da-politica- Configure um evento CLI.
event cli { async [ skip ] | sync } mode { execute | help | tab } pattern regular-expevent hotplug [ insert | remove ] slot slot-numberevent interface lista-de-interface monitor-obj monitor-obj start-op
start-op start-val start-val restart-op restart-op restart-val
restart-val [ interval interval ]event process { exception | restart | shutdown | start } [ name
nome-do-processo [ instance id-da-instância ] ] [ slot número-do-slot ]event snmp oid oid monitor-obj { get | next } start-op start-op
start-val start-val restart-op restart-op restart-val restart-val
[ interval interval ]event snmp-notification oid oid oid-val oid-val op op [ drop ]event syslog prioridade prioridade msg msg ocorre vezes período períodoevent track lista-de-rastreamento state { negative | positive } [ suppress-time
tempo-de-supressão ]- Escolha as seguintes tarefas conforme necessário:
- Configure uma ação CLI.
action number cli command-lineaction number reboot [ slot slot-number ]
action number switchoveraction number syslog priority priority facility local-number msg
msg-bodyuser-role nome-da-funçãorunning-time timecommitConfigurando uma política de monitoramento usando Tcl
Sobre scripts Tcl
Um script Tcl contém duas partes: Linha 1 e as demais linhas.
- Linha 1
A Linha 1 define o evento, funções de usuário e tempo de execução da ação da política. Após criar e habilitar uma política de monitoramento Tcl, o dispositivo imediatamente analisa, entrega e executa a Linha 1.
A Linha 1 deve seguir o seguinte formato:
::comware::rtm::event_register event-type arg1 arg2 arg3 … user-role
role-name1 | [ user-role role-name2 | [ … ] ] [ running-time
running-time ]
- Os argumentos arg1 arg2 arg3 … representam regras de correspondência de eventos. Se um valor de argumento contiver espaços, use aspas duplas ("") para cercar o valor. Por exemplo, "a b c".
- Os requisitos de configuração para os argumentos tipo-de-evento, função-de-usuário e tempo-de-execução são os mesmos que os de uma política de monitoramento definida por CLI.
A partir da segunda linha, o script Tcl define as ações a serem executadas quando a política de monitoramento é acionada. Você pode usar várias linhas para definir várias ações. O sistema executa essas ações em sequência. As seguintes ações estão disponíveis:
- Comandos Tcl padrão.
- Ações Tcl específicas do EAA:
- switchover ( ::comware::rtm::action switchover )
- syslog (::comware::rtm::action syslog priority priority facility local-number msg msg-body). Para mais informações sobre esses argumentos, consulte Comandos EAA no Referência de Comandos de Gerenciamento e Monitoramento de Rede.
- Comandos suportados pelo dispositivo.
Restrições e diretrizes
Para revisar o script Tcl de uma política, você deve suspender todas as políticas de monitoramento primeiro e, em seguida, retomar as políticas após concluir a revisão do script. O sistema não pode executar uma política definida por Tcl se você editar seu script Tcl sem suspender essas políticas.
Procedimento
- Baixe o arquivo de script Tcl para o dispositivo usando FTP ou TFTP.
- Crie e habilite uma política de monitoramento Tcl.
- Entre na visão do sistema.
Para mais informações sobre o uso de FTP e TFTP, consulte o Guia de Configuração de Fundamentos.
system-viewrtm tcl-policy policy-name tcl-filenamePor padrão, não existem políticas Tcl.
Assegure-se de que o arquivo de script esteja salvo em todos os dispositivos membros do IRF. Esta prática garante que a política possa ser executada corretamente após ocorrer uma troca de mestre/subordinado ou o dispositivo membro onde o arquivo de script está localizado sair do IRF.
Suspender políticas de monitoramento
Sobre a suspensão de políticas de monitoramento
Esta tarefa suspende todas as políticas de monitoramento definidas por CLI e por Tcl. Se uma política estiver em execução quando você realizar esta tarefa, o sistema suspende a política após executar todas as ações.
Restrições e diretrizes
Para restaurar o funcionamento das políticas suspensas, execute o comando undo rtm scheduler suspend.
- Entre na visão do sistema.
system-viewrtm scheduler suspendComandos de exibição e manutenção para EAA
| Tarefa | Comando | ||
| Exibir a configuração em execução de todas as políticas de monitoramento definidas por CLI. | display current-configuration | ||
| Exibir variáveis de ambiente do EAA definidas pelo usuário. | display rtm environment [ var-name ] | ||
| Exibir políticas de monitoramento EAA. | display rtm policy { active | registered [ verbose ] } [ policy-name ] | ||
| Exibir a configuração em execução de uma política de monitoramento definida por CLI na visão de política de monitoramento definida por CLI. | display this |
Exemplos de configuração do EAA
Exemplo: Configurando uma política de monitoramento de eventos CLI usando Tcl
Configuração de rede
Conforme mostrado na Figura 2, use Tcl para criar uma política de monitoramento no Dispositivo. Esta política deve atender aos seguintes requisitos:
center>
- O EAA envia a mensagem de log "rtm_tcl_test está em execução" quando um comando que contém a string display this é inserido.
- O sistema executa o comando somente depois de executar a política com sucesso.
Procedimento
::comware::rtm::event_register cli sync mode execute pattern display this user-role network-admin
::comware::rtm::action syslog priority 1 facility local4 msg rtm_tcl_test is running
Baixe o arquivo de script Tcl do servidor TFTP em 1.2.1.1.
<Sysname> tftp 1.2.1.1 get rtm_tcl_test.tcl
Crie uma política definida por Tcl chamada test e vincule-a ao arquivo de script Tcl.
<Sysname> system-view
[Sysname] rtm tcl-policy test rtm_tcl_test.tcl
[Sysname] quit
Verificando a configuração
Execute o comando display rtm policy registered para verificar se uma política definida por Tcl chamada test é exibida na saída do comando.<Sysname> display rtm policy registered
Total number: 1
Type Event TimeRegistered PolicyName
TCL CLI Jan 01 09:47:12 2019 test
Internet
Device PC
TFTP client TFTP server
1.1.1.1/16 1.2.1.1/16
<Sysname> terminal monitor
The current terminal is enabled to display logs.
<Sysname> system-view
[Sysname] info-center enable
Information center is enabled..
[Sysname] quit
Execute o comando display this. Verifique se o sistema exibe uma mensagem "rtm_tcl_test está em execução" e uma mensagem de que a política está sendo executada com sucesso.
<Sysname> display this
%Jan 1 09:50:04:634 2019 Sysname RTM/1/RTM_ACTION:rtm_tcl_test is running
%Jan 1 09:50:04:636 2019 Sysname RTM/6/RTM_POLICY: TCL policy test is running
successfully.
#
returnExemplo: Configurando uma política de monitoramento de eventos CLI a partir da CLI
Configuração de rede
Configure uma política a partir da CLI para monitorar o evento que ocorre quando um ponto de interrogação (?) é inserido na linha de comando que contém letras e dígitos.
Quando o evento ocorre, o sistema executa o comando e envia a mensagem de log "hello world" para o centro de informações.
Procedimento
Crie a política definida por CLI test e entre em sua visualização.
<Sysname> system-view
[Sysname] rtm cli-policy test
Adicione um evento CLI que ocorre quando um ponto de interrogação (?) é inserido em qualquer linha de comando que contenha letras e dígitos.
[Sysname-rtm-test] event cli async mode help pattern [a-zA-Z0-9]Adicione uma ação que envia a mensagem "hello world" com prioridade 4 da facilidade de log local3 quando o evento ocorre.
[Sysname-rtm-test] action 0 syslog priority 4 facility local3 msg “hello world”Adicione uma ação que entra na visualização do sistema quando o evento ocorre.
[Sysname-rtm-test] action 2 cli system-viewAdicione uma ação que cria a VLAN 2 quando o evento ocorre.
[Sysname-rtm-test] action 3 cli vlan 2Defina o tempo de execução da ação da política para 2000 segundos.
[Sysname-rtm-test] running-time 2000Especifique a função de usuário network-admin para executar a política.
[Sysname-rtm-test] user-role network-adminHabilite a política.
[Sysname-rtm-test] commitVerificação da configuração
Execute o comando display rtm policy registered para verificar se uma política definida por CLI chamada test está sendo exibida na saída do comando.
[Sysname-rtm-test] display rtm policy registered
Total number: 1
Type Event TimeRegistered PolicyName
CLI CLI Jan 1 14:56:50 2019 test
Habilite o centro de informações para exibir mensagens de log no terminal de monitoramento atual.
[Sysname-rtm-test] return
Sysname> terminal monitor
The current terminal is enabled to display logs.
Sysname> system-view
[Sysname] info-center enable
Information center is enabled.
[Sysname] quit
Insira um ponto de interrogação (?) em uma linha de comando que contenha uma letra d. Verifique se o sistema exibe uma mensagem "hello world" e uma mensagem de que a política está sendo executada com sucesso na tela do terminal.
<Sysname> d?
debugging
delete
diagnostic-logfile
dir
display
<Sysname>d%Jan 1 14:57:20:218 2019 Sysname RTM/4/RTM_ACTION: "hello world"
%Jan 1 14:58:11:170 2019 Sysname RTM/6/RTM_POLICY: CLI policy test is running
successfully.
Exemplo: Configuração de uma política de monitoramento de evento CLI com variáveis de ambiente EAA do CLI
Configuração da rede
Defina uma variável de ambiente para corresponder ao endereço IP 1.1.1.1.
Configure uma política do CLI para monitorar o evento que ocorre quando uma linha de comando que contém loopback0 é executada. Na política, use a variável de ambiente para atribuição de endereço IP.
Quando o evento ocorrer, o sistema executa as seguintes tarefas:
- Cria a interface Loopback 0.
- Atribui 1.1.1.1/24 à interface.
- Envia a linha de comando correspondente ao centro de informações.
Procedimento
# Configure uma variável de ambiente EAA para atribuição de endereço IP. O nome da variável é loopback0IP, e o valor da variável é 1.1.1.1.
<Sysname> system-view
[Sysname] rtm environment loopback0IP 1.1.1.1
# Crie a política definida por CLI test e entre em sua visualização.
[Sysname] rtm cli-policy test
# Adicione um evento CLI que ocorre quando uma linha de comando que contém loopback0 é executada.
[Sysname-rtm-test] event cli async mode execute pattern loopback0
# Adicione uma ação que entra na visualização do sistema quando o evento ocorre.
[Sysname-rtm-test] action 0 cli system-view
# Adicione uma ação que cria a interface Loopback 0 e entra na visualização da interface de loopback.
[Sysname-rtm-test] action 1 cli interface loopback 0
# Adicione uma ação que atribui o endereço IP 1.1.1.1 ao Loopback 0. A variável loopback0IP é usada na ação para atribuição de endereço IP.
[Sysname-rtm-test] action 2 cli ip address $loopback0IP 24
# Adicione uma ação que envia a linha de comando loopback0 correspondente com uma prioridade de 0 a partir da instalação de log local7 quando o evento ocorre.
[Sysname-rtm-test] action 3 syslog priority 0 facility local7 msg $_cmd
# Especifique a função de usuário network-admin para executar a política.
[Sysname-rtm-test] user-role network-admin
# Habilite a política.
[Sysname-rtm-test] commit
[Sysname-rtm-test] return
<Sysname>
Verificação da configuração
# Habilite o centro de informações para exibir mensagens de log no terminal de monitoramento atual.
<Sysname> terminal monitor
The current terminal is enabled to display logs.
<Sysname> terminal log level debugging
<Sysname> system-view
[Sysname] info-center enable
Information center is enabled.
# Execute o comando interface loopback0. Verifique se o sistema exibe uma mensagem "interface loopback0" e uma mensagem de que a política está sendo executada com sucesso na tela do terminal.
[Sysname] interface loopback0
[Sysname-LoopBack0]%Jan 1 09:46:10:592 2019 Sysname RTM/7/RTM_ACTION: interface loopback0
%Jan 1 09:46:10:613 2019 Sysname RTM/6/RTM_POLICY: CLI policy test is running
successfully.
# Verifique se uma interface Loopback 0 foi criada e seu endereço IP é 1.1.1.1.
[Sysname-LoopBack0] display interface loopback brief
Brief information on interfaces in route mode:
Link: ADM - administratively down; Stby - standby
Protocol: (s) - spoofing
Interface Link Protocol Primary IP Description
Loop0 UP UP(s) 1.1.1.1
Monitorando e mantendo processos
Sobre monitoramento e manutenção de processos
O software do sistema do dispositivo é um sistema operacional de rede completo, modular e escalável, baseado no kernel Linux. As características do software do sistema executam os seguintes tipos de processos independentes:
- Processo do usuário - Executa no espaço do usuário. A maioria das características do software do sistema executa processos do usuário. Cada processo é executado em um espaço independente, portanto, a falha de um processo não afeta outros processos. O sistema monitora automaticamente os processos do usuário. O sistema suporta multithreading preemptivo. Um processo pode executar várias threads para suportar múltiplas atividades. Se um processo suporta multithreading depende da implementação do software.
- Thread do kernel - Executa no espaço do kernel. Uma thread do kernel executa código do kernel. Ela possui um nível de segurança mais alto do que um processo do usuário. Se uma thread do kernel falhar, o sistema entra em colapso. Você pode monitorar o status de execução das threads do kernel.
Tarefas de monitoramento e manutenção de processos em um relance
Para monitorar e manter processos, execute as seguintes tarefas:
- Monitorar e manter processos do usuário
- Monitorar e manter processos
Os comandos desta seção se aplicam tanto a processos do usuário quanto a threads do kernel.
- Monitorar e manter processos do usuário
Os comandos desta seção se aplicam apenas a processos do usuário.
- Monitorar e manter processos
- Monitorar e manter threads do kernel
- Monitorar e manter processos
Os comandos desta seção se aplicam tanto a processos do usuário quanto a threads do kernel.
- Monitorar e manter threads do kernel
Os comandos desta seção se aplicam apenas a threads do kernel.
- Monitorar e manter processos
Monitorando e mantendo processos
Sobre monitoramento e manutenção de processos
Os comandos nesta seção se aplicam tanto a processos do usuário quanto a threads do kernel. Você pode usar os comandos para os seguintes propósitos:
- Exibir o uso geral da memória.
- Exibir os processos em execução e seu uso de memória e CPU.
- Localizar processos anormais.
Se um processo consome recursos de memória ou CPU excessivos, o sistema identifica o processo como um processo anormal.
- Se um processo anormal for um processo do usuário, solucione o problema do processo conforme descrito em "Monitorando e mantendo processos do usuário".
- Se um processo anormal for uma thread do kernel, solucione o problema da thread conforme descrito em "Monitorando e mantendo threads do kernel".
Procedimento
Execute os seguintes comandos em qualquer visualização.
| Tarefa | Comando | ||
| Exibir uso de memória. | display memory [ summary ] [ slot slot-number [ cpu cpu-number ] ] | ||
| Exibir informações de estado do processo. | display process [ all | job job-id | name process-name ] [ slot slot-number [ cpu cpu-number ] ] | ||
| Exibir uso da CPU para todos os processos. | display process cpu [ slot slot-number [ cpu cpu-number ] ] | ||
| Monitorar estado de execução do processo. | monitor process [ dumbtty ] [ iteration number ] [ slot slot-number [ cpu cpu-number ] ] | ||
| Monitorar estado de execução da thread. | monitor thread [ dumbtty ] [ iteration number ] [ slot slot-number [ cpu cpu-number ] ] |
Para mais informações sobre o comando display memory, consulte o Guia de Referência de Comandos Fundamentais.
Monitoramento e manutenção de processos do usuário
Sobre o monitoramento e a manutenção de processos do usuário
Use este recurso para monitorar processos de usuário anormais e localizar problemas.
Configurando o despejo principal
Sobre o despejo principal
O recurso de despejo principal permite que o sistema gere um arquivo de despejo principal toda vez que um processo falha até que o número máximo de arquivos de despejo principal seja alcançado. Um arquivo de despejo principal armazena informações sobre o processo. Você pode enviar os arquivos de despejo principal para a equipe de suporte técnico da Intelbras para solucionar os problemas.
Restrições e diretrizes
Os arquivos de despejo principal consomem recursos de armazenamento. Ative o despejo principal apenas para processos que possam ter problemas.
Procedimento
Execute os seguintes comandos na visualização do usuário:
- (Opcional.) Especifique o diretório para salvar os arquivos de despejo principal.
exception filepath diretórioPor padrão, o diretório para salvar os arquivos de despejo principal é o diretório raiz do sistema de arquivos padrão. Para obter mais informações sobre o sistema de arquivos padrão, consulte o guia de configuração do sistema de arquivos em Guia de Configuração Fundamentais.
process core { maxcore valor | off } { job job-id | name nome-do-processo }Por padrão, um processo gera um arquivo de despejo principal para a primeira exceção e não gera nenhum arquivo de despejo principal para exceções subsequentes.
Comandos de exibição e manutenção para processos do usuário
Execute comandos de exibição em qualquer visualização e outros comandos na visualização do usuário.
| Tarefa | Comando | ||
| Exibir informações de contexto para exceções de processo. | display exception context [ count valor ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir o diretório do arquivo de despejo principal. | display exception filepath [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir informações de log para todos os processos do usuário. | display process log [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir uso de memória para todos os processos do usuário. | display process memory [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir uso de memória de heap para um processo do usuário. | display process memory heap job job-id [ verbose ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir conteúdo de memória a partir de um bloco de memória especificado para um processo do usuário. | display process memory heap job job-id address starting-address length memory-length [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir os endereços dos blocos de memória com um tamanho especificado usados por um processo do usuário. | display process memory heap job job-id size memory-size [ offset offset-size ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Limpar informações de contexto para exceções de processo. | reset exception context [ slot número-do-slot [ cpu número-da-cpu ] ] |
Monitoramento e manutenção de threads do kernel
Configurando detecção de loop de thread do kernel
Sobre a detecção de loop de thread do kernel
As threads do kernel compartilham recursos. Se uma thread do kernel monopoliza a CPU, outras threads não podem ser executadas, resultando em um loop de deadlock.
Este recurso permite que o dispositivo detecte deadlocks. Se uma thread ocupa a CPU por um intervalo específico, o dispositivo determina que ocorreu um deadlock e gera uma mensagem de deadlock.
Restrições e diretrizes
Altere as configurações de detecção de loop de thread do kernel apenas sob a orientação da equipe de suporte técnico da Intelbras. A configuração inadequada pode causar falha do sistema.
Procedimento
- Entre na visualização do sistema.
system-viewmonitor kernel deadloop enable [ slot número-do-slot [ cpu número-da-cpu [ core número-do-núcleo&<1-64> ] ] ]Por padrão, a detecção de loop de thread do kernel está habilitada.
monitor kernel deadloop time tempo [ slot número-do-slot [ cpu número-da-cpu ] ]O padrão é de 20 segundos.
monitor kernel deadloop exclude-thread tid [ slot número-do-slot [ cpu número-da-cpu ] ]Quando habilitada, a detecção de loop de thread do kernel monitora todas as threads do kernel por padrão.
monitor kernel deadloop action { reboot | record-only } [ slot número-do-slot [ cpu número-da-cpu ] ]A ação padrão é reiniciar.
Configurando detecção de inanição de thread do kernel
Sobre a detecção de inanição de thread do kernel
A inanição ocorre quando uma thread não consegue acessar recursos compartilhados.
A detecção de inanição de thread do kernel permite que o sistema detecte e relate a inanição de thread. Se uma thread não for executada dentro de um intervalo específico, o sistema determina que ocorreu uma inanição e gera uma mensagem de inanição.
A inanição de thread não afeta a operação do sistema. Uma thread inativa pode ser executada automaticamente quando certas condições são atendidas.
Restrições e diretrizes
Configure a detecção de inanição de thread do kernel apenas sob a orientação da equipe de suporte técnico da Intelbras. A configuração inadequada pode causar falha do sistema.
Procedimento
- Entre na visualização do sistema.
system-viewmonitor kernel starvation enable [ slot número-do-slot [ cpu número-da-cpu ] ]Por padrão, a detecção de inanição de thread do kernel está desativada.
monitor kernel starvation time tempo [ slot número-do-slot [ cpu número-da-cpu ] ]O padrão é de 120 segundos.
monitor kernel starvation exclude-thread tid [ slot número-do-slot [ cpu número-da-cpu ] ]Quando habilitada, a detecção de inanição de thread do kernel monitora todas as threads do kernel por padrão.
Comandos de exibição e manutenção para threads do kernel
Execute comandos de exibição em qualquer visualização e comandos de redefinição na visualização do usuário.
| Tarefa | Comando | ||
| Exibir configuração de detecção de loop de thread do kernel. | display kernel deadloop configuration [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir informações de loop de thread do kernel. | display kernel deadloop show-number [ offset ] [ verbose ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir informações de exceção de thread do kernel. | display kernel exception show-number [ offset ] [ verbose ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir informações de reinicialização de thread do kernel. | display kernel reboot show-number [ offset ] [ verbose ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir configuração de detecção de inanição de thread do kernel. | display kernel starvation configuration [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir informações de inanição de thread do kernel. | display kernel starvation show-number [ offset ] [ verbose ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Limpar informações de detecção de loop de thread do kernel. | reset kernel deadloop [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Limpar informações de exceção de thread do kernel. | reset kernel exception [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Limpar informações de reinicialização de thread do kernel. | reset kernel reboot [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Limpar informações de inanição de thread do kernel. | reset kernel starvation [ slot número-do-slot [ cpu número-da-cpu ] ] |
Configurando o espelhamento de porta
Sobre o espelhamento de porta
O espelhamento de porta copia os pacotes que passam por uma porta para uma porta que se conecta a um dispositivo de monitoramento de dados para análise de pacotes.
Terminologia
Os seguintes termos são usados na configuração de espelhamento de porta.
Fonte de espelhamento
As fontes de espelhamento podem ser uma ou mais portas monitoradas chamadas portas de origem. Os pacotes que passam pelas fontes de espelhamento são copiados para uma porta conectada a um dispositivo de monitoramento de dados para análise de pacotes. As cópias são chamadas de pacotes espelhados.
Dispositivo de origem
O dispositivo onde as fontes de espelhamento residem é chamado de dispositivo de origem.
Destino de espelhamento
O destino de espelhamento se conecta a um dispositivo de monitoramento de dados e é a porta de destino (também conhecida como porta de monitoramento) dos pacotes espelhados. Os pacotes espelhados são enviados para fora da porta de monitoramento para o dispositivo de monitoramento de dados. Uma porta de monitoramento pode receber várias cópias de um pacote quando monitora várias fontes de espelhamento. Por exemplo, duas cópias de um pacote são recebidas na Porta A quando as seguintes condições existem:
A Porta A está monitorando o tráfego bidirecional da Porta B e da Porta C no mesmo dispositivo.
O pacote viaja da Porta B para a Porta C.
Dispositivo de destino
O dispositivo onde a porta de monitoramento reside é chamado de dispositivo de destino.
Direção de espelhamento
A direção de espelhamento especifica a direção do tráfego que é copiado em uma fonte de espelhamento.
Entrada—Copia pacotes recebidos.
Saída—Copia pacotes enviados.
Bidirecional—Copia pacotes recebidos e enviados.
Grupo de espelhamento
O espelhamento de porta é implementado por meio de grupos de espelhamento. Os grupos de espelhamento podem ser classificados em grupos de espelhamento local, grupos de fonte remota e grupos de destino remoto.
Porta de refletor, porta de saída e VLAN de sonda remota
Portas refletoras, VLANs de sonda remota e portas de saída são usadas para o espelhamento de porta remota da Camada 2. A VLAN de sonda remota é uma VLAN dedicada para transmitir pacotes espelhados para o dispositivo de destino. Tanto a porta refletora quanto a porta de saída residem em um dispositivo de origem e enviam pacotes espelhados para a VLAN de sonda remota. Em dispositivos de espelhamento de porta, todas as portas, exceto portas de origem, destino, refletoras e de saída, são chamadas de portas comuns.
Classificação de espelhamento de porta
O espelhamento de porta pode ser classificado em espelhamento de porta local e espelhamento de porta remota.
Porta de espelhamento local—O dispositivo de origem está diretamente conectado a um dispositivo de monitoramento de dados. O dispositivo de origem também atua como dispositivo de destino e encaminha pacotes espelhados diretamente para o dispositivo de monitoramento de dados.
Porta de espelhamento remota—O dispositivo de origem não está diretamente conectado a um dispositivo de monitoramento de dados. O dispositivo de origem envia pacotes espelhados para o dispositivo de destino, que encaminha os pacotes para o dispositivo de monitoramento de dados. O espelhamento de porta remota também é conhecido como espelhamento de porta remota da Camada 2 porque o dispositivo de origem e o dispositivo de destino estão na mesma rede da Camada 2.
Local Port Mirroring
Como mostrado na Figura 1, a porta de origem (Porta A) e a porta de monitoramento (Porta B) residem no mesmo dispositivo. Os pacotes recebidos na Porta A são copiados para a Porta B. A Porta B então encaminha os pacotes para o dispositivo de monitoramento de dados para análise.
center>
Mirroring Remoto de Porta em Camada 2
No mirroring remoto de porta em camada 2, as fontes de espelhamento e o destino residem em dispositivos diferentes e estão em grupos de espelhamento diferentes.
Um grupo de fontes remoto é um grupo de espelhamento que contém as fontes de espelhamento. Um grupo de destino remoto é um grupo de espelhamento que contém o destino de espelhamento. Os dispositivos intermediários são os dispositivos entre o dispositivo de origem e o dispositivo de destino.
O mirroring de porta remoto em camada 2 pode ser implementado através do método da porta refletora ou do método da porta de saída.
Método da Porta Refletora
No mirroring remoto de porta em camada 2 que utiliza o método da porta refletora, os pacotes são espelhados da seguinte forma:
- O dispositivo de origem copia os pacotes recebidos nas fontes de espelhamento para a porta refletora.
- A porta refletora transmite os pacotes espelhados na VLAN de sonda remota.
- Os dispositivos intermediários transmitem os pacotes espelhados para o dispositivo de destino através da VLAN de sonda remota.
- Ao receber os pacotes espelhados, o dispositivo de destino determina se o ID dos pacotes espelhados é o mesmo que o ID da VLAN de sonda remota. Se os dois IDs de VLAN corresponderem, o dispositivo de destino encaminha os pacotes espelhados para o dispositivo de monitoramento de dados através da porta de monitoramento.
Método da Porta de Egresso
No mirroring remoto de porta em camada 2 que utiliza o método da porta de egresso, os pacotes são espelhados da seguinte forma:
- O dispositivo de origem copia os pacotes recebidos nas fontes de espelhamento para a porta de egresso.
- A porta de egresso encaminha os pacotes espelhados para os dispositivos intermediários.
- Os dispositivos intermediários inundam os pacotes espelhados na VLAN de sonda remota e transmitem os pacotes espelhados para o dispositivo de destino.
- Ao receber os pacotes espelhados, o dispositivo de destino determina se o ID dos pacotes espelhados é o mesmo que o ID da VLAN de sonda remota. Se os dois IDs de VLAN corresponderem, o dispositivo de destino encaminha os pacotes espelhados para o dispositivo de monitoramento de dados através da porta de monitoramento.
Restrições e diretrizes: Configuração de espelhamento de porta
O método de porta refletora para espelhamento de porta remota de Camada 2 pode ser usado para implementar o espelhamento de porta local com vários dispositivos de monitoramento de dados.
No método de porta refletora, a porta refletora transmite pacotes espelhados na VLAN de sonda remota. Ao atribuir as portas que se conectam aos dispositivos de monitoramento de dados à VLAN de sonda remota, você pode implementar o espelhamento de porta local para espelhar pacotes para vários dispositivos de monitoramento de dados. O método de porta de saída não pode implementar o espelhamento de porta local dessa maneira.
Para espelhamento de tráfego de entrada, a tag VLAN no pacote original é copiada para o pacote espelhado. Para espelhamento de tráfego de saída, a tag VLAN no pacote espelhado identifica a VLAN à qual o pacote pertence antes de ser enviado para fora da porta de origem.
Configurando o espelhamento de porta local
Restrições e diretrizes para a configuração de espelhamento de porta local
Um grupo de espelhamento local entra em vigor somente após ser configurado com a porta de monitoramento e fontes de espelhamento.
Uma interface agregada de Camada 2 ou Camada 3, interface de túnel ou interface VLAN não pode ser configurada como uma porta de origem de um grupo de espelhamento local. Você pode configurar portas membros de uma interface agregada de Camada 2 ou Camada 3 como portas de origem de espelhamento.
Uma interface agregada de Camada 2 ou Camada 3 não pode ser configurada como a porta de monitoramento de um grupo de espelhamento local.
A porta membro de uma interface agregada não pode ser configurada como porta de monitoramento.
Tarefas de espelhamento de porta local em um relance
Para configurar o espelhamento de porta local, execute as seguintes tarefas:
- Criando um grupo de espelhamento local
- Configurando fontes de espelhamento
- Configurando a porta de monitoramento
Criando um grupo de espelhamento local
Enter system view.
system-view
Create a local mirroring group.
mirroring-group group-id local
Configurando fontes de espelhamento
Restrições e diretrizes para a configuração de fonte de espelhamento
Ao configurar portas de origem para um grupo de espelhamento local, siga estas restrições e diretrizes:
- Um grupo de espelhamento pode conter várias portas de origem.
- Uma porta pode atuar como porta de origem para apenas um grupo de espelhamento.
- Uma porta de origem não pode ser configurada como porta refletora, porta de saída ou porta de monitoramento.
- Uma interface agregada de Camada 2 ou Camada 3, interface de túnel ou interface VLAN não pode ser configurada como porta de origem de um grupo de espelhamento local.
Configuração de portas de origem
- Configure as portas de origem no modo de sistema:
- a. Entre no modo de sistema.
system-viewmirroring-group group-id mirroring-port interface-list { both | inbound | outbound }Por padrão, nenhuma porta de origem é configurada para um grupo de espelhamento local.
- a. Entre no modo de sistema.
system-viewinterface interface-type interface-numbermirroring-group group-id mirroring-port { both | inbound | outbound }Por padrão, uma porta não atua como porta de origem para nenhum grupo de espelhamento local.
Configuração da porta de monitoramento
Restrições e diretrizes
- Não habilite o recurso de spanning tree na porta de monitoramento.
- Use uma porta de monitoramento apenas para espelhamento de porta, para que o dispositivo de monitoramento de dados receba apenas o tráfego espelhado.
- Apenas uma porta de monitoramento pode ser configurada para um grupo de espelhamento.
- A porta membro de uma interface agregada não pode ser configurada como porta de monitoramento.
Procedimento
- Configure a porta de monitoramento no modo de sistema:
- a. Entre no modo de sistema.
system-viewmirroring-group group-id monitor-port interface-type interface-numberPor padrão, nenhuma porta de monitoramento é configurada para um grupo de espelhamento local.
- a. Entre no modo de sistema.
system-viewinterface interface-type interface-numbermirroring-group group-id monitor-portPor padrão, uma porta não atua como a porta de monitoramento para nenhum grupo de espelhamento local.
Configuração do grupo de espelhamento de porta local com múltiplos dispositivos de monitoramento
Sobre o espelhamento de porta local com múltiplos dispositivos de monitoramento
Para monitorar o tráfego interessante passando por um dispositivo em vários dispositivos de monitoramento de dados diretamente conectados, configure o espelhamento de porta local com uma VLAN de sonda remota da seguinte maneira:
- Configure um grupo de origem remota no dispositivo.
- Configure fontes de espelhamento e uma porta refletora para o grupo de origem remota.
- Especifique uma VLAN como a VLAN de sonda remota e atribua as portas conectando aos dispositivos de monitoramento de dados à VLAN.
Esta configuração permite que o dispositivo copie pacotes recebidos nas fontes de espelhamento para a porta refletora, que transmite os pacotes na VLAN de sonda remota. Os pacotes são então enviados para fora das portas membros da VLAN de sonda remota para os dispositivos de monitoramento de dados.
Restrições e diretrizes
- A porta refletora deve ser uma porta não utilizada. Não conecte um cabo de rede à porta refletora.
- Quando uma porta é configurada como porta refletora, a porta é restaurada para as configurações padrão de fábrica. Você não pode configurar outros recursos na porta refletora.
- Não atribua uma porta de origem de um grupo de espelhamento à VLAN de sonda remota do grupo de espelhamento.
- Uma VLAN pode atuar como a VLAN de sonda remota para apenas um grupo de origem remota. Como prática recomendada, use a VLAN exclusivamente para o espelhamento de porta. Não crie uma interface VLAN para a VLAN ou configure outros recursos para a VLAN.
- A VLAN de sonda remota deve ser uma VLAN estática.
- Para excluir uma VLAN que foi configurada como a VLAN de sonda remota para um grupo de espelhamento, remova a VLAN de sonda remota do grupo de espelhamento primeiro.
- O dispositivo suporta apenas uma VLAN de sonda remota.
Procedimento
- Entre na visualização do sistema.
system-viewmirroring-group group-id remote-source- Configure as portas de espelhamento na visualização do sistema.
mirroring-group group-id mirroring-port interface-list { both | inbound | outbound }interface interface-type interface-numbermirroring-group group-id mirroring-port { both | inbound | outbound }quitmirroring-group group-id reflector-port reflector-portPor padrão, nenhuma porta refletora é configurada para um grupo de origem remota.
vlan vlan-idport interface-listPor padrão, uma VLAN não contém nenhuma porta.
quitmirroring-group group-id remote-probe vlan vlan-idPor padrão, nenhuma VLAN de sonda remota é configurada para um grupo de origem remota.
Configurando o espelhamento de porta remota de Camada 2
Restrições e diretrizes para a configuração do espelhamento de porta remota de Camada 2
Para garantir o espelhamento de tráfego bem-sucedido, configure os dispositivos na ordem do dispositivo de destino, dos dispositivos intermediários e do dispositivo de origem.
Se houver dispositivos intermediários, configure-os para permitir que a VLAN de sonda remota passe.
Para que um pacote espelhado chegue com sucesso ao dispositivo de destino remoto, verifique se seu ID de VLAN não é removido ou alterado.
Não configure tanto o MVRP quanto o espelhamento de porta remota de Camada 2. Caso contrário, o MVRP pode registrar a VLAN de sonda remota com portas incorretas, o que faria com que a porta de monitoramento recebesse cópias indesejadas. Para mais informações sobre o MVRP, consulte o Guia de Configuração de Comutação de LAN de Camada 2.
Para monitorar o tráfego bidirecional de uma porta de origem, desative a aprendizagem de endereço MAC para a VLAN de sonda remota nos dispositivos de origem, intermediários e de destino. Para mais informações sobre aprendizagem de endereço MAC, consulte o Guia de Configuração de Comutação de LAN de Camada 2.
A porta membro de uma interface agregada de Camada 2 não pode ser configurada como a porta de monitoramento para o espelhamento de porta remota de Camada 2.
Lista de tarefas de configuração do espelhamento de porta remota de Camada 2 com método de porta refletora
Configurando o dispositivo de destino
- Criar um grupo de destino remoto
- Configurar a porta de monitoramento
- Configurar a VLAN de sonda remota
- Atribuir a porta de monitoramento à VLAN de sonda remota
Configurando o dispositivo de origem
- Criar um grupo de origem remoto
- Configurar fontes de espelhamento
- Configurar a porta refletora
- Configurar a VLAN de sonda remota
Lista de tarefas de configuração do espelhamento de porta remota de Camada 2 com método de porta de saída
Configurando o dispositivo de destino
- Criar um grupo de destino remoto
- Configurar a porta de monitoramento
- Configurar a VLAN de sonda remota
- Atribuir a porta de monitoramento à VLAN de sonda remota
Configurando o dispositivo de origem
- Criar um grupo de origem remoto
- Configurar fontes de espelhamento
- Configurar a porta de saída
- Configurar a VLAN de sonda remota
Criando um grupo de destino remoto
Restrições e diretrizes
Execute esta tarefa apenas no dispositivo de destino.
Procedimento
- Entre na visualização do sistema.
system-viewmirroring-group group-id remote-destinationConfigurando a porta de monitoramento
Restrições e diretrizes para a configuração da porta de monitoramento
Execute esta tarefa apenas no dispositivo de destino.
- Não habilite o recurso de spanning tree na porta de monitoramento.
- Use uma porta de monitoramento apenas para espelhamento de porta, para que o dispositivo de monitoramento de dados receba apenas o tráfego espelhado.
- Uma porta de monitoramento pode pertencer a apenas um grupo de espelhamento.
- Uma interface agregada de Camada 2 não pode ser configurada como a porta de monitoramento para um grupo de espelhamento.
Configurando a porta de monitoramento na visualização do sistema
- Entre na visualização do sistema.
system-viewmirroring-group group-id monitor-port interface-type interface-numberPor padrão, nenhuma porta de monitoramento é configurada para um grupo de destino remoto.
Configurando a porta de monitoramento na visualização da interface
- Entre na visualização do sistema.
system-viewinterface interface-type interface-numbermirroring-group group-id monitor-portPor padrão, uma porta não atua como a porta de monitoramento para nenhum grupo de destino remoto.
Configurando a VLAN de sonda remota
Restrições e diretrizes
Esta tarefa é necessária tanto nos dispositivos de origem quanto nos de destino.
- Apenas uma VLAN estática existente pode ser configurada como uma VLAN de sonda remota.
- Quando uma VLAN é configurada como uma VLAN de sonda remota, use-a exclusivamente para espelhamento de porta.
- Configure a mesma VLAN de sonda remota para o grupo de origem remoto e o grupo de destino remoto.
- O dispositivo suporta apenas uma VLAN de sonda remota.
Procedimento
- Entre na visualização do sistema.
system-viewmirroring-group group-id remote-probe vlan vlan-idPor padrão, nenhuma VLAN de sonda remota é configurada para um grupo de origem ou destino remoto.
Atribuindo a porta de monitoramento à VLAN de sonda remota
Restrições e diretrizes
Execute esta tarefa apenas no dispositivo de destino.
Procedimento
- Entre na visualização do sistema.
system-viewinterface interface-type interface-number- Atribua uma porta de acesso à VLAN de sonda remota.
port access vlan vlan-idport trunk permit vlan vlan-idport hybrid vlan vlan-id { tagged | untagged }Para mais informações sobre os comandos port access vlan, port trunk permit vlan e port hybrid vlan, consulte o Guia de Referência de Comandos de Comutação de LAN de Camada 2.
Criando um grupo de origem remoto
Restrições e diretrizes
Execute esta tarefa apenas no dispositivo de origem.
Procedimento
- Entre na visualização do sistema.
system-viewmirroring-group group-id remote-sourceConfigurando fontes de espelhamento
Restrições e diretrizes para a configuração de fonte de espelhamento
Execute esta tarefa apenas no dispositivo de origem.
Quando você configura portas de origem para um grupo de origem remoto, siga estas restrições e diretrizes:
- Não atribua uma porta de origem de um grupo de espelhamento à VLAN de sonda remota do grupo de espelhamento.
- Um grupo de espelhamento pode conter várias portas de origem.
- Uma porta pode ser configurada como porta de origem unidirecional para no máximo dois grupos de espelhamento: um para o espelhamento de tráfego de entrada e outro para o espelhamento de tráfego de saída. Como porta de origem bidirecional, uma porta pode ser atribuída a apenas um grupo de espelhamento.
- O dispositivo suporta apenas um grupo de espelhamento para espelhamento de tráfego de saída ou bidirecional.
- Uma porta de origem não pode ser configurada como porta refletora, porta de monitoramento ou porta de saída.
- Uma interface agregada de Camada 2 não pode ser configurada como porta de origem para um grupo de espelhamento.
Configurando portas de origem
Configure portas de origem na visualização do sistema:
- Entre na visualização do sistema.
system-viewmirroring-group group-id mirroring-port interface-list { both | inbound | outbound }Por padrão, nenhuma porta de origem é configurada para um grupo de origem remoto.
Configure portas de origem na visualização da interface:
- Entre na visualização do sistema.
system-viewinterface interface-type interface-numbermirroring-group group-id mirroring-port { both | inbound | outbound }Por padrão, uma porta não atua como porta de origem para nenhum grupo de origem remoto.
Configurando a porta refletora
Restrições e diretrizes para a configuração da porta refletora
Execute esta tarefa apenas no dispositivo de origem.
Um grupo de origem remoto suporta apenas uma porta refletora.
Configurando a porta refletora na visualização do sistema
- Entre na visualização do sistema.
system-viewmirroring-group group-id reflector-port interface-type interface-numberATENÇÃO:
- A porta a ser configurada como porta refletora deve ser uma porta não utilizada. Não conecte um cabo de rede a uma porta refletora.
- Quando uma porta é configurada como porta refletora, as configurações padrão da porta são restauradas automaticamente. Você não pode configurar outros recursos na porta refletora.
- Se uma porta IRF estiver vinculada a apenas uma interface física, não configure a interface física como uma porta refletora. Caso contrário, o IRF pode se dividir.
Por padrão, nenhuma porta refletora é configurada para um grupo de origem remoto.
Configurando a porta refletora na visualização da interface
- Entre na visualização do sistema.
system-viewinterface interface-type interface-numbermirroring-group group-id reflector-portATENÇÃO:
- A porta a ser configurada como porta refletora deve ser uma porta não utilizada. Não conecte um cabo de rede a uma porta refletora.
- Quando uma porta é configurada como porta refletora, as configurações padrão da porta são restauradas automaticamente. Você não pode configurar outros recursos na porta refletora.
- Se uma porta IRF estiver vinculada a apenas uma interface física, não configure a interface física como uma porta refletora. Caso contrário, o IRF pode se dividir.
Por padrão, uma porta não atua como a porta refletora para nenhum grupo de origem remoto.
Configurando a porta de saída
Restrições e diretrizes para a configuração da porta de saída
Execute esta tarefa apenas no dispositivo de origem.
Desabilite os seguintes recursos na porta de saída:
- Spanning tree.
- 802.1X.
- IGMP snooping.
- Static ARP.
- Aprendizado de endereço MAC.
- Uma porta de um grupo de espelhamento existente não pode ser configurada como uma porta de saída.
- Um grupo de espelhamento suporta apenas uma porta de saída.
Configurando a porta de saída na visualização do sistema
- Entre na visualização do sistema.
system-viewmirroring-group group-id monitor-egress interface-type interface-numberPor padrão, nenhuma porta de saída é configurada para um grupo de origem remoto.
interface interface-type interface-number- Atribua uma porta de trunk à VLAN de sonda remota.
port trunk permit vlan vlan-idport hybrid vlan vlan-id { tagged | untagged }Para mais informações sobre os comandos port trunk permit vlan e port hybrid vlan, consulte o Guia de Referência de Comandos de Comutação de LAN de Camada 2.
Configurando a porta de saída na visualização da interface
- Entre na visualização do sistema.
system-viewinterface interface-type interface-numbermirroring-group group-id monitor-egressPor padrão, uma porta não atua como a porta de saída para nenhum grupo de origem remoto.
Comandos de exibição e manutenção para espelhamento de portas
Execute os comandos de exibição em qualquer modo.
| Tarefa | Comando | ||
| Exibir informações do grupo de espelhamento. | |
Exemplos de configuração de espelhamento de porta
Exemplo: Configurando espelhamento de porta local
Configuração da rede:
Como mostrado, configure o espelhamento de porta local no modo de porta de origem para permitir que o servidor monitore o tráfego bidirecional dos dois departamentos.
Procedimento
# Criar o grupo de espelhamento local 1.device> system-view
[device] mirroring-group 1 local# Configurar GigabitEthernet 1/0/1 e GigabitEthernet 1/0/2 como portas de origem para o grupo de espelhamento local 1.
[device] mirroring-group 1 mirroring-port gigabitethernet 1/0/1 gigabitethernet 1/0/2 both# Configurar GigabitEthernet 1/0/3 como a porta de monitoramento para o grupo de espelhamento local 1.
[device] mirroring-group 1 monitor-port gigabitethernet 1/0/3# Desativar o recurso de spanning tree na porta de monitoramento (GigabitEthernet 1/0/3).
[device] interface gigabitethernet 1/0/3
[device-GigabitEthernet1/0/3] undo stp enable
[device-GigabitEthernet1/0/3] quit
Verificando a configuração
# Verificar a configuração do grupo de espelhamento.
[device] display mirroring-group all
Grupo de espelhamento 1:
Tipo: Local
Status: Ativo
Porta de espelhamento:
GigabitEthernet1/0/1 Ambos
GigabitEthernet1/0/2 Ambos
Porta de monitoramento: GigabitEthernet1/0/3
Exemplo: Configurando o espelhamento de porta remota de Camada 2 (com porta de refletor)
Configuração da rede:
Conforme mostrado , configure o espelhamento de porta remota de Camada 2 para permitir que o servidor monitore o tráfego bidirecional do Departamento de Marketing.
Procedimento
-
# Configure a GigabitEthernet 1/0/1 como uma porta trunk e atribua a porta à VLAN 2.
<DeviceC> system-view [DeviceC] interface gigabitethernet 1/0/1 [DeviceC-GigabitEthernet1/0/1] port link-type trunk [DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 2 [DeviceC-GigabitEthernet1/0/1] quit -
Criar a VLAN 2.
<DeviceB> system-view [DeviceB] vlan 2 [DeviceB] undo mac-address mac-learning enable [DeviceB] quit -
Configurar a GigabitEthernet 1/0/1 como uma porta trunk e atribuir a porta à VLAN 2.
[DeviceB] interface gigabitethernet 1/0/1 [DeviceB-GigabitEthernet1/0/1] port link-type trunk [DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 2 [DeviceB-GigabitEthernet1/0/1] quit -
Configurar a GigabitEthernet 1/0/2 como uma porta trunk e atribuir a porta à VLAN 2.
[DeviceB] interface gigabitethernet 1/0/2 [DeviceB-GigabitEthernet1/0/2] port link-type trunk [DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 2 [DeviceB-GigabitEthernet1/0/2] quit
Procedimento para Configuração do Dispositivo A (o dispositivo de origem):
-
Criar um grupo de origem remoto.
<DeviceA> system-view [DeviceA] mirroring-group 1 remote-source -
Criar a VLAN 2.
[DeviceA] vlan 2 [DeviceA-vlan2] undo mac-address mac-learning enable [DeviceA-vlan2] quit -
Configurar a VLAN 2 como a VLAN de sonda remota para o grupo de espelhamento.
[DeviceA] mirroring-group 1 remote-probe vlan 2 -
Configurar a GigabitEthernet 1/0/1 como uma porta de origem para o grupo de espelhamento.
[DeviceA] mirroring-group 1 mirroring-port gigabitethernet 1/0/1 both -
Configurar a GigabitEthernet 1/0/3 como a porta refletora para o grupo de espelhamento.
[DeviceA] mirroring-group 1 reflector-port gigabitethernet 1/0/3 -
Configurar a GigabitEthernet 1/0/2 como uma porta trunk e atribuir a porta à VLAN 2.
[DeviceA] interface gigabitethernet 1/0/2 [DeviceA-GigabitEthernet1/0/2] port link-type trunk [DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 2 [DeviceA-GigabitEthernet1/0/2] quit
Verificando a Configuração dos Grupos de Espelhamento em Device C:
[DeviceC] display mirroring-group all
Mirroring group 2:
Type: Remote destination
Status: Active
Monitor port: GigabitEthernet1/0/2
Remote probe VLAN: 2
Verificando a Configuração dos Grupos de Espelhamento em Device A:
[DeviceA] display mirroring-group all
Mirroring group 1:
Type: Remote source
Status: Active
Mirroring port: GigabitEthernet1/0/1 Both
Reflector port: GigabitEthernet1/0/3
Remote probe VLAN: 2
Exemplo: Configurando o Espelhamento de Porta Remota Layer 2 (com porta de saída)
Configuração da Rede
configure o espelhamento remoto de porta Layer 2 para permitir que o servidor monitore o tráfego bidirecional do Departamento de Marketing.
Configure a GigabitEthernet 1/0/1 como uma porta trunk e atribua a porta à VLAN 2.
Procedimento
- Configurar o Dispositivo C (o dispositivo de destino):
# Configure GigabitEthernet 1/0/1 as a trunk port, and assign the port to VLAN 2.
system-view
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] port link-type trunk
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 2
[DeviceC-GigabitEthernet1/0/1] quit
# Create a remote destination group.
[DeviceC] mirroring-group 2 remote-destination
# Create VLAN 2.
[DeviceC] vlan 2
# Disable MAC address learning for VLAN 2.
[DeviceC-vlan2] undo mac-address mac-learning enable
[DeviceC-vlan2] quit
# Configure VLAN 2 as the remote probe VLAN for the mirroring group.
[DeviceC] mirroring-group 2 remote-probe vlan 2
# Configure GigabitEthernet 1/0/2 as the monitor port for the mirroring group.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] mirroring-group 2 monitor-port
# Disable the spanning tree feature on GigabitEthernet 1/0/2.
[DeviceC-GigabitEthernet1/0/2] undo stp enable
# Assign GigabitEthernet 1/0/2 to VLAN 2 as an access port.
[DeviceC-GigabitEthernet1/0/2] port access vlan 2
[DeviceC-GigabitEthernet1/0/2] quit
- Configurar o Dispositivo B (o dispositivo intermediário):
Dispositivo de origem Dispositivo A GE1/0/1 GE1/0/2 Servidor Departamento de Marketing Dispositivo intermediário Dispositivo B Dispositivo de destino Dispositivo C GE1/0/1 GE1/0/2 GE1/0/1 GE1/0/2 Porta comum Porta de origem Porta de saída Porta de monitoramento VLAN 2 VLAN 2 18
# Criar VLAN 2.
system-view
[DeviceB] vlan 2
# Desabilitar o aprendizado de endereço MAC para a VLAN 2.
[DeviceB-vlan2] undo mac-address mac-learning enable
[DeviceB-vlan2] quit
# Configurar GigabitEthernet 1/0/1 como uma porta trunk e atribuir a porta à VLAN 2.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type trunk
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 2
[DeviceB-GigabitEthernet1/0/1] quit
# Configurar GigabitEthernet 1/0/2 como uma porta trunk e atribuir a porta à VLAN 2.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 2
[DeviceB-GigabitEthernet1/0/2] quit
- Configurar o Dispositivo A (o dispositivo de origem):
# Criar um grupo de origem remota.
system-view
[DeviceA] mirroring-group 1 remote-source # Criar VLAN 2.
[DeviceA] vlan 2# Desabilitar o aprendizado de endereço MAC para a VLAN 2.
[DeviceA-vlan2] undo mac-address mac-learning enable
[DeviceA-vlan2] quit# Configurar VLAN 2 como a VLAN de sonda remota do grupo de espelhamento.
[DeviceA] mirroring-group 1 remote-probe vlan 2# Configurar GigabitEthernet 1/0/1 como uma porta de origem para o grupo de espelhamento.
[DeviceA] mirroring-group 1 mirroring-port gigabitethernet 1/0/1 both# Configurar GigabitEthernet 1/0/2 como a porta de saída para o grupo de espelhamento.
[DeviceA] mirroring-group 1 monitor-egress gigabitethernet 1/0/2# Configurar GigabitEthernet 1/0/2 como uma porta trunk e atribuir a porta à VLAN 2.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 2# Desabilitar o recurso de spanning tree na porta.
[DeviceA-GigabitEthernet1/0/2] undo stp enable
[DeviceA-GigabitEthernet1/0/2] quit
Verificando a configuração
# Verificar a configuração do grupo de espelhamento no Dispositivo C.
[DeviceC] display mirroring-group all
Mirroring group 2:
Type: Remote destination
Status: Active
Monitor port: GigabitEthernet1/0/2
Remote probe VLAN: 2# Verificar a configuração do grupo de espelhamento no Dispositivo A.
[DeviceA] display mirroring-group all
Mirroring group 1:
Type: Remote source
Status: Active
Mirroring port:
GigabitEthernet1/0/1 Both
Monitor egress port: GigabitEthernet1/0/2
Remote probe VLAN: 2
Configurando o espelhamento de fluxo
Sobre o espelhamento de fluxo
O espelhamento de fluxo copia pacotes que correspondem a uma classe para um destino para análise e monitoramento de pacotes. É implementado por meio de QoS. Para implementar o espelhamento de fluxo por meio de QoS, execute as seguintes tarefas:
- Definir classes de tráfego e configurar critérios de correspondência para classificar pacotes a serem espelhados. O espelhamento de fluxo permite classificar pacotes a serem analisados de forma flexível, definindo critérios de correspondência.
- Configurar comportamentos de tráfego para espelhar os pacotes correspondentes para o destino especificado. Você pode configurar uma ação para espelhar os pacotes correspondentes para um dos seguintes destinos:
- Interface - Os pacotes correspondentes são copiados para uma interface e depois encaminhados para um dispositivo de monitoramento de dados para análise.
- CPU - Os pacotes correspondentes são copiados para a CPU de um dispositivo membro do IRF. A CPU analisa os pacotes ou os entrega para camadas superiores.
Restrições e diretrizes: Configuração de espelhamento de fluxo
Para obter informações sobre os comandos de configuração exceto o comando mirror-to, consulte o Guia de Referência de Comandos de ACL e QoS.
Tarefas de espelhamento de fluxo em resumo
Para configurar o espelhamento de fluxo, execute as seguintes tarefas:
- Configurando uma classe de tráfego
- Configurando um comportamento de tráfego
- Configurando uma política de QoS
- Aplicando uma política de QoS
Configurando uma classe de tráfego
system-view
traffic classifier classifier-name [ operator { and | or } ]
if-match match-criteria
display traffic classifier
Configurando um comportamento de tráfego
system-view
traffic behavior behavior-name
mirror-to interface interface-type interface-number
mirror-to cpu
display traffic behavior
Configurando uma política de QoS
system-view
qos policy policy-name
classifier classifier-name behavior behavior-name
display qos policy
Aplicando uma política de QoS
Aplicando uma política de QoS a uma interface
system-view
interface interface-type interface-number
qos apply policy policy-name inbound
display qos policy interface
Aplicando uma política de QoS a VLANs
system-view
qos vlan-policy policy-name vlan vlan-id-list inbound
display qos vlan-policy
Aplicando uma política de QoS globalmente
system-view
qos apply policy policy-name global inbound
display qos policy global
Exemplos de configuração de espelhamento de fluxo
Exemplo: Configurando o espelhamento de fluxo
Configuração da rede
Configure o espelhamento de fluxo para que o servidor possa monitorar o seguinte tráfego:
- Todo o tráfego que o Departamento Técnico envia para acessar a Internet.
- O tráfego IP que o Departamento Técnico envia para o Departamento de Marketing durante o horário de trabalho (8:00 às 18:00) nos dias úteis.
Figura 7 Diagrama de rede
Procedimento
Criar o intervalo de horas de trabalho, "work", em que o horário de trabalho é das 8:00 às 18:00 nos dias úteis.
system-view
[Device] time-range work 8:00 to 18:00 working-day
Criar a ACL IPv4 avançada 3000 para permitir pacotes do Departamento Técnico acessarem a Internet e o Departamento de Marketing durante o horário de trabalho.
[Device] acl advanced 3000
[Device-acl-ipv4-adv-3000] rule permit tcp source 192.168.2.0 0.0.0.255 destination-port eq www
[Device-acl-ipv4-adv-3000] rule permit ip source 192.168.2.0 0.0.0.255 destination 192.168.1.0 0.0.0.255 time-range work
[Device-acl-ipv4-adv-3000] quit
Criar a classe de tráfego "tech_c" e configurar o critério de correspondência como ACL 3000.
[Device] traffic classifier tech_c
[Device-classifier-tech_c] if-match acl 3000
[Device-classifier-tech_c] quit
Criar o comportamento de tráfego "tech_b", configurar a ação de espelhamento do tráfego para GigabitEthernet 1/0/3.
[Device] traffic behavior tech_b
[Device-behavior-tech_b] mirror-to interface gigabitethernet 1/0/3
[Device-behavior-tech_b] quit
Criar a política de QoS "tech_p" e associar a classe de tráfego "tech_c" ao comportamento de tráfego "tech_b" na política de QoS.
[Device] qos policy tech_p
[Device-qospolicy-tech_p] classifier tech_c behavior tech_b
[Device-qospolicy-tech_p] quit
Aplicar a política de QoS "tech_p" aos pacotes de entrada de GigabitEthernet 1/0/4.
[Device] interface gigabitethernet 1/0/4
[Device-GigabitEthernet1/0/4] qos apply policy tech_p inbound
[Device-GigabitEthernet1/0/4] quit
Verificação da configuração
Verificar se o servidor pode monitorar o seguinte tráfego:
- Todo o tráfego enviado pelo Departamento Técnico para acessar a Internet.
- O tráfego IP que o Departamento Técnico envia para o Departamento de Marketing durante o horário de trabalho nos dias úteis.
(Detalhes não mostrados.)
Configurando sFlow
Sobre sFlow
sFlow é uma tecnologia de monitoramento de tráfego.
O sistema sFlow envolve um agente sFlow incorporado em um dispositivo e um coletor sFlow remoto. O agente sFlow coleta informações de contadores de interface e informações de pacotes e encapsula as informações amostradas em pacotes sFlow. Quando o buffer de pacotes sFlow está cheio, ou o temporizador de envelhecimento (fixado em 1 segundo) expira, o agente sFlow realiza as seguintes ações:
- Encapsula os pacotes sFlow nos datagramas UDP.
- Envia os datagramas UDP para o coletor sFlow especificado.
O coletor sFlow analisa as informações e exibe os resultados. Um coletor sFlow pode monitorar vários agentes sFlow.
O sFlow fornece os seguintes mecanismos de amostragem:
- Amostragem de fluxo - Obtém informações de pacotes.
- Amostragem de contador - Obtém informações de contadores de interface.
O sFlow pode usar amostragem de fluxo e amostragem de contador ao mesmo tempo.
Figura 1 - Sistema sFlow
Protocolos e padrões
- RFC 3176, sFlow da InMon Corporation: Um Método para Monitorar o Tráfego em Redes Comutadas e Roteadas
- sFlow.org, sFlow Versão 5
Configurando informações básicas do sFlow
Restrições e diretrizes
Como prática recomendada, configure manualmente um endereço IP para o agente sFlow. O dispositivo verifica periodicamente se o agente sFlow possui um endereço IP. Se o agente sFlow não tiver um endereço IP, o dispositivo seleciona automaticamente um endereço IPv4 para o agente sFlow, mas não salva o endereço IPv4 no arquivo de configuração.
Apenas um endereço IP pode ser configurado para o agente sFlow no dispositivo, e um endereço IP recém-configurado sobrescreve o existente.
Coletor sFlow do dispositivo
Ethernet
header
UDP
header Datagrama sFlow IP
Amostragem de cabeçalho de fluxo
Amostragem de contador
Agente sFlow
Procedimento
- Entre no modo de sistema.
system-view
sflow agent { ip endereço-ipv4 | ipv6 endereço-ipv6 }
Por padrão, nenhum endereço IP é configurado para o agente sFlow.
sflow collector id-coletor { ip endereço-ipv4 | ipv6 endereço-ipv6 }
[ porta número-porta | tamanho-datagrama tamanho | tempo-espera segundos | descrição
string ] *
Por padrão, nenhuma informação do coletor sFlow é configurada.
sflow source { ip endereço-ipv4 | ipv6 endereço-ipv6 } *
Por padrão, o endereço IP de origem é determinado pelo roteamento.
Configurando amostragem de fluxo
Sobre amostragem de fluxo
Execute esta tarefa para configurar a amostragem de fluxo em uma interface Ethernet. O agente sFlow realiza as seguintes tarefas:
- Entre no modo de sistema.
system-view
interface interface-type interface-number
sflow sampling-mode random
Por padrão, a amostragem aleatória é usada.
sflow sampling-rate rate
Por padrão, a amostragem de fluxo está desativada. Como prática recomendada, defina o intervalo de amostragem para 2n, que é maior ou igual a 8192, por exemplo, 32768.
sflow flow max-header length
A configuração padrão é de 128 bytes. Como prática recomendada, use a configuração padrão.
sflow flow [ instância id-instância ] collector id-coletor
Por padrão, nenhuma instância sFlow ou coletor sFlow é especificado para a amostragem de fluxo.
Configurando amostragem de contador
Sobre amostragem de fluxo
Execute esta tarefa para configurar a amostragem de contadores em uma interface Ethernet. O agente sFlow realiza as seguintes tarefas:
- Entre no modo de sistema.
system-view
interface interface-type interface-number
sflow counter interval interval
Por padrão, a amostragem de contadores está desativada.
sflow counter [ instância id-instância ] collector id-coletor
Por padrão, nenhuma instância sFlow ou coletor sFlow é especificado para a amostragem de contadores.
Comandos de exibição e manutenção para sFlow
Execute os comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir configuração do sFlow. | display sflow |
Exemplos de configuração sFlow
Exemplo: Configurando sFlow
Configuração de rede
Execute as seguintes tarefas:
- Configure o sampling de fluxo no modo aleatório e o sampling de contagem no GigabitEthernet 1/0/1 do dispositivo para monitorar o tráfego na porta.
- Configure o dispositivo para enviar informações amostradas em pacotes sFlow através do GigabitEthernet 1/0/3 para o coletor sFlow.

Procedimento
- Configure os endereços IP e máscaras de sub-rede para as interfaces, conforme mostrado (Detalhes não mostrados.)
- Configure o agente sFlow e configure informações sobre o coletor sFlow:
# Configure o endereço IP para o agente sFlow.
<Device> system-view
[Device] sflow agent ip 3.3.3.1# Configure informações sobre o coletor sFlow. Especifique o ID do coletor sFlow como 1, endereço IP como 3.3.3.2, número da porta como 6343 (padrão) e descrição como netserver.
[Device] sflow collector 1 ip 3.3.3.2 description netserver- Configure o sampling de contagem:
# Ative o sampling de contagem e defina o intervalo de amostragem de contagem como 120 segundos no GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] sflow counter interval 120# Especifique o coletor sFlow 1 para o sampling de contagem.
[Device-GigabitEthernet1/0/1] sflow counter collector 1- Configure o sampling de fluxo:
# Ative o sampling de fluxo e defina o modo de sampling de fluxo como aleatório e o intervalo de amostragem como 32768.
[Device-GigabitEthernet1/0/1] sflow sampling-mode random
[Device-GigabitEthernet1/0/1] sflow sampling-rate 32768# Especifique o coletor sFlow 1 para o sampling de fluxo.
[Device-GigabitEthernet1/0/1] sflow flow collector 1Verificação da configuração
# Verifique os seguintes itens: • GigabitEthernet 1/0/1 habilitado com sFlow está ativo. • O intervalo de amostragem de contagem é de 120 segundos. • O intervalo de amostragem de fluxo é de 4000 (um pacote é amostrado a cada 4000 pacotes).
[Device-GigabitEthernet1/0/1] display sflow
Informações de solução de problemas sFlow
O coletor sFlow remoto não consegue receber pacotes sFlow
Sintoma
O coletor sFlow remoto não consegue receber pacotes sFlow.
Análise
As possíveis razões incluem:
- O coletor sFlow não está especificado.
- O sFlow não está configurado na interface.
- O endereço IP do coletor sFlow especificado no agente sFlow é diferente do do coletor sFlow remoto.
- O link físico entre o dispositivo e o coletor sFlow falha.
- O comprimento de um pacote sFlow é inferior à soma dos dois seguintes valores:
- O comprimento do cabeçalho do pacote sFlow.
- O número de bytes que o sampling de fluxo pode copiar por pacote.
Solução
Para resolver o problema:
- Use o comando display sflow para verificar se o sFlow está configurado corretamente.
- Verifique se um endereço IP correto está configurado para o dispositivo se comunicar com o coletor sFlow.
- Verifique se o link físico entre o dispositivo e o coletor sFlow está ativo.
- Verifique se o comprimento de um pacote sFlow é maior que a soma dos dois seguintes valores:
- O comprimento do cabeçalho do pacote sFlow.
- O número de bytes (como prática recomendada, use a configuração padrão) que o sampling de fluxo pode copiar por pacote.
Configurando o centro de informações
Sobre o centro de informações
O centro de informações no dispositivo recebe logs gerados por módulos de origem e os envia para destinos diferentes de acordo com as regras de saída de logs. Com base nos logs, você pode monitorar o desempenho do dispositivo e solucionar problemas de rede.
Figura 1 Diagrama do centro de informações
Tipos de logs
Os logs são classificados nos seguintes tipos:
- Logs padrão do sistema - Registram informações comuns do sistema. A menos que especificado de outra forma, o termo "logs" neste documento refere-se aos logs padrão do sistema.
- Logs de diagnóstico - Registram mensagens de depuração.
- Logs de segurança - Registram informações de segurança, como informações de autenticação e autorização.
- Logs ocultos - Registram informações de log que não são exibidas no terminal, como comandos de entrada.
- Logs de rastreamento - Registram rastreamento do sistema e mensagens de depuração, que só podem ser visualizados após a instalação do pacote devkit.
Níveis de log
Os logs são classificados em oito níveis de gravidade de 0 a 7 em ordem decrescente. O centro de informações emite logs com um nível de gravidade que é maior ou igual ao nível especificado. Por exemplo, se você especificar um nível de gravidade de 6 (informativo), os logs que têm um nível de gravidade de 0 a 6 são emitidos.
| Valor de gravidade | Nível | Descrição | |||
| 0 | Emergência | O sistema está inutilizável. Por exemplo, a autorização do sistema expirou. | |||
| 1 | Alerta | Ação deve ser tomada imediatamente. Por exemplo, o tráfego em uma interface excede o limite superior. | |||
| 2 | Crítico | Condição crítica. Por exemplo, a temperatura do dispositivo excede o limite superior, o módulo de energia falha ou a bandeja do ventilador falha. | |||
| 3 | Erro | Condição de erro. Por exemplo, o estado do link muda. | |||
| 4 | Aviso | Condição de aviso. Por exemplo, uma interface está desconectada ou os recursos de memória são esgotados. | |||
| 5 | Notificação | Condição normal, mas significativa. Por exemplo, um terminal faz login no dispositivo ou o dispositivo reinicia. | |||
| 6 | Informativo | Mensagem informativa. Por exemplo, um comando ou uma operação de ping é executado. | |||
| 7 | Depuração | Mensagem de depuração. |
Destinos de logs
O sistema envia logs para os seguintes destinos: console, terminal de monitoramento, buffer de log, host de log e arquivo de log. Os destinos de saída de log são independentes e podem ser configurados após a ativação do centro de informações. Um log pode ser enviado para vários destinos.
Regras de saída de logs padrão
Uma regra de saída de log especifica os módulos de origem e o nível de gravidade dos logs que podem ser enviados para um destino. Os logs que correspondem à regra de saída são enviados para o destino. A Tabela 2 mostra as regras de saída de log padrão.
| Destino | Módulos de origem de log | Interruptor de saída | Gravidade | ||||
| Console | Todos os módulos suportados | Ativado | Depuração | ||||
| Terminal de monitoramento | Todos os módulos suportados | Desativado | Depuração | ||||
| Host de log | Todos os módulos suportados | Ativado | Informativo | ||||
| Buffer de log | Todos os módulos suportados | Ativado | Informativo | ||||
| Arquivo de log | Todos os módulos suportados | Ativado | Informativo |
Regras de saída de logs padrão para logs de diagnóstico
Logs de diagnóstico só podem ser enviados para o arquivo de log de diagnóstico e não podem ser filtrados por módulos de origem e níveis de gravidade. A Tabela 3 mostra a regra de saída padrão para logs de diagnóstico.
| Destino | Módulos de origem de log | Interruptor de saída | Gravidade | ||||
| Arquivo de log de diagnóstico | Todos os módulos suportados | Ativado | Depuração |
Regras de saída de logs padrão para logs de segurança
Logs de segurança só podem ser enviados para o arquivo de log de segurança e não podem ser filtrados por módulos de origem e níveis de gravidade. A Tabela 4 mostra a regra de saída padrão para logs de segurança.
| Destino | Módulos de origem de log | Interruptor de saída | Gravidade | ||||
| Arquivo de log de segurança | Todos os módulos suportados | Desativado | Depuração |
Regras de saída de logs padrão para logs ocultos
Logs ocultos podem ser enviados para o host de log, o buffer de log e o arquivo de log. A Tabela 5 mostra as regras de saída padrão para logs ocultos.
| Destino | Módulos de origem de log | Interruptor de saída | Gravidade | ||||
| Host de log | Todos os módulos suportados | Ativado | Informativo | ||||
| Buffer de log | Todos os módulos suportados | Ativado | Informativo | ||||
| Arquivo de log | Todos os módulos suportados | Ativado | Informativo |
Regras de saída de logs padrão para logs de rastreamento
Logs de rastreamento só podem ser enviados para o arquivo de log de rastreamento e não podem ser filtrados por módulos de origem e níveis de gravidade. A Tabela 6 mostra as regras de saída padrão para logs de rastreamento.
| Destino | Módulos de origem de log | Interruptor de saída | Gravidade | ||||
| Arquivo de log de rastreamento | Todos os módulos suportados | Ativado | Depuração |
Formatos de log e descrições de campos
Formatos de log
O formato dos logs varia de acordo com os destinos de saída. A Tabela 7 mostra o formato original das informações de log, que pode ser diferente do que você vê. O formato real varia de acordo com a ferramenta de resolução de log usada.
| Destino de saída | Formato | ||
| Console, terminal de monitoramento, buffer de log ou arquivo de log | Prefixo Timestamp Sysname Módulo/Nível/Mnemônico: Conteúdo | ||
| Host de log | • Formato padrão: |
| |
Exemplo:
%Nov 24 14:21:43:502 2016 Sysname SHELL/5/SHELL_LOGIN: VTY logged in from 192.168.1.26
• Host de log
• Formato padrão: <PRI>Timestamp Sysname %%vvMódulo/Nível/Mnemônico: Fonte; Conteúdo
Exemplo:
<190>Nov 24 16:22:21 2016 Sysname %%10 SHELL/5/SHELL_LOGIN: -DevIP=1.1.1.1; VTY logged in from 192.168.1.26
<190>Nov 24 16:22:21 2016 Sysname %%10SHELL/5/SHELL_LOGIN: -DevIP=1.1.1.1; VTY logged in from 192.168.1.26
• Formato Unicom: <PRI>Timestamp Hostip vvMódulo/Nível/Serial_number: Conteúdo
Exemplo:
<189>Oct 13 16:48:08 2016 10.1.1.1 10SHELL/5/210231a64jx073000020: VTY logged in from 192.168.1.21
• Formato CMCC: <PRI>Timestamp Sysname %vvMódulo/Nível/Mnemônico: Fonte; Conteúdo
Exemplo:
<189>Oct 9 14:59:04 2016 Sysname %10SHELL/5/SHELL_LOGIN: -DevIP=1.1.1.1; VTY logged in from 192.168.1.21
| Campo | Descrição | ||
| Prefixo (tipo de informação) | Um log enviado para um destino que não seja o host de log tem um identificador na frente do carimbo de data e hora:
| ||
| PRI (prioridade) | Um log destinado ao host de log possui um identificador de prioridade na frente do carimbo de data e hora. A prioridade é calculada usando a seguinte fórmula: facility*8+level, onde:
| ||
| Timestamp | Registra a hora em que o log foi gerado. Logs enviados para o host de log e aqueles enviados para outros destinos têm precisões de timestamp diferentes, e seus formatos de timestamp são configurados com comandos diferentes. Para obter mais informações, consulte a Tabela 9 e a Tabela 10. | ||
| Hostip | Endereço IP de origem do log. Se o comando info-center loghost source estiver configurado, este campo exibe o endereço IP da interface de origem especificada. Caso contrário, este campo exibe o sysname. Este campo existe apenas em logs enviados para o host de log no formato unicom. | ||
| Número de série | Número de série do dispositivo que gerou o log. Este campo existe apenas em logs enviados para o host de log no formato unicom. | ||
| Sysname (nome do host ou endereço IP do host) | O sysname é o nome do host ou endereço IP do dispositivo que gerou o log. Você pode usar o comando sysname para modificar o nome do dispositivo. | ||
| %% (ID do fornecedor) | Indica que a informação foi gerada por um dispositivo Intelbras. Este campo existe apenas em logs enviados para o host de log. | ||
| vv (informações da versão) | Identifica a versão do log e tem um valor de 10. Este campo existe apenas em logs enviados para o host de log. | ||
| Módulo | Especifica o nome do módulo que gerou o log. Você pode inserir o comando info-center source ? no modo de sistema para visualizar a lista de módulos. | ||
| Nível | Identifica o nível do log. Consulte a Tabela 1 para obter mais informações sobre os níveis de gravidade. | ||
| Mnemônico | Descreve o conteúdo do log. Ele contém uma sequência de até 32 caracteres. | ||
| Origem | Campo opcional que identifica o remetente do log. Este campo existe apenas em logs enviados para o host de log no formato unicom ou padrão. | ||
| Conteúdo | Fornece o conteúdo do log. |
| Parâmetro de Timestamp | Descrição | ||
| boot | Tempo decorrido desde a inicialização do sistema, no formato de xxx.yyy. xxx representa os 32 bits superiores e yyy representa os 32 bits inferiores dos milissegundos decorridos. Logs que são enviados para todos os destinos, exceto um host de log, suportam este parâmetro. | ||
| date | Data e hora atuais. Para logs enviados para um host de log, o timestamp pode estar no formato de MMM DD hh:mm:ss YYYY (preciso até segundos) ou MMM DD hh:mm:ss.ms YYYY (preciso até milissegundos). Para logs enviados para outros destinos, o timestamp está no formato de MMM DD hh:mm:ss:ms YYYY. | ||
| iso | Formato de timestamp estipulado na norma ISO 8601, preciso até segundos (padrão) ou milissegundos. Somente logs que são enviados para um host de log suportam este parâmetro. | ||
| none | Nenhum timestamp é incluído. Todos os logs suportam este parâmetro. | ||
| no-year-date | Data e hora atuais sem ano ou informações de milissegundos, no formato de MMM DD hh:mm:ss. Somente logs que são enviados para um host de log suportam este parâmetro. |
Conformidade com FIPS
O dispositivo suporta o modo FIPS que está em conformidade com os requisitos do NIST FIPS 140-2. O suporte para recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não-FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de Configuração de Segurança.
Tarefas do Centro de Informações em Resumo
Gerenciando Logs do Sistema Padrão
- Habilitando o centro de informações
- Enviando logs para vários destinos
- Escolha as seguintes tarefas conforme necessário:
- Enviando logs para o console
- Enviando logs para o terminal de monitoramento
- Enviando logs para hosts de log
- Enviando logs para o buffer de log
- Salvando logs no arquivo de log
- (Opcional.) Definindo o período mínimo de armazenamento para logs
- (Opcional.) Habilitando saída de informações síncrona
- (Opcional.) Configurando supressão de logs
- Habilitando supressão de logs duplicados
- Configurando supressão de logs para um módulo
- Desabilitando uma interface para gerar logs de link up ou link down
- (Opcional.) Habilitando notificações SNMP para logs do sistema
Gerenciando Logs Ocultos
- Habilitando o centro de informações
- Enviando logs para vários destinos
- Escolha as seguintes tarefas conforme necessário:
- Enviando logs para hosts de log
- Enviando logs para o buffer de log
- Salvando logs no arquivo de log
- (Opcional.) Definindo o período mínimo de armazenamento para logs
- (Opcional.) Configurando supressão de logs
- Habilitando supressão de logs duplicados
- Configurando supressão de logs para um módulo
Gerenciando Logs de Segurança
- Habilitando o centro de informações
- (Opcional.) Configurando supressão de logs
- Habilitando supressão de logs duplicados
- Configurando supressão de logs para um módulo
- Gerenciando logs de segurança
- Salvando logs de segurança no arquivo de log de segurança
- Gerenciando o arquivo de log de segurança
Gerenciando Logs de Diagnóstico
- Habilitando o centro de informações
- (Opcional.) Configurando supressão de logs
- Habilitando supressão de logs duplicados
- Configurando supressão de logs para um módulo
- Salvando logs de diagnóstico no arquivo de log de diagnóstico
Gerenciando Logs de Rastreamento
- Habilitando o centro de informações
- (Opcional.) Configurando supressão de logs
- Habilitando supressão de logs duplicados
- Configurando supressão de logs para um módulo
- Definindo o tamanho máximo do arquivo de log de rastreamento
Habilitando o Centro de Informações
Sobre habilitar o centro de informações
O centro de informações só pode enviar logs depois de ser habilitado.
Procedimento
- Acesse a visualização do sistema.
system-viewinfo-center enableEnviando logs para vários destinos
Enviando logs para o console
Restrições e diretrizes
Os comandos terminal monitor, terminal debugging e terminal logging só têm efeito para a conexão atual entre o terminal e o dispositivo. Se uma nova conexão for estabelecida, o padrão será restaurado.
Procedimento
- Acesse a visualização do sistema.
system-viewinfo-center source { module-name | default } console { deny | level severity }Para obter informações sobre as regras de saída padrão, consulte "Regras de saída padrão para logs".
info-center timestamp { boot | date | none }O formato padrão do carimbo de data e hora é data.
quitterminal monitorPor padrão, a saída de log para o console está habilitada.
terminal debuggingPor padrão, a exibição de informações de depuração no terminal atual está desabilitada.
terminal logging level severityA configuração padrão é 6 (informativa).
Enviando logs para o terminal de monitoramento
Sobre terminais de monitoramento
Os terminais de monitoramento se referem aos terminais que acessam o dispositivo através da linha AUX, VTY ou TTY.
Restrições e diretrizes
Os comandos terminal monitor, terminal debugging e terminal logging só têm efeito para a conexão atual entre o terminal e o dispositivo. Se uma nova conexão for estabelecida, o padrão será restaurado.
Procedimento
- Acesse a visualização do sistema.
system-viewinfo-center source { module-name | default } monitor { deny | level severity }Para obter informações sobre as regras de saída padrão, consulte "Regras de saída padrão para logs".
info-center timestamp { boot | date | none }O formato padrão do carimbo de data e hora é data.
quitterminal monitorPor padrão, a saída de log para o terminal de monitoramento está desabilitada.
terminal debuggingPor padrão, a exibição de informações de depuração no terminal atual está desabilitada.
terminal logging level severityA configuração padrão é 6 (informativa).
Enviando logs para hosts de log
Restrições e diretrizes
O dispositivo suporta os seguintes métodos (em ordem decrescente de prioridade) para enviar logs de um módulo para hosts de log designados:
- Saída de log rápida. Para informações sobre os módulos que suportam a saída rápida de log e como configurá-la, consulte "Configurando saída rápida de log".
- Log de fluxo. Para informações sobre os módulos que suportam a saída de log de fluxo e como configurá-la, consulte "Configurando log de fluxo".
- Centro de informações. Se você configurar vários métodos de saída de log para um módulo, apenas o método com a prioridade mais alta será eficaz.
Procedimento
- Acesse a visualização do sistema.
system-view- Configure um filtro de saída de log.
info-center filter filter-name { module-name | default } { deny | level severity }Você pode criar vários filtros de saída de log. Ao especificar um host de log, você pode aplicar um filtro de saída de log ao host de log para controlar a saída de log.
info-center source { module-name | default } loghost { deny | level severity }Para obter informações sobre as regras de saída de log padrão para o destino de saída do host de log, consulte "Regras de saída padrão para logs".
info-center loghost source interface-type interface-numberPor padrão, o endereço IP de origem dos logs enviados para hosts de log é o endereço IP primário de suas interfaces de saída.
info-center format { unicom | cmcc }Por padrão, os logs são enviados para hosts de log no formato padrão.
info-center timestamp loghost { date [ with-milliseconds ] | iso [ with-milliseconds | with-timezone ] * | no-year-date | none }O formato padrão do carimbo de data e hora é data.
info-center loghost { hostname | ipv4-address | ipv6 ipv6-address } [ port port-number ] [ dscp dscp-value ] [ facility local-number ] [ filter filter-name ]Por padrão, nenhum host de log ou parâmetros relacionados são especificados.
Enviando logs para hospedeiros de log
Restrições e diretrizes
O dispositivo suporta os seguintes métodos (em ordem decrescente de prioridade) para a saída de logs de um módulo para hospedeiros de log designados:
- Output de log rápido. Para obter informações sobre os módulos que suportam output de log rápido e como configurar o output de log rápido, consulte "Configurando output de log rápido".
- Log de fluxo. Para obter informações sobre os módulos que suportam output de log de fluxo e como configurar o output de log de fluxo, consulte "Configurando log de fluxo".
- Centro de informações. Se você configurar vários métodos de output de log para um módulo, apenas o método com a prioridade mais alta terá efeito.
Procedimento
- Acesse a visualização do sistema.
system-view- Configure um filtro de saída de log.
info-center filter filter-name { module-name | default } { deny | level severity }Você pode criar vários filtros de saída de log. Ao especificar um hospedeiro de log, você pode aplicar um filtro de saída de log ao hospedeiro de log para controlar a saída de log.
info-center source { module-name | default } loghost { deny | level severity }Para obter informações sobre as regras de saída de log padrão para o destino de saída do hospedeiro de log, consulte "Regras de saída padrão para logs".
info-center loghost source interface-type interface-numberPor padrão, o endereço IP de origem dos logs enviados para hospedeiros de log é o endereço IP primário de suas interfaces de saída.
info-center format { unicom | cmcc }Por padrão, os logs são enviados para hospedeiros de log no formato padrão.
info-center timestamp loghost { date [ with-milliseconds ] | iso [ with-milliseconds | with-timezone ] * | no-year-date | none }O formato padrão do carimbo de data e hora é data.
info-center loghost { hostname | ipv4-address | ipv6 ipv6-address } [ port port-number ] [ dscp dscp-value ] [ facility local-number ] [ filter filter-name ]Por padrão, nenhum hospedeiro de log ou parâmetro relacionado é especificado.
Configurado a supressão de logs
Habilitando a supressão de logs duplicados
Sobre a supressão de logs duplicados
O centro de informações no dispositivo emite logs gerados por módulos de serviço. O dispositivo identifica logs que possuem o mesmo nome de módulo, nível, mnemônico, localização e texto como logs duplicados.
Em alguns cenários, por exemplo, ataque ARP ou falha de link, os módulos de serviço gerarão uma grande quantidade de logs duplicados durante um curto período de tempo. A gravação e a saída de logs duplicados consecutivos desperdiçam recursos do sistema e da rede. Para resolver esse problema, você pode habilitar a supressão de logs duplicados.
Com essa função habilitada, quando um módulo de serviço gera um log, o centro de informações emite o log e inicia o temporizador de supressão de logs duplicados. O período de supressão do temporizador de supressão de logs duplicados é incremental em fases. Os períodos de supressão na fase 1, 2 e em fases posteriores são 30 segundos, 2 minutos e 10 minutos, respectivamente.
Após habilitar a supressão de logs duplicados, o sistema inicia a supressão ao emitir um log:
- Se apenas logs duplicados do log forem recebidos durante o período de supressão de uma fase, o centro de informações não emite os logs duplicados. Quando o período de supressão da fase expira, o centro de informações emite o log suprimido e o número de vezes que o log é suprimido e inicia a próxima fase de supressão.
- Se um log diferente for recebido durante o período de supressão de uma fase, o centro de informações realiza as seguintes operações:
- Interrompe a supressão no log e emite o log suprimido e o número de vezes que o log é suprimido.
- Emite o log diferente e inicia a supressão da fase 1 para esse log.
- Se nenhum log for recebido durante o período de supressão de qualquer fase, o centro de informações interrompe a supressão no log e não emite nenhum log.
Procedimento
- Acesse a visualização do sistema.
system-viewinfo-center logging suppress duplicatesPor padrão, a supressão de logs duplicados está desativada.
Exemplo
O seguinte exemplo utiliza logs SHELL_CMD para verificar a funcionalidade de supressão de logs duplicados. Após o usuário executar um comando no dispositivo, o centro de informações recebe um log SHELL_CMD gerado pelo módulo shell, encapsula o log e então o envia para o buffer de logs.
- Verifique o efeito de supressão nas fases 1, 2, 3 e 4 de um log (com período de supressão de 30 segundos, 2 minutos, 10 minutos e 10 minutos):
- Em um ambiente de laboratório, execute continuamente o comando
display logbufferpor 25 minutos. - Visualize os logs de saída no buffer de logs.
Sysname> display logbuffer Log buffer: Enabled Max buffer size: 1024 Actual buffer size: 512 Dropped messages: 0 Overwritten messages: 0 Current messages: 5 %Jul 20 13:01:20:615 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer %Jul 20 13:01:50:718 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 2 times in last 30 seconds. %Jul 20 13:03:50:732 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 5 times in last 2 minutes. %Jul 20 13:13:50:830 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 10 times in last 10 minutes. %Jul 20 13:23:50:211 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 6 times in last 10 minutes. - Em um ambiente de laboratório, execute continuamente o comando
Exemplo
O seguinte exemplo continua a verificar como a supressão de logs duplicados funciona quando um log diferente é recebido durante o período de supressão de um log:
- Continue verificando como a supressão de logs duplicados funciona quando um log diferente é recebido durante o período de supressão de um log:
- Execute o comando
display logbuffertrês vezes e, em seguida, execute o comandodisplay interface brief. - Visualize os logs de saída no buffer de logs.
Sysname> display logbuffer Log buffer: Enabled Max buffer size: 1024 Actual buffer size: 512 Dropped messages: 0 Overwritten messages: 0 Current messages: 5 %Jul 20 13:01:20:615 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer %Jul 20 13:01:50:718 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 2 times in last 30 seconds. %Jul 20 13:03:50:732 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 5 times in last 2 minutes. %Jul 20 13:13:50:830 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 10 times in last 10 minutes. %Jul 20 13:23:50:211 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 6 times in last 10 minutes. %Jul 20 13:24:56:205 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 3 times in last 1 minute 6 seconds. %Jul 20 13:25:41:205 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display interface brief.A saída mostra as seguintes informações:
- O centro de informações interrompeu a supressão para o log SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer.
- O centro de informações enviou o log SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display interface brief e iniciou a supressão para ele.
- Execute o comando
Configurando a supressão de logs para um módulo
Sobre a Supressão de Logs para um Módulo
Essa funcionalidade suprime a saída de logs de módulos específicos ou com valores de mnemônicos específicos. Isso permite filtrar os logs com os quais você não está preocupado.
Realize a seguinte tarefa para configurar uma regra de supressão de logs:
Procedimento
- Entre no modo de visualização do sistema.
system-viewinfo-center logging suppress module nome-do-módulo mnemônico { todos | valor-mnemônico }Por padrão, o dispositivo não suprime a saída de nenhum log de nenhum módulo.
Desativando uma Interface de Gerar Logs de Link Up ou Link Down
Sobre a Desativação de uma Interface de Gerar Logs de Link Up ou Link Down
Essa funcionalidade permite desativar determinadas interfaces de gerar informações de log de link up ou link down.
Procedimento
- Entre no modo de visualização do sistema.
system-viewinterface tipo-de-interface número-da-interfaceundo enable log updownPor padrão, uma interface gera logs de link up e link down quando o estado da interface muda.
Habilitando Notificações SNMP para Logs do Sistema
Sobre a Habilitação de Notificações SNMP para Logs do Sistema
Essa funcionalidade permite que o dispositivo envie notificações SNMP para cada mensagem de log que ele produz.
Procedimento
- Entre no modo de visualização do sistema.
system-viewsnmp-agent trap enable syslogPor padrão, o dispositivo não envia notificações SNMP para logs do sistema.
info-center syslog trap buffersize buffersizePor padrão, o buffer de armadilhas de log pode armazenar no máximo 1024 armadilhas.
Gerenciamento de Logs de Segurança
Salvando Logs de Segurança no Arquivo de Log de Segurança
Sobre o Gerenciamento de Logs de Segurança:
Os logs de segurança são cruciais para identificar e solucionar problemas de rede. No entanto, podem ser desafiadores de distinguir entre outros logs. Para resolver esse problema, você pode salvar os logs de segurança em um arquivo de log de segurança dedicado.
Depois de habilitado, o sistema trata os logs de segurança da seguinte forma:
- Envia logs de segurança para o buffer do arquivo de log de segurança.
- Salva logs do buffer para o arquivo de log de segurança em intervalos especificados.
- Limpa o buffer após salvar os logs no arquivo.
Procedimento
- Entre no modo de visualização do sistema.
system-viewinfo-center security-logfile enablePor padrão, esse recurso está desativado.
info-center security-logfile frequency freq-secO intervalo padrão é de 86400 segundos.
info-center security-logfile size-quota sizeO tamanho máximo padrão é de 10 MB.
info-center security-logfile alarm-threshold usagePor padrão, o limite é definido como 80%.
Gerenciando o Arquivo de Log de Segurança
Procedimento
- Entre no modo de visualização do sistema.
system-viewinfo-center security-logfile directory dir-namePor padrão, ele é salvo no diretório seclog na raiz do dispositivo de armazenamento.
security-logfile saveEste comando está disponível em qualquer visualização.
display security-logfile summaryEste comando está disponível em qualquer visualização.
Salvando logs de diagnóstico no arquivo de log de diagnóstico
Sobre a salvamento de logs de diagnóstico
Por padrão, o recurso de arquivo de log de diagnóstico salva logs de diagnóstico do buffer de arquivo de log de diagnóstico para o arquivo de log de diagnóstico no intervalo de salvamento especificado. Você também pode acionar manualmente um salvamento imediato de logs de diagnóstico para o arquivo de log de diagnóstico. Após salvar os logs de diagnóstico no arquivo de log de diagnóstico, o sistema limpa o buffer de arquivo de log de diagnóstico.
O dispositivo suporta apenas um arquivo de log de diagnóstico. O arquivo de log de diagnóstico tem uma capacidade máxima. Quando a capacidade é atingida, o sistema substitui os logs de diagnóstico mais antigos por novos logs.
Procedimento
- Entre na visão do sistema.
system-viewinfo-center diagnostic-logfile enablePor padrão, o recurso de arquivo de log de diagnóstico está ativado.
info-center diagnostic-logfile quota sizePor padrão, o tamanho máximo do arquivo de log de diagnóstico é 10 MB.
info-center diagnostic-logfile directory dir-nameO diretório padrão do arquivo de log de diagnóstico é flash:/diagfile. Este comando não sobrevive a um reboot IRF ou a uma troca de mestre/subordinado.
- Configure o intervalo de salvamento automático do arquivo de log de diagnóstico.
info-center diagnostic-logfile frequency freq-secO intervalo de salvamento padrão é 86400 segundos.
diagnostic-logfile saveEste comando está disponível em qualquer visão.
Definindo o tamanho máximo do arquivo de log de rastreamento
Sobre a definição do tamanho máximo do arquivo de log de rastreamento
O dispositivo possui apenas um arquivo de log de rastreamento. Quando o arquivo de log de rastreamento está cheio, o dispositivo sobrescreve os logs de rastreamento mais antigos com novos.
Procedimento
- Entre na visão do sistema.
system-viewinfo-center trace-logfile quota sizeComandos de exibição e manutenção para o centro de informações
Execute comandos de exibição em qualquer visão e comandos de reset na visão do usuário.
| Tarefa | Comando | ||
| Exibir a configuração do arquivo de log de diagnóstico. | | ||
| Exibir a configuração do centro de informações. | | ||
| Exibir informações sobre filtros de saída de log. | | ||
| Exibir informações do buffer de log e logs bufferizados. | | ||
| Exibir o resumo do buffer de log. | | ||
| Exibir o conteúdo do buffer do arquivo de log. | | ||
| Exibir a configuração do arquivo de log. | | ||
| Exibir o conteúdo do buffer do arquivo de log de segurança. (Para executar este comando, você deve ter a função de usuário de auditoria de segurança.) | | ||
| Exibir informações resumidas do arquivo de log de segurança. (Para executar este comando, você deve ter a função de usuário de auditoria de segurança.) | | ||
| Limpar o buffer de log. | |
Exemplos de configuração do centro de informações
Exemplo: Emitindo logs para o console
Configuração de rede
Configure o dispositivo para emitir no console os logs FTP que têm um nível de severidade mínimo de aviso.
Procedimento
- Ative o centro de informações.
<Device> system-view
[Device] info-center enable[Device] info-center source default console denyPara evitar a saída de informações desnecessárias, desative todos os módulos de emitir informações de log para o destino especificado (console neste exemplo) antes de configurar a regra de saída.
[Device] info-center source ftp console level warning
[Device] quit<Device> terminal logging level 6
<Device> terminal monitorO terminal atual está habilitado para exibir logs.
Agora, se o módulo FTP gerar logs, o centro de informações automaticamente envia os logs para o console, e o console exibe os logs.
Exemplo: Emitindo logs para um host de log UNIX
Configuração de rede
Configure o dispositivo para emitir para o host de log UNIX os logs FTP que têm um nível de severidade mínimo de informativo.
Procedimento
- Certifique-se de que o dispositivo e o host de log possam se comunicar. (Detalhes não mostrados.)
- Configure o dispositivo:
- Ative o centro de informações.
<Device> system-view [Device] info-center enable - Especifique o host de log 1.2.0.1/16 com local4 como a instalação de logging.
[Device] info-center loghost 1.2.0.1 facility local4[Device] info-center source default loghost denyPara evitar a saída de informações desnecessárias, desative todos os módulos de emitir logs para o destino especificado (loghost neste exemplo) antes de configurar uma regra de saída.
[Device] info-center source ftp loghost level informational- Faça login no host de log como usuário root.
- Crie um subdiretório chamado Device no diretório /var/log/, e então crie o arquivo info.log no diretório Device para salvar os logs do dispositivo.
# mkdir /var/log/Device
# touch /var/log/Device/info.log# Mensagens de configuração do dispositivo
local4.info /var/log/Device/info.logNesta configuração, local4 é o nome da instalação de logging que o host de log usa para receber logs. O valor info indica o nível de severidade informativo. O sistema UNIX registra as informações de log que têm um nível de severidade mínimo de informativo no arquivo /var/log/Device/info.log.
# ps -ae | grep syslogd
# kill -HUP 147
# syslogd -r &Agora, o dispositivo pode emitir logs FTP para o host de log, que armazena os logs no arquivo especificado.
Exemplo: Emitindo logs para um host de log Linux
Configuração de rede
Configure o dispositivo para emitir para o host de log Linux 1.2.0.1/16 os logs FTP que têm um nível de severidade mínimo de informativo.
Procedimento
- Garanta que o dispositivo e o host de log possam se comunicar. (Detalhes não mostrados.)
- Configure o dispositivo:
- Ative o centro de informações.
<Device> system-view [Device] info-center enable - Especifique o host de log 1.2.0.1/16 com local5 como a facilidade de log.
[Device] info-center loghost 1.2.0.1 facility local5[Device] info-center source default loghost denyPara evitar a emissão de informações desnecessárias, desabilite todos os módulos de envio de informação de log para o destino especificado (host de log neste exemplo) antes de configurar uma regra de saída.
[Device] info-center source ftp loghost level informationalO procedimento de configuração do host de log varia de acordo com o fornecedor do sistema operacional Linux. O exemplo a seguir mostra uma configuração:
- Faça login no host de log como usuário root.
- Crie um subdiretório chamado Device no diretório /var/log/ e, em seguida, crie o arquivo info.log no diretório Device para salvar os logs do dispositivo.
# mkdir /var/log/Device
# touch /var/log/Device/info.log# Mensagens de configuração do dispositivo
local5.info /var/log/Device/info.logNesta configuração, local5 é o nome da unidade de log que o host de log usa para receber os logs. O valor info indica o nível de gravidade informacional. O sistema Linux armazenará as informações de log com um nível de gravidade igual ou superior a informacional no arquivo /var/log/Device/info.log.
# ps -ae | grep syslogd
# kill -9 147
# syslogd -r &Agora, o dispositivo pode emitir logs de FTP para o host de log, que armazena os logs no arquivo especificado.
Configurando VCF fabric (faltando)
Faltando esse cap
Configuração de Ligações à Nuvem
Sobre as Ligações à Nuvem
Uma ligação à nuvem é um túnel de gestão estabelecido entre um dispositivo local e o servidor de nuvem Intelbras. Permite-lhe gerir o dispositivo local a partir do servidor em nuvem sem aceder à rede onde o dispositivo reside.
Subconexões Múltiplas
Depois que um dispositivo local estabelece uma conexão com o servidor em nuvem, os módulos de serviço no dispositivo local podem estabelecer várias subconexões com os microsserviços no servidor em nuvem. Essas subconexões são independentes umas das outras e fornecem canais de comunicação separados para serviços diferentes. Este mecanismo evita a interferência entre diferentes serviços.
Estabelecimento de Ligação à Nuvem
- O dispositivo envia um pedido de autenticação para o servidor em nuvem.
- O servidor de nuvem envia um pacote de sucesso de autenticação para o dispositivo. O dispositivo só passa na autenticação se o número de série do dispositivo tiver sido adicionado ao servidor de nuvem. Se a autenticação falhar, o servidor de nuvem envia um pacote de falha de autenticação para o dispositivo.
- O dispositivo envia um pedido de registo para o servidor de nuvem.
- O servidor de nuvem envia uma resposta de registo ao dispositivo. A resposta de registo contém o localizador uniforme de recursos (URL) utilizado para estabelecer uma ligação à nuvem.
- O dispositivo utiliza o URL para enviar um pedido de aperto de mão (alterando o protocolo de HTTP para WebSocket) para o servidor de nuvem.
- O servidor de nuvem envia uma resposta de aperto de mão ao dispositivo para concluir o estabelecimento da ligação à nuvem.
- O dispositivo envia um pedido de URL de subconexão para o servidor de nuvem.
- O servidor de nuvem envia uma resposta que contém a lista de microsserviços e todos os URLs de subconexão para o dispositivo.
- O módulo de serviço regista-se no módulo de gestão da ligação à nuvem.
- O módulo de gestão da ligação à nuvem envia os URLs correspondentes para o serviço.
- O módulo de serviço estabelece subconexões com o servidor de nuvem.
Figura 1 Estabelecer uma ligação à nuvem
Configurar uma Ligação à Nuvem
Sobre a Configuração de uma Ligação à Nuvem
Para que um dispositivo estabeleça uma ligação à nuvem com o servidor de nuvem, execute uma das seguintes tarefas:
- Especifique o nome de domínio do servidor de nuvem no dispositivo através da CLI.
- Configure o dispositivo como um cliente DHCP e o servidor de nuvem como o servidor DHCP. O dispositivo obtém o endereço IP do servidor DHCP e analisa o campo da opção 253 nos pacotes DHCP para obter o nome de domínio do servidor de nuvem. Para obter mais informações sobre o campo da opção 253, consulte Configuração do DHCP no Guia de configuração de serviços IP de camada 3.
Para estabelecer conexões de nuvem com o servidor de nuvem, é necessária uma senha. Um dispositivo pode usar um dos seguintes métodos para obter a senha para estabelecer conexões de nuvem com o servidor de nuvem:
- Execute o comando senha do servidor de gerenciamento de nuvem no dispositivo para especificar a senha para estabelecer conexões de nuvem com o servidor de nuvem.
- Configure o dispositivo como um cliente DHCP e o servidor de nuvem como o servidor DHCP. O dispositivo obtém o endereço IP do servidor DHCP e analisa o campo da opção 252 nos pacotes DHCP para obter a palavra-passe para ligação ao servidor de nuvem. Para obter mais informações sobre o campo da opção 252, consulte Configuração do DHCP no Guia de Configuração dos Serviços da Camada 3IP.
Depois de estabelecer a ligação à nuvem, o dispositivo local envia periodicamente pacotes de manutenção (keepalive) para o servidor de nuvem. Se o dispositivo não receber uma resposta do servidor de nuvem no prazo de três intervalos de keepalive, o dispositivo envia um pedido de registo para restabelecer a ligação à nuvem.
Restrições e Orientações
- O nome de domínio obtido através do DHCP tem uma prioridade mais elevada do que o nome de domínio configurado manualmente.
- Se um dispositivo obtiver o nome de domínio do servidor de nuvem através de DHCP depois de estabelecer uma ligação de nuvem ao servidor de nuvem com o nome de domínio configurado manualmente, o dispositivo executa as seguintes tarefas:
- Se os nomes de domínio obtidos automaticamente e configurados manualmente forem idênticos, o dispositivo mantém a ligação à nuvem.
- Se os nomes de domínio obtidos automaticamente e configurados manualmente forem diferentes, o dispositivo corta a ligação à nuvem e, em seguida, estabelece uma ligação à nuvem para o servidor de nuvem com o nome de domínio obtido automaticamente.
- A palavra-passe obtida através do DHCP tem uma prioridade mais elevada do que a palavra-passe configurada manualmente.
- Se um dispositivo obtiver a palavra-passe para ligação ao servidor de nuvem através de DHCP depois de estabelecer uma ligação de nuvem ao servidor de nuvem com a palavra-passe configurada manualmente, o dispositivo executa as seguintes tarefas:
- Se as palavras-passe obtidas automaticamente e configuradas manualmente forem idênticas, o dispositivo mantém a ligação à nuvem.
- Se as palavras-passe obtidas automaticamente e as palavras-passe configuradas manualmente forem diferentes, o dispositivo corta a ligação à nuvem e, em seguida, estabelece uma ligação à nuvem ao servidor da nuvem com a palavra-passe obtida automaticamente.
Pré-requisitos
- Adicione o número de série do dispositivo a ser gerido ao servidor de nuvem.
- Configure o DNS para garantir que o nome de domínio do servidor de nuvem possa ser traduzido em um endereço IP.
- Para obter o nome de domínio do servidor de nuvem automaticamente, primeiro configure o campo da opção 253 como o nome de domínio do servidor de nuvem.
Procedimento
- Entrar na vista do sistema.
system-viewcloud-management server domain domain-nameAs predefinições são as seguintes:
- O nome de domínio do servidor de nuvem não está configurado para um switch que é iniciado com a configuração inicial.
- O nome de domínio do servidor de nuvem é oasis.intelbras.com para um switch que é iniciado com os padrões de fábrica.
Para mais informações sobre a configuração inicial e as predefinições de fábrica, consulte a gestão de ficheiros de configuração no Guia de Configuração dos Fundamentos.
cloud-management keepalive intervalIntervalo de Manutenção da Gestão da Nuvem
Por predefinição, o intervalo de keepalive é de 180 segundos.
cloud-management server password { cipher | simple } stringPor padrão, nenhuma senha é definida para estabelecer conexões de nuvem com o servidor de nuvem.
Comandos de Visualização e Manutenção para Ligações à Nuvem
| Tarefa | Comando |
|---|---|
| Apresenta informações sobre o estado da ligação à nuvem. | display cloud-management state |
| Restabelecer a ligação à nuvem para o servidor de nuvem. | reset cloud-management tunnel |
Exemplos de Configuração de Ligação à Nuvem
Exemplo: Configurar uma Ligação à Nuvem
Configuração da Rede
Como mostra a Figura 2, configure o dispositivo para estabelecer uma ligação à nuvem com o servidor de nuvem.

Procedimento
- Configure os endereços IP para as interfaces e configure um protocolo de encaminhamento para garantir que os dispositivos possam alcançar uns aos outros. (Detalhes não mostrados.)
- Inicie sessão no servidor de nuvem para adicionar o número de série do dispositivo ao servidor. (Detalhes não mostrados.)
- Configure o nome de domínio do servidor de nuvem como cloud.com.
O endereço IP do servidor de nuvem é 10.1.1.1/24 e o nome de domínio é cloud.com.
system-view
[Device] cloud-management server domain cloud.com #Mapear o endereço IP 10.1.1.1 para o nome do anfitrião cloud.com
cloud.com. [Device] ip host cloud.com 10.1.1.1Verificar a configuração
# Verifique se o dispositivo e o servidor de nuvem estabeleceram uma ligação à nuvem.
[Device] display cloud-management state
Cloud connection state : Established
Device state : Request_success
Cloud server address : 10.1.1.1
Cloud server domain name : cloud.com
Cloud server port : 443
Connected at : Wed Jan 27 14:18:40 2016
Duration : 00d 00h 02m 01s
11 - Telemetria
Configuração do gRPC
Sobre o gRPC
O gRPC é um sistema de chamada de procedimento remoto (RPC) de código aberto desenvolvido inicialmente no Google. Ele usa HTTP 2.0 para transporte e fornece métodos de configuração e gerenciamento de dispositivos de rede compatíveis com várias linguagens de programação.
Camadas da pilha de protocolos gRPC
A Tabela 1 descreve as camadas da pilha de protocolos gRPC.
Tabela 1 Camadas da pilha de protocolos gRPC
| Camada | Descrição |
| Camada de conteúdo | Define os dados do módulo de serviço. Dois pares devem notificar um ao outro sobre os modelos de dados que estão usando. |
| Camada de codificação de buffer de protocolo | Codifica dados usando o formato de código de buffer de protocolo. |
| Camada gRPC | Define o formato de interação do protocolo para chamadas de procedimento remoto. |
| Camada HTTP 2.0 | Carrega o gRPC. |
| Camada TCP | Fornece links de dados confiáveis orientados por conexão. |
Arquitetura de rede
Conforme mostrado na Figura 1, a rede gRPC usa o modelo cliente/servidor. Ela usa HTTP 2.0 para o transporte de pacotes.

Figura 1 Arquitetura da rede gRPC
A rede gRPC usa o seguinte mecanismo:
- O servidor gRPC escuta as solicitações de conexão dos clientes na porta de serviço gRPC.
- Um usuário executa o aplicativo cliente gRPC para fazer login no servidor gRPC e usa os métodos fornecidos no arquivo .proto para enviar solicitações.
- O servidor gRPC responde às solicitações do cliente gRPC. O dispositivo pode atuar como servidor ou cliente gRPC.
Tecnologia de telemetria baseada em gRPC
A telemetria é uma tecnologia de coleta remota de dados para monitorar o desempenho e o status operacional do dispositivo. A tecnologia de telemetria da Intelbras usa o gRPC para enviar dados do dispositivo para os coletores nos NMSs. Conforme mostrado na Figura 2, depois que uma conexão gRPC é estabelecida entre o dispositivo e os NMSs, os NMSs podem se inscrever para obter dados de módulos no dispositivo.
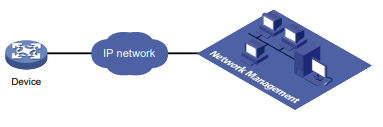
Figura 2 Tecnologia de telemetria baseada em gRPC
Modos de telemetria
O dispositivo é compatível com os seguintes modos de telemetria:
- Modo de discagem - O dispositivo atua como um servidor gRPC e os coletores atuam como clientes gRPC. Um coletor inicia uma conexão gRPC com o dispositivo para assinar os dados do dispositivo.
- Modo de discagem - O dispositivo atua como um cliente gRPC e os coletores atuam como servidores gRPC. O dispositivo inicia uma conexão gRPC com os coletores e envia os dados do dispositivo subscrito para os coletores.
O modo de discagem se aplica a redes pequenas em que os coletores precisam implementar configurações nos dispositivos.
O modo de discagem se aplica a redes maiores em que os dispositivos precisam enviar os dados do dispositivo para os coletores.
Protocolos
RFC 7540, Protocolo de transferência de hipertexto versão 2 (HTTP/2)
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não-FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de configuração de segurança.
O gRPC não é compatível com o modo FIPS.
Pré-requisitos para o gRPC
Antes de configurar o gRPC, você deve instalar uma imagem de software do recurso gRPC compatível com a versão do software do dispositivo. Para obter informações sobre o procedimento de instalação, consulte atualização de software no Fundamentals Configuration Guide.
Configuração do modo de discagem gRPC
Visão geral das tarefas de configuração do modo de discagem gRPC
Para configurar o modo de discagem gRPC, execute as seguintes tarefas:
- Configuração do serviço gRPC
- Configuração de um usuário gRPC
Configuração do serviço gRPC
Restrições e diretrizes
Se o serviço gRPC não for ativado, use o comando display tcp ou display ipv6 tcp para verificar se o número da porta do serviço gRPC foi usado por outro recurso. Em caso afirmativo, especifique uma porta livre como o número da porta do serviço gRPC e tente ativar o serviço gRPC novamente. Para obter mais informações sobre os comandos display tcp e display ipv6 tcp, consulte Referência do comando Layer 3-IP Services.
Procedimento
- Entre na visualização do sistema.
system-viewgrpc port port-numberPor padrão, o número da porta do serviço gRPC é 50051.
A alteração do número da porta do serviço gRPC quando o serviço gRPC está ativado reinicia o serviço gRPC e fecha as conexões gRPC com os clientes gRPC. Os clientes gRPC devem reiniciar as conexões.
grpc enablePor padrão, o serviço gRPC está desativado.
grpc idle-timeout minutesPor padrão, o cronômetro de tempo limite de inatividade da sessão gRPC é de 5 minutos.
Configuração de um usuário gRPC
Sobre os usuários do gRPC
Para que os clientes gRPC estabeleçam sessões gRPC com o dispositivo, é necessário configurar usuários locais para os clientes gRPC.
Procedimento
- Entre na visualização do sistema.
system-viewlocal-user user-name [ class manage ]password [ { hash | simple } password ]Por padrão, nenhuma senha é configurada para um usuário local. Um usuário não protegido por senha pode passar na autenticação depois de fornecer o nome de usuário correto e passar nas verificações de atributos.
service-type httpsPor padrão, nenhum tipo de serviço é autorizado a um usuário local.
Para obter mais informações sobre local-user, password, authorization-attribute e
comandos de tipo de serviço, consulte Configuração AAA na Referência de comandos de segurança.
Configuração do modo de discagem gRPC
Visão geral das tarefas de configuração do modo de discagem gRPC
Para configurar o modo de discagem gRPC, execute as seguintes tarefas:
- Ativação do serviço gRPC
- Configuração de sensores
- Configuração de coletores
- Configuração de uma assinatura
Ativação do serviço gRPC
- Entre na visualização do sistema.
system-viewgrpc enablePor padrão, o serviço gRPC está desativado.
Configuração de sensores
Sobre os sensores
O dispositivo usa sensores para coletar dados. Um caminho de sensor indica uma fonte de dados. Os tipos de amostragem de dados suportados incluem:
- Amostragem acionada por evento - Os sensores em um grupo de sensores coletam dados quando determinados eventos
ocorrer. Para conhecer os caminhos do sensor desse tipo de amostragem de dados, consulte Referência de eventos da API NETCONF XML
para o módulo.
- Amostragem periódica - Os sensores em um grupo de sensores coletam dados em intervalos. Para obter os caminhos do sensor desse tipo de amostragem de dados, consulte as referências da API NETCONF XML para o módulo, exceto para a Referência de evento da API NETCONF XML.
Procedimento
- Entre na visualização do sistema.
system-viewtelemetrysensor-group group-namesensor path pathPara especificar vários caminhos de sensores, execute esse comando várias vezes.
Configuração de coletores
Sobre os colecionadores
Os coletores são usados para receber dados de amostragem dos dispositivos de rede. Para que o dispositivo se comunique com os coletores, você deve criar um grupo de destino e adicionar coletores ao grupo de destino.
Você pode adicionar coletores a um grupo de destino por seus endereços IP. A partir da versão 6343P08, também é possível adicionar coletores a um grupo de destino por seus nomes de domínio. Ao especificar os coletores por seus nomes de domínio, use as restrições e diretrizes a seguir:
- Você deve configurar o DNS para garantir que o dispositivo possa traduzir os nomes de domínio dos coletores para endereços IP. Para obter mais informações sobre DNS, consulte o Guia de configuração de serviços de IP de camada 3.
- Para visualizar os mapeamentos de nomes de domínio e endereços IP, use o comando display dns host. Se um nome de domínio for mapeado para vários endereços IP, o dispositivo enviará os dados para o primeiro endereço IP acessível.
Restrições e diretrizes
Como prática recomendada, configure um máximo de cinco grupos de destino. Se você configurar muitos grupos de destino , o desempenho do sistema poderá ser prejudicado.
Procedimento
- Entre na visualização do sistema.
system-viewtelemetrydestination-group group-nameipv4-address ipv4-address [ port port-number ]IPv6:
ipv6-address ipv6-address [ port port-number ]Para adicionar vários coletores, repita esse comando. Um coletor é identificado exclusivamente por uma tripla de endereço IP, número de porta e nome da instância da VPN. Um coletor deve ter um endereço IP, número de porta ou nome de instância de VPN diferente dos outros coletores do grupo de destino .
domain-name domain-name [ port port-number ] [ vpn-instance vpn-instance-name ]Esse comando é compatível apenas com a versão 6343P08 e posteriores. IPv6:
ipv6 domain-name domain-name [ port port-number ] [ vpn-instance vpn-instance-name ]Esse comando é compatível apenas com a versão 6343P08 e posteriores.
Para adicionar vários coletores, repita esse comando. Um coletor é identificado exclusivamente por um
três tuplas de nome de domínio, número da porta e nome da instância da VPN. Um coletor deve ter um nome de domínio, número de porta ou nome de instância de VPN diferente dos outros coletores no grupo de destino.
Configuração de uma assinatura
Sobre a configuração de uma assinatura
Uma assinatura vincula grupos de sensores a grupos de destino. Em seguida, o dispositivo envia os dados dos sensores especificados para os coletores.
Procedimento
- Entre na visualização do sistema.
system-viewtelemetrysubscription subscription-namesource-address { ipv4-address | interface interface-type interface-number | ipv6 ipv6-address }Por padrão, o dispositivo usa o endereço IPv4 primário da interface de saída da rota para os coletores como endereço de origem.
A alteração do endereço IP de origem dos pacotes enviados aos coletores faz com que o dispositivo restabeleça a conexão com o servidor gRPC.
sensor-group group-name [ sample-interval interval ]Especifique a opção de intervalo de intervalo de amostragem para caminhos de sensores periódicos e somente para caminhos de sensores periódicos.
- Se você especificar a opção para caminhos de sensor acionados por eventos, os caminhos de sensor não terão efeito.
- Se você não especificar a opção para caminhos periódicos do sensor, o dispositivo não fará amostragem ou enviará dados.
destination-group group-nameComandos de exibição e manutenção para gRPC
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir informações sobre gRPC. | display grpc [ verbose ] A palavra-chave verbose é compatível apenas com a versão 6343P08 e posteriores. |
Exemplos de configuração de gRPC
Esses exemplos de configuração descrevem apenas as tarefas de configuração da CLI no dispositivo. Os coletores precisam executar um aplicativo adicional. Para obter informações sobre o desenvolvimento do aplicativo no lado do coletor, consulte "Desenvolvimento do aplicativo no lado do coletor".
Exemplo: Configuração do modo de discagem gRPC
Configuração de rede
Conforme mostrado na Figura 3, configure o modo de discagem gRPC no dispositivo para que o dispositivo atue como servidor gRPC e o cliente gRPC possa se inscrever em eventos LLDP no dispositivo.

Figura 3 Diagrama de rede
Pré-requisitos
Antes de poder configurar o gRPC, você deve instalar uma imagem de software do recurso gRPC compatível com a versão do software do dispositivo. Para obter mais informações sobre o procedimento de instalação, consulte a configuração de atualização de software no Guia de Configuração dos Fundamentos.
Para instalar uma imagem de software do recurso gRPC:
- Faça o download da imagem do software do recurso gRPC compatível com a versão do software do dispositivo do site da Intelbras para o diretório raiz da memória flash no dispositivo. Em uma malha IRF, use os comandos FTP ou TFTP para transferir o arquivo de imagem para o diretório raiz do sistema de arquivos padrão no dispositivo mestre. (Detalhes não mostrados.)
- Instale a imagem do software de recursos no dispositivo e confirme a alteração do software. Em uma malha IRF, instale a imagem em cada dispositivo membro. Por exemplo, instale a imagem no dispositivo membro com uma ID de membro IRF de 1 para o número do slot.
<Device> install activate feature flash:/grpc-01.bin slot 1
Verifying the file flash:/grpc-01.bin on slot 1....Done.
Identifying the upgrade methods....Done.
Upgrade summary according to following table:
flash:/grpc-01.bin
Running Version New Version
None Demo 01
Slot Upgrade Way
1 Service Upgrade
Upgrading software images to compatible versions. Continue? [Y/N]:y
This operation might take several minutes, please wait....................Done.
<Device> install commit
This operation will take several minutes, please wait.......................Done.
Essa operação levará vários minutos, aguarde Concluído.
- Faça login no dispositivo ou na malha IRF novamente.
Procedimento
- Atribua endereços IP a interfaces no servidor e no cliente gRPC e configure rotas. Certifique-se de que o servidor e o cliente possam se comunicar entre si.
- Configure o dispositivo como o servidor gRPC: # Habilite o serviço gRPC.
<Device> system-view
[Device] grpc enable
# Crie um usuário local chamado test. Defina a senha como teste e atribua a função de usuário network-admin e o serviço HTTPS ao usuário.
[Device] local-user test
[Device-luser-manage-test] password simple test
[Device-luser-manage-test] authorization-attribute user-role network-admin
[Device-luser-manage-test] service-type https
[Device-luser-manage-test] quit
- Configure o cliente gRPC.
- Prepare um PC e instale o ambiente gRPC no PC. Para obter mais informações, consulte o guia do usuário do ambiente gRPC.
- Obtém o arquivo de definição Intelbras proto e usa o compilador de buffer de protocolo para gerar código de uma linguagem específica, por exemplo, Java, Python, C/C++ ou Go.
- Crie um aplicativo cliente para chamar o código gerado.
- Inicie o aplicativo para fazer login no servidor gRPC.
Verificação da configuração
Quando ocorrer um evento LLDP no servidor gRPC, verifique se o cliente gRPC recebe o evento.
Exemplo: Configuração do modo de discagem gRPC
Configuração de rede
Conforme mostrado na Figura 4, o dispositivo está conectado a um coletor. O coletor usa a porta 50050.
Configure o modo de discagem gRPC no dispositivo para que ele envie as informações de capacidade do dispositivo de seu módulo de interface para o coletor em intervalos de 10 segundos.
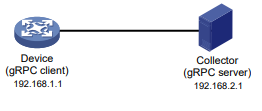
Figura 4 Diagrama de rede
Pré-requisitos
Antes de poder configurar o gRPC, você deve instalar uma imagem de software do recurso gRPC compatível com a versão do software do dispositivo. Para obter mais informações sobre o procedimento de instalação, consulte a configuração de atualização de software no Fundamentals Configuration Guide.
Para instalar uma imagem de software do recurso gRPC:
- Faça o download da imagem do software do recurso gRPC compatível com a versão do software do dispositivo do site da Intelbras para o diretório raiz da memória flash no dispositivo. Em uma malha IRF, use os comandos FTP ou TFTP para transferir o arquivo de imagem ou o patch para o diretório raiz do sistema de arquivos padrão no dispositivo mestre. (Detalhes não mostrados.)
- Instale a imagem do software de recursos no dispositivo e confirme a alteração do software. Em uma malha IRF, instale a imagem em cada dispositivo membro. Por exemplo, instale a imagem no dispositivo membro com um ID de membro IRF de 1 para o número do slot.
<Device> install activate feature flash:/grpc-01.bin slot 1
Verifying the file flash:/grpc-01.bin on slot 1....Done.
Identifying the upgrade methods....Done.
Upgrade summary according to following table:
flash:/grpc-01.bin
Running Version New Version
None Demo 01
Slot Upgrade Way
1 Service Upgrade
Upgrading software images to compatible versions. Continue? [Y/N]:y
This operation might take several minutes, please wait....................Done.
<Device> install commit
This operation will take several minutes, please wait.......................Done.
- Faça login no dispositivo ou na malha IRF novamente.
Procedimento
# Configure os endereços IP conforme necessário para que o dispositivo e o coletor possam se comunicar. (Detalhes não mostrados.)
# Habilite o serviço gRPC.
<Device> system-view
[Device] grpc enable
# Crie um grupo de sensores chamado test e adicione o caminho do sensor ifmgr/devicecapabilities/.
[Device] telemetry
[Device-telemetry] sensor-group test
[Device-telemetry-sensor-group-test] sensor path ifmgr/devicecapabilities/
[Device-telemetry-sensor-group-test] quit# Crie um grupo de destino chamado collector1. Especifique um coletor que use o endereço IPv4 192.168. 2.1 e o número de porta 50050.
[Device-telemetry] destination-group collector1
[Device-telemetry-destination-group-collector1] ipv4-address 192.168.2.1 port 50050
[Device-telemetry-destination-group-collector1] quit# Configure uma assinatura chamada A para vincular o teste do grupo de sensores ao grupo de destino collector1. Defina o intervalo de amostragem como 10 segundos.
[Device-telemetry] subscription A
[Device-telemetry-subscription-A] sensor-group test sample-interval 10
[Device-telemetry-subscription-A] destination-group collector1
[Device-telemetry-subscription-A] quitVerificação da configuração
# Verifique se o coletor recebe as informações de capacidade do dispositivo do módulo de interface do dispositivo em intervalos de 10 segundos. (Detalhes não mostrados).
Código do buffer de protocolo
Formato do código do buffer de protocolo
Os buffers de protocolo do Google oferecem um mecanismo flexível para serializar dados estruturados. Diferentemente do código XML e do código JSON, o código do buffer de protocolo é binário e oferece maior desempenho.
A Tabela 2 compara um exemplo de formato de código de buffer de protocolo e o formato de código JSON correspondente exemplo.
Tabela 2 Exemplos de buffer de protocolo e formato de código JSON
| Exemplo de formato de código de buffer de protocolo | Exemplo de formato de código JSON correspondente |
| { | |
| { | "producerName": "Intelbras", |
| 1: "Intelbras" | "deviceName": "Intelbras", |
| 2: "Intelbras" | "deviceModel": "Intelbras Simware", |
| 3: "Intelbras Simware" | "sensorPath": "Syslog/LogBuffer", |
| 4: "Syslog/LogBuffer" | "jsonData": { |
| 5: "notification": { | "notification": { |
| "Syslog": { | "Syslog": { |
| "LogBuffer": { | "LogBuffer": { |
| "BufferSize": 512, | "BufferSize": 512, |
| "BufferSizeLimit": 1024, | "BufferSizeLimit": 1024, |
| "DroppedLogsCount": 0, | "DroppedLogsCount": 0, |
| "LogsCount": 100, | "LogsCount": 100, |
| "LogsCountPerSeverity": { | "LogsCountPerSeverity": { |
| "Alert": 0, | "Alert": 0, |
| "Crítico": 1, | "Crítico": 1, |
| "Debug": 0, | "Debug": 0, |
| "Emergência": 0, | "Emergência": 0, |
| "Erro": 3, | "Erro": 3, |
| "Informativo": 80, | "Informativo": 80, |
| "Aviso": 15, | "Aviso": 15, |
| "Advertência": 1 | "Advertência": 1 |
| }, | }, |
| "OverwrittenLogsCount": 0, | "OverwrittenLogsCount": 0, |
| "Estado": "enable" | "Estado": "enable" |
| } | } |
| }, | }, |
| "Timestamp": "1527206160022" | "Timestamp": "1527206160022" |
| } | } |
| } | } |
| } |
Arquivos de definição de proto
É possível definir estruturas de dados em um arquivo de definição proto. Em seguida, você pode compilar o arquivo com o utilitário protoc para gerar código em uma linguagem de programação, como Java e C++. Usando o código gerado, você pode desenvolver um aplicativo para que um coletor se comunique com o dispositivo.
A Intelbras fornece arquivos de definição de proto para os modos dial-in e dial-out.
Arquivos de definição de proto no modo dial-in
Arquivos públicos de definição de proto
O arquivo grpc_service.proto define os métodos RPC públicos no modo de discagem, por exemplo, o método de login e o método de logout.
A seguir, o conteúdo do arquivo grpc_service.proto:
syntax = "proto2";
package grpc_service;
message GetJsonReply { // Reply to the Get method
required string result = 1;
}
message SubscribeReply { // Subscription result
required string result = 1;
}
message ConfigReply { // Configuration result
required string result = 1;
}
message ReportEvent { // Subscribed event
required string token_id = 1; // Login token_id
required string stream_name = 2; // Event stream name
required string event_name = 3; // Event name
required string json_text = 4; // Subscription result, a JSON string
}
message GetReportRequest{ // Obtains the event subscription result
required string token_id = 1; // Returns the token_id upon a successful login
}
message LoginRequest { // Login request parameters
required string user_name = 1; // Username
required string password = 2; // Password
}
message LoginReply { // Reply to a login request
required string token_id = 1; // Returns the token_id upon a successful login
}
message LogoutRequest { // Logout parameter
required string token_id = 1; // token_id
}
message LogoutReply { // Reply to a logout request
required string result = 1; // Logout result
}
message SubscribeRequest { // Event stream name
required string stream_name = 1;
}
service GrpcService { // gRPC methods
rpc Login (LoginRequest) returns (LoginReply) {} // Login method
rpc Logout (LogoutRequest) returns (LogoutReply) {} // Logout method
rpc SubscribeByStreamName (SubscribeRequest) returns (SubscribeReply) {} // Event subscription method
rpc GetEventReport (GetReportRequest) returns (stream ReportEvent) {} // Method for obtaining the subscribed event
}
Arquivo de definição de proto no modo dial-out
O arquivo grpc_dialout.proto define os métodos RPC públicos no modo dial-out. O conteúdo do arquivo é o seguinte:
syntax = "proto2";
package grpc_dialout;
message DeviceInfo{ // Pushed device information
required string producerName = 1; // Vendor name
required string deviceName = 2; // Device name
required string deviceModel = 3; // Device model
optional string deviceIpAddr = 4; // Device IP
optional string eventType = 5; // Type of the sensor path
optional string deviceSerialNumber = 6; // Serial number of the device
optional string deviceMac= 7; // Bridge MAC address of the device
}
message DialoutMsg{ // Format of the pushed data
required DeviceInfo deviceMsg = 1; // Device information described by DeviceInfo
required string sensorPath = 2; // Sensor path, which corresponds to xpath in NETCONF
required string jsonData = 3; // Sampled data, a JSON string
}
message DialoutResponse{ // Response from the collector. Reserved. The value is not
processed.
required string response = 1;
}
service gRPCDialout { // Data push method
rpc Dialout(stream DialoutMsg) returns (DialoutResponse);
}
Obtenção de arquivos de definição de proto
Entre em contato com o suporte técnico.
Exemplo: Desenvolvimento de um aplicativo do lado do coletor gRPC
Use uma linguagem (por exemplo, C++) para desenvolver um aplicativo do lado do coletor gRPC no Linux para permitir que um coletor colete dados do dispositivo.
Pré-requisitos
Geração do código C++ para os arquivos de definição de proto
Modo de discagem
# Copie os arquivos de definição de proto necessários para o diretório atual, por exemplo, grpc_service.proto e BufferMonitor.proto.
$protoc --plugin=./grpc_cpp_plugin --grpc_out=. --cpp_out=. *.protoModo de discagem
# Copiar o arquivo de definição de proto grpc_dialout.proto para o diretório atual.
$ protoc --plugin=./grpc_cpp_plugin --grpc_out=. --cpp_out=. *.protoDesenvolvimento do aplicativo do lado do coletor
Modo de discagem
No modo dial-in, o aplicativo precisa fornecer o código a ser executado no cliente gRPC.
O código C++ gerado a partir dos arquivos de definição de proto já encapsula as classes de serviço, que são GrpcService e BufferMonitorService neste exemplo. Para que o cliente gRPC inicie solicitações RPC, basta chamar o método RPC no aplicativo.
O aplicativo executa as seguintes operações:
- Faça login para obter o token_id.
- Preparar parâmetros para o método RPC, usar as classes de serviço geradas a partir dos arquivos de definição de proto para chamar o método RPC e resolver o resultado retornado.
- Fazer logout.
Para desenvolver o aplicativo do lado do coletor no modo dial-in:
- Crie uma classe GrpcServiceTest.
# Na classe, use a classe GrpcService::Stub gerada em grpc_service.proto. Implemente o login e o logout com os métodos Login e Logout gerados em grpc_service.proto.
class GrpcServiceTest
{
public:
/* Constructor functions */
GrpcServiceTest(std::shared_ptr<Channel> channel):
GrpcServiceStub(GrpcService::NewStub(channel)) {}
/* Member functions */
int Login(const std::string& username, const std::string& password);
void Logout();
void listen();
/* Member variable */
std::string token;
private:
std::unique_ptr<GrpcService::Stub> GrpcServiceStub; // Use the
GrpcService::Stub class generated from grpc_service.proto.
};
# Chame o método Login da classe GrpcService::Stub para permitir que um usuário que forneça o nome de usuário e a senha corretos faça login.
int GrpcServiceTest::Login(const std::string& username, const std::string& password)
{
LoginRequest request; // Username and password.
request.set_user_name(username);
request.set_password(password);
LoginReply reply;
ClientContext context;
// Call the Login method.
Status status = GrpcServiceStub->Login(&context, request, &reply);
if (status.ok())
{
std::cout << "login ok!" << std::endl;
std::cout << "token id is :" << reply.token_id() << std::endl;
token = reply.token_id(); // The login succeeds. The token is obtained.
return 0;
}
else
{
std::cout << status.error_code() << ": " << status.error_message()
<< ". Login failed!" << std::endl;
return -1;
}
}
rpc SubscribePortQueDropEvent(PortQueDropEvent) retorna (grpc_service.SubscribeReply) {}# Use a classe BufferMonitorService::Stub gerada a partir de BufferMonitor.proto para chamar o método RPC.
class BufMon_GrpcClient
{
public:
BufMon_GrpcClient(std::shared_ptr<Channel> channel):
mStub(BufferMonitorService::NewStub(channel))
{
}
std::string BufMon_Sub_AllEvent(std::string token);
std::string BufMon_Sub_BoardEvent(std::string token);
std::string BufMon_Sub_PortOverrunEvent(std::string token);
std::string BufMon_Sub_PortDropEvent(std::string token);
/* Get entries */
std::string BufMon_Sub_GetStatistics(std::string token);
std::string BufMon_Sub_GetGlobalCfg(std::string token);
std::string BufMon_Sub_GetBoardCfg(std::string token);
std::string BufMon_Sub_GetNodeQueCfg(std::string token);
std::string BufMon_Sub_GetPortQueCfg(std::string token);
private:
std::unique_ptr<BufferMonitorService::Stub> mStub; // Use the class generated
from BufferMonitor.proto.
};
class BufMon_GrpcClient
{
public:
BufMon_GrpcClient(std::shared_ptr<Channel> channel):
mStub(BufferMonitorService::NewStub(channel))
{
}
std::string BufMon_Sub_AllEvent(std::string token);
std::string BufMon_Sub_BoardEvent(std::string token);
std::string BufMon_Sub_PortOverrunEvent(std::string token);
std::string BufMon_Sub_PortDropEvent(std::string token);
/* Get entries */
std::string BufMon_Sub_GetStatistics(std::string token);
std::string BufMon_Sub_GetGlobalCfg(std::string token);
std::string BufMon_Sub_GetBoardCfg(std::string token);
std::string BufMon_Sub_GetNodeQueCfg(std::string token);
std::string BufMon_Sub_GetPortQueCfg(std::string token);
private:
std::unique_ptr<BufferMonitorService::Stub> mStub; // Use the class generated
from BufferMonitor.proto.
};
# Implemente esse método na classe GrpcServiceTest.
void GrpcServiceTest::listen()
{
GetReportRequest reportRequest;
ClientContext context;
ReportEvent reportedEvent;
/* Add the token to the request */
reportRequest.set_token_id(token);
std::unique_ptr<ClientReader<ReportEvent>>
reader(GrpcServiceStub->GetEventReport(&context, reportRequest)); // Use
GetEventReport (which is generated from grpc_service.proto) to obtain event
information.
std::string streamName;
std::string eventName;
std::string jsonText;
std::string token;
JsonFormatTool jsonTool;
std::cout << "Listen to server for Event" << std::endl;
while(reader->Read(&reportedEvent)) // Read the received event report.
{
streamName = reportedEvent.stream_name();
eventName = reportedEvent.event_name();
jsonText = reportedEvent.json_text();
token = reportedEvent.token_id();
std::cout << "/**********************EVENT COME************************/" <<
std::endl;
std::cout << "TOKEN: " << token << std::endl;
std::cout << "StreamName: "<< streamName << std::endl;
std::cout << "EventName: " << eventName << std::endl;
std::cout << "JsonText without format: " << std::endl << jsonText << std::endl;
std::cout << std::endl;
std::cout << "JsonText Formated: " << jsonTool.formatJson(jsonText) <<
std::endl;
std::cout << std::endl;
}
Status status = reader->Finish();
std::cout << "Status Message:" << status.error_message() << "ERROR code :" <<
status.error_code();
} // Login and RPC request finished
Dial-out mode
No modo dial-out, o aplicativo precisa fornecer o código do servidor gRPC para que o coletor possa receber e resolver os dados obtidos do dispositivo.
O aplicativo realiza as seguintes operações:
- Herdar a classe GRPCDialout::Service gerada automaticamente, sobrecarregar o serviço RPC Dialout gerado automaticamente e resolver os campos.
- Registre o serviço RPC com a porta de escuta especificada. Para desenvolver o aplicativo do lado do coletor no modo de discagem:
- Herdar e sobrecarregar o serviço RPC Dialout.
# Criar a classe DialoutTest e herdar GRPCDialout::Service.
class DialoutTest final : public GRPCDialout::Service { // Sobrecarrega a classe abstrata gerada automaticamente.
Status Dialout(ServerContext* context, ServerReader<DialoutMsg>* reader, DialoutResponse* response) override; // Implementar o método RPC Dialout.
};
using grpc::Server;
using grpc::ServerBuilder;
std::string server_address("0.0.0.0:60057"); // Specify the address and port to
listen to.
DialoutTest dialout_test; // Define the object declared in step 1.
ServerBuilder builder;
builder.AddListeningPort(server_address, grpc::InsecureServerCredentials());// Add
the listening port.
builder.RegisterService(&dialout_test); // Register the service.
std::unique_ptr
<<Server << server(builder.BuildAndStart()); // Start the service.
server->Wait();
Status DialoutTest::Dialout(ServerContext* context, ServerReader<DialoutMsg>* reader, DialoutResponse* response)
{
DialoutMsg msg;
while(reader->Read(&msg))
{
const DeviceInfo &device_msg = msg.devicemsg();
std::cout<< "Producer-Name: " << device_msg.producername() << std::endl;
std::cout<< "Device-Name: " << device_msg.devicename() << std::endl;
std::cout<< "Device-Model: " << device_msg.devicemodel() << std::endl;
std::cout<<"Sensor-Path: " << msg.sensorpath()<<std::endl;
std::cout<<"Json-Data: " << msg.jsondata()<<std::endl;
std::cout<<std::endl;
}
response->set_response("test");
return Status::OK;
}
12 - OpenFlow
Guia de configuração do OpenFlow
Sobre o OpenFlow
O OpenFlow é a interface de comunicação definida entre as camadas de controle e encaminhamento de uma arquitetura de rede definida por software. Com o OpenFlow, você pode realizar o gerenciamento centralizado do encaminhamento de dados para dispositivos físicos e virtuais por meio de controladores.
Componentes de rede OpenFlow
O OpenFlow separa as funções de encaminhamento de dados e de decisão de roteamento. Ele mantém a função de encaminhamento baseada em fluxo e emprega um controlador separado para tomar decisões de roteamento. Um switch OpenFlow se comunica com o controlador por meio de um canal OpenFlow. Um canal OpenFlow pode ser criptografado usando TLS ou executado diretamente sobre TCP. Um switch OpenFlow troca mensagens de controle com o controlador por meio de um canal OpenFlow para realizar as seguintes operações:
- Receber entradas da tabela de fluxo ou dados do controlador.
- Relatar informações ao controlador.
Salvo indicação em contrário, um switch se refere a um switch OpenFlow neste documento.

Figura 1 Diagrama de rede OpenFlow
Switch OpenFlow
Os switches OpenFlow incluem os seguintes tipos:
- OpenFlow-only-Suporta apenas a operação OpenFlow.
- OpenFlow-híbrido - suporta tanto a operação OpenFlow quanto a operação de comutação Ethernet tradicional.
Porta OpenFlow
O OpenFlow é compatível com os seguintes tipos de portas:
- Porta física - Corresponde a uma interface de hardware, como uma interface Ethernet. Uma porta física pode ser uma porta de entrada ou uma porta de saída.
- Porta lógica - Não corresponde a uma interface de hardware e pode ser definida por
métodos não OpenFlow. Por exemplo, as interfaces agregadas são portas lógicas. Uma porta lógica pode ser uma porta de entrada ou uma porta de saída.
- Porta reservada - Definida pelo OpenFlow para especificar ações de encaminhamento. As portas reservadas incluem os seguintes tipos:
- All - Todas as portas que podem ser usadas para encaminhar um pacote.
- Controlador - controlador OpenFlow.
- Na porta - porta de entrada do pacote.
- Qualquer descrição de porta genérica.
- CPU local-local.
- Normal - Processo de encaminhamento normal.
- Inundação-Inundação.
Exceto o tipo Any, todas as portas reservadas podem ser usadas como portas de saída. Somente os tipos Controller e
Os tipos locais podem ser usados como portas de entrada.
Instância OpenFlow
Salvo indicação em contrário, um switch OpenFlow refere-se a uma instância OpenFlow neste documento.
Você pode configurar uma ou mais instâncias do OpenFlow no mesmo dispositivo. Um controlador considera cada instância do OpenFlow como um switch OpenFlow separado e implementa instruções de encaminhamento para ele.
Modo de instância OpenFlow
Uma instância do OpenFlow está associada a VLANs. As entradas de fluxo têm efeito apenas em pacotes dentro de VLANs associadas à instância do OpenFlow.
Ativação e reativação
As configurações de uma instância do OpenFlow entram em vigor somente depois que a instância do OpenFlow é ativada.
O controlador pode implementar entradas de fluxo em uma instância OpenFlow somente depois que a instância OpenFlow relatar as seguintes informações do dispositivo ao controlador:
- Recursos suportados pelo OpenFlow.
- Informações sobre as portas que pertencem à instância do OpenFlow.
Uma instância OpenFlow ativada deve ser reativada quando qualquer configuração de instância OpenFlow for alterada.
Após a reativação, a instância do OpenFlow é desconectada de todos os controladores e, em seguida, reconectada a eles.
Porta de instância OpenFlow
Um switch OpenFlow envia informações sobre as seguintes portas para o controlador:
- Portas físicas.
- Portas lógicas.
- Portas reservadas do tipo Local.
No modo solto, uma porta pertence à instância do OpenFlow quando as VLANs associadas à instância do OpenFlow se sobrepõem às VLANs permitidas da porta. Caso contrário, uma porta pertence a uma instância do OpenFlow somente quando as VLANs associadas à instância do OpenFlow estiverem dentro da lista de VLANs permitidas da porta.
Tabela de fluxo OpenFlow
Um switch OpenFlow faz a correspondência de pacotes com uma ou mais tabelas de fluxo. Uma tabela de fluxo contém entradas de fluxo e os pacotes são combinados com base na precedência de correspondência das entradas de fluxo.
Tipos de tabelas de fluxo
As tabelas de fluxo OpenFlow incluem os seguintes tipos:
- MAC-IP - Combina a tabela de endereços MAC e a tabela FIB. Uma tabela de fluxo MAC-IP fornece os seguintes campos de correspondência:
- Endereço MAC de destino.
- VLAN.
- Endereço IP de destino.
Uma tabela de fluxo MAC-IP fornece as seguintes ações:
- Modificação do endereço MAC de destino.
- Modificação do endereço MAC de origem.
- Modificação da VLAN.
- Especificar a porta de saída.
Para obter mais informações, consulte "Apêndice B Tabela de fluxo MAC-IP".
- Extensibilidade - Usa ACLs para fazer a correspondência de pacotes.
Entrada de fluxo
Uma entrada de fluxo contém os seguintes campos:
- Campos de correspondência - Regras de correspondência da entrada de fluxo. Elas contêm a porta de entrada, os cabeçalhos de pacotes e os metadados especificados na tabela anterior.
- Prioridade - precedência de correspondência da entrada de fluxo. Quando um pacote é correspondido com a tabela de fluxo, somente a entrada de fluxo de prioridade mais alta que corresponde ao pacote é selecionada.
- Contadores - Contagens dos pacotes e bytes que correspondem à entrada de fluxo.
- Instruções - Usadas para modificar o conjunto de ações ou o processamento do pipeline. As instruções incluem os seguintes tipos:
- Meter - Direciona os pacotes para o medidor especificado para limitar a taxa dos pacotes.
- Apply-Actions (Aplicar ações) - Aplica imediatamente as ações especificadas na lista de ações.
- Clear-Actions (Limpar ações) - Limpa imediatamente todas as ações do conjunto de ações.
- Write-Actions - Modifica imediatamente todas as ações no conjunto de ações.
- Goto-Table - Indica a próxima tabela de fluxo no pipeline de processamento.
- Conjunto de ações - Quando o conjunto de instruções de uma entrada de fluxo não contém uma instrução da tabela Goto, o processamento do pipeline é interrompido. Em seguida, as ações no conjunto de ações são executadas na ordem especificada pela lista de instruções. Um conjunto de ações contém no máximo uma ação de cada tipo.
- Lista de ações - As ações na lista de ações são executadas imediatamente na ordem especificada pela lista de ações. O efeito dessas ações é cumulativo.
As ações incluem os seguintes tipos:
- (Obrigatório.) Saída - A ação Saída encaminha um pacote para a porta OpenFlow especificada.
- (Obrigatório.) Drop - Os pacotes sem ações de saída são descartados.
- (Obrigatório.) Group - Processa o pacote por meio do grupo especificado.
- (Opcional.) Set-Queue - Define a ID da fila para um pacote.
- (Opcional.) Set-Field - Modifica os valores dos campos de cabeçalho no pacote.
- Timeouts - Tempo máximo ocioso ou de tempo difícil para a entrada de fluxo.
- Tempo ocioso - A entrada de fluxo é removida após um tempo sem corresponder a pacotes.
- Hard time - A entrada de fluxo é removida após o tempo limite, independentemente de correspondência.
- Cookie - Dados personalizados especificados pelo controlador.
- Sinalizadores - Modifica o gerenciamento de entrada de fluxo.
Figura 2 Componentes da entrada de fluxo
Pipeline OpenFlow
O processamento do pipeline OpenFlow define como os pacotes interagem com as tabelas de fluxo contidas em um switch.
As tabelas de fluxo são numeradas sequencialmente, começando em 0. O pacote é primeiramente combinado com as entradas de fluxo da tabela de fluxo 0.
Quando um pacote corresponde a uma entrada de fluxo, o OpenFlow Switch atualiza o conjunto de ações para o pacote e passa o pacote para a próxima tabela de fluxo.
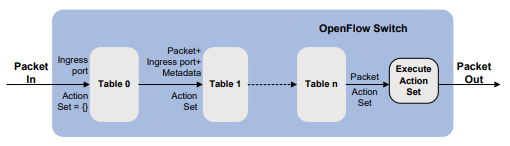
Figura 3 Fluxo de trabalho de encaminhamento do OpenFlow
Entrada de fluxo ausente na tabela
Toda tabela de fluxo deve suportar uma entrada de fluxo table-miss para processar as falhas na tabela.
A entrada de fluxo table-miss tem a prioridade mais baixa e se comporta como qualquer outra entrada de fluxo.
Tabela de grupos
Uma entrada de fluxo pode apontar para um grupo, representando métodos adicionais de encaminhamento.
- Identificador do grupo - Número inteiro sem sinal de 32 bits que identifica o grupo.
- Group Type - Tipo de grupo, como All para encaminhamento de multicast ou broadcast.
- Contadores - Atualizados quando os pacotes são processados por um grupo.
- Compartimentos de ações - Lista ordenada de compartimentos de ações com um conjunto de ações a serem executadas.

Figura 4 Componentes de entrada de grupo
Tabela de medidores
Os medidores permitem a implementação de QoS, como limitação de taxa.
- Identificador do medidor - Número inteiro sem sinal de 32 bits que identifica o medidor.
- Bandas do medidor - Define a taxa à qual a banda se aplica e a maneira como os pacotes são processados.
- Contadores - Atualizados quando os pacotes são processados por um medidor.

Figura 5 Componentes de entrada do medidor
Uma banda de medidor contém os seguintes campos:
- Tipo de banda - (Opcional.) Métodos de processamento de pacotes. As opções são:
- Drop - Descarta o pacote quando a taxa do pacote excede a taxa de banda.
- DSCP Remark (Observação de DSCP) - Marca o campo DSCP no cabeçalho IP do pacote.
- Taxa - Define a taxa mais baixa à qual a banda pode ser aplicada.
- Contadores - Atualizados quando os pacotes são processados por uma banda.
- Argumentos específicos do tipo - Alguns tipos de banda têm argumentos específicos.

Figura 6 Componentes da banda
Canal OpenFlow
O canal OpenFlow é a interface que conecta cada switch OpenFlow a um controlador. O controlador usa o canal OpenFlow para trocar mensagens de controle com o switch para realizar as seguintes operações:
- Configurar e gerenciar o switch.
- Receber eventos do switch.
- Enviar pacotes para o switch.
O canal OpenFlow geralmente é criptografado usando TLS. Além disso, um canal OpenFlow pode ser executado diretamente sobre TCP.
O protocolo OpenFlow é compatível com os seguintes tipos de mensagens: controlador-para-comutador, assíncrono e simétrico. Cada tipo de mensagem tem seus próprios subtipos.
Mensagens do controlador para o comutador
As mensagens do controlador para o switch são iniciadas pelo controlador e usadas para gerenciar ou inspecionar diretamente o estado do switch. As mensagens do controlador para o switch podem ou não exigir uma resposta do switch.
As mensagens do controlador para o comutador incluem os seguintes subtipos:
- Recursos - O controlador solicita os recursos básicos de um switch enviando uma solicitação de recursos. O switch deve responder com uma resposta de recursos que especifique os recursos básicos do switch.
- Configuração - O controlador define e consulta os parâmetros de configuração no switch. O switch responde apenas a uma consulta do controlador.
- Modify-State - O controlador envia mensagens Modify-State para gerenciar o estado nos switches. Seu objetivo principal é adicionar, excluir e modificar entradas de fluxo ou grupo nas tabelas OpenFlow e definir as propriedades da porta do switch.
- Read-State - O controlador envia mensagens Read-State para coletar várias informações do switch, como a configuração atual e as estatísticas.
- Packet-out - São usadas pelo controlador para enviar pacotes para fora da porta especificada no switch ou para encaminhar pacotes recebidos por meio de mensagens packet-in. As mensagens de saída de pacote devem conter um pacote completo ou um ID de buffer que represente um pacote armazenado no switch. A mensagem também deve conter uma lista de ações a serem aplicadas na ordem em que foram especificadas. Uma lista de ações vazia descarta o pacote.
- Barreira - As mensagens de barreira são usadas para confirmar a conclusão das operações anteriores. O controlador envia uma solicitação de Barrier. O switch deve enviar uma resposta de Barrier quando todas as operações anteriores forem concluídas.
- As mensagens Role-Request-Role-Request são usadas pelo controlador para definir a função de seu canal OpenFlow ou consultar essa função. Normalmente, são usadas quando o switch se conecta a vários controladores.
- Asynchronous-Configuration - São usados pelo controlador para definir um filtro adicional nas mensagens assíncronas que ele deseja receber ou para consultar esse filtro. Normalmente, é usado quando o switch se conecta a vários controladores.
Mensagens assíncronas
Os switches enviam mensagens assíncronas aos controladores para informar a chegada de um pacote ou a mudança de estado do switch. Por exemplo, quando uma entrada de fluxo é removida devido ao tempo limite, o switch envia uma mensagem de fluxo removido para informar o controlador.
As mensagens assíncronas incluem os seguintes subtipos:
- Packet-In-Transfere o controle de um pacote para o controlador. Para todos os pacotes encaminhados à porta reservada do controlador usando uma entrada de fluxo ou a entrada de fluxo table-miss, um evento de packet-in é sempre enviado aos controladores. Outros processamentos, como a verificação de TTL, também podem gerar eventos de packet-in para enviar pacotes ao controlador. Os eventos de packet-in podem incluir o
pacote ou pode ser configurado para armazenar pacotes em buffer no switch. Se o evento de entrada de pacote estiver configurado para armazenar pacotes em buffer, os eventos de entrada de pacote conterão apenas uma fração do cabeçalho do pacote e um ID de buffer. O controlador processa o pacote completo ou a combinação do cabeçalho do pacote e a ID do buffer. Em seguida, o controlador envia uma mensagem de saída de pacote para instruir o switch a processar o pacote.
- Flow-Removed - Informa o controlador sobre a remoção de uma entrada de fluxo de uma tabela de fluxo. Elas são geradas devido a uma solicitação de exclusão de fluxo do controlador ou ao processo de expiração do fluxo do switch quando um dos tempos limite do fluxo é excedido.
- Port-status-Informe o controlador sobre uma mudança de estado ou de configuração em uma porta.
- Error-Informe o controlador sobre um problema ou erro.
Mensagens simétricas
As mensagens simétricas são enviadas sem solicitação, em qualquer direção. As mensagens simétricas contêm os seguintes subtipos:
- As mensagens Hello-Hello são trocadas entre o switch e o controlador após a conexão
inicialização.
- As mensagens de solicitação ou resposta de eco podem ser enviadas pelo switch ou pelo controlador e devem retornar uma resposta de eco. Elas são usadas principalmente para verificar a vivacidade de uma conexão entre o controlador e o switch e também podem ser usadas para medir a latência ou a largura de banda.
- Experimenter - Esta é uma área de teste para recursos destinados a futuras revisões do OpenFlow.
Temporizadores OpenFlow
Um switch OpenFlow suporta os seguintes temporizadores:
- Intervalo de detecção de conexão - Intervalo no qual o switch OpenFlow envia uma mensagem de solicitação de eco para um controlador. Quando o switch OpenFlow não recebe nenhuma mensagem Echo Reply em três intervalos, o switch OpenFlow é desconectado do controlador.
- Intervalo de reconexão - Intervalo que o switch OpenFlow deve aguardar antes de tentar se reconectar a um controlador.
Controlador OpenFlow
Funções do controlador
Um switch pode estabelecer conexões com vários controladores. Quando a operação do OpenFlow é iniciada, um switch é conectado simultaneamente a vários controladores no estado Equal. Um controlador pode solicitar a alteração de sua função a qualquer momento. A função de controlador contém os seguintes tipos:
- Igual - Nessa função, o controlador tem acesso total ao switch e é igual a outros controladores na mesma função. Por padrão, o controlador recebe todas as mensagens assíncronas do switch, como mensagens de entrada de pacote e de remoção de fluxo. O controlador pode enviar mensagens de controlador para switch para modificar o estado do switch.
- Mestre - Essa função é semelhante à função Igual e tem acesso total ao switch. A diferença é que, em um switch, é permitido até um controlador com essa função.
- Escravo - Nessa função, o controlador tem acesso somente de leitura ao switch.
O controlador não pode enviar mensagens de controlador para comutador para realizar as seguintes operações:
- Implante entradas de fluxo, entradas de grupo e entradas de medidor.
- Modificar as configurações da porta e do switch.
- Enviar mensagens de saída de pacote.
Por padrão, o controlador não recebe mensagens assíncronas de switch, exceto mensagens de status de porta. O controlador pode enviar mensagens Asynchronous-Configuration para definir os tipos de mensagens assíncronas que deseja receber.
Modos de conexão do controlador
Uma instância do OpenFlow pode se conectar a um ou mais controladores, dependendo do modo de conexão do controlador usado pela instância do OpenFlow:
- Único - A instância do OpenFlow se conecta a apenas um controlador por vez. Quando a comunicação com o controlador atual falha, a instância do OpenFlow usa outro controlador.
- Múltiplos - A instância do OpenFlow pode se conectar simultaneamente a vários controladores. Quando a comunicação com qualquer controlador falha, a instância do OpenFlow tenta se reconectar ao controlador após um intervalo de reconexão.
Conexões principais e auxiliares
O canal OpenFlow pode ter uma conexão principal e várias conexões auxiliares.
- Conexão principal - processa mensagens de controle para concluir operações como implantação de entradas, obtenção de dados e envio de informações. A conexão principal deve ser uma conexão TCP ou SSL confiável.
- Conexão auxiliar - Melhora o desempenho da comunicação entre o controlador e os switches OpenFlow. Uma conexão auxiliar pode ter um endereço IP de destino e um número de porta diferentes dos da conexão principal.
Modo de interrupção da conexão
Quando um switch OpenFlow é desconectado de todos os controladores, o switch OpenFlow é configurado em um dos seguintes modos:
- Seguro - O switch OpenFlow encaminha o tráfego com base em tabelas de fluxo e não remove entradas de fluxo não expiradas. Se a ação de saída em uma entrada de fluxo correspondente for encaminhar o tráfego para um controlador, o tráfego será descartado. Esse é o modo de encaminhamento padrão.
- Inteligente - O switch OpenFlow encaminha o tráfego com base em tabelas de fluxo e não remove entradas de fluxo não expiradas. Se a ação de saída em uma entrada de fluxo correspondente for encaminhar o tráfego para um controlador, o tráfego será encaminhado no processo normal.
- Independente - O switch OpenFlow usa o processo de encaminhamento normal.
O switch OpenFlow encaminha o tráfego com base nas tabelas de fluxo quando se reconecta a um controlador com êxito.
Protocolos e padrões
Especificação de switch OpenFlow versão 1.3.3
Configuração de instâncias OpenFlow
Criação de uma instância OpenFlow
-
Entre na visualização do sistema.
system-view -
Crie uma instância OpenFlow e entre em sua visualização.
openflow instance instance-id -
(Opcional) Defina a ID do caminho de dados.
datapath-id idPor padrão, o ID do caminho de dados de uma instância do OpenFlow contém o ID da instância e o endereço MAC da ponte do dispositivo. Os 16 bits superiores são o ID da instância e os 48 bits inferiores são o endereço MAC da ponte do dispositivo.
O ID do caminho de dados identifica exclusivamente um switch OpenFlow (instância OpenFlow). Não defina o mesmo ID de caminho de dados para diferentes switches OpenFlow.
-
Definir um valor DSCP para pacotes OpenFlow.
tcp dscp dscp-valuePor padrão, nenhum valor DSCP é definido para os pacotes OpenFlow.
Configuração do modo de instância OpenFlow
Restrições e diretrizes
Quando você associar uma instância do OpenFlow a VLANs, siga estas diretrizes:
- Para que o tráfego de VLAN seja processado corretamente, associe diferentes instâncias do OpenFlow a diferentes VLANs.
- Quando você ativa uma instância do OpenFlow que está associada a VLANs inexistentes, o sistema cria automaticamente as VLANs.
- Não associe VLANs permitidas em uma porta a diferentes instâncias do OpenFlow. Caso contrário, as mensagens de modificação de porta de diferentes instâncias OpenFlow implementadas a partir de diferentes controladores se sobrepõem umas às outras.
- Não configure o BFD MAD na interface de VLAN para uma VLAN associada a uma instância do OpenFlow. Para obter mais informações sobre o BFD MAD, consulte o Virtual Technologies Configuration Guide.
Ativação do modo VLAN para uma instância OpenFlow
-
Entre na visualização do sistema.
system-view -
Entre na visualização da instância OpenFlow.
openflow instance instance-id -
Configure o modo de instância do OpenFlow.
classification vlan vlan-id [ mask vlan-mask ] [ loosen ]Por padrão, o modo de instância do OpenFlow não está configurado.
Configuração de VLANs de gerenciamento em banda
O tráfego nas VLANs de gerenciamento em banda é encaminhado no processo de encaminhamento normal, em vez de no processo de encaminhamento do OpenFlow. As VLANs de gerenciamento de banda interna são usadas por uma instância do OpenFlow para estabelecer canais do OpenFlow para os controladores.
Restrições e diretrizes
As portas atribuídas apenas a VLANs de gerenciamento em banda não são portas OpenFlow.
As VLANs de gerenciamento de banda interna configuradas para uma instância do OpenFlow no modo VLAN devem estar na lista de VLANs associadas à instância do OpenFlow.
Se uma instância OpenFlow no modo global ou VLAN se conectar a um controlador por meio de uma interface Ethernet que não seja de gerenciamento, configure a VLAN à qual a interface pertence como uma VLAN de gerenciamento em banda.
Procedimento
-
Entre na visualização do sistema.
system-view -
Entre na visualização da instância OpenFlow.
openflow instance instance-id -
Configure as VLANs de gerenciamento em banda para a instância do OpenFlow.
in-band management vlan vlan-id-listPor padrão, nenhuma VLAN de gerenciamento em banda é configurada para uma instância do OpenFlow.
Configuração de tabelas de fluxo e entradas de fluxo para uma instância OpenFlow
Restrições e diretrizes
A ID da tabela de fluxo de extensibilidade deve ser maior que a ID da tabela de fluxo MAC-IP.
Procedimento
-
Entre na visualização do sistema.
system-view -
Entre na visualização da instância OpenFlow.
openflow instance instance-id -
Configure tabelas de fluxo para a instância do OpenFlow.
flow-table { extensibility extensibility-table-id | mac-ip mac-ip-table-id }*Por padrão, uma instância do OpenFlow contém uma tabela de fluxo de extensibilidade com ID 0.
-
Defina o número máximo de entradas de fluxo que cada tabela de fluxo de extensibilidade suporta.
flow-entry max-limit limit-valueA configuração padrão é 65535.
Quando o número máximo é atingido, a instância do OpenFlow não aceita novas entradas de fluxo para essa tabela e envia uma notificação de falha de implementação para o controlador.
-
Configure a instância do OpenFlow para permitir que as entradas ARP dinâmicas substituam as entradas ARP do OpenFlow.
precedência arp dinâmicaPor padrão, uma instância do OpenFlow não permite que entradas ARP dinâmicas substituam entradas ARP do OpenFlow.
Somente as tabelas de fluxo MAC-IP suportam esse recurso.
-
Permitir que as tabelas de fluxo implantadas incluam portas membros de agregação de links.
permit-port-type member-portPor padrão, as tabelas de fluxo implantadas não podem incluir portas-membro de agregação de links.
-
Configure a ação padrão das entradas de fluxo table-miss para encaminhar os pacotes ao pipeline normal.
default table-miss permit
Por padrão, a ação padrão das entradas de fluxo table-miss é descartar os pacotes.
Configuração do modo de conexão do controlador
Procedimento
-
Entre na visualização do sistema.
system-view -
Entre na visualização da instância OpenFlow.
openflow instance instance-id -
Definir o modo de conexão do controlador. controller mode { multiple | single }
Por padrão, o modo múltiplo é usado.
Impedir que uma instância OpenFlow informe os tipos de portas especificados aos controladores
Sobre a prevenção de relatórios de tipo de porta
Execute esta tarefa para impedir que uma instância do OpenFlow relate informações de controladores sobre os seguintes tipos de interfaces que pertencem à instância do OpenFlow:
Procedimento
-
Entre na visualização do sistema.
system-view -
Entrar na visualização da instância OpenFlow
openflow instance instance-id -
Impedir que uma instância OpenFlow informe os tipos de portas especificados aos controladores.
forbidden port { l3-physical-interface | vlan-interface | vsi-interface } *Por padrão, nenhum tipo de porta é impedido de ser relatado aos controladores. Todas as portas que pertencem a uma instância do OpenFlow são informadas aos controladores.
As palavras-chave l3-physical-interface e vsi-interface não são compatíveis com a versão atual do software.
Ativação ou reativação de uma instância OpenFlow
-
Entre na visualização do sistema.
system-view -
Entre na visualização da instância OpenFlow.
openflow instance instance-id -
Ativar ou reativar a instância do OpenFlow.
active instancePor padrão, uma instância do OpenFlow não é ativada.
Configuração dos atributos da instância OpenFlow
Restrições e diretrizes
As configurações de atributo de instância OpenFlow de uma instância OpenFlow podem entrar em vigor sem a ativação da instância OpenFlow.
Procedimento
-
Entre na visualização do sistema.
system-view -
Entre na visualização da instância OpenFlow.
openflow instance instance-id -
Configure uma descrição para a instância do OpenFlow.
texto de descrição
Por padrão, uma instância do OpenFlow não tem uma descrição.
-
Defina os temporizadores do OpenFlow.
-
Defina o intervalo de detecção de conexão.
controller echo-request interval intervalA configuração padrão é de 5 segundos.
-
Defina o intervalo de reconexão.
controller connect interval intervalA configuração padrão é 60 segundos.
-
Defina o intervalo de detecção de conexão.
-
Configurar os recursos relacionados ao endereço MAC.
-
Proibir o aprendizado de endereço MAC para VLANs associadas à instância do OpenFlow.
mac-learning forbiddenPor padrão, o aprendizado de endereço MAC é permitido para VLANs associadas a uma instância do OpenFlow.
A configuração não entra em vigor nas VLANs de gerenciamento em banda.
-
Configure a instância do OpenFlow para suportar a correspondência dos endereços MAC dinâmicos nas instruções de entrada de fluxo de consulta e exclusão enviadas pelos controladores.
mac-ip dynamic-mac awarePor padrão, uma instância do OpenFlow ignora os endereços MAC dinâmicos nas instruções de entrada de fluxo de consulta e exclusão enviadas pelos controladores.
Somente as tabelas de fluxo MAC-IP suportam esse recurso.
-
Proibir o aprendizado de endereço MAC para VLANs associadas à instância do OpenFlow.
-
Impedir que a instância OpenFlow informe pacotes ARP aos controladores especificados.
lista de identificação de controlador de arp de pacote proibido
Por padrão, não há controladores configurados para os quais os pacotes ARP são proibidos de serem relatados.
Esse recurso proíbe uma instância do OpenFlow de relatar pacotes ARP aos controladores especificados para evitar que os controladores sejam afetados por um grande número de pacotes.
-
Desative o registro em log das modificações bem-sucedidas da tabela de fluxo.
flow-log disablePor padrão, o registro em log das modificações bem-sucedidas da tabela de fluxo está ativado.
-
Ativar a proteção de loop para a instância do OpenFlow.
loop-protection enablePor padrão, a proteção de loop está desativada para uma instância do OpenFlow.
Depois que uma instância do OpenFlow for desativada, você poderá ativar a proteção de loop para a instância do OpenFlow a fim de evitar loops. Esse recurso permite que a instância OpenFlow desativada crie uma entrada de fluxo para descartar todo o tráfego nessas VLANs.
Configuração de controladores para um switch OpenFlow
Restrições e diretrizes
Certifique-se de que a configuração de uma conexão auxiliar não esteja em conflito com a configuração da conexão principal . Caso contrário, a conexão auxiliar não poderá ser estabelecida.
Procedimento
-
Entre na visualização do sistema.
system-view -
Entre na visualização da instância OpenFlow.
openflow instance instance-id -
Especifique um controlador e configure a conexão principal com o controlador.
controller controller-id address { ip ipv4-address | ipv6 ipv6-address } [ port port-number ] [ local address { ip local-ipv4-address | ipv6 local-ipv6-address } [ port local-port-number ] ] [ ssl ssl-policy-name ] -
(Opcional) Especifique um controlador e configure uma conexão auxiliar com o controlador.
controller id auxiliary auxiliary-id transport { tcp | udp | ssl ssl-policy-name } [ address { ip ipv4-address | ipv6 ipv6-address } ] [ port port-number ] -
(Opcional) Defina o modo de interrupção da conexão.
fail-open mode { secure | smart | standalone } -
(Opcional) Habilite o backup da conexão OpenFlow.
tcp-connection backup
Por padrão, uma instância do OpenFlow não tem uma conexão principal com um controlador. O endereço IP de origem deve ser o endereço IP de uma porta pertencente a uma instância do OpenFlow. Caso contrário, o switch OpenFlow pode não conseguir estabelecer uma conexão com o controlador. Por padrão, uma instância do OpenFlow não tem conexões auxiliares com um controlador. Se nenhum endereço IP de destino e número de porta forem especificados, a conexão auxiliar usará o endereço IP de destino e o número de porta configurados para a conexão principal. Por padrão, o modo seguro é usado. Por padrão, o backup da conexão OpenFlow está ativado. Esse recurso evita a interrupção da conexão quando ocorre uma alternância entre ativo e em espera. Esse recurso está disponível somente em uma malha IRF com dois dispositivos membros. Esse recurso está disponível apenas para conexões OpenFlow estabelecidas por TCP.
Configuração de uma instância do OpenFlow
Sobre a configuração do servidor SSL para uma instância do OpenFlow
Normalmente, uma instância do OpenFlow se conecta ativamente ao controlador atuando como um cliente TCP/SSL. Depois que o servidor SSL é ativado para uma instância do OpenFlow, o controlador atua como cliente SSL e se conecta ativamente à instância do OpenFlow. Para obter mais informações sobre SSL, consulte o Guia de configuração de segurança.
Restrições e diretrizes
Esse recurso pode entrar em vigor sem a ativação de uma instância do OpenFlow.
Para reconfigurar o servidor SSL, primeiro execute a forma undo do comando para excluir a configuração existente do servidor SSL.
Procedimento
-
Entre na visualização do sistema.
system-view -
Entre na visualização da instância OpenFlow.
openflow instance instance-id -
Configure uma instância do OpenFlow para atuar como um servidor SSL para ouvir os controladores.
listening port port-number ssl ssl-policy-name
Por padrão, uma instância do OpenFlow não está configurada para atuar como um servidor SSL que escuta os controladores.
Atualização de todas as entradas de fluxo da Camada 3 nas tabelas de fluxo MAC-IP para uma instância OpenFlow
Sobre a atualização de todas as entradas de fluxo da Camada 3 nas tabelas de fluxo MAC-IP
Execute esta tarefa para obter todas as entradas de fluxo da Camada 3 nas tabelas de fluxo MAC-IP do controlador novamente se as entradas de fluxo da Camada 3 tiverem sido substituídas.
Restrições e diretrizes
-
Entre na visualização do sistema.
system-view -
Entre na visualização da instância OpenFlow.
openflow instance instance-id -
Atualizar todas as entradas de fluxo da Camada 3 nas tabelas de fluxo MAC-IP.
refresh ip-flow
Desligamento de uma interface pelo OpenFlow
Sobre o desligamento da interface
Depois que uma interface é desligada pelo OpenFlow, o campo Estado atual exibe OFP DOWN no campo
saída do comando da interface de exibição.
Você pode usar o comando undo openflow shutdown para ativar uma interface desativada pelo OpenFlow. A interface também pode ser ativada por mensagens de modificação de porta dos controladores.
Procedimento
-
Entre na visualização do sistema.
system-view -
Entre na visualização da interface.
interface interface-type interface-number -
Desligar uma interface pelo OpenFlow.
openflow shutdown
Por padrão, uma interface não é desligada pelo OpenFlow.
Comandos de exibição e manutenção para OpenFlow
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando |
| Exibir as informações detalhadas de uma instância OpenFlow. | exibir instância de fluxo aberto [ instance-id ] |
| Exibir informações do controlador para uma instância OpenFlow. | exibir o ID da instância do openflow { controller [ controller-id ] | listado } |
| Exibir informações de conexão auxiliar. | display openflow instance instance-id auxiliary [ controller-id [ auxiliary-id ] ] ] |
| Exibir entradas da tabela de fluxo para uma instância OpenFlow. | exibir o ID da instância do openflow tabela de fluxo [ table-id ] |
| Exibir informações da tabela de grupos para uma instância do OpenFlow. | exibir o ID da instância do openflow grupo [ group-id ] |
| Exibir informações da tabela de medidores para uma instância OpenFlow. | exibir o ID da instância do openflow medidor [ meter-id ] |
| Exibir informações resumidas da instância OpenFlow. | exibir resumo do fluxo aberto |
| Limpar estatísticas sobre pacotes que um controlador envia e recebe para uma instância OpenFlow. | reset openflow instance instance-id { controller [ controller-id ] | listado } estatísticas |
Exemplos de configuração do OpenFlow
Exemplo: Configuração do OpenFlow no modo VLAN
Configuração de rede
Conforme mostrado na Figura 7, um switch OpenFlow se comunica com o controlador. Execute as seguintes tarefas no switch OpenFlow:
- Crie a instância 1 do OpenFlow, associe as VLANs 4092 e 4094 à instância do OpenFlow e ative a instância do OpenFlow.
- Configure o endereço IP do controlador 1 para que o controlador gerencie o switch OpenFlow.
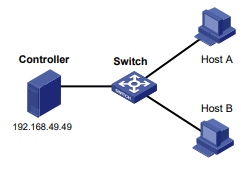
Figura 7 Diagrama de rede
Procedimento
# Crie as VLANs 4092 e 4094.
<Switch> system-view
[Switch] vlan 4092
[Switch-vlan4092] quit
[Switch] vlan 4094
[Switch-vlan4094] quit# Crie a instância 1 do OpenFlow e associe VLANs a ela.
[Switch] openflow instance 1
[Switch-of-inst-1] classification vlan 4092 mask 4093# Especifique o controlador 1 para a instância 1 do OpenFlow e ative a instância.
[Switch-of-inst-1] controller 1 address ip 192.168.49.49
[Switch-of-inst-1] active instance
[Switch-of-inst-1] quitVerificação da configuração
# Exibir informações detalhadas sobre a instância do OpenFlow.
[Switch] display openflow instance 1
Instance 1 information:
Configuration information:
Description : --
Active status : Active
Inactive configuration:
None
Active configuration:
Controller Switch Host A
Host B
192.168.49.49
17
Classification VLAN, total VLANs(2)
4092, 4094
In-band management VLAN, total VLANs(0)
Empty VLAN
Connect mode: Multiple
Mac-address learning: Enabled
Flow table:
Table ID(type): 0(Extensibility), count: 0
Flow-entry max-limit: 65535
Datapath ID: 0x0064001122000101
Default table-miss: Permit
Forbidden port: VLAN interface
Qinq Network: Disabled
TCP connection backup: Enabled
Port information:
GigabitEthernet1/0/3
Active channel information:
Controller 1 IP address: 192.168.49.49 port: 6633
Apêndice A Restrições do aplicativo
Restrições de entrada de fluxo
Restrições de correspondência
Correspondência de VLAN
A Tabela 1 descreve as restrições de correspondência de VLAN quando uma instância do OpenFlow está associada a VLANs.
| VLAN | Máscara | Pacotes de correspondência |
| - | - | Todos os pacotes nas VLANs que estão associadas à instância do OpenFlow. |
| 0 | - | Pacotes sem uma tag de VLAN. O PVID da porta de entrada deve estar associado à instância do OpenFlow. |
| 0 | Valor | Sem suporte. |
| VLAN válida | -/valor | Sem suporte. |
| 0x1000 | -/valor (exceto 0x1000) | Sem suporte. |
| 0x1000 | 0x1000 | Pacotes com uma tag de VLAN. A VLAN ID da tag de VLAN deve estar associada à instância do OpenFlow. |
| VLAN válida 0x1000 | -/valor | Correspondência de pacotes pela combinação da VLAN ID e da máscara de VLAN. As VLANs obtidas por meio da combinação da VLAN ID e da máscara de VLAN devem ser associadas à instância do OpenFlow. |
| Outros | Outros | Sem suporte. |
Correspondência de pacotes de protocolo
Se os protocolos estiverem ativados, os pacotes de protocolo (exceto os quadros LLDP) serão processados pelos protocolos correspondentes em vez do protocolo OpenFlow.
Para obter mais informações sobre a correspondência de quadros LLDP, consulte "Correspondência de quadros LLDP".
Correspondência de metadados
Os metadados passam informações correspondentes entre as tabelas de fluxo. O controlador implementa entradas de correspondência de metadados somente em tabelas de fluxo que não sejam as primeiras. Se o controlador implantar uma entrada de correspondência de metadados na primeira tabela de fluxo, o switch retornará um erro de fluxo não suportado.
Restrições de instrução
| Tipo de instrução | Restrições |
| Ações claras | A instrução Clear-Actions tem as seguintes restrições: Para a tabela de fluxo único, as entradas de fluxo da tabela não podem incluir essa instrução e outras instruções ao mesmo tempo. Para várias tabelas de fluxo do pipeline, somente as entradas de fluxo da primeira tabela de fluxo podem incluir essa instrução e outras instruções ao mesmo tempo. |
| Aplicar ações | A lista de ações da instrução Apply-Actions não pode incluir várias ações de Saída. Quando a lista de ações inclui apenas uma ação de Saída, o switch processa a lista de ações conforme descrito em "Restrições para mesclar a lista de ações no conjunto de ações". |
| Escrever metadados/máscara | As entradas de fluxo da última tabela do pipeline não podem incluir essa instrução. Caso contrário, o switch retorna um erro de fluxo não suportado. |
| Mesa Goto |
Restrições para mesclar a lista de ações no conjunto de ações
O switch segue as seguintes restrições para mesclar a lista de ações no conjunto de ações.
Ações que não são de saída
Quando o conjunto de ações e a lista de ações não contiverem a ação Saída ou Grupo, aplicam-se as seguintes regras:
- Se as ações do conjunto de ações não entrarem em conflito com as ações da lista de ações, o switch mescla a lista de ações com o conjunto de ações.
- Se as ações do conjunto de ações entrarem em conflito com as ações da lista de ações, as ações da lista de ações serão substituídas pelas ações do conjunto de ações.
Ações de saída
Quando o conjunto de ações e a lista de ações contêm a ação Saída ou a ação Grupo, as seguintes regras se aplicam:
- Se tanto a lista de ações quanto o conjunto de ações contiverem uma ação de Saída, a ação de Saída na lista de ações terá precedência. A ação de Saída na lista de ações não modifica o pacote. A ação de Saída no conjunto de ações é executada na última etapa do processamento do pipeline para modificar o pacote.
- Se a lista de ações ou o conjunto de ações contiver uma ação de Saída, a porta especificada pela ação de Saída será tratada como a porta de saída. As ações são executadas na ordem definida pelas regras do conjunto de ações.
- Se a lista de ações contiver uma ação de Saída e o conjunto de ações contiver uma ação de Grupo, aplicam-se as seguintes regras:
- A ação Output não modifica o pacote.
- A ação Group é executada.
Restrições de mensagens de saída de pacotes
Porta de entrada
A porta de entrada deve ser uma porta física ou lógica quando uma das seguintes portas reservadas for a porta de saída em uma mensagem de saída de pacote:
- Normal.
- Local.
- No porto.
- Controlador.
ID do buffer coexistente com o pacote
Se uma mensagem de saída de pacote contiver o pacote e o ID do buffer que representa o pacote armazenado no switch, o switch processará somente o pacote armazenado no buffer. O switch ignora o pacote na mensagem.
Pacotes sem uma etiqueta de VLAN
Se o pacote contido em uma mensagem de saída de pacote não tiver uma tag de VLAN, o switch executará as seguintes operações:
- Marca o pacote com o PVID da porta de entrada.
- Encaminha o pacote dentro da VLAN.
O switch processa o pacote da seguinte forma quando a porta de entrada é uma porta reservada:
- Se a porta de saída for uma porta física ou lógica, o switch marcará o pacote com o PVID da porta de saída e encaminhará o pacote dentro da VLAN.
- Se a porta de saída for a porta Flood ou All reserved, o switch processará o pacote conforme descrito em "Porta de saída".
Porta de saída
Se a porta de saída em uma mensagem de saída de pacote for a porta Flood ou All reserved, o switch processará o pacote contido na mensagem de saída de pacote da seguinte forma:
- Quando a porta de saída é a porta reservada do Flood:
- Se o pacote tiver uma tag de VLAN, o switch transmitirá o pacote dentro da VLAN.
- Se o pacote não tiver nenhuma tag de VLAN e a porta de entrada for uma porta física ou lógica, o switch marca o pacote com o PVID da porta de entrada. Em seguida, o switch encaminha o pacote dentro da VLAN.
- Se o pacote não tiver etiqueta de VLAN e a porta de entrada for a porta reservada do Controlador, o switch encaminhará o pacote para todas as portas OpenFlow.
- Quando a porta de saída é a porta Todos reservados:
- Se o pacote tiver uma tag de VLAN, o switch transmitirá o pacote dentro da VLAN.
- Se o pacote não tiver etiqueta de VLAN, o switch encaminha o pacote para todas as portas OpenFlow , independentemente do tipo de porta de entrada.
Restrições de mensagens de entrada de pacotes
Processamento de tags de VLAN
Ao enviar uma mensagem de entrada de pacote para o controlador, o switch processa a tag de VLAN do pacote contido na mensagem de saída de pacote da seguinte forma:
- Se a tag de VLAN do pacote for a mesma do PVID da porta de entrada, o switch removerá a tag de VLAN.
- Se a tag de VLAN do pacote for diferente do PVID da porta de entrada, o switch não removerá a tag de VLAN.
Buffer de pacotes
Se uma mensagem de pacote de entrada for enviada ao controlador devido à ausência de entrada de fluxo correspondente, o switch suporta o armazenamento em buffer do pacote contido na mensagem de pacote de entrada. O tamanho do buffer é de 1K pacotes.
Se uma mensagem de entrada de pacote for enviada ao controlador por outros motivos, o switch não suporta o armazenamento em buffer do pacote contido na mensagem de entrada de pacote. O switch deve enviar o pacote completo ao controlador, e o campo cookie do pacote é definido como 0xFFFFFFFFFFFFFFFF.
Correspondência de quadros LLDP
O LLDP é usado para realizar a descoberta de topologia em uma rede OpenFlow. O LLDP deve ser ativado globalmente em um dispositivo. Um switch envia um quadro LLDP para o controlador por meio da mensagem de entrada de pacote quando as condições a seguir estão presentes:
- A porta que recebe o quadro LLDP do controlador pertence às instâncias do OpenFlow.
- As tabelas de fluxo na instância do OpenFlow têm uma entrada de fluxo que corresponde ao quadro LLDP (a porta de saída é a porta reservada do Controlador).
Restrições de mensagens de modificação da tabela de fluxo
As mensagens de modificação da tabela de fluxo têm as seguintes restrições para a entrada de fluxo table-miss e entradas de fluxo comuns.
Entrada de fluxo ausente na tabela
O controlador implementa a entrada de fluxo table-miss (a ação é Drop) em uma instância OpenFlow depois que a instância OpenFlow é ativada.
O controlador não pode consultar a entrada de fluxo table-miss por meio de mensagens Multipart.
O controlador não pode modificar a entrada de fluxo de falta de tabela por meio da solicitação Modificar. O controlador só pode modificar a entrada de fluxo de falta de tabela por meio da solicitação Add (Adicionar).
O controlador pode modificar ou excluir a entrada de fluxo de falta de tabela somente por meio da versão restrita da solicitação Modificar ou Excluir. O controlador não pode modificar ou remover a entrada de fluxo de falta de tabela por meio da versão não restrita da solicitação Modificar ou Excluir, apesar de os campos de correspondência serem curingas.
O controlador implementa uma entrada de fluxo table-miss (a ação é Drop) em uma instância OpenFlow depois que a entrada de fluxo table-miss atual é excluída.
Entradas de fluxo comuns
O controlador não pode modificar ou remover todas as entradas de fluxo comuns por meio da versão não restrita da solicitação Modificar ou Excluir, apesar de os campos de correspondência serem curingas.
Apêndice B Tabela de fluxo MAC-IP
Recursos suportados pela tabela de fluxo MAC-IP
O controlador deve incluir os campos e ações de correspondência necessários e pode incluir os campos e ações de correspondência opcionais nas entradas de fluxo implantadas na tabela de fluxo MAC-IP. Se o controlador não incluir os campos e ações de correspondência opcionais nas entradas de fluxo, o switch os adicionará às entradas de fluxo por padrão.
As entradas de fluxo da camada 2 são implementadas usando entradas de endereço MAC. A Tabela 3 descreve os recursos suportados pelas entradas de fluxo da Camada 2.
Tabela 3 Recursos suportados pelas entradas de fluxo da Camada 2
| Item | Recursos |
| Campos de correspondência obrigatórios | A tabela de fluxo MAC-IP deve suportar os seguintes campos de correspondência: VLAN ID. Endereço MAC de destino unicast. |
| Campos de correspondência opcionais | N/A |
| Ações necessárias | Especificar a porta de saída. |
As entradas de fluxo da camada 3 são implementadas por meio de entradas de roteamento. A Tabela 4 descreve os recursos suportados pelas entradas de fluxo da Camada 3.
Tabela 4 Recursos suportados pelas entradas de fluxo da Camada 3
| Item | Recursos |
| Campos de correspondência obrigatórios | A tabela de fluxo MAC-IP deve suportar os seguintes campos de correspondência: VLAN ID. Endereço IP de destino unicast. Endereço MAC de destino unicast, que deve ser o endereço MAC da interface de VLAN para a VLAN correspondente. |
| Campos de correspondência opcionais | N/A |
| Ações necessárias | Especificar a porta de saída. |
Restrições da tabela de fluxo MAC-IP
O controlador deve seguir as restrições das tabelas a seguir para implementar entradas de fluxo na tabela de fluxo MAC-IP. Caso contrário, poderá ocorrer falha no encaminhamento.
Tabela 5 Restrições para a implementação de entradas de fluxo de camada 2 para a tabela de fluxo MAC-IP
| Item | Restrições |
| Campos de correspondência | O endereço MAC de destino não pode ser o endereço MAC do switch para o qual a entrada de fluxo foi implantada. |
| Ações | A porta de saída deve pertencer à VLAN correspondente. |
Tabela 6 Restrições para a implementação de entradas de fluxo da camada 3 para a tabela de fluxo MAC-IP
| Item | Restrições |
| Campos de correspondência | A interface VLAN da VLAN correspondente está em estado ativo. O endereço MAC de destino é o endereço MAC da interface de VLAN para a VLAN correspondente. O endereço IP de destino não pode ser o endereço IP do switch no qual a entrada de fluxo está implantada. |
| Ações | A porta de saída especificada deve pertencer à VLAN de destino. O endereço MAC de destino não pode ser o endereço MAC do switch para o qual a entrada de fluxo foi implantada. Se o switch modificar o endereço MAC de origem, o endereço MAC de origem deverá ser o endereço MAC da interface da VLAN para a VLAN à qual a porta de saída está conectada. |
Para implementar uma entrada de fluxo da Camada 3, certifique-se de que os seguintes requisitos sejam atendidos:
- A interface VLAN da VLAN correspondente está em estado ativo.
- O switch envia ao controlador um pacote que indica que a interface VLAN atua como uma porta OpenFlow. O estado do link e o endereço MAC da interface VLAN também são incluídos no pacote.
O switch informa a exclusão da interface VLAN ao controlador e o controlador remove a entrada de fluxo da Camada 3 correspondente.
O controlador garante a exatidão das entradas de fluxo da Camada 3. O switch não verifica as restrições das entradas de fluxo da Camada 3.
Entrada de fluxo de falha de tabela de tabelas de fluxo MAC-IP
A entrada de fluxo table-miss de uma tabela de fluxo MAC-IP é compatível com as seguintes ações de saída:
- Goto-Table - Direciona o pacote para a próxima tabela.
- Drop - Soltar o pacote.
- Controlador - Envie o pacote para o controlador.
- Normal - encaminha o pacote para o pipeline normal.
Consciente dinâmico
Em um switch OpenFlow compatível com tabelas de fluxo MAC-IP, você pode configurar o OpenFlow para suportar a consulta e a exclusão de entradas de fluxo de endereço MAC dinâmico.
O controlador pode consultar e excluir entradas dinâmicas de fluxo de endereço MAC especificando uma VLAN, um endereço MAC ou a combinação de um endereço MAC e uma VLAN.
Tabela de fluxo MAC-IP que coopera com a tabela de fluxo de extensibilidade
Metadados/máscara
A tabela de fluxo MAC-IP é compatível com a instrução Write Metadata/mask (Gravar metadados/máscara) e a tabela de fluxo de extensibilidade é compatível com a correspondência de metadados/máscara. A tabela de fluxo MAC-IP pode cooperar com uma tabela de fluxo de extensibilidade para executar o processo de pipeline de várias tabelas usando metadados/máscara.
Cada bit de máscara de metadados tem um significado diferente. A definição do bit de metadados correspondente indica que o bit de máscara de metadados é correspondido. Quando o bit de metadados correspondente não está definido, o bit de máscara de metadados é curinga.
Tabela 7 Significados das máscaras de metadados
| Bit de máscara de metadados | Significado | Metadados |
| Bit 0 | Endereço MAC de destino | 1-Set. Corresponde ao endereço MAC de destino. 0-Não definido. Não corresponde ao endereço MAC de destino. |
| Bit 1 | Endereço MAC de origem | 1-Set. Corresponde ao endereço MAC de origem. 0-Não definido. Não corresponde ao endereço MAC de origem. |
| Bit 2 | Endereço IP de destino | 1-Set. Corresponde ao endereço IP de destino. 0-Não definido. Não corresponde ao endereço IP de destino. |
| Bit de máscara de metadados | Significado | Metadados |
| Outros | Reservado | Reservado. |
Restrições de correspondência
Quando a ação de saída em uma tabela de fluxo de extensibilidade não é Normal, as seguintes regras se aplicam:
- A tabela de fluxo MAC-IP não entra em vigor.
- Todas as ações são executadas de acordo com a tabela de fluxo de extensibilidade.
Quando a ação de saída em uma tabela de fluxo de extensibilidade é Normal, as seguintes regras se aplicam:
- A ação de saída é executada de acordo com a tabela de fluxo MAC-IP.
- As outras ações são executadas de acordo com a tabela de fluxo de extensibilidade.
Termo de garantia
Para a sua comodidade, preencha os dados abaixo, pois, somente com a apresentação deste em conjunto com a nota fiscal de compra do produto, você poderá utilizar os benefícios que lhe são assegurados.
Nome do cliente:
Assinatura do cliente:
Nº da nota fiscal:
Data da compra:
Modelo:
Nº de série:
Revendedor:
Fica expresso que esta garantia contratual é conferida mediante as seguintes condições:
1. Todas as partes, peças e componentes do produto são garantidos contra eventuais defeitos de fabricação, que porventura venham a apresentar, pelo prazo de 3 (três) anos – sendo 3 (três) meses de garantia legal e 33 (trinta e três) meses de garantia contratual –, contado a partir da data de entrega do produto ao Senhor Consumidor, conforme consta na nota fiscal de compra do produto, que é parte integrante deste Termo em todo o território nacional. Esta garantia contratual compreende a troca gratuita de partes, peças e componentes que apresentarem defeito de fabricação, incluindo a mão de obra utilizada nesse reparo. Caso não seja constatado defeito de fabricação, e sim defeito(s) proveniente(s) de uso inadequado, o Senhor Consumidor arcará com essas despesas.
2. A instalação do produto deve ser feita de acordo com o Manual do Produto e/ou Guia de Instalação. Caso seu produto necessite a instalação e configuração por um técnico capacitado, procure um profissional idôneo e especializado, sendo que os custos desses serviços não estão inclusos no valor do produto.
3. Na eventualidade de o Senhor Consumidor solicitar atendimento domiciliar, deverá encaminhar-se ao Serviço Autorizado mais próximo para consulta da taxa de visita técnica. Caso seja constatada a necessidade da retirada do produto, as despesas decorrentes de transporte e segurança de ida e volta do produto ficam sob a responsabilidade do Senhor Consumidor.
4. Na eventualidade de o Senhor Consumidor solicitar atendimento domiciliar, deverá encaminhar-se ao Serviço Autorizado mais próximo para consulta da taxa de visita técnica. Caso seja constatada a necessidade da retirada do produto, as despesas decorrentes, como as de transporte e segurança de ida e volta do produto, ficam sob a responsabilidade do Senhor Consumidor.
5. A garantia perderá totalmente sua validade na ocorrência de quaisquer das hipóteses a seguir: a) se o vício não for de fabricação, mas sim causado pelo Senhor Consumidor ou por terceiros estranhos ao fabricante; b) se os danos ao produto forem oriundos de acidentes, sinistros, agentes da natureza (raios, inundações, desabamentos, etc.), umidade, tensão na rede elétrica (sobretensão provocada por acidentes ou flutuações excessivas na rede), instalação/uso em desacordo com o manual do usuário ou decorrentes do desgaste natural das partes, peças e componentes; c) se o produto tiver sofrido influência de natureza química, eletromagnética, elétrica ou animal (insetos, etc.); d) se o número de série do produto tiver sido adulterado ou rasurado; e) se o equipamento tiver sido violado.
6. Esta garantia não cobre perda de dados, portanto, recomenda-se, se for o caso do produto, que o Consumidor faça uma cópia de segurança regularmente dos dados que constam no produto.
7. A Intelbras não se responsabiliza pela instalação deste produto, e também por eventuais tentativas de fraudes e/ou sabotagens em seus produtos. Mantenha as atualizações do software e aplicativos utilizados em dia, se for o caso, assim como as proteções de rede necessárias para proteção contra invasões (hackers). O equipamento é garantido contra vícios dentro das suas condições normais de uso, sendo importante que se tenha ciência de que, por ser um equipamento eletrônico, não está livre de fraudes e burlas que possam interferir no seu correto funcionamento.
A garantia contratual deste termo é complementar à legal, portanto, a Intelbras S/A reserva-se o direito de alterar as características gerais, técnicas e estéticas de seus produtos sem aviso prévio.
Sendo estas as condições deste Termo de Garantia complementar, a Intelbras S/A se reserva o direito de alterar as características gerais, técnicas e estéticas de seus produtos sem aviso prévio.
Todas as imagens deste manual são ilustrativas.

Suporte a clientes: (48) 2106 0006
Fórum: forum.intelbras.com.br
Suporte via chat: intelbras.com.br/suporte-tecnico
Suporte via e-mail: suporte@intelbras.com.br
SAC: 0800 7042767
Intelbras S/A – Indústria de Telecomunicação Eletrônica Brasileira
Rodovia SC 281, km 4,5 – Sertão do Maruim – São José/SC - 88122-001
CNPJ 82.901.000/0014-41 - www.intelbras.com.br
Indústria Brasileira