
03 - Configurando as interfaces Ethernet
Configurando interfaces Ethernet
Sobre a interface Ethernet
A série de switches é compatível com interfaces Ethernet e interfaces de console. Para saber os tipos de interface e o número de interfaces suportadas por um modelo de switch, consulte o guia de instalação.
Este capítulo descreve como configurar as interfaces Ethernet de gerenciamento e as interfaces Ethernet.
Convenções de nomenclatura de interface Ethernet
As interfaces Ethernet são nomeadas no formato de tipo de interface A/B/C. As letras que seguem o tipo de interface representam os seguintes elementos:
ID do membro A-IRF. Se o switch não estiver em uma malha IRF, A será 1 por padrão.
Número do slot do cartão B. 0 indica que a interface é uma interface fixa do switch.
Índice da porta C.
Configuração de definições comuns da interface Ethernet
Configuração do tipo físico para uma interface combinada (interface combinada única)
Sobre a interface combo
Uma interface combo é uma interface lógica que compreende fisicamente uma porta combo de fibra e uma porta combo de cobre. As duas portas compartilham um canal de encaminhamento e uma visualização de interface. Como resultado, elas não podem funcionar simultaneamente. Quando você ativa uma porta, a outra porta é automaticamente desativada. Se você executar o comando combo enable auto em uma interface combo, a interface identificará automaticamente a mídia inserida e ativará a porta combo correspondente. Na visualização da interface, você pode ativar a porta combo de fibra ou de cobre e configurar outros atributos da porta, como a taxa de interface e o modo duplex.
Restrições e diretrizes de configuração
Esse recurso está disponível somente em dispositivos que suportam interfaces combinadas.
Pré-requisitos
Antes de configurar as interfaces combo, conclua as seguintes tarefas:
Determine as interfaces combinadas em seu dispositivo. Identifique as duas interfaces físicas que pertencem a cada interface combinada de acordo com as marcas no painel do dispositivo.
Use o comando display interface para determinar qual porta (fibra ou cobre) de cada interface combo está ativa:
Se a porta de cobre estiver ativa, a saída incluirá "O tipo de mídia é par trançado".
Se a porta de fibra estiver ativa, a saída não incluirá essas informações.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberAtivar a porta combo de cobre ou a porta combo de fibra. combo enable { auto | copper | fiber } O padrão é auto.
Configuração das definições básicas de uma interface Ethernet
Sobre as configurações básicas da interface Ethernet
Você pode configurar uma interface Ethernet para operar em um dos seguintes modos duplex:
Modo full-duplex - A interface pode enviar e receber pacotes simultaneamente.
Modo half-duplex - A interface só pode enviar ou receber pacotes em um determinado momento.
Modo de negociação automática - A interface negocia um modo duplex com seu par.
Você pode definir a velocidade de uma interface Ethernet ou permitir que ela negocie automaticamente uma velocidade com seu par. Para uma interface Ethernet de camada 2 de 100 Mbps ou 1000 Mbps, você também pode definir opções de velocidade para negociação automática. As duas extremidades podem selecionar uma velocidade somente entre as opções disponíveis. Para obter mais informações, consulte "Definição de opções de velocidade para autonegociação em uma interface Ethernet".
Restrições e diretrizes
O comando shutdown não pode ser configurado em uma interface em um teste de loopback.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberDefina a descrição da interface Ethernet.
description text A configuração padrão é interface-nome da interface. Por exemplo, GigabitEthernet1/0/1 Interface.
Defina o modo duplex para a interface Ethernet.
duplex { auto | full | half } Por padrão, o modo duplex é automático para interfaces Ethernet.
As portas de cobre Ethernet que operam em 1000 Mbps ou 10000 Mbps e as portas de fibra não suportam a palavra-chave half.
Defina a velocidade da interface Ethernet.
speed { 10 | 100 | 1000 | 2500 | 5000 | 10000 | auto }Por padrão, uma interface Ethernet negocia uma velocidade com seu par.
Defina a largura de banda esperada para a interface Ethernet.
Por padrão, a largura de banda esperada (em kbps) é a taxa de transmissão da interface dividida por 1000.
Abra a interface Ethernet.
undo shutdownPor padrão, as interfaces Ethernet estão no estado "up".
Ativação da negociação automática para redução de velocidade
Sobre a negociação automática para redução de velocidade
Execute esta tarefa para permitir que as interfaces em duas extremidades de um link negociem automaticamente o downgrade de velocidade quando houver as seguintes condições:
As interfaces negociam automaticamente uma velocidade de 1000 Mbps.
As interfaces não podem operar a 1000 Mbps devido a restrições de link.
Restrições e diretrizes
Esse recurso está disponível apenas em interfaces GE.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberHabilitar a negociação automática para redução de velocidade.
speed auto downgradePor padrão, a negociação automática para redução de velocidade está ativada.
Configuração do suporte a jumbo frame
Sobre o jumbo frame
Os quadros Jumbo são quadros maiores que 1522 bytes e normalmente são recebidos por uma interface Ethernet durante trocas de dados de alto rendimento, como transferências de arquivos.
A interface Ethernet processa os quadros jumbo das seguintes maneiras:
Quando a interface Ethernet está configurada para negar quadros jumbo (usando o comando undo jumboframe enable), a interface Ethernet descarta os quadros jumbo.
Quando a interface Ethernet é configurada com suporte a jumbo frame, a interface Ethernet executa as seguintes operações:
Processa quadros jumbo com o comprimento especificado.
Descarta os quadros jumbo que excedem o comprimento especificado.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberConfigurar o suporte a jumbo frame.
jumboframe enable [ size ]Por padrão, o dispositivo permite a passagem de quadros jumbo de até 10240 bytes.
Se você definir o argumento size várias vezes, a configuração mais recente entrará em vigor.
Configuração da supressão de alterações de estado físico em uma interface Ethernet
Sobre a supressão da mudança de estado físico
O estado do link físico de uma interface Ethernet é ativo ou inativo. Toda vez que o link físico de uma interface é ativado ou desativado, a interface informa imediatamente a alteração à CPU. Em seguida, a CPU executa as seguintes operações:
Notifica os módulos de protocolo da camada superior (como os módulos de roteamento e encaminhamento) sobre a alteração para orientar o encaminhamento de pacotes.
Gera automaticamente traps e logs para informar os usuários para que tomem as medidas corretas.
Para evitar que a oscilação frequente de links físicos afete o desempenho do sistema, configure a supressão de alterações de estado físico. Você pode configurar esse recurso para suprimir somente eventos de link-down, somente eventos de link-up ou ambos. Se um evento do tipo especificado ainda existir quando o intervalo de supressão expirar, o sistema informará o evento à CPU.
Você pode configurar diferentes intervalos de supressão para eventos de link-up e link-down.
Se você executar o comando link-delay várias vezes em uma interface, as regras a seguir serão aplicadas:
Você pode configurar os intervalos de supressão para eventos de link-up e link-down separadamente.
Se você configurar o intervalo de supressão várias vezes para eventos de link-up ou link-down, a configuração mais recente entrará em vigor.
Os comandos link-delay, dampening e port link-flap protect enable são mutuamente exclusivos em uma interface Ethernet.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberConfigurar a supressão da alteração do estado físico.
link-delay { down | up } [ msec ] delay-timePor padrão, toda vez que o link físico de uma interface sobe ou desce, a interface informa imediatamente a alteração à CPU.
Configuração do amortecimento em uma interface Ethernet
Sobre o amortecimento
O recurso de amortecimento de interface usa um mecanismo de decaimento exponencial para evitar que eventos de oscilação excessiva de interface afetem negativamente os protocolos de roteamento e as tabelas de roteamento na rede. A supressão dos eventos de alteração de estado da interface protege os recursos do sistema.
Se uma interface não for atenuada, suas alterações de estado serão relatadas. Para cada alteração de estado, o sistema também gera uma mensagem de registro e uma armadilha SNMP.
Depois que uma interface de flapping é atenuada, ela não informa suas alterações de estado à CPU. Para eventos de alteração de estado, a interface gera apenas mensagens de registro e de interceptação de SNMP.
Parâmetros
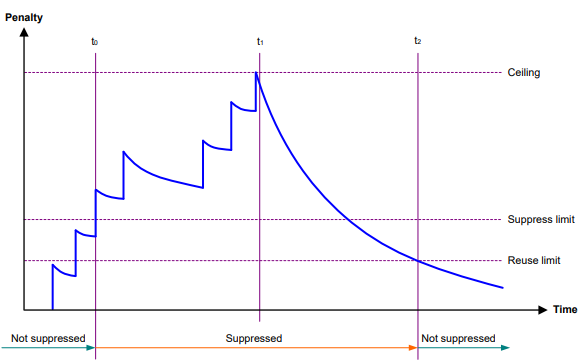
Penalidade - A interface tem uma penalidade inicial de 0. Quando a interface se move, a penalidade aumenta em 1.000 para cada evento de descida até que o teto seja atingido. Ela não aumenta para eventos de subida. Quando a interface para de se movimentar, a penalidade diminui pela metade a cada vez que o cronômetro de meia-vida expira, até que a penalidade caia para o limite de reutilização.
Teto - A penalidade para de aumentar quando atinge o teto.
Suppress-limit - A penalidade acumulada que aciona o dispositivo para atenuar a interface. No estado amortecido, a interface não informa suas alterações de estado à CPU. Para eventos de alteração de estado, a interface gera apenas traps SNMP e mensagens de registro.
Limite de reutilização - Quando a penalidade acumulada diminui para esse limite de reutilização, a interface não é atenuada. As alterações de estado da interface são informadas às camadas superiores. Para cada alteração de estado, o sistema também gera uma armadilha SNMP e uma mensagem de registro.
Decaimento - O período de tempo (em segundos) após o qual uma penalidade é reduzida.
Max-suppress-time - O período máximo de tempo em que a interface pode ser atenuada. Se a penalidade ainda for maior do que o limite de reutilização quando esse temporizador expirar, a penalidade deixará de aumentar para eventos de inatividade. A penalidade começa a diminuir até ficar abaixo do limite de reutilização.
Ao executar o comando de amortecimento, siga estas regras para definir os valores mencionados acima:
O teto é igual a 2(Max-suppress-time/Decay) × reuse-limit. Não é configurável pelo usuário.
O limite de supressão configurado é menor ou igual ao teto.
O teto é menor ou igual ao limite máximo de supressão suportado.
A Figura 1 mostra a regra de alteração do valor da penalidade. As linhas t0 e t2 indicam a hora de início e a hora de término da supressão, respectivamente. O período de t0 a t2 indica o período de supressão, t0 a t1 indica o tempo máximo de supressão e t1 a t2 indica o período de decaimento completo.
Figura 1 Regra de alteração do valor da penalidade
Restrições e diretrizes
Os comandos dampening, link-delay e port link-flap protect enable são mutuamente exclusivos em uma interface.
O comando de atenuação não tem efeito sobre os eventos de inatividade administrativa. Quando você executa o comando shutdown, a penalidade é restaurada para 0 e a interface informa o evento de inatividade aos protocolos da camada superior.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberAtivar o amortecimento na interface.
dampening [ half-life reuse suppress max-suppress-time ]Por padrão, o amortecimento da interface é desativado nas interfaces Ethernet.
Ativação da proteção contra flapping de link em uma interface
Sobre a proteção contra oscilação do link
A oscilação de link em uma interface altera a topologia da rede e aumenta a sobrecarga do sistema. Por exemplo, em um cenário de link ativo/em espera, quando o status da interface no link ativo muda entre UP e DOWN, o tráfego alterna entre os links ativo e em espera. Para resolver esse problema, configure esse recurso na interface.
Com esse recurso ativado em uma interface, quando a interface é desativada, o sistema ativa a detecção de flapping de link. Durante o intervalo de detecção de flapping de link, se o número de flaps detectados atingir ou exceder o limite de detecção de flapping de link, o sistema desligará a interface.
Restrições e diretrizes
Esse recurso só terá efeito se for configurado na visualização do sistema e na visualização da interface Ethernet.
A estabilidade do sistema IRF pode ser afetada pelo flapping do link físico IRF. Para a estabilidade do sistema da IRF, esse recurso é ativado por padrão nas interfaces físicas da IRF e o status de ativação desse recurso não é afetado pelo status da proteção global contra flapping de link. Quando o número de flaps detectados em uma interface física IRF excede o limite dentro do intervalo de detecção, o dispositivo emite um registro em vez de desligar a interface física IRF.
Os comandos dampening, link-delay e port link-flap protect enable são mutuamente exclusivos em uma interface Ethernet.
Para ativar uma interface que tenha sido desligada pela proteção de flapping de link, execute o comando undo shutdown.
Na saída do comando Exibir interface, o valor Link-Flap DOWN do estado atual
indica que a interface foi desligada por proteção contra flapping de link.
Procedimento
Entre na visualização do sistema.
System ViewHabilite a proteção contra flapping de link globalmente.
link-flap protect enablePor padrão, a proteção contra flapping de link é desativada globalmente.
Entre na visualização da interface Ethernet.
interface interface-type interface-numberHabilite a proteção contra flapping de link na interface Ethernet.
port link-flap protect enable [ interval interval | threshold
threshold ] *Por padrão, a proteção contra flapping de link é desativada em uma interface Ethernet.
Configuração da supressão de tempestades
Sobre a supressão de tempestades
O recurso de supressão de tempestades garante que o tamanho de um tipo específico de tráfego (broadcast, multicast ou tráfego unicast desconhecido) não exceda o limite em uma interface. Quando o tráfego de broadcast, multicast ou unicast desconhecido na interface excede esse limite, o sistema descarta os pacotes até que o tráfego caia abaixo desse limite.
Tanto a supressão quanto o controle de tempestades podem suprimir tempestades em uma interface. A supressão de tempestades usa o chip para suprimir o tráfego. A supressão de tempestades tem menos impacto sobre o desempenho do dispositivo do que o controle de tempestades , que usa software para suprimir o tráfego.
Restrições e diretrizes
Para que o resultado da supressão de tráfego seja determinado, não configure o controle de tempestade juntamente com a supressão de tempestade para o mesmo tipo de tráfego. Para obter mais informações sobre o controle de tempestade, consulte "Configuração do controle de tempestade em uma interface Ethernet".
Quando você configura o limite de supressão em kbps, o limite de supressão real pode ser diferente do configurado, como segue:
Se o valor configurado for menor que 64, o valor de 64 entrará em vigor.
Se o valor configurado for maior que 64, mas não for um múltiplo inteiro de 64, o múltiplo inteiro de 64 que for maior e mais próximo do valor configurado entrará em vigor.
Para saber o limite de supressão que entra em vigor, consulte o prompt no dispositivo.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberHabilite a supressão de broadcast e defina o limite de supressão de broadcast. broadcast-suppression { ratio | pps max-pps | kbps max-kbps } Por padrão, a supressão de broadcast está desativada.
Habilite a supressão de multicast e defina o limite de supressão de multicast. multicast-suppression { ratio | pps max-pps | kbps max-kbps } Por padrão, a supressão de multicast está desativada.
Habilite a supressão de unicast desconhecido e defina o limite de supressão de unicast desconhecido.
unicast-suppression { ratio | pps max-pps | kbps max-kbps }Por padrão, a supressão de unicast desconhecido está desativada.
Configuração do controle de fluxo genérico em uma interface Ethernet
Sobre o controle de fluxo genérico
Para evitar o descarte de pacotes em um link, é possível ativar o controle de fluxo genérico em ambas as extremidades do link. Quando ocorre congestionamento de tráfego na extremidade receptora, esta envia um controle de fluxo (Pausa)
para solicitar que a extremidade de envio suspenda o envio de pacotes. O controle de fluxo genérico inclui os seguintes tipos:
Controle de fluxo genérico no modo TxRx - Ativado com o uso do comando flow-control. Com o controle de fluxo genérico no modo TxRx ativado, uma interface pode enviar e receber quadros de controle de fluxo:
Quando ocorre um congestionamento, a interface envia um quadro de controle de fluxo ao seu par.
Quando a interface recebe um quadro de controle de fluxo de seu par, ela suspende o envio de pacotes para seu par.
Controle de fluxo genérico no modo Rx - Ativado com o uso do comando flow-control receive enable. Com o controle de fluxo genérico no modo Rx ativado, uma interface pode receber quadros de controle de fluxo, mas não pode enviar quadros de controle de fluxo:
Quando ocorre um congestionamento, a interface não pode enviar quadros de controle de fluxo para seu par.
Quando a interface recebe um quadro de controle de fluxo de seu par, ela suspende o envio de pacotes para seu par.
Para lidar com o congestionamento de tráfego unidirecional em um link, configure o comando flow-control receive enable em uma extremidade e o comando flow-control na outra extremidade. Para permitir que ambas as extremidades de um link lidem com o congestionamento de tráfego, configure o comando flow-control em ambas as extremidades.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberHabilita o controle de fluxo genérico.
Habilita o controle de fluxo genérico no modo TxRx.
flow-controlHabilita o controle de fluxo genérico no modo Rx.
flow-control receive enable lPor padrão, o controle de fluxo genérico é desativado em uma interface Ethernet.
Ativação de recursos de economia de energia em uma interface Ethernet
Sobre os recursos de economia de energia em uma interface Ethernet
Esse recurso contém desligamento automático e Energy Efficient Ethernet (EEE) em uma interface Ethernet.
Quando uma interface Ethernet com desligamento automático ativado fica inativa por um determinado período de tempo, ocorrem os dois eventos a seguir:
O dispositivo interrompe automaticamente o fornecimento de energia à interface Ethernet.
A interface Ethernet entra no modo de economia de energia.
O período de tempo depende das especificações do chip e não é configurável. Quando a interface Ethernet é ativada, ocorrem os dois eventos a seguir:
O dispositivo restaura automaticamente a fonte de alimentação da interface Ethernet.
A interface Ethernet volta ao seu estado normal.
Com o Energy Efficient Ethernet (EEE) ativado, uma interface de link-up entra no estado de baixo consumo de energia se não tiver recebido nenhum pacote por um período de tempo. O período de tempo depende das especificações do chip e não é configurável. Quando um pacote chega mais tarde, o dispositivo restaura automaticamente o fornecimento de energia à interface e ela volta ao estado normal.
Restrições e diretrizes
As portas de fibra não são compatíveis com esse recurso.
Configuração do desligamento automático em uma interface Ethernet
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberAtivar o desligamento automático na interface Ethernet.
port auto-power-down Por padrão, o desligamento automático é desativado em uma interface Ethernet.
Configuração do EEE em uma interface Ethernet
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberHabilite o EEE na interface Ethernet.
eee enablePor padrão, o EEE está desativado em uma interface Ethernet.
Configuração do intervalo de sondagem de estatísticas
Sobre o intervalo de sondagem de estatísticas
Para exibir as estatísticas da interface coletadas no último intervalo de sondagem de estatísticas, use o comando display interface. Para limpar as estatísticas da interface, use o comando reset counters interface.
Um dispositivo é compatível com as configurações de visualização do sistema ou com as configurações de visualização da interface Ethernet.
O intervalo de sondagem de estatísticas configurado na visualização do sistema entra em vigor em todas as interfaces Ethernet.
O intervalo de sondagem de estatísticas configurado na visualização da interface Ethernet tem efeito apenas na interface atual.
Para uma interface Ethernet, o intervalo de sondagem de estatísticas configurado na visualização da interface Ethernet tem prioridade.
Restrições e diretrizes para a configuração do intervalo de sondagem de estatísticas
A configuração do intervalo de sondagem de estatísticas na visualização do sistema é compatível apenas com a versão 6328 e posteriores.
Como prática recomendada, use a configuração padrão ao definir o intervalo de sondagem de estatísticas na visualização do sistema. Um intervalo curto de sondagem de estatísticas pode diminuir o desempenho do sistema e resultar em estatísticas imprecisas.
Definição do intervalo de sondagem de estatísticas na visualização do sistema
Entre na visualização do sistema.
System ViewDefina o intervalo de sondagem de estatísticas. intervalo de intervalo de fluxo A configuração padrão é 300 segundos.
Configuração do intervalo de sondagem de estatísticas na visualização da interface Ethernet
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberDefina o intervalo de sondagem de estatísticas para a interface Ethernet.
flow-interval interval Por padrão, o intervalo de sondagem de estatísticas é de 300 segundos.
Ativação do teste de loopback em uma interface Ethernet
Sobre o teste de loopback
Execute essa tarefa para determinar se um link Ethernet funciona corretamente. O teste de loopback inclui os seguintes tipos:
Teste de loopback interno - Testa o dispositivo onde reside a interface Ethernet. O teste
A interface Ethernet envia pacotes de saída de volta para o dispositivo local. Se o dispositivo não conseguir receber os pacotes, ele falhará.
Teste de loopback externo - Testa a função de hardware da interface Ethernet. A interface Ethernet envia pacotes de saída para o dispositivo local por meio de um plugue de loop automático. Se o dispositivo não receber os pacotes, haverá falha na função de hardware da interface Ethernet.
Restrições e diretrizes
Depois que você ativar esse recurso em uma interface Ethernet, a interface não encaminhará o tráfego de dados.
Uma interface Ethernet em um teste de loopback não pode encaminhar corretamente os pacotes de dados.
Não é possível executar um teste de loopback em interfaces Ethernet desativadas manualmente (exibidas como no estado ADM ou Administratively DOWN).
Os comandos speed, duplex, mdix-mode e shutdown não podem ser configurados em uma interface Ethernet em um teste de loopback.
Depois de ativar esse recurso em uma interface Ethernet, a interface Ethernet muda para o modo full duplex. Depois de desativar esse recurso, a interface Ethernet volta à sua configuração duplex.
Os comandos shutdown, port up-mode e loopback são mutuamente exclusivos.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberConfigure o teste de loopback na interface Ethernet.
Ativar o teste de loopback na interface Ethernet.
loopback{ external | internal }Por padrão, o teste de loopback é desativado em uma interface Ethernet.
Realize um teste de loopback.
loopback-test{ external | internal }OBSERVAÇÃO:
Esse comando é compatível apenas com a versão 6346 e posteriores.
Ativação forçada de uma porta de fibra
Sobre esta tarefa
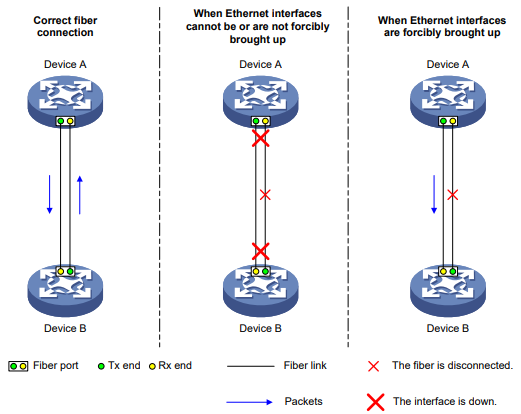
Conforme mostrado na Figura 2, uma porta de fibra usa fibras separadas para transmitir e receber pacotes. O estado físico da porta de fibra está ativo somente quando as fibras de transmissão e recepção estão fisicamente conectadas. Se uma das fibras estiver desconectada, a porta de fibra não funcionará.
Para permitir que uma porta de fibra encaminhe o tráfego por um único link, você pode usar o comando port up-mode. Esse comando força a ativação de uma porta de fibra, mesmo quando não há links de fibra ou módulos transceptores presentes para a porta de fibra. Quando um link de fibra está presente e ativo, a porta de fibra pode encaminhar pacotes pelo link de forma unidirecional.
Figura 2 Ativação forçada de uma porta de fibra
Restrições e diretrizes
As portas de cobre e as interfaces combinadas não são compatíveis com esse recurso. Esse recurso é compatível apenas com a versão 6312 e posteriores.
Os comandos de modo de atividade, desligamento e loopback da porta são mutuamente exclusivos. Uma porta de fibra não é compatível com esse recurso se a porta se unir a um grupo de agregação da Camada 2.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberAbra a porta de fibra à força.
port up-mode Por padrão, uma porta de fibra não é ativada à força.
Configuração das funções de alarme da interface
Sobre esta tarefa
Com as funções de alarme de interface ativadas, quando o número de pacotes de erro em uma interface em estado normal dentro do intervalo especificado excede o limite superior, a interface gera um alarme de excesso de limite superior e entra no estado de alarme. Quando o número de pacotes de erro em uma interface no estado de alarme dentro do intervalo especificado cai abaixo do limite inferior, a interface gera um alarme de recuperação e volta ao estado normal.
Compatibilidade de software e recursos
Esse recurso é compatível apenas com a versão 6342 e posteriores.
Restrições e diretrizes
Você pode configurar os parâmetros do alarme de pacote de erro na visualização do sistema e na visualização da interface.
A configuração na visualização do sistema entra em vigor em todas as interfaces do slot especificado. A configuração na visualização da interface tem efeito apenas na interface atual.
Para uma interface, a configuração na visualização da interface tem prioridade, e a configuração na visualização do sistema é usada somente quando nenhuma configuração é feita na visualização da interface.
Uma interface que é desligada devido a alarmes de pacotes de erros não pode se recuperar automaticamente. Para ativar a interface, execute o comando undo shutdown na interface.
Para que as estatísticas de pacotes de erros sejam precisas, defina o intervalo de coleta e comparação de estatísticas como superior a 7 segundos usando a palavra-chave interval interval.
Ativação das funções de alarme da interface
Entre na visualização do sistema.
System ViewAtivar funções de alarme para o módulo de monitoramento de interface.
snmp-agent trap enable ifmonitor [ crc-error | input-error | output-error ] * Por padrão, todas as funções de alarme são ativadas para as interfaces.
Configuração dos parâmetros do pacote de erro CRC
Entre na visualização do sistema.
System ViewConfigurar parâmetros globais de alarme de pacote de erro de CRC.
ifmonitor crc-error slot slot-number high-threshold high-value
low-threshold low-value interval interval [ shutdown ] Por padrão, o limite superior é 1000, o limite inferior é 100 e o intervalo de coleta e comparação de estatísticas é de 10 segundos para pacotes de erro CRC.
Entre na visualização da interface Ethernet.
interface interface-type interface-numberConfigurar parâmetros de alarme de pacote de erro de CRC para a interface.
port ifmonitor crc-error high-threshold high-value low-threshold low-value interval interval [ shutdown ] Por padrão, uma interface usa os parâmetros globais de alarme de pacote de erro de CRC.
Configuração dos parâmetros de alarme do pacote de erros de entrada
Entre na visualização do sistema.
System ViewConfigurar parâmetros globais de alarme de pacote de erros de entrada.
ifmonitor input-error slot slot-number high-threshold high-value low-threshold low-value interval interval [ shutdown ] Por padrão, o limite superior é 1000, o limite inferior é 100 e o intervalo de coleta e comparação de estatísticas é de 10 segundos para pacotes de erros de entrada.
Entre na visualização da interface Ethernet.
interface interface-type interface-numberConfigurar parâmetros de alarme de pacote de erro de entrada para a interface.
port ifmonitor input-error high-threshold high-value low-threshold low-value interval interval [ shutdown ] Por padrão, uma interface usa os parâmetros globais de alarme de pacote de erro de entrada.
Configuração dos parâmetros de alarme do pacote de erros de saída
Entre na visualização do sistema.
System ViewConfigurar parâmetros globais de alarme de pacote de erro de saída.
ifmonitor output-error slot slot-number high-threshold high-value low-threshold low-value interval interval [ shutdown ] Por padrão, o limite superior é 1000, o limite inferior é 100 e a coleta de estatísticas e o intervalo de comparação é de 10 segundos para pacotes de erro de saída.
Entre na visualização da interface Ethernet.
interface interface-type interface-numberConfigurar os parâmetros de alarme do pacote de erros de saída.
port ifmonitor output-error high-threshold high-value low-threshold low-value interval interval [ shutdown ]Por padrão, uma interface usa os parâmetros globais de alarme de pacote de erro de saída.
Restaurar as configurações padrão de uma interface
Restrições e diretrizes
Esse recurso pode interromper os serviços de rede em andamento. Certifique-se de estar totalmente ciente dos impactos desse recurso ao usá-lo em uma rede ativa.
Esse recurso pode não conseguir restaurar as configurações padrão de alguns comandos devido a dependências de comandos ou restrições do sistema. Você pode usar o comando display this na visualização da interface para verificar esses comandos e executar suas formas de desfazer ou seguir a referência do comando para restaurar suas configurações padrão. Se a tentativa de restauração ainda falhar, siga a mensagem de erro para resolver o problema.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberRestaurar as configurações padrão da interface.
defaultConfiguração de uma interface Ethernet de camada 2
Configuração das opções de velocidade para autonegociação em uma interface Ethernet
Sobre as opções de velocidade para autonegociação
Por padrão, a autonegociação de velocidade permite que uma interface Ethernet negocie com seu par a velocidade mais alta que ambas as extremidades suportam. Você pode restringir a lista de opções de velocidade para negociação.
Figura 3 Cenário de aplicação da autonegociação de velocidade
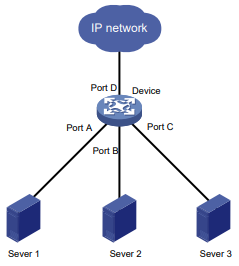
Conforme mostrado na Figura 3:
Todas as interfaces do dispositivo estão operando no modo de autonegociação de velocidade, com a velocidade mais alta de 1000 Mbps.
A porta D fornece acesso à Internet para os servidores.
Se a taxa de transmissão de cada servidor no cluster de servidores for de 1000 Mbps, a taxa de transmissão total excederá a capacidade da Porta D.
Para evitar congestionamento na Porta D, configure 100 Mbps como a única opção disponível para negociação de velocidade nas interfaces Porta A, Porta B e Porta C. Como resultado, a taxa de transmissão em cada interface conectada a um servidor é limitada a 100 Mbps.
Restrições e diretrizes
Os comandos speed e speed auto substituem um ao outro, e o que for configurado por último entra em vigor.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberDefinir opções de velocidade para autonegociação.
speed auto { 10 | 100 | 1000 } *Nenhuma opção de velocidade é definida para a negociação automática.
Configuração do modo MDIX de uma interface Ethernet
As portas de fibra não são compatíveis com a configuração do modo MDIX.
Sobre o modo MDIX
Uma interface Ethernet física tem oito pinos, cada um dos quais desempenha uma função específica. Por exemplo, os pinos 1 e 2 transmitem sinais e os pinos 3 e 6 recebem sinais. Você pode usar cabos Ethernet cruzados e diretos para conectar interfaces Ethernet de cobre. Para acomodar esses tipos de cabos, uma interface Ethernet de cobre pode operar em um dos seguintes modos MDIX (Medium Dependent Interface-Crossover):
Modo MDIX - Os pinos 1 e 2 são pinos de recepção e os pinos 3 e 6 são pinos de transmissão.
Modo MDI - Os pinos 1 e 2 são pinos de transmissão e os pinos 3 e 6 são pinos de recepção.
Modo AutoMDIX - A interface negocia as funções de pino com seu par.
OBSERVAÇÃO:
Esse recurso não tem efeito nos pinos 4, 5, 7 e 8 das interfaces Ethernet físicas.
Os pinos 4, 5, 7 e 8 das interfaces que operam a 10 Mbps ou 100 Mbps não recebem nem transmitem sinais.
Os pinos 4, 5, 7 e 8 das interfaces que operam com taxas de 1000 Mbps ou mais recebem e transmitem sinais.
Restrições e diretrizes
Para permitir que uma interface Ethernet de cobre se comunique com seu par, defina o modo MDIX da interface seguindo estas diretrizes:
Normalmente, defina o modo MDIX da interface como AutoMDIX. Defina o modo MDIX da interface como MDI ou MDIX somente quando o dispositivo não puder determinar o tipo de cabo.
Quando um cabo direto for usado, configure a interface para operar em um modo MDIX diferente do seu par.
Quando um cabo crossover for usado, execute uma das seguintes tarefas:
Configure a interface para operar no mesmo modo MDIX que seu par.
Configure uma das extremidades para operar no modo AutoMDIX.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberDefinir o modo MDIX da interface Ethernet.
mdix-mode { automdix | mdi | mdix }Por padrão, uma interface Ethernet de cobre opera no modo automático para negociar funções de pino com seu par.
Configuração do controle de tempestades em uma interface Ethernet
Sobre o controle de tempestades
O controle de tempestades compara o tráfego de broadcast, multicast e unicast desconhecido regularmente com seus respectivos limites de tráfego em uma interface Ethernet. Para cada tipo de tráfego, o controle de tempestade fornece um limite inferior e um limite superior.
Dependendo de sua configuração, quando um tipo específico de tráfego excede o limite superior, a interface executa uma das seguintes operações:
Bloqueia esse tipo de tráfego e encaminha outros tipos de tráfego - Mesmo que a interface não encaminhe o tráfego bloqueado, ela ainda conta o tráfego. Quando o tráfego bloqueado cai abaixo do limite inferior, a interface começa a encaminhar o tráfego.
Desativa-se automaticamente - A interface se desativa automaticamente e deixa de encaminhar qualquer tráfego. Quando o tráfego bloqueado cai abaixo do limite inferior, a interface não é ativada automaticamente. Para ativar a interface, use o comando undo shutdown ou desative o recurso de controle de tempestade.
Você pode configurar uma interface Ethernet para emitir traps de eventos de limite e mensagens de registro quando o tráfego monitorado atender a uma das seguintes condições:
Excede o limite superior.
Cai abaixo do limite inferior.
Tanto a supressão quanto o controle de tempestades podem suprimir tempestades em uma interface. A supressão de tempestades usa o chip para suprimir o tráfego. A supressão de tempestades tem menos impacto sobre o desempenho do dispositivo do que o controle de tempestades, que usa software para suprimir o tráfego. Para obter mais informações sobre a supressão de tempestades, consulte "Configuração da supressão de tempestades".
O controle de tempestade usa um ciclo completo de sondagem para coletar dados de tráfego e analisa os dados no próximo ciclo. Uma interface leva de um a dois intervalos de sondagem para tomar uma ação de controle de tempestade.
Restrições e diretrizes
Para que o resultado da supressão de tráfego seja determinado, não configure o controle de tempestade juntamente com a supressão de tempestade para o mesmo tipo de tráfego.
Procedimento
Entre na visualização do sistema.
System View(Opcional.) Defina o intervalo de sondagem de estatísticas do módulo de controle de tempestade.
intervalo de restrição de tempestade intervalo
A configuração padrão é de 10 segundos.
Para estabilidade da rede, use o padrão ou defina um intervalo de sondagem de estatísticas mais longo.
Entre na visualização da interface Ethernet.
interface interface-type interface-numberHabilite o controle de tempestades e defina os limites inferior e superior para tráfego de broadcast, multicast ou unicast desconhecido.
storm-constrain { broadcast | multicast | unicast } { pps | kbps | ratio } upperlimit lowerlimit Por padrão, o controle de tempestade está desativado.
Defina a ação de controle a ser tomada quando o tráfego monitorado exceder o limite superior.
storm-constrain control { block | shutdown }Por padrão, o controle de tempestade está desativado.
Habilite a interface Ethernet para emitir mensagens de registro quando detectar eventos de limite de controle de tempestade.
storm-constrain enable logPor padrão, a interface Ethernet emite mensagens de registro quando o tráfego monitorado excede o limite superior ou cai abaixo do limite inferior a partir de um valor acima do limite superior.
Habilite a interface Ethernet para enviar traps de eventos de limite de controle de tempestade.
storm-constrain enable trapPor padrão, a interface Ethernet envia traps quando o tráfego monitorado excede o limite superior ou cai abaixo do limite inferior a partir do limite superior de um valor acima do limite superior .
Teste da conexão do cabo de uma interface Ethernet
Se o link de uma interface Ethernet estiver ativo, o teste da conexão do cabo fará com que o link caia e depois volte a funcionar.
Sobre como testar a conexão do cabo de uma interface Ethernet
Esse recurso testa a conexão do cabo de uma interface Ethernet e exibe o resultado do teste do cabo em 5 segundos. O resultado do teste inclui o status do cabo e alguns parâmetros físicos. Se alguma falha for detectada, o resultado do teste mostrará o comprimento da porta local até o ponto defeituoso.
Restrições e diretrizes
As portas de fibra não são compatíveis com esse recurso.
Procedimento
Digite qualquer visualização.
Realize um teste para o cabo conectado a uma interface Ethernet.
virtual-cable-test interface [ interface-type interface-number | interface-name ]A interface [ interface-type interface-number | interface-name ]
é compatível apenas com as versões R6350 e posteriores.
Ao executar essa operação em uma interface Ethernet, o link será automaticamente desativado e ativado uma vez, se já estiver ativado.
Ativação de bridging em uma interface Ethernet
Sobre a ativação de bridging em uma interface Ethernet
Por padrão, o dispositivo descarta os pacotes cuja interface de saída e a interface de entrada são as mesmas.
Para permitir que o dispositivo encaminhe esses pacotes em vez de descartá-los, ative o recurso de ponte na visualização da interface Ethernet.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet.
interface interface-type interface-numberHabilite a ponte na interface Ethernet.
port bridge enable Por padrão, o bridging é desativado em uma interface Ethernet.
Configurando as interfaces loopback, nulas e inloopback
Sobre interfaces de loopback, nulas e inloopback
Sobre as interfaces de loopback
Uma interface de loopback é uma interface virtual. O estado da camada física de uma interface de loopback está sempre ativo, a menos que a interface de loopback seja desligada manualmente. Devido a esse benefício, as interfaces de loopback são amplamente usadas nos seguintes cenários:
Configuração de um endereço de interface de loopback como o endereço de origem dos pacotes IP gerados pelo dispositivo - Como os endereços de interface de loopback são endereços unicast estáveis, geralmente são usados como identificações de dispositivos.
Ao configurar uma regra em um servidor de autenticação ou de segurança, você pode configurá-la para permitir ou negar pacotes que tenham o endereço da interface de loopback de um dispositivo. Isso simplifica sua configuração e obtém o efeito de permitir ou negar os pacotes gerados pelo dispositivo. Para usar um endereço de interface de loopback como endereço de origem de pacotes IP, certifique-se de que a interface de loopback seja acessível a partir do par, executando a configuração de roteamento. Todos os pacotes de dados enviados para a interface de loopback são considerados pacotes enviados para o próprio dispositivo, portanto, o dispositivo não encaminha esses pacotes.
Uso de uma interface de loopback em protocolos de roteamento dinâmico - Sem nenhuma ID de roteador configurada para um protocolo de roteamento dinâmico, o sistema seleciona o endereço IP mais alto da interface de loopback como ID de roteador.
Sobre interfaces nulas
Uma interface nula é uma interface virtual e está sempre ativa, mas você não pode usá-la para encaminhar pacotes de dados nem configurá-la com um endereço IP ou protocolo de camada de link. A interface nula oferece uma maneira mais simples de filtrar pacotes do que a ACL. Você pode filtrar o tráfego indesejado transmitindo-o para uma interface nula em vez de aplicar uma ACL. Por exemplo, se você especificar uma interface nula como o próximo salto de uma rota estática para um segmento de rede , todos os pacotes roteados para o segmento de rede serão descartados.
Sobre as interfaces inloopback
Uma interface inloopback é uma interface virtual criada pelo sistema, que não pode ser configurada ou excluída. Os estados do protocolo da camada física e da camada de link de uma interface de inloopback estão sempre ativos. Todos os pacotes IP enviados para uma interface inloopback são considerados pacotes enviados para o próprio dispositivo e não são encaminhados.
Configuração de uma interface de loopback
Entre na visualização do sistema.
System ViewCrie uma interface de loopback e entre na visualização da interface de loopback.
interface loopback interface-number Configure a descrição da interface.
description text A configuração padrão é o nome da interface Interface (por exemplo, Interface LoopBack1).
Configure a largura de banda esperada da interface de loopback.
bandwidth bandwidth-valuePor padrão, a largura de banda esperada de uma interface de loopback é de 0 kbps.
Ative a interface de loopback.
undo shutdown Por padrão, uma interface de loopback está ativa.
Configuração de uma interface nula
Entre na visualização do sistema.
System ViewEntre na visualização de interface nula.
interface null 0 A Interface Null 0 é a interface nula padrão do dispositivo e não pode ser criada ou removida manualmente.
Somente uma interface nula, Null 0, é compatível com o dispositivo. O número da interface nula é sempre 0.
Configure a descrição da interface.
description text A configuração padrão é Interface NULL0.
Restaurar as configurações padrão de uma interface
Restrições e diretrizes
Esse recurso pode interromper os serviços de rede em andamento. Certifique-se de estar totalmente ciente do impacto desse recurso ao usá-lo em uma rede ativa.
Esse recurso pode não conseguir restaurar as configurações padrão de alguns comandos devido a dependências de comandos ou restrições do sistema. Você pode usar o comando display this na visualização da interface para verificar esses comandos e executar suas formas de desfazer ou seguir a referência do comando para restaurar suas configurações padrão. Se a tentativa de restauração ainda falhar, siga a mensagem de erro para resolver o problema.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface de loopback ou da interface nula.
interface loopback interface-number interface nula 0
Restaurar as configurações padrão da interface.
defaultConfigurando as interfaces em massa
Sobre a configuração em massa da interface
Você pode entrar na visualização de intervalo de interfaces para configurar em massa várias interfaces com o mesmo recurso, em vez de configurá-las uma a uma. Por exemplo, você pode executar o comando shutdown na visualização de intervalo de interfaces para desligar um intervalo de interfaces.
Para configurar interfaces em massa, você deve configurar um intervalo de interfaces e entrar em sua visualização usando a opção
comando de intervalo de interface ou nome do intervalo de interface.
O intervalo de interfaces criado com o uso do comando de intervalo de interfaces não é salvo na configuração em execução. Não é possível usar o intervalo de interface repetidamente. Para criar um intervalo de interface que possa ser usado repetidamente, use o comando nome do intervalo de interface.
Restrições e diretrizes: Configuração de interface em massa
Quando você configurar interfaces em bloco na visualização de intervalo de interfaces, siga estas restrições e diretrizes:
Na visualização de intervalo de interfaces, somente os comandos suportados pela primeira interface na lista de interfaces especificada (em ordem alfabética) estão disponíveis para configuração.
Antes de configurar uma interface como a primeira interface em um intervalo de interfaces, certifique-se de que é possível entrar na visualização da interface usando o comando interface interface-type
comando interface-número.
Não atribua uma interface agregada e nenhuma de suas interfaces membros a um intervalo de interface. Alguns comandos, depois de serem executados em uma interface agregada e em suas interfaces membros, podem interromper a agregação.
Entenda que quanto mais interfaces você especificar, maior será o tempo de execução do comando.
Para garantir o desempenho da configuração da interface em massa, configure menos de 1.000 nomes de intervalos de interface.
O dispositivo não emite mensagens de alerta ou alarme durante o processo de configuração da interface em massa. Certifique-se de que você está totalmente ciente dos impactos da configuração da interface em massa.
Depois que um comando é executado na visualização de intervalo de interface, pode ocorrer uma das seguintes situações:
O sistema exibe uma mensagem de erro e permanece na visualização do intervalo de interfaces. Isso significa que a execução falhou em uma ou várias interfaces de membro.
Se a execução falhar na primeira interface membro, o comando não será executado em nenhuma interface membro.
Se a execução falhar em uma interface de membro que não seja a primeira, o comando entrará em vigor nas interfaces de membro restantes.
O sistema retorna à visualização do sistema. Isso significa que:
O comando é compatível tanto com a visualização do sistema quanto com a visualização da interface.
A execução falhou em uma interface membro na visualização do intervalo de interfaces e foi bem-sucedida na visualização do sistema.
O comando não é executado nas interfaces de membro subsequentes.
Você pode usar o comando display this para verificar a configuração na visualização da interface de cada interface membro. Além disso, se a configuração na visualização do sistema não for necessária, use a forma undo do comando para remover a configuração.
Procedimento
Entre na visualização do sistema.
System ViewCrie um intervalo de interface e entre na visualização de intervalo de interface.
Criar um intervalo de interface sem especificar um nome.
interface range { interface-type interface-number [ to interface-type interface-number ] } &<1-24>Crie um intervalo de interface nomeado.
interface range name name [ interface { interface-type interface-number [ to interface-type interface-number ] } &<1-24> ](Opcional.) Exibir comandos disponíveis para a primeira interface no intervalo de interfaces. Digite um ponto de interrogação (?) no prompt do intervalo de interfaces.
Use os comandos disponíveis para configurar as interfaces. Os comandos disponíveis dependem da interface.
(Opcional.) Verifique a configuração.
display thisConfigurando a tabela de endereços MAC
Sobre a tabela de endereços MAC
Um dispositivo Ethernet usa uma tabela de endereços MAC para encaminhar quadros. Uma entrada de endereço MAC inclui um endereço MAC de destino, uma interface de saída e um ID de VLAN. Quando o dispositivo recebe um quadro, ele usa o endereço MAC de destino do quadro para procurar uma correspondência na tabela de endereços MAC.
O dispositivo encaminha o quadro para fora da interface de saída na entrada correspondente se for encontrada uma correspondência.
O dispositivo inunda o quadro na VLAN do quadro se nenhuma correspondência for encontrada.
Como uma entrada de endereço MAC é criada
As entradas na tabela de endereços MAC incluem entradas aprendidas automaticamente pelo dispositivo e entradas adicionadas manualmente.
Aprendizado de endereço MAC
O dispositivo pode preencher automaticamente sua tabela de endereços MAC aprendendo os endereços MAC de origem dos quadros de entrada em cada interface.
O dispositivo executa as seguintes operações para saber o endereço MAC de origem dos pacotes de entrada:
Verifica o endereço MAC de origem (por exemplo, MAC-SOURCE) do quadro.
Procura o endereço MAC de origem na tabela de endereços MAC.
O dispositivo atualiza a entrada se for encontrada uma entrada.
O dispositivo adiciona uma entrada para MAC-SOURCE e a porta de entrada se nenhuma entrada for encontrada.
Quando o dispositivo recebe um quadro destinado ao MAC-SOURCE depois de aprender esse endereço MAC de origem, o dispositivo executa as seguintes operações:
Localiza a entrada MAC-SOURCE na tabela de endereços MAC.
Encaminha o quadro para fora da porta na entrada.
O dispositivo executa o processo de aprendizado para cada quadro de entrada com um endereço MAC de origem desconhecida até que a tabela esteja totalmente preenchida.
Configuração manual de entradas de endereço MAC
O aprendizado dinâmico de endereço MAC não faz distinção entre quadros ilegítimos e legítimos, o que pode acarretar riscos à segurança. Quando o host A estiver conectado à porta A, uma entrada de endereço MAC será aprendida para o endereço MAC do host A (por exemplo, MAC A). Quando um usuário ilegal envia quadros com MAC A como endereço MAC de origem para a Porta B, o dispositivo executa as seguintes operações:
Aprende uma nova entrada de endereço MAC com a Porta B como interface de saída e sobrescreve a antiga entrada para o MAC A.
Encaminha os quadros destinados ao MAC A para fora da porta B para o usuário ilegal.
Como resultado, o usuário ilegal obtém os dados do Host A. Para aumentar a segurança do Host A, configure manualmente uma entrada estática para vincular o Host A à Porta A. Em seguida, os quadros destinados ao Host A são sempre enviados pela Porta A. Outros hosts que usam o endereço MAC forjado do Host A não podem obter os quadros destinados ao Host A.
Tipos de entradas de endereço MAC
Uma tabela de endereços MAC pode conter os seguintes tipos de entradas:
Entradas estáticas - Uma entrada estática é adicionada manualmente para encaminhar quadros com um endereço MAC de destino específico para fora da interface associada e nunca se esgota. Uma entrada estática tem prioridade mais alta do que uma entrada aprendida dinamicamente.
Entradas dinâmicas - Uma entrada dinâmica pode ser configurada manualmente ou aprendida dinamicamente para encaminhar quadros com um endereço MAC de destino específico para fora da interface associada. Uma entrada dinâmica pode envelhecer. Uma entrada dinâmica configurada manualmente tem a mesma prioridade que uma entrada aprendida dinamicamente.
Entradas de blackhole - Uma entrada de blackhole é configurada manualmente e nunca se esgota. Uma entrada de blackhole é configurada para filtrar quadros com um endereço MAC de origem ou destino específico. Por exemplo, para bloquear todos os quadros destinados a um usuário ou originados por ele, é possível configurar o endereço MAC do usuário como uma entrada de endereço MAC blackhole. Uma entrada de blackhole tem prioridade mais alta do que uma entrada aprendida dinamicamente.
Entradas unicast multiportas - Uma entrada unicast multiportas é adicionada manualmente para enviar quadros com um endereço MAC de destino unicast específico a partir de várias portas e nunca se esgota. Uma entrada unicast multiportas tem prioridade mais alta do que uma entrada aprendida dinamicamente.
Uma entrada de endereço MAC unicast estático, blackhole ou multiportas pode sobrescrever uma entrada de endereço MAC dinâmico, mas não vice-versa. Uma entrada estática, uma entrada blackhole e uma entrada unicast multiportas não podem se sobrepor umas às outras.
Este documento não abrange a configuração de entradas de endereço MAC multicast estático. Para obter mais informações sobre a configuração de entradas de endereço MAC de multicast estático, consulte IGMP snooping no Guia de configuração de multicast IP.
Configuração de entradas de endereço MAC
Sobre o encaminhamento de quadros baseado em entradas de endereço MAC
Um quadro cujo endereço MAC de origem corresponde a diferentes tipos de entradas de endereço MAC é processado de forma diferente.
Restrições e diretrizes para a configuração de entradas de endereços MAC
Uma entrada de endereço MAC dinâmico configurada manualmente substituirá uma entrada aprendida que já exista com uma interface de saída diferente para o endereço MAC.
As entradas de endereço MAC unicast estático, blackhole e multiportas configuradas manualmente não sobreviverão a uma reinicialização se você não salvar a configuração. As entradas de endereço MAC dinâmico configuradas manualmente são perdidas após a reinicialização, independentemente de você salvar ou não a configuração.
Não configure os endereços MAC reservados do dispositivo como endereços MAC unicast estáticos, dinâmicos, blackhole ou multiportas. Os endereços MAC reservados de um dispositivo são endereços MAC do endereço MAC de ponte do dispositivo até o endereço MAC de ponte mais 95. Para obter informações sobre endereços MAC de ponte, consulte IRF no Guia de Configuração de Tecnologias Virtuais.
Pré-requisitos para a configuração da entrada de endereço MAC
Antes de configurar manualmente uma entrada de endereço MAC para uma interface, certifique-se de que a VLAN na entrada tenha sido criada.
Adição ou modificação de uma entrada de endereço MAC estático ou dinâmico
Adição ou modificação de uma entrada de endereço MAC estático ou dinâmico globalmente
Entre na visualização do sistema.
System ViewAdicionar ou modificar uma entrada de endereço MAC estático ou dinâmico.
mac-address { dynamic | static } mac-address interface interface-type interface-number vlan vlan-idPor padrão, nenhuma entrada de endereço MAC é configurada globalmente. Certifique-se de ter atribuído a interface à VLAN.
Adição ou modificação de uma entrada de endereço MAC estático ou dinâmico em uma interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberAdicionar ou modificar uma entrada de endereço MAC estático ou dinâmico.
mac-address { dynamic | static } mac-address vlan vlan-idPor padrão, nenhuma entrada de endereço MAC é configurada em uma interface. Certifique-se de ter atribuído a interface à VLAN.
Adição ou modificação de uma entrada de endereço MAC de blackhole
Entre na visualização do sistema.
System ViewAdicionar ou modificar uma entrada de endereço MAC de blackhole.
mac-address blackhole mac-address vlan vlan-idPor padrão, nenhuma entrada de endereço MAC de blackhole é configurada.
Adição ou modificação de uma entrada de endereço MAC unicast multiportas
Sobre a configuração de entrada de endereço MAC unicast multiportas
Você pode configurar uma entrada de endereço MAC unicast multiportas para associar um endereço MAC de destino unicast a várias portas. O quadro com um endereço MAC de destino que corresponda à entrada é enviado por várias portas.
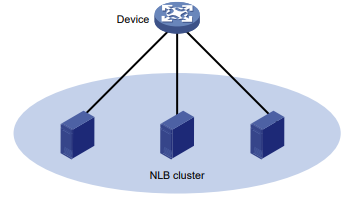
Por exemplo, no modo unicast NLB (consulte a Figura 1):
Todos os servidores em um cluster usam o endereço MAC do cluster como seu próprio endereço.
Os quadros destinados ao cluster são encaminhados a todos os servidores do grupo.
Nesse caso, você pode configurar uma entrada de endereço MAC unicast multiportas no dispositivo conectado ao grupo de servidores. Em seguida, o dispositivo encaminha o quadro destinado ao grupo de servidores para cada servidor por meio de todas as portas conectadas aos servidores dentro do cluster.
Figura 1 Cluster NLB
É possível configurar uma entrada de endereço MAC unicast multiportas globalmente ou em uma interface.
Configuração de uma entrada de endereço MAC unicast multiportas globalmente
Entre na visualização do sistema.
System ViewAdicionar ou modificar uma entrada de endereço MAC unicast multiportas.
mac-address multiport mac-address interface interface-list vlanPor padrão, nenhuma entrada de endereço MAC unicast multiportas é configurada globalmente. Certifique-se de ter atribuído a interface à VLAN.
Configuração de uma entrada de endereço MAC unicast multiportas em uma interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberAdicione a interface a uma entrada de endereço MAC unicast multiportas.
mac-address multiport mac-address vlan vlan-idPor padrão, nenhuma entrada de endereço MAC unicast multiportas é configurada em uma interface. Certifique-se de ter atribuído a interface à VLAN.
Configuração do timer de envelhecimento para entradas dinâmicas de endereço MAC
Sobre o cronômetro de envelhecimento para entradas de endereço MAC dinâmico
Para segurança e uso eficiente do espaço da tabela, a tabela de endereços MAC usa um cronômetro de envelhecimento para cada entrada de endereço MAC dinâmico. Se uma entrada de endereço MAC dinâmico não for atualizada antes que o cronômetro de envelhecimento expire, o dispositivo excluirá a entrada. Esse mecanismo de envelhecimento garante que a tabela de endereços MAC possa ser atualizada prontamente para acomodar as últimas alterações na topologia da rede.
Uma rede estável requer um intervalo de envelhecimento mais longo, e uma rede instável requer um intervalo de envelhecimento mais curto.
Um intervalo de envelhecimento muito longo pode fazer com que a tabela de endereços MAC retenha entradas desatualizadas. Como resultado, os recursos da tabela de endereços MAC podem se esgotar e a tabela de endereços MAC pode não conseguir atualizar suas entradas para acomodar as alterações mais recentes na rede.
Um intervalo muito curto pode resultar na remoção de entradas válidas, o que causaria inundações desnecessárias e possivelmente afetaria o desempenho do dispositivo.
Para reduzir as inundações em uma rede estável, defina um temporizador de envelhecimento longo ou desative o temporizador para evitar que as entradas dinâmicas envelheçam desnecessariamente. A redução das inundações melhora o desempenho da rede. A redução das inundações também melhora a segurança, pois reduz as chances de um quadro de dados chegar a destinos não intencionais.
Procedimento
Entre na visualização do sistema.
System ViewDefina o cronômetro de envelhecimento para entradas de endereço MAC dinâmico.
mac-address timer { aging seconds | no-aging }Por padrão, o cronômetro de envelhecimento é de 300 segundos para entradas de endereço MAC dinâmico.
Desativação do aprendizado de endereço MAC
Sobre a desativação do aprendizado de endereço MAC
O aprendizado de endereço MAC é ativado por padrão. Para evitar que a tabela de endereços MAC fique saturada quando o dispositivo estiver sofrendo ataques, desative o aprendizado de endereços MAC. Por exemplo, você pode desativar o aprendizado de endereço MAC para evitar que o dispositivo seja atacado por uma grande quantidade de quadros com diferentes endereços MAC de origem.
Depois que o aprendizado de endereço MAC é desativado, o dispositivo exclui imediatamente as entradas de endereço MAC dinâmico existentes.
Desativação do aprendizado global de endereço MAC
Restrições e diretrizes
Depois que você desativar o aprendizado de endereço MAC global, o dispositivo não poderá aprender endereços MAC em nenhuma interface .
Procedimento
Entre na visualização do sistema.
System ViewDesativar o aprendizado global de endereço MAC.
undo mac-address mac-learning enablePor padrão, o aprendizado global de endereço MAC está ativado.
Desativar o aprendizado de endereço MAC em uma interface
Sobre como desativar o aprendizado de endereço MAC em uma interface
Quando o aprendizado de endereço MAC global está ativado, é possível desativar o aprendizado de endereço MAC em uma única interface.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDesativar o aprendizado de endereço MAC na interface.
undo mac-address mac-learning enablePor padrão, o aprendizado de endereço MAC é ativado em uma interface.
Desativação do aprendizado de endereço MAC em uma VLAN
Sobre como desativar o aprendizado de endereço MAC em uma VLAN
Quando o aprendizado de endereço MAC global está ativado, você pode desativar o aprendizado de endereço MAC por VLAN.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização de VLAN.
vlan vlan-idDesativar o aprendizado de endereço MAC na VLAN.
undo mac-address mac-learning enablePor padrão, o aprendizado de endereço MAC na VLAN está ativado.
Configuração do limite de aprendizagem de MAC
Sobre o limite de aprendizado MAC baseado em interface
Esse recurso limita o tamanho da tabela de endereços MAC. Uma tabela de endereços MAC grande prejudicará o desempenho do encaminhamento .
Restrições e diretrizes
O limite de aprendizagem de MAC não controla o número de endereços MAC aprendidos em Voice Vlan. Para obter mais informações, consulte "Configuração de Voice Vlan".
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberDefinir o limite de aprendizado de MAC na interface.
mac-address max-mac-count countPor padrão, nenhum limite de aprendizagem de MAC é configurado em uma interface.
Configuração da regra de encaminhamento de quadros desconhecidos após o limite de aprendizagem de MAC ser atingido
Neste documento, os quadros desconhecidos referem-se a quadros cujos endereços MAC de origem não estão na tabela de endereços MAC.
Sobre a configuração da regra de encaminhamento de quadros desconhecidos
Você pode ativar ou desativar o encaminhamento de quadros desconhecidos depois que o limite de aprendizagem de MAC for atingido.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure o dispositivo para encaminhar quadros desconhecidos recebidos na interface depois que o limite de aprendizado de MAC na interface for atingido.
mac-address max-mac-count enable-forwardingPor padrão, o dispositivo pode encaminhar quadros desconhecidos recebidos em uma interface depois que o limite de aprendizagem de MAC na interface for atingido.
Ativação da sincronização de endereços MAC
Sobre a sincronização de endereços MAC
Para evitar inundações desnecessárias e aumentar a velocidade de encaminhamento, certifique-se de que todos os dispositivos membros tenham a mesma tabela de endereços MAC. Depois que você ativa a sincronização de endereços MAC, cada dispositivo membro anuncia as entradas de endereços MAC aprendidos para outros dispositivos membros.
Conforme mostrado na Figura 2:
Figura 2 Tabelas de endereços MAC de dispositivos quando o cliente A acessa o AP C
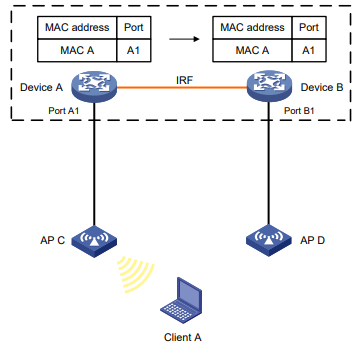
Procedimento
Entre na visualização do sistema.
System ViewAtivar a sincronização de endereços MAC.
mac-address mac-roaming enablePor padrão, a sincronização de endereços MAC está desativada.
Configuração de notificações e supressão de movimentação de endereço MAC
Sobre notificações e supressão de movimentação de endereço MAC
A interface de saída de uma entrada de endereço MAC aprendida na interface A é alterada para a interface B quando existem as seguintes condições:
A interface B recebe um pacote com o endereço MAC como endereço MAC de origem.
A interface B pertence à mesma VLAN que a interface A.
Nesse caso, o endereço MAC é movido da interface A para a interface B, e ocorre uma movimentação de endereço MAC.
O recurso de notificações de movimentação de endereço MAC permite que o dispositivo emita registros de movimentação de endereço MAC quando forem detectadas movimentações de endereço MAC.
Se um endereço MAC for movido continuamente entre as duas interfaces, poderão ocorrer loops de camada 2. Para detectar e localizar loops, você pode visualizar as informações de movimentação do endereço MAC. Para exibir os registros de movimentação de endereço MAC depois que o dispositivo for iniciado, use o comando display mac-address mac-move.
Se o sistema detectar que as movimentações de endereço MAC ocorrem com frequência em uma interface, você poderá configurar a supressão de movimentação de endereço MAC para desligar a interface. A interface é ativada automaticamente após um intervalo de supressão. Ou você pode ativar manualmente a interface.
Restrições e diretrizes
Depois de configurar as notificações de movimentação de endereço MAC, o sistema envia apenas mensagens de registro para o módulo do centro de informações. Se o dispositivo também estiver configurado com o comando snmp-agent trap enable mac-address, o sistema também enviará notificações de SNMP para o módulo SNMP.
Procedimento
Entre na visualização do sistema.
System ViewHabilite as notificações de movimentação de endereço MAC e, opcionalmente, especifique um intervalo de detecção de movimentação de MAC.
mac-address notification mac-move [ interval interval ]Por padrão, as notificações de mudança de endereço MAC estão desativadas.
(Opcional.) Defina os parâmetros de supressão de movimentação de endereço MAC.
mac-address notification mac-move suppression { interval interval | threshold threshold }Por padrão, o intervalo de supressão é de 30 segundos e o limite de supressão é 3.
Para que os parâmetros de supressão de movimentação de endereço MAC tenham efeito, ative a supressão de movimentação de endereço MAC em uma porta.
Entre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberAtivar a supressão de movimentação de endereço MAC.
mac-address notification mac-move suppression Por padrão, a supressão de movimentação de endereço MAC está desativada.
Ativação da atualização rápida do ARP para mudanças de endereço MAC
Sobre a atualização rápida de ARP para mudanças de endereço MAC
A atualização rápida de ARP para mudanças de endereço MAC permite que o dispositivo atualize uma entrada ARP imediatamente após a mudança da interface de saída de um endereço MAC. Esse recurso garante a conexão de dados sem interrupção.
Conforme mostrado na Figura 4, um laptop de usuário móvel acessa a rede conectando-se ao AP 1 ou AP 2. Quando o AP ao qual o usuário se conecta muda, o dispositivo atualiza a entrada ARP para o usuário imediatamente após detectar uma mudança de endereço MAC.
Figura 4 Cenário do aplicativo de atualização rápida de ARP
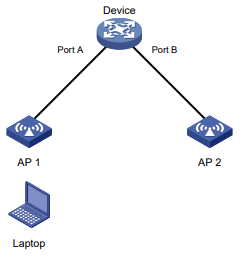
Procedimento
Entre na visualização do sistema.
System ViewHabilite a atualização rápida do ARP para mudanças de endereço MAC.
mac-address mac-move fast-updatePor padrão, a atualização rápida do ARP para mudanças de endereço MAC está desativada.
Configuração do tamanho do intervalo de hash da tabela de endereços MAC
Sobre o tamanho do intervalo de hash da tabela de endereços MAC
O dispositivo salva a tabela de endereços MAC por meio de cadeias de hash. Se vários endereços MAC obtiverem a mesma chave por meio de hash, ocorrerão conflitos de hash de endereço MAC, e o dispositivo não poderá aprender alguns desses endereços MAC. O dispositivo transmitirá o tráfego destinado aos endereços MAC desconhecidos, o que consome largura de banda e recursos.
Você pode aumentar o tamanho do intervalo de hash da tabela de endereços MAC para reduzir os conflitos de hash de endereços MAC. Um tamanho maior do intervalo de hash requer mais recursos do sistema. Defina o tamanho do intervalo de hash
adequadamente, dependendo dos recursos do sistema. Você pode usar o comando display mac-address hash-bucket-size para visualizar o tamanho atual do hash bucket e o tamanho do hash bucket que entrará em vigor na próxima inicialização.
Restrições e diretrizes
O tamanho do intervalo de hash definido entra em vigor na próxima inicialização.
Procedimento
Entre na visualização do sistema.
System ViewDefina o tamanho do intervalo de hash da tabela de endereços MAC.
mac-address hash-bucket-size sizePor padrão, o tamanho do intervalo de hash da tabela de endereços MAC é 4.
Ativação do registro de conflitos de hashing de MAC
Sobre esta tarefa
O registro de conflitos de hashing de MAC permite que o dispositivo gere mensagens de registro para os conflitos de hashing de MAC que ocorrem no aprendizado de endereços MAC. Você pode usar esse recurso para identificar os endereços MAC que o dispositivo não consegue aprender devido a conflitos de hashing. Para exibir as mensagens de registro geradas para conflitos de hashing de MAC, execute o comando display mac-address hash-conflict-record.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6328 e posteriores.
Restrições e diretrizes
Esse recurso consome recursos do sistema. Ao ativá-lo no dispositivo, certifique-se de estar totalmente ciente do impacto no desempenho do dispositivo.
Procedimento
Entre na visualização do sistema.
System ViewHabilite o registro de conflitos de hashing de MAC.
mac-address hash-conflict-record enable slot slot-numberPor padrão, o registro de conflitos de hashing de MAC está desativado.
Desativar o filtro de pacotes quando o endereço MAC de origem for um endereço MAC de multicast ou broadcast
Sobre esta tarefa
Por padrão, o dispositivo descartará um quadro cujo endereço MAC de origem seja um endereço MAC de multicast ou broadcast. Para evitar a perda de tráfego do usuário e garantir que o tráfego do usuário seja encaminhado corretamente nesse cenário, você pode desativar o filtro de pacotes no dispositivo quando o endereço MAC de origem for um endereço MAC de multicast ou broadcast.
Procedimento
Entre na visualização do sistema.
System ViewDesative o filtro de pacotes quando o endereço MAC de origem for um endereço MAC de multicast ou broadcast.
undo mac-address multicast-source packet-filterPor padrão, o filtro de pacotes é ativado no dispositivo em que o endereço MAC de origem é um endereço MAC de multicast ou broadcast.
Ativação de notificações SNMP para a tabela de endereços MAC
Sobre as notificações SNMP para a tabela de endereços MAC
Para relatar eventos críticos de movimentação de endereço MAC a um NMS, ative as notificações de SNMP para a tabela de endereços MAC. Para que as notificações de eventos de mudança de endereço MAC sejam enviadas corretamente, você também deve configurar o SNMP no dispositivo.
Quando as notificações SNMP estão desativadas para a tabela de endereços MAC, o dispositivo envia os registros gerados para o centro de informações. Para exibir os registros, configure o destino do registro e a configuração da regra de saída no centro de informações.
Para obter mais informações sobre o SNMP e a configuração do centro de informações, consulte o guia de configuração de monitoramento e gerenciamento de rede do dispositivo.
Procedimento
Entre na visualização do sistema.
System ViewAtive as notificações SNMP para a tabela de endereços MAC.
snmp-agent trap enable mac-address [ mac-move ]Por padrão, as notificações SNMP são ativadas para a tabela de endereços MAC.
Quando as notificações SNMP são desativadas para a tabela de endereços MAC, as mensagens syslog são enviadas para notificar eventos importantes no módulo da tabela de endereços MAC.
Exemplos de configuração da tabela de endereços MAC
Configuração de rede
Conforme mostrado na Figura 5:
O host A com endereço MAC 000f-e235-dc71 está conectado à GigabitEthernet 1/0/1 do dispositivo e pertence à VLAN 1.
O host B com endereço MAC 000f-e235-abcd, que se comportou de forma suspeita na rede, também pertence à VLAN 1.
Configure a tabela de endereços MAC da seguinte forma:
Para evitar a falsificação de endereços MAC, adicione uma entrada estática para o Host A na tabela de endereços MAC do Device.
Para descartar todos os quadros destinados ao Host B, adicione uma entrada de endereço MAC blackhole para o Host B.
Defina o cronômetro de envelhecimento como 500 segundos para entradas dinâmicas de endereço MAC.
Figura 5 Diagrama de rede

Procedimento
# Adicione uma entrada de endereço MAC estático para o endereço MAC 000f-e235-dc71 na GigabitEthernet 1/0/1 que pertence à VLAN 1.
<Device> system-view
[Device] mac-address static 000f-e235-dc71 interface gigabitethernet 1/0/1 vlan 1 # Adicione uma entrada de endereço MAC blackhole para o endereço MAC 000f-e235-abcd que pertence à VLAN 1.
[Dispositivo] mac-address blackhole 000f-e235-abcd vlan 1# Defina o cronômetro de envelhecimento para 500 segundos para entradas de endereço MAC dinâmico.
[Dispositivo] mac-address timer aging 500Verificação da configuração
# Exibir as entradas de endereço MAC estático para GigabitEthernet 1/0/1.
display mac-address static interface GigabitEthernet 1/0/1# Exibir o tempo de envelhecimento das entradas de endereço MAC dinâmico.
[Device] display mac-address aging-time Tempo de envelhecimento do endereço MAC: 500s.Configuração de informações de MAC
Configurando as informações MAC
Sobre as informações do MAC
O recurso Informações de MAC pode gerar mensagens de syslog ou notificações de SNMP quando as entradas de endereço MAC são aprendidas ou excluídas. Você pode usar essas mensagens para monitorar a saída ou entrada de usuários na rede e analisar o tráfego da rede.
O recurso Informações de MAC armazena em uma fila as mensagens de syslog de alteração de MAC ou as notificações de SNMP. O dispositivo substitui a alteração de endereço MAC mais antiga gravada na fila pela alteração de endereço MAC mais recente quando existem as seguintes condições:
O intervalo de notificação de alteração de MAC não expira.
A fila foi esgotada.
Para enviar uma mensagem syslog ou uma notificação SNMP imediatamente após sua criação, defina o comprimento da fila como zero.
Ativação de informações de MAC
Restrições e diretrizes
Para que as informações de MAC tenham efeito, você deve ativar as informações de MAC globalmente e nas interfaces.
Procedimento
Entre na visualização do sistema.
System ViewAtivar informações de MAC globalmente.
mac-address information enable Por padrão, as informações de MAC são desativadas globalmente.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberAtivar informações de MAC na interface.
mac-address information enable { added | deleted }Por padrão, as informações de MAC são desativadas em uma interface.
Configuração do modo de informações do MAC
Sobre os modos de informações do MAC
Os seguintes modos de informações de MAC estão disponíveis para o envio de alterações de endereço MAC:
Syslog - O dispositivo envia mensagens syslog para notificar alterações de endereço MAC. O dispositivo envia mensagens syslog para o centro de informações, que as envia para o terminal de monitoramento. Para obter mais informações sobre a central de informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Trap - O dispositivo envia notificações SNMP para notificar alterações de endereço MAC. O dispositivo envia notificações de SNMP para o NMS. Para obter mais informações sobre SNMP, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Procedimento
Entre na visualização do sistema.
System ViewConfigure o modo de informações do MAC.
mac-address information mode { syslog | trap } A configuração padrão é trap.
Configuração do intervalo de notificação de alteração de MAC
Sobre o intervalo de notificação de alteração de MAC
Para evitar que as mensagens de syslog ou as notificações de SNMP sejam enviadas com muita frequência, você pode definir o intervalo de notificação de alteração de MAC para um valor maior.
Procedimento
Entre na visualização do sistema.
System ViewDefina o intervalo de notificação de alteração de MAC.
mac-address information interval intervalA configuração padrão é de 1 segundo.
Configuração do comprimento da fila de informações do MAC
Sobre o comprimento da fila de informações MAC
Se o comprimento da fila de informações de MAC for 0, o dispositivo enviará uma mensagem syslog ou uma notificação SNMP imediatamente após o aprendizado ou a exclusão de um endereço MAC.
Se o comprimento da fila de informações de MAC não for 0, o dispositivo armazenará as alterações de MAC na fila:
O dispositivo substitui a alteração de MAC mais antiga gravada na fila pela alteração de MAC mais recente quando existem as seguintes condições:
O intervalo de notificação de alteração de MAC não expira.
A fila foi esgotada.
O dispositivo envia mensagens de syslog ou notificações de SNMP somente se o intervalo de notificação de alteração de MAC expirar.
Procedimento
Entre na visualização do sistema.
System ViewDefina o comprimento da fila de informações do MAC.
mac-address information queue-length value A configuração padrão é 50.
Exemplos de configuração de informações de MAC
Configuração de rede
Ative as informações de MAC na GigabitEthernet 1/0/1 no dispositivo da Figura 6 para enviar alterações de endereço MAC em mensagens de syslog para o host de registro, Host B, por meio da interface GigabitEthernet 1/0/2.
Figura 6 Diagrama de rede
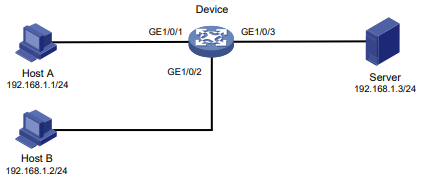
Restrições e diretrizes
Quando você editar o arquivo /etc/syslog.conf, siga estas restrições e diretrizes:
Os comentários devem estar em uma linha separada e devem começar com um sinal de libra (#).
Não são permitidos espaços redundantes após o nome do arquivo.
O nome do recurso de registro e o nível de gravidade especificados no arquivo /etc/syslog.conf devem ser os mesmos que os configurados no dispositivo. Caso contrário, as informações de registro podem não ser enviadas corretamente para o host de registro. O nome do recurso de registro e o nível de gravidade são configurados usando os comandos info-center loghost e info-center source, respectivamente.
Procedimento
Configure o dispositivo para enviar mensagens de syslog ao Host B: # Habilite o centro de informações.
<Device> system-view
[Device] info-center enable # Especifique o host de registro 192.168.1.2/24 e especifique local4 como o recurso de registro.
[Device] info-center loghost 192.168.1.2 facility local4# Desativar a saída de registro para o host de registro.
[Device] info-center source default loghost denyPara evitar a saída de informações desnecessárias, desative a saída de logs de todos os módulos para o destino especificado (loghost, neste exemplo) antes de configurar uma regra de saída.
# Configure uma regra de saída para enviar ao host de registro os registros de endereço MAC que tenham um nível de gravidade não inferior a informativo.
[Device] info-center source mac loghost level informationalConfigure o host de registro, Host B:
Configure o Solaris da seguinte forma. Configure outros sistemas operacionais UNIX da mesma forma que o Solaris.
Faça login no host de registro como usuário root.
Crie um subdiretório chamado Device no diretório /var/log/.
# mkdir /var/log/Device Crie o arquivo info.log no diretório do dispositivo para salvar os registros do dispositivo.
# touch /var/log/Device/info.log Edite o arquivo syslog.conf no diretório /etc/ e adicione o seguinte conteúdo:
# Mensagens de configuração do dispositivo local4.info /var/log/Device/info.log
Nessa configuração, local4 é o nome do recurso de registro que o host de registro usa para receber os registros e info é o nível informativo. O sistema UNIX registra as informações de log que têm um nível de gravidade não inferior a informational no arquivo
# Device configuration messages
local4.info /var/log/Device/info.log Exibir a ID do processo do syslogd, encerrar o processo do syslogd e, em seguida, reiniciar o syslogd
usando a opção -r para que a nova configuração entre em vigor.
# ps -ae | grep syslogd
147
# kill -HUP 147
# syslogd -r & O dispositivo pode enviar os registros de endereços MAC para o host de registro, que armazena os registros no arquivo especificado.
Ativar informações de MAC no dispositivo: # Habilitar informações de MAC globalmente.
[Device] mac-address information enable # Configure o modo de informações do MAC como syslog.
[Device] mac-address information mode syslog # Habilite as informações de MAC na GigabitEthernet 1/0/1 para permitir que a porta registre as informações de alteração de endereço MAC quando a interface executar uma das seguintes operações:
Aprende um novo endereço MAC.
Exclui um endereço MAC existente.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] mac-address information enable added
[Device-GigabitEthernet1/0/1] mac-address information enable deleted
[Device-GigabitEthernet1/0/1] quit # Defina o comprimento da fila de informações do MAC como 100.
[Device] mac-address information queue-length 100Configuração da agregação de links Ethernet
Sobre a agregação de links Ethernet
A agregação de links Ethernet agrupa vários links Ethernet físicos em um único link lógico (chamado de link agregado). A agregação de links oferece os seguintes benefícios:
Maior largura de banda além dos limites de um único link individual. Em um link agregado, o tráfego é distribuído entre as portas membros.
Maior confiabilidade do link. As portas membros fazem backup dinamicamente umas das outras. Quando uma porta membro falha, seu tráfego é automaticamente transferido para outras portas membro.
Cenário de aplicação de agregação de link Ethernet
Conforme mostrado na Figura 1, o Dispositivo A e o Dispositivo B estão conectados por três links físicos de Ethernet. Esses links Ethernet físicos são combinados em um link agregado chamado agregação de link 1. A largura de banda desse link agregado pode atingir até a largura de banda total dos três links Ethernet físicos. Ao mesmo tempo, os três links Ethernet fazem backup um do outro. Quando um link Ethernet físico falha, o tráfego transmitido no link com falha é alternado para os outros dois links.
Figura 1 Diagrama de agregação de link Ethernet

Interface agregada, grupo de agregação e porta membro
Cada agregação de link é representada por uma interface de agregação lógica. Cada interface agregada tem um grupo de agregação criado automaticamente, que contém portas-membro a serem usadas para a agregação . O tipo e o número de um grupo de agregação são os mesmos de sua interface agregada.
Tipos de interface agregada compatíveis
O dispositivo suporta interfaces agregadas de camada 2. Uma interface agregada de camada 2 é criada manualmente. As portas membros em um grupo de agregação de camada 2 só podem ser interfaces Ethernet de camada 2.
A taxa de porta de uma interface agregada é igual à taxa total de suas portas membros selecionadas. Seu modo duplex é o mesmo das portas membros selecionadas. Para obter mais informações sobre as portas membro selecionadas, consulte "Estados de agregação das portas membro em um grupo de agregação".
Estados de agregação das portas membros em um grupo de agregação
Uma porta membro em um grupo de agregação pode estar em qualquer um dos seguintes estados de agregação:
Selected - Uma porta selecionada pode encaminhar tráfego.
Unselected (Não selecionado) - Uma porta não selecionada não pode encaminhar tráfego.
Individual - Uma porta Individual pode encaminhar o tráfego como uma porta física normal. Esse estado é peculiar às portas membros das interfaces agregadas de borda. Uma porta membro é colocada no estado Individual se não tiver recebido LACPDUs antes da primeira expiração do cronômetro de tempo limite do LACP após a ocorrência de um dos eventos a seguir:
A interface agregada é configurada como uma interface agregada de borda.
A porta membro fica inativa e volta a funcionar depois de ser colocada no estado Unselected (não selecionado) ou Selected (selecionado).
Para obter mais informações sobre interfaces agregadas de borda, consulte "Interface agregada de borda".
Chave operacional
Ao agregar portas, o sistema atribui automaticamente a cada porta uma chave operacional com base nas informações da porta, como a taxa da porta e o modo duplex. Qualquer alteração nessas informações aciona um novo cálculo da chave operacional.
Em um grupo de agregação, todas as portas selecionadas têm a mesma chave operacional.
Tipos de configuração
A configuração da porta inclui a configuração do atributo e a configuração do protocolo. A configuração do atributo afeta o estado de agregação da porta, mas a configuração do protocolo não.
Configuração de atributos
Para se tornar uma porta selecionada, uma porta membro deve ter a mesma configuração de atributos que a interface agregada. A Tabela 1 descreve a configuração de atributos.
Tabela 1 Configuração de atributos
Configuração do protocolo
A configuração do protocolo de uma porta membro não afeta o estado de agregação da porta membro. As configurações de aprendizado de endereço MAC e Spanning Tree são exemplos de configuração de protocolo.
Modos de agregação de links
Um grupo de agregação opera em um dos seguintes modos:
A agregação estática é estável. Um grupo de agregação em modo estático é chamado de grupo de agregação estática. Os estados de agregação das portas membros em um grupo de agregação estática não são afetados pelas portas pares.
Dinâmico - Um grupo de agregação em modo dinâmico é chamado de grupo de agregação dinâmica. A agregação dinâmica é implementada por meio do protocolo de controle de agregação de links IEEE 802.3ad
(LACP). O sistema local e o sistema par mantêm automaticamente os estados de agregação das portas membros. A agregação dinâmica de links reduz a carga de trabalho dos administradores.
Agregação dinâmica de links
Sobre o LACP
A agregação dinâmica é implementada por meio do protocolo de controle de agregação de links (LACP) IEEE 802.3ad.
O LACP usa LACPDUs para trocar informações de agregação entre dispositivos habilitados para LACP. Cada porta membro em um grupo de agregação dinâmica pode trocar informações com seu par. Quando uma porta membro recebe um LACPDU, ela compara as informações recebidas com as informações recebidas
nas outras portas membros. Dessa forma, os dois sistemas chegam a um acordo sobre quais portas são colocadas no estado Selecionado.
Funções do LACP
O LACP oferece funções básicas do LACP e funções estendidas do LACP, conforme descrito na Tabela 2.
Tabela 2 Funções básicas e estendidas do LACP
Modos de operação do LACP
O LACP pode operar em modo ativo ou passivo.
Quando o LACP está operando em modo passivo em uma porta membro local e em sua porta par, ambas as portas não podem enviar LACPDUs. Quando o LACP está operando em modo ativo em qualquer extremidade de um link, ambas as portas podem enviar LACPDUs.
Prioridades do LACP
As prioridades do LACP incluem a prioridade do sistema LACP e a prioridade da porta, conforme descrito na Tabela 3. Quanto menor o valor da prioridade, maior a prioridade.
Tabela 3 Prioridades do LACP
Intervalo de tempo limite do LACP
O intervalo de tempo limite do LACP especifica o tempo que uma porta membro aguarda para receber LACPDUs da porta par. Se uma porta membro local não tiver recebido LACPDUs do par dentro do intervalo de tempo limite do LACP mais 3 segundos, a porta membro considerará o par como falho.
O intervalo de tempo limite do LACP também determina a taxa de envio de LACPDUs do par. Os intervalos de tempo limite do LACP incluem os seguintes tipos:
Intervalo de tempo limite curto - 3 segundos. Se você usar o intervalo de tempo limite curto, o par enviará um LACPDU por segundo.
Intervalo de tempo limite longo - 90 segundos. Se você usar o intervalo de tempo limite longo, o par enviará um LACPDU a cada 30 segundos.
Métodos para atribuir interfaces a um grupo de agregação de links dinâmicos
Você pode usar um dos métodos a seguir para atribuir interfaces a um grupo de agregação dinâmica de links:
Atribuição manual - Atribui manualmente as interfaces ao grupo de agregação dinâmica de links.
Atribuição automática - Habilite a atribuição automática em interfaces para que elas entrem automaticamente em um grupo de agregação de links dinâmicos, dependendo das informações de pares nos LACPDUs recebidos.
OBSERVAÇÃO:
Quando você usa a atribuição automática em uma extremidade, deve usar a atribuição manual na outra extremidade.
Como alternativa, você pode usar a agregação automática de links para que dois dispositivos criem automaticamente uma agregação de links dinâmicos entre eles usando o LLDP.
Atribuição automática de porta membro
Esse recurso automatiza a atribuição de portas de membros de agregação a um grupo de agregação. Você pode usar esse recurso ao configurar um link de agregação para um servidor.
Conforme mostrado na Figura 3, uma interface habilitada com atribuição automática entra em um grupo de agregação dinâmica com base nas informações do par nos LACPDUs recebidos do par de agregação. Se nenhum dos grupos de agregação dinâmica existentes for qualificado, o dispositivo criará automaticamente um novo grupo de agregação dinâmica. Em seguida, o dispositivo atribui a interface a esse grupo e sincroniza as configurações de atributos da interface com a interface agregada.
Um grupo de agregação dinâmica que contém portas-membro atribuídas automaticamente seleciona uma porta de referência e portas selecionadas, conforme descrito em "Como funciona a agregação dinâmica de links". Os métodos de atribuição de portas-membro não alteram os processos de seleção de porta de referência e de seleção de porta selecionada.
Figura 3 Processo de atribuição automática de porta membro
Agregação automática de links
A agregação automática de links permite que dois dispositivos criem automaticamente uma agregação dinâmica de links entre eles usando o LLDP.
Depois que você ativar a agregação automática de links e o LLDP em dois dispositivos conectados, eles estabelecerão automaticamente uma agregação dinâmica de links com base nas informações dos quadros LLDP recebidos. Cada um dos dispositivos cria automaticamente uma interface agregada dinâmica e atribui as portas redundantes conectadas ao par ao grupo de agregação dessa interface. Ao atribuir a primeira porta membro ao grupo agregado, o dispositivo sincroniza a configuração de atributos da porta membro com a interface agregada.
Um grupo de agregação dinâmica criado automaticamente seleciona uma porta de referência e portas selecionadas, conforme descrito em "Como funciona a agregação dinâmica de links". Os métodos de criação de grupos de agregação não alteram os processos de seleção da porta de referência e da porta selecionada.
Como prática recomendada para garantir a operação correta dos grupos de agregação dinâmica, não use a agregação automática de links e a atribuição automática de porta membro juntas.
Como funciona a agregação dinâmica de links
Escolha de uma porta de referência
O sistema escolhe uma porta de referência entre as portas membro em estado ativo. Uma porta selecionada deve ter as mesmas configurações de chave operacional e atributo que a porta de referência.
O sistema local (o ator) e o sistema par (o parceiro) negociam uma porta de referência usando o seguinte fluxo de trabalho:
Os dois sistemas determinam o sistema com a ID de sistema menor.
Um ID do sistema contém a prioridade do sistema LACP e o endereço MAC do sistema.
Os dois sistemas comparam seus valores de prioridade LACP.
Quanto menor for a prioridade do LACP, menor será a ID do sistema. Se os valores de prioridade do LACP forem os mesmos, os dois sistemas prosseguirão para a etapa b.
Os dois sistemas comparam seus endereços MAC.
Quanto menor for o endereço MAC, menor será a ID do sistema.
O sistema com a menor ID de sistema escolhe a porta com a menor ID de porta como a porta de referência.
Um ID de porta contém uma prioridade de porta e um número de porta. Quanto mais baixa for a prioridade da porta, menor será a ID da porta .
O sistema escolhe a porta com o valor de prioridade mais baixo como a porta de referência. Se as portas tiverem a mesma prioridade, o sistema prossegue para a etapa b.
O sistema compara seus números de porta.
Quanto menor for o número da porta, menor será a ID da porta.
A porta com o menor número de porta e as mesmas configurações de atributo que a interface agregada é escolhida como a porta de referência.
OBSERVAÇÃO:
Para identificar os números das portas dos membros da agregação, execute o comando display
comando link-aggregation verbose e examine o campo Index na saída do comando.
Configuração do estado de agregação de cada porta membro
Depois que a porta de referência é escolhida, o sistema com a ID de sistema menor define o estado de cada porta membro em seu lado.
Figura 4 Configuração do estado de uma porta membro em um grupo de agregação dinâmica
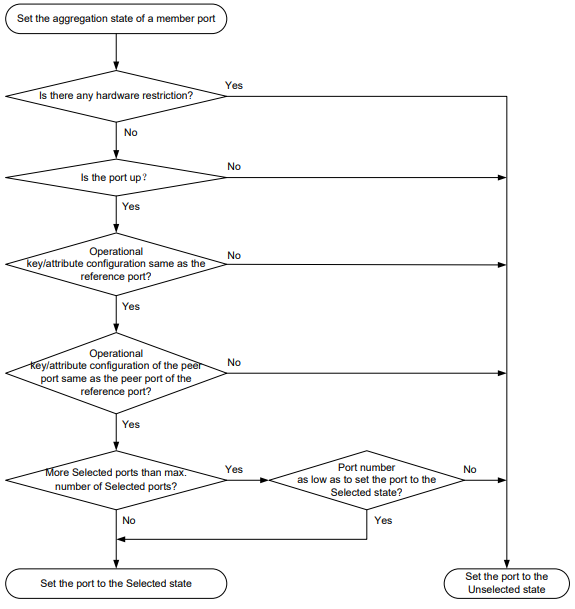
O sistema com o maior ID de sistema pode detectar as alterações de estado de agregação no sistema par. O sistema com o ID de sistema maior define o estado de agregação das portas membros locais da mesma forma que as portas pares.
Quando você agregar interfaces no modo dinâmico, siga estas diretrizes:
Um grupo de agregação dinâmica de links escolhe apenas portas full-duplex como portas selecionadas.
Para obter uma agregação estável e a continuidade do serviço, não altere a chave operacional ou as configurações de atributo em nenhuma porta membro.
Quando uma porta membro muda para o estado Selecionado ou Não selecionado, sua porta par muda para o mesmo estado de agregação.
Depois que o limite de portas selecionadas for atingido, uma porta recém-ingressada se tornará uma porta selecionada se for mais qualificada do que uma porta selecionada atual.
S-MLAG
A agregação de link simples de vários chassis (S-MLAG) aprimora a agregação de link dinâmico para estabelecer uma agregação que abrange vários dispositivos em um dispositivo remoto.
Uma agregação de vários chassis S-MLAG conecta uma interface agregada dinâmica de camada 2 em cada dispositivo S-MLAG ao dispositivo remoto, conforme mostrado na Figura 5.
O S-MLAG usa um grupo S-MLAG para gerenciar as interfaces agregadas para cada agregação e executa o LACP para manter cada agregação, assim como a agregação dinâmica de links. Para o dispositivo remoto, os dispositivos S-MLAG aparecem como um sistema de agregação de pares.
Figura 5 Cenário de aplicação do S-MLAG
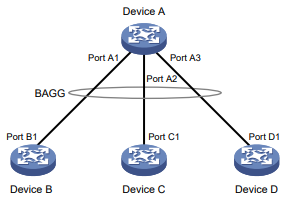
Configuração de uma agregação manual de links
Restrições e diretrizes para a configuração do grupo de agregação
Restrições do grupo de agregação da camada 2
Não é possível atribuir uma interface a um grupo de agregação de camada 2 se algum recurso da Tabela 4 estiver configurado nessa interface.
Tabela 4 Recursos incompatíveis com portas de membro de agregação de camada 2
Restrições da porta do membro de agregação
A exclusão de uma interface agregada também exclui seu grupo de agregação e faz com que todas as portas membros deixem o grupo de agregação.
Uma interface não poderá participar de um grupo de agregação se tiver configurações de atributos diferentes das da interface agregada. Após ingressar em um grupo de agregação, uma interface herda as configurações de atributos da interface agregada. Você pode modificar as configurações de atributos somente na interface agregada.
Não atribua uma porta refletora para espelhamento de porta a um grupo de agregação. Para obter mais informações sobre portas refletoras, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Restrições de configuração de atributos e protocolos
Em um grupo de agregação de links, as configurações de atributos são configuráveis somente na interface de agregação e são automaticamente sincronizadas com todas as portas membros. Não é possível definir as configurações de atributos em uma porta membro até que ela seja removida do grupo de agregação de links. As configurações que foram sincronizadas a partir da interface agregada são mantidas nas portas membros mesmo depois que a interface agregada é excluída.
Se uma configuração de atributo na interface agregada não for sincronizada com uma porta membro selecionada, a porta poderá mudar para o estado não selecionado.
As configurações de protocolo de uma interface agregada têm efeito apenas na interface agregada atual. As configurações de protocolo de uma porta membro entram em vigor somente quando a porta deixa o grupo de agregação.
Requisitos de consistência de configuração
Você deve configurar o mesmo modo de agregação nas duas extremidades de um link agregado.
Para que a agregação estática seja bem-sucedida, certifique-se de que as portas em ambas as extremidades de cada link estejam no mesmo estado de agregação.
Para uma agregação dinâmica bem-sucedida:
Certifique-se de que as portas em ambas as extremidades de um link estejam atribuídas ao grupo de agregação correto. As duas extremidades podem negociar automaticamente o estado de agregação de cada porta membro.
Se você usar a atribuição automática de interface em uma extremidade, deverá usar a atribuição manual na outra extremidade.
Configuração de um grupo de agregação de camada 2
Configuração de um grupo de agregação estática de camada 2
Entre na visualização do sistema.
System ViewCrie uma interface agregada de camada 2 e entre na visualização da interface agregada de camada 2.
interface bridge-aggregation interface-numberQuando você cria uma interface agregada de camada 2, o sistema cria automaticamente um grupo de agregação estática de camada 2 com o mesmo número dessa interface.
Retornar à visualização do sistema.
quitAtribuir uma interface ao grupo de agregação da Camada 2:
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberAtribua a interface ao grupo de agregação da Camada 2.
port link-aggregation group group-id [ force ]
Repita as subetapas para atribuir mais interfaces ao grupo de agregação.
Para sincronizar as configurações de atributo da interface agregada quando a interface atual ingressar no grupo de agregação, especifique a palavra-chave force.
(Opcional.) Defina a prioridade da porta da interface.
link-aggregation port-priority priority A prioridade de porta padrão de uma interface é 32768.
Configuração de um grupo de agregação dinâmica de camada 2
Entre na visualização do sistema.
System ViewDefinir a prioridade do sistema LACP.
lacp system-priority priority (prioridade do sistema lacp)Por padrão, a prioridade do sistema LACP é 32768.
A alteração da prioridade do sistema LACP pode afetar os estados de agregação das portas em um grupo de agregação dinâmica.
Crie uma interface agregada de camada 2 e entre na visualização da interface agregada de camada 2.
interface bridge-aggregation interface-numberQuando você cria uma interface agregada de camada 2, o sistema cria automaticamente um grupo de agregação estática de camada 2 com o mesmo número dessa interface.
Configure o grupo de agregação para operar no modo dinâmico.
link-aggregation mode dynamic Por padrão, um grupo de agregação opera em modo estático.
Retornar à visualização do sistema.
quitAtribuir uma interface ao grupo de agregação da Camada 2:
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberAtribua a interface ao grupo de agregação da Camada 2 ou ative a atribuição automática nessa interface.
port link-aggregation group { group-id [ force ] | auto [ group-id ] }Repita essas duas subetapas para atribuir mais interfaces Ethernet de camada 2 ao grupo de agregação.
Para sincronizar as configurações de atributo da interface agregada quando a interface atual entrar no grupo de agregação, especifique a palavra-chave force.
Para ativar a atribuição automática, especifique a palavra-chave auto. Como prática recomendada, não modifique a configuração em uma interface agregada criada automaticamente ou em suas portas membros.
Definir o modo de operação do LACP para a interface.
Defina o modo de operação do LACP como passivo.
lacp mode passive Defina o modo de operação do LACP como ativo.
undo lacp modePor padrão, o LACP está operando no modo ativo.
(Opcional.) Defina a prioridade da porta para a interface.
link-aggregation port-priority priority A configuração padrão é 32768.
(Opcional.) Defina o intervalo de tempo limite curto do LACP (3 segundos) para a interface.
lacp period short Por padrão, o intervalo de tempo limite longo do LACP (90 segundos) é usado pela interface.
Configuração do S-MLAG
Restrições e diretrizes
Use o S-MLAG para configurar agregações de link somente com servidores.
O S-MLAG foi projetado para um ambiente não IRF. Não o configure em uma malha IRF. Para obter mais informações sobre IRF, consulte o Guia de configuração de tecnologias virtuais.
Cada grupo S-MLAG pode conter apenas uma interface agregada em cada dispositivo. Não defina as seguintes configurações nos dispositivos S-MLAG:
LACP MAD.
Redirecionamento de tráfego de agregação de links.
Número máximo ou mínimo de portas selecionadas.
Atribuição automática de porta membro.
Como prática recomendada, mantenha a consistência entre os dispositivos S-MLAG na configuração dos recursos de serviço.
Pré-requisitos
Defina as configurações de agregação de link que não sejam as configurações do S-MLAG em cada dispositivo S-MLAG. Certifique-se de que as configurações sejam consistentes entre os dispositivos S-MLAG.
Procedimento
Entre na visualização do sistema.
System ViewDefina o endereço MAC do sistema LACP.
lacp system-mac mac-addressPor padrão, o endereço MAC do sistema LACP é o endereço MAC da ponte do dispositivo. Todos os dispositivos S-MLAG devem usar o mesmo endereço MAC do sistema LACP.
Definir a prioridade do sistema LACP.
lacp system-priority priority (prioridade do sistema lacp)Por padrão, a prioridade do sistema LACP é 32768.
Todos os dispositivos S-MLAG devem usar a mesma prioridade de sistema LACP.
Defina o número do sistema LACP.
lacp system-number number numberPor padrão, o número do sistema LACP não é definido.
Você deve atribuir um número de sistema LACP exclusivo a cada dispositivo S-MLAG.
Entre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefina o modo de agregação de link como dinâmico.
link-aggregation mode dynamic Por padrão, um grupo de agregação opera em modo estático.
Atribuir a interface agregada a um grupo S-MLAG.
port s-mlag group group-idPor padrão, uma interface agregada não é atribuída a nenhum grupo S-MLAG.
Configuração de uma interface agregada
A maioria das configurações que podem ser feitas nas interfaces Ethernet de camada 2 também pode ser feita nas interfaces agregadas de camada 2.
Configuração da descrição de uma interface agregada
Sobre a descrição da interface agregada
Você pode configurar a descrição de uma interface agregada para fins administrativos, por exemplo, descrevendo a finalidade da interface.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-numberConfigure a descrição da interface.
description text Por padrão, a descrição de uma interface é interface-name Interface.
Configuração do suporte a jumbo frame
Sobre os quadros jumbo
Uma interface agregada pode receber quadros maiores que 1522 bytes durante trocas de dados de alto rendimento, como transferências de arquivos. Esses quadros são chamados de quadros jumbo.
O modo como uma interface agregada processa os quadros jumbo depende do fato de o suporte a quadros jumbo estar ativado na interface.
Se estiver configurada para negar quadros jumbo, a interface agregada descartará os quadros jumbo.
Se estiver habilitada com suporte a jumbo frame, a interface agregada executará as seguintes operações:
Processa quadros jumbo que estão dentro do comprimento permitido.
Descarta os quadros jumbo que excedem o comprimento permitido.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberPermitir quadros jumbo.
jumboframe enable [ size ]Por padrão, uma interface agregada permite a passagem de jumbo frames com um comprimento máximo de 10240 bytes.
Se você executar esse comando várias vezes, a configuração mais recente entrará em vigor.
Definição da largura de banda esperada para uma interface agregada
Sobre a largura de banda esperada
A largura de banda esperada é um parâmetro informativo usado apenas por protocolos de camada superior para cálculo. Não é possível ajustar a largura de banda real de uma interface com a execução dessa tarefa.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefina a largura de banda esperada para a interface.
Por padrão, a largura de banda esperada (em kbps) é a taxa de transmissão da interface dividida por 1000.
Configuração de uma interface agregada de borda
Restrições e diretrizes
Você só pode configurar uma interface agregada no modo dinâmico como uma interface de borda.
Configure apenas as interfaces de agregação conectadas a pontos de extremidade, como servidores, como interfaces de agregação de borda. Não conecte interfaces de agregação de borda a dispositivos de rede.
O redirecionamento de tráfego de agregação de links não pode funcionar corretamente em uma interface agregada de borda. Para obter mais informações sobre o redirecionamento de tráfego de agregação de links, consulte "Como ativar o redirecionamento de tráfego de agregação de links".
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-numberConfigure a interface agregada como uma interface agregada de borda.
lacp edge-portPor padrão, uma interface agregada não funciona como uma interface agregada de borda.
Configuração da supressão de alterações de estado físico em uma interface agregada
Sobre a supressão da mudança de estado físico
O estado do link físico de uma interface agregada é ativo ou inativo. Toda vez que o link físico de uma interface é ativado ou desativado, o sistema informa imediatamente a alteração à CPU. Em seguida, a CPU executa as seguintes operações:
Notifica os módulos de protocolo da camada superior (como os módulos de roteamento e encaminhamento) sobre a alteração para orientar o encaminhamento de pacotes.
Gera automaticamente traps e logs para informar os usuários para que tomem as medidas corretas.
Para evitar que a oscilação frequente de links físicos afete o desempenho do sistema, configure a supressão de alterações de estado físico. Você pode configurar esse recurso para suprimir eventos de link-down, eventos de link-up ou ambos. Se um evento do tipo especificado ainda existir quando o intervalo de supressão expirar, o sistema informará o evento à CPU.
Restrições e diretrizes
Não use esse recurso em combinação com o S-MLAG.
Ao usar esse recurso em uma interface agregada, verifique se o par dela também é uma interface agregada. Além disso, você deve definir o intervalo de supressão de alteração de estado físico com o mesmo valor nessas interfaces agregadas.
Em uma interface, é possível configurar diferentes intervalos de supressão para eventos de link-up e link-down. Se você executar o comando link-delay várias vezes para um tipo de evento, a configuração mais recente terá efeito sobre esse tipo de evento.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberConfigurar a supressão da alteração do estado físico.
link-delay { down | up } [ msec ] delay-timePor padrão, sempre que o link físico de uma interface agregada sobe ou desce, o sistema informa imediatamente a alteração à CPU.
Desligamento de uma interface agregada
Restrições e diretrizes
O comando shutdown desconectará todos os links estabelecidos em uma interface. Certifique-se de estar totalmente ciente dos impactos desse comando ao usá-lo em uma rede ativa.
O desligamento ou a ativação de uma interface de agregação afeta os estados de agregação e os estados de link das portas membros no grupo de agregação correspondente, como segue:
Quando uma interface agregada é desligada, todas as suas portas selecionadas se tornam não selecionadas e todas as portas membros são desligadas.
Quando uma interface agregada é ativada, os estados de agregação de todas as suas portas membros são recalculados.
Quando você desliga ou ativa uma interface agregada de camada 3, todas as suas subinterfaces agregadas também são desligadas ou ativadas. O desligamento ou a ativação de uma subinterface agregada de camada 3 não afeta o estado da interface agregada principal.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDesligue a interface.
ShutdownRestauração das configurações padrão de uma interface agregada
Restrições e diretrizes
O comando padrão pode interromper os serviços de rede em andamento. Certifique-se de estar totalmente ciente dos impactos desse comando ao executá-lo em uma rede ativa.
O comando padrão pode não conseguir restaurar as configurações padrão de alguns comandos por motivos como dependências de comandos e restrições do sistema.
Para resolver esse problema:
Use o comando display this na visualização da interface para identificar esses comandos.
Use seus formulários de desfazer ou siga a referência do comando para restaurar suas configurações padrão.
Se a tentativa de restauração ainda falhar, siga as instruções da mensagem de erro para resolver o problema.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberRestaurar as configurações padrão da interface agregada.
defaultConfiguração dos números mínimo e máximo de portas selecionadas para um grupo de agregação
Sobre os números mínimo e máximo de portas selecionadas para um grupo de agregação
A largura de banda de um link agregado aumenta à medida que aumenta o número de portas membros selecionadas. Para evitar congestionamento, você pode definir o número mínimo de portas selecionadas necessárias para ativar uma interface agregada.
Essa configuração de limite mínimo afeta os estados de agregação das portas membros da agregação e o estado da interface agregada.
Quando o número de portas membro qualificadas para serem portas selecionadas é menor do que o limite mínimo, ocorrem os seguintes eventos:
As portas membros elegíveis são colocadas no estado Não selecionado.
O estado da camada de link da interface agregada fica inativo.
Quando o número de portas membro qualificadas para serem portas selecionadas atinge ou excede o limite mínimo, ocorrem os seguintes eventos:
Os portos membros elegíveis são colocados em Estado selecionado.
O estado da camada de link da interface agregada torna-se ativo.
O número máximo de portas selecionadas permitidas em um grupo de agregação é limitado pela configuração manual ou pela limitação de hardware, o que for menor.
Você pode implementar o backup entre duas portas executando as seguintes tarefas:
Atribuição de duas portas a um grupo de agregação.
Definir o número máximo de portas selecionadas como 1 para o grupo de agregação.
Então, somente uma porta selecionada é permitida no grupo de agregação, e a porta não selecionada atua como uma porta de backup.
Restrições e diretrizes
Depois que você definir a porcentagem mínima de portas selecionadas para um grupo de agregação, poderá ocorrer oscilação na interface agregada quando as portas entrarem ou saírem de um grupo de agregação. Certifique-se de que esteja totalmente ciente dos impactos dessa configuração ao configurá-la em uma rede ativa.
Você pode definir o número mínimo ou a porcentagem mínima de portas selecionadas para um grupo de agregação. Se você definir as duas configurações em uma interface de agregação, o limite mais alto do número de portas selecionadas terá efeito.
Os números mínimo e máximo de portas selecionadas devem ser os mesmos entre as duas extremidades de um link agregado.
A porcentagem mínima de portas selecionadas deve ser a mesma entre as duas extremidades de um link agregado.
Para um grupo de agregação, o número máximo de portas selecionadas deve ser igual ou superior ao número mínimo de portas selecionadas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-numberDefina o número mínimo de portas selecionadas para o grupo de agregação. Escolha um dos métodos a seguir:
Defina o número mínimo de portas selecionadas.
link-aggregation selected-port minimum min-numberDefina a porcentagem mínima de portas selecionadas.
link-aggregation selected-port minimum min-number Por padrão, o número mínimo de portas selecionadas não é especificado para um grupo de agregação.
Defina o número máximo de portas selecionadas para o grupo de agregação.
link-aggregation selected-port maximum max-numberPor padrão, um grupo de agregação pode ter um máximo de 8 portas selecionadas.
Desativar a ação padrão de selecionar uma porta selecionada para grupos de agregação dinâmica que não tenham recebido LACPDUs
Sobre a ação de seleção de porta padrão
A ação de seleção de porta padrão se aplica a grupos de agregação dinâmica.
Essa ação escolhe automaticamente a porta com o ID mais baixo entre todas as portas membros em funcionamento como uma porta selecionada se nenhuma delas tiver recebido LACPDUs antes que o intervalo de tempo limite do LACP expire.
Depois que essa ação for desativada, um grupo de agregação dinâmica não terá nenhuma porta selecionada para encaminhar o tráfego se não tiver recebido LACPDUs antes que o intervalo de tempo limite do LACP expire.
Procedimento
Entre na visualização do sistema.
System ViewDesativar a ação de seleção de porta padrão.
lacp default-selected-port disablePor padrão, a ação de seleção de porta padrão é ativada para grupos de agregação dinâmica.
Configuração de um grupo de agregação dinâmica para usar a velocidade da porta como critério prioritário para a seleção da porta de referência
Sobre a priorização da velocidade da porta na seleção da porta de referência
Execute esta tarefa para garantir que um grupo de agregação dinâmica selecione uma porta membro de alta velocidade como a porta de referência. Depois que você executar essa tarefa, a porta de referência será selecionada com base nos critérios em ordem de ID do dispositivo, velocidade da porta e ID da porta.
Compatibilidade de recursos e versões de software
Esse recurso é compatível apenas com a versão 6348P01 e versões posteriores.
Restrições e diretrizes
A alteração dos critérios de seleção da porta de referência pode causar interrupção transitória do tráfego. Certifique-se de compreender o impacto dessa tarefa em sua rede.
Você deve executar essa tarefa em ambas as extremidades do link agregado para que os sistemas de agregação de pares usem os mesmos critérios para a seleção da porta de referência.
Como prática recomendada, desligue as interfaces de agregação de pares antes de executar esse comando e ative as interfaces depois que esse comando for executado em ambas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberEspecifique a velocidade da porta como o critério priorizado para a seleção da porta de referência.
lacp select speedPor padrão, o ID da porta é o critério priorizado para a seleção da porta de referência de um grupo de agregação dinâmica .
Configuração do compartilhamento de carga para grupos de agregação de links
Configuração dos modos de compartilhamento de carga para grupos de agregação de links
Sobre os modos de compartilhamento de carga
É possível definir um modo de compartilhamento de carga global para todos os grupos de agregação de links.
Restrições e diretrizes
Os modos de compartilhamento de carga global suportados no dispositivo são os seguintes:
O modo de compartilhamento de carga é determinado automaticamente com base no tipo de pacote.
- IP de origem.
- IP de destino.
- Fonte MAC.
- MAC de destino.
- Porta de origem.
- Porta de destino.
- Porta de entrada.
Qualquer combinação de porta de entrada, IP de origem, porta de origem, IP de destino e porta de destino.
Qualquer combinação de porta de entrada, porta de origem, MAC de origem, porta de destino e MAC de destino .
Procedimento
Entre na visualização do sistema.
System ViewDefinir o modo de compartilhamento de carga de agregação de links global.
link-aggregation global load-sharing mode { destination-ip | destination-mac | destination-port | ingress-port | source-ip | source-mac | source-port } *Por padrão, os pacotes são compartilhados com base nas seguintes informações:
- Endereços IP de origem e destino.
- Endereços MAC de origem e destino.
Habilitação do compartilhamento de carga local-primeiro para agregação de links
Sobre o compartilhamento de carga local-primeiro para agregação de links
Use o compartilhamento de carga local-primeiro em um cenário de agregação de link de vários dispositivos para distribuir o tráfego preferencialmente entre as portas dos membros no slot de entrada.
Quando você agrega portas em diferentes dispositivos membros em uma malha IRF, pode usar o compartilhamento de carga local primeiro para reduzir o tráfego nos links IRF, conforme mostrado na Figura 6. Para obter mais informações sobre IRF, consulte o Guia de Configuração de Tecnologias Virtuais.
Figura 6 Compartilhamento de carga para agregação de links de vários dispositivos em uma malha IRF
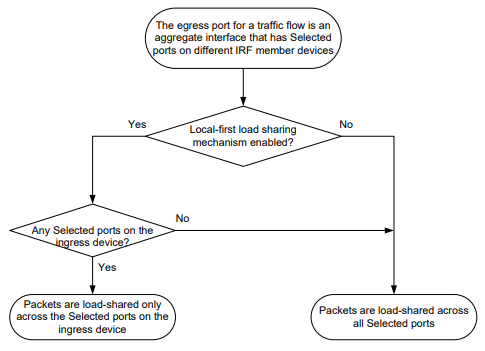
Ativação do compartilhamento de carga local-primeiro para agregação de links globalmente
Entre na visualização do sistema.
System ViewHabilite o compartilhamento de carga local-primeiro para a agregação de links globalmente.
link-aggregation load-sharing mode local-first Por padrão, o compartilhamento de carga local-first é ativado globalmente.
Ativação do redirecionamento de tráfego de agregação de links
Sobre o redirecionamento de tráfego de agregação de links
Esse recurso opera em grupos de agregação de links dinâmicos. Ele redireciona o tráfego em uma porta selecionada para as portas selecionadas disponíveis restantes de um grupo de agregação se ocorrer um dos eventos a seguir:
A porta é desligada usando o comando shutdown.
O slot que hospeda a porta é reinicializado e o grupo de agregação abrange vários slots.
OBSERVAÇÃO:
O dispositivo não redireciona o tráfego para as portas membro que se tornam selecionadas durante o processo de redirecionamento de tráfego.
Esse recurso garante perda zero de pacotes para tráfego unicast conhecido, mas não protege o tráfego unicast desconhecido.
Você pode ativar o redirecionamento de tráfego de agregação de links globalmente ou para um grupo de agregação. As configurações globais de redirecionamento de tráfego de agregação de links têm efeito em todos os grupos de agregação. Um grupo de agregação de links usa preferencialmente as configurações de redirecionamento de tráfego de agregação de links específicas do grupo. Se o redirecionamento de tráfego de agregação de links específico do grupo não estiver configurado, o grupo usará as configurações globais de redirecionamento de tráfego de agregação de links.
Restrições e diretrizes para redirecionamento de tráfego de agregação de links
O redirecionamento de tráfego de agregação de links aplica-se somente a grupos de agregação de links dinâmicos.
Como prática recomendada, ative o redirecionamento de tráfego de agregação de links por interface. Se você ativar esse recurso globalmente, a comunicação com um dispositivo par de terceiros poderá ser afetada se o par não for compatível com esse recurso.
Para evitar a interrupção do tráfego, ative o redirecionamento do tráfego de agregação de links em ambas as extremidades do link agregado.
Para evitar a perda de pacotes que pode ocorrer em uma reinicialização de slot, não ative o recurso spanning tree junto com o redirecionamento de tráfego de agregação de links.
O redirecionamento de tráfego de agregação de links não funciona corretamente em uma interface agregada de borda.
Ativação do redirecionamento de tráfego de agregação de links globalmente
Entre na visualização do sistema.
System ViewAtivar o redirecionamento de tráfego de agregação de links globalmente.
link-aggregation lacp traffic-redirect-notification enable Por padrão, o redirecionamento de tráfego de agregação de links é desativado globalmente.
Ativação do redirecionamento de tráfego de agregação de links para um grupo de agregação
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberAtivar o redirecionamento de tráfego de agregação de links para o grupo de agregação.
link-aggregation lacp traffic-redirect-notification enable Por padrão, o redirecionamento de tráfego de agregação de links é desativado para um grupo de agregação.
Ativação do BFD para um grupo de agregação
Sobre o BFD para agregação de links Ethernet
Você pode usar o BFD para monitorar o status do link do membro em um grupo de agregação. Depois de ativar o BFD em uma interface de agregação, cada porta selecionada no grupo de agregação estabelece uma sessão BFD com sua porta par. O BFD funciona de forma diferente, dependendo do modo de agregação.
BFD em uma agregação estática - Quando o BFD detecta uma falha de link, o BFD notifica o módulo de agregação de link Ethernet de que a porta par não pode ser acessada. A porta local é então colocada no estado Não selecionado. No entanto, a sessão BFD entre as portas local e de pares permanece e a porta local continua enviando pacotes BFD. Quando o BFD na porta local recebe pacotes da porta de par após a recuperação do link, o BFD notifica o módulo de agregação de link Ethernet de que a porta de par está acessível. Em seguida, a porta local é colocada novamente no estado Selecionado. Esse mecanismo garante que as portas locais e pares de um link agregado estático tenham o mesmo estado de agregação.
BFD em uma agregação dinâmica - Quando o BFD detecta uma falha de link, o BFD notifica o módulo de agregação de link Ethernet de que a porta do par não pode ser acessada. Ao mesmo tempo, o BFD limpa a sessão e interrompe o envio de pacotes BFD. Quando a porta local é colocada no estado Selecionado novamente após a recuperação do link, a porta local estabelece uma nova sessão com a porta par e o BFD notifica o módulo de agregação de link Ethernet de que a porta par está acessível. Como o BFD oferece detecção rápida de falhas, os sistemas locais e pares de um link agregado dinâmico podem negociar mais rapidamente o estado de agregação de suas portas membros.
Para obter mais informações sobre o BFD, consulte o Guia de configuração de alta disponibilidade.
Restrições e diretrizes
Quando você ativar o BFD para um grupo de agregação, siga estas restrições e diretrizes:
Certifique-se de que os endereços IP de origem e destino estejam invertidos entre as duas extremidades de um link agregado. Por exemplo, se você executar link-aggregation bfd ipv4 source
1.1.1.1 destino 2.2.2.2 na extremidade local, execute link-aggregation bfd ipv4 fonte 2.2.2.2 destino 1.1.1.1 na extremidade do par. Os endereços IP de origem e destino não podem ser os mesmos.
Os parâmetros de BFD configurados em uma interface agregada têm efeito em todas as sessões de BFD estabelecidas pelas portas membros em seu grupo de agregação. O BFD em um link agregado suporta apenas o modo de pacote de controle para o estabelecimento e a manutenção da sessão. As duas extremidades de uma sessão BFD estabelecida só podem operar no modo assíncrono.
Como prática recomendada, não configure o BFD para nenhum protocolo em uma interface agregada habilitada para BFD.
Certifique-se de que o número de portas-membro em um grupo de agregação habilitado para BFD seja menor ou idêntico ao número de sessões BFD suportadas pelo dispositivo. Se o grupo de agregação contiver mais portas-membro do que as sessões suportadas, algumas portas selecionadas poderão mudar para o estado Não selecionado.
Se o número de sessões BFD for diferente entre as duas extremidades de um link agregado, verifique se há inconsistência nas configurações do número máximo de portas selecionadas. Você deve se certificar de que as duas extremidades tenham a mesma configuração para o número máximo de portas selecionadas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberHabilite o BFD para o grupo de agregação.
link-aggregation bfd ipv4 source ip-address destination ip-addressPor padrão, o BFD está desativado para um grupo de agregação.
Exemplos de configuração de agregação de link Ethernet
Exemplo: Configuração de um grupo de agregação estática de camada 2
Configuração de rede
Na rede mostrada na Figura 7, execute as seguintes tarefas:
Configure um grupo de agregação estática de camada 2 no dispositivo A e no dispositivo B.
Habilite a VLAN 10 em uma extremidade do link agregado para se comunicar com a VLAN 10 na outra extremidade.
Habilite a VLAN 20 em uma extremidade do link agregado para se comunicar com a VLAN 20 na outra extremidade .
Figura 7 Diagrama de rede
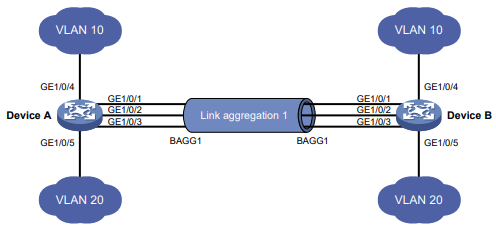
Procedimento
Configurar o dispositivo A:
# Crie a VLAN 10 e atribua a porta GigabitEthernet 1/0/4 à VLAN 10.
<DeviceA> system-view
[DeviceA] vlan 10
[DeviceA-vlan10] port gigabitethernet 1/0/4
[DeviceA-vlan10] quit# Crie a VLAN 20 e atribua a porta GigabitEthernet 1/0/5 à VLAN 20.
[DeviceA] vlan 20
[DeviceA-vlan20] port gigabitethernet 1/0/5
[DeviceA-vlan20] quit # Criar interface agregada de camada 2 Bridge-Aggregation 1.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] quit # Atribua as portas GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 ao grupo de agregação de links 1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-aggregation group 1
[DeviceA-GigabitEthernet1/0/1] quit
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-aggregation group 1
[DeviceA-GigabitEthernet1/0/2] quit
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port link-aggregation group 1
[DeviceA-GigabitEthernet1/0/3] quit# Configure a interface agregada de camada 2 Bridge-Aggregation 1 como uma porta tronco e atribua-a às VLANs 10 e 20.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] port link-type trunk
[DeviceA-Bridge-Aggregation1] port trunk permit vlan 10 20
[DeviceA-Bridge-Aggregation1] quitConfigure o Dispositivo B da mesma forma que o Dispositivo A está configurado. (Detalhes não mostrados).
Verificação da configuração
# Exibir informações detalhadas sobre todos os grupos de agregação no Dispositivo A.
[DeviceA] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Port: A -- Auto port, M -- Management port, R -- Reference port
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Bridge-Aggregation1
Aggregation Mode: Static
Loadsharing Type: Shar
Management VLANs: None
Port Status Priority Oper-Key
GE1/0/1(R) S 32768 1
GE1/0/2 S 32768 1
GE1/0/3 S 32768 1A saída mostra que o grupo de agregação de links 1 é um grupo de agregação estática de camada 2 que contém três portas selecionadas.
Exemplo: Configuração de um grupo de agregação dinâmica de camada 2
Configuração de rede
Na rede mostrada na Figura 8, execute as seguintes tarefas:
Configure um grupo de agregação dinâmica de camada 2 no Dispositivo A e no Dispositivo B.
Habilite a VLAN 10 em uma extremidade do link agregado para se comunicar com a VLAN 10 na outra extremidade.
Habilite a VLAN 20 em uma extremidade do link agregado para se comunicar com a VLAN 20 na outra extremidade.
Figura 8 Diagrama de rede
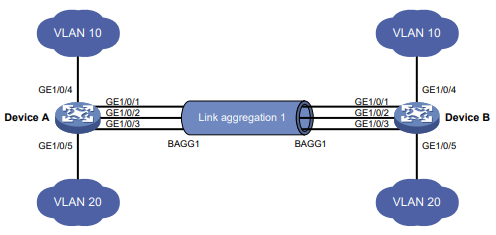
Procedimento
Configurar o dispositivo A:
# Crie a VLAN 10 e atribua a porta GigabitEthernet 1/0/4 à VLAN 10.
<DeviceA>
system-view [DeviceA] vlan 10
[DeviceA-vlan10] port gigabitethernet 1/0/4
[DeviceA-vlan10] quit# Crie a VLAN 20 e atribua a porta GigabitEthernet 1/0/5 à VLAN 20.
[DeviceA] vlan 20
[DeviceA-vlan20] port gigabitethernet 1/0/5
[DeviceA-vlan20] quit# Crie a interface agregada de camada 2 Bridge-Aggregation 1 e defina o modo de agregação de link como dinâmico.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] link-aggregation mode dynamic
[DeviceA-Bridge-Aggregation1] quit# Atribua as portas GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 ao grupo de agregação de links 1.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-aggregation group 1
[DeviceA-GigabitEthernet1/0/1] quit
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-aggregation group 1
[DeviceA-GigabitEthernet1/0/2] quit
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port link-aggregation group 1
[DeviceA-GigabitEthernet1/0/3] quit# Configure a interface agregada de camada 2 Bridge-Aggregation 1 como uma porta tronco e atribua-a às VLANs 10 e 20.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] port link-type trunk
[DeviceA-Bridge-Aggregation1] port trunk permit vlan 10 20
[DeviceA-Bridge-Aggregation1] quitConfigure o Dispositivo B da mesma forma que o Dispositivo A está configurado. (Detalhes não mostrados).
Verificação da configuração
# Exibir informações detalhadas sobre todos os grupos de agregação no Dispositivo A.
[DeviceA] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Port: A -- Auto port, M -- Management port, R -- Reference port
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Bridge-Aggregation1
Aggregation Mode: Static
Loadsharing Type: Shar
Management VLANs: None
Port Status Priority Oper-Key
GE1/0/1(R) S 32768 1
GE1/0/2 S 32768 1
GE1/0/3 S 32768 1
A saída mostra que o grupo de agregação de links 1 é um grupo de agregação dinâmica de camada 2 que contém três portas selecionadas.
Exemplo: Configuração de uma interface agregada de borda de camada 2
Configuração de rede
Conforme mostrado na Figura 9, um grupo de agregação dinâmica de camada 2 está configurado no dispositivo. O servidor não está configurado com agregação dinâmica de links.
Configure uma interface agregada de borda de modo que tanto a GigabitEthernet 1/0/1 quanto a GigabitEthernet 1/0/2 possam encaminhar o tráfego para aumentar a confiabilidade do link.
Figura 9 Diagrama de rede

Procedimento
# Crie a interface agregada de camada 2 Bridge-Aggregation 1 e defina o modo de agregação de link como dinâmico.
<Device> system-view
[DeviceA] vlan 10
[DeviceA-vlan10] port gigabitethernet 1/0/4
[DeviceA-vlan10] quit # Configure a interface de agregação da camada 2 Bridge-Aggregation 1 como uma interface de agregação de borda.
[DeviceA] vlan 20
[DeviceA-vlan20] port gigabitethernet 1/0/5
[DeviceA-vlan20] quit# Atribua as portas GigabitEthernet 1/0/1 e GigabitEthernet 1/0/2 ao grupo de agregação de links 1.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] link-aggregation mode dynamic
[DeviceA-Bridge-Aggregation1] quitVerificação da configuração
# Exibir informações detalhadas sobre todos os grupos de agregação no dispositivo quando o servidor não estiver configurado com agregação dinâmica de links.
[Device] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Port: A -- Auto port, M -- Management port, R -- Reference port
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Bridge-Aggregation1
Creation Mode: Manual
Aggregation Mode: Dynamic
Loadsharing Type: Shar
Management VLANs: None
System ID: 0x8000, 000f-e267-6c6a
Local:
Port Status Priority Index Oper-Key
GE1/0/1 I 32768 11 1
GE1/0/2 I 32768 12 1
Remote:
Actor Priority Index Oper-Key SystemID Flag
GE1/0/1 32768 81 0 0x8000, 0000-0000-0000 {DEF}
32768
GE1/0/2 32768 82 0 0x8000, 0000-0000-0000 {DEF}
A saída mostra que a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 estão no estado Individual quando não recebem LACPDUs do servidor. Tanto a GigabitEthernet 1/0/1 quanto a GigabitEthernet 1/0/2 podem encaminhar tráfego. Quando uma porta falha, seu tráfego é automaticamente transferido para a outra porta.
Exemplo: Configuração do S-MLAG
Configuração de rede
Conforme mostrado na Figura 10, configure o Dispositivo B, o Dispositivo C e o Dispositivo D como dispositivos S-MLAG para estabelecer um link agregado de vários dispositivos com o Dispositivo A.
Figura 10 Diagrama de rede
Procedimento
Configure o dispositivo A:
# Crie a interface agregada de camada 2 Bridge-Aggregation 10 e defina o modo de agregação de link como dinâmico.
<DeviceA> system-view
[DeviceA] interface bridge-aggregation 10
[DeviceA-Bridge-Aggregation10] link-aggregation mode dynamic
[DeviceA-Bridge-Aggregation10] quit# Atribuir GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 ao grupo de agregação 10.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-aggregation group 10
[DeviceA-GigabitEthernet1/0/1] quit
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-aggregation group 10
[DeviceA-GigabitEthernet1/0/2] quit
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port link-aggregation group 10
[DeviceA-GigabitEthernet1/0/3] quit Configurar o dispositivo B:
# Defina o endereço MAC do sistema LACP como 0001-0001-0001.
<DeviceB> system-view [DeviceB] lacp system-mac 1-1-1# Defina a prioridade do sistema LACP como 123.
[DeviceB] lacp system-priority 123 # Defina o número do sistema LACP como 1.
[DeviceB] lacp system-number 1# Crie uma interface de agregação de camada 2 Bridge-Aggregation 2 e defina o modo de agregação de link como dinâmico.
[DeviceB] interface bridge-aggregation 2
[DeviceB-Bridge-Aggregation2] link-aggregation mode dynamic # Atribua a Bridge-Aggregation 2 ao grupo S-MLAG 100. [Atribuir GigabitEthernet 1/0/1 ao grupo de agregação 2. [DeviceB] interface gigabitethernet 1/0/1
[DeviceB-Bridge-Aggregation2] port s-mlag group 100Configurar o dispositivo C:
# Defina o endereço MAC do sistema LACP como 0001-0001-0001.
<Device> system-view
[DeviceC] lacp system-mac 1-1-1 # Defina a prioridade do sistema LACP como 123. [Defina o número do sistema LACP como 2.
[DeviceC] lacp system-number 2# Crie uma interface de agregação de camada 2 Bridge-Aggregation 3 e defina o modo de agregação de link como dinâmico.
[DeviceC] interface bridge-aggregation 3
[DeviceC-Bridge-Aggregation3] link-aggregation mode dynamic# Atribua a Bridge-Aggregation 3 ao grupo S-MLAG 100.
[DeviceC-Bridge-Aggregation3] port s-mlag group 100Configurar o dispositivo D:
# Defina o endereço MAC do sistema LACP como 0001-0001-0001.
<DeviceD> system-view
[DeviceD] lacp system-mac 1-1-1# Defina a prioridade do sistema LACP como 123.
[DeviceD] lacp system-priority 123# Crie a interface agregada de camada 2 Bridge-Aggregation 4 e defina o modo de agregação de link como dinâmico.
[DeviceD] interface bridge-aggregation 4
[DeviceD-Bridge-Aggregation4] link-aggregation mode dynamic# Atribua a Bridge-Aggregation 4 ao grupo S-MLAG 100. [Atribuir GigabitEthernet 1/0/1 ao grupo de agregação 4. [DeviceD] interface gigabitethernet 1/0/1
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] port link-aggregation group 4
[DeviceD-GigabitEthernet1/0/1] quitVerificação da configuração
# Verifique se as portas GigabitEthernet 1/0/1 a GigabitEthernet 1/0/3 no Dispositivo A são portas selecionadas.
[DeviceA] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Port: A -- Auto port, M -- Management port, R -- Reference port
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Bridge-Aggregation10
Creation Mode: Manual
Aggregation Mode: Dynamic
Loadsharing Type: Shar
Management VLANs: None
System ID: 0x8000, 40fa-264f-0100
Local:
Port Status Priority Index Oper-Key Flag
GE1/0/1(R) S 32768 1 1 {ACDEF}
GE1/0/2 S 32768 2 1 {ACDEF}
GE1/0/3 S 32768 3 1 {ACDEF}
Remote:
Actor Priority Index Oper-Key SystemID Flag
GE1/0/1 32768 16385 50100 0x7b , 0001-0001-0001 {ACDEF}
GE1/0/2 32768 32769 50100 0x7b , 0001-0001-0001 {ACDEF}
GE1/0/3 32768 49153 50100 0x7b , 0001-0001-0001 {ACDEF}
Configuração do isolamento de portas
Sobre o isolamento de portas
O recurso de isolamento de porta isola o tráfego da Camada 2 para privacidade e segurança dos dados sem usar VLANs.
As portas em um grupo de isolamento não podem se comunicar umas com as outras. No entanto, elas podem se comunicar com portas fora do grupo de isolamento.
Atribuição de uma porta a um grupo de isolamento
Sobre a atribuição de portas a um grupo de isolamento
O dispositivo suporta vários grupos de isolamento, que podem ser configurados manualmente. O número de portas atribuídas a um grupo de isolamento não é limitado.
Restrições e diretrizes
Você pode atribuir uma porta a apenas um grupo de isolamento. Se você executar o comando port-isolate enable group várias vezes, a configuração mais recente entrará em vigor.
A configuração na visualização da interface Ethernet de camada 2 se aplica somente à interface.
A configuração na visualização da interface agregada da Camada 2 aplica-se à interface agregada da Camada 2 e às suas portas-membro de agregação. Se o dispositivo não conseguir aplicar a configuração à interface agregada, ele não atribuirá nenhuma porta membro de agregação ao grupo de isolamento. Se a falha ocorrer em uma porta membro de agregação, o dispositivo ignorará a porta e continuará a atribuir outras portas membros de agregação ao grupo de isolamento.
Procedimento
Entre na visualização do sistema.
System ViewCrie um grupo de isolamento.
port-isolate group group-idEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberAtribuir a porta ao grupo de isolamento.
port-isolate group group-idPor padrão, a porta não está em nenhum grupo de isolamento.
Exemplos de configuração de isolamento de porta
Exemplo: Configuração do isolamento de portas
Configuração de rede
Conforme mostrado na Figura 1:
Os usuários da LAN Host A, Host B e Host C estão conectados à GigabitEthernet 1/0/1, GigabitEthernet 1/0/2 e GigabitEthernet 1/0/3 no dispositivo, respectivamente.
O dispositivo se conecta à Internet por meio da GigabitEthernet 1/0/4.
Configure o dispositivo para fornecer acesso à Internet para os hosts e isole-os uns dos outros na Camada 2.
Figura 1 Diagrama de rede
Procedimento
# Criar o grupo de isolamento 2.
<Device> system-view
[Grupo de isolamento de porta 2]
# Atribuir GigabitEthernet 1/0/1, GigabitEthernet 1/0/2 e GigabitEthernet 1/0/3 ao grupo de isolamento 2.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] port-isolate enable group 2
[Device-GigabitEthernet1/0/1] quit
[Device] interface gigabitethernet 1/0/2
[Device-GigabitEthernet1/0/2] port-isolate enable group 2
[Device-GigabitEthernet1/0/2] quit
[Device] interface gigabitethernet 1/0/3
[Device-GigabitEthernet1/0/3] port-isolate enable group 2
[Device-GigabitEthernet1/0/3] quitVerificação da configuração
# Exibir informações sobre o grupo de isolamento 2.
[Device] display port-isolate group 2
Port isolation group information:
Group ID: 2
Group members:
GigabitEthernet1/0/1 GigabitEthernet1/0/2 GigabitEthernet1/0/3A saída mostra que a GigabitEthernet 1/0/1, a GigabitEthernet 1/0/2 e a GigabitEthernet 1/0/3 estão atribuídas ao grupo de isolamento 2. Como resultado, o host A, o host B e o host C estão isolados uns dos outros na camada 2.
Visão geral do protocolo Spanning Tree
Sobre a STP
O STP foi desenvolvido com base no padrão 802.1d do IEEE para eliminar loops na camada de link de dados em uma LAN. As redes geralmente têm links redundantes como backups em caso de falhas, mas os loops são um problema muito sério. Os dispositivos que executam o STP detectam loops na rede trocando informações entre si. Eles eliminam os loops bloqueando seletivamente determinadas portas para podar a estrutura de loop em uma estrutura de árvore sem loop. Isso evita a proliferação e o ciclo infinito de pacotes que ocorreriam em uma rede com loop.
Em um sentido restrito, STP refere-se ao IEEE 802.1d STP. Em um sentido amplo, STP refere-se ao IEEE 802.1d STP e a vários protocolos de spanning tree aprimorados derivados desse protocolo.
Quadros do protocolo STP
O STP usa unidades de dados de protocolo de ponte (BPDUs), também conhecidas como mensagens de configuração, como seus quadros de protocolo. Este capítulo usa BPDUs para representar todos os tipos de quadros de protocolo Spanning Tree.
Os dispositivos habilitados para STP trocam BPDUs para estabelecer uma árvore de abrangência. Os BPDUs contêm informações suficientes para que os dispositivos concluam o cálculo da árvore de abrangência.
O STP usa dois tipos de BPDUs, BPDUs de configuração e BPDUs de notificação de alteração de topologia (TCN).
BPDUs de configuração
Os dispositivos trocam BPDUs de configuração para eleger a ponte raiz e determinar as funções das portas. A Figura 1 mostra o formato do BPDU de configuração.
Figura 1 Formato do BPDU de configuração
Os dispositivos usam o ID da ponte raiz, o custo do caminho da raiz, o ID da ponte designada, o ID da porta designada, a idade da mensagem, a idade máxima, o tempo de espera e o atraso de encaminhamento para o cálculo da árvore de abrangência.
BPDUs TCN
Os dispositivos usam TCN BPDUs para anunciar alterações na topologia da rede. A Figura 2 mostra o formato do TCN BPDU.
Figura 2 Formato TCN BPDU
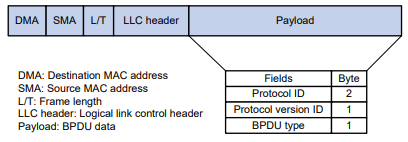
DMA: Endereço MAC de destino SMA: Endereço MAC de origem L/T: Comprimento do quadro
Cabeçalho LLC: Cabeçalho de controle de link lógico Carga útil: Dados BPDU
A carga útil de uma BPDU TCN inclui os seguintes campos:
ID do protocolo - Fixado em 0x0000, que representa o IEEE 802.1d.
ID da versão do protocolo - ID da versão do protocolo da árvore de planejamento. A ID da versão do protocolo para STP é 0x00.
Tipo de BPDU - Tipo de BPDU. O valor é 0x80 para um BPDU TCN.
Uma ponte não raiz envia BPDUs TCN quando um dos eventos a seguir ocorre na ponte:
Uma porta passa para o estado de encaminhamento, e a ponte tem no mínimo uma porta designada.
Uma porta passa do estado de encaminhamento ou aprendizado para o estado de bloqueio.
A ponte não raiz usa BPDUs TCN para notificar a ponte raiz quando a topologia da rede é alterada. A ponte raiz define o sinalizador TC em sua configuração BPDU e o propaga para as outras pontes.
Conceitos básicos do STP
Ponte raiz
Uma rede em árvore deve ter uma ponte raiz. A rede inteira contém apenas uma ponte raiz, e todas as outras pontes da rede são chamadas de nós folha. A ponte raiz não é permanente, mas pode mudar com as alterações na topologia da rede.
Após a inicialização de uma rede, cada dispositivo gera e envia periodicamente BPDUs de configuração, sendo ele próprio a ponte raiz. Após a convergência da rede, somente a ponte raiz gera e envia periodicamente BPDUs de configuração. Os outros dispositivos apenas encaminham os BPDUs.
Porta raiz
Em uma ponte não raiz, a porta mais próxima da ponte raiz é a porta raiz. A porta raiz se comunica com a ponte raiz. Cada ponte não-raiz tem apenas uma porta raiz. A ponte raiz não tem porta raiz.
Ponte designada e porto designado
Conforme mostrado na Figura 3, o Dispositivo B e o Dispositivo C estão diretamente conectados a uma LAN.
Se o Dispositivo A encaminhar BPDUs ao Dispositivo B pela porta A1, a ponte designada e a porta designada serão as seguintes:
A ponte designada para o Dispositivo B é o Dispositivo A.
A porta designada para o Dispositivo B é a porta A1 no Dispositivo A.
Se o dispositivo B encaminhar BPDUs para a LAN, a ponte designada e a porta designada serão as seguintes:
A ponte designada para a LAN é o Dispositivo B.
A porta designada para a LAN é a porta B2 no Dispositivo B.
Figura 3 Pontes designadas e portas designadas
O custo do caminho é um valor de referência usado para a seleção de links no STP. Para podar a rede em uma árvore sem loop, o STP calcula os custos de caminho para selecionar os links mais robustos e bloquear os links redundantes que são menos robustos.
Processo de cálculo do algoritmo STP
No cálculo do STP, um dispositivo compara as prioridades dos BPDUs de configuração recebidos de diferentes portas e elege a ponte raiz, as portas raiz e as portas designadas. Quando o cálculo da spanning tree é concluído, forma-se uma topologia em forma de árvore.
O processo de cálculo da árvore de abrangência descrito nas seções a seguir é um exemplo de um processo simplificado.
Inicialização da rede
Após a inicialização de um dispositivo, cada porta gera um BPDU com o seguinte conteúdo:
A porta como a porta designada.
O dispositivo como ponte raiz.
0 como o custo do caminho da raiz.
A ID do dispositivo como a ID da ponte designada.
Seleção da ponte raiz
A ponte raiz pode ser selecionada pelos seguintes métodos:
Eleição automática - Inicialmente, cada dispositivo habilitado para STP na rede assume ser a ponte raiz, com seu próprio ID de dispositivo como o ID da ponte raiz. Ao trocar BPDUs de configuração, os dispositivos comparam seus IDs de root bridge para eleger o dispositivo com o menor ID de root bridge como root bridge.
Atribuição manual - Você pode configurar um dispositivo como root bridge ou root bridge secundária de uma spanning tree.
Uma árvore de abrangência pode ter apenas uma ponte raiz. Se você configurar vários dispositivos como root bridge para uma spanning tree, o dispositivo com o endereço MAC mais baixo será selecionado.
Você pode configurar uma ou várias pontes raiz secundárias para uma árvore de abrangência. Quando a ponte raiz falha ou é desligada, uma ponte raiz secundária pode assumir o controle. Se várias pontes raiz secundárias estiverem configuradas, a que tiver o endereço MAC mais baixo será selecionada. Entretanto, se uma nova ponte raiz for configurada, a ponte raiz secundária não será selecionada.
Seleção da porta raiz e das portas designadas nas pontes não raiz
Quando a topologia da rede está estável, somente a porta raiz e as portas designadas encaminham o tráfego do usuário. As outras portas estão todas no estado de bloqueio para receber BPDUs, mas não para encaminhar BPDUs ou tráfego de usuários.
Tabela 2 Seleção da configuração ideal BPDU
A seguir, os princípios da comparação de BPDUs de configuração:
O BPDU de configuração com o ID de ponte raiz mais baixo tem a prioridade mais alta.
Se os BPDUs de configuração tiverem o mesmo ID de ponte raiz, seus custos de caminho raiz serão comparados. Por exemplo, o custo do caminho raiz em um BPDU de configuração mais o custo do caminho de uma porta receptora é S. O BPDU de configuração com o menor valor S tem a prioridade mais alta.
Se todos os BPDUs de configuração tiverem o mesmo ID de ponte raiz e valor S, os seguintes atributos serão comparados em sequência:
IDs de pontes designadas.
IDs de portas designadas.
IDs das portas de recebimento.
O BPDU de configuração que contém uma ID de ponte designada, ID de porta designada ou ID de porta receptora menor é selecionado.
Uma topologia em forma de árvore se forma quando a ponte raiz, as portas raiz e as portas designadas são selecionadas.
O mecanismo de encaminhamento de BPDU de configuração do STP
Os BPDUs de configuração do STP são encaminhados de acordo com essas diretrizes:
Após o início da rede, cada dispositivo se considera a ponte raiz e gera BPDUs de configuração com ele mesmo como raiz. Em seguida, ele envia os BPDUs de configuração em um intervalo regular de "hello".
Se a porta raiz receber um BPDU de configuração superior ao BPDU de configuração da porta, o dispositivo executará as seguintes operações:
Aumenta a idade da mensagem transportada no BPDU de configuração.
Inicia um cronômetro para cronometrar o BPDU de configuração.
Envia esse BPDU de configuração pela porta designada.
Se uma porta designada receber um BPDU de configuração com uma prioridade mais baixa do que seu BPDU de configuração, a porta responderá imediatamente com seu BPDU de configuração.
Se um caminho falhar, a porta raiz nesse caminho não receberá mais novos BPDUs de configuração e os BPDUs de configuração antigos serão descartados devido ao tempo limite. O dispositivo gera um BPDU de configuração com ele mesmo como a raiz e envia os BPDUs e os BPDUs TCN. Isso aciona um novo processo de cálculo da spanning tree para estabelecer um novo caminho e restaurar a conectividade da rede.
No entanto, a BPDU de configuração recém-calculada não pode ser propagada imediatamente por toda a rede. Como resultado, as portas raiz antigas e as portas designadas que não detectaram a mudança de topologia continuam encaminhando dados pelo caminho antigo. Se as novas portas raiz e as portas designadas começarem a encaminhar dados assim que forem eleitas, poderá ocorrer um loop temporário.
Temporizadores STP
Os parâmetros de tempo mais importantes no cálculo do STP são o atraso de encaminhamento, o tempo de espera e a idade máxima.
Atraso de encaminhamento
O atraso de encaminhamento é o tempo de atraso para a transição do estado da porta. Por padrão, o atraso de encaminhamento é de 15 segundos.
Uma falha de caminho pode causar o recálculo da árvore de abrangência para adaptar a estrutura da árvore de abrangência à alteração. No entanto, a nova configuração BPDU resultante não pode se propagar pela rede imediatamente. Se as portas-raiz recém-eleitas e as portas designadas começarem a encaminhar dados imediatamente, provavelmente ocorrerá um loop temporário.
As portas raiz recém-eleitas ou as portas designadas devem passar pelos estados de escuta e aprendizado antes de passar para o estado de encaminhamento. Isso requer o dobro do tempo de atraso de encaminhamento e permite que a nova configuração BPDU se propague por toda a rede.
Olá, hora
O dispositivo envia BPDUs de configuração no intervalo de tempo hello para os dispositivos vizinhos para garantir que os caminhos estejam livres de falhas. Por padrão, o hello time é de 2 segundos. Se o dispositivo não receber BPDUs de configuração dentro do período de tempo limite, ele recalculará a árvore de abrangência. A fórmula para calcular o período de tempo limite é: período de tempo limite = fator de tempo limite × 3 × hello time.
Idade máxima
O dispositivo usa a idade máxima para determinar se um BPDU de configuração armazenado expirou e o descarta se a idade máxima for excedida. Por padrão, a idade máxima é de 20 segundos. No CIST de uma rede MSTP, o dispositivo usa o timer de idade máxima para determinar se um BPDU de configuração recebido por uma porta expirou. Se ele tiver expirado, um novo processo de cálculo da árvore de abrangência será iniciado. O timer de idade máxima não entra em vigor nos MSTIs.
Se uma porta não receber nenhum BPDU de configuração dentro do período de tempo limite, a porta passa para o estado de escuta. O dispositivo recalculará a árvore de abrangência. A porta leva 50 segundos para voltar ao estado de encaminhamento. Esse período inclui 20 segundos para a idade máxima, 15 segundos para o estado de escuta e 15 segundos para o estado de aprendizado.
Para garantir uma convergência rápida da topologia, certifique-se de que as configurações do temporizador atendam às seguintes fórmulas:
2 × (atraso de encaminhamento - 1 segundo) ≥ idade máxima
Idade máxima ≥ 2 × (tempo de espera + 1 segundo)
Sobre o RSTP
O RSTP consegue uma convergência rápida da rede, permitindo que uma porta raiz recém-eleita ou uma porta designada entre no estado de encaminhamento muito mais rapidamente do que o STP.
Quadros do protocolo RSTP
Um BPDU RSTP usa o mesmo formato de um BPDU STP, exceto pelo fato de que um campo de comprimento da versão 1 é adicionado à carga útil dos BPDUs RSTP. As diferenças entre um BPDU RSTP e um BPDU STP são as seguintes:
ID da versão do protocolo - O valor é 0x02 para RSTP.
Tipo de BPDU - O valor é 0x02 para BPDUs RSTP.
Flags - Todos os 8 bits são usados.
Comprimento da versão 1 - O valor é 0x00, o que significa que não há informações sobre o protocolo da versão 1.
O RSTP não usa BPDUs TCN para anunciar alterações de topologia. O RSTP inunda BPDUs com o sinalizador TC definido na rede para anunciar alterações de topologia.
Conceitos básicos do RSTP
Funções de porta
Além da porta raiz e da porta designada, o RSTP também usa as seguintes funções de porta:
Porta alternativa - Atua como porta de backup para uma porta raiz. Quando a porta raiz é bloqueada, a porta alternativa assume o controle.
Porta de backup - Atua como porta de backup de uma porta designada. Quando a porta designada é inválida, a porta de backup torna-se a nova porta designada. Um loop ocorre quando duas portas do mesmo dispositivo de spanning tree estão conectadas, de modo que o dispositivo bloqueia uma das portas. A porta bloqueada é a porta de backup.
Porta de borda - conecta-se diretamente a um host de usuário em vez de a um dispositivo de rede ou segmento de rede.
Estados das portas
O RSTP usa o estado de descarte para substituir os estados de desativação, bloqueio e escuta no STP. A Tabela 5 mostra as diferenças entre os estados das portas no RSTP e no STP.
Tabela 5 Diferenças de estado de porta entre RSTP e STP
Como o RSTP funciona
Durante o cálculo do RSTP, ocorrem os seguintes eventos:
Se uma porta em estado de descarte se tornar uma porta alternativa, ela manterá seu estado.
Se uma porta no estado de descarte for eleita como porta raiz ou porta designada, ela entrará no estado de aprendizado após o atraso no encaminhamento. A porta aprende os endereços MAC e entra no estado de encaminhamento após outro atraso de encaminhamento.
Uma porta raiz RSTP recém-eleita entra rapidamente no estado de encaminhamento se os seguintes requisitos forem atendidos:
A porta raiz antiga do dispositivo parou de encaminhar dados.
A porta designada upstream começou a encaminhar dados.
Uma porta designada RSTP recém-eleita entra rapidamente no estado de encaminhamento se um dos requisitos a seguir for atendido:
A porta designada é configurada como uma porta de borda que se conecta diretamente a um terminal de usuário.
A porta designada se conecta a um link ponto a ponto e recebe uma resposta de handshake do dispositivo conectado diretamente.
Processamento de BPDUs RSTP
No RSTP, uma ponte não raiz envia ativamente BPDUs RSTP no momento do "hello" por meio de portas designadas, sem esperar que a ponte raiz envie BPDUs RSTP. Isso permite que o RSTP detecte rapidamente o link
falhas. Se um dispositivo não receber nenhum BPDU RSTP em uma porta dentro do triplo do tempo de espera, o dispositivo considerará que ocorreu uma falha de link. Após a expiração do BPDU de configuração armazenada, o dispositivo inunda BPDUs RSTP com o sinalizador TC definido para iniciar um novo cálculo RSTP.
No RSTP, uma porta em estado de bloqueio pode responder imediatamente a um BPDU do RSTP com uma prioridade mais baixa do que seu próprio BPDU.
Conforme mostrado na Figura 6, o Dispositivo A é a ponte raiz. A prioridade do Dispositivo B é maior que a prioridade do Dispositivo C. A porta C2 no Dispositivo C está bloqueada.
Quando o link entre o Dispositivo A e o Dispositivo B falha, ocorrem os seguintes eventos:
O dispositivo B envia um BPDU RSTP com ele mesmo como a ponte raiz para o dispositivo C.
O dispositivo C compara o BPDU do RSTP com seu próprio BPDU.
Como o BPDU RSTP do Dispositivo B tem uma prioridade mais baixa, o Dispositivo C envia seu próprio BPDU para Dispositivo B.
O dispositivo B considera que a porta B2 é a porta raiz e para de enviar BPDUs RSTP para o dispositivo C.
Figura 6 Processamento de BPDU no RSTP
Sobre o PVST
Em uma LAN habilitada para STP ou RSTP, todas as pontes compartilham uma árvore de abrangência. O tráfego de todas as VLANs é encaminhado ao longo da árvore de abrangência, e as portas não podem ser bloqueadas por VLAN para podar loops.
O PVST permite que cada VLAN tenha sua própria spanning tree, o que aumenta o uso de links e largura de banda. Como cada VLAN executa o RSTP de forma independente, uma árvore de abrangência atende apenas à sua VLAN.
Um dispositivo INTELBRAS habilitado para PVST pode se comunicar com um dispositivo de terceiros que esteja executando Rapid PVST ou PVST. O dispositivo INTELBRAS habilitado para PVST suporta convergência de rede rápida como RSTP quando conectado a dispositivos INTELBRAS habilitados para PVST ou a dispositivos de terceiros habilitados com Rapid PVST.
Quadros do protocolo PVST
Conforme mostrado na Figura 7, um BPDU PVST usa o mesmo formato de um BPDU RSTP, exceto pelas seguintes diferenças:
O endereço MAC de destino de um BPDU PVST é 01-00-0c-cc-cc-cd, que é um endereço MAC privado.
Cada BPDU PVST contém uma tag de VLAN. A tag de VLAN identifica a VLAN à qual o BPDU PVST pertence.
Os campos de código de organização e PID são adicionados ao cabeçalho LLC do BPDU PVST.
Figura 7 Formato BPDU do PVST
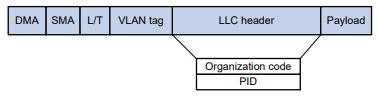
O tipo de link de uma porta determina o tipo de BPDUs que a porta envia.
Uma porta de acesso envia BPDUs RSTP.
Uma porta tronco ou híbrida envia BPDUs RSTP na VLAN padrão e envia BPDUs PVST em outras VLANs.
Como o PVST funciona
O PVST implementa o cálculo da árvore de abrangência por VLAN mapeando cada VLAN para um MSTI. No PVST, cada VLAN executa o RSTP de forma independente para manter sua própria árvore de abrangência sem afetar as árvores de abrangência de outras VLANs. Dessa forma, os loops em cada VLAN são eliminados e o tráfego de diferentes VLANs é compartilhado por links. O PVST usa BPDUs do RSTP na VLAN padrão e BPDUs do PVST em outras VLANs para o cálculo da árvore de abrangência.
O PVST usa as mesmas funções e estados de porta que o RSTP para a transição rápida. Para obter mais informações, consulte "Conceitos básicos do RSTP".
Sobre a MSTP
Recursos do MSTP
Desenvolvido com base no IEEE 802.1s, o MSTP supera as limitações do STP, RSTP e PVST. Além de dar suporte à rápida convergência da rede, ele permite que os fluxos de dados de diferentes VLANs sejam encaminhados por caminhos separados. Isso proporciona um melhor mecanismo de compartilhamento de carga para links redundantes.
O MSTP oferece os seguintes recursos:
O MSTP divide uma rede comutada em várias regiões, cada uma das quais contém várias spanning trees independentes umas das outras.
O MSTP suporta o mapeamento de VLANs para instâncias de spanning tree por meio de uma tabela de mapeamento de VLAN para instância. O MSTP pode reduzir as despesas gerais de comunicação e o uso de recursos mapeando várias VLANs para uma instância.
O MSTP poda uma rede de loop em uma árvore sem loop, o que evita a proliferação e o ciclo interminável de quadros em uma rede de loop. Além disso, ele oferece suporte ao balanceamento de carga de dados de VLAN, fornecendo vários caminhos redundantes para o encaminhamento de dados.
O MSTP é compatível com o STP e o RSTP, e parcialmente compatível com o PVST.
Conceitos básicos do MSTP
A Figura 9 mostra uma rede comutada que contém quatro regiões MST, cada região MST contendo quatro dispositivos MSTP. A Figura 10 mostra a topologia de rede da região 3 da MST.
Figura 9 Conceitos básicos do MSTP
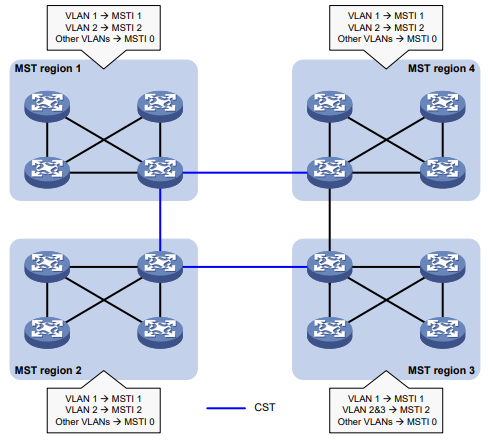
Figura 10 Diagrama de rede e topologia da região 3 do MST
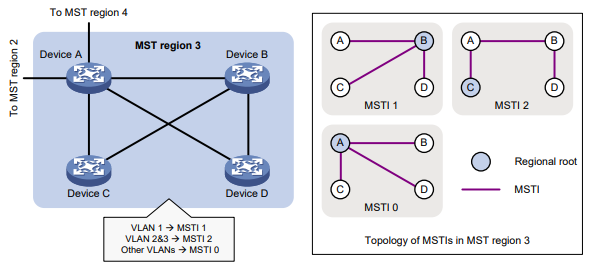
Para a região 4 da MST
Região MST
Uma região Spanning Tree múltipla (região MST) consiste em vários dispositivos em uma rede comutada e nos segmentos de rede entre eles. Todos esses dispositivos têm as seguintes características:
Um protocolo de spanning tree ativado
Mesmo nome de região
Mesma configuração de mapeamento de VLAN para instância
Mesmo nível de revisão do MSTP
Fisicamente ligados entre si
Podem existir várias regiões MST em uma rede comutada. Você pode atribuir vários dispositivos à mesma região MST.
A rede comutada contém quatro regiões MST, da região MST 1 à região MST 4.
Todos os dispositivos em cada região MST têm a mesma configuração de região MST.
MSTI
O MSTP pode gerar várias spanning trees independentes em uma região MST, e cada spanning tree é mapeada para VLANs específicas. Cada árvore de abrangência é chamada de instância Spanning Tree múltipla (MSTI).
Tabela de mapeamento de VLAN para instância
Como atributo de uma região MST, a tabela de mapeamento VLAN-para-instância descreve as relações de mapeamento entre VLANs e MSTIs.
O MSTP realiza o balanceamento de carga por meio da tabela de mapeamento de VLAN para instância.
CST
A árvore de abrangência comum (CST) é uma única árvore de abrangência que conecta todas as regiões MST em uma rede comutada. Se você considerar cada região MST como um dispositivo, a CST é uma árvore de abrangência calculada por esses dispositivos por meio do STP ou do RSTP.
Uma árvore de abrangência interna (IST) é uma árvore de abrangência que é executada em uma região MST. Também é chamada de MSTI 0, uma MSTI especial para a qual todas as VLANs são mapeadas por padrão.
A árvore de abrangência comum e interna (CIST) é uma única árvore de abrangência que conecta todos os dispositivos em uma rede comutada. Ela consiste nas ISTs em todas as regiões MST e na CST.
Raiz regional
A ponte raiz do IST ou de um MSTI em uma região MST é a raiz regional do IST ou do MSTI. Com base na topologia, diferentes spanning trees em uma região MST podem ter diferentes raízes regionais, conforme mostrado na região MST 3
Ponte raiz comum
A ponte raiz comum é a ponte raiz do CIST.
Funções de porta
Uma porta pode desempenhar diferentes funções em diferentes MSTIs. Conforme mostrado na Figura 11, uma região MST contém o Dispositivo A, o Dispositivo B, o Dispositivo C e o Dispositivo D. A porta A1 e a porta A2 do Dispositivo A se conectam à ponte raiz comum. A porta B2 e a porta B3 do Dispositivo B formam um loop. Porta C3 e Porta C4 do Dispositivo C conectam-se a outras regiões MST. A porta D3 do dispositivo D se conecta diretamente a um host.
Figura 11 Funções da porta
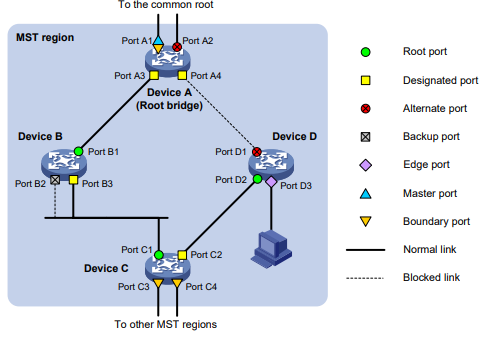
Para a raiz comum
Porta raiz Porta designada Porta alternativa
Porta de backup
Porta de borda Porta mestre Porta de limite Link normal Link bloqueado
Para outras regiões MST
O cálculo do MSTP envolve as seguintes funções de porta:
Porta raiz - encaminha dados de uma ponte não raiz para a ponte raiz. A ponte raiz não tem nenhuma porta raiz.
Porta designada - encaminha dados para o segmento de rede ou dispositivo downstream.
Porta alternativa - Atua como porta de backup para uma porta raiz ou porta principal. Quando a porta raiz ou a porta principal é bloqueada, a porta alternativa assume o controle.
Porta de backup - Atua como porta de backup de uma porta designada. Quando a porta designada é inválida, a porta de backup torna-se a nova porta designada. Um loop ocorre quando duas portas do mesmo dispositivo de spanning tree estão conectadas, de modo que o dispositivo bloqueia uma das portas. A porta bloqueada atua como backup.
Porta de borda - conecta-se diretamente a um host de usuário em vez de a um dispositivo de rede ou segmento de rede.
Porta mestre - Atua como uma porta no caminho mais curto da região MST local até a ponte raiz comum. A porta mestre nem sempre está localizada na raiz regional. Ela é uma porta raiz no IST ou CIST e ainda é uma porta mestre nos outros MSTIs.
Porta de limite - Conecta uma região MST a outra região MST ou a um dispositivo em execução STP/RSTP. No cálculo do MSTP, a função de uma porta de limite em um MSTI é consistente com sua função na região MST.
Estados das portas
CIST. Entretanto, isso não é verdade com as portas mestras. Uma porta mestre em MSTIs é uma porta raiz no CIST.
No MSTP, uma porta pode estar em um dos seguintes estados:
Encaminhamento - A porta recebe e envia BPDUs, aprende endereços MAC e encaminha o tráfego de usuários.
Aprendizagem - A porta recebe e envia BPDUs, aprende endereços MAC, mas não encaminha tráfego de usuário. O aprendizado é um estado intermediário da porta.
Descarte - A porta recebe e envia BPDUs, mas não aprende endereços MAC nem encaminha tráfego de usuários.
OBSERVAÇÃO:
Quando em MSTIs diferentes, uma porta pode estar em estados diferentes.
Um estado de porta não está associado exclusivamente a uma função de porta. A Tabela 6 lista os estados de porta que cada função de porta suporta. (Uma marca de seleção [√] indica que a porta é compatível com esse estado, enquanto um traço [-] indica que a porta não é compatível com esse estado).
Tabela 6 Estados de porta que diferentes funções de porta suportam
Como o MSTP funciona
O MSTP divide toda uma rede de Camada 2 em várias regiões MST, que são conectadas por um CST calculado. Dentro de uma região MST, são calculadas várias spanning trees, chamadas MSTIs. Entre essas MSTIs, a MSTI 0 é a IST.
Assim como o STP, o MSTP usa BPDUs de configuração para calcular as árvores de abrangência. Uma diferença importante é que um BPDU MSTP carrega a configuração MSTP da ponte da qual o BPDU é enviado.
Cálculo do CIST
Durante o cálculo do CIST, ocorre o seguinte processo:
O dispositivo com a prioridade mais alta é eleito como a ponte raiz do CIST.
O MSTP gera um IST em cada região MST por meio de cálculos.
O MSTP considera cada região MST como um único dispositivo e gera um CST entre essas regiões MST por meio de cálculos.
O CST e os ISTs constituem o CIST de toda a rede.
Cálculo de MSTI
Em uma região MST, o MSTP gera MSTIs diferentes para VLANs diferentes com base nos mapeamentos de VLAN para instância. Para cada árvore de abrangência, o MSTP executa um processo de cálculo separado semelhante ao cálculo da árvore de abrangência no STP. Para obter mais informações, consulte "Processo de cálculo do algoritmo STP".
No MSTP, um quadro de VLAN é encaminhado pelos seguintes caminhos:
Em uma região MST, o quadro é encaminhado ao longo do MSTI correspondente.
Entre duas regiões MST, o quadro é encaminhado ao longo da CST.
Implementação do MSTP em dispositivos
O MSTP é compatível com o STP e o RSTP. Os dispositivos que estão executando o MSTP e que são usados para o cálculo da árvore de abrangência podem identificar os quadros dos protocolos STP e RSTP.
Além dos recursos básicos do MSTP, os seguintes recursos são fornecidos para facilitar o gerenciamento:
Retenção da ponte raiz.
Backup da ponte raiz.
Proteção da raiz.
Proteção de BPDU.
Proteção do laço.
Proteção TC-BPDU.
Restrição de função de porta.
Restrição de transmissão TC-BPDU.
Mecanismo de transição rápida
No STP, uma porta deve esperar o dobro do atraso de encaminhamento (30 segundos por padrão) antes de passar do estado de bloqueio para o estado de encaminhamento. O atraso de encaminhamento está relacionado ao hello time e ao diâmetro da rede. Se o atraso de encaminhamento for muito curto, poderão ocorrer loops. Isso afeta a estabilidade da rede.
O RSTP, o PVST e o MSTP usam o mecanismo de transição rápida para acelerar a transição do estado da porta para portas de borda, portas raiz e portas designadas. O mecanismo de transição rápida para portas designadas também é conhecido como transição de proposta/acordo (P/A).
Transição rápida da porta de borda
Conforme mostrado na Figura 12, a porta C3 é uma porta de borda conectada a um host. Quando ocorre uma mudança na topologia da rede, a porta pode transitar imediatamente do estado de bloqueio para o estado de encaminhamento, pois não será causado nenhum loop.
Como um dispositivo não pode determinar se uma porta está diretamente conectada a um terminal, você deve configurar manualmente a porta como uma porta de borda.
Figura 12 Transição rápida da porta de borda
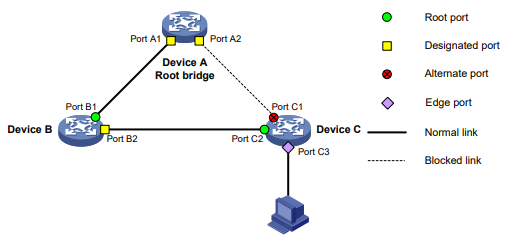
Transição rápida da porta raiz
Quando uma porta raiz for bloqueada, a ponte elegerá a porta alternativa com a prioridade mais alta como a nova porta raiz. Se o par da nova porta raiz estiver no estado de encaminhamento, a nova porta raiz passará imediatamente para o estado de encaminhamento.
Conforme mostrado na Figura 13, a porta C2 no dispositivo C é uma porta raiz e a porta C1 é uma porta alternativa. Quando a porta C2 passa para o estado de bloqueio, a porta C1 é eleita como a porta raiz e passa imediatamente para o estado de encaminhamento .
Figura 13 Transição rápida da porta raiz
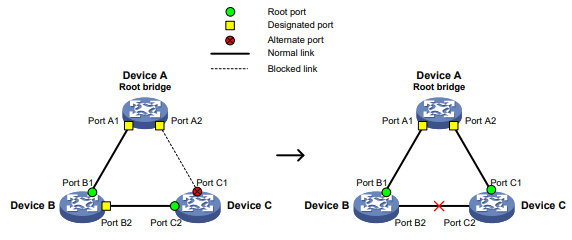
Transição P/A
A transição P/A permite que uma porta designada passe rapidamente para o estado de encaminhamento após um handshake com seu par. A transição P/A aplica-se somente a links ponto a ponto.
Transição P/A para RSTP e PVST.
No RSTP ou PVST, as portas em um novo link ou em um link recuperado são portas designadas em estado de bloqueio. Quando uma das portas designadas passa para o estado de descarte ou aprendizado, ela define o sinalizador de proposta em seu BPDU. Sua ponte par recebe o BPDU e determina se a porta receptora é a porta raiz. Se for a porta raiz, a ponte bloqueia as outras portas, exceto as portas de borda. Em seguida, a ponte responde um BPDU de acordo para a porta designada. A porta designada passa imediatamente para o estado de encaminhamento ao receber o BPDU de acordo. Se a porta designada não receber o BPDU de acordo, ela aguardará o dobro do atraso de encaminhamento para passar para o estado de encaminhamento.
Conforme mostrado na Figura 14, a transição P/A funciona da seguinte forma:
O dispositivo A envia uma proposta BPDU ao dispositivo B por meio da porta A1.
O dispositivo B recebe a proposta BPDU na porta B2. A porta B2 é eleita como a porta raiz.
O dispositivo B bloqueia sua porta designada, a porta B1, e a porta alternativa, a porta B3, para eliminar os loops.
A porta raiz, a porta B2, passa para o estado de encaminhamento e envia um BPDU de acordo para o dispositivo A.
A porta designada Porta A1 no Dispositivo A passa imediatamente para o estado de encaminhamento após receber o BPDU de acordo.
Figura 14 Transição P/A para RSTP e PVST
Transição P/A para MSTP.
No MSTP, uma ponte upstream define os sinalizadores de proposta e de acordo em seu BPDU. Se uma ponte downstream receber o BPDU e sua porta receptora for eleita como a porta raiz, a ponte bloqueará todas as outras portas, exceto as portas de borda. Em seguida, a ponte de downstream responde um BPDU de acordo para a ponte de upstream. A porta upstream passa imediatamente para o estado de encaminhamento ao receber o BPDU de acordo. Se a porta upstream não receber o BPDU de acordo, ela aguardará o dobro do atraso de encaminhamento para passar para o estado de encaminhamento.
Conforme mostrado na Figura 15, a transição P/A funciona da seguinte forma:
O dispositivo A define os sinalizadores de proposta e acordo em seu BPDU e o envia ao dispositivo B por meio da porta A1 do .
O dispositivo B recebe o BPDU. A porta B1 do dispositivo B é eleita como a porta raiz.
O dispositivo B bloqueia todas as suas portas, exceto as portas de borda.
A porta raiz Porta B1 do Dispositivo B passa para o estado de encaminhamento e envia um acordo BPDU para o Dispositivo A.
A porta A1 do dispositivo A passa imediatamente para o estado de encaminhamento ao receber o acordo BPDU.
Figura 15 Transição P/A para MSTP
Protocolos e padrões
O MSTP está documentado nos seguintes protocolos e padrões:
IEEE 802.1d, pontes de controle de acesso à mídia (MAC)
IEEE 802.1w, Parte 3: Pontes de controle de acesso ao meio (MAC) - Alteração 2: Reconfiguração rápida
IEEE 802.1s, redes locais com pontes virtuais - Alteração 3: múltiplas árvores de varredura
IEEE 802.1Q-REV/D1.3, pontes de controle de acesso a mídia (MAC) e redes locais com pontes virtuais - Cláusula 13: Protocolos Spanning Tree
Configuração dos protocolos de spanning tree
Configurando o protocolo Spanning Tree
Restrições e diretrizes: configuração do protocolo spanning tree
Restrições: Configuração da interface
Alguns recursos da árvore de abrangência são suportados na visualização da interface Ethernet da Camada 2 e na visualização da interface agregada da Camada 2. Salvo indicação em contrário, essas visualizações são coletivamente chamadas de visualização de interface neste documento. O BPDU drop pode ser configurado somente na visualização da interface Ethernet da camada 2.
As configurações feitas na visualização do sistema entram em vigor globalmente. As configurações feitas na visualização da interface Ethernet de camada 2 têm efeito apenas na interface. As configurações feitas na visualização da interface agregada da camada 2 têm efeito apenas na interface agregada. As configurações feitas em uma porta de membro de agregação podem entrar em vigor somente depois que a porta for removida do grupo de agregação.
Depois que você ativa um protocolo Spanning Tree em uma interface agregada da Camada 2, o sistema executa o cálculo da árvore de abrangência na interface agregada da Camada 2. Ele não realiza o cálculo da árvore de abrangência nas portas-membro de agregação. O estado de ativação do protocolo spanning tree e o estado de encaminhamento de cada porta membro selecionada são consistentes com os da interface agregada de camada 2 correspondente.
As portas membros de um grupo de agregação não participam do cálculo da árvore de abrangência. No entanto, as portas ainda reservam suas configurações Spanning Tree para participar do cálculo da árvore de abrangência após deixarem o grupo de agregação.
Configuração do modo Spanning Tree
Sobre o modo spanning tree
Os modos Spanning Tree incluem:
Modo STP - Todas as portas do dispositivo enviam BPDUs STP. Selecione esse modo quando o dispositivo par de uma porta for compatível apenas com STP.
Modo RSTP - Todas as portas do dispositivo enviam BPDUs RSTP. Uma porta nesse modo passa automaticamente para o modo STP quando recebe BPDUs STP do dispositivo par. Uma porta nesse modo não passa para o modo MSTP quando recebe BPDUs MSTP do dispositivo par.
Modo PVST - Todas as portas do dispositivo enviam BPDUs PVST. Cada VLAN mantém uma árvore de abrangência. Em uma rede, a quantidade de árvores de abrangência mantidas por todos os dispositivos é igual ao número de VLANs habilitadas para PVST multiplicado pelo número de portas habilitadas para PVST. Se a quantidade de spanning trees exceder a capacidade da rede, as CPUs dos dispositivos ficarão sobrecarregadas. O encaminhamento de pacotes será interrompido e a rede se tornará instável. O dispositivo pode manter árvores de abrangência para 128 VLANs.
Modo MSTP - Todas as portas do dispositivo enviam BPDUs MSTP. Uma porta nesse modo passa automaticamente para o modo STP quando recebe BPDUs STP do dispositivo par. Uma porta nesse modo não passa para o modo RSTP quando recebe BPDUs RSTP do dispositivo par.
Restrições e diretrizes
O modo MSTP é compatível com o modo RSTP, e o modo RSTP é compatível com o modo STP.
A compatibilidade do modo PVST depende do tipo de link de uma porta.
Em uma porta de acesso, o modo PVST é compatível com outros modos de spanning tree em todas as VLANs.
Em uma porta tronco ou porta híbrida, o modo PVST é compatível com outros modos de spanning tree somente na VLAN padrão.
Procedimento
Entre na visualização do sistema.
System ViewDefinir o modo Spanning Tree.
stp mode { mstp | pvst | rstp | stp }A configuração padrão é o modo MSTP.
Configuração de uma região MST
Sobre a região MST
Os dispositivos Spanning Tree pertencem à mesma região MST se ambos estiverem conectados por meio de um link físico e configurados com os seguintes detalhes:
Seletor de formato (0 por padrão, não configurável).
Nome da região MST.
Nível de revisão da região MST.
Entradas de mapeamento de VLAN para instância na região MST.
A configuração dos parâmetros relacionados à região MST (especialmente a tabela de mapeamento VLAN-para-instância) pode fazer com que o MSTP inicie um novo cálculo Spanning Tree. Para reduzir a possibilidade de instabilidade da topologia, a configuração da região MST entra em vigor somente depois de ser ativada por meio de uma das ações a seguir:
Use o comando active region-configuration.
Ative um protocolo Spanning Tree usando o comando stp global enable se o protocolo Spanning Tree estiver desativado.
Restrições e diretrizes
No modo STP, RSTP ou PVST, as configurações de região MST não têm efeito.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da região MST.
stp region-configuration Configure o nome da região MST.
region-name name A configuração padrão é o endereço MAC.
Configure a tabela de mapeamento de VLAN para instância. Escolha uma opção conforme necessário:
Mapear uma lista de VLANs para um MSTI.
instance instance-id vlan vlan-id-listCrie rapidamente uma tabela de mapeamento de VLAN para instância.
vlan-mapping modulo moduloPor padrão, todas as VLANs em uma região MST são mapeadas para o CIST (ou MSTI 0).
Configure o nível de revisão MSTP da região MST.
revision-level levelA configuração padrão é 0.
(Opcional.) Exibe as configurações de região MST que ainda não foram ativadas.
check region-configuration Ativar manualmente a configuração da região MST.
active region-configurationConfiguração da ponte raiz ou de uma ponte raiz secundária
Restrições e diretrizes
Você pode fazer com que o protocolo da árvore de abrangência determine a ponte raiz de uma árvore de abrangência por meio de cálculo. Você também pode especificar um dispositivo como root bridge ou como root bridge secundária.
Quando você especificar um dispositivo como root bridge ou como root bridge secundário, siga estas restrições e diretrizes:
Um dispositivo tem funções independentes em diferentes spanning trees. Ele pode atuar como root bridge em uma spanning tree e como root bridge secundária em outra. Entretanto, um dispositivo não pode ser a ponte raiz e uma ponte raiz secundária na mesma árvore de abrangência.
Se você especificar a root bridge para uma spanning tree, nenhuma nova root bridge será eleita de acordo com as configurações de prioridade do dispositivo. Depois de especificar um dispositivo como root bridge ou root bridge secundária, você não poderá alterar a prioridade do dispositivo.
Você pode configurar um dispositivo como a ponte raiz definindo a prioridade do dispositivo como 0. Para a configuração da prioridade do dispositivo, consulte "Configuração da prioridade do dispositivo".
Configuração do dispositivo como a ponte raiz de uma árvore de abrangência
Entre na visualização do sistema.
System ViewConfigure o dispositivo como a ponte raiz.
No modo STP/RSTP:
stp root primary No modo PVST:
stp vlan vlan-id-list root primaryNo modo MSTP:
stp [ instance instance-list ] root primaryPor padrão, o dispositivo não é uma ponte raiz.
Configuração do dispositivo como uma ponte raiz secundária de uma árvore de abrangência
Entre na visualização do sistema.
System ViewConfigure o dispositivo como uma ponte raiz secundária.
No modo STP/RSTP:
stp root secondaryNo modo PVST:
stp vlan vlan-id-list root secondaryNo modo MSTP:
stp [ instance instance-list ] root secondaryPor padrão, o dispositivo não é uma ponte raiz secundária.
Configuração da prioridade do dispositivo
Sobre a prioridade do dispositivo
A prioridade do dispositivo é um fator no cálculo da árvore de abrangência. A prioridade de um dispositivo determina se ele pode ser eleito como a ponte raiz de uma árvore de abrangência. Um valor mais baixo indica uma prioridade mais alta. Você pode definir a prioridade de um dispositivo com um valor baixo para especificar o dispositivo como a ponte raiz da árvore de abrangência. Um dispositivo Spanning Tree pode ter prioridades diferentes em árvores de abrangência diferentes.
Durante a seleção da root bridge, se todos os dispositivos em uma spanning tree tiverem a mesma prioridade, será selecionado aquele com o endereço MAC mais baixo. Não é possível alterar a prioridade de um dispositivo depois que ele estiver configurado como root bridge ou como root bridge secundária.
Procedimento
Entre na visualização do sistema.
System ViewConfigure a prioridade do dispositivo.
No modo STP/RSTP:
stp priority priorityNo modo PVST:
stp vlan vlan-id-list priority priorityNo modo MSTP:
stp [ instance instance-list ] priority priorityA configuração padrão é 32768.
Configuração do número máximo de saltos de uma região MST
Sobre o número máximo de saltos de uma região MST
Restrinja o tamanho da região definindo o máximo de saltos de uma região MST. O limite de saltos configurado na ponte raiz regional é usado como o limite de saltos para a região MST.
Os BPDUs de configuração enviados pela ponte raiz regional sempre têm uma contagem de saltos definida como o valor máximo. Quando um dispositivo recebe esse BPDU de configuração, ele diminui a contagem de saltos em um e usa a nova contagem de saltos nos BPDUs que propaga. Quando a contagem de saltos de um BPDU chega a zero, ele é descartado pelo dispositivo que o recebeu. Os dispositivos além do alcance do máximo de saltos não podem mais participar dos cálculos da spanning tree, portanto o tamanho da região MST é limitado.
Restrições e diretrizes
Faça essa configuração somente na ponte raiz. Todos os outros dispositivos na região MST usam o valor de salto máximo definido para a ponte raiz.
Você pode configurar o máximo de hops de uma região MST com base no tamanho da rede STP. Como prática recomendada, defina o máximo de saltos para um valor maior do que o máximo de saltos de cada dispositivo de borda para a ponte raiz.
Procedimento
Entre na visualização do sistema.
System ViewConfigure o número máximo de saltos da região MST.
stp max-hops hopsA configuração padrão é 20.
Configuração do diâmetro da rede de uma rede comutada
Sobre o diâmetro da rede
Quaisquer dois dispositivos terminais em uma rede comutada podem alcançar um ao outro por meio de um caminho específico, e há uma série de dispositivos no caminho. O diâmetro da rede comutada é o número máximo de dispositivos no caminho para um dispositivo de borda alcançar outro dispositivo na rede comutada por meio da ponte raiz. O diâmetro da rede indica o tamanho da rede. Quanto maior o diâmetro, maior o tamanho da rede.
Com base no diâmetro da rede que você configurou, o sistema define automaticamente um hello time, um forward delay e um max age ideais para o dispositivo.
No modo STP, RSTP ou MSTP, cada região MST é considerada um dispositivo. O diâmetro de rede configurado entra em vigor somente no CIST (ou na ponte raiz comum), mas não em outros MSTIs.
No modo PVST, o diâmetro de rede configurado entra em vigor somente nas pontes-raiz das VLANs especificadas.
Procedimento
Entre na visualização do sistema.
System ViewConfigure o diâmetro da rede comutada.
No modo STP/RSTP/MSTP:
stp bridge-diameter diameterNo modo PVST:
stp vlan vlan-id-list bridge-diameter diameterA configuração padrão é 7.
Configuração de temporizadores de spanning tree
Sobre os temporizadores de spanning tree
Os seguintes temporizadores são usados para o cálculo da árvore de abrangência:
Atraso de encaminhamento - Tempo de atraso para a transição do estado da porta. Para evitar loops temporários em uma rede, o recurso spanning tree define um estado de porta intermediário (o estado de aprendizagem) antes que ela transite do estado de descarte para o estado de encaminhamento. O recurso também exige que a porta transite em seu estado após um cronômetro de atraso de encaminhamento. Isso garante que a transição de estado da porta local permaneça sincronizada com o par.
Hello time-Intervalo no qual o dispositivo envia BPDUs de configuração para detectar falhas de link. Se o dispositivo não receber BPDUs de configuração dentro do período de tempo limite, ele recalculará a árvore de abrangência. A fórmula para calcular o período de tempo limite é: período de tempo limite = fator de tempo limite × 3 × tempo de espera.
Idade máxima-No CIST de uma rede MSTP, o dispositivo usa o timer de idade máxima para determinar se um BPDU de configuração recebido por uma porta expirou. Se ele tiver expirado, um novo processo de cálculo da árvore de abrangência será iniciado. O cronômetro de idade máxima não entra em vigor nos MSTIs.
Para garantir uma convergência rápida da topologia, certifique-se de que as configurações do timer atendam às seguintes fórmulas:
2 × (atraso de encaminhamento - 1 segundo) ≥ idade máxima
Idade máxima ≥ 2 × (tempo de espera + 1 segundo)
Como prática recomendada, especifique o diâmetro da rede e deixe que os protocolos Spanning Tree calculem automaticamente os timers com base no diâmetro da rede, em vez de definir manualmente os timers da árvore de abrangência. Se o diâmetro da rede usar o valor padrão, os temporizadores também usarão seus valores padrão.
Defina os temporizadores somente na ponte raiz. As configurações de temporizador na ponte raiz se aplicam a todos os dispositivos em toda a rede comutada.
Restrições e diretrizes
A duração do atraso de encaminhamento está relacionada ao diâmetro da rede comutada. Quanto maior for o diâmetro da rede, maior deverá ser o tempo de atraso de encaminhamento. Como prática recomendada, use o valor calculado automaticamente porque a configuração inadequada do atraso de encaminhamento pode causar caminhos redundantes temporários ou aumentar o tempo de convergência da rede.
Uma configuração adequada do hello time permite que o dispositivo detecte prontamente falhas de link na rede sem usar recursos excessivos da rede. Se o hello time for muito longo, o dispositivo confunde a perda de pacotes com uma falha de link e aciona um novo processo de cálculo da spanning tree. Se o hello time for muito curto, o dispositivo enviará frequentemente os mesmos BPDUs de configuração, o que desperdiça recursos do dispositivo e da rede. Como prática recomendada, use o valor calculado automaticamente.
Se o timer de idade máxima for muito curto, o dispositivo iniciará frequentemente os cálculos da árvore de abrangência e poderá confundir o congestionamento da rede com uma falha de link. Se o timer de idade máxima for muito longo, o dispositivo poderá não conseguir detectar prontamente as falhas de link e iniciar rapidamente os cálculos da árvore de abrangência, reduzindo
Procedimento
o recurso de detecção automática da rede. Como prática recomendada, use o valor calculado automaticamente.
Entre na visualização do sistema.
System ViewDefina o cronômetro de atraso de encaminhamento.
No modo STP/RSTP/MSTP:
stp timer forward-delay timeNo modo PVST:
stp vlan vlan-id-list timer forward-delay timeA configuração padrão é de 15 segundos.
Defina o temporizador de "hello".
No modo STP/RSTP/MSTP:
stp timer hello timeNo modo PVST:
stp vlan vlan-id-list timer hello timeA configuração padrão é de 2 segundos.
Defina o cronômetro de idade máxima.
No modo STP/RSTP/MSTP:
stp timer max-age timeNo modo PVST:
stp vlan vlan-id-list timer max-age timeA configuração padrão é de 20 segundos.
Configuração do fator de tempo limite
Sobre o fator de tempo limite
O fator de tempo limite é um parâmetro usado para decidir o período de tempo limite. A fórmula para calcular o período de tempo limite é: período de tempo limite = fator de tempo limite × 3 × tempo de espera.
Em uma rede estável, cada dispositivo não raiz-ponte encaminha BPDUs de configuração para os dispositivos downstream no intervalo de tempo hello para detectar falhas de link. Se um dispositivo não receber um BPDU do dispositivo upstream em um intervalo de nove vezes o tempo de "hello", ele presumirá que o dispositivo upstream falhou. Em seguida, ele inicia um novo processo de cálculo da spanning tree.
Restrições e diretrizes
Como prática recomendada, defina o fator de tempo limite como 5, 6 ou 7 nas seguintes situações:
Para evitar cálculos indesejados da spanning tree. Um dispositivo upstream pode estar ocupado demais para encaminhar BPDUs de configuração a tempo; por exemplo, muitas interfaces de camada 2 estão configuradas no dispositivo upstream. Nesse caso, o dispositivo downstream não recebe um BPDU dentro do período de tempo limite e, em seguida, inicia um cálculo indesejado da árvore de abrangência.
Para economizar recursos de rede em uma rede estável.
Procedimento
Entre na visualização do sistema.
System ViewDefina o fator de tempo limite do dispositivo.
stp timer-factor factorA configuração padrão é 3.
Configuração da taxa de transmissão de BPDU
Sobre a taxa de transmissão de BPDU
O número máximo de BPDUs que uma porta pode enviar em cada hello time é igual à taxa de transmissão de BPDU mais o valor do temporizador de hello.
Quanto mais alta for a taxa de transmissão de BPDU, mais BPDUs serão enviados em cada hello time e mais recursos do sistema serão usados. Ao definir uma taxa de transmissão de BPDU apropriada, você pode limitar a taxa na qual a porta envia BPDUs. A definição de uma taxa adequada também evita que os protocolos Spanning Tree usem recursos de rede excessivos quando a topologia da rede muda.
Restrições e diretrizes
A taxa de transmissão de BPDU depende do status físico da porta e da estrutura da rede. Como prática recomendada, use a configuração padrão.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure a taxa de transmissão de BPDU das portas.
stp transmit-limit limitA configuração padrão é 10.
Configuração de portas de borda
Sobre a porta de borda
Se uma porta se conectar diretamente a um terminal de usuário em vez de a outro dispositivo ou a um segmento de LAN compartilhado, essa porta será considerada uma porta de borda. Quando ocorrer uma mudança na topologia da rede, uma porta de borda não causará um loop temporário. Como um dispositivo não determina se uma porta está diretamente conectada a um terminal, você deve configurar manualmente a porta como uma porta de borda. Depois disso, a porta pode transitar rapidamente do estado de bloqueio para o estado de encaminhamento.
Restrições e diretrizes
Se a proteção de BPDU estiver desativada em uma porta configurada como uma porta de borda, ela se tornará uma porta não de borda novamente se receber um BPDU de outra porta. Para restaurar a porta de borda, reative-a.
Se uma porta se conectar diretamente a um terminal de usuário, configure-a como uma porta de borda e ative a proteção de BPDU para ela. Isso permite que a porta passe rapidamente para o estado de encaminhamento ao garantir a segurança da rede.
Em uma porta, o recurso de proteção de loop e a configuração de porta de borda são mutuamente exclusivos.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure a porta como uma porta de borda.
stp edged-portPor padrão, todas as portas são portas sem borda.
Configuração dos custos de caminho das portas
Sobre o custo do caminho
O custo do caminho é um parâmetro relacionado à velocidade do link de uma porta. Em um dispositivo spanning tree, uma porta pode ter diferentes custos de caminho em diferentes MSTIs. A definição de custos de caminho apropriados permite que os fluxos de tráfego de VLAN sejam encaminhados ao longo de diferentes links físicos, alcançando o balanceamento de carga baseado em VLAN.
Você pode fazer com que o dispositivo calcule automaticamente o custo padrão do caminho ou pode configurar o custo do caminho para as portas.
Especificação de um padrão para o cálculo do custo do caminho padrão
Sobre o padrão para o cálculo do custo do caminho padrão
Você pode especificar um padrão para o dispositivo usar no cálculo automático do custo do caminho padrão
Restrições e diretrizes
Se você alterar o padrão para o cálculo do custo do caminho padrão, os custos do caminho serão restaurados para o padrão.
Quando o dispositivo calcula o custo do caminho para uma interface agregada, o IEEE 802.1t leva em conta o número de portas selecionadas em seu grupo de agregação. Entretanto, o IEEE 802.1d-1998 não leva em conta o número de portas selecionadas. A fórmula de cálculo do IEEE 802.1t é: Custo do caminho = 200.000.000/velocidade do link (em 100 kbps). A velocidade do link é a soma dos valores de velocidade do link das portas selecionadas no grupo de agregação.
Procedimento
Entre na visualização do sistema.
System ViewEspecifique um padrão para o cálculo de custos de caminho padrão.
stp pathcost-standard { dot1d-1998 | dot1t | legacy }Por padrão, o dispositivo usa o legado para calcular os custos de caminho padrão de suas portas.
Configuração de custos de caminho das portas
Restrições e diretrizes
Quando o custo do caminho de uma porta muda, o sistema recalcula a função da porta e inicia uma transição de estado.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure o custo do caminho das portas.
No modo STP/RSTP:
stp cost cost-valueNo modo PVST:
stp vlan vlan-id-list cost cost-valueNo modo MSTP:
stp [ instance instance-list ] cost cost-valuePor padrão, o sistema calcula automaticamente o custo do caminho de cada porta.
Configuração da prioridade da porta
Sobre a prioridade da porta
A prioridade de uma porta é um fator que determina se a porta pode ser eleita como a porta raiz de um dispositivo. Se todas as outras condições forem as mesmas, a porta com a prioridade mais alta será eleita como a porta raiz.
Em um dispositivo Spanning Tree, uma porta pode ter prioridades diferentes e desempenhar funções diferentes em árvores de abrangência diferentes. Como resultado, os dados de diferentes VLANs podem ser propagados por diferentes caminhos físicos, implementando o balanceamento de carga por VLAN. Você pode definir valores de prioridade de porta com base nos requisitos reais de rede.
Restrições e diretrizes
Quando a prioridade de uma porta muda, o sistema recalcula a função da porta e inicia uma transição de estado. Prepare-se para a alteração da topologia da rede antes de configurar a prioridade da porta.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigurar a prioridade da porta.
No modo STP/RSTP:
stp port priority priority No modo PVST:
stp vlan vlan-id-list port priority priority No modo MSTP:
stp [ instance instance-list ] port priority priorityA configuração padrão é 128 para todas as portas.
Configuração do tipo de link de porta
Sobre o tipo de link de porta
Um link ponto a ponto conecta diretamente dois dispositivos. Se duas portas-raiz ou portas designadas estiverem conectadas em um link ponto a ponto, elas poderão passar rapidamente para o estado de encaminhamento após um processo de handshake de proposta e acordo .
Restrições e diretrizes
Você pode configurar o tipo de link como ponto a ponto para uma interface agregada de Camada 2 ou uma porta que opere no modo full duplex. Como prática recomendada, use a configuração padrão e deixe que o dispositivo detecte automaticamente o tipo de link da porta.
No modo PVST ou MSTP, os comandos stp point-to-point force-false ou stp
O comando force-true ponto a ponto configurado em uma porta entra em vigor em todas as VLANs ou em todos os MSTIs.
Antes de definir o tipo de link de uma porta como ponto a ponto, certifique-se de que a porta esteja conectada a um link ponto a ponto . Caso contrário, poderá ocorrer um loop temporário.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure o tipo de link da porta.
stp ponto a ponto { auto | force-false | force-true }Por padrão, o tipo de link é automático, em que a porta detecta automaticamente o tipo de link.
Configuração do modo que uma porta usa para reconhecer e enviar quadros MSTP
Sobre o formato de quadro MSTP
Uma porta pode receber e enviar quadros MSTP nos seguintes formatos:
formato padrão compatível com dot1s-802.1s
Formato compatível com o legado
Por padrão, o modo de reconhecimento de formato de quadro de uma porta é automático. A porta distingue automaticamente os dois formatos de quadro MSTP e determina o formato dos quadros que enviará com base no formato reconhecido.
Você pode configurar o formato de quadro MSTP em uma porta. Em seguida, a porta envia somente quadros MSTP do formato configurado para se comunicar com dispositivos que enviam quadros do mesmo formato.
Por padrão, uma porta no modo automático envia quadros MSTP 802.1s. Quando a porta recebe um quadro MSTP de um formato legado, ela começa a enviar quadros somente do formato legado. Isso evita que a porta altere frequentemente o formato dos quadros enviados. Para configurar a porta para enviar quadros MSTP 802.1s, desligue e, em seguida, abra a porta.
Restrições e diretrizes
Quando o número de MSTIs existentes for superior a 48, a porta poderá enviar somente quadros MSTP 802.1s.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure o modo que a porta usa para reconhecer/enviar quadros MSTP.
stp compliance { auto | dot1s | legacy }A configuração padrão é automática.
Ativação da saída de informações sobre a transição do estado da porta
Sobre a saída de informações de transição de estado da porta
Em uma rede spanning tree de grande escala, você pode permitir que os dispositivos emitam as informações de transição do estado da porta. Assim, você pode monitorar os estados das portas em tempo real.
Procedimento
Entre na visualização do sistema.
System ViewHabilita a saída de informações sobre a transição do estado da porta.
No modo STP/RSTP:
stp port-log instance 0 No modo PVST:
stp port-log vlan vlan-id-list No modo MSTP:
stp port-log { all | instance instance-list } O padrão varia de acordo com a versão do software, conforme mostrado abaixo:
Para obter mais informações sobre a configuração inicial e os padrões de fábrica, consulte o gerenciamento de arquivos de configuração no Guia de Configuração dos Fundamentos.
Ativação do recurso spanning tree
Restrições e diretrizes
Você deve ativar o recurso Spanning Tree para o dispositivo antes que qualquer outra configuração relacionada à árvore de abrangência possa ter efeito. No modo STP, RSTP ou MSTP, certifique-se de que o recurso de spanning tree esteja ativado globalmente e nas portas desejadas. No modo PVST, certifique-se de que o recurso Spanning Tree esteja ativado globalmente, nas VLANs desejadas e nas portas desejadas.
Para excluir portas específicas do cálculo da árvore de abrangência e economizar recursos da CPU, desative o recurso Spanning Tree para essas portas com o comando undo stp enable. Certifique-se de que não ocorram loops na rede depois que você desativar o recurso de spanning tree nessas portas.
Ativação do recurso spanning tree no modo STP/RSTP/MSTP
Entre na visualização do sistema.
System ViewHabilite o recurso Spanning Tree.
stp global enablePara as séries de switches S5000V3-EI, S5000V5-EI, S5000E-X, S5000X-EI e WAS6000, o recurso spanning tree é desativado globalmente por padrão.
Para outras séries de switches:
Quando o dispositivo é iniciado com as configurações iniciais, o recurso spanning tree é desativado globalmente por padrão.
Quando o dispositivo é iniciado com os padrões de fábrica, o recurso spanning tree é ativado globalmente por padrão.
Para obter mais informações sobre as configurações iniciais e os padrões de fábrica, consulte o Fundamentals Configuration Guide.
Entre na visualização da interface.
interface interface-type interface-numberAtivar o recurso de spanning tree para a porta.
stp enable Por padrão, o recurso spanning tree está ativado em todas as portas.
Ativação do recurso de spanning tree no modo PVST
Entre na visualização do sistema.
System ViewAtivar o recurso Spanning Tree.
stp global enableQuando o dispositivo é iniciado com as configurações iniciais, o recurso spanning tree é desativado globalmente por padrão.
Quando o dispositivo é iniciado com os padrões de fábrica, o recurso spanning tree é ativado globalmente por padrão.
Para obter mais informações sobre as configurações iniciais e os padrões de fábrica, consulte o Fundamentals Configuration Guide.
Habilite o recurso Spanning Tree em VLANs.
stp vlan vlan-id-list enablePor padrão, o recurso spanning tree é ativado nas VLANs.
Entre na visualização da interface.
interface interface-type interface-numberAtivar o recurso de spanning tree na porta.
stp enable Por padrão, o recurso spanning tree está ativado em todas as portas.
Execução do mCheck
Sobre o mCheck
O recurso mCheck permite a intervenção do usuário no processo de transição do estado da porta.
Quando uma porta em um dispositivo MSTP, RSTP ou PVST se conecta a um dispositivo STP e recebe BPDUs STP, a porta passa automaticamente para o modo STP. Entretanto, a porta não pode voltar automaticamente ao modo original quando as seguintes condições existirem:
O dispositivo STP par é desligado ou removido.
A porta não consegue detectar a alteração.
Para forçar a porta a operar no modo original, você pode executar uma operação mCheck.
Por exemplo, o Dispositivo A, o Dispositivo B e o Dispositivo C estão conectados em sequência. O dispositivo A executa o STP, o dispositivo B não executa nenhum protocolo de spanning tree e o dispositivo C executa o RSTP, o PVST ou o MSTP. Nesse caso, quando o Dispositivo C recebe um BPDU STP transmitido de forma transparente pelo Dispositivo B, a porta receptora passa para o modo STP. Se você configurar o Dispositivo B para executar RSTP, PVST ou MSTP com o Dispositivo C, deverá executar operações de mCheck nas portas que interconectam o Dispositivo B e o Dispositivo C.
Restrições e diretrizes
A operação mCheck entra em vigor em dispositivos que operam no modo MSTP, PVST ou RSTP.
Executando o mCheck globalmente
Entre na visualização do sistema.
System ViewExecute o mCheck.
stp global mcheckExecução do mCheck na visualização da interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberExecute o mCheck.
stp mcheck Desativação da proteção PVID inconsistente
Sobre a proteção PVID inconsistente
No PVST, se duas portas conectadas usarem PVIDs diferentes, poderão ocorrer erros de cálculo do PVST. Por padrão, a proteção de PVID inconsistente é ativada para evitar erros de cálculo de PVST. Se a inconsistência do PVID for detectada em uma porta, o sistema bloqueará a porta.
Restrições e diretrizes
Se forem necessários PVIDs diferentes em duas portas conectadas, desative a proteção de PVID inconsistente nos dispositivos que hospedam as portas. Para evitar erros de cálculo do PVST, certifique-se de que os seguintes requisitos sejam atendidos:
Certifique-se de que as VLANs em um dispositivo não usem o mesmo ID que o PVID de sua porta par (exceto a VLAN padrão) em outro dispositivo.
Se a porta local ou seu par for uma porta híbrida, não configure as portas local e do par como membros sem marcação da mesma VLAN.
Desative a proteção PVID inconsistente no dispositivo local e no dispositivo par. Esse recurso entra em vigor somente quando o dispositivo está operando no modo PVST.
Procedimento
Entre na visualização do sistema.
System ViewDesative o recurso de proteção de PVID inconsistente.
stp ignore-pvid-inconsistencyPor padrão, o recurso de proteção de PVID inconsistente está ativado.
Configuração do Digest Snooping
Sobre o Digest Snooping
Conforme definido no IEEE 802.1s, os dispositivos conectados estão na mesma região somente quando têm as mesmas configurações relacionadas à região MST, incluindo:
Nome da região.
Nível de revisão.
Mapeamentos de VLAN para instância.
Um dispositivo de spanning tree identifica dispositivos na mesma região MST determinando o ID de configuração em BPDUs. O ID de configuração inclui o nome da região, o nível de revisão e o resumo da configuração. Ele tem 16 bytes de comprimento e é o resultado calculado pelo algoritmo HMAC-MD5 com base nos mapeamentos de VLAN para instância.
Como as implementações de spanning tree variam de acordo com o fornecedor, os resumos de configuração calculados por meio de chaves privadas são diferentes. Os dispositivos de diferentes fornecedores na mesma região MST não podem se comunicar entre si.
Para permitir a comunicação entre um dispositivo INTELBRAS e um dispositivo de terceiros na mesma região MST, ative o Digest Snooping na porta do dispositivo INTELBRAS que os conecta.
Restrições e diretrizes
Tenha cuidado com o Digest Snooping global nas seguintes situações:
Quando você modifica os mapeamentos de VLAN para instância.
Quando você restaura a configuração padrão da região MST.
Se o dispositivo local tiver mapeamentos de VLAN para instância diferentes dos dispositivos vizinhos, ocorrerão loops ou interrupção do tráfego.
Antes de ativar o Digest Snooping, certifique-se de que os dispositivos associados de diferentes fornecedores estejam conectados e executem protocolos de spanning tree.
Com o Digest Snooping ativado, a verificação na mesma região não requer a comparação do resumo da configuração. Os mapeamentos de VLAN para instância devem ser os mesmos nas portas associadas.
Para que o Digest Snooping entre em vigor, você deve ativar o Digest Snooping globalmente e nas portas associadas. Como prática recomendada, ative primeiro o Digest Snooping em todas as portas associadas e, em seguida, ative-o globalmente. Isso fará com que a configuração tenha efeito em todas as portas configuradas e reduzirá o impacto na rede.
Para evitar loops, não ative o Digest Snooping nas portas de borda da região MST.
Como prática recomendada, ative o Digest Snooping primeiro e, em seguida, ative o recurso de spanning tree. Para evitar a interrupção do tráfego, não configure o Digest Snooping quando a rede já estiver funcionando bem.
Pré-requisitos
Antes de configurar o Digest Snooping, você precisa se certificar de que o dispositivo INTELBRAS e o dispositivo de terceiros executam corretamente os protocolos de spanning tree.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberAtivar o Digest Snooping na interface.
stp config-digest-snoopingPor padrão, o Digest Snooping está desativado nas portas.
Retornar à visualização do sistema.
quitHabilite o Digest Snooping globalmente.
stp global config-digest-snoopingPor padrão, o Digest Snooping é desativado globalmente.
Configuração da verificação de ausência de acordo
Sobre o No Agreement Check
No RSTP e no MSTP, os seguintes tipos de mensagens são usados para a rápida transição de estado nas portas designadas:
Proposta - Enviada por portos designados para solicitar uma transição rápida
Acordo - Usado para reconhecer solicitações de transição rápida
Os dispositivos RSTP e MSTP podem realizar a transição rápida em uma porta designada somente quando a porta recebe um pacote de acordo do dispositivo downstream. Os dispositivos RSTP e MSTP têm as seguintes diferenças:
Para o MSTP, a porta raiz do dispositivo downstream envia um pacote de acordo somente depois de receber um pacote de acordo do dispositivo upstream.
Para o RSTP, o dispositivo downstream envia um pacote de acordo, independentemente de ter recebido ou não um pacote de acordo do dispositivo upstream.
Figura 16 Transição rápida de estado de uma porta designada MSTP
Figura 17 Transição rápida de estado de uma porta designada RSTP
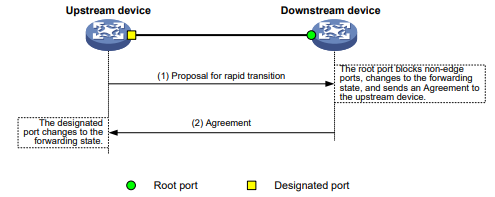
Se o dispositivo upstream for um dispositivo de terceiros, a implementação da transição rápida de estado poderá ser limitada da seguinte forma:
O dispositivo upstream usa um mecanismo de transição rápida semelhante ao do RSTP.
O dispositivo downstream executa o MSTP e não opera no modo RSTP. Nesse caso, ocorre o seguinte:
A porta raiz no dispositivo downstream não recebe nenhum acordo do dispositivo upstream.
Ele não envia nenhum acordo para o dispositivo upstream.
Como resultado, a porta designada do dispositivo upstream pode passar para o estado de encaminhamento somente após um período duas vezes maior que o atraso de encaminhamento.
Para permitir que a porta designada do dispositivo upstream transite rapidamente em seu estado, ative No Agreement Check na porta do dispositivo downstream.
Restrições e diretrizes
Configure No Agreement Check na porta raiz de seu dispositivo, pois esse recurso entra em vigor somente se estiver configurado nas portas raiz.
Pré-requisitos
Antes de configurar o recurso No Agreement Check, conclua as seguintes tarefas:
Conecte um dispositivo a um dispositivo upstream de terceiros que ofereça suporte a protocolos de spanning tree por meio de um link ponto a ponto.
Configure o mesmo nome de região, nível de revisão e mapeamentos de VLAN para instância nos dois dispositivos.
Procedimento
Habilite o recurso No Agreement Check na porta raiz.
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberAtivar a verificação de ausência de acordo.
stp no-agreement-checkPor padrão, No Agreement Check está desativado.
Configuração do TC Snooping
Sobre o TC Snooping
Conforme mostrado na Figura 18, uma malha IRF se conecta a duas redes de usuários por meio de links duplos.
O dispositivo A e o dispositivo B formam a malha IRF.
O recurso spanning tree está desativado no Dispositivo A e no Dispositivo B e ativado em todos os dispositivos da rede de usuários 1 e da rede de usuários 2.
A malha IRF transmite BPDUs de forma transparente para ambas as redes de usuários e não está envolvida no cálculo das árvores de abrangência.
Quando a topologia da rede muda, leva tempo para que a malha IRF atualize sua tabela de endereços MAC e a tabela ARP. Durante esse período, o tráfego na rede pode ser interrompido.
Figura 18 Cenário do aplicativo TC Snooping
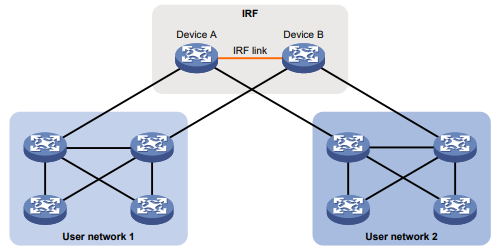
Para evitar a interrupção do tráfego, você pode ativar o TC Snooping na malha IRF. Após receber um TC-BPDU por meio de uma porta, a malha IRF atualiza a tabela de endereços MAC e as entradas da tabela ARP associadas à VLAN da porta. Dessa forma, o TC Snooping evita que a mudança de topologia interrompa o encaminhamento de tráfego na rede. Para obter mais informações sobre a tabela de endereços MAC e a tabela ARP, consulte "Configuração da tabela de endereços MAC" e o Guia de configuração de serviços de IP de camada 3.
Restrições e diretrizes
O TC Snooping e o recurso Spanning Tree são mutuamente exclusivos. Você deve desativar globalmente o recurso de spanning tree antes de ativar o TC Snooping.
A prioridade do tunelamento de BPDU é maior do que a do TC Snooping. Quando o tunelamento de BPDU é ativado em uma porta, o recurso TC Snooping não entra em vigor na porta.
O TC Snooping não é compatível com o modo PVST.
Procedimento
Entre na visualização do sistema.
System ViewDesativar globalmente o recurso de spanning tree.
undo stp global enablePara as séries de switches S5000V3-EI, S5000V5-EI, S5000E-X, S5000X-EI e WAS6000, o recurso spanning tree é desativado globalmente por padrão.
Para outras séries de switches:
Quando o dispositivo é iniciado com as configurações iniciais, o recurso spanning tree é desativado globalmente por padrão.
Quando o dispositivo é iniciado com os padrões de fábrica, o recurso spanning tree é ativado globalmente por padrão.
Para obter mais informações sobre as configurações iniciais e os padrões de fábrica, consulte o Fundamentals Configuration Guide.
Ativar o TC Snooping.
stp tc-snoopingPor padrão, o TC Snooping está desativado.
Configuração de recursos de proteção
Configuração da proteção BPDU
Sobre a proteção de BPDU
Para dispositivos da camada de acesso, as portas de acesso podem se conectar diretamente aos terminais de usuário (como PCs) ou servidores de arquivos. As portas de acesso são configuradas como portas de borda para permitir uma transição rápida. Quando essas portas recebem BPDUs de configuração, o sistema define automaticamente as portas como portas que não são de borda e inicia um novo processo de cálculo da árvore de abrangência. Isso causa uma alteração na topologia da rede. Em condições normais, essas portas não devem receber BPDUs de configuração. Entretanto, se alguém usar BPDUs de configuração de forma maliciosa para atacar os dispositivos, a rede se tornará instável.
O protocolo spanning tree fornece o recurso BPDU guard para proteger o sistema contra esses ataques. Quando as portas com o BPDU guard ativado recebem BPDUs de configuração em um dispositivo, o dispositivo executa as seguintes operações:
Fecha essas portas.
Notifica o NMS de que essas portas foram fechadas pelo protocolo spanning tree.
O dispositivo reativa as portas que foram desligadas quando o temporizador de detecção de status da porta expira. Você pode definir esse cronômetro usando o comando shutdown-interval. Para obter mais informações sobre esse comando, consulte os comandos de gerenciamento de dispositivos na Referência de comandos básicos.
Restrições e diretrizes
Você pode configurar o recurso de proteção de BPDU na visualização do sistema ou por porta. Uma porta usa preferencialmente a configuração de proteção de BPDU específica da porta. Se a configuração de proteção de BPDU específica da porta não estiver disponível, a porta usará a configuração de proteção de BPDU global.
A configuração global de proteção de BPDU entra em vigor somente nas portas de borda configuradas com o comando stp edged-port. Para que a configuração de proteção de BPDU tenha efeito em portas que não sejam de borda, é necessário configurar o recurso por porta. A configuração de proteção de BPDU específica da porta entra em vigor tanto nas portas de borda quanto nas que não são de borda.
Configure o BPDU guard nas portas que se conectam diretamente a um terminal de usuário em vez de outro dispositivo ou segmento de LAN compartilhado.
O BPDU guard não entra em vigor nas portas habilitadas para teste de loopback. Para obter mais informações sobre o teste de loopback do site , consulte Configuração da interface Ethernet no Guia de Configuração da Interface.
Ativação da proteção BPDU na visualização do sistema
Entre na visualização do sistema.
System ViewAtivar a proteção de BPDU globalmente.
stp bpdu-protectionPor padrão, a proteção de BPDU está globalmente desativada.
Configuração do BPDU guard na visualização da interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigurar a proteção de BPDU.
stp port bpdu-protection { enable | disable }Por padrão, o status de ativação do BPDU guard em uma interface é o mesmo do BPDU guard global, e o BPDU guard não é configurado para portas que não sejam de borda.
Ativação da proteção de raiz
Sobre o root guard
Configure o root guard em uma porta designada.
A root bridge e a root bridge secundária de uma spanning tree devem estar localizadas na mesma região MST. Especialmente no caso do CIST, a root bridge e a root bridge secundária são colocadas em uma região central de alta largura de banda durante o projeto da rede. Entretanto, devido a possíveis erros de configuração ou ataques mal-intencionados na rede, a ponte raiz legal pode receber um BPDU de configuração com prioridade mais alta. Outro dispositivo substitui a atual ponte raiz legal, causando uma alteração indesejada na topologia da rede. O tráfego que deveria passar por links de alta velocidade é transferido para links de baixa velocidade, resultando em congestionamento da rede.
Para evitar essa situação, o MSTP oferece o recurso de root guard. Se o root guard estiver ativado em uma porta de uma ponte raiz, essa porta desempenhará a função de porta designada em todos os MSTIs. Depois que essa porta recebe um BPDU de configuração com uma prioridade mais alta de um MSTI, ela executa as seguintes operações:
Define imediatamente essa porta para o estado de escuta no MSTI.
Não encaminha os dados de usuário recebidos.
Isso equivale a desconectar o link conectado a essa porta no MSTI. Se a porta não receber BPDUs com prioridade mais alta dentro do dobro do atraso de encaminhamento, ela voltará ao seu estado original.
Restrições e diretrizes
Em uma porta, o recurso de proteção de loop e o recurso de proteção de raiz são mutuamente exclusivos.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberHabilite o recurso de proteção de raiz.
stp root-protectionPor padrão, a proteção de raiz está desativada.
Ativação da proteção de loop
Sobre o loop guard
Configure o loop guard na porta raiz e nas portas alternativas de um dispositivo.
Ao continuar a receber BPDUs do dispositivo upstream, um dispositivo pode manter o estado da porta raiz e das portas bloqueadas. Entretanto, o congestionamento do link ou as falhas unidirecionais do link podem fazer com que essas portas não recebam BPDUs dos dispositivos upstream. Nessa situação, o dispositivo seleciona novamente as seguintes funções de porta:
As portas em estado de encaminhamento que não conseguiram receber BPDUs de upstream tornam-se portas designadas.
As portas bloqueadas passam para o estado de encaminhamento.
Como resultado, ocorrem loops na rede comutada. O recurso de proteção de loop pode suprimir a ocorrência desses loops.
O estado inicial de uma porta habilitada para proteção de loop é o descarte em cada MSTI. Quando a porta recebe BPDUs, ela muda de estado. Caso contrário, ela permanece no estado de descarte para evitar loops temporários.
Restrições e diretrizes
Não ative o loop guard em uma porta que conecte terminais de usuários. Caso contrário, a porta permanecerá no estado de descarte em todos os MSTIs porque não poderá receber BPDUs.
Em uma porta, o recurso de proteção de loop é mutuamente exclusivo do recurso de proteção de raiz ou da configuração da porta de borda.
Uma interface habilitada para proteção de loop pode receber BPDUs e passar do estado de descarte para o estado de encaminhamento após dois atrasos de encaminhamento se ocorrer um dos eventos a seguir:
O estado da interface muda de baixo para cima.
O recurso de spanning tree está ativado na interface up.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberHabilite o recurso de proteção de loop.
stp loop-protectionPor padrão, a proteção de loop está desativada.
Configuração da restrição de função de porta
Sobre a restrição de função de porta
Faça essa configuração na porta que se conecta à rede de acesso do usuário.
A alteração da bridge ID de um dispositivo na rede de acesso do usuário pode causar uma alteração na topologia da spanning tree na rede principal. Para evitar esse problema, você pode ativar a restrição de função de porta em uma porta. Com esse recurso ativado, quando a porta recebe um BPDU superior, ela se torna uma porta alternativa em vez de uma porta raiz.
Restrições e diretrizes
Use esse recurso com cuidado, pois a ativação da restrição de função de porta em uma porta pode afetar a conectividade da topologia da árvore de abrangência.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberAtivar restrição de função de porta.
stp role-restrictionPor padrão, a restrição de função de porta está desativada.
Configuração da restrição de transmissão TC-BPDU
Sobre a restrição de transmissão TC-BPDU
Faça essa configuração na porta que se conecta à rede de acesso do usuário.
A alteração da topologia da rede de acesso do usuário pode causar alterações no endereço de encaminhamento da rede principal. Quando a topologia da rede de acesso do usuário é instável, a rede de acesso do usuário pode afetar a rede principal. Para evitar esse problema, você pode ativar a restrição de transmissão TC-BPDU em
uma porta. Com esse recurso ativado, quando a porta recebe um TC-BPDU, ela não encaminha o TC-BPDU para outras portas.
Restrições e diretrizes
A ativação da restrição de transmissão TC-BPDU em uma porta pode fazer com que a tabela de endereços de encaminhamento anterior não seja atualizada quando a topologia for alterada.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberAtivar a restrição de transmissão TC-BPDU.
stp tc-restrictionPor padrão, a restrição de transmissão TC-BPDU está desativada.
Ativação da proteção TC-BPDU
Sobre a proteção TC-BPDU
Quando um dispositivo recebe BPDUs de alteração de topologia (TC) (os BPDUs que notificam os dispositivos sobre alterações de topologia), ele libera suas entradas de endereço de encaminhamento. Se alguém usar TC-BPDUs para atacar o dispositivo, ele receberá um grande número de TC-BPDUs em um curto espaço de tempo. Em seguida, o dispositivo estará ocupado com a descarga de entradas de endereços de encaminhamento. Isso afeta a estabilidade da rede.
O TC-BPDU guard permite definir o número máximo de descargas imediatas de entradas de endereços de encaminhamento realizadas dentro de 10 segundos após o dispositivo receber o primeiro TC-BPDU. Para TC-BPDUs recebidos além do limite, o dispositivo executa uma limpeza de entrada de endereço de encaminhamento quando o período de tempo expira. Isso evita a descarga frequente de entradas de endereços de encaminhamento.
Restrições e diretrizes
Como prática recomendada, ative a proteção TC-BPDU.
Procedimento
Entre na visualização do sistema.
System ViewAtivar o recurso de proteção TC-BPDU.
stp tc-protectionPor padrão, a proteção TC-BPDU está ativada.
(Opcional.) Configure o número máximo de descargas de entradas de endereços de encaminhamento que o dispositivo pode executar a cada 10 segundos.
stp tc-protection threshold numberA configuração padrão é 6.
Habilitação de queda de BPDU
Sobre a queda de BPDU
Em uma rede spanning tree, cada BPDU que chega ao dispositivo aciona um processo de cálculo STP e, em seguida, é encaminhado para outros dispositivos na rede. Os invasores mal-intencionados podem usar a vulnerabilidade para atacar a rede forjando BPDUs. Ao enviar continuamente BPDUs forjados, eles podem fazer com que todos os dispositivos da rede continuem executando cálculos STP. Como resultado, ocorrem problemas como sobrecarga da CPU e erros de status do protocolo BPDU.
Para evitar esse problema, você pode ativar o BPDU drop nas portas. Uma porta com BPDU drop ativado não recebe BPDUs e é invulnerável a ataques de BPDUs forjados.
Restrições e diretrizes
Esse recurso permite que o dispositivo descarte BPDUs de STP, RSTP, MSTP, PVST, LACP e LLDP. Certifique-se de estar totalmente ciente do impacto desse recurso ao usá-lo em uma rede ativa.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberHabilita a queda de BPDU na interface.
bpdu-drop anyPor padrão, o BPDU drop está desativado.
Ativação da proteção BPDU do PVST
Sobre a proteção BPDU do PVST
Esse recurso entra em vigor somente quando o dispositivo está operando no modo MSTP.
Um dispositivo habilitado para MSTP encaminha BPDUs PVST como tráfego de dados porque não pode reconhecer BPDUs PVST. Se um dispositivo habilitado para PVST em outra rede independente receber os BPDUs PVST, poderá ocorrer um erro de cálculo de PVST. Para evitar erros de cálculo de PVST, habilite o PVST BPDU guard em o dispositivo habilitado para MSTP. O dispositivo desliga uma porta se ela receber BPDUs PVST.
Procedimento
Entre na visualização do sistema.
System ViewAtivar a proteção BPDU do PVST.
stp pvst-bpdu-protectionPor padrão, a proteção BPDU do PVST está desativada.
Desativação da proteção contra disputas
Sobre a proteção contra disputas
O Dispute Guard pode ser acionado por falhas de link unidirecional. Se uma porta upstream receber BPDUs inferiores de uma porta designada downstream em estado de encaminhamento ou aprendizado devido a uma falha de link unidirecional, será exibido um loop. O Dispute Guard bloqueia a porta designada upstream para evitar o loop.
Conforme mostrado na Figura 19, em condições normais, o resultado do cálculo da árvore de abrangência é o seguinte:
O dispositivo A é a ponte raiz e a porta A1 é uma porta designada.
A porta B1 está bloqueada.
Quando o link entre a porta A1 e a porta B1 falha na direção da porta A1 para a porta B1 e se torna unidirecional, ocorrem os seguintes eventos:
A porta A1 só pode receber BPDUs e não pode enviar BPDUs para a porta B1.
A porta B1 não recebe BPDUs da porta A1 por um determinado período de tempo.
O dispositivo B se determina como a ponte raiz.
A porta B1 envia seus BPDUs para a porta A1.
A porta A1 determina que os BPDUs recebidos são inferiores aos seus próprios BPDUs. Uma disputa é detectada.
O Dispute Guard é acionado e bloqueia a porta A1 para evitar um loop.
Figura 19 Cenário de acionamento da proteção contra disputas
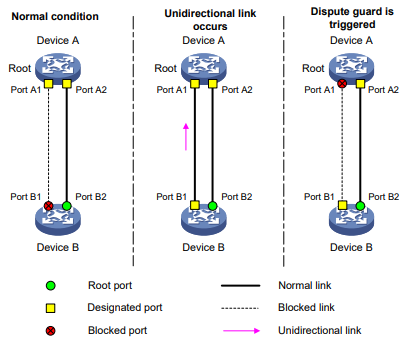
No entanto, o dispute guard pode interromper a conectividade da rede. Você pode desativar o dispute guard para evitar a perda de conectividade em redes VLAN. Conforme mostrado na Figura 20, o recurso spanning tree está desativado no Dispositivo B e ativado no Dispositivo A e no Dispositivo C. O Dispositivo B transmite BPDUs de forma transparente.
O dispositivo C não pode receber BPDUs superiores da VLAN 1 do dispositivo A porque a porta B1 do dispositivo B está configurada para negar pacotes da VLAN 1. O dispositivo C se determina como a ponte raiz após um determinado período de tempo. Em seguida, a porta C1 envia um BPDU inferior da VLAN 100 para o dispositivo A.
Quando o Dispositivo A recebe o BPDU inferior, o dispute guard bloqueia a Porta A1, o que causa a interrupção do tráfego. Para garantir a continuidade do serviço, você pode desativar o dispute guard no Dispositivo A para evitar que o link seja bloqueado.
Figura 20 Cenário de desativação do aplicativo de proteção contra disputas
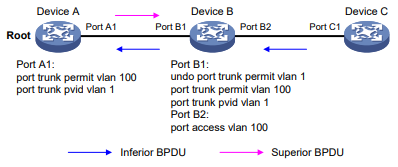
Restrições e diretrizes
Você pode desativar o dispute guard se a rede não tiver falhas de link unidirecionais.
Procedimento
Entre na visualização do sistema.
System ViewDesativar a proteção contra disputas.
undo stp dispute-protectionPor padrão, a proteção contra disputas está ativada.
Habilitação do dispositivo para registrar eventos de detecção ou recebimento de BPDUs TC
Sobre o registro de eventos TC BPDU da árvore de abrangência
Esse recurso permite que o dispositivo gere registros quando detecta ou recebe BPDUs TC. Esse recurso se aplica somente ao modo PVST.
Procedimento
Entre na visualização do sistema.
System ViewPermita que o dispositivo registre eventos de recebimento ou detecção de BPDUs TC.
stp log enable tcPor padrão, o dispositivo não gera registros quando detecta ou recebe TC BPDUs.
Desativação do dispositivo para reativar portas de borda desligadas pela proteção de BPDU
Sobre a desativação do dispositivo para reativar as portas de borda desligadas pela proteção de BPDU
O BPDU guard desliga as portas de borda que receberam BPDUs de configuração e notifica o NMS sobre o evento de desligamento.
O dispositivo reativa as portas que foram desligadas quando o temporizador de detecção de status da porta expira. Você pode definir esse cronômetro usando o comando shutdown-interval. Para obter mais informações sobre esse comando, consulte os comandos de gerenciamento de dispositivos em Referência de comandos básicos.
Restrições e diretrizes
Esse recurso impede que o dispositivo reative as portas de borda desligadas pelo BPDU Guard depois que esse recurso for configurado. O dispositivo não ativará as portas desligadas se você executar o comando undo stp port shutdown permanent. Para ativar essas portas, use o comando undo shutdown.
Procedimento
Entre na visualização do sistema.
System ViewDesative o dispositivo para reativar as portas de borda desligadas pela proteção de BPDU.
stp port shutdown permanentPor padrão, o dispositivo reativa uma porta de borda desligada pela proteção de BPDU depois que o temporizador de detecção de status da porta expira.
Ativação de notificações SNMP para eleição de nova raiz e eventos de alteração de topologia
Sobre as notificações SNMP de spanning tree
Essa tarefa permite que o dispositivo gere registros e relate eventos de eleição de nova raiz ou alterações na topologia da árvore de abrangência para o SNMP. Para que as notificações de eventos sejam enviadas corretamente, você também deve configurar o SNMP no dispositivo. Para obter mais informações sobre a configuração do SNMP, consulte o guia de configuração de monitoramento e gerenciamento de rede do dispositivo.
Quando você usar o comando snmp-agent trap enable stp [ new-root | tc ], siga estas diretrizes:
A palavra-chave new-root se aplica somente aos modos STP, MSTP e RSTP.
A palavra-chave tc se aplica somente ao modo PVST.
No modo STP, MSTP ou RSTP, o comando snmp-agent trap enable stp ativa as notificações SNMP para eventos de eleição de nova raiz.
No modo PVST, o comando snmp-agent trap enable stp ativa as notificações SNMP para alterações na topologia da árvore de abrangência.
Procedimento
Entre na visualização do sistema.
System ViewHabilite as notificações SNMP para eventos de eleição de novo root e de alteração de topologia.
snmp-agent trap enable stp [ new-root | tc ]As configurações padrão são as seguintes:
As notificações SNMP são desativadas para eventos de eleição de nova raiz.
No modo MSTP, as notificações SNMP são ativadas no MSTI 0 e desativadas em outros MSTIs para alterações na topologia da árvore de abrangência.
No modo PVST, as notificações SNMP são desativadas para alterações na topologia da árvore de abrangência em todas as VLANs.
Exemplos de configuração Spanning Tree
Exemplo: Configuração do MSTP
Configuração de rede
Conforme mostrado na Figura 21, todos os dispositivos da rede estão na mesma região MST. O dispositivo A e o dispositivo B trabalham na camada de distribuição. O dispositivo C e o dispositivo D trabalham na camada de acesso.
Configure o MSTP para que os quadros de diferentes VLANs sejam encaminhados por diferentes spanning trees.
Os quadros da VLAN 10 são encaminhados ao longo da MSTI 1.
Os quadros da VLAN 30 são encaminhados ao longo da MSTI 3.
Os quadros da VLAN 40 são encaminhados ao longo da MSTI 4.
Os quadros da VLAN 20 são encaminhados ao longo da MSTI 0.
A VLAN 10 e a VLAN 30 são terminadas nos dispositivos da camada de distribuição e a VLAN 40 é terminada nos dispositivos da camada de acesso. As pontes raiz da MSTI 1 e da MSTI 3 são os dispositivos A e B, respectivamente, e a ponte raiz da MSTI 4 é o dispositivo C.
Figura 21 Diagrama de rede
Procedimento
Configurar VLANs e portas membros da VLAN. (Detalhes não mostrados.)
Crie a VLAN 10, a VLAN 20 e a VLAN 30 no Dispositivo A e no Dispositivo B.
Crie a VLAN 10, a VLAN 20 e a VLAN 40 no dispositivo C.
Crie a VLAN 20, a VLAN 30 e a VLAN 40 no dispositivo D.
Configure as portas desses dispositivos como portas tronco e atribua-as às VLANs relacionadas.
Configurar o dispositivo A:
# Entre na visualização da região MST e configure o nome da região MST como exemplo.
<DeviceA> system-view
[DeviceA] stp region-configuration
[DeviceA-mst-region] region-name example # Mapeie a VLAN 10, a VLAN 30 e a VLAN 40 para MSTI 1, MSTI 3 e MSTI 4, respectivamente.
[DeviceA-mst-region] instance 1 vlan 10
[DeviceA-mst-region] instance 3 vlan 30
[DeviceA-mst-region] instance 4 vlan 40 # Configure o nível de revisão da região MST como 0.
[DeviceA-mst-region] revision-level 0 # Ativar a configuração da região MST.
[DeviceA-mst-region] active region-configuration
[DeviceA-mst-region] quit# Configure o dispositivo A como a ponte raiz do MSTI 1.
[DeviceA] stp instance 1 root primary# Habilite o recurso de spanning tree globalmente.
[DeviceA] stp global enableConfigurar o dispositivo B:
# Entre na visualização da região MST e configure o nome da região MST como exemplo.
<DeviceB> system-view
[DeviceB] stp region-configuration
[DeviceB-mst-region] region-name example# Mapeie a VLAN 10, a VLAN 30 e a VLAN 40 para MSTI 1, MSTI 3 e MSTI 4, respectivamente.
[DeviceB-mst-region] instance 1 vlan 10
[DeviceB-mst-region] instance 3 vlan 30
[DeviceB-mst-region] instance 4 vlan 40
# Configure o nível de revisão da região MST como 0.
[DeviceB-mst-region] revision-level 0# Ativar a configuração da região MST.
[DeviceB-mst-region] active region-configuration
[DeviceB-mst-region] quit# Configure o dispositivo B como a ponte raiz da MSTI 3.
[DeviceB] stp instance 3 root primary Configurar o dispositivo C:
# Entre na visualização da região MST e configure o nome da região MST como exemplo.
<DeviceC> system-view
[DeviceC] stp region-configuration
[DeviceC-mst-region] region-name example # Mapeie a VLAN 10, a VLAN 30 e a VLAN 40 para MSTI 1, MSTI 3 e MSTI 4, respectivamente.
[DeviceC-mst-region] instance 1 vlan 10
[DeviceC-mst-region] instance 3 vlan 30
[DeviceC-mst-region] instance 4 vlan 40 # Configure o nível de revisão da região MST como 0.
[DeviceC-mst-region] revision-level 0# Ativar a configuração da região MST.
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit # Configure o dispositivo C como a ponte raiz da MSTI 4.
[DeviceC] stp instance 4 root primaryConfigurar o dispositivo D:
# Entre na visualização da região MST e configure o nome da região MST como exemplo.
<DeviceD> system-view
[DeviceD] stp region-configuration
[DeviceD-mst-region] region-name example# Mapeie a VLAN 10, a VLAN 30 e a VLAN 40 para MSTI 1, MSTI 3 e MSTI 4, respectivamente.
[DeviceD-mst-region] instance 1 vlan 10
[DeviceD-mst-region] instance 3 vlan 30
[DeviceD-mst-region] instance 4 vlan 40 # Configure o nível de revisão da região MST como 0.
[DeviceD-mst-region] nível de revisão 0# Ativar a configuração da região MST.
[DeviceD-mst-region] active region-configuration
[DeviceD-mst-region] quit# Habilite o recurso Spanning Tree globalmente.
[DeviceD] stp global enableVerificação da configuração
Neste exemplo, o Dispositivo B tem o ID de ponte raiz mais baixo. Como resultado, o Dispositivo B é eleito como a ponte raiz no MSTI 0.
Quando a rede estiver estável, você poderá usar o comando display stp brief para exibir informações breves sobre a árvore de abrangência em cada dispositivo.
# Exibir informações breves sobre a árvore de abrangência no Dispositivo A.
[DeviceA] display stp brief
MST ID Port Role STP State Protection
0 GigabitEthernet1/0/1 ALTE DISCARDING NONE
0 GigabitEthernet1/0/2 DESI FORWARDING NONE
0 GigabitEthernet1/0/3 ROOT FORWARDING NONE
1 GigabitEthernet1/0/1 DESI FORWARDING NONE
1 GigabitEthernet1/0/3 DESI FORWARDING NONE
3 GigabitEthernet1/0/2 DESI FORWARDING NONE
3 GigabitEthernet1/0/3 ROOT FORWARDING NONE# Exibir informações breves sobre a árvore de abrangência no Dispositivo B.
[DeviceB] display stp brief
MST ID Port Role STP State Protection
0 GigabitEthernet1/0/1 ALTE DISCARDING NONE
0 GigabitEthernet1/0/2 DESI FORWARDING NONE
0 GigabitEthernet1/0/3 ROOT FORWARDING NONE
1 GigabitEthernet1/0/1 DESI FORWARDING NONE
1 GigabitEthernet1/0/3 DESI FORWARDING NONE
3 GigabitEthernet1/0/2 DESI FORWARDING NONE
3 GigabitEthernet1/0/3 ROOT FORWARDING NONE# Exibir informações breves sobre a árvore de abrangência no Dispositivo C.
[DeviceC] display stp brief
MST ID Port Role STP State Protection
0 GigabitEthernet1/0/1 ALTE DISCARDING NONE
0 GigabitEthernet1/0/2 DESI FORWARDING NONE
0 GigabitEthernet1/0/3 ROOT FORWARDING NONE
1 GigabitEthernet1/0/1 DESI FORWARDING NONE
1 GigabitEthernet1/0/3 DESI FORWARDING NONE
3 GigabitEthernet1/0/2 DESI FORWARDING NONE
3 GigabitEthernet1/0/3 ROOT FORWARDING NONE# Exibir informações breves sobre a árvore de abrangência no Dispositivo D.
[DeviceD] display stp brief
MST ID Port Role STP State Protection
0 GigabitEthernet1/0/1 ALTE DISCARDING NONE
0 GigabitEthernet1/0/2 DESI FORWARDING NONE
0 GigabitEthernet1/0/3 ROOT FORWARDING NONE
1 GigabitEthernet1/0/1 DESI FORWARDING NONE
1 GigabitEthernet1/0/3 DESI FORWARDING NONE
3 GigabitEthernet1/0/2 DESI FORWARDING NONE
3 GigabitEthernet1/0/3 ROOT FORWARDING NONECom base na saída, você pode desenhar cada MSTI mapeado para cada VLAN, conforme mostrado na Figura 22.
Figura 22 MSTIs mapeados para diferentes VLANs
Exemplo: Configuração do PVST
Configuração de rede
Conforme mostrado na Figura 23, o Dispositivo A e o Dispositivo B funcionam na camada de distribuição, e o Dispositivo C e o Dispositivo D funcionam na camada de acesso.
Configure o PVST para atender aos seguintes requisitos:
Os quadros de uma VLAN são encaminhados ao longo das árvores de abrangência da VLAN.
A VLAN 10, a VLAN 20 e a VLAN 30 são terminadas nos dispositivos da camada de distribuição e a VLAN 40 é terminada nos dispositivos da camada de acesso.
A ponte raiz da VLAN 10 e da VLAN 20 é o Dispositivo A.
A ponte raiz da VLAN 30 é o Dispositivo B.
A ponte raiz da VLAN 40 é o Dispositivo C.
Figura 23 Diagrama de rede
Procedimento
Configurar VLANs e portas membros da VLAN. (Detalhes não mostrados).
Crie a VLAN 10, a VLAN 20 e a VLAN 30 no Dispositivo A e no Dispositivo B.
Crie a VLAN 10, a VLAN 20 e a VLAN 40 no dispositivo C.
Crie a VLAN 20, a VLAN 30 e a VLAN 40 no dispositivo D.
Configure as portas desses dispositivos como portas tronco e atribua-as às VLANs relacionadas.
Configurar o dispositivo A:
# Defina o modo Spanning Tree como PVST.
<DeviceA> system-view
[DeviceA] stp mode pvst# Configure o dispositivo como a ponte raiz da VLAN 10 e da VLAN 20.
[DeviceA] stp vlan 10 20 root primary# Habilite o recurso spanning tree globalmente e na VLAN 10, VLAN 20 e VLAN 30.
[DeviceA] stp global enable [DeviceA] stp vlan 10 20 30 enableConfigurar o dispositivo B:
# Defina o modo Spanning Tree como PVST.
<DeviceB> system-view
[DeviceB] stp mode pvst# Configure o dispositivo como a ponte raiz da VLAN 30.
[DeviceB] stp vlan 30 root primary# Habilite o recurso spanning tree globalmente e na VLAN 10, VLAN 20 e VLAN 30.
[DeviceB] stp global enable
[DeviceB] stp vlan 10 20 30 enableConfigurar o dispositivo C:
# Defina o modo Spanning Tree como PVST.
<DeviceC> system-view
[DeviceC] stp mode pvst# Configure o dispositivo como a ponte raiz da VLAN 40.
[DeviceC] stp vlan 40 root primary# Habilite o recurso spanning tree globalmente e na VLAN 10, VLAN 20 e VLAN 40.
[DeviceC] stp global enable
[DeviceC] stp vlan 10 20 40 enable Configurar o dispositivo D:
# Defina o modo Spanning Tree como PVST.
<DeviceD> system-view
[DeviceD] stp mode pvst # Habilite o recurso spanning tree globalmente e na VLAN 20, VLAN 30 e VLAN 40.
[DeviceD] stp global enable
[DeviceD] stp vlan 20 30 40 enable Verificação da configuração
Quando a rede estiver estável, você poderá usar o comando display stp brief para exibir informações breves sobre a árvore de abrangência em cada dispositivo.
# Exibir informações breves sobre a árvore de abrangência no Dispositivo A.
[DeviceA] display stp brief
VLAN ID Port Role STP State Protection
10 GigabitEthernet1/0/1 DESI FORWARDING NONE
10 GigabitEthernet1/0/3 DESI FORWARDING NONE
20 GigabitEthernet1/0/1 DESI FORWARDING NONE
20 GigabitEthernet1/0/2 DESI FORWARDING NONE
20 GigabitEthernet1/0/3 DESI FORWARDING NONE
30 GigabitEthernet1/0/2 DESI FORWARDING NONE
30 GigabitEthernet1/0/3 ROOT FORWARDING NONE# Exibir informações breves sobre a árvore de abrangência no Dispositivo B.
[DeviceB] display stp brief
VLAN ID Port Role STP State Protection
10 GigabitEthernet1/0/2 DESI FORWARDING NONE
10 GigabitEthernet1/0/3 ROOT FORWARDING NONE
20 GigabitEthernet1/0/1 DESI FORWARDING NONE
20 GigabitEthernet1/0/2 DESI FORWARDING NONE
20 GigabitEthernet1/0/3 ROOT FORWARDING NONE
30 GigabitEthernet1/0/1 DESI FORWARDING NONE
30 GigabitEthernet1/0/3 DESI FORWARDING NONE # Exibir informações breves sobre a árvore de abrangência no Dispositivo C.
[DeviceC] display stp brief
VLAN ID Port Role STP State Protection
10 GigabitEthernet1/0/1 ROOT FORWARDING NONE
10 GigabitEthernet1/0/2 ALTE DISCARDING NONE
20 GigabitEthernet1/0/1 ROOT FORWARDING NONE
20 GigabitEthernet1/0/2 ALTE DISCARDING NONE
20 GigabitEthernet1/0/3 DESI FORWARDING NONE
40 GigabitEthernet1/0/3 DESI FORWARDING NONE # Exibir informações breves sobre a árvore de abrangência no Dispositivo D.
[DeviceD] display stp brief
Com base na saída, você pode desenhar uma topologia para cada árvore de abrangência de VLAN, conforme mostrado na Figura 24.
Figura 24 Topologias Spanning Tree de VLAN
Configuração da detecção de loop
Sobre a detecção de loop
O mecanismo de detecção de loop realiza verificações periódicas de loops da Camada 2. O mecanismo gera imediatamente um registro quando ocorre um loop, para que você seja imediatamente notificado para ajustar as conexões e configurações da rede. Você pode configurar a detecção de loop para desligar a porta com loop. Os registros são mantidos no centro de informações. Para obter mais informações, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
Mecanismo de detecção de loop
O dispositivo detecta loops enviando quadros de detecção e verificando se esses quadros retornam a qualquer porta do dispositivo. Se isso acontecer, o dispositivo considera que a porta está em um link com loop.
A detecção de loop geralmente funciona dentro de uma VLAN. Se um quadro de detecção for devolvido com uma tag de VLAN diferente daquela com a qual foi enviado, ocorreu um loop entre VLANs. Para remover o loop, examine a configuração de mapeamento de QinQ ou VLAN em busca de configurações incorretas. Para obter mais informações sobre QinQ e mapeamento de VLAN, consulte "Configuração de QinQ" e "Configuração de mapeamento de VLAN".
Figura 1 Cabeçalho do quadro Ethernet para detecção de loop
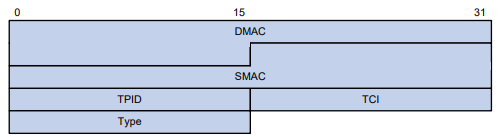
O cabeçalho do quadro Ethernet de um pacote de detecção de loop contém os seguintes campos:
DMAC - Endereço MAC de destino do quadro, que é o endereço MAC multicast.
010f-e200-0007. Quando um dispositivo habilitado para detecção de loop recebe um quadro com esse endereço MAC de destino, ele executa as seguintes operações:
Envia o quadro para a CPU.
Inunda o quadro na VLAN da qual o quadro foi originalmente recebido.
SMAC - Endereço MAC de origem do quadro, que é o endereço MAC da ponte do dispositivo de envio.
TPID-Tipo de tag de VLAN, com o valor de 0x8100.
TCI-Informações da tag de VLAN, incluindo a prioridade e o ID da VLAN.
Type - Tipo de protocolo, com o valor 0x8918.
Figura 2 Cabeçalho interno do quadro para detecção de loop

O cabeçalho interno do quadro de um pacote de detecção de loop contém os seguintes campos:
Subtipo Code-Protocol, que é 0x0001, indicando o protocolo de detecção de loop.
Versão - versão do protocolo, que é sempre 0x0000.
Comprimento - Comprimento do quadro. O valor inclui o cabeçalho interno, mas exclui o cabeçalho Ethernet.
Reservado - Esse campo é reservado.
Os quadros para detecção de loop são encapsulados como tripletos de TLV.
Intervalo de detecção de loop
A detecção de loop é um processo contínuo à medida que a rede muda. Os quadros de detecção de loop são enviados no intervalo de detecção de loop para determinar se ocorrem loops nas portas e se os loops são removidos.
Ações de proteção de loop
Quando o dispositivo detecta um loop em uma porta, ele gera um registro, mas não executa nenhuma ação na porta por padrão. Você pode configurar o dispositivo para executar uma das seguintes ações:
Block (Bloquear) - Desabilita a porta de aprender endereços MAC e bloqueia a porta.
Sem aprendizado - Desabilita a porta de aprender endereços MAC.
Shutdown - Desativa a porta para impedir que ela receba e envie quadros.
Recuperação automática do status da porta
Quando o dispositivo configurado com a ação de loop de bloqueio ou de não aprendizado detecta um loop em uma porta, ele executa a ação e aguarda três intervalos de detecção de loop. Se o dispositivo não receber um quadro de detecção de loop em três intervalos de detecção de loop, ele executará as seguintes operações:
Define automaticamente a porta para o estado de encaminhamento.
Notifica o usuário sobre o evento.
Quando o dispositivo configurado com a ação de desligamento detecta um loop em uma porta, ocorrem os seguintes eventos:
O dispositivo desliga automaticamente a porta.
O dispositivo define automaticamente a porta para o estado de encaminhamento após a expiração do cronômetro de detecção definido com o uso do comando shutdown-interval. Para obter mais informações sobre o comando shutdown-interval, consulte a Referência de comandos básicos.
O dispositivo desligará a porta novamente se um loop ainda for detectado na porta quando o cronômetro de detecção expirar.
Esse processo é repetido até que o loop seja removido.
OBSERVAÇÃO:
Pode ocorrer uma recuperação incorreta quando os quadros de detecção de loop são descartados para reduzir a carga. Para evitar isso, use a ação de desligamento ou remova manualmente o loop.
Ativação da detecção de loop
Restrições e diretrizes para a configuração da detecção de loop
Você pode ativar a detecção de loop globalmente ou por porta. Quando uma porta recebe um quadro de detecção em qualquer VLAN, a ação de proteção de loop é acionada nessa porta, independentemente de a detecção de loop estar ativada nela.
O recurso de detecção de loop é mutuamente exclusivo dos recursos de prevenção de loop da Camada 2, inclusive:
O recurso Spanning Tree.
RRPP.
ERPS.
Para evitar problemas inesperados na rede, não use o recurso de detecção de loop e nenhum desses recursos de prevenção de loop da Camada 2 juntos. Para obter mais informações sobre o recurso spanning tree, consulte "Configuração dos protocolos spanning tree". Para obter mais informações sobre RRPP e ERPS, consulte o High Availability Configuration Guide.
Ativação da detecção de loop globalmente
Entre na visualização do sistema.
System ViewAtivar globalmente a detecção de loop.
loopback-detection global enable vlan { vlan-id--list | all }Por padrão, a detecção de loop está globalmente desativada.
Ativação da detecção de loop em uma porta
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2 ou na visualização da interface agregada de camada 2.
interface interface-type interface-numberAtivar a detecção de loop na porta.
loopback-detection enable vlan { vlan-id--list | all }Por padrão, a detecção de loop está desativada nas portas.
Configuração da ação de proteção de loop
Restrições e diretrizes para a configuração da ação de proteção de loop
Você pode definir a ação de proteção de loop globalmente ou por porta. A ação global se aplica a todas as portas. A ação por porta se aplica às portas individuais. A ação por porta tem precedência sobre a ação global.
Definição da ação de proteção de loop global
Entre na visualização do sistema.
System ViewDefina a ação de proteção de loop global.
loopback-detection global action shutdownPor padrão, o dispositivo gera um registro, mas não executa nenhuma ação na porta em que um loop é detectado.
Configuração da ação de proteção de loop em uma interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberDefina a ação de proteção de loop na interface.
loopback-detection action { block | no-learning | shutdown }Por padrão, o dispositivo gera um registro, mas não executa nenhuma ação na porta em que um loop é detectado.
O suporte para as palavras-chave desse comando varia de acordo com o tipo de interface. Para obter mais informações, consulte
Referência de comandos de switching de LAN de camada 2.
Configuração do intervalo de detecção de loop
Sobre o intervalo de detecção de loop
Com a detecção de loop ativada, o dispositivo envia quadros de detecção de loop no intervalo de detecção de loopback. Um intervalo mais curto oferece uma detecção mais sensível, mas consome mais recursos. Considere o desempenho do sistema e a velocidade de detecção de loop ao definir o intervalo de detecção de loop.
Procedimento
Entre na visualização do sistema.
System ViewDefina o intervalo de detecção de loop.
loopback-detection interval-time intervalA configuração padrão é de 30 segundos.
Exemplos de configuração de detecção de loop
Exemplo: Configuração das funções básicas de detecção de loop
Configuração de rede
Conforme mostrado na Figura 3, configure a detecção de loop no Dispositivo A para atender aos seguintes requisitos:
O dispositivo A gera um registro como uma notificação.
O dispositivo A desliga automaticamente a porta na qual foi detectado um loop.
Figura 3 Diagrama de rede
Procedimento
Configurar o dispositivo A:
# Crie a VLAN 100 e ative globalmente a detecção de loop para a VLAN.
<DeviceA> system-view
[DeviceA] vlan 100
[DeviceA-vlan100] quit
[DeviceA] loopback-detection global enable vlan 100# Configure a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 como portas tronco e atribua-as à VLAN 100.
[DeviceA] interface GigabitEthernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type trunk
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan 100
[DeviceA-GigabitEthernet1/0/1] quit
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 100
[DeviceA-GigabitEthernet1/0/2] quit# Defina a ação de proteção de loop global como desligamento.
[DeviceA] loopback-detection global action shutdown # Defina o intervalo de detecção de loop para 35 segundos.
[DeviceA] loopback-detection interval-time 35 Configure o dispositivo B:
# Criar VLAN 100.
<DeviceB> system-view
[DeviceB] vlan 100
[DeviceB–vlan100] quit
# Configure a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 como portas tronco e atribua-as à VLAN 100.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type trunk
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 100
[DeviceB-GigabitEthernet1/0/1] quit
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 100
[DeviceB-GigabitEthernet1/0/2] quit
Configure o dispositivo C:
# Criar VLAN 100.
<DeviceC> system-view
[DeviceC] vlan 100
[DeviceC–vlan100] quit
# Configure a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 como portas tronco e atribua-as à VLAN 100.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] port link-type trunk
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 100
[DeviceC-GigabitEthernet1/0/1] quit
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan 100
[DeviceC-GigabitEthernet1/0/2] quit
Verificação da configuração
# View the system logs on devices, for example, Device A.
[DispositivoA]
%Feb 24 15:04:29:663 2013 DeviceA LPDT/4/LPDT_LOOPED: Foi detectado um loop na GigabitEthernet1/0/1.
%Feb 24 15:04:29:664 2013 DeviceA LPDT/4/LPDT_VLAN_LOOPED: Foi detectado um loop na GigabitEthernet1/0/1 na VLAN 100.
%Feb 24 15:04:29:667 2013 DeviceA LPDT/4/LPDT_LOOPED: Foi detectado um loop na GigabitEthernet1/0/2.
%Feb 24 15:04:29:668 2013 DeviceA LPDT/4/LPDT_VLAN_LOOPED: Foi detectado um loop na GigabitEthernet1/0/2 na VLAN 100.
%Feb 24 15:04:44:243 2013 DeviceA LPDT/5/LPDT_VLAN_RECOVERED: Um loop foi removido na GigabitEthernet1/0/1 na VLAN 100.
%Feb 24 15:04:44:243 2013 DeviceA LPDT/5/LPDT_RECOVERED: Todos os loops foram removidos em GigabitEthernet1/0/1.
%Feb 24 15:04:44:248 2013 DeviceA LPDT/5/LPDT_VLAN_RECOVERED: Um loop foi removido na GigabitEthernet1/0/2 na VLAN 100.
%Feb 24 15:04:44:248 2013 DeviceA LPDT/5/LPDT_RECOVERED: Todos os loops foram removidos em GigabitEthernet1/0/2.O resultado mostra as seguintes informações:
O dispositivo A detectou loops na GigabitEthernet 1/0/1 e na GigabitEthernet 1/0/2 em um intervalo de detecção de loop.
Os loops na GigabitEthernet 1/0/1 e na GigabitEthernet 1/0/2 foram removidos.
# Use o comando display loopback-detection para exibir a configuração e o status da detecção de loop nos dispositivos, por exemplo, no Dispositivo A.
[DeviceA] display loopback-detection
Loop detection is enabled.
Loop detection interval is 35 second(s).
Loop is detected on following interfaces:
Interface Action mode VLANs
GigabitEthernet1/0/1 Shutdown 100
GigabitEthernet1/0/2 Shutdown 100
A saída mostra que o dispositivo removeu os loops da GigabitEthernet 1/0/1 e da GigabitEthernet 1/0/2 de acordo com a ação de desligamento.
# Exibir o status da GigabitEthernet 1/0/1 nos dispositivos, por exemplo, no Dispositivo A.
[DeviceA] display interface gigabitethernet 1/0/1
GigabitEthernet1/0/1 current state: DOWN (Loop detection down)
...A saída mostra que a GigabitEthernet 1/0/1 já foi desligada pelo módulo de detecção de loop.
# Exibir o status da GigabitEthernet 1/0/2 nos dispositivos, por exemplo, no Dispositivo A.
[DeviceA] display interface gigabitethernet 1/0/2
GigabitEthernet1/0/2 current state: DOWN (Loop detection down) A saída mostra que a GigabitEthernet 1/0/2 já foi desligada pelo módulo de detecção de loop.
Configuração de VLANs
Sobre VLANs
A tecnologia de rede local virtual (VLAN) divide uma LAN física em várias LANs lógicas. Ela tem os seguintes benefícios:
Segurança - Os hosts da mesma VLAN podem se comunicar entre si na Camada 2, mas são isolados dos hosts de outras VLANs na Camada 2.
Isolamento de tráfego de broadcast - Cada VLAN é um domínio de broadcast que limita a transmissão de pacotes de broadcast.
Flexibilidade - Uma VLAN pode ser dividida logicamente com base em um grupo de trabalho. Os hosts do mesmo grupo de trabalho podem ser atribuídos à mesma VLAN, independentemente de suas localizações físicas.
Encapsulamento de quadros VLAN
Para identificar quadros Ethernet de VLANs diferentes, o IEEE 802.1Q insere uma tag de VLAN de quatro bytes entre o campo de endereço MAC de destino e de origem (DA&SA) e o campo Type.
Figura 1 Posicionamento e formato da tag VLAN

Uma tag de VLAN inclui os seguintes campos:
TPID - identificador de protocolo de tag de 16 bits que indica se um quadro é marcado por VLAN. Por padrão, o valor hexadecimal TPID 8100 identifica um quadro com marcação de VLAN. Um fornecedor de dispositivos pode definir o TPID com um valor diferente. Para fins de compatibilidade com um dispositivo vizinho, defina o valor TPID no dispositivo para ser o mesmo que o do dispositivo vizinho. Para obter mais informações sobre como definir o valor TPID, consulte os comandos QinQ em Layer 2-LAN Switching Command Reference.
Prioridade - 3 bits de comprimento, identifica a prioridade 802.1p do quadro. Para obter mais informações, consulte o Guia de configuração de ACL e QoS.
CFI - indicador de formato canônico longo de 1 bit que indica se os endereços MAC são encapsulados no formato padrão quando os pacotes são transmitidos por diferentes mídias. Os valores disponíveis incluem:
0 (padrão) - Os endereços MAC são encapsulados no formato padrão.
1 - Os endereços MAC são encapsulados em um formato não padrão. Esse campo é sempre definido como 0 para Ethernet.
VLAN ID - 12 bits de comprimento, identifica a VLAN à qual o quadro pertence. O intervalo de VLAN ID é de 0 a 4095. As VLAN IDs 0 e 4095 são reservadas e as VLAN IDs 1 a 4094 são configuráveis pelo usuário.
A maneira como um dispositivo de rede trata um quadro de entrada depende do fato de o quadro ter uma tag de VLAN e do valor da tag de VLAN (se houver).
A Ethernet é compatível com os formatos de encapsulamento Ethernet II, 802.3/802.2 LLC, 802.3/802.2 SNAP e
802.3 raw. O formato de encapsulamento Ethernet II é usado aqui. Para obter informações sobre os campos de tag de VLAN em outros formatos de encapsulamento de quadros, consulte os protocolos e padrões relacionados.
Para um quadro que tenha várias tags de VLAN, o dispositivo o trata de acordo com a tag de VLAN mais externa e transmite as tags de VLAN internas como carga útil.
VLANs baseadas em portas
As VLANs baseadas em portas agrupam os membros da VLAN por porta. Uma porta encaminha pacotes de uma VLAN somente depois de ser atribuída à VLAN.
Tipo de link de porta
Você pode definir o tipo de link de uma porta como acesso, tronco ou híbrido. O tipo de link da porta determina se a porta pode ser atribuída a várias VLANs. Os tipos de link usam os seguintes métodos de manipulação de tags de VLAN:
Acesso - Uma porta de acesso pode encaminhar pacotes somente de uma VLAN e enviar esses pacotes sem marcação. Uma porta de acesso é normalmente usada nas seguintes condições:
Conexão a um dispositivo terminal que não oferece suporte a pacotes VLAN.
Em cenários que não distinguem VLANs.
Tronco - Uma porta tronco pode encaminhar pacotes de várias VLANs. Com exceção dos pacotes da porta VLAN ID (PVID), os pacotes enviados por uma porta tronco são marcados com VLAN. As portas que conectam dispositivos de rede geralmente são configuradas como portas tronco.
Híbrida - Uma porta híbrida pode encaminhar pacotes de várias VLANs. O status de marcação dos pacotes encaminhados por uma porta híbrida depende da configuração da porta. No mapeamento de VLAN de uma para duas, as portas híbridas são usadas para remover as tags de SVLAN do tráfego de downlink. Para obter mais informações sobre o mapeamento de VLAN de uma para duas, consulte "Configuração do mapeamento de VLAN".
PVID
O PVID identifica a VLAN padrão de uma porta. Os pacotes não marcados recebidos em uma porta são considerados como pacotes do PVID da porta.
Uma porta de acesso pode participar de apenas uma VLAN. A VLAN à qual a porta de acesso pertence é o PVID da porta. Uma porta tronco ou híbrida suporta várias VLANs e a configuração do PVID.
VLANs baseadas em MAC
O recurso de VLAN baseada em MAC atribui hosts a uma VLAN com base em seus endereços MAC. Esse recurso também é chamado de VLAN baseada no usuário porque a configuração da VLAN permanece a mesma, independentemente da localização física do usuário.
Atribuição estática de VLAN baseada em MAC
Use a atribuição estática de VLAN baseada em MAC em redes que tenham um pequeno número de usuários de VLAN. Para configurar a atribuição estática de VLAN baseada em MAC em uma porta, execute as seguintes tarefas:
Criar entradas de MAC para VLAN.
Habilite o recurso de VLAN baseada em MAC na porta.
Atribuir a porta à VLAN baseada em MAC.
Uma porta configurada com atribuição estática de VLAN baseada em MAC processa um quadro recebido da seguinte forma antes de enviá-lo:
Para um quadro sem marcação, a porta determina sua VLAN ID no seguinte fluxo de trabalho:
A porta realiza primeiro uma correspondência exata. Ela procura entradas de MAC para VLAN cujas máscaras sejam todas Fs. Se o endereço MAC de origem do quadro corresponder exatamente ao endereço MAC de uma entrada MAC-para-VLAN, a porta marcará o quadro com a VLAN ID específica dessa entrada.
Se a correspondência exata falhar, a porta executará um fuzzy da seguinte forma:
Procura as entradas de MAC para VLAN cujas máscaras não sejam todas Fs.
Executa uma operação AND lógica no endereço MAC de origem e em cada uma dessas máscaras.
Se o resultado de uma operação AND corresponder ao endereço MAC em uma entrada MAC-to-VLAN, a porta marca o quadro com a VLAN ID específica dessa entrada.
Se nenhuma VLAN ID correspondente for encontrada, a porta determinará a VLAN para o pacote usando a seguinte ordem de correspondência:
VLAN baseada em sub-rede IP.
VLAN baseada em protocolo.
VLAN baseada em porta.
Quando uma correspondência é encontrada, a porta marca o pacote com a VLAN ID correspondente.
Para um quadro marcado, a porta determina se a VLAN ID do quadro é permitida na porta.
Se a VLAN ID do quadro for permitida na porta, a porta encaminhará o quadro.
Se a VLAN ID do quadro não for permitida na porta, a porta descartará o quadro.
Atribuição dinâmica de VLAN baseada em MAC
Quando você não puder determinar as VLANs de destino baseadas em MAC de uma porta, use a atribuição dinâmica de VLAN baseada em MAC na porta. Para usar a atribuição dinâmica de VLAN baseada em MAC, execute as seguintes tarefas:
Criar entradas de MAC para VLAN.
Habilite o recurso de VLAN baseada em MAC na porta.
Ativar a atribuição dinâmica de VLAN baseada em MAC na porta.
A atribuição dinâmica de VLAN baseada em MAC usa o seguinte fluxo de trabalho, conforme mostrado na Figura 2:
Quando uma porta recebe um quadro, ela primeiro determina se o quadro está marcado.
Se o quadro estiver marcado, a porta receberá o endereço MAC de origem do quadro.
Se o quadro não estiver marcado, a porta seleciona uma VLAN para o quadro usando a seguinte ordem de correspondência:
VLAN baseada em MAC (correspondência de endereço MAC difusa e exata).
VLAN baseada em sub-rede IP.
VLAN baseada em protocolo.
VLAN baseada em porta.
Depois de marcar o quadro com a VLAN selecionada, a porta obtém o endereço MAC de origem do quadro.
A porta usa o endereço MAC de origem e a VLAN do quadro para fazer a correspondência entre as entradas MAC e VLAN.
Se o endereço MAC de origem do quadro corresponder exatamente ao endereço MAC em um
MAC-para-VLAN, a porta verifica se a VLAN ID do quadro corresponde à VLAN na entrada.
Se as duas VLAN IDs coincidirem, a porta se juntará à VLAN e encaminhará o quadro.
Se as duas VLAN IDs não corresponderem, a porta descarta o quadro.
Se o endereço MAC de origem do quadro não corresponder exatamente a nenhum endereço MAC nas entradas MAC-to-VLAN, a porta verificará se o VLAN ID do quadro é seu PVID.
Se o VLAN ID do quadro for o PVID da porta, a porta determinará se permite o PVID.
Se o PVID for permitido, a porta encaminhará o quadro dentro do PVID. Se o PVID não for permitido, a porta descarta o quadro.
Se o VLAN ID do quadro não for o PVID da porta, a porta determinará se o VLAN ID é o VLAN ID primário e o PVID da porta é um VLAN ID secundário. Em caso afirmativo, a porta encaminha o quadro. Caso contrário, a porta descarta o quadro.
Figura 2 Fluxograma para o processamento de um quadro na atribuição dinâmica de VLAN baseada em MAC
VLAN baseada em MAC atribuída ao servidor
Use esse recurso com autenticação de acesso, como a autenticação 802.1X baseada em MAC, para implementar um acesso seguro e flexível ao terminal.
Para implementar a VLAN baseada em MAC atribuída ao servidor, execute as seguintes tarefas:
Configure o recurso de VLAN baseada em MAC atribuído pelo servidor no dispositivo de acesso.
Configure as entradas de nome de usuário para VLAN no servidor de autenticação de acesso.
Quando um usuário passa na autenticação do servidor de autenticação de acesso, o servidor atribui ao dispositivo as informações da VLAN de autorização do usuário. Em seguida, o dispositivo executa as seguintes operações :
Gera uma entrada MAC para VLAN usando o endereço MAC de origem do pacote do usuário e as informações da VLAN de autorização. A VLAN de autorização é uma VLAN baseada em MAC.
A entrada MAC-para-VLAN gerada não pode entrar em conflito com as entradas estáticas MAC-para-VLAN existentes. Se houver um conflito, a entrada dinâmica de MAC para VLAN não poderá ser gerada.
Atribui a porta que conecta o usuário à VLAN baseada em MAC.
Quando o usuário fica off-line, o dispositivo exclui automaticamente a entrada MAC-to-VLAN e remove a porta da VLAN baseada em MAC. Para obter mais informações sobre a autenticação 802.1X e MAC, consulte o Guia de configuração de segurança.
VLANs baseadas em sub-rede IP
O recurso de VLAN baseada em sub-rede IP atribui pacotes não marcados a VLANs com base em seus endereços IP de origem e máscaras de sub-rede.
Use esse recurso quando os pacotes sem marcação de uma sub-rede IP ou endereço IP precisarem ser transmitidos em uma VLAN.
VLANs baseadas em protocolos
O recurso de VLAN baseada em protocolo atribui pacotes de entrada a diferentes VLANs com base em seus tipos de protocolo e formatos de encapsulamento. Os protocolos disponíveis para atribuição de VLAN incluem IP, IPX e AT. Os formatos de encapsulamento incluem Ethernet II, 802.3 raw, 802.2 LLC e 802.2 SNAP.
Esse recurso associa os tipos de serviço de rede disponíveis às VLANs e facilita o gerenciamento e a manutenção da rede.
Comunicação de camada 3 entre VLANs
Os hosts de diferentes VLANs usam interfaces de VLAN para se comunicar na Camada 3. As interfaces de VLAN são interfaces virtuais que não existem como entidades físicas nos dispositivos. Para cada VLAN, você pode criar uma interface de VLAN e atribuir um endereço IP a ela. A interface de VLAN atua como gateway da VLAN para encaminhar pacotes destinados a outra sub-rede IP na Camada 3.
Protocolos e padrões
IEEE 802.1Q, padrão IEEE para redes locais e metropolitanas: Redes locais com ponte virtual
Configuração de uma VLAN
Restrições e diretrizes
Como a VLAN padrão do sistema, a VLAN 1 não pode ser criada ou excluída.
Antes de excluir uma VLAN dinâmica ou uma VLAN bloqueada por um aplicativo, você deve primeiro remover a configuração da VLAN.
Criação de VLANs
Entre na visualização do sistema.
System ViewCrie uma ou várias VLANs.
Crie uma VLAN e entre em sua visualização.
vlan vlan-idCrie várias VLANs e entre na visualização de VLAN. Criar VLANs.
vlan { vlan-id-list | all }Entre no modo de exibição VLAN.
vlan vlan-idPor padrão, existe apenas a VLAN padrão do sistema (VLAN 1).
(Opcional.) Defina um nome para a VLAN.
name textPor padrão, o nome de uma VLAN é VLAN vlan-id. O argumento vlan-id especifica a VLAN ID em um formato de quatro dígitos. Se a VLAN ID tiver menos de quatro dígitos, serão adicionados zeros à esquerda. Por exemplo, o nome da VLAN 100 é VLAN 0100.
(Opcional.) Configure a descrição da VLAN.
description text Por padrão, a descrição de uma VLAN é VLAN vlan-id. O argumento vlan-id especifica a VLAN ID em um formato de quatro dígitos. Se a VLAN ID tiver menos de quatro dígitos, serão adicionados zeros à esquerda. Por exemplo, a descrição padrão da VLAN 100 é VLAN 0100.
Configuração de VLANs baseadas em portas
Restrições e diretrizes para VLANs baseadas em portas
Quando você usa o comando undo vlan para excluir o PVID de uma porta, ocorre um dos seguintes eventos, dependendo do tipo de link da porta:
Para uma porta de acesso, o PVID da porta muda para a VLAN 1.
Para uma porta híbrida ou tronco, a configuração PVID da porta não é alterada.
Você pode usar uma VLAN inexistente como PVID para uma porta híbrida ou tronco, mas não para uma porta de acesso.
Como prática recomendada, defina o mesmo PVID para uma porta local e seu par.
Para evitar que uma porta descarte pacotes não marcados ou pacotes marcados com PVID, atribua à porta seu PVID.
Atribuição de uma porta de acesso a uma VLAN
Sobre a atribuição de uma porta de acesso a uma VLAN
Você pode atribuir uma porta de acesso a uma VLAN na visualização de VLAN ou na visualização de interface.
Atribuição de uma ou várias portas de acesso a uma VLAN na visualização de VLAN
Entre na visualização do sistema.
System ViewEntre na visualização de VLAN.
vlan vlan-idAtribua uma ou várias portas de acesso à VLAN.
port interface-listPor padrão, todas as portas pertencem à VLAN 1.
Atribuição de uma porta de acesso a uma VLAN na visualização da interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefina o tipo de link da porta como acesso.
port link-type accessPor padrão, todas as portas são portas de acesso.
Atribuir a porta de acesso a uma VLAN.
port access vlan vlan-id Por padrão, todas as portas de acesso pertencem à VLAN 1.
Atribuição de uma porta tronco a uma VLAN
Sobre a atribuição de uma porta tronco a uma VLAN
Uma porta tronco suporta várias VLANs. Você pode atribuí-la a uma VLAN na visualização da interface.
Restrições e diretrizes
Para alterar o tipo de link de uma porta de tronco para híbrido, defina primeiro o tipo de link como acesso.
Para permitir que uma porta tronco transmita pacotes de seu PVID, você deve atribuir a porta tronco ao PVID usando o comando port trunk permit vlan.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefina o tipo de link da porta como tronco.
port link-type trunkPor padrão, todas as portas são portas de acesso.
Atribuir a porta tronco às VLANs especificadas.
port trunk permit vlan { vlan-id-list | all }Por padrão, uma porta tronco permite apenas a VLAN 1.
(Opcional.) Defina o PVID para a porta tronco.
port trunk pvid vlan vlan-idA configuração padrão é VLAN 1.
Atribuição de uma porta híbrida a uma VLAN
Sobre a atribuição de uma porta híbrida a uma VLAN
Uma porta híbrida suporta várias VLANs. Você pode atribuí-la às VLANs especificadas na visualização da interface. Certifique-se de que as VLANs tenham sido criadas.
Restrições e diretrizes
Para alterar o tipo de link de uma porta de tronco para híbrido, defina primeiro o tipo de link como acesso.
Para permitir que uma porta híbrida transmita pacotes de seu PVID, você deve atribuir a porta híbrida ao PVID usando o comando port hybrid vlan.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-numberDefina o tipo de link da porta como híbrido.
port link-type hybridPor padrão, todas as portas são portas de acesso.
Atribuir a porta híbrida às VLANs especificadas.
port hybrid vlan vlan-id-list { tagged | untagged }Por padrão, a porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é access.
(Opcional.) Defina o PVID para a porta híbrida.
port hybrid pvid vlan vlan-id Por padrão, o PVID de uma porta híbrida é o ID da VLAN à qual a porta pertence quando seu tipo de link é de acesso.
Configuração de VLANs baseadas em MAC
Restrições e diretrizes para VLANs baseadas em MAC
As VLANs baseadas em MAC estão disponíveis somente em portas híbridas.
O recurso de VLAN baseada em MAC é configurado principalmente nas portas de downlink dos dispositivos de acesso do usuário. Não use esse recurso com agregação de links.
Configuração da atribuição estática de VLAN baseada em MAC
Entre na visualização do sistema.
System ViewCriar uma entrada de MAC para VLAN.
mac-vlan mac-address mac-address [ mask mac-mask ] vlan vlan-id [ dot1p priority ]Por padrão, não existem entradas de MAC para VLAN.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberDefina o tipo de link da porta como híbrido.
port link-type hybridPor padrão, todas as portas são portas de acesso.
Atribuir a porta híbrida às VLANs baseadas em MAC.
port hybrid vlan vlan-id-list { tagged | untagged }Por padrão, uma porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é de acesso.
Habilite o recurso de VLAN baseada em MAC.
mac-vlan enablePor padrão, esse recurso está desativado.
(Opcional.) Configure o sistema para atribuir preferencialmente VLANs com base no endereço MAC.
vlan precedence mac-vlanPor padrão, o sistema atribui VLANs com base no endereço MAC preferencialmente quando tanto a VLAN baseada em MAC quanto a VLAN baseada em sub-rede IP estão configuradas em uma porta.
Configuração da atribuição dinâmica de VLAN baseada em MAC
Sobre a atribuição dinâmica de VLAN baseada em MAC
Para que a atribuição dinâmica de VLAN baseada em MAC seja bem-sucedida, use VLANs estáticas ao criar entradas de MAC para VLAN.
Quando uma porta se junta a uma VLAN especificada na entrada MAC-to-VLAN, ocorre um dos seguintes eventos, dependendo da configuração da porta:
Se a porta não tiver sido configurada para permitir a passagem de pacotes da VLAN, ela se juntará à VLAN como um membro sem marcação.
Se a porta tiver sido configurada para permitir a passagem de pacotes da VLAN, a configuração da porta permanecerá a mesma.
A prioridade 802.1p da VLAN em uma entrada MAC para VLAN determina a prioridade de transmissão dos pacotes correspondentes.
Restrições e diretrizes
Se você configurar atribuições de VLAN estáticas e dinâmicas baseadas em MAC em uma porta, a atribuição dinâmica de VLAN baseada em MAC entrará em vigor.
Como prática recomendada para garantir a operação correta da autenticação 802.1X e MAC, não use a atribuição dinâmica de VLAN baseada em MAC com a autenticação 802.1X ou MAC.
Como prática recomendada, não configure a atribuição dinâmica de VLAN baseada em MAC e desative o aprendizado de endereço MAC em uma porta. Se os dois recursos forem configurados juntos em uma porta, ela encaminhará apenas os pacotes que correspondem exatamente às entradas de MAC para VLAN e descartará os pacotes que não correspondem exatamente.
Como prática recomendada, não configure a atribuição dinâmica de VLAN baseada em MAC e o limite de aprendizado de MAC em uma porta.
Se os dois recursos forem configurados juntos em uma porta e a porta aprender o número máximo configurado de entradas de endereço MAC, a porta processará os pacotes da seguinte forma:
Encaminha apenas os pacotes que correspondem às entradas de endereço MAC aprendidas pela porta.
Descarta pacotes não correspondentes.
Como prática recomendada, não use a atribuição dinâmica de VLAN baseada em MAC com o MSTP. No modo MSTP, se uma porta estiver bloqueada no MSTI de sua VLAN de destino, ela descartará os pacotes recebidos em vez de entregá-los à CPU. Como resultado, a porta não será atribuída dinamicamente à VLAN de destino.
Como prática recomendada, não use a atribuição dinâmica de VLAN baseada em MAC com o PVST. No modo PVST, se a VLAN de destino de uma porta não for permitida na porta, ela será colocada em estado de bloqueio. A porta descarta os pacotes recebidos em vez de entregá-los à CPU. Como resultado, a porta não será atribuída dinamicamente à VLAN de destino.
Como prática recomendada, não configure a atribuição dinâmica de VLAN baseada em MAC e o modo de atribuição automática de Voice Vlan em uma porta. Eles podem ter um impacto negativo um sobre o outro.
Procedimento
Entre na visualização do sistema.
System ViewCriar uma entrada de MAC para VLAN.
mac-vlan mac-address mac-address vlan vlan-id [ dot1p priority ]Por padrão, não existem entradas de MAC para VLAN.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberDefina o tipo de link da porta como híbrido.
port link-type hybridPor padrão, todas as portas são portas de acesso.
Habilite o recurso de VLAN baseada em MAC.
mac-vlan enablePor padrão, a VLAN baseada em MAC está desativada.
Ativar a atribuição dinâmica de VLAN baseada em MAC.
mac-vlan trigger enablePor padrão, a atribuição dinâmica de VLAN baseada em MAC está desativada.
A atribuição de VLAN para uma porta é acionada somente quando o endereço MAC de origem do pacote recebido corresponde exatamente ao endereço MAC em uma entrada MAC para VLAN.
(Opcional.) Configure o sistema para atribuir preferencialmente VLANs com base no endereço MAC.
vlan precedence mac-vlanPor padrão, o sistema atribui VLANs com base no endereço MAC preferencialmente quando tanto a VLAN baseada em MAC quanto a VLAN baseada em sub-rede IP estão configuradas em uma porta.
(Opcional.) Desative a porta para que não encaminhe pacotes que não correspondam ao endereço MAC exato em seu PVID.
port pvid forbidden Por padrão, quando uma porta recebe pacotes cujos endereços MAC de origem não correspondem à correspondência exata, a porta os encaminha em seu PVID.
Configuração de VLAN baseada em MAC atribuída ao servidor
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberDefina o tipo de link da porta como híbrido.
port link-type hybridPor padrão, todas as portas são portas de acesso.
Atribuir a porta híbrida às VLANs baseadas em MAC.
port hybrid vlan vlan-id-list { tagged | untagged }Por padrão, uma porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é access.
Habilite o recurso de VLAN baseada em MAC.
mac-vlan enablePor padrão, a VLAN baseada em MAC está desativada.
Configure a autenticação 802.1X ou MAC.
Para obter mais informações, consulte Referência de comandos de segurança.
Configuração de VLANs baseadas em sub-rede IP
Restrições e diretrizes
Esse recurso está disponível somente em portas híbridas e processa apenas pacotes sem marcação.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização de VLAN.
vlan vlan-idAssocie a VLAN a uma sub-rede IP ou a um endereço IP.
ip-subnet-vlan [ ip-subnet-index ] ip ip-address [ mask ]Por padrão, uma VLAN não está associada a uma sub-rede IP ou a um endereço IP.
Uma sub-rede multicast ou um endereço multicast não pode ser associado a uma VLAN.
Retornar à visualização do sistema.
quitEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefina o tipo de link da porta como híbrido.
port link-type hybridPor padrão, todas as portas são portas de acesso.
Atribuir a porta híbrida às VLANs baseadas em sub-rede IP especificadas.
port hybrid vlan vlan-id-list { tagged | untagged }Por padrão, uma porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é access.
Associar a porta híbrida à VLAN baseada em sub-rede IP especificada.
port hybrid ip-subnet-vlan vlan vlan-idPor padrão, uma porta híbrida não está associada a uma VLAN baseada em sub-rede.
Configuração de um grupo de VLAN
Sobre um grupo de VLAN
Um grupo de VLANs inclui um conjunto de VLANs.
Em um servidor de autenticação, um nome de grupo de VLAN representa um grupo de VLANs de autorização. Quando um usuário de autenticação 802.1X ou MAC é aprovado na autenticação, o servidor de autenticação atribui um nome de grupo de VLAN ao dispositivo. Em seguida, o dispositivo usa o nome do grupo de VLAN recebido para fazer a correspondência com os nomes de grupos de VLAN configurados localmente. Se for encontrada uma correspondência, o dispositivo selecionará uma VLAN do grupo e atribuirá a VLAN ao usuário. Para obter mais informações sobre a autenticação 802.1X e MAC, consulte Security Configuration Guide.
Procedimento
Entre na visualização do sistema.
System ViewCrie um grupo de VLAN e entre em sua visualização.
vlan-group group-nameAdicione VLANs ao grupo de VLANs.
vlan-list vlan-id-listPor padrão, não existem VLANs em um grupo de VLANs.
Você pode adicionar várias listas de VLAN a um grupo de VLAN.
Configuração de interfaces VLAN
Restrições e diretrizes
Você não pode criar interfaces de VLAN para VLANs secundárias que tenham as seguintes características:
Associado à mesma VLAN primária.
Ativado com comunicação de camada 3 na visualização da interface de VLAN da interface de VLAN primária. Para obter mais informações sobre VLANs secundárias, consulte "Configuração de VLAN privada".
Criação de uma interface VLAN
Entre na visualização do sistema.
System ViewCrie uma interface VLAN e entre em sua visualização.
interface vlan-interface interface-númeroAtribua um endereço IP à interface da VLAN.
ip address ip-address { mask | mask-length } [ sub ]Por padrão, nenhum endereço IP é atribuído a uma interface de VLAN.
(Opcional.) Configure a descrição da interface de VLAN.
description text A configuração padrão é o nome da interface da VLAN. Por exemplo, Interface Vlan-interface1.
(Opcional.) Defina o MTU para a interface VLAN.
mtu sizePor padrão, o MTU de uma interface VLAN é de 1500 bytes.
(Opcional.) Defina a largura de banda esperada para a interface.
bandwidth bandwidth-valuePor padrão, a largura de banda esperada (em kbps) é a taxa de transmissão da interface dividida por 1000.
Abra a interface da VLAN.
undo shutdown Por padrão, uma interface de VLAN não é desligada manualmente. O status da interface de VLAN depende do status das portas membros da VLAN.
Restaurar as configurações padrão da interface VLAN
Restrições e diretrizes
Esse recurso pode não conseguir restaurar as configurações padrão de alguns comandos por motivos como dependências de comandos ou restrições do sistema. Use o comando display this na visualização da interface para identificar esses comandos e, em seguida, use suas formas de desfazer ou siga a referência do comando para restaurar suas configurações padrão. Se a tentativa de restauração ainda falhar, siga as instruções da mensagem de erro para resolver o problema.
Procedimento
Entre na visualização do sistema.
System ViewEntre em uma visualização de interface de VLAN.
interface vlan-interface interface-númeroRestaurar as configurações padrão da interface VLAN.
defaultEsse recurso pode interromper os serviços de rede em andamento. Certifique-se de estar totalmente ciente do impacto desse recurso ao usá-lo em uma rede ativa.
Exemplos de configuração VLAN
Exemplo: Configuração de VLANs baseadas em portas
Configuração de rede
Conforme mostrado na Figura 3:
Configure VLANs baseadas em portas para que somente os hosts do mesmo departamento possam se comunicar entre si.
Figura 3 Diagrama de rede
Procedimento
Configurar o dispositivo A:
# Crie a VLAN 100 e atribua a GigabitEthernet 1/0/1 à VLAN 100.
<DeviceA> system-view
[DeviceA] vlan 100
[DeviceA-vlan100] port gigabitethernet 1/0/1
[DeviceA-vlan100] quit# Crie a VLAN 200 e atribua a GigabitEthernet 1/0/2 à VLAN 200.
[DeviceA] vlan 200
[DeviceA-vlan200] port gigabitethernet 1/0/2
[DeviceA-vlan200] quit # Configure a GigabitEthernet 1/0/3 como uma porta tronco e atribua a porta às VLANs 100 e 200.
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port link-type trunk
[DeviceA-GigabitEthernet1/0/3] port trunk permit vlan 100 200
Please wait... Done Configure o Dispositivo B da mesma forma que o Dispositivo A está configurado. (Detalhes não mostrados).
Configurar hosts:
Configure o Host A e o Host C para estarem na mesma sub-rede IP. Por exemplo, 192.168.100.0/24.
Configure o Host B e o Host D para que estejam na mesma sub-rede IP. Por exemplo, 192.168.200.0/24.
Verificação da configuração
# Verifique se o Host A e o Host C conseguem fazer o ping um do outro, mas ambos não conseguem fazer o ping do Host B e do Host D. (Os detalhes não são mostrados).
# Verifique se o Host B e o Host D conseguem executar o ping um do outro, mas ambos não conseguem executar o ping do Host A e do Host C. (Os detalhes não são mostrados).
# Verifique se as VLANs 100 e 200 estão configuradas corretamente no dispositivo A.
[DeviceA-GigabitEthernet1/0/3] display vlan 100
VLAN ID: 100
VLAN type: Static
Route interface: Not configured
Description: VLAN 0100
Name: VLAN 0100
Tagged ports:
GigabitEthernet1/0/3
Untagged ports:
GigabitEthernet1/0/1
[DeviceA-GigabitEthernet1/0/3] display vlan 200
VLAN ID: 200
VLAN type: Static
Route interface: Not configured
Description: VLAN 0200
Name: VLAN 0200
Tagged ports:
GigabitEthernet1/0/3
Untagged ports:
GigabitEthernet1/0/2Exemplo: Configuração de VLANs baseadas em MAC
Configuração de rede
Conforme mostrado na Figura 4:
A GigabitEthernet 1/0/1 do Dispositivo A e o Dispositivo C estão conectados a uma sala de reunião. O Laptop 1 e o Laptop 2 são usados para reuniões e podem ser usados em qualquer uma das duas salas de reunião.
Um departamento usa a VLAN 100 e possui o laptop 1. O outro departamento usa a VLAN 200 e possui o laptop 2.
Configure VLANs baseadas em MAC, de modo que o Laptop 1 e o Laptop 2 possam acessar o Servidor 1 e o Servidor 2, respectivamente, independentemente da sala de reunião em que estejam sendo usados.
Figura 4 Diagrama de rede
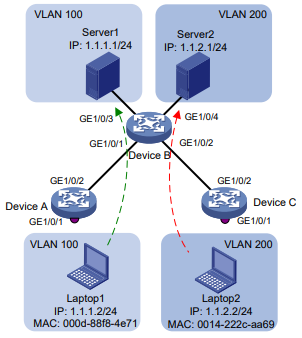
Procedimento
Configure o dispositivo A:
# Crie as VLANs 100 e 200.
<DeviceA> system-view
[DeviceA] vlan 100
[DeviceA-vlan100] quit
[DeviceA] vlan 200
[DeviceA-vlan200] quit [DeviceA] mac-vlan mac-address 000d-88f8-4e71 vlan 100
[DeviceA] mac-vlan mac-address 0014-222c-aa69 vlan 200 # Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua-a às VLANs 100 e 200 como um membro de VLAN sem marcação.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type hybrid
[DeviceA-GigabitEthernet1/0/1] port hybrid vlan 100 200 untagged # Configure a porta de uplink (GigabitEthernet 1/0/2) como uma porta tronco e atribua-a às VLANs 100 e 200.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 100 200
[DeviceA-GigabitEthernet1/0/2] quitConfigurar o dispositivo B:
# Crie a VLAN 100 e atribua a GigabitEthernet 1/0/3 à VLAN 100.
<DeviceA> system-view
[DeviceB] vlan 100
[DeviceB-vlan100] port gigabitethernet 1/0/3
[DeviceB-vlan100] quit # Crie a VLAN 200 e atribua a GigabitEthernet 1/0/4 à VLAN 200.
[DeviceB] vlan 200
[DeviceB-vlan200] port gigabitethernet 1/0/4
[DeviceB-vlan200] quit # Configure a GigabitEthernet 1/0/1 como uma porta tronco e atribua a porta às VLANs 100 e 200.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type trunk
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 100 200
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco e atribua a porta às VLANs 100 e 200.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 100 200
[DeviceB-GigabitEthernet1/0/2] quit Configure o Dispositivo C da mesma forma que o Dispositivo A está configurado. (Detalhes não mostrados.)
Verificação da configuração
# Verifique se o laptop 1 pode acessar somente o servidor 1 e se o laptop 2 pode acessar somente o servidor 2. (Os detalhes não são mostrados).
# Verifique as entradas MAC-to-VLAN no Dispositivo A e no Dispositivo C, por exemplo, no Dispositivo A.
[DeviceA] display mac-vlan all
The following MAC VLAN addresses exist:
S:Static D:Dynamic
MAC address Mask VLAN ID Dot1p State
000d-88f8-4e71 ffff-ffff-ffff 100 0 S
0014-222c-aa69 ffff-ffff-ffff 200 0 S
Total MAC VLAN address count: 2Exemplo: Configuração de VLANs baseadas em sub-rede IP
Configuração de rede
Conforme mostrado na Figura 5, os hosts do escritório pertencem a diferentes sub-redes IP.
Configure o Dispositivo C para transmitir pacotes de 192.168.5.0/24 e 192.168.50.0/24 nas VLANs 100 e 200, respectivamente.
Figura 5 Diagrama de rede
Procedimento
Configurar o dispositivo C:
# Associe a sub-rede IP 192.168.5.0/24 à VLAN 100.
<DeviceC> system-view
[DeviceC] vlan 100
[DeviceC-vlan100] ip-subnet-vlan ip 192.168.5.0 255.255.255.0
[DeviceC-vlan100] quit# Associe a sub-rede IP 192.168.50.0/24 à VLAN 200.
[DeviceC] vlan 200
[DeviceC-vlan200] ip-subnet-vlan ip 192.168.50.0 255.255.255.0
[DeviceC-vlan200] quit# Configure a GigabitEthernet 1/0/2 como uma porta híbrida e atribua-a à VLAN 100 como membro de uma VLAN marcada.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] port link-type hybrid
[DeviceC-GigabitEthernet1/0/2] port hybrid vlan 100 tagged
[DeviceC-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 como uma porta híbrida e atribua-a à VLAN 200 como membro de uma VLAN marcada.
[DeviceC] interface gigabitethernet 1/0/3
[DeviceC-GigabitEthernet1/0/3] port link-type hybrid
[DeviceC-GigabitEthernet1/0/3] port hybrid vlan 200 tagged
[DeviceC-GigabitEthernet1/0/3] quit# Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua-a às VLANs 100 e 200 como uma porta híbrida membro de VLAN sem marcação.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] port link-type hybrid
[DeviceC-GigabitEthernet1/0/1] port hybrid vlan 100 200 untagged# Associe a GigabitEthernet 1/0/1 às VLANs 100 e 200 baseadas em sub-rede IP.
[DeviceC-GigabitEthernet1/0/1] port hybrid ip-subnet-vlan vlan 100
[DeviceC-GigabitEthernet1/0/1] port hybrid ip-subnet-vlan vlan 200
[DeviceC-GigabitEthernet1/0/1] quitConfigure o Dispositivo A e o Dispositivo B para encaminhar pacotes das VLANs 100 e 200, respectivamente. (Detalhes não mostrados).
Verificação da configuração
# Verifique a configuração da VLAN baseada em sub-rede IP no Dispositivo C.
[DeviceC] display ip-subnet-vlan vlan all
VLAN ID: 100
Subnet index IP address Subnet mask
0 192.168.5.0 255.255.255.0
VLAN ID: 200
Subnet index IP address Subnet mask
0 192.168.50.0 255.255.255.0# Verifique a configuração da VLAN baseada em sub-rede IP na GigabitEthernet 1/0/1 do Dispositivo C.
[DeviceC] display ip-subnet-vlan interface gigabitethernet 1/0/1
Interface: GigabitEthernet1/0/1Exemplo: Configuração de VLANs baseadas em protocolo
Configuração de rede
Conforme mostrado na Figura 6:
A maioria dos hosts em um ambiente de laboratório executa o protocolo IPv4.
Os outros hosts executam o protocolo IPv6 para fins didáticos.
Para isolar o tráfego IPv4 e IPv6 na Camada 2, configure VLANs baseadas em protocolo para associar os protocolos IPv4 e ARP à VLAN 100 e associar o protocolo IPv6 à VLAN 200.
Figura 6 Diagrama de rede
Procedimento
Neste exemplo, o Comutador L2 A e o Comutador L2 B usam a configuração de fábrica.
Configurar dispositivo:
# Crie a VLAN 100 e configure a descrição da VLAN 100 como VLAN de protocolo para IPv4.
<Device> system-view
[Device] vlan 100
[Device-vlan100] description protocol VLAN for IPv4
# Atribua a GigabitEthernet 1/0/3 à VLAN 100. [Device-vlan100] port gigabitethernet 1/0/3 [Device-vlan100] quit
# Crie a VLAN 200 e configure a descrição da VLAN 200 como VLAN de protocolo para IPv6.
[Device-vlan100] port gigabitethernet 1/0/3
[Device-vlan100] quit# Atribua a GigabitEthernet 1/0/4 à VLAN 200.
[Device-vlan200] port gigabitethernet 1/0/4# Configure a VLAN 200 como uma VLAN baseada em protocolo e crie um modelo de protocolo IPv6 com o índice 1 para a VLAN 200.
[Device-vlan200] protocol-vlan 1 ipv6
[Device-vlan200] quit# Configure a VLAN 100 como uma VLAN baseada em protocolo. Crie um modelo de protocolo IPv4 com o parâmetro
índice 1 e crie um modelo de protocolo ARP com o índice 2. (No encapsulamento Ethernet II, o ID do tipo de protocolo para ARP é 0806 em notação hexadecimal).
[Device] vlan 100
[Device-vlan100] protocol-vlan 1 ipv4
[Device-vlan100] protocol-vlan 2 mode ethernetii etype 0806
[Device-vlan100] quit# Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua-a às VLANs 100 e 200 como um membro de VLAN sem marcação.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] port link-type hybrid
[Device-GigabitEthernet1/0/1] port hybrid vlan 100 200 untagged # Associe a GigabitEthernet 1/0/1 aos modelos de protocolo IPv4 e ARP da VLAN 100 e ao modelo de protocolo IPv6 da VLAN 200.
[Device-GigabitEthernet1/0/1] port hybrid protocol-vlan vlan 100 1 to 2
[Device-GigabitEthernet1/0/1] port hybrid protocol-vlan vlan 200 1
[Device-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta híbrida e atribua-a às VLANs 100 e 200 como um membro de VLAN sem marcação.
[Device] interface gigabitethernet 1/0/2
[Device-GigabitEthernet1/0/2] port link-type hybrid
[Device-GigabitEthernet1/0/2] port hybrid vlan 100 200 untagged # Associe a GigabitEthernet 1/0/2 aos modelos de protocolo IPv4 e ARP da VLAN 100 e ao modelo de protocolo IPv6 da VLAN 200.
[Device-GigabitEthernet1/0/2] port hybrid protocol-vlan vlan 100 1 to 2
[Device-GigabitEthernet1/0/2] port hybrid protocol-vlan vlan 200 1
[Device-GigabitEthernet1/0/2] quit Configurar hosts e servidores:
Configure o host IPv4 A, o host IPv4 B e o servidor IPv4 para que estejam no mesmo segmento de rede (192.168.100.0/24, por exemplo). (Detalhes não mostrados.)
Configure o Host A IPv6, o Host B IPv6 e o servidor IPv6 para que estejam no mesmo segmento de rede (2001::1/64, por exemplo). (Detalhes não mostrados.)
Verificação da configuração
Verifique o seguinte:
Os hosts e o servidor na VLAN 100 podem fazer ping entre si com sucesso. (Detalhes não mostrados.)
Os hosts e o servidor na VLAN 200 podem fazer ping entre si com êxito. (Detalhes não mostrados.)
Os hosts ou o servidor da VLAN 100 não podem fazer ping nos hosts ou no servidor da VLAN 200. (Detalhes não mostrados.)
Verifique a configuração da VLAN baseada em protocolo: # Exibir VLANs baseadas em protocolo no dispositivo.
[Device] display protocol-vlan vlan all
VLAN ID: 100
Protocol index Protocol type
1 IPv4
2 Ethernet II Etype 0x0806
VLAN ID: 200
Protocol index Protocol type
1 IPv6
# Exibir VLANs baseadas em protocolo nas portas do dispositivo.
[Device] display protocol-vlan interface all
Interface: GigabitEthernet1/0/1
VLAN ID Protocol index Protocol type
Status
100 1 IPv4 Active
100 2 Ethernet II Etype 0x0806 Active
200 1 IPv6 Active
Interface: GigabitEthernet 1/0/2
VLAN ID Protocol index Protocol type Status
100 1 IPv4 Active
100 2 Ethernet II Etype 0x0806 Active
200 1 IPv6 Active
Configurando VLANs privadas
Sobre a VLAN privada
Aplicavel somente na linha S3300G
A tecnologia VLAN oferece um método para isolar o tráfego dos clientes. Na camada de acesso de uma rede, o tráfego de clientes deve ser isolado para fins de segurança ou contabilidade. Se as VLANs forem atribuídas por usuário, será necessário um grande número de VLANs.
O recurso de VLAN privada economiza recursos de VLAN. Ele usa uma estrutura de VLAN de dois níveis, como segue:
VLAN primária - Usada para conectar o dispositivo upstream. Uma VLAN primária pode ser associada a várias VLANs secundárias. O dispositivo upstream identifica apenas a VLAN primária.
VLANs secundárias - Usadas para conectar usuários. As VLANs secundárias são isoladas na Camada 2. Para implementar a comunicação na camada 3 entre as VLANs secundárias associadas à VLAN primária, ative o proxy ARP local ou ND no dispositivo upstream (por exemplo, o dispositivo L3 A na Figura 7).
Conforme mostrado na Figura 7, o recurso de VLAN privada está ativado no Dispositivo L2 B. A VLAN 10 é a VLAN primária. As VLANs 2, 5 e 8 são VLANs secundárias associadas à VLAN 10. O dispositivo L3 A está ciente apenas da VLAN 10.
Figura 7 Exemplo de VLAN privada
Se o recurso de VLAN privada estiver configurado em um dispositivo de Camada 3, use um dos seguintes métodos no dispositivo de Camada 3 para ativar a comunicação de Camada 3. A comunicação da Camada 3 pode ser necessária entre VLANs secundárias associadas à mesma VLAN primária ou entre VLANs secundárias e outras redes.
Método 1:
Crie interfaces de VLAN para as VLANs secundárias.
Atribua endereços IP às interfaces de VLAN secundárias.
Método 2:
Habilite a comunicação da Camada 3 entre as VLANs secundárias associadas à VLAN primária .
Crie a interface de VLAN para a VLAN primária e atribua um endereço IP a ela. (Não crie interfaces de VLAN secundárias se você usar esse método).
Habilite o proxy ARP ou ND local na interface VLAN primária.
Restrições e diretrizes: Configuração de VLAN privada
Certifique-se de que os seguintes requisitos sejam atendidos:
Para uma porta promíscua:
A VLAN primária é o PVID da porta.
A porta é um membro sem marcação da VLAN primária e das VLANs secundárias.
Para uma porta de host:
O PVID da porta é uma VLAN secundária.
A porta é um membro sem marcação da VLAN primária e da VLAN secundária.
Uma porta tronco promíscua ou porta tronco secundária deve ser um membro marcado das VLANs primária e secundária.
A VLAN 1 (VLAN padrão do sistema) não é compatível com a configuração de VLAN privada.
Criação de uma VLAN primária
Entre na visualização do sistema.
System ViewCrie uma VLAN e entre na visualização de VLAN.
vlan vlan-idConfigure a VLAN como uma VLAN primária.
private-vlan primaryPor padrão, uma VLAN não é uma VLAN primária.
Criação de VLANs secundárias
Entre na visualização do sistema.
System ViewCrie uma ou várias VLANs secundárias.
vlan { vlan-id-list | all }Associação da VLAN primária com VLANs secundárias
Entre na visualização do sistema.
System ViewCrie uma visualização de VLAN da VLAN primária.
vlan vlan-idAssocie a VLAN primária às VLANs secundárias.
private-vlan secondary vlan-id-listPor padrão, uma VLAN primária não está associada a nenhuma VLAN secundária.
Configuração da porta de uplink
Sobre a porta de uplink
Configure a porta de uplink (por exemplo, a porta que conecta o dispositivo L2 B ao dispositivo L3 A na Figura 7) da seguinte forma:
Se a porta permitir apenas uma VLAN primária, configure-a como uma porta promíscua da VLAN primária. A porta promíscua pode ser atribuída automaticamente à VLAN primária e às suas VLANs secundárias associadas.
Se a porta permitir várias VLANs primárias, configure-a como uma porta promíscua de tronco das VLANs primárias. A porta promíscua de tronco pode ser automaticamente atribuída às VLANs primárias e às VLANs secundárias associadas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface da porta de uplink.
interface interface-type interface-numberConfigure a porta de uplink como uma porta promíscua ou tronco promíscuo das VLANs especificadas.
Configure a porta de uplink como uma porta promíscua da VLAN especificada.
port private-vlan vlan-id promiscuousConfigure a porta de uplink como uma porta promíscua de tronco das VLANs especificadas.
port private-vlan vlan-id-list trunk promiscuousPor padrão, uma porta não é uma porta promíscua ou tronco promíscuo de nenhuma VLAN.
Configuração de uma porta de downlink
Sobre a porta de downlink
Configure uma porta de downlink da seguinte forma:
Se uma porta de downlink permitir apenas uma VLAN secundária (por exemplo, a porta que conecta o Dispositivo L2 B a um host na Figura 7), configure a porta como uma porta de host. A porta do host pode ser atribuída automaticamente à VLAN secundária e à VLAN primária associada.
Se uma porta de downlink permitir várias VLANs secundárias, configure a porta como uma porta secundária tronco. A porta secundária tronco pode ser atribuída automaticamente às VLANs secundárias e às VLANs primárias associadas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface da porta de downlink.
interface interface-type interface-numberAtribuir a porta de downlink a VLANs secundárias.
Definir o tipo de link da porta.
port link-type { access | hybrid | trunk }Atribuir a porta de acesso à VLAN especificada.
port access vlan vlan-id Atribuir a porta tronco às VLANs especificadas.
port trunk permit vlan { vlan-id-list | all }Atribuir a porta híbrida às VLANs especificadas.
port hybrid vlan vlan-id-list { tagged | untagged }Selecione a subetapa b, c ou d, dependendo do tipo de link de porta.
Configure a porta de downlink como uma porta secundária de host ou de tronco.
Configure a porta de downlink como uma porta de host.
port private-vlan hostConfigure a porta de downlink como uma porta secundária de tronco das VLANs especificadas.
port trunk permit vlan { vlan-id-list | all } Por padrão, uma porta não é uma porta secundária de host ou de tronco.
Retornar à visualização do sistema.
quitEntre na visualização de VLAN de uma VLAN secundária.
vlan vlan-id(Opcional.) Habilite a comunicação da Camada 2 para portas na mesma VLAN secundária. Escolha um comando conforme necessário:
undo private-vlan isolated private-vlan communityPor padrão, as portas na mesma VLAN secundária podem se comunicar entre si na Camada 2.
Configuração da comunicação da camada 3 para VLANs secundárias
Entre na visualização do sistema.
System ViewEntre na visualização da interface de VLAN da interface de VLAN primária.
interface vlan-interface interface-númeroHabilita a comunicação da Camada 3 entre VLANs secundárias associadas à VLAN primária.
private-vlan secondary vlan-id-listPor padrão, as VLANs secundárias não podem se comunicar entre si na Camada 3.
Atribua um endereço IP à interface VLAN primária.
IPv4:
ip address ip-address { mask-length | mask } [ sub IPv6:
ipv6 address { ipv6-address prefix-length | ipv6-address/prefix-length }padrão, nenhum endereço IP é configurado para uma interface VLAN.
Habilite o proxy local ARP ou ND. IPv4:
local-proxy-arp enablePor padrão, o proxy ARP local está desativado.
Para obter mais informações sobre o ARP de proxy local, consulte o Guia de configuração de serviços de IP de camada 3. IPv6:
local-proxy-nd enablePor padrão, o proxy local ND está desativado.
Para obter mais informações sobre o proxy local ND, consulte o Guia de Configuração de Serviços de Camada 3 IP.
Comandos de exibição e manutenção para a VLAN privada
display private-vlan [ primary-vlan-id ]Executar comandos de exibição em qualquer visualização.
Exemplos de configuração de VLAN privada
Exemplo: Configuração de portas promíscuas
Configuração de rede
Conforme mostrado na Figura 8, configure o recurso de VLAN privada para atender aos seguintes requisitos:
No Dispositivo B, a VLAN 5 é uma VLAN primária associada às VLANs secundárias 2 e 3. A GigabitEthernet 1/0/5 está na VLAN 5. A GigabitEthernet 1/0/2 está na VLAN 2. A GigabitEthernet 1/0/3 está na VLAN 3.
No Dispositivo C, a VLAN 6 é uma VLAN primária associada às VLANs secundárias 3 e 4. A GigabitEthernet 1/0/5 está na VLAN 6. A GigabitEthernet 1/0/3 está na VLAN 3. A GigabitEthernet 1/0/4 está na VLAN 4.
O dispositivo A está ciente apenas da VLAN 5 no dispositivo B e da VLAN 6 no dispositivo C.
Figura 8 Diagrama de rede
Procedimento
Este exemplo descreve as configurações no Dispositivo B e no Dispositivo C.
Configurar o dispositivo B:
# Configure a VLAN 5 e 10 VLANS primária.
<DeviceB> system-view
[DeviceB] vlan 5
[DeviceB-vlan5] private-vlan primary
[DeviceB-vlan5] quit # Crie as VLANs 2 e 3.
[DeviceB] vlan 2 a 3# Associe as VLANs secundárias 2 e 3 à VLAN primária 5.
[DeviceB] vlan 5
[DeviceB-vlan5] private-vlan secondary 2 to 3
[DeviceB-vlan5] quit # Configure a porta de uplink (GigabitEthernet 1/0/5) como uma porta promíscua da VLAN 5.
[DeviceB] interface gigabitethernet 1/0/5
[DeviceB-GigabitEthernet1/0/5] port private-vlan 5 promiscuous
[DeviceB-GigabitEthernet1/0/5] quit# Atribua a porta de downlink GigabitEthernet 1/0/2 à VLAN 2 e configure a porta como uma porta de host.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port access vlan 2
[DeviceB-GigabitEthernet1/0/2] port private-vlan host
[DeviceB-GigabitEthernet1/0/2] quit # Atribua a porta de downlink GigabitEthernet 1/0/3 à VLAN 3 e configure a porta como uma porta de host.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] port access vlan 3
[DeviceB-GigabitEthernet1/0/3] port private-vlan host
[DeviceB-GigabitEthernet1/0/3] quit Configurar o dispositivo C:
# Configure a VLAN 6 como uma VLAN primária.
<DeviceC> system-view
[DeviceC] vlan 6
[DeviceC–vlan6] private-vlan primary
[DeviceC–vlan6] quit# Crie as VLANs 3 e 4.
[DeviceC] vlan 3 to 4 # Associe as VLANs secundárias 3 e 4 à VLAN primária 6.
[DeviceC] vlan 6
[DeviceC-vlan6] private-vlan secondary 3 to 4
[DeviceC-vlan6] quit
# Configure a porta de uplink (GigabitEthernet 1/0/5) como uma porta promíscua da VLAN 6.
[DeviceC] interface gigabitethernet 1/0/5
[DeviceC-GigabitEthernet1/0/5] port private-vlan 6 promiscuous
[DeviceC-GigabitEthernet1/0/5] quit
# Atribua a porta de downlink GigabitEthernet 1/0/3 à VLAN 3 e configure a porta como uma porta de host.
[DeviceC] interface gigabitethernet 1/0/3
[DeviceC-GigabitEthernet1/0/3] port access vlan 3
[DeviceC-GigabitEthernet1/0/3] port private-vlan host
[DeviceC-GigabitEthernet1/0/3] quit
# Atribua a porta de downlink GigabitEthernet 1/0/4 à VLAN 4 e configure a porta como uma porta de host.
[DeviceC] interface gigabitethernet 1/0/4
[DeviceC-GigabitEthernet1/0/4] port access vlan 4
[DeviceC-GigabitEthernet1/0/4] port private-vlan host
[DeviceC-GigabitEthernet1/0/4] quit
Verificação da configuração
# Verifique as configurações de VLAN privada nos dispositivos, por exemplo, no Dispositivo B.
[DeviceB] display private-vlan
Primary VLAN ID: 5
Secondary VLAN ID: 2-3
VLAN ID: 5
VLAN type: Static
Private VLAN type: Primary
Route interface: Not configured
Description: VLAN 0005
Name: VLAN 0005
Tagged ports:
None
Untagged ports:
GigabitEthernet1/0/2
GigabitEthernet1/0/3
GigabitEthernet1/0/5
VLAN ID: 2
VLAN type: Static
Private VLAN type: Secondary
31
Route interface: Not configured
Description: VLAN 0002
Name: VLAN 0002
Tagged ports:
None
Untagged ports:
GigabitEthernet1/0/2
GigabitEthernet1/0/5
VLAN ID: 3
VLAN type: Static
Private VLAN type: Secondary
Route interface: Not configured
Description: VLAN 0003
Name: VLAN 0003
Tagged Ports:
None
Untagged Ports:
GigabitEthernet1/0/3
GigabitEthernet1/0/5
O resultado mostra isso:
A porta promíscua (GigabitEthernet 1/0/5) é um membro sem marcação da VLAN 5 primária e das VLANs 2 e 3 secundárias.
A porta do host GigabitEthernet 1/0/2 é um membro sem marcação da VLAN 5 primária e da VLAN 2 secundária.
A porta do host GigabitEthernet 1/0/3 é um membro sem marcação da VLAN 5 primária e da VLAN 3 secundária.
Exemplo: Configuração de portas promíscuas de tronco
Configuração de rede
Conforme mostrado na Figura 9, configure o recurso de VLAN privada para atender aos seguintes requisitos:
As VLANs 5 e 10 são VLANs primárias no Dispositivo B. A porta de uplink (GigabitEthernet 1/0/1) no Dispositivo B permite que os pacotes das VLANs 5 e 10 passem marcados.
No Dispositivo B, a porta de downlink GigabitEthernet 1/0/2 permite a VLAN 2 secundária. A porta de downlink GigabitEthernet 1/0/3 permite a VLAN secundária 3. As VLANs secundárias 2 e 3 estão associadas à VLAN primária 5.
No Dispositivo B, a porta de downlink GigabitEthernet 1/0/4 permite a VLAN secundária 6. A porta de downlink GigabitEthernet 1/0/5 permite a VLAN secundária 8. As VLANs secundárias 6 e 8 estão associadas à VLAN primária 10.
O dispositivo A está ciente apenas das VLANs 5 e 10 no dispositivo B.
Figura 9 Diagrama de rede
Procedimento
Configurar o dispositivo B:
# Configure as VLANs 5 como VLANs primárias.
<DeviceB> system-view
[DeviceB] vlan 5
[DeviceB-vlan5] private-vlan primary
[DeviceB-vlan5] quit# Crie as VLANs 2, 3
[DeviceB] vlan 2 to 3# Associe as VLANs secundárias 2 e 3 à VLAN primária 5.
[DeviceB] vlan 5
[DeviceB-vlan5] private-vlan secondary 2 to 3
[DeviceB-vlan5] quit # Associe as VLANs secundárias 6 e 8 à VLAN primária 10.
[DeviceB] vlan 10
[DeviceB-vlan10] private-vlan secondary 6 8 [DeviceB-vlan10] quit
# Configure a porta de uplink (GigabitEthernet 1/0/1) como uma porta promíscua de tronco das VLANs 5 e 10.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port private-vlan 5 10 trunk promiscuous [DeviceB-GigabitEthernet1/0/1] quit
# Atribua a porta de downlink GigabitEthernet 1/0/2 à VLAN 2 e configure a porta como uma porta de host.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port access vlan 2
[DeviceB-GigabitEthernet1/0/2] port private-vlan host
[DeviceB-GigabitEthernet1/0/2] quit # Atribua a porta de downlink GigabitEthernet 1/0/3 à VLAN 3 e configure a porta como uma porta de host.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] port access vlan 3
[DeviceB-GigabitEthernet1/0/3] port private-vlan host
[DeviceB-GigabitEthernet1/0/3] quit # Atribua a porta de downlink GigabitEthernet 1/0/4 à VLAN 6 e configure a porta como uma porta de host.
[DeviceB] interface gigabitethernet 1/0/4
[DeviceB-GigabitEthernet1/0/4] port access vlan 6
[DeviceB-GigabitEthernet1/0/4] port private-vlan host
[DeviceB-GigabitEthernet1/0/4] quit # Atribua a porta de downlink GigabitEthernet 1/0/5 à VLAN 8 e configure a porta como uma porta de host.
[DeviceB] interface gigabitethernet 1/0/5
[DeviceB-GigabitEthernet1/0/5] port access vlan 8
[DeviceB-GigabitEthernet1/0/5] port private-vlan host
[DeviceB-GigabitEthernet1/0/5] quitConfigure o dispositivo A:
# Crie as VLANs 5 e 10.
[DeviceA] vlan 5
[DeviceA-vlan5] quit
[DeviceA] vlan 10
[DeviceA-vlan10] quit # Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua-a às VLANs 5 e 10 como um membro de VLAN marcada.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type hybrid
[DeviceA-GigabitEthernet1/0/1] port hybrid vlan 5 10 tagged
[DeviceA-GigabitEthernet1/0/1] quit Verificação da configuração
# Verifique as configurações da VLAN primária no Dispositivo B. A saída a seguir usa a VLAN primária 5 como exemplo.
[DeviceB] display private-vlan 5
Primary VLAN ID: 5
Secondary VLAN ID: 2-3
VLAN ID: 5
VLAN type: Static
Private VLAN type: Primary
Route interface: Not configured
Description: VLAN 0005
Name: VLAN 0005
Tagged ports:
GigabitEthernet1/0/1
Untagged ports:
GigabitEthernet1/0/2
GigabitEthernet1/0/3
VLAN ID: 2
VLAN type: Static
Private VLAN type: Secondary
Route interface: Not configured
Description: VLAN 0002
Name: VLAN 0002
Tagged ports:
GigabitEthernet1/0/1
Untagged ports:
GigabitEthernet1/0/2
VLAN ID: 3
VLAN type: Static
Private VLAN type: Secondary
Route interface: Not configured
Description: VLAN 0003
Name: VLAN 0003
Tagged ports:
GigabitEthernet1/0/1
Untagged ports:
GigabitEthernet1/0/3
O resultado mostra isso:
A porta promíscua do tronco (GigabitEthernet 1/0/1) é um membro marcado da VLAN 5 primária e das VLANs 2 e 3 secundárias.
A porta do host GigabitEthernet 1/0/2 é um membro sem marcação da VLAN 5 primária e da VLAN 2 secundária.
A porta do host GigabitEthernet 1/0/3 é um membro sem marcação da VLAN 5 primária e da VLAN 3 secundária.
Exemplo: Configuração de portas tronco promíscuas e tronco secundárias
Configuração de rede
Conforme mostrado na Figura 10, configure o recurso de VLAN privada para atender aos seguintes requisitos:
As VLANs 10 e 20 são VLANs primárias no Dispositivo A. A porta de uplink (GigabitEthernet 1/0/5) no Dispositivo A permite que os pacotes das VLANs 10 e 20 passem marcados.
As VLANs 11, 12, 21 e 22 são VLANs secundárias no Dispositivo A.
A porta de downlink GigabitEthernet 1/0/2 permite que os pacotes das VLANs secundárias 11 e 21 passem com tags.
A porta de downlink GigabitEthernet 1/0/1 permite a VLAN 22 secundária.
A porta de downlink GigabitEthernet 1/0/3 permite a VLAN 12 secundária.
As VLANs secundárias 11 e 12 estão associadas à VLAN primária 10.
As VLANs secundárias 21 e 22 estão associadas à VLAN primária 20.
Figura 10 Diagrama de rede
Procedimento
Configurar o dispositivo A:
# Configure as VLANs 10 e 20 como VLANs primárias.
<DeviceA> system-view
[DeviceA] vlan 10
[DeviceA-vlan10] private-vlan primary
[DeviceA-vlan10] quit
[DeviceA] vlan 20
[DeviceA-vlan20] private-vlan primary
[DeviceA-vlan20] quit # Crie as VLANs 11, 12, 21 e 22.
[DeviceA] vlan 11 to 12
[DeviceA] vlan 21 to 22 # Associe as VLANs secundárias 11 e 12 à VLAN primária 10.
[DeviceA] vlan 10
[DeviceA-vlan10] private-vlan secondary 11 12
[DeviceA-vlan10] quit # Associe as VLANs secundárias 21 e 22 à VLAN primária 20.
[DeviceA] vlan 20
[DeviceA-vlan20] private-vlan secondary 21 22
[DeviceA-vlan20] quit # Configure a porta de uplink (GigabitEthernet 1/0/5) como uma porta promíscua de tronco das VLANs 10 e 20.
[DeviceA] interface gigabitethernet 1/0/5
[DeviceA-GigabitEthernet1/0/5] port private-vlan 10 20 trunk promiscuous
[DeviceA-GigabitEthernet1/0/5] quit # Atribua a porta de downlink GigabitEthernet 1/0/1 à VLAN 22 e configure a porta como uma porta de host.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port access vlan 22
[DeviceA-GigabitEthernet1/0/1] port private-vlan host
[DeviceA-GigabitEthernet1/0/1] quit# Atribua a porta de downlink GigabitEthernet 1/0/3 à VLAN 12 e configure a porta como uma porta de host.
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port access vlan 12
[DeviceA-GigabitEthernet1/0/3] port private-vlan host
[DeviceA-GigabitEthernet1/0/3] quit # Configure a porta de downlink GigabitEthernet 1/0/2 como uma porta tronco secundária das VLANs 11 e 21.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port private-vlan 11 21 trunk secondary
[DeviceA-GigabitEthernet1/0/2] quit Configurar o dispositivo B:
# Crie as VLANs 11 e 21.
<DeviceB> system-view
[DeviceB] vlan 11
[DeviceB-vlan11] quit
[DeviceB] vlan 21
[DeviceB-vlan21] quit # Configure a GigabitEthernet 1/0/2 como uma porta híbrida e atribua-a às VLANs 11 e 21 como um membro de VLAN marcada.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type hybrid
[DeviceB-GigabitEthernet1/0/2] port hybrid vlan 11 21 tagged
[DeviceB-GigabitEthernet1/0/2] quit# Atribua a GigabitEthernet 1/0/3 à VLAN 11.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] port access vlan 11
[DeviceB-GigabitEthernet1/0/3] quit# Atribua a GigabitEthernet 1/0/4 à VLAN 21.
[DeviceB] interface gigabitethernet 1/0/4
[DeviceB-GigabitEthernet1/0/4] port access vlan 21
[DeviceB-GigabitEthernet1/0/4] quitConfigurar o dispositivo C:
# Crie as VLANs 10 e 20.
<DeviceC> system-view
[DeviceC] vlan 10
[DeviceC-vlan10] quit
[DeviceC] vlan 20
[DeviceC-vlan20] quit # Configure a GigabitEthernet 1/0/5 como uma porta híbrida e atribua-a às VLANs 10 e 20 como um membro de VLAN marcada.
[DeviceC] interface gigabitethernet 1/0/5
[DeviceC-GigabitEthernet1/0/5] port link-type hybrid
[DeviceC-GigabitEthernet1/0/5] port hybrid vlan 10 20 tagged
[DeviceC-GigabitEthernet1/0/5] quitVerificação da configuração
# Verifique as configurações da VLAN primária no dispositivo A. A saída a seguir usa a VLAN primária 10 como exemplo.
[DeviceA] display private-vlan 10
Primary VLAN ID: 10
Secondary VLAN ID: 11-12
VLAN ID: 10
VLAN type: Static
Private-vlan type: Primary
Route interface: Not configured
Description: VLAN 0010
Name: VLAN 0010
Tagged ports:
GigabitEthernet1/0/2
GigabitEthernet1/0/5
Untagged ports:
GigabitEthernet1/0/3
VLAN ID: 11
VLAN type: Static
Private-vlan type: Secondary
Route interface: Not configured
Description: VLAN 0011
Name: VLAN 0011
Tagged ports:
GigabitEthernet1/0/2
GigabitEthernet1/0/5
Untagged ports: None
VLAN ID: 12
VLAN type: Static
Private-vlan type: Secondary
Route interface: Not configured
Description: VLAN 0012
Name: VLAN 0012
Tagged ports:
GigabitEthernet1/0/5
Untagged ports:
GigabitEthernet1/0/3O resultado mostra isso:
A porta promíscua do tronco (GigabitEthernet 1/0/5) é um membro marcado da VLAN 10 primária e das VLANs 11 e 12 secundárias.
A porta tronco secundária (GigabitEthernet 1/0/2) é um membro marcado da VLAN 10 primária e da VLAN 11 secundária.
A porta do host (GigabitEthernet 1/0/3) é um membro sem marcação da VLAN 10 primária e da VLAN 12 secundária.
Exemplo: Configuração da comunicação da camada 3 para VLANs secundárias
Configuração de rede
Conforme mostrado na Figura 11, configure o recurso de VLAN privada para atender aos seguintes requisitos:
A VLAN primária 10 no Dispositivo A está associada às VLANs secundárias 2 e 3. O endereço IP da interface VLAN 10 é 192.168.1.1/24.
A GigabitEthernet 1/0/1 pertence à VLAN 10. A GigabitEthernet 1/0/2 e a GigabitEthernet 1/0/3 pertencem à VLAN 2 e à VLAN 3, respectivamente.
As VLANs secundárias são isoladas na Camada 2, mas interoperáveis na Camada 3.
Figura 11 Diagrama de rede
Procedimento
# Crie a VLAN 10 e configure-a como uma VLAN primária.
<DeviceA> system-view
[DeviceA] vlan 10
[DeviceA-vlan10] private-vlan primary
[DeviceA-vlan10] quit# Crie as VLANs 2 e 3.
<DeviceA> system-view
[DeviceA] vlan 2 to 3 # Associe a VLAN 10 primária às VLANs 2 e 3 secundárias.
[DeviceA] vlan 10
[DeviceA-vlan10] private-vlan primary
[DeviceA-vlan10] private-vlan secondary 2 3
[DeviceA-vlan10] quit # Configure a porta de uplink (GigabitEthernet 1/0/1) como uma porta promíscua da VLAN 10.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port private-vlan 10 promiscuous
[DeviceA-GigabitEthernet1/0/1] quit# Atribua a porta de downlink GigabitEthernet 1/0/2 à VLAN 2 e configure a porta como uma porta de host.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port access vlan 2
[DeviceA-GigabitEthernet1/0/2] port private-vlan host
[DeviceA-GigabitEthernet1/0/2] quit# Atribua a porta de downlink GigabitEthernet 1/0/3 à VLAN 3 e configure a porta como uma porta de host.
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port access vlan 3
[DeviceA-GigabitEthernet1/0/3] port private-vlan host
[DeviceA-GigabitEthernet1/0/3] quit# Habilite a comunicação de camada 3 entre as VLANs secundárias 2 e 3 que estão associadas à VLAN primária 10.
[DeviceA] interface vlan-interface 10
[DeviceA-Vlan-interface10] private-vlan secondary 2 3 # Atribua o endereço IP 192.168.1.1/24 à interface VLAN 10.
[DeviceA-Vlan-interface10] ip address 192.168.1.1 255.255.255.0# Habilite o proxy ARP local na interface VLAN 10. [DeviceA-Vlan-interface10] local-proxy-arp enable [DeviceA-Vlan-interface10] quit
Verificação da configuração
# Exibir a configuração da VLAN 10 primária.
[DeviceA] display private-vlan 10
Primary VLAN ID: 10
Secondary VLAN ID: 2-3
VLAN ID: 10
VLAN type: Static
Private VLAN type: Primary
Route interface: Configured
IPv4 address: 192.168.1.1
IPv4 subnet mask: 255.255.255.0
Description: VLAN 0010
Name: VLAN 0010
Tagged ports: None
Untagged ports:
GigabitEthernet1/0/1
GigabitEthernet1/0/2
GigabitEthernet1/0/3
VLAN ID: 2
VLAN type: Static
Private VLAN type: Secondary
Route interface: Configured
IPv4 address: 192.168.1.1
IPv4 subnet mask: 255.255.255.0
Description: VLAN 0002
Name: VLAN 0002
Tagged ports: None
Untagged ports:
GigabitEthernet1/0/1
GigabitEthernet1/0/2
VLAN ID: 3
VLAN type: Static
Private VLAN type: Secondary
Route interface: Configured
IPv4 address: 192.168.1.1
IPv4 subnet mask: 255.255.255.0
Description: VLAN 0003
Name: VLAN 0003
Tagged ports: None
Untagged ports:
GigabitEthernet1/0/1
GigabitEthernet1/0/3 O campo Interface de rota na saída é Configurado, indicando que as VLANs secundárias 2 e 3 são interoperáveis na Camada 3.
Configuração de Voice Vlan
Sobre a Voice Vlan
Uma Voice Vlan é usada para transmitir tráfego de voz. O dispositivo pode configurar parâmetros de QoS para pacotes de voz para garantir maior prioridade de transmissão dos pacotes de voz.
Os dispositivos de voz comuns incluem telefones IP e dispositivos de acesso integrado (IADs). Este capítulo usa como exemplo os telefones IP .
Mecanismo de trabalho
Quando um telefone IP acessa um dispositivo, o dispositivo executa as seguintes operações:
Identifica o telefone IP na rede e obtém o endereço MAC do telefone IP.
Anuncia as informações da Voice Vlan para o telefone IP.
Após receber as informações da Voice Vlan, o telefone IP realiza a configuração automática. Os pacotes de voz enviados pelo telefone IP podem ser transmitidos dentro da Voice Vlan.
Métodos de identificação de telefones IP
Os dispositivos podem usar os endereços OUI ou LLDP para identificar os telefones IP.
Identificação de telefones IP por meio de endereços OUI
Um dispositivo identifica os pacotes de voz com base em seus endereços MAC de origem. Um pacote cujo endereço MAC de origem esteja de acordo com um endereço OUI (Organizationally Unique Identifier) do dispositivo é considerado um pacote de voz.
Você pode usar os endereços OUI padrão do sistema (consulte a Tabela 1) ou configurar endereços OUI para o dispositivo. Você pode remover ou adicionar manualmente os endereços OUI padrão do sistema.
Tabela 1 Endereços OUI padrão
Normalmente, um endereço OUI refere-se aos primeiros 24 bits de um endereço MAC (em notação binária) e é um identificador globalmente exclusivo que o IEEE atribui a um fornecedor. No entanto, os endereços OUI deste capítulo são endereços que o sistema usa para identificar os pacotes de voz. Eles são os resultados lógicos AND dos argumentos mac-address e oui-mask no comando voice-vlan mac-address.
Identificação automática de telefones IP por meio de LLDP
Se os telefones IP forem compatíveis com LLDP, configure o LLDP para a descoberta automática de telefones IP no dispositivo. O dispositivo pode então descobrir automaticamente o par por meio do LLDP e trocar TLVs LLDP com o par.
Se o LLDP System Capabilities TLV recebido em uma porta indicar que o par pode atuar como um telefone, o dispositivo executará as seguintes operações:
Envia um LLDP TLV com a configuração da Voice Vlan para o par.
Atribui a porta receptora à Voice Vlan.
Aumenta a prioridade de transmissão dos pacotes de voz enviados pelo telefone IP.
Adiciona o endereço MAC do telefone IP à tabela de endereços MAC para garantir que o telefone IP possa passar pela autenticação.
Use o LLDP em vez da lista OUI para identificar telefones IP se a rede tiver mais categorias de telefones IP do que o número máximo de endereços OUI suportados pelo dispositivo. O LLDP tem prioridade mais alta do que a lista OUI.
Para obter mais informações sobre o LLDP, consulte "Configuração do LLDP".
Anunciar as informações da Voice Vlan para os telefones IP
A Figura 12 mostra o fluxo de trabalho da publicidade das informações da Voice Vlan para os telefones IP.
Figura 12 Fluxo de trabalho da publicidade das informações da Voice Vlan para telefones IP
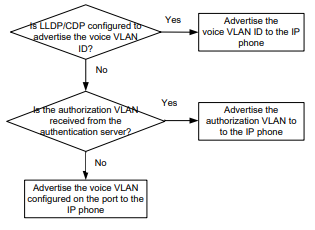
Métodos de acesso ao telefone IP
Conectando o host e o telefone IP em série
Conforme mostrado na Figura 13, o host está conectado ao telefone IP e o telefone IP está conectado ao dispositivo. Nesse cenário, os seguintes requisitos devem ser atendidos:
O host e o telefone IP usam VLANs diferentes.
O telefone IP pode enviar pacotes com marcação de VLAN, para que o dispositivo possa diferenciar o tráfego do host e do telefone IP.
A porta que se conecta ao telefone IP encaminha pacotes da Voice Vlan e do PVID.
Figura 13 Conexão do host e do telefone IP em série
Conexão do telefone IP ao dispositivo
Conforme mostrado na Figura 14, os telefones IP são conectados ao dispositivo sem a presença do host. Use esse método de conexão quando os telefones IP enviarem pacotes de voz não marcados. Nesse cenário, você deve configurar a Voice Vlan como o PVID da porta de acesso do telefone IP e configurar a porta para encaminhar os pacotes do PVID.
Figura 14 Conexão do telefone IP ao dispositivo
Modos de atribuição de Voice Vlan
Uma porta pode ser atribuída a uma Voice Vlan automática ou manualmente.
Modo automático
Use o modo automático quando os PCs e os telefones IP estiverem conectados em série para acessar a rede por meio do dispositivo, conforme mostrado na Figura 13. As portas do dispositivo transmitem tráfego de voz e tráfego de dados.
Quando um telefone IP é ligado, ele envia pacotes de protocolo. Depois de receber esses pacotes de protocolo, o dispositivo usa o endereço MAC de origem dos pacotes de protocolo para fazer a correspondência com seus endereços OUI. Se a correspondência for bem-sucedida, o dispositivo executará as seguintes operações:
Atribui a porta receptora dos pacotes de protocolo à Voice Vlan.
Emite regras de ACL para definir a precedência do pacote.
Inicia o cronômetro de envelhecimento da Voice Vlan.
Se nenhum pacote de voz for recebido da porta antes da expiração do cronômetro de envelhecimento, o dispositivo removerá a porta da Voice Vlan. O cronômetro de envelhecimento também é configurável.
Quando o telefone IP é reinicializado, a porta é reatribuída à Voice Vlan para garantir a operação correta das conexões de voz existentes. A reatribuição ocorre automaticamente sem ser acionada pelo tráfego de voz, desde que a Voice Vlan funcione corretamente.
Modo manual
Use o modo manual quando apenas os telefones IP acessarem a rede por meio do dispositivo, conforme mostrado na Figura
14. Nesse modo, as portas são atribuídas a uma Voice Vlan que transmite exclusivamente o tráfego de voz. Nenhum tráfego de dados afeta a transmissão do tráfego de voz.
Você deve atribuir manualmente a porta que se conecta ao telefone IP a uma Voice Vlan. O dispositivo usa o endereço MAC de origem dos pacotes de voz recebidos para fazer a correspondência com seus endereços OUI. Se a correspondência for bem-sucedida, o dispositivo emitirá regras de ACL para definir a precedência do pacote.
Para remover a porta da Voice Vlan, você deve removê-la manualmente.
Cooperação dos modos de atribuição de Voice Vlan e telefones IP
Alguns telefones IP enviam pacotes com marcação de VLAN e outros enviam apenas pacotes sem marcação. Para o processamento correto dos pacotes, as portas de diferentes tipos de links devem atender a requisitos específicos de configuração em diferentes modos de atribuição de Voice Vlan.
Se um telefone IP enviar tráfego de voz marcado e sua porta de acesso estiver configurada com autenticação 802.1X, VLAN de convidado, VLAN de falha de autenticação ou VLAN crítica, as IDs de VLAN deverão ser diferentes para as seguintes VLANs:
Voice Vlan.
PVID da porta de acesso.
802.1X guest, Auth-Fail ou VLAN crítica.
Se um telefone IP enviar tráfego de voz sem marcação, o PVID da porta de acesso deverá ser a Voice Vlan. Nesse cenário, não há suporte para a autenticação 802.1X.
As portas de acesso não transmitem pacotes marcados.
Requisitos de configuração para a transmissão de tráfego de voz com tags
Requisitos de configuração para a transmissão de tráfego de voz sem marcação
Quando os telefones IP enviam pacotes não marcados, você deve definir o modo de atribuição de Voice Vlan como manual.
Tabela 2 Requisitos de configuração para portas no modo manual para suportar tráfego de voz sem marcação
Modo de segurança e modo normal de Voice Vlan
Dependendo dos mecanismos de filtragem dos pacotes de entrada, uma porta habilitada para Voice Vlan pode operar em um dos seguintes modos:
Modo normal - A porta recebe pacotes com marcação de Voice Vlan e os encaminha para a Voice Vlan sem examinar seus endereços MAC. Se o PVID da porta for a Voice Vlan e a porta operar no modo de atribuição manual de VLAN, a porta encaminhará todos os pacotes não marcados recebidos na Voice Vlan.
Nesse modo, as Voice Vlan são vulneráveis a ataques de tráfego. Usuários mal-intencionados podem enviar um grande número de pacotes falsificados com ou sem marcação de Voice Vlan para afetar a comunicação de voz.
Modo de segurança - A porta usa os endereços MAC de origem dos pacotes de voz para corresponder aos endereços OUI do dispositivo. Os pacotes que não corresponderem serão descartados.
Em uma rede segura, você pode configurar as Voice Vlan para operar no modo normal. Esse modo reduz o consumo de recursos do sistema na verificação do endereço MAC de origem.
Em ambos os modos, o dispositivo modifica a prioridade de transmissão somente para pacotes de Voice Vlan cujos endereços MAC de origem correspondam aos endereços OUI do dispositivo.
Como prática recomendada, não transmita tráfego de voz e tráfego que não seja de voz em uma Voice Vlan. Se for necessário transmitir tráfego diferente em uma Voice Vlan, verifique se o modo de segurança da Voice Vlan está desativado.
Tabela 3 Processamento de pacotes em uma porta habilitada para Voice Vlan no modo normal ou de segurança
Restrições e diretrizes: Configuração da Voice Vlan
O cronômetro de envelhecimento de uma Voice Vlan começa somente quando a entrada de endereço MAC dinâmico da Voice Vlan se esgota. O período de envelhecimento da Voice Vlan é igual à soma do temporizador de envelhecimento da Voice Vlan e do temporizador de envelhecimento de sua entrada de endereço MAC dinâmico. Para obter mais informações sobre o cronômetro de envelhecimento das entradas de endereço MAC dinâmico, consulte "Configuração da tabela de endereços MAC".
Como prática recomendada, não configure a Voice Vlan e desative o aprendizado de endereço MAC em uma porta. Se os dois recursos forem configurados juntos em uma porta, ela encaminhará somente os pacotes que correspondem exatamente aos endereços OUI e descartará os pacotes que não correspondem exatamente.
Como prática recomendada, não configure a Voice Vlan e o limite de aprendizagem de MAC em uma porta. Se os dois recursos forem configurados juntos em uma porta e a porta aprender o número máximo configurado de entradas de endereço MAC, a porta processará os pacotes da seguinte forma:
Encaminha apenas os pacotes que correspondem às entradas de endereço MAC aprendidas pela porta e pelos endereços OUI.
Descarta pacotes não correspondentes.
Configuração dos modos de atribuição de Voice Vlan para uma porta
Configuração de uma porta para operar no modo de atribuição automática de Voice Vlan
Restrições e diretrizes
Não configure uma VLAN como uma Voice Vlan e uma VLAN baseada em protocolo.
Uma Voice Vlan em modo automático em uma porta híbrida processa apenas o tráfego de voz de entrada marcado.
Uma VLAN baseada em protocolo em uma porta híbrida processa somente os pacotes de entrada não marcados. Para obter mais informações sobre VLANs baseadas em protocolo, consulte "Configuração de VLANs baseadas em protocolo".
Como prática recomendada, não use esse modo com MSTP. No modo MSTP, se uma porta estiver bloqueada no MSTI da Voice Vlan de destino, a porta descartará os pacotes recebidos em vez de entregá-los à CPU. Como resultado, a porta não será atribuída dinamicamente à Voice Vlan.
Como prática recomendada, não use esse modo com PVST. No modo PVST, se a Voice Vlan de destino não for permitida em uma porta, ela será colocada em estado bloqueado. A porta descarta os pacotes recebidos em vez de entregá-los à CPU. Como resultado, a porta não será atribuída dinamicamente à Voice Vlan.
Como prática recomendada, não configure a atribuição dinâmica de VLAN baseada em MAC e o modo de atribuição automática de Voice Vlan em uma porta. Eles podem ter um impacto negativo um sobre o outro.
Procedimento
Entre na visualização do sistema.
System View(Opcional.) Defina o cronômetro de envelhecimento da Voice Vlan.
voice-vlan aging minutes Por padrão, o cronômetro de envelhecimento de uma Voice Vlan é de 1440 minutos.
O cronômetro de envelhecimento da Voice Vlan entra em vigor somente nas portas no modo de atribuição automática de Voice Vlan.
(Opcional.) Habilite o modo de segurança da Voice Vlan.
voice-vlan security enablePor padrão, o modo de segurança da Voice Vlan está ativado.
(Opcional.) Adicione um endereço OUI para identificação do pacote de voz.
voice-vlan mac-address oui mask oui-mask [ description text ]Por padrão, existem endereços OUI padrão do sistema. Para obter mais informações, consulte a Tabela 1.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure o tipo de link da porta.
porta link-type tronco
porta tipo link híbrido
Configure a porta para operar no modo de atribuição automática de Voice Vlan.
voice-vlan mode autoPor padrão, o modo de atribuição automática de Voice Vlan está ativado.
Habilite o recurso de Voice Vlan na porta.
voice-vlan vlan-id enablePor padrão, o recurso de Voice Vlan está desativado.
Antes de executar esse comando, verifique se a VLAN especificada já existe.
Configuração de uma porta para operar no modo de atribuição manual de Voice Vlan
Restrições e diretrizes
Você pode configurar Voice Vlan diferentes para portas diferentes no mesmo dispositivo. Certifique-se de que os seguintes requisitos sejam atendidos:
Uma porta pode ser configurada com apenas uma Voice Vlan.
As Voice Vlan devem ser VLANs estáticas existentes.
Não ative a Voice Vlan nas portas membros de um grupo de agregação de links. Para obter mais informações sobre agregação de links, consulte "Configuração da agregação de links Ethernet".
Para que uma Voice Vlan entre em vigor em uma porta operando no modo manual, é necessário atribuir manualmente a porta à Voice Vlan.
Procedimento
Entre na visualização do sistema.
System View(Opcional.) Habilite o modo de segurança da Voice Vlan.
voice-vlan security enablePor padrão, o modo de segurança da Voice Vlan está ativado.
(Opcional.) Adicione um endereço OUI para identificação do pacote de voz.
voice-vlan mac-address oui mask oui-mask [ description text ]Por padrão, existem endereços OUI padrão do sistema. Para obter mais informações, consulte a Tabela 1.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure a porta para operar no modo de atribuição manual de Voice Vlan.
undo voice-vlan mode autoPor padrão, uma porta opera no modo de atribuição automática de Voice Vlan.
Atribua a porta de acesso, tronco ou híbrida à Voice Vlan.
Para a porta de acesso, consulte "Atribuição de uma porta de acesso a uma VLAN".
Para a porta tronco, consulte "Atribuição de uma porta tronco a uma VLAN".
Para a porta híbrida, consulte "Atribuição de uma porta híbrida a uma VLAN".
Depois que você atribuir uma porta de acesso à Voice Vlan, a Voice Vlan se tornará o PVID da porta .
(Opcional.) Configure a Voice Vlan como o PVID do tronco ou da porta híbrida.
Para a porta tronco, consulte "Atribuição de uma porta tronco a uma VLAN".
Para a porta híbrida, consulte "Atribuição de uma porta híbrida a uma VLAN".
Essa etapa é necessária para o tráfego de voz de entrada sem tags e proibida para o tráfego de voz de entrada com tags.
Habilite o recurso de Voice Vlan na porta.
voice-vlan vlan-id enablePor padrão, o recurso de Voice Vlan está desativado.
Antes de executar esse comando, verifique se a VLAN especificada já existe.
Ativação do LLDP para descoberta automática de telefones IP
Restrições e diretrizes
Antes de ativar esse recurso, ative o LLDP globalmente e nas portas de acesso.
Use esse recurso somente com o modo de atribuição automática de Voice Vlan.
Se você usar esse recurso junto com a compatibilidade com CDP, as configurações de Voice Vlan serão excluídas quando os vizinhos de CDP forem excluídos, o que faz com que os telefones IP descobertos automaticamente por meio de LLDP fiquem off-line. Não use esse recurso junto com a compatibilidade com CDP.
Depois que você ativar esse recurso no dispositivo, cada porta do dispositivo poderá ser conectada a um máximo de cinco telefones IP.
Procedimento
Entre na visualização do sistema.
System ViewHabilite o LLDP para a descoberta automática de telefones IP.
voice-vlan track lldpPor padrão, esse recurso está desativado.
Configuração de LLDP ou CDP para anunciar uma Voice Vlan
Sobre a configuração do LLDP para anunciar uma Voice Vlan
Para telefones IP compatíveis com LLDP, o dispositivo anuncia as informações da Voice Vlan para os telefones IP por meio dos TLVs LLDP-MED.
Pré-requisitos
Antes de configurar esse recurso, ative o LLDP globalmente e nas portas de acesso.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure uma VLAN ID de voz anunciada.
lldp tlv-enable med-tlv network-policy vlan-idPor padrão, nenhuma VLAN ID de voz anunciada é configurada.
Para obter mais informações sobre o comando, consulte Layer 2-LAN Switching Command Reference.
(Opcional.) Exibir a Voice Vlan anunciada pelo LLDP.
display lldp local-informationPara obter mais informações sobre o comando, consulte Layer 2-LAN Switching Command Reference.
Configuração do CDP para anunciar uma Voice Vlan
Sobre como configurar o CDP para anunciar uma Voice Vlan
Se um telefone IP for compatível com CDP, mas não com LLDP, ele enviará pacotes CDP ao dispositivo para solicitar a VLAN ID de voz. Se o telefone IP não receber a VLAN ID de voz em um determinado período de tempo, ele enviará pacotes sem marcação. O dispositivo não pode diferenciar os pacotes de voz sem marcação de outros tipos de pacotes.
Você pode configurar a compatibilidade do CDP no dispositivo para permitir que ele execute as seguintes operações:
Receber e identificar pacotes CDP do telefone IP.
Envie pacotes CDP para o telefone IP. As informações da Voice Vlan são transportadas nos pacotes CDP.
Após receber as informações da VLAN anunciada, o telefone IP executa a configuração automática da Voice Vlan. Os pacotes do telefone IP serão transmitidos na Voice Vlan dedicada.
Os pacotes LLDP enviados pelo dispositivo contêm as informações de prioridade. Os pacotes CDP enviados pelo dispositivo não contêm as informações de prioridade.
Pré-requisitos
Antes de configurar esse recurso, ative o LLDP globalmente e nas portas de acesso.
Procedimento
Entre na visualização do sistema.
System ViewHabilitar a compatibilidade com CDP.
cdp de conformidade lldpPor padrão, a compatibilidade com CDP está desativada.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure o LLDP compatível com CDP para operar no modo TxRx.
lldp compliance admin-status cdp txrxPor padrão, o LLDP compatível com CDP opera no modo Disable (Desativado).
Configure uma VLAN ID de voz anunciada.
cdp voice-vlan vlan-idPor padrão, nenhuma VLAN ID de voz anunciada é configurada.
Para obter mais informações sobre o comando, consulte Layer 2-LAN Switching Command Reference.
Exemplos de configuração de Voice Vlan
Exemplo: Configuração do modo de atribuição automática de Voice Vlan
Configuração de rede
Conforme mostrado na Figura 15, o Dispositivo A transmite o tráfego de telefones IP e hosts. Para a transmissão correta do tráfego de voz, execute as seguintes tarefas no Dispositivo A:
Configure as Voice Vlan 2 e 3 para transmitir pacotes de voz do telefone IP A e do telefone IP B,
respectivamente.
Configure a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 para operar no modo de atribuição automática de Voice Vlan.
Adicione os endereços MAC dos telefones IP A e B ao dispositivo para identificação dos pacotes de voz. A máscara dos dois endereços MAC é FFFF-FF00-0000.
Defina um cronômetro de envelhecimento para Voice Vlan.
Figura 15 Diagrama de rede
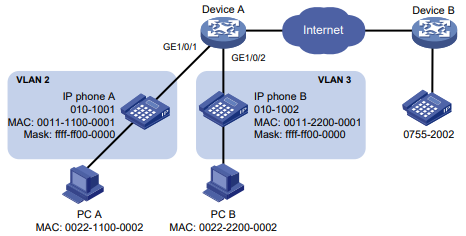
Procedimento
Configure as Voice Vlan:
# Crie as VLANs 2 e 3.
<DeviceA> system-view
[DeviceA] vlan 2 to 3 # Defina o cronômetro de envelhecimento da Voice Vlan para 30 minutos.
[DeviceA] voice-vlan aging 30# Ativar o modo de segurança para Voice Vlan.
[DeviceA] voice-vlan security enable# Adicione os endereços MAC dos telefones IP A e B ao dispositivo com a máscara FFFF-FF00-0000.
[DeviceA] voice-vlan mac-address 0011-1100-0001 mask ffff-ff00-0000 description IP phone A
[DeviceA] voice-vlan mac-address 0011-2200-0001 mask ffff-ff00-0000 description IP phone BConfigure a GigabitEthernet 1/0/1:
# Configure a GigabitEthernet 1/0/1 como uma porta híbrida.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type hybrid# Configure a GigabitEthernet 1/0/1 para operar no modo de atribuição automática de Voice Vlan.
[DeviceA-GigabitEthernet1/0/1] voice-vlan mode auto# Habilite a Voice Vlan na GigabitEthernet 1/0/1 e configure a VLAN 2 como a Voice Vlan para ela.
[DeviceA-GigabitEthernet1/0/1] voice-vlan 2 enable
[DeviceA-GigabitEthernet1/0/1] quitConfigure a GigabitEthernet 1/0/2:
# Configure a GigabitEthernet 1/0/2 como uma porta híbrida.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type hybrid# Configure a GigabitEthernet 1/0/2 para operar no modo de atribuição automática de Voice Vlan.
[DeviceA-GigabitEthernet1/0/2] voice-vlan mode auto# Habilite a Voice Vlan na GigabitEthernet 1/0/2 e configure a VLAN 3 como a Voice Vlan para ela.
[DeviceA-GigabitEthernet1/0/2] voice-vlan 3 enable
[DeviceA-GigabitEthernet1/0/2] quitVerificação da configuração
# Exibir os endereços OUI compatíveis com o dispositivo A.
[DeviceA] display voice-vlan mac-address
OUI Address
Mask
Description
0001-e300-0000 ffff-ff00-0000 Siemens phone
0003-6b00-0000 ffff-ff00-0000 Cisco phone
0004-0d00-0000 ffff-ff00-0000 Avaya phone
000f-e200-0000 ffff-ff00-0000 INTELBRAS Aolynk phone
0011-1100-0000 ffff-ff00-0000 IP phone A
0011-2200-0000 ffff-ff00-0000 IP phone B
0060-b900-0000 ffff-ff00-0000 Philips/NEC phone
00d0-1e00-0000 ffff-ff00-0000 Pingtel phone
00e0-7500-0000 ffff-ff00-0000 Polycom phone
00e0-bb00-0000 ffff-ff00-0000 3Com phone# Exibir o estado da Voice Vlan.
[DeviceA] display voice-vlan state
Current voice VLANs: 2
Voice VLAN security mode: Security
Voice VLAN aging time: 30 minutes
Voice VLAN enabled ports and their modes:
Port VLAN Mode CoS DSCP
GE1/0/1 2 Auto 6 46
GE1/0/2 3 Auto 6 46
Exemplo: Configuração do modo de atribuição manual de Voice Vlan
Configuração de rede
Conforme mostrado na Figura 16, o telefone IP A envia tráfego de voz sem marcação.
Para ativar a GigabitEthernet 1/0/1 para transmitir somente pacotes de voz, execute as seguintes tarefas no Dispositivo A:
Crie a VLAN 2. Essa VLAN será usada como uma Voice Vlan.
Configure a GigabitEthernet 1/0/1 para operar no modo de atribuição manual de Voice Vlan e adicione-a à VLAN 2.
Adicione o endereço OUI do telefone IP A à lista OUI do dispositivo A.
Figura 16 Diagrama de rede
Procedimento
# Habilitar o modo de segurança para Voice Vlan.
<DeviceA> system-view
[DeviceA] voice-vlan security enable# Adicione o endereço MAC 0011-2200-0001 com a máscara FFFF-FF00-0000.
[DeviceA] voice-vlan mac-address 0011-2200-0001 mask ffff-ff00-0000 description test # Criar a VLAN 2.
[DeviceA] vlan 2
[DeviceA-vlan2] quit
# Configure a GigabitEthernet 1/0/1 para operar no modo de atribuição manual de Voice Vlan.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] undo voice-vlan mode auto # Configure a GigabitEthernet 1/0/1 como uma porta híbrida.
[DeviceA-GigabitEthernet1/0/1] port link-type hybrid# Defina o PVID da GigabitEthernet 1/0/1 como VLAN 2.
[DeviceA-GigabitEthernet1/0/1] port hybrid pvid vlan 2# Atribua a GigabitEthernet 1/0/1 à VLAN 2 como um membro de VLAN sem marcação.
[DeviceA-GigabitEthernet1/0/1] port hybrid vlan 2 untagged# Habilite a Voice Vlan e configure a VLAN 2 como a Voice Vlan na GigabitEthernet 1/0/1.
[DeviceA-GigabitEthernet1/0/1] voice-vlan 2 enable [DeviceA-GigabitEthernet1/0/1] quitVerificação da configuração
# Exibir os endereços OUI compatíveis com o dispositivo A.
[DeviceA] display voice-vlan mac-address
OUI Address
Mask
Description
0001-e300-0000 ffff-ff00-0000 Siemens phone
0003-6b00-0000 ffff-ff00-0000 Cisco phone
0004-0d00-0000 ffff-ff00-0000 Avaya phone
000f-e200-0000 ffff-ff00-0000 INTELBRAS Aolynk phone
0011-1100-0000 ffff-ff00-0000 IP phone A
0011-2200-0000 ffff-ff00-0000 IP phone B
0060-b900-0000 ffff-ff00-0000 Philips/NEC phone
00d0-1e00-0000 ffff-ff00-0000 Pingtel phone
00e0-7500-0000 ffff-ff00-0000 Polycom phone
00e0-bb00-0000 ffff-ff00-0000 3Com phone# Exibir o estado da Voice Vlan.
[DeviceA] display voice-vlan state Voice Vlan atuais: 1
Modo de segurança da Voice Vlan: Segurança Tempo de envelhecimento da Voice Vlan: 1440 minutos
Portas habilitadas para Voice VLAN e seus modos:
Configuração do MVRP
Sobre a MVRP
O MRP (Multiple Registration Protocol) é um protocolo de registro de atributos usado para transmitir valores de atributos. O protocolo de registro de múltiplas VLANs (MVRP) é um aplicativo MRP típico. Ele sincroniza as informações de VLAN entre os dispositivos e reduz bastante a carga de trabalho dos administradores de rede.
Implementação do MRP
Uma porta habilitada para MRP é chamada de participante de MRP. Uma porta habilitada para MVRP é chamada de participante de MVRP.
Conforme mostrado na Figura 1, um participante do MRP envia declarações e retiradas para notificar outros participantes a registrar e cancelar o registro de seus valores de atributo. Ele também registra e cancela o registro dos valores de atributos de outros participantes de acordo com as declarações e retiradas recebidas. O MRP propaga rapidamente as informações de configuração de um participante do MRP por toda a LAN.
Figura 1 Implementação do MRP
Por exemplo, o MRP registra e cancela o registro de atributos de VLAN da seguinte forma:
Quando uma porta recebe uma declaração para uma VLAN, a porta registra a VLAN e entra na VLAN.
Quando uma porta recebe uma retirada para uma VLAN, a porta cancela o registro da VLAN e sai da VLAN.
O MRP permite que os dispositivos na mesma LAN transmitam valores de atributos por MSTI. A Figura 1 mostra uma implementação simples de MRP em um MSTI. Em uma rede com vários MSTIs, o MRP realiza o registro e o cancelamento do registro de atributos por MSTI. Para obter mais informações sobre MSTIs, consulte "Configuração de protocolos Spanning Tree".
Mensagens MRP
As mensagens MRP incluem os seguintes tipos:
Declaração - Inclui mensagens de ingresso e novas mensagens.
Retirada-Inclui as mensagens Leave e LeaveAll.
Junte-se à mensagem
Um participante do MRP envia uma mensagem Join para solicitar que o participante par registre atributos na mensagem Join.
Ao receber uma mensagem Join do participante par, um participante MRP executa as seguintes tarefas:
Registra os atributos na mensagem Join.
Propaga a mensagem Join para todos os outros participantes no dispositivo.
Depois de receber a mensagem Join, os outros participantes enviam a mensagem Join para seus respectivos pares de participantes.
As mensagens de ingresso enviadas de um participante local para seu participante par incluem os seguintes tipos:
JoinEmpty-Declara um atributo não registrado. Por exemplo, quando um participante do MRP se junta a uma VLAN estática não registrada, ele envia uma mensagem JoinEmpty.
As VLANs criadas manual e localmente são chamadas de VLANs estáticas. As VLANs aprendidas por meio do MRP são chamadas de VLANs dinâmicas.
JoinIn - Declara um atributo registrado. Uma mensagem JoinIn é usada em uma das seguintes situações:
Um participante do MRP se junta a uma VLAN estática existente e envia uma mensagem JoinIn após registrar a VLAN.
O participante do MRP recebe uma mensagem Join propagada por outro participante no dispositivo e envia uma mensagem JoinIn após registrar a VLAN.
Nova mensagem
Semelhante a uma mensagem Join, uma mensagem New permite que os participantes do MRP registrem atributos.
Quando a topologia do MSTP muda, um participante do MRP envia uma mensagem New ao participante par para declarar a mudança de topologia.
Ao receber uma mensagem New do participante par, um participante MRP executa as seguintes tarefas:
Registra os atributos na mensagem.
Propaga a mensagem Nova para todos os outros participantes no dispositivo.
Depois de receber a mensagem New, os outros participantes enviam a mensagem New para seus respectivos participantes pares.
Deixar mensagem
Um participante MRP envia uma mensagem Leave (Deixar) para o participante par quando deseja que o participante par cancele o registro de atributos que ele cancelou.
Quando o participante par recebe a mensagem Leave, ele executa as seguintes tarefas:
Cancela o registro do atributo na mensagem de saída.
Propaga a mensagem Leave (Sair) para todos os outros participantes no dispositivo.
Depois que um participante no dispositivo recebe a mensagem Leave (Sair), ele determina se deve enviar a mensagem Leave (Sair) para o participante par, dependendo do status do atributo no dispositivo.
Se a VLAN na mensagem Leave for uma VLAN dinâmica não registrada por nenhum participante no dispositivo, ocorrerão os dois eventos a seguir:
A VLAN é excluída no dispositivo.
O participante envia a mensagem Leave (Sair) para o participante par.
Se a VLAN na mensagem Leave for uma VLAN estática, o participante não enviará a mensagem Leave para o participante par.
Mensagem LeaveAll
Cada participante do MRP inicia seu cronômetro LeaveAll ao iniciar. Quando o cronômetro expira, o participante MRP envia mensagens LeaveAll para o participante par.
Ao enviar ou receber uma mensagem LeaveAll, o participante local inicia o cronômetro Leave. O participante local determina se deve enviar uma mensagem Join dependendo de seu status de atributo. Um participante pode registrar novamente os atributos na mensagem Join recebida antes que o temporizador Leave expire.
Quando o temporizador Leave expira, um participante cancela o registro de todos os atributos que não foram registrados novamente para limpar periodicamente os atributos inúteis na rede.
Temporizadores MRP
O MRP usa os seguintes temporizadores para controlar a transmissão de mensagens.
Temporizador periódico
O timer Periodic controla a transmissão de mensagens MRP. Um participante do MRP inicia seu próprio timer Periodic na inicialização e armazena mensagens MRP a serem enviadas antes que o timer Periodic expire. Quando o timer Periodic expira, o MRP envia mensagens MRP armazenadas no menor número possível de quadros MRP e reinicia o timer Periodic. Esse mecanismo reduz o número de quadros MRP enviados.
Você pode ativar ou desativar o timer Periodic. Quando o timer Periodic está desativado, o MRP não envia mensagens MRP periodicamente. Em vez disso, um participante do MRP envia mensagens MRP quando o temporizador LeaveAll expira ou quando o participante recebe uma mensagem LeaveAll do participante par.
Aderir ao cronômetro
O temporizador de associação controla a transmissão de mensagens de associação. Um participante do MRP inicia o cronômetro de associação depois de enviar uma mensagem de associação ao participante par. Antes que o cronômetro de Join expire, o participante não reenvia a mensagem Join quando as condições a seguir existem:
O participante recebe uma mensagem JoinIn do participante par.
A mensagem JoinIn recebida tem os mesmos atributos da mensagem Join enviada.
Quando o cronômetro de ingresso e o cronômetro periódico expiram, o participante reenvia a mensagem de ingresso.
Deixar o cronômetro
O temporizador Leave controla o cancelamento do registro de atributos.
Um participante do MRP inicia o cronômetro de licença em uma das seguintes condições:
O participante recebe uma mensagem Leave (Sair) de seu colega participante.
O participante recebe ou envia uma mensagem LeaveAll.
O participante do MRP não cancela o registro dos atributos na mensagem Leave ou LeaveAll se as seguintes condições existirem:
O participante recebe uma mensagem Join antes que o cronômetro Leave expire.
A mensagem Join inclui os atributos que foram encapsulados na mensagem Leave ou LeaveAll.
Se o participante não receber uma mensagem Join para esses atributos antes que o temporizador Leave expire, o MRP cancela o registro dos atributos.
Temporizador LeaveAll
Após a inicialização, um participante do MRP inicia seu próprio cronômetro LeaveAll. Quando o cronômetro LeaveAll expira, o participante do MRP envia uma mensagem LeaveAll e reinicia o cronômetro LeaveAll.
Ao receber a mensagem LeaveAll, os outros participantes reiniciam o cronômetro LeaveAll. O valor do cronômetro LeaveAll é selecionado aleatoriamente entre o cronômetro LeaveAll e 1,5 vezes o cronômetro LeaveAll. Esse mecanismo oferece os seguintes benefícios:
Reduz efetivamente o número de mensagens LeaveAll na rede.
Impede que o cronômetro LeaveAll de um determinado participante expire sempre primeiro.
Modos de registro do MVRP
As informações de VLAN propagadas pelo MVRP incluem informações de VLAN dinâmicas de outros dispositivos e informações de VLAN estáticas locais.
Com base em como um participante do MVRP lida com o registro de VLANs dinâmicas, o MVRP tem os seguintes modos de registro:
Normal - Um participante do MVRP no modo de registro normal registra e cancela o registro de VLANs dinâmicas.
Fixo - Um participante do MVRP no modo de registro fixo desativa o cancelamento do registro de VLANs dinâmicas e descarta os quadros MVRP recebidos. O participante do MVRP não cancela o registro de VLANs dinâmicas nem registra novas VLANs dinâmicas.
Forbidden (Proibido) - Um participante do MVRP no modo de registro proibido desativa o registro de VLANs dinâmicas e descarta os quadros MVRP recebidos. Quando você define o modo de registro proibido para uma porta, a VLAN 1 da porta é mantida e todas as VLANs registradas dinamicamente da porta são excluídas.
Protocolos e padrões
IEEE 802.1ak, Padrão IEEE para redes locais e metropolitanas: Virtual Bridged Local Area Networks - Emenda 07: Protocolo de registro múltiplo
Restrições e diretrizes: Configuração do MVRP
Quando você configurar o MVRP, siga estas restrições e diretrizes:
O MVRP pode funcionar com STP, RSTP ou MSTP. As portas bloqueadas pelo STP, RSTP ou MSTP podem receber e enviar quadros MVRP. Não configure o MVRP com outros protocolos de topologia de camada de link, como PVST, RRPP e Smart Link.
Para obter mais informações sobre STP, RSTP, MSTP e PVST, consulte "Configuração de protocolos de spanning tree". Para obter mais informações sobre RRPP e Smart Link, consulte o Guia de configuração de alta disponibilidade.
Não configure o MVRP e o espelhamento de porta remota em uma porta. Caso contrário, o MVRP poderá registrar a VLAN da sonda remota com portas incorretas, o que faria com que a porta do monitor recebesse cópias indesejadas. Para obter mais informações sobre espelhamento de porta, consulte o Guia de configuração de monitoramento e gerenciamento de rede.
A ativação do MVRP em uma interface agregada de camada 2 tem efeito na interface agregada e em todas as portas membros selecionadas no grupo de agregação de links.
A configuração do MVRP feita em uma porta membro do grupo de agregação entra em vigor somente depois que a porta é removida do grupo de agregação.
Visão geral das tarefas do MVRP
Para configurar o MVRP, execute as seguintes tarefas:
Ativação do MVRP
Configuração de um modo de registro MVRP
(Opcional.) Configuração de temporizadores MRP
(Opcional.) Ativação da compatibilidade com GVRP
Pré-requisitos
Antes de configurar o MVRP, conclua as seguintes tarefas:
Mapeie cada MSTI usado pelo MVRP para uma VLAN existente em cada dispositivo da rede.
Defina o tipo de link de porta dos participantes do MVRP como tronco, pois o MVRP tem efeito somente nas portas tronco. Para obter mais informações sobre portas tronco, consulte "Configuração de VLANs".
Ativação do MVRP
Entre na visualização do sistema.
System ViewAtivar o MVRP globalmente.
mvrp global enablePor padrão, o MVRP está globalmente desativado.
Para que o MVRP entre em vigor em uma porta, ative o MVRP na porta e globalmente.
Entre na visualização da interface Ethernet de camada 2 ou na visualização da interface agregada de camada 2.
interface interface-type interface-numberConfigure a porta como uma porta tronco.
port link-type trunkPor padrão, cada porta é uma porta de acesso. Para obter mais informações sobre o comando port link-type trunk, consulte Referência de comandos de comutação de Layer 2-LAN.
Configure a porta tronco para permitir as VLANs especificadas. port trunk permit vlan { vlan-id-list | all } Por padrão, uma porta tronco permite apenas a VLAN 1.
Certifique-se de que a porta tronco permita todas as VLANs registradas.
Para obter mais informações sobre o comando port trunk permit vlan, consulte Layer 2-LAN Switching Command Reference.
Habilita o MVRP na porta.
mvrp enablePor padrão, o MVRP está desativado em uma porta.
Configuração de um modo de registro MVRP
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet da Camada 2 ou na visualização da interface agregada da Camada 2.
interface interface-type interface-numberDefina um modo de registro MVRP para a porta.
registro mvrp { fixo | proibido | normal }
A configuração padrão é o modo de registro normal.
Configuração de temporizadores MRP
Restrições e diretrizes
Quando você definir os temporizadores MVRP, siga estas restrições e diretrizes:
Siga os requisitos de intervalo de valores para os temporizadores Join, Leave e LeaveAll e suas dependências, conforme descrito na Tabela 1. Se você definir um temporizador com um valor além do intervalo de valores permitido, sua configuração falhará. Você pode definir um temporizador ajustando o valor de qualquer outro temporizador. O valor de cada timer deve ser um número inteiro múltiplo de 20 centissegundos.
Tabela 1 Dependências dos temporizadores Join, Leave e LeaveAll
Para evitar registros e cancelamentos de registros de VLAN frequentes, use os mesmos temporizadores MRP em toda a rede.
Cada porta mantém seus próprios timers Periodic, Join e LeaveAll, e cada atributo de uma porta mantém um timer Leave.
Como prática recomendada, restaure os cronômetros na ordem de Join, Leave e LeaveAll ao restaurar esses cronômetros para seus valores padrão.
Você pode restaurar o timer Periodic ao seu valor padrão a qualquer momento.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2 ou na visualização da interface agregada de camada 2.
interface interface-type interface-numberDefina o cronômetro LeaveAll.
mrp timer leaveall timer-valueA configuração padrão é 1000 centissegundos.
mrp timer join timer-value Valor do timer de ingresso no timer do mrp
A configuração padrão é 20 centissegundos.
Defina o cronômetro de licença.
mrp timer leave timer-valueA configuração padrão é 60 centissegundos.
Defina o cronômetro Periodic.
mrp timer periodic timer-value A configuração padrão é 100 centissegundos.
Ativação da compatibilidade com GVRP
Sobre a compatibilidade com GVRP
Execute esta tarefa para permitir que o dispositivo receba e envie quadros MVRP e GVRP quando o dispositivo par suportar GVRP. Para obter mais informações sobre o GVRP, consulte o padrão IEEE 802.1Q.
Restrições e diretrizes
Quando você ativar a compatibilidade com GVRP, siga estas restrições e diretrizes:
A compatibilidade do GVRP permite que o MVRP funcione com o STP ou o RSTP, mas não com o MSTP.
Quando o sistema estiver ocupado, desative o timer Period para evitar que o participante registre ou cancele o registro de atributos com frequência.
Procedimento
Entre na visualização do sistema.
System ViewHabilitar a compatibilidade com GVRP.
mvrp gvrp-compliance enablePor padrão, a compatibilidade com GVRP está desativada.
Exemplos de configuração de MVRP
Exemplo: Configuração das funções básicas do MVRP
Configuração de rede
Conforme mostrado na Figura 2:
Crie a VLAN 10 no dispositivo A e a VLAN 20 no dispositivo B.
Configure o MSTP, mapeie a VLAN 10 para o MSTI 1, mapeie a VLAN 20 para o MSTI 2 e mapeie as outras VLANs para o MSTI 0.
Configure o MVRP no Dispositivo A, Dispositivo B, Dispositivo C e Dispositivo D para atender aos seguintes requisitos:
Os dispositivos podem registrar e cancelar o registro de VLANs dinâmicas.
Os dispositivos podem manter configurações de VLAN idênticas para cada MSTI.
Figura 2 Diagrama de rede
Procedimento
Configurar o dispositivo A:
# Entre na visualização da região MST.
<DeviceA> system-view
[DeviceA] stp region-configuration# Configure o nome da região MST, os mapeamentos de VLAN para instância e o nível de revisão.
[DeviceA-mst-region] region-name example
[DeviceA-mst-region] instance 1 vlan 10
[DeviceA-mst-region] instance 2 vlan 20
[DeviceA-mst-region] revision-level 0 # Ativar manualmente a configuração da região MST.
[DeviceA-mst-region] active region-configuration
[DeviceA-mst-region] quit # Configure o dispositivo A como a ponte raiz primária do MSTI 1.
[DeviceA] stp instance 1 root primary # Ativa globalmente o recurso de spanning tree.
[DeviceA] stp global enable# Ativar globalmente o MVRP.
[DeviceA] mvrp global enable# Configure a GigabitEthernet 1/0/1 como uma porta tronco e configure-a para permitir todas as VLANs.
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] port link-type trunk
[DeviceA-GigabitEthernet1/0/1] port trunk permit vlan all # Configure a GigabitEthernet 1/0/2 como uma porta tronco e configure-a para permitir a VLAN 40.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 40 # Enable MVRP on GigabitEthernet 1/0/2.
[DeviceA-GigabitEthernet1/0/2] mvrp enable
[DeviceA-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 como uma porta tronco e configure-a para permitir todas as VLANs.
[DeviceA] interface gigabitethernet 1/0/3
[DeviceA-GigabitEthernet1/0/3] port link-type trunk
[DeviceA-GigabitEthernet1/0/3] port trunk permit vlan all# Habilite o MVRP na GigabitEthernet 1/0/3.
[DeviceA-GigabitEthernet1/0/3] mvrp enable
[DeviceA-GigabitEthernet1/0/3] quit# Criar a VLAN 10
[DeviceA] vlan 10
[DeviceA-vlan10] quitConfigurar o dispositivo B:
# Entre na visualização da região MST.
<DeviceB> system-view
[DeviceB] stp region-configuration# Configure o nome da região MST, os mapeamentos de VLAN para instância e o nível de revisão.
[DeviceB-mst-region] region-name example
[DeviceB-mst-region] instance 1 vlan 10
[DeviceB-mst-region] instance 2 vlan 20
[DeviceB-mst-region] revision-level 0# Ativar manualmente a configuração da região MST.
[DeviceB-mst-region] active region-configuration
[DeviceB-mst-region] quit# Configure o dispositivo B como a ponte raiz primária do MSTI 2.
[DeviceB] stp instance 2 root primary# Habilita globalmente o recurso de spanning tree.
[DeviceB] stp global enable # Ativar globalmente o MVRP.
[DeviceB] mvrp global enable # Configure a GigabitEthernet 1/0/1 como uma porta tronco e configure-a para permitir as VLANs 20 e 40.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type trunk
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 20 40# Habilite o MVRP na GigabitEthernet 1/0/1.
[DeviceB-GigabitEthernet1/0/1] mvrp enable
[DeviceB-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco e configure-a para permitir todas as VLANs.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan all# Habilite o MVRP na GigabitEthernet 1/0/2.
[DeviceB-GigabitEthernet1/0/2] mvrp enable
[DeviceB-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 como uma porta tronco e configure-a para permitir todas as VLANs.
[DeviceB] interface gigabitethernet 1/0/3
[DeviceB-GigabitEthernet1/0/3] port link-type trunk
[DeviceB-GigabitEthernet1/0/3] port trunk permit vlan all# Habilite o MVRP na GigabitEthernet 1/0/3.
[DeviceB-GigabitEthernet1/0/3] mvrp enable
[DeviceB-GigabitEthernet1/0/3] quit# Criar VLAN 20.
[DeviceB] vlan 20 [DeviceB-vlan20] quiConfigurar o dispositivo C:
# Entre na visualização da região MST.
<DeviceC> system-view
[DeviceC] stp region-configuration# Configure o nome da região MST, os mapeamentos de VLAN para instância e o nível de revisão.
[DeviceC-mst-region] region-name example
[DeviceC-mst-region] instance 1 vlan 10
[DeviceC-mst-region] instance 2 vlan 20
[DeviceC-mst-region] revision-level 0# Ativar manualmente a configuração da região MST.
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit# Configure o dispositivo C como a ponte raiz do MSTI 0.
[DeviceC] stp instance 0 root primary# Habilita globalmente o recurso de spanning tree.
[DeviceC] stp global enable# Ativar globalmente o MVRP.
[DeviceC] mvrp global enable# Configure a GigabitEthernet 1/0/1 como uma porta tronco e configure-a para permitir todas as VLANs.
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] port link-type trunk
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan all# Configure a GigabitEthernet 1/0/2 como uma porta tronco e configure-a para permitir todas as VLANs.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] port link-type trunk
[DeviceC-GigabitEthernet1/0/2] port trunk permit vlan all# Habilite o MVRP na GigabitEthernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] mvrp enable
[DeviceC-GigabitEthernet1/0/2] quitConfigurar o dispositivo D:
# Entre na visualização da região MST.
><DeviceD> system-view
[DeviceD] stp region-configuration # Configure o nome da região MST, os mapeamentos de VLAN para instância e o nível de revisão.
[DeviceD-mst-region] region-name example
[DeviceD-mst-region] instance 1 vlan 10
[DeviceD-mst-region] instance 2 vlan 20
[DeviceD-mst-region] revision-level 0# Ativar manualmente a configuração da região MST.
[DeviceD-mst-region] active region-configuration
[DeviceD-mst-region] quit# Ativar globalmente o recurso Spanning Tree.
[Ativar globalmente o MVRP. [DeviceD] mvrp global enable# Configure a GigabitEthernet 1/0/1 como uma porta tronco e configure-a para permitir as VLANs 20 e 40.
[DeviceD] interface gigabitethernet 1/0/1
[DeviceD-GigabitEthernet1/0/1] port link-type trunk
[DeviceD-GigabitEthernet1/0/1] port trunk permit vlan 20 40# Habilite o MVRP na GigabitEthernet 1/0/1.
[DeviceD-GigabitEthernet1/0/1] mvrp enable
[DeviceD-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco e configure-a para permitir a VLAN 40.
[DeviceD] interface gigabitethernet 1/0/2
[DeviceD-GigabitEthernet1/0/2] port link-type trunk
[DeviceD-GigabitEthernet1/0/2] port trunk permit vlan 40Verificação da configuração
Verifique a configuração do modo de registro normal. # Exibir informações da VLAN local no Dispositivo A.
[DeviceA] display mvrp running-status
-------[MVRP Global Info]-------
Global Status : Enabled
Compliance-GVRP : False
----[GigabitEthernet1/0/1]----
Config Status : Enabled
Running Status : Enabled
Join Timer : 20 (centiseconds)
Leave Timer : 60 (centiseconds)
Periodic Timer : 100 (centiseconds)
LeaveAll Timer : 100 (centiseconds)
Registration Type : Normal
Registered VLANs :
1(default)
Declared VLANs :
1(default), 10, 20
Propagated VLANs :
1(default)
----[GigabitEthernet1/0/2]----
Config Status : Enabled
Running Status : Enabled
Join Timer : 20 (centiseconds)
Leave Timer : 60 (centiseconds)
Periodic Timer : 100 (centiseconds)
LeaveAll Timer : 1000 (centiseconds)
Registration Type : Normal
Registered VLANs :
None
Declared VLANs :
1(default)
Propagated VLANs :
None
----[GigabitEthernet1/0/3]----
Config Status : Enabled
Running Status : Enabled
Join Timer : 20 (centiseconds)
Leave Timer : 60 (centiseconds)
Periodic Timer : 100 (centiseconds)
LeaveAll Timer : 1000 (centiseconds)
Registration Type : Normal
Registered VLANs :
20
Declared VLANs :
1(default) 10
Propagated VLANs :
20
A saída mostra que os seguintes eventos ocorreram:
A GigabitEthernet 1/0/1 registrou a VLAN 1, declarou a VLAN 1, a VLAN 10 e a VLAN 20, e propagou a VLAN 1 por meio do MVRP.
A GigabitEthernet 1/0/2 declarou a VLAN 1 e não registrou e propagou nenhuma VLAN.
A GigabitEthernet 1/0/3 registrou a VLAN 20, declarou a VLAN 1 e a VLAN 10 e propagou a VLAN 20 por meio do MVRP.
Configuração do QinQ
Sobre a QinQ
Aplicavel somente a Serie S3300G
O Q-in-802.1Q (QinQ) adiciona uma tag 802.1Q ao tráfego de clientes com tags 802.1Q. Ele permite que um provedor de serviços estenda as conexões de camada 2 em uma rede Ethernet entre os sites dos clientes.
Benefícios do QinQ
O QinQ oferece os seguintes benefícios:
Permite que um provedor de serviços use uma única SVLAN para transmitir várias CVLANs para um cliente.
Permite que os clientes planejem CVLANs sem entrar em conflito com SVLANs.
Permite que os clientes mantenham seus esquemas de atribuição de VLAN inalterados quando o provedor de serviços altera seu esquema de atribuição de VLAN.
Permite que clientes diferentes usem CVLAN IDs sobrepostas. Os dispositivos na rede do provedor de serviços tomam decisões de encaminhamento com base em SVLAN IDs em vez de CVLAN IDs.
Como o QinQ funciona
Conforme mostrado na Figura 1, um quadro QinQ transmitido pela rede do provedor de serviços contém as seguintes tags:
Etiqueta CVLAN - Identifica a VLAN à qual o quadro pertence quando é transmitido na rede do cliente.
Etiqueta SVLAN - Identifica a VLAN à qual o quadro QinQ pertence quando é transmitido na rede do provedor de serviços. O provedor de serviços aloca a tag SVLAN para o cliente.
Os dispositivos na rede do provedor de serviços encaminham um quadro com tag de acordo apenas com sua tag SVLAN. A tag CVLAN é transmitida como parte da carga útil do quadro.
Figura 1 Cabeçalho de quadro Ethernet com marcação única e cabeçalho de quadro Ethernet com marcação dupla
Conforme mostrado na Figura 2, o cliente A tem sites remotos CE 1 e CE 4. O cliente B tem sites remotos CE 2 e CE 3. As CVLANs dos dois clientes se sobrepõem. O provedor de serviços atribui SVLANs 3 e 4 aos clientes A e B, respectivamente.
Quando um quadro Ethernet marcado do CE 1 chega ao PE 1, o PE marca o quadro com SVLAN 3. O quadro Ethernet com marcação dupla viaja pela rede do provedor de serviços até chegar ao PE 2. O PE 2 remove a tag SVLAN do quadro e, em seguida, envia o quadro para o CE 4.
Figura 2 Cenário típico de aplicação do QinQ
Implementações de QinQ
O QinQ é ativado por porta. O tipo de link de uma porta habilitada para QinQ pode ser de acesso, híbrido ou tronco. Os comportamentos de marcação de QinQ são os mesmos entre esses tipos de portas.
Uma porta habilitada para QinQ marca todos os quadros de entrada (marcados ou não marcados) com a tag PVID.
Se um quadro de entrada já tiver uma tag, ele se tornará um quadro com tag dupla.
Se o quadro não tiver nenhuma tag 802.1Q, ele se tornará um quadro marcado com o PVID.
O QinQ fornece o método mais básico de manipulação de VLAN para marcar todos os quadros de entrada (marcados ou não marcados) com a marca PVID. Para realizar manipulações avançadas de VLAN, use mapeamentos de VLAN ou políticas de QoS da seguinte forma:
Para adicionar SVLANs diferentes para tags de CVLAN diferentes, use mapeamentos de VLAN um para dois.
Para usar critérios diferentes do CVLAN ID para combinar pacotes para marcação de SVLAN, use a ação de aninhamento de QoS. A ação de aninhamento de QoS também pode ser usada com outras ações no mesmo comportamento de tráfego.
Para obter mais informações sobre mapeamentos de VLAN, consulte "Configuração do mapeamento de VLAN". Para obter mais informações sobre QoS no site , consulte o Guia de configuração de ACL e QoS.
Restrições e diretrizes: Configuração do QinQ
Quando você configurar o QinQ, siga estas restrições e diretrizes:
A etiqueta 802.1Q interna dos quadros QinQ é tratada como parte da carga útil. Como prática recomendada para garantir a transmissão correta de quadros QinQ, defina o MTU para um mínimo de 1504 bytes para cada porta em seu caminho de encaminhamento. Esse valor é a soma do MTU padrão da interface Ethernet (1500 bytes) com o comprimento (4 bytes) de uma tag de VLAN.
É possível usar um mapeamento de VLAN e QinQ em uma porta para manipulação de tags de VLAN. Se suas configurações entrarem em conflito, o mapeamento de VLAN terá prioridade mais alta.
Não ative o QinQ e aplique uma política de QoS que contenha uma ação de aninhamento na mesma interface. Caso contrário, o QinQ ou a política de QoS poderá não entrar em vigor.
Ativação do QinQ
Sobre a habilitação do QinQ
Habilite o QinQ nas portas do lado do cliente dos PEs. Uma porta habilitada para QinQ marca um quadro de entrada com seu PVID.
Restrições e diretrizes
Antes de ativar ou desativar o QinQ em uma porta, você deve remover qualquer mapeamento de VLAN na porta. Para obter mais informações sobre mapeamento de VLAN, consulte o Layer 2-LAN Switching Configuration Guide.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2 ou na visualização da interface agregada de camada 2.
interface interface-type interface-numberDefinir o tipo de link da porta.
port link-type { access | hybrid | trunk }Por padrão, o tipo de link de uma porta é acesso.
Configure a porta para permitir a passagem de pacotes de seu PVID.
Atribuir a porta de acesso à VLAN especificada.
port access vlan vlan-id Por padrão, todas as portas de acesso pertencem à VLAN 1.
O PVID de uma porta de acesso é a VLAN à qual a porta pertence. A porta envia pacotes da VLAN sem marcação.
Configure a porta híbrida para enviar pacotes de seu PVID sem marcação.
port hybrid vlan vlan-id-list untaggedPor padrão, a porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é de acesso.
Configure a porta tronco para permitir a passagem de pacotes de seu PVID.
port trunk permit vlan { vlan-id-list | all }Por padrão, uma porta tronco permite a passagem de pacotes apenas da VLAN 1.
Habilite o QinQ na porta.
qinq enablePor padrão, o QinQ está desativado na porta.
Configuração da transmissão para VLANs transparentes
Sobre a VLAN transparente
É possível excluir uma VLAN (por exemplo, a VLAN de gerenciamento) da ação de marcação QinQ em uma porta do lado do cliente. Essa VLAN é chamada de VLAN transparente.
Restrições e diretrizes
Não configure nenhuma outra ação de manipulação de VLAN para a VLAN transparente na porta.
Certifique-se de que todas as portas no caminho do tráfego permitam a passagem da VLAN transparente.
Se você usar VLANs transparentes e mapeamentos de VLAN em uma interface, as VLANs transparentes não poderão ser as seguintes VLANs:
VLANs originais ou traduzidas de mapeamentos de VLANs um-para-um, um-para-dois e muitos-para-um.
VLANs externas originais ou traduzidas de mapeamentos de VLAN de duas para duas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2 ou na visualização da interface agregada de camada 2.
interface interface-type interface-numberDefinir o tipo de link da porta.
port link-type { hybrid | trunk }Por padrão, o tipo de link de uma porta é acesso.
Configure a porta para permitir a passagem de pacotes das VLANs transparentes.
Configure a porta híbrida para permitir a passagem de pacotes das VLANs transparentes.
port hybrid vlan vlan-id-list { tagged | untagged }Por padrão, uma porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é de acesso.
Configure a porta tronco para permitir a passagem de pacotes das VLANs transparentes.
port trunk permit vlan { vlan-id-list | all }Por padrão, uma porta tronco permite a passagem de pacotes apenas da VLAN 1.
Especificar VLANs transparentes para a porta.
qinq transparent-vlan vlan-id-listPor padrão, a transmissão transparente não é configurada para nenhuma VLAN.
Configuração do TPID para tags de VLAN
Sobre a TPID
O TPID identifica um quadro como um quadro marcado com 802.1Q. O valor do TPID varia de acordo com o fornecedor. Em um dispositivo INTELBRAS, o TPID na etiqueta 802.1Q adicionada em uma porta habilitada para QinQ é 0x8100 por padrão, em
conformidade com o IEEE 802.1Q. Em uma rede de vários fornecedores, certifique-se de que a configuração TPID seja a mesma entre os dispositivos conectados diretamente para que os quadros marcados com 802.1Q possam ser identificados corretamente.
As configurações de TPID incluem CVLAN TPID e SVLAN TPID.
Uma porta habilitada para QinQ usa o TPID da CVLAN para corresponder aos quadros marcados que chegam. Um quadro de entrada é tratado como não marcado se seu TPID for diferente do TPID da CVLAN.
Os SVLAN TPIDs são configuráveis por porta. Uma porta do lado do provedor de serviços usa o SVLAN TPID para substituir o TPID nas etiquetas SVLAN dos quadros de saída e corresponder aos quadros etiquetados de entrada. Um quadro de entrada é tratado como não marcado se o TPID em sua etiqueta de VLAN externa for diferente do SVLAN TPID.
Por exemplo, um dispositivo PE está conectado a um dispositivo de cliente que usa o TPID 0x8200 e a um dispositivo de provedor que usa o TPID 0x9100. Para o processamento correto dos pacotes, você deve definir o CVLAN TPID e o SVLAN TPID como 0x8200 e 0x9100 no PE, respectivamente.
O campo TPID está na mesma posição que o campo EtherType em um quadro Ethernet não marcado. Para garantir a identificação correta do tipo de pacote, não defina o valor TPID como nenhum dos valores listados na Tabela 1.
Tabela 1 Valores reservados do EtherType
Restrições e diretrizes
O valor TPID nas tags CVLAN é normalmente configurado nos PEs. O valor TPID nas tags SVLAN é normalmente configurado nas portas do lado do provedor de serviços dos PEs.
Configuração do TPID para tags CVLAN
Entre na visualização do sistema.
System ViewDefina o TPID para tags CVLAN.
qinq ethernet-type customer-tag hex-valuePor padrão, o TPID é 0x8100 para tags CVLAN.
Configuração do TPID para tags SVLAN
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet da Camada 2 ou na visualização da interface agregada da Camada 2.
interface interface-type interface-numberDefina o TPID para tags SVLAN.
qinq ethernet-type service-tag hex-valuePor padrão, o TPID é 0x8100 para tags SVLAN.
Exemplos de configuração do QinQ
Configuração de rede
Conforme mostrado na Figura 3:
O provedor de serviços atribui a VLAN 100 às VLANs 10 a 70 da Empresa A.
O provedor de serviços atribui a VLAN 200 às VLANs 30 a 90 da Empresa B.
Os dispositivos entre o PE 1 e o PE 2 na rede do provedor de serviços usam um valor TPID de 0x8200.
Configure o QinQ no PE 1 e no PE 2 para transmitir o tráfego nas VLANs 100 e 200 para a Empresa A e a Empresa B, respectivamente.
Para que os quadros QinQ sejam identificados corretamente, defina o SVLAN TPID como 0x8200 nas portas do lado do provedor de serviços do PE 1 e do PE 2.
Figura 3 Diagrama de rede
Procedimento
Configurar o PE 1:
# Configure a GigabitEthernet 1/0/1 como uma porta tronco e atribua-a à VLAN 100.
<PE1> system-view
[PE1] interface gigabitethernet 1/0/1
[PE1-GigabitEthernet1/0/1] port link-type trunk
[PE1-GigabitEthernet1/0/1] port trunk permit vlan 100# Defina o PVID da GigabitEthernet 1/0/1 como VLAN 100.
[PE1-GigabitEthernet1/0/1] porta tronco pvid vlan 100# Habilite o QinQ na GigabitEthernet 1/0/1.
[PE1-GigabitEthernet1/0/1] qinq enable
[PE1-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco e atribua-a às VLANs 100 e 200.
[PE1] interface gigabitethernet 1/0/2
[PE1-GigabitEthernet1/0/2] port link-type trunk
[PE1-GigabitEthernet1/0/2] port trunk permit vlan 100 200# Defina o valor TPID nas tags SVLAN como 0x8200 na GigabitEthernet 1/0/2.
[PE1-GigabitEthernet1/0/2] qinq ethernet-type service-tag 8200
[PE1-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 como uma porta tronco e atribua-a à VLAN 200.
system-view
[PE2] interface gigabitethernet 1/0/1
[PE2-GigabitEthernet1/0/1] port link-type trunk
[PE2-GigabitEthernet1/0/1] port trunk permit vlan 200 # Defina o PVID da GigabitEthernet 1/0/3 como VLAN 200.
[PE2-GigabitEthernet1/0/1] port trunk pvid vlan 200 # Habilite o QinQ na GigabitEthernet 1/0/3.
[PE2-GigabitEthernet1/0/1] qinq enable
[PE2-GigabitEthernet1/0/1] quitConfigurar o PE 2:
# Configure a GigabitEthernet 1/0/1 como uma porta tronco e atribua-a à VLAN 200.
[PE2] interface gigabitethernet 1/0/2
[PE2-GigabitEthernet1/0/2] port link-type trunk
[PE2-GigabitEthernet1/0/2] port trunk permit vlan 100 200# Defina o PVID da GigabitEthernet 1/0/1 como VLAN 200.
[PE2-GigabitEthernet1/0/1] porta tronco pvid vlan 200# Habilite o QinQ na GigabitEthernet 1/0/1.
[PE2-GigabitEthernet1/0/1] qinq
enable [PE2-GigabitEthernet1/0/1] quit# Configure a GigabitEthernet 1/0/2 como uma porta tronco e atribua-a às VLANs 100 e 200.
[PE2] interface gigabitethernet 1/0/3
[PE2-GigabitEthernet1/0/3] port link-type trunk
[PE2-GigabitEthernet1/0/3] port trunk permit vlan 100# Defina o valor TPID nas tags SVLAN como 0x8200 na GigabitEthernet 1/0/2.
[PE2-GigabitEthernet1/0/2] qinq ethernet-type service-tag 8200
[PE2-GigabitEthernet1/0/2] quit# Configure a GigabitEthernet 1/0/3 como uma porta tronco e atribua-a à VLAN 100.
[PE2] interface gigabitethernet 1/0/3
[PE2-GigabitEthernet1/0/3] port link-type trunk
[PE2-GigabitEthernet1/0/3] port trunk permit vlan 100# Defina o PVID da GigabitEthernet 1/0/3 como VLAN 100.
[PE2-GigabitEthernet1/0/3] port trunk pvid vlan 100# Habilite o QinQ na GigabitEthernet 1/0/3.
[PE2-GigabitEthernet1/0/3] qinq enable
[PE2-GigabitEthernet1/0/3] quitConfigure os dispositivos entre o PE 1 e o PE 2:
# Defina o MTU para um mínimo de 1504 bytes para cada porta no caminho dos quadros QinQ. (Detalhes não mostrados.)
# Configure todas as portas no caminho de encaminhamento para permitir que os quadros das VLANs 100 e 200 passem sem remover a tag da VLAN. (Detalhes não mostrados.)
Exemplo: Configuração da Transmissão Transparente de VLAN
Configuração de Rede
Conforme mostrado na Figura 4:
- O provedor de serviços atribui a VLAN 100 às VLANs 10 a 50 de uma empresa.
- A VLAN 3000 é a VLAN dedicada da empresa na rede do provedor de serviços.
- Configure o QinQ no PE 1 e no PE 2 para fornecer conectividade de camada 2 para as CVLANs 10 a 50 na rede do provedor de serviços.
- Configure a transmissão transparente de VLAN para a VLAN 3000 no PE 1 e no PE 2 para permitir que os hosts na VLAN 3000 se comuniquem sem usar uma SVLAN.
Figura 4: Diagrama de Rede
Procedimento
Configurar o PE 1:
<PE1> system-view
[PE1] interface gigabitethernet 1/0/1
[PE1-GigabitEthernet1/0/1] port link-type trunk
[PE1-GigabitEthernet1/0/1] port trunk permit vlan 100 3000
[PE1-GigabitEthernet1/0/1] port trunk pvid vlan 100
[PE1-GigabitEthernet1/0/1] qinq enable
[PE1-GigabitEthernet1/0/1] qinq transparent-vlan 3000
[PE1-GigabitEthernet1/0/1] quit
Configurar o PE 2:
<PE2> system-view
[PE2] interface gigabitethernet 1/0/1
[PE2-GigabitEthernet1/0/1] port link-type trunk
[PE2-GigabitEthernet1/0/1] port trunk permit vlan 100 3000
[PE2-GigabitEthernet1/0/1] port trunk pvid vlan 100
[PE2-GigabitEthernet1/0/1] qinq enable
[PE2-GigabitEthernet1/0/1] qinq transparent-vlan 3000
[PE2-GigabitEthernet1/0/1] quit
- Defina o MTU para um mínimo de 1504 bytes para cada porta no caminho dos quadros QinQ. (Detalhes não mostrados.)
- Configure todas as portas no caminho de encaminhamento para permitir a passagem de quadros das VLANs 100 e 3000 sem remover a tag da VLAN. (Detalhes não mostrados.)
Configuração do mapeamento de VLAN
Sobre o mapeamento de VLAN
O mapeamento de VLAN remarca o tráfego de VLAN com novas VLAN IDs.
Tipos de mapeamento de VLAN
A INTELBRAS oferece os seguintes tipos de mapeamento de VLAN:
Mapeamento de VLAN um para um - Substitui uma tag de VLAN por outra.
Mapeamento de VLAN de muitos para um - Substitui várias tags de VLAN pela mesma tag de VLAN.
Mapeamento de uma para duas VLANs - Marca pacotes com uma única tag com uma tag de VLAN externa.
Cenários de aplicativos de mapeamento de VLAN
Mapeamento de VLAN um para um e muitos para um
O mapeamento de VLANs um para um e muitos para um é normalmente usado por uma comunidade para acesso à Internet de banda larga, conforme mostrado na Figura 1.
Figura 1 Cenário de aplicação do mapeamento de VLANs um-para-um e muitos-para-um
Conforme mostrado na Figura 1, a rede é implementada da seguinte forma:
Cada gateway doméstico usa VLANs diferentes para transmitir os serviços de PC, VoD e VoIP.
Para subclassificar ainda mais cada tipo de tráfego por cliente, configure o mapeamento de VLAN um para um nos switches do conjunto de fiação. Esse recurso atribui uma VLAN separada a cada tipo de tráfego de cada cliente. O número total necessário de VLANs na rede pode ser muito grande.
Para evitar que o número máximo de VLANs seja excedido no dispositivo da camada de distribuição, configure o mapeamento de VLANs muitas para uma no switch do campus. Esse recurso atribui a mesma VLAN ao mesmo tipo de tráfego de clientes diferentes.
Mapeamento de VLAN um para dois
Conforme mostrado na Figura 2, o mapeamento de uma para duas VLANs é usado para transmitir diferentes tipos de pacotes CVLAN com diferentes tags SVLAN pela rede do provedor de serviços.
Figura 2 Cenário de aplicação do mapeamento de uma para duas VLANs
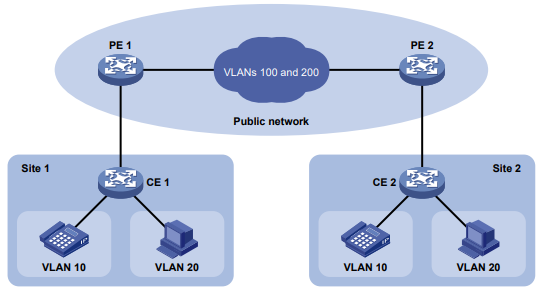
Conforme mostrado na Figura 2, os usuários do Site 1 e do Site 2 estão na VLAN 10 e na VLAN 20. O provedor de serviços atribui a VLAN 100 e a VLAN 200 à rede do cliente. Quando os pacotes do Site 1 chegam ao PE 1, o PE 1 adiciona uma tag SVLAN aos pacotes com base no tipo de pacote.
O mapeamento de uma para duas VLANs permite que o cliente planeje CVLANs sem entrar em conflito com SVLANs. O provedor de serviços pode distinguir o tráfego da rede do cliente com diferentes SVLANs e aplicar políticas de transmissão ao tráfego do cliente.
Implementações de mapeamento de VLAN
A Figura 3 mostra uma rede simplificada que ilustra os termos básicos de mapeamento de VLAN. Os termos básicos de mapeamento de VLAN incluem o seguinte:
Tráfego de uplink - Tráfego transmitido da rede do cliente para a rede do provedor de serviços.
Tráfego de downlink - Tráfego transmitido da rede do provedor de serviços para a rede do cliente.
Porta do lado da rede - Uma porta conectada à rede do provedor de serviços ou mais próxima a ela.
Porta do lado do cliente - Uma porta conectada à rede do cliente ou mais próxima a ela.
Figura 3 Termos básicos de mapeamento de VLAN
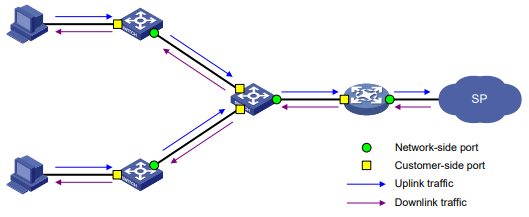
Mapeamento de VLAN um a um
Conforme mostrado na Figura 4, o mapeamento de VLAN um para um é implementado na porta do lado do cliente e substitui as tags de VLAN da seguinte forma:
Substitui a CVLAN pela SVLAN para o tráfego de uplink.
Substitui a SVLAN pela CVLAN para o tráfego de downlink.
Figura 4 Implementação de mapeamento de VLAN um para um
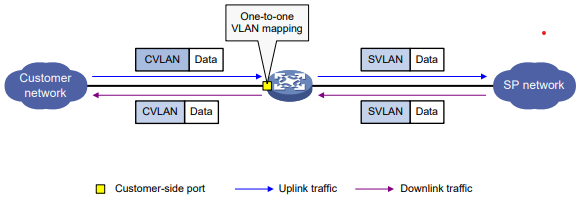
Porta do lado do cliente Tráfego de uplink Tráfego de downlink
Mapeamento de VLANs muitos para um
Conforme mostrado na Figura 5, o mapeamento de VLANs muitos-para-um é implementado nas portas do lado do cliente e do lado da rede, como segue:
Para o tráfego de uplink, o mapeamento de VLANs muitas para uma no lado do cliente substitui várias CVLANs pela mesma SVLAN.
Para o tráfego de downlink, o dispositivo executa as seguintes operações:
Procura na tabela de endereços MAC uma entrada que corresponda ao endereço MAC de destino dos pacotes de downlink.
Substitui a tag SVLAN por uma tag CVLAN com base na entrada de mapeamento correspondente de muitos para um.
Para obter mais informações sobre a tabela de endereços MAC, consulte "Configuração da tabela de endereços MAC".
Figura 5 Implementação do mapeamento de VLANs muitos-para-um
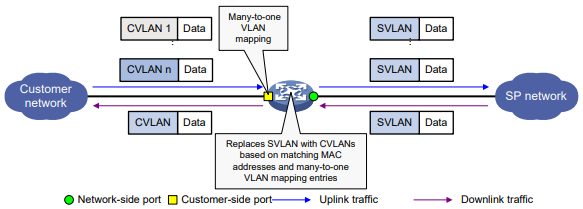
Mapeamento de VLAN um para dois
Conforme mostrado na Figura 6, o mapeamento de uma para duas VLANs é implementado na porta do lado do cliente para adicionar a tag SVLAN ao tráfego de uplink.
Para que o tráfego de downlink seja enviado corretamente para a rede do cliente, certifique-se de que a tag SVLAN seja removida na porta do lado do cliente antes da transmissão. Use um dos métodos a seguir para remover a tag SVLAN do tráfego de downlink:
Configure a porta do lado do cliente como uma porta híbrida e atribua a porta à SVLAN como um membro sem marcação.
Configure a porta do lado do cliente como uma porta tronco e defina o PVID da porta como SVLAN.
Figura 6 Implementação de mapeamento de VLAN um para dois
Restrições e diretrizes: Configuração de mapeamento de VLAN
Para adicionar tags de VLAN aos pacotes, você pode configurar o mapeamento de VLAN e o QinQ. O mapeamento de VLAN entra em vigor se ocorrer um conflito de configuração. Para obter mais informações sobre QinQ, consulte "Configuração de QinQ".
Para adicionar ou substituir tags de VLAN para pacotes, você pode configurar o mapeamento de VLAN e uma política de QoS. O mapeamento de VLAN entra em vigor se ocorrer um conflito de configuração. Para obter informações sobre políticas de QoS, consulte ACL and QoS Configuration Guide.
Configuração do Mapeamento de VLAN um para um
Sobre o Mapeamento de VLAN um para um
Configure o mapeamento de VLANs um a um nas portas do lado do cliente dos switches do gabinete de fiação (consulte Figura 1) para isolar o tráfego do mesmo tipo de serviço de residências diferentes.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefinir o tipo de link da porta.
port link-type { hybrid | trunk } Por padrão, o tipo de link de uma porta é acesso.
Atribua a porta à VLAN original e à VLAN traduzida.
Atribua a porta tronco à VLAN original e à VLAN traduzida.
port trunk permit vlan vlan-id-listPor padrão, uma porta tronco é atribuída à VLAN 1.
Atribua a porta híbrida à VLAN original e a VLAN traduzida como um membro marcado.
port hybrid vlan vlan-id-list taggedPor padrão, uma porta híbrida é um membro sem marcação da VLAN à qual a porta pertence quando seu tipo de link é de acesso.
Configure um mapeamento de VLAN um para um.
vlan mapping vlan-id translated-vlan vlan-idPor padrão, nenhum mapeamento de VLAN é configurado em uma interface.
Configuração do Mapeamento de VLANs Muitos para Um
Sobre o Mapeamento de VLANs Muitos para Um
Para conservar os recursos de VLAN, configure o mapeamento de VLANs muitos-para-um nos switches do campus (consulte a Figura 1) para transmitir o mesmo tipo de tráfego de diferentes usuários em uma VLAN.
Compatibilidade de Recursos e Versões de Software
Esse recurso é compatível apenas com as versões R6350 e superiores.
Restrições e Diretrizes para o Mapeamento de VLANs Muitos-para-Um
Para garantir o encaminhamento correto do tráfego da rede do provedor de serviços para a rede do cliente, não configure mapeamentos de VLAN muitos para um junto com os seguintes recursos:
- Desativar o aprendizado de endereço MAC.
- Configuração do limite de aprendizagem de MAC.
Para obter mais informações sobre o aprendizado de endereços MAC, consulte "Configuração da Tabela de Endereços MAC".
Para estabelecer a conectividade de rede com êxito em um ambiente de mapeamento de VLANs muitos-para-um, certifique-se de que as solicitações ARP sejam enviadas do lado do cliente para acionar a conexão com o lado da rede.
Visão Geral das Tarefas de Mapeamento de VLANs Muitas para Uma
Configuração da Porta do Lado do Cliente
Configuração da Porta do Lado da Rede
Configuração da Porta do Lado do Cliente
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefina o tipo de link da porta como híbrido ou tronco.
port link-type { hybrid | trunk } Por padrão, o tipo de link de uma porta é acesso.
Atribua a porta às VLANs originais.
Atribua a porta tronco às VLANs originais.
port trunk permit vlan vlan-id-list
Atribua a porta híbrida às VLANs originais como um membro marcado.
port hybrid vlan vlan-id-list tagged
Configure um mapeamento de VLAN muitos-para-um.
vlan mapping uni { range vlan-range-list | single vlan-id-list } translated-vlan vlan-id
Configuração da Porta do Lado da Rede
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da Camada 2.
interface bridge-aggregation interface-numberDefina o tipo de link da porta como híbrido ou tronco.
port link-type { hybrid | trunk } Por padrão, o tipo de link de uma porta é acesso.
Atribua a porta à VLAN traduzida.
port trunk permit vlan vlan-id-list
Atribua a porta híbrida à VLAN traduzida como um membro marcado.
port hybrid vlan vlan-id-list tagged
Configuração do mapeamento de VLAN um para dois
Sobre o mapeamento de VLAN um para dois
Configure o mapeamento de VLAN um para dois nas portas do lado do cliente dos dispositivos de borda a partir dos quais o tráfego do cliente entra nas redes SP, por exemplo, nos PEs 1 e 4 da Figura 2. O mapeamento de VLAN de uma para duas permite que os dispositivos de borda adicionem uma tag SVLAN a cada pacote recebido.
Restrições e diretrizes
Somente uma tag SVLAN pode ser adicionada a pacotes da mesma CVLAN. Para adicionar diferentes tags de SVLAN a diferentes pacotes de CVLAN em uma porta, defina o tipo de link da porta como híbrido e configure vários mapeamentos de VLAN de um para dois.
O MTU de uma interface é de 1500 bytes por padrão. Depois que uma tag de VLAN é adicionada a um pacote, o comprimento do pacote é acrescido de 4 bytes. Como prática recomendada, defina o MTU para um mínimo de 1504 bytes para as portas no caminho de encaminhamento do pacote na rede do provedor de serviços.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
Entre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-numberDefinir o tipo de link da porta.
port link-type { hybrid | trunk }Por padrão, o tipo de link de uma porta é acesso.
Configure a porta para permitir que os pacotes da SVLAN passem sem marcação.
Configure a SVLAN como o PVID da porta tronco e atribua a porta tronco à SVLAN.
porta tronco pvid vlan vlan-idport trunk permit vlan { vlan-id-list | all }Atribuir a porta híbrida à SVLAN como um membro sem marcação.
port hybrid vlan vlan-id-list untaggedConfigure um mapeamento de VLAN de uma para duas.
vlan mapping nest { range vlan-range-list | single vlan-id-list }nested-vlan vlan-idPor padrão, nenhum mapeamento de VLAN é configurado em uma interface.
Exemplos de configuração de mapeamento VLAN
Exemplo: Configuração do Mapeamento de VLANs um para um
Procedimento
Configure o Switch A:
# Criar as VLANs originais.
<SwitchA> system-view
[SwitchA] vlan 2 a 3# Crie as VLANs traduzidas.
# Configure a porta GigabitEthernet 1/0/1 do lado do cliente como uma porta tronco.
<SwitchA> system-view
[Interface gigabitethernet 1/0/1
[SwitchA-GigabitEthernet1/0/1] port link-type trunk
[SwitchA-GigabitEthernet1/0/1] port trunk permit vlan 1 2 3 101 201 301
[SwitchA-GigabitEthernet1/0/1] vlan mapping 1 translated-vlan 101
[SwitchA-GigabitEthernet1/0/1] vlan mapping 2 translated-vlan 201
[SwitchA-GigabitEthernet1/0/1] vlan mapping 3 translated-vlan 301
[SwitchA-GigabitEthernet1/0/1] quit# Configure a porta GigabitEthernet 1/0/2 do lado do cliente como uma porta tronco.
[Interface gigabitethernet 1/0/2
[SwitchA-GigabitEthernet1/0/2] port link-type trunk
[SwitchA-GigabitEthernet1/0/2] port trunk permit vlan 1 2 3 102 202 302
[SwitchA-GigabitEthernet1/0/2] vlan mapping 1 translated-vlan 102
[SwitchA-GigabitEthernet1/0/2] vlan mapping 2 translated-vlan 202
[SwitchA-GigabitEthernet1/0/2] vlan mapping 3 translated-vlan 302
[SwitchA-GigabitEthernet1/0/2] quit# Configure a porta do lado da rede (GigabitEthernet 1/0/3) como uma porta tronco.
[SwitchA] interface gigabitethernet 1/0/3
[SwitchA-GigabitEthernet1/0/3] port link-type trunk
[SwitchA-GigabitEthernet1/0/3] port trunk permit vlan 101 201 301 102 202 302
[SwitchA-GigabitEthernet1/0/3] quitConfigure o Switch B da mesma forma que o Switch A está configurado. (Os detalhes não são mostrados).
Verificação da Configuração
# Verifique as informações de mapeamento de VLAN nos switches do conjunto de fiação, por exemplo, Switch A.
[SwitchA] display vlan mapping
Interface GigabitEthernet1/0/1:
Interface GigabitEthernet1/0/2:Exemplo: Configuração do Mapeamento de VLANs Muitos para Um
Configuração de Rede
Conforme mostrado na Figura 8:
- Crie a VLAN 2, a VLAN 3 e a VLAN 4 nos switches do gabinete de fiação para isolar o tráfego do mesmo tipo de serviço de diferentes residências.
- Configure mapeamentos de VLAN muitos para um no switch do campus para atribuir uma VLAN para transportar todos os tipos de tráfego de diferentes residências. Neste exemplo, mapeie as VLANs 2 a 4 para a VLAN 10.
Figura 8: Diagrama de Rede
Procedimento
Configure o Switch A:
- Criar VLAN 2.
<SwitchA> system-view
[SwitchA] vlan 2
[SwitchA-vlan2] quit- Atribua as portas GigabitEthernet 1/0/1 e GigabitEthernet 1/0/2 à VLAN 2.
[SwitchA] interface range gigabitethernet 1/0/1 to gigabitethernet 1/0/2
[SwitchA-if-range] port access vlan 2
[SwitchA-if-range] quitConfigure o Switch B e o Switch C da mesma forma que o Switch A está configurado. (Os detalhes não são mostrados).
Configurar o Switch D:
- Crie as VLANs 2, 3 e 4.
- Atribuir as portas GigabitEthernet 1/0/1 à VLAN 2, GigabitEthernet 1/0/2 à VLAN 3 e GigabitEthernet 1/0/3 para a VLAN 4.
- Configure a porta GigabitEthernet 1/0/4 como uma porta tronco e atribua-a às VLANs 2 a 4.
Configurar o Switch E:
- Crie as VLANs 2, 3 e 4 (as VLANs originais no mapeamento de VLAN a ser criado).
- Configure a porta do lado do cliente (GigabitEthernet 1/0/1) como uma porta tronco e atribua-a às VLANs originais.
- Configure o mapeamento de VLANs muitos para um na GigabitEthernet 1/0/1, que substitui a tag de VLAN 2 até a tag de VLAN 4 pela tag de VLAN 10.
<SwitchE> system-view
[SwitchE] interface gigabitethernet 1/0/1
[SwitchE-GigabitEthernet1/0/1] port link-type trunk
[SwitchE-GigabitEthernet1/0/1] port trunk permit vlan 2 to 4
[SwitchE-GigabitEthernet1/0/1] vlan mapping uni range 2 to 4 translated-vlan 10
[SwitchE-GigabitEthernet1/0/1] quitVerificação da Configuração
# Verificar as informações de mapeamento de VLAN no Switch E.
[SwitchE] display vlan mapping
Interface GigabitEthernet1/0/1:Exemplo: Configuração do Mapeamento de Uma para Duas VLANs
Configuração de Rede
Conforme mostrado na Figura 9, o Site 1 e o Site 2 de uma empresa usam a VLAN 10 e a VLAN 20 para transmitir o tráfego de VoIP e de PC, respectivamente. O provedor de serviços atribui a VLAN 100 e a VLAN 200 à rede do cliente.
Configure mapeamentos de VLAN um para dois para permitir que a rede do provedor de serviços transmita tráfego de VoIP e PC com SVLAN 100 e SVLAN 200, respectivamente.
Figura 9: Diagrama de Rede
Procedimento
Configurar o PE 1:
- Crie as VLANs 10, 20, 100 e 200.
<PE1> system-view
[PE1] vlan 10
[PE1-vlan10] quit
[PE1] vlan 20
[PE1-vlan20] quit
[PE1] vlan 100
[PE1-vlan100] quit
[PE1] vlan 200
[PE1-vlan200] quit- Configure um mapeamento de VLAN de um para dois na porta do lado do cliente (GigabitEthernet 1/0/1) para adicionar a tag SVLAN 100 aos pacotes da CVLAN 10.
[PE1] interface gigabitethernet 1/0/1
[PE1-GigabitEthernet1/0/1] vlan mapping nest single 10 nested-vlan 100- Configure um mapeamento de VLAN de um para dois na GigabitEthernet 1/0/1 para adicionar a tag SVLAN 200 aos pacotes da CVLAN 20.
[PE1-GigabitEthernet1/0/1] vlan mapping nest single 20 nested-vlan 200- Configure a GigabitEthernet 1/0/1 como uma porta híbrida e atribua-a às VLANs 100 e 200 como um membro untagged.
[PE1-GigabitEthernet1/0/1] port link-type hybrid
[PE1-GigabitEthernet1/0/1] port hybrid vlan 100 200 untagged
[PE1-GigabitEthernet1/0/1] quit- Configure a porta do lado da rede (GigabitEthernet 1/0/2) como uma porta tronco e atribua a porta às VLANs 100 e 200.
[PE1] interface gigabitethernet 1/0/2
[PE1-GigabitEthernet1/0/2] port link-type trunk
[PE1-GigabitEthernet1/0/2] port trunk permit vlan 100 200
[PE1-GigabitEthernet1/0/2] quitConfigure o PE 2 da mesma forma que o PE 1 está configurado. (Detalhes não mostrados).
Verificação da Configuração
# Verificar as informações de mapeamento de VLAN no PE 1.
[PE1] display vlan mapping Interface GigabitEthernet1/0/1:# Verificar as informações de mapeamento de VLAN no PE 2.
[PE2] display vlan mapping Interface GigabitEthernet1/0/2:Configuração do LLDP
Sobre o LLDP
O Link Layer Discovery Protocol (LLDP) é um protocolo de camada de link padrão que permite que dispositivos de rede de diferentes fornecedores descubram vizinhos e troquem informações de sistema e configuração.
Em uma rede habilitada para LLDP, um dispositivo anuncia informações sobre o dispositivo local em unidades de dados LLDP (LLDPDUs) para os dispositivos diretamente conectados. As informações distribuídas por meio do LLDP são armazenadas por seus destinatários em MIBs padrão, possibilitando que as informações sejam acessadas por um sistema de gerenciamento de rede (NMS) por meio de SNMP.
As informações que podem ser distribuídas por meio do LLDP incluem (mas não se limitam a):
Principais recursos do sistema.
Endereço IP de gerenciamento do sistema.
ID do dispositivo.
ID da porta.
Agentes LLDP e modos de ponte
Um agente LLDP é um mapeamento de uma entidade de protocolo que implementa o LLDP. Vários agentes LLDP podem ser executados na mesma interface.
Os agentes LLDP são classificados nos seguintes tipos:
Agente de ponte mais próximo.
Agente de ponte do cliente mais próximo.
Agente de ponte não-TPMR mais próximo.
Um MAC Relay de duas portas (TPMR) é um tipo de ponte que tem apenas duas portas de ponte acessíveis externamente. Ele é compatível com um subconjunto dos recursos de uma ponte MAC. Um TPMR é transparente para todos os protocolos independentes de mídia baseados em quadros, exceto para os seguintes protocolos:
Protocolos destinados ao TPMR.
Protocolos destinados a endereços MAC reservados que o recurso de retransmissão do TPMR está configurado para não encaminhar.
O LLDP troca pacotes entre agentes vizinhos e cria e mantém informações de vizinhança para eles. A Figura 1 mostra as relações de vizinhança para esses agentes LLDP.
Figura 1 Relações de vizinhança LLDP
Os tipos de agentes LLDP suportados variam de acordo com o modo de ponte em que o LLDP opera. O LLDP suporta os seguintes modos de ponte: ponte de cliente (CB) e ponte de serviço (SB).
Modo de ponte do cliente - O LLDP suporta o agente de ponte mais próximo, o agente de ponte não TPMR mais próximo e o agente de ponte do cliente mais próximo. O LLDP processa os quadros LLDP com endereços MAC de destino para esses agentes e transmite de forma transparente os quadros LLDP com outros endereços MAC de destino em VLANs.
Modo de ponte de serviço - O LLDP suporta o agente de ponte mais próximo e o agente de ponte não-TPMR mais próximo. O LLDP processa os quadros LLDP com endereços MAC de destino para esses agentes e o transmite de forma transparente os quadros LLDP com outros endereços MAC de destino em VLANs.
Formatos de quadros LLDP
O LLDP envia informações do dispositivo em quadros LLDP. Os quadros LLDP são encapsulados no formato Ethernet II ou SNAP (Subnetwork Access Protocol).
Quadro LLDP encapsulado em Ethernet II
Figura 2 Quadro LLDP encapsulado em Ethernet II
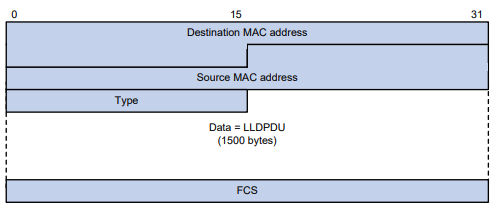
LLDPDUs
Cada quadro LLDP contém uma LLDPDU. Cada LLDPDU é uma sequência de estruturas do tipo valor-comprimento-valor (TLV) .
Figura 4 Formato de encapsulamento da LLDPDU

TLVs
Conforme mostrado na Figura 4, cada LLDPDU começa com os seguintes TLVs obrigatórios: TLV de ID do chassi, TLV de ID da porta e TLV de tempo de vida. As TLVs obrigatórias são seguidas por um máximo de 29 TLVs opcionais.
Um TLV é um elemento de informação que contém os campos de tipo, comprimento e valor. As TLVs da LLDPDU incluem as seguintes categorias:
TLVs de gerenciamento básico.
TLVs específicos da organização (IEEE 802.1 e IEEE 802.3).
TLVs LLDP-MED (descoberta de ponto final de mídia).
Os TLVs de gerenciamento básico são essenciais para o gerenciamento do dispositivo.
TLVs específicos da organização e TLVs LLDP-MED são usados para o gerenciamento aprimorado do dispositivo. Eles são definidos pela padronização ou por outras organizações e são opcionais para LLDPDUs.
TLVs de gerenciamento básico
A Tabela 3 lista os tipos de TLV de gerenciamento básico. Alguns deles são obrigatórios para LLDPDUs.
Tabela 3 TLVs de gerenciamento básico
TLVs específicos da organização IEEE 802.1
A Tabela 4 lista os TLVs específicos da organização do IEEE 802.1.
O dispositivo pode receber TLVs de identidade de protocolo e TLVs de resumo de uso de VID, mas não pode enviar esses TLVs.
Tabela 4 TLVs específicos da organização IEEE 802.1
TLVs específicos da organização IEEE 802.3
A Tabela 5 mostra os TLVs específicos da organização do IEEE 802.3.
A TLV de controle de estado de energia é definida no IEEE P802.3at D1.0 e não é compatível com versões posteriores. O dispositivo envia esse tipo de TLVs somente depois de recebê-los.
Tabela 5 TLVs específicos da organização IEEE 802.3
TLVs LLDP-MED
As TLVs LLDP-MED oferecem vários aplicativos avançados para voz sobre IP (VoIP), como configuração básica, configuração de políticas de rede e gerenciamento de endereços e diretórios. As TLVs LLDP-MED oferecem uma solução econômica e fácil de usar para a implementação de dispositivos de voz na Ethernet. As TLVs LLDP-MED são mostradas na Tabela 6.
Se o TLV de configuração/status do MAC/PHY não for anunciável, nenhum dos TLVs do LLDP-MED será anunciado, mesmo que seja anunciável.
Se o TLV de recursos do LLDP-MED não for anunciável, os outros TLVs do LLDP-MED não serão anunciados, mesmo que sejam anunciáveis.
Tabela 6 TLVs LLDP-MED
TLVs proprietários da INTELBRAS
Os TLVs proprietários da INTELBRAS são usados para atender a requisitos específicos de transmissão no gerenciamento de rede. Os dispositivos de outros fornecedores não podem identificar os TLVs proprietários da INTELBRAS transportados no LLDPDUS.
Somente os TLVs de potência real são compatíveis com a versão atual do software. Esse tipo de TLVs fornece informações sobre a potência PoE em uma interface.
Endereço de gerenciamento
O sistema de gerenciamento de rede usa o endereço de gerenciamento de um dispositivo para identificar e gerenciar o dispositivo para manutenção da topologia e gerenciamento da rede. O endereço de gerenciamento é encapsulado no endereço de gerenciamento TLV.
Modos de operação do LLDP
Um agente LLDP pode operar em um dos seguintes modos:
Modo TxRx - Um agente LLDP nesse modo pode enviar e receber quadros LLDP.
Modo Tx - Um agente LLDP nesse modo só pode enviar quadros LLDP.
Modo Rx - Um agente LLDP nesse modo só pode receber quadros LLDP.
Modo desativado - Um agente LLDP nesse modo não pode enviar ou receber quadros LLDP.
Toda vez que o modo operacional de um agente LLDP é alterado, sua máquina de estado do protocolo LLDP é reinicializada. Um atraso de reinicialização configurável evita inicializações frequentes causadas por alterações frequentes no modo de operação. Se você configurar o atraso de reinicialização, um agente LLDP deverá aguardar o período de tempo especificado para inicializar o LLDP depois que o modo operacional do LLDP for alterado.
Transmissão e recebimento de quadros LLDP
Transmissão de quadros LLDP
Um agente LLDP operando no modo TxRx ou no modo Tx envia quadros LLDP para seus dispositivos diretamente conectados periodicamente e quando a configuração local é alterada. Para evitar que os quadros LLDP sobrecarreguem a rede durante os períodos de alterações frequentes nas informações do dispositivo local, o LLDP usa o mecanismo de token bucket para limitar a taxa de quadros LLDP. Para obter mais informações sobre o mecanismo de token bucket, consulte o Guia de configuração de ACL e QoS.
O LLDP ativa automaticamente o mecanismo de transmissão rápida de quadros LLDP em qualquer um dos seguintes casos:
Um novo quadro LLDP é recebido e contém novas informações sobre o dispositivo local.
O modo de operação LLDP do agente LLDP muda de Disable ou Rx para TxRx ou Tx.
O mecanismo de transmissão rápida de quadros LLDP envia sucessivamente o número especificado de quadros LLDP em um intervalo configurável de transmissão rápida de quadros LLDP. O mecanismo ajuda os vizinhos LLDP a descobrir o dispositivo local o mais rápido possível. Em seguida, o intervalo normal de transmissão de quadros LLDP é retomado.
Recebimento de quadros LLDP
Um agente LLDP operando no modo TxRx ou no modo Rx confirma a validade dos TLVs transportados em cada quadro LLDP recebido. Se os TLVs forem válidos, o agente LLDP salvará as informações e iniciará um cronômetro de envelhecimento. O valor inicial do cronômetro de envelhecimento é igual ao valor TTL no TLV Time To Live transportado no quadro LLDP. Quando o agente LLDP recebe um novo quadro LLDP, o cronômetro de envelhecimento é reiniciado. Quando o cronômetro de envelhecimento chega a zero, todas as informações salvas envelhecem.
Colaboração com a trilha
Você pode configurar uma entrada de rastreamento e associá-la a uma interface LLDP. O módulo LLDP verifica a disponibilidade de vizinhos da interface LLDP e informa o resultado da verificação ao módulo Track. O módulo Track altera o status da entrada de rastreamento adequadamente para que o módulo de aplicativo associado possa tomar as medidas corretas.
O módulo Track altera o status da entrada de rastreamento com base na disponibilidade de vizinhos de uma interface LLDP monitorada da seguinte forma:
Se o vizinho da interface LLDP estiver disponível, o módulo Track define a entrada da trilha para o estado Positivo.
Se o vizinho da interface LLDP não estiver disponível, o módulo Track definirá a entrada da trilha para o estado Negativo.
Para obter mais informações sobre a colaboração entre o Track e o LLDP, consulte a configuração do track em
Protocolos e padrões
IEEE 802.1AB-2005, descoberta de conectividade de controle de acesso a mídia e estação
IEEE 802.1AB-2009, descoberta de conectividade de controle de acesso a mídia e estação
ANSI/TIA-1057, Protocolo de descoberta de camada de enlace para dispositivos de ponto de extremidade de mídia
IEEE Std 802.1Qaz-2011, pontes de controle de acesso a mídia (MAC) e redes locais com pontes virtuais - Alteração 18: seleção de transmissão aprimorada para compartilhamento de largura de banda entre classes de tráfego
Restrições e diretrizes: Configuração do LLDP
Quando você configurar o LLDP, siga estas restrições e diretrizes:
Algumas das tarefas de configuração do LLDP estão disponíveis em diferentes visualizações de interface (consulte a Tabela 7).
Tabela 7 Suporte das tarefas de configuração do LLDP em diferentes visualizações
Para usar o LLDP junto com o OpenFlow, você deve ativar o LLDP globalmente nos switches OpenFlow. Para evitar que o LLDP afete a descoberta de topologia dos controladores OpenFlow, desative o LLDP nas portas das instâncias OpenFlow. Para obter mais informações sobre o OpenFlow, consulte o Guia de configuração do OpenFlow.
Ativação do LLDP
Restrições e diretrizes
Para que o LLDP entre em vigor em portas específicas, você deve ativar o LLDP globalmente e nessas portas.
Procedimento
Entre na visualização do sistema.
System ViewHabilite o LLDP globalmente. lldp global enable Por padrão:
Se o dispositivo for iniciado com a configuração inicial, o LLDP será desativado globalmente.
Se o dispositivo for iniciado com os padrões de fábrica, o LLDP será ativado globalmente.
Para obter mais informações sobre a inicialização do dispositivo com a configuração inicial ou os padrões de fábrica, consulte
Guia de configuração de fundamentos.
Entre na visualização da interface.
interface interface-type interface-numberHabilitar LLDP.
lldp enablePor padrão, o LLDP está ativado em uma porta.
Configuração do modo de ponte LLDP
Entre na visualização do sistema.
System ViewDefinir o modo de ponte LLDP.
Defina o modo de ponte LLDP como ponte de serviço.
lldp mode service-bridgePor padrão, o LLDP opera no modo de ponte do cliente.
Defina o modo de ponte LLDP como ponte de cliente.
undo lldp modePor padrão, o LLDP opera no modo de ponte do cliente.
Configuração do Modo de Operação LLDP
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberDefinir o modo de operação do LLDP.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp [ agent { nearest-customer | nearest-nontpmr } ] admin-status { disable | rx | tx | txrx }Na visualização da interface Ethernet, se você não especificar um tipo de agente, o comando definirá o modo de operação do agente de ponte mais próximo.
Na visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr } admin-status { disable | rx | tx | txrx }Por padrão:
- O agente de ponte mais próximo opera no modo TxRx.
- O agente de ponte de cliente mais próximo e o agente de ponte não TPMR mais próximo operam no modo Desativado.
Configuração do Atraso de Reinicialização do LLDP
Sobre o Atraso de Reinicialização do LLDP
Quando o modo operacional do LLDP muda em uma porta, ela inicializa as máquinas de estado do protocolo após um atraso de reinicialização do LLDP. Ao ajustar o atraso, você pode evitar inicializações frequentes causadas por alterações frequentes no modo de operação LLDP em uma porta.
Procedimento:
Entre na visualização do sistema.
System ViewDefina o atraso de reinicialização do LLDP.
lldp reinit-delay timer-delayO atraso padrão de reinicialização do LLDP é de 2 segundos.
Configuração dos TLVs anunciáveis
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure os TLVs anunciáveis.
Na visualização da interface Ethernet de camada 2:
lldp tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ipv6 ] [ ip-address | interface loopback interface-number ] } | Dot1-tlv { all | port-vlan-id | link-aggregation | protocol-vlan-id [ vlan-id ] | vlan-name [ vlan-id ] | management-vid [ mvlan-id ] } | Dot3-tlv { all | link-aggregation | mac-physic | max-frame-size | power } | med-tlv { all | capability | inventory | network-policy [ vlan-id ] | power-over-ethernet | location-id { civic-address device-type country-code { ca-type ca-value }<1-10> | elin-address tel-number } } }lldp tlv-enable private-tlv actual-powerOs dispositivos não PoE não são compatíveis com o comando lldp tlv-enable private-tlv actual-power.
O comando lldp tlv-enable private-tlv actual-power está disponível somente na versão 6343P08 e posteriores.
Por padrão, o agente de ponte mais próximo anuncia todos os TLVs suportados, exceto os seguintes TLVs:
- TLVs de identificação de local.
- TLVs de VLAN ID de porta e protocolo.
- TLVs de nome de VLAN.
- TLVs de ID da VLAN de gerenciamento.
lldp agent nearest-nontpmr tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ipv6 ] [ ip-address ] } | dot1-tlv { all | port-vlan-id | link-aggregation } dot3-tlv { all | port-vlan-id | link-aggregation } link-aggregation } }lldp tlv-enable dot1-tlv { protocol-vlan-id [ vlan-id ] | vlan-name [ vlan-id ] | management-vid [ mvlan-id ] }lldp agent nearest-nontpmr tlv-enable private-tlv actual-powerOs dispositivos não PoE não são compatíveis com o comando lldp tlv-enable private-tlv actual-power.
O comando lldp tlv-enable private-tlv actual-power está disponível somente na versão 6343P08 e posteriores.
Por padrão, o agente de ponte não TPMR mais próximo não anuncia nenhum TLV.
lldp agent nearest-customer tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ipv6 ] [ ip-address ] } | dot1-tlv { all | port-vlan-id | link-aggregation } | dot3-tlv { all | link-aggregation } }lldp tlv-enable dot1-tlv { protocol-vlan-id [ vlan-id ] | vlan-name [ vlan-id ] | management-vid [ mvlan-id ] }lldp agent nearest-customer tlv-enable private-tlv actual-powerOs dispositivos não PoE não são compatíveis com o comando lldp agent nearest-customer tlv-enable private-tlv actual-power.
O comando lldp agent nearest-customer tlv-enable private-tlv actual-power está disponível somente na versão 6343P08 e posteriores.
Por padrão, o agente de ponte do cliente mais próximo anuncia todos os TLVs de gerenciamento básico suportados e os TLVs específicos da organização IEEE 802.1.
Na visualização da interface Ethernet de gerenciamento:
lldp tlv-enable { basic-tlv { all | port-description | capacidade do sistema | descrição do sistema | nome do sistema | management-address-tlv [ ipv6 ] [ ip-address ] } | Dot1-tlv { all | link-aggregation } | dot3-tlv { all | link-aggregation | mac-physic | max-frame-size | power } | med-tlv { all | capability | inventory | power-over-ethernet | location-id { civic-address device-type country-code { ca-type ca-value }<1-10> | elin-address tel-number } } }Por padrão, o agente de ponte mais próximo anuncia os seguintes TLVs:
- TLVs de agregação de links no conjunto de TLVs específicos da organização 802.1.
- Todos os TLVs específicos da organização 802.3 suportados.
- Todos os TLVs LLDP-MED suportados, exceto os TLVs de política de rede.
lldp agent { nearest-nontpmr | nearest-customer } tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ipv6 ] [ ip-address ] } | Dot1-tlv { all | link-aggregation } | dot3-tlv { all | link-aggregation } }Por padrão:
- O agente de ponte não-TPMR mais próximo não anuncia nenhumTLV.
- O agente de ponte do cliente mais próximo anuncia todos os TLVs de gerenciamento básico e TLVs de agregação de links suportados no conjunto de TLVs específicos da organização IEEE 802.1.
Na visualização da interface agregada da Camada 2:
lldp tlv-enable dot1-tlv { protocol-vlan-id [ vlan-id ] | vlan-name [ vlan-id ] | management-vid [ mvlan-id ] }lldp agent nearest-nontpmr tlv-enable { basic-tlv { all | management-address-tlv [ ipv6 ] [ ip-address ] | port-description | system-capability | system-description | system-name } | dot1-tlv { all | port-vlan-id } }lldp agent nearest-customer tlv-enable { basic-tlv { all | management-address-tlv [ ipv6 ] [ ip-address ] | port-description | system-capability | system-description | system-name } | dot1-tlv { all | port-vlan-id } }Por padrão, o agente de ponte do cliente mais próximo anuncia todos os TLVs de gerenciamento básico suportados e os seguintes TLVs específicos da organização IEEE 802.1:
- TLVs de VLAN ID de porta e protocolo.
- TLVs de nome de VLAN.
- TLVs de ID da VLAN de gerenciamento.
Não há suporte para o agente de ponte mais próximo.
Configuração do anúncio do endereço de gerenciamento TLV
Sobre o anúncio do endereço de gerenciamento TLV
O LLDP codifica endereços de gerenciamento em formato numérico ou de cadeia de caracteres em TLVs de endereço de gerenciamento.
Se um vizinho codificar seu endereço de gerenciamento em formato de cadeia de caracteres, defina o formato de codificação do endereço de gerenciamento como cadeia de caracteres na porta de conexão. Isso garante a comunicação normal com o vizinho.
Você pode configurar o anúncio do endereço de gerenciamento TLV globalmente ou por interface. O dispositivo seleciona a configuração de anúncio de TLV de endereço de gerenciamento para uma interface na seguinte ordem:
Definição baseada na interface, configurada pelo uso do comando lldp tlv-enable com a opção
palavra-chave management-address-tlv.
Definição global, configurada com o comando lldp global tlv-enable basic-tlv management-address-tlv.
Configuração padrão para a interface. Por padrão:
Procedimento
O agente de ponte mais próximo e o agente de ponte do cliente mais próximo anunciam o endereço de gerenciamento TLV.
O agente de ponte não-TPMR mais próximo não anuncia o endereço de gerenciamento TLV.
Entre na visualização do sistema.
System ViewHabilite o anúncio do endereço de gerenciamento TLV globalmente e defina o endereço de gerenciamento a ser anunciado.
lldp [ agent { nearest-customer | nearest-nontpmr } ] global tlv-enable
basic-tlv management-address-tlv [ ipv6 ] { ip-address | interface
loopback interface-number | interface m-gigabitethernet
interface-number | interface vlan-interface interface-number }Por padrão, o anúncio do endereço de gerenciamento TLV é desativado globalmente.
Entre na visualização da interface.
interface interface-type interface-numberHabilite o anúncio do endereço de gerenciamento TLV na interface e defina o endereço de gerenciamento a ser anunciado.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp tlv-enable basic-tlv management-address-tlv [ ipv6 ]
[ ip-address | interface loopback interface-number ]
lldp agent { nearest-customer | nearest-nontpmr } tlv-enable
basic-tlv management-address-tlv [ ipv6 ] [ ip-address ]Na visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr } tlv-enable
basic-tlv management-address-tlv [ ipv6 ] [ ip-address ]Por padrão:
O agente de ponte mais próximo e o agente de ponte do cliente mais próximo anunciam os TLVs de endereço de gerenciamento.
O agente de ponte não-TPMR mais próximo não anuncia o endereço de gerenciamento TLV. O dispositivo suporta apenas o formato de codificação numérica para endereços de gerenciamento IPv6.
Defina o formato de codificação do endereço de gerenciamento como string.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp [ agent { nearest-customer | nearest-nontpmr } ]
management-address-format stringNa visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr }
management-address-format string O formato padrão de codificação do endereço de gerenciamento é numérico.
Configuração do formato de encapsulamento para quadros LLDP
Sobre a configuração do formato de encapsulamento do quadro LLDP
As versões anteriores do LLDP exigem o mesmo formato de encapsulamento em ambas as extremidades para processar os quadros LLDP. Para se comunicar com sucesso com um dispositivo vizinho que esteja executando uma versão anterior do LLDP, o dispositivo local deve ser configurado com o mesmo formato de encapsulamento.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberDefina o formato de encapsulamento dos quadros LLDP como SNAP.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp [ agente { nearest-customer | nearest-nontpmr } ] encapsulamento snap Na visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr } encapsulation snap Por padrão, é usado o formato de encapsulamento Ethernet II.
Configuração dos parâmetros de transmissão de quadros LLDP
Sobre a configuração dos parâmetros de transmissão de quadros LLDP
O TLV Time to Live transportado em um LLDPDU determina por quanto tempo as informações do dispositivo transportadas no LLDPDU podem ser salvas em um dispositivo destinatário.
Ao definir o multiplicador de TTL, você pode configurar o TTL dos LLDPDUs enviados localmente. O TTL é expresso por meio da seguinte fórmula:
TTL = Mínimo (65535, (multiplicador TTL × intervalo de transmissão do quadro LLDP + 1))
Como mostra a expressão, o TTL pode ser de até 65535 segundos. Os TTLs maiores que 65535 serão arredondados para 65535 segundos.
Procedimento
Entre na visualização do sistema.
System ViewDefina o multiplicador TTL.
lldp hold-multiplier valueA configuração padrão é 4.
Defina o intervalo de transmissão de quadros LLDP. lldp timer tx-interval interval A configuração padrão é 30 segundos.
Defina o tamanho do bloco de tokens para o envio de quadros LLDP.
lldp max-credit valor de créditoA configuração padrão é 5.
Defina o número de quadros LLDP enviados sempre que a transmissão rápida de quadros LLDP for acionada.
lldp fast-count count countA configuração padrão é 4.
Defina o intervalo de transmissão rápida de quadros LLDP. lldp timer fast-interval interval A configuração padrão é 1 segundo.
Configuração do tipo de TLVs de ID de porta anunciados pelo LLDP
Sobre esta tarefa
Esta tarefa permite que um dispositivo INTELBRAS anuncie apenas TLVs de ID de porta que contenham nomes de interface. Por padrão, um dispositivo INTELBRAS anuncia TLVs de ID de porta que contêm endereços MAC de interface ou nomes de interface. Os dispositivos de mídia de alguns fornecedores podem obter informações de interface dos dispositivos INTELBRAS somente por meio de LLDP. Para que os dispositivos de mídia obtenham os nomes das interfaces, é necessário configurar os dispositivos INTELBRAS para gerar TLVs de ID de porta com base nos nomes das interfaces.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6331 e posteriores.
Restrições e diretrizes
Execute essa tarefa somente quando os vizinhos LLDP precisarem obter nomes de interface de LLDPDUs. Não execute essa tarefa em nenhum outro cenário.
Você pode configurar o tipo de porta ID TLV na visualização do sistema ou da interface. A configuração específica da interface tem precedência sobre a configuração global.
Configuração do tipo de TLVs de ID de porta anunciados pelo LLDP globalmente
Entre na visualização do sistema.
System ViewConfigure o tipo de TLVs de ID de porta anunciados pelo LLDP.
lldp [ agent { nearest-customer | nearest-nontpmr } ] global tlv-config basic-tlv port-id type-idPor padrão, uma interface anuncia TLVs de ID de porta que contêm endereços MAC de interface se receber TLVs LLDP-MED e anuncia TLVs de ID de porta que contêm nomes de interface se nenhum TLV LLDP-MED for recebido.
Configuração do tipo de TLVs de ID de porta anunciados pelo LLDP em uma interface
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberConfigure o tipo de TLVs de ID de porta anunciados pelo LLDP.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp [ agent { nearest-customer | nearest-nontpmr } ] tlv-config basic-tlv port-id type-idNa visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr } tlv-config basic-tlv port-id type-idPor padrão, a configuração global do tipo de TLV de ID de porta entra em vigor.
Ativação da exibição de informações locais do LLDP sobre todas as interfaces
Sobre esta tarefa
Essa tarefa ativa o comando display lldp local-information para exibir informações locais do LLDP sobre todas as interfaces.
Por padrão, o comando display lldp local-information exibe informações sobre as interfaces fisicamente ativas. Os dispositivos de mídia de alguns fornecedores podem obter informações de interface dos dispositivos INTELBRAS somente por meio de LLDP. Para que os dispositivos de mídia obtenham todas as informações da interface, ative o comando display lldp local-information para exibir informações locais do LLDP sobre todas as interfaces.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6331 e posteriores.
Restrições e diretrizes
Execute essa tarefa somente quando os vizinhos do LLDP puderem obter informações sobre a interface do dispositivo por meio do LLDP.
Procedimento
Entre na visualização do sistema.
System ViewPermitir a exibição de informações locais do LLDP sobre todas as interfaces.
lldp local-information all-interfacePor padrão, o comando display lldp local-information exibe informações sobre interfaces fisicamente ativas.
Ativação de sondagem LLDP
Sobre a sondagem LLDP
Com o polling LLDP ativado, um dispositivo procura periodicamente por alterações na configuração local. Quando o dispositivo detecta uma alteração de configuração, ele envia quadros LLDP para informar os dispositivos vizinhos sobre a alteração.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberHabilite a sondagem LLDP e defina o intervalo de sondagem.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp [ agent { nearest-customer | nearest-nontpmr } ]intervalo de intervalo de alteração de verificação
Na visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr }intervalo de intervalo de alteração de verificação
Por padrão, o polling LLDP está desativado.
Desativação da verificação de inconsistência do PVID do LLDP
Sobre a verificação de inconsistência do PVID do LLDP
Por padrão, quando o sistema recebe um pacote LLDP, ele compara o valor do PVID contido no pacote com o PVID configurado na interface receptora. Se os dois PVIDs não corresponderem, será impressa uma mensagem de registro para notificar o usuário.
Você pode desativar a verificação de inconsistência de PVID se forem necessários PVIDs diferentes em um link.
Procedimento
Entre na visualização do sistema.
System ViewDesativar a verificação de inconsistência do PVID do LLDP.
lldp ignore-pvid-inconsistencyPor padrão, a verificação de inconsistência do PVID do LLDP está ativada.
Configuração da compatibilidade do CDP
Sobre a compatibilidade do CDP
Para permitir que seu dispositivo troque informações com um dispositivo Cisco conectado diretamente que suporte apenas CDP, você deve ativar a compatibilidade com CDP.
A compatibilidade com o CDP permite que seu dispositivo receba e reconheça os pacotes CDP do dispositivo CDP vizinho e envie pacotes CDP para o dispositivo vizinho. Os pacotes CDP enviados ao dispositivo CDP vizinho contêm as seguintes informações:
ID do dispositivo.
ID da porta que se conecta ao dispositivo vizinho.
Endereço IP da porta.
TTL.
O endereço IP da porta é o endereço IP primário de uma interface de VLAN em estado ativo. A VLAN ID da interface VLAN deve ser a mais baixa entre as VLANs permitidas na porta. Se não for atribuído um endereço IP a nenhuma interface VLAN das VLANs permitidas ou se todas as interfaces VLAN estiverem inativas, nenhum endereço IP de porta será anunciado.
Você pode visualizar as informações do dispositivo CDP vizinho que podem ser reconhecidas pelo dispositivo na saída do comando display lldp neighbor-information. Para obter mais informações sobre o comando display lldp neighbor-information, consulte Comandos LLDP em Layer 2-LAN Switching Command Reference.
Para que seu dispositivo funcione com os telefones IP da Cisco, é necessário ativar a compatibilidade com o CDP.
Se o seu dispositivo habilitado para LLDP não puder reconhecer os pacotes CDP, ele não responderá às solicitações dos telefones IP da Cisco para a VLAN ID de voz configurada no dispositivo. Como resultado, um telefone IP Cisco solicitante envia tráfego de voz sem nenhuma tag para o seu dispositivo. Seu dispositivo não consegue diferenciar o tráfego de voz de outros tipos de tráfego.
A compatibilidade com CDP permite que seu dispositivo receba e reconheça os pacotes CDP de um telefone IP da Cisco e responda com pacotes CDP que contenham TLVs com a Voice Vlan configurada. Se nenhuma Voice Vlan estiver configurada para pacotes CDP, os pacotes CDP transportarão a Voice Vlan da porta ou a Voice Vlan atribuída pelo servidor RADIUS. A Voice Vlan atribuída tem uma prioridade mais alta. De acordo com os TLVs com a configuração da Voice Vlan, o telefone IP configura automaticamente a Voice Vlan. Como resultado, o tráfego de voz é confinado na Voice Vlan configurada e é diferenciado de outros tipos de tráfego.
Para obter mais informações sobre Voice Vlan, consulte "Configuração de Voice Vlan".
Quando o dispositivo está conectado a um telefone IP da Cisco que tem um host conectado à sua porta de dados, o host deve acessar a rede por meio do telefone IP da Cisco. Se a porta de dados cair, o telefone IP enviará um pacote CDP ao dispositivo para que ele possa fazer o logout do usuário.
O LLDP compatível com CDP opera em um dos seguintes modos:
Os pacotes TxRx-CDP podem ser transmitidos e recebidos.
Os pacotes Rx-CDP podem ser recebidos, mas não podem ser transmitidos.
Desativar - os pacotes CDP não podem ser transmitidos ou recebidos.
Restrições e diretrizes
Quando você configurar a compatibilidade de CDP para LLDP, siga estas restrições e diretrizes:
Para que o LLDP compatível com CDP entre em vigor em uma porta, siga estas etapas:
Habilitar LLDP compatível com CDP globalmente.
Configure o LLDP compatível com CDP para operar no modo TxRx na porta.
O valor máximo de TTL permitido pelo CDP é de 255 segundos. Para que o LLDP compatível com CDP funcione corretamente com os telefones IP da Cisco, configure o intervalo de transmissão do quadro LLDP para que não seja superior a 1/3 do valor TTL.
Pré-requisitos
Antes de configurar a compatibilidade do CDP, conclua as seguintes tarefas:
Ativar globalmente o LLDP.
Habilite o LLDP na porta que se conecta a um dispositivo CDP.
Configure o LLDP para operar no modo TxRx na porta.
Procedimento
Entre na visualização do sistema.
System ViewHabilite a compatibilidade do CDP globalmente.
cdp de conformidade lldpPor padrão, a compatibilidade do CDP é desativada globalmente.
Entre na visualização da interface Ethernet de camada 2 ou na visualização da interface Ethernet de gerenciamento.
interface interface-type interface-numberConfigure o LLDP compatível com CDP para operar no modo TxRx.
lldp compliance admin-status cdp txrxPor padrão, o LLDP compatível com CDP opera no modo de desativação .
Defina a VLAN ID de voz transportada nos pacotes CDP.
cdp voice-vlan vlan-idPor padrão, nenhuma VLAN ID de voz é configurada para ser transportada em pacotes CDP.
Configuração do trapping LLDP e do trapping LLDP-MED
Sobre o trapping LLDP e o trapping LLDP-MED
O trapping LLDP ou o trapping LLDP-MED notifica o sistema de gerenciamento de rede sobre eventos, como dispositivos vizinhos recém-detectados e falhas de link.
Para evitar o envio excessivo de traps LLDP quando a topologia estiver instável, defina um intervalo de transmissão de traps para LLDP.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface.
interface interface-type interface-numberAtivar o rastreamento de LLDP.
Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento:
lldp [ agent { nearest-customer | nearest-nontpmr } ] notification remote-change enableNa visualização da interface agregada da Camada 2:
lldp agent { nearest-customer | nearest-nontpmr } notification remote-change enablePor padrão, o rastreamento de LLDP está desativado.
(Na visualização da interface Ethernet de camada 2 ou da interface Ethernet de gerenciamento.) Habilite o rastreamento LLDP-MED.
lldp notification med-topology-change enablePor padrão, o rastreamento LLDP-MED está desativado.
Retornar à visualização do sistema.
quit(Opcional.) Defina o intervalo de transmissão de interceptação LLDP.
lldp timer notification-interval intervalA configuração padrão é de 30 segundos.
Configuração do aprendizado de endereço MAC para DCN
Definição do endereço MAC de origem dos quadros LLDP
Sobre a configuração do endereço MAC de origem dos quadros LLDP
Na visualização da interface Ethernet de camada 2, esse recurso deve ser configurado com a geração de entradas ARP ou ND para TLVs de endereço de gerenciamento recebidos para atender aos seguintes requisitos:
O endereço MAC de origem dos quadros LLDP de saída é o endereço MAC de uma interface VLAN, em vez do endereço MAC da interface de saída.
O dispositivo vizinho pode gerar entradas ARP ou ND corretas para o dispositivo local.
Na visualização da interface Ethernet de camada 2, esse recurso define o endereço MAC de origem dos quadros LLDP de saída como o endereço MAC de uma interface VLAN à qual pertence a VLAN ID especificada. O endereço MAC de origem dos quadros LLDP de saída é o endereço MAC da interface Ethernet de camada 2 nas seguintes situações:
A VLAN especificada ou a interface VLAN correspondente não existe.
A interface da VLAN à qual pertence a VLAN ID está fisicamente inativa.
Restrições e diretrizes
Na visualização da interface Ethernet de camada 2, você deve configurar esse recurso para que a interface possa usar o endereço MAC de uma interface VLAN em vez de seu próprio endereço MAC como o endereço MAC de origem do LLDP
frames. Isso garante que o dispositivo vizinho possa gerar entradas ARP ou ND corretas para o dispositivo local.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberDefina o endereço MAC de origem dos quadros LLDP como o endereço MAC de uma interface VLAN.
lldp source-mac vlan vlan-idPor padrão, o endereço MAC de origem dos quadros LLDP é o endereço MAC da interface de saída .
Ativação da geração de entradas ARP ou ND para TLVs de endereço de gerenciamento recebidos
Sobre a geração de entradas ARP ou ND para TLVs de endereço de gerenciamento recebidos
Esse recurso permite que o dispositivo gere uma entrada ARP ou ND após receber um quadro LLDP contendo um endereço de gerenciamento TLV em uma interface. A entrada ARP ou ND mapeia o endereço de gerenciamento anunciado para o endereço MAC de origem do quadro.
Você pode ativar a geração de entradas ARP e ND em uma interface. Se o endereço de gerenciamento TLV contiver um endereço IPv4, o dispositivo gerará uma entrada ARP. Se o endereço de gerenciamento TLV contiver um endereço IPv6, o dispositivo gerará uma entrada ND.
Na visualização da interface Ethernet de Camada 2, esse recurso define a interface Ethernet de Camada 2 como a interface de saída nas entradas geradas. A VLAN à qual as entradas pertencem é a VLAN especificada por esse recurso. O dispositivo não pode gerar entradas ARP ou ND em uma das seguintes situações:
A VLAN especificada ou a interface VLAN correspondente não existe.
A interface da VLAN à qual pertence a VLAN ID está fisicamente inativa.
Restrições e diretrizes
Na visualização da interface Ethernet de camada 2, você deve configurar a interface para usar o endereço MAC de uma interface VLAN em vez de seu próprio endereço MAC como endereço MAC de origem dos quadros LLDP. Esse garante que o dispositivo vizinho possa gerar entradas ARP ou ND corretas.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberHabilita a geração de entradas ARP ou ND para TLVs de endereço de gerenciamento recebidos na interface.
lldp management-address { arp-learning | nd-learning } vlan vlan-id
Por padrão, a geração de entradas ARP ou ND para TLVs de endereços de gerenciamento recebidos é desativada em uma interface.
Na visualização da interface Ethernet de camada 2, a opção vlan vlan-id especifica a ID da VLAN à qual pertence a entrada ARP ou ND gerada. Para evitar que as entradas ARP ou ND se sobreponham umas às outras, não especifique a mesma ID de VLAN para diferentes interfaces Ethernet de camada 2.
Você pode ativar a geração de entradas ARP e ND em uma interface.
Exemplos de configuração LLDP
Exemplo: Configuração das funções básicas do LLDP
Configuração de rede
Conforme mostrado na Figura 5, habilite o LLDP globalmente no Switch A e no Switch B para realizar as seguintes tarefas:
- Monitore o link entre o Switch A e o Switch B no NMS.
- Monitore o link entre o Switch A e o dispositivo MED no NMS.
Figura 5 Diagrama de rede
Procedimento
Configure o Switch A:
# Habilite o LLDP globalmente.
<SwitchA> system-view
[SwitchA] lldp enable global# Habilite o LLDP na GigabitEthernet 1/0/1. Por padrão, o LLDP está ativado nas portas.
[SwitchA] interface gigabitethernet 1/0/1
[SwitchA-GigabitEthernet1/0/1] lldp enable# Defina o modo de operação LLDP como Rx na GigabitEthernet 1/0/1.
[SwitchA-GigabitEthernet1/0/1] lldp admin-status rx
[SwitchA-GigabitEthernet1/0/1] quit# Habilite o LLDP na GigabitEthernet 1/0/2. Por padrão, o LLDP está habilitado nas portas.
[SwitchA] interface gigabitethernet1/2
[SwitchA-GigabitEthernet1/0/2] lldp enable# Defina o modo de operação LLDP como Rx na GigabitEthernet 1/0/2.
[SwitchA-GigabitEthernet1/0/2] lldp admin-status rx
[SwitchA-GigabitEthernet1/0/2] quitConfigurar o Switch B:
# Habilite o LLDP globalmente.
<SwitchB> system-view
[SwitchB] lldp enable global# Habilite o LLDP na GigabitEthernet 1/0/1. Por padrão, o LLDP está ativado nas portas.
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] lldp enable# Defina o modo de operação do LLDP como Tx na GigabitEthernet 1/0/1.
[SwitchB-GigabitEthernet1/0/1] lldp admin-status tx
[SwitchB-GigabitEthernet1/0/1] quitVerificação da configuração
# Verifique os seguintes itens:
- A GigabitEthernet 1/0/1 do Switch A se conecta a um dispositivo MED.
- A GigabitEthernet 1/0/2 do Switch A se conecta a um dispositivo não-MED.
- Ambas as portas operam no modo Rx e podem receber quadros LLDP, mas não podem enviar quadros LLDP.
[SwitchA] display lldp status
LLDP global status: Enable
LLDP bridge mode: customer-bridge
Current number of LLDP neighbors: 2
Current number of CDP neighbors: 0
Last LLDP neighbor information change: 0 days, 0 hours, 4 minutes, 40 seconds
Transmission interval: 30s
Rapid transmission interval: 1s
Maximum transmission credit: 5
Retention multiplier: 4
Reinitialization delay: 2s
Trap interval: 30s
Quick start times: 4# Remova o link entre o Switch A e o Switch B.
# Verifique se a GigabitEthernet 1/0/2 do Switch A não se conecta a nenhum dispositivo vizinho.
[SwitchA] display lldp status
LLDP global status: Enable (Activate)
Current number of LLDP neighbors: 1
Current number of CDP neighbors: 0
Last LLDP neighbor information change: 0 days, 0 hours, 5 minutes, 20 seconds
Transmission interval: 30s
Rapid transmission interval: 1s
Maximum transmission credit: 5
Retention multiplier: 4
Reinitialization delay: 2s
Trap interval: 30s
Quick start times: 4Configuração do L2PT
Sobre a L2PT
O L2PT (Layer 2 Protocol Tunneling) pode enviar pacotes de protocolo de camada 2 de forma transparente a partir de redes de clientes geograficamente dispersas em uma rede de provedor de serviços ou descartá-los.
Cenário do aplicativo L2PT
As linhas dedicadas são usadas em uma rede de provedor de serviços para criar redes de Camada 2 específicas do usuário. Como resultado, uma rede de clientes contém sites localizados em lados diferentes da rede do provedor de serviços.
Conforme mostrado na Figura 1, a rede do Cliente A é dividida em rede 1 e rede 2, que são conectadas pela rede do provedor de serviços. Para que a rede do Cliente A implemente os cálculos do protocolo da Camada 2, os pacotes do protocolo da Camada 2 devem ser transmitidos pela rede do provedor de serviços.
Ao receber um pacote de protocolo de camada 2, os PEs não podem determinar se o pacote é da rede do cliente ou da rede do provedor de serviços. Eles devem entregar o pacote à CPU para processamento. Nesse caso, o cálculo do protocolo da Camada 2 na rede do Cliente A é misturado com o cálculo do protocolo da Camada 2 na rede do provedor de serviços. Nem a rede do cliente nem a rede do provedor de serviços podem implementar cálculos de protocolo de Camada 2 independentes.
Figura 1 Cenário do aplicativo L2PT
O L2PT foi introduzido para resolver o problema. O L2PT oferece as seguintes funções:
Multicasts de pacotes de protocolo de Camada 2 de uma rede de clientes em uma VLAN. As redes de clientes dispersas podem concluir um cálculo de protocolo de camada 2 independente, que é transparente para a rede do provedor de serviços.
Isola os pacotes de protocolo da Camada 2 de diferentes redes de clientes por meio de diferentes VLANs.
Mecanismo operacional L2PT
Conforme mostrado na Figura 2, o L2PT funciona da seguinte forma:
Quando uma porta do PE 1 recebe um pacote de protocolo de camada 2 da rede do cliente em uma VLAN, ela executa as seguintes operações:
Multicasts o pacote para fora de todas as portas voltadas para o cliente na VLAN, exceto a porta receptora.
Encapsula o pacote com um endereço multicast de destino especificado e o envia para todas as portas voltadas para o ISP na VLAN. O pacote encapsulado é chamado de pacote com túnel BPDU.
Quando uma porta do PE 2 na VLAN recebe o pacote com túnel da rede do provedor de serviços, ela executa as seguintes operações:
Multicasts o pacote para fora de todas as portas voltadas para o ISP na VLAN, exceto a porta receptora.
Decapsula o pacote e faz multicasts do pacote decapsulado para todas as portas voltadas para o cliente na VLAN.
Figura 2 Mecanismo operacional do L2PT
Por exemplo, conforme mostrado na Figura 3, o PE 1 recebe um pacote STP (BPDU) da rede 1 para a rede 2. Os CEs são os dispositivos de borda na rede do cliente e os PEs são os dispositivos de borda na rede do provedor de serviços. O L2PT processa o pacote da seguinte forma:
O PE 1 realiza as seguintes operações:
Encapsula o pacote com um endereço MAC multicast de destino especificado (010f-e200-0003 por padrão).
Envia o pacote com túnel para fora de todas as portas voltadas para o ISP na VLAN do pacote.
Ao receber o pacote tunelado, o PE 2 decapsula o pacote e envia o BPDU para o CE 2.
Por meio do L2PT, tanto a rede do ISP quanto a rede do Cliente A podem realizar cálculos independentes de spanning tree.
Figura 3 Diagrama de rede L2PT
Visão geral das tarefas do L2PT
Para configurar o L2PT, execute as seguintes tarefas:
Ativação do L2PT
Esse recurso é aplicável somente a portas voltadas para o cliente.
(Opcional.) Configuração do endereço MAC multicast de destino para pacotes tunelados
Ativação do L2PT
Restrições e diretrizes para L2PT
Para ativar o L2PT para um protocolo de camada 2 em uma porta, execute as seguintes tarefas:
Habilite o protocolo no EC conectado e desabilite o protocolo na porta.
Quando um PE estabelece uma conexão com um dispositivo de rede dentro da rede do provedor de serviços por meio do CDP, você deve ativar a compatibilidade do CDP para LLDP no PE. A compatibilidade de CDP para LLDP só pode ser ativada globalmente e não pode ser desativada separadamente nas interfaces voltadas para o cliente. Como resultado, os pacotes CDP do CE não podem ser transmitidos de forma transparente dentro da rede do provedor de serviços. Nesse caso, como prática recomendada, não habilite o L2PT para CDP no PE. Para que o L2PT tenha efeito sobre o CDP no PE, você deve desativar a compatibilidade do CDP para LLDP globalmente no PE, o que fará com que o PE não consiga se comunicar com os dispositivos de rede dentro da rede do provedor de serviços por meio do CDP. Antes de desativar a compatibilidade de CDP para LLDP no PE, certifique-se de conhecer sua influência na rede. Para obter mais informações sobre a compatibilidade de CDP do LLDP, consulte "Configuração do LLDP".
Desative o protocolo (por exemplo, STP) nas portas PE que se conectam a uma interface agregada em um CE quando houver as seguintes condições:
O protocolo está sendo executado na interface agregada do CE.
A interface agregada no CE conecta-se a uma porta habilitada para L2PT no PE.
Ativar o L2PT nas portas PE conectadas a uma rede de clientes. Se você ativar o L2PT nas portas conectadas à rede do provedor de serviços, o L2PT determinará que as portas estão conectadas a uma rede do cliente.
Certifique-se de que as tags de VLAN dos pacotes de protocolo da Camada 2 não sejam alteradas ou excluídas para que os pacotes tunelados sejam transmitidos corretamente pela rede do provedor de serviços.
O L2PT para LLDP suporta pacotes LLDP somente dos agentes de ponte mais próximos.
É possível ativar o L2PT em uma porta membro de um grupo de agregação de Camada 2, mas a configuração não tem efeito.
Ativação do L2PT para um protocolo na visualização da interface Ethernet de camada 2
Restrições e diretrizes
O LACP e o EOAM exigem transmissão ponto a ponto. Se você ativar o L2PT em uma interface Ethernet de Camada 2 para LACP ou EOAM, o L2PT fará multicasts de pacotes LACP ou EOAM para fora das portas voltadas para o cliente. Como resultado, a transmissão entre dois CEs não é ponto a ponto. Para garantir a transmissão ponto a ponto dos pacotes LACP ou EOAM, você deve configurar outros recursos (por exemplo, VLAN).
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberAtivar o L2PT para um protocolo.
l2protocol { cdp | cfd | dldp | dtp | eoam | gvrp | lacp | lldp | mvrp | pagp
| pvst | stp | udld | vtp } tunnel dot1q Por padrão, o L2PT está desativado para todos os protocolos.
As palavras-chave dtp e cfd são compatíveis apenas com a versão 6331 e posteriores.
Ativação do L2PT para um protocolo na visualização da interface agregada da Camada 2
Entre na visualização do sistema.
System ViewEntre na visualização da interface agregada da camada 2.
interface bridge-aggregation interface-type interface-number
Ativar o L2PT para um protocolo.
l2protocol { cdp | cfd | gvrp | lacp | lldp | mvrp | pagp | pvst | stp
| udld | vtp } tunnel dot1qPor padrão, o L2PT está desativado para todos os protocolos.
A palavra-chave cfd é compatível apenas com a versão 6331 e posteriores.
Configuração do endereço MAC multicast de destino para pacotes com túnel
Sobre o endereço MAC multicast de destino para pacotes tunelados
O endereço MAC multicast de destino padrão para pacotes com túnel é 010f-e200-0003. Você pode modificar o endereço MAC multicast de destino para pacotes com túnel de um protocolo específico ou de todos os protocolos.
Restrições e diretrizes
O comando l2protocol tunnel-dmac define o endereço MAC multicast de destino para pacotes com túnel de todos os protocolos. O comando l2protocol type tunnel-dmac define o endereço
endereço MAC multicast de destino para pacotes com túnel do protocolo especificado. Se ambos os comandos forem executados, o comando l2protocol type tunnel-dmac terá prioridade.
Para que os pacotes tunelados sejam reconhecidos, defina os mesmos endereços MAC multicast de destino para pacotes do mesmo protocolo em PEs que estejam conectados à mesma rede de clientes.
Como prática recomendada, defina endereços MAC multicast de destino diferentes em PEs conectados a redes de clientes diferentes. Isso evita que o L2PT envie pacotes de uma rede de clientes para outra rede de clientes.
Procedimento
Entre na visualização do sistema.
System ViewExecute pelo menos uma das seguintes tarefas:
Defina o endereço MAC multicast de destino para pacotes tunelados de todos os protocolos.
l2protocol tunnel-dmac mac-addressDefine o endereço MAC multicast de destino para pacotes tunelados do protocolo especificado.
l2protocol type { cdp | cfd | dldp | dtp | eoam | gvrp | lacp | lldp
| mvrp | pagp | pvst | stp | udld | vtp } tunnel-dmac mac-address Esse comando é compatível apenas com a versão 6331 e posteriores.
Por padrão, 010f-e200-0003 é usado para pacotes com túnel.
Exemplos de configuração L2PT
Exemplo: Configuração de L2PT para STP
Configuração de rede
Conforme mostrado na Figura 4, os endereços MAC de CE 1 e CE 2 são 00e0-fc02-5800 e 00e0-fc02-5802, respectivamente. O MSTP está ativado na rede do Cliente A e as configurações padrão do MSTP são usadas.
Execute as seguintes tarefas nos PEs:
- Configure as portas que se conectam aos CEs como portas de acesso e configure as portas na rede do provedor de serviços como portas tronco. Configure as portas na rede do provedor de serviços para permitir a passagem de pacotes de qualquer VLAN.
- Ative o L2PT para STP para permitir que a rede do Cliente A implemente o cálculo independente da árvore de abrangência na rede do provedor de serviços.
- Defina o endereço MAC multicast de destino como 0100-0ccd-cdd0 para pacotes com túnel.
Figura 4 Diagrama de rede
Procedimento
Configurar o PE 1:
# Defina o endereço multicast de destino como 0100-0ccd-cdd0 para pacotes com túnel.
<PE1> system-view
[PE1] l2protocol tunnel-dmac 0100-0ccd-cdd0# Crie a VLAN 2.
[PE1] vlan 2
[PE1-vlan2] quit# Configure a GigabitEthernet 1/0/1 como uma porta de acesso e atribua a porta à VLAN 2.
[PE1] interface gigabitethernet 1/0/1
[PE1-GigabitEthernet1/0/1] port access vlan 2# Desative o STP e ative o L2PT para STP na GigabitEthernet 1/0/1.
[PE1-GigabitEthernet1/0/1] undo stp enable
[PE1-GigabitEthernet1/0/1] l2protocol-tunnel stp enable# Configure a GigabitEthernet 1/0/2 conectada à rede do provedor de serviços como uma porta tronco e atribua a porta a todas as VLANs.
[PE1] interface gigabitethernet 1/0/2
[PE1-GigabitEthernet1/0/2] port link-type trunk
[PE1-GigabitEthernet1/0/2] port trunk permit vlan allConfigure o PE 2 da mesma forma que o PE 1 está configurado. (Detalhes não mostrados).
Verificação da configuração
# Verifique se a ponte raiz da rede do cliente A é a CE 1.
<CE2> display stp rootMST ID Root Bridge ID ExtPathCost IntPathCost Root Port
0 32768.00e0-fc02-5800 0 0
# Verificar se a ponte raiz da rede do provedor de serviços não é a CE 1.
[PE1] display stp rootMST ID Root Bridge ID ExtPathCost IntPathCost Root Port
0 32768.0cda-41c5-ba50 0 0
Exemplo: Configuração de L2PT para LACP
Configuração de rede
Conforme mostrado na Figura 5, os endereços MAC de CE 1 e CE 2 são 0001-0000-0000 e 0004-0000-0000, respectivamente.
Execute as seguintes tarefas:
- Configure a agregação do link Ethernet no CE 1 e no CE 2.
- Configure a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 no CE 1 para formar links agregados com a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 no CE 2, respectivamente.
- Habilite o L2PT para LACP para permitir que o CE 1 e o CE 2 implementem a agregação de links Ethernet na rede do provedor de serviços.
Figura 5 Diagrama de rede
Análise de requisitos
Para atender aos requisitos de rede, execute as seguintes tarefas:
- Para que a agregação de links Ethernet funcione corretamente, configure as VLANs nos PEs para garantir a transmissão ponto a ponto entre o CE 1 e o CE 2 em um grupo de agregação.
- Defina os PVIDs como VLAN 2 e VLAN 3 para GigabitEthernet 1/0/1 e GigabitEthernet 1/0/2 no PE 1, respectivamente.
- Configure o PE 2 da mesma forma que o PE 1 está configurado.
- Configure as portas que se conectam aos CEs como portas tronco.
- Para manter a tag de VLAN da rede do cliente, ative o QinQ na GigabitEthernet 1/0/1 e na GigabitEthernet 1/0/2 no PE 1 e no PE 2.
- Para que os pacotes de qualquer VLAN sejam transmitidos, configure todas as portas da rede do provedor de serviços como portas tronco.
Procedimento
Configurar o CE 1:
# Configure o grupo de agregação da camada 2 Bridge-Aggregation 1 para operar no modo de agregação dinâmica.
<CE1> system-view
[CE1] interface bridge-aggregation 1
[CE1-Bridge-Aggregation1] port link-type access
[CE1-Bridge-Aggregation1] link-aggregation mode dynamic
[CE1-Bridge-Aggregation1] quit# Atribua a GigabitEthernet 1/0/1 e a GigabitEthernet 1/0/2 ao Bridge-Aggregation 1.
[CE1] interface gigabitethernet 1/0/1
[CE1-GigabitEthernet1/0/1] port link-aggregation group 1
[CE1-GigabitEthernet1/0/1] quit
[CE1] interface gigabitethernet 1/0/2
[CE1-GigabitEthernet1/0/2] port link-aggregation group 1
[CE1-GigabitEthernet1/0/2] quitConfigure o CE 2 da mesma forma que o CE 1 está configurado. (Os detalhes não são mostrados).
Configurar o PE 1:
# Crie as VLANs 2 e 3.
<PE1> system-view
[PE1] vlan 2
[PE1-vlan2] quit
[PE1] vlan 3
[PE1-vlan3] quit# Configure a GigabitEthernet 1/0/1 como uma porta tronco, atribua a porta à VLAN 2 e defina o PVID como VLAN 2.
[PE1] interface gigabitethernet 1/0/1
[PE1-GigabitEthernet1/0/1] port link-mode bridge
[PE1-GigabitEthernet1/0/1] port link-type trunk
[PE1-GigabitEthernet1/0/1] port trunk permit vlan 2
[PE1-GigabitEthernet1/0/1] port trunk pvid vlan 2
[PE1-GigabitEthernet1/0/1] qinq enable
[PE1-GigabitEthernet1/0/1] l2protocol lacp tunnel dot1q
[PE1-GigabitEthernet1/0/1] quit# Habilite o L2PT para LACP na GigabitEthernet 1/0/1.
[PE1-GigabitEthernet1/0/1] l2protocol-tunnel lacp enable# Configure a GigabitEthernet 1/0/2 como uma porta tronco, atribua a porta à VLAN 3 e defina o PVID para a VLAN 3.
[PE1] interface gigabitethernet 1/0/2
[PE1-GigabitEthernet1/0/2] port link-mode bridge
[PE1-GigabitEthernet1/0/2] port link-type trunk
[PE1-GigabitEthernet1/0/2] port trunk permit vlan 3
[PE1-GigabitEthernet1/0/2] port trunk pvid vlan 3
[PE1-GigabitEthernet1/0/2] qinq enable
[PE1-GigabitEthernet1/0/2] l2protocol-tunnel lacp enable
[PE1-GigabitEthernet1/0/2] quitConfigure o PE 2 da mesma forma que o PE 1 está configurado. (Detalhes não mostrados).
Verificação da configuração
# Verifique se o CE 1 e o CE 2 concluíram a agregação do link Ethernet com êxito.
[CE1] display link-aggregation verbose Bridge-Aggregation1[CE2] display link-aggregation verbose Bridge-Aggregation1Configuração do relé PPPoE
Sobre o PPPoE
O PPPoE (Point-to-Point Protocol over Ethernet) amplia o PPP transportando quadros PPP encapsulados em Ethernet por links ponto a ponto.
O PPPoE especifica os métodos para estabelecer sessões PPPoE e encapsular quadros PPP sobre Ethernet. O PPPoE requer uma relação ponto a ponto entre pares, em vez de uma relação ponto a multiponto como em ambientes de acesso múltiplo, como a Ethernet. O PPPoE fornece acesso à Internet para os hosts em uma Ethernet por meio de um dispositivo de acesso remoto e implementa controle de acesso, autenticação e contabilidade por host. Integrando o baixo custo da Ethernet e as funções de escalabilidade e gerenciamento do PPP, o PPPoE ganhou popularidade em vários ambientes de aplicativos, como redes de acesso residencial.
Para obter mais informações sobre o PPPoE, consulte a RFC 2516.
Estrutura de rede PPPoE
O PPPoE usa o modelo cliente/servidor. O cliente PPPoE inicia uma solicitação de conexão com o servidor PPPoE. Após a conclusão da negociação da sessão entre eles, uma sessão é estabelecida entre eles e o servidor PPPoE fornece controle de acesso, autenticação e contabilidade ao cliente PPPoE.
Para gerenciar de forma granular os clientes PPPoE com base em suas informações de localização, você pode implantar um relé PPPoE entre os clientes PPPoE e o servidor PPPoE.
As estruturas de rede PPPoE são classificadas em estruturas de rede iniciadas pelo roteador e iniciadas pelo host, dependendo do ponto de partida da sessão PPPoE.
Estrutura de rede iniciada pelo roteador
Conforme mostrado na Figura 1, a sessão PPPoE é estabelecida entre os roteadores (Roteador A e Roteador B). Todos os hosts compartilham uma sessão PPPoE para a transmissão de dados sem que seja instalado um software cliente PPPoE. Essa estrutura de rede é normalmente usada por empresas.
Figura 1 Estrutura de rede iniciada por roteador
Estrutura de rede iniciada pelo host
Conforme mostrado na Figura 2, uma sessão PPPoE é estabelecida entre cada host (cliente PPPoE) e o roteador da operadora (servidor PPPoE). O provedor de serviços atribui uma conta a cada host para cobrança e controle. O host deve ser instalado com o software cliente PPPoE.
Figura 2 Estrutura de rede iniciada pelo host
Fundamentos do relé PPPoE
O relé PPPoE controla o encaminhamento de pacotes de protocolo por meio do monitoramento da troca de pacotes de protocolo entre o cliente PPPoE e o servidor PPPoE. A Figura 3 mostra o processo detalhado.
Figura 3 Procedimento de acesso do cliente PPPoE em uma rede de retransmissão PPPoE
O cliente PPPoE transmite um pacote PADI.
Ao receber o pacote PADI, o relé PPPoE adiciona o campo de tag específico do fornecedor ao pacote PADI e transmite o pacote para todas as portas confiáveis.
A tag específica do fornecedor em um pacote PPPoE identifica as informações de localização (por exemplo, a porta de acesso e as VLANs) de um cliente PPPoE.
Ao receber os pacotes PADI, o servidor PPPoE responde com um pacote PADO para o cliente PPPoE.
Ao receber o pacote PADO, o relé PPPoE encaminha o pacote para o cliente PPPoE.
Ao receber o pacote PADO, o cliente PPPoE envia um pacote PADR para o servidor PPPoE para solicitar o serviço PPPoE.
Ao receber o pacote PADR, o relé PPPoE adiciona a tag específica do fornecedor ao pacote e procura uma interface de saída com base no endereço MAC de destino do pacote PADR.
Se a interface de saída for uma porta confiável, o relé PPPoE encaminhará o pacote para fora da porta.
Se a interface de saída for uma porta não confiável, o relé PPPoE descartará o pacote PADR.
Ao receber o pacote PADR, o servidor PPPoE atribui um ID de sessão ao cliente PPPoE e vincula o ID de sessão à tag específica do fornecedor. Em seguida, o servidor PPPoE responde com um pacote PADS para o cliente PPPoE.
Ao receber o pacote PADS, o relé PPPoE encaminha o pacote para o cliente PPPoE.
Ao receber o pacote PADS, o cliente PPPoE inicia a negociação LCP e a autenticação com o servidor PPPoE.
Durante a fase de autenticação, o servidor PPPoE enviará as informações de localização, o nome de usuário e a senha do cliente PPPoE ao servidor RADIUS para autenticação.
O servidor RADIUS compara as informações de localização, o nome de usuário e a senha salvos no banco de dados com os do cliente PPPoE. Se forem iguais, o cliente PPPoE passa na autenticação.
Depois que o cliente PPPoE passa pela autenticação, o cliente PPPoE inicia a negociação NCP com o servidor PPPoE. Depois que a negociação NCP for bem-sucedida, o cliente PPPoE ficará on-line com êxito.
Configuração do relé PPPoE
Visão geral das tarefas de retransmissão do PPPoE
Para configurar o relé PPPoE, execute as seguintes tarefas:
Ativação da função de retransmissão PPPoE
Configuração de portas confiáveis de retransmissão PPPoE
(Opcional.) Ativação de uma interface para remover as tags específicas do fornecedor dos pacotes do lado do servidor PPPoE
(Opcional.) Configuração dos formatos de preenchimento do ID do circuito e do ID remoto para os pacotes PPPoE do lado do cliente no relé PPPoE
(Opcional.) Configuração da política de processamento de tags específicas do fornecedor para os pacotes PPPoE do lado do cliente no relé PPPoE
Ativação da função de retransmissão PPPoE
Sobre a função de retransmissão PPPoE
Para que as configurações relacionadas ao relé PPPoE tenham efeito, você deve ativar a função de relé PPPoE.
Procedimento
Entre na visualização do sistema.
System ViewAtivar a função de retransmissão PPPoE.
pppoe-relay enable
Por padrão, a função de retransmissão PPPoE está desativada.
Configuração de portas confiáveis de retransmissão PPPoE
Sobre as portas confiáveis de retransmissão PPPoE
Um dispositivo habilitado para retransmissão PPPoE processa os pacotes do protocolo PPPoE da seguinte forma:
Ao receber PADI, PADR e PADT em portas não confiáveis, o dispositivo pode encaminhar os pacotes apenas para as portas confiáveis.
Ao receber pacotes PADO e PADS em portas não confiáveis, o dispositivo descarta diretamente os pacotes.
Ao receber pacotes PADO, PADS e PADT em portas confiáveis, o dispositivo pode encaminhar os pacotes para qualquer porta.
Ao receber pacotes PADI e PADR em portas confiáveis, o dispositivo pode encaminhar os pacotes somente para as portas confiáveis.
Para que um relé PPPoE encaminhe e processe corretamente os pacotes do protocolo PPPoE, você deve configurar as interfaces voltadas para o servidor PPPoE no relé PPPoE como portas confiáveis e configurar as interfaces voltadas para o cliente PPPoE no relé PPPoE como portas não confiáveis.
Restrições e diretrizes
Esse comando não é compatível com as portas membro do grupo de agregação da Camada 2. Se uma interface Ethernet de camada 2 for configurada com esse comando antes de entrar em um grupo de agregação de camada 2, o comando será apagado na porta membro depois que ela entrar no grupo de agregação.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure a interface como uma porta confiável de retransmissão PPPoE.
pppoe-relay trustPor padrão, uma interface não é configurada como uma porta confiável de retransmissão PPPoE.
Ativação de uma interface para remover as tags específicas do fornecedor dos pacotes do lado do servidor PPPoE
Sobre a remoção das tags específicas do fornecedor dos pacotes do lado do servidor PPPoE
Quando o retransmissor PPPoE recebe pacotes PADO e PADS do servidor PPPoE em uma porta confiável do retransmissor PPPoE com esse recurso ativado, o retransmissor PPPoE remove as tags específicas do fornecedor dos pacotes antes de encaminhá-los.
Restrições e diretrizes
Esse recurso entra em vigor somente em pacotes recebidos em portas confiáveis de retransmissão PPPoE.
Esse comando não é compatível com as portas membro do grupo de agregação da Camada 2. Se uma interface Ethernet de camada 2 for configurada com esse comando antes de entrar em um grupo de agregação de camada 2, o comando será apagado na porta membro depois que ela entrar no grupo de agregação.
Procedimento
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberHabilite a interface para remover as tags específicas do fornecedor dos pacotes do lado do servidor PPPoE.
faixa específica do fornecedor de informações do servidor de pppoe-relay
Por padrão, a função de remoção de tags específicas do fornecedor dos pacotes do lado do servidor PPPoE está desativada.
Configuração dos formatos de preenchimento do ID do circuito e do ID remoto para os pacotes PPPoE do lado do cliente no relé PPPoE
Sobre os formatos de preenchimento de ID de circuito e ID remota para os pacotes PPPoE do lado do cliente no relé PPPoE
Quando o relé PPPoE recebe pacotes PPPoE do cliente PPPoE, o relé PPPoE preenche a ID do circuito e a ID remota com o conteúdo no formato configurado usando esse comando.
Tanto a ID do circuito quanto a ID remota têm até 63 caracteres. Quando o conteúdo a ser preenchido exceder 63 caracteres, os primeiros 63 caracteres serão preenchidos.
Procedimento
Entre na visualização do sistema.
System ViewConfigure os formatos de preenchimento do ID do circuito e do ID remoto para os pacotes PPPoE do lado do cliente no relé PPPoE.
pppoe-relay client-information format { circuit-id | remote-id }
{ ascii | hex | user-defined text } Por padrão, tanto o formato de preenchimento do ID do circuito quanto o formato de preenchimento do ID remoto para os pacotes PPPoE do lado do cliente são o formato de cadeia ASCII no relé PPPoE.
Configuração da política de processamento de tags específicas do fornecedor para os pacotes PPPoE do lado do cliente no relé PPPoE
Sobre a política de processamento de tags específicas do fornecedor para os pacotes PPPoE do lado do cliente no relé PPPoE
Quando o retransmissor PPPoE recebe pacotes PADI ou PADR, o retransmissor PPPoE processa o pacote de acordo com o fato de os pacotes conterem a etiqueta específica do fornecedor e a política de processamento de etiqueta específica do fornecedor configurada. Em seguida, o relé PPPoE envia os pacotes para o servidor PPPoE. A Tabela 1 mostra o processo detalhado.
Tabela 1 Política de processamento de tags específica do fornecedor no relé PPPoE
Restrições e diretrizes
Esse recurso pode ser configurado tanto na visualização do sistema quanto na visualização da interface. A configuração na visualização do sistema tem efeito em todas as interfaces. A configuração na visualização da interface tem efeito apenas na interface atual. A configuração na visualização da interface tem precedência sobre a configuração na visualização do sistema.
A política de processamento entra em vigor somente nos pacotes de entrada das interfaces.
Esse comando não é compatível com as portas membro do grupo de agregação da Camada 2. Se uma interface Ethernet de camada 2 for configurada com esse comando antes de entrar em um grupo de agregação de camada 2, o comando será apagado na porta membro depois que ela entrar no grupo de agregação.
Configuração da política global de processamento de tags específicas do fornecedor para os pacotes PADI e PADR do lado do cliente no relé PPPoE
Entre na visualização do sistema.
System ViewConfigure a política global de processamento de tags específicas do fornecedor para os pacotes PADI e PADR do lado do cliente no relé PPPoE.
pppoe-relay client-information strategy { drop | keep | replace }Por padrão, a política de processamento de tag específica do fornecedor global para os pacotes PADI e PADR do lado do cliente no relé PPPoE é substituir.
Configuração de uma política de processamento de tags específica do fornecedor em nível de interface para os pacotes PADI e PADR do lado do cliente no relé PPPoE
Entre na visualização do sistema.
System ViewEntre na visualização da interface Ethernet de camada 2.
interface interface-type interface-numberConfigure a política de processamento de tags específica do fornecedor para os pacotes PADI e PADR do lado do cliente para a interface no relé PPPoE.
pppoe-relay client-information strategy { drop | keep | replace }Por padrão, nenhuma política de processamento de tags específica do fornecedor para os pacotes PADI e PADR do lado do cliente é configurada para uma interface no relé PPPoE.
Exemplos de configuração PPPoE
Exemplo: Configuração do relé PPPoE
Configuração de rede
O host usa o método de acesso PPPoE para se conectar ao roteador por meio do switch. O switch atua como retransmissor de PPPoE. O roteador atua como servidor PPPoE e atribui endereços IPv4 ao cliente PPPoE por meio de um pool de endereços PPP.
Figura 4 Diagrama de rede
Procedimento
Configure o switch como o relé PPPoE:
# Habilite a função de retransmissão do PPPoE.
<Switch> system-view
[Switch] pppoe-relay enable# Configure a interface GigabitEthernet 1/0/2 voltada para o servidor como uma porta confiável de retransmissão de PPPoE.
[Interface GigabitEthernet 1/0/2
[Switch-GigabitEthernet1/0/2] pppoe-relay trustConfigure o roteador como um servidor PPPoE:
# Crie um usuário PPPoE.
<Router> system-view
[Router] local-user user1 class network
[Router-luser-network-user1] password simple pass1
[Router-luser-network-user1] service-type ppp
[Router-luser-network-user1] quit# Configure o Virtual-Template 1 para usar CHAP para autenticação e usar um pool de endereços PPP para atribuição de endereços IP. Defina o endereço IP do servidor DNS para o par.
[Interface virtual-template 1
[Router-Virtual-Template1] ppp authentication-mode chap domain system
[Router-Virtual-Template1] ppp chap user user1
[Router-Virtual-Template1] remote address pool 1
[Router-Virtual-Template1] ppp ipcp dns 8.8.8.8
[Router-Virtual-Template1] quit# Configure um pool de endereços PPP que contenha nove endereços IP atribuíveis e configure um endereço de gateway para o pool de endereços PPP.
[Router] ip pool 1 1.1.1.2 1.1.1.10
[Router] ip pool 1 gateway 1.1.1.1# Habilite o servidor PPPoE na GigabitEthernet 1/0/1 e vincule a interface ao Virtual-Template 1.
[Interface gigabitethernet 1/0/1
[Router-GigabitEthernet1/0/1] pppoe-server bind virtual-template 1
[Router-GigabitEthernet1/0/1] quit# Configure o domínio ISP padrão (sistema) para usar o esquema RADIUS para autenticação, autorização e contabilidade.
[Router] domain system
[Router-isp-system] authentication ppp radius-scheme rs1
[Router-isp-system] authorization ppp radius-scheme rs1
[Router-isp-system] accounting ppp radius-scheme rs1
[Router-isp-system] quit# Configure um esquema RADIUS e especifique o servidor de autenticação principal e o servidor de contabilidade principal.
[Router] radius scheme rs1
[Router-radius-rs1] primary authentication 11.110.91.146
[Router-radius-rs1] primary accounting 11.110.91.146
[Router-radius-rs1] key authentication simple expert
[Router-radius-rs1] key accounting simple expert
[Router-radius-rs1] quitConfigure o servidor RADIUS:
# Configure as senhas de autenticação e contabilidade como especialista.
# Adicione um usuário PPPoE com nome de usuário user1 e senha 123456. Para obter mais informações, consulte o manual do usuário do servidor RADIUS.
Verificação da configuração
# Instale o software cliente PPPoE e configure o nome de usuário e a senha (user1 e pass1 neste exemplo) nos hosts. Em seguida, os hosts podem usar o PPPoE para acessar a Internet por meio do roteador.