
10 - Gerenciamento e Monitoramento
Uso de ping, tracert e depuração do sistema
Ping
Sobre o ping
Utilize a ferramenta ping para determinar se um endereço é alcançável.
O ping envia solicitações de eco ICMP (ECHO-REQUEST) para o dispositivo de destino. Ao receber as solicitações, o dispositivo de destino responde com respostas de eco ICMP (ECHO-REPLY) para o dispositivo de origem. O dispositivo de origem exibe estatísticas sobre a operação do ping, incluindo o número de pacotes enviados, número de respostas de eco recebidas e o tempo de ida e volta. Você pode medir o desempenho da rede analisando essas estatísticas.
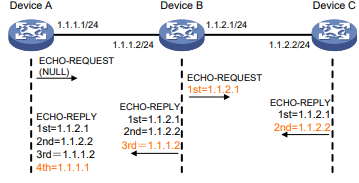
Você pode usar o comando ping –r para exibir os roteadores pelos quais as solicitações de eco ICMP passaram. O procedimento de teste do ping –r é mostrado na Figura 1:
- O dispositivo de origem (Dispositivo A) envia uma solicitação de eco ICMP para o dispositivo de destino (Dispositivo C) com a opção RR vazia.
- O dispositivo intermediário (Dispositivo B) adiciona o endereço IP de sua interface de saída (1.1.2.1) à opção RR da solicitação de eco ICMP e encaminha o pacote.
- Ao receber a solicitação, o dispositivo de destino copia a opção RR na solicitação e adiciona o endereço IP de sua interface de saída (1.1.2.2) à opção RR. Então, o dispositivo de destino envia uma resposta de eco ICMP.
- O dispositivo intermediário adiciona o endereço IP de sua interface de saída (1.1.1.2) à opção RR na resposta de eco ICMP e, em seguida, encaminha a resposta.
- Ao receber a resposta, o dispositivo de origem adiciona o endereço IP de sua interface de entrada (1.1.1.1) à opção RR. As informações detalhadas das rotas do Dispositivo A para o Dispositivo C são formatadas como: 1.1.1.1 <-> {1.1.1.2; 1.1.2.1} <-> 1.1.2.2.
Figura 1 Operação de ping
Uso de um comando ping para testar a conectividade da rede
Execute as seguintes tarefas em qualquer visualização:
- Determinar se um endereço IPv4 é alcançável.
ping [ ip ] [ -a source-ip | -c count | -f | -h ttl | -i interface-type
interface-number | -m interval | -n | -p pad | -q | -r | -s packet-size | -t
timeout | -tos tos | -v ] * hostAumente o tempo limite (indicado pela palavra-chave -t) em uma rede de baixa velocidade.
- Determinar se um endereço IPv6 pode ser acessado.
ping ipv6 [ -a source-ipv6 | -c count | -i interface-type
interface-number | -m interval | -q | -s packet-size | -t timeout | -tc
traffic-class | -v ] * host hostAumente o tempo de timeout (indicado pela palavra-chave -t) em uma rede de baixa velocidade.
Exemplo: Usando o utilitário ping
Configuração de rede
Conforme mostrado na Figura 2, determine se o Dispositivo A e o Dispositivo C podem se comunicar.
Figura 2 Diagrama de rede

Dispositivo Dispositivo DispositivoC
Procedimento
# Teste a conectividade entre o dispositivo A e o dispositivo C.
<DeviceA> ping 1.1.2.2
Ping 1.1.2.2 (1.1.2.2): 56 data bytes, press CTRL_C to break
56 bytes from 1.1.2.2: icmp_seq=0 ttl=254 time=2.137 ms
56 bytes from 1.1.2.2: icmp_seq=1 ttl=254 time=2.051 ms
56 bytes from 1.1.2.2: icmp_seq=2 ttl=254 time=1.996 ms
56 bytes from 1.1.2.2: icmp_seq=3 ttl=254 time=1.963 ms
56 bytes from 1.1.2.2: icmp_seq=4 ttl=254 time=1.991 ms
--- Ping statistics for 1.1.2.2 ---
5 packet(s) transmitted, 5 packet(s) received, 0.0% packet loss
round-trip min/avg/max/std-dev = 1.963/2.028/2.137/0.062 ms
A saída mostra as seguintes informações:
- O dispositivo A envia cinco pacotes ICMP para o dispositivo C e o dispositivo A recebe cinco pacotes ICMP.
- Nenhum pacote ICMP é perdido.
- A rota pode ser acessada.
Tracert
Sobre o tracert
O Tracert (também chamado de Traceroute) permite a recuperação dos endereços IP dos dispositivos da Camada 3 no caminho para um destino. Em caso de falha na rede, use o tracert para testar a conectividade da rede e identificar os nós com falha.
Figura 3 Operação do Tracert
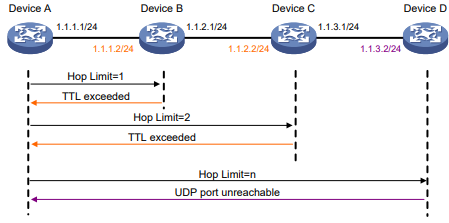
O Tracert usa mensagens de erro ICMP recebidas para obter os endereços IP dos dispositivos. O Tracert funciona como mostrado na Figura 3:
- O dispositivo de origem envia um pacote UDP com um valor TTL de 1 para o dispositivo de destino. A porta UDP de destino não é usada por nenhum aplicativo no dispositivo de destino.
- O primeiro salto (Dispositivo B, o primeiro dispositivo da Camada 3 que recebe o pacote) responde enviando uma mensagem de erro ICMP com TTL expirado para a origem, com seu endereço IP (1.1.1.2) encapsulado. Dessa forma, o dispositivo de origem pode obter o endereço do primeiro dispositivo da Camada 3 (1.1.1.2).
- O dispositivo de origem envia um pacote com um valor TTL de 2 para o dispositivo de destino.
- O segundo salto (Dispositivo C) responde com uma mensagem de erro ICMP expirada por TTL, que fornece ao dispositivo de origem o endereço do segundo dispositivo da Camada 3 (1.1.2.2).
- Esse processo continua até que um pacote enviado pelo dispositivo de origem chegue ao dispositivo de destino final. Como nenhum aplicativo usa a porta de destino especificada no pacote, o dispositivo de destino responde com uma mensagem ICMP de porta inalcançável para o dispositivo de origem, com seu endereço IP encapsulado. Dessa forma, o dispositivo de origem obtém o endereço IP do dispositivo de destino (1.1.3.2).
- O dispositivo de origem determina isso:
- O pacote chegou ao dispositivo de destino depois de receber a mensagem ICMP de porta inalcançável.
- O caminho para o dispositivo de destino é de 1.1.1.2 a 1.1.2.2 a 1.1.3.2.
Pré-requisitos
Antes de usar um comando tracert, execute as tarefas desta seção. Para uma rede IPv4:
- Habilite o envio de pacotes de tempo limite ICMP nos dispositivos intermediários (dispositivos entre o
dispositivos de origem e destino). Se os dispositivos intermediários forem dispositivos Intelbras, execute o comando ip ttl-expires enable nos dispositivos. Para obter mais informações sobre esse comando, consulte Referência de comandos de serviços da camada 3IP.
- Habilite o envio de pacotes ICMP de destino inacessível no dispositivo de destino. Se o dispositivo de destino for um dispositivo Intelbras, execute o comando ip unreachables enable. Para obter mais informações sobre esse comando, consulte Referência de comandos de serviços da camada 3IP.
Para uma rede IPv6:
- Habilite o envio de pacotes de tempo limite ICMPv6 nos dispositivos intermediários (dispositivos entre os dispositivos de origem e de destino). Se os dispositivos intermediários forem dispositivos Intelbras, execute o comando
comando ipv6 hoplimit-expires enable nos dispositivos. Para obter mais informações sobre esse comando, consulte Referência de comandos de serviços de IP de camada 3.
- Habilite o envio de pacotes ICMPv6 de destino inacessível no dispositivo de destino. Se o dispositivo de destino for um dispositivo Intelbras, execute o comando ipv6 unreachables enable. Para obter mais informações sobre esse comando, consulte Referência de comandos de serviços da camada 3IP.
Uso de um comando tracert para identificar falhas ou todos os nós em um caminho
Execute as seguintes tarefas em qualquer visualização:
- Rastrear a rota para um destino IPv4.
tracert [ -a source-ip | -f first-ttl | -m max-ttl | -p port | -q
packet-number | -t tos | -w timeout ] * host
- Rastrear a rota para um destino IPv6.
tracert ipv6 [ -f first-hop | -m max-hops | -p port | -q packet-number | -t
traffic-class | -w timeout ] * host
Exemplo: Usando o utilitário tracert
Configuração de rede
Conforme mostrado na Figura 4, o Dispositivo A não conseguiu fazer Telnet no Dispositivo C.
Teste a conectividade de rede entre o Dispositivo A e o Dispositivo C. Se eles não conseguirem se comunicar, localize os nós com falha na rede.
Figura 4 Diagrama de rede

Dispositivo Dispositivo DispositivoC
Procedimento
- Configure endereços IP para os dispositivos, conforme mostrado na Figura 4.
- Configure uma rota estática no Dispositivo A.
<DeviceA> system-view
[DeviceA] ip route-static 0.0.0.0 0.0.0.0 1.1.1.2
- Teste a conectividade entre o dispositivo A e o dispositivo C.
[DeviceA] ping 1.1.2.2
Ping 1.1.2.2(1.1.2.2): 56 -data bytes, press CTRL_C to break
Request time out
Request time out
Request time out
Request time out
Request time out
--- Ping statistics for 1.1.2.2 ---
5 packet(s) transmitted,0 packet(s) received,100.0% packet loss
A saída mostra que o Dispositivo A e o Dispositivo C não conseguem se comunicar.
- Identificar nós com falha:
# Habilite o envio de pacotes de tempo limite ICMP no Dispositivo B.
<DeviceB> system-view
[DeviceB] ip ttl-expires enable# Habilite o envio de pacotes ICMP de destino inalcançável no Dispositivo C.
<DeviceC> system-view
[DeviceC] ip unreachables enable
# Identificar os nós com falha.
[DeviceA] tracert 1.1.2.2
traceroute to 1.1.2.2 (1.1.2.2) 30 hops at most,40 bytes each packet, press CTRL_C
to break
1 1.1.1.2 (1.1.1.2) 1 ms 2 ms 1 ms
2 * * *
3 * * *
4 * * *
5
[DeviceA]
A saída mostra que o Dispositivo A pode alcançar o Dispositivo B, mas não pode alcançar o Dispositivo C. Ocorreu um erro na conexão entre o Dispositivo B e o Dispositivo C.
- Para identificar a causa do problema, execute os seguintes comandos no Dispositivo A e no Dispositivo C:
- Execute o comando debugging ip icmp e verifique se o Dispositivo A e o Dispositivo C podem enviar e receber os pacotes ICMP corretos.
- Execute o comando display ip routing-table para verificar se o Dispositivo A e o Dispositivo C têm uma rota entre si.
Depuração do sistema
Sobre a depuração do sistema
O dispositivo suporta depuração para a maioria dos protocolos e recursos e fornece informações de depuração para ajudar os usuários a diagnosticar erros.
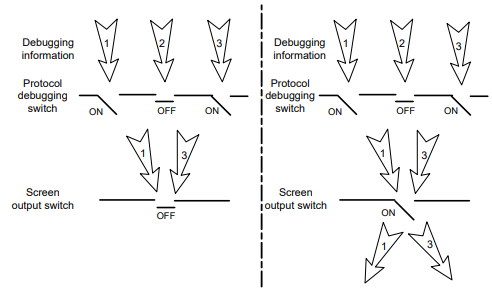
Os seguintes switches controlam a exibição das informações de depuração:
Chave de depuração de módulo - Controla se as informações de depuração específicas do módulo devem ser geradas.
Chave de saída de tela - Controla se as informações de depuração devem ser exibidas em uma determinada tela. Use os comandos terminal monitor e terminal logging level para ativar a chave de saída de tela. Para obter mais informações sobre esses dois comandos, consulte Referência de comandos de gerenciamento e monitoramento de rede.
Conforme mostrado na Figura 5, o dispositivo pode fornecer depuração para os três módulos 1, 2 e 3. As informações de depuração podem ser exibidas em um terminal somente quando a chave de depuração do módulo e a chave de saída da tela estiverem ativadas.
Normalmente, as informações de depuração são exibidas em um console. Você também pode enviar informações de depuração para outros destinos. Para obter mais informações, consulte "Configuração do centro de informações".
Figura 5 Relação entre o módulo e a chave de saída da tela
Depuração de um módulo de recurso
Restrições e diretrizes
 CUIDADO:
CUIDADO:
A saída de mensagens de depuração excessivas aumenta o uso da CPU e reduz o desempenho do sistema. Para garantir o desempenho do sistema, ative a depuração somente para módulos que estejam em uma condição excepcional.
Habilite a depuração de módulos para fins de solução de problemas. Quando a depuração estiver concluída, use o comando
comando undo debugging all para desativar todas as funções de depuração.
Procedimento
- Ativar a depuração de um módulo.
debugging module-name [ option ]Por padrão, a depuração é desativada para todos os módulos. Esse comando está disponível na visualização do usuário.
- (Opcional.) Exibir os recursos de depuração ativados.
display debugging [ module-name ]Configuração do NQA
Sobre o NQA
O analisador de qualidade de rede (NQA) permite medir o desempenho da rede, verificar os níveis de serviço para serviços e aplicativos IP e solucionar problemas de rede.
Mecanismo operacional do NQA
Uma operação de NQA contém um conjunto de parâmetros, como o tipo de operação, o endereço IP de destino e o número da porta, para definir como a operação é executada. Cada operação do NQA é identificada pela combinação do nome do administrador e da tag da operação. Você pode configurar o cliente NQA para executar as operações em períodos de tempo programados.
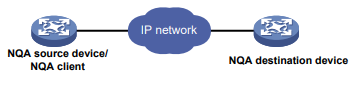
Conforme mostrado na Figura 1, o dispositivo de origem do NQA (cliente NQA) envia dados para o dispositivo de destino do NQA simulando serviços e aplicativos IP para medir o desempenho da rede.
Todos os tipos de operações de NQA requerem o cliente NQA, mas somente as operações de TCP, eco UDP, jitter UDP e voz requerem o servidor NQA. As operações de NQA para serviços que já são fornecidos pelo dispositivo de destino, como FTP, não precisam do servidor NQA. Você pode configurar o servidor NQA para escutar e responder a endereços IP e portas específicos para atender a várias necessidades de teste.
Figura 1 Diagrama de rede
Depois de iniciar uma operação de NQA, o cliente NQA executa periodicamente a operação no intervalo especificado usando o comando frequency.
Você pode definir o número de sondas que o cliente NQA executa em uma operação usando o comando probe count. Para as operações de voz e de jitter de caminho, o cliente NQA executa apenas uma sonda por operação e o comando de contagem de sondas não está disponível.
Colaboração com a trilha
O NQA pode colaborar com o módulo Track para notificar os módulos de aplicativos sobre alterações de estado ou desempenho, de modo que os módulos de aplicativos possam tomar ações predefinidas.
A colaboração NQA + Track está disponível para os seguintes módulos de aplicativos:
- VRRP
- Roteamento estático.
- Roteamento baseado em políticas.
- Redirecionamento de tráfego
- Link inteligente
A seguir, descrevemos como uma rota estática destinada a 192.168.0.88 é monitorada por meio de colaboração:
- O NQA monitora a capacidade de alcance do 192.168.0.88.
- Quando o 192.168.0.88 se torna inacessível, o NQA notifica o módulo Track sobre a alteração.
- O módulo Track notifica o módulo de roteamento estático sobre a mudança de estado.
- O módulo de roteamento estático define a rota estática como inválida de acordo com uma ação predefinida. Para obter mais informações sobre colaboração, consulte o Guia de configuração de alta disponibilidade.
Monitoramento de limites
O monitoramento de limites permite que o cliente NQA tome uma ação predefinida quando as métricas de desempenho da operação do NQA violam os limites especificados.
A Tabela 1 descreve as relações entre as métricas de desempenho e os tipos de operação do NQA.
Tabela 1 Métricas de desempenho e tipos de operação do NQA
| Métrica de desempenho | Tipos de operação NQA que podem coletar a métrica | ||
| Duração da sonda | Todos os tipos de operação NQA, exceto jitter UDP, tracert UDP, jitter de caminho e voz | ||
| Número de falhas na sonda | Todos os tipos de operação NQA, exceto jitter UDP, tracert UDP, jitter de caminho e voz | ||
| Tempo de ida e volta | Jitter ICMP, jitter UDP e voz | ||
| Número de pacotes descartados | Jitter ICMP, jitter UDP e voz | ||
| Jitter unidirecional (origem para destino ou destino para origem) | Jitter ICMP, jitter UDP e voz | ||
| Atraso unidirecional (origem para destino ou destino para origem) | Jitter ICMP, jitter UDP e voz | ||
| Fator de comprometimento do planejamento calculado (ICPIF) (consulte "Configuração da operação de voz") | Voz | ||
| Mean Opinion Scores (MOS) (consulte "Configuração da operação de voz") | Voz |
Modelos NQA
Um modelo de NQA é um conjunto de parâmetros (como endereço de destino e número de porta) que define como uma operação de NQA é executada. Os recursos podem usar o modelo de NQA para coletar estatísticas.
Você pode criar vários modelos de NQA no cliente NQA. Cada modelo deve ser identificado por um nome de modelo exclusivo.
Visão geral das tarefas do NQA
Para configurar o NQA, execute as seguintes tarefas:
- Configuração do servidor NQA
Execute essa tarefa no dispositivo de destino antes de configurar as operações de TCP, eco UDP, jitter UDP, e voz.
- Ativação do cliente NQA
- Configuração de operações de NQA ou modelos de NQA Selecione as seguintes tarefas, conforme necessário:
- Configuração de operações de NQA no cliente NQA
- Configuração de modelos de NQA no cliente NQA
Depois de configurar uma operação de NQA, você pode programar o cliente NQA para executar a operação de NQA.
Um modelo de NQA não é executado imediatamente após ser configurado. O modelo cria e executa a operação NQA somente quando ela é exigida pelo recurso (como balanceamento de carga) ao qual o modelo é aplicado.
Configuração do servidor NQA
Restrições e diretrizes
Para executar operações de TCP, eco UDP, jitter UDP e voz, você deve configurar o servidor NQA no dispositivo de destino. O servidor NQA escuta e responde a solicitações nos endereços IP e portas especificados.
É possível configurar vários serviços de escuta TCP ou UDP em um servidor NQA, sendo que cada um corresponde a um endereço IP e a um número de porta específicos.
O endereço IP e o número da porta de um serviço de escuta devem ser exclusivos no servidor NQA e corresponder à configuração no cliente NQA.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o servidor NQA.
nqa server enablePor padrão, o servidor NQA está desativado.
- Configure um serviço de escuta TCP.
nqa server tcp-connect ip-address port-number [ tos tos ]Essa tarefa é necessária apenas para operações TCP.
- Configure um serviço de escuta UDP.
nqa server udp-echo ip-address port-number [ tos tos ]Essa tarefa é necessária apenas para operações de eco UDP, jitter UDP e voz.
Ativação do cliente NQA
- Entre na visualização do sistema.
system-view- Ativar o cliente NQA.
nqa agent enablePor padrão, o cliente NQA está ativado.
A configuração do cliente NQA entra em vigor depois que você ativa o cliente NQA.
Configuração de operações de NQA no cliente NQA
Visão geral das tarefas de operações do NQA
Para configurar as operações de NQA, execute as seguintes tarefas:
- Configuração de uma operação de NQA
- Configuração da operação de eco ICMP
- Configuração da operação de jitter ICMP
- Configuração da operação DHCP
- Configuração da operação de DNS
- Configuração da operação de FTP
- Configuração da operação HTTP
- Configuração da operação de jitter UDP
- Configuração da operação de SNMP
- Configuração da operação TCP
- Configuração da operação de eco UDP
- Configuração da operação UDP tracert
- Configuração da operação de voz
- Configuração da operação DLSw
- Configuração da operação de jitter de caminho
- (Opcional.) Configuração de parâmetros opcionais para a operação de NQA
- (Opcional.) Configuração do recurso de colaboração
- (Opcional.) Configuração do monitoramento de limites
- (Opcional.) Configuração do recurso de coleta de estatísticas NQA
- (Opcional.) Configuração do salvamento dos registros do histórico de NQA
- Agendamento da operação de NQA no cliente NQA
Configuração da operação de eco ICMP
Sobre a operação de eco ICMP
A operação ICMP echo mede a capacidade de alcance de um dispositivo de destino. Ela tem a mesma função que o comando ping, mas fornece mais informações de saída. Além disso, se houver vários caminhos entre os dispositivos de origem e de destino, você poderá especificar o próximo salto para a operação de eco ICMP.
A operação de eco ICMP envia uma solicitação de eco ICMP para o dispositivo de destino por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de eco ICMP e entre em sua visualização.
type icmp-echo- Especifique o endereço IP de destino para solicitações de eco ICMP. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o endereço IP de origem para solicitações de eco ICMP. Escolha uma das tarefas a seguir:
- Use o endereço IP da interface especificada como o endereço IP de origem.
source interface interface-type interface-numberPor padrão, o endereço IP de origem das solicitações de eco ICMP é o endereço IP principal da interface de saída.
A interface de origem especificada deve estar ativa.
- Especifique o endereço IPv4 de origem.
source ip ip-addressPor padrão, o endereço IPv4 de origem das solicitações de eco ICMP é o endereço IPv4 primário da interface de saída.
O endereço IPv4 de origem especificado deve ser o endereço IPv4 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique o endereço IPv6 de origem.
source ipv6 ipv6-addressPor padrão, o endereço IPv6 de origem das solicitações de eco ICMP é o endereço IPv6 primário da interface de saída.
O endereço IPv6 de origem especificado deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique a interface de saída ou o endereço IP do próximo salto para solicitações de eco ICMP. Escolha uma das tarefas a seguir:
- Especifique a interface de saída para solicitações de eco ICMP.
out interface interface-type interface-numberPor padrão, a interface de saída para solicitações de eco ICMP não é especificada. O cliente NQA determina a interface de saída com base na pesquisa da tabela de roteamento.
- Especifique o endereço IPv4 do próximo salto.
next-hop ip ip-addressPor padrão, nenhum endereço IPv4 de próximo salto é especificado.
- Especifique o endereço IPv6 do próximo salto.
next-hop ipv6 ipv6-addressPor padrão, nenhum endereço IPv6 de próximo salto é especificado.
- (Opcional.) Defina o tamanho da carga útil para cada solicitação de eco ICMP.
data-size sizeO tamanho padrão da carga útil é de 100 bytes.
- (Opcional.) Especifique a cadeia de caracteres de preenchimento de carga útil para solicitações de eco ICMP.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
Configuração da operação de jitter ICMP
Sobre a operação de jitter ICMP
A operação de jitter ICMP mede jitters unidirecionais e bidirecionais. O resultado da operação o ajuda a determinar se a rede pode transportar serviços sensíveis a jitter, como serviços de voz e vídeo em tempo real.
A operação de jitter do ICMP funciona da seguinte forma:
- O cliente NQA envia pacotes ICMP para o dispositivo de destino.
- O dispositivo de destino marca a hora de cada pacote que recebe e, em seguida, envia o pacote de volta ao cliente NQA.
- Ao receber as respostas, o cliente NQA calcula o jitter de acordo com os registros de data e hora.
A operação de jitter ICMP envia um número de pacotes ICMP para o dispositivo de destino por sonda. O número de pacotes a serem enviados é determinado pelo uso do comando probe packet-number.
Restrições e diretrizes
O comando display nqa history não exibe os resultados ou as estatísticas da operação de jitter ICMP. Para exibir os resultados ou as estatísticas da operação, use o comando display nqa result ou display nqa statistics.
Antes de iniciar a operação, certifique-se de que os dispositivos de rede estejam sincronizados com a hora usando NTP. Para obter mais informações sobre o NTP, consulte "Configuração do NTP".
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de jitter ICMP e entre em sua visualização.
type icmp-jitter- Especifique o endereço IP de destino para pacotes ICMP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Defina o número de pacotes ICMP enviados por sonda.
probe packet-number packet-numberA configuração padrão é 10.
probe packet-interval intervalA configuração padrão é 20 milissegundos.
probe packet-timeout timeoutA configuração padrão é 3000 milissegundos.
- Especifique o endereço IP de origem para pacotes ICMP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes ICMP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote ICMP poderá ser enviado.
Configuração da operação DHCP
Sobre a operação do DHCP
A operação DHCP mede se o servidor DHCP pode ou não responder às solicitações do cliente. O DHCP também mede a quantidade de tempo que o cliente NQA leva para obter um endereço IP de um servidor DHCP.
O cliente NQA simula o agente de retransmissão DHCP para encaminhar solicitações DHCP para aquisição de endereço IP do servidor DHCP. A interface que executa a operação DHCP não altera seu endereço IP. Quando a operação de DHCP é concluída, o cliente NQA envia um pacote para liberar o endereço IP obtido.
A operação DHCP adquire um endereço IP do servidor DHCP por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de DHCP e entre em sua visualização.
type dhcp- Especifique o endereço IP do servidor DHCP como o endereço IP de destino dos pacotes DHCP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique a interface de saída para os pacotes de solicitação de DHCP.
out interface interface-type interface-numberPor padrão, o cliente NQA determina a interface de saída com base na pesquisa da tabela de roteamento.
- Especifique o endereço IP de origem dos pacotes de solicitação de DHCP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes de solicitação de DHCP é o endereço IP primário de sua interface de saída.
O endereço IP de origem especificado deve ser o endereço IP de uma interface local, e a interface local deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
Configuração da operação de DNS
Sobre a operação do DNS
A operação de DNS simula a resolução de nomes de domínio e mede o tempo que o cliente NQA leva para resolver um nome de domínio em um endereço IP por meio de um servidor DNS. A entrada de DNS obtida não é salva.
A operação de DNS resolve um nome de domínio em um endereço IP por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de DNS e entre em sua visualização.
type dns- Especifique o endereço IP do servidor DNS como o endereço IP de destino dos pacotes DNS.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o nome de domínio a ser traduzido.
resolve-target domain-namePor padrão, nenhum nome de domínio é especificado.
Configuração da operação de FTP
Sobre a operação de FTP
A operação FTP mede o tempo para o cliente NQA transferir um arquivo para um servidor FTP ou fazer download de um arquivo a partir dele.
A operação FTP faz upload ou download de um arquivo de um servidor FTP por sonda.
Restrições e diretrizes
Para carregar (colocar) um arquivo no servidor FTP, use o comando filename para especificar o nome do arquivo que deseja carregar. O arquivo deve existir no cliente NQA.
Para fazer download (obter) de um arquivo do servidor FTP, inclua o nome do arquivo que deseja fazer download no comando url. O arquivo deve existir no servidor FTP. O cliente NQA não salva o arquivo obtido do servidor FTP.
Use um arquivo pequeno para a operação de FTP. Um arquivo grande pode resultar em falha na transferência devido ao tempo limite ou pode afetar outros serviços devido à quantidade de largura de banda da rede que ele ocupa.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de FTP e entre em sua visualização.
type ftp- Especifique um nome de usuário de login de FTP.
username usernamePor padrão, nenhum nome de usuário de login de FTP é especificado.
- Especifique uma senha de login de FTP.
password { cipher | simple } stringPor padrão, nenhuma senha de login de FTP é especificada.
- Especifique o endereço IP de origem dos pacotes de solicitação de FTP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes de solicitação de FTP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhuma solicitação de FTP poderá ser enviada.
- Defina o modo de transmissão de dados.
mode { active | passive }O modo padrão é active.
operation { get | put }O tipo de operação FTP padrão é get.
- Especifique o URL de destino para a operação de FTP.
url urlPor padrão, nenhum URL de destino é especificado para uma operação de FTP. Digite o URL em um dos seguintes formatos:
ftp://host/filename.ftp://host:port/filename.O argumento filename é necessário apenas para a operação get.
- Especifique o nome do arquivo a ser carregado.
filename file-namePor padrão, nenhum arquivo é especificado.
Essa tarefa é necessária apenas para a operação de colocação.
A configuração não entra em vigor para a operação get.
Configuração da operação HTTP
Sobre a operação HTTP
A operação HTTP mede o tempo que o cliente NQA leva para obter respostas de um servidor HTTP. A operação HTTP é compatível com os seguintes tipos de operação:
Get - Recupera dados, como uma página da Web, do servidor HTTP.
Post - Envia dados para o servidor HTTP para processamento.
Raw - Envia uma solicitação HTTP definida pelo usuário para o servidor HTTP. Você deve configurar manualmente o conteúdo da solicitação HTTP a ser enviada.
A operação HTTP conclui a operação do tipo especificado por probe.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de HTTP e insira sua visualização.
type http- Especifique o URL de destino para a operação HTTP.
url urlPor padrão, nenhum URL de destino é especificado para uma operação HTTP. Digite o URL em um dos seguintes formatos:
http://host/resourcehttp://host:port/resourcehttp://host:port/resource- Especifique um nome de usuário de login HTTP.
username usernamePor padrão, nenhum nome de usuário de login HTTP é especificado.
password { cipher | simple } stringPor padrão, nenhuma senha de login HTTP é especificada.
- Especifique a versão do HTTP.
version { v1.0 | v1.1 }Por padrão, o HTTP 1.0 é usado.
operation { get | post | raw }O tipo de operação HTTP padrão é get.
Se você definir o tipo de operação como bruto, o cliente adicionará o conteúdo configurado na exibição de solicitação bruta à solicitação HTTP a ser enviada ao servidor HTTP.
- Configure a solicitação bruta de HTTP.
- Entrar na visualização de solicitação bruta.
raw-requestToda vez que você entra na visualização de solicitação bruta, o conteúdo da solicitação bruta configurada anteriormente é apagado.
- Digite ou cole o conteúdo da solicitação.
Por padrão, nenhum conteúdo de solicitação é configurado.
Para garantir operações bem-sucedidas, certifique-se de que o conteúdo da solicitação não contenha aliases de comando configurados usando o comando alias. Para obter mais informações sobre o comando alias, consulte Comandos da CLI em Referência de comandos básicos.
- Salve a entrada e retorne à visualização da operação HTTP:
quitEssa etapa é necessária somente quando o tipo de operação é definido como bruto.
- Especifique o endereço IP de origem para os pacotes HTTP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes HTTP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de solicitação poderá ser enviado.
Configuração da operação de jitter UDP
Sobre a operação de jitter UDP
A operação de jitter UDP mede jitters unidirecionais e bidirecionais. O resultado da operação o ajuda a determinar se a rede pode transportar serviços sensíveis a jitter, como serviços de voz e vídeo em tempo real.
A operação de jitter UDP funciona da seguinte forma:
- O cliente NQA envia pacotes UDP para a porta de destino.
- O dispositivo de destino marca a hora de cada pacote que recebe e, em seguida, envia o pacote de volta ao cliente NQA.
- Ao receber as respostas, o cliente NQA calcula o jitter de acordo com os registros de data e hora.
A operação de jitter UDP envia um número de pacotes UDP para o dispositivo de destino por sonda. O número de pacotes a serem enviados é determinado pelo uso do comando probe packet-number.
A operação de jitter UDP requer tanto o servidor NQA quanto o cliente NQA. Antes de executar a operação de jitter UDP, configure o serviço de escuta UDP no servidor NQA. Para obter mais informações sobre a configuração do serviço de escuta UDP, consulte "Configuração do servidor NQA".
Restrições e diretrizes
Para garantir o sucesso das operações de jitter UDP e evitar afetar os serviços existentes, não execute as operações em portas conhecidas de 1 a 1023.
O comando display nqa history não exibe os resultados ou as estatísticas da operação de jitter UDP. Para exibir os resultados ou as estatísticas da operação de jitter UDP, use o comando display nqa result ou display nqa statistics.
Antes de iniciar a operação, certifique-se de que os dispositivos de rede estejam sincronizados com a hora usando NTP. Para obter mais informações sobre o NTP, consulte "Configuração do NTP".
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de jitter UDP e entre em sua visualização.
type udp-jitter- Especifique o endereço IP de destino para pacotes UDP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
O endereço IP de destino deve ser o mesmo que o endereço IP do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o número da porta de destino para pacotes UDP.
destination ip ip-addressPor padrão, nenhum número de porta de destino é especificado.
O número da porta de destino deve ser o mesmo que o número da porta do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o endereço IP de origem para pacotes UDP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes UDP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote UDP poderá ser enviado.
- Especifique o número da porta de origem para pacotes UDP.
destination port port-numberPor padrão, o cliente NQA escolhe aleatoriamente uma porta não utilizada como a porta de origem quando a operação é iniciada.
- Defina o número de pacotes UDP enviados por sonda. sonda número de pacotes número de pacotes A configuração padrão é 10.
- Defina o intervalo para o envio de pacotes UDP.
probe packet-interval intervalA configuração padrão é 20 milissegundos.
probe packet-timeout timeoutA configuração padrão é 3000 milissegundos.
- (Opcional.) Defina o tamanho da carga útil de cada pacote UDP.
data-size sizeO tamanho padrão da carga útil é de 100 bytes.
- (Opcional.) Especifique a cadeia de caracteres de preenchimento de carga útil para pacotes UDP.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
Configuração da operação de SNMP
Sobre a operação SNMP
A operação SNMP testa se o serviço SNMP está disponível em um agente SNMP.
A operação SNMP envia um pacote SNMPv1, um pacote SNMPv2c e um pacote SNMPv3 para o agente SNMP por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de SNMP e entre em sua visualização.
type snmp- Especifique o endereço de destino dos pacotes SNMP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o endereço IP de origem dos pacotes SNMP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes SNMP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote SNMP poderá ser enviado.
- Especifique o número da porta de origem dos pacotes SNMP.
destination port port-numberPor padrão, o cliente NQA escolhe aleatoriamente uma porta não utilizada como a porta de origem quando a operação é iniciada.
- Especifique o nome da comunidade transportado nos pacotes SNMPv1 e SNMPv2c.
community read { cipher | simple } community-namePor padrão, os pacotes SNMPv1 e SNMPv2c contêm o nome de comunidade public.
Certifique-se de que o nome da comunidade especificado seja o mesmo que o nome da comunidade configurado no agente SNMP.
Configuração da operação TCP
Sobre a operação do TCP
A operação TCP mede o tempo que o cliente NQA leva para estabelecer uma conexão TCP com uma porta no servidor NQA.
A operação TCP requer tanto o servidor NQA quanto o cliente NQA. Antes de executar uma operação TCP, configure um serviço de escuta TCP no servidor NQA. Para obter mais informações sobre a configuração do serviço de escuta TCP, consulte "Configuração do servidor NQA".
A operação TCP configura uma conexão TCP por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de TCP e entre em sua visualização.
type tcp- Especifique o endereço de destino dos pacotes TCP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
O endereço de destino deve ser o mesmo que o endereço IP do serviço de escuta TCP configurado no servidor NQA. Para configurar um serviço de escuta TCP no servidor, use o comando nqa server tcp-connect.
- Especifique a porta de destino para pacotes TCP.
destination ip ip-addressPor padrão, nenhum número de porta de destino é configurado.
O número da porta de destino deve ser o mesmo que o número da porta do serviço de escuta TCP configurado no servidor NQA. Para configurar um serviço de escuta TCP no servidor, use o comando nqa server tcp-connect.
- Especifique o endereço IP de origem para pacotes TCP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes TCP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote TCP poderá ser enviado.
Configuração da operação de eco UDP
Sobre a operação de eco UDP
A operação de eco UDP mede o tempo de ida e volta entre o cliente e uma porta UDP no servidor NQA.
A operação de eco UDP requer tanto o servidor NQA quanto o cliente NQA. Antes de executar uma operação de eco UDP, configure um serviço de escuta UDP no servidor NQA. Para obter mais informações sobre a configuração do serviço de escuta UDP, consulte "Configuração do servidor NQA".
A operação de eco UDP envia um pacote UDP para o dispositivo de destino por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de eco UDP e entre em sua visualização.
type udp-echo- Especifique o endereço de destino para pacotes UDP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
O endereço de destino deve ser o mesmo que o endereço IP do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o número da porta de destino para pacotes UDP.
destination ip ip-addressPor padrão, nenhum número de porta de destino é especificado.
O número da porta de destino deve ser o mesmo que o número da porta do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o endereço IP de origem para pacotes UDP.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes UDP é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote UDP poderá ser enviado.
- Especifique o número da porta de origem para pacotes UDP.
destination port port-numberPor padrão, o cliente NQA escolhe aleatoriamente uma porta não utilizada como a porta de origem quando a operação é iniciada.
- (Opcional.) Defina o tamanho da carga útil para cada pacote UDP.
data-size sizeA configuração padrão é 100 bytes.
- (Opcional.) Especifique a cadeia de caracteres de preenchimento de carga útil para pacotes UDP.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
Configuração da operação UDP tracert
Sobre a operação de tracert UDP
A operação UDP tracert determina o caminho de roteamento do dispositivo de origem para o dispositivo de destino.
A operação UDP tracert envia um pacote UDP para um salto ao longo do caminho por sonda.
Restrições e diretrizes
A operação de tracert UDP não é compatível com redes IPv6. Para determinar o caminho de roteamento que os pacotes IPv6 percorrem da origem até o destino, use o comando tracert ipv6. Para obter mais informações sobre o comando, consulte Referência de comandos de gerenciamento e monitoramento de rede.
Pré-requisitos
Antes de configurar a operação UDP tracert, você deve executar as seguintes tarefas:
Habilite o envio de mensagens ICMP de tempo excedido nos dispositivos intermediários entre os dispositivos de origem e de destino. Se os dispositivos intermediários forem dispositivos Intelbras, use o comando ip ttl-expires enable.
Habilite o envio de mensagens ICMP de destino inalcançável no dispositivo de destino. Se o dispositivo de destino for um dispositivo Intelbras, use o comando ip unreachables enable.
Para obter mais informações sobre os comandos ip ttl-expires enable e ip unreachables enable, consulte Referência de comandos de serviços da camada 3IP.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de operação UDP tracert e entre em sua visualização.
type udp-tracert- Especifique o dispositivo de destino para a operação. Escolha uma das tarefas a seguir:
- Especifique o dispositivo de destino por seu nome de host.
destination host host-namePor padrão, nenhum nome de host de destino é especificado.
- Especifique o dispositivo de destino por seu endereço IP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o número da porta de destino para pacotes UDP.
destination ip ip-addressPor padrão, o número da porta de destino é 33434.
Esse número de porta deve ser um número não utilizado no dispositivo de destino, para que o dispositivo de destino possa responder com mensagens ICMP de porta inalcançável.
- Especifique uma interface de saída para pacotes UDP.
out interface interface-type interface-numberPor padrão, o cliente NQA determina a interface de saída com base na pesquisa da tabela de roteamento.
- Especifique o endereço IP de origem para pacotes UDP.
- Especifique o endereço IP da interface especificada como o endereço IP de origem.
source interface interface-type interface-numberPor padrão, o endereço IP de origem dos pacotes UDP é o endereço IP primário de sua interface de saída.
- Especifique o endereço IP de origem.
source ip ip-addressA interface de origem especificada deve estar ativa. O endereço IP de origem deve ser o endereço IP de uma interface local, e a interface local deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique o número da porta de origem para pacotes UDP.
destination port port-numberPor padrão, o cliente NQA escolhe aleatoriamente uma porta não utilizada como a porta de origem quando a operação é iniciada.
- Defina o número máximo de falhas consecutivas da sonda.
max-failure timesA configuração padrão é 5.
- Definir o valor TTL inicial para pacotes UDP.
init-ttl valueA configuração padrão é 1.
- (Opcional.) Defina o tamanho da carga útil para cada pacote UDP.
data-size sizeA configuração padrão é 100 bytes.
- (Opcional.) Habilite o recurso de não fragmentação.
no-fragment enablePor padrão, o recurso de não fragmentação está desativado.
Configuração da operação de Voice
Sobre a operação de Voice
A operação de voz mede o desempenho da rede VoIP. A operação de voz funciona da seguinte forma:
- O cliente NQA envia pacotes de voz em intervalos de envio para o dispositivo de destino (NQA servidor).
Os pacotes de voz são de um dos seguintes tipos de codec:
- G.711 A-law.
- G.711 µ-law.
- G.729 A-law.
- O dispositivo de destino registra a hora de cada pacote de voz que recebe e o envia de volta à origem.
A operação de voz envia um número de pacotes de voz para o dispositivo de destino por sonda. O número de pacotes a serem enviados por sonda é determinado pelo uso do comando probe packet-number.
Os seguintes parâmetros que refletem o desempenho da rede VoIP podem ser calculados usando as métricas coletadas pela operação de voz:
Calculated Planning Impairment Factor (ICPIF) - Mede o comprometimento da qualidade da voz em uma rede VoIP. É determinado pela perda de pacotes e pelo atraso. Um valor mais alto representa uma qualidade de serviço inferior.
Mean Opinion Scores (MOS) - Um valor MOS pode ser avaliado usando o valor ICPIF, no intervalo de 1 a 5. Um valor mais alto representa uma qualidade de serviço superior.
A avaliação da qualidade de voz depende da tolerância dos usuários à qualidade de voz. Para usuários com maior tolerância à qualidade de voz, use o comando advantage-factor para definir um fator de vantagem. Quando o sistema calcula o valor ICPIF, ele subtrai o fator de vantagem para modificar os valores ICPIF e MOS para avaliação da qualidade de voz.
A operação de voz requer tanto o servidor NQA quanto o cliente NQA. Antes de executar uma operação de voz, configure um serviço de escuta UDP no servidor NQA. Para obter mais informações sobre a configuração do serviço de escuta UDP, consulte "Configuração do servidor NQA".
Restrições e diretrizes
Para garantir o sucesso das operações de voz e evitar afetar os serviços existentes, não execute as operações em portas conhecidas de 1 a 1023.
O comando display nqa history não exibe os resultados ou as estatísticas da operação de voz. Para exibir os resultados ou as estatísticas da operação de voz, use o comando display nqa result ou display nqa statistics.
Antes de iniciar a operação, certifique-se de que os dispositivos de rede estejam sincronizados com a hora usando NTP. Para obter mais informações sobre o NTP, consulte "Configuração do NTP".
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de voz e entre em sua visualização.
type voice- Especifique o endereço IP de destino para pacotes de voz.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é configurado.
O endereço IP de destino deve ser o mesmo que o endereço IP do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o número da porta de destino dos pacotes de voz.
destination ip ip-addressPor padrão, nenhum número de porta de destino é configurado.
O número da porta de destino deve ser o mesmo que o número da porta do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o endereço IP de origem dos pacotes de voz.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes de voz é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de voz poderá ser enviado.
- Especifique o número da porta de origem dos pacotes de voz.
destination port port-numberPor padrão, o cliente NQA escolhe aleatoriamente uma porta não utilizada como a porta de origem quando a operação é iniciada.
- Configure os parâmetros básicos de operação de voz.
- Especifique o tipo de codec.
codec-type { g711a | g711u | g729a }Por padrão, o tipo de codec é G.711 A-law.
- Defina o fator de vantagem para calcular os valores de MOS e ICPIF.
advantage-factor factorPor padrão, o fator de vantagem é 0.
- Configure os parâmetros da sonda para a operação de voz.
- Defina o número de pacotes de voz a serem enviados por sonda.
probe packet-number packet-numberA configuração padrão é 1000.
-
Defina o intervalo para o envio de pacotes de voz.
A configuração padrão é 20 milissegundos.probe packet-interval interval - Especifique por quanto tempo o cliente NQA aguarda uma resposta do servidor antes de considerar que a resposta expirou.
probe packet-timeout timeoutA configuração padrão é 5000 milissegundos.
- Configure os parâmetros de carga útil.
- Defina o tamanho da carga útil dos pacotes de voz.
data-size sizePor padrão, o tamanho do pacote de voz varia de acordo com o tipo de codec. O tamanho padrão do pacote é 172 bytes para o tipo de codec G.711A-law e G.711 µ-law, e 32 bytes para o tipo de codec G.729 A-law.
- (Opcional.) Especifique a cadeia de caracteres de preenchimento de carga útil para pacotes de voz.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
Configuração da operação DLSw
Sobre a operação do DLSw
A operação DLSw mede o tempo de resposta de um dispositivo DLSw. Ela configura uma conexão DLSw com o dispositivo DLSw por sonda.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de DLSw e entre em sua visualização.
type dlsw- Especifique o endereço IP de destino para os pacotes de sondagem.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o endereço IP de origem para os pacotes de sondagem.
source ip ip-addressPor padrão, o endereço IP de origem dos pacotes de sondagem é o endereço IP primário de sua interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
Configuração da operação de jitter de caminho
Sobre a operação de jitter de caminho
A operação de jitter de caminho mede o jitter, os jitters negativos e os jitters positivos do cliente NQA para cada salto no caminho para o destino.
A operação de jitter de caminho executa as seguintes etapas por sonda:
- Obtém o caminho do cliente NQA até o destino por meio do tracert. Um máximo de 64 saltos pode ser detectado.
- Envia um número de solicitações de eco ICMP para cada salto ao longo do caminho. O número de solicitações de eco ICMP a serem enviadas é definido com o uso do comando probe packet-number.
Pré-requisitos
Antes de configurar a operação de jitter de caminho, você deve executar as seguintes tarefas:
Habilite o envio de mensagens ICMP de tempo excedido nos dispositivos intermediários entre os dispositivos de origem e de destino. Se os dispositivos intermediários forem dispositivos Intelbras, use o comando ip ttl-expires enable.
Habilite o envio de mensagens ICMP de destino inalcançável no dispositivo de destino. Se o dispositivo de destino for um dispositivo Intelbras, use o comando ip unreachables enable.
Para obter mais informações sobre os comandos ip ttl-expires enable e ip unreachables enable, consulte Referência de comandos de serviços de IP de camada 3.
Procedimento
- Entre na visualização do sistema.
system-view- Crie uma operação de NQA e entre na visualização de operação de NQA.
nqa entry admin-name operation-tag- Especifique o tipo de jitter de caminho e entre em sua visualização.
type path-jitter- Especifique o endereço IP de destino para solicitações de eco ICMP.
destination ip ip-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o endereço IP de origem para solicitações de eco ICMP.
source ip ip-addressPor padrão, o endereço IP de origem das solicitações de eco ICMP é o endereço IP principal da interface de saída.
O endereço IP de origem deve ser o endereço IP de uma interface local e a interface deve estar ativa. Caso contrário, nenhuma solicitação de eco ICMP poderá ser enviada.
- Configure os parâmetros da sonda para a operação de jitter de caminho.
- Defina o número de solicitações de eco ICMP a serem enviadas por sonda.
probe packet-number packet-numberA configuração padrão é 10.
- Defina o intervalo para o envio de solicitações de eco ICMP.
probe packet-interval intervalA configuração padrão é 20 milissegundos.
- Especifique por quanto tempo o cliente NQA aguarda uma resposta do servidor antes de considerar que a resposta expirou.
probe packet-timeout timeoutA configuração padrão é 3000 milissegundos.
- (Opcional.) Especifique um caminho LSR.
lsr-path ip-address&<1-8>lPor padrão, nenhum caminho LSR é especificado.
A operação de jitter de caminho usa o tracert para detectar o caminho LSR até o destino e envia solicitações de eco ICMP para cada salto no caminho LSR.
- Execute a operação de jitter de caminho somente no endereço de destino.
target-onlyPor padrão, a operação de jitter de caminho é executada em cada salto do caminho até o destino.
- (Opcional.) Defina o tamanho da carga útil para cada solicitação de eco ICMP.
data-size sizeA configuração padrão é 100 bytes.
- (Opcional.) Especifique a cadeia de caracteres de preenchimento de carga útil para solicitações de eco ICMP.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
Configuração de parâmetros opcionais para a operação do NQA
Restrições e diretrizes
A menos que especificado de outra forma, os seguintes parâmetros opcionais se aplicam a todos os tipos de operações de NQA. As configurações dos parâmetros entram em vigor somente na operação atual.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização de uma operação NQA existente.
nqa entry admin-name operation-tag- Configure uma descrição para a operação.
description textPor padrão, nenhuma descrição é configurada.
- Defina o intervalo em que a operação NQA se repete.
frequency intervalPara uma operação de jitter de voz ou de caminho, a configuração padrão é 60000 milissegundos.
Para outros tipos de operações, a configuração padrão é 0 milissegundos, e apenas uma operação é executada.
Quando o intervalo expirar, mas a operação não for concluída ou não tiver atingido o tempo limite, a próxima operação não será iniciada.
- Especifique os tempos da sonda.
probe count timesEm uma operação de tracert UDP, o cliente NQA executa três sondas para cada salto até o destino por padrão.
Em outros tipos de operações, o cliente NQA executa uma sonda para o destino por operação por padrão.
Esse comando não está disponível para as operações de voz e de jitter de caminho. Cada uma dessas operações executa apenas uma sonda.
- Defina o tempo limite da sonda.
probe timeout timeoutA configuração padrão é 3000 milissegundos.
Esse comando não está disponível para as operações de jitter ICMP, jitter UDP, voz ou jitter de caminho.
- Defina o número máximo de saltos que os pacotes de sonda podem percorrer.
ttl valueA configuração padrão é 30 para pacotes de sondagem da operação UDP tracert e 20 para pacotes de sondagem de outros tipos de operações.
Esse comando não está disponível para as operações de DHCP ou de jitter de caminho.
- Defina o valor ToS no cabeçalho IP dos pacotes de sondagem.
tos valueA configuração padrão é 0.
- Ativar o recurso de desvio da tabela de roteamento.
opção de rota bypass-route
Por padrão, o recurso de desvio da tabela de roteamento está desativado.
Esse comando não está disponível para as operações de DHCP ou de jitter de caminho.
Esse comando não terá efeito se o endereço de destino da operação NQA for um endereço IPv6.
Configuração do recurso de colaboração
Sobre o recurso de colaboração
A colaboração é implementada pela associação de uma entrada de reação de uma operação de NQA a uma entrada de trilha. A entrada de reação monitora a operação de NQA. Se o número de falhas na operação atingir o limite especificado em , a ação configurada será acionada.
Restrições e diretrizes
O recurso de colaboração não está disponível para os seguintes tipos de operações:
Operação de jitter ICMP.
Operação de jitter UDP.
Operação de tracert UDP.
Operação de voz.
Operação de jitter de caminho.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização de uma operação NQA existente.
nqa entry admin-name operation-tag- Configurar uma entrada de reação.
reaction item-number checked-element probe-fail threshold-type consecutive consecutive-occurrences action-type trigger-onlyNão é possível modificar o conteúdo de uma entrada de reação existente.
- Retornar à visualização do sistema.
quit- Trilha de associado com NQA.
Para obter informações sobre a configuração, consulte o Guia de configuração de alta disponibilidade.
- Associe o Track a um módulo de aplicativo.
Para obter informações sobre a configuração, consulte o Guia de configuração de alta disponibilidade.
Configuração do monitoramento de limites
Sobre o monitoramento de limites
Esse recurso permite monitorar o status de execução da operação de NQA. Uma operação de NQA suporta os seguintes tipos de limite:
média-Se o valor médio da métrica de desempenho monitorada exceder o limite superior de ou ficar abaixo do limite inferior, ocorre uma violação do limite.
acumular-Se o número total de vezes que o índice de desempenho monitorado estiver fora do intervalo de valores especificado atingir ou exceder o limite especificado, ocorrerá uma violação do limite.
consecutivo-Se o número de vezes consecutivas em que o índice de desempenho monitorado estiver fora do intervalo de valores especificado atingir ou exceder o limite especificado, ocorrerá uma violação do limite.
As violações de limite para o tipo de limite médio ou acumulado são determinadas em uma base por operação NQA. As violações de limite para o tipo consecutivo são determinadas a partir do momento em que a operação de NQA é iniciada.
As seguintes ações podem ser acionadas:
none-O NQA exibe os resultados apenas na tela do terminal. Ele não envia traps para o NMS.
trap-only-NQA exibe os resultados na tela do terminal e, enquanto isso, envia traps para o NMS.
Para enviar traps para o NMS, o endereço do NMS deve ser especificado usando o comando snmp-agent target-host. Para obter mais informações sobre o comando, consulte Referência de comandos de gerenciamento e monitoramento de rede.
O NQA somente de acionamento exibe os resultados na tela do terminal e, enquanto isso, aciona outros módulos para colaboração.
Em uma entrada de reação, configure um elemento monitorado, um tipo de limite e uma ação a ser acionada para implementar o monitoramento de limite.
O estado de uma entrada de reação pode ser inválido, acima do limite ou abaixo do limite.
Antes do início de uma operação de NQA, a entrada de reação está em um estado inválido.
Se o limite for violado, o estado da entrada será definido como acima do limite. Caso contrário, o estado da entrada será definido como abaixo do limite.
Restrições e diretrizes
O recurso de monitoramento de limite não está disponível para as operações de jitter de caminho.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização de uma operação NQA existente.
nqa entry admin-name operation-tag- Habilite o envio de traps para o NMS quando condições específicas forem atendidas.
reaction trap { path-change | probe-failure
consecutive-probe-failures | test-complete | test-failure
[ accumulate-probe-failures ] }
Por padrão, nenhuma armadilha é enviada ao NMS.
As operações ICMP jitter, UDP jitter e voz suportam apenas a palavra-chave test-complete. Os parâmetros a seguir não estão disponíveis para a operação UDP tracert:
- A opção probe-failure consecutive-probe-failures.
- O argumento accumulate-probe-failures.
- Configure o monitoramento de limites. Escolha as opções para configurar conforme necessário:
- Monitore a duração da operação.
reaction item-number checked-element probe-duration
threshold-type { accumulate accumulate-occurrences | average |
consecutive consecutive-occurrences } threshold-value
upper-threshold lower-threshold [ action-type { none | trap-only } ]
Essa entrada de reação não é compatível com as operações de jitter ICMP, jitter UDP, tracert UDP ou voz
- Monitore os tempos de falha.
reaction item-number checked-element probe-fail threshold-type
{ accumulate accumulate-occurrences | consecutive
consecutive-occurrences } [ action-type { none | trap-only } ]
Essa entrada de reação não é compatível com as operações de jitter ICMP, jitter UDP, tracert UDP ou voz.
- Monitore o tempo de ida e volta.
reaction item-number checked-element rtt threshold-type
{ accumulate accumulate-occurrences | average } threshold-value
upper-threshold lower-threshold [ action-type { none | trap-only } ]
Somente as operações de jitter ICMP, jitter UDP e voz suportam essa entrada de reação.
- Monitore a perda de pacotes.
reaction item-number checked-element packet-loss threshold-type
accumulate accumulate-occurrences [ action-type { none |
trap-only } ]
Somente as operações de jitter ICMP, jitter UDP e voz suportam essa entrada de reação.
- Monitore o jitter unidirecional.
reaction item-number checked-element { jitter-ds | jitter-sd }
threshold-type { accumulate accumulate-occurrences | average }
threshold-value upper-threshold lower-threshold [ action-type
{ none | trap-only } ]
Somente as operações de jitter ICMP, jitter UDP e voz suportam essa entrada de reação.
- Monitore o atraso unidirecional.
reaction item-number checked-element { owd-ds | owd-sd }
threshold-value upper-threshold lower-threshold
Somente as operações de jitter ICMP, jitter UDP e voz suportam essa entrada de reação.
- Monitore o valor ICPIF.
reaction item-number checked-element icpif threshold-value
upper-threshold lower-threshold [ action-type { none | trap-only } ]
Somente a operação de voz suporta essa entrada de reação.
- Monitore o valor de MOS.
reaction item-number checked-element mos threshold-value
upper-threshold lower-threshold [ action-type { none | trap-only } ]
Somente a operação de voz suporta essa entrada de reação.
A operação DNS não oferece suporte à ação de enviar mensagens de interceptação. Para a operação de DNS, o tipo de ação só pode ser nenhum.
Configuração do recurso de coleta de estatísticas do NQA
Sobre a coleta de estatísticas do NQA
O NQA forma estatísticas dentro do mesmo intervalo de coleta como um grupo de estatísticas. Para exibir informações sobre os grupos de estatísticas, use o comando display nqa statistics.
Quando o número máximo de grupos de estatísticas é atingido, o cliente NQA exclui o grupo de estatísticas mais antigo para salvar um novo.
Um grupo de estatísticas é automaticamente excluído quando seu tempo de espera expira.
Restrições e diretrizes
O recurso de coleta de estatísticas do NQA não está disponível para as operações de tracert UDP.
Se você usar o comando frequency para definir o intervalo como 0 milissegundos para uma operação de NQA, o NQA não gerará nenhum grupo de estatísticas para a operação.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização de uma operação NQA existente.
nqa entry admin-name operation-tag- Defina o intervalo de coleta de estatísticas. intervalo de intervalo de estatísticas A configuração padrão é 60 minutos.
- Defina o número máximo de grupos de estatísticas que podem ser salvos.
statistics max-group number
Por padrão, o cliente NQA pode salvar no máximo dois grupos de estatísticas para uma operação. Para desativar o recurso de coleta de estatísticas do NQA, defina o argumento number como 0.
- Defina o tempo de espera dos grupos de estatísticas. statistics hold-time hold-time A configuração padrão é 120 minutos.
Configuração do salvamento de registros de histórico de NQA
Sobre o salvamento do registro do histórico do NQA
Essa tarefa permite que o cliente NQA salve os registros do histórico do NQA. É possível usar o comando display nqa history para exibir os registros de histórico do NQA.
Restrições e diretrizes
O recurso de salvamento do registro do histórico do NQA não está disponível para os seguintes tipos de operações:
Operação de jitter ICMP.
Operação de jitter UDP.
Operação de voz.
Operação de jitter de caminho.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização de uma operação NQA existente.
nqa entry admin-name operation-tag- Habilite o salvamento de registros de histórico para a operação NQA.
history-record enablePor padrão, esse recurso é ativado somente para a operação UDP tracert.
- Defina o tempo de vida dos registros do histórico.
history-record keep-time keep-timeA configuração padrão é 120 minutos.
Um registro é excluído quando sua vida útil é atingida.
- Defina o número máximo de registros de histórico que podem ser salvos.
history-record number numberA configuração padrão é 50.
Quando o número máximo de registros de histórico for atingido, o sistema excluirá o registro mais antigo para salvar um novo.
Agendamento da operação de NQA no cliente NQA
Sobre a programação de operações do NQA
A operação NQA é executada entre a hora de início e a hora de término especificadas (a hora de início mais a duração da operação). Se a hora de início especificada estiver adiantada em relação à hora do sistema, a operação será iniciada imediatamente. Se tanto a hora de início quanto a hora de término especificadas estiverem adiantadas em relação à hora do sistema, a operação não será iniciada. Para exibir a hora atual do sistema, use o comando display clock.
Restrições e diretrizes
Não é possível entrar na visualização do tipo de operação ou na visualização de uma operação NQA programada.
Um ajuste de hora do sistema não afeta as operações de NQA iniciadas ou concluídas. Ele afeta apenas as operações de NQA que não foram iniciadas.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique os parâmetros de agendamento para uma operação de NQA.
nqa schedule admin-name operation-tag start-time { hh:mm:ss
[ yyyy/mm/dd | mm/dd/yyyy ] | now } lifetime { lifetime | forever }
[ recurring ]
Configuração de modelos de NQA no cliente NQA
Restrições e diretrizes
Alguns parâmetros de operação de um modelo NQA podem ser especificados pela configuração do modelo ou pelo recurso que usa o modelo. Quando ambos são especificados, os parâmetros na configuração do modelo entram em vigor.
Visão geral das tarefas do modelo NQA
Para configurar modelos de NQA, execute as seguintes tarefas:
- Execute pelo menos uma das seguintes tarefas:
- Configuração do modelo ICMP
- Configuração do modelo de DNS
- Configuração do modelo TCP
- Configuração do modelo TCP semiaberto
- Configuração do modelo UDP
- Configuração do modelo HTTP
- Configuração do modelo HTTPS
- Configuração do modelo de FTP
- Configuração do modelo RADIUS
- Configuração do modelo SSL
- (Opcional.) Configuração de parâmetros opcionais para o modelo NQA
Configuração do modelo ICMP
Sobre o modelo ICMP
Um recurso que usa o modelo ICMP executa a operação ICMP para medir a capacidade de alcance de um dispositivo de destino. O modelo ICMP é compatível com redes IPv4 e IPv6.
Procedimento
system-view- Crie um modelo ICMP e entre em sua visualização.
nqa template icmp name- Especifique o endereço IP de destino para a operação. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é configurado.
- Especifique o endereço IP de origem para solicitações de eco ICMP. Escolha uma das tarefas a seguir:
- Use o endereço IP da interface especificada como o endereço IP de origem.
source interface interface-type interface-numberPor padrão, o endereço IP primário da interface de saída é usado como endereço IP de origem das solicitações de eco ICMP.
A interface de origem especificada deve estar ativa.
- Especifique o endereço IPv4 de origem.
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como endereço IPv4 de origem das solicitações de eco ICMP.
O endereço IPv4 de origem especificado deve ser o endereço IPv4 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique o endereço IPv6 de origem.
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como endereço IPv6 de origem das solicitações de eco ICMP.
O endereço IPv6 de origem especificado deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique o endereço IP do próximo salto para solicitações de eco ICMP. IPv4:
next-hop ip ip-addressIPv6:
next-hop ipv6 ipv6-addressPor padrão, nenhum endereço IP do próximo salto é configurado.
- Configure o envio do resultado da sonda por sonda.
reaction trigger per-probePor padrão, o resultado da sonda é enviado ao recurso que usa o modelo após três sondas consecutivas com falha ou sucesso.
Se você executar os comandos reaction trigger per-probe e reaction trigger probe-pass várias vezes, a configuração mais recente entrará em vigor.
Se você executar os comandos reaction trigger per-probe e reaction trigger probe-fail várias vezes, a configuração mais recente entrará em vigor.
- (Opcional.) Defina o tamanho da carga útil para cada solicitação ICMP.
data-size sizeA configuração padrão é 100 bytes.
- (Opcional.) Especifique a cadeia de caracteres de preenchimento de carga útil para solicitações de eco ICMP.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
Configuração do modelo de DNS
Sobre o modelo de DNS
Um recurso que usa o modelo de DNS executa a operação de DNS para determinar o status do servidor. O modelo de DNS é compatível com redes IPv4 e IPv6.
Na visualização do modelo de DNS, você pode especificar o endereço que se espera que seja retornado. Se os endereços IP retornados incluírem o endereço esperado, o servidor DNS é válido e a operação é bem-sucedida. Caso contrário, a operação falhará.
Pré-requisitos
Crie um mapeamento entre o nome de domínio e um endereço antes de executar a operação de DNS. Para obter informações sobre a configuração do servidor DNS, consulte os documentos sobre a configuração do servidor DNS .
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo de DNS e entre na visualização do modelo de DNS.
nqa template icmp name- Especifique o endereço IP de destino para os pacotes de sondagem. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço de destino é especificado.
- Especifique o número da porta de destino para os pacotes de sondagem.
destination ip ip-addressPor padrão, o número da porta de destino é 53.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 de origem dos pacotes de sondagem é o endereço IPv4 primário de sua interface de saída.
O endereço IPv4 de origem deve ser o endereço IPv4 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 de origem dos pacotes de sondagem é o endereço IPv6 primário de sua interface de saída.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique o número da porta de origem para os pacotes de sondagem.
destination port port-numberPor padrão, nenhum número de porta de origem é especificado.
- Especifique o nome de domínio a ser traduzido.
resolve-target domain-namePor padrão, nenhum nome de domínio é especificado.
- Especifique o tipo de resolução de nome de domínio.
resolve-type { A | AAAA }Por padrão, o tipo é o tipo A.
Uma consulta do tipo A resolve um nome de domínio para um endereço IPv4 mapeado, e uma consulta do tipo AAAA para um endereço IPv6 mapeado.
- (Opcional.) Especifique o endereço IP que se espera que seja retornado. IPv4:
expect ip ip-addressIPv6:
expect ipv6 ipv6-addressPor padrão, nenhum endereço IP esperado é especificado.
Configuração do modelo TCP
Sobre o modelo TCP
Um recurso que usa o modelo TCP executa a operação TCP para testar se o cliente NQA pode estabelecer uma conexão TCP com uma porta específica no servidor.
Na visualização do modelo TCP, você pode especificar os dados esperados a serem retornados. Se você não especificar os dados esperados, a operação TCP testará apenas se o cliente pode estabelecer uma conexão TCP com o servidor.
A operação TCP requer tanto o servidor NQA quanto o cliente NQA. Antes de executar uma operação TCP, configure um serviço de escuta TCP no servidor NQA. Para obter mais informações sobre a configuração do serviço de escuta TCP , consulte "Configuração do servidor NQA".
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo TCP e insira sua visualização.
nqa template tcp name- Especifique o endereço IP de destino para os pacotes de sondagem. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é especificado.
O endereço de destino deve ser o mesmo que o endereço IP do serviço de escuta TCP configurado no servidor NQA. Para configurar um serviço de escuta TCP no servidor, use o comando nqa server tcp-connect.
- Especifique o número da porta de destino para a operação.
destination ip ip-addressPor padrão, nenhum número de porta de destino é especificado.
O número da porta de destino deve ser o mesmo que o número da porta do serviço de escuta TCP configurado no servidor NQA. Para configurar um serviço de escuta TCP no servidor, use o comando nqa server tcp-connect.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IP de origem deve ser o endereço IPv4 de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- (Opcional.) Especifique a string de preenchimento de carga útil para os pacotes de sonda.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
- (Opcional.) Configure os dados esperados.
expect data expression [ offset number ]Por padrão, nenhum dado esperado é configurado.
O cliente NQA executa a verificação de dados esperados somente quando você configura o preenchimento de dados e a verificação de dados esperados, comandos expect-data.
Configuração do modelo TCP semiaberto
Sobre o modelo TCP meio aberto
Um recurso que usa o modelo TCP semiaberto executa a operação TCP semiaberto para testar se o serviço TCP está disponível no servidor. A operação de TCP semiaberto é usada quando o recurso não consegue obter uma resposta do servidor TCP por meio de uma conexão TCP existente.
Na operação TCP semiaberta, o cliente NQA envia um pacote TCP ACK para o servidor. Se o cliente receber um pacote RST, ele considerará que o serviço TCP está disponível no servidor.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo TCP semiaberto e entre em sua visualização.
nqa template tcphalfopen name- Especifique o endereço IP de destino da operação. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é especificado.
O endereço de destino deve ser o mesmo que o endereço IP do serviço de escuta TCP configurado no servidor NQA. Para configurar um serviço de escuta TCP no servidor, use o comando nqa server tcp-connect.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IPv4 de origem deve ser o endereço IPv4 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique o endereço IP do próximo salto para os pacotes de sondagem. IPv4:
next-hop ip ip-addressIPv6:
next-hop ipv6 ipv6-addressPor padrão, o endereço IP do próximo salto é configurado.
- Configure o envio do resultado da sonda por sonda.
reaction trigger per-probePor padrão, o resultado da sonda é enviado ao recurso que usa o modelo após três sondas consecutivas com falha ou sucesso.
Se você executar os comandos reaction trigger per-probe e reaction trigger probe-pass várias vezes, a configuração mais recente entrará em vigor.
Se você executar os comandos reaction trigger per-probe e reaction trigger probe-fail várias vezes, a configuração mais recente entrará em vigor.
Configuração do modelo UDP
Sobre o modelo UDP
Um recurso que usa o modelo UDP executa a operação UDP para testar os seguintes itens:
Alcançabilidade de uma porta específica no servidor NQA.
Disponibilidade do serviço solicitado no servidor do NQA.
Na visualização do modelo UDP, você pode especificar os dados esperados a serem retornados. Se você não especificar os dados esperados, a operação UDP testará apenas se o cliente pode receber o pacote de resposta do servidor.
A operação UDP requer tanto o servidor NQA quanto o cliente NQA. Antes de executar uma operação UDP, configure um serviço de escuta UDP no servidor NQA. Para obter mais informações sobre a configuração do serviço de escuta UDP, consulte "Configuração do servidor NQA".
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo UDP e insira sua visualização.
nqa template udp name- Especifique o endereço IP de destino da operação. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é especificado.
O endereço de destino deve ser o mesmo que o endereço IP do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o número da porta de destino para a operação.
destination ip ip-addressPor padrão, nenhum número de porta de destino é especificado.
O número da porta de destino deve ser o mesmo que o número da porta do serviço de escuta UDP configurado no servidor NQA. Para configurar um serviço de escuta UDP no servidor, use o comando nqa server udp-echo.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IP de origem deve ser o endereço IPv4 de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Especifique a cadeia de caracteres de preenchimento de carga útil para os pacotes de sondagem.
data-fill stringA cadeia de caracteres de preenchimento de carga útil padrão é a cadeia hexadecimal 00010203040506070809.
- (Opcional.) Defina o tamanho da carga útil para os pacotes de sondagem.
data-size sizeA configuração padrão é 100 bytes.
- (Opcional.) Configure os dados esperados.
expect data expression [ offset number ]Por padrão, nenhum dado esperado é configurado.
A verificação de dados esperados é realizada somente quando o comando de preenchimento de dados e o comando de dados esperados estão configurados.
Configuração do modelo HTTP
Sobre o modelo HTTP
Um recurso que usa o modelo HTTP executa a operação HTTP para medir o tempo que o cliente NQA leva para obter dados de um servidor HTTP.
Os dados esperados são verificados somente quando os dados são configurados e a resposta HTTP contém o campo Content-Length no cabeçalho HTTP.
O código de status do pacote HTTP é um campo de três dígitos em notação decimal e inclui as informações de status do servidor HTTP. O primeiro dígito define a classe da resposta.
Pré-requisitos
Antes de executar a operação HTTP, você deve configurar o servidor HTTP.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo HTTP e insira sua visualização.
nqa template http name- Especifique o URL de destino para o modelo HTTP.
url urlPor padrão, nenhum URL de destino é especificado para um modelo HTTP. Digite o URL em um dos seguintes formatos:
http://host/resourcehttp://host:port/resource- Especifique um nome de usuário de login HTTP.
username usernamePor padrão, nenhum nome de usuário de login HTTP é especificado.
password { cipher | simple } stringPor padrão, nenhuma senha de login HTTP é especificada.
- Especifique a versão do HTTP.
version { v1.0 | v1.1 }Por padrão, o HTTP 1.0 é usado.
operation { get | post | raw }Por padrão, o tipo de operação HTTP é get.
Se você definir o tipo de operação como bruto, o cliente adicionará o conteúdo configurado na exibição de solicitação bruta à solicitação HTTP a ser enviada ao servidor HTTP.
- Configure o conteúdo da solicitação bruta HTTP.
- Entrar na visualização de solicitação bruta.
raw-requestToda vez que você entra na visualização de solicitação bruta, o conteúdo da solicitação bruta configurado anteriormente é apagado.
- Digite ou cole o conteúdo da solicitação.
Por padrão, nenhum conteúdo de solicitação é configurado.
Para garantir operações bem-sucedidas, certifique-se de que o conteúdo da solicitação não contenha aliases de comando configurados usando o comando alias. Para obter mais informações sobre o comando alias, consulte Comandos da CLI em Referência de comandos básicos.
- Retornar à visualização do modelo HTTP.
quitO sistema salva automaticamente a configuração na visualização de solicitação bruta antes de retornar à visualização de modelo HTTP.
Essa etapa é necessária somente quando o tipo de operação é definido como bruto.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IPv4 de origem deve ser o endereço IPv4 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- (Opcional.) Configure os códigos de status esperados.
expect status status-listPor padrão, nenhum código de status esperado é configurado.
- (Opcional.) Configure os dados esperados.
expect data expression [ offset number ]Por padrão, nenhum dado esperado é configurado.
Configuração do modelo HTTPS
Sobre o modelo HTTPS
Um recurso que usa o modelo HTTPS executa a operação HTTPS para medir o tempo que o cliente NQA leva para obter dados de um servidor HTTPS.
Os dados esperados são verificados somente quando os dados esperados são configurados e a resposta HTTPS contém o campo Content-Length no cabeçalho HTTPS.
O código de status do pacote HTTPS é um campo de três dígitos em notação decimal e inclui as informações de status do servidor HTTPS. O primeiro dígito define a classe da resposta.
Pré-requisitos
Antes de executar a operação HTTPS, configure o servidor HTTPS e a política de cliente SSL para o cliente SSL. Para obter informações sobre a configuração de políticas de cliente SSL, consulte o Guia de Configuração de Segurança.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo HTTPS e insira sua visualização.
nqa template https name- Especifique o URL de destino para o modelo HTTPS.
url urlPor padrão, nenhum URL de destino é especificado para um modelo HTTPS. Digite o URL em um dos seguintes formatos:
:
https://host/resource
https://host:port/resourceusername usernamePor padrão, nenhum nome de usuário de login HTTPS é especificado.
password { cipher | simple } stringPor padrão, nenhuma senha de login HTTPS é especificada.
- Especifique uma política de cliente SSL.
ssl-client-policy policy-namePor padrão, nenhuma política de cliente SSL é especificada.
- Especifique a versão do HTTPS.
version { v1.0 | v1.1 }Por padrão, é usado o HTTPS 1.0.
operation { get | post | raw }Por padrão, o tipo de operação HTTPS é get.
Se você definir o tipo de operação como bruto, o cliente adicionará o conteúdo configurado na exibição de solicitação bruta à solicitação HTTPS a ser enviada ao servidor HTTPS.
- Configure o conteúdo da solicitação bruta HTTPS.
- Entrar na visualização de solicitação bruta.
raw-requestToda vez que você entra na visualização de solicitação bruta, o conteúdo da solicitação bruta configurado anteriormente é apagado.
- Digite ou cole o conteúdo da solicitação.
Por padrão, nenhum conteúdo de solicitação é configurado.
Para garantir operações bem-sucedidas, certifique-se de que o conteúdo da solicitação não contenha aliases de comando configurados usando o comando alias. Para obter mais informações sobre o comando alias, consulte Comandos da CLI em Referência de comandos básicos.
- Retornar à visualização do modelo HTTPS.
quitO sistema salva automaticamente a configuração na visualização de solicitação bruta antes de retornar à visualização do modelo HTTPS.
Essa etapa é necessária somente quando o tipo de operação é definido como bruto.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IP de origem deve ser o endereço IPv4 de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- (Opcional.) Configure os dados esperados.
expect data expression [ offset number ]Por padrão, nenhum dado esperado é configurado.
- (Opcional.) Configure os códigos de status esperados.
expect status status-listPor padrão, nenhum código de status esperado é configurado.
Configuração do modelo de FTP
Sobre o modelo FTP
Um recurso que usa o modelo FTP executa a operação FTP. A operação mede o tempo que o cliente NQA leva para transferir um arquivo para um servidor FTP ou fazer download de um arquivo a partir dele.
Configure o nome de usuário e a senha para que o cliente FTP faça login no servidor FTP antes de executar uma operação de FTP. Para obter informações sobre como configurar o servidor FTP, consulte o Fundamentals Configuration Guide.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo de FTP e insira sua visualização.
nqa template ftp name- Especifique um nome de usuário de login de FTP.
username usernamePor padrão, nenhum nome de usuário de login de FTP é especificado.
- Especifique uma senha de login de FTP.
password { cipher | simple } stingPor padrão, nenhuma senha de login de FTP é especificada.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IP de origem deve ser o endereço IPv4 de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
- Defina o modo de transmissão de dados.
mode { active | passive }O modo padrão é active.
operation { get | put }Por padrão, o tipo de operação FTP é get, o que significa obter arquivos do servidor FTP.
- Especifique o URL de destino para o modelo de FTP.
url urlPor padrão, nenhum URL de destino é especificado para um modelo de FTP. Digite o URL em um dos seguintes formatos:
ftp://host/filename.
ftp://host:port/filename.
Quando você executa a operação get, o nome do arquivo é obrigatório.
Quando você executa a operação put, o argumento filename não tem efeito, mesmo que esteja especificado. O nome do arquivo para a operação put é determinado com o uso do comando filename.
- Especifique o nome de um arquivo a ser transferido.
filename filenamePor padrão, nenhum arquivo é especificado.
Essa tarefa é necessária apenas para a operação de colocação.
A configuração não entra em vigor para a operação get.
Configuração do modelo RADIUS
Sobre a operação de autenticação RADIUS baseada em modelo
Um recurso que usa o modelo RADIUS executa a operação de autenticação RADIUS para verificar a disponibilidade do serviço de autenticação no servidor RADIUS.
O fluxo de trabalho da operação de autenticação RADIUS é o seguinte:
- O cliente NQA envia uma solicitação de autenticação (Access-Request) para o servidor RADIUS. A solicitação inclui o nome de usuário e a senha. A senha é criptografada usando o algoritmo MD5 e a chave compartilhada.
- O servidor RADIUS autentica o nome de usuário e a senha.
- Se a autenticação for bem-sucedida, o servidor enviará um pacote Access-Accept para o cliente NQA.
- Se a autenticação falhar, o servidor enviará um pacote Access-Reject para o cliente NQA.
- O cliente NQA determina a disponibilidade do serviço de autenticação no servidor RADIUS com base no pacote de resposta recebido:
- Se um pacote Access-Accept for recebido, o serviço de autenticação estará disponível no servidor RADIUS.
- Se um pacote Access-Reject for recebido, o serviço de autenticação não estará disponível no servidor RADIUS.
Pré-requisitos
Antes de configurar o modelo RADIUS, especifique um nome de usuário, uma senha e uma chave compartilhada no servidor RADIUS. Para obter mais informações sobre a configuração do servidor RADIUS, consulte AAA no Security Configuration Guide.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo RADIUS e entre em sua visualização.
nqa template radius name- Especifique o endereço IP de destino da operação. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o número da porta de destino para a operação.
destination ip ip-addressPor padrão, o número da porta de destino é 1812.
- Especifique um nome de usuário.
username usernamePor padrão, nenhum nome de usuário é especificado.
- Especifique uma senha.
password { cipher | simple } stringPor padrão, nenhuma senha é especificada.
- Especifique uma chave compartilhada para autenticação RADIUS segura.
key { cipher | simple } string
Por padrão, nenhuma chave compartilhada é especificada para a autenticação RADIUS.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IP de origem deve ser o endereço IPv4 de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
Configuração do modelo SSL
Sobre o modelo SSL
Um recurso que usa o modelo SSL executa a operação SSL para medir o tempo necessário para estabelecer uma conexão SSL com um servidor SSL.
Pré-requisitos
Antes de configurar o modelo SSL, você deve configurar a política de cliente SSL. Para obter informações sobre a configuração de políticas de cliente SSL, consulte o Guia de Configuração de Segurança.
Procedimento
- Entre na visualização do sistema.
system-view- Crie um modelo SSL e insira sua visualização.
nqa template ssl name- Especifique o endereço IP de destino da operação. IPv4:
destination ip ip-addressIPv6:
destination ipv6 ipv6-addressPor padrão, nenhum endereço IP de destino é especificado.
- Especifique o número da porta de destino para a operação.
destination ip ip-addressPor padrão, o número da porta de destino não é especificado.
- Especifique uma política de cliente SSL.
ssl-client-policy policy-namePor padrão, nenhuma política de cliente SSL é especificada.
- Especifique o endereço IP de origem para os pacotes de sondagem. IPv4:
source ip ip-addressPor padrão, o endereço IPv4 primário da interface de saída é usado como o endereço IPv4 de origem dos pacotes de sondagem.
O endereço IP de origem deve ser o endereço IPv4 de uma interface local e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
IPv6:
source ipv6 ipv6-addressPor padrão, o endereço IPv6 primário da interface de saída é usado como o endereço IPv6 de origem dos pacotes de sondagem.
O endereço IPv6 de origem deve ser o endereço IPv6 de uma interface local, e a interface deve estar ativa. Caso contrário, nenhum pacote de sondagem poderá ser enviado.
Configuração de parâmetros opcionais para o modelo NQA
Restrições e diretrizes
A menos que especificado de outra forma, os seguintes parâmetros opcionais se aplicam a todos os tipos de modelos de NQA. As configurações dos parâmetros têm efeito somente no modelo NQA atual.
Procedimento
- Entre na visualização do sistema.
system-view- Insira a visualização de um modelo de NQA existente.
nqa template { dns | ftp | http | https | icmp | radius | ssl | tcp |
tcphalfopen | udp } name- Configure uma descrição.
description textPor padrão, nenhuma descrição é configurada.
- Defina o intervalo em que a operação NQA se repete.
frequency intervalA configuração padrão é 5000 milissegundos.
Quando o intervalo expirar, mas a operação não for concluída ou não tiver atingido o tempo limite, a próxima operação não será iniciada.
- Defina o tempo limite da sonda.
probe timeout timeoutA configuração padrão é 3000 milissegundos.
- Defina o TTL para os pacotes de sonda.
ttl valueA configuração padrão é 20.
Esse comando não está disponível para o modelo ARP.
- Defina o valor ToS no cabeçalho IP dos pacotes de sondagem.
tos valueA configuração padrão é 0.
Esse comando não está disponível para o modelo ARP.
- Defina o número de sondas consecutivas bem-sucedidas para determinar um evento de operação bem-sucedida.
reaction trigger probe-pass countA configuração padrão é 3.
Se o número de sondas consecutivas bem-sucedidas para uma operação de NQA for atingido, o cliente do NQA notificará o recurso que usa o modelo do evento de operação bem-sucedida.
- Defina o número de falhas consecutivas da sonda para determinar uma falha de operação.
reaction trigger probe-fail countA configuração padrão é 3.
Se o número de falhas consecutivas da sonda para uma operação de NQA for atingido, o cliente de NQA notificará o recurso que usa o modelo de NQA sobre a falha na operação.
Comandos de exibição e manutenção para NQA
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir registros de histórico das operações do NQA. | display nqa history [ nome-do-administrador-tag-da-operação ] | ||
| Exibir os resultados atuais de monitoramento das entradas de reação. | display nqa reaction counters [ admin-name operation-tag [ item-number ] ] | ||
| Exibe o resultado mais recente da operação de NQA. | display nqa result [ admin-name operation-tag ] | ||
| Exibir o status do servidor NQA. | display nqa server status | ||
| Exibir estatísticas de NQA. | display nqa statistics [ admin-name operation-tag ] |
Exemplos de configuração do NQA
Exemplo: Configuração da operação de eco ICMP
Configuração de rede
Conforme mostrado na Figura 2, configure uma operação de eco ICMP no cliente NQA (Dispositivo A) para testar o tempo de ida e volta até o Dispositivo B. O próximo salto do Dispositivo A é o Dispositivo C.
Figura 2 Diagrama de rede
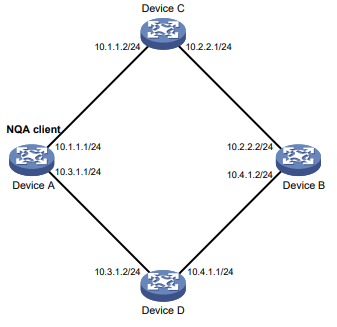
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 2. (Detalhes não mostrados.)
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar uma operação de eco ICMP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type icmp-echo# Especifique 10.2.2.2 como o endereço IP de destino das solicitações de eco ICMP.
[DeviceA-nqa-admin-test1-icmp-echo] destination ip 10.2.2.2# Especifique 10.1.1.2 como o próximo salto. As solicitações de eco ICMP são enviadas pelo Dispositivo C para o Dispositivo B.
[DeviceA-nqa-admin-test1-icmp-echo] next-hop ip 10.1.1.2# Configure a operação de eco ICMP para realizar 10 sondagens.
[DeviceA-nqa-admin-test1-icmp-echo] probe count 10# Defina o tempo limite da sonda como 500 milissegundos para a operação de eco ICMP.
[DeviceA-nqa-admin-test1-icmp-echo] probe timeout 500# Configure a operação de eco ICMP para se repetir a cada 5000 milissegundos.
[DeviceA-nqa-admin-test1-icmp-echo] frequency 5000# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-icmp-echo] history-record enable# Defina o número máximo de registros de histórico como 10.
[DeviceA-nqa-admin-test1-icmp-echo] history-record number 10
[DeviceA-nqa-admin-test1-icmp-echo] quit# Iniciar a operação de eco ICMP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever
# Depois que a operação de eco ICMP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de eco ICMP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 10 Receive response times: 10
Min/Max/Average round trip time: 2/5/3
Square-Sum of round trip time: 96
Last succeeded probe time: 2011-08-23 15:00:01.2
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação de eco ICMP.
[DeviceA] display nqa history admin test1
Registros de histórico de entrada de NQA (admin admin, tag test):
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test) history records:
Index Response Status Time
370 3 Succeeded 2007-08-23 15:00:01.2
369 3 Succeeded 2007-08-23 15:00:01.2
368 3 Succeeded 2007-08-23 15:00:01.2
367 5 Succeeded 2007-08-23 15:00:01.2
366 3 Succeeded 2007-08-23 15:00:01.2
365 3 Succeeded 2007-08-23 15:00:01.2
364 3 Succeeded 2007-08-23 15:00:01.1
363 2 Succeeded 2007-08-23 15:00:01.1
362 3 Succeeded 2007-08-23 15:00:01.1
361 2 Succeeded 2007-08-23 15:00:01.1A saída mostra que os pacotes enviados pelo Dispositivo A podem chegar ao Dispositivo B por meio do Dispositivo C. Não há perda de pacotes durante a operação. Os tempos mínimo, máximo e médio de ida e volta são 2, 5 e 3 milissegundos, respectivamente.
Exemplo: Configuração da operação de jitter ICMP
Configuração de rede
Conforme mostrado na Figura 3, configure uma operação de jitter ICMP para testar o jitter entre o Dispositivo A e o Dispositivo B.
Figura 3 Diagrama de rede
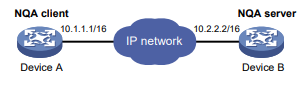
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 3. (Detalhes não mostrados.)
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo A:
# Criar uma operação de jitter ICMP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type icmp-jitter# Especifique 10.2.2.2 como o endereço de destino da operação.
[DeviceA-nqa-admin-test1-icmp-jitter] destination ip 10.2.2.2# Configure a operação para ser repetida a cada 1000 milissegundos.
[DeviceA-nqa-admin-test1-icmp-jitter] frequency 1000
[DeviceA-nqa-admin-test1-icmp-jitter] quit# Iniciar a operação de jitter ICMP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação de jitter ICMP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de jitter ICMP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 10 Receive response times: 10
Min/Max/Average round trip time: 1/2/1
Square-Sum of round trip time: 13
Last packet received time: 2015-03-09 17:40:29.8
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
ICMP-jitter results:
RTT number: 10
Min positive SD: 0 Min positive DS: 0
Max positive SD: 0 Max positive DS: 0
Positive SD number: 0 Positive DS number: 0
Positive SD sum: 0 Positive DS sum: 0
Positive SD average: 0 Positive DS average: 0
Positive SD square-sum: 0 Positive DS square-sum: 0
IP network
NQA server
Min negative SD: 1 Min negative DS: 2
Max negative SD: 1 Max negative DS: 2
Negative SD number: 1 Negative DS number: 1
Negative SD sum: 1 Negative DS sum: 2
Negative SD average: 1 Negative DS average: 2
Negative SD square-sum: 1 Negative DS square-sum: 4
SD average: 1 DS average: 2
One way results:
Max SD delay: 1 Max DS delay: 2
Min SD delay: 1 Min DS delay: 2
Number of SD delay: 1 Number of DS delay: 1
Sum of SD delay: 1 Sum of DS delay: 2
Square-Sum of SD delay: 1 Square-Sum of DS delay: 4
Lost packets for unknown reason: 0# Exibir as estatísticas da operação de jitter ICMP.
[DeviceA] display nqa statistics admin test1
NQA entry (admin admin, tag test1) test statistics:
NO. : 1
Start time: 2015-03-09 17:42:10.7
Life time: 156 seconds
Send operation times: 1560 Receive response times: 1560
Min/Max/Average round trip time: 1/2/1
Square-Sum of round trip time: 1563
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
ICMP-jitter results:
RTT number: 1560
Min positive SD: 1 Min positive DS: 1
Max positive SD: 1 Max positive DS: 2
Positive SD number: 18 Positive DS number: 46
Positive SD sum: 18 Positive DS sum: 49
Positive SD average: 1 Positive DS average: 1
Positive SD square-sum: 18 Positive DS square-sum: 55
Min negative SD: 1 Min negative DS: 1
Max negative SD: 1 Max negative DS: 2
Negative SD number: 24 Negative DS number: 57
Negative SD sum: 24 Negative DS sum: 58
Negative SD average: 1 Negative DS average: 1
Negative SD square-sum: 24 Negative DS square-sum: 60
SD average: 16 DS average: 2
One way results:
Max SD delay: 1 Max DS delay: 2
Min SD delay: 1 Min DS delay: 1
Number of SD delay: 4 Number of DS delay: 4
Sum of SD delay: 4 Sum of DS delay: 5
Square-Sum of SD delay: 4 Square-Sum of DS delay: 7
Lost packets for unknown reason: 0Exemplo: Configuração da operação DHCP
Configuração de rede
Conforme mostrado na Figura 4, configure uma operação de DHCP para testar o tempo necessário para que o Switch A obtenha um endereço IP do servidor DHCP (Switch B).
Figura 4 Diagrama de rede
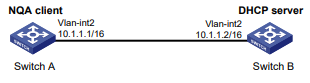
Interruptor InterruptorB
Procedimento
# Criar uma operação DHCP.
<SwitchA> system-view
[SwitchA] nqa entry admin test1
[SwitchA-nqa-admin-test1] type dhcp# Especifique o endereço do servidor DHCP (10.1.1.2) como o endereço de destino.
[SwitchA-nqa-admin-test1-dhcp] destination ip 10.1.1.2# Habilite o salvamento de registros de histórico.
[SwitchA-nqa-admin-test1-dhcp] history-record enable
[SwitchA-nqa-admin-test1-dhcp] quit# Iniciar a operação DHCP.
[SwitchA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação DHCP for executada por um período de tempo, interrompa a operação.
[SwitchA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação DHCP.
[SwitchA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 512/512/512
Square-Sum of round trip time: 262144
Last succeeded probe time: 2011-11-22 09:56:03.2
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
# Exibir os registros de histórico da operação DHCP.
[SwitchA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 512 Succeeded 2011-11-22 09:56:03.2
A saída mostra que o Switch A levou 512 milissegundos para obter um endereço IP do servidor DHCP.
Exemplo: Configuração da operação de DNS
Configuração de rede
Conforme mostrado na Figura 5, configure uma operação de DNS para testar se o Dispositivo A pode realizar a resolução de endereços por meio do servidor DNS e testar o tempo de resolução.
Figura 5 Diagrama de rede
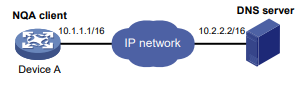
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 5. (Detalhes não mostrados.)
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar uma operação de DNS.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type dns
# Especifique o endereço IP do servidor DNS (10.2.2.2) como o endereço de destino.
[DeviceA-nqa-admin-test1-dns] destination ip 10.2.2.2# Especifique host.com como o nome de domínio a ser traduzido.
[DeviceA-nqa-admin-test1-dns] resolve-target host.com# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-dns] history-record enable
[DeviceA-nqa-admin-test1-dns] quit# Iniciar a operação de DNS.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever
# Depois que a operação do DNS for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de DNS.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 62/62/62
Square-Sum of round trip time: 3844
Last succeeded probe time: 2011-11-10 10:49:37.3
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação de DNS.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test) history records:
Index Response Status Time
1 62 Succeeded 2011-11-10 10:49:37.3A saída mostra que o Dispositivo A levou 62 milissegundos para traduzir o nome de domínio host.com em um endereço IP.
Exemplo: Configuração da operação de FTP
Configuração de rede
Conforme mostrado na Figura 6, configure uma operação de FTP para testar o tempo necessário para o Dispositivo A carregar um arquivo no servidor FTP. O nome de usuário e a senha de login são admin e systemtest, respectivamente. O arquivo a ser transferido para o servidor FTP é config.txt.
Figura 6 Diagrama de rede
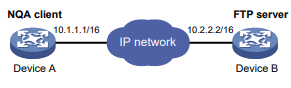
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 6. (Detalhes não mostrados.)
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar uma operação de FTP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type ftp# Especifique o URL do servidor FTP.
[DeviceA-nqa-admin-test-ftp] url ftp://10.2.2.2# Especifique 10.1.1.1 como o endereço IP de origem.
[DeviceA-nqa-admin-test1-ftp] source ip 10.1.1.1# Configure o dispositivo para fazer upload do arquivo config.txt para o servidor FTP.
[DeviceA-nqa-admin-test1-ftp] operation put
[DeviceA-nqa-admin-test1-ftp] filename config.txt# Defina a senha para systemtest para a operação de FTP.
[DeviceA-nqa-admin-test1-ftp] password simple systemtest# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-ftp] history-record enable
[DeviceA-nqa-admin-test1-ftp] quit# Iniciar a operação de FTP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação de FTP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de FTP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 173/173/173
Square-Sum of round trip time: 29929
Last succeeded probe time: 2011-11-22 10:07:28.6
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to disconnect: 0
Failures due to no connection: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação de FTP.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 173 Succeeded 2011-11-22 10:07:28.6A saída mostra que o Dispositivo A levou 173 milissegundos para carregar um arquivo no servidor FTP.
Exemplo: Configuração da operação HTTP
Configuração de rede
Conforme mostrado na Figura 7, configure uma operação HTTP no cliente NQA para testar o tempo necessário para obter dados do servidor HTTP.
Figura 7 Diagrama de rede
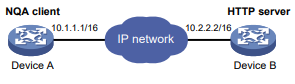
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 7. (Detalhes não mostrados.)
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Crie uma operação HTTP.
system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type http
# Especifique o URL do servidor HTTP.
[DeviceA-nqa-admin-test1-http] url http://10.2.2.2/index.htm# Configure a operação HTTP para obter dados do servidor HTTP.
[DeviceA-nqa-admin-test1-http] operation get# Configure a operação para usar a versão 1.0 do HTTP.
[DeviceA-nqa-admin-test1-http] version v1.0# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-http] history-record enable
[DeviceA-nqa-admin-test1-http] quit# Iniciar a operação HTTP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação HTTP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação HTTP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 64/64/64
Square-Sum of round trip time: 4096
Last succeeded probe time: 2011-11-22 10:12:47.9
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to disconnect: 0
Failures due to no connection: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação HTTP.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 64 Succeeded 2011-11-22 10:12:47.9A saída mostra que o Dispositivo A levou 64 milissegundos para obter dados do servidor HTTP.
Exemplo: Configuração da operação de jitter UDP
Configuração de rede
Conforme mostrado na Figura 8, configure uma operação de jitter UDP para testar o jitter, o atraso e o tempo de ida e volta entre o Dispositivo A e o Dispositivo B.
Figura 8 Diagrama de rede
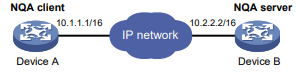
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 8. (Detalhes não mostrados.)
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilitar o servidor NQA.
system-view
[DeviceB] nqa server enable
# Configure um serviço de escuta para escutar a porta UDP 9000 no endereço IP 10.2.2.2.
[DeviceB] nqa server udp-echo 10.2.2.2 9000- Configurar o dispositivo A:
# Criar uma operação de jitter UDP.
system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type udp-jitter
# Especifique 10.2.2.2 como o endereço de destino da operação.
[DeviceA-nqa-admin-test1-udp-jitter] destination ip 10.2.2.2# Defina o número da porta de destino como 9000.
[DeviceA-nqa-admin-test1-udp-jitter] destination port 9000Configure a operação para se repetir a cada 1000 milissegundos.
[DeviceA-nqa-admin-test1-udp-jitter] frequency 1000
[DeviceA-nqa-admin-test1-udp-jitter] quit# Iniciar a operação de jitter UDP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação de jitter UDP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de jitter UDP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 10 Receive response times: 10
Min/Max/Average round trip time: 15/32/17
Square-Sum of round trip time: 3235
Last packet received time: 2011-05-29 13:56:17.6
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
UDP-jitter results:
RTT number: 10
Min positive SD: 4 Min positive DS: 1
Max positive SD: 21 Max positive DS: 28
Positive SD number: 5 Positive DS number: 4
Positive SD sum: 52 Positive DS sum: 38
Positive SD average: 10 Positive DS average: 10
Positive SD square-sum: 754 Positive DS square-sum: 460
Min negative SD: 1 Min negative DS: 6
Max negative SD: 13 Max negative DS: 22
Negative SD number: 4 Negative DS number: 5
Negative SD sum: 38 Negative DS sum: 52
Negative SD average: 10 Negative DS average: 10
Negative SD square-sum: 460 Negative DS square-sum: 754
SD average: 10 DS average: 10
One way results:
Max SD delay: 15 Max DS delay: 16
Min SD delay: 7 Min DS delay: 7
Number of SD delay: 10 Number of DS delay: 10
Sum of SD delay: 78 Sum of DS delay: 85
Square-Sum of SD delay: 666 Square-Sum of DS delay: 787
SD lost packets: 0 DS lost packets: 0
Lost packets for unknown reason: 0# Exibir as estatísticas da operação de jitter UDP.
[DeviceA] display nqa statistics admin test1
NQA entry (admin admin, tag test1) test statistics:
NO. : 1
Start time: 2011-05-29 13:56:14.0
Life time: 47 seconds
Send operation times: 410 Receive response times: 410
Min/Max/Average round trip time: 1/93/19
Square-Sum of round trip time: 206176
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
UDP-jitter results:
RTT number: 410
Min positive SD: 3 Min positive DS: 1
Max positive SD: 30 Max positive DS: 79
Positive SD number: 186 Positive DS number: 158
Positive SD sum: 2602 Positive DS sum: 1928
Positive SD average: 13 Positive DS average: 12
Positive SD square-sum: 45304 Positive DS square-sum: 31682
Min negative SD: 1 Min negative DS: 1
Max negative SD: 30 Max negative DS: 78
Negative SD number: 181 Negative DS number: 209
Negative SD sum: 181 Negative DS sum: 209
Negative SD average: 13 Negative DS average: 14
Negative SD square-sum: 46994 Negative DS square-sum: 3030
SD average: 9 DS average: 1
One way results:
Max SD delay: 46 Max DS delay: 46
Min SD delay: 7 Min DS delay: 7
Number of SD delay: 410 Number of DS delay: 410
Sum of SD delay: 3705 Sum of DS delay: 3891
Square-Sum of SD delay: 45987 Square-Sum of DS delay: 49393
SD lost packets: 0 DS lost packets: 0
Lost packets for unknown reason: 0
Exemplo: Configuração da operação SNMP
Configuração de rede
Conforme mostrado na Figura 9, configure uma operação SNMP para testar o tempo que o cliente NQA usa para obter uma resposta do agente SNMP.
Figura 9 Diagrama de rede

Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 9. (Detalhes não mostrados.)
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configure o agente SNMP (Dispositivo B): # Defina a versão do SNMP como all.
<DeviceB> system-view
[DeviceB] snmp-agent sys-info version all# Defina a comunidade de leitura como pública.
[DeviceB] snmp-agent community read public# Defina a comunidade de gravação como privada.
[DeviceB] snmp-agent community write private- Configurar o dispositivo A:
# Criar uma operação SNMP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type snmp# Especifique 10.2.2.2 como o endereço IP de destino da operação SNMP.
[DeviceA-nqa-admin-test1-snmp] destination ip 10.2.2.2# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-snmp] history-record enable
[DeviceA-nqa-admin-test1-snmp] quit# Iniciar a operação SNMP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação SNMP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação SNMP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 50/50/50
Square-Sum of round trip time: 2500
Last succeeded probe time: 2011-11-22 10:24:41.1
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação SNMP.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 50 Succeeded 2011-11-22 10:24:41.1
A saída mostra que o Dispositivo A levou 50 milissegundos para receber uma resposta do agente SNMP.
Exemplo: Configuração da operação TCP
Configuração de rede
Conforme mostrado na Figura 10, configure uma operação TCP para testar o tempo necessário para que o Dispositivo A estabeleça uma conexão TCP com o Dispositivo B.
Figura 10 Diagrama de rede

Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 10. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilitar o servidor NQA.
system-view
[DeviceB] nqa server enable
# Configure um serviço de escuta para escutar a porta TCP 9000 no endereço IP 10.2.2.2.
[DeviceB] nqa server tcp-connect 10.2.2.2 9000
- Configurar o dispositivo A:
# Crie uma operação TCP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type tcp
# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqa-admin-test1-tcp] destination ip 10.2.2.2# Defina o número da porta de destino como 9000.
[DeviceA-nqa-admin-test1-tcp] destination port 9000# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-tcp] history-record enable
[DeviceA-nqa-admin-test1-tcp] quit# Iniciar a operação TCP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação TCP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação TCP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 13/13/13
Square-Sum of round trip time: 169
Last succeeded probe time: 2011-11-22 10:27:25.1
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to disconnect: 0
Failures due to no connection: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação TCP.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 13 Succeeded 2011-11-22 10:27:25.1A saída mostra que o Dispositivo A levou 13 milissegundos para estabelecer uma conexão TCP com a porta 9000 no servidor NQA.
Exemplo: Configuração da operação de echo UDP
Configuração de rede
Conforme mostrado na Figura 11, configure uma operação de eco UDP no cliente NQA para testar o tempo de ida e volta para o Dispositivo B. O número da porta de destino é 8000.
Figura 11 Diagrama de rede
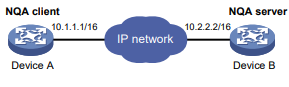
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 11. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilitar o servidor NQA.
system-view
[DeviceB] nqa server enable
# Configure um serviço de escuta para escutar a porta UDP 8000 no endereço IP 10.2.2.2.
[DeviceB] nqa server udp-echo 10.2.2.2 8000- Configurar o dispositivo A:
# Criar uma operação de eco UDP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type udp-echo# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqa-admin-test1-udp-echo] destination ip 10.2.2.2# Defina o número da porta de destino como 8000.
[DeviceA-nqa-admin-test1-udp-echo] destination port 8000# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-udp-echo] history-record enable
[DeviceA-nqa-admin-test1-udp-echo] quit# Iniciar a operação de eco UDP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação de eco UDP for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de eco UDP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 25/25/25
Square-Sum of round trip time: 625
Last succeeded probe time: 2011-11-22 10:36:17.9
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação de eco UDP.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 25 Succeeded 2011-11-22 10:36:17.9A saída mostra que o tempo de ida e volta entre o Dispositivo A e a porta 8000 no Dispositivo B é de 25 milissegundos.
Exemplo: Configuração da operação UDP tracert
Configuração de rede
Conforme mostrado na Figura 12, configure uma operação de tracert UDP para determinar o caminho de roteamento do Dispositivo A para o Dispositivo B.
Figura 12 Diagrama de rede
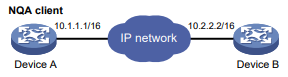
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 12. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Execute o comando ip ttl-expires enable nos dispositivos intermediários e execute o comando ip unreachables enable no Dispositivo B.
- Configurar o dispositivo A:
# Criar uma operação de tracert UDP.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type udp-tracert# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqa-admin-test1-udp-tracert] destination ip 10.2.2.2# Defina o número da porta de destino como 33434.
[DeviceA-nqa-admin-test1-udp-tracert] destination port 33434# Configure o dispositivo A para executar três sondas em cada salto.
[DeviceA-nqa-admin-test1-udp-tracert] probe count 3Defina o tempo limite da sonda como 500 milissegundos.
[DeviceA-nqa-admin-test1-udp-tracert] probe timeout 500# Configure a operação de tracert UDP para ser repetida a cada 5000 milissegundos.
[DeviceA-nqa-admin-test1-udp-tracert] frequency 5000# Especifique GigabitEthernet 1/0/1 como a interface de saída para pacotes UDP.
[DeviceA-nqa-admin-test1-udp-tracert] out interface gigabitethernet 1/0/1# Habilite o recurso de não fragmentação.
[DeviceA-nqa-admin-test1-udp-tracert] no-fragment enableDefina o número máximo de falhas consecutivas da sonda como 6.
[DeviceA-nqa-admin-test1-udp-tracert] max-failure 6# Defina o valor TTL como 1 para pacotes UDP na rodada inicial da operação de tracert UDP.
[DeviceA-nqa-admin-test1-udp-tracert] init-ttl 1# Iniciar a operação de tracert UDP.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação UDP tracert for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de tracert UDP.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 6 Receive response times: 6
Min/Max/Average round trip time: 1/1/1
Square-Sum of round trip time: 1
Last succeeded probe time: 2013-09-09 14:46:06.2
Extended results:
Packet loss in test: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
UDP-tracert results:
TTL Hop IP Time
1 3.1.1.1 2013-09-09 14:46:03.2
2 10.2.2.2 2013-09-09 14:46:06.2
# Exibir os registros de histórico da operação UDP tracert.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index TTL Response Hop IP Status Time
1 2 2 10.2.2.2 Succeeded 2013-09-09 14:46:06.2
1 2 1 10.2.2.2 Succeeded 2013-09-09 14:46:05.2
1 2 2 10.2.2.2 Succeeded 2013-09-09 14:46:04.2
1 1 1 3.1.1.1 Succeeded 2013-09-09 14:46:03.2
1 1 2 3.1.1.1 Succeeded 2013-09-09 14:46:02.2
1 1 1 3.1.1.1 Succeeded 2013-09-09 14:46:01.2
Exemplo: Configuração da operação de voz
Configuração de rede
Conforme mostrado na Figura 13, configure uma operação de voz para testar jitters, atraso, MOS e ICPIF entre o Dispositivo A e o Dispositivo B.
Figura 13 Diagrama de rede
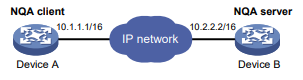
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 13. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilitar o servidor NQA.
system-view
[DeviceB] nqa server enable
# Configure um serviço de escuta para escutar a porta UDP 9000 no endereço IP 10.2.2.2.
[DeviceB] nqa server udp-echo 10.2.2.2 9000
- Configure o dispositivo A:
# Criar uma operação de voz.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type voice
# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqa-admin-test1-voice] destination ip 10.2.2.2# Defina o número da porta de destino como 9000.
[DeviceA-nqa-admin-test1-voice] destination port 9000
[DeviceA-nqa-admin-test1-voice] quit# Iniciar a operação de voz.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação de voz for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de voz.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1000 Receive response times: 1000
Min/Max/Average round trip time: 31/1328/33
Square-Sum of round trip time: 2844813
Last packet received time: 2011-06-13 09:49:31.1
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
Voice results:
RTT number: 1000
Min positive SD: 1 Min positive DS: 1
Max positive SD: 204 Max positive DS: 1297
Positive SD number: 257 Positive DS number: 259
Positive SD sum: 759 Positive DS sum: 1797
Positive SD average: 2 Positive DS average: 6
Positive SD square-sum: 54127 Positive DS square-sum: 1691967
Min negative SD: 1 Min negative DS: 1
Max negative SD: 203 Max negative DS: 1297
Negative SD number: 255 Negative DS number: 259
Negative SD sum: 759 Negative DS sum: 1796
Negative SD average: 2 Negative DS average: 6
Negative SD square-sum: 53655 Negative DS square-sum: 1691776
SD average: 2 DS average: 6
One way results:
Max SD delay: 343 Max DS delay: 985
Min SD delay: 343 Min DS delay: 985
Number of SD delay: 1 Number of DS delay: 1
Sum of SD delay: 343 Sum of DS delay: 985
Square-Sum of SD delay: 117649 Square-Sum of DS delay: 970225
SD lost packets: 0 DS lost packets: 0
Lost packets for unknown reason: 0
Voice scores:
MOS value: 4.38 ICPIF value: 0# Exibir as estatísticas da operação de voz.
[DeviceA] display nqa statistics admin test1
NQA entry (admin admin, tag test1) test statistics:
NO. : 1
Start time: 2011-06-13 09:45:37.8
Life time: 331 seconds
Send operation times: 4000 Receive response times: 4000
Min/Max/Average round trip time: 15/1328/32
Square-Sum of round trip time: 7160528
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
Voice results:
RTT number: 4000
Min positive SD: 1 Min positive DS: 1
Max positive SD: 360 Max positive DS: 1297
Positive SD number: 1030 Positive DS number: 1024
Positive SD sum: 4363 Positive DS sum: 5423
Positive SD average: 4 Positive DS average: 5
Positive SD square-sum: 497725 Positive DS square-sum: 2254957
Min negative SD: 1 Min negative DS: 1
Max negative SD: 360 Max negative DS: 1297
Negative SD number: 1028 Negative DS number: 1022
Negative SD sum: 1028 Negative DS sum: 1022
Negative SD average: 4 Negative DS average: 5
Negative SD square-sum: 495901 Negative DS square-sum: 5419
SD average: 16 DS average: 2
One way results:
Max SD delay: 359 Max DS delay: 985
Min SD delay: 0 Min DS delay: 0
Number of SD delay: 4 Number of DS delay: 4
Sum of SD delay: 1390 Sum of DS delay: 1079
Square-Sum of SD delay: 483202 Square-Sum of DS delay: 973651
SD lost packets: 0 DS lost packets: 0
Lost packets for unknown reason: 0
Voice scores:
Max MOS value: 4.38 Min MOS value: 4.38
Max ICPIF value: 0 Min ICPIF value: 0Exemplo: Configuração da operação DLSw
Configuração de rede
Conforme mostrado na Figura 14, configure uma operação DLSw para testar o tempo de resposta do dispositivo DLSw.
Figura 14 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 14. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar uma operação DLSw.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type dlsw# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqa-admin-test1-dlsw] destination ip 10.2.2.2# Habilite o salvamento de registros de histórico.
[DeviceA-nqa-admin-test1-dlsw] history-record enable
[DeviceA-nqa-admin-test1-dlsw] quit# Iniciar a operação DLSw.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever
# Depois que a operação DLSw for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação DLSw.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Send operation times: 1 Receive response times: 1
Min/Max/Average round trip time: 19/19/19
Square-Sum of round trip time: 361
Last succeeded probe time: 2011-11-22 10:40:27.7
Extended results:
Packet loss ratio: 0%
Failures due to timeout: 0
Failures due to disconnect: 0
Failures due to no connection: 0
Failures due to internal error: 0
Failures due to other errors: 0# Exibir os registros de histórico da operação DLSw.
[DeviceA] display nqa history admin test1
NQA entry (admin admin, tag test1) history records:
Index Response Status Time
1 19 Succeeded 2011-11-22 10:40:27.7A saída mostra que o tempo de resposta do dispositivo DLSw é de 19 milissegundos.
Exemplo: Configuração da operação de jitter de caminho
Configuração de rede
Conforme mostrado na Figura 15, configure uma operação de jitter de caminho para testar o tempo de ida e volta e os jitters do Dispositivo A para o Dispositivo B e o Dispositivo C.
Figura 15 Diagrama de rede
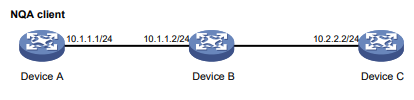
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 15. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Execute o comando ip ttl-expires enable no Dispositivo B e execute o comando ip unreachables enable no Dispositivo C.
# Criar uma operação de jitter de caminho.
<DeviceA> system-view
[DeviceA] nqa entry admin test1
[DeviceA-nqa-admin-test1] type path-jitter
# Especifique 10.2.2.2 como o endereço IP de destino das solicitações de eco ICMP.
[DeviceA-nqa-admin-test1-path-jitter] destination ip 10.2.2.2# Configure a operação de jitter de caminho para ser repetida a cada 10.000 milissegundos.
[DeviceA-nqa-admin-test1-path-jitter] frequency 10000
[DeviceA-nqa-admin-test1-path-jitter] quit# Iniciar a operação de jitter de caminho.
[DeviceA] nqa schedule admin test1 start-time now lifetime forever# Depois que a operação de jitter de caminho for executada por um período de tempo, interrompa a operação.
[DeviceA] undo nqa schedule admin test1Verificação da configuração
# Exibir o resultado mais recente da operação de jitter de caminho.
[DeviceA] display nqa result admin test1
NQA entry (admin admin, tag test1) test results:
Hop IP 10.1.1.2
Basic Results
Send operation times: 10 Receive response times: 10
Min/Max/Average round trip time: 9/21/14
Square-Sum of round trip time: 2419
Extended Results
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
Path-Jitter Results
Jitter number: 9
Min/Max/Average jitter: 1/10/4
Positive jitter number: 6
Min/Max/Average positive jitter: 1/9/4
Sum/Square-Sum positive jitter: 25/173
Negative jitter number: 3
Min/Max/Average negative jitter: 2/10/6
Sum/Square-Sum positive jitter: 19/153
Hop IP 10.2.2.2
Basic Results
Send operation times: 10 Receive response times: 10
Min/Max/Average round trip time: 15/40/28
Square-Sum of round trip time: 4493
Extended Results
Failures due to timeout: 0
Failures due to internal error: 0
Failures due to other errors: 0
Packets out of sequence: 0
Packets arrived late: 0
Path-Jitter Results
Jitter number: 9
Min/Max/Average jitter: 1/10/4
Positive jitter number: 6
Min/Max/Average positive jitter: 1/9/4
Sum/Square-Sum positive jitter: 25/173
Negative jitter number: 3
Min/Max/Average negative jitter: 2/10/6
Sum/Square-Sum positive jitter: 19/153Exemplo: Configuração da colaboração NQA
Configuração de rede
Conforme mostrado na Figura 16, configure uma rota estática para o Switch C com o Switch B como o próximo salto no Switch
A. Associe a rota estática, uma entrada de trilha e uma operação de eco ICMP para monitorar o estado da rota estática .
Figura 16 Diagrama de rede
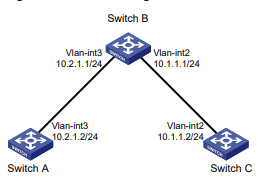
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 16. (Detalhes não mostrados).
- No Switch A, configure uma rota estática e associe a rota estática à entrada de trilha 1.
<SwitchA> system-view
[SwitchA] ip route-static 10.1.1.2 24 10.2.1.1 track 1- No Switch A, configure uma operação de eco ICMP:
# Criar uma operação NQA com o nome de administrador admin e a tag de operação test1.
[SwitchA] nqa entry admin test1# Configure o tipo de operação do NQA como eco ICMP.
[SwitchA-nqa-admin-test1] type icmp-echo# Especifique 10.2.1.1 como o endereço IP de destino.
[SwitchA-nqa-admin-test1-icmp-echo] destination ip 10.2.1.1[Configure a operação para se repetir a cada 100 milissegundos.
[SwitchA-nqa-admin-test1-icmp-echo] frequency 100# Criar entrada de reação 1. Se o número de falhas consecutivas da sonda chegar a 5, a colaboração será acionada.
[SwitchA-nqa-admin-test1-icmp-echo] reaction 1 checked-element probe-fail
threshold-type consecutive 5 action-type trigger-only
[SwitchA-nqa-admin-test1-icmp-echo] quit# Iniciar a operação ICMP.
[SwitchA] nqa schedule admin test1 start-time now lifetime forever- No Switch A, crie a entrada de trilha 1 e associe-a à entrada de reação 1 da operação NQA.
[SwitchA] track 1 nqa entry admin test1 reaction 1Verificação da configuração
# Exibir informações sobre todas as entradas de trilha no Switch A.
[SwitchA] display track all
Track ID: 1
State: Positive
Duration: 0 days 0 hours 0 minutes 0 seconds
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
NQA entry: admin test1
Reaction: 1# Exibir informações breves sobre as rotas ativas na tabela de roteamento do Switch A.
[SwitchA] display ip routing-table
Destinations : 13 Routes : 13
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
10.1.1.0/24 Static 60 0 10.2.1.1 Vlan3
10.2.1.0/24 Direct 0 0 10.2.1.2 Vlan3
10.2.1.0/32 Direct 0 0 10.2.1.2 Vlan3
10.2.1.2/32 Direct 0 0 127.0.0.1 InLoop0
10.2.1.255/32 Direct 0 0 10.2.1.2 Vlan3
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
127.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
224.0.0.0/4 Direct 0 0 0.0.0.0 NULL0
224.0.0.0/24 Direct 0 0 0.0.0.0 NULL0
255.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0A saída mostra que a rota estática com o próximo salto 10.2.1.1 está ativa e o status da entrada da trilha é positivo.
# Remova o endereço IP da interface VLAN 3 no Switch B.
<SwitchB> system-view
[SwitchB] interface vlan-interface 3
[SwitchB-Vlan-interface3] undo ip address# Exibir informações sobre todas as entradas de trilha no Switch A.
[SwitchA] display track all
Track ID: 1
State: Negative
Duration: 0 days 0 hours 0 minutes 0 seconds
Notification delay: Positive 0, Negative 0 (in seconds)
Tracked object:
NQA entry: admin test1
Reaction: 1# Exibir informações breves sobre as rotas ativas na tabela de roteamento do Switch A.
[SwitchA] display ip routing-table
Destinations : 12 Routes : 12
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
10.2.1.0/24 Direct 0 0 10.2.1.2 Vlan3
10.2.1.0/32 Direct 0 0 10.2.1.2 Vlan3
10.2.1.2/32 Direct 0 0 127.0.0.1 InLoop0
10.2.1.255/32 Direct 0 0 10.2.1.2 Vlan3
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
127.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0
224.0.0.0/4 Direct 0 0 0.0.0.0 NULL0
224.0.0.0/24 Direct 0 0 0.0.0.0 NULL0
255.255.255.255/32 Direct 0 0 127.0.0.1 InLoop0A saída mostra que a rota estática não existe e o status da entrada de trilha é negativo.
Exemplo: Configuração do modelo ICMP
Configuração de rede
Conforme mostrado na Figura 17, configure um modelo ICMP para que um recurso execute a operação de eco ICMP do Dispositivo A para o Dispositivo B.
Figura 17 Diagrama de rede
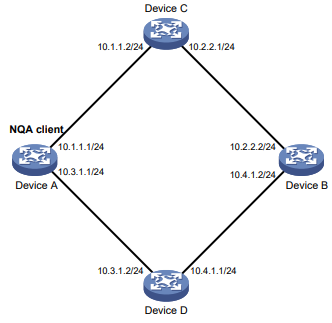
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 17. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar modelo ICMP icmp.
<DeviceA> system-view
[DeviceA] nqa template icmp icmp# Especifique 10.2.2.2 como o endereço IP de destino das solicitações de eco ICMP.
[DeviceA-nqatplt-icmp-icmp] destination ip 10.2.2.2# Defina o tempo limite da sonda como 500 milissegundos para a operação de eco ICMP.
[DeviceA-nqatplt-icmp-icmp] probe timeout 500# Configure a operação de eco ICMP para se repetir a cada 3000 milissegundos.
[DeviceA-nqatplt-icmp-icmp] frequency 3000# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-icmp-icmp] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-icmp-icmp] reaction trigger probe-fail 2Exemplo: Configuração do modelo de DNS
Configuração de rede
Conforme mostrado na Figura 18, configure um modelo de DNS para que um recurso execute a operação de DNS. A operação testa se o Dispositivo A pode executar a resolução de endereços por meio do servidor DNS.
Figura 18 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 18. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar modelo de DNS dns.
<DeviceA> system-view
[DeviceA] nqa template dns dns# Especifique o endereço IP do servidor DNS (10.2.2.2) como o endereço IP de destino.
[DeviceA-nqatplt-dns-dns] destination ip 10.2.2.2# Especifique host.com como o nome de domínio a ser traduzido.
[DeviceA-nqatplt-dns-dns] resolve-target host.com# Defina o tipo de resolução de nome de domínio como tipo A.
[DeviceA-nqatplt-dns-dns] resolve-type A# Especifique 3.3.3.3 como o endereço IP esperado.
[DeviceA-nqatplt-dns-dns] expect ip 3.3.3.3# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-dns-dns] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-dns-dns] reaction trigger probe-fail 2Exemplo: Configuração do modelo TCP
Configuração de rede
Conforme mostrado na Figura 19, configure um modelo TCP para que um recurso execute a operação TCP. A operação testa se o Dispositivo A pode estabelecer uma conexão TCP com o Dispositivo B.
Figura 19 Diagrama de rede
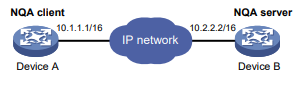
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 19. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilitar o servidor NQA.
system-view
[DeviceB] nqa server enable
# Configure um serviço de escuta para escutar a porta TCP 9000 no endereço IP 10.2.2.2.
[DeviceB] nqa server tcp-connect 10.2.2.2 9000
- Configurar o dispositivo A:
# Criar modelo TCP tcp.
<DeviceA> system-view
[DeviceA] nqa template tcp tcp# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqatplt-tcp-tcp] destination ip 10.2.2.2# Defina o número da porta de destino como 9000.
[DeviceA-nqatplt-tcp-tcp] destination port 9000# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-tcp-tcp] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-tcp-tcp] reaction trigger probe-fail 2Exemplo: Configuração do modelo TCP semiaberto
Configuração de rede
Conforme mostrado na Figura 20, configure um modelo TCP semiaberto para um recurso para testar se o Dispositivo B pode fornecer o serviço TCP para o Dispositivo A.
Figura 20 Diagrama de rede

Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 20. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo A:
# Criar teste de modelo TCP semiaberto.
<DeviceA> system-view
[DeviceA] nqa template tcphalfopen test# Especifique 10.2.2.2 como o endereço IP de destino.
[DeviceA-nqatplt-tcphalfopen-test] destination ip 10.2.2.2# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-tcphalfopen-test] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-tcphalfopen-test] reaction trigger probe-fail 2Exemplo: Configuração do modelo UDP
Configuração de rede
Conforme mostrado na Figura 21, configure um modelo UDP para que um recurso execute a operação UDP. A operação testa se o Dispositivo A pode receber uma resposta do Dispositivo B.
Figura 21 Diagrama de rede
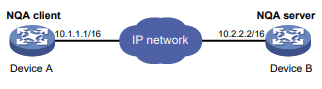
Procedimento
- Atribua endereços IP às interfaces, conforme mostrado na Figura 21. (Detalhes não mostrados).
- Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilitar o servidor NQA.
<DeviceB> system-view
[DeviceB] nqa server enable
# Configure um serviço de escuta para escutar a porta UDP 9000 no endereço IP 10.2.2.2.
[DeviceB] nqa server udp-echo 10.2.2.2 9000
- Configurar o dispositivo A:
# Criar modelo UDP udp.
<DeviceA> system-view
[DeviceB] nqa server enableExemplo: Configuração do modelo HTTP
Configuração de rede
Conforme mostrado na Figura 22, configure um modelo HTTP para que um recurso execute a operação HTTP. A operação testa se o cliente NQA pode obter dados do servidor HTTP.
Figura 22 Diagrama de rede

Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 22. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar modelo HTTP http.
<DeviceA> system-view
[DeviceA] nqa template http http# Especifique http://10.2.2.2/index.htm como o URL do servidor HTTP.
[DeviceA-nqatplt-http-http] url http://10.2.2.2/index.htm# Defina o tipo de operação HTTP como get.
[DeviceA-nqatplt-http-http] operation get# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-http-http] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-http-http] reaction trigger probe-fail 2Exemplo: Configuração do modelo HTTPS
Configuração de rede
Conforme mostrado na Figura 23, configure um modelo HTTPS para um recurso para testar se o cliente NQA pode obter dados do servidor HTTPS (Dispositivo B).
Figura 23 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 23. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Configure uma política de cliente SSL chamada abc no Dispositivo A e certifique-se de que o Dispositivo A possa usar a política para se conectar ao servidor HTTPS. (Detalhes não mostrados.)
# Criar teste de modelo HTTPS.
system-view
[DeviceA] nqa template https https
# Especifique http://10.2.2.2/index.htm como o URL do servidor HTTPS.
[DeviceA-nqatplt-https-https] url https://10.2.2.2/index.htm# Especifique a política de cliente SSL abc para o modelo HTTPS.
[DeviceA-nqatplt-https- https] ssl-client-policy abc# Defina o tipo de operação HTTPS como get (o tipo de operação HTTPS padrão).
[DeviceA-nqatplt-https-https] operation get# Defina a versão do HTTPS como 1.0 (a versão padrão do HTTPS).
[DeviceA-nqatplt-https-https] version v1.0# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-https-https] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-https-https] reaction trigger probe-fail 2Exemplo: Configuração do modelo de FTP
Configuração de rede
Conforme mostrado na Figura 24, configure um modelo de FTP para que um recurso execute a operação de FTP. A operação testa se o Dispositivo A pode carregar um arquivo no servidor FTP. O nome de usuário e a senha de login são admin e systemtest, respectivamente. O arquivo a ser transferido para o servidor FTP é config.txt.
Figura 24 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 24. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Criar modelo de FTP ftp.
<DeviceA> system-view
[DeviceA] nqa template ftp ftp# Especifique o URL do servidor FTP.
[DeviceA-nqatplt-ftp-ftp] url ftp://10.2.2.2# Especifique 10.1.1.1 como o endereço IP de origem.
[DeviceA-nqatplt-ftp-ftp] source ip 10.1.1.1# Configure o dispositivo para fazer upload do arquivo config.txt para o servidor FTP.
[DeviceA-nqatplt-ftp-ftp] operation put
[DeviceA-nqatplt-ftp-ftp] filename config.txt# Defina o nome de usuário como admin para o login no servidor FTP.
[DeviceA-nqatplt-ftp-ftp] password simple systemtest# Defina a senha como systemtest para o login do servidor FTP.
[DeviceA-nqatplt-ftp-ftp] password simple systemtest
# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-ftp-ftp] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-ftp-ftp] reaction trigger probe-fail 2Exemplo: Configuração do modelo RADIUS
Configuração de rede
Conforme mostrado na Figura 25, configure um modelo RADIUS para um recurso para testar se o servidor RADIUS (Dispositivo B) pode fornecer serviço de autenticação para o Dispositivo A. O nome de usuário e a senha são admin e systemtest, respectivamente. A chave compartilhada é 123456 para autenticação RADIUS segura.
Figura 25 Diagrama de rede

Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 25. (Os detalhes não são mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Configurar o servidor RADIUS. (Detalhes não mostrados.) # Criar modelo RADIUS radius.
<DeviceA> system-view
[DeviceA] nqa template radius radius# Especifique 10.2.2.2 como o endereço IP de destino da operação.
[DeviceA-nqatplt-radius-radius] destination ip 10.2.2.2# Defina o nome de usuário como admin.
[DeviceA-nqatplt-radius-radius] username admin# Defina a senha como systemtest.
[DeviceA-nqatplt-radius-radius] password simple systemtest# Defina a chave compartilhada como 123456 em texto simples para autenticação RADIUS segura.
[DeviceA-nqatplt-radius-radius] key simple 123456# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-radius-radius] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-radius-radius] reaction trigger probe-fail 2Exemplo: Configuração do modelo SSL
Configuração de rede
Conforme mostrado na Figura 26, configure um modelo SSL para um recurso para testar se o Dispositivo A pode estabelecer uma conexão SSL com o servidor SSL no Dispositivo B.
Figura 26 Diagrama de rede
Procedimento
# Atribua endereços IP às interfaces, conforme mostrado na Figura 26. (Detalhes não mostrados).
# Configure rotas estáticas ou um protocolo de roteamento para garantir que os dispositivos possam se comunicar entre si. (Detalhes não mostrados.)
# Configure uma política de cliente SSL chamada abc no Dispositivo A e certifique-se de que o Dispositivo A possa usar a política para se conectar ao servidor SSL no Dispositivo B. (Detalhes não mostrados).
# Criar modelo SSL ssl.
system-view
[DeviceA] nqa template ssl ssl # Defina o endereço IP de destino e o número da porta como 10.2.2.2 e 9000, respectivamente.
[DeviceA-nqatplt-ssl-ssl] destination ip 10.2.2.2
[DeviceA-nqatplt-ssl-ssl] destination port 9000# Especifique a política de cliente SSL abc para o modelo SSL.
[DeviceA-nqatplt-ssl-ssl] ssl-client-policy abc# Configure o cliente NQA para notificar o recurso do evento de operação bem-sucedida se o número de sondas consecutivas bem-sucedidas chegar a 2.
[DeviceA-nqatplt-ssl-ssl] reaction trigger probe-pass 2# Configure o cliente NQA para notificar o recurso sobre a falha na operação se o número de sondas consecutivas com falha chegar a 2.
[DeviceA-nqatplt-ssl-ssl] reaction trigger probe-fail 2Configuração do NTP
Sobre a NTP
O NTP é usado para sincronizar os relógios do sistema entre servidores de horário distribuídos e clientes em uma rede. O NTP é executado por UDP e usa a porta UDP 123.
Cenários de aplicativos NTP
Várias tarefas, inclusive gerenciamento de rede, cobrança, auditoria e computação distribuída, dependem da configuração precisa e sincronizada da hora do sistema nos dispositivos de rede. Normalmente, o NTP é usado em grandes redes para sincronizar dinamicamente a hora entre os dispositivos de rede.
O NTP garante maior precisão do relógio do que a configuração manual do relógio do sistema. Em uma rede pequena que não exige alta precisão do relógio, é possível manter o tempo sincronizado entre os dispositivos alterando os relógios do sistema um a um.
Mecanismo de funcionamento do NTP
A Figura 1 mostra como o NTP sincroniza a hora do sistema entre dois dispositivos (Dispositivo A e Dispositivo B, neste exemplo). Suponha que:
Antes da sincronização de horário, o horário é definido como 10:00:00 am para o Dispositivo A e 11:00:00 am para o Dispositivo B.
O dispositivo B é usado como servidor NTP. O dispositivo A deve ser sincronizado com o dispositivo B.
Uma mensagem NTP leva 1 segundo para ir do Dispositivo A ao Dispositivo B e do Dispositivo B ao Dispositivo A.
O Dispositivo B leva 1 segundo para processar a mensagem NTP.
Figura 1 Fluxo de trabalho básico
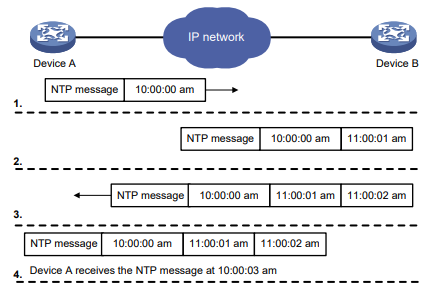
O processo de sincronização é o seguinte:
- O Dispositivo A envia ao Dispositivo B uma mensagem NTP, que recebe um registro de data e hora quando sai do Dispositivo A. O registro de data e hora é 10:00:00 am (T1).
- Quando essa mensagem NTP chega ao Dispositivo B, o Dispositivo B adiciona um registro de data e hora mostrando a hora em que a mensagem chegou ao Dispositivo B. O registro de data e hora é 11:00:01 am (T2).
- Quando a mensagem NTP sai do Dispositivo B, o Dispositivo B adiciona um registro de data e hora mostrando a hora em que a mensagem saiu do Dispositivo B. O registro de data e hora é 11:00:02 am (T3).
- Quando o Dispositivo A recebe a mensagem NTP, a hora local do Dispositivo A é 10:00:03 am (T4). Até o momento, o Dispositivo A pode calcular os seguintes parâmetros com base nos registros de data e hora:
O atraso de ida e volta da mensagem NTP: Atraso = (T4 - T1) - (T3 - T2) = 2 segundos.
Diferença de tempo entre o Dispositivo A e o Dispositivo B: Deslocamento = [ (T2 - T1) + (T3 - T4) ] /2 = 1 hora. Com base nesses parâmetros, o Dispositivo A pode ser sincronizado com o Dispositivo B.
Esta é apenas uma descrição aproximada do mecanismo de trabalho do NTP. Para obter mais informações, consulte os protocolos e padrões relacionados em .
Arquitetura NTP
O NTP usa estratos de 1 a 16 para definir a precisão do relógio, conforme mostrado na Figura 2. Um valor de estrato mais baixo representa maior precisão. Os relógios nos estratos 1 a 15 estão em estado sincronizado, e os relógios no estrato 16 não estão sincronizados.
Figura 2 Arquitetura do NTP
Um servidor NTP de estrato 1 obtém sua hora de uma fonte de hora autorizada, como um relógio atômico. Ele fornece a hora para outros dispositivos como o servidor NTP principal. Um servidor de horário de estrato 2 recebe seu horário de um servidor de horário de estrato 1, e assim por diante.
Para garantir a precisão e a disponibilidade do tempo, você pode especificar vários servidores NTP para um dispositivo. O dispositivo seleciona um servidor NTP ideal como a fonte do relógio com base em parâmetros como estrato. O relógio que o dispositivo seleciona é chamado de fonte de referência. Para obter mais informações sobre a seleção do relógio, consulte os protocolos e padrões relacionados.
Se os dispositivos em uma rede não puderem ser sincronizados com uma fonte de hora autorizada, você poderá executar as seguintes tarefas:
Selecione um dispositivo que tenha um relógio relativamente preciso na rede.
Use o relógio local do dispositivo como relógio de referência para sincronizar outros dispositivos na rede .
Modos de associação NTP
O NTP é compatível com os seguintes modos de associação:
Modo cliente/servidor
Modo ativo/passivo simétrico
Modo de transmissão
Modo multicast
Você pode selecionar um ou mais modos de associação para sincronização de horário. A Tabela 1 fornece uma descrição detalhada dos quatro modos de associação.
Neste documento, um "servidor NTP" ou um "servidor" refere-se a um dispositivo que opera como um servidor NTP no modo cliente/servidor. Servidores de horário referem-se a todos os dispositivos que podem fornecer sincronização de horário, incluindo servidores NTP, pares simétricos NTP, servidores de broadcast e servidores multicast.
Tabela 1 Modos de associação NTP
| Modo | Processo de trabalho | Princípio | Cenário de aplicação | ||||
| No cliente, especifique o endereço IP do servidor NTP. | |||||||
| Cliente/servidor | Um cliente envia uma mensagem de sincronização de relógio para os servidores NTP. Ao receber a mensagem, os servidores operam automaticamente no modo de servidor e enviam uma resposta. Se o cliente puder ser sincronizado com vários servidores de horário, ele selecionará um relógio ideal e sincronizará seu relógio local com a fonte de referência ideal após receber as respostas dos servidores. | Um cliente pode sincronizar com um servidor, mas um servidor não pode sincronizar com um cliente. | Como mostra a Figura 2, esse modo é destinado a configurações em que os dispositivos de um estrato mais alto sincronizam com dispositivos de um estrato mais baixo. | ||||
| No par ativo simétrico, especifique o endereço IP do par passivo simétrico. | |||||||
| Ativo/passivo simétrico | Um par ativo simétrico envia periodicamente mensagens de sincronização de relógio para um par passivo simétrico. O par passivo simétrico opera automaticamente no modo passivo simétrico e envia uma resposta. Se o par ativo simétrico puder ser sincronizado com vários servidores de horário, ele selecionará um relógio ideal e sincronizará seu relógio local com a fonte de referência ideal após receber as respostas dos servidores. | Um par ativo simétrico e um par passivo simétrico podem ser sincronizados um com o outro. Se ambos estiverem sincronizados, o par com um estrato mais alto será sincronizado com o par com um estrato mais baixo. | Como mostra a Figura 2, esse modo é usado com mais frequência entre servidores com o mesmo estrato para operar como backup um para o outro. Se um servidor não conseguir se comunicar com todos os servidores de um estrato inferior, ele ainda poderá se sincronizar com os servidores do mesmo estrato. | ||||
| Transmissão | Um servidor envia periodicamente mensagens de sincronização de relógio para o endereço de transmissão | Um cliente de transmissão pode sincronizar com um servidor de transmissão, mas um | Um servidor de transmissão envia sincronização de relógio mensagens para sincronizar | ||||
| 255.255.255.255. Os clientes ouvem as mensagens de broadcast dos servidores para sincronizar com o servidor de acordo com as mensagens de broadcast. Quando um cliente recebe a primeira mensagem de broadcast, o cliente e o servidor começam a trocar mensagens para calcular o atraso da rede entre eles. Então, somente o servidor de transmissão envia mensagens de sincronização de relógio. | O servidor de transmissão não pode sincronizar com um cliente de transmissão. | clientes na mesma sub-rede. Como mostra a Figura 2, o modo de broadcast é destinado a configurações que envolvem um ou poucos servidores e uma população de clientes potencialmente grande. O modo de broadcast tem menor precisão de tempo do que os modos cliente/servidor e ativo/passivo simétrico porque somente os servidores de broadcast enviam mensagens de sincronização de relógio. | |||||
| Multicast | Um servidor multicast envia periodicamente mensagens de sincronização de relógio para o endereço multicast configurado pelo usuário. Os clientes ouvem as mensagens multicast dos servidores e sincronizam com o servidor de acordo com as mensagens recebidas. | Um cliente multicast pode sincronizar-se com um servidor multicast, mas um servidor multicast não pode sincronizar-se com um cliente multicast. | Um servidor multicast pode fornecer sincronização de horário para clientes na mesma sub-rede ou em sub-redes diferentes. O modo multicast tem menor precisão de tempo do que os modos cliente/servidor e ativo/passivo simétrico. |
Segurança NTP
Para aumentar a segurança da sincronização de horário, o NTP fornece as funções de controle de acesso e autenticação.
Controle de acesso ao NTP
Você pode controlar o acesso ao NTP usando uma ACL. Os direitos de acesso estão na seguinte ordem, do menos restritivo para o mais restritivo:
Peer - Permite solicitações de horário e consultas de controle NTP (como alarmes, status de autenticação e informações do servidor de horário) e permite que o dispositivo local se sincronize com um dispositivo par.
Server - Permite solicitações de horário e consultas de controle NTP, mas não permite que o dispositivo local se sincronize com um dispositivo par.
Sincronização - Permite apenas solicitações de tempo de um sistema cujo endereço atenda aos critérios da lista de acesso.
Query (Consulta) - Permite apenas consultas de controle NTP de um dispositivo par para o dispositivo local.
Quando o dispositivo recebe uma solicitação NTP, ele compara a solicitação com os direitos de acesso na ordem do menos restritivo para o mais restritivo: par, servidor, sincronização e consulta.
Se nenhum controle de acesso ao NTP estiver configurado, aplica-se o direito de acesso de pares.
Se o endereço IP do dispositivo par corresponder a uma instrução de permissão em uma ACL, o direito de acesso será concedido ao dispositivo par. Se uma instrução deny ou nenhuma ACL corresponder, nenhum direito de acesso será concedido.
Se nenhuma ACL for especificada para um direito de acesso ou se a ACL especificada para o direito de acesso não for criada, o direito de acesso não será concedido.
Se nenhuma das ACLs especificadas para os direitos de acesso for criada, será aplicado o direito de acesso do par.
Se nenhuma das ACLs especificadas para os direitos de acesso contiver regras, nenhum direito de acesso será concedido.
Esse recurso oferece segurança mínima para um sistema que executa NTP. Um método mais seguro é a autenticação NTP.
Autenticação NTP
Use esse recurso para autenticar as mensagens NTP para fins de segurança. Se uma mensagem NTP for aprovada na autenticação, o dispositivo poderá recebê-la e obter informações de sincronização de horário. Caso contrário, o dispositivo descartará a mensagem. Essa função garante que o dispositivo não sincronize com um servidor de horário não autorizado .
Figura 3 Autenticação NTP
Conforme mostrado na Figura 3, a autenticação NTP é realizada da seguinte forma:
- O remetente usa a chave identificada pelo ID da chave para calcular um resumo da mensagem NTP por meio do algoritmo de autenticação MD5/HMAC. Em seguida, ele envia o resumo calculado juntamente com a mensagem NTP e o ID da chave para o receptor.
- Ao receber a mensagem, o receptor executa as seguintes ações:
- Encontra a chave de acordo com o ID da chave na mensagem.
- Usa a chave e o algoritmo de autenticação MD5/HMAC para calcular o resumo da mensagem .
- Compara o digest com o digest contido na mensagem NTP.
- Se forem diferentes, o receptor descartará a mensagem.
- Se forem iguais e não for necessário estabelecer uma associação NTP, o receptor fornecerá um pacote de resposta. Para obter informações sobre associações NTP, consulte "Configuração do número máximo de associações dinâmicas".
- Se forem iguais e for necessário estabelecer ou já existir uma associação NTP, o dispositivo local determinará se o remetente tem permissão para usar o ID de autenticação. Se o remetente tiver permissão para usar o ID de autenticação, o receptor aceitará a mensagem. Se o remetente não tiver permissão para usar a ID de autenticação, o receptor descartará a mensagem .
Protocolos e padrões
RFC 1305, Especificação, implementação e análise do Network Time Protocol (versão 3)
RFC 5905, Network Time Protocol Version 4: Especificação de protocolo e algoritmos
Restrições e diretrizes: Configuração do NTP
Não é possível configurar o NTP e o SNTP no mesmo dispositivo.
O NTP é compatível apenas com as interfaces da Camada 3.
Não configure o NTP em uma porta de membro agregado.
O serviço NTP e o serviço SNTP são mutuamente exclusivos. Você só pode ativar o serviço NTP ou o serviço SNTP de cada vez.
Para evitar mudanças frequentes de horário ou até mesmo falhas de sincronização, não especifique mais de uma fonte de referência em uma rede.
∙ Para usar o NTP para sincronização de horário, você deve usar o comando clock protocol para especificar o NTP para obter o horário. Para obter mais informações sobre o comando clock protocol, consulte os comandos de gerenciamento de dispositivos na Referência de comandos básicos.
Visão geral das tarefas NTP
Para configurar o NTP, execute as seguintes tarefas:
- Ativação do serviço NTP
- Configuração do modo de associação NTP
- Configuração do NTP no modo cliente/servidor
- Configuração do NTP no modo ativo/passivo simétrico
- Configuração do NTP no modo de broadcast
- Configuração do NTP no modo multicast
- (Opcional.) Configurar o relógio local como a fonte de referência
- (Opcional.) Configuração dos direitos de controle de acesso
- (Opcional.) Configuração da autenticação NTP
- Configuração da autenticação NTP no modo cliente/servidor
- Configuração da autenticação NTP no modo ativo/passivo simétrico
- Configuração da autenticação NTP no modo de broadcast
- Configuração da autenticação NTP no modo multicast
- (Opcional.) Controle do envio e recebimento de pacotes NTP
- Especificação de um endereço de origem para mensagens NTP
- Desativar o recebimento de mensagens NTP por uma interface
- Configuração do número máximo de associações dinâmicas
- Definição de um valor DSCP para pacotes NTP
- (Opcional.) Especificação dos limites de deslocamento de tempo do NTP para saídas de registro e de interceptação
- Entre na visualização do sistema.
Ativação do serviço NTP
Restrições e diretrizes
O NTP e o SNTP são mutuamente exclusivos. Antes de ativar o NTP, certifique-se de que o SNTP esteja desativado.
Procedimento
system-view- Habilite o serviço NTP.
ntp-service enablePor padrão, o serviço NTP está desativado.
Configuração do modo de associação NTP
Configuração do NTP no modo cliente/servidor
Restrições e diretrizes
Para configurar o NTP no modo cliente/servidor, especifique um servidor NTP para o cliente.
Para que um cliente sincronize com um servidor NTP, certifique-se de que o servidor esteja sincronizado por outros dispositivos ou use seu relógio local como fonte de referência.
Se o nível de estrato de um servidor for maior ou igual ao de um cliente, o cliente não sincronizará com esse servidor.
Você pode especificar vários servidores para um cliente executando o comando ntp-service unicast-server ou
comando ntp-service ipv6 unicast-server várias vezes.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique um servidor NTP para o dispositivo. IPv4:
ntp-service unicast-server { server-name | ip-address }
[ authentication-keyid keyid | maxpoll maxpoll-interval | minpoll
minpoll-interval | priority | source interface-type interface-number |
version number ] *IPv6:
ntp-service ipv6 unicast-server { server-name | ipv6-address }
[ authentication-keyid keyid | maxpoll maxpoll-interval | minpoll
minpoll-interval | priority | source interface-type interface-number ]
*Por padrão, nenhum servidor NTP é especificado.
Configuração do NTP no modo ativo/passivo simétrico
Restrições e diretrizes
Para configurar o NTP no modo ativo/passivo simétrico, especifique um par passivo simétrico para o par ativo.
Para que um par passivo simétrico processe mensagens NTP de um par ativo simétrico, execute o comando
comando ntp-service enable no par passivo simétrico para ativar o NTP.
Para sincronização de horário entre o par ativo simétrico e o par passivo simétrico, certifique-se de que um ou ambos estejam em estado sincronizado.
Você pode especificar vários pares passivos simétricos executando o comando ntp-service unicast-peer ou ntp-service ipv6 unicast-peer várias vezes.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique um par passivo simétrico para o dispositivo. IPv4:
ntp-service unicast-peer { peer-name | ip-address }
[ authentication-keyid keyid | maxpoll maxpoll-interval | minpoll
minpoll-interval | priority | source interface-type interface-number |
version number ] *IPv6:
ntp-service ipv6 unicast-peer { peer-name | ipv6-address }
[ authentication-keyid keyid | maxpoll maxpoll-interval | minpoll
minpoll-interval | priority | source interface-type interface-number ]
*Por padrão, nenhum par passivo simétrico é especificado.
Configuração do NTP no modo de broadcast
Restrições e diretrizes
Para configurar o NTP no modo de broadcast, você deve configurar um cliente de broadcast NTP e um servidor de broadcast NTP.
Para que um cliente de transmissão sincronize com um servidor de transmissão, certifique-se de que o servidor de transmissão esteja sincronizado por outros dispositivos ou use seu relógio local como fonte de referência.
Configuração do cliente de transmissão
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o dispositivo para operar no modo de cliente de broadcast.
ntp-service broadcast-clientPor padrão, o dispositivo não opera em nenhum modo de associação NTP.
Depois que você executar o comando, o dispositivo receberá mensagens de broadcast NTP da interface especificada .
Configuração do servidor de transmissão
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o dispositivo para operar no modo de servidor de transmissão NTP.
ntp-service broadcast-server [ authentication-keyid keyid | version number ] *Por padrão, o dispositivo não opera em nenhum modo de associação NTP.
Depois que você executar o comando, o dispositivo enviará mensagens de broadcast NTP a partir da interface especificada.
Configuração do NTP no modo multicast
Restrições e diretrizes
Para configurar o NTP no modo multicast, você deve configurar um cliente NTP multicast e um servidor NTP multicast.
Para que um cliente multicast sincronize com um servidor multicast, certifique-se de que o servidor multicast esteja sincronizado por outros dispositivos ou use seu relógio local como fonte de referência.
Configuração de um cliente multicast
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o dispositivo para operar no modo de cliente multicast. IPv4:
ntp-service multicast-client [ ip-address ]IPv6:
ntp-service ipv6 multicast-client ipv6-address
Por padrão, o dispositivo não opera em nenhum modo de associação NTP.
Depois que você executar o comando, o dispositivo receberá mensagens multicast NTP da interface especificada .
Configuração do servidor multicast
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Configure o dispositivo para operar no modo de servidor multicast. IPv4:
ntp-service multicast-server [ ip-address ] [ authentication-keyid
keyid | ttl ttl-number | version number ] *
IPv6:
ntp-service ipv6 multicast-server ipv6-address [ authentication-keyid
keyid | ttl ttl-number ] *Por padrão, o dispositivo não opera em nenhum modo de associação NTP.
Depois que você executar o comando, o dispositivo enviará mensagens multicast de NTP a partir da interface especificada.
Configuração do relógio local como fonte de referência
Sobre como configurar o relógio local como a fonte de referência
Essa tarefa permite que o dispositivo use o relógio local como referência para que o dispositivo seja sincronizado.
Restrições e diretrizes
Certifique-se de que o relógio local possa fornecer a precisão de tempo necessária para a rede. Depois de configurar o relógio local como fonte de referência, o relógio local é sincronizado e pode funcionar como um servidor de horário para sincronizar outros dispositivos na rede. Se o relógio local estiver incorreto, ocorrerão erros de sincronização.
A hora do sistema é revertida para o padrão inicial do BIOS após uma reinicialização a frio. Como prática recomendada, não configure o relógio local como a fonte de referência nem configure o dispositivo como um servidor de horário.
Os dispositivos diferem em termos de precisão do relógio. Como prática recomendada para evitar oscilações na rede e falhas na sincronização do relógio, configure apenas um relógio de referência no mesmo segmento de rede e certifique-se de que o relógio tenha alta precisão.
Pré-requisitos
Antes de configurar esse recurso, ajuste a hora do sistema local para garantir que ela seja precisa.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o relógio local como a fonte de referência.
ntp-service refclock-master [ ip-address ] [ stratum ]Por padrão, o dispositivo não usa o relógio local como fonte de referência.
Configuração dos direitos de controle de acesso
Pré-requisitos
Antes de configurar o direito de os dispositivos pares acessarem os serviços NTP no dispositivo local, crie e configure as ACLs associadas ao direito de acesso. Para obter informações sobre a configuração de uma ACL, consulte o Guia de configuração de ACL e QoS.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o direito dos dispositivos pares de acessar os serviços NTP no dispositivo local. IPv4:
ntp-service access { peer | query | server | synchronization } acl
ipv4-acl-number
IPv6:
ntp-service ipv6 { peer | query | server | synchronization } acl
ipv6-acl-numberPor padrão, o direito dos dispositivos pares de acessar os serviços NTP no dispositivo local é peer.
Configuração da autenticação NTP
Configuração da autenticação NTP no modo cliente/servidor
Restrições e diretrizes
Para garantir uma autenticação NTP bem-sucedida no modo cliente/servidor, configure o mesmo ID de chave de autenticação, algoritmo e chave no servidor e no cliente. Certifique-se de que o dispositivo par tenha permissão para usar o ID da chave para autenticação no dispositivo local.
Os resultados da autenticação NTP diferem quando são realizadas configurações diferentes no cliente e no servidor. Para obter mais informações, consulte a Tabela 2. (N/A na tabela significa que o fato de a configuração ser ou não realizada não faz diferença).
Tabela 2 Resultados da autenticação NTP
| Cliente | Servidor | ||||||||||
| Ativar a autenticação NTP | Especifique o servidor e a chave | Chave confiável | Ativar a autenticação NTP | Chave confiável | |||||||
| Autenticação bem-sucedida | |||||||||||
| Sim | Sim | Sim | Sim | Sim | |||||||
| Falha na autenticação | |||||||||||
| Sim | Sim | Sim | Sim | Não | |||||||
| Sim | Sim | Sim | Não | N/A | |||||||
| Sim | Sim | Não | N/A | N/A | |||||||
| Autenticação não realizada | |||||||||||
| Sim | Não | N/A | N/A | N/A | |||||||
| Não | N/A | N/A | N/A | N/A |
Configuração da autenticação NTP para um cliente
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configure uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
- Associar a chave especificada a um servidor NTP. IPv4:
ntp-service unicast-server { server-name | ip-address }
keyid de autenticação keyid
IPv6:
ntp-service ipv6 unicast-server { server-name | ipv6-address }
keyid de autenticação keyid
Configuração da autenticação NTP para um servidor
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configurar uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
Configuração da autenticação NTP no modo ativo/passivo simétrico
Restrições e diretrizes
Para garantir uma autenticação NTP bem-sucedida no modo ativo/passivo simétrico, configure o mesmo ID de chave de autenticação, algoritmo e chave no par ativo e no par passivo. Certifique-se de que o dispositivo par tenha permissão para usar o ID da chave para autenticação no dispositivo local.
Os resultados da autenticação NTP diferem quando configurações diferentes são realizadas no par ativo e no par passivo. Para obter mais informações, consulte a Tabela 3. (N/A na tabela significa que o fato de a configuração ser ou não realizada não faz diferença).
Tabela 3 Resultados da autenticação NTP
| Par ativo | Par passivo | ||||||||||
| Ativar a autenticação NTP | Especifique o par e a chave | Chave confiável | Nível de estrato | Ativar a autenticação NTP | Chave confiável | ||||||
| Autenticação bem-sucedida | |||||||||||
| Sim | Sim | Sim | N/A | Sim | Sim | ||||||
| Falha na autenticação | |||||||||||
| Sim | Sim | Sim | N/A | Sim | Não | ||||||
| Sim | Sim | Sim | N/A | Não | N/A | ||||||
| Sim | Não | N/A | N/A | Sim | N/A | ||||||
| Não | N/A | N/A | N/A | Sim | N/A | ||||||
| Sim | Sim | Não | Maior do que o par passivo | N/A | N/A | ||||||
| Sim | Sim | Não | Menor que o par passivo | Sim | N/A | ||||||
| Autenticação não realizada | |||||||||||
| Sim | Não | N/A | N/A | Não | N/A | ||||||
| Não | N/A | N/A | N/A | Não | N/A | ||||||
| Sim | Sim | Não | Menor que o par passivo | Não | N/A |
Configuração da autenticação NTP para um par ativo
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configure uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
- Associar a chave especificada a um par passivo. IPv4:
ntp-service unicast-peer { ip-address | peer-name }
authentication-keyid keyidIPv6:
ntp-service ipv6 unicast-peer { ipv6-address | peer-name }
authentication-keyid keyidConfiguração da autenticação NTP para um par passivo
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configurar uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
Configuração da autenticação NTP no modo de broadcast
Restrições e diretrizes
Para garantir uma autenticação NTP bem-sucedida no modo de transmissão, configure o mesmo ID de chave de autenticação, algoritmo e chave no servidor e no cliente de transmissão. Certifique-se de que o dispositivo par tenha permissão para usar o ID da chave para autenticação no dispositivo local.
Os resultados da autenticação NTP diferem quando são realizadas configurações diferentes no cliente e no servidor de transmissão. Para obter mais informações, consulte a Tabela 4. (N/A na tabela significa que o fato de a configuração ser ou não realizada não faz diferença).
Tabela 4 Resultados da autenticação NTP
| Servidor de transmissão | Cliente de transmissão | ||||||||
| Ativar a autenticação NTP | Especifique o servidor e a chave | Chave confiável | Ativar a autenticação NTP | Chave confiável | |||||
| Autenticação bem-sucedida | |||||||||
| Sim | Sim | Sim | Sim | Sim | |||||
| Falha na autenticação | |||||||||
| Sim | Sim | Sim | Sim | Não | |||||
| Sim | Sim | Sim | Não | N/A | |||||
| Sim | Sim | Não | Sim | N/A | |||||
| Sim | Não | N/A | Sim | N/A | |||||
| Não | N/A | N/A | Sim | N/A | |||||
| Autenticação não realizada | |||||||||
| Sim | Sim | Não | Não | N/A | |||||
| Sim | Não | N/A | Não | N/A | |||||
| Não | N/A | N/A | Não | N/A |
Configuração da autenticação NTP para um cliente de broadcast
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configurar uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
Configuração da autenticação NTP para um servidor de transmissão
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configurar uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
- Entre na visualização da interface.
interface interface-type interface-number- Associar a chave especificada ao servidor de transmissão.
ntp-service broadcast-server authentication-keyid keyidPor padrão, o servidor de transmissão não está associado a uma chave.
Configuração da autenticação NTP no modo multicast
Restrições e diretrizes
Para garantir uma autenticação NTP bem-sucedida no modo multicast, configure o mesmo ID de chave de autenticação, algoritmo e chave no servidor e no cliente multicast. Certifique-se de que o dispositivo par tenha permissão para usar o ID da chave para autenticação no dispositivo local.
Os resultados da autenticação NTP diferem quando são realizadas configurações diferentes no cliente e no servidor de transmissão. Para obter mais informações, consulte a Tabela 5. (N/A na tabela significa que o fato de a configuração ser ou não realizada não faz diferença).
Tabela 5 Resultados da autenticação NTP
| Servidor multicast | Cliente multicast | ||||||||
| Ativar a autenticação NTP | Especifique o servidor e a chave | Chave confiável | Ativar a autenticação NTP | Chave confiável | |||||
| Autenticação bem-sucedida | |||||||||
| Sim | Sim | Sim | Sim | Sim | |||||
| Falha na autenticação | |||||||||
| Sim | Sim | Sim | Sim | Não | |||||
| Sim | Sim | Sim | Não | N/A | |||||
| Sim | Sim | Não | Sim | N/A | |||||
| Sim | Não | N/A | Sim | N/A | |||||
| Não | N/A | N/A | Sim | N/A | |||||
| Autenticação não realizada | |||||||||
| Sim | Sim | Não | Não | N/A | |||||
| Sim | Não | N/A | Não | N/A | |||||
| Não | N/A | N/A | Não | N/A |
Configuração da autenticação NTP para um cliente multicast
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configure uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
Configuração da autenticação NTP para um servidor multicast
- Entre na visualização do sistema.
system-view- Ativar a autenticação NTP.
ntp-service authentication enablePor padrão, a autenticação NTP está desativada.
- Configure uma chave de autenticação NTP.
ntp-service authentication-keyid keyid authentication-mode
{ hmac-sha-1 | hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 }
{ cipher | simple } string [ acl ipv4-acl-number | ipv6 acl
ipv6-acl-number ] *
Por padrão, não existe nenhuma chave de autenticação NTP.
- Configure a chave como uma chave confiável.
ntp-service reliable authentication-keyid keyidPor padrão, nenhuma chave de autenticação é configurada como uma chave confiável.
- Entre na visualização da interface.
interface interface-type interface-number- Associar a chave especificada a um servidor multicast. IPv4:
ntp-service multicast-server [ ip-address ] authentication-keyid keyidIPv6:
ntp-service ipv6 multicast-server ipv6-multicast-address
authentication-keyid keyidPor padrão, nenhum servidor multicast é associado à chave especificada.
Controle do envio e recebimento de pacotes NTP
Especificação de um endereço de origem para mensagens NTP
Sobre a especificação de um endereço de origem para mensagens NTP
Você pode especificar um endereço de origem ou uma interface de origem para as mensagens NTP. Se você especificar uma interface de origem para as mensagens NTP, o dispositivo usará o endereço IP da interface especificada como endereço de origem para enviar mensagens NTP.
Restrições e diretrizes
Para evitar que as alterações de status da interface causem falhas na comunicação NTP, especifique uma interface que esteja sempre ativa como a interface de origem, uma interface de loopback, por exemplo.
Quando o dispositivo responde a uma solicitação NTP, o endereço IP de origem da resposta NTP é sempre o endereço IP da interface que recebeu a solicitação NTP.
Se você tiver especificado a interface de origem das mensagens NTP no comando ntp-service unicast-server/ntp-service ipv6 unicast-server ou ntp-service unicast-peer/ntp-service ipv6 unicast-peer, o endereço IP da interface especificada será usado como endereço IP de origem das mensagens NTP.
Se você tiver configurado o comando ntp-service broadcast-server ou ntp-service multicast-server/ntp-service ipv6 multicast-server em uma visualização de interface, o endereço IP da interface será usado como endereço IP de origem para mensagens NTP de broadcast ou multicast.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique o endereço de origem das mensagens NTP. IPv4:
ntp-service source { interface-type interface-number | ip-address }IPv6:
ntp-service ipv6 source interface-type interface-numberPor padrão, nenhum endereço de origem é especificado para mensagens NTP.
Desativar o recebimento de mensagens NTP por uma interface
Sobre a desativação do recebimento de mensagens NTP por uma interface
Quando o NTP está ativado, todas as interfaces, por padrão, podem receber mensagens NTP. Para fins de segurança, você pode desativar o recebimento de mensagens NTP em algumas interfaces.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface.
interface interface-type interface-number- Desative o recebimento de pacotes NTP pela interface. IPv4:
undo ntp-service inbound enableIPv6:
undo ntp-service ipv6 inbound enablePor padrão, uma interface recebe mensagens NTP.
Configuração do número máximo de associações dinâmicas
Sobre a configuração do número máximo de associações dinâmicas
Execute esta tarefa para restringir o número de associações dinâmicas e evitar que elas ocupem muitos recursos do sistema.
O NTP tem os seguintes tipos de associações:
Associação estática - Uma associação criada manualmente.
Associação dinâmica - Associação temporária criada pelo sistema durante a operação do NTP. Uma associação dinâmica é removida se nenhuma mensagem for trocada em cerca de 12 minutos.
A seguir, descrevemos como uma associação é estabelecida em diferentes modos de associação:
Modo cliente/servidor - Depois que você especifica um servidor NTP, o sistema cria uma associação estática no cliente. O servidor simplesmente responde passivamente após o recebimento de uma mensagem, em vez de criar uma associação (estática ou dinâmica).
Modo ativo/passivo simétrico - Depois que você especificar um par passivo simétrico em um par ativo simétrico, as associações estáticas serão criadas no par ativo simétrico e as associações dinâmicas serão criadas no par passivo simétrico.
Modo de broadcast ou multicast - As associações estáticas são criadas no servidor e as associações dinâmicas são criadas no cliente.
Restrições e diretrizes
Um único dispositivo pode ter um máximo de 128 associações simultâneas, incluindo associações estáticas e dinâmicas.
Procedimento
- Entre na visualização do sistema.
system-view- Configure o número máximo de sessões dinâmicas.
ntp-service max-dynamic-sessions numberPor padrão, o número máximo de sessões dinâmicas é 100.
Definição de um valor DSCP para pacotes NTP
Sobre os valores DSCP para pacotes NTP
O valor DSCP determina a precedência de envio de um pacote NTP.
Procedimento
- Entre na visualização do sistema.
system-view- Defina um valor DSCP para os pacotes NTP. IPv4:
ntp-service dscp dscp-valueIPv6:
ntp-service ipv6 dscp dscp-valueO valor DSCP padrão é 48 para pacotes IPv4 e 56 para pacotes IPv6.
Especificação dos limites de deslocamento de tempo do NTP para saídas de log e trap
Sobre os limites de deslocamento de tempo do NTP para saídas de log e trap
Por padrão, o sistema sincroniza o horário do cliente NTP com o servidor e emite um registro e uma interceptação quando a diferença de horário excede 128 ms por várias vezes.
Depois de definir os limites de deslocamento de tempo do NTP para saídas de logs e traps, o sistema sincroniza a hora do cliente com o servidor quando o deslocamento de tempo excede 128 ms por várias vezes, mas emite logs e traps somente quando o deslocamento de tempo excede os limites especificados, respectivamente.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique os limites de deslocamento de tempo do NTP para saídas de registro e de interceptação.
ntp-service time-offset-threshold { log log-threshold | trap trap-threshold } *Por padrão, nenhum limite de deslocamento de tempo NTP é definido para saídas de registro e de interceptação.
Comandos de exibição e manutenção para NTP
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir informações sobre associações NTP IPv6. | display ntp-service ipv6 sessions [ verbose ] | ||
| Exibir informações sobre associações NTP IPv4. | display ntp-service sessions [ verbose ] | ||
| Exibir informações sobre o status do serviço NTP. | display ntp-service status | ||
| Exibir informações breves sobre os servidores NTP, desde o dispositivo local até o servidor NTP primário. | display ntp-service trace [ source interface-type interface-number ] |
Exemplos de configuração de NTP
Exemplo: Configuração do modo de associação cliente/servidor NTP
Configuração de rede
Conforme mostrado na Figura 4, execute as seguintes tarefas:
Configure o relógio local do Dispositivo A como sua fonte de referência, com nível de estrato 2.
Configure o Dispositivo B para operar no modo cliente e especifique o Dispositivo A como o servidor NTP do Dispositivo B.
Figura 4 Diagrama de rede

Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Dispositivo A e o Dispositivo B possam se comunicar, conforme mostrado na Figura 4. (Detalhes não mostrados.)
- Configurar o dispositivo A:
# Habilite o serviço NTP.
<DeviceA> system-view
[DeviceA] ntp-service enable
# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[DeviceA] ntp-service refclock-master 2- Configurar o dispositivo B:
# Habilite o serviço NTP.
<DeviceB> system-view
[DeviceB] ntp-service enable# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Especifique o dispositivo A como o servidor NTP do dispositivo B.
[DeviceB] ntp-service unicast-server 1.0.1.11Verificação da configuração
# Verifique se o Dispositivo B sincronizou sua hora com o Dispositivo A e se o nível de estrato do relógio do Dispositivo B é 3.
[DeviceB] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 1.0.1.11
Local mode: client
Reference clock ID: 1.0.1.11
Leap indicator: 00
Clock jitter: 0.000977 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00383 ms
Root dispersion: 16.26572 ms
Reference time: d0c6033f.b9923965 Wed, Dec 29 2010 18:58:07.724
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Dispositivo B e o Dispositivo A.
[DeviceB] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[12345]1.0.1.11 127.127.1.0 2 1 64 15 -4.0 0.0038 16.262
Notes: 1 source(master), 2 source(peer), 3 selected, 4 candidate, 5 configured.
Total sessions: 1Exemplo: Configuração do modo de associação cliente/servidor NTP IPv6
Configuração de rede
Conforme mostrado na Figura 5, execute as seguintes tarefas:
Configure o relógio local do Dispositivo A como sua fonte de referência, com nível de estrato 2.
Configure o Dispositivo B para operar no modo cliente e especifique o Dispositivo A como o servidor NTP IPv6 do Dispositivo B.
Figura 5 Diagrama de rede
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Dispositivo A e o Dispositivo B possam se comunicar, conforme mostrado na Figura 5. (Detalhes não mostrados.)
- Configurar o dispositivo A:
# Habilite o serviço NTP.
<DeviceA> system-view
[DeviceA] ntp-service enable
# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[DeviceA] ntp-service refclock-master 2- Configurar o dispositivo B:
# Habilite o serviço NTP.
<DeviceB> system-view
[DeviceB] ntp-service enable# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Especifique o dispositivo A como o servidor NTP IPv6 do dispositivo B.
[DeviceB] ntp-service ipv6 unicast-server 3000::34Verificação da configuração
# Verifique se o Dispositivo B sincronizou sua hora com o Dispositivo A e se o nível de estrato do relógio do Dispositivo B é 3.
[DeviceB] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3000::34
Local mode: client
Reference clock ID: 163.29.247.19
Leap indicator: 00
Clock jitter: 0.000977 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.02649 ms
Root dispersion: 12.24641 ms
Reference time: d0c60419.9952fb3e Wed, Dec 29 2010 19:01:45.598
System poll interval: 64 s# Verifique se uma associação NTP IPv6 foi estabelecida entre o Dispositivo B e o Dispositivo A.
[DeviceB] display ntp-service ipv6 sessions
Notes: 1 source(master), 2 source(peer), 3 selected, 4 candidate, 5 configured.
Source: [12345]3000::34
Reference: 127.127.1.0 Clock stratum: 2
Reachabilities: 15 Poll interval: 64
Last receive time: 19 Offset: 0.0
Roundtrip delay: 0.0 Dispersion: 0.0
Total sessions: 1Exemplo: Configuração do modo de associação ativo/passivo simétrico do NTP
Configuração de rede
Conforme mostrado na Figura 6, execute as seguintes tarefas:
Configure o relógio local do Dispositivo A como sua fonte de referência, com nível de estrato 2.
Configure o Dispositivo A para operar no modo ativo simétrico e especifique o Dispositivo B como o par passivo do Dispositivo A.
Figura 6 Diagrama de rede
Dispositivo DispositivoB
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Dispositivo A e o Dispositivo B possam se comunicar, conforme mostrado na Figura 6. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilite o serviço NTP.
<DeviceB> system-view
[DeviceB] ntp-service enable# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp- Configurar o dispositivo A:
# Habilite o serviço NTP.
<DeviceA> system-view
[DeviceA] ntp-service enable
# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[DeviceA] ntp-service refclock-master 2# Configure o dispositivo B como o par passivo simétrico.
[DeviceA] ntp-service unicast-peer 3.0.1.32Verificação da configuração
# Verifique se o dispositivo B sincronizou sua hora com o dispositivo A.
[DeviceB] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3.0.1.31
Local mode: sym_passive
Reference clock ID: 3.0.1.31
Leap indicator: 00
Clock jitter: 0.000916 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00609 ms
Root dispersion: 1.95859 ms
Reference time: 83aec681.deb6d3e5 Wed, Jan 8 2014 14:33:11.081
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Dispositivo B e o Dispositivo A.
[DeviceB] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[12]3.0.1.31 127.127.1.0 2 62 64 34 0.4251 6.0882 1392.1
Notes: 1 source(master), 2 source(peer), 3 selected, 4 candidate, 5 configured.
Total sessions: 1
Exemplo: Configuração do modo de associação ativo/passivo simétrico do NTP IPv6
Configuração de rede
Conforme mostrado na Figura 7, execute as seguintes tarefas:
Configure o relógio local do Dispositivo A como sua fonte de referência, com nível de estrato 2.
Configure o Dispositivo A para operar no modo ativo simétrico e especifique o Dispositivo B como o par passivo do IPv6 do Dispositivo A.
Figura 7 Diagrama de rede
Dispositivo DispositivoB
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Dispositivo A e o Dispositivo B possam se comunicar, conforme mostrado na Figura 7. (Detalhes não mostrados.)
- Configurar o dispositivo B:
# Habilite o serviço NTP.
<DeviceB> system-view
[DeviceB] ntp-service enable# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp- Configurar o dispositivo A:
# Habilite o serviço NTP.
<DeviceA> system-view
[DeviceA] ntp-service enable
# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[DeviceA] ntp-service refclock-master 2# Configure o dispositivo B como o par passivo simétrico IPv6.
[DeviceA] ntp-service ipv6 unicast-peer 3000::36Verificação da configuração
# Verifique se o dispositivo B sincronizou sua hora com o dispositivo A.
[DeviceB] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3000::35
Local mode: sym_passive
Reference clock ID: 251.73.79.32
Leap indicator: 11
Clock jitter: 0.000977 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.01855 ms
Root dispersion: 9.23483 ms
Reference time: d0c6047c.97199f9f Wed, Dec 29 2010 19:03:24.590
System poll interval: 64 s# Verifique se uma associação NTP IPv6 foi estabelecida entre o Dispositivo B e o Dispositivo A.
[DeviceB] display ntp-service ipv6 sessions
Notes: 1 source(master), 2 source(peer), 3 selected, 4 candidate, 5 configured.
Source: [1234]3000::35
Reference: 127.127.1.0 Clock stratum: 2
Reachabilities: 15 Poll interval: 64
Last receive time: 19 Offset: 0.0
Roundtrip delay: 0.0 Dispersion: 0.0
Total sessions: 1Exemplo: Configuração do modo de associação de transmissão NTP
Configuração de rede
Conforme mostrado na Figura 8, configure o Switch C como servidor NTP para vários dispositivos em um segmento de rede para sincronizar a hora dos dispositivos.
Configure o relógio local do Switch C como sua fonte de referência, com nível de estrato 2.
Configure o Switch C para operar no modo de servidor de broadcast e enviar mensagens de broadcast da interface VLAN 2.
Configure o Switch A e o Switch B para operar no modo de cliente de broadcast e ouvir mensagens de broadcast na interface VLAN 2.
Figura 8 Diagrama de rede
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Comutador A, o Comutador B e o Comutador C possam se comunicar entre si, conforme mostrado na Figura 8. (Detalhes não mostrados.)
- Configurar o switch C:
# Habilite o serviço NTP.
<SwitchC> system-view
[SwitchC] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchC] clock protocol ntp# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[SwitchC] ntp-service refclock-master 2# Configure o Switch C para operar no modo de servidor de broadcast e enviar mensagens de broadcast da interface VLAN 2.
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] ntp-service broadcast-server- Configure o Switch A:
# Habilite o serviço NTP.
<SwitchA> system-view
[SwitchA] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchA] clock protocol ntp# Configure o Switch A para operar no modo de cliente de broadcast e receber mensagens de broadcast na interface VLAN 2.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ntp-service broadcast-client- Configure o Switch B:
# Habilite o serviço NTP.
<SwitchB> system-view
[SwitchB] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchB] clock protocol ntp# Configure o Switch B para operar no modo de cliente de broadcast e receber mensagens de broadcast na interface VLAN 2.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ntp-service broadcast-clientVerificação da configuração
O procedimento a seguir usa o Switch A como exemplo para verificar a configuração.
# Verifique se o Switch A está sincronizado com o Switch C e se o nível de estrato do relógio é 3 no Switch A e 2 no Switch C.
[SwitchA-Vlan-interface2] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3.0.1.31
Local mode: bclient
Reference clock ID: 3.0.1.31
Leap indicator: 00
Clock jitter: 0.044281 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00229 ms
Root dispersion: 4.12572 ms
Reference time: d0d289fe.ec43c720 Sat, Jan 8 2011 7:00:14.922
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Switch A e o Switch C.
[SwitchA-Vlan-interface2] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[1245]3.0.1.31 127.127.1.0 2 1 64 519 -0.0 0.0022 4.1257
Notes: 1 source(master),2 source(peer),3 selected,4 candidate,5 configured.
Total sessions: 1Exemplo: Configuração do modo de associação multicast do NTP
Configuração de rede
Conforme mostrado na Figura 9, configure o Switch C como servidor NTP para vários dispositivos em diferentes segmentos de rede para sincronizar a hora dos dispositivos.
Configure o relógio local do Switch C como sua fonte de referência, com nível de estrato 2.
Configure o Switch C para operar no modo de servidor multicast e enviar mensagens multicast da interface VLAN 2.
Configure o Switch A e o Switch D para operar no modo de cliente multicast e receber mensagens multicast na interface VLAN 3 e na interface VLAN 2, respectivamente.
Figura 9 Diagrama de rede
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que os switches possam alcançar um ao outro, conforme mostrado na Figura 9. (Detalhes não mostrados.)
- Configurar o switch C:
# Habilite o serviço NTP.
<SwitchC> system-view
[SwitchC] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchC] clock protocol ntp# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[SwitchC] ntp-service refclock-master 2# Configure o Switch C para operar no modo de servidor multicast e enviar mensagens multicast da interface VLAN 2.
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] ntp-service multicast-server
- Configurar o Switch D:
# Habilite o serviço NTP.
<SwitchD> system-view
[SwitchD] ntp-service enable
# Especifique o NTP para obter a hora.
[SwitchD] clock protocol ntp# Configure o Switch D para operar no modo de cliente multicast e receber mensagens multicast na interface VLAN 2.
[SwitchD] interface vlan-interface 2
[SwitchD-Vlan-interface2] ntp-service multicast-client- Verifique a configuração:
# Verifique se o Switch D está sincronizado com o Switch C e se o nível de estrato do relógio é 3 no Switch D e 2 no Switch C.
O Switch D e o Switch C estão na mesma sub-rede, portanto o Switch D pode receber as mensagens multicast do Switch C sem estar habilitado com as funções multicast.
[SwitchD-Vlan-interface2] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3.0.1.31
Local mode: bclient
Reference clock ID: 3.0.1.31
Leap indicator: 00
Clock jitter: 0.044281 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00229 ms
Root dispersion: 4.12572 ms
Reference time: d0d289fe.ec43c720 Sat, Jan 8 2011 7:00:14.922
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Switch D e o Switch C.
[SwitchD-Vlan-interface2] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[1245]3.0.1.31 127.127.1.0 2 1 64 519 -0.0 0.0022 4.1257
Notes: 1 source(master),2 source(peer),3 selected,4 candidate,5 configured.
Total sessions: 1- Configurar o Switch B:
Como o Switch A e o Switch C estão em sub-redes diferentes, você deve ativar as funções multicast no Switch B antes que o Switch A possa receber mensagens multicast do Switch C.
# Habilite as funções de multicast de IP.
<SwitchB> system-view
[SwitchB] multicast routing
[SwitchB-mrib] quit
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] pim dm
[SwitchB-Vlan-interface2] quit
[SwitchB] vlan 3
[SwitchB-vlan3] port gigabitethernet 1/0/1
[SwitchB-vlan3] quit
[SwitchB] interface vlan-interface 3
[SwitchB-Vlan-interface3] igmp enable
[SwitchB-Vlan-interface3] igmp static-group 224.0.1.1
[SwitchB-Vlan-interface3] quit
[SwitchB] igmp-snooping
[SwitchB-igmp-snooping] quit
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] igmp-snooping static-group 224.0.1.1 vlan 3- Configure o Switch A:
# Habilite o serviço NTP.
<SwitchA> system-view
[SwitchA] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchA] clock protocol ntp# Configure o Switch A para operar no modo de cliente multicast e receber mensagens multicast na interface VLAN 3.
[SwitchA] interface vlan-interface 3
[SwitchA-Vlan-interface3] ntp-service multicast-clientVerificação da configuração
# Verifique se o Switch A sincronizou sua hora com o Switch C e se o nível de estrato do relógio do Switch A é 3.
[SwitchA-Vlan-interface3] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3.0.1.31
Local mode: bclient
Reference clock ID: 3.0.1.31
Leap indicator: 00
Clock jitter: 0.165741 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00534 ms
Root dispersion: 4.51282 ms
Reference time: d0c61289.10b1193f Wed, Dec 29 2010 20:03:21.065
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Switch A e o Switch C.
[SwitchA-Vlan-interface3] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[1234]3.0.1.31 127.127.1.0 2 247 64 381 -0.0 0.0053 4.5128
Notes: 1 source(master),2 source(peer),3 selected,4 candidate,5 configured.
Total sessions: 1Exemplo: Configuração do modo de associação multicast do NTP IPv6
Configuração de rede
Conforme mostrado na Figura 10, configure o Switch C como servidor NTP para vários dispositivos em diferentes segmentos de rede para sincronizar a hora dos dispositivos.
Configure o relógio local do Switch C como sua fonte de referência, com nível de estrato 2.
Configure o Switch C para operar no modo de servidor multicast IPv6 e enviar mensagens multicast IPv6 da interface VLAN 2.
Configure o Switch A e o Switch D para operar no modo de cliente multicast IPv6 e receber mensagens multicast IPv6 na interface VLAN 3 e na interface VLAN 2, respectivamente.
Figura 10 Diagrama de rede
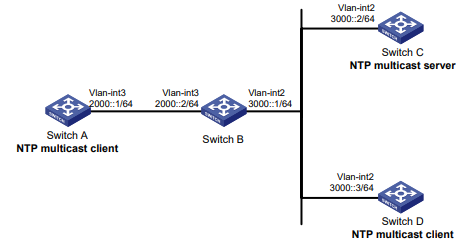
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que os switches possam se comunicar entre si, conforme mostrado na Figura 10. (Detalhes não mostrados.)
- Configurar o switch C:
# Habilite o serviço NTP.
<SwitchC> system-view
[SwitchC] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchC] clock protocol ntp# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[SwitchC] ntp-service refclock-master 2# Configure o Switch C para operar no modo de servidor multicast IPv6 e enviar mensagens multicast da interface VLAN 2.
[SwitchD] interface vlan-interface 2
[SwitchD-Vlan-interface2] ntp-service ipv6 multicast-client ff24::1
- Configurar o Switch D:
# Habilite o serviço NTP.
<SwitchD> system-view
[SwitchD] ntp-service enable
# Especifique o NTP para obter a hora.
[SwitchD] clock protocol ntp# Configure o Switch D para operar no modo de cliente multicast IPv6 e receber mensagens multicast na interface VLAN 2.
[SwitchD] interface vlan-interface 2
[SwitchD-Vlan-interface2] ntp-service ipv6 multicast-client ff24::1
- Verifique a configuração:
# Verifique se o Switch D sincronizou sua hora com o Switch C e se o nível de estrato do relógio do Switch D é 3.
O Switch D e o Switch C estão na mesma sub-rede, portanto o Switch D pode receber as mensagens multicast IPv6 do Switch C sem estar habilitado com as funções multicast IPv6.
[SwitchD-Vlan-interface2] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3000::2
Local mode: bclient
Reference clock ID: 165.84.121.65
Leap indicator: 00
Clock jitter: 0.000977 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00000 ms
Root dispersion: 8.00578 ms
Reference time: d0c60680.9754fb17 Wed, Dec 29 2010 19:12:00.591
System poll interval: 64 s- Configurar o Switch B:
Como o Switch A e o Switch C estão em sub-redes diferentes, você deve ativar as funções de multicast IPv6 no Switch B antes que o Switch A possa receber mensagens de multicast IPv6 do Switch C.
# Habilite as funções de multicast IPv6.
<SwitchB> system-view
[SwitchB] ipv6 multicast routing
[SwitchB-mrib6] quit
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ipv6 pim dm
[SwitchB-Vlan-interface2] quit
[SwitchB] vlan 3
[SwitchB-vlan3] port gigabitethernet 1/0/1
[SwitchB-vlan3] quit
[SwitchB] interface vlan-interface 3
[SwitchB-Vlan-interface3] mld enable
[SwitchB-Vlan-interface3] mld static-group ff24::1
[SwitchB-Vlan-interface3] quit
[SwitchB] mld-snooping
[SwitchB-mld-snooping] quit
[SwitchB] interface gigabitethernet 1/0/1
[SwitchB-GigabitEthernet1/0/1] mld-snooping static-group ff24::1 vlan 3- Configure o Switch A:
# Habilite o serviço NTP.
<SwitchA> system-view
[SwitchA] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchA] clock protocol ntp# Configure o Switch A para operar no modo de cliente multicast IPv6 e receber mensagens multicast IPv6 na interface VLAN 3.
[SwitchA] interface vlan-interface 3
[SwitchA-Vlan-interface3] ntp-service ipv6 multicast-client ff24::1Verificação da configuração
# Verifique se o Switch A está sincronizado com o Switch C e se o nível de estrato do relógio é 3 no Switch A e 2 no Switch C.
[SwitchA-Vlan-interface3] display ntp-service status
Clock status: synchronized
Clock stratum: 3
System peer: 3000::2
Local mode: bclient
Reference clock ID: 165.84.121.65
Leap indicator: 00
Clock jitter: 0.165741 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00534 ms
Root dispersion: 4.51282 ms
Reference time: d0c61289.10b1193f Wed, Dec 29 2010 20:03:21.065
System poll interval: 64 sExemplo: Configuração do modo de associação cliente/servidor NTP com autenticação
Configuração de rede
Conforme mostrado na Figura 11, execute as seguintes tarefas:
Configure o relógio local do Dispositivo A como sua fonte de referência, com nível de estrato 2.
Configure o Dispositivo B para operar no modo cliente e especifique o Dispositivo A como o servidor NTP do Dispositivo B.
Configure a autenticação NTP no Dispositivo A e no Dispositivo B.
Figura 11 Diagrama de rede
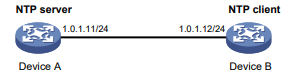
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Dispositivo A e o Dispositivo B possam se comunicar, conforme mostrado na Figura 11. (Detalhes não mostrados.)
- Configurar o dispositivo A:
# Habilite o serviço NTP.
<DeviceA> system-view
[DeviceA] ntp-service enable
# Especifique o relógio local como a fonte de referência, com nível de estrato 2.
[DeviceA] ntp-service refclock-master 2- Configurar o dispositivo B:
# Habilite o serviço NTP.
<DeviceB> system-view
[DeviceB] ntp-service enable# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Habilite a autenticação NTP no Dispositivo B.
[DeviceB] ntp-service authentication enable# Crie uma chave de autenticação de texto simples, com ID de chave 42 e valor de chave aNiceKey.
[DeviceB] ntp-service authentication-keyid 42 authentication-mode md5 simple aNiceKey# Especifique a chave como uma chave confiável.
[DeviceB] ntp-service reliable authentication-keyid 42# Especifique o Dispositivo A como o servidor NTP do Dispositivo B e associe o servidor à chave 42.
[DeviceB] ntp-service unicast-server 1.0.1.11 authentication-keyid 42Para permitir que o Dispositivo B sincronize seu relógio com o Dispositivo A, ative a autenticação NTP no Dispositivo A.
- Configure a autenticação NTP no Dispositivo A: # Habilite a autenticação NTP.
[DeviceA] ntp-service authentication enable# Crie uma chave de autenticação de texto simples, com ID de chave 42 e valor de chave aNiceKey.
[DeviceA] ntp-service authentication-keyid 42 authentication-mode md5 simple aNiceKey# Especifique a chave como uma chave confiável.
[[DeviceA] ntp-service reliable authentication-keyid 42Verificação da configuração
# Verifique se o Dispositivo B sincronizou sua hora com o Dispositivo A e se o nível de estrato do relógio do Dispositivo B é 3.
[DeviceB] display ntp-service status
Clock status: synchronized
Clock stratum: 3
1.0.1.11/24 1.0.1.12/24
Device A Device B
NTP server NTP client
34
System peer: 1.0.1.11
Local mode: client
Reference clock ID: 1.0.1.11
Leap indicator: 00
Clock jitter: 0.005096 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00655 ms
Root dispersion: 1.15869 ms
Reference time: d0c62687.ab1bba7d Wed, Dec 29 2010 21:28:39.668
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Dispositivo B e o Dispositivo A.
[DeviceB] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[1245]1.0.1.11 127.127.1.0 2 1 64 519 -0.0 0.0065 0.0
Notes: 1 source(master),2 source(peer),3 selected,4 candidate,5 configured.
Total sessions: 1Exemplo: Configuração do modo de associação de transmissão NTP com autenticação
Configuração de rede
Conforme mostrado na Figura 12, configure o Switch C como servidor NTP para vários dispositivos no mesmo segmento de rede para sincronizar a hora dos dispositivos. Configure o Switch A e o Switch B para autenticar o servidor NTP.
Configure o relógio local do Switch C como sua fonte de referência, com nível de estrato 3.
Configure o Switch C para operar no modo de servidor de broadcast e enviar mensagens de broadcast da interface VLAN 2.
Configure o Switch A e o Switch B para operar no modo de cliente de broadcast e receber mensagens de broadcast na interface VLAN 2.
Habilite a autenticação NTP no Switch A, Switch B e Switch C.
Figura 12 Diagrama de rede
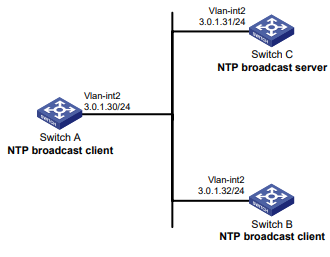
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Switch A, o Switch B e o Switch C possam se comunicar entre si, conforme mostrado na Figura 12. (Detalhes não mostrados).
- Configure o Switch A:
# Habilite o serviço NTP.
<SwitchA> system-view
[SwitchA] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchA] clock protocol ntp# Habilite a autenticação NTP no Switch A. Crie uma chave de autenticação NTP de texto simples, com ID de chave 88 e valor de chave 123456. Especifique-a como uma chave confiável.
[SwitchA] ntp-service authentication enable
[SwitchA] ntp-service authentication-keyid 88 authentication-mode md5 simple 123456
[SwitchA] ntp-service reliable authentication-keyid 88
# Configure o Switch A para operar no modo de cliente de broadcast NTP e receber mensagens de broadcast NTP na interface VLAN 2.
[SwitchA] interface vlan-interface 2
[SwitchA-Vlan-interface2] ntp-service broadcast-client- Configure o Switch B:
# Habilite o serviço NTP.
<SwitchB> system-view
[SwitchB] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchB] clock protocol ntp# Habilite a autenticação NTP no Switch B. Crie uma chave de autenticação NTP de texto simples, com ID de chave 88 e valor de chave 123456. Especifique-a como uma chave confiável.
[SwitchB] ntp-service authentication enable
[SwitchB] ntp-service authentication-keyid 88 authentication-mode md5 simple 123456
[SwitchB] ntp-service reliable authentication-keyid 88# Configure o Switch B para operar no modo de cliente de broadcast e receber mensagens de broadcast NTP na interface VLAN 2.
[SwitchB] interface vlan-interface 2
[SwitchB-Vlan-interface2] ntp-service broadcast-client- Configurar o switch C:
# Habilite o serviço NTP.
<SwitchC> system-view
[SwitchC] ntp-service enable# Especifique o NTP para obter a hora.
[SwitchC] clock protocol ntp# Especifique o relógio local como a fonte de referência, com nível de estrato 3.
[SwitchC] ntp-service refclock-master 3# Configure o Switch C para operar no modo de servidor de transmissão NTP e use a interface VLAN 2 para enviar pacotes de transmissão NTP.
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] ntp-service broadcast-server
[SwitchC-Vlan-interface2] quit- Verifique a configuração:
A autenticação NTP está ativada no Switch A e no Switch B, mas não no Switch C, portanto o Switch A e o Switch B não podem sincronizar seus relógios locais com o Switch C.
[SwitchB-Vlan-interface2] display ntp-service status
Clock status: unsynchronized
Clock stratum: 16
Reference clock ID: none- Habilite a autenticação NTP no Switch C:
# Habilite a autenticação NTP no Switch C. Crie uma chave de autenticação NTP de texto simples, com ID de chave 88 e valor de chave 123456. Especifique-a como uma chave confiável.
[SwitchC] ntp-service authentication enable
[SwitchC] ntp-service authentication-keyid 88 authentication-mode md5 simple 123456
[SwitchC] ntp-service reliable authentication-keyid 88# Especifique o Switch C como um servidor de transmissão NTP e associe a chave 88 ao Switch C.
[SwitchC] interface vlan-interface 2
[SwitchC-Vlan-interface2] ntp-service broadcast-server authentication-keyid 88Verificação da configuração
# Verifique se o Switch B sincronizou sua hora com o Switch C e se o nível de estrato do relógio do Switch B é 4.
[SwitchB-Vlan-interface2] display ntp-service status
Clock status: synchronized
Clock stratum: 4
System peer: 3.0.1.31
Local mode: bclient
Reference clock ID: 3.0.1.31
Leap indicator: 00
Clock jitter: 0.006683 s
Stability: 0.000 pps
Clock precision: 2^-19
Root delay: 0.00127 ms
Root dispersion: 2.89877 ms
Reference time: d0d287a7.3119666f Sat, Jan 8 2011 6:50:15.191
System poll interval: 64 s# Verifique se uma associação NTP IPv4 foi estabelecida entre o Switch B e o Switch C.
[SwitchB-Vlan-interface2] display ntp-service sessions
source reference stra reach poll now offset delay disper
********************************************************************************
[1245]3.0.1.31 127.127.1.0 3 3 64 68 -0.0 0.0000 0.0
Notes: 1 source(master),2 source(peer),3 selected,4 candidate,5 configured.
Total sessions: 1Configuração do SNTP
Sobre o SNTP
O SNTP é uma versão simplificada do NTP, somente para clientes, especificada na RFC 4330. Ele usa o mesmo formato de pacote e procedimento de troca de pacotes que o NTP, mas oferece sincronização mais rápida ao preço da precisão do tempo.
Modo de trabalho SNTP
O SNTP suporta apenas o modo cliente/servidor. Um dispositivo habilitado para SNTP pode receber a hora dos servidores NTP, mas não pode fornecer serviços de hora a outros dispositivos.
Se você especificar vários servidores NTP para um cliente SNTP, será selecionado o servidor com o melhor estrato. Se vários servidores estiverem no mesmo estrato, será selecionado o servidor NTP cujo pacote de hora for recebido primeiro.
Protocolos e padrões
RFC 4330, Simple Network Time Protocol (SNTP) Versão 4 para IPv4, IPv6 e OSI
Restrições e diretrizes: Configuração do SNTP
Ao configurar o SNTP, siga estas restrições e diretrizes:
Não é possível configurar o NTP e o SNTP no mesmo dispositivo.
∙ Para usar o NTP para sincronização de horário, você deve usar o comando clock protocol para especificar o NTP para obter o horário. Para obter mais informações sobre o comando clock protocol, consulte os comandos de gerenciamento de dispositivos no Fundamentals Configuration Guide.
Visão geral das tarefas do SNTP
Para configurar o SNTP, execute as seguintes tarefas:
- Ativação do serviço SNTP
- Especificação de um servidor NTP para o dispositivo
- (Opcional.) Configuração da autenticação SNTP
- (Opcional.) Especificação dos limites de intervalo de tempo do SNTP para saídas de registro e de interceptação
Ativação do serviço SNTP
Restrições e diretrizes
O serviço NTP e o serviço SNTP são mutuamente exclusivos. Antes de ativar o SNTP, certifique-se de que o NTP esteja desativado.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o serviço SNTP.
sntp enablePor padrão, o serviço SNTP está desativado.
Especificação de um servidor NTP para o dispositivo
Restrições e diretrizes
Para usar um servidor NTP como fonte de horário, certifique-se de que seu relógio tenha sido sincronizado. Se o nível de estrato do servidor NTP for maior ou igual ao do cliente, o cliente não sincronizará com o servidor NTP.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique um servidor NTP para o dispositivo. IPv4:
sntp unicast-server { server-name | ip-address }
[ authentication-keyid keyid | source interface-type interface-number
| version number ] *
IPv6:
sntp ipv6 unicast-server { server-name | ipv6-address }
[ authentication-keyid keyid | source interface-type interface-number ]
*Por padrão, nenhum servidor NTP é especificado para o dispositivo.
Você pode especificar vários servidores NTP para o cliente repetindo essa etapa.
Para executar a autenticação, você precisa especificar a opção authentication-keyid keyid.
Configuração da autenticação SNTP
Sobre a autenticação SNTP
A autenticação SNTP garante que um cliente SNTP seja sincronizado somente com um servidor NTP autenticado e confiável.
Restrições e diretrizes
Ative a autenticação no servidor NTP e no cliente SNTP.
Use o mesmo ID de chave de autenticação, algoritmo e chave no servidor NTP e no cliente SNTP. Especifique a chave como uma chave confiável tanto no servidor NTP quanto no cliente SNTP. Para obter informações sobre como configurar a autenticação NTP em um servidor NTP, consulte "Configuração do NTP".
No cliente SNTP, associe a chave especificada ao servidor NTP. Certifique-se de que o servidor tenha permissão para usar o ID da chave para autenticação no cliente.
Com a autenticação desativada, o cliente SNTP pode sincronizar com o servidor NTP, independentemente de o servidor NTP estar habilitado com autenticação.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a autenticação SNTP.
sntp authentication enablePor padrão, a autenticação SNTP está desativada.
- Configurar uma chave de autenticação SNTP.
sntp authentication-keyid keyid authentication-mode { hmac-sha-1 |
hmac-sha-256 | hmac-sha-384 | hmac-sha-512 | md5 } { cipher | simple } string
[ acl ipv4-acl-number | ipv6 acl ipv6-acl-number ] *Por padrão, não existe nenhuma chave de autenticação SNTP.
- Especifique a chave como uma chave confiável.
sntp reliable authentication-keyid keyidPor padrão, nenhuma chave confiável é especificada.
- Associe a chave de autenticação SNTP a um servidor NTP. IPv4:
sntp unicast-server { server-name | ip-address } authentication-keyid
keyidkeyidIPv6:
sntp ipv6 unicast-server { server-name | ipv6-address }
authentication-keyid keyidPor padrão, nenhum servidor NTP é especificado.
Especificação dos limites de deslocamento de tempo do SNTP para saídas de log e trap
Sobre os limites de intervalo de tempo do SNTP para saídas de log e trap
Por padrão, o sistema sincroniza o horário do cliente SNTP com o servidor e emite um registro e uma interceptação quando a diferença de horário excede 128 ms por várias vezes.
Depois de definir os limites de desvio de tempo do SNTP para saídas de logs e traps, o sistema sincroniza a hora do cliente com o servidor quando o desvio de tempo excede 128 ms por várias vezes, mas emite logs e traps somente quando o desvio de tempo excede os limites especificados, respectivamente.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique os limites de deslocamento de tempo do SNTP para saídas de registro e de interceptação.
sntp time-offset-threshold { log log-threshold | trap trap-threshold }*Por padrão, nenhum limite de deslocamento de tempo SNTP é definido para saídas de registro e trap.
Comandos de exibição e manutenção para SNTP
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir informações sobre todas as associações SNTP IPv6. | display sntp ipv6 sessions | ||
| Exibir informações sobre todas as associações SNTP IPv4. | display sntp sessions |
Exemplos de configuração de SNTP
Exemplo: Configurando SNTP
Configuração de rede
Conforme mostrado na Figura 13, execute as seguintes tarefas:
Configure o relógio local do Dispositivo A como sua fonte de referência, com nível de estrato 2.
Configure o Dispositivo B para operar no modo de cliente SNTP e especifique o Dispositivo A como o servidor NTP.
Configure a autenticação NTP no Dispositivo A e a autenticação SNTP no Dispositivo B.
Figura 13 Diagrama de rede
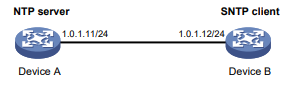
Procedimento
- Atribua um endereço IP a cada interface e certifique-se de que o Dispositivo A e o Dispositivo B possam se comunicar, conforme mostrado na Figura 13. (Detalhes não mostrados.)
- Configurar o dispositivo A:
# Habilite o serviço NTP.
<DeviceA> system-view
[DeviceA] ntp-service enable
# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Configure o relógio local como a fonte de referência, com nível de estrato 2.
[DeviceA] ntp-service refclock-master 2# Habilite a autenticação NTP no dispositivo A.
[DeviceA] ntp-service authentication enable# Configure uma chave de autenticação NTP de texto simples, com ID de chave 10 e valor de chave aNiceKey.
[DeviceA] ntp-service authentication-keyid 10 authentication-mode md5 simple
aNiceKey# Especifique a chave como uma chave confiável.
[DeviceA] ntp-service reliable authentication-keyid 10- Configurar o dispositivo B:
# Habilite o serviço SNTP.
<DeviceB> system-view
[DeviceB] sntp enable
# Especifique o NTP para obter a hora.
[DeviceB] clock protocol ntp# Habilite a autenticação SNTP no Dispositivo B.
[DeviceB] clock protocol ntp# Configure uma chave de autenticação de texto simples, com ID de chave 10 e valor de chave aNiceKey.
[DeviceB] sntp authentication-keyid 10 authentication-mode md5 simple aNiceKey# Especifique a chave como uma chave confiável.
[DeviceB] sntp authentication enable# Especifique o Dispositivo A como o servidor NTP do Dispositivo B e associe o servidor à chave 10.
[DeviceB] sntp reliable authentication-keyid 10Verificação da configuração
# Verifique se uma associação SNTP foi estabelecida entre o Dispositivo B e o Dispositivo A, e se o Dispositivo B sincronizou sua hora com o Dispositivo A.
[DeviceB] display sntp sessions
NTP server Stratum Version Last receive time
1.0.1.11 2 4 Tue, May 17 2011 9:11:20.833 (Synced)Configuração de PoE
Sobre o PoE
O Power over Ethernet (PoE) permite que um dispositivo de rede forneça energia aos terminais por meio de cabos de par trançado .
Sistema PoE
Conforme mostrado na Figura 1, um sistema PoE inclui os seguintes elementos:
Fonte de alimentação PoE - Uma fonte de alimentação PoE fornece energia para todo o sistema PoE.
PSE - Um equipamento de fornecimento de energia (PSE) fornece energia aos PDs. Os dispositivos PSE são classificados em dispositivos PSE únicos e dispositivos PSE múltiplos.
Um dispositivo de PSE único tem apenas um firmware PSE.
Um dispositivo com vários PSEs tem vários PSEs. Um dispositivo com vários PSEs usa IDs de PSE para identificar diferentes PSEs. Para visualizar o mapeamento entre a ID e o número do slot de um PSE, execute o comando display poe device.
PI - Uma interface de energia (PI) é uma interface Ethernet compatível com PoE em um PSE.
PD - Um dispositivo alimentado (PD) recebe energia de um PSE. Os PDs incluem telefones IP, APs, carregadores portáteis, terminais POS e câmeras Web. Você também pode conectar um PD a uma fonte de alimentação redundante para obter confiabilidade.
Figura 1 Diagrama do sistema PoE
AI-driven PoE
O PoE orientado por IA integra de forma inovadora as tecnologias de IA aos switches PoE e oferece os seguintes benefícios:
Gerenciamento adaptativo da fonte de alimentação
O PoE orientado por IA pode ajustar de forma adaptativa os parâmetros da fonte de alimentação para atender às necessidades de energia em vários cenários, como vários tipos de PDs, e resolver problemas como falta de fonte de alimentação para um PD e falha de energia, minimizando a intervenção humana.
Gerenciamento de energia baseado em prioridades
Quando a energia exigida pelos PDs excede a energia que pode ser fornecida pelo switch PoE, o sistema fornece energia aos PDs com base nas prioridades do PI para garantir o fornecimento de energia aos negócios críticos e reduzir o fornecimento de energia aos PIs de prioridades mais baixas.
Gerenciamento inteligente do módulo de energia
Para um switch PoE com arquitetura de módulo de alimentação duplo, o PoE orientado por IA pode calcular e regular automaticamente a saída de energia de cada módulo de alimentação com base no tipo e na quantidade dos módulos de alimentação, maximizando o uso de energia de cada módulo de alimentação. Quando um módulo de energia é removido, o AI-driven PoE recalcula para garantir preferencialmente o fornecimento de energia aos PDs que estão sendo alimentados.
Alta segurança PoE
Quando ocorre uma exceção, como curto-circuito ou interrupção do circuito, o PoE orientado por IA inicia imediatamente a autoproteção para proteger o switch PoE contra danos ou queimaduras.
PoE perpétuo
Durante uma reinicialização a quente do switch PoE a partir do comando de reinicialização, o PoE orientado por IA monitora continuamente os estados dos PDs e garante o fornecimento contínuo de energia aos PDs, mantendo a estabilidade do serviço do terminal.
PoE remoto
O PoE orientado por IA ajusta de forma adaptativa a largura de banda da rede com base na distância de transmissão entre um PSE e um PD. Quando a distância de transmissão ultrapassa 100 m (328,08 pés), o sistema diminui automaticamente a taxa da porta para reduzir a perda de linha e garantir a qualidade da transmissão de sinal e energia. Com o PoE orientado por IA ativado, um PSE pode transmitir energia para um PD de 200 a 250 m (656,17 a 820,21 pés) de distância.
Protocolos e padrões
802.3af-2003, IEEE Standard for Information Technology - Telecommunications and Information Exchange Between Systems - Local and Metropolitan Area Networks - Specific Requirements - Part 3: Carrier Sense Multiple Access with Collision Detection (CSMA/CD) Access Method and Physical Layer Specifications - Data Terminal Equipment (DTE) Power Via Media Dependent Interface (MDI)
802.3at-2009, Padrão IEEE para tecnologia da informação - Redes de área local e metropolitana - Requisitos específicos - Parte 3: Método de acesso CSMA/CD e especificações da camada física - Alteração 3: Alimentação do equipamento terminal de dados (DTE) por meio de melhorias na interface dependente de mídia (MDI)
Restrições: Compatibilidade de hardware com PoE
Somente os modelos PoE suportam o recurso PoE.
Restrições e diretrizes: Configuração de PoE
Você pode configurar um PI por meio de uma das seguintes maneiras:
Configure as definições diretamente no PI.
Configure um perfil PoE e aplique-o ao PI. Se você aplicar um perfil PoE a vários PIs, esses PIs terão os mesmos recursos PoE. Se você conectar um PD a outro PI, poderá aplicar o perfil PoE do PI original ao novo PI. Esse método alivia a tarefa de configurar o PoE no novo PI.
Você só pode usar uma maneira de configurar um parâmetro para um PI. Para usar a outra maneira de reconfigurar um parâmetro, você deve primeiro remover a configuração original.
Você deve usar o mesmo método de configuração para os comandos poe max-power max-power e poe priority { critical | high | low }.
Visão geral das tarefas de configuração do PoE
Para configurar o PoE, execute as seguintes tarefas:
- Ativação de PoE em um PI
- (Opcional.) Ativação do PoE orientado por IA
- (Opcional.) Ativação de PoE rápido para um PSE
- (Opcional) Permitir correntes de inrush consumidas por PDs
- (Opcional.) Ativação do ciclo de energia do PI em uma reinicialização a quente do sistema
- (Opcional.) Configuração da detecção de PD
- Ativação da detecção de PD não padrão
- Configuração de um modo de detecção de PD
- (Opcional.) Configuração da energia PoE
- Configuração da potência máxima de PI
- (Opcional.) Configuração da política de prioridade PI
- (Opcional.) Configuração do monitoramento de PoE
- Configuração do monitoramento de energia do PSE
- Associação de PoE com trilha
- (Opcional.) Atualização do firmware do PSE em serviço
- (Opcional.) Ativação da fonte de alimentação PoE forçada
- (Opcional.) Configuração do TMPDO para o MPS
Para usar um perfil PoE para ativar o PoE e configurar a prioridade e a potência máxima para um PI, consulte "Configuração de um PI usando um perfil PoE".
Pré-requisitos para configurar o PoE
Antes de configurar o PoE, verifique se a fonte de alimentação PoE e os PSEs estão funcionando corretamente.
Diminuir velocidade das portas para estender o alcance do PoE
É possível utilizar uma velocidade de transferência de 10Mbps para aumentar o alcance da alimentação do PoE para até 250 metros.
Para garantir desempenho e segurança, recomenda-se o uso de cabos de rede homologados, 100% em cobre, conforme as normas de qualidade. Outros tipos de cabos, como de alumínio cobreado (CCA), não são indicados, pois apresentam maior resistência elétrica e podem causar quedas de tensão, instabilidade na alimentação PoE e degradação do sinal de dados.
Procedimento:
- Entre na visualização do sistema.
system-view- Acesse a porta desejada
interface interface-type interface-number- Diminua a velocidade da porta para 10Mbps
speed 10Ativação de PoE em um PI
Sobre a ativação do PoE em um PI
Depois que você ativar o PoE em um PI, o PI fornecerá energia ao PD conectado se o PI não resultar em sobrecarga de energia do PSE. A sobrecarga do PSE ocorre quando a soma do consumo de energia de todos os PIs excede a potência máxima do PSE.
Se o PI resultar em sobrecarga de energia PSE, as seguintes restrições se aplicam:
Se a política de prioridade do PI não estiver ativada, o PI não fornecerá energia ao PD conectado.
Se a política de prioridade do PI estiver ativada, o fato de os PDs poderem ser alimentados depende da prioridade do PI.
Para obter mais informações sobre a política de prioridade do PI, consulte "Configuração da política de prioridade do PI".
Restrições e diretrizes
A energia pode ser transmitida por um cabo de par trançado em um dos seguintes modos:
Modo de par de sinais - Os pares de sinais 1, 2, 3 e 6 do cabo de par trançado são usados para transmissão de energia.
Modo de par sobressalente - Os pares sobressalentes 4, 5, 7 e 8 do cabo de par trançado são usados para transmissão de energia.
Um PI pode fornecer energia a um PD somente quando o PI e o PD usam o mesmo modo de transmissão de energia. Se o PI e o PD usarem modos de transmissão de energia diferentes, será necessária uma reconexão.
O dispositivo suporta a transmissão de energia somente em pares de sinais.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar na visualização PI.
interface interface-type interface-number- (Opcional.) Configure uma descrição para o PD conectado ao PI.
poe pd-description textPor padrão, nenhuma descrição é configurada para o PD conectado ao PI.
O PoE é ativado nos PIs se o dispositivo for iniciado com os padrões de fábrica e é desativado nos PIs quando o dispositivo é iniciado com a configuração inicial.
Para obter mais informações sobre a configuração inicial do dispositivo e os padrões de fábrica, consulte o gerenciamento de arquivos de configuração.
Habilitando o PoE orientado por IA
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o PoE orientado por IA.
poe ai enablePor padrão, o PoE orientado por IA está desativado.
O AI-driven PoE ajusta automaticamente os parâmetros da fonte de alimentação para atender às necessidades de energia. Se você desativar o AI-driven PoE, o sistema reverterá os parâmetros para as configurações anteriores ao ajuste.
Habilitação de PoE rápido para um PSE
Sobre o PoE rápido para um PSE
Esse recurso permite que um PI em um PSE forneça energia aos PDs imediatamente após o PSE ser ligado.
Restrições e diretrizes
Você deve reconfigurar esse recurso se tiver modificado outras configurações de PoE após a configuração desse recurso.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o PoE rápido para um PSE.
poe fast-on enable pse pse-idPor padrão, o PoE rápido está desativado em um PSE.
Esse comando é compatível apenas com a versão 6328 e posteriores.
Permitir correntes de inrush consumidas por PDs
Sobre a permissão de correntes de inrush consumidas por PDs
A corrente de irrupção pode ocorrer na inicialização do PD e acionar a autoproteção do PSE. Como resultado, o PSE para de fornecer energia aos PDs. Para continuar o fornecimento de energia aos PDs, configure esse recurso para permitir correntes de pico consumidas pelos PDs.
O IEEE 802.3af e o IEEE 802.3at definem especificações para a corrente de irrupção. O suporte para as especificações definidas pelo IEEE 802.3af e/ou IEEE 802.3at depende do modelo do dispositivo.
Restrições e diretrizes
 CUIDADO:
CUIDADO:
As correntes de irrupção podem danificar os componentes do dispositivo. Use esse recurso com cuidado.
Esse recurso está disponível somente para um PSE que tenha um nome de modelo terminado com um caractere B, LSPPSE48B, por exemplo. Para obter o nome do modelo do PSE, execute o comando display poe pse .
Procedimento
- Entre na visualização do sistema.
system-view- Permitir correntes de inrush consumidas pelos PDs.
poe high-inrush enable pse pse-idPor padrão, as correntes de irrupção consumidas pelos PDs não são permitidas.
Ativação do ciclo de energia do PI em uma reinicialização a quente do sistema
Sobre a ativação do ciclo de energia do PI em uma reinicialização a quente do sistema
Durante o processo de reinicialização a quente do sistema (após a execução do comando de reinicialização), os PIs continuam fornecendo energia aos PDs, mas as conexões de dados entre os PDs e o dispositivo são interrompidas. Após a reinicialização do sistema, os PDs podem não reiniciar as conexões de dados com o dispositivo. O ciclo de energia dos PIs em uma reinicialização a quente do sistema permite que os PDs restabeleçam as conexões de dados com o dispositivo após uma reinicialização a quente.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar no ciclo de energia do PI em uma reinicialização a quente do sistema.
poe reset enablePor padrão, o ciclo de energia do PI em uma reinicialização a quente do sistema está desativado.
Configuração da detecção de PD
Ativação da detecção de PD não padrão
Sobre a ativação da detecção de PD não padrão
Os PDs são classificados em PDs padrão e PDs não padrão. Os PDs padrão estão em conformidade com o IEEE 802.3af e o IEEE 802.3at. Um PSE fornece energia a um PD não padrão somente depois que a detecção de PD não padrão é ativada.
O dispositivo suporta a detecção de PD não padrão baseada em PSE e PI. A ativação da detecção de DP não padrão para um PSE habilita esse recurso para todos os PIs no PSE. Como prática recomendada para desativar a detecção de DP não padrão para todos os PIs com êxito em uma única operação, desative esse recurso na visualização do sistema e na visualização da interface.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite a detecção de PD não padrão. Escolha uma opção conforme necessário.
- Ativar a detecção de PD não padrão para o PSE.
poe legacy enable pse pse-idPor padrão, a detecção de PD não padrão está desativada para um PSE.
- Execute os seguintes comandos em sequência para ativar a detecção de PD não padrão para um PI:
interface interface-type interface-numberpoe legacy enablePor padrão, a detecção de PD fora do padrão é desativada para um PI.
Configuração de um modo de detecção de PD
Sobre os modos de detecção de PD
O dispositivo detecta PDs em um dos seguintes modos:
Nenhum - O dispositivo fornece energia aos PDs que estão conectados corretamente ao dispositivo sem causar curto-circuito.
Simples - O dispositivo fornece energia a PDs que atendem aos requisitos básicos do 802.3af ou 802.3at.
Rigoroso - O dispositivo fornece energia a PDs que atendem a todos os requisitos da norma 802.3af ou 802.3at.
Restrições e diretrizes
 CUIDADO:
CUIDADO:
Um dispositivo não-PD pode ser danificado quando a energia é fornecida a ele. Para evitar danos ao dispositivo, não use o modo nenhum quando o PI se conectar a um dispositivo não-PD.
Essa tarefa está disponível somente para um PSE que tenha um nome de modelo terminado com um caractere B, LSPPSE48B, por exemplo. Para obter o nome do modelo do PSE, execute o comando display poe pse.
Para que essa tarefa tenha efeito em PDs não padrão, você deve ativar a detecção para PDs não padrão usando o comando poe legacy enable.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar na visualização PI.
interface interface-type interface-number- Configure o modo de detecção de PD.
poe detection-mode { none | simple | strict }O padrão varia de acordo com a versão do software
Configuração de energia PoE
Configuração da potência máxima de PI
Sobre a potência máxima de PI
A potência máxima do PI é a potência máxima que um PI pode fornecer ao PD conectado. Se o PD exigir mais energia do que a energia máxima do PI, o PI não fornecerá energia ao PD.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar na visualização PI.
interface interface-type interface-number- Configure a potência máxima para o PI.
poe max-power max-powerO padrão varia de acordo com a versão do software
Configuração da política de prioridade PI
Sobre a política de prioridade PI
A política de prioridade de PI permite que o PSE realize a alocação de energia com base em prioridade para PIs quando ocorrer sobrecarga de energia do PSE. Os níveis de prioridade para PIs são crítico, alto e baixo em ordem decrescente.
Quando ocorre uma sobrecarga de energia do PSE, o PSE fornece energia aos PDs da seguinte forma:
Se a política de prioridade PI estiver desativada, o PSE fornecerá energia aos PDs, dependendo de você ter configurado a energia máxima do PSE.
Se você tiver configurado a potência máxima do PSE, o PSE não fornecerá energia ao PD recém-adicionado ou existente que cause sobrecarga de energia do PSE.
Se você não tiver configurado a potência máxima do PSE, o mecanismo de autoproteção do PoE será acionado. O PSE interrompe o fornecimento de energia a todos os PDs.
Se a política de prioridade PI estiver ativada, o PSE fornecerá energia aos PDs da seguinte forma:
Se um PD que estiver sendo alimentado causar sobrecarga de energia ao PSE, o PSE deixará de fornecer energia ao PD.
Se um PD recém-adicionado causar sobrecarga de energia do PSE, o PSE fornecerá energia aos PDs em ordem decrescente de prioridade dos PIs aos quais estão conectados. Se o PD recém-adicionado e um PD que está sendo alimentado tiverem a mesma prioridade, o PD que está sendo alimentado terá precedência. Se vários PIs que estão sendo alimentados tiverem a mesma prioridade, os PIs com IDs menores terão precedência.
Restrições e diretrizes
Antes de configurar um PI com prioridade crítica, verifique se a potência restante da potência máxima do PSE menos as potências máximas dos PIs existentes com prioridade crítica é maior do que a potência máxima do PI.
A configuração de um PI cuja energia é antecipada permanece inalterada.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar a política de prioridade PI.
poe pd-policy priorityPor padrão, a política de prioridade PI está desativada.
- Entrar na visualização PI.
interface interface-type interface-number- (Opcional.) Configure uma prioridade para o PI.
poe priority { critical | high | low }Por padrão, a prioridade de um PI é baixa.
Configuração do monitoramento de PoE
Configuração do monitoramento de energia do PSE
Sobre o monitoramento de energia PSE
O sistema monitora a utilização de energia PSE e envia mensagens de notificação quando a utilização de energia PSE excede ou cai abaixo do limite. Se a utilização da energia PSE ultrapassar o limite várias vezes seguidas, o sistema enviará mensagens de notificação somente para o primeiro cruzamento. Para mais informações sobre a mensagem de notificação, consulte "Configuração de SNMP".
Procedimento
- Entre na visualização do sistema.
system-view- Configure um limite de alarme de energia para um PSE.
poe utilization-threshold value pse pse-idPor padrão, o limite de alarme de energia para um PSE é de 80%.
Associação de PoE com trilha
Sobre esta tarefa
O módulo PoE pode colaborar com o módulo Track para monitorar o status do link entre o dispositivo e um PD. Por exemplo, se o PD suportar o teste de eco ICMP NQA, você poderá especificar uma entrada de rastreamento associada ao NQA para testar a acessibilidade do PD. O teste de eco NQA ICMP deve ser configurado em uma interface de camada 3. O PI é uma interface de camada 2. É necessário criar uma interface VLAN para o teste de eco ICMP e atribuir o PI à VLAN.
O módulo Track notifica o módulo PoE sobre os seguintes resultados de monitoramento:
Positivo - O objeto monitorado pode ser acessado.
Negativo - O objeto monitorado não pode ser acessado.
NotReady - O resultado do monitoramento não está pronto por motivos como a inexistência do grupo NQA associado à entrada da trilha.
Quando o módulo Track detecta uma falha no link, ele altera o estado da entrada do track de positivo para negativo, o que faz com que o módulo PoE execute as seguintes ações:
somente alarme: Emite uma notificação e um registro SNMP.
alarm-reboot-pd: Emite uma notificação e um registro SNMP e reinicializa o PD conectado ao PI.
Para obter informações sobre as notificações de SNMP, consulte Configuração de SNMP no Guia de configuração de monitoramento e gerenciamento de rede.
Para obter informações sobre registros, consulte a configuração do centro de informações no Guia de configuração de monitoramento e gerenciamento de rede.
Para obter informações sobre o módulo Track, consulte a configuração do track no Guia de configuração de alta disponibilidade.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com a versão 6348P01 e posteriores.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar na visualização PI.
interface interface-type interface-number- Associe o PI a uma entrada de trilha.
poe track track-entry-number action { alarm | alarm-reboot-pd }Por padrão, um PI não está associado a uma entrada de trilha.
Configuração de um PI usando um perfil PoE
Restrições e diretrizes
Para modificar um perfil PoE aplicado em um PI, primeiro remova o perfil PoE do PI.
Você pode configurar um PI no PI ou usando um perfil PoE. Os comandos poe max-power max-power e poe priority { critical | high | low } devem ser configurados usando o mesmo método.
Configuração de um perfil PoE
- Entre na visualização do sistema.
system-view- Crie um perfil PoE e entre em sua visualização.
poe-profile profile-name [ index ]Por padrão, não existem perfis PoE.
- Ativar PoE.
poe enablePor padrão, o PoE está desativado.
- (Opcional.) Configure a potência máxima de PI.
poe max-power max-powerO padrão varia de acordo com a versão do software
- (Opcional.) Configure uma prioridade PI.
poe priority { critical | high | low }A prioridade padrão é baixa.
Esse comando entra em vigor somente depois que a política de prioridade PI é ativada.
Aplicação de um perfil PoE
Restrições e diretrizes
Você pode aplicar um perfil PoE a vários PIs na visualização do sistema ou a um único PI na visualização do PI. Se você executar a operação em ambas as visualizações para o mesmo PI, a operação mais recente terá efeito.
Você pode aplicar apenas um perfil PoE a um PI.
Aplicação de um perfil PoE na visualização do sistema
- Entre na visualização do sistema.
system-view- Aplicar um perfil PoE aos PIs.
apply poe-profile { index index | name profile-name } interface
interface-rangePor padrão, um perfil PoE não é aplicado a um PI.
Aplicação de um perfil PoE na visualização PI
- Entre na visualização do sistema.
system-view- Entrar na visualização PI.
interface interface-type interface-number- Aplicar o perfil PoE à interface.
apply poe-profile { index index | name profile-name }
Por padrão, um perfil PoE não é aplicado a um PI.
Atualização do firmware do PSE em serviço
Sobre a atualização do firmware do PSE em serviço
Você pode atualizar o firmware do PSE em serviço nos seguintes modos:
Refresh mode (Modo de atualização) - Atualiza o firmware do PSE sem excluí-lo. Você pode usar o modo de atualização na maioria dos casos.
Full mode (Modo completo) - Exclui o firmware atual do PSE e recarrega um novo. Use o modo completo se o firmware do PSE estiver danificado e você não puder executar nenhum comando PoE.
Restrições e diretrizes
Se a atualização do firmware do PSE falhar devido a uma interrupção, como a reinicialização do dispositivo, você poderá reiniciar o dispositivo e atualizá-lo novamente no modo completo. Após a atualização, reinicie o dispositivo manualmente para que o novo firmware do PSE entre em vigor.
Procedimento
- Entre na visualização do sistema.
system-view- Atualize o firmware do PSE em serviço.
poe update { full | refresh } filename [ pse pse-id ]Ativação da fonte de alimentação PoE forçada
Sobre esta tarefa
Antes de fornecer energia a um PD, o dispositivo realiza uma detecção do PD. Ele fornece energia ao PD somente depois que o PD passa na detecção. Se o PD falhar na detecção, mas a energia fornecida pelo dispositivo atender às especificações do PD, você poderá configurar essa tarefa para ativar a fonte de alimentação forçada para o PD.
Restrições e diretrizes
 CUIDADO:
CUIDADO:
Essa tarefa permite que o dispositivo forneça energia a um PD diretamente sem realizar uma detecção do PD. Para evitar danos ao PD, certifique-se de que a energia fornecida pelo dispositivo atenda às especificações do PD antes de configurar esse comando.
Essa tarefa é compatível apenas com a versão 6340 e posteriores.
Procedimento
- Entre na visualização do sistema.
system-view- Entrar na visualização PI.
interface interface-type interface-number- Ativar a fonte de alimentação PoE forçada.
poe force-powerPor padrão, a fonte de alimentação PoE forçada está desativada.
Configuração do TMPDO para o MPS
Sobre esta tarefa
A MPS (Maintain Power Signature, assinatura de manutenção de energia) é uma assinatura elétrica fornecida por um PD. O PD usa essa assinatura para manter a conexão com o PSE no modo de suspensão. O PD envia periodicamente uma corrente de pulso compatível com PoE para o PSE. Se o PSE detectar a corrente de pulso compatível com PoE do PD dentro do TMPDO, ele fornecerá energia ao PD. Se o PSE não detectar a corrente de pulso compatível com PoE do PD dentro do TMPDO, ele não fornecerá energia ao PD.
Para enviar correntes de pulso em intervalos maiores para reduzir a energia de espera, você pode usar esse comando para alterar o TMPDO para que seja mais longo.
Versão do software e compatibilidade de recursos
Esse recurso é compatível apenas com o R6350 e versões posteriores.
Restrições e diretrizes
Somente os módulos PSE que têm um nome de modelo LSPPSE**A são compatíveis com esse recurso. Para visualizar os modelos PSE, execute o comando display poe pse.
Se você executar o comando várias vezes, a configuração mais recente entrará em vigor.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o TMPDO para o MPS.
poe mps pse pse-id tmpdo { timer | long |normal }Por padrão, o modo TMPDO normal é usado para o MPS. O TMPDO para o MPS é de 324 milissegundos.
Comandos de exibição e manutenção para PoE
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir informações gerais do PSE. | display poe device [ slot slot-number ] | ||
| Exibe as informações de fornecimento de energia para o PI especificado. | display poe interface [ interface-type interface-number ] | ||
| Exibir informações de energia para PIs. | display poe interface power [ interface-type interface-number ] | ||
| Exibir informações detalhadas do PSE. | display poe pse [ pse-id ] | ||
| Exibe as informações de fornecimento de energia para todos os PIs em um PSE. | display poe pse pse-id interface | ||
| Exibir informações de energia para todos os PIs em um PSE. | display poe pse pse-id interface power | ||
| Exibir todas as informações sobre o perfil PoE. | display poe-profile [ index index | name profile-name ] | ||
| Exibe todas as informações sobre o perfil PoE aplicado ao PI especificado. | display poe-profile interface interface-type interface-number |
Exemplos de configuração de PoE
Exemplo: Configurando PoE
Configuração de rede
Conforme mostrado na Figura 2, configure o PoE da seguinte forma:
Habilite o dispositivo para fornecer energia a telefones IP e APs.
Permita que o dispositivo forneça energia aos telefones IP primeiro quando houver sobrecarga.
Forneça ao AP B uma potência máxima de 9000 miliwatts.
Figura 2 Diagrama de rede
Procedimento
# Habilitar a política de prioridade PI.
<PSE> system-view
[PSE] poe pd-policy priority
# Habilite o PoE na GigabitEthernet 1/0/1, GigabitEthernet 1/0/2 e GigabitEthernet 1/0/3 e configure a prioridade da fonte de alimentação como crítica.
[PSE] interface gigabitethernet 1/0/1
[PSE-GigabitEthernet1/0/1] poe enable
[PSE-GigabitEthernet1/0/1] poe priority critical
[PSE-GigabitEthernet1/0/1] quit
[PSE] interface gigabitethernet 1/0/2
[PSE-GigabitEthernet1/0/2] poe enable
[PSE-GigabitEthernet1/0/2] poe priority critical
[PSE-GigabitEthernet1/0/2] quit
[PSE] interface gigabitethernet 1/0/3
[PSE-GigabitEthernet1/0/3] poe enable
[PSE-GigabitEthernet1/0/3] poe priority critical
[PSE-GigabitEthernet1/0/3] quit# Habilite o PoE na GigabitEthernet 1/0/4 e na GigabitEthernet 1/0/5 e defina a potência máxima da GigabitEthernet 1/0/5 como 9000 miliwatts.
[PSE] interface gigabitethernet 1/0/4
[PSE-GigabitEthernet1/0/4] poe enable
[PSE-GigabitEthernet1/0/4] quit
[PSE] interface gigabitethernet 1/0/5
[PSE-GigabitEthernet1/0/5] poe enable
[PSE-GigabitEthernet1/0/5] poe max-power 9000
Verificação da configuração
# Conecte os telefones IP e os APs ao PSE para verificar se eles podem obter energia e operar o corretamente. (Detalhes não mostrados.)
Solução de problemas de PoE
Falha ao definir a prioridade de um PI como crítica
Sintoma
Falha na configuração da prioridade da fonte de alimentação para um PI.
Solução
Para resolver o problema:
- Identifique se a potência garantida restante do PSE é menor do que a potência máxima do PI. Se for, aumente a potência máxima do PSE ou reduza a potência máxima do PI.
- Identifique se a prioridade foi configurada por meio de outros métodos. Se a prioridade tiver sido configurada, remova a configuração.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Falha ao aplicar um perfil PoE a um PI
Sintoma
Falha na aplicação do perfil PoE para um PI.
Solução
Para resolver o problema:
- Identifique se algumas configurações no perfil PoE foram configuradas. Se tiverem sido configuradas, remova a configuração.
- Identifique se as configurações do perfil PoE atendem aos requisitos do PI. Se não atenderem, modifique as configurações no perfil PoE.
- Identifique se outro perfil PoE já está aplicado ao PI. Se estiver, remova o aplicativo.
- Se o problema persistir, entre em contato com o Suporte da Intelbras.
Configuração de SNMP
Sobre o SNMP
O Simple Network Management Protocol (SNMP) é usado para que uma estação de gerenciamento acesse e opere os dispositivos em uma rede, independentemente de seus fornecedores, características físicas e tecnologias de interconexão.
O SNMP permite que os administradores de rede leiam e definam as variáveis nos dispositivos gerenciados para monitoramento de estado, solução de problemas, coleta de estatísticas e outros fins de gerenciamento.
Estrutura SNMP
A estrutura do SNMP contém os seguintes elementos:
Gerenciador de SNMP - Funciona em um NMS para monitorar e gerenciar os dispositivos compatíveis com SNMP na rede. Ele pode obter e definir valores de objetos MIB no agente.
Agente SNMP - Funciona em um dispositivo gerenciado para receber e tratar solicitações do NMS e envia notificações ao NMS quando ocorrem eventos, como uma alteração no estado da interface.
Management Information Base (MIB) - Especifica as variáveis (por exemplo, status da interface e uso da CPU) mantidas pelo agente SNMP para que o gerente SNMP leia e defina.
Figura 1 Relação entre NMS, agente e MIB
Controle de acesso ao MIB e ao MIB baseado em visualização
Um MIB armazena variáveis chamadas "nós" ou "objetos" em uma hierarquia de árvore e identifica cada nó com um OID exclusivo. Um OID é uma cadeia numérica pontilhada que identifica exclusivamente o caminho do nó raiz para um nó folha. Por exemplo, o objeto B na Figura 2 é identificado exclusivamente pelo OID {1.2.1.1}.
Figura 2 Árvore MIB
Uma visualização MIB representa um conjunto de objetos MIB (ou hierarquias de objetos MIB) com determinados privilégios de acesso e é identificada por um nome de visualização. Os objetos MIB incluídos na visualização MIB são acessíveis, enquanto os excluídos da visualização MIB são inacessíveis.
Uma visualização MIB pode ter vários registros de visualização, cada um identificado por um par de árvore oid view-name. Você controla o acesso ao MIB atribuindo visualizações do MIB a grupos ou comunidades SNMP.
Operações SNMP
O SNMP oferece as seguintes operações básicas:
Get-NMS recupera o valor de um nó de objeto em um MIB de agente.
O Set-NMS modifica o valor de um nó de objeto em um MIB de agente.
Notificação - As notificações de SNMP incluem traps e informs. O agente SNMP envia traps ou informs para relatar eventos ao NMS. A diferença entre esses dois tipos de notificação é que as informações exigem confirmação, mas as armadilhas não. As informações são mais confiáveis, mas também consomem muitos recursos. As traps estão disponíveis em SNMPv1, SNMPv2c e SNMPv3. Os informes são disponíveis somente em SNMPv2c e SNMPv3.
Versões de protocolo
O dispositivo suporta SNMPv1, SNMPv2c e SNMPv3 no modo não-FIPS e suporta apenas SNMPv3 no modo FIPS. Um NMS e um agente SNMP devem usar a mesma versão SNMP para se comunicarem entre si.
SNMPv1 - Usa nomes de comunidade para autenticação. Para acessar um agente SNMP, um NMS deve usar o mesmo nome de comunidade definido no agente SNMP. Se o nome da comunidade usado pelo NMS for diferente do nome da comunidade definido no agente, o NMS não poderá estabelecer uma sessão SNMP para acessar o agente ou receber traps do agente.
SNMPv2c - Usa nomes de comunidade para autenticação. O SNMPv2c é compatível com o SNMPv1, mas oferece suporte a mais tipos de operação, tipos de dados e códigos de erro.
SNMPv3 - Usa um modelo de segurança baseado no usuário (USM) para proteger a comunicação SNMP. Você pode configurar mecanismos de autenticação e privacidade para autenticar e criptografar pacotes SNMP para integridade, autenticidade e confidencialidade.
Modos de controle de acesso
O SNMP usa os seguintes modos para controlar o acesso aos objetos MIB:
O modo View-based Access Control Model-VACM controla o acesso a objetos MIB atribuindo visualizações MIB a comunidades ou usuários de SNMP.
Controle de acesso baseado em função - o modo RBAC controla o acesso a objetos MIB atribuindo funções de usuário a comunidades ou usuários de SNMP.
⚪ As comunidades SNMP ou os usuários com função de usuário predefinida network-admin ou level-15 têm acesso de leitura e gravação a todos os objetos MIB.
⚪ As comunidades SNMP ou os usuários com função de usuário predefinida network-operator têm acesso somente de leitura a todos os objetos MIB.
⚪ As comunidades SNMP ou os usuários com uma função de usuário definida pelo usuário têm direitos de acesso aos objetos MIB, conforme especificado pelo comando rule.
O modo RBAC controla o acesso por objeto MIB e o modo VACM controla o acesso por visualização MIB. Como prática recomendada para aumentar a segurança do MIB, use o modo RBAC.
Se você criar a mesma comunidade ou usuário SNMP com ambos os modos várias vezes, a configuração mais recente terá efeito. Para obter mais informações sobre RBAC, consulte Referência de comandos básicos.
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não-FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de configuração de segurança.
Visão geral das tarefas de SNMP
Para configurar o SNMP, execute as seguintes tarefas:
- Ativação do agente SNMP
- Ativação de versões SNMP
- Configuração dos parâmetros básicos do SNMP
- (Opcional.) Configuração dos parâmetros comuns do SNMP
- Configuração de uma comunidade SNMPv1 ou SNMPv2c
- Configuração de um grupo e usuário SNMPv3
- (Opcional.) Configuração de notificações SNMP
- (Opcional.) Examinar a configuração do sistema em busca de alterações
- (Opcional.) Examinar a configuração do sistema em busca de alterações
Sobre esta tarefa
O módulo SNMP examina periodicamente a configuração de execução do sistema, a configuração de inicialização e o arquivo de configuração da próxima inicialização em busca de alterações e gera um registro se for encontrada alguma alteração. Se a notificação SNMP para alterações de configuração tiver sido ativada, o sistema também gerará uma notificação SNMP .
Procedimento
- Entre na visualização do sistema.
system-view- Defina o intervalo em que o módulo SNMP examina a configuração do sistema em busca de alterações.
snmp-agent configuration-examine interval intervalPor padrão, o módulo SNMP examina a configuração do sistema em busca de alterações em intervalos de 600 segundos.
- Ativar a notificação SNMP para alterações na configuração do sistema.
snmp-agent trap enable configurationPor padrão, a notificação SNMP é ativada para alterações na configuração do sistema.
- Configuração do registro de SNMP
Ativação do agente SNMP
Restrições e diretrizes
O agente SNMP é ativado quando você usa qualquer comando que comece com snmp-agent, exceto o comando snmp-agent calculate-password.
O agente SNMP não será ativado quando a porta na qual o agente escutará for usada por outro serviço. Você pode usar o comando snmp-agent port para especificar uma porta de escuta. Para exibir as informações de uso da porta UDP, execute o comando display udp verbose. Para obter mais informações sobre o comando display udp verbose, consulte Comandos de otimização de desempenho de IP no Guia de Configuração de Serviços de Camada 3 IP.
Se você desativar o agente SNMP, as configurações de SNMP não terão efeito. O comando display current-configuration não exibe as configurações de SNMP. As definições de SNMP não serão salvas no arquivo de configuração. Para que as configurações de SNMP tenham efeito, ative o agente SNMP.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o agente SNMP.
snmp-agentPor padrão, o status de ativação do agente SNMP é o seguinte:
- Nos seguintes switches, o agente SNMP está desativado.
- Série de switches S3300G e S2300G
Ativação de versões SNMP
Restrições e diretrizes
O dispositivo suporta SNMPv1, SNMPv2c e SNMPv3 no modo não-FIPS e suporta apenas SNMPv3 no modo FIPS. Um NMS e um agente SNMP devem usar a mesma versão de SNMP para se comunicarem entre si.
Para usar as notificações SNMP no IPv6, ative o SNMPv2c ou o SNMPv3.
Procedimento
- Entre na visualização do sistema.
system-view- Habilitar versões SNMP. No modo não-FIPS:
snmp-agent sys-info version { all | { v1 | v2c | v3 } * }No modo FIPS:
snmp-agent sys-info version { all | v3 }Por padrão, o SNMPv3 está ativado.
Se você executar o comando várias vezes com opções diferentes, todas as configurações terão efeito , mas somente uma versão de SNMP será usada pelo agente e pelo NMS para comunicação.
Configuração dos parâmetros comuns do SNMP
Restrições e diretrizes
Uma ID de mecanismo SNMP identifica exclusivamente um dispositivo em uma rede gerenciada por SNMP. Certifique-se de que a ID do mecanismo SNMP local seja exclusiva em sua rede gerenciada por SNMP para evitar problemas de comunicação. Por padrão, o dispositivo recebe uma ID de mecanismo SNMP exclusiva.
Se você tiver configurado usuários SNMPv3, altere a ID do mecanismo SNMP local somente quando necessário. A alteração pode anular os nomes de usuário SNMPv3 e as chaves criptografadas que você configurou.
O agente SNMP não será ativado quando a porta na qual o agente escutará for usada por outro serviço. Você pode usar o comando snmp-agent port para alterar a porta de escuta do SNMP. Como prática recomendada, execute o comando display udp verbose para visualizar as informações de uso da porta UDP antes de especificar uma nova porta de escuta do SNMP. Para obter mais informações sobre o comando display udp verbose, consulte Comandos de otimização de desempenho de IP no Guia de configuração de serviços de IP de camada 3.
Procedimento
- Entre na visualização do sistema.
system-view- Especifique uma porta de escuta SNMP.
snmp-agent port port-numberPor padrão, a porta de escuta do SNMP é a porta UDP 161.
- Definir uma ID de mecanismo SNMP local.
snmp-agent local-engineid engineidPor padrão, o ID do mecanismo SNMP local é o ID da empresa mais o ID do dispositivo. Cada dispositivo tem uma ID de dispositivo exclusiva.
- Definir uma ID de mecanismo para uma entidade SNMP remota.
snmp-agent remote { ipv4-address | ipv6 ipv6-address } engineid engineidPor padrão, não existem IDs de mecanismo de entidade remota.
Essa etapa é necessária para que o dispositivo envie notificações SNMPv3 a um host, normalmente o NMS.
- Criar ou atualizar uma visualização MIB.
snmp-agent mib-view { excluded | included } view-name oid-tree [ mask mask-value ]Por padrão, a visualização MIB ViewDefault é predefinida. Nessa visualização, todos os objetos MIB na subárvore iso, exceto as subárvores snmpUsmMIB, snmpVacmMIB e snmpModules.18, são acessíveis.
Cada par oid-árvore view-name representa um registro de visualização. Se você especificar o mesmo registro com diferentes máscaras de sub-árvore MIB várias vezes, a configuração mais recente terá efeito.
- Configurar as informações de gerenciamento do sistema.
- Configure o contato do sistema.
snmp-agent sys-info contact sys-contact- Configure o local do sistema.
snmp-agent sys-info location sys-locationPor padrão, o local do sistema é Brasil.
- Criar um contexto SNMP.
snmp-agent context context-namePor padrão, não existem contextos SNMP.
- Configure o tamanho máximo do pacote SNMP (em bytes) que o agente SNMP pode manipular.
snmp-agent packet max-size byte-countPor padrão, um agente SNMP pode processar pacotes SNMP com um tamanho máximo de 1500 bytes.
- Definir o valor DSCP para respostas SNMP.
snmp-agent packet response dscp dscp-valuePor padrão, o valor DSCP para respostas SNMP é 0.
Configuração de uma comunidade SNMPv1 ou SNMPv2c
Sobre a configuração de uma comunidade SNMPv1 ou SNMPv2c
É possível criar uma comunidade SNMPv1 ou SNMPv2c usando um nome de comunidade ou criando um usuário SNMPv1 ou SNMPv2c. Depois de criar um usuário SNMPv1 ou SNMPv2c, o sistema cria automaticamente uma comunidade usando o nome de usuário como o nome da comunidade.
Restrições e diretrizes para a configuração de uma comunidade SNMPv1 ou SNMPv2c
As configurações SNMPv1 e SNMPv2c não são compatíveis com o modo FIPS. Certifique-se de que o NMS e o agente usem o mesmo nome de comunidade SNMP.
Somente usuários com a função de usuário network-admin ou nível 15 podem criar comunidades, usuários ou grupos SNMPv1 ou SNMPv2c. Os usuários com outras funções de usuário não podem criar comunidades, usuários ou grupos SNMPv1 ou SNMPv2c, mesmo que essas funções tenham acesso a comandos relacionados ou comandos do recurso SNMPv1 ou SNMPv2c.
Configuração de uma comunidade SNMPv1/v2c por um nome de comunidade
- Entre na visualização do sistema.
system-view- Crie uma comunidade SNMPv1/v2c. Escolha uma opção conforme necessário.
- No modo VACM:
snmp-agent community { read | write } [ simple | cipher ]
community-name [ mib-view view-name ] [ acl { ipv4-acl-number | name
ipv4-acl-name } | acl ipv6 { ipv6-acl-number | name ipv6-acl-name } ]
*- No modo RBAC:
snmp-agent community [ simple | cipher ] community-name user-role
role-name [ acl { ipv4-acl-number | name ipv4-acl-name } | acl ipv6
{ ipv6-acl-number | name ipv6-acl-name } ] *- (Opcional.) Mapeie o nome da comunidade SNMP para um contexto SNMP.
snmp-agent community-map community-name context context-nameConfiguração de uma comunidade SNMPv1/v2c por meio da criação de um usuário SNMPv1/v2c
- Entre na visualização do sistema.
system-view- Criar um grupo SNMPv1/v2c.
snmp-agent group { v1 | v2c } group-name [ notify-view view-name |
read-view view-name | write-view view-name ] * [ acl { ipv4-acl-number |
name ipv4-acl-name } | acl ipv6 { ipv6-acl-number | name
ipv6-acl-name } ] *- Adicione um usuário SNMPv1/v2c ao grupo.
snmp-agent usm-user { v1 | v2c } user-name group-name [ acl
{ ipv4-acl-number | name ipv4-acl-name } | acl ipv6 { ipv6-acl-number
| name ipv6-acl-name } ] *
O sistema cria automaticamente uma comunidade SNMP usando o nome de usuário como o nome da comunidade.
- (Opcional.) Mapeie o nome da comunidade SNMP para um contexto SNMP.
snmp-agent community-map community-name context context-nameConfiguração de um grupo e usuário SNMPv3
Restrições e diretrizes para a configuração de um grupo e usuário SNMPv3
Somente usuários com a função de usuário network-admin ou nível 15 podem criar usuários ou grupos SNMPv3. Usuários com outras funções de usuário não podem criar usuários ou grupos SNMPv3, mesmo que essas funções tenham acesso a comandos relacionados ou comandos do recurso SNMPv3.
Os usuários de SNMPv3 são gerenciados em grupos. Todos os usuários de SNMPv3 em um grupo compartilham o mesmo modelo de segurança, mas podem usar chaves e algoritmos de autenticação e criptografia diferentes. A Tabela 1 descreve os requisitos básicos de configuração para diferentes modelos de segurança.
Tabela 1 Requisitos básicos de configuração para diferentes modelos de segurança
| Modelo de segurança | Palavra-chave para o grupo | Parâmetros para o usuário | Observações | ||||
| Autenticação com privacidade | privacidade | Algoritmos e chaves de autenticação e criptografia | Para que um NMS acesse o agente, certifique-se de que o NMS e o agente usem as mesmas chaves de autenticação e criptografia. | ||||
| Autenticação sem privacidade | autenticação | Algoritmo e chave de autenticação | Para que um NMS acesse o agente, certifique-se de que o NMS e o agente usem a mesma chave de autenticação. | ||||
| Sem autenticação, sem privacidade | N/A | N/A | As chaves de autenticação e criptografia, se configuradas, não entram em vigor. |
Configuração de um grupo e usuário SNMPv3 no modo não-FIPS
- Entre na visualização do sistema.
system-view- Criar um grupo SNMPv3.
snmp-agent group v3 group-name [ authentication | privacy ]
[ notify-view view-name | read-view view-name | write-view view-name ] *
[ acl { ipv4-acl-number | name ipv4-acl-name } | acl ipv6
{ ipv6-acl-number | name ipv6-acl-name } ] *
- (Opcional.) Calcule a forma criptografada para a chave em forma de texto simples.
snmp-agent calculate-password plain-password mode { 3desmd5 | 3dessha |
aes192md5 | aes192sha | aes256md5 | aes256sha | md5 | sha }
{ local-engineid | specified-engineid engineid }
- Crie um usuário SNMPv3. Escolha uma opção conforme necessário.
- No modo VACM:
snmp-agent usm-user v3 user-name group-name [ remote { ipv4-address |
ipv6 ipv6-address } ] [ { cipher | simple } authentication-mode { md5 |
sha } auth-password [ privacy-mode { 3des | aes128 | aes192 | aes256 |
des56 } priv-password ] ] [ acl { ipv4-acl-number | name
ipv4-acl-name } | acl ipv6 { ipv6-acl-number | name ipv6-acl-name } ]
*- No modo RBAC:
snmp-agent usm-user v3 user-name user-role role-name [ remote
{ ipv4-address | ipv6 ipv6-address } ] [ { cipher | simple }
authentication-mode { md5 | sha } auth-password [ privacy-mode { 3des
| aes128 | aes192 | aes256 | des56 } priv-password ] ] [ acl
{ ipv4-acl-number | name ipv4-acl-name } | acl ipv6 { ipv6-acl-number
| name ipv6-acl-name } ] *Para enviar notificações a um NMS SNMPv3, você deve especificar a palavra-chave remote.
- (Opcional.) Atribua uma função de usuário ao usuário SNMPv3 criado no modo RBAC.
snmp-agent usm-user v3 user-name user-role role-namePor padrão, um usuário SNMPv3 tem a função de usuário atribuída a ele em sua criação.
Configuração de um grupo e usuário SNMPv3 no modo FIPS
- Entre na visualização do sistema.
system-view- Criar um grupo SNMPv3.
snmp-agent group v3 group-name { authentication | privacy }
[ notify-view view-name | read-view view-name | write-view view-name ]
* [ acl { ipv4-acl-number | name ipv4-acl-name } | acl ipv6
{ ipv6-acl-number | name ipv6-acl-name } ] *- (Opcional.) Calcule a forma criptografada para a chave em forma de texto simples.
snmp-agent calculate-password plain-password mode { aes192sha |
aes256sha | sha } { local-engineid | specified-engineid engineid }
- Crie um usuário SNMPv3. Escolha uma opção conforme necessário.
- No modo VACM:
snmp-agent usm-user v3 user-name group-name [ remote { ipv4-address |
ipv6 ipv6-address } ] { cipher | simple } authentication-mode sha
auth-password [ privacy-mode { aes128 | aes192 | aes256 }
priv-password ] [ acl { ipv4-acl-number | name ipv4-acl-name } | acl
ipv6 { ipv6-acl-number | name ipv6-acl-name } ] *
- No modo RBAC:
snmp-agent usm-user v3 user-name user-role role-name [ remote
{ ipv4-address | ipv6 ipv6-address } ] { cipher | simple }
authentication-mode sha auth-password [ privacy-mode { aes128 |
aes192 | aes256 } priv-password ] [ acl { ipv4-acl-number | name
ipv4-acl-name } | acl ipv6 { ipv6-acl-number | name ipv6-acl-name } ]
*Para enviar notificações a um NMS SNMPv3, você deve especificar a palavra-chave remote.
- (Opcional.) Atribua uma função de usuário ao usuário SNMPv3 criado no modo RBAC.
snmp-agent usm-user v3 user-name user-role role-namePor padrão, um usuário SNMPv3 tem a função de usuário atribuída a ele em sua criação.
Configuração de notificações SNMP
Sobre as notificações SNMP
O agente SNMP envia notificações (traps e informs) para informar o NMS sobre eventos significativos, como alterações no estado do link e logins ou logouts de usuários. Depois que você ativa as notificações para um módulo, o módulo envia as notificações geradas para o agente SNMP. O agente SNMP envia as notificações recebidas como traps ou informs com base na configuração atual. Salvo indicação em contrário, a palavra-chave trap na linha de comando inclui tanto traps quanto informs.
Ativação de notificações SNMP
Restrições e diretrizes
Ative uma notificação de SNMP somente se necessário. As notificações de SNMP consomem muita memória e podem afetar o desempenho do dispositivo.
Para gerar notificações de linkUp ou linkDown quando o estado do link de uma interface for alterado, você deve executar as seguintes tarefas:
Habilite a notificação de linkUp ou linkDown globalmente usando o comando snmp-agent trap enable standard [ linkdown | linkup ] *.
Habilite a notificação de linkUp ou linkDown na interface usando o comando enable snmp trap updown.
Depois que você ativar as notificações para um módulo, o fato de o módulo gerar ou não notificações também depende da configuração do módulo. Para obter mais informações, consulte o guia de configuração de cada módulo.
Para usar as notificações SNMP no IPv6, ative o SNMPv2c ou o SNMPv3.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar notificações SNMP.
snmp-agent trap enable [ configuration | protocol | standard
[ authentication | coldstart | linkdown | linkup | warmstart ] * |
system ]
Por padrão, as notificações de configuração SNMP, as notificações padrão e as notificações do sistema estão ativadas. A ativação de outras notificações SNMP varia de acordo com os módulos.
Para que o dispositivo envie notificações SNMP para um protocolo, primeiro ative o protocolo.
- Entre na visualização da interface.
interface interface-type interface-number- Ativar notificações de estado do link.
enable snmp trap updownPor padrão, as notificações de estado do link estão ativadas.
Configuração de parâmetros para o envio de notificações SNMP
Sobre os parâmetros para o envio de notificações SNMP
Você pode configurar o agente SNMP para enviar notificações como traps ou informs a um host, normalmente um NMS, para análise e gerenciamento. As traps são menos confiáveis e usam menos recursos do que as informs, pois um NMS não envia uma confirmação quando recebe uma trap.
Quando ocorre congestionamento na rede ou o destino não pode ser alcançado, o agente SNMP armazena as notificações em uma fila. Você pode definir o tamanho da fila e o tempo de vida da notificação (o tempo máximo que uma notificação pode permanecer na fila). Quando o tamanho da fila é atingido, o sistema descarta a nova notificação recebida. Se a modificação do tamanho da fila fizer com que o número de notificações na fila ultrapasse o tamanho da fila, as notificações mais antigas serão descartadas para receber novas notificações. Uma notificação é excluída quando sua vida útil expira.
Você pode estender as notificações padrão de linkUp/linkDown para incluir a descrição da interface e o tipo de interface , mas deve se certificar de que o NMS seja compatível com as mensagens SNMP estendidas.
Configuração dos parâmetros para envio de traps de SNMP
- Entre na visualização do sistema.
System View
- Configure um host de destino. No modo não-FIPS:
snmp-agent target-host trap address udp-domain { ipv4-target-host |
ipv6 ipv6-target-host } [ udp-port port-number ] [ dscp dscp-value ]
params securityname security-string [ v1 | v2c | v3 [ authentication |
privacy ] ]No modo FIPS:
snmp-agent target-host trap address udp-domain { ipv4-target-host |
ipv6 ipv6-target-host } [ udp-port port-number ] [ dscp dscp-value ]
params securityname security-string v3 { authentication | privacy }Por padrão, nenhum host de destino é configurado.
- (Opcional.) Configure um endereço de origem para o envio de traps.
snmp-agent trap source interface-type interface-numberPor padrão, o SNMP usa o endereço IP da interface roteada de saída como o endereço IP de origem .
Configuração dos parâmetros para envio de informações SNMP
- Entre na visualização do sistema.
system-view- Configure um host de destino. No modo não-FIPS:
snmp-agent target-host inform address udp-domain { ipv4-target-host |
ipv6 ipv6-target-host } [ udp-port port-number ] params securityname
security-string { v2c | v3 [ authentication | privacy ] }
No modo FIPS:
snmp-agent target-host inform address udp-domain { ipv4-target-host |
ipv6 ipv6-target-host } [ udp-port port-number ] params securityname
security-string v3 { authentication | privacy }Por padrão, nenhum host de destino é configurado.
Somente o SNMPv2c e o SNMPv3 suportam pacotes de informações.
- (Opcional.) Configure um endereço de origem para o envio de informações.
snmp-agent inform source interface-type interface-numberPor padrão, o SNMP usa o endereço IP da interface roteada de saída como o endereço IP de origem.
Configuração de parâmetros comuns para o envio de notificações
- Entre na visualização do sistema.
system-view- (Opcional.) Habilite notificações estendidas de linkUp/linkDown.
snmp-agent trap if-mib link extendedPor padrão, o agente SNMP envia notificações padrão de linkUp/linkDown.
Se o NMS não for compatível com notificações estendidas de linkUp/linkDown, não use esse comando.
- (Opcional.) Defina o tamanho da fila de notificação.
snmp-agent trap queue-size sizePor padrão, a fila de notificação pode conter 100 mensagens de notificação.
- (Opcional.) Defina o tempo de vida da notificação.
snmp-agent trap life secondsA duração padrão da notificação é de 120 segundos.
Examinar a configuração do sistema em busca de alterações
Sobre esta tarefa
O módulo SNMP examina periodicamente a configuração de execução do sistema, a configuração de inicialização e o arquivo de configuração da próxima inicialização em busca de alterações e gera um registro se for encontrada alguma alteração. Se a notificação SNMP para alterações de configuração tiver sido ativada, o sistema também gerará uma notificação SNMP.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o intervalo em que o módulo SNMP examina a configuração do sistema em busca de alterações.
snmp-agent configuration-examine interval intervalPor padrão, o módulo SNMP examina a configuração do sistema em busca de alterações em intervalos de 600 segundos.
Esse comando é compatível apenas com a versão 6340 e posteriores.
- Ativar a notificação SNMP para alterações na configuração do sistema.
snmp-agent trap enable configurationPor padrão, a notificação SNMP é ativada para alterações na configuração do sistema.
Configuração do registro de SNMP
Sobre o registro de SNMP
O agente SNMP registra solicitações Get, solicitações Set, respostas Set, notificações SNMP e falhas de autenticação SNMP, mas não registra respostas Get.
Operação Get - O agente registra o endereço IP do NMS, o nome do nó acessado e o OID do nó.
Operação Set - O agente registra o endereço IP do NMS, o nome do nó acessado, o OID do nó, o valor da variável, o código de erro e o índice da operação Set.
Rastreamento de notificações - O agente registra as notificações de SNMP depois de enviá-las ao NMS.
Falha de autenticação de SNMP - O agente registra informações relacionadas quando um NMS não consegue ser autenticado pelo agente.
O módulo SNMP envia esses registros para o centro de informações. É possível configurar o centro de informações para enviar essas mensagens a determinados destinos, como o console e o buffer de log. O tamanho total de saída para o campo do nó (nome do nó MIB) e o campo do valor (valor do nó MIB) em cada entrada de registro é de 1024 bytes. Se esse limite for excedido, o centro de informações truncará os dados nos campos. Para obter mais informações sobre o centro de informações, consulte "Configuração do centro de informações".
Restrições e diretrizes
Ative o registro de SNMP somente se necessário. O registro em log de SNMP consome muita memória e pode afetar o desempenho do dispositivo.
Procedimento
- Entre na visualização do sistema.
system-view- Ativar o registro de SNMP.
snmp-agent log { all | authfail | get-operation | set-operation }Por padrão, o registro de SNMP está desativado.
- Ativar o registro de notificações SNMP.
snmp-agent trap logPor padrão, o registro de notificações SNMP está desativado.
Comandos de exibição e manutenção para SNMP
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir informações da comunidade SNMPv1 ou SNMPv2c. (Esse comando não é compatível com o modo FIPS). | display snmp-agent community [ read | write ] | ||
| Exibir contextos SNMP. | display snmp-agent context [ context-name ] | ||
| Exibir informações do grupo SNMP. | display snmp-agent group [ group-name ] | ||
| Exibe a ID do mecanismo local. | display snmp-agent local-engineid | ||
| Exibir informações do nó SNMP MIB. | display snmp-agent mib-node [ details | index-node | trap-node | verbose ] | ||
| Exibir informações de visualização do MIB. | display snmp-agent mib-view [ exclude | include | viewwname view-name ] | ||
| Exibir IDs de motores remotos. | display snmp-agent remote [ { ipv4-address | ipv6 ipv6-address } ] | ||
| Exibir estatísticas do agente SNMP. | display snmp-agent statistics | ||
| Exibir informações do sistema do agente SNMP. | display snmp-agent sys-info [ contact | location | version ] * | ||
| Exibir informações básicas sobre a fila de notificação. | display snmp-agent trap queue | ||
| Exibir o status de habilitação de notificações SNMP para módulos. | display snmp-agent trap-list | ||
| Exibir informações do usuário SNMPv3. | display snmp-agent usm-user [ engineid engineid | username user-name | group group-name ] * |
Exemplos de configuração de SNMP
Exemplo: Configuração de SNMPv1/SNMPv2c
O dispositivo não é compatível com esse exemplo de configuração no modo FIPS.
O procedimento de configuração é o mesmo para SNMPv1 e SNMPv2c. Este exemplo usa o SNMPv1.
Configuração de rede
Conforme mostrado na Figura 3, o NMS (1.1.1.2/24) usa o SNMPv1 para gerenciar o agente SNMP (1.1.1.1/24), e o agente envia automaticamente notificações para informar eventos ao NMS.
Figura 3 Diagrama de rede
center>
Procedimento
- Configurar o agente SNMP:
# Atribua o endereço IP 1.1.1.1/24 ao agente e certifique-se de que o agente e o NMS possam se comunicar. (Detalhes não mostrados.)
# Especifique o SNMPv1 e crie uma comunidade somente de leitura pública e uma comunidade de leitura e gravação privado.
<Agent> system-view
[Agent] snmp-agent sys-info version v1
[Agent] snmp-agent community read public
[Agent] snmp-agent community write private# Configure as informações de contato e localização física do agente.
[Agent] snmp-agent sys-info contact Mr.Wang-Tel:3306
[Agent] snmp-agent sys-info location telephone-closet,3rd-floor# Habilite as notificações de SNMP, especifique o NMS em 1.1.1.2 como um destino de trap de SNMP e use public como o nome da comunidade. (Para garantir que o NMS possa receber traps, especifique a mesma versão de SNMP no comando snmp-agent target-host que está configurado no NMS).
[Agent] snmp-agent trap enable
[Agent] snmp-agent target-host trap address udp-domain 1.1.1.2 params securityname
public v1- Configure o SNMP NMS:
- Especifique SNMPv1.
- Crie uma comunidade somente de leitura pública e uma comunidade de leitura e gravação privada.
- Defina o cronômetro de tempo limite e o número máximo de novas tentativas, conforme necessário. Para obter informações sobre como configurar o NMS, consulte o manual do NMS.
OBSERVAÇÃO:
As configurações de SNMP do agente e do NMS devem corresponder.
Verificação da configuração
# Tentativa de obter o valor MTU da interface NULL0 do agente. A tentativa foi bem-sucedida.
Send request to 1.1.1.1/161 ...
Protocol version: SNMPv1
Operation: Get
Request binding:
1: 1.3.6.1.2.1.2.2.1.4.135471
Response binding:
1: Oid=ifMtu.135471 Syntax=INT Value=1500
Get finished
# Use um nome de comunidade incorreto para obter o valor de um nó MIB no agente. Você pode ver uma interceptação de falha de autenticação no NMS.
1.1.1.1/2934 V1 Trap = authenticationFailure
SNMP Version = V1
Community = public
Command = Trap
Enterprise = 1.3.6.1.4.1.43.1.16.4.3.50
GenericID = 4
SpecificID = 0
Time Stamp = 8:35:25.68Exemplo: Configuração do SNMPv3
Configuração de rede
Conforme mostrado na Figura 4, o NMS (1.1.1.2/24) usa o SNMPv3 para monitorar e gerenciar o agente (1.1.1.1/24). O agente envia automaticamente notificações para informar eventos ao NMS. A porta UDP 162 padrão é usada para notificações de SNMP.
O NMS e o agente realizam a autenticação quando estabelecem uma sessão SNMP. O algoritmo de autenticação é SHA-1 e a chave de autenticação é 123456TESTauth&!. O NMS e o agente também criptografam os pacotes SNMP entre eles usando o algoritmo AES e a chave de criptografia 123456TESTencr&!.
Figura 4 Diagrama de rede
center>
Configuração do SNMPv3 no modo RBAC
- Configurar o agente:
# Atribua o endereço IP 1.1.1.1/24 ao agente e certifique-se de que o agente e o NMS possam se comunicar. (Detalhes não mostrados.)
#Crie a função de usuário test e atribua a test acesso somente leitura aos objetos no snmpMIB
(OID:1.3.6.1.6.3.1), incluindo os objetos linkUp e linkDown.
<Agent> system-view
[Agent] role name test
[Agent-role-test] rule 1 permit read oid 1.3.6.1.6.3.1# Atribua ao usuário teste de função acesso somente de leitura ao nó do sistema (OID:1.3.6.1.2.1.1) e acesso de leitura e gravação ao nó das interfaces (OID:1.3.6.1.2.1.2).
[Agent-role-test] rule 2 permit read oid 1.3.6.1.2.1.1
[Agent-role-test] rule 3 permit read write oid 1.3.6.1.2.1.2
[Agent-role-test] quit# Criar usuário SNMPv3 RBACtest. Atribua a função de usuário test ao RBACtest. Definir a autenticação
algoritmo para SHA-1, chave de autenticação para 123456TESTauth&!, algoritmo de criptografia para AES e chave de criptografia para 123456TESTencr&!
[Agent] snmp-agent usm-user v3 RBACtest user-role test simple authentication-mode sha
123456TESTauth&! privacy-mode aes128 123456TESTencr&!#Configure as informações de contato e localização física do agente.
[Agent] snmp-agent sys-info contact Mr.Wang-Tel:3306
[Agent] snmp-agent sys-info location telephone-closet,3rd-floor#Habilite as notificações no agente. Especifique o NMS em 1.1.1.2 como o destino da notificação e RBACtest como o nome de usuário.
[Agent] snmp-agent trap enable
[Agent] snmp-agent target-host trap address udp-domain 1.1.1.2 params
securitynameRBACtest v3 privacy- Configure o NMS:
- Especifique SNMPv3.
- Criar o usuário SNMPv3 RBACtest.
- Habilite a autenticação e a criptografia. Defina o algoritmo de autenticação como SHA-1, a chave de autenticação como 123456TESTauth&!, o algoritmo de criptografia como AES e a chave de criptografia como 123456TESTencr&!
- Defina o cronômetro de tempo limite e o número máximo de novas tentativas.
Para obter informações sobre como configurar o NMS, consulte o manual do NMS.
OBSERVAÇÃO:
As configurações de SNMP no agente e no NMS devem corresponder.
Configuração do SNMPv3 no modo VACM
- Configure o agente:
# Atribua o endereço IP 1.1.1.1/24 ao agente e certifique-se de que o agente e o NMS possam se comunicar. (Detalhes não mostrados.)
# Crie o grupo SNMPv3 managev3group e atribua ao managev3group acesso somente leitura aos objetos sob o nó snmpMIB (OID: 1.3.6.1.2.1.2.2) na visualização de teste, incluindo os objetos linkUp e linkDown.
<Agent> system-view
[Agent] undo snmp-agent mib-view ViewDefault
[Agent] snmp-agent mib-view included test snmpMIB
[Agent] snmp-agent group v3 managev3group privacy read-view test#Atribuir ao grupo SNMPv3 managev3group acesso de leitura e gravação aos objetos do sistema
(OID: 1.3.6.1.2.1.1) e o nó de interfaces (OID: 1.3.6.1.2.1.2) na visualização de teste.
[Agent] snmp-agent mib-view included test 1.3.6.1.2.1.1
[Agent] snmp-agent mib-view included test 1.3.6.1.2.1.2
[Agent] snmp-agent group v3 managev3group privacy read-view test write-view test# Adicione o usuário VACMtest ao grupo SNMPv3 managev3group e defina o algoritmo de autenticação como SHA-1, a chave de autenticação como 123456TESTauth&!, o algoritmo de criptografia como AES e a chave de criptografia como 123456TESTencr&!
[Agent] snmp-agent usm-user v3 VACMtest managev3group simple authentication-mode sha
123456TESTauth&! privacy-mode aes128 123456TESTencr&!# Configure as informações de contato e localização física do agente.
[Agent] snmp-agent sys-info contact Mr.Wang-Tel:3306
[Agent] snmp-agent sys-info location telephone-closet,3rd-floor# Habilite as notificações no agente. Especifique o NMS em 1.1.1.2 como o destino do trap e VACMtest como o nome de usuário.
[Agent] snmp-agent sys-info contact Mr.Wang-Tel:3306
[Agent] snmp-agent sys-info location telephone-closet,3rd-floor- Configurar o SNMP NMS:
- Especifique SNMPv3.
- Criar o usuário VACMtest do SNMPv3.
- Habilite a autenticação e a criptografia. Defina o algoritmo de autenticação como SHA-1, a chave de autenticação como 123456TESTauth&!, o algoritmo de criptografia como AES e a chave de criptografia como 123456TESTencr&!
- Defina o cronômetro de tempo limite e o número máximo de novas tentativas.
Para obter informações sobre como configurar o NMS, consulte o manual do NMS.
OBSERVAÇÃO:
As configurações de SNMP no agente e no NMS devem corresponder.
Verificação da configuração
Use o nome de usuário RBACtest para acessar o agente.
# Recupere o valor do nó sysName. O valor Agent é retornado.
# Defina o valor do nó sysName como Sysname. A operação falha porque o NMS não tem acesso de gravação ao nó.
# Desligar ou ativar uma interface no agente. O NMS recebe notificações de linkUP (OID: 1.3.6.1.6.3.1.1.5.4) ou linkDown (OID: 1.3.6.1.6.3.1.1.5.3).
Use o nome de usuário VACMtest para acessar o agente.
# Recupere o valor do nó sysName. O valor Agent é retornado.
# Defina o valor do nó sysName como Sysname. A operação foi bem-sucedida.
# Desligar ou ativar uma interface no agente. O NMS recebe notificações de linkUP (OID: 1.3.6.1.6.3.1.1.5.4) ou linkDown (OID: 1.3.6.1.6.3.1.1.5.3).
Configuração do RMON
Sobre a RMON
O Remote Network Monitoring (RMON) é um protocolo de gerenciamento de rede baseado em SNMP. Ele permite o monitoramento e gerenciamento remoto proativo de dispositivos de rede.
Mecanismo de funcionamento do RMON
O RMON pode coletar periódica ou continuamente estatísticas de tráfego para uma porta Ethernet e monitorar os valores dos objetos MIB em um dispositivo. Quando um valor atinge o limite, o dispositivo registra automaticamente o evento ou envia uma notificação ao NMS. O NMS não precisa pesquisar constantemente as variáveis MIB e comparar os resultados.
O RMON usa notificações SNMP para notificar os NMSs sobre várias condições de alarme. O SNMP informa ao NMS as alterações de status operacional da função e da interface, como link up, link down e falha de módulo.
Grupos RMON
Entre os grupos RMON padrão, o dispositivo implementa o grupo de estatísticas, o grupo de histórico, o grupo de eventos, o grupo de alarmes, o grupo de configuração da sonda e o grupo de histórico do usuário. O sistema Comware também implementa um grupo de alarme privado, que aprimora o grupo de alarme padrão. O grupo de configuração da sonda e o grupo de histórico do usuário não são configuráveis na CLI. Para configurar esses dois grupos , é necessário acessar o MIB.
Grupo de estatísticas
O grupo de estatísticas coleta amostras de estatísticas de tráfego para interfaces Ethernet monitoradas e armazena as estatísticas na tabela de estatísticas Ethernet (ethernetStatsTable). As estatísticas incluem:
Número de colisões.
Erros de alinhamento de CRC.
Número de pacotes de tamanho menor ou maior que o normal.
Número de transmissões.
Número de multicasts.
Número de bytes recebidos.
Número de pacotes recebidos.
As estatísticas na tabela de estatísticas da Ethernet são somas cumulativas.
Grupo de história
O grupo de histórico coleta periodicamente amostras de estatísticas de tráfego em interfaces e salva as amostras de histórico na tabela de histórico (etherHistoryTable). As estatísticas incluem:
Utilização da largura de banda.
Número de pacotes de erro.
Número total de pacotes.
A tabela de histórico armazena as estatísticas de tráfego coletadas para cada intervalo de amostragem.
Grupo de eventos
O grupo de eventos controla a geração e as notificações de eventos acionados pelos alarmes definidos no grupo de alarmes e no grupo de alarmes privados. Os métodos de tratamento de eventos de alarme RMON são os seguintes:
Log - Registra informações de eventos (incluindo hora e descrição do evento) na tabela de registro de eventos para que o dispositivo de gerenciamento possa obter os registros por meio de SNMP.
Trap - Envia uma notificação SNMP quando o evento ocorre.
Log-Trap - Registra informações de eventos na tabela de registro de eventos e envia uma notificação SNMP quando o evento ocorre.
Nenhum - Não realiza nenhuma ação.
Grupo de alarmes
O grupo de alarmes RMON monitora variáveis de alarme, como a contagem de pacotes de entrada (etherStatsPkts) em uma interface. Depois que você cria uma entrada de alarme, o agente RMON coleta amostras do valor da variável de alarme monitorada regularmente. Se o valor da variável monitorada for maior ou igual ao limite crescente, um evento de alarme crescente será acionado. Se o valor da variável monitorada for menor ou igual ao limite de queda, será acionado um evento de alarme de queda. O grupo de eventos define a ação a ser tomada no evento de alarme.
Se uma entrada de alarme cruzar um limite várias vezes seguidas, o agente RMON gera um evento de alarme apenas para o primeiro cruzamento. Por exemplo, se o valor de uma variável de alarme amostrada cruzar o limite de subida várias vezes antes de cruzar o limite de descida, somente o primeiro cruzamento acionará um evento de alarme de subida, conforme mostrado na Figura 1.
Figura 1 Eventos de alarme ascendente e descendente
Grupo de alarme privado
O grupo de alarmes privados permite que você realize operações matemáticas básicas em várias variáveis e compare o resultado do cálculo com os limites de subida e descida.
O agente RMON faz uma amostragem das variáveis e executa uma ação de alarme com base em uma entrada de alarme particular, como segue:
- Amostrar as variáveis de alarme privadas na fórmula definida pelo usuário.
- Processa os valores amostrados com a fórmula.
- Compara o resultado do cálculo com os limites predefinidos e, em seguida, executa uma das seguintes ações:
- Aciona o evento associado ao evento de alarme crescente se o resultado for igual ou maior que o limite crescente.
- Aciona o evento associado ao evento de alarme de queda se o resultado for igual ou menor que o limite de queda.
Se uma entrada de alarme particular cruzar um limite várias vezes seguidas, o agente RMON gerará um evento de alarme apenas para o primeiro cruzamento. Por exemplo, se o valor de uma variável de alarme amostrada
cruzar o limite de subida várias vezes antes de cruzar o limite de descida, somente o primeiro cruzamento aciona um evento de alarme de subida.
Tipos de amostra para o grupo de alarme e o grupo de alarme privado
O agente RMON é compatível com os seguintes tipos de amostra:
absoluto - O RMON compara o valor da variável monitorada com os limites de subida e descida no final do intervalo de amostragem.
O delta-RMON subtrai o valor da variável monitorada na amostra anterior do valor atual e, em seguida, compara a diferença com os limites de subida e descida.
Protocolos e padrões
RFC 4502, Base de Informações de Gerenciamento de Monitoramento Remoto de Rede Versão 2
RFC 2819, Base de informações de gerenciamento de monitoramento remoto de rede Status deste memorando
Configuração da função de estatísticas RMON
Sobre a função de estatísticas RMON
O RMON implementa a função de estatísticas por meio do grupo de estatísticas Ethernet e do grupo de histórico.
O grupo de estatísticas Ethernet fornece a estatística cumulativa de uma variável desde o momento em que a entrada de estatísticas é criada até a hora atual.
O grupo de histórico fornece estatísticas que são amostradas para uma variável para cada intervalo de amostragem. O grupo de histórico usa a tabela de controle de histórico para controlar a amostragem e armazena amostras na tabela de histórico.
Criação de uma entrada de estatísticas RMON Ethernet
Restrições e diretrizes
O índice de uma entrada de estatísticas RMON deve ser globalmente exclusivo. Se o índice tiver sido usado por outra interface, a operação de criação falhará.
Você pode criar apenas uma entrada de estatísticas RMON para uma interface Ethernet.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface Ethernet.
interface interface-type interface-number- Criar uma entrada de estatísticas RMON Ethernet.
rmon statistics entry-number [ owner text ]Criação de uma entrada de controle de histórico RMON
Restrições e diretrizes
É possível configurar várias entradas de controle de histórico para uma interface, mas é preciso garantir que os números de entrada e os intervalos de amostragem sejam diferentes.
É possível criar uma entrada de controle de histórico com êxito, mesmo que o tamanho do compartimento especificado exceda o tamanho da tabela de histórico disponível. O RMON definirá o tamanho do compartimento o mais próximo possível do tamanho esperado do compartimento.
Procedimento
- Entre na visualização do sistema.
system-view- Entre na visualização da interface Ethernet.
interface interface-type interface-number- Crie uma entrada de controle de histórico RMON.
rmon history entry-number buckets number interval interval [ owner text ]Por padrão, não existem entradas de controle de histórico do RMON.
É possível criar várias entradas de controle de histórico do RMON para uma interface Ethernet.
Configuração da função de alarme RMON
Restrições e diretrizes
Ao criar um novo evento, alarme ou entrada de alarme particular, siga estas restrições e diretrizes:
A entrada não deve ter o mesmo conjunto de parâmetros que uma entrada existente.
O número máximo de entradas não foi atingido.
A Tabela 1 mostra os parâmetros a serem comparados para duplicação e os limites de entrada.
Tabela 1 Restrições de configuração do RMON
| Entrada | Parâmetros a serem comparados | Número máximo de entradas | |||
| Evento | Descrição do evento (descrição string) Tipo de evento (log, trap, logtrap ou nenhum) Nome da comunidade (security-string) | 60 | |||
| Alarme | Variável de alarme (variável de alarme) Intervalo de amostragem (intervalo de amostragem) Tipo de amostra (absoluta ou delta) Limite crescente (valor limiar1) Limite de queda (valor limiar2) | 60 | |||
| Alarme privado | Fórmula de variável de alarme (prialarm-formula) Intervalo de amostragem (intervalo de amostragem) Tipo de amostra (absoluta ou delta) Limite crescente (valor limiar1) Limite de queda (valor limiar2) | 50 |
Pré-requisitos
Para enviar notificações ao NMS quando um alarme for acionado, configure o agente SNMP conforme descrito em em "Configuração de SNMP" antes de configurar a função de alarme RMON.
Procedimento
- Entre na visualização do sistema.
system-view- (Opcional.) Crie uma entrada de evento RMON.
rmon event entry-number [ description string ] { log | log-trap
security-string | none | trap security-string } [ owner text ]
Por padrão, não existem entradas de eventos RMON.
- Criar uma entrada de alarme RMON.
- Criar uma entrada de alarme RMON.
rmon alarm entry-number alarm-variable sampling-interval
{ absolute | delta } [ startup-alarm { falling | rising |
rising-falling } ] rising-threshold threshold-value1 event-entry1
falling-threshold threshold-value2 event-entry2 [ owner text ]- Criar uma entrada de alarme privado RMON.
rmon prialarm entry-number prialarm-formula prialarm-des
sampling-interval { absolute | delta } [ startup-alarm { falling |
rising | rising-falling } ] rising-threshold threshold-value1
event-entry1 falling-threshold threshold-value2 event-entry2
entrytype { forever | cycle cycle-period } [ owner text ]Por padrão, não existem entradas de alarme RMON ou entradas de alarme privado RMON.
Você pode associar um alarme a um evento que ainda não foi criado. O alarme acionará o evento somente depois que o evento for criado.
Comandos de exibição e manutenção para RMON
Executar comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir entradas de alarme RMON. | display rmon alarm [ entry-number ] | ||
| Exibir entradas de eventos RMON. | display rmon event [ entry-number ] | ||
| Exibir informações de registro para entradas de eventos. | display rmon eventlog [ entry-number ] | ||
| Exibir entradas de controle de histórico RMON e amostras de histórico. | display rmon history [ interface-type interface-number ] | ||
| Exibir entradas de alarme privado RMON. | display rmon prialarm [ entry-number ] | ||
| Exibir estatísticas RMON. | display rmon statistics [ interface-type interface-number] |
Exemplos de configuração RMON
Exemplo: Configuração da função de estatísticas de Ethernet
Configuração de rede
Conforme mostrado na Figura 2, crie uma entrada de estatísticas RMON Ethernet no dispositivo para coletar estatísticas de tráfego cumulativas para GigabitEthernet 1/0/1.
Figura 2 Diagrama de rede
Procedimento
# Criar uma entrada de estatísticas RMON Ethernet para GigabitEthernet 1/0/1.
<Sysname> system-view
[Sysname] interface gigabitethernet 1/0/1
[Sysname-GigabitEthernet1/0/1] rmon statistics 1 owner user1Verificação da configuração
# Exibir estatísticas coletadas para a GigabitEthernet 1/0/1.
display rmon statistics gigabitethernet 1/0/1
EtherStatsEntry 1 owned by user1 is VALID.
Interface : GigabitEthernet1/0/1
etherStatsOctets : 21657 , etherStatsPkts : 307
etherStatsBroadcastPkts : 56 , etherStatsMulticastPkts : 34
etherStatsUndersizePkts : 0 , etherStatsOversizePkts : 0
etherStatsFragments : 0 , etherStatsJabbers : 0
etherStatsCRCAlignErrors : 0 , etherStatsCollisions : 0
etherStatsDropEvents (insufficient resources): 0
Incoming packets by size:
64 : 235 , 65-127 : 67 , 128-255 : 4
256-511: 1 , 512-1023: 0 , 1024-1518: 0 # Obtenha as estatísticas de tráfego do NMS por meio de SNMP. (Detalhes não mostrados.)
Exemplo: Configuração da função de estatísticas de histórico
Configuração de rede
Conforme mostrado na Figura 3, crie uma entrada de controle de histórico RMON no dispositivo para obter amostras das estatísticas de tráfego da GigabitEthernet 1/0/1 a cada minuto.
Figura 3 Diagrama de rede

Procedimento
# Crie uma entrada de controle de histórico RMON para obter amostras de estatísticas de tráfego a cada minuto para a GigabitEthernet 1/0/1. Mantenha um máximo de oito amostras para a interface na tabela de estatísticas do histórico.
<Sysname> system-view
[Sysname] interface gigabitethernet 1/0/1
[Sysname-GigabitEthernet1/0/1] rmon history 1 buckets 8 interval 60 owner user1Verificação da configuração
# Exibir as estatísticas de histórico coletadas para a GigabitEthernet 1/0/1. [Sysname-GigabitEthernet1/0/1] display rmon history HistoryControlEntry 1 owned by user1 is VALID
[Sysname-GigabitEthernet1/0/1] display rmon history
HistoryControlEntry 1 owned by user1 is VALID
Sampled interface : GigabitEthernet1/0/1
Sampling interval : 60(sec) with 8 buckets max
Sampling record 1 :
dropevents : 0 , octets : 834
packets : 8 , broadcast packets : 1
multicast packets : 6 , CRC alignment errors : 0
undersize packets : 0 , oversize packets : 0
fragments : 0 , jabbers : 0
collisions : 0 , utilization : 0
Sampling record 2 :
dropevents : 0 , octets : 962
packets : 10 , broadcast packets : 3
multicast packets : 6 , CRC alignment errors : 0
undersize packets : 0 , oversize packets : 0
fragments : 0 , jabbers : 0
collisions : 0 , utilization : 0 # Obtenha as estatísticas de tráfego do NMS por meio de SNMP. (Detalhes não mostrados).
Exemplo: Configuração da função de alarme
Configuração de rede
Conforme mostrado na Figura 4, configure o dispositivo para monitorar a estatística de tráfego de entrada na GigabitEthernet 1/0/1 e enviar alarmes RMON quando uma das condições a seguir for atendida:
A amostra delta de 5 segundos para a estatística de tráfego ultrapassa o limite de aumento (100).
A amostra delta de 5 segundos para a estatística de tráfego cai abaixo do limite de queda (50).
Figura 4 Diagrama de rede

Procedimento
# Configure o agente SNMP (o dispositivo) com as mesmas configurações de SNMP que o NMS em 1.1.1.2. Este exemplo usa SNMPv1, comunidade de leitura pública e comunidade de gravação privada.
<Sysname> system-view
[Sysname] snmp-agent
[Sysname] snmp-agent community read public
[Sysname] snmp-agent community write private
[Sysname] snmp-agent sys-info version v1
[Sysname] snmp-agent trap enable
[Sysname] snmp-agent trap log
[Sysname] snmp-agent target-host trap address udp-domain 1.1.1.2 params securityname
public# Criar uma entrada de estatísticas RMON Ethernet para GigabitEthernet 1/0/1.
[Sysname] interface gigabitethernet 1/0/1
[Sysname-GigabitEthernet1/0/1] rmon statistics 1 owner user1
[Sysname-GigabitEthernet1/0/1] quit# Crie uma entrada de evento RMON e uma entrada de alarme RMON para enviar notificações SNMP quando a amostra delta para 1.3.6.1.2.1.16.1.1.1.4.1 exceder 100 ou cair abaixo de 50.
[Sysname] rmon event 1 trap public owner user1
[Sysname] rmon alarm 1 1.3.6.1.2.1.16.1.1.1.4.1 5 delta rising-threshold 100 1
falling-threshold 50 1 owner user1OBSERVAÇÃO:
A string 1.3.6.1.2.1.16.1.1.1.4.1 é a instância do objeto para GigabitEthernet 1/0/1. Os dígitos antes do último dígito (1.3.6.1.2.1.16.1.1.1.4) representam o objeto para estatísticas de tráfego total de entrada. O último dígito (1) é o índice de entrada de estatísticas RMON Ethernet para GigabitEthernet 1/0/1.
Verificação da configuração
# Exibir a entrada de alarme RMON.
display rmon alarm 1
AlarmEntry 1 owned by user1 is VALID.
Sample type : delta
Sampled variable : 1.3.6.1.2.1.16.1.1.1.4.1
Sampling interval (in seconds) : 5
Rising threshold : 100(associated with event 1)
Falling threshold : 50(associated with event 1)
Alarm sent upon entry startup : risingOrFallingAlarm
Latest value : 0 # Exibir estatísticas da GigabitEthernet 1/0/1.
<Sysname> display rmon statistics gigabitethernet 1/0/1
Interface : GigabitEthernet1/0/1
etherStatsOctets : 57329 , etherStatsPkts : 455
etherStatsBroadcastPkts : 53 , etherStatsMulticastPkts : 353
etherStatsUndersizePkts : 0 , etherStatsOversizePkts : 0
etherStatsFragments : 0 , etherStatsJabbers : 0
etherStatsCRCAlignErrors : 0 , etherStatsCollisions : 0
etherStatsDropEvents (insufficient resources): 0
Incoming packets by size :
64 : 7 , 65-127 : 413 , 128-255 : 35
256-511: 0 , 512-1023: 0 , 1024-1518: 0 O NMS recebe a notificação quando o alarme é acionado.
Configuração do NETCONF
Sobre a NETCONF
O Network Configuration Protocol (NETCONF) é um protocolo de gerenciamento de rede baseado em XML. Ele fornece mecanismos programáveis para gerenciar e configurar dispositivos de rede. Por meio do NETCONF, você pode configurar parâmetros de dispositivos, recuperar valores de parâmetros e coletar estatísticas. Para uma rede que tenha dispositivos de fornecedores, você pode desenvolver um sistema NMS baseado em NETCONF para configurar e gerenciar dispositivos de forma simples e eficaz.
Estrutura do NETCONF
O NETCONF tem as seguintes camadas: camada de conteúdo, camada de operações, camada de RPC e camada de protocolo de transporte.
Formato da mensagem NETCONF
NETCONF
Todas as mensagens NETCONF são baseadas em XML e estão em conformidade com a RFC 4741. Uma mensagem NETCONF recebida deve passar pela verificação do esquema XML antes de ser processada. Se uma mensagem NETCONF não passar na verificação do esquema XML, o dispositivo enviará uma mensagem de erro ao cliente.
Para obter informações sobre as operações do NETCONF compatíveis com o dispositivo e os dados operáveis, consulte a referência da API XML do NETCONF para o dispositivo.
O exemplo a seguir mostra uma mensagem NETCONF para obter todos os parâmetros de todas as interfaces do dispositivo:
<?xml version="1.0" encoding="utf-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-bulk>
<filtro type="subtree">
<top xmlns="http://www.intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface/>
</Interfaces>
</Ifmgr>
</top>
</filtro>
</get-bulk>
</rpc>NETCONF sobre SOAP
Todas as mensagens NETCONF sobre SOAP são baseadas em XML e estão em conformidade com a RFC 4741. As mensagens NETCONF estão contidas no elemento
das mensagens SOAP. As mensagens NETCONF sobre SOAP também estão em conformidade com as seguintes regras:As mensagens SOAP devem usar os namespaces do Envelope SOAP.
As mensagens SOAP devem usar os namespaces SOAP Encoding.
As mensagens SOAP não podem conter as seguintes informações:
⚪ Referência de DTD.
⚪ Instruções de processamento de XML.
O exemplo a seguir mostra uma mensagem NETCONF sobre SOAP para obter todos os parâmetros de todas as interfaces do dispositivo:
<env:Envelope xmlns:env="http://www.w3.org/2003/05/soap-envelope">
<env:Header>
<auth:Authentication env:mustUnderstand="1"
xmlns:auth="http://www.Intelbras.com/netconf/base:1.0">
<auth:AuthInfo>800207F0120020C</auth:AuthInfo>
</auth:Authentication>
</env:Header>
<env:Body>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-bulk>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface/>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get-bulk>
</rpc>
</env:Body>
</env:Envelope>
Como usar o NETCONF
Você pode usar o NETCONF para gerenciar e configurar o dispositivo usando os métodos da Tabela 2.
Tabela 2 Métodos NETCONF para configurar o dispositivo
| Ferramenta de configuração | Método de login | Observações | |||
| CLI | Porta do console SSH Telnet | Para executar operações NETCONF, copie as mensagens NETCONF válidas para a CLI no modo de exibição XML. | |||
| Interface da Web padrão para o dispositivo | HTTP HTTPS | O sistema converte automaticamente as operações de configuração na interface da Web em mensagens NETCONF e as envia ao dispositivo para realizar operações NETCONF. | |||
| Interface de usuário personalizada | N/A | Para usar esse método, você deve ativar o NETCONF sobre SOAP. As mensagens NETCONF serão encapsuladas em SOAP para transmissão. |
Protocolos e padrões
RFC 3339, Data e hora na Internet: Timestamps
RFC 4741, Protocolo de Configuração NETCONF
RFC 4742, Usando o protocolo de configuração NETCONF sobre Secure SHell (SSH)
RFC 4743, Uso do NETCONF sobre o protocolo SOAP (Simple Object Access Protocol)
RFC 5277, Notificações de eventos NETCONF
RFC 5381, Experiência de implementação do NETCONF sobre SOAP
RFC 5539, NETCONF sobre segurança da camada de transporte (TLS)
RFC 6241, Protocolo de Configuração de Rede
Conformidade com FIPS
O dispositivo é compatível com o modo FIPS que atende aos requisitos do NIST FIPS 140-2. O suporte a recursos, comandos e parâmetros pode ser diferente no modo FIPS (consulte o Guia de configuração de segurança) e no modo não-FIPS.
Visão geral das tarefas do NETCONF
Para configurar o NETCONF, execute as seguintes tarefas:
- Estabelecimento de uma sessão NETCONF
- (Opcional.) Configuração dos atributos da sessão NETCONF
- Estabelecimento de sessões NETCONF sobre SOAP
- Estabelecimento de sessões NETCONF sobre SSH
- Estabelecimento de sessões NETCONF sobre Telnet ou NETCONF sobre console
- Troca de recursos
- (Opcional.) Recuperação de informações de configuração do dispositivo
- Recuperação de informações de configuração e estado do dispositivo
- Recuperação de configurações não padrão
- Recuperação de informações do NETCONF
- Recuperação do conteúdo do arquivo YANG
- Recuperação de informações da sessão NETCONF
- (Opcional.) Filtragem de dados
Filtragem baseada em tabela
Filtragem baseada em colunas
- (Opcional.) Bloqueio ou desbloqueio da configuração em execução
- Bloqueio da configuração em execução
- Desbloqueio da configuração em execução
- (Opcional.) Modificação da configuração
- (Opcional.) Gerenciamento de arquivos de configuração
- Salvando a configuração em execução
- Carregando a configuração
- Reverter a configuração
- (Opcional.) Realização de operações da CLI por meio do NETCONF
- (Opcional.) Assinatura de eventos
- Assinatura de eventos syslog
- Assinatura de eventos monitorados pelo NETCONF
- Assinatura de eventos relatados por módulos
- (Opcional.) Encerramento de sessões NETCONF
- (Opcional.) Retornar à CLI
Estabelecimento de uma sessão NETCONF
Restrições e diretrizes para o estabelecimento de sessões NETCONF
Depois que uma sessão NETCONF é estabelecida, o dispositivo envia automaticamente seus recursos para o cliente. Você deve enviar os recursos do cliente para o dispositivo antes de poder executar qualquer outra operação NETCONF.
Antes de executar uma operação NETCONF, certifique-se de que nenhum outro usuário esteja configurando ou gerenciando o dispositivo. Se vários usuários configurarem ou gerenciarem o dispositivo simultaneamente, o resultado poderá ser diferente do esperado.
Você pode usar o comando aaa session-limit para definir o número máximo de sessões NETCONF que o dispositivo pode suportar. Se o limite superior for atingido, novos usuários do NETCONF não poderão acessar o dispositivo. Para obter informações sobre esse comando, consulte AAA no Guia de Configuração de Segurança.
Configuração dos atributos da sessão NETCONF
Sobre os namespaces específicos do módulo para NETCONF
O NETCONF oferece suporte aos seguintes tipos de namespaces:
Espaço de nomes comum - O espaço de nomes comum é compartilhado por todos os módulos. Em um pacote que usa o namespace comum, o namespace é indicado no elemento
Exemplo:
<rpc message-id="100" xmlns="urn:ietf:Params:xml:ns:netconf:base:1.0">
<get-bulk>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get-bulk>
</rpc>
Espaço de nomes específico do módulo - Cada módulo tem seu próprio espaço de nomes. Um pacote que usa um namespace específico de módulo não tem o elemento
Exemplo:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-bulk>
<filter type="subtree">
<Ifmgr xmlns="http://www.Intelbras.com/netconf/data:1.0-Ifmgr">
<Interfaces>
</Interfaces>
</Ifmgr>
</filter>
</get-bulk>
</rpc>
O espaço de nomes comum é incompatível com os espaços de nomes específicos do módulo. Para configurar uma sessão NETCONF, o dispositivo e o cliente devem usar o mesmo tipo de espaço de nomes. Por padrão, o espaço de nomes comum é usado. Se o cliente não for compatível com o espaço de nomes comum, use esse recurso para configurar o dispositivo para usar espaços de nomes específicos do módulo.
Procedimento
- Entre na visualização do sistema.
system-view- Defina o tempo limite de inatividade da sessão NETCONF.
netconf { agent | soap } idle-timeout minute;| Palavra-chave | Descrição | ||
| agent | Especifica as seguintes sessões: NETCONF em sessões SSH. NETCONF em sessões Telnet. NETCONF em sessões de console. Por padrão, o tempo limite de inatividade é 0, e as sessões nunca atingem o tempo limite. | ||
| soap | Especifica as seguintes sessões: NETCONF sobre SOAP sobre sessões HTTP. NETCONF sobre SOAP sobre sessões HTTPS. A configuração padrão é 10 minutos. |
- Ativar o registro de NETCONF.
netconf log source { all | { agent | soap | web } * } { protocol-operation
{ all | { action | config | get | set | session | syntax | others } * }
| row-operation | verbose }
Por padrão, o registro em log do NETCONF está desativado.
- Configure o NETCONF para usar namespaces específicos do módulo.
netconf capability specific-namespacePor padrão, o namespace comum é usado.
Para que a configuração tenha efeito, você deve restabelecer a sessão NETCONF.
Estabelecimento de sessões NETCONF sobre SOAP
Sobre o NETCONF sobre SOAP
É possível usar uma interface de usuário personalizada para estabelecer uma sessão NETCONF sobre SOAP para o dispositivo e realizar operações NETCONF. O NETCONF sobre SOAP encapsula as mensagens NETCONF em mensagens SOAP e transmite as mensagens SOAP por HTTP ou HTTPS.
Restrições e diretrizes
Você pode adicionar um domínio de autenticação ao parâmetro
O domínio de autenticação obrigatório configurado usando o comando netconf soap domain tem precedência sobre o domínio de autenticação especificado no parâmetro
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o NETCONF por SOAP. No modo não-FIPS:
netconf soap { http | https } enableNo modo FIPS:
netconf soap https enablePor padrão, o recurso NETCONF over SOAP é desativado se o dispositivo for iniciado com a configuração inicial.
Se o dispositivo for iniciado com os padrões de fábrica, o estado de ativação do NETCONF over SOAP varia de acordo com a plataforma de hardware e a versão do software, conforme mostrado na Tabela 3.
Para obter mais informações sobre configuração inicial, padrões de fábrica e configuração de inicialização, consulte o gerenciamento de arquivos de configuração no Guia de Configuração Básica.
- Defina o valor DSCP para pacotes NETCONF sobre SOAP. No modo não-FIPS:
netconf soap { http | https } dscp dscp-valueNo modo FIPS:
netconf soap https dscp dscp-valuePor padrão, o valor DSCP é 0 para pacotes NETCONF sobre SOAP.
- Use uma ACL IPv4 para controlar o acesso ao NETCONF sobre SOAP. No modo não-FIPS:
netconf soap { http | https } acl { ipv4-acl-number | name ipv4-acl-name }No modo FIPS:
netconf soap https acl { ipv4-acl-number | name ipv4-acl-name }Por padrão, nenhuma ACL IPv4 é aplicada para controlar o acesso ao NETCONF sobre SOAP.
Somente os clientes permitidos pela ACL IPv4 podem estabelecer sessões NETCONF sobre SOAP.
- Especifique um domínio de autenticação obrigatório para usuários do NETCONF.
netconf soap domain domain-namePor padrão, nenhum domínio de autenticação obrigatório é especificado para os usuários do NETCONF. Para obter informações sobre domínios de autenticação, consulte o Guia de Configuração de Segurança.
- Use a interface de usuário personalizada para estabelecer uma sessão NETCONF sobre SOAP com o dispositivo. Para obter informações sobre a interface de usuário personalizada, consulte o guia do usuário da interface.
Estabelecimento de sessões NETCONF sobre SSH
Pré-requisitos
Antes de estabelecer uma sessão NETCONF sobre SSH, certifique-se de que a interface de usuário personalizada possa acessar o dispositivo por meio de SSH.
Procedimento
- Entre na visualização do sistema.
system-view- Habilite o NETCONF por SSH.
netconf ssh server enablePor padrão, o NETCONF sobre SSH está desativado.
- Especifique a porta de escuta para pacotes NETCONF sobre SSH.
netconf ssh server port port-numberPor padrão, o número da porta de escuta é 830.
- Use a interface de usuário personalizada para estabelecer uma sessão NETCONF sobre SSH com o dispositivo. Para obter informações sobre a interface de usuário personalizada, consulte o guia do usuário da interface.
Estabelecimento de sessões NETCONF sobre Telnet ou NETCONF sobre console
Restrições e diretrizes
Para garantir a correção do formato de uma mensagem NETCONF, não insira a mensagem manualmente. Copie e cole a mensagem.
Enquanto o dispositivo estiver executando uma operação NETCONF, não execute nenhuma outra operação, como colar uma mensagem NETCONF ou pressionar Enter.
Para que o dispositivo identifique as mensagens NETCONF, você deve adicionar a marca de fim ]]>]]> no final de cada mensagem NETCONF. Os exemplos deste documento não têm necessariamente essa marca de fim. Adicione a marca de fim em operações reais.
Pré-requisitos
Para estabelecer uma sessão NETCONF sobre Telnet ou uma sessão NETCONF sobre console, primeiro faça login no dispositivo por meio de Telnet ou da porta do console.
Procedimento
Para entrar na visualização XML, execute o seguinte comando na visualização do usuário:
xmlSe o prompt da visualização XML for exibido, a sessão NETCONF sobre Telnet ou NETCONF sobre console foi estabelecida com êxito.
Troca de recursos
Sobre o intercâmbio de capacidades
Depois que uma sessão NETCONF é estabelecida, o dispositivo envia seus recursos para o cliente. Você deve usar uma mensagem hello para enviar os recursos do cliente ao dispositivo antes de poder executar qualquer outra operação NETCONF.
Mensagem Hello do dispositivo para o cliente
<?xml version="1.0" encoding="UTF-8"?>
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>urn:ietf:params:netconf:base:1.1</capability>
<capability>urn:ietf:params:netconf:writable-running</capability>
<capability>urn:ietf:params:netconf:capability:notification:1.0</capability>
<capability>urn:ietf:params:netconf:capability:validate:1.1</capability>
<capability>urn:ietf:params:netconf:capability:interleave:1.0</capability>
<capability>urn:Intelbras:params:netconf:capability:Intelbras-netconf-ext:1.0</capability>
</capabilities>
<session-id>1</session-id>
</hello>
O elemento
O elemento
Mensagem Hello do cliente para o dispositivo
Depois de receber a mensagem hello do dispositivo, copie a seguinte mensagem hello para notificar o dispositivo sobre os recursos suportados pelo cliente:
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>conjunto de capacidades</capability>
</capabilities>
</hello>
| Item | Descrição | ||
| capability-set |
Especifica um conjunto de recursos compatíveis com o cliente. Use as tags |
Recuperação de informações de configuração do dispositivo
Restrições e diretrizes para a recuperação da configuração do dispositivo
Durante uma operação
<?xml version="1.0"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<data/>
</rpc-reply>
A operação
Para obter mais informações sobre as operações do NETCONF, consulte as referências da API XML do NETCONF para o dispositivo.
Recuperação de informações de configuração e estado do dispositivo
Você pode usar as seguintes operações NETCONF para recuperar informações de configuração e estado do dispositivo:
Operação
Operação
A mensagem
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<getoperation>
<filter>
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
Specify the module, submodule, table name, and column name
</top>
</filter>
</getoperation>
</rpc>
| Item | Descrição | ||
| getoperation | Nome da operação, get ou get-bulk. | ||
| filter | Especifica as condições de filtragem, como o nome do módulo, o nome do submódulo, o nome da tabela e o nome da coluna. Se você especificar um nome de módulo, a operação recuperará os dados do módulo especificado. Se você não especificar um nome de módulo, a operação recuperará os dados de todos os módulos. Se você especificar um nome de submódulo, a operação recuperará os dados do submódulo especificado. Se você não especificar um nome de submódulo, a operação recuperará os dados de todos os submódulos. Se você especificar um nome de tabela, a operação recuperará os dados da tabela especificada. Se você não especificar um nome de tabela, a operação recuperará os dados de todas as tabelas. Se você especificar apenas a coluna de índice, a operação recuperará os dados de todas as colunas. Se você especificar a coluna de índice e quaisquer outras colunas, a operação recuperará os dados da coluna de índice e das colunas especificadas. |
Uma mensagem
| Item | Descrição | ||
| índex | Especifica o índice. Se você não especificar esse item, o valor do índice começará com 1 por padrão. | ||
| count |
Especifica a quantidade de entrada de dados. O atributo count está em conformidade com as seguintes regras: O atributo count pode ser colocado no nó do módulo e no nó da tabela. Em outros nós, ele não pode ser resolvido. Quando o atributo de contagem é colocado no nó do módulo, um nó descendente herda esse atributo de contagem se o nó descendente não contiver o atributo de contagem. A operação |
| |
O exemplo de mensagem
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:xc="http://www.Intelbras.com/netconf/base:1.0">
<get-bulk>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0"
xmlns:base="http://www.Intelbras.com/netconf/base:1.0">
<Syslog>
<Logs xc:count="5">
<Log>
<Index>10</Index>
</Log>
</Logs>
</Syslog>
</top>
</filter>
</get-bulk>
</rpc>
Ao recuperar as informações da interface, o dispositivo não consegue identificar se um valor inteiro para o
O elemento
atributo valuetype para especificar o tipo de valor. O atributo valuetype tem os seguintes valores:
| Valor | Descrição | ||
| name | O elemento está carregando um nome. | ||
| index | O elemento está carregando um índice. | ||
| auto | Valor padrão. O dispositivo usa o valor do elemento como um nome para correspondência de informações. Se nenhuma correspondência for encontrada, o dispositivo usará o valor como um índice para correspondência de interface ou de informações. |
O exemplo a seguir especifica um valor de tipo de índice para o elemento
<rpc xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<getoperation>
<filter>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0" xmlns:base="http://www.Intelbras.com/netconf/base:1.0">
<VLAN>
<TrunkInterfaces>
<Interface>
<IfIndex base:valuetype="index">1</IfIndex>
</Interface>
</TrunkInterfaces>
</VLAN>
</top>
</filter>
</getoperation>
</rpc>
Se a operação
<?xml version="1.0"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<data>
Estado do dispositivo e dados de configuração
</data>
</rpc-reply>
Recuperação de configurações não padrão
As operações
As mensagens
As mensagens
<?xml version="1.0"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-config>
<source>
<running/>
</source>
<filter>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
Especifique o nome do módulo, o nome do submódulo, o nome da tabela e o nome da coluna
</top>
</filter>
</get-config>
</rpc>
Se a operação
<?xml version="1.0"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<data>
Dados que correspondem ao filtro especificado
</data>
</rpc-reply>
Recuperação de informações do NETCONF
Use a mensagem
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="m-641" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get>
<filter type='subtree'>
<netconf-state xmlns='urn:ietf:params:xml:ns:yang:ietf-netconf-monitoring'>
<getType/>
</netconf-state>
</filter>
</get>
</rpc>
Se você não especificar um valor para getType, a operação de recuperação recuperará todas as informações do NETCONF. O valor de getType pode ser uma das seguintes operações:
| Operação | Descrição | ||
| capacidades | Recupera os recursos do dispositivo. | ||
| armazenamentos de dados | Recupera bancos de dados do dispositivo. | ||
| esquemas | Recupera a lista de nomes de arquivos YANG do dispositivo. | ||
| sessões | Recupera informações da sessão do dispositivo. | ||
| estatísticas | Recupera as estatísticas do NETCONF. |
Se a operação
<?xml version="1.0"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<data>
Informações NETCONF recuperadas
</data>
</rpc-reply>
Recuperação do conteúdo do arquivo YANG
Os arquivos YANG salvam as operações NETCONF compatíveis com o dispositivo. Um usuário pode conhecer as operações compatíveis recuperando e analisando o conteúdo dos arquivos YANG.
Os arquivos YANG estão integrados no software do dispositivo e são nomeados no formato yang_identifier@yang_version.yang. Não é possível visualizar os nomes dos arquivos YANG executando o comando dir. Para obter informações sobre como recuperar os nomes dos arquivos YANG, consulte "Recuperação de informações NETCONF".
# Copie o texto a seguir para o cliente para recuperar o arquivo YANG chamado
<?xml version="1.0"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-schema xmlns='urn:ietf:params:xml:ns:yang:ietf-netconf-monitoring'>
<identifier>syslog-data</identifier>
<version>2017-01-01</version>
<format>yang</format>
</get-schema>
</rpc>
Se a operação
<?xml version="1.0"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<data>
Conteúdo do arquivo YANG especificado
</data>
</rpc-reply>
Recuperação de informações da sessão NETCONF
Use a operação
# Copie a seguinte mensagem para o cliente para recuperar as informações da sessão NETCONF do dispositivo:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-sessions/>
</rpc>
Se a operação
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-sessions>
<Session>
<SessionID>ID da sessão de configuração</SessionID>
<Line>Informações da linha</Line>
<UserName>Nome do usuário que está criando a sessão</UserName>
<Since>Hora em que a sessão foi criada</Since>
<LockHeld>Se a sessão mantém um bloqueio</LockHeld>
</Session>
</get-sessions>
</rpc-reply>
Exemplo: Recuperação de uma entrada de dados para a tabela de interface
Configuração de rede
Recupera uma entrada de dados para a tabela de interface.
Procedimento
# Entre na exibição XML.
<Sysname> xml# Notificar o dispositivo sobre os recursos do NETCONF compatíveis com o cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>urn:ietf:params:netconf:base:1.0</capability>
</capabilities>
</hello>
# Recuperar uma entrada de dados para a tabela de interface.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:web="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-bulk>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0" xmlns:web="http://www.Intelbras.com/netconf/base:1.0">
<Ifmgr>
<Interfaces web:count="1">
</Interfaces>
</Ifmgr>
</top>
</filter>
</get-bulk>
</rpc>
Verificação da configuração
Se o cliente receber o texto a seguir, a operação
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:web="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="100">
<data>
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<IfIndex>3</IfIndex>
<Name>GigabitEthernet1/0/2</Name>
<AbbreviatedName>GE1/0/2</AbbreviatedName>
<PortIndex>3</PortIndex>
<ifTypeExt>22</ifTypeExt>
<ifType>6</ifType>
<Description>Interface GigabitEthernet1/0/2</Description>
<AdminStatus>2</AdminStatus>
<OperStatus>2</OperStatus>
<ConfigSpeed>0</ConfigSpeed>
<ActualSpeed>100000</ActualSpeed>
<ConfigDuplex>3</ConfigDuplex>
<ActualDuplex>1</ActualDuplex>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</data>
</rpc-reply>
Exemplo: Recuperação de dados de configuração não padrão
Configuração de rede
Recupera todos os dados de configuração não padrão.
Procedimento
# Entre na exibição XML.
<Sysname> xml# Notificar o dispositivo sobre os recursos do NETCONF compatíveis com o cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello>
# Recuperar todos os dados de configuração não padrão.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-config>
<source>
<running/>
</source>
</get-config>
</rpc>
Verificação da configuração
Se o cliente receber o texto a seguir, a operação
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:web="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="100">
<data>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<IfIndex>1307</IfIndex>
<Shutdown>1</Shutdown>
</Interface>
<Interface>
<IfIndex>1308</IfIndex>
<Shutdown>1</Shutdown>
</Interface>
<Interface>
<IfIndex>1309</IfIndex>
<Shutdown>1</Shutdown>
</Interface>
<Interface>
<IfIndex>1311</IfIndex>
<VlanType>2</VlanType>
</Interface>
<Interface>
<IfIndex>1313</IfIndex>
<VlanType>2</VlanType>
</Interface>
</Interfaces>
</Ifmgr>
<Syslog>
<LogBuffer>
<BufferSize>120</BufferSize>
</LogBuffer>
</Syslog>
<System>
<Device>
<SysName>Sysname</SysName>
<TimeZone>
<Zone>+11:44</Zone>
<ZoneName>beijing</ZoneName>
</TimeZone>
</Device>
</System>
</top>
</data>
</rpc-reply>
Exemplo: Recuperação de dados de configuração do syslog
Configuração de rede
Recuperar dados de configuração do módulo Syslog.
Procedimento
# Entre na exibição XML.
<Sysname> xml# Notificar o dispositivo sobre os recursos do NETCONF compatíveis com o cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello>
# Recuperar dados de configuração para o módulo Syslog.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-config>
<source>
<running/>
</source>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Syslog/>
</top>
</filter>
</get-config>
</rpc>
Verificação da configuração
Se o cliente receber o texto a seguir, a operação
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="100">
<data>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Syslog>
<LogBuffer>
<BufferSize>120</BufferSize>
</LogBuffer>
</Syslog>
</top>
</data>
</rpc-reply>
Exemplo: Recuperação de informações da sessão NETCONF
Configuração de rede
Obter informações sobre a sessão NETCONF.
Procedimento
# Entre na visualização XML.
<Sysname> xml# Copie a seguinte mensagem para o cliente para trocar recursos com o dispositivo:
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello>
# Copie a seguinte mensagem para o cliente para obter as informações da sessão NETCONF atual no dispositivo:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-sessions/>
</rpc>
Verificação da configuração
Se o cliente receber uma mensagem como a seguinte, a operação será bem-sucedida:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="100">
<get-sessions>
<Session>
<SessionID>1</SessionID>
<Line>vty0</Line>
<UserName></UserName>
<Since>2017-01-07T00:24:57</Since>
<LockHeld>false</LockHeld>
</Session>
</get-sessions>
</rpc-reply>
O resultado mostra as seguintes informações:
A ID da sessão de uma sessão NETCONF existente é 1.
O tipo de usuário de login é vty0.
O horário de login é 2017-01-07T00:24:57.
O usuário não detém o bloqueio da configuração.
Filtragem de dados
Sobre a filtragem de dados
Você pode definir um filtro para filtrar as informações ao executar um comando
operação
Filtragem baseada em tabela - filtra as informações da tabela.
Filtragem baseada em coluna - filtra informações de uma única coluna.
Restrições e diretrizes para filtragem de dados
Para que a filtragem baseada em tabela tenha efeito, você deve configurar a filtragem baseada em tabela antes da filtragem baseada em coluna.
Filtragem baseada em tabela
Sobre a filtragem baseada em tabelas
O namespace é http://www.Intelbras.com/netconf/base:1.0. O nome do atributo é filter (filtro). Para obter informações sobre o suporte à correspondência baseada em tabela, consulte as referências da API XML do NETCONF.
# Copie o texto a seguir para o cliente para recuperar os dados mais longos com o endereço IP 1.1.1.0 e o comprimento da máscara 24 da tabela de roteamento IPv4:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0">
<get>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Route>
<Ipv4Routes>
<RouteEntry Intelbras:filter="IP 1.1.1.0 MaskLen 24 longer"/>
</Ipv4Routes>
</Route>
</top>
</filter>
</get>
</rpc>
Restrições e diretrizes
Para usar a filtragem baseada em tabela, especifique um critério de correspondência para o atributo de linha de filtro.
Filtragem baseada em colunas
Sobre a filtragem baseada em colunas
A filtragem baseada em colunas inclui a filtragem de correspondência completa, a filtragem de correspondência de expressão regular e a filtragem de correspondência condicional. A filtragem de correspondência completa tem a prioridade mais alta e a filtragem de correspondência condicional tem a prioridade mais baixa. Quando mais de um critério de filtragem é especificado, o que tiver a prioridade mais alta entra em vigor.
Filtragem de correspondência completa
Você pode especificar um valor de elemento em uma mensagem XML para implementar a filtragem de correspondência completa. Se forem fornecidos vários valores de elemento, o sistema retornará os dados que correspondem a todos os valores especificados.
# Copie o texto a seguir para o cliente para recuperar os dados de configuração de todas as interfaces no estado UP:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<AdminStatus>1</AdminStatus>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get>
</rpc>
Você também pode especificar um nome de atributo que seja igual a um nome de coluna da tabela atual na linha para implementar a filtragem de correspondência completa. O sistema retorna apenas os dados de configuração que correspondem a esse nome de atributo. A mensagem XML equivalente à filtragem de correspondência completa baseada em valor de elemento acima é a seguinte:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0" xmlns:data="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface data:AdminStatus="1"/>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get>
</rpc>
Os exemplos acima mostram que tanto a filtragem de correspondência completa baseada em valor de elemento quanto a filtragem de correspondência completa baseada em nome de atributo podem recuperar as mesmas informações de índice e coluna para todas as interfaces em estado ativo.
Filtragem de correspondências de expressões regulares
Para implementar uma filtragem de dados complexa com caracteres, você pode adicionar um atributo regExp para um elemento específico.
Os tipos de dados compatíveis incluem inteiro, data e hora, cadeia de caracteres, endereço IPv4, máscara IPv4, endereço IPv6, endereço MAC, OID e fuso horário.
# Copie o texto a seguir para o cliente para recuperar as descrições das interfaces, sendo que todos os caracteres devem ser letras maiúsculas de A a Z:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0">
<get-config>
<source>
<running/>
</source>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<Description Intelbras:regExp="^[A-Z]*$"/>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get-config>
</rpc>
Filtragem de correspondência condicional
Para implementar uma filtragem de dados complexa com dígitos e cadeias de caracteres, você pode adicionar uma correspondência
para um elemento específico. A Tabela 4 lista os operadores de correspondência condicional.
Tabela 4 Operadores de correspondência condicional
| Operação | Operador | Observações | |||
| Mais de | match="more:value" | Mais do que o valor especificado. Os tipos de dados compatíveis incluem data, dígito e cadeia de caracteres. | |||
| Menos de | match="less:value" | Menor que o valor especificado. Os tipos de dados compatíveis incluem data, dígito e cadeia de caracteres. | |||
| Não menos que | match="notLess:value" | Não menor que o valor especificado. Os tipos de dados compatíveis incluem data, dígito e cadeia de caracteres. | |||
| Não mais do que | match="notMore:value" | Não mais do que o valor especificado. Os tipos de dados compatíveis incluem data, dígito e cadeia de caracteres. | |||
| Igual | match="equal:value" | Igual ao valor especificado. Os tipos de dados compatíveis incluem data, dígito, cadeia de caracteres, OID e BOOL. | |||
| Não igual | match="notEqual:value" | Não é igual ao valor especificado. Os tipos de dados compatíveis incluem data, dígito, cadeia de caracteres, OID e BOOL. | |||
| Incluir | match="include:string" | Inclui a string especificada. Os tipos de dados compatíveis incluem apenas a cadeia de caracteres. | |||
| Não inclui | match="exclude:string" | Exclui a string especificada. Os tipos de dados compatíveis incluem apenas a cadeia de caracteres. | |||
| Comece com | match="startWith:string" | Começa com a cadeia de caracteres especificada. Os tipos de dados compatíveis incluem cadeia de caracteres e OID. | |||
| Terminar com | match="endWith:string" | Termina com a cadeia de caracteres especificada. Os tipos de dados compatíveis incluem apenas cadeia de caracteres. |
# Copie o texto a seguir para o cliente para recuperar informações de extensão sobre a entidade cujo uso da CPU é superior a 50%:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0">
<get>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Device>
<ExtPhysicalEntities>
<Entity>
<CpuUsage Intelbras:match="more:50"/>
</Entity>
</ExtPhysicalEntities>
</Device>
</top>
</filter>
</get>
</rpc>
Exemplo: Filtragem de dados com correspondência de expressão regular
Configuração de rede
Recupere todos os dados, inclusive Gigabit, na coluna Description (Descrição) da tabela Interfaces no módulo Ifmgr.
Procedimento
# Entre na visualização XML.
<Sysname> xml# Notifique o dispositivo sobre os recursos do NETCONF compatíveis com o cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello>
# Recupere todos os dados, incluindo Gigabit, na coluna Description (Descrição) da tabela Interfaces no módulo Ifmgr.
<?xml version="1.0"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0">
<get>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<Description Intelbras:regExp="(Gigabit)+"/>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get>
</rpc>
Verificação da configuração
Se o cliente receber o texto a seguir, a operação foi bem-sucedida:
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<IfIndex>2681</IfIndex>
<Descrição>Interface GigabitEthernet1/0/1</Descrição>
</Interface>
<Interface>
<IfIndex>2685</IfIndex>
<Descrição>Interface GigabitEthernet1/0/2</Descrição>
</Interface>
<Interface>
<IfIndex>2689</IfIndex>
<Descrição>Interface GigabitEthernet1/0/3</Descrição>
</Interface>
</Interfaces>
</Ifmgr>
</top>
Exemplo: Filtragem de dados por correspondência condicional
Configuração de rede
Recupere dados na coluna Name com o valor ifindex não inferior a 5000 na tabela Interfaces do módulo Ifmgr.
Procedimento
# Entre na exibição XML.
<Sysname> xml# Notificar o dispositivo sobre os recursos do NETCONF compatíveis com o cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capacidade>urn:ietf:params:netconf:base:1.0</capacidade>
</capabilities>
</hello># Recupere dados na coluna Name com o valor ifindex não inferior a 5000 na tabela Interfaces do módulo Ifmgr.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0">
<get>
<filtro type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<IfIndex Intelbras:match="notLess:5000"/>
<Nome/>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</filtro>
</get>
</rpc>Verificação da configuração
Se o cliente receber o texto a seguir, a operação foi bem-sucedida:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0" message-id="100">
<data>
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<IfIndex>7241</IfIndex>
<Nome>NULL0</Nome>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</data>
</rpc-reply>Bloqueio ou desbloqueio da configuração em execução
Sobre o bloqueio e o desbloqueio da configuração
Há vários métodos disponíveis para configurar o dispositivo, como CLI, NETCONF e SNMP. Antes de configurar, gerenciar ou solucionar problemas do dispositivo, você pode bloquear a configuração para impedir que outros usuários alterem a configuração do dispositivo. Depois de bloquear a configuração, somente você poderá executar as operações
Sobre o bloqueio e o desbloqueio da configuração
Há vários métodos disponíveis para configurar o dispositivo, como CLI, NETCONF e SNMP. Antes de configurar, gerenciar ou solucionar problemas do dispositivo, você pode bloquear a configuração para impedir que outros usuários alterem a configuração do dispositivo. Depois de bloquear a configuração, somente você poderá executar as operações
Restrições e diretrizes para bloqueio e desbloqueio de configurações
A operação
Bloqueio da configuração em execução
Copie o seguinte texto para o cliente para bloquear a configuração em execução:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<lock>
<target>
<running/>
</target>
</lock>
</rpc>
Se a operação de
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Desbloqueio da configuração em execução
Copie o seguinte texto para o cliente para desbloquear a configuração em execução:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<unlock>
<target>
<running/>
</target>
</unlock>
</rpc>
Se a operação de
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Exemplo: Bloqueando a configuração em execução
Configuração de rede
Bloqueie a configuração do dispositivo para que outros usuários não possam alterá-la.
Procedimento
- Entre no modo XML.
<Sysname> xml<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello><?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<lock>
<target>
<running/>
</target>
</lock>
</rpc>Verificando a configuração
Se o cliente receber a seguinte resposta, a operação de
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Se outro cliente enviar uma solicitação de bloqueio, o dispositivo retornará a seguinte resposta:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rpc-error>
<error-type>protocol</error-type>
<error-tag>lock-denied</error-tag>
<error-severity>error</error-severity>
<error-message xml:lang="en">Lock failed because the NETCONF lock is held by another session.</error-message>
<error-info>
<session-id>1</session-id>
</error-info>
</rpc-error>
</rpc-reply>
A saída mostra que a operação de
Modificando as configurações
Sobre a operação
A operação
Procedimento
Copie o seguinte texto para realizar a operação
<?xml version="1.0"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target><running></running></target>
<error-option>
error-option
</error-option>
<config>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
Especifique o nome do módulo, nome do submódulo, nome da tabela e nome da coluna
</top>
</config>
</edit-config>
</rpc>
O elemento
| Valor | Descrição | ||
| stop-on-error |
Interrompe a operação
| ||
| continue-on-error |
Continua a operação
| ||
| rollback-on-error |
Reverte a configuração para a configuração anterior à operação
|
Por padrão, uma operação
Para permitir que uma operação
Se a operação
<?xml version="1.0"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>
Você também pode realizar a operação
Exemplo: Modificando a Configuração
Configuração de Rede
Altere o tamanho do buffer de log para o módulo Syslog para 512.
Procedimento
Entre na visualização XML.
<Sysname> xmlInforme o dispositivo das capacidades NETCONF suportadas no cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>urn:ietf:params:netconf:base:1.0</capability>
</capabilities>
</hello>Altere o tamanho do buffer de log para o módulo Syslog para 512.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:web="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target>
<running/>
</target>
<config>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0" web:operation="merge">
<Syslog>
<LogBuffer>
<BufferSize>512</BufferSize>
</LogBuffer>
</Syslog>
</top>
</config>
</edit-config>
</rpc>Verificando a Configuração
Se o cliente receber o seguinte texto, a operação
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Salvando a Configuração Atual
Sobre a operação
A operação
Restrições e diretrizes
A operação
Procedimento
Copie o seguinte texto para o cliente:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save OverWrite="false" Binary-only="false">
<file>Nome do arquivo de configuração</file>
</save>
</rpc>file
Especifica um arquivo de configuração .cfg pelo seu nome. O nome deve começar com o nome do meio de armazenamento. Se você especificar a coluna do arquivo, um nome de arquivo é necessário.
Se o atributo Binary-only for falso, o dispositivo salva a configuração em execução nos arquivos de configuração de texto e binário.
- Se o arquivo .cfg especificado não existir, o dispositivo cria os arquivos de configuração binária e de texto para salvar a configuração em execução.
- Se você não especificar a coluna do arquivo, o dispositivo salva a configuração em execução nos arquivos de configuração de texto e binário da próxima inicialização.
OverWrite
Determina se deve sobrescrever o arquivo especificado se o arquivo já existir. Os seguintes valores estão disponíveis:
- true - Sobrescreva o arquivo.
- false - Não sobrescreva o arquivo. A configuração em execução não pode ser salva, e o sistema exibe uma mensagem de erro. O valor padrão é verdadeiro.
Binary-only
Determina se deve salvar a configuração em execução apenas no arquivo de configuração binária. Os seguintes valores estão disponíveis:
- true - Salve a configuração em execução apenas no arquivo de configuração binária.
- false - Salve a configuração em execução nos arquivos de configuração de texto e binário. Para mais informações, consulte a descrição para a coluna do arquivo nesta tabela. O valor padrão é falso.
Salvando a Configuração em Execução em Ambos os Arquivos de Configuração de Texto e Binário
A operação
Se a operação
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Exemplo: Salvando a Configuração em Execução
Configuração de Rede
Salve a configuração em execução no arquivo config.cfg.
Procedimento
Entre na visualização XML.
<Sysname> xmlInforme o dispositivo das capacidades NETCONF suportadas no cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>urn:ietf:params:netconf:base:1.0</capability>
</capabilities>
</hello>Salve a configuração em execução do dispositivo no arquivo config.cfg.
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save>
<file>config.cfg</file>
</save>
</rpc>Verificando a Configuração
Se o cliente receber a seguinte resposta, a operação
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Carregando a Configuração
Sobre a operação
A operação
- Carrega as configurações que não existem na configuração em execução.
- Sobrescreve as configurações que já existem na configuração em execução.
Restrições e diretrizes
Ao realizar uma operação
-
A operação
é intensiva em recursos. Não execute esta operação quando os recursos do sistema estiverem fortemente ocupados. - Algumas configurações em um arquivo de configuração podem conflitar com as configurações existentes. Para que as configurações no arquivo tenham efeito, exclua as configurações conflitantes existentes e, em seguida, carregue o arquivo de configuração.
Procedimento
Copie o seguinte texto para o cliente para carregar um arquivo de configuração para o dispositivo:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<load>
<file>Nome do arquivo de configuração</file>
</load>
</rpc>O nome do arquivo de configuração deve começar com o nome do meio de armazenamento e terminar com a extensão .cfg.
Se a operação
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Revertendo a configuração
Restrições e diretrizes
A operação
Por padrão, uma operação
Revertendo a configuração com base em um arquivo de configuração
Copie o seguinte texto para o cliente para reverter a configuração em execução para a configuração em um arquivo de configuração:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rollback>
<file>Especifique o nome do arquivo de configuração</file>
</rollback>
</rpc>
Se a operação
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Revertendo a configuração com base em um ponto de reversão
Sobre a reversão de configuração com base em um ponto de reversão
Você pode reverter a configuração em execução com base em um ponto de reversão quando uma das seguintes situações ocorrer:
- Um cliente NETCONF envia uma solicitação de reversão.
- O tempo ocioso da sessão NETCONF é maior que o tempo limite ocioso de reversão.
- Um cliente NETCONF é desconectado inesperadamente do dispositivo.
Restrições e diretrizes
Vários usuários podem configurar o dispositivo simultaneamente. Como melhor prática, bloqueie o sistema antes de reverter a configuração para evitar que outros usuários modifiquem a configuração em execução.
Procedimento
- Bloqueie a configuração em execução. Para mais informações, consulte "Bloqueando ou desbloqueando a configuração em execução".
- Habilitar a reversão de configuração com base em um ponto de reversão.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save-point>
<begin>
<confirm-timeout>100</confirm-timeout>
</begin>
</save-point>
</rpc><rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save-point>
<commit>
<label>SUPPORT VLAN</label>
<comment>VLAN 1 a 100 e interfaces.</comment>
</commit>
</save-point>
</rpc><rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save-point>
<get-commits>
<commit-label>SUPPORT VLAN</commit-label>
</get-commits>
</save-point>
</rpc><rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save-point>
<get-commit-information>
<commit-information>
<commit-label>SUPPORT VLAN</commit-label>
</commit-information>
</get-commit-information>
</save-point>
</rpc><rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save-point>
<rollback>
<commit-label>SUPPORT VLAN</commit-label>
</rollback>
</save-point>
</rpc><rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save-point>
<end/>
</save-point>
</rpc>Realizando Operações de CLI através do NETCONF
Sobre Operações de CLI através do NETCONF
Você pode inserir linhas de comando em mensagens XML para configurar o dispositivo.
Restrições e diretrizes
Realizar operações de CLI através do NETCONF consome recursos. Como melhor prática, não realize as seguintes tarefas:
- Inserir várias linhas de comando em uma única mensagem XML.
- Usar o NETCONF para realizar uma operação de CLI quando outros usuários estiverem realizando operações de CLI do NETCONF.
Procedimento
- Copie o seguinte texto para o cliente para executar os comandos:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<CLI>
<Execution>
Comandos
</Execution>
</CLI>
</rpc><?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<CLI>
<Execution>
<![CDATA[Respostas aos comandos]]>
</Execution>
</CLI>
</rpc-reply>Exemplo: Realizando Operações de CLI
Configuração de Rede
Envie o comando de exibição de VLAN para o dispositivo.
Procedimento
- Entre na visualização XML.
<Sysname> xml<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello><?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<CLI>
<Execution>
display vlan
</Execution>
</CLI>
</rpc>Se o cliente receber o seguinte texto, a operação foi bem-sucedida:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<CLI>
<Execution><![CDATA[
<Sysname>display vlan
Total VLANs: 1
As VLANs incluem:
1 (padrão)
]]></Execution>
</CLI>
</rpc-reply>Assinatura de Eventos
Sobre Assinatura de Eventos
Quando um evento ocorre no dispositivo, o dispositivo envia informações sobre o evento para clientes NETCONF que se inscreveram no evento.
Restrições e diretrizes
- A assinatura de evento não é suportada para sessões NETCONF sobre SOAP.
- Uma assinatura entra em vigor apenas na sessão atual. É cancelada quando a sessão é terminada.
- Se você não especificar o fluxo de evento a ser inscrito, o dispositivo enviará notificações de eventos do syslog para o cliente NETCONF.
Inscrição em eventos de syslog
Copie a seguinte mensagem para o cliente para concluir a assinatura:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<create-subscription xmlns="urn:ietf:params:xml:ns:netconf:notification:1.0">
<stream>NETCONF</stream>
<filter>
<event xmlns="http://www.Intelbras.com/netconf/event:1.0">
<Code>code</Code>
<Group>group</Group>
<Severity>severity</Severity>
</event>
</filter>
<startTime>start-time</startTime>
<stopTime>stop-time</stopTime>
</create-subscription>
</rpc>Item Descrição
-
streamEspecifica o fluxo de evento. O nome para o fluxo de evento syslog é NETCONF. -
eventEspecifica o evento. Para obter informações sobre os eventos aos quais você pode se inscrever, consulte as referências de mensagem de log do sistema para o dispositivo. codeEspecifica o símbolo mnemônico da mensagem de log.groupEspecifica o nome do módulo da mensagem de log.severityEspecifica o nível de gravidade da mensagem de log.start-timeEspecifica o horário de início da assinatura.stop-timeEspecifica o horário de término da assinatura.
Se a inscrição for bem-sucedida, o dispositivo retornará uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns:netconf="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>Se a inscrição falhar, o dispositivo retornará uma mensagem de erro no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rpc-error>
<error-type>error-type</error-type>
<error-tag>error-tag</error-tag>
<error-severity>error-severity</error-severity>
<error-message xml:lang="en">error-message</error-message>
</rpc-error>
</rpc-reply>Para obter mais informações sobre mensagens de erro, consulte o RFC 4741.
Inscrição em eventos monitorados pelo NETCONF
Depois que você se inscreve em eventos conforme descrito nesta seção, o NETCONF regularmente verifica os eventos inscritos e envia os eventos que correspondem à condição de inscrição para o cliente NETCONF.
# Copie a seguinte mensagem para o cliente para completar a inscrição:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<create-subscription xmlns='urn:ietf:params:xml:ns:netconf:notification:1.0'>
<stream>NETCONF_MONITOR_EXTENSION</stream>
<filter>
<NetconfMonitor xmlns='http://www.Intelbras.com/netconf/monitor:1.0'>
<XPath>XPath</XPath>
<Interval>interval</Interval>
<ColumnConditions>
<ColumnCondition>
<ColumnName>ColumnName</ColumnName>
<ColumnValue>ColumnValue</ColumnValue>
<ColumnCondition>ColumnCondition</ColumnCondition>
</ColumnCondition>
</ColumnConditions>
<MustIncludeResultColumns>
<ColumnName>columnName</ColumnName>
</MustIncludeResultColumns>
</NetconfMonitor>
</filter>
<startTime>start-time</startTime>
<stopTime>stop-time</stopTime>
</create-subscription>
</rpc>
Descrição do Item
stream Especifica o fluxo de eventos. O nome do fluxo de eventos é NETCONF_MONITOR_EXTENSION.
NetconfMonitor Especifica as informações de filtragem para o evento.
XPath Especifica o caminho do evento no formato de ModuleName[/SubmoduleName]/TableName.
interval Especifica o intervalo para o NETCONF obter eventos que correspondam à condição de inscrição. A faixa de valores é de 1 a 4294967 segundos. O valor padrão é 300 segundos.
ColumnName Especifica o nome de uma coluna no formato [GroupName.]ColumnName.
ColumnValue Especifica o valor de referência.
ColumnCondition Especifica o operador:
- more.
- less.
- notLess.
- notMore.
- equal.
- notEqual.
- include.
- exclude.
- startWith.
- endWith.
Escolha um operador de acordo com o tipo do valor de referência.
start-time Especifica o horário de início da inscrição.
stop-time Especifica o horário de término da inscrição.
Se a inscrição for bem-sucedida, o dispositivo retorna uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns:netconf="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>
Inscrevendo-se em eventos relatados por módulos
Após se inscrever em eventos conforme descrito nesta seção, os módulos especificados relatam eventos inscritos ao NETCONF. O NETCONF envia os eventos para o cliente NETCONF.
# Copie a seguinte mensagem para o cliente para completar a inscrição:
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:xs="http://www.Intelbras.com/netconf/base:1.0">
<create-subscription xmlns="urn:ietf:params:xml:ns:netconf:notification:1.0">
<stream>XXX_STREAM</stream>
<filter type="subtree">
<event xmlns="http://www.Intelbras.com/netconf/event:1.0/xxx-features-list-name:1.0">
<ColumnName xs:condition="Condition">value</ColumnName>
</event>
</filter>
<startTime>start-time</startTime>
<stopTime>stop-time</stopTime>
</create-subscription>
</rpc>
Descrição do Item
| stream | Especifica o fluxo de eventos. Os fluxos de eventos suportados variam de acordo com o modelo do dispositivo. | ||
| event | Especifica o nome do evento. Um fluxo de eventos inclui múltiplos eventos. Os eventos usam os mesmos namespaces do fluxo de eventos. | ||
| ColumnName | Especifica o nome de uma coluna. | ||
| ColumnCondition |
Especifica o operador:
| ||
| value | Especifica o valor de referência para a coluna. | ||
| start-time | Especifica o horário de início da inscrição. | ||
| stop-time | Especifica o horário de término da inscrição. |
Se a inscrição for bem-sucedida, o dispositivo retorna uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns:netconf="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>
Cancelando uma inscrição
Você pode cancelar uma inscrição que você configurou na sessão atual.
# Copie a seguinte mensagem para o cliente para cancelar uma inscrição:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<cancel-subscription xmlns="urn:ietf:params:xml:ns:netconf:notification:1.0">
<stream>XXX_STREAM</stream>
</cancel-subscription>
</rpc>
Descrição do Item
stream Especifica o fluxo de eventos.
Se a operação de cancelamento for bem-sucedida, o dispositivo retorna uma resposta no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="100">
<ok/>
</rpc-reply>
Se a inscrição não existir, o dispositivo retorna uma mensagem de erro no seguinte formato:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rpc-error>
<error-type>error-type</error-type>
<error-tag>error-tag</error-tag>
<error-severity>error-severity</error-severity>
<error-message xml:lang="en">A inscrição do fluxo a ser cancelado não existe: Nome do fluxo = XXX_STREAM.</error-message>
</rpc-error>
</rpc-reply>
Exemplo: Inscrevendo-se em eventos de syslog
Configuração de rede
Configure um cliente para se inscrever em eventos de syslog sem limite de tempo. Após a inscrição, todos os eventos no dispositivo são enviados para o cliente antes que a sessão entre o dispositivo e o cliente seja terminada.
Procedimento
# Entre na visualização XML.
<Sysname> xml# Notifique o dispositivo das capacidades NETCONF suportadas no cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello>
# Inscreva-se em eventos de syslog sem limite de tempo.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<create-subscription xmlns="urn:ietf:params:xml:ns:netconf:notification:1.0">
<stream>NETCONF</stream>
</create-subscription>
</rpc>
Verificando a configuração
# Se o cliente receber a seguinte resposta, a inscrição foi bem-sucedida:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="100">
<ok/>
</rpc-reply>
# Quando outro cliente (192.168.100.130) fizer login no dispositivo, o dispositivo enviará uma notificação para o cliente que se inscreveu em todos os eventos:
<?xml version="1.0" encoding="UTF-8"?>
<notification xmlns="urn:ietf:params:xml:ns:netconf:notification:1.0">
<eventTime>2011-01-04T12:30:52</eventTime>
<event xmlns="http://www.Intelbras.com/netconf/event:1.0">
<Group>SHELL</Group>
<Code>SHELL_LOGIN</Code>
<Slot>1</Slot>
<Severity>Notification</Severity>
<context>VTY logado de 192.168.100.130.</context>
</event>
</notification>
Término de sessões NETCONF
Sobre o término de sessões NETCONF
O NETCONF permite que um cliente termine as sessões NETCONF de outros clientes. Um cliente cuja sessão é terminada retorna à visualização do usuário.
Procedimento
# Copie a seguinte mensagem para o cliente para encerrar uma sessão NETCONF:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<kill-session>
<session-id>
Especificar session-ID
</session-id>
</kill-session>
</rpc>
Se a operação
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>
Exemplo: Terminando outra sessão NETCONF
Configuração de rede
O usuário cujo ID de sessão é 1 termina a sessão com o ID de sessão 2.
Procedimento
# Entre na visualização XML.
<Sysname> xml# Notifique o dispositivo das capacidades NETCONF suportadas no cliente.
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>
urn:ietf:params:netconf:base:1.0
</capability>
</capabilities>
</hello>
# Termine a sessão com o ID de sessão 2.
<rpc message-id="100"xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<kill-session>
<session-id>2</session-id>
</kill-session>
</rpc>
Verificando a configuração
Se o cliente receber o seguinte texto, a sessão NETCONF com o ID de sessão 2 foi encerrada, e o cliente com o ID de sessão 2 retornou da visualização XML para a visualização do usuário:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>
Retornando para a CLI
Restrições e diretrizes
Antes de retornar da visualização XML para o CLI, você deve primeiro completar a troca de capacidade entre o dispositivo e o cliente.
Procedimento
# Copie o seguinte texto para o cliente para retornar da visualização XML para o CLI:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<close-session/>
</rpc>
Quando o dispositivo recebe a solicitação de fechar a sessão, ele envia a seguinte resposta e retorna para a visualização do usuário do CLI:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<ok/>
</rpc-reply>
Operações NETCONF Suportadas
Este capítulo descreve as operações NETCONF disponíveis com o Comware 7.
action
Guia de uso
Esta operação emite ações para configurações não padrão, por exemplo, ação de reinicialização.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<action>
<top xmlns="http://www.Intelbras.com/netconf/action:1.0">
<Ifmgr>
<ClearAllIfStatistics>
<Clear>
</Clear>
</ClearAllIfStatistics>
</Ifmgr>
</top>
</action>
</rpc>
CLI
Recomendações de uso
Esta operação executa comandos da CLI.
Uma mensagem de solicitação envolve os comandos no elemento
Você pode usar os seguintes elementos para executar comandos:
- Execução - Executa comandos na visualização do usuário.
-
Configuração - Executa comandos na visualização do sistema. Para executar comandos em uma visualização de nível inferior da visualização do sistema, use o elemento
para entrar na visualização primeiro. Para usar este elemento, inclua o atributo exec-use-channel e especifique um valor para o atributo: - false - Executa comandos sem usar um canal.
- true - Executa comandos usando um canal temporário. O canal é fechado automaticamente após a execução.
- persist - Executa comandos usando o canal persistente para a sessão. Para usar o canal persistente, primeiro execute uma operação
para abrir o canal persistente. Se você não fizer isso, o sistema abrirá automaticamente o canal persistente. Após usar o canal persistente, execute uma operação para fechar o canal e retornar à visualização do sistema. Se você não executar uma operação , o sistema permanecerá na visualização e executará os comandos subsequentes na visualização.
Você também pode especificar o atributo error-when-rollback no elemento
- true - Rejeita solicitações de operação da CLI e retorna mensagens de erro.
- false (o padrão) - Permite operações da CLI.
Para que as operações da CLI sejam executadas corretamente, defina o valor do atributo error-when-rollback como true.
Uma sessão NETCONF suporta apenas um canal persistente, mas suporta vários canais temporários.
O NETCONF não suporta a execução de comandos interativos.
Você não pode executar o comando quit usando um canal para sair da visualização do usuário.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<CLI>
<Configuration exec-use-channel="false" error-when-rollback="true">vlan 3</Configuration>
</CLI>
</rpc>
close-session
Recomendações de uso
Esta operação termina a sessão NETCONF atual, desbloqueia a configuração e libera os recursos (por exemplo, memória) usados pela sessão. Após esta operação, você sai da visualização XML.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<close-session/>
</rpc>
edit-config: create
Recomendações de uso
Esta operação cria itens de configuração de destino.
Para usar o atributo create em uma operação
- Se a tabela suportar a criação de um item de configuração de destino e o item não existir, a operação criará o item e configurará o item.
- Se o item especificado já existir, uma mensagem de erro de data-exist será retornada.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:xc="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target>
<running/>
</target>
<config>
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Syslog xmlns="http://www.Intelbras.com/netconf/config:1.0" xc:operation="create">
<LogBuffer>
<BufferSize>120</BufferSize>
</LogBuffer>
</Syslog>
</top>
</config>
</edit-config>
</rpc>
edit-config: delete
Recomendações de uso
Esta operação exclui a configuração especificada.
- Se o destino especificado tiver apenas o índice da tabela, a operação removerá toda a configuração do destino especificado e o próprio destino.
- Se o destino especificado tiver o índice da tabela e dados de configuração, a operação removerá os dados de configuração especificados deste destino.
- Se o destino especificado não existir, uma mensagem de erro será retornada, mostrando que o destino não existe.
Exemplo XML
A sintaxe é a mesma que a mensagem edit-config com o atributo create. Altere o atributo operation de create para delete.
edit-config: merge
Recomendações de uso
Esta operação confirma itens de configuração de destino para a configuração em execução.
Para usar o atributo merge em uma operação
- Se o item especificado existir, a operação atualiza diretamente a configuração do item.
- Se o item especificado não existir, a operação cria o item e configura o item.
- Se o item especificado não existir e não puder ser criado, uma mensagem de erro será retornada.
Exemplo XML
O formato de dados XML é o mesmo que a mensagem edit-config com o atributo create. Altere o atributo operation de create para merge.
edit-config: remove
Recomendações de uso
Esta operação remove a configuração especificada.
- Se o destino especificado tiver apenas o índice da tabela, a operação removerá toda a configuração do destino especificado e o próprio destino.
- Se o destino especificado tiver o índice da tabela e dados de configuração, a operação removerá os dados de configuração especificados deste destino.
- Se o destino especificado não existir, ou a mensagem XML não especificar quaisquer destinos, uma mensagem de sucesso será retornada.
Exemplo XML
A sintaxe é a mesma que a mensagem edit-config com o atributo create. Altere o atributo operation de create para remove.
edit-config: replace
Recomendações de uso
Esta operação substitui a configuração especificada.
- Se o destino especificado existir, a operação substitui a configuração do destino pela configuração carregada na mensagem.
- Se o destino especificado não existir, mas for permitido ser criado, a operação cria o destino e depois aplica a configuração.
- Se o destino especificado não existir e não for permitido ser criado, a operação não é realizada e uma mensagem de erro de valor inválido é retornada.
Exemplo XML
A sintaxe é a mesma da mensagem edit-config com o atributo create. Altere o atributo operation de create para replace.
edit-config: test-option
Recomendações de uso
Esta operação determina se deve ou não confirmar um item de configuração em uma operação
O elemento
- test-then-set—Realiza uma verificação de sintaxe e confirma um item se o item passar na verificação. Se o item falhar na verificação, o item não é confirmado. Este é o valor padrão de test-option.
- set—Confirma o item sem realizar uma verificação de sintaxe.
- test-only—Realiza apenas uma verificação de sintaxe. Se o item passar na verificação, uma mensagem de sucesso é retornada. Caso contrário, uma mensagem de erro é retornada.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target>
<running/>
</target>
<test-option>test-only</test-option>
<config xmlns:xc="urn:ietf:params:xml:ns:netconf:base:1.0">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr xc:operation="merge">
<Interfaces>
<Interface>
<IfIndex>262</IfIndex>
<Description>222</Description>
<ConfigSpeed>2</ConfigSpeed>
<ConfigDuplex>1</ConfigDuplex>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</config>
</edit-config>
</rpc>
edit-config: default-operation
Recomendações de uso
Esta operação modifica a configuração em execução do dispositivo usando o método de operação padrão.
O NETCONF usa um dos seguintes atributos de operação para modificar a configuração: merge, create, delete e replace. Se você não especificar um atributo de operação para uma mensagem
O elemento
- merge—Valor padrão para o elemento
. - replace—Valor usado quando o atributo de operação não é especificado e o método de operação padrão é especificado como replace.
-
none—Valor usado quando o atributo de operação não é especificado e o método de operação padrão é especificado como none. Se este valor for especificado, a operação
é usada apenas para verificação de esquema em vez de emitir uma configuração. Se a verificação de esquema for aprovada, uma mensagem de sucesso é retornada. Caso contrário, uma mensagem de erro é retornada.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target>
<running/>
</target>
<default-operation>none</default-operation>
<config xmlns:xc="urn:ietf:params:xml:ns:netconf:base:1.0">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr>
<Interfaces>
<Interface>
<IfIndex>262</IfIndex>
<Description>222222</Description>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</config>
</edit-config>
</rpc>
edit-config: error-option
Recomendações de uso
Esta operação determina a ação a ser tomada em caso de erro de configuração.
O elemento
- stop-on-error—Interrompe a operação e retorna uma mensagem de erro. Este é o valor padrão de error-option.
- continue-on-error—Continua a operação e retorna uma mensagem de erro.
- rollback-on-error—Reverte a configuração.
Exemplo XML
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<edit-config>
<target>
<running/>
</target>
<error-option>continue-on-error</error-option>
<config xmlns:xc="urn:ietf:params:xml:ns:netconf:base:1.0">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr xc:operation="merge">
<Interfaces>
<Interface>
<IfIndex>262</IfIndex>
<Description>222</Description>
<ConfigSpeed>1024</ConfigSpeed>
<ConfigDuplex>1</ConfigDuplex>
</Interface>
<Interface>
<IfIndex>263</IfIndex>
<Description>333</Description>
<ConfigSpeed>1024</ConfigSpeed>
<ConfigDuplex>1</ConfigDuplex>
</Interface>
</Interfaces>
</Ifmgr>
</top>
</config>
</edit-config>
</rpc>
edit-config: incremental
Guia de uso
Essa operação adiciona dados de configuração a uma coluna sem afetar os dados originais.
O atributo incremental se aplica a uma coluna de lista, como a coluna vlan permitlist.
Você pode usar o atributo incremental para operações
O suporte para o atributo incremental varia por módulo. Para mais informações, consulte os documentos XML da API NETCONF.
Exemplo XML
# Adicionar VLANs 1 a 10 a uma lista de VLANs não marcadas que tem VLANs não marcadas 12 a 15.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:Intelbras="http://www.Intelbras.com/netconf/base:1.0">
<edit-config>
<target>
<running/>
</target>
<config xmlns:xc="urn:ietf:params:xml:ns:netconf:base:1.0">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<VLAN xc:operation="merge">
<HybridInterfaces>
<Interface>
<IfIndex>262</IfIndex>
<UntaggedVlanList Intelbras: incremental="true">1-10</UntaggedVlanList>
</Interface>
</HybridInterfaces>
</VLAN>
</top>
</config>
</edit-config>
</rpc>
get
Guia de uso
Essa operação recupera informações de configuração e estado do dispositivo.
Exemplo XML
# Recuperar informações de configuração e estado do dispositivo para o módulo Syslog.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:xc="http://www.Intelbras.com/netconf/base:1.0">
<get>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Syslog>
</Syslog>
</top>
</filter>
</get>
</rpc>
get-bulk
Guia de uso
Essa operação recupera um número de entradas de dados (incluindo informações de configuração e estado do dispositivo) começando pela entrada de dados seguinte àquela com o índice especificado.
Exemplo XML
# Recuperar informações de configuração e estado do dispositivo para todas as interfaces.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-bulk>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/data:1.0">
<Ifmgr>
<Interfaces xc:count="5" xmlns:xc="http://www.Intelbras.com/netconf/base:1.0">
<Interface/>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get-bulk>
</rpc>
get-bulk-config
Guia de uso
Essa operação recupera um número de entradas de dados de configuração não padrão começando pela entrada de dados seguinte àquela com o índice especificado.
Exemplo XML
# Recuperar configuração não padrão para todas as interfaces.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-bulk-config>
<source>
<running/>
</source>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr>
</Ifmgr>
</top>
</filter>
</get-bulk-config>
</rpc>
get-config
Guia de uso
Essa operação recupera dados de configuração não padrão. Se não houver dados de configuração não padrão, o dispositivo retorna uma resposta com dados vazios.
Exemplo XML
# Recuperar dados de configuração não padrão para a tabela de interfaces.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"
xmlns:xc="http://www.Intelbras.com/netconf/base:1.0">
<get-config>
<source>
<running/>
</source>
<filter type="subtree">
<top xmlns="http://www.Intelbras.com/netconf/config:1.0">
<Ifmgr>
<Interfaces>
<Interface/>
</Interfaces>
</Ifmgr>
</top>
</filter>
</get-config>
</rpc>
get-sessions
Guia de uso
Essa operação recupera informações sobre todas as sessões NETCONF no sistema. Você não pode especificar um ID de sessão para recuperar informações sobre uma sessão NETCONF específica.
Exemplo XML# Recuperar informações sobre todas as sessões NETCONF no sistema.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get-sessions/>
</rpc>
kill-session
Guia de uso
Essa operação termina a sessão NETCONF para outro usuário. Essa operação não pode terminar a sessão NETCONF para o usuário atual.
Exemplo XML
# Terminar a sessão NETCONF com o ID da sessão 1.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<kill-session>
<session-id>1</session-id>
</kill-session>
</rpc>
load
Guia de uso
Essa operação carrega a configuração. Após o dispositivo terminar uma operação
Exemplo XML
# Mesclar a configuração no arquivo a1.cfg na configuração em execução do dispositivo.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<load>
<file>a1.cfg</file>
</load>
</rpc>
lock
Guia de uso
Essa operação trava a configuração. Após a configuração ser bloqueada, você não pode executar operações
Depois que um usuário trava a configuração, outros usuários não podem usar o NETCONF ou quaisquer outros métodos de configuração, como CLI e SNMP, para configurar o dispositivo.
Exemplo XML
# Travar a configuração.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<lock>
<target>
<running/>
</target>
</lock>
</rpc>
rollback
Guia de uso
Essa operação reverte a configuração. Para fazer isso, você deve especificar o arquivo de configuração no elemento
Exemplo XML
# Reverter a configuração em execução para a configuração no arquivo 1A.cfg.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rollback>
<file>1A.cfg</file>
</rollback>
</rpc>
save
Guia de uso
Essa operação salva a configuração em execução. Você pode usar o elemento
O atributo OverWrite determina se a configuração em execução substitui o arquivo de configuração original quando o arquivo especificado já existe.
O atributo Binary-only determina se salvar a configuração em execução apenas para o arquivo de configuração binária.
Exemplo XML
# Salvar a configuração em execução no arquivo test.cfg.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<save OverWrite="false" Binary-only="true">
<file>test.cfg</file>
</save>
</rpc>
unlock
Guia de uso
Essa operação desbloqueia a configuração para que outros usuários possam configurar o dispositivo.
Terminar uma sessão NETCONF automaticamente desbloqueia a configuração.
Exemplo XML
# Desbloquear a configuração.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<unlock>
<target>
<running/>
</target>
</unlock>
</rpc>
Configurando CWMP
Sobre CWMP
O Protocolo de Gerenciamento da WAN do Equipamento do Cliente (CWMP), também chamado de "TR-069", é uma especificação técnica do Fórum DSL para o gerenciamento remoto de dispositivos de rede.
O protocolo foi inicialmente projetado para fornecer autoconfiguração remota através de um servidor para um grande número de dispositivos de usuário final dispersos em uma rede. O CWMP pode ser usado em diferentes tipos de redes, incluindo Ethernet.
Estrutura da Rede CWMP
A Figura 1 mostra uma estrutura básica da rede CWMP.
Como o CWMP funciona
Método RPC
O CWMP usa métodos de chamada de procedimento remoto (RPC) para comunicação bidirecional entre CPE e ACS. Os métodos RPC são encapsulados em HTTP ou HTTPS.
| Método RPC | Descrição | ||
Get
| O ACS obtém os valores dos parâmetros no CPE. | ||
Set
| O ACS modifica os valores dos parâmetros no CPE. | ||
Inform
| O CPE envia uma mensagem Inform para o ACS com os seguintes propósitos: | ||
| |||
Download
| O ACS solicita que o CPE baixe um arquivo de imagem de configuração ou software de uma URL específica para atualização de software ou configuração. | ||
Upload
| O ACS solicita que o CPE faça upload de um arquivo para uma URL específica. | ||
Reboot
| O ACS reinicia o CPE remotamente para que o CPE conclua uma atualização ou se recupere de uma condição de erro. |
Autoconexão entre ACS e CPE
O CPE inicia automaticamente uma conexão com o ACS quando um dos seguintes eventos ocorre:
- Mudança na URL do ACS. O CPE inicia uma solicitação de conexão para a nova URL do ACS.
- Inicialização do CPE. O CPE inicia uma conexão com o ACS após a inicialização.
- Expiração do intervalo Inform periódico. O CPE reinicia uma conexão com o ACS no intervalo Inform.
- Expiração do tempo de inicialização da conexão agendada. O CPE inicia uma conexão com o ACS no horário agendado.
Estabelecimento de conexão CWMP
Os passos de 1 a 5 na Figura 2 mostram o procedimento de estabelecimento de conexão entre o CPE e o ACS.
- Após obter os parâmetros básicos do ACS, o CPE inicia uma conexão TCP com o ACS.
- Se o HTTPS for usado, o CPE e o ACS inicializam o SSL para uma conexão HTTP segura.
- O CPE envia uma mensagem Inform em HTTPS para iniciar uma sessão CWMP.
- Após o CPE passar pela autenticação, o ACS retorna uma resposta Inform para estabelecer a sessão.
- Após enviar todas as solicitações, o CPE envia uma mensagem de postagem HTTP vazia.
Troca de ACS principal/secundário
Típicamente, dois ACSs são usados em uma rede CWMP para monitorar consecutivamente os CPEs. Quando o ACS principal precisa reiniciar, ele aponta o CPE para o ACS secundário. Os passos 6 a 11 na Figura 3 mostram o procedimento de troca entre o ACS principal e secundário.
- Antes do ACS principal reiniciar, ele consulta a URL do ACS definida no CPE.
- O CPE responde com sua configuração de URL do ACS.
- O ACS principal envia uma solicitação de definição para alterar a URL do ACS no CPE para a URL do ACS secundário.
- Após a modificação da URL do ACS, o CPE envia uma resposta.
- O ACS principal envia uma mensagem HTTP vazia para notificar o CPE de que não possui outras solicitações.
- O CPE fecha a conexão e, em seguida, inicia uma nova conexão com a URL do ACS secundário.
Restrições e diretrizes: Configuração CWMP
Você pode configurar atributos do ACS e do CPE a partir da CLI do CPE, do servidor DHCP ou do ACS. Para um atributo, os valores atribuídos pela CLI e pelo ACS têm prioridade mais alta do que o valor atribuído pelo DHCP. Os valores atribuídos pela CLI e pelo ACS sobrescrevem um ao outro, o que for atribuído por último.
Este documento descreve apenas a configuração de atributos do ACS e do CPE a partir da CLI e do servidor DHCP. Para obter mais informações sobre a configuração e o uso do ACS, consulte a documentação do ACS.
Tarefas CWMP em uma visão geral
Para configurar CWMP, execute as seguintes tarefas:
- Habilitar CWMP pela CLI
- Você também pode habilitar CWMP a partir de um servidor DHCP.
- Configurar atributos do ACS
- Configurar os atributos preferidos do ACS
- (Opcional) Configurar os atributos padrão do ACS pela CLI
- Configurar atributos do CPE
- Especificar uma política de cliente SSL para conexão HTTPS ao ACS
- (Opcional) Configurar parâmetros de autenticação do ACS
- (Opcional) Configurar o código de provisionamento
- (Opcional) Configurar a interface de conexão CWMP
- (Opcional) Configurar parâmetros de autoconexão
- (Opcional) Definir o temporizador close-wait
- (Opcional) Habilitar travessia NAT para o CPE
Habilitando CWMP pela CLI
- Entrar no modo de visualização do sistema.
system-viewcwmpcwmp enablePor padrão, o CWMP está desabilitado.
Configurando atributos do ACS
Sobre os atributos do ACS
Você pode configurar dois conjuntos de atributos do ACS para o CPE: preferido e padrão.
- Os atributos do ACS preferidos são configuráveis a partir da CLI do CPE, do servidor DHCP e do ACS.
- Os atributos do ACS padrão são configuráveis apenas pela CLI.
Se os atributos do ACS preferidos não estiverem configurados, o CPE usará os atributos do ACS padrão para o estabelecimento de conexão.
Configurando os atributos do ACS preferidos
Atribuindo atributos do ACS a partir do servidor DHCP
O servidor DHCP em uma rede CWMP atribui as seguintes informações aos CPEs:
- Endereços IP para os CPEs.
- Endereço do servidor DNS.
- URL do ACS e informações de autenticação de login do ACS.
Esta seção apresenta como usar a opção DHCP 43 para atribuir a URL do ACS e o nome de usuário e senha de autenticação de login do ACS. Para obter mais informações sobre DHCP e DNS, consulte o Guia de Configuração de Serviços IP da Camada 3.
Se o servidor DHCP for um dispositivo Intelbras, você pode configurar a opção DHCP 43 usando o comando option 43 hex 01length URL username password.
- length - Um número hexadecimal que indica o comprimento total dos argumentos de comprimento, URL, nome de usuário e senha, incluindo os espaços entre esses argumentos. Nenhum espaço é permitido entre a palavra-chave 01 e o valor do comprimento.
- URL - URL do ACS.
- username - Nome de usuário para o CPE se autenticar no ACS.
- password - Senha para o CPE se autenticar no ACS.
NOTA: A URL do ACS, nome de usuário e senha devem usar o formato hexadecimal e ser separados por espaços.
O exemplo a seguir configura o endereço do ACS como http://169.254.76.31:7547/acs, nome de usuário como 1234 e senha como 5678:
Sysname> system-view
Sysname] dhcp server ip-pool 0
Sysname-dhcp-pool-0] option 43 hex
0127687474703A2F2F3136392E3235342E37362E33313A373534372F61637320313233342035363738
| Atributo | Valor do atributo | Forma hexadecimal | |||
| Comprimento | 39 caracteres | 27 | |||
| URL do ACS | http://169.254.76.31:7547/acs | 687474703A2F2F3136392E3235342E37362E33313A373534372F61637320 | |||
| Nome de usuário do ACS | 1234 | 3132333420 | |||
| Senha do ACS | 5678 | 35363738 |
Configurando Atributos ACS Preferidos pela CLI
- Entrar na visão do sistema.
system-viewcwmpcwmp acs preferred-url urlPor padrão, nenhuma URL ACS preferida foi configurada.
cwmp acs preferred-username usernamePor padrão, nenhum nome de usuário foi configurado para autenticação na URL ACS preferida.
cwmp acs preferred-password { cipher | simple } stringPor padrão, nenhuma senha foi configurada para autenticação na URL ACS preferida.
Configurando Atributos ACS Padrão pela CLI
- Entrar na visão do sistema.
system-viewcwmpcwmp acs default-url urlPor padrão, nenhuma URL ACS padrão foi configurada.
cwmp acs default-username usernamePor padrão, nenhum nome de usuário foi configurado para autenticação na URL ACS padrão.
cwmp acs default-password { cipher | simple } stringPor padrão, nenhuma senha foi configurada para autenticação na URL ACS padrão.
Configurando Atributos CPE
Especificando uma Política de Cliente SSL para Conexão HTTPS ao ACS
Sobre Especificar uma Política de Cliente SSL para Conexão HTTPS ao ACS
Esta tarefa é necessária quando o ACS usa HTTPS para acesso seguro. CWMP usa HTTP ou HTTPS para transmissão de dados. Quando HTTPS é usado, a URL ACS começa com https://. Você deve especificar uma política de cliente SSL para o CPE autenticar o ACS para o estabelecimento de conexão HTTPS.
Pré-requisitos
Antes de realizar esta tarefa, primeiro crie uma política de cliente SSL. Para obter mais informações sobre como configurar políticas de cliente SSL, consulte o Guia de Configuração de Segurança.
Procedimento
- Entrar na visão do sistema.
system-viewcwmpssl client-policy nome-politicaPor padrão, nenhuma política de cliente SSL é especificada.
Configurando Parâmetros de Autenticação ACS
Sobre os Parâmetros de Autenticação ACS
Para proteger o CPE contra acessos não autorizados, configure um nome de usuário e uma senha do CPE para autenticação ACS. Quando um ACS inicia uma conexão com o CPE, o ACS deve fornecer o nome de usuário e a senha corretos.
Procedimento
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe username usernamePor padrão, nenhum nome de usuário foi configurado para autenticação no CPE.
cwmp cpe password { cipher | simple } stringPor padrão, nenhuma senha foi configurada para autenticação no CPE.
A configuração de senha é opcional. Você pode especificar apenas um nome de usuário para autenticação.
Configurando o Código de Provisão
Sobre o Código de Provisão
O ACS pode usar o código de provisão para identificar serviços atribuídos a cada CPE. Para implantação correta da configuração, certifique-se de que o mesmo código de provisão seja configurado no CPE e no ACS. Para informações sobre o suporte do seu ACS para códigos de provisão, consulte a documentação do ACS.
Procedimento
- Entrar na visão do sistema.
system-view
system-viewcwmpcwmp cpe provision-code provision-codeO código de provisão padrão é PROVISIONINGCODE.
Configurando a Interface de Conexão CWMP
Sobre a Configuração da Interface de Conexão CWMP
A interface de conexão CWMP é a interface que o CPE usa para se comunicar com o ACS. Para estabelecer uma conexão CWMP, o CPE envia o endereço IP desta interface nos mensagens Inform, e o ACS responde a este endereço IP.
Tipicamente, o CPE seleciona a interface de conexão CWMP automaticamente. Se a interface de conexão CWMP não for a interface que conecta o CPE ao ACS, o CPE falhará em estabelecer uma conexão CWMP com o ACS. Nesse caso, você precisa configurar manualmente a interface de conexão CWMP.
Procedimento
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe connect interface interface-type interface-numberPor padrão, nenhuma interface de conexão CWMP é especificada.
Configurando Parâmetros de Autoconexão
Sobre os Parâmetros de Autoconexão
Você pode configurar o CPE para se conectar ao ACS periodicamente, ou em um horário agendado para configuração ou atualização de software.
O CPE tenta uma conexão automaticamente quando um dos seguintes eventos ocorre:
- O CPE falha em se conectar ao ACS. O CPE considera uma tentativa de conexão como falhada quando o temporizador close-wait expira. Este temporizador começa quando o CPE envia uma solicitação Inform. Se o CPE falhar em receber uma resposta antes do temporizador expirar, o CPE reenvia a solicitação Inform.
- A conexão é desconectada antes que a sessão na conexão seja concluída.
Para proteger os recursos do sistema, limite o número de tentativas que o CPE pode fazer para se conectar ao ACS.
Configurando o Recurso de Informe Periódico
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe inform interval enablePor padrão, esta função está desabilitada.
cwmp cpe inform interval intervalPor padrão, o CPE envia uma mensagem Inform para iniciar uma sessão a cada 600 segundos.
Agendando uma Inicialização de Conexão
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe inform time timePor padrão, nenhuma inicialização de conexão foi agendada.
Configurando o Número Máximo de Tentativas de Conexão
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe connect retry retriesPor padrão, o CPE tenta uma conexão falhada até que a conexão seja estabelecida.
Configurando o Temporizador de Espera de Fechamento
Sobre o Temporizador de Espera de Fechamento
O temporizador de espera de fechamento especifica o seguinte:
- O tempo máximo que o CPE espera pela resposta a uma solicitação de sessão. O CPE determina que sua tentativa de sessão falhou quando o temporizador expira.
- O tempo que a conexão com o ACS pode ficar ociosa antes de ser terminada. O CPE termina a conexão com o ACS se nenhum tráfego for enviado ou recebido antes que o temporizador expire.
Procedimento
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe wait timeout secondsPor padrão, o temporizador de espera de fechamento é 30 segundos.
Habilitando Traversal NAT para o CPE
Sobre Traversal NAT
Para que a solicitação de conexão iniciada do ACS alcance o CPE, é necessário habilitar o Traversal NAT no CPE quando um gateway NAT reside entre o CPE e o ACS.
O recurso de Traversal NAT está em conformidade com o RFC 3489 Simple Traversal of UDP Through NATs (STUN). O recurso permite que o CPE descubra o gateway NAT e obtenha um vínculo NAT aberto (um endereço IP público e vínculo de porta) pelo qual o ACS pode enviar pacotes não solicitados. O CPE envia o vínculo para o ACS quando inicia uma conexão com o ACS. Para que as solicitações de conexão enviadas pelo ACS a qualquer momento alcancem o CPE, o CPE mantém o vínculo NAT aberto. Para obter mais informações sobre NAT, consulte o Guia de Configuração de Serviços IP - Camada 3.
Procedimento
- Entrar na visão do sistema.
system-viewcwmpcwmp cpe stun enablePor padrão, o Traversal NAT está desabilitado no CPE.
Comandos de Exibição e Manutenção para CWMP
Execute os comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir configuração CWMP. | display cwmp configuration | ||
| Exibir o status atual do CWMP. | display cwmp status |
Exemplos de Configuração CWMP
Exemplo: Configurando CWMP
Configuração de rede
Conforme mostrado na Figura 4, use Intelbras IMC BIMS como o ACS para configurar em massa os dispositivos (CPEs) e atribuir atributos ACS aos CPEs a partir do servidor DHCP.
Os arquivos de configuração para os CPEs nas salas de equipamentos A e B são configure1.cfg e configure2.cfg, respectivamente.
| Item | Setting | ||
| Preferred ACS URL | http://10.185.10.41:9090 | ||
| ACS username | admin | ||
| ACS password | 12345 |
| Room | Device | Serial number | |||
| A | CPE 1 | 210231A95YH10C000045 | |||
| CPE 2 | 210235AOLNH12000010 | ||||
| B | CPE 3 | 210235AOLNH12000015 | |||
| CPE 4 | 210235AOLNH12000017 | ||||
| CPE 5 | 210235AOLNH12000020 | ||||
| CPE 6 | 210235AOLNH12000022 |
Configurando o ACS:
- Conecte-se ao ACS:
- Inicie um navegador da Web no terminal de configuração do ACS.
- Na barra de endereço do navegador da Web, insira o URL e o número da porta do ACS. Neste exemplo, utilizaremos http://10.185.10.41:8080/imc.
- Na página de login, insira o nome de usuário e a senha de login do ACS e clique em "Login".
- Crie um grupo de CPE para cada sala de equipamentos:
- Selecione Serviço > BIMS > Grupo de CPE na barra de navegação superior.
- A página do Grupo de CPE será exibida.
- Clique em "Adicionar".
- Insira um nome de usuário e clique em "OK".
- Repita os passos anteriores para criar um grupo de CPE para as CPEs na Sala B.
- Adicione as CPEs ao grupo de CPE para cada sala de equipamentos:
- Selecione Serviço > BIMS > Gerenciamento de Recursos > Adicionar CPE na barra de navegação superior.
- Na página Adicionar CPE, configure os parâmetros a seguir:
- Tipo de Autenticação - Selecione Nome de Usuário ACS.
- Nome da CPE - Insira um nome para a CPE.
- Nome de Usuário ACS - Insira "admin".
- Senha ACS Gerada - Selecione Entrada Manual.
- Senha ACS - Insira uma senha para autenticação ACS.
- Confirmar Senha ACS - Reinsira a senha.
- Modelo de CPE - Selecione o modelo de CPE.
- Grupo de CPE - Selecione o grupo de CPE.
- Clique em "OK".
- Verifique se a CPE foi adicionada com sucesso na página Todas as CPEs. Figure 8 Viewing CPEs
- Repita as etapas anteriores para adicionar CPE 2 e CPE 3 ao grupo de CPE para a Sala A, e adicione as CPEs na Sala B ao grupo de CPE para a Sala B.
- Configure um modelo de configuração para cada sala de equipamentos:
- Selecione Serviço > BIMS > Gerenciamento de Configuração > Modelos de Configuração na barra de navegação superior. Figure 9 Configuration Templates page
- Clique em "Importar".
- Selecione um arquivo de configuração de origem, selecione Segmento de Configuração como tipo de modelo e clique em "OK".
- O modelo de configuração criado será exibido na lista de Modelos de Configuração após uma importação de arquivo bem-sucedida.
- IMPORTANTE: Se o primeiro comando no arquivo de modelo de configuração for system-view, verifique se não há caracteres na frente do comando.
Figura 10 Importando um modelo de configuração

Figura 11 Lista de Modelos de Configuração

Repita as etapas anteriores para configurar um modelo de configuração para a Sala B.
- Adicione entradas à biblioteca de software:
- Selecione Serviço > BIMS > Gerenciamento de Configuração > Biblioteca de Software na barra de navegação superior.
- Clique em "Importar".
- Selecione um arquivo de origem e clique em "OK".
- Repita as etapas anteriores para adicionar entradas de biblioteca de software para CPEs de diferentes modelos.
- Crie uma tarefa de implantação automática para cada sala de equipamentos:
- Selecione Serviço > BIMS > Gerenciamento de Configuração > Guia de Implantação na barra de navegação superior.
- Clique em Por Modelo de CPE no campo Configuração de Implantação Automática.
- Selecione um modelo de configuração, selecione Configuração de Inicialização na lista Tipo de Arquivo a ser Implantaodo e clique em Selecionar Modelo para selecionar as CPEs na Sala A. Em seguida, clique em "OK".
- Clique em "OK" na página Configuração de Implantação Automática.
- Repita as etapas anteriores para adicionar uma tarefa de implantação para as CPEs na Sala B.
Figura 12 Página da Biblioteca de Software

Figura 13 Importando Software para CPEs

Figura 14 Guia de Implantação

Você pode pesquisar as CPEs pelo grupo de CPEs.
Figura 15 Configuração de Implantação Automática

Figura 16 Resultado da Operação

Configurando o servidor DHCP
Neste exemplo, um dispositivo Intelbras está operando como servidor DHCP.
- Configure um pool de endereços IP para atribuir endereços IP e o endereço do servidor DNS aos CPEs.
Neste exemplo, é usada a sub-rede 10.185.10.0/24 para a atribuição de endereços IP.
Ativar DHCP.
<DHCP_server> system-view
[DHCP_server] dhcp enable
Ativar servidor DHCP na VLAN-interface 1.
interface vlan-interface 1
dhcp select server
quit
Excluir o endereço do servidor DNS 10.185.10.60 e o endereço IP ACS 10.185.10.41 da alocação dinâmica.
dhcp server forbidden-ip 10.185.10.41
dhcp server forbidden-ip 10.185.10.60
Criar pool de endereços DHCP 0.
dhcp server ip-pool 0
Atribuir a sub-rede 10.185.10.0/24 ao pool de endereços e especificar o endereço do servidor DNS 10.185.10.60 no pool de endereços.
network 10.185.10.0 mask 255.255.255.0
dns-list 10.185.10.60
2. Configure a opção DHCP 43 para conter a URL do ACS, nome de usuário e senha em formato hexadecimal.
option 43 hex
013B687474703A2F2F6163732E64617461626173653A393039302F616373207669636B792031323345
Configurando o servidor DNS
Mapear http://acs.database:9090 para http://10.185.1.41:9090 no servidor DNS. Para mais informações sobre a configuração do DNS, consulte a documentação do servidor DNS.
Conectando os CPEs à rede
# Conectar o CPE 1 à rede e, em seguida, ligar o CPE. (Detalhes não mostrados.)
# Fazer login no CPE 1 e configurar a VLAN-interface 2 para usar DHCP para a aquisição de endereço IP, e atribuir GigabitEthernet 1/0/1 à VLAN-interface 2. Na inicialização, o CPE obtém o endereço IP e as informações do ACS do servidor DHCP para iniciar uma conexão com o ACS. Após a conexão ser estabelecida, o CPE interage com o ACS para concluir a autoconfiguração.
<CPE1> system-view
[CPE1] vlan 2
[CPE1-vlan2] quit
[CPE1] interface gigabitethernet 1/0/1
[CPE1-GigabitEthernet1/0/1] port access vlan 2
[CPE1-GigabitEthernet1/0/1] quit
[CPE1] interface vlan-interface 2
[CPE1-Vlan-interface2] ip address dhcp-alloc
# Repetir as etapas anteriores para configurar os outros CPEs.
Verificando a configuração
# Execute o comando display current-configuration para verificar se as configurações em execução nos CPEs são as mesmas que as configurações emitidas pelo ACS.
Configurando EAA
Sobre EAA
A Arquitetura de Automação Incorporada (EAA) é uma estrutura de monitoramento que permite que você defina eventos monitorados e ações a serem tomadas em resposta a um evento. Ele permite que você crie políticas de monitoramento usando a CLI ou scripts Tcl.
Estrutura do EAA
A estrutura do EAA inclui:
- Um conjunto de fontes de eventos
- Um conjunto de monitores de eventos
- Um gerenciador de eventos em tempo real (RTM)
- Um conjunto de políticas de monitoramento definidas pelo usuário
Veja a Figura 1 para uma representação visual da estrutura do EAA.
Fontes de eventos
As fontes de eventos são módulos de software ou hardware que disparam eventos. Por exemplo:
- O módulo CLI dispara um evento quando você insere um comando.
- O módulo Syslog (o centro de informações) dispara um evento quando recebe uma mensagem de log.
Monitores de eventos
O EAA cria um monitor de evento para monitorar o sistema para o evento especificado em cada política de monitoramento. Um monitor de evento notifica o RTM para executar a política de monitoramento quando o evento monitorado ocorre.
RTM
O RTM gerencia a criação, a máquina de estados e a execução de políticas de monitoramento.
Políticas de monitoramento do EAA
Uma política de monitoramento especifica o evento a ser monitorado e as ações a serem tomadas quando o evento ocorre. Você pode configurar políticas de monitoramento do EAA usando a CLI ou Tcl.
Uma política de monitoramento contém os seguintes elementos:
- Um evento
- No mínimo, uma ação
- No mínimo, uma função de usuário
- Uma configuração de tempo de execução
Para obter mais informações sobre esses elementos, consulte "Elementos em uma política de monitoramento".
Elementos em uma política de monitoramento
Elementos em uma política de monitoramento do EAA incluem:
- Evento
- Ação
- Papel de usuário
- Tempo de execução
Evento
A Tabela 1 mostra os tipos de eventos que o EAA pode monitorar.
| Tipo de Evento | Descrição | ||
| CLI | O evento CLI ocorre em resposta a operações monitoradas realizadas na CLI. | ||
| Syslog | O evento Syslog ocorre quando o centro de informações recebe o log monitorado dentro de um período específico. | ||
| Processo | O evento de processo ocorre em resposta a uma alteração de estado do processo monitorado (como uma exceção, desligamento, início ou reinício). Mudanças de estado manuais e automáticas podem causar o evento. | ||
| Hotplug | O evento de hotplug ocorre quando o dispositivo membro monitorado entra ou sai da rede IRF. | ||
| Interface |
Cada evento de interface está associado a dois limites definidos pelo usuário: início e reinício. Um evento de interface ocorre quando a estatística de tráfego da interface monitorada ultrapassa o limite de início nas seguintes situações:
• A estatística ultrapassa o limite de início pela primeira vez. • A estatística ultrapassa o limite de início cada vez após ultrapassar o limite de reinício. | ||
| SNMP |
Cada evento SNMP está associado a dois limites definidos pelo usuário: início e reinício. Um evento SNMP ocorre quando o valor da variável MIB monitorada ultrapassa o limite de início nas seguintes situações:
• O valor da variável monitorada ultrapassa o limite de início pela primeira vez. • O valor da variável monitorada ultrapassa o limite de início cada vez após ultrapassar o limite de reinício. | ||
| SNMP-Notification | O evento de notificação SNMP ocorre quando o valor da variável MIB monitorada em uma notificação SNMP corresponde à condição especificada. | ||
| Rastreamento | O evento de rastreamento ocorre quando o estado da entrada de rastreamento muda de Positivo para Negativo ou de Negativo para Positivo. |
Ação
Você pode criar uma série de ações dependentes da ordem para responder ao evento especificado na política de monitoramento.
As seguintes ações estão disponíveis:
- Executar um comando.
- Enviar um log.
- Habilitar uma troca ativa/passiva.
- Executar um reinício sem salvar a configuração em execução.
Papel de usuário
Para que o EAA execute uma ação em uma política de monitoramento, você deve atribuir à política o papel de usuário que tem acesso aos comandos e recursos específicos da ação.
Para obter mais informações sobre papéis de usuário, consulte o RBAC no Guia de Configuração Fundamental.
Tempo de Execução
O tempo de execução limita a quantidade de tempo que a política de monitoramento executa suas ações a partir do momento em que é acionada.
Variáveis de Ambiente do EAA
As variáveis de ambiente do EAA desvinculam a configuração dos argumentos de ação da política de monitoramento para que você possa modificar uma política facilmente.
Variáveis definidas pelo sistema são fornecidas por padrão e não podem ser criadas, excluídas ou modificadas pelos usuários.
Tabela 2 Variáveis de ambiente do EAA definidas pelo sistema por tipo de evento
| Evento | Nome da Variável e Descrição | ||
| Qualquer evento |
| ||
| CLI |
| ||
| Syslog |
| ||
| Hotplug |
| ||
| Interface |
| ||
| SNMP |
| ||
| SNMP-Notification |
| ||
| Processo |
|
Variáveis definidas pelo usuário
Você pode usar variáveis definidas pelo usuário para todos os tipos de eventos.
Os nomes das variáveis definidas pelo usuário podem conter dígitos, caracteres e o sinal de sublinhado (_), exceto que o sinal de sublinhado não pode ser o caractere principal.
Configurando uma variável de ambiente do EAA definida pelo usuário
Sobre a configuração de uma variável de ambiente do EAA definida pelo usuário
Configure variáveis de ambiente do EAA definidas pelo usuário para que você possa usá-las ao criar políticas de monitoramento do EAA.
Procedimento
- Entre no modo de visualização do sistema.
system-viewrtm environment var-name var-valuePara as variáveis definidas pelo sistema, consulte a Tabela 2.
Configurando uma política de monitoramento
Restrições e diretrizes
Garanta que as ações em diferentes políticas não entrem em conflito. O resultado da execução da política será imprevisível se políticas que conflitam em ações estiverem sendo executadas simultaneamente.
Você pode atribuir o mesmo nome de política a uma política definida por CLI e a uma política definida por Tcl. No entanto, não pode atribuir o mesmo nome a políticas que são do mesmo tipo.
Uma política de monitoramento suporta apenas um evento e tempo de execução. Se você configurar vários eventos para uma política, o mais recente entrará em vigor.
Uma política de monitoramento suporta no máximo 64 papéis de usuário válidos. Os papéis de usuário adicionados após atingir esse limite não terão efeito.
Configurando uma política de monitoramento a partir da CLI
Restrições e diretrizes
Você pode configurar uma série de ações a serem executadas em resposta ao evento especificado em uma política de monitoramento. O EAA executa as ações em ordem crescente de IDs de ação. Ao adicionar ações a uma política, você deve garantir que a ordem de execução esteja correta. Se duas ações tiverem o mesmo ID, a mais recente entrará em vigor.
Procedimento
- Entre no modo de visualização do sistema.
system-viewrtm event syslog buffer-size buffer-sizePor padrão, o buffer de log monitorado pelo EAA armazena no máximo 50000 logs.
rtm cli-policy nome-da-politica- Configure um evento CLI.
event cli { async [ skip ] | sync } mode { execute | help | tab } pattern regular-expevent hotplug [ insert | remove ] slot slot-numberevent interface lista-de-interface monitor-obj monitor-obj start-op
start-op start-val start-val restart-op restart-op restart-val
restart-val [ interval interval ]event process { exception | restart | shutdown | start } [ name
nome-do-processo [ instance id-da-instância ] ] [ slot número-do-slot ]event snmp oid oid monitor-obj { get | next } start-op start-op
start-val start-val restart-op restart-op restart-val restart-val
[ interval interval ]event snmp-notification oid oid oid-val oid-val op op [ drop ]event syslog prioridade prioridade msg msg ocorre vezes período períodoevent track lista-de-rastreamento state { negative | positive } [ suppress-time
tempo-de-supressão ]- Escolha as seguintes tarefas conforme necessário:
- Configure uma ação CLI.
action number cli command-lineaction number reboot [ slot slot-number ]
action number switchoveraction number syslog priority priority facility local-number msg
msg-bodyuser-role nome-da-funçãorunning-time timecommitConfigurando uma política de monitoramento usando Tcl
Sobre scripts Tcl
Um script Tcl contém duas partes: Linha 1 e as demais linhas.
- Linha 1
A Linha 1 define o evento, funções de usuário e tempo de execução da ação da política. Após criar e habilitar uma política de monitoramento Tcl, o dispositivo imediatamente analisa, entrega e executa a Linha 1.
A Linha 1 deve seguir o seguinte formato:
::comware::rtm::event_register event-type arg1 arg2 arg3 … user-role
role-name1 | [ user-role role-name2 | [ … ] ] [ running-time
running-time ]
- Os argumentos arg1 arg2 arg3 … representam regras de correspondência de eventos. Se um valor de argumento contiver espaços, use aspas duplas ("") para cercar o valor. Por exemplo, "a b c".
- Os requisitos de configuração para os argumentos tipo-de-evento, função-de-usuário e tempo-de-execução são os mesmos que os de uma política de monitoramento definida por CLI.
A partir da segunda linha, o script Tcl define as ações a serem executadas quando a política de monitoramento é acionada. Você pode usar várias linhas para definir várias ações. O sistema executa essas ações em sequência. As seguintes ações estão disponíveis:
- Comandos Tcl padrão.
- Ações Tcl específicas do EAA:
- switchover ( ::comware::rtm::action switchover )
- syslog (::comware::rtm::action syslog priority priority facility local-number msg msg-body). Para mais informações sobre esses argumentos, consulte Comandos EAA no Referência de Comandos de Gerenciamento e Monitoramento de Rede.
- Comandos suportados pelo dispositivo.
Restrições e diretrizes
Para revisar o script Tcl de uma política, você deve suspender todas as políticas de monitoramento primeiro e, em seguida, retomar as políticas após concluir a revisão do script. O sistema não pode executar uma política definida por Tcl se você editar seu script Tcl sem suspender essas políticas.
Procedimento
- Baixe o arquivo de script Tcl para o dispositivo usando FTP ou TFTP.
- Crie e habilite uma política de monitoramento Tcl.
- Entre na visão do sistema.
Para mais informações sobre o uso de FTP e TFTP, consulte o Guia de Configuração de Fundamentos.
system-viewrtm tcl-policy policy-name tcl-filenamePor padrão, não existem políticas Tcl.
Assegure-se de que o arquivo de script esteja salvo em todos os dispositivos membros do IRF. Esta prática garante que a política possa ser executada corretamente após ocorrer uma troca de mestre/subordinado ou o dispositivo membro onde o arquivo de script está localizado sair do IRF.
Suspender políticas de monitoramento
Sobre a suspensão de políticas de monitoramento
Esta tarefa suspende todas as políticas de monitoramento definidas por CLI e por Tcl. Se uma política estiver em execução quando você realizar esta tarefa, o sistema suspende a política após executar todas as ações.
Restrições e diretrizes
Para restaurar o funcionamento das políticas suspensas, execute o comando undo rtm scheduler suspend.
- Entre na visão do sistema.
system-viewrtm scheduler suspendComandos de exibição e manutenção para EAA
| Tarefa | Comando | ||
| Exibir a configuração em execução de todas as políticas de monitoramento definidas por CLI. | display current-configuration | ||
| Exibir variáveis de ambiente do EAA definidas pelo usuário. | display rtm environment [ var-name ] | ||
| Exibir políticas de monitoramento EAA. | display rtm policy { active | registered [ verbose ] } [ policy-name ] | ||
| Exibir a configuração em execução de uma política de monitoramento definida por CLI na visão de política de monitoramento definida por CLI. | display this |
Exemplos de configuração do EAA
Exemplo: Configurando uma política de monitoramento de eventos CLI usando Tcl
Configuração de rede
Conforme mostrado na Figura 2, use Tcl para criar uma política de monitoramento no Dispositivo. Esta política deve atender aos seguintes requisitos:
center>
- O EAA envia a mensagem de log "rtm_tcl_test está em execução" quando um comando que contém a string display this é inserido.
- O sistema executa o comando somente depois de executar a política com sucesso.
Procedimento
::comware::rtm::event_register cli sync mode execute pattern display this user-role network-admin
::comware::rtm::action syslog priority 1 facility local4 msg rtm_tcl_test is running
Baixe o arquivo de script Tcl do servidor TFTP em 1.2.1.1.
<Sysname> tftp 1.2.1.1 get rtm_tcl_test.tcl
Crie uma política definida por Tcl chamada test e vincule-a ao arquivo de script Tcl.
<Sysname> system-view
[Sysname] rtm tcl-policy test rtm_tcl_test.tcl
[Sysname] quit
Verificando a configuração
Execute o comando display rtm policy registered para verificar se uma política definida por Tcl chamada test é exibida na saída do comando.<Sysname> display rtm policy registered
Total number: 1
Type Event TimeRegistered PolicyName
TCL CLI Jan 01 09:47:12 2019 test
Internet
Device PC
TFTP client TFTP server
1.1.1.1/16 1.2.1.1/16
<Sysname> terminal monitor
The current terminal is enabled to display logs.
<Sysname> system-view
[Sysname] info-center enable
Information center is enabled..
[Sysname] quit
Execute o comando display this. Verifique se o sistema exibe uma mensagem "rtm_tcl_test está em execução" e uma mensagem de que a política está sendo executada com sucesso.
<Sysname> display this
%Jan 1 09:50:04:634 2019 Sysname RTM/1/RTM_ACTION:rtm_tcl_test is running
%Jan 1 09:50:04:636 2019 Sysname RTM/6/RTM_POLICY: TCL policy test is running
successfully.
#
returnExemplo: Configurando uma política de monitoramento de eventos CLI a partir da CLI
Configuração de rede
Configure uma política a partir da CLI para monitorar o evento que ocorre quando um ponto de interrogação (?) é inserido na linha de comando que contém letras e dígitos.
Quando o evento ocorre, o sistema executa o comando e envia a mensagem de log "hello world" para o centro de informações.
Procedimento
Crie a política definida por CLI test e entre em sua visualização.
<Sysname> system-view
[Sysname] rtm cli-policy test
Adicione um evento CLI que ocorre quando um ponto de interrogação (?) é inserido em qualquer linha de comando que contenha letras e dígitos.
[Sysname-rtm-test] event cli async mode help pattern [a-zA-Z0-9]Adicione uma ação que envia a mensagem "hello world" com prioridade 4 da facilidade de log local3 quando o evento ocorre.
[Sysname-rtm-test] action 0 syslog priority 4 facility local3 msg “hello world”Adicione uma ação que entra na visualização do sistema quando o evento ocorre.
[Sysname-rtm-test] action 2 cli system-viewAdicione uma ação que cria a VLAN 2 quando o evento ocorre.
[Sysname-rtm-test] action 3 cli vlan 2Defina o tempo de execução da ação da política para 2000 segundos.
[Sysname-rtm-test] running-time 2000Especifique a função de usuário network-admin para executar a política.
[Sysname-rtm-test] user-role network-adminHabilite a política.
[Sysname-rtm-test] commitVerificação da configuração
Execute o comando display rtm policy registered para verificar se uma política definida por CLI chamada test está sendo exibida na saída do comando.
[Sysname-rtm-test] display rtm policy registered
Total number: 1
Type Event TimeRegistered PolicyName
CLI CLI Jan 1 14:56:50 2019 test
Habilite o centro de informações para exibir mensagens de log no terminal de monitoramento atual.
[Sysname-rtm-test] return
Sysname> terminal monitor
The current terminal is enabled to display logs.
Sysname> system-view
[Sysname] info-center enable
Information center is enabled.
[Sysname] quit
Insira um ponto de interrogação (?) em uma linha de comando que contenha uma letra d. Verifique se o sistema exibe uma mensagem "hello world" e uma mensagem de que a política está sendo executada com sucesso na tela do terminal.
<Sysname> d?
debugging
delete
diagnostic-logfile
dir
display
<Sysname>d%Jan 1 14:57:20:218 2019 Sysname RTM/4/RTM_ACTION: "hello world"
%Jan 1 14:58:11:170 2019 Sysname RTM/6/RTM_POLICY: CLI policy test is running
successfully.
Exemplo: Configuração de uma política de monitoramento de evento CLI com variáveis de ambiente EAA do CLI
Configuração da rede
Defina uma variável de ambiente para corresponder ao endereço IP 1.1.1.1.
Configure uma política do CLI para monitorar o evento que ocorre quando uma linha de comando que contém loopback0 é executada. Na política, use a variável de ambiente para atribuição de endereço IP.
Quando o evento ocorrer, o sistema executa as seguintes tarefas:
- Cria a interface Loopback 0.
- Atribui 1.1.1.1/24 à interface.
- Envia a linha de comando correspondente ao centro de informações.
Procedimento
# Configure uma variável de ambiente EAA para atribuição de endereço IP. O nome da variável é loopback0IP, e o valor da variável é 1.1.1.1.
<Sysname> system-view
[Sysname] rtm environment loopback0IP 1.1.1.1
# Crie a política definida por CLI test e entre em sua visualização.
[Sysname] rtm cli-policy test
# Adicione um evento CLI que ocorre quando uma linha de comando que contém loopback0 é executada.
[Sysname-rtm-test] event cli async mode execute pattern loopback0
# Adicione uma ação que entra na visualização do sistema quando o evento ocorre.
[Sysname-rtm-test] action 0 cli system-view
# Adicione uma ação que cria a interface Loopback 0 e entra na visualização da interface de loopback.
[Sysname-rtm-test] action 1 cli interface loopback 0
# Adicione uma ação que atribui o endereço IP 1.1.1.1 ao Loopback 0. A variável loopback0IP é usada na ação para atribuição de endereço IP.
[Sysname-rtm-test] action 2 cli ip address $loopback0IP 24
# Adicione uma ação que envia a linha de comando loopback0 correspondente com uma prioridade de 0 a partir da instalação de log local7 quando o evento ocorre.
[Sysname-rtm-test] action 3 syslog priority 0 facility local7 msg $_cmd
# Especifique a função de usuário network-admin para executar a política.
[Sysname-rtm-test] user-role network-admin
# Habilite a política.
[Sysname-rtm-test] commit
[Sysname-rtm-test] return
<Sysname>
Verificação da configuração
# Habilite o centro de informações para exibir mensagens de log no terminal de monitoramento atual.
<Sysname> terminal monitor
The current terminal is enabled to display logs.
<Sysname> terminal log level debugging
<Sysname> system-view
[Sysname] info-center enable
Information center is enabled.
# Execute o comando interface loopback0. Verifique se o sistema exibe uma mensagem "interface loopback0" e uma mensagem de que a política está sendo executada com sucesso na tela do terminal.
[Sysname] interface loopback0
[Sysname-LoopBack0]%Jan 1 09:46:10:592 2019 Sysname RTM/7/RTM_ACTION: interface loopback0
%Jan 1 09:46:10:613 2019 Sysname RTM/6/RTM_POLICY: CLI policy test is running
successfully.
# Verifique se uma interface Loopback 0 foi criada e seu endereço IP é 1.1.1.1.
[Sysname-LoopBack0] display interface loopback brief
Brief information on interfaces in route mode:
Link: ADM - administratively down; Stby - standby
Protocol: (s) - spoofing
Interface Link Protocol Primary IP Description
Loop0 UP UP(s) 1.1.1.1
Monitorando e mantendo processos
Sobre monitoramento e manutenção de processos
O software do sistema do dispositivo é um sistema operacional de rede completo, modular e escalável, baseado no kernel Linux. As características do software do sistema executam os seguintes tipos de processos independentes:
- Processo do usuário - Executa no espaço do usuário. A maioria das características do software do sistema executa processos do usuário. Cada processo é executado em um espaço independente, portanto, a falha de um processo não afeta outros processos. O sistema monitora automaticamente os processos do usuário. O sistema suporta multithreading preemptivo. Um processo pode executar várias threads para suportar múltiplas atividades. Se um processo suporta multithreading depende da implementação do software.
- Thread do kernel - Executa no espaço do kernel. Uma thread do kernel executa código do kernel. Ela possui um nível de segurança mais alto do que um processo do usuário. Se uma thread do kernel falhar, o sistema entra em colapso. Você pode monitorar o status de execução das threads do kernel.
Tarefas de monitoramento e manutenção de processos em um relance
Para monitorar e manter processos, execute as seguintes tarefas:
-
Monitorar e manter processos do usuário
-
Monitorar e manter processos
Os comandos desta seção se aplicam tanto a processos do usuário quanto a threads do kernel.
-
Monitorar e manter processos do usuário
Os comandos desta seção se aplicam apenas a processos do usuário.
-
Monitorar e manter processos
-
Monitorar e manter threads do kernel
-
Monitorar e manter processos
Os comandos desta seção se aplicam tanto a processos do usuário quanto a threads do kernel.
-
Monitorar e manter threads do kernel
Os comandos desta seção se aplicam apenas a threads do kernel.
-
Monitorar e manter processos
Monitorando e mantendo processos
Sobre monitoramento e manutenção de processos
Os comandos nesta seção se aplicam tanto a processos do usuário quanto a threads do kernel. Você pode usar os comandos para os seguintes propósitos:
- Exibir o uso geral da memória.
- Exibir os processos em execução e seu uso de memória e CPU.
- Localizar processos anormais.
Se um processo consome recursos de memória ou CPU excessivos, o sistema identifica o processo como um processo anormal.
- Se um processo anormal for um processo do usuário, solucione o problema do processo conforme descrito em "Monitorando e mantendo processos do usuário".
- Se um processo anormal for uma thread do kernel, solucione o problema da thread conforme descrito em "Monitorando e mantendo threads do kernel".
Procedimento
Execute os seguintes comandos em qualquer visualização.
| Tarefa | Comando | ||
| Exibir uso de memória. | display memory [ summary ] [ slot slot-number [ cpu cpu-number ] ] | ||
| Exibir informações de estado do processo. | display process [ all | job job-id | name process-name ] [ slot slot-number [ cpu cpu-number ] ] | ||
| Exibir uso da CPU para todos os processos. | display process cpu [ slot slot-number [ cpu cpu-number ] ] | ||
| Monitorar estado de execução do processo. | monitor process [ dumbtty ] [ iteration number ] [ slot slot-number [ cpu cpu-number ] ] | ||
| Monitorar estado de execução da thread. | monitor thread [ dumbtty ] [ iteration number ] [ slot slot-number [ cpu cpu-number ] ] |
Para mais informações sobre o comando display memory, consulte o Guia de Referência de Comandos Fundamentais.
Monitoramento e manutenção de processos do usuário
Sobre o monitoramento e a manutenção de processos do usuário
Use este recurso para monitorar processos de usuário anormais e localizar problemas.
Configurando o despejo principal
Sobre o despejo principal
O recurso de despejo principal permite que o sistema gere um arquivo de despejo principal toda vez que um processo falha até que o número máximo de arquivos de despejo principal seja alcançado. Um arquivo de despejo principal armazena informações sobre o processo. Você pode enviar os arquivos de despejo principal para a equipe de suporte técnico da Intelbras para solucionar os problemas.
Restrições e diretrizes
Os arquivos de despejo principal consomem recursos de armazenamento. Ative o despejo principal apenas para processos que possam ter problemas.
Procedimento
Execute os seguintes comandos na visualização do usuário:
- (Opcional.) Especifique o diretório para salvar os arquivos de despejo principal.
exception filepath diretórioPor padrão, o diretório para salvar os arquivos de despejo principal é o diretório raiz do sistema de arquivos padrão. Para obter mais informações sobre o sistema de arquivos padrão, consulte o guia de configuração do sistema de arquivos em Guia de Configuração Fundamentais.
process core { maxcore valor | off } { job job-id | name nome-do-processo }Por padrão, um processo gera um arquivo de despejo principal para a primeira exceção e não gera nenhum arquivo de despejo principal para exceções subsequentes.
Comandos de exibição e manutenção para processos do usuário
Execute comandos de exibição em qualquer visualização e outros comandos na visualização do usuário.
| Tarefa | Comando | ||
| Exibir informações de contexto para exceções de processo. | display exception context [ count valor ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir o diretório do arquivo de despejo principal. | display exception filepath [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir informações de log para todos os processos do usuário. | display process log [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir uso de memória para todos os processos do usuário. | display process memory [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir uso de memória de heap para um processo do usuário. | display process memory heap job job-id [ verbose ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir conteúdo de memória a partir de um bloco de memória especificado para um processo do usuário. | display process memory heap job job-id address starting-address length memory-length [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir os endereços dos blocos de memória com um tamanho especificado usados por um processo do usuário. | display process memory heap job job-id size memory-size [ offset offset-size ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Limpar informações de contexto para exceções de processo. | reset exception context [ slot número-do-slot [ cpu número-da-cpu ] ] |
Monitoramento e manutenção de threads do kernel
Configurando detecção de loop de thread do kernel
Sobre a detecção de loop de thread do kernel
As threads do kernel compartilham recursos. Se uma thread do kernel monopoliza a CPU, outras threads não podem ser executadas, resultando em um loop de deadlock.
Este recurso permite que o dispositivo detecte deadlocks. Se uma thread ocupa a CPU por um intervalo específico, o dispositivo determina que ocorreu um deadlock e gera uma mensagem de deadlock.
Restrições e diretrizes
Altere as configurações de detecção de loop de thread do kernel apenas sob a orientação da equipe de suporte técnico da Intelbras. A configuração inadequada pode causar falha do sistema.
Procedimento
- Entre na visualização do sistema.
system-viewmonitor kernel deadloop enable [ slot número-do-slot [ cpu número-da-cpu [ core número-do-núcleo&<1-64> ] ] ]Por padrão, a detecção de loop de thread do kernel está habilitada.
monitor kernel deadloop time tempo [ slot número-do-slot [ cpu número-da-cpu ] ]O padrão é de 20 segundos.
monitor kernel deadloop exclude-thread tid [ slot número-do-slot [ cpu número-da-cpu ] ]Quando habilitada, a detecção de loop de thread do kernel monitora todas as threads do kernel por padrão.
monitor kernel deadloop action { reboot | record-only } [ slot número-do-slot [ cpu número-da-cpu ] ]A ação padrão é reiniciar.
Configurando detecção de inanição de thread do kernel
Sobre a detecção de inanição de thread do kernel
A inanição ocorre quando uma thread não consegue acessar recursos compartilhados.
A detecção de inanição de thread do kernel permite que o sistema detecte e relate a inanição de thread. Se uma thread não for executada dentro de um intervalo específico, o sistema determina que ocorreu uma inanição e gera uma mensagem de inanição.
A inanição de thread não afeta a operação do sistema. Uma thread inativa pode ser executada automaticamente quando certas condições são atendidas.
Restrições e diretrizes
Configure a detecção de inanição de thread do kernel apenas sob a orientação da equipe de suporte técnico da Intelbras. A configuração inadequada pode causar falha do sistema.
Procedimento
- Entre na visualização do sistema.
system-viewmonitor kernel starvation enable [ slot número-do-slot [ cpu número-da-cpu ] ]Por padrão, a detecção de inanição de thread do kernel está desativada.
monitor kernel starvation time tempo [ slot número-do-slot [ cpu número-da-cpu ] ]O padrão é de 120 segundos.
monitor kernel starvation exclude-thread tid [ slot número-do-slot [ cpu número-da-cpu ] ]Quando habilitada, a detecção de inanição de thread do kernel monitora todas as threads do kernel por padrão.
Comandos de exibição e manutenção para threads do kernel
Execute comandos de exibição em qualquer visualização e comandos de redefinição na visualização do usuário.
| Tarefa | Comando | ||
| Exibir configuração de detecção de loop de thread do kernel. | display kernel deadloop configuration [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir informações de loop de thread do kernel. | display kernel deadloop show-number [ offset ] [ verbose ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir informações de exceção de thread do kernel. | display kernel exception show-number [ offset ] [ verbose ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir informações de reinicialização de thread do kernel. | display kernel reboot show-number [ offset ] [ verbose ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir configuração de detecção de inanição de thread do kernel. | display kernel starvation configuration [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Exibir informações de inanição de thread do kernel. | display kernel starvation show-number [ offset ] [ verbose ] [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Limpar informações de detecção de loop de thread do kernel. | reset kernel deadloop [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Limpar informações de exceção de thread do kernel. | reset kernel exception [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Limpar informações de reinicialização de thread do kernel. | reset kernel reboot [ slot número-do-slot [ cpu número-da-cpu ] ] | ||
| Limpar informações de inanição de thread do kernel. | reset kernel starvation [ slot número-do-slot [ cpu número-da-cpu ] ] |
Configurando o espelhamento de porta
Sobre o espelhamento de porta
O espelhamento de porta copia os pacotes que passam por uma porta para uma porta que se conecta a um dispositivo de monitoramento de dados para análise de pacotes.
Terminologia
Os seguintes termos são usados na configuração de espelhamento de porta.
Fonte de espelhamento
As fontes de espelhamento podem ser uma ou mais portas monitoradas chamadas portas de origem. Os pacotes que passam pelas fontes de espelhamento são copiados para uma porta conectada a um dispositivo de monitoramento de dados para análise de pacotes. As cópias são chamadas de pacotes espelhados.
Dispositivo de origem
O dispositivo onde as fontes de espelhamento residem é chamado de dispositivo de origem.
Destino de espelhamento
O destino de espelhamento se conecta a um dispositivo de monitoramento de dados e é a porta de destino (também conhecida como porta de monitoramento) dos pacotes espelhados. Os pacotes espelhados são enviados para fora da porta de monitoramento para o dispositivo de monitoramento de dados. Uma porta de monitoramento pode receber várias cópias de um pacote quando monitora várias fontes de espelhamento. Por exemplo, duas cópias de um pacote são recebidas na Porta A quando as seguintes condições existem:
A Porta A está monitorando o tráfego bidirecional da Porta B e da Porta C no mesmo dispositivo.
O pacote viaja da Porta B para a Porta C.
Dispositivo de destino
O dispositivo onde a porta de monitoramento reside é chamado de dispositivo de destino.
Direção de espelhamento
A direção de espelhamento especifica a direção do tráfego que é copiado em uma fonte de espelhamento.
Entrada—Copia pacotes recebidos.
Saída—Copia pacotes enviados.
Bidirecional—Copia pacotes recebidos e enviados.
Grupo de espelhamento
O espelhamento de porta é implementado por meio de grupos de espelhamento. Os grupos de espelhamento podem ser classificados em grupos de espelhamento local, grupos de fonte remota e grupos de destino remoto.
Porta de refletor, porta de saída e VLAN de sonda remota
Portas refletoras, VLANs de sonda remota e portas de saída são usadas para o espelhamento de porta remota da Camada 2. A VLAN de sonda remota é uma VLAN dedicada para transmitir pacotes espelhados para o dispositivo de destino. Tanto a porta refletora quanto a porta de saída residem em um dispositivo de origem e enviam pacotes espelhados para a VLAN de sonda remota. Em dispositivos de espelhamento de porta, todas as portas, exceto portas de origem, destino, refletoras e de saída, são chamadas de portas comuns.
Classificação de espelhamento de porta
O espelhamento de porta pode ser classificado em espelhamento de porta local e espelhamento de porta remota.
Porta de espelhamento local—O dispositivo de origem está diretamente conectado a um dispositivo de monitoramento de dados. O dispositivo de origem também atua como dispositivo de destino e encaminha pacotes espelhados diretamente para o dispositivo de monitoramento de dados.
Porta de espelhamento remota—O dispositivo de origem não está diretamente conectado a um dispositivo de monitoramento de dados. O dispositivo de origem envia pacotes espelhados para o dispositivo de destino, que encaminha os pacotes para o dispositivo de monitoramento de dados. O espelhamento de porta remota também é conhecido como espelhamento de porta remota da Camada 2 porque o dispositivo de origem e o dispositivo de destino estão na mesma rede da Camada 2.
Local Port Mirroring
Como mostrado na Figura 1, a porta de origem (Porta A) e a porta de monitoramento (Porta B) residem no mesmo dispositivo. Os pacotes recebidos na Porta A são copiados para a Porta B. A Porta B então encaminha os pacotes para o dispositivo de monitoramento de dados para análise.
center>
Mirroring Remoto de Porta em Camada 2
No mirroring remoto de porta em camada 2, as fontes de espelhamento e o destino residem em dispositivos diferentes e estão em grupos de espelhamento diferentes.
Um grupo de fontes remoto é um grupo de espelhamento que contém as fontes de espelhamento. Um grupo de destino remoto é um grupo de espelhamento que contém o destino de espelhamento. Os dispositivos intermediários são os dispositivos entre o dispositivo de origem e o dispositivo de destino.
O mirroring de porta remoto em camada 2 pode ser implementado através do método da porta refletora ou do método da porta de saída.
Método da Porta Refletora
No mirroring remoto de porta em camada 2 que utiliza o método da porta refletora, os pacotes são espelhados da seguinte forma:
- O dispositivo de origem copia os pacotes recebidos nas fontes de espelhamento para a porta refletora.
- A porta refletora transmite os pacotes espelhados na VLAN de sonda remota.
- Os dispositivos intermediários transmitem os pacotes espelhados para o dispositivo de destino através da VLAN de sonda remota.
- Ao receber os pacotes espelhados, o dispositivo de destino determina se o ID dos pacotes espelhados é o mesmo que o ID da VLAN de sonda remota. Se os dois IDs de VLAN corresponderem, o dispositivo de destino encaminha os pacotes espelhados para o dispositivo de monitoramento de dados através da porta de monitoramento.
Método da Porta de Egresso
No mirroring remoto de porta em camada 2 que utiliza o método da porta de egresso, os pacotes são espelhados da seguinte forma:
- O dispositivo de origem copia os pacotes recebidos nas fontes de espelhamento para a porta de egresso.
- A porta de egresso encaminha os pacotes espelhados para os dispositivos intermediários.
- Os dispositivos intermediários inundam os pacotes espelhados na VLAN de sonda remota e transmitem os pacotes espelhados para o dispositivo de destino.
- Ao receber os pacotes espelhados, o dispositivo de destino determina se o ID dos pacotes espelhados é o mesmo que o ID da VLAN de sonda remota. Se os dois IDs de VLAN corresponderem, o dispositivo de destino encaminha os pacotes espelhados para o dispositivo de monitoramento de dados através da porta de monitoramento.
Restrições e diretrizes: Configuração de espelhamento de porta
O método de porta refletora para espelhamento de porta remota de Camada 2 pode ser usado para implementar o espelhamento de porta local com vários dispositivos de monitoramento de dados.
No método de porta refletora, a porta refletora transmite pacotes espelhados na VLAN de sonda remota. Ao atribuir as portas que se conectam aos dispositivos de monitoramento de dados à VLAN de sonda remota, você pode implementar o espelhamento de porta local para espelhar pacotes para vários dispositivos de monitoramento de dados. O método de porta de saída não pode implementar o espelhamento de porta local dessa maneira.
Para espelhamento de tráfego de entrada, a tag VLAN no pacote original é copiada para o pacote espelhado. Para espelhamento de tráfego de saída, a tag VLAN no pacote espelhado identifica a VLAN à qual o pacote pertence antes de ser enviado para fora da porta de origem.
Configurando o espelhamento de porta local
Restrições e diretrizes para a configuração de espelhamento de porta local
Um grupo de espelhamento local entra em vigor somente após ser configurado com a porta de monitoramento e fontes de espelhamento.
Uma interface agregada de Camada 2 ou Camada 3, interface de túnel ou interface VLAN não pode ser configurada como uma porta de origem de um grupo de espelhamento local. Você pode configurar portas membros de uma interface agregada de Camada 2 ou Camada 3 como portas de origem de espelhamento.
Uma interface agregada de Camada 2 ou Camada 3 não pode ser configurada como a porta de monitoramento de um grupo de espelhamento local.
A porta membro de uma interface agregada não pode ser configurada como porta de monitoramento.
Tarefas de espelhamento de porta local em um relance
Para configurar o espelhamento de porta local, execute as seguintes tarefas:
- Criando um grupo de espelhamento local
- Configurando fontes de espelhamento
- Configurando a porta de monitoramento
Criando um grupo de espelhamento local
Enter system view.
system-view
Create a local mirroring group.
mirroring-group group-id local
Configurando fontes de espelhamento
Restrições e diretrizes para a configuração de fonte de espelhamento
Ao configurar portas de origem para um grupo de espelhamento local, siga estas restrições e diretrizes:
- Um grupo de espelhamento pode conter várias portas de origem.
- Uma porta pode atuar como porta de origem para apenas um grupo de espelhamento.
- Uma porta de origem não pode ser configurada como porta refletora, porta de saída ou porta de monitoramento.
- Uma interface agregada de Camada 2 ou Camada 3, interface de túnel ou interface VLAN não pode ser configurada como porta de origem de um grupo de espelhamento local.
Configuração de portas de origem
- Configure as portas de origem no modo de sistema:
- a. Entre no modo de sistema.
system-viewmirroring-group group-id mirroring-port interface-list { both | inbound | outbound }Por padrão, nenhuma porta de origem é configurada para um grupo de espelhamento local.
- a. Entre no modo de sistema.
system-viewinterface interface-type interface-numbermirroring-group group-id mirroring-port { both | inbound | outbound }Por padrão, uma porta não atua como porta de origem para nenhum grupo de espelhamento local.
Configuração da porta de monitoramento
Restrições e diretrizes
- Não habilite o recurso de spanning tree na porta de monitoramento.
- Use uma porta de monitoramento apenas para espelhamento de porta, para que o dispositivo de monitoramento de dados receba apenas o tráfego espelhado.
- Apenas uma porta de monitoramento pode ser configurada para um grupo de espelhamento.
- A porta membro de uma interface agregada não pode ser configurada como porta de monitoramento.
Procedimento
- Configure a porta de monitoramento no modo de sistema:
- a. Entre no modo de sistema.
system-viewmirroring-group group-id monitor-port interface-type interface-numberPor padrão, nenhuma porta de monitoramento é configurada para um grupo de espelhamento local.
- a. Entre no modo de sistema.
system-viewinterface interface-type interface-numbermirroring-group group-id monitor-portPor padrão, uma porta não atua como a porta de monitoramento para nenhum grupo de espelhamento local.
Configuração do grupo de espelhamento de porta local com múltiplos dispositivos de monitoramento
Sobre o espelhamento de porta local com múltiplos dispositivos de monitoramento
Para monitorar o tráfego interessante passando por um dispositivo em vários dispositivos de monitoramento de dados diretamente conectados, configure o espelhamento de porta local com uma VLAN de sonda remota da seguinte maneira:
- Configure um grupo de origem remota no dispositivo.
- Configure fontes de espelhamento e uma porta refletora para o grupo de origem remota.
- Especifique uma VLAN como a VLAN de sonda remota e atribua as portas conectando aos dispositivos de monitoramento de dados à VLAN.
Esta configuração permite que o dispositivo copie pacotes recebidos nas fontes de espelhamento para a porta refletora, que transmite os pacotes na VLAN de sonda remota. Os pacotes são então enviados para fora das portas membros da VLAN de sonda remota para os dispositivos de monitoramento de dados.
Restrições e diretrizes
- A porta refletora deve ser uma porta não utilizada. Não conecte um cabo de rede à porta refletora.
- Quando uma porta é configurada como porta refletora, a porta é restaurada para as configurações padrão de fábrica. Você não pode configurar outros recursos na porta refletora.
- Não atribua uma porta de origem de um grupo de espelhamento à VLAN de sonda remota do grupo de espelhamento.
- Uma VLAN pode atuar como a VLAN de sonda remota para apenas um grupo de origem remota. Como prática recomendada, use a VLAN exclusivamente para o espelhamento de porta. Não crie uma interface VLAN para a VLAN ou configure outros recursos para a VLAN.
- A VLAN de sonda remota deve ser uma VLAN estática.
- Para excluir uma VLAN que foi configurada como a VLAN de sonda remota para um grupo de espelhamento, remova a VLAN de sonda remota do grupo de espelhamento primeiro.
- O dispositivo suporta apenas uma VLAN de sonda remota.
Procedimento
- Entre na visualização do sistema.
system-viewmirroring-group group-id remote-source- Configure as portas de espelhamento na visualização do sistema.
mirroring-group group-id mirroring-port interface-list { both | inbound | outbound }interface interface-type interface-numbermirroring-group group-id mirroring-port { both | inbound | outbound }quitmirroring-group group-id reflector-port reflector-portPor padrão, nenhuma porta refletora é configurada para um grupo de origem remota.
vlan vlan-idport interface-listPor padrão, uma VLAN não contém nenhuma porta.
quitmirroring-group group-id remote-probe vlan vlan-idPor padrão, nenhuma VLAN de sonda remota é configurada para um grupo de origem remota.
Configurando o espelhamento de porta remota de Camada 2
Restrições e diretrizes para a configuração do espelhamento de porta remota de Camada 2
Para garantir o espelhamento de tráfego bem-sucedido, configure os dispositivos na ordem do dispositivo de destino, dos dispositivos intermediários e do dispositivo de origem.
Se houver dispositivos intermediários, configure-os para permitir que a VLAN de sonda remota passe.
Para que um pacote espelhado chegue com sucesso ao dispositivo de destino remoto, verifique se seu ID de VLAN não é removido ou alterado.
Não configure tanto o MVRP quanto o espelhamento de porta remota de Camada 2. Caso contrário, o MVRP pode registrar a VLAN de sonda remota com portas incorretas, o que faria com que a porta de monitoramento recebesse cópias indesejadas. Para mais informações sobre o MVRP, consulte o Guia de Configuração de Comutação de LAN de Camada 2.
Para monitorar o tráfego bidirecional de uma porta de origem, desative a aprendizagem de endereço MAC para a VLAN de sonda remota nos dispositivos de origem, intermediários e de destino. Para mais informações sobre aprendizagem de endereço MAC, consulte o Guia de Configuração de Comutação de LAN de Camada 2.
A porta membro de uma interface agregada de Camada 2 não pode ser configurada como a porta de monitoramento para o espelhamento de porta remota de Camada 2.
Lista de tarefas de configuração do espelhamento de porta remota de Camada 2 com método de porta refletora
Configurando o dispositivo de destino
- Criar um grupo de destino remoto
- Configurar a porta de monitoramento
- Configurar a VLAN de sonda remota
- Atribuir a porta de monitoramento à VLAN de sonda remota
Configurando o dispositivo de origem
- Criar um grupo de origem remoto
- Configurar fontes de espelhamento
- Configurar a porta refletora
- Configurar a VLAN de sonda remota
Lista de tarefas de configuração do espelhamento de porta remota de Camada 2 com método de porta de saída
Configurando o dispositivo de destino
- Criar um grupo de destino remoto
- Configurar a porta de monitoramento
- Configurar a VLAN de sonda remota
- Atribuir a porta de monitoramento à VLAN de sonda remota
Configurando o dispositivo de origem
- Criar um grupo de origem remoto
- Configurar fontes de espelhamento
- Configurar a porta de saída
- Configurar a VLAN de sonda remota
Criando um grupo de destino remoto
Restrições e diretrizes
Execute esta tarefa apenas no dispositivo de destino.
Procedimento
- Entre na visualização do sistema.
system-viewmirroring-group group-id remote-destinationConfigurando a porta de monitoramento
Restrições e diretrizes para a configuração da porta de monitoramento
Execute esta tarefa apenas no dispositivo de destino.
- Não habilite o recurso de spanning tree na porta de monitoramento.
- Use uma porta de monitoramento apenas para espelhamento de porta, para que o dispositivo de monitoramento de dados receba apenas o tráfego espelhado.
- Uma porta de monitoramento pode pertencer a apenas um grupo de espelhamento.
- Uma interface agregada de Camada 2 não pode ser configurada como a porta de monitoramento para um grupo de espelhamento.
Configurando a porta de monitoramento na visualização do sistema
- Entre na visualização do sistema.
system-viewmirroring-group group-id monitor-port interface-type interface-numberPor padrão, nenhuma porta de monitoramento é configurada para um grupo de destino remoto.
Configurando a porta de monitoramento na visualização da interface
- Entre na visualização do sistema.
system-viewinterface interface-type interface-numbermirroring-group group-id monitor-portPor padrão, uma porta não atua como a porta de monitoramento para nenhum grupo de destino remoto.
Configurando a VLAN de sonda remota
Restrições e diretrizes
Esta tarefa é necessária tanto nos dispositivos de origem quanto nos de destino.
- Apenas uma VLAN estática existente pode ser configurada como uma VLAN de sonda remota.
- Quando uma VLAN é configurada como uma VLAN de sonda remota, use-a exclusivamente para espelhamento de porta.
- Configure a mesma VLAN de sonda remota para o grupo de origem remoto e o grupo de destino remoto.
- O dispositivo suporta apenas uma VLAN de sonda remota.
Procedimento
- Entre na visualização do sistema.
system-viewmirroring-group group-id remote-probe vlan vlan-idPor padrão, nenhuma VLAN de sonda remota é configurada para um grupo de origem ou destino remoto.
Atribuindo a porta de monitoramento à VLAN de sonda remota
Restrições e diretrizes
Execute esta tarefa apenas no dispositivo de destino.
Procedimento
- Entre na visualização do sistema.
system-viewinterface interface-type interface-number- Atribua uma porta de acesso à VLAN de sonda remota.
port access vlan vlan-idport trunk permit vlan vlan-idport hybrid vlan vlan-id { tagged | untagged }
Para mais informações sobre os comandos port access vlan, port trunk permit vlan e port hybrid vlan, consulte o Guia de Referência de Comandos de Comutação de LAN de Camada 2.
Criando um grupo de origem remoto
Restrições e diretrizes
Execute esta tarefa apenas no dispositivo de origem.
Procedimento
- Entre na visualização do sistema.
system-viewmirroring-group group-id remote-sourceConfigurando fontes de espelhamento
Restrições e diretrizes para a configuração de fonte de espelhamento
Execute esta tarefa apenas no dispositivo de origem.
Quando você configura portas de origem para um grupo de origem remoto, siga estas restrições e diretrizes:
- Não atribua uma porta de origem de um grupo de espelhamento à VLAN de sonda remota do grupo de espelhamento.
- Um grupo de espelhamento pode conter várias portas de origem.
- Uma porta pode ser configurada como porta de origem unidirecional para no máximo dois grupos de espelhamento: um para o espelhamento de tráfego de entrada e outro para o espelhamento de tráfego de saída. Como porta de origem bidirecional, uma porta pode ser atribuída a apenas um grupo de espelhamento.
- O dispositivo suporta apenas um grupo de espelhamento para espelhamento de tráfego de saída ou bidirecional.
- Uma porta de origem não pode ser configurada como porta refletora, porta de monitoramento ou porta de saída.
- Uma interface agregada de Camada 2 não pode ser configurada como porta de origem para um grupo de espelhamento.
Configurando portas de origem
Configure portas de origem na visualização do sistema:
- Entre na visualização do sistema.
system-viewmirroring-group group-id mirroring-port interface-list { both | inbound | outbound }Por padrão, nenhuma porta de origem é configurada para um grupo de origem remoto.
Configure portas de origem na visualização da interface:
- Entre na visualização do sistema.
system-viewinterface interface-type interface-numbermirroring-group group-id mirroring-port { both | inbound | outbound }Por padrão, uma porta não atua como porta de origem para nenhum grupo de origem remoto.
Configurando a porta refletora
Restrições e diretrizes para a configuração da porta refletora
Execute esta tarefa apenas no dispositivo de origem.
Um grupo de origem remoto suporta apenas uma porta refletora.
Configurando a porta refletora na visualização do sistema
- Entre na visualização do sistema.
system-viewmirroring-group group-id reflector-port interface-type interface-numberATENÇÃO:
- A porta a ser configurada como porta refletora deve ser uma porta não utilizada. Não conecte um cabo de rede a uma porta refletora.
- Quando uma porta é configurada como porta refletora, as configurações padrão da porta são restauradas automaticamente. Você não pode configurar outros recursos na porta refletora.
- Se uma porta IRF estiver vinculada a apenas uma interface física, não configure a interface física como uma porta refletora. Caso contrário, o IRF pode se dividir.
Por padrão, nenhuma porta refletora é configurada para um grupo de origem remoto.
Configurando a porta refletora na visualização da interface
- Entre na visualização do sistema.
system-viewinterface interface-type interface-numbermirroring-group group-id reflector-portATENÇÃO:
- A porta a ser configurada como porta refletora deve ser uma porta não utilizada. Não conecte um cabo de rede a uma porta refletora.
- Quando uma porta é configurada como porta refletora, as configurações padrão da porta são restauradas automaticamente. Você não pode configurar outros recursos na porta refletora.
- Se uma porta IRF estiver vinculada a apenas uma interface física, não configure a interface física como uma porta refletora. Caso contrário, o IRF pode se dividir.
Por padrão, uma porta não atua como a porta refletora para nenhum grupo de origem remoto.
Configurando a porta de saída
Restrições e diretrizes para a configuração da porta de saída
Execute esta tarefa apenas no dispositivo de origem.
Desabilite os seguintes recursos na porta de saída:
- Spanning tree.
- 802.1X.
- IGMP snooping.
- Static ARP.
- Aprendizado de endereço MAC.
- Uma porta de um grupo de espelhamento existente não pode ser configurada como uma porta de saída.
- Um grupo de espelhamento suporta apenas uma porta de saída.
Configurando a porta de saída na visualização do sistema
- Entre na visualização do sistema.
system-viewmirroring-group group-id monitor-egress interface-type interface-numberPor padrão, nenhuma porta de saída é configurada para um grupo de origem remoto.
interface interface-type interface-number- Atribua uma porta de trunk à VLAN de sonda remota.
port trunk permit vlan vlan-idport hybrid vlan vlan-id { tagged | untagged }
Para mais informações sobre os comandos port trunk permit vlan e port hybrid vlan, consulte o Guia de Referência de Comandos de Comutação de LAN de Camada 2.
Configurando a porta de saída na visualização da interface
- Entre na visualização do sistema.
system-viewinterface interface-type interface-numbermirroring-group group-id monitor-egressPor padrão, uma porta não atua como a porta de saída para nenhum grupo de origem remoto.
Comandos de exibição e manutenção para espelhamento de portas
Execute os comandos de exibição em qualquer modo.
| Tarefa | Comando | ||
| Exibir informações do grupo de espelhamento. |
|
Exemplos de configuração de espelhamento de porta
Exemplo: Configurando espelhamento de porta local
Configuração da rede:
Como mostrado, configure o espelhamento de porta local no modo de porta de origem para permitir que o servidor monitore o tráfego bidirecional dos dois departamentos.
Procedimento
# Criar o grupo de espelhamento local 1.device> system-view
[device] mirroring-group 1 local# Configurar GigabitEthernet 1/0/1 e GigabitEthernet 1/0/2 como portas de origem para o grupo de espelhamento local 1.
[device] mirroring-group 1 mirroring-port gigabitethernet 1/0/1 gigabitethernet 1/0/2 both# Configurar GigabitEthernet 1/0/3 como a porta de monitoramento para o grupo de espelhamento local 1.
[device] mirroring-group 1 monitor-port gigabitethernet 1/0/3# Desativar o recurso de spanning tree na porta de monitoramento (GigabitEthernet 1/0/3).
[device] interface gigabitethernet 1/0/3
[device-GigabitEthernet1/0/3] undo stp enable
[device-GigabitEthernet1/0/3] quit
Verificando a configuração
# Verificar a configuração do grupo de espelhamento.
[device] display mirroring-group all
Grupo de espelhamento 1:
Tipo: Local
Status: Ativo
Porta de espelhamento:
GigabitEthernet1/0/1 Ambos
GigabitEthernet1/0/2 Ambos
Porta de monitoramento: GigabitEthernet1/0/3
Exemplo: Configurando o espelhamento de porta remota de Camada 2 (com porta de refletor)
Configuração da rede:
Conforme mostrado , configure o espelhamento de porta remota de Camada 2 para permitir que o servidor monitore o tráfego bidirecional do Departamento de Marketing.
Procedimento
-
# Configure a GigabitEthernet 1/0/1 como uma porta trunk e atribua a porta à VLAN 2.
<DeviceC> system-view [DeviceC] interface gigabitethernet 1/0/1 [DeviceC-GigabitEthernet1/0/1] port link-type trunk [DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 2 [DeviceC-GigabitEthernet1/0/1] quit -
Criar a VLAN 2.
<DeviceB> system-view [DeviceB] vlan 2 [DeviceB] undo mac-address mac-learning enable [DeviceB] quit -
Configurar a GigabitEthernet 1/0/1 como uma porta trunk e atribuir a porta à VLAN 2.
[DeviceB] interface gigabitethernet 1/0/1 [DeviceB-GigabitEthernet1/0/1] port link-type trunk [DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 2 [DeviceB-GigabitEthernet1/0/1] quit -
Configurar a GigabitEthernet 1/0/2 como uma porta trunk e atribuir a porta à VLAN 2.
[DeviceB] interface gigabitethernet 1/0/2 [DeviceB-GigabitEthernet1/0/2] port link-type trunk [DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 2 [DeviceB-GigabitEthernet1/0/2] quit
Procedimento para Configuração do Dispositivo A (o dispositivo de origem):
-
Criar um grupo de origem remoto.
<DeviceA> system-view [DeviceA] mirroring-group 1 remote-source -
Criar a VLAN 2.
[DeviceA] vlan 2 [DeviceA-vlan2] undo mac-address mac-learning enable [DeviceA-vlan2] quit -
Configurar a VLAN 2 como a VLAN de sonda remota para o grupo de espelhamento.
[DeviceA] mirroring-group 1 remote-probe vlan 2 -
Configurar a GigabitEthernet 1/0/1 como uma porta de origem para o grupo de espelhamento.
[DeviceA] mirroring-group 1 mirroring-port gigabitethernet 1/0/1 both -
Configurar a GigabitEthernet 1/0/3 como a porta refletora para o grupo de espelhamento.
[DeviceA] mirroring-group 1 reflector-port gigabitethernet 1/0/3 -
Configurar a GigabitEthernet 1/0/2 como uma porta trunk e atribuir a porta à VLAN 2.
[DeviceA] interface gigabitethernet 1/0/2 [DeviceA-GigabitEthernet1/0/2] port link-type trunk [DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 2 [DeviceA-GigabitEthernet1/0/2] quit
Verificando a Configuração dos Grupos de Espelhamento em Device C:
[DeviceC] display mirroring-group all
Mirroring group 2:
Type: Remote destination
Status: Active
Monitor port: GigabitEthernet1/0/2
Remote probe VLAN: 2
Verificando a Configuração dos Grupos de Espelhamento em Device A:
[DeviceA] display mirroring-group all
Mirroring group 1:
Type: Remote source
Status: Active
Mirroring port: GigabitEthernet1/0/1 Both
Reflector port: GigabitEthernet1/0/3
Remote probe VLAN: 2
Exemplo: Configurando o Espelhamento de Porta Remota Layer 2 (com porta de saída)
Configuração da Rede
configure o espelhamento remoto de porta Layer 2 para permitir que o servidor monitore o tráfego bidirecional do Departamento de Marketing.
Configure a GigabitEthernet 1/0/1 como uma porta trunk e atribua a porta à VLAN 2.
Procedimento
- Configurar o Dispositivo C (o dispositivo de destino):
# Configure GigabitEthernet 1/0/1 as a trunk port, and assign the port to VLAN 2.
system-view
[DeviceC] interface gigabitethernet 1/0/1
[DeviceC-GigabitEthernet1/0/1] port link-type trunk
[DeviceC-GigabitEthernet1/0/1] port trunk permit vlan 2
[DeviceC-GigabitEthernet1/0/1] quit
# Create a remote destination group.
[DeviceC] mirroring-group 2 remote-destination
# Create VLAN 2.
[DeviceC] vlan 2
# Disable MAC address learning for VLAN 2.
[DeviceC-vlan2] undo mac-address mac-learning enable
[DeviceC-vlan2] quit
# Configure VLAN 2 as the remote probe VLAN for the mirroring group.
[DeviceC] mirroring-group 2 remote-probe vlan 2
# Configure GigabitEthernet 1/0/2 as the monitor port for the mirroring group.
[DeviceC] interface gigabitethernet 1/0/2
[DeviceC-GigabitEthernet1/0/2] mirroring-group 2 monitor-port
# Disable the spanning tree feature on GigabitEthernet 1/0/2.
[DeviceC-GigabitEthernet1/0/2] undo stp enable
# Assign GigabitEthernet 1/0/2 to VLAN 2 as an access port.
[DeviceC-GigabitEthernet1/0/2] port access vlan 2
[DeviceC-GigabitEthernet1/0/2] quit
- Configurar o Dispositivo B (o dispositivo intermediário):
Dispositivo de origem Dispositivo A GE1/0/1 GE1/0/2 Servidor Departamento de Marketing Dispositivo intermediário Dispositivo B Dispositivo de destino Dispositivo C GE1/0/1 GE1/0/2 GE1/0/1 GE1/0/2 Porta comum Porta de origem Porta de saída Porta de monitoramento VLAN 2 VLAN 2 18
# Criar VLAN 2.
system-view
[DeviceB] vlan 2
# Desabilitar o aprendizado de endereço MAC para a VLAN 2.
[DeviceB-vlan2] undo mac-address mac-learning enable
[DeviceB-vlan2] quit
# Configurar GigabitEthernet 1/0/1 como uma porta trunk e atribuir a porta à VLAN 2.
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] port link-type trunk
[DeviceB-GigabitEthernet1/0/1] port trunk permit vlan 2
[DeviceB-GigabitEthernet1/0/1] quit
# Configurar GigabitEthernet 1/0/2 como uma porta trunk e atribuir a porta à VLAN 2.
[DeviceB] interface gigabitethernet 1/0/2
[DeviceB-GigabitEthernet1/0/2] port link-type trunk
[DeviceB-GigabitEthernet1/0/2] port trunk permit vlan 2
[DeviceB-GigabitEthernet1/0/2] quit
- Configurar o Dispositivo A (o dispositivo de origem):
# Criar um grupo de origem remota.
system-view
[DeviceA] mirroring-group 1 remote-source # Criar VLAN 2.
[DeviceA] vlan 2# Desabilitar o aprendizado de endereço MAC para a VLAN 2.
[DeviceA-vlan2] undo mac-address mac-learning enable
[DeviceA-vlan2] quit# Configurar VLAN 2 como a VLAN de sonda remota do grupo de espelhamento.
[DeviceA] mirroring-group 1 remote-probe vlan 2# Configurar GigabitEthernet 1/0/1 como uma porta de origem para o grupo de espelhamento.
[DeviceA] mirroring-group 1 mirroring-port gigabitethernet 1/0/1 both# Configurar GigabitEthernet 1/0/2 como a porta de saída para o grupo de espelhamento.
[DeviceA] mirroring-group 1 monitor-egress gigabitethernet 1/0/2# Configurar GigabitEthernet 1/0/2 como uma porta trunk e atribuir a porta à VLAN 2.
[DeviceA] interface gigabitethernet 1/0/2
[DeviceA-GigabitEthernet1/0/2] port link-type trunk
[DeviceA-GigabitEthernet1/0/2] port trunk permit vlan 2# Desabilitar o recurso de spanning tree na porta.
[DeviceA-GigabitEthernet1/0/2] undo stp enable
[DeviceA-GigabitEthernet1/0/2] quit
Verificando a configuração
# Verificar a configuração do grupo de espelhamento no Dispositivo C.
[DeviceC] display mirroring-group all
Mirroring group 2:
Type: Remote destination
Status: Active
Monitor port: GigabitEthernet1/0/2
Remote probe VLAN: 2# Verificar a configuração do grupo de espelhamento no Dispositivo A.
[DeviceA] display mirroring-group all
Mirroring group 1:
Type: Remote source
Status: Active
Mirroring port:
GigabitEthernet1/0/1 Both
Monitor egress port: GigabitEthernet1/0/2
Remote probe VLAN: 2
Configurando o espelhamento de fluxo
Sobre o espelhamento de fluxo
O espelhamento de fluxo copia pacotes que correspondem a uma classe para um destino para análise e monitoramento de pacotes. É implementado por meio de QoS. Para implementar o espelhamento de fluxo por meio de QoS, execute as seguintes tarefas:
- Definir classes de tráfego e configurar critérios de correspondência para classificar pacotes a serem espelhados. O espelhamento de fluxo permite classificar pacotes a serem analisados de forma flexível, definindo critérios de correspondência.
-
Configurar comportamentos de tráfego para espelhar os pacotes correspondentes para o destino especificado. Você pode configurar uma ação para espelhar os pacotes correspondentes para um dos seguintes destinos:
- Interface - Os pacotes correspondentes são copiados para uma interface e depois encaminhados para um dispositivo de monitoramento de dados para análise.
- CPU - Os pacotes correspondentes são copiados para a CPU de um dispositivo membro do IRF. A CPU analisa os pacotes ou os entrega para camadas superiores.
Restrições e diretrizes: Configuração de espelhamento de fluxo
Para obter informações sobre os comandos de configuração exceto o comando mirror-to, consulte o Guia de Referência de Comandos de ACL e QoS.
Tarefas de espelhamento de fluxo em resumo
Para configurar o espelhamento de fluxo, execute as seguintes tarefas:
- Configurando uma classe de tráfego
- Configurando um comportamento de tráfego
- Configurando uma política de QoS
- Aplicando uma política de QoS
Configurando uma classe de tráfego
system-view
traffic classifier classifier-name [ operator { and | or } ]
if-match match-criteria
display traffic classifier
Configurando um comportamento de tráfego
system-view
traffic behavior behavior-name
mirror-to interface interface-type interface-number
mirror-to cpu
display traffic behavior
Configurando uma política de QoS
system-view
qos policy policy-name
classifier classifier-name behavior behavior-name
display qos policy
Aplicando uma política de QoS
Aplicando uma política de QoS a uma interface
system-view
interface interface-type interface-number
qos apply policy policy-name inbound
display qos policy interface
Aplicando uma política de QoS a VLANs
system-view
qos vlan-policy policy-name vlan vlan-id-list inbound
display qos vlan-policy
Aplicando uma política de QoS globalmente
system-view
qos apply policy policy-name global inbound
display qos policy global
Exemplos de configuração de espelhamento de fluxo
Exemplo: Configurando o espelhamento de fluxo
Configuração da rede
Configure o espelhamento de fluxo para que o servidor possa monitorar o seguinte tráfego:
- Todo o tráfego que o Departamento Técnico envia para acessar a Internet.
- O tráfego IP que o Departamento Técnico envia para o Departamento de Marketing durante o horário de trabalho (8:00 às 18:00) nos dias úteis.
Figura 7 Diagrama de rede
Procedimento
Criar o intervalo de horas de trabalho, "work", em que o horário de trabalho é das 8:00 às 18:00 nos dias úteis.
system-view
[Device] time-range work 8:00 to 18:00 working-day
Criar a ACL IPv4 avançada 3000 para permitir pacotes do Departamento Técnico acessarem a Internet e o Departamento de Marketing durante o horário de trabalho.
[Device] acl advanced 3000
[Device-acl-ipv4-adv-3000] rule permit tcp source 192.168.2.0 0.0.0.255 destination-port eq www
[Device-acl-ipv4-adv-3000] rule permit ip source 192.168.2.0 0.0.0.255 destination 192.168.1.0 0.0.0.255 time-range work
[Device-acl-ipv4-adv-3000] quit
Criar a classe de tráfego "tech_c" e configurar o critério de correspondência como ACL 3000.
[Device] traffic classifier tech_c
[Device-classifier-tech_c] if-match acl 3000
[Device-classifier-tech_c] quit
Criar o comportamento de tráfego "tech_b", configurar a ação de espelhamento do tráfego para GigabitEthernet 1/0/3.
[Device] traffic behavior tech_b
[Device-behavior-tech_b] mirror-to interface gigabitethernet 1/0/3
[Device-behavior-tech_b] quit
Criar a política de QoS "tech_p" e associar a classe de tráfego "tech_c" ao comportamento de tráfego "tech_b" na política de QoS.
[Device] qos policy tech_p
[Device-qospolicy-tech_p] classifier tech_c behavior tech_b
[Device-qospolicy-tech_p] quit
Aplicar a política de QoS "tech_p" aos pacotes de entrada de GigabitEthernet 1/0/4.
[Device] interface gigabitethernet 1/0/4
[Device-GigabitEthernet1/0/4] qos apply policy tech_p inbound
[Device-GigabitEthernet1/0/4] quit
Verificação da configuração
Verificar se o servidor pode monitorar o seguinte tráfego:
- Todo o tráfego enviado pelo Departamento Técnico para acessar a Internet.
- O tráfego IP que o Departamento Técnico envia para o Departamento de Marketing durante o horário de trabalho nos dias úteis.
(Detalhes não mostrados.)
Configurando sFlow
Sobre sFlow
sFlow é uma tecnologia de monitoramento de tráfego.
O sistema sFlow envolve um agente sFlow incorporado em um dispositivo e um coletor sFlow remoto. O agente sFlow coleta informações de contadores de interface e informações de pacotes e encapsula as informações amostradas em pacotes sFlow. Quando o buffer de pacotes sFlow está cheio, ou o temporizador de envelhecimento (fixado em 1 segundo) expira, o agente sFlow realiza as seguintes ações:
- Encapsula os pacotes sFlow nos datagramas UDP.
- Envia os datagramas UDP para o coletor sFlow especificado.
O coletor sFlow analisa as informações e exibe os resultados. Um coletor sFlow pode monitorar vários agentes sFlow.
O sFlow fornece os seguintes mecanismos de amostragem:
- Amostragem de fluxo - Obtém informações de pacotes.
- Amostragem de contador - Obtém informações de contadores de interface.
O sFlow pode usar amostragem de fluxo e amostragem de contador ao mesmo tempo.
Figura 1 - Sistema sFlow
Protocolos e padrões
- RFC 3176, sFlow da InMon Corporation: Um Método para Monitorar o Tráfego em Redes Comutadas e Roteadas
- sFlow.org, sFlow Versão 5
Configurando informações básicas do sFlow
Restrições e diretrizes
Como prática recomendada, configure manualmente um endereço IP para o agente sFlow. O dispositivo verifica periodicamente se o agente sFlow possui um endereço IP. Se o agente sFlow não tiver um endereço IP, o dispositivo seleciona automaticamente um endereço IPv4 para o agente sFlow, mas não salva o endereço IPv4 no arquivo de configuração.
Apenas um endereço IP pode ser configurado para o agente sFlow no dispositivo, e um endereço IP recém-configurado sobrescreve o existente.
Coletor sFlow do dispositivo
Ethernet
header
UDP
header Datagrama sFlow IP
Amostragem de cabeçalho de fluxo
Amostragem de contador
Agente sFlow
Procedimento
- Entre no modo de sistema.
system-view
sflow agent { ip endereço-ipv4 | ipv6 endereço-ipv6 }
Por padrão, nenhum endereço IP é configurado para o agente sFlow.
sflow collector id-coletor { ip endereço-ipv4 | ipv6 endereço-ipv6 }
[ porta número-porta | tamanho-datagrama tamanho | tempo-espera segundos | descrição
string ] *
Por padrão, nenhuma informação do coletor sFlow é configurada.
sflow source { ip endereço-ipv4 | ipv6 endereço-ipv6 } *
Por padrão, o endereço IP de origem é determinado pelo roteamento.
Configurando amostragem de fluxo
Sobre amostragem de fluxo
Execute esta tarefa para configurar a amostragem de fluxo em uma interface Ethernet. O agente sFlow realiza as seguintes tarefas:
- Entre no modo de sistema.
system-view
interface interface-type interface-number
sflow sampling-mode random
Por padrão, a amostragem aleatória é usada.
sflow sampling-rate rate
Por padrão, a amostragem de fluxo está desativada. Como prática recomendada, defina o intervalo de amostragem para 2n, que é maior ou igual a 8192, por exemplo, 32768.
sflow flow max-header length
A configuração padrão é de 128 bytes. Como prática recomendada, use a configuração padrão.
sflow flow [ instância id-instância ] collector id-coletor
Por padrão, nenhuma instância sFlow ou coletor sFlow é especificado para a amostragem de fluxo.
Configurando amostragem de contador
Sobre amostragem de fluxo
Execute esta tarefa para configurar a amostragem de contadores em uma interface Ethernet. O agente sFlow realiza as seguintes tarefas:
- Entre no modo de sistema.
system-view
interface interface-type interface-number
sflow counter interval interval
Por padrão, a amostragem de contadores está desativada.
sflow counter [ instância id-instância ] collector id-coletor
Por padrão, nenhuma instância sFlow ou coletor sFlow é especificado para a amostragem de contadores.
Comandos de exibição e manutenção para sFlow
Execute os comandos de exibição em qualquer visualização.
| Tarefa | Comando | ||
| Exibir configuração do sFlow. | display sflow |
Exemplos de configuração sFlow
Exemplo: Configurando sFlow
Configuração de rede
Execute as seguintes tarefas:
- Configure o sampling de fluxo no modo aleatório e o sampling de contagem no GigabitEthernet 1/0/1 do dispositivo para monitorar o tráfego na porta.
- Configure o dispositivo para enviar informações amostradas em pacotes sFlow através do GigabitEthernet 1/0/3 para o coletor sFlow.

Procedimento
- Configure os endereços IP e máscaras de sub-rede para as interfaces, conforme mostrado (Detalhes não mostrados.)
- Configure o agente sFlow e configure informações sobre o coletor sFlow:
# Configure o endereço IP para o agente sFlow.
<Device> system-view
[Device] sflow agent ip 3.3.3.1# Configure informações sobre o coletor sFlow. Especifique o ID do coletor sFlow como 1, endereço IP como 3.3.3.2, número da porta como 6343 (padrão) e descrição como netserver.
[Device] sflow collector 1 ip 3.3.3.2 description netserver- Configure o sampling de contagem:
# Ative o sampling de contagem e defina o intervalo de amostragem de contagem como 120 segundos no GigabitEthernet 1/0/1.
[Device] interface gigabitethernet 1/0/1
[Device-GigabitEthernet1/0/1] sflow counter interval 120# Especifique o coletor sFlow 1 para o sampling de contagem.
[Device-GigabitEthernet1/0/1] sflow counter collector 1- Configure o sampling de fluxo:
# Ative o sampling de fluxo e defina o modo de sampling de fluxo como aleatório e o intervalo de amostragem como 32768.
[Device-GigabitEthernet1/0/1] sflow sampling-mode random
[Device-GigabitEthernet1/0/1] sflow sampling-rate 32768# Especifique o coletor sFlow 1 para o sampling de fluxo.
[Device-GigabitEthernet1/0/1] sflow flow collector 1Verificação da configuração
# Verifique os seguintes itens: • GigabitEthernet 1/0/1 habilitado com sFlow está ativo. • O intervalo de amostragem de contagem é de 120 segundos. • O intervalo de amostragem de fluxo é de 4000 (um pacote é amostrado a cada 4000 pacotes).
[Device-GigabitEthernet1/0/1] display sflow
Informações de solução de problemas sFlow
O coletor sFlow remoto não consegue receber pacotes sFlow
Sintoma
O coletor sFlow remoto não consegue receber pacotes sFlow.
Análise
As possíveis razões incluem:
- O coletor sFlow não está especificado.
- O sFlow não está configurado na interface.
- O endereço IP do coletor sFlow especificado no agente sFlow é diferente do do coletor sFlow remoto.
- O link físico entre o dispositivo e o coletor sFlow falha.
- O comprimento de um pacote sFlow é inferior à soma dos dois seguintes valores:
- O comprimento do cabeçalho do pacote sFlow.
- O número de bytes que o sampling de fluxo pode copiar por pacote.
Solução
Para resolver o problema:
- Use o comando display sflow para verificar se o sFlow está configurado corretamente.
- Verifique se um endereço IP correto está configurado para o dispositivo se comunicar com o coletor sFlow.
- Verifique se o link físico entre o dispositivo e o coletor sFlow está ativo.
- Verifique se o comprimento de um pacote sFlow é maior que a soma dos dois seguintes valores:
- O comprimento do cabeçalho do pacote sFlow.
- O número de bytes (como prática recomendada, use a configuração padrão) que o sampling de fluxo pode copiar por pacote.
Configurando o centro de informações
Sobre o centro de informações
O centro de informações no dispositivo recebe logs gerados por módulos de origem e os envia para destinos diferentes de acordo com as regras de saída de logs. Com base nos logs, você pode monitorar o desempenho do dispositivo e solucionar problemas de rede.
Figura 1 Diagrama do centro de informações
Tipos de logs
Os logs são classificados nos seguintes tipos:
- Logs padrão do sistema - Registram informações comuns do sistema. A menos que especificado de outra forma, o termo "logs" neste documento refere-se aos logs padrão do sistema.
- Logs de diagnóstico - Registram mensagens de depuração.
- Logs de segurança - Registram informações de segurança, como informações de autenticação e autorização.
- Logs ocultos - Registram informações de log que não são exibidas no terminal, como comandos de entrada.
- Logs de rastreamento - Registram rastreamento do sistema e mensagens de depuração, que só podem ser visualizados após a instalação do pacote devkit.
Níveis de log
Os logs são classificados em oito níveis de gravidade de 0 a 7 em ordem decrescente. O centro de informações emite logs com um nível de gravidade que é maior ou igual ao nível especificado. Por exemplo, se você especificar um nível de gravidade de 6 (informativo), os logs que têm um nível de gravidade de 0 a 6 são emitidos.
| Valor de gravidade | Nível | Descrição | |||
| 0 | Emergência | O sistema está inutilizável. Por exemplo, a autorização do sistema expirou. | |||
| 1 | Alerta | Ação deve ser tomada imediatamente. Por exemplo, o tráfego em uma interface excede o limite superior. | |||
| 2 | Crítico | Condição crítica. Por exemplo, a temperatura do dispositivo excede o limite superior, o módulo de energia falha ou a bandeja do ventilador falha. | |||
| 3 | Erro | Condição de erro. Por exemplo, o estado do link muda. | |||
| 4 | Aviso | Condição de aviso. Por exemplo, uma interface está desconectada ou os recursos de memória são esgotados. | |||
| 5 | Notificação | Condição normal, mas significativa. Por exemplo, um terminal faz login no dispositivo ou o dispositivo reinicia. | |||
| 6 | Informativo | Mensagem informativa. Por exemplo, um comando ou uma operação de ping é executado. | |||
| 7 | Depuração | Mensagem de depuração. |
Destinos de logs
O sistema envia logs para os seguintes destinos: console, terminal de monitoramento, buffer de log, host de log e arquivo de log. Os destinos de saída de log são independentes e podem ser configurados após a ativação do centro de informações. Um log pode ser enviado para vários destinos.
Regras de saída de logs padrão
Uma regra de saída de log especifica os módulos de origem e o nível de gravidade dos logs que podem ser enviados para um destino. Os logs que correspondem à regra de saída são enviados para o destino. A Tabela 2 mostra as regras de saída de log padrão.
| Destino | Módulos de origem de log | Interruptor de saída | Gravidade | ||||
| Console | Todos os módulos suportados | Ativado | Depuração | ||||
| Terminal de monitoramento | Todos os módulos suportados | Desativado | Depuração | ||||
| Host de log | Todos os módulos suportados | Ativado | Informativo | ||||
| Buffer de log | Todos os módulos suportados | Ativado | Informativo | ||||
| Arquivo de log | Todos os módulos suportados | Ativado | Informativo |
Regras de saída de logs padrão para logs de diagnóstico
Logs de diagnóstico só podem ser enviados para o arquivo de log de diagnóstico e não podem ser filtrados por módulos de origem e níveis de gravidade. A Tabela 3 mostra a regra de saída padrão para logs de diagnóstico.
| Destino | Módulos de origem de log | Interruptor de saída | Gravidade | ||||
| Arquivo de log de diagnóstico | Todos os módulos suportados | Ativado | Depuração |
Regras de saída de logs padrão para logs de segurança
Logs de segurança só podem ser enviados para o arquivo de log de segurança e não podem ser filtrados por módulos de origem e níveis de gravidade. A Tabela 4 mostra a regra de saída padrão para logs de segurança.
| Destino | Módulos de origem de log | Interruptor de saída | Gravidade | ||||
| Arquivo de log de segurança | Todos os módulos suportados | Desativado | Depuração |
Regras de saída de logs padrão para logs ocultos
Logs ocultos podem ser enviados para o host de log, o buffer de log e o arquivo de log. A Tabela 5 mostra as regras de saída padrão para logs ocultos.
| Destino | Módulos de origem de log | Interruptor de saída | Gravidade | ||||
| Host de log | Todos os módulos suportados | Ativado | Informativo | ||||
| Buffer de log | Todos os módulos suportados | Ativado | Informativo | ||||
| Arquivo de log | Todos os módulos suportados | Ativado | Informativo |
Regras de saída de logs padrão para logs de rastreamento
Logs de rastreamento só podem ser enviados para o arquivo de log de rastreamento e não podem ser filtrados por módulos de origem e níveis de gravidade. A Tabela 6 mostra as regras de saída padrão para logs de rastreamento.
| Destino | Módulos de origem de log | Interruptor de saída | Gravidade | ||||
| Arquivo de log de rastreamento | Todos os módulos suportados | Ativado | Depuração |
Formatos de log e descrições de campos
Formatos de log
O formato dos logs varia de acordo com os destinos de saída. A Tabela 7 mostra o formato original das informações de log, que pode ser diferente do que você vê. O formato real varia de acordo com a ferramenta de resolução de log usada.
| Destino de saída | Formato | ||
| Console, terminal de monitoramento, buffer de log ou arquivo de log | Prefixo Timestamp Sysname Módulo/Nível/Mnemônico: Conteúdo | ||
| Host de log |
• Formato padrão: | | |
Exemplo:
%Nov 24 14:21:43:502 2016 Sysname SHELL/5/SHELL_LOGIN: VTY logged in from 192.168.1.26
• Host de log
• Formato padrão:
Exemplo:
<190>Nov 24 16:22:21 2016 Sysname %%10 SHELL/5/SHELL_LOGIN: -DevIP=1.1.1.1; VTY logged in from 192.168.1.26
<190>Nov 24 16:22:21 2016 Sysname %%10SHELL/5/SHELL_LOGIN: -DevIP=1.1.1.1; VTY logged in from 192.168.1.26
• Formato Unicom:
Exemplo:
<189>Oct 13 16:48:08 2016 10.1.1.1 10SHELL/5/210231a64jx073000020: VTY logged in from 192.168.1.21
• Formato CMCC:
Exemplo:
<189>Oct 9 14:59:04 2016 Sysname %10SHELL/5/SHELL_LOGIN: -DevIP=1.1.1.1; VTY logged in from 192.168.1.21
| Campo | Descrição | ||
| Prefixo (tipo de informação) |
Um log enviado para um destino que não seja o host de log tem um identificador na frente do carimbo de data e hora:
| ||
| PRI (prioridade) |
Um log destinado ao host de log possui um identificador de prioridade na frente do carimbo de data e hora. A prioridade é calculada usando a seguinte fórmula: facility*8+level, onde:
| ||
| Timestamp | Registra a hora em que o log foi gerado. Logs enviados para o host de log e aqueles enviados para outros destinos têm precisões de timestamp diferentes, e seus formatos de timestamp são configurados com comandos diferentes. Para obter mais informações, consulte a Tabela 9 e a Tabela 10. | ||
| Hostip | Endereço IP de origem do log. Se o comando info-center loghost source estiver configurado, este campo exibe o endereço IP da interface de origem especificada. Caso contrário, este campo exibe o sysname. Este campo existe apenas em logs enviados para o host de log no formato unicom. | ||
| Número de série | Número de série do dispositivo que gerou o log. Este campo existe apenas em logs enviados para o host de log no formato unicom. | ||
| Sysname (nome do host ou endereço IP do host) | O sysname é o nome do host ou endereço IP do dispositivo que gerou o log. Você pode usar o comando sysname para modificar o nome do dispositivo. | ||
| %% (ID do fornecedor) | Indica que a informação foi gerada por um dispositivo Intelbras. Este campo existe apenas em logs enviados para o host de log. | ||
| vv (informações da versão) | Identifica a versão do log e tem um valor de 10. Este campo existe apenas em logs enviados para o host de log. | ||
| Módulo | Especifica o nome do módulo que gerou o log. Você pode inserir o comando info-center source ? no modo de sistema para visualizar a lista de módulos. | ||
| Nível | Identifica o nível do log. Consulte a Tabela 1 para obter mais informações sobre os níveis de gravidade. | ||
| Mnemônico | Descreve o conteúdo do log. Ele contém uma sequência de até 32 caracteres. | ||
| Origem | Campo opcional que identifica o remetente do log. Este campo existe apenas em logs enviados para o host de log no formato unicom ou padrão. | ||
| Conteúdo | Fornece o conteúdo do log. |
| Parâmetro de Timestamp | Descrição | ||
| boot | Tempo decorrido desde a inicialização do sistema, no formato de xxx.yyy. xxx representa os 32 bits superiores e yyy representa os 32 bits inferiores dos milissegundos decorridos. Logs que são enviados para todos os destinos, exceto um host de log, suportam este parâmetro. | ||
| date | Data e hora atuais. Para logs enviados para um host de log, o timestamp pode estar no formato de MMM DD hh:mm:ss YYYY (preciso até segundos) ou MMM DD hh:mm:ss.ms YYYY (preciso até milissegundos). Para logs enviados para outros destinos, o timestamp está no formato de MMM DD hh:mm:ss:ms YYYY. | ||
| iso | Formato de timestamp estipulado na norma ISO 8601, preciso até segundos (padrão) ou milissegundos. Somente logs que são enviados para um host de log suportam este parâmetro. | ||
| none | Nenhum timestamp é incluído. Todos os logs suportam este parâmetro. | ||
| no-year-date | Data e hora atuais sem ano ou informações de milissegundos, no formato de MMM DD hh:mm:ss. Somente logs que são enviados para um host de log suportam este parâmetro. |
Conformidade com FIPS
O dispositivo suporta o modo FIPS que está em conformidade com os requisitos do NIST FIPS 140-2. O suporte para recursos, comandos e parâmetros pode ser diferente no modo FIPS e no modo não-FIPS. Para obter mais informações sobre o modo FIPS, consulte o Guia de Configuração de Segurança.
Tarefas do Centro de Informações em Resumo
Gerenciando Logs do Sistema Padrão
- Habilitando o centro de informações
- Enviando logs para vários destinos
- Escolha as seguintes tarefas conforme necessário:
- Enviando logs para o console
- Enviando logs para o terminal de monitoramento
- Enviando logs para hosts de log
- Enviando logs para o buffer de log
- Salvando logs no arquivo de log
- (Opcional.) Definindo o período mínimo de armazenamento para logs
- (Opcional.) Habilitando saída de informações síncrona
- (Opcional.) Configurando supressão de logs
- Habilitando supressão de logs duplicados
- Configurando supressão de logs para um módulo
- Desabilitando uma interface para gerar logs de link up ou link down
- (Opcional.) Habilitando notificações SNMP para logs do sistema
Gerenciando Logs Ocultos
- Habilitando o centro de informações
- Enviando logs para vários destinos
- Escolha as seguintes tarefas conforme necessário:
- Enviando logs para hosts de log
- Enviando logs para o buffer de log
- Salvando logs no arquivo de log
- (Opcional.) Definindo o período mínimo de armazenamento para logs
- (Opcional.) Configurando supressão de logs
- Habilitando supressão de logs duplicados
- Configurando supressão de logs para um módulo
Gerenciando Logs de Segurança
- Habilitando o centro de informações
- (Opcional.) Configurando supressão de logs
- Habilitando supressão de logs duplicados
- Configurando supressão de logs para um módulo
- Gerenciando logs de segurança
- Salvando logs de segurança no arquivo de log de segurança
- Gerenciando o arquivo de log de segurança
Gerenciando Logs de Diagnóstico
- Habilitando o centro de informações
- (Opcional.) Configurando supressão de logs
- Habilitando supressão de logs duplicados
- Configurando supressão de logs para um módulo
- Salvando logs de diagnóstico no arquivo de log de diagnóstico
Gerenciando Logs de Rastreamento
- Habilitando o centro de informações
- (Opcional.) Configurando supressão de logs
- Habilitando supressão de logs duplicados
- Configurando supressão de logs para um módulo
- Definindo o tamanho máximo do arquivo de log de rastreamento
Habilitando o Centro de Informações
Sobre habilitar o centro de informações
O centro de informações só pode enviar logs depois de ser habilitado.
Procedimento
- Acesse a visualização do sistema.
system-viewinfo-center enableEnviando logs para vários destinos
Enviando logs para o console
Restrições e diretrizes
Os comandos terminal monitor, terminal debugging e terminal logging só têm efeito para a conexão atual entre o terminal e o dispositivo. Se uma nova conexão for estabelecida, o padrão será restaurado.
Procedimento
- Acesse a visualização do sistema.
system-viewinfo-center source { module-name | default } console { deny | level severity }Para obter informações sobre as regras de saída padrão, consulte "Regras de saída padrão para logs".
info-center timestamp { boot | date | none }O formato padrão do carimbo de data e hora é data.
quitterminal monitorPor padrão, a saída de log para o console está habilitada.
terminal debuggingPor padrão, a exibição de informações de depuração no terminal atual está desabilitada.
terminal logging level severityA configuração padrão é 6 (informativa).
Enviando logs para o terminal de monitoramento
Sobre terminais de monitoramento
Os terminais de monitoramento se referem aos terminais que acessam o dispositivo através da linha AUX, VTY ou TTY.
Restrições e diretrizes
Os comandos terminal monitor, terminal debugging e terminal logging só têm efeito para a conexão atual entre o terminal e o dispositivo. Se uma nova conexão for estabelecida, o padrão será restaurado.
Procedimento
- Acesse a visualização do sistema.
system-viewinfo-center source { module-name | default } monitor { deny | level severity }Para obter informações sobre as regras de saída padrão, consulte "Regras de saída padrão para logs".
info-center timestamp { boot | date | none }O formato padrão do carimbo de data e hora é data.
quitterminal monitorPor padrão, a saída de log para o terminal de monitoramento está desabilitada.
terminal debuggingPor padrão, a exibição de informações de depuração no terminal atual está desabilitada.
terminal logging level severityA configuração padrão é 6 (informativa).
Enviando logs para hosts de log
Restrições e diretrizes
O dispositivo suporta os seguintes métodos (em ordem decrescente de prioridade) para enviar logs de um módulo para hosts de log designados:
- Saída de log rápida. Para informações sobre os módulos que suportam a saída rápida de log e como configurá-la, consulte "Configurando saída rápida de log".
- Log de fluxo. Para informações sobre os módulos que suportam a saída de log de fluxo e como configurá-la, consulte "Configurando log de fluxo".
- Centro de informações. Se você configurar vários métodos de saída de log para um módulo, apenas o método com a prioridade mais alta será eficaz.
Procedimento
- Acesse a visualização do sistema.
system-view- Configure um filtro de saída de log.
info-center filter filter-name { module-name | default } { deny | level severity }Você pode criar vários filtros de saída de log. Ao especificar um host de log, você pode aplicar um filtro de saída de log ao host de log para controlar a saída de log.
info-center source { module-name | default } loghost { deny | level severity }Para obter informações sobre as regras de saída de log padrão para o destino de saída do host de log, consulte "Regras de saída padrão para logs".
info-center loghost source interface-type interface-numberPor padrão, o endereço IP de origem dos logs enviados para hosts de log é o endereço IP primário de suas interfaces de saída.
info-center format { unicom | cmcc }Por padrão, os logs são enviados para hosts de log no formato padrão.
info-center timestamp loghost { date [ with-milliseconds ] | iso [ with-milliseconds | with-timezone ] * | no-year-date | none }O formato padrão do carimbo de data e hora é data.
info-center loghost { hostname | ipv4-address | ipv6 ipv6-address } [ port port-number ] [ dscp dscp-value ] [ facility local-number ] [ filter filter-name ]Por padrão, nenhum host de log ou parâmetros relacionados são especificados.
Enviando logs para hospedeiros de log
Restrições e diretrizes
O dispositivo suporta os seguintes métodos (em ordem decrescente de prioridade) para a saída de logs de um módulo para hospedeiros de log designados:
- Output de log rápido. Para obter informações sobre os módulos que suportam output de log rápido e como configurar o output de log rápido, consulte "Configurando output de log rápido".
- Log de fluxo. Para obter informações sobre os módulos que suportam output de log de fluxo e como configurar o output de log de fluxo, consulte "Configurando log de fluxo".
- Centro de informações. Se você configurar vários métodos de output de log para um módulo, apenas o método com a prioridade mais alta terá efeito.
Procedimento
- Acesse a visualização do sistema.
system-view- Configure um filtro de saída de log.
info-center filter filter-name { module-name | default } { deny | level severity }Você pode criar vários filtros de saída de log. Ao especificar um hospedeiro de log, você pode aplicar um filtro de saída de log ao hospedeiro de log para controlar a saída de log.
info-center source { module-name | default } loghost { deny | level severity }Para obter informações sobre as regras de saída de log padrão para o destino de saída do hospedeiro de log, consulte "Regras de saída padrão para logs".
info-center loghost source interface-type interface-numberPor padrão, o endereço IP de origem dos logs enviados para hospedeiros de log é o endereço IP primário de suas interfaces de saída.
info-center format { unicom | cmcc }Por padrão, os logs são enviados para hospedeiros de log no formato padrão.
info-center timestamp loghost { date [ with-milliseconds ] | iso [ with-milliseconds | with-timezone ] * | no-year-date | none }O formato padrão do carimbo de data e hora é data.
info-center loghost { hostname | ipv4-address | ipv6 ipv6-address } [ port port-number ] [ dscp dscp-value ] [ facility local-number ] [ filter filter-name ]Por padrão, nenhum hospedeiro de log ou parâmetro relacionado é especificado.
Configurado a supressão de logs
Habilitando a supressão de logs duplicados
Sobre a supressão de logs duplicados
O centro de informações no dispositivo emite logs gerados por módulos de serviço. O dispositivo identifica logs que possuem o mesmo nome de módulo, nível, mnemônico, localização e texto como logs duplicados.
Em alguns cenários, por exemplo, ataque ARP ou falha de link, os módulos de serviço gerarão uma grande quantidade de logs duplicados durante um curto período de tempo. A gravação e a saída de logs duplicados consecutivos desperdiçam recursos do sistema e da rede. Para resolver esse problema, você pode habilitar a supressão de logs duplicados.
Com essa função habilitada, quando um módulo de serviço gera um log, o centro de informações emite o log e inicia o temporizador de supressão de logs duplicados. O período de supressão do temporizador de supressão de logs duplicados é incremental em fases. Os períodos de supressão na fase 1, 2 e em fases posteriores são 30 segundos, 2 minutos e 10 minutos, respectivamente.
Após habilitar a supressão de logs duplicados, o sistema inicia a supressão ao emitir um log:
- Se apenas logs duplicados do log forem recebidos durante o período de supressão de uma fase, o centro de informações não emite os logs duplicados. Quando o período de supressão da fase expira, o centro de informações emite o log suprimido e o número de vezes que o log é suprimido e inicia a próxima fase de supressão.
-
Se um log diferente for recebido durante o período de supressão de uma fase, o centro de informações realiza as seguintes operações:
- Interrompe a supressão no log e emite o log suprimido e o número de vezes que o log é suprimido.
- Emite o log diferente e inicia a supressão da fase 1 para esse log.
- Se nenhum log for recebido durante o período de supressão de qualquer fase, o centro de informações interrompe a supressão no log e não emite nenhum log.
Procedimento
- Acesse a visualização do sistema.
system-viewinfo-center logging suppress duplicatesPor padrão, a supressão de logs duplicados está desativada.
Exemplo
O seguinte exemplo utiliza logs SHELL_CMD para verificar a funcionalidade de supressão de logs duplicados. Após o usuário executar um comando no dispositivo, o centro de informações recebe um log SHELL_CMD gerado pelo módulo shell, encapsula o log e então o envia para o buffer de logs.
-
Verifique o efeito de supressão nas fases 1, 2, 3 e 4 de um log (com período de supressão de 30 segundos, 2 minutos, 10 minutos e 10 minutos):
-
Em um ambiente de laboratório, execute continuamente o comando
display logbufferpor 25 minutos. - Visualize os logs de saída no buffer de logs.
Sysname> display logbuffer Log buffer: Enabled Max buffer size: 1024 Actual buffer size: 512 Dropped messages: 0 Overwritten messages: 0 Current messages: 5 %Jul 20 13:01:20:615 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer %Jul 20 13:01:50:718 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 2 times in last 30 seconds. %Jul 20 13:03:50:732 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 5 times in last 2 minutes. %Jul 20 13:13:50:830 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 10 times in last 10 minutes. %Jul 20 13:23:50:211 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 6 times in last 10 minutes. -
Em um ambiente de laboratório, execute continuamente o comando
Exemplo
O seguinte exemplo continua a verificar como a supressão de logs duplicados funciona quando um log diferente é recebido durante o período de supressão de um log:
-
Continue verificando como a supressão de logs duplicados funciona quando um log diferente é recebido durante o período de supressão de um log:
-
Execute o comando
display logbuffertrês vezes e, em seguida, execute o comandodisplay interface brief. - Visualize os logs de saída no buffer de logs.
Sysname> display logbuffer Log buffer: Enabled Max buffer size: 1024 Actual buffer size: 512 Dropped messages: 0 Overwritten messages: 0 Current messages: 5 %Jul 20 13:01:20:615 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer %Jul 20 13:01:50:718 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 2 times in last 30 seconds. %Jul 20 13:03:50:732 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 5 times in last 2 minutes. %Jul 20 13:13:50:830 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 10 times in last 10 minutes. %Jul 20 13:23:50:211 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 6 times in last 10 minutes. %Jul 20 13:24:56:205 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer This message repeated 3 times in last 1 minute 6 seconds. %Jul 20 13:25:41:205 2022 Sysname SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display interface brief.A saída mostra as seguintes informações:
- O centro de informações interrompeu a supressão para o log SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display logbuffer.
- O centro de informações enviou o log SHELL/6/SHELL_CMD: -Line=con0-IPAddr=**-User=**; Command is display interface brief e iniciou a supressão para ele.
-
Execute o comando
Configurando a supressão de logs para um módulo
Sobre a Supressão de Logs para um Módulo
Essa funcionalidade suprime a saída de logs de módulos específicos ou com valores de mnemônicos específicos. Isso permite filtrar os logs com os quais você não está preocupado.
Realize a seguinte tarefa para configurar uma regra de supressão de logs:
Procedimento
- Entre no modo de visualização do sistema.
system-viewinfo-center logging suppress module nome-do-módulo mnemônico { todos | valor-mnemônico }Por padrão, o dispositivo não suprime a saída de nenhum log de nenhum módulo.
Desativando uma Interface de Gerar Logs de Link Up ou Link Down
Sobre a Desativação de uma Interface de Gerar Logs de Link Up ou Link Down
Essa funcionalidade permite desativar determinadas interfaces de gerar informações de log de link up ou link down.
Procedimento
- Entre no modo de visualização do sistema.
system-viewinterface tipo-de-interface número-da-interfaceundo enable log updownPor padrão, uma interface gera logs de link up e link down quando o estado da interface muda.
Habilitando Notificações SNMP para Logs do Sistema
Sobre a Habilitação de Notificações SNMP para Logs do Sistema
Essa funcionalidade permite que o dispositivo envie notificações SNMP para cada mensagem de log que ele produz.
Procedimento
- Entre no modo de visualização do sistema.
system-viewsnmp-agent trap enable syslogPor padrão, o dispositivo não envia notificações SNMP para logs do sistema.
info-center syslog trap buffersize buffersizePor padrão, o buffer de armadilhas de log pode armazenar no máximo 1024 armadilhas.
Gerenciamento de Logs de Segurança
Salvando Logs de Segurança no Arquivo de Log de Segurança
Sobre o Gerenciamento de Logs de Segurança:
Os logs de segurança são cruciais para identificar e solucionar problemas de rede. No entanto, podem ser desafiadores de distinguir entre outros logs. Para resolver esse problema, você pode salvar os logs de segurança em um arquivo de log de segurança dedicado.
Depois de habilitado, o sistema trata os logs de segurança da seguinte forma:
- Envia logs de segurança para o buffer do arquivo de log de segurança.
- Salva logs do buffer para o arquivo de log de segurança em intervalos especificados.
- Limpa o buffer após salvar os logs no arquivo.
Procedimento
- Entre no modo de visualização do sistema.
system-viewinfo-center security-logfile enablePor padrão, esse recurso está desativado.
info-center security-logfile frequency freq-secO intervalo padrão é de 86400 segundos.
info-center security-logfile size-quota sizeO tamanho máximo padrão é de 10 MB.
info-center security-logfile alarm-threshold usagePor padrão, o limite é definido como 80%.
Gerenciando o Arquivo de Log de Segurança
Procedimento
- Entre no modo de visualização do sistema.
system-viewinfo-center security-logfile directory dir-namePor padrão, ele é salvo no diretório seclog na raiz do dispositivo de armazenamento.
security-logfile saveEste comando está disponível em qualquer visualização.
display security-logfile summaryEste comando está disponível em qualquer visualização.
Salvando logs de diagnóstico no arquivo de log de diagnóstico
Sobre a salvamento de logs de diagnóstico
Por padrão, o recurso de arquivo de log de diagnóstico salva logs de diagnóstico do buffer de arquivo de log de diagnóstico para o arquivo de log de diagnóstico no intervalo de salvamento especificado. Você também pode acionar manualmente um salvamento imediato de logs de diagnóstico para o arquivo de log de diagnóstico. Após salvar os logs de diagnóstico no arquivo de log de diagnóstico, o sistema limpa o buffer de arquivo de log de diagnóstico.
O dispositivo suporta apenas um arquivo de log de diagnóstico. O arquivo de log de diagnóstico tem uma capacidade máxima. Quando a capacidade é atingida, o sistema substitui os logs de diagnóstico mais antigos por novos logs.
Procedimento
- Entre na visão do sistema.
system-viewinfo-center diagnostic-logfile enablePor padrão, o recurso de arquivo de log de diagnóstico está ativado.
info-center diagnostic-logfile quota sizePor padrão, o tamanho máximo do arquivo de log de diagnóstico é 10 MB.
info-center diagnostic-logfile directory dir-nameO diretório padrão do arquivo de log de diagnóstico é flash:/diagfile. Este comando não sobrevive a um reboot IRF ou a uma troca de mestre/subordinado.
- Configure o intervalo de salvamento automático do arquivo de log de diagnóstico.
info-center diagnostic-logfile frequency freq-secO intervalo de salvamento padrão é 86400 segundos.
diagnostic-logfile saveEste comando está disponível em qualquer visão.
Definindo o tamanho máximo do arquivo de log de rastreamento
Sobre a definição do tamanho máximo do arquivo de log de rastreamento
O dispositivo possui apenas um arquivo de log de rastreamento. Quando o arquivo de log de rastreamento está cheio, o dispositivo sobrescreve os logs de rastreamento mais antigos com novos.
Procedimento
- Entre na visão do sistema.
system-viewinfo-center trace-logfile quota sizeComandos de exibição e manutenção para o centro de informações
Execute comandos de exibição em qualquer visão e comandos de reset na visão do usuário.
| Tarefa | Comando | ||
| Exibir a configuração do arquivo de log de diagnóstico. |
| ||
| Exibir a configuração do centro de informações. |
| ||
| Exibir informações sobre filtros de saída de log. |
| ||
| Exibir informações do buffer de log e logs bufferizados. |
| ||
| Exibir o resumo do buffer de log. |
| ||
| Exibir o conteúdo do buffer do arquivo de log. |
| ||
| Exibir a configuração do arquivo de log. |
| ||
| Exibir o conteúdo do buffer do arquivo de log de segurança. (Para executar este comando, você deve ter a função de usuário de auditoria de segurança.) |
| ||
| Exibir informações resumidas do arquivo de log de segurança. (Para executar este comando, você deve ter a função de usuário de auditoria de segurança.) |
| ||
| Limpar o buffer de log. |
|
Exemplos de configuração do centro de informações
Exemplo: Emitindo logs para o console
Configuração de rede
Configure o dispositivo para emitir no console os logs FTP que têm um nível de severidade mínimo de aviso.
Procedimento
- Ative o centro de informações.
<Device> system-view
[Device] info-center enable[Device] info-center source default console denyPara evitar a saída de informações desnecessárias, desative todos os módulos de emitir informações de log para o destino especificado (console neste exemplo) antes de configurar a regra de saída.
[Device] info-center source ftp console level warning
[Device] quit<Device> terminal logging level 6
<Device> terminal monitorO terminal atual está habilitado para exibir logs.
Agora, se o módulo FTP gerar logs, o centro de informações automaticamente envia os logs para o console, e o console exibe os logs.
Exemplo: Emitindo logs para um host de log UNIX
Configuração de rede
Configure o dispositivo para emitir para o host de log UNIX os logs FTP que têm um nível de severidade mínimo de informativo.
Procedimento
- Certifique-se de que o dispositivo e o host de log possam se comunicar. (Detalhes não mostrados.)
-
Configure o dispositivo:
- Ative o centro de informações.
<Device> system-view [Device] info-center enable - Especifique o host de log 1.2.0.1/16 com local4 como a instalação de logging.
[Device] info-center loghost 1.2.0.1 facility local4[Device] info-center source default loghost denyPara evitar a saída de informações desnecessárias, desative todos os módulos de emitir logs para o destino especificado (loghost neste exemplo) antes de configurar uma regra de saída.
[Device] info-center source ftp loghost level informational- Faça login no host de log como usuário root.
- Crie um subdiretório chamado Device no diretório /var/log/, e então crie o arquivo info.log no diretório Device para salvar os logs do dispositivo.
# mkdir /var/log/Device
# touch /var/log/Device/info.log# Mensagens de configuração do dispositivo
local4.info /var/log/Device/info.logNesta configuração, local4 é o nome da instalação de logging que o host de log usa para receber logs. O valor info indica o nível de severidade informativo. O sistema UNIX registra as informações de log que têm um nível de severidade mínimo de informativo no arquivo /var/log/Device/info.log.
# ps -ae | grep syslogd
# kill -HUP 147
# syslogd -r &Agora, o dispositivo pode emitir logs FTP para o host de log, que armazena os logs no arquivo especificado.
Exemplo: Emitindo logs para um host de log Linux
Configuração de rede
Configure o dispositivo para emitir para o host de log Linux 1.2.0.1/16 os logs FTP que têm um nível de severidade mínimo de informativo.
Procedimento
- Garanta que o dispositivo e o host de log possam se comunicar. (Detalhes não mostrados.)
-
Configure o dispositivo:
- Ative o centro de informações.
<Device> system-view [Device] info-center enable - Especifique o host de log 1.2.0.1/16 com local5 como a facilidade de log.
[Device] info-center loghost 1.2.0.1 facility local5[Device] info-center source default loghost denyPara evitar a emissão de informações desnecessárias, desabilite todos os módulos de envio de informação de log para o destino especificado (host de log neste exemplo) antes de configurar uma regra de saída.
[Device] info-center source ftp loghost level informationalO procedimento de configuração do host de log varia de acordo com o fornecedor do sistema operacional Linux. O exemplo a seguir mostra uma configuração:
- Faça login no host de log como usuário root.
- Crie um subdiretório chamado Device no diretório /var/log/ e, em seguida, crie o arquivo info.log no diretório Device para salvar os logs do dispositivo.
# mkdir /var/log/Device
# touch /var/log/Device/info.log# Mensagens de configuração do dispositivo
local5.info /var/log/Device/info.logNesta configuração, local5 é o nome da unidade de log que o host de log usa para receber os logs. O valor info indica o nível de gravidade informacional. O sistema Linux armazenará as informações de log com um nível de gravidade igual ou superior a informacional no arquivo /var/log/Device/info.log.
# ps -ae | grep syslogd
# kill -9 147
# syslogd -r &Agora, o dispositivo pode emitir logs de FTP para o host de log, que armazena os logs no arquivo especificado.
Configuração de Ligações à Nuvem
Sobre as Ligações à Nuvem
Uma ligação à nuvem é um túnel de gestão estabelecido entre um dispositivo local e o servidor de nuvem Intelbras. Permite-lhe gerir o dispositivo local a partir do servidor em nuvem sem aceder à rede onde o dispositivo reside.
Subconexões Múltiplas
Depois que um dispositivo local estabelece uma conexão com o servidor em nuvem, os módulos de serviço no dispositivo local podem estabelecer várias subconexões com os microsserviços no servidor em nuvem. Essas subconexões são independentes umas das outras e fornecem canais de comunicação separados para serviços diferentes. Este mecanismo evita a interferência entre diferentes serviços.
Estabelecimento de Ligação à Nuvem
- O dispositivo envia um pedido de autenticação para o servidor em nuvem.
- O servidor de nuvem envia um pacote de sucesso de autenticação para o dispositivo. O dispositivo só passa na autenticação se o número de série do dispositivo tiver sido adicionado ao servidor de nuvem. Se a autenticação falhar, o servidor de nuvem envia um pacote de falha de autenticação para o dispositivo.
- O dispositivo envia um pedido de registo para o servidor de nuvem.
- O servidor de nuvem envia uma resposta de registo ao dispositivo. A resposta de registo contém o localizador uniforme de recursos (URL) utilizado para estabelecer uma ligação à nuvem.
- O dispositivo utiliza o URL para enviar um pedido de aperto de mão (alterando o protocolo de HTTP para WebSocket) para o servidor de nuvem.
- O servidor de nuvem envia uma resposta de aperto de mão ao dispositivo para concluir o estabelecimento da ligação à nuvem.
- O dispositivo envia um pedido de URL de subconexão para o servidor de nuvem.
- O servidor de nuvem envia uma resposta que contém a lista de microsserviços e todos os URLs de subconexão para o dispositivo.
- O módulo de serviço regista-se no módulo de gestão da ligação à nuvem.
- O módulo de gestão da ligação à nuvem envia os URLs correspondentes para o serviço.
- O módulo de serviço estabelece subconexões com o servidor de nuvem.
Figura 1 Estabelecer uma ligação à nuvem
Configurar uma Ligação à Nuvem
Sobre a Configuração de uma Ligação à Nuvem
Para que um dispositivo estabeleça uma ligação à nuvem com o servidor de nuvem, execute uma das seguintes tarefas:
- Especifique o nome de domínio do servidor de nuvem no dispositivo através da CLI.
- Configure o dispositivo como um cliente DHCP e o servidor de nuvem como o servidor DHCP. O dispositivo obtém o endereço IP do servidor DHCP e analisa o campo da opção 253 nos pacotes DHCP para obter o nome de domínio do servidor de nuvem. Para obter mais informações sobre o campo da opção 253, consulte Configuração do DHCP no Guia de configuração de serviços IP de camada 3.
Para estabelecer conexões de nuvem com o servidor de nuvem, é necessária uma senha. Um dispositivo pode usar um dos seguintes métodos para obter a senha para estabelecer conexões de nuvem com o servidor de nuvem:
- Execute o comando senha do servidor de gerenciamento de nuvem no dispositivo para especificar a senha para estabelecer conexões de nuvem com o servidor de nuvem.
- Configure o dispositivo como um cliente DHCP e o servidor de nuvem como o servidor DHCP. O dispositivo obtém o endereço IP do servidor DHCP e analisa o campo da opção 252 nos pacotes DHCP para obter a palavra-passe para ligação ao servidor de nuvem. Para obter mais informações sobre o campo da opção 252, consulte Configuração do DHCP no Guia de Configuração dos Serviços da Camada 3IP.
Depois de estabelecer a ligação à nuvem, o dispositivo local envia periodicamente pacotes de manutenção (keepalive) para o servidor de nuvem. Se o dispositivo não receber uma resposta do servidor de nuvem no prazo de três intervalos de keepalive, o dispositivo envia um pedido de registo para restabelecer a ligação à nuvem.
Restrições e Orientações
- O nome de domínio obtido através do DHCP tem uma prioridade mais elevada do que o nome de domínio configurado manualmente.
- Se um dispositivo obtiver o nome de domínio do servidor de nuvem através de DHCP depois de estabelecer uma ligação de nuvem ao servidor de nuvem com o nome de domínio configurado manualmente, o dispositivo executa as seguintes tarefas:
- Se os nomes de domínio obtidos automaticamente e configurados manualmente forem idênticos, o dispositivo mantém a ligação à nuvem.
- Se os nomes de domínio obtidos automaticamente e configurados manualmente forem diferentes, o dispositivo corta a ligação à nuvem e, em seguida, estabelece uma ligação à nuvem para o servidor de nuvem com o nome de domínio obtido automaticamente.
- A palavra-passe obtida através do DHCP tem uma prioridade mais elevada do que a palavra-passe configurada manualmente.
- Se um dispositivo obtiver a palavra-passe para ligação ao servidor de nuvem através de DHCP depois de estabelecer uma ligação de nuvem ao servidor de nuvem com a palavra-passe configurada manualmente, o dispositivo executa as seguintes tarefas:
- Se as palavras-passe obtidas automaticamente e configuradas manualmente forem idênticas, o dispositivo mantém a ligação à nuvem.
- Se as palavras-passe obtidas automaticamente e as palavras-passe configuradas manualmente forem diferentes, o dispositivo corta a ligação à nuvem e, em seguida, estabelece uma ligação à nuvem ao servidor da nuvem com a palavra-passe obtida automaticamente.
Pré-requisitos
- Adicione o número de série do dispositivo a ser gerido ao servidor de nuvem.
- Configure o DNS para garantir que o nome de domínio do servidor de nuvem possa ser traduzido em um endereço IP.
- Para obter o nome de domínio do servidor de nuvem automaticamente, primeiro configure o campo da opção 253 como o nome de domínio do servidor de nuvem.
Procedimento
- Entrar na vista do sistema.
system-viewcloud-management server domain domain-nameAs predefinições são as seguintes:
- O nome de domínio do servidor de nuvem não está configurado para um switch que é iniciado com a configuração inicial.
- O nome de domínio do servidor de nuvem é oasis.intelbras.com para um switch que é iniciado com os padrões de fábrica.
Para mais informações sobre a configuração inicial e as predefinições de fábrica, consulte a gestão de ficheiros de configuração no Guia de Configuração dos Fundamentos.
cloud-management keepalive intervalIntervalo de Manutenção da Gestão da Nuvem
Por predefinição, o intervalo de keepalive é de 180 segundos.
cloud-management server password { cipher | simple } stringPor padrão, nenhuma senha é definida para estabelecer conexões de nuvem com o servidor de nuvem.
Comandos de Visualização e Manutenção para Ligações à Nuvem
| Tarefa | Comando |
|---|---|
| Apresenta informações sobre o estado da ligação à nuvem. | display cloud-management state |
| Restabelecer a ligação à nuvem para o servidor de nuvem. | reset cloud-management tunnel |
Exemplos de Configuração de Ligação à Nuvem
Exemplo: Configurar uma Ligação à Nuvem
Configuração da Rede
Como mostra a Figura 2, configure o dispositivo para estabelecer uma ligação à nuvem com o servidor de nuvem.

Procedimento
- Configure os endereços IP para as interfaces e configure um protocolo de encaminhamento para garantir que os dispositivos possam alcançar uns aos outros. (Detalhes não mostrados.)
- Inicie sessão no servidor de nuvem para adicionar o número de série do dispositivo ao servidor. (Detalhes não mostrados.)
- Configure o nome de domínio do servidor de nuvem como cloud.com.
O endereço IP do servidor de nuvem é 10.1.1.1/24 e o nome de domínio é cloud.com.
system-view
[Device] cloud-management server domain cloud.com #Mapear o endereço IP 10.1.1.1 para o nome do anfitrião cloud.com
cloud.com. [Device] ip host cloud.com 10.1.1.1Verificar a configuração
# Verifique se o dispositivo e o servidor de nuvem estabeleceram uma ligação à nuvem.
[Device] display cloud-management state
Cloud connection state : Established
Device state : Request_success
Cloud server address : 10.1.1.1
Cloud server domain name : cloud.com
Cloud server port : 443
Connected at : Wed Jan 27 14:18:40 2016
Duration : 00d 00h 02m 01s