
Serie3000 | Manual CLI
Versão deste manual: 1.0.0
Serie3000 | Manual CLI
Parabéns, você acaba de adquirir um produto com a qualidade e segurança Intelbras.
Estes produtos são homologados pela Anatel, o número de homologação se encontra na etiqueta dos produtos, para consultas utilize o link sistemas.anatel.gov.br/sch
O Manual de Linha de Comandos do Usuário, está divido em 12 capítulos para melhor oranização e compreenção do contéudo. Segue a lista com redirecionamento para URL de cada capítulo.
- 01 Fundamentos e Gerenciamento do Sistema
- 02 Interfaces Físicas e Lógicas
- 03 Ethernet Switching
- 04 Protocolo IP e Serviços
- 05 Roteamento Unicast
- 06 Multicast
- 07 QoS
- 08 Segurança
- 09 Alta Disponibilidade
- 10 Gerenciamento e Monitoramento
- 11 Virtualização
- 12 Data Center Features (Aplicável somente ao modelo S3054G-B)
01 Fundamentos e Gerenciamento do Sistema
Noções básicas de operação do sistema
Visão geral
Noções básicas de operação do sistema descrevem principalmente o conhecimento básico das operações do dispositivo, incluindo funções básicas de operação do sistema, modos de configuração do dispositivo, modos de comando e interface de linha de comando.
Funções básicas de operação do sistema
Tabela 1 - 1 Lista de configuração das funções básicas de operação do sistema
| Tarefa de configuração | |
| Modo de configuração do dispositivo | Modo de configuração do dispositivo |
| Modo de operação de comando | Modo de operação de comando |
| Interface da Linha de comando | Interface da Linha de comando |
Modos de configuração do dispositivo
Os usuários podem fazer login no dispositivo para configuração e gerenciamento em diferentes modos. (Para detalhes dos modos de login, consulte o capítulo "Login do sistema" no guia de configuração.) O dispositivo oferece cinco modos de configuração típicos:
- Fazendo login no dispositivo localmente por meio da porta do console. Por padrão, os usuários podem configurar o dispositivo diretamente neste modo.
- Efetuando login no dispositivo por discagem remota por meio de um modem. O dispositivo não pode ser configurado diretamente neste modo . Isso é, antes da configuração, alguns preparativos precisam ser feitos.
- Fazendo login no dispositivo remotamente através do Telnet. O dispositivo não pode ser configurado diretamente neste modo . Isso é, antes da configuração, alguns preparativos precisam ser feitos.
- Fazer login no dispositivo remotamente por meio de SSH. O dispositivo não pode ser configurado diretamente neste modo . Isso é, antes da configuração, alguns preparativos precisam ser feitos.
- Fazendo login no dispositivo remotamente através da web. O dispositivo não pode ser configurado diretamente neste modo . Isso é, antes da configuração, alguns preparativos precisam ser feitos.
Modos de operação de comando
O dispositivo fornece um subsistema de processamento de comandos para gerenciamento e execução de comandos do sistema. O shell do subsistema fornece as seguintes funções principais:
- Registro de comandos do sistema
- Edição de comandos de configuração do sistema pelos usuários
- Análise dos comandos que foram inseridos pelos usuários
- Execução de comandos do sistema
Se um usuário configurar o dispositivo por meio de comandos shell, o sistema fornecerá vários modos de operação para a execução dos comandos. Cada modo de comando suporta comandos de configuração específicos. Desta forma, a proteção hierárquica é fornecida ao sistema, protegendo o sistema contra acesso não autorizado.
O subsistema shell fornece vários modos para a operação de comandos de configuração. Esses modos têm prompts de sistema diferentes, solicitando o modo de sistema atual do usuário. A seguir lista os modos de configuração comuns:
- Modo de usuário comum (usuário EXEC)
- Modo de usuário privilegiado (privilégio EXEC)
- Modo de configuração global (configuração global)
- Modo de configuração de interface (configuração de interface)
- Modo de configuração do sistema de arquivos (configuração do sistema de arquivos)
- Modo de configuração da lista de acesso (configuração da lista de acesso)
- Outros modos de configuração (Eles serão descritos nas seções e capítulos relacionados.)
A tabela a seguir mostra como entrar nos modos de comando comuns e alternar entre os modos.
Tabela 1 -2 Modos do sistema e métodos de alternância entre os modos
| Modo | Como entrar no modo | Prompt do sistema | Como sair do modo | Funções |
| Modo de usuário comum | Faça login no dispositivo. | Hostname> | Execute a exit comando para sair do modo. | Altera as configurações do terminal. Realiza testes básicos. Exibe as informações do sistema. |
| Modo de usuário privilegiado | No modo de usuário comum, execute o comando enable . | Hostname# | Execute a disable ou comando exit para sair para o modo de usuário comum . | Configure os parâmetros operacionais do dispositivo. Exibe as informações de operação do dispositivo. |
| Modo de configuração global | No modo de usuário privilegiado, execute o terminal configure comando. | Hostname(config)# | Execute o comando exit para sair para o modo de usuário privilegiado . | Configura os parâmetros globais necessários para a operação do dispositivo. |
| Modo de configuração da interface | No modo de configuração global, execute o comando interface (enquanto especifica a interface ou grupo de interface correspondente). | Hostname(config-if-xxx[number])# or Hostname(config-if-group[number])# | Execute o comando exit para sair para o modo de configuração global. Execute o comando end para sair para o modo de usuário privilegiado. | Neste modo, configura interfaces de dispositivos, incluindo: Interfaces de vários tipos Grupos de interface |
| Modo de configuração do sistema de arquivos | No modo de usuário privilegiado, execute o comando filesystem . | Hostname(config-fs)# | Execute o comando exit para sair para o modo de usuário privilegiado . | Gerencia o sistema de arquivos do dispositivo. |
| Modo de configuração da lista de acesso | No modo de configuração global, execute o IP lista de acesso padrão ou ip lista de acesso estendido comando. | Hostname(config-std-nacl)# Hostname(config-ext-nacl)# | Execute o comando exit para sair para o modo de configuração global. Execute o end comando para sair para o modo de usuário privilegiado. | Configura a Lista de Controle de Acesso (ACL). As tarefas de configuração incluem: Configurando listas de controle de acesso padrão. Configurando listas de controle de acesso estendidas. |
Hostname é o nome do sistema. No modo de configuração global, um usuário pode executar o comando hostname para modificar o nome do sistema e a modificação entrará em vigor imediatamente.
Se um usuário não estiver no modo de usuário privilegiado enquanto o usuário deseja executar um comando de modo privilegiado, o usuário pode usar o comando do para executar o comando necessário sem a necessidade de retornar ao modo privilegiado.
(Para obter detalhes, consulte as seções relacionadas em "Noções básicas de operação do sistema" do manual de comando.) Observe que o comando de alternância de modo, como do configure terminal não está incluído.
Interface da Linha de comando
A interface de linha de comando é uma interface homem-máquina fornecida pelo subsistema shell para configurar e usar o dispositivo. Por meio da interface de linha de comando, os usuários podem inserir e editar comandos para executar as tarefas de configuração necessárias, além de consultar as informações do sistema e conhecer o status de operação do sistema.
A interface de linha de comando fornece as seguintes funções para os usuários:
- Gerenciamento de informações de ajuda do sistema
- Inserção e edição de comandos do sistema
- Gerenciamento de comandos de histórico
- Gerenciamento do sistema de exibição do terminal
Ajuda on-line da linha de comando
A linha de comando fornece os seguintes tipos de ajuda online:
- Ajuda
- Ajuda completa
- Ajuda parcial
Por meio dos tipos de ajuda on-line acima, os usuários podem obter várias informações de ajuda. A seguir, alguns exemplos.
- Para obter uma breve descrição do sistema de ajuda online, execute a ajuda comando em qualquer modo de comando.
Hostname#helpHelp may be requested at any point in a command by enteringa question mark '?'. If nothing matches, the help list willbe empty and you must backup until entering a '?' shows theavailable options.Two styles of help for command are provided:1. Full help is available when you are ready to enter acommand argument (e.g. 'show ?') and describes each possibleargument.2. Partial help is provided when an abbreviated argument is enteredand you want to know what arguments match the input(e.g. 'show pr?'.)And "Edit key" usage is the following:CTRL+A -- go to home of current lineCTRL+E -- go to end of current lineCTRL+U -- erase all character from home to current cursorCTRL+K -- erase all character from current cursor to endCTRL+W -- erase a word on the left of current cursorCTRL+R -- erase a word on the right of current cursorCTRL+D,DEL -- erase a character on current cursorBACKSPACE -- erase a character on the left of current cursorCTRL+B,LEFT -- current cursor backward a characterCTRL+F,RIGHT -- current cursor forward a character
- Para listar todos os comandos e sua breve descrição em qualquer modo de comando, digite "?" no modo de comando.
Hostname#configure terminalHostname(config)#?aaa Authentication, Authorization and Accountingaccess-list Access Listalarm Set alarm option of systemarl Address translation itemarp Set a static ARP entryarp-security To CPU arp securityautosave Auto save the startup configurationbanner Define a login bannerbgp BGP informationcable-diagnostics Cable Diagnostics on physical interface..................................................... ......... ......
- Digite um comando seguido de "?", e todos os subcomandos que podem ser executados no modo atual são exibidos.
Hostname#show ?access-list List access listsacl-object Show acl objectarl Address translation itemarp Command arparp-security To CPU arp securitybfd BFD Protocol informationbgp BGP informationcable-diagnostics Cable Diagnostics on physical interfacecard_list Show information of hardware modulesclock Print system clock informationcluster Config clustercpu Show CPU use per process..................................................... .....
- Digite uma sequência de caracteres seguida de "?", e todas as palavras-chave que começam com a sequência de caracteres e sua descrição são exibidas.
Hostname#show a?access-list List access listsacl-object Show acl objectarl Address translation itemarp Command arparp-security To CPU arp security
Mensagens de erro de linha de comando
Para todos os comandos digitados pelos usuários, a linha de comando executa uma verificação de sintaxe. Se os comandos passarem na verificação de sintaxe, eles serão executados corretamente; caso contrário, o sistema relata mensagens de erro aos usuários. A tabela a seguir mostra mensagens de erro comuns.
Tabela 1-3 Mensagens de erro de linha de comando
| Mensagem de erro | Causa do erro |
| % Invalid input detected at '^' marker. | Nenhum comando ou palavra-chave foi encontrado, o tipo de parâmetro está incorreto ou o valor do parâmetro não está dentro do intervalo válido. |
| Type “*** ?” for a list of subcommands or % Incomplete command | O comando inserido está incompleto. |
| Hostname#wh % Ambiguous command: wh % Please select: whoami who | A cadeia de caracteres inserida é um comando difuso. |
Comandos de histórico
A interface de linha de comando fornece uma função semelhante à função Doskey. O sistema salva automaticamente os comandos inseridos pelo usuário no cache de comandos do histórico. Em seguida, os usuários podem invocar os comandos de histórico salvos pela interface de linha de comando a qualquer momento e executar o comando repetidamente, reduzindo esforços desnecessários para redigitar os comandos. A interface de linha de comando salva até 10 comandos para cada usuário conectado ao dispositivo. Em seguida, novos comandos substituem os antigos.
Tabela 1 - 4 Acessando os comandos de histórico da interface de linha de comando
| Para... | Imprensa... | Resultado da execução |
| Acesse o comando de histórico anterior | A tecla de seta para cima ↑ ou as teclas Ctrl+P | Se um comando de histórico anterior estiver disponível, ele será exibido. Se nenhum comando de histórico anterior estiver disponível, um som de alarme é reproduzido. |
| Acesse o próximo comando de histórico | A tecla de seta para baixo ↓ ou as teclas Ctrl+P | Se um comando de histórico posterior estiver disponível, ele será exibido. Se nenhum comando posterior estiver disponível, os comandos serão apagados e um som de alarme será reproduzido. |
Se você quiser acessar os comandos do histórico usando as teclas de seta para cima e para baixo, quando fizer telnet para o dispositivo no sistema operacional Windows 98 ou Windows NT, defina Terminais > Opções preferenciais > Opções de simulação como VT-100/ANSI.
A exibição do comando de histórico é baseada no modo de comando atual. Por exemplo, se você estiver no modo privilegiado, apenas os comandos de histórico no modo privilegiado serão exibidos.
Recursos de edição
A interface de linha de comando fornece funções básicas de edição de comandos. Ele suporta edição de várias linhas. Cada linha de comando pode conter até 256 caracteres. A tabela a seguir lista as funções básicas de edição fornecidas pelo subsistema shell para a interface de linha de comando.
Tabela 1 -5 Funções básicas de edição
| Chave | Função |
| Uma chave comum | Se o buffer de edição não estiver cheio, o caractere é inserido na posição do cursor e o cursor se move para a direita. Se o buffer de edição estiver cheio, um som de alarme é reproduzido. |
| A tecla de retrocesso | Exclui o caractere antes do cursor e move o cursor para trás. Se o cursor atingir o início do comando, um som de alarme é reproduzido. |
| A tecla Excluir | Exclui o caractere atrás do cursor. Se o cursor atingir o final do comando, um som de alarme é reproduzido. |
| A tecla de seta para a esquerda ← ou as teclas Ctrl+B | Move o cursor um caractere para a esquerda. Se o cursor atingir o início do comando, um som de alarme é reproduzido. |
| A tecla de seta para a direita → ou as teclas Ctrl+F | Move o cursor um caractere para a direita. Se o cursor atingir o final do comando, um som de alarme é reproduzido. |
| As teclas de seta para cima e para baixo ↑↓ | Exibir comandos de histórico. |
| Ctrl+A | Move o cursor para o início da linha de comando. |
| Ctrl+E | Move o cursor para o final da linha de comando. |
| Ctrl+U | Exclui todos os caracteres à esquerda do cursor até o início da linha de comando. |
Recursos de exibição
Para facilitar os usuários, a interface de linha de comando fornece os seguintes recursos de exibição:
Se a informação a ser exibida for mais de uma tela, a função de pausa é fornecida e o prompt "---MORE---" é exibido no canto inferior esquerdo da tela. Neste momento, as opções exibidas na tabela a seguir estão disponíveis para os usuários.
Tabela 1 - 6 Recursos de exibição
| Chave | Função |
| Tecla de espaço, tecla de seta para baixo ↓ ou Ctrl-F | Exiba a próxima tela. |
| A tecla de seta para cima ↑ ou as teclas Ctrl-B | Exibe a tela anterior. |
| A tecla Enter, tecla de seta para a direita → ou tecla igual = | Role as informações exibidas uma linha para baixo. |
| A tecla de seta para a esquerda ← ou a tecla de menos - | Role as informações exibidas uma linha para cima. |
| Ctrl-H | Retorna à parte superior das informações exibidas. |
| Quaisquer outras chaves | Sai do visor. Então, as informações que não foram exibidas não serão exibidas. |
Login do sistema
Visão geral
O dispositivo suporta os seguintes modos de login do sistema:
- Fazendo login no dispositivo por meio da porta do console para gerenciamento e manutenção.
- Telnet (login remoto). Os usuários podem gerenciar e manter o dispositivo remotamente neste modo.
- Shell Seguro (SSH). Por meio de sua tecnologia de criptografia e autenticação, o SSH fornece serviços de gerenciamento de login remoto seguro para os usuários.
- WEB (login remoto). Os usuários podem gerenciar e manter o dispositivo remotamente neste modo.
Configuração da Função de Login do Sistema
Tabela 2 - 1 Lista de configuração da função de login do sistema
| Tarefas de configuração | |
| Fazendo login no dispositivo através da porta do console | - |
| Fazendo login no dispositivo através da porta AUX | - |
| Configurando o login remoto via Telnet |
Habilite o serviço Telnet do dispositivo.
O dispositivo atua como um cliente Telnet para login remoto. |
| Configurando o login remoto por meio de SSH |
Habilite o serviço SSH do dispositivo.
O dispositivo atua como um cliente SSH para login remoto. |
| Configurando o login remoto pela web | Configure o login no dispositivo via HTTP Configure o login no dispositivo via HTTPS |
Para a configuração de usuário relacionada de Telnet , SSH e login remoto da Web, consulte o manual de controle e gerenciamento de login.
Faça login no dispositivo pela porta do console
Para conectar um terminal ao dispositivo através da porta Console para configurar o dispositivo, execute as seguintes etapas:
- Passo 1: Selecione um terminal.
O terminal pode ser um terminal com porta serial RS-232 padrão ou um PC comum, sendo este último o mais utilizado. Se o modo de login dial-up remoto for selecionado, dois Modems serão necessários.
- Passo 2: Conecte a conexão física da porta Console.
Certifique-se de que o terminal ou o dispositivo que fornece a porta Console foi desligado e, em seguida, conecte a porta serial RS-232 do terminal à porta Console do dispositivo. A figura a seguir mostra a conexão.

Figura 2 -1 Conexão para Login viaConsole Port
- Passo 3: Configure o HyperTerminal.
Depois de ligar o terminal, você precisa definir os parâmetros de comunicação do terminal, ou seja, taxa de transmissão de 9600 bps, 8 bits de dados, 1 bit de parada, sem verificação de paridade e sem controle de fluxo de dados. Para um PC com sistema operacional Windows XP ou Windows NT, execute o programa HyperTerminal e defina os parâmetros de comunicação da porta serial do HyperTerminal de acordo com as configurações mencionadas anteriormente. A seguir, o HyperTerminal no sistema operacional Windows NT, por exemplo.
- Crie uma conexão:
Insira um nome de conexão e selecione um ícone do Windows para a conexão.
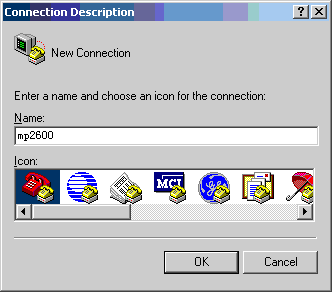
Figura 2 -2 Criando uma conexão
- Selecione uma porta de comunicação serial:
De acordo com a porta de comunicação serial que foi conectada, selecione COM1 ou COM2.
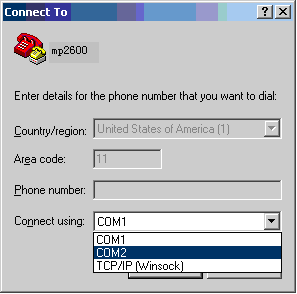
Figura 2 -3 Selecionando umSerial Communication Port
- Configure os parâmetros para a porta de comunicação serial:
Taxa de transmissão: 9600 bps
Bit de dados: 8 bits
Verificação de paridade: Nenhuma
Bit de parada: 1 bit
Controle de fluxo de dados: Nenhum
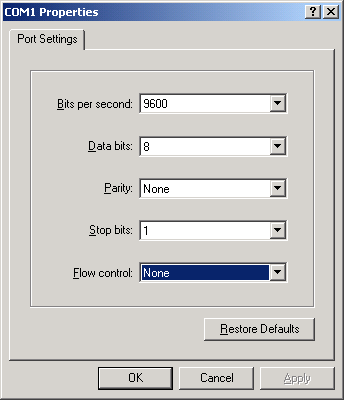
Figura 2 -4 Configurando Parâmetros para oSerial Communication Port
- Autenticação de sucesso de login:
Depois que o dispositivo com a porta Console é ligado, as informações de inicialização do dispositivo são exibidas no terminal. Após a conclusão da inicialização, o botão "Pressione qualquer tecla para iniciar o shell!" mensagem é exibida. Se a autenticação de login estiver configurada para ser necessária, insira o nome de usuário e a senha; caso contrário, pressione qualquer tecla para fazer login diretamente. Depois que o login for bem-sucedido, o prompt "Hostname>" será exibido no terminal. Em seguida, você pode configurar o dispositivo.
Configurar o login remoto via Telnet
Condição de configuração
Nenhum
Habilitar serviço Telnet do Dispositivo
Um usuário pode efetuar login no dispositivo remotamente por meio de Telnet para gerenciamento e manutenção. Antes de usar o serviço Telnet, habilite o serviço Telnet do dispositivo. Depois que o serviço Telnet do dispositivo é ativado, a porta de serviço Telnet 23 é monitorada.
Tabela 2 -2 Habilitando o serviço Telnet do dispositivo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite o serviço Telnet do dispositivo. | telnet server enable | Obrigatório. Por padrão, o serviço Telnet está habilitado. |
Tomar o dispositivo como cliente Telnet para login remoto
O usuário usa o dispositivo como um cliente Telnet para efetuar login no servidor Telnet especificado para configuração e gerenciamento.
Tabela 2 - 3 Tomando o dispositivo como um cliente Telnet para login remoto
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite o cliente Telnet do dispositivo. | telnet client enable | Opcional. Por padrão, o cliente Telnet está habilitado. |
| Leve o dispositivo como um cliente Telnet para login remoto. | telnet { hostname | remote-host } [ port-number ] [ ipv4 | ipv6 ] [ source-interface interface-name ] | Obrigatório. |
O cliente Telnet pode efetuar login em um dispositivo remoto somente quando a função de servidor Telnet do dispositivo remoto estiver habilitada e a rede entre o cliente Telnet e o dispositivo remoto estiver normal.
Configurar o login remoto via SSH
Condição de configuração
Nenhum
Habilitar o Serviço SSH do Dispositivo
Depois que o servidor SSH de um dispositivo é habilitado, o dispositivo aceita a solicitação de conexão iniciada pelo usuário do cliente SSHv1 ou SSHv2. Depois que o cliente passa a autenticação, o cliente pode acessar o dispositivo. Depois que o serviço SSH do dispositivo é habilitado, a porta de serviço SSH 22 é monitorada. Se o comando ip ssh server for usado sem o parâmetro sshv1-compatible , isso indica que um cliente SSH pode efetuar login somente por meio de SSHv2.
Tabela 2 - 4 Habilitando o serviço SSH do dispositivo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | config terminal | - |
| Habilite o serviço SSH do dispositivo. | ip ssh server [ listen-port ][ sshv1-compatible ] [ listen-port ] | Obrigatório. Por padrão, o serviço SSH está desabilitado. |
Pegue o dispositivo como um cliente SSH para login remoto
O dispositivo atua como um cliente SSH para efetuar login no servidor SSH especificado remotamente por meio do protocolo SSHv1 ou SSHv2. Durante o login, um nome de usuário e uma senha são necessários para autenticação do servidor SSH.
Tabela 2 - 5 Tomando um cliente SSH para login remoto
| Etapa | Comando | Descrição |
| Leve o dispositivo como um cliente SSH para login remoto. | ssh version 1 remote-host port-number [ source-interface interface-name ] user [timeout] ssh version 2 remote-host port-number [source-interface interface-name] user [timeout | prefer-key { diffie-hellman-group-exchange-sha256 | diffie-hellman-group-exchange-sha1 | diffie-hellman-group14-sha1 | diffie-hellman-group1-sha1} | prefer-identity-key { ssh-rsa | ssh-dss } | prefer-ctos-cipher { aes128-cbc | 3des-cbc | blowfish-cbc | cast128-cbc | arcfour128 | arcfour256 | arcfour | aes192-cbc | aes256-cbc | rijndael-cbc-lysator.liu.se | sm4-cbc | aes128-ctr | aes192-ctr | aes256-ctr} | prefer-ctos-hmac { hmac-md5 | hmac-sha1 | umac-64-openssh.com | hmac-ripemd160 | hmac-ripemd160-openssh.com | hmac-sha1-96 | hmac-md5-96}] | Obrigatório. |
O cliente SSH pode efetuar login em um dispositivo remoto somente quando o serviço SSH do dispositivo remoto estiver ativado e a rede entre o cliente SSH e o dispositivo remoto estiver normal.
Leve o dispositivo como um cliente SFTP para acessar o servidor SFTP
O dispositivo atua como um cliente S FTP para efetuar login no servidor S FTP especificado remotamente por meio do protocolo SSHv2. Durante o login, um nome de usuário e uma senha são necessários para autenticação do servidor FTP S. Depois que o cliente FTP S estiver conectado ao servidor FTP S , faça download ou upload dos arquivos no servidor.
Tabela 2 - 6 Tomando o dispositivo como cliente SFTP para acessar o servidor SFTP
| Etapa | Comando | Descrição |
| Tome o dispositivo como o cliente SFTP para acessar o servidor SFTP. | sftp {get | put} remote-host port-number [ source-interface interface-name ] user password src-filename dst-filename [compress] | Obrigatório |
O SFTP o cliente pode efetuar login em um dispositivo remoto somente quando o serviço SSH do dispositivo remoto estiver ativado e a rede entre o cliente SFTP e o dispositivo remoto estiver normal.
Configurar login remoto via WEB
Para facilitar a configuração e manutenção de equipamentos de rede, o dispositivo oferece a função de gerenciamento de rede Web. O dispositivo fornece um servidor web integrado. Você pode fazer login no dispositivo por meio de um navegador no PC e configurar e manter o dispositivo de forma intuitiva usando a interface da web. O dispositivo suporta dois modos de login na web integrados: modo de login http e modo de login HTTPS. O dispositivo suporta login na web IPv4 e login na web IPv6.
Condições de configuração
Não
Configurar o login no dispositivo via HTTP
Os usuários podem fazer login no dispositivo remotamente por meio de HTTP para gerenciamento e manutenção relacionados.
Tabela 2 - 7 Configure o login no dispositivo via HTTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configurar _ terminal | - |
| Habilitar o servidor HTTP | servidor http ip | Obrigatório Por padrão, não habilite o servidor web. |
| Configurar a porta do servidor HTTP | porta ip http port_number | Opcional Por padrão, o número da porta do servidor HTTP é 80. |
Antes de iniciar o servidor HTTP, você deve copiar o arquivo WEB ROM correspondente para /flash.
Configurar o login no dispositivo via HTTPS
Os usuários podem efetuar login remotamente no dispositivo por meio do modo HTTPS para gerenciamento e manutenção relacionados, mas antes de efetuar login no dispositivo por meio do modo HTTPS, eles precisam iniciar o serviço HTTPS do dispositivo.
Tabela 2 – 8 Configure o login no dispositivo via HTTPS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilitar o servidor HTTP | ip http server | Obrigatório Por padrão, não habilite o servidor WEB. |
| Habilitar o servidor HTTPS | ip http secure-server | Obrigatório Por padrão, não habilite o servidor WEB. |
| Configurar a porta do servidor HTTPS | ip http port port_number | Opcional Por padrão, o número da porta do servidor HTTPS é 443. |
| Configure o certificado usado pelo serviço HTTPS | ip http certificate ca-store | Opcional Por padrão, o serviço HTTPS usa o certificado autoassinado . |
Para a configuração do domínio de confiança e a importação do certificado, consulte as seções relevantes da PKI.
Monitoramento e manutenção de login do sistema
Tabela 2 - 9 Monitoramento e manutenção de login do sistema
| Comando | Descrição |
| show fingerprint | Exiba as informações de impressão digital da chave pública SSH. |
| show ip http | Exiba as informações de configuração da WEB |
| show ip http login-user | Exibir as informações do usuário que logou via WEB com sucesso |
| show ip http restricted-user | Exibe as informações do usuário que não consegue logar via WEB |
| show ip http statistics | Exiba as informações de estatísticas do servidor WEB |
Exemplo de configuração típico de login do sistema
Configurar um terminal local para Telnet para o dispositivo
Requisitos de rede
- Um PC é usado como um terminal local para fazer login no dispositivo por meio do Telnet.
- Uma rota deve estar disponível entre o PC e o dispositivo.
Topologia de rede

Figura 2 - 5 Topologia de rede para configurar um terminal local para Telnet para o dispositivo
Etapas de configuração
- Passo 1: Crie Redes Locais Virtuais (VLANs) e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configura endereços IP para as portas. (Omitido)
- Passo 3: Configure a senha deativação .
Device#configure terminalDevice(config)#enable password admin
- Passo 4: Telnet para o dispositivo.
#No PC, execute o programa Telnet e insira o endereço IP da VLAN 2.
- Passo 5: Confira o resultado.
#Se o login for bem-sucedido, uma janela conforme a figura a seguir será exibida.

Figura 2 -6 Janela exibida após o sucesso do Telnet
Depois de fazer login no dispositivo com sucesso, insira a senha de habilitação correta para obter os direitos de operação necessários do dispositivo. Para sair do dispositivo, insira a saída comandar continuamente.
Se a mensagem "Muitos clientes ou acesso inválido" for exibida, isso indica que o número de usuários de login atingiu o número máximo permitido de usuários de login do dispositivo. Nesse caso, aguarde um pouco e tente fazer login novamente.
Se a mensagem "%enable operation is closed by login-secure service" for exibida, isso indica que o número de erros de entrada de senha de ativação excede o número de falhas contínuas de autenticação de login. Se o número de erros de entrada de senha de ativação atingir o número especificado pelo sistema, o sistema rejeitará a solicitação de conexão de login do endereço IP durante o tempo especificado.
Se a mensagem "Senha necessária, mas nenhuma definida" for exibida, isso indica que nenhuma senha de login foi configurada.
Configurar um dispositivo local para fazer login em um dispositivo remoto via Telnet
Requisitos de rede
- O dispositivo local Device1 atua como o cliente Telnet, enquanto o dispositivo remoto Device2 atua como o servidor Telnet.
- Uma rota deve estar disponível entre os dois dispositivos.
- O PC normalmente pode fazer login no Device1.
Topologia de rede

Figura 2 - 7 Topologia de rede para configurar um dispositivo local para Telnet para um dispositivo remoto
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configura endereços IP para as portas. (Omitido)
- Passo 3: Faça login no Device1 através do PC. (Omitido)
- Passo 4: Em Device1, execute o seguinte comando para Telnet to Device2.
Device1#telnet 2.0.0.1#Enter the shell screen of Device2.Connect to 2.0.0.1 ...doneDevice2>
Após efetuar login no Device2 com sucesso, insira a senha de habilitação correta para obter os direitos de operação necessários do dispositivo. Para fazer logoff do dispositivo, insira o comando de saída continuamente.
Se a mensagem "Muitos clientes ou acesso inválido" for exibida, isso indica que o número de usuários de login atingiu o número máximo permitido de usuários de login do dispositivo. Nesse caso, aguarde um pouco e tente fazer login novamente.
Se a mensagem "%enable operation is closed by login-secure service" for exibida, isso indica que o número de erros de entrada de senha de ativação excede o número de falhas contínuas de autenticação de login. Se o número de erros de entrada de senha de ativação atingir o número especificado pelo sistema, o sistema rejeitará a solicitação de conexão de login do endereço IP durante o tempo especificado.
Se a mensagem "Senha necessária, mas nenhuma definida" for exibida, isso indica que nenhuma senha de login foi configurada na linha vty.
Configurar um dispositivo local para fazer login em um dispositivo remoto via SSH
Requisitos de rede
- O dispositivo local Device1 atua como cliente SSH, enquanto o dispositivo remoto Device2 atua como servidor SSH.
- Uma rota deve estar disponível entre os dois dispositivos.
- O PC normalmente pode fazer login no Device1.
Topologia de rede

Figura 2 -8 Topologia de rede para configurar um dispositivo local para fazer login em um dispositivo remoto via SSH
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configura endereços IP para as portas. (Omitido)
- Passo 3: Configure um usuário local e as propriedades relacionadas.
#Configure o nome de usuário e a senha do Device2.
Device2#configure terminalDevice2(config)#local-user admin1 class managerDevice2(config-user-manager-admin1)#service-type sshDevice2(config-user-manager-admin1)#password 0 admin1Device2(config-user-manager-admin1)#exit
- Passo 4: Habilite a função de servidor SSH do Device2.
Device2(config)#ip ssh server- Passo 5: Defina o modo de autenticação de login para autenticação local.
Device2(config)#line vty 0 15Device2(config-line)#login aaaDevice2(config-line)#exit
- Passo 6: #No Dispositivo1, faça login no Dispositivo2 por meio de SSH.
#Configure Device1 para fazer login no Device2 por meio de SSH.
Device1#ssh version 2 2.0.0.1 22 admin1The authenticity of host '2.0.0.1' can't be establishedRSA key fingerprint is 7b:ed:cc:81:cf:12:36:6f:f7:ff:29:15:63:75:64:10.Are you sure you want to continue connecting (yes/no)? yesadmin1@2.0.0.1's password:Device2>
- Passo 7: Confira o resultado.
Se o login for bem-sucedido, a tela de shell do Device2 será exibida.
Se a mensagem "Conexão fechada por host estrangeiro" for exibida, isso indica que o serviço SSH do ponto final está desabilitado ou o nome de usuário ou a senha inseridos estão incorretos.
O servidor SSH pode ser configurado para não usar autenticação. Se o servidor SSH não usar autenticação, quando um cliente fizer login, um usuário poderá usar qualquer cadeia de caracteres como nome de usuário e senha.
Configurar um dispositivo como cliente SFTP
Requisitos de rede
- O PC atua como o servidor SFTP, o Dispositivo atua como o cliente SFTP e a rede entre o servidor e o dispositivo está conectada.
- No servidor SFTP, defina o nome de usuário do dispositivo conectado ao servidor FTP para admin e a senha para admin; coloque os arquivos a serem baixados no diretório do servidor SFTP.
- O dispositivo atua como cliente SFTP para carregar e baixar o arquivo com o servidor SFTP.
Topologia de rede

Figura 2 -9 Topologia de rede para configurar o dispositivo como cliente SFTP
Etapas de configuração
- Pasos 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Pasos 2: Configure o servidor SFTP e coloque os arquivos a serem baixados no diretório do servidor SFTP (omitido).
- Pasos 3: Configure o endereço IP do dispositivo, fazendo com que a rede entre o cliente e o servidor seja conectada (omitida).
- Pasos 4: O dispositivo atua como cliente SFTP para fazer download e upload do arquivo com o servidor SFTP.
# Baixe um arquivo do servidor SFTP para o sistema de arquivos do dispositivo.
Device#sftp get 2.0.0.1 22 admin admin sp8-g-6.6.7(46)-dbg.pck sp8-g-6.6.7(46)-dbg.pckThe authenticity of host '2.0.0.1 (2.0.0.1)' can't be established.RSA key fingerprint is e4:dd:11:2e:82:34:ab:62:59:1c:c8:62:1d:4b:48:99.Are you sure you want to continue connecting (yes/no)? yesDownloading########################################################################################################################################OK!
# Carregue o arquivo de inicialização no sistema de arquivos do dispositivo para o servidor SFTP.
Device#sftp put 2.0.0.1 22 admin admin startup startup.txtThe authenticity of host '2.0.0.1 (2.0.0.1)' can't be established.RSA key fingerprint is e4:dd:11:2e:82:34:ab:62:59:1c:c8:62:1d:4b:48:99.Are you sure you want to continue connecting (yes/no)? yesUploading###############################################################################################################################################################OK!
- Passo 5:Confira o resultado.
# Após a cópia, você pode ver se o arquivo baixado existe no sistema de arquivos do dispositivo e se o arquivo carregado existe no servidor SFTP (omitido).
Device(config-fs)#dirsize date time name-------- ------ ------ --------101526 MAR-01-2015 01:17:18 logging10147 MAR-26-2015 07:58:50 startup10207 MAR-01-2015 01:17:54 history11676148 MAR-26-2013 07:51:32 sp8-g-6.6.7(46)-dbg.pck2048 JAN-10-2015 17:30:20 snmp <DIR>
Configurar um dispositivo como servidor SFTP
Requisitos de rede
- O dispositivo atua como servidor SFTP, o PC atua como cliente SFTP e a rede entre o cliente e o servidor está conectada.
- No dispositivo do servidor SFTP, defina o nome de usuário como admin 1 e a senha como admin 1 ; o diretório do sistema de arquivos do Dispositivo atua como o diretório raiz do servidor SFTP.
- O PC atua como cliente SFTP para carregar e baixar o arquivo com o dispositivo do servidor SFTP.
Topologia de rede

Figura 2 -10 Topologia de rede para configurar o dispositivo como servidor SFTP
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure o endereço IP da interface, fazendo com que a rede entre PC e Dispositivo seja conectada (omitida).
- Passo 3: No dispositivo, habilite o serviço SFTP e configure o nome de usuário e a senha autorizados.
# No dispositivo do servidor SFTP, configure o nome de usuário e a senha autorizados.
Device#configure terminalDevice(config)#local-user admin1 class managerDevice(config-user-manager-admin1)#service-type sshDevice(config-user-manager-admin1)#password 0 admin1Device(config-user-manager-admin1)#exit
Habilite o serviço SSH no dispositivo (SFTP é um submódulo do protocolo SSH.
Device(config)#ip ssh server- Passo 4: Use o PC como cliente SFTP para fazer upload e download de um arquivo para o dispositivo do servidor SFTP.
# A seguir, o sistema Linux é um exemplo para descrever o processo relacionado.
# Insira o endereço IP e nome de usuário corretos, senha para fazer login no servidor SFTP.
[root@aas ~]# sftp admin1@2.1.1.1Connecting to 2.1.1.1...admin@2.1.1.1's password:sftp>
# Obtenha o arquivo de inicialização no sistema de arquivos do dispositivo do servidor SFTP.
sftp> get startup startupFetching /flash/startup to startup/flash/startup 100% 13KB 12.9KB/s 00:00
#Após copiar o arquivo, você pode encontrar o arquivo relacionado no diretório operado.
sftp> lssp8-g-6.6.7(74)-dbg.pck sp8-g-6.6.7(76)-dbg.pck startup tech test_pcsftp>
# Carregue o arquivo no PC para o sistema de arquivos do dispositivo do servidor SFTP.
sftp> put sp8-g-6.6.7(76)-dbg.pck sp8-g-6.6.7(76)-dbg.pckUploading sp8-g-6.6.7(76)-dbg.pck to /flash/ sp8-g-6.6.7(76)-dbg.pcksp8-g-6.6.7(76)-dbg.pck 100% 11424KB 16.0KB/s 00:00
#Depois de carregar o arquivo, você pode encontrar o arquivo correspondente no sistema de arquivos do Dispositivo.
Device(config-fs)#dirsize date time name------------ ------ ------ --------2048 JUN-30-2015 16:35:50 tech <DIR>10229 JUN-12-2015 14:31:22 history101890 JUN-30-2015 17:46:40 logging39755 JUN-30-2015 16:33:56 startup740574 MAY-27-2014 18:55:14 web-Spl-1.1.243.rom2048 JUN-27-2015 16:26:10 snmp <DIR>11698172 JUN-30-2015 10:36:18 sp8-g-6.6.7(76)-dbg.pck
Configurar um dispositivo local para fazer login em um dispositivo remoto por meio do modo de autenticação de chave pública SSH
Requisitos de rede
- O PC atua como terminal local e instala o software SecureCRT.
- O PC atua como o terminal local e pode acessar o Dispositivo por meio da chave pública SSH.
Topologia de rede

Figura 2 -11 Topologia de rede para configurar um dispositivo local para efetuar login em um dispositivo remoto pelo modo de autenticação de chave pública SSH
Etapas de configuração
- Passo 1: Configure o endereço IP da interface e configure o protocolo de roteamento para fazer o PC e o Dispositivo se comunicarem entre si (omitido).
- Passo 2: Configure o serviço SSH e a função FTP.
Device#configure terminalDevice(config)#ip ssh server
- Passo 3: Configure o nome de usuário de login do Dispositivo.
Device(config)#local-user user1 class managerDevice(config-user-manager-user1)#service-type sshDevice(config-user-manager-user1)#exit
- Passo 4: No PC, gere o arquivo de chave pública SSH.
#O documento toma como exemplo o sistema operacional Windows. SecureCRT usa a Versão 6.1.2. No PC, abra a barra de ferramentas do software SecureCRT e clique no botão Ferramentas . No menu suspenso, clique em Criar chave pública (C) para exibir o assistente de geração da chave e clique em Avançar .

#Tipo de chave: selecione qualquer um entre DSA e RSA. Aqui, use o DSA como exemplo e clique em Avançar .
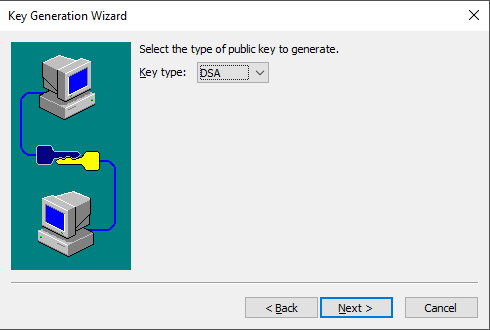
# A senha está em vigor no local e você pode ignorá-la. Cliqueem Avançar.
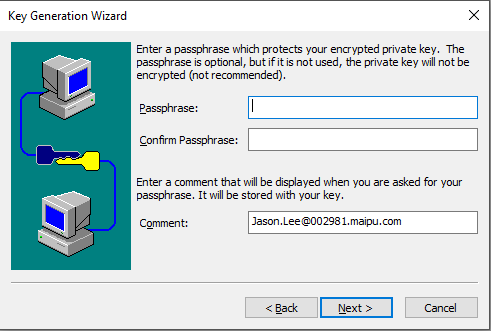
# Preencha o tamanho da chave de acordo com a descrição e clique emNext.
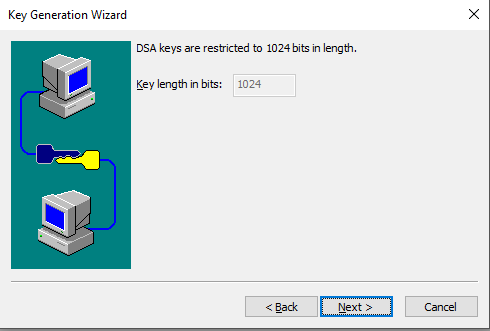
# Para gerar a chave, você precisa mover o mouse continuamente. Após gerar a chave, clique em Avançar .
#Selecione o formato de armazenamento da chave. Aqui, selecione o formato de chave OpenSSH e clique em Concluir .
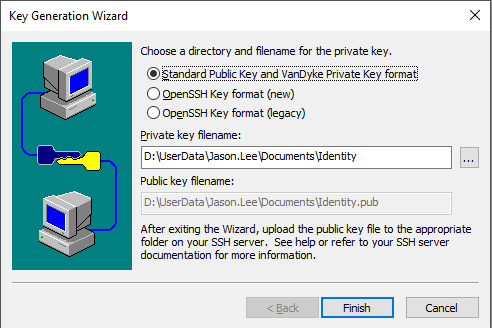
#No caminho do servidor FTP do PC, crie o arquivo “ authorized_keys ” , copie todo o conteúdo do arquivo de chave pública “ Identity.pub ” para “ authorized_keys ” e copie o arquivo “ authorized_keys ” para /flash/sshpubkey/user1/ .
Device#filesystemDevice(config-fs)#mkdir sshpubkeyDevice(config-fs)#cd sshpubkeyDevice(config-fs)#mkdir user1Device(config-fs)#cd user1Device(config-fs)#copy ftp 2.0.0.1 username password authorized_keys file-system authorized_keys
Para o formato de armazenamento da chave, selecione OpenSSH e os outros formatos não são suportados. Ao copiar o conteúdo “ Identity.pub ” , selecione tudo e depois copie, não sendo necessário alterar uma linha.
Quando vários clientes usam um usuário para fazer login, altere uma linha após as informações da chave pública armazenadas por “ authorized_keys ” , cole as informações de outra chave pública e sobreponha .
Por padrão, o dispositivo não possui o diretório /flash/sshpubkey/user1/, e você precisa criar no sistema de arquivos. U ser1 no diretório é o nome de usuário usado pela autenticação. O nome de usuário é o usuário no dispositivo. Se o nome de usuário for user2, crie /flash/sshpubkey/user2/.
A autenticação de chave pública SSH não oferece suporte a SSHv1.
- Passo 5: Confira o resultado.
O PC usa o software SecureCRT para configurar a conexão SSH, use a chave pública primeiro ou autenticação exclusiva, clique em Conectar e você verá que a conexão não é necessária para inserir a senha, mas pode fazer login diretamente no dispositivo.
Configure o dispositivo local para fazer login em um dispositivo remoto via WEB
Requisitos de rede
- Use o PC como terminal local para fazer login no dispositivo pela web.
- A rota entre os dois dispositivos deve ser alcançável.
Topologia de rede

Figura 2 -12 Configure o dispositivo local para fazer login no dispositivo remoto via web
Etapas de configuração
- Passo 1: Configure o usuário local e os atributos relacionados.
Device>enableDevice#configure terminalDevice(config)#local-user admin class mangerDevice(config-user-manager-admin)password 0 adminDevice(config-user-manager-admin)service-type web
- Passo 2: Habilite o serviço https.
Device2(config)#ip http server- Passo 3: Confira o resultado.
Abra o navegador no PC e digite http://2.0.0.1 na barra de endereços do navegador, após o login na web bem-sucedido, você entrará na interface web do dispositivo.
Controle e Gerenciamento do Sistema
Visão geral
Para aumentar a segurança de operação do dispositivo, no login do usuário ou habilitar a operação, o dispositivo fornece vários tipos de gerenciamento de autenticação (incluindo AAA. Consulte as seções e capítulos relacionados no manual de configuração AAA.) Somente o usuário com os direitos de operação necessários pode fazer login ou execute a operação de ativação com sucesso.
Para autorizar diferentes conjuntos de comandos executáveis para diferentes níveis de usuários, os comandos do dispositivo são divididos em níveis de 0 a 15 e os níveis de usuário são divididos em níveis de 0 a 15. Entre os níveis, o nível 0 tem os direitos mais baixos, enquanto o nível 15 tem os direitos mais altos.
Configuração da função de controle e gerenciamento de login
Tabela 3 - 1 Lista de configuração de controle e gerenciamento de login
| Tarefas de configuração | |
| Alterne entre os níveis de usuário. | Alterne entre os níveis de usuário. |
| Configure o nível de comando. | Configure o nível de comando. |
| Configure a senha de ativação . | Configure a senha de ativação . |
| Configure usuários e as propriedades relacionadas. |
Configurar comandos automáticos.
Configure nenhuma autenticação de senha durante o login. Configurar senhas de usuário. Configure o nível de privilégio do usuário. |
| Configure as propriedades da linha. |
Entre no modo de configuração de linha da porta do console.
Entre no modo de configuração de linha do usuário Telnet ou SSH. Configure o tempo absoluto para a operação do usuário de login. Configure o nível de privilégio do usuário de login. Configure os usuários para executar comandos automaticamente após o login. Configure as opções de execução de comando automático. Configure o tempo limite de inatividade do usuário de login. Configure a senha da linha. Configure o modo de autenticação de login. Configure o modo de autorização de linha. Configure o modo de contabilidade de linha. Habilite a função Modem da porta Console. Configure o tempo limite de login do usuário. |
Alternar entre os níveis de usuário
Se um nome de usuário e senha do nível correspondente estiverem configurados, o usuário poderá executar o comando enable level (0-15) e, em seguida, digite a senha correta para inserir o nível de usuário necessário. Enquanto isso, o usuário tem a permissão de execução do nível de usuário e dos níveis inferiores.
Se o nível de usuário atual for superior ao nível de usuário que o usuário deseja inserir, nenhuma autenticação será necessária e o usuário entrará diretamente no nível de usuário necessário. Se o nível de usuário que o usuário deseja inserir for superior ao nível de usuário atual, a autenticação será necessária de acordo com a configuração atual e o modo de autenticação será selecionado de acordo com a configuração.
Se a senha de ativação do nível correspondente tiver sido configurada (usando o comando enable password level ), enquanto a autenticação de ativação de autorização, autenticação e contabilidade (AAA) não estiver configurada ou a autenticação de ativação AAA estiver configurada para usar o método de ativação, use a senha de ativação para autenticação.
Se a senha de ativação do nível necessário não tiver sido configurada, mas o método de autenticação de ativação estiver definido para usar a senha de ativação local para autenticação, haverá dois casos:
a) No caso de um usuário Telnet, o login falha. Se o AAA não tiver sido configurado, a mensagem "% No password set" será solicitada. Se o AAA tiver sido configurado, a mensagem " % Error in authentication " será exibida.
b) Para um usuário da porta Console, se o AAA foi configurado, tente usar a senha de ativação para autenticação durante o login. Se a senha de ativação não tiver sido configurada, use o método de autenticação none . Ou seja, o login passa a autenticação por padrão. Se o AAA não tiver sido configurado, a mensagem "% No password set" será solicitada e a autenticação falhará.
Se a habilitação de autenticação for bem-sucedida, o usuário entrará no nível de usuário especificado e terá permissão de execução do nível. Para consultar o nível de usuário do usuário atual, execute o comando show privilégio .
Se o método de habilitação de autenticação aaa estiver configurado e uma lista de métodos relacionados for usada para habilitar a autenticação, o método relacionado será necessário para autenticação, incluindo:
a) Se método de habilitação de autenticação aaa nenhum está configurado, nenhuma senha é necessária.
b) Se a habilitação do método de autenticação aaa estiver configurada e a senha de habilitação estiver configurada, use a senha para autenticação. Caso contrário, a mensagem "% Bad passwords " será exibida e a autenticação falhará.
c) Se o raio padrão da habilitação da autenticação aaa estiver configurado, a autenticação Remote Authentication Dial in User Service (RADIUS) será usada. Observe que os nomes de usuário de autenticação de habilitação para RADIUS são fixos, ou seja, $enab+level$. Aqui "nível" é um número no intervalo de 1 a 15, ou seja, o nível que o usuário deseja inserir. Os nomes de usuário RADIUS são fixos, portanto, durante a autenticação, nenhum nome de usuário é necessário. O usuário precisa apenas inserir a senha. Se as senhas foram definidas para usuários de diferentes níveis no servidor RADIUS, após inserir a senha correta, o login é bem-sucedido; caso contrário, o login falhará. Por exemplo, ao executar o enable 10 , o nome de usuário fixo é $enab10$. Se o nome de usuário existir no servidor RADIUS, insira a senha correspondente ao nome de usuário e a autenticação será bem-sucedida.
c) Se o tacacs padrão da habilitação da autenticação aaa estiver configurado, a autenticação do sistema de controle de acesso do controlador de acesso do terminal (TACACS) é usada. Se o nome de usuário for exibido durante o login, mantenha o nome de usuário para login e insira a senha de ativação do nome de usuário. Caso contrário, insira um nome de usuário e a senha de ativação do nome de usuário. Se o nome de usuário inserido existir no servidor TACACS e a senha de habilitação do TACACS tiver sido definida, a autenticação será bem-sucedida; caso contrário, a autenticação falhará.
Os métodos de autenticação de habilitação mencionados anteriormente podem formar uma combinação em uso.
Condição de configuração
Nenhum
Alternar entre os níveis de usuário
Se um usuário tiver a autoridade correspondente, o usuário poderá alternar do modo de usuário comum para o modo de usuário privilegiado alternando entre os níveis de usuário com um comando. Então, o usuário tem a autoridade do nível de usuário. Se um usuário executar o comando no modo de usuário privilegiado , a alternância de nível de usuário será realizada de acordo com o parâmetro de comando.
Tabela 3 - 2 Alternando entre os níveis de usuário
| Etapa | Comando | Descrição |
| Alterne entre os níveis de usuário. | enable [ level-number ] | Obrigatório. Por padrão, o nível de usuário é o nível 15. |
Configurar o Nível de Comando
Condição de configuração
Nenhum
Configurar o Nível de Comando
No programa aplicativo, cada comando shell tem um nível padrão, que pode ser modificado através do privilégio comando. Um usuário pode executar apenas os comandos com nível igual ou menor que o nível do usuário. Por exemplo, um usuário com o nível de usuário 12 pode executar apenas os comandos com os níveis 0-12. Ao configurar o nível de comando, você precisa usar os modos de comando. Você pode modificar o nível de um único comando ou de todos os comandos em um modo de comando especificado.
Tabela 3 - 3 Configurando o Nível de Comando
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o nível de comando. | privilege privilege-mode level level-number [ all | command command-line ] | Obrigatório. |
Configure a habilitação senha
Condição de configuração
Nenhum
Configure a senha de ativação
A senha de ativação é a senha usada por um nível de usuários para entrar no nível local. Se nenhum nível for especificado no comando enable, a senha será definida como a senha de ativação do nível 15 por padrão.
Tabela 3 - 4 Configurando a senha de ativação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a senha de ativação . | enable password [ level level-number ] [ 0 ] password | Obrigatório. Por padrão, nenhuma senha de ativação é configurada. |
Configurar Propriedades da Linha
O dispositivo suporta até um usuário da porta Console e 16 usuários Telnet ou SSH para efetuar login ao mesmo tempo. Os comandos de linha podem definir diferentes propriedades de autenticação e autorização para os usuários de login.
Condição de configuração
Nenhum
Entre no modo de configuração de linha deConsole Port
Para configurar as propriedades da porta do console, você precisa entrar no modo de configuração de linha da porta do console.
Tabela 3 - 5 Entrando no modo de configuração de linha doConsole Port
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entra no modo de configuração de linha da porta Console. | line con 0 | Obrigatório |
Entre no modo de configuração de linha do usuário Telnet ou SSH
Para configurar as propriedades do Telnet ou SSH, você precisa entrar no modo de configuração de linha do Telnet do SSH.
Tabela 3 - 6 Entrando no modo de configuração de linha do usuário Telnet ou SSH
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de linha do usuário Telnet ou SSH. | line vty { vty-min-number } [ vty-max-number ] | Obrigatório |
Configurar Tempo Absoluto para Operação do Usuário de Login
O tempo absoluto para a operação de login do usuário refere-se ao tempo limite desde o login bem-sucedido de um usuário até a saída automática do usuário, na unidade de minuto. Se o tempo absoluto for definido como 0, indica que o tempo não é limitado. Por padrão, o tempo é 0. Além disso, cinco segundos antes do tempo configurado expirar, a seguinte mensagem de prompt é exibida: Tempo limite da linha expirado.
Tabela 3 - 7 Configurando o Tempo Absoluto para a Operação de Login do Usuário
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de linha da porta do console ou Terminal de tipo virtual (VTY). | line { con 0 | vty vty-min-number [ vty-max-number ] } | Obrigatório |
| Configure o tempo absoluto para a operação do usuário de login. | absolute-timeout absolute-timeout-number | Obrigatório. Por padrão, o tempo absoluto é 0, ou seja, sem limite de tempo. |
Configurar o nível de privilégio do usuário de login
Configure o nível de privilégio do usuário de login. O nível de privilégio padrão é 1. Um usuário pode executar apenas os comandos com nível igual ou menor que o nível atual.
Tabela 3 - 8 Configurando o nível de privilégio do usuário de login
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de linha da porta Console ou VTY. | line { con 0 | vty vty-min-number [ vty-max-number ] } | Obrigatório. |
| Configure o nível de privilégio do usuário de login. | privilege level level-number | Obrigatório. O nível de privilégio é 1. |
Configurar lista de controle de acesso
Defina a lista de controle de acesso do usuário. Somente os hosts permitidos pela lista de controle de acesso podem fazer login no dispositivo.
Tabela 3 - 9 Configurar a lista de controle de acesso à linha
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração de linha da porta Console ou VTY. | line { vty vty-min-number [ vty-max-number ] } | Obrigatório |
| Configurar a lista de controle de acesso | access-class { access-list-number | access-list-name} { in | out} | Obrigatório |
| Configurar ipv6 ACL lista de controle | ipv6 access-class{access-list-number | access-list-name }{ in | out} | opcional _ |
Configurar usuários para executar comandos automaticamente após o login
Configure os comandos para serem executados automaticamente após os usuários efetuarem login com sucesso. Por padrão, nenhum comando deve ser executado automaticamente.
Tabela 3 - 10 Configurando os comandos para serem executados automaticamente após o login bem-sucedido
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de linha da porta Console ou VTY. | line { con 0 | vty vty-min-number [ vty-max-number ] } | Obrigatório |
| Configure os comandos para serem executados automaticamente após o login bem-sucedido. | autocommand command-line | Obrigatório |
Configurar opções de execução de comandos automáticos
Você pode configurar o tempo de atraso para comandos automáticos e configurar se deseja desconectar a conexão do usuário após os comandos serem executados automaticamente. Por padrão, a execução do comando não é atrasada e a conexão do usuário é desconectada depois que os comandos são executados automaticamente.
As opções de execução de comando automático incluem atraso e se a conexão do usuário deve ser desconectada após a execução do comando.
Tabela 3 - 11 Configurando opções de execução de comando automático
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de linha da porta Console ou VTY. | line { con 0 | vty vty-min-number [ vty-max-number ] } | Obrigatório. |
| Configure as opções de execução de comando automático. | autocommand-option { nohangup [ delay delay-time-number ] | delay delay-time-number [ nohangup ] } | Obrigatório . |
O comando autocommand-option é válido somente após a configuração da função autocommand.
Configurar o tempo limite de inatividade do usuário de login
Se o tempo em que o usuário de login não executa nenhuma operação no dispositivo for maior que o tempo limite de inatividade, o dispositivo fará com que o usuário de login atual saia. O tempo de saída do tempo limite de inatividade padrão é de 5 minutos. Se o tempo for definido como 0, o tempo limite ocioso não terá efeito.
Tabela 3 - 12 Configurando o tempo de saída do tempo limite de inatividade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de linha da porta Console ou VTY. | line { con 0 | vty vty-min-number [ vty-max-number ] } | Obrigatório |
| Configurando o tempo de saída do tempo limite ocioso. | exec-timeout exec-timeout-minute_number [ exec-timeout-second_number ] | Obrigatório O tempo de saída do tempo limite de inatividade padrão é de 5 minutos. |
Configurar a senha da linha
Use 0 e 7 para indicar se a senha de linha está em texto simples ou texto cifrado. 0 indica que a senha está em texto simples, enquanto 7 indica que a senha está em texto cifrado. No modo de interação, somente a senha de texto simples é permitida. Ou seja, neste modo, o valor do parâmetro 0 é usado.
Tabela 3 - 13 Configurando a senha da linha
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de linha da porta Console ou VTY. | line { con 0 | vty vty-min-number [ vty-max-number ] } | Obrigatório |
| Configure a senha da linha. | password 0 password | Obrigatório |
Configurar o modo de autenticação de login
O dispositivo suporta os seguintes modos de autenticação de login:
- Modo de autenticação de senha de login: Usa autenticação de senha de linha.
- Modo de autenticação aaa do login: usa a autenticação AAA.
- Nenhum login indica que nenhuma autenticação é necessária para o login.
- Por padrão, o modo de autenticação sem login é usado para Telnet e o modo de autenticação de usuário local é usado para SSH.
Tabela 3 - 14 Configurando o modo de autenticação de login
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de linha da porta Console ou VTY. | line { con 0 | vty vty-min-number [ vty-max-number ] } | Obrigatório |
| Configure o modo de autenticação de login. | login {aaa [ domain-name | default] | password} | O comando afetará a autenticação, autorização e contabilidade AAA. |
Configurar o tempo limite de login do usuário
Durante o login, se o tempo de espera para o usuário inserir o nome de usuário ou a senha expirar, o sistema avisará que o login falhou. Por padrão, o tempo limite de login é de 30 segundos. Para modificar o tempo limite de espera, use esta função.
Tabela 3 - 15 Configurando o tempo limite de espera de login do usuário
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de linha da porta Console ou VTY. | line { con 0 | vty vty-min-number [ vty-max-number ] } | Obrigatório. |
| Configure o tempo limite de espera de login do usuário. | timeout login respond respond-time-value | Obrigatório. Por padrão, o tempo de espera para o usuário inserir o nome de usuário ou a senha é de 30 segundos. |
Controle e Gerenciamento do Sistema Monitoramento e Manutenção
Tabela 3 - 16 Controle e Gerenciamento do Sistema Monitoramento e Manutenção
| Comando | Descrição |
| clear line { con con-number | vty vty-number } | Limpe um serviço de terminal. |
| show privilege | Visualize o nível de privilégio do usuário atual. |
| show users | Exiba as informações do usuário configurado. |
FTP, FTPS, TFTP e SFTP
Visão geral
File Transfer Protocol (FTP) é usado entre um servidor e um cliente para transmitir arquivos. Ele melhora o compartilhamento de arquivos e fornece um modo de transmissão de dados eficiente e confiável entre o usuário e o computador remoto. O protocolo FTP geralmente usa as portas TCP 20 e 21 para transmissão. A porta 20 transmite dados no modo ativo e a porta 21 transmite mensagens de controle.
Semelhante à maioria dos serviços da Internet, o FTP usa o mecanismo de comunicação cliente/servidor. Para se conectar a um servidor FTP, geralmente é necessário ter a conta autorizada do servidor FTP. Na Internet, um grande número de servidores FTP são servidores FTP anônimos, que visam fornecer serviços de cópia de arquivos ao público. Para este tipo de servidor FTP, os usuários não precisam se registrar no servidor ou obter autorização dos servidores FTP.
O FTP suporta dois tipos de modos de transmissão de arquivos:
- Modo de transmissão ASCII, no qual os arquivos de texto são transmitidos.
- Modo de transmissão binário, no qual os arquivos de programa são transmitidos.
Se o dispositivo atua como um cliente FTP, apenas o modo de transmissão binário é suportado. Se o dispositivo funcionar como um servidor FTP, ambos os modos de transmissão são suportados.
FTP suporta dois modos de trabalho:
- Modo ativo: Um cliente FTP primeiro estabelece uma conexão com um servidor FTP através da porta TCP21 e envia comandos através deste canal. Caso o cliente FTP queira receber dados, ele envia o comando PORT através deste canal. O comando PORT contém através de qual porta o cliente recebe os dados. Em seguida, o servidor FTP conecta sua porta TCP20 à porta especificada do cliente FTP para transmitir dados. O servidor FTP deve configurar uma nova conexão com o cliente FTP para transmitir dados.
- Modo passivo: O método de configuração do canal de controle no modo passivo é semelhante ao do modo ativo. No entanto, após a configuração da conexão, o comando PASV em vez do comando PORT é enviado. Após o servidor FTP receber o comando PASV, ele abre uma porta high end (com o número da porta maior que 1024) e informa ao cliente para transmitir dados através desta porta. O cliente FTP se conecta à porta do servidor FTP e, em seguida, o servidor FTP transmite dados por essa porta.
Muitos clientes de Intranet não podem efetuar login no servidor FTP no modo ativo, porque o servidor não consegue configurar uma nova conexão com um cliente de Intranet.
Quando o dispositivo atua como um cliente FTP, ele configura uma conexão de dados no modo ativo.
FTPS é um protocolo FTP aprimorado que usa o protocolo e comandos FTP padrão, adicionando a função de segurança SSL para o protocolo FTP e o canal de dados. FTPS também é chamado de FTP-SSL e FTP-sobre-SSL . SSL é um protocolo de criptografia e descriptografia dos dados na conexão de segurança entre o cliente e o servidor com a função SSL. No dispositivo, apenas o cliente FTP suporta a função.
O Trivial File Transfer Protocol (TFTP) é um protocolo simples de transferência de arquivos baseado no User Datagram Protocol (UDP). Ele transmite dados através da porta UDP 69. O protocolo é projetado para transmissão de pequenos arquivos ; portanto, não possui tantas funções quanto o protocolo FTP. Não suporta lista de diretórios ou autenticação. O dispositivo implementa apenas as funções do cliente TFTP.
SFTP ( Secure File Transfer Protocol/Secure FTP ) é a nova função do SSH 2.0 . O SFTP é baseado na conexão SSH para que o usuário remoto possa efetuar login no dispositivo com segurança para gerenciar o arquivo, transmitir o arquivo e outras operações, proporcionando maior garantia de segurança para a transmissão dos dados. O SFTP fornece um método seguro para transmitir o arquivo. SFTP é a função sol do SSH, realizando a transmissão segura do arquivo. O SFTP criptografa as informações de autenticação transmitidas e os dados transmitidos, portanto, o uso do SFTP é seguro. Se o requisito para a segurança da rede for maior, você pode usar o SFTP para substituir o FTP, mas a transmissão do arquivo SFTP adota a tecnologia de criptografia/descriptografia, portanto, a eficiência da transmissão é menor que a transmissão do arquivo FTP.
Configuração de funções FTP, FTPS, TFTP e SFTP
Tabela 4 - 1 Lista de configuração de funções de FTP e TFTP
| Tarefas de configuração | |
| Configure um servidor FTP. | Configure as funções de um servidor FTP. |
| Configure um cliente FTP. | Configure as funções de um cliente FTP. |
| Configure um cliente TFTP. | Configure as funções de um cliente TFTP. |
| Configurar um servidor SFTP | Configurar as funções do servidor SFTP |
| Configurar um cliente SFTP | Configure as funções do cliente SFTP |
Configurar um servidor FTP
Condição de configuração
Nenhum
Configurar as funções de um servidor FTP
Antes de configurar o dispositivo como servidor FTP, ative primeiro a função de servidor FTP. Em seguida, o cliente FTP pode acessar o servidor FTP. Por questões de segurança, o dispositivo fornece o serviço FTP apenas para usuários autorizados e limita o número máximo permitido de usuários de login simultâneos.
Tabela 4 – 2 Configurando as funções de um servidor FTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Ative a função do servidor FTP. | ftp enable | Obrigatório. Por padrão, a função do servidor FTP está desabilitada. |
| Configure o nome de usuário e a senha autorizados. | user username password 0 password | Obrigatório. Por padrão, o nome de usuário e a senha autorizados não são configurados. Para obter detalhes do comando, consulte as seções relacionadas em "Controle e gerenciamento do sistema". |
| Configurar o número da porta de escuta do serviço FTP | ftp listen-port [ port-num ] | Opcional Por padrão, o número da porta de escuta do serviço FTP é 21. |
| Configure o número máximo permitido de usuários de login simultâneos. | ftp max-user-num user-num | Opcional . Por padrão, o número máximo permitido de usuários de login simultâneos é 1. |
| Configure o tempo limite de conexão. | ftp timeout time | Opcional. Por padrão, o tempo limite de conexão é de 300 segundos. |
Configurar um cliente FTP
Condição de configuração
Nenhum
Configurar as funções de um cliente FTP
No dispositivo, quando você usa o cópia de comando para copiar arquivos (consulte as seções relacionadas em "Gerenciamento do sistema de arquivos") ou use o sysupdate comando para atualizar a versão do software (consulte as seções relacionadas em "Atualização do software"), o dispositivo pode ser acionado para atuar como cliente FTP e configurar uma conexão com o servidor FTP remoto.
A conexão entre um cliente FTP e um servidor FTP usa o endereço da interface de saída da rota para o servidor FTP como endereço de origem por padrão. Os usuários também podem usar o ip ftp comandos source-address ou ip ftp source-interface para especificar o endereço de origem do cliente FTP ou a interface de origem.
Tabela 4 - 3 Configurando as funções de um cliente FTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o endereço de origem do cliente FTP. | ip ftp { source-interface interface-name | source-address ip-address } | Opcional. Por padrão, o cliente FTP usa o endereço da interface de saída da rota para o servidor FTP como seu endereço de origem para se comunicar com o servidor FTP. |
| Configure o cliente FTP para usar primeiro o modo de porta | ip ftp port-first | Opcional. Por padrão, primeiro use o modo passivo e o servidor para configurar a conexão de dados. |
Por questões de segurança, algumas redes podem restringir a comunicação entre o endereço da interface de saída da rota do dispositivo para o servidor FTP e o servidor FTP, mas os outros endereços de interface de serviço estão disponíveis. Neste caso, os usuários podem usar o ip ftp endereço de origem ou Comandos ip ftp source-interface para especificar o endereço de origem do cliente FTP ou a interface de origem.
Configurar cliente FTPS
Condição de configuração
Nenhum
Configurar a função do cliente FTPS
Ao copiar arquivos no dispositivo com o comando copy (consulte o capítulo relevante de "Gerenciamento do sistema de arquivos"), o dispositivo pode ser acionado para estabelecer uma conexão com o servidor FTPS remoto como um cliente FTPS.
Tabela 4 -4 C onfigurar a função do cliente FTPS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| C onfigurar o nome de domínio de confiança PKI do cliente FTPS | ip ftp secure-identity ca-name | Mandatório _ Por padrão, não configure o nome de domínio de confiança PKI do cliente FTPS. |
Configurar um cliente TFTP
Condição de configuração
Nenhum
Configurar as funções de um cliente TFTP
No dispositivo, quando você usa o cópia de comando para copiar arquivos (consulte as seções relacionadas em "Gerenciamento do sistema de arquivos") ou use o comando sysupdate para atualizar a versão do software (consulte as seções relacionadas em "Atualização de software"), o dispositivo pode ser acionado para atuar como o TFTP cliente e configure uma conexão com o servidor TFTP remoto.
A conexão entre um cliente TFTP e um servidor TFTP usa o endereço da interface de saída da rota para o servidor TFTP como endereço de origem por padrão. Os usuários também podem usar o ip tftp comandos source-address ou ip tftp source-interface para especificar o endereço de origem do cliente TFTP ou a interface de origem.
Tabela 4 - 5 Configurando as funções de um cliente TFTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o endereço de origem do cliente TFTP. | ip tftp { source-interface interface-name | source-address ip-address } | - |
Por questões de segurança, algumas redes podem restringir a comunicação entre o endereço da interface de saída da rota do dispositivo para o servidor TFTP e o servidor TFTP, mas os outros endereços de interface de serviço estão disponíveis. Neste caso, os usuários podem usar o ip tftp Endereço de Origem ou comandos ip tftp source-interface para especificar o endereço de origem do cliente TFTP ou a interface de origem.
Configurar um servidor TFTP
Condição de configuração
Nenhum
Configurar as funções de um servidor TFTP
Para configurar um dispositivo como servidor TFTP, primeiro habilite a função do servidor TFTP para que o cliente TFTP possa acessar.
Tabela 4 - 6 Configurando as Funções de um Servidor TFTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite as funções do servidor TFTP | tftp enable | Obrigatório Por padrão, não habilite as funções do servidor TFTP. |
Configurar um servidor SFTP
Condição de configuração
Nenhum
Configurar as funções de um servidor SFTP
Antes de configurar o dispositivo como servidor FTP S , primeiro habilite a função do servidor FTP S. Então, o cliente FTP S pode acessar o servidor FTP S. Como o SFTP é uma função subsidiária do SSH , para habilitar a função de servidor SFTP do dispositivo, você também precisa habilitar a função de servidor SSH do dispositivo.
Tabela 4 - 7 Configurando a função do servidor SFTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a função do servidor IPv4 SSH | ip ssh server [ sshv1-compatible ] [ listen-port ] | Obrigatório Por padrão , não ative a função do servidor IPv4 SSH . |
| Habilite a função do servidor SFTP | sftp server enable | Mandatório _ Por padrão, não habilite a função do servidor SFTP. |
Tabela 4 - 8 Configurar a função do servidor IPv6 SFTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a função do servidor IPv6 SSH | ipv6 ssh server [ sshv1-compatible ] [ listen-port ] | Mandatório _ Por padrão, não ative a função do servidor IPv6 SSH. |
| Habilite a função do servidor SFTP | sftp server enable | Mandatório _ Por padrão, não habilite a função do servidor SFTP. |
Configurar um cliente SFTP
Condição de configuração
Nenhum
Configurar as funções de um cliente SFTP
O dispositivo serve como cliente SFTP e conecta o servidor SFTP, baixando o arquivo do servidor SFTP ou carregando o arquivo no servidor SFTP.
Tabela 4 - 9 Configurando a função de um cliente SFTP
| Etapa | Comando | Descrição |
| Configure o dispositivo como o cliente SFTP para carregar ou baixar o arquivo para o servidor SFTP | sftp { get | put } host-ip-address port-number [source-interface interface-name] user password src-filename dest-filename [compress] | Opcional |
FTP e TFTP Monitoramento e Manutenção
Nenhum
Exemplo de configuração típico de FTP e TFTP
Configurar um dispositivo como um cliente FTP
Requisitos de rede
- Um PC atua como um servidor FTP e o Dispositivo atua como um cliente FTP. A rede entre o servidor e o dispositivo está normal.
- No servidor FTP, o nome de usuário de um dispositivo para efetuar login no servidor FTP é admin e a senha é admin. Os arquivos a serem baixados são colocados no diretório do servidor FTP.
- O dispositivo atua como cliente FTP para carregar e baixar arquivos do servidor FTP.
Topologia de rede

Figura 4 - 1 Rede para configurar um dispositivo como um cliente FTP
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure um servidor FTP e coloque os arquivos a serem baixados no diretório do servidor FTP. (Omitido)
- Passo 3: Configure os endereços IP dos dispositivos para que a rede entre o cliente e o servidor seja normal. (Omitido)
- Passo 4: O dispositivo atua como cliente FTP para fazer upload e download de arquivos do servidor FTP.
#No modo de sistema de arquivos do Dispositivo, copie um arquivo do servidor FTP para o sistema de arquivos do Dispositivo.
Device#filesystemDevice(config-fs)#copy ftp 2.0.0.1 admin admin sp4-g-6.5.0(41).pck file-system sp4-g-6.5.0(41).pckDevice (config-fs)#exit
#No modo de sistema de arquivos do Dispositivo, copie o arquivo de inicialização do Dispositivo no servidor FTP.
Device#filesystemDevice(config-fs)#copy file-system startup ftp 2.0.0.1 admin admin startup.txt
- Passo 5: Confira o resultado.
#Após a conclusão do processo de cópia, verifique se o arquivo baixado existe no sistema de arquivos do Dispositivo. No servidor FTP, verifique se o arquivo carregado existe. (Omitido)
Device(config-fs)#dirsize date time name-------- ------ ------ --------101526 MAR-01-2013 01:17:18 logging10147 MAR-26-2013 07:58:50 startup10207 MAR-01-2013 01:17:54 history1372 MAR-23-2013 08:18:38 devInfo6598624 MAR-26-2013 07:51:32 sp4-g-6.5.0(41).pck1024 JAN-10-2013 17:30:20 snmp <DIR>0 JAN-31-2013 14:29:50 syslog736512 MAR-27-2013 10:30:48 web-Spl-1.1.168.rom
Se a mensagem "FTP: Ctrl socket connect error(0x 3c): Operation timed out" for impressa, isso indica que o servidor não pode ser alcançado e a causa pode ser que a rota não está disponível ou o servidor não foi iniciado.
Se a mensagem "Baixando##OK!" mensagem é impressa, indica que o arquivo foi copiado com sucesso.
Configurar um dispositivo como um servidor FTP
Requisitos de rede
- Device1 atua como um servidor FTP, enquanto PC e Device2 atuam como clientes FTP. A rede entre o cliente e o servidor é normal.
- No servidor FTP Device1, o nome de usuário é admin1 e a senha é admin1. O diretório do sistema de arquivos do Device1 atua como o diretório raiz do servidor FTP.
- PC e Device2 atuam como o cliente FTP para carregar e baixar arquivos do servidor FTP Device1.
Topologia de rede

Figura 4 – 2 Rede em que um dispositivo atua como um servidor FTP
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP das interfaces para que a rede entre o PC, Dispositivo 2 e Dispositivo 1 seja normal. (Omitido)
- Passo 3: Em Device1, habilite o serviço FTP e configure o nome de usuário e a senha autorizados.
# No Device1, habilite o serviço FTP e configure o nome de usuário e a senha autorizados.
Device1#configure terminalDevice1(config)#local-user admin1 class managerDevice1(config-user-manager-admin1)#service-type ftpDevice1(config-user-manager-admin1)#password 0 admin1Device1(config-user-manager-admin1)#exit
#No Dispositivo1, habilite o serviço FTP.
Device1(config)#ftp enable#No Dispositivo1, defina o número máximo de usuários simultâneos para 2.
Device1(config)#ftp max-user-num 2- Passo 4: Confira o resultado.
#Verifique se a função de serviço FTP está habilitada no Device1.
Device#show ip socketsActive Internet connections (including servers)PCB Proto Recv-Q Send-Q Local Address Foreign Address (state)-------- ----- ------ ------ ---------------------- ---------------------- -------27cf8a4 TCP 0 0 0.0.0.0.80 0.0.0.0.0 LISTEN27ce0a4 TCP 0 0 130.255.104.43.22 130.255.98.2.3590 ESTABLISHED27d0be4 TCP 0 0 0.0.0.0.21 0.0.0.0.0 LISTEN27d0824 TCP 0 0 127.0.0.1.2622 127.0.0.1.1026 ESTABLISHED
Se a função de serviço FTP estiver habilitada, você poderá descobrir que a porta 21 está no estado de escuta.
- Passo 5: Use Device2 como um cliente FTP para copiar um arquivo de inicialização do servidor FTP Device1 para Device2.
Device2#filesystemDevice2(config-fs)#copy ftp 2.0.0.1 admin1 admin1 startup file-system startup
- Passo 6: Use o PC como um cliente FTP para copiar um arquivo de inicialização do servidor FTP Device1 para o PC.
#Na parte seguinte, as telas do Windows DOS são tomadas como exemplo para ilustrar o processo .
#Na tela do DOS do Windows, insira o endereço IP, nome de usuário e senha corretos para fazer login no servidor FTP.
D:\>ftp 2.0.0.1Connected to 2.0.0.1.220 FTP server readyUser (2.0.0.1:(none)): admin331 Password requiredPassword:230 User logged inftp>
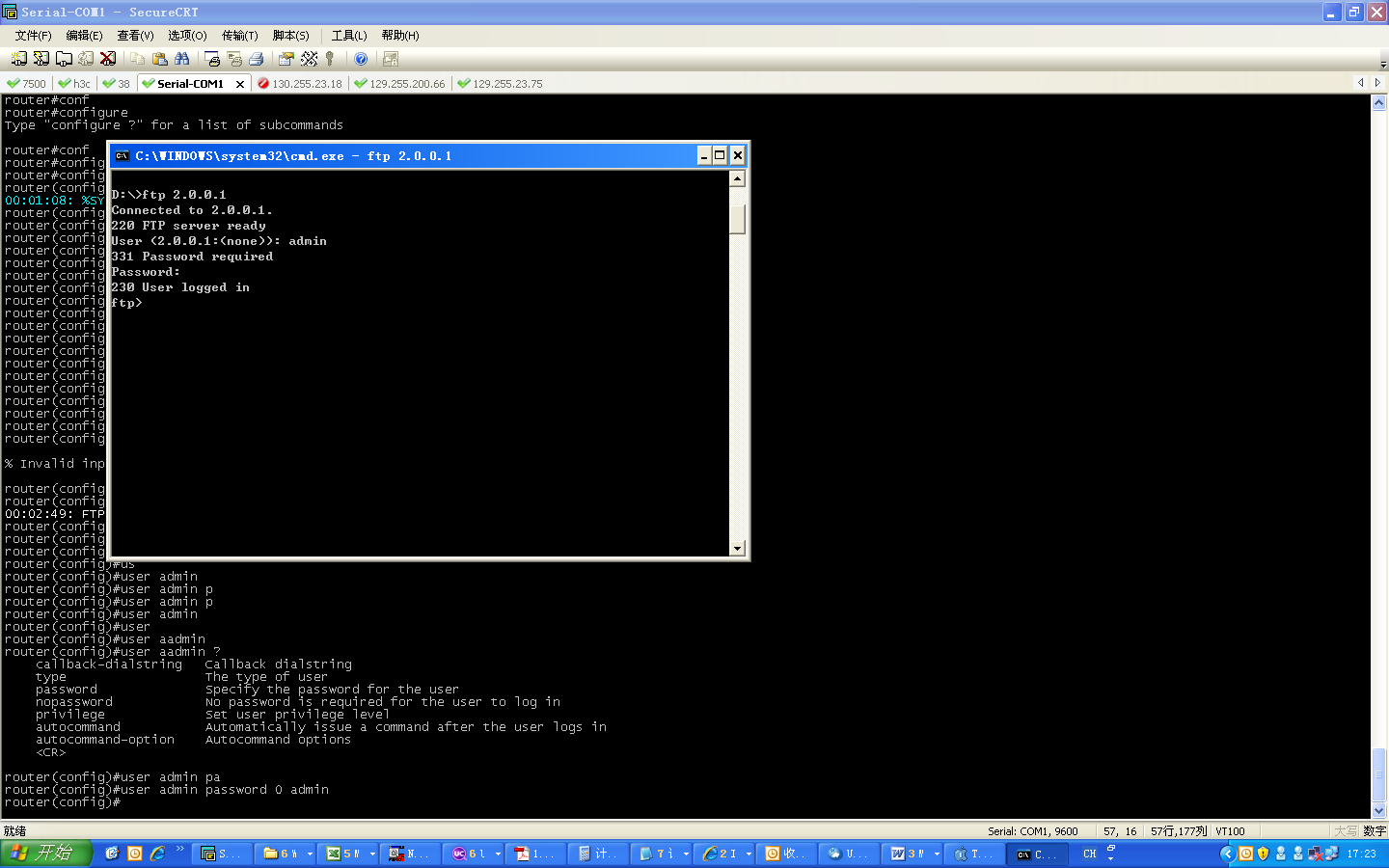
Figura 4 - 3 Fazendo login no servidor FTP através da tela do Windows DOS
#Configure o PC e o servidor FTP para transmitir dados em modo binário.
ftp>binary
Figura 4 - 4 Configurando o PC e o Servidor FTP para Transmitir Dados no Modo Binário
#Obter o arquivo de inicialização no sistema de arquivos do servidor FTP Device1.
ftp>get startup

Figura 4 - 5 Copiando um arquivo de configuração do servidor FTP
Após a conclusão do processo de cópia do arquivo, o arquivo estará disponível no diretório Windows especificado.
Se a mensagem "421 Sessão limite atingido, fechando conexão de controle" for impressa, isso indica que o número de conexões excedeu o número máximo permitido pelo servidor.
Quando você usa um dispositivo para copiar um arquivo, se a mensagem " Ctrl socket connect error(0x 3c): Operation timed out" for impressa, a causa pode ser que a função do servidor não esteja habilitada ou a rota entre o servidor e o cliente não é alcançável.
Quando você conecta o servidor FTP através do PC cliente FTP, se o "connect :Unknown error number" for impresso, a causa pode ser que a função do servidor não esteja habilitada ou a rota entre o servidor e o cliente não esteja acessível.
Como servidor FTP, o dispositivo está restrito ao modo estrito. Por padrão, apenas suportando o modo passivo para transmitir arquivos. Ele precisa usar o modo de segurança solto para modificar o modo para o modo solto para oferecer suporte ao modo ativo para transmissão de arquivos.
Configurar um dispositivo como cliente TFTP
Requisitos de rede
- Um PC atua como um servidor TFTP e o Dispositivo atua como um cliente TFTP. A rede entre o servidor e o dispositivo está normal. Os arquivos a serem baixados são colocados no diretório do servidor TFTP.
- O dispositivo atua como cliente TFTP para carregar e baixar arquivos do servidor TFTP.
Topologia de rede

Figura 4 - 6 Rede para configurar um dispositivo como um cliente TFTP
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP das interfaces para que a rede entre o cliente e o servidor seja normal. (Omitido)
- Passo 3: Habilite a função do servidor TFTP no PC e coloque os arquivos a serem baixados no diretório do servidor TFTP. (Omitido)
- Passo 4: O dispositivo atua como o cliente TFTP para fazer upload e download de arquivos do servidor TFTP.
#No Dispositivo, copie um arquivo do servidor TFTP para o sistema de arquivos do Dispositivo.
Device#filesystemDevice(config-fs)#copy tftp 2.1.2.1 sp4-g-6.5.0(41).pck file-system sp4-g-6.5.0(41).pckDevice(config-fs)#exit
#No dispositivo, copie o arquivo de inicialização do dispositivo para o servidor TFTP.
Device#filesystemDevice(config-fs)#copy startup-config tftp 2.1.2.1 startup.txt
- Passo 5: Confira o resultado.
Após a conclusão do processo de cópia, verifique se o arquivo baixado existe no sistema de arquivos do Dispositivo. No servidor TFTP, verifique se o arquivo carregado existe. (Omitido)
Device(config-fs)#dirsize date time name-------- ------ ------ --------102227 MAR-01-2013 05:24:32 logging10147 MAR-26-2013 07:58:50 startup10202 MAR-01-2013 05:26:46 history6598624 MAR-26-2013 07:51:32 sp4-g-6.5.0(41).pck1024 JAN-10-2013 17:30:20 snmp <DIR>0 JAN-31-2013 14:29:50 syslog736512 MAR-27-2013 10:30:48 web-Spl-1.1.168.rom
Se a mensagem "Baixando####OK!" mensagem for impressa, isso indica que a cópia do arquivo foi bem-sucedida. A mensagem mostra o tamanho do arquivo, que é determinado pelo tamanho real do arquivo.
Quando você usa um dispositivo para copiar um arquivo, se o "Failed! ErrorNum: 0x41, ErrorType: Host unreach." mensagem for impressa, a causa pode ser que a função do servidor TFTP não esteja habilitada ou a rota entre o servidor e o cliente não esteja acessível.
Configurar um dispositivo como um cliente SFTP
Requisitos de rede
- Um PC atua como um servidor FTP S e o Dispositivo atua como um cliente FTP S. A rede entre o servidor e o dispositivo está normal.
- No servidor FTP S , o nome de usuário de um dispositivo para efetuar login no servidor FTP S é admin e a senha é admin. Os arquivos a serem baixados são colocados no diretório do servidor FTP S.
- O dispositivo atua como o cliente FTP S para carregar e baixar arquivos do servidor FTP S.
Topologia de rede

Figura 4 - 7 Rede para configurar um dispositivo como um cliente n SFTP
Etapas de configuração
- Passo 1: Configure um servidor FTP S e coloque os arquivos a serem baixados no diretório do servidor FTP S. (Omitido)
- Passo 2: Configure os endereços IP dos dispositivos para que a rede entre o cliente e o servidor seja normal. (Omitido)
- Passo 3: O dispositivo atua como o cliente FTP S para fazer upload e download de arquivos do servidor FTP S.
# Baixe um arquivo do servidor SFTP para o sistema de arquivos do dispositivo.
Device#sftp get 2.0.0.1 22 admin admin sp8-g-6.6.7(46)-dbg.pck sp8-g-6.6.7(46)-dbg.pckThe authenticity of host '2.0.0.1 (2.0.0.1)' can't be established.RSA key fingerprint is e4:dd:11:2e:82:34:ab:62:59:1c:c8:62:1d:4b:48:99.Are you sure you want to continue connecting (yes/no)? yesDownloading########################################################################################################################################OK!
# Carregue o arquivo de inicialização do sistema de arquivos do dispositivo para o servidor SFTP.
Device#sftp put 2.0.0.1 22 admin admin startup startup.txtThe authenticity of host '2.0.0.1 (2.0.0.1)' can't be established.RSA key fingerprint is e4:dd:11:2e:82:34:ab:62:59:1c:c8:62:1d:4b:48:99.Are you sure you want to continue connecting (yes/no)? yesUploading###############################################################################################################################################################OK!
- Passo 4: Confira o resultado.
# Após copiar, você pode ver se o arquivo baixado existe no sistema de arquivos do dispositivo; ver se o arquivo carregado existe no servidor SFTP (omitido).
Device(config-fs)#dirsize date time name-------- ------ ------ --------101526 MAR-01-2015 01:17:18 logging10147 MAR-26-2015 07:58:50 startup10207 MAR-01-2015 01:17:54 history11676148 MAR-26-2013 07:51:32 sp8-g-6.6.7(46)-dbg.pck2048 JAN-10-2015 17:30:20 snmp <DIR>
Configurar um dispositivo como um servidor SFTP
Requisitos de rede
- Um PC atua como um servidor FTP S e o Dispositivo atua como um cliente FTP S. A rede entre o servidor e o dispositivo está normal.
- No servidor S FTP, o nome de usuário de um dispositivo para efetuar login no servidor S FTP é admin1 e a senha é admin1. O diretório do sistema de arquivos do Dispositivo serve como o diretório raiz do servidor SFTP.
- O PC atua como o cliente FTP S para carregar e baixar arquivos do servidor FTP S.
Topologia de rede
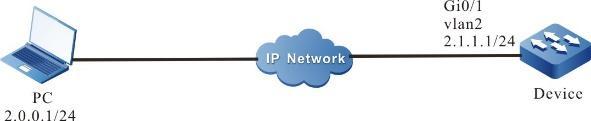
Figura 4 - 8 Rede para configurar um dispositivo como um servidor n SFTP
Etapas de configuração
- Passo 1: Configure o endereço IP da interface para que a rede entre o PC e o Dispositivo seja normal. (Omitido)
- Passo 2: No dispositivo, ative o servidor SFTP e configure o nome de usuário e a senha autorizados.
# No dispositivo do servidor SFTP, configure o nome de usuário e a senha autorizados.
Device#configure terminalDevice(config)#local-user admin1 class managerDevice(config-user-manager-admin1)#service-type sshDevice(config-user-manager-admin1)#password 0 admin1Device(config-user-manager-admin1)#exit
# No dispositivo, habilite o serviço SSH (SFTP é um submódulo do protocolo SSH).
Device(config)#ip ssh server- Passo 3:Use o PC como cliente SFTP para fazer upload e download de um arquivo para o dispositivo do servidor SFTP.
# A seguir, o sistema Linux é um exemplo para descrever o processo relacionado.
# Insira o endereço IP e nome de usuário corretos, senha para fazer login no servidor SFTP.
[root@aas ~]# sftp admin1@2.1.1.1Connecting to 2.1.1.1...Admin1@2.1.1.1's password:sftp>
# Obtenha o arquivo de inicialização no sistema de arquivos do dispositivo do servidor SFTP.
sftp> get startup startupFetching /flash/startup to startup/flash/startup 100% 13KB 12.9KB/s 00:00
#Depois de copiar o arquivo, você pode encontrar o arquivo relacionado no diretório de operação.
sftp> lssp8-g-6.6.7(74)-dbg.pck sp8-g-6.6.7(76)-dbg.pck startup tech test_pcsftp>
# Carregue o arquivo no PC para o sistema de arquivos do dispositivo servidor SFTP.
sftp> put sp8-g-6.6.7(76)-dbg.pck sp8-g-6.6.7(76)-dbg.pckUploading sp8-g-6.6.7(76)-dbg.pck to /flash/ sp8-g-6.6.7(76)-dbg.pcksp8-g-6.6.7(76)-dbg.pck 100% 11424KB 16.0KB/s 00:00
#Depois de carregar o arquivo, você pode encontrar o arquivo correspondente no sistema de arquivos do Dispositivo.
Device(config-fs)#dirsize date time name------------ ------ ------ --------2048 JUN-30-2015 16:35:50 tech <DIR>10229 JUN-12-2015 14:31:22 history101890 JUN-30-2015 17:46:40 logging39755 JUN-30-2015 16:33:56 startup740574 MAY-27-2014 18:55:14 web-Spl-1.1.243.rom2048 JUN-27-2015 16:26:10 snmp <DIR>11698172 JUN-30-2015 10:36:18 sp8-g-6.6.7(76)-dbg.pck
Configurar um dispositivo como um cliente FTPS
Requisitos de rede
- Um PC atua como um servidor FTP e o Dispositivo atua como um cliente FTP. A rede entre o Dispositivo e o Cliente está normal.
- Configure o canal de dados de segurança entre o Servidor FTP e o Cliente FTP, fornecendo a garantia de segurança para a transmissão dos dados.
- O arquivo pode ser carregado e baixado entre o cliente FTP e o servidor FTP.
Topologia de rede

Figura 4 - 9 Rede para configurar um dispositivo como um cliente n FTPS
Etapas de configuração
- Passo 1: Configure o endereço IPv4 da interface (omitido).
- Passo 2: Instale o certificado no servidor FTP e defina o caminho do certificado do usuário FTP, o caminho da chave privada e o caminho do certificado da CA :
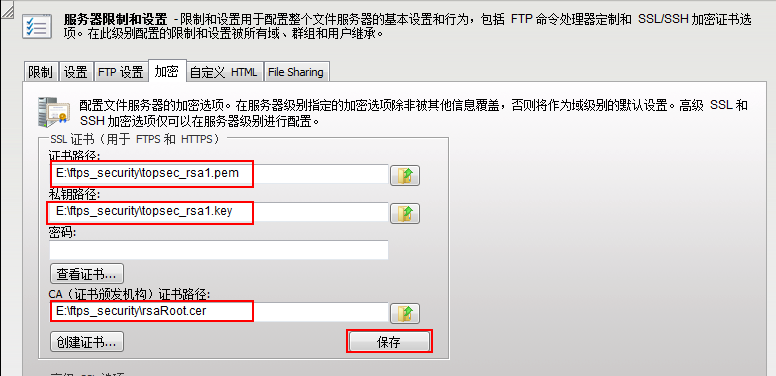
- Passo 3: Cliente FTP importa o certificado de CA de FTP, certificado de usuário e chave privada.
#Crie um teste de domínio no dispositivo:
Device#configure terminalDevice(config)#crypto ca identity testDevice(ca-identity)#exit
#Vincule o FTP com o teste de domínio :
Device(config)#ip ftp secure-identity test#Abra o certificado da CA ( rsaRoot.cer ) pelo bloco de notas, copie o conteúdo, insira o certificado de importação do crypto ca para testar no shell e importe o certificado para o teste de domínio do dispositivo de acordo com o prompt:
Device(config)#crypto ca import certificate to test% Input the certificate data, press <Enter> twice to finish:-----BEGIN CERTIFICATE-----MIIDBzCCAnCgAwIBAgIITpXH17Hj/AswDQYJKoZIhvcNAQEFBQAwYjELMAkGA1UEBhMCQ04xEDAOBgNVBAgMB0JFSUpJTkcxDjAMBgNVBAoMBUNJRUNDMQ8wDQYDVQQLDAZHRkEgQ0ExIDAeBgNVBAMMF01pbmlDQSBGcmVCU0QgUm9vdCBDZXJ0MB4XDTA5MDgwMzA2MDY1MloXDTE5MDgwMzA2MDY1MlowYjELMAkGA1UEBhMCQ04xEDAOBgNVBAgMB0JFSUpJTkcxDjAMBgNVBAoMBUNJRUNDMQ8wDQYDVQQLDAZHRkEgQ0ExIDAeBgNVBAMMF01pbmlDQSBGcmVCU0QgUm9vdCBDZXJ0MIGeMA0GCSqGSIb3DQEBAQUAA4GMADCBiAKBgHXZMtpxzH8p0uUt6QomUhuJNcy9iyYhoJVx4I3T6kpmx9cdzapMRoKUa9eB/jCzhgctQc7ZDuKP+gafHWgZtbzwwSVksVsNmFqBivixveGx9dCrtequ+vDiXVyDVPSNDDTmamMGYyCb0N7aSOzdgv6BYyQKyy/Y0FK6/v/v4NUxAgMBAAGjgcYwgcMwPQYDVR0fBDYwNDAyoDCgLoYsaHR0cDovLzE2OC4xNjguMTcuNDY6OTAwMC9nZmEvY3JsL2dmYWFwcC5jcmwwSAYDVR0gBEEwPzA9BggrBgEEAYcrMjAxMC8GCCsGAQUFBwIBFiNodHRwOi8vd3d3LmdmYXBraS5jb20uY24vcG9saWN5LmRvYzALBgNVHQ8EBAMCAuQwDAYDVR0TBAUwAwEB/zAdBgNVHQ4EFgQUhnY8uZXbE2iX1mXOipvfuDUgAeswDQYJKoZIhvcNAQEFBQADgYEAcNPdTE+YpfOQn8lW1oF7TkGJ/Vzdc0O5UUB+jPhYkj+fXUX8WyxabOxgl3u+7DJ/3gHw1rO8ZcDO94Wz+nBsile5tFv7/bHz0yqJVoUJMIaWOdmLXJj5fI5GeBCprzLM88RJCv6LBHfg4ThOC4Ds80Ssive1eAod+7kbmVPOZg8=-----END CERTIFICATE-----% Input the private key data, press <Enter> twice after data to finish or press <Enter> without data to ignore:% The Root CA Certificate has the following attributes:Serial Number: 4e95c7d7b1e3fc0bSubject: C=CN, ST=BEIJING, O=CIECC, OU=GFA CA, CN=MiniCA FreBSD Root CertIssuer : C=CN, ST=BEIJING, O=CIECC, OU=GFA CA, CN=MiniCA FreBSD Root CertValidityStart date: 2009-08-03 06:06:52End date: 2019-08-03 06:06:52Usage: GeneralFingerprint(sm3) :18d39e4c50c9ad8b11446ac7ac1736f853ac92e769994b98233b48787562429cFingerprint(sha1):ab3559e26384539ffcac3c76b5a5e7a1f7073dfb% Do you accept this root ca-certificate[yes]/[no]:% Please answer 'yes' or 'no'.% Do you accept this root ca-certificate[yes]/[no]:Nov 11 2015 19:06:04: %PKI-CERTIFICATE_STATECHG-5: Certificate(issuer:C=CN, ST=BEIJING, O=CIECC, OU=GFA CA, CN=MiniCA FreBSD Root Cert, sn:4E95C7D7B1E3FC0B, subject:C=CN, ST=BEIJING, O=CIECC, OU=GFA CA, CN=MiniCA FreBSD Root Cert) state valid% PKI: Import Certificate success.
#Abra o certificado do usuário ( topsec_rsa2_myself.pem ) e o certificado de chave privada ( topsec_rsa2_myself.key ) pelo bloco de notas, copie o conteúdo, insira o comando crypto ca import certificate to test no shell, e importe os certificados para o device domain test de acordo com o prompt, por sua vez:
Device(config)#crypto ca import certificate to test% Input the certificate data, press <Enter> twice to finish:-----BEGIN CERTIFICATE-----MIIDVTCCAr6gAwIBAgIQEJ7twbl3pDlzJz99DFOKOzANBgkqhkiG9w0BAQUFADBiMQswCQYDVQQGEwJDTjEQMA4GA1UECAwHQkVJSklORzEOMAwGA1UECgwFQ0lFQ0MxDzANBgNVBAsMBkdGQSBDQTEgMB4GA1UEAwwXTWluaUNBIEZyZUJTRCBSb290IENlcnQwHhcNMTIwNjI2MDUwMTIzWhcNMzIwNjI2MDUwMTIzWjB/MQswCQYDVQQGEwJDTjEQMA4GA1UECAwHYmVpamluZzESMBAGA1UEBwwJZG9uZ2NoZW5nMQ4wDAYDVQQKDAVjaWVjYzEMMAoGA1UECwwDZ2ZhMR0wGwYJKoZIhvcNAQkBFg50ZXN0QGVjLmNvbS5jbjENMAsGA1UEAwwEcnNhMjCBnzANBgkqhkiG9w0BAQEFAAOBjQAwgYkCgYEA6AlNqTnNsV9Yyij2tTMppB9C5VCLtkPh9KlIq/ZTlVhrJED+N5HVfQQyZYS/z4JWAip50dyP1+NP+bvP+pb9CfEaJ8+ObYQnfUH6qiPccLkWO3XYanu6Dw5EMJYntwglSKmk1Pcc+j+yzWnwYMDFcbSsQ+8J5UzlesFhU7GnXacCAwEAAaOB7jCB6zA+BgNVHR8ENzA1MDOgMaAvhi1odHRwczovLzIxMS44OC4yNS4xODo4NDQ0L2dmYS9jcmwvUlNBMTAyNC5jcmwwUQYDVR0gBEowSDBGBggrBgEEAYcrMjA6MDgGCCsGAQUFBwIBFixodHRwczovLzIxMS44OC4yNS4xODo4NDQ0L2dmYS9jcmwvUlNBMTAyNC5wbDALBgNVHQ8EBAMCA/gwCQYDVR0TBAIwADAdBgNVHQ4EFgQUp/9/ODGLR84syxPaBkLG3mCpU5YwHwYDVR0jBBgwFoAUhnY8uZXbE2iX1mXOipvfuDUgAeswDQYJKoZIhvcNAQEFBQADgYEAYrFZQrINHoLN9odcGctzTRGVmMcv9sJ0ncgUEfbrLu6QUodQy3jjxWFIxheJK1btfF66/ShuKtZpqJ1WE9l92tfIHwLpXT0gujtxNi02TOPBNEU7P9nUgxgfDG+uhyPTeufSkfn3LCTHmGfVORF2soGSlaUPV1Zy5E9hmFZoMhs=-----END CERTIFICATE-----% Input the private key data, press <Enter> twice after data to finish or press <Enter> without data to ignore:-----BEGIN RSA PRIVATE KEY-----MIICXQIBAAKBgQDoCU2pOc2xX1jKKPa1MymkH0LlUIu2Q+H0qUir9lOVWGskQP43kdV9BDJlhL/PglYCKnnR3I/X40/5u8/6lv0J8Ronz45thCd9QfqqI9xwuRY7ddhqe7oPDkQwlie3CCVIqaTU9xz6P7LNafBgwMVxtKxD7wnlTOV6wWFTsaddpwIDAQABAoGBAMnJNWliJFgI4+1CvHGN4buhmApWBnnmBL1A7jrlh4CMGPi5MJrgzvjeSnlwfWIXJXbSu4feuJT1UFqMkuyIm9l+k8Rm3hjClXIlfNV/ykG6a6GIVFYGxQWhaL50Pm6S7xXL9Ryd6hnOHUUtwuLvkpBTx/4qvrIABDtXRjVglvApAkEA9BN1ZxM31BOyeB6KXvvmXD6/+dGaDfE4Dbcijy1LgKliaEBJ00e/0R9ekg6myGTU2asJvPtkaXPqcwvU6+e2mwJBAPNfRTk9LzUlNmTV2DrsE9k3rbPnqqS9wb/mLUNdv2FQeoY/Zf4qh0WXsug2q/6GPsvLUA7mbdArGFUwwQbw3+UCQQC8r25LSOgX40JM6g8+bq4fEcOHdSoLLTeQIststC9yP3/75/cqhoUbPYz2jK0SriB+RWM53X46p4nPdo4b8P2RAkBGjoBLL+nXxooWgcjGjFrUxsedOLTIPhtFvz2wIiWx2NsswISZQ0skae58VB1ZFSJvguoa58M+bsAHMrNDh+HhAkBcNAjKBDdVw0ll6bNoRGugEvuo3Z3O0kbVcjzZld+4aVG4DzvEp1ZbsYRv9YPMtpnzmB7WZUshAL99nHnHxtbh-----END RSA PRIVATE KEY-----Nov 11 2015 19:06:56: %PKI-CERTIFICATE_STATECHG-5: Certificate(issuer:C=CN, ST=BEIJING, O=CIECC, OU=GFA CA, CN=MiniCA FreBSD Root Cert, sn:109EEDC1B977A43973273F7D0C538A3B, subject:C=CN, ST=beijing, L=dongcheng, O=ciecc, OU=gfa, E=test@ec.com.cn, CN=rsa2) state valid% PKI: Import Certificate success.
#Depois de importar o certificado com sucesso, você pode usar o comando show crypto ca certificates para ver se o status é válido.
Device#show crypto ca certificatesRoot CA Certificate:Status: ValidSerial Number: 4e95c7d7b1e3fc0bSubject: C=CN, ST=BEIJING, O=CIECC, OU=GFA CA, CN=MiniCA FreBSD Root CertIssuer : C=CN, ST=BEIJING, O=CIECC, OU=GFA CA, CN=MiniCA FreBSD Root CertValidityStart date: 2009-08-03 06:06:52End date: 2019-08-03 06:06:52Key Type: RSA(1023 bit)Usage: GeneralFingerprint(sm3):18d39e4c50c9ad8b11446ac7ac1736f853ac92e769994b98233b48787562429cFingerprint(sha1):ab3559e26384539ffcac3c76b5a5e7a1f7073dfbAssociated Identity: testindex: 3My Certificate:Status: ValidSerial Number: 109eedc1b977a43973273f7d0c538a3bSubject: C=CN, ST=beijing, L=dongcheng, O=ciecc, OU=gfa, E=test@ec.com.cn, CN=rsa2Issuer : C=CN, ST=BEIJING, O=CIECC, OU=GFA CA, CN=MiniCA FreBSD Root CertValidityStart date: 2012-06-26 05:01:23End date: 2032-06-26 05:01:23Key Type: RSA(1024 bit)Usage: GeneralFingerprint(sm3):504599a2f170c51b62b2f8b0850f33a5595bc9e592d14eae9c90b1e59de35a89Fingerprint(sha1):080614a82cc4f3786458c585f9a58edf19da19bdAssociated Identity: testindex: 4
- Passo 4: Carregue e baixe o arquivo entre o Cliente FTP e o Servidor FTP .
# Cliente FTP carrega o arquivo para o Servidor FTP.
Device#filesystemDevice1(config-fs)#copy file-system startup ftps 1.0.0.1 a a startup VerifyType peerCopying!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!Total 103440 bytes copying completed.
# Cliente FTP baixa o arquivo do Servidor FTP.
Device(config-fs)#ftpscopy 1.0.0.1 a a test.doc test.doc VerifyType peerDownloading########################################################################################################################################################################################################################################################################################### OK!
- Passo 5: Confira o resultado.
# Após o download, visualize o arquivo baixado no sistema de arquivos do dispositivo.
Device(config-fs)#dirsize date time name------------ ------ ------ --------10189 NOV-04-2015 20:27:03 history436578 NOV-04-2015 20:33:08 test.doc
Gerenciamento do sistema de arquivos
Visão geral
A seguir lista o meio de armazenamento do dispositivo e suas funções:
- SDRAM: Synchronous Dynamic Random Access Memory (SDRAM) fornece o espaço para execução de programas aplicativos do dispositivo.
- FLASH: Armazena programas aplicativos, arquivos de configuração, programas BootROM e assim por diante.
- EEPROM: A memória somente leitura eletricamente apagável e programável (EEPROM) armazena arquivos de configuração do sistema e informações do usuário que são alteradas com frequência.
- USB: Usado para salvar os dados do usuário.
O dispositivo gerencia os seguintes tipos de arquivos:
- Arquivos BootROM: Armazena dados básicos para inicialização do sistema.
- Programas de aplicativos de dispositivos: implemente tarefas como encaminhamento de rotas, gerenciamento de arquivos e gerenciamento do sistema.
- Arquivos de configuração: Armazenar os parâmetros do sistema que são configurados pelos usuários.
- Arquivos de log: armazena informações de log do sistema.
O comando filesystem é usado para entrar no sistema de arquivos e pode ser usado tanto no controle mestre quanto no controle de espera.
Configuração da Função de Gerenciamento do Sistema de Arquivos
Tabela 5 - 1 Lista de funções de gerenciamento do sistema de arquivos
| Tarefas de configuração | |
| Gerenciar dispositivos de armazenamento. |
Exibe as informações sobre um dispositivo de armazenamento.
Formate um dispositivo de armazenamento. |
| Gerenciar diretórios de arquivos. |
Exibe as informações sobre um diretório de arquivos.
Exibe o caminho de trabalho atual. Altere o caminho de trabalho atual. Crie um diretório. Excluir um diretório. |
| Gerenciar operações de arquivo |
Copie um arquivo.
Renomeie um arquivo. Exibe o conteúdo de um arquivo. Excluir um arquivo. |
| Execute um arquivo de configuração manualmente. | Execute um arquivo de configuração manualmente. |
| Configure os parâmetros de inicialização. | Configure os parâmetros de inicialização. |
Gerenciar dispositivos de armazenamento
Condição de configuração
Antes de realizar operações em dispositivos de armazenamento, certifique-se de que:
- O sistema iniciou normalmente.
Exibir as informações sobre um dispositivo de armazenamento
Ao exibir as informações sobre um dispositivo de armazenamento, você pode visualizar os recursos do dispositivo de armazenamento e o tamanho do espaço restante.
Tabela 5 - 2 Exibindo as informações sobre um dispositivo de armazenamento
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | filesystem | - |
| Exibe as informações sobre um dispositivo de armazenamento. | volume | Obrigatório |
Formate os dispositivos de armazenamento
Se o espaço de um dispositivo de armazenamento não estiver disponível, você pode usar o comando format para formatar o dispositivo de armazenamento.
Tabela 5 - 3 Formatando um dispositivo de armazenamento
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | filesystem | - |
| Formate um dispositivo de armazenamento. | format { /flash | /syslog | /usb } | Opcional |
Tenha cuidado ao formatar um dispositivo de armazenamento, pois a operação pode causar a perda permanente de todos os arquivos no dispositivo de armazenamento e os arquivos não podem ser recuperados.
Gerenciar diretórios de arquivos
Condição de configuração
Antes de executar operações em diretórios de arquivos, certifique-se de que:
- O sistema iniciou normalmente.
Exibir as informações sobre um diretório de arquivos
Ao exibir as informações sobre um diretório de arquivos, você pode visualizar os detalhes dos arquivos no diretório especificado.
Tabela 5 - 4 Exibindo as informações sobre um diretório de arquivos
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos . | filesystem | - |
| Exibe as informações sobre um diretório. | dir [ path ] | Obrigatório |
Exibir o caminho de trabalho atual
Ao exibir o caminho de trabalho atual, você pode visualizar os detalhes do caminho atual.
Tabela 5 - 5 Exibindo o Caminho de Trabalho Atual
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | filesystem | - |
| Exibe o caminho de trabalho atual. | dir [ path ] | Obrigatório |
Alterar o Caminho de Trabalho Atual
Ao alterar o caminho de trabalho atual, você pode alternar um usuário para o diretório especificado.
Tabela 5 - 6 Alterando o Caminho de Trabalho Atual
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | filesystem | - |
| Altere o caminho de trabalho atual. | cd path | Obrigatório |
Criar e um Diretório
Se você deseja criar um diretório no sistema de arquivos, execute esta operação.
Tabela 5 - 7 Criando um diretório
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | filesystem | - |
| Crie um diretório. | mkdir directory | Obrigatório |
Excluir um diretório
Se você excluir um diretório por meio dessa operação, todos os subdiretórios e arquivos no diretório serão excluídos.
Tabela 5 - 8 Excluindo um diretório
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | filesystem | - |
| Excluir um diretório. | rmdir directory [ force ] | Obrigatório |
Tenha cuidado ao excluir um diretório, pois a operação de exclusão do diretório pode excluir permanentemente todos os subdiretórios e arquivos no diretório e os arquivos não podem ser recuperados.
Gerenciar Operações de Arquivo
Condição de configuração
Antes de realizar operações em arquivos, certifique-se de que:
- O sistema iniciou normalmente.
Copiar um arquivo
No sistema de arquivos, você pode copiar um arquivo para o diretório especificado.
Tabela 5 - 9 Copiando um arquivo
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | filesystem | - |
| Copie um arquivo. | copy src-parameter dest-parameter | Obrigatório |
O comando copy pode ser usado para copiar arquivos entre o sistema de arquivos, o servidor FTP e o servidor TFTP. Para detalhes, consulte a descrição da cópia comando no manual técnico .
Renomear um arquivo
No sistema de arquivos, você pode alterar o nome de um arquivo para um nome especificado.
Tabela 5 - 10 Renomeando um Arquivo
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | sistema de arquivo | - |
| Renomeie um arquivo. | renomear src - nome do arquivo dest - nome do arquivo | Obrigatório |
Exibir o conteúdo de um arquivo
No sistema de arquivos, você pode visualizar o conteúdo de um arquivo.
Tabela 5 - 11 Exibindo o conteúdo de um arquivo
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | filesystem | - |
| Exibe o conteúdo de um arquivo. | type path/filename | Obrigatório |
Excluir um arquivo
No sistema de arquivos, você pode excluir um arquivo que não seja mais necessário.
Tabela 5 - 12 Exclusão de um arquivo
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | filesystem | - |
| Excluir um arquivo. | delete path/filename | Obrigatório |
Tenha cuidado ao usar o comando delete porque ele exclui permanentemente um arquivo e o arquivo não pode ser recuperado.
Baixar um arquivo do FTP
Condição de configuração
Antes de baixar manualmente o arquivo do FTP, primeiro conclua as seguintes tarefas:
- O sistema iniciou normalmente.
- Assegure-se de que a rota entre o servidor FTP e a interface do dispositivo seja alcançável e a rota possa ser pingada .
Baixar um arquivo do servidor FTP
Use um comando para baixar o arquivo do FTP e você pode baixar o arquivo relacionado no servidor F TP para o sistema de arquivos
Tabela 5 -13 Baixe um arquivo do servidor FTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração do arquivo | filesystem | - |
| Baixe o arquivo do servidor FTP | ftpcopy host-ip-address usrname password src-filename { /flash | /syslog | /usb | dest-filename } ftpscopy host-ip-address usrname password src-filename { /flash | /syslog | /usb | dest-filename } VerifyType { none | peer } | Opcional |
O ftpcopy e ftpscopy O comando pode ser usado para baixar o arquivo do servidor FTP para o sistema de arquivos. Para detalhes sobre a operação, consulte o método de uso da cópia ftp e ftpscopy comando no manual técnico .
Configurar Parâmetros de Inicialização
Condição de configuração
Antes de configurar os parâmetros de inicialização, certifique-se de que:
- O sistema iniciou normalmente.
Configurar Parâmetros de Inicialização
Ao configurar os parâmetros de inicialização, você pode configurar o arquivo do programa aplicativo que deve ser usado na próxima inicialização.
Tabela 5 - 14 Configurando os Parâmetros de Inicialização
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | filesystem | - |
| Configure os parâmetros de inicialização. | boot-loader path/filename [ bootline-number ] | Obrigatório |
Gerenciamento, monitoramento e manutenção do sistema de arquivos
Tabela 5 - 15 Sistema de Arquivos Gerenciando, Monitorando e Mantendo
| Comando | Descrição |
| clear boot-loader [ bootline-number ] | Limpa os parâmetros de inicialização com o índice especificado. |
| show filesystem | Exiba as informações sobre o sistema de arquivos. |
| show file location | Exiba as informações do local de armazenamento do arquivo do sistema no sistema de arquivos |
| show file descriptor | Exiba as informações do descritor de arquivo do arquivo do sistema no sistema de arquivos |
| show boot-loader | Exiba os parâmetros de inicialização do sistema. |
Exemplo de configuração típico de gerenciamento de sistema de arquivos
Configurar Parâmetros de Inicialização
Requisitos de rede
Nenhum
Topologia de rede
Nenhum
Etapas de configuração
- Passo 1: Entre no modo de configuração do sistema de arquivos.
- Passo 2: Configure as opções de inicialização do sistema.
#Visualize os parâmetros de inicialização do sistema.
Device#filesystemDevice(config-fs)#show boot-loaderThe app to boot at the next time is: flash0: /flash/sp26-g-9.5.0.2(20)(R).pckThe app to boot at the this time is: flash0: /flash/sp26-g-9.5.0.2(20)(R).pckBoot-loader0: flash0: /flash/sp26-g-9.5.0.2(20)(R).pckDevice(config-fs)#exit
#Modifique o arquivo para a próxima inicialização para o arquivo sp26-g-9.5.0.2(20)(R).pck que está armazenado no flash e defina a prioridade para 0.
Device#filesystemDevice(config-fs)#boot-loader /flash/sp26-g-9.5.0.2(20)(R).pckBoot-loader0 set OKDevice(config-fs)#exit
# Visualize o resultado da configuração.
Device(config-fs)#show boot-loaderThe app to boot at the next time is: flash0: /flash/sp26-g-9.5.0.2(20)(R).pckThe app to boot at the this time is: flash0: /flash/sp26-g-9.5.0.2(20)(R).pckBoot-loader0: flash0: /flash/sp26-g-9.5.0.2(20)(R).pckBoot-loader4: backup0: sp26-g-9.5.0.2(20)(R).pckDevice(config-fs)#exit
Gerenciamento dos arquivos de configuração
Visão geral
O Gerenciamento dos arquivos de configuração é uma função usada para gerenciar arquivos de configuração de dispositivos. Por meio da interface de linha de comando fornecida pelo dispositivo, os usuários podem gerenciar facilmente os arquivos de configuração. Se o dispositivo precisar carregar automaticamente a configuração atual dos usuários após a reinicialização, os comandos de configuração atuais devem ser salvos no arquivo de configuração antes da reinicialização do dispositivo. Os usuários podem fazer upload de arquivos de configuração ou fazer download de arquivos de configuração de outro dispositivo por meio de FTP ou TFTP, realizando a configuração do dispositivo em lote. A configuração do dispositivo é categorizada nos dois tipos a seguir:
Configuração de inicialização:
Quando o dispositivo é iniciado, ele carrega o arquivo de configuração de inicialização com o nome "startup" por padrão e conclui a configuração de inicialização do dispositivo. Essa configuração é chamada de configuração de inicialização. Aqui o dispositivo tem dois arquivos de configuração de inicialização, um é o arquivo de configuração de inicialização padrão e o outro é o arquivo de configuração de inicialização de backup. Quando o dispositivo é iniciado, se o arquivo de configuração de inicialização padrão não existir, o sistema copia o arquivo de configuração de inicialização de backup para o local do arquivo de configuração de inicialização padrão e carrega esse arquivo de configuração de inicialização.
Configuração atual:
A configuração atual é um conjunto de comandos que estão em vigor no momento. Consiste na configuração de inicialização e na configuração que é adicionada ou modificada pelo usuário após a inicialização. A configuração atual é salva no banco de dados de memória. Se a configuração atual não for salva no arquivo de configuração de inicialização, as informações de configuração serão perdidas após a reinicialização do dispositivo.
O seguinte descreve o conteúdo e os formatos dos arquivos de configuração:
- Os arquivos de configuração são salvos no sistema de arquivos na forma de arquivos de texto.
- O conteúdo dos arquivos de configuração é salvo na forma de comandos de configuração e somente a configuração não padrão é salva.
- Os arquivos de configuração são organizados com base nos modos de comando. Todos os comandos em um modo de comando são organizados juntos para formar um parágrafo.
- Os parágrafos são organizados de acordo com uma determinada regra: modo de configuração do sistema, modo de configuração da interface e modos de configuração de diferentes protocolos.
- Os comandos são organizados de acordo com suas relações. Os comandos relacionados formam um grupo e os diferentes grupos são separados por linhas em branco.
Configuração da Função de Gerenciamento de Arquivos de Configuração
Tabela 6 - 1 Lista de gerenciamento de arquivos de configuração
| Tarefas de configuração | |
| Salve a configuração atual. | Salve a configuração atual. |
| Faça backup da configuração do dispositivo. | Faça backup da configuração atual. Faça backup da configuração de inicialização. |
| Restaure a configuração de inicialização. | Restaure a configuração de inicialização. |
| Criptografe o arquivo de configuração | Criptografe a configuração de inicialização |
| Uma configuração de salvamento automático | Uma configuração de salvamento automático |
Salve a configuração atual
Condição de configuração
Nenhum
Salve a configuração atual
Se a configuração atual do usuário puder entrar em vigor somente após o início do dispositivo, você precisará salvar a configuração atual no arquivo de configuração de inicialização.
Tabela 6 - 2 Salvando a configuração atual
| Etapa | Comando | Descrição |
| Salve a configuração atual no arquivo de configuração de inicialização. | write | Obrigatório |
Se o dispositivo for reiniciado ou desligado enquanto o arquivo de configuração estiver sendo salvo, as informações de configuração podem ser perdidas.
Salvar a configuração atual não apenas salva a configuração no arquivo de configuração de inicialização, mas também salva a configuração no arquivo de configuração de inicialização de backup.
Configurar o sistema de backup
Condição de configuração
Antes de configurar os parâmetros do sistema de backup, certifique-se de que:
- A rota entre o dispositivo e o servidor é alcançável.
- O arquivo de configuração do qual será feito backup existe; caso contrário, o backup falhará.
Fazer backup da configuração atual
Ao fazer backup da configuração atual, você pode usar um comando para fazer backup da configuração atual no servidor FTP.
Tabela 6 - 3 Fazendo backup da configuração atual
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | filesystem | - |
| Faça backup da configuração atual em um host remoto por meio do protocolo FTP. | copy running-config { file-system dest-filename | ftp { hostname | ip-address } username password dest-filename | startup-config | tftp { hostname | ip-address } dest-filename ftps { hostname | ip-address } username password dest-filename VerifyType { none | peer } } | Obrigatório |
Backup da configuração de inicialização
Ao fazer backup da configuração de inicialização, você pode usar um comando para fazer backup da configuração de inicialização no servidor FTP.
Tabela 6 - 4 Fazendo backup da configuração de inicialização
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | enable | - |
| Salve a configuração de inicialização em um host remoto por meio do protocolo FTP. | copy startup-config { file-system dest-filename | ftp { hostname | ip-address } username password dest-filename | ftps{ hostname | ip-address } username password dest-filename VerifyType { none | peer }| tftp { hostname | ip-address } dest-filename } | Obrigatório |
Restaurar a configuração de inicialização
Condição de configuração
Antes de restaurar a configuração de inicialização, certifique-se de que:
- A rota entre o dispositivo e o servidor é alcançável.
- O arquivo de configuração que deve ser restaurado existe.
Restaurar a configuração de inicialização
Ao restaurar a configuração de inicialização, você pode usar um comando para fazer download do arquivo de configuração de inicialização do servidor FTP e defini-lo como o arquivo de configuração de inicialização usado após a reinicialização. Desta forma, após o dispositivo ser reiniciado, o dispositivo pode carregar o arquivo de configuração de inicialização.
Tabela 6 - 5 Restaurando a configuração de inicialização
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema de arquivos. | filesystem | - |
| Restaure a configuração de inicialização. | copy { file-system src-filename | ftp { hostname | ip-address } username password src-filename | ftps { hostname | ip-address } username password src-filename | tftp { hostname | ip-address } src-filename } { file-system dest-filename | startup-config } | Obrigatório |
Antes de substituir a configuração de inicialização local, certifique-se de que o arquivo de configuração corresponda ao tipo de dispositivo e corresponda à versão atual do sistema.
Após realizar a operação de restauração da configuração de inicialização, a configuração atual não é alterada. Depois que o dispositivo é reiniciado, a configuração de inicialização é restaurada.
Criptografia do arquivo de configuração
Condição de configuração
- Para criptografar o arquivo de configuração, você precisa inserir o dispositivo USB.
Configurar a criptografia do arquivo de configuração
A criptografia do arquivo de configuração adota o algoritmo SM4 para criptografar o arquivo de configuração. A chave é especificada pelo usuário. Depois que o usuário especificar a chave, criptografe o arquivo de configuração ao executar a ação de gravação na próxima vez.
criptografia de registro de operação adota o algoritmo SM4 para criptografar a configuração e a chave é especificada pelo usuário. Depois que o usuário especificar a chave, comece a criptografar o registro de operação subsequente.
Tabela 6 - 6 Criptografia de arquivo de configuração e criptografia de registro de operação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Criptografia do arquivo de configuração | service encryption startup algorithms SM4 key password | Criptografia do arquivo de configuração, o usuário especifica a chave |
| Criptografia de registro de operação | service encryption history algorithms SM4 key password | Criptografia de registro de operação, o usuário especifica a chave |
A criptografia do arquivo de configuração entra em vigor durante a próxima ação de gravação após a configuração da função de criptografia . A criptografia do registro da operação entra em vigor imediatamente após a configuração da função de criptografia.
Para configurar a função de criptografia, você precisa inserir o dispositivo USB externo. A função de criptografia de registro de operação não precisa do dispositivo USB.
Salvamento Automático
Condição de configuração
Nenhum
Salvamento Automático
O salvamento automático refere-se ao salvamento automático da configuração de operação do dispositivo após a abertura do dispositivo de acordo com as regras de configuração.
Tabela 6 -7 Uma configuração de salvamento automático
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| E habilite o salvamento automático | configuration-file auto-save enable | Habilite a função de salvar automaticamente a configuração |
| C onfigurar o intervalo de salvamento automático | configuration-file auto-save interval interval | O intervalo para salvar automaticamente a configuração. O intervalo de valores é 30-43200, em minutos. O valor padrão é 30. |
| C onfigurar o limite de utilização da CPU com salvamento automático | configuration-file auto-save cpu-limit cpu-usage | Salve automaticamente o limite de utilização da CPU configurado. O intervalo de valores é de 1 a 100 e o valor padrão é 50. |
| C onfigurar o tempo de atraso do salvamento automático | configuration-file auto-save delay delay-interval | O tempo de atraso para salvar automaticamente a configuração após as alterações de configuração. O intervalo de valores é de 1 a 60, em minutos. O valor padrão é 5. |
Quando ocorrerem as seguintes condições, o sistema cancelará a operação de salvar automaticamente o arquivo de configuração: Atualmente existe uma operação de gravação do arquivo de configuração.
O dispositivo está em processo de recuperação de configuração. A utilização da CPU é alta.
Gerenciamento, monitoramento e manutenção do arquivo de configuração
Tabela 6 - 8 G erenciamento, monitoramento e manutenção de arquivos de configuração
| Comando | Descrição |
| show running-config [ after-interface | before-interface | interface [ interface-name ] | [ configuration ] ] [ | { { begin | exclude | include } expression | redirect { file file-name | ftp { hostname | ip-address } user-name password file-name } } | ftps { hostname | ip-address } user-name password file-name } } ] | Exibe as informações de configuração atuais. |
| show startup-config [ file-number | { | { { begin | exclude | include [ context ] } expression | redirect { file filename | ftp { { hostname | ip-address } user-name password file-name } | | ftps { { hostname | ip-address } user-name password file-name } } } ] | Exiba as informações de configuração de inicialização. |
Administração do sistema
Visão geral
- Por meio do gerenciamento do sistema, os usuários podem consultar o status de funcionamento atual do sistema, configurar parâmetros básicos de função do dispositivo e realizar operações básicas de manutenção e gerenciamento no dispositivo. As funções de gerenciamento do sistema incluem: Configurando o nome do dispositivo
- Configurando a hora do sistema e o fuso horário
- Configurando a mensagem de boas-vindas de login
- Configurando o modo de processamento de exceção do sistema
- Reiniciando o dispositivo
- Configurando o serviço de criptografia de senha
- Configurando a função de salvamento do comando de histórico
- Configurando o serviço de segurança de login
- Configurando o monitoramento da CPU
- Configurando a exibição de propriedades em páginas
Configuração da Função de Gerenciamento do Sistema
Tabela 7 - 1 Lista de Funções de Gerenciamento do Sistema
| Tarefas de configuração | |
| Configure o nome do dispositivo. | Configure o nome do dispositivo. |
| Configure a hora e o fuso horário do sistema. | Configure a hora e o fuso horário do sistema. |
| Configure a mensagem de boas-vindas de login. | Configure a mensagem de boas-vindas de login. |
| Configure o modo de processamento de exceção do sistema. | Configure o modo de processamento de exceção do sistema. |
| Configure para reiniciar o dispositivo. | Configure para reiniciar o dispositivo. |
| Configure o serviço de criptografia. | Configure o serviço de criptografia. |
| Configure a função de salvamento do comando de histórico. | Configure a função de salvamento do comando de histórico. |
| Configure o serviço de segurança de login. | Configure o serviço de segurança de login. |
| Configure o monitoramento da CPU. | Configure o monitoramento da CPU. |
| Configure a exibição de propriedades em páginas. | Configure a exibição de propriedades em páginas. |
Configurar o nome do dispositivo
Condição de configuração
Nenhum
Configurar o nome do dispositivo
Um nome de dispositivo é usado para identificar um dispositivo. Um usuário pode alterar o nome do dispositivo de acordo com o requisito real. A modificação entra em vigor imediatamente, ou seja, o novo nome do dispositivo é exibido no próximo prompt do sistema.
Tabela 7 - 2 Configurando o nome do dispositivo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o nome do dispositivo. | hostname host-name | Obrigatório |
Configurar a hora do sistema e o fuso horário
Condição de configuração
Nenhum
Configurar a hora do sistema e o fuso horário
A hora e o fuso horário do sistema são a hora exibida no registro de data e hora das informações do sistema. A hora é determinada pela hora e fuso horário configurados. Você pode executar o comando show clock para visualizar as informações de tempo do sistema. Para que o dispositivo funcione normalmente com outros dispositivos, a hora do sistema e o fuso horário devem ser precisos.
Tabela 7 - 3 Configurando a hora do sistema e o fuso horário
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a hora do sistema. | clock timezone timezone-name-string hour-offset-number [ minute -offset-number ] | Obrigatório . O padrão é Universal Time Coordinated (UTC). |
| Entre no modo de usuário privilegiado. | exit | - |
| Configure a hora do sistema. | clock year-number [ month-number [ day-number [ hour-number [ minute-number [ second-number ] ] ] ] ] | Obrigatório |
Configurar a mensagem de boas-vindas de login
Condição de configuração
Nenhum
Configurar a mensagem de boas-vindas de login
Quando um usuário faz login no dispositivo para autenticação de login, a mensagem de boas-vindas de login é exibida. A mensagem de boas-vindas pode ser configurada de acordo com o requisito.
Tabela 7 - 4 Configurando a mensagem de boas-vindas de login
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a mensagem de boas-vindas de login. | banner motd banner-line | Obrigatório |
Configurar o Modo de Processamento de Exceções do Sistema
Condição de configuração
Nenhum
Configurar o Modo de Processamento de Exceções do Sistema
Quando ocorre uma exceção do sistema, o sistema é reiniciado diretamente para restaurá-lo. O modo de processamento de exceções do sistema é configurado em três aspectos: O primeiro é habilitar a detecção periódica de exceções. O sistema detecta periodicamente o status da tarefa, segmento de código e bloqueio de semáforo com um ciclo de 10s, 10s e 30s, respectivamente. Em segundo lugar, um nível de exceção é configurado. Se ocorrerem exceções de nível e níveis mais altos, o dispositivo é reiniciado. Os níveis de exceção incluem: alerta, crítico, emergência, erro e aviso. Além disso, você pode configurar o modo de processamento da exceção de detecção de integridade e os modos de processamento incluem ignorar e reiniciar.
Tabela 7 - 5 Configurando o Modo de Processamento de Exceções do Sistema
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar o modo de processamento de exceção do sistema | exception { period-detect enable | reboot [ level { alert | critical | emergency | error | warn } ] | detect-health {ignore | reload} } | Obrigatório . Por padrão, a detecção de exceção periódica está habilitada e o nível de exceção definido para reinicialização do dispositivo é crítico. Por padrão, a detecção de integridade está habilitada. Depois que a detecção de integridade do dispositivo se torna anormal, o modo de processamento é ignorado por padrão. |
| Configure o modo de processamento da anormalidade no modo VST | exception { period-detect enable | reboot {device device-num | level device device-num { alert | critical | emergency | error | warn } } | detect-health device-num {ignore | reload} } | Obrigatório . Por padrão, a detecção anormal periódica está habilitada. Quando a anormalidade aparece, o nível anormal de reinicialização do dispositivo é crítico. Por padrão, a detecção de integridade está habilitada. Depois que a detecção de integridade do dispositivo se torna anormal, o modo de processamento é ignorado por padrão. |
Depois que um nível de exceção for configurado para reinicialização do dispositivo, se ocorrer uma exceção no nível ou em um nível superior, o dispositivo será reiniciado.
De alto a baixo, os níveis de exceção incluem emergência, alerta, crítico, erro e aviso.
Configurar para reiniciar um dispositivo
Condição de configuração
Nenhum
Reiniciar um dispositivo
Quando ocorre uma falha do dispositivo, você pode optar por reiniciar o dispositivo de acordo com a situação real para eliminar a falha. Os modos de reinicialização do dispositivo incluem reinicialização a frio e reinicialização a quente. Em uma reinicialização a frio, o usuário pode desligar diretamente o dispositivo e ligá-lo novamente. Em uma reinicialização a quente, o usuário reinicia o dispositivo usando um comando de reinicialização. Durante o processo de reinicialização a quente, o dispositivo não é desligado.
Tabela 7 - 6 Reiniciando um dispositivo
| Etapa | Comando | Descrição |
| Use um comando para reiniciar o dispositivo ou no modo VST, use o comando para reiniciar todos os dispositivos de comutação virtual in-loco no domínio VST | reload | Obrigatório |
Se você desligar e reiniciar forçadamente um dispositivo que está no status operacional, podem ocorrer danos ao hardware ou perda de dados. Portanto, esse modo de reinicialização geralmente não é recomendado.
Se você usar o comando reload para reiniciar o dispositivo, todos os serviços do dispositivo serão interrompidos. Tenha cuidado ao realizar esta operação.
Configurar a função de salvamento do comando de histórico
Condição de configuração
Nenhum
Configurar a função de salvamento do comando de histórico
Através da função de salvamento de comandos de histórico, você pode consultar e coletar os comandos de histórico que foram executados. Antes que a função de salvamento do comando de histórico seja configurada, os comandos de histórico são salvos no sistema de arquivos de memória. Após a configuração da função, o sistema salva automaticamente os comandos de histórico no sistema de arquivos flash.
Tabela 7 - 7 Configurando a função de salvamento do comando de histórico
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure para salvar os comandos do histórico. | shell-history save | Obrigatório. Por padrão, a função de salvamento do comando de histórico está habilitada. |
Configurar o Serviço de Segurança de Login
Condição de configuração
Nenhum
Habilitar o Serviço de Segurança de Login do Sistema
Para aumentar a segurança do sistema, o dispositivo fornece a função de serviço de segurança de login do sistema. As funções incluem:
- Impede a quebra de força bruta de senhas de login do usuário.
- Impede a função de conexão rápida.
A função de prevenção de cracking de força bruta impede que usuários ilegais maliciosos quebrem o nome de usuário e a senha para fazer login no dispositivo. Se o sistema descobrir que o número de falhas contínuas de autenticação de login de um usuário atinge o número especificado pelo sistema, o sistema rejeita a solicitação de login do endereço IP ou a solicitação de login do usuário dentro do período de tempo especificado .
A função de impedir conexões rápidas impede que usuários ilegais iniciem um grande número de solicitações de login em um curto período de tempo, pois isso pode ocupar muitos recursos do sistema e da rede. Se o número de conexões de login repetidas de um usuário atingir um número especificado, o sistema rejeitará as solicitações de conexão de login do endereço IP dentro do período de tempo especificado.
Tabela 7 - 8 Habilitando o Serviço de Segurança de Login do Sistema
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Ative o serviço de segurança de login do sistema. | service login-secure { telnet | ssh | ftp | snmp} | Obrigatório. Por padrão, o serviço de segurança de login do sistema está ativado . |
Configurar os Parâmetros do Serviço de Segurança de Login do Sistema
Tabela 7 - 9 Configurando os parâmetros do serviço de segurança de login do sistema
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o horário de login do endereço IP proibido pelo módulo Telnet | login-secure telnet ip-addr forbid-time forbid-time-number | Obrigatório Por padrão, são 10 minutos. |
| Configure os tempos máximos de falha de autenticação de login sucessiva do endereço IP proibido pelo módulo Telnet | login-secure telnet ip-addr max-try-time max-try-time-number | Obrigatório Por padrão, é 5 vezes. |
| Configure o tempo de idade das informações registradas pelo endereço IP proibido pelo módulo Telnet | login-secure telnet ip-addr record-aging-time record-aging-time-number | Obrigatório Por padrão, são 15 minutos. |
Configurar monitoramento de CPU
Condição de configuração
Nenhum
Configurar Monitoramento de CPU
Por meio do monitoramento da CPU, o sistema monitora a ocupação da CPU para saber o status de operação atual da CPU. O seguinte mostra o conteúdo do monitoramento da CPU:
- Monitora a ocupação da CPU de cada processo. Após a configuração da função, você pode visualizar as informações relacionadas usando o comando show cpu .
- Habilita a função de estatísticas de histórico da ocupação da CPU. Depois que a função é configurada, você pode visualizar as informações relacionadas usando o show CPU comando monitor .
Tabela 7 - 10 Configurando o monitoramento da CPU
| Etapa | Comando | Descrição |
| Entre no modo privilegiado | enable | - |
| Habilite o monitoramento de ocupação de CPU dos processos. | spy cpu | Obrigatório. Por padrão, o monitoramento de ocupação da CPU está desabilitado. |
| Habilite as estatísticas do histórico de ocupação da CPU. | monitor cpu | Obrigatório. Por padrão, as estatísticas de histórico de ocupação da CPU estão habilitadas . |
Configurar Exibição de Propriedades em Páginas
Condição de configuração
Nenhum
Configurar Exibição de Propriedades em Páginas
As informações do sistema podem ser exibidas em páginas, facilitando a visualização das informações pelos usuários. Os usuários podem configurar para exibir as informações do dispositivo em páginas de acordo com o requisito real.
Tabela 7 - 11 Configurando a exibição de propriedades em páginas
| Etapa | Comando | Descrição |
| Entre no modo privilegiado. | enable | - |
| Configure a exibição de propriedades em páginas. | more { on | off | displine [ num ] } | Obrigatório. Por padrão, a função de exibição em páginas está habilitada. Por padrão, 24 linhas são exibidas em disciplina . |
Gerenciamento de arquivo de registro de operação
Condição de configuração
Nenhum
Configurar arquivo de registro de operação
O registro da operação é salvo no flash por padrão. O gerenciamento do arquivo de registro de operação é principalmente para alterar o local de salvamento do registro de operação.
Tabela 7 -14 Criptografia de arquivo de configuração, criptografia de registro de operação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | config terminal | - |
| Gerenciamento de arquivo de registro de operação | shell-history location device-name | O usuário especifica o local de salvamento do registro de operação. |
| Especifique o tamanho do arquivo de registro de operação | shell-history file max-size num | O usuário especifica o tamanho do arquivo de registro de operação. |
Monitoramento e manutenção do gerenciamento do sistema
Tabela 7 - 12 Monitoramento e manutenção do gerenciamento do sistema
| Comando | Descrição |
| show clock | Exibe as informações sobre o relógio do sistema. |
| show cpu | Exiba as informações sobre o uso da CPU. |
| show device | Exibe as informações do dispositivo do sistema. |
| show environment | Exibe as informações sobre a temperatura da placa. |
| show history | { begin expression | exclude expression | include expression | redirect { file file-name | ftp { hostname | ip-address } user-name password file-name | ftps { hostname | ip-address } user-name password file-name } } | Exiba as informações sobre os comandos do histórico. |
| show language | Exibe as informações sobre a versão do idioma do sistema. |
| show login-secure { telnet | ssh | ftp | snmp}{ip-addr | user | quick-connect} | Exiba as informações sobre o serviço de segurança de login do sistema. |
| show login-secure quick-connect | Exiba as informações de conexão rápida sobre a segurança de login do sistema. |
| show mbuf allocated [ pool-name ] | Exiba as informações do mbuf. |
| show memory | Exibe as informações da memória. |
| show pool [ detail | information ] | Exiba as informações sobre o pool de memória. |
| show process [ task-name ] | Exibe as principais tarefas do sistema e seus status operacionais. |
| show semaphore { sem-name | all | binary | counting | list | mutex } [ any | pended | unpended ] | Exiba as informações sobre o semáforo do sistema. |
| show spy | Exibe o status da chave de monitoramento. |
| show stack | Exiba o uso de cada pilha de tarefas no sistema. |
| show system fan [brief] | Exibe as informações do ventilador. |
| show system lpu [ lpu-num | brief ] | Exiba as informações da LPU |
| show system module brief | Exibe informações breves sobre todas as partes do módulo do dispositivo. |
| show system mpu [brief | mpu-num ] | Exiba as informações do MPU. |
| show system power [ power-num | brief ] | Exibe as informações da fonte de alimentação. |
| show tech-support { sys-base [ detail ] | drv-base [ detail ] | l2-base [ detail ] | l3-base [ detail ] | all } [ page | to-memory | to-flash ] | Exiba as informações de suporte técnico. |
| show version [ detail ] | Exiba as informações da versão do sistema. |
Exemplo de configuração típico de gerenciamento de sistema
Configurar o limite de login com base no usuário e no IP
Requisitos de rede
- PC1 e PC2 servem como terminais locais e podem fazer login no dispositivo via telnet, ssh.
- O dispositivo pode limitar o login para PC1 e PC2 via usuário e IP.
Topologia de rede
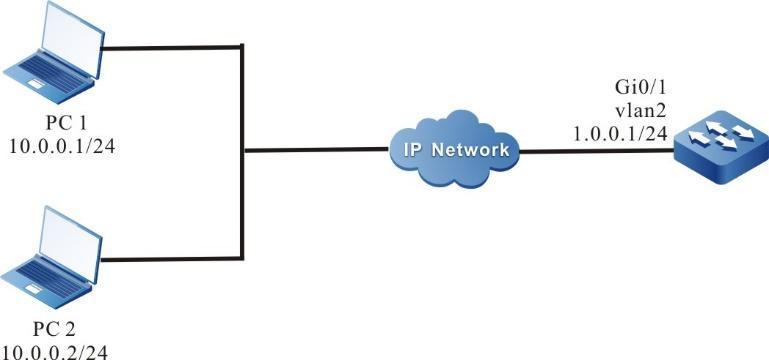
Figura 7 -1 Rede para configurar o limite de login com base no usuário, IP
Etapas de configuração
- Passo 1: Configure o endereço IP da interface e configure o protocolo de roteamento para que PC1, PC2 e Dispositivo se comuniquem entre si (omitido).
- Passo 2: Configure a função de limite de login com base no usuário, IP.
# Habilite a função de segurança de login telnet, ssh.
Device#configure terminalDevice(config)#service login-secure telnetDevice(config)#service login-secure ssh
# Configure os tempos máximos de tentativa do IP telnet e ssh como 5 respectivamente, e os tempos máximos de tentativa do usuário são 5.
Device(config)#login-secure telnet ip-addr max-try-time 5Device(config)#login-secure telnet user max-try-time 5Device(config)#login-secure ssh ip-addr max-try-time 5Device(config)#login-secure ssh user max-try-time 5
- Passo 3:Habilite o serviço ssh do dispositivo, configure o nome de usuário e a senha e defina usando o login de autenticação local.
Device(config)#ip ssh serverDevice(config)#local-user user1 class managerDevice(config-user-manager-user1)#service-type sshDevice(config-user-manager-user1)#password 0 adminDevice(config-user-manager-user1)#exitDevice(config)#line vty 0 15Device(config-line)#login aaaDevice(config-line)#exit
- Passo 4: Confira o resultado.
#PC1 tenta fazer login no dispositivo via telnet e o nome de usuário é user1. Depois de inserir a senha errada por 6 vezes sucessivas, visualize as informações do usuário das estatísticas de segurança de login do telnet no dispositivo:
Device#show login-secure telnet usertelnet module forbidden user information:user try-time forbid-time number record-time--------- -------- ----------- ------ -----------user1 6 00:09:00 0 00:01:00
Você pode ver que user1 é considerado o usuário de ataque de login e não pode fazer login no dispositivo via telnet em 10 minutos.
Aqui, o PC1 tenta usar o usuário1 para fazer login no dispositivo via telnet novamente e o sistema solicita que o login seja proibido.
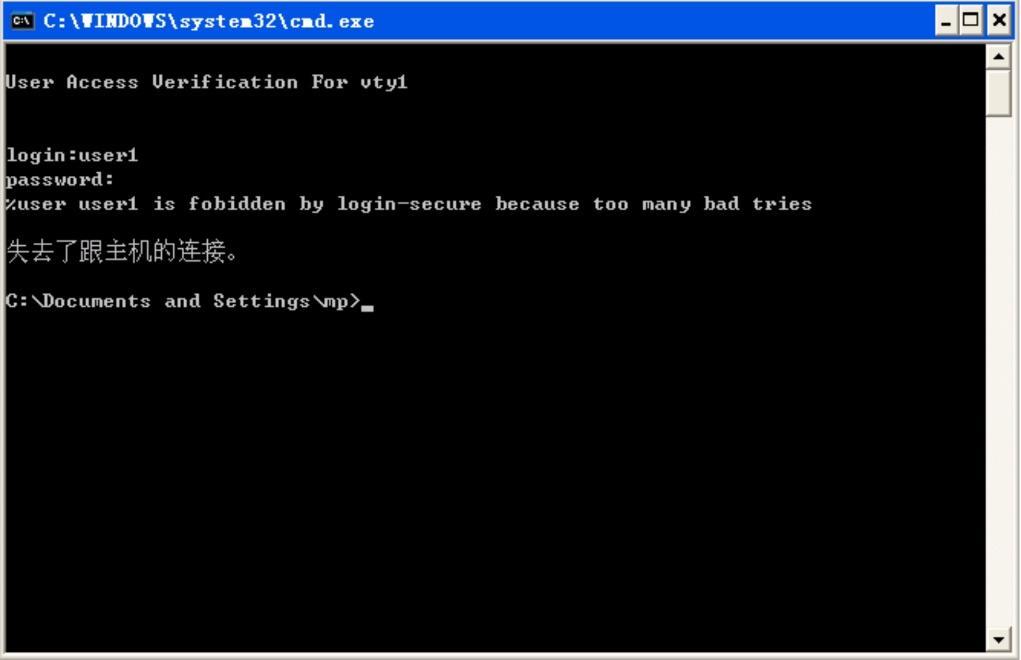
# PC2 tenta fazer login no Device via ssh e usa s o nome de usuário não configurado de Device . Após efetuar login por 6 vezes sucessivas, visualize as informações de ip das estatísticas de segurança de login ssh:
Device#show login-secure ssh ip-addrssh module forbidden login address:client address try-time forbid-time type number record-time-------------- -------- ----------- ------ ------ -----------10.0.0.2 6 00:09:00 login 0 00:01:00
Você pode ver que o endereço IP do PC2 é considerado o usuário do ataque de login e não pode fazer login no dispositivo via ssh dentro de 10 minutos.
Aqui, o PC1 tenta fazer login no dispositivo via ssh novamente e o sistema solicita que o login seja proibido.
É considerado um ataque de login e é proibido somente após os tempos de login excederem os tempos máximos de repetição configurados. Quando os tempos de login são iguais aos tempos máximos configurados, não é proibido.
Alguns clientes ssh no PC tentarão novamente depois que o log falhar. Nesse caso, o dispositivo ainda é registrado como vários logins.
Por padrão, o dispositivo habilita a função de segurança de login telnetm ssh.
Configurar Limite de Login Rápido
Requisitos de rede
- PC1 e PC2 servem como terminais locais e podem fazer login no dispositivo via telnet.
- Após o login rápido do PC1 no dispositivo repetidamente, o login é limitado e o PC2 não é afetado.
Topologia de rede
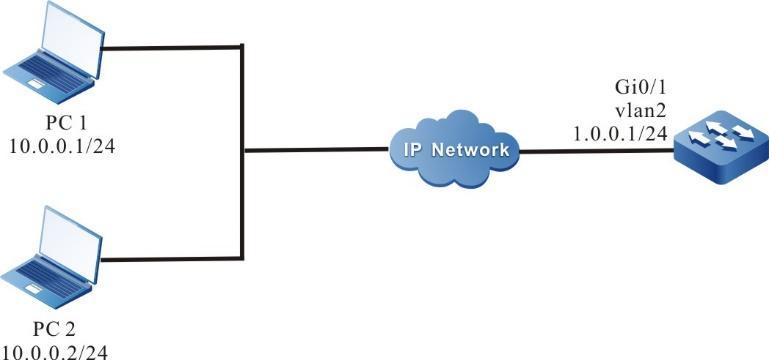
Figura 7 -2 Rede para configurar o limite de login rápido
Etapas de configuração
- Passo 1: Configure o endereço IP da interface e configure o protocolo de roteamento para que PC1, PC2 e Dispositivo se comuniquem entre si (omitido).
- Passo 2: Configure a função de limite de login rápido de telnet.
# Habilite a função de segurança de login telnet e configure os tempos máximos de login rápido como 20 e o tempo de proibição como 10.
Device#configure terminalDevice(config)#service login-secure telnetDevice(config)#login-secure telnet quick-connect max-times 20Device(config)#login-secure telnet quick-connect forbid-time 10
- Passo 3: Configure o nome de usuário e a senha de login do Dispositivo e defina usando o login de autenticação local.
Device(config)#local-user user1 class managerDevice(config-user-manager-user1)#service-type sshDevice(config-user-manager-user1)#password 0 adminDevice(config-user-manager-user1)#exitDevice(config)#line vty 0 15Device(config-line)#login aaaDevice(config-line)#exit
- Passo 4: Confira o resultado.
# PC1 usa user1 para fazer login e logout repetidamente por 21 vezes via telnet, o intervalo de login não excede 30s e visualizar as informações de conexão rápida das estatísticas de segurança de login do telnet.
Device#show login-secure telnet quick-connecttelnet module quick connect info:connect ip connect times last connect time forbid-time record-time---------- ------------- ----------------- ----------- -----------10.0.0.1 21 TUE AUG 11 20:22:38 2015 00:09:00 00:01:00
Você pode ver que PC1 é considerado o endereço de ataque de login e não tem permissão para fazer login no dispositivo via telnet por 10 minutos.
PC2 pode fazer login no dispositivo via telnet com sucesso.
Alarme do sistema
Visão geral
Com a função de alarme do sistema, se ocorrer uma exceção, o sistema envia uma mensagem de alerta de alarme para que o usuário possa prestar atenção à exceção do dispositivo e tomar as medidas correspondentes para garantir o funcionamento estável do dispositivo. Os alarmes do sistema incluem alarmes de temperatura, alarmes de anormalidade da fonte de alimentação e alarmes de anormalidade do ventilador. Para os alarmes de temperatura do sistema, se o chip da chave ou a temperatura da placa principal atingir o limite, informações anormais de registro de alarme do sistema são geradas. Por padrão, o limite de temperatura do alarme do chip do switch é 115° e o limite do alarme de temperatura da placa principal é 115°. As exceções da fonte de alimentação e do ventilador também geram informações anormais no registro de alarmes do sistema.
Configuração da função de alarme do sistema
Tabela 8 - 1 Lista de Funções de Alarme do Sistema
| Tarefas de configuração | |
| Configure os alarmes de temperatura do sistema. | Configure os alarmes de temperatura do sistema. |
| Configurar o alarme da CPU do sistema | Configurar o alarme da CPU do sistema |
| Configurar o alarme de memória do sistema | Configurar o alarme de memória do sistema |
| Configure os alarmes da fonte de alimentação do sistema. | Configure os alarmes da fonte de alimentação do sistema. |
| Configure os alarmes do ventilador do sistema. | Configure os alarmes do ventilador do sistema. |
Configurar alarmes de temperatura do sistema
Condição de configuração
Antes de configurar os alarmes do sistema, certifique-se de que:
- Depois que o sistema é iniciado e funciona de forma estável, todas as placas são carregadas com sucesso.
- Depois que o sistema é iniciado e funciona de forma estável, a fonte de alimentação e os ventiladores funcionam normalmente.
Configurar alarmes de temperatura do sistema
Ao configurar os alarmes de temperatura do sistema, você precisa configurar a temperatura para o chip do switch ou alarmes da placa principal. Se o chip do switch ou a temperatura da placa principal atingir o limite, as informações do registro de alarme do sistema serão geradas. Por padrão, o limite de temperatura do alarme do chip do switch é de 115° e o limite de temperatura do alarme da placa principal é de 115°.
Tabela 8 - 2 Configuração dos alarmes de temperatura do sistema
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | config terminal | - |
| Configure o limite para alarmes de temperatura do chip do switch ou da placa-mãe. | alarm temperature mpu { switch | mainboard} temperature | Obrigatório. |
| No modo VST, configure o chip do switch ou o limite de alarme de temperatura da placa principal de um dispositivo membro do switch virtual no local | alarm temperature device device-num mpu { switch| mainboard} temperature | Obrigatório. |
Configurar o alarme da CPU do sistema
Condição de configuração
Antes de configurar o alarme do sistema, primeiro complete a seguinte tarefa:
- Depois que o sistema é iniciado e funciona de forma estável, todas as placas são carregadas com sucesso.
Configurar o alarme da CPU do sistema
A configuração do alarme de CPU do sistema indica que após configurar o limite do monitor de utilização da CPU, gera o alarme anormal de utilização da CPU ao exceder o limite do monitor.
Tabela 8 - 3 Configure o alarme da CPU do sistema
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o limite do alarme de utilização da CPU do sistema | cpu utilization warner-threashold [ rate-value ] | Opcional |
Configurar limite de uso de pouca memória
Condições de configuração
Antes de configurar o alarme de limite do sistema, primeiro complete a seguinte tarefa :
- Depois que o sistema é iniciado e funciona de forma estável, todos os cartões são carregados com sucesso.
Configurar limite de uso de memória do sistema baixo
Configurar o limite de uso de memória do sistema baixo indica que após configurar o limite de uso de memória do sistema baixo e a memória do sistema for inferior ao limite baixo, insira o status de falta do sistema.
Tabela 8 - 4 Configurar o alarme de limite de memória do sistema
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar o alarme de limite de memória do sistema | memory threshold low low-value | Opcional Por padrão, o limite baixo de memória do sistema é 8M. |
Configurar alarme de memória do sistema
Condição de configuração
Antes de configurar o alarme do sistema, primeiro complete a seguinte tarefa:
- Depois que o sistema é iniciado e funciona de forma estável, todas as placas são carregadas com sucesso.
Configurar alarme de memória do sistema
A configuração do alarme de memória do sistema indica que após configurar o limite do monitor de utilização da memória do sistema, gere o alarme anormal de utilização da memória do sistema ao exceder o limite do monitor.
Tabela 8 - 5 Configurar o alarme de memória do sistema
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar o limite do alarme de utilização da memória do sistema | memory utilization warner-threashold [ rate-value ] | Opcional Por padrão, o limite do alarme de utilização da memória do sistema é de 95 %. |
Configurar alarmes da fonte de alimentação do sistema
Condição de configuração
Nenhum
Configurar alarmes da fonte de alimentação do sistema
Se ocorrer uma falha ou exceção da fonte de alimentação, o sistema gera imediatamente informações de registro sobre os alarmes da fonte de alimentação do sistema. Isso ajuda o usuário a prestar atenção à exceção da fonte de alimentação do dispositivo e tomar as medidas correspondentes para eliminar a falha e garantir a operação estável do dispositivo. Por padrão, a função de alarme da fonte de alimentação do sistema está habilitada.
Configurar alarmes do ventilador do sistema
Condição de configuração
Nenhum
Configurar alarmes do ventilador do sistema
Se ocorrer uma falha ou exceção do ventilador do sistema, o sistema gerará imediatamente informações de registro sobre o alarme do ventilador do sistema. Isso ajuda o usuário a prestar atenção à exceção dos ventiladores do dispositivo e tomar as medidas correspondentes para se livrar da falha e garantir a operação estável do dispositivo. Por padrão, a função de alarme do ventilador do sistema está habilitada.
Configuração do registro do sistema
Visão geral
As informações de log são categorizadas em oito níveis, incluindo: emergências , alertas , críticos , erros , avisos , notificações , informativos e depuração . Aqui os níveis 0-6 são informações de log e o nível 2 são informações de depuração. Para obter detalhes, consulte a tabela a seguir.
Tabela 9 - 1 Descrição dos campos de nível de log do sistema
| Campo | Nível | Descrição |
| e emergências | 0 | Falha fatal. O sistema está indisponível, o dispositivo para e precisa ser reiniciado. |
| uma carta | 1 | Erro grave. Funções de um determinado tipo ficam indisponíveis e os serviços são interrompidos. |
| crítico | 2 | Erro crítico. Problemas irreversíveis ocorrem nas funções de um determinado tipo e algumas funções são afetadas. |
| erros | 3 | Mensagem de erro. |
| avisos | 4 | Mensagem de aviso. |
| notificações | 5 | Mensagem de notificação de evento. |
| informativo | 6 | Prompt de mensagem e notificação. |
| d ebugging | 7 | Mensagem de depuração. |
As informações de log são enviadas para cinco direções: console de controle (terminal do console), console do monitor (terminal Telnet ou SSH), servidor de log, arquivos de log (arquivos de log de memória e arquivos de log flash) e e-mail. A saída para os cinco diretamente é controlada pelos respectivos comandos de configuração. As informações de depuração são enviadas para duas direções, console de controle e console do monitor. As informações de log também podem ser configuradas para saída para o servidor de log ou arquivos de log.
Tabela 9 - 2 Direções de Saída de Log
| Direção de saída de registro | Descrição |
| Console de controle | As informações de log são enviadas para o terminal do console. |
| Monitorar console | As informações de log são enviadas para o terminal Telnet ou SSH. |
| Servidor de registro | As informações de log são enviadas para o servidor de log. Por padrão, os logs de níveis 0-5 são enviados para o servidor de log. |
| Arquivos de registro | As informações de registro são enviadas para a memória do sistema ou memória flash. Por padrão, as informações de log dos níveis de 0 a 5 são enviadas para a memória do sistema e as informações de log dos níveis de 0 a 5 são enviadas para a memória flash. |
| o email | As informações de log são enviadas para o e-mail. Por padrão, os logs dos níveis 0-4 são enviados para o e-mail de log. |
O módulo de log é executado em um processo syslog separado. A thread principal do processo syslog recebe as informações de log enviadas pelo sistema. Em primeiro lugar, processe os dados de log e distribua o espaço de cache. Em seguida, carregue as ações de saída configuradas na fila de buffer correspondente de cada terminal de saída.
Devido à limitação de comprimento da fila de cache, quando um grande número de informações de log é gerado, há uma perda de informações de log. Neste momento, o módulo de log contará as mensagens perdidas. Existem dois encadeamentos na saída do agendamento de log (quando as informações de log são enviadas para o console, monitor, servidor de log, são executadas no mesmo sub-thread dos arquivos de log; quando as informações de log são enviadas para e-mail, são executadas em outro sub-thread -fio).
Na thread de agendamento, habilite um temporizador para cada direção de saída e, após responder a cada vez, o temporizador obtém os dados de informações de log da fila correspondente ao terminal e as saídas para o terminal correspondente de acordo com a configuração do usuário.
Configuração da Função de Log do Sistema
Tabela 9 - 3 Lista de Funções de Log do Sistema
| Tarefas de configuração | |
| Configurar funções de saída de log |
Configure a saída de log para o console de controle.
Configure a saída de log para o console do monitor. Configure a saída de log para o servidor. Configure a saída de log para arquivos. Configurar saída de log para e-mail. |
| Configure o carimbo de data/hora para logs. | Configure o carimbo de data/hora para logs. |
| Configure o log de operação a ser enviado ao servidor de log | Configure o log de operação a ser enviado ao servidor de log |
| Configure a função de supressão de repetição de log | Configure a função de supressão de repetição de log |
| Configure a capacidade do arquivo de log. | Configure a capacidade do arquivo de log. |
| Configurar a função de criptografia do arquivo de log | Configurar a função de criptografia do arquivo de log |
| Configure as cores de exibição do log. | Configure as cores de exibição do log. |
| C onfigurar a função de filtro de log | C onfigurar a função de filtro de log |
| Configurar o código de origem do dispositivo | Configurar o código de origem do dispositivo |
Configurar funções de saída de log
Condição de configuração
Nenhum
Configurar saída de log para o console de controle
O console de controle se refere a um terminal Console. É um canal através do qual o sistema envia informações de log para o console de controle.
Tabela 9 - 4 Configurando a saída de log para o console de controle
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Ative a função de saída de log. | logging enable | Opcional. Por padrão, a função de saída de log está habilitada. |
| Habilite a exibição de log no console de controle. | logging source { module-name | default } console { level severity | deny } | Opcional. Por padrão, a exibição de log no console de controle está habilitada. |
Configurar saída de log para o console do monitor
O console do monitor se refere ao terminal Telnet ou SSH. É usado para gerenciamento remoto de dispositivos. Para configurar a saída do log para o console do monitor, você precisa habilitar a exibição do log no terminal atual.
Tabela 9 - 5 Configurando a saída de log para o console do monitor
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Ative a função de saída de log. | logging enable | Opcional. Por padrão, a função de saída de log está habilitada. |
| Ative a exibição de log no console do monitor. | logging source { module-name | default } monitor { level severity | deny } | Opcional. Por padrão, a função de exibição de log do console do monitor global está habilitada. |
| Ative a exibição de log do console do monitor atual. | terminal monitor | Obrigatório. Por padrão, a exibição de log no console do monitor atual está desabilitada. |
Configurar saída de log para o servidor
Para registrar as informações de log de maneira mais abrangente, você pode configurar a saída das informações de log para o servidor de log, o que é conveniente para a manutenção e gerenciamento do sistema. Ao configurar a saída de log para o servidor de log, você precisa configurar o endereço do host ou o nome de domínio do servidor de log.
Tabela 9 - 6 Configurando a saída de log para o servidor de log
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Ative a função de saída de log. | logging enable | Opcional. Por padrão, a função de saída de log está habilitada. |
| Configure a saída de log para o servidor de log | logging server server-name { ip ip-address | ipv6 ipv6-address | hostname host-name} [ port port-num ] [ facility facility-name ] [level severity] | Obrigatório Por padrão, não configure a saída de log para o servidor de log. |
| Configure o endereço de origem IP para enviar as informações de log | logging server source { ip ip-address | ipv6 ipv6-address | interface interface-name } | Opcional Por padrão, confirme a interface de saída de envio das informações de log pela rota e use o endereço IP mestre da interface de saída como o endereço IP de origem das informações de log enviadas. |
| C onfigurar as informações de log da saída de nível especificada para o servidor de log | logging source { module-name | default } server [ server-name &<1-8> ] { level severity | deny } | Opcional Por padrão, as informações de log de nível 0-5 podem ser enviadas para o host de log. |
Configurar saída de log para arquivos
Os arquivos de log podem ser armazenados de duas maneiras, na memória e na memória flash. A memória armazena apenas as informações de log desde a inicialização do syslog do dispositivo até a reinicialização do sistema ou antes da reinicialização do processo do syslog. Por padrão, as informações de log de nível 5 (notificações) e níveis superiores são armazenadas. Por padrão, a memória flash armazena informações de log de nível 5 ( notificações ) e níveis superiores. Para os níveis de logs, consulte a descrição detalhada na Tabela 9-1. Ambos os dois tipos de arquivos de log têm limite de capacidade. Se o tamanho dos arquivos de log atingir a capacidade máxima configurada, primeiro exclua o arquivo de log mais antigo (as informações de log são registradas por vários arquivos de log) ao adicionar um log e, em seguida, adicione um arquivo de log e registre as informações de log no novo log Arquivo.
Tabela 9 - 7 Configurando a saída de log para arquivos
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Ative a função de saída de log. | logging enable | Opcional. Por padrão, a função de saída de log está habilitada. |
| Configure a saída de log para Flash | logging source { module-name | default } file { level severity | deny } | Opcional Por padrão, as informações de log do nível 0-5 são salvas no Flash. |
| Configure a saída do log para a memória | logging source { module-name | default } buffer { level severity | deny } | Opcional Por padrão, as informações de registro do nível 0-5 são salvas na memória. |
| Configurar o alarme de capacidade do arquivo de log | logging { buffer | file } warning warning-value recover-value | Opcional Por padrão, o valor de aviso de informações de log é 90% e o valor de recuperação é 70%. |
| Configurar a compactação do arquivo de log | logging compress [ gunzip ] logging compress max-num value | Opcional Por padrão, não ative a função de compactação de log. |
Configurar saída de log para e-mail
Para registrar as informações de log de forma mais abrangente, podemos configurar as informações de log para serem enviadas para a caixa de e-mail do destinatário e copiadora por e-mail.
Tabela 9 - 8 Configurando a saída de log para e-mail
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Ative a função de saída de log. | logging enable | Opcional. Por padrão, a função de saída de log está habilitada. |
| Configurar o perfil de e-mail | logging email email-profile | Obrigatório Por padrão, não configure o perfil de saída do log para e-mail. |
| Configure o endereço de e-mail do destinatário das informações de log | mail recipient mail-address | Obrigatório Por padrão, não configure o endereço de e-mail do destinatário das informações de log. |
| Configure o endereço de e-mail da copiadora para receber as informações de log | mail copyto mail-address | Opcional Por padrão, não configure o endereço de e-mail da copiadora para receber as informações de log. |
| Configure o endereço de e-mail do remetente das informações de log | mail sender mail-address | Obrigatório Por padrão, não configure o endereço de e-mail do remetente das informações de log . |
| Configure a senha de e-mail do remetente das informações de log | mail sender password password-string | Obrigatório Por padrão, não configure a senha de e-mail do remetente das informações de log . |
| Configure o endereço de nome de domínio de e-mail do destinatário das informações de log | mail server server-name | Opcional _ Por padrão, use os caracteres após o @ no endereço de e-mail do remetente como o endereço do nome de domínio do remetente. |
| Configure o assunto do email de envio das informações de log | mail subject subject-name | Opcional Por padrão, não configure o assunto do email de envio das informações de log. |
| Configure as informações de log da saída de nível especificada para a caixa de e-mail do receptor e copiadora via e-mail | logging source { module-name | default } email { level severity | deny } | Opcional Por padrão, as informações de log do nível 0-4 são enviadas para o e-mail. |
Configurar o carimbo de data/hora dos registros
Condição de configuração
Nenhum
Configurar o carimbo de data/hora dos registros
O carimbo de data/hora de um log registra em detalhes a hora em que o log é gerado. Por padrão, os carimbos de data/hora de log adotam o formato de tempo absoluto, mas também suportam o formato de tempo de atividade (tempo relativo). O formato de hora absoluta registra o ano e a hora com precisão de milissegundos. Ele gera a hora dos logs em detalhes.
Tabela 9 – 9 Configurando o carimbo de data/hora para logs
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o tipo de carimbo de data/hora das informações de log | logging timestamps uptime | Opcional Por padrão, as informações de log adotam o tipo de carimbo absoluto. |
| Configure o formato de carimbo de data/hora para logs. | logging timestamp-format { msec | timezone | year } | Opcional Por padrão, as informações de log adotam o formato de carimbo de data/hora com o ano a ser exibido. |
O tempo de atividade refere-se ao tempo de execução que começa com a inicialização do dispositivo. A data e hora refere-se à hora do relógio de tempo real. A hora local refere-se à hora local.
Configurar a saída do log de operação para o host de log
Condição de configuração
Você precisa configurar a saída de log para o host primeiro.
Configurar a saída do log de operação para o servidor de log
Depois de configurar a saída do log de operação ao servidor de log, você pode consultar o log de operação do usuário no servidor de log.
Tabela 9 – 10 Configure a saída do log de operação para o host de log
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a função de saída de log | logging enable | Opcional Por padrão, a função de saída de log está habilitada. |
| Configurar o host de log | logging server server-name { ip ip-address | ipv6 ipv6-address | hostname host-name } [ port port-num ] [ facility facility-name ] [level severity] | Obrigatório Por padrão, a função de enviar as informações de log para o servidor de log não está habilitada. |
| Configure o log de operação enviado ao servidor de log | logging operation to-server | Obrigatório Por padrão, a função de envio do log de operação para o servidor de log não está habilitada. |
Configurar supressão de repetição de log
Condição de configuração
Nenhum
Configurar supressão de informações de repetição de log
Em alguns casos, o módulo pode produzir continuamente o mesmo log, afetando a observação de outros logs. Neste momento, você pode ativar a função de supressão de repetição das informações de log. As informações de log repetidas são emitidas uma vez em cada período de supressão e as vezes em que o log é suprimido no período de supressão é emitida no final do período de supressão.
Tabela 9 – 11 Configure a supressão de repetição de log
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a função de supressão das informações de repetição de log | logging suppress duplicates interval interval-num | Obrigatório Por padrão, a função de supressão de log está habilitada. |
Configurar a capacidade do arquivo de log
Condição de configuração
Nenhum
Configurar a capacidade do arquivo de log
Limitada pela capacidade da memória flash, a capacidade do arquivo de log pode ser configurada de 1M a 16M bytes. Quando o tamanho das informações de log armazenadas excede o limite máximo de capacidade, o novo log sobrescreve as informações de log antigas (tome o arquivo como a unidade para cobrir o arquivo de informações de log antigo).
Tabela 9 - 12 Configurando a capacidade do arquivo de log
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a capacidade do arquivo de log. | logging file size file-max-size | Opcional. Por padrão, a capacidade do arquivo de log é de 1M bytes. |
Configurar a criptografia do arquivo de log
Condição de configuração
Nenhum
Configurar a capacidade do arquivo de log
Considerando a segurança das informações de log, os arquivos de log armazenados em flash podem ser criptografados. Ao configurar a função de criptografia dos arquivos de log, os logs gerados subsequentemente serão armazenados no arquivo de log como texto cifrado. Se a senha dos arquivos de log for alterada, os logs armazenados anteriormente em texto cifrado não serão exibidos em texto simples. As informações de log serão armazenadas na forma de texto simples somente quando a senha for reconfigurada como a senha quando o log for gerado.
Tabela 9 - 13 Configurar a criptografia do arquivo de log
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar a criptografia do arquivo de log | logging file encryption alogrithms SMV4 key password | Opcional Por padrão, não configure a função de criptografia para o arquivo de log no Flash. |
Configurar Cores de Exibição de Log
Condição de configuração
Nenhum
Configurar Cores de Exibição de Log
Quando as informações de log são exibidas, você pode modificar as informações de log de diferentes níveis para que sejam exibidas em cores diferentes. Desta forma, os graus de importância dos logs são diferenciados. Por padrão, a função de cor de exibição de log está habilitada. A tabela a seguir mostra as cores padrão correspondentes aos níveis de log.
Tabela 9 - 14 Descrição das Cores do Log
| Campo | Descrição |
| emergências | Red |
| alertas | Roxo |
| uma carta | Azul |
| erros | Marrom |
| avisos | Ciano |
| notificações | Branco |
| informativo | Verde |
| depuração | Verde |
Tabela 9 - 15 Configurando cores de exibição de log
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma cor para os logs de um nível. | logging color [ logging-level logging-color ] | Opcional. Por padrão, cada nível de log tem uma cor de exibição de log correspondente. |
Se o console de controle ou o console do monitor precisarem emitir informações de log em cores diferentes, será necessário configurar a opção de cor dos terminais; caso contrário, nenhuma cor será exibida para as informações de log.
Configurar a função de filtro de log
Condição de configuração
Nenhum
Configurar a função de filtro de log
Ao configurar a filtragem de log, você pode especificar para exibir não apenas as informações de log que contêm a string de filtro, mas também as informações de log sem a string de filtro e o intervalo de nível de informações de log. Ao usar este comando, a string de filtro precisa ser usada junto com o intervalo de nível de log.
Tabela 9 -16 C onfigurar a função de filtro de log
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| C onfigurar a função de filtro de log | logging filter { exclude exclude-string | include include-string | level high-level low-level } | opcional _ Por padrão, a função de filtro de log não está habilitada. |
Configurar ID de origem do dispositivo
Condição de configuração
Nenhum
Configurar ID de origem do dispositivo
Ao configurar o dispositivo origin-id , suporte max. 63 caracteres. Após configurar o origin-id , o campo hostname do log enviado ao servidor de log será substituído pela string origin-id .
Tabela 9 -17 Configurar o código de origem do dispositivo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar o código de origem do dispositivo | logging origin-id string origin-id | Opcional _ _ Por padrão, não configure o device origin-id . |
Monitoramento e manutenção de logs
Tabela 9 - 18 Monitoramento e manutenção de log
| Comando | Descrição |
| clear logging [ buffer | file ] | Limpe as informações de log armazenadas na memória ou Flash |
| show logging [ buffer | file ] | Exiba as informações de registro armazenadas na memória ou na memória flash. |
| show logging { file | buffer } desc | Exibe inversamente as informações de log armazenadas na memória ou Flash |
| show logging filter | Exibir as informações de configuração de filtragem de log |
| show logging operation | Exibe as informações de log armazenadas no arquivo de log de operação |
| show logging [ { file | buffer } [ begin-level level-value / [ start-time stime [ end-time etime ] ] [ detail ] ] ] | Exibir as informações de log armazenadas em arquivos de log, filtrando para exibir as informações de log com a opção de filtragem de tempo e nível |
| show logging { file | buffer } message-counter | Exibe o tamanho do arquivo de log e o número de entradas de informações de log armazenadas no Flash ou na memória. |
Atualização de software
Visão geral
A atualização de software fornece uma versão de software mais estável e recursos de software mais abundantes para o usuário.
Os programas atualizados são armazenados nos meios de armazenamento do dispositivo na forma de arquivos ou blocos de dados. Os módulos de software com diferentes funções cooperam para manter o dispositivo em um estado de funcionamento estável e suportam os recursos de hardware do dispositivo e os serviços de aplicativos dos usuários.
Os usuários podem atualizar o software através do modo de transmissão de rede TFTP/FTP/SFTP, modo de diretório local especificado ou modo de transmissão Xmodem da porta Console. Ao atualizar softwares de diferentes tipos, os usuários devem ler atentamente as etapas de operação e as notas e cuidados descritos nos manuais relacionados à atualização do software.
Na atualização de software, geralmente é necessário atualizar software de cada tipo. Se o software de um tipo não for atualizado durante o processo de atualização, você não precisará atualizar o software novamente. Normalmente, você pode reiniciar o dispositivo somente depois que todas as versões do software forem atualizadas.
Os seguintes tipos de software estão disponíveis:
- O pacote de programa de imagem : O pacote de programa da placa principal com o sufixo pck. Ele contém um grupo de programas necessários para a operação normal do sistema, incluindo o sistema operacional e os programas aplicativos.
- FPGA ( Campo Programado Portão Programa Array ): o programa com o sufixo bin, que é usado principalmente para realizar o controle lógico dos dispositivos e o envio e recebimento de dados de serviço.
- O programa Bootloader: O programa com o sufixo .bin ou. pck, o programa boatloader da placa de controle principal, fixado na ROM da placa de controle principal e na placa principal da placa de negócios, é executado primeiro após o dispositivo ser ligado . Este programa inicializa o sistema básico e sua função principal é guiar o sistema operacional para carregar.
- Devinfo : programa OEM, incluindo ID de modelo e ID de função de vários dispositivos e placas. É usado principalmente para atualização quando o dispositivo é modificado.
- Patch : O hot patch é uma maneira rápida e de baixo custo de reparar defeitos nas versões de software do produto. Comparado com a atualização da versão do software, a principal vantagem do hot patch é que ele não interromperá o funcionamento atual do dispositivo, ou seja, ele pode reparar os defeitos da versão atual do software do dispositivo sem reiniciar o dispositivo.
- Recurso : O pacote incremental de recursos é uma maneira rápida e de baixo custo de reparar defeitos de versão de software do produto. Ele pode substituir o arquivo de programa de processo de negócios e o arquivo de programa de biblioteca dinâmica na versão do software. Depois que o arquivo de programa de processo de negócios for substituído, ele será reiniciado automaticamente e entrará em vigor, e o arquivo de programa de biblioteca dinâmica entrará em vigor após a reinicialização do dispositivo. Comparado com a atualização da versão do software, a principal vantagem de atualizar o arquivo do programa do processo de negócios é que ele não interromperá o funcionamento atual do dispositivo por um longo tempo, ou seja, os defeitos da versão atual do software do dispositivo podem ser reparado sem reiniciar o dispositivo; O tempo de atualização dos arquivos de programa de biblioteca dinâmica é relativamente curto, o que pode concluir rapidamente a substituição de versão e o reparo de defeitos.
- Programa de pacote : O arquivo de pacote com a imagem, Bootloader, cmm, programa devinfo, que pode atualizar vários tipos de programas de software uma vez.
- ISSU (In-Service Software Upgrade ) : A atualização ininterrupta da versão do serviço é um método de atualização para garantir um serviço ininterrupto ou um curto tempo de interrupção durante o processo de atualização. As funções relacionadas ao ISSU são usadas para atualizar a versão do dispositivo principal em ambientes de rede importantes (como data center) sem interromper o tráfego de negócios. A premissa da atualização do ISSU é que o dispositivo tenha backup. Anteriormente, o download da nova versão do programa era concluído por meio de comandos relacionados ao sysupdate.
A relação aplicável entre os tipos de software de atualização acima e cada tipo de placa de placa é mostrada na tabela:
Tabela 10 - 1 Relação aplicável entre programas de atualização e placas
| imagem pacote de programa | carga de inicialização programa | devinfo arquivo | correção arquivo | característica arquivo | pacote arquivo de pacote | ISSU | |
| Placa de controle principal | √ | √ | √ | √ | √ | √ | √ |
Configuração da função de atualização de software
Tabela 10 - 2 Lista de funções de atualização de software
| Tarefas de configuração | |
| Atualize o pacote do programa de imagem. | Atualize o pacote de programa de imagem da placa de controle principal no modo de atualização TFTP/FTP/SFTP/local. |
| Atualize o programa Bootloader. | Atualize o programa Bootloader no modo de atualização TFTP/FTP/SFTP/local. |
| Atualize o arquivo devinfo | Atualize o pacote de arquivos devinfo no modo de atualização TFTP/FTP/SFTP/local. |
| Atualize o arquivo de patch | Atualize o patch quente no modo de atualização TFTP/FTP/SFTP/local. |
| Atualize o arquivo de recurso | Atualize o pacote incremental de recursos no modo de atualização TFTP/FTP/SFTP/local. |
| Atualize o programa do pacote. | Atualize o programa de pacote através do modo TFTP/FTP/SFTP |
| Atualizar ISSU | Atualize o programa de versão sem interromper o tráfego comercial ou interromper o tráfego comercial por um curto período |
Atualize o pacote de programas de imagem
O pacote de programa de imagem é usado para atualizar a placa de controle principal.
Preparativos de configuração
Antes de atualizar o pacote do programa de imagem, certifique-se de que:
- A rota entre o servidor TFTP/FTP/SFTP e a interface do dispositivo é alcançável, e o servidor TFTP/FTP/SFTP e o dispositivo podem efetuar ping entre si com sucesso.
- A configuração do servidor TFTP/FTP/SFTP está correta e o programa de imagem está armazenado no diretório especificado do servidor TFTP/FTP/SFTP .
- Ao atualizar por meio de atualização local, você precisa garantir que a versão esteja no diretório especificado. Você pode especificar o arquivo de versão no diretório de dispositivos de armazenamento, como USB.
- O espaço restante do flash é suficiente. Se o espaço for insuficiente, exclua manualmente os arquivos desnecessários no flash.
- Os arquivos de configuração foram copiados.
Atualize o pacote de programas de imagem em TFTP/FTP / SFTP/Modo de atualização local
Entre no modo de usuário privilegiado, certifique-se de que o dispositivo possa obter o programa de atualização por meio do servidor TFTP/FTP/SFTP externo e, em seguida, use o comando sysupdate image para atualizar o pacote do programa.
Tabela 10 - 3 Atualizando o pacote de programa de imagem no modo TFTP/FTP/SFTP/upgrade local
| Etapa | Comando | Descrição |
| Entre no modo de usuário privilegiado. | Nenhum | Obrigatório. |
| Atualize o pacote do programa de imagem. | sysupdate image [ device { memberId | all } ] mpu {file-system filename | {dest-ip-address | dest-ipv6-address} filename [ ftp | sftp username password ]} [ reload ] | Obrigatório. Se a opção FTP/SFTP não for especificada, o TFTP será usado para atualização por padrão. |
Exemplo: No modo autônomo, utilize o servidor FTP 130.255.168.45 para atualizar o pacote de programas de imagem da central online.
Hostname#sysupdate image mpu 130.255.168.45 sp35-g-9.7.20.1(R).pck ftp a a#O dispositivo fornece as seguintes mensagens de prompt:
checking "sp35-g-9.7.20.1(R).pck" : ...OKdownloading "sp35-g-9.7.20.1(R).pck" : ######################################OKDownload "sp35-g-9.7.20.1(R).pck" (177498836 Bytes) successfully.Verify the image...validWriting file to filesystem............................................OK!Start backup ios to raw flash...OK%Sysupdate image is in process, please wait...%Sysupdate image finished.sysupdate image result information list:----------------------------------------------------------------Card result information----------------------------------------------------------------Mpu upgrade successfully!
Exemplo: No modo autônomo, atualize o programa de imagem da placa de controle principal através do sistema de arquivos.
Hostname#sysupdate image mpu file-system /flash/sp35-g-9.7.20.1(R).pck#O dispositivo fornece as seguintes mensagens de prompt:
checking "/flash/ sp35-g-9.7.20.1(R).pck" : ...OKCopying "/flash/ sp35-g-9.7.20.1(R).pck" : #####################################OKCopy "/flash/ sp35-g-9.7.20.1(R).pck" (177498836 Bytes) successfully.Verify the image...validWriting file to filesystem..........................................OKStart backup ios to raw flash........................................OK%Sysupdate image is in process, please wait...%Sysupdate image finished.sysupdate image result information list:----------------------------------------------------------------Card result information----------------------------------------------------------------
#A mensagem acima indica que o programa de imagem dos cartões de controle ativo e de espera online foi atualizado com sucesso.
Se a opção de comando recarregar for adicionada, o sistema perguntará se deseja salvar a configuração e se deseja reiniciar o dispositivo. Normalmente, o dispositivo é iniciado após a atualização de todos os programas. Portanto, a opção de recarregamento não é recomendada.
Antes da atualização, certifique-se de que haja espaço suficiente na memória flash . Se o espaço for insuficiente, a atualização falhará. Nesse caso, você pode excluir manualmente os arquivos desnecessários do flash para obter mais espaço para atualizar os programas aplicativos.
O espaço flash dos cartões de controle ativos e em espera for insuficiente, ele perguntará se os arquivos de imagem redundantes devem ser excluídos. Se o espaço ainda for insuficiente após a exclusão, a atualização falhará.
Demora muito tempo para atualizar o pacote do programa de imagem. Um espaço restante menor no flash resulta em maior tempo de atualização. Após a conclusão da atualização, para executar o novo programa de imagem, reinicie o dispositivo.
Se o dispositivo não iniciar normalmente, abra a tela Bootloader, modifique o modo de inicialização para inicialização de rede. Depois que o dispositivo for iniciado com sucesso, inicie a atualização. Para o método, consulte a seção relacionada no manual de configuração do Bootloader e no manual de comando.
Durante o processo de atualização, você não pode desligar o dispositivo ou trocar ou reiniciar a placa de controle principal . Caso contrário, o sistema pode falhar ao iniciar ou o sistema de arquivos flash da placa de controle principal pode ser danificado.
Atualize o Programa Bootloader
O programa Bootloader é usado para atualizar o cartão de controle principal.
Preparativos de configuração
Antes de atualizar o programa Bootloader, certifique-se de que:
- A rota entre o servidor TFTP/FTP/SFTP e a interface do dispositivo é alcançável, e o servidor TFTP/FTP/SFTP e o dispositivo podem efetuar ping entre si com sucesso.
- A configuração do servidor TFTP/FTP/SFTP está correta e o programa Bootloader está armazenado no diretório especificado do servidor TFTP/FTP/SFTP.
- Ao atualizar por meio de atualização local, você precisa garantir que a versão esteja no diretório especificado. Você pode especificar o arquivo de versão no diretório de dispositivos de armazenamento, como USB.
- Faça backup do arquivo de configuração.
Atualize o programa Bootloader no modo TFTP/FTP/SFTP/Modo de atualização local
Entre no modo de usuário privilegiado, certifique-se de que o dispositivo possa obter o programa de atualização por meio do servidor TFTP/FTP/SFTP externo e, em seguida, use o comando sysupdate bootloader para atualizar o pacote do programa.
Tabela 10 - 4 Atualizando o programa Bootloader em TFTP/FTP/SFTP/modo de atualização local
| Etapa | Comando | Descrição |
| Entre no modo de usuário privilegiado. | Nenhum | Obrigatório. |
| Atualize o programa Bootloader . | sysupdate bootloader [ device { memberId | all } ] mpu {file-system filename | {dest-ip-address | dest-ipv6-address} filename [ ftp | sftp username password ]} [ reload ] | Obrigatório. Se a opção FTP/SFTP não for especificada, o TFTP será usado para atualização por padrão. |
Exemplo:
No modo autônomo, use o servidor FTP 130.255.168.45 para atualizar o programa bootloader de todas as placas de controle principais online.
Hostname#sysupdate bootloader mpu 130.255.168.45 sz03-tboots2-b6b7-9.6.2.5.pck ftp a a#O dispositivo solicitará as seguintes informações:
checking " sz03-tboots2-b6b7-9.6.2.5.pck " : ...OKdownloading " sz03-tboots2-b6b7-9.6.2.5.pck" : ####OKDownload " sz03-tboots2-b6b7-9.6.2.5.pck " (3637108 Bytes) successfully.Update bootloader start.....................................OK.%Sysupdate bootloader is in process, please wait...%Sysupdate bootloader finished.sysupdate bootloader result information list:----------------------------------------------------------------Card result information----------------------------------------------------------------Mpu upgrade successfully!
# A mensagem acima indica que o programa Bootloader da placa de controle principal online foi atualizado com sucesso.
Exemplo: No modo autônomo, a atualização local é realizada através do sistema de arquivos para atualizar os programas bootloader de todas as placas de controle principais existentes.
Hostname#sysupdate bootloader mpu file-system /flash/sz03-tboots2-b6b7-9.6.2.5.pck#O dispositivo solicitará as seguintes informações:
checking "/flash/sz03-tboots2-b6b7-9.6.2.5.pck " : ...OKCopying "/flash/sz03-tboots2-b6b7-9.6.2.5.pck" : ####OKCopy "/flash/sz03-tboots2-b6b7-9.6.2.5.pck " (3637108 Bytes) successfully.Update bootloader start.....................................OK.%Sysupdate bootloader is in process, please wait...%Sysupdate bootloader finished.sysupdate bootloader result information list:----------------------------------------------------------------Card result information----------------------------------------------------------------Mpu upgrade successfully!
Ao atualizar, selecione a versão correta do Bootloader para evitar situações anormais. Se a opção de comando recarregar for adicionada, o sistema perguntará se a configuração deve ser salva e se o dispositivo deve ser reiniciado imediatamente. No entanto, geralmente o dispositivo é iniciado depois que todos os programas são atualizados. Portanto, a opção de recarregamento não é recomendada.
Após a conclusão da atualização, se você precisar executar um novo programa de bootloader, será necessário reiniciar a placa ou todo o dispositivo. Por favor, selecione a versão correta do bootloader para atualizar para evitar anormalidades.
Durante o processo de atualização, você não pode desligar o dispositivo ou trocar ou reiniciar a placa de controle principal e a placa de serviço . Caso contrário, o sistema pode falhar ao iniciar ou o arquivo Bootloader da placa da placa pode ser danificado.
Atualize o programa Bootloader através da porta do console
Certifique-se de que o HyperTerminal possa acessar o dispositivo pela porta do console. Entre no modo Bootloader, ajuste a taxa de transmissão e execute a atualização através do ymodem do HyperTerminal. Se houver duas placas mestras no dispositivo, você precisará atualizá-las separadamente.
Para detalhes dos comandos, consulte o capítulo relacionado do manual de comandos “Bootloader”.
Tabela 10 - 5 Atualizando o programa Bootloader por meio da porta do console
| Etapa | Comando | Descrição |
| Defina o HyperTerminal. | Nenhum | Obrigatório. Execute o programa HyperTerminal, selecione a porta serial correspondente (como com1) e defina suas propriedades. Defina a taxa de transmissão para 9600 bps, controle de fluxo suave, 8 bits de dados, sem verificação de paridade e 1 bit de parada. |
| Entre no modo Bootloader. | Nenhum | Obrigatório. Quando o dispositivo for reiniciado, pressione Ctrl + C para entrar no modo Bootloader. |
| Modifique a taxa de transmissão da porta do console e do HyperTerminal para melhorar a velocidade de atualização. | srate { speed } | Opcional. Modifique a taxa de transmissão da porta do console do dispositivo para 115200 bps. Em seguida, desconecte o HyperTerminal e modifique a taxa de transmissão do HyperTerminal para 115200 bps e, em seguida, conecte o HyperTerminal novamente. |
| Atualize o programa Bootloader . | mupdate Bootloader | Obrigatório. No modo Bootloader, insira o comando mupdate Bootloader , selecione o protocolo ymodem do HyperTerminal e selecione o programa Bootloader para iniciar a transmissão. |
Exemplo:
O exemplo a seguir mostra como atualizar o programa Bootloader da placa de controle ativa por meio da porta Console.
#O dispositivo fornece as seguintes mensagens de prompt:
PMON> mupdate bootloaderdownload bootloader via y modem protocol......CCCStarting ymodem transfer. Press Ctrl+C to cancel.Transferring sz03-tboots2-b6b7-9.6.2.5.pck...100% 1020 KB 7 KB/sec 00:02:24 0 Errors## Total Size = 0x000ff0f4 = 1044724 Bytessuccess!Update bootloader start...Erase Master Flash OK ...-Flash Program OK ...Verifying flash data...Verify OK ...Update bootloader OK.PMON>
#A mensagem acima indica que o programa bootloader da placa de controle ativa foi atualizado com sucesso.
Ao atualizar o programa bootloader da placa de controle em espera pela porta do console, o processo de operação é consistente com o da placa de controle ativa.
Ao atualizar o programa Bootloader, certifique-se de que a taxa do HyperTerminal seja igual à taxa da porta do console do dispositivo.
Ao atualizar o programa Bootloader, recomenda-se que a velocidade de transmissão seja definida para 115200 bps. Desta forma, o tempo de transmissão da atualização é menor.
Se a taxa padrão da porta do console foi modificada no upgrade do programa Bootloader, ao carregar o pacote do programa de imagem , a taxa da porta do console do dispositivo volta automaticamente para 9600bps. Neste momento, a taxa do HyperTerminal precisa ser modificada de forma síncrona.
É recomendado que você atualize o programa Bootloader no modo TFTP/FTP/SFTP. O modo de atualização da porta do console é usado somente quando as condições de atualização do primeiro modo de atualização não são atendidas.
Durante o processo de atualização, você não pode desligar o dispositivo ou trocar ou reiniciar a placa de controle principal . Caso contrário, o sistema pode falhar ao iniciar ou o arquivo Bootloader da placa da placa pode ser danificado.
Atualize o arquivo devinfo
O arquivo devinfo é usado para atualizar a placa de controle principal.
Preparativos de configuração
Antes de atualizar o arquivo devinfo , certifique-se de que:
- A rota entre o servidor TFTP/FTP/SFTP e a interface do dispositivo é alcançável, e o servidor TFTP/FTP/SFTP e o dispositivo podem efetuar ping entre si com sucesso.
- A configuração do servidor TFTP/FTP/SFTP está correta e o arquivo devinfo está armazenado no diretório especificado do servidor TFTP/FTP/SFTP.
- Ao atualizar por meio de atualização local, você precisa garantir que a versão esteja no diretório especificado. Você pode especificar o arquivo de versão no diretório de dispositivos de armazenamento, como USB.
- Faça backup do arquivo de configuração.
Atualize o arquivo devinfo em TFTP/FTP/SFTP/Modo de atualização local
Entre no modo de usuário privilegiado, certifique-se de que o dispositivo possa obter o programa de atualização por meio do servidor TFTP/FTP/SFTP externo e, em seguida, use o comando sysupdate devinfo para atualizar.
Tabela 10 - 6 Atualizando o arquivo devinfo em TFTP /FTP/SFTP/modo de atualização local
| Etapa | Comando | Descrição |
| Entre no modo de usuário privilegiado. | enable | Obrigatório. |
| Atualize o arquivo devinfo | sysupdate devinfo [ device { memberId | all } ] mpu {file-system filename | {dest-ip-address | dest-ipv6-address} filename [ ftp | sftp username password ]} [ reload ] | Obrigatório Se a opção FTP/SFTP não for especificada, o TFTP será usado para atualização por padrão. |
Exemplo:
No modo autônomo, use o servidor FTP 130.255.168.45 para atualizar os arquivos devinfo s da placa de controle principal online.
Hostname#sysupdate devinfo mpu 130.255.168.45 devInfo_sw_intelbras_V2.155 ftp a a#O dispositivo fornece as seguintes mensagens de prompt:
checking " devInfo_sw_intelbras_V2.155" : ...OKdownloading " devInfo_sw_intelbras_V2.155" : #OKDownload " devInfo_sw_intelbras_V2.155" (6275 Bytes) successfully.Writing file to filesystem....OK!%Sysupdate devinfo is in process, please wait...%Sysupdate devinfo finished.sysupdate devinfo result information list:----------------------------------------------------------------Card result information----------------------------------------------------------------Mpu upgrade successfully!
Exemplo: No modo autônomo, a atualização local é realizada através do sistema de arquivos para atualizar o arquivo devinfo da placa de controle principal online.
Hostname#sysupdate devinfo mpu file-system /flash/devInfo_sw_intelbras_V2.155#O dispositivo fornece as seguintes mensagens de prompt:
checking "/flash/devInfo_sw_intelbras_V2.155" : ...OKCopying "/flash/devInfo_sw_intelbras_V2.155" : #OKCopy "/flash/devInfo_sw_intelbras_V2.155" (6275 Bytes) successfully.Writing file to filesystem....OK!%Sysupdate devinfo is in process, please wait...%Sysupdate devinfo finished.sysupdate devinfo result information list:----------------------------------------------------------------Card result information----------------------------------------------------------------Mpu upgrade successfully!
#A mensagem acima indica que o arquivo devinfo do cartão de controle principal foi atualizado com sucesso.
Se a opção de comando recarregar for adicionada, o sistema perguntará se deseja salvar a configuração e se deseja reiniciar o dispositivo. Normalmente, o dispositivo é iniciado após a atualização de todos os programas. Portanto, a opção de recarregamento não é recomendada. Após a conclusão da atualização, para executar o novo arquivo devinfo , reinicie o dispositivo. Selecione a versão correta do arquivo devinfo para atualizar para evitar exceções.
Durante o processo de atualização, você não pode desligar o dispositivo ou trocar ou reiniciar a placa de controle principal . Caso contrário, o sistema pode falhar ao iniciar ou o arquivo devinfo pode ser danificado.
Atualize o arquivo de patch
O arquivo de patch é aplicável para atualizar a placa de controle principal.
Preparativos de configuração
Antes de atualizar o arquivo de patch , certifique-se de que:
- A rota entre o servidor TFTP/FTP/SFTP e a interface do dispositivo é alcançável, e o servidor TFTP/FTP/SFTP e o dispositivo podem efetuar ping entre si com sucesso.
- A configuração do servidor TFTP/FTP/SFTP está correta e o arquivo de correção está armazenado no diretório especificado do servidor TFTP/FTP/SFTP.
- Ao atualizar por meio de atualização local, você precisa garantir que a versão esteja no diretório especificado. Você pode especificar o arquivo de versão no diretório de dispositivos de armazenamento, como USB.
- Faça backup do arquivo de configuração.
Atualize o arquivo de patch em TFTP /FTP/SFTP/Modo de atualização local
Entre no modo de usuário privilegiado, certifique-se de que o dispositivo possa obter o programa de atualização por meio do servidor TFTP/FTP/SFTP externo e, em seguida, use o comando sysupdate patch para atualizar.
Tabela 10 - 7 Atualizando o patch arquivo em TFTP /FTP/SFTP/modo de atualização local
| Etapa | Comando | Descrição |
| Entre no modo de usuário privilegiado. | enable | Obrigatório. |
| Melhoria o arquivo de correção | sysupdate patch [ device { memberId | all } ] mpu {file-system filename | {dest-ip-address | dest-ipv6-address} filename [ ftp | sftp username password ]} | Mandatório _ Se a opção FTP/SFTP não for especificada, o TFTP será usado para atualização por padrão. |
Exemplo:
No modo autônomo, use o servidor FTP 130.255.168.45 para atualizar os arquivos de patch da placa de controle principal online.
Hostname#sysupdate patch mpu 130.255.168.45 sp35-g-9.7.20.1.HP001.pat ftp a 123456downloading " sp35-g-9.7.20.1.HP001.pat" : #OKDownload " sp35-g-9.7.20.1.HP001.pat" (8693 Bytes) successfully.Writing file to filesystem........OKUpgrading, please wait for a moment...Load the patch package successfully.Active the patch package successfully.Run the patch package successfully.Upgrade the patch package finished.Upgrade patch of master MPU:OK%Sysupdate patch is in process, please wait...%Sysupdate patch finished.sysupdate patch result information list:----------------------------------------------------------------Card result information----------------------------------------------------------------Mpu 0 upgrade successfully!
Exemplo: No modo stand-alone, a atualização local é realizada através do sistema de arquivos para atualizar o arquivo de patch da placa de controle principal online.
Hostname#sysupdate patch mpu file-system /flash/sp35-g-9.7.20.1.HP001.patCopying "/flash/sp35-g-9.7.20.1.HP001.pat" : #OKCopy "/flash/sp35-g-9.7.20.1.HP001.pat" (8693 Bytes) successfully.Writing file to filesystem........OKUpgrading, please wait for a moment...Load the patch package successfully.Active the patch package successfully.Run the patch package successfully.Upgrade the patch package finished.Upgrade patch of master MPU:OK%Sysupdate patch is in process, please wait...%Sysupdate patch finished.sysupdate patch result information list:----------------------------------------------------------------Card result information----------------------------------------------------------------Mpu 0 upgrade successfully!
#As informações acima indicam que o arquivo de patch do cartão de controle online foi atualizado com sucesso. Você pode ver a correção bem-sucedida através da versão do Hotpatch na versão show. O número da versão é o número da versão do arquivo de patch.
Após a atualização, o arquivo de patch entrará em vigor imediatamente. Selecione a versão correta do arquivo de patch para atualizar para evitar exceções.
Durante o processo de atualização, você não pode desligar o dispositivo ou trocar ou reiniciar a placa de controle principal . Caso contrário, o sistema pode falhar ao iniciar ou o arquivo de correção pode ser danificado.
Deletar Pacote de Patch
Entre no modo de usuário privilegiado e exclua o pacote de hot patch por meio do comando patch delete .
Tabela 10 - 8 D elete o pacote de hot patch por meio do comando patch delete
| Etapa | Comando | Descrição |
| Entre no modo de usuário privilegiado. | Nenhum | Obrigatório |
| Delete o pacote de hot patch | patch delete [ device { memberId | all } ] mpu | Obrigatório |
Exemplo: No modo autônomo, exclua o pacote de hot patch por meio do patch delete comando.
Hostname#patch deleteThis will delete the package. Are you sure?(Yes|No)?yesPackage deleting, please wait for a moment...Rollback the patch package successfully.Delete the patch package file successfully.
# As informações acima indicam que o pacote de patch do cartão de controle foi excluído com sucesso e o hot patch não é mais eficaz.
Após a exclusão, o pacote de hot patch será excluído Confirme claramente antes de executar este comando. Após a execução, o hot patch será inválido para evitar exceções.
Monitoramento e manutenção de atualização de patches
Tabela 10 - 9 monitoramento e manutenção de atualização de patch
| Etapa | Comando | Descrição |
| Entre no modo de usuário privilegiado. | Nenhum | Obrigatório. |
| Exiba as informações de instalação e operação do pacote de patch | show patch [ device { memberId | all } ] mpu | Exiba as informações sobre os arquivos e versões de instalação do hot patch |
| Debugar o processo de instalação do pacote de patch | [ no ] debug hpmm | D ebugar o processo de instalação do pacote de hot patch |
Atualize o arquivo de recurso
O arquivo de recursos é aplicável para atualizar o cartão de controle.
Preparativos de configuração
Antes de atualizar o arquivo de recurso , certifique-se de que:
- A rota entre o servidor TFTP/FTP/SFTP e a interface do dispositivo é alcançável, e o servidor TFTP/FTP/SFTP e o dispositivo podem efetuar ping entre si com sucesso.
- A configuração do servidor TFTP/FTP/SFTP está correta e o arquivo de recurso está armazenado no diretório especificado do servidor TFTP/FTP/SFTP.
- Ao atualizar por meio de atualização local, você precisa garantir que a versão esteja no diretório especificado. Você pode especificar o arquivo de versão no diretório de dispositivos de armazenamento, como USB.
- Faça backup do arquivo de configuração.
Atualize o arquivo de recurso em TFTP /FTP/SFTP/Modo de atualização local
Entre no modo de usuário privilegiado, certifique-se de que o dispositivo possa obter o programa de atualização por meio do servidor TFTP/FTP/SFTP externo e, em seguida, use o comando sysupdate feature para atualizar.
Tabela 10 - 10 Atualizando o recurso arquivo em TFTP /FTP/SFTP/modo de atualização local
| Etapa | Comando | Descrição |
| Entre no modo de usuário privilegiado. | enable | Obrigatório. |
| Atualize o arquivo de recurso | sysupdate feature [ device { memberId | all } ] mpu {file-system filename | {dest-ip-address | dest-ipv6-address} filename [ ftp | sftp username password ] } | Se a opção FTP/SFTP não for especificada, o TFTP será usado para atualização por padrão. |
Exemplo: No modo autônomo, use o servidor FTP 130.255.168.45 para atualizar o arquivo de recurso da placa de controle principal online.
Hostname#sysupdate feature mpu 130.255.168.45 sp35-g-9.7.20.1.FEATURE001.bin ftp a 123456downloading " sp35-g-9.7.20.1.FEATURE001.bin " : #OKDownload " sp35-g-9.7.20.1.FEATURE001.bin " (9657 Bytes) successfully.Writing file to filesystem........OKUpgrading, please wait for a moment...Load the feature package successfully.Active the feature package successfully.Run the feature package successfully.Upgrade the feature package finished.Upgrade feature of master MPU:OK%Sysupdate feature is in process, please wait...%Sysupdate feature finished.sysupdate feature result information list:----------------------------------------------------------------Card result information----------------------------------------------------------------Mpu 0 upgrade successfully!
Exemplo: No modo autônomo, a atualização local é realizada através do sistema de arquivos para atualizar o arquivo de características da placa de controle principal online.
Hostname#sysupdate feature mpu file-system /flash/sp35-g-9.7.20.1.FEATURE001.binCopying "/flash/sp35-g-9.7.20.1.FEATURE001.bin " : #OKCopy "/flash/sp35-g-9.7.20.1.FEATURE001.bin " (9657 Bytes) successfully.Writing file to filesystem........OKUpgrading, please wait for a moment...Load the feature package successfully.Active the feature package successfully.Run the feature package successfully.Upgrade the feature package finished.Upgrade feature of master MPU:OK%Sysupdate feature is in process, please wait...%Sysupdate feature finished.sysupdate feature result information list:----------------------------------------------------------------Card result information----------------------------------------------------------------Mpu 0 upgrade successfully!
# As informações acima indicam que o arquivo de recursos do cartão de controle online foi atualizado com sucesso. Você pode ver o patch bem-sucedido através da versão do recurso na versão show. O número da versão é o número da versão do arquivo de patch.
Após o upgrade, o arquivo de programa de processo de negócios no arquivo de recurso entrará em vigor automaticamente e o arquivo de programa de biblioteca dinâmica entrará em vigor depois que o sistema for reiniciado. Selecione a versão correta do arquivo de recurso para atualizar para evitar exceções.
Durante o processo de atualização, você não pode desligar o dispositivo ou trocar ou reiniciar a placa de controle principal . Caso contrário, o sistema pode falhar ao iniciar ou o arquivo de recurso pode ser danificado.
Excluir pacote incremental de recurso
Entre no modo de usuário privilegiado e exclua o pacote de incremento de recurso por meio do comando feature delete .
Tabela 10 -11 Exclua o pacote de incremento de recurso por meio do comando feature delete
| Etapa | Comando | Descrição |
| Entre no modo de usuário privilegiado. | Nenhum | Obrigatório |
| D ele o pacote de incremento de recursos | feature delete [ device { memberId | all } ] mpu | Obrigatório |
Exemplo: No modo autônomo, exclua o pacote de incremento de recurso por meio do comando feature delete .
Hostname#feature deleteThis will delete the package. Are you sure?(Yes|No)?yesPackage deleting, please wait for a moment...Rollback the feature package successfully.Delete the feature package file successfully.
# As informações acima indicam que o pacote incremental de recursos do cartão de controle foi excluído com sucesso e o pacote incremental de recursos não é mais eficaz.
Quando a exclusão for concluída, o pacote incremental de recursos será excluído. Confirme claramente antes de executar este comando para evitar exceções. Após a execução, o processo de negócios correspondente no pacote será reiniciado automaticamente com o arquivo de programa de processo de negócios antigo. O arquivo de programa de biblioteca dinâmica continuará a usar o antigo após reiniciar o dispositivo, ou seja, o arquivo de programa de processo de negócios atualizado anteriormente se tornará inválido automaticamente e o arquivo de programa de biblioteca dinâmica se tornará inválido após reiniciar o dispositivo.
Monitoramento e manutenção de atualização de recursos
Tabela 10 -12 monitoramento e manutenção de atualização de recursos
| Etapa | Comando | Descrição |
| Entre no modo de usuário privilegiado. | Nenhum | Obrigatório. |
| Exiba as informações de instalação e operação do pacote incremental de recursos | show feature [ device { memberId | all } ] mpu | Exiba as informações sobre os arquivos e versões de instalação do pacote incremental de recursos |
| Depure o processo de instalação do pacote incremental de recursos | [ no ] debug hpmm | Depure o processo de instalação do pacote incremental de recursos |
Atualize o arquivo do pacote
O arquivo do pacote contém a imagem, os arquivos do carregador de inicialização, que podem ser atualizados uma vez por meio do arquivo do pacote.
Preparativos de configuração
do pacote, você precisa concluir a seguinte tarefa:
- Certifique-se de que a rota entre o servidor T FTP/FTP/SFTP e a interface do dispositivo seja alcançável e que eles possam efetuar ping entre si.
- O servidor TFTP/FTP/SFTP está configurado corretamente e o arquivo do pacote está corretamente colocado no diretório especificado de TFTP/FTP/SFTP .
- Ao atualizar por meio de atualização local, você precisa garantir que a versão esteja no diretório especificado. Você pode especificar o arquivo de versão no diretório de dispositivos de armazenamento, como USB.
- Faça backup do arquivo de configuração.
Arquivo de pacote de atualização via TFTP /FTP/ SFTP/Modo de atualização local
Entre no modo de usuário privilegiado, certifique-se de que o dispositivo possa obter o programa de atualização do servidor TFTP/FTP /SFTP externo e, em seguida, atualize através do pacote sysupdate comando.
Tabela 10 - 13 Atualizar o arquivo de pacote via TFTP /FTP /SFTP/modo de atualização local
| Etapa | Comando | Descrição |
| Entre no modo de usuário privilegiado. | enable | Obrigatório. |
| Atualize o arquivo do pacote | sysupdate package [ device { memberId | all } ] {file-system filename | {dest-ip-address | dest-ipv6-address} filename[ftp | sftp username password ]} [ no-comparision] [ reload] | Obrigatório Se não especificar a opção FTP, use TFTP para atualizar por padrão. |
Exemplo: No modo autônomo, empacote e atualize os programas de todos os tipos de placas online através do servidor FTP 130.255.168.45 .
Hostname#sysupdate package 130.255.168.45 sp35-g-9.7.20.1(R)-001.pkg FTP a a# O dispositivo solicita as seguintes informações:
Downloading "sp35-g-9.7.20.1(R)-001.pkg" header...OK!Checking "sp35-g-9.7.20.1(R)-001.pkg" header...OK!image file version comparision:----------------------------------------------------------------Component Component version File version----------------------------------------------------------------Mpu 0 9.7.20.1(R) 9.7.20.1(R)The current-version of cards is greater than or equal to that in package.NOTICE:input 'Yes' to upgrade all files in the package, 'No' to ignore the above component(s). (Yes|No)?YesDownloading "sp35-g-9.7.20.1(R)-001.pkg" : ##############################################################################################################################################################################OK!Download "sp35-g-9.7.20.1(R)-001.pkg" (181635232 Bytes) successfully!Checking package file...OK!Verify the image...validThe file sp35-g-9.7.20.1(R).pck already exists on Mpu 0, overwrite it?(Yes|No):YesWriting file to filesystem.......................................................OK!Start backup ios to raw flash...OK%Sysupdate image is in process, please wait...%Sysupdate image finished.Update bootloader start....OK.%Sysupdate bootloader is in process, please wait...%Sysupdate bootloader finished..%Sysupdate devinfo is in process, please wait...%Sysupdate devinfo finished..%Sysupdate pkgInfo is in process, please wait...%Sysupdate pkgInfo finished.package sysupdate result information list:----------------------------------------------------------------sp35-g-9.7.20.1(R).pck sysupdate result information list:----------------------------------------------------------------Mpu 0 - upgrade successfully!sz03-tboots2-b6b7-9.6.2.5.pck sysupdate result information list:----------------------------------------------------------------Mpu 0 - upgrade successfully!devInfo_sw_intelbras_V2.155 sysupdate result information list:----------------------------------------------------------------Mpu 0 - upgrade successfully!pkg_info.txt sysupdate result information list:----------------------------------------------------------------Mpu 0 - upgrade successfully!
Exemplo: No modo autônomo, execute a atualização local através do sistema de arquivos e empacote e atualize os programas de todos os tipos de placas online.
Hostname#sysupdate package file-system sp35-g-9.7.20.1(R)-001.pkg# O dispositivo solicita as seguintes informações:
Downloading "sp35-g-9.7.20.1(R)-001.pkg" header...OK!Checking "sp35-g-9.7.20.1(R)-001.pkg" header...OK!image file version comparision:----------------------------------------------------------------Component Component version File version----------------------------------------------------------------Mpu 0 9.7.20.1(R) 9.7.20.1(R)The current-version of cards is greater than or equal to that in package.NOTICE:input 'Yes' to upgrade all files in the package, 'No' to ignore the above component(s). (Yes|No)?YesCopying "sp35-g-9.7.20.1(R)-001.pkg" : #################################################OK!Copy "sp35-g-9.7.20.1(R)-001.pkg" (181635232 Bytes) successfully!Checking package file...OK!Verify the image...validThe file sp35-g-9.7.20.1(R).pck already exists on Mpu 0, overwrite it?(Yes|No):YesWriting file to filesystem.......................................................OK!Start backup ios to raw flash...OK%Sysupdate image is in process, please wait...%Sysupdate image finished.Update bootloader start....OK.%Sysupdate bootloader is in process, please wait...%Sysupdate bootloader finished..%Sysupdate devinfo is in process, please wait...%Sysupdate devinfo finished..%Sysupdate pkgInfo is in process, please wait...%Sysupdate pkgInfo finished.package sysupdate result information list:----------------------------------------------------------------sp35-g-9.7.20.1(R).pck sysupdate result information list:----------------------------------------------------------------Mpu 0 - upgrade successfully!sz03-tboots2-b6b7-9.6.2.5.pck sysupdate result information list:----------------------------------------------------------------Mpu 0 - upgrade successfully!devInfo_sw_intelbras_V2.155 sysupdate result information list:----------------------------------------------------------------Mpu 0 - upgrade successfully!pkg_info.txt sysupdate result information list:----------------------------------------------------------------Mpu 0 - upgrade successfully!
# As informações acima indicam que os arquivos empacotados de todos os tipos de placas online foram atualizados com sucesso.
Se a opção de comando recarregar for adicionada, o sistema perguntará se a configuração deve ser salva e se o dispositivo deve ser reiniciado imediatamente. No entanto, geralmente o dispositivo é iniciado depois que todos os programas são atualizados. Portanto, a opção de recarregamento não é recomendada.
Durante o processo de atualização, o dispositivo não deve ser desligado. Caso contrário, o sistema pode falhar ao iniciar ou o arquivo pode ser danificado.
Atualizar ISSU
ISSU é usado para concluir a atualização do programa de versão do dispositivo sem interromper o tráfego comercial ou interromper o tráfego de serviço por um curto período.
Etapas de comando relacionadas
Entre no modo de usuário privilegiado e conclua o upgrade sem interromper o tráfego de negócios por meio dos comandos da série ISSU.
Tabela 10 -14 comandos de operação da série issu
| Etapa | Comando | Descrição |
| Entre no modo de usuário privilegiado. | enable | Obrigatório. |
| Alterne o tráfego comercial do dispositivo em espera para o dispositivo ativo. | issu start | Obrigatório O cenário de empilhamento executa esse comando no dispositivo ativo e o MLAG e o cenário de backup independente executam esse comando no dispositivo em espera. |
| Retorne o tráfego comercial do dispositivo em espera | issu switchback | Mandatório _ Execute o comando no dispositivo de espera. |
| Mudar o tráfego de serviço do dispositivo ativo para o dispositivo em espera | issu switchover | Mandatório _ Execute o comando no dispositivo ativo. |
| Retorne o tráfego comercial do dispositivo ativo | issu switchback | Mandatório _ O cenário de empilhamento executa esse comando no dispositivo de espera original e os cenários de backup MLAG e autônomo executam esse comando no dispositivo ativo. |
Certifique-se de que o dispositivo não possa ser desligado durante o processo de atualização. Siga rigorosamente o processo de atualização. Caso contrário, o tempo de perda de pacotes do tráfego de serviço pode exceder os requisitos.
Monitoramento e manutenção de atualização de software
Tabela 10 -15 Monitoramento e manutenção de atualização de software
| Comando | Descrição |
| show issu | Exibe se o dispositivo atual está no estado de atualização de emissão. |
Exemplo de configuração típico de atualização de software
Arquivo de pacote de atualização
Requisitos de rede
- Um PC atua como um servidor FTP e o Dispositivo atua como um cliente FTP. A rede entre o servidor e o cliente é normal.
- No servidor FTP, defina o nome de usuário de um dispositivo para fazer login no servidor FTP como admin e a senha como admin. Coloque o programa do pacote a ser atualizado no diretório do servidor FTP e atualize todas as versões de software do dispositivo que suportam o upgrade do pacote.
Topologia de rede

Figura 10 - 1 Rede para atualização de todas as versões de software suportadas no pacote
Etapas de configuração
- Passo 1: Configure um servidor FTP e coloque o programa de atualização do pacote no diretório do servidor FTP. (Omitido)
- Passo 2: Faça backup do arquivo de configuração do dispositivo. (omitido)
- Passo 3: Configure os endereços IP das interfaces para que a rede entre o Dispositivo e o servidor FTP seja normal. (Omitido)
- Passo 4: Atualize o programa de atualização do pacote.
# Use sysupdate para atualizar o programa de atualização de pacotes.
Device#sysupdate package 2.0.1.1 sp35-g-9.7.20.1(R)-001.pkg ftp admin admin no-comparisionApós a conclusão da atualização, uma lista de resultados de atualização será impressa para os usuários determinarem os resultados de atualização de todos os programas de atualização incluídos no arquivo de atualização do pacote no dispositivo:
package sysupdate result information list:----------------------------------------------------------------sp35-g-9.7.20.1(R).pck sysupdate result information list:----------------------------------------------------------------Mpu 0 - upgrade successfully!sz03-tboots2-b6b7-9.6.2.5.pck sysupdate result information list:----------------------------------------------------------------Mpu 0 - upgrade successfully!pkg_info.txt sysupdate result information list:----------------------------------------------------------------Mpu 0 - upgrade successfully!
Antes de atualizar no pacote, certifique-se de que todos os cartões estejam no lugar e o status seja Iniciar OK. Durante a atualização, não troque o cartão, evitando que a atualização anormal do cartão afete o início subsequente do cartão.
Se selecionar o parâmetro "sem comparação", atualize a versão do programa de atualização empacotado diretamente sem comparação de versão de imagem. Se este parâmetro não for selecionado, a versão da imagem será comparada. Se a versão da imagem no programa de atualização empacotado for inferior à versão em execução no dispositivo ou igual à versão em execução do dispositivo, o dispositivo solicitará ao usuário e aguardará que o usuário confirme se deseja atualizar o programa de atualização de imagem em o pacote. Se o usuário optar por atualizar o programa ou não, isso não afetará a atualização dos outros arquivos de atualização no pacote de atualização. Se houver apenas o arquivo de imagem no pacote de atualização empacotado e o usuário optar por não atualizar, a atualização empacotada será encerrada.
Este comando também pode ser adicionado com um parâmetro "reload". Se o parâmetro for adicionado, reinicie o dispositivo diretamente após a conclusão da atualização.
- Passo 5: Use o comando para reiniciar o dispositivo.
#Use o comando reload para reiniciar o dispositivo.
Device #reloadSave current configuration to startup-config(Yes|No)?yPlease confirm system to reload(Yes|No)?y
Antes de reiniciar, salvar a configuração depende das necessidades reais do usuário.
Se o comando de atualização contiver o parâmetro “reload”, omita a etapa.
- Passo 6: Confira o resultado.
# Depois de concluir a atualização e reiniciar o dispositivo, consulte as informações da versão do arquivo atualizado no programa de atualização empacotado por meio do comando show package version .
Device # show package versionpackage :sp35-g-9.7.20.1(R)-001.pkgimage :sp35-g-9.7.20.1(R).pckbootloader :sz03-tboots2-b6b7-9.6.2.5.pck
# Consulta o número da versão do programa através do comando show system version brief para verificar se ele está atualizado.
Device #show system version briefversion information display:Module Online State Name BootLoader IOS CMM PCB CPLD FPGA-----------------------------------------------------------------------------------------------------------------------------Mpu 0 online Start Ok MyPower S3330-28GXF(V1) 9.6.2.5 9.7.20.1 (integrity) / 001 / /
Consulte a versão do arquivo de atualização no programa de atualização empacotado por meio do mostrar a versão do pacote command e consulte o resultado final da atualização por meio do comando show system version brief .
Atualizar todas as versões de software
Requisitos de rede
- Um PC atua como um servidor FTP e o Dispositivo atua como um cliente FTP. A rede entre o servidor e o dispositivo está normal.
- No servidor FTP, o nome de usuário de um dispositivo para efetuar login no servidor FTP é admin e a senha é admin. O programa de imagem e o programa bootloader a serem atualizados são colocados no diretório do servidor FTP. Atualize completamente todas as versões de software do dispositivo.
Topologia de rede

Figura 10 - 2 Rede para atualização de todas as versões de software
Etapas de configuração
- Passo 1: Configure um servidor FTP e coloque o programa de imagem e o programa bootloader no diretório do servidor FTP. (Omitido)
- Passo 2: Faça backup dos arquivos de configuração do dispositivo. (Omitido)
- Passo 3: Configure os endereços IP das interfaces para que a rede entre o Dispositivo e o servidor FTP seja normal. (Omitido)
- Passo 4: Atualize o programa de imagem.
#Antes de atualizar o programa de imagem, verifique se há espaço suficiente no sistema de arquivos.
Device#filesystemDevice(config-fs)#volume
#Use o comando sysupdate para atualizar o programa de imagem da placa de controle.
Device#sysupdate image mpu 2.0.0.1 sp35-g-9.7.20.1(R).pck ftp admin adminPara o procedimento de atualização do programa de imagem e as informações de impressão que indicam se a atualização foi bem-sucedida, consulte o " Atualizando o pacote do programa de imagem " em " Configurando as funções de atualização do software ".
- Passo 5: Atualize o programa bootloader .
#Use o comando sysupdate para atualizar o programa bootloader da placa de controle.
Device# sysupdate bootloader mpu 2.0.0.1 sz03-tboots2-b6b7-9.6.2.5.pck ftp admin adminPara obter o procedimento de atualização do programa bootloader e as informações de impressão que indicam se a atualização foi bem-sucedida, consulte "Atualizando o programa bootloader " em "Configurando funções de atualização de software".
- Passo 6: Atualize o programa devinfo.
#Use o sysupdate para atualizar o programa devinfo do cartão de controle.
Device# sysupdate devinfo mpu 2.0.0.1 devInfo_sw_intelbras_V2.155 ftp admin adminPara o processo de atualização do programa DEVINFO e as informações de impressão sobre se a atualização foi bem-sucedida, consulte o conteúdo relevante de " Atualização Devinfo " em "Configuração da função de atualização de software".
Use um comando para reiniciar o dispositivo.
#Use orecarregarcomando para reiniciar o dispositivo.
Device #reloadSave current configuration to startup-config(Yes|No)?yPlease confirm system to reload(Yes|No)?y
Antes da reinicialização, determine se deseja salvar a configuração de acordo com o requisito real .
- Passo 7: Confira o resultado.
#Depois que a atualização for concluída e o dispositivo for reiniciado, veja os números de versão dos programas para verificar se as versões foram atualizadas.
#Verifique se os programas de imagem e bootloader das placas de controle ativa e de espera foram atualizados com sucesso.
Device#show system mpuSystem Card Information(Mpu 0 - ONLINE)----------------------------------------------------------------Type: MyPower S3330-28GXF(V1)Status: Start OkLast-Alarm: NormalCard-Port-Num: 28Card-SubSlot-Num: 0Power-INTF-Status: NormalPower-Card-Status: OnSerial No.: ABCDEFGDescription:Hardware-Information:PCB-Version: 001Software-Information:Bootloader-Version: 9.6.2.5Software-Version: 9.7.20.1(integrity)Temperature-Information:Temperature-State:Switch-Temperature = 70 CLast-Alarm = Normal.Mainboard-Temperature = 40 CLast-Alarm = Normal.CPU-On-Card-Information: < 1 CPUs>CPU-Idx: 00Status: NormalCore-Num: 0001Core-State:Core-Idx-00Core-Status: 0000Core-Utilization: 39%MEM-On-Card-Information: <1 MEMs>MEM-Idx: 00MEM-State:BytesFree = 104468480 bytesBytesAlloc = 340127744 bytesBlocksFree = 3 blocksBlocksAlloc = 6446 blocksMaxBlockSizeFree = 39845888 bytesSizeTotal = 444596224 bytesDISK-On-Card-Information: <1 DISKs>DISK-Idx: 00Type: FlashStatus: OnlineDISK-State:SizeTotal = 162299904 bytesSizeFree = 54534144 bytes----------------------------------------------------------------STATISTICS: 1 IN, 0 OUT, 0 IERR, 0 OERRDevice#show devInfovendor : Intelbrasproduct Type : SWITCHdevInfo version: V 2.155
A interface acessível entre o dispositivo e o servidor FTP pode ser a interface de gerenciamento fora de banda dc0 ou a interface de serviço. Não importa se o programa bootloader ou o programa bootloader é atualizado primeiro, mas o dispositivo pode ser reiniciado somente depois que todos os programas tiverem sido atualizados.
Antes da atualização, certifique-se de que haja espaço suficiente no sistema de arquivos flash da placa de controle principal ativa/em espera para salvar o arquivo de imagem usado para atualização. Se não houver espaço suficiente no dispositivo, exclua os arquivos desnecessários do sistema de arquivos do dispositivo. Recomenda-se que o espaço flash restante do cartão de controle principal ativo/em espera seja grande o suficiente antes da atualização. Caso contrário, o tempo de atualização pode ser maior.
Se alguns programas na versão recém-lançada não tiverem sido alterados, os programas inalterados não poderão ser atualizados. No processo de atualização, se algumas placas não atualizarem devido a condições anormais, elas poderão ser atualizadas separadamente.
Atualize o programa bootloader através da porta do console
Requisitos de rede
- O PC e a porta Console do dispositivo estão diretamente conectados.
- O programa bootloader das placas de controle ativo e standby deve ser atualizado através da porta Console.
Topologia de rede
Figura 10 - 3 Atualizando o programa bootloader através da porta do console
Etapas de configuração
- Passo 1: Conecte o PC e a porta Console do dispositivo corretamente. (Omitido)
- Passo 2: Abra a tela do carregador de inicialização.
Quando o dispositivo for iniciado e a mensagem "Pressione ctrl+c para entrar no modo bootloader: 0" for impressa, pressione e segure Ctrl + C para abrir a tela do bootloader
- Passo 3: Defina a taxa de transmissão para 115200 bps para melhorar a velocidade de atualização.
Bootloader#srate 115200#Depois de configurar a velocidade de transmissão da porta Console do bootloader, você deve configurar a velocidade de transmissão do HyperTerminal também para 115200 bps.
- Passo 4: Na tela do bootloader, atualize a versão do bootloader.
Bootloader#mupdate bootloader#Insira o comando mupdate bootloader e use ymodem para transmitir o arquivo bootloader que foi salvo no PC.
- Passo 5: Confira o resultado.
#Depois que a atualização é concluída e o dispositivo é reiniciado, o sistema é inicializado pelo novo bootloader e a seguinte mensagem é impressa:
9.6.2.5 compiled at Mar 03 2020 - 01:15:27warm boot from master sectorPress ctrl+c to enter bootloader mode: 0
A atualização pela porta do console é complexa e lenta, portanto, o modo de atualização TFTP/FTP é recomendado. O modo de atualização da porta do console é usado somente quando as condições de atualização do modo de atualização TFTP/FTP não são satisfeitas.
Após a conclusão da atualização, use o comando reset para sair do programa bootloader. Em seguida, o novo programa bootloader inicializa o carregamento do programa de imagem.
Se a taxa padrão da porta Console foi modificada ao atualizar o programa bootloader, ao carregar o pacote do programa de imagem, a taxa da porta Console do dispositivo é automaticamente retomada para 9600 bps. Neste momento, a taxa do HyperTerminal precisa ser modificada de forma síncrona.
Bootloader
Visão geral
Em um sistema incorporado, o Bootloader é executado antes da execução do kernel do sistema operacional (SO). Bootloader é usado para inicializar dispositivos de hardware (incluindo a porta Console, porta Ethernet e flash) e configurar o mapeamento do espaço de memória para trazer o hardware e o software do sistema para um estado adequado. Finalmente, ele prepara um ambiente adequado para inicializar o kernel do sistema operacional. No sistema incorporado, não existe um programa de firmware como o BIOS, portanto, a inicialização de todo o sistema é implementada pelo Bootloader .
O sistema Bootloader fornece principalmente as seguintes funções:
- Define o parâmetro de inicialização para carregar o programa de imagem e seleciona o modo de carregamento do programa de imagem.
- Atualiza o programa Bootloader .
- Faz backup do programa bootloader .
Configuração da função do carregador de inicialização
Tabela 11 -1 Lista de configuração da função do carregador de inicialização
| Tarefas de configuração | |
| no modo de configuração do bootloader | Entre no modo de configuração do bootloader ao iniciar |
| Defina os parâmetros de inicialização do Bootloader | Defina os parâmetros de inicialização do Bootloader |
| Configurar o endereço IP da porta Ethernet de gerenciamento do bootloader | Configurar o endereço IP da porta Ethernet de gerenciamento do bootloader |
| Atualize o programa Bootloader | Atualize o programa Bootloader |
Preparação antes de configurar as funções do carregador de inicialização
Antes de configurar as funções do Bootloader , você precisa configurar um ambiente de configuração local. Conecte a porta serial do host (ou terminal) à porta Console do dispositivo através de um cabo de configuração. A configuração dos parâmetros de comunicação do host (ou terminal) deve ser igual à configuração padrão da porta Console do dispositivo. A configuração padrão da porta Console do dispositivo é a seguinte:
- Velocidade de transmissão: 9600 bps
- Modo de controle de fluxo: Nenhum
- Modo de verificação: Nenhum
- Bit de parada: 1 bit
- Bit de dados: 8 bits
Entre no modo de configuração do carregador de inicialização
Condição de configuração
Nenhum
Entre no bootloader Modo de configuração
Tabela 11 -2 Entre no modo de configuração do bootloader
| Etapa | Comando | Descrição |
| Entre no modo de configuração do Bootloader | Nenhum | Obrigatório Depois que o dispositivo for ligado, pressione as teclas Ctrl + C para entrar no modo de configuração do Bootloader . Depois de entrar no modo, o " bootloader-b6# #" é solicitado. |
Depois de entrar no modo de configuração do carregador de inicialização, você pode executar as funções fornecidas pelo modo do carregador de inicialização.
Definir os parâmetros de inicialização do carregador de inicialização
Condição de configuração
Nenhum
Definir parâmetros de inicialização do carregador de inicialização
Tabela11 -3 Defina os parâmetros de inicialização do Bootloader
| Etapa | Comando | Descrição |
| Entre no modo de configuração do Bootloader | Nenhum | Obrigatório. Depois que o dispositivo for ligado, pressione as teclas Ctrl + C para entrar no modo de configuração do Bootloader . Depois de entrar no modo, o " bootloader-b6# #" é solicitado. |
| Defina os parâmetros de inicialização do IOS no bootloader | change index[0~3] ge0-3 filename local-ip-addr host-ip-addr [gatewayip] [ netmask] change index[0~3] flash0 filename | Obrigatório O comando da primeira linha é o parâmetro de configuração de inicialização da rede. Se estiver atualizando em todo o segmento, é necessário adicionar o gateway e a máscara. O comando da segunda linha é o parâmetro de configuração de inicialização do dispositivo de armazenamento flash. |
Atualmente, o programa bootloader do switch pode definir o parâmetro de inicialização para iniciar o programa de imagem através da rede.
Atualize o programa Bootloader
Condição de configuração
Nenhum
Atualize o programa Bootloader
Tabela11 -4 Atualize o programa Bootloader
| Etapa | Comando | Descrição |
| Entre no modo de configuração do Bootloader | Nenhum | Obrigatório. Depois que o dispositivo for ligado, pressione as teclas Ctrl + C para entrar no modo de configuração do Bootloader . Depois de entrar no modo, o " bootloader-b6# #" é solicitado. |
| Inicie o serviço tftp no PC | Nenhum | Obrigatório Copie a nova versão do bootloader usada para atualizar para o diretório raiz do tftp, usado pelo dispositivo para baixar o arquivo de versão via tftp. |
| Atualize o programa Bootloader | update bootloaderfilename ge0-3 local-ip-addr host-ip-addr [gatewayip] [ netmask] | Obrigatório |
| Faça backup do programa bootloader | bootloaderbak | Opcional |
O programa do sistema Bootloader adota o modo de backup dual-bootloader, que é dividido no programa master bootloader e no programa standby bootloader. Com o comando upgrade, você só pode atualizar a versão do carregador de inicialização mestre, enquanto o programa do carregador de inicialização em espera permanecerá inalterado.
Após atualizar o programa de sistema Bootloader, use o comando reset ou power off para reiniciar o dispositivo e, em seguida, você pode usar o programa de sistema Bootloader mais recente. Depois que o sistema é carregado com sucesso , você pode usar o atualização do sistema comando para atualizar.
Monitoramento e manutenção do carregador de inicialização
Tabela 11 -5 monitoramento e manutenção do bootloader
| Comando | Descrição |
| version | Exibe o número da versão do programa bootloader |
| print index[0~4] | Exibe as informações do parâmetro de inicialização especificado pelo índice |
| boot index[0~4] | Carregue as informações do parâmetro de inicialização especificadas pelo índice |
| clear index[0~4] | Apagar as informações do parâmetro de inicialização especificadas pelo índice |
| grate | Obtenha a taxa da porta serial atual |
| Srate ratenum | Obtenha a taxa da porta serial atual, 9600 ou 115200 |
Exemplo de configuração típico do bootloader
Configure o bootloader para iniciar o programa de imagem pela rede
Requisitos de rede
- O PC atua como o servidor TFTP, o Dispositivo atua como o cliente TFTP e o servidor e o dispositivo são conectados através da rede.
- No servidor TFTP, coloque o programa de imagem e o programa bootloader a serem atualizados no diretório do servidor TFTP.
Topologia de rede
Figura 11 -1 Rede para configurar o bootloader para iniciar o programa de imagem através da rede
Etapas de configuração
- Passo 1: Configure o servidor TFTP e coloque o programa de imagem no diretório do servidor TFTP. (omitido)
- Passo 2: Depois que o dispositivo estiver ligado, pressione “Ctrl + C” para entrar no modo de configuração do bootloader.
- Passo 3: Configure os parâmetros de inicialização para iniciar o programa de imagem da rede.
bootloader-b7# # change 0 ge0 sp35-g-9.7.20.1(R).pck 1.1.1.2 1.1.1.1bootloader-b7# # boot 0
Conecte a primeira porta do dispositivo ao servidor tftp. Após definir as informações de inicialização acima, o dispositivo pode se comunicar com o servidor t ftp normalmente antes de executar a inicialização.
Gerenciamento do PoE
Visão geral
A Ethernet existente, com sua estrutura básica de cabeamento Cat.5 inalterada, não apenas transmite sinais de dados para terminais baseados em IP (como telefones IP, pontos de acesso WLAN e câmeras de rede), mas também fornece alimentação CC para os dispositivos . Essa tecnologia é chamada de Power over Ethernet (PoE). A tecnologia PoE garante não apenas a segurança do cabeamento estruturado existente, mas também a operação normal da rede existente, reduzindo bastante o custo.
PoE também é chamado de Power over LAN (PoL) ou Active Ethernet. É a especificação padrão mais recente para fazer uso do cabo de transmissão Ethernet padrão existente para transmitir dados e fornecer energia. É compatível com os sistemas e usuários Ethernet existentes. IEEE 802.3af e IEEE802.3at são os padrões técnicos que o PoE deve cumprir. IEEE802.3af é o padrão básico da tecnologia PoE. Ele é baseado no IEEE 802.3, e são adicionados os padrões relacionados à alimentação direta através de cabos de rede. É uma extensão dos padrões Ethernet existentes. IEEE802.3at é uma extensão baseada no IEEE802.3af.
De acordo com a definição do padrão IEEE802.3af, um sistema completo de fonte de alimentação PoE consiste em dois tipos de dispositivos: Power Sourcing Equipment (PSE) e Power Device (PD).
- PSE: Fornece energia para outros dispositivos.
- PD: Dispositivos que recebem energia. A potência dos dispositivos geralmente não é grande.
Especificações da Interface PSE/PD
Para as redes 10BASE-T e 100BASE-TX IEEE802.3af, IEEE802.3af define Power Interfaces (PIs), que são interfaces entre PSE/PD e cabos de rede. Atualmente, ele definiu dois modos de alimentação, Alternativa A (1, 2, 3, 6 pares de fios de sinal) e Alternativa B (pares de fios inativos 4, 5, 7 e 8). A seguir está uma descrição dos dois modos de fonte de alimentação:
1. Fonte de alimentação através de pares de fios de sinal (Alternativa A)
Conforme mostrado na figura a seguir, um PSE pode fornecer energia a um PD através de pares de fios de sinal. Como a CC e a frequência de dados não interferem entre si, a corrente elétrica e os dados podem ser transmitidos pelo mesmo par de fios. Para cabos elétricos, isso é uma espécie de "multiplexação". Os fios 1 e 2 são conectados para formar uma polaridade positiva (ou negativa), e os fios 3 e 6 são conectados para formar uma polaridade negativa (ou positiva).

Figura 12 - 1 Modo de fonte de alimentação alternativo A com 10BASE-T e 100BASE-TX
2. Fonte de alimentação através de pares de fios inativos (Alternativa B)
Conforme mostrado na figura a seguir, um PSE pode fornecer energia a um PD por meio de pares de fios inativos. Os fios 4 e 5 são conectados para formar uma polaridade positiva e os fios 7 e 8 são conectados para formar uma polaridade negativa.

Figura 12 - 2 Modo Alternativo de Fonte de Alimentação B com 10BASE-T e 100BASE-TX
De acordo com IEEE802.3af, os PDs padrão devem suportar tanto a fonte de alimentação por meio de pares de fios de sinal quanto a fonte de alimentação por meio de pares de fios inativos, enquanto os PSEs precisam suportar apenas um dos dois modos.
Processo de fonte de alimentação PoE
Se um PSE estiver instalado em uma rede, o processo de fornecimento de energia PoE Ethernet é o seguinte:

Figura 12 - 3 Processo de Fonte de Alimentação PSE
- Detecção: Depois que um dispositivo de rede é conectado a um PSE, o PSE primeiro detecta se o dispositivo é um PD para garantir que a corrente não seja fornecida a não-PDs, pois fornecer energia a um dispositivo que não é um PD pode danificar o dispositivo. O PSE detecta a capacitância de resistência entre os pares de fios de saída de energia para determinar se existem PDs. O PSE prossegue para a próxima etapa somente após detectar PDs.
- Classificação: Após detectar PDs, o PSE classifica os PDs. Determina o grau de potência dos PDs detectando a corrente de saída de potência. Durante o processo de fornecimento de energia, a classificação é opcional.
- Power Up: Dentro de um período de inicialização configurável (geralmente inferior a 15 us), o PSE começa a fornecer baixa tensão de alimentação aos PDs e aumenta gradualmente a tensão de alimentação para 48 V DC.
- Gerenciamento de energia: O PSE fornece energia 48 estável e confiável V DCpara PDs. Uma vez que o PSE começa a fornecer energia, ele detecta continuamente as entradas de corrente PD. Se o consumo de corrente de um PD cair abaixo do valor mínimo devido a várias causas, como o PD estar desconectado, o PD encontrar sobrecarga ou curto-circuito no consumo de energia e a carga de energia exceder a carga da fonte de alimentação do PSE, o PSE considera o PD como fora de posição ou anormal. Neste caso, o PSE deixa de fornecer energia ao PD.
- Desconexão: O PSE detecta a corrente dos PDs para determinar se os PDs estão desconectados. Se um PD for desconectado, o PSE parará de fornecer energia ao PD rapidamente (geralmente dentro de 300 a 400 ms) e, em seguida, o PSE retornará ao status Detecção.
Configuração da função PoE
Tabela 12 - 1 Lista de Funções PoE
| Tarefas de configuração | |
| Configure as funções básicas do PoE. |
Habilite a função PoE global.
Habilite a função de interface PoE. Habilite a função de alimentação forçada de uma interface. Habilite a função de fonte de alimentação automática da interface |
| Configure a alimentação PoE. |
Configure a potência total do PoE.
Configure o poder de proteção do PoE. Configure o modo de limite de potência máxima de saída de uma interface. Configure a potência máxima de saída de uma interface. |
| Configure as prioridades da fonte de alimentação. |
Configure um modo de gerenciamento de energia PoE.
Configure a prioridade da fonte de alimentação de uma interface. |
| Configure os parâmetros de ativação e desativação do PD. |
Configure o modo de detecção de PD de uma interface.
Configure o modo de classificação da interface . Configure o modo de corrente de impulso de inicialização de uma interface. par de fios da fonte de alimentação da interface. Configure o modo de detecção de desligamento da interface. |
| Configure a função de recuperação de anormalidades. |
Configure o tempo de recuperação de uma anormalidade na fonte de alimentação de uma interface.
Reinicie a fonte de alimentação PoE. |
| Configure a função de alarme de energia POE | Configure limite de alarme de energia PoE |
Configuração de Função Básica PoE
A função PoE é controlada configurando o PoE global e a interface PoE, ou seja, a função PoE pode ser utilizada somente quando o PoE global e a interface PoE estiverem habilitados. Se você executar o comando para desabilitar o PoE global, as funções PoE de todas as interfaces serão desabilitadas. Se você executar o comando para desabilitar a função PoE da interface, você pode optar por desabilitar a função PoE de alguma interface. A função de interface PoE é um modo de fonte de alimentação padrão, enquanto a função de fonte de alimentação forçada de interface é um modo de fonte de alimentação especial. Você pode selecionar apenas um modo de cada vez. No entanto, ambos os modos são válidos somente após a ativação da função PoE global.
Condição de configuração
Nenhum
Habilitar a Função PoE Global
Tabela 12 - 2 Habilitando a Função PoE Global
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a função PoE global. | power enable | Opcional. Por padrão, a função PoE global está habilitada. |
Habilitar a função Interface PoE
Tabela 12 - 3 Habilitando a Função PoE de Interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a função PoE global. | power enable | Opcional. Por padrão, a função PoE global está habilitada. |
| Entre no modo de configuração da interface Ethernet de camada 2. | interface interface-name | - |
| Habilite a função de interface PoE. | power enable | Opcional. Por padrão, a função de interface PoE está habilitada. |
Habilitar a função de fonte de alimentação forçada de uma interface
Tabela 12 - 4 Habilitando a função de fonte de alimentação forçada de uma interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a função PoE global. | power enable | Opcional. Por padrão, a função PoE global está habilitada. |
| Entre no modo de configuração da interface Ethernet L2. | interface interface-name | - |
| Habilite a função de alimentação forçada de uma interface. | power force | Obrigatório. Por padrão, a função de alimentação forçada de uma interface está desabilitada. |
A fonte de alimentação forçada é um modo de fonte de alimentação especial, que não requer a ativação da função de interface PoE.
Configurar Potência PoE
Condição de configuração
Antes de configurar a alimentação PoE, certifique-se de que:
- A função PoE global está habilitada.
- A função de interface PoE está habilitada.
Configurar Potência Total de PoE
Ao configurar a potência total do PoE, você pode limitar a potência máxima de saída do dispositivo. Se a potência total exigida por todos os PDs exceder a potência total configurada, o fornecimento de energia para alguns PDs é interrompido de acordo com o modo de prioridade da fonte de alimentação atual.
Tabela 12 - 5 Configurando a Potência Total do PoE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a potência total do PoE. | power total-power { all | system-id { all | subsystem-id } } power-value | Opcional. Por padrão, a potência total é a potência total máxima que a fonte de alimentação do dispositivo pode fornecer. |
Configurar o poder de proteção do PoE
Quando um PD é alimentado normalmente, a energia consumida flutua dentro de um determinado intervalo. Para evitar o desligamento do PD devido à flutuação de energia, parte da energia é reservada da energia total do dispositivo para atuar como energia de proteção. Quando a potência consumida do PD aumenta, a parte aumentada é alocada da potência de proteção.
A potência de proteção também pode ser alocada como fonte de alimentação normal. Quando a potência disponível for insuficiente para fornecer energia aos PDs recém-conectados, se a potência disponível do dispositivo e a potência de proteção for igual ou maior que a potência máxima de saída da interface do novo PD, é alocada potência suficiente da proteção poder para o novo PD.
Tabela 12 - 6 Configurando o poder de proteção do PoE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o poder de proteção do PoE. | power guard-band { all | system-id { all | subsystem-id } } guard-band-value | Opcional. Por padrão, a potência de proteção da fonte de alimentação é de 40,0 watts. |
Configurar o Modo de Limite de Potência Máxima de Saída de uma Interface
A potência máxima de saída de uma interface é determinada pelo tipo de classificação PD. Você também pode personalizar a potência máxima de saída de uma interface.
Tabela 12 - 7 Configurando o Modo de Limite de Potência Máxima de Saída de uma Interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet de camada 2. | interface interface-name | - |
| Configure o modo de limite de potência de saída máxima de uma interface. | power threshold-mode { classification | user } | Opcional. Por padrão, o modo de limite de potência máxima de saída é o modo de personalização do usuário. |
Configurar a Potência Máxima de Saída de uma Interface
Você pode limitar a potência máxima que um PSE pode fornecer a um PD por meio de uma interface. Se a potência exigida por um PD exceder a potência máxima de saída da interface, o PSE interrompe o fornecimento de energia a ele.
Tabela 12 - 8 Configurando a Potência Máxima de Saída de uma Interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet de camada 2. | interface interface-name | - |
| Configure o modo de limite máximo de potência de saída para o modo de personalização do usuário. | power threshold-mode user | Obrigatório. Por padrão, o modo de limite de potência máxima de saída é o modo de personalização do usuário. |
| Configure a potência máxima de saída de uma interface. | power port-max-power max-power-value | Opcional. Por padrão, a potência máxima de saída é de 30,0 watts. |
Configurar as prioridades da fonte de alimentação
Com a função de prioridade da fonte de alimentação, se a potência total de um PSE for insuficiente para alimentar todos os PDs, os PDs principais têm prioridade para obter energia. Através desta função, você pode configurar o modo em que os PDs chave são alimentados.
Condição de configuração
Antes de configurar as prioridades da fonte de alimentação, certifique-se de que:
- A função PoE global está habilitada.
- A função de interface PoE está habilitada.
Configurar um modo de gerenciamento de energia PoE
Tabela 12 - 9 Configurando um modo de gerenciamento de energia PoE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o modo de gerenciamento de energia PoE. | power manage { all | system-id { all | subsystem-id } } { dynamic-fifs | dynamic-priority } | Opcional. O modo de gerenciamento de energia padrão é o dinâmico First In First Served (FIFS). |
Configurar a prioridade da fonte de alimentação de uma interface
Se o modo de gerenciamento de energia PoE for o modo de prioridade dinâmica, quando a alimentação do PSE for insuficiente, o PD conectado à interface com uma prioridade de alimentação mais alta é alimentado primeiro. Se as prioridades de alimentação das interfaces forem as mesmas, o PD conectado à interface com menor número é alimentado primeiro.
Tabela 12 - 10 Configurando a prioridade da fonte de alimentação de uma interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o gerenciamento de energia PoE para prioridade dinâmica. | power manage { all | system-id { all | subsystem-id } } dynamic-priority | Opcional. O modo de gerenciamento de energia padrão é a prioridade dinâmica. |
| Entre no modo de configuração da interface Ethernet de camada 2. | interface interface-name | - |
| Configure a prioridade da fonte de alimentação de uma interface. | power priority { critical | high | medium | low } | Opcional. A prioridade da fonte de alimentação padrão é baixa. |
Configurar os parâmetros de ativação e desativação do PD
O processo de inicialização do PoE se enquadra nos seguintes estágios:
1. Detecção: O PSE detecta se existem PDs.
2. Classificação: O PSE classifica os PDs e determina o consumo de energia dos PDs. Esta etapa é opcional.
3. Power-Up: O PSE fornece energia aos PDs.
Você pode ajustar os parâmetros definidos para os estágios anteriores e fornecer energia para PDs de diferentes tipos.
Condição de configuração
Antes de configurar os parâmetros de inicialização do PD, certifique-se de que:
- A função PoE global está habilitada.
- A função de interface PoE está habilitada.
Configurar o Modo de Detecção de PD de uma Interface
Depois que a função PoE de uma interface é habilitada, o PSE detecta a capacitância de resistência entre os pares de fios de saída de energia para determinar se existem PDs. O modo de detecção padrão detecta apenas PDs em conformidade com IEEE802.3af e IEEE802.3at. As normas definem PDs e não-PDs, mas existe um tipo de dispositivos com capacitância de resistência entre os de PDs e não-PDs. O modo compatível pode detectar este tipo de dispositivos.
Tabela 12 - 11 Configurando o modo de detecção de PD de uma interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet de camada 2. | interface interface-name | - |
| Configure o modo de detecção de PD de uma interface. | power detect-mode { compatible | standard } | Opcional. O modo de detecção de PD padrão é o modo padrão. |
Configurar o Modo de Classificação da Interface
Depois que a função de interface PoE é habilitada, o PSE detecta a corrente de saída da fonte de alimentação para determinar os graus de potência dos PDs. A potência é alocada aos PDs de acordo com os graus de potência dos PDs. A classificação PD é uma etapa opcional. Você pode pular a etapa definindo o modo de não classificação.
Tabela 12 - 12 Configurando o Modo de Classificação da Interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet de camada 2. | interface interface-name | - |
| Configure o modo de classificação da interface. | power class-mode { standard | never } | Opcional. Por padrão, nenhuma classificação é suportada. |
Alguns PDs não padronizados podem não suportar a classificação. Este tipo de PDs é classificado como classe0 por padrão, e a potência máxima de saída da interface é de 15,4 watts.
Configurar o modo de corrente de impulso de inicialização de uma interface
O padrão PoE define a corrente de impulso de inicialização do PD. O parâmetro está relacionado ao PSE, capacitância (parasitária) do PD e potência do PD. Para os PDs que atendem ou não ao padrão, a corrente de impulso de inicialização necessária pode ser diferente. Para diferentes PDs, o modo de corrente de impulso de inicialização relacionado deve ser configurado.
Tabela 12 - 13 Configurando o modo de corrente de impulso de inicialização de uma interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet de camada 2. | interface interface-name | - |
| Configure o modo de corrente de impulso de inicialização de uma interface. | power power-up-mode { 802.3af | high | Pre-802.3at | 802.3at } | Opcional. O modo de corrente de inicialização padrão é alto. |
Configurar o modo de detecção de desligamento da interface
Os interruptores PSE podem fornecer diferentes modos de detecção de falha de energia de acordo com o tipo atual de fonte de alimentação, CC ou CA.
Tabela 12 - 14 Configurar o modo de detecção de desligamento da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| interface Ethernet L2/L3 modo de configuração | interface interface-name | - |
| Configure o modo de detecção de desligamento da interface | power disconnect{ ac | dc } | Opcional Por padrão, o modo de detecção de desligamento é DC. |
A função PoE do equipamento PSE é integrada ao switch. O modo de detecção de desligamento da interface no dispositivo é DC por padrão e suporta apenas o modo DC.
Configurar Função de Recuperação de Anormalidade
Quando há uma anormalidade na fonte de alimentação PoE, a função de recuperação de anormalidades é suportada, incluindo recuperação automática e recuperação manual.
Condição de configuração
Antes de configurar a função de recuperação de anormalidades, certifique-se de que:
- A função PoE global está habilitada.
- A função de interface PoE está habilitada.
Configurar o tempo de recuperação de uma anormalidade da fonte de alimentação de uma interface
Se um PSE detectar o status anormal da fonte de alimentação de uma interface enquanto alimenta os PDs, ele desabilita automaticamente a função PoE da interface. Após o tempo de recuperação de uma anormalidade na fonte de alimentação, ele habilita a função PoE novamente e tenta fornecer energia ao PD da interface.
Tabela 12 - 15 Configurando o Tempo de Recuperação de uma Anormalidade da Fonte de Alimentação de uma Interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet de camada 2. | interface interface-name | - |
| Configure o tempo de recuperação de uma anormalidade na fonte de alimentação de uma interface. | power recover-time time-value | Opcional. Por padrão, o tempo de recuperação de uma anormalidade na fonte de alimentação é 0 minuto, indicando recuperação imediata. |
Reinicie a fonte de alimentação PoE
Quando ocorre uma anormalidade na fonte de alimentação PoE ou a fonte de alimentação PoE é anormal, você pode reiniciar manualmente a fonte de alimentação PoE para tentar se recuperar do status anormal.
Tabela 12 - 16 Configurando o Tempo de Recuperação de uma Anormalidade da Fonte de Alimentação de uma Interface
| Etapa | Comando | Descrição |
| Reinicie a fonte de alimentação PoE. | power reload { all | system- id } | Obrigatório. |
No processo de reinicialização de energia, o módulo será inicializado e a operação repetida de recarga de energia deve ser evitada e será executada após a conclusão da reinicialização de energia.
Configurar o limite de alarme de energia PoE
Condição de configuração
Antes de configurar a alimentação PoE, primeiro complete a seguinte tarefa:
- Ativar função PoE global
- Ativar a função PoE da interface
Configurar o limite de alarme de energia PoE
Quando a utilização de energia PoE atingir ou for inferior ao limite de energia definido, envie o prompt de alarme Trap.
Tabela 12 - 17 Configure o limite de alarme de energia PoE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o limite de alarme de energia PoE | power alarm-threshold { all | system-id { all | subsystem-id } } threshold-value | Opcional Por padrão, o limite do alarme de energia é 99%. |
Monitoramento e manutenção de PoE
Tabela 12 - 18 Monitoramento e manutenção de PoE
| Comando | Descrição |
| show power { manage | summary | configure interface interface-name | detect interface interface-name | pd-status interface interface-name | system-to-port [ system-id ] | version } | Exiba a configuração PoE , as informações de status da fonte de alimentação e as informações de relação de energia correspondente. Há sistema para porta apenas no modo VST. |
PDI
Visão geral
PDI: inspeção do dispositivo PD, que se refere a uma forma especialmente fornecida para Po E para detectar se o terminal PD está online. Caso detecte que o PD não está online, será considerado anormal e notificará o Poe para reiniciar a alimentação.
A função PDI precisa ser controlada configurando a habilitação da interface PDI, ou seja, a função PDI deve ser habilitada na interface antes que a função PDI possa ser usada.
Configurar funções básicas do PDI
Tabela 13 -1 Habilite a função de interface PDI
| Etapa | Comando | Descrição |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | - |
| Habilite a função de interface PDI | pdi enable | Obrigatório Por padrão, a função PDI da interface não está habilitada. |
Configurar o intervalo de envio de pacotes ARP
Tabela 13 -2 Configure o intervalo da interface enviando os pacotes ARP
| Etapa | Comando | Descrição |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | - |
| Configure o intervalo da interface enviando os pacotes ARP | pdi inspection-interval | Opcional Por padrão, o intervalo da interface que envia os pacotes ARP é de 3s. |
Configurar tempos de retransmissão de pacotes ARP
Tabela 13 - 3 Configure os tempos -de retransmissão dos pacotes arp
| Etapa | Comando | Descrição |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | - |
| Configure os tempos de retransmissão dos pacotes arp | pdi inspection-retry | Opcional Por padrão, os tempos da interface retransmitindo os pacotes ARP são 3. |
Configurar entrada de detecção de IP
Tabela 13 -4 Configure a entrada de detecção de IP
| Etapa | Comando | Descrição |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | - |
| Configure a entrada de detecção de ip do PD | pdi ip-address | Opcional |
Monitoramento e manutenção de PDI
Tabela 13 -5 Monitoramento e manutenção de PDI
| Comando | Descrição |
| show pdi { | brief | interface interface-name | ip-entry interface interface-name | statistic interface interface-name } | Exibe a estrutura global do PDI, informações breves da porta, informações detalhadas, etc. |
LUM
Visão geral
LUM (Local User Manager): O banco de dados do usuário local usado para fornecer a autenticação local AAA.
RBAC ( Controle de acesso baseado em função ): Ao estabelecer a associação de "Autoridade <-> Função", atribua a autoridade à função e, ao estabelecer a associação de "Função <-> Usuário", especifique a função para o usuário, para que o usuário pode obter a autoridade da função correspondente. A ideia básica do RBAC é especificar funções para usuários. Essas funções definem quais funções do sistema e objetos de recursos os usuários podem operar.
Devido à separação da autoridade e do usuário, o RBAC tem as seguintes vantagens:
- O administrador não precisa especificar as autoridades uma a uma para os usuários, ele só precisa definir antecipadamente as funções com as autoridades correspondentes e, em seguida, atribuir as funções aos usuários. Portanto, o RBAC pode se adaptar melhor às mudanças de usuários e melhorar a flexibilidade da alocação de autoridade de usuário.
- Como o relacionamento entre funções e usuários geralmente muda, mas o relacionamento entre funções e autoridades é relativamente estável, o uso dessa associação estável pode reduzir a complexidade do gerenciamento de autorização do usuário e do custo de gerenciamento.
Função: O conjunto de regras
Regra : A autoridade de permissão/negação dos comandos dos recursos especificados ou de todos os recursos
Recurso: Módulo
Configuração da função LUM
Tabela 14 -1 Lista de configuração da função LUM
| Tarefa de configuração | |
| Configurar a função do usuário | Configurar a função do usuário |
| Configurar o esquema de administrador | Configurar o administrador Configurar o grupo de usuários do administrador |
| Configurar o esquema de usuário de acesso | Configurar o usuário de acesso Configurar o grupo de usuários |
Configurar a função
Por padrão, existem quatro funções: Administrador de segurança, Administrador de rede, Administrador de auditoria e Operador de rede. As autoridades desses quatro papéis não podem ser alteradas.
Personalizar autoridades de função como um subconjunto de autoridades de função de administrador de rede. Não é permitido configurar autoridades de módulo que receberam funções de administrador de segurança e administrador de auditor. Para autoridades detalhadas, consulte a tabela a seguir:
Tabela 14 -2 As autoridades correspondentes das funções
| Registro | História | Gerenciamento de usuários, autenticação de usuários | Outros módulos | |
| Público | NÃO | NÃO | Modificar a própria senha | Mostrar correr, sair e assim por diante |
| Administrador de segurança | Consulta de log de operação e comandos de configuração relacionados | Configuração e operação do histórico | OK | Lai módulo, linha, serviço, AAA |
| Administrador de auditoria | Comandos de consulta e configuração de log de dados | NÃO | NÃO | NÃO |
| Administrador de rede | Todos os outros comandos, exceto o log de operação e o log de dados | Configuração e operação do histórico | NÃO | OK |
| Operador de rede | Todos os comandos show na autoridade de administrador de rede | mostrar comando | NÃO | Todos os comandos show na autoridade de administrador de rede |
Por padrão, o usuário não configura o atributo role. Quando o atributo role entra em vigor, o nível de usuário não entra mais em vigor, e o papel substitui o nível de usuário como critério básico de autorização de instrução: os usuários têm as autoridades de execução de instruções diferentes de acordo com seus papéis.
Condições de configuração
Nenhum
Configurar funções de usuário
Tabela 14 -3 Configurar a função do usuário
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie uma função de usuário e entre no modo de função de usuário | role role-name | Obrigatório Por padrão, existem quatro funções: Administrador de segurança, Administrador de rede, Administrador de auditoria e Operador de rede. As autoridades desses quatro papéis não podem ser alteradas. |
| Criar uma regra para a função de usuário | rule number { deny | permit } feature {all | feature-name } | Por padrão, não defina uma regra para a nova função de usuário, ou seja, a função de usuário atual não possui autoridades. A modificação da regra não tem efeito para o atual online user, mas entra em vigor para o futuro usuário que efetuar login e usar a regra da função. Quanto menor o ID da regra, maior a prioridade da regra. |
Configurar o usuário local
Os usuários locais são os usuários armazenados nos dispositivos: incluindo administradores locais e usuários de acesso local. Somente quando o método de autenticação for local ele terá efeito. Ao criar um usuário local, você especifica se é um administrador ou um usuário de acesso.
Condições de configuração
Nenhum
Configurar usuário administrador local
Tabela 14 -4 Configurar o administrador
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| C rie um usuário administrador e entre no modo de usuário administrador | local-user user-name class manager | Obrigatório Por padrão, não configure o usuário administrador. |
Configurar usuário de acesso local
Tabela 14 -5 Configurar o usuário de acesso
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um usuário de acesso e entre no modo de usuário de acesso | local-user user-name class network | Obrigatório Por padrão, não configure o usuário de acesso. |
Configurar o atributo de usuário administrador
O administrador indica o usuário fazendo login no dispositivo.
Ao configurar o atributo do usuário administrador local, existem as seguintes restrições e instruções de configuração:
- Se o usuário autorizar a função por meio de AAA no momento do login, o fato de o usuário poder executar o comando após fazer login no dispositivo depende da função. Se não autorizar a função por meio de AAA no momento do login, se o usuário pode executar o comando após fazer login no dispositivo depende do nível do usuário.
- Para usuários SSH, ao usar a autenticação de chave pública, quando o modo de autenticação de login no dispositivo não estiver configurado na visualização de linha do usuário, os comandos que eles podem usar são baseados na função do usuário ou no nível de usuário definido na visualização do usuário do administrador local com o mesmo nome do usuário SSH (a prioridade da função do usuário é maior que o nível do usuário). Para obter uma introdução detalhada às funções do usuário, consulte “Funções de configuração” no “Guia de configuração do LUM”.
- Os tempos máximos de tentativa da senha do usuário podem ser configurados na visualização do usuário do administrador local e na visualização do grupo de usuários do administrador. A ordem de prioridade da configuração em cada visualização é: visualização do usuário administrador local - > visualização do grupo de usuários administrador.
- O ciclo de vida da senha do usuário pode ser configurado na visualização do usuário administrador local, na visualização do grupo de usuários do administrador e na visualização global. A ordem de prioridade da configuração em cada visualização é: visualização do usuário administrador local - > visualização do grupo de usuários do administrador - > visualização global.
Condições de configuração
Nenhum
Configurar o atributo do usuário administrador
Tabela 14 -6 Configure o atributo do usuário administrador
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Criar um administrador usuário e entre no modo de usuário administrador | local-user user-name class manager | Obrigatório Por padrão, não crie o usuário administrador. |
| Configurar o administrador senha do usuário | password 0 password | Obrigatório Por padrão, o usuário não possui senha. |
| Defina o tipo de servidor que o usuário pode adotar | service-type { ssh | telnet | console | ftp | web} | Obrigatório Por padrão, o usuário não suporta nenhum tipo de serviço. |
| Defina a função de usuário do usuário local | user-role role-name | Opcional Por padrão, não configure a função de administrador. A prioridade da função de administrador é superior ao nível de administrador, ou seja, quando o usuário administrador é configurado com a função, a autoridade de administrador é baseada na função de administrador . |
| Defina o grupo de usuários do usuário administrador | group group-name | Opcional Por padrão, não configure o grupo de usuários. |
| Configure o nível de autorização do usuário de login | privilege privilege-level-number | Opcional Por padrão, o nível padrão é 1. |
| Configure o comando que o usuário automaticamente executa | autocommand command-line | Opcional Por padrão, não configure o comando que o usuário executa automaticamente. |
| Configure a opção que o usuário executa automaticamente o comando | autocommand-option { nohangup [ delay delay-time-number ] |delay delay-time-number [ nohangup ] } | Opcional Por padrão, desconecte após executar o comando automaticamente e o tempo de atraso da execução automática do comando é 0. |
| Configurar o período de vida do usuário | password-control livetime user-live-time | Opcional Por padrão, não limite o período de vida do usuário. |
| Configure os tempos máximos de falha sucessiva de autenticação de login do usuário administrador | password-control max-try-time max-try-time-number | Opcional Por padrão, o gerenciamento de usuários não limita os tempos máximos de tentativa. |
| Configurar a quantidade máxima online de um usuário | max-online-num user-number | Opcional Por padrão, não limite a quantidade máxima online de um usuário. |
| Configurar a autoridade de arquivo que o usuário pode usar | filesys-control{read | write | execute | none} | Opcional Por padrão, o usuário possui as autoridades de arquivo de leitura, gravação e execução. |
| C onfigurar o diretório fornecido pelo dispositivo para o administrador acessar ou gerenciar | work-directory directory | Opcional Por padrão, é o diretório /flash . Atualmente, o atributo funciona apenas no diretório de arquivos de configuração do dispositivo de login do usuário ftp. |
Configurar o atributo de usuário de acesso
O usuário de acesso é o usuário que está conectado à rede através do dispositivo.
Condições de configuração
Nenhum
Configurar o usuário de acesso
Tabela 14 -7 Configurar o usuário de acesso
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um usuário de acesso e entre no modo de usuário de acesso | local-user user-name class network | Obrigatório Por padrão, não configure o usuário de acesso. |
| Configurar a senha do usuário de acesso | password 0 password | Obrigatório Por padrão, o usuário não possui senha e, como resultado, talvez o usuário não possa fazer login no dispositivo. |
| Defina o tipo de servidor que o usuário de acesso pode usar | service-type { xauth } | Obrigatório Por padrão, o usuário não suporta nenhum tipo de serviço. |
| Defina o grupo de usuários do usuário de acesso | group group-name | Opcional Por padrão, não configure o grupo de usuários do usuário de acesso. |
| Configurar o status do usuário | stat { active / block } | Opcional Por padrão, o status do usuário é ativo. |
Configurar o grupo de usuários locais
Os usuários locais são divididos em grupo de usuários administrador e grupo de usuários de acesso.
O grupo de usuários administrador é um conjunto de atributos de usuário administrador, que suporta a configuração do tempo de vida da senha e o número máximo de falhas sucessivas de autenticação de login.
Grupo de usuários de acesso é o gerenciamento de usuários de acesso, com aninhamento hierárquico, que reflete de forma mais vívida a estrutura organizacional da empresa ou departamento. O grupo de usuários de acesso não oferece suporte a nenhum atributo de usuário de acesso.
Condições de configuração
Nenhum
Configurar grupo de usuários do administrador
Tabela 14 -8 Configurar o grupo de usuários do administrador
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Criar um administrador grupo de usuários e entre em seu modo | manager-group group-name | Obrigatório Por padrão, não configure o grupo de usuários administrador. |
| Configure o tempo de vida da senha do usuário no grupo de usuários do administrador | password-control livetime user-live-time | Opcional Por padrão, não limite o tempo de vida do usuário administrador no grupo de usuários, ou seja, dê prioridade ao tempo de vida da senha configurado na visualização do usuário administrador. |
| Configure os tempos máximos de falha de autenticação de login sucessiva do usuário no administrador grupo de usuários | password-control max-try-time max-try-time-number | Opcional Por padrão, não limite os tempos de falha de autenticação de login sucessiva do usuário no grupo de usuários administrador, ou seja, dê prioridade aos tempos máximos de falha de autenticação de login sucessiva configurada na visualização do usuário administrador. |
Configurar grupo de usuários de acesso
Tabela 14 -9 Configurar o grupo de usuários de acesso
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um grupo de usuários de acesso e entre em seu modo | user-group group-name | Obrigatório Por padrão, não configure o grupo de usuários de acesso. |
| Configurar o grupo pai do grupo de usuários de acesso | parent group-name | Opcional Por padrão, o grupo pai padrão é o caminho pai no caminho do nome do grupo. |
Configurar a política de senha
Para nosso sistema, existe uma política de segurança de senha forte. Garanta a segurança da senha em relação à complexidade da senha, force a modificação da senha para o login inicial e tempos máximos de tentativa da senha. A política de segurança de senha é válida apenas para usuários administradores locais.
Complexidade da senha:
- O limite mínimo de comprimento de senha permite que os administradores limitem o comprimento mínimo de senha para administradores. Ao definir uma senha de usuário, o sistema não permitirá que a senha seja definida se o comprimento da senha inserida for menor que o comprimento mínimo definido. E prompt: "Senha incorreta: Deve conter pelo menos 2 caracteres."
- Função de detecção de combinação de senha: O administrador pode definir o tipo de combinação de componentes de senha do usuário. Os elementos de uma senha incluem os quatro tipos a seguir:
- Letras maiúsculas : AZ
- Letras minúsculas: az
- Dígitos decimais: 0-9
- 31 caracteres especiais : (`~!@$%^&*()_+-= {}[]|\:;”'<>,./')
- O tipo de combinação 1 indica que há pelo menos um elemento na senha.
- O tipo de combinação 2 significa que há pelo menos dois elementos na senha.
- O tipo de combinação 3 significa que há pelo menos três elementos em uma senha.
- O tipo de combinação 4 significa que todos os quatro elementos devem ser incluídos na senha.
- A senha não pode ser igual ao nome de usuário. Ao definir a senha do usuário administrador, se a senha inserida for igual ao nome do usuário, o sistema não permitirá que a senha seja definida.
Existem quatro tipos de combinação de elementos de senha, que têm os seguintes significados específicos:
Quando o usuário definir a senha, o sistema verificará se a senha definida atende aos requisitos de configuração. Apenas a senha que atende aos requisitos pode ser definida com sucesso.
Forçar a modificação da senha para o login inicial:
Quando a função "Forçar a modificação da senha quando o usuário fizer login pela primeira vez" estiver habilitada, quando o usuário fizer login pela primeira vez no dispositivo, o sistema emitirá as informações de prompt correspondentes para solicitar que o usuário modifique a senha. Caso contrário, o usuário não terá permissão para fazer login no dispositivo. Quando o nome de usuário do administrador for "admin", estando ou não habilitada a função "Forçar a modificação da senha quando o usuário efetuar login pela primeira vez", o usuário será forçado a modificar a senha ao efetuar login no dispositivo para a primeira vez.
Vida útil da senha:
O tempo de vida da senha é usado para limitar o tempo de uso da senha do usuário. Quando a senha é usada por mais tempo que o tempo de vida da senha, o usuário precisa alterar a senha. Quando um usuário fizer login e inserir uma senha expirada, o sistema avisará ao usuário que a senha expirou e a senha deve ser redefinida antes do login local. Se a senha digitada não atender aos requisitos, ou se as novas senhas digitadas duas vezes forem inconsistentes, o sistema recusará este login. Para o modo não interativo de login, como usuários de FTP, após o tempo de vida da senha expirar, o usuário poderá efetuar login somente após o administrador modificar a senha dos usuários de FTP; mas se a senha expirar durante o período de login, isso não afetará a operação deste login, mas o próximo comando FTP será acionado offline. Em particular, se for necessário alterar a senha para o primeiro login, a senha de fato atingiu o tempo de expiração e o login exigirá uma alteração de senha unificada apenas uma vez.
Tempos máximos de tentativa da senha:
Os tempos máximos de tentativa do usuário podem ser usados para evitar que usuários mal-intencionados tentem descriptografar o código. Quando a tentativa de senha falhar mais do que o tempo máximo de tentativas, o sistema colocará o usuário na lista negra no módulo de segurança de login e a conta do usuário será bloqueada por um período de tempo.
Condições de configuração
Nenhum
Configurar a política de senha
Tabela 14 -10 Configurar a política de senha
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar a complexidade da senha | password-control complexity {min-length len| with user-name-check | composition type-number type-number } | opcional _ Por padrão, o comprimento mínimo da senha do usuário é 6, o tipo de combinação dos elementos de senha contém dois tipos e não permite que o nome do usuário seja igual à senha. |
| Configure o forçamento para modificar a senha quando o usuário fizer login pela primeira vez | password-control firstmodify enable | opcional _ Por padrão, não force o usuário a modificar a senha quando fizer login pela primeira vez. Quando o usuário chamado “admin” não habilita o comando, também é necessário modificar a senha ao efetuar login pela primeira vez. |
| Configurar o tempo ao vivo do usuário | password-control livetime user-live-time | Opcional Por padrão, não limite o tempo ao vivo do usuário. |
| Configure os tempos máximos de falha sucessiva de autenticação de login do usuário administrador | password-control max-try-time max-try-time-number | Opcional O comando é configurado no grupo de usuários administrador e no usuário administrador. Por padrão, a autenticação de login sucessiva a falha do usuário no grupo de usuários administrador não está configurada, ou seja, toma como principal os tempos máximos da falha sucessiva de autenticação de login configurada na visualização do usuário administrador. |
Monitoramento e manutenção de LUM
Tabela 14 -11 Monitoramento e manutenção de LUM
| Comando | Descrição |
| debug user { manager | network} | Habilite as informações de depuração do gerenciamento de usuários |
| show users class { manager | network } [ username ] | Exibir as informações de configuração do usuário |
| show role [ rolename ] | Exibir as informações de configuração de todas as funções ou função especificada |
Exemplo de configuração típica de LUM
Configurar administrador de rede U ser
Requisito de rede
- Configure o usuário administrador de rede e verifique se ele tem autoridade de administrador de rede.
Topologia de rede

Figura 14 -1 Rede para configurar o grupo de usuários do administrador de rede
Etapas de configuração
- Passo 1: Configure o endereço IP da interface. (omitido)
- Passo 2: Configure os atributos de administrador.
# Configure o usuário como admin e a senha como admin.
Device#configure terminalDevice(config)#local-user admin class managerDevice(config-user-manager-admin)#password 0 admin
#Configure o tipo de serviço.
Device(config-user-manager-admin)#service-type telnet ftp web console ssh#Configure a função do usuário local como administrador da rede.
Device(config-user-manager-admin)#user-role network-admin#Configure a autorização local , fazendo com que a função tenha efeito.
Device(config-user-manager-admin)#exitDevice(config)#domain systemDevice(config-isp-system)#aaa authentication login localDevice(config-isp-system)#aaa authorization login localDevice(config-isp-system)#exit
#Configure usando a autenticação aaa de login na linha vty.
Device(config)#line vty 0 15Device(config-line)#login aaa
- Passo 3:No cliente Telnet, insira o nome de usuário admin e a senha admin e faça login no dispositivo com sucesso.
# Veja se o usuário administrador pode executar o comando administrador show logging para visualizar os logs.
Device#show loggingLogging source configurationsconsole is enabled,level: 7(debugging)monitor is enabled,level: 7(debugging)buffer is enabled,level: 5(notifications)file is enabled,level: 7(debugging)The Context of logging file:
#Verifique se o administrador da rede não pode executar os comandos de outros administradores.
Device#show roleYou may not be authorized to perform this operation,please check.
As funções padrão do administrador são administrador de segurança, operador de rede, administrador de auditoria e administrador de rede. Você pode definir a função de administrador de acordo com a demanda e também a função personalizada.
ZTP
Visão geral
ZTP (zero touch provisioning) refere-se à função de carregar automaticamente os arquivos de versão (incluindo software do sistema, arquivos de configuração, arquivos de licença, arquivos de patch e arquivos personalizados) quando o novo dispositivo de configuração de fábrica ou vazio é ligado e iniciado.
O objetivo é resolver o problema de que quando o equipamento de rede é implantado, o administrador precisa ir ao local de instalação para depurar o software do equipamento após a conclusão da instalação do hardware do equipamento. Quando o número de dispositivos é grande e a distribuição é ampla, os administradores precisam configurar manualmente cada dispositivo, o que não apenas afeta a eficiência da implantação, mas também exige altos custos de mão de obra. Com a função ZTP, o dispositivo pode obter o arquivo de versão do disco U ou servidor de arquivos e carregá-lo automaticamente, de modo a realizar o dispositivo livre de configuração e implantação no local, de modo a reduzir o custo do trabalho e melhorar a eficiência da implantação.
O ZTP não é um protocolo padrão, mas sim uma solução de configuração zero de equipamentos propostos por diversos fabricantes de acordo com a demanda do mercado. Existem diferenças nos detalhes de implementação, mas o processo básico é consistente. ZTP tem muitas maneiras de começar. Intelbras atualmente suporta inicialização de configuração zero de DHCP , inicialização de configuração zero de USB e inicialização de e - mail . O processo é que após o dispositivo habilitar a função ZTP, a configuração vazia que inicia automaticamente entra no processo ZTP . Primeiro, tente completar a abertura automática através do disco U inserido. Se a abertura do disco U falhar , tente completar a abertura automática através do DHCP.
A rede típica do DHCP zero - configuração inicial é mostrada na Figura 14-1. Quando o dispositivo de configuração nulo entra no processo de início de configuração de zero -c do DHCP, ele primeiro difundirá o pacote de descoberta DHCP através do cliente DHCP. Se o servidor DHCP e o dispositivo de início de configuração zero não estiverem no mesmo segmento de rede, ele precisará configurar a retransmissão de DHCP para enviar a mensagem de descoberta de DHCP pelos segmentos de rede. Quando o servidor DHCP recebe o pacote de descoberta DHCP , ele atribuirá o endereço IP temporário, gateway padrão e outras informações . Ao mesmo tempo, o endereço do servidor de arquivos intermediário é retornado. Em seguida, o cliente DHCP recebe o pacote de resposta do servidor DHCP, analisa o endereço do servidor de arquivos intermediário e outras informações e baixa o arquivo intermediário por meio de FTP/TFTP/SFTP. Intelbras atualmente suporta o arquivo intermediário do formato XML. Por fim, analise o arquivo intermediário, baixe e atualize a versão e configuração correspondentes do servidor de arquivos intermediário de acordo com o S N (número de série) do dispositivo e reinicie o dispositivo para entrar em vigor.

Figura 15 -1 Rede típica de DHCP
Servidor DHCP : É usado para atribuir endereço IP de gerenciamento temporário, gateway padrão, endereço do servidor de arquivos intermediário e outras informações ao dispositivo que executa o ZTP.
DHCP relay : quando o dispositivo que executa o ZTP e o servidor DHCP estão localizados em segmentos de rede diferentes, é necessário encaminhar o pacote interativo DHCP através do DHCP relay.
Servidor de arquivos intermediário : É usado para salvar os arquivos intermediários (o tipo de arquivo intermediário é o formato XML), arquivos de versão e arquivos de configuração necessários ao dispositivo no processo ZTP. O dispositivo que executa o ZTP pode obter o endereço do servidor de arquivos, o arquivo de versão correspondente e o caminho de armazenamento do arquivo de configuração e outras informações analisando o arquivo intermediário. O servidor de arquivos intermediário suporta TFTP, FTP e SFTP.
Servidor de arquivos de versão : usado para salvar os arquivos de versão necessários ao dispositivo, como software do sistema e arquivos de configuração. O servidor de arquivos de versão e o servidor de arquivos intermediário podem ser implantados no mesmo servidor de arquivos e oferecem suporte a três tipos de TFTP, FTP e SFTP.
Processo de inicialização de configuração zero USB : os usuários editam o arquivo intermediário, versão do sistema, arquivo de configuração e outras informações com antecedência e salvam-nos em USB e, em seguida, inserem o USB no dispositivo para iniciar a configuração zero . Quando o dispositivo é ligado e detecta o USB com o arquivo intermediário atendendo às condições, ele entrará no processo de início de configuração zero do USB , percorrerá o arquivo intermediário de acordo com o SN do dispositivo, copiará a versão e configuração do sistema correspondente arquivo do USB e, em seguida, reinicie o dispositivo para entrar em vigor.
Configuração da função ZTP
Ativar ou desativar a função ZTP
Tabela 15 -1 Habilite ou desabilite a função ZTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a função ZTP | ztp enable | Por padrão, o dispositivo não habilita a função ZTP . |
| Desative a função ZTP | no ztp enable | - |
ZTP Monitoramento e Manutenção
Tabela 15 -2 Monitoramento e manutenção de ZTP
| Comando | Descrição |
| show ztp | Exiba as informações do ZTP |
| [no] debug ztp | Habilite ou desabilite a depuração ZTP |
Exemplo de configuração típica de ZTP
Configurar o ZTP para usar arquivos intermediários comuns para implantação de configuração zero via DHCP
Requisito de rede
- O PC, como terminal de controle do console, é usado para monitorar o processo de inicialização do ZTP do dispositivo.
- Como servidor DHCP, o Device2 fornece o serviço DHCP para o processo de inicialização do ZTP.
- Como servidor de arquivos, o Server1 fornece serviços FTP (ou serviços TFTP , SFTP) exigidos pelo processo de inicialização do ZTP.
- Como servidor de log, o Server2 recebe as informações de log geradas durante a inicialização do ZTP.
Topologia de rede
Figura 15 -2 Rede para configurar o dispositivo para usar o arquivo intermediário comum para configuração zero na implantação via DHCP
Etapas de configuração
- Passo 1: Para configurar o servidor FTP, você precisará colocar os arquivos de versão dos arquivos intermediários (como ztp.xml) e arquivo de configuração do dispositivo a ser baixado no diretório do servidor FTP. (omitido)
#O método de edição de arquivos intermediários comuns é o seguinte:
Clique com o botão direito para abrir a edição no modo Excel
Figura 15 -3 Gráfico de arquivo XML aberto com Excel para editar
Selecione como a tabela XML e clique em OK.
Figura 15 -4 Abra como tabela XML.
Você pode editá-lo no Excel. Preencha o número de série do dispositivo, nome do arquivo de versão, nome do arquivo de versão, valor de verificação MD5, nome do arquivo de configuração, informações de descrição da soma de verificação MD5 do arquivo de configuração e, finalmente, salve-o. Observe que o salvamento está no modo XML.

Figura 15 -5 E dite a versão e o nome do arquivo de configuração no arquivo XML
- Passo 2: Configure o serviço DHCP do Device2.
Device2#configure terminalDevice2(config)#ip dhcp pool ztpDevice2 (dhcp-config)#range 1.0.0.4 1.0.0.10 255.255.255.0
# Configure a opção de nome de arquivo intermediário.
Device2 (dhcp-config)#option 67 ascii ztp.xml# Configure o método de download do arquivo e o endereço do servidor, nome de usuário e opções de senha
Device2 (dhcp-config)#option 66 ascii ftp://a:a@1.0.0.2# Configure a opção de endereço do servidor de log.
Device2 (dhcp-config)#option 7 ip 1.0.0.3Device2 (dhcp-config)#exit
#O servidor habilita o serviço DHCP.
Device2(config)#interface vlan2Device2 (config-if-vlan2)#ip address 1.0.0.1/24Device2 (config-if-vlan2)#ip dhcp serverDevice2 (config-if-vlan2)#end
- Passo 3: Device1 inicia com configuração vazia, entra no processo ZTP, baixa a atualização da versão e carrega o arquivo de configuração.
#Através do log a seguir, você pode ver que o dispositivo entra no processo ZTP e envia a solicitação DHCP.
Apr 22 2020 06:03:58 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789, Now starting dhcp upgrade...Apr 22 2020 06:03:58 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789, DHCP discovery phase started…
# Durante o período de solicitação ZTP, você pode sair do processo ZTP através de Ctrl + C, para que a configuração nula possa ser iniciada. Se você não pressionar Ctrl + C, poderá continuar seguindo o processo ZTP.
Apr 22 2020 06:04:00 Device1MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789, Press (ctrl + c) to abort Dhcp Upgrade# Obtenha o endereço com sucesso e baixe o arquivo intermediário comum.
Apr 22 2020 06:04:35 Device1 MPU0 %DHCP-ASSIGNED_EXT-5:Interface vlan1 assigned DHCP address 1.0.0.4, mask 255.255.255.0.Apr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789, Dhcp discovery phase successApr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789, Start to download temp file ztp.xml...
#Análise o arquivo intermediário e baixe as informações da versão.
Apr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789,Download temp file ztp.xml is successApr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789,Start to parse temp file...Apr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789,parse temp file is successApr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789,Start to download the Image file ztp.pck
# Baixe a versão e o arquivo de configuração com sucesso e reinicie o dispositivo automaticamente através do ZTP.
Apr 22 2020 06:09:26 Device1 MPU0 %SYS_UPDATE-RESULT-5:image : Mpu 0 upgrade successfully!Apr 22 2020 06:12:26 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789,Download the Image file is successApr 22 2020 06:12:26 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789,Start to download the config file startup_ztp...Apr 22 2020 06:12:26 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789,Download the config file is successApr 22 2020 06:12:26 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789,Dhcp upgrade is successApr 22 2020 06:12:26 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789,System will rebooted by DHCP upgrade
- Passo 4: Confira o resultado.
Verifique o status do ZTP através de show ztp , execute os comandos show running config e show version , e você verá que a configuração e a versão entram em vigor.
Device1#show ztpLast ztp method: DHCP upgrade methodZtp state: ZTP DHCP upgrade successZtp important inforamtion:FTP server IP: 1.0.0.2Temporary file name: ztp.xmlStartup file name:startup_ztpImage file name:ztp.pck
Current ztp method: None upgrade method
O dispositivo obtém o método de download de arquivos através da opção 66 do protocolo DHCP, suportando FTP, TFTP e SFTP. Você pode escolher qualquer método de download durante a configuração.
Se as informações da versão do arquivo intermediário comum estiverem vazias, o processo ZTP do dispositivo não atualizará a versão, mas apenas carregará a configuração e continuará o processo ZTP, mas o arquivo de configuração não poderá estar vazio.
O MD5 do arquivo de versão e o MD5 do arquivo de configuração são usados para verificar a integridade do arquivo de versão e do arquivo de configuração. Se a opção 66 não for emitida, o endereço do servidor TFTP também pode ser emitido diretamente através da opção 150. Neste momento, o arquivo intermediário, o arquivo de versão e o arquivo de configuração podem ser baixados através do servidor TFTP.
Configurar ZTP para usar arquivos intermediários python para implantação de configuração zero via DHCP
Requisito de rede
- O PC, como terminal de controle do console, é usado para monitorar o processo de inicialização do ZTP do dispositivo.
- Como servidor DHCP, o Device2 fornece o serviço DHCP para o processo de inicialização do ZTP.
- Como servidor de arquivos, o Server1 fornece serviços FTP (ou serviços FTP e SFTP) exigidos pelo processo de inicialização do ZTP.
- Como servidor de log, o Server2 recebe as informações de log geradas durante a inicialização do ZTP.
Topologia de rede

Figura 15 -6 Rede para configurar o dispositivo para usar o arquivo intermediário python para implantação de configuração zero via DHCP
Etapas de configuração
- Passo 1: Para configurar o servidor FTP, você precisará colocar os arquivos de versão dos arquivos intermediários (como ztp.xml) e o arquivo de configuração do dispositivo a ser baixado no diretório do servidor FTP. (omitido)
#Os arquivos Python comuns podem ser editados com qualquer editor de código
#Configure o espaço de arquivo total exigido pelo ZTP.
required_space = 100#Configure o modo de download do arquivo e o tempo limite do download.
protocol = "tftp"username = ""password = ""hostname = "1.0.0.2"timeout = 1200
#A versão pode ser encontrada através da série de versões, e a série de versões pode ser consultada através da lista de entrega.
REMOTE_IMAGE _FILE = {'NSS4330' : 'nss4330.pck'}
#Configure o caminho remoto para facilitar a busca no servidor quando o TFTP baixar arquivos.
remote_config_path = "/flash"remote_pck_path = ""
#Configure o checksum MD5 .
remote_config_is_exist_md5 = Falseremote_pck_is_exist_md5 = False
- Passo 2: Configure o serviço DHCP do Device2.
Device2#configure terminalDevice2(config)# ip dhcp pool ztpDevice2 (dhcp-config)#range 1.0.0.4 1.0.0.10 255.255.255.0
#Configure a opção de nome de arquivo intermediário.
Device2 (dhcp-config)#option 67 ascii ztp.py#Configure o método de download do arquivo e as opções de endereço do servidor, nome de usuário e senha.
Device2 (dhcp-config)#option 66 ascii tftp://1.0.0.2# Configure a opção de endereço do servidor de log.
Device2 (dhcp-config)#option 7 ip 1.0.0.3Device2 (dhcp-config)#exit
#O servidor habilita o serviço DHCP.
Device2(config)#interface vlan2Device2 (config-if-vlan2)#ip address 1.0.0.1/24Device2 (config-if-vlan2)#ip dhcp serverDevice2 (config-if-vlan2)#end
- Passo 3: Device1 inicia com configuração vazia, entra no processo ZTP, baixa a atualização da versão e carrega o arquivo de configuração.
#Através do log a seguir, você pode ver que o dispositivo entra no processo ZTP e envia a solicitação DHCP.
Apr 22 2020 06:03:58 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789, Now starting dhcp upgrade...Apr 22 2020 06:03:58 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789, DHCP discovery phase started...
# Durante o período de solicitação ZTP, você pode sair do processo ZTP através de Ctrl + C, para que a configuraçãos nula possa ser iniciada. Se você não pressionar ctrl+c , poderá continuar seguindo o processo ZTP.
Apr 22 2020 06:04:00 Device1MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789, Press (ctrl + c) to abort Dhcp Upgrade#Gete o endereço com sucesso e baixe o arquivo intermediário comum.
Apr 22 2020 06:04:35 Device1 MPU0 %DHCP-ASSIGNED_EXT-5:Interface vlan1 assigned DHCP address 1.0.0.4, mask 255.255.255.0.Apr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789, Dhcp discovery phase successApr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789, Start to download temp file ztp.py...Apr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789, Download temp file ztp.py is successApr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789, Start to parse temp file…
#Executa diretamente o script python .
Execute python script start .../flash free space is 168(M).Start to get remote and local file path.remote config path is /flash/123456789.cfgGet remote and local file path is success.remote PCK path is ztp.pckStart to download image file ztp.pck...Download image file is successStart to set boot image file /flash/ztp.pck...
# Baixe a versão e o arquivo de configuração com sucesso e reinicie o dispositivo automaticamente através do ZTP
Apr 22 2020 06:09:26 Device1 MPU0 %SYS_UPDATE-RESULT-5:image : Mpu 0 upgrade successfully!Set boot image file is success.Start to download config file /flash/123456789.cfg...Download config file is success.Start to parse config file /flash/startup...Parse config file is success.Execute python script success.Apr 22 2020 06:12:26 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789,script execute successApr 22 2020 06:12:26 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:123456789,System will rebooted by DHCP upgrade
- Passo 4: Confira o resultado.
Verifique o status do ZTP através de show ztp , execute os comandos show running config e show version , e você verá que a configuração e a versão entram em vigor.
Device1#show ztpLast ztp method: DHCP upgrade methodZtp state: ZTP DHCP upgrade successZtp important inforamtion:TFTP server IP: 1.0.0.2Temporary file name: ztp.pyCurrent ztp method: None upgrade method
Next ztp state: disable
O dispositivo pode obter o modo de download de arquivos através da opção 66 do protocolo DHCP e suporta FTP, TFTP e SFTP. Você pode escolher qualquer modo de download durante a configuração. O modo de download do servidor emitido pelo servidor DHCP é usado para baixar arquivos intermediários, enquanto o modo de download definido no arquivo Python é usado para baixar arquivos de versão e arquivos de configuração. Não existe uma correlação inevitável entre os dois.
Se as informações da versão não forem encontradas na sequência do dispositivo, o processo ZTP do dispositivo não atualizará a versão, mas apenas carregará a configuração e continuará o processo ZTP, mas o arquivo de configuração não poderá ficar vazio.
Se o método de download do arquivo for TFTP, as colunas de nome de usuário e senha devem ser strings vazias e os dois parâmetros não podem ser excluídos diretamente. O nome do arquivo de configuração baixado pelo dispositivo é composto pelo número de série e pelo sufixo .md5. Por exemplo, se o número de série do dispositivo for 12345, o nome do arquivo de configuração será 12345.md5 e o arquivo de verificação MD5 será 12345 cfg.md5.
Depois de baixar o arquivo python, o dispositivo executará o arquivo python diretamente, portanto, o arquivo python deve estar em conformidade com a sintaxe python.
Configurar o ZTP para usar arquivos intermediários comuns para implantação de configuração zero via USB
Requisito de rede
- O PC, como terminal de controle do console, é usado para monitorar o processo de inicialização do ZTP do dispositivo.
- Device1 é inserido no dispositivo USB. O dispositivo USB contém arquivo intermediário, arquivo de versão e arquivo de configuração do dispositivo.
Topologia de rede
Figura 15 -7 Rede para configurar o dispositivo para usar o arquivo intermediário comum para implantação de configuração zero via DHCP
Etapas de configuração
- Passo 1: Coloque o arquivo intermediário no diretório raiz USB e nomeie como ztp_config.xml, que é /usb/ztp_config.xml.
#O método de edição do arquivo intermediário comum é o seguinte:
Clique com o botão direito do mouse e abra pelo Excel para editar.

Figura 15 -8 Gráfico de arquivo XML aberto com Excel para editar
Selecione como a tabela XML e clique em OK.
Você pode editá-lo no Excel. Preencha o número de série do dispositivo, nome do arquivo de versão, nome do arquivo de versão, valor de verificação MD5, nome do arquivo de configuração, informações de descrição da soma de verificação MD5 do arquivo de configuração e, finalmente, salve-o. Observe que o salvamento é feito no modo XML .

Figura 15 -9 Edite a versão e o nome do arquivo de configuração no arquivo XML
XXX é o nome da versão do IOS correspondente em USB. O arquivo intermediário XML é obtido do caminho ZTP do manual de lançamento do software.
No arquivo intermediário XML, os campos obrigatórios são número de série, versão e arquivo de configuração, e o número de série pode ser obtido na lista de entrega do equipamento; o nome da versão e o nome do arquivo de configuração preenchidos no arquivo intermediário XML devem ser consistentes com o nome do arquivo de versão do IOS e o nome do arquivo de configuração em USB . Caso contrário , a abertura falha.
O código MD5, o código MD5 do arquivo de configuração e as informações de descrição no arquivo intermediário XML são opcionais. Se o código MD5 for necessário, ele pode ser gerado pela ferramenta geral de cálculo de código MD5.
- Passo 2: Coloque o arquivo de versão e o arquivo de configuração correspondente ao número de série do dispositivo no arquivo intermediário no diretório raiz USB e o nome é consistente com a descrição do arquivo intermediário. (omitido)
- Passo 3: Ligue o dispositivo, entre no processo ztp e execute a implantação por USB.
#A configuração do dispositivo está vazia e entre no processo de implantação USB.
the current config file /flash/startup does not exist.The backup file /backupramfs/startup is not exist.The current config file /backup/startup does not exist.May 6 2020 15:16:15 Device1 MPU0 %ZTP-USB_UPGRADE-5:SerialNum:123456789,Now starting USB upgrade...
#Pesquise e analise o arquivo intermediário.
May 6 2020 15:16:15 Device1 MPU0 %ZTP-USB_UPGRADE-5:SerialNum:123456789,Start to copy the temporary file /usb/ztp_config.xml...May 6 2020 15:16:15 Device1 MPU0 %ZTP-USB_UPGRADE-5:SerialNum:123456789,Copy the temporary file is success.May 6 2020 15:16:15 Device1 MPU0 %ZTP-USB_UPGRADE-5:SerialNum:123456789,Start to parse the temporary file /flash/ztp_config.xml
#Atualize a versão e configuração.
May 6 2020 15:16:15 Device1 MPU0 %ZTP-USB_UPGRADE-5:SerialNum:123456789,Parse temporary file is successMay 6 2020 15:19:53 Device1 MPU0 %ZTP-USB_UPGRADE-5:SerialNum:123456789,Sysupdate image is successMay 6 2020 15:19:53 Device1 MPU0 %ZTP-USB_UPGRADE-5:SerialNum:123456789,Start to copy config...May 6 2020 15:19:54 Device1 MPU0 %ZTP-USB_UPGRADE-5:SerialNum:123456789,Copy config is success
#Restart após a atualização.
May 6 2020 15:19:54 Device1 MPU0 %ZTP-USB_UPGRADE-4:SerialNum:123456789,System will be rebooted by USB Upgrade- Passo 5: Confira o resultado.
#Verifique o status do ZTP através do comando mostre ztp . Execute os comandos show running-config e show version , e você verá que a configuração e a versão entram em vigor.
Device1#show ztpLast ztp method: USB upgrade methodZtp state: ZTP USB Upgrade successZtp important information:Temporary file name:/usb/ztp_config.xmlStartup file name:startupImage file name:ztp.pckCurrent ztp method: None upgrade methodNext ztp state: disable
Se as informações gerais da versão do arquivo intermediário estiverem vazias, o processo ZTP do dispositivo não atualizará a versão, mas apenas carregará a configuração e continuará o processo ZTP, mas o arquivo de configuração não poderá estar vazio.
O dispositivo irá copiar e baixar o arquivo de versão e configuração do USB, então é necessário colocar o arquivo de versão e configuração no USB. O nome do arquivo intermediário comum em USB só pode ser ZTP_config.xml.
Configurar ZTP para usar arquivos intermediários python para implantação de configuração zero via USB
Requisito de rede
- O PC, como terminal de controle do console, é usado para monitorar o processo de inicialização do ZTP do dispositivo.
- Device1 é inserido no dispositivo USB. O dispositivo USB contém arquivo intermediário, arquivo de versão e arquivo de configuração do dispositivo.
Topologia de rede
Figura 15 -10 Rede para configurar o dispositivo para usar o arquivo intermediário python para implantação sem configuração via USB
Etapas de configuração
#Os arquivos Python comuns podem ser editados com qualquer editor de código.
#Configure o espaço total no arquivo requerido pelo ZTP, e a unidade é MB.
required_space = 100# Pesquise a versão através da série de versões, e a série de versões pode ser consultada através da lista de entrega
REMOTE_IMAGE _FILE = {'MyPower S3330' : 'ztp.pck'}
#Configure o caminho remoto e procure o arquivo de versão e o arquivo de configuração no caminho /usb .
remote_config_path = "/usb"remote_pck_path = "/usb"
- Passo 2: Copie o arquivo de versão e o arquivo de configuração do dispositivo para o diretório raiz USB. O nome da versão é consistente com o arquivo de versão correspondente ao número de série do dispositivo. O nome do arquivo de configuração é um arquivo composto pelo número de série do dispositivo e o sufixo .cfg . Por exemplo, se o número de série do dispositivo for 12345, o nome do arquivo de configuração será 12345.cfg. (omitido)
- Passo 3:Insira o USB no dispositivo, ligue, entre no processo ZTP e comece com o USB.
# Se o arquivo de configuração não existir, o USB é inserido no dispositivo para entrar no processo de inicialização do USB do ZTP
The current config file /flash/startup does not exist.The backup file /backupramfs/startup is not exist.The current config file /backup/startup does not exist.Apr 30 2020 11:10:12 Device1 MPU0 %SYS_UPDATE-RESULT-5:SerialNum:123456789,Now starting USB upgrade...
#Procure e analise o arquivo intermediário.
Apr 30 2020 11:10:12 Device1 MPU0 %SYS_UPDATE-RESULT-5:SerialNum:123456789,Start to copy the temporary file /usb/ztp_script.py...Apr 30 2020 11:10:12 Device1 MPU0 %SYS_UPDATE-RESULT-5:SerialNum:123456789,Copy the temporary file is success.Apr 30 2020 11:10:12 Device1 MPU0 %SYS_UPDATE-RESULT-5:SerialNum:123456789,:Start to parse the temporary file /flash/ztp_script.py
#C tudo python para executar o arquivo intermediário.
Execute python script start ...#Verifique o espaço restante.
/flash free space is 159(M).#Baixe os arquivos de configuração e versão.
Start to get remote and local file path.Get remote and local file path is success.Start to set boot image file /usb/ztp.pck...Apr 30 2020 11:13:51 Device1 MPU0 %SYS_UPDATE-RESULT-5:SerialNum:123456789,image : Mpu 0 upgrade successfully!Set boot image file is success.Start to copy config file /usb/12345.cfg...Copy config file is success.Start to parse config file /flash/startup...Parse config file is success.
#Download é carregado com sucesso e reinicie a versão e a configuração efetivas.
Execute python script success, reboot device.Apr 30 2020 11:13:54 Device1 MPU0 %SYS_UPDATE-RESULT-5:SerialNum:123456789,script execute successApr 30 2020 11:13:54 Device1 MPU0 %SYS_UPDATE-RESULT-4:SerialNum:123456789,System will be rebooted by USB Upgrade
- Passo 4: Confira o resultado.
#Verifique o status do ZTP através do comando show ztp . Execute os comandos show running-config e show version , e você verá que a configuração e a versão entram em vigor.
Device1#show ztpLast ztp method: USB upgrade methodZtp state: ZTP USB Upgrade successZtp important information:Temporary file name:/usb/ztp_script.pyStartup file name:startupImage file name:ztp.pckCurrent ztp method: None upgrade method
Next ztp state: disable
Depois de baixar o arquivo python, o dispositivo executará o arquivo python diretamente, portanto, o arquivo python deve estar em conformidade com a sintaxe python.
O dispositivo pode obter o modo de download de arquivos através da opção 66 do protocolo DHCP e suporta FTP, SFTP e TFTP. Você pode escolher qualquer modo de download durante a configuração. Se as informações da versão não forem encontradas na sequência do dispositivo, o processo ZTP do dispositivo não atualizará a versão, mas apenas carregará a configuração e continuará o processo ZTP, mas o arquivo de configuração não poderá ficar vazio.
O nome do arquivo de configuração baixado pelo dispositivo é composto pelo número de série e pelo sufixo .md5. Por exemplo, se o número de série do dispositivo for 12345, o nome do arquivo de configuração será 12345.md5 e o arquivo de verificação MD5 será 12345 cfg.md5.
O dispositivo irá copiar e baixar o arquivo de versão e configuração do USB, então é necessário colocar o arquivo de versão e configuração no USB. O nome do arquivo intermediário comum em USB só pode ser ztp_script.py .
Configurar o ZTP para usar arquivos intermediários python para empilhamento automático via DHCP
Requisito de rede
- O PC1, como terminal de controle do console, é usado para monitorar o processo de inicialização ZTP do dispositivo.
- Como servidor DHCP, Device3 fornece o serviço DHCP para o processo de inicialização do ZTP.
- Como servidor de arquivos, o Server1 fornece serviços FTP (ou serviços SFTP e TFTP) exigidos pelo processo de inicialização do ZTP.
- Como servidor de log, o Server2 recebe as informações de log geradas durante a inicialização do ZTP.
- O empilhamento de Device1 e Device2 é concluído usando T Te0/50 como o link de empilhamento.
Topologia de rede

Figura 15 -11 Rede para configurar o ZTP para usar o arquivo intermediário python para empilhamento automático via DHCP
Etapas de configuração
#Os arquivos Python comuns podem ser editados com qualquer editor de código.
#Configure o espaço total de arquivos exigido pelo ZTP
required_space = 100#Configurar o modo de download de arquivo e o tempo limite de download.
protocol = "ftp"username = "a"password = "a"hostname = "1.0.0.2"timeout = 1200
#Pesquise a versão através da série de versões, e a série de versões pode ser consultada pela lista de entrega.
REMOTE_IMAGE _ FILE = {'MyPower S3330' : 'ztp.pck'}
# Configure o caminho remoto para que o FTP possa encontrar arquivos no servidor ao baixar arquivos
remote_config_path = ""remote_pck_path = ""remote_stack_path = ""
#Configurar o cheque MD5.
remote_config_is_exist_md5 = Trueremote_pck_is_exist_md5 = Trueremote_stack_is_exist_md5 = True
- Passo 2: Edite os arquivos de empilhamento e os arquivos de configuração e carregue-os no servidor para download do processo ZTP.
Aqui, assumimos que o número de série do Device1 é 12345 e o do Device2 é 12340.
#Edite o arquivo de empilhamento.
O arquivo de empilhamento é nomeado pelo número de série mais .stack. O nome do arquivo de empilhamento de Device1 é 12345. stack, e o arquivo de verificação MD5 correspondente é 12345 stack.md5 O nome do arquivo de empilhamento de Device2 é 12340. Stack, e o arquivo de verificação MD5 correspondente é 12340 cfg.md5 。
O conteúdo do arquivo de empilhamento: contém número de série, número de domínio de empilhamento, membro do dispositivo de empilhamento
O conteúdo do arquivo de empilhamento de Device1 é:
12345 101 1O conteúdo do arquivo de empilhamento de Device2 é:
12340 101 0#Edite o arquivo de configuração. O nome do arquivo de configuração é o número de série do dispositivo mais o sufixo .cfg, então o nome do arquivo de configuração do Dispositivo1 é 12345.cfg e o arquivo de verificação MD5 correspondente é 12345 cfg.md5 O nome do arquivo de configuração do Dispositivo2 é 12340.cfg, e o arquivo de verificação MD5 correspondente é 12340 cfg.md5.
A parte de empilhamento no arquivo de configuração deve conter !VST_CONFIG_BEGIN e !VST_CONFIG_END . A configuração da porta do slot deve conter ! PORTA _CONFIG_BEGIN e ! PORTA _CONFIG_END . A dimensão de interface definida no arquivo de configuração deve ser uma dimensão de interface de empilhamento, não uma dimensão independente.
Portanto, o arquivo de configuração do Device1 contém
!VST_CONFIG_BEGIN!mode vsl informationvsl-channel 1/1exit!mode vsl end!slot 0/0interface tengigabitethernet1/0/50vsl-channel 1/1 mode onexit!PORT_CONFIG_END!VST_CONFIG_END
O arquivo de configuração do Device2 contém:
!VST_CONFIG_BEGIN!mode vsl informationvsl-channel 0/1exit!mode vsl end!slot 0/0interface tengigabitethernet0/0/50vsl-channel 0/1 mode onexit!PORT_CONFIG_END!VST_CONFIG_END
Após o upload dos arquivos de configuração e arquivos de pilha para o servidor, existem os arquivos: 12345.cfg, 12340.cfg, 12345.cfg.md5, 12340.cfg.md5 .
- Passo 3: Configure o serviço DHCP do Device3.
Device3#configure terminalDevice3(config)# ip dhcp pool ztpDevice3(dhcp-config)#range 1.0.0.4 1.0.0.10 255.255.255.0
#Configure a opção de nome de arquivo intermediário.
Device3(dhcp-config)#option 67 ascii ztp.py#C configure o método de download do arquivo e o endereço do servidor, nome de usuário e senha.
Device3(dhcp-config)#option 66 ascii ftp://a:a@1.0.0.2#C onfigurar a opção de endereço do servidor de log.
Device3(dhcp-config)#option 7 ip 1.0.0.3Device3(dhcp-config)#exit
#O servidor habilita o serviço DHCP.
Device3(config)#interface vlan2Device3(config-if-vlan2)#ip address 1.0.0.1/24Device3(config-if-vlan2)#ip dhcp serverDevice3(config-if-vlan2)#end
- Passo 4: Device1 e Device2 iniciam com configuração vazia, entram no processo ZTP, baixam a atualização da versão e carregam o arquivo de configuração.
Dispositivo1:
# Nos logs a seguir, você pode ver que o dispositivo entra no processo ATP e envia a solicitação DHCP.
Apr 22 2020 06:03:58 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12345, Now starting dhcp upgrade...Apr 22 2020 06:03:58 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12345, DHCP discovery phase started...
# Durante o período de solicitação do ZTP, você pode sair do processo ZTP através de ctrl+c , para iniciar com a configuração vazia. Se você não pressionar Ctrl + C, poderá continuar seguindo o processo ZTP.
Apr 22 2020 06:04:00 Device1MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12345, Press (ctrl + c) to abort Dhcp Upgrade#G ete o endereço com sucesso e baixe o arquivo intermediário comum.
Apr 22 2020 06:04:35 Device1 MPU0 %DHCP-ASSIGNED_EXT-5:Interface vlan1 assigned DHCP address 1.0.0.4, mask 255.255.255.0.Apr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12345, Dhcp discovery phase successApr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12345, Start to download temp file ztp.py...Apr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12345, Download temp file ztp.py is successApr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12345, Start to parse temp file...
#Executa diretamente o script python .
/flash free space is 100(M).Start to get remote and local file path.Get remote and local file path is success.
#D faça o download da versão.
Start to download image file /flash/ztp.pck...Download image file is successStart to set boot image file /flash/ztp.pck....
#D possui e analisa o arquivo de empilhamento e o arquivo de configuração.
Start to download stack file /flash/12345.stack...Download stack file is success.Start to download config file /flash/12345.cfg...Download config file is success.Start to parse config file /flash/startup...Parse config file is success.Execute python script success.
#D faça o download da versão e do arquivo de configuração com sucesso e, em seguida, reinicie automaticamente o dispositivo via ZTP.
Apr 22 2020 06:12:26 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12345,script execute successApr 22 2020 06:12:26 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12345,System will rebooted by DHCP upgrade
Dispositivo2:
# Nos logs a seguir, você pode ver que o dispositivo entra no processo ATP e envia a solicitação DHCP.
Apr 22 2020 06:03:58 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12340, Now starting dhcp upgrade...Apr 22 2020 06:03:58 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12340, DHCP discovery phase started...
# Durante o período de solicitação do ZTP, você pode sair do processo ZTP através de ctrl+c , para iniciar com a configuração vazia. Se você não pressionar Ctrl + C, poderá continuar seguindo o processo ZTP.
Apr 22 2020 06:04:00 Device1MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12340, Press (ctrl + c) to abort Dhcp Upgrade#G ete o endereço com sucesso e baixe o arquivo intermediário comum.
Apr 22 2020 06:04:35 Device1 MPU0 %DHCP-ASSIGNED_EXT-5:Interface vlan1 assigned DHCP address 1.0.0.5, mask 255.255.255.0.Apr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12340, Dhcp discovery phase successApr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12340, Start to download temp file ztp.py...Apr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12340, Download temp file ztp.py is successApr 22 2020 06:04:35 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12340, Start to parse temp file...
#Executa diretamente o script python .
/flash free space is 101(M).Start to get remote and local file path.Get remote and local file path is success.
#D faça o download da versão.
Start to download image file /flash/ztp.pck...Download image file is successStart to set boot image file /flash/ztp.pck....
#D possui e analisa o arquivo de empilhamento e o arquivo de configuração.
Start to download stack file /flash/12340.stack...Download stack file is success.Start to download config file /flash/12340.cfg...Download config file is success.Start to parse config file /flash/startup...Parse config file is success.Execute python script success.
#D faça o download da versão e do arquivo de configuração com sucesso e, em seguida, reinicie automaticamente o dispositivo via ZTP.
Apr 22 2020 06:12:26 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12340,script execute successApr 22 2020 06:12:26 Device1 MPU0 %ZTP-DHCP_UPGRADE-5:SerialNum:12340,System will rebooted by DHCP upgrade
- Passo 5: Confira o resultado.
#Verifique o status do ZTP através do comando show ztp . Execute os comandos show running-config e show version , e você verá que a configuração e a versão entram em vigor. Execute o comando show vst-config e você verá que o empilhamento entra em vigor.
switch#show ztpLast ztp method: DHCP upgrade methodZtp state: ZTP DHCP upgrade successZtp important inforamtion:FTP server IP: 1.0.0.2Temporary file name: ztp.pyCurrent ztp method: None upgrade methodNext ztp state: Next ztp state: disable(Stack mode does not support ztp.)switch X#show vst-configBuilding Configuration...!mode member informationswitch mode virtualswitch virtual member 0domain 101exitswitch virtual member 1domain 101exit!mode member end!mode vsl informationvsl-channel 0/1exitvsl-channel 1/1exit!mode vsl end!slot_0_ MyPower-S3330-28TXP(V1)!vsl mode!slot 0/0interface tengigabitethernet0/0/50vsl-channel 0/1 mode onexit!end!slot_14_ MyPower-S3330-28TXP(V1)!vsl mode!slot 1/0interface tengigabitethernet1/0/50vsl-channel 1/1 mode onexit!end
O dispositivo pode obter o modo de download de arquivos através da opção 66 do protocolo DHCP e suporta FTP, SFTP e TFTP. Você pode escolher qualquer modo de download durante a configuração. O MD5 do arquivo de versão, arquivo de configuração e arquivo de pilha são armazenados separadamente, e o nome é seu próprio arquivo mais o sufixo .md5.
Ao empilhar automaticamente, a dimensão da interface no arquivo de configuração deve ser a dimensão da interface após o empilhamento, não a dimensão da interface quando for uma única máquina.
Depois de baixar o arquivo python, o dispositivo executará o arquivo python diretamente, portanto, o arquivo python deve estar em conformidade com a sintaxe python.
Se as informações da versão não forem encontradas na sequência do dispositivo, o processo ZTP do dispositivo não atualizará a versão, mas apenas carregará a configuração e continuará o processo ZTP, mas o arquivo de configuração não poderá ficar vazio.
02 Interfaces Físicas e Lógicas
Interfaces Físicas e Lógicas
Visão geral
As interfaces suportadas pelo dispositivo podem ser divididas em interface física e interface lógica. A interface física inclui interface Ethernet L2 e interface Ethernet L3 ; interface lógica inclui interface link aggregation, interface VLAN, interface Loopback, interface nula, interface tunnel e assim por diante.
A interface Ethernet L2, também chamada de porta, é uma interface física. Ele funciona na camada 2 no modelo de referência OSI-camada de enlace de dados e é usado principalmente para o encaminhamento de quadros de dados e aprendizado de endereços MAC.
A interface Ethernet L3 é uma interface física e funciona na camada 3 na camada de rede do modelo de referência OSI . Ele pode configurar o endereço IP e é usado principalmente para encaminhar pacotes.
A interface link aggregation é uma interface lógica, formada pela ligação de vários links físicos entre dois dispositivos. Ele também funciona na camada de enlace de dados e é usado principalmente para expandir a largura de banda do enlace e melhorar a confiabilidade do enlace.
A interface VLAN é uma interface lógica, usada para ser vinculada à VLAN e completar o encaminhamento de pacotes entre diferentes VLANs.
A interface loopback, também chamada de interface loopback local, é uma interface lógica. Para os pacotes enviados para a interface Loopback, o dispositivo considera que os pacotes são enviados para o próprio dispositivo , portanto, não encaminha os pacotes.
A interface null é uma interface lógica. Qualquer pacote enviado para a interface Null é descartado.
A interface tunnel é uma interface lógica, fornecendo o link de transmissão para o modo ponto a ponto.
Para diferentes interfaces, existem modos de configuração correspondentes. Os modos de configuração relacionados das interfaces incluem:
- Modo de configuração da interface, correspondente à interface VLAN, interface Loopback, interface Null e interface Tunnel
- Modo de configuração da interface Ethernet L2, correspondente à interface Ethernet L2
- Modo de configuração da interface Ethernet L 3 , correspondente à interface Ethernet L 3
- Modo de configuração do grupo de agregação, correspondente à interface do grupo de agregação
Este capítulo descreve principalmente a configuração de função comum de várias interfaces. Para a configuração de funções de várias interfaces, consulte o capítulo de interface correspondente.
Configuração de Funções B á sicas de Interfaces
Tabela 1 ‑1 Lista de configuração de Funções Básicas das Interfaces
| Tarefa de configuração | |
| Configure as funções básicas das interfaces |
Ativar/desativar interface
Configurar descrição da interface Configure o intervalo de estatísticas do tráfego de interface |
| Configurar a função do grupo de interface | Configurar grupo de interface |
| Configure a camada em questão do proxy SNMP de status da interface | Configure a camada em questão do proxy SNMP de status da interface |
Configurar Funções Básicas das Interfaces
Condições de configuração
Não
Ativar/Desativar Interface
Depois que a porta é desabilitada, ela não pode receber ou enviar pacotes, mas depois que a interface Ethernet é habilitada, se ela pode receber e enviar pacotes também depende de outras configurações, como se a interface Ethernet peer está habilitada, as taxas do local e interfaces Ethernet peer , se o modo duplex combina com MDIX (Media Dependent Interface Crossover).
Depois que a interface link aggregation é desabilitada, todas as portas do membro são desabilitadas; depois que a interface link aggregation é habilitada, podemos desabilitar ou habilitar uma porta membro separadamente.
Tabela 1 ‑2 Ativar/desativar interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name |
Qualquer
Depois de entrar no modo de configuração da interface, a configuração subsequente apenas entra em vigor na interface atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor na interface do grupo de agregação; depois de entrar no modo de configuração da interface Ethernet L2 /L3 , a configuração subsequente apenas entra em vigor na porta atual ; depois de entrar no modo de interface de link de switch virtual, a configuração subsequente apenas entra em vigor na interface de link de switch virtual atual. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | |
| Entre no modo de configuração da interface de link do switch virtual | vsl-channel vsl-channel-id | |
| Ativar interface | no shutdown | Obrigatório Por padrão, a interface está habilitada. |
| Desativar interface | shutdown | Obrigatório Por padrão, a interface está habilitada. |
A interface Null não suporta a função de configuração da descrição da interface.
Configurar descrição da interface
A descrição da interface é usada para nomear diferentes interfaces, ajudando o usuário a distinguir diferentes tipos de interface e funções de serviço reais. É conveniente para o usuário gerenciar várias interfaces.
Tabela 1 ‑3 Configurar informações de descrição da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface, a configuração subsequente apenas entra em vigor na interface atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor na interface do grupo de agregação; depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual ; depois de entrar no modo de interface de link de switch virtual, a configuração subsequente apenas entra em vigor na interface de link de switch virtual atual. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | |
| Entre no modo de configuração da interface de link do switch virtual | vsl-channel vsl-channel-id | |
| Configurar informações de descrição da interface | description description-name | Obrigatório Por padrão, as informações de descrição da interface não estão configuradas. |
| peer-description description-name | Obrigatório Por padrão, não configure as informações de descrição da interface de peer. |
A interface Null não suporta a função de configuração da descrição da interface.
Configurar intervalo de estatísticas de tráfego de interface
Interfaces diferentes transportam tráfegos de serviço diferentes. Ajustar o intervalo de estatísticas do tráfego da interface pode ajudar o usuário a se preocupar com os registros do histórico do tráfego da interface de forma seletiva, prevendo a tendência futura do tráfego da interface de forma mais correta. É conveniente para o usuário analisar e ajustar os serviços entediados da interface.
Tabela 1 ‑4 Configurar intervalo de estatísticas de tráfego de interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface, a configuração subsequente apenas entra em vigor na interface atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor na interface do grupo de agregação; depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual ; depois de entrar no modo de interface de link de switch virtual, a configuração subsequente apenas entra em vigor na interface de link de switch virtual atual. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | |
| Entre no modo de interface de link de switch virtual | vsl-channel vsl-channel-id | |
| Configure o intervalo de estatísticas do tráfego de interface | load-interval load-interval-value | Obrigatório Por padrão, o intervalo de estatísticas do tráfego da interface é de 300s. |
A interface Null não suporta a função de configuração da descrição da interface.
Configurar funções do grupo da interface
Vincule várias interfaces como um grupo de interfaces. Configurar vários comandos de interface no grupo de interface é equivalente a configurar em todas as interfaces do grupo de interface, embora não seja necessário configurar repetidamente em cada interface. Exibir as informações de um grupo de interfaces é exibir as informações de todas as interfaces do grupo de interfaces.
Condição de configuração
As interfaces cobertas pelo grupo de interfaces já devem existir.
Configurar grupo de interface
Tabela 1 ‑5 Configurar grupo de interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Criar grupo de interface no modo de lista | interface group group-id enum interface-name1 interface-name2 … interface-nameN [ point-to-point | multipoint ] | Obrigatório Por padrão, o grupo de interface não é criado. |
| Entre no modo de configuração global | configure terminal | - |
| Criar grupo de interface especificando o modo de intervalo | interface group group-id range start-interface-name end-interface-name [ point-to-point | multipoint ] | Obrigatório Por padrão, o grupo de interface não é criado. |
Os tipos de interface no grupo de interface devem ser os mesmos. O usuário pode configurar vários grupos de interface conforme desejado. O usuário pode configurar os comandos suportados por todos os tipos de interfaces no grupo de interface, mas se as interfaces cobertas pelo grupo de interface não suportarem, os comandos não terão efeito e pode não haver prompt de erro. Verifique se os comandos têm efeito visualizando a configuração. Se o grupo de interfaces abranger a interface lógica e quando a interface lógica for excluída, a interface lógica no grupo de interfaces também será excluída automaticamente.
Configurar o proxy SNMP da camada de status da interface em questão
De fato, o status UP/DOWN da interface inclui o status de duas camadas no sistema. Um é o status da camada de link L2 e o outro é o status da camada de protocolo L3. Você pode usar o comando show ip interface brief para visualizar. Os dois status mudam com a mudança UP/DOWN da interface física, mas ao configurar o gateway keepalive na interface Ethernet , o status da camada de protocolo L3 é controlado pelo status de detecção keepalive.
Se a função de proxy SNMP estiver habilitada no dispositivo, o servidor de gerenciamento de rede pode obter as informações de status da interface por meio da mib pública e também pode enviar as informações de alteração de status da interface para o servidor de gerenciamento de rede quando o SNMP Trap estiver habilitado.
Com o comando function, você pode definir a camada de status da interface em questão do proxy SNMP. Por padrão, a camada de status da interface em questão do proxy SNMP é a camada de link L2, mas quando a interface Ethernet configura o gateway de manutenção, para perceber que o status de interface exibido do servidor de gerenciamento de rede se vincula consistentemente com o status de detecção de manutenção, é necessário defina a camada de status da interface em questão do proxy SNMP como camada de protocolo L3. Portanto, no ambiente habilitado com a detecção de keepalive (como o ambiente de linha WAN MSTP), sugere-se definir o link-status-care l3.
Condição de configuração
Não
Configurar grupo de interface
Tabela 1 ‑6 Configure a camada em questão do proxy SNMP de status da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a camada de gerenciamento de rede do status da interface | link-status-care { l2 | l3 } |
Obrigatório
Por padrão, a camada em questão do proxy SNMP de status da interface é a camada de link L2. |
| Sair do modo de configuração global | exit | - |
Monitoramento B á sico e Manutenção de Interfaces
Tabela 1 ‑6 Monitoramento básico e manutenção de interfaces
| Comando | Descrição |
| clear interface group group-id | Limpe as informações de estatísticas de todas as interfaces no grupo de interfaces. |
| interface group group-id display | Exibe todas as interfaces contidas no grupo de interface atual |
| show interface group group-id | Exiba as informações de todas as interfaces no grupo de interfaces. |
| show interface snmp ifindex | Exiba o valor do índice de gerenciamento de rede SNMP de todas as interfaces no grupo de interfaces |
Interface Ethernet
Visão geral
A interface Ethernet inclui interface Ethernet L2 e interface Ethernet L3.
A interface Ethernet L2 , também chamada de porta, é uma interface física. Ele funciona na camada 2 na camada de enlace de dados de modelo de referência OSI. É usado principalmente para executar duas operações básicas:
Encaminhamento de quadro de dados: De acordo com o endereço MAC (que é o endereço físico) do quadro de dados, encaminhe o quadro de dados. A interface Ethernet L2 só pode realizar o encaminhamento de comutação L2 para os pacotes recebidos, ou seja, só pode receber e enviar os pacotes cujo IP de origem e IP de destino estejam no mesmo segmento.
Aprendizagem de endereços MAC: Construa e mantenha a tabela de endereços MAC, usada para suportar o encaminhamento dos quadros de dados.
L3 é uma interface física. Ele funciona na camada 3 na camada de link de dados do modelo de referência OSI. É usado principalmente para executar duas operações básicas:
Encaminhamento de pacotes: Execute o encaminhamento de rota dos pacotes de acordo com o endereço IP (Internet Protocol) (que é o endereço net5work) do pacote. A interface Ethernet L3 só pode realizar o encaminhamento de rota L3 para o pacote recebido, ou seja, pode receber e enviar o pacote cujo IP de origem e IP de destino estejam em segmentos diferentes.
De acordo com a taxa máxima suportada pela interface Ethernet , o tipo de interface Ethernet pode ser dividido em quatro :
- fastethernet: a interface Ethernet 100M pode ser abreviada como Fa, como fastethernet 0/1 ou Fa0/1 ;
- gigabitethernet: interface Ethernet 1000M , pode ser abreviado como Gi, como gigabitethernet0/25 ou Gi0/25;
- tengigabitethernet: interface Ethernet 10 G , pode ser abreviado como Te, como tengigabitethernet1/1 ou Te1/1.
- 25ge: interface Ethernet 25G
- 40ge: interface Ethernet 40G
De acordo com o tipo de mídia da interface Ethernet , o tipo de interface Ethernet pode ser dividido em cobre (porta elétrica) e fibra (porta óptica).
Configuração da Função da Interface Ethernet
Tabela 2 ‑1 Lista de configuração de funções da interface Ethernet
| Tarefa de configuração | |
| Configurar funções básicas da interface Ethernet |
Entre no modo de configuração da interface Ethernet
Entre no modo de configuração em lote da interface Ethernet L2 Configure a taxa e o modo duplex Configurar FEC Configurar o modo MDIX (Media Dependent Interface Crossover) Configurar o tipo de mídia Configurar MTU (Unidade Máxima de Transmissão) Configurar controle de fluxo Configurar tempo de atraso Configurar economia de energia automática Configure a função Ethernet energeticamente eficiente Configure o tipo de módulo óptico suportado pela porta Configure o forçamento para cancelar o estado desabilitado para OMM da interface |
| Configure a função de detecção de interface Ethernet | Configurar a detecção de flap de status Habilitar o teste de loopback |
| Configure a supressão de tempestade da interface Ethernet L2 |
Configurar o parâmetro de supressão de tempestade
Configure a ação executada após a supressão de tempestade |
| Configure o atributo UNI/NNI | Configure o atributo UNI/NNI Configurar a conectividade da porta uni |
| Configure as funções básicas da interface Ethernet L3 | Configurar a interface Ethernet L3 |
Configurar funções básicas da interface Ethernet
Condição de configuração
Não
Entrar no modo de configuração da interface Ethernet
Para configurar na porta especificada, primeiro entre no modo de configuração da interface Ethernet L2 da interface Ethernet ou modo de configuração da interface Ethernet L3 e, em seguida, execute o comando de configuração correspondente.
Tabela 2 ‑2 Entre no modo de configuração da interface Ethernet L2
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name |
Obrigatório
Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na interface atual. |
A regra de nomenclatura do número da interface Ethernet é U/ S/P ( Unidade/ Slot/Porta). A unidade indica o dispositivo no estado de empilhamento, numerado a partir de 0. Quando o dispositivo é inicializado, é necessário confirmar se o dispositivo está no estado de empilhamento. Se não, o número do dispositivo é 0 e oculto por padrão. Slot indica o slot no dispositivo, numerado a partir de 0. Se houver porta fixa, o slot 0 é reservado para a porta fixa. O slot de serviço é numerado a partir de 1. A porta indica a interface Ethernet no dispositivo ou placa de interface . A interface Ethernet em cada dispositivo e placa de interface é numerada a partir de 1.
A regra de nomenclatura do nome da interface Ethernet nome da interface é o tipo de interface Ethernet + interface Ethernet número. Por exemplo, gigabitethernet0/1 indica a interface Ethernet 1000M numerada 1; tengigabitethernet1/2 indica a interface Gigabit Ethernet numerada 2 no slot de serviço numerado 1 . No modo VST, gigabitethernet 0/1/2 indica interface Ethernet 1000M numerada 2 no slot de serviço numerado 1 do dispositivo membro numerado 0.
Entre no modo de configuração em lote da interface Ethernet L2
Ao realizar a mesma configuração em várias portas, para melhorar a eficiência da configuração e reduzir as etapas repetidas, selecione entrar no modo de configuração em lote da interface Ethernet L2, incluindo os três casos a seguir: porta única, como gigabitethernet 0/1; portas sucessivas, usando “-” para indicar uma seção de portas sucessivas, como gigabitethernet 0/3-0/5, indicando porta 0/3, 0/4, 0/5; porta única e portas sucessivas, usando vírgula para separar, como “gigabitethernet 0/1, 0/3-0/4, 0/6”, indicando porta 0/1, 0/3, 0/4, 0/6.
Tabela 2 ‑3 Entre no modo de configuração em lote da interface Ethernet L2
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração em lote da interface Ethernet L2 | interface interface-list | Obrigatório |
A interface Ethernet L3 não suporta o modo de configuração em lote.
Configurar taxa e modo duplex
A configuração da taxa da interface Ethernet inclui dois casos:
Uma é definir a taxa fixa de acordo com o conjunto de capacidade de taxa de interface Ethernet . Os parâmetros opcionais incluem 10 (10M), 100 (100M), 1000 (1000M), 10000 (10000M) , 25000 (25000M), 40000 (40000M)
A outra é definir a taxa como auto (autonegociação), especificando que a taxa é negociada pelas interfaces Ethernet local e de mesmo nível .
Da mesma forma, configurar o modo duplex da interface Ethernet inclui dois casos:
Uma é definir o modo duplex da interface Ethernet de acordo com o conjunto de recursos do modo duplex da interface Ethernet . Os parâmetros opcionais incluem full (modo full-duplex), indicando que a interface Ethernet pode enviar pacotes ao receber os pacotes; half (modo half-duplex), indicando que a interface Ethernet só pode receber ou enviar pacotes em um momento, mas não pode executar ao mesmo tempo;
A outra é definir o modo duplex como auto (autonegociação), indicando que o modo duplex é negociado automaticamente pelas interfaces Ethernet local e peer .
Tabela 2 ‑4 Configure a taxa e o modo duplex
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na interface atual. |
| Configure a taxa da interface Ethernet | speed { 10 | 100 | 1000 | 10000 | |25000|40000|auto } | Obrigatório |
| Configure o modo duplex da interface Ethernet | duplex { auto | full | half} | Obrigatório |
Quando a interface Ethernet é a porta óptica de 100M, a taxa suportada é 100M e automática, e o modo duplex suportado é o modo automático e full-duplex; quando a interface Ethernet é uma porta óptica de 1000M, a taxa suportada é de 100M, 1000M e automática, o modo duplex suportado é o modo automático e full-duplex; quando a porta é a porta óptica de 10 gigabit, a taxa suportada é 1000M e 10000M, e o modo duplex suportado é o modo automático e full-duplex.
Configurar FEC
FEC (correção direta de erros) é um tipo de método de correção de erros. Ele pode melhorar a qualidade do sinal adicionando informações de correção de erro ao pacote na porta de envio e usando informações de correção de erro para corrigir o código de erro gerado durante a transmissão do pacote na extremidade receptora, mas também trará algum atraso ao sinal . O usuário pode optar por desabilitar ou habilitar esta função de acordo com a situação real.
O status FEC da porta pode ser configurado manualmente ou de forma adaptativa. Caso o usuário não configure o tipo de módulo óptico suportado na porta, ao inserir o módulo ou configurar a taxa de porta, o FEC será configurado de forma adaptativa de acordo com o tipo de módulo e taxa inserida na porta atual. Se houver configuração do usuário na porta, ela estará sujeita à configuração do usuário e não será adaptável quando a porta for inserida no módulo ou configurada com velocidade.
Tabela 2 ‑5 Configurar o status FEC da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na interface atual. |
| Configurar o status FEC da porta | [no] fec mode {base-r {auto|manual} |rs { auto|manual }|none manual} | Obrigatório Por padrão, a porta não habilita o FEC. |
Quando a taxa não é 25G ou 100G, o FEC não pode ser configurado. Quando a porta possui configuração manual de FEC, você não pode alternar a taxa para não 25G ou 100G. Esta função não pode ser configurada na porta membro VSL. Auto está configurado para ser distribuído de forma adaptável. Antes de reiniciar o dispositivo, o usuário precisa usar o comando write para salvar a configuração. Apenas as interfaces 25GE e 100GE suportam esta função. A configuração FEC terá efeito somente quando a velocidade real for 25G ou 100G.
Configurar o modo MDIX
Os sinais podem ser enviados somente depois que as interfaces Ethernet local e de peer estiverem conectadas . Portanto, o modo MDIX é usado com cabos de conexão.
Os cabos que conectam as interfaces Ethernet são divididos em dois tipos: cabo direto e cabo cruzado. Para suportar os dois tipos de cabos, forneça três tipos de modos MDIX: normal, cruzado e automático.
A porta óptica suporta apenas cabo direto.
A porta elétrica é formada por oito pinos. Você pode alterar as funções dos pinos configurando o modo MDIX. Ao configurar normalmente, use os pinos 1 e 2 para enviar sinais e os pinos 3, 6 para receber sinais; ao configurar como cruzado, use pino 1, 2 para receber sinais, pino 3, 6 para enviar sinais; ao definir como auto, as portas elétricas locais e peer negociam automaticamente as funções dos pinos conectando os cabos.
Ao usar o cabo direto, os modos MDIX das interfaces Ethernet local e de peer não pode ser o mesmo.
Ao usar o cabo cruzado, os modos MDIX das interfaces Ethernet local e de peer devem ser os mesmos ou pelo menos um é automático.
Tabela 2 ‑6 Configurar o modo MDIX
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na interface atual. |
| Configure o modo de recebimento e envio de sinais via cabo de rede | mdix { auto | cross | normal } |
Obrigatório
Por padrão, o modo MDIX da porta elétrica é automático e o modo MDIX da porta óptica é normal. |
A porta óptica não suporta a configuração.
Configurar tipo de mídia
Mude para usar a porta óptica ou porta elétrica na porta Combo configurando o tipo de mídia da interface Ethernet . A porta óptica e a porta elétrica correspondente não podem funcionar ao mesmo tempo. Ao especificar um tipo de mídia na porta Combo, o outro tipo de mídia é desabilitado automaticamente.
Tabela 2 ‑7 Configurar tipo de mídia
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na interface atual. |
| Configurar tipo de mídia | media-type { auto | copper | fiber } |
Obrigatório
Por padrão, o tipo de mídia da porta elétrica é cobre; o tipo de mídia da porta óptica é fibra; o tipo de mídia da porta Combo é cobre. |
Ao alternar a porta óptica e a porta elétrica na porta Combo, a configuração da interface Ethernet após a comutação, como taxa, modo duplex e modo MDIX, é inicializada com os valores padrão.
Configurar MTU
A MTU configurada na interface Ethernet L2 entra em vigor ao mesmo tempo para os pacotes de entrada e saída, e os valores definidos são os mesmos. Quando o comprimento dos pacotes recebidos e enviados excede o valor definido, os pacotes são descartados diretamente.
Em contraste, o MTU configurado na interface Ethernet L3 entra em vigor para os pacotes de entrada e saída. Quando o comprimento do pacote enviado pelo dispositivo local excede o valor definido, o pacote primeiro realiza a fragmentação do IP, fazendo com que o comprimento do pacote fragmentado não ultrapasse o valor definido, para então enviá-lo.
Tabela 2 ‑8 Configurar MTU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na interface atual. |
| Configurar MTU | mtu mtu-value |
Obrigatório
Por padrão, a MTU da interface Ethernet L2 é de 1824 bytes e a MTU da interface Ethernet L3 é de 1500 bytes. |
Configurar controle de fluxo
Quando o buffer de envio ou recebimento estiver cheio e se o modo duplex da porta for half-duplex, envie os sinais de bloqueio de volta à extremidade da fonte pelo modo de contrapressão; se o modo duplex da porta for o modo full-duplex, a porta informa a extremidade de origem para interromper o envio pelo modo de controle de fluxo.
Tabela 2 ‑9 Configurar controle de fluxo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configurar controle de fluxo | flowcontrol { on | off } | Obrigatório Por padrão, a função de controle de fluxo da porta está desabilitada. |
O controle de fluxo local pode ser realizado somente quando as extremidades local e de peer habilitam a função de controle de fluxo. A interface Ethernet L3 não suporta controle de fluxo.
Configurar tempo de atraso
Quando a porta muda de Up para Down, primeiro insira o período de tempo de supressão definido e a mudança do status da porta não é sentida pelo sistema; e, em seguida, após o tempo de supressão definido , informe a alteração do status da porta ao sistema. Desta forma, podemos evitar o custo de funcionamento desnecessário causado pela comutação frequente do estado das portas em curto espaço de tempo.
Tabela 2 ‑10 Configurar tempo de atraso
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configurar tempo de atraso | link-delay link-delay-value |
Obrigatório
Por padrão, o tempo do relatório de atraso da porta que muda de Up para Down é 0, ou seja, desabilita a função de relatório de atraso; quando a porta mudar de Up para Down, relate e processe imediatamente. |
A interface Ethernet L3 não suporta a configuração do tempo de atraso.
Configurar economia de energia automática
Ao desabilitar ou habilitar a economia de energia automática da porta, mas não conectar cabos, a porta interna está sempre no estado de porta de polling . Para reduzir o consumo de energia desnecessário, alterne automaticamente para o estado de baixo consumo de energia quando a porta estiver ociosa, configurando a economia de energia automática da porta.
Tabela 2 ‑11 Configurar economia de energia automática da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configurar economia de energia automática | auto-power-down enable | Obrigatório Por padrão, a função de economia de energia automática da porta está desabilitada. |
A interface Ethernet L3 não suporta a configuração de economia de energia automática.
Configurar a função Ethernet com eficiência energética
Quando nenhum tráfego de dados passa, a interface Ethernet interna está sempre pesquisando o estado da porta. Para reduzir esse consumo desnecessário, você pode configurar a função Ethernet energeticamente eficiente. Quando a interface está ociosa, ela é automaticamente comutada para o estado de baixa energia. Quando os dados forem transmitidos normalmente, recupere a fonte de alimentação.
Tabela 2 ‑12 Configurar a função Ethernet energeticamente eficiente
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na interface atual. |
| Configure a função Ethernet eficiente em energia | energy-efficient-ethernet enable | Opcional Por padrão, a função Ethernet energeticamente eficiente da interface Ethernet está desabilitada. |
Depois que as interfaces Ethernet em ambos os lados do cabo forem habilitadas com a função Ethernet energeticamente eficiente, a função poderá entrar em vigor. A interface óptica não suporta a função Ethernet energeticamente eficiente. A interface com a taxa de 10 Mbps e com o modo duplex como qualquer modo e a interface com a taxa de 100 Mbps e o modo duplex não como o modo de negociação automática não suportam a função Ethernet energeticamente eficiente.
Configurar o tipo de módulo óptico suportado pela porta
As interfaces ópticas Gigabit e Ethernet 10G estão no estado OMM desabilitado quando os módulos ópticos não estão inseridos. Esta porta pode ser habilitada somente quando o tipo de módulo óptico inserido na porta for o mesmo suportado pela configuração da porta. Portanto, é necessário configurar o tipo de módulo óptico suportado pela porta, que pode ser configurado manualmente pelo usuário ou configurado de forma adaptativa. Se o usuário não configurar o tipo de módulo óptico suportado na porta, o tipo de módulo óptico suportado pela porta será configurado de forma adaptativa de acordo com o tipo de módulo inserido na porta, para que a porta possa usar o módulo óptico correspondente normalmente. Se houver configuração do usuário na porta, ela estará sujeita à configuração do usuário e não será adaptável de acordo com o tipo de módulo inserido na porta.
Os tipos de módulos ópticos incluem módulo fotoelétrico Gigabit, módulo fotoelétrico 10G, módulo óptico comum e módulo óptico não reconhecido. Os módulos ópticos comuns incluem módulo óptico Gigabit, módulo óptico 10G, cabo de alta velocidade 10G, módulo óptico 40G, cabo de alta velocidade 40G e outros módulos ópticos. Módulos ópticos não reconhecidos não podem ser usados normalmente.
Por padrão, a porta suporta módulos ópticos comuns.
Devido aos diferentes níveis de capacidade de velocidade suportados por diferentes tipos de módulos, quando a porta de configuração suporta diferentes tipos de módulos ópticos (incluindo configuração de usuário e configuração adaptativa), a configuração de velocidade da porta pode ser modificada de forma síncrona.
Tabela 2 ‑13 Configure o tipo de módulo óptico suportado pela porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na interface atual. |
| Configure o módulo óptico suportado pela porta | optical fiber-to-copper { get | xget } | Obrigatório Por padrão, a porta suporta o módulo óptico comum. |
| Limpe a configuração do tipo de módulo óptico suportado pela porta | no optical fiber-to-copper { get [auto] | xget [auto] | unknown-module auto } |
Obrigatório
O comando auto é usado para limpar a configuração autoadaptável, mas não pode limpar a configuração do usuário. Depois que a configuração autoadaptável é limpa, a porta suporta o módulo óptico comum por padrão. Neste momento, o auto-adaptativo será acionado somente após a troca do módulo óptico ou a reinicialização do dispositivo. O comando non auto é usado para limpar a configuração do usuário e se readaptar automaticamente de acordo com o tipo de módulo óptico inserido na porta. |
Você pode configurar a função apenas na interface óptica Ethernet, mas não pode configurar na porta elétrica ou na porta combinada. Esta função não pode ser configurada na porta membro VSL. A função não pode ser configurada na porta 40G ou 100G. Auto está configurado para ser distribuído de forma adaptável. Antes de reiniciar o dispositivo, o usuário precisa usar o comando write para salvar a configuração.
Configurar forçar para cancelar o estado desabilitado para OMM da interface
Quando a interface óptica Ethernet não estiver inserida no módulo óptico, a porta estará no estado OMM-disabled, incapaz de receber e enviar pacotes. Após inserir um módulo óptico válido, o estado OMM desabilitado da interface óptica Ethernet será cancelado automaticamente. No entanto, às vezes a porta Ethernet também pode estar ativa sem o módulo óptico inserido, como habilitar a função de detecção de loopback. Neste momento, você pode configurar para cancelar à força o estado desabilitado do OMM da interface óptica Ethernet.
Somente quando o módulo óptico não estiver inserido na interface óptica Ethernet, ele estará no estado OMM desabilitado. A interface elétrica e a interface combinada não serão configuradas para o estado desabilitado do OMM, portanto, essa função é desnecessária.
Tabela 2 ‑14 Configurar forçar para cancelar o estado desabilitado para OMM da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na interface atual. |
| Habilitar forçar para cancelar o estado desabilitado para OMM da interface | optical enable port manual | Obrigatório Por padrão, a função está desabilitada. |
| Desabilitar forçando para cancelar o estado desabilitado para OMM da interface | no optical enable port manual | Obrigatório Por padrão, a função está desabilitada. |
Você pode configurar a função apenas na interface óptica Ethernet, mas não pode configurar na porta elétrica ou na porta combinada. Esta função não pode ser configurada na porta membro VSL.
Configurar a função de detecção de interface Ethernet
Configurar detecção de aba de status
Quando a interface Ethernet muda de Down para Up e se a detecção de flap de status da porta estiver configurada e atender à condição de detecção, considera-se que o flap de status acontece com a interface Ethernet especificada ou chamada Link-Flap e a interface Ethernet é automaticamente desabilitada e definido como Error-Disabled.
Tabela 2 ‑15 Configurar detecção de flap de status
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar detecção de flap | errdisable flap-setting cause link-flap max-flaps max-flaps-number time time-value |
Obrigatório
Por padrão, a condição de disparo da execução do Link-Flap é: dentro de 10s, a interface Ethernet detectada torna-se Ativa por pelo menos 5 vezes. |
Quando a interface Ethernet é desabilitada pela função Link-Flap e definida como Error-Disabled e se for necessário recuperar automaticamente, você pode configurar o comando errável recuperação causa para definir a função acima.
Ativar teste de loopback
Ao realizar alguma solução de problemas, como localizar a falha da interface Ethernet inicialmente, você pode habilitar a função de teste de loopback da interface Ethernet . A interface Ethernet habilitada com a função de teste de loopback não pode encaminhar pacotes normalmente.
A função de teste de loopback da interface Ethernet inclui teste de loopback interno e teste de loopback externo.
Durante o teste de loopback interno, altere a extremidade de recepção interna e a extremidade de envio da interface Ethernet especificada para fazer com que os pacotes enviados pela interface Ethernet façam um loopback no dispositivo e sejam recebidos pela interface Ethernet . Se o teste de loopback interno for bem-sucedido, isso indica que a interface Ethernet interna funciona normalmente. A interface óptica Ethernet estará no estado OMM-disabled quando não for inserida com o módulo óptico e o loop interno configurado não pode estar UP. Neste momento, o estado de porta OMM-disabled precisa ser cancelado primeiro.
Durante o teste de loopback externo, primeiro insira um cabo de loop automático na interface Ethernet e os pacotes enviados pela interface Ethernet especificada retornam à interface Ethernet através do cabo de loop automático e são recebidos pela interface Ethernet . Se o teste de loopback externo for bem-sucedido, isso indica que a interface Ethernet funciona normalmente.
Tabela 2 ‑16 Ativar teste de loopback
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na interface atual. |
| Ativar teste de loopback | loopback { internal | external } |
Obrigatório
Por padrão, a função de teste de loopback da interface Ethernet não está habilitada. |
O dispositivo não suporta a função de teste de loopback externo.
Configurar a supressão de tempestade da interface Ethernet L2
Configurar parâmetros de supressão de tempestade
Limite o tráfego de broadcast, multicast ou unicast desconhecido na porta configurando os parâmetros de supressão de tempestade. Quando o tráfego de broadcast, multicast desconhecido ou unicast desconhecido na porta excede o limite definido, o sistema descarta os pacotes excessivos, de modo a reduzir a proporção do tráfego de broadcast, multicast ou unicast desconhecido na porta para o intervalo limitado e garantir o funcionamento normal dos serviços de rede.
Tabela 2 ‑17 Configurar parâmetros de supressão de tempestade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configurar parâmetros de supressão de tempestade | storm-control { broadcast | multicast | unicast } { percent-value | kbps bps-value | pps pps-value } | Obrigatório Por padrão, não configure a supressão de tempestade de portas. |
A interface Ethernet L3 não suporta o parâmetro de supressão de tempestade.
Configurar ação executada após a supressão de tempestade
Quando a tempestade é detectada na porta especificada e a supressão de tempestade está habilitada, você pode selecionar três políticas para processar as tempestades na porta:
Uma é gravar no dispositivo e imprimir e enviar as informações de alarme de tempestade detectadas no terminal. No modo, a porta ainda está habilitada, então a porta pode receber o tráfego subsequente e a tempestade na porta não pode ser removida.
Uma é desabilitar a porta, gravar no dispositivo e imprimir e enviar as informações de alarme de tempestade detectada no terminal e enviar as informações de alarme de detecção de tempestade e desabilitar a porta para o servidor de log configurado via trap. No modo, a porta está desabilitada, então a porta não pode receber o tráfego subsequente e a tempestade na porta é removida imediatamente.
Outra é gravar no dispositivo e imprimir e enviar as informações de alarme de tempestade detectadas no terminal, e enviar as informações de alarme de detecção de tempestade para o servidor de log configurado via trap. No modo, a porta está habilitada, então a porta pode receber o tráfego subsequente e a tempestade na porta não pode ser removida.
Tabela 2 ‑18 Configurar ação executada após a supressão de tempestade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configure a ação executada após a supressão de tempestade | storm-control action { shutdown | trap | logging } |
Obrigatório
Por padrão, a ação executada após a interface detectar a tempestade é gravar no dispositivo e imprimir e enviar as informações de alarme de tempestade detectadas no terminal . |
Quando a porta está desabilitada pela função de supressão de tempestade e definida como Error-Disabled e é necessário recuperar automaticamente, você pode definir a função acima configurando o comando errdisable recuperação causa . A interface Ethernet L3 não suporta a configuração da ação executada após a ocorrência da supressão de tempestade.
Configurar Blindagem de Pacote de Transmissão
O pacote unicast desconhecido, o pacote multicast desconhecido e o pacote broadcast serão transmitidos na VLAN. Em alguns aplicativos, a porta não precisa enviar esses pacotes. Habilite a função de blindagem de pacotes de transmissão nessas portas e essas portas não enviarão esses pacotes. Esta função terá efeito na direção de saída da porta.
Condição de configuração
Nenhum
Configurar a blindagem de pacotes de transmissão
Tabela 2 ‑19 Configurar blindagem de pacotes de transmissão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configurar a blindagem do pacote de transmissão | flood-control { bcast | unknown-mcast | unknown-ucast } | Obrigatório Por padrão, não proteja os pacotes broadcast, pacotes multicast desconhecidos e pacotes unicast desconhecidos nas portas de saída . |
Configurar tipo UNI/NNI
Configurar tipo UNI/NNI
A porta Uni é a porta de conexão entre o dispositivo do usuário e a rede; A porta nni é a interface de conexão entre redes. Em um dispositivo, a porta nni e a porta uni ou as portas nni são interconectadas; as portas uni são separadas umas das outras.
Tabela 2 ‑20 Configurar atributo UNI/NNI
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o atributo UNI/NNI | port-type { nni | uni } | Obrigatório Por padrão, o tipo UNI/NNI da interface Ethernet L2 e do grupo de agregação é nni. |
A interface Ethernet L3 não suporta a configuração do tipo UNI/NNI.
Configurar a conectividade da porta uni
Por padrão, todas as portas uni de um dispositivo são separadas umas das outras. No entanto, para realizar a intercomunicação entre as várias portas uni especificadas, mas não alterar a relação de separação entre essas portas uni e outras portas uni, você pode configurar a conectividade da porta uni.
Ao configurar a conectividade na porta uni especificada, você só pode definir se a porta uni pode encaminhar pacotes para outras portas uni, sem afetar se outras portas uni podem encaminhar pacotes para a porta uni especificada. Portanto, para realizar a intercomunicação entre várias portas uni, você deve configurar como comunidade nessas portas uni, respectivamente.
Tabela 2 ‑21 Configurar a conectividade da porta uni
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure a conectividade da porta uni | uni-isolate { community | isolated } | Obrigatório Por padrão, a porta uni não pode encaminhar pacotes para outras portas uni. |
O comando só pode ter efeito na porta uni. A interface Ethernet L3 não suporta a configuração da conectividade da porta uni.
Configurar funções b á sicas da interface Ethernet L3
De acordo com a camada de processamento da interface Ethernet para o pacote, a interface Ethernet pode funcionar no modo L2 ou no modo L3. Se definir o modo de trabalho da interface Ethernet como o modo L2, ele é usado como uma interface Ethernet L2. Se definir o modo de trabalho da interface Ethernet como modo L3, ela é usada como uma interface Ethernet L3 e sua função é equivalente à interface VLAN.
Condição de configuração
Não
Configurar Interface Ethernet L3
Tabela 2 ‑22 Configurar interface Ethernet L3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | - |
| Configurar a interface Ethernet L3 | no switchport |
Obrigatório
Por padrão, a interface Ethernet funciona no modo L2 e é usada como uma interface Ethernet L2. |
Após o modo de trabalho dos switches da interface Ethernet, as outras configurações da interface Ethernet, exceto descrição, desligamento, velocidade, duplex, tipo de mídia, mdix, eee , todas restauram a configuração padrão no novo modo. Quando a interface Ethernet serve como uma interface L3, para a configuração das funções básicas da interface Ethernet L3, consulte a configuração das funções básicas da interface VLAN.
Monitoramento e manutenção da interface Ethernet
Tabela 2 ‑23 Monitoramento e manutenção da interface Ethernet
| Comando | Descrição |
| clear interface interface-name | Limpe as informações estatísticas da interface Ethernet L3 especificada |
| clear interface { interface-list | switchport } statistics | Limpe as informações de estatísticas de pacote e tráfego da porta |
| clear optical { all | interface interface-list } exception statistic | Limpe as informações de estatísticas de anormalidade do módulo óptico inserido na interface Ethernet |
| show errdisable flap-values | Exibe a configuração atual de acionamento executando a função Link-Flap |
| show interface { interface-list [ group ] | switchport [ brief [ down | up | vsl ]] } | Exibe todas as informações ou informações abstratas da interface Ethernet ou porta membro do link do switch virtual |
| show interface interface-list statistics | Exibe as informações de estatísticas de pacote e tráfego da porta |
| show interface switchport statistics [ packet | rate | ratio ] | Exiba as informações de estatísticas de pacotes e tráfego de todas as portas do dispositivo |
| show optical { all | interface interface-list } [ detail | exception statistic ] | Exibir as informações do módulo óptico inserido na interface Ethernet |
| show port-type [ interface-list | { uni | nni } [ interface interface-list ] ] | Exiba as informações do atributo UNI/NNI da porta |
| show interface interface-list rate-peak [ input | output] | Exibir as informações de monitoramento de fluxo da porta especificada |
| show storm-control [ interface interface-list ] | Exibir a configuração de supressão de tempestade da porta especificada |
| show optical { all | interface interface-list } omm-disabled status | Exiba se a porta está no estado desabilitado para OMM e o motivo pelo qual a porta está no estado desabilitado para OMM |
Exemplo de configuração típica de interface Ethernet
Configurar Função de Supressão de Tempestades
Requisitos de rede
Configure a função de supressão de tempestade na porta do dispositivo para suprimir os pacotes broadcast, unicast desconhecido e multicast desconhecido, percebendo que o PC2 pode acessar a Internet normalmente quando o PC1 envia muitos pacotes broadcast, unicast desconhecido e multicast desconhecido .
Topologia de rede
Figura 2 ‑1 Topologia de rede de configuração da supressão de tempestade
Etapas de configuração
- Passo 1 : Configure a VLAN e o tipo de link de porta no dispositivo.
# Cria VLAN2 no dispositivo.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
# Configura o tipo de link da porta gigabitethernet 0/1 e gigabitethernet 0/2 no dispositivo como acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1,0/2Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
#Configure o tipo de link da porta gigabitethernet 0/3 no dispositivo como tronco, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/3Device(config-if-gigabitethernet0/3)#switchport mode trunkDevice(config-if-gigabitethernet0/3)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/3)#exit
- Passo 2: Configurar a função de supressão de tempestade
# Adote o modo de limitação b ps para suprimir os pacotes broadcast, unicast desconhecido e multicast desconhecido na porta gigabitethernet0/1 e a taxa de supressão é de 1024 b ps .
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#storm-control broadcast kbps 1024Device(config-if-gigabitethernet0/1)#storm-control unicast kbps 1024Device(config-if-gigabitethernet0/1)#storm-control multicast kbps 1024Device(config-if-gigabitethernet0/1)#exit
- Passo 3: Confira o resultado
#Visualize as informações de supressão de tempestade da porta gigabitethernet0/1 no dispositivo.
Device#show storm-control interface gigabitethernet 0/1Interface Unicast Broadcast Multicast Action---------------------------------------------------------------------------gi0/1 enable enable enable logging
# Quando o PC1 envia muitos pacotes broadcast, unicast desconhecido e multicast desconhecido , o PC2 também pode acessar a Internet normalmente.
Interface Link Aggregation
Visão geral
A interface link aggregation é uma interface lógica. Ao habilitar a função de agregação de link em várias portas, as várias portas com o mesmo recurso de agregação de link formam o grupo de agregação e são abstraídas para a interface link aggregation; enquanto isso, as várias portas com o mesmo atributo são chamadas de portas membro do grupo de agregação. É usado principalmente para expandir a largura de banda do link e melhorar a confiabilidade da conexão.
Configuração da função da interface link aggregation
Tabela 3 ‑1 Lista de configuração de função da interface link aggregation
| Tarefa de configuração | |
| Configure as funções básicas da interface link aggregation |
Entre no modo de configuração do grupo de agregação
Configurar o modo de encaminhamento do grupo de agregação |
Configurar funções básicas da interface link aggregation
Condição de configuração
Não
Entrar no modo de configuração do grupo de agregação
Tabela 3 ‑2 Entre no modo de configuração do grupo de agregação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | Obrigatório |
Antes de entrar no modo de configuração do grupo de agregação especificado, primeiro crie o grupo de agregação correspondente.
Configurar o modo de encaminhamento do grupo de agregação
No ambiente VST, para reduzir a carga do link VSL, o tráfego de serviço recebido do dispositivo membro é primeiro encaminhado da outra interface Ethernet do dispositivo local por padrão, ou seja, adote a política de encaminhamento local anterior. Na agregação de link entre dispositivos, a carga do tráfego de serviço de link de membro no grupo de agregação não é balanceada. O usuário pode definir o modo de encaminhamento do grupo de agregação de acordo com o cenário real da rede. Quando o modo de encaminhamento é definido como o balanceamento de carga global, na agregação de link entre dispositivos, a carga do tráfego de serviço de link de membro no grupo de agregação é distribuída uniformemente.
Tabela 3 ‑3 Configurar o modo de encaminhamento do grupo de agregação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o modo de encaminhamento do grupo de agregação | link-aggregation forward-mode { global-fair | local-prior } |
Obrigatório
Por padrão, o modo de encaminhamento do grupo de agregação é o balanceamento de carga global |
Quando o dispositivo funciona no modo VST, ele pode configurar a agregação de link modo de avanço { feira global | comando local-prior } .
Monitoramento e manutenção da interface link aggregation
Tabela 3 ‑4 Monitoramento e manutenção da interface link aggregation
| Comando | Descrição |
| clear interface switchport link-aggregation link-aggregation-id statistics | Limpe as informações de estatísticas de pacote e tráfego do grupo de agregação especificado |
| show interface switchport link-aggregation [ link-aggregation-id | brief ] | Exibir todas as informações do grupo de agregação |
| show interface link-aggregation link-aggregation-id statistics | Exiba as informações de estatísticas de pacote e tráfego do grupo de agregação especificado |
| show interface link-aggregation link-aggregation-id rate-peak [ input | output ] | Exibir as informações de monitoramento de fluxo do grupo de agregação especificado |
| show port-type interface link-aggregation link-aggregation-id | Exiba as informações de atributo UNI/NNI do grupo de agregação |
Interface VLAN
Visão geral
A interface VLAN é uma interface lógica, usada para ser vinculada à VLAN e completar o encaminhamento de pacotes entre diferentes VLANs. Uma VLAN só pode ser vinculada a uma interface VLAN. Uma interface VLAN também só pode ser vinculada a uma VLAN.
Configuração da função da interface VLAN
Tabela 4 ‑1 lista de configuração da função da interface VLAN
| Tarefa de configuração | |
| Configure as funções básicas da interface VLAN |
Configurar interface VLAN
Configure a largura de banda lógica da interface Configurar o atraso da interface Configurar interface MTU |
Configurar funções básicas da interface VLAN
Condição de configuração
Não
Configurar interface VLAN
Tabela 4 ‑2 Configurar interface VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Criar interface VLAN | interface vlan vlan-id | Obrigatório Por padrão, não crie uma interface VLAN. |
A interface VLAN é uma interface lógica. Para funcionar normalmente, você precisa criar a VLAN correspondente e adicionar a porta física à VLAN. Para saber como criar VLAN e adicionar porta física à VLAN, consulte o capítulo VLAN do manual de configuração. Não há nenhum requisito de ordem para criar a interface VLAN, criar VLAN e adicionar porta física à VLAN.
Configurar a largura de banda lógica da interface
A largura de banda lógica da interface afeta o cálculo do custo da rota e QoS, mas não afeta a largura de banda física da interface. Normalmente, quando a interface está conectada à WAN, sugere-se que a largura de banda lógica da interface de configuração do usuário seja consistente com a largura de banda real da linha alugada.
Tabela 4 ‑3 Configurar a largura de banda lógica da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface vlan vlan-id | - |
| Configure a largura de banda lógica da interface VLAN | bandwidth width-value | Opcional Por padrão, a largura de banda lógica da interface VLAN é de 100.000 Kbps. |
Configurar atraso de interface
A configuração do atraso da interface afeta o cálculo do custo do protocolo de roteamento, mas não afeta o atraso real da transmissão da interface. O usuário pode alterar o custo do protocolo de roteamento configurando o atraso da interface.
Tabela 4 ‑4 Configurar o atraso da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface vlan vlan-id | - |
| Configurar o atraso da interface VLAN | delay delay-time | Opcional Por padrão, o atraso da interface VLAN é 10 e a unidade é 10 microssegundos. |
Configurar interface MTU
A interface MTU decide o comprimento máximo do pacote de fragmento IP e o usuário pode configurar manualmente.
Tabela 4 ‑5 Configurar interface MTU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface vlan vlan-id | - |
| Configurar interface VLAN MTU | mtu mtu-size | Obrigatório Por padrão, o MTU da interface VLAN é de 1500 bytes. |
Monitoramento e manutenção da interface VLAN
Tabela 4 ‑6 Monitoramento e manutenção da interface VLAN
| Comando | Descrição |
| clear interface vlan vlan-id | Limpe as informações estatísticas da interface VLAN especificada |
| show interface vlan vlan-id | Veja as informações da interface VLAN especificada |
| show interface vlan vlan-id original statistics | Veja as informações estatísticas da interface VLAN especificada |
Exemplo de configuração típico da interface VLAN
Configurar interface VLAN
Requisitos de rede
Configure a interface VLAN no dispositivo para realizar a intercomunicação entre PC1 e PC2 de diferentes VLANs.
Topologia de rede
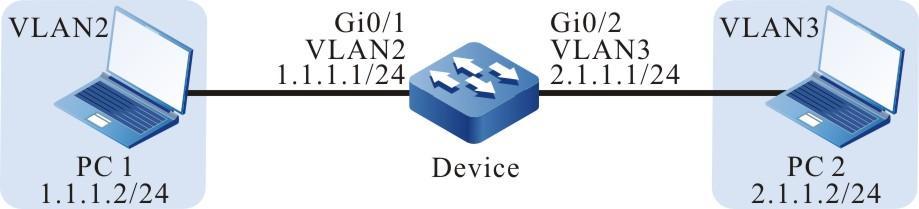
Figura 4 ‑1 Topologia de rede de configuração da interface VLAN
Etapas de configuração
- Passo 1: Configure a VLAN e o tipo de link de porta no dispositivo.
# Crie VLAN2 e VLAN3 no dispositivo.
Device#configure terminalDevice(config)#vlan 2-3
# Configure o tipo de link da porta gigabitethernet 0/1 e gigabitethernet 0/2 no dispositivo como acesso. A porta gigabitethernet 0/1 permite a passagem dos serviços da VLAN2 e a gigabitethernet 0/2 permite a passagem dos serviços da VLAN3.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2Device(config-if-gigabitethernet0/1)#exitDevice(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode accessDevice(config-if-gigabitethernet0/2)#switchport access vlan 3Device(config-if-gigabitethernet0/2)#exit
- Passo 2: Configure a interface VLAN e o endereço IP no dispositivo.
#Crie VLAN2 no dispositivo cujo endereço IP é 1.1.1.1 e máscara de sub-rede é 255.255.255.0; crie uma interface VLAN3 cujo endereço IP seja 2.1.1.1 e a máscara de sub-rede seja 255.255.255.0.
Device(config)#interface vlan 2Device(config-if-vlan2)#ip address 1.1.1.1 255.255.255.0Device(config-if-vlan2)#exitDevice(config)#interface vlan 3Device(config-if-vlan3)#ip address 2.1.1.1 255.255.255.0Device(config-if-vlan3)#exit
- Passo 3: Confira o resultado.
#Visualize as informações da interface VLAN no dispositivo.
Device#show interface vlan 2vlan2:line protocol is upFlags: (0xc008063) BROADCAST MULTICAST ARP RUNNINGType: ETHERNET_CSMACDInternet address: 1.1.1.1/24Broadcast address: 1.1.1.255Metric: 0, MTU: 1500, BW: 100000 Kbps, DLY: 100 usec, VRF: globalReliability 255/255, Txload 1/255, Rxload 1/255Ethernet address is 0012.2355.99135 minutes input rate 0 bits/sec, 0 packets/sec5 minutes output rate 0 bits/sec, 0 packets/sec0 packets received; 1 packets sent0 multicast packets received1 multicast packets sent0 input errors; 0 output errors0 collisions; 0 droppedUnknown protocol 0Device#show interface vlan 3vlan3:line protocol is upFlags: (0xc008063) BROADCAST MULTICAST ARP RUNNINGType: ETHERNET_CSMACDInternet address: 2.1.1.1/24Broadcast address: 2.1.1.255Metric: 0, MTU: 1500, BW: 100000 Kbps, DLY: 100 usec, VRF: globalReliability 255/255, Txload 1/255, Rxload 1/255Ethernet address is 0012.2355.99135 minutes input rate 0 bits/sec, 0 packets/sec5 minutes output rate 0 bits/sec, 0 packets/sec0 packets received; 1 packets sent0 multicast packets received1 multicast packets sent0 input errors; 0 output errors0 collisions; 0 droppedUnknown protocol 0
#PC1 pode fazer ping no PC2.
Interface Loopback
Visão geral
A interface loopback, também chamada de interface loopback local, é uma interface virtual lógica realizada por software. A interface não é afetada pelo status físico. Desde que não desabilitando manualmente, seu status está sempre habilitado. No protocolo de roteamento dinâmico, como OSPF, você pode selecionar o endereço IP da interface Loopback como Router ID. Para os pacotes enviados para a interface Loopback, o dispositivo considera que os pacotes são enviados para si mesmo, portanto não encaminha os pacotes.
Configuração da função de interface loopback
Tabela 5 ‑1 Lista de configuração de funções da interface Loopback
| Tarefa de configuração | |
| Configure as funções básicas da interface Loopback |
Configurar interface loopback
Configure a largura de banda lógica da interface Configurar o atraso da interface |
Configurar funções básicas da interface loopback
Condição de configuração
Não
Configurar interface loopback
Tabela 5 ‑2 Configurar interface loopback
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Criar interface loopback | interface loopback unit –number | Obrigatório Por padrão, não crie uma interface Loopback. |
Configurar a largura de banda lógica da interface
A largura de banda lógica da interface afeta o cálculo do custo da rota e QoS, mas não afeta a largura de banda física da interface. Normalmente, quando a interface está conectada à WAN, sugere-se que a largura de banda lógica da interface de configuração do usuário seja consistente com a largura de banda real da linha alugada.
Tabela 5 ‑3 Configure a largura de banda lógica da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure a largura de banda lógica da interface | bandwidth width-value | Opcional Por padrão, a largura de banda lógica da interface Loopback é de 8.000.000 Kbps. |
Configurar atraso de interface
A configuração do atraso da interface afeta o cálculo do custo do protocolo de roteamento, mas não afeta o atraso real da transmissão da interface. O usuário pode alterar o custo do protocolo de roteamento configurando o atraso da interface.
Tabela 5 ‑4 Configurar o atraso da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o atraso da interface | delay delay-time | Opcional Por padrão, o atraso da interface Loopback é de 5000 e a unidade é de 10 ms. |
Interface Null
Visão geral
A interface null é uma interface lógica realizada por software. Qualquer pacote enviado para a interface Null é descartado. O protocolo de roteamento dinâmico, como o OSPF, gera a rota resumida automaticamente. A interface de saída aponta para a interface Null e pode evitar o loop de rota efetivamente. A interface Null0 é criada pelo dispositivo por padrão e o usuário não pode desativá-la ou excluí-la.
Configuração da função de interface null
Tabela 6 – 1 Lista de configuração de funções da interface Nula
| Tarefa de configuração | |
| Configure as funções básicas da interface Null | Configure as funções básicas da interface Null |
Configurar funções básicas da interface null
Condição de configuração
Não
Configurar funções básicas da interface null
Tabela 6 – 2 Configurar funções básicas da interface Null
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração de interface null | interface null 0 | Obrigatório |
| Configure a proibição de enviar o pacote de erro de ICMP inacessível | no ip unreachables | Opcional Por padrão, proíbe o envio do pacote de erro de ICMP inacessível. |
A interface null apenas suporta a configuração de permissão ou proibição de envio do pacote de erro de ICMP inacessível. O pacote que atinge a interface Null é descartado e não é necessário enviar o erro de ICMP inacessível.
Interface VSL
Introdução à interface VSL
Vincule várias portas físicas para formar uma interface de link de switch virtual (VSL-Channel). canal VSL é o canal de link lógico de troca de pacotes de protocolo e encaminhamento de dados de serviço entre os comutadores membros no sistema VSL. Cada porta física é chamada de porta membro do link do switch virtual.
Os switches membros são adicionados a um domínio de switch e são interconectados através da interface VSL, formando um switch virtual.
Configuração da Função da Interface VSL
Tabela 7 - 1 A lista de configuração do canal VSL funções
| Tarefa de configuração | |
| Configurar as funções do canal VSL | Entre no modo de configuração do canal VSL |
Configurar a função de interface VSL
Condição de configuração
Não
Entrar no modo de configuração da interface VSL
Tabela 7 - 2 Entre no modo de configuração do canal VSL
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| modo de configuração do canal VSL | vsl-channel vsl-channel-id |
Obrigatório
No modo autônomo, vsl-channel- id é um valor unidimensional, indicando o número do canal VSL; no modo VST, é o valor bidimensional. A primeira dimensão é o número do membro do switch virtual e a segunda dimensão é o número do canal VSL. |
Antes de entrar no modo de configuração do canal VSL, primeiro crie o canal VSL correspondente.
Monitoramento e manutenção da interface VSL
Tabela 7 - 3 Monitoramento e manutenção da interface VSL
| Comando | Descrição |
| clear vsl-channel vsl-channel-id statistics | Limpe as informações de estatísticas de pacote e fluxo da interface VSL especificada |
| show vsl-channel vsl-channel-id rate-peak [ input | output ] | Exiba as informações de monitoramento de fluxo da interface VSL especificada |
| show vsl-channel vsl-channel-id statistics | Exiba as informações de estatísticas de pacote e fluxo da interface VSL especificada |
Interface Tunnel (Aplicável somente ao modelo S3054G-B)
Visão geral
Túnel é a tecnologia de usar um protocolo de rede para transmitir outro protocolo de rede. Inclui o processo de encapsulamento, transmissão e desencapsulação de dados. O caminho percorrido pelo pacote encapsulado ao ser transmitido na rede é chamado de túnel. O túnel é uma conexão virtual ponto a ponto. Os dispositivos nos dois lados do túnel são chamados de endpoints do túnel e são responsáveis por encapsular e desencapsular pacotes.
Configuração da Função da Interface do Túnel
Tabela 8 ‑1 Lista de configuração de função da interface de túnel
| Tarefa de configuração | |
| Configure as funções básicas da interface do túnel | Configure as funções básicas da interface do túnel |
Configurar a interface do túnel
Condição de configuração
Nenhum
Configurar funções básicas da interface tunnel
Tabela 8 ‑2 Configurar funções básicas da interface de túnel
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Crie uma interface tunnel e entre em seu modo de configuração | interface tunnel tunnel-unit | Obrigatório Por padrão, a interface do túnel não é criada no dispositivo. |
| Configurar o modo de trabalho da interface do túnel | tunnel mode { gre[ ip | ipv6] | ipip | ipipv6| ipv6ipv6 | ipv6ip [6to4 | isatap] } | Opcional Por padrão, o modo de trabalho da interface do túnel é GRE sobre IPv4. |
| Configurar TOS da interface do túnel | tunnel tos tos-value | Opcional Por padrão, a interface do túnel não está configurada com TOS. |
| Configurar o TTL da interface do túnel | tunnel ttl ttl-value | Opcional Por padrão, o valor TTL da interface do túnel é 255. |
O TOS configurado na interface tunnel é usado para preencher o campo TOS no cabeçalho do pacote IPv4 externo durante o encapsulamento. Se o valor TOS não estiver configurado na interface do túnel, use o valor TOS no cabeçalho do pacote IPv4 interno. O valor TTL configurado na interface do túnel é usado para preencher o campo TTL no cabeçalho do pacote IPv4 externo durante o encapsulamento.
Monitoramento e manutenção da interface do t ú nel
Tabela 8 ‑3 Monitoramento e manutenção da interface do túnel
| Comando | Descrição |
| enable | O modo privilegiado |
| debug tunnel {all | config | event | forward| packet } | Habilite as informações de depuração do túnel |
| show tunnel [tunnel-id] [slot slot-num] | Exibir as informações do túnel |
GRE (Aplicável somente ao modelo S3054G-B)
Visão geral
O Encapsulamento de Roteamento Genérico (GRE) é um protocolo de encapsulamento de túnel genérico que definiu como usar um protocolo de rede para encapsular outro protocolo de rede.
O túnel GRE é uma tecnologia de túnel entre muitas tecnologias de túnel. O ponto inicial e o ponto final de um túnel precisam ser configurados manualmente. O túnel é uma conexão virtual de ponta a ponta. Ele fornece um canal de transmissão para os pacotes encapsulados. As duas extremidades do túnel encapsulam e desencapsulam os pacotes de dados, respectivamente.
- Encapsulamento GRE:
Se um pacote de dados precisar ser transmitido através de um túnel GRE, o túnel adiciona um cabeçalho GRE ao cabeçalho do pacote e adiciona um cabeçalho IP ao cabeçalho GRE. Defina o número do protocolo do cabeçalho IP para 47 (número do protocolo GRE no cabeçalho IP), defina o endereço de origem do cabeçalho IP para o endereço de origem do túnel e defina o endereço de destino do cabeçalho IP para o endereço de destino de o tunel.
- Estrutura do pacote GRE
Pacote de carga útil: O pacote da camada de rede (como o pacote IP) antes de entrar no túnel é considerado a carga útil válida do pacote de túnel. O protocolo do pacote é chamado de protocolo de passageiros do túnel GRE.
Cabeçalho GRE: Refere-se ao cabeçalho GRE que é adicionado ao pacote de carga útil após o pacote de carga útil entrar no túnel. O cabeçalho GRE contém o protocolo GRE e algumas informações relacionadas ao protocolo do passageiro.
Cabeçalho de entrega: O cabeçalho de protocolo externo encapsulado (como cabeçalho IP) é o cabeçalho do protocolo para a rede na qual o túnel está localizado. É uma ferramenta de transmissão que ajuda um pacote de protocolo a atravessar a rede de outro protocolo.
- Encaminhamento de pacotes GRE
Depois que um pacote é encapsulado no ponto inicial de um túnel GRE, ele seleciona uma rota de acordo com o destino após o encapsulamento e, em seguida, é enviado pela interface de rede correspondente. Os dispositivos intermediários tomam o pacote como um pacote comum até que o pacote chegue ao fim do túnel.
- Decapsulação GRE:
A decapsulação é o processo inverso do encapsulamento. Após o ponto final do túnel receber o pacote, ele analisa o cabeçalho de entrega. Se o ponto final do túnel descobrir que o destino é seu próprio endereço, ele verifica o campo de protocolo do cabeçalho IP. Se o campo de protocolo for 47 (número do protocolo GRE), o ponto final do túnel entrega o pacote ao túnel GRE para processamento. O túnel primeiro remove o cabeçalho de entrega e, em seguida, verifica o número do protocolo, a soma de verificação e a palavra-chave no cabeçalho GRE. Após o processamento necessário, o túnel remove o cabeçalho GRE e entrega o pacote de carga útil ao protocolo do passageiro para processamento posterior. Em seguida, a decapsulação é concluída.
Configuração da função GRE
Tabela 10 ‑1 lista de funções GRE
| Tarefas de configuração | |
| Configure um túnel GRE. | Configure um túnel GRE. |
Configurar um túnel GRE
Condição de configuração
Antes de configurar um túnel GRE, certifique-se de que:
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
- Interfaces de túnel foram criadas e os parâmetros básicos foram configurados. (Consulte o manual de configuração da interface de túnel.)
- Um protocolo unicast foi configurado para que as rotas nas duas extremidades do túnel sejam alcançáveis.
Configurar um túnel GRE
Tabela 10 ‑2 Configurando um túnel GRE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface tunnel . | interface tunnel tunnel-number | - |
| interface do túnel Morada | ip address ip-address { mask | mask-length } | Obrigatório Por padrão, nenhum endereço é configurado para a interface do túnel. |
| Configure o modo de interface tunnel para GRE sobre IPv4. | tunnel mode gre ip | Opcional. Por padrão, o modo de interface tunnel é GRE sobre IPv4. |
| Configure o endereço de origem ou o nome da interface na interface do túnel. | tunnel source { ip-address | interface-name } |
Obrigatório
. Por padrão, o endereço de origem e o nome da interface não são configurados na interface do túnel. |
| Configure o endereço de destino ou o nome do host na interface do túnel. | tunnel destination { ip-address | hostname } |
Obrigatório
. Por padrão, o endereço de destino e o nome do host não são configurados na interface do túnel. |
l Nas duas extremidades de um túnel, os endereços de origem e de destino devem ser configurados. O endereço de origem de uma extremidade é a extremidade de destino da outra extremidade. l Ao configurar a origem de um túnel, se o modo de interface for adotado, o endereço primário da interface de origem será usado como endereço de origem do túnel. l As duas extremidades de um túnel devem ser configuradas com o mesmo modo de túnel; caso contrário, a transmissão através do túnel falha. l Em um dispositivo, dois ou mais túneis com o mesmo modo de túnel, endereço de origem e endereço de destino não são permitidos.
Monitoramento e manutenção de GRE
Consulte a Seção 8.2.2 Monitoramento e Manutenção da Interface do Túnel no Manual de Configuração da Interface da Interface do Túnel.
Exemplo de configuração típica de GRE
Configurar funções básicas do GRE
Requisitos de rede
- IP Network1 e IP Network2 são duas redes privadas de Device1 e Device3.
- IP Network1 e IP Network2 se comunicam através do túnel GRE entre Device1 e Device3.
Topologia de rede
Figura 10 ‑1 Rede para configurar funções básicas do GRE
Etapas de configuração
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
# Consulta a tabela de roteamento do Device3.
Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setO 1.0.0.0/24 [110/65536] via 2.0.0.1, 00:18:40, vlan2C 2.0.0.0/24 is directly connected, 00:22:27, vlan2 C 192.168.100.0/24 is directly connected, 00:00:28, vlan3
O método para consultar a tabela de roteamento do Dispositivo 1 e do Dispositivo2 é o mesmo do Dispositivo 3, portanto, os processos não são descritos aqui.
- Passo 4: Configure um túnel GRE.
#No Dispositivo1, configure o túnel1 do túnel GRE, defina o endereço de origem para 1.0.0.1, o endereço de destino para 2.0.0.2 e o endereço IP para 10.0.0.1.
Device1(config)#interface tunnel 1Device1(config-if-tunnel1)#tunnel source 1.0.0.1Device1(config-if-tunnel1)#tunnel destination 2.0.0.2Device1(config-if-tunnel1)#ip address 10.0.0.1 255.255.255.0Device1(config-if-tunnel1)#exit
#No Dispositivo3, configure o túnel1 do túnel GRE, defina o endereço de origem para 2.0.0.2, o endereço de destino para 1.0.0.1 e o endereço IP para 10.0.0.2.
Device3(config)#interface tunnel 1Device3(config-if-tunnel1)#tunnel source 2.0.0.2Device3(config-if-tunnel1)#tunnel destination 1.0.0.1Device3(config-if-tunnel1)#ip address 10.0.0.2 255.255.255.0Device3(config-if-tunnel1)#exit
#Consulte as informações do túnel GRE do Device3.
Device3#show tunnel 1Tunnel 1:Tunnel mode is gre ipGre checksum validation is disabledGre key is not setGre keepalive is disabledSource ipv4 address is 2.0.0.2(Source ipv4 address is up on source interface vlan2)Destination ipv4 address is 1.0.0.1Tunnel state is upEncapsulation vrf is global(0x0)TTL(time-to-live) is 255TOS(type of service) is not settotal(1)
O método para consultar as informações do túnel GRE do Dispositivo 1 é o mesmo do Dispositivo 3, portanto, o processo não é descrito aqui. l Se um túnel estiver localizado em segmentos de rede diferentes, os dois dispositivos nas duas extremidades do túnel devem ser configurados com uma rota estática que alcance o túnel de mesmo nível com a interface do túnel como interface de saída.
#No Device1, configure a rota estática para a interface de saída tunnel1 do IP Network2.
Device1(config)#ip route 192.168.100.0 255.255.255.0 tunnel1#No Device3, configure a rota estática para a interface de saída tunnel1 do IP Network1.
Device3(config)#ip route 192.168.1.0 255.255.255.0 tunnel1#Visualize a tabela de rotas do Device3.
Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setO 1.0.0.0/24 [110/65536] via 2.0.0.1, 00:43:30, vlan2 C 2.0.0.0/24 is directly connected, 00:47:17, vlan2C 10.0.0.0/24 is directly connected, 00:17:12, tunnel1S 192.168.1.0/24 [1/100000] is directly connected, 00:00:10, tunnel1
O método para consultar a tabela de roteamento do Dispositivo 1 é o mesmo do Dispositivo 3, portanto, o processo não é descrito aqui.
IPIP (Aplicável somente ao modelo S3054G-B)
Visão geral
O túnel IPIP (IPv4 sobre IPv4 ) é uma das tecnologias de túnel. Semelhante ao túnel GRE (Generic Routing Encapsulation), o início e o fim do túnel IPIP são configurados manualmente. Ele serve um link PTP virtual e fornece um túnel de transmissão para o pacote encapsulado. O início e o fim do túnel encapsulam e desencapsulam o pacote de dados. O túnel IPIP encapsula apenas os pacotes de dados IPv4 e permite que os pacotes de dados encapsulados sejam transmitidos por outra rede IPv4.
- Encapsulamento IPIP
Quando o pacote de dados IP é transmitido pelo túnel IPIP, o túnel adiciona um cabeçalho de pacote IP. No cabeçalho do pacote IP, o número do protocolo é definido como 4, o endereço IP de origem é definido como o endereço IP de origem do túnel e o endereço IP de destino é definido como o endereço IP de destino do túnel.
- Estrutura do pacote IPIP

Carga útil IP: indica a carga útil do pacote IP antes do pacote entrar no túnel. É uma carga útil válida do pacote de túnel.
Cabeçalho IP: indica o cabeçalho do pacote IP antes do pacote entrar no túnel.
Cabeçalho IP externo: indica o cabeçalho do pacote IP externo encapsulado. É uma ferramenta de transmissão que permite que o pacote IP seja transmitido por outra rede IP.
- Encaminhamento de pacotes IPIP
Depois que o pacote é encapsulado no início do túnel IPIP, um roteamento é selecionado para o pacote com base no endereço IP de destino encapsulado e, em seguida, o pacote é enviado da interface de rede correspondente. O equipamento intermediário encaminha o pacote como o pacote IP comum até que o pacote chegue ao final do túnel.
- Decapsulação IPIP
Ao contrário do processo de encapsulamento, no processo de desencapsulamento, a extremidade do túnel analisa primeiro o cabeçalho IP externo ao receber o pacote. Se o endereço IP de destino for o endereço IP do final do túnel, verifique o campo de protocolo do cabeçalho do pacote IP. Se o campo de protocolo for 4, transmita o pacote para o túnel IPIP para manipulação. O túnel remove o cabeçalho IP externo do pacote e escolhe um roteamento para o pacote com base no endereço IP de destino do pacote desencapsulado. A manipulação subsequente é realizada com base no resultado do roteamento.
Função IPIP
Tabela 10 ‑1 lista de funções IPIP
| Tarefa de configuração | |
| Configurar o túnel IPIP | Configurar o túnel IPIP |
Configurar t ú nel IPIP
Condição de configuração
Antes de configurar o túnel IPIP, primeiro conclua as seguintes tarefas:
- Configure o endereço IP da interface, permitindo que os nós adjacentes na camada de rede sejam alcançáveis.
- Crie a interface do túnel e configure os parâmetros básicos. Para obter detalhes, consulte o Manual de configuração da interface do túnel .
- Configure qualquer protocolo de roteamento unicast, permitindo que o roteamento para ambas as extremidades do túnel seja alcançável.
Configurar túnel IPIP
Tabela 10 ‑2 Configurar o túnel IPIP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface tunnel | interface tunnel tunnel-number | - |
| Configurar o endereço IP da interface tunnel | ip address ip-address { mask | mask-length } | Obrigatório Por padrão, o endereço IP na interface do túnel não está configurado. |
| Configure o modo de interface tunnel como IPv4 sobre IPv4 | tunnel mode ipip | Obrigatório Por padrão, o modo de interface tunnel é GRE sobre IPv4. |
| Configure o endereço IP de origem ou o nome da interface para a interface tunnel | tunnel source { ip-address | interface-name } |
Obrigatório
Por padrão, o endereço IP de origem e o nome da interface não são configurados para a interface de túnel. |
| Configure o endereço IP de destino ou o nome do host para a interface do túnel | tunnel destination { ip-address | hostname } |
Obrigatório
Por padrão, o endereço IP de destino e o nome do host não são configurados para a interface tunnel . |
O endereço da interface do túnel precisa ser configurado com endereço IPv4 e o protocolo só pode ser protocolo IPv4.
O início e o fim do túnel devem ser configurados com o endereço IP de origem e o endereço IP de destino. O endereço IP no início e no final do túnel são endereços IP de origem e endereços IP de destino complementares um para o outro.
Ao configurar o endereço IP de origem do túnel, o endereço IP de origem do túnel adota o endereço IP mestre do endereço IP de origem se o modo de interface for usado.
O início e o fim do túnel devem ser configurados com o mesmo modo de túnel. Caso contrário, a transmissão do túnel falha.
Dois ou mais túneis com o mesmo modo de túnel, endereço IP de origem e endereço IP de destino não podem ser configurados no mesmo dispositivo.
Monitoramento e manutenção do IPIP
Consulte a Seção 8.2.2 Monitoramento e Manutenção da Interface do Túnel no Manual de Configuração da Interface da Interface do Túnel.
Exemplo de configuração t í pica de IPIP
Configurar a função b á sica IPIP
Requisitos de rede
- IP Network1 e IP Network2 são duas redes privadas para Device1 e Device3, respectivamente.
- O IP Network1 se comunica com o IP Network2 através do túnel IPIP entre Device1 e Device3.
Topologia de rede

Figura 10 ‑1 Rede de configuração da função básica IPIP
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. (omitido)
- Passo 2: Configure os endereços IP para todas as interfaces. (Omitido)
- Passo 3: Configure o OSPF.
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
# Configure Device3 .
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
#Visualize a tabela de roteamento do Device3.
Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setO 1.0.0.0/24 [110/65536] via 2.0.0.1, 00:18:40, vlan2C 2.0.0.0/24 is directly connected, 00:22:27, vlan2 C 192.168.100.0/24 is directly connected, 00:00:28, vlan3
Device1 e Device2 são vistos da mesma forma que Device3. O processo de visualização é omitido.
- Passo 4: Configure o túnel IPIP.
#Configure o túnel IPIP, tunnel1 no Device1 com o endereço IP de origem como 1.0.0.1, o endereço IP de destino como 2.0.0.2 e o endereço IP como 10.0.0.1.
Device1(config)#interface tunnel 1Device1(config-if-tunnel1)#tunnel mode ipipDevice1(config-if-tunnel1)#tunnel source 1.0.0.1Device1(config-if-tunnel1)#tunnel destination 2.0.0.2Device1(config-if-tunnel1)#ip address 10.0.0.1 255.255.255.0Device1(config-if-tunnel1)#exit
#Configure o túnel IPIP, tunnel1 no Device3 com o endereço IP de origem como 2.0.0.2, o endereço IP de destino como 1.0.0.1 e o endereço IP como 10.0.0.2.
Device3(config)#interface tunnel 1Device3(config-if-tunnel1)#tunnel mode ipipDevice3(config-if-tunnel1)#tunnel source 2.0.0.2Device3(config-if-tunnel1)#tunnel destination 1.0.0.1Device3(config-if-tunnel1)#ip address 10.0.0.2 255.255.255.0Device3(config-if-tunnel1)#exit
#Visualize as informações do túnel IPIP do Device3.
Device3#show tunnel 1Tunnel 1:Tunnel mode is ipipSource ipv4 address is 2.0.0.2(Source ipv4 address is up on source interface vlan2)Destination ipv4 address is 1.0.0.1Tunnel state is upEncapsulation vrf is global(0x0)TTL(time-to-live) is 255TOS(type of service) is not settotal(1)
Device1 é visto da mesma forma que Device3. O processo de visualização é omitido. o túnel não existe no mesmo segmento de rede, os dispositivos nas duas extremidades do túnel são configurados com um roteamento estático para a extremidade do peer. E a interface de saída é a interface tunnel .
- Passo 5: Configure a rota estática.
#No Device1, configure a rota estática para a interface de saída tunnel1 do IP Network2.
Device1(config)#ip route 192.168.100.0 255.255.255.0 tunnel1#No Device3, configure a rota estática para a interface de saída tunnel1 do IP Network1.
Device3(config)#ip route 192.168.1.0 255.255.255.0 tunnel1#Visualize a tabela de rotas do Device3.
Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setO 1.0.0.0/24 [110/65536] via 2.0.0.1, 00:43:30, vlan2 C 2.0.0.0/24 is directly connected, 00:47:17, vlan2C 10.0.0.0/24 is directly connected, 00:17:12, tunnel1S 192.168.1.0/24 [1/100000] is directly connected, 00:00:10, tunnel1
Device1 é visto da mesma forma que Device3. O processo de visualização é omitido.
T ú nel de Transição (Aplicável somente ao modelo S3054G-B)
Visão geral
A tecnologia de túnel de transição (IPv6 sobre IPv4) fornece uma maneira de transferir os dados IPv6 com o sistema de roteamento IPv4 existente: o pacote IPv6 é encapsulado no pacote IPv4 como dados não estruturados e transmitido pela rede IPv4. De acordo com os diferentes modos de configuração, os túneis de transição podem ser divididos em túneis manuais e túneis automáticos. A tecnologia de túnel de transição utiliza habilmente a rede IPv4 existente, sua importância está em fornecer uma maneira de permitir que os nós IPv6 se comuniquem durante o período de transição, mas não pode resolver o problema de intercomunicação entre nós IPv6 e nós IPv4. Os túneis de transição são divididos em tipo manual e tipo automático. A relação correspondente entre os tipos e os modos é a seguinte:
Tabela 11 ‑1 Modo de túnel de transição
| Tipo de túnel | Modo túnel | Endereço de origem/destino do túnel | Endereço da interface do túnel |
| Túnel manual | IPv6 sobre IPv4 túnel manual | O endereço de origem/destino é o endereço IPv4 configurado manualmente | Endereço IPv6 |
| Túnel automático | Túnel automático IPv6 compatível com Pv4 6 a 4 túnel ISATAP túnel |
O endereço de origem é o endereço IPv4 configurado manualmente e o endereço de destino não precisa ser configurado |
Endereço IPv6 compatível com IPv4, o formato é ::abcd/96
6to4, o formato é: 2002:abcd::/48 Endereço ISATAP, o formato é : Prefixo:0:5EFE:abcd/64 |
- Túnel manual IPv6 sobre IPv4
Este tipo de túnel é estabelecido manualmente. O endereço do terminal do túnel é determinado pela configuração. Não é necessário atribuir endereços IPv6 especiais aos nós. É adequado para os nós IPv6 que frequentemente se comunicam.
- Túnel automático IPv6 compatível com IPv4
Os túneis automáticos IPv6 compatíveis com IPv4 são túneis ponto a multiponto. Endereços IPv6 especiais são adotados em ambas as extremidades do túnel na forma de: abcd/96, em que abcd é o endereço IPv4. Este endereço IPv4 incorporado é usado automaticamente como o fim do túnel no processo de encapsulamento do túnel, o que torna o estabelecimento do túnel muito conveniente. Mas o endereço IPv6 compatível com IPv4 ainda depende do endereço IPv4 na aplicação, e essa limitação não pode ser alterada, então a IETF abandonou esse tipo de endereço no novo padrão, e esse tipo de túnel será eliminado gradualmente.
- 6 a 4 túnel
O túnel 6to4 é um túnel ponto a multiponto. Endereços IPv6 especiais são necessários em ambas as extremidades do túnel no formato 2002:abcd:/48, em que 2002 representa um prefixo de endereço IPv6 fixo e abcd representa o endereço IPv4 exclusivo de 32 bits correspondente ao túnel 6to4. Esse endereço IPv4 incorporado é usado automaticamente como ponto final do túnel no processo de encapsulamento do túnel, o que torna o estabelecimento do túnel muito conveniente. Portanto, os nós que usam o mecanismo 6to4 devem ter pelo menos um endereço IPv4 exclusivo no mundo. Este mecanismo é adequado para a intercomunicação entre os nós que executam IPv6. Como os primeiros 48 bits no prefixo do endereço IPv6 de 6to4 foram determinados pelo número fixo mais o endereço IPv4, os 16 bits restantes do número de sub-rede podem ser definidos pelo próprio usuário, o que torna mais flexível o uso da rede IPv4 para realizar a interligação da rede IPv6. 6to4 supera a limitação do túnel automático IPv6 compatível com IPv4.
- ISATAP túnel
Os túneis ISATAP (Intra-Site Automatic Tunnel Addressing Protocol) são túneis automáticos ponto a multiponto. Endereços IPv6 especiais são necessários em ambas as extremidades do túnel no formato de Prefixo: 0:5EFE: abcd/64, onde Prefixo representa qualquer prefixo de endereço unicast IPv6 válido e abcd representa um endereço IPv4 de 32 bits (não é necessário ser globalmente exclusivo ). O endereço IPv4 incorporado é usado automaticamente como ponto final do túnel durante o encapsulamento do túnel, portanto, esse tipo de túnel também é construído automaticamente.
- Encapsulamento do túnel de transição
Quando os pacotes IPv6 são enviados através de túneis de transição, um cabeçalho IP é adicionado ao cabeçalho do túnel, o número do protocolo no cabeçalho IP é 41, o endereço de origem no cabeçalho IP é definido como o endereço de origem do túnel e o endereço de destino no cabeçalho IP é definido de acordo com o tipo de túnel: se for um túnel manual, é definido como o endereço de destino do túnel configurado, e se for um túnel automático, é definido como o endereço IPv4 embutido no IPv6 Morada.
- A estrutura do pacote do túnel de transição

Carga útil do pacote IPv6: A carga útil do pacote IPv6 antes de entrar no túnel, que serve como a carga útil válida do pacote do túnel.
Cabeçalho IPv6: O cabeçalho do pacote IPv6 antes de entrar no túnel.
Cabeçalho IPv4: O cabeçalho IPv4 externo encapsulado, que é a ferramenta de transmissão do pacote IPv6 pela rede IPv4.
- O encaminhamento do pacote do túnel de transição
Após o pacote ser encapsulado no início do túnel de transição, selecione a rota de acordo com o endereço de destino encapsulado e, em seguida, envie o pacote da interface de rede correspondente. O dispositivo intermediário o encaminha como um pacote IP comum até que o pacote chegue ao final do túnel.
- O encapsulamento/desencapsulação do pacote do túnel de transição
O processo de decapsulação e o processo de encapsulamento são opostos. A extremidade do túnel analisa primeiro o cabeçalho IPv4 depois de receber o pacote. Se o endereço de destino for seu próprio endereço, verifique o campo de protocolo do cabeçalho IP. Se o campo de protocolo for 41, entregue o pacote ao túnel de transição para processamento. Após o túnel remover o cabeçalho IPv4 do pacote, selecione a rota de acordo com o endereço de destino do pacote após o desencapsulamento e execute o processamento subsequente de acordo com o resultado da seleção da rota.
Configuração da Função do T ú nel de Transição
Tabela 11 ‑2 Lista de configuração da função do t ú nel de transição
| Tarefa de configuração | |
| Configurar o túnel de transição | Configurar o túnel manual IPv6 sobre IPv4 Configurar o 6to4 túnel Configurar o ISATAP túnel |
Para os comandos de configuração do túnel de transição, consulte o capítulo de Túnel IP no manual de configuração.
Antes de configurar o túnel manual IPv6 sobre IPv4, conclua as seguintes tarefas: Tabela 11 ‑3 Configurar o túnel manual IPv6 sobre IPv4
l O endereço de origem e o endereço de destino devem ser configurados em ambas as extremidades do túnel, e os endereços das duas extremidades são mutuamente o endereço de origem e o endereço de destino. l Se estiver adotando o modo de interface ao configurar a origem do túnel, o endereço de origem do túnel é o endereço mestre da interface de origem. l As duas extremidades do túnel devem ser configuradas como o mesmo modo de túnel. Caso contrário, a transmissão através do túnel falha. l Em um dispositivo, você não pode configurar vários túneis cujo modo de túnel, endereço de origem e endereço de destino são todos iguais.
Antes de configurar o túnel 6to4, conclua as seguintes tarefas: Tabela 11 ‑4 Configurar o 6to4 túnel
l Não é necessário configurar o endereço de destino para o túnel 6to4. O endereço de destino usado durante o encapsulamento do túnel é obtido automaticamente do endereço IPv4 embutido no endereço IPv6 do túnel 6to4. l Se estiver adotando o modo de interface ao configurar a origem do túnel, o endereço de origem do túnel é o endereço mestre da interface de origem. l As duas extremidades do túnel devem ser configuradas como o mesmo modo de túnel. Caso contrário, a transmissão através do túnel falha. l Em um dispositivo, você só pode configurar um túnel 6to4.
Antes de configurar o túnel ISATAP, conclua as seguintes tarefas: Tabela 11 ‑5 Configurar o ISATAP túnel
l Não é necessário configurar o endereço de destino para o túnel 6to4. O endereço de destino usado durante o encapsulamento do túnel é obtido automaticamente do endereço IPv4 embutido no endereço IPv6 do túnel 6to4. l Se estiver adotando o modo de interface ao configurar a origem do túnel, o endereço de origem do túnel é o endereço mestre da interface de origem. l As duas extremidades do túnel devem ser configuradas como o mesmo modo de túnel. Caso contrário, a transmissão através do túnel falha. l Em um dispositivo, você não pode configurar vários túneis ISATAP com o mesmo endereço de origem ao mesmo tempo.
Consulte a Seção 8.2.2 Monitoramento e Manutenção da Interface do Túnel no Manual de Configuração da Interface da Interface do Túnel.
Configurar o túnel manual IPv6 sobre IPv4
Condições de configuração
Configurar o túnel manual IPv6 sobre IPv4
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração do túnel
interface tunnel tunnel-number
-
Configurar o endereço da interface do túnel
Configure o endereço unicast global IPv6 ou o endereço anycast ou o endereço local do site ou o endereço de obtenção automática
ipv6 address { ipv6-address/prefix-length [ anycast | eui-64 ] | autoconfig }
Obrigatório
Por padrão, não configure o endereço IPv6 na interface do túnel.
Configure o endereço local do link IPv6
ipv6 address ipv6-address link-local
Opcional Por padrão, após habilitar o IPv6 na interface, gera automaticamente o endereço local do link.
de interface tunnel como o túnel manual IPv6 sobre IPv4
tunnel mode ipv6ip
Obrigatório
Por padrão, o modo de interface do túnel é GRE sobre IPv4 .
Configure o endereço de origem ou o nome da interface do túnel
tunnel source { ip-address | interface-name }
Obrigatório
Por padrão, não configure o endereço de origem ou o nome da interface na interface do túnel.
Configure o endereço de destino ou o nome do host da interface do túnel
tunnel destination { ip-address | hostname }
Obrigatório
Por padrão, não configure o endereço de destino ou o nome do host na interface do túnel.
Configurar o 6to4 Túnel
Condições de configuração
Configurar o 6to4 Túnel
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração do túnel
interface tunnel tunnel-number
-
Configurar o endereço da interface do túnel
Configure o endereço unicast global IPv6 ou o endereço anycast ou o endereço local do site ou o endereço de obtenção automática
ipv6 address { ipv6-address/prefix-length [ anycast | eui-64 ] | autoconfig }
Obrigatório
Por padrão, não configure o endereço IPv6 na interface do túnel.
Configure o endereço local do link IPv6
ipv6 address ipv6-address link-local
Opcional Por padrão, após habilitar o IPv6 na interface, gera automaticamente o endereço local do link.
Configure o modo de interface tunnel como túnel 6to4
tunnel mode ipv6ip 6to4
Obrigatório
Por padrão, o modo de interface do túnel é GRE sobre IPv4 .
Configure o endereço de origem ou o nome da interface do túnel
tunnel source { ip-address | interface-name }
Obrigatório
Por padrão, não configure o endereço de origem ou o nome da interface na interface do túnel.
Configurar o ISATAP Túnel
Condições de configuração
Configurar o ISATAP Túnel
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração do túnel
interface tunnel tunnel-number
-
Configurar o endereço da interface do túnel
Configure o endereço unicast global IPv6 ou o endereço anycast ou o endereço local do site ou o endereço de obtenção automática
ipv6 address { ipv6-address/prefix-length [ anycast | eui-64 ] | autoconfig }
Obrigatório
Por padrão, não configure o endereço IPv6 na interface do túnel.
Configure o endereço local do link IPv6
ipv6 address ipv6-address link-local
Opcional Por padrão, após habilitar o IPv6 na interface, gera automaticamente o endereço local do link.
Configure o modo de interface tunnel como o túnel automático IPv6 compatível com IPv4
tunnel mode ipv6ip isatap
Obrigatório
Por padrão, o modo de interface do túnel é GRE sobre IPv4 .
Configure o endereço de origem ou o nome da interface do túnel
tunnel source { ip-address | interface-name }
Obrigatório
Por padrão, não configure o endereço de origem ou o nome da interface na interface do túnel.
Monitoramento e Manutenção do Túnel de Transição
Exemplos de configuração t í picos do t ú nel de transição
Configurar funções básicas do túnel manual IPv6 sobre IPv4
Requisitos de rede
- IPv6 Network1 e IPv6 Network2 são a rede IPv6 privada de Device1 e Device3, respectivamente.
- IPv6 Network1 e IPv6 Network2 se comunicam através do túnel manual IPv6 sobre IPv4 entre Device1 e Device3 .
Topologia de rede
Figura 11 ‑1 Rede para configurar as funções básicas do túnel manual IPv6 sobre IPv4
Etapas de configuração
- Passo 1: Configure o endereço IP da interface (omitido).
- Passo 2: Configure o endereço IP da interface (omitido).
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
# Consulta a tabela de rotas do Device3.
Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setO 1.0.0.0/24 [110/65536] via 2.0.0.1, 00:18:40, vlan2C 2.0.0.0/24 is directly connected, 00:22:27, vlan2
l Os métodos de consulta de Device1 e Device2 são os mesmos de Device3, portanto, o processo de consulta é omitido.
- Passo 3: túnel manual IPv6 sobre IPv4 .
#No Dispositivo1, configure IPv6 sobre IPv4 túnel túnel1 manual, o endereço de origem é 1.0.0.1 , o endereço de destino é 2.0.0.2 e o endereço IPv6 é 10::1 .
Device1(config)#interface tunnel 1Device1(config-if-tunnel1)#tunnel mode ipv6ipDevice1(config-if-tunnel1)#tunnel source 1.0.0.1Device1(config-if-tunnel1)#tunnel destination 2.0.0.2Device1(config-if-tunnel1)#ipv6 address 10::1/64Device1(config-if-tunnel1)#exit
#No Dispositivo 3 , configure IPv6 sobre IPv4 túnel túnel manual1, o endereço de origem é 2 .0.0. 2, o endereço de destino é 1 .0.0. 1, e o endereço IPv6 é 10:: 2.
Device3(config)#interface tunnel 1Device3(config-if-tunnel1)#tunnel mode ipv6ipDevice3(config-if-tunnel1)#tunnel source 2.0.0.2Device3(config-if-tunnel1)#tunnel destination 1.0.0.1Device3(config-if-tunnel1)#ipv6 address 10::2/64Device3(config-if-tunnel1)#exit
# Consulta as informações de túnel manual IPv6 sobre IPv4 do Device3.
Device3#show tunnel 1Tunnel 1:Tunnel mode is ipv6ipSource ipv4 address is 2.0.0.2 (Source ipv4 address is up on source interface vlan2)Destination ipv4 address is 1.0.0.1Tunnel state is upEncapsulation vrf is global(0x0)TTL(time-to-live) is 255TOS(type of service) is not settotal(1)
O método de consulta de Device1 é igual ao de Device3, portanto, o processo de consulta é omitido. l Quando o túnel não está no mesmo segmento de rede, é necessário configurar a rota estática para o túnel de mesmo nível nos dispositivos em ambas as extremidades do túnel, e a interface de saída é a interface do túnel.
- Passo 4: Configure a rota estática .
#No Device1, configure a rota estática para IPv6 Network2 com a interface de saída tunnel1 .
Device1(config)#ipv6 route 3002::/64 tunnel1
#No dispositivo 3 , configure a rota estática para a rede IPv6 1 com a interface de saída tunnel1 .
Device3(config)#ipv6 route 3001::/64 tunnel1
#Consulte a tabela de rotas IPv6 do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w6d:20:35:50, lo0C 10::/64 [0/0]via ::, 00:03:31, tunnel1L 10::2/128 [0/0]via ::, 00:03:29, lo0S 3001::/64 [1/100000]via ::, 00:00:01, tunnel1C 3002::/64 [0/0]via ::, 00:00:06, vlan3L 3002::1/128 [0/0]via ::, 00:00:04, lo0
O método de consulta de Device1 é igual ao de Device3, portanto, o processo de consulta é omitido.
Configurar as funções básicas do túnel 6to4
Requisitos de rede
- IPv6 Network1 e IPv6 Network2 são a rede IPv6 privada de Device1 e Device3, respectivamente.
- PC1 em IPv6 Network1 e PC2 em IPv6 Network2 se comunicam através do túnel 6to4 entre Device1 e Device3.
Topologia de rede
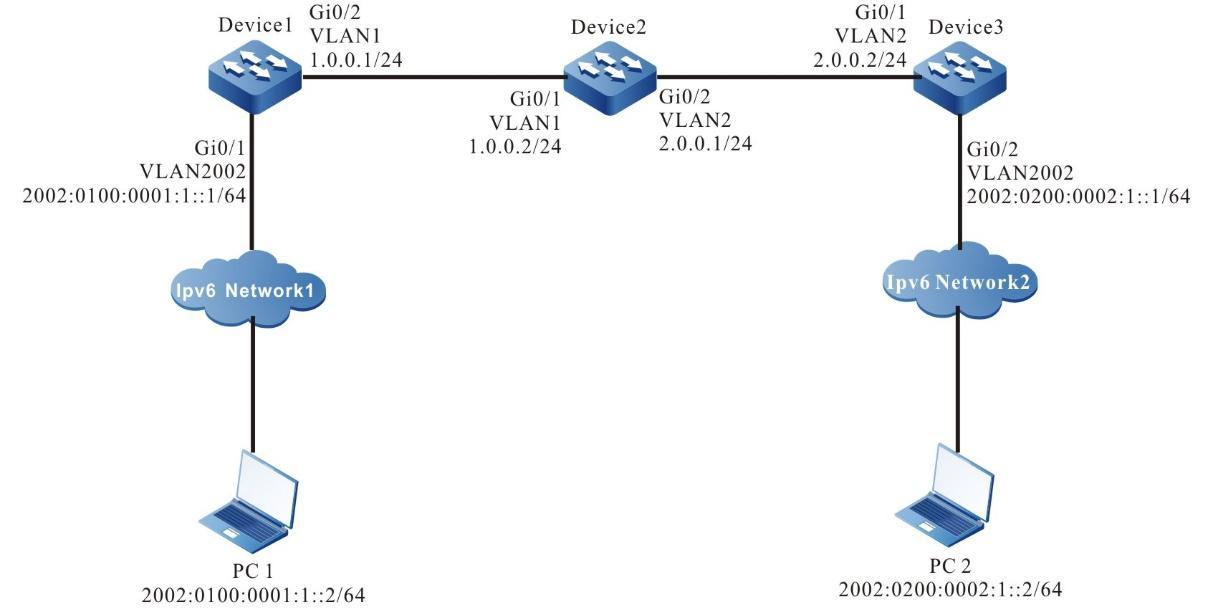
Figura 11 ‑2 Rede para configuração as funções básicas do 6to4 t unnel
Etapas de configuração
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
#Consulte a tabela de rotas do Device3.
Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setO 1.0.0.0/24 [110/65536] via 2.0.0.1, 00:18:40, vlan2C 2.0.0.0/24 is directly connected, 00:22:27, vlan2
Os métodos de consulta de Device1 e Device2 são os mesmos de Device3, portanto, o processo de consulta é omitido.
- Passo 3: Configure serviceloop-group.
#No Device1, crie serviceloop-group e, em seguida, adicione route-port ao serviceloop-group.
Device1(config)#erviceloop-group 1Device1(config)#interface gigabitethernet0/5Device1(config-if-gigabitethernet0/5)#no switchportDevice1(config-if-gigabitethernet0/5)#serviceloop-group 1 active
Se o serviceloop-group for usado para encapsular, certifique-se de que a interface mude para a porta roteada,
Este comando limpará todas as configurações da interface, certifique-se de que a interface esteja no estado padrão. Você quer prosseguir? (sim|não)?sim
Device1(config-if-gigabitethernet0/5)#exit
# No Device3 , crie serviceloop-group e adicione route-port ao serviceloop-group .
Device1(config)#erviceloop-group 1Device1(config)#interface gigabitethernet0/5Device1(config-if-gigabitethernet0/5)#no switchportDevice1(config-if-gigabitethernet0/5)#serviceloop-group 1 active
Se o serviceloop-group for usado para encapsular, certifique-se de que a interface mude para a porta roteada,
Este comando limpará todas as configurações da interface, certifique-se de que a interface esteja no estado padrão. Você quer prosseguir? (sim|não)?sim
Device1(config-if-gigabitethernet0/5)#exit
- Passo 4: Configure o túnel 6to4
#No Device1, configure o túnel 6to4 (tunnel1), o endereço de origem é 1.0.0.1 , serviceloop-group é 1 e o endereço IPv6 é 2002:100:1::1.
Device1(config)#interface tunnel 1Device1(config-if-tunnel1)#tunnel mode ipv6ip 6to4Device1(config-if-tunnel1)#tunnel service-loop 1Device1(config-if-tunnel1)#tunnel source 1.0.0.1Device1(config-if-tunnel1)#ipv6 address 2002:100:1::1/64Device1(config-if-tunnel1)#exit
#No Device3, configure o túnel 6to4 (tunnel1), o endereço de origem é 2.0.0.2 , serviceloop-group é 1 e o endereço IPv6 é 2002:200:2::1.
Device3(config)#interface tunnel 1Device3(config-if-tunnel1)#tunnel mode ipv6ip 6to4Device1(config-if-tunnel1)#tunnel service-loop 1Device3(config-if-tunnel1)#tunnel source 2.0.0.2Device3(config-if-tunnel1)#ipv6 address 2002:200:2::1/64Device3(config-if-tunnel1)#exit
#Consulte as informações do túnel 6to4 do Device3.
Device3# show tunnel 1Tunnel 1:Tunnel mode is ipv6ip 6to4Source ipv4 address is 2.0.0.2(Source ipv4 address is up on source interface vlan2)Tunnel state is upEncapsulation vrf is global(0x0)TTL(time-to-live) is 255TOS(type of service) is not settotal(1)
O método de consulta de Device1 é igual ao de Device3, portanto, o processo de consulta é omitido. l Quando o túnel não está no mesmo segmento de rede, é necessário configurar o roteamento estático para o túnel de mesmo nível nos dispositivos em ambas as extremidades do túnel, e a interface de saída é a interface do túnel.
- Passo 5: Configure a rota estática.
#No Device1, configure a rota estática para o segmento 2002::/16 com a interface de saída (tunnel1).
Device1(config)#ipv6 route 2002::/16 tunnel1
#No dispositivo 3 , configure a rota estática para o segmento 2002::/16 com a interface de saída (túnel1).
Device3(config)#ipv6 route 2002::/16tunnel1
#Consulte a tabela de rotas IPv6 do Device3.
Device#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 6d:05:16:46, lo0C 2001::/64 [0/0]via ::, 00:07:56, tunnel1L 2001::5efe:100:1/128 [0/0]via ::, 00:07:54, lo0C 3001::/64 [0/0]via ::, 02:42:37, vlan3001L 3001::1/128 [0/0]via ::, 02:42:36, lo0
O método de consulta de Device1 é igual ao de Device3, portanto, o processo de consulta é omitido.
- Passo 6: Confira o resultado.
#No PC1, faça ping no endereço do PC2 2002:200:2:1:: 2 .
C:\>ping6 2002:200:2:1::2 –s 2002:0100:0001:1::2Pinging 2002:200:2:1::2 with 32 bytes of data:Reply from 2002:200:2:1::2: time<1msReply from 2002:200:2:1::2: time<1msReply from 2002:200:2:1::2: time<1msReply from 2002:200:2:1::2: time<1msPing statistics for 2002:200:2:1::2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0ms
#PC1 pode fazer ping no endereço PC2 2002:200:2:1:: 2 .
Configurar as funções básicas do túnel ISATAP
Requisitos de rede
- O dispositivo e o PC2 se comunicam por meio da rede IPv4.
- PC2 é o host ISATAP , configurando o túnel ISATAP com Device.
- PC1 na rede IPv6 e PC2 na rede IP realizam a comunicação IPv6 através do túnel ISATAP .
Topologia de rede
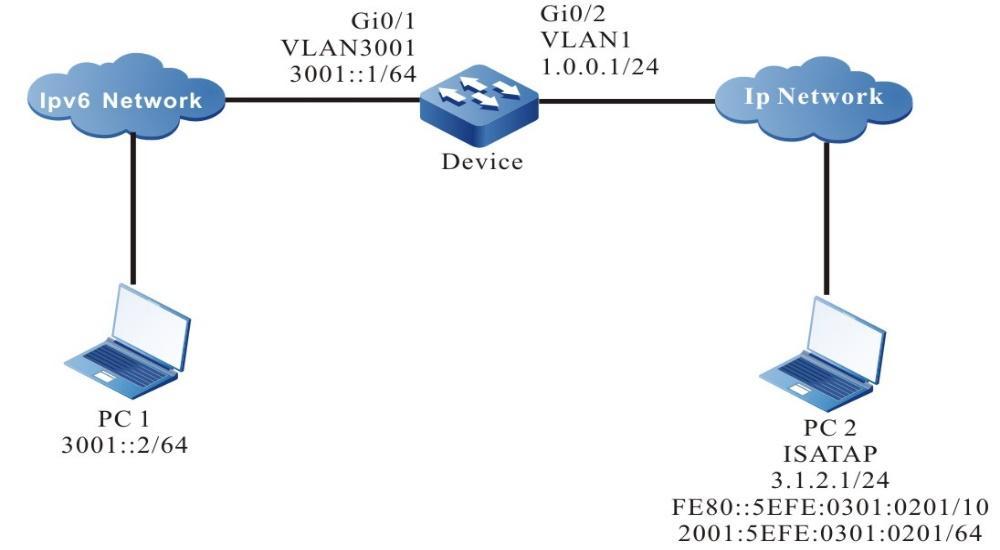
Figura 11 ‑3 Rede para configuração as funções básicas de o túnel ISATAP
Etapas de configuração
- Passo 1: Configure o endereço IP da interface (omitido).
- Passo 2: Configure serviceloop-group.
#No dispositivo, crie serviceloop-group e adicione route-port ao serviceloop-group.
Device(config)#erviceloop-group 1Device(config)#interface gigabitethernet0/5Device(config-if-gigabitethernet0/5)#no switchportDevice(config-if-gigabitethernet0/5)#serviceloop-group 1 activeIf the serviceloop-group is used to tunnel, Please make sure the interface switch to routed-port,This command will clear all config in the interface, Please make sure the interface in default state. Do you want to proceed? (yes|no)?yesDevice(config-if-gigabitethernet0/5)#exit
- Passo 3: Em Dispositivo, configure o túnel ISATAP.
#No dispositivo, configure o túnel ISATAP (tunnel1), o endereço de origem é 1.0.0.1 e o endereço IPv6 é 2001::5efe:100:1.
Device#configure terminalDevice(config)#interface tunnel 1Device(config-if-tunnel1)#tunnel mode ipv6ip isatapDevice(config-if-tunnel1)#tunnel service-loop 1Device(config-if-tunnel1)#tunnel source 1.0.0.1Device(config-if-tunnel1)#ipv6 address 2001::5efe:100:1/64Device(config-if-tunnel1)#exit
#Consulte a tabela de rotas IPv6 do dispositivo.
Device#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 6d:05:16:46, lo0C 2001::/64 [0/0]via ::, 00:07:56, tunnel1L 2001::5efe:100:1/128 [0/0]via ::, 00:07:54, lo0C 3001::/64 [0/0]via ::, 02:42:37, vlan3001L 3001::1/128 [0/0]via ::, 02:42:36, lo0
#Consulte as informações do túnel ISATAP do dispositivo.
Device#show tunnel 1Tunnel 1:Tunnel mode is ipv6ip isatapSource ipv4 address is 1.0.0.1(Source ipv4 address is up on source interface vlan1)Tunnel state is upEncapsulation vrf is global(0x0)TTL(time-to-live) is 255TOS(type of service) is not settotal(1)
- Passo 4: No dispositivo, desabilite a função de supressão de resposta RA do Tunnel1.
#No Device, desabilite função de supressão de resposta RA do Tunnel1.
.Device(config)#interface tunnel 1Device(config-if-tunnel1)#no ipv6 nd suppress-ra responseDevice(config-if-tunnel1)#exit
- Passo 5: Configure o PC2 host ISATAP.
#No host, a configuração do túnel ISATAP varia de acordo com o sistema operacional. Este texto usa o sistema operacional Windows XP como exemplo para descrever. No PC2, instale o protocolo IPv6.
C:\>ipv6 install#Geralmente, depois que o Windows XP é instalado com sucesso com o protocolo IPv6, a interface IPv6 2 é a interface ISATAP . No PC2, consulte as informações da interface IPv6 2.
C:\>ipv6 if 2Interface 2: Automatic Tunneling Pseudo-InterfaceGuid {48FCE3FC-EC30-E50E-F1A7-71172AEEE3AE}does not use Neighbor Discoverydoes not use Router Discoveryrouting preference 1EUI-64 embedded IPv4 address: 0.0.0.0router link-layer address: 0.0.0.0preferred link-local fe80::5efe:3.1.2.1, life infinitelink MTU 1280 (true link MTU 65515)current hop limit 128reachable time 42500ms (base 30000ms)retransmission interval 1000msDAD transmits 0default site prefix length 48
A interface IPv6 2 do PC2 gera automaticamente o endereço link-local do formato ISATAP fe80::5efe:3.1.2.1, e não obtém o prefixo do endereço.
#Na interface IPv6 2 do PC2, configure o endereço de destino do túnel ISATAP como 1.0.0.1 .
C:\>ipv6 rlu 2 1.0.0.1#No PC2, consulte as informações da interface IPv6 2.
C:\>ipv6 if 2Interface 2: Automatic Tunneling Pseudo-InterfaceGuid {48FCE3FC-EC30-E50E-F1A7-71172AEEE3AE}does not use Neighbor Discoveryuses Router Discoveryrouting preference 1EUI-64 embedded IPv4 address: 3.1.2.1router link-layer address: 1.0.0.1preferred global 2001::5efe:3.1.2.1, life 29d23h59m46s/6d23h59m46s (public)preferred link-local fe80::5efe:3.1.2.1, life infinitelink MTU 1500 (true link MTU 65515)current hop limit 255reachable time 42500ms (base 30000ms)retransmission interval 1000msDAD transmits 0default site prefix length 48
A interface IPv6 2 do PC2 obtém o prefixo de endereço 2001::/64 e gera o endereço unicast global 2001::5efe:3.1.2.1.
- Passo 6: Confira o resultado.
#No PC1, faça ping no endereço da interface IPv6 do PC2 2 2001::5efe:3.1.2.1.
C:\>ping 2001::5efe:3.1.2.1Pinging 2001::5efe:3.1.2.1 with 32 bytes of data:Reply from 2001::5efe:3.1.2.1: time<1msReply from 2001::5efe:3.1.2.1: time<1msReply from 2001::5efe:3.1.2.1 :time<1msReply from 2001::5efe:3.1.2.1: time<1msPing statistics for 2001::5efe:3.1.2.1:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0ms
#PC1 pode pingar o endereço do PC2 IPv6 interface2 2001::5efe:3.1.2.1.
Interface Tunnel IPv6 (Aplicável somente ao modelo S3054G-B)
Visão geral
O túnel IPv6 (IPv4 sobre IPv6 / IPv6 sobre IPv6) é uma das muitas tecnologias de túnel, que é semelhante ao túnel GRE (encapsulamento de roteamento genérico (pacote de roteamento geral), o início e o fim do túnel precisam ser configurados manualmente. conexão ponto a ponto virtual, que fornece um canal de transmissão para o pacote encapsulado. As duas extremidades do túnel encapsulam e desencapsulam separadamente o pacote. O túnel IPv6 pode encapsular pacotes de dados IPv4 e pacotes IPv6, para que esses pacotes encapsulados pode ser transmitido na rede IPv6. Quando o pacote é um pacote IPv4, ele é chamado de IPv4 sobre túnel IPv6. Quando o pacote de dados é um pacote IPv6, ele é chamado de IPv6 sobre túnel IPv6. Se o pacote não for diferenciado do pacote IPv4 ou do pacote IPv6 , é chamado de túnel IPv6.
- IPv4 sobre IPv6/IPv6 sobre Interface Tunnel IPv6 + encapsulamento
Quando o pacote IPv6 / IPv4 deve ser enviado através do túnel IPv6, o túnel adiciona um cabeçalho de pacote IPv6 em seu cabeçalho, o número do protocolo no cabeçalho do pacote IPv6 é definido como 4, o endereço de origem no cabeçalho do pacote IPv6 é definido como a origem endereço do túnel e o endereço de destino no cabeçalho do pacote IPv6 é definido como o endereço do túnel.
- IPv4 sobre IPv6/IPv6 sobre estrutura de pacotes IPv6

Carga útil IP/IPv6: a carga do pacote IP/IPv6 antes de entrar no túnel como a carga útil do pacote do túnel.
Cabeçalho IP / IPv6: o cabeçalho do pacote IP / IPv6 antes de entrar no túnel.
Cabeçalho IPv6 externo: o cabeçalho do pacote IP externo encapsulado, que é uma ferramenta de transmissão para realizar o pacote IP / IPv6 que passa pela rede IPv6.
- IPv4 sobre IPv6/IPv6 sobre encaminhamento de pacotes IPv6
Depois que os pacotes são encapsulados no ponto inicial do IPv4 sobre IPv6 / IPv6 sobre o túnel IPv6, eles são roteados de acordo com o endereço de destino encapsulado e, em seguida, enviados da interface de rede correspondente. O equipamento intermediário o encaminha como um pacote IPv6 comum até que o pacote chegue ao final do túnel.
- Decapsulação IPv4 sobre IPv6/IPv6 sobre IPv6
O processo de decapsulação é oposto ao processo de encapsulamento. Depois de receber o pacote, o final do túnel analisa primeiro o cabeçalho IP externo. Se o endereço de destino for seu próprio endereço, verifique o campo de protocolo do cabeçalho do pacote IPv6. Se o campo de protocolo for 41, o pacote será enviado para o túnel IPv4 sobre IPv6/IPv6 sobre IPv6 para processamento. Depois que o cabeçalho IPv6 de saída do pacote é removido do túnel, a rota é selecionada de acordo com o endereço de destino do pacote desencapsulado e o processamento subsequente é realizado de acordo com o resultado da seleção da rota.
Configuração da Função do T ú nel IPv6
Tabela 12 ‑1 Lista de configuração da função de t ú nel IPv6
| Tarefa de configuração | |
| Configurar o túnel IPv6 | Configurar o túnel IPv4 sobre IPv6 Configurar o túnel IPv6 sobre IPv6 |
Configurar o t ú nel IPv4 sobre IPv6
Condições de configuração
Antes de configurar o túnel IPv4 sobre IPv6 , conclua as seguintes tarefas :
- Configure o endereço IP 4 da interface, tornando os nós vizinhos alcançáveis na camada de rede
- Crie uma interface tunnel e configure os parâmetros básicos (consulte o manual de configuração da interface tunnel )
- Configure qualquer protocolo de roteamento unicast, tornando a rota nas duas extremidades do túnel alcançável
Configurar IPv4 sobre o túnel IPv6
Tabela 12 ‑2 Configurar o túnel IPv4 sobre IPv 6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do túnel | interface tunnel tunnel-number | - |
| Configurar o endereço da interface do túnel | ip address ip-address { mask | mask-length } | Obrigatório Por padrão, o endereço não é configurado na interface do túnel. |
| Configure o modo de interface do túnel como IPv4 sobre IPv6 | tunnel mode ipv4ipv6 | Opcional Por padrão, o modo da interface do túnel é GRE sobre IPv4. |
| Configure o endereço de origem ou o nome da interface da interface do túnel | tunnel source { ipv6-address | interface-name } |
Obrigatório
Por padrão, não configure o endereço de origem ou o nome da interface na interface do túnel. |
| Configure o endereço de destino da interface do túnel | tunnel destination { ipv6-address } | Obrigatório Por padrão, o endereço de destino não está configurado na interface do túnel. |
O endereço da interface do túnel precisa ser configurado com endereço IPv4 e o protocolo só pode ser protocolo IPv4. As duas extremidades do túnel devem ser configuradas com o endereço IP de origem e o endereço IP de destino. Os endereços IP no início e no final do túnel são endereços IP de origem e endereços IP de destino complementares um para o outro. Ao configurar a origem do túnel e se o modo de interface for adotado, o endereço de origem do túnel adota o primeiro endereço IPv6 da interface de origem (endereço não linklocal). O início e o fim do túnel devem ser configurados com o mesmo modo de túnel. Caso contrário, a transmissão do túnel falha.
Configurar o t ú nel IPv6 sobre IPv6
Condições de configuração
Antes de configurar o túnel IPv6 sobre IPv6 , conclua as seguintes tarefas :
- Configure o endereço IP 6 da interface, tornando os nós vizinhos alcançáveis na camada de rede
- Crie uma interface tunnel e configure os parâmetros básicos (consulte o manual de configuração da interface tunnel )
- Configure qualquer protocolo de roteamento unicast, tornando a rota nas duas extremidades do túnel alcançável
Configurar IPv6 sobre o túnel IPv6
Tabela 12 ‑3 Configurar o túnel IPv6 sobre IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do túnel | interface tunnel tunnel-number | - |
| Configurar o endereço da interface do túnel | Ipv6 address ipv6-address { mask | mask-length } | Obrigatório Por padrão, o endereço não é configurado na interface do túnel. |
| Configure o modo de interface do túnel como IPv6 sobre IPv6 | tunnel mode ipv6ipv6 | Opcional Por padrão, o modo da interface do túnel é GRE sobre IPv4. |
| Configure o endereço de origem ou o nome da interface da interface do túnel | tunnel source { ipv6-address | interface-name } |
Obrigatório
Por padrão, não configure o endereço de origem ou o nome da interface na interface do túnel. |
| Configure o endereço de destino da interface do túnel | tunnel destination { ipv6-address } | Obrigatório Por padrão, o endereço de destino não está configurado na interface do túnel. |
O endereço da interface do túnel precisa ser configurado com o endereço IPv6 e o protocolo só pode ser o protocolo IPv6. As duas extremidades do túnel devem ser configuradas com o endereço IP de origem e o endereço IP de destino. Os endereços IP no início e no final do túnel são endereços IP de origem e endereços IP de destino complementares um para o outro. Ao configurar a origem do túnel e se o modo de interface for adotado, o endereço de origem do túnel adota o primeiro endereço IPv6 da interface de origem (endereço não linklocal). l O início e o fim do túnel devem ser configurados com o mesmo modo de túnel. Caso contrário, a transmissão do túnel falha.
Monitoramento e manutenção de t ú nel IPv6
Consulte a Seção 8.2.2 Monitoramento e Manutenção da Interface do Túnel no Manual de Configuração da Interface da Interface do Túnel.
Exemplos de configuração t í picos de IPv6
Configurar funções b á sicas de IPv4 sobre IPv6
Requisitos de rede
- IP Network1 e IP Network2 são a rede IP privada de Device1 e Device3 respectivamente.
- IP Network1 e IP Network2 se comunicam através do túnel IPv6 entre Device1 e Device3 .
Topologia de rede
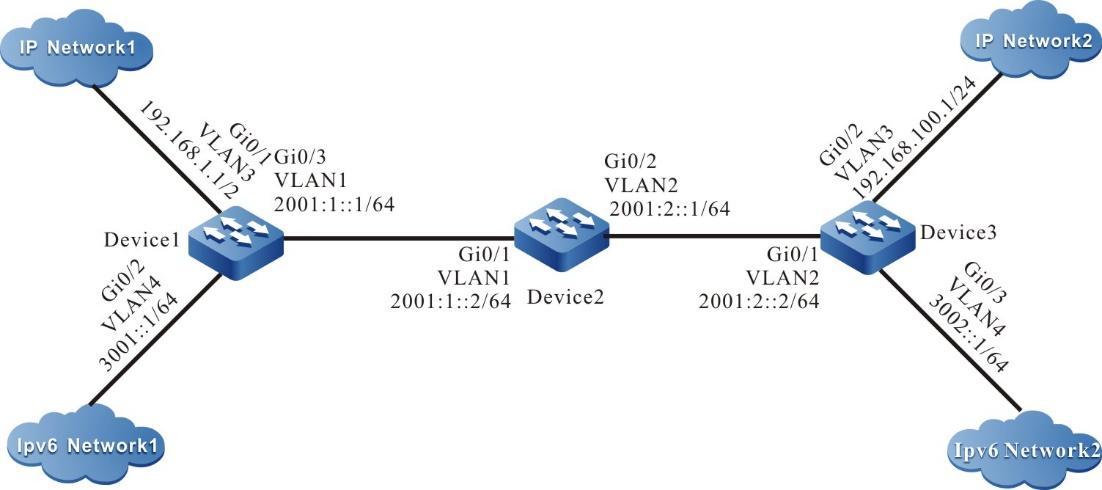
Figura 12 ‑1 Rede para configurar as funções b á sicas do t ú nel IPv6
Etapas de configuração
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)#router-id 1.1.75.1Device1(config-ospf6)#exitDevice1(config)#interface vlan1Device1(config-if-vlan1)#ipv6 router ospf tag 100 area 0Device1(config-if-vlan1)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 1.2.75.1Device2(config-ospf6)#exitDevice2(config)#interface vlan1Device2(config-if-vlan1)#ipv6 router ospf tag 100 area 0Device2(config-if-vlan1)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 router ospf tag 100 area 0Device2(config-if- vlan2)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 1.1.73.1Device3(config-ospf6)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ipv6 router ospf tag 100 area 0Device3(config-if-vlan2)#exit
#Consulte a tabela de rotas IPv6 f Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 6w0d:23:09:31, lo0O 2001:1::/64 [110/2]via fe80::508b:fff:fee4:ff6, 00:08:37, vlan2C 2001:2::/64 [0/0]via ::, 00:15:51, vlan2L 2001:2::2/128 [0/0]via ::, 00:15:50, lo0C 3002::/64 [0/0]via ::, 00:15:06, vlan4L 3002::1/128 [0/0]via ::, 00:15:04, lo0
Os métodos de consulta de Device1 e Device2 são os mesmos de Device3, portanto, o processo de consulta é omitido.
- Passo 3: Configure o túnel IPv6.
#No Dispositivo1, configure o túnel IPv6 tunnel1, o endereço de origem é 2001:1::1 , o endereço de destino é 2001:2::2, o endereço IP é 10.0.0.1 e o endereço IPv6 é 10::1.
Device1(config)#interface tunnel 1Device1(config-if-tunnel1)#tunnel mode ipipv6Device1(config-if-tunnel1)#tunnel source 2001:1::1Device1(config-if-tunnel1)#tunnel destination 2001:2::2Device1(config-if-tunnel1)#ip address 10.0.0.1 255.255.255.0Device1(config-if-tunnel1)#ipv6 address 10::1/64Device1(config-if-tunnel1)#exit
#No Dispositivo3, configure o túnel IPv6 tunnel1, o endereço de origem é 2001:2::2 , o endereço de destino é 2001:2::2, o endereço IP é 10.0.0.2 e o endereço IPv6 é 10::2
Device3(config)#interface tunnel 1Device3(config-if-tunnel1)#tunnel mode ipipv6Device3(config-if-tunnel1)#tunnel source 2001:2::2Device3(config-if-tunnel1)#tunnel destination 2001:1::1Device3(config-if-tunnel1)#ip address 10.0.0.2 255.255.255.0Device3(config-if-tunnel1)#ipv6 address 10::2/64Device3(config-if-tunnel1)#exit
#Consulte as informações do túnel IPv6 do Device3.
Device3#show tunnel 1Tunnel 1:Tunnel mode is ipipv6Source ipv6 address is 2001:2::2(Source ipv6 address is up on source interface vlan2)Destination ipv6 address is 2001:1::1Tunnel state is upEncapsulation vrf is global(0x0)TTL(time-to-live) is 255TOS(type of service) is not settotal(1)
O método de consulta de Device1 é igual ao de Device3, portanto, o processo de consulta é omitido. Quando o túnel não está no mesmo segmento de rede, é necessário configurar a rota estática para o túnel de mesmo nível nos dispositivos em ambas as extremidades do túnel, e a interface de saída é a interface do túnel.
- Passo 4: Configure a rota estática.
#No Device1, configure a rota estática para IP Network2 com a interface de saída tunnel1 .
Device1(config)#ip route 192.168.100.0 255.255.255.0 tunnel1#No Device3, configure a rota estática para IP Network1 com a interface de saída tunnel1 .
Device3(config)#ip route 192.168.1.0 255.255.255.0 tunnel1#Consulte a tabela de rotas do Device3.
Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 10.0.0.0/24 is directly connected, 00:17:12, tunnel1S 192.168.1.0/24 [1/100000] is directly connected, 00:00:10, tunnel1C 192.168.100.0/24 is directly connected, 00:00:28, vlan3
O método de consulta de Device1 é igual ao de Device3, portanto, o processo de consulta é omitido.
Configurar funções b á sicas de IPv6 sobre IPv6
Requisitos de rede
- IPv6 Network1 e IPv6 Network2 são a rede IP v6 privada de Device1 e Device3, respectivamente.
- IPv6 Network1 e IPv6 Network2 se comunicam através do túnel IPv6 entre Device1 e Device3 .
Topologia de rede
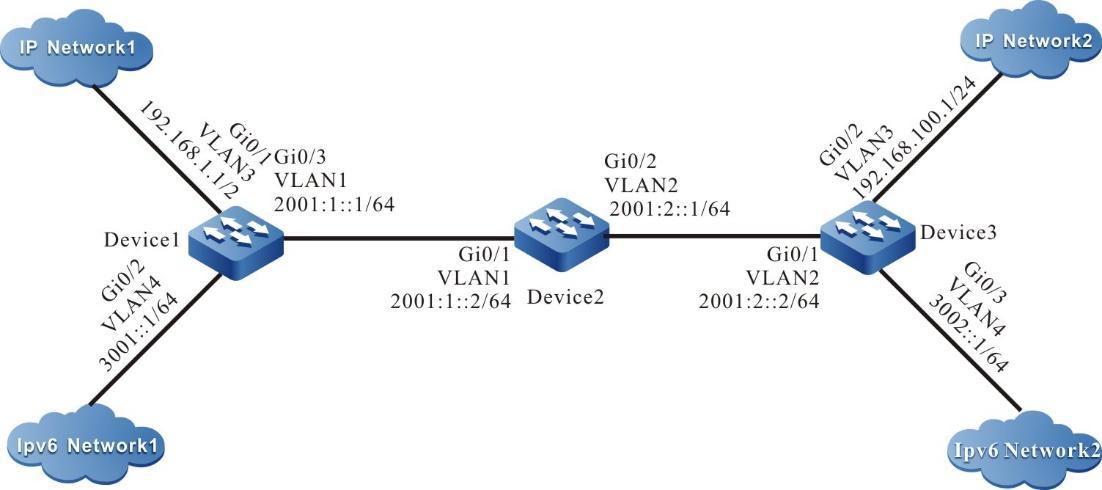
Figura 12 ‑2 Rede para configurar as funções básicas do túnel IPv6
Etapas de configuração
- Passo 1: Configure o endereço IP da interface (omitido).
- Passo 2: Configure o OSPFv3, tornando Device1, Device2 e Device3 se comunicam.
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)#router-id 1.1.75.1Device1(config-ospf6)#exitDevice1(config)#interface vlan1Device1(config-if-vlan1)#ipv6 router ospf tag 100 area 0Device1(config-if-vlan1)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 1.2.75.1Device2(config-ospf6)#exitDevice2(config)#interface vlan1Device2(config-if-vlan1)#ipv6 router ospf tag 100 area 0Device2(config-if-vlan1)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 router ospf tag 100 area 0Device2(config-if- vlan2)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 1.1.73.1Device3(config-ospf6)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ipv6 router ospf tag 100 area 0Device3(config-if-vlan2)#exit
#Consulte a tabela de rotas IPv6 do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 6w0d:23:09:31, lo0O 2001:1::/64 [110/2]via fe80::508b:fff:fee4:ff6, 00:08:37, vlan2C 2001:2::/64 [0/0]via ::, 00:15:51, vlan2L 2001:2::2/128 [0/0]via ::, 00:15:50, lo0C 3002::/64 [0/0]via ::, 00:15:06, vlan4L 3002::1/128 [0/0]via ::, 00:15:04, lo0
Os métodos de consulta de Device1 e Device2 são os mesmos de Device3, portanto, o processo de consulta é omitido.
- Passo 3: Configure o túnel IPv6.
#No Dispositivo1, configure o túnel IPv6 tunnel1, o endereço de origem é 2001:1::1 , o endereço de destino é 2001:2::2, o endereço IP é 10.0.0.1 e o endereço IPv6 é 10::1.
Device1(config)#interface tunnel 1Device1(config-if-tunnel1)#tunnel mode ipv6ipv6Device1(config-if-tunnel1)#tunnel source 2001:1::1Device1(config-if-tunnel1)#tunnel destination 2001:2::2Device1(config-if-tunnel1)#ip address 10.0.0.1 255.255.255.0Device1(config-if-tunnel1)#ipv6 address 10::1/64Device1(config-if-tunnel1)#exit
#No Dispositivo3, configure o túnel IPv6 tunnel1, o endereço de origem é 2001:2::2 , o endereço de destino é 2001:1::1, o endereço IP é 10.0.0.2 e o endereço IPv6 é 10::2.
Device3(config)#interface tunnel 1Device3(config-if-tunnel1)#tunnel mode ipv6ipv6Device3(config-if-tunnel1)#tunnel source 2001:2::2Device3(config-if-tunnel1)#tunnel destination 2001:1::1Device3(config-if-tunnel1)#ip address 10.0.0.2 255.255.255.0Device3(config-if-tunnel1)#ipv6 address 10::2/64Device3(config-if-tunnel1)#exit
#Consulte as informações do túnel IPv6 do Device3.
Device3#show tunnel 1Tunnel 1:Tunnel mode is ipv6ipv6Source ipv6 address is 2001:2::2(Source ipv6 address is up on source interface vlan2)Destination ipv6 address is 2001:1::1Tunnel state is upEncapsulation vrf is global(0x0)TTL(time-to-live) is 255TOS(type of service) is not settotal(1)
O método de consulta de Device1 é igual ao de Device3, portanto, o processo de consulta é omitido. Quando o túnel não está no mesmo segmento de rede, é necessário configurar a rota estática para o túnel de mesmo nível nos dispositivos em ambas as extremidades do túnel, e a interface de saída é a interface do túnel.
Passo 4: Configure a rota estática.
#No Device1, configure a rota estática para IPv6 Network2 com a interface de saída tunnel1 .
Device1(config)#ipv6 route 3002::/64 tunnel1
#No Device3, configure a rota estática para IPv6 Network1 com a interface de saída tunnel1 .
Device3(config)# ipv6 route 3001::/64 tunnel1
#Consulte a tabela de rotas IPv6 do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 6w0d:23:50:28, lo0C 10::/64 [0/0]via ::, 00:12:23, tunnel1L 10::2/128 [0/0]via ::, 00:12:22, lo0O 2001:1::/64 [110/2]via fe80::508b:fff:fee4:ff6, 00:49:34, vlan2C 2001:2::/64 [0/0]via ::, 00:56:48, vlan2L 2001:2::2/128 [0/0]via ::, 00:56:46, lo0S 3001::/64 [1/100000]via ::, 00:00:14, tunnel1C 3002::/64 [0/0]via ::, 00:56:02, vlan4L 3002::1/128 [0/0]via ::, 00:56:01, lo0
O método de consulta de Device1 é igual ao de Device3, portanto, o processo de consulta é omitido.
Interface de grupo de loopback (Aplicável somente ao modelo S3054G-B)
Visão geral
A interface do grupo de loopback é um tipo de interface virtual lógica. Cada interface de grupo de loopback inclui uma interface Ethernet L2/interface Ethernet L3/grupo de convergência estática L2/grupo de convergência estática L3. A porta que se junta ao grupo de loopback é chamada de porta de loopback. O status da porta de loopback está sempre habilitado. Para os pacotes enviados para a porta de loopback, o dispositivo considera que são enviados para si mesmo e não encaminhará os pacotes.
Loopback
T abela 13 ‑1 Lista de configuração de funções de interface de grupo de loopback
| Tarefa de configuração | |
| Configurar as funções básicas da interface do grupo de loopback |
Entre no modo de configuração global
Crie um grupo de loopback Entrar no modo de configuração da interface Ethernet L2/modo de configuração da interface Ethernet L3/modo de configuração do grupo de agregação Configurar a porta de loopback ou o grupo de agregação de loopback |
Configurar funções básicas da interface de grupo de loopback
Condições de configuração
Nenhum
Configurar funções básicas da interface de grupo de loopback
Tabela 13 ‑2 Entre no modo de configuração do grupo de agregação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | Obrigatório |
| Crie um grupo de loopback | serviceloop-group serviceloop-group-id [description description-name] | Obrigatório |
| L2 /L3 | interface interface-name | E também Após entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente só terá efeito na interface atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente terá efeito em todas as portas membros da agregação |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar a porta de loopback | serviceloop-group serviceloop-group-id active | Obrigatório |
O grupo de agregação correspondente deve ser criado antes de entrar no modo de configuração do grupo de agregação especificado. Suporta apenas a configuração da interface Ethernet L2, interface Ethernet L3, grupo de convergência estática L2 e grupo de convergência estática L3 como loopback.
Monitoramento e manutenção da interface do grupo de loopback
Tabela 13 ‑3 Monitoramento e manutenção da interface do grupo de loopback
| Comando | Descrição |
| show serviceloop-group [serviceloop-group-id] | Exibir as informações do grupo de loopback |
| show serviceloop debug | Visualize as informações do switch de depuração do grupo de loopback habilitado |
| [no] debug serviceloop [ config | event | sync | rpc | publisher] | Habilite ou desabilite o switch de depuração do módulo de grupo de loopback |
03 Ethernet Switching
Link Aggregation
Visão geral do link aggregation
Por meio da agregação de link, vários links físicos entre dois dispositivos são vinculados para formar um link lógico para expandir a capacidade do link. Dentro do link lógico, os links físicos atuam como redundância e backup dinâmico uns dos outros, proporcionando maior confiabilidade de conexão de rede.
Conceitos Básicos
Link Aggregation e Portas Membros
Várias portas físicas são vinculadas para formar um link aggregation e as portas físicas são portas membro do link aggregation.
Status da porta do membro
As portas membro de um link aggregation têm os dois status a seguir :
- Selecionado: As portas membro que estão neste status podem participar do encaminhamento de tráfego do serviço de usuário. As portas membro neste status são chamadas de "portas selecionadas".
- Desmarcado: As portas membro que estão neste status não podem participar do encaminhamento de tráfego de serviço do usuário. As portas membro neste status são chamadas de "portas não selecionadas".
A taxa e o modo duplex de um link aggregation são determinados pelas portas selecionadas no link aggregation. A taxa de um link aggregation é a soma de todas as portas selecionadas e o modo duplex do link aggregation é o mesmo que o modo duplex das portas selecionadas.
Chave de operação
Uma chave de operação é a configuração de propriedade das portas membro. Ele consiste na taxa, modo duplex e chave administrativa (ou seja, o número do link aggregation). Na configuração da propriedade, a alteração do modo ou taxa duplex pode causar o recálculo da chave de operação.
Em um link aggregation, se os modos duplex ou as taxas das portas membro forem diferentes, as chaves de operação geradas serão diferentes. No entanto, as portas membro que estão no status selecionado devem ter a mesma chave de operação.
LACP
O Link Aggregation Control Protocol (LACP) é um protocolo baseado em IEEE802.3ad. No LACP, as Unidades de Dados do Protocolo de Controle de Agregação de Link (LACPDUs) são usadas para trocar mensagens com o ponto final .
Prioridades LACP
As prioridades LACP são categorizadas em dois tipos: prioridades LACP do sistema e prioridades LACP da porta.
- Prioridades do sistema LACP: Eles são usados para determinar a ordem de prioridade LACP dos dispositivos nas duas extremidades.
- Prioridades de porta LACP: Elas são usadas para determinar a ordem de prioridade na qual as portas membro do dispositivo local são selecionadas.
ID do sistema e ID da porta
ID do sistema: propriedade de agregação de um dispositivo. Consiste na prioridade LACP do sistema do dispositivo e no endereço MAC do sistema. Quanto maior for a prioridade do LACP do sistema, melhor será o ID do sistema do dispositivo. Se as prioridades do sistema LACP forem as mesmas, quanto menor for o endereço MAC do sistema, melhor será o ID do sistema do dispositivo.
Port ID: propriedade de agregação de uma porta. Consiste na prioridade LACP da porta e no número da porta. Quanto maior a prioridade do LACP da porta, melhor é o ID da porta. Se as prioridades do LACP da porta forem as mesmas, quanto menor o número da porta, melhor será o ID da porta.
Porta raiz de um link aggregation
Os protocolos aplicados em um link aggregation recebem e enviam pacotes de protocolo pela porta raiz do link aggregation. A porta raiz de um link aggregation é selecionada das portas membro do link aggregation. O link físico da porta raiz deve estar no status ativo.
Modos de link aggregation
Os modos de agregação de link incluem o modo de agregação estática e o modo de agregação dinâmica. Os link aggregation são categorizados em link aggregation estáticos e grupos de agregação dinâmicos.
Modo de agregação estática
No modo de agregação estática, o protocolo LACP das portas membro dos dispositivos nas duas extremidades está no status desabilitado. No link aggregation estático do dispositivo local, defina o status selecionado e não selecionado para as portas membro seguindo as diretrizes descritas abaixo:
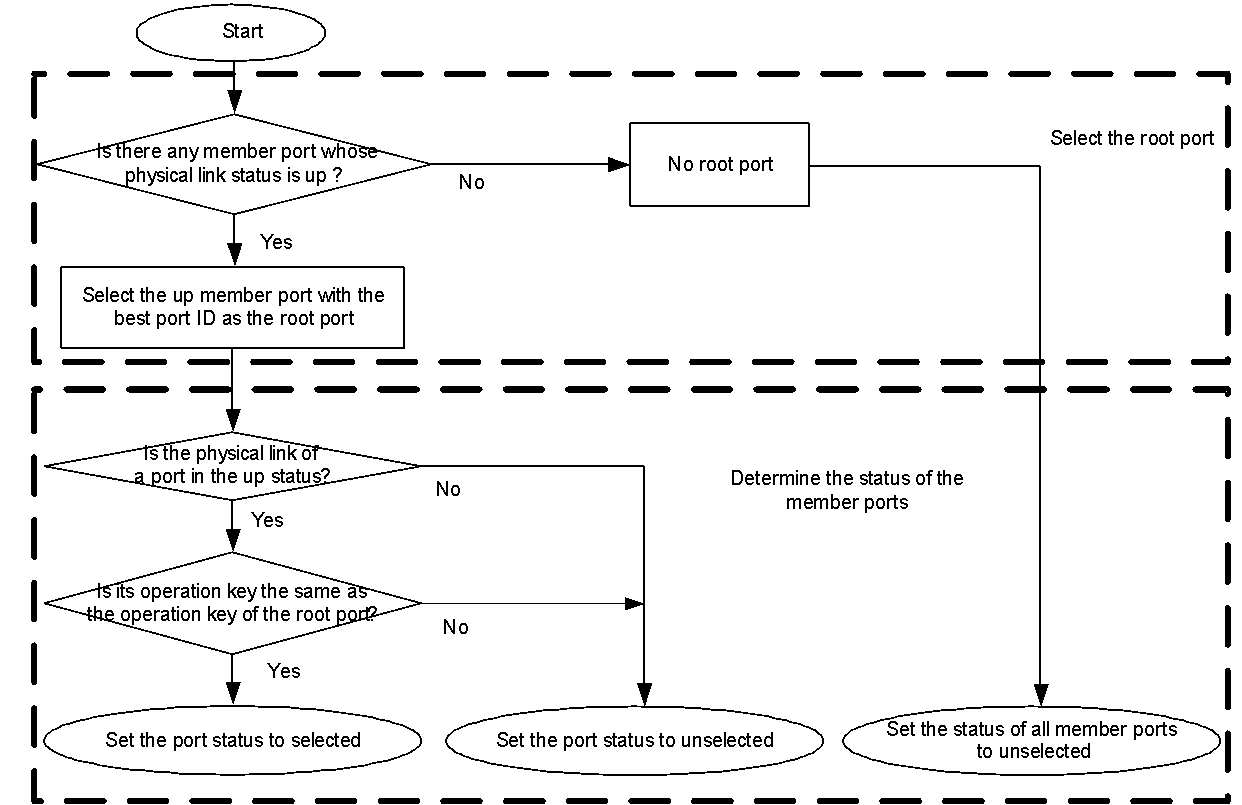
Figura 1 -1 Configurando o status das portas membro no modo de agregação estática
Modo de agregação dinâmica
Em portas de agregação dinâmica, uma porta pode ingressar em um link aggregation dinâmico em dois modos, ativo ou passivo.
- Se o modo duplex da porta for full duplex:
Se a porta ingressar em um link aggregation dinâmico no modo ativo, o protocolo LACP será habilitado para a porta.
Se a porta ingressar em um link aggregation dinâmico no modo passivo, o protocolo LACP será desabilitado para a porta. Depois de receber os pacotes LACPDU da porta de mesmo nível, o protocolo LACP é ativado.
- Se o modo duplex da porta for half duplex, independentemente de a porta ingressar em um link aggregation dinâmico em qualquer modo, o protocolo LACP será desabilitado para a porta.
No link aggregation dinâmico, defina o status selecionado e não selecionado para as portas membro seguindo as diretrizes descritas abaixo:
Primeiro, determine o dispositivo com um ID de sistema melhor. Em seguida, o dispositivo determina os status das portas membro dos dispositivos nas duas extremidades. O dispositivo com a melhor ID do sistema define o status selecionado e não selecionado para as portas membro seguindo as diretrizes descritas abaixo:

Figura 1 -2 Configurando o Status das Portas Membros no Modo de Agregação Dinâmica
Modos de load balance de link aggregation
Sete modos de load balance estão disponíveis e os usuários podem selecionar um modo de acordo com o requisito real.
- Load Balance com base nos endereços IP de destino: o link aggregation implementa o load balance agregado de acordo com os endereços IP de destino dos pacotes.
- Load Balance com base nos endereços MAC de destino: o link aggregation implementa o load balance agregado com base nos endereços MAC de destino dos pacotes.
- Load Balance com base nos endereços IP de origem e destino: o grupo de agregação implementa o load balance agregado com base nos endereços IP de origem e destino dos pacotes.
- Load Balance com base nos endereços MAC de origem e destino: o grupo de agregação implementa o load balance agregado com base nos endereços MAC de origem e destino dos pacotes.
- Load Balance com base nos endereços IP de origem: o link aggregation implementa o load balance agregado com base nos endereços IP de origem dos pacotes.
- Load Balance com base nos endereços MAC de origem: o link aggregation implementa o load balance agregado com base nos endereços MAC de origem dos pacotes.
- Load Balance aprimorado: se o número de portas que participam do encaminhamento de tráfego do usuário for um número ímpar, este modo ajuda a melhorar a capacidade de load balance de links com números ímpares. Após configurar como o modo, a configuração do perfil de load balance adotado pelo modo de load balance entra em vigor. Se nenhum perfil de carga for criado, adote o perfil padrão.
Visão geral do perfil de load balance
Load Balance
Load-Balance significa que quando a saída do tráfego é o link aggregation, o chip pode realizar o load balance do tráfego entre as portas membros do link aggregation de acordo com as condições atuais de configuração HASH, de modo a melhorar a utilização da largura de banda de o link aggregation.
HASH KEY
HASH KEY significa que quando o tráfego escolhe a porta de saída específica do grupo de agregação, o chip calcula o valor da KEY utilizada pela porta via HASH. De um modo geral, diferentes tipos de pacotes suportam diferentes valores de HASH KEY e diferentes chips de switch suportam diferentes valores de HASH KEY. Os valores de HASH KEY suportados por diferentes pacotes são mostrados na Tabela 1-1.
Tabela 1 -1 Os valores de HASH KEY suportados por diferentes tipos de pacotes e seus significados
| Tipo de CHAVE HASH | Descrição |
| dst-mac | Com base no endereço MAC de destino: realize o load balance de agregação pelo endereço MAC de destino do pacote |
| src-mac | Com base no endereço MAC de origem : realize o load balance de agregação pelo endereço MAC de origem do pacote |
| interface src | Com base na interface de origem de recebimento : Realize o load balance de agregação pela interface de origem de recebimento do pacote |
| vlan | Baseado em VLAN: Realize o load balance de agregação pela VLAN do pacote |
| dst-ip | Com base no endereço IP de destino: realize o load balance de agregação pelo endereço IP de destino do pacote |
| l4-dst-port | Com base no número da porta de destino L4 : Realize o load balance de agregação pelo número da porta de destino L4 do pacote |
| rótulo de fluxo | Baseado no rótulo de fluxo IPv6: Realize o load balance de agregação pelo rótulo de fluxo IPv6 do pacote |
| protocolo | Baseado no protocolo IP: Realiza o load balance de agregação pelo protocolo IP do pacote |
| src-ip | Com base no endereço IP de origem : realize o load balance de agregação pelo endereço IP de origem do pacote |
| l4-src-port | Com base na fonte L4 número da porta : Realiza o load balance de agregação pela fonte L4 número da porta do pacote |
No dispositivo local, os valores de HASH KEY suportados por diferentes pacotes são mostrados na tabela a seguir:
Tabela 1 -2 Os valores de HASH KEY suportados por diferentes pacotes
| Tipo de pacote | CHAVE HASH suportada |
| Pacote unicast conhecido L2 | dst-mac, src-mac, src-interface, vlan |
| Pacote unicast conhecido L3 | dst-ip, l4-dst-port, flow-label, protocol, src-ip, l4-src-port, src-interface , src-mac, dst-mac, vlan |
| Outros pacotes L2 | dst-mac, src-mac, src-interface |
| pacotes L3 (IPv4/IPv6 ) | dst-ip, src-ip, src-interface |
A HASH KEY do pacote unicast conhecido de L2 pode suportar a combinação de uma ou mais HASH KEYs. A HASH KEY do pacote unicast conhecido de L3 pode suportar a combinação de uma ou mais HASH KEYs. Os valores HASH KEY de outros pacotes L2 são fixos e não podem ser configurados, fixos para usar dst-mac, src-mac, src-interface para realizar o balanceamento de carga. Os valores HASH KEY de outros pacotes L3 (IPv4/IPv6) são fixos, e não podem ser configurados, fixos para usar dst-mac, src-mac, src-interface, l4-src-port e l4-dst-port para realizar o load balance.
Perfil de load balance
O perfil de load balance é um conceito de "Perfil de usuário" especialmente introduzido para proteger as diferenças de chips entre os diferentes fabricantes de chips. Entre eles, "Usuário" refere-se a todos os negócios que precisam usar o balanceamento de carga do chip (ou seja, módulos de negócios, como agregação LAC); "Perfil" é um esquema de configuração HASH reutilizável que abstrai os recursos HASH subjacentes.
Os perfis de load balance são diferenciados por nomes de perfil, que não têm mais de 31 caracteres. Por padrão, haverá um perfil HASH padrão chamado "default", “ ecmp_default ”. Além disso, de acordo com o modo de operação atual (máquina única, modo de empilhamento) e recursos do chip, os usuários também podem receber perfis personalizáveis. Cada perfil geralmente é composto da configuração HASH KEY do pacote L2 e da configuração HASH KEY do pacote L3.
Os usuários podem configurar com flexibilidade o perfil de load balance e a HASH KEY do perfil de acordo com as necessidades reais. Após a conclusão da configuração, faça referência ou vincule o perfil correspondente para obter o equilíbrio de carga do tráfego de acordo com a configuração do perfil correspondente.
O comprimento do nome do perfil de load balance não excede 31 caracteres. O nome padrão do perfil de load balance é “default” “ ecmp_default ” , que não pode ser modificado. O perfil de load balance padrão “default” “ ecmp_default ” não pode ser excluído, mas pode ser configurado.
Configuração da função do perfil de load balance
Tabela 1 -3 Lista de configuração da função do perfil de balanceamento de carga
| Tarefas de configuração | |
| Função de configuração do perfil de load balance |
Crie um perfil de load balance e entre no modo de configuração do perfil
Configurar HASH KEY do perfil de load balance Excluir o perfil de load balance |
Criar um perfil de load balance
Depois de criar um perfil de load balance com sucesso, insira o modo de configuração do perfil de load balance correspondente.
O usuário autônomo pode criar no máximo um perfil personalizado. O usuário da pilha não pode criar um perfil personalizado.
Condições de configuração
Nenhum
Criar um perfil de load balance
Tabela 1 -4 Crie um perfil de load balance
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Criar um perfil de load balance | load-balance profile { profile-name | default } | Mandatório. |
padrão, o sistema já cria o perfil “default” “ ecmp_default ” e o usuário pode entrar diretamente no modo de configuração do perfil “default” “ ecmp_default ” através do comando de criação de um perfil. O nome do perfil criado suporta apenas o inglês e o comprimento não pode exceder 31 caracteres.
Configurar HASH KEY do perfil de load balance
Depois de criar um perfil de load balance com sucesso e entrar no modo de configuração de perfil, você pode configurar o valor HASH KEY do perfil de balanceamento de carga.
O perfil padrão do sistema “default” “ ecmp_default ” será configurado com um HASHKEY padrão, podendo os usuários também modificar sua configuração de acordo com as necessidades reais. A configuração padrão do perfil “default” “ ecmp_default ” é: L2:src-mac, dst-mac ; Ip:src-ip, dst-ip; l4-src-port, l4-dst-port .
Depois de criar um perfil personalizado de usuário, o novo perfil não é configurado com nenhum valor HASH KEY por padrão e o usuário precisa configurar HASH KEY corretamente para que o perfil possa ser vinculado ao serviço.
Condições de configuração
Nenhum
Configurar HASH KEY do perfil de load balance
Tabela 1 -5 Configure a HASH KEY do perfil de load balance
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração do perfil de load balance | load-balance profile { profile-name | default } | Obrigatório. O mesmo que o comando de criar um perfil de load balance |
| Configure a HASH KEY usada pelo carregamento de pacote unicast conhecido L2 | l2 { [ dst-mac ] [ src-mac ] [ src-interface ] [ vlan ] } | Obrigatório. Você pode configurar uma ou mais HASH KEY. |
| Configure a HASH KEY usada pelo carregamento de pacote unicast conhecido de L 3 | ip { [ dst-ip ] [ l4-src-port ] [ l4-dst-port ] [ protocol ] [ src-interface ] [ src-ip ] [ flow-label ]} | Obrigatório. Você pode configurar uma ou mais HASH KEY. |
| Configurar a HASH KEY usada pelo carregamento do pacote mpls | Mpls{[src-ip] [dst-ip] [top-lable] [2nd -lable] [3rd-lable]} | Mandatório. Você pode configurar uma ou várias combinações de HASHKEY . |
| Ative a configuração atual da HASH KEY | active configuration pending | Obrigatório. |
| configuração atual da HASH KEY | abort configuration pending | Obrigatório. |
O valor HASH KEY configurado pelo comando l2 ou ip está no estado pendente e não entrará em vigor imediatamente. Ele pode entrar em vigor somente após a execução do comando active configuration pendente . O valor HASH KEY configurado pelo comando l2 ou ip está no estado pendente e não entrará em vigor imediatamente. O usuário pode cancelar a configuração atual através do comando abortar configuração pendente . Ao configurar uma nova HASH KEY, ela não cobrirá a HASH KEY original. Após a ativação através do comando active , o resultado é a comunicação da HASH KEY original e da nova HASH KEY. Quando a HASH KEY no estado pendente é cancelada através do comando abort, ela modificará a HASH KEY original. Quando não for ativado, ele limpará a HASH KEY no estado pendente. Normalmente, a falha de ativação ocorre porque a HASH KEY configurada não atende ao requisito. Você pode configurar qualquer HASH KEY para o perfil de load balance personalizado pelo usuário. No entanto, quando usado pela vinculação de serviço, L2 e L3 do perfil vinculado precisam ter pelo menos uma HASH KEY efetiva . Os modelos "default" e "ecmp_default" exigem que pelo menos uma hash key seja configurada para as chaves de hash L2 e L3.
Configurar HASHKEY Shift Selection do perfil de load balance
No modo global, configure a seleção de deslocamento do valor da hash key do perfil de load balance correspondente.
Condições de configuração
Modo global
Configurar HASH KEY do perfil de load balance
Tabela 1 - 6 Configurar a seleção de deslocamento HASH KEY do perfil de balanceamento de carga
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar HASHKEY Shift Selection | load-balance hash-control shift{src-mac | dst-mac|src-ip|dst-ip|vlan|l4-src-port|l4-dst-port|src-interface| flow-label| protocol } 0~5 | - |
Configurar algoritmo de análise de profundidade do pacote IP do perfil de load balance
Depois de criar o perfil de load balance e entrar com sucesso no modo de configuração de perfil, o algoritmo de análise de profundidade de pacotes IP para o perfil de load balance correspondente pode ser configurado.
Condições de configuração
No modo de configuração do perfil
Configurar algoritmo de análise de profundidade do pacote IP do perfil de balanceamento de carga
Tabela 1 -5 Configurar o algoritmo de análise de profundidade do pacote IP do perfil de load balance
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração do perfil de load balance | load-balance profile { profile-name | default } | Obrigatório. O mesmo que o comando de criar um perfil de load balance |
| Configurar o algoritmo de análise de profundidade do pacote IP | hash-control depta-parse ip { [enable][disable] } | enable: O pacote IP executa o hash com base no cabeçalho IP desabilitar : O pacote IP executa o hash com base no mac |
Excluir perfil de load balance
O comando é usado para excluir o perfil de load balance.
O perfil “default” “ ecmp_default ” criado por padrão do sistema não pode ser excluído. O perfil vinculado ou referenciado pelo serviço não pode ser excluído. Para excluí-lo, você precisa remover todas as relações de referência e vinculação primeiro. O perfil inexistente não pode ser excluído.
Condições de configuração
Nenhum
Excluir perfil de load balance
Tabela 1 -7 Excluir o perfil de load balance
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração do perfil de load balance | no load-balance profile { profile-name } | Obrigatório. |
Configuração da função de link aggregation
Tabela 1 -8 Lista de funções de link aggregation
| Tarefas de configuração | |
| Configure um link aggregation. | Crie um link aggregation. Adicione portas ao link aggregation. |
| Configure o link aggregation para fazer referência ao perfil de balanceamento de carga | Configure o link aggregation para fazer referência ao perfil de balanceamento de carga |
| Configure as prioridades do LACP. | Configure a prioridade LACP do sistema. Configure a prioridade LACP da porta. |
| Configurar o endereço MAC do sistema LACP do link aggregation | Configurar o endereço MAC do sistema LACP do link aggregation |
| Configure a extensão de ID da porta do link aggregation | Configurar a extensão de ID da porta do link aggregation |
| Configure a taxa de porta do link aggregation a ser selecionada primeiro | Configure a taxa de porta do link aggregation a ser selecionada primeiro |
| Configure o hot-swap para alternar rapidamente a porta raiz | Configure o hot-swap para alternar rapidamente a porta raiz |
Configurar um Link Aggregation
Depois de configurar um link aggregation, você pode gerenciar várias portas físicas de maneira centralizada. Opcional. configuração no link aggregation será aplicada a cada porta membro.
Um máximo de oito portas podem ingressar em um link aggregation ao mesmo tempo .
Condição de configuração
Nenhum
Criar e um Link Aggregation
Os link aggregation nas duas extremidades de um link agregado devem ser configurados para o mesmo tipo. A descrição pode ser adicionada a cada link aggregation para tornar mais fácil para os administradores de rede distinguir os link aggregation.
Tabela 1 -9 Criando um Link Aggregation
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um link aggregation. | link-aggregation link-aggregation-id mode { manual | lacp } [ member-number member-number-value ] | Obrigatório. Por padrão, nenhum link aggregation é criado. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | - |
| Configure a descrição do link aggregation. | description description-name | Opcional. Por padrão, nenhuma descrição é adicionada ao link aggregation. |
| Configure as informações de descrição de peer do link aggregation | peer-description description-name | Opcional. Por padrão, o link aggregation não possui as informações de descrição do par. |
Os protocolos aplicados em um link aggregation recebem e enviam pacotes de protocolo pela porta raiz do link aggregation. No modo de agregação estática, como as portas membro entre os dispositivos nas duas extremidades não trocam pacotes LACPDU, as portas raiz dos dois dispositivos podem estar em links físicos diferentes. Dessa forma, outros pacotes de protocolo no link aggregation podem não ser recebidos ou enviados. Para evitar esse problema, certifique-se de que as portas raiz dos dispositivos nas duas extremidades estejam no mesmo link físico. No modo de agregação dinâmica, as portas membro dos dispositivos nas duas extremidades trocam pacotes LACPDU. A negociação entre as duas portas membro garante que as portas raiz dos dois dispositivos estejam no mesmo link físico. Depois que um link aggregation é excluído, todas as portas de membro do grupo de agregação são removidas do link aggregation e, em seguida, todas as portas de membro adotam as configurações padrão. Isso pode resultar em loops na rede. Portanto, antes de excluir um link aggregation, certifique-se de que a função spanning tree esteja habilitada ou certifique-se de que nenhum loop possa ocorrer na rede.
Adicionar portas ao link aggregation
Quando um link aggregation é criado, trata-se apenas de uma interface lógica que não contém nenhuma porta física. Nesse caso, a função de agregação não tem efeito. A função de agregação entra em vigor depois que as portas são adicionadas a um link aggregation estática. A função de agregação entra em vigor depois que as portas locais ou de mesmo nível são adicionadas a um link aggregation dinâmico.
Tabela 1 -10 Adicionando uma porta ao link aggregation
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | - |
| Adicione a porta ao link aggregation. | link-aggregation link-aggregation-id { manual | active | passive } | Por padrão, uma porta não é adicionada a nenhum link aggregation. |
Antes de incluir uma porta em um link aggregation, o link aggregation deve ter sido criado; caso contrário, uma mensagem de erro será exibida. Uma porta pode ser adicionada um link aggregation por vez. Depois que uma porta for adicionada a um link aggregation, algumas configurações existentes (como loopback detection e VLAN) serão removidas da porta. Algumas funções (como loopback detection) não podem ser configuradas em uma porta membro em um link aggregation; caso contrário, uma mensagem de erro será exibida. Se uma porta for adicionada a um link aggregation dinâmico no modo passivo, sua porta de mesmo nível deverá ser adicionada ao link aggregation dinâmico no modo ativo. Caso contrário, as duas portas estarão no status não selecionado e não poderão participar do encaminhamento de tráfego de serviço do usuário. A porta configurada como serviceloop-group não pode ser adicionada ao grupo de agregação.
Configurar o link aggregation para o perfil de load balance de referência
Ao configurar o link aggregation para fazer referência ao perfil de load balance, você pode obter o load balance do tráfego de serviço no link aggregation de maneira flexível.
Condição de configuração
Nenhum
Configurar o Link Aggregation para Referenciar o Perfil de Balanceamento de Carga
Tabela 1 -11 Configurando o Link Aggregation para Referenciar o Perfil de Balanceamento de Carga
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração do link aggregation | interface link-aggregation link-aggregation-id | - |
| Configure o link aggregation para fazer referência ao modo de balanceamento de carga | load-balance profile profile-name | Obrigatório. Por padrão, o link aggregation faz referência ao perfil padrão para realizar o load balance de agregação. |
Configurar prioridades LACP
Condição de configuração
Nenhum
Configurar a prioridade do sistema LACP
A configuração da prioridade LACP do sistema pode afetar o ID do sistema e, finalmente, afetar o status selecionado/não selecionado das portas membro dos link aggregation dinâmica.
Tabela 1 -12 Configurando a Prioridade LACP do Sistema
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a prioridade LACP do sistema. | lacp system-priority system-priority-value | Obrigatório. Por padrão, a prioridade do sistema LACP é 32768. |
Configurar a Prioridade da Porta LACP
A configuração da prioridade LACP da porta pode afetar o ID da porta e, finalmente, afetar o status selecionado/não selecionado das portas membro dos link aggregation.
Tabela 1 -13 Configurando a Prioridade da Porta LACP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | - |
| Configure a prioridade LACP da porta. | lacp port-priority port-priority-value | Obrigatório. Por padrão, a prioridade LACP da porta é 32768. |
Configurar o endereço MAC do sistema LACP do link aggregation
Configure o endereço MAC do sistema LACP do link aggregation. Quando as prioridades do sistema LACP em ambas as extremidades do link aggregation são as mesmas, quanto menor o endereço MAC do sistema LACP, menor o ID do sistema LACP (maior a prioridade).
Tabela 1 -14 Configurar o endereço MAC do sistema LACP do link aggregation
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração do link aggregation | interface link-aggregation link-aggregation-id | - |
| Configure o endereço MAC do sistema LACP do link aggregation | lacp system-mac mac-address | Opcional. Por padrão, o endereço MAC do sistema LACP do link aggregation é o endereço MAC da bridge do dispositivo. |
Configurar Extensão de ID de Porta do Link Aggregation
Se a extensão de ID de porta do link aggregation estiver configurada, o número da porta de cada porta membro do link aggregation no protocolo LACP será aumentado em 32768. Essa função geralmente é usada em cenários de empilhamento para evitar conflitos de ID de porta.
Tabela 1 -15 Configurar a extensão de ID da porta do link aggregation
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração do link aggregation | interface link-aggregation link-aggregation-id | - |
| Configurar a extensão de ID da porta do link aggregation | lacp port-id extend | Opcional. Por padrão, não configure a extensão de ID da porta do link aggregation. |
Configurar a taxa de porta do link aggregation a ser selecionado primeiro
Por padrão, o link aggregation pode selecionar a porta com taxa baixa como porta de referência. Configurando esta função, o usuário pode selecionar preferencialmente a porta de alta taxa como porta de referência. Após configurar esta função, o link aggregation selecionará a porta de referência de acordo com a prioridade do ID do sistema - > prioridade da porta - > taxa da porta - > número da porta.
Tabela 1 -16 Configurar a taxa de porta do link aggregation a ser selecionado primeiro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração do link aggregation | interface link-aggregation link-aggregation-id | - |
| Configurar a taxa de porta do link aggregation a ser selecionado primeiro | lacp select speed | Opcional. Por padrão, não configure a taxa de porta do link aggregation a ser selecionado primeiro. |
Configurar a função de encaminhamento de atraso da porta do membro do grupo de agregação
Configure a função de encaminhamento de atraso da porta do membro do link aggregation. A porta do membro do link aggregation em uma placa recém-inserida ou dispositivo recém-adicionado atrasará por um certo tempo para carregar o tráfego.
Tabela 1 -17 Configure a função de encaminhamento de atraso da porta do membro do link aggregation
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a função de encaminhamento de atraso da porta do membro do grupo de agregação | lacp delay-forward time | Mandatório. Por padrão, a função está habilitada e o tempo de atraso é de 150s. |
Configurar o hot-swap para a porta raiz do switch rápido
Ao configurar o hot-swap para alternar rapidamente a porta raiz, podemos trocar o cartão da porta raiz, informar rapidamente o peer para selecionar novamente a porta raiz, conveniente para o link aggregation convergir rapidamente.
Ao retirar o cartão da porta raiz, envie o aviso de comutação rápida. O link aggregation estático não envia o aviso de troca rápida.
Condição de configuração
Nenhum
Configurar o hot-swap para a porta raiz do switch rápido
Tabela 1 -18 Configure o hot-swap para alternar rapidamente a porta raiz
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o hot-swap para alternar rapidamente a porta raiz | link-aggregation hotswap fast-change-rootport | Obrigatório. Por padrão, não configure o hot-swap para alternar rapidamente a porta raiz. |
Configurar o modo de encaminhamento do link aggregation
Em ambiente VST, para reduzir a carga do link VSL, o tráfego de serviço recebido pelo dispositivo membro pode ser configurado para encaminhar de outras interfaces Ethernet do dispositivo, ou seja, adotar política de encaminhamento prévio local. No caso de agregação de link entre dispositivos, a carga de tráfego de cada link de membro no link aggregation é desequilibrada. Os usuários podem definir o modo de encaminhamento do link aggregation de acordo com o cenário real da rede. Quando o modo de encaminhamento é definido para load balance global, no caso de agregação de link entre dispositivos, a carga de tráfego de cada link de membro no link aggregation é balanceada.
Tabela 1 -14 Configurar o modo de encaminhamento do link aggregation
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração do link aggregation | interface link-aggregation link-aggregation-id | Mandatório. |
| Configurar o modo de encaminhamento do link aggregation | forward-mode { global-fair | local-prior } | Mandatório. Por padrão, o modo de encaminhamento do link aggregation é o balanceamento de carga global. |
modo de encaminhamento de comando { feira global | local-prior } pode ser configurado somente quando o dispositivo estiver funcionando no modo VST. Quando o link aggregation tem portas de membro, o modo de encaminhamento do grupo de agregação não pode ser comutado.
Monitoramento e manutenção de link aggregation
Tabela 1 -19 Monitoramento e manutenção de link aggregation
| Comando | Descrição |
| show link-aggregation group [ link-aggregation-id ] | Exibe informações breves sobre um link aggregation especificado ou todos os grupos de agregação existentes. |
| show link-aggregation interface [ interface-name ] | Exibe os detalhes de uma porta membro especificada de um link aggregation ou detalhes de todas as portas membro do link aggregation. |
Exemplo de configuração típico de link aggregation
Configurar um link aggregation estático
Requisitos de rede
- Device1 está conectado ao PC1, Device2 está conectado ao PC2 e PC3 e os três PCs estão no mesmo segmento de rede. Device1 e Device2 são interconectados por meio de portas Trunk.
- Um link aggregation estático é configurado entre Device1 e Device2 para aumento de largura de banda, compartilhamento de carga e backup de serviço.
Topologia de rede

Figura 1 -3 Rede para configurar um link aggregation estático
Etapas de configuração
- Passo 1: Crie um link aggregation estático.
#No Dispositivo1, crie o link aggregation estático 1.
Device1#configure terminalDevice1(config)#link-aggregation 1 mode manual
#No Dispositivo2, crie o link aggregation estático 2.
Device2#configure terminalDevice2(config)#link-aggregation 1 mode manual
- Passo 2: Adicione portas ao link aggregation.
#No Device1, adicione as portas gigabitethernet0/1 e gigabitethernet0/2 no link aggregation 1 no modo Manual.
Device1(config)#interface gigabitethernet 0/1,0/2Device1(config-if-range)#link-aggregation 1 manualDevice1(config-if-range)#exit
#No Device2, adicione as portas gigabitethernet0 /1 e gigabitethernet0/2 no grupo de agregação 1 no modo Manual.
Device2(config)#interface gigabitethernet 0/1,0/2Device2(config-if-range)#link-aggregation 1 manualDevice2(config-if-range)#exit
#Após a configuração ser concluída, verifique o status do link aggregation 1 nos dispositivos.
Aqui pega Device1 por exemplo:
Device1#show link-aggregation group 1Link Aggregation 1Type: switchportMode: ManualUser: LACDescription:Peer-description:Load balance profile: defaultNumber of ports in total: 2Number of ports attached: 2Root port: gigabitethernet0/1gigabitethernet0/1: ATTACHED gigabitethernet0/2: ATTACHED
De acordo com a exibição do sistema, as portas gigabitethernet0/1 e gigabitethernet0/2 no Device1 estão no estado ATTACHED no link aggregation 1 e a agregação do link aggregation 1 é bem-sucedida.
Para o método de verificação de Device2, consulte o método de verificação de Device1.
- Passo 3: Configure o link aggregation para fazer referência ao perfil de load balance.
# Em Device1, crie o perfil de load balance linkagg-profile .
Device1(config)#load-balance profile linkagg-profile#No Dispositivo1, configure a hash key de carregamento do pacote no perfil de load balance linkagg-profile, configure o pacote L2 para carregar pelo MAC de destino e configure o pacote IP para carregar pelo IP de destino.
Device1(config-hashprofile)#l2 dst-macDevice1(config-hashprofile)#ip dst-ipDevice1(config-hashprofile)#active configuration pending
# Em Device1, configure o perfil de load balance referenciado pelo grupo de agregação 1 como linkagg-profile .
Device1(config)#interface link-aggregation 1Device1(config-link-aggregation1)#load-balance profile linkagg-profile
- Passo 4: Configure uma VLAN e configure o tipo de link do link aggregation e das portas.
#No Dispositivo1, crie a VLAN2, configure o tipo de link do link aggregation 1 para Trunk e permita que os serviços da VLAN2 passem e defina o Port VLAN ID (PVID) como 2.
Device1(config)#vlan 2Device1(config-vlan2)#exitDevice1(config)#interface link-aggregation 1Device1(config-link-aggregation1)#switchport mode trunkDevice1(config-link-aggregation1)#switchport trunk allowed vlan add 2Device1(config-link-aggregation1)#switchport trunk pvid vlan 2Device1(config-link-aggregation1)#exit
#No Device1, configure o tipo de link da porta gigabitethernet0/3 para acessar e permitir que os serviços da VLAN2 passem.
Device1(config)#interface gigabitethernet 0/3Device1(config-if-gigabitethernet0/3)#switchport mode accessDevice1(config-if-gigabitethernet0/3)#switchport access vlan 2Device1(config-if-gigabitethernet0/3)#exit
#No Device2, crie a VLAN2, configure o tipo de link do link aggregation 1 para Trunk e permita que os serviços da VLAN2 passem e defina PVID como 2. (Omitido)
#No Device2, configure o tipo de link das portas gigabitethernet0/3 e gigabitethernet0/4 para acessar e permitir que os serviços da VLAN2 passem. (Omitido)
#Nos dispositivos, verifique a largura de banda agregada do link aggregation 1.
Aqui pega Device1 por exemplo:
Device1#show interface link-aggregation 1link-aggregation 1 configuration informationDescription :Peer-description :Status : EnabledLink : UpAct Speed : 2000Act Duplex : FullPort Type : NniPvid : 2
De acordo com a exibição do sistema, a largura de banda da interface do link aggregation 1 no Device1 é de 2000 M.
Para o método de verificação de Device2, consulte o método de verificação de Device1.
#No Dispositivo1, visualize o perfil de load balance efetivo atual do grupo de agregação1.
Device1#show link-aggregation group 1Link Aggregation 1Type: switchportMode: ManualUser: LACDescription:Peer-description :Load balance profile: linkagg-profileNumber of ports in total: 2Number of ports attached: 2Root port: gigabitethernet0/1gigabitethernet0/1: ATTACHEDgigabitethernet0/2: ATTACHED
De acordo com a exibição do sistema, o perfil de load balance atual do grupo de agregação 1 é linkagg-profile .
#Durante o processo de interação de serviço entre PC1 e PC2 e PC3, o load balance de dados é obtido nos links agregados. Se um link no link aggregation apresentar falhas, os outros links fornecerão backup de serviço.
Configurar um Link Aggregation Dinâmico
Requisitos de rede
- Device1 está conectado ao PC1, Device2 está conectado ao PC2 e PC3 e os três PCs estão no mesmo segmento de rede. Device1 e Device2 são interconectados por meio de portas Trunk.
- Um link aggregation dinâmico é configurado entre Device1 e Device2 para aumento de largura de banda, compartilhamento de carga e backup de serviço.
Topologia de rede
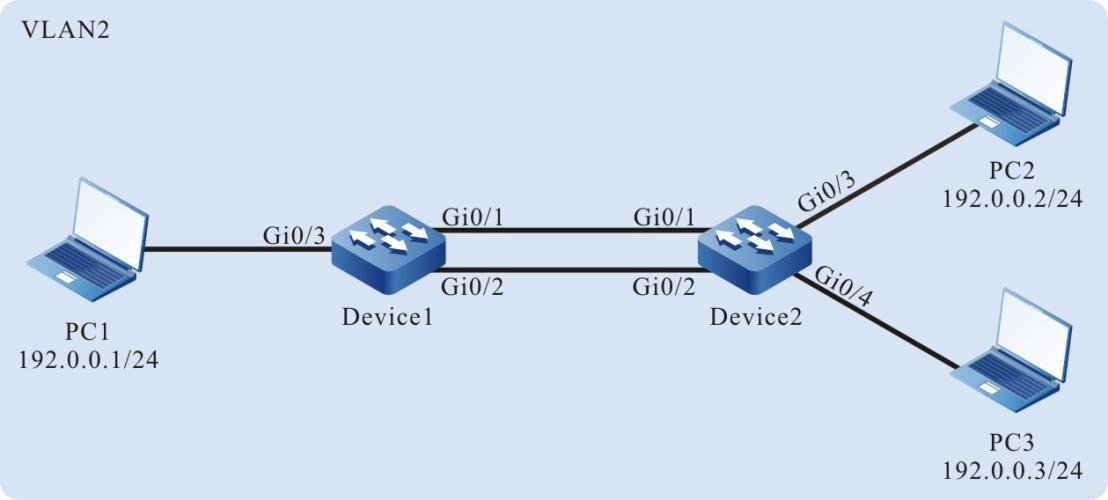
Figura 1 -4 Rede para configurar um link aggregation dinâmico
Etapas de configuração
- Passo 1: Crie um link aggregation dinâmico.
#No Dispositivo1, crie o link aggregation dinâmico 1.
Device1#configure terminalDevice1(config)#link-aggregation 1 mode lacp
#No Dispositivo2, crie o link aggregation dinâmico 1.
Device2#configure terminalDevice2(config)#link-aggregation 1 mode lacp
#No Dispositivo1, adicione as portas gigabitethernet0/1 e gigabitethernet0/2 no grupo de agregação 1 no modo Ativo.
Device1(config)#interface gigabitethernet 0/1,0/2Device1(config-if-range)#link-aggregation 1 activeDevice1(config-if-range)#exit
#No Device2, adicione as portas gigabitethernet0/1 e gigabitethernet0/2 no link aggregation 1 no modo Ativo.
Device2(config)#interface gigabitethernet 0/1,0/2Device2(config-if-range)#link-aggregation 1 activeDevice2(config-if-range)#exit
#Após a configuração ser concluída, verifique o status do link aggregation 1 nos dispositivos.
Aqui pega Device1 por exemplo:
Device1#show link-aggregation group 1Link Aggregation 1Type: switchportMode: LACPUser: LACDescription:Peer-description:Load balance profile: defaultNumber of ports in total: 2Number of ports attached: 2Root port: gigabitethernet0/1gigabitethernet0/1: ATTACHED gigabitethernet0/2: ATTACHED
De acordo com a exibição do sistema, as portas gigabitethernet0/1 e gigabitethernet0/2 no Device1 estão no estado ATTACHED no link aggregation 1 e a agregação do link aggregation 1 é bem-sucedida.
Para o método de verificação de Device2, consulte o método de verificação de Device1.
- Passo 3: Configure o link aggregation para fazer referência ao perfil de load balance.
# Em Device1, crie o perfil de load balance linkagg -profile .
Device1(config)#load-balance profile linkagg-profile# No Device1, configure a hash-key de carregamento do pacote no perfil de balanceamento de carga linkagg-profile, configure o pacote L2 para carregar pelo MAC de destino, configure o pacote IP para carregar pelo IP de destino .
Device1(config-hashprofile)#l2 dst-macDevice1(config-hashprofile)#ip dst-ipDevice1(config-hashprofile)#active configuration pending
# Em Device1, configure o perfil de load balance referenciado pelo grupo de agregação 1 como linkagg-profile .
Device1(config)#interface link-aggregation 1Device1(config-link-aggregation1)#load-balance profile linkagg-profile
# No Device2, crie o perfil de load balance perfil linkagg (omitido).
# No Device2, configure o load hash-key do pacote no perfil de load balance linkagg-profile , configure o pacote L2 para carregar pelo MAC de destino, configure o pacote IP para carregar pelo IP de destino . (Omitido)
# Em Device2, configure o perfil de load balance referenciado pelo grupo de agregação 1 como linkagg-profile . (Omitido)
- Passo 4: Configure uma VLAN e configure o tipo de link do link aggregation e das portas.
#No Dispositivo1, crie a VLAN2, configure o tipo de link do link aggregation 1 para Trunk e permita que os serviços da VLAN2 passem e defina PVID como 2.
Device1(config)#vlan 2Device1(config-vlan2)#exitDevice1(config)#interface link-aggregation 1Device1(config-link-aggregation1)#switchport mode trunkDevice1(config-link-aggregation1)#switchport trunk allowed vlan add 2Device1(config-link-aggregation1)#switchport trunk pvid vlan 2Device1(config-link-aggregation1)#exit
#No Device1, configure o tipo de link da porta gigabitethernet0/3 para acessar e permitir que os serviços da VLAN2 passem.
Device1(config)#interface gigabitethernet 0/3Device1(config-if-gigabitethernet0/3)#switchport mode accessDevice1(config-if-gigabitethernet0/3)#switchport access vlan 2Device1(config-if-gigabitethernet0/3)#exit
#No Device2, crie a VLAN2, configure o tipo de link do link aggregation 1 para Trunk e permita que os serviços da VLAN2 passem e defina PVID para 2.(Omitido)
#No Device2, configure o tipo de link das portas gigabitethernet0/3 e gigabitethernet0/4 para acessar e permitir a passagem dos serviços da VLAN2. (Omitido)
- Passo 5: Confira o resultado.
#Nos dispositivos, verifique a largura de banda agregada do link aggregation 1.
Tome Device1 por exemplo:
Device1#show interface link-aggregation 1link-aggregation 1 configuration informationDescription :Peer-description :Status : EnabledLink : UpAct Speed : 2000Act Duplex : FullPort Type : NniPvid : 2
De acordo com a exibição do sistema, a largura de banda da interface do link aggregation no Device1 é de 2000 M.
Para o método de verificação de Device2, consulte o método de verificação de Device1.
# Após a configuração, visualize o perfil de load balance configurado no Device1.
Device1#show load-balance configurationProfile:defaultConfiguration Valid currently:L2: src-mac dst-macIp: src-ip dst-ipConfiguration Valid-pending to be applied:L2:Ip:Configuration Invalid-pending to be applied:L2:Ip:Profile:linkagg-profileConfiguration Valid currently:L2: dst-macIp: dst-ipConfiguration Valid-pending to be applied:L2:Ip:Configuration Invalid-pending to be applied:L2:Ip:
#Depois que a configuração for concluída, verifique o perfil de load balance atual no Device1.
Device1#show link-aggregation group 1Link Aggregation 1Type: switchportMode: LACPUser: LACDescription:Peer-description :Load balance profile: linkagg-profileNumber of ports in total: 2Number of ports attached: 2Root port: gigabitethernet0/1gigabitethernet0/1: ATTACHEDgigabitethernet0/2: ATTACHED
De acordo com a exibição do sistema, o perfil de load balance atual referenciado pelo link aggregation 1 é linkagg-profile .
#Durante o processo de interação de serviço entre PC1 e PC2 e PC3, o load balance de dados é obtido nos links agregados. Se um link no link aggregation apresentar falhas, os outros links fornecerão backup de serviço.
Port Isolation
Visão geral
O port isolation é um recurso de segurança baseado em portas. De acordo com o requisito real, você pode configurar determinadas portas para serem isoladas de uma determinada porta, ou seja, configurar algumas portas isoladas para uma determinada porta. Desta forma, os pacotes que são recebidos pela porta especificada não podem ser encaminhados para as portas isoladas. Isso aumenta a segurança da rede e também fornece um esquema de rede flexível.
Configuração da função de port isolation
Tabela 2-1 Lista de Funções de Port Isolation
| Tarefas de configuração | |
| Configure a função básica de port isolation. | Configure o port isolation. |
| Configure a função de isolamento para portas membro do link aggregation. | Configure a função de isolamento para portas membro do link aggregation. |
Configurar funções básicas de port isolation
A função de port isolation realiza o isolamento de pacote unidirecional. Supondo que a porta B esteja configurada como a porta isolada da porta A, se um pacote cuja porta de destino é a porta B entrar na porta A, a porta será descartada diretamente. No entanto, se um pacote cuja porta de destino é a porta B entrar na porta B, a porta normalmente é encaminhada. A porta isolada pode ser uma porta ou um link aggregation.
O port isolation é configurado com base no grupo de isolamento.
- As portas em um grupo de isolamento são isoladas umas das outras.
As portas no grupo de isolamento podem ser configuradas como entrada, saída, ambos os modos e as resoluções são as seguintes:
Tabela 2 -2 Tabela de encaminhamento do modo de configuração
| Modo de porta de entrada de pacote | Modo de porta de saída de pacote | Encaminhar normalmente ou não |
| Modo de entrada | modo de entrada | Encaminhar normalmente |
| modo de entrada | modo de saída | Proibir encaminhamento |
| modo de entrada | ambos os modos | Proibir encaminhamento |
| modo de saída | modo de entrada | Encaminhar normalmente |
| modo de saída | modo de saída | Encaminhar normalmente |
| modo de saída | ambos os modos | Encaminhar normalmente |
| ambos os modos | modo de entrada | Encaminhar normalmente |
| ambos os modos | modo de saída | Proibir encaminhamento |
| ambos os modos | ambos os modos | Proibir encaminhamento |
- As portas do grupo de isolamento se comunicam normalmente com as portas não adicionadas ao grupo de isolamento.
Os portos de diferentes grupos de isolamento podem se comunicar normalmente.
Condição de configuração
O grupo de isolamento já está criado.
Configurar port isolation
Tabela 2-3 Configurando o port isolation
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração do grupo de isolamento | isolate group group-id | Mandatório. |
| a porta ao grupo de isolamento | interface link-aggregation link-aggregation-id [ ingress | egress | both ] | Mandatório. Por padrão, a porta não é adicionada ao grupo de isolamento. |
| de agregação ao grupo de isolamento | link-aggregation link-aggregation-id [ ingress | egress | both ] | Mandatório. Por padrão, o link aggregation não é adicionado ao grupo de isolamento. |
Ao adicionar uma porta ao grupo de isolamento, o grupo de isolamento precisa ser criado.
Monitoramento e Manutenção do Port Isolation
Tabela 2 -4 Monitoramento e Manutenção do Port Isolation
| Comando | Descrição |
| show isolate { group [ group-id ] | interface interface-list | interface link-aggregation link-aggregation-id } | Exibe as informações de port isolation. |
Exemplo de configuração típica de port isolation
Configurar port isolation
Requisitos de rede
- PC1 e PC2 estão conectados ao dispositivo e estão na mesma VLAN, VLAN2.
- No dispositivo, o port isolation foi configurado; portanto, PC1 e PC2 não podem se comunicar entre si.
Topologia de rede

Figura 2 -1 Rede para configurar o port isolation
Etapas de configuração
- Passo 1: Configure uma VLAN e configure o tipo de link das portas.
#No dispositivo, crie VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#No Dispositivo, configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 para acessar e permitir a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1-0/2Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
- Passo 2: Configure o port isolation.
#No dispositivo, configure o port isolation entre a porta gigabitethernet0/1 e a porta gigabitethernet0/2.
Device#config terminalDevice(config)#isolate group 1Device(config-isolate-group1)#Device(config-isolate-group1)#endDevice#show isolate group 1--------------------------------------------------------isolate group 1ingress member:egress member :both member :
#No dispositivo, consulte as informações de port isolation.
Device#show isolate interface gigabitethernet 0/1-0/2interface gigabitethernet0/1 isolated informationisolate group 1 mode: bothisolated interface:gi0/2interface gigabitethernet0/2 isolated informationisolate group 1 mode: bothisolated interface:gi0/1
- Passo 3: Confira o resultado.
#PC1 e PC2 não podem se comunicar.
VLAN
Visão geral
Em uma Ethernet comutada, cada porta no dispositivo é um domínio de colisão independente, mas todas as portas pertencem a um domínio de broadcast. Quando um dispositivo terminal envia pacotes de difusão, todos os dispositivos na rede local (LAN) podem receber os pacotes. Isso não apenas desperdiça a largura de banda da rede, mas também traz problemas ocultos.
Virtual Local Area Network (VLAN) é uma tecnologia através da qual os dispositivos na mesma LAN podem ser divididos de forma lógica. Os dispositivos na mesma VLAN podem se comunicar entre si na camada 2, enquanto os dispositivos de diferentes VLANs são isolados na camada 2. Dessa forma, os pacotes de broadcast são limitados dentro de uma VLAN.
As VLANs estão em conformidade com IEEE 802.1Q. Esse padrão define um novo formato de encapsulamento de quadro, no qual uma tag de VLAN de 4 bytes contendo informações de VLAN é adicionada após o endereço MAC de origem de um quadro de dados tradicional.
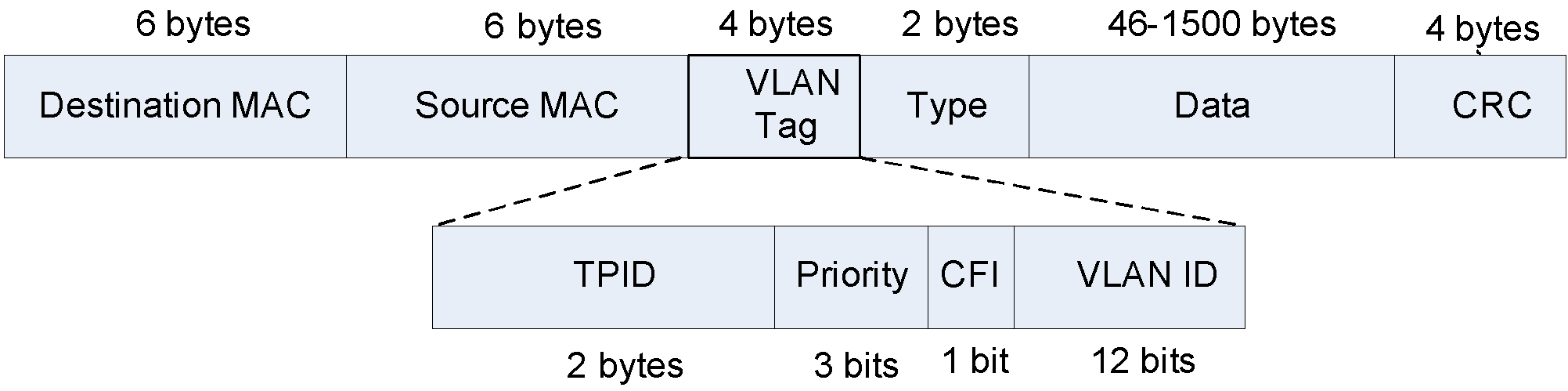
Figura 3 -1 Formato de encapsulamento de quadro IEEE 802.1Q
Uma tag VLAN contém os quatro campos a seguir:
- Tag Protocol Identifier (TPID): É usado para determinar se uma tag VLAN é transportada pelo quadro de dados. O comprimento é de 2 bytes e o valor é fixado em 0x8100, indicando uma tag 802.1Q padrão.
- Prioridade: É a prioridade 802.1p. O comprimento é de 3 bits e o intervalo de valores é de 0 a 7. Pacotes com diferentes prioridades podem obter serviços de diferentes níveis.
- Indicador de formato canônico (CFI): Indica se o endereço MAC está encapsulado em um formato padrão para transmissão em diferentes mídias. O comprimento é de 1 bit. O valor 0 indica que o endereço MAC está encapsulado em um formato padrão, enquanto o valor 1 indica que o endereço MAC está encapsulado em um formato não padrão.
- ID da VLAN: Indica a VLAN à qual o pacote pertence. O comprimento é de 12 bits e o intervalo de valores é de 0 a 4095, em que 0 e 4095 são valores reservados ao protocolo e os IDs de VLAN disponíveis estão no intervalo de 1 a 4094.
As VLANs têm as seguintes vantagens:
- Estabelece grupos de trabalho virtuais de forma flexível. Usuários com os mesmos requisitos podem ser divididos em uma VLAN, sem serem limitados por suas localizações físicas.
- Limita os domínios de broadcast. Uma VLAN é um domínio de broadcast. Os quadros unicast, multicast e broadcast da camada 2 podem ser encaminhados apenas dentro do domínio e não podem entrar diretamente em outras VLANs. Isso evita tempestades de transmissão.
- Melhora a segurança da rede. Diferentes VLANs são isoladas na camada dois e as VLANs não podem se comunicar diretamente umas com as outras.
De acordo com as aplicações, as VLANs são categorizadas nos quatro tipos a seguir:
- VLANs baseadas em porta
- VLANs baseadas em endereço MAC
- VLANs baseadas em sub-rede IP
- VLANs baseadas em protocolo
Por padrão, na ordem de prioridade de alta para baixa, os quatro tipos de VLANs são: VLANs baseadas em sub-rede IP, VLANs baseadas em MAC, VLANs baseadas em protocolo e VLANs baseadas em porta. Em uma porta, as VLANs entram em vigor de acordo com os níveis de prioridade e apenas um tipo de VLAN entra em vigor.
Configuração da função VLAN
Tabela 3-1 Lista de funções de VLAN
| Tarefas de configuração | |
| Configurando atributos básicos de VLANs | Configure uma VLAN. Configure o nome da VLAN. |
| Configure uma VLAN baseada em porta. |
Configure o tipo de link de porta.
Adicione uma porta de acesso à VLAN. Configure uma porta Trunk para permitir a passagem de serviços de uma VLAN. Adicione uma porta híbrida na VLAN. Configure PVIDs para portas. |
| Configure uma VLAN baseada em endereço MAC. | Configure uma VLAN baseada em endereço MAC. |
| Configure uma VLAN baseada em sub-rede IP. | Configure uma VLAN baseada em sub-rede IP. |
| Configure uma VLAN baseada em protocolo. | Configure uma VLAN baseada em protocolo. |
| Configure os tipos de quadros que podem ser recebidos pela porta. | Configure os tipos de quadros que podem ser recebidos pela porta. |
Configurar atributos básicos de VLANs
Condição de configuração
Nenhum
Configurar uma VLAN
Cada VLAN corresponde a um domínio de broadcast. Os usuários na mesma VLAN podem se comunicar entre si na camada 2, enquanto os usuários de diferentes VLANs são isolados uns dos outros na camada 2.
Tabela 3 -2 Configurando uma VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie uma VLAN. | vlan vlan-list | Obrigatório. Por padrão, o sistema cria automaticamente a VLAN1. Ao criar uma única VLAN, após a criação de uma VLAN, você entrará no modo de configuração da VLAN. Ao criar várias VLANs, após a criação de uma VLAN, você ainda está no modo de configuração atual. |
Configure o nome da VLAN
Para facilitar a memória e o gerenciamento, você pode configurar o nome de uma VLAN de acordo com o tipo de serviço, função e conexão da VLAN.
Tabela 3 -3 Configure o nome da VLAN.
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entra no modo de configuração de VLAN. | vlan vlan-id | - |
| Configure o nome da VLAN. | name vlan-name | Obrigatório. Por padrão, o nome da VLAN1 é DEFAULT, e os nomes das outras VLANs seguem o formato "VLAN vlan-id" , como VLAN100. |
Configurar uma VLAN baseada em porta
Uma VLAN baseada em porta, também chamada de VLAN de porta, é uma VLAN do tipo de divisão mais simples. Depois que uma porta é adicionada à VLAN, a porta pode encaminhar pacotes que pertencem à VLAN.
Condição de configuração
Nenhum
Configurar o tipo de link de porta
Uma porta lida com tags de VLAN em diferentes modos antes de encaminhar pacotes. De acordo com os modos de manipulação de tags VLAN, os três tipos de link a seguir estão disponíveis:
- Tipo de acesso: Os pacotes que foram encaminhados não carregam tags VLAN. As portas desse tipo geralmente são conectadas aos dispositivos do usuário.
- Tipo de tronco: Os pacotes das VLANs nas quais o PVID está localizado não carregam tags de VLAN, enquanto os pacotes de outras VLANs ainda carregam tags de VLAN.
- Tipo híbrido: Os pacotes da VLAN especificada podem ser configurados para não transportar ou transportar tags de VLAN. As portas do tipo podem ser conectadas a dispositivos de usuário ou interconectadas com dispositivos de rede.
As portas do tipo Trunk e as portas do tipo Híbrido não podem ser convertidas uma na outra diretamente. Eles precisam ser convertidos para o tipo Access antes de serem convertidos para outro tipo.
Tabela 3 -4 Configurando o tipo de link de porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure o tipo de link de porta. | switchport mode { access | hybrid | trunk } | Obrigatório. Por padrão, o tipo de link de porta é o tipo de acesso. |
Alguns comandos podem ser configurados apenas nas portas com o tipo de link especificado . Portanto , se o tipo de link de porta for convertido para outro tipo, as funções configuradas na porta com o tipo de link original podem se tornar inválidas.
Adicione uma porta de acesso na VLAN
Uma porta de acesso pode pertencer a apenas uma VLAN. Quando uma porta de acesso é adicionada a uma VLAN especificada, ela sai da VLAN atual e entra na VLAN especificada. Se a VLAN à qual a porta de acesso deve ser adicionada não existir, a VLAN será criada automaticamente.
Tabela 3 -5 Adicionando uma porta de acesso à VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure o tipo de link de porta para o tipo de acesso. | switchport mode access | Obrigatório. Por padrão, o tipo de link de porta é o tipo de acesso. |
| Adicione uma porta de acesso à VLAN especificada. | switchport access vlan vlan-id | Obrigatório. Por padrão, a porta de acesso é adicionada à VLAN1. |
Configurar uma porta de tronco para permitir a passagem de serviços de uma VLAN
Se uma porta Trunk permite a passagem de serviços de uma VLAN existente, a porta permite o encaminhamento de pacotes da VLAN. Se a VLAN que a porta Trunk permite passar não existir, a VLAN não será criada automaticamente e você deverá criar a VLAN antes que a porta permita o encaminhamento de pacotes da VLAN.
Tabela 3 -6 Configurando uma porta de tronco para permitir a passagem de serviços de uma VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure o tipo de link de porta para o tipo de tronco. | switchport mode trunk | Obrigatório. Por padrão, o tipo de link de porta é o tipo de acesso. |
| Configure uma porta Trunk para permitir a passagem de uma VLAN. | switchport trunk allowed vlan { all | add vlan-list } | Obrigatório. Por padrão, a porta Trunk permite a passagem de VLAN1. |
| Configure os pacotes da VLAN em que o PVID está localizado para serem encaminhados com as tags VLAN reservadas. | vlan dot1q tag pvid | Opcional. Por padrão, os pacotes da VLAN em que o PVID está localizado são encaminhados sem tags de VLAN. |
Adicione uma porta híbrida na VLAN
Se a VLAN à qual a porta de acesso deve ser adicionada não existir, a VLAN será criada automaticamente.
Tabela 3 -7 Adicionando uma porta híbrida na VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure o tipo de link de porta para o tipo Híbrido. | switchport mode hybrid | Obrigatório. Por padrão, o tipo de link de porta é o tipo de acesso. |
| Adicione uma porta híbrida a uma VLAN especificada em um modo especificado. | switchport hybrid { untagged | tagged } vlan vlan-list | Obrigatório. Por padrão, a porta híbrida é adicionada à VLAN1 no modo Untagged. |
Configurar PVIDs para Portas
Port VLAN ID (PVID) é um parâmetro importante de uma porta. Quando uma porta recebe um pacote Untag, ela adiciona uma etiqueta VLAN ao pacote, e o ID da VLAN da etiqueta VLAN é o PVID da porta.
O PVID de uma porta de acesso é o ID da VLAN à qual ela pertence, portanto, o PVID da porta de acesso pode ser configurado apenas alterando a VLAN à qual ela pertence. A porta Trunk e a porta híbrida podem pertencer a várias VLANs e seus PVIDs podem ser configurados de acordo com a necessidade real.
A porta Trunk e a porta híbrida devem ser adicionadas à VLAN à qual seus PVIDs pertencem; caso contrário, os pacotes da VLAN à qual seus PVIDs pertencem não podem ser encaminhados, e a porta descarta os pacotes Untag recebidos.
Tabela 3 -8 Configurando PVIDs para Portas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configurando o PVID para a porta Trunk. | switchport trunk pvid vlan vlan-id | Obrigatório. Selecione uma opção de acordo com o tipo de link de porta. Por padrão, a porta PVID é VLAN1. |
| Configurando o PVID para a porta híbrida. | switchport hybrid pvid vlan vlan-id |
Ao configurar o PVID para uma porta, a VLAN à qual o PVID pertence deve ter sido criada; caso contrário, a configuração falhará e uma mensagem de erro será exibida.
Configurar uma VLAN baseada em endereço MAC
As VLANs baseadas em endereço MAC, também chamadas de VLANs MAC, são classificadas de acordo com os endereços MAC de origem dos pacotes. Depois que uma VLAN MAC é configurada, se a porta receber um pacote Untag e o endereço MAC de origem do pacote corresponder a uma entrada MAC VLAN, o sistema adicionará uma tag VLAN para o pacote, na qual o ID da VLAN corresponde ao ID da VLAN no MAC Entrada de VLAN.
Depois que a localização física do usuário for alterada, se o endereço MAC do usuário não for alterado, a VLAN à qual a porta do usuário pertence não precisará ser reconfigurada.
Condição de configuração
Nenhum
Configurar uma VLAN baseada em endereço MAC
Tabela 3 -9 Configurando uma VLAN baseada em endereço MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma entrada MAC VLAN. | mac-vlan mac-address mac-address vlan vlan-id | Obrigatório. Por padrão, nenhuma entrada MAC VLAN é configurada. |
| Entre no modo de configuração da interface Ethernet L2. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Habilite a função MAC VLAN da porta. | mac-vlan enable | Obrigatório. Por padrão, a função MAC VLAN está desabilitada na porta. |
A porta na qual a função MAC VLAN está habilitada deve ser adicionada à VLAN que corresponde à entrada; caso contrário, a porta não poderá encaminhar pacotes da VLAN e os pacotes que corresponderem ao endereço MAC de origem serão descartados.
Configurar uma VLAN baseada em sub-rede IP
As VLANs baseadas em sub-rede IP, também chamadas de VLANs de sub-rede IP, são classificadas de acordo com os endereços IP de origem dos pacotes. Após a configuração de uma VLAN de sub-rede IP, se a porta receber um pacote de desmarcação e o endereço IP de origem do pacote corresponder a uma entrada de VLAN de sub-rede IP, o sistema adicionará uma etiqueta de VLAN para o pacote, na qual o ID de VLAN corresponde ao ID de VLAN em a entrada VLAN da sub-rede IP.
Depois que a localização física do usuário for alterada, se o endereço IP do usuário não for alterado, a VLAN à qual a porta do usuário pertence não precisará ser reconfigurada.
Condição de configuração
Nenhum
Configurar uma VLAN baseada em sub-rede IP
Tabela 3 -10 Configurando uma VLAN baseada em sub-rede IP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma entrada VLAN de sub-rede IP. | ip-subnet-vlan ipv4 ip-address mask mask vlan vlan-id | Obrigatório. Por padrão, nenhuma entrada de VLAN de sub-rede IP é configurada. |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Habilite a função VLAN da sub-rede IP da porta. | ip-subnet-vlan enable | Obrigatório. Por padrão, a função VLAN de sub-rede IP está desabilitada na porta. |
A porta na qual a função VLAN da sub-rede IP está habilitada deve ser adicionada à VLAN que corresponde à entrada; caso contrário, a porta não poderá encaminhar pacotes da VLAN e os pacotes que corresponderem ao endereço IP de origem serão descartados.
Configurar uma VLAN baseada em sub-rede IPv6
As VLANs baseadas em sub-rede IPv6, também chamadas de VLANs de sub-rede IPv6, são classificadas de acordo com os endereços IPv6 de origem dos pacotes. Depois que uma VLAN de sub-rede IPv6 for configurada, se a porta receber um pacote de desmarcar e o endereço IPv6 de origem do pacote corresponder a uma entrada de VLAN de sub-rede IPv6, o sistema adicionará uma etiqueta de VLAN para o pacote, na qual o ID de VLAN é o ID de VLAN em a entrada correspondente.
Depois que a localização física do usuário for alterada, se o endereço IPv6 do usuário não for alterado, a VLAN à qual a porta do usuário pertence não precisará ser reconfigurada.
Condições de configuração
Nenhum
Configurar VLAN baseada em sub-rede IPv6
Tabela 3 -11 Configurar VLAN baseada em sub-rede Pv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma entrada de VLAN de sub-rede IPv6. | ipv6-subnet-vlan ipv6 prefix-address vlan vlan-id | Mandatório. Por padrão, nenhuma entrada de VLAN de sub-rede IPv6 é configurada. |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Habilite a função VLAN de sub-rede IPv6 da porta. | ipv6-subnet-vlan enable | Mandatório. Por padrão, a função VLAN de sub-rede IPv6 está desabilitada na porta. |
A porta na qual a função VLAN de sub-rede IPv6 está habilitada deve ser adicionada à VLAN que corresponde à entrada; caso contrário, a porta não poderá encaminhar pacotes da VLAN e os pacotes que corresponderem ao endereço IPv6 de origem serão descartados.
Configurar uma VLAN baseada em protocolo
As VLANs baseadas em protocolo, também chamadas de VLANs de protocolo, são classificadas de acordo com os formatos de encapsulamento de quadro e os tipos de protocolo dos pacotes. Depois que um perfil de protocolo é definido, uma porta é configurada para corresponder a um perfil de protocolo e a função de protocolo VLAN é habilitada para a porta, se a porta receber um pacote Untag que corresponda ao perfil de protocolo, a porta adiciona uma tag VLAN para o pacote . O ID de VLAN corresponde ao ID de VLAN definido no perfil.
Depois que a localização física do usuário for alterada, se o formato de encapsulamento do quadro dos pacotes do usuário e o tipo de protocolo não forem alterados, a VLAN à qual a porta do usuário pertence não precisa ser reconfigurada.
Condição de configuração
Nenhum
Configurar uma VLAN baseada em protocolo
Tabela 3 -11 Configurando uma VLAN baseada em protocolo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Defina um perfil de protocolo. | protocol-vlan profile profile-index frame-type frame-type ether-type ether-type vlan vlan-id | Obrigatório. Por padrão, nenhum perfil de protocolo é definido. |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Habilite a função de protocolo VLAN da porta. | protocol-vlan enable | Obrigatório. Por padrão, a função de protocolo VLAN está desabilitada na porta. |
A porta para a qual um perfil de protocolo correspondente foi configurado e a função VLAN de protocolo foi habilitada deve ser adicionada à VLAN correspondente ao perfil de protocolo correspondente; caso contrário, a porta não pode encaminhar pacotes da VLAN e os pacotes correspondentes ao protocolo serão descartados.
Configurar os Tipos de Quadros que Podem Ser Recebidos pela Porta
Condição de configuração
Nenhum
Configurar os Tipos de Quadros que Podem Ser Recebidos pela Porta
Você pode configurar os tipos de quadros que podem ser recebidos por uma porta para que a porta receba apenas pacotes Untag, receba apenas pacotes Tag ou receba ambos. Os pacotes que não atenderem ao requisito serão descartados.
Tabela 3 -12 Configurando os tipos de quadros que podem ser recebidos pela porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure os tipos de quadros que podem ser recebidos pela porta. | switchport accept frame-type { all | untag | tag } | Obrigatório. Por padrão, o tipo de quadros que pode ser recebido por uma porta é all, ou seja, receber pacotes Untag e Tag. |
Monitoramento e manutenção de VLAN
Tabela 3 -13 Monitoramento e manutenção de VLAN
| Comando | Descrição |
| show ip-subnet-vlan | Exibe as informações sobre VLANs de sub-rede IP. |
| show mac-vlan | Exibe as informações sobre MAC VLANs. |
| show protocol-vlan [ profile ] | Exibe as informações sobre VLANs de protocolo. |
| show running-config vlan | Exibe informações de configuração de VLAN. |
| show vlan [ vlan-id ] | Exibe as informações sobre uma VLAN especificada ou todas as VLANs existentes. |
| show vlan statistics | Exibe o número de VLANs existentes. |
| show vlan summary | Exibe as informações de VLAN aprendidas estáticas criadas e dinâmicas |
| show { interface interface-name | interface link-aggregation link-aggregation-id } vlan status | Exibe as informações de VLAN na porta ou link aggregation especificado. |
Exemplo de configuração típica de VLAN
Configurar VLANs baseadas em porta
Requisitos de rede
- Server1 e PC1 estão na rede do escritório, enquanto Server2 e PC2 estão na rede de produção.
- Você precisa configurar as funções de VLAN baseadas em porta para isolar PC1 e PC2 para que PC1 possa acessar apenas Server1 e PC2 possa acessar apenas Server2.
Topologia de rede
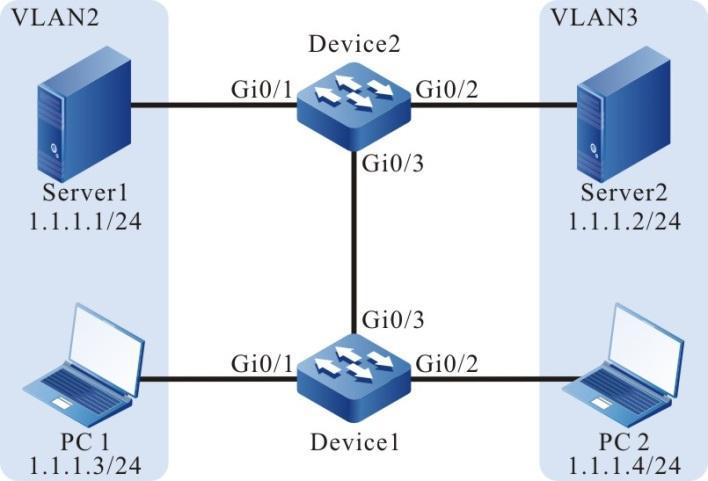
Figura 3 -2 Rede para configurar VLANs baseadas em porta
Etapas de configuração
- Passo 1:Em Device1, configure VLANs e configure os tipos de link de porta das portas.
#No Dispositivo1, crie VLAN2 e VLAN3.
Device1#configure terminalDevice1(config)#vlan 2-3
#No Device1, configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 para acessar. Configure gigabitethernet0/1 para permitir que serviços de VLAN2 passem e configure gigabitethernet0/2 para permitir que serviços de VLAN3 passem.
Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#switchport mode accessDevice1(config-if-gigabitethernet0/1)#switchport access vlan 2Device1(config-if-gigabitethernet0/1)#exitDevice1(config)#interface gigabitethernet0/2Device1(config-if-gigabitethernet0/2)#switchport mode accessDevice1(config-if-gigabitethernet0/2)#switchport access vlan 3Device1(config-if-gigabitethernet0/2)#exit
#No Device1, configure o tipo de link da porta gigabitethernet0/3 para Trunk e permita a passagem de serviços de VLAN2 e VLAN3.
Device1(config)#interface gigabitethernet 0/3Device1(config-if-gigabitethernet0/3)#switchport mode trunkDevice1(config-if-gigabitethernet0/3)#switchport trunk allowed vlan add 2-3Device1(config-if-gigabitethernet0/3)#exit
- Passo 2: Em Device3, configure VLANs e configure os tipos de link de porta das portas
#No Dispositivo2, crie VLAN2 e VLAN3.
Device2#configure terminalDevice2(config)#vlan 2-3
#No Device2, configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 para acessar. Configure gigabitethernet0/1 para permitir que serviços de VLAN2 passem e configure gigabitethernet0/2 para permitir que serviços de VLAN3 passem.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode accessDevice2(config-if-gigabitethernet0/1)#switchport access vlan 2Device2(config-if-gigabitethernet0/1)#exitDevice2(config)#interface gigabitethernet0/2Device2(config-if-gigabitethernet0/2)#switchport mode accessDevice2(config-if-gigabitethernet0/2)#switchport access vlan 3Device2(config-if-gigabitethernet0/2)#exit
#No Device2, configure o tipo de link da porta gigabitethernet0/3 para Trunk e permita a passagem de serviços de VLAN2 e VLAN3.
Device2(config)#interface gigabitethernet 0/3Device2(config-if-gigabitethernet0/3)#switchport mode trunkDevice2(config-if-gigabitethernet0/3)#switchport trunk allowed vlan add 2-3Device2(config-if-gigabitethernet0/3)#exit
- Etapa 3: Confira o resultado.
#Consulte as informações de VLAN no Device1.
Device1#show vlan 2---- ---- -------------------------------- ------- --------- -----------------------------NO. VID VLAN-Name Owner Mode Interface---- ---- -------------------------------- ------- --------- -----------------------------1 2 VLAN0002 static Tagged gi0/3Untagged gi0/1Device1#show vlan 3---- ---- -------------------------------- ------- --------- -----------------------------NO. VID VLAN-Name Owner Mode Interface---- ---- -------------------------------- ------- --------- -----------------------------1 3 VLAN0003 static Tagged gi0/3Untagged gi0/2
#PC1 e PC2 não podem se comunicar, PC1 pode acessar apenas Server1 e PC2 pode acessar apenas Server2.
Configurar VLANs baseadas em endereço MAC
Requisitos de rede
- PC1 e PC2 podem acessar a rede através de diferentes portas do Dispositivo.
- As funções de VLAN baseadas em endereço MAC precisam ser configuradas para que os PCs com os endereços MAC especificados possam acessar o servidor por meio de diferentes portas. Os PCs que não possuem um endereço MAC especificado podem acessar o servidor somente por meio de uma porta especificada.
Topologia de rede
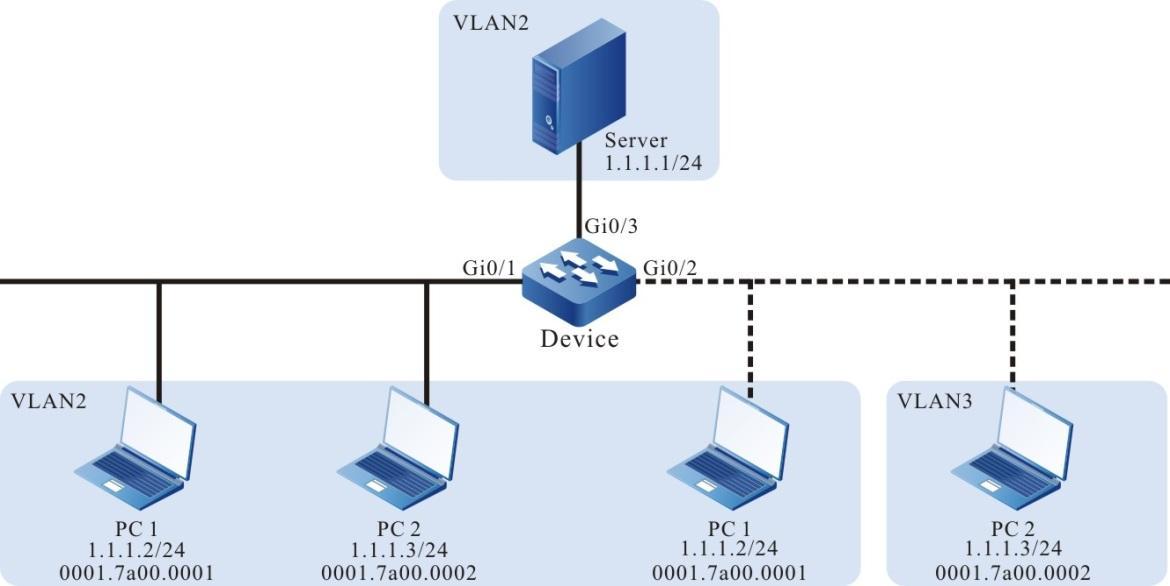
Figura 3 -3 Rede para configurar VLANs baseadas em endereço MAC
Etapas de configuração
- Passo 1: Em Dispositivo, configure VLANs e configure os tipos de link de porta das portas.
No dispositivo, crie VLAN2 e VLAN3.
Device#configure terminalDevice(config)#vlan 2-3
#No Device2, configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/3 para acessar e permitir que os serviços da VLAN2 passem.
Device(config)#interface gigabitethernet 0/1,0/3Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
#No Dispositivo, configure o tipo de link da porta gigabitethernet0/2 para Híbrido e permita que os serviços de VLAN2 e VLAN3 passem e defina PVID como 3.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode hybridDevice(config-if-gigabitethernet0/2)#switchport hybrid untagged vlan 2-3Device(config-if-gigabitethernet0/2)#switchport hybrid pvid vlan 3Device(config-if-gigabitethernet0/2)#exit
- Passo 2: Configure a função VLAN baseada em endereço MAC.
#No dispositivo, configure uma entrada de VLAN baseada em endereço MAC para que os pacotes com o endereço MAC de origem 0001.7a00.0001 possam ser encaminhados na VLAN2.
Device(config)#mac-vlan mac-address 0001.7a00.0001 vlan 2#Na porta gigabitethernet0/2 do dispositivo, habilite a função VLAN baseada em endereço MAC.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#mac-vlan enableDevice(config-if-gigabitethernet0/2)#exit
- Passo 3: Confira o resultado.
#No dispositivo, consulte as entradas MAC VLAN e o status de habilitação da porta.
Device#show mac-vlantotal 256, used 1, left 255--------------------------------MAC-VLAN---------------------------------NO. Mac Address Dynamic Vlan Static Vlan Current Pri Static Pri----- --------------- ------------- ------------ ------------ -----------1 0001.7a00.0001 0 2 - ------------------------------ENABLE MAC-VLAN-----------------------------gi0/2
O #PC1 pode acessar o servidor pela porta gigabitethernet0/1 ou gigabitethernet0/2, enquanto o PC2 pode acessar o servidor apenas pela porta gigabitethernet0/1.
Configurar VLANs baseadas em sub-rede IP
Requisitos de rede
- Server1 é o servidor na rede do escritório e Server2 é o servidor na rede de produção.
- As funções de VLAN baseadas em sub-rede IP precisam ser configuradas para que o PC1 possa acessar apenas o Server1 e o PC2 possa acessar apenas o Server2.
Topologia de rede

Figura 3-4 Configurando uma VLAN baseada em sub-rede IP
Etapas de configuração
- Passo 1: Em Dispositivo, configure VLANs e configure os tipos de link de porta das portas.
#No dispositivo, crie VLAN2 e VLAN3.
Device#configure terminalDevice(config)#vlan 2-3
#No Dispositivo, configure o tipo de link da porta gigabitethernet0/1 para Híbrido e permita que os serviços de VLAN2 e VLAN3 passem e defina PVID como 2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode hybridDevice(config-if-gigabitethernet0/1)#switchport hybrid untagged vlan 2-3Device(config-if-gigabitethernet0/1)#switchport hybrid pvid vlan 2Device(config-if-gigabitethernet0/1)#exit
#No Dispositivo, configure o tipo de link das portas gigabitethernet0/2 e gigabitethernet0/3 para acessar. Configure gigabitethernet0/2 para permitir que serviços de VLAN2 passem e configure gigabitethernet0/3 para permitir que serviços de VLAN3 passem.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode accessDevice(config-if-gigabitethernet0/2)#switchport access vlan 2Device(config)#interface gigabitethernet 0/3Device(config-if-gigabitethernet0/3)#switchport mode accessDevice(config-if-gigabitethernet0/3)#switchport access vlan 3Device(config-if-gigabitethernet0/3)#exit
- Passo 2:Configure as funções de VLAN baseadas em sub-rede IP.
#No dispositivo, configure as entradas de VLAN baseadas em sub-rede IP para que os pacotes com o endereço IP de origem na sub-rede 2.1.1.0/24 possam ser encaminhados na VLAN3.
Device(config)#ip-subnet-vlan ipv4 2.1.1.0 mask 255.255.255.0 vlan 3#Na porta gigabitethernet0/1 do dispositivo, habilite a função VLAN baseada em sub-rede IP.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ip-subnet-vlan enableDevice(config-if-gigabitethernet0/1)#exit
- Passo 3: Confira o resultado.
#No dispositivo, consulte as entradas da VLAN da sub-rede IP e o status de habilitação da porta.
Device(config)#show ip-subnet-vlan-------------------------IP-SUBNET-VLAN------------------------NO. IP MASK VLAN PRI------ ------------------ ------------------ ------- ----------1 2.1.1.0 255.255.255.0 3 -----------------------Enable SUBNET-VLAN-----------------------gi0/1------------------Enable SUBNET-VLAN Priority------------------
#PC1 pode acessar apenas o Server1 e o PC2 pode acessar apenas o Server2.
Configurar VLANs baseadas em protocolo
Requisitos de rede
- PC é um host na Ethernet e Server1 e Server2 são dois servidores na Ethernet.
- A função VLAN baseada em protocolo precisa ser configurada para que o PC possa acessar apenas o Servidor 1 antes que a função VLAN baseada em protocolo seja habilitada na porta do Dispositivo. Depois que a função VLAN baseada em protocolo é habilitada na porta, o PC pode acessar apenas o Server2.
Topologia de rede

Figura 3-5 Rede para configurar VLANs baseadas em protocolo
Etapas de configuração
- Passo 1: Em Dispositivo, configure VLANs e configure os tipos de link de porta das portas.
#No dispositivo, crie VLAN2 e VLAN3.
Device#configure terminalDevice(config)#vlan 2-3
#No Dispositivo, configure o tipo de link da porta gigabitethernet0/1 para Híbrido e permita que os serviços de VLAN2 e VLAN3 passem e defina PVID como 2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport hybrid untagged vlan 2-3Device(config-if-gigabitethernet0/1)#switchport hybrid pvid vlan 2
#No Dispositivo, configure o tipo de link das portas gigabitethernet0/2 e gigabitethernet0/3 para acessar. Configure gigabitethernet0/2 para permitir que serviços de VLAN2 passem e configure gigabitethernet0/3 para permitir que serviços de VLAN3 passem.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode accessDevice(config-if-gigabitethernet0/2)#switchport access vlan 2Device(config-if-gigabitethernet0/2)#exitDevice(config)#interface gigabitethernet 0/3Device(config-if-gigabitethernet0/3)#switchport mode accessDevice(config-if-gigabitethernet0/3)#switchport access vlan 3Device(config-if-gigabitethernet0/3)#exit
- Passo 2: Configure a função VLAN baseada em protocolo.
#No dispositivo, configure um perfil de protocolo para pacotes IP(0x0800) baseados no encapsulamento ETHERII.
Device(config)#protocol-vlan profile 1 frame-type ETHERII ether-type 0x0800#Na porta gigabitethernet0/1 do dispositivo, os pacotes que correspondem ao perfil do protocolo são encaminhados na VLAN3 e a função VLAN do protocolo é habilitada.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#protocol-vlan enableDevice(config-if-gigabitethernet0/1)#protocol-vlan profile 1 vlan 3Device(config-if-gigabitethernet0/1)#exit
- Passo 3: Confira o resultado.
#No dispositivo, consulte as entradas da VLAN do protocolo e o status de habilitação da porta.
Device#show protocol-vlan profile---------------------------PROTOTOCL-VLAN-------------------------Profile Frame-type Ether-type------------------------------------------------------------------1 ETHERII 0x800-----------------------Enable PROTOCOL-VLAN-----------------------gi0/1-------------------Enable PROTOCOL-VLAN Profile-------------------gi0/1: total-profiles 1vlan 3, profile 1
# Quando a função VLAN baseada em protocolo não está habilitada na porta gigabitethernet0/1, o PC pode acessar apenas o Server1. Depois que a função VLAN baseada em protocolo é habilitada na porta gigabitethernet0/1, o PC pode acessar apenas o Server2.
Mapeamento QinQ e VLAN
Visão geral
O 802.1Q em 802.1Q (QinQ), que é uma extensão do protocolo 802.1Q, adiciona uma camada de tag 802.1Q (tag VLAN) com base no cabeçalho do pacote 802.1Q original. Com o uso de duas camadas de tags VLAN, o número de VLANs é aumentado para 4094x4094. QinQ encapsula tags de VLAN de rede privada do usuário em tags de VLAN de rede pública para que os pacotes sejam transmitidos na rede de backbone da operadora (rede pública) com duas camadas de tags de VLAN. Na rede pública, os pacotes são transmitidos com base nas tags VLAN externas (ou seja, tags VLAN da rede pública) e as tags VLAN da rede privada do usuário são blindadas. Isso economiza IDs de VLAN de rede pública e fornece túneis de rede privada virtual (VPN) L2 simples para os usuários.
De acordo com as regras de adição de tags VLAN, o QinQ se enquadra nos seguintes tipos:
- QinQ básico
- QinQ flexível baseado em porta
O mapeamento de VLAN também é uma extensão do 802.1Q. É diferente do QinQ no seguinte aspecto: Em vez de encapsular outra camada de tag VLAN com base na tag VLAN original de um pacote, o mapeamento VLAN substitui a tag VLAN original de um pacote por uma nova tag VLAN. Desta forma, o pacote ainda possui apenas uma camada de tag VLAN.
De acordo com as regras de mapeamento , o mapeamento de VLAN se enquadra nos seguintes tipos:
- Mapeamento de VLAN 1:1. Apenas uma VLAN de rede privada pode ser mapeada em uma VLAN de rede pública.
- Mapeamento de VLAN N:1. Ou seja, uma ou mais VLANs privadas podem ser mapeadas para uma VLAN pública.
Para QinQ flexível baseado em porta, mapeamento de VLAN 1:1, VLAN de rede privada para entradas de mapeamento de VLAN de rede pública devem ser configuradas. Um usuário pode configurar no máximo 4.096 entradas de mapeamento.
Configuração da função de mapeamento QinQ e VLAN
Tabela 4-1 Lista de funções de mapeamento de QinQ e VLAN
| Tarefas de configuração | |
| Configure a função básica QinQ. | Ative a função básica QinQ. |
| Configure a função QinQ flexível baseada em porta. | Configure a função QinQ flexível baseada em porta. |
| Configure a função de mapeamento de VLAN 1:1. | Configure a função de mapeamento de VLAN 1:1. |
| Configure a função de mapeamento de VLAN N :1. | Configure a função de mapeamento de VLAN N :1. |
| Configure o tipo de protocolo da tag VLAN externa de uma porta. | Configure o tipo de protocolo da tag VLAN externa de uma porta. |
| Configure a função de duplicação de prioridade. | Ative a função de duplicação de prioridade. |
| Configurar a função QinQ Drop | Configurar a função QinQ Drop |
Configurar a função básica do QinQ
Depois que a função básica do QinQ é configurada em uma porta, o dispositivo adiciona outra camada de tags VLAN para os pacotes recebidos da porta. O ID de VLAN das tags de VLAN é o PVID da porta.
Condição de configuração
Antes de configurar a função básica do QinQ, certifique-se de que:
- O PVID da porta foi configurado. O PVID é o ID de VLAN das tags de VLAN externas que são adicionadas aos pacotes depois que a função básica QinQ da porta é habilitada.
Ativar a função básica de QinQ
Tabela 4-2 Habilitando a Função Básica QinQ
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois que você entrar no modo de configuração da interface Ethernet L2 , a configuração subsequente terá efeito apenas na porta atual. Depois que você entrar no modo de configuração do link aggregation, a configuração subsequente terá efeito apenas dentro do grupo de agregação. |
| Entre no modo de configuração do link aggregation. | link-aggregation link-aggregation-id | |
| Ative a função básica QinQ. | vlan dot1q-tunnel enable | Obrigatório. Por padrão, a função básica do QinQ está desabilitada. |
Em uma porta, a função QinQ básica não pode coexistir com as seguintes funções: QinQ Evc, QINQ flexível, mapeamento de VLAN 1:1, mapeamento de VLAN N:1, configurar o tipo de protocolo das tags VLAN externas da porta como um não padrão valor .
Configurar a função QinQ flexível baseada em porta
Depois que uma porta é configurada com o QinQ flexível baseado em porta, se o ID de VLAN da camada mais externa da tag VLAN de um pacote corresponder a uma entrada do QinQ flexível baseado em porta, uma tag VLAN externa especificada é adicionada ao pacote. Se o ID de VLAN da camada mais externa da etiqueta de VLAN de um pacote não corresponder a uma entrada do QinQ flexível baseado em porta, uma camada de etiqueta de VLAN é adicionada ao pacote e o ID de VLAN da etiqueta de VLAN é o PVID de o Porto.
Condição de configuração
Antes de configurar a função QinQ flexível baseada em porta, certifique-se de que:
- O tipo de link de porta é configurado para o tipo de tronco ou o tipo híbrido.
- Um PVID foi configurado para a porta.
- A VLAN das tags VLAN externas a serem adicionadas foi configurada para a porta e os pacotes aos quais as tags VLAN externas foram adicionadas podem passar pela VLAN.
Configurar a função QinQ flexível baseada em porta
Tabela 4-3 Configurando a Função QinQ Flexível Baseada em Porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois que você entrar no modo de configuração da interface Ethernet L2 , a configuração subsequente terá efeito apenas na porta atual. Depois que você entrar no modo de configuração do link aggregation, a configuração subsequente terá efeito apenas dentro do grupo de agregação. |
| Entre no modo de configuração do link aggregation. | link-aggregation link-aggregation-id | |
| Configure entradas QinQ flexíveis baseadas em porta. | vlan dot1q-tunnel inner-vlan-list outer-vlan-id | Obrigatório. Por padrão, as entradas QinQ flexíveis baseadas em porta não são configuradas. |
Em uma porta, a função Qin Q flexível baseada em porta não pode coexistir com as seguintes funções: QinQ Evc, QINQ básico, mapeamento de VLAN 1:1, mapeamento de VLAN N:1. Quando a entrada QinQ flexível baseada em porta configurada entrar em conflito com a entrada QinQ flexível baseada em porta existente da porta, um conflito será solicitado.
Configurar a função de mapeamento de VLAN 1:1
Para uma porta, a entrada de mapeamento de VLAN 1:1 é um mapeamento um para um, ou seja, a entrada de mapeamento de VLAN 1:1 mapeia uma VLAN de rede privada para uma VLAN de rede pública.
Depois que uma porta é configurada com mapeamento de VLAN 1:1, se a tag de VLAN mais externa de um pacote corresponder a uma entrada de mapeamento de VLAN 1:1, a porta substituirá o ID de VLAN da tag de VLAN mais externa pelo ID de VLAN especificado. Se a etiqueta de VLAN mais externa de um pacote não corresponder a uma entrada de mapeamento de VLAN 1:1, a porta adiciona uma camada de etiqueta de VLAN ao pacote e o ID de VLAN da etiqueta de VLAN é o PVID da porta.
Condição de configuração
Antes de configurar a função de mapeamento de VLAN 1:1, certifique-se de que:
- O tipo de link de porta é configurado para o tipo de tronco ou o tipo híbrido.
- Um PVID foi configurado para a porta.
- A VLAN da nova etiqueta de VLAN externa usada para substituir a etiqueta de VLAN existente foi configurada para a porta e os pacotes para os quais as etiquetas de VLAN externas foram substituídas podem passar pela VLAN.
Configurar a função de mapeamento de VLAN 1:1
Tabela 4-4 Configurando a função de mapeamento de VLAN 1:1
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois que você entrar no modo de configuração da interface Ethernet L2 , a configuração subsequente terá efeito apenas na porta atual. Depois que você entrar no modo de configuração do link aggregation, a configuração subsequente terá efeito apenas dentro do grupo de agregação. |
| Entre no modo de configuração do link aggregation. | link-aggregation link-aggregation-id | |
| Configure entradas de função de mapeamento de VLAN 1:1. | vlan dot1q-tunnel mapping former-vlan-id mapping-vlan-id | Obrigatório. Por padrão, as entradas de mapeamento de VLAN 1:1 não são configuradas. |
Em uma porta, a função de mapeamento de VLAN 1:1 não pode coexistir com as seguintes funções: QinQ Evc, QINQ básico, QINQ flexível, mapeamento de VLAN N:1. Se a entrada de mapeamento VLAN 1:1 configurada entrar em conflito com uma entrada de mapeamento VLAN 1:1 baseada em porta existente, o conflito será solicitado.
Configurar a função de mapeamento VLAN N:1
Para uma porta, várias entradas de mapeamento de VLAN N:1 podem ser configuradas. Cada entrada de mapeamento de VLAN N:1 pode ser o relacionamento múltiplo-para-um, ou seja, uma ou mais VLANs privadas podem ser mapeadas para uma VLAN pública.
Depois que a porta for configurada com mapeamento de VLAN N:1, se o ID de VLAN da tag de VLAN mais externa do pacote corresponder à entrada de mapeamento de VLAN N:1, substitua o ID de VLAN da tag de VLAN mais externa do pacote pela VLAN especificada EU IRIA; se não, o mapeamento VLAN N:1 não processará o pacote.
Condição de configuração
Antes de configurar a função de mapeamento de VLAN N :1, certifique-se de que:
- O tipo de link de porta é configurado para o tipo de tronco ou o tipo híbrido.
- Configure a porta para adicionar a VLAN da etiqueta de VLAN externa substituída para garantir que o pacote após a substituição da etiqueta de VLAN externa possa passar.
Configurar N:1 Função de Mapeamento VLAN
Tabela 4 -5 Configurar função de mapeamento de VLAN N:1
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L 2. | interface interface-name | Opcional. Depois que você entrar no modo de configuração da interface Ethernet L 2, a configuração subsequente terá efeito apenas na porta atual. Depois que você entrar no modo de configuração do link aggregation, a configuração subsequente terá efeito apenas dentro do grupo de agregação. |
| Entre no modo de configuração do link aggregation. | link-aggregation link-aggregation-id | |
| Habilite a função de mapeamento de VLAN N:1 | vlan dot1q-tunnel mapping n-to-1 enable | Obrigatório. Por padrão, não habilite a função de mapeamento VLAN N:1 |
| Configure a entrada do mapeamento N:1 VLAN | vlan dot1q-tunnel mapping n-to-1 former-vlan-list mapping-vlan-id | Obrigatório. Por padrão, não configure a entrada do mapeamento N:1 VLAN. |
Em uma porta, a função de mapeamento de VLAN N:1 não pode coexistir com as seguintes funções: QinQ Evc, Qin Q básico, QINQ flexível baseado em porta, mapeamento de VLAN 1:1, configure o tipo de protocolo das tags VLAN externas da porta como um valor não padrão.
Configurar o tipo de protocolo da etiqueta de VLAN externa de uma porta
Uma porta determina se um pacote carrega a tag VLAN correspondente com base no Tag Protocol Identifier (TPID). Depois que uma porta recebe um pacote, ela compara o TPID configurado na porta com o campo correspondente no pacote. Se forem iguais, indica que o pacote carrega a tag VLAN correspondente. Se forem diferentes, o dispositivo considera e trata o pacote recebido como um pacote Untag.
Dispositivos de alguns fabricantes podem definir o campo TPID de tags VLAN externas de pacotes QinQ para 0x9100 ou outros valores. Para ser compatível com os dispositivos, o valor TPID das tags VLAN externas da porta do dispositivo local deve ser configurado para o mesmo valor.
Condição de configuração
Nenhum
Configurar o tipo de protocolo da etiqueta de VLAN externa de uma porta
Um dispositivo suporta dois valores TPID. O intervalo de valores dos TPIDs é 0x0001-0xffff e não pode ser o campo de protocolo reservado, como 0x0806 e 0x0800.
Tabela 4-6 Configurando o tipo de protocolo da etiqueta VLAN externa de uma porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois que você entrar no modo de configuração da interface Ethernet L2 , a configuração subsequente terá efeito apenas na porta atual. Depois que você entrar no modo de configuração do link aggregation, a configuração subsequente terá efeito apenas dentro do grupo de agregação. |
| Entre no modo de configuração do link aggregation. | link-aggregation link-aggregation-id | |
| Configure o tipo de protocolo da tag VLAN externa de uma porta. | frame-tag tpid type-value | Opcional. Por padrão, o valor do tipo de protocolo das tags VLAN externas de uma porta é 0x8100. |
Em uma porta, configure o tipo de protocolo da etiqueta VLAN externa da porta como o valor não padrão, que não pode coexistir com as seguintes funções: QinQ Evc, Qin Q básico, QINQ flexível, mapeamento VLAN 1:1, mapeamento VLAN N:1.
Configurar a função de duplicação de prioridade
Depois que uma porta é configurada com a função de duplicação de prioridade, ela duplica o campo de prioridade da etiqueta de VLAN mais externa de um pacote original para o campo de prioridade da etiqueta de VLAN mais externa do pacote.
Condição de configuração
Para configurar a função de duplicação de prioridade, primeiro complete a seguinte tarefa :
- Configure a função QinQ básica e a função QinQ flexível baseada em porta ou a função de mapeamento de VLAN 1:1.
Ative a função de duplicação de prioridade
Tabela 4-7 Habilitando a função de duplicação de prioridade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois que você entrar no modo de configuração da interface Ethernet L2 , a configuração subsequente terá efeito apenas na porta atual. Depois que você entrar no modo de configuração do link aggregation, a configuração subsequente terá efeito apenas dentro do grupo de agregação. |
| Entre no modo de configuração do link aggregation. | link-aggregation link-aggregation-id | |
| Ative a função de duplicação de prioridade | inner-priority-trust enable | Obrigatório. Por padrão, a função de duplicação de prioridade está desabilitada. |
Configurar a função de queda QinQ
Depois que a porta for configurada com a função QinQ drop, se a porta receber um pacote que não corresponde à entrada QinQ flexível baseada em porta, entrada de mapeamento VLAN 1:1 e entrada de mapeamento VLAN N:1, o pacote será descartado.
Condição de configuração
Para configurar a função QinQ Drop , primeiro complete a seguinte tarefa :
- Configure a função QinQ básica e a função QinQ flexível baseada em porta ou a função de mapeamento de VLAN 1:1.
Ativar função de queda QinQ
Tabela 4 -8 Ativar a função QinQ Drop
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois que você entrar no modo de configuração da interface Ethernet L2 , a configuração subsequente terá efeito apenas na porta atual. Depois que você entrar no modo de configuração do link aggregation, a configuração subsequente terá efeito apenas dentro do grupo de agregação. |
| Entre no modo de configuração do link aggregation. | link-aggregation link-aggregation-id | |
| Ativar a função QinQ Drop | vlan dot1q-tunnel drop | Obrigatório. Por padrão, a função QinQ Drop não está habilitada. |
Em uma porta, a função QinQ Drop não pode coexistir com QinQ Evc.
Monitoramento e manutenção de mapeamento de QinQ e VLAN
Tabela 4-9 Monitoramento e manutenção de mapeamento de QinQ e VLAN
| Comando | Descrição |
| show vlan dot1q-tunnel | Exibe a configuração QinQ flexível baseada em porta. |
| show vlan dot1q-tunnel mapping | Exibe a configuração de mapeamento de VLAN 1:1. |
| show vlan dot1q-tunnel mapping n-to-1 configuration | Exibe a configuração de mapeamento de VLAN N :1. |
Exemplo de configuração típico de mapeamento de QinQ e VLAN
Configurar QinQ Básico
Requisitos de rede
- Os usuários de intranet CE1 e CE2, e CE3 e CE4 se comunicam através da rede da operadora. CE1 e CE2 usam a Intranet VLAN10-VLAN20, CE3 e CE4 usam Intranet VLAN15-VLAN30, e PE1 e PE2 são dois dispositivos de borda na rede da operadora.
- O QinQ básico é configurado em PE1 e PE2. Então , CE1 e CE2 podem se comunicar entre si através da VLAN00 da rede pública da operadora, CE3 e CE4 podem se comunicar entre si através da VLAN101 da rede pública da operadora, e os pacotes que são transmitidos na rede pública da operadora contêm duas camadas de tags .
Topologia de rede
Figura 4-1 Rede para configurar o QinQ básico
Etapas de configuração
- Passo 1: Configurar PE1.
#No PE1, crie VLAN10-VLAN30 e VLAN100-VLAN101.
PE1#configure terminalPE1(config)#vlan 10-30,100-101
#No PE1, configure o tipo de link da porta gigabitethernet0/1 para Trunk e permita a passagem de serviços de VLAN10-VLAN20 e VLAN100, e defina PVID para 100.
PE1(config)#interface gigabitethernet 0/1PE1(config-if-gigabitethernet0/1)#switchport mode trunkPE1(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 10-20,100PE1(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 100PE1(config-if-gigabitethernet0/1)#exit
#No PE1, configure o tipo de link da porta gigabitethernet0/2 para Trunk e permita a passagem de serviços de VLAN15-VLAN30 e VLAN 101, e defina PVID para 101.
PE1(config)#interface gigabitethernet 0/2PE1(config-if-gigabitethernet0/2)#switchport mode trunkPE1(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 15-30,101PE1(config-if-gigabitethernet0/2)#switchport trunk pvid vlan 101PE1(config-if-gigabitethernet0/2)#exit
#No PE1, configure o tipo de link da porta gigabitethernet0/3 para Trunk e permita a passagem de serviços de VLAN100 e VLAN101, e defina PVID para 1.
PE1(config)#interface gigabitethernet0/3PE1(config-if-gigabitethernet0/3)#switchport mode trunkPE1(config-if-gigabitethernet0/3)#switchport trunk allowed vlan add 100,101PE1(config-if-gigabitethernet0/3)#switchport trunk pvid vlan 1PE1(config-if-gigabitethernet0/3)#exit
#Nas portas gigabitethernet 0/1 e gigabitethernet 0/2 do PE1, habilite a função básica QinQ.
PE1(config)#interface gigabitethernet 0/1PE1(config-if-gigabitethernet0/1)#vlan dot1q-tunnel enablePE1(config-if-gigabitethernet0/1)#exitPE1(config)#interface gigabitethernet 0/2PE1(config-if-gigabitethernet0/2)#vlan dot1q-tunnel enablePE1(config-if-gigabitethernet0/2)#exit
- Passo 2: Configurar PE2.
#No PE2, crie VLAN10-VLAN30 e VLAN100-VLAN101.
PE2#configure terminalPE2(config)#vlan 10-30,100-101
#No PE2, configure o tipo de link da porta gigabitethernet0/1 para Trunk e permita a passagem de serviços de VLAN10-VLAN20 e VLAN100, e defina PVID para 100.
PE2(config)#interface gigabitethernet 0/1PE2(config-if-gigabitethernet0/1)#switchport mode trunkPE2(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 10-20,100PE2(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 100PE2(config-if-gigabitethernet0/1)#exit
#No PE2, configure o tipo de link da porta gigabitethernet0/2 para Trunk e permita a passagem de serviços de VLAN15-VLAN30 e VLAN 101, e defina PVID para 101.
PE2(config)#interface gigabitethernet 0/2PE2(config-if-gigabitethernet0/2)#switchport mode trunkPE2(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 15-30,101PE2(config-if-gigabitethernet0/2)#switchport trunk pvid vlan 101PE2(config-if-gigabitethernet0/2)#exit
#No PE2, configure o tipo de link da porta gigabitethernet0/3 para Trunk e permita a passagem de serviços de VLAN100 e VLAN101, e defina PVID para 1.
PE2(config)#interface gigabitethernet 0/3PE2(config-if-gigabitethernet0/3)#switchport mode trunkPE2(config-if-gigabitethernet0/3)#switchport trunk allowed vlan add 100,101PE2(config-if-gigabitethernet0/3)#switchport trunk pvid vlan 1PE2(config-if-gigabitethernet0/3)#exit
#Nas portas gigabitethernet 0/1 e gigabitethernet 0/2 do PE2, habilite a função básica QinQ.
PE2(config)#interface gigabitethernet 0/1PE2(config-if-gigabitethernet0/1)#vlan dot1q-tunnel enablePE2(config-if-gigabitethernet0/1)#exitPE2(config)#interface gigabitethernet 0/2PE2(config-if-gigabitethernet0/2)#vlan dot1q-tunnel enablePE2(config-if-gigabitethernet0/2)#exit
- Passo 3: Confira o resultado.
#Através do PE1 e PE2, os serviços dos usuários da Intranet CE1 e CE2 podem ser transmitidos na VLAN100 da rede da operadora com duas camadas de tags. Através do PE1 e PE2, os serviços dos usuários da Intranet CE3 e CE4 podem ser transmitidos na VLAN101 da rede da operadora com duas camadas de tags.
Configurar QinQ Flexível
Requisitos de rede
- Os usuários de intranet CE1 e CE2, e CE3 e CE4 se comunicam através da rede da operadora. CE1 e CE2 usam a Intranet VLAN10-VLAN20, CE3 e CE4 usam Intranet VLAN15-VLAN30, e PE1 e PE2 são dois dispositivos de borda na rede da operadora.
- Flexível QinQ é configurado em PE1 e PE2. Então, CE1 e CE2 podem se comunicar entre si através da VLAN00 da rede pública da operadora, CE3 e CE4 podem se comunicar entre si através da VLAN101 da rede pública da operadora, e os pacotes que são transmitidos na rede pública da operadora contêm duas camadas de tags .
Topologia de rede
Figura 4-2 Rede para configurar o QinQ flexível
Etapas de configuração
- Passo 1: Configurar PE1.
#No PE1, crie VLAN10-VLAN30 e VLAN100-VLAN101.
PE1#configure terminalPE1(config)#vlan 10-30,100-101
#No PE1, configure o tipo de link da porta gigabitethernet0/1 para Trunk e permita a passagem de serviços de VLAN10-VLAN20 e VLAN100, e defina PVID para 100.
PE1(config)#interface gigabitethernet 0/1PE1(config-if-gigabitethernet0/1)#switchport mode trunkPE1(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 10-20,100PE1(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 100PE1(config-if-gigabitethernet0/1)#exit
#No PE1, configure o tipo de link da porta gigabitethernet0/2 para Trunk e permita a passagem de serviços de VLAN15-VLAN30 e VLAN 1, e defina PVID para 101.
PE1(config)#interface gigabitethernet 0/2PE1(config-if-gigabitethernet0/2)#switchport mode trunkPE1(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 15-30,101PE1(config-if-gigabitethernet0/2)#switchport trunk pvid vlan 101PE1(config-if-gigabitethernet0/2)#exit
#No PE1, configure o tipo de link da porta gigabitethernet0/3 para Trunk e permita a passagem de serviços de VLAN100 e VLAN101, e defina PVID para 1.
PE1(config)#interface gigabitethernet 0/3PE1(config-if-gigabitethernet0/3)#switchport mode trunkPE1(config-if-gigabitethernet0/3)#switchport trunk allowed vlan add 100,101PE1(config-if-gigabitethernet0/3)#switchport trunk pvid vlan 1PE1(config-if-gigabitethernet0/3)#exit
#Na porta gigabitethernet 0/1 do PE1, configure a função QinQ flexível para que as tags VLAN de VLAN100 sejam adicionadas aos pacotes de VLAN10-VLAN20.
PE1(config)#interface gigabitethernet 0/1PE1(config-if-gigabitethernet0/1)#vlan dot1q-tunnel enablePE1(config-if-gigabitethernet0/1)#vlan dot1q-tunnel 10-20 100PE1(config-if-gigabitethernet0/1)#exit
#Na porta gigabitethernet 0/2 do PE1, configure a função QinQ flexível para que as tags VLAN de VLAN101 sejam adicionadas aos pacotes de VLAN15-VLAN30.
PE1(config)#interface gigabitethernet 0/2PE1(config-if-gigabitethernet0/2)#vlan dot1q-tunnel enablePE1(config-if-gigabitethernet0/2)#vlan dot1q-tunnel 15-30 101PE1(config-if-gigabitethernet0/2)#exit
#No PE1, consulte as informações sobre entradas flexíveis de QinQ.
PE1#show vlan dot1q-tunnelInterface priority-default Inner VlanId Outer VlanId inner-priority-trust Inner VlanId Count------------------- ---------------- ------------ ------------ -------------------- -----------------gi0/1 disable 10-20 100 / 11gi0/2 disable 15-30 101 / 16
- Passo 2: Configurar PE2.
#No PE2, crie VLAN10-VLAN30 e VLAN100-VLAN101.
PE2#configure terminalPE2(config)#vlan 10-30,100-101
#No PE2, configure o tipo de link da porta gigabitethernet0/1 para Trunk e permita a passagem de serviços de VLAN10-VLAN20 e VLAN100, e defina PVID para 100.
PE2(config)#interface gigabitethernet 0/1PE2(config-if-gigabitethernet0/1)#switchport mode trunkPE2(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 10-20,100PE2(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 100PE2(config-if-gigabitethernet0/1)#exit
#No PE2, configure o tipo de link da porta gigabitethernet0/2 para Trunk e permita a passagem de serviços de VLAN15-VLAN30 e VLAN 1, e defina PVID para 101.
PE2(config)#interface gigabitethernet 0/2PE2(config-if-gigabitethernet0/2)#switchport mode trunkPE2(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 15-30,101PE2(config-if-gigabitethernet0/2)#switchport trunk pvid vlan 101PE2(config-if-gigabitethernet0/2)#exit
#No PE2, configure o tipo de link da porta gigabitethernet0/3 para Trunk e permita a passagem de serviços de VLAN100 e VLAN101, e defina PVID para 1.
PE2(config)#interface gigabitethernet 0/3PE2(config-if-gigabitethernet0/3)#switchport mode trunkPE2(config-if-gigabitethernet0/3)#switchport trunk allowed vlan add 100,101PE2(config-if-gigabitethernet0/3)#switchport trunk pvid vlan 1PE2(config-if-gigabitethernet0/3)#exit
#Na porta gigabitethernet 0/1 do PE2, configure a função QinQ flexível para que as tags VLAN de VLAN100 sejam adicionadas aos pacotes de VLAN10-VLAN20.
PE2(config)#interface gigabitethernet 0/1PE2(config-if-gigabitethernet0/1)#vlan dot1q-tunnel enablePE2(config-if-gigabitethernet0/1)#vlan dot1q-tunnel 10-20 100PE2(config-if-gigabitethernet0/1)#exit
#Na porta gigabitethernet 0/2 do PE2, configure a função QinQ flexível para que as tags VLAN de VLAN101 sejam adicionadas aos pacotes de VLAN15-VLA30.
PE2(config)#interface gigabitethernet 0/2PE2(config-if-gigabitethernet0/2)#vlan dot1q-tunnel enablePE2(config-if-gigabitethernet0/2)#vlan dot1q-tunnel 15-30 101PE2(config-if-gigabitethernet0/2)#exit
#No PE2, consulte as informações sobre entradas QinQ flexíveis.
PE2#show vlan dot1q-tunnelInterface priority-default Inner VlanId Outer VlanId inner-priority-trust Inner VlanId Count------------------- ---------------- ------------ ------------ -------------------- -----------------gi0/1 disable 10-20 100 / 11gi0/2 disable 15-30 101 / 16
- Passo 3: Confira o resultado.
#Através do PE1 e PE2, os serviços dos usuários da Intranet CE1 e CE2 podem ser transmitidos na VLAN100 da rede da operadora com duas camadas de tags. Através do PE1 e PE2, os serviços dos usuários da Intranet CE3 e CE4 podem ser transmitidos na VLAN101 da rede da operadora com duas camadas de tags.
Configurar o mapeamento de VLAN 1:1
Requisitos de rede
- Os usuários de intranet CE1 e CE2, e CE3 e CE4 se comunicam através da rede da operadora. CE1 e CE2 usam a Intranet VLAN2, CE3 e CE4 usam Intranet VLAN3, e PE1 e PE2 são dois dispositivos de borda na rede da operadora.
- O mapeamento de VLAN 1:1 é configurado em PE1 e PE2. Então, CE1 e CE2 podem se comunicar entre si através da VLAN00 da rede pública da operadora, CE3 e CE4 podem se comunicar entre si através da VLAN101 da rede pública da operadora, e os pacotes que são transmitidos na rede pública da operadora contêm duas camadas de tags .
Topologia de rede
Figura 4-3 Configurando o mapeamento de VLAN 1:1
Etapas de configuração
- Passo 1: Configurar PE1.
#No PE1, crie VLAN2-VLAN3 e VLAN100-VLAN101.
PE1#configure terminalPE1(config)#vlan 2-3,100-101
#No PE1, configure o tipo de link da porta gigabitethernet0/1 para Trunk e permita a passagem de serviços de VLAN2 e VLAN100, e defina PVID para 1.
PE1(config)#interface gigabitethernet 0/1PE1(config-if-gigabitethernet0/1)#switchport mode trunkPE1(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2,100PE1(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 1PE1(config-if-gigabitethernet0/1)#exit
#No PE1, configure o tipo de link da porta gigabitethernet0/2 para Trunk e permita a passagem de serviços de VLAN3 e VLAN101, e defina PVID para 1.
PE1(config)#interface gigabitethernet 0/2PE1(config-if-gigabitethernet0/2)#switchport mode trunkPE1(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 3,101PE1(config-if-gigabitethernet0/2)#switchport trunk pvid vlan 1PE1(config-if-gigabitethernet0/2)#exit
#No PE1, configure o tipo de link da porta gigabitethernet0/3 para Trunk e permita a passagem de serviços de VLAN100 e VLAN101, e defina PVID para 1.
PE1(config)#interface gigabitethernet 0/3PE1(config-if-gigabitethernet0/3)#switchport mode trunkPE1(config-if-gigabitethernet0/3)#switchport trunk allowed vlan add 100,101PE1(config-if-gigabitethernet0/3)#switchport trunk pvid vlan 1PE1(config-if-gigabitethernet0/3)#exit
#Na porta gigabitethernet 0/1 do PE1, configure a função de mapeamento de VLAN 1:1 para que os dados de VLAN2 sejam alterados para VLAN100.
PE1(config)#interface gigabitethernet 0/1PE1(config-if-gigabitethernet0/1)#vlan dot1q-tunnel enablePE1(config-if-gigabitethernet0/1)#vlan dot1q-tunnel mapping 2 100PE1(config-if-gigabitethernet0/1)#exit
#Na porta gigabitethernet 0/2 do PE1, configure a função de mapeamento de VLAN 1:1 para que os dados de VLAN3 sejam alterados para VLAN101.
PE1(config)#interface gigabitethernet 0/2PE1(config-if-gigabitethernet0/2)#vlan dot1q-tunnel enablePE1(config-if-gigabitethernet0/2)# vlan dot1q-tunnel mapping 3 101PE1(config-if-gigabitethernet0/2)#exit
#No PE1, consulte as informações sobre entradas de mapeamento de VLAN 1:1.
PE1#show vlan dot1q-tunnel mapping----------------------------------- -------VLAN DOT1Q-TUNNEL MAPPING------ -------------------------------------------Interface priority-default Former VlanId Mapping VlanId inner-priority-trust Former VlanId Count-------------------- --------------------- -------------- ---------------- ---------------------- -------------------gi0/1 disable 2 100 / 1gi0/2 disable 3 101 / 1
- Passo 2: Configurar PE2.
#No PE2, crie VLAN2-VLAN3 e VLAN100-VLAN101.
PE2#configure terminalPE2(config)#vlan 2-3,100-101
#No PE2, configure o tipo de link da porta gigabitethernet0/1 para Trunk e permita a passagem de serviços de VLAN2 e VLAN100, e defina PVID para 1.
PE2(config)#interface gigabitethernet 0/1PE2(config-if-gigabitethernet0/1)#switchport mode trunkPE2(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2,100PE2(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 1PE2(config-if-gigabitethernet0/1)#exit
#No PE2, configure o tipo de link da porta gigabitethernet0/2 para Trunk e permita que os serviços de VLAN3 e VLAN101 passem, e defina PVID para 1.
PE2(config)#interface gigabitethernet 0/2PE2(config-if-gigabitethernet0/2)#switchport mode trunkPE2(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 3,101PE2(config-if-gigabitethernet0/2)#switchport trunk pvid vlan 1PE2(config-if-gigabitethernet0/2)#exit
#No PE2, configure o tipo de link da porta gigabitethernet0/3 para Trunk e permita a passagem de serviços de VLAN100 e VLAN101, e defina PVID para 1.
PE2(config)#interface gigabitethernet 0/3PE2(config-if-gigabitethernet0/3)#switchport mode trunkPE2(config-if-gigabitethernet0/3)#switchport trunk allowed vlan add 100,101PE2(config-if-gigabitethernet0/3)#switchport trunk pvid vlan 1PE2(config-if-gigabitethernet0/3)#exit
#Na porta gigabitethernet 0/1 do PE2, configure a função de mapeamento de VLAN 1:1 para que os dados de VLAN2 sejam alterados para VLAN100.
PE2(config)#interface gigabitethernet 0/1PE2(config-if-gigabitethernet0/1)#vlan dot1q-tunnel enablePE2(config-if-gigabitethernet0/1)#vlan dot1q-tunnel mapping 2 100PE2(config-if-gigabitethernet0/1)#exit
#Na porta gigabitethernet 0/2 do PE2, configure a função de mapeamento de VLAN 1:1 para que os dados de VLAN3 sejam alterados para VLAN101.
PE2(config)#interface gigabitethernet 0/2PE2(config-if-gigabitethernet0/2)#vlan dot1q-tunnel enablePE2(config-if-gigabitethernet0/2)#vlan dot1q-tunnel mapping 3 101PE2(config-if-gigabitethernet0/2)#exit
#No PE2, consulte as informações sobre as entradas de mapeamento de VLAN 1:1.
PE2#show vlan dot1q-tunnel mapping----------------------------------- -------VLAN DOT1Q-TUNNEL MAPPING------ -------------------------------------------Interface priority-default Former VlanId Mapping VlanId inner-priority-trust Former VlanId Count-------------------- --------------------- -------------- ---------------- ---------------------- -------------------gi0/1 disable 2 100 / 1gi0/2 disable 3 101 / 1
- Passo 3:Confira o resultado.
#Através do PE1 e PE2, os serviços dos usuários da Intranet CE1 e CE2 podem ser transmitidos na VLAN100 da rede da operadora com uma camada de tags. Através do PE1 e PE2, os serviços dos usuários da Intranet CE3 e CE4 podem ser transmitidos na VLAN101 da rede da operadora com uma camada de tags.
Configurar o mapeamento de VLAN N:1
Requisitos de rede
- No dispositivo2, PC1 e PC2 são isolados um do outro em VLANs diferentes.
- Configure a função de mapeamento de VLAN N:1 no dispositivo1 para realizar a transmissão de pacotes de serviço PC1 e PC2 na mesma VLAN ao passar pelo dispositivo1, de modo a economizar recursos de VLAN.
Topologia de rede

Figura 4 -4 Configurando o mapeamento de VLAN N:1
Etapas de configuração
- Passo 1:Configurar dispositivo1.
# Crie VLAN2-VLAN4 no Device1.
Device1#configure terminalDevice1(config)#vlan 2-4
#No Dispositivo 1, configure o tipo de link da porta gigabitethernet0/1 para Trunk e permita a passagem de serviços de VLAN2 e VLAN100, e defina PVID para 1.
Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#switchport mode trunkDevice1(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2-4Device1(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 1
# Configure a função de mapeamento de VLAN N:1 na porta gigabitothernet0 / 1 de Device1 para mapear VLAN2 e VLAN3 para vlan4.
Device1(config-if-gigabitethernet0/1)#vlan dot1q-tunnel mapping n-to-1 enableDevice1(config-if-gigabitethernet0/1)#vlan dot1q-tunnel mapping n-to-1 2-3 4Device1(config-if-gigabitethernet0/1)#exit
#Configure o tipo de link da porta gigabitethernet0/2 no Device1 como trunk, que permite a passagem dos serviços vlan2 - vlan4, e o PVID é configurado como 1.
Device1(config)#interface gigabitethernet 0/2Device1(config-if-gigabitethernet0/2)#switchport mode trunkDevice1(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2-4Device1(config-if-gigabitethernet0/2)#switchport trunk pvid vlan 1Device1(config-if-gigabitethernet0/2)#exit
- Passo 2: Configurar dispositivo2.
# Crie VLAN2 e VLAN3 no Device2.
Device2#configure terminalDevice2(config)#vlan 2-3
#No Device2 , configure o tipo de link da porta gigabitethernet0/1 para acessar e permita que os serviços da VLAN2 passem.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode accessDevice2(config-if-gigabitethernet0/1)#switchport access vlan 2Device2(config-if-gigabitethernet0/1)#exit
#No Device2 , configure o tipo de link da porta gigabitethernet0/1 para acessar e permita que os serviços da VLAN 3 passem.
Device2(config)#interface gigabitethernet 0/2Device2(config-if-gigabitethernet0/2)#switchport mode accessDevice2(config-if-gigabitethernet0/2)#switchport access vlan 3Device2(config-if-gigabitethernet0/2)#exit
#No Device2 , configure o tipo de link da porta gigabitethernet0/1 para Trunk e permita que os serviços de VLAN 2 e VLAN3 passem , e configure PVID para 1.
Device2(config)#interface gigabitethernet 0/3Device2(config-if-gigabitethernet0/3)#switchport mode trunkDevice2(config-if-gigabitethernet0/3)#switchport trunk allowed vlan add 2-3Device2(config-if-gigabitethernet0/3)#switchport trunk pvid vlan 1Device2(config-if-gigabitethernet0/3)#exit
- Passo 3: Confira o resultado.
#No Device1, consulte as informações de entrada do mapeamento de VLAN N:1.
Device1# show vlan dot1q-tunnel mapping n-to-1 configuration---- ------------------- ------- ----------------------------------- -------------NO. Name Status Customer Member Service VLAN---- ------------------- ------- ----------------------------------- -------------1 gi0/1 enable 2-3 4
#No Dispositivo2, os serviços de PC1 e PC2 são isolados um do outro, os pacotes de serviço de PC1 são transmitidos em VLAN2 e os pacotes de serviço de PC2 são transmitidos em VLAN3.
#Os pacotes de serviço de PC1 e PC2 acessando a rede IP são encaminhados através da VLAN4 do Device1.
Super VLAN
Visão geral
Diferentes VLANs são isoladas umas das outras na camada 2. Para permitir que elas se comuniquem, você deve configurar uma interface VLAN e um endereço IP para cada VLAN. No entanto, esse modo consome um grande número de recursos de endereço IP escassos. A Super-VLAN, também chamada de agregação de VLAN, pode resolver esse problema de forma eficaz. Uma VLAN comum, após ser adicionada a uma super-VLAN, torna-se uma sub-VLAN da super-VLAN. Se a função de proxy Address Resolution Protocol (ARP) /ND estiver habilitada para a super-VLAN, a super-VLAN compartilha sua interface de VLAN com suas sub-VLANs. Dessa forma, as sub-VLANs usam o endereço IP da interface VLAN da super-VLAN como gateway para implementar a comunicação da camada 3. Isso economiza recursos de endereço IP /IPv6 .
Configuração da função VLAN
Tabela 5-1 Lista de Funções de Super-VLAN
| Tarefas de configuração | |
| Configure uma super VLAN. | Configure uma super VLAN. |
| Configure os membros da sub-VLAN da super-VLAN. | Configure os membros da sub-VLAN da super-VLAN. |
| Ative a função de proxy ARP. | Ative a função de proxy ARP. |
| função de proxy ND | função de proxy ND |
Configurar uma Super VLAN
Condição de configuração
Nenhum
Configurar uma Super VLAN
Em uma super-VLAN, uma interface VLAN pode ser configurada, mas nenhuma porta pode ser adicionada. A super-VLAN criada não deve ser uma VLAN ou sub-VLAN existente.
Tabela 5-2 Configurando uma Super VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie uma super-VLAN. | super-vlan vlan-id | Obrigatório. Por padrão, nenhuma super-VLAN é criada. Após criar uma super-VLAN, você entrará no modo de configuração da super-VLAN automaticamente. |
| Configure a descrição de uma super-VLAN. | description description | Opcional. Por padrão, a descrição de uma super-VLAN é "SuperVLAN vlan-id", como SuperVLAN0100. |
Configurar membros da Sub-VLAN de uma Super-VLAN
Condição de configuração
Nenhum
Configurar membros da Sub-VLAN de uma Super-VLAN
Uma super-VLAN suporta no máximo 128 membros de sub-VLAN e uma VLAN pode se tornar o membro de sub-VLAN de apenas uma super-VLAN. Em uma sub-VLAN, uma interface VLAN não pode ser configurada, mas uma porta pode ser adicionada a ela. O método para adicionar uma porta a uma sub-VLAN é o mesmo que o método para adicionar uma porta a uma VLAN comum. O ID de VLAN de uma sub-VLAN não deve ser idêntico ao ID de VLAN de uma super-VLAN existente.
Tabela 5-3 Configurando Membros de Sub-VLAN de uma Super-VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração super-VLAN. | super-vlan vlan-id | - |
| Configure os membros da sub-VLAN da super-VLAN. | sub-vlan vlan-list | Obrigatório. Por padrão, uma super-VLAN não é configurada com membros de sub-VLAN. |
A Sub-VLAN configurada não pode ser configurada como a vlan de controle EIPS.
Ativar a função de proxy ARP
Condição de configuração
Antes de habilitar a função de proxy ARP, certifique-se de que:
- A interface VLAN correspondente à super-VLAN e o endereço IP foram configurados.
Configurar a função de proxy ARP
Depois que a função proxy ARP de uma super-VLAN é configurada, as sub-VLANs podem se comunicar umas com as outras na camada 3 por meio do proxy ARP.
Tabela 5-4 Ativando a função de proxy ARP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração super-VLAN. | super-vlan vlan-id | - |
| Ative a função de proxy ARP. | arp proxy enable | Obrigatório. Por padrão, a função de proxy ARP está desabilitada. |
A função proxy ARP depende da função de encaminhamento da camada 3. Se o dispositivo não suportar a função de encaminhamento de camada 3, a função proxy ARP não terá efeito.
Ative a função ND Proxy
Condição de configuração
Antes de habilitar a função de proxy ND , certifique-se de que:
- A interface VLAN correspondente à super-VLAN e o endereço IP v6 foram configurados.
Configurar a função ND Proxy
Depois de habilitar a função de proxy ND da Super-VLAN, o interfuncionamento IPv6 L3 pode ser realizado entre a Sub-VLAN por meio do proxy ND.
Tabela 5 -5 Ative a função de proxy ND
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração super-VLAN. | super-vlan vlan-id | - |
| Ative a função de proxy ND | nd local-proxy enable | Obrigatório. Por padrão, não habilite a função de proxy ND. |
A função de proxy ND depende da função de encaminhamento L3. Se o dispositivo não suportar a função de encaminhamento L3 IPv6, a função de proxy ND não terá efeito.
Monitoramento e manutenção de VLAN
Tabela 5-6 Monitoramento e manutenção de Super-VLAN
| Comando | Descrição |
| show super-vlan [ vlan-id ] | Exibe as informações sobre a super-VLAN especificada. |
Exemplo de configuração típica de Super-VLAN
Configurar uma Super VLAN
Requisitos de rede
- PC1 e PC2 são dois hosts em Sub-VLAN2, PC3 é um host em Sub-VLAN3 e Server é um servidor em VLAN5.
- A função super-VLAN foi configurada no dispositivo. Então, PC1 e PC2 podem se comunicar entre si na camada2. O PC1 e o PC2 podem se comunicar com o PC3 na camada3 e podem acessar o servidor.
Topologia de rede
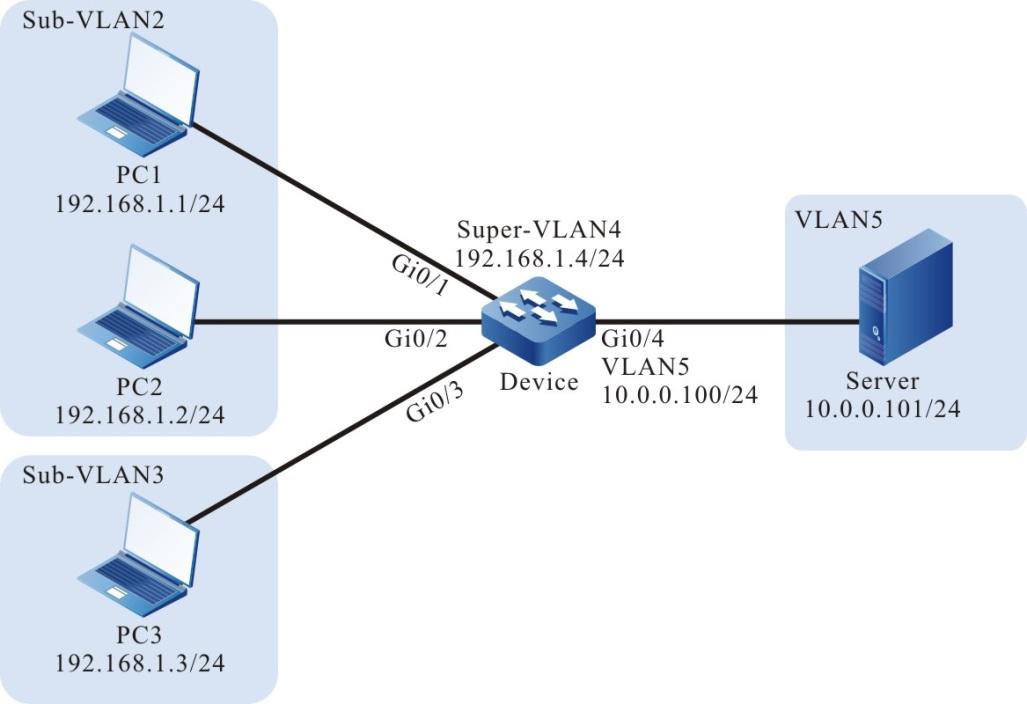
Figura 5-1 Rede para configurar uma Super-VLAN
Etapas de configuração
- Passo 1: Em Dispositivo, configure VLANs e configure os tipos de link de porta das portas.
#No dispositivo, crie VLAN2, VLAN3, VLAN5.
Device#configure terminalDevice(config)#vlan 2-3,5
#No dispositivo, defina o endereço IP da interface VLAN 4 como 192.168.1.4 e a máscara como 255.255.255.0, e defina o endereço IP da interface VLAN 5 como 10.0.0.100 e a máscara como 255.255.255.0.
Device(config)#interface vlan 4Device(config-if-vlan4)#ip address 192.168.1.4 255.255.255.0Device(config-if-vlan4)#exitDevice(config)#interface vlan 5Device(config-if-vlan5)#ip address 10.0.0.100 255.255.255.0Device(config-if-vlan5)#exit
#No dispositivo, configure o tipo de link das portas gigabitethernet 0/1 e gigabitethernet0/2 para acessar e permitir que os serviços da VLAN2 passem.
Device(config)#interface gigabitethernet 0/1,0/2Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
#No dispositivo, configure o tipo de link da porta gigabitethernet 0/3 para acessar e permita a passagem dos serviços da VLAN3.
Device(config)#interface gigabitethernet 0/3Device(config-if-gigabitethernet0/3)#switchport mode accessDevice(config-if-gigabitethernet0/3)#switchport access vlan 3Device(config-if-gigabitethernet0/3)#exit
#No dispositivo, configure o tipo de link da porta gigabitethernet 0/4 para acessar e permita que os serviços da VLAN5 passem.
Device(config)#interface gigabitethernet 0/4Device(config-if-gigabitethernet0/4)#switchport mode accessDevice(config-if-gigabitethernet0/4)#switchport access vlan 5Device(config-if-gigabitethernet0/4)#exit
#Consulte as informações da VLAN e da porta do dispositivo.
Device#show vlan 2---- ---- -------------------------------- ------- --------- -----------------------------NO. VID VLAN-Name Owner Mode Interface---- ---- -------------------------------- ------- --------- -----------------------------1 2 VLAN0002 static Untagged gi0/1 gi0/2Device#show vlan 3---- ---- -------------------------------- ------- --------- -----------------------------NO. VID VLAN-Name Owner Mode Interface---- ---- -------------------------------- ------- --------- -----------------------------1 3 VLAN0003 static Untagged gi0/3Device#show vlan 5---- ---- -------------------------------- ------- --------- -----------------------------NO. VID VLAN-Name Owner Mode Interface---- ---- -------------------------------- ------- --------- -----------------------------1 5 VLAN0005 static Untagged gi0/4
- Passo 2: No dispositivo, configure a função super-VLAN.
#No dispositivo, configure VLAN4 como super-VLAN, VLAN2 e VLAN3 como sub-VLANs e habilite o proxy ARP.
Device(config)#super-vlan 4Device(config-super-vlan4)#sub-vlan 2,3Device(config-super-vlan4)#arp proxy enableDevice(config-super-vlan4)#exit
#Consulte as informações da super-VLAN do dispositivo.
Device#show super-vlan-------------------------------------------------------------------------------NO. SuperVlan Description Arp Proxy SubVlan Member--------------------------------------------------------------------------------1 4 SuperVLAN0004 enable 2-3
Para permitir que os hosts em diferentes sub-VLANs se comuniquem na camada 3, a função proxy ARP deve ser habilitada. S uper - VLAN e S ub - VLAN devem estar em uma instância de spanning tree.
- Passo 3: Confira o resultado. Use o comando ping para verificar a conectividade entre PC1, PC2, PC3 e o servidor.
#PC1 e PC2 na Sub-VLAN2 podem efetuar ping entre si com sucesso.
#PC1 e PC2 na Sub-VLAN2 e PC3 na Sub-VLAN3 podem efetuar ping entre si com sucesso.
#PC1, PC2 e PC3 em Sub-VLANs e o servidor podem executar ping entre si com sucesso.
PVLAN
Visão geral
Para realizar o isolamento entre os usuários, mas torná-los ainda capazes de acessar recursos públicos, geralmente uma VLAN precisa ser criada para um usuário. No entanto, o número total de VLANs é de apenas 4094, se o número de usuários for maior que o número de VLANs, o número de VLANs se torna um gargalo. Além disso, não é fácil configurar, gerenciar e manter um grande número de VLANs. Para resolver o requisito, surge a VLAN privada (PVLAN). Ele fornece um modo de configuração de VLAN flexível no qual os recursos de VLAN e endereço IP podem ser alocados e usados de forma razoável, simplificando a configuração da rede.
Em uma PVLAN, é usada uma estrutura de VLAN de duas camadas, ou seja, VLAN primária e VLAN secundária. As VLANs primárias geralmente são conectadas a dispositivos upstream e as VLANs secundárias geralmente são conectadas a dispositivos downstream. De acordo com as regras de encaminhamento da camada 2, as VLANs secundárias são categorizadas nos dois tipos a seguir:
- VLAN isolada: As portas membro em uma VLAN isolada são isoladas umas das outras na camada 2, e as portas membro de diferentes VLANs isoladas também são isoladas umas das outras. Para obter o isolamento dos usuários, você só precisa adicionar as portas às quais os usuários estão conectados para isolar as VLANs.
- VLAN da comunidade: As regras de encaminhamento de uma VLAN da comunidade são as mesmas de uma VLAN comum. As portas membro na mesma VLAN da comunidade podem se comunicar entre si na camada 2, enquanto as portas são isoladas das portas membro em outras VLANs da comunidade ou VLANs isoladas.
Depois que uma VLAN primária estabelece uma relação de associação com VLANs secundárias, as portas membro nas VLANs secundárias podem se comunicar com as portas membro na VLAN primária na camada 2 e as portas membro nas VLANs secundárias podem se comunicar com dispositivos externos na camada 3 através da interface VLAN da VLAN primária.
As PVLANs têm dois tipos especiais de link de porta, Promíscuo e Host. As portas promíscuas só podem ser adicionadas a VLANs primárias e as portas de host só podem ser adicionadas a VLANs secundárias. As portas do Host que são adicionadas às VLANs da comunidade também são chamadas de portas da comunidade e as portas do Host que são adicionadas às VLANs isoladas também são chamadas de portas isoladas.
Configuração da função PVLAN
Tabela 6 -1 Lista de Funções PVLAN
| Tarefas de configuração | |
| Configure uma VLAN primária. | Configure uma VLAN primária. |
| Adicione portas em uma VLAN primária. | Adicione portas em uma VLAN primária. |
| Configure VLANs secundárias. | Configure VLANs secundárias. |
| Adicione portas em VLANs secundárias. | Adicione portas em VLANs secundárias. |
| Configure uma relação de associação entre uma VLAN primária e VLANs secundárias. | Configure uma relação de associação entre uma VLAN primária e VLANs secundárias. |
Configurar uma VLAN primária
Os dispositivos upstream reconhecem apenas a VLAN primária enquanto não se importam com as VLANs secundárias associadas.
Condição de configuração
Nenhum
Configurar uma VLAN primária
Tabela 6 -2 Configurando uma VLAN Primária
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração VLAN. | vlan vlan-id | - |
| Configure o VLAN para o tipo de VLAN primário. | private-vlan primary | Obrigatório. Por padrão, todas as VLANs são VLANs comuns. |
Adicionar portas em uma VLAN primária
Somente as portas cujo tipo de link é Promíscuo podem ser adicionadas a uma VLAN primária. As portas que são adicionadas a uma VLAN primária podem se comunicar na camada dois com as outras portas membro na VLAN primária e as portas membro das VLANs secundárias associadas. Portas promíscuas geralmente são usadas como portas upstream.
Condição de configuração
Antes de adicionar portas em uma VLAN primária, certifique-se de que:
- A VLAN na qual as portas são adicionadas é do tipo VLAN primária.
Adicionar portas em uma VLAN primária
Tabela 6 -3 Adicionando portas em uma VLAN primária
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet de camada 2. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | link-aggregation link-aggregation-id | |
| Configure o tipo de link de porta para Promíscuo. | switchport mode private-vlan promiscuous | Obrigatório. Por padrão, o tipo de link de porta é o tipo de acesso. |
| Adicione portas promíscuas na VLAN primária. | private-vlan promiscuous vlan-id | Obrigatório. Por padrão, uma porta Promíscua não é adicionada a nenhuma VLAN. |
Se você configurar um tipo de link de porta como Promíscuo, mas não adicionar a porta a uma VLAN primária, a função PVLAN da porta não terá efeito. Além disso, a porta do tipo Promíscuo é dedicada para PVLAN, e as demais funções configuradas na porta Promíscuo são inválidas. Portanto, é recomendável seguir as etapas anteriores para concluir a configuração.
Configurar VLANs secundárias
Os dispositivos downstream reconhecem apenas VLANs secundárias enquanto não se importam com a VLAN primária associada.
Condição de configuração
Nenhum
Configurar VLANs secundárias
Tabela 6 -4 Configurando VLANs Secundárias
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração VLAN. | vlan vlan-id | - |
| Configure VLANs para o tipo de VLAN secundária. | private-vlan { community | isolated } | Obrigatório. Por padrão, todas as VLANs são VLANs comuns. |
Adicionar portas em VLANs secundárias
Somente as portas cujo tipo de link é Host podem ser adicionadas a VLANs secundárias. As VLANs secundárias são categorizadas em dois tipos: VLANs comunitárias e VLANs isoladas. As portas que são adicionadas a uma VLAN de comunidade só podem se comunicar na camada 2 com as outras portas de membro da VLAN de comunidade e as portas de membro da VLAN primária associada. As portas que são adicionadas a uma VLAN isolada só podem se comunicar na camada 2 com as portas membro da VLAN primária associada. As portas do host geralmente são usadas como portas downstream.
Condição de configuração
Antes de adicionar portas em uma VLAN secundária, certifique-se de que:
- A VLAN na qual as portas são adicionadas é do tipo VLAN secundária.
Adicionar portas em VLANs secundárias
Tabela 6 -5 Adicionando portas em VLANs secundárias
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entra no modo de configuração da interface. | interface interface-name | Opcional. Depois que você entrar no modo de configuração de interface, a configuração subsequente terá efeito apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no grupo de agregação. |
| Entre no modo de configuração do link aggregation. | link-aggregation link-aggregation-id | |
| Configure o tipo de link de porta para o tipo de host. | switchport mode private-vlan host | Obrigatório. Por padrão, o tipo de link de porta é o tipo de acesso. |
| Adicione portas de host nas VLANs secundárias. | private-vlan host vlan-id | Obrigatório. Por padrão, uma porta de host não é adicionada a nenhuma VLAN. |
Os hosts em uma VLAN secundária não podem se comunicar com a interface VLAN do dispositivo na camada 3. Se você configurar um tipo de link de porta para Host, mas não adicionar a porta a uma VLAN secundária, a função PVLAN da porta não terá efeito. Além disso, a porta do tipo Host é dedicada para PVLAN e as demais funções configuradas na porta Host são inválidas. Portanto, é recomendável seguir as etapas anteriores para concluir a configuração.
Configure uma relação de associação entre uma VLAN primária e uma VLAN secundária
Depois que uma relação de associação é estabelecida, os hosts em uma VLAN primária podem se comunicar na camada 2 com o host nas VLANs secundárias associadas. Uma VLAN primária pode ser associada a no máximo uma VLAN isolada e 192 VLANs de comunidade. Uma VLAN secundária pode ser associada apenas a uma VLAN primária.
Condição de configuração
Antes de configurar uma relação de associação entre uma VLAN primária e uma VLAN secundária, certifique-se de que:
- A VLAN no modo de configuração de VLAN atual é do tipo VLAN primária.
Configure uma relação de associação entre uma VLAN primária e uma VLAN secundária
Tabela 6 -6 Configurando uma relação de associação entre uma VLAN primária e VLANs secundárias
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração VLAN. | vlan vlan-id | - |
| Configure uma relação de associação entre a VLAN primária e as VLANs secundárias. | private-vlan association add vlan-list | Obrigatório. Por padrão, uma VLAN primária não está associada a nenhuma VLAN secundária. |
Se uma VLAN primária estiver associada a uma VLAN comum, a associação será inválida. Para que a associação tenha efeito, modifique o tipo de VLAN para VLAN secundária. Se uma VLAN secundária estiver associada a uma VLAN primária, as entradas de endereço MAC que são aprendidas dinamicamente pela VLAN secundária serão registradas na tabela FDB como VLANs primárias em vez de VLANs secundárias associadas à VLAN secundária.
Monitoramento e manutenção de PVLAN
Tabela 6 -7 Monitoramento e manutenção de PVLAN
| Comando | Descrição |
| show private-vlan [ vlan-id ] | Exibe as informações sobre o PVLAN. |
Exemplo de configuração típica de PVLAN
Configurar uma PVLAN
Requisitos de rede
- PC1 e PC2 pertencem à VLAN2 secundária, PC3 e PC4 pertencem à VLAN3 secundária e o Servidor pertence à VLAN4 primária.
- PVLAN é configurado no dispositivo. Em seguida, a interconexão é permitida na VLAN 2 secundária, o isolamento é implementado na VLAN3 secundária, a VLAN2 secundária e a VLAN3 secundária são isoladas uma da outra, e a VLAN2 secundária e a VLAN3 secundária podem se interconectar com a VLAN4 primária.
Topologia de rede
Figura 6-1 Rede para configurar um PVLAN
Etapas de configuração
- Passo 1: Configure VLANs no dispositivo.
#No dispositivo, crie VLAN2-VLAN4.
Device#configure terminalDevice(config)#vlan 2-4
- Passo 2: No dispositivo, configure a função PVLAN.
#No dispositivo, configure VLAN4 para VLAN primária, configure VLAN2 para VLAN de comunidade e configure VLAN3 para VLAN isolada.
Device(config)#vlan 4Device(config-vlan4)#private-vlan primaryDevice(config-vlan4)#vlan 2Device(config-vlan2)#private-vlan communityDevice(config-vlan2)#vlan 3Device(config-vlan3)#private-vlan isolatedDevice(config-vlan3)#exit
#No dispositivo, associe a VLAN4 primária com a comunidade VLAN2 e VLAN3 isolada.
Device(config)#vlan 4Device(config-vlan4)#private-vlan association add 2,3Device(config-vlan4)#exit
#No Dispositivo, configure o tipo de link das portas gigabitethernet 0/1 e gigabitethernet 0/2 para Host e adicione as portas à VLAN2 secundária.
Device(config)#interface gigabitethernet 0/1-0/2Device(config-if-range)#switchport mode private-vlan hostDevice(config-if-range)#private-vlan host 2Device(config-if-range)#exit
#No Dispositivo, configure o tipo de link das portas gigabitethernet 0/3 e gigabitethernet 0/4 para Host e adicione as portas à VLAN3 secundária.
Device(config)#interface gigabitethernet 0/3-0/4Device(config-if-range)#switchport mode private-vlan hostDevice(config-if-range)#private-vlan host 3Device(config-if-range)#exit
#No dispositivo, configure o tipo de link da porta gigabitethernet 0/5 para Promiscuous e adicione as portas à VLAN4 primária.
Device(config)#interface gigabitethernet 0/5Device(config-if-gigabitethernet0/5)#switchport mode private-vlan promiscuousDevice(config-if-gigabitethernet0/5)#private-vlan promiscuous 4Device(config-if-gigabitethernet0/5)#exit
- Passo 3: Confira o resultado.
#Consulte as informações de PVLAN no dispositivo.
Device#show private-vlan---- -------- ---------- ---------------- --------------------------------- ---------------------------------NO. Primary Secondary Type Interface(Primary) Interface(Secondary)---- -------- ---------- ---------------- --------------------------------- ---------------------------------1 4 3 isolated gi0/5 gi0/3 gi0/42 4 2 community gi0/5 gi0/1 gi0/2
#PC1 e PC2 na comunidade VLAN2 podem pingar um ao outro com sucesso.
#PC3 e PC4 em VLAN3 isoladas podem efetuar ping entre si com sucesso.
#PC1 e PC2 na comunidade VLAN2 e PC3 e PC4 na VLAN3 isolada não podem efetuar ping entre si.
#PC1 e PC2 na comunidade VLAN2 podem executar ping no servidor com sucesso.
#PC3 e PC4 em VLAN3 isoladas podem executar ping no servidor com sucesso.
Voice-VLAN
Visão geral
Voice-VLAN é um mecanismo que fornece segurança e garantia de Qualidade de Serviço (QoS) para fluxos de dados de voz. Em uma rede, geralmente coexistem dois tipos de tráfego, dados de voz e dados de serviço. Durante a transmissão, os dados de voz têm uma prioridade mais alta do que os dados de serviço para reduzir o atraso e a perda de pacotes que podem ocorrer durante o processo de transmissão. Voice-VLAN pode reconhecer automaticamente o tráfego de voz e distribuir o tráfego de voz para uma VLAN específica com garantia de QoS.
Configuração da Função Voice-VLAN
Tabela 7-1 Lista de Funções de Voice-VLAN
| Tarefas de configuração | |
| Configure uma Voice-VLAN. | Configure uma Voice-VLAN. |
| Configure um endereço OUI. | Configure um endereço OUI. |
| Habilite a função de Voice-VLAN de uma porta. | Habilite a função de Voice-VLAN de uma porta. |
| Configure o modo de trabalho de Voice-VLAN na porta. | Configure uma Voice-VLAN para o modo automático. Configure uma Voice-VLAN para o modo manual. |
| Habilite o modo de segurança do Voice-VLAN | Habilite o modo de segurança do Voice-VLAN |
| modo de autenticação lldp-med do Voice-VLAN | modo de autenticação lldp-med do Voice-VLAN |
Configurar uma Voice-VLAN
Uma Voice-VLAN é usada para transmitir pacotes de voz. As prioridades 802.1 dos pacotes de voz reconhecidos são substituídas pela prioridade da Voice-VLAN. Em seguida, os pacotes são distribuídos na Voice-VLAN para encaminhamento. Um dispositivo suporta no máximo uma Voice-VLAN.
Condição de configuração
Antes de configurar uma Voice-VLAN, certifique-se de que:
- A VLAN a ser configurada como Voice-VLAN já foi criada.
Configurar uma Voice-VLAN
Tabela 7-2 Configurando uma Voice-VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma VLAN especificada para Voice-VLAN. | voice vlan vlan-id cos priority | Obrigatório. Por padrão, o Voice-VLAN não está configurado, ou seja, a função Voice-VLAN não está habilitada globalmente. |
Configurar um endereço OUI
Condição de configuração
Antes de configurar um endereço OUI, certifique-se de que:
- A função de Voice-VLAN é habilitada globalmente.
- A função de Voice-VLAN está habilitada na porta.
Configurar um endereço OUI
Identificadores Únicos Organizacionais (OUIs) são usados para identificar pacotes de voz que são enviados por dispositivos de voz de fabricantes. Depois que uma porta que funciona no modo automático de Voice-VLAN recebe um pacote Untag, ela retira o endereço MAC do pacote e executa a operação AND com a máscara OUI. Se o intervalo de endereços obtido for o mesmo que o endereço OUI, isso indica que a correspondência do endereço OUI foi bem-sucedida e o pacote é reconhecido como um pacote de voz.
Tabela 7-3 Configurando um endereço OUI
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure um endereço OUI. | voice vlan oui-mac oui-mac-address mask mask name oui-name | Obrigatório. Por padrão, cinco endereços OUI estão disponíveis. Um dispositivo suporta no máximo 32 endereços OUI. |
Habilite a função Voice-VLAN
Depois que a função de Voice-VLAN é habilitada em uma porta, a porta usa um método de acordo com o modo de trabalho de Voice-VLAN para reconhecer automaticamente os pacotes recebidos.
Condição de configuração
Antes de habilitar a função de Voice-VLAN de uma porta, certifique-se de que:
- A função de Voice-VLAN foi habilitada globalmente.
- A porta foi adicionada à Voice-VLAN.
Habilite a função Voice-VLAN de uma porta
Tabela 7-4 Habilitando a função Voice-VLAN de uma porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | link-aggregation link-aggregation-id | |
| Habilite a função de Voice-VLAN de uma porta. | voice vlan enable | Obrigatório. Por padrão, a função de Voice-VLAN está desabilitada na porta. |
O modo de segurança do Voice-VLAN não suporta o grupo de agregação, ou seja, quando o dispositivo habilita o modo de segurança do Voice-VLAN, o link aggregation não pode habilitar a função Voice-VLAN; ou quando o dispositivo tem o link aggregation habilitado com a função Voice-VLAN, o modo de segurança do Voice-VLAN não pode ser habilitado. O modo de autenticação lldp-med do Voice-VLAN não suporta o link aggregation, ou seja, quando o dispositivo habilita o modo de autenticação lldp-med do Voice-VLAN, o grupo de agregação não pode habilitar a função Voice-VLAN; ou quando o dispositivo tem o link aggregation habilitado com a função Voice-VLAN, o modo de autenticação lldp-med de Voice-VLAN não pode ser habilitado.
Configure o modo de trabalho Voice-VLAN na porta
A Voice-VLAN de uma porta pode funcionar em modo automático ou manual. As portas que trabalham em diferentes modos de Voice-VLAN reconhecem os pacotes de voz de maneiras diferentes.
- Modo automático: Se os pacotes recebidos pela porta forem pacotes Untag ou o pacote Tag com o Voice-VLAN ID e o endereço MAC de origem dos pacotes corresponder a um endereço OUI, os pacotes serão considerados como pacotes de voz.
- Modo manual: Os pacotes recebidos pela porta são todos considerados como pacotes de voz.
Condição de configuração
Antes de configurar o modo de trabalho de Voice-VLAN de uma porta, certifique-se de que:
- A função de Voice-VLAN foi habilitada globalmente.
- A função de Voice-VLAN da porta foi habilitada.
Configurar um Voice-VLAN para o modo automático
Tabela 7-5 Configurando um Voice-VLAN para o modo automático
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | link-aggregation link-aggregation-id | |
| Configure a porta para funcionar no modo automático de Voice-VLAN. | voice vlan mode auto | Obrigatório. Por padrão, a porta funciona no modo automático de Voice-VLAN. |
Configurar um Voice-VLAN para o modo manual
Tabela 7-6 Configurando um Voice-VLAN para o modo manual
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | link-aggregation link-aggregation-id | |
| Configure a porta para funcionar no modo manual de Voice-VLAN. | no voice vlan mode auto | Obrigatório. Por padrão, a porta funciona no modo automático de Voice-VLAN. |
Se a porta for usada para transmitir os dados de voz Tagged, o tipo de porta só pode ser configurado como Trunk ou Hybrid, e o PVID não pode ser Voice-VLAN. Se a porta funcionar no modo manual de Voice-VLAN e for usada para transmitir os dados de voz não marcados, o PVID deve ser Voice-VLAN. O modo de autenticação lldp-med do Voice-VLAN não suporta o modo manual das portas, ou seja, quando os dispositivos habilitam o modo de autenticação lldp-med do Voice-VLAN, as portas não podem ser configuradas como o modo manual do Voice-VLAN ; ou quando há uma porta configurada como o modo manual do Voice-VLAN, o modo de autenticação lldp-med do Voice-VLAN não pode ser habilitado.
Habilite o Modo de Segurança de Voice-VLAN
Após habilitar o modo de segurança do Voice-VLAN, o dispositivo verificará o endereço MAC de origem de cada pacote que entrar no Voice-VLAN para transmissão e descartará o pacote que não corresponder ao endereço OUI.
Condição de configuração
Antes de habilitar o modo de segurança do Voice-VLAN, conclua a seguinte tarefa:
- Habilite globalmente a função Voice-VLAN
Habilite o Modo de Segurança de Voice-VLAN
Tabela 6 -7 Habilite o modo de segurança de Voice-VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite o modo de segurança do Voice-VLAN | voice vlan security enable | Obrigatório. Por padrão, não habilite o modo de segurança do Voice-VLAN. |
O modo de segurança do Voice-VLAN não suporta grupo de agregação, ou seja, quando o dispositivo possui o grupo de agregação habilitado com a função Voice-VLAN, o modo de segurança do Voice-VLAN não pode ser habilitado; ou quando o dispositivo habilita o modo de segurança de Voice-VLAN, o link aggregation não pode habilitar a função Voice-VLAN.
Habilite o modo de autenticação lldp-med de Voice-VLAN
Depois que o modo de autenticação lldp-med do Voice-VLAN é ativado, o dispositivo usa o OUI configurado pelo usuário ou o OUI padrão como a lista de permissões de autenticação, realizando a verificação correspondente para o endereço MAC de origem do dispositivo de voz notificado pelo lldp-med, e os pacotes de voz enviados pelo dispositivo de voz que corresponde à lista branca podem entrar no Voice-VLAN para transmissão.
Condição de configuração
Antes de habilitar o modo de autenticação lldp-med do Voice-VLAN, conclua a seguinte tarefa:
- Habilite globalmente a função Voice-VLAN
o modo de autenticação lldp-med de Voice - VLAN
Tabela 6 -8 Habilite o modo de autenticação lldp-med de Voice-VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite o modo de autenticação lldp-med do Voice-VLAN | voice vlan lldp-med authentication | Obrigatório. Por padrão, não habilite o modo de autenticação lldp-med de Voice-VLAN |
O modo de autenticação lldp-med do Voice-VLAN não suporta o link aggregation, ou seja, quando o dispositivo tem o link aggregation habilitado com a função Voice-VLAN, o modo de autenticação lldp-med do Voice-VLAN não pode ser habilitado; ou quando o dispositivo habilita o modo de autenticação lldp-med de Voice-VLAN, o link aggregation não pode habilitar a função Voice-VLAN. O modo de autenticação lldp-med do Voice-VLAN não suporta o modo manual de portas, ou seja, quando há uma porta configurada como o modo manual do Voice-VLAN, o modo de autenticação lldp-med do Voice-VLAN não pode ser habilitado ; ou quando o dispositivo habilita o modo de autenticação lldp-med de Voice-VLAN, a porta não pode ser configurada como o modo manual de Voice-VLAN. Depois que o modo de autenticação lldp Med da Voice-VLAN é habilitado, o telefone que não suporta lldp não pode funcionar normalmente.
Monitoramento e manutenção de Voice-VLAN
Tabela 7-9 Monitoramento e manutenção de Voice-VLAN
| Comando | Descrição |
| show voice vlan { all | interface [ interface-name ] | link-aggregation [ link-aggregation-id ] | oui | lldp-med authenticated-mac } | Exibe as informações sobre a Voice-VLAN. |
Exemplo de configuração típica de Voice-VLAN
Configurar um Voice-VLAN para o modo manual
Requisitos de rede
- O Telefone IP e o PC podem acessar a Rede IP através do Dispositivo.
- A Voice-VLAN no modo manual foi configurada no dispositivo. Se a rede estiver normal, o Telefone IP e o PC podem acessar normalmente a Rede IP. Se a rede estiver congestionada, o Telefone IP tem uma prioridade mais alta do que o PC no acesso à Rede IP.
Topologia de rede
Figura 7-1 Rede para configurar uma Voice-VLAN para o modo manual
Etapas de configuração
- Passo 1: Configure uma VLAN e configure o tipo de link das portas.
#No dispositivo, crie VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#No Device2, configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 para acessar e permitir que os serviços da VLAN2 passem.
Device(config)#interface gigabitethernet 0/1,0/2Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
#No Dispositivo, configure o tipo de link da porta gigabitethernet0/3 para Trunk e permita a passagem de serviços de VLAN2.
Device(config)#interface gigabitethernet 0/3Device(config-if-gigabitethernet0/3)#switchport mode trunkDevice(config-if-gigabitethernet0/3)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/3)#exit
- Passo 2: Configure a função de Voice-VLAN.
#No dispositivo, configure VLAN2 para Voice-VLAN e configure o valor Cos para 7.
Device(config)#voice vlan 2 cos 7#Na porta gigabitethernet 0/1 do dispositivo, configure o modo Voice-VLAN para o modo manual.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#voice vlan enableDevice(config-if-gigabitethernet0/1)#no voice vlan mode autoDevice(config-if-gigabitethernet0/1)#exit
#No dispositivo, consulte as informações de Voice-VLAN.
Device#show voice vlan allVoice Vlan Global Information: Voice Vlan enableVoice Vlan security: disableVoice Vlan lldp-med authentication: disableVoice Vlan VID: 2, Cos: 7Default OUI number: 5User config OUI number: 0Voice vlan interface information:Interface Mode--------------------------------------gi0/1 Manual-ModeVoice Vlan OUI information: Total: 5MacAddr Mask Name-------------------------------------------------------------0003.6b00.0000 ffff.ff00.0000 Cisco-phone default006b.e200.0000 ffff.ff00.0000 H3C-Aolynk-phone default00d0.1e00.0000 ffff.ff00.0000 Pingtel-phone default00e0.7500.0000 ffff.ff00.0000 Polycom-phone default00e0.bb00.0000 ffff.ff00.0000 3Com-phone default
- Passo 3: Confira o resultado.
# A prioridade 802.1 dos pacotes enviados para o Telefone IP é modificada para 7, e a prioridade 802.1P dos pacotes enviados pelo PC para a Rede IP não é modificada.
#Quando a rede está normal, o Telefone IP e o PC podem acessar normalmente a Rede IP.
# Se a rede estiver congestionada, o Telefone IP pode acessar a Rede IP com prioridade superior ao PC.
Configurar um Voice-VLAN para o modo automático
Requisitos de rede
- Telefone IP e PC acessam a Rede IP através da porta gigabitethernet0/1 do Dispositivo. O endereço MAC do Telefone IP é 0001.0001.0001 e o endereço MAC do PC é 0002.0002.0002.
- A Voice-VLAN no modo automático foi configurada. Desta forma, se a rede estiver normal, o Telefone IP e o PC podem acessar normalmente a rede IP. Se a rede estiver congestionada, o Telefone IP tem uma prioridade mais alta do que o PC no acesso à Rede IP.
Topologia de rede
Figura 7-2 Rede para configurar uma Voice-VLAN para o modo automático
Etapas de configuração
- Passo 1: Configure uma VLAN e configure o tipo de link das portas.
#No dispositivo, crie VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#No Dispositivo, configure o tipo de link da porta gigabitethernet0/1 para Trunk e permita a passagem de serviços de VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)# switchport mode trunkDevice(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/1)#exit
#No Dispositivo, configure o tipo de link da porta gigabitethernet0/2 para Trunk e permita a passagem de serviços de VLAN2.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode trunkDevice(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/2)#exit
- Passo 2: Configure a função de Voice-VLAN.
#No dispositivo, configure VLAN2 para Voice-VLAN e modifique o valor de Cos para 7.
Device(config)#voice vlan 2 cos 7#Na porta gigabitethernet 0/1 do dispositivo, configure o modo Voice-VLAN para modo automático.
Device(config)# interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#voice vlan enableDevice(config-if-gigabitethernet0/1)#voice vlan mode autoDevice(config-if-gigabitethernet0/1)#exit
#No Dispositivo, configure o endereço OUI correspondente ao endereço MAC 0001.0001.0001 do Telefone IP.
Device(config)#voice vlan oui-mac 0001.0001.0001 mask ffff.ffff.0000 name Voice-VLAN#No dispositivo, consulte as informações de Voice-VLAN.
Device#show voice vlan allVoice Vlan Global Information: Voice Vlan enableVoice Vlan security: disableVoice Vlan lldp-med authentication: disableVoice Vlan VID: 2, Cos: 7Default OUI number: 5User config OUI number: 1Voice vlan interface information:Interface Mode--------------------------------------gi0/1 Auto-ModeVoice Vlan OUI information: Total: 6MacAddr Mask Name-------------------------------------------------------------0001.0001.0000 ffff.ffff.0000 Voice-VLAN0003.6b00.0000 ffff.ff00.0000 Cisco-phone default006b.e200.0000 ffff.ff00.0000 H3C-Aolynk-phone default00d0.1e00.0000 ffff.ff00.0000 Pingtel-phone default00e0.7500.0000 ffff.ff00.0000 Polycom-phone default00e0.bb00.0000 ffff.ff00.0000 3Com-phone default
- Passo 3: Confira o resultado.
# A prioridade 802.1 dos pacotes enviados para o Telefone IP é modificada para 7, e a prioridade 802.1P dos pacotes enviados pelo PC para a Rede IP não é modificada.
#Quando a rede está normal, o Telefone IP e o PC podem acessar normalmente a Rede IP.
# Se a rede estiver congestionada, o Telefone IP pode acessar a Rede IP com prioridade superior ao PC.
Configurar o modo de segurança do Voice-VLAN
Requisitos de rede
- Telefone IP e PC acessam a Rede IP através da porta gigabitethernet0/1 do Dispositivo. O endereço MAC do Telefone IP é 0001.0001.0001 e o endereço MAC do PC é 0002.0002.0002.
- No Dispositivo, configure o modo de segurança da Voice-VLAN, percebendo que o Telefone IP pode acessar a Rede IP normalmente e o PC não pode acessar a Rede IP.
Topologia de rede
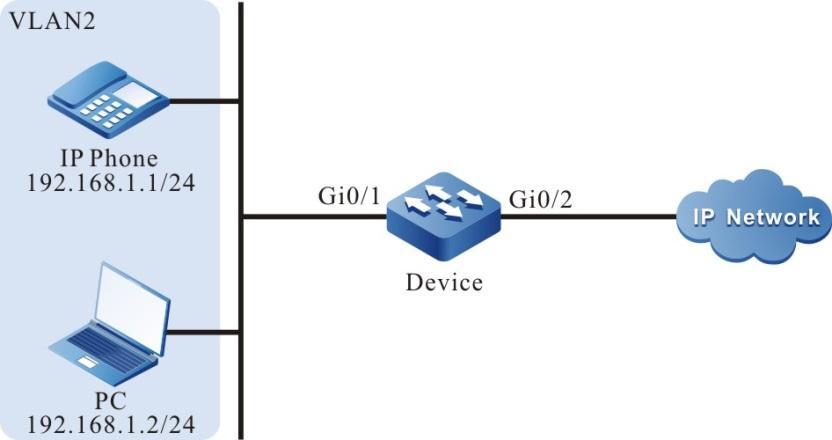
Figura 7 -3 Rede para configurar o modo de segurança do Voice-VLAN
Etapas de configuração
- Passo 1: Configure uma VLAN e configure o tipo de link das portas.
# No dispositivo, crie VLAN2 .
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#No Dispositivo, configure o tipo de link da porta gigabitethernet0/1 para Trunk e permita a passagem de serviços de VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode trunkDevice(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/1)#exit
#No Dispositivo, configure o tipo de link da porta gigabitethernet0/2 para Trunk e permita a passagem de serviços de VLAN2.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode trunkDevice(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/2)#exit
- Passo 2: Configure a função de Voice-VLAN.
#No dispositivo, configure VLAN2 para Voice-VLAN e modifique o valor de Cos para 7.
Device(config)#voice vlan 2 cos 7# No dispositivo, ative globalmente o modo de segurança de Voice-VLAN .
Device(config)# voice vlan security enable#Na porta gigabitethernet 0/1 do dispositivo, configure o modo automático de Voice-VLAN.
Device(config)# interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#voice vlan enableDevice(config-if-gigabitethernet0/1)#voice vlan mode autoDevice(config-if-gigabitethernet0/1)#exit
# No dispositivo, configure o endereço OUI do endereço MAC 0001.0001.0001 do Telefone IP.
Device(config)#voice vlan oui-mac 0001.0001.0001 mask ffff.ffff.0000 name Voice-VLAN# No dispositivo, visualize as informações de Voice-VLAN.
Device#show voice vlan allVoice Vlan Global Information: Voice Vlan enableVoice Vlan security: enableVoice Vlan lldp-med authentication: disableVoice Vlan VID: 2, Cos: 7Default OUI number: 5User config OUI number: 1Voice vlan interface information:Interface Mode--------------------------------------gi0/1 Auto-ModeVoice Vlan OUI information: Total: 6MacAddr Mask Name-------------------------------------------------------------0001.0001.0000 ffff.ffff.0000 Voice-VLAN0003.6b00.0000 ffff.ff00.0000 Cisco-phone default006b.e200.0000 ffff.ff00.0000 H3C-Aolynk-phone default00d0.1e00.0000 ffff.ff00.0000 Pingtel-phone default00e0.7500.0000 ffff.ff00.0000 Polycom-phone default00e0.bb00.0000 ffff.ff00.0000 3Com-phone default
- Passo 3: Confira o resultado.
#A prioridade 802.1 dos pacotes que o Telefone IP envia para a Rede IP é modificada para 7.
# O PC normalmente não pode acessar a rede IP.
Configurar o modo de autenticação lldp-med de Voice-VLAN
Requisitos de rede
- Telefone IP (o telefone IP pode enviar o pacote LLDP com o campo de voz) e PC acessa a Rede IP através da porta gigabitethernet0/1 do Dispositivo. O endereço MAC do Telefone IP é 0001.0001.0001 e o endereço MAC do PC é 0002.0002.0002.
- Ton Device, configure o modo de autenticação lldp-med de Voice-VLAN para que o Telefone IP possa acessar normalmente a rede IP e o PC não possa acessar a rede IP.
Topologia de rede
Figura 7 -4 Rede para configurar o modo de autenticação lldp-med de Voice-VLAN
Etapas de configuração
- Passo 1: Configure uma VLAN e configure o tipo de link das portas.
# No dispositivo, crie VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#No Dispositivo, configure o tipo de link da porta gigabitethernet0/1 para Trunk e permita a passagem de serviços de VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode trunkDevice(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/1)#exit
#No Dispositivo, configure o tipo de link da porta gigabitethernet0/2 para Trunk e permita a passagem de serviços de VLAN2.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode trunkDevice(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/2)#exit
- Passo 2: Configure a função Voice-VLAN.
#No dispositivo, configure VLAN2 como Voice-VLAN e modifique o valor de Cos para 7.
Device(config)#voice vlan 2 cos 7# No dispositivo, habilite globalmente o modo de autenticação lldp-med de Voice-VLAN.
Device(config)#voice vlan lldp-med authentication# Na porta gigabitethernet 0/1 do dispositivo, configure o modo automático Voice-VLAN .
Device(config)# interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#voice vlan enableDevice(config-if-gigabitethernet0/1)#voice vlan mode autoDevice(config-if-gigabitethernet0/1)#exit
# No dispositivo, configure o endereço OUI do endereço MAC do Telefone IP 0001.0001.0001.
Device(config)#voice vlan oui-mac 0001.0001.0001 mask ffff.ffff.0000 name Voice-VLAN# No dispositivo, visualize as informações de Voice-VLAN.
Device#show voice vlan allVoice Vlan Global Information: Voice Vlan enableVoice Vlan security: disableVoice Vlan lldp-med authentication: enableVoice Vlan VID: 2, Cos: 7Default OUI number: 5User config OUI number: 1Voice vlan interface information:Interface Mode--------------------------------------gi0/1 Auto-ModeVoice Vlan OUI information: Total: 6MacAddr Mask Name-------------------------------------------------------------0001.0001.0000 ffff.ffff.0000 Voice-VLAN0003.6b00.0000 ffff.ff00.0000 Cisco-phone default006b.e200.0000 ffff.ff00.0000 H3C-Aolynk-phone default00d0.1e00.0000 ffff.ff00.0000 Pingtel-phone default00e0.7500.0000 ffff.ff00.0000 Polycom-phone default00e0.bb00.0000 ffff.ff00.0000 3Com-phone defaultVoice Vlan lldp-med authenticated mac information:MacAddr Interface-------------------------------------------------0001.0001.0001 gi0/1
- Passo 3: Confira o resultado.
# A prioridade 802.1P do pacote enviado pelo Telefone IP para a Rede IP é modificada para 7.
# O PC não pode acessar a rede IP.
Gerenciamento da tabela de endereços MAC
Visão geral
Uma entrada de endereço MAC consiste no endereço MAC de um terminal, a porta do dispositivo que está conectada ao terminal e o ID da VLAN à qual a porta pertence. Depois que um dispositivo recebe um pacote de dados, ele combina o endereço MAC de destino do pacote com as entradas da tabela de endereços MAC que são salvas no dispositivo para localizar uma porta de encaminhamento de pacote com eficiência.
Os endereços MAC são categorizados em dois tipos: endereços MAC dinâmicos e endereços MAC estáticos. Os endereços MAC estáticos são categorizados em endereços MAC de encaminhamento estáticos e endereços MAC de filtragem estática.
O aprendizado de endereço MAC dinâmico é o modo básico de aprendizado de endereço MAC dos dispositivos. Cada entrada de endereço MAC dinâmico tem tempo de envelhecimento. Se nenhum pacote cujo endereço MAC de origem corresponda a uma entrada de endereço MAC for recebido pela VLAN e porta correspondentes, o dispositivo excluirá a entrada de endereço MAC.
O processo dinâmico de aprendizado/encaminhamento do endereço MAC é o seguinte:
- Quando um dispositivo recebe um pacote, ele procura na tabela de endereços MAC da VLAN correspondente a entrada de endereço MAC que corresponde ao endereço MAC de origem do pacote. Se nenhuma entrada correspondente estiver disponível, o endereço MAC de origem do pacote é gravado na tabela de endereços MAC e o temporizador de tempo de envelhecimento da nova entrada de endereço MAC é iniciado. Se uma entrada de endereço MAC correspondente for encontrada, o tempo de duração da entrada de endereço MAC será atualizado.
- Na VLAN correspondente, o dispositivo procura na tabela de endereços MAC uma entrada de endereço MAC que corresponda ao endereço MAC de destino do pacote. Se nenhuma entrada correspondente estiver disponível, o pacote será inundado para as outras portas com o mesmo ID de VLAN. Se uma entrada de endereço MAC correspondente estiver disponível, o pacote será encaminhado pela porta especificada.
Os endereços MAC de filtragem estática são usados para isolar dispositivos agressivos, impedindo que os dispositivos se comuniquem com dispositivos externos.
O processo de configuração/encaminhamento de endereços MAC de filtragem estática é o seguinte:
- Os endereços MAC de filtragem estática só podem ser configurados pelos usuários.
- Se o endereço MAC de origem ou o endereço MAC de destino de um pacote corresponder a uma entrada de endereço MAC de filtragem estática na VLAN correspondente, o pacote será descartado.
Os endereços MAC de encaminhamento estático são usados para controlar o princípio de roteamento de pacotes e evitar a migração frequente de endereços MAC de entradas de endereços MAC na tabela. A migração de endereço MAC significa que: Um dispositivo aprende um endereço MAC da porta A, então o dispositivo recebe pacotes cujo endereço MAC de origem é o mesmo que o endereço MAC da porta B, e a porta B e a porta A pertencem à mesma VLAN. Neste momento, a porta de encaminhamento salva na entrada de endereço MAC é atualizada da porta A para a porta B.
O processo de configuração/encaminhamento de endereços MAC de encaminhamento estáticos é o seguinte:
- Os endereços MAC de encaminhamento estático são configurados pelos usuários.
- Se o endereço MAC de destino de um pacote corresponder a uma entrada de endereço MAC estático na VLAN correspondente, o pacote será encaminhado pela porta especificada.
Uma porta pode aprender o mesmo endereço MAC de diferentes VLANs, mas um endereço MAC só pode ser aprendido por uma porta em uma VLAN.
Configuração da Função de Gerenciamento de Endereço MAC
Tabela 8-1 Lista de Funções de Gerenciamento de Endereço MAC
| Tarefas de configuração | |
| Configure as propriedades de gerenciamento de endereços MAC. |
Configure o tempo de envelhecimento do endereço MAC.
Configure o recurso de aprendizado de endereço MAC. |
| Configure limitações no aprendizado de endereços MAC. |
Configure limitações no aprendizado de endereço MAC dinâmico baseado em porta.
Configure limitações no aprendizado de endereço MAC dinâmico baseado em VLAN. Configure limitações no aprendizado de endereço MAC dinâmico baseado em sistema. |
| Configure endereços MAC estáticos. |
Configure endereços MAC de filtragem estática.
Configure endereços MAC de encaminhamento estáticos que estão vinculados a uma porta. Configure endereços MAC de encaminhamento estáticos que estão vinculados a um link aggregation. Configurar o endereço MAC de encaminhamento estático de várias interfaces de saída |
Configurar propriedades de gerenciamento de endereços MAC
As propriedades de gerenciamento de endereço MAC incluem: tempo de envelhecimento do endereço MAC e a capacidade de aprendizado de endereço MAC das portas.
Cada entrada de endereço MAC dinâmico tem tempo de envelhecimento. Se nenhum pacote cujo endereço MAC de origem corresponda a uma entrada de endereço MAC for recebido pela VLAN especificada, o dispositivo excluirá a entrada de endereço MAC. Se a VLAN especificada receber um pacote cujo endereço MAC de origem corresponda a uma entrada de endereço MAC, o dispositivo redefine o tempo de duração da entrada de endereço MAC.
Os endereços MAC estáticos só podem ser configurados e excluídos pelos usuários, portanto, os endereços MAC estáticos não podem envelhecer.
Se os dispositivos na rede tiverem portas ociosas e as portas não permitirem uso livre, o recurso de aprendizado de endereço MAC poderá ser desabilitado na porta. Então, os pacotes recebidos pela porta serão todos descartados. Dessa forma, essas portas não podem acessar a rede e, portanto, a segurança da rede é aprimorada.
Condição de configuração
Nenhum
Configurar o tempo de envelhecimento do endereço MAC
O tempo de envelhecimento do endereço MAC dinâmico definido em um dispositivo entra em vigor globalmente. O intervalo de valores do tempo de envelhecimento do endereço MAC é:
- 0: os endereços MAC não envelhecem, ou seja, os endereços MAC dinâmicos aprendidos não envelhecem.
- 60-1000000: Tempo de envelhecimento de endereços MAC dinâmicos. Unidade: segundo. Padrão: 300.
Se o tempo de envelhecimento estiver configurado muito longo, a tabela de endereços MAC no dispositivo pode conter um grande número de entradas de endereços MAC que não estão em uso há muito tempo. Dessa forma, o grande número de entradas inválidas pode usar recursos de endereço MAC e novas entradas de endereço MAC válidas não podem ser adicionadas ao dispositivo. Se o tempo de envelhecimento estiver configurado muito curto, o dispositivo pode excluir frequentemente entradas de endereço MAC válidas, afetando o desempenho de encaminhamento do dispositivo. Portanto, você precisa configurar um valor razoável para o tempo de envelhecimento de acordo com o ambiente real.
Tabela 8-2 Configurando o tempo de envelhecimento do endereço MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o tempo de envelhecimento do endereço MAC. | mac-address aging-time aging-time-value | Obrigatório. Por padrão, o tempo de envelhecimento do endereço MAC é definido como 300 segundos. |
Configurar a função de inibição de migração MAC
Por padrão, a função de inibição de migração de endereço MAC está desabilitada na porta. Neste momento, a porta normalmente aprende a entrada da tabela de endereços MAC e encaminha o pacote correspondente; Se a função de inibição de migração de endereço MAC estiver habilitada na porta, o MAC aprendido pela porta será detectado para migração de endereço. Se for detectado que o endereço MAC da porta migrou além das condições normais, você pode fazer uma política para o MAC migrado. O controle de política inclui aprendizado de limite de velocidade para o MAC migrado e errdisable down para a porta.
Tabela 8 -3 Configurar a função de inibição de migração de endereço MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Habilite o recurso de aprendizado de endereço MAC em uma porta ou link aggregation. | mac-address learning | Obrigatório. Por padrão, o recurso de aprendizado de endereço MAC está habilitado em uma porta. |
ErrDisable Down da inibição de migração de endereço está desabilitada. Para habilitá-lo, você precisa habilitar ErrDisable da migração de endereço.
Configurar o recurso de aprendizado de endereço MAC
O recurso de aprendizado de endereço MAC pode ser habilitado e desabilitado somente para aprendizado de endereço MAC dinâmico. Por padrão, o recurso de aprendizado de endereço MAC está habilitado em uma porta. Em seguida, a porta aprende as entradas de endereço MAC e encaminha os pacotes correspondentes. Se o recurso de aprendizado de endereço MAC estiver habilitado em uma porta, a porta não aprenderá endereços MAC dinâmicos e os pacotes recebidos serão descartados.
Tabela 8-4 Configurando o recurso de aprendizado de endereço MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Habilite a função de aprendizado do endereço MAC do link aggregation ou porta | mac-address learning action forward | Obrigatório. Por padrão, habilite a função de aprendizado de endereço MAC na porta. |
Configurar a Função de Aprendizagem de Endereço MAC
Ativar/desativar a função de aprendizado de endereço MAC é válido para aprender o endereço MAC dinâmico e encaminhar o pacote. Por padrão, a função de aprendizado de endereço MAC está habilitada na porta, e a porta pode aprender a entrada do endereço MAC e encaminhar o pacote. Se a função de aprendizado de endereço MAC estiver desabilitada na porta, a porta não aprenderá mais o endereço MAC dinâmico, mas ainda poderá encaminhar o pacote.
Tabela 8-5 Configurando a função de aprendizado de endereço MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure limitações no aprendizado de endereço MAC dinâmico baseado em porta. | mac-address max-mac-count max-mac-count-value | Obrigatório. Por padrão, não há limitações no aprendizado de endereços MAC dinâmicos em uma porta. O intervalo do número máximo de endereços MAC dinâmicos aprendidos é de 1 ao máximo de entradas de endereço que o chip de hardware pode aprender. |
Configurar limitações no aprendizado de endereço MAC
As limitações no aprendizado de endereço MAC são categorizadas em dois tipos: limitações no aprendizado de endereço MAC dinâmico baseado em porta e limitações no aprendizado de endereço MAC dinâmico baseado em VLAN
Se um grande número de entradas de endereços MAC dinâmicos tiver sido aprendido pelo dispositivo, levará muito tempo para o dispositivo pesquisar a tabela de endereços MAC antes de encaminhar os pacotes, e isso pode causar degradação do desempenho do dispositivo. Portanto, você pode configurar limitações no aprendizado de endereço MAC dinâmico para melhorar o desempenho do dispositivo. Se você configurar limitações no aprendizado de endereço MAC dinâmico em uma porta ou VLAN, o número de terminais de acesso poderá ser controlado.
Condição de configuração
Nenhum
Configurar limitações no aprendizado de endereço MAC dinâmico baseado em porta
Se o número de entradas de endereço MAC que foram aprendidas por uma porta atingiu o valor limite, a porta descarta os pacotes cujos endereços MAC de origem não estão na tabela de encaminhamento de endereços MAC.
Tabela 8-6 Configurando limitações no aprendizado de endereço MAC dinâmico baseado em porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure limitações no aprendizado de endereço MAC dinâmico baseado em VLAN. | mac-address vlan vlan-id max-mac-count max-mac-count-value | Obrigatório. Por padrão, não há limitações no aprendizado de endereços MAC dinâmicos em uma VLAN. O intervalo do número máximo de endereços MAC dinâmicos aprendidos é de 1 ao máximo de entradas de endereço que o chip de hardware pode aprender. |
Ao configurar limitações no aprendizado de endereço MAC dinâmico baseado em porta, se o valor de limite configurado for menor que o número de entradas de endereço MAC dinâmico existentes na porta, o dispositivo solicitará a limpeza manual de algumas entradas de endereço MAC dinâmico existentes. Depois que os endereços MAC são apagados, a configuração entra em vigor imediatamente.
Configurar limitações no aprendizado de endereço MAC dinâmico baseado em VLAN
Se o número de entradas de endereço MAC que foram aprendidas por uma VLAN especificada atingiu o valor limite, a VLAN descarta os pacotes cujos endereços MAC de origem não estão na tabela de encaminhamento de endereços MAC.
Tabela 8 -7 Configurando Limitações no Aprendizado de Endereço MAC Dinâmico Baseado em VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure limitações no aprendizado de endereço MAC dinâmico baseado em sistema. | mac-address system max-mac-count max-mac-count-value | Obrigatório. Por padrão, não há limitações no aprendizado de endereços MAC. O intervalo do número máximo de endereços MAC dinâmicos aprendidos é de 1 ao máximo de entradas de endereço que o chip de hardware pode aprender. |
Ao configurar limitações no aprendizado de endereço MAC dinâmico baseado em VLAN, se o valor de limite configurado for menor que o número de entradas de endereço MAC dinâmico existentes na VLAN atual, o dispositivo solicitará a limpeza manual de algumas entradas de endereço MAC dinâmico existentes. Depois que os endereços MAC são apagados, a configuração entra em vigor imediatamente.
Configurar endereços MAC estáticos
Os endereços MAC estáticos são categorizados em dois tipos: endereços MAC de encaminhamento estáticos e endereços MAC de filtragem estática.
Os endereços MAC configurados devem ser endereços MAC unicast legais em vez de endereços multicast de difusão.
Um endereço MAC só pode ser configurado como um endereço MAC de encaminhamento estático ou um endereço MAC de filtragem estática em uma VLAN.
Condição de configuração
Nenhum
Configurar endereços MAC de filtragem estática
Depois que as entradas de endereço MAC de filtragem estática forem configuradas, se os endereços MAC de origem ou destino dos pacotes recebidos pela VLAN correspondente corresponderem às entradas de endereço MAC de filtragem estática, os pacotes serão descartados. Essa função impede que dispositivos sem confiança acessem a rede e evita fraudes e atividades de ataque de usuários ilegais.
Tabela 8-8 Configurando endereços MAC de filtragem estática
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure endereços MAC de filtragem estática. | mac-address static mac-address-value vlan vlan-id drop | Obrigatório. Por padrão, um dispositivo não está configurado com endereços MAC de filtragem estática. |
Configurar endereços MAC de encaminhamento estático vinculados a uma porta
Com as entradas de endereço MAC de encaminhamento estático configuradas, após a VLAN correspondente receber os pacotes, a porta corresponde aos endereços MAC de destino dos pacotes com as entradas de endereço MAC de encaminhamento estático configuradas no dispositivo. Se eles corresponderem com sucesso, o dispositivo encaminhará os pacotes pela porta especificada. Essa função ajuda a controlar o princípio de roteamento de pacotes de forma mais flexível e evita a migração frequente de entradas de endereço MAC na tabela.
Tabela 8-9 Configurando endereços MAC de encaminhamento estático vinculados a uma porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure endereços MAC de encaminhamento estáticos que estão vinculados a uma porta. | mac-address static mac-address-value vlan vlan-id interface interface-name | Obrigatório. Por padrão, um dispositivo não está configurado com endereços MAC de encaminhamento estáticos. |
Configurar endereços MAC de encaminhamento estático vinculados a um link aggregation
Com as entradas de endereço MAC de encaminhamento estático configuradas, depois que o link aggregation recebe os pacotes, a porta corresponde aos endereços MAC de destino dos pacotes com as entradas de endereço MAC de encaminhamento estático configuradas no dispositivo. Se eles corresponderem com sucesso, o dispositivo encaminhará os pacotes por meio do grupo de agregação especificado. Essa função ajuda a controlar o princípio de roteamento de pacotes de forma mais flexível e evita a migração frequente de entradas de endereço MAC na tabela.
Tabela 8-10 Configurando endereços MAC de encaminhamento estático vinculados a um link aggregation
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure endereços MAC de encaminhamento estáticos que estão vinculados a um link aggregation. | mac-address static mac-address-value vlan vlan-id interface link-aggregation link-aggregation-id | Obrigatório. Por padrão, um dispositivo não está configurado com endereços MAC de encaminhamento estáticos. |
Antes de configurar o comando, certifique-se de que o link aggregation especificado foi criado.
Configurar endereço MAC de BPDU estático
Depois que a entrada da tabela de endereços MAC BPDU estático for configurada, quando o valor do endereço MAC de destino do pacote recebido corresponder à entrada da tabela de endereços MAC BPDU, o pacote será descartado.
Tabela 8 -11 Configurar o endereço MAC BPDU estático
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar o endereço MAC de filtragem estática | mac-address bpdu mac-address-value | Mandatório. Por padrão, não configure o endereço MAC BPDU estático no dispositivo. |
Os seguintes vários tipos de BPDU mac podem ser configurados: (001) 010f-e200-0001 (002) 0180-c200-0000 (003) 0180-c200-0001 (004) 0180-c200-0002 (005) 0180-c200-0003 (006) 0180-c200-0004 (007) 0180-c200-0005 (008) 0180-c200-0006 (009) 0180-c200-0007 (010) 0180-c200-0008 (011) 0180-c200-0009 (012) 0180-c200-000a (013) 0180-c200-000b (014) 0180-c200-000c (015) 0180-c200-000d (016) 0180-c200-000e (017) 0180-c200-000f (018) 0180-c200-0010 (019) 0180-c200-0020/ffff-ffff-fff0 (020) 0180-c200-008a (021) 0180-c200-8585
Monitoramento e manutenção de gerenciamento de endereço MAC
Tabela 8-11 Monitoramento e manutenção do gerenciamento de endereço MAC
| Comando | Descrição |
| clear mac-address dynamic { mac-address-value | all | interface interface-list | interface link-aggregation link-aggregation-id | vlan vlan-id [ mac-address-value | interface interface-list | interface link-aggregation link-aggregation-id ] } | Limpa as entradas de endereço MAC que são aprendidas dinamicamente. |
| show mac-address interface interface-list { all | dynamic | static [ config ] } | Exibe as informações de entrada de endereço MAC na porta |
| show mac-address interface link-aggregation link-aggregation-id { all | dynamic | static [ config ] } | Exibe entradas de endereço MAC em um link aggregation. |
| show mac-address vlan vlan-id { all | dynamic | static [ config ] } | Exibe entradas de endereço MAC em uma VLAN. |
| show mac-address drop [ mac-address-value | config ] | Exibe entradas de endereço MAC de filtragem estática no sistema. |
| show mac-address dynamic [mac-address-value ] | Exibe entradas de endereços MAC dinâmicos no sistema. |
| show mac-address static [ mac-address-value | config ] | Exibe entradas de endereço MAC de encaminhamento estático no sistema. |
| show mac-address system-mac | Exibe o endereço MAC do sistema. |
| show mac-address { mac-address-value | all } | Exibe as informações sobre as entradas de endereço MAC do sistema ou uma entrada de endereço MAC especificada. |
| show mac-address aging-time | Exibe o tempo de envelhecimento das entradas de endereços MAC dinâmicos. |
| show mac-address max-mac-count { interface interface-name | interface link-aggregation link-aggregation-id | system | vlan { vlan-id | all } } | Exibe limitações no aprendizado de endereço MAC dinâmico no sistema. |
| show mac-address count [ interface interface-name | interface link-aggregation link-aggregation-id | vlan vlan-id ] | Exibe estatísticas de entrada de endereço MAC no sistema. |
| show mac-address bpdu | D exibe o endereço MAC BPDU configurado no sistema |
| show mac-address software-learning | Exibe se o método de aprendizado de endereço MAC atual do sistema é aprendizado de software ou aprendizado de hardware |
| show mac-address vxlan [vxlan-id |count|dynamic|interface interface-list |ip ip-address | static ] | Exibe as informações de entrada da tabela de endereços MAC da VXLAN especificada |
Configuração da Função de Aprendizagem de Software
Configuração da Função de Aprendizagem de Software
Depois que a função de aprendizado do software estiver habilitada , aprenda a entrada do endereço MAC através do software.
Condição de configuração
Não
Ativar função de aprendizado de software
Tabela 8 -12 Ativar a função de aprendizado de software
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Ative a função de aprendizado de software | mac-address software-learning enable | Por padrão, está desabilitado. |
Desativar função de aprendizado de software
Tabela 8 -13 Desative a função de aprendizado de software
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Desative a função de aprendizado de software | no mac-address software-learning enable | Depois de desabilitar o aprendizado do software, saiba que a entrada do endereço MAC é aprendida através do chip. |
No modo autônomo, é o aprendizado de hardware por padrão . Se você configurar esse comando, poderá alternar para o aprendizado de software, mas precisará reiniciar o dispositivo para entrar em vigor. No modo de pilha , é o aprendizado de software por padrão e não é recomendável alternar para o aprendizado de hardware. A função MLAG oferece suporte apenas ao aprendizado de software, não ao aprendizado de hardware.
Monitoramento e manutenção da função de aprendizado de software
Tabela 8 -14 Monitoramento e manutenção de aprendizado de software
| Comando | Descrição |
| show mac-address software-learning | Veja se o aprendizado de software está ativado ou desativado |
Configuração da função de log de movimentação de endereço MAC
Configurar a função de log de movimentação de endereço MAC
A função de registro de movimentação de endereço MAC pode ser habilitada e desabilitada manualmente. Depois de habilitar a função de log de movimentação de endereço MAC, registre um log de movimentação de endereço quando o endereço da entrada de endereço MAC for movido.
Condição de configuração
Nenhum
Ativar a função de log de movimentação de endereço MAC
Tabela 8-15 Habilite a função de log de movimentação do endereço MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | config terminal | - |
| Habilite a função de log de movimentação de endereço | mac-address move log | Por padrão, está habilitada. |
Desativar a função de log de movimentação de endereço MAC
Tabela 8 -16 Desabilite a função de log de movimentação de endereço MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | config terminal | - |
| Desative a função de log de movimentação de endereço MAC | no mac-address move log | Após desabilitar a função de log de movimentação de endereço, não registre as informações de log quando o endereço da entrada de endereço MAC for movido. |
Monitoramento e manutenção da função de log de movimentação de endereço MAC
Tabela 8-17 Endereço MAC movendo monitoramento e manutenção
| Comando | Descrição |
| clear mac-address move log{mac-address} | Limpa os logs de movimentação do endereço MAC |
| show mac-address move config | Exibe as informações de configuração da função de log de movimentação do endereço MAC |
| show mac-address move log {mac-address-value | count count | hardlearn | start-time [time] end-time [time] } | Exibe o log de movimentação do endereço MAC |
Spanning Tree
Visão geral
O IEEE 802.1D define o padrão Spanning Tree Protocol (STP) para eliminar loops de rede, evitando que os quadros de dados circulem ou se multipliquem em loops, o que pode resultar em congestionamento de rede e afetar a comunicação normal na rede. Por meio do algoritmo spanning tree, o STP pode determinar onde podem existir loops em uma rede, bloquear portas em links redundantes e aparar a rede em uma estrutura de árvore na qual não existam loops para evitar que os dispositivos recebam quadros de dados duplicados. Quando o caminho ativo está com defeito, o STP recupera a conectividade dos links redundantes bloqueados para garantir serviços normais. Com base no STP, são desenvolvidos o Rapid Spanning Tree Protocol (RSTP) e o Multiple Spanning Tree Protocol (MSTP). Os princípios básicos dos três protocolos são os mesmos, enquanto RSTP e MSTP são versões aprimoradas do STP. implementa os protocolos de spanning tree VIST e Rapid-VIST compatíveis com o spanning tree da Cisco. O Rapid-VIST melhora o desempenho da convergência e herda a função de eliminação do anel VIST.
Em STP, são definidos os seguintes conceitos básicos:
- Ponte raiz: Raiz da estrutura de árvore finalmente formada de uma rede. O dispositivo com a prioridade mais alta atua como a Root Bridge.
- Porta Raiz (RP): A porta mais próxima da Root Bridge. A porta não está na Root Bridge e se comunica com a bridge raiz.
- Ponte designada: Se o dispositivo enviar informações de configuração da Unidade de Dados de Protocolo de Ponte (BPDU) para um dispositivo diretamente conectado ou uma LAN diretamente conectada, o dispositivo será considerado a bridge designada do dispositivo diretamente conectado ou da LAN diretamente conectada.
- Porta designada: A bridge designada encaminha informações de configuração de BPDU através da porta designada.
- Custo do caminho: indica a qualidade do link e está relacionado à taxa do link. Normalmente, uma taxa de link mais alta significa um custo de caminho menor e o link é melhor.
Os dispositivos que executam o STP implementam o cálculo da spanning tree trocando pacotes BPDU e, finalmente, formam uma estrutura de topologia estável. Os pacotes BPDU são categorizados nos dois tipos a seguir:
- BPDUs de configuração: Eles também são chamados de mensagens de configuração de BPDU que são usadas para calcular e manter a topologia de spanning tree.
- BPDUs de Notificação de Mudança de Topologia (TCN): Quando a estrutura de topologia da rede muda, eles são usados para informar outros dispositivos sobre a mudança.
Os pacotes BPDU contêm informações que são necessárias no cálculo da spanning tree. As principais informações incluem:
- ID da Root Bridge: consiste na prioridade da Root Bridge e no endereço MAC.
- Custo do caminho raiz: É o custo mínimo do caminho para a Root Bridge.
- ID da bridge designada: Consiste na prioridade da bridge designada e no endereço MAC.
- ID da porta designada: Consiste na prioridade da porta designada e no número da porta.
- Idade da Mensagem: Ciclo de vida das mensagens de configuração de BPDU enquanto são transmitidas em uma rede.
- Hello Time: Ciclo de transmissão de mensagens de configuração de BPDU.
- Atraso de encaminhamento: atraso na migração do status da porta.
- Max Age: Ciclo de vida máximo das mensagens de configuração em um dispositivo.
O processo eleitoral de STP é o seguinte:
- Estado inicial.
O dispositivo local assume-se como a Root Bridge para gerar mensagens de configuração BPDU e enviar as mensagens. Nos pacotes BPDU, a ID da Root Bridge e a ID da bridge designada são a ID da bridge local, e o custo do caminho raiz é 0, e a porta especificada é a porta de transmissão.
Cada porta do dispositivo gera uma mensagem de configuração de porta que é usada para cálculo de spanning tree. Na mensagem de configuração da porta, a ID da Root Bridge e a ID da bridge designada são a ID da bridge local, o custo do caminho raiz é 0 e a porta especificada é a porta local.
- Atualizar mensagens de configuração de porta.
Depois que o dispositivo local recebe uma mensagem de configuração de BPDU de outro dispositivo, ele compara a mensagem com a mensagem de configuração da porta receptora. Se a mensagem de configuração recebida for melhor, o dispositivo usa a mensagem de configuração BPDU recebida para substituir a mensagem de configuração da porta. Se a mensagem de configuração da porta for melhor, o dispositivo não realiza nenhuma operação.
O princípio de comparação é o seguinte: Os IDs de Root Bridge, custo do caminho raiz, IDs de bridge designados, IDs de porta designada e IDs de porta de recebimento devem ser comparados em ordem. O menor valor é melhor. Se os valores do item anterior forem iguais, compare o próximo item.
- Selecione a Root Bridge.
O dispositivo que envia a mensagem de configuração ideal em toda a rede é selecionado como Root Bridge.
- Selecione as funções da porta e o status da porta.
Todas as portas da Root Bridge são portas designadas e as portas estão no status Forwarding. A bridge designada seleciona a mensagem de configuração de porta ideal de todas as portas. A porta de recebimento da mensagem é selecionada como a porta raiz e a porta raiz está no status de encaminhamento. As outras portas calculam as mensagens de configuração da porta designada de acordo com a mensagem de configuração da porta raiz.
O método de cálculo é o seguinte: O ID da Root Bridge é o ID da rota da mensagem de configuração da porta raiz, o custo do caminho raiz é a soma do custo do caminho raiz da mensagem de configuração da porta raiz e o custo do caminho da porta raiz, a bridge designada ID é o ID da bridge do dispositivo local e a porta designada é a porta local.
Com base na mensagem de configuração da porta e na mensagem de configuração da porta designada calculada, determine as regras da porta: Se a mensagem de configuração da porta designada for melhor, a porta local será selecionada como a porta designada e a porta estará no status Encaminhamento. Em seguida, a mensagem de configuração de porta é substituída pela mensagem de configuração de porta designada e a porta designada envia mensagens de configuração de porta periodicamente no intervalo de Hello Time. Se a mensagem de configuração da porta for melhor, a porta está bloqueada. A porta está então no status Descartando e a mensagem de configuração da porta não é modificada.
Depois que a Root Bridge, a porta raiz e a porta designada são selecionadas, a topologia de rede da estrutura em árvore é configurada com sucesso. Somente a porta raiz e a porta designada podem encaminhar dados. As outras portas estão no status Descartando. Eles só podem receber mensagens de configuração, mas não podem enviar mensagens de configuração ou encaminhar dados.
Se a porta raiz de uma bridge não raiz não receber mensagens de configuração periodicamente, o caminho ativo será considerado defeituoso. O dispositivo gera novamente uma mensagem de configuração BPDU e TCN BPDU com ele mesmo como a Root Bridge e envia as mensagens. As mensagens causam o recálculo do spanning tree e então um novo caminho ativo é obtido.
Antes de receber novas mensagens de configuração, os outros dispositivos não encontram a mudança de topologia da rede, portanto, suas portas raiz e porta designada ainda encaminham dados pelo caminho original. A porta raiz recém-selecionada e a porta designada migram para o status de encaminhamento após dois períodos de atraso de encaminhamento para garantir que a nova mensagem de configuração foi transmitida para toda a rede e evitar a ocorrência de loops temporários que podem ser causados se as portas raiz antigas e novas e designar portas de encaminhamento de dados.
O RSTP definido no IEEE 802.1w é desenvolvido com base no STP e é a versão melhorada do STP. O RSTP realiza uma migração rápida do status da porta e, portanto, reduz o tempo necessário para uma rede configurar uma topologia estável. O RSTP é melhorado nos seguintes aspectos:
- Ele define uma porta de backup, ou seja, uma porta alternativa, para a porta raiz. Se a porta raiz estiver bloqueada, a porta alternativa pode alternar rapidamente para se tornar uma nova porta raiz.
- Ele define uma porta de backup, ou seja, uma porta de backup, para a porta designada. Se a porta designada estiver bloqueada, a porta de backup pode alternar rapidamente para se tornar uma nova porta designada.
- Em um link ponto a ponto de dois dispositivos conectados diretamente, a porta designada pode entrar no status de encaminhamento sem atraso somente após um handshake com a bridge a jusante.
- Algumas portas não são conectadas a outras bridges ou links compartilhados, ao invés disso, elas são conectadas diretamente aos terminais do usuário. Essas portas são definidas como portas de borda. As alterações de status das portas de borda não afetam a conectividade da rede, portanto, as portas podem entrar no status de encaminhamento sem demora.
No entanto, tanto o RSTP quanto o STP formam uma única árvore geradora, que possui as seguintes deficiências:
- Apenas um spanning tree está disponível em toda a rede. Se o tamanho da rede for grande, a convergência da rede levará muito tempo.
- Os pacotes de todas as VLANs são encaminhados por meio de um spanning tree, portanto, nenhum balanceamento de carga é alcançado.
O MSTP definido no IEEE 802.1s é uma melhoria do STP e do RSTP e é compatível com versões anteriores do STP e do RSTP. O MSTP introduz o conceito de região e instância. O MSTP divide uma rede em várias regiões. Cada região contém várias instâncias, uma instância pode configurar o mapeamento com uma ou mais VLANs e uma instância corresponde a uma spanning tree. Uma porta pode ter função e status de porta diferentes em diferentes instâncias. Desta forma, os pacotes de diferentes VLANs são encaminhados em seus próprios caminhos.
No MSTP, é adicionada a definição dos seguintes conceitos:
- Região MST: Consiste em vários dispositivos na rede de comutação e na rede entre os dispositivos. Os dispositivos em uma região MST devem atender aos seguintes requisitos: A função spanning tree foi habilitada nos dispositivos. Eles têm a mesma região MST, nível MSTP e tabela de mapeamento de VLAN. Eles estão diretamente conectados fisicamente.
- Internal Spanning Tree (IST): É o spanning tree da instância 0 em cada região.
- Common Spanning Tree (CST): Se cada região MST for considerada como um dispositivo, as árvores geradoras que conectam as regiões MST são CSTs.
- Common and Internal Spanning Tree (CIST): Consiste nos ISTs das regiões do MST e nos CSTs entre as regiões do MST. É um único spanning tree que conecta todos os dispositivos na rede.
- Multiple Spanning Tree Instance (MSTI): Spanning tree em regiões MST. Cada instância tem um MSTI independente.
- Raiz comum: Raiz CIST.
- Raiz da região: Raiz de cada IST e MSTI nas regiões do MST. Nos domínios MST, cada instância tem uma spanning tree independente, portanto, as raízes da região podem ser diferentes. A Root Bridge da instância 0 é a raiz da região da região.
- Portas de borda de região: estão localizadas na borda de uma região MST e são usadas para conectar portas de diferentes regiões MST.
- Custo do caminho externo: É o custo mínimo do caminho de uma porta até a raiz comum.
- Custo do caminho interno: É o custo mínimo do caminho de uma porta até a raiz da região.
- Porta mestre: É a porta de borda da região com o custo mínimo de caminho para a raiz comum em uma região MST. A função de uma porta mestre em um MSTI é a mesma que sua função em um CIST.
A regra de eleição do MSTP é semelhante à do STP , ou seja, elege a bridge com maior prioridade na rede como Root Bridge do CIST comparando as mensagens de configuração. Cada região MST calcula seu IST e as regiões MST calculam CSTs e todas as construções CIST em toda a rede. Com base no mapeamento entre VLANs e instâncias de spanning tree, cada região MST calcula um MSTI de spanning tree independente para cada instância.
O protocolo de spanning tree privado da Cisco define os protocolos PVST e RPVST, ambos introduzindo o conceito de instância. Uma VLAN corresponde a uma instância. Em diferentes instâncias, as portas podem ter diferentes funções de porta e estados de porta, o que realiza o encaminhamento de pacotes de diferentes VLANs de acordo com seus caminhos.
Nova definição de MSTP no ambiente MLAG e precauções:
- MLAG-MSTI: A instância MSTI correspondente de MLAG-VLAN
- prioridade de raiz: a prioridade de Root Bridge especificada de MLAG
- prioridade de bridge: A prioridade de bridge especificada de MLAG
- stp-pseudo: O modo de pseudo-informação
As restrições de configuração do modo de pseudo-informação:
- A prioridade da raiz (o valor padrão é 0) do CIST e todos os MLAG-MSTI nas pseudoinformações devem ser melhores que a prioridade de todas as bridges (incluindo os nós MLAG) em toda a rede (o valor padrão é 32768);
- Além de garantir que o nó de emparelhamento seja a bridge raiz (a prioridade da raiz é a melhor em toda a rede), também é necessário iniciar a função de proteção de raiz nas portas de acesso (todas as portas não peer link) dos nós MLAG ( root guard não tem suporte no modo vist) para evitar erros de cálculo de spanning tree causados pelo recebimento de BPDU com prioridade mais alta.
- A função Bridge-Assurance precisa ser configurada no link de peer.
- Para a instância CIST e instância MLAG-MSTI, a prioridade raiz dos dois nós deve ser configurada para ser a mesma, de modo que os dois nós apresentem a mesma Root Bridge para DHD e SD; para que os dois nós apresentem duas bridges de rede completamente independentes para que o SD participe do cálculo da spanning tree, a prioridade de raiz dos dois nós deve ser configurada de forma diferente
Configuração da função de spanning tree
Tabela 9-1 Lista de funções da spanning tree
| Tarefas de configuração | |
| Configure as funções básicas da spanning tree. |
Habilite a função spanning tree.
Configurar domínio MST . Configurar a função de saída do log de spanning tree |
| Configure as propriedades da bridge. |
Configure a prioridade de uma bridge.
Configure o horário de saudação. Configure o Atraso de Encaminhamento. Configurar idade máxima. Configure o número máximo de saltos em um domínio MST. |
| Configure as propriedades da porta de spanning tree. |
Configure a prioridade de uma porta.
Configure o padrão de custo de caminho padrão para uma porta. Configure o custo do caminho de uma porta. Configurar a verificação do comprimento do pacote BPDU Configure o comprimento máximo do pacote BPDU Configure a taxa máxima de transmissão do pacote BPDU Configure a verificação do mac de origem do pacote BPDU Configure o fator de tempo limite do pacote BPDU Configure uma porta de borda. Configure a detecção automática da porta de borda Forçar a detecção automática da porta de borda Configure o tipo de link de porta. |
| Configure o modo de trabalho de um spanning tree. | Configure o modo de trabalho de um spanning tree. |
| Configure a função de proteção de spanning tree. |
Configure a função BPDU Guard.
Configure a função Filtro BPDU. Configure a função Flap Guard. Configure a função Loop Guard. Configure a função Root Guard. Configure a função TC Guard. Configure a função de proteção TC. |
Configurar funções básicas de uma spanning tree
Condição de configuração
Nenhum
Ativar a função Spanning Tree
Depois que a função spanning tree é habilitada, os dispositivos começam a executar o protocolo spanning tree. Os dispositivos trocam pacotes BPDU para formar uma topologia de rede em árvore estável e os loops de rede são eliminados.
Tabela 9-2 Habilitando a função Spanning Tree
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilitando a função spanning tree globalmente. | spanning-tree enable | Obrigatório. Por padrão, a função spanning tree está desabilitada globalmente. |
| Entre no modo de configuração da interface Ethernet L2 . | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Ativando a função spanning tree em uma porta. | spanning-tree enable | Opcional. Por padrão, a função spanning tree está habilitada em uma porta. |
Configurar regiões MST
Dividir uma rede inteira em várias regiões MST ajuda a reduzir o tempo de convergência da rede. Os pacotes VLAN são transmitidos através dos MSTIs correspondentes nas regiões MST e transmitidos através dos CSTs entre as regiões MST.
Tabela 9-3 Configurando Regiões MST
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da região MST. | spanning-tree mst configuration | - |
| Configure um nome de região MST. | region-name region-name | Obrigatório. Por padrão, o nome de uma região MST é o endereço MAC do dispositivo local. |
| Configure o nível de revisão MSTP. | revision-level revision-level | Obrigatório. Por padrão, o nível de revisão do MSTP é 0. |
| Configure uma tabela de mapeamento de VLAN. | instance instance-id vlan vlan-list | Obrigatório. Por padrão, todas as VLANs são mapeadas para a instância 0. |
| Ative a configuração do parâmetro da região MST. | active configuration pending | Obrigatório. Por padrão, os parâmetros da região MST não entram em vigor imediatamente após a modificação. |
Os parâmetros da região MST não entram em vigor imediatamente após serem modificados. Em vez disso, você precisa executar o comando active configuration pendente para ativar os parâmetros e acionar o recálculo da spanning tree. Para cancelar a configuração do parâmetro da região do MST, use o comando abort configuration pendente .
Configurar propriedades da bridge
Condição de configuração
Nenhum
Configurar a prioridade de uma bridge
A prioridade da bridge e o endereço MAC formam o ID da bridge. Um ID menor indica uma prioridade mais alta. A bridge com a prioridade mais alta é eleita como a Root Bridge. Um dispositivo pode ter prioridade de bridge diferente em diferentes instâncias de spanning tree.
Tabela 9-5 Configurando a prioridade de uma bridge
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a prioridade de uma bridge. | spanning-tree mst instance instance-id priority priority-value | Obrigatório. Por padrão, a prioridade da bridge em todas as instâncias de spanning tree é 32768. |
| No modo vist/rapid-vist, configure a prioridade da bridge | spanning-tree vlan vlan-id priority priority-value | Obrigatório. Por padrão, a prioridade da bridge do dispositivo em todas as instâncias de spanning tree é 32768. |
A etapa das prioridades da bridge é 4096, ou seja, os valores válidos incluem: 0, 4096, 8192, 12288, 16384, 20480, 24576, 28672, 32768, 36864, 40960, 45056, 49152, 53248, 57344, 61440.
Configurar horário de saudação
Depois que a topologia da rede se torna estável, a bridge raiz envia pacotes BPDU no intervalo de Hello Time para informar outras bridges sobre seu papel como Root Bridge para que as outras bridges possam reconhecer sua função. A bridge designada mantém a topologia de spanning tree existente de acordo com o pacote BPDU e encaminha o pacote BPDU para outros dispositivos. Normalmente, se a bridge designada não receber pacotes BPDU dentro de três vezes do tempo limite ( 3*Hello Time ), ela considera o link com defeito. Desta forma, a spanning tree recalcula a topologia da rede para obter um novo caminho ativo, garantindo a conectividade da rede.
Tabela 9-6 Configurando o Hello Time
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o horário de saudação. | spanning-tree mst hello-time seconds | Obrigatório. Por padrão, o Hello Time é de 2 segundos. |
| Em vist/rapid-vist, configure o Hello Time | spanning-tree vlan vlan-id hello-time seconds | Obrigatório. Por padrão, o Hello Time é 2s. |
Forward Delay , Hello Time e Max Age devem atender ao seguinte requisito; caso contrário, a falha frequente da rede pode ser a causa. 2 × (Forward_Delay – 1,0 segundos) ≥ Max_Age Max_Age ≥ 2 × (Hello_Time + 1,0 segundos)
Configurar atraso de encaminhamento
No STP, quando a porta raiz ou a porta designada migra do status Descartando para o status Encaminhando, a mudança de topologia não pode ser aprendida por toda a rede imediatamente. Para evitar loops temporários, a porta migra para o status Learning no primeiro Forward Delay e, em seguida, aguarda outro Forward Delay para migrar para o status Forwarding.
Tabela 9-7 Configurando o atraso de encaminhamento
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o Atraso de Encaminhamento. | spanning-tree mst forward-time seconds | Obrigatório. Por padrão, o Atraso de Encaminhamento é de 15 segundos. |
| No modo vist/rapid-vist, configure o Forward Delay | spanning-tree vlan vlan-id forward-time seconds | Obrigatório. Por padrão, o Atraso de Encaminhamento é de 15 segundos. |
Configurar idade máxima
Max Age refere-se ao ciclo de vida das mensagens de configuração de BPDU enquanto elas são transmitidas em uma rede. Quando uma mensagem de configuração é transmitida cruzando regiões, após passar por uma região do MST, uma é adicionada a Message Age na mensagem de configuração. Se o dispositivo receber uma mensagem de configuração e descobrir que o valor de Message Age na mensagem de configuração mais 1 é igual ao valor de Max Age, o dispositivo descarta a mensagem de configuração e a mensagem de configuração não é mais usada no cálculo da spanning tree.
Tabela 9-8 Configurando a idade máxima
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar idade máxima. | spanning-tree mst max-age seconds | Obrigatório. Por padrão, a idade máxima é de 20 segundos. |
| No modo vist/rapid-vist, configure Max Age | spanning-tree vlan vlan-id max-age seconds | Obrigatório. Por padrão, a idade máxima é de 20 segundos. |
Configurar o número máximo de saltos em uma região MST
Você pode limitar o tamanho de uma região MST configurando o número máximo de saltos na região MST. Um número maior de saltos em uma região MST significa uma região MST maior. Em uma região MST, a partir da raiz da região, uma vez que a mensagem de configuração é encaminhada por um dispositivo, o número de saltos é reduzido em um. Se o número de saltos de uma mensagem de configuração for 0, o dispositivo descarta a mensagem de configuração. Portanto, o dispositivo que está além do número máximo de saltos não pode participar do cálculo de spanning tree na região.
Tabela 9-9 Configurando o número máximo de saltos em uma região MST
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o número máximo de saltos em uma região MST. | spanning-tree mst max-hops max-hops-value | Obrigatório. Por padrão, o número máximo de saltos em uma região MST é 20. |
Configurar as propriedades da porta da Spanning Tree
Condição de configuração
Nenhum
Configurar a prioridade de uma porta
Um ID de porta consiste em prioridade de porta e índice de porta. O ID da porta afeta a eleição da função da porta. Um ID de porta menor indica uma prioridade mais alta. Uma porta pode ter prioridade de porta diferente em diferentes instâncias de spanning tree.
Tabela 9-10 Configurando a Prioridade de uma Porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure a prioridade de uma porta. | spanning-tree mst instance instance-id port-priority priority-value | Obrigatório. Por padrão, a prioridade da porta em todas as instâncias de spanning tree é 128. |
| No modo vist/rapid-vist, configure a prioridade de uma porta. | spanning-tree vlan vlan-id port-priority priority-value | Obrigatório. Por padrão, a prioridade da porta em todas as instâncias de spanning tree é 128. |
A etapa de prioridades de porta é 16, ou seja, os valores válidos incluem: 0, 16, 32 , 48 , 64 , 80 , 96, 112 , 128 , 144, 160 , 176 , 192 , 208, 224 e 240 .
Configurar o padrão de custo de caminho padrão para uma porta
Comparado com o custo do caminho calculado com base no padrão IEEE 802.1D-1998, o custo do caminho calculado com base no IEEE 802.1T-2001 é maior. Com o aumento da taxa de link, o valor do custo do caminho diminui rapidamente.
Tabela 9-11 Configurando o Padrão de Custo de Caminho Padrão para uma Porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o padrão de custo de caminho padrão para uma porta. | spanning-tree pathcost method { dot1D-1998 | dot1T-2001 } | Obrigatório. Por padrão, o padrão IEEE 802.1T-2001 é usado para calcular o custo de caminho padrão da porta. |
Configurar o custo do caminho de uma porta
O custo do caminho da porta afeta a escolha da função da porta. Um custo de caminho de porta menor significa um link melhor. Uma porta pode ter um custo de caminho de porta diferente em diferentes instâncias de spanning tree.
Tabela 9-12 Configurando o custo do caminho de uma porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure o custo do caminho de uma porta. | spanning-tree mst instance instance-id cost cost-value | Obrigatório. Por padrão, o custo do caminho é calculado automaticamente de acordo com a taxa de porta. |
| No modo vist/rapid-vist, configure o custo do caminho da porta | spanning-tree vlan vlan-id cost cost-value | Obrigatório. Por padrão, o custo do caminho é calculado automaticamente de acordo com a taxa de porta. |
Configurar verificação de comprimento do pacote BPDU
Configurar a verificação de comprimento do pacote BPDU pode permitir que a porta verifique o comprimento do pacote BPDU recebido, de modo a evitar o ataque do pacote BPDU com o comprimento inválido.
Tabela 9 -13 Configure a verificação de comprimento do pacote BPDU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a verificação de comprimento do pacote BPDU | spanning-tree bpdu length-check | Obrigatório. Por padrão, não habilite a verificação de comprimento do pacote BPDU. |
Configurar o comprimento máximo do pacote BPDU
Configure o comprimento máximo do pacote BPDU válido ao verificar o comprimento do pacote BPDU.
Tabela 9 -14 Configure o comprimento máximo do pacote BPDU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o comprimento máximo do pacote BPDU | spanning-tree bpdu max-length max-length | Obrigatório. Por padrão, o comprimento máximo é de 1500 bytes. |
Configurar Taxa Máxima de Transmissão de Pacotes BPDU
A taxa máxima de transmissão de pacotes BPDU limita o número de pacotes BPDU que podem ser transmitidos durante o Hello Time de um dispositivo. Isso evita que o dispositivo envie muitos pacotes BPDU, o que pode causar cálculos de spanning tree frequentes para outros dispositivos.
Tabela 9 - 15 Configurando a taxa máxima de transmissão de pacotes BPDU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a taxa máxima de transmissão de pacotes BPDU. | spanning-tree transmit hold-count hold-count-number | Por padrão, uma porta pode enviar no máximo 6 pacotes BPDU dentro do Hello Time. |
Configurar a verificação de MAC de origem do pacote BPDU
Configurar a verificação do mac de origem do pacote BPDU pode permitir que a porta verifique o MAC de origem do pacote BPDU recebido, para evitar o ataque do pacote BPDU do dispositivo inválido.
Tabela 9 -16 Configure a verificação do mac de origem do pacote BPDU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation | interface link-aggregation link-aggregation-id | |
| Configure a verificação do mac de origem do pacote BPDU | spanning-tree bpdu src-mac-match src-mac | Obrigatório. Por padrão, a porta não habilita a verificação MAC de origem do pacote BPDU. |
Configurar o fator de tempo limite de ackets BPDU P
Em uma topologia de rede estável, a porta designada enviará um pacote BPDU para o dispositivo vizinho a cada HELLO TIME. Normalmente, se o dispositivo não receber o pacote BPDU dos dispositivos superiores dentro de três vezes do tempo limite (3*HELLO TIME), considera-se que a topologia da rede muda s , o que iniciará uma reeleição de spanning tree.
No entanto, em uma topologia de rede estável, se o dispositivo superior não puder receber o pacote BPDU no caso de ocupado ou qualquer outro motivo, ele iniciará uma reeleição de spanning tree. Neste caso, você pode configurar o fator de tempo limite para evitar tal cálculo.
Tabela 9 - 17 Configurar o fator de tempo limite dos pacotes BPDU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o fator de tempo dos pacotes BPDU | spanning-tree timer-facor times-number | Por padrão, se o dispositivo não receber o pacote BPDU dos dispositivos superiores dentro de três vezes do timeout (3*HELLO TIME), considera-se que a topologia da rede muda , o que iniciará uma reeleição de spanning tree. Em ambiente de empilhamento, é recomendável configurar o fator de tempo limite como 6. |
| No modo vist/rapid-vist, configure o fator de tempo dos pacotes BPDU | spanning-tree vlan vlan-id timer-facor times-number | Por padrão, se o dispositivo não receber o pacote BPDU dos dispositivos superiores dentro de três vezes do timeout (3*HELLO TIME), considera-se que a topologia da rede muda, o que iniciará uma reeleição de spanning tree. Em ambiente de empilhamento, é recomendável configurar o fator de tempo limite como 6. |
Configurar uma porta de borda
As portas de borda são as portas que estão diretamente conectadas aos terminais do usuário. Se uma porta de borda estiver UP/DOWN, ela não causará loops temporários. Portanto, uma porta de borda pode migrar rapidamente do status Descartando para o status Encaminhando sem tempo de atraso. Além disso, se uma porta de borda estiver UP/DOWN, ela não enviará TC BPDUs. Isso evita o recálculo desnecessário da spanning tree.
Se uma porta de borda receber pacotes BPDU, ela se tornará uma porta sem borda novamente. Então, a porta pode se tornar a porta de borda novamente somente após ser redefinida.
Tabela 9-18 Configurando a porta de borda
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure uma porta de borda. | spanning-tree portfast edgeport | Obrigatório. Por padrão, uma porta não é uma porta de borda. |
Antes de especificar a porta como porta de borda, confirme se a porta está conectada diretamente ao terminal do usuário. Caso contrário, pode causar o loop temporário após configurar como porta de borda. Se a porta de borda de spanning tree é efetiva ou não depende da configuração da porta. Quando a porta não está configurada, se a porta de borda global estiver habilitada, a porta de borda da porta é habilitada por padrão; caso contrário, a porta de borda da porta é desabilitada por padrão.
Configurar a detecção automática da porta de borda
A configuração da detecção automática da porta de borda pode permitir que a porta conectada ao terminal seja identificada automaticamente como porta de borda, de modo a evitar que o on-line/off-line do dispositivo terminal faça com que o recálculo da spanning tree cause o choque da rede.
Se receber o pacote BPDU após ser identificado como a porta de borda, ele muda para a porta sem borda novamente.
Tabela 9 -20 Configure a detecção automática da porta de borda
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation | interface link-aggregation link-aggregation-id | |
| Configure a detecção automática da porta de borda | spanning-tree portfast autoedge | Obrigatório. Por padrão, a detecção automática da porta de borda é habilitada no modo de máquina única e desabilitada no modo de empilhamento. |
Forçar detecção automática da porta de borda
incorretamente como porta de borda ou porta sem borda . Aqui, o usuário pode executar o comando para acionar a porta para realizar a detecção da porta de borda para que a porta possa identificar se ela própria é a porta de borda corretamente .
Tabela 9 -21 Configure a detecção automática da porta de borda
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation | interface link-aggregation link-aggregation-id | |
| Forçar a detecção automática da porta de borda | spanning-tree portfast autoedge force | Obrigatório. |
O comando pode ter efeito somente quando a porta habilita a detecção automática de porta de borda.
Configurar o tipo de link de porta
Se dois dispositivos estiverem conectados diretamente, você pode configurar o tipo de link de porta para link ponto a ponto. As portas do tipo de link ponto a ponto podem migrar rapidamente do status Descartando para o status Encaminhando sem tempo de atraso.
Tabela 9-22 Configurando o tipo de link de porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure o tipo de link de porta. | spanning-tree link-type { point-to-point | shared } | Obrigatório. Por padrão, o tipo de link da porta é definido de acordo com o modo duplex da porta. Se a porta funcionar no modo full duplex, a porta será definida para o tipo de link ponto a ponto. Se a porta funcionar no modo half duplex, a porta será definida para o tipo de link compartilhado. |
O tipo de link de porta deve ser configurado de acordo com o link físico real. Se o link físico real da porta não for um link ponto a ponto e estiver configurado incorretamente como link ponto a ponto, isso poderá causar o loop temporário. Quando o tipo de link de porta local é o tipo de link de compartilhamento, a porta local não suporta a função de identificação automática da porta de borda. Se a porta peer realizar a identificação automática da porta de borda, pode fazer com que a porta de mesmo nível seja identificada incorretamente como porta de borda.
Configurar a função de garantia da bridge da porta
Depois que a função de garantia de bridge estiver habilitada na porta atual, a porta enviará BPDU independentemente de sua função de spanning tree (mesmo AlternatePort ou BackupPort ). Se a porta não receber BPDU do dispositivo par por um período de tempo, o estado da porta mudará para o estado Bloqueio e não participará do cálculo da árvore de abrangência. Se o BPDU do dispositivo de mesmo nível for recebido no futuro, a porta atual retomará o cálculo normal de spanning tree.
Tabela 9 -23 Configurar a função de garantia de bridge de porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configurar o tipo de link de porta | spanning-tree bridge-assurance enable | Mandatório. Por padrão, a função Bridge Assurance da porta não está habilitada. |
As restrições de configuração do Bridge-Assurance: É mutuamente exclusivo com BPDU-Guard , BPDU-Filter , Port-Fast ( adminEdge , autoEdge ) da porta. Se uma dessas funções estiver configurada na porta, o Bridge-Assurance não poderá ser configurado (haverá um prompt de impressão). No modo STP, RP e AP não podem enviar BPDU à vontade, então a configuração de Bridge-Assurance no modo STP não é efetiva, mas pode ser configurada.
Configurar o modo de trabalho de uma Spanning Tree
O modo de funcionamento de um spanning tree determina o modo no qual os dispositivos são executados e determina o formato de encapsulamento dos pacotes BPDU que são enviados. Se uma porta que funciona no modo MSTP está conectada a um dispositivo que executa RSTP, a porta migra automaticamente para o modo RSTP. Se uma porta que funciona no modo MSTP ou no modo MSTP estiver conectada a um dispositivo que executa STP, a porta migra automaticamente para o modo compatível com STP.
Condição de configuração
Nenhum
Configurar o modo de trabalho de um Spanning Tree
Tabela 9-24 Configurando o Modo de Trabalho de uma Spanning Tree
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o modo de trabalho de um spanning tree. | spanning-tree mode { stp | rstp | mstp | vist | rapid-vist} | Obrigatório. Por padrão, o modo de trabalho de um spanning tree é MSTP. |
Configurar a função de proteção de Spanning Tree
Condição de configuração
Nenhum
Configurar a função de guarda BPDU
Para um dispositivo de camada de acesso, a porta de acesso geralmente é conectada diretamente ao terminal do usuário ou servidor de arquivos. Neste momento, a porta é configurada para a porta de borda para realizar a migração rápida dos status da porta. Quando uma porta de borda recebe pacotes BPDU, ela muda automaticamente para uma porta sem borda para causar a regeneração da spanning tree. Normalmente, uma porta de borda não recebe pacotes BPDU. No entanto, se alguém enviar pacotes BPDU falsificados para atacar o dispositivo de maneira maliciosa, poderá ocorrer uma falha na rede . A função BPDU Guard é usada para prevenir tais ataques. Se uma porta de borda na qual a função BPDU Guard estiver habilitada receber pacotes BPDU, a porta será fechada.
Tabela 9 -25 Configurar a função global do BPDU Guard
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure a função BPDU Guard. | spanning-tree bpdu guard | Obrigatório. Por padrão, a função BPDU Guard está desabilitada na porta. |
Se a função de guarda de BPDU da porta de spanning tree é efetiva ou não depende da configuração da porta. Quando a porta não está configurada, se a proteção de BPDU global estiver habilitada, a função de proteção de BPDU da porta é habilitada por padrão; caso contrário, a função de guarda BPDU da porta é desabilitada por padrão.
Configurar a função de filtro BPDU
Depois que a função Filtro BPDU é habilitada em uma porta de borda, a porta não envia nem recebe pacotes BPDU.
Tabela 9 -27 Configurando a função de filtro BPDU global
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure a função Filtro BPDU. | spanning-tree bpdu filter | Obrigatório. Por padrão, a função Filtro BPDU está desabilitada. |
Se a função de filtro BPDU da porta spanning tree é efetiva ou não depende da configuração da porta. Quando a porta não está configurada, se o filtro BPDU global estiver habilitado, a função de filtro BPDU da porta é habilitada por padrão; caso contrário, a função de filtro BPDU da porta é desabilitada por padrão.
Configurar a função Flap Guard
Em um ambiente de topologia estável, a porta raiz geralmente não é alterada. No entanto, se os links na rede não forem estáveis ou a rede sofrer ataques com pacotes BPDU externos, a alternância frequente das portas raiz pode ser causada e, finalmente, a oscilação da rede é causada.
A função Flap Guard evita a troca frequente de portas raiz. Depois que a função Flap Guard for habilitada, se a frequência de alteração da função da porta raiz de uma instância de spanning tree exceder o limite especificado, a porta raiz da instância entrará no status Flap Guard. Nesse caso, a porta raiz está sempre no status Descartando e inicia o cálculo de spanning tree normal somente após o tempo de recuperação expirar.
Tabela 9-29 Configurando a função Flap Guard
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a função Flap Guard. | spanning-tree flap-guard enable | Obrigatório. Por padrão, a função Flap Guard está desabilitada. |
| Configure o número máximo de alterações de porta raiz que são permitidas em um período de detecção. | spanning-tree flap-guard max-flaps max-flaps-number time seconds | Opcional. Por padrão, depois que a função Flap Guard for habilitada, se ocorrerem cinco alterações de função de porta raiz para uma instância em 10 segundos, a porta entrará no status Flap Guard. |
| Configure o tempo de recuperação do Flap Guard. | spanning-tree flap-guard recovery-time seconds | Opcional. Por padrão, o tempo de recuperação do Flap Guard é de 30 segundos. |
Configurar a função de proteção de loop
O dispositivo local mantém os status da porta raiz e outras portas bloqueadas de acordo com os pacotes BPDU que são enviados periodicamente pelo dispositivo upstream. No caso de congestionamento de link ou falha de link unidirecional, as portas não recebem pacotes BPDU do dispositivo upstream, a mensagem de spanning tree na porta expira. Em seguida, os dispositivos downstream reelegem as funções de porta. As portas do dispositivo downstream que não recebem os pacotes BPDU mudam para a porta designada, enquanto as portas bloqueadas migram para o status Forwarding, resultando em loops na rede de comutação.
A função Loop Guard pode restringir a geração de tais loops. Depois que a função Loop Guard é habilitada em uma porta, se a porta expirar devido à falha ao receber pacotes BPDU do dispositivo upstream, ao recalcular a função da porta, a porta é definida para o status Descartando e a porta não não participar do cálculo do spanning tree. Se uma instância na porta receber pacotes BPDU novamente, a porta participará novamente do cálculo de spanning tree.
Tabela 9-30 Configurando a função Loop Guard
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure a função Loop Guard. | spanning-tree guard { loop | root | none } | Obrigatório. Por padrão, a função Loop Guard está desabilitada na porta. |
Em uma porta, tanto a função Root Guard quanto a função Loop Guard podem ser habilitadas por vez.
Configurar a função de proteção de raiz
A Root Bridge e a Root Bridge de backup de um spanning tree devem estar na mesma região, especialmente a Root Bridge CIST e sua bridge de backup. No projeto de rede, geralmente a Root Bridge CIST e sua bridge de backup são colocadas na região central com alta largura de banda. No entanto, devido a configuração incorreta ou ataques maliciosos na rede, a Root Bridge legal na rede pode receber um pacote BPDU com prioridade mais alta. Dessa forma, a bridge legal atual pode perder seu papel como Root Bridge, causando uma alteração imprópria da topologia da rede. A alteração ilegal pode levar o tráfego que deveria ser transmitido através de um link de alta velocidade para um link de baixa velocidade, causando congestionamento na rede.
A função Root Guard previne a ocorrência de tal caso. Se a função Root Guard estiver habilitada em uma porta, a porta só pode atuar como a porta designada em todas as instâncias. Se a porta receber uma mensagem de configuração de BPDU melhor, a porta será configurada para o status Descartando. Se não receber a melhor mensagem de configuração de BPDU em um período de tempo, a porta retoma seu status anterior. É recomendável habilitar a função Root Guard na porta especificada.
Tabela 9-31 Configurando a Função Root Guard
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation. | interface link-aggregation link-aggregation-id | |
| Configure a função Root Guard. | spanning-tree guard { loop | root | none } | Obrigatório. Por padrão, a função Root Guard está desabilitada na porta. |
Em uma porta, tanto a função Root Guard quanto a função Loop Guard podem ser habilitadas por vez.
Configurar a função TC Guard
Quando o dispositivo detectar a alteração da topologia da rede, gere o pacote TC e informe aos demais dispositivos no ambiente que a topologia da rede foi alterada. Depois que o dispositivo receber o pacote TC, atualize o endereço. Quando a topologia não é estável ou está construindo os pacotes TC artificialmente para atacar, gera TC com frequência na rede e como resultado, o dispositivo atualiza o endereço repetidamente, afetando o cálculo da spanning tree e resultando na alta ocupação da CPU.
O TC GUARD pode prevenir o caso. Após configurar o TC GUARD na porta atual e o dispositivo receber o pacote TC, não processe mais o sinalizador TC ou espalhe o TC, para evitar que os pacotes TC ataquem a rede de forma eficiente.
Tabela 9 -32 Configurar a função TC Guard
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do link aggregation | interface link-aggregation link-aggregation-id | |
| Configurar a função TC Guard | spanning-tree tc-guard enable | Obrigatório. Por padrão, não habilite a função TC Guard da porta. |
Configurar a função de proteção TC
Se a topologia da rede for alterada, para garantir o encaminhamento normal dos dados do serviço durante o processo de alteração da topologia, quando os dispositivos manipularem os pacotes TC, eles atualizarão os endereços MAC. Ataques com pacotes TC falsificados podem fazer com que os dispositivos atualizem endereços MAC com frequência. Isso afeta o cálculo da spanning tree e leva a uma alta ocupação da CPU.
A função de proteção TC previne a ocorrência de tal caso. Depois que a função de proteção TC é habilitada, uma vez que um pacote TC é recebido dentro do intervalo de proteção TC, o contador TC conta um. Se o contador TC for igual ou maior que o limite, ele entrará em um status suprimido. Em seguida, os dispositivos não atualizam os endereços MAC ao lidar com os pacotes TC posteriores. Após o intervalo de proteção do TC, o status suprimido é alterado para o status normal e o contador do TC é zerado e reiniciado.
Tabela 9-33 Configurando a Função de Proteção TC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a função de proteção TC. | spanning-tree tc-protection enable | Opcional. Por padrão, a função de proteção TC está desabilitada. |
| Configure um intervalo de proteção TC. | spanning-tree tc-protection interval seconds | Obrigatório. Por padrão, o intervalo de proteção do TC é de 2 segundos. |
| Configure o limite de proteção TC. | spanning-tree tc-protection threshold threshold-value | Obrigatório. Por padrão, o limite de proteção TC é 3. |
Configurar pseudo informações do spanning tree
Condição de configuração
A pseudo informação do spanning tree é aplicada no ambiente MALG . No nó virtual MALG , o método convencional de configuração de prioridade da spanning tree não será efetivo. Modifique a prioridade da instância correspondente ao nó MALG configurando as pseudoinformações da árvore geradora. Neste momento, a informação de prioridade de instância da BPDU enviada pelo GRUPO MLAG é a pseudo informação da spanning tree que configuramos, garantindo que dois dispositivos de nó MLAG sejam apresentados externamente como um cálculo de árvore de abrangência de um dispositivo. Observe que, durante a configuração, assegure-se de que a configuração de pseudo-informações de spanning tree nos dispositivos MLAG ativo e em espera seja consistente e que os parâmetros configurados no modo de configuração de pseudo-informações tenham efeito apenas no ambiente MLAG .
Configurar a prioridade de Root Bridge da instância
Configure a prioridade da Root Bridge da instância de spanning tree especificada nas pseudoinformações.
Tabela 9 -34 Configurar a prioridade de Root Bridge da instância
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar inserindo as pseudoinformações | spanning-tree pseudo-information | Mandatório. |
| Configurar a prioridade da Root Bridge da instância de spanning tree especificada | mst instance [instance-id] root-priority[priority-value] | Mandatório. Por padrão, configure a prioridade de root bridge de cada instância de spanning tree nas pseudoinformações de configuração como 0 (a prioridade mais alta). instance-id : ID da instância da árvore de abrangência, com um intervalo de valores de 0 a 63. priority-value : configura a prioridade do root bridge do dispositivo na instância de spanning tree especificada. Quanto menor o valor, maior a prioridade |
Configurar a prioridade de bridge especificada da instância
Configure a prioridade de bridge especificada da instância de spanning tree nas pseudoinformações de configuração.
Tabela 9 -35 Configurar a prioridade de bridge especificada da instância
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar inserindo as pseudoinformações | spanning-tree pseudo-information | Obrigatório. |
| Configurar a prioridade de bridge especificada da instância de spanning tree especificada nas pseudoinformações | mst instance instance-id designated-priority [priority-value] | Obrigatório. Por padrão, configure a prioridade de bridge especificada para cada instância de spanning tree nas pseudoinformações como 32768. instance-id : o ID da instância da spanning tree, o intervalo de valores é de 0 a 63 priority-value : Configure a prioridade da bridge raiz do dispositivo na instância de spanning tree especificada. Quanto menor o valor, maior a prioridade |
A etapa de configuração do valor de prioridade de bridge especificado é 4096, que pode ser configurado como: 0, 4096, 8192, 12288, 16384, 20480, 24576, 28672, 32768, 36864, 40960, 45056, 49152, 53248, 57344, 61440.
Configurar a prioridade do Root Bridge da lista de VLAN especificada
Configurar a prioridade do root bridge do dispositivo na lista de VLANs especificada.
Tabela 9 -36 Configurar a prioridade da Root Bridge da lista de VLAN especificada
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar inserindo as pseudoinformações | spanning-tree pseudo-information | Obrigatório. |
| Configure a prioridade de root bridge do dispositivo na lista de VLAN especificada | vist vlan vlan-list root-priority [priority-value] | Obrigatório. Por padrão, configure a prioridade de root bridge de cada VLAN nas pseudoinformações como 0 (a prioridade mais alta). priority-value : Configure a prioridade da bridge raiz do dispositivo na instância de spanning tree especificada. Quanto menor o valor, maior a prioridade |
A etapa de configuração do valor de prioridade da Root Bridge é 4096, que pode ser configurada como: 0, 4096, 8192, 12288, 16384, 20480, 24576, 28672, 32768, 36864, 40960, 45056, 49152, 53248, 57344, 61440. No dispositivo MLAG emparelhado, as prioridades da Root Bridge de todas as VLANs configuradas nas pseudoinformações dos dois dispositivos devem ser consistentes.
Configurar a prioridade da bridge da lista de VLAN especificada
Configurar a prioridade da bridge do dispositivo na lista de VLAN especificada.
Tabela 9 -37 Configurar a prioridade da bridge da lista de VLAN especificada
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar inserindo as pseudoinformações | spanning-tree pseudo-information | Obrigatório. |
| Configure a prioridade da bridge do dispositivo na lista de VLAN especificada | vist vlan vlan-list designated-priority [priority-value] | Obrigatório. Por padrão, configure a prioridade de bridge especificada de cada instância de spanning tree nas pseudoinformações como 32768. priority-value : Configure a prioridade da bridge raiz do dispositivo na instância de spanning tree especificada. Quanto menor o valor, maior a prioridade |
A etapa de configuração do valor de prioridade de bridge especificado é 4096, que pode ser configurado como: 0, 4096, 8192, 12288, 16384, 20480, 24576, 28672, 32768, 36864, 40960, 45056, 49152, 53248, 57344, 61440.
Monitoramento e manutenção da spanning tree
Tabela 9-38 Monitoramento e manutenção da spanning tree
| Comando | Descrição |
| clear spanning-tree detected-protocols | Execute a operação mc heck globalmente ou na porta especificada |
| clear spanning-tree bpdu statistics [interface interface-name | interface link-aggregation link-aggregation-id ] | Limpe todas as informações de estatísticas de BPDU ou na porta especificada |
| show spanning-tree detail | Exibir as informações de status detalhadas da árvore geradora |
| show spanning-tree guard [ current [interface interface-name | interface link-aggregation link-aggregation-id]] | Exibe as informações de configuração e status da função de proteção de spanning tree na porta |
| show spanning-tree { interface interface-name | interface link-aggregation link-aggregation-id } [detail] | Exibir as informações de status da árvore de abrangência da porta ou link aggregation especificado |
| show spanning-tree mst [ configuration [ current | pending ] | detail | instance instance-id [ detail ] | { interface interface-name | interface link-aggregation link-aggregation-id } [ instance instance-id ] ] | Exiba as informações de configuração e status sobre a spanning tree. |
| show configuration { current | pending } | Exibe a configuração das regiões MST. |
| show spanning-tree vlan vlan-id [detail] | No modo vist/rapid-vist, indique as informações de status da spanning tree da VLAN especificada |
Exemplo de configuração típica de Spanning Tree
Aplicação típica de MSTP
Requisitos de rede
- Quatro dispositivos na rede estão no mesmo domínio MST. Dispositivos de camada de convergência Device1 e Device2, enquanto Device3 e Device4 são dispositivos de camada de acesso.
- Para equilibrar razoavelmente o tráfego nos links para realizar o compartilhamento de carga e o backup de redundância, configure os pacotes da VLAN2 para serem encaminhados após a instância 1. A Root Bridge da instância 1 é Device1. Os pacotes de VLAN3 são encaminhados após a instância 2. A Root Bridge da instância 2 é Device2. Os pacotes de VLAN4 são encaminhados após a instância 0.
Topologia de rede
Figura 9 -1 Rede para aplicação típica de MSTP
Etapas de configuração
- Passo 1: Configure VLAN s e configure o tipo de link das portas.
#No Device1, crie VLAN2-VLAN4, configure o tipo de link da porta gigabitethernet0/1 para Trunk e permita que os serviços de VLAN2-VLAN4 passem.
Device1(config)#vlan 2-4Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#switchport mode trunkDevice1(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2-4Device1(config-if-gigabitethernet0/1)#exit
#No Device1, configure o tipo de link da porta gigabitethernet0/2 para Trunk e permita a passagem de serviços de VLAN3 e VLAN4. Configure o tipo de link da porta gigabitethernet0/3 para Trunk e permita que os serviços de VLAN2 e VLAN4 passem. (Omitido)
# Em Device2, crie VLAN2-VLAN4. Configure o tipo de link das portas gigabitethernet0/1-gigabitethernet0/3 para Trunk, configure gigabitethernet0/1 para permitir que serviços de VLAN2-VLAN4 passem, gigabitethernet0/2 para permitir que serviços de VLAN2 e VLAN4 passem e gigabitethernet0/3 para permitir serviços de VLAN3 e VLAN4 para passar. (Omitido)
#No Device3, crie VLAN2-VLAN4, configure o tipo de link da porta gigabitethernet0/1-gigabitethernet0/2 para Trunk e permita que os serviços de VLAN2-VLAN4 passem. (Omitido)
#No Device4, crie VLAN3 e VLAN4, configure o tipo de link da porta gigabitethernet0/1-gigabitethernet0/2 para Trunk e permita a passagem de serviços de VLAN3 e VLAN4. (Omitido)
- Passo 2: Configure uma região MST.
#No Device1, configure uma região MST. Defina o nome de domínio para admin, o nível de revisão para 1, mapeie a instância 1 para VLAN2, mapeie a instância 2 para VLAN3 e ative a região MST.
Device1#configure terminalDevice1(config)#spanning-tree mst configurationDevice1(config-mst)#region-name adminDevice1(config-mst)#revision-level 1Device1(config-mst)#instance 1 vlan 2Device1(config-mst)#instance 2 vlan 3Device1(config-mst)#active configuration pendingDevice1(config-mst)#exit
A configuração da região MST de Device2, Device3 e Device 4 é muito diferente daquela de Device1. (Omitido)
#No Device1, configure a prioridade do MSTI 1 para 0. No Device2, configure a prioridade do MSTI 2 para 0.
Device1(config)#spanning-tree mst instance 1 priority 0Device2(config)#spanning-tree mst instance 2 priority 0
#No Device1, habilite a spanning tree globalmente.
Device1(config)#spanning-tree enable A configuração para habilitar a spanning tree globalmente em Device2, Device3 e Device 4 é muito diferente daquela em Device1. (Omitido)
- Passo 3: Confira o resultado.
#Depois que a topologia de rede estiver estável, verifique o resultado do cálculo de todas as instâncias de spanning tree.
Device1#show spanning-tree mstSpanning-tree enabled protocol mstpMST Instance 00 vlans mapped: 1,4-4094Bridge address 0000.0000.008b priority 32768Region root address 0000.0000.008b priority 32768Designated root address 0000.0000.008b priority 32768root: 0, rpc: 0, epc: 0, hop: 20Operational hello time 2, forward time 15, max age 20Configured hello time 2, forward time 15, max age 20, max hops 20, hold count 6Flap guard : admin false, max count 5, detect period 10s, recovery period 30sTc protection: admin true, threshold 3, interval 2s, rxTcCnt 0, status:NORMALBpdu length-check: false, bpdu illegal length packets count: 0Autoedge swap-check: trueSwap-delay time: 30Configured timer factor: 3Topology Change Count:4, last change occured:0 hour 1 minute 0 second(60 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- --------- --------------------------gi0/1 Desg FWD 20000 128.001 P2Pgi0/2 Desg FWD 20000 128.002 P2Pgi0/3 Desg FWD 20000 128.003 P2PMST Instance 01 vlans mapped: 2Bridge ID address 0000.0000.008b priority 1/0Designated root address 0000.0000.008b priority 1root: 0, rpc: 0, hop: 20Topology Change Count:4, last change occured:0 hour 1 minute 0 second(60 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- --------- --------------------------gi0/1 Desg FWD 20000 128.001 P2Pgi0/3 Desg FWD 20000 128.003 P2PMST Instance 02 vlans mapped: 3Bridge ID address 0000.0000.008b priority 32770/32768Designated root address 0001.7a54.5c96 priority 2root: 32769, rpc: 20000, hop: 19Topology Change Count:4, last change occured:0 hour 1 minute 0 second(60 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- --------- --------------------------gi0/1 Root FWD 20000 128.001 P2Pgi0/2 Desg FWD 20000 128.002 P2P
#No Dispositivo2, consulte o resultado do cálculo de todas as instâncias de spanning tree. De acordo com o resultado, a porta gigabitethernet0/2 do Device2 está bloqueada na instância 0 e na instância 1.
Device2#show spanning-tree mstSpanning-tree enabled protocol mstpMST Instance 00 vlans mapped: 1,4-4094Bridge address 0001.7a54.5c96 priority 32768Region root address 0000.0000.008b priority 32768Designated root address 0000.0000.008b priority 32768root: 32769, rpc: 20000, epc: 0, hop: 19Operational hello time 2, forward time 15, max age 20Configured hello time 2, forward time 15, max age 20, max hops 20, hold count 6Flap guard : admin false, max count 5, detect period 10s, recovery period 30sTc protection: admin true, threshold 3, interval 2s, rxTcCnt 0, status:NORMALBpdu length-check: false, bpdu illegal length packets count: 0Autoedge swap-check: trueSwap-delay time: 30Configured timer factor: 3Topology Change Count:4, last change occured:0 hour 1 minute 0 second(60 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- --------- --------------------------gi0/1 Root FWD 20000 128.001 P2Pgi0/2 Alte DIS 20000 128.002 P2Pgi0/3 Desg FWD 20000 128.003 P2PMST Instance 01 vlans mapped: 2Bridge ID address 0001.7a54.5c96 priority 32769/32768Designated root address 0000.0000.008b priority 1root: 32769, rpc: 20000, hop: 19Topology Change Count:4, last change occured:0 hour 1 minute 0 second(60 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- --------- --------------------------gi0/1 Root FWD 20000 128.001 P2Pgi0/2 Alte DIS 20000 128.002 P2PMST Instance 02 vlans mapped: 3Bridge ID address 0001.7a54.5c96 priority 2/0Designated root address 0001.7a54.5c96 priority 2root: 0, rpc: 0, hop: 20Topology Change Count:4, last change occured:0 hour 1 minute 0 second(60 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- --------- --------------------------gi0/1 Desg FWD 20000 128.001 P2Pgi0/3 Desg FWD 20000 128.003 P2P
#No Device3, consulte o resultado do cálculo de todas as instâncias de spanning tree.
Device3#show spanning-tree mstSpanning-tree enabled protocol mstpMST Instance 00 vlans mapped: 1,4-4094Bridge address 0000.0305.070a priority 32768Region root address 0000.0000.008b priority 32768Designated root address 0000.0000.008b priority 32768root: 32769, rpc: 20000, epc: 0, hop: 19Operational hello time 2, forward time 15, max age 20Configured hello time 2, forward time 15, max age 20, max hops 20, hold count 6Flap guard : admin false, max count 5, detect period 10s, recovery period 30sTc protection: admin true, threshold 3, interval 2s, rxTcCnt 0, status:NORMALBpdu length-check: false, bpdu illegal length packets count: 0Autoedge swap-check: trueSwap-delay time: 30Configured timer factor: 3Topology Change Count:4, last change occured:0 hour 1 minute 0 second(60 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- --------- --------------------------gi0/1 Root FWD 20000 128.001 P2Pgi0/2 Desg FWD 20000 128.002 P2PMST Instance 01 vlans mapped: 2Bridge ID address 0000.0305.070a priority 32769/32768Designated root address 0000.0000.008b priority 1root: 32769, rpc: 20000, hop: 19Topology Change Count:4, last change occured:0 hour 1 minute 0 second(60 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- --------- --------------------------gi0/1 Root FWD 20000 128.001 P2Pgi0/2 Desg FWD 20000 128.002 P2P
#No Device4, consulte o resultado do cálculo de todas as instâncias de spanning tree. De acordo com o resultado, a porta gigabitethernet0/1 do Device4 está bloqueada na instância 0 e a porta gigabitethernet0/2 está bloqueada na instância 2.
Device4#show spanning-tree mstSpanning-tree enabled protocol mstpMST Instance 00 vlans mapped: 1,4-4094Bridge address 0001.7a58.dc0c priority 32768Region root address 0000.0000.008b priority 32768Designated root address 0000.0000.008b priority 32768root: 32769, rpc: 20000, epc: 0, hop: 19Operational hello time 2, forward time 15, max age 20Configured hello time 2, forward time 15, max age 20, max hops 20, hold count 6Flap guard : admin false, max count 5, detect period 10s, recovery period 30sTc protection: admin true, threshold 3, interval 2s, rxTcCnt 0, status:NORMALBpdu length-check: false, bpdu illegal length packets count: 0Autoedge swap-check: trueSwap-delay time: 30Configured timer factor: 3Topology Change Count:4, last change occured:0 hour 1 minute 0 second(60 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- --------- --------------------------gi0/1 Alte DIS 20000 128.001 P2Pgi0/2 Root FWD 20000 128.002 P2PMST Instance 02 vlans mapped: 3Bridge ID address 0001.7a58.dc0c priority 32770/32768Designated root address 0001.7a54.5c96 priority 2root: 32769, rpc: 20000, hop: 19Topology Change Count:4, last change occured:0 hour 1 minute 0 second(60 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- --------- --------------------------gi0/1 Root FWD 20000 128.001 P2Pgi0/2 Alte DIS 20000 128.002 P2P
Com base no resultado do cálculo de spanning tree dos quatro dispositivos, são obtidos os diagramas de árvore correspondentes a MSTI 0 (mapeado para VLAN4), MSTI 1 (mapeado para VLAN2) e MSTI 2 (mapeado para VLAN3).
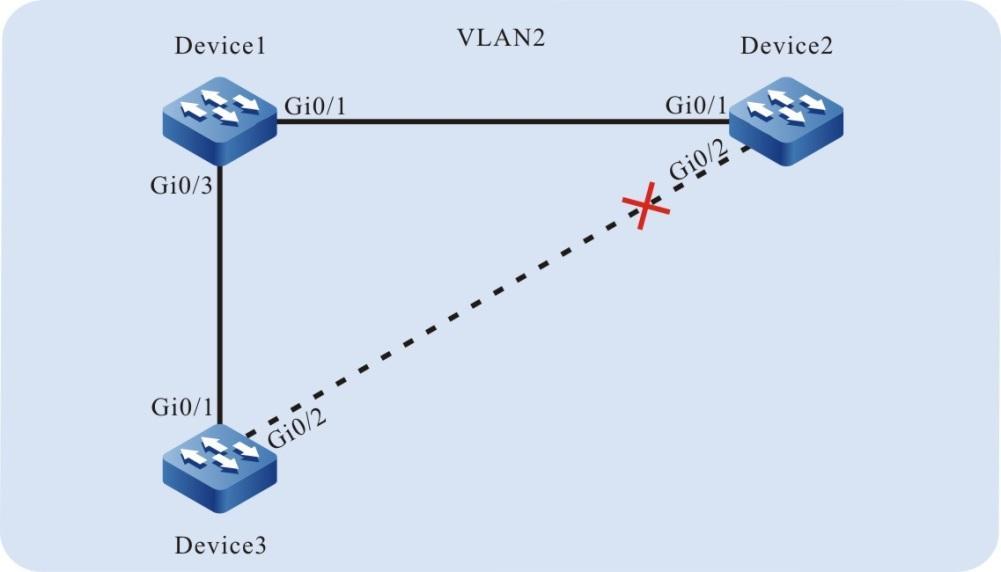

Aplicar funções básicas do MSTP no ambiente MLAG
Requisitos de rede
- Os quatro dispositivos na rede estão todos no mesmo domínio MST e a prioridade de bridge do dispositivo MLAG é a mais alta.
Topologia de rede
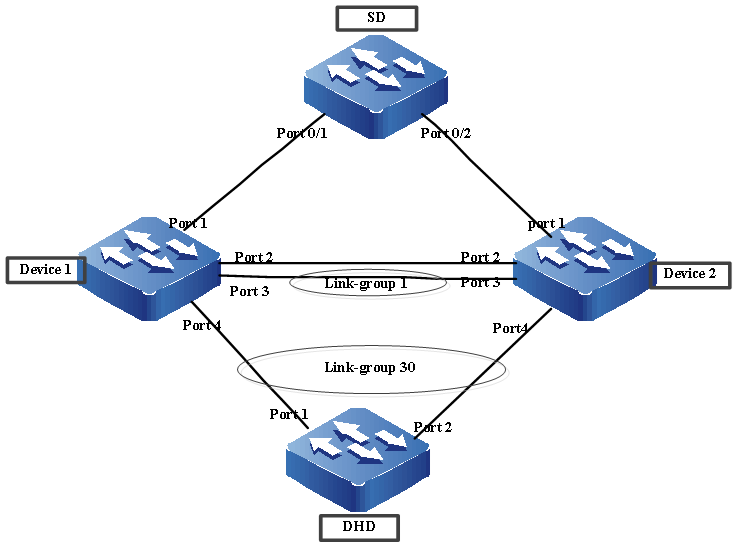
Figura 9 -2 Networking para aplicação de MSTP em MLAG
Etapas de configuração
- Etapa 1: Adicione a interface ao link aggregation e adicione à VLAN. (omitido)
- Etapa 2: Configurar o domínio MLAG . (omitido)
- Etapa 3 : Configurar o domínio MST.
#Configure o domínio MST em Device1, configure o nome de domínio como admin e o nível de revisão como 1 para ativar o domínio MST.
Device1#configure terminalDevice1(config)#spanning-tree mst configurationDevice1(config-mst)#region-name adminDevice1(config-mst)#revision-level 1Device1(config-mst)#active configuration pendingDevice1(config-mst)#exit
A configuração de domínio MST de Device2, SD e DHD é a mesma que Device1. (omitido)
Visualize as informações de cada spanning tree de dispositivos.
#Aggregation 1 em Device1 e Device2 é a porta de interconexão.
Device1#show spanning-treeSpanning-tree enabled protocol mstpMST Instance 00 vlans mapped: 1-4094 Bridge address 0001.7a95.000b priority 0 Region root address 0001.7a95.000b priority 0 Designated root address 0001.7a95.000b priority 0 root: 0, rpc: 0, epc: 0, hop: 20 We are the root of the spanning tree Operational hello time 2, forward time 15, max age 20, message age 0 Configured hello time 2, forward time 15, max age 20, max hops 20, hold count 10Flap guard : admin false, max count 5, detect period 10s, recovery period 30sTc protection: admin true, threshold 2, interval 20s, rxTcCnt 0, status:NORMALARL flush: enabledBpdu length-check: false, bpdu illegal length packets count: 0Autoedge swap-check: trueSwap-delay time: 30Configured timer factor: 3Topology Change Count:6, last change occured:118 weeks 5 days(71863322 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- ---------- --------------------------te0/1 Desg FWD 20000 128.0036 P2P link-agg1 Desg FWD 1950 128.0193 P2P (MLAG peer-link) link-agg30 Desg FWD 19500 128.0222 P2P (MLAG 100)Device2#show spanning-treeSpanning-tree enabled protocol mstpMST Instance 00 vlans mapped: 1-4094 Bridge address 0001.7a95.000b priority 0 Region root address 0001.7a95.000b priority 0 Designated root address 0001.7a95.000b priority 0 root: 0, rpc: 0, epc: 0, hop: 20 We are the root of the spanning tree Operational hello time 2, forward time 15, max age 20, message age 0 Configured hello time 2, forward time 15, max age 20, max hops 20, hold count 6Flap guard : admin false, max count 5, detect period 10s, recovery period 30sTc protection: admin true, threshold 1, interval 4s, rxTcCnt 0, status:NORMALARL flush: enabledBpdu length-check: false, bpdu illegal length packets count: 0Autoedge swap-check: trueSwap-delay time: 30Configured timer factor: 3Topology Change Count:7, last change occured:118 weeks 4 days(71776558 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- ---------- --------------------------gi0/1 Desg FWD 20000 128.0332 P2P link-agg1 IRoot FWD 1950 128.0385 P2P (MLAG peer-link) link-agg30 Desg FWD 19500 128.0414 P2P (MLAG 100)
#SD conecta a porta do Device2 e o cálculo da spanning tree é block, e o mlag-group do DHD é Root.
SD#show spanning-treeSpanning-tree enabled protocol mstpMST Instance 00 vlans mapped: 1-4094 Bridge address 0001.7a7a.3c10 priority 32768 Region root address 0001.7a95.000b priority 0 Designated root address 0001.7a95.000b priority 0 root: 32804, rpc: 20000, epc: 0, hop: 19 Operational hello time 2, forward time 15, max age 20, message age 0 Configured hello time 2, forward time 15, max age 20, max hops 20, hold count 6Flap guard : admin false, max count 5, detect period 10s, recovery period 30sTc protection: admin true, threshold 1, interval 4s, rxTcCnt 0, status:NORMALARL flush: enabledBpdu length-check: false, bpdu illegal length packets count: 0Autoedge swap-check: trueSwap-delay time: 30Configured timer factor: 1Topology Change Count:36, last change occured:118 weeks 5 days(71863036 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- ---------- --------------------------gi0/1 Root FWD 20000 128.0012 P2P gi0/2 Alte DIS 20000 128.0036 P2PDHD#show spanning-treeSpanning-tree enabled protocol mstpMST Instance 00 vlans mapped: 1-4094 Bridge address 0001.7a6a.0148 priority 32768 Region root address 0001.7a95.000b priority 0 Designated root address 0001.7a95.000b priority 0 root: 33662, rpc: 18000, epc: 0, hop: 19 Operational hello time 2, forward time 15, max age 20, message age 0 Configured hello time 2, forward time 15, max age 20, max hops 20, hold count 6Flap guard : admin false, max count 5, detect period 10s, recovery period 30sTc protection: admin true, threshold 1, interval 4s, rxTcCnt 0, status:NORMALARL flush: enabledBpdu length-check: false, bpdu illegal length packets count: 0Autoedge swap-check: trueSwap-delay time: 30Configured timer factor: 6Topology Change Count:20, last change occured:118 weeks 5 days(71863409 seconds)Interface Role Sts Cost Prio.Nbr Type -------------------- ----- ---- --------- ---------- -------------------------- link-agg30 Root FWD 18000 128.0894 P2P
- Etapa 4: Modifique a prioridade da bridge especificada de Device2, para que a porta bloqueada de SA seja calculada como 0/1.
Device2#conf tDevice2(config)#spanning-tree pseudo-informationDevice2 (config-stp-pseudo)#mst instance 0 designated-priority 4096SD# show spanning-treeSpanning-tree enabled protocol mstpMST Instance 00 vlans mapped: 1-4094 Bridge address 0001.7a7a.3c10 priority 32768 Region root address 0001.7a95.000b priority 0 Designated root address 0001.7a95.000b priority 0 root: 32780, rpc: 20000, epc: 0, hop: 19 Operational hello time 2, forward time 15, max age 20, message age 0 Configured hello time 2, forward time 15, max age 20, max hops 20, hold count 6Flap guard : admin false, max count 5, detect period 10s, recovery period 30sTc protection: admin true, threshold 1, interval 4s, rxTcCnt 0, status:NORMALARL flush: enabledBpdu length-check: false, bpdu illegal length packets count: 0Autoedge swap-check: trueSwap-delay time: 30Configured timer factor: 1Topology Change Count:37, last change occured:118 weeks 5 days(71864200 seconds)Interface Role Sts Cost Prio.Nbr Type-------------------- ----- ---- --------- ---------- --------------------------gi0/1 Root FWD 20000 128.0012 P2P gi0/2 Alte DIS 20000 128.0036 P2P
- Etapa 5: Habilite a função BA na porta de interconexão de Device1 e Device2.
Device1(config)#interface link-aggregation 1Device1(config-if-link-aggregation1)#spanning-tree bridge-assurance enableDevice2(config)#interface link-aggregation 1Device2(config-if-link-aggregation1)#spanning-tree bridge-assurance enable
Loopback Detection
Visão geral
Na Ethernet, se o destino de algum pacote não for reconhecido, ele será inundado em uma VLAN. Se existir um loop na rede, os pacotes circulam e se multiplicam sem limite e, finalmente, eles esgotam a largura de banda. Então, a rede não fornece comunicação normal.
Existem dois tipos de loops, loop entre diferentes interfaces Ethernet de um dispositivo e loop em uma interface Ethernet de um dispositivo. Os dois tipos de loops podem ser detectados através da detecção de loopback.
Depois que a função de loopback detection é habilitada, a interface Ethernet envia pacotes de detecção de loopback com um intervalo para verificar se existe um loop na rede. Quando a interface Ethernet recebe o pacote de loopback detection enviado pelo dispositivo local, ela determina que existe um loop na rede. Em seguida, a interface Ethernet é desabilitada para evitar que o loop local afete toda a rede.
Configuração da função de loopback detection
Tabela 10-1 Lista de funções de loopback detection
| Tarefas de configuração | |
| Configure funções básicas de detecção de loopback. |
Habilite a chave de controle de detecção de loopback global.
Habilite o switch de controle de loopback detection da interface Ethernet ou grupo de agregação. |
| Configure os parâmetros básicos de detecção de loopback. |
Configure o intervalo no qual os pacotes de loopback detection são enviados.
Configure a ação Error-Disable na interface Ethernet. |
Configurar funções básicas de loopback detection
Condição de configuração
Nenhum
Ativar o controle de loopback detection globalmente
A chave de controle de loopback detection global é usada para habilitar a função de loopback detection global. A configuração de loopback detection da interface Ethernet entra em vigor somente depois que a chave de controle de loopback detection global é habilitada.
Tabela 10-2 Habilitar o controle de loopback detection globalmente
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a chave de controle de detecção de loopback global. | loopback-detection enable | Obrigatório. Por padrão, a chave de controle de detecção de loopback global está desabilitada. |
Habilite o controle de loopback detection na interface Ethernet ou link aggregation
Depois que a função de loopback detection é habilitada, o A interface Ethernet envia pacotes de detecção de loopback com um intervalo para verificar se existe um loop na rede.
Tabela 10-3 Habilitando o Loopback Detection na Interface Ethernet ou Link Agregation
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L3/L2. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2 /L3 , a configuração subsequente entra em vigor apenas na interface Ethernet atual . Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do grupo de agregação. | interface link-aggregation link-aggregation-id | |
| Habilite o switch de controle de detecção de loopback da interface Ethernet ou grupo de agregação. | loopback-detection enable | Obrigatório. Por padrão, o loopback detection da interface Ethernet ou grupo de agregação está desabilitada. |
Em uma tarefa de configuração de detecção de loopback, você deve habilitar o switch de controle de loopback detection global antes que a configuração de loopback detection na interface Ethernet entre em vigor.
Configurar parâmetros básicos de loopback detection
Condição de configuração
Nenhum
Configurar período de envio de pacotes de detecção de loopback
Na loopback detection, os pacotes de detecção de loopback são enviados periodicamente para detectar loops na rede. Você pode modificar o intervalo no qual os pacotes de loopback detection são enviados de acordo com o requisito real da rede.
Tabela 10-4 Configurar o período de envio dos pacotes de loopback detection
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na interface Ethernet atual . Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do grupo de agregação. | interface link-aggregation link-aggregation-id | |
| Configure o intervalo no qual os pacotes de loopback detection são enviados. | loopback-detection enable interval-time interval-time-value | Obrigatório. Por padrão, o intervalo no qual os pacotes de loopback detection são enviados é de 30 segundos. |
Configurar ação de desativação de erro da interface Ethernet
Se a interface Ethernet permitir a ação Error-Disable, a interface Ethernet é controlada. Depois que uma porta detecta um loop, ela executa a ação Error-Disable para fechar a interface Ethernet e eliminar o loop. Se a interface Ethernet não estiver no status controlado, a interface Ethernet apenas imprime a mensagem de prompt de loop em vez de fechar a interface Ethernet . Neste caso, o loop não foi eliminado.
Tabela 10-5 Configurando a ação Error-Disable na interface Ethernet
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3. | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2 /L3 , a configuração subsequente terá efeito apenas na interface Ethernet atual . Depois de entrar no modo de configuração do link aggregation, a configuração subsequente entra em vigor apenas no link aggregation. |
| Entre no modo de configuração do grupo de agregação. | interface link-aggregation link-aggregation-id | |
| Configure se a interface Ethernet permite a função Error-Disable. | loopback-detection enable control | Obrigatório. Por padrão, após a interface Ethernet detectar um loop, ela executa a ação Error-Disable. |
Monitoramento e manutenção de loopback detection
Tabela 10 - 6 Monitoramento e manutenção de loopback detection
| Comando | Descrição |
| show loopback-detection [ interface interface-name | interface link-aggregation link-aggregation-id ] | Exibe as informações de configuração de todas as interfaces Ethernet ou uma interface Ethernet especificada na loopback detection. |
Exemplo de configuração típico de loopback detection
Configurar loopback detection remoto
Requisitos de rede
- Device1 e Device2 são conectados diretamente, e Device2 tem duas interfaces Ethernet L2 que formam um auto-loop.
- No Device1, a loopback detection foi habilitada.
- Depois que o Device1 detecta um loop, ele fecha as interfaces Ethernet interconectadas para eliminar o loop.
Topologia de rede

Figura 10 -1 Rede para configurar a função de loopback detection remoto
Etapas de configuração da interface Ethernet L2
- Passo 1: Configure VLANs e configure o tipo de link da interface Ethernet L2 .
#No Dispositivo1, crie a VLAN2.
Device1#configure terminalDevice1(config)#vlan 2Device1(config-vlan2)#exit
#No Device1, configure o tipo de link da interface Ethernet L2 gigabitethernet0/1 para Trunk e permita a passagem de serviços de VLAN2.
Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#switchport mode trunkDevice1(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2Device1(config-if-gigabitethernet0/1)#exit
#No Dispositivo2, crie VLAN2.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exit
# No Device2, configure o tipo de link da interface Ethernet L2 gigabitethernet0/1 , gigabitethernet 0/2 e gigabitethernet 0/3 para Trunk e permita a passagem dos serviços da VLAN2. Configure a interface Ethernet L2 gigabitethernet 0/2 e gigabitethernet 0/3 para fechar a spanning tree .
Device2(config)#interface gigabitethernet 0/1-0/3Device2(config-if-range)#switchport mode trunkDevice2(config-if-range)#no switchport trunk allowed vlan 1Device2(config-if-range)#switchport trunk allowed vlan add 2Device2(config-if-range)#exitDevice2(config)#interface gigabitethernet 0/2-0/3Device2(config-if-range)#no spanning-tree enableDevice2(config-if-range)#exit
- Passo 2: Ative a função de loopback detection.
#No Device1, habilite a função de loopback detection globalmente.
Device1(config)#loopback-detection enable#No Dispositivo1, consulte o status de detecção de loopback.
Device1#show loopback-detection-------------------------------------------------------------Global loopback-detection : ENABLE-------------------- -------- ------- ------------ -------Interface Loopback Time(s) State Control-------------------- -------- ------- ------------ -------gi0/1 DISABLE 30 NORMAL TRUEgi0/2 DISABLE 30 NORMAL TRUE
# A interface Ethernet L2 gigabitethernet 0/1 do Device1 habilita a função de loopback detection.
Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#loopback-detection enableDevice1(config-if-gigabitethernet0/1)#exit
- Passo 3: Confira o resultado.
#No Dispositivo1, consulte o status de detecção de loopback.
Depois que um loop é detectado:
Device1#show loopback-detection-------------------------------------------------------------Global loopback-detection : ENABLE-------------------- -------- ------- ------------ -------Interface Loopback Time(s) State Control-------------------- -------- ------- ------------ -------gi0/1 ENABLE 30 ERR-DISABLE TRUEgi0/2 DISABLE 30 NORMAL TRUE
#Um loop foi detectado no Device1. A interface Ethernet L2 gigabitethernet0/1 é fechada e o dispositivo emite as seguintes informações de prompt:
Jul 30 2014 03:30:30: %LOOP-BACK-DETECTED : loop-back send tag packet in vlan2 on gigabitethernet0/1, detected in vlan2 from gigabitethernet0/1Jul 30 2014 03:30:30: %LINK-INTERFACE_DOWN-4: interface gigabitethernet0/1, changed state to downJul 30 2014 03:30:30: %LINEPROTO-5-UPDOWN : gigabitethernet0/1 link-status changed to err-disable
#No Dispositivo1, consulte o status da interface Ethernet L2 gigabitethernet0/1 e você descobrirá que o status do link da interface Ethernet L2 gigabitethernet0/1 é alterado para Baixo.
Device1#show interface gigabitethernet 0/1gigabitethernet0/1 configuration informationDescription :Status : EnabledLink : Down (Err-disabled)Set Speed : AutoAct Speed : UnknownSet Duplex : AutoAct Duplex : UnknownSet Flow Control : OffAct Flow Control : OffMdix : AutoMtu : 1824Port mode : LANPort ability : 10M HD,10M FD,100M HD,100M FD,1000M FDLink Delay : No DelayStorm Control : Unicast DisabledStorm Control : Broadcast DisabledStorm Control : Multicast DisabledStorm Action : NonePort Type : NniPvid : 1Set Medium : CopperAct Medium : CopperMac Address : 0000.0000.008b
Etapas de configuração da interface Ethernet L3
- Passo 1: Configure a VLAN e configure o tipo de link da interface Ethernet L2 .
# Cria VLAN2 no Device2.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exit
# No Device2, configure o tipo de link da interface Ethernet L2 gigabitethernet0/1 , gigabitethernet 0/2 e gigabitethernet 0/3 para Trunk e permita a passagem dos serviços da VLAN2. Configure a interface Ethernet L2 gigabitethernet 0/2 e gigabitethernet 0/3 para fechar a spanning tree .
Device2(config)#interface gigabitethernet 0/1-0/3Device2(config-if-range)#switchport mode trunkDevice2(config-if-range)#no switchport trunk allowed vlan 1Device2(config-if-range)#switchport trunk allowed vlan add 2Device2(config-if-range)#switchport trunk pvid vlan 2Device2(config-if-range)#exitDevice2(config)#interface gigabitethernet 0/2-0/3Device2(config-if-range)#no spanning-tree enableDevice2(config-if-range)#exit
- Passo 2:Ative a função de loopback detection.
# No Device1, habilite a função de loopback detection globalmente.
Device1(config)#loopback-detection enable#No Dispositivo1, visualize o status de detecção de loopback.
Device1#show loopback-detection-------------------------------------------------------------Global loopback-detection : ENABLE-------------------- -------- ------- ------------ -------Interface Loopback Time(s) State Control-------------------- -------- ------- ------------ -------gi0/1 DISABLE 30 NORMAL TRUEgi0/2 DISABLE 30 NORMAL TRUE
# No Device1, configure a interface Ethernet L2 g igabitethernet 0/1 como interface Ethernet L3.
Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#no switchport
# A interface Ethernet L3 gigabitethernet 0/1 no Device1 habilita a função de loopback detection.
Device1(config-if-gigabitethernet0/1)#loopback-detection enableDevice1(config-if-gigabitethernet0/1)#exit
- Passo 3: Confira o resultado.
#No Dispositivo1, consulte o status de detecção de loopback.
Depois que um loop é detectado:
Device1#show loopback-detection-------------------------------------------------------------Global loopback-detection : ENABLE-------------------- -------- ------- ------------ -------Interface Loopback Time(s) State Control-------------------- -------- ------- ------------ -------gi0/1 ENABLE 30 ERR-DISABLE TRUEgi0/2 DISABLE 30 NORMAL TRUE
#Um loop foi detectado no Device1. A interface Ethernet L2 gigabitethernet0/1 é fechada e o dispositivo emite as seguintes informações de prompt:
Jul 31 2014 11:29:30: %LOOP-BACK-DETECTED : loop-back send packet on gigabitethernet0/1, detected from gigabitethernet0/1Jul 31 2014 11:29:30: %LINEPROTO-5-UPDOWN : gigabitethernet0/1 link-status changed to err-disableJul 31 2014 11:29:30: %LINK-INTERFACE_DOWN-3: Interface gigabitethernet0/1, changed state to down.Jul 31 2014 11:29:30: %LINK-LINEPROTO_DOWN-3: Line protocol on interface gigabitethernet0/1, changed state to down.
#No Dispositivo1, veja o status da interface Ethernet L3 gigabitethernet0/1 e você pode ver que o status da interface Ethernet L3 muda para err-disabled .
Device1#show interface gigabitethernet 0/1 status err-disabledInterface Status Reason---------------------------------------------------------------gi0/1 err-disabled loopback-detect
Configurar loopback detection local
Requisitos de rede
- Device1 e Device2 formam um loop por meio de dois links, e todas as interfaces Ethernet L2 no loop estão em uma VLAN.
- No Device1, a loopback detection foi habilitada.
- Depois que o Device1 detecta um loop, ele fecha as interfaces Ethernet L2 interconectadas para eliminar o loop.
Topologia de rede

Figura 10-2 Rede para configurar a função de loopback detection local
Etapas de configuração
- Passo 1: Configure VLANs e configure o tipo de link da interface Ethernet L2 .
#No Dispositivo1, crie a VLAN2.
Device1#configure terminalDevice1(config)#vlan 2Device1(config-vlan2)#exit
#No Device1, configure o tipo de link da interface Ethernet L2 gigabitethernet0/1 e gigabitethernet0/2 para Trunk e permita que os serviços de VLAN2 passem.
Device1(config)# interface gigabitethernet 0/1-0/2Device1(config-if-range)#switchport mode trunkDevice1(config-if-range)#switchport trunk allowed vlan add 2Device1(config-if-range)#exit
#No Dispositivo2, crie VLAN2.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exit
#Configure o tipo de link da interface Ethernet L2 gigabitethernet0/1 e gigabitethernet0/2 para Trunk , permita que os serviços da VLAN2 passem e feche a spanning tree.
Device2(config)# interface gigabitethernet 0/1-0/2Device2(config-if-range)#switchport mode trunkDevice2(config-if-range)#no switchport trunk allowed vlan 1Device2(config-if-range)#switchport trunk allowed vlan add 2Device2(config-if-range)#no spanning-tree enableDevice2(config-if-range)#exit
- Passo 2: Ative a função de loopback detection.
#No Device1, habilite a função de loopback detection globalmente.
Device1(config)#loopback-detection enable#No Dispositivo1, consulte o status de detecção de loopback.
Device1#show loopback-detection-------------------------------------------------------------Global loopback-detection : ENABLE-------------------- -------- ------- ------------ -------Interface Loopback Time(s) State Control-------------------- -------- ------- ------------ -------gi0/1 DISABLE 30 NORMAL TRUEgi0/2 DISABLE 30 NORMAL TRUE
interface Ethernet L2 gigabitethernet 0/1 no Device1 habilita a função de loopback detection.
Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#loopback-detection enableDevice1(config-if-gigabitethernet0/1)#exit
- Passo 3: Confira o resultado.
#No Dispositivo1, consulte o status de detecção de loopback.
Depois que um loop é detectado:
Device1#show loopback-detection-------------------------------------------------------------Global loopback-detection : ENABLE-------------------- -------- ------- ------------ -------Interface Loopback Time(s) State Control-------------------- -------- ------- ------------ -------gi0/1 ENABLE 30 ERR-DISABLE TRUE
gi0/2 DISABLE 30 NORMAL TRUE
#Um loop foi detectado no Device1. A interface Ethernet L2 gigabitethernet0/1 é fechada e o dispositivo emite as seguintes informações de prompt:
Jul 30 2014 03:29:59: %LOOP-BACK-DETECTED : loop-back send tag packet in vlan2 on gigabitethernet0/1, detected in vlan2 from gigabitethernet0/2Jul 30 2014 03:29:59: %LINK-INTERFACE_DOWN-4: interface gigabitethernet0/1, changed state to downJul 30 2014 03:29:59: %LINEPROTO-5-UPDOWN : gigabitethernet0/1 link-status changed to err-disable
#No Dispositivo1, consulte o status da interface Ethernet L2 gigabitethernet0/1 e você descobrirá que o status do link da interface Ethernet L2 gigabitethernet0/1 foi alterado para Inativo.
Device1#show interface gigabitethernet 0/1gigabitethernet0/1 configuration informationDescription :Status : EnabledLink : Down (Err-disabled)Set Speed : AutoAct Speed : UnknownSet Duplex : AutoAct Duplex : UnknownSet Flow Control : OffAct Flow Control : OffMdix : AutoMtu : 1824Port mode : LANPort ability : 10M HD,10M FD,100M HD,100M FD,1000M FDLink Delay : No DelayStorm Control : Unicast DisabledStorm Control : Broadcast DisabledStorm Control : Multicast DisabledStorm Action : NonePort Type : NniPvid : 1Set Medium : CopperAct Medium : CopperMac Address : 0000.0000.008b
Quando gigabitethernet 0/1 ou gigabitethernet 0/2 de Device1 é interface Ethernet L3, não há loop no ambiente de rede.
Gerenciamento do Error-Disable
Visão geral
A função Error-Disable é um mecanismo de detecção de erros e recuperação de falhas nas portas.
Exceções nas portas podem degradar o desempenho de toda a rede ou derrubar toda a rede. A função Error-Disable pode limitar a anormalidade em um único dispositivo ou parte da rede, impedindo que a anormalidade afete outras portas normais e impedindo que a anormalidade se espalhe.
Se uma exceção for detectada em uma porta aberta, a porta será fechada automaticamente para que a porta não encaminhe pacotes. Ou seja, se uma condição de erro for acionada na porta, a porta será automaticamente desabilitada. Esta é a função de gerenciamento Error-Disable, e o status da porta é o status Error-Disabled.
Atualmente, as seguintes funções são suportadas: supressão de tempestade, segurança de porta, oscilação de link, limite de taxa DHCP, BPDU Guard, detecção de ARP, túnel de protocolo L2, loopback detection, OAM, link de monitor e falha de malha .
Se uma exceção for detectada em uma porta por meio das funções acima, a porta será fechada automaticamente e será definida para o status Error-Disabled. No entanto, esse status não pode continuar. Depois que a falha for eliminada, a porta precisa ser habilitada novamente e o status Error-Disabled da porta precisa ser limpo para que a porta possa continuar a encaminhar pacotes. Aqui está envolvido o mecanismo de recuperação automática da função de gerenciamento Error-Disable.
Configuração da função de gerenciamento de error-disable
Tabela 11-1 Lista de Funções de Gerenciamento do Error-Disable
| Tarefas de configuração | |
| Configurar funções básicas Error-Disable. | Configure a detecção de erro Error-Disable. |
| Configure a recuperação automática Error-Disable. |
Configure a recuperação automática Error-Disable.
Configure o intervalo para descoberta automática Error-Disable. |
Configurar funções básicas de error-disable
Condição de configuração
Nenhum
Configurar detecção do Error-Disable
Depois que a detecção Error-Disable da função de especificação for configurada, se uma exceção for detectada na porta, o sistema fechará automaticamente a porta e definirá a porta para o status Error-Disabled.
Tabela 11 -2 Configurando a detecção do Error-Disable
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a detecção de erro Error-Disable. | errdisable detect cause { all | bpduguard | dai | dhcp-snooping | monitor-link | torm-control | link-flap | l2pt | oam | port-security | loopback-detect | transceiver-power-low } | Obrigatório. Por padrão, é permitido que todas as funções listadas fechem uma porta e definam a porta para o status Error-Disabled. |
Configurar recuperação automática do Error-Disable
Configurar recuperação automática do Error-Disable
O mecanismo de detecção de erros Error-Disable permite que funções especificadas fechem uma porta. Para recuperar rapidamente a porta para que ela possa continuar a encaminhar pacotes, é fornecido um mecanismo de recuperação automática. Com o mecanismo, a porta é reativada automaticamente após um intervalo especificado.
Tabela 11-3 Configurando a recuperação automática de error-disable
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a recuperação automática Error-Disable. | errdisable recovery cause { all | bpduguard | dai | dhcp-snooping | eips-udld | l2pt | link-flap | loopback-detect | oamport-security | storm-control | transceiver-power-low | ulfd } | Obrigatório. Por padrão, uma porta não pode ser habilitada automaticamente e o status Error-Disabled definido pelas funções listadas não pode ser apagado automaticamente. No entanto, por padrão, uma porta pode ser habilitada automaticamente e o status Error-Disabled pode ser apagado automaticamente se seu status for definido pela função Link-Flap. |
Configurar o intervalo para descoberta automática do Error-Disable
Você pode configurar o intervalo para que uma porta se recupere automaticamente após o fechamento da porta pelo mecanismo de detecção de erro Error-Disable.
Tabela 11 -4 Configurando o intervalo para descoberta automática do Error-Disable
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o intervalo para descoberta automática Error-Disable. | errdisable recovery interval interval-value | Obrigatório. Por padrão, o intervalo no qual uma porta é habilitada e seu status Error-Disabled é apagado é de 300 segundos. |
Monitoramento e Manutenção de Gerenciamento do Error-Disable
Tabela 11 -5 Monitoramento e Manutenção de Gerenciamento do Error-Disable
| Comando | Descrição |
| show errdisable detect | Exibe se é permitido que todas as funções listadas fechem uma porta e definam a porta para o status Error-Disabled. |
| show errdisable recovery | Exibe se uma porta pode ser habilitada automaticamente e se o status Error-Disabled definido pelas funções listadas pode ser apagado automaticamente. |
| show { interface interface-list | interface link-aggregation link-aggregation-id } status err-disabled | Exibe as informações sobre a configuração de status Error-Disabled de uma porta ou grupo de agregação especificado. |
Exemplo de configuração típico de gerenciamento do Error-Disable
Combinação do Error-Disable e Storm Suppression
Requisitos de rede
- PC acessa a rede IP através do dispositivo. No dispositivo, as funções de supressão de tempestade e desabilitação de erro foram habilitadas.
- Se uma porta de um dispositivo recebe um grande número de pacotes de transmissão, você pode desabilitar a porta via Error-Disable e o Error-Disable pode reativar a porta de acordo com a política.
Topologia de rede
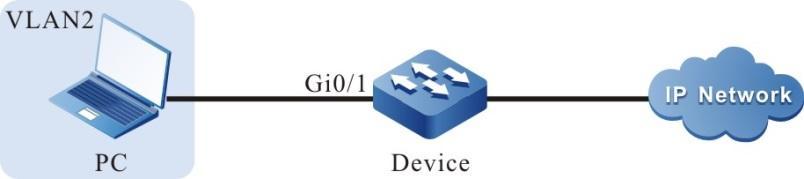
Figura 11-1 Rede para Combinação de Error-Disable e Storm Suppression
Etapas de configuração
- Passo 1: Configure uma VLAN e configure o tipo de link das portas.
#No dispositivo, crie VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2Device(config-if-gigabitethernet0/1)#exit
- Passo 2: Configure a função de supressão de tempestade.
#Na porta gigabitethernet0/1 do dispositivo, habilite a função de supressão de tempestade, e o modo pps é usado para suprimir pacotes de broadcast, e a taxa de supressão é de 20pps. Durante a tempestade, feche o porto.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#storm-control action shutdownDevice(config-if-gigabitethernet0/1)#storm-control broadcast pps 20Device(config-if-gigabitethernet0/1)#exit
- Passo 3: Configure a função Error-Disable.
#Ative a função de recuperação de supressão de tempestade em Error-Disable e defina o tempo de recuperação para 30 segundos.
Device(config)#errdisable recovery cause storm-controlDevice(config)#errdisable recovery interval 30
- Passo 4: Confira o resultado.
#Consulte a configuração relacionada a Error-Disable.
Device#show errdisable recoveryError disable auto recovery configinterval:30 secondsErrDisable Reason Timer Status--------------- ------------bpduguard Disableddai Disableddhcp-snooping Disabledeips-udld Disabledl2pt Disabledlink-flap Enabledloopback-detect Disabledoam Disabledport-security Disabledstorm-control Enabledulfd Disabledtransceiver-power-low Disabled
#Quando o PC envia um grande número de pacotes de broadcast, a porta gigabitethernet0/1 é fechada e as seguintes informações são impressas:
Nov 24 2014 15:37:13: %STORM_CONTROL-3: A storm detected on interface gigabitethernet0/1,
ActionType:shutdown, StormType: broadcast storm
Nov 24 2014 15:37:13: %PORTMGR-LINEPROTO_DOWN-3: Line protocol on interface gigabitethernet0/1, changed state to down
#Consulte o status da porta gigabitethernet0/1.
Device#show interface gigabitethernet 0/1gigabitethernet0/1 configuration informationDescription :Status : EnabledLink : Down (Err-disabled)Set Speed : AutoAct Speed : UnknownSet Duplex : AutoAct Duplex : UnknownSet Flow Control : OffAct Flow Control : OffMdix : AutoMtu : 1824Port mode : LANPort ability : 10M FD, 100M FD,1000M FDLink Delay : No DelayStorm Control : Unicast Pps 1500Storm Control : Broadcast Pps 20Storm Control : Multicast Pps 1500Storm Action : ShutdownPort Type : NniPvid : 2Set Medium : CopperAct Medium : CopperMac Address : 0001.7a54.5ca5
#Após 30s, habilite a porta gigabitethernet0/1 e imprima as seguintes informações de prompt.
Nov 24 2014 15:37:43: %PORTMGR-AUTO_RECOVERY-5: auto recovery timer expired on interface gigabitethernet0/1, module: STROM CONTROL ACTION.Nov 24 2014 15:37:45: %PORTMGR-LINEPROTO_UP-5: Line protocol on interface gigabitethernet0/1, changed state to up.
#Consulte o status da porta gigabitethernet0/1.
Device#show interface gigabitethernet 0/1gigabitethernet0/1 configuration informationDescription :Status : EnabledLink : UpSet Speed : AutoAct Speed : 1000Set Duplex : AutoAct Duplex : FullSet Flow Control : OffAct Flow Control : OffMdix : AutoMtu : 1824Port mode : LANPort ability : 10M FD, 100M FD,1000M FDLink Delay : No DelayStorm Control : Unicast Pps 1500Storm Control : Broadcast Pps 20Storm Control : Multicast Pps 1500Storm Action : ShutdownPort Type : NniPvid : 2Set Medium : CopperAct Medium : CopperMac Address : 0001.7a54.5ca5
GVRP
Visão geral
GVRP (GARP VLAN Registration Protocol), conhecido como GARP VLAN Registration Protocol, é um protocolo de aplicação definido pelo GARP. Ele mantém dinamicamente as informações de VLAN em switches com base no mecanismo de protocolo do GARP. Todos os switches que suportam o recurso GVRP podem receber informações de registro de VLAN de outros switches e atualizar dinamicamente informações de registro de VLAN local, incluindo VLAN atual no switch e quais portas essas VLANs contêm, etc. outros switches, de modo a tornar a configuração de VLAN de todos os dispositivos que suportam recursos GVRP na mesma rede de switch seja consistente em termos de interoperabilidade. As informações de registro de VLAN transmitidas pelo GVRP incluem não apenas as informações de VLAN estáticas configuradas manualmente localmente, mas também as informações de VLAN dinâmicas de outros switches. Observe que a mensagem de licença do GVRP não pode excluir a VLAN configurada manualmente localmente, ou seja, a prioridade da VLAN configurada manualmente é maior que a do GVRP.
O GVRP realiza o registro dinâmico, a manutenção e o logout das informações dos membros da porta VLAN. Se a VLAN não existir, a VLAN será criada dinamicamente; se o número de membros da porta VLAN for 0, a VLAN será excluída dinamicamente, ou seja, a porta será adicionada à VLAN ou excluída da VLAN dinamicamente, o que também realiza a configuração dinâmica da VLAN no switch.
O GVRP pode configurar VLANs dinamicamente, portanto, não é necessário configurar todas as VLANs de todos os dispositivos, mas apenas alguns dispositivos, especialmente dispositivos de borda e algumas VLANs especiais. Outros dispositivos serão configurados automaticamente por meio do GVRP. Agora, a rede corporativa geralmente é grande e há muitas VLANs. A função GVRP reduz bastante o trabalho de configuração dos administradores e reduz a possibilidade de erro manual. Além disso, quando a topologia da rede muda, a VLAN pode ser configurada automaticamente para garantir a conectividade entre as VLANs.
Configuração da função GVRP
Tabela 12 -1 Lista de configuração da função GVRP
| Tarefa de configuração | |
| Habilite a função GVRP | Habilite a função GVRP globalmente |
| Configurar a porta GVRP |
Configure a porta como modo de tronco e VLAN permitida
Habilite a função GVRP na porta Configure o modo GVRP da porta |
Ative a função GVRP
Condição de configuração
Não
Habilite a função GVRP globalmente
Habilite a função GVRP globalmente.
Tabela 12 -2 Habilite a função GVRP globalmente
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a função GVRP globalmente | gvrp enable | Obrigatório. |
Configurar a porta GVRP
Condição de configuração
Não
Configurar a porta GVRP
Adicione a configuração na porta que precisa habilitar a função GVRP, incluindo o modo GVRP e a VLAN permitida.
Tabela 12 -3 Habilite a função GVRP da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta Ethernet atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure a porta como o modo de tronco | switchport mode trunk | Obrigatório. |
| Configure a VLAN permitida pela porta | switchport trunk allowed vlan all | Obrigatório. |
| Habilite o GVRP da porta | gvrp enable | Obrigatório. |
VLAN Isolation
Visão geral
Na rede de acesso do usuário, para obter o isolamento entre diferentes grupos de usuários, diferentes grupos de usuários precisam ser divididos em diferentes VLANs. Caso os usuários do mesmo grupo de usuários desejem realizar o isolamento entre usuários, a tecnologia de isolamento de porta pode ser utilizada, mas esta tecnologia exige que o administrador conheça claramente a localização da porta da rede de acesso do usuário, o que torna a configuração e a manutenção do gerenciamento inconvenientes . A tecnologia de VLAN isolation resolve esse problema habilmente. Os administradores só precisam configurar o VLAN isolation para a VLAN do grupo de usuários e cada usuário no grupo de usuários será isolado um do outro. Ao configurar a porta de uplink do VLAN isolation, os usuários do grupo de usuários podem acessar a rede pública por meio da porta de uplink. Essa tecnologia fornece um esquema mais seguro e flexível para rede.
Configuração da função de VLAN isolation
Tabela 13 -1 lista de configuração de função global de VLAN
| Tarefa de configuração | |
| Configurar o isolamento VLAN | Habilite a função de isolamento de VLAN Configurar a porta de uplink do isolamento VLAN |
Configurar o isolamento de VLAN
Condição de configuração
Nenhum
Ative a função de VLAN isolation
Ao habilitar a função de VLAN isolation, as portas membro na VLAN podem ser isoladas umas das outras.
Tabela 13 -2 Habilite o VLAN isolation global
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração VLAN | vlan vlan-id | - |
| Habilite a função de isolamento de VLAN | vlanIsolat enable | Mandatório. Por padrão, não habilite a função de VLAN isolation. |
Configurar a porta de uplink do VLAN isolation
Depois de configurar a porta de uplink do VLAN isolation, as portas de downlink na VLAN ainda estão isoladas umas das outras, mas as portas de uplink e portas de uplink e as portas de uplink e portas de downlink podem se comunicar umas com as outras.
Tabela 13 -3 Configurar a porta de uplink do isolamento global de VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configurar a porta de uplink do global VLAN isolation | vlanIsolate uplink-port vlan vlan-id | Mandatório. Por padrão, não configure a porta de uplink do VLAN isolation. |
Depois que a função de isolamento de VLAN global é desabilitada, a porta de uplink configurada do isolamento de VLAN é cancelada automaticamente, o VLAN isolation é habilitado e todas as portas na VLAN são portas de downlink por padrão.
Monitoramento e manutenção de VLAN isolation
Tabela 13 -4 Monitoramento e manutenção do global VLAN isolation
| Comando | Descrição |
| show vlan-isolate( [ vlan vlan-id ]) | Exiba as informações de VLAN isolation |
MLAG
Visão geral
MLAG é um mecanismo para realizar a agregação de link entre dispositivos, que reúne um dispositivo e dois outros dispositivos emparelhados para formar um sistema dual-ativo.
Como uma tecnologia de virtualização horizontal de associação fraca, o MLAG não só tem as vantagens de aumentar a largura de banda, fornecer confiabilidade de link e compartilhamento de carga, mas também tem as seguintes vantagens:
- MLAG melhora a confiabilidade do link do nível da placa ao nível do dispositivo. Para agregação de link cross-board comum, se uma placa falhar, todo o link de agregação ainda poderá funcionar normalmente; para agregação de link entre dispositivos MLAG, mesmo que um dispositivo falhe, todo o link de agregação ainda pode funcionar normalmente.
- Simplifique a rede: MLAG, como uma tecnologia de virtualização horizontal, virtualiza logicamente dois dispositivos emparelhados conectados por dual homing em um dispositivo. O MLAG fornece uma topologia de duas camadas sem loop e realiza backup redundante, de modo que o lado do acesso não precisa do protocolo de spanning tree, o que simplifica muito a rede e a configuração.
- Atualização independente : dois dispositivos emparelhados podem ser atualizados separadamente para garantir que um dispositivo funcione normalmente, com pouco impacto nos negócios em execução.
As definições de conceitos relacionados ao MLAG:
- Domínio MLAG (Multi-Chassis Link Aggregation Group): consiste em dois nós de emparelhamento MLAG, formando um sistema ativo duplo.
- Nó de emparelhamento MLAG: no nó de emparelhamento MLAG, existe um nó cujo papel é mestre e outro nó cuja função é escravo.
- Peer link: o link de agregação de conexão direta entre nós de emparelhamento MLAG, que é usado para interagir com pacotes de protocolo MLAG e transmitir parte do tráfego de dados.
- Keep alive: detecção de keep alive entre nós de emparelhamento MLAG, que é realizada através do link L3. A função do MLAG é julgar se o link de peer ainda está ativo após a falha do link de peer.
- PTS (Peer-Link Transport Server): Serviço confiável de transmissão de pacotes baseado em peer link.
- DHD (Double-Homed Device): Um dispositivo (ou servidor) que está conectado ao sistema MLAG dual-active via dual-homing. O próprio DHD pode ser um sistema MLAG dual-active.
- SD ( Single-Hod Device): Um dispositivo (ou servidor) que está conectado ao sistema MLAG dual-active via single-homing.
- MLAG-Port: Indica o grupo de agregação entre dispositivos entre o sistema DHD e MLAG dual-active.
- MLAG Member Port: Indica a porta do membro do link aggregation entre dispositivos entre o sistema DHD e MLAG dual-active.
- Orphan-Port: Refere-se à porta de acesso single-homed no nó de emparelhamento MLAG, incluindo o link aggregation de acesso single-homed. Ao dizer que a porta órfã pertence ao MLAG VLAN, pode não pertencer ao MLAG VLAN.
- MLAG-VLAN: A VLAN à qual o Peer-Link é adicionado, todas as VLANs das portas MLAG devem ser adicionadas ao MLAG-VLAN
- não-MLAG-VLAN: A VLAN que não contém Peer-Link, não-MLAG-VLAN não contém a porta MLAG
- MLAG-VLANIF : interface VLANIF correspondente ao MLAG-VLAN
- não-MLAG-VLANIF: interface VLANIF correspondente a não-MLAG-VLA
- Unpaired: Após a porta do peer link, se o keepalive estiver normal, considera-se que ocorreu uma falha desemparelhada, que fará com que a porta MLAG e MLAG-VLANIF no nó escravo fiquem no estado suspenso, fazendo com que o uplink e o downlink tráfego seja encaminhado através do nó mestre.
- Up-Delay: Quando o nó de emparelhamento MLAG é reiniciado ou a falha do link de peer se recupera, a porta MLAG atrasará por um período de tempo antes de ser definida para o estado UP.
- Recuperação automática: Após um período de tempo, quando o nó MLAG local é considerado completamente desconectado do nó MLAG par (o nó MLAG par real pode falhar ou ainda sobreviver), o nó MLAG local se considera o único nó, torna-se o nó mestre e encaminha o tráfego.
- Dual-Master: Se tanto o peer link quanto o keepalive falharem, o nó escravo julgar estar completamente desconectado do nó mestre, o nó escravo será atualizado para o nó mestre, enquanto o nó mestre original ainda existir. Neste momento, existem dois nós mestres, ou seja, dual-master. O encaminhamento de tráfego pode ser anormal no estado de mestre duplo.
- Pacote de protocolo de controle (também conhecido como pacote de peering): os pacotes de protocolo interagiram entre os nós MLAG, usados para emparelhamento de nós, eleição de papéis, etc., e enviados e recebidos através de UDP.
- Pacote de sincronização de dados (também chamado de pacote de sincronização): ou seja, o pacote de sincronização interagido entre nós MLAG, que é usado para transmitir informações de controle, pacote de protocolo de serviço de retransmissão, entrada de serviço de sincronização, etc. para cada negócio. O pacote de sincronização é encapsulado com as informações do cabeçalho PTS e é enviado e recebido através do TCP.
- VLAN de controle: uma VLAN L3 (VLAN de interface) usada para transmitir pacotes síncronos PTS. Somente o link de peer tem permissão para ingressar na VLAN e outras portas não têm permissão para ingressar na VLAN.
- Suspender: neste artigo, refere-se ao desligamento, que geralmente se refere ao desligamento do grupo de agregação MLAG ou da interface MLAG-VLANIF.
Configuração da função MLAG
Tabela 13 -1 lista de configuração da função MLAG
| Tarefa de configuração | |
| Criar um domínio MLAG | Criar um domínio MLAG |
| Configurar os parâmetros MLAG |
Configure o tempo de atraso da recuperação automática após a reinicialização do nó
Especifique a interface VLAN local Configurar o ID do nó MLAG Configure a prioridade da função do nó MLAG Especifique o endereço IP do peer Configurar o modo de preempção Configure o endereço MAC do sistema MLAG Configure a prioridade do sistema MLAG Configure o tempo de atraso do estado de ativação e o tempo de intervalo do estado de ativação |
| Configurar os parâmetros Keepalive |
Configure a origem, o endereço de origem e outros parâmetros do pacote Keepalive
Defina o intervalo de envio e o tempo limite de recebimento do pacote Keepalive Definir o período de silêncio Keepalive |
| Configurar o Peer-Link | Configure a interface de agregação L2 como a porta Peer-link |
| Configurar a porta MLAG | Configurar a porta MLAG |
| Configurar a Orphan Port | Configure a Orphan Port do nó escravo para ser configurada para o estado de desligamento quando o link de peer falhar, mas manter ativo é normal |
Criar um domínio MLAG
Nos nós de emparelhamento MLAG, o ID de domínio MLAG deve ser consistente.
Condição de configuração
Antes de criar o domínio MLAG, primeiro conclua a seguinte tarefa:
- Nos nós de emparelhamento MLAG, existem outros domínios MLAG diferentes
Criar um domínio MLAG
Crie um domínio MLAG.
Tabela 13 -2 Criar um domínio MLAG
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Criar um domínio MLAG | mlag domain domain-id | Obrigatório. Por padrão, nenhum domínio MLAG é criado e o intervalo de valores do ID do domínio é de 1 a 255 |
Configurar os parâmetros MLAG
Condição de configuração
Antes de configurar os parâmetros MLAG, primeiro conclua a seguinte tarefa:
- Criar um domínio MLAG
Configurar o atraso de recuperação automática após a reinicialização do nó
Depois que o dispositivo for iniciado, inicie o temporizador de recuperação automática com o tempo de atraso de recuperação automática configurado. Se nenhum pacote de manutenção de atividade ou pacote de peering for recebido até que o temporizador expire e o link de peer estiver sempre inativo, o nó de peer será considerado inexistente e o nó se tornará mestre.
Tabela 13 -3 Configure o tempo de recuperação automática após a reinicialização do nó
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de domínio MLAG. | mlag domain domain-id | - |
| Configure o tempo de recuperação automática após a reinicialização do nó | auto-recovery reload-delay delay_value | Opcional Por padrão, o atraso de recuperação automática é de 240 segundos e o intervalo de tempo do atraso de recuperação automática é de 240 a 3600 segundos. |
Especificar a interface VLAN local
A L3 VLAN (interface VLAN) usada para transmitir o pacote síncrono PTS só permite que o link de peer se junte à VLAN, e outras portas não podem ingressar na VLAN.
Tabela 13 -4 Especifique a interface VLAN local
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de domínio MLAG. | mlag domain domain-id | - |
| Especifique a interface VLAN local | local-interface vlan vlan-id [vrf vrf_name] | Obrigatório. Por padrão, o valor padrão do nome VRF é global. O comprimento máximo do nome VRF é de 31 caracteres e o intervalo de VLAN é 2-4094. |
Configurar ID do nó MLAG
No mesmo domínio MLAG, os IDs de nó MLAG são diferentes e exclusivos.
Tabela 13 -5 Configurar o ID do nó MLAG
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de domínio MLAG. | mlag domain domain-id | - |
| Configurar o ID do nó MLAG | node id id-number | Obrigatório. Por padrão, não configure o ID do nó MLAG e o intervalo de IDs do nó MLAG é 1 e 2. |
Configurar a prioridade da função do nó MLAG
A prioridade da função do nó é usada para selecionar a função mestre-escravo entre dois nós no mesmo domínio MLAG. Quanto menor o valor, maior a prioridade, e aquele com maior prioridade se torna o dispositivo mestre. Se a prioridade do nó for a mesma, compare os endereços MAC de bridge dos dois dispositivos e aquele com endereço MAC de bridge menor se tornará o dispositivo mestre.
Tabela 13 -6 Configurar a prioridade da função do nó MLAG
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de domínio MLAG. | mlag domain domain-id | - |
| Configure a prioridade da função do nó MLAG | node role-priority priority-value | Opcional Por padrão, a prioridade do nó MLAG é 100 e a prioridade do nó MLAG varia de 1 a 254 |
Especificar o endereço IP do par
Especifique o endereço IP de destino do pacote PTS.
Tabela 13 -7 Especifique o endereço IP do peer
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de domínio MLAG. | mlag domain domain-id | - |
| Especifique o endereço IP do peer | peer-address ip-address | Obrigatório. Por padrão, não configure o endereço IP do peer. |
Configurar o modo de preempção
Se o modo de preempção estiver configurado, o papel anterior do nó será ignorado quando o papel mestre-escravo for eleito, e o papel do nó será determinado com base no resultado da comparação de prioridade do nó e MAC da bridge: Quanto menor a prioridade valor do nó, quanto maior a prioridade, o nó com maior prioridade se torna o dispositivo mestre; se a prioridade do nó for a mesma, compare os endereços MAC da bridge dos dois dispositivos e, quanto menor o endereço MAC da bridge, torna-se o dispositivo mestre.
Tabela 13 -8 Configurar o modo de preempção
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de domínio MLAG. | mlag domain domain-id | - |
| Configurar o modo de preempção | role preempt | Opcional Por padrão, não configure o modo de preempção. |
Configure o endereço MAC do sistema MLAG
Para permitir que o dispositivo de acesso trate dois nós no domínio MLAG como um dispositivo, os endereços MAC do sistema MLAG dos dois nós devem ser os mesmos.
Tabela 13 -9 Configurar o endereço MAC do sistema MLAG
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de domínio MLAG. | mlag domain domain-id | - |
| Configure o endereço MAC do sistema MLAG | system-mac mac_address | Opcional Por padrão, o endereço MAC do sistema MLAG não está configurado. O endereço MAC do sistema MLAG dos dois nós é gerado automaticamente de acordo com o ID do domínio e permanece o mesmo . |
Configurar a prioridade do sistema MLAG
Para permitir que o dispositivo de acesso trate dois nós no domínio MLAG como um dispositivo, os endereços MAC do sistema MLAG dos dois nós devem ser os mesmos.
Tabela 13 -10 Configurar a prioridade do sistema MLAG
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de domínio MLAG. | mlag domain domain-id | - |
| Configure a prioridade do sistema MLAG | system-priority priority_value | Opcional Por padrão, a prioridade do sistema MLAG é 32768 e o intervalo de prioridade do sistema MLAG é 1-65535. |
Configure o atraso do estado UP e o intervalo do estado UP
Quando o dispositivo ingressar no domínio MLAG como um nó escravo, a interface MLAG será configurada para o estado ativo somente após o tempo de atraso do estado ativo. Durante o atraso do estado ativo, a tabela de endereços MAC, a tabela ARP e outras informações serão sincronizadas, portanto, se houver muitas entradas, o temporizador pode ser estendido adequadamente para evitar a perda de pacotes.
Tabela 13 -11 Configure o tempo de atraso do estado UP e o intervalo do estado UP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de domínio MLAG. | mlag domain domain-id | - |
| Configure o tempo de atraso do estado UP e o intervalo do estado UP | up-delay delay_seconds [interval interval_mseconds] | Opcional Por padrão, o tempo de atraso do estado ativo é de 90 segundos, o tempo de intervalo do estado ativo é de 1000 milissegundos, o intervalo de tempo de atraso do estado ativo é de 1 a 3600 e o tempo de intervalo do estado ativo é de 1 a 300000 milissegundos |
Configurar os parâmetros Keepalive
Condição de configuração
Antes de configurar os parâmetros Keepalive, primeiro conclua a seguinte tarefa:
- Criar um domínio MLAG
Configurar Origem, Endereço de Destino e Outros Parâmetros do Pacote Keepalive
Para estabelecer o sistema MLAG corretamente, os endereços de origem e destino do pacote keepalive devem ser configurados e a camada L3 entre dois nós é alcançável.
A VLAN correspondente à interface L3 à qual o endereço IP de origem do pacote keepalive pertence não pode ser incluída na VLAN onde a interface de link de peer está localizada.
Tabela 13 -12 Configure a origem, endereço de destino e outros parâmetros do pacote Keepalive
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de domínio MLAG. | mlag domain domain-id | - |
| Configure os endereços de origem, destino e outros parâmetros do pacote Keepalive | keepalive ip destination ipv4_address source ipv4_address [udp-port udp-number] [vrf vrf_name] | Obrigatório. Por padrão, a porta udp é 53910, o nome VRF é global, o intervalo de porta udp é 1-65535 e o nome VRF suporta até 31 caracteres. |
Configurar o intervalo de envio e o tempo limite de recebimento do pacote Keepalive
Ao receber o pacote keepalive anterior ou ao iniciar a escuta, inicie o timer de tempo limite de recebimento com o tempo limite de recebimento. Se o temporizador não receber o próximo pacote keepalive antes da expiração, ele será considerado PERDIDO.
Tabela 13 -13 Configure o intervalo de envio e o tempo limite de recebimento do pacote Keepalive
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de domínio MLAG. | mlag domain domain-id | - |
| Configure o intervalo de envio e o tempo limite de recebimento do pacote Keepalive | keepalive interval mseconds [timeout seconds] | Opcional Por padrão, o intervalo de transmissão do pacote keepalive é de 1000ms, o tempo limite de recebimento do pacote keepalive é de 6 s , o intervalo do intervalo de envio do pacote keepalive é 100-10000 e o tempo limite de recebimento do pacote keepalive é de 1-20s |
Configurar o tempo de silêncio do pacote Keepalive
Depois que o peer-link está inativo, o nó escravo entra no período de silêncio. Os pacotes keepalive recebidos durante o período de silêncio serão ignorados e não serão processados. Os pacotes keepalive recebidos após o período de silêncio serão processados. O período de silêncio é esperar que os pacotes keepalive no link sejam recebidos e enviados completamente, para evitar a detecção falsa devido ao atraso do pacote.
Tabela 13 -14 Configure o tempo de silêncio do pacote Keepalive
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração de domínio MLAG. | mlag domain domain-id | - |
| Configure o tempo de silêncio do pacote Keepalive | keepalive quiet-time mseconds | Opcional Por padrão, o período de silêncio do pacote Keepalive é de 1000ms e o intervalo de valores do tempo de silêncio é de 1 a 10.000ms. |
Configurar o peer-link
Condição de configuração
Antes de configurar o Peer-link, primeiro conclua a seguinte tarefa:
- Criar um domínio MLAG
Configurar a interface de agregação L2 como porta peer-link
Peer-link é um link de agregação de link conectado diretamente entre dois dispositivos MLAG, que é usado para interagir com pacotes de protocolo MLAG e transmitir parte do tráfego de dados.
Tabela 13 -15 Configurar a interface de agregação L2 como porta Peer-Link
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface de agregação L2 | interface link-aggregation link-aggregation-id | - |
| Configure a interface de agregação L2 como porta Peer-Link | mlag peer-link | Obrigatório. Por padrão, não configure a porta Peer-Link. |
Configurar a porta MLAG
Condição de configuração
Antes de configurar a porta MLAG, primeiro complete a seguinte tarefa:
- Criar um domínio MLAG
Configurar a porta MLAG
Para fornecer confiabilidade e evitar loops no processo de configuração, em dois nós de emparelhamento MLAG, configure o acoplamento do grupo de agregação com o mesmo grupo de convergência no DHD como o mesmo ID de porta MLAG para formar um grupo de agregação de link entre dispositivos.
Tabela 13 -16 Configurar a porta MLAG
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface de agregação L2 | interface link-aggregation link-aggregation-id | - |
| Configurar a porta MLAG | mlag group mlag-id | Obrigatório. Por padrão, não configure a porta MLAG e o ID da porta MLAG é 1-1000. |
Sugere-se configurar o grupo de link aggregation como o grupo de agregação dinâmica.
Configurar a Orphan Port
Condição de configuração
Antes de configurar a Orphan Port, primeiro conclua a seguinte tarefa:
- Criar um domínio MLAG
Configure a Orphan Port do nó SLAVE como desligamento quando o peer-link falha, mas o Keepalive é normal
Por padrão, quando o link de peer falha, mas keepalive é normal, todas as portas MLAG do nó escravo serão configuradas para o estado de desligamento, mas as portas órfãs não serão configuradas para o estado de desligamento. Se você deseja definir algumas portas órfãs para o estado de desligamento, você precisa configurar este comando para essas portas órfãs
Tabela 13 -17 Configure a porta órfã do nó escravo para desligar quando o Peer-link falhar, mas o Keepalive é normal
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Modo de configuração da interface Ethernet L2 | interface interface-name | Opcional. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração da interface de agregação L2, a configuração subsequente entra em vigor apenas no grupo de agregação. |
| Entre no modo de configuração da interface de agregação L2 | interface link-aggregation link-aggregation-id | |
| Configure a Orphan Port do nó escravo para desligar quando o Peer-link falhar, mas o Keepalive é normal | mlag unpaired orphan-port suspend | Opcional Por padrão, não configure o comando. |
Monitoramento e manutenção de MLAG
Tabela 13 -18 Monitoramento e Manutenção de MLAG
| Comando | Descrição |
| clear mlag packet keepalive statistics [tx | rx] | Limpar estatísticas de pacote de manutenção de atividade MLAG |
| clear mlag packet peering statistics [tx | rx] | Limpar estatísticas do pacote de emparelhamento MLAG |
| clear mlag packet statistics pts [application app-id] [tx | rx] | Limpar estatísticas do pacote MLAG PTS |
| clear mlag packet sync statistics [tx | rx] | Limpar estatísticas do pacote MLAG Sync |
| show mlag pts application | Exibir todas as informações de serviço da MLAG |
| show mlag brief | Exibir as informações breves do MLAG |
| show mlag group [mlag-id] | Exibir as informações do grupo de agregação MLAG |
| show mlag keepalive | Exibir as informações do MLAG Keepalive |
| show mlag node | Exibir as informações do nó MLAG |
| show mlag packet pts [application [app-id]] statistics | Exibe as informações estatísticas dos pacotes PTS recebidos e enviados de todos os serviços MLAG ou serviço MLAG especificado |
| show mlag packet keepalive statistics | Exiba as informações estatísticas do pacote MLAG Keepalive |
| show mlag packet peering statistics | Exibir as informações estatísticas de pacotes de emparelhamento MLAG |
| show mlag packet sync statistics | Exibir as informações estatísticas dos pacotes de sincronização MLAG |
| show mlag suspend | Exibir as interfaces suspensas |
| show mlag up-delay | Exibe as interfaces aguardando o tempo limite do temporizador de atraso de ativação |
Exemplo de configuração típica de MLAG
Configurar funções básicas de MLAG
Requisitos de rede
- Todos os dispositivos estão em uma rede L2.
Topologia de rede
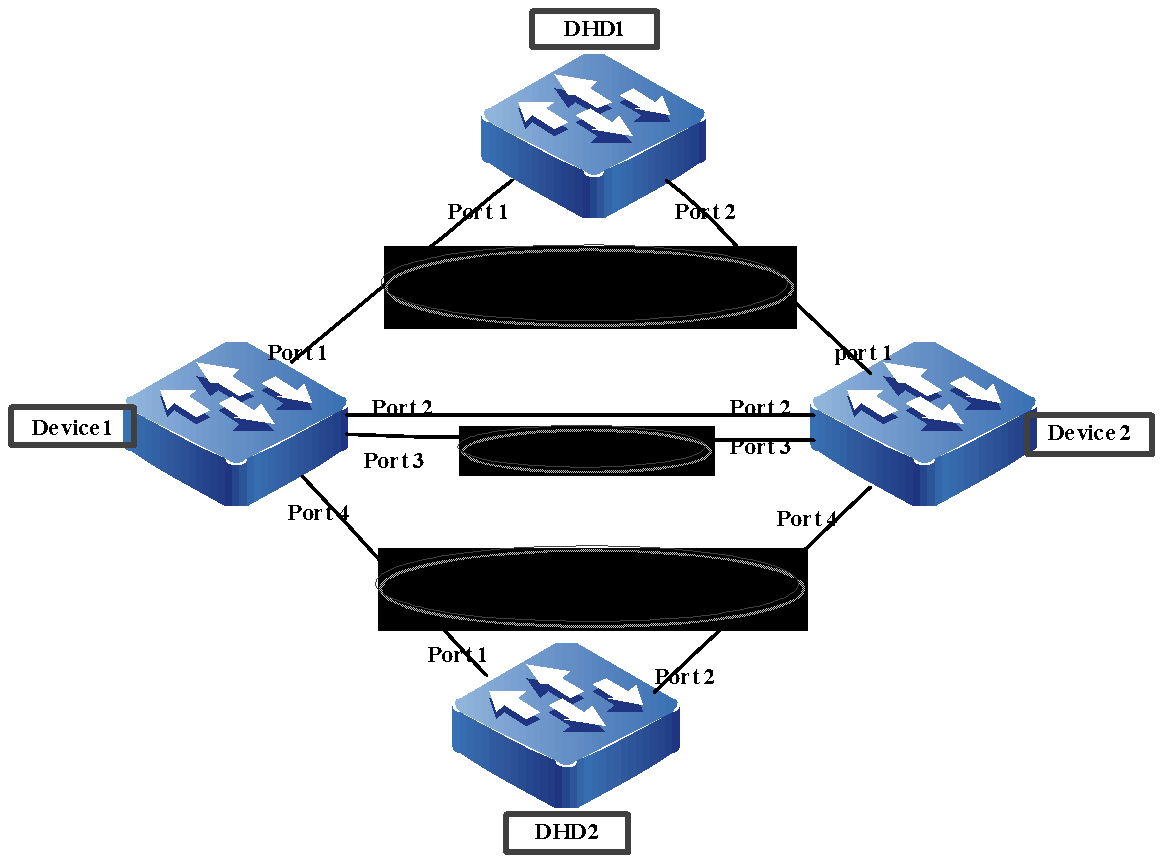
Figura 13 -1 Configurar funções básicas do MLAG
Etapas de configuração
- Passo 1: Adicione a interface ao link aggregation e adicione à vlan. (omitido)
- Passo 2: Configure o domínio MLAG.
#Configure Device1 e configure a instância de domínio MLAG.
Device1#configure terminalDevice1(config)#mlag domain 1Device1(config-mlag-domain)#node id 1Device1(config-mlag-domain)#local-interface vlan 100Device1(config-mlag-domain)#peer-address 20.0.0.10Device1(config-mlag-domain)#keepalive ip destination 30.0.0.10 source 30.0.0.20Device1(config-mlag-domain)#exit
##Configure Device2 e configure a instância de domínio MLAG.
Device2#configure terminalDevice2(config)#mlag domain 1Device2(config-mlag-domain)#node id 2Device2(config-mlag-domain)#local-interface vlan 100Device2(config-mlag-domain)#peer-address 20.0.0.20Device2(config-mlag-domain)#keepalive ip destination 30.0.0.20 source 30.0.0.10Device2(config-mlag-domain)#exit
Descrição:
Os IDs de domínio de dois nós MLAG devem ser iguais.
Os IDs de nó de dois nós MLAG não podem ser iguais.
- Passo 3: Configure a interface local vlan e a interface ip keepalive.
#Configure Device1, e configure a interface local vlan e a interface keepalive ip.
Device1(config)#interface vlan 100Device1(config-if-vlan100)#ip address 20.0.0.10 24Device1(config-if-vlan100)#exitDevice1(config)#interface vlan 4094Device1(config-if-vlan4094)#ip address 30.0.0.10 24Device1(config-if-vlan4094)#exitDevice1(config)#
#Configure Device2, e configure a interface local vlan e a interface keepalive ip.
Device2(config)#interface vlan 100Device2(config-if-vlan100)#ip address 20.0.0.20 24Device2(config-if-vlan100)#exitDevice2(config)#interface vlan 4094Device2(config-if-vlan4094)#ip address 30.0.0.20 24Device2(config-if-vlan4094)#exitDevice2(config)#
- Passo 4: Configure o grupo mlag e o grupo de links de pares.
#Configure Device1 e configure o grupo mlag e o grupo peer-link.
Device1(config)#interface link-aggregation 1Device1(config-link-aggregation1)#mlag group 1Device1(config-link-aggregation1)#exitDevice1(config)#Device1(config)# interface link-aggregation 10Device1(config-link-aggregation10)#mlag peer-linkDevice1(config-link-aggregation1)#exitDevice1(config)#Device1(config)# interface link-aggregation 20Device1(config-link-aggregation20)#mlag group 20Device1(config-link-aggregation20)#exit>Device1(config)#
#Configure Device2 e configure o grupo mlag e o grupo peer-link.
Device2(config)# interface link-aggregation 1Device2(config-link-aggregation1)#mlag group 1Device2(config-link-aggregation1)#exitDevice2(config)#Device2(config)# interface link-aggregation 10Device2(config-link-aggregation10)#mlag peer-linkDevice2(config-link-aggregation1)#exitDevice2(config)#Device2(config)# interface link-aggregation 20Device2(config-link-aggregation20)#mlag group 20Device2(config-link-aggregation20)#exitDevice2(config)#
#Consulte as informações do MLAG no Device1.
Device1#sho mlag briefMLAG domain id : 1Role FSM status : SLAVEPeering FSM status : ESTABLISHEDKeepalive FSM status : ALIVEPTS Service : ONUp-delay : 90secLocal-interface vlan : 100Graceful-restart : DisabledNumber of mlags configured : 2-----------------------------------------------------Peer-Link Link-status Data-status Active-vlans-------------------- ----------- ----------- --------link-aggregation 10 LINKUP UP 2-4093-----------------------------------------------------Node ID Role System-MAC System-Priority------- ---- ------- --------------- ----------------Self 1 SLAVE 0001.7a95.000b 32768Remote 2 MASTER 0001.7a95.000b 32768Device1#Device1#show mlag groupNumber of mlags configured : 2mlag-id: 1 (link-aggregation1)--Link status: LINKUP--Data status: UP--Active mlag vlans: 2-4093--Redirect FSM state: INVALID--Isolate FSM state: ISOLATE--Block FSM state: UNBLOCK--Remote interface: link-aggregation 1--Remote link status: LINKUP--Remote data status: UPmlag-id: 20 (link-aggregation 20)--Link status: LINKUP--Data status: UP--Active mlag vlans: 2-4093--Redirect FSM state: INVALID--Isolate FSM state: ISOLATE--Block FSM state: UNBLOCK--Remote interface: link-aggregation 20--Remote link status: LINKUP--Remote data status: UPDevice1#
04 Protocolo IP e Serviços
ARP
Visão geral
O Address Resolution Protocol (ARP) fornece mapeamento dinâmico de endereços IP para endereços MAC. Os quadros Ethernet a serem transmitidos na Ethernet podem ser encapsulados adequadamente somente depois que os endereços MAC forem especificados. O protocolo ARP é usado para obter endereços MAC que correspondem a endereços IP.
Configuração da função ARP
Tabela 1 -1 Lista de funções ARP
| Tarefas de configuração | |
| Configure as funções básicas do ARP. |
Configurar ARP estático
Configurar a publicidade ARP local Configure o número máximo de entradas ARP dinâmicas. Configure o tempo de envelhecimento ARP dinâmico. Ative a função de aprendizado dinâmico do APP função de aprendizado passivo dinâmico ARP Configure a profundidade da fila de recebimento ARP. Configure o proxy ARP. |
Configurar funções básicas do ARP
Condição de configuração
Nenhum
Configurar uma entrada ARP estática
Configurar o ARP estático significa que um usuário especifica manualmente o mapeamento entre endereços IP e endereços MAC.
Tabela 1-2 Configurando ARP Estático
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma entrada ARP estática. | arp [ vrf vrf-name ] { ip-address | host-name } mac-address [alias [ advertise ] | advertise [ alias ] ] [vlan vlan-id {{ interface if-name} | { link-aggregation link-aggregation-id }}] | Obrigatório . |
Quando a entrada ARP estática configurada contém um alias , se uma solicitação ARP para esse endereço IP for recebida, o endereço MAC na entrada ARP estática será usado para resposta. Quando a entrada ARP estática configurada contém uma opção de anúncio, o ARP estático será anunciado regularmente quando o anúncio ARP estático estiver habilitado. Quando o ARP estático está vinculado à porta ou grupo de agregação específico, o ARP estático apenas entra em vigor na porta ou no grupo de agregação.
publicidade ARP local
O pacote de solicitação ARP é o pacote de transmissão . Quando há muitas solicitações ARP na rede, é fácil gerar a tempestade de broadcast na rede e, como resultado, os pacotes de solicitação ARP normais podem ser inundados e não podem aprender o ARP. No caso, podemos configurar a função de publicidade ARP local para reduzir as solicitações ARP e a possibilidade de tempestade de transmissão.
Tabela 1 -3 Configurar a publicidade ARP local
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar publicidade ARP local | arp local-announce enable | Obrigatório |
| Configure o intervalo da publicidade ARP local | arp local-announce interval seconds | Opcional Por padrão, é 10s. |
| Configure a taxa de publicidade ARP local | arp local-announce rate speed | Opcional Por padrão, é um pacote a cada segundo. |
Configurar o número máximo de entradas ARP dinâmicas
A finalidade de configurar o número máximo de entradas ARP dinâmicas é impedir que o ARP aprendido dinamicamente ocupe muitos recursos do sistema.
Tabela 1 - 4 Configurando o Número Máximo de Entradas ARP Dinâmicas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o número máximo de entradas ARP dinâmicas. | arp limited max-entries | Obrigatório . Por padrão, o número máximo de entradas ARP dinâmicas é 5.000 . |
Configurar o tempo de envelhecimento ARP dinâmico
O ciclo de vida de uma entrada ARP aprendida dinamicamente é o tempo de envelhecimento. Dentro do tempo de envelhecimento, o dispositivo envia solicitações ARP periodicamente. Se receber uma resposta ARP, ele redefine o tempo de envelhecimento. Se o tempo de envelhecimento expirar, o dispositivo exclui a entrada ARP dinâmica.
Tabela 1 -5 Configurando o tempo de envelhecimento ARP dinâmico
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o tempo de envelhecimento ARP dinâmico. | arp timeout { second | disable } | Obrigatório . O tempo de envelhecimento padrão é de 1200 segundos. |
Ativar função aprendida de ARP dinâmico
Por padrão, um dispositivo pode realizar o aprendizado passivo de APR dinâmico . Para evitar que o ARP aprendido dinâmico ocupe muitos recursos do sistema, você pode desabilitar a função de aprendizado passivo do ARP dinâmico. Depois que o aprendizado passivo ARP dinâmico é desabilitado, depois que o dispositivo local recebe uma solicitação ARP para o endereço MAC do dispositivo local, ele envia uma resposta ARP , mas não gera nenhuma entrada ARP relacionada. Uma entrada ARP é gerada somente quando o dispositivo local solicita ativamente o endereço MAC de um dispositivo de mesmo nível.
Tabela 1 -6 Ativar a função de aprendizado passivo ARP dinâmico
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Ative a função de aprendizado passivo ARP dinâmico. | arp learn-active | Obrigatório Por padrão, ative a função de aprendizado passivo ARP dinâmico. |
Ativar aprendizado ARP dinâmico
Por padrão, a interface pode realizar o aprendizado ARP dinâmico. Para obter uma segurança mais confiável, o usuário pode desabilitar a função de aprendizado ARP dinâmico da interface e usar o ARP estático, para evitar a falsificação de ARP.
Tabela 1 -7 Habilitando o Aprendizado ARP Dinâmico
| Etapa | Comando | Descrição |
| Entre no modo de configuração da interface. | configure terminal | - |
| Habilite o aprendizado ARP dinâmico. | arp learn-active | Obrigatório . Por padrão, o aprendizado ARP dinâmico está habilitado. |
Configurar o comprimento da fila de recebimento ARP
Os pacotes ARP recebidos pelo dispositivo serão primeiro armazenados em cache na fila de recebimento ARP. O sistema lerá os pacotes da fila em ordem e, em seguida, tratará os pacotes. Quando o cache Os pacotes ARP atingem a profundidade da fila, os pacotes APR recebidos subsequentemente serão descartados. O usuário pode ajustar o comprimento da fila de recebimento ARP com base na emergência ARP da rede.
Tabela 1 -8 Configurar o comprimento da fila de recebimento ARP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o comprimento da fila de recebimento ARP | arp queue-length length | Obrigatório O comprimento da fila é 200 por padrão |
Configurar proxy ARP
Uma solicitação ARP é enviada pelo host de uma rede para outra rede, e o dispositivo intermediário entre as duas redes pode responder à solicitação ARP. Esse processo é chamado de proxy ARP.
Tabela 1 -9 Configurando o proxy ARP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o proxy ARP. | ip proxy-arp | Obrigatório . Por padrão, a função de proxy ARP está habilitada. |
Monitoramento e manutenção de ARP
Tabela 1 -10 Monitoramento e manutenção de ARP
| Comando | Descrição |
| show arp [ vrf vrf-name ] | Consulta a tabela ARP. |
| show arp attack-detection | Exibe as informações sobre o host suspeito de iniciar ataques ARP. |
Exemplo de configuração típica de ARP
Configurar proxy ARP
Requisitos de rede
- O dispositivo é conectado diretamente ao PC1 e ao PC2, respectivamente. O número de rede da LAN em que PC1 e PC2 estão localizados é 10.0.0.0/16.
- O endereço MAC da interface VLAN2 do dispositivo é 0001.7a13.0102.
- Por meio do proxy ARP do dispositivo, o PC1 pode executar ping no PC2 com êxito e o PC1 pode aprender o endereço MAC do PC2.
Topologia de rede

Figura 1 -1 Rede para configurar o proxy ARP
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Confira o resultado.
#Ping o endereço IP do PC2 10.0.1.2 do PC1.
C:\Documents and Settings>ping 10.0.1.2Pinging 10.0.1.2 with 32 bytes of data:Reply from 10.0.1.2: bytes=32 time<1ms TTL=255Reply from 10.0.1.2: bytes=32 time<1ms TTL=255Reply from 10.0.1.2: bytes=32 time<1ms TTL=255Reply from 10.0.1.2: bytes=32 time<1ms TTL=255Ping statistics for 10.0.1.2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0ms
#Consulte a entrada ARP do Dispositivo.
Device#show arpProtocol Address Age (min) Hardware Addr Type Interface SwithportInternet 10.0.0.1 - 0001.7a13.0102 ARPA vlan2 ---Internet 10.0.0.2 1 B8AC.6F2D.4498 ARPA vlan2 gigabitethernet0/1Internet 10.0.1.1 - 0001.7a13.0103 ARPA vlan3 ---Internet 10.0.1.2 1 4437.e603.0d63 ARPA vlan3 gigabitethernet0/2
#Consulte a entrada ARP do PC1.
C:\Documents and Settings>arp -aInterface: 10.0.0.2 --- 0x5Internet Address Physical Address Type10.0.0.1 00-01-7a-13-01-02 dynamic10.0.1.2 00-01-7a-13-01-02 dynamic
# Pingde PC1 para PC2 é bem sucedido . O PC1 aprendeu o endereço MAC do PC2.
Por padrão, o proxy ARP está habilitado para um dispositivo.
Configurar uma entrada ARP estática
Requisitos de rede
- O dispositivo e o PC estão diretamente conectados.
- O endereço MAC do PC é 4437.e603.0d63.
- O endereço IP e o endereço MAC do PC estão vinculados ao Dispositivo.
- O PC pode executar ping com sucesso no endereço da interface VLAN2 do dispositivo.
Topologia de rede
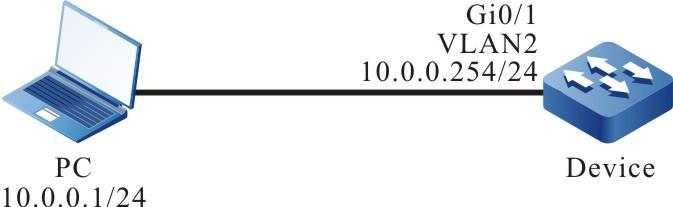
Figura 1 -2 Rede para configurar uma entrada ARP estática
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Vincule o endereço IP e o endereço MAC do PC ao dispositivo.
#Configurar dispositivo.
Vincule o endereço IP e o endereço MAC do PC ao dispositivo.
Device(config)#arp 10.0.0.1 4437.e603.0d63- Passo 4: Confira o resultado.
#Consulte a entrada ARP do Dispositivo.
Device1#show arpProtocol Address Age (min) Hardware Addr Type Interface SwitchportInternet 10.0.0.1 - 4437.e603.0d63 ARPA vlan2 gigabitethernet0/1Internet 10.0.0.254 - 0001.7a13.0102 ARPA vlan2 ---
# PC pode executar ping com sucesso no endereço 10.0.0.254 da interface VLAN2 do dispositivo.
C:\Documents and Settings>ping 10.0.0.254Pinging 10.0.0.254 with 32 bytes of data:Reply from 10.0.0.254: bytes=32 time<1ms TTL=255Reply from 10.0.0.254: bytes=32 time<1ms TTL=255Reply from 10.0.0.254: bytes=32 time<1ms TTL=255Reply from 10.0.0.254: bytes=32 time<1ms TTL=255Ping statistics for 10.0.0.254:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0ms
# O PC pode executar ping com sucesso no endereço da interface VLAN2 do dispositivo.
Base IPv4
Visão geral
O Internet Protocol (IP) é baseado em pacotes de dados. É usado na troca de dados entre redes de computadores. Os protocolos suportados pelo dispositivo incluem: IP, Internet Control Message Protocol (ICMP), Transfer Control Protocol (TCP), User Datagram Protocol (UDP) e Socket.
Entre eles, os pacotes IP são a base da pilha de protocolos TCP/IP. A camada IP é responsável pelo endereçamento, fragmentação, remontagem e particionamento de informações de protocolo. Como protocolo da camada de rede, o protocolo IP realiza o endereçamento de rotas e controla a transmissão de pacotes.
O protocolo UDP e o protocolo UDP são configurados com base no protocolo IP. Eles fornecem serviços de transmissão de dados confiáveis baseados em conexão e serviços de transmissão de dados não confiáveis baseados em conexão, respectivamente.
O ICMP é usado principalmente para fornecer serviços de detecção de rede. Ele também fornece um relatório de erro se a camada de rede ou o protocolo da camada de transmissão se tornar anormal e informa o dispositivo relacionado sobre a anormalidade para facilitar o gerenciamento do controle de rede.
Configuração de função básica de IP
Tabela 2 -1 Lista de funções básicas de IP
| Tarefas de configuração | |
| Configure um endereço IP. |
Configure um endereço IP para uma interface.
Configure um endereço IP não numerado para uma interface. |
| Configure as funções básicas do protocolo IP. |
Configure a profundidade da fila de recebimento de pacotes IP.
Configure o Time To Live (TTL) dos pacotes IP transmitidos. Configure o tempo limite para remontagem do pacote. Habilite a verificação de recebimento de pacote IP e verifique. Configure os pacotes IP transmitidos para calcular uma soma de verificação. Habilite o cache de roteamento IP. |
| Configure as funções básicas do protocolo ICMP. |
Habilite o redirecionamento ICMP global.
Habilite o redirecionamento ICMP global. Ativar destino ICMP inacessível. Configurar limitação de velocidade ICMP |
| Configure as funções básicas do protocolo TCP. |
Configure o tamanho do cache de recebimento TCP.
Configure o tamanho do cache de transmissão TCP. Configure o número máximo de retransmissões TCP. Configure o comprimento máximo dos pacotes TCP. Configure o tempo máximo de ida e volta do TCP. Configure o tempo ocioso da conexão TCP. Configure o tempo de espera da configuração da conexão TCP. Configure o número máximo de tempos de keep-alive do TCP. Ative o carimbo de data/hora TCP. Habilite a retransmissão seletiva TCP. |
| Configure as funções básicas do protocolo UDP. |
Configure o TTL de pacotes UDP.
Configure o tamanho do cache de recebimento UDP. Configure o tamanho do cache de transmissão UDP. Habilite a verificação UDP e verifique. Preencha a soma de verificação do pacote UDP. |
Configurar um endereço IP
Um endereço IP é um número de 32 bits que identifica exclusivamente um dispositivo de rede que executa o protocolo IP na Internet.
Um endereço IP consiste nas duas partes a seguir:
- Número da rede (Net-id): Identifica a rede na qual o dispositivo está localizado.
- Número do host (Host-id): Especifica o número do host na rede do dispositivo.
Para facilitar o gerenciamento de endereços IP, os endereços IP são categorizados em cinco classes, e cada classe de endereço IP tem suas próprias funções. Os endereços IP das classes A a C são usados para alocação de endereços, os endereços IP da classe D são usados em aplicativos multicast e os endereços IP da classe E são usados para fins de teste. A tabela a seguir mostra as classes de endereços IP e seus intervalos.
Tabela 2 -2 Classes de endereços IP e seus intervalos
| Tipo de endereço | Disponível Network Address Range | Descrição |
| A | 1.0.0.0-127.0.0.0 | O número de rede 127 é usado para interfaces de loopback. |
| B | 128.0.0.0-191.255.0.0 | - |
| C | 192.0.0.0-223.255.255.0 | - |
| D | 224.0.0.0-239.255.255.255 | Os endereços de classe D são usados para multicast. |
| E | 240.0.0.0- 255.255.255.254 | Os endereços de classe E são usados para fins de teste. |
Com o desenvolvimento da Internet, os recursos de endereços IP foram gradualmente consumidos. A alocação de endereços baseada em classes causa desperdício de endereços, então o conceito de "sub-rede" é introduzido. "Sub-rede" recebe alguns números de host nos endereços IP como números de sub-rede. Dessa forma, uma grande rede é dividida em várias sub-redes. Isso facilita o planejamento e a implantação da rede.
Os três segmentos de endereço, 10.0.0.0-10.255.255.255, 172.16.0.0-172.31.255.255 e 192.168.0.0-192.168.255.255 são endereços privados e reservados e não podem ser alocados à rede pública.
Esta seção descreve como configurar um endereço IP de interface e como configurar um endereço IP de interface não numerado.
Condição de configuração
Nenhum
Configurar um endereço IP para uma interface
Um endereço IP só pode ser configurado para uma interface que suporte o protocolo IP. Uma interface só pode ser configurada com um endereço IP primário, mas pode ser configurada com vários endereços IP secundários.
Tabela 2 -3 Configurando um endereço IP para uma interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure um endereço IP para uma interface. | ip address ip-address { network-mask | mask-len } [ secondary ] | Obrigatório . |
Uma interface só pode ser configurada com um endereço IP primário, portanto, o endereço IP primário recém-configurado substitui o endereço IP primário original. Antes de uma interface ser configurada com endereços IP secundários, a interface deve ser configurada como um endereço IP primário. Uma interface pode ser configurada com no máximo 100 endereços IP secundários. Os endereços IP de interfaces diferentes não devem estar no mesmo segmento de rede, mas os endereços IP primário e secundário de uma interface podem estar no mesmo segmento de rede.
Configurar um endereço IP não numerado para uma interface
Endereços IP não numerados salvam endereços IP. No caso de endereços IP não numerados, os endereços IP de outras interfaces podem ser emprestados em vez de alocados independentemente. Se uma interface não numerada gerar um pacote IP, o endereço IP de origem do pacote será o endereço IP primário de uma interface emprestada. Ao configurar um endereço IP não numerado para uma interface, a interface a ser emprestada deve ser especificada, para que o endereço IP da interface possa ser emprestado.
Tabela 2 -4 Configurando um endereço IP não numerado para uma interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure um endereço IP não numerado para uma interface. | ip unnumbered reference-interface | Obrigatório . |
A interface emprestada deve ser configurada com o endereço IP primário e a interface não deve ser configurada com um endereço IP não numerado. O endereço IP primário de uma interface pode ser emprestado por várias interfaces, mas somente o endereço IP primário da interface pode ser emprestado.
Configurar funções básicas do protocolo IP
Na pilha de protocolos TCP/IP, o protocolo IP é o protocolo principal da camada de rede responsável pela interconexão da rede. O protocolo IP é um protocolo sem conexão. Antes de transmitir dados, você não precisa configurar uma conexão. O protocolo IP tenta entregar os pacotes da melhor forma, mas não garante que todos os pacotes possam chegar ao destino ordenadamente.
Condição de configuração
Nenhum
Configurar a profundidade da fila de recebimento de pacotes IP
Os pacotes IP recebidos por um dispositivo são primeiro armazenados em cache na fila de recebimento de pacotes IP de uma interface. O sistema lê os pacotes ordenadamente na fila para processamento. Se os pacotes IP armazenados em cache atingirem a profundidade da fila especificada, os pacotes IP posteriores serão descartados. Você pode ajustar a profundidade da fila de recebimento de pacotes IP de acordo com a rajada de pacotes IP na rede.
Tabela 2 -5 Configurando a Profundidade da Fila de Recebimento de Pacotes IP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a profundidade da fila de recebimento de pacotes IP para um valor especificado. | ip option queue-length queue-size | Obrigatório . Por padrão, a profundidade da fila de recebimento de pacotes IP é 200. |
| Configure a profundidade da fila de recebimento de pacotes IP para o valor padrão. | default ip option queue-length | Opcional . |
Configurar o TTL de pacotes IP transmitidos
O cabeçalho de um pacote IP contém o campo Time-To-Live (TTL), que é reduzido em um quando o pacote IP passa por um dispositivo de roteamento. Quando o TTL é 0, o dispositivo descarta o pacote IP. Por padrão, o TTL dos pacotes IP transmitidos pelo dispositivo é 255, ou seja, o pacote só pode ser transmitido por até 255 vezes. Se você quiser limitar o número de vezes de encaminhamento de pacotes, ajuste o valor TTL para os pacotes IP transmitidos.
Tabela 2 -6 Configurando o TTL de pacotes IP transmitidos
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o TTL dos pacotes IP transmitidos para um valor especificado. | ip option default-ttl ttl -value | Obrigatório . Por padrão, o TTL dos pacotes IP transmitidos é 255. |
| Configure o TTL dos pacotes IP transmitidos para um valor padrão. | default ip option default-ttl | Opcional . |
Configurar tempo limite para remontagem de pacotes
Se um pacote IP for fragmentado durante a transmissão, após os fragmentos chegarem ao destino, eles precisam ser reagrupados para formar um pacote IP completo. Antes de todos os fragmentos serem recebidos, os fragmentos recebidos são armazenados em cache temporariamente. Se a remontagem expirar antes que todos os fragmentos cheguem ao destino, os fragmentos recebidos serão descartados.
Tabela 2 -7 Configurando o tempo limite para remontagem de pacotes
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurando o tempo limite para remontagem do pacote para um valor especificado. | ip option fragment-ttl ttl-value |
Obrigatório
. Por padrão, o tempo limite para remontagem do pacote é 60 e a unidade é 0,5 segundo. |
| Configurando o tempo limite para remontagem do pacote para o valor padrão. | default ip option fragment-ttl | Opcional . |
A unidade para o tempo limite de remontagem do pacote é 0,5 segundo.
Habilite a Verificação de Recebimento de Pacotes IP e Verifique
Você pode habilitar esta função para verificar e verificar os pacotes IP recebidos. Se a soma de verificação estiver incorreta, o pacote será descartado.
Tabela 2 -8 Habilitando a Verificação e Verificação de Recebimento de Pacotes IP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a verificação de recebimento de pacote IP e verifique. | ip option recv-checksum | Obrigatório . Por padrão, a função está habilitada. |
| Configure o método para verificar e verificar os pacotes IP recebidos para o valor padrão. | default ip option recv-checksum | Opcional . |
Ativar cache de roteamento IP
Após o envio de um pacote do socket para a camada IP, se o endereço de destino for o mesmo do pacote anterior e a rota for válida, o pacote utilizará diretamente a rota no cache sem a necessidade de procurar outra rota.
Tabela 2 -9 Habilitando o Cache de Roteamento IP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite o cache de roteamento IP. | ip upper-cache | Obrigatório . Por padrão, a função de cache de roteamento IP está habilitada. |
Configurar funções básicas do protocolo ICMP
Na pilha de protocolos TCP/IP, o ICMP é usado principalmente para fornecer serviços de detecção de rede. Ele também fornece um relatório de erro se a camada de rede ou o protocolo da camada de transmissão se tornar anormal e informa o dispositivo relacionado sobre a anormalidade para facilitar o gerenciamento do controle de rede.
Condição de configuração
Nenhum
Ativar redirecionamento ICMP global
Depois que um dispositivo recebe um pacote IP para ser encaminhado, se for constatado que a interface de recebimento do pacote e a interface de transmissão do pacote são as mesmas através da seleção de rota, o dispositivo encaminha o pacote e envia de volta um pacote de redirecionamento ICMP para o final de origem, solicitando que o final de origem selecione novamente o próximo salto correto para transmissão de pacotes posteriores. Por padrão, um dispositivo pode enviar pacotes de redirecionamento ICMP. Em alguns casos especiais, você pode proibir um dispositivo de enviar pacotes de redirecionamento ICMP.
Tabela 2 -10 Ativando o redirecionamento ICMP global
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite o redirecionamento ICMP global. | ip redirect | Obrigatório . ICMP global está desabilitada. |
Ativar redirecionamento ICMP global
Ao enviar pacotes de redirecionamento ICMP, se você precisar enviar pacotes de redirecionamento ICMP, será necessário habilitar a função de redirecionamento ICMP na interface.
Tabela 2 -11 Ativando o redirecionamento ICMP global
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Habilite o redirecionamento ICMP em uma interface. | ip redirects | Obrigatório . Por padrão, a função de redirecionamento ICMP está habilitada em uma interface. |
Você pode enviar pacotes de redirecionamento ICMP somente quando a função de redirecionamento ICMP estiver habilitada globalmente e na interface.
Ativar rede de destino ICMP inacessível
Após o dispositivo receber um pacote IP, se ocorrer um erro inacessível na rede de destino, descarte o pacote e envie o pacote de erro inacessível da rede de destino ICMP para a origem.
- Para o pacote IP encaminhado, se estiver pesquisando para a falha da rota, envie o pacote de erro ICMP “Rede inacessível” de volta para a extremidade de origem.
Tabela 2 -12 Habilitar destino ICMP na rede inacessível
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilitar destinos ICMP inacessíveis na rede | ip network unreachables reply | Opcional Por padrão, não habilite a rede de destino ICMP inacessível. |
Ativar destino ICMP inacessível
Depois que um dispositivo recebe pacotes de dados IP, se o destino estiver inacessível, o pacote será descartado e o pacote de erro inacessível de destino ICMP será enviado de volta para a extremidade de origem.
- Se a seleção de rota de um pacote IP encaminhado falhar, o pacote de erro ICMP do host inacessível é enviado de volta para a extremidade de origem.
- Para um pacote IP que pode ser encaminhado, se você precisar fragmentar o pacote IP, mas um bit Não fragmentar (DF) estiver definido no pacote, um pacote de erro ICMP indicando que "a segmentação é necessária, mas um bit DF está definido" é enviado para a extremidade de origem.
- Para um pacote IP cujo endereço de destino é o dispositivo local, se o dispositivo não suportar o protocolo de camada superior do dispositivo, ele enviará um pacote de erro ICMP "protocolo inacessível" para a extremidade de origem.
- Para um pacote IP cujo endereço de destino é o dispositivo local, se a porta da camada de transporte do pacote do pacote não corresponder à porta que o processo do dispositivo monitora, o dispositivo envia de volta um pacote de erro ICMP "porta inacessível" para a extremidade de origem .
Se um dispositivo encontrar um ataque mal-intencionado por um grande número de pacotes inacessíveis de destino ICMP, o desempenho do dispositivo será prejudicado e o tráfego de rede será aumentado. Para evitar esse caso, você pode desabilitar a função de enviar pacotes inacessíveis de destino ICMP.
Tabela 2 -13 Ativando o destino ICMP inacessível
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Ativar destino ICMP inacessível. | ip unreachables | Opcional . Por padrão, a função de destino inacessível ICMP está habilitada. |
Configurar a limitação de velocidade ICMP
Se o dispositivo sofrer ataques maliciosos que precisam enviar um grande número de mensagens de erro ICMP, o desempenho do dispositivo será reduzido e o tráfego de rede será aumentado. Para evitar essa situação, você pode configurar o limite de velocidade do pacote ICMP para manipular. Entre eles, os tipos de pacotes de erro ICMP incluem: pacote inacessível, pacote de redirecionamento, pacote de tempo limite TTL e pacote de erro de parâmetro. A taxa de limite de velocidade padrão desses pacotes é 10pps, e a taxa de envio padrão de outros tipos de pacotes é 0, ou seja, sem limite de velocidade. Além disso, os usuários podem configurar diferentes tipos de taxas de transmissão separadamente. Caso contrário, o valor padrão prevalecerá.
Tabela 2 -14 Configurar limitação de velocidade ICMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Ativar a limitação de velocidade ICMP | ip icmp ratelimit enable | Mandatório _ Por padrão, a função está habilitada. |
| Configurar limitação de velocidade ICMP | ip icmp ratelimit { default pps | echo-reply { pps | unlimit } | mask-reply { pps | unlimit } | param-problem { pps | unlimit } | redirect { pps | unlimit } | time-exceed { pps | unlimit } | time-stamp-reply { pps | unlimit } | unreach { pps | unlimit } } | Mandatório _ Por padrão, a função de limitação de velocidade ICMP está habilitada. |
Configurar funções básicas do protocolo TCP
Na pilha de protocolos TCP/IP, o TCP é um protocolo da camada de transporte orientado à conexão. Antes de enviar dados através do protocolo TCP, você deve primeiro configurar uma conexão. O protocolo TCP fornece controle de congestionamento e garante a transmissão de dados confiável.
Condição de configuração
Nenhum
Configurar o tamanho do cache de recebimento TCP
Em algum ambiente de rede especial, você pode configurar o tamanho do cache de recebimento e o tamanho do cache de transmissão de uma conexão TCP para que a rede possa atingir o desempenho ideal. Se o cache de recebimento da conexão TCP não estiver configurado, o tamanho do cache de recebimento será o valor padrão.
Tabela 2 -15 Configurando o tamanho do cache de recebimento TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o tamanho do cache de recebimento TCP. | ip tcp recvbuffers buff-size | Obrigatório . Por padrão, o tamanho do cache de recebimento é 8192 bytes. |
Configurar o tamanho do cache de transmissão TCP
Em algum ambiente de rede especial, você pode configurar o tamanho do cache de recebimento e o tamanho do cache de transmissão de uma conexão TCP para que a rede possa atingir o desempenho ideal. Se o cache de transmissão da conexão TCP não estiver configurado, o tamanho do cache de transmissão será o valor padrão.
Tabela 2 -16 Configurando o tamanho do cache de transmissão TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o tamanho do cache de transmissão TCP. | ip tcp sendbuffers buff-size | Opcional . Por padrão, o tamanho do cache de transmissão é 8192 bytes. |
Configurar o número máximo de retransmissões TCP
Após o servidor enviar um pacote SYN-ACK, se não receber um pacote de resposta do cliente, o servidor retransmite o pacote. Se o número de retransmissões exceder o número máximo de retransmissões definido pelo sistema, o sistema desconecta a conexão TCP.
Tabela 2 -17 Configurando o número máximo de retransmissões TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o número máximo de retransmissões TCP. | ip tcp retransmits retransmits-count | Obrigatório . Por padrão, o número máximo de retransmissões TCP é 3. |
Configurar o comprimento máximo dos pacotes TCP
O comprimento máximo dos pacotes TCP é o comprimento máximo dos blocos de dados que são enviados pela extremidade transmissora de uma conexão TCP para a extremidade receptora. Quando uma conexão é configurada, o menor comprimento máximo de pacote das duas extremidades é usado como o comprimento máximo de pacote no envio de pacotes TCP pelas duas extremidades. Se um pacote TCP exceder o comprimento máximo do pacote, as extremidades de transmissão fragmentam o pacote antes de enviá-lo.
Tabela 2 -18 Configurando o comprimento máximo dos pacotes TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o comprimento máximo dos pacotes TCP. | ip tcp segment-size seg-size | Opcional . Por padrão, o comprimento máximo dos pacotes TCP é de 512 bytes. |
Configurar o tempo máximo de ida e volta TCP
O tempo de ida e volta TCP refere-se ao tempo entre o ponto de tempo em que a extremidade de transmissão envia um pacote TCP e o ponto de tempo em que a extremidade de transmissão recebe o pacote de resposta. O tempo máximo de ida e volta do TCP configurado durante a configuração da conexão TCP é considerado o valor inicial do tempo de ida e volta do TCP. O tempo de ida e volta do TCP posterior é calculado de acordo com o tempo real de ida e volta. Por padrão, o tempo máximo de ida e volta do TCP é de 3 segundos.
Tabela 2 -19 Configurando o tempo máximo de ida e volta do TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o tempo máximo de ida e volta do TCP. | ip tcp round-trip round-trip-time | Obrigatório . Por padrão, o tempo máximo de ida e volta do TCP é de 3 segundos. |
Configurar o tempo ocioso da conexão TCP
Depois que uma conexão TCP é configurada, se nenhum dado for trocado, o tempo ocioso da conexão TCP expira. Em seguida, o TCP executa um teste keep-alive. Depois que o número máximo de tempos de keep-alive for atingido, a conexão TCP será desconectada. Por padrão, o tempo ocioso da conexão TCP é de 2 horas.
Tabela 2 -20 Configurando o tempo ocioso da conexão TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o tempo ocioso da conexão TCP. | ip tcp idle-timeout idle-time | Obrigatório . Por padrão, o tempo ocioso da conexão TCP é 14400 e a unidade é 0,5 segundo. |
A unidade do tempo ocioso da conexão TCP é 0,5 segundo.
Configurar o tempo de espera da configuração da conexão TCP
A configuração de uma conexão TCP requer três handshakes. Depois que um cliente TCP envia um pacote de solicitação de conexão, ele aguarda a resposta do servidor TCP antes de concluir a configuração da conexão. Após o tempo de espera pelo tempo limite de configuração da conexão antes que uma resposta seja recebida, a configuração da conexão é encerrada. Por padrão, o tempo de espera para configurar uma conexão TCP é de 75 segundos.
Tabela 2 -21 Configurando o tempo de espera da configuração da conexão TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o tempo de espera da configuração da conexão TCP. | ip tcp init-timeout init-time |
Obrigatório
. Por padrão, o tempo de espera para configurar uma conexão TCP é de 150 segundos e a unidade é de 0,5 segundo. |
A unidade do tempo de espera da configuração da conexão TCP é 0,5 segundo.
Configurar o número máximo de tempos de manutenção do TCP
Se nenhum dado for trocado em uma conexão TCP durante o tempo ocioso da conexão TCP, um pacote de manutenção de atividade TCP será enviado para teste de manutenção de atividade. Se o teste keep-alive falhar, um teste keep-alive será executado novamente. Se o número máximo de tempos de keep-alive TCP exceder o limite, a conexão TCP será desconectada. Por padrão, o número máximo de tempos de keep-alive do TCP é 3.
Tabela 2 -22 Configurando o Número Máximo de Tempos de Keep-Alive de TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o número máximo de tempos de keep-alive do TCP. | ip tcp keep-count keep-count | Obrigatório . Por padrão, o número máximo de tempos de keep-alive do TCP é 3. |
Habilitar o carimbo de data/hora TCP
O TCP calcula automaticamente o tempo de ida e volta do pacote de acordo com o número de série do pacote de solicitação e o do pacote de resposta. No entanto, o cálculo não é preciso. O uso de carimbos de data/hora TCP pode revisar o problema. A extremidade transmissora adiciona um carimbo de data/hora em um pacote e a extremidade receptora envia de volta o carimbo de data/hora no pacote de resposta. A extremidade transmissora calcula o tempo de ida e volta do pacote de acordo com o carimbo de data/hora retornado. Por padrão, a função está desabilitada.
Tabela 2 -23 Habilitando o carimbo de data/hora TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Ative o carimbo de data/hora TCP. | ip tcp timestamp | Obrigatório . Por padrão, a função está desabilitada. |
Ativar retransmissão seletiva TCP
Após o TCP enviar uma série de pacotes, se a transmissão de um pacote falhar, a série de pacotes precisa ser retransmitida. Depois que a transmissão seletiva TCP é habilitada, somente o pacote que não consegue ser transmitido precisa ser retransmitido. Isso reduz o custo do sistema e da linha. Por padrão, a função está desabilitada.
Tabela 2 -24 Ativando a retransmissão seletiva TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a retransmissão seletiva TCP. | ip tcp selective-ack | Obrigatório . Por padrão, a função está desabilitada. |
Configurar a função anti-ataque do protocolo TCP
Se o servidor TCP recebe muitos pacotes SYN, mas o peer não responde à resposta SYN+ACK do servidor, muita memória do servidor é consumida e a fila de meia conexão do servidor é ocupada . Como resultado, o servidor TCP não pode fornecer o serviço de solicitação normal. Quanto ao ataque, você pode configurar a função anti-ataque TCP.
Condição de configuração
Nenhum
Ativar função de sincronização TCP
Ao receber o pacote SYN, não distribua o TCB de uma vez, mas primeiro retorne um pacote SYN ACK e salve as informações de meia conexão na tabela HASH privada (Cache) até receber o pacote ACK de resposta correto e, em seguida, distribua o TCB.
Tabela 2 -25 Habilite a função de sincronização TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a função de sincronização TCP | ip tcp syncache | Obrigatório Por padrão, a função está desabilitada. |
Ativar função de syncookies TCP
A função não usa nenhum recurso armazenado, mas adota um algoritmo especial para gerar o Sequence Number . O algoritmo considera o IP do peer, a porta, o próprio IP e as informações fixas da porta, além de outras informações fixas, como MSS e hora. Após receber o pacote ACK do peer, recalcule e veja se é igual à Sequence Number-1 no pacote de resposta do peer, para decidir se deve distribuir os recursos TCB.
Tabela 2 -26 Habilite a função de syncookies TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a função de syncookies TCP | ip tcp syncookies | Obrigatório Por padrão, a função está desabilitada. |
Configurar funções básicas do protocolo UDP
Na pilha de protocolos TCP/IP, o UDP é um protocolo de camada de transporte orientado a conexões sem conexão. Antes de enviar dados através do protocolo TCP, você não precisa configurar uma conexão. O protocolo UDP fornece transmissão de dados não confiável sem controle de congestionamento.
Condição de configuração
Nenhum
Configurar TTL de pacotes UDP
Configurar o TTL de pacotes UDP significa preencher o valor TTL no cabeçalho IP dos pacotes UDP. O cabeçalho de um pacote IP contém o campo Time-To-Live (TTL), que é reduzido em um quando o pacote IP passa por um dispositivo de roteamento. Quando o TTL é 0, o dispositivo descarta o pacote IP. Por padrão, o valor TTL do pacote IP de um pacote UDP é 64.
Tabela 2 -27 Configurando TTL de pacotes UDP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o TTL de pacotes UDP. | ip udp default-ttl time-to-live | Obrigatório . Por padrão, o valor TTL do pacote IP de um pacote UDP é 64. |
Configurar o tamanho do cache de recebimento UDP
Em algum ambiente de rede especial, você pode configurar o tamanho do cache de recebimento e o tamanho do cache de transmissão de uma conexão UDP para que a rede possa atingir o desempenho ideal. Se o cache de recebimento da conexão UDP não estiver configurado, o tamanho do cache de recebimento será o valor padrão, 41600 bytes.
Tabela 2 -28 Configurando o tamanho do cache de recebimento UDP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o tamanho do cache de recebimento UDP. | ip udp recvbuffers buffer-size | Obrigatório . Por padrão, o tamanho do cache de recebimento UDP é de 41.600 bytes. |
Configurar o tamanho do cache de transmissão UDP
Em algum ambiente de rede especial, você pode configurar o tamanho do cache de recebimento e o tamanho do cache de transmissão de uma conexão UDP para que a rede possa atingir o desempenho ideal. Se o cache de transmissão da conexão UDP não estiver configurado, o tamanho do cache de transmissão será o valor padrão, 9216 bytes.
Tabela 2 -29 Configurando o tamanho do cache de transmissão UDP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o tamanho do cache de transmissão UDP. | ip udp sendbuffers buffer-size | Obrigatório . Por padrão, o tamanho do cache de transmissão UDP é 9216 bytes. |
Ativar verificação e verificação de UDP
Para evitar erros que ocorrem durante a transmissão de pacotes UDP, após o recebimento dos pacotes UDP, a verificação e a verificação do UDP precisam ser executadas. O sistema compara o campo de verificação do pacote UDP calculado pela extremidade receptora e o campo de soma de verificação do cabeçalho do pacote UDP. Se os dois valores forem diferentes, o sistema determina que ocorreu um erro de transmissão e descarta o pacote. Por padrão, a função está habilitada.
Tabela 2 -30 Ativando a verificação e verificação de UDP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a verificação UDP e verifique. | ip udp recv-checksum | Obrigatório . Por padrão, a função está habilitada. |
Preencha a soma de verificação do pacote UDP
Para evitar que os pacotes UDP encontrem erros de transmissão, na transmissão de pacotes UDP, a extremidade transmissora preenche a soma de verificação do pacote UDP a ser calculada no campo de soma de verificação do cabeçalho do pacote UDP para a extremidade receptora realizar a verificação da soma de verificação. Por padrão, a função está habilitada.
Tabela 2 - 31 Preenchendo a soma de verificação do pacote UDP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure para preencher a soma de verificação do pacote na transmissão de pacotes UDP. | ip udp send-checksum | Obrigatório . Por padrão, a função está habilitada. |
Monitoramento e manutenção básicos de IP
Tabela 2 -32 Monitoramento e manutenção básicos de IP
| Comando | Descrição |
| clear ip icmpstat | Limpa as estatísticas do protocolo ICMP. |
| clear ip statistics | Limpa as estatísticas do protocolo IP. |
| clear ip tcp syncache statistics | Limpa a sincronização informações estatísticas do protocolo TCP |
| clear ip tcpstat | Limpa as estatísticas do protocolo TCP. |
| clear ip udpstat | Limpa as estatísticas do protocolo UDP. |
| show ip icmpstat | Exibe as estatísticas do protocolo ICMP. |
| show ip interface [ interface-name | brief ] | Exibe o endereço IP da interface. |
| show ip sockets | Exibe os detalhes do soquete. |
| show ip statistics | Exibe estatísticas do protocolo IP. |
| show ip tcpstat | Exibe estatísticas do protocolo TCP. |
| show ip tcp syncache statistics | Exibe as informações de estatísticas de sincronização TCP |
| show ip udpstat | Exibe estatísticas do protocolo UDP. |
| show ip tcp syncache detail | Exibe as informações de entrada de syncache do protocolo TCP |
| show tcp tcb [ detail ] | Exibe detalhes do bloco de controle do protocolo TCP. |
DHCP
Visão geral
É difícil gerenciar uma grande rede. Por exemplo, em uma rede na qual os endereços IP são alocados manualmente, os conflitos de endereço IP são comuns. A única maneira de resolver o problema é alocar dinamicamente endereços IP aos hosts. O Dynamic Host Configuration Protocol (DHCP) aloca endereços IP para hosts solicitantes de um pool de endereços IP. O DHCP também fornece outras informações, como IP do gateway e endereço do servidor DNS. O DHCP reduz a carga de trabalho do administrador ao registrar e rastrear endereços IP alocados manualmente.
DHCP é um protocolo baseado em transmissão UDP. O processo para um cliente DHCP obter um endereço IP e outras informações de configuração contém quatro fases.
fase DESCOBRIR. Quando o cliente DHCP acessa a rede pela primeira vez, ele envia um pacote DHCP DISCOVER com o endereço de origem 0.0.0.0 e o endereço de destino 255.255.255.255 para a rede.
Fase OFERTA. Depois que o servidor DHCP recebe o pacote de transmissão DHCP DISCOVER enviado pelo cliente, ele seleciona um endereço IP do pool de endereços IP correspondente de acordo com a política e envia o endereço IP e outros parâmetros ao cliente em um pacote DHCP OFFER.
FASE DE PEDIDO. Se o cliente DHCP receber mensagens de resposta de vários servidores DHCP na rede, ele selecionará uma OFERTA DHCP (geralmente a que chegar primeiro). Em seguida, ele envia um pacote DHCP REQUEST para a rede, informando a todos os servidores DHCP o endereço IP de qual servidor ele aceitará.
Fase ACK. Depois que o servidor DHCP recebe o pacote DHCP REQUEST do cliente DHCP, ele envia uma mensagem DHCP ACK contendo o endereço IP fornecido e outras configurações para o cliente DHCP, informando ao cliente DHCP que o cliente DHCP pode usar o endereço IP fornecido.
O endereço IP que o servidor DHCP aloca ao cliente DHCP tem uma concessão. Depois que a concessão expirar, o servidor recuperará o endereço IP alocado. Quando o prazo de concessão do endereço IP do cliente DHCP tiver passado metade do tempo, o cliente DHCP envia um pacote DHCP REQUEST para o servidor DHCP solicitando a atualização de sua concessão de endereço IP. Se o servidor DHCP permitir que o cliente DHCP use seu endereço IP, o servidor DHCP responderá com um pacote DHCP ACK, solicitando ao cliente DHCP que atualize a concessão. Se o servidor DHCP não permitir que o cliente DHCP continue a usar o endereço IP, o servidor DHCP responderá com um pacote DHCP NAK.
Durante a aquisição de endereço IP dinâmico, os pacotes de solicitação são enviados no modo de transmissão; portanto, o DHCP é aplicado somente quando o cliente e o servidor DHCP estão na mesma sub-rede. Se existirem várias sub-redes em uma rede e os hosts das sub-redes precisarem obter informações de configuração, como endereço IP por meio do servidor DHCP, os hosts das sub-redes se comunicarão com o servidor DHCP por meio de um retransmissor DHCP para obter endereços IP e outras informações de configuração.
Configuração da função DHCP
Tabela 3 -1 Lista de funções DHCP
| Tarefas de configuração | |
| Configurar um pool de endereços DHCP |
Crie um pool de endereços DHCP e especifique os atributos VRF
Configure um intervalo de endereços IP. Configure um endereço de servidor DNS. Configure a rota padrão. Configure a concessão de um endereço IP. Vincule um endereço IP e um endereço MAC. Configure as opções definidas pelo usuário. Configure o pool de endereços do fabricante especificado. |
| Configure outros parâmetros de um servidor DHCP. |
Configurar o servidor DHCP
Configurar o intervalo de endereços IP reservado Configure os parâmetros de detecção de ping DHCP. Configurar a função de registro de dados DHCP |
| Configure as funções de um cliente DHCP. |
Configure um cliente DHCP.
Configurar o ID do fabricante Configurar a distância da rota DHCP Configurar a função de opção DHCP 60 Configure o cliente DHCP para não solicitar a opção de rota padrão |
| Configurar a função de retransmissão DHCP |
Configure o relé DHCP da interface.
Configure a função Option82. Configure o endereço de origem do pacote de retransmissão DHCP da interface Configurar o endereço do servidor DHCP |
Configurar um pool de endereços DHCP
Condição de configuração
Nenhum
Criar um pool de endereços DHCP
Um servidor DHCP precisa selecionar e alocar endereços IP e outros parâmetros de um pool de endereços DHCP. Portanto, um pool de endereços DHCP deve ser criado para o servidor DHCP.
Tabela 3 -2 Criando um pool de endereços DHCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um pool de endereços DHCP e entre no modo de configuração DHCP. | ip dhcp pool pool-name [ vrf vrf-name ] | Obrigatório . Por padrão, nenhum pool de endereços DHCP foi criado pelo sistema. |
Os pools de endereços se dividem em dois tipos: Rede e Intervalo. Os dois tipos de pools de endereços podem ser configurados respectivamente através dos comandos network e range.
Configurar um intervalo de endereços IP
Em um servidor DHCP, cada pool de endereços DHCP deve ser configurado com um intervalo de endereços IP para alocar endereços IP a clientes DHCP.
Tabela 3 -3 Configurando um intervalo de endereços IP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração DHCP. | ip dhcp pool pool-name [ vrf vrf-name ] | - |
| Configure um intervalo de endereços IP para um pool de endereços do tipo Rede. | network ip-address [network-mask | mask-len] |
Opcional
. Por padrão, um intervalo de endereços IP não é configurado para um pool de endereços. |
| Configure um intervalo de endereços IP para um pool de endereços do tipo Range. | range low-ip-addres high-ip-address [network-mask | mask-len ] |
Opcional
. Por padrão, um intervalo de endereços IP não é configurado para um pool de endereços. |
Depois que um intervalo de endereços IP for configurado para um pool de endereços usando o comando network ou range , se você executar a rede ou range novamente, a nova configuração de intervalo de endereços IP sobrescreve a configuração existente.
Modifique o tipo de rede do conjunto de endereços para o tipo de intervalo (ou altere o tipo de intervalo do conjunto de endereços para o tipo de rede). Se o novo intervalo de endereços cruzar com o intervalo de endereços antigo, a linha de comando solicitará ao usuário se deve realizar a operação. Se sim, exclua todas as configurações de endereço (vinculação estática, subconjunto do fornecedor) na concessão dinâmica; se o intervalo efetivo real do novo endereço contiver o intervalo efetivo real do endereço antigo, o pool de endereços reservará todas as configurações de endereço no pool de endereços (vinculação estática, subconjunto do fornecedor), mas excluirá o intervalo de ip configurado e locação dinâmica do subconjunto de fornecedores.
Configurar um endereço de servidor DNS
Em um servidor DHCP, você pode configurar o endereço do servidor DNS respectivamente para cada pool de endereços DHCP. Quando um servidor DHCP aloca um endereço IP para um cliente DHCP, ele também envia o endereço do servidor DNS para o cliente.
Quando o cliente DHCP inicia a resolução dinâmica de nomes de domínio, ele consulta o servidor DNS.
Tabela 3 -4 Configurando um endereço de servidor DNS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração DHCP. | ip dhcp pool pool-name [ vrf vrf-name ] | - |
| Configure um endereço de servidor DNS. | dns-server { ip-address&<1-8> | autoconfig } | Obrigatório . Por padrão, o endereço do servidor DNS não está configurado. |
Configure oDefault Route
Em um servidor DHCP, você pode especificar o endereço de um gateway correspondente aos clientes para cada pool de endereços DHCP. Quando o servidor aloca um endereço IP para um cliente, ele também envia o endereço do gateway para o cliente.
Quando um cliente DHCP acessa um servidor ou host que não está no segmento de rede, seus dados são encaminhados pelo gateway.
Tabela 3 -5 Configurando oDefault Route
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração DHCP. | ip dhcp pool pool-name [ vrf vrf-name ] | - |
| Configure a rota padrão. | default-router ip-address&<1-8> | Obrigatório . Por padrão, nenhuma rota padrão é configurada. |
Configurar a concessão de um endereço IP
O endereço IP que o servidor DHCP aloca ao cliente DHCP tem uma concessão. Depois que a concessão expirar, o servidor recuperará o endereço IP alocado. Se o cliente DHCP quiser continuar a usar o endereço IP, ele deverá ter a concessão do endereço IP atualizada.
No servidor DHCP, você pode configurar uma concessão de endereço IP para cada pool de endereços DHCP.
Tabela 3 -6 Configurando a concessão de um endereço IP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração DHCP. | ip dhcp pool pool-name [ vrf vrf-name ] | - |
| Configure uma concessão de endereço IP. | lease days [ hours [ minutes ] ] | Obrigatório . Por padrão, o valor de dias é 1, o valor de horas é 6 e o valor de minutos é 0. |
Vincular um endereço IP e um endereço MAC
Depois que os endereços IP e os endereços MAC são vinculados, quando o cliente com um endereço MAC especificado envia uma solicitação de endereço IP ao servidor DHCP, o servidor DHCP aloca o endereço IP vinculado ao endereço IP ao cliente. Desta forma, desde que o endereço MAC do cliente não seja alterado (substituindo o adaptador de rede), o cliente obterá sempre o mesmo endereço IP do servidor.
Tabela 3 -7 Vinculando endereços IP e endereços MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração DHCP. | ip dhcp pool pool-name [ vrf vrf-name ] | - |
| Vincule um endereço IP e um endereço MAC. | bind { ip-address mac-address | automatic} | Obrigatório . Por padrão, nenhuma ligação de endereço IP e endereço MAC é configurada. |
Configurar opções definidas pelo usuário
Para algumas opções, o RFC não fornece especificações; portanto, você pode definir essas opções de acordo com a necessidade real.
Tabela 3 -8 Configurando opções definidas pelo usuário
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração DHCP. | ip dhcp pool pool-name [ vrf vrf-name ] | - |
| Configurando opções definidas pelo usuário. | option option-code { ascii ascii-string | hex hex-string | ip ip-address&<1-8> } | Obrigatório . Por padrão, as opções definidas pelo usuário não são configuradas. |
Configurar o pool de endereços do fabricante DHCP
Quando o cliente solicita o endereço IP, pode levar a opção 60, indicando o ID do fabricante. O cliente pode especificar diferentes seções de endereço IP para diferentes fabricantes.
Tabela 3 -9 Configurar o pool de endereços do fabricante DHCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração DHCP. | ip dhcp pool pool-name [ vrf vrf-name ] | - |
| Configure o pool de endereços do fabricante e entre no modo de configuração do pool de endereços do fabricante DHCP | vendor-class-identifier vendor_id | Por padrão, não configure o pool de endereços do fabricante . |
| Configurar o intervalo do pool de endereços do fabricante | ip range low-ip-address high-ip-address | Por padrão, não configure o intervalo. |
| Configure o conteúdo da opção 43 retornada para o fabricante especificado | option 43 { ascii ascii-string | hex hex-string | ip ip-address&<1-8> } | Por padrão, não configure. |
Configurar outros parâmetros de um servidor DHCP
Condição de configuração
Nenhum
Configurar um servidor DHCP
Após configurar a interface para funcionar no modo servidor DHCP, quando a interface receber o pacote de solicitação DHCP enviado pelo cliente DHCP, o servidor DHCP distribuirá o endereço IP e outros parâmetros de rede para o cliente.
Tabela 3 -10 Configurar um servidor DHCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a função do servidor DHCP | ip dhcp server | Obrigatório Por padrão, não configure a função do servidor DHCP. |
Configurar o intervalo de endereços IP reservados
Em um pool de endereços DHCP, alguns endereços IP são reservados para alguns dispositivos especiais e alguns endereços IP entram em conflito com os endereços IP de outros hosts na rede. Portanto, os endereços IP não podem ser alocados dinamicamente.
Tabela 3 -11 Configurando o intervalo de endereços IP reservados
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o intervalo de endereços IP reservados. | ip dhcp excluded-address low-ip-address [ high-ip-address ] [ vrf vrf-name ] |
Obrigatório
. Por padrão, o intervalo de endereços IP reservados não está configurado. Os endereços IP no intervalo de endereços IP reservados não serão alocados. |
parâmetros de detecção de DHCPPing
Para evitar um conflito de endereço IP, antes de alocar dinamicamente um endereço IP a um cliente DHCP, um servidor DHCP deve detectar o endereço IP. A operação de detecção é realizada através da operação de ping. O servidor DHCP determina se existe um conflito de endereço IP verificando se um pacote de resposta de eco ICMP é recebido dentro do tempo especificado.
Tabela 3 -12 Configurando Parâmetros de Detecção de DHCPPing
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure os parâmetros de detecção de ping DHCP. | ip dhcp ping { packets packet-num | timeout milliseconds } | Obrigatório . Por padrão, o número de pacotes de ping é 1 e o tempo limite é de 500 ms. |
Configurar a função de registro de dados DHCP
Depois de habilitar a função de registro de dados do servidor DHCP, o pool de endereços distribuído no servidor DHCP é registrado no registro de dados.
Tabela 3 -13 Configurar a função de registro de dados DHCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a função de registro de dados do servidor DHCP | ip dhcp logging security-data | Obrigatório Por padrão, não ative a função de registro de dados. |
Configurar as funções de um cliente DHCP
Condição de configuração
Nenhum
Configurar um cliente DHCP
Uma interface de cliente DHCP obtém um endereço IP e outros parâmetros por meio do DHCP.
Tabela 3 -14 Configurando um cliente DHCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o cliente DHCP para obter um endereço IP. | ip address dhcp [ request-ip-address ip-address ] | Obrigatório . Por padrão, o cliente DHCP não está configurado para obter um endereço IP. |
Configurar a distância da rota DHCP
Na tabela de roteamento IP, cada protocolo possui uma distância de gerenciamento para controlar o roteamento, ou seja, a distância de roteamento. A distância de roteamento é usada para tomar decisões de roteamento para as mesmas rotas de segmento de protocolos diferentes. A rota com pequena distância de roteamento é anterior.
Tabela 3 -15 Configurar a distância da rota DHCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar a distância da rota DHCP | ip dhcp route-distance distance | Obrigatório Por padrão, a distância da rota DHCP é 254. |
Configurar opção 60 Função
O conteúdo da opção DHCP 60 é o ID do fabricante. Quando o cliente DHCP solicita, ele pode carregar a opção 60. O servidor pode personalizar a política de distribuição de endereços IP de acordo com a opção.
Tabela 3 -16 Configurar a função da opção 60 do DHCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure a função da opção 60 | ip dhcp vendor-class-identifier {disable | content hex-string} | Por padrão, carregue a opção 60 opção. |
Configurar o cliente DHCP para não solicitar a opção de rota padrão
Quando o cliente DHCP solicitar o endereço IP, solicite a rota padrão por padrão. O usuário pode especificar que o cliente DHCP não solicite a rota padrão, mas configure a rota por conta própria.
Tabela 3 -17 Configure o cliente DHCP para não solicitar a opção de rota padrão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o cliente DHCP para não solicitar a opção de rota padrão | ip dhcp router-option disable | Obrigatório Por padrão, o cliente DHCP solicita a opção de rota padrão. |
Configurar a função de um relé DHCP
Condição de configuração
Nenhum
Configurar um relé DHCP
Se existirem várias sub-redes em uma rede e os hosts das sub-redes precisarem obter informações de configuração, como endereço IP por meio do servidor DHCP, os hosts das sub-redes se comunicarão com o servidor DHCP por meio de um retransmissor DHCP para obter endereços IP e outras configurações em formação. Se uma interface estiver configurada para funcionar no modo de retransmissão DHCP, depois que a interface receber pacotes DHCP de um cliente DHCP, ela retransmitirá o pacote para o servidor DHCP especificado. O servidor DHCP então aloca um endereço IP.
Tabela 3 -18 Configurando um relé DHCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure a função de retransmissão DHCP. | ip dhcp relay | Obrigatório . Por padrão, a função de retransmissão DHCP não está configurada. |
Configurar a função Option82
Option82 é uma opção de informações de tronco, que registra a localização do cliente DHCP. Se habilitar a retransmissão DH CP para suportar a função Opção 82, após a retransmissão DHCP receber o pacote de solicitação enviado pelo cliente DHCP ao servidor DHCP e o pacote de solicitação não tiver a opção Opção 82, adicione a opção 82 no pacote de solicitação, e encaminhar para o servidor DHCP. Se habilitar o DHCP relay para dar suporte à Opção 82, e o pacote de solicitação tiver a opção Opção 82, execute o próximo processamento de acordo com a ação configurada pelo comando ip dhcp relay information strategy e, em seguida, encaminhe o pacote para o servidor. Se o pacote de resposta DHCP recebido pelo retransmissor DHCP contiver a opção Opção 82, exclua a opção Opção 82 e, em seguida, encaminhe o pacote para o cliente DHCP.
Tabela 3 -19 Configurando a Função Option82
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| opção Option 82 | ip dhcp relay information option | Obrigatório Por padrão, não habilite a retransmissão DHCP para dar suporte à Opção 82 . |
| Configure a política de processamento quando o DHCP relay recebe o pacote de solicitação com a opção 82 enviada pelo cliente | ip dhcp relay information strategy{drop | keep | replace} | Opcional Use a ação de substituição para o pacote com a Opção 82. |
| Configure a função Option82. | ip dhcp relay information option | remote-id { ascii ascii-string | hex hex-string }| circuit-id { ascii ascii-string | hex hex-string } } | Obrigatório . Por padrão, a função Option82 não está configurada. |
Configurar o endereço de origem do relé DHCP
O DHCP retransmite o cliente DHCP para o endereço de origem do pacote do servidor. Por padrão, use o endereço da interface de saída da rota para o servidor DHCP. Em algum ambiente especial, o servidor DHCP não pode se comunicar com o endereço. Portanto, os usuários podem configurar o endereço de origem do pacote de retransmissão DHCP para o servidor DHCP e o campo giaddr no pacote por meio do comando ip dhcp relay source-address . Os usuários também podem configurar o endereço de origem do relé DHCP para ser o endereço de interface do pacote de cliente DHCP recebido por meio do ip dhcp relay endereço de origem endereço de relé comando nd.
Tabela 3 -20 Configure o endereço de origem do pacote de retransmissão DHCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o endereço de origem do pacote de retransmissão DHCP | ip dhcp relay source-address relay-address |
Obrigatório
Por padrão, o endereço de origem do pacote de retransmissão DHCP é o endereço da interface de saída da rota para o servidor DHCP. |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o endereço de origem do pacote de retransmissão DHCP | ip dhcp relay source-address ip-address |
Obrigatório
Por padrão, o endereço de origem do pacote de retransmissão DHCP é o endereço da interface de saída da rota para o servidor DHCP. |
O endereço de origem configurado pelo comando ip dhcp relay source-address ip-address deve ser o endereço de interface do dispositivo. Enquanto isso, o endereço da interface deve pertencer ao mesmo vrf que a interface de retransmissão. Caso contrário, o pacote de retransmissão não pode ser enviado com sucesso. Se o comando ip dhcp relay source-address ip-address estiver configurado no modo de interface e o comando ip dhcp relay source-address relay-address estiver configurado no modo global, a prioridade do primeiro é maior que a do último. A retransmissão DHCP usará o endereço IP configurado para preencher o endereço de origem do pacote enviado pela retransmissão DHCP ao servidor DHCP.
Configurar o endereço do servidor DHCP
Quando a interface recebe o pacote DHCP enviado pelo cliente DHCP, retransmita o pacote para o servidor DHCP configurado, que distribui o endereço IP.
Tabela 3 -21 Configurar o endereço do servidor DHCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o endereço do servidor DHCP | ip dhcp relay server -address ip-address | Obrigatório Por padrão, não configure o endereço do servidor DHCP. |
Monitoramento e manutenção de DHCP
Tabela 3 -22 Monitoramento e manutenção de DHCP
| Comando | Descrição |
| clear ip dhcp pool pool-name { lease | conflict [ip-address] } | Limpe as informações de concessão dinâmica ou informações de endereço de conflito no pool de endereços |
| clear ip dhcp server interface [interface-name ] statistics | Limpe as estatísticas de informações chave quando o servidor DHCP interage com os pacotes com o cliente ou retransmissão |
| clear ip dhcp relay statistics | Limpe as informações de estatísticas no dispositivo de retransmissão DHCP |
| show ip dhcp server interface interface-name [statistics] | Exiba as informações do pool de endereços associado na interface especificada ou exiba as estatísticas de informações chave quando o servidor DHCP na interface especificada interage com os pacotes com o cliente ou retransmissão |
| show ip dhcp pool pool-name { summary | ping_list | offer_list | excluded_list | conflict_list | lease | binding } | pool de endereços especificado ou as informações de endereço da verificação de ping ou as informações sobre o endereço que enviou o pacote OFFER e está aguardando o cliente DHCP responder ao pacote REQUEST ou exibir a exclusão informações de endereço no conjunto de endereços ou exibir as informações de endereço de conflito no conjunto de endereços ou exibir as informações de concessão dinâmica no conjunto de endereços ou exibir as informações de ligação estática no conjunto de endereços. |
| show ip dhcp pool pool-name specific { ip-address ip-address | mac-address mac-address } | Exiba o endereço IP especificado ou as informações do endereço mac no pool de endereços |
| show ip dhcp relay [interface interface-name ] | Exiba as informações de estatísticas do pacote no dispositivo de retransmissão DHCP |
Exemplo de configuração típica de DHCP
Configurar um servidor DHCP para alocar endereços IP estaticamente
Requisitos de rede
- Device2 atua como um servidor DHCP para alocar endereços IP, endereços IP de gateway e endereços IP do servidor DNS de maneira estática.
- O servidor DHCP aloca um endereço IP ao PC no modo de ligação MAC.
Topologia de rede
Figura 3 -1 Configurando um servidor DHCP para alocar endereços IP estaticamente
Etapas de configuração
- Passo 1: Configure o endereço IP da interface Device2 e trabalhe no modo de servidor DHCP.
Device2#configure terminalDevice2(config)#interface vlan2Device2(config-if-vlan2)#ip address 1.0.0.3 255.255.255.0Device2(config-if-vlan2)#ip dhcp serverDevice2(config-if-vlan2)#exit
- Passo 2: Configure o conjunto de endereços de ligação estática e os parâmetros.
#Configure o pool de endereços mac-binding e adote o modo static mac binding para distribuir o endereço IP para o PC.
Device2(config)#ip dhcp pool mac-bindingDevice2(dhcp-config)#range 1.0.0.4 1.0.0.254 255.255.255.0Device2(dhcp-config)#bind 1.0.0.11 00e0.00c1.013dDevice2(dhcp-config)#default-router 1.0.0.1Device2(dhcp-config)#dns-server 1.0.0.2Device2(dhcp-config)#exit
- Passo 3: Confira o resultado.
#No Device2, consulte o pool de endereços associado da interface por meio da interface do servidor show ip dhcp vlan2 comando.
Device2(config)#exitDevice2#show ip dhcp server interface vlan2DHCP server status information:DHCP server is enabled on interface: vlan2Vrf : globalDHCP server pool information:Available directly-connected pool:Interface IP Pool name Pool Range Pool utilization----------- ------------------ ------------------- ----------------1.0.0.3/24 mac-binding 1.0.0.4 – 1.0.0.254 0.00%
#No Device2, consulte o endereço IP de ligação distribuído para o PC através do show ip dhcp pool mac-binding command.
Device2#show ip dhcp pool mac-binding bindingIP Address MAC Address Vendor Id Type Time Left(s)------------ ----------------- ------------- -------- -------------1.0.0.11 00e0.00c1.013d Global Binding NA
#No Device2, consulte o endereço distribuído para o PC por meio da concessão show ip dhcp pool mac-binding comando.
Device#show ip dhcp pool danymic-pool2 leaseIP Address MAC Address Vendor Id Type Time Left(s)------------ ------------------ ------------------- -------- -------------1.0.0.11 00e0.00c1.013d Global Lease 107980
No PC, verifique se o endereço IP obtido, o endereço IP do gateway e o endereço do servidor DNS estão corretos.
Configurar um servidor DHCP para alocar endereços IP dinamicamente
Requisitos de rede
- Duas VLANs de interface do Dispositivo, VLAN2 e VLAN3, são configuradas respectivamente com endereços IP nos 1.0.0segmentos de rede .3/24 e 2.0.0.3/24.
- O dispositivo do servidor DHCP aloca dinamicamente endereços IP nos 1.0.0segmentos de rede .0/24 e 2.0.0.0.0/24 para os dois clientes na rede física conectada diretamente.
- Os endereços IP no segmento de rede 1.0.0.0/24 têm uma concessão de um dia, o endereço do gateway é 1.0.0.3, o endereço do servidor DNS é 2.0.0.4. Os endereços IP no segmento de rede 2.0.0.0/24 têm uma concessão de três dias, o endereço do gateway é 2.0.0.3, o endereço do servidor DNS é 2.0.0.4.
- Os primeiros 10 endereços IP nos segmentos de rede 1.0.0.0/24 são reservados e não podem ser alocados.
Topologia de rede

Figura 3 -2 Rede para configurar DHCP para alocar endereços IP dinamicamente
Etapas de configuração
- Passo 1: Configure o endereço IP da interface do dispositivo e faça a interface funcionar no modo de servidor DHCP.
Device(config)#interface vlan2Device(config-if- vlan2)#ip address 1.0.0.3 255.255.255.0Device(config-if- vlan2)#ip dhcp serverDevice(config-if- vlan2)#exitDevice(config)#interface vlan3Device(config-if- vlan3)#ip address 2.0.0.3 255.255.255.0Device(config-if- vlan3)#ip dhcp serverDevice(config-if- vlan3)#exit
- Passo 2: No dispositivo do servidor DHCP, configure dois pools de endereços dinâmicos e seus parâmetros.
#Configura os primeiros 10 endereços IP nos dois pools de endereços como endereços reservados.
Device(config)#ip dhcp excluded-address 1.0.0.1 1.0.0.10Device(config)#ip dhcp excluded-address 2.0.0.1 2.0.0.10
#Configure o pool de endereços chamado dynamic-pool1 e os parâmetros (intervalo de endereços, gateway, endereço dns e concessão de endereço).
Device(config)#ip dhcp pool dynamic-pool1Device(dhcp-config)#network 1.0.0.0 255.255.255.0Device(dhcp-config)#default-router 1.0.0.3Device(dhcp-config)#dns-server 2.0.0.4Device(dhcp-config)#lease 1 0 0Device(dhcp-config)#exit
#Configure o pool de endereços chamado dynamic-pool 2 e os parâmetros (intervalo de endereços, gateway, endereço dns e concessão de endereço).
Device(config)#ip dhcp pool dynamic-pool2Device(dhcp-config)#network 2.0.0.0 255.255.255.0Device(dhcp-config)#default-router 2.0.0.3Device(dhcp-config)#dns-server 2.0.0.4Device(dhcp-config)#lease 3 0 0Device(dhcp-config)#exit
- Passo 3: Confira o resultado.
#Consulte as informações do pool de endereços associado do servidor no dispositivo.
Device(config)#exitDevice#show ip dhcp server interface vlan2DHCP server status information:DHCP server is enabled on interface: vlan2Vrf : globalDHCP server pool information:Available directly-connected pool:Interface IP Pool name Pool Range Pool utilization----------- ------------------ ------------------- ----------------1.0.0.3/24 dynamic-pool1 1.0.0.0 – 1.0.0.255 0.00%Device#show ip dhcp server interface vlan3DHCP server status information:DHCP server is enabled on interface: vlan3Vrf : globalDHCP server pool information:Available directly-connected pool:Interface IP Pool name Pool Range Pool utilization----------- ------------------ ------------------- ----------------1.0.0.3/24 dynamic-pool2 2.0.0.0 – 2.0.0.255 0.00%
#Consulte as informações de endereço IP distribuídas para o cliente no dispositivo.
Device#show ip dhcp pool danymic-pool1 leaseIP Address MAC Address Vendor Id Type Time Left(s)------------ ---------------- ---------------- -------- -------------1.0.0.11 0001.7a6a.0268 Global Lease 86390Device#show ip dhcp pool danymic-pool2 leaseIP Address MAC Address Vendor Id Type Time Left(s)------------ ------------------ -------------- -------- -------------2.0.0.11 0001.7a6a.0269 Global Lease 259194
#Consulte a distribuição informações estatísticas do pool de endereços IP configurado no dispositivo.
Device#show ip dhcp pool dynamic-pool1 summaryPool: dynamic-pool1Pool Configuration : 1.0.0.0 255.255.255.0Pool Range : 1.0.0.0 1.0.0.255Pool Utilization : 0.39%VRF : globalDNS Server : 2.0.0.4Default Router : 1.0.0.3Lease Time : 1 Days 0 Hours 0 MinutesFree Addresses : 243Static Bind : 0Lease Count : 1PingList : 0OfferList : 0ConflictList : 0ExcludeList : 12Device#show ip dhcp pool dynamic-pool2 summaryPool: dynamic-pool2Pool Configuration : 2.0.0.0 255.255.255.0Pool Range : 2.0.0.0 2.0.0.255Pool Utilization : 0.39%VRF : globalDNS Server : 2.0.0.4Default Router : 2.0.0.3Lease Time : 3 Days 0 Hours 0 MinutesFree Addresses : 243Static Bind : 0Lease Count : 1PingList : 0OfferList : 0ConflictList : 0ExcludeList : 12
No cliente DHCP, consulte se os endereços IP foram obtidos corretamente.
O endereço IP no pool de endereços deve pertencer ao intervalo de segmentos da interface que fornece o serviço.
Configurar um relé DHCP
Requisitos de rede
- Device1 é o servidor DHCP e a interface de Device2 habilita a função de retransmissão DHCP.
- O servidor DHCP fornece o serviço para o cliente do segmento 1.0.0.0/24 e os primeiros dez endereços IP são reservados.
- O cliente DHCP obtém o endereço IP via retransmissão DHCP.
Topologia de rede
Figura 3 -3 Rede para configurar um relé DHCP
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. Configure o endereço IP da interface (omitido).
- Passo 2: Configure o pool de endereços IP do Device1 e o endereço IP reservado e trabalhe no modo de servidor DHCP.
#Configure o servidor DHCP.
Device1(config)#interface vlan2Device1(config-if-vlan2)#ip dhcp serverDevice1(config-if-vlan2)#exit
#Configure os endereços IP de 1.0.0.1 a 1.0.0.10 para não serem distribuídos.
Device1#configure terminalDevice1(config)#ip dhcp excluded-address 1.0.0.1 1.0.0.10
#Configurar o pool de endereços IP do pool dinâmico Device1 .
Device1(config)#ip dhcp pool dynamic-poolDevice1(dhcp-config)#network 1.0.0.0 255.255.255.0Device1(dhcp-config)#default-router 1.0.0.1Device1(dhcp-config)#lease 1 0 0Device1(dhcp-config)#exit
#Configure a rota estática para o segmento 1.0.0.0/24 .
Device1(config)#ip route 1.0.0.0 255.255.255.0 2.0.0.2- Passo 3: Na interface vlan3 do Device2, configure o endereço do servidor DHCP como 2.0.0.1 e faça a interface funcionar no modo de retransmissão.
Device2(config)#interface vlan3Device2(config-if-vlan3)#ip dhcp relayDevice2(config-if-vlan3)#ip dhcp relay server-addres 2.0.0.1Device2(config-if-vlan3)#exit
- Passo 4: Confira o resultado.
#Consulte as informações do endereço IP distribuído no Device1.
Device1#show ip dhcp pool dynamic-pool leaseIP Address MAC Address Vendor Id Type Time Left(s)------------ -------------- --------------- -------- -----------1.0.0.11 0001.7a6a.0268 Global Lease 86387
Use a concessão de pool dinâmico show ip dhcp pool comando para consultar o endereço IP que foi alocado ao cliente. O resultado mostra que o cliente obteve o endereço IP 1.0.0.12 .
Configure o relé DHCP para dar suporte à opção 82
Requisitos de rede
- No dispositivo de retransmissão DHCP, Option82 está habilitado.
- Para ID remoto da subopção da Opção 82, especifique o conteúdo como 0102030405.
- O DHCP relay Device2 adiciona a opção 82 inum pacote de solicitação e encaminha a solicitação para o servidor DHCP. O servidor DHCP então aloca endereços IP no 1.0.0segmento de rede .0/24 para o cliente.
Topologia de rede
Figura 3 -4 Rede para configurar o relé DHCP para oferecer suporte à opção 82
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. Configure o endereço IP da interface (omitido).
- Passo 2: Configure o servidor DHCP.
Device1# configure terminalDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip dhcp serverDevice1(config-if-vlan2)#exitDevice1(config)#ip dhcp pool dynamic-poolDevice1(dhcp-config)#network 1.0.0.0 255.255.255.0Device1(dhcp-config)#default-router 1.0.0.1Device1(dhcp-config)#exit
#Configure a rota estática para o segmento 1.0.0.0/24.
Device1(config)#ip route 1.0.0.0 255.255.255.0 2.0.0.2- Passo 3: Configure os parâmetros Device2 e Option82 do dispositivo de retransmissão DHCP.
#Configure o endereço IP do servidor de retransmissão DHCP como 2.0.0.1.
Device2(config)#interface vlan3Device2(config-if-vlan3)#ip dhcp relayDevice2(config-if-vlan3)#ip dhcp relay server-address 2.0.0.1
#Enable Option82 e configure a subopção remote-ID como 0102030405.
Device2(config)#ip dhcp relay information optionDevice2(config)#ip dhcp relay information remote-id hex 0102030405
- Passo 4: Confira o resultado.
Consulte as informações do endereço IP distribuído para o cliente no Device1.
Device1#show ip dhcp pool danymic-pool1 leaseIP Address MAC Address Vendor Id Type Time Left(s)------------ ------------------ ------------------- -------- -------------1.0.0.2 0001.7a6a.0268 Global Lease 107992
No cliente DHCP, consulte um endereço IP do segmento 1.0.0.0/24 obtido pela placa de rede.
No servidor DHCP, capture o pacote e você poderá verificar se o ID remoto da opção82 no pacote de descoberta recebido pelo servidor é 0102030405 .
Depois que a Opção 82 é habilitada, sua subopção Circuit ID é preenchida com o índice da interface de recebimento e a ID do sistema do dispositivo de relé.
DNS
Visão geral
O Domain Name System (DNS) é um banco de dados distribuído que mapeia nomes de domínio e endereços IP. Ele fornece conversão entre nomes de domínio e endereços IP. Com o uso do DNS, quando os usuários acessam a Internet, eles podem usar nomes de domínio fáceis de memorizar e significativos. Em seguida, o servidor de nomes de domínio na rede resolve os nomes de domínio em endereços IP corretos. O DNS é categorizado em DNS estático e DNS dinâmico.
A resolução de nomes de domínio estático é conduzida por meio de uma tabela DNS estática. Na tabela DNS estática, os nomes de domínio e endereços IP são mapeados e alguns nomes de domínio usados com frequência são adicionados. Quando um cliente solicita o endereço IP de um nome de domínio, o servidor DNS primeiro pesquisa a tabela DNS estática pelo endereço IP correspondente. Isso melhora a eficiência da resolução de nomes de domínio.
A resolução dinâmica de nomes de domínio é implementada consultando o DNS. Um cliente DNS envia uma solicitação de resolução de nome de domínio para um servidor DNS. Depois que o servidor DNS recebe a solicitação de resolução de nome de domínio, ele primeiro determina se o nome de domínio solicitado está localizado em seu subdomínio de gerenciamento autorizado. Se sim, ele procura no banco de dados o endereço IP necessário e envia o resultado da consulta para o cliente. Se o nome de domínio não estiver no subdomínio de gerenciamento autorizado, o servidor DNS iniciará uma resolução recursiva com outro servidor DNS e enviará o resultado da resolução ao cliente. Alternativamente, ele especifica o endereço do próximo servidor DNS no pacote de resposta ao cliente DNS. Em seguida, o cliente envia outra solicitação de resolução de nome de domínio para o servidor de nome de domínio. Este é o chamado modo de resolução iterativa.
Configuração da função DNS
Tabela 4 -1 Lista de funções DNS
| Tarefas de configuração | |
| especificação de cache DNS |
Configure a especificação máxima do cache estático
Configure a especificação máxima do cache dinâmico |
| Configure a função do cliente DNS. |
Configure a resolução de nome de domínio estático.
Configure a resolução de nome de domínio dinâmico. |
| Configurar a função de detecção de DNS | Configurar a lista de nomes de domínio Detectar a resolução do nome de domínio |
Configurar Especificação de Cache DNS
Condição de configuração
Nenhum
Configurar especificação de DNS
Ao modificar a especificação máxima suportada pelo DNS, se a especificação atual for M, a quantidade atual for n e a especificação configurada for N. Existem os seguintes cenários:
-
Especificação estática: Se N > M ou n < N < M , a configuração tem efeito imediato; se N
- Especificação dinâmica: Se N > M ou n < N < M , a configuração tem efeito imediato; se N
- Especificação dinâmica: Se N > M ou n < N < M , a configuração tem efeito imediato; se N
Tabela 4 -2 Configure a lista de métodos de autenticação do modo privilegiado
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a especificação máxima suportada pelo DNS estático | dns static max-count number | Opcional Por padrão, o cache estático suporta no máximo 64. |
| Configure a especificação máxima suportada pelo cache de DNS dinâmico | dns dynamic max-count number | Opcional Por padrão, o cache dinâmico suporta no máximo 10K. |
Configurar a função de cliente DNS
Condição de configuração
Nenhum
Configurar resolução de nome de domínio estático
Ao configurar a resolução de nomes de domínio estático, você pode configurar nomes de domínio para mapear o endereço IPv4 e o endereço IPv6.
Tabela 4 -3 Configurando a resolução de nome de domínio estático
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o endereço IPv4 correspondente do nome de domínio estático | ip host [ vrf vrf-name ] domain-name ip-address | Obrigatório Por padrão, não configure o endereço IPv4 correspondente do nome de domínio. |
| Configure o endereço IPv6 correspondente do nome de domínio estático | ipv6 host [ vrf vrf-name ] domain-name ipv6-address | Obrigatório Por padrão, não configure o endereço IPv6 correspondente do nome de domínio. |
Configurar resolução de nome de domínio dinâmico
Ao configurar a resolução dinâmica de nomes de domínio, você precisa configurar o endereço IP de um servidor de nomes de domínio. Em seguida, as solicitações de resolução de domínio podem ser enviadas ao servidor de domínio adequado para resolução.
Os usuários podem pré-configurar um sufixo de domínio. Então, quando os usuários usam um nome de domínio, eles podem inserir apenas campos de parte do nome de domínio e o sistema adiciona automaticamente o sufixo de domínio pré-configurado para resolução.
Tabela 4 -4 Configurando a resolução de nome de domínio dinâmico
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure um sufixo de domínio. | ip domain-name [ vrf vrf-name ] domain-name | Obrigatório . Por padrão, nenhum sufixo de domínio é configurado. |
| Configure um endereço de servidor DNS. | ip name-server [ vrf vrf-name ] ip-address | Obrigatório . Por padrão, o endereço do servidor DNS não está configurado. |
| Configure a ordem de resolução de nomes de domínio. | ip name-order { dns-first | dns-only | local-first } | Opcional . Por padrão, a ordem de resolução do sistema é local primeiro. |
Configurar a função de detecção de DNS
Condição de configuração
Nenhum
Configurar lista de nomes de domínio
Configure a lista de nomes de domínio e você pode adicionar alguns nomes de domínio comuns à lista de nomes de domínio para salvar. Quando for necessário usar, especifique diretamente o nome da lista de nomes de domínio.
Tabela 4 -5 Configurar a lista de nomes de domínio
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie uma lista de nomes de domínio e entre no modo de configuração da lista de nomes de domínio | dns domain-list list-name | Obrigatório Por padrão, não configure a lista de nomes de domínio. |
| Configurar o nome de domínio | domain domain-name | Obrigatório Por padrão, não configure o nome de domínio na lista de nomes de domínio. |
Detectar resolução de nome de domínio
Detecte a resolução do nome de domínio e você poderá detectar se o servidor DNS pode resolver corretamente o nome de domínio especificado.
Tabela 4 -6 Detectar a resolução do nome de domínio
| Etapa | Comando | Descrição |
| Detectar a resolução do nome de domínio | dns query [ vrf vrf-name ] ip-address [ name domain-name | name-list list-name ] [ timeout time ] | Obrigatório Por padrão, não detecte a resolução do nome de domínio. |
Monitoramento e manutenção de DNS
Tabela 4 -7 Monitoramento e manutenção de DNS
| Comando | Descrição |
| debug dns {all | config | event | mpos | packet | timer} | Habilite as informações de depuração de DNS |
| show dns domain-list [list-name] | Exibir a lista de nomes de domínio |
| show hosts | Exibir as entradas da lista de resolução de nomes de domínio |
| show name-server [vrf vrf-name] | Exibir as informações do servidor DNS |
Exemplo de configuração típica de DNS
Configurar resolução de nome de domínio estático
Requisitos de rede
- O dispositivo e o PC estão interconectados e a rota é alcançável.
- O nome do host do PC é host.xxyyzz.com e o endereço IP é 1.0.0.2/24.
- No Dispositivo, acesse o host host.xxyyzz.com por meio da resolução de nome de domínio estático.
Topologia de rede
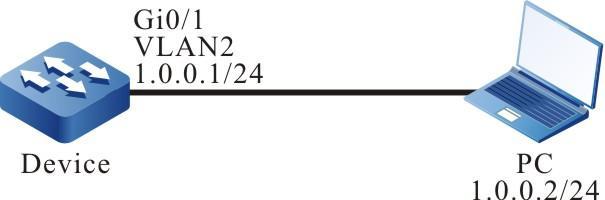
Figura 4 -1 Rede para configurar a resolução de nome de domínio estático
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure endereços IP para as portas. (Omitido)
- Passo 3: Configure um nome de domínio estático.
#No Dispositivo, configure o nome do host host.xxyyzz.com para corresponder ao endereço IP 1.0.0.2.
Device#configure terminalDevice(config)#ip host host.xxyyzz.com 1.0.0.2Device(config)#exit
- Passo 4: Confira o resultado.
#No dispositivo, ping h ost h ost.xxyyzz.com. O dispositivo obtém o endereço IP 1.0.0.2 que corresponde ao nome do host por meio da resolução de nome de domínio local.
Device#ping host.xxyyzz.comPress key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to 1.0.0.2 , timeout is 2 seconds:!!!!!Success rate is 100% (5/5). Round-trip min/avg/max = 0/6/16 ms.
Ao executar ping em um nome de host, o endereço IPv6 correspondente ao nome do host é resolvido primeiro e, em seguida, o endereço IPv4.
Configurar resolução de nome de domínio dinâmico
Requisitos de rede
- O endereço IP do servidor DNS é 1.0.0.3/24, o endereço IP do Dispositivo é 1.0.0.1/24 e o endereço IP do PC é 1.0.0.2/24.
- O servidor DNS, o dispositivo e o PC estão interconectados por meio de uma LAN e a rota é alcançável. No servidor DNS, existe o registro DNS de host.xxyyzz.com e 1.0.0.2.
- Dispositivo de acesso ao PC através da resolução dinâmica de host.xxyyzz.com através do servidor DNS.
Topologia de rede
Figura 4 -2 Rede para configurar a resolução de nome de domínio dinâmico
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure o servidor DNS. (Omitido)
- Passo 4: Configure o cliente DNS.
#Especifique um servidor DNS para o cliente e o endereço IP é 1.0.0.3.
Device#configure terminalDevice(config)#ip name-server 1.0.0.3Device(config)#exit
- Passo 5: Confira o resultado.
#No dispositivo, faça ping no host host.xxyyzz.com. O dispositivo obtém o endereço IP 1.0.0.2 que corresponde ao nome do host por meio do servidor DNS.
Device#ping host.xxyyzz.comPress key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to 1.0.0.2 , timeout is 2 seconds:!!!!!Success rate is 100% (5/5). Round-trip min/avg/max = 0/6/16 ms.
Base IPv6
Visão geral
IPv6 ( Internet Protocol Version 6) é o protocolo padrão de segunda geração do protocolo da camada de rede, também conhecido como IPng (IP Next Generation). É um conjunto de especificações desenhadas pela IETF (Internet Engineering Task Force) e uma versão atualizada do IPv4.
Proxy ND de interface L3
O proxy ND de interface L3 é usado para realizar o interfuncionamento de diferentes segmentos de rede conectados por meio de duas interfaces. Geralmente, o dispositivo não responderá à solicitação NS cujo destino não é o segmento de rede correspondente à interface de recebimento de pacotes, portanto, segmentos de rede diferentes não podem se comunicar diretamente entre si. Quando a função de proxy ND está habilitada na interface L3, se o dispositivo recebe da interface NS pertencente a outros segmentos de rede de interface, ele também pode responder a NA. Assim, os hosts pertencentes a diferentes segmentos de rede também podem estabelecer entradas vizinhas e se comunicar normalmente. Seu cenário de aplicação típico é a rede de segmentos de rede grandes e pequenos.
Configuração básica da função IPv6
Tabela 5 -1 lista de configuração de funções básicas do IPv6
| Tarefas de configuração | |
| Configurar o endereço IPv6 | Configure o endereço IPv6 da interface |
| Configurar funções básicas do IPv6 |
Habilite a função de encaminhamento unicast IPv6
função de interface IPv6 limite de salto de pacote IPv6 Configure o IPv6 MTU da interface |
| Configurar o protocolo de descoberta do vizinho IPv6 |
Configurar o vizinho estático IPv6
Configure o tempo de envelhecimento da entrada do vizinho IPv6 no estado STALE Configure o intervalo de retransmissão do pacote NS Configure os horários de envio do pacote NS quando o IPv6 repete a detecção de endereço Configure os parâmetros relacionados do pacote RA Habilite a função da interface enviando o pacote de redirecionamento |
| Ative a função de resposta rápida ND | Ative a função de resposta rápida ND |
| Configurar a função de proxy ND da interface L3 | Configurar a função de proxy ND da interface L3 |
| Configurar a função ICMPv6 |
Configure a taxa de envio do pacote de erro ICMPv6
Habilite a função de envio do pacote ICMPv6 com destino inacessível |
| Configurar a função anti-ataque IPv6 TCP | Habilite o syncache TCP função Habilite os syncookies TCP função |
Endereço IPv6 da interface
A diferença mais marcante entre IPv6 e IPv4 é que o comprimento do endereço IP aumenta de 32 bits para 128 bits. O endereço IPv6 é representado como uma série de números hexadecimais de 16 bits separados por dois pontos (:). Cada endereço IPv6 é dividido em oito grupos, cada grupo de 16 bits representado por quatro dígitos hexadecimais, e os grupos são separados por dois pontos, como 2000:0000:240F:0000:0000:0CB0:123A:15AB.
Para simplificar a representação do endereço IPv6, processe o “0” no endereço IPV6 da seguinte forma:
- O preâmbulo “0” em cada grupo pode ser omitido, ou seja, o endereço acima pode ser representado como 200 0 :0: 24 0F:0:0: CB 0: 123 A:1 5A B.
- Se o endereço contém dois ou mais grupos consecutivos de zero, ele pode ser substituído por dois pontos "::" ou seja, o endereço acima pode ser representado como 2000:0:240F:: CB0:123A:15AB.
- Os dois pontos "::" só podem ser usados uma vez em um endereço IPv6 . Caso contrário , o número de zeros representado por "::" não pode ser determinado quando o dispositivo converte "::" em zero para recuperar endereços de 128 bits.
O endereço IPv6 consiste em duas partes: prefixo de endereço e identificador de interface. O prefixo de endereço é equivalente ao campo de número de rede no endereço IPv4 e o identificador de interface é equivalente ao campo de número de host no endereço IPv4.
O prefixo do endereço IPv6 é expresso como: endereço IPv6/comprimento do prefixo. O endereço IPv6 é qualquer uma das formas listadas acima, e o comprimento do prefixo é um número decimal que indica quantos bits na frente do endereço IPv6 é o prefixo do endereço.
Existem três tipos de endereços IP v6 , ou seja, endereço unicast, endereço multicast e endereço anycast:
- Endereço unicast: usado para identificar exclusivamente uma interface, semelhante ao endereço unicast IPv4. Os pacotes enviados para um endereço unicast serão enviados para a interface identificada por este endereço.
- Endereço multicast: usado para identificar um conjunto de interfaces, semelhante ao endereço multicast IPv4. Os pacotes enviados para um endereço multicast são enviados para todas as interfaces identificadas por este endereço.
- Endereço Anycast: utilizado para identificar um grupo de interfaces e o pacote cujo destino é um endereço anycast é enviado apenas para uma interface do grupo. De acordo com o protocolo de roteamento, a interface de recebimento do pacote é a interface mais próxima da origem.
O tipo de endereço IPv6 é especificado pelos primeiros bits do endereço, chamado de prefixo de formato. A relação correspondente entre o tipo de endereço principal e o prefixo do formato é mostrada na Tabela 1-2.
Tabela 5 -2 A relação correspondente entre o tipo de endereço IPv6 e o prefixo do formato
| Tipo de endereço | Prefixo de formato (binário) | ID do prefixo | |
| Endereço unicast |
Endereço não especificado
Endereço de retorno O endereço local do link O endereço local do site Endereço unicast global |
00...0 (128 bits) 00...1 (128 bits) 1111111010 1111111011 Outras formas |
::/128 ::1/128 FE80::/10 FEC0::/10 - |
| Endereço multicast | 11111111 | FF00::/8 | |
| Endereço Anycast | Distribuído do espaço de endereço unicast, use o formato do endereço unicast |
Os endereços unicast IPv6 podem ser de vários tipos, incluindo endereços unicast globais, endereços locais de link e endereços locais do site.
- O endereço unicast global é equivalente ao endereço de rede pública IPv4, que é fornecido ao provedor de serviços de Internet. Este tipo de endereços permite a agregação de prefixos de roteamento, limitando assim o número de entradas de roteamento global.
- Os endereços locais de link são usados para a comunicação entre os nós locais no link no protocolo de descoberta de vizinhança e na configuração automática sem estado. O pacote que usa o endereço local do link como endereço de origem ou destino não é encaminhado para outros links.
- O endereço local do site é semelhante ao endereço privado no IPv4. O pacote que usa o endereço local do site como endereço de origem ou destino não é encaminhado para outros sites fora do site.
- Endereço de loopback: O endereço de unicast 0:0:0:0:0:0:0:0:0:1 (simplificado como: 1) é chamado de endereço de loopback e não pode ser atribuído a nenhuma interface física. Sua função é a mesma do endereço de loopback no IPv4, ou seja, o nó envia pacotes IPv6 para si mesmo.
- Endereço não especificado: O endereço “ :: ” é chamado de endereço não especificado e não pode ser atribuído a nenhum nó. Antes que um nó obtenha um endereço IPv6 válido, ele pode ser inserido no campo de endereço de origem do pacote IPv6 enviado, mas não como endereço de destino do pacote IPv6.
Os endereços multicast especiais reservados pelo IPv6 são mostrados na tabela 1-3.
Tabela 5 -3 A lista especial de endereços multicast do IPv6
| Um endereço | Uso |
| FF01::1 | O endereço multicast de todos os nós no escopo local do nó |
| FF02::1 | O endereço multicast de todos os nós no escopo local do link |
| FF01::2 | O endereço multicast de todos os roteadores no escopo local do nó |
| FF02::2 | O endereço multicast de todos os roteadores no escopo local do link |
| FF05::2 | O endereço multicast de todos os roteadores no escopo local do site |
Condição de configuração
Nenhum
Configurar o endereço IPv6 da interface
Tabela 5 -4 Configure o endereço IPv6 da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o endereço IPv6 da interface | ipv6 address { linklocal-address link-local | prefix-address [ anycast | eui-64 ] | autoconfig } | Obrigatório Por padrão, a interface não está configurada com o endereço IPv6. |
Uma interface pode ser configurada com vários endereços IPv6 . Depois que uma interface for configurada com o endereço IPv6, ative automaticamente a função IPv6.
Configurar funções básicas do IPv6
Condição de configuração
Nenhum
Ativar função de encaminhamento Unicast IPv6
Por padrão, a função de encaminhamento unicast IPv6 está habilitada. Em alguns casos especiais, o usuário pode desabilitar a função de encaminhamento unicast IPv6. Após desabilitar a função, não encaminhe o pacote IPv6.
Tabela 5 -5 Ativar a função de encaminhamento unicast IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar a função de encaminhamento unicast IPv6 | ipv6 unicast-routing | Obrigatório Por padrão, a função de encaminhamento unicast IPv6 está habilitada. |
Ativar a função IPv6 da interface
Antes de realizar a configuração IPv6 em uma interface, primeiro habilite a função IPv6. Caso contrário, alguma configuração não terá efeito.
Tabela 5 -6 Habilite a função IPv6 da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite a função IPv6 da interface | ipv6 enable | Obrigatório Por padrão, a função IPv6 da interface está desabilitada. |
Configurar o limite de salto do pacote IPv6
O cabeçalho IPv6 contém o campo Hop Limit, cuja função é a mesma do campo TTL no cabeçalho IPv4, representando os tempos em que o pacote pode ser encaminhado pelo roteador pela rede.
Com o comando, você pode configurar o limite de saltos no cabeçalho do pacote IPv6 gerado pelo dispositivo.
Tabela 5 -7 Configure o limite de salto do pacote IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o limite de saltos do pacote IPv6 | ipv6 hop-limit value | Obrigatório Por padrão, o limite de salto do pacote IPv6 enviado pelo dispositivo é 64. |
Configurar o MTU IPv6 da interface
Tabela 5 - 8 Configurar o IPv6 MTU da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o IPv6 MTU da interface | ipv6 mtu value | Obrigatório Por padrão, não configure o IPv6 MTU da interface |
Configurar o protocolo de descoberta de vizinhos IPv6
O protocolo IPv6 Neighbor Discovery inclui as seguintes funções: resolução de endereço, detecção de vizinho inacessível, detecção de endereço duplicado, descoberta de roteador/descoberta de prefixo, configuração automática de endereço e redirecionamento.
O tipo de pacote ICMPv6 usado pelo protocolo ND e suas funções são mostrados na tabela a seguir.
Tabela 5 -9 O tipo de pacote ICMPv6 usado pelo protocolo ND e suas funções
| ICMPv6 Tipo de pacote | Tipo No. | Função |
| Pacote de solicitação de roteador (RS: Solicitação de roteador) | 133 | Após o início de um nó, ele envia uma solicitação ao roteador via pacote RS, solicitando o prefixo e outras informações de configuração, usadas para configuração automática do nó |
| Pacote de anúncio de roteador (RA: anúncio de roteador) | 134 | Responda pelo pacote RS Sem suprimir o envio de pacotes RA, o roteador envia periodicamente pacotes RA, incluindo opções de informações de prefixo e alguns bits de sinalização. |
| Pacote de solicitação de vizinho (NS : Solicitação de vizinho) | 135 | Obtenha o endereço da camada de link do vizinho Verifique se o vizinho está acessível Execute a detecção de endereço repetido |
| Pacote de anúncio de vizinho (NA: anúncio de vizinho) | 136 | Responda pelo pacote NS O nó envia o pacote NA automaticamente quando a camada de enlace muda, anunciando as informações de mudança do nó para o nó vizinho. |
| Pacote de redirecionamento (Redirecionamento) | 137 | Ao atender a uma determinada condição, o gateway padrão envia um pacote de redirecionamento para o host de origem, fazendo com que o host selecione novamente o endereço de próximo salto correto para a transmissão de pacotes subsequente. |
- Resolução de endereço
Obtenha o endereço da camada de link do nó vizinho em um link, que é realizado pelo pacote NS e pelo pacote NA
- Detecção de vizinho inacessível
Depois de obter o endereço da camada de enlace do nó vizinho, verifique se o nó vizinho é alcançável através do pacote NS e do pacote NA .
- O nó envia o pacote NS, cujo endereço de destino é o endereço IPv6 do nó vizinho
- Se receber o pacote de confirmação do nó vizinho, considera-se que o vizinho é alcançável. Caso contrário, considera-se que o vizinho não é alcançável.
- Detecção de endereço duplicado
Após o nó obter um endereço IPv6, é necessário usar a função de detecção de endereço duplicado para confirmar se o endereço é usado por outros nós.
- Descoberta de roteador/descoberta de prefixo e configuração automática de endereço
Descoberta de roteador/descoberta de prefixo indica que o nó obtém o roteador vizinho e seu prefixo de rede do pacote RA recebido, bem como outros parâmetros de configuração.
A configuração automática sem estado de endereço indica que o nó configura automaticamente o endereço IPv6 de acordo com as informações obtidas pela descoberta do roteador/descoberta de prefixo.
A descoberta de roteador/prefixo é obtida por meio de pacotes RS e pacotes RA.
- Redirecionamento
Quando o host é iniciado, pode haver apenas uma rota padrão para o gateway padrão em sua tabela de roteamento. Ao atender a determinadas condições, o gateway padrão envia pacotes de redirecionamento ICMPv6 para o host de origem, informando ao host para escolher um próximo salto melhor para enviar os pacotes subsequentes.
Condição de configuração
Nenhum
Configurar vizinho estático IPv6
A resolução do endereço IPv6 do nó vizinho no endereço da camada de link pode ser realizada pela função de resolução de endereço do protocolo IPv6 ND ou pela configuração manual do vizinho estático.
O vizinho IPv6 é identificado exclusivamente pelo endereço IPv6 do nó vizinho e pela interface L3 conectada ao nó vizinho.
Tabela 5 -10 Configurar o vizinho estático IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o vizinho estático IPv6 | ipv6 neighbor ipv6-address interface-name mac-address | Obrigatório Por padrão, não configure o vizinho estático IPv6. |
Configurar o tempo de idade da entrada do vizinho IPv6 no estado STALE
As entradas de vizinhos IPv6 têm cinco estados de acessibilidade: INCOMPLETE, REACHABLE, STALE, DELAY e PROBE. O estado STALE indica não saber se o vizinho é alcançável ou não. A entrada vizinha no estado STALE tem um tempo de envelhecimento, e as entradas vizinhas no estado STALE que atingem o tempo de envelhecimento migrarão para o estado DELAY.
Tabela 5 -11 Configure a hora da entrada do vizinho IPv6 no estado STALE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o tempo de idade da entrada do vizinho IPv6 no estado STALE | ipv6 neighbor stale-aging aging-time | Opcional Por padrão, o tempo de idade da entrada do vizinho IPv6 no estado STALE é 7200s. |
Configurar o intervalo de retransmissão do pacote NS
Quando o dispositivo envia um pacote NS e não recebe uma resposta dentro de um intervalo de tempo especificado, ele reenviará o pacote NS. O intervalo para reenvio do pacote NS pode ser configurado pelo seguinte comando.
Tabela 5 -12 Configure o intervalo de reenvio do pacote NS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o intervalo de retransmissão do pacote NS | ipv6 nd ns-interval value | Obrigatório Por padrão, o intervalo de envio do pacote NS é de 1000ms. |
Configurar os horários da detecção de endereço duplicado IPv6 enviando o pacote NS
Após a interface ser configurada com o endereço IPv6, o pacote NS é enviado para detecção de endereço duplicado. Se nenhuma resposta for recebida dentro de um determinado período de tempo, o pacote NS continua a ser enviado. Quando o número de pacotes NS enviados atinge o valor definido, nenhuma resposta é recebida, o endereço é considerado disponível.
Tabela 5-13 Configure os tempos de detecção de endereço duplicado IPv6 enviando o pacote NS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure os horários da detecção de endereço duplicado IPv6 enviando o pacote NS | ipv6 nd dad attempts value |
Obrigatório
Por padrão, os tempos de detecção de endereço duplicado IPv6 enviando o pacote NS são 1. |
Configurar os parâmetros relacionados do pacote RA
Os usuários podem configurar se a interface envia o pacote RA e o intervalo de envio do pacote RA de acordo com a situação real, podendo configurar os parâmetros do pacote RA para informar o host. Quando o host recebe a mensagem RA, ele pode usar esses parâmetros para fazer a operação correspondente.
Tabela 5 -14 Os parâmetros e descrições no pacote RA
| Parâmetro | Descrição |
| Limite de salto | Ao enviar o pacote IPv6, o host preencherá o campo Hop Limit no cabeçalho IPv6 usando este valor de parâmetro. Ao mesmo tempo, o valor do parâmetro também é usado como o valor do campo Hop Limit no pacote de resposta do dispositivo. |
| MTU | O MTU do link liberado, que pode ser usado para garantir que todos os nós em um link adotem o mesmo valor de MTU |
| Vida útil do roteador | Usado para definir a hora do roteador que envia o pacote RA servindo como roteador padrão do host. O host pode determinar se o roteador que envia o pacote RA deve ser considerado o roteador padrão com base no valor do parâmetro de vida útil do roteador do pacote RA recebido. |
| O tempo do vizinho mantendo o estado alcançável (Reachable Time) | Quando a detecção de acessibilidade do vizinho confirma que o vizinho é alcançável, o dispositivo assume que o vizinho é alcançável dentro do tempo de alcance definido; se um pacote precisar ser enviado ao vizinho após o tempo definido, reconfirme que o vizinho é alcançável. |
Tabela 5 -15 Configure os parâmetros relacionados do pacote RA
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure as informações de opção de prefixo no pacote RA | ipv6 nd prefix { ipv6-prefix | default } [ valid-lifetime | infinite | no-advertise | no-autoconfig | off-link ] [ prefered-lifetime | infinite ] | Obrigatório Por padrão, não configure as informações da opção de prefixo. |
| Configure o valor do campo Hop Limit no pacote RA enviado pela interface a ser obtido da configuração global | ipv6 nd ra hop-limit |
Opcional
Por padrão, não configure o valor do campo Hop Limit no pacote RA enviado pela interface a ser obtido da configuração global , e o valor do campo Hop Limit é 0. |
| Configure o intervalo máximo e o intervalo mínimo de envio do pacote RA | ipv6 nd ra interval max-value [ min-value ] |
Opcional
Por padrão, o intervalo máximo de envio do pacote RA é de 600s e o intervalo mínimo é de 198s. |
| Configure o pacote RA para transportar a opção MTU | ipv6 nd ra mtu | Opcional Por padrão, o pacote RA não carrega a opção MTU. |
| Configure o tempo de vida do roteador no pacote RA | ipv6 nd ra-lifetime value | Opcional Por padrão, o tempo de vida do roteador no pacote RA é 1800s. |
| Proibir a interface de enviar o pacote RA periodicamente | ipv6 nd suppress-ra period | Opcional Por padrão, a interface não envia o pacote RA periodicamente. |
| Proibir a interface de responder ao pacote RS | ipv6 nd suppress-ra response | Opcional Por padrão , a interface não responde o pacote RA ao receber o pacote RS. |
Habilite a interface para enviar o pacote de redirecionamento
Após receber o pacote IPv6 que precisa ser encaminhado, o dispositivo descobre que a interface de recebimento do pacote é a mesma da interface de envio selecionando a rota. Neste momento, o dispositivo encaminha o pacote e envia de volta o pacote de redirecionamento para a origem, informando a origem para selecionar novamente o próximo salto correto para enviar os pacotes subsequentes. Por padrão, um dispositivo pode enviar um pacote de redirecionamento, mas em alguns casos específicos, o usuário pode impedir que o dispositivo envie um pacote de redirecionamento.
Tabela 5 -16 Habilite a função da interface enviando o pacote de redirecionamento
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite a função da interface enviando o pacote de redirecionamento | ipv6 redirects |
Opcional
Por padrão, a função da interface que envia o pacote de redirecionamento está habilitada. |
Ativar função de resposta rápida ND
Condição de configuração
Nenhum
Ativar função de resposta rápida ND
Tabela 5 -17 Ative a função de resposta rápida ND
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ative a função de resposta rápida ND | nd fast-response | Obrigatório Por padrão, a função de resposta rápida ND global está habilitada. |
Configurar Interface ND Proxy L3
Condição de configuração
Nenhum
Configurar Interface ND Proxy L3
Tabela 5 -18 Configurar interface ND proxy L3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface L3 | interface interface-name |
Obrigatório
Depois de entrar no modo de configuração da interface L3, a configuração subsequente entra em vigor apenas na interface atual. |
| Entre no modo de configuração global | configure terminal | - |
| Configure a função de proxy ND da interface L3 | nd proxy enable | Obrigatório Por padrão, a interface não habilita a função proxy. |
Configurar a função ICMPv6
Na pilha de protocolos IPv6, o Internet Control Message Protocol é usado principalmente para fornecer serviços de detecção de rede e fornecer relatórios de erros para informar os dispositivos correspondentes quando a camada de rede ou o protocolo da camada de transporte estiver anormal, para controlar e gerenciar a rede.
Condição de configuração
Nenhum
Configurar a taxa de envio do pacote de erro ICMPv6
Se houver muitos pacotes de erro ICMPv6 enviados na rede, isso pode levar ao congestionamento da rede. Para evitar isso, os usuários podem configurar o número máximo de pacotes de erro ICMPv6 enviados dentro de um tempo especificado.
Tabela 5 -19 Configure a taxa de envio dos pacotes de erro ICMPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a taxa de envio dos pacotes de erro ICMPv6 | ipv6 icmp error-interval interval [ buckets ] |
Opcional
Por padrão, o período de envio dos pacotes de erro ICMPv6 é 100ms e o número máximo de pacotes de erro ICMPv6 enviados no período é 10. |
Habilite a função de enviar o pacote ICMP v6 com destino inacessível
A função de enviar o pacote ICMPv6 com o destino inacessível indica que após receber um pacote IPv6 e se seu destino for alcançável, o dispositivo descarta o pacote e envia o pacote de erro ICMPv6 inacessível para a origem.
O dispositivo enviará um pacote de erro inacessível ICMPv6 ao atender às seguintes condições:
- Ao encaminhar pacotes, e se não conseguir encontrar a rota, o dispositivo envia o pacote de erro ICMPv6 "Sem rota para o endereço de destino" para a origem.
- Quando um dispositivo encaminha um pacote e não consegue enviá-lo devido a uma política de gerenciamento (como firewall, ACL), ele envia um pacote de erro ICMPv6 "a comunicação com o endereço de destino é proibida pela política de gerenciamento" para a origem.
- Se o endereço IPv6 de destino do pacote exceder o intervalo do endereço IPv6 de origem (por exemplo, o endereço IPv6 de origem do pacote é o endereço local do link e o endereço IPv6 de destino do pacote é o endereço unicast global) ao encaminhar um pacote e, como resultado, o pacote não pode chegar ao destino, o dispositivo enviará o pacote de erro ICMPv6 "fora do intervalo de endereços de origem" para a origem.
- Se o dispositivo não resolver o endereço da camada de link do endereço IPv6 de destino ao encaminhar o pacote, ele enviará o pacote de erro ICMPv6 "endereço inacessível" para a origem.
- Quando um dispositivo recebe um pacote IPv6 cujo endereço de destino é o local e o protocolo da camada de transporte é UDP, e se o número da porta de destino do pacote não corresponder ao processo em uso, ele envia um pacote de erro ICMPv6 "port unreachable" para a origem .
Como as informações transmitidas ao processo do usuário pelo pacote de erro inacessível de destino ICMPv6 são inacessíveis, se houver um ataque malicioso, isso pode afetar o uso normal dos usuários do terminal. Para evitar esses fenômenos, o usuário pode desabilitar a função de enviar o pacote de erro inacessível de destino ICMPv6.
Tabela 5 -20 Habilite a função de envio do pacote ICMPv6 com destino inacessível
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função de enviar o pacote ICMPv6 com o destino inacessível | ipv6 unreachables |
Opcional
_ Por padrão, a função de enviar o pacote ICMPv6 com o destino inacessível está habilitada. |
Configurar a função anti-ataque IPv6 TCP
Se o servidor TCP IPv6 receber um grande número de pacotes SYN, mas o peer não responder a resposta SYN+ACK ao servidor, isso levará a um grande consumo de memória no servidor, ocupando a fila semi-conectada do servidor. servidor e, como resultado, o servidor TCP IPv6 não pode atender à solicitação normal. Este ataque pode ser evitado configurando a função anti-ataque IPv6 TCP.
Condição de configuração
Nenhum
Ativar sincronização TCP IPv6 Função
Em vez de se apressar para alocar TCB ao receber pacotes SYN, a função primeiro responde a um pacote SYN + ACK e armazena essas informações de conexão semiaberta em um cache dedicado até que o pacote ACK correto seja recebido e, em seguida, realoca o TCB.
Tabela 5 -21 Ativar sincronização TCP IPv6 função
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| função de sincronização TCP IPv6 | ipv6 tcp syncache | Obrigatório Por padrão, a função de sincronização TCP IPv6 está desabilitada. |
Ativar cookies de sincronização TCP IPv6 Função
Esta função não usa nenhum recurso de armazenamento. Ele usa um algoritmo especial para gerar o Número de Sequência. Esse algoritmo leva em consideração o endereço IPv6 e a porta da parte peer, o endereço IPv6 e as informações fixas da porta da própria parte e algumas informações fixas da própria parte que a parte peer não pode saber, como MSS e hora. Após receber o pacote ACK da parte peer, recalcule-o para ver se é o mesmo que a Sequência Número-1 no pacote de resposta da parte peer, para decidir se aloca recursos TCB.
Tabela 5 -22 Habilite os syncookies TCP IPv6 função
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite os syncookies TCP IPv6 função | ipv6 tcp syncookies | Obrigatório Por padrão, os syncookies TCP IPv6 função está desabilitada. |
Monitoramento e manutenção básicos de IPv6
Tabela 5 -23 Monitoramento e manutenção básicos do IPv6
| Comando | Descrição |
| clear nd fast-response statistics | Limpe as estatísticas de resposta rápida do ND |
| clear ipv6 icmp6stat | informações de estática do ICMPv6 |
| clear ipv6 interface statistics | Limpe as informações de estatísticas do pacote IPv6 da interface |
| clear ipv6 mtu | Limpe as informações de MTU do caminho IPv6 |
| clear ipv6 neighbors | entrada do vizinho dinâmico IPv6 |
| clear ipv6 statistics | Limpar as informações de estatísticas básicas do IPv6 |
| clear ipv6 tcp syncache statistics | Limpe as informações de estatísticas de sincronização do protocolo TCP IPv6 |
| clear ipv6 tcp6stat | Limpar as informações de estatísticas TCP IPv6 |
| clear ipv6 udp6stat | Limpe as informações de estatísticas do IPv6 UDP |
| show nd fast-response statistics | Exibir as estatísticas de resposta rápida do ND |
| show ipv6 hop-limit | Mostrar o valor global Hop Limit IPv6 |
| show ipv6 frag-queue | Mostrar o pacote de fragmento IPv6 em cache |
| show ipv6 icmp6state | Mostrar as informações de estatísticas do ICMPv6 |
| show ipv6 interface | Mostrar as informações IPv6 da interface |
| show ipv6 interface statistics | Mostrar as informações de estatísticas IPv6 da interface |
| show ipv6 max-mtu | Mostrar o valor máximo de IPv6 MTU suportado pelo sistema |
| show ipv6 mtu | Mostre as informações de MTU do caminho IPv6 |
| show ipv6 neighbors | informações do vizinho IPv6 |
| show ipv6 prefix | informações de prefixo de endereço IPv6 |
| show ipv6 sockets | informações do soquete IPv6 |
| show ipv6 statistics | informações básicas de estatísticas do IPv6 |
| show ipv6 tcp syncache detail | Mostrar as informações de entrada de sincronização do protocolo TCP IPv6 |
| show ipv6 tcp syncache statistics | Mostrar as informações de estatísticas de sincronização do protocolo TCP IPv6 |
| show ipv6 tcp6state | Mostrar as informações de estatísticas TCP IPv6 |
| show ipv6 udp6state | informações de estatísticas do IPv6 UDP |
Exemplo de configuração básica de IPv6
Configurar o endereço IPv6 da interface
Requisitos de rede
- Dois dispositivos são conectados através da porta Ethernet , configure o endereço unicast global IPv6 para a interface e verifique a conectividade entre eles.
Topologia de rede

Figura 5 -1 Rede para configurar o endereço IPv6 da interface
Etapas de configuração
- Passo 1: Habilite o recurso de encaminhamento IPv6 do dispositivo.
# Configure Device1 .
Device1#configure terminalDevice1(config)#ipv6 unicast-routing
#Configurar Dispositivo2 .
Device2#configure terminalDevice2(config)#ipv6 unicast-routing
- Passo 2: Configure o endereço unicast global da interface.
#Configure o endereço unicast global da interface Device1 gigabitethernet0/0/1 como 2001:1::1/64.
Device1(config)#interface gigabitethernet0/0/1Device1(config-if-gigabitethernet0/0/1)#ipv6 address 2001:1::1/64Device1(config-if-gigabitethernet0/0/1)#exit
#Configure o endereço unicast global da interface do dispositivo 2 gigabitethernet0/0/1 como 2001:1::2/64.
Device2(config)# interface gigabitethernet0/0/1Device2(config-if-gigabitethernet0/0/1)#ipv6 address 2001:1::2/64Device2(config-if-gigabitethernet0/0/1)#exit
- Passo 3: Confira o resultado.
#Visualize as informações da interface Device1.
Device1#show ipv6 interface gigabitethernet0/0/1gigabitethernet0/0/1 is upVRF: globalIPv6 is enable, link-local address is fe80::0201:7aff:fe46:a64dGlobal unicast address(es):2001:0001::0001, subnet is 2001:0001::/64Joined group address(es):ff02::0001:ff00:0001ff02::0001:ff00:0ff02::0002ff02::0001ff02::0001:ff46:a64dND control flags: 0x1MTU is 1500 bytesICMP redirects are enabledICMP unreachables are enabledND DAD is enabled, number of DAD attempts: 1ND reachable time is 30000 millisecondsND advertised reachable time is 0 (unspecified)ND advertised retransmit interval is 0 (unspecified)
Após configurar o endereço IPv6, habilite a função do protocolo IPv6 na interface automaticamente, gere o endereço local do link automaticamente e adicione ao grupo multicast correspondente.
#Visualize as informações da interface do Device2.
Device2#show ipv6 interface gigabitethernet0/0/1gigabitethernet0/0/1 is upVRF: globalIPv6 is enable, link-local address is fe80::0201:7aff:fe22:e222Global unicast address(es):2001:0001::0002, subnet is 2001:0001::/64Joined group address(es):ff02::0001:ff00:0002ff02::0001:ff00:0ff02::0002ff02::0001ff02::0001:ff22:e222ND control flags: 0x1MTU is 1500 bytesICMP redirects are enabledICMP unreachables are enabledND DAD is enabled, number of DAD attempts: 1ND reachable time is 30000 millisecondsND advertised reachable time is 0 (unspecified)ND advertised retransmit interval is 0 (unspecified)
#Ping o endereço local do link do Device2 fe80::0201:7aff:fe22:e222 no Device1.
Device1#ping fe80::0201:7aff:fe22:e222Press key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to fe80::201:7aff:fe22:e222 , timeout is 2 seconds:Output Interface: gigabitethernet0/0/1!!!!!Success rate is 100% (5/5). Round-trip min/avg/max = 0/96/483 ms.
Ao executar ping no endereço local do link, é necessário especificar a interface de saída, que é a interface no mesmo link do endereço local do link de ping.
#Em Device1, faça ping no endereço unicast global de Device2 2001:1::2.
Device1#ping 2001:1::2Press key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to 2001:1::2 , timeout is 2 seconds:!!!!!Success rate is 100% (5/5). Round-trip min/avg/max = 0/36/183 ms.
Device1 e Device2 podem fazer ping um no outro.
Configurar a descoberta de vizinhos IPv6
Requisitos de rede
- Dispositivo e PC pertencem a uma LAN.
- Configure a interface do dispositivo gigabitethernet0/0/1 com o endereço EUI-64 .
- O PC obtém o prefixo do endereço IPv6 através do protocolo de descoberta de vizinhos IPv6, configura o endereço IPv6 de acordo com o endereço obtido automaticamente. Realize a comunicação do protocolo IPv6 entre PC e Dispositivo.
Topologia de rede

Figura 5 -2 Rede para configuração Descoberta de vizinhos IPv6
Etapas de configuração
- Passo 1:Habilite o recurso de encaminhamento IPv6 do dispositivo.
Device#configure terminalDevice(config)#ipv6 unicast-routing
- Passo 2:
#Configurar o dispositivo gigabitethernet0/0/1 com o endereço EUI-64 e habilitar a função de publicidade RA de gigabitethernet0/0/1.
Device(config)#interface gigabitethernet0/0/1Device(config-if-gigabitethernet0/0/1)#ipv6 address 2001:1::/64 eui-64Device(config-if-gigabitethernet0/0/1)#no ipv6 nd suppress-ra periodDevice(config-if-gigabitethernet0/0/1)#no ipv6 nd suppress-ra responseDevice(config-if-gigabitethernet0/0/1)#exit
Por padrão, a função de publicidade RA está desabilitada.
#Visualize as informações da interface do Dispositivo.
Device#show ipv6 interface gigabitethernet0/0/1gigabitethernet0/0/1 is upVRF: globalIPv6 is enable, link-local address is fe80::0201:7aff:fe5d:e7d3Global unicast address(es):2001:0001::0201:7aff:fe5d:e7d3, subnet is 2001:0001::/64 [EUI]Joined group address(es):ff02::0001:ff00:0ff02::0002ff02::0001ff02::0001:ff5d:e7d3ND control flags: 0x85MTU is 1500 bytesICMP redirects are enabledICMP unreachables are enabledND DAD is enabled, number of DAD attempts: 1ND reachable time is 30000 millisecondsND advertised reachable time is 0 (unspecified)ND advertised retransmit interval is 0 (unspecified)ND config flags is 0x0ND MaxRtrAdvInterval is 600ND MinRtrAdvInterval is 198ND AdvDefaultLifetime is 1800”
- Passo 3: Configure o PC .
# No PC, instale o protocolo I p v6 . A configuração IPv6 depende do sistema operacional. Este texto usa o Windows XP como exemplo para descrever.
C:\>ipv6 installInstalling...Succeeded.
- Passo 4: Confira o resultado.
# Visualize as informações da interface do PC.
C:\>ipconfig…………(some displayed information is omitted)Ethernet adapter 130:Connection-specific DNS Suffix . :IP Address. . . . . . . . . . . . : 130.255.128.100Subnet Mask . . . . . . . . . . . : 255.255.0.0IP Address. . . . . . . . . . . . : 2001:1::15b3:d4:f13d:c3daIP Address. . . . . . . . . . . . : 2001:1::3a83:45ff:feef:c724IP Address. . . . . . . . . . . . : fe80::3a83:45ff:feef:c724%6Default Gateway . . . . . . . . . : fe80::201:7aff:fe5e:cfc1%6
Você pode ver que o PC obtém o prefixo de endereço I pv6 2001:1::/64 e gera o endereço unicast global de acordo com o prefixo automaticamente.
Depois que o host do Windows XP obtém o prefixo de endereço, ele gera dois endereços unicast globais. O ID de interface de um endereço é gerado de acordo com o endereço MAC da interface e o ID de interface do outro endereço é gerado aleatoriamente.
#No dispositivo, execute ping no endereço local do link do PC fe80::3a83:45ff:feef:c724.
Device#ping fe80::3a83:45ff:feef:c724Press key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to fe80::3a83:45ff:feef:c724 , timeout is 2 seconds:Output Interface: gigabitethernet0/0/1!!!!!Success rate is 100% (5/5). Round-trip min/avg/max = 0/29/149 ms.
#No dispositivo, execute ping no endereço unicast global gerado automaticamente 2001:1::15b3:d4:f13d:c3da e 2001:1::3a83:45ff:feef:c724 no PC.
Device#ping 2001:1::15b3:d4:f13d:c3daPress key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to 2001:1::15b3:d4:f13d:c3da , timeout is 2 seconds:!!!!!Success rate is 100% (5/5). Round-trip min/avg/max = 0/36/183 ms.Device#ping 2001:1::3a83:45ff:feef:c724Press key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to 2001:1::3a83:45ff:feef:c724 , timeout is 2 seconds:!!!!!Success rate is 100% (5/5). Round-trip min/avg/max = 0/26/133 ms.
O PC e o dispositivo podem fazer ping um no outro.
Ao executar ping no endereço local do link, é necessário especificar a interface de saída, que é a interface no mesmo link do endereço local do link de ping.
DHCPv6
Visão geral
É difícil gerenciar uma grande rede. Por exemplo, em uma rede na qual os endereços IPv6 são alocados manualmente, os conflitos de endereço IPv6 são comuns. A única maneira de resolver o problema é alocar dinamicamente endereços IPv6 aos hosts. O Dynamic Host Configuration Protocol (DHCPv6) aloca o endereço IPv6 aos hosts solicitantes de um pool de endereços. O DHCPv6 também fornece outras informações, como o endereço do servidor DNS. O DHCPv6 reduz a carga de trabalho do administrador ao registrar e rastrear endereços IPv6 alocados manualmente.
DHCPv6 é um protocolo baseado em transmissão UDP. O processo para um cliente DHCPv6 obter um endereço IPv6 e outras informações de configuração contém quatro fases:
SOLICITAR . Quando o cliente DHCPv6 loga na rede pela primeira vez, ele envia um pacote DHCP SOLICT , cujo endereço de origem é o endereço linklocal do cliente e o endereço de destino é ff02::1:2 .
Fase de ANUNCIAR. Depois que o servidor DHCPv6 recebe o pacote de transmissão DHCP SOLICT enviado pelo cliente, ele seleciona um endereço IPv6 do pool de endereços IP correspondente de acordo com a política e envia o endereço IP e outros parâmetros ao cliente em um pacote DHCP ADVERTISE.
FASE DE PEDIDO. Se o cliente DHCP receber mensagens de resposta de vários servidores DHCP na rede, ele selecionará uma OFERTA DHCP (geralmente a que chegar primeiro). Em seguida, ele envia um pacote DHCP REQUEST para a rede, informando a todos os servidores DHCP o endereço IP de qual servidor ele aceitará.
Fase de RESPOSTA . Depois que o servidor DHCPv6 recebe o pacote DHCPv6 REQUEST do cliente DHCPv6, ele envia uma mensagem DHCP AC K contendo o endereço IPv6 fornecido e outras configurações para o cliente DHCPv6, informando ao cliente DHCPv6 que o cliente DHCPv6 pode usar o endereço IPv6 fornecido.
O endereço IPv6 que o servidor DHCPv6 aloca ao cliente DHCPv6 tem uma concessão. Depois que a concessão expirar, o servidor DHCPv6 recuperará o endereço IPv6 alocado. Quando o prazo de concessão do endereço IPv6 do cliente DHCPv6 tiver passado metade do tempo, o cliente DHCPv6 enviará um pacote DHCP ENEW ao servidor DHCPv6 solicitando a atualização de sua concessão de endereço IPv6. Se o cliente DHCPv6 puder continuar a usar o endereço IPv6, o servidor DHCPv6 responderá com um pacote DHCP REPLY, solicitando que o cliente DHCPv6 atualize a concessão. Se o cliente DHCPv6 DHCP não puder continuar a usar o endereço IPv6, o servidor DHCPv6 não responderá.
Durante a aquisição de endereços IPv6 dinâmicos, os pacotes de solicitação são enviados em modo broadcast; portanto, o DHCPv6 é aplicado somente quando o cliente e o servidor DHCPv6 estão na mesma sub-rede. Se existirem várias sub-redes em uma rede e os hosts das sub-redes precisarem obter informações de configuração, como endereço IPv6 por meio do servidor DHCPv6, os hosts das sub-redes se comunicarão com o servidor DHCPv6 por meio de uma retransmissão DHCPv6 para obter endereços IPv6 e outras informações de configuração.
Configuração da função DHCPv6
Tabela 6 -1 Lista de Funções DHCPv6
| Tarefas de configuração | |
| Configurar um pool de endereços DHCPv6 |
Criar um pool de endereços DHCPv6
Configurar um intervalo de endereços IPv6 Configurar um endereço de servidor DNS Configurar a concessão de um endereço IPv6 Configure o IPv6 para vincular com DUID e IAID |
| Configurar outros parâmetros de um servidor DHCPv6 |
Configurar o servidor DHCPv6
Configurar o intervalo de endereços IPv6 reservados Configure os parâmetros de detecção de ping DHCPv6. Configure a função de registro de dados do servidor DHCPv6 |
| Configurar as funções de um cliente DHCPv6 | Configurar um cliente DHCPv6 Configurar o DHCP v6 Função da opção 16 |
| Configurar a função de retransmissão DHCPv6 |
Configure um relé DHCPv6.
Configure o endereço de origem do pacote de retransmissão DHCP v6 Configurar o endereço do servidor DHCPv6 Configurar a opção de identificação de interface DHCPv6 |
Configurar um pool de endereços DHCPv6
Condição de configuração
Nenhum
Criar um pool de endereços DHCPv6
Um servidor DHCPv6 precisa selecionar e alocar endereços IPv6 e outros parâmetros de um pool de endereços DHCPv6. Portanto, um pool de endereços DHCPv6 deve ser criado para o servidor DHCPv6.
Tabela 6 -2 Criando um pool de endereços DHCPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um pool de endereços DHCPv6 e entre no modo de configuração DHCPv6 | ipv6 dhcp pool pool-name[ vrf vrf-name ] | Obrigatório Por padrão, o sistema não cria o pool de endereços DHCPv6. |
Os pools de endereços se dividem em dois tipos: Rede e Intervalo. Os dois tipos de pools de endereços podem ser configurados respectivamente através dos comandos network e range.
Configurar um intervalo de endereços IPv6
Em um servidor DHCPv6, cada pool de endereços DHCPv6 deve ser configurado com um intervalo de endereços IPv6 para alocar endereços IPv6 a clientes DHCPv6.
Tabela 6 -3 Configurando um intervalo de endereços IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração DHCPv6 | ipv6 dhcp pool pool-name[ vrf vrf-name ] | - |
| Configure um intervalo de endereços IPv6 para um pool de endereços do tipo Rede. | network ipv6-address/prefix-length |
Opcional
. Por padrão, um intervalo de endereços IPv6 não está configurado para um pool de endereços. |
| Configure um intervalo de endereços IPv6 para um pool de endereços do tipo Intervalo. | range low-ipv6-address high-ipv6-address prefix-length |
Opcional
. Por padrão, um intervalo de endereços IPv6 não está configurado para um pool de endereços. |
Modifique o tipo de pool de endereços de rede para intervalo (ou de intervalo para rede). Se o novo intervalo de endereços cruzar com o intervalo de endereços antigo, a linha de comando solicitará ao usuário se deve realizar a operação. Se sim, ele excluirá a configuração de endereço (vinculação estática) e a concessão dinâmica relacionada ao pool de endereços; se o intervalo efetivo real do novo endereço incluir o intervalo efetivo real do endereço antigo, o pool de endereços reservará a configuração de endereço relevante (vinculação estática) no pool de endereços. Mas as concessões dinâmicas são excluídas.
Configurar um endereço de servidor DNS
Em um servidor DHCPv6, você pode configurar o endereço do servidor DNS, respectivamente, para cada pool de endereços DHCPv6. Quando um servidor DHCPv6 aloca um endereço IPv6 para um cliente DHCPv6, ele também envia o endereço do servidor DNS para o cliente.
Quando o cliente DHCPv6 inicia a resolução dinâmica de nomes de domínio, ele consulta o servidor DNS.
Tabela 6 -4 Configurando um endereço de servidor DNS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração DHCPv6 | ipv6 dhcp pool pool-name[ vrf vrf-name ] | - |
| Configurar um endereço de servidor DNS | dns-server { ipv6-address&<1-8> | autoconfig } | Obrigatório . Por padrão, o endereço do servidor DNS não está configurado. |
Configurar a concessão de um endereço IPv6
O endereço IPv6 que o servidor DHCPv6 aloca ao cliente DHCPv6 tem uma concessão. Depois que a concessão expirar, o servidor recuperará o endereço IPv6 alocado. Se o cliente DHCPv6 quiser continuar usando o endereço IPv6, ele deverá ter a concessão do endereço IPv6 atualizada.
No servidor DHCPv6, você pode configurar uma concessão de endereço IPv6 para cada pool de endereços DHCPv6.
Tabela 6 -5 Configurando a concessão de um endereço IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração DHCPv6 | ipv6 dhcp pool pool-name[ vrf vrf-name ] | - |
| Configure a concessão do endereço IPv6 | lease preferred-lifetime preferred-lifetime valid-lifetime valid-lifetime |
Obrigatório
Por padrão, o tempo de vida preferido é 604800 (sete dias) e o tempo de vida válido é 2592000s (30 dias). |
Configurar IPv6 para vincular com DUID, IAID
Configure o IPv6 para vincular com o cliente DUID e IAID. Ao especificar o cliente de DUID e IAID para solicitar a alocação do endereço IPv6 ao servidor DHCPv6, o servidor DHCPv6 alocará o endereço IPv6 ao qual se vincula. Enquanto o DIID e o IAID do cliente permanecerem inalterados, o endereço IPv6 adquirido pelo cliente do servidor será sempre o mesmo.
Tabela 6 -6 Configure Ipv6 para vincular com DUID, IAID
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração DHCPv6 | ipv6 dhcp pool pool-name[ vrf vrf-name ] | - |
| Configure I pv6 para vincular com DUID, IAID | bind ipv6-address duid duid [ iaid iaid ] | Obrigatório Por padrão, não configure IPv6 para vincular com DUID, IAID. |
O comando é válido apenas para os pools de endereços Range e Network. duid e iaid, o pool de endereços permite vincular cinco endereços IPv6. Quando a vinculação estática configurada especifica apenas duid, não especificando iaid, o pool de endereços permite vincular apenas um endereço IPv6.
Configurar outros parâmetros de um servidor DHCPv6
Condição de configuração
Nenhum
Configurar o servidor DHCPv6
Após configurar a interface para funcionar no modo servidor DHCPv6, o servidor DHCPv6 distribuirá o endereço IPv6 e outros parâmetros de rede para o cliente quando a interface receber o pacote de solicitação DHCPv6 do cliente DHCPv6.
Tabela 6 -7 Configurar o servidor DHCPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o servidor DHCPv6 | ipv6 dhcp server | Obrigatório Por padrão, não configure o servidor DHCPv6. |
Configurar o intervalo de endereços IPv6 reservados
Em um pool de endereços DHCPv6, alguns endereços IPv6 são reservados para alguns dispositivos especiais e alguns endereços IPv6 entram em conflito com os endereços IPv6 de outros hosts na rede. Portanto, os endereços IPv6 não podem ser alocados dinamicamente.
Tabela 6 -8 Configurar o intervalo de endereços IPv6 reservados
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o intervalo de endereços IPv6 reservados. | ipv6 dhcp excluded-address low-ipv6-address [ high-ipv6-address ] [vrf vrf-name] |
Obrigatório
. Por padrão, o intervalo de endereços IPv6 reservados não está configurado. Os endereços IPv6 no intervalo de endereços IP reservados não serão alocados. |
Configurar parâmetros de detecção de ping DHCPv6
Para evitar um conflito de endereço IPv6, antes de alocar dinamicamente um endereço IPv6 a um cliente DHCPv6, um servidor DHCPv6 deve detectar o endereço IPv6. A operação de detecção é realizada através da operação de ping. O servidor DHCPv6 determina se existe um conflito de endereço IPv6 verificando se um pacote de resposta de eco ICMP é recebido dentro do tempo especificado.
Tabela 6 -9 Configurando os Parâmetros de Detecção de Ping DHCPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar parâmetros de detecção de ping DHCPv6 | ipv6 dhcp ping { packets packet-num | timeout milliseconds } | Obrigatório . Por padrão, o número de pacotes de ping é 1 e o tempo limite é de 50 ms. |
Configurar a função de registro de dados do servidor DHCPv6
A função de registro de dados do servidor DHCPv6, a distribuição do pool de endereços no servidor DHCPv6 é registrada no registro de dados.
Tabela 6 -10 Configurando a função de registro de dados do servidor DHCPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite a função de registro de dados do servidor DHCPv6 | ipv6 dhcp logging security-data | Obrigatório Por padrão, não ative a função de registro de dados. |
Configurar as funções de um cliente DHCPv6
Condição de configuração
Nenhum
Configurar um cliente DHCPv6
A interface do cliente DHCPv6 obtém um endereço IPv6 e outros parâmetros por meio do DHCP.
Tabela 6 -11 Configurando um cliente DHCPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o cliente DHCPv6 para obter um endereço IPv6 | ipv6 dhcp client address [ rapid-commit ] | Obrigatório . Por padrão, o cliente DHCPv6 não está configurado para obter um endereço IPv6. |
| Configure o cliente DHCPv6 para obter o prefixo IPv6 | ipv6 dhcp client pd pool-name [ rapid-commit ] | Obrigatório Por padrão, não configure o cliente DHCPv6 para obter o prefixo IPv6. |
Configurar a função de um relé DHCPv6
Condição de configuração
Nenhum
Configurar um relé DHCPv6
retransmissão DHCPv6 para obter endereços IPv6 e outras configurações em formação. Se uma interface estiver configurada para funcionar no modo de retransmissão DHCPv6, depois que a interface receber pacotes DHCPv6 de um cliente DHCPv6, ela retransmitirá o pacote para o servidor DHCPv6 especificado. O servidor DHCPv6 então aloca um endereço IP.
Tabela 6 -12 Configurando um relé DHCPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a função de retransmissão DHCPv6 | ipv6 dhcp relay | Obrigatório Por padrão, não configure a função de retransmissão DHCPv6. |
Configurar o endereço de origem do relé DHCPv6
DHCPv6 retransmite o cliente DHCPv6 para o endereço de origem do pacote do servidor. Por padrão, use o endereço da interface de saída da rota para o servidor DHCPv6. Em algum ambiente especial, o servidor DHCPv6 não pode se comunicar com o endereço. Portanto, os usuários podem configurar o endereço de origem do pacote de retransmissão DHCPv6 para o servidor DHCPv6 e o campo LinkAddr no pacote por meio do comando ipv6 dhcp relay source-address .
Tabela 6 -13 Configure o endereço de origem do pacote de retransmissão DHCPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o endereço de origem do relé DHCPv6 | ipv6 dhcp relay source-address ipv6-address | Obrigatório Por padrão, não configure o endereço de origem do pacote de retransmissão DHCPv6. |
Configurar o endereço do servidor DHCP v6
Quando a interface recebe o pacote DHCP v6 enviado pelo cliente DHCP v6 , retransmita o pacote para o servidor DHCP v6 configurado , que distribui o endereço IP v6 .
Tabela 6 -14 Configurar o endereço do servidor DHCPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o endereço do servidor DHCPv6 | ipv6 dhcp relay server -address ipv6-address | Obrigatório Por padrão, não configure o endereço do servidor DHCPv6. |
Configurar opção de identificação de interface DHCPv6
O comando é usado para configurar a opção interface-id suportada pelo relé DHCPv6.
Tabela 6 -15 Configurar opção de ID de interface DHCPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar opção de ID de interface DHCPv6 | ipv6 dhcp relay interface –id [ interface | user-define defined-string] | Obrigatório Por padrão, não configure a opção de identificação de interface DHCPv6 . |
Configurar opção de identificação remota DHCPv6
Este comando é usado para configurar o modo de preenchimento da opção de ID remota suportada pelo relé DHCPv6.
Tabela 6 -16 Configurar o endereço do servidor DHCPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configurar a opção de identificação remota DHCPv6 | ipv6 dhcp relay remote–id user-define defined-string | Mandatório _ Por padrão, não configure o modo de preenchimento da opção remote-id. |
Monitoramento e manutenção de DHCPv6
Tabela 6 -17 Monitoramento e manutenção de DHCPv6
| Comando | Descrição |
| clear ipv6 dhcp pool pool-name { lease | conflict [ipv6-address] } | Limpe as informações de concessão dinâmica ou informações de endereço de conflito no pool de endereços |
| clear ipv6 dhcp server interface [interface-name ] statistics | Limpe as estatísticas de informações importantes quando o servidor DHCP v6 interagir com os pacotes com o cliente ou retransmissão |
| clear ipv6 dhcp relay statistics | Limpe as informações de estatísticas no dispositivo de retransmissão DHCPv6 |
| show ipv6 dhcp server interface interface-name [statistics] | Exiba as informações do pool de endereços associado na interface especificada ou exiba as estatísticas de informações importantes quando o servidor DHCPv6 na interface especificada interage com os pacotes com o cliente ou retransmissão |
| show ipv6 dhcp pool pool-name { summary | ping_list | offer_list | excluded_list | conflict_list | lease | binding } | pool de endereços especificado ou as informações de endereço da verificação de ping ou as informações sobre o endereço que enviou o pacote OFFER e está aguardando o cliente DHCP v6 responder ao pacote REQUEST ou exibir a exclusão informações de endereço no conjunto de endereços ou exibir as informações de endereço de conflito no conjunto de endereços ou exibir as informações de concessão dinâmica no conjunto de endereços ou exibir as informações de ligação estática no conjunto de endereços. |
| show ipv6 dhcp pool pool-name specific { ipv6-address ipv6-address | duid duid } | Exiba o endereço IP v6 especificado ou as informações do DUID do cliente no pool de endereços |
| show ipv6 dhcp relay [interface interface-name ] | Exiba as informações de estatísticas do pacote no dispositivo de retransmissão DHCP v6 |
Exemplo de configuração típica de DHCPv6
Configurar um servidor DHCPv6 para alocar estaticamente endereços IPv6
Requisitos de rede
- Device2 atua como um servidor DHCPv6 para alocar endereços IPv6 e endereços IPv6 de servidor DNS de maneira estática.
- O servidor DHCPv6 aloca um endereço IP para PC1 no modo de ligação DUID e aloca um endereço IPv6 para PC2 no modo de ligação DUID+IAID.
Topologia de rede
Figura 6 -1 Configurando um servidor DHCPv6 para alocar estaticamente endereços IPv6
Etapas de configuração
- Passo 1: Configure o endereço IP v6 da interface Device2 e o servidor DHCP v6 .
Device2#configure terminalDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 address 1::3/64Device2(config-if-vlan2)#ipv6 dhcp serverDevice2(config-if-vlan2)#exit
- Passo 2: Configure o conjunto de endereços de ligação estática e os parâmetros.
#Configure a ligação do pool de endereços e adote o modo de ligação DUID para distribuir o endereço IPv6 para PC1. Adote o modo de ligação estático DUID+IAID para distribuir o endereço IPv6 para PC2.
Device2(config)#ipv6 dhcp pool bindingDevice2(dhcp6-config)#bind 1::11 duid 000200001613303030313761636635646634Device2(dhcp6-config)#bind 1::12 duid 000200001613636364383166313037616239 iaid 00010071Device2(dhcp6-config)#dns-server 1::2Device2(dhcp6-config)#exit
- Passo 3: Confira o resultado.
# Verifique a associação da interface do servidor e endereço.
Device2#show ipv6 dhcp server interface vlan2DHCPv6 server status information:DHCP server is enabled on interface: vlan2Vrf : globalDHCPv6 server pool information:Available directly-connected pool:Interface IP: 1::1/64Pool name: bindingRange:min: 101::max: 101::ffff:ffff:ffff:ffffutilization: 0.00%
#Verifique a ligação estática do servidor.
Device2#show ipv6 dhcp pool binding bindingIPv6 Address Duid Iaid Type Time Left(s)------------ ------------------------------------ -------- ------- ------------1::11 000200001613303030313761636635646634 00000000 Binding NA1::12 000200001613636364383166313037616239 00010071 Binding NA
# No Device2, consulte os endereços IPv6 distribuídos para PC1 e PC2 através do show ipv6 dhcp pool binding lease comando.
Device2#show ipv6 dhcp pool mac-binding leaseIPv6 Address Duid Iaid Type Time Left(s) ------------ ------------------------------------ -------- ------- ------------1::11 000200001613303030313761636635646634 00000000 Lease 25919741::12 000200001613636364383166313037616239 00010071 Lease 2591974
No PC1 e PC2, verifique se os endereços IPv6 obtidos e o endereço IPv6 do servidor DNS estão corretos.
Configurar um servidor DHCPv6 para alocar dinamicamente endereços IPv6
Requisitos de rede
- Duas VLANs de interface de Dispositivo, VLAN2 e VLAN3, são configuradas respectivamente com endereços IPv6 1::3/64 e 2::3/64 .
- O dispositivo do servidor DHCPv6 aloca dinamicamente os endereços IPv6 1::/64 e 2 :: /64 para os dois clientes na rede física conectada diretamente.
- Os endereços no segmento de rede 1 :: / 6 4 têm uma concessão de um dia, o endereço do servidor DNS é 2 :: 4. Os endereços no segmento de rede 2 :: / 6 4 têm uma concessão de três dias o endereço do gateway é 2 :: 3, o endereço do servidor DNS é 2 :: 4.
- Os primeiros 10 endereços IPv6 nos segmentos de rede 1 :: / 6 4 e 2 :: / 6 4 são reservados e não podem ser alocados.
Topologia de rede
Figura 6 -2 Configurando um servidor DHCPv6 para alocar dinamicamente endereços IPv6
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. Configure o endereço IPv6 da interface (omitido).
- Passo 2: No servidor DHCPv6 Device1, configure dois pools de endereços dinâmicos e seus parâmetros.
#Configure o servidor DHCPv6.
Device(config)#interface vlan2Device(config-if-vlan2)#ipv6 dhcp serverDevice(config-if-vlan2)#exitDevice(config)#interface vlan3Device(config-if-vlan3)#ipv6 dhcp serverDevice(config-if-vlan3)#exit
#Configure os primeiros 10 endereços IP nos dois pools de endereços a serem reservados.
Device(config)#ipv6 dhcp excluded-address 1::0 1::9Device(config)#ipv6 dhcp excluded-address 2::0 2::9
#Configure o pool de endereços dynamic-pool1 e seus parâmetros (incluindo intervalo de endereços, endereço DNS, concessão de endereço).
Device(config)#ipv6 dhcp pool dynamic-pool1Device(dhcp6-config)#network 1::/64Device(dhcp6-config)#dns-server 2::4Device(dhcp6-config)#lease preferred-lifetime 86300 valid-lifetime 86400Device(dhcp6-config)#exit
#Configure o pool de endereços dynamic-pool2 e seus parâmetros (incluindo intervalo de endereços, endereço DNS, concessão de endereço).
Device(config)#ip DHCPv6 pool dynamic-pool2Device(dhcp6-config)#network 2::/64Device(dhcp6-config)#dns-server 2::4Device(dhcp6-config)#lease preferred-lifetime 259100 valid-lifetime 259200Device(dhcp6-config)#exit
- Passo 3:Confira o resultado.
#No Dispositivo, consulte os endereços IPv6 alocados aos clientes.
Device#show ipv6 dhcp pool dynamic-pool1 leaseIPv6 Address Duid Iaid Type Time Left(s)------------ --------------------------- -------- ------- ------------1::a 000200001613303030313761636635646634 00000000 Lease 86390Device2#show ipv6 dhcp pool dynamic-pool2 leaseIPv6 Address Duid Iaid Type Time Left(s)------------ -------------------------- -------- ------- ------------2::a 000200001613303030313761636635646634 00000000 Lease 2591974
Nos clientes DHCPv6, consulte se os endereços IPv6 foram obtidos corretamente.
Os endereços IPv6 no pool de endereços devem estar dentro do intervalo de segmentos de rede da interface que fornece o serviço.
Configurar o relé DHCPv6
Requisitos de rede
- Device1 é o servidor DHCP v6 , e a interface de Device2 habilita a função de retransmissão DHCP v6 .
- O servidor DHCPv6 fornece o serviço para o cliente do segmento 1::/64 e os dez primeiros endereços IPv6 são reservados.
- O cliente DHCPv6 obtém o endereço IPv6 via retransmissão DHCPv6.
Topologia de rede

Figura 6 -3 Rede para configurar um relé DHCPv6
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. Configure o endereço IPv6 da interface (omitido).
- Passo 2: Configure um pool de endereços IPv6 para o Dispositivo 1 e configure os endereços IPv6 reservados.
#Configure Device1 como servidor DHCPv6.
Device1#configure terminalDevice1(config)#interface vlan3Device2(config-if-vlan3)#ipv6 dhcp serverDevice2(config-if-vlan3)#exit
# Configure os endereços IPv6 que são de 1::0 a 1::9 para não serem alocados.
Device1(config)#ipv6 dhcp excluded-address 1::0 1::9#Configure o pool dinâmico do pool de endereços IPv6 para Device1.
Device1(config)#ipv6 dhcp pool dynamic-poolDevice1(dhcp6-config)#network 1::/64Device1(dhcp6-config)#lease preferred-lifetime 300 valid-lifetime 600Device1(dhcp6-config)#exit
# Configure uma rota estática para o segmento de rede 1::/64.
Device1(config)#ipv6 route 1::0/64 2::2- Passo 3: Na interface vlan2 do Device2, habilite a retransmissão DHCPv6 e configure o endereço do servidor DHCPv6 2::1.
Device2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 dhcp relayDevice2(config-if-vlan2)#ipv6 dhcp relay server-address 2::1Device2(config-if-vlan2)#exit
- Passo 4: Confira o resultado.
#No Device1, consulte os endereços IPv6 que foram alocados.
Device1#show ipv6 dhcp pool dynamic-pool leaseIPv6 Address Duid Iaid Type Time Left(s)------------ ----------------------------------- -------- ------- ------------1::0 000200001613303030313761636635646634 00000000 Lease 574
Use o comando show ipv6 dhcp pool dynamic-pool lease para consultar os endereços IPv6 que foram alocados aos clientes. O resultado mostra que um cliente obteve o endereço IPv6 1::0 .
05 Roteamento Unicast
Noções básicas de roteamento
Visão geral
Depois que um dispositivo recebe um pacote por meio de uma interface, o dispositivo seleciona uma rota de acordo com o destino da rota e encaminha o pacote para outra interface. Esse processo é chamado de roteamento. Em dispositivos de rede, as rotas são armazenadas em um banco de dados de tabela de roteamento. Os pacotes pesquisam a tabela de roteamento para determinar o próximo salto e a interface de saída de acordo com o destino dos pacotes. As rotas são categorizadas em três tipos de acordo com suas origens.
- Rota direta: A rota é gerada com base no endereço da interface. Depois que um usuário configura o endereço IP de uma interface, o dispositivo gera uma rota direta do segmento de rede de acordo com o endereço IP e a máscara.
- Rota estática: A rota é configurada manualmente pelo usuário.
- Rota dinâmica: A rota é descoberta por meio do protocolo de descoberta de rota dinâmica. Com base em se o protocolo de roteamento dinâmico é usado dentro de um domínio autônomo, dois tipos de protocolos de roteamento dinâmico estão disponíveis: Interior Gateway Protocol (IGP) e Exterior Gateway Protocol (EGP). Aqui, um domínio autônomo se refere a uma rede que possui uma organização de gerenciamento unificada e uma política de roteamento unificada. Um protocolo de roteamento usado em um domínio autônomo é um IGP. IGPs comuns incluem Routing Information Protocol (RIP) e Open Shortest Path First (OSPF). Os EGPs geralmente são usados para roteamento entre vários domínios autônomos. Um EGP comum é o BGP.
O roteamento oferece suporte ao balanceamento de carga, ou seja, várias rotas para o mesmo destino. No encaminhamento de pacotes, um dispositivo transmite pacotes no modo de balanceamento de carga de acordo com o resultado da pesquisa da tabela de roteamento.
Configuração de função básica de roteamento
Tabela 1 -1 Lista de funções básicas de roteamento
| Tarefas de configuração | |
| Configure o balanceamento de carga para roteamento. | Configure entradas de balanceamento de carga . |
| Configure a capacidade da rota VRF | Configure a capacidade da rota VRF. |
Configurar balanceamento de carga para roteamento
Condição de configuração
Nenhum
Configurar o número máximo de entradas de balanceamento de carga
Se os custos de vários caminhos para um destino forem os mesmos, os caminhos formam o balanceamento de carga. Configurar o número máximo de entradas de balanceamento de carga ajuda a melhorar a taxa de utilitário de link e reduzir a carga de links.
Tabela 1 -2 Configurando o número máximo de entradas de balanceamento de carga
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure o número máximo de entradas de balanceamento de carga. | route path-limit max-number | Opcional. Por padrão, o número máximo de entradas de balanceamento de carga para roteamento é 4. |
Configurar a Capacidade de Rotas VRF (Aplicável somente ao modelo S3054G-B)
Condição de configuração
Nenhum
Configurar a capacidade de rotas VRF
Para garantir o uso normal dos dispositivos e evitar que um grande número de rotas consuma muitos recursos, você pode usar a tabela de roteamento limite comando para limitar a capacidade de rotas para cada Encaminhamento de Rota Virtual (VRF). Quando a capacidade das rotas atinge o limite, um alarme é gerado.
Tabela 1 -3 Configurando a capacidade de rotas VRF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração VRF. | ip vrf vrf-name | - |
| Configure a capacidade da rota VRF. | routing-table limit limit-value { threshold-value | syslog-alert } | Opcional. Por padrão, a capacidade da rota é de 88 0000. Quando o número de rotas atinge 80% da capacidade total, as informações de alarme são impressas. |
Este comando não pode limitar a capacidade de rotas para VRF global. Se o número de entradas de roteamento exceder o limite, novas informações de roteamento serão perdidas.
Monitoramento e Manutenção básicos de roteamento
Tabela 1 -4 Monitoramento e Manutenção básicos de roteamento
| Comando | Descrição |
| clear ip route [ vrf vrf-name ] { ip-address mask | all } | Limpa a rota IP especificada na tabela de roteamento. |
| show ip route [ vrf vrf-name ] [ bgp | connected | irmp | isis | ospf | rip | static | statistic [ all ] | ip-address { mask | mask-len } ] | Exibir informações de rota IP. |
Noções básicas de roteamento IPv6
Visão geral
Depois que um dispositivo recebe um pacote IPv6 por meio de uma interface, o dispositivo seleciona uma rota de acordo com o endereço de destino do pacote IPv6 e encaminha o pacote para outra interface. Esse processo é chamado de roteamento. Em dispositivos de rede, as rotas são armazenadas em um banco de dados de tabela de roteamento. Os pacotes pesquisam a tabela de roteamento para determinar o próximo salto e a interface de saída de acordo com o endereço de destino do pacote. As rotas são categorizadas em três tipos de acordo com suas origens.
- Rota direta: A rota é gerada com base no endereço da interface. Depois que um usuário configura o endereço IPv6 de uma interface, o dispositivo gera uma rota direta do segmento de rede de acordo com o endereço e a máscara.
- Rota estática: A rota é configurada manualmente pelo usuário.
- Rota dinâmica: A rota é descoberta por meio do protocolo de rota dinâmica. Com base em se o protocolo de roteamento dinâmico é usado dentro de um domínio autônomo, dois tipos de protocolos de roteamento dinâmico estão disponíveis: Interior Gateway Protocol (IGP) e Exterior Gateway Protocol (EGP). Aqui, um domínio autônomo se refere a uma rede que possui uma organização de gerenciamento unificada e uma política de roteamento unificada. Um protocolo de roteamento usado em um domínio autônomo é um IGP. IGPs comuns incluem RIPng, OSPFv6 . Os EGPs geralmente são usados para roteamento entre vários domínios autônomos. Um EGP comum é o IPv6 BGP.
O roteamento oferece suporte ao balanceamento de carga, ou seja, várias rotas para o mesmo destino. No encaminhamento de pacotes, um dispositivo transmite pacotes no modo de balanceamento de carga de acordo com o resultado da pesquisa da tabela de roteamento.
Configuração da Função Base de Roteamento IPv6
Tabela 2 -1 lista de configuração de função de base de roteamento IPv6
| Tarefa de configuração | |
| Configurar balanceamento de carga da rota IPv6 |
Configure entradas máximas de balanceamento de carga do IPv6
Configure modo de cálculo de balanceamento de carga IPv6 |
Configurar o balanceamento de carga da rota IPv6
Condição de configuração
Nenhum
Configurar o modo de cálculo do balanceamento de carga IPv6
O balanceamento de carga tem os três tipos de modos de cálculo a seguir:
- Modo de cálculo baseado nos endereços de origem e destino: Identifique um fluxo com o endereço de origem e o endereço de destino. Os pacotes do mesmo fluxo usam o mesmo caminho e não são desordenados. Quando as cargas dos fluxos são desequilibradas, pode levar a uma carga de linha desequilibrada.
- Cálculo baseado no endereço de origem: Somente o endereço de origem é usado para identificar um fluxo. Os pacotes do mesmo fluxo usam o mesmo caminho para garantir que o mesmo fluxo siga o mesmo caminho sem desordem. Quando as cargas dos fluxos são desequilibradas, pode levar a uma carga de linha desequilibrada.
- Cálculo baseado em pacotes: Os pacotes para o mesmo destino adotam caminhos diferentes para atingir o balanceamento de carga em cada caminho na medida do possível, mas podem ser desordenados.
Tabela 2 -2 Configurar o modo de cálculo de balanceamento de carga IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global e | configure terminal | - |
| Configure o modo de balanceamento de carga do pacote IPv6 | ipv6 load-sharing { per-destination | per-packet | per-source } | Opcional. Por padrão, use o modo de cálculo com base nos endereços de origem e destino. |
Monitoramento e Manutenção da Base de Rota IPv6
Tabela 2 -3 Monitoramento e Manutenção da base de rotas IPv6
| Comando | Descrição |
| clear ipv6 route { ipv6-address | ipv6-prefix | all } | Limpe a rota IPv6 especificada na tabela de rotas |
| show ipv6 route [ vrf vrf-name ] [ ipv6-address | ipv6-prefix | bgp | brief | connected | isis | linklocal | local | ospf | rip | static | statistic | all] | informações de rota IPv6 |
Rotas estáticas IPv4
Visão geral
Uma rota estática é uma rota autodefinida que é configurada manualmente por um usuário. Ele especifica um caminho para transmitir pacotes IP que são direcionados a um destino especificado.
Comparado com o roteamento dinâmico, o roteamento estático tem maior segurança e menor ocupação de recursos do dispositivo. A desvantagem é que quando a topologia da rede muda, a configuração manual é necessária e não há mecanismo de reconfiguração automática.
As rotas estáticas não ocupam largura de banda de linha nem ocupam CPU para calcular e anunciar rotas periodicamente, melhorando o desempenho do dispositivo e da rede.
As rotas estáticas podem ser usadas para garantir a segurança de uma rede de pequena escala, por exemplo, em uma rede onde há apenas um caminho conectando a uma rede externa. Em uma rede em grande escala, as rotas estáticas podem implementar o controle de segurança em serviços ou links de determinados tipos. A maioria das redes adota protocolos de roteamento dinâmico, mas você ainda pode configurar algumas rotas estáticas para fins especiais.
As rotas estáticas podem ser redistribuídas para um protocolo de roteamento dinâmico, mas as rotas dinâmicas não podem ser redistribuídas para rotas estáticas. Observe que a configuração de rota estática inadequada pode causar loops de roteamento.
A rota padrão é uma rota especial que pode ser uma rota estática. Em uma tabela de roteamento, a rota padrão é uma rota para a rede 0.0.0.0 com a máscara 0.0.0.0. Você pode usar o comando show ip route para verificar se a rota é válida. Quando o endereço de destino de um pacote recebido não corresponde a nenhuma entrada na tabela de roteamento, o pacote segue a rota padrão. Se nenhuma rota padrão estiver disponível e o destino não estiver na tabela de roteamento, o pacote será descartado e um pacote ICMP será retornado à extremidade de origem informando que o endereço de destino ou a rede não podem ser alcançados. Para evitar que a tabela de roteamento fique muito grande, você pode definir uma rota padrão. O pacote que não consegue encontrar uma entrada correspondente na tabela de roteamento toma a rota padrão para encaminhamento.
Null0 é uma rota especial, com a interface de saída da rota como a interface Null0. A interface Null0 está sempre no status UP, mas não pode encaminhar pacotes. Os pacotes que são enviados para a interface serão descartados. Se você configurar uma rota estática e especificar a interface de saída de um determinado segmento de rede para Null0, os pacotes enviados ao segmento de rede serão descartados. Portanto, você pode configurar realizar filtragem de pacotes configurando rotas estáticas Null0.
Configuração da Função de Roteamento Estático
Tabela 3 -1 Lista de funções de configuração de rota estática
| Tarefas de configuração | |
| Configure uma rota estática. | Configure uma rota estática. |
| Configure a distância administrativa padrão. | Configure a distância administrativa padrão. |
| Configure a função recursiva. | Configure a função recursiva. |
| Configurar rotas de balanceamento de carga. | Configurar rotas de balanceamento de carga. |
| Configure uma rota flutuante. | Configure uma rota flutuante. |
| Configure uma rota estática para coordenar com BFD. | Configure uma rota estática para coordenar com BFD. |
| Configure uma rota estática para coordenar com o rack T. | Configure uma rota estática para coordenar com o rack T. |
Configurar uma rota estática
Condição de configuração
Antes de configurar uma rota estática, certifique-se de que:
- O protocolo da camada de link foi configurado para garantir a comunicação normal na camada de link.
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
Configurar uma rota estática
De acordo com os parâmetros que foram especificados, as rotas estáticas são categorizadas nos três tipos a seguir:
- Rota de interface: para uma rota de interface, somente a interface de saída é especificada.
- Rota de gateway: para uma rota de gateway, apenas o endereço de gateway é especificado.
- Rota de gateway de interface: para uma rota de gateway de interface, a interface de saída e o endereço de gateway são especificados.
As rotas estáticas configuradas se tornam inválidas se algumas das seguintes condições forem atendidas:
- O endereço de destino é o endereço da interface local.
- O endereço de destino é a rede da interface direta local.
- A distância administrativa da rota é de 255 .
- A interface de saída da rota está DOWN.
- Nenhum endereço IP foi configurado para a interface de saída da rota.
- O endereço do gateway não está acessível.
- A interface de saída e o gateway do conflito de rota.
- A interface de saída da rota não existe.
- O objeto TRACK que está associado à rota é "falso".
- O status da sessão Bidirectional Forwarding Detection (BFD) que está associada à rota é DOWN.
Se uma rota de interface atender a qualquer condição entre 1, 2, 3, 4, 5, 9 e 10, a rota é inválida. Se uma rota de gateway atender a qualquer condição entre 1, 2, 3, 4, 6, 8, 9 e 10, a rota é inválida. Se uma rota de gateway de interface atender a qualquer uma das condições acima, a rota será inválida.
Tabela 3 -2 Configurando uma rota estática
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma rota estática. | ip route [ vrf vrf-name1] destination-ip-address destination-mask { interface-name / [ nexthop-ip-address [ vrf vrf-name2 ] ] } [ name nexthop-name ] [ tag tag-value ] [ track track-id ] [ administrative-distance ] |
Obrigatório.
O campo administrativo - distância é a distância administrativa da rota estática . Se não for especificado, a distância administrativa padrão será usada. |
Para uma rota padrão, a rede e a máscara de destino devem ser definidas como 0.0.0.0. A interface de saída da rota Null0 é Null0. A interface de saída da interface Null0 não precisa ser configurada com um endereço IP.
Configurar a distância administrativa padrão
Condição de configuração
Nenhum
Configurar a distância administrativa padrão
Quanto menor for a distância administrativa especificada para uma rota estática na configuração da rota estática, maior será a prioridade da rota. Se a distância administrativa não for especificada, a distância administrativa padrão será usada. Você pode modificar a distância administrativa padrão dinamicamente. Após a reconfiguração da distância administrativa padrão, a nova distância administrativa padrão é válida apenas para novas rotas estáticas.
Tabela 3 -3 Configurando a distância administrativa padrão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entra no modo de configuração de rota estática. | router static | - |
| Configure a distância administrativa padrão. | distance administration-distance | Opcional. O valor padrão da distância administrativa padrão é 1. |
Ao usar o comando ip route para configurar uma rota estática, você pode especificar uma distância administrativa independente para a rota. Se você não especificar a distância administrativa, a distância administrativa padrão será usada.
Configurar a função recursiva
Condição de configuração
Nenhum
Configurar a função recursiva
Se o endereço do gateway configurado para uma rota for válido somente quando uma rota para o gateway for alcançável, você deverá habilitar a função recursiva da rota estática para validar a rota. Por padrão, a função recursiva é habilitada para uma rota estática.
Tabela 3 -4 Configurar a função recursiva
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entra no modo de configuração de rota estática. | router static | - |
| Configure uma rota estática para dar suporte à função recursiva. | recursion | Opcional. Por padrão, uma rota estática é compatível com a função recursiva para roteamento. |
Configurar rotas de balanceamento de carga
Condição de configuração
Nenhum
Configurar rotas de balanceamento de carga
As rotas de balanceamento de carga significam que várias rotas são configuradas para a mesma rede de destino. As interfaces de saída e os endereços de gateway das rotas são diferentes, mas as distâncias administrativas (prioridades) das rotas são as mesmas. As rotas de balanceamento de carga ajudam a melhorar a taxa de utilidade do link.
Tabela 3 -5 Configurando rotas de balanceamento de carga
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a primeira rota de balanceamento de carga. | ip route destination-ip-address destination-mask interface-name1 distance | Obrigatório. A interface de saída é interface-name1. |
| Configure a segunda rota de balanceamento de carga. | ip route destination-ip-address destination-mask interface-name2 distance | Obrigatório. A interface de saída é interface-name2. |
Na configuração de rotas de balanceamento de carga, você deve configurar os valores de distância das rotas para as mesmas.
Configurar uma rota flutuante
Condição de configuração
Nenhum
Configurar uma rota flutuante
Várias rotas estão disponíveis para a mesma rede de destino. As interfaces de saída ou endereços de gateway das rotas são diferentes e as prioridades das rotas também são diferentes. A rota com a prioridade mais alta se torna a rota principal enquanto a rota com a prioridade mais baixa se torna a rota flutuante. Na tabela de roteamento, apenas a rota primária é visível. A tabela flutuante aparece na tabela de roteamento somente quando a rota primária se torna inválida. Portanto, a rota flutuante geralmente é usada como rota de backup.
Tabela 3 -6 Configurando uma Rota Flutuante
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a rota primária. | ip route destination-ip-address destination-mask interface-name1 distance1 |
Obrigatório.
A interface de saída da rota primária é interface-name1 e a prioridade da rota é distance1 . |
| Configure a rota flutuante. | ip route destination-ip-address destination-mask interface-name2 distance2 |
Obrigatório.
A interface de saída da rota flutuante é interface-name2 , a prioridade é distance2 . O valor de distance2 deve ser maior que o valor de distance1 . |
Na configuração das prioridades das rotas, não que quanto menor o valor da distância , maior a prioridade.
Configurar uma rota estática para coordenar com BFD (Aplicável somente ao modelo S3054G-B)
Condição de configuração
Nenhum
Configurar uma rota estática para coordenar com BFD
O protocolo Bidirectional Forwarding Detection (BFD) fornece um método para detectar a conectividade do caminho de encaminhamento entre dois roteadores adjacentes com carga leve. Um vizinho de protocolo pode detectar rapidamente a falha de conectividade de um caminho de encaminhamento. Diferente de outras rotas de protocolo dinâmico, as rotas estáticas não podem aprender falhas de link de comunicação. O BFD fornece um método para detectar rapidamente falhas de link de comunicação para rotas estáticas. Depois que uma rota estática é configurada para coordenar com BFD, a troca rápida de rotas pode ser implementada. Atualmente, uma rota estática suporta apenas o modo de detecção BFD assíncrona. Portanto, você precisa configurar a rota para coordenar com BFD nos dispositivos nas duas extremidades do link.
Se o status do BFD coordenado com a rota estática for DOWN, a rota estática se tornará inválida.
Tabela 3 -7 Configurando uma rota estática para coordenar com BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma rota estática. | ip route destination-ip-address destination-mask interface-name nexthop-ip-address |
Obrigatório.
Somente a rota estática com interface de saída e endereço de gateway especificados pode coordenar com BFD. |
| Configure a interface de saída e o endereço do próximo salto para a rota coordenada com o BFD. | ip route static bfd interface-name nexthop-ip-address |
Obrigatório.
O campo nexthop-ip-address especifica o endereço do próximo salto diretamente conectado. |
Para introdução do BFD e como configurar suas funções básicas, consulte o manual de configuração do BFD.
Configurar uma rota estática para coordenar com o rack T
Condição de configuração
Nenhum
Configurar uma rota estática para coordenar com o rack T
Alguns módulos no sistema precisam monitorar algumas informações do sistema e, em seguida, determinar seus modos de trabalho com base nas informações. Os objetos que são monitorados pelos outros módulos são chamados de objetos de monitoramento. Para simplificar as relações entre os módulos e os objetos de monitoramento, são usados os objetos Track. Um objeto Track pode conter vários objetos de monitoramento e exibe o status abrangente do objeto de monitoramento para módulos externos. Os módulos externos estão associados apenas aos objetos Track e não se preocupam mais com os objetos de monitoramento contidos nos objetos Track. Um objeto Track tem dois status, "true" e "false". Os módulos externos associados ao objeto Track determinam seus modos de trabalho de acordo com o status do objeto Track.
Uma rota estática pode ser associada a um objeto Track para monitorar as informações do sistema e determinar se a rota é válida de acordo com o status relatado pelo objeto Track. Se o objeto Track relatar "true", as condições exigidas pela rota estática serão atendidas e a rota será adicionada à tabela de roteamento. Se o objeto Track relatar "false", a rota será excluída da tabela de roteamento.
Tabela 3 -8 Configurando uma rota estática para coordenar com a trilha
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um objeto Track e entre no modo de configuração do objeto Track. | track track-id | Obrigatório. |
| Configure o objeto de rastreamento para monitorar o status do link da interface especificada. | interface interface-name line-protocol | Opcional. |
| Retorne ao modo de configuração global. | exit | - |
| Configure uma rota estática e associe-a ao objeto Track. | ip route destination-ip-address destination-mask interface-name track track-id |
Obrigatório.
Quando a camada de link da interface de monitoramento está UP, a rota é válida; caso contrário, a rota é inválida. |
Configurar Reencaminhamento Rápido de Rota Estática (Aplicável somente ao modelo S3054G-B)
Condição de configuração
Antes de configurar o reencaminhamento rápido da rota estática, conclua primeiro as seguintes tarefas:
- Use o mapa de rotas para especificar a interface de saída e o próximo salto da rota em espera;
Configurar o reencaminhamento rápido da rota estática
Na rede com roteamento estático, a interrupção de tráfego causada por falha de link ou dispositivo continuará até que o protocolo detecte a falha de link, e a rota flutuante não se recuperará até que a rota flutuante entre em vigor, o que geralmente dura vários segundos. A fim de reduzir o tempo de interrupção do tráfego, o reencaminhamento rápido da rota estática pode ser configurado. Através da aplicação do mapa de roteamento, o próximo salto de backup é definido para a rota correspondente. Uma vez que o link ativo falhe, o tráfego que passa pelo link ativo será imediatamente comutado para o link em espera, de modo a atingir o objetivo de comutação rápida.
Tabela 3 -9 Configurar o reencaminhamento rápido da rota estática
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema | configure terminal | - |
| Configurar o reencaminhamento rápido da rota estática | ip route static fast-reroute route-map map-name | Obrigatório. Por padrão, não habilite o reencaminhamento rápido. |
Somente rotas estáticas com interface de saída e endereços de gateway podem ser reencaminhadas rapidamente;
Monitoramento e Manutenção de rota estática
Tabela 3 -10 Monitoramento e Manutenção de Rota Estática
| Comando | Descrição |
| show ip route [ vrf vrf-name ] static | Exiba as rotas estáticas na tabela de roteamento. |
| show running-config ip route | Exiba as informações de configuração sobre rotas estáticas. |
Exemplo de configuração típico de rotas estáticas
Configurar funções básicas de roteamento estático
Requisito de rede
- Em Device1, Device2 e Device3, configure rotas estáticas para que PC1 e PC2 possam se comunicar entre si.
Topologia de rede

Figura 3 -1 Rede para configurar funções básicas de roteamento estático
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure rotas estáticas.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ip route 20.1.1.0 255.255.255.0 10.1.1.2Device1(config)#ip route 100.1.1.0 255.255.255.0 10.1.1.2
# Configurar dispositivo 2.
Device2#configure terminalDevice2(config)#ip route 110.1.1.0 255.255.255.0 10.1.1.1Device2(config)#ip route 100.1.1.0 255.255.255.0 20.1.1.2
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ip route 0.0.0.0 0.0.0.0 20.1.1.1
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.1.1.0/24 is directly connected, 00:06:47, vlan3S 20.1.1.0/24 [1/100] via 10.1.1.2, 00:00:13, vlan3S 100.1.1.0/24 [1/100] via 10.1.1.2, 00:00:05, vlan3C 110.1.1.0/24 is directly connected, 00:08:21, vlan2C 127.0.0.0/8 is directly connected, 28:48:33, lo0
#Consulte a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.1.1.0/24 is directly connected, 00:00:37, vlan2C 20.1.1.0/24 is directly connected, 00:00:27, vlan3S 100.1.1.0/24 [1/100] via 20.1.1.2, 00:00:05, vlan3S 110.1.1.0/24 [1/100] via 10.1.1.1, 00:00:13, vlan2C 127.0.0.0/8 is directly connected, 30:13:18, lo0
#Consulte a tabela de roteamento do Device3.
Device3#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalS 0.0.0.0/0 [1/100] via 20.1.1.1, 00:00:07, vlan2C 20.1.1.0/24 is directly connected, 00:00:08, vlan2C 100.1.1.0/24 is directly connected, 00:00:13, vlan3C 127.0.0.0/8 is directly connected, 29:17:19, lo0
- Passo 4: Confira o resultado. Use o comando ping para verificar a conectividade entre PC1 e PC2
#No PC1, use o comando ping para verificar a conectividade.
C:\Documents and Settings\Administrator>ping 100.1.1.2Pinging 100.1.1.2 with 32 bytes of data:Reply from 100.1.1.2: bytes=32 time<1ms TTL=125Reply from 100.1.1.2: bytes=32 time<1ms TTL=125Reply from 100.1.1.2: bytes=32 time<1ms TTL=125Reply from 100.1.1.2: bytes=32 time<1ms TTL=125Ping statistics for 100.1.1.2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0ms
PC1 e PC2 podem se comunicar entre si.
Configurar uma rota estática flutuante
Requisitos de rede
- Em Device1, configure duas rotas estáticas para alcançar o segmento de rede 192.168.1.0/24. Uma rota passa Device2 e a outra rota passa Device3.
- Device1 primeiro usa a rota entre Device1 e Device2 para encaminhar pacotes. Se o link estiver com defeito, Device1 muda para a rota entre Device1 e Device3 para comunicação.
Topologia de rede

Figura 3 -2 Rede para configurar uma rota estática flutuante
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure rotas estáticas.
#Em Device1, configure duas rotas para o segmento de rede 192.168.1.0/24 por meio de Device2 e Device3.
Device1#configure terminalDevice1(config)#ip route 192.168.1.0 255.255.255.0 10.1.1.2Device1(config)#ip route 192.168.1.0 255.255.255.0 20.1.1.2
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.1.1.0/24 is directly connected, 02:16:43, vlan2C 20.1.1.0/24 is directly connected, 03:04:15, vlan3C 127.0.0.0/8 is directly connected, 14:53:00, lo0S 192.168.1.0/24 [1/100] via 10.1.1.2, 00:00:05, vlan2[1/100] via 20.1.1.2, 00:00:02, vlan3
De acordo com as tabelas de roteamento, duas rotas de Device1 para o segmento de rede 192.168.1.0/24 são alcançáveis, e a rota forma balanceamento de carga.
- Passo 4: Configure uma rota flutuante.
#Configurar dispositivo1. Modifique o intervalo administrativo da rota com o endereço de gateway 20.1.1.2 a 15 para que a rota se torne uma rota flutuante.
Device1(config)#ip route 192.168.1.0 255.255.255.0 20.1.1.2 15- Passo 5: Confira o resultado.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.1.1.0/24 is directly connected, 02:28:25, vlan2C 20.1.1.0/24 is directly connected, 03:15:58, vlan3C 127.0.0.0/8 is directly connected, 15:04:42, lo0S 192.168.1.0/24 [1/100] via 10.1.1.2, 00:11:47, vlan2
De acordo com a tabela de roteamento, como a rota com o intervalo administrativo 1 tem uma prioridade mais alta do que a rota com o intervalo administrativo 15, a rota com o gateway 20.1.1.2 é excluída.
#Depois que a rota entre Device1 e Device2 estiver com defeito, consulte a tabela de roteamento de Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 20.1.1.0/24 is directly connected, 03:23:44, vlan3C 127.0.0.0/8 is directly connected, 15:12:28, lo0S 192.168.1.0/24 [15/100] via 20.1.1.2, 00:00:02, vlan3
De acordo com a tabela de roteamento, a rota com um intervalo administrativo maior foi adicionada à tabela de roteamento para encaminhar pacotes através do Device3.
O recurso mais significativo da rota estática flutuante é que ela atua como uma rota de backup.
Configurar uma rota estática com a interface Null0
Requisitos de rede
- Em Device1 e Device2, configure uma rota estática padrão, respectivamente, e configure os endereços de gateway para os endereços de interface de peer dos dois dispositivos. No Device1, configure um estático com a interface Null0 para filtrar apenas os dados enviados ao PC2.
Topologia de rede

Figura 3 -3 Rede para configurar uma rota estática com a interface Null0
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure rotas estáticas.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ip route 0.0.0.0 0.0.0.0 50.1.1.2
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ip route 0.0.0.0 0.0.0.0 50.1.1.1
#No PC1, use o comando ping para verificar a conectividade com o PC2.
C:\Documents and Settings\Administrator>ping 100.1.1.2Pinging 100.1.1.2 with 32 bytes of data:Reply from 100.1.1.2: bytes=32 time<1ms TTL=126Reply from 100.1.1.2: bytes=32 time<1ms TTL=126Reply from 100.1.1.2: bytes=32 time<1ms TTL=126Reply from 100.1.1.2: bytes=32 time<1ms TTL=126Ping statistics for 100.1.1.2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0ms
- Passo 4: Configure uma rota estática com a interface Null0.
# Configurar dispositivo1.
Device1(config)#ip route 100.1.1.2 255.255.255.255 null0- Passo 5: Confira o resultado.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalS 0.0.0.0/0 [1/100] via 50.1.1.2, 00:07:28, vlan2C 50.1.1.0/24 is directly connected, 00:07:34, vlan2C 110.1.1.0/24 is directly connected, 00:00:08, vlan3C 127.0.0.0/8 is directly connected, 11:46:35, lo0S 100.1.1.2/32 [1/1] is directly connected, 00:02:31, null0
Na tabela de roteamento, foi adicionada a rota estática com a interface Null0.
#No PC1, use opingcomando para verificar a conectividade com o PC2.
C:\Documents and Settings\Administrator>ping 100.1.1.2Pinging 100.1.1.2 with 32 bytes of data:Request timed out.Request timed out.Request timed out.Request timed out.Ping statistics for 100.1.1.2:Packets: Sent = 4, Received = 0, Lost = 4 (100% loss)
Os pacotes ICMP enviados pelo PC1 são direcionados para a interface Null0 de acordo com a tabela de roteamento no Device1; portanto, os pacotes são descartados. Dessa forma, o PC1 não consegue se comunicar com o PC2.
Uma rota estática com a interface Null0 é uma rota especial. Os pacotes enviados para a interface Null0 serão descartados. Portanto, configurar uma rota com a interface Null0 implementa a filtragem de pacotes.
Configurar uma rota recursiva estática
Requisitos de rede
- Em Device1, configure duas rotas estáticas para alcançar o segmento de rede 192.168.1.1/32. Uma rota passa pelo Device2 e a outra passa pelo Device3. Device1 primeiro usa a rota que passa Device3 para encaminhar pacotes.
- No Device1, configure uma rota recursiva estática para alcançar o segmento de rede 200.0.0.0/24, com o endereço do gateway sendo o endereço da interface de loopback 192.168.1.1 do Device3. Depois que a rota entre Device1 e Device3 estiver com defeito, Device1 alterna para a rota que passa Device2 para comunicação.
Topologia de rede
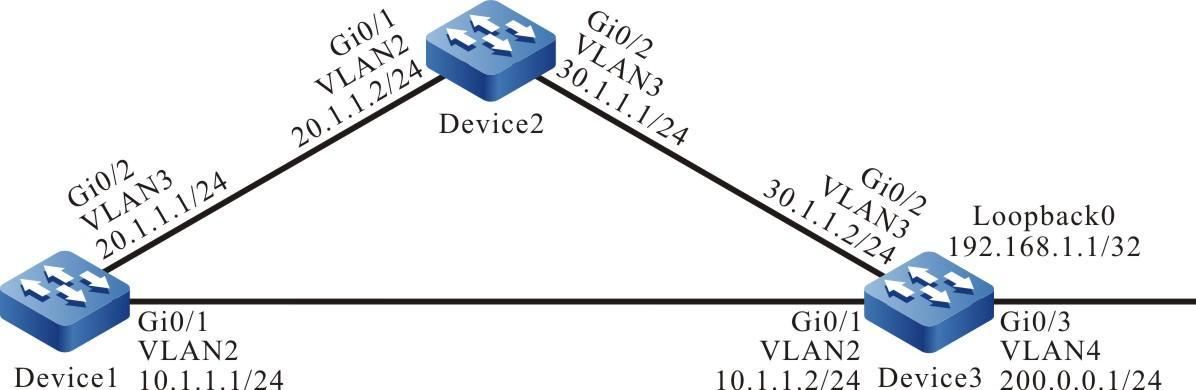
Figura 3 -4 Rede para configurar uma rota estática recursiva estática
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure rotas estáticas.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ip route 192.168.1.1 255.255.255.255 10.1.1.2Device1(config)#ip route 192.168.1.1 255.255.255.255 20.1.1.2 10
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ip route 192.168.1.1 255.255.255.255 30.1.1.2
- Passo 4: Configure uma rota recursiva estática.
# Configurar dispositivo1.
Device1(config)#ip route 200.0.0.0 255.255.255.0 192.168.1.1#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.1.1.0/24 is directly connected, 00:04:07, vlan2C 20.1.1.0/24 is directly connected, 00:03:58, vlan3C 127.0.0.0/8 is directly connected, 73:10:12, lo0S 200.0.0.0/24 [1/100] via 192.168.1.1, 00:00:08, vlan2S 192.168.1.1/32 [1/100] via 10.1.1.2, 00:01:46, vlan2
De acordo com a tabela de roteamento, o endereço do gateway da rota para 200.0.0.0/24 é 192.168.1.1, a interface de saída é VLAN2 e a rota depende da rota para 192.168.1.1/32.
- Passo 5: Confira o resultado.
#Depois que a rota entre Device1 e Device3 estiver com defeito, consulte a tabela de roteamento de Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 20.1.1.0/24 is directly connected, 00:09:04, vlan3C 127.0.0.0/8 is directly connected, 73:15:18, lo0S 200.0.0.0/24 [1/100] via 192.168.1.1, 00:00:02, vlan3S 192.168.1.1/32 [10/100] via 20.1.1.2, 00:00:02, vlan3
Comparando as informações da tabela de roteamento com as informações da tabela de roteamento na Etapa 3, a interface de saída foi alterada para VLAN3, indicando que a rota foi alterada para a rota para Device2.
Configurar uma rota estática para coordenar com BFD (Aplicável somente ao modelo S3054G-B)
Requisitos de rede
- Em Device1, configure duas rotas estáticas para o segmento de rede 201.0.0.0/24. Uma rota passa Device2 enquanto a outra rota passa Route3. O dispositivo primeiro usa a rota que passa pelo dispositivo 3 para encaminhar pacotes. Da mesma forma, em Device3, configure duas rotas estáticas para o segmento de rede 200.0.0.0/24. Device3 primeiro usa a rota que passa Device1 para encaminhar pacotes.
- Em Device1 e Device3, configure rotas estáticas para coordenar com BFD. Quando a rota entre Device1 e Device3 está com defeito, eles podem alternar rapidamente para a rota que passa pelo Device2.
Topologia de rede
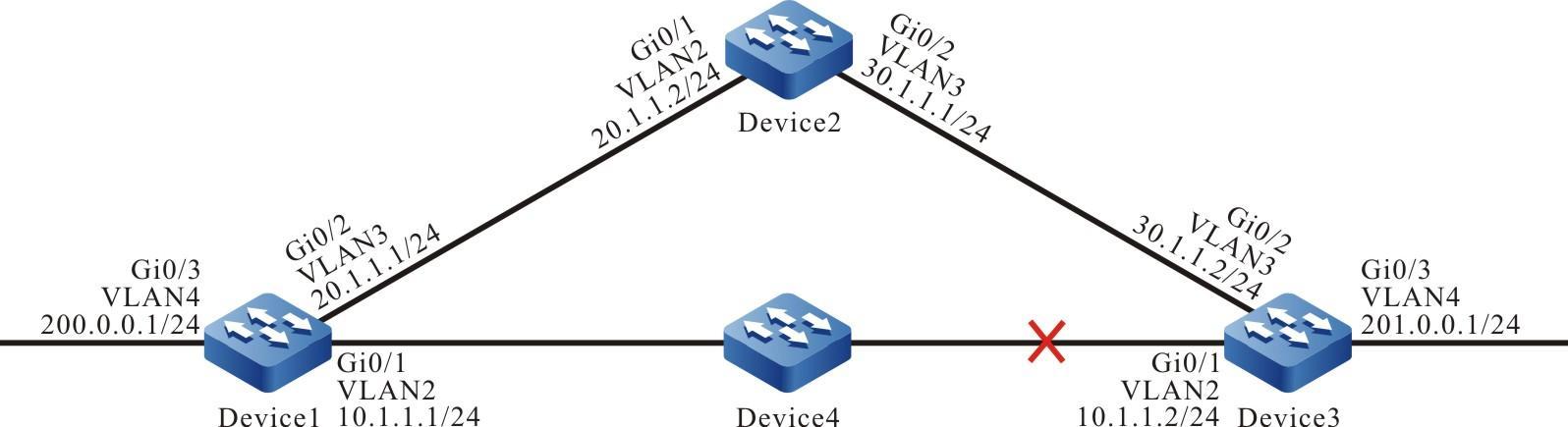
Figura 3 -5 Rede para configurar uma rota estática para coordenar com BFD
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure rotas estáticas.
#No Device1, configure duas rotas estáticas para o segmento de rede 201.0.0.0/24 .
Device1#configure terminalDevice1(config)#ip route 201.0.0.0 255.255.255.0 vlan2 10.1.1.2Device1(config)#ip route 201.0.0.0 255.255.255.0 vlan3 20.1.1.2 10
#No Device2, configure duas rotas estáticas para os segmentos de rede 200.0.0.0/24 e 201.0.0.0/24, respectivamente.
Device2#configure terminalDevice2(config)#ip route 200.0.0.0 255.255.255.0 20.1.1.1Device2(config)#ip route 201.0.0.0 255.255.255.0 30.1.1.2
#No Device3, configure duas rotas estáticas para o segmento de rede 200.0.0.0/24 .
Device3#configure terminalDevice3(config)#ip route 200.0.0.0 255.255.255.0 vlan2 10.1.1.1Device3(config)#ip route 200.0.0.0 255.255.255.0 vlan3 30.1.1.1 10
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.1.1.0/24 is directly connected, 00:07:41, vlan2C 20.1.1.0/24 is directly connected, 00:07:29, vlan3C 127.0.0.0/8 is directly connected, 101:56:14, lo0C 200.0.0.0/24 is directly connected, 00:15:33, vlan4S 201.0.0.0/24 [1/100] via 10.1.1.2, 00:02:23, vlan2
#Consulte a tabela de roteamento do Device3.
Device3#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.1.1.0/24 is directly connected, 00:10:21, vlan2C 30.1.1.0/24 is directly connected, 00:10:09, vlan3C 127.0.0.0/8 is directly connected, 126:44:08, lo0S 200.0.0.0/24 [1/100] via 10.1.1.1, 00:06:12, vlan2C 201.0.0.0/24 is directly connected, 00:20:37, vlan4
- Passo 4: Configure uma rota estática para coordenar com BFD.
# Configurar dispositivo1.
Device1(config)#bfd fast-detectDevice1(config)#ip route static bfd vlan2 10.1.1.2
# Configurar dispositivo3.
Device1(config)#bfd fast-detectDevice3(config)#ip route static bfd vlan2 10.1.1.1
- Passo 5: Confira o resultado.
#Consulte a sessão BFD do Device1.
Device1#show bfd sessionOurAddr NeighAddr LD/RD State Holddown interface10.1.1.1 10.1.1.2 15/22 UP 5000 vlan2
#Consulte a sessão BFD do Device3.
Device3#show bfd sessionOurAddr NeighAddr LD/RD State Holddown interface10.1.1.2 10.1.1.1 22/15 UP 5000 vlan2
As sessões BFD foram normalmente configuradas em Device1 e Device3, indicando que as rotas estáticas estão configuradas para coordenar com BFD com sucesso.
#Quando a rota entre Device1 e Device3 está com defeito, o BFD detecta rapidamente a falha de linha e muda para a rota que passa pelo Device2 para comunicação. Consulte a sessão BFD e a tabela de roteamento do Device1.
Device1#show bfd sessionOurAddr NeighAddr LD/RD State Holddown interface10.1.1.1 10.1.1.2 15/0 DOWN 5000 vlan2Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.1.1.0/24 is directly connected, 00:29:07, vlan2C 20.1.1.0/24 is directly connected, 00:28:55, vlan3C 127.0.0.0/8 is directly connected, 102:17:40, lo0C 200.0.0.0/24 is directly connected, 00:36:58, vlan4S 201.0.0.0/24 [10/100] via 20.1.1.2, 00:00:09, vlan3
O método de manipulação BFD no Device3 é o mesmo que no Device1.
Rotas estáticas IPv6
Visão geral
O protocolo de roteamento estático IPv6 e o protocolo de roteamento estático têm os mesmos comportamentos, exceto a estrutura de endereço IP no pacote. Consulte a introdução do roteamento estático.
Configuração da Função de Roteamento Estático IPv6
Tabela 4 -1 Lista de funções de configuração de rota estática IPv6
| Tarefas de configuração | |
| Configure uma rota estática IPv6. | Configure uma rota estática IPv6. |
| Configure as rotas de balanceamento de carga IPv6. | Configure as rotas de balanceamento de carga IPv6. |
| Configure uma rota flutuante IPv6. | Configure uma rota flutuante IPv6. |
| Configure uma rota estática IPv6 para coordenar com o rack T. | Configure uma rota estática IPv6 para coordenar com o rack T. |
Configurar uma rota estática IPv6
Condição de configuração
Antes de configurar uma rota estática IPv6, certifique-se de que:
- O protocolo da camada de link foi configurado para garantir a comunicação normal na camada de link.
- Os endereços IPv6 da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
Configurar uma rota estática IPv6
De acordo com os parâmetros especificados, as rotas estáticas IPv6 são divididas em três tipos:
- Rota de interface: para uma rota de interface, somente a interface de saída é especificada.
- Rota de gateway: para uma rota de gateway, apenas o endereço de gateway é especificado.
- Rota de gateway de interface: para uma rota de gateway de interface, a interface de saída e o endereço de gateway são especificados.
As rotas estáticas IPv6 configuradas se tornam inválidas se algumas das seguintes condições forem atendidas:
- O endereço de destino é o endereço da interface local.
- A distância administrativa da rota é de 255 .
- A interface de saída da rota está DOWN.
- A interface de saída da rota não habilita o IPv6.
- O endereço do gateway não está acessível.
- O endereço do gateway está em conflito com o endereço local.
- A interface de saída e o gateway do conflito de rota.
- A interface de saída da rota não existe.
- O objeto TRACK que está associado à rota é "falso".
Se uma rota de interface atender a qualquer condição entre 1, 2, 3, 4, 8 e 9, a rota é inválida. Se uma rota de gateway atender a qualquer condição entre 1, 2, 5, 6 e 9, a rota é inválida. Se uma rota de gateway de interface atender a qualquer uma das condições acima, a rota será inválida.
Tabela 4 -2 Configurando uma rota estática IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma rota estática IPv6. | ipv6 route destination-ipv6-address/destination-mask { interface-name / [ nexthop-ipv6-address ] } [ name nexthop-name ] [ tag tag-value ] [ track track-id ] [ administrative-distance ] |
Obrigatório.
O campo administrativo - distância é a distância administrativa da rota estática. Se não for especificado, a distância administrativa padrão será usada. |
Ao configurar a rota padrão, a rede e a máscara de destino devem ser definidas como 0::/0. A interface de saída da rota Null0 deve ser configurada para Null0. A interface de saída da interface Null0 não precisa ser configurada com um endereço IPv6.
Configurar rotas de balanceamento de carga IPv6
Condição de configuração
Nenhum
Configurar rotas de balanceamento de carga IPv6
A rota de balanceamento de carga IPv6 significa que existem várias rotas para a mesma rede de destino. As interfaces de saída e os endereços de gateway das rotas são diferentes, mas as distâncias administrativas (prioridades) das rotas são as mesmas. As rotas de balanceamento de carga ajudam a melhorar a taxa de utilidade do link.
Tabela 4 -3 Configurando rotas de balanceamento de carga IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a primeira rota de balanceamento de carga IPv6. | ipv6 route destination-ipv6-address/destination-mask interface-name1 distance | Obrigatório. A interface de saída é interface-name1. |
| Configure a segunda rota de balanceamento de carga IPv6. | ipv6 route destination-ipv6-address/destination-mask interface-name2 distance | Obrigatório. A interface de saída é interface-name2. |
Na configuração de rotas de balanceamento de carga, você deve configurar os valores de distância das rotas para as mesmas.
Configurar rota flutuante IPv6
Condição de configuração
Nenhum
Configurar uma rota flutuante IPv6
IPv6 indica que há várias rotas para a mesma rede de destino. As interfaces de saída ou endereços de gateway das rotas são diferentes e as prioridades das rotas também são diferentes. A rota com a prioridade mais alta se torna a rota principal enquanto a rota com a prioridade mais baixa se torna a rota flutuante. Na tabela de roteamento, apenas a rota primária é visível. A tabela flutuante aparece na tabela de roteamento somente quando a rota primária se torna inválida. Portanto, a rota flutuante geralmente é usada como rota de backup.
Tabela 4 -4 Configurando uma rota flutuante
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure a rota primária IPv6. | ipv6 route destination-ipv6-address/destination-mask interface-name1 distance1 |
Obrigatório.
A interface de saída da rota primária é interface-name1 e a prioridade da rota é distance1 . |
| Configure a rota flutuante IPv6. | ipv6 route destination-ipv6-address/destination-mask interface-name2 distance2 |
Obrigatório.
A interface de saída da rota flutuante é interface-name2 , a prioridade é distance2 . O valor de distância2 deve ser maior que o valor de distância1 . |
Na configuração das prioridades das rotas, quanto menor for o valor da distância , maior será a prioridade.
Configure a rota estática IPv6 para coordenar com o rack T
Condição de configuração
Nenhum
Configurar uma rota estática IPv6 para coordenar com o rack T
Alguns módulos no sistema precisam monitorar algumas informações do sistema e, em seguida, determinar seus modos de trabalho com base nas informações. Os objetos que são monitorados pelos outros módulos são chamados de objetos de monitoramento. Para simplificar as relações entre os módulos e os objetos de monitoramento, são usados os objetos Track. Um objeto Track pode conter vários objetos de monitoramento e exibe o status abrangente do objeto de monitoramento para módulos externos. Os módulos externos estão associados apenas aos objetos Track e não se preocupam mais com os objetos de monitoramento contidos nos objetos Track. Um objeto Track tem dois status, "true" e "false". Os módulos externos associados ao objeto Track determinam seus modos de trabalho de acordo com o status do objeto Track.
Uma rota estática pode ser associada a um objeto Track para monitorar as informações do sistema e determinar se a rota é válida de acordo com o status relatado pelo objeto Track. Se o objeto Track relatar "true", as condições exigidas pela rota estática serão atendidas e a rota será adicionada à tabela de roteamento. Se o objeto Track relatar "false", a rota será excluída da tabela de roteamento.
Tabela 4 -5 Configurando uma rota estática IPv6 para coordenar com a trilha
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um objeto Track e entre no modo de configuração do objeto Track. | track track-id | Obrigatório. |
| Configure o objeto de rastreamento para monitorar o status do link da interface especificada. | interface interface-name line-protocol |
Opcional.
Por padrão, o objeto track não está configurado para monitorar o status do link da interface especificada . |
| Retorne ao modo de configuração global. | exit | - |
| Configure uma rota estática e associe-a ao objeto Track. | Ipv6 route destination-ip-address destination-mask interface-name track track-id |
Obrigatório.
Quando a camada de link da interface de monitoramento está UP, a rota é válida; caso contrário, a rota é inválida. |
Configurar Reencaminhamento Rápido de Rota Estática IPv6 (Aplicável somente ao modelo S3054G-B)
Condição de configuração
Antes de configurar o reencaminhamento rápido da rota estática IPv6, conclua primeiro as seguintes tarefas:
- Configure o reencaminhamento rápido baseado no mapa de rotas, o mapa de rotas associado já está configurado;
Configurar o reencaminhamento rápido da rota estática
Na rede com roteamento estático IPv6, a interrupção de tráfego causada por falha de link ou dispositivo continuará até que o protocolo detecte a falha de link, e a rota flutuante não se recuperará até que a rota flutuante entre em vigor, o que geralmente dura vários segundos. A fim de reduzir o tempo de interrupção do tráfego, o reencaminhamento rápido da rota estática pode ser configurado. Através da aplicação do mapa de roteamento, o próximo salto de backup é definido para a rota correspondente. Uma vez que o link ativo falhe, o tráfego que passa pelo link ativo será imediatamente comutado para o link em espera, de modo a atingir o objetivo de comutação rápida.
Tabela 4 -6 Configurar o reencaminhamento rápido da rota estática IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema | configure terminal | - |
| Configurar o reencaminhamento rápido com base no mapa de rotas | ipv6 route static fast-reroute route-map map-name | Obrigatório. Por padrão, não habilite o reencaminhamento rápido. |
| Configurar o reencaminhamento rápido automático da rota estática | ipv6 route static pic | Obrigatório. Por padrão, não ative o reencaminhamento rápido automático. |
Somente rotas estáticas com interface de saída e endereços de gateway especificados podem ser reencaminhadas rapidamente. Quando a configuração de backup-nexthop de reencaminhamento rápido com base no mapa de rotas é automática, o protocolo fará o reencaminhamento rápido automaticamente. Quando o modo pic é usado, o protocolo será redirecionado automaticamente rapidamente. Os vários modos de permitir o reencaminhamento rápido são mutuamente exclusivos.
Monitoramento e Manutenção de rota estática IPv6
Tabela 4 -7 Monitoramento e Manutenção de rotas estáticas IPv6
| Comando | Descrição |
| show ipv6 route [ vrf vrf-name] static | Exiba as rotas estáticas IPv6 na tabela de roteamento. |
| show ipv6 static route [ipv6-address/mask-length] | Exiba a rota estática IPv6. |
| show running-config ipv6 route | Exiba as informações de configuração sobre rotas estáticas IPv6. |
Exemplos de configuração típicos de rota estática IPv6
Configurar funções básicas da rota estática IPv6
Requisitos de rede
- Device1, Device2 e Device3 configuram a rota estática IPv6, fazendo com que PC1 e PC2 se comuniquem entre si.
Topologia de rede
Figura 4 -1 Rede para configurar as funções básicas da rota estática IPv6
Etapas de configuração
- Passo 1: Configure o endereço IPv6 da interface (omitido).
- Passo 2: Configure a rota estática IPv6.
# Configure a rota IPv6 no Device1.
Device1#configure terminalDevice1(config)#ipv6 route 2001:4::/64 2001:2::2
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 route 2001:1::/64 2001:2::1Device2(config)#ipv6 route 2001:4::/64 2001:3::2
# Em Device3, configure a rota IPv6.
Device3#configure terminalDevice3(config)#ipv6 route 2001:1::/64 2001:3::1
# Consulta a tabela de rotas IPv6 de Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementS 2001:4::/64 [1/10]via 2001:2::2, 00:03:14, gigabitethernet0/2/1L ::1/128 [0/0]via ::, 2w0d:01:09:06, lo0C 2001:1::/64 [0/0]via ::, 00:25:55, gigabitethernet0/2/0L 2001:1::1/128 [0/0]via ::, 00:25:53, lo0C 2001:2::/64 [0/0]via ::, 04:01:46, gigabitethernet0/2/1L 2001:2::1/128 [0/0]via ::, 04:01:45, lo0
# Consulta a tabela de rotas IPv6 de Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 5w2d:23:52:04, lo0S 2001:1::/64 [1/10]via 2001:2::1, 00:02:56, gigabitethernet0/2/0C 2001:2::/64 [0/0]via ::, 04:00:52, gigabitethernet0/2/0L 2001:2::2/128 [0/0]via ::, 04:00:50, lo0C 2001:3::/64 [0/0]via ::, 04:00:20, gigabitethernet0/2/1L 2001:3::1/128 [0/0]via ::, 04:00:19, lo0S 2001:4::/64 [1/10]via 2001:3::2, 00:02:36, gigabitethernet0/2/1
# Consulta a tabela de rotas IPv6 de Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementS 2001:1::/64 [1/10]via 2001:3::1, 00:00:08, gigabitethernet0/2/0L ::1/128 [0/0]via ::, 1w2d:20:54:36, lo0C 2001:3::/64 [0/0]via ::, 03:58:28, gigabitethernet0/2/0L 2001:3::2/128 [0/0]via ::, 03:58:26, lo0C 2001:4::/64 [0/0]via ::, 00:11:13, gigabitethernet0/2/1L 2001:4::1/128 [0/0]via ::, 00:11:12, lo0
- Passo 3: Confira o resultado. Use o comando ping para verificar a conectividade de PC1 e PC2.
# No PC1 , use o comando ping para verificar a conectividade.
C:\Documents and Settings\Administrator>ping 2001:4::2Pinging 2001:4::2 with 32 bytes of data:Reply from 2001:4::2: bytes=32 time<1ms TTL=128Reply from 2001:4::2: bytes=32 time<1ms TTL=128Reply from 2001:4::2: bytes=32 time<1ms TTL=128Reply from 2001:4::2: bytes=32 time<1ms TTL=128Ping statistics for 2001:4::2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0ms
PC1 e PC2 podem se comunicar entre si.
Configurar rota flutuante estática IPv6
Requisitos de rede
- Em Device1, configure duas rotas estáticas para o segmento 2001:3:: / 6 4: uma é alcançável via Device2 e a outra é alcançável via Device3.
- Device1 primeiro usa a linha com Device2 para encaminhar o pacote. Quando a linha falhar, mude para Device3 para comunicação.
Topologia de rede

Figura 4 -2 Rede para configurar a rota flutuante estática IPv6
Etapas de configuração
- Passo 1: Configure o endereço IPv6 da interface (omitido).
- Passo 2: Configure a rota estática IPv6.
#No Device1, configure duas rotas estáticas IPv6 para o segmento 2001:3:: / 6 4 passando Device2 e Device3 respectivamente.
Device1#configure terminalDevice1(config)#ipv6 route 2001:3::/64 2001:1::2Device1(config)#ipv6 route 2001:3::/64 2001:2::2
# Consulta a tabela de rotas IPv6 de Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w0d:02:13:16, lo0C 2001:1::/64 [0/0]via ::, 00:22:33, gigabitethernet0/2/0L 2001:1::1/128 [0/0]via ::, 00:22:32, lo0C 2001:2::/64 [0/0]via ::, 00:17:47, gigabitethernet0/2/1L 2001:2::1/128 [0/0]via ::, 00:17:46, lo0S 2001:3::/64 [1/10]via 2001:1::2, 00:01:47, gigabitethernet0/2/0[1/10]via 2001:2::2, 00:01:36, gigabitethernet0/2/1
Você pode ver que existem duas rotas para o segmento 2001:3:: / 6 4 no Device1, formando o balanceamento de carga.
- Passo 3: Configure a rota flutuante IPv6.
# Configure Device1, modifique a distância de gerenciamento da rota com o gateway 2001:2::2 como 15, tornando-a rota flutuante.
Device1(config)#ipv6 route 2001:3::/64 2001:2::2 15- Passo 4: Confira o resultado.
# Consulta a tabela de rotas IPv6 de Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w0d:02:16:38, lo0C 2001:1::/64 [0/0]via ::, 00:25:56, gigabitethernet0/2/0L 2001:1::1/128 [0/0]via ::, 00:25:55, lo0C 2001:2::/64 [0/0]via ::, 00:21:10, gigabitethernet0/2/1L 2001:2::1/128 [0/0]via ::, 00:21:09, lo0S 2001:3::/64 [1/10]via 2001:1::2, 00:05:10, gigabitethernet0/2/0
Na tabela de rotas IPv6, você pode ver que a rota com a distância de gerenciamento 1 é anterior à rota com a distância de gerenciamento 15, portanto, a rota com o gateway 2001:2::2 é excluída.
#Depois que a linha entre Device1 e Device2 falhar, consulte a tabela de rotas de Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w0d:02:21:06, lo0C 2001:2::/64 [0/0]via ::, 00:25:38, gigabitethernet0/2/1L 2001:2::1/128 [0/0]via ::, 00:25:37, lo0S 2001:3::/64 [15/10]via 2001:2::2, 00:00:05, gigabitethernet0/2/1
Na tabela de rotas IPv6 , você pode ver que a rota com a maior distância de gerenciamento é adicionada à tabela de rotas e Device3 encaminha os dados.
O maior recurso da rota flutuante estática é que ela pode fazer backup da rota.
Configurar IPv6 Static NULL0 Interface Route
Requisitos de rede
- Device2 , configure uma rota padrão estática respectivamente, e os endereços de gateway são os endereços de interface peer dos dois dispositivos. Em Device1, configure a rota de interface Null0 estática e pode filtrar os dados para PC2.
Topologia de rede
Figura 4 -3 Rede para configurar a rota de interface NULL0 estática IPv6
Etapas de configuração
- Passo 1: Configure o endereço IPv6 da interface (omitido).
- Passo 2: Configure a rota estática IPv6.
# Configurar Device1 .
Device1#configure terminalDevice1(config)#ipv6 route ::/0 2001:2::2
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 route ::/0 2001:2::1
# No PC1, use o comando ping para verificar a conectividade.
C:\Documents and Settings\Administrator>ping 2001:3::2Pinging 2001:3::2 with 32 bytes of data:Reply from 2001:3::2: bytes=32 time<1ms TTL=128Reply from 2001:3::2: bytes=32 time<1ms TTL=128Reply from 2001:3::2: bytes=32 time<1ms TTL=128Reply from 2001:3::2: bytes=32 time<1ms TTL=128Ping statistics for 2001:3::2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0ms
- Passo 3: Configure a rota de interface Null0 estática IPv6.
# Configurar Device1 .
Device1(config)#ipv6 route 2001:3::2/128 null0- Passo 4: Confira o resultado.
# Consulta a tabela de rotas IPv6 de Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementS ::/0 [1/10]via 2001:1::2, 00:04:55, gigabitethernet0/2/1L ::1/128 [0/0]via ::, 2w0d:03:36:10, lo0C 2001:1::/64 [0/0]via ::, 00:08:54, gigabitethernet0/2/1L 2001:1::1/128 [0/0]via ::, 00:08:53, lo0C 2001:2::/64 [0/0]via ::, 00:08:32, gigabitethernet0/2/0L 2001:2::1/128 [0/0]via ::, 00:08:30, lo0S 2001:3::2/128 [1/1]via ::, 00:00:34, null0
Na tabela de rotas IPv6, a rota de interface IPv6 estática Null0 é adicionada .
# No PC1, use o comando ping para verificar a conectividade com o PC2.
C:\Documents and Settings\Administrator>ping 2001:3::2Pinging 2001:3::2 with 32 bytes of data:Request timed out.Request timed out.Request timed out.Request timed out.Ping statistics for 2001:3::2:Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
a tabela de rotas para o pacote ICMP enviado pelo PC1 no Device1, descubra que a interface de saída é Null0 e descarte diretamente. Portanto, o PC1 não pode se comunicar com o PC2.
A rota estática da interface Null0 é uma rota especial, e os pacotes enviados para a interface Null0 são todos descartados. Portanto, configurar a rota de interface estática Null0 pode realizar a filtragem dos pacotes.
Configurar rota recursiva estática IPv6
Requisitos de rede
- Em Device1, configure duas rotas estáticas para o segmento 192 ::3 / 128 : uma é alcançável via Device2 e a outra é alcançável via Device3. Device1 primeiro usa a linha com Device3 para encaminhar o pacote.
- No Device1, configure uma rota recursiva estática para o segmento 2001:4:: / 64 e o endereço do gateway é o endereço da interface de loopback do Device3 192::3 . Depois que a linha entre Device1 e Device3 falha, a rota pode alternar para Device2 para comunicação.
Topologia de rede

Figura 4 -4 Rede para configurar a rota recursiva estática IPv6
Etapas de configuração
- Passo 1: Configure o endereço IPv6 da interface (omitido).
- Passo 2: Configure a rota estática IPv6.
# Configurar Device1 .
Device1#configure terminalDevice1(config)#ipv6 route 192::3/128 2001:1::2Device1(config)#ipv6 route 192::3/128 2001:2::2 10
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 route 192::3/128 2001:3::2
- Passo 3: Configure a rota recursiva estática IPv6.
# Configurar Device1 .
Device1(config)#ipv6 route 2001:4::/64 192::3# Consulta a tabela de rotas IPv6 de Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w0d:03:12:46, lo0S 192::3/128 [1/10]via 2001:1::2, 00:04:54, gigabitethernet0/2/0C 2001:1::/64 [0/0]via ::, 00:22:47, gigabitethernet0/2/0L 2001:1::1/128 [0/0]via ::, 00:22:45, lo0C 2001:2::/64 [0/0]via ::, 00:16:16, gigabitethernet0/2/1L 2001:2::1/128 [0/0]via ::, 00:16:15, lo0S 2001:4::/64 [1/10]via 192::3, 00:00:43, gigabitethernet0/2/0
Na tabela de rotas IPv6, você pode ver que o endereço de gateway da rota 2001:4::/64 é 192::3, a interface de saída é gigabitethernet0 /2/0 e a rota depende da rota 192::3 /128 .
- Passo 4:Confira o resultado.
# Depois que a linha entre Device1 e Device3 falhar, consulte a tabela de rotas IPv6 de Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w0d:03:17:48, lo0S 192::3/128 [10/10]via 2001:2::2, 00:00:06, gigabitethernet0/2/1C 2001:2::/64 [0/0]via ::, 00:21:18, gigabitethernet0/2/1L 2001:2::1/128 [0/0]via ::, 00:21:17, lo0S 2001:4::/64 [1/10]via 192::3, 00:00:06, gigabitethernet0/2/1
Comparado com a tabela de rotas da etapa 3, você pode ver que a interface de saída da rota 2001:4::/64 é gigabitethernet 0/2/1 , indicando que a rota já muda para Device2 para comunicação.
RIP
Visão geral
Na Internet atual, é impossível executar apenas um protocolo de gateway. Você pode dividi-lo em vários sistemas autônomos (ASs), cada um com sua própria tecnologia de roteamento. Os protocolos de roteamento interno dentro de um AS são Interior Gateway Protocols (IGPs). O Routing Information Protocol (RIP) é um tipo de IGP. O RIP adota o algoritmo Vector-Distance. O RIP possui recursos simples e fáceis de usar, por isso é amplamente utilizado em várias redes de pequeno porte.
O RIP tem duas versões: RIPv1 e RIPv2. O RIPv1 não oferece suporte ao roteamento sem classes e o RIPv2 oferece suporte ao roteamento sem classes. Normalmente, o RIPv2 é usado.
RIP é um protocolo simples que fornece configuração simples. No entanto, o número de rotas a serem anunciadas pelo RIP é diretamente proporcional ao número de rotas na tabela de roteamento. Se o número de rotas for grande, muitos recursos do dispositivo e da rede serão consumidos. Além disso, o RIP especifica que o número máximo de saltos que um caminho de roteamento que passa pelos roteadores é 15, portanto, o RIP é aplicável apenas a redes simples de pequeno e médio porte. O RIP é aplicável à maioria das redes e LANs de campus com uma estrutura simples e forte continuidade. Para um ambiente mais complexo, o RIP não é recomendado.
O RIPv1 foi introduzido anteriormente no RFC1058, mas possui muitas deficiências. Para melhorar as deficiências do RIPv1, o RFC1388 introduziu o RIPv2, que foi revisado no RFC 1723 e RFC 2453.
Configuração da função RIP
Tabela 5 -1 Lista de funções RIP
| Tarefas de configuração | |
| Configure as funções básicas do RIP. | Ativa o RIP globalmente. Habilite o RIP para VRF. Configurar versões RIP. |
| Configure a geração de rotas RIP. | Configure o RIP para anunciar a rota padrão. Configure o RIP para redistribuir rotas. |
| Configure o controle de rota RIP. |
Configure a distância administrativa do RIP.
Configure um resumo de rota RIP. Configure o deslocamento da métrica RIP. Configure a filtragem de rota RIP. Configure a métrica da interface RIP. Configure o sinalizador de roteamento para uma interface RIP. Configure o balanceamento de carga máximo para RIP. |
| Configure a autenticação de rede RIP. | Configure a autenticação de rede RIP. |
| Configure a otimização de rede RIP. |
Configurar temporizadores RIP.
Configure o horizonte dividido do RIP e o reverso da toxicidade do RIP. Configure a verificação de endereço de origem. Configure um vizinho RIP estático. Configure uma interface RIP passiva. Configure o RIP para acionar atualizações. Configure uma interface de backup RIP. |
| Configure o RIP para coordenar com o BFD. | Configure o RIP para coordenar com o BFD. |
Configurar funções básicas do RIP
Condição de configuração
Antes de configurar as funções básicas do RIP, certifique-se de que:
- O protocolo da camada de link foi configurado para garantir a comunicação normal na camada de link.
- Os endereços da camada de rede das interfaces foram configurados para que os nós de rede adjacentes sejam alcançáveis na camada de rede.
Ativar RIP globalmente
Antes de usar o RIP, faça as seguintes configurações:
- Crie um processo RIP.
- Configure o RIP para cobrir uma rede ou interface conectada diretamente.
Tabela 5 -2 Habilitando o RIP globalmente
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um processo RIP e entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Configure o RIP para cobrir um segmento ou interface de rede especificado. | network { ip-address | interface-name } | Obrigatório. Por padrão, o RIP não cobre nenhuma rede ou interface diretamente conectada. |
O segmento de rede coberto é categorizado em endereços classful. Você não pode usar a rede ip - comando de endereço para cobrir endereços de super-rede. Para cobrir endereços de super-rede, use a rede nome da interface comando.
Ativar RIP para VRF
Para permitir que o RIP suporte funções VRF, faça as seguintes configurações:
- Configure um VRF e adicione uma interface ao VRF.
- Habilite a função RIP na família de endereços VRF.
- Configure o RIP para cobrir uma rede ou interface VRF conectada diretamente.
Tabela 5 -3 Ativar RIP para VRF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um processo RIP e entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Entre no modo de configuração da família de endereços VRF do protocolo RIP. | address-family { ipv4 vrf vrf-name } | Obrigatório. Por padrão, o modo de família de endereços VRF está desabilitado. |
| Configure o RIP para cobrir um segmento ou interface de rede especificado. | network { ip-address | interface-name } | Obrigatório. Por padrão, o RIP não cobre nenhuma rede ou interface diretamente conectada. |
Para habilitar o RIP no modo VRF, você deve primeiro criar configurações relacionadas ao VRF.
versões RIP
O RIP tem duas versões, RIPv1 e RIPv2. Eles podem ser configurados em três modos: modo de configuração global, modo de configuração VRF e modo de configuração de interface.
- Por padrão, o RIPv1 está habilitado no modo de configuração global e no modo de configuração VRF, e não está configurado no modo de configuração de interface.
- O comando version configuration no modo de configuração de interface é uma prioridade mais alta do que o comando version configuration no modo de configuração global ou VRF.
- Se o comando de configuração da versão não estiver configurado, é usado o comando no modo de configuração do VRF da interface à qual o VRF pertence ou o modo de configuração global do comando.
- No modo de configuração de interface, a versão de transmissão RIP e a versão de recepção RIP podem ser configuradas independentemente.
- Depois que as versões são configuradas, o RIP tem um processamento estrito de transmissão e recebimento de pacotes: No caso de RIPv1, a interface transmite e recebe apenas pacotes RIPv1 broadcast e unicast. No caso de RIPv2, a interface pode transmitir e receber pacotes RIPv2 unicast, multicast e broadcast. No caso do modo compatível com RIPv1, a interface pode transmitir pacotes RIPv2 unicast e broadcast.
Tabela 5 -4 Configurando versões RIP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um processo RIP e entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Configure a versão RIP global. | version { 1 | 2 } | Obrigatório. Por padrão, o RIPv1 está habilitado. |
| Entre no modo de configuração RIP VRF. | address-family { ipv4 vrf vrf-name } | Obrigatório. Por padrão, o modo de família de endereços VRF está desabilitado. |
| Configure a versão RIP no modo de configuração RIP VRF. | version { 1 / 2 } | Obrigatório. Por padrão, o RIPv1 está habilitado. |
| Retorne ao modo de configuração RIP. | exit-address-family | - |
| Retorne ao modo de configuração global. | exit | - |
| Entre no modo de configuração da interface. | interface interface_name | - |
| Configure a versão de transmissão RIP da interface. | ip rip send version {{ 1 / 2 } | 1-compatible } | Opcional. Por padrão, a interface transmite pacotes com base na versão RIP global. |
| Configure a versão de recebimento RIP da interface. | ip rip receive version { 1 / 2 } | Opcional. Por padrão, a interface recebe pacotes com base na versão RIP global. |
Configurar geração de rota RIP
Condição de configuração
Antes de configurar a geração de rota RIP, certifique-se de que:
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
- O RIP está ativado.
Configurar o RIP para anunciar a rota padrão
Por meio da configuração, um dispositivo pode enviar a rota padrão em todas as interfaces RIP para se definir como o gateway padrão de outros dispositivos vizinhos.
Tabela 5 -5 Configurar o RIP para anunciar a rota padrão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Configure o RIP para anunciar a rota padrão. | default-information originate {only | originate [metric value] } | Obrigatório. Por padrão, o RIP não anuncia a rota padrão. |
Se uma rota padrão ( 0.0.0 .0/0 ) for aprendida, a rota padrão ( 0.0.0.0/0 ) anunciada pelo dispositivo local será substituída. Quando existe um loop em uma rede, podem ocorrer oscilações de rede. Ao usar este comando, evite que outros dispositivos no mesmo domínio de roteamento ativem o comando ao mesmo tempo.
Configurar RIP para redistribuir rotas
Ao redistribuir as rotas, você pode introduzir as rotas geradas por outros protocolos no RIP.
Tabela 5 -6 Configurando o RIP para redistribuir rotas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Configure a métrica padrão para as rotas de outros protocolos introduzidos no RIP. | default-metric metric-value | Opcional. Por padrão, a métrica padrão das rotas introduzidas de outros protocolos é 1. |
| Configure o RIP para redistribuir rotas. | redistribute protocol [ protocol-id ] [ metric metric-value ] [ route-map route-map-name ] [ match route-sub-type ] | Obrigatório. Por padrão, a redistribuição de rota não está configurada. |
Se a opção de comando de métrica for especificada durante a redistribuição, a rota redistribuída adotará a métrica. Ao configurar o RIP para redistribuir rotas, as opções de correspondência disponíveis para a política de roteamento aplicada incluem endereço IP, tipo de rota e tag, e as opções de conjunto disponíveis para a política de roteamento aplicada incluem interface, próximo salto de ip, origem da rota e métrica.
Configurar controle de rota RIP
Condição de configuração
Antes de configurar o controle de rota RIP, certifique-se de que:
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
- O RIP está ativado.
Configurar a distância administrativa do RIP
Um dispositivo pode executar vários protocolos de roteamento ao mesmo tempo. O dispositivo seleciona a rota ideal das rotas que são aprendidas de diferentes protocolos com base nas distâncias administrativas. Quanto menor a distância administrativa, maior a prioridade.
Tabela 5 -7 Configurando a distância administrativa do RIP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIP. | router rip | - |
| Configure a distância administrativa do RIP. | distance distance-value | Obrigatório. Por padrão, a distância administrativa do RIP é 120. |
Configurar um resumo de rota RIP
Por meio do resumo de rota RIP, um dispositivo de roteamento resume as rotas de sub-rede em um segmento de rede natural para formar uma rota de resumo. A rota de resumo e as rotas de sub-rede originais existem na tabela de roteamento RIP.
Depois que o resumo da rota RIP é configurado, o dispositivo anuncia apenas o resumo da rota. Isso diminui bastante o tamanho das tabelas de roteamento RIP adjacentes em uma rede de tamanho médio e grande e diminui o consumo da largura de banda da rede por pacotes de protocolo de roteamento.
Um resumo de rota usa o valor mínimo entre as métricas de todas as rotas de sub-rede como sua métrica.
O RIPv1 suporta o modo de resumo de rota automático e o RIPv2 suporta o modo de resumo de rota automático e o modo de resumo manual.
- Resumo da rota automática RIP
Diferente do resumo de rota manual, o resumo de rota automático permite que o RIP gere automaticamente uma rota de máscara natural com base em rotas de sub-rede em um segmento de rede natural.
Tabela 5 -8 Configurar a função de resumo de rota automática
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Configure a função de resumo de rota automática. | auto-summary | Obrigatório. Por padrão, não ative a função de resumo de rota automática . |
RIPv1 não suporta o comando route summary. A etiqueta de um resumo de rota é 0 e a métrica mínima das rotas é considerada como a métrica de resumo de rota. Se o resumo da rota automática estiver configurado, o resumo da rota automática terá prioridade. Tenha cuidado ao usar a função de resumo de rota automática. Certifique-se de que é necessário realizar o resumo de rota automática; caso contrário, loops de roteamento podem ser causados. Quando a função de resumo de rota automática do RIPv2 estiver habilitada, se a interface da rota anunciada e a rota estiverem no mesmo segmento de rede natural, o pacote de atualização enviado da interface não resultará no resumo de todas as rotas de sub-rede no segmento de rede natural ; caso contrário, as rotas são reunidas para formar um segmento de rede natural e então ele é anunciado.
- Resumo da rota manual
No resumo de rota manual, uma combinação de um endereço de destino e uma máscara precisa ser configurada. A combinação reúne todas as rotas no segmento de rede coberto para resumo da rota.
Tabela 5 -9 Configurando a Função de Resumo de Rota Manual
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure a função de resumo de rota manual do RIPv2 na interface. | ip summary-address rip prefix-address | - |
Configurar o deslocamento da métrica RIP
Por padrão, o RIP aplica a métrica de rota anunciada pelo dispositivo vizinho às rotas recebidas. Para modificar a métrica em alguns cenários de aplicativos especiais, você pode configurar o deslocamento da métrica RIP para corrigir a métrica da rota especificada.
Se a métrica na direção de entrada estiver configurada, o RIP modifica a métrica das rotas recebidas e salva as rotas na tabela de roteamento. Quando o RIP anuncia uma métrica para os dispositivos vizinhos, ele anuncia a nova métrica. Se a métrica na direção de saída estiver configurada, a métrica será modificada somente quando o RIP anunciar uma métrica para os dispositivos vizinhos.
Tabela 5 -10 Configurando o deslocamento da métrica RIP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Configure o RIP para modificar a métrica da rota especificada. | offset-list access-list-name { in | out } metric-offset [ interface-name ] | Obrigatório. Por padrão, nenhuma métrica é configurada para qualquer interface. |
O deslocamento métrico de rota é compatível apenas com uma lista de acesso padrão.
Configurar filtragem de rota RIP
Um roteador pode filtrar as rotas recebidas ou anunciadas configurando uma lista de controle de acesso (ACL) ou uma lista de prefixos. Ao receber rotas RIP, você pode filtrar algumas rotas aprendidas; ou ao anunciar rotas RIP, você pode filtrar algumas rotas anunciadas para dispositivos vizinhos.
Tabela 5 -11 Configurando a filtragem de rota RIP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Configure a função de filtragem de rota RIP. | distribute-list { access-list-name | prefix prefix-list-name } { in | out } [ interface-name ] |
Obrigatório.
Por padrão, a função de filtragem de rota não está configurada. Durante o processo de configuração da função de filtragem de rotas, se nenhuma interface for especificada, a filtragem de rotas é habilitada para todas as rotas recebidas e transmitidas por todas as interfaces cobertas pelo RIP. |
Na filtragem baseada em ACL, apenas uma ACL padrão é suportada.
Configurar a métrica da interface RIP
Se uma interface for substituída por um processo RIP, a rota direta correspondente será gerada no banco de dados, com a métrica padrão 1. Quando a rota estiver no banco de dados RIP ou for anunciada para dispositivos vizinhos, se a interface estiver configurada com uma métrica , a métrica da interface é usada como a métrica da rota.
Se a métrica da interface for alterada, o banco de dados RIP atualizará imediatamente a rota direta correspondente do RIP e anunciará a nova métrica aos dispositivos vizinhos.
Tabela 5 -12 Configurando a métrica da interface RIP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure a métrica da interface RIP. | ip rip metric metric-value | Obrigatório. Por padrão, a métrica da interface RIP é 1. |
A configuração da métrica da interface RIP afeta apenas a métrica da sub-rede direta da interface, mas não afeta a métrica aprendida pelas rotas.
Configurar o sinalizador de roteamento para uma interface RIP
O administrador da rede pode anexar tags a algumas rotas. Então, ao aplicar uma política de roteamento, o administrador de rede pode realizar filtragem de rota ou anúncio de propriedade de rota com base nas tags.
Apenas as tags de roteamento do RIPv2 são suportadas.
Tabela 5 -13 Configurando o sinalizador de roteamento para uma interface RIP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure uma tag para a rota da sub-rede direta da interface. | ip rip tag tag-value | - |
Configurar o número máximo de entradas de balanceamento de carga RIP
Este comando ajuda você a controlar o número de entradas de balanceamento de carga RIP para roteamento.
Tabela 5 -14 Configurando o número máximo de entradas de balanceamento de carga RIP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Configure o número máximo de entradas de balanceamento de carga RIP. | maximum-paths max-number | Opcional. Por padrão, o número máximo de entradas de balanceamento de carga RIP é 4. |
Configurar autenticação de rede RIP
O RIPv2 suporta autenticação de pacotes de protocolo, portanto, pode satisfazer os requisitos de alta segurança de algumas redes. Atualmente, a autenticação de texto simples e a autenticação MD5, SM3 são suportadas. A transmissão de texto simples apresenta baixa segurança, as duas últimas transmitem converte o código de autenticação em código MD5 ou código SM3 para transmissão, garantindo maior segurança.
Devido ao limite de pacotes RIPv2, um pacote que anuncia uma rota contém apenas 16 bytes. Portanto, o comprimento de uma string de autenticação de texto simples não deve exceder 16 bytes. Enquanto isso, o código MD5 que é convertido de qualquer cadeia de caracteres é um código padrão de 16 bytes, atendendo ao requisito de comprimento da cadeia.
Tabela 5 -15 Configurando a autenticação de rede RIP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure a autenticação de rede RIPv2. | ip rip authentication { { key { 0 | 7 } key-string } | { key-chain key-chain-name } | { mode { text | md5 | sm3 } } } | Obrigatório. Por padrão, a função de autenticação IPv2 não está configurada. |
Antes de implementar a autenticação MD5 ou SM3, preste atenção aos seguintes pontos: RIPv1 não suporta autenticação de rede. O RIPv2 oferece suporte a um modo de autenticação por vez. O ID da chave deve ser carregado nas informações de autenticação MD5 ou SM3. Se você usar o comando ip rip authentication key para configurar uma senha, o ID da chave será 1. Se você usar o ip rip authentication key-chain comando para configurar uma senha, o ID da chave é o ID da chave na cadeia de chaves. Ao obter uma senha de autenticação de transmissão de pacote do Key-chain, selecione um ID de chave na sequência de pequeno a grande. Portanto, a ID da chave com a menor senha de transmissão válida será selecionada. Ao obter uma senha de autenticação de recebimento de pacote do Key-chain, selecione a primeira senha de recebimento válida cujo ID de chave seja igual ou maior que o ID de chave de recebimento de pacote. Portanto, se os IDs de chave forem diferentes para as duas extremidades da autenticação, o final com o ID de chave maior pode passar na autenticação enquanto o final com o ID de chave menor falha na autenticação.
Configurar otimização de rede RIP
Condição de configuração
Antes de configurar a otimização de rede RIP, certifique-se de que:
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
- O RIP está ativado.
Configurar temporizadores RIP
RIP não mantém relações de vizinhos e não suporta rota retirada; portanto, o protocolo fornece quatro temporizadores configuráveis para controlar a velocidade de convergência da rede. Os quatro temporizadores são: temporizador de atualização de rota, temporizador de tempo limite do roteador, temporizador de atualização de amortecimento de rota e temporizador de limpeza de rota.
O tempo limite da rota deve ser pelo menos três vezes o tempo de atualização da rota. Se nenhum pacote de atualização de rota for recebido dentro do tempo limite da rota, a rota se tornará inválida e entrará em um ciclo de amortecimento. A duração do ciclo de amortecimento é determinada pelo tempo de atualização do amortecimento. Durante o ciclo, a rota não será limpa. Após a conclusão do ciclo de amortecimento, a rota entra no ciclo de limpeza. Durante o ciclo, a rota pode ser atualizada. No entanto, se nenhum pacote de atualização de rota for recebido durante o ciclo, a rota será excluída.
Tabela 5 -16 Configurando temporizadores RIP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Configurar temporizadores RIP. | timers basic update-interval invalid-interval holddown-interval flush-interval | Opcional. Por padrão, o intervalo de atualização do RIP é 30s, o tempo válido para anúncio é 180s, o tempo de amortecimento é 180s e o tempo de limpeza é 240s. |
No mesmo domínio de roteamento RIP, as configurações básicas do temporizador em todos os dispositivos devem ser as mesmas para evitar oscilações de rede.
Configurar RIP Split Horizon e Toxicity Reverse of RIP
Split horizon e toxicidade reversa são mecanismos que são usados para evitar loops de rota.
- Configurar horizonte dividido.
O RIP não anuncia as rotas que aprendeu de uma interface para a interface, evitando loops de roteamento .
Tabela 5 -17 Configurando o RIP Split Horizon
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configurando o horizonte dividido do RIP. | ip split-horizon | Obrigatório. Por padrão, a função split horizon está desabilitada. |
- Configure o reverso da toxicidade.
O RIP anuncia rotas que foram aprendidas de uma interface para a interface, mas a métrica de rota é o número máximo de saltos, 16, evitando loops de roteamento.
Tabela 5 -18 Configurando a Reversão de Toxicidade RIP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o reverso da toxicidade do RIP. | ip split-horizon poisoned | Opcional. Por padrão, a função de reversão de toxicidade está habilitada. |
As funções split horizon e toxic reverse são válidas apenas para as rotas aprendidas, rotas diretas na rede coberta pelo RIP e as rotas redistribuídas diretas e estáticas. A função split horizon e a função de reversão de toxicidade não podem ser usadas ao mesmo tempo.
Configurar verificação de endereço de origem RIP
Através da verificação do endereço de origem, o RIP verifica os endereços de origem dos pacotes recebidos. O RIP processa apenas os pacotes cujos endereços de origem atendem aos requisitos. Os itens de verificação incluem: o endereço de origem do pacote está no mesmo segmento de rede que o endereço da interface de entrada; o endereço de origem do pacote corresponde ao endereço final do peer da interface ponto a ponto (P2P).
Por padrão, o RIP está habilitado para verificar se os endereços de origem recebidos pela porta Ethernet estão no mesmo segmento de rede que o endereço da interface, e esta função não pode ser cancelada.
Tabela 5 -19 Configurando a Verificação de Endereço de Origem RIP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Configure o RIP para iniciar a verificação do endereço de origem na interface P2P. | validate-update-source check-p2p-destination | Obrigatório. Por padrão, o endereço de peer da interface P2P não é verificado. |
Configurar um vizinho RIP estático
O RIP não mantém relações de vizinhança, portanto não possui o conceito de vizinho. Aqui o vizinho refere-se ao dispositivo de roteamento RIP vizinho. Depois que um vizinho RIP estático é especificado, o RIP envia pacotes RIP para o vizinho no modo unicast. A configuração é aplicada a uma rede que não oferece suporte a broadcast ou multicast, como links ponto a ponto. Se a configuração for aplicada a uma rede de difusão ou multicast, poderá causar pacotes RIP repetidos na rede.
Tabela 5 -20 Configurando um vizinho RIP estático
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Configure o anúncio de rotas para um vizinho no modo unicast. | neighbor ip-address | Obrigatório. O parâmetro ip-address é o endereço IP da interface peer direct - connect. |
O RIP anuncia rotas apenas para as interfaces que cobre e a interface passiva A configuração não pode impedir que uma interface envie pacotes para seu vizinho estático.
Configurar uma interface RIP passiva
Para diminuir a largura de banda da rede consumida pelo protocolo de roteamento, o protocolo de roteamento dinâmico usa a função de interface passiva. O RIP recebe apenas pacotes de atualização de rota em uma interface passiva e não envia pacotes de atualização de rota na interface passiva. Em uma rede de baixa velocidade com largura de banda pequena, a função de interface passiva e a função de vizinho cooperam para reduzir efetivamente as interações das rotas RIP.
Tabela 5 -21 Configurando uma interface RIP passiva
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Configure uma interface RIP passiva. | passive-interface { default | interface-name } | Obrigatório. Por padrão, nenhuma interface passiva é configurada. |
A função de interface passiva não restringe uma interface de enviar atualizações de rota unicast para seus dispositivos vizinhos. Quando a função de interface passiva é usada com o vizinho comando, a função não restringe uma interface de enviar atualizações de rota unicast para seus dispositivos vizinhos. Este modo de aplicação controla um roteador para que ele envie atualizações de rota apenas para alguns dispositivos vizinhos em modo unicast em vez de enviar atualizações de rota para todos os dispositivos vizinhos em modo broadcast (ou modo multicast no caso de RIPv2).
Configurar RIP para acionar atualizações
Depois que um dispositivo recebe um pacote de atualização RIP, para reduzir a possibilidade de introdução de loops que possuem diferenças na tabela de roteamento, o dispositivo anuncia o pacote de atualização da rota para seus dispositivos vizinhos imediatamente, em vez de esperar que o temporizador de atualização expire antes de uma atualização. O mecanismo de disparo de atualização acelera a convergência da rede.
Tabela 5 -22 Configurando o RIP para acionar atualizações
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o RIP para acionar atualizações na interface. | ip rip triggered | Opcional. Por padrão, a função de gatilho de atualização está desabilitada. |
Configurar uma interface de espera RIP
Para acelerar a convergência da rota de backup, o RIP suporta recentemente uma função de interface de backup (interface de espera). Na interface de rota principal do RIP, especifique uma interface de backup para a interface principal. Em um ambiente de aplicativo específico, o RIP aprende as rotas RIP apenas de uma linha, e a linha de backup não fornece interação de informações de roteamento. Se a interface principal ficar off-line, o RIP enviará pacotes de solicitação para o ponto final por meio da interface de backup periodicamente (padrão: 1s) para solicitar todas as rotas. Se a interface de backup receber um pacote de resposta da rota de peer, o RIP cancela o envio de pacotes de solicitação. Ele atualiza a tabela de roteamento local e anuncia a tabela de roteamento local para a interface de backup. Se a interface de backup não receber um pacote de resposta do ponto final antes do tempo limite, o RIP cancela o envio de pacotes de solicitação.
Tabela 5 -23 Configurando uma interface de backup RIP.
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure uma interface de backup RIP. | ip rip standby interface-name [ timeout timeout-value ] | Opcional. Por padrão, a função de interface de backup está desabilitada e o valor de tempo limite padrão é 300s. |
Configurar RIP para Coordenar com BFD (Aplicável somente ao modelo S3054G-B)
Uma interface de backup pode ser usada apenas em um ambiente de aplicativo específico, mas não pode atender ao requisito de backup em tempo real. Neste momento, o RIP fornece a função Bidirectional Forwarding Detection (BFD) ponto-a-ponto para realizar a rápida convergência e alternância de rotas. O BFD fornece um método para detectar rapidamente o status de uma linha entre dois dispositivos. Quando a detecção de BFD está habilitada entre dois dispositivos RIP adjacentes, se a linha entre os dois dispositivos estiver com defeito, o BFD pode encontrar rapidamente a falha e notificar o RIP. O RIP então exclui a rota RIP que está associada à interface BFD. Se a rota tiver uma rota de backup, uma alternância para a rota de backup será realizada em um período de tempo muito curto (que é determinado pelas configurações do BFD). Atualmente, o RIP oferece suporte apenas à detecção BFD bidirecional de salto único.
Tabela 5 -24 Configurando RIP para Coordenar com BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIP. | router rip | Obrigatório. Por padrão, o processo RIP está desabilitado. |
| Habilite a função BFD em todas as interfaces cobertas pelo processo RIP. | bfd all-interfaces |
Obrigatório.
Por padrão, a função BFD está desabilitada em todas as interfaces cobertas pelo processo RIP. |
| Retorne ao modo de configuração global. | exit | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Habilite a função BFD na interface. | ip rip bfd | Obrigatório. Por padrão, a função BFD está desabilitada na interface. |
Para a configuração relacionada do BFD, consulte a tecnologia de confiabilidade-BFD Technical M anual.
Monitoramento e Manutenção RIP
Tabela 5 -25 Monitoramento e Manutenção RIP
| Comando | Descrição |
| show ip rip [ vrf vrf-name ] | Exiba as informações básicas sobre o protocolo RIP. |
| show ip rip [ vrf vrf-name ] database [ detail | prefix/mask [ [ detail | longer-prefixes [ detail ] ] ] ] | Exiba as informações sobre o banco de dados de roteamento RIP. |
| show ip rip [ vrf vrf-name ] statistics | Exiba as estatísticas do protocolo RIP. |
| show ip rip interface [ interface-name ] | Exiba as informações da interface RIP. |
| clear ip rip [ vrf vrf-name ] { process | statistics } | Limpa o processo RIP e as estatísticas. |
Exemplo de configuração típica de RIP
Configurar a versão RIP
Requisitos de rede
- RIPv2 é executado entre Device1 e Device2 para interação de rota.
Topologia de rede

Figura 5 -1 Rede para configurar a versão RIP
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configurar RIP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ripDevice1(config-rip)#network 1.0.0.0Device1(config-rip)#network 100.0.0.0Device1(config-rip)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ripDevice2(config-rip)#network 1.0.0.0Device2(config-rip)#network 50.0.0.0Device2(config-rip)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:23:06, vlan3R 50.0.0.0/8 [120/1] via 1.0.0.2, 00:13:26, vlan3C 100.0.0.0/24 is directly connected, 00:23:06, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0
#Consulte a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:23:06, vlan2C 50.0.0/24 is directly connected, 00:23:06, vlan3R 100.0.0.0/8 [120/1] via 1.0.0.1, 00:13:26, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0
De acordo com a tabela de roteamento, a rota anunciada pelo dispositivo usa uma máscara natural de n 8 bits.
- Passo 4: Configure a versão RIP.
# Configurar dispositivo1.
Device1(config)#router ripDevice1(config-rip)#version 2Device1(config-rip)#exit
# Configurar dispositivo2.
Device2(config)#router ripDevice2(config-rip)#version 2Device2(config-rip)#exit
- Passo 5: Confira o resultado.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:23:06, vlan3R 50.0.0.0/24 [120/1] via 1.0.0.2, 00:13:26, vlan3C 100.0.0.0/24 is directly connected, 00:23:06, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0
#Consulte a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:23:06, vlan2C 50.0.0/24 is directly connected, 00:23:06, vlan3R 100.0.0.0/24 [120/1] via 1.0.0.1, 00:13:26, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0
De acordo com a tabela de roteamento, a rota anunciada pelo dispositivo usa uma máscara precisa de 24 bits.
Configurar RIP para redistribuir rotas
Requisitos de rede
- OSPF é executado entre Device1 e Device2. Device2 aprende as rotas OSPF 100.0.0.0/24 e 200.0.0.0/24 anunciadas por Device1.
- RIPv2 é executado entre Device2 e Device3. Device2 redistribui a rota OSPF 100.0.0.0/24 para RIP e anuncia a rota para Device3.
Topologia de rede
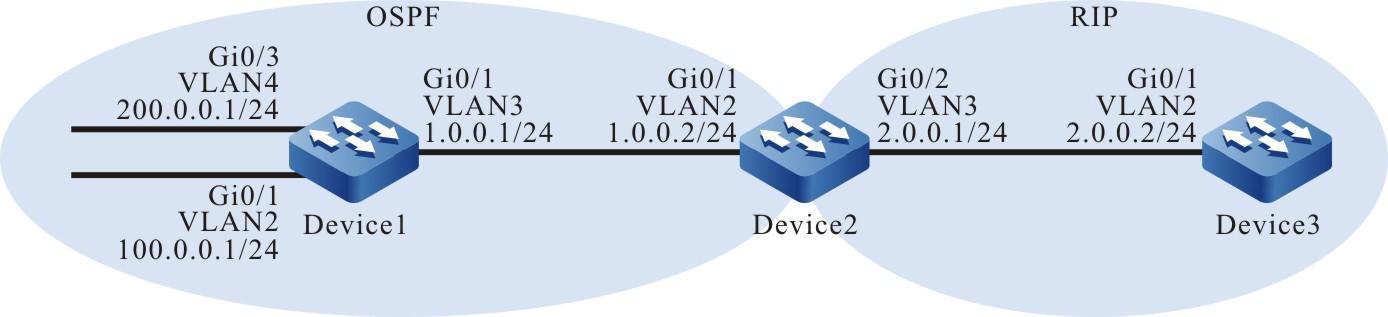
Figura 5 -2 Rede para configurar RIP para redistribuir rotas
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configurar OSPF.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 100.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 200.0.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Consulte a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:23:06, vlan2C 2.0.0.0/24 is directly connected, 00:13:06, vlan3O 100.0.0.0/24 [110/2] via 1.0.0.1, 00:04:12, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0O 200.0.0.0/24 [110/2] via 1.0.0.1, 00:04:12, vlan2
De acordo com a tabela de roteamento, Device2 aprendeu as rotas OSPF que foram anunciadas pelo Device1.
- Passo 4: Configurar RIP.
# Configurar dispositivo2.
Device2(config)#router ripDevice2(config-rip)#version 2Device2(config-rip)#network 2.0.0.0Device2(config-rip)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ripDevice3(config-rip)#version 2Device3(config-rip)#network 2.0.0.0Device3(config-rip)#exit
- Passo 5: Configure a política de roteamento.
#No Device2, configure o mapa de rotas para invocar a ACL para corresponder a 100.0.0.0/24 e filtrar 200.0.0.0/24.
Device2(config)#ip access-list standard 1Device2(config-std-nacl)#permit 100.0.0.0 0.0.0.255Device2(config-std-nacl)#commitDevice2(config-std-nacl)#exitDevice2(config)#route-map OSPFtoRIPDevice2(config-route-map)#match ip address 1Device2(config-route-map)#exit
Ao configurar uma política de roteamento, você pode criar uma regra de filtragem com base em uma lista de prefixos ou ACL. A lista de prefixos pode corresponder precisamente às máscaras de roteamento, enquanto a ACL não pode corresponder às máscaras de roteamento.
- Passo 6: Configure o RIP para redistribuir rotas.
# Configurar dispositivo2.
Device2(config)#router ripDevice2(config-rip)#redistribute ospf 100 route-map OSPFtoRIPDevice2(config-rip)#exit
- Passo 7: Confira o resultado.
#Consulte a tabela de roteamento RIP do Device2.
Device2#show ip rip databaseTypes: N - Network, L - Learn, R - Redistribute, D - Default config, S - Static configProto: C - connected, S - static, R - RIP, O - OSPF, E - IRMP,o - SNSP, B - BGP, i-ISISRIP routing database in VRF kernel (Counter 3):T/P Network ProID Metric Next-Hop From Time Tag InterfaceN/C 2.0.0.0/24 none 1 -- -- -- 0 vlan3R/O 100.0.0.0/24 1 1 1.0.0.1 -- -- 0 vlan2
#Consulte a tabela de roteamento do Device3.
Device3#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 2.0.0.0/24 is directly connected, 00:23:06, vlan2R 100.0.0.0/24 [120/1] via 2.0.0.1, 00:13:26, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0
Ao consultar a tabela de roteamento RIP em Device2 e consultar a tabela de roteamento em Device3, verifica-se que a rota 100.0.0.0/24 em Device2 foi redistribuída para RIP e a rota 200.0.0.0/24 foi filtrada com sucesso.
Em um aplicativo real, se houver dois ou mais roteadores de limite AS, é recomendável não redistribuir rotas entre diferentes protocolos de roteamento. Se a redistribuição de rota precisar ser configurada, você deverá configurar políticas de controle de rota, como filtragem de rota e resumo de filtragem nos roteadores de limite AS para evitar loops de roteamento.
Configurar o deslocamento da métrica RIP
Requisitos de rede
- O RIPv2 é executado entre Device1, Device2, Device3 e Device4.
- Device1 aprende a rota 200.0.0.0/24 de Device2 e Device3.
- Em Device1, defina o deslocamento métrico de rota na direção de recebimento para que Device1 selecione a rota anunciada por Device2 com prioridade.
Topologia de rede
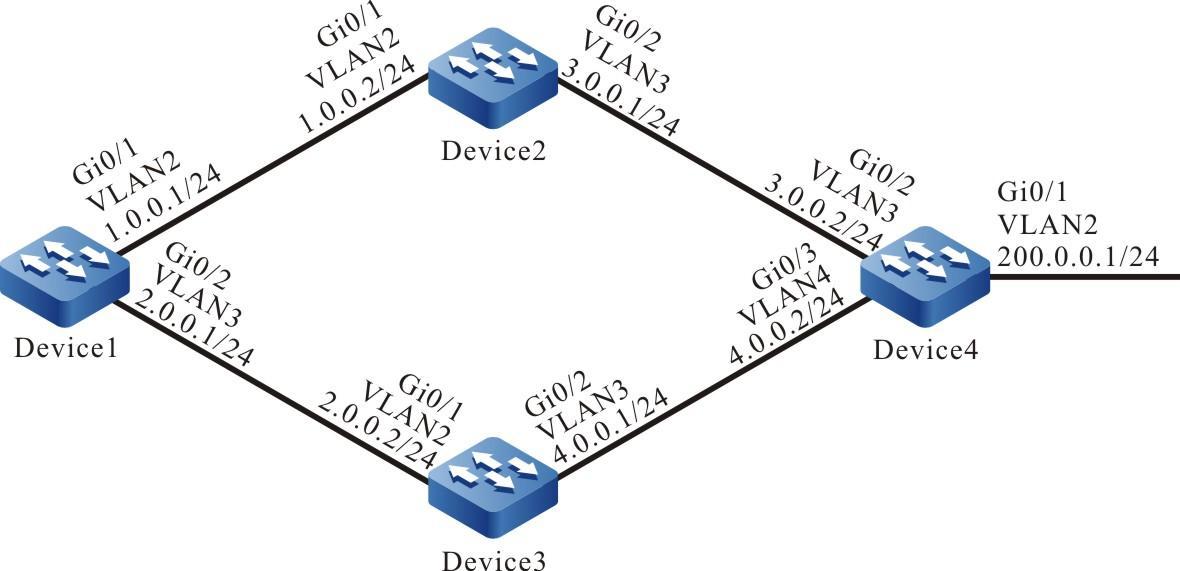
Figura 5 -3 Rede para configurar o deslocamento da métrica RIP
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configurar RIP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ripDevice1(config-rip)#version 2Device1(config-rip)#network 1.0.0.0Device1(config-rip)#network 2.0.0.0Device1(config-rip)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ripDevice2(config-rip)#version 2Device2(config-rip)#network 1.0.0.0Device2(config-rip)#network 3.0.0.0Device2(config-rip)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ripDevice3(config-rip)#version 2Device3(config-rip)#network 2.0.0.0Device3(config-rip)#network 4.0.0.0Device3(config-rip)#exit
# Configurar dispositivo4.
Device4#configure terminalDevice4(config)#router ripDevice4(config-rip)#version 2Device4(config-rip)#network 3.0.0.0Device4(config-rip)#network 4.0.0.0Device4(config-rip)#network 200.0.0.0Device4(config-rip)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:23:06, vlan2C 2.0.0.0/24 is directly connected, 00:22:56, vlan3R 3.0.0.0/24 [120/1] via 1.0.0.2, 00:13:26, vlan2R 4.0.0.0/24 [120/1] via 2.0.0.2, 00:11:04, vlan3C 127.0.0.0/8 is directly connected, 76:51:00, lo0R 200.0.0.0/24 [120/2] via 1.0.0.2, 00:08:31, vlan2[120/2] via 2.0.0.2, 00:08:31, vlan3
De acordo com a tabela de roteamento do Device1, duas rotas para 200.0.0.0/24 estão disponíveis.
- Passo 4: Configure a ACL .
# Configurar dispositivo1.
Device1(config)#ip access-list standard 1Device1(config-std-nacl)#permit 200.0.0.0 0.0.0.255Device1(config-std-nacl)#commitDevice1(config-std-nacl)#exit
- Passo 5: Configure um deslocamento métrico.
#No Device1, configure a lista de deslocamento métrico e aumente a métrica da rota que foi aprendida da interface VLAN3 e corresponde AL a 3.
Device1(config)#router ripDevice1(config-rip)#offset-list 1 in 3 vlan3Device1(config-rip)#exit
- Passo 6: Confira o resultado.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:33:59, vlan2C 2.0.0.0/24 is directly connected, 00:33:50, vlan3R 3.0.0.0/24 [120/1] via 1.0.0.2, 00:24:20, vlan2R 4.0.0.0/24 [120/1] via 2.0.0.2, 00:21:57, vlan3C 127.0.0.0/8 is directly connected, 77:01:54, lo0R 200.0.0.0/24 [120/2] via 1.0.0.2, 00:19:25, vlan2
De acordo com a tabela de roteamento de Device1, a interface de saída do próximo salto da rota 200.0.0.0/24 é apenas VLAN2, indicando que Device1 selecionou a rota anunciada por Device2 com prioridade.
A lista de deslocamento métrico de rota pode ser aplicada a todas as interfaces ou a uma interface especificada e pode ser usada nas direções de recebimento e anúncio.
Configurar filtragem de rota RIP
Requisitos de rede
- RIPv2 é executado entre Device1 e Device2 para interação de rota.
- Device1 aprende duas rotas 2.0.0.0/24 e 3.0.0.0/24 que foram anunciadas por Device2 e, em seguida, filtra a rota 3.0.0.0/24 na direção de anúncio de Device2.
Topologia de rede
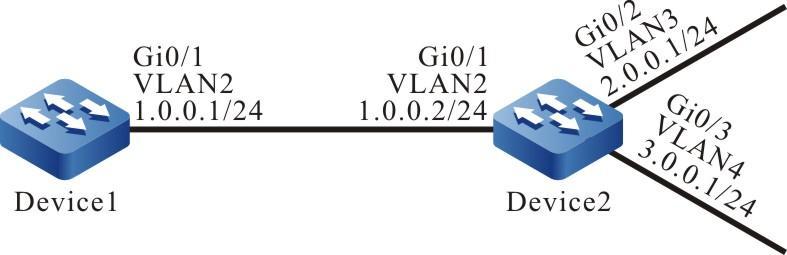
Figura 5 -4 Rede para configurar a filtragem de rota RIP
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configurar RIP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ripDevice1(config-rip)#version 2Device1(config-rip)#network 1.0.0.0Device1(config-rip)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ripDevice2(config-rip)#version 2Device2(config-rip)#network 1.0.0.0Device2(config-rip)#network 2.0.0.0Device2(config-rip)#network 3.0.0.0Device2(config-rip)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:23:06, vlan2R 2.0.0.0/24 [120/1] via 1.0.0.2, 00:13:26, vlan2R 3.0.0.0/24 [120/1] via 1.0.0.2, 00:13:26, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0
De acordo com a tabela de roteamento, Device1 aprendeu duas rotas anunciadas por Device2.
- Passo 4: Configure a ACL.
# Configurar dispositivo2.
Device2(config)#ip access-list standard 1Device2(config-std-nacl)#permit 2.0.0.0 0.0.0.255Device2(config-std-nacl)#commitDevice2(config-std-nacl)#exit
Ao configurar a filtragem de rota, você pode criar uma regra de filtragem com base em uma lista de prefixos ou ACL. A lista de prefixos pode corresponder precisamente às máscaras de roteamento, enquanto a ACL não pode corresponder às máscaras de roteamento.
- Passo 5: Configure a filtragem de rota.
#Configure a filtragem de rota na direção de saída da interface VLAN2 do Device2.
Device2(config)#router ripDevice2(config-rip)#distribute-list 1 out vlan2Device2(config-rip)#exit
- Passo 6: Confira o resultado.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:23:06, vlan2R 2.0.0.0/24 [120/1] via 1.0.0.2, 00:13:26, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0
De acordo com a tabela de roteamento, Device2 não anuncia a rota 3.0.0.0/24 para Device1, mas a rota é excluída da tabela de roteamento de Device somente após o tempo limite da rota.
A lista de distribuição pode ser aplicada a todas as interfaces ou a uma interface especificada e pode ser usada nas direções de recebimento e anúncio.
Configurar um resumo de rota RIP
Requisitos de rede
- O RIPv2 é executado entre Device1, Device2, Device3 e Device4 para interação de rota.
- Device1 aprende duas rotas 100.1.0.0/24 e 100.2.0.0/24 de Device2. Para reduzir o tamanho da tabela de roteamento de Device1, é necessário que Device anuncie apenas o resumo da rota das duas rotas para Device1.
Topologia de rede
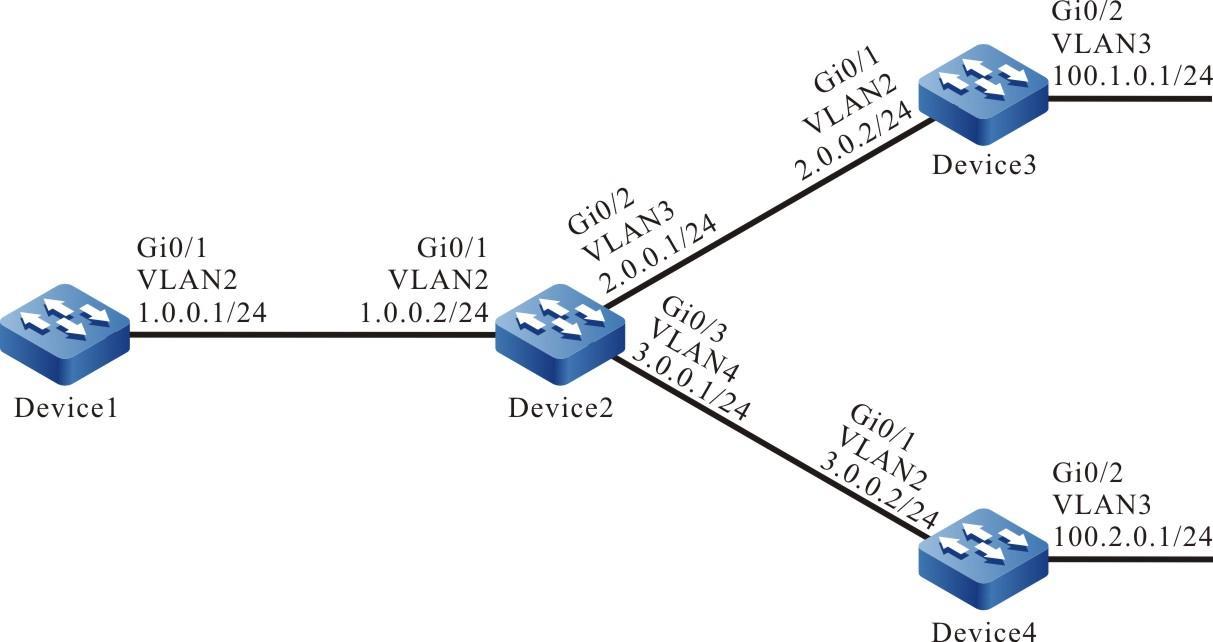
Figura 5 -5 Rede para configurar o resumo da rota RIP
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configurar RIP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ripDevice1(config-rip)#version 2Device1(config-rip)#network 1.0.0.0Device1(config-rip)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ripDevice2(config-rip)#version 2Device2(config-rip)#network 1.0.0.0Device2(config-rip)#network 2.0.0.0Device2(config-rip)#network 3.0.0.0Device2(config-rip)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ripDevice3(config-rip)#version 2Device3(config-rip)#network 2.0.0.0Device3(config-rip)#network 100.0.0.0Device3(config-rip)#exit
# Configurar dispositivo4.
Device4#configure terminalDevice4(config)#router ripDevice4(config-rip)#version 2Device4(config-rip)#network 3.0.0.0Device4(config-rip)#network 100.0.0.0Device4(config-rip)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:23:06, vlan2R 2.0.0.0/24 [120/1] via 1.0.0.2, 00:13:26, vlan2R 3.0.0.0/24 [120/1] via 1.0.0.2, 00:13:26, vlan2R 100.1.0.0/24 [120/2] via 1.0.0.2, 00:08:31, vlan2R 100.2.0.0/24 [120/2] via 1.0.0.2, 00:08:31, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0
- Passo 4: Configure um resumo de rotas em uma interface n .
#No Device2, configure um resumo de rota 100.0.0.0/8.
Device2(config)#interface vlan2Device2(config-if-vlan2)#ip summary-address rip 100.0.0.0/8Device2(config-if-vlan2)#exit
- Passo 5: Confira o resultado.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:24:06, vlan2R 2.0.0.0/24 [120/1] via 1.0.0.2, 00:14:26, vlan2R 3.0.0.0/24 [120/1] via 1.0.0.2, 00:14:26, vlan2R 100.0.0.0/8 [120/2] via 1.0.0.2, 00:00:31, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0
No Device1, o resumo de rota 100.0.0.0/8 anunciado pelo Device2 e aprendido pelo Device1 é exibido. As duas rotas contidas no resumo da rota podem ser excluídas somente após o tempo limite.
O RIP suporta resumo de rota automática global e resumo de rota manual de interface. No RIPv2, a função de resumo de rota automática global está desabilitada.
Configurar RIP para coordenar com BFD
Requisitos de rede
- O RIPv2 é executado entre Device1, Device2 e Device3 para interação de rota.
- Device1 aprende a rota 3.0.0.0/24 de Device2 e Device3. Em seguida, configure o deslocamento métrico de rota para que Device1 selecione a rota anunciada por Device2 com prioridade. Neste momento, a linha entre Device1 e Device2 torna-se a linha principal da rota. A linha entre Device1 e Device3 torna-se uma linha de backup da rota.
- Configure o BFD entre Device1 e Device2. Quando a linha entre Device1 e Device2 estiver com defeito, configure o RIP para coordenar com BFD entre Device1 e Device2 para detectar rapidamente falhas de linha. Quando o BFD encontra uma falha na linha principal, ele aciona uma atualização de rota RIP. Em seguida, a rota 3.0.0.0/24 é comutada para a linha de backup.
Topologia de rede
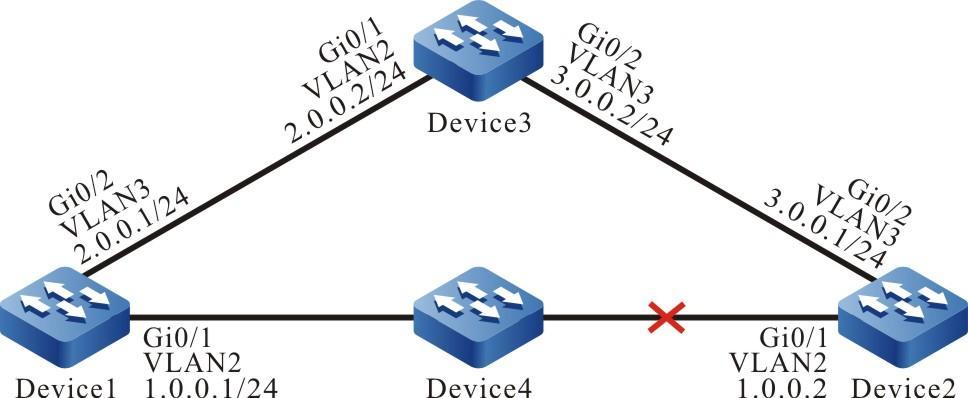
Figura 5 -6 Rede para configurar RIP para coordenar com BFD
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configurar RIP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ripDevice1(config-rip)#version 2Device1(config-rip)#network 1.0.0.0Device1(config-rip)#network 2.0.0.0Device1(config-rip)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ripDevice2(config-rip)#version 2Device2(config-rip)#network 1.0.0.0Device2(config-rip)#network 3.0.0.0Device2(config-rip)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ripDevice3(config-rip)#version 2Device3(config-rip)#network 2.0.0.0Device3(config-rip)#network 3.0.0.0Device3(config-rip)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 01:30:23, vlan2C 2.0.0.0/24 is directly connected, 01:30:14, vlan3R 3.0.0.0/24 [120/1] via 1.0.0.2, 01:20:44, vlan2[120/1] via 2.0.0.2, 00:00:02, vlan3C 127.0.0.0/8 is directly connected, 77:58:18, lo0
Device1 aprendeu a rota 3.0.0.0/24 de Device2 e Device3.
- Passo 4: Configure um deslocamento métrico de rota.
#No Dispositivo1, configure um deslocamento métrico de rota na direção de entrada da interface VLAN3 para que a métrica das rotas que correspondem à ACL seja aumentada para 3.
Device1(config)#ip access-list standard 1Device1(config-std-nacl)#permit 3.0.0.0 0.0.0.255Device1(config-std-nacl)#commitDevice1(config)#exitDevice1(config)#router ripDevice1(config-rip)#offset-list 1 in 3 vlan3Device1(config-rip)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 01:30:23, vlan2C 2.0.0.0/24 is directly connected, 01:30:14, vlan3R 3.0.0.0/24 [120/1] via 1.0.0.2, 01:20:44, vlan2C 127.0.0.0/8 is directly connected, 77:58:18, lo0
Depois que um deslocamento métrico de rota é configurado, Device1 seleciona a rota 3.0.0.0/24 anunciada por Device2.
- Passo 5: Configurar BFD.
# Configurar dispositivo1.
Device1(config)#bfd fast-detectDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip rip bfdDevice1(config-if-vlan2)#exit
# Configurar dispositivo2.
Device2(config)#bfd fast-detectDevice2(config)#interface vlan2Device2(config-if-vlan2)#ip rip bfdDevice2(config-if-vlan2)#exit
- Passo 6: Confira o resultado.
#No Dispositivo1, consulte as informações do BFD.
Device1#show bfd sessionOurAddr NeighAddr LD/RD State Holddown interface1.0.0.1 1.0.0.2 2/4 UP 5000 vlan2
#Se a linha entre Device1 e Device2 estiver com defeito, a rota pode mudar rapidamente para a linha de backup.
#No Dispositivo1, consulte as informações da rota.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 2.0.0.0/24 is directly connected, 02:07:47, vlan3R 3.0.0.0/24 [120/4] via 2.0.0.2, 00:01:14, vlan3C 127.0.0.0/8 is directly connected, 78:35:51, lo0
Configurar uma interface de backup RIP
Requisitos de rede
- O RIPv2 é executado entre Device1, Device2 e Device3 para interação de rota.
- Device1 aprende a rota 3.0.0.0/24 de Device2 e Device3. Em seguida, configure o deslocamento métrico de rota para que Device1 selecione a rota anunciada por Device2 com prioridade. Neste momento, a linha entre Device1 e Device2 torna-se a linha principal da rota. A linha entre Device1 e Device3 torna-se uma linha de backup da rota.
- Em Device1, configure uma interface de backup RIP. Se a linha principal for normal, a rota passa pela linha principal. Se a linha principal estiver com defeito, a rota muda rapidamente para a linha de backup.
Topologia de rede
Figura 5 -7 Rede para configurar uma interface de backup RIP
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configurar RIP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ripDevice1(config-rip)#version 2Device1(config-rip)#network 1.0.0.0Device1(config-rip)#network 2.0.0.0Device1(config-rip)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ripDevice2(config-rip)#version 2Device2(config-rip)#network 1.0.0.0Device2(config-rip)#network 3.0.0.0Device2(config-rip)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ripDevice3(config-rip)#version 2Device3(config-rip)#network 2.0.0.0Device3(config-rip)#network 3.0.0.0Device3(config-rip)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 01:30:23, vlan2C 2.0.0.0/24 is directly connected, 01:30:14, vlan3R 3.0.0.0/24 [120/1] via 1.0.0.2, 01:20:44, vlan2[120/1] via 2.0.0.2, 00:00:02, vlan3C 127.0.0.0/8 is directly connected, 77:58:18, lo0
Device1 aprendeu a rota 3.0.0.0/24 de Device2 e Device3.
- Passo 4: Configure um deslocamento métrico de rota.
#No Dispositivo1, configure um deslocamento métrico de rota na direção de entrada da interface VLAN3 para que a métrica das rotas que correspondem à ACL seja aumentada para 3.
Device1(config)#ip access-list standard 1Device1(config-std-nacl)#permit 3.0.0.0 0.0.0.255Device1(config-std-nacl)#commitDevice1(config)#exitDevice1(config)#router ripDevice1(config-rip)#offset-list 1 in 3 vlan3Device1(config-rip)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 01:30:23, vlan2C 2.0.0.0/24 is directly connected, 01:30:14, vlan3R 3.0.0.0/24 [120/1] via 1.0.0.2, 01:20:44, vlan2C 127.0.0.0/8 is directly connected, 77:58:18, lo0
Depois que o deslocamento métrico de rota é configurado, Device1 seleciona a rota 3.0.0.0/24 anunciada por Device2.
- Passo 5: Configure uma interface de backup.
#No Dispositivo1, configure a interface VLAN3 como a interface de backup RIP da VLAN2.
Device1(config)#interface vlan2Device1(config-if-vlan2)#ip rip standby vlan3Device1(config-if-vlan2)#exit
- Passo 6: Confira o resultado.
#Se a linha entre Device1 e Device2 estiver com defeito, a rota pode alternar rapidamente para a linha de backup entre Device1 e Device3.
#No Dispositivo1, consulte as informações da rota.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 2.0.0.0/24 is directly connected, 02:07:47, vlan3R 3.0.0.0/24 [120/4] via 2.0.0.2, 00:01:14, vlan3C 127.0.0.0/8 is directly connected, 78:35:51, lo0
Configurar uma interface RIP passiva
Requisitos de rede
- RIPv2 é executado entre Device1 e Device2 para interação de rota.
- Em Device1, configure uma interface passiva que não envie pacotes de atualização para Device2.
Topologia de rede

Figura 5 -8 Rede para configurar uma interface passiva RIP
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configurar RIP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ripDevice1(config-rip)#version 2Device1(config-rip)#network 1.0.0.0Device1(config-rip)#network 100.0.0.0Device1(config-rip)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ripDevice2(config-rip)#version 2Device2(config-rip)#network 1.0.0.0Device2(config-rip)#network 50.0.0.0Device2(config-rip)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:23:06, vlan3R 50.0.0.0/24 [120/1] via 1.0.0.2, 00:13:26, vlan3C 100.0.0.0/24 is directly connected, 00:23:06, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0
#Consulte a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:23:06, vlan2C 50.0.0/24 is directly connected, 00:23:06, vlan3R 100.0.0.0/24 [120/1] via 1.0.0.1, 00:13:26, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0
- Passo 4: Configure uma interface passiva.
# Configurar dispositivo1.
Device1(config)#router ripDevice1(config-rip)#passive-interface vlan3Device1(config-rip)#exit
A VLAN3 de Device1 está configurada como uma interface passiva que não envia pacotes de atualização para Device2, mas Device2 ainda pode receber pacotes de atualização.
- Passo 5: Confira o resultado.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:23:06, vlan3R 50.0.0.0/24 [120/1] via 1.0.0.2, 00:13:26, vlan3C 100.0.0.0/24 is directly connected, 00:23:06, vlan2C 127.0.0.0/8 is directly connected, 76:51:00, lo0
A rota 50.0.0.0/24 ainda é mantida no Device1. No Device2, depois que a rota RIP expira e é excluída, a rota 100.0.0.0/24 é excluída da tabela de roteamento.
#Consulte a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:25:06, vlan2C 50.0.0/24 is directly connected, 00:25:06, vlan3C 127.0.0.0/8 is directly connected, 77:51:00, lo0
RIPng
Visão geral
RIPng, também conhecido como protocolo RIP de próxima geração, é um protocolo de roteamento dinâmico usado pelas redes IPv6 para fornecer informações de roteamento para o encaminhamento de pacotes IPv6. O RIPng é estendido no RIP-2. O princípio de funcionamento do protocolo RIPng é basicamente o mesmo do protocolo RIP. Para se adaptar à rede IPv6, a RIPng fez as seguintes alterações no protocolo RIP original:
- Número da porta UDP: O protocolo RIPng usa o número da porta UDP 521 para enviar e receber os pacotes de protocolo;
- Endereço multicast: O protocolo RIPng usa FF02::9 como o endereço multicast do roteador RIPng no intervalo local do link e não suporta broadcast.
- Comprimento do prefixo: O endereço de destino da rota do protocolo RIPng usa o comprimento do prefixo de 128 bits;
- Endereço do próximo salto: O protocolo RIPng usa o endereço IPv6 de 128 bits;
- Endereço de origem: O protocolo RIPng usa o endereço local do link FE80:/10 como endereço de origem para enviar o pacote do protocolo RIPng.
As especificações de protocolo relacionadas ao RIPng incluem RFC2080 e RFC2081.
RIPng Configuração da Função
Tabela 6 -1 Tabela de configuração da função RIPng
| Tarefas de configuração | |
| Configurar funções básicas de RIP | Permite RIPng globalmente |
| Configurar geração de rota RIPng | Configure o RIPng para anunciar a rota padrão. Configurar o RIP para redistribuir rotas |
| Configurar controle de rota RIPng |
Configure a distância administrativa do RIPng
Configure um resumo de rota RIPng. Configure o deslocamento métrico RIPng. Configurar filtragem de rota RIPng. Configure a métrica da interface RIPng. Configure o sinalizador de roteamento para uma interface RIPng. Configurar o balanceamento de carga máximo para RIPng. |
| Configurar otimização de rede RIPng |
Configure temporizadores RIPng.
Configure o horizonte dividido do RIPng e o reverso da toxicidade do RIP. Configure um vizinho estático RIPng. Configure uma interface passiva RIPng. |
Configurar funções básicas do RIPng
Condição de configuração
Antes de configurar as funções básicas do RIPng, certifique-se de que:
- O protocolo da camada de link foi configurado para garantir a comunicação normal na camada de link.
- A capacidade IPv6 da interface está habilitada.
Ativar RIPng globalmente
Antes de usar o RIPng, faça as seguintes configurações:
- Crie um processo RIPng.
- Habilite o protocolo RIPng na interface
Tabela 6 -2 Habilitando RIPng globalmente
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um processo RIPng e entre no modo de configuração RIPng. | ipv6 router rip process-id | Obrigatório. Por padrão, o processo RIPng está desabilitado. |
| Retornar ao modo de configuração global | exit | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite o protocolo RIPng na interface | ipv6 rip enable process-id | Obrigatório. Por padrão, não habilite o protocolo RIPng na interface. |
Configurar geração de rota RIPng
Condição de configuração
Antes de configurar a geração de rota RIPng, certifique-se de que:
- A capacidade de IPv6 da interface está habilitada.
- RIPng está ativado.
Configurar RIPng para anunciar a rota padrão
Por meio da configuração, um dispositivo pode enviar a rota padrão em todas as interfaces RIPng para se definir como o gateway padrão de outros dispositivos vizinhos.
Tabela 6 -3 Configurar RIPng para anunciar a rota padrão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIPng. | ipv6 router rip process-id | Obrigatório. Por padrão, o processo RIPng está desabilitado. |
| Configure o RIPng para anunciar a rota padrão. | default-information originate [ metric value ] | Obrigatório. Por padrão, o RIPng não anuncia a rota padrão. |
Se uma rota padrão ( ::/0 ) for aprendida, a rota padrão ( ::/0 ) anunciada pelo dispositivo local será substituída. Quando existem loops em uma rede, podem ocorrer oscilações na rede. Ao usar este comando, evite que outros dispositivos no mesmo domínio de roteamento ativem o comando ao mesmo tempo.
Configurar RIPng para redistribuir rotas
Ao redistribuir as rotas, você pode introduzir as rotas geradas por outros protocolos no RIPng.
Tabela 6 -4 Configurar RIPng para redistribuir rotas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIPng. | ipv6 router rip process-id | Obrigatório. Por padrão, o processo RIPng está desabilitado. |
| Configure a métrica padrão para as rotas de outros protocolos introduzidos no RIPng. | default-metric metric-value | Opcional. Por padrão, a métrica padrão das rotas introduzidas de outros protocolos é 1. |
| Configure o RIPng para redistribuir rotas. | redistribute protocol [ protocol-id ] [ metric metric-value ] [ route-map route-map-name ] [ match route-sub-type ] | Obrigatório. Por padrão, a redistribuição de rota não está configurada. |
Se a opção de comando de métrica for especificada durante a redistribuição, a rota redistribuída adotará a métrica. Ao configurar o RIPng para redistribuir rotas para aplicação do mapa de rotas, as opções de correspondência disponíveis incluem endereço ipv6, tipo de rota, tag, interface, ipv6 nexthop, ipv6 route-source , e métrica , e as opções de conjunto disponíveis incluem métrica e tag.
Configurar RIPng Route Control
Condição de configuração
Antes de configurar o controle de rota RIPng, certifique-se de que:
- A capacidade IPv6 da interface está habilitada.
- RIPng está ativado.
Configurar a distância administrativa do RIPng
Um dispositivo pode executar vários protocolos de roteamento ao mesmo tempo. O dispositivo seleciona a rota ideal das rotas que são aprendidas de diferentes protocolos com base nas distâncias administrativas. Quanto menor a distância administrativa, maior a prioridade.
Tabela 6 -5 Configurar a distância administrativa do RIPng
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIPng. | ipv6 router rip process-id | - |
| Configure a distância administrativa do RIPng. | distance distance-value | Obrigatório. Por padrão, a distância administrativa do RIPng é 120. |
Configurar um resumo de rota RIPng
RIPng sempre indica a configuração de um par de endereços e máscaras de destino, que resume as rotas no segmento de rede coberto.
Depois que o resumo da rota RIP é configurado, o dispositivo anuncia apenas a rota resumida. Isso diminui muito o tamanho das tabelas de rotas RIPng adjacentes nas redes médias e grandes e diminui o consumo dos pacotes de protocolo de roteamento para a largura de banda da rede.
A métrica da rota de resumo adota o mínimo de todas as métricas de rota de sub-rede.
Tabela 6 -6 Configurar a função de resumo da rota RIPng
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure a função de resumo de rota do RIPng na interface | ipv6 rip summary-address prefix-address | Obrigatório. Por padrão, não configure a função de resumo de rota. |
Configurar o deslocamento da métrica RIPng
Por padrão, o RIPng adota a métrica de rota anunciada pelo dispositivo vizinho para as rotas recebidas. Para modificar a métrica em alguns cenários de aplicativos especiais, você pode configurar o deslocamento da métrica RIP para corrigir a métrica da rota especificada.
Se a métrica na direção de entrada estiver configurada, o RIPng modifica a métrica das rotas recebidas e salva as rotas na tabela de roteamento. Quando o RIPng anuncia uma métrica para os dispositivos vizinhos, ele anuncia a nova métrica. Se a métrica na direção de saída estiver configurada, a métrica será modificada somente quando o RIPng anunciar uma métrica para os dispositivos vizinhos.
Tabela 6 -7 Configurar o deslocamento métrico RIPng
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIPng. | ipv6 router rip process-id | Obrigatório. Por padrão, o processo RIPng está desabilitado. |
| Configure o RIPng para modificar a métrica da rota especificada. | offset-list access-list-name { in | out } metric-offset [ interface-name ] | Obrigatório. Por padrão, nenhuma métrica é configurada para qualquer interface. |
Configurar filtragem de rota RIPng
Um roteador pode filtrar as rotas recebidas ou anunciadas configurando uma lista de controle de acesso (ACL) ou uma lista de prefixos. Ao receber rotas RIPng, você pode filtrar algumas rotas aprendidas; ou ao anunciar rotas RIPng, você pode filtrar algumas rotas que são anunciadas para dispositivos vizinhos.
Tabela 6 -8 Configurar filtragem de rota RIPng
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIPng. | ipv6 router rip process-id | Obrigatório. Por padrão, o processo RIPng está desabilitado. |
| Configurar a filtragem de rota RIPng função | distribute-list { access-list-name | prefix prefix-list-name | route-map route-map-name} { in | out } [ interface-name ] |
Obrigatório.
Por padrão, a filtragem de rotas função não está configurada. Durante o processo de configuração da filtragem de rotas função, se nenhuma interface for especificada, filtragem de rota está habilitado para todas as interfaces RIPng. |
Configurar a Métrica da Interface RIPng
Após a interface habilitar o RIPng, a rota direta correspondente é gerada no banco de dados, com a métrica padrão 1. Quando a rota estiver no banco de dados RIPng ou for anunciada para dispositivos vizinhos, e se a métrica estiver configurada na interface, adote a métrica de interface.
Se a métrica da interface for alterada, o banco de dados RIPng atualiza imediatamente a rota direta correspondente do RIPng e anuncia a nova métrica para os dispositivos vizinhos.
Tabela 6 -9 Configurar a métrica da interface RIPng
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configurar a métrica da interface RIPng | ipv6 rip metric metric-value | Obrigatório. Por padrão, a métrica da interface RIPng é 1. |
A configuração da métrica da interface RIPng afeta apenas a métrica da sub-rede direta na interface, mas não afeta a métrica aprendida pela rota.
Configurar a tag de roteamento para uma interface RIPng
O administrador da rede pode anexar tags a algumas rotas. Em seguida, ao aplicar uma política de roteamento, execute a filtragem de rotas ou rotear anúncio de propriedade com base nas tags.
Tabela 6 -10 Configurar o sinalizador de roteamento para uma interface RIPng
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure uma tag de rota RIPng da sub-rede direta na interface. | ipv6 rip tag tag-value | Obrigatório. Por padrão, não configure a tag de rota. |
Configurar o número máximo de entradas de balanceamento de carga RIPng
Este comando ajuda você a controlar o número de entradas de balanceamento de carga da rota RIPng.
Tabela 6 -11 Configurar o número máximo de entradas de balanceamento de carga RIPng
| Etapa | Comando | Descrição |
| modo de configuração global . | configure terminal | - |
| Entre no modo de configuração RIPng. | ipv6 router rip process-id | Obrigatório. Por padrão, o processo RIPng está desabilitado. |
| Configure o número máximo de entradas de balanceamento de carga RIPng | maximum-paths max-number | Opcional. Por padrão, o número máximo de entradas de balanceamento de carga RIPng é 4. |
Configurar otimização de rede RIPng
Condição de configuração
Antes de configurar a otimização de rede RIPng, certifique-se de que:
- Configure a interface para habilitar o recurso IPv6
- Habilite o protocolo RIPng
Configurar temporizadores RIPng
RIPng não mantém relações de vizinhos e não suporta rota retirada; portanto, o protocolo fornece quatro temporizadores configuráveis para controlar a velocidade de convergência da rede. Os quatro temporizadores são: temporizador de atualização de rota, temporizador de tempo limite do roteador, temporizador de atualização de amortecimento de rota e temporizador de limpeza de rota.
O tempo limite da rota deve ser pelo menos três vezes o tempo de atualização da rota. Se nenhum pacote de atualização de rota for recebido dentro do tempo limite da rota, a rota se tornará inválida e entrará em um ciclo de amortecimento. A duração do ciclo de amortecimento é determinada pelo tempo de atualização do amortecimento. Durante o ciclo, a rota não será limpa. Após a conclusão do ciclo de amortecimento, a rota entra no ciclo de limpeza. Durante o ciclo, a rota pode ser atualizada. No entanto, se nenhum pacote de atualização de rota for recebido durante o ciclo, a rota será excluída.
Tabela 6 -12 Configurando temporizadores RIPng
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIPng. | ipv6 router rip process-id | Obrigatório. Por padrão, o processo RIPng está desabilitado. |
| Configurar temporizadores RIPng | timers update-interval invalid-interval holddown-interval flush-interval | Opcional. Por padrão, o intervalo de atualização do RIPng é 30s, o tempo válido para anúncio é 180s, o tempo de amortecimento é 0s e o tempo de limpeza é 120s. |
No mesmo domínio de roteamento RIPng, as configurações do temporizador em todos os dispositivos devem ser as mesmas para evitar oscilações de rede.
Configurar RIPng Split Horizon e Toxicity Reverse of RIP
Split horizon e toxicidade reversa são mecanismos que são usados para evitar loops de rota.
- Configurar horizonte dividido.
O RIPng não anuncia as rotas que aprendeu de uma interface para a interface, evitando loops de roteamento .
Tabela 6 -13 Configurando RIPng split horizon
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configurando RIPng split horizon. | no ipv6 rip split-horizon [ disable ] | Opcional. Por padrão, a função split horizon está habilitada. |
- Configure o reverso da toxicidade.
O RIPng anuncia as rotas que foram aprendidas de uma interface para a interface, mas a métrica de rota é o número máximo de saltos 16, evitando loops de roteamento.
Tabela 6 -14 Configuração reversa de toxicidade RIPng
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configurar reversão de toxicidade RIPng | ipv6 rip split-horizon poison-reverse | Obrigatório. Por padrão, a função de reversão de toxicidade está desabilitada. |
As funções split horizon e toxic reverse são válidas apenas para as rotas aprendidas, rotas diretas da interface RIPng e as rotas redistribuídas diretas e estáticas. A função split horizon e a função de reversão de toxicidade não podem ser usadas ao mesmo tempo.
Configurar um vizinho RIPng estático
O RIPng não mantém relações de vizinhança, portanto não possui o conceito de vizinho. Aqui o vizinho refere-se ao dispositivo de roteamento RIPng vizinho. Depois que um vizinho RIPng estático é especificado, o RIPng envia pacotes RIPng para o vizinho no modo unicast. A configuração é aplicada a uma rede que não oferece suporte a broadcast ou multicast, como links ponto a ponto. Se a configuração for aplicada a uma rede de difusão ou multicast, poderá causar pacotes RIPng repetidos na rede.
Tabela 6 -15 Configurar um vizinho RIPng estático
| Etapa | Comando | Descrição |
| modo de configuração global . | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o anúncio de rotas para um vizinho no modo unicast. | ipv6 rip neighbor ipv6-address | Obrigatório. O parâmetro ipv6-address é o endereço IPv6 da interface peer direct - connect. |
RIPng anuncia rotas apenas para as interfaces que ele cobre, e ipv6 rip passiva não pode impedir uma interface de enviar pacotes para seu vizinho estático.
Configurar uma interface RIPng passiva
Para diminuir a largura de banda da rede consumida pelo protocolo de roteamento, o protocolo de roteamento dinâmico usa a função de interface passiva. O RIPng recebe apenas pacotes de atualização de rota em uma interface passiva e não envia pacotes de atualização de rota na interface passiva. Em uma rede de baixa velocidade com largura de banda pequena, a função de interface passiva e a função de vizinho cooperam para reduzir efetivamente as interações das rotas RIPng.
Tabela 6 -16 Configurar uma interface RIPng passiva
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure uma interface RIPng passiva. | ipv6 rip passive | Obrigatório. Por padrão, nenhuma interface passiva é configurada. |
IPv6 rip passiva não restringe uma interface de enviar atualizações de rota unicast para seus dispositivos vizinhos. Ao ser usado com o vizinho comando, ipv6 rip passiva não restringe uma interface de enviar atualizações de rota unicast para seus dispositivos vizinhos. Este modo de aplicação pode controlar um roteador para que ele envie atualizações de rota apenas para alguns dispositivos vizinhos no modo unicast, em vez de enviar atualizações de rota para todos os dispositivos vizinhos no modo multicast.
Configurar RIPng para Coordenar com BFD (Aplicável somente ao modelo S3054G-B)
Uma interface de backup pode ser usada apenas em um ambiente de aplicativo específico, mas não pode atender ao requisito de backup em tempo real. Neste momento, o RIPng fornece a função de Detecção de Encaminhamento Bidirecional (BFD) ponto a ponto para realizar uma rápida convergência e alternância de rotas. O BFD fornece um método para detectar rapidamente o status de uma linha entre dois dispositivos. Quando a detecção de BFD é habilitada entre dois dispositivos RIPng adjacentes, se a linha entre os dois dispositivos estiver com defeito, o BFD pode encontrar rapidamente a falha e notificar o RIPng. O RIP então exclui a rota RIPng que está associada à interface BFD. Se a rota tiver uma rota de backup, uma alternância para a rota de backup será realizada em um período de tempo muito curto (que é determinado pelas configurações do BFD). Atualmente, o RIPng suporta apenas detecção de BFD bidirecional de salto único.
Tabela 6 -17 Configurar RIPng para coordenar com BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração RIPng. | ipv6 router rip 100 | Obrigatório. Por padrão, o processo RIPng está desabilitado. |
| Habilite a função BFD em todas as interfaces cobertas pelo RIP ngprocess. | bfd all-interfaces |
Obrigatório.
Por padrão, a função BFD está desabilitada em todas as interfaces cobertas pelo processo RIPng. |
| Retorne ao modo de configuração global. | exit | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Habilite a função BFD na interface. | ipv6 rip bfd | Obrigatório. Por padrão, a função BFD está desabilitada na interface. |
Para a configuração relacionada do BFD, consulte a tecnologia de confiabilidade-BFD Command M anual.
Monitoramento e Manutenção RIPng
Tabela 6 -18 Monitoramento e Manutenção RIPng
| Comando | Descrição |
| clear ipv6 rip [ process-id ]{ process | statistics } | Limpa o processo RIPng e as informações estatísticas |
| show ipv6 rip [process-id] | Exibe as informações básicas do protocolo RIPng |
| show ipv6 rip [ process-id ] database [ detail | ipv6-address/mask-length [ detail | longer-prefixes ] ] | Exibe as informações do banco de dados de rota RIPng |
| show ipv6 rip [ process-id ] statistics [ interface-name ] | Exibe as informações de estatísticas da interface RIPng |
| show ipv6 rip interface [ interface-name ] | Exibe as informações da interface RIPng |
Exemplo de configuração típica de RIPng
Configurar funções básicas do RIPng
Requisitos de rede
- Execute RIPng entre Device1 e Device2 para interação de rota.
Topologia de rede

Figura 6 -1 Rede para configurar funções básicas de RIPng
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure o endereço IPv6 de uma interface (omitido).
- Passo 3: Configurar RIPng.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router rip 100Device1(config-ripng)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 rip enable 100Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 rip enable 100Device1(config-if-vlan3)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router rip 100Device2(config-ripng)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 rip enable 100Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 rip enable 100Device2(config-if-vlan3)#exit
- Passo 4: Confira o resultado.
# Visualize a tabela de rotas IPv6 do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w4d:19:31:05, lo0C 2001:1::/64 [0/0]via ::, 00:21:42, vlan2L 2001:1::1/128 [0/0]via ::, 00:21:40, lo0C 2001:2::/64 [0/0]via ::, 00:21:34, vlan3L 2001:2::1/128 [0/0]via ::, 00:21:33, lo0R 2001:3::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:11:19, vlan3
#Consulte a tabela de roteamento IPv6 do Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 3d:22:39:31, lo0R 2001:1::/64 [120/2]via fe80::201:7aff:fe01:204, 00:12:00, vlan2C 2001:2::/64 [0/0]via ::, 00:30:46, vlan2L 2001:2::2/128 [0/0]via ::, 00:30:45, lo0C 2001:3::/64 [0/0]via ::, 00:29:12, vlan3L 2001:3::1/128 [0/0]via ::, 00:29:11, lo0
De acordo com a tabela de roteamento, você pode ver que a rota anunciada pelo dispositivo usa uma máscara exata de 64 bits.
Configurar RIPng para redistribuir rotas
Requisitos de rede
- Execute o protocolo IPv6 OSPF entre Device1 e Device2, Device2 aprende a rota IPv6 OSPF liberada por Device1 2001:1::/64, 2001:2::/64 .
- Execute o protocolo RIPng entre Device2 e Device3, Device2 apenas distribui a rota IPv6 OSPF 2001:1::/64 para RIPng e anuncia a rota para Device3.
Topologia de rede
Figura 6 -2 Rede para configurar RIPng para redistribuir a rota
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure o endereço IPv6 de uma interface (omitido).
- Passo 3: Configurar IPv6 OSPF .
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)# router-id 1.1.1.1Device1(config-ospf6)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 router ospf tag 100 area 0Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 router ospf tag 100 area 0Device1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ipv6 router ospf tag 100 area 0Device1(config-if-vlan4)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 router ospf tag 100 area 0Device2(config-if-vlan2)#exit
#Consulte a tabela de rotas IPv6 do Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 4d:00:09:49, lo0O 2001:1::/64 [110/2]via fe80::201:7aff:fe01:204, 00:12:16, vlan2O 2001:2::/64 [110/2]via fe80::201:7aff:fe01:204, 00:12:16, vlan2C 2001:3::/64 [0/0]via ::, 00:19:51, vlan2L 2001:3::2/128 [0/0]via ::, 00:19:50, lo0C 2001:4::/64 [0/0]via ::, 00:45:13, vlan3L 2001:4::1/128 [0/0]via ::, 00:45:12, lo0
De acordo com a tabela de roteamento, você pode ver que Device2 aprendeu a rota IPv6 OSPF anunciada por Device1.
- Passo 4: Configurar RIPng.
# Configurar dispositivo2.
Device2(config)#ipv6 router rip 100Device2(config-ripng)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 rip enable 100Device2(config-if-vlan3)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router rip 100Device3(config-ripng)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ipv6 rip enable 100Device3(config-if-vlan2)#exit
- Passo 5: Configure a política de roteamento.
# No Device2, configure o mapa de rotas para invocar a lista de prefixos para corresponder a 2001:1::/64 e filtrar 2001:2::/64 .
Device2(config)#ipv6 prefix-list OSPF permit 2001:1::/64Device2(config)#route-map OSPFtoRIPDevice2(config-route-map)#match ipv6 address prefix-list OSPFDevice2(config-route-map)#exit
Ao configurar uma política de roteamento, você pode criar uma regra de filtragem com base em uma lista de prefixos ou ACL. A lista de prefixos pode corresponder precisamente às máscaras de roteamento, enquanto a ACL não pode corresponder às máscaras de roteamento.
- Passo 6: Configure o RIPng para redistribuir as rotas IPv6 OSPF.
# Configure o RIPng para redistribuir as rotas IPv6 OSPF.
Device2(config)#ipv6 router rip 100Device2(config-ripng)#redistribute ospf 100 route-map OSPFtoRIPDevice2(config-ripng)#exit
- Passo 7: Confira o resultado.
# Consulta o banco de dados RIPng do Device2.
Device2#show ipv6 rip databaseType : N - Network interface, L - Learn, R - Redistribute, D - Default config,S - Static configProto: C - connected, S - static, R - RIP, O - OSPF, E - IRMP,o - SNSP, B - BGP, i-ISISRIPng process 100 routing database (VRF Kernel, Counter 2):[Type/Proto][R/O] 2001:1::/64 metric 1via vlan2, fe80::201:7aff:fe01:204, no expires[N/C] 2001:4::/64 metric 1, installedvia vlan3, ::, no expires
# Consulta a tabela de rotas IPv6 de Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w0d:20:00:11, lo0R 2001:1::/64 [120/2]via fe80::201:7aff:fec3:38a5, 02:50:14, vlan2C 2001:4::/64 [0/0]via ::, 03:56:24, vlan2L 2001:4::2/128 [0/0]via ::, 03:56:23, lo0
Ao consultar o banco de dados de Device2 e a tabela de rotas de Device3, verifica- se que a rota em Device2 2001:1::/64 é redistribuída para RIP ng e é anunciada com sucesso para Device3, enquanto a rota 2001: 2 :: /64 foi filtrado com sucesso.
Em um aplicativo real, se houver dois ou mais roteadores de limite AS, é recomendável não redistribuir rotas entre diferentes protocolos de roteamento. Se a redistribuição de rota precisar ser configurada, você deverá configurar políticas de controle de rota, como filtragem de rota e resumo de filtragem nos roteadores de limite AS para evitar loops de roteamento.
Configurar deslocamento de métrica RIPng
Requisitos de rede
- Device1, Device2, Device3 e Device4 executam o protocolo RIPng e se interconectam.
- Device1 aprende a rota 200 1:5::/64 de Device2 e Device3.
- Em Device1, defina o deslocamento métrico de rota na direção de recebimento para que Device1 selecione a rota anunciada por Device2 com prioridade.
Topologia de rede

Figura 6 -3 Rede para configurar o deslocamento da métrica RIPng
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure o endereço IPv6 de uma interface (omitido).
- Passo 3: Configurar RIPng.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router rip 100Device1(config-ripng)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 rip enable 100Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 rip enable 100Device1(config-if-vlan3)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router rip 100Device2(config-ripng)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 rip enable 100Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 rip enable 100Device2(config-if-vlan3)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router rip 100Device3(config-ripng)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ipv6 rip enable 100Device3(config-if-vlan2)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 rip enable 100Device3(config-if-vlan3)#exit
# Configurar dispositivo4.
Device4#configure terminalDevice4(config)#ipv6 router rip 100Device4(config-ripng)#exitDevice4(config)#interface vlan2Device4(config-if-vlan2)#ipv6 rip enable 100Device4(config-if-vlan2)#exitDevice4(config)#interface vlan3Device4(config-if-vlan3)#ipv6 rip enable 100Device4(config-if-vlan3)#exitDevice4(config)#interface vlan4Device4(config-if-vlan4)#ipv6 rip enable 100Device4(config-if-vlan4)#exit
# Visualize a tabela de rotas IPv6 do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w5d:06:21:24, lo0C 2001:1::/64 [0/0]via ::, 00:02:05, vlan2L 2001:1::1/128 [0/0]via ::, 00:02:04, lo0C 2001:2::/64 [0/0]via ::, 00:02:02, vlan3L 2001:2::1/128 [0/0]via ::, 00:02:01, lo0R 2001:3::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:02:03, vlan2R 2001:4::/64 [120/2]via fe80::201:7aff:fe11:2214, 00:00:48, vlan3R 2001:5::/64 [120/3]via fe80::201:7aff:fec3:38a4, 00:02:03, vlan2[120/3]via fe80::201:7aff:fe11:2214, 00:00:48, vlan3
Na tabela de rotas de Device1, você pode ver duas rotas para 2001:5::/64.
- Passo 4: Configure a lista de acesso.
Device1(config)#ipv6 access-list extended RIPngDevice1(config-v6-list)#permit 10 2001:5::/64 anyDevice1(config-v6-list)#commitDevice1(config-v6-list)#exit
- Passo 5: Configure um deslocamento métrico.
# No Device1, configure a lista de deslocamento métrico e aumente a métrica da rota que foi aprendida da interface vlan3 e corresponde A C L a 3.
Device1(config)# ipv6 router rip 100Device1(config-ripng)#offset-list RIPng in 3 vlan3Device1(config-ripng)#exit
- Passo 6: Confira o resultado.
# Visualize a tabela de rotas IPv6 do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w5d:06:34:28, lo0C 2001:1::/64 [0/0]via ::, 00:15:09, vlan2L 2001:1::1/128 [0/0]via ::, 00:15:08, lo0C 2001:2::/64 [0/0]via ::, 00:15:06, vlan3L 2001:2::1/128 [0/0]via ::, 00:15:05, lo0R 2001:3::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:03:10, vlan2R 2001:4::/64 [120/2]via fe80::201:7aff:fe11:2214, 00:03:10, vlan3R 2001:5::/64 [120/3]via fe80::201:7aff:fec3:38a4, 00:03:10, vlan2
De acordo com a tabela de roteamento de Device1, a interface de saída do próximo salto da rota 2001:5::/64 é apenas vlan2, indicando que Device1 selecionou a rota anunciada por Device2 com prioridade.
A lista de deslocamento métrico de rota pode ser aplicada a todas as interfaces ou a uma interface especificada e pode ser usada na direção de recebimento ou publicidade.
Configurar filtragem de rota RIPng
Requisitos de rede
- Execute RIPng entre Device1 e Device2 para interação de rota.
- Device1 aprendeu as duas rotas 2001:2::/64 e 2001:3::/64 anunciadas por Device2 e, em seguida, a rota 2001:3::/64 é filtrada na direção de publicidade de Device2.
Topologia de rede

Figura 6 -4 Rede para configurar a filtragem de rota RIPng
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure o endereço IPv6 de uma interface (omitido).
- Passo 3: Configurar RIPng.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router rip 100Device1(config-ripng)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 rip enable 100Device1(config-if-vlan2)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router rip 100Device2(config-ripng)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 rip enable 100Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 rip enable 100Device2(config-if-vlan3)#exitDevice2(config)#interface vlan4Device2(config-if-vlan4)#ipv6 rip enable 100Device2(config-if-vlan4)#exit
# Visualize a tabela de rotas IPv6 do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w5d:02:47:44, lo0C 2001:1::/64 [0/0]via ::, 00:56:34, vlan2L 2001:1::1/128 [0/0]via ::, 00:56:32, lo0R 2001:2::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:27:11, vlan2R 2001:3::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:27:11, vlan2
Você pode ver que o Device1 aprendeu as duas rotas anunciadas pelo Device2.
- Passo 4: Configure a lista de prefixos IPv6.
Device2(config)#ipv6 prefix-list RIPng deny 2001:3::/64- Passo 5: Configure a filtragem de rota.
# Configurar filtragem de rotas na direção de saída da interface vlan2 do Device2.
Device2(config)#ipv6 router rip 100Device2(config-ripng)#distribute-list prefix RIPng out vlan2Device2(config-ripng)#exit
- Passo 6: Confira o resultado.
#Visualize a tabela de rotas IPv6 de Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w5d:03:03:49, lo0C 2001:1::/64 [0/0]via ::, 01:12:39, vlan2L 2001:1::1/128 [0/0]via ::, 01:12:38, lo0R 2001:2::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:43:16, vlan2
De acordo com a tabela de roteamento, Device2 não anuncia a rota 2001:3::/64 para Device1, mas a rota é excluída da tabela de roteamento de Device1 somente após o tempo limite da rota.
A lista de distribuição pode ser aplicada a todas as interfaces ou a uma interface especificada e pode ser usada na direção de recebimento ou publicidade.
Configurar filtragem de rota RIPng
Requisitos de rede
- Execute RIPng entre Device1 e Device2 para interação de rota.
- Device1 aprendeu as duas rotas 2001:2::/64 e 2001:3::/64 anunciadas por Device2 e, em seguida, a rota 2001:3::/64 é filtrada na direção de publicidade de Device2.
Topologia de rede
Figura 6 -4 Rede para configurar a filtragem de rota RIPng
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure o endereço IPv6 de uma interface (omitido).
- Passo 3: Configurar RIPng.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router rip 100Device1(config-ripng)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 rip enable 100Device1(config-if-vlan2)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router rip 100Device2(config-ripng)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 rip enable 100Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 rip enable 100Device2(config-if-vlan3)#exitDevice2(config)#interface vlan4Device2(config-if-vlan4)#ipv6 rip enable 100Device2(config-if-vlan4)#exit
# Visualize a tabela de rotas IPv6 do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w5d:02:47:44, lo0C 2001:1::/64 [0/0]via ::, 00:56:34, vlan2L 2001:1::1/128 [0/0]via ::, 00:56:32, lo0R 2001:2::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:27:11, vlan2R 2001:3::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:27:11, vlan2
Você pode ver que o Device1 aprendeu as duas rotas anunciadas pelo Device2.
- Passo 4: Configure a lista de prefixos IPv6.
Device2(config)#ipv6 prefix-list RIPng deny 2001:3::/64- Passo 5: Configure a filtragem de rota.
# Configurar filtragem de rotas na direção de saída da interface vlan2 do Device2.
Device2(config)#ipv6 router rip 100Device2(config-ripng)#distribute-list prefix RIPng out vlan2Device2(config-ripng)#exit
- Passo 6: Confira o resultado.
#Visualize a tabela de rotas IPv6 de Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w5d:03:03:49, lo0C 2001:1::/64 [0/0]via ::, 01:12:39, vlan2L 2001:1::1/128 [0/0]via ::, 01:12:38, lo0R 2001:2::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:43:16, vlan2
De acordo com a tabela de roteamento, Device2 não anuncia a rota 2001:3::/64 para Device1, mas a rota é excluída da tabela de roteamento de Device1 somente após o tempo limite da rota.
A lista de distribuição pode ser aplicada a todas as interfaces ou a uma interface especificada e pode ser usada na direção de recebimento ou publicidade.
Configurar resumo da rota RIPng
Requisitos de rede
- Device1, Device2, Device3 e Device4 executam o protocolo RIPng para a interação de rota.
- Device1 aprendeu duas rotas 2001:4:1:1::/64 e 2001:4:1:2::/64 de Device2. Para reduzir o tamanho da tabela de rotas, Device2 precisa anunciar a rota de resumo das duas rotas para Device1.
Topologia de rede
Figura 6 -5 Rede para configurar o resumo da rota RIPng
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure o endereço IPv6 de uma interface (omitido).
- Passo 3: Configurar RIPng.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router rip 100Device1(config-ripng)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 rip enable 100Device1(config-if-vlan2)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router rip 100Device2(config-ripng)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 rip enable 100Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 rip enable 100Device2(config-if-vlan3)#exitDevice2(config)#interface vlan4Device2(config-if-vlan4)#ipv6 rip enable 100Device2(config-if-vlan4)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router rip 100Device3(config-ripng)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ipv6 rip enable 100Device3(config-if-vlan2)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 rip enable 100Device3(config-if-vlan3)#exit
# Configurar dispositivo4.
Device4#configure terminalDevice4(config)#ipv6 router rip 100Device4(config-ripng)#exitDevice4(config)#interface vlan2Device4(config-if-vlan2)#ipv6 rip enable 100Device4(config-if-vlan2)#exitDevice4(config)#interface vlan3Device4(config-if-vlan3)#ipv6 rip enable 100Device4(config-if-vlan3)#exit
# Visualize a tabela de rotas IPv6 do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w5d:02:27:40, lo0C 2001:1::/64 [0/0]via ::, 00:36:29, vlan2L 2001:1::1/128 [0/0]via ::, 00:36:28, lo0R 2001:2::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:07:06, vlan2R 2001:3::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:07:06, vlan2R 2001:4:1:1::/64 [120/3]via fe80::201:7aff:fec3:38a4, 00:07:06, vlan2R 2001:4:1:2::/64 [120/3]via fe80::201:7aff:fec3:38a4, 00:06:55, vlan2
- Passo 4: Configure o resumo da rota da interface.
# No Device2, configure a rota de resumo 2001: 4 : 1 ::/48.
Device2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 rip summary-address 2001:4:1::/48Device2(config-if-vlan2)#exit
- Passo 5: Confira o resultado.
# Visualize a tabela de rotas IPv6 do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w5d:02:35:44, lo0C 2001:1::/64 [0/0]via ::, 00:44:33, vlan2L 2001:1::1/128 [0/0]via ::, 00:44:32, lo0R 2001:2::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:15:10, vlan2R 2001:3::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:15:10, vlan2R 2001:4:1::/48 [120/3]via fe80::201:7aff:fec3:38a4, 00:05:19, vlan2
Você pode ver que Device1 aprendeu a rota de resumo 2001: 4 : 1 ::/48 anunciada por Device2, mas as duas rotas detalhadas podem ser excluídas da tabela de rotas somente após o tempo limite.
Configurar Interface RIPng Passiva
Requisitos de rede
- RIPng é executado entre Device1 e Device2 para interação de rota.
- Em Device1, configure uma interface passiva, que não envia pacotes de atualização para Device2.
Topologia de rede

Figura 6 -6 Rede para configurar uma interface passiva RIPng
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure o endereço IPv6 de uma interface (omitido).
- Passo 3: Configurar RIPng.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router rip 100Device1(config-ripng)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 rip enable 100Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 rip enable 100Device1(config-if-vlan3)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router rip 100Device2(config-ripng)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 rip enable 100Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 rip enable 100Device2(config-if-vlan3)#exit
# Visualize a tabela de rotas IPv6 do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w4d:19:31:05, lo0C 2001:1::/64 [0/0]via ::, 00:21:42, vlan2L 2001:1::1/128 [0/0]via ::, 00:21:40, lo0C 2001:2::/64 [0/0]via ::, 00:21:34, vlan3L 2001:2::1/128 [0/0]via ::, 00:21:33, lo0R 2001:3::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:11:19, vlan3
# Consulta a tabela de rotas IPv6 de Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 3d:22:39:31, lo0R 2001:1::/64 [120/2]via fe80::201:7aff:fe01:204, 00:12:00, vlan2C 2001:2::/64 [0/0]via ::, 00:30:46, vlan2L 2001:2::2/128 [0/0]via ::, 00:30:45, lo0C 2001:3::/64 [0/0]via ::, 00:29:12, vlan3L 2001:3::1/128 [0/0]via ::, 00:29:11, lo0
- Passo 4: Configure uma interface passiva.
# Configurar dispositivo1.
Device1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 rip passiveDevice1(config-if-vlan3)#exit
vlan3 de Device1 está configurado como uma interface passiva, que não envia pacotes de atualização para Device2, mas ainda pode receber pacotes de atualização.
- Passo 5: Confira o resultado.
# Visualize a tabela de rotas IPv6 do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w4d:19:55:37, lo0C 2001:1::/64 [0/0]via ::, 00:46:14, vlan2L 2001:1::1/128 [0/0]via ::, 00:46:12, lo0C 2001:2::/64 [0/0]via ::, 00:46:06, vlan3L 2001:2::1/128 [0/0]via ::, 00:46:05, lo0R 2001:3::/64 [120/2]via fe80::201:7aff:fec3:38a4, 00:35:51, vlan3
O Route 2001:3::/6 4 ainda é mantido no Device1. No Device2, depois que a rota RIPng expira e é excluída, a rota 2001:1::/6 4 é excluída da tabela de roteamento.
# Consulta a tabela de rotas IPv6 de Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 3d:23:05:24, lo0C 2001:2::/64 [0/0]via ::, 00:56:39, vlan2L 2001:2::2/128 [0/0]via ::, 00:56:38, lo0C 2001:3::/64 [0/0]via ::, 00:55:05, vlan3L 2001:3::1/128 [0/0]via ::, 00:55:04, lo0
OSPF
Visão geral
Open Shortest Path First (OSPF) é um protocolo de roteamento dinâmico baseado em status de link. Ele usa o algoritmo Shortest Path First (SPF) de Dijkstra para calcular rotas dentro de um único Sistema Autônomo (AS).
OSPF, que é desenvolvido pela Internet Engineering Task Force (IETF), resolve os problemas de convergência lenta e responsabilidade para formar loops para rotas de vetor de distância. É aplicável a redes de médio e grande porte. Atualmente, a versão 2 do OSPF está disponível. Ele está em conformidade com RFC2328 e suporta funções estendidas OSPF definidas em outros RFCs relacionados.
No OSPF, cada dispositivo mantém um banco de dados que descreve o status do link de uma rede AS. Os bancos de dados de dispositivos na mesma área são os mesmos. Depois que os bancos de dados estiverem completamente sincronizados, cada dispositivo assume a si mesmo como raiz e usa o algoritmo SPF para calcular a árvore de caminho mais curto sem loops para descrever os caminhos mais curtos que conhece para chegar a cada destino. Em seguida, cada dispositivo constrói sua tabela de roteamento com base na árvore do caminho mais curto.
As principais características do OSPF incluem:
- Convergência rápida: Após a alteração da topologia da rede, ela envia um pacote de atualização imediatamente para que a alteração seja sincronizada no AS.
- Sem loop: o OSPF executa o SPF para calcular rotas com base no banco de dados de status do link. O algoritmo garante que nenhum loop de roteamento seja formado.
- Divisão de áreas: OSPF permite dividir um AS em várias áreas para reduzir a ocupação da largura de banda da rede, possibilitando a construção de uma rede em camadas.
- Suporte de autenticação: Assim que um dispositivo OSPF recebe um pacote de protocolo de roteamento, ele verifica as informações de autenticação contidas no pacote para evitar vazamento de informações ou ataques maliciosos na rede.
- Suporta sub-rede com comprimentos diferentes: As rotas anunciadas pelo OSPF carregam máscaras de rede para suportar sub-redes com comprimentos diferentes.
- Suporte ao balanceamento de carga: OSPF oferece suporte a várias rotas equivalentes para o mesmo destino.
Configuração da Função OSPF
Tabela 7 -1 Lista de Funções OSPF
| Tarefas de configuração | |
| Configure as funções básicas do OSPF. | Habilite OSPF. |
| Configurar áreas OSPF. |
Configure uma área OSPF NSSA.
Configure uma área de stub OSPF. Configure um link virtual OSPF. |
| Configure o tipo de rede OSPF. |
Configure o tipo de rede de uma interface OSPF para transmissão.
Configure o tipo de rede de uma interface OSPF para P2P. Configure o tipo de rede de uma interface OSPF para NBMA. Configure o tipo de rede de uma interface OSPF para P2MP. |
| Configure a autenticação de rede OSPF. | Configure a autenticação de área OSPF. Configure a autenticação da interface OSPF. |
| Configure a geração de rotas OSPF. |
Configure o OSPF para redistribuir rotas.
Configure a rota OSPF padrão. Configure a rota do host OSPF. |
| Configure o controle de rota OSPF. |
Configure o resumo da rota em rotas OSPF entre áreas.
Configure o resumo da rota externa OSPF. Configure a filtragem de rotas em rotas OSPF entre áreas. Configure a filtragem de rota externa OSPF. Configure a filtragem de instalação de rota OSPF. Configure o valor de custo de uma interface OSPF. Configure a largura de banda de referência OSPF. Configure a distância administrativa OSPF. Configure o número máximo de rotas de balanceamento de carga OSPF. Configure o OSPF para ser compatível com RFC1583. |
| Configure a otimização de rede OSPF. |
Configure o tempo de atividade de um vizinho OSPF.
Configure uma interface passiva OSPF. Configure um circuito de demanda OSPF. Configure a prioridade de uma interface OSPF. Configure o MTU de uma interface OSPF. Configure o atraso de transmissão LSA de uma interface OSPF. Configure a retransmissão OSPF LSA. Configure o OSPF para evitar inundação de LSA. Configure o tempo de cálculo OSPF SPF. Configure o estouro do banco de dados OSPF. |
| Configure o OSPF para coordenar com o BFD. | Configure o OSPF para coordenar com o BFD. |
| Configurar OSPF GR | Configurar reinicializador OSPF GR Configurar o Auxiliar OSPF GR |
Configurar funções básicas do OSPF
Antes de configurar as funções OSPF, você deve primeiro habilitar o protocolo OSPF antes que as outras funções entrem em vigor.
Condições de configuração
Antes de configurar as funções básicas do OSPF, certifique-se de que:
- O protocolo da camada de link foi configurado para garantir a comunicação normal na camada de link.
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
Ativar OSPF
Para habilitar o OSPF, você deve criar um processo OSPF, especificar o intervalo de endereços das redes às quais o processo está associado e especificar a área à qual o intervalo de endereços pertence. Se o endereço IP de uma interface estiver no segmento de rede de uma área, a interface pertence à área e a função OSPF está habilitada, e o OSPF anuncia a rota direta da interface.
Um dispositivo que executa OSPF deve ter um Router ID, que é usado para identificar exclusivamente um dispositivo em um OSPF AS. Você deve garantir que os IDs do roteador sejam exclusivos em um AS; caso contrário, a configuração de vizinhos e o aprendizado de rotas são afetados. Um Router ID pode ser especificado quando o processo OSPF é criado. Se o ID do roteador não for especificado, ele poderá ser escolhido de acordo com as seguintes regras:
- Selecione o maior endereço IP dos endereços IP da interface de loopback como o ID do roteador.
- Se nenhuma interface de loopback estiver configurada com um endereço IP, selecione o maior endereço IP dos endereços IP de outras interfaces como a ID do roteador.
- Somente quando uma interface está no status UP, o endereço IP da interface pode ser eleito como o Router ID.
OSPF suporta vários processos, que são identificados por diferentes números de processo. Os processos são independentes uns dos outros e não afetam uns aos outros.
Tabela 7 -2 Ativando OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um processo OSPF e entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | Obrigatório. Habilite o processo OSPF ou habilite o processo OSPF do VRF. Por padrão, o OSPF está desabilitado. Se você habilita o OSPF do VRF, o processo OSPF que pertence a um VRF pode gerenciar somente interfaces sob o VRF. |
| Configure segmentos de rede cobertos por uma área OSPF. | network ip-address wildcard-mask area area-id | Obrigatório. Por padrão, uma interface não pertence a nenhum processo ou área OSPF. Uma interface n só pode pertencer a um processo e área OSPF. |
| Configure o Router ID do processo OSPF. | router-id ip-address | Opcional. Por padrão, gere o Router ID de acordo com a regra de eleição. Modificar o ID do roteador não tornará o vizinho OSPF inválido. Para que o novo ID do Roteador tenha efeito, você precisa redefinir o processo manualmente. |
Configurar áreas OSPF
Para evitar que uma grande quantidade de informações do banco de dados ocupe muita CPU e memória, você pode dividir um OSPF AS em várias áreas. Uma área pode ser identificada com um ID de área de 32 bits, um número decimal no intervalo de 0-4294967295 ou um endereço IP no intervalo de 0.0.0.0-255.255.255.255. A área 0 ou 0.0.0.0 representa uma área de backbone OSPF, enquanto outras áreas diferentes de zero são áreas sem backbone. Todas as informações de roteamento entre as áreas devem ser encaminhadas através da área de backbone. As áreas sem backbone não podem trocar informações de roteamento diretamente.
OSPF define vários tipos de roteadores:
- Roteador interno: Todas as interfaces pertencem aos dispositivos em uma área.
- Area Border Router (ABR): É conectado a dispositivos de diferentes áreas.
- Autonomous System Boundary Router (ASBR): É um dispositivo que introduz rotas externas para o OSPF AS.
Condição de configuração
Antes de configurar uma área OSPF, certifique-se de que:
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite OSPF.
Configurar uma área OSPF NSSA
A Not-So-Stub-Area (NSSA) não permite a injeção de Type-5 Link State Advertisement (LSA), mas permite a injeção de Type-7 LSA. As rotas externas podem ser introduzidas em uma área NSSA por meio da redistribuição da configuração. O ASBR na área NSSA gera LSAs Tipo-7 e inunda LSAs para a área NSSA. O ABR em uma área NSSA converte LSAs Tipo-7 em LSAs Tipo-5 e inunda os LSAs Tipo-5 convertidos em todo o AS.
A área OSPF NSSA que é configurada usando a área ID de área O comando nssa no-summary é chamado de área totalmente NSSA. Uma área OSPF totalmente NSSA não permite que rotas transversais inundem a área. Neste momento, o ABR gera uma rota padrão e a inunda na área NSSA. Os dispositivos na área NSSA acessam uma rede fora da área por meio da rota padrão.
Tabela 7 -3 Configurando uma área OSPF NSSA
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure uma área NSSA. | area area-id nssa [ [ default-information-originate [ metric metric-value / metric-type type-value ] / no-redistribution / no-summary / translator-role { always | candidate | never } ] | [ translate-always | translate-candidate | translate-never ] ] | Obrigatório. Por padrão, uma área não é uma área NSSA. |
Uma área de backbone não pode ser configurada como uma área NSSA. Todos os dispositivos em uma área NSSA devem ser configurados como áreas NSSA, pois dispositivos com tipos de área diferentes não podem formar relações de vizinhança.
Configurar uma área de stub OSPF
Uma área Stub não permite que uma rota externa fora de um AS inunde a área para reduzir o tamanho do banco de dados de status do link. Depois que uma área é configurada como uma área Stub, o ABR que está localizado na borda Stub gera uma rota padrão e inunda a rota na área Stub. Os dispositivos na área Stub acessam uma rede fora da área por meio da rota padrão.
A área OSPF Stub que é configurada usando a área ID de área toco comando no-summary é chamado de área totalmente Stub. Uma área OSPF totalmente Stub não permite que rotas inter-áreas e rotas externas inundem a área. Os dispositivos na área acessam uma rede fora da área e fora do OSPF AS através da rota padrão.
Tabela 7 -4 Configurando uma área de stub OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure uma área de stub. | area area-id stub [ no-summary ] | Obrigatório. Por padrão, uma área não é uma área Stub. |
| Configure o ABR na área Stub para gerar o valor de custo da rota padrão. | area area-id default-cost cost-value | Opcional. Por padrão, o ABR da área Stub define o valor de custo da rota padrão para 1. |
Uma área de backbone não pode ser configurada como uma área Stub. Todos os dispositivos em uma área Stub devem ser configurados como áreas Stub, pois dispositivos com tipos de área diferentes não podem formar relações de vizinhança.
Configurar um link virtual OSPF
As áreas sem backbone no OSPF devem sincronizar e trocar dados através da área de backbone. Portanto, todas as áreas que não são de backbone devem permanecer conectadas à área de backbone.
Se o requisito não for atendido em determinados casos, você poderá resolver o problema configurando um link virtual. Depois de configurar um link virtual, você pode configurar um modo de autenticação para o link virtual e modificar o intervalo Hello. Os significados dos parâmetros são os mesmos que os significados do parâmetro de interfaces OSPF comuns.
Tabela 7 -5 Configurando um Link Virtual OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure um link virtual OSPF. | area transit-area-id virtual-link neighbor-id [ [ authentication [ message-digest | null ] | authentication-key key | message-digest-key key-id md5 key ] / dead-interval seconds hello-interval seconds / retransmit-interval seconds / transmit-delay seconds ] | Obrigatório. Por padrão, nenhum link virtual é criado. |
Um link virtual deve ser configurado entre dois ABRs. Dois ABRs nos quais o link virtual está configurado devem estar na mesma área pública. Essa área também é chamada de área de trânsito do link virtual. A área de trânsito de um link virtual não deve ser uma área Stub ou uma área NSSA.
Configurar o tipo de rede OSPF
De acordo com os tipos de protocolo de link, o OSPF classifica as redes em quatro tipos:
- Rede de transmissão: Quando o protocolo de link da rede é Ethernet ou Interface de dados distribuídos por fibra (FDDI), o tipo de rede OSPF padrão é rede de transmissão.
- Rede ponto a ponto (rede P2P): quando o protocolo de link é protocolo ponto a ponto (PPP), procedimento de acesso de link balanceado (LAPB) ou controle de link de dados de alto nível (HDLC), o tipo de rede OSPF padrão é rede P2P.
- Rede de multi-acesso sem difusão (rede NBMA): Quando o protocolo de link é ATM, frame relay ou X.25, o tipo de rede OSPF padrão é NBMA.
- Rede ponto a multiponto (P2MP): Nenhum protocolo de link será considerado pelo OSPF como a rede P2MP por padrão. Normalmente, a rede NBMA que não está totalmente conectada é configurada como rede OSPF P2MP.
Você pode modificar o tipo de rede de uma interface OSPF de acordo com o requisito real. Os tipos de rede das interfaces através das quais os vizinhos OSPF são configurados devem ser os mesmos; caso contrário, o aprendizado normal de rotas é afetado.
Condição de configuração
Antes de configurar o tipo de rede OSPF, certifique-se de que:
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite OSPF.
Configurar o tipo de rede de uma interface OSPF para transmissão
Uma rede de transmissão suporta vários dispositivos (mais de dois dispositivos). Esses dispositivos podem trocar informações com todos os dispositivos da rede. O OSPF usa pacotes Hello para descobrir vizinhos dinamicamente.
Tabela 7 -6 Configurando o tipo de rede de uma interface OSPF para transmissão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o tipo de rede de uma interface OSPF para transmissão. | ip ospf network broadcast | Obrigatório. Por padrão, o tipo de rede de uma interface OSPF é determinado pelo protocolo da camada de link. |
Configurar o tipo de rede de uma interface OSPF para P2P
Uma rede P2P é uma rede que consiste em dois dispositivos. Cada dispositivo está localizado em uma extremidade de um link P2P. O OSPF usa pacotes Hello para descobrir vizinhos dinamicamente.
Tabela 7 -7 Configurando o tipo de rede de uma interface OSPF para P2P
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o tipo de rede OSPF para P2P. | ip ospf network point-to-point | Obrigatório. Por padrão, o tipo de rede de uma interface OSPF é determinado pelo protocolo da camada de link. |
Configurar o tipo de rede de uma interface OSPF para NBMA
Uma rede NBMA suporta vários dispositivos (mais de dois dispositivos), mas os dispositivos não têm capacidade de transmissão, portanto, você deve especificar um vizinho manualmente.
Tabela 7 -8 Configurando o tipo de rede de uma interface OSPF para NBMA
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o tipo de rede OSPF para NBMA. | ip ospf network non-broadcast | Obrigatório. Por padrão, o tipo de rede de uma interface OSPF é determinado pelo protocolo da camada de link. |
| Entre no modo de configuração global. | exit | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure um vizinho para a rede NBMA. | neighbor neighbor-ip-address [ cost cost-value / priority priority-value / poll-interval interval-value ] | Obrigatório. Em uma rede NBMA, um vizinho deve ser especificado manualmente. |
Configurar o tipo de rede de uma interface OSPF para P2MP
Quando uma rede NBMA não está totalmente conectada, você pode configurar seu tipo de rede para P2MP para economizar sobrecarga de rede. Se o tipo de rede estiver configurado para unicast P2MP, você precisará especificar um vizinho manualmente.
Tabela 7 -9 Configurando o tipo de rede de uma interface OSPF para P2MP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o tipo de rede OSPF para P2MP. | ip ospf network point-to-multipoint [ non-broadcast ] | Obrigatório. Por padrão, o tipo de rede de uma interface OSPF é determinado pelo protocolo da camada de link. |
| Entre no modo de configuração global. | exit | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure um vizinho para a rede unicast P2MP. | neighbor neighbor-ip-address [ cost cost-value / priority priority-value / poll-interval interval-value ] | Se o tipo de rede de interface estiver definido como unicast P2MP, é obrigatório. |
Configurar a autenticação de rede OSPF
Para evitar vazamento de informações ou ataques maliciosos a dispositivos OSPF, todas as interações de pacotes entre vizinhos OSPF têm o recurso de autenticação. Os tipos de autenticação incluem: NULL (sem autenticação), autenticação de texto simples , autenticação MD5, autenticação SM3 e autenticação de cadeia de chaves.
Se a autenticação estiver configurada, uma interface OSPF requer autenticação antes de receber pacotes de protocolo OSPF. A interface OSPF recebe apenas pacotes que passaram na autenticação. Portanto, as interfaces OSPF através das quais as relações de vizinhos são configuradas, seus modos de autenticação, IDs de chave e senhas de autenticação devem ser os mesmos.
Um modo de autenticação e uma senha de autenticação são configurados independentemente. Se uma senha de autenticação tiver sido configurada, mas nenhum modo de autenticação estiver configurado, o modo de autenticação correspondente à senha de autenticação será configurado automaticamente.
Um modo de autenticação OSPF pode ser configurado em uma área, interface ou endereço de interface. As prioridades classificadas de baixo para alto incluem: autenticação de área, autenticação de interface e autenticação de endereço de interface. Ou seja, a autenticação de endereço de interface é usada primeiro, depois a autenticação de interface e, finalmente, a autenticação de área.
Condição de configuração
Antes de configurar a autenticação OSPF, certifique-se de que:
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite OSPF.
Configurar autenticação de área OSPF
Para validar a autenticação de área OSPF, você deve configurar não apenas o modo de autenticação de área, mas também a senha de autenticação correspondente na interface.
Tabela 7 -10 Configurando a autenticação de área OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure o modo de autenticação de área. | area area-id authentication [ message-digest | key-chain] | Obrigatório. Por padrão, a autenticação de área não está configurada. A palavra-chave message-digest no comando indica autenticação MD5; a palavra chave cadeia de chaves indica a autenticação da cadeia de chaves; caso contrário, a autenticação de texto simples é configurada. |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure uma senha para autenticação de texto simples. | ip ospf [ ip-address ] authentication-key { 0 | 7 } password | Obrigatório. Por padrão, nenhuma senha é configurada para autenticação de texto simples. |
| Configure uma senha para autenticação MD5/SM3. | ip ospf [ ip-address ] message-digest-key key-id { md5 | sm3} { 0 | 7 } password | Obrigatório. Por padrão, nenhuma senha é configurada para autenticação MD5/SM3. |
| Configurar a autenticação do chaveiro | ip ospf [ ip-address ] key-chain key-chain name | Obrigatório Por padrão, não configure a autenticação do chaveiro. |
Configurar autenticação de interface OSPF
Se uma interface OSPF tiver vários endereços IP, você poderá definir um modo de autenticação ou uma senha de autenticação para um endereço IP da interface. Se você não especificar um endereço de interface, todos os endereços da interface usarão o modo de autenticação ou a senha de autenticação especificados.
Tabela 7 -11 Configurando a autenticação da interface OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o modo de autenticação da interface. | ip ospf [ ip-address ] authentication [ key-chain | message-digest | null ] | Obrigatório. Por padrão, o modo de autenticação de interface não está configurado. A palavra-chave message-digest no comando indica autenticação MD5 e a palavra-chave null indica nenhuma autenticação; a palavra chave cadeia de chaves indica a autenticação da cadeia de chaves; caso contrário, a autenticação de texto simples é configurada. |
| Configure uma senha para autenticação de texto simples. | ip ospf [ ip-address ] authentication-key { 0 | 7 } password | Obrigatório. Por padrão, nenhuma senha é configurada para autenticação de texto simples. |
| Configure uma senha para autenticação MD5/SM3. | ip ospf [ ip-address ] message-digest-key key-id {md5 | sm3} { 0 | 7 } password | Obrigatório. Por padrão, nenhuma senha é configurada para autenticação MD5/SM3. |
| Configurar a autenticação do chaveiro | ip ospf [ ip-address ] key-chain key-chain name | Obrigatório Por padrão, não configure a autenticação do chaveiro. |
Configurar geração de rota OSPF
O OSPF usa o comando network para cobrir as rotas do segmento de rede conectado diretamente. Ele também pode redistribuir rotas externas ou usar o comando host para adicionar rotas de host.
Condição de configuração
Antes de configurar a geração de rotas OSPF, certifique-se de que:
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite OSPF.
Configurar o OSPF para redistribuir rotas
Se vários protocolos de roteamento forem executados em um dispositivo, as rotas de outros protocolos poderão ser introduzidas no OSPF por meio da redistribuição. Por padrão, as rotas externas de classe 2 do OSPF são geradas, com a métrica de roteamento 20. Ao introduzir rotas externas por meio de redistribuição, você pode modificar o tipo de rota externa, métrica e campo de tag e configurar a política de roteamento necessária para realizar o controle de rota e gestão.
Tabela 7 -12 Configurando o OSPF para redistribuir rotas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure o OSPF para redistribuir rotas. | redistribute protocol [ protocol-id ] [ metric metric-value / metric-type metric-type / tag tag-value / route-map route-map-name / match route-type ] | Obrigatório. Por padrão, a redistribuição de rotas não está configurada para OSPF. |
| Configure a métrica das rotas externas OSPF. | default-metric metric-value | Opcional. |
| Configure o número máximo de rotas externas redistribuídas pelo OSPF | redistribute maximum-prefix maximum-prefix-value [threshold-value [warning-only] / warning-only] | Opcional Por padrão, o OSPF não limita o número de rotas externas redistribuídas. |
Se o valor da métrica das rotas externas for configurado usando tanto o redistribute protocol [ protocol-id ] comando metric e o comando default-metric , o valor que é configurado usando o comando anterior tem uma prioridade mais alta.
Configurar a rota OSPF padrão
Depois que uma área OSPF Stub ou uma área totalmente NSSA é configurada, uma rota padrão Tipo 3 é gerada. Para uma área NSSA, nenhuma rota padrão é gerada automaticamente. Você pode usar a área ID de área nssa origem-informação-padrão comando para introduzir uma rota padrão Type-7 para a área NSSA.
O OSPF não pode usar o comando redistribute para introduzir uma rota padrão Tipo-5. Para fazer isso, use o informações padrão originar [ sempre ] comando.
Tabela 7 -13 Configurando a rota OSPF padrão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure o OSPF para introduzir uma rota padrão. | default-information originate [ always / metric metric-value / metric-type metric-type / route-map route-map-name ] | Obrigatório. Por padrão, nenhuma rota padrão externa é introduzida em um OSPF AS. A métrica padrão da rota padrão introduzida é 1 e o tipo é externo tipo 2. O campo sempre meios para forçar o OSPF AS a gerar uma rota padrão; caso contrário, a rota padrão será gerada somente quando houver uma rota padrão na tabela de roteamento local. |
Configurar a rota de host OSPF
Tabela 7 -14 Configurando a rota de host OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure a rota do host OSPF. | host ip-address area area-id [ cost cost ] | Obrigatório. Por padrão, nenhuma rota de host é gerada. |
Configurar o controle de rota OSPF
Condição de configuração
Antes de configurar o controle de rota OSPF, certifique-se de que:
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite OSPF.
Configurar o resumo da rota em rotas OSPF entre áreas
Quando um ABR no OSPF anuncia rotas entre áreas para outras áreas, ele anuncia cada rota separadamente na forma de LSA Tipo 3. Você pode usar a função de resumo de rota entre áreas para resumir alguns segmentos de rede contínuos para formar uma rota de resumo. Em seguida, o ABR anuncia a rota de resumo, reduzindo o tamanho dos bancos de dados OSPF.
Tabela 7 -15 Configurando o resumo de rotas em rotas OSPF entre áreas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure o resumo da rota em rotas OSPF entre áreas. | area area-id range ip-address/mask-length [ advertise [ cost cost ] | cost cost | not-advertise ] | Obrigatório. Por padrão, um ABR não resume as rotas entre áreas. |
A função de resumo de rotas entre áreas OSPF é válida apenas para ABRs. Por padrão, o valor de custo mínimo entre os valores de custo das rotas no resumo da rota é usado como valor de custo do resumo da rota.
Configurar o resumo da rota externa OSPF
o OSPF redistribui rotas externas, ele anuncia cada rota separadamente na forma de LSA externo. Você pode usar a função de resumo de rota externa para resumir alguns segmentos de rede contínuos para formar uma rota de resumo. Em seguida, o OSPF anuncia a rota de resumo, reduzindo o tamanho dos bancos de dados OSPF.
Se você executar o comando summary-address em um ASBR, poderá resumir todos os LSAs Tipo 5 e LSAs Tipo 7 dentro do intervalo de endereços.
Tabela 7 -16 Configurando o resumo da rota externa OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure o OSPF para resumir rotas externas. | summary-address ip-address mask [ not-advertise | tag tag-value ] | Obrigatório. Por padrão, um ABR não resume as rotas externas. |
A função de resumo de rota externa OSPF é válida apenas para ASBRs.
Configurar filtragem de rota em rotas OSPF entre áreas
Quando um ABR recebe rotas entre áreas, ele realiza a filtragem na direção de entrada com base em um ACL ou lista de prefixos. Quando o ABR anuncia rotas entre áreas, ele realiza a filtragem na direção de saída com base em um ACL ou lista de prefixos.
Tabela 7 -17 Configurando a filtragem de rota em rotas OSPF entre áreas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure a filtragem de rotas em rotas OSPF intra-área. | area area-id filter-list { access { access-list-name | access-list-number } | prefix prefix-list-name } { in | out } | Obrigatório. Por padrão, um ABR não filtra rotas entre áreas. |
Na filtragem baseada em ACL, apenas uma ACL padrão é suportada. A função de filtragem de rotas entre áreas OSPF é válida apenas para ABRs.
Configurar filtragem de rota externa OSPF
Configurar a filtragem de rota externa OSPF é aplicar uma ACL ou lista de prefixos para permitir ou não permitir que rotas externas de um OSPF AS inundem no OSPF AS.
Tabela 7 -18 Configurando a filtragem de rota externa OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure uma lista de distribuição para filtrar rotas externas. | distribute-list { access-list-name | access-list-number | prefix prefix-list-name } out [ routing-protocol [ process-id ] ] | Obrigatório. Por padrão, um ASBR não filtra rotas externas. |
Na filtragem baseada em ACL, apenas uma ACL padrão é suportada. A função de filtragem de rota externa OSPF é válida apenas para ASBRs.
Configurar filtragem de instalação de rota OSPF
Depois que o OSPF calcula as rotas por meio do LSA, para evitar que determinadas rotas sejam adicionadas à tabela de roteamento, o OSPF filtra as informações de roteamento calculadas do OSPF.
Três métodos de filtragem estão disponíveis:
- Filtração com base no prefixo. Uma lista de ACL ou prefixo é usada para filtrar os endereços de destino das rotas.
- Filtração com base no próximo salto. Uma lista de prefixos é usada para filtrar os próximos saltos das rotas. Você também pode usar uma lista de prefixos para filtrar os endereços de destino e os próximos saltos das rotas.
- Filtragem de rotas com base na política de roteamento.
Tabela 7 -19 Configurando a filtragem de instalação de rota OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure o OSPF para proibir rotas instaladas. | distribute-list { access-list-name | access-lsit-number | gateway prefix-list-name1 | prefix prefix-list-name2 [ gateway prefix-list-name3 ] | route-map route-map-name } in [ interface-name ] | Obrigatório. Por padrão, as rotas instaladas não são filtradas. |
A filtragem baseada em prefixo, gateway e mapa de rotas é mutuamente exclusiva com filtragem baseada em ACL. Por exemplo, se você configurou a filtragem com base no prefixo, não poderá configurar a filtragem com base na ACL novamente. A filtragem baseada no mapa de rotas e no prefixo é mutuamente exclusiva com a filtragem baseada no gateway. A filtragem com base no prefixo e a filtragem com base no gateway se sobrescrevem.
Configurar o valor de custo de uma interface OSPF
Por padrão, o custo de uma interface OSPF é calculado com base na seguinte fórmula: Largura de banda de referência/Largura de banda da interface.
Tabela 7 -20 Configurando o valor de custo de uma interface OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o valor de custo de uma interface OSPF. | ip ospf [ ip-address ] cost cost-value | Opcional. Por padrão, o valor do custo é calculado por meio da fórmula Largura de banda de referência/Largura de banda de interface. |
Configurar a largura de banda de referência OSPF
A largura de banda de referência de uma interface é usada para calcular o valor de custo da interface. O valor padrão é 100 Mbit/s. A fórmula para calcular o valor de custo da interface OSPF é: Largura de banda de referência/Largura de banda da interface. Se o resultado do cálculo for maior que 1, use a parte inteira. Se o resultado do cálculo for menor que 1, use o valor 1. Portanto, em uma rede cuja largura de banda é maior que 100Mbit/s, a rota ótima não é selecionada. Nesse caso, você pode usar o custo automático comando reference-bandwidth para configurar uma largura de banda de referência adequada para resolver o problema.
Tabela 7 -21 Configurando a largura de banda de referência OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configurando a largura de banda de referência da interface OSPF. | auto-cost reference-bandwidth reference-bandwidth | Opcional. Por padrão, a largura de banda de referência é 100 Mbit/s. |
Configurar a distância administrativa OSPF
Uma distância administrativa é usada para indicar a confiabilidade do protocolo de roteamento. Se as rotas para a mesma rede de destino forem aprendidas por protocolos de roteamento diferentes, a rota com a menor distância administrativa será selecionada com prioridade.
Tabela 7 -22 Configurar a distância administrativa OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure a distância administrativa OSPF. | distance { distance [ ip-address wildcard-mask ] [ access-list-name | access-list-number ] | ospf { external distance | inter-area distance | intra-area distance } } | Opcional. Por padrão, a distância administrativa das rotas OSPF intra-área e interárea é 110 e a distância administrativa das rotas externas é 150. |
Configurar o número máximo de rotas de balanceamento de carga OSPF
Se vários caminhos equivalentes estiverem disponíveis para alcançar o mesmo destino, o balanceamento de carga será alcançado. Isso melhora a taxa de utilidade dos links e reduz a carga dos links.
Tabela 7 -23 Configurando o número máximo de rotas de balanceamento de carga OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure o número máximo de rotas de balanceamento de carga OSPF. | maximum-path max-number | Opcional. Por padrão, o número máximo de rotas de balanceamento de carga OSPF é 4. |
Configurar OSPF para ser compatível com RFC1583
Se existirem vários caminhos para um endereço de encaminhamento de rota externa ou ASBR, RFC1583 e RFC2328 definem regras de roteamento diferentes. Se o OSPF estiver configurado para ser compatível com RFC1583, os caminhos intra-área ou inter-área na área do backbone serão selecionados com prioridade. Se o OSPF estiver configurado para não ser compatível com RFC1583, os caminhos intra-área em redes sem backbone serão selecionados com prioridade.
Tabela 7 -24 Configurando o OSPF para ser compatível com RFC1583
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure o OSPF para ser compatível com RFC1583. | compatible rfc1583 | Obrigatório. Por padrão, OSPF não é compatível com RFC1583. |
Em um OSPF AS, as regras de roteamento de todos os dispositivos devem ser as mesmas, ou seja, todos devem ser configurados para serem compatíveis ou não compatíveis com RFC1583 para evitar loops de roteamento.
Configurar a otimização de rede OSPF
Condição de configuração
Antes de configurar a otimização de rede OSPF, certifique-se de que:
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite OSPF.
Configurar o tempo de manutenção de atividade de um vizinho OSPF
Os pacotes OSPF Hello são usados para estabelecer relações de vizinhança e manter as relações vivas. O intervalo de transmissão padrão dos pacotes Hello é determinado pelo tipo de rede. Para redes de broadcast e redes P2P, o intervalo de transmissão padrão dos pacotes Hello é 10s. Para redes P2MP e redes NBMA, o intervalo de transmissão padrão dos pacotes Hello é 30s.
O tempo morto do vizinho é usado para determinar a validade de um vizinho. Por padrão, o tempo morto do vizinho é quatro vezes o intervalo Hello. Se um dispositivo OSPF não receber pacotes de saudação de um vizinho após o tempo morto do vizinho expirar, o dispositivo OSPF considera o vizinho inválido e, em seguida, exclui o vizinho de maneira ativa.
Tabela 7 -25 Configurando o Keepalive Time de um vizinho OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure um intervalo de Olá OSPF. | ip ospf [ ip-address ] hello-interval interval-value | Opcional. O valor padrão é determinado pelo tipo de rede. Para redes de transmissão e redes P2P, o valor padrão é 10s. Para redes P2MP e redes NBMA, o valor padrão é 30s. |
| Configure o tempo morto do vizinho OSPF. | ip ospf [ ip-address ] dead-interval interval-value | Opcional. Por padrão, o tempo é quatro vezes o intervalo Hello. |
O intervalo de saudação e o tempo morto dos vizinhos OSPF devem ser os mesmos; caso contrário, eles não podem estabelecer relações de vizinhança. Quando você modifica o intervalo Hello, se o tempo morto do vizinho atual for quatro vezes o intervalo Hello, o tempo morto do vizinho será modificado automaticamente para ainda ser quatro vezes o novo intervalo Hello. Se o tempo morto do vizinho atual não for quatro vezes o intervalo Hello, o tempo morto do vizinho permanecerá inalterado. Se você modificar o tempo morto do vizinho, o intervalo Hello não será afetado.
Configurar uma interface passiva OSPF
O protocolo de roteamento dinâmico adota uma interface passiva para diminuir efetivamente a largura de banda da rede consumida pelo protocolo de roteamento. Depois que uma interface passiva OSPF é configurada, você pode usar o comando network para anunciar as rotas do segmento de rede diretamente conectado no qual a interface está localizada, mas o recebimento e a transmissão de pacotes OSPF são amortecidos na interface.
Tabela 7 -26 Configurando uma interface passiva OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure uma interface passiva OSPF. | passive-interface { interface-name [ ip-address ] | default } | Obrigatório. Por padrão, nenhuma interface passiva OSPF é configurada. |
Configurar um circuito de demanda OSPF
Em links P2P e P2MP, para diminuir o custo da linha, você pode configurar um circuito de demanda OSPF para suprimir a transmissão periódica de pacotes Hello e a atualização periódica de pacotes LSA. Esta função é aplicada principalmente em links carregados como ISDN, SVC e X.25.
Tabela 7 -27 Configurando um circuito de demanda OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure um circuito de demanda OSPF. | ip ospf [ ip-address ] demand-circuit | Obrigatório. Por padrão, nenhum circuito de demanda OSPF está habilitado. |
Configurar a prioridade de uma interface OSPF
As prioridades de interface são usadas principalmente na eleição de Roteador Designado (DR) e Roteador Designado de Backup (BDR) em redes de transmissão e redes NBMA. O intervalo de valores é 0-255. Quanto maior o valor, maior a prioridade. O valor padrão é 1.
O DR e o BDR são selecionados de todos os dispositivos em um segmento de rede com base em prioridades de interface e IDs de roteador por meio de pacotes Hello. As regras são as seguintes:
- Primeiro, o dispositivo cuja interface tem a prioridade mais alta é eleito como DR, e o dispositivo cuja interface tem a segunda prioridade mais alta é eleito como BDR. O dispositivo cuja interface tem prioridade 0 não participa da eleição.
- Se as prioridades de interface de dois dispositivos forem as mesmas, o dispositivo com o maior Router ID é eleito como o DR e o dispositivo com o segundo maior Router ID é eleito como o BDR.
- Se o DR falhar, o BDR se torna o DR imediatamente e um novo BDR é eleito.
Tabela 7 -28 Configurando a prioridade de uma interface OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure a prioridade de uma interface OSPF. | ip ospf priority priority-value | Opcional. Por padrão, a prioridade da interface OSPF é 1. |
As prioridades da interface afetam apenas um processo eleitoral. Caso o DR e o BDR já tenham sido eleitos, a modificação das prioridades da interface não afeta o resultado da eleição; em vez disso, afeta a próxima eleição de DR ou BDR. Portanto, o DR pode não ter a interface com a prioridade mais alta e o BDR pode não ter a interface com a segunda prioridade mais alta.
Configurar o MTU de uma interface OSPF
Ao encapsular pacotes OSPF, para evitar a fragmentação, você precisa limitar o tamanho do pacote para igual ou menor que a Unidade Máxima de Transmissão (MTU) da interface. Quando os dispositivos OSPF adjacentes trocam pacotes DD, as MTUs são verificadas por padrão. Se as MTUs forem diferentes, os dispositivos não podem formar uma relação de vizinhança. Se você configurou o OSPF para ignorar a verificação de MTU da interface, mesmo que os MTUs sejam diferentes, eles podem configurar uma relação de vizinho.
Tabela 7 -29 Configurando o MTU de uma Interface OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o MTU de uma interface OSPF. | ip ospf mtu mtu-value | Opcional. |
| Configure a interface OSPF para ignorar a verificação de consistência de MTU. | ip ospf [ ip-address ] mtu-ignore | Obrigatório. Por padrão, uma verificação de consistência de MTU será executada. |
Configurar o atraso de transmissão LSA de uma interface OSPF
O atraso de transmissão do LSA refere-se ao tempo que leva para um LSA inundar outros dispositivos. O dispositivo que envia o LSA adiciona o atraso de transmissão da interface ao tempo de envelhecimento do LSA. Por padrão, quando o LSA de inundação passa por um dispositivo, o tempo de envelhecimento é aumentado em 1. Você pode configurar o atraso de transmissão do LSA de acordo com as condições da rede. O intervalo de valores é 1-840. O atraso de transmissão LSA geralmente é configurado em links de baixa velocidade.
Tabela 7 -30 Configurando o atraso de transmissão LSA de uma interface OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o atraso de transmissão LSA de uma interface OSPF. | ip ospf transmit-delay delay-value | Opcional. Por padrão, o atraso de transmissão LSA é 1s. |
Configurar retransmissão OSPF LSA
Para garantir a confiabilidade da troca de dados, o OSPF adota o mecanismo de reconhecimento. Se um LSA inunda em uma interface de dispositivo, o LSA é adicionado à lista de retransmissão do vizinho. Se nenhuma mensagem de confirmação for recebida do vizinho após o tempo limite de retransmissão, o LSA será retransmitido até que uma mensagem de confirmação seja recebida.
Tabela 7 -31 Configurando a retransmissão OSPF LSA
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o intervalo de retransmissão OSPF LSA. | ip ospf retransmit-interval interval-value | Opcional. Por padrão, o intervalo de retransmissão é de 5s. |
Configurar o OSPF para evitar inundações de LSA
Em aplicações de rede reais, links redundantes podem ser usados entre vizinhos OSPF em algumas circunstâncias. Essa configuração ajuda a diminuir a inundação de pacotes de atualização OSPF em links redundantes.
Tabela 7 -32 Configurando o OSPF para evitar inundações de LSA
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure a interface OSPF para evitar inundação de LS-UPD. | ip ospf database-filter all out | Obrigatório. Por padrão, a interface OSPF não impede a inundação de LSA. |
Configurar o OSPF para evitar a propagação de LSA pode resultar na perda de algumas informações de roteamento.
Configurar o tempo de cálculo OSPF SPF
Se a topologia da rede OSPF for alterada, as rotas precisam ser recalculadas. Quando a rede continua a mudar, o cálculo de rotas frequentes ocupa muitos recursos do sistema. Você pode ajustar os parâmetros de tempo de cálculo do SPF para evitar que alterações frequentes na rede consumam muitos recursos do sistema.
Tabela 7 -33 Configurando o tempo de cálculo do SPF do OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure o tempo de cálculo OSPF SPF. | timers throttle spf delay-time hold-time max-time | Opcional. Por padrão, o tempo de atraso é de 5.000 ms, o tempo de espera é de 10.000 ms e o tempo máximo é de 10.000 ms. |
O parâmetro delay-time indica o atraso inicial do cálculo, hold-time indica o tempo de supressão e max-time indica o tempo máximo de espera entre dois cálculos de FPS. Se as mudanças de rede não forem frequentes, você pode reduzir o intervalo de cálculo de rota contínua para tempo de atraso . Se as mudanças de rede forem frequentes, você pode ajustar os parâmetros, aumentar o tempo de supressão para tempo de espera ×2 n-2 (n é o número de tempos de disparo de cálculo de rota), estender o tempo de espera com base no incremento de tempo de espera configurado e o valor máximo não deve exceder max-time .
Configurar o estouro de banco de dados OSPF
O estouro de banco de dados OSPF é usado para limitar o número de LSAs Tipo 5 no banco de dados.
Tabela 7 -34 Configurando o estouro de bancos de dados OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Configure o estouro do banco de dados OSPF. | overflow database external max-number seconds | Obrigatório. Por padrão, a função de estouro do banco de dados OSPF está desabilitada. |
Depois que a função de estouro de banco de dados é habilitada, os bancos de dados na área OSPF podem se tornar inconsistentes e algumas rotas podem ser perdidas.
Configurar OSPF para Coordenar com BFD (Aplicável somente ao modelo S3054G-B)
Condição de configuração
Antes de configurar o OSPF para coordenar com o BFD, certifique-se de que:
- Os endereços IP da interface foram configurados para que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite OSPF.
Configurar OSPF para coordenar com BFD
A detecção de encaminhamento bidirecional (BFD) fornece um método para detectar rapidamente o status de uma linha entre dois dispositivos. Se o BFD for iniciado entre dois dispositivos OSPF adjacentes, se a linha entre dois dispositivos estiver com defeito, o BFD detecta rapidamente a falha e informa o OSPF da falha. Em seguida, ele aciona o OSPF para iniciar o cálculo da rota e alternar para a linha de backup, obtendo uma rápida alternância de rotas.
Tabela 7 -35 Configurando o OSPF para coordenar com o BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Habilite ou desabilite o BFD na interface OSPF especificada. | ip ospf bfd [ ip-address | disable ] | Obrigatório. Por padrão, a função BFD está desabilitada. |
| Entre no modo de configuração global. | exit | - |
| Entre no modo de configuração OSPF. | router ospf process-id [ vrf vrf-name ] | - |
| Habilite o BFD em todas as interfaces do processo OSPF. | bfd all-interface | Opcional. |
Se o BFD estiver configurado no modo de configuração OSPF e no modo de configuração da interface, a configuração do BFD na interface terá a prioridade mais alta.
Configurar OSPF Fast Re-routing (Aplicável somente ao modelo S3054G-B)
Condição de configuração
Antes de configurar o reencaminhamento rápido do OSPF, primeiro conclua a seguinte tarefa:
- O endereço IP da interface é configurado para tornar acessível a camada de rede dos nós vizinhos.
- Habilite o protocolo OSPF.
Configurar o reencaminhamento rápido do OSPF
Na rede OSPF, a interrupção do tráfego causada pela falha do link ou do dispositivo continuará até que o protocolo detecte a falha do link, e a rota flutuante não se recuperará até que a rota flutuante entre em vigor, o que geralmente dura vários segundos. Para reduzir o tempo de interrupção do tráfego, o reencaminhamento rápido do OSPF pode ser configurado. Através da aplicação do mapa de roteamento, o próximo salto de backup é definido para a rota correspondente. Uma vez que o link ativo falhe, o tráfego que passa pelo link ativo será imediatamente comutado para o link em espera, de modo a atingir o objetivo de comutação rápida.
Tabela 7 -36 Configurar o reencaminhamento rápido do OSPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPF | router ospf process-id [ vrf vrf-name ] | - |
| Configurar o processo OSPF para habilitar a função de reencaminhamento rápido | fast-reroute route-map route-map-name | Obrigatório. Por padrão, não habilite a função de redirecionamento rápido do OSPF. |
Configurar OSPF GR
informações de rota da camada de encaminhamento entre o dispositivo local e o dispositivo vizinho inalteradas durante a alternância ativa/em espera dos dispositivos e o encaminhamento não é afetado. Após alternar o dispositivo e executar novamente, a camada de protocolo dos dois dispositivos sincroniza as informações de rota e atualiza a camada de encaminhamento para que o encaminhamento de dados não seja interrompido durante a alternância do dispositivo .
Existem dois papéis durante o GR:
- GR Restarter : O dispositivo que executa a reinicialização normal do protocolo
- GR Helper : O dispositivo que auxilia a reinicialização graciosa do protocolo
O dispositivo distribuído pode servir como GR Restarter e GR Helper, enquanto o dispositivo centralizado pode servir apenas como GR Helper, auxiliando o Restarter a completar o GR.
Condição de configuração
Antes de configurar o OSPF GR, primeiro complete a seguinte tarefa:
- Configure o endereço IP da interface, disponibilizando o nó vizinho
- Habilite o protocolo OSPF
Configurar OSPF GR Reinicialização
Tabela 7 -37 Configurar OSPF GR Restarter
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração OSPF | router ospf process-id [ vrf vrf-name ] | - |
| Configurar OSPF GR | nsf ietf | Obrigatório Por padrão, não habilite a função GR. A função entra em vigor e o protocolo precisa suportar a função O paque- LSA. Por padrão, suporte a função O paque- LSA. |
| Configurar o período OSPF GR | nsf interval grace-period | Opcional Por padrão, o período GR é 95s. |
função OSPF GR pode ser usado apenas no ambiente de empilhamento ou ambiente de controle duplo.
Configurar OSPF GR Ajudante
O GR Helper ajuda o Restarter a completar o GR. Por padrão, o dispositivo habilita a função. o nsf ietf ajudante desativar comando é usado para desabilitar a função GR Helper . o nsf ietf ajudante O comando strict-lsa-checking é usado para configurar o Helper para executar a verificação estrita do LSA durante o GR. Se achar que o LSA não muda, saia do modo GR Helper.
Tabela 7 -38 Configurar OSPF GR Helper
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração OSPF | router ospf process-id [ vrf vrf-name ] | - |
| Configurar o Auxiliar OSPF GR | nsf ietf helper [ disable | strict-lsa-checking ] | Opcional Por padrão, habilite a função Auxiliar e não execute a verificação estrita para LSA. |
Monitoramento e Manutenção do OSPF
Tabela 7 -39 Monitoramento e Manutenção do OSPF
| Comando | Descrição |
| clear ip ospf [ process-id ] process | Redefine um processo OSPF. |
| clear ip ospf process-id neighbor neighbor-ip-address [ neighbor-router-id ] | Redefine um vizinho OSPF. |
| clear ip ospf statistics [ interface-name ] | Limpa as estatísticas da interface OSPF. |
| clear ip ospf [ process-id ] redistribution | Re-anuncia rotas externas. |
| clear ip ospf [ process-id ] route | Recalcula as rotas OSPF. |
| show ip ospf [ process-id ] | Exiba as informações básicas do OSPF. |
| show ip ospf [ process-id ] border-routers | Exiba as informações sobre as rotas que alcançaram os dispositivos de limite no OSPF. |
| show ip ospf [ process-id ] buffers | Exibe o tamanho do buffer de transmissão e recebimento do pacote OSPF. |
| show ip ospf [ process-id ] database [ adv-router router-id | age lsa_age | database-summary | max-age | [ asbr-summary | external | network | nssa-external | opaque-area | opaque-as | opaque-link | router | self-originate | summary ] [ [ link-state-id ] [ adv-router advertising-router-id ] | self-originate | summary ] ] | Exiba as informações sobre um banco de dados OSPF. |
| show ip ospf interface [ interface-name [ detail ] ] | Exiba as informações sobre uma interface OSPF. |
| show ip ospf [ process-id ] neighbor [ neighbor-id | all | detail [ all ] | interface ip-address [ detail ] | statistic ] | Exiba as informações sobre os vizinhos OSPF. |
| show ip ospf [ process-id ] route [ ip-address mask | ip-address/mask-length | external | inter-area | intra-area | statistic ] | Exiba as informações sobre rotas OSPF. |
| show ip ospf [ process-id ] virtual-links | Exiba as informações sobre links virtuais OSPF. |
| show ip ospf [ process-id ] sham-links | Exiba as informações sobre uma interface na qual os links simulados do OSPF estão configurados. As informações incluem o status da interface, valor de custo e status do vizinho. |
Exemplo de configuração típica do OSPF
Configurar funções básicas do OSPF
Requisitos de rede
- Configure o OSPF para todos os dispositivos e divida os dispositivos em três áreas: Área 0, Área 1 e Área 2. Após a configuração, todos os dispositivos devem ser capazes de aprender rotas uns dos outros.
- Em uma interface Ethernet back-to-back, para acelerar o conjunto de vizinhos OSPF, você pode alterar o tipo de rede da interface OSPF para P2P. Modifique o tipo de rede das interfaces na Área 2 para P2P. Após a configuração, todos os dispositivos podem aprender rotas uns dos outros.
Topologia de rede

Figura 7 -1 Rede para configurar funções básicas do OSPF
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure um processo OSPF e deixe a interface cobrir diferentes áreas.
#No Device1, configure um processo OSPF e configure as interfaces para cobrir a área 1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#router-id 1.1.1.1Device1(config-ospf)#network 10.0.0.0 0.0.0.255 area 1Device1(config-ospf)#network 100.0.0.0 0.0.0.255 area 1Device1(config-ospf)#exit
#No Device2, configure um processo OSPF e configure as interfaces para cobrir a Área 0 e a Área 1.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#router-id 2.2.2.2Device2(config-ospf)#network 20.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 10.0.0.0 0.0.0.255 area 1Device2(config-ospf)#exit
#No Device3, configure um processo OSPF e configure as interfaces para cobrir a Área 0 e a Área 2.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#router-id 3.3.3.3Device3(config-ospf)#network 20.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 30.0.0.0 0.0.0.255 area 2Device3(config-ospf)#exit
#No Device4, configure um processo OSPF e configure as interfaces para cobrir a área 2.
Device4#configure terminalDevice4(config)#router ospf 100Device4(config-ospf)#router-id 4.4.4.4Device4(config-ospf)#network 30.0.0.0 0.0.0.255 area 2Device4(config-ospf)#network 200.0.0.0 0.0.0.255 area 2Device4(config-ospf)#exit
Um Router IDs pode ser configurado manualmente ou gerado automaticamente. Se uma ID de roteador não for configurada manualmente, o dispositivo selecionará automaticamente uma ID de roteador. O dispositivo primeiro seleciona o maior endereço IP entre os endereços IP da interface Loopback como o ID do roteador. Se o dispositivo não estiver configurado com endereços IP de interface Loopback, ele selecionará os maiores endereços IP entre os endereços IP de interface comum como o ID do roteador. Somente quando uma interface está no status UP, o endereço IP da interface pode ser selecionado como o Router ID. Ao usar o comando network , a máscara curinga não precisa corresponder exatamente ao comprimento da máscara dos endereços IP da interface, mas o segmento de rede precisa cobrir os endereços IP da interface. Por exemplo, a rede 0.0.0.0 255.255.255.255 significa cobrir todas as interfaces.
#Consulte os vizinhos OSPF e a tabela de roteamento do Device1.
Device1#show ip ospf neighborOSPF process 100:Neighbor ID Pri State Dead Time Address Interface2.2.2.2 1 Full/DR 00:00:36 10.0.0.2 vlan3Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 02:26:21, vlan3O 20.0.0.0/24 [110/2] via 10.0.0.2, 02:25:36, vlan3O 30.0.0.0/24 [110/3] via 10.0.0.2, 02:25:36, vlan3C 100.0.0.0/24 is directly connected, 02:26:23, vlan2C 127.0.0.0/8 is directly connected, 18:09:44, lo0O 200.0.0.0/24 [110/4] via 10.0.0.2, 02:25:36, vlan3
#Consulte os vizinhos OSPF e a tabela de roteamento do Device2.
Device2#show ip ospf neighborOSPF process 100:Neighbor ID Pri State Dead Time Address Interface1.1.1.1 1 Full/Backup 00:00:37 10.0.0.1 vlan23.3.3.3 1 Full/DR 00:00:38 20.0.0.2 vlan3Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 02:31:15, vlan2C 20.0.0.0/24 is directly connected, 02:31:50, vlan3O 30.0.0.0/24 [110/2] via 20.0.0.2, 02:31:40, vlan3O 100.0.0.0/24 [110/2] via 10.0.0.1, 02:30:29, vlan2C 127.0.0.0/8 is directly connected, 240:21:34, lo0O 200.0.0.0/24 [110/3] via 20.0.0.2, 02:31:40, vlan3
#Query OSPF Link Status Database (LSDB) do Device2.
Device2#show ip ospf databaseOSPF Router with ID (2.2.2.2) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count2.2.2.2 2.2.2.2 1777 0x8000000c 0xcb20 13.3.3.3 3.3.3.3 309 0x8000000a 0x9153 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum20.0.0.2 3.3.3.3 369 0x80000006 0xec12Summary Link States (Area 0)Link ID ADV Router Age Seq# CkSum Route10.0.0.0 2.2.2.2 1757 0x80000005 0xcc59 10.0.0.0/24100.0.0.0 2.2.2.2 1356 0x80000005 0x408a 100.0.0.0/2430.0.0.0 3.3.3.3 9 0x80000006 0xa765 30.0.0.0/24200.0.0.0 3.3.3.3 149 0x80000006 0x075a 200.0.0.0/24Router Link States (Area 1)Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 1775 0x80000009 0xbbda 22.2.2.2 2.2.2.2 1737 0x80000008 0x2dd5 1Net Link States (Area 1)Link ID ADV Router Age Seq# CkSum10.0.0.2 2.2.2.2 34 0x80000006 0x39dbSummary Link States (Area 1)Link ID ADV Router Age Seq# CkSum Route20.0.0.0 2.2.2.2 144 0x80000006 0x48d2 20.0.0.0/2430.0.0.0 2.2.2.2 1186 0x80000005 0xd13f 30.0.0.0/24200.0.0.0 2.2.2.2 14 0x80000006 0x2f35 200.0.0.0/24
Para Device2, as rotas 30.0.0.0/24 e 200.0.0.0/24 são rotas entre áreas. Você pode consultar as informações de LSA das rotas relacionadas em Summary Link States (Área 0). No caso de rotas intra-área, execute o show IP ospf base de dados roteador comando para consultar as informações LSA das rotas relacionadas.
- Passo 4: Configure o tipo de rede de interfaces OSPF para P2P.
#No Device3, configure o tipo de rede OSPF da interface VLAN3 para P2P.
Device3(config)#interface vlan3Device3(config-if-vlan3)#ip ospf network point-to-pointDevice3(config-if-vlan3)#exit
#No Device4, configure o tipo de rede OSPF da interface VLAN2 para P2P.
Device4(config)#interface vlan2Device4(config-if-vlan2)#ip ospf network point-to-pointDevice4(config-if-vlan2)#exit
- Passo 5: Confira o resultado.
#Consulte os vizinhos OSPF e a tabela de roteamento do Device3.
Device3#show ip ospf neighborOSPF process 100:Neighbor ID Pri State Dead Time Address Interface2.2.2.2 1 Full/Backup 00:00:36 20.0.0.1 vlan24.4.4.4 1 Full/ - 00:00:39 30.0.0.2 vlan3Device3#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 10.0.0.0/24 [110/2] via 20.0.0.1, 00:02:53, vlan2C 20.0.0.0/24 is directly connected, 03:20:36, vlan2C 30.0.0.0/24 is directly connected, 03:20:26, vlan3O 100.0.0.0/24 [110/3] via 20.0.0.1, 00:01:51, vlan2C 127.0.0.0/8 is directly connected, 262:01:24, lo0O 200.0.0.0/24 [110/2] via 30.0.0.2, 00:00:11, vlan3
Se as relações de vizinhos OSPF forem configuradas em uma rede P2P, nenhuma eleição de DR ou BDR será realizada.
#Consulte os vizinhos OSPF e a tabela de roteamento do Device4.
Device4#show ip ospf neighborOSPF process 100:Neighbor ID Pri State Dead Time Address Interface3.3.3.3 1 Full/ - 00:00:39 30.0.0.1 vlan2Device4#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 10.0.0.0/24 [110/3] via 30.0.0.1, 00:01:04, vlan2O 20.0.0.0/24 [110/2] via 30.0.0.1, 00:01:04, vlan2C 30.0.0.0/24 is directly connected, 03:20:25, vlan2O 100.0.0.0/24 [110/4] via 30.0.0.1, 00:01:04, vlan2C 127.0.0.0/8 is directly connected, 22:52:36, lo0C 200.0.0.0/24 is directly connected, 03:20:13, vlan3
Depois que o tipo de rede das interfaces OSPF é modificado para P2P, os vizinhos podem ser configurados normalmente e as rotas podem ser aprendidas normalmente.
Ao configurar os tipos de rede para interfaces OSPF, os tipos de rede das interfaces OSPF nas duas extremidades dos vizinhos devem ser os mesmos; caso contrário, o aprendizado de roteamento e a inundação serão afetados. Por padrão, o tipo de rede de uma interface OSPF é determinado pelo tipo de rede da interface física.
Configurando a autenticação OSPF
Requisitos de rede
- Configure o OSPF para todos os dispositivos, execute o OSPF e configure a autenticação de área para os dispositivos. Configure a autenticação de texto simples para a Área 0 e configure a autenticação MD5 para a Área 1.
- Configure a autenticação da interface OSPF, configure a autenticação da interface da Área 0 para autenticação de texto simples e configure a autenticação da interface da Área 1 para a autenticação MD5.
- Após a conclusão da configuração, os dispositivos devem ser capazes de configurar normalmente as relações de vizinhos e aprender a rota uns dos outros.
Topologia de rede
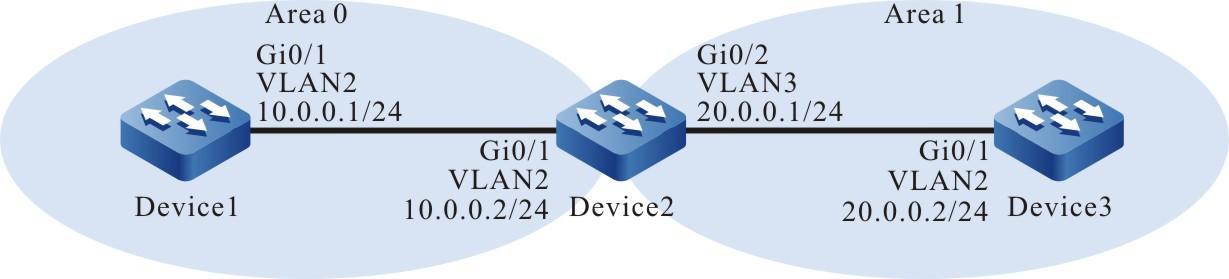
Figura 7 -2 Rede para configurar a autenticação OSPF
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure um processo OSPF e configure as interfaces para cobrir diferentes áreas e habilite a autenticação de área. Configure a autenticação de texto simples para a Área 0 e configure a autenticação MD5 para a Área 1.
#No Device1, configure um processo OSPF e configure a função de autenticação de área.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#router-id 1.1.1.1Device1(config-ospf)#area 0 authenticationDevice1(config-ospf)#network 10.0.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
#No Device2, configure um processo OSPF e configure a função de autenticação de área.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#router-id 2.2.2.2Device2(config-ospf)#area 0 authenticationDevice2(config-ospf)#area 1 authentication message-digestDevice2(config-ospf)#network 10.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 20.0.0.0 0.0.0.255 area 1Device2(config-ospf)#exit
#No Device3, configure um processo OSPF e configure a função de autenticação de área.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#router-id 3.3.3.3Device3(config-ospf)#area 1 authentication message-digestDevice3(config-ospf)#network 20.0.0.0 0.0.0.255 area 1Device3(config-ospf)#exit
#Consulte as informações do processo OSPF do Device1.
Device1#show ip ospf 100Routing Process "ospf 100" with ID 1.1.1.1Process bound to VRF defaultProcess uptime is 30 minutesIETF NSF restarter support disabledIETF NSF helper support enabledConforms to RFC2328, and RFC1583Compatibility flag is disabledSupports only single TOS(TOS0) routesSupports opaque LSASupports Graceful RestartInitial SPF schedule delay 5000 msecsMinimum hold time between two consecutive SPFs 10000 msecsMaximum wait time between two consecutive SPFs 10000 msecsRefresh timer 10 secsNumber of external LSA 0. Checksum Sum 0x000000Number of opaque AS LSA 0. Checksum Sum 0x000000Number of non-default external LSA is 0External LSA database is unlimited.Not Support Demand Circuit lsa number is 0, autonomy system support flood DoNotAge LsaNumber of areas attached to this router: 1Area 0 (BACKBONE) Number of interfaces in this area is 1(1)Number of fully adjacent neighbors in this area is 1Number of fully adjacent sham-link neighbors in this area is 0Area has simple password authenticationSPF algorithm last executed 00:27:43.916 agoSPF algorithm executed 3 timesNumber of LSA 4. Checksum Sum 0x0160f7Not Support Demand Circuit lsa number is 0,Indication lsa (by other routers) number is: 0,Area support flood DoNotAge Lsa
De acordo com as informações consultadas, a autenticação de área é o modo texto simples .
#Consulte os vizinhos OSPF e a tabela de roteamento do Device1.
Device1#show ip ospf neighborOSPF process 100:Neighbor ID Pri State Dead Time Address Interface2.2.2.2 1 Full/DR 00:00:38 10.0.0.2 vlan2Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:14:01, vlan2O 20.0.0.0/24 [110/2] via 10.0.0.2, 00:10:38, vlan2C 127.0.0.0/8 is directly connected, 20:55:08, lo0
No Device1, os vizinhos podem ser configurados normalmente e as rotas podem ser aprendidas normalmente.
#Consulte as informações do processo OSPF do Device3.
Device3#show ip ospf 100Routing Process "ospf 100" with ID 3.3.3.3Process bound to VRF defaultProcess uptime is 28 minutesIETF NSF restarter support disabledIETF NSF helper support enabledConforms to RFC2328, and RFC1583Compatibility flag is disabledSupports only single TOS(TOS0) routesSupports opaque LSASupports Graceful RestartInitial SPF schedule delay 5000 msecsMinimum hold time between two consecutive SPFs 10000 msecsMaximum wait time between two consecutive SPFs 10000 msecsRefresh timer 10 secsNumber of external LSA 0. Checksum Sum 0x000000Number of opaque AS LSA 0. Checksum Sum 0x000000Number of non-default external LSA is 0External LSA database is unlimited.Not Support Demand Circuit lsa number is 0, autonomy system support flood DoNotAge LsaNumber of areas attached to this router: 1Area 1 Number of interfaces in this area is 1(1)Number of fully adjacent neighbors in this area is 1Number of fully adjacent sham-link neighbors in this area is 0Number of fully adjacent virtual neighbors through this area is 0Area has message digest authenticationSPF algorithm last executed 00:24:01.783 agoSPF algorithm executed 5 timesNumber of LSA 4. Checksum Sum 0x0337cfNot Support Demand Circuit lsa number is 0,Indication lsa (by other routers) number is: 0,Area support flood DoNotAge Lsa
De acordo com as informações consultadas, a autenticação de área é o modo de autenticação MD5.
#Consulte os vizinhos OSPF e a tabela de roteamento do Device3.
Device3#show ip ospf neighborOSPF process 100:Neighbor ID Pri State Dead Time Address Interface2.2.2.2 1 Full/Backup 00:00:33 20.0.0.1 vlan2Device3#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 10.0.0.0/24 [110/2] via 20.0.0.1, 00:09:31, vlan2C 20.0.0.0/24 is directly connected, 00:20:36, vlan2C 127.0.0.0/8 is directly connected, 24:00:06, lo0
No Device3, os vizinhos podem ser configurados normalmente e as rotas podem ser aprendidas normalmente.
- Passo 4: Configure a autenticação da interface OSPF.
#No Device1, configure a interface VLAN2 com autenticação de texto simples e defina a senha para admin.
Device1(config)#interface vlan2Device1(config-if-vlan2)#ip ospf authenticationDevice1(config-if-vlan2)#ip ospf authentication-key 0 adminDevice1(config-if-vlan2)#exit
#No Device2, configure a interface VLAN2 com autenticação de texto simples e defina a senha para admin. Configure a interface VLAN3 com autenticação MD5, defina o ID da chave para 1 e defina a senha para admin.
Device2(config)#interface vlan2Device2(config-if-vlan2)#ip ospf authenticationDevice2(config-if-vlan2)#ip ospf authentication-key 0 adminDevice2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ip ospf authentication message-digestDevice2(config-if-vlan3)#ip ospf message-digest-key 1 md5 0 adminDevice2(config-if-vlan3)#exit
# No Device3, configure a interface VLAN2 com autenticação MD5, defina o ID da chave para 1 e defina a senha para admin.
Device3(config)#interface vlan2Device3(config-if-vlan2)#ip ospf authentication message-digestDevice3(config-if-vlan2)#ip ospf message-digest-key 1 md5 0 adminDevice3(config-if-vlan2)#exit
- Passo 5: Confira o resultado.
#Consulte as informações do vizinho OSPF do Device2.
Device2#show ip ospf neighborOSPF process 100:Neighbor ID Pri State Dead Time Address Interface1.1.1.1 1 Full/Backup 00:00:33 10.0.0.1 vlan23.3.3.3 1 Full/DR 00:00:39 20.0.0.2 vlan3
#Consulte as informações da interface OSPF do Device2.
Device2#show ip ospf interface vlan2vlan2 is up, line protocol is upInternet Address 10.0.0.2, 10.0.0.255( a[10.0.0.2] d[10.0.0.255]) Area 0, MTU 1500Process ID 100, Router ID 2.2.2.2, Network Type BROADCAST, Cost: 1Transmit Delay is 1 sec, State DR, Priority 1, TE Metric 0Designated Router (ID) 2.2.2.2, Interface Address 10.0.0.2Backup Designated Router (ID) 1.1.1.1, Interface Address 10.0.0.1Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5Hello due in 00:00:04Neighbor Count is 1, Adjacent neighbor count is 1Crypt Sequence Number is 0Graceful restart proxy id is 0x0Hello received 406 sent 454, DD received 8 sent 6LS-Req received 2 sent 2, LS-Upd received 11(LSA: 15) sent 10(LSA: 14)LS-Ack received 10 sent 0, Discarded 0Device2#show ip ospf interface vlan3vlan3 is up, line protocol is upInternet Address 20.0.0.1, 20.0.0.255( a[20.0.0.1] d[20.0.0.255]) Area 1, MTU 1500Process ID 100, Router ID 2.2.2.2, Network Type BROADCAST, Cost: 1Transmit Delay is 1 sec, State Backup, Priority 1, TE Metric 0Designated Router (ID) 3.3.3.3, Interface Address 20.0.0.2Backup Designated Router (ID) 2.2.2.2, Interface Address 20.0.0.1Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5Hello due in 00:00:00Neighbor Count is 1, Adjacent neighbor count is 1Crypt Sequence Number is 485Graceful restart proxy id is 0x0Hello received 412 sent 454, DD received 9 sent 12LS-Req received 3 sent 3, LS-Upd received 9(LSA: 10) sent 13(LSA: 16)LS-Ack received 13 sent 8, Discarded 0
Depois que a autenticação MD5 é configurada, um número de sequência de criptografia é gerado. No caso de autenticação de texto simples , nenhum número de sequência é gerado.
Ao configurar a autenticação OSPF, você pode configurar apenas autenticação de área ou autenticação de interface ou configurar ambas. Se a autenticação de área e a autenticação de interface estiverem configuradas, a autenticação de interface entrará em vigor primeiro.
Configurando o OSPF para redistribuir rotas
Requisitos de rede
- Execute OSPF entre Device1 e Device2 e execute RIPv2 entre Device2 e Device3.
- Device2 redistribui rotas RIP para OSPF e usa uma política de rota para controlar o dispositivo para redistribuir apenas a rota 100.0.0.0/24.
Topologia de rede

Figura 7 -3 Rede para configurar o OSPF para redistribuir rotas
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure o OSPF entre Device e Device2. Configure o RIPv2 entre Device2 e Device3.
#Configure OSPF para Device1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#router-id 1.1.1.1Device1(config-ospf)#network 10.0.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configure OSPF e RIPv2 para Device2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#router-id 2.2.2.2Device2(config-ospf)#network 10.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exitDevice2(config)#router ripDevice2(config-rip)#version 2Device2(config-rip)#network 20.0.0.0Device2(config-rip)#exit
#Configure RIPv2 para Device3.
Device3#configure terminalDevice3(config)#router ripDevice3(config-rip)#version 2Device3(config-rip)#network 20.0.0.0Device3(config-rip)#network 100.0.0.0Device3(config-rip)#network 110.0.0.0Device3(config-rip)#exit
#Consulte as informações do vizinho OSPF do Device2.
Device2#show ip ospf neighborOSPF process 100:Neighbor ID Pri State Dead Time Address Interface1.1.1.1 1 Full/Backup 00:00:32 10.0.0.1 vlan2
#Consulte as informações do vizinho OSPF do Device2.
Device2#show ip ospf vizinho
Processo OSPF 100:
Interface de endereço de tempo morto do estado Pri da ID do vizinho
1.1.1.1 1 Completo/Backup 00:00:32 10.0.0.1 vlan2
#Consulte a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:21:17, vlan2C 20.0.0.0/24 is directly connected, 00:21:33, vlan3R 100.0.0.0/24 [120/1] via 20.0.0.2, 00:10:58, vlan3R 110.0.0.0/24 [120/1] via 20.0.0.2, 00:10:58, vlan3C 127.0.0.0/8 is directly connected, 30:20:17, lo0
As rotas RIP foram aprendidas pelo Device2.
- Passo 4: Configure a política de roteamento.
# Configurar dispositivo2.
Device2(config)#ip access-list standard 1Device2(config-std-nacl)#permit 100.0.0.0 0.0.0.255Device2(config-std-nacl)#exitDevice2(config)#route-map RIPtoOSPFDevice2(config-route-map)#match ip address 1Device2(config-route-map)#exit
O mapa de rotas é configurado para invocar uma ACL para corresponder apenas a 100.0.0.0/24 enquanto filtra outro segmento de rede, como 20.0.0.0/24 e 110.0.0.0/24.
- Passo 5: Configure o OSPF para redistribuir rotas RIP e associar uma política de roteamento.
# Configurar dispositivo2.
Device2(config)#router ospf 100Device2(config-ospf)#redistribute rip route-map RIPtoOSPFDevice2(config-ospf)#exit
Na redistribuição de rotas RIP, a regra de correspondência de mapa de rotas é invocada para filtragem.
- Passo 6: Confira o resultado.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:47:27, vlan2OE 100.0.0.0/24 [150/20] via 10.0.0.2, 00:21:39, vlan2C 127.0.0.0/8 is directly connected, 21:40:06, lo0
A tabela de roteamento de Device1 aprendeu apenas a rota externa OSPF 100.0.0.0/24 enquanto as rotas 20.0.0.0/24 e 110.0.0.0/24 foram filtradas.
#Consulte as informações do processo OSPF e banco de dados do Device2.
Device2#show ip ospf 100Routing Process "ospf 100" with ID 2.2.2.2Process bound to VRF defaultProcess uptime is 1 hour 4 minutesIETF NSF restarter support disabledIETF NSF helper support enabledConforms to RFC2328, and RFC1583Compatibility flag is disabledSupports only single TOS(TOS0) routesSupports opaque LSASupports Graceful RestartThis router is an ASBR (injecting external routing information)Initial SPF schedule delay 5000 msecsMinimum hold time between two consecutive SPFs 10000 msecsMaximum wait time between two consecutive SPFs 10000 msecsRefresh timer 10 secsNumber of external LSA 2. Checksum Sum 0x0161F5Number of opaque AS LSA 0. Checksum Sum 0x000000Number of non-default external LSA is 2External LSA database is unlimited.Not Support Demand Circuit lsa number is 0, autonomy system support flood DoNotAge LsaNumber of areas attached to this router: 1Area 0 (BACKBONE) Number of interfaces in this area is 1(1)Number of fully adjacent neighbors in this area is 1Number of fully adjacent sham-link neighbors in this area is 0Area has no authenticationSPF algorithm last executed 00:37:52.833 agoSPF algorithm executed 3 timesNumber of LSA 3. Checksum Sum 0x00e746Not Support Demand Circuit lsa number is 0,Indication lsa (by other routers) number is: 0,Area support flood DoNotAge LsaDevice2#show ip ospf 100 databaseOSPF Router with ID (2.2.2.2) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 191 0x80000004 0x70a0 12.2.2.2 2.2.2.2 537 0x80000005 0x36ce 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum10.0.0.2 2.2.2.2 818 0x80000003 0x3fd8AS External Link StatesLink ID ADV Router Age Seq# CkSum Route100.0.0.0 2.2.2.2 718 0x80000002 0x72be E2 100.0.0.0/24 [0x0]
De acordo com as informações sobre o processo OSPF 100, Device2 mudou sua função para se tornar um ASBR, e apenas um LSA externo foi gerado no banco de dados.
Em um aplicativo real, se houver dois ou mais roteadores de limite AS, é recomendável não redistribuir rotas entre diferentes protocolos de roteamento. Se você realmente precisar redistribuir rotas entre diferentes protocolos de roteamento, configure uma política de roteamento para evitar loops de roteamento.
Configurar multiprocessos OSPF
Requisitos de rede
- Configure o OSPF em todos os dispositivos. Em Device2, habilite dois processos OSPF. Configure o OSPF 100 do Device1 e o do Device2 para configurar uma relação de vizinho. Configure o OSPF 200 do Device3 e o do Device2 para configurar uma relação de vizinho.
- Os dois processos OSPF no Device2 redistribuem rotas entre si. O processo OSPF 100 usa uma política de roteamento para controlar a redistribuição apenas da rota 110.0.0.0/24. O processo OSPF 200 usa uma política de roteamento para controlar a redistribuição apenas da rota 100.0.0.0/24.
Topologia de rede

Figura 7 -4 Rede para configurar multiprocessos OSPF
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure o protocolo OSPF.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#router-id 1.1.1.1Device1(config-ospf)#network 10.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 100.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 100.1.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
#No Device2, crie dois processos OSPF, processo 100 e processo 200.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#router-id 2.2.2.2Device2(config-ospf)#network 10.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exitDevice2(config)#router ospf 200Device2(config-ospf)#router-id 2.2.2.3Device2(config-ospf)#network 20.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 200Device3(config-ospf)#router-id 3.3.3.3Device3(config-ospf)#network 20.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 110.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 110.1.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
Se houver vários processos OSPF, é recomendável configurar diferentes IDs de roteador para os processos OSPF para evitar conflito de ID de roteador.
#Consulte as informações do LSDB e do vizinho do Device2.
Device2#show ip ospf neighborOSPF process 100:Neighbor ID Pri State Dead Time Address Interface1.1.1.1 1 Full/Backup 00:00:30 10.0.0.1 vlan2OSPF process 200:Neighbor ID Pri State Dead Time Address Interface3.3.3.3 1 Full/DR 00:00:33 20.0.0.2 vlan3Device2#show ip ospf databaseOSPF Router with ID (2.2.2.2) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 19 0x80000016 0x53bf 32.2.2.2 2.2.2.2 15 0x80000010 0x1ae1 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum10.0.0.2 2.2.2.2 21 0x80000001 0x43d6OSPF Router with ID (2.2.2.3) (Process ID 200)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count2.2.2.3 2.2.2.3 14 0x8000000f 0xb235 13.3.3.3 3.3.3.3 15 0x8000001b 0x696b 3Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum20.0.0.2 3.3.3.3 15 0x80000002 0x03fe
Os vizinhos foram configurados respectivamente para OSPF 100 e OSPF 200 do Device2, e os dois processos têm seus respectivos bancos de dados OSPF.
#Consulte a tabela de roteamento OSPF do Device2.
Device2#show ip ospf routeOSPF process 100:Codes: C - connected, D - Discard, O - OSPF, IA - OSPF inter areaN1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2E1 - OSPF external type 1, E2 - OSPF external type 2O 10.0.0.0/24 [1] is directly connected, vlan2, Area 0O 100.0.0.0/24 [2] via 10.0.0.1, vlan2, Area 0O 100.1.0.0/24 [2] via 10.0.0.1, vlan2, Area 0OSPF process 200:Codes: C - connected, D - Discard, O - OSPF, IA - OSPF inter areaN1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2E1 - OSPF external type 1, E2 - OSPF external type 2O 20.0.0.0/24 [1] is directly connected, vlan3, Area 0O 110.0.0.0/24 [2] via 20.0.0.2, vlan3, Area 0O 110.1.0.0/24 [2] via 20.0.0.2, vlan3, Area 0
O processo OSPF 100 e o processo 200 calcularam suas próprias rotas.
#Consulte a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:05:34, vlan2C 20.0.0.0/24 is directly connected, 00:05:28, vlan3O 100.0.0.0/24 [110/2] via 10.0.0.1, 00:04:42, vlan2O 100.1.0.0/24 [110/2] via 10.0.0.1, 00:04:42, vlan2O 110.0.0.0/24 [110/2] via 20.0.0.2, 00:04:41, vlan3O 110.1.0.0/24 [110/2] via 20.0.0.2, 00:04:41, vlan3C 127.0.0.0/8 is directly connected, 48:40:33, lo0
- Passo 4: Configure a política de roteamento.
# Configurar dispositivo2.
Device2(config)#ip prefix-list 1 permit 110.0.0.0/24Device2(config)#ip prefix-list 2 permit 100.0.0.0/24Device2(config)#route-map OSPF200to100Device2(config-route-map)#match ip address prefix-list 1Device2(config-route-map)#exitDevice2(config)#route-map OSPF100to200Device2(config-route-map)#match ip address prefix-list 2Device2(config-route-map)#exit
Os mapas de rotas foram configurados para invocar a lista de prefixos 1 e a lista de prefixos 2 para corresponder ao segmento de rede 110.0.0.0/24 e 100.0.0.0/24, respectivamente.
Ao configurar uma política de roteamento, você pode criar uma regra de filtragem com base em uma lista de prefixos ou ACL. A lista de prefixos pode corresponder precisamente às máscaras de roteamento, enquanto a ACL não pode corresponder às máscaras de roteamento.
- Passo 5: Configure processos OSPF para redistribuir rotas RIP entre si e associar políticas de roteamento.
# Configurar dispositivo2.
Device2(config)#router ospf 100Device2(config-ospf)#redistribute ospf 200 route-map OSPF200to100Device2(config-ospf)#exitDevice2(config)#router ospf 200Device2(config-ospf)#redistribute ospf 100 route-map OSPF100to200Device2(config-ospf)#exit
- Passo 6: Confira o resultado.
#Consulta OSPF LSDB do Device2.
Device2#show ip ospf databaseOSPF Router with ID (2.2.2.2) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 1663 0x80000016 0x53bf 32.2.2.2 2.2.2.2 216 0x80000011 0x1eda 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum10.0.0.2 2.2.2.2 1664 0x80000001 0x43d6AS External Link StatesLink ID ADV Router Age Seq# CkSum Route110.0.0.0 2.2.2.2 216 0x80000001 0x3dfc E2 110.0.0.0/24 [0x0]OSPF Router with ID (2.2.2.3) (Process ID 200)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count2.2.2.3 2.2.2.3 205 0x80000010 0xb62e 13.3.3.3 3.3.3.3 1658 0x8000001b 0x696b 3Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum20.0.0.2 3.3.3.3 1658 0x80000002 0x03feAS External Link StatesLink ID ADV Router Age Seq# CkSum Route100.0.0.0 2.2.2.3 205 0x80000001 0xb989 E2 100.0.0.0/24 [0x0]
De acordo com as informações consultadas, o processo OSPF 100 possui apenas o LSA da rota externa 110.0.0.0/24, e as demais rotas 110.1.0.0/24 e 20.0.0.0/24 foram filtradas pela política de roteamento OSPF200to100. Da mesma forma, o processo OSPF 200 tem apenas o LSA da rota externa 100.0.0.0/24, e as outras rotas 100.1.0.0/24 e 10.0.0.0/24 foram filtradas pela política de roteamento OSPF100to200.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:40:20, vlan2C 100.0.0.0/24 is directly connected, 03:11:36, vlan3C 100.1.0.0/24 is directly connected, 01:00:22, vlan4OE 110.0.0.0/24 [150/2] via 10.0.0.2, 00:15:27, vlan2C 127.0.0.0/8 is directly connected, 97:08:23, lo0
Device1 aprendeu apenas a rota 110.0.0.0/24.
#Consulte a tabela de roteamento do Device3.
Device3#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 20.0.0.0/24 is directly connected, 00:42:44, vlan2OE 100.0.0.0/24 [150/2] via 20.0.0.1, 00:17:45, vlan2C 110.0.0.0/24 is directly connected, 01:02:03, vlan3C 110.1.0.0/24 is directly connected, 01:02:14, vlan4C 127.0.0.0/8 is directly connected, 41:02:01, lo0
Device3 aprendeu apenas a rota 100.0.0.0/24.
Em um aplicativo real, se houver dois ou mais roteadores de limite AS, é recomendável não redistribuir rotas entre diferentes processos OSPF. Se você realmente precisar redistribuir rotas entre diferentes processos OSPF, configure uma política de filtragem de rotas para evitar loops de roteamento.
Configurar o resumo da rota externa OSPF
Requisitos de rede
- Execute OSPF entre Device1 e Device2 e execute RIPv2 entre Device2 e Device3.
- Device2 redistribui rotas RIP para OSPF. Para diminuir o número de rotas no Device1, resuma as rotas RIP redistribuídas na rota de resumo 20.0.0.0/16.
Topologia de rede
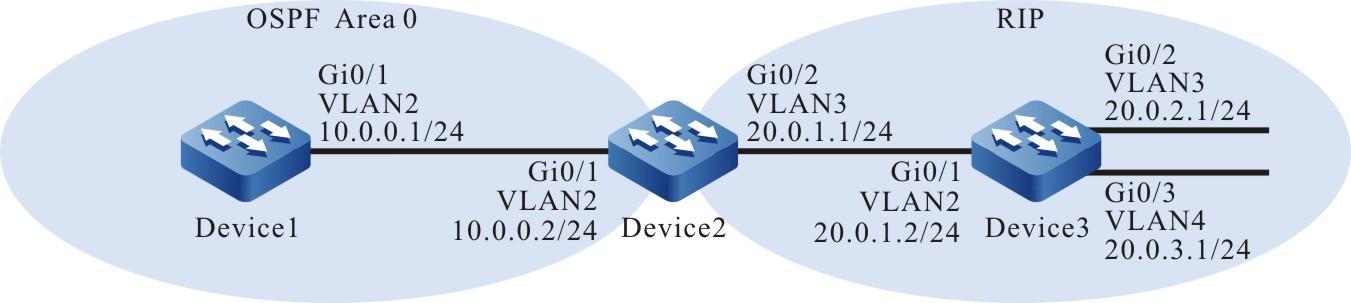
Figura 7 -5 Rede para configurar o resumo da rota externa OSPF
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: #Configure OSPF e RIPv2.
#Configure OSPF para Device1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#router-id 1.1.1.1Device1(config-ospf)#network 10.0.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configure OSPF e RIPv2 para Device2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#router-id 2.2.2.2Device2(config-ospf)#network 10.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exitDevice2(config)#router ripDevice2(config-rip)#version 2Device2(config-rip)#network 20.0.0.0Device2(config-rip)#exit
#Configure RIPv2 para Device3.
Device3#configure terminalDevice3(config)#router ripDevice3(config-rip)#version 2Device3(config-rip)#network 20.0.0.0Device3(config-rip)#exit
#Consulte a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:15:46, vlan2C 20.0.1.0/24 is directly connected, 00:15:23, vlan3R 20.0.2.0/24 [120/1] via 20.0.1.2, 00:12:17, vlan3R 20.0.3.0/24 [120/1] via 20.0.1.2, 00:12:06, vlan3C 127.0.0.0/8 is directly connected, 03:34:27, lo0
- Passo 4: Configure o OSPF para redistribuir as rotas RIP.
# Configurar dispositivo2.
Device2(config)#router ospf 100Device2(config-ospf)#redistribute ripDevice2(config-ospf)#exit
#Consulta OSPF LSDB do Device2.
Device2#show ip ospf databaseOSPF Router with ID (2.2.2.2) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 1071 0x80000003 0x729f 12.2.2.2 2.2.2.2 873 0x80000004 0x38cd 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum10.0.0.2 2.2.2.2 1070 0x80000001 0x43d6AS External Link StatesLink ID ADV Router Age Seq# CkSum Route20.0.1.0 2.2.2.2 365 0x80000001 0x7d04 E2 20.0.1.0/24 [0x0]20.0.2.0 2.2.2.2 365 0x80000001 0x720e E2 20.0.2.0/24 [0x0]20.0.3.0 2.2.2.2 365 0x80000001 0x6718 E2 20.0.3.0/24 [0x0]
De acordo com o banco de dados OSPF, três LSAs externos foram gerados, indicando que as rotas RIP foram redistribuídas para OSPF.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:56:40, vlan2OE 20.0.1.0/24 [150/20] via 10.0.0.2, 00:02:40, vlan2OE 20.0.2.0/24 [150/20] via 10.0.0.2, 00:02:40, vlan2OE 20.0.3.0/24 [150/20] via 10.0.0.2, 00:02:40, vlan2C 127.0.0.0/8 is directly connected, 115:12:28, lo0
Device1 aprendeu rotas RIP redistribuídas.
- Passo 5: No ASBR, configure o resumo de rota externa OSPF. Agora Device2 é o ASBR.
#Configure Device2 e resuma as rotas RIP redistribuídas em 20.0.0.0/16.
Device2(config)#router ospf 100Device2(config-ospf)#summary-address 20.0.0.0 255.255.0.0Device2(config-ospf)#exit
- Passo 6: Confira o resultado.
#Consulta OSPF LSDB do Device2.
Device2#show ip ospf databaseOSPF Router with ID (2.2.2.2) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 1437 0x80000003 0x729f 12.2.2.2 2.2.2.2 1240 0x80000004 0x38cd 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum10.0.0.2 2.2.2.2 144 0x80000002 0x41d7AS External Link StatesLink ID ADV Router Age Seq# CkSum Route20.0.0.0 2.2.2.2 84 0x80000001 0x88f9 E2 20.0.0.0/16 [0x0]
Comparando o resultado com o resultado da Etapa 3, você descobrirá que os três LSAs externos foram excluídos e um LSA externo resumido foi gerado.
#Consulte a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:28:03, vlan2O 20.0.0.0/16 [110/1] is directly connected, 00:04:48, null0C 20.0.1.0/24 is directly connected, 00:27:40, vlan3R 20.0.2.0/24 [120/1] via 20.0.1.2, 00:24:34, vlan3R 20.0.3.0/24 [120/1] via 20.0.1.2, 00:24:23, vlan3C 127.0.0.0/8 is directly connected, 03:46:44, lo0
Na tabela de roteamento de Device2, uma rota de resumo 20.0.0.0/16 com a interface de saída sendo Null0 foi adicionada automaticamente. Essa rota ajuda a evitar loops de roteamento.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:58:40, vlan2OE 20.0.0.0/16 [150/20] via 10.0.0.2, 00:15:26, vlan2C 127.0.0.0/8 is directly connected, 115:17:28, lo0
A tabela de roteamento de Device1 só aprendeu a rota de resumo 20.0.0.0/16.
Configurar o resumo da rota em rotas OSPF entre áreas
Requisitos de rede
- Configure o OSPF para todos os dispositivos e divida os dispositivos em duas áreas, Área 0 e Área 1.
- Para diminuir o número de rotas entre áreas, as rotas entre áreas são resumidas no ABR. As rotas na Área 0 são resumidas para formar 10.0.0.0/16. As rotas na Área 1 são resumidas para formar 20.0.0.0/16.
Topologia de rede

Figura 7 -6 Rede para configurar resumo de rota em rotas OSPF entre áreas
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure um processo OSPF e deixe a interface cobrir diferentes áreas.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#router-id 1.1.1.1Device1(config-ospf)#network 10.0.1.0 0.0.0.255 area 0Device1(config-ospf)#network 10.0.2.0 0.0.0.255 area 0Device1(config-ospf)#network 10.0.3.0 0.0.0.255 area 0Device1(config-ospf)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#router-id 2.2.2.2Device2(config-ospf)#network 10.0.1.0 0.0.0.255 area 0Device2(config-ospf)#network 20.0.1.0 0.0.0.255 area 1Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#router-id 3.3.3.3Device3(config-ospf)#network 20.0.1.0 0.0.0.255 area 1Device3(config-ospf)#network 20.0.2.0 0.0.0.255 area 1Device3(config-ospf)#network 20.0.3.0 0.0.0.255 area 1Device3(config-ospf)#exit
#Consulte o OSPF LSDB e a tabela de roteamento do Device2.
Device2#show ip ospf databaseOSPF Router with ID (2.2.2.2) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 1419 0x80000007 0x4f81 32.2.2.2 2.2.2.2 1414 0x80000004 0x4bb9 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum10.0.1.2 2.2.2.2 1419 0x80000001 0x38e0Summary Link States (Area 0)Link ID ADV Router Age Seq# CkSum Route20.0.1.0 2.2.2.2 1437 0x80000001 0x47d7 20.0.1.0/2420.0.2.0 2.2.2.2 1363 0x80000001 0x46d6 20.0.2.0/2420.0.3.0 2.2.2.2 1363 0x80000001 0x3be0 20.0.3.0/24Router Link States (Area 1)Link ID ADV Router Age Seq# CkSum Link count2.2.2.2 2.2.2.2 1368 0x80000004 0xe70b 13.3.3.3 3.3.3.3 1341 0x80000006 0x6138 3Net Link States (Area 1)Link ID ADV Router Age Seq# CkSum20.0.1.1 2.2.2.2 1368 0x80000001 0x24e3Summary Link States (Area 1)Link ID ADV Router Age Seq# CkSum Route10.0.1.0 2.2.2.2 1442 0x80000001 0xc95f 10.0.1.0/2410.0.2.0 2.2.2.2 1409 0x80000001 0xc85e 10.0.2.0/2410.0.3.0 2.2.2.2 1409 0x80000001 0xbd68 10.0.3.0/24Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.1.0/24 is directly connected, 00:30:31, vlan2O 10.0.2.0/24 [110/2] via 10.0.1.1, 00:23:37, vlan2O 10.0.3.0/24 [110/2] via 10.0.1.1, 00:23:37, vlan2C 20.0.1.0/24 is directly connected, 02:09:10, vlan3O 20.0.2.0/24 [110/2] via 20.0.1.2, 00:22:51, vlan3O 20.0.3.0/24 [110/2] via 20.0.1.2, 00:22:51, vlan3C 127.0.0.0/8 is directly connected, 05:28:14, lo0
No banco de dados OSPF do Device2, três LSAs inter-área são gerados respectivamente para Área 0 e Área 1. As rotas intra-área das áreas também foram adicionadas à tabela de roteamento.
#Consulte o OSPF LSDB e a tabela de roteamento do Device1.
Device1#show ip ospf databaseOSPF Router with ID (1.1.1.1) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 249 0x80000008 0x4d82 32.2.2.2 2.2.2.2 191 0x80000005 0x49ba 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum10.0.1.2 2.2.2.2 471 0x80000002 0x36e1Summary Link States (Area 0)Link ID ADV Router Age Seq# CkSum Route20.0.1.0 2.2.2.2 251 0x80000002 0x45d8 20.0.1.0/2420.0.2.0 2.2.2.2 1988 0x80000001 0x46d6 20.0.2.0/2420.0.3.0 2.2.2.2 1988 0x80000001 0x3be0 20.0.3.0/24Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.1.0/24 is directly connected, 00:25:11, vlan2C 10.0.2.0/24 is directly connected, 00:24:58, vlan3C 10.0.3.0/24 is directly connected, 00:24:44, vlan4O 20.0.1.0/24 [110/2] via 10.0.1.2, 00:14:59, vlan2O 20.0.2.0/24 [110/3] via 10.0.1.2, 00:14:12, vlan2O 20.0.3.0/24 [110/3] via 10.0.1.2, 00:14:12, vlan2C 127.0.0.0/8 is directly connected, 116:19:42, lo0
O banco de dados OSPF de Device1 contém três LSAs entre áreas e as três rotas foram adicionadas à tabela de roteamento.
#Consulte o OSPF LSDB e a tabela de roteamento do Device3.
Device3#show ip ospf databaseOSPF Router with ID (3.3.3.3) (Process ID 100)Router Link States (Area 1)Link ID ADV Router Age Seq# CkSum Link count2.2.2.2 2.2.2.2 532 0x80000005 0xe50c 13.3.3.3 3.3.3.3 506 0x80000007 0x5f39 3Net Link States (Area 1)Link ID ADV Router Age Seq# CkSum20.0.1.1 2.2.2.2 532 0x80000002 0x22e4Summary Link States (Area 1)Link ID ADV Router Age Seq# CkSum Route10.0.1.0 2.2.2.2 82 0x80000002 0xc760 10.0.1.0/2410.0.2.0 2.2.2.2 382 0x80000002 0xc65f 10.0.2.0/2410.0.3.0 2.2.2.2 262 0x80000002 0xbb69 10.0.3.0/24Device3#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 10.0.1.0/24 [110/2] via 20.0.1.1, 00:24:04, vlan2O 10.0.2.0/24 [110/3] via 20.0.1.1, 00:24:04, vlan2O 10.0.3.0/24 [110/3] via 20.0.1.1, 00:24:04, vlan2C 20.0.1.0/24 is directly connected, 02:09:51, vlan2C 20.0.2.0/24 is directly connected, 02:07:21, vlan3C 20.0.3.0/24 is directly connected, 02:07:09, vlan4C 127.0.0.0/8 is directly connected, 360:20:45, lo0
Da mesma forma, o banco de dados OSPF de Device3 contém três LSAs entre áreas e as três rotas foram adicionadas à tabela de roteamento.
- Passo 4: No ABR, configure o resumo da rota entre áreas. Agora Device2 é o ABR.
#No Dispositivo2, resuma as rotas na Área 0 para formar a rota 10.0.0.0/16 e resuma as rotas na Área 1 para formar a rota 20.0.0.0/16.
Device2(config)#router ospf 100Device2(config-ospf)#area 0 range 10.0.0.0/16Device2(config-ospf)#area 1 range 20.0.0.0/16Device2(config-ospf)#exit
- Passo 5: Confira o resultado.
#Consulte o OSPF LSDB e a tabela de roteamento do Device2.
Device2#show ip ospf databaseOSPF Router with ID (2.2.2.2) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 305 0x80000009 0x4b83 32.2.2.2 2.2.2.2 297 0x80000006 0x47bb 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum10.0.1.2 2.2.2.2 527 0x80000003 0x34e2Summary Link States (Area 0)Link ID ADV Router Age Seq# CkSum Route20.0.0.0 2.2.2.2 23 0x80000001 0x52cd 20.0.0.0/16Router Link States (Area 1)Link ID ADV Router Age Seq# CkSum Link count2.2.2.2 2.2.2.2 277 0x80000006 0xe30d 13.3.3.3 3.3.3.3 332 0x80000008 0x5d3a 3Net Link States (Area 1)Link ID ADV Router Age Seq# CkSum20.0.1.1 2.2.2.2 317 0x80000003 0x20e5Summary Link States (Area 1)Link ID ADV Router Age Seq# CkSum Route10.0.0.0 2.2.2.2 26 0x80000001 0xd455 10.0.0.0/16Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 10.0.0.0/16 [110/1] is directly connected, 00:00:31, null0C 10.0.1.0/24 is directly connected, 00:40:31, vlan2O 10.0.2.0/24 [110/2] via 10.0.1.1, 00:33:37, vlan2O 10.0.3.0/24 [110/2] via 10.0.1.1, 00:33:37, vlan2O 20.0.0.0/16 [110/1] is directly connected, 00:00:27, null0C 20.0.1.0/24 is directly connected, 02:19:10, vlan3O 20.0.2.0/24 [110/2] via 20.0.1.2, 00:32:51, vlan3O 20.0.3.0/24 [110/2] via 20.0.1.2, 00:32:51, vlan3C 127.0.0.0/8 is directly connected, 05:38:14, lo0
Comparando o resultado com o resultado da Etapa 2, você descobrirá que apenas um LSA entre áreas resumido é gerado respectivamente para Área 0 e Área 1 no banco de dados OSPF do Dispositivo2. Da mesma forma, uma rota de resumo com a interface de saída sendo Null0 é adicionada automaticamente à tabela de roteamento.
#Consulte o OSPF LSDB e a tabela de roteamento do Device1.
Device1#show ip ospf databaseOSPF Router with ID (1.1.1.1) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 1338 0x80000009 0x4b83 32.2.2.2 2.2.2.2 1332 0x80000006 0x47bb 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum10.0.1.2 2.2.2.2 1563 0x80000003 0x34e2Summary Link States (Area 0)Link ID ADV Router Age Seq# CkSum Route20.0.0.0 2.2.2.2 90 0x80000001 0x52cd 20.0.0.0/16Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.1.0/24 is directly connected, 00:40:11, vlan2C 10.0.2.0/24 is directly connected, 00:39:58, vlan3C 10.0.3.0/24 is directly connected, 00:39:44, vlan4O 20.0.0.0/16 [110/2] via 10.0.1.2, 00:02:18, vlan2C 127.0.0.0/8 is directly connected, 116:44:42, lo0
No Device1, você descobrirá que o banco de dados OSPF contém apenas o LSA entre áreas resumido, e a tabela de roteamento inclina apenas a rota de resumo 20.0.0.0/16 da Área 1. Da mesma forma, o Device3 aprende apenas a rota de resumo 10.0.0.0/16 da Área 0.
Configurar filtragem de rota em rotas OSPF entre áreas
Requisitos de rede
- Configure o OSPF para todos os dispositivos e divida os dispositivos em duas áreas, Área 0 e Área 1.
- No ABR, configure a filtragem de rota entre áreas. De acordo com a filtragem da rota, a Área 0 não permite a injeção da rota 20.0.3.0/24, e a 10.0.3.0/24 não tem permissão para inundar outras áreas.
Topologia de rede
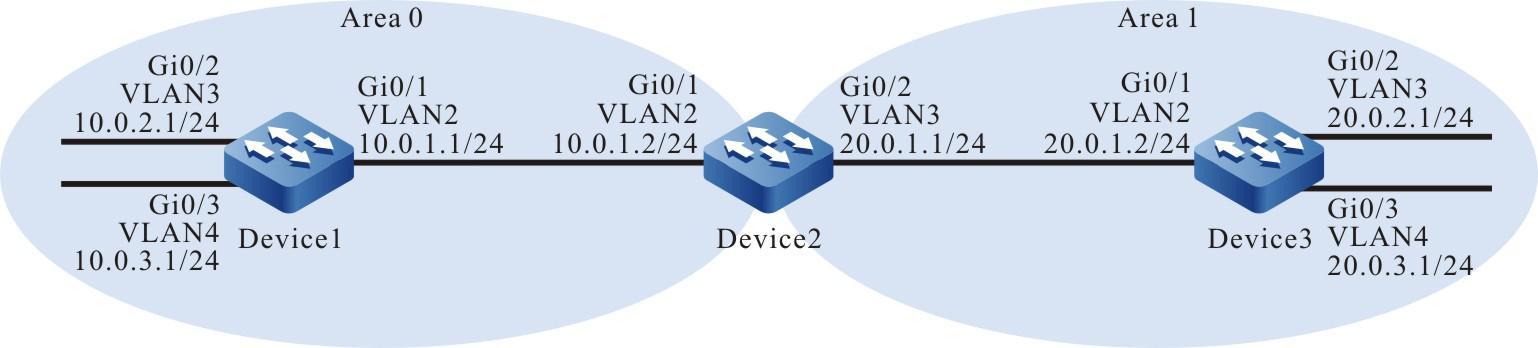
Figura 7 -7 Rede para configurar filtragem de rota em rotas OSPF entre áreas
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure um processo OSPF e deixe a interface cobrir diferentes áreas.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#router-id 1.1.1.1Device1(config-ospf)#network 10.0.1.0 0.0.0.255 area 0Device1(config-ospf)#network 10.0.2.0 0.0.0.255 area 0Device1(config-ospf)#network 10.0.3.0 0.0.0.255 area 0Device1(config-ospf)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#router-id 2.2.2.2Device2(config-ospf)#network 10.0.1.0 0.0.0.255 area 0Device2(config-ospf)#network 20.0.1.0 0.0.0.255 area 1Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#router-id 3.3.3.3Device3(config-ospf)#network 20.0.1.0 0.0.0.255 area 1Device3(config-ospf)#network 20.0.2.0 0.0.0.255 area 1Device3(config-ospf)#network 20.0.3.0 0.0.0.255 area 1Device3(config-ospf)#exit
#Consulte o OSPF LSDB e a tabela de roteamento do Device2.
Device2#show ip ospf databaseOSPF Router with ID (2.2.2.2) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 329 0x8000005b 0xa6d5 32.2.2.2 2.2.2.2 324 0x80000051 0xb007 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum10.0.1.2 2.2.2.2 324 0x8000004e 0x9d2eSummary Link States (Area 0)Link ID ADV Router Age Seq# CkSum Route20.0.1.0 2.2.2.2 324 0x8000004e 0xac25 20.0.1.0/2420.0.2.0 2.2.2.2 324 0x8000004d 0xad23 20.0.2.0/2420.0.3.0 2.2.2.2 259 0x80000001 0x3be0 20.0.3.0/24Router Link States (Area 1)Link ID ADV Router Age Seq# CkSum Link count2.2.2.2 2.2.2.2 334 0x80000055 0x4f51 13.3.3.3 3.3.3.3 335 0x80000059 0xca7a 3Net Link States (Area 1)Link ID ADV Router Age Seq# CkSum20.0.1.2 3.3.3.3 340 0x80000001 0xeb17Summary Link States (Area 1)Link ID ADV Router Age Seq# CkSum Route10.0.1.0 2.2.2.2 365 0x80000001 0xc95f 10.0.1.0/2410.0.2.0 2.2.2.2 319 0x80000001 0xc85e 10.0.2.0/2410.0.3.0 2.2.2.2 256 0x80000001 0xbd68 10.0.3.0/24Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.1.0/24 is directly connected, 00:06:13, vlan2O 10.0.2.0/24 [110/2] via 10.0.1.1, 00:05:22, vlan2O 10.0.3.0/24 [110/2] via 10.0.1.1, 00:05:22, vlan2C 20.0.1.0/24 is directly connected, 00:06:19, vlan3O 20.0.2.0/24 [110/2] via 20.0.1.2, 00:05:32, vlan3O 20.0.3.0/24 [110/2] via 20.0.1.2, 00:05:32, vlan3C 127.0.0.0/8 is directly connected, 94:42:22, lo0
No banco de dados OSPF do Device2, três LSAs inter-área são gerados respectivamente para Área 0 e Área 1. As rotas intra-área das áreas também foram adicionadas à tabela de roteamento.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.1.0/24 is directly connected, 00:08:41, vlan2C 10.0.2.0/24 is directly connected, 37:59:10, vlan3C 10.0.3.0/24 is directly connected, 38:05:36, vlan4O 20.0.1.0/24 [110/2] via 10.0.1.2, 00:07:55, vlan2O 20.0.2.0/24 [110/3] via 10.0.1.2, 00:07:55, vlan2O 20.0.3.0/24 [110/3] via 10.0.1.2, 00:06:50, vlan2C 127.0.0.0/8 is directly connected, 70:07:32, lo0
Device1 aprendeu rotas da Área 1.
#Consulte a tabela de roteamento do Device3.
Device3#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 10.0.1.0/24 [110/2] via 20.0.1.1, 00:08:44, vlan2O 10.0.2.0/24 [110/3] via 20.0.1.1, 00:08:33, vlan2O 10.0.3.0/24 [110/3] via 20.0.1.1, 00:07:30, vlan2C 20.0.1.0/24 is directly connected, 00:09:31, vlan2C 20.0.2.0/24 is directly connected, 37:59:57, vlan3C 20.0.3.0/24 is directly connected, 38:03:35, vlan4C 127.0.0.0/8 is directly connected, 61:26:38, lo0
Device3 aprendeu rotas da Área 0.
- Passo 4: Configure uma política de filtragem de rota.
# Configurar dispositivo2.
Device2(config)#ip prefix-list 1 deny 10.0.3.0/24Device2(config)#ip prefix-list 1 permit 0.0.0.0/0 le 32Device2(config)#ip prefix-list 2 deny 20.0.3.0/24Device2(config)#ip prefix-list 2 permit 0.0.0.0/0 le 32Device2(config)#exit
A lista de prefixos 1 filtra a rede 10.0.3.0/24 e permite todas as outras redes. A lista de prefixos 2 filtra a rede 20.0.3.0/24 e permite todas as outras redes.
- Passo 5: No ABR, configure a filtragem de rotas entre áreas e invoque as regras de correspondência de uma lista de prefixos.
# Configurar dispositivo2.
Device2(config)#router ospf 100Device2(config-ospf)#area 0 filter-list prefix 1 outDevice2(config-ospf)#area 0 filter-list prefix 2 inDevice2(config-ospf)#exit
- Passo 6: Confira o resultado.
#Consulta OSPF LSDB do Device2.
Device2#show ip ospf databaseOSPF Router with ID (2.2.2.2) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 679 0x8000005b 0xa6d5 32.2.2.2 2.2.2.2 673 0x80000051 0xb007 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum10.0.1.2 2.2.2.2 673 0x8000004e 0x9d2eSummary Link States (Area 0)Link ID ADV Router Age Seq# CkSum Route20.0.1.0 2.2.2.2 673 0x8000004e 0xac25 20.0.1.0/2420.0.2.0 2.2.2.2 673 0x8000004d 0xad23 20.0.2.0/24Router Link States (Area 1)Link ID ADV Router Age Seq# CkSum Link count2.2.2.2 2.2.2.2 683 0x80000055 0x4f51 13.3.3.3 3.3.3.3 684 0x80000059 0xca7a 3Net Link States (Area 1)Link ID ADV Router Age Seq# CkSum20.0.1.2 3.3.3.3 689 0x80000001 0xeb17Summary Link States (Area 1)Link ID ADV Router Age Seq# CkSum Route10.0.1.0 2.2.2.2 714 0x80000001 0xc95f 10.0.1.0/2410.0.2.0 2.2.2.2 668 0x80000001 0xc85e 10.0.2.0/24
Comparando o resultado com o resultado da Etapa 2, o LSA da rede 20.0.3.0/24 foi excluído da Área 0 no banco de dados OSPF. Da mesma forma, o LSA da rede 10.0.3.0/24 foi excluído da Área 1.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.1.0/24 is directly connected, 00:12:57, vlan2C 10.0.2.0/24 is directly connected, 38:03:25, vlan3C 10.0.3.0/24 is directly connected, 38:09:52, vlan4O 20.0.1.0/24 [110/2] via 10.0.1.2, 00:12:11, vlan2O 20.0.2.0/24 [110/3] via 10.0.1.2, 00:12:11, vlan2C 127.0.0.0/8 is directly connected, 70:11:48, lo0
A rota 20.0.3.0/24 não existe na tabela de roteamento do Device1.
#Consulte a tabela de roteamento do Device3.
Device3#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 10.0.1.0/24 [110/2] via 20.0.1.1, 00:13:09, vlan2O 10.0.2.0/24 [110/3] via 20.0.1.1, 00:12:58, vlan2C 20.0.1.0/24 is directly connected, 00:13:56, vlan2C 20.0.2.0/24 is directly connected, 38:04:22, vlan3C 20.0.3.0/24 is directly connected, 38:08:00, vlan4C 127.0.0.0/8 is directly connected, 64:31:03, lo0
A rota 10.0.3.0/24 não existe na tabela de roteamento do Device3.
Configurar uma área totalmente stub OSPF
Requisitos de rede
- Configure o OSPF para todos os dispositivos e divida os dispositivos em três áreas: Área 0, Área 1 e Área 2. Configure a Área 1 como uma área totalmente Stub.
- No Device4, redistribua uma rota estática para OSPF. Após a conclusão da configuração, a área totalmente Stub não pode aprender rotas entre áreas e rotas externas, enquanto os dispositivos de outras áreas podem aprender rotas entre áreas e rotas externas.
Topologia de rede

Figura 7 -8 Rede para configurar uma área totalmente stub OSPF
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure um processo OSPF e deixe as interfaces cobrirem as áreas relacionadas.
#Configurar dispositivo1. Configure a Área 1 para uma área Stub.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#router-id 1.1.1.1Device1(config-ospf)#area 1 stubDevice1(config-ospf)#network 10.0.0.0 0.0.0.255 area 1Device1(config-ospf)#network 100.0.0.0 0.0.0.255 area 1Device1(config-ospf)#exit
#Configurar dispositivo2. Configure a Área 1 para uma área totalmente Stub. Devce2 é um ABR, e o comando no-summary tem efeito apenas em um ABR.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#router-id 2.2.2.2Device2(config-ospf)#area 1 stub no-summaryDevice2(config-ospf)#network 10.0.0.0 0.0.0.255 area 1Device2(config-ospf)#network 20.0.1.0 0.0.0.255 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#router-id 3.3.3.3Device3(config-ospf)#network 20.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 30.0.0.0 0.0.0.255 area 2Device3(config-ospf)#exit
# Configurar dispositivo4.
Device4#configure terminalDevice4(config)#router ospf 100Device4(config-ospf)#router-id 4.4.4.4Device4(config-ospf)#network 30.0.0.0 0.0.0.255 area 2Device4(config-ospf)#network 110.0.0.0 0.0.0.255 area 2Device4(config-ospf)#exit
- Passo 4: No Device4, configure uma rota estática e redistribua a rota no OSPF.
# Configurar dispositivo4.
Device4(config)#ip route 200.1.1.0 255.255.255.0 110.0.0.2Device4(config)#router ospf 100Device4(config-ospf)#redistribute staticDevice4(config-ospf)#exit
- Passo 5: Confira o resultado.
#Consulte o OSPF LSDB e a tabela de roteamento do Device1.
Device1#show ip ospf databaseOSPF Router with ID (1.1.1.1) (Process ID 100)Router Link States (Area 1 [Stub])Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 19 0x80000009 0x8513 22.2.2.2 2.2.2.2 22 0x80000005 0x51b6 1Net Link States (Area 1 [Stub])Link ID ADV Router Age Seq# CkSum10.0.0.2 2.2.2.2 22 0x80000001 0x61baSummary Link States (Area 1 [Stub])Link ID ADV Router Age Seq# CkSum Route0.0.0.0 2.2.2.2 55 0x80000002 0x73c1 0.0.0.0/0Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 0.0.0.0/0 [110/2] via 10.0.0.2, 00:00:19, vlan3C 10.0.0.0/24 is directly connected, 00:01:04, vlan3C 100.0.0.0/24 is directly connected, 00:11:55, vlan2C 127.0.0.0/8 is directly connected, 30:46:57, lo0
De acordo com as informações do banco de dados OSPF, apenas a Área 1 possui um LSA para a rota interárea 0.0.0.0/0, enquanto as demais áreas não possuem LSA para as rotas interáreas ou externas. O ABR na área do Stub gera uma rota inter-área 0.0.0.0/0, que inunda totalmente a área do Stub. Os dados são encaminhados para fora da área ou AS através da rota padrão.
#Consulte a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:01:02, vlan2C 20.0.0.0/24 is directly connected, 00:00:59, vlan3O 30.0.0.0/24 [110/2] via 20.0.0.2, 00:00:17, vlan3O 100.0.0.0/24 [110/2] via 10.0.0.1, 00:00:10, vlan2O 110.0.0.0/24 [110/3] via 20.0.0.2, 00:00:17, vlan3C 127.0.0.0/8 is directly connected, 56:07:04, lo0OE 200.1.1.0/24 [150/20] via 20.0.0.2, 00:00:16, vlan3
De acordo com as informações consultadas, você descobrirá que o Device2 é capaz de aprender rotas inter-áreas e externas.
Se você executar a área ID de área toco comando, mas não execute o comando no-summary , o dispositivo na área pode aprender rotas entre áreas, mas não pode aprender rotas externas. O acesso a uma rede fora do AS ainda é realizado pela rota padrão.
Configurar uma área OSPF NSSA
Requisitos de rede
- Configure o OSPF para todos os dispositivos e divida os dispositivos em três áreas: Área 0, Área 1 e Área 2. Configure a Área 1 e a Área 2 como áreas NSSA.
- No Device4, redistribua uma rota estática para OSPF. Após a conclusão da configuração, todos os dispositivos podem aprender rotas intra-áreas e inter-áreas, mas as rotas externas não podem ser injetadas na Área 1.
- Introduza uma rota padrão ao ABR da Área 1 para que o Device1 possa acessar uma rede externa por meio da rota padrão.
Topologia de rede

Figura 7 -9 Rede para configurar uma área OSPF NSSA
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure um processo OSPF e deixe as interfaces cobrirem as áreas relacionadas.
#Configurar dispositivo1. Configure a Área 1 para uma área NSSA.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#router-id 1.1.1.1Device1(config-ospf)#area 1 nssaDevice1(config-ospf)#network 10.0.0.0 0.0.0.255 area 1Device1(config-ospf)#network 100.0.0.0 0.0.0.255 area 1Device1(config-ospf)#exit
#Configurar dispositivo2. Configure a Área 1 para uma área NSSA.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#router-id 2.2.2.2Device2(config-ospf)#area 1 nssaDevice2(config-ospf)#network 10.0.0.0 0.0.0.255 area 1Device2(config-ospf)#network 20.0.1.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Configurar dispositivo3. Configure a Área 2 para uma área NSSA.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#router-id 3.3.3.3Device3(config-ospf)#area 2 nssaDevice3(config-ospf)#network 20.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 30.0.0.0 0.0.0.255 area 2Device3(config-ospf)#exit
#Configurar dispositivo4. Configure a Área 2 para uma área NSSA.
Device4#configure terminalDevice4(config)#router ospf 100Device4(config-ospf)#router-id 4.4.4.4Device4(config-ospf)#area 2 nssaDevice4(config-ospf)#network 30.0.0.0 0.0.0.255 area 2Device4(config-ospf)#network 110.0.0.0 0.0.0.255 area 2Device4(config-ospf)#exit
- Passo 4: No Device4, configure uma rota estática e redistribua a rota no OSPF
# Configurar dispositivo4.
Device4(config)#ip route 200.1.1.0 255.255.255.0 110.0.0.2Device4(config)#router ospf 100Device4(config-ospf)#redistribute staticDevice4(config-ospf)#exit
#Consulta OSPF LSDB do Device3.
Device3#show ip ospf databaseOSPF Router with ID (3.3.3.3) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count2.2.2.2 2.2.2.2 179 0x80000004 0xe110 13.3.3.3 3.3.3.3 177 0x80000004 0xa345 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum20.0.0.2 3.3.3.3 182 0x80000001 0xf60dSummary Link States (Area 0)Link ID ADV Router Age Seq# CkSum Route10.0.0.0 2.2.2.2 214 0x80000001 0xd455 10.0.0.0/24100.0.0.0 2.2.2.2 173 0x80000001 0x4886 100.0.0.0/2430.0.0.0 3.3.3.3 208 0x80000001 0xb160 30.0.0.0/24110.0.0.0 3.3.3.3 171 0x80000001 0xa719 110.0.0.0/24ASBR-Summary Link States (Area 0)Link ID ADV Router Age Seq# CkSum4.4.4.4 3.3.3.3 171 0x80000001 0x72acRouter Link States (Area 2 [NSSA])Link ID ADV Router Age Seq# CkSum Link count3.3.3.3 3.3.3.3 175 0x80000004 0x686f 14.4.4.4 4.4.4.4 177 0x80000005 0xe46a 2Net Link States (Area 2 [NSSA])Link ID ADV Router Age Seq# CkSum30.0.0.2 4.4.4.4 177 0x80000001 0xc827Summary Link States (Area 2 [NSSA])Link ID ADV Router Age Seq# CkSum Route10.0.0.0 3.3.3.3 172 0x80000001 0xde48 10.0.0.0/2420.0.0.0 3.3.3.3 214 0x80000001 0x52cb 20.0.0.0/24100.0.0.0 3.3.3.3 172 0x80000001 0x5279 100.0.0.0/24NSSA-external Link States (Area 2 [NSSA])Link ID ADV Router Age Seq# CkSum Route200.1.1.0 4.4.4.4 247 0x80000001 0x6cde N2 200.1.1.0/24 [0x0]AS External Link StatesLink ID ADV Router Age Seq# CkSum Route200.1.1.0 3.3.3.3 176 0x80000001 0x0156 E2 200.1.1.0/24 [0x0]
De acordo com o banco de dados OSPF, o ABR na área NSSA (Área 2) converte LSAs externos NSSA em LSAs externos AS. Portanto, as outras áreas normalmente podem aprender rotas externas que são redistribuídas da área NSSA (Área 2).
#Consulte a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:02:53, vlan2C 20.0.0.0/24 is directly connected, 00:02:51, vlan3O 30.0.0.0/24 [110/2] via 20.0.0.2, 00:02:04, vlan3O 100.0.0.0/24 [110/2] via 10.0.0.1, 00:02:04, vlan2O 110.0.0.0/24 [110/3] via 20.0.0.2, 00:02:02, vlan3C 127.0.0.0/8 is directly connected, 06:47:22, lo0OE 200.1.1.0/24 [150/20] via 20.0.0.2, 00:02:02, vlan3
Device2 aprendeu as rotas externas que foram redistribuídas da área NSSA (Área 2).
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:02:29, vlan3O 20.0.0.0/24 [110/2] via 10.0.0.2, 00:01:44, vlan3O 30.0.0.0/24 [110/3] via 10.0.0.2, 00:01:41, vlan3C 100.0.0.0/24 is directly connected, 01:53:00, vlan2O 110.0.0.0/24 [110/4] via 10.0.0.2, 00:01:40, vlan3C 127.0.0.0/8 is directly connected, 383:45:55, lo0
De acordo com as informações consultadas, a rota 200.1.1.0/24 não existe na tabela de roteamento do Device1, indicando que a rota externa redistribuída pelo Device4 não foi injetada na área NSSA (Área 1), enquanto as rotas das demais áreas foi adicionado à tabela de roteamento.
- Passo 5: Configure Device2 e introduza uma rota padrão para a Área 1.
#Configurar dispositivo2. Neste momento, Device2 é o ABR da Área 1.
Device2(config)#router ospf 100Device2(config-ospf)#router-id 2.2.2.2Device2(config-ospf)#area 1 nssa default-information-originateDevice2(config-ospf)#exit
Depois de área O comando area-id nssa no-summary é executado no ABR da área NSSA, a área é chamada de área totalmente NSSA. Neste momento, o ABR gera uma rota padrão e inunda a rota padrão na área NSSA. Depois que o comando for configurado, o número de LSAs de resumo e as rotas entre áreas correspondentes serão reduzidos ainda mais . Os dispositivos na área acessam uma rede fora da área ou fora do AS através da rota padrão.
- Passo 6: Confira o resultado.
#Consulta OSPF LSDB do Device2.
Device2#show ip ospf databaseOSPF Router with ID (2.2.2.2) (Process ID 100)Router Link States (Area 0)Link ID ADV Router Age Seq# CkSum Link count2.2.2.2 2.2.2.2 455 0x80000004 0xe110 13.3.3.3 3.3.3.3 455 0x80000004 0xa345 1Net Link States (Area 0)Link ID ADV Router Age Seq# CkSum20.0.0.2 3.3.3.3 461 0x80000001 0xf60dSummary Link States (Area 0)Link ID ADV Router Age Seq# CkSum Route10.0.0.0 2.2.2.2 492 0x80000001 0xd455 10.0.0.0/24100.0.0.0 2.2.2.2 449 0x80000001 0x4886 100.0.0.0/2430.0.0.0 3.3.3.3 487 0x80000001 0xb160 30.0.0.0/24110.0.0.0 3.3.3.3 449 0x80000001 0xa719 110.0.0.0/24ASBR-Summary Link States (Area 0)Link ID ADV Router Age Seq# CkSum4.4.4.4 3.3.3.3 449 0x80000001 0x72acRouter Link States (Area 1 [NSSA])Link ID ADV Router Age Seq# CkSum Link count1.1.1.1 1.1.1.1 456 0x80000005 0x8d0f 22.2.2.2 2.2.2.2 457 0x80000004 0x59ad 1Net Link States (Area 1 [NSSA])Link ID ADV Router Age Seq# CkSum10.0.0.2 2.2.2.2 457 0x80000001 0x61baSummary Link States (Area 1 [NSSA])Link ID ADV Router Age Seq# CkSum Route20.0.0.0 2.2.2.2 492 0x80000001 0x70b1 20.0.0.0/2430.0.0.0 2.2.2.2 449 0x80000001 0xf71f 30.0.0.0/24110.0.0.0 2.2.2.2 448 0x80000001 0xedd7 110.0.0.0/24NSSA-external Link States (Area 1 [NSSA])Link ID ADV Router Age Seq# CkSum Route0.0.0.0 2.2.2.2 31 0x80000001 0x5b42 N2 0.0.0.0/0 [0x0]AS External Link StatesLink ID ADV Router Age Seq# CkSum Route200.1.1.0 3.3.3.3 454 0x80000001 0x0156 E2 200.1.1.0/24 [0x0]
O OSPF gerou um LSA externo a NSSA para a rota padrão.
#Consulte a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalOE 0.0.0.0/0 [150/1] via 10.0.0.2, 00:00:22, vlan3C 10.0.0.0/24 is directly connected, 00:07:29, vlan3O 20.0.0.0/24 [110/2] via 10.0.0.2, 00:06:44, vlan3O 30.0.0.0/24 [110/3] via 10.0.0.2, 00:06:41, vlan3C 100.0.0.0/24 is directly connected, 01:58:00, vlan2O 110.0.0.0/24 [110/4] via 10.0.0.2, 00:06:40, vlan3C 127.0.0.0/8 is directly connected, 383:50:55, lo0
A tabela de roteamento de Device1 aprendeu a rota padrão 0.0.0.0, e Device1 se comunica com a rede fora do AS por meio da rota padrão.
Configurar OSPF para Coordenar com BFD (Aplicável somente ao modelo S3054G-B)
Requisitos de rede
- Configure o OSPF para todos os dispositivos.
- Habilite a função de detecção BFD na linha entre Device1 e Device3. Se a linha apresentar falha, o BFD detecta rapidamente a falha e notifica o OSPF sobre a falha. Em seguida, o OSPF alterna a rota para Device2 para comunicação.
Topologia de rede
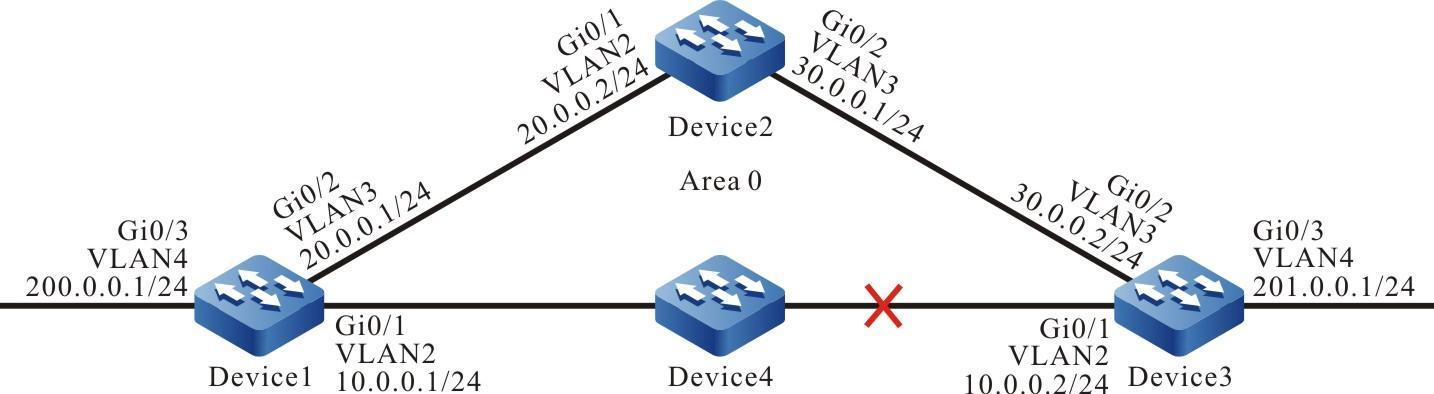
Figura 7 -10 Rede para configurar o OSPF para coordenar com o BFD
Etapas de configuração
- Passo 1: Crie VLANs e adicione portas às VLANs necessárias. (Omitido)
- Passo 2: Configure os endereços IP para as portas. (Omitido)
- Passo 3: Configure um processo OSPF.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#router-id 1.1.1.1Device1(config-ospf)#network 10.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 20.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 200.0.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#router-id 2.2.2.2Device2(config-ospf)#network 20.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 30.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#router-id 3.3.3.3Device3(config-ospf)#network 10.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 30.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 201.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
- Passo 4: Configure o OSPF para coordenar com o BFD.
# Configurar dispositivo1.
Device1(config)#bfd fast-detectDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip ospf bfdDevice1(config-if-vlan2)#exit
# Configurar dispositivo3.
Device3(config)#bfd fast-detectDevice3(config)#interface vlan2Device3(config-if-vlan2)#ip ospf bfdDevice3(config-if-vlan2)#exit
- Passo 5: Confira o resultado.
#Consulte os vizinhos OSPF e a tabela de roteamento do Device1.
Device1#show ip ospf neighbor 3.3.3.3OSPF process 100:Neighbor 3.3.3.3, interface address 10.0.0.2In the area 0 via interface vlan2, BFD enabledNeighbor priority is 1, State is Full, 5 state changesDR is 10.0.0.2, BDR is 10.0.0.1Options is 0x42 (-|O|-|-|-|-|E|-)Dead timer due in 00:00:31Neighbor is up for 00:02:46Database Summary List 0Link State Request List 0Link State Retransmission List 0Crypt Sequence Number is 0Graceful restart proxy id is 0x0Thread Inactivity Timer onThread Database Description Retransmission off, 0 timesThread Link State Request Retransmission off, 0 timesThread Link State Update Retransmission off, 0 timesDevice1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:01:09, vlan2C 20.0.0.0/24 is directly connected, 00:55:37, vlan3O 30.0.0.0/24 [110/2] via 20.0.0.2, 00:02:50, vlan3[110/2] via 10.0.0.2, 00:01:30, vlan2C 127.0.0.0/8 is directly connected, 05:51:09, lo0C 200.0.0.0/24 is directly connected, 00:55:12, vlan4O 201.0.0.0/24 [110/2] via 10.0.0.2, 00:01:30, vlan2
De acordo com as informações do vizinho OSPF, o BFD foi habilitado e a rota 201.0.0.0/24 seleciona a linha entre Device1 e Device3 com prioridade para comunicação.
#Consulte a sessão BFD do Device1.
Device1#show bfd session detailTotal session number: 1OurAddr NeighAddr LD/RD State Holddown interface10.0.0.1 10.0.0.2 7/14 UP 5000 vlan2Type:directLocal State:UP Remote State:UP Up for: 0h:2m:37s Number of times UP:1Send Interval:1000ms Detection time:5000ms(1000ms*5)Local Diag:0 Demand mode:0 Poll bit:0MinTxInt:1000 MinRxInt:1000 Multiplier:5Remote MinTxInt:1000 Remote MinRxInt:1000 Remote Multiplier:5Registered protocols:OSPF
De acordo com as informações consultadas, o OSPF foi configurado com sucesso para coordenar com o BFD e a sessão foi configurada normalmente.
#Se a linha entre Device1 e Device3 estiver com defeito, o BFD detecta rapidamente a falha e informa o OSPF da falha. OSPF então mude a rota para Device2 para comunicação. Consulte a tabela de roteamento de Device1.
%BFD-5-Session [10.0.0.2,10.0.0.1,vlan2,10] DOWN (Detection time expired)%OSPF-5-ADJCHG: Process 100 Nbr [vlan2:10.0.0.1-3.3.3.3] from Full to Down,KillNbr: BFD session downDevice1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:01:59, vlan2C 20.0.0.0/24 is directly connected, 00:56:13, vlan3O 30.0.0.0/24 [110/2] via 20.0.0.2, 00:03:40, vlan3C 127.0.0.0/8 is directly connected, 05:52:41, lo0C 200.0.0.0/24 is directly connected, 00:56:02, vlan4O 201.0.0.0/24 [110/3] via 20.0.0.2, 00:00:06, vlan3
A ação do Device3 é semelhante à do Device1.
OSPFv3
Visão geral
OSPFv3 é a abreviação de OSPF (Open Shortest Path First) Versão 3. Ele fornece suporte principalmente para IPv6, segue RFC2328, RFC2740 e suporta extensões OSPF definidas por outros RFCs relacionados.
OSPFv3 é basicamente o mesmo que OSPFv2, mas existem algumas modificações correspondentes para diferentes protocolos IP e famílias de endereços. Suas diferenças se manifestam principalmente em:
- OSPFv3 é executado com base no link e OSPFv2 é executado com base no segmento
- Cada link OSPFv3 suporta várias instâncias
- O OSPFv3 identifica o vizinho por meio do ID do roteador e o OSPFv2 identifica o vizinho por meio do endereço IP.
Configuração da Função OSPFv3
Tabela 8 -1 Lista de funções OSPFv3
| Tarefas de configuração | |
| Configure as funções básicas do OSPFv3. | Habilite OSPFv3. |
| Configure áreas OSPFv3. |
Configure uma área OSPFv3 NSSA.
Configure uma área de stub OSPFv3. Configure um link virtual OSPFv3. |
| Configure o tipo de rede OSPFv3. |
Configure o tipo de rede de uma interface OSPFv3 para transmissão.
Configure o tipo de rede de uma interface OSPFv3 para P2P. Configure o tipo de rede de uma interface OSPFv3 para NBMA. Configure o tipo de rede de uma interface OSPFv3 para P2MP. |
| Configure a autenticação de rede OSPFv3. | Configure a autenticação de área OSPFv3. Configure a autenticação da interface OSPFv3. |
| Configure a geração de rotas OSPFv3. | Configure o OSPFv3 para redistribuir rotas. Configure a rota OSPFv3 padrão. |
| Configure o controle de rota OSPFv3. |
Configure o resumo de rotas em rotas OSPFv3 entre áreas.
Configure o resumo da rota externa OSPFv3. Configurar filtragem de rotas em rotas OSPFv3 entre áreas. Configure a filtragem de rota externa OSPFv3. Configure a filtragem de instalação de rota OSPFv3. Configure o valor de custo de uma interface OSPFv3. Configure a largura de banda de referência OSPFv3. Configure a distância administrativa OSPFv3. Configure o número máximo de rotas de balanceamento de carga OSPFv3. |
| Configure a otimização de rede OSPFv3. |
Configure o tempo de manutenção de atividade de um vizinho OSPFv3.
Configure uma interface passiva OSPFv3. Configure um circuito de demanda OSPFv3. Configure a prioridade de uma interface OSPFv3. Configure o MTU de uma interface OSPFv3. Configure o atraso de transmissão LSA de uma interface OSPFv3. Configure a retransmissão LSA OSPFv3. Configure o tempo de cálculo do SPF OSPFv3. |
| Configurar OSPFv3 GR | Configurar OSPFv3 GR Restarter Configurar OSPFv3 GR Helper |
| Configure o OSPFv3 para coordenar com o BFD. | Configure o OSPFv3 para coordenar com o BFD. |
Configurar funções básicas do OSPFv3
Antes de configurar as funções do OSPFv3, você deve primeiro habilitar o protocolo OSPFv3 antes que as outras funções entrem em vigor.
Condições de configuração
Antes de configurar as funções básicas do OSPFv3, certifique-se de que:
- O protocolo da camada de link foi configurado para garantir a comunicação normal na camada de link.
- Habilite as funções de encaminhamento IPv6
Ativar OSPFv3
Para habilitar o OSPFv3, você deve criar um processo OSPFv3, especificar a ID do roteador do processo e habilitar o protocolo OSPFv3 na interface.
Um dispositivo que executa o protocolo OSPFv3 deve ter um Router ID, que é usado para identificar exclusivamente um dispositivo em um OSPFv3 AS. Você deve garantir que o ID do roteador seja exclusivo em um AS; caso contrário, a configuração de vizinhos e o aprendizado de rotas são afetados. No OSPFv3, você precisa configurar manualmente um Router ID do formato de endereço IPv4.
O OSPFv3 oferece suporte a vários processos e usa o número do processo para identificar um processo. Diferentes processos são independentes uns dos outros e não têm influência um sobre o outro.
Tabela 8 -2 Habilite o protocolo OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um processo OSPFv3 e entre no modo de configuração OSPF. | ipv6 router ospf process-id [vrf vrf-name ] |
Obrigatório.
Habilite o processo OSPFv3 ou habilite o processo OSPF do VRF. Por padrão, o protocolo OSPFv3 está desabilitado. Se você habilita o OSPFv3 do VRF, o processo OSPFv3 que pertence a um VRF pode gerenciar somente interfaces sob o VRF. |
| Configure o ID do roteador do processo OSPFv3. | router-id ipv4-address | Obrigatório. |
| Retornar ao modo de configuração global | exit | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure a habilitação do protocolo OSPFv3 na interface | ipv6 router ospf process-id area area-id [ instance-id instance-id ] | Obrigatório. Por padrão, o protocolo OPSFv3 está desabilitado na interface. |
Configurar a área OSPFv3
Para evitar que uma grande quantidade de informações do banco de dados ocupe muita CPU e memória, você pode dividir um OSPFv3 AS em várias áreas. Uma área pode ser identificada com um ID de área de 32 bits, um número decimal no intervalo de 0-4294967295 ou um endereço IP no intervalo de 0.0.0.0-255.255.255.255. A área 0 ou 0.0.0.0 representa uma área de backbone OSPFv3, enquanto outras áreas diferentes de zero são áreas sem backbone. Todas as informações de roteamento entre as áreas devem ser encaminhadas através da área de backbone. As áreas sem backbone não podem trocar informações de roteamento diretamente.
OSPFv3 define vários tipos de roteadores:
- Roteador interno: Todas as interfaces pertencem aos dispositivos em uma área.
- Area Border Router (ABR): É conectado a dispositivos de diferentes áreas.
- Autonomous System Boundary Router (ASBR): É um dispositivo que introduz rotas externas para o OSPFv3 AS.
Condição de configuração
Antes de configurar uma área OSPFv3, certifique-se de que:
- Ative a função de encaminhamento IPv6
- Habilite o protocolo OSPFv3
Configurar uma área NSSA OSPFv3
A Not-So-Stub-Area (NSSA) não permite a injeção de Type-5 Link State Advertisement (LSA), mas permite a injeção de Type-7 LSA. As rotas externas podem ser introduzidas em uma área NSSA por meio da redistribuição da configuração. O ASBR na área NSSA gera LSAs Tipo-7 e inunda LSAs para a área NSSA. O ABR em uma área NSSA converte LSAs Tipo-7 em LSAs Tipo-5 e inunda os LSAs Tipo-5 convertidos em todo o AS.
A área OSPFv3 NSSA que é configurada usando a área ID de área O comando nssa no-summary é chamado de área totalmente NSSA. Uma área OSPFv3 totalmente NSSA não permite que rotas entre áreas inundem a área. Neste momento, o ABR gera uma rota padrão e a inunda na área NSSA. Os dispositivos na área NSSA acessam uma rede fora da área por meio da rota padrão.
Tabela 8 -3 Configurar uma área OSPFv3 NSSA
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure uma área NSSA. | area area-id nssa [ no-redistribution / no-summary / default-information-originate [ metric metric-value / metric-type type-value ] ] | Obrigatório. Por padrão, uma área OSPFv3 não é a área NSSA. |
Uma área de backbone não pode ser configurada como uma área NSSA. Todos os dispositivos em uma área NSSA devem ser configurados como áreas NSSA, pois dispositivos com tipos de área diferentes não podem formar relações de vizinhança.
Configurar uma área de stub OSPFv3
Uma área Stub não permite que uma rota externa fora de um AS inunde a área para reduzir o tamanho do banco de dados de status do link. Depois que uma área é configurada como uma área Stub, o ABR que está localizado na borda Stub gera uma rota padrão e inunda a rota na área Stub. Os dispositivos na área Stub acessam uma rede fora da área por meio da rota padrão.
A área de Stub OSPFv3 que é configurada usando a área ID de área toco comando no-summary é chamado de área totalmente Stub. Uma área OSPFv3 totalmente Stub não permite que rotas entre áreas e rotas externas inundem a área. Os dispositivos na área acessam uma rede fora da área e fora do OSPFv3 AS por meio da rota padrão.
Tabela 8 -4 Configurar uma área de Stub OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure uma área de stub. | area area-id stub [ no-summary ] | Obrigatório. Por padrão, uma área OSPFv3 não é a área Stub. |
Uma área de backbone não pode ser configurada como uma área Stub. Todos os dispositivos em uma área Stub devem ser configurados como áreas Stub, pois dispositivos com tipos de área diferentes não podem formar relações de vizinhança.
Configurar um link virtual OSPFv3
As áreas sem backbone no OSPFv3 devem sincronizar e trocar dados através da área de backbone. Portanto, todas as áreas que não são de backbone devem permanecer conectadas à área de backbone.
Se o requisito não for atendido em determinados casos, você poderá resolver o problema configurando um link virtual. Depois de configurar um link virtual, você pode configurar um modo de autenticação para o link virtual e modificar o intervalo Hello. Os significados dos parâmetros são os mesmos que os significados do parâmetro de interfaces OSPFv3 comuns.
Tabela 8 -5 Configurar um link virtual OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure um link virtual OSPFv3. | area transit-area-id virtual-link neighbor-id [ dead-interval seconds / hello-interval seconds / retransmit-interval seconds / transmit-delay seconds ] | andatória. Por padrão, nenhum link virtual é criado. |
Um link virtual deve ser configurado entre dois ABRs. Dois ABRs nos quais o link virtual está configurado devem estar na mesma área pública. Essa área também é chamada de área de trânsito do link virtual. A área de trânsito de um link virtual não deve ser uma área Stub ou uma área NSSA.
Configurar o tipo de rede OSPFv3
De acordo com os tipos de protocolo de link, o OSPF v3 classifica as redes em quatro tipos:
- Broadcast Network: Quando o protocolo de link da rede é Ethernet ou Fiber Distributed Data Interface (FDDI), o tipo de rede OSPFv3 padrão é broadcast.
- Rede ponto a ponto (rede P2P): quando o protocolo de link é protocolo ponto a ponto (PPP), procedimento de acesso de link balanceado (LAPB) ou controle de link de dados de alto nível (HDLC), o tipo de rede OSPFv3 padrão é P2P.
- Rede de multi-acesso sem difusão (rede NBMA): Quando o protocolo de link é ATM, frame relay ou X.25, o tipo de rede OSPFv3 padrão é NBMA.
- Rede ponto a multiponto (P2MP): Nenhum protocolo de link será considerado pelo OSPFv3 como a rede P2MP por padrão. Normalmente, a rede NBMA que não está totalmente conectada é configurada como rede OSPFv3 P2MP.
Você pode modificar o tipo de rede de uma interface OSPFv3 de acordo com o requisito real. Os tipos de rede das interfaces através das quais os vizinhos OSPFv3 são configurados devem ser os mesmos; caso contrário, o aprendizado normal de rotas é afetado.
Condição de configuração
Antes de configurar o tipo de rede OSPFv3, certifique-se de que:
- Ative a função de encaminhamento IPv6
- Habilite o protocolo OSPFv3
Configurar o tipo de rede de uma interface OSPFv3 para transmissão
Uma rede de transmissão suporta vários dispositivos (mais de dois dispositivos). Esses dispositivos podem trocar informações com todos os dispositivos da rede. OSPFv3 usa pacotes Hello para descobrir vizinhos dinamicamente.
Tabela 8 -6 Configure o tipo de rede de uma interface OSPFv3 para transmissão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o tipo de rede de uma interface OSPFv3 para transmissão. | ipv6 ospf network broadcast |
Obrigatório.
Por padrão, o tipo de rede de uma interface OSPFv3 é determinado pelo protocolo da camada de link. |
Configurar o tipo de rede de uma interface OSPFv3 para P2P
Uma rede P2P é uma rede que consiste em dois dispositivos. Cada dispositivo está localizado em uma extremidade de um link P2P. OSPFv3 usa pacotes Hello para descobrir vizinhos dinamicamente.
Tabela 8 -7 Configurar o tipo de rede de uma interface OSPFv3 para P2 P
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o tipo de rede OSPFv3 para P2P. | ipv6 ospf network point-to-point |
Obrigatório.
Por padrão, o tipo de rede de uma interface OSPFv3 é determinado pelo protocolo da camada de link. |
Configurar o tipo de rede de uma interface OSPFv3 para NBMA
Uma rede NBMA suporta vários dispositivos (mais de dois dispositivos), mas os dispositivos não têm capacidade de transmissão, portanto, você deve especificar um vizinho manualmente.
Tabela 8 -8 Configurar o tipo de rede de uma interface OSPFv3 para NBMA
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o tipo de rede da interface OSPFv3 para NBMA. | ipv6 ospf network non-broadcast |
Obrigatório.
Por padrão, o tipo de rede de uma interface OSPFv3 é determinado pelo protocolo da camada de link. |
| Configure um vizinho para a rede NBMA. | ipv6 ospf neighbor neighbor-ipv6-address [ priority priority-value / poll-interval interval-value / cost cost-value ] [ instance-id instance-id ] | Obrigatório. Em uma rede NBMA, um vizinho deve ser especificado manualmente. |
Configurar o tipo de rede de uma interface OSPFv3 para P2MP
Quando uma rede NBMA não está totalmente conectada, você pode configurar seu tipo de rede para P2MP para economizar sobrecarga de rede. Se o tipo de rede estiver configurado para unicast P2MP, você precisará especificar um vizinho manualmente.
Tabela 8 -9 Configurar o tipo de rede de uma interface OSPFv3 para P2MP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o tipo de rede OSPFv3 para P2MP. | ipv6 ospf network point-to-multipoint [ non-broadcast ] | andatória. Por padrão, o tipo de rede de uma interface OSPFv3 é determinado pelo protocolo da camada de link. |
| Configure um vizinho para a rede unicast P2MP. | ipv6 ospf neighbor neighbor-ipv6-address [ priority priority-value / poll-interval interval-value / cost cost-value ] [ instance-id instance-id ] | Se o tipo de rede de interface estiver definido como unicast P2MP, é obrigatório. |
Configurar autenticação de rede OSPFv3
Para evitar vazamento de informações ou ataques maliciosos a dispositivos OSPFv3, todas as interações de pacotes entre vizinhos OSPFv3 têm o recurso de autenticação criptografada . Os tipos e algoritmos de autenticação criptografados incluem: NULL (sem autenticação), autenticação SHA1 e autenticação MD5, que é especificada pela política de autenticação criptografada IPSec.
Após configurar a autenticação, os recursos de segurança IPSec criptografam e autenticam os pacotes do protocolo OSPFv3. O protocolo OSPFv3 pode receber pacotes somente após a autenticação de descriptografia. Portanto, as interfaces OSPFv3 que estabelecem o relacionamento de adjacência devem ter o mesmo método de autenticação, Spi ID e política de autenticação de criptografia IPSec da configuração de senha de autenticação. O modo de autenticação OSPFv3 pode ser configurado na área e na interface, e sua prioridade é de baixa a alta: autenticação de área, autenticação de interface. Ou seja, primeiro use o modo de autenticação de interface e, em seguida, use o modo de autenticação de área.
Condição de configuração
Antes de configurar a autenticação de rede OSPFv3, certifique-se de que:
- A função de encaminhamento IPv6 está habilitada.
- O protocolo OSPFv3 está habilitado.
Configurar autenticação de área OSPFv3
Configurar a autenticação de área na área de processo OSPFv3 pode fazer com que todas as interfaces na área usem o modo de autenticação de área e evitem efetivamente configurar a mesma rede modo de autenticação na interface repetidamente.
Tabela 8 -10 Configurar autenticação de área OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure o modo de autenticação de área. | area area-id ipsec-tunnel tunnel-name | Obrigatório. Por padrão, o OSPFv3 não está configurado com a autenticação de área. |
Configurar autenticação de interface OSPFv3
Se uma interface tiver várias instâncias OSPFv3, você poderá especificar o modo de autenticação e a senha para uma instância. Se você não especificar a instância de autenticação de interface na interface, adote o modo de autenticação especificado na área.
Tabela 8 -11 Configurar autenticação de interface OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o modo de autenticação da interface. | ipv6 ospf ipsec-tunnel tunnel-name{instance-id instance-id} | Obrigatório. Por padrão, o OSPFv3 não está configurado com o modo de autenticação de interface. |
Configurar geração de rota OSPFv3
Condição de configuração
Antes de configurar a geração de rotas OSPFv3, certifique-se de que:
- A função de encaminhamento IPv6 está habilitada.
- O protocolo OSPFv3 está habilitado.
Configurar a redistribuição de rota OSPFv3
Se vários protocolos de roteamento forem executados em um dispositivo, as rotas de outros protocolos poderão ser introduzidas no OSPF por meio da redistribuição. Por padrão, as rotas externas de classe 2 do OSPFv3 são geradas com a métrica de rota 20. Ao introduzir rotas externas por meio de redistribuição, você pode modificar o tipo de rota externa, métrica e campo de tag e associar a política de roteamento especificada para realizar o controle de rota e gestão.
Tabela 8 -12 Configurar redistribuição de rota OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configurar redistribuição de rota OSPFv3 | redistribute routing-protocol [ protocol-id-or-name ] [ metric metric-value / metric-type type-value / tag tag-value / route-map map-name / match route-type ] | Obrigatório. Por padrão, o OSPFv3 não está configurado com a redistribuição de rota. |
| Configure a métrica da rota externa OSPFv3. | default-metric metric-value | Opcional |
Se o valor da métrica das rotas externas for configurado usando tanto o redistribute protocol [ protocol-id ] comando metric e o comando default-metric , o valor que é configurado usando o comando anterior tem uma prioridade mais alta.
Configurar a rota padrão OSPFv3
Depois que uma área OSPFv3 Stub ou uma área totalmente NSSA é configurada, uma rota padrão Tipo-3 é gerada. Para uma área NSSA, nenhuma rota padrão é gerada automaticamente. Você pode usar a área ID de área nssa origem-informação-padrão comando para introduzir uma rota padrão Type-7 para a área NSSA.
OSPFv3 não pode usar o comando redistribute para introduzir uma rota padrão Tipo-5. Para fazer isso, use o informações padrão originar [ sempre ] comando.
Tabela 8 -13 Configurar a rota padrão OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure o OSPFv3 para introduzir uma rota padrão. | default-information originate [ always / metric metric-value / metric-type metric-type / route-map route-map-name ] |
Obrigatório.
Por padrão, nenhuma rota padrão externa é introduzida a um OSPFv3 AS. A métrica padrão da rota padrão introduzida é 1 e o tipo é externo tipo 2. O campo sempre significa forçar o OSPFv3 AS a gerar uma rota padrão; caso contrário, a rota padrão será gerada somente quando houver uma rota padrão na tabela de roteamento local. |
Configurar o controle de rota OSPFv3
Condição de configuração
Antes de configurar o controle de rota OSPFv3, certifique-se de que:
- A função de encaminhamento IPv6 está habilitada.
- O protocolo OSPFv3 está habilitado.
Configurar resumo de rota entre áreas OSPFv3
Quando um ABR no OSPFv3 anuncia rotas entre áreas para outras áreas, ele anuncia cada rota separadamente na forma de LSA Tipo 3. Você pode usar a função de resumo de rota entre áreas para resumir alguns segmentos de rede contínuos para formar uma rota de resumo. Em seguida, o ABR anuncia a rota de resumo, reduzindo o tamanho dos bancos de dados OSPFv3.
Tabela 8 -14 Configurar resumo de rota entre áreas OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure o resumo da rota entre as áreas OSPFv3 | area area-id range ipv6-prefix/prefix-length [ advertise | not-advertise] | Obrigatório. Por padrão, o ABR não realiza o resumo de rotas entre as áreas. |
A função de resumo de rotas entre áreas OSPFv3 é válida apenas para ABRs. Por padrão, o valor de custo mínimo entre os valores de custo das rotas é usado como valor de custo do resumo da rota.
Configurar o resumo da rota externa OSPFv3
o OSPF redistribui rotas externas, ele anuncia cada rota separadamente na forma de LSA externo. Você pode usar a função de resumo de rota externa para resumir alguns segmentos de rede contínuos para formar uma rota de resumo. Em seguida, o OSPF anuncia a rota de resumo, reduzindo o tamanho dos bancos de dados OSPF.
Se você executar o comando summary-address em um ASBR, poderá resumir todos os LSAs Tipo 5 e LSAs Tipo 7 dentro do intervalo de endereços.
Tabela 8 -15 Configurar resumo da rota externa OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure o OSPFv3 para resumir as rotas externas. | summary-prefix ipv6-prefix/prefix-length [ not-advertise | tag tag-value ] | Obrigatório. Por padrão, um ABR não resume as rotas externas. |
A função de resumo de rota externa OSPFv3 é válida apenas para ASBRs.
Configurar filtragem de rota entre áreas OSPFv3
Quando um ABR recebe rotas entre áreas, ele realiza a filtragem na direção de entrada com base em um ACL ou lista de prefixos. Quando o ABR anuncia rotas entre áreas, ele realiza a filtragem na direção de saída com base em um ACL ou lista de prefixos.
Tabela 8 -16 Configurar filtragem de rota entre OSPF v3 áreas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure a filtragem de rotas entre áreas OSPFv3 | area area-id filter-list { access { access-list-name | access-list-number } | prefix prefix-list-name } { in | out } | Obrigatório. Por padrão, o ABR não realiza a filtragem de rotas entre áreas. |
A filtragem de rotas entre áreas OSPFv3 função é válida apenas para ABRs.
Configurar filtragem de rota externa OSPFv3
Configurando a filtragem de rota externa OSPFv3 é aplicar um ACL ou lista de prefixos para permitir ou não permitir que rotas externas de um OSPFv3 AS inundem no OSPF AS.
Tabela 8 -17 Configurar filtragem de rota externa OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure a filtragem de rota externa OSPFv3 | distribute-list { access { access-list-name | access-list-number } | prefix prefix-list-name } out [ routing-protocol [ process-id ] ] | Obrigatório. Por padrão, o ASBR não executa a filtragem de rota externa. |
A filtragem de rotas externas OSPFv3 função é válida apenas para ASBRs.
Configurar filtragem de instalação de rota OSPFv3
Depois que o OSPFv3 calcula as rotas por meio do LSA, para evitar que certas rotas sejam adicionadas à tabela de roteamento, o OSPFv3 filtra as informações de rota do OSPFv3 calculadas.
Tabela 8 -18 Configurar filtragem de instalação de rota OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configurar filtragem de instalação de rota OSPF v3 | distribute-list { access { access-list-name | access-list-number } | gateway prefix-list-name1 | prefix prefix-list-name2 [gateway prefix-list-name3 ] | route-map route-map-name} in [ interface-name ] | Obrigatório. Por padrão, não configure a filtragem de instalação de rota OSPFv3. |
A filtragem baseada em prefixo, gateway e mapa de rotas é mutuamente exclusiva com filtragem baseada em ACL. Por exemplo, se você configurou a filtragem com base no prefixo, não poderá configurar a filtragem com base na ACL novamente. A filtragem baseada no mapa de rotas e no prefixo é mutuamente exclusiva com a filtragem baseada no gateway. A filtragem com base no prefixo e a filtragem com base no gateway se sobrescrevem.
Configurar o valor de custo de uma interface OSPFv3
Por padrão, o custo de uma interface OSPFv3 é calculado com base na seguinte fórmula: Largura de banda de referência/Largura de banda da interface.
Tabela 8 -19 Configurar o valor de custo de uma interface OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o valor de custo de uma interface OSPFv3. | ipv6 ospf cost cost [ instance-id instance-id ] | Opcional. Por padrão, o valor do custo é calculado por meio da fórmula Largura de banda de referência/Largura de banda de interface. |
Configurar a largura de banda de referência OSPFv3
A largura de banda de referência de uma interface é usada para calcular o valor de custo da interface. O valor padrão é 100 Mbit/s. A fórmula para calcular o valor de custo da interface OSPFv3 é: Largura de banda de referência/Largura de banda da interface. Se o resultado do cálculo for maior que 1, use a parte inteira. Se o resultado do cálculo for menor que 1, use o valor 1. Portanto, em uma rede cuja largura de banda é maior que 100Mbit/s, a rota ótima não é selecionada. Nesse caso, você pode usar o custo automático comando reference-bandwidth para configurar uma largura de banda de referência adequada para resolver o problema.
Tabela 8 -20 Configurar a largura de banda de referência OSPF v3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configurando a largura de banda de referência OSPFv3. | auto-cost reference-bandwidth reference-bandwidth | Opcional. Por padrão, a largura de banda de referência é 100 Mbit/s |
Configurar a distância administrativa OSPFv3
Uma distância administrativa é usada para indicar a confiabilidade do protocolo de roteamento. Se as rotas para a mesma rede de destino forem aprendidas por diferentes protocolos de roteamento, a rota com a menor distância administrativa será selecionada primeiro.
Tabela 8 -21 Configurar a distância administrativa do OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure a distância administrativa OSPFv3. | distance [ ospf { external distance / inter-area distance / intra-area distance } | distance ] | Opcional. Por padrão, a distância administrativa das rotas OSPFv3 intra-área e inter-área é 110 e a distância administrativa das rotas externas é 150 |
Configurar o número máximo de rotas de balanceamento de carga OSPFv3
Se vários caminhos equivalentes estiverem disponíveis para alcançar o mesmo destino, o balanceamento de carga será alcançado. Isso melhora a taxa de utilidade dos links e reduz a carga dos links.
Tabela 8 -22 Configure o número máximo de rotas de balanceamento de carga OSPF v3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure o número máximo de rotas de balanceamento de carga OSPFv3. | maximum-paths max-number | Opcional. Por padrão, o número máximo de rotas de balanceamento de carga OSPFv3 é 4. |
Configurar a otimização de rede OSPFv3
Condição de configuração
Antes de configurar a otimização de rede OSPFv3, certifique-se de que:
- A função de encaminhamento IPv6 está habilitada.
- O protocolo OSPFv3 está habilitado.
Configurar o tempo de manutenção de um vizinho OSPFv3
Os pacotes Hello OSPFv3 são usados para configurar relações de vizinhos e manter as relações vivas. O intervalo de transmissão padrão dos pacotes Hello é determinado pelo tipo de rede. Para redes de broadcast e redes P2P, o intervalo de transmissão padrão dos pacotes Hello é 10s. Para redes P2MP e redes NBMA, o intervalo de transmissão padrão dos pacotes Hello é 30s.
O tempo morto do vizinho é usado para determinar a validade de um vizinho. Por padrão, o tempo morto do vizinho é quatro vezes o intervalo Hello. Se um dispositivo OSPFv3 não receber pacotes de saudação de um vizinho após o tempo morto do vizinho expirar, o dispositivo OSPFv3 considera o vizinho inválido e, em seguida, exclui o vizinho de maneira ativa.
Tabela 8 -23 Configurar o tempo de manutenção de atividade de um vizinho OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure um intervalo de Olá OSPFv3. | ipv6 ospf hello-interval interval-value [ instance-id instance-id ] | Opcional. O valor padrão é determinado pelo tipo de rede. Para redes de transmissão e redes P2P, o valor padrão é 10s. Para redes P2MP e redes NBMA, o valor padrão é 30s. |
| Configure o tempo morto do vizinho OSPFv3. | ipv6 ospf dead-interval interval-value [ instance-id instance-id ] | Opcional. Por padrão, o tempo morto é quatro vezes o intervalo Hello. |
O intervalo de saudação e o tempo morto dos vizinhos OSPFv3 devem ser os mesmos; caso contrário, eles não podem estabelecer relações de vizinhança. Quando você modifica o intervalo Hello, se o tempo morto do vizinho atual for quatro vezes o intervalo Hello, o tempo morto do vizinho será modificado automaticamente para ser ainda quatro vezes do novo intervalo Hello. Se o tempo morto do vizinho atual não for quatro vezes o intervalo Hello, o tempo morto do vizinho permanecerá inalterado. Se você modificar o tempo morto do vizinho, o intervalo Hello não será afetado.
Configurar uma interface passiva OSPFv3
O protocolo de roteamento dinâmico adota uma interface passiva para diminuir efetivamente a largura de banda da rede consumida pelo protocolo de roteamento. Depois que uma interface passiva OSPFv3 é configurada, você pode usar o enable comando da interface para anunciar as rotas do segmento de rede diretamente conectado no qual a interface está localizada, mas o recebimento e a transmissão de pacotes OSPFv3 são amortecidos na interface.
Tabela 8 -24 Configurar uma interface passiva OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure uma interface passiva OSPFv3. | passive-interface {interface-name|default} | Obrigatório. Por padrão, nenhuma interface passiva OSPFv3 é configurada. |
Configurar um circuito de demanda OSPFv3
Em links P2P e P2MP, para diminuir o custo da linha, você pode configurar um circuito de demanda OSPFv3 para suprimir a transmissão periódica de pacotes Hello e a atualização periódica de pacotes LSA. Esta função é aplicada principalmente em links carregados como ISDN, SVC e X.25.
Tabela 8 -25 Configurar um circuito de demanda OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure um circuito de demanda OSPFv3. | ipv6 ospf demand-circuit [ instance-id instance-id ] | Obrigatório. Por padrão, nenhum circuito de demanda OSPFv3 está habilitado. |
Configurar a prioridade de uma interface OSPFv3
As prioridades de interface são usadas principalmente na eleição de Roteador Designado (DR) e Roteador Designado de Backup (BDR) em redes de transmissão e redes NBMA. O intervalo de valores é 0-255. Quanto maior o valor, maior a prioridade. O valor padrão é 1.
O DR e o BDR são selecionados de todos os dispositivos em um segmento de rede com base em prioridades de interface e IDs de roteador por meio de pacotes Hello. As regras são as seguintes:
- Primeiro, o dispositivo cuja interface tem a prioridade mais alta é eleito como DR, e o dispositivo cuja interface tem a segunda prioridade mais alta é eleito como BDR. O dispositivo cuja interface tem prioridade 0 não participa da eleição.
- Se as prioridades de interface de dois dispositivos forem as mesmas, o dispositivo com o maior Router ID é eleito como o DR e o dispositivo com o segundo maior Router ID é eleito como o BDR.
- Se o DR falhar, o BDR se torna o DR imediatamente e um novo BDR é eleito.
Tabela 8 -26 Configurar a prioridade de uma interface OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure a prioridade de uma interface OSPFv3. | ipv6 ospf priority priority-value [ instance-id instance-id ] | Opcional. Por padrão, a prioridade da interface OSPFv3 é 1. |
As prioridades da interface afetam apenas um processo eleitoral. Caso o DR e o BDR já tenham sido eleitos, a modificação das prioridades da interface não afeta o resultado da eleição; em vez disso, afeta a próxima eleição de DR ou BDR. Portanto, o DR pode não ter a interface com a prioridade mais alta e o BDR pode não ter a interface com a segunda prioridade mais alta.
Configurar a interface OSPFv3 para ignorar MTU
Quando os dispositivos OSPF adjacentes trocam pacotes DD, as MTUs são verificadas por padrão. Se as MTUs forem diferentes, os dispositivos não podem formar uma relação de vizinhança. Se você configurou o OSPFv3 para ignorar a verificação de MTU da interface, mesmo que os MTUs sejam diferentes, eles podem configurar uma relação de vizinho.
Tabela 8 -27 Configurar uma interface OSPFv3 para ignorar MTU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure a interface OSPFv3 para ignorar o MTU. | ipv6 ospf mtu-ignore [ instance-id instance-id ] | Obrigatório. Por padrão, a interface OSPFv3 executa a verificação de consistência de MTU. |
Configurar o atraso de transmissão LSA de uma interface OSPFv3
O atraso de transmissão do LSA refere-se ao tempo que leva para um LSA inundar outros dispositivos. O dispositivo que envia o LSA adiciona o atraso de transmissão da interface ao tempo de envelhecimento do LSA. Por padrão, quando o LSA de inundação passa por um dispositivo, o tempo de envelhecimento é aumentado em 1. Você pode configurar o atraso de transmissão do LSA de acordo com as condições da rede. O intervalo de valores é 1-840. O atraso de transmissão LSA geralmente é configurado em links de baixa velocidade.
Tabela 8 -28 Configure o atraso de transmissão LSA de uma interface OSPF v3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o atraso de transmissão LSA de uma interface OSPFv3. | ipv6 ospf transmit-delay delay-value instance-id [ instance-id ] | Opcional. Por padrão, o atraso de transmissão LSA é 1s. |
Configurar retransmissão LSA OSPFv3
Para garantir a confiabilidade da troca de dados, o OSPFv3 adota o mecanismo de confirmação. Se um LSA inunda em uma interface de dispositivo, o LSA é adicionado à lista de retransmissão do vizinho. Se nenhuma mensagem de confirmação for recebida do vizinho após o tempo limite de retransmissão, o LSA será retransmitido até que uma mensagem de confirmação seja recebida.
Tabela 8 -29 Configurar retransmissão LSA OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o intervalo de retransmissão do OSPFv3 LSA. | ipv6 ospf retransmit-interval interval-value [ instance-id instance-id ] | Opcional. Por padrão, o intervalo de retransmissão é de 5s. |
Configurar o tempo de cálculo do SPF OSPFv3
Se a topologia da rede OSPFv3 for alterada, as rotas precisam ser recalculadas. Quando a rede continua a mudar, o cálculo de rotas frequentes ocupa muitos recursos do sistema. Você pode ajustar os parâmetros de tempo de cálculo do SPF para evitar que alterações frequentes na rede consumam muitos recursos do sistema.
Tabela 8 -30 Configure o tempo de cálculo do SPF do OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configure o tempo de cálculo do SPF OSPFv3. | timers throttle spf delay-time hold-time max-time | Opcional. Por padrão, o tempo de atraso é de 5.000 ms, o tempo de espera é de 10.000 ms e o tempo máximo é de 10.000 ms. |
O parâmetro delay-time indica o atraso inicial do cálculo, hold-time indica o tempo de supressão e max-time indica o tempo máximo de espera entre dois cálculos de FPS. Se as mudanças de rede não forem frequentes, você pode reduzir o intervalo de cálculo de rota contínua para tempo de atraso . Se as mudanças de rede forem frequentes, você pode ajustar os parâmetros, aumentar o tempo de supressão para tempo de espera ×2 n-2 (n é o número de tempos de disparo de cálculo de rota), estender o tempo de espera com base no incremento de tempo de espera configurado e o valor máximo não deve exceder max-time .
Configurar OSPFv3 Fast Re-routing (Aplicável somente ao modelo S3054G-B)
Condição de configuração
Antes de configurar o reencaminhamento rápido do OSPFv3, primeiro conclua a seguinte tarefa:
- Ative a função de encaminhamento IPv6.
- Habilite o protocolo OSPFv3.
Configurar o reencaminhamento rápido do OSPFv3
Na rede OSPFv3, a interrupção de tráfego causada por falha de link ou dispositivo continuará até que o protocolo detecte a falha de link, e a rota flutuante não se recuperará até que a rota flutuante entre em vigor, o que geralmente dura vários segundos. Para reduzir o tempo de interrupção do tráfego, o reencaminhamento rápido do OSPFv3 pode ser configurado. Através da aplicação do mapa de roteamento, o próximo salto de backup é definido para a rota correspondente. Uma vez que o link ativo falhe, o tráfego que passa pelo link ativo será imediatamente comutado para o link em espera, de modo a atingir o objetivo de comutação rápida.
Tabela 8 -31 Configurar o reencaminhamento rápido do OSPFv3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Configurar o processo OSPFv3 para habilitar a função de reencaminhamento rápido estático | fast-reroute route-map route-map-name | Obrigatório. Por padrão, não habilite a função de redirecionamento rápido estático do OSPFv3 . |
| Configurar o processo OSPFv3 para habilitar a função de redirecionamento rápido dinâmico | fast-reroute loop-free-alternate [route-map route-map-name] | Obrigatório. Por padrão, não ative a função de redirecionamento rápido dinâmico OSPFv3 . |
| Configurar o processo OSPFv3 para habilitar a função pic | pic |
Obrigatório.
a função pic, habilite a função de reencaminhamento rápido automático. Por padrão, não habilite a função pic OSPFv3 . |
A função de redirecionamento rápido do OSPFv3 é dividida em redirecionamento rápido estático e redirecionamento rápido dinâmico. A função de reencaminhamento rápido estático precisa associar o mapa de rotas e definir a interface do próximo salto e o endereço da rota de backup no mapa de rotas. Atualmente, o reencaminhamento rápido dinâmico suporta apenas rede ponto a ponto, ou seja, todos os tipos de rede de interface de saída do dispositivo são ponto a ponto. Depois de configurar o redirecionamento rápido dinâmico, o dispositivo calculará e definirá automaticamente a interface e o endereço de backup do próximo salto. O reencaminhamento rápido dinâmico também pode ser associado ao mapa de rotas e definir a interface e o endereço do próximo salto de backup apenas para o mapa de rotas correspondente à rota. As várias maneiras de habilitar o reencaminhamento são mutuamente exclusivas.
Configurar OSPFv3 GR
informações de rota da camada de encaminhamento entre o dispositivo local e o dispositivo vizinho inalteradas durante a alternância ativa/em espera dos dispositivos e o encaminhamento não é afetado. Após alternar o dispositivo e executar novamente, a camada de protocolo dos dois dispositivos sincroniza as informações de rota e atualiza a camada de encaminhamento para que o encaminhamento de dados não seja interrompido durante a alternância do dispositivo .
Existem dois papéis durante o GR:
- GR Restarter : O dispositivo que executa a reinicialização normal do protocolo
- GR Helper : O dispositivo que auxilia a reinicialização graciosa do protocolo
O dispositivo distribuído pode servir como GR Restarter e GR Helper, enquanto o dispositivo centralizado pode servir apenas como GR Helper, auxiliando o Restarter a completar o GR.
Condição de configuração
Antes de configurar o OSPF v3 GR, primeiro conclua a seguinte tarefa:
- A função de encaminhamento IPv6 está habilitada.
- O protocolo OSPFv3 está habilitado.
Configurar OSPFv3 GR Reinicialização
Tabela 8 -32 Configurar OSPFv3 GR Restarter
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [ vrf vrf-name ] | - |
| Configurar OSPF v3 GR | nsf ietf |
Obrigatório.
Por padrão, não habilite a função GR. A função entra em vigor e o protocolo precisa suportar a função O paque- LSA. Por padrão, suporte a função O paque- LSA. |
| Configurar o período OSPFv3 GR | nsf interval grace-period | Opcional. Por padrão, o período GR é 95s. |
Configurar OSPFv3 GR Ajudante
O GR Helper ajuda o Restarter a completar o GR. Por padrão, o dispositivo habilita a função. o nsf ietf ajudante desativar comando é usado para desabilitar a função GR Helper . o nsf ietf ajudante O comando strict-lsa-checking é usado para configurar o Helper para executar a verificação estrita do LSA durante o GR. Se achar que o LSA não muda, saia do modo GR Helper.
Tabela 8 -33 Configurar OSPF v3 GR Helper
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [ vrf vrf-name ] | - |
| Configurar OSPF v3 GR Helper | nsf ietf helper [ disable | strict-lsa-checking ] | Opcional. Por padrão, habilite a função Helper e não execute a verificação estrita para LSA |
Configurar OSPFv3 para Coordenar com BFD (Aplicável somente ao modelo S3054G-B)
Condição de configuração
Antes de configurar o OSPFv3 para coordenar com o BFD, certifique-se de que:
- A função de encaminhamento IPv6 está habilitada.
- O protocolo OSPFv3 está habilitado.
Configurar OSPFv3 para coordenar com BFD
A detecção de encaminhamento bidirecional (BFD) fornece um método para detectar rapidamente o status de uma linha entre dois dispositivos. Se o BFD for iniciado entre dois dispositivos OSPFv3 adjacentes, se a linha entre dois dispositivos estiver com defeito, o BFD detecta rapidamente a falha e informa o OSPFv3 sobre a falha. Em seguida, ele aciona o OSPFv3 para iniciar o cálculo da rota e alternar para a linha de backup, obtendo uma rápida alternância de rotas.
Tabela 8 -34 Configure o OSPF v3 para coordenar com o BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Habilite ou desabilite o BFD na interface OSPFv3 especificada. | ipv6 ospf bfd [disable] [ instance-id instance-id ] | Obrigatório. Por padrão, a função BFD está desabilitada. |
| Entre no modo de configuração global. | exit | - |
| Entre no modo de configuração OSPFv3. | ipv6 router ospf process-id [vrf vrf-name ] | - |
| Habilite o BFD em todas as interfaces do processo OSPFv3. | bfd all-interfaces | opcional _ |
Se o BFD estiver configurado no modo de configuração OSPFv3 e no modo de configuração da interface, a configuração do BFD na interface terá a prioridade mais alta.
Monitoramento e Manutenção do OSPFv3
Tabela 8 -35 Monitoramento e Manutenção do OSPFv3
| Comando | Descrição |
| clear ipv6 ospf err-statistic | Limpe as informações de estatísticas de erro do OSPF v3 . |
| clear ipv6 ospf [ process-id ] process | Redefina um processo OSPFv3. |
| clear ipv6 ospf [ process-id ] redistribution | Re-anuncie rotas externas. |
| clear ipv6 ospf [ process-id ] route | Recalcule as rotas OSPFv3. |
| clear ipv6 ospf statistics [ interface-name ] | Limpe as informações de estatísticas da interface OSPFv3 |
| show ipv6 ospf [ process-id ] | Exiba as informações básicas do OSPFv3. |
| show ipv6 ospf [ process-id ] border-routers | Exiba as informações sobre as rotas para os dispositivos de limite no OSPFv3. |
| show ipv6 ospf core-info | Exiba as informações principais do processo OSPFv3 |
| show ipv6 ospf [ process-id ] database [ database-summary | external | inter-prefix | inter-router | intra-prefix | link | network | nssa-external | grace | router | adv-router router-id | age lsa_age | max-age | self-originate] | Exiba as informações sobre um banco de dados OSPFv3. |
| show ipv6 ospf error-statistic | informações de estatísticas de erro do OSPF v3 |
| show ipv6 ospf event-list | Exiba as informações da fila de recebimento do pacote OSPFv3 |
| show ipv6 ospf interface [ interface-name [ detail ] ] | Exiba as informações sobre uma interface OSPFv3. |
| show ipv6 ospf [ process-id ] neighbor [ neighbor-id | all | detail [ all ] | interface interface-name [ detail ] | statistics ] | Exiba as informações sobre os vizinhos OSPFv3. |
| show ipv6 ospf [ process-id ] route [ ipv6-prefix/prefix-length | connected | external | inter-area | intra-area | statistic ] | Exiba as informações sobre rotas OSPFv3. |
| show ipv6 ospf [ process-id ] sham-links | Exiba as informações sobre o link simulado OSPFv3 configurado, incluindo status da interface, valor de custo e status do vizinho. |
| show ipv6 ospf [ process-id ] topology area [ area-id ] | Exibir as informações de topologia OSPFv3 |
| show ipv6 ospf [ process- id] virtual-links | Exibir as informações do link virtual OSPFv3 |
| show ipv6 ospf [ vrf vrf-name] | Exiba todas as informações e parâmetros do processo OSPFv3 no vrf especificado |
| show running-config ipv6 router ospf | Exiba a configuração de execução do OSPFv3 |
Exemplo de configuração típica do OSPFv3
Configurar as funções básicas do OSPFv3
Requisitos de rede
- Configure o protocolo OSPFv3 para todos os dispositivos e divida os dispositivos em três áreas: Área 0, Área 1 e Área 2. Após a configuração, todos os dispositivos devem ser capazes de aprender rotas uns dos outros.
- Em uma interface Ethernet back-to-back, para acelerar o conjunto de vizinhos OSPFv3, você pode alterar o tipo de rede da interface OSPFv3 para P2P. Modifique o tipo de rede das interfaces na Área 2 para P2P. Após a configuração, todos os dispositivos podem aprender rotas uns dos outros.
Topologia de rede

Figura 8 -1 Rede para configurar funções básicas do OSPFv3
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente (omitida).
- Passo 2: Configure os endereços IPv6 das interfaces. (Omitido)
- Passo 3: Configure um processo OSPFv3 e deixe a interface cobrir diferentes áreas.
#No Device1, configure um processo OSPFv3 e configure as interfaces para cobrir a área 1.
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)#router-id 1.1.1.1Device1(config-ospf6)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 router ospf 100 area 1Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 router ospf 100 area 1Device1(config-if-vlan3)#exit
#No Device2, configure um processo OSPFv3 e configure as interfaces para cobrir a Área 0 e a Área 1.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 router ospf 100 area 1Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 router ospf 100 area 0Device2(config-if-vlan3)#exit
#No Device3, configure um processo OSPFv3 e configure as interfaces para cobrir a Área 0 e a Área 2.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ipv6 router ospf 100 area 0Device3(config-if-vlan2)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 router ospf 100 area 2Device3(config-if-vlan3)#exit
#No Device4, configure um processo OSPFv3 e configure as interfaces para cobrir a área 2.
Device4#configure terminalDevice4(config)#ipv6 router ospf 100Device4(config-ospf6)#router-id 4.4.4.4Device4(config-ospf6)#exitDevice4(config)#interface vlan2Device4(config-if-vlan2)#ipv6 router ospf 100 area 2Device4(config-if-vlan2)#exitDevice4(config)#interface vlan3Device4(config-if-vlan3)#ipv6 router ospf 100 area 2Device4(config-if-vlan3)#exit
O Router ID no OSFPv3 deve ser configurado manualmente, e os Router IDs de quaisquer dois roteadores no AS não podem ser os mesmos. Quando uma interface está habilitada para OSPFv3, é necessário especificar qual instância de interface está habilitada para o processo OSPFv3, e os dois números de instância devem ser consistentes. Por padrão, está na instância 0.
#Consulte as informações do vizinho OSPFv3 e a tabela de roteamento do Device1.
Device1#show ipv6 ospf neighborOSPFv3 Process (100)Neighbor ID Pri State Dead Time Interface Instance ID2.2.2.2 1 Full/DR 00:00:38 vlan3 0Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 00:41:07, lo0C 2001:1::/64 [0/0]via ::, 00:32:19, vlan3L 2001:1::1/128 [0/0]via ::, 00:32:18, lo0O 2001:2::/64 [110/2]via fe80::201:7aff:fe5e:6d45, 00:23:06, vlan3O 2001:3::/64 [110/3]via fe80::201:7aff:fe5e:6d45, 00:23:00, vlan3C 2001:4::/64 [0/0]via ::, 00:16:46, vlan2L 2001:4::1/128 [0/0]via ::, 00:16:45, lo0O 2001:5::/64 [110/4]via fe80::201:7aff:fe5e:6d45, 00:01:42, vlan3
#Consulte os vizinhos OSPFv3 e a tabela de roteamento do Device2.
Device2#show ipv6 ospf neighborOSPFv3 Process (100)Neighbor ID Pri State Dead Time Interface Instance ID1.1.1.1 1 Full/Backup 00:00:34 vlan2 03.3.3.3 1 Full/DR 00:00:33 vlan3 0Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 00:50:36, lo0C 2001:1::/64 [0/0]via ::, 00:43:05, vlan2L 2001:1::2/128 [0/0]via ::, 00:43:04, lo0C 2001:2::/64 [0/0]via ::, 00:40:01, vlan3L 2001:2::1/128 [0/0]via ::, 00:39:57, lo0O 2001:3::/64 [110/2]via fe80::2212:1ff:fe01:101, 00:34:00, vlan3O 2001:4::/64 [110/2]via fe80::201:7aff:fe61:7a24, 00:27:28, vlan2O 2001:5::/64 [110/3]via fe80::2212:1ff:fe01:101, 00:12:41, vlan3
#Query OSPFv3 Link Status Database (LSDB) do Device2.
Device2#show ipv6 ospf databaseOSPFv3 Router with ID (2.2.2.2) (Process 100)Link-LSA (Interface vlan2)Link State ID ADV Router Age Seq# CkSum Prefix0.0.0.1 1.1.1.1 81 0x80000001 0x8d18 10.0.0.1 2.2.2.2 78 0x80000001 0xf996 1Link-LSA (Interface vlan3)Link State ID ADV Router Age Seq# CkSum Prefix0.0.0.2 2.2.2.2 71 0x80000003 0x2467 10.0.0.1 3.3.3.3 35 0x80000003 0xcd12 1Router-LSA (Area 0.0.0.0)Link State ID ADV Router Age Seq# CkSum Link0.0.0.0 2.2.2.2 37 0x80000004 0x0dd6 10.0.0.0 3.3.3.3 25 0x80000007 0xda03 1Network-LSA (Area 0.0.0.0)Link State ID ADV Router Age Seq# CkSum0.0.0.1 3.3.3.3 35 0x80000001 0x5790Inter-Area-Prefix-LSA (Area 0.0.0.0)Link State ID ADV Router Age Seq# CkSum Prefix0.0.0.2 2.2.2.2 42 0x80000007 0x9e25 2001:1::/640.0.0.3 2.2.2.2 23 0x80000002 0xcef4 2001:4::/640.0.0.1 3.3.3.3 35 0x80000005 0xaa16 2001:3::/640.0.0.3 3.3.3.3 55 0x80000001 0xc0fe 2001:5::/64Intra-Area-Prefix-LSA (Area 0.0.0.0)Link State ID ADV Router Age Seq# CkSum Prefix Reference0.0.0.3 3.3.3.3 34 0x80000001 0xb2d3 1 Network-LSARouter-LSA (Area 0.0.0.1)Link State ID ADV Router Age Seq# CkSum Link0.0.0.0 1.1.1.1 41 0x80000004 0xc726 10.0.0.0 2.2.2.2 37 0x80000004 0xac3c 1Network-LSA (Area 0.0.0.1)Link State ID ADV Router Age Seq# CkSum0.0.0.1 2.2.2.2 42 0x80000001 0x21d2Inter-Area-Prefix-LSA (Area 0.0.0.1)Link State ID ADV Router Age Seq# CkSum Prefix0.0.0.1 2.2.2.2 42 0x80000004 0xbc0a 2001:2::/640.0.0.4 2.2.2.2 19 0x80000001 0xb80c 2001:3::/640.0.0.5 2.2.2.2 19 0x80000001 0xd0ef 2001:5::/64Intra-Area-Prefix-LSA (Area 0.0.0.1)Link State ID ADV Router Age Seq# CkSum Prefix Reference0.0.0.1 1.1.1.1 35 0x80000005 0xc4ce 1 Router-LSA0.0.0.3 2.2.2.2 41 0x80000001 0x8807 1 Network-LSA
Para Device2, rotas 2001:3::/642 e 2001: 5 ::/64 são rotas inter-áreas. Você pode consultar as informações de LSA das rotas relacionadas em Inter-Area-Prefix-LSA (Área 0.0.0.0). No caso de rotas intra-área, execute o comando show ipv6 ospf database intra-prefix para consultar as informações de LSA das rotas relacionadas.
- Passo 4: Configure o tipo de rede de interfaces OSPFv3 para P2P.
#No Device3, configure o tipo de rede OSPFv3 da interface vlan3 para P2P.
Device3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 ospf network point-to-pointDevice3(config-if-vlan3)#exit
#No Device4, configure o tipo de rede OSPFv3 da interface vlan2 para P2P.
Device4(config)#interface vlan2Device4(config-if-vlan2)#ipv6 ospf network point-to-pointDevice4(config-if-vlan2)#exit
- Passo 5: Confira o resultado.
#Consulte os vizinhos OSPFv3 e a tabela de roteamento do Device3.
Device3#show ipv6 ospf neighborOSPFv3 Process (100)Neighbor ID Pri State Dead Time Interface Instance ID2.2.2.2 1 Full/Backup 00:00:39 vlan2 04.4.4.4 1 Full/ - 00:00:39 vlan3 0Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1d:09:10:10, lo0O 2001:1::/64 [110/2]via fe80::201:7aff:fe5e:6d46, 02:07:25, vlan2C 2001:2::/64 [0/0]via ::, 03:07:51, vlan2L 2001:2::2/128 [0/0]via ::, 03:07:48, lo0C 2001:3::/64 [0/0]via ::, 03:07:41, vlan3L 2001:3::1/128 [0/0]via ::, 03:07:39, lo0O 2001:4::/64 [110/3]via fe80::201:7aff:fe5e:6d46, 02:07:25, vlan2O 2001:5::/64 [110/2]via fe80::201:2ff:fe03:405, 00:00:22, vlan3
Se as relações de vizinhos OSPFv3 forem configuradas em uma rede P2P, nenhuma eleição de DR ou BDR será realizada.
#Consulte os vizinhos OSPFv3 e a tabela de roteamento do Device4.
Device4#show ipv6 ospf neighborOSPFv3 Process (100)Neighbor ID Pri State Dead Time Interface Instance ID3.3.3.3 1 Full/ - 00:00:38 vlan2 0Device4#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 00:05:34, lo0O 2001:1::/64 [110/3]via fe80::2212:1ff:fe01:102, 00:03:12, vlan2O 2001:2::/64 [110/2]via fe80::2212:1ff:fe01:102, 00:03:12, vlan2C 2001:3::/64 [0/0]via ::, 00:04:34, vlan2L 2001:3::2/128 [0/0]via ::, 00:04:31, lo0O 2001:4::/64 [110/4]via fe80::2212:1ff:fe01:102, 00:03:12, vlan2C 2001:5::/64 [0/0]via ::, 00:03:14, vlan3L 2001:5::1/128 [0/0]via ::, 00:03:13, lo0
Depois que o tipo de rede das interfaces OSPFv3 é modificado para P2P, os vizinhos podem ser configurados normalmente e as rotas podem ser aprendidas normalmente.
Configurar OSPFv3 usar autenticação criptografada IPsec
Requisitos de rede
- Todos os roteadores executam OSPFv3 e todo o AS é dividido em duas áreas .
- Device1, Device2 e Device3 usam o túnel IPSec para criptografar e autenticar os pacotes do protocolo OSPFv3. Device1 e Device2 usam o modo de transmissão e encapsulamento ESP, o algoritmo de criptografia é 3des e o algoritmo de autenticação é sha1. Device2 e Device3 usam o modo de transmissão e encapsulamento ESP, o algoritmo de criptografia é aes128 e o algoritmo de autenticação ESP é sm3.
- Após a configuração, o dispositivo pode normalmente configurar o vizinho e aprender as rotas de um para o outro.
Topologia de rede

Figura 8 -2 Rede para configurar o OSPFv3 para usar autenticação criptografada IPSec
Etapas de configuração
- Passo 1: Configure os endereços IPv6 das interfaces. (Omitido)
- Passo 2: Configure um processo OSPFv3 e ative a função OSPFv3 na interface correspondente.
# Configura o processo OSPFv3 es de Device1, Device2 e Device3 e habilite OSPFv3 na interface.
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)#router-id 1.1.1.1Device1(config-ospf6)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 router ospf 100 area 1Device1(config-if-vlan2)#exitDevice2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 router ospf 100 area 1Device2(config-if- vlan2)#exitDevice2(config)#interface vlan3Device2(config-if- vlan3)#ipv6 router ospf 100 area 0 Device2(config-if- vlan3)#exitDevice3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ipv6 router ospf 100 area 0Device3(config-if-vlan2)#exit
- Passo 3: Configure a proposta IPSec e o túnel manual.
#Configure Device1, crie a proposta IPSec a, adote o modo de transmissão e encapsulamento ESP, o algoritmo criptografado 3des e o algoritmo de autenticação sha1, crie o túnel manual IPSec a e configure o SPI e a chave.
Device1(config)#crypto ipsec proposal aDevice1(config-ipsec-prop)#mode transportDevice1(config-ipsec-prop)#esp 3des sha1Device1(config-ipsec-prop)#exitDevice1(config)#crypto ipv6-tunnel a manualDevice1(config-manual-tunnel-ipv6)#set ipsec proposal aDevice1(config-manual-tunnel-ipv6)#set inbound esp 1000 encryption 0 111111111111111111111111 authentication 0 aaaaaaaaaaaaaaaaaaaaDevice1(config-manual-tunnel-ipv6)#set outbound esp 1001 encryption 0 aaaaaaaaaaaaaaaaaaaaaaaa authentication 0 11111111111111111111Device1(config-manual-tunnel-ipv6)#exit
#Configure Device2, crie a proposta IPSec a, adote o modo de transmissão e encapsulamento ESP, o algoritmo criptografado 3des e o algoritmo de autenticação sha1, crie o túnel manual IPSec a e configure o SPI e a chave. Criar proposta IPSec b, adotar o modo de transmissão ESP, algoritmo criptografado aes128 e algoritmo de autenticação sm3 ; crie o túnel manual Ipsec b e configure o SPI e a chave.
Device2(config)#crypto ipsec proposal aDevice2(config-ipsec-prop)#mode transportDevice2(config-ipsec-prop)#esp 3des sha1Device2(config-ipsec-prop)#exitDevice2(config)# crypto ipv6-tunnel a manualDevice2(config-manual-tunnel-ipv6)#set ipsec proposal aDevice2(config-manual-tunnel-ipv6)#set inbound esp 1001 encryption 0 aaaaaaaaaaaaaaaaaaaaaaaa authentication 0 11111111111111111111Device2(config-manual-tunnel-ipv6)#set outbound esp 1000 encryption 0 111111111111111111111111 authentication 0 aaaaaaaaaaaaaaaaaaaaDevice2(config-manual-tunnel-ipv6)#exitDevice2(config)#crypto ipsec proposal bDevice2(config-ipsec-prop)#mode transportDevice2(config-ipsec-prop)#esp aes128 sm3Device2(config-ipsec-prop)#exitDevice2(config)# crypto ipv6-tunnel b manualDevice2(config-manual-tunnel-ipv6)#set ipsec proposal bDevice2(config-manual-tunnel-ipv6)#set inbound esp 2001 encryption 0 1111111111111111 authentication 0 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaDevice2(config-manual-tunnel-ipv6)#set outbound esp 2000 encryption 0 1111111111111111 authentication 0 11111111111111111111111111111111Device2(config-manual-tunnel-ipv6)#exit
#Configure Device3, crie a proposta IPSec b, adote o modo de transmissão e encapsulamento ESP, algoritmo criptografado aes128 e algoritmo de autenticação sm3, crie o túnel manual IPSec b e configure SPI e chave.
Device3(config)#crypto ipsec proposal bDevice3(config-ipsec-prop)#mode transportDevice3(config-ipsec-prop)#esp aes128 sm3Device3(config-ipsec-prop)#exitDevice3(config)# crypto ipv6-tunnel b manualDevice3(config-manual-tunnel-ipv6)#set ipsec proposal bDevice3(config-manual-tunnel-ipv6)#set inbound esp 2000 encryption 0 1111111111111111 authentication 0 11111111111111111111111111111111Device3(config-manual-tunnel-ipv6)#set outbound esp 2001 encryption 0 1111111111111111 authentication 0 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaDevice3(config-manual-tunnel-ipv6)#exit
- Passo 4: No processo OSPFv3, vincule a área ao túnel IPSec correspondente.
# No processo OSPFv3 de Device1, vincule a área 1 com o túnel IPSec a.
Device1(config)#ipv6 router ospf 100Device1(config-ospf6)#area 1 ipsec-tunnel aDevice1(config-ospf6)#exit
#No processo OSPFv3 de Device2, vincule a área 1 com o túnel IPSec a e vincule a área 0 com o túnel Ipsec b.
Device2(config)#ipv6 router ospf 100Device2(config-ospf6)#area 1 ipsec-tunnel aDevice2(config-ospf6)#area 0 ipsec-tunnel bDevice1(config-ospf6)#exit
# No processo OSPFv3 de Device3, vincule a área 0 com o túnel IPSec b.
Device3(config)#ipv6 router ospf 100Device3(config-ospf6)#area 0 ipsec-tunnel bDevice3(config-ospf6)#exit
- Passo 5: Confira o resultado.
# Consulta as informações do processo OSPFv3 de Device1.
Device1#show ipv6 ospf 100Routing Process "OSPFv3 (100)" with ID 1.1.1.1Process bound to VRF defaultIETF graceful-restarter support disabledIETF gr helper support enabledInitial SPF schedule delay 5000 msecsMinimum hold time between two consecutive SPFs 10000 msecsMaximum wait time between two consecutive SPFs 10000 msecsMinimum LSA interval 5 secs, Minimum LSA arrival 1 secsNumber of external LSA 0. Checksum Sum 0x0000Number of AS-Scoped Unknown LSA 0Number of LSA originated 5Number of LSA received 5Number of areas in this router is 1Not Support Demand Circuit lsa number is 0Autonomy system support flood DoNotAge LsaArea 0.0.0.1Number of interfaces in this area is 1IPSec Tunnel Name:a , ID: 154Number of fully adjacent neighbors in this area is 1Number of fully adjacent sham-link neighbors in this area is 0Number of fully adjacent virtual neighbors through this area is 0SPF algorithm executed 4 timesLSA walker due in 00:00:02Number of LSA 4. Checksum Sum 0x2FC53Number of Unknown LSA 0Not Support Demand Circuit lsa number is 0Indication lsa (by other routers) number is: 0,area support flood DoNotAge Lsa
Você pode ver que a área está vinculada ao túnel IPSec a e o ID é um valor aleatório de 0 a 1023.
# Consulta as informações do túnel IPSec do Device1.
Device1# show crypto ipv6-tunnel aget the manual ipv6 tunnelCrypto tunnelv6 a : MANUALpolicy name : (null)peer address :local interface : (null) address :Ipsec proposal : aInbound :esp : spi: 1000 encription key: ******** authentication key: ********ah spi: 0 authentication key: (null)Outbound :esp spi: 1001 encryption key: ******** authentication key: ********ah spi: 0 authentication key: (null)route ref : 1route asyn : 1route rt_id : 154
Você pode ver que a rota rt_id é igual ao ID em show ipv6 ospf 100.
# Consulta as informações do tipo de criptografia do túnel IPSec do Device1.
Device1# show crypto ipsec sa ipv6-tunnel aroute policy:the pairs of ESP ipsec sa : id :0 , algorithm : 3DES HMAC-SHA1-96inbound esp ipsec sa : spi : 0x3e8(1000) crypto m_context(s_context) : 0x4cd3ba78 / 0x4cd3bae0current input 26 packets, 2 kbytesencapsulation mode : Transportreplay protection : OFFremaining lifetime (seconds/kbytes) : 0/0uptime is 0 hour 4 minute 45 secondoutbound esp ipsec sa : spi : 0x3e9(1001) crypto m_context(s_context) : 0x4cd3bb48 / 0x4cd3bbb0current output 39 packets, 3 kbytesencapsulation mode : Transportreplay protection : OFFremaining lifetime (seconds/kbytes) : 0/0uptime is 0 hour 4 minute 45 secondtotal sa and sa group is 1
Você pode ver que o túnel IPSec a adota o modo de transmissão e encapsulamento ESP, o algoritmo de criptografia é 3des e o algoritmo de autenticação é sha1.
# Consulta as informações da interface OSPFv3 do Device1.
Device1#show ipv6 ospf interface vlan2vlan2 is up, line protocol is upInterface ID 50331913IPv6 Prefixesfe80::201:7aff:fecf:fbec/10 (Link-Local Address)2001 :1::1/64Interface ID 13OSPFv3 Process (100), Area 0.0.0.1, Instance ID 0, Enabled 00:41:10, MTU 1500Router ID 1.1.1.1, Network Type BROADCAST, Cost: 1IPSec tunnel(Area):a, ID:154Transmit Delay is 1 sec, State Backup, 3 state change, Priority 1Designated Router (ID) 2.2.2.2Interface Address fe80::200:1ff:fe7a:adf0Backup Designated Router (ID) 1.1.1.1Interface Address fe80::201:7aff:fecf:fbecTimer interval configured, Hello 10, Dead 39, Wait 39, Retransmit 5Hello due in 00:00:06Neighbor Count is 1, Adjacent neighbor count is 1Hello received 2 sent 3, DD received 3 sent 4LS-Req received 1 sent 1, LS-Upd received 5 sent 3LS-Ack received 3 sent 2, Discarded 0
Você pode ver que a interface está vinculada ao túnel IPSec a e o ID é um valor aleatório de 0 a 1023.
# Consulta as informações do vizinho OSPFv3 e a tabela de roteamento principal do Device1 .
Device1#show ipv6 ospf neighborOSPFv3 Process (100)Neighbor ID Pri State Dead Time Interface Instance ID2.2.2.2 1 Full/DR 00:00:39 vlan2 0Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 4d:04:06:36, lo0C 2001:1::/64 [0/0]via ::, 03:00:53, vlan2L 2001:1::1/128 [0/0]via ::, 03:00:49, lo0O 2001:2::/64 [110/2]via fe80::201:7aff:fec9:1cdd, 2d:00:03:49, vlan2
Device1 , o vizinho é configurado normalmente e o aprendizado de rota é normal.
# Consulta as informações do processo OSPFv3 do Device3.
Device3#show ipv6 ospf 100Routing Process "OSPFv3 (100)" with ID 3.3.3.3Process bound to VRF defaultIETF graceful-restarter support disabledIETF gr helper support enabledInitial SPF schedule delay 5000 msecsMinimum hold time between two consecutive SPFs 10000 msecsMaximum wait time between two consecutive SPFs 10000 msecsMinimum LSA interval 5 secs, Minimum LSA arrival 1 secsNumber of external LSA 0. Checksum Sum 0x0000Number of AS-Scoped Unknown LSA 0Number of LSA originated 5Number of LSA received 6Number of areas in this router is 1Not Support Demand Circuit lsa number is 0Autonomy system support flood DoNotAge LsaArea BACKBONE(0)Number of interfaces in this area is 1IPSec Tunnel Name:b , ID: 2Number of fully adjacent neighbors in this area is 1Number of fully adjacent sham-link neighbors in this area is 0SPF algorithm executed 4 timesLSA walker due in 00:00:02Number of LSA 4. Checksum Sum 0x24272Number of Unknown LSA 0Not Support Demand Circuit lsa number is 0Indication lsa (by other routers) number is: 0,area support flood DoNotAge Lsa
Você pode ver que a área está vinculada ao túnel IPSec b e o ID é um valor aleatório de 0 a 1023.
# Consulta as informações do túnel IPSec do Device3 .
Device3# show crypto ipv6-tunnel bget the manual ipv6 tunnelCrypto tunnelv6 a : MANUALpolicy name : (null)peer address :local interface : (null) address :Ipsec proposal : bInbound :esp : spi: 2000 encription key: ******** authentication key: ********ah spi: 0 authentication key: (null)Outbound :esp spi: 2001 encryption key: ******** authentication key: ********ah spi: 0 authentication key: (null)route ref : 1route asyn : 1route rt_id : 2
Você pode ver que a rota rt_id é igual ao ID em show ipv6 ospf 100.
# Consulta as informações do tipo de criptografia do túnel IPSec do Device3.
Device3#show crypto ipsec sa ipv6-tunnel broute policy:the pairs of ESP ipsec sa : id : 0, algorithm : AES128 HMAC-SM3inbound esp ipsec sa : spi : 0x7d0(2000) crypto m_context(s_context) : 0x6a0d9a98 /0x6a0d9a30current input 53 packets, 5 kbytesencapsulation mode : Transportreplay protection : OFFremaining lifetime (seconds/kbytes) : 0/0uptime is 0 hour 6 minute 40 secondoutbound esp ipsec sa : spi : 0x7d1(2001) crypto m_context(s_context) : 0x6a0d99c8 /0x6a0d9960current output 52 packets, 5 kbytesencapsulation mode : Transportreplay protection : OFFremaining lifetime (seconds/kbytes) : 0/0uptime is 0 hour 6 minute 40 secondtotal sa and sa group is 1
Você pode ver que o túnel IPSec adota o modo de transmissão e encapsulamento ESP, o algoritmo de criptografia é aes128 e o algoritmo de autenticação é sm3.
# Consulta as informações da interface OSPFv3 do Device3.
Device3#show ipv6 ospf interface vlan2vlan2 is up, line protocol is upInterface ID 50331899IPv6 Prefixesfe80::200:1ff:fe7a:adf0/10 (Link-Local Address)2001 :2::1/64Interface ID 9OSPFv3 Process (100), Area 0.0.0.1, Instance ID 0, Enabled 00:50:39, MTU 1500Router ID 3.3.3.3, Network Type BROADCAST, Cost: 1IPSec tunnel(Area):b, ID:2Transmit Delay is 1 sec, State DR, 4 state change, Priority 1Designated Router (ID) 2.2.2.2Interface Address fe80::200:1ff:fe7a:adf0Backup Designated Router (ID) 1.1.1.1Interface Address fe80::201:7aff:fecf:fbecTimer interval configured, Hello 10, Dead 39, Wait 39, Retransmit 5Hello due in 00:00:02Neighbor Count is 1, Adjacent neighbor count is 1Hello received 272 sent 316, DD received 12 sent 9LS-Req received 3 sent 5, LS-Upd received 19 sent 18LS-Ack received 11 sent 13, Discarded 0
Você pode ver que a interface está vinculada ao túnel IPSec b e o ID é um valor aleatório de 0 a 1023.
# Consulta as informações do vizinho OSPFv3 e a tabela de roteamento principal do Device3 .
Device3#show ipv6 ospf neighborOSPFv3 Process (100)Neighbor ID Pri State Dead Time Interface Instance ID2.2.2.2 1 Full/Backup 00:00:35 vlan2 0Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M – ManagementL ::1/128 [0/0]via ::, 09:53:53, lo0O 2001:1::/64 [110/2]via fe80::ae9c:e4ff:fe77:889e, 00:23:36, vlan2C 2001:2::/64 [0/0]via ::, 03:05:16, vlan2L 2001:2::2/128 [0/0]via ::, 03:05:13, lo0
Device3 , o vizinho é configurado normalmente e o aprendizado de rota é normal.
- Passo 6: Na interface OSPFv3, vincule o túnel IPSec correspondente.
# Configure Device1 e ligue a interface vlan2 com o túnel IPSec a.
Device1(config)#interface vlan2
Device1(config-if- vlan2)#ipv6 ospf ipsec-tunnel a
Device1(config-if- vlan2)#exit# Configurar Device2, e vincular a interface vlan2 com o túnel IPSec a ; vincular a interface vlan3 com o túnel IPSec b.
Device2(config)#interface vlan2Device2(config-if- vlan2)#ipv6 ospf ipsec-tunnel a Device2(config-if- vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 ospf ipsec-tunnel bDevice2(config-if-vlan3)#exit
# Configure Device3 e ligue a interface vlan2 com o túnel IPSec b.
Device3(config)#interface vlan2
Device3(config-if- vlan2)#ipv6 ospf ipsec-tunnel b
Device3(config-if- vlan2)#exit- Passo 7: Confira o resultado.
# Consulta as informações da interface OSPFv3 do Device1.
Device1#show ipv6 ospf interface vlan2vlan2 is up, line protocol is upInterface ID 50331913IPv6 Prefixesfe80::201:7aff:fecf:fbec/10 (Link-Local Address)2001 :1::1/64Interface ID 13OSPFv3 Process (100), Area 0.0.0.1, Instance ID 0, Enabled 00:41:10, MTU 1500Router ID 1.1.1.1, Network Type BROADCAST, Cost: 1IPSec tunnel:a, ID:154Transmit Delay is 1 sec, State Backup, 3 state change, Priority 1Designated Router (ID) 2.2.2.2Interface Address fe80::200:1ff:fe7a:adf0Backup Designated Router (ID) 1.1.1.1Interface Address fe80::201:7aff:fecf:fbecTimer interval configured, Hello 10, Dead 39, Wait 39, Retransmit 5Hello due in 00:00:06Neighbor Count is 1, Adjacent neighbor count is 1Hello received 2 sent 3, DD received 3 sent 4LS-Req received 1 sent 1, LS-Upd received 5 sent 3LS-Ack received 3 sent 2, Discarded 0
Você pode ver que a interface está vinculada ao túnel IPSec a e o ID é um valor aleatório de 0 a 1023.
# Consulta a tabela de roteamento principal OSPFv3 de Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 4d:04:06:36, lo0C 2001:1::/64 [0/0]via ::, 03:00:53, vlan2L 2001:1::1/128 [0/0]via ::, 03:00:49, lo0O 2001:2::/64 [110/2]via fe80::201:7aff:fec9:1cdd, 2d:00:03:49, vlan2
No Dispositivo1, o aprendizado de rota é normal.
# Consulta as informações da interface OSPFv3 do Device3.
Device3#show ipv6 ospf interface vlan2vlan2 is up, line protocol is upInterface ID 50331899IPv6 Prefixesfe80::200:1ff:fe7a:adf0/10 (Link-Local Address)2001 :2::1/64Interface ID 9OSPFv3 Process (100), Area 0.0.0.1, Instance ID 0, Enabled 00:50:39, MTU 1500Router ID 3.3.3.3, Network Type BROADCAST, Cost: 1IPSec tunnel:b, ID:2Transmit Delay is 1 sec, State DR, 4 state change, Priority 1Designated Router (ID) 2.2.2.2Interface Address fe80::200:1ff:fe7a:adf0Backup Designated Router (ID) 1.1.1.1Interface Address fe80::201:7aff:fecf:fbecTimer interval configured, Hello 10, Dead 39, Wait 39, Retransmit 5Hello due in 00:00:02Neighbor Count is 1, Adjacent neighbor count is 1Hello received 272 sent 316, DD received 12 sent 9LS-Req received 3 sent 5, LS-Upd received 19 sent 18LS-Ack received 11 sent 13, Discarded 0
Você pode ver que a interface está vinculada ao túnel IPSec b e o ID é um valor aleatório de 0 a 1023.
# Consulta a tabela de roteamento principal OSPFv3 de Device3 .
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M – ManagementL ::1/128 [0/0]via ::, 09:53:53, lo0O 2001:1::/64 [110/2]via fe80::ae9c:e4ff:fe77:889e, 00:23:36, vlan2C 2001:2::/64 [0/0]via ::, 03:05:16, vlan2L 2001:2::2/128 [0/0]via ::, 03:05:13, lo0
No Device3, o aprendizado de rota é normal.
Ao configurar o OSPFv3 para vincular com o túnel IPSec, você só pode configurar a vinculação de área ou a vinculação de interface e também pode configurar a vinculação de área e a vinculação de interface ao mesmo tempo. Quando a vinculação de área e a vinculação de interface são configuradas para o túnel IPSec na mesma interface, a vinculação de interface é anterior.
Configurar OSPFv3 para coordenar com BFD
Requisitos de rede
- Configure o OSPFv3 para todos os dispositivos.
- Habilite a função de detecção BFD na linha entre Device1 e Device3. Se a linha apresentar falha, o BFD detecta rapidamente a falha e notifica o OSPFv3 sobre a falha. Em seguida, o OSPFv3 alterna a rota para Device2 para comunicação.
Topologia de rede
Figura 8 -3 Rede para configurar o OSPFv3 para coordenar com BFD
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente (omitida).
- Passo 2: Configure os endereços IPv6 das interfaces. (Omitido)
- Passo 3: Configure um processo OSPFv3.
# Configurar Device1 .
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)#router-id 1.1.1.1Device1(config-ospf6)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 router ospf 100 area 0Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 router ospf 100 area 0Device1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ipv6 router ospf 100 area 0Device1(config-if-vlan4)#exit
# Configurar Device2 .
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 router ospf 100 area 0Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 router ospf 100 area 0Device2(config-if-vlan3)#exit
# Configurar Device3 .
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ipv6 router ospf 100 area 0Device3(config-if-vlan2)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 router ospf 100 area 0Device3(config-if-vlan3)#exitDevice3(config)#interface vlan4Device3(config-if-vlan4)#ipv6 router ospf 100 area 0Device3(config-if-vlan4)#exit
- Passo 4: Configure o OSPFv3 para coordenar com o BFD.
# Configurar Device1 .
Device1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 ospf bfdDevice1(config-if-vlan2)#exit
# Configurar Device3 .
Device3(config)#interface vlan2Device3(config-if-vlan2)#ipv6 ospf bfdDevice3(config-if-vlan2)#exit
- Passo 5: Confira o resultado.
# Visualize as informações do vizinho OSPFv3 e a tabela de rotas do Device1 .
Device1#show ipv6 ospf neighbor 3.3.3.3OSPFv3 Process (100)Neighbor 3.3.3.3,interface address fe80::2212:1ff:fe01:104In the area 0.0.0.0 via interface vlan4, BFD enabledDR is 3.3.3.3 BDR is 1.1.1.1Neighbor priority is 1, State is Full, 6 state changesOptions is 0x13 (-|R|-|-|E|V6)Dead timer due in 00:00:37Neighbor is up for 00:01:31Database Summary List 0Link State Request List 0Link State Retransmission List 0Thread Inactivity Timer onThread Database Description Retransmission off, 0 timesThread Link State Request Retransmission off, 0 timesThread Link State Update Retransmission off, 0 timesDevice1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 01:15:27, lo0C 1001:1::/64 [0/0]via ::, 01:15:27, vlan4L 1001:1::1/128 [0/0]via ::, 01:15:27, lo0O 1001:2::/64 [110/2]via fe80::2212:1ff:fe01:104, 00:02:40, vlan2C 2001:1::/64 [0/0]via ::, 01:15:27, vlan2L 2001:1::1/128 [0/0]via ::, 01:15:27, lo0C 2001:2::/64 [0/0]via ::, 01:15:27, vlan3L 2001:2::1/128 [0/0]via ::, 01:15:27, lo0O 2001:3::/64 [110/2]via fe80::201:7aff:fe5e:6d45, 00:02:40, vlan3[110/2]via fe80::2212:1ff:fe01:104, 00:02:40, vlan2
De acordo com as informações do vizinho OSPFv3, o BFD foi habilitado e a rota 1001:2::/64 primeiro seleciona a linha entre Device1 e Device3 para comunicação.
#Visualize a sessão BFD do Device1.
Device1#show bfd session ipv6 detailTotal ipv6 session number: 1OurAddr NeighAddr State Holddown Interfacefe80::201:7aff:fe61:7a25 fe80::2212:1ff:fe01:104 UP 5000 vlan2Type:ipv6 directLocal State:UP Remote State:UP Up for: 0h:0m:4s Number of times UP:1Local Discriminator:5 Remote Discriminator:95Send Interval:1000ms Detection time:5000ms(1000ms*5)Local Diag:0 Demand mode:0 Poll bit:0MinTxInt:1000 MinRxInt:1000 Multiplier:5Remote MinTxInt:1000 Remote MinRxInt:1000 Remote Multiplier:5Registered protocols:OSPFv3
O OSPFv3 coordenou com sucesso com o BFD e a sessão foi configurada normalmente.
#Se a linha entre Device1 e Device3 estiver com defeito, o BFD detecta rapidamente a falha e informa o OSPFv3 da falha e, em seguida, o OSPFv3 alterna a rota para Device2 para comunicação. Veja a tabela de rotas de Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 01:16:10, lo0C 1001:1::/64 [0/0]via ::, 01:16:10, vlan4L 1001:1::1/128 [0/0]via ::, 01:16:10, lo0O 1001:2::/64 [110/3]via fe80::201:7aff:fe5e:6d45, 00:00:07, vlan3C 2001:1::/64 [0/0]via ::, 01:16:10, vlan2L 2001:1::1/128 [0/0]via ::, 01:16:10, lo0C 2001:2::/64 [0/0]via ::, 01:16:10, vlan3L 2001:2::1/128 [0/0]via ::, 01:16:10, lo0O 2001:3::/64 [110/2]via fe80::201:7aff:fe5e:6d45, 00:03:22, vlan3
A ação do Device3 é semelhante à do Device1.
IS-IS (Aplicável somente ao modelo S3054G-B)
Visão geral
O IS-IS (Intermediate System to Intermediate System) é o IGP (Interior Gateway Protocol) baseado no algoritmo SPF. A teoria básica de projeto e o algoritmo para o protocolo IS-IS são consistentes com o OSPF. O protocolo IS-IS é o protocolo de roteamento baseado na camada de enlace, que é irrelevante para a camada de rede (IPv4, IPv6 e OSI). Não é restrito pela camada de rede e, portanto, possui boa extensibilidade.
O protocolo IS-IS pode suportar o roteamento de pilhas de vários protocolos , incluindo IPv4, IPv6 e OSI. O protocolo IS-IS é inicialmente aplicado à pilha de protocolos OSI (ISO10589) e depois estendido para o roteamento da pilha de protocolos IPv4 (RFC1195) e da pilha de protocolos IPv6 (RFC5308). o MPLS-TE (RFC3784).
O protocolo IS-IS é caracterizado com boa capacidade (funções estendidas inconsistentes entre dispositivos podem ser perfeitamente compatíveis), grande capacidade de rede, capaz de suportar pilhas multi-protocolo , capaz de atualizar sem problemas, improvável de apresentar falhas em comparação com o OSPF. Portanto, o protocolo IS-IS se aplica à rede de backbone de núcleo de grande porte. Esta seção descreve como configurar o protocolo de roteamento dinâmico IS-IS no dispositivo para interconexão de rede.
Configuração da Função IS-IS
Tabela 9 -1 Lista de funções IS-IS
| Tarefa de configuração | |
| Configurar a função básica IS-IS | Habilite o protocolo IS-IS Configure o atributo IS-IS VRF |
| Configurar o atributo de camada IS-IS | Configurar o atributo de camada IS-IS |
| Configurar a geração de rota IS-IS | Configurar a rota padrão IS-IS Configurar a redistribuição de roteamento IS-IS |
| Configurar o controle de roteamento IS-IS |
Configurar o estilo de métrica IS-IS
Configurar o valor da métrica da interface IS-IS Configurar a distância administrativa IS-IS Configurar o resumo da rota IS-IS Configure o número máximo de rotas com balanceamento de carga para o IS-IS Configure o vazamento de rota entre camadas IS-IS Configurar o bit IS-IS ATT |
| Configurar a otimização de rede IS-IS |
Configurar a prioridade da interface IS-IS
Configurar a interface passiva IS-IS Configure o parâmetro de pacote IS-IS Hello Configurar o parâmetro de pacote IS-IS LSP Configure o parâmetro de pacote IS-IS SNP Configure o intervalo de cálculo IS-IS SPF Configure o número máximo de áreas para o IS-IS Configurar o mapeamento de nome de host IS-IS Configure a interface IS-IS a ser adicionada ao grupo de malha |
| Configurar a autenticação de rede IS-IS | Configurar a autenticação vizinha IS-IS Configurar a autenticação de rota IS-IS |
| Configure o IS-IS para coordenar com o BFD | Configure o IS-IS para coordenar com o BFD |
| Configurar IS-IS GR | Configurar IS-IS GR |
Configurar a função básica IS-IS
Condição de configuração
Antes de usar o protocolo IS-IS, primeiro complete as seguintes tarefas :
- Configure o protocolo da camada de link para garantir a comunicação normal na camada de link.
- Configure o endereço IP da camada de rede da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
Ativar protocolo IS-IS
Vários processos IS-IS podem operar ao mesmo tempo no sistema. Cada processo é identificado por diferentes nomes de processo.
Tabela 9 -2 Habilite o protocolo IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Crie o processo IS-IS e entre no modo de configuração IS-IS | router isis [area-tag ] | Obrigatório. Por padrão, o processo IS-IS não opera no sistema. O nome do processo é area-tag . |
| Configure o título da entidade de rede para o IS-IS | net entry-title | Obrigatório. Por padrão, o título da entidade de rede não está configurado para o IS-IS. |
| Retornar ao modo de configuração global | exit | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite o protocolo IS-IS na interface | ip router isis [area-tag ] | Obrigatório. Por padrão, o protocolo IS-IS não está habilitado na interface. |
O protocolo IS-IS não pode operar sem o título de entidade de rede.
Configurar o atributo IS-IS VRF
Vários processos IS-IS podem existir no mesmo VRF, mas apenas um processo IS-IS com atributo de nível 2 no VRF.
Tabela 9 -3 Configurar o atributo IS-IS VRF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Incorpore o atributo VRF para o IS-IS | vrf vrf-name | Opcional. Por padrão, o processo IS-IS localiza-se no VRF global. |
Configurar atributo de camada IS-IS
Condição de configuração
Antes de configurar o atributo de camada IS-IS, primeiro complete as seguintes tarefas :
- Configure o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IS-IS .
Configurar atributo de camada IS-IS
O atributo de camada IS-IS é dividido em atributo de camada global e atributo de camada de interface. O atributo da camada global é o sistema intermediário IS-IS, que é classificado nos três tipos a seguir:
- Sistema intermediário de nível 1: apenas o banco de dados de status de link do nível 1 está disponível e apenas o roteamento na área do nível 1 pode ser anunciado e aprendido.
- Sistema intermediário de nível 2: apenas o banco de dados de status de link do nível 2 está disponível e apenas o roteamento na área do nível 2 pode ser anunciado e aprendido.
- Sistema intermediário de nível 1-2: Ambos os bancos de dados de status de link do Nível 1 e Nível 2 estão disponíveis e o roteamento na área Nível 1 e Nível 2 pode ser anunciado e aprendido. O sistema intermediário Level-1-2 é o dispositivo de interconexão na área Level-1 e Level-2.
O atributo de camada da interface IS-IS é classificado nos três tipos a seguir:
- Interface de atributo de nível 1: apenas o pacote de nível 1 do protocolo IS-IS pode ser transmitido e recebido e apenas o vizinho do nível 1 pode ser estabelecido.
- Interface de atributo de nível 2: apenas o pacote de nível 2 do protocolo IS-IS pode ser transmitido e recebido e apenas o vizinho de nível 2 pode ser estabelecido.
- Interface de atributo de nível 1-2: Tanto o pacote de nível 1 quanto o pacote de nível 2 do protocolo IS-IS podem ser transmitidos e recebidos e os vizinhos de nível 1 e nível 2 podem ser estabelecidos.
O atributo de camada de interface IS-IS depende do atributo de camada global IS-IS. O sistema intermediário de nível 1 possui apenas a interface do atributo de nível 1, o sistema intermediário de nível 2 possui apenas a interface do atributo de nível 2 e o sistema intermediário de nível 1-2 pode ter interfaces de todos os atributos.
Tabela 9 -4 Configurar o atributo de camada global IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configure o atributo de camada global IS-IS | is-type { level-1 | level-1-2 | level-2-only } | Opcional. Por padrão, o atributo de camada global IS-IS é Level-1-2. |
Tabela 9 -5 Configurar o atributo de camada de interface IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o atributo da camada de interface | isis circuit-type [ level-1 | level-1-2 | level-2 ] |
Opcional.
Por padrão, o atributo de camada de interface é consistente com o atributo de camada global quando o atributo de camada de interface não é especificado. |
Apenas um processo IS-IS com o atributo Level-2 está disponível em um VRF.
Configurar geração de rota IS-IS
Condição de configuração
Antes de configurar a geração de rota IS-IS, primeiro complete as seguintes tarefas:
- Configure o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IS-IS.
Configurar rota padrão IS-IS
A área de Nível 2 do protocolo IS-IS não pode gerar a rota padrão durante a operação. Você pode configurar para adicionar uma rota padrão com o endereço IP de destino como 0.0.0.0/0 no LSP de nível 2 e liberá -lo. Quando outras áreas do mesmo nível no sistema intermediário receberem as informações de rota, uma rota padrão será adicionada à tabela de roteamento.
Tabela 9 -6 Configurar a rota padrão IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| IS IPv4 | address-family ipv4 unicast | - |
| Configurar o IS-IS para liberar a rota padrão | default-information originate | Obrigatório. Por padrão, a rota padrão não é liberada. |
Configurar redistribuição de roteamento IS-IS
A redistribuição de roteamento pode ser usada para introduzir as informações de roteamento de outros protocolos de roteamento no protocolo IS-IS. Isso permite a interconexão entre o sistema autônomo do protocolo IS-IS e o sistema autônomo de outros protocolos de roteamento ou da área de roteamento. Quando o roteamento externo é introduzido, a política de introdução de roteamento e o atributo da camada de roteamento após a introdução são especificados.
Tabela 9 -7 Configurar a redistribuição de roteamento IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| IS IPv4 | address-family ipv4 unicast | - |
| Configurar a redistribuição de roteamento IS-IS | redistribute protocol [ protocol-id ] [ level-1 / level-1-2 / level-2 / metric metric-value / metric-type { external | internal } / route-map route-map-name / match route-sub-type ] |
Obrigatório.
Por padrão, as informações de outros protocolos de roteamento não são redistribuídas. |
Configurar controle de roteamento S-IS
Condição de configuração
Antes de configurar o recurso de roteamento IS-IS, primeiro conclua as seguintes tarefas:
- Configure o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IS-IS .
Configurar estilo de métrica IS-IS
Inicialmente, o IS-IS tem apenas o estilo métrico estreito. Quando o estilo métrico estreito é usado, o valor máximo da métrica é 63. Com a expansão da escala de rede, o estilo métrico não pode satisfazer os requisitos. Portanto, surge o estilo de métrica ampla cujo valor de métrica pode chegar a 16777214. Os dispositivos que usam estilos de métrica diferentes não podem anunciar e aprender as informações de roteamento uns dos outros. Para realizar a transição entre os dois estilos de métrica, é fornecido o método de configuração para o estilo de métrica de transição.
O estilo métrico largo é recomendado.
Tabela 9 -8 Configurar o estilo de métrica IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o estilo de métrica da interface | metric-style {narrow | narrow transition | transition | wide | wide transition} [level-1 | level-1-2 | level-2] | Opcional. Por padrão, o estilo métrico estreito é usado. |
Configurar o valor da métrica da interface IS-IS
Quando o protocolo IS-IS está habilitado na interface, a métrica de roteamento IS-IS é o valor da métrica global. O comando a seguir pode ser usado para especificar um valor de métrica para cada interface.
Tabela 9 -9 Configurar o valor da métrica da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o valor da métrica global IS-IS | metric metric-value [ level-1 | level-2 ] | Opcional. Por padrão, o valor da métrica global é 10. |
| Retornar ao modo de configuração global | exit | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o valor da métrica da interface | isis ipv4 metric {metric-value | maximum} [level-1 | level-2] | Opcional. Por padrão, o valor da métrica global é usado. |
Configurar distância administrativa IS-IS
O sistema escolhe o roteamento primário com base na distância administrativa. Quanto menor a distância administrativa, maior a prioridade do roteamento.
Tabela 9 -10 Configurar a distância administrativa IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| IS IPv4 | address-family ipv4 unicast | - |
| Configurar a distância administrativa de roteamento IS-IS | distance distance-value | Opcional. Por padrão, a distância administrativa é 115. |
Configurar resumo da rota IS-IS
O resumo da rota resume várias informações de roteamento como uma parte das informações de roteamento. Depois que o resumo da rota é configurado para o IS-IS, o número de anúncios para a sub-rede reduz efetivamente e o banco de dados de status do link e o tamanho da tabela de roteamento diminuem. Isso economiza efetivamente os recursos de memória e CPU. Essa configuração geralmente é aplicada ao dispositivo de borda Nível 1-2, reduzindo as informações de roteamento do anúncio da camada.
Tabela 9 -11 Configurar o resumo da rota IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Entre no modo de configuração da família de endereços IPv4 | address-family ipv4 unicast | - |
| Configurar o resumo da rota IS-IS | summary-prefix prefix-value [ metric metric-value / route-type {internal | external} / metric-type {internal | external} / tag tag-value / not-advertise / level-1 / level-2 / level-1-2 ] | Obrigatório. Por padrão, o resumo da rota não é executado. |
Configure o número máximo de rotas com balanceamento de carga para o IS-IS
Existem vários caminhos com o mesmo custo para o mesmo endereço IP de destino. Esses ECMP (roteamento multipath de custo igual) podem melhorar a taxa de utilização do link. O usuário pode controlar o número máximo de ECMPs IS-IS.
Tabela 9 -12 Configure o número máximo de rotas com balanceamento de carga para o IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Entre no modo de configuração da família de endereços IPv4 | address-family ipv4 unicast | - |
| Configure o número máximo de rotas com balanceamento de carga para o IS-IS | maximum-paths max-number | Opcional. Por padrão, o número máximo de caminhos para balanceamento de carga é 4. |
Configurar o vazamento de rota entre camadas IS-IS
Por padrão, o IS-IS apenas vaza o roteamento de nível 1 para o nível 2, mas a área de nível 1 não pode saber o roteamento da área de nível 2. O vazamento de rota entre camadas pode ser configurado para introduzir o roteamento de Nível 2 para a área de Nível 1. Ao configurar o vazamento de rota entre camadas, a política de roteamento pode ser especificada para vazar apenas a rota que corresponde à condição.
Tabela 9 -13 Configure o vazamento de rota entre camadas IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Entre no modo de configuração da família de endereços IS-IS IPv4 | address-family ipv4 unicast | - |
| Configure o vazamento de rota entre a camada IS-IS | propagate { level-1 into level-2 | level-2 into level-1 } [ distribute-list access-list-name | route-map route-map-name ] | Obrigatório. Por padrão, o Level-1 vaza sua rota para o Level-2. |
Configurar IS-IS ATT-bit
No dispositivo Level-1-2, o bit ATT é utilizado para informar a outros nós se este nó possui conexão com outras áreas. Se sim, o bit ATT será definido como 1 automaticamente e outros nós irão gerar uma rota padrão para este nó. Isso aumenta a carga de serviço desse nó. Para evitar essa situação, o bit ATT pode ser forçosamente definido como 0.
Tabela 9 -14 Configurar o bit IS-IS ATT
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| IS IPv4 | address-family ipv4 unicast | - |
| Configurar o bit IS-IS ATT | set-attached-bit { on | off } |
Obrigatório.
Por padrão, o bit ATT é definido com base em se o nó está conectado a outras áreas. |
Configurar otimização de rede IS-IS
Condição de configuração
Antes de configurar o ajuste e a otimização IS-IS, primeiro complete as seguintes tarefas:
- Configure o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IS-IS.
Configurar prioridade de interface IS-IS
O IS-IS escolhe um nó no link de broadcast como o nó DIS. O nó DIS envia o pacote CSNP periodicamente para sincronizar o banco de dados de status do link em toda a rede. O Level-1 e Level-2 selecionam o nó DIS respectivamente. A interface com a prioridade mais alta é selecionada como o nó DIS. O nó com o endereço MAC grande é selecionado como o nó DIS para os nós com a mesma prioridade.
Tabela 9 -15 Configurar a prioridade da interface IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a prioridade da interface IS-IS | isis priority priority-value [ level-1 | level-2 ] | Opcional. Por padrão, a prioridade da interface é 64. |
Configurar interface passiva IS-IS
A interface passiva não recebe e transmite o pacote de protocolo IS-IS, mas ainda libera as informações de roteamento de rede diretamente conectadas dessa interface. O IS-IS pode reduzir a largura de banda e o tempo de manipulação da CPU através da configuração da interface passiva. Com base nessa configuração, o IS-IS pode ser especificado para liberar apenas as informações de roteamento de rede diretamente conectadas das interfaces passivas e não liberar as informações de roteamento de rede diretamente conectadas das interfaces não passivas.
Tabela 9 -16 Configurar a interface passiva IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Configurar a interface passiva IS-IS | passive-interface interface-name | Obrigatório. Por padrão, o IS-IS não possui a interface passiva. |
| Configure o IS-IS apenas para liberar as informações de roteamento da interface passiva | advertise-passive-only |
Opcional.
Por padrão, as informações de roteamento de rede diretamente conectadas da interface habilitada com o protocolo IS-IS são liberadas. |
Configurar parâmetro de pacote IS-IS Hello
- Configure o intervalo de entrega do pacote Hello.
A interface habilitada com o protocolo IS-IS enviará o pacote Hello para manter a relação de vizinhança com os dispositivos vizinhos . Quanto menor o intervalo de entrega do pacote Hello, mais rápida é a convergência da rede. No entanto, mais largura de banda será ocupada.
Tabela 9 -17 Configurar intervalo de entrega para o pacote Hello
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o intervalo de entrega do pacote Hello na interface | isis hello-interval { interval | minimal } [ level-1 | level-2 ] | Opcional. Por padrão, o intervalo de entrega do pacote Hello é de 10s. |
- Configure o número de pacotes Hello inválidos.
O IS-IS calcula o tempo de retenção do relacionamento vizinho com base no número de pacotes Hello inválidos e informa o tempo de retenção ao dispositivo vizinho. Se o dispositivo vizinho não receber o pacote Hello deste dispositivo durante esse período, a relação de vizinho é inválida e o cálculo de roteamento será recalculado.
Tabela 9 -18 Configurar o número de pacotes Hello inválidos
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o número de pacotes Hello inválidos na interface | isis hello-multiplier multiplier [ level-1 | level-2 ] | Opcional. Por padrão, o número de pacotes Hello inválidos é 3. |
- Configure para cancelar a função de preenchimento do pacote Hello.
Se os valores de MTU na interface em ambos os lados do link forem inconsistentes, como resultado, pacotes menores podem ser transmitidos, mas pacotes maiores não podem ser transmitidos. Para evitar tal situação, o IS-IS adota o pacote Hello de preenchimento para o valor MTU da interface para fazer com que a relação de vizinho não possa ser estabelecida. No entanto, este método desperdiça a largura de banda. Na rede real, não há necessidade de configurar o pacote Hello de preenchimento. Apenas os pequenos pacotes Hello são transmitidos.
Tabela 9 -19 Configure para cancelar a função de preenchimento do pacote Hello
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Cancelar a função de preenchimento do pacote Hello | no isis hello padding | Obrigatório. Por padrão, a função de preenchimento de pacote Hello está habilitada. |
Configurar parâmetro de pacote IS-IS LSP
- Configure o tempo máximo de sobrevivência para o pacote LSP.
Cada pacote LSP tem um tempo máximo de sobrevivência. Quando o tempo de sobrevivência do pacote LSP for reduzido para 0, o pacote LSP será excluído do banco de dados de status do link. O tempo máximo de sobrevivência do pacote LSP deve ser maior que o intervalo de atualização do pacote LSP.
Tabela 9 -20 Configurar o parâmetro de pacote IS-IS LSP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o tempo máximo de sobrevivência para o pacote LSP | max-lsp-lifetime life-time | Opcional. Por padrão, o tempo máximo de sobrevivência do LSP é 1200s. |
- Configure o intervalo de atualização do pacote LSP.
O protocolo IS-IS anuncia e aprende o roteamento por meio da interação de cada pacote LSP. Os nós salvam os pacotes LSP recebidos no banco de dados de status do link. Cada pacote LSP tem um tempo máximo de sobrevivência e cada nó precisa atualizar seu pacote LSP periodicamente para evitar que o tempo máximo de sobrevivência do pacote LSP seja reduzido para 0 e manter o pacote LSP em toda a área de sincronização. Reduzir o intervalo de entrega de pacotes LSP pode acelerar a velocidade de convergência da rede, mas ocupará mais largura de banda.
Tabela 9 -21 Configurar o pacote de atualização do pacote LSP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o intervalo de atualização do pacote LSP | lsp-refresh-interval refresh-interval |
Opcional.
Por padrão, o intervalo de atualização do pacote para a entrega periódica do pacote é 900s. |
- Configure o intervalo de geração do pacote LSP.
A atualização periódica irá gerar um novo pacote LSP. Além disso, as alterações do status da interface e do status da rede também acionarão a geração de novos pacotes LSP. Para evitar que os pacotes LSP gerados com frequência ocupem muitos recursos da CPU, o usuário pode configurar o intervalo mínimo de geração de pacotes LSP.
Tabela 9 -22 Configurar o intervalo de geração do pacote LSP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o intervalo de geração do pacote LSP | lsp-gen-interval [ level-1 | level-2 ] max-interval [ initial-interval [ secondary-interval ]] |
Opcional.
Por padrão, o limite superior do intervalo de geração dos pacotes LSP é de 10s e o limite inferior é de 50ms. |
- Configure o intervalo de entrega do pacote LSP.
Cada pacote LSP gerado será entregue na interface. Para evitar o pacote LSP gerado com freqüência, ocupará muito a largura de banda da interface. Cada interface é configurada com o intervalo mínimo de entrega do pacote LSP.
Tabela 9 -23 Configurar o intervalo de entrega do pacote LSP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o intervalo de entrega do pacote LSP | isis lsp-interval min-interval | Opcional. Por padrão, o intervalo de entrega do pacote LSP é de 33 ms. |
- Configure o tempo de retransmissão do pacote LSP.
No link ponto a ponto, o IS-IS envia o pacote LSP e, em seguida, exige que o peer end envie a mensagem de confirmação PSNP. Se o IS-IS não receber a mensagem de confirmação, o IS-IS enviará o pacote LSP novamente. O tempo de espera da mensagem de confirmação é o intervalo de retransmissão do pacote LSP. O intervalo de retransmissão pode ser definido conforme exigido pelo usuário para evitar a retransmissão do pacote LSP quando a mensagem de confirmação não for recebida devido a um grande atraso.
Tabela 9 -24 Configurar o tempo de retransmissão do pacote LSP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o tempo de retransmissão do pacote LSP | isis retransmit-interval interval [ level-1 | level-2 ] | Opcional. Por padrão, o tempo de retransmissão é de 5s. |
- Configure o valor LSP MTU.
O pacote de protocolo IS-IS não pode realizar a fragmentação automática. Para não afetar a propagação normal do pacote LSP, o comprimento máximo do pacote LSP em um domínio de roteamento não pode exceder o valor mínimo de MTU nas interfaces IS-IS de todos os dispositivos. Portanto, quando os valores de MTU da interface são inconsistentes em dispositivos no domínio de roteamento, é recomendável que o comprimento máximo do pacote LSP seja definido de maneira uniforme.
Tabela 9 -25 Configurar o valor LSP MTU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o valor MTU do pacote LSP | lsp-mtu mtu-size [ level-1 | level-2 ] | Opcional. Por padrão, o valor MTU do pacote LSP é 1492 bytes. |
Configurar o parâmetro de pacote IS-IS SNP
- Configure o intervalo de entrega do pacote CSNP.
Os nós selecionados no link de broadcast precisam enviar o pacote CSNP periodicamente para sincronizar o banco de dados de status do link em toda a rede. O intervalo de entrega de pacotes CSNP é ajustado com base na situação real.
Tabela 9 -26 Configurar o intervalo de entrega do pacote CSNP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o intervalo de entrega do pacote CSNP | isis csnp-interval interval [ level-1 | level-2 ] | Opcional. Por padrão, o intervalo de entrega do pacote CSNP é 10s. |
- Configurar o intervalo de entrega do pacote PSNP
No link de transmissão, o pacote PSNP sincroniza o banco de dados de status do link em toda a rede. No link ponto a ponto, o pacote PSNP confirma o pacote LSP recebido. Para evitar que um grande número de pacotes PSNP sejam entregues pela interface. Um intervalo mínimo de entrega é definido para o pacote PSNP e o usuário pode alterar o intervalo dinamicamente. O intervalo de entrega do pacote PSNP não pode ser definido com um valor muito grande. Se o intervalo de entrega do pacote for definido com um valor muito grande, a sincronização do banco de dados de status do link em toda a rede será afetada para o link de transmissão e o pacote LSP poderá ser reenviado devido ao recebimento não oportuno da mensagem de confirmação para o ponto a destino. -ponto de ligação.
Tabela 9 -27 Configurar o intervalo de entrega do pacote PSNP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o intervalo de entrega do pacote PSNP | isis psnp-interval min-interval [ level-1 | level-2 ] | Opcional. Por padrão, o intervalo de entrega do pacote PSNP é de 2s. |
Configurar intervalo de cálculo IS-IS SPF
As alterações do banco de dados de status do link IS-IS acionarão o cálculo de roteamento SPF. O cálculo frequente do SPF consumirá uma massa de recursos da CPU e o usuário poderá configurar o intervalo de cálculo do SPF.
Tabela 9 -28 Configurar o intervalo de cálculo IS-IS SPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Entre no modo de configuração da família de endereços IS-IS IPv4 | address-family ipv4 unicast | - |
| Configure o intervalo de cálculo IS-IS SPF | spf-interval [ level-1 | level-2 ] maximum-interval [ min-initial-delay [ min-second-delay ]] | Opcional |
Configurar o número máximo de áreas para IS-IS
Endereços IP de várias áreas podem ser configurados em um processo IS-IS . Os endereços IP de área múltipla são aplicados principalmente nas duas situações a seguir em que várias áreas de Nível 1 são combinadas como uma área de Nível 1 ou uma área de Nível 1 é dividida em várias áreas de Nível 1.
Tabela 9 -29Configurar o número máximo de áreas para o IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Configure o número máximo de áreas para o IS-IS | max-area-addresses max-number | Opcional. Por padrão, o número máximo de endereços IP de área é 3. |
Essa configuração deve ser consistente em todo o domínio de roteamento IS-IS Nível 1. Caso contrário, o vizinho de Nível 1 não pode ser estabelecido normalmente. O vizinho de Nível 2 não é afetado.
Configurar mapeamento de nome de host IS-IS
O IS-IS identifica exclusivamente um sistema intermediário n usando o ID do sistema com um comprimento fixo de 6 bytes. Ao visualizar as informações do sistema, como o relacionamento de vizinhos e o banco de dados de status do link, o ID do sistema não pode permitir que o usuário associe visualmente o ID do sistema ao nome do host. O IS-IS suporta o mapeamento entre o ID do sistema e o nome do host para permitir que o usuário visualize as informações do sistema de forma mais visual e conveniente. O mapeamento do nome do host IS-IS pode ser configurado nos dois métodos a seguir:
- Configure o mapeamento de nome de host estático IS-IS.
O mapeamento do nome do host estático IS-IS é estabelecido manualmente pelo usuário entre o ID do sistema e o nome do host para o dispositivo remoto.
Tabela 9 -30 Configurar o mapeamento de nome de host estático IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Configurar o mapeamento de nome de host estático IS-IS | hostname static system-id host-name | Obrigatório |
- Configure o mapeamento de nome de host dinâmico IS-IS.
O mapeamento estático do nome do host requer que o usuário configure o ID do sistema e o mapeamento do nome do host de outros dispositivos em cada dispositivo na rede, que tem uma carga de trabalho pesada. O mapeamento dinâmico do nome do host configura apenas o nome do host para cada dispositivo, e outros dispositivos na rede podem aprender o nome do host do dispositivo quando a função de anúncio do nome do host está habilitada.
Tabela 9 -31 Configurar o mapeamento de nome de host dinâmico IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o mapeamento de nome de host dinâmico IS-IS | hostname dynamic { host-name | area-tag | recv-only | system-name } |
Obrigatório.
Por padrão, apenas os nomes de host anunciados por outros dispositivos são aprendidos. |
Configure a interface IS-IS para ser adicionada ao grupo de malha
Quando a interface IS-IS não é adicionada ao grupo de malha, o pacote LSP recebido de uma interface será enviado em todas as outras interfaces IS-IS. Isso resulta em grande desperdício de largura de banda em uma rede conectada em malha completa. Para evitar essa situação, várias interfaces IS-IS podem ser adicionadas a um grupo de malha. Quando uma interface recebe o pacote LSP, ela apenas envia o pacote LSP para a interface que não está no mesmo grupo de malha com esta interface.
Tabela 9 -32 Configure a interface IS-IS a ser adicionada ao grupo de malha
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure a interface IS-IS a ser adicionada ao grupo de malha | isis mesh-group { group-number | blocked } | Obrigatório. Por padrão, a interface IS-IS não é adicionada ao grupo de malha. |
O comando isis mesh-group bloqueado pode ser usado para configurar a interface como a interface obstrutiva. A interface obstrutiva não enviará o pacote LSP ativamente e somente enviará o pacote LSP quando receber a solicitação LSP.
Configurar autenticação de rede IS-IS
Condição de configuração
Antes de configurar a autenticação de rede IS-IS, primeiro conclua as seguintes tarefas:
- Configure o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IS-IS .
Configurar autenticação de vizinhança IS-IS
Quando a autenticação de relacionamento de vizinho estiver habilitada para o IS-IS, as informações de autenticação serão adicionadas ao pacote Hello entregue e o pacote Hello recebido será autenticado. Se a autenticação falhar, o relacionamento de vizinhos não será estabelecido. Isso pode impedir que o relacionamento de vizinhos seja estabelecido com os dispositivos não confiáveis.
Tabela 9 -33 Configurar a autenticação vizinha IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o modo de autenticação do pacote Hello | isis authentication mode { md5 | sm3 | text } [ level-1 | level-2 ] | Obrigatório. Por padrão, a função de autenticação não está habilitada. |
| Configurar a senha de autenticação do pacote Hello | isis authentication key { 0 | 7 } password [ level-1 | level-2 ] | Qualquer Por padrão, a senha de autenticação não está configurada. A senha de autenticação pode ser configurada usando a cadeia de senhas. Para obter detalhes sobre a configuração da cadeia de senhas, consulte o capítulo de configuração da cadeia de senhas no manual de configuração. |
| isis authentication key-chain key-chain-name [ level-1 | level-2 ] |
Configurar autenticação de rota IS-IS
Quando a autenticação de informações de roteamento estiver habilitada para o IS-IS, as informações de autenticação serão adicionadas aos pacotes LSP e SNP e os pacotes LSP e SNP recebidos serão autenticados. Se a autenticação falhar, o pacote será descartado diretamente. Isso pode impedir que as informações de roteamento não confiáveis se espalhem para a rede IS-IS.
Tabela 9 -34 Configurar a autenticação de rota IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configure o modo de autenticação do pacote de informações de roteamento | authentication mode { md5 | sm3 | text } [ level-1 | level-2 ] | Obrigatório. Por padrão, a função de autenticação não está habilitada. |
| Configure a senha de autenticação do pacote de informações de roteamento | authentication key { 0 | 7 } password [ level-1 | level-2 ] | Qualquer Por padrão, a senha de autenticação não está configurada. A senha de autenticação pode ser configurada usando a cadeia de senhas. Para obter detalhes sobre a configuração da cadeia de senhas, consulte o capítulo de configuração da cadeia de senhas no manual de configuração. |
| authentication key-chain key-chain-name [ level-1 | level-2 ] |
Configure o IS-IS para coordenar com o BFD
O IS-IS para coordenar com o BFD é configurado para detectar rapidamente as falhas do link e habilitar o link de backup para comunicação. O IS-IS para coordenar com o BFD pode ser configurado nos dois métodos a seguir: Todas as interfaces habilitadas com o protocolo IS-IS são coordenadas com o BFD e a interface é especificada para coordenar com o BFD.
Para obter detalhes sobre as informações do parâmetro BFD, consulte o manual de configuração do BFD.
Condição de configuração
Antes de configurar o IS-IS para coordenar com o BFD, primeiro complete a seguinte tarefa:
- Configure o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IS-IS.
Configurar IS-IS para coordenar com BFD
Tabela 9 -35 Configure o IS-IS para coordenar com o BFD
| Etapa | Comando |
| Entre no modo de configuração global | configure terminal |
| Entre no modo de configuração da interface | interface interface-name |
| Configure a interface para habilitar a função de detecção de link BFD | isis bfd |
| Retornar ao modo de configuração global | exit |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] |
| Configure todas as interfaces IS-IS para habilitar a função de detecção de link BFD | bfd all-interfaces |
Configurar o reencaminhamento rápido do IS-IS
Condição de configuração
Antes de configurar o reencaminhamento rápido IS-IS, primeiro complete a seguinte tarefa:
- Configure o endereço IP da interface, tornando acessível a camada de rede dos nós vizinhos
- Habilite o protocolo IS-IS.
Configurar o reencaminhamento rápido do IS-IS
Na rede IS-IS, a interrupção do tráfego causada pela falha do link ou do dispositivo continuará até que o protocolo detecte a falha do link, e a rota flutuante não se recuperará até que a rota flutuante entre em vigor, o que geralmente dura vários segundos. Para reduzir o tempo de interrupção do tráfego, o reencaminhamento rápido IS-IS pode ser configurado. Através da aplicação do mapa de roteamento, o próximo salto de backup é definido para a rota correspondente. Uma vez que o link ativo falhe, o tráfego que passa pelo link ativo será imediatamente comutado para o link em espera, de modo a atingir o objetivo de comutação rápida.
Tabela 9 -36 Configurar o reencaminhamento rápido IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| IS -IS | router isis [ area-tag ] | - |
| Entre no modo de configuração da família de endereços IS- IS IPv4 | address-family ipv4 unicast | - |
| Configurar o IS-IS para habilitar a função de reencaminhamento rápido | fast-reroute route-map route-map-name | Obrigatório. Por padrão, não ative a função de redirecionamento rápido IS-IS. |
Configurar IS-IS GR
informações de rota da camada de encaminhamento do dispositivo local e do dispositivo vizinho inalteradas durante o switchover ativo/standby, não afetando o encaminhamento. Depois de alternar o dispositivo e executar novamente, a camada de protocolo dos dois dispositivos sincroniza as informações de rota e atualiza a camada de encaminhamento, de modo a manter o encaminhamento de dados ininterrupto durante a alternância do dispositivo.
Existem dois papéis no processo de GR:
GR Restarter : o dispositivo que executa o protocolo de reinicialização normal
GR Helper : o dispositivo que ajuda a reinicialização graciosa do protocolo
O dispositivo distribuído pode atuar como GR Restarter e GR Helper, enquanto o dispositivo centralizado pode atuar apenas como GR Helper, auxiliando o Restarter a completar o GR.
Condição de configuração
Antes de configurar o IS-IS GR, primeiro complete a seguinte tarefa:
- Configure o endereço IP da interface, tornando a camada de rede do nó vizinho acessível
- Habilite o protocolo IS-IS
Configurar reinicializador IS-IS GR
Tabela 9 -37 Configurar reinicializador IS-IS GR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Configure IS-IS para habilitar a função GR | nsf ietf | Obrigatório. Por padrão, não habilite a função GR. |
| Configure os tempos de retransmissão da mensagem de publicidade para entrar no processo de GR | nsf interface-expire resend-cnt | Opcional. Por padrão, os tempos de retransmissão são 3. |
| Configure o tempo de espera para entrar na retransmissão da mensagem para entrar no processo GR | nsf interface-timer wait-time | Opcional. Por padrão, o tempo de espera é de 10s. |
Configurar IS-IS GR Helper
O GR Helper ajuda o Restarter a completar o GR. Por padrão, o dispositivo habilita a função e o usuário pode desabilitar a função através do comando.
Tabela 9 -38 Configurar reinicializador IS-IS GR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Configure o IS-IS GR Helper para não ter o recurso Helper | nsf ietfhelper-disable | Obrigatório. Configure o IS-IS GR Helper para não ter o recurso Helper |
Monitoramento e Manutenção de IS-IS
Tabela 9 -39 Monitoramento e Manutenção do IS-IS
| Comando | Descrição |
| clear isis [ instance -null | area-tag ] statistics [ interface_name ] | Limpe as informações estatísticas da operação do protocolo IS-IS |
| clear isis [ instance -null | area-tag ] process | Reinicie o processo do protocolo IS-IS |
| show isis [ instance -null | area-tag ] | Exibir as informações do processo IS-IS |
| show isis instance { -null | area-tag } ipv4 bfd-sessions | Exiba as informações da sessão BFD do processo IS-IS |
| show isis [ instance -null | area-tag ] database [ lsp_id ] [ detail ] [ l1 / l2 ] [ level-1 / level-2 ] [ self ] [ verbose ] | Exibir as informações do banco de dados de status do link IS-IS |
| show isis interface [ interface-name ] [ detail ] | Exibir as informações da operação da interface do protocolo IS-IS |
| show isis [ instance –null | area-tag ] ipv4 reach-info | Exibir as informações alcançáveis da sub-rede IS-IS IPv4 |
| show isis [ instance –null | area-tag ] ipv4 route | Exibir as informações de roteamento IS-IS IPv4 |
| show isis [ instance –null | area-tag ] ipv4 topology | Exiba as informações de topologia IS-IS IPv4 |
| show isis [ instance – null | area-tag ] is-reach-info [ level-1 | level-2 ] | Exibir as informações do nó vizinho IS-IS |
| show isis [instance –null | area-tag] mesh-groups | Exibir o grupo de malha IS-IS |
| show isis [ instance –null | area-tag ] neighbors [ interface-name ] [ detail ] | Exibir as informações do vizinho IS-IS |
| show isis [ instance –null | area-tag ] statistics [ interface-name ] | Exibe as informações estatísticas da operação do protocolo IS-IS |
| show isis router | Exibir as informações do nome do host IS-IS |
Exemplo de configuração típica de IS-IS
Configurar a função básica IS-IS
Requisitos de rede
- Configure o protocolo IS-IS para realizar a interconexão de rede entre os dispositivos.
- Device1 é o roteador de nível 1 e Device2 é o roteador de nível 1-2. Device1 e Device2 estão na mesma área, Área 10. Device3 é o roteador de Nível 2 na Área 20. Device2 conecta as duas áreas.
Topologia de rede

Figura 9 – 1 Rede das funções básicas do IS-IS
Etapas de configuração
- Passo 1: Configure o endereço IP das interfaces. (Omitido)
- Passo 2: Configure o IS-IS e habilite o processo na interface.
# Configure o processo IS-IS como 100, número de área como 10, digite como Level-1 e habilite o processo na interface no Device1.
Device1#configure terminalDevice1(config)#router isis 100Device1(config-isis)#net 10.0000.0000.0001.00Device1(config-isis)#is-type level-1Device1(config-isis)#metric-style wideDevice1(config-isis)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip router isis 100Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ip router isis 100Device1(config-if-vlan3)#exit
# Configure o processo IS-IS como 100, número de área como 10, digite como Level-1-2 e habilite o processo na interface no Device2.
Device2#configure terminalDevice2(config)#router isis 100Device2(config-isis)#net 10.0000.0000.0002.00Device2(config-isis)#metric-style wideDevice2(config-isis)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ip router isis 100Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ip router isis 100Device2(config-if-vlan3)#exit
# Configure o processo IS-IS como 100, número de área como 20, digite como Level-2 e habilite o processo na interface no Device3.
Device3#configure terminalDevice3(config)#router isis 100Device3(config-isis)#net 20.0000.0000.0003.00Device3(config-isis)#is-type level-2Device3(config-isis)#metric-style wideDevice3(config-isis)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ip router isis 100Device3(config-if-vlan2)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ip router isis 100Device3(config-if-vlan3)#exit
- Passo 3: Confira o resultado.
# Visualize as informações vizinhas IS-IS do Device1.
Device1#show isis neighborsIS-IS Instance 100 Neighbors (Counter 1):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL1-LAN 0000.0000.0002 vlan3 Up 29 sec L1 capable 64 0000.0000.0001.01
# Visualize as informações vizinhas do IS-IS no Device2.
Device2#show isis neighborsIS-IS Instance 100 Neighbors (Counter 2):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL2-LAN 0000.0000.0003 vlan2 Up 9 sec L2 capable 64 0000.0000.0003.01L1-LAN 0000.0000.0001 vlan3 Up 8 sec L1 capable 64 0000.0000.0001.01
Device2 constrói o vizinho IS-IS com Device1 e Device3, respectivamente.
# Visualize as informações vizinhas IS-IS do Device3.
Device3#show isis neighborsIS-IS Instance 100 Neighbors (Counter 1):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL2-LAN 0000.0000.0002 vlan3 Up 22 sec L2 capable 64 0000.0000.0003.01
# Visualize as informações de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externali 0.0.0.0/0 [115/10] via 100.1.1.2, 17:44:09, vlan3C 10.1.1.0/24 is directly connected, 16:56:18, vlan2C 100.1.1.0/24 is directly connected, 18:37:57, vlan3C 127.0.0.0/8 is directly connected, 284:02:13, lo0i 200.1.1.0/24 [115/20] via 100.1.1.2, 17:44:09, vlan3Device1#show isis ipv4 routeIS-IS Instance 100, VRF Kernel, IPv4 routes table (Counter 4):L1 0.0.0.0/0, flags none, metric 10, from learned, installedvia 100.1.1.2, vlan3, neighbor 0000.0000.0002L1 10.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan2L1 100.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan3L1 200.1.1.0/24, flags none, metric 20, from learned, installedvia 100.1.1.2, vlan3, neighbor 0000.0000.0002
Um roteamento padrão está na tabela de roteamento de Device1 e o próximo salto é Device2.
# Visualize as informações de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externali 10.1.1.0/24 [115/20] via 100.1.1.1, 16:58:26, vlan3C 100.1.1.0/24 is directly connected, 18:39:58, vlan3C 127.0.0.0/8 is directly connected, 20:16:34, lo0C 200.1.1.0/24 is directly connected, 18:39:37, vlan2i 210.1.1.0/24 [115/20] via 200.1.1.2, 16:57:56, vlan2Device2#show isis ipv4 routeIS-IS Instance 100, VRF Kernel, IPv4 routes table (Counter 4):L1 10.1.1.0/24, flags none, metric 20, from learned, installedvia 100.1.1.1, vlan3, neighbor 0000.0000.0001L1 100.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan3L1 200.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan2L2 210.1.1.0/24, flags none, metric 20, from learned, installedvia 200.1.1.2, vlan2, neighbor 0000.0000.0003
Device2 contém o roteamento de Nível 1 e Nível 2.
# Visualize as informações de roteamento do Device3.
Device3#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externali 10.1.1.0/24 [115/30] via 200.1.1.1, 16:59:29, vlan2i 100.1.1.0/24 [115/20] via 200.1.1.1, 17:47:29, vlan2C 127.0.0.0/8 is directly connected, 945:29:12, lo0C 200.1.1.0/24 is directly connected, 18:40:27, vlan2C 210.1.1.0/24 is directly connected, 16:59:04, vlan3Device3#show isis ipv4 routeIS-IS Instance 100, VRF Kernel, IPv4 routes table (Counter 4):L2 10.1.1.0/24, flags none, metric 30, from learned, installedvia 200.1.1.1, vlan2, neighbor 0000.0000.0002L2 100.1.1.0/24, flags none, metric 20, from learned, installedvia 200.1.1.1, vlan2, neighbor 0000.0000.0002L2 200.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan2L2 210.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan3
Device3 aprende o roteamento de nível 1 e o nível 1 vaza o roteamento para o nível 2 por padrão.
O tipo de métrica é a métrica estreita por padrão. A métrica ampla é recomendada. O atributo de entidade IS-IS é Level-1-2 por padrão.
Configurar a seleção do nó IS-IS DIS
Requisitos de rede
- Especifique o dispositivo como o nó DIS alterando a prioridade.
- Device1 e Device2 são os dispositivos Level-1-2, Device3 é o dispositivo Level-1 e Device4 é o dispositivo Level-2. Device1, Device2, Device3 e Device4 estão na mesma rede de transmissão e na mesma área, Área 10.
Topologia de rede

Figura 9 – 2 Rede de configuração da seleção IS-IS DIS
Etapas de configuração
- Passo 1: Configure o endereço IP das interfaces. (Omitido)
- Passo 2: Configure o IS-IS e habilite o processo na interface.
# Configure o processo IS-IS como 100, número de área como 10 e digite como Level-1-2 e habilite o processo na interface no Device1.
Device1#configure terminalDevice1(config)#router isis 100Device1(config-isis)#net 10.0000.0000.0001.00Device1(config-isis)#metric-style wideDevice1(config-isis)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip router isis 100Device1(config-if-vlan2)#exit
# Configure o processo IS-IS como 100, número de área como 10, digite como Level-1-2 e habilite o processo na interface no Device2.
Device2#configure terminalDevice2(config)#router isis 100Device2(config-isis)#net 10.0000.0000.0002.00Device2(config-isis)#metric-style wideDevice2(config-isis)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ip router isis 100Device2(config-if-vlan2)#exit
# Configure o processo IS-IS como 100, número de área como 10, digite como Level-1 e habilite o processo na interface no Device3.
Device3#configure terminalDevice3(config)#router isis 100Device3(config-isis)#net 10.0000.0000.0003.00Device3(config-isis)#is-type level-1Device3(config-isis)#metric-style wideDevice3(config-isis)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ip router isis 100Device3(config-if-vlan2)#exit
# Configure o processo IS-IS como 100, número de área como 20, digite como Level-2 e habilite o processo na interface no Device4.
Device4#configure terminalDevice4(config)#router isis 100Device4(config-isis)#net 20.0000.0000.0004.00Device4(config-isis)#is-type level-2Device4(config-isis)#metric-style wideDevice4(config-isis)#exitDevice4(config)#interface vlan2Device4(config-if-vlan2)#ip router isis 100Device4(config-if-vlan2)#exitDevice1#show isis neighborsIS-IS Instance 100 Neighbors (Counter 4):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL1-LAN 0000.0000.0002 vlan2 Up 23 sec L1 capable 64 0000.0000.0003.01L2-LAN 0000.0000.0002 vlan2 Up 23 sec L2 capable 64 0000.0000.0004.01L1-LAN 0000.0000.0003 vlan2 Up 8 sec L1 capable 64 0000.0000.0003.01L2-LAN 0000.0000.0004 vlan2 Up 8 sec L2 capable 64 0000.0000.0004.01
O pseudo nó do Nível-1 é 0000.0000.0003.01 e Device3 é o nó DIS do Nível-1. O pseudo nó do Nível-2 é 0000.0000.0004.01 e Device1 é o nó DIS do Nível-2.
# Execute a interface show isis comando para visualizar o endereço MAC da interface. Na prioridade padrão, o nó DIS é selecionado com base no princípio de que um endereço MAC maior da interface física tem uma prioridade mais alta.
- Passo 3: Modifique a prioridade da interface.
# Modifique a prioridade da interface do Device1.
Device1(config)#interface vlan2Device1(config-if-vlan2)#isis priority 100Device1(config-if-vlan2)#exit
- Passo 4: Confira o resultado.
# Visualize as informações vizinhas IS-IS do Device1.
Device1#show isis neighborsIS-IS Instance 100 Neighbors (Counter 4):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL1-LAN 0000.0000.0002 vlan2 Up 24 sec L1 capable 64 0000.0000.0001.01L2-LAN 0000.0000.0002 vlan2 Up 23 sec L2 capable 64 0000.0000.0001.01L1-LAN 0000.0000.0003 vlan2 Up 20 sec L1 capable 64 0000.0000.0001.01L2-LAN 0000.0000.0004 vlan2 Up 24 sec L2 capable 64 0000.0000.0001.01
O pseudo nó de Level-1-2 é 0000.0000.0001.01 e Device1 é o nó DIS de Levev-1-2.
A prioridade da interface IS-IS é 64 por padrão.
Configurar o vazamento de rota entre camadas IS-IS
Requisitos de rede
- Configure o vazamento entre camadas no Level-1-2 para vazar o roteamento do Level-2 para o Level-1.
- Device1 é o roteador de nível 1, Device2 é o roteador de nível 1-2 e Device1 e Device2 estão na mesma área, área 10. Device3 é o roteador de nível 2 na área 20. Device2 conecta as duas áreas.
Topologia de rede
Figura 9 – 3 Rede do vazamento entre camadas IS-IS
Etapas de configuração
- Passo 1: Configure o endereço IP das interfaces. (Omitido)
- Passo 2: Configure o IS-IS e habilite o processo na interface.
# Configure o processo IS-IS como 100, número de área como 10, digite como Level-1 e habilite o processo na interface no Device1.
Device1#configure terminalDevice1(config)#router isis 100Device1(config-isis)#net 10.0000.0000.0001.00Device1(config-isis)#is-type level-1Device1(config-isis)#metric-style wideDevice1(config-isis)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip router isis 100Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ip router isis 100Device1(config-if-vlan3)#exit
# Configure o processo IS-IS como 100, número de área como 10, digite como Level-1-2 e habilite o processo na interface no Device2.
Device2#configure terminalDevice2(config)#router isis 100Device2(config-isis)#net 10.0000.0000.0002.00Device2(config-isis)#metric-style wideDevice2(config-isis)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ip router isis 100Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ip router isis 100Device2(config-if-vlan3)#exit
# Configure o processo IS-IS como 100, número de área como 20, digite como Level-2 e habilite o processo na interface no Device3.
Device3#configure terminalDevice3#configure terminalDevice3(config)#router isis 100Device3(config-isis)#net 20.0000.0000.0003.00Device3(config-isis)#is-type level-2Device3(config-isis)#metric-style wideDevice3(config-isis)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ip router isis 100Device3(config-if-vlan2)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ip router isis 100Device3(config-if-vlan3)#exit
# Visualize as informações de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externali 0.0.0.0/0 [115/10] via 100.1.1.2, 17:44:09, vlan3C 10.1.1.0/24 is directly connected, 16:56:18, vlan2C 100.1.1.0/24 is directly connected, 18:37:57, vlan3C 127.0.0.0/8 is directly connected, 284:02:13, lo0i 200.1.1.0/24 [115/20] via 100.1.1.2, 17:44:09, vlan3Device1#show isis ipv4 routeIS-IS Instance 100, VRF Kernel, IPv4 routes table (Counter 4):L1 0.0.0.0/0, flags none, metric 10, from learned, installedvia 100.1.1.2, vlan3, neighbor 0000.0000.0002L1 10.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan2L1 100.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan3L1 200.1.1.0/24, flags none, metric 20, from learned, installedvia 100.1.1.2, vlan3, neighbor 0000.0000.0002Device1#show isis database detailIS-IS Instance 100 Level-1 Link State Database (Counter 3, LSP-MTU 1492):LSPID LSP Seq Num LSP Checksum LSP Holdtime Length ATT/P/OL0000.0000.0001.00-00* 0x0000007E 0xD5DA 1067 71 0/0/0NLPID: IPv4Area Address: 10IP Address: 100.1.1.1Metric: 10 IS-Extended 0000.0000.0001.01Metric: 10 IP-Extended 10.1.1.0/24Metric: 10 IP-Extended 100.1.1.0/240000.0000.0001.01-00* 0x00000073 0xAAAF 471 51 0/0/0Metric: 0 IS-Extended 0000.0000.0001.00Metric: 0 IS-Extended 0000.0000.0002.000000.0000.0002.00-00 0x00000081 0x5926 887 71 1/0/0NLPID: IPv4Area Address: 10IP Address: 200.1.1.1Metric: 10 IS-Extended 0000.0000.0001.01Metric: 10 IP-Extended 100.1.1.0/24Metric: 10 IP-Extended 200.1.1.0/24
Um roteamento padrão está na tabela de roteamento e o próximo salto é Device2. Nenhum roteamento de nível 2 anunciado pelo Device3 está na tabela de roteamento.
# Visualize as informações de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externali 10.1.1.0/24 [115/20] via 100.1.1.1, 16:58:26,vlan3C 100.1.1.0/24 is directly connected, 18:39:58, vlan3C 127.0.0.0/8 is directly connected, 20:16:34, lo0C 200.1.1.0/24 is directly connected, 18:39:37, vlan2i 210.1.1.0/24 [115/20] via 200.1.1.2, 16:57:56, vlan2Device2#show isis ipv4 routeIS-IS Instance 100, VRF Kernel, IPv4 routes table (Counter 4):L1 10.1.1.0/24, flags none, metric 20, from learned, installedvia 100.1.1.1, vlan3, neighbor 0000.0000.0001L1 100.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan3L1 200.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan2L2 210.1.1.0/24, flags none, metric 20, from learned, installedvia 200.1.1.2, vlan2, neighbor 0000.0000.0003Device2#show isis database detailIS-IS Instance 100 Level-1 Link State Database (Counter 3, LSP-MTU 1492):LSPID LSP Seq Num LSP Checksum LSP Holdtime Length ATT/P/OL0000.0000.0001.00-00 0x0000007E 0xD5DA 507 71 0/0/0NLPID: IPv4Area Address: 10IP Address: 100.1.1.1Metric: 10 IS-Extended 0000.0000.0001.01Metric: 10 IP-Extended 10.1.1.0/24Metric: 10 IP-Extended 100.1.1.0/240000.0000.0001.01-00 0x00000074 0xA8B0 799 51 0/0/0Metric: 0 IS-Extended 0000.0000.0001.00Metric: 0 IS-Extended 0000.0000.0002.000000.0000.0002.00-00* 0x00000082 0x5727 1146 71 1/0/0NLPID: IPv4Area Address: 10IP Address: 200.1.1.1Metric: 10 IS-Extended 0000.0000.0001.01Metric: 10 IP-Extended 100.1.1.0/24Metric: 10 IP-Extended 200.1.1.0/24IS-IS Instance 100 Level-2 Link State Database (Counter 3, LSP-MTU 1492):LSPID LSP Seq Num LSP Checksum LSP Holdtime Length ATT/P/OL0000.0000.0002.00-00* 0x00000081 0x84C0 1047 79 0/0/0NLPID: IPv4Area Address: 10IP Address: 200.1.1.1Metric: 10 IS-Extended 0000.0000.0003.01Metric: 20 IP-Extended 10.1.1.0/24Metric: 10 IP-Extended 100.1.1.0/24Metric: 10 IP-Extended 200.1.1.0/240000.0000.0003.00-00 0x00000315 0x9DC7 543 71 0/0/0NLPID: IPv4Area Address: 20IP Address: 210.1.1.1Metric: 10 IS-Extended 0000.0000.0003.01Metric: 10 IP-Extended 200.1.1.0/24Metric: 10 IP-Extended 210.1.1.0/240000.0000.0003.01-00 0x00000070 0xBF97 526 51 0/0/0Metric: 0 IS-Extended 0000.0000.0002.00Metric: 0 IS-Extended 0000.0000.0003.00
Device2 contém o roteamento de Nível 1 e Nível 2.
#Visualize as informações de roteamento de Device3 e Device3 contém o roteamento de nível 1 anunciado por Device1.
Device3#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externali 10.1.1.0/24 [115/30] via 200.1.1.1, 16:59:29, vlan2i 100.1.1.0/24 [115/20] via 200.1.1.1, 17:47:29, vlan2C 127.0.0.0/8 is directly connected, 945:29:12, lo0C 200.1.1.0/24 is directly connected, 18:40:27, vlan2C 210.1.1.0/24 is directly connected, 16:59:04, vlan3Device3#show isis ipv4 routeIS-IS Instance 100, VRF Kernel, IPv4 routes table (Counter 4):L2 10.1.1.0/24, flags none, metric 30, from learned, installedvia 200.1.1.1, vlan2, neighbor 0000.0000.0002L2 100.1.1.0/24, flags none, metric 20, from learned, installedvia 200.1.1.1, vlan2, neighbor 0000.0000.0002L2 200.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan2L2 210.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan3Device3#show isis database detailIS-IS Instance 100 Level-2 Link State Database (Counter 3, LSP-MTU 1492):LSPID LSP Seq Num LSP Checksum LSP Holdtime Length ATT/P/OL0000.0000.0002.00-00 0x00000081 0x84C0 880 79 0/0/0NLPID: IPv4Area Address: 10IP Address: 200.1.1.1Metric: 10 IS-Extended 0000.0000.0003.01Metric: 20 IP-Extended 10.1.1.0/24Metric: 10 IP-Extended 100.1.1.0/24Metric: 10 IP-Extended 200.1.1.0/240000.0000.0003.00-00* 0x00000316 0x9BC8 1197 71 0/0/0NLPID: IPv4Area Address: 20IP Address: 210.1.1.1Metric: 10 IS-Extended 0000.0000.0003.01Metric: 10 IP-Extended 200.1.1.0/24Metric: 10 IP-Extended 210.1.1.0/240000.0000.0003.01-00* 0x00000070 0xBF97 359 51 0/0/0Metric: 0 IS-Extended 0000.0000.0002.00Metric: 0 IS-Extended 0000.0000.0003.00
- Passo 3: Configure o vazamento entre camadas.
# Configure o vazamento entre camadas para Device2.
Device2(config)#router isis 100Device2(config-isis)#address-family ipv4 unicastDevice2(config-isis-af)#propagate level-2 into level-1Device2(config-isis-af)#exitDevice2(config-isis)#exit
- Passo 4: Confira o resultado.
# Visualize as informações de roteamento do Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externali 0.0.0.0/0 [115/10] via 100.1.1.2, 17:44:09, vlan3C 10.1.1.0/24 is directly connected, 16:56:18, vlan2C 100.1.1.0/24 is directly connected, 18:37:57, vlan3C 127.0.0.0/8 is directly connected, 284:02:13, lo0i 200.1.1.0/24 [115/20] via 100.1.1.2, 17:44:09, vlan3i 210.1.1.0/24 [115/30] via 100.1.1.2, 00:00:01, vlan3Device1#show isis ipv4 routeL1 0.0.0.0/0, flags none, metric 10, from learned, installedvia 100.1.1.2, vlan3, neighbor 0000.0000.0002L1 100.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan3L1 200.1.1.0/24, flags none, metric 20, from learned, installedvia 100.1.1.2,vlan3, neighbor 0000.0000.0002L1 210.1.1.0/24, flags inter-area, metric 30, from learned, installedvia 100.1.1.2, vlan3, neighbor 0000.0000.0002Device1#show isis database detailIS-IS Instance 100 Level-1 Link State Database (Counter 3, LSP-MTU 1492):LSPID LSP Seq Num LSP Checksum LSP Holdtime Length ATT/P/OL0000.0000.0001.00-00* 0x0000007F 0xD3DB 668 71 0/0/0NLPID: IPv4Area Address: 10IP Address: 100.1.1.1Metric: 10 IS-Extended 0000.0000.0001.01Metric: 10 IP-Extended 10.1.1.0/24Metric: 10 IP-Extended 100.1.1.0/240000.0000.0001.01-00* 0x00000075 0xA6B1 995 51 0/0/0Metric: 0 IS-Extended 0000.0000.0001.00Metric: 0 IS-Extended 0000.0000.0002.000000.0000.0002.00-00 0x00000083 0x4DA6 984 79 1/0/0NLPID: IPv4Area Address: 10IP Address: 200.1.1.1Metric: 10 IS-Extended 0000.0000.0001.01Metric: 10 IP-Extended 100.1.1.0/24Metric: 10 IP-Extended 200.1.1.0/24Metric: 20 IP-Extended ia 210.1.1.0/24
Além do roteamento padrão, o Device1 também aprende o roteamento de nível 2 anunciado pelo Device3.
Configurar redistribuição de roteamento IS-IS
Requisitos de rede
- Configure a redistribuição para introduzir o roteamento externo ao IS-IS, permitindo a interconexão de rede entre os dispositivos.
- Device1 e Device2 são os roteadores de nível 2. Configure o IS-IS e a Área 10. Configure o OSPF em Device2 e Device3. Redistribua o roteamento OSPF para o IS-IS através da configuração no Device2.
Topologia de rede
Figura 9 – 4 Rede da redistribuição de roteamento IS-IS
Etapas de configuração
- Passo 1: Configure o endereço IP das interfaces. (Omitido)
- Passo 2: Configure o IS-IS e habilite o processo na interface.
# Configure o processo IS-IS como 100, número de área como 10, digite como Level - 2 e habilite o processo na interface no Device1.
Device1#configure terminalDevice1(config)#router isis 100Device1(config-isis)#net 10.0000.0000.0001.00Device1(config-isis)#is-type level-2Device1(config-isis)#metric-style wideDevice1(config-isis)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip router isis 100Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ip router isis 100Device1(config-if-vlan3)#exit
# Configure o processo IS-IS como 100, número de área como 10, digite como Level-1-2 e habilite o processo na interface no Device2.
Device2#configure terminalDevice2(config)#router isis 100Device2(config-isis)#net 10.0000.0000.0002.00Device2(config-isis)#is-type level-2Device2(config-isis)#metric-style wideDevice2(config-isis)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ip router isis 100Device2(config-if-vlan3)#exit
- Passo 3: Configure o OSPF.
# Configurar dispositivo2.
Device2(config)#router ospf 100Device2(config-ospf)#network 200.1.1.0 0.0.0.255 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 210.1.1.0 0.0.0.255 area 0Device3(config-ospf)#network 200.1.1.0 0.0.0.255 area 0Device3(config-ospf)#exit
# Visualize a tabela de roteamento do Device1. Device1 não aprende o roteamento OSPF redistribuído pelo Device2.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.1.1.0/24 is directly connected, 00:58:39, vlan2C 100.1.1.0/24 is directly connected, 06:55:35, vlan3C 127.0.0.0/8 is directly connected, 603:06:22, lo0Device1#show isis ipv4 routeIS-IS Instance 100, VRF Kernel, IPv4 routes table (Counter 2):L2 10.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan2L2 100.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan3Device1#show isis database detailIS-IS Instance 100 Level-2 Link State Database (Counter 3, LSP-MTU 1492):LSPID LSP Seq Num LSP Checksum LSP Holdtime Length ATT/P/OL0000.0000.0001.00-00* 0x00000046 0x489E 1123 71 0/0/0NLPID: IPv4Area Address: 10IP Address: 100.1.1.1Metric: 10 IS-Extended 0000.0000.0001.01Metric: 10 IP-Extended 10.1.1.0/24Metric: 10 IP-Extended 100.1.1.0/240000.0000.0001.01-00* 0x00000045 0x097D 1103 51 0/0/0Metric: 0 IS-Extended 0000.0000.0001.00Metric: 0 IS-Extended 0000.0000.0002.000000.0000.0002.00-00 0x000000CB 0xEEA6 679 63 0/0/0NLPID: IPv4Area Address: 10IP Address: 100.1.1.2Metric: 10 IS-Extended 0000.0000.0001.01Metric: 10 IP-Extended 100.1.1.0/24
# Visualize a tabela de roteamento do Device2. Device2 aprende o roteamento IS-IS e OSPF.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externali 10.1.1.0/24 [115/20] via 100.1.1.1, 15:45:37, vlan3C 100.1.1.0/24 is directly connected, 22:38:58, vlan3C 127.0.0.0/8 is directly connected, 300:03:03, lo0C 200.1.1.0/24 is directly connected, 22:38:58, vlan2O 210.1.1.1/32 [110/2] via 200.1.1.2, 15:43:35, vlan2Device2#show isis ipv4 routeIS-IS Instance 100, VRF Kernel, IPv4 routes table (Counter 2):L2 10.1.1.0/24, flags none, metric 20, from learned, installedvia 100.1.1.1, vlan3, neighbor 0000.0000.0001L2 100.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan3Device2#show isis database detailIS-IS Instance 100 Level-2 Link State Database (Counter 3, LSP-MTU 1492):LSPID LSP Seq Num LSP Checksum LSP Holdtime Length ATT/P/OL0000.0000.0001.00-00 0x00000046 0x489E 911 71 0/0/0NLPID: IPv4Area Address: 10IP Address: 100.1.1.1Metric: 10 IS-Extended 0000.0000.0001.01Metric: 10 IP-Extended 10.1.1.0/24Metric: 10 IP-Extended 100.1.1.0/240000.0000.0001.01-00 0x00000045 0x097D 892 51 0/0/0Metric: 0 IS-Extended 0000.0000.0001.00Metric: 0 IS-Extended 0000.0000.0002.000000.0000.0002.00-00* 0x000000CB 0xEEA6 467 63 0/0/0NLPID: IPv4Area Address: 10IP Address: 100.1.1.2Metric: 10 IS-Extended 0000.0000.0001.01Metric: 10 IP-Extended 100.1.1.0/24
- Passo 4: Configure o IS-IS para redistribuir o roteamento OSPF.
#Configure o roteamento OSPF a ser redistribuído para IS-IS Level-2 no Device2.
Device2(config)#router isis 100Device2(config-isis)#address-family ipv4 unicastDevice2(config-isis-af)#redistribute ospf 100 level-2Device2(config-isis-af)#exitDevice2(config-isis)#exit
- Passo 5: Confira o resultado.
#Visualize as informações de roteamento do Device1. Device1 inclina o roteamento OSPF redistribuído pelo Device2.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.1.1.0/24 is directly connected, 16:47:30, vlan2C 100.1.1.0/24 is directly connected, 22:44:27, vlan3C 127.0.0.0/8 is directly connected, 618:55:13, lo0i 200.1.1.0/24 [115/10] via 100.1.1.2, 00:00:05, vlan3i 210.1.1.1/32 [115/10] via 100.1.1.2, 00:00:05, vlan3Device1#show isis ipv4 routeIS-IS Instance 100, VRF Kernel, IPv4 routes table (Counter 4):L2 10.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan2L2 100.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan3L2 200.1.1.0/24, flags none, metric 10, from learned, installedvia 100.1.1.2, vlan3, neighbor 0000.0000.0002L2 210.1.1.1/32, flags none, metric 10, from learned, installedvia 100.1.1.2, vlan3, neighbor 0000.0000.0002Device1#show isis database detailIS-IS Instance 100 Level-2 Link State Database (Counter 3, LSP-MTU 1492):LSPID LSP Seq Num LSP Checksum LSP Holdtime Length ATT/P/OL0000.0000.0001.00-00* 0x00000046 0x489E 626 71 0/0/0NLPID: IPv4Area Address: 10IP Address: 100.1.1.1Metric: 10 IS-Extended 0000.0000.0001.01Metric: 10 IP-Extended 10.1.1.0/24Metric: 10 IP-Extended 100.1.1.0/240000.0000.0001.01-00* 0x00000045 0x097D 606 51 0/0/0Metric: 0 IS-Extended 0000.0000.0001.00Metric: 0 IS-Extended 0000.0000.0002.000000.0000.0002.00-00 0x000000CD 0xC6E2 1184 80 0/0/0NLPID: IPv4Area Address: 10IP Address: 100.1.1.2Metric: 10 IS-Extended 0000.0000.0001.01Metric: 10 IP-Extended 100.1.1.0/24Metric: 0 IP-Extended 200.1.1.0/24Metric: 0 IP-Extended 210.1.1.1/32
Device1 aprende o roteamento OSPF redistribuído.
Configurar autenticação de vizinhança IS-IS
Requisitos de rede
- Habilite a autenticação na interface para habilitar os dispositivos configurados com a mesma senha estabelecendo a relação de vizinho.
- Device1 é o roteador de nível 1, Device2 é o roteador de nível 1-2 e Device1 e Device2 estão na mesma área, área 10. Device3 é o roteador de nível 2 na área 20. Device2 conecta as duas áreas.
Topologia de rede

Figura 9 – 5 Networking da autenticação do vizinho IS-IS
Etapas de configuração
- Passo 1: Configure o endereço IP das interfaces. (Omitido)
- Passo 2: Configure o IS-IS e habilite o processo na interface.
# Configure o processo IS-IS como 100, número de área como 10, digite como Level-1 e habilite o processo na interface no Device1.
Device1#configure terminalDevice1(config)#router isis 100Device1(config-isis)#net 10.0000.0000.0001.00Device1(config-isis)#is-type level-1Device1(config-isis)#metric-style wideDevice1(config-isis)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip router isis 100Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ip router isis 100Device1(config-if-vlan3)#exit
# Configure o processo IS-IS como 100, número de área como 10, digite como Level-1-2 e habilite o processo na interface no Device2.
Device2#configure terminalDevice2(config)#router isis 100Device2(config-isis)#net 10.0000.0000.0002.00Device2(config-isis)#metric-style wideDevice2(config-isis)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ip router isis 100Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ip router isis 100Device2(config-if-vlan3)#exit
# Configure o processo IS-IS como 100, número de área como 20, digite como Level-2 e habilite o processo na interface no Device3.
Device3#configure terminalDevice3(config)#router isis 100Device3(config-isis)#net 20.0000.0000.0003.00Device3(config-isis)#is-type level-2Device3(config-isis)#metric-style wideDevice3(config-isis)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ip router isis 100Device3(config-if-vlan2)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ip router isis 100Device3(config-if-vlan3)#exit
# Visualize as informações vizinhas IS-IS do Device1.
Device1#show isis neighborsIS-IS Instance 100 Neighbors (Counter 1):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL1-LAN 0000.0000.0002 vlan3 Up 29 sec L1 capable 64 0000.0000.0001.01
# Visualize as informações vizinhas do IS-IS no Device2.
Device2#show isis neighborsIS-IS Instance 100 Neighbors (Counter 2):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL2-LAN 0000.0000.0003 vlan2 Up 9 sec L2 capable 64 0000.0000.0003.01L1-LAN 0000.0000.0001 vlan3 Up 7 sec L1 capable 64 0000.0000.0001.01
# Visualize as informações vizinhas IS-IS do Device3.
Device3#show isis neighborsIS-IS Instance 100 Neighbors (Counter 1):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL2-LAN 0000.0000.0002 vlan2 Up 24 sec L2 capable 64 0000.0000.0003.01
- Passo 3: Configure a autenticação.
# Configure a autenticação MD5 e a senha admin na interface do Device2.
Device2(config)#interface vlan2Device2(config-if-vlan2)#isis authentication mode md5Device2(config-if-vlan2)#isis authentication key 0 adminDevice2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#isis authentication mode md5Device2(config-if-vlan3)#isis authentication key 0 adminDevice2(config-if-vlan3)#exit
#Visualize o vizinho IS-IS do Device2.
Device2#show isis neighborsIS-IS Instance 100 Neighbors (Counter 0):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit ID
Neste momento, Device1 e Device3 não estão configurados com a autenticação. Device2 não _ estabelecer o vizinho IS-IS.
# Configure a autenticação MD5 e a senha admin na interface valn3 do Device1.
Device1(config)#interface vlan3Device1(config-if-vlan3)#isis authentication mode md5Device1(config-if-vlan3)#isis authentication key 0 adminDevice1(config-if-vlan3)#exit
# Configure a autenticação MD5 e a senha admin na interface valn2 do Device3.
Device3(config)#interface vlan2Device3(config-if-vlan2)#isis authentication mode md5Device3(config-if-vlan2)#isis authentication key 0 adminDevice3(config-if-vlan2)#exit
- Passo 4: Confira o resultado.
# Visualize as informações vizinhas IS-IS do Device1.
Device1#show isis neighborsIS-IS Instance 100 Neighbors (Counter 1):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL1-LAN 0000.0000.0002 vlan3 Up 29 sec L1 capable 64 0000.0000.0001.01
Pode-se observar que o vizinho IS-IS é estabelecido com sucesso entre Device1 e Device2. Indica que a autenticação foi bem-sucedida.
# Visualize as informações vizinhas do IS-IS no Device2.
Device2#show isis neighborsIS-IS Instance 100 Neighbors (Counter 2):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL2-LAN 0000.0000.0003 vlan2 Up 9 sec L2 capable 64 0000.0000.0003.01L1-LAN 0000.0000.0001 vlan3 Up 7 sec L1 capable 64 0000.0000.0001.01
Pode-se observar que o vizinho IS-IS é estabelecido com sucesso entre Device2 e Device1/Device3. Indica que a autenticação foi bem-sucedida.
# Visualize as informações vizinhas IS-IS do Device3.
Device3#show isis neighborsIS-IS Instance 100 Neighbors (Counter 1):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL2-LAN 0000.0000.0002 vlan2 Up 24 sec L2 capable 64 0000.0000.0003.01
Pode-se observar que o vizinho IS-IS é estabelecido com sucesso entre Device3 e Device2. Indica que a autenticação foi bem-sucedida.
#Visualize as informações de roteamento do Device2. Device2 normalmente pode receber o roteamento anunciado por Device1 e Device3.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externali 10.1.1.0/24 [115/20] via 100.1.1.1, 16:58:26, vlan3C 100.1.1.0/24 is directly connected, 18:39:58, vlan3C 127.0.0.0/8 is directly connected, 20:16:34, lo0C 200.1.1.0/24 is directly connected, 18:39:37, vlan2i 210.1.1.0/24 [115/20] via 200.1.1.2, 16:57:56, vlan2Device2#show isis ipv4 routeIS-IS Instance 100, VRF Kernel, IPv4 routes table (Counter 4):L1 10.1.1.0/24, flags none, metric 20, from learned, installedvia 100.1.1.1, vlan3, neighbor 0000.0000.0001L1 100.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan3L1 200.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan2L2 210.1.1.0/24, flags none, metric 20, from learned, installedvia 200.1.1.2, vlan2, neighbor 0000.0000.0003
Configurar IS-IS para coordenar com BFD
Requisitos de rede
- Configure a coordenação BFD entre dispositivos. Quando a linha principal está com defeito, os serviços podem ser alternados rapidamente para a linha de backup.
- Device1, Device2 e Device3 são os roteadores de Nível 2 na mesma área, Área 10. Configure o BFD em Device1 e Device3 para iniciar uma sessão. Quando a linha entre Device1 e Device3 é desconectada, Device1 pode realizar a comutação rapidamente e aprender o roteamento 10.1.1.1/24 do Device2.
Topologia de rede
Figura 9 – 6 Rede do IS-IS coordenando com o BFD
Etapas de configuração
- Passo 1: Configure o endereço IP das interfaces. (Omitido)
- Passo 2: Configure o IS-IS e habilite o processo na interface.
# Configure o processo IS-IS como 100, número de área como 10, digite como Level - 2 e habilite o processo na interface no Device1.
Device1#configure terminalDevice1(config)#router isis 100Device1(config-isis)#net 10.0000.0000.0001.00Device1(config-isis)#is-type level-2Device1(config-isis)#metric-style wideDevice1(config-isis)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip router isis 100Device1(config-if- vlan2)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ip router isis 100Device1(config-if-vlan4)#exit
# Configure o processo IS-IS como 100, número de área como 10, digite como Level - 2 e habilite o processo na interface do Device 2 .
Device2#configure terminalDevice2(config)#router isis 100Device2(config-isis)#net 10.0000.0000.0002.00Device2(config-isis)#is-type level-2Device2(config-isis)#metric-style wideDevice2(config-isis)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#ip router isis 100Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ip router isis 100Device2(config-if-vlan3)#exit
# Configure o processo IS-IS como 100, número de área como 10, digite como Level - 2 e habilite o processo na interface do Device 3 .
Device3#configure terminalDevice3(config)#router isis 100Device3(config-isis)#net 10.0000.0000.0003.00Device3(config-isis)#is-type level-2Device3(config-isis)#metric-style wideDevice3(config-isis)#exitDevice3(config)#interface vlan2Device3(config-if-vlan2)#ip router isis 100Device3(config-if-vlan2)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ip router isis 100Device3(config-if-vlan3)#exitDevice3(config)#interface vlan4Device3(config-if-vlan4)#ip router isis 100Device3(config-if-vlan4)#exit
#Visualize as informações de roteamento do Device1. Device1 escolhe preferencialmente o roteamento 10.1.1.0/24 anunciado pelo Device3.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externali 10.1.1.0/24 [115/20] via 100.1.1.2, 00:00:15, vlan4C 100.1.1.0/24 is directly connected, 00:09:15, vlan4C 127.0.0.0/8 is directly connected, 253:58:17, lo0C 200.1.1.0/24 is directly connected, 00:11:29, vlan2i 210.1.1.0/24 [115/20] via 100.1.1.2, 00:00:15, vlan4[115/20] via 200.1.1.2, 00:00:15, vlan2Device1#show isis ipv4 routeIS-IS Instance 100, VRF Kernel, IPv4 routes table (Counter 4):L2 10.1.1.0/24, flags none, metric 20, from learned, installedvia 100.1.1.2, vlan4, neighbor 0000.0000.0003L2 100.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan4L2 200.1.1.0/24, flags none, metric 10, from network connectedvia 0.0.0.0, vlan2L2 210.1.1.0/24, flags none, metric 20, from learned, installedvia 100.1.1.2, vlan4, neighbor 0000.0000.0003via 200.1.1.2, vlan2, neighbor 0000.0000.0002
- Passo 3: Configure o BFD.
#Habilite o BFD na interface do Device1.
Device1(config)#bfd fast-detectDevice1(config)#interface vlan4Device1(config-if-vlan4)#isis bfdDevice1(config-if-vlan4)#exit
# Habilite o BFD na interface do Dispositivo 3.
Device3(config)#bfd fast-detectDevice3(config)#interface vlan4Device3(config-if-vlan4)#isis bfdDevice3(config-if-vlan4)#exit
#Visualize as informações do BFD do Device1.
Device1#show bfd sessionOurAddr NeighAddr LD/RD State100.1.1.2 100.1.1.1 1/1 UPHolddown interface5000 vlan4
- Passo 4: Confira o resultado.
#Quando a linha entre Device1 e Device3 está com defeito, o BFD detecta rapidamente a falha e informa a falha ao IS-IS. O ISIS comuta o roteamento para Device2 para comunicação. Visualize a tabela de roteamento de Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externali 10.1.1.0/24 [115/30] via 200.1.1.2, 00:00:14, vlan2C 127.0.0.0/8 is directly connected, 112:55:25, lo0C 200.1.1.0/24 is directly connected, 101:20:08, vlan2Device1#show isis ipv4 routeIS-IS Instance 100, VRF Kernel, IPv4 routes table (Counter 2):L2 10.1.1.0/24, flags none, metric 30, from l earned, installedvia 200.1.1.2, vlan2, neighbor 0000.0000.0003L2 200.1.1.0/24, flags none, metric 20, from network connectedvia 0.0.0.0, vlan2
#Pode-se ver que os dados fluem do Device1 para o segmento de rede 10.1.1.0/24 antes do Device2 .
IPv6 IS-IS (Aplicável somente ao modelo S3054G-B)
Visão geral
O protocolo de roteamento IS-IS IPv6 e o protocolo de roteamento IS-IS têm os mesmos comportamentos, exceto pela estrutura de endereço IP no pacote. Consulte a breve introdução do protocolo de roteamento IS-IS.
IPv6 IS-IS
Tabela 10 -1 Lista de funções IPV6 IS-IS
| Tarefa de configuração | |
| Configure a função básica IPV6 IS-IS | Habilite o protocolo IPV6 IS-IS Configure o atributo IPV6 IS-IS VRF |
| Configure o atributo de camada IPV6 IS-IS | Configure o atributo de camada IPV6 IS-IS |
| Configurar a geração de rota IPV6 IS-IS | Configurar a rota padrão IPV6 IS-IS Configure a redistribuição de roteamento IPV6 IS-IS |
| Configure o controle de roteamento IPV6 IS-IS |
Configurar o estilo de métrica IPV6 IS-IS
Configure o valor da métrica da interface IPV6 IS-IS Configurar a distância administrativa IPV6 IS-IS Configurar o resumo da rota IPV6 IS-IS Configure o número máximo de rotas com balanceamento de carga para o IPV6 IS-IS Configure o vazamento de rota entre camadas IPV6 IS-IS Configure o bit IPV6 IS-IS ATT |
| Configure a otimização de rede IPV6 IS-IS |
Configure a prioridade da interface IPV6 IS-IS
Configurar a interface passiva IPV6 IS-IS Configure o parâmetro de pacote IPV6 IS-IS Hello Configure o parâmetro de pacote IPV6 IS-IS LSP Configure o parâmetro de pacote IPV6 IS-IS SNP Configure o intervalo de cálculo IPV6 IS-IS SPF Configure o número máximo de áreas para o IPV6 IS-IS Configure o mapeamento de nome de host IPV6 IS-IS Configure a interface IPV6 IS-IS a ser adicionada ao grupo de malha |
| Configure a autenticação de rede IPV6 IS-IS | Configure a autenticação vizinha IPV6 IS-IS Configurar a autenticação de rota IPV6 IS-IS |
| Configurar o IPV6 IS-IS GR | Configurar o IPV6 IS-IS GR |
Configurar a função básica IPV6 IS-IS
Condição de configuração
Antes de usar o protocolo IPV6 IS-IS, primeiro complete as seguintes tarefas :
- Configure o protocolo da camada de link para garantir a comunicação normal na camada de link.
- Configure o endereço IP da camada de rede da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
Ativar protocolo IPV6 IS-IS
Vários processos IPV6 IS-IS podem operar ao mesmo tempo no sistema. Cada processo é identificado por diferentes nomes de processo.
Tabela 10 -2 Habilite o protocolo IPV6 IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Crie o processo IPV6 IS-IS e entre no modo de configuração IPV6 IS-IS | router isis [area-tag ] |
Obrigatório.
Por padrão, o processo IPV6 IS-IS não opera no sistema. O nome do processo é area-tag . |
| Configure o título da entidade de rede para o IPV6 IS-IS | net entry-title | Obrigatório. Por padrão, o título da entidade de rede não está configurado para o IPV6 IS-IS. |
| Retornar ao modo de configuração global | exit | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite o protocolo IPV6 IS-IS na interface | ip router isis [area-tag ] | Obrigatório. Por padrão, o protocolo IPV6 IS-IS não está habilitado na interface. |
O protocolo IS-IS não pode operar sem o título de entidade de rede.
Configurar o atributo IS-IS VRF
Pode haver vários processos IS-IS em um VRF.
Tabela 10 -3 Configurar o atributo IS-IS VRF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IPV6 IS-IS | router isis [ area-tag ] | - |
| Incorpore o atributo VRF para o IS-IS | vrf vrf-name | Opcional. Por padrão, o processo IS-IS localiza-se no VRF global. |
Configurar o atributo de camada IPV6 IS-IS
Condição de configuração
Antes de configurar o atributo de camada IPV6 IS-IS, primeiro complete as seguintes tarefas :
- Configure o endereço IPv6 da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IPV6 IS-IS .
Configurar atributo de camada IS-IS
O atributo de camada IS-IS é dividido em atributo de camada global e atributo de camada de interface. O atributo da camada global é o sistema intermediário IS-IS, que é classificado nos três tipos a seguir:
- Sistema intermediário de nível 1: apenas o banco de dados de status de link do nível 1 está disponível e apenas o roteamento na área do nível 1 pode ser anunciado e aprendido.
- Sistema intermediário de nível 2: apenas o banco de dados de status de link do nível 2 está disponível e apenas o roteamento na área do nível 2 pode ser anunciado e aprendido.
- Sistema intermediário de nível 1-2: tanto o banco de dados de status de link do nível 1 quanto do nível 2 estão disponíveis e o roteamento na área de nível 1 e nível 2 pode ser anunciado e aprendido. O sistema intermediário Level-1-2 é o dispositivo de interconexão na área Level-1 e Level-2.
O atributo de camada da interface IS-IS é classificado nos três tipos a seguir:
- Interface de atributo de nível 1: apenas o pacote de nível 1 do protocolo IS-IS pode ser transmitido e recebido e apenas o vizinho do nível 1 pode ser estabelecido.
- Interface de atributo de nível 2: apenas o pacote de nível 2 do protocolo IS-IS pode ser transmitido e recebido e apenas o vizinho de nível 2 pode ser estabelecido.
- Interface de atributo de nível 1-2: Tanto o pacote de nível 1 quanto o pacote de nível 2 do protocolo IS-IS podem ser transmitidos e recebidos e os vizinhos de nível 1 e nível 2 podem ser estabelecidos.
O atributo de camada de interface IS-IS depende do atributo de camada global IS-IS. O sistema intermediário de nível 1 possui apenas a interface do atributo de nível 1, o sistema intermediário de nível 2 possui apenas a interface do atributo de nível 2 e o sistema intermediário de nível 1-2 pode ter interfaces de todos os atributos.
Tabela 10 -4 Configurar o atributo de camada global IPV6 IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configure o atributo de camada global IS-IS | is-type { level-1 | level-1-2 | level-2-only } | Opcional. Por padrão, o atributo da camada global IS-IS é Level-1-2. |
Tabela 10 -5 Configurar o atributo de camada de interface IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o atributo da camada de interface | isis circuit-type [ level-1 | level-1-2 | level-2-only ] |
Opcional.
Por padrão, o atributo de camada de interface é consistente com o atributo de camada global quando o atributo de camada de interface não é especificado. |
Configurar geração de rota IPV6 IS-IS
Condição de configuração
Antes de configurar a geração de rotas IPV6 IS-IS, primeiro complete as seguintes tarefas:
- Configure o endereço IPv6 para a interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IPV6 IS-IS.
Configurar a rota padrão IPV6 IS-IS
A área de Nível 2 do protocolo IS-IS não pode gerar a rota padrão durante a operação. Você pode configurar para adicionar uma rota padrão com o endereço IP de destino como 0.0.0.0/0 no LSP de nível 2 e liberá -lo. Quando outras áreas do mesmo nível no sistema intermediário receberem as informações de rota, uma rota padrão será adicionada à tabela de roteamento.
Tabela 10 -6 Configurar a rota padrão IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| modo de configuração da família de endereços IS -IS IPv6 | address-family ipv6 unicast | - |
| Configurar o IS-IS para liberar a rota padrão | default-information originate | Obrigatório. Por padrão, a rota padrão não é liberada. |
Configurar redistribuição de roteamento IPV6 IS-IS
A redistribuição de roteamento pode ser usada para introduzir as informações de roteamento de outros protocolos de roteamento no protocolo IS-IS. Isso permite a interconexão entre o sistema autônomo do protocolo IS-IS e o sistema autônomo de outros protocolos de roteamento ou da área de roteamento. Quando o roteamento externo é introduzido, a política de introdução de roteamento e o atributo da camada de roteamento após a introdução são especificados.
Tabela 10 -7 Configurar a redistribuição de roteamento IPV6 IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| modo de configuração da família de endereços IS -IS IPv6 | address-family ipv6 unicast | - |
| Configurar a redistribuição de roteamento IS-IS | redistribute protocol [ protocol-id ] [ level-1 / level-1-2 / level-2 / metric metric-value / metric-type { external | internal } / route-map route-map-name / match route-sub-type ] |
Obrigatório.
Por padrão, as informações de outros protocolos de roteamento não são redistribuídas. |
Configurar o controle de roteamento IPv6 I S-IS
Condição de configuração
Antes de configurar o recurso de roteamento IPV6 IS-IS, primeiro conclua as seguintes tarefas:
- Configure o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IPV6 IS-IS .
Configurar estilo de métrica IPV6 IS-IS
Inicialmente, o IS-IS tem apenas o estilo métrico estreito. Quando o estilo métrico estreito é usado, o valor máximo da métrica é 63. Com a expansão da escala de rede, o estilo métrico não pode satisfazer os requisitos. Portanto, surge o estilo de métrica ampla cujo valor de métrica pode chegar a 16777214. Os dispositivos que usam estilos de métrica diferentes não podem anunciar e aprender as informações de roteamento uns dos outros. Para realizar a transição entre os dois estilos de métrica, é fornecido o método de configuração para o estilo de métrica de transição.
O estilo métrico largo é recomendado.
Tabela 10 -8 Configurar o estilo de métrica IPV6 IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o estilo de métrica da interface | metric-style {narrow | narrow transition | transition | wide | wide transition} [level-1 | level-1-2 | level-2] | Opcional. Por padrão, o estilo métrico estreito é usado. |
Configurar o valor da métrica da interface IPV6 IS-IS
Quando o protocolo IS-IS está habilitado na interface, a métrica de roteamento IS-IS é o valor da métrica global. O comando a seguir pode ser usado para especificar um valor de métrica para cada interface.
Tabela 10 -9 Configurar o valor da métrica da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o valor da métrica global IS-IS | metric metric-value [ level-1 | level-2 ] | Opcional. Por padrão, o valor da métrica global é 10. |
| Retornar ao modo de configuração global | exit | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o valor da métrica da interface | isis ipv6 metric {metric-value | maximum} [level-1 | level-2] | Opcional. Por padrão, o valor da métrica global é usado. |
Configurar distância administrativa IPV6 IS-IS
O sistema escolhe o roteamento primário com base na distância administrativa. Quanto menor a distância administrativa, maior a prioridade do roteamento.
Tabela 10 -10 Configurar a distância administrativa IPV6 IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IPV6 IS-IS | router isis [area-tag] | - |
| modo de configuração da família de endereços IS -IS IPv6 | address-family ipv6 unicast | - |
| Configurar a distância administrativa de roteamento IS-IS | distance distance-value | Opcional. Por padrão, a distância administrativa é 115. |
Configurar o resumo da rota IPV6 IS-IS
O resumo da rota resume várias informações de roteamento como uma parte das informações de roteamento. Depois que o resumo da rota é configurado para o IS-IS, o número de anúncios para a sub-rede reduz efetivamente e o banco de dados de status do link e o tamanho da tabela de roteamento diminuem. Isso economiza efetivamente os recursos de memória e CPU. Essa configuração geralmente é aplicada ao dispositivo de borda Nível 1-2, reduzindo as informações de roteamento do anúncio da camada.
Tabela 10 -11 Configurar o resumo da rota IPV6 IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Entre no modo de configuração da família de endereços IPv6 | address-family ipv6 unicast | - |
| Configurar o resumo da rota IS-IS | summary-prefix prefix-value [ metric metric-value / route-type {internal | external} / metric-type {internal | external} / tag tag-value / not-advertise / level-1 / level-2 / level-1-2 ] | Obrigatório. Por padrão, o resumo da rota não é executado. |
Configure o número máximo de rotas com balanceamento de carga para o IPV6 IS-IS
Existem vários caminhos com o mesmo custo para o mesmo endereço IP de destino. Esses ECMP (roteamento multipath de custo igual) podem melhorar a taxa de utilização do link. O usuário pode controlar o número máximo de ECMPs IS-IS.
Tabela 10 -12 Configure o número máximo de rotas com balanceamento de carga para o IPV6 IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Entre no modo de configuração da família de endereços IPv6 | address-family ipv6 unicast | - |
| Configure o número máximo de rotas com balanceamento de carga para o IS-IS | maximum-paths max-number | Opcional. Por padrão, o número máximo de caminhos para balanceamento de carga é 4. |
Configurar o vazamento de rota entre camadas IPV6 IS-IS
Por padrão, o IS-IS apenas vaza o roteamento de nível 1 para o nível 2, mas a área de nível 1 não pode saber o roteamento da área de nível 2. O vazamento de rota entre camadas pode ser configurado para introduzir o roteamento de Nível 2 para a área de Nível 1. Ao configurar o vazamento de rota entre camadas, a política de roteamento pode ser especificada para vazar apenas a rota que corresponde à condição.
Tabela 10 -13 Configure o vazamento de rota entre camadas IPV6 IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Entre no modo de configuração da família de endereços IS-IS IPv6 | address-family ipv6 unicast | - |
| Configure o vazamento de rota entre a camada IS-IS | propagate { level-1 into level-2 | level-2 into level-1 } [ distribute-list access-list-name | route-map route-map-name ] | Obrigatório. Por padrão, o Level-1 vaza sua rota para o Level-2. |
Configurar IPV6 IS-IS ATT-bit
No dispositivo Level-1-2, o bit ATT é utilizado para informar a outros nós se este nó possui conexão com outras áreas. Se sim, o bit ATT será definido como 1 automaticamente e outros nós irão gerar uma rota padrão para este nó. Isso aumenta a carga de serviço desse nó. Para evitar essa situação, o bit ATT pode ser forçosamente definido como 0.
Tabela 10 -14 Configurar o bit IPV6 IS-IS ATT
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| modo de configuração da família de endereços IS -IS IPv6 | address-family ipv6 unicast | - |
| Configurar o bit IS-IS ATT | set-attached-bit { on | off } |
Obrigatório.
Por padrão, o bit ATT é definido com base em se o nó está conectado a outras áreas. |
Configurar otimização de rede IPV6 IS-IS
Condição de configuração
Antes de configurar o ajuste e a otimização do IPV6 IS-IS, primeiro conclua as seguintes tarefas:
- Configure o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IPV6 IS-IS.
Configurar prioridade de interface IPV6 IS-IS
O IS-IS escolhe um nó no link de broadcast como o nó DIS. O nó DIS envia o pacote CSNP periodicamente para sincronizar o banco de dados de status do link em toda a rede. O Level-1 e Level-2 selecionam o nó DIS respectivamente. A interface com a prioridade mais alta é selecionada como o nó DIS. O nó com o endereço MAC grande é selecionado como o nó DIS para os nós com a mesma prioridade.
Tabela 10 -15 Configurar a prioridade da interface IPV6 IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a prioridade da interface IS-IS | isis priority priority-value [ level-1 | level-2 ] | Opcional. Por padrão, a prioridade da interface é 64. |
Configurar interface passiva IPV6 IS-IS
A interface passiva não recebe e transmite o pacote de protocolo IS-IS, mas ainda libera as informações de roteamento de rede diretamente conectadas dessa interface. O IS-IS pode reduzir a largura de banda e o tempo de manipulação da CPU através da configuração da interface passiva. Com base nessa configuração, o IS-IS pode ser especificado para liberar apenas as informações de roteamento de rede diretamente conectadas das interfaces passivas e não liberar as informações de roteamento de rede diretamente conectadas das interfaces não passivas.
Tabela 10 -16 Configurar a interface passiva IPV6 IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Configurar a interface passiva IS-IS | passive-interface interface-name | Obrigatório. Por padrão, o IS-IS não possui a interface passiva. |
| Configure o IS-IS apenas para liberar as informações de roteamento da interface passiva | advertise-passive-only |
Opcional.
Por padrão, as informações de roteamento de rede diretamente conectadas da interface habilitada com o protocolo IS-IS são liberadas. |
Configurar parâmetro de pacote Hello IPV6 IS-IS
- Configure o intervalo de entrega do pacote Hello.
A interface habilitada com o protocolo IS-IS enviará o pacote Hello para manter a relação de vizinhança com os dispositivos vizinhos . Quanto menor o intervalo de entrega do pacote Hello, mais rápida é a convergência da rede. No entanto, mais largura de banda será ocupada.
Tabela 10 -17 Configurar intervalo de entrega para o pacote Hello
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o intervalo de entrega do pacote Hello na interface | isis hello-interval { interval | minimal } [ level-1 | level-2 ] | Opcional. Por padrão, o intervalo de entrega do pacote Hello é de 10s. |
- Configure o número de pacotes Hello inválidos.
O IPV6 IS-IS calcula o tempo de retenção do relacionamento vizinho com base no número de pacotes Hello inválidos e informa o tempo de retenção ao dispositivo vizinho. Se o dispositivo vizinho não receber o pacote Hello deste dispositivo durante esse período, a relação de vizinho é inválida e o cálculo de roteamento será recalculado.
Tabela 10 -18 Configurar o número de pacotes Hello inválidos
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o número de pacotes Hello inválidos na interface | isis hello-multiplier multiplier [ level-1 | level-2 ] | Opcional. Por padrão, o número de pacotes Hello inválidos é 3. |
- Configure para cancelar a função de preenchimento do pacote Hello.
Se os valores de MTU na interface em ambos os lados do link forem inconsistentes, como resultado, pacotes menores podem ser transmitidos, mas pacotes maiores não podem ser transmitidos. Para evitar tal situação, o IS-IS adota o pacote Hello de preenchimento para o valor MTU da interface para fazer com que a relação de vizinho não possa ser estabelecida. No entanto, este método desperdiça a largura de banda. Na rede real, não há necessidade de configurar o pacote Hello de preenchimento. Apenas os pequenos pacotes Hello são transmitidos.
Tabela 10 -19 Configure para cancelar a função de preenchimento do pacote Hello
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Cancelar a função de preenchimento do pacote Hello | no isis hello padding | Obrigatório. Por padrão, a função de preenchimento de pacote Hello está habilitada. |
Configurar parâmetro de pacote IPV6 IS-IS LSP
- Configure o tempo máximo de sobrevivência para o pacote LSP.
Cada pacote LSP tem um tempo máximo de sobrevivência. Quando o tempo de sobrevivência do pacote LSP for reduzido para 0, o pacote LSP será excluído do banco de dados de status do link. O tempo máximo de sobrevivência do pacote LSP deve ser maior que o intervalo de atualização do pacote LSP.
Tabela 10 -20 Configurar o parâmetro do pacote IPV6 IS-IS LSP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o tempo máximo de sobrevivência para o pacote LSP | max-lsp-lifetime life-time | Opcional. Por padrão, o tempo máximo de sobrevivência do LSP é 1200s. |
- Configure o intervalo de atualização do pacote LSP.
O protocolo IS-IS anuncia e aprende o roteamento por meio da interação de cada pacote LSP. Os nós salvam os pacotes LSP recebidos no banco de dados de status do link. Cada pacote LSP tem um tempo máximo de sobrevivência e cada nó precisa atualizar seu pacote LSP periodicamente para evitar que o tempo máximo de sobrevivência do pacote LSP seja reduzido para 0 e manter o pacote LSP em toda a área de sincronização. Reduzir o intervalo de entrega de pacotes LSP pode acelerar a velocidade de convergência da rede, mas ocupará mais largura de banda.
Tabela 10 -21 Configurar o pacote de atualização do pacote LSP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o intervalo de atualização do pacote LSP | lsp-refresh-interval refresh-interval |
Opcional.
Por padrão, o intervalo de atualização do pacote para a entrega periódica do pacote é 900s. |
- Configure o intervalo de geração do pacote LSP.
A atualização periódica irá gerar um novo pacote LSP. Além disso, as alterações do status da interface e do status da rede também acionarão a geração de novos pacotes LSP. Para evitar que os pacotes LSP gerados com frequência ocupem muitos recursos da CPU, o usuário pode configurar o intervalo mínimo de geração de pacotes LSP.
Tabela 10 -22 Configurar o intervalo de geração do pacote LSP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o intervalo de geração do pacote LSP | lsp-gen-interval [ level-1 | level-2 ] max-interval [ initial-interval [ secondary-interval ]] | Opcional. Por padrão, o intervalo de geração do pacote LSP é de 50 ms. |
- Configure o intervalo de entrega do pacote LSP.
Cada pacote LSP gerado será entregue na interface. Para evitar o pacote LSP gerado com freqüência, ocupará muito a largura de banda da interface. Cada interface é configurada com o intervalo mínimo de entrega do pacote LSP.
Tabela 10 -23 Configurar o intervalo de entrega do pacote LSP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o intervalo de entrega do pacote LSP | isis lsp-interval min-interval | Opcional. Por padrão, o intervalo de entrega do pacote LSP é de 33 ms. |
- Configure o tempo de retransmissão do pacote LSP.
No link ponto a ponto, o IS-IS envia o pacote LSP e, em seguida, exige que o peer end envie a mensagem de confirmação PSNP. Se o IS-IS não receber a mensagem de confirmação, o IS-IS enviará o pacote LSP novamente. O tempo de espera da mensagem de confirmação é o intervalo de retransmissão do pacote LSP. O intervalo de retransmissão pode ser definido conforme exigido pelo usuário para evitar a retransmissão do pacote LSP quando a mensagem de confirmação não for recebida devido a um grande atraso.
Tabela 10 -24 Configurar o tempo de retransmissão do pacote LSP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o tempo de retransmissão do pacote LSP | isis retransmit-interval interval [ level-1 | level-2 ] | Opcional. Por padrão, o tempo de retransmissão é de 5s. |
- Configure o valor LSP MTU.
O pacote de protocolo IS-IS não pode realizar a fragmentação automática. Para não afetar a propagação normal do pacote LSP, o comprimento máximo do pacote LSP em um domínio de roteamento não pode exceder o valor mínimo de MTU nas interfaces IS-IS de todos os dispositivos. Portanto, quando os valores de MTU da interface são inconsistentes em dispositivos no domínio de roteamento, é recomendável que o comprimento máximo do pacote LSP seja definido de maneira uniforme.
Tabela 10 -25 Configurar o valor LSP MTU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o valor MTU do pacote LSP | lsp-mtu mtu-size [ level-1 | level-2 ] | Opcional. Por padrão, o valor MTU do pacote LSP é 1492 bytes. |
Configurar o parâmetro de pacote SNP IPV6 IS-IS
- Configure o intervalo de entrega do pacote CSNP.
Os nós selecionados no link de broadcast precisam enviar o pacote CSNP periodicamente para sincronizar o banco de dados de status do link em toda a rede. O intervalo de entrega de pacotes CSNP é ajustado com base na situação real.
Tabela 10 -26 Configurar o intervalo de entrega do pacote CSNP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o intervalo de entrega do pacote CSNP | isis csnp-interval interval [ level-1 | level-2 ] | Opcional. Por padrão, o intervalo de entrega do pacote CSNP é 10s. |
- Configurar o intervalo de entrega do pacote PSNP
No link de transmissão, o pacote PSNP sincroniza o banco de dados de status do link em toda a rede. No link ponto a ponto, o pacote PSNP confirma o pacote LSP recebido. Para evitar que um grande número de pacotes PSNP sejam entregues pela interface. Um intervalo mínimo de entrega é definido para o pacote PSNP e o usuário pode alterar o intervalo dinamicamente. O intervalo de entrega do pacote PSNP não pode ser definido com um valor muito grande. Se o intervalo de entrega do pacote for definido com um valor muito grande, a sincronização do banco de dados de status do link em toda a rede será afetada para o link de transmissão e o pacote LSP poderá ser reenviado devido ao recebimento não oportuno da mensagem de confirmação para o ponto a destino. -ponto de ligação.
Tabela 10 -27 Configurar o intervalo de entrega do pacote PSNP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o intervalo de entrega do pacote PSNP | isis psnp-interval min-interval [ level-1 | level-2 ] | Opcional. Por padrão, o intervalo de entrega do pacote PSNP é de 2s. |
Configurar o intervalo de cálculo do SPF IPV6 IS-IS
As alterações do banco de dados de status do link IS-IS acionarão o cálculo de roteamento SPF. O cálculo frequente do SPF consumirá uma massa de recursos da CPU e o usuário poderá configurar o intervalo de cálculo do SPF.
Tabela 10 -28 Configurar o intervalo de cálculo IPV6 IS-IS SPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Entre no modo de configuração da família de endereços IS-IS IPv6 | address-family ipv6 unicast | - |
| Configure o intervalo de cálculo IS-IS SPF | spf-interval [ level-1 | level-2 ] maximum-interval [ min-initial-delay [ min-second-delay ]] | Opcional |
Configurar o número máximo de áreas para IPV6 IS-IS
Endereços IP de várias áreas podem ser configurados em um processo IS - IS . Os endereços de área múltipla são aplicados principalmente nas duas situações a seguir em que várias áreas de Nível 1 são combinadas como uma área de Nível 1 ou uma área de Nível 1 é dividida em várias áreas de Nível 1.
Tabela 10 -29 Configure o número máximo de áreas para o IPV6 IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Configure o número máximo de áreas para o IS-IS | max-area-addresses max-number | Opcional. Por padrão, o número máximo de endereços de área é 3. |
Essa configuração deve ser consistente em todo o domínio de roteamento IS-IS Nível 1. Caso contrário, o vizinho de Nível 1 não pode ser estabelecido normalmente. O vizinho de Nível 2 não é afetado.
Configurar mapeamento de nome de host IS-IS IPV6
O IS-IS identifica exclusivamente um sistema intermediário usando o ID do sistema com um comprimento fixo de 6 bytes. Ao visualizar as informações do sistema, como o relacionamento de vizinhos e o banco de dados de status do link, o ID do sistema não pode permitir que o usuário associe visualmente o ID do sistema ao nome do host. O IS-IS suporta o mapeamento entre o ID do sistema e o nome do host para permitir que o usuário visualize as informações do sistema de forma mais visual e conveniente. O mapeamento do nome do host IS-IS pode ser configurado nos dois métodos a seguir:
- Configure o mapeamento de nome de host estático IS-IS.
O mapeamento do nome do host estático IS-IS é estabelecido manualmente pelo usuário entre o ID do sistema e o nome do host para o dispositivo remoto.
Tabela 10 -30 Configurar o mapeamento de nome de host estático IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Configurar o mapeamento de nome de host estático IS-IS | hostname static system-id host-name | Obrigatório |
- Configure o mapeamento de nome de host dinâmico IS-IS.
O mapeamento estático do nome do host requer que o usuário configure o ID do sistema e o mapeamento do nome do host de outros dispositivos em cada dispositivo na rede, que tem uma carga de trabalho pesada. O mapeamento dinâmico do nome do host configura apenas o nome do host para cada dispositivo, e outros dispositivos na rede podem aprender o nome do host do dispositivo quando a função de anúncio do nome do host está habilitada.
Tabela 10 -31 Configurar o mapeamento de nome de host dinâmico IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configurar o mapeamento de nome de host dinâmico IS-IS | hostname dynamic { host-name | area-tag | recv-only | system-name } |
Obrigatório.
Por padrão, apenas os nomes de host anunciados por outros dispositivos são aprendidos. |
Configurar a interface IPV6 IS-IS a ser adicionada ao grupo de malha
Quando a interface IS-IS não é adicionada ao grupo de malha, o pacote LSP recebido de uma interface será enviado em todas as outras interfaces IS-IS. Isso resulta em grande desperdício de largura de banda em uma rede conectada em malha completa. Para evitar essa situação, várias interfaces IS-IS podem ser adicionadas a um grupo de malha. Quando uma interface recebe o pacote LSP, ela apenas envia o pacote LSP para a interface que não está no mesmo grupo de malha com esta interface.
Tabela 10 -32 Configure a interface IS-IS a ser adicionada ao grupo de malha
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure a interface IS-IS a ser adicionada ao grupo de malha | isis mesh-group { group-number | blocked } | Obrigatório. Por padrão, a interface IS-IS não é adicionada ao grupo de malha. |
O comando isis mesh-group bloqueado pode ser usado para configurar a interface como a interface obstrutiva. A interface obstrutiva não enviará o pacote LSP ativamente e somente enviará o pacote LSP quando receber a solicitação LSP.
Configurar autenticação de rede IPV6 IS-IS
Condição de configuração
Antes de configurar a autenticação de rede IPV6 IS-IS, primeiro conclua as seguintes tarefas:
- Configure o endereço IPv6 da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IPV6 IS-IS .
Configurar a autenticação vizinha IPV6 IS-IS
Quando a autenticação de relacionamento de vizinho estiver habilitada para o IS-IS, as informações de autenticação serão adicionadas ao pacote Hello entregue e o pacote Hello recebido será autenticado. Se a autenticação falhar, o relacionamento de vizinhos não será estabelecido. Isso pode impedir que o relacionamento de vizinhos seja estabelecido com os dispositivos não confiáveis.
Tabela 10 -33 Configurar a autenticação vizinha IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o modo de autenticação do pacote Hello | isis authentication mode { md5 | text } [ level-1 | level-2 ] | Obrigatório. Por padrão, a função de autenticação não está habilitada. |
| Configurar a senha de autenticação do pacote Hello | isis authentication key { 0 | 7 } password [ level-1 | level-2 ] | Qualquer Por padrão, a senha de autenticação não está configurada. A senha de autenticação pode ser configurada usando a cadeia de senhas. Para obter detalhes sobre a configuração da cadeia de senhas, consulte o capítulo de configuração da cadeia de senhas no manual de configuração. |
| isis authentication key-chain key-chain-name [ level-1 | level-2 ] |
Configurar autenticação de rota IPV6 IS-IS
Quando a autenticação de informações de roteamento estiver habilitada para o IS-IS, as informações de autenticação serão adicionadas aos pacotes LSP e SNP e os pacotes LSP e SNP recebidos serão autenticados. Se a autenticação falhar, o pacote será descartado diretamente. Isso pode impedir que as informações de roteamento não confiáveis se espalhem para a rede IS-IS.
Tabela 10 -34 Configurar a autenticação de rota IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [area-tag] | - |
| Configure o modo de autenticação do pacote de informações de roteamento | authentication mode { md5 | text } [ level-1 | level-2 ] | Obrigatório. Por padrão, a função de autenticação não está habilitada. |
| Configure a senha de autenticação do pacote de informações de roteamento | authentication key { 0 | 7 } password [ level-1 | level-2 ] | Qualquer Por padrão, a senha de autenticação não está configurada. A senha de autenticação pode ser configurada usando a cadeia de senhas. Para obter detalhes sobre a configuração da cadeia de senhas, consulte o capítulo de configuração da cadeia de senhas no manual de configuração. |
| authentication key-chain key-chain-name [ level-1 | level-2 ] |
Configurar o reencaminhamento rápido de IPv6 IS-IS
Condição de configuração
Antes de configurar o reencaminhamento rápido IPv6 IS-IS, primeiro conclua a seguinte tarefa:
- Configure o endereço IPv6 da interface, tornando acessível a camada de rede dos nós vizinhos
- Habilite o protocolo IPv6 IS-IS.
Configurar o reencaminhamento rápido de IPv6 IS-IS
Na rede IPv6 IS-IS, a interrupção do tráfego causada pela falha do link ou do dispositivo continuará até que o protocolo detecte a falha do link, e a rota flutuante não se recuperará até que a rota flutuante entre em vigor, o que geralmente dura vários segundos. Para reduzir o tempo de interrupção do tráfego, o reencaminhamento rápido IPv6 IS-IS pode ser configurado. Através da aplicação do mapa de roteamento, o próximo salto de backup é definido para a rota correspondente. Uma vez que o link ativo falhe, o tráfego que passa pelo link ativo será imediatamente comutado para o link em espera, de modo a atingir o objetivo de comutação rápida.
Tabela 10 -35 Configurar o reencaminhamento rápido do IPv6 IS-IS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| IS -IS | router isis [ area-tag ] | - |
| Entre no modo de configuração da família de endereços IS-IS IPv6 | address-family ipv6 unicast | - |
| Configurar IPv6 IS-IS para habilitar a função de reencaminhamento rápido | fast-reroute route-map route-map-name | Obrigatório. Por padrão, não ative a função de redirecionamento rápido IPv6 IS-IS. |
| Configurar IPv6 IS-IS para habilitar a função de reencaminhamento rápido dinâmico | fast-reroute loop-free-alternate [route-map route-map-name] | Obrigatório. Por padrão, não ative a função de redirecionamento rápido dinâmico IS-IS IPv6 . |
| Configurar IPv6 IS-IS para habilitar a função pic | pic |
Obrigatório.
a função pic, habilite a função de reencaminhamento rápido automático. Por padrão, não ative a função IPv6 IS-IS pic. |
A função de redirecionamento rápido IS-IS do IPv6 é dividida em redirecionamento rápido estático e redirecionamento rápido dinâmico. A função de reencaminhamento rápido estático precisa associar o mapa de rotas e definir a interface do próximo salto e o endereço da rota de backup no mapa de rotas. Atualmente, o reencaminhamento rápido dinâmico suporta apenas rede ponto a ponto, ou seja, todos os tipos de rede de interface de saída do dispositivo são ponto a ponto. Depois de configurar o redirecionamento rápido dinâmico, o dispositivo calculará e definirá automaticamente a interface e o endereço de backup do próximo salto. O reencaminhamento rápido dinâmico também pode ser associado ao mapa de rotas e definir a interface e o endereço do próximo salto de backup apenas para o mapa de rotas correspondente à rota. As várias maneiras de habilitar o reencaminhamento são mutuamente exclusivas.
Configurar IPv6 IS-IS GR
informações de rota da camada de encaminhamento entre o dispositivo local e o dispositivo vizinho inalteradas durante a alternância ativa/em espera dos dispositivos e o encaminhamento não é afetado. Após alternar o dispositivo e executar novamente, a camada de protocolo dos dois dispositivos sincroniza as informações de rota e atualiza a camada de encaminhamento para que o encaminhamento de dados não seja interrompido durante a alternância do dispositivo .
Existem dois papéis durante o GR:
- GR Restarter : O dispositivo que executa a reinicialização normal do protocolo
- GR Helper : O dispositivo que auxilia a reinicialização graciosa do protocolo
O dispositivo distribuído pode servir como GR Restarter e GR Helper, enquanto o dispositivo centralizado pode servir apenas como GR Helper, auxiliando o Restarter a completar o GR.
Condição de configuração
Antes de configurar o IPv6 IS-IS GR, primeiro conclua as seguintes tarefas:
- Configure o endereço IPv6 da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IPV6 IS-IS .
Configurar IPv6 IS-IS GR Helper
O GR Helper ajuda o Restarter a completar o GR. Por padrão, o dispositivo habilita a função e o usuário pode desabilitar a função por meio do comando.
Tabela 10 -36 Configurar o auxiliar IS-IS GR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IS-IS | router isis [ area-tag ] | - |
| Configure o IS-IS GR Helper para desabilitar o recurso Helper | nsf ietf helper disable | Obrigatório. Configure o IS-IS GR Helper para desabilitar o recurso Helper. |
Monitoramento e Manutenção de IPV6 IS-IS
Tabela 10 -37 Monitoramento e Manutenção do IPV6 IS-IS
| Comando | Descrição |
| clear isis [ instance -null | area-tag ] statistics [ interface_name ] | Limpe as informações estatísticas da operação do protocolo IPV6 IS-IS |
| clear isis [ instance -null | area-tag ] process | Reinicie o processo do protocolo IPV6 IS-IS |
| show isis [ instance -null | area-tag ] | Exibir as informações do processo IPV6 IS-IS |
| show isis instance { -null | area-tag } bfd-sessions | Exiba as informações da sessão BFD do processo IPV6 IS-IS |
| show isis [ instance -null | area-tag ] database [ lsp_id ] [ detail ] [ l1 / l2 ] [ level-1 / level-2 ] [ self ] [ verbose ] | Exibir as informações do banco de dados de status do link IPV6 IS-IS |
| show isis interface [ interface-name ] [ detail ] | Exibir as informações da operação da interface do protocolo IPV6 IS-IS |
| show isis [ instance –null | area-tag ] ipv6 reach-info | Exiba as informações alcançáveis da sub-rede IPv4 IS-IS IPV6 |
| show isis [ instance –null | area-tag ] ipv6 route | Exiba as informações de roteamento IPV6 IS-IS IPv4 |
| show isis [ instance –null | area-tag ] ipv6 topology | Exiba as informações de topologia IPv4 IS-IS IPV6 |
| show isis [ instance – null | area-tag ] is-reach-info [ level-1 | level-2 ] | Exibir as informações do nó vizinho IPV6 IS-IS |
| show isis [instance –null | area-tag] mesh-groups | Exibir o grupo de malha IPV6 IS-IS |
| show isis [ instance –null | area-tag ] neighbors [ interface-name ] [ detail ] | Exiba as informações do vizinho IPV6 IS-IS |
| show isis [ instance –null | area-tag ] statistics [ interface-name ] | Exibir as informações estatísticas da operação do protocolo IPV6 IS-IS |
| show isis router | Exiba as informações do nome do host IPV6 IS-IS |
Exemplo de configuração típica do IS-IS IPv6
função básica do IS-IS v6
Requisitos de rede
- Configure o protocolo IS-ISv6 para realizar a interconexão de rede entre os dispositivos.
- Device1 é o roteador de nível 1 e Device2 é o roteador de nível 1-2. Device1 e Device2 estão na mesma área, Área 10. Device3 é o roteador de Nível 2 na Área 20. Device2 conecta as duas áreas.
Topologia de rede

Figura 10 – 1 Rede de configuração das funções básicas do IS-ISv6
Etapas de configuração
- Passo 1: Configure o endereço IP v6 das interfaces. (Omitido)
- Passo 2: Configure o IS-IS v6 e habilite o processo na interface.
# Configure o processo IS-ISv6 como 100, número de área como 10, digite como Level-1 e habilite o processo na interface do Device1.
enable the process on the interface of Device1.Device1#configure terminalDevice1(config)#router isis 100Device1(config-isis)#net 10.0000.0000.0001.00Device1(config-isis)#is-type level-1Device1(config-isis)#metric-style wideDevice1(config-isis)#address-family ipv6 unicastDevice1(config-isis-af)#multi-topologyDevice1(config-isis-af)#exit-address-familyDevice1(config-isis)#exitDevice1(config)#interface gigabitethernet 0Device1(config-if-gigabitethernet0)#ipv6 router isis 100Device1(config-if-gigabitethernet0)#exitDevice1(config)#interface gigabitethernet 1Device1(config-if-gigabitethernet1)#ipv6 router isis 100Device1(config-if-gigabitethernet1)#exit
# Configure o processo IS-ISv6 como 100, número de área como 10, digite como Level-1-2 e habilite o processo na interface do Device2.
Device2#configure terminalDevice2(config)#router isis 100Device2(config-isis)#net 10.0000.0000.0002.00Device2(config-isis)#metric-style wideDevice2(config-isis)#address-family ipv6 unicastDevice2(config-isis-af)#multi-topologyDevice2(config-isis-af)#exit-address-familyDevice2(config-isis)#exitDevice2(config)#interface gigabitethernet 0Device2(config-if-gigabitethernet0)#ipv6 router isis 100Device2(config-if-gigabitethernet0)#exitDevice2(config)#interface gigabitethernet 1Device2(config-if-gigabitethernet1)#ipv6 router isis 100Device2(config-if-gigabitethernet1)#exit
# Configure o processo IS-ISv6 como 100, número de área como 20, digite como Level-2 e habilite o processo na interface do Device3.
Device3#configure terminalDevice3(config)#router isis 100Device3(config-isis)#net 20.0000.0000.0003.00Device3(config-isis)#is-type level-2Device3(config-isis)#metric-style wideDevice3(config-isis)#address-family ipv6 unicastDevice3(config-isis-af)#multi-topologyDevice3(config-isis-af)#exit-address-familyDevice3(config-isis)#exitDevice3(config)#interface gigabitethernet0Device3(config-if-gigabitethernet0)#ipv6 router isis 100Device3(config-if-gigabitethernet0)#exitDevice3(config)#interface gigabitethernet1Device3(config-if-gigabitethernet1)#ipv6 router isis 100Device3(config-if-gigabitethernet1)#exit
- Passo 3: Confira o resultado.
# Visualize as informações vizinhas do IS-I Sv6 do Device1.
Device1#show isis neighborsIS-IS Instance 100 Neighbors (Counter 1): Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL1-LAN 0000.0000.0002 gigabitethernet0/2/1 Up 25 sec L1 capable 64 0000.0000.0001.02
# Visualize as informações vizinhas do IS-IS v6 no Device2.
Device2#show isis neighborsIS-IS Instance 100 Neighbors (Counter 2):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL1-LAN 0000.0000.0001 gigabitethernet0/2/0 Up 8 sec L1 capable 64 0000.0000.0001.02L2-LAN 0000.0000.0003 gigabitethernet0/2/1 Up 7 sec L2 capable 64 0000.0000.0003.01
Device2 constrói o vizinho IS-ISv6 com Device1 e Device3, respectivamente.
# Visualize as informações vizinhas do IS-IS v6 do Device3.
Device3#show isis neighborsIS-IS Instance 100 Neighbors (Counter 1):Type System ID Interface State Holdtime Level IETF-NSF Priority Circuit IDL2-LAN 0000.0000.0002 gigabitethernet0/2/0 Up 23 sec L2 capable 64 0000.0000.0003.01
# Visualize as informações de roteamento do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Managementi ::/0 [115/10]via fe80::201:7aff:fe5e:6d45, 00:03:17, gigabitethernet0/2/1L ::1/128 [0/0]via ::, 16:03:18, lo0C 2001:1::/64 [0/0]via ::, 00:20:11, gigabitethernet0/2/0L 2001:1::1/128 [0/0]via ::, 00:20:10, lo0C 2001:2::/64 [0/0]via ::, 00:19:50, gigabitethernet0/2/1L 2001:2::1/128 [0/0]via ::, 00:19:49, lo0i 2001:3::/64 [115/20]via fe80::201:7aff:fe5e:6d45, 00:06:48, gigabitethernet0/2/1Device1#show isis ipv6 routeIS-IS Instance 100, VRF Kernel, IPv6 routes table (Counter 4):L1 ::/0, flags none, metric 10, from learned, installedvia fe80::201:7aff:fe5e:6d45, gigabitethernet1, neighbor 0000.0000.0002L1 2001:1::/64, flags none, metric 10, from network connectedvia ::, gigabitethernet0L1 2001:2::/64, flags none, metric 10, from network connectedvia ::, gigabitethernet1L1 2001:3::/64, flags none, metric 20, from learned, installedvia fe80::201:7aff:fe5e:6d45, gigabitethernet1, neighbor 0000.0000.0002
Um roteamento padrão está na tabela de roteamento de Device1 e o próximo salto é Device2.
# Visualize as informações de roteamento do Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1d:12:42:31, lo0i 2001:1::/64 [115/20]via fe80::201:7aff:fe61:7a24, 00:08:32, gigabitethernet0/2/0C 2001:2::/64 [0/0]via ::, 23:41:09, gigabitethernet0/2/0L 2001:2::2/128 [0/0]via ::, 23:41:06, lo0C 2001:3::/64 [0/0]via ::, 17:39:09, gigabitethernet0/2/1L 2001:3::1/128 [0/0]via ::, 17:39:06, lo0i 2001:4::/64 [115/20]via fe80::2212:1ff:fe01:101, 00:04:52, gigabitethernet0/2/1Device2#show isis ipv6 routeIS-IS Instance 100, VRF Kernel, IPv6 routes table (Counter 4):L1 2001:1::/64, flags none, metric 20, from learned, installedvia fe80::201:7aff:fe61:7a24, gigabitethernet0, neighbor 0000.0000.0001L1 2001:2::/64, flags none, metric 10, from network connectedvia ::, gigabitethernet0/2/0L1 2001:3::/64, flags none, metric 10, from network connectedvia ::, gigabitethernet0/2/1L2 2001:4::/64, flags none, metric 20, from learned, installedvia fe80::2212:1ff:fe01:101, gigabitethernet1, neighbor 0000.0000.0003
Device2 contém o roteamento de Nível 1 e Nível 2.
# Visualize as informações de roteamento do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 00:00:12, lo0i 2001:1::/64 [115/30]via fe80::201:7aff:fe5e:6d46, 00:00:12, gigabitethernet0/2/0i 2001:2::/64 [115/20]via fe80::201:7aff:fe5e:6d46, 00:00:12, gigabitethernet0/2/0C 2001:3::/64 [0/0]via ::, 00:00:12, gigabitethernet0/2/0L 2001:3::2/128 [0/0]via ::, 00:00:12, lo0C 2001:4::/64 [0/0]via ::, 00:00:12, gigabitethernet0/2/1L 2001:4::1/128 [0/0]via ::, 00:00:12, lo0Device3#show isis ipv6 routeIS-IS Instance 100, VRF Kernel, IPv6 routes table (Counter 4):L2 2001:1::/64, flags none, metric 30, from learned, installedvia fe80::201:7aff:fe5e:6d46, gigabitethernet0, neighbor 0000.0000.0002L2 2001:2::/64, flags none, metric 20, from learned, installedvia fe80::201:7aff:fe5e:6d46, gigabitethernet0, neighbor 0000.0000.0002L2 2001:3::/64, flags none, metric 10, from network connectedvia ::, gigabitethernet0/2/0L2 2001:4::/64, flags none, metric 10, from network connectedvia ::, gigabitethernet0/2/1
O Device3 aprende a rota de Nível-1 e e o Nível-1 vaza a rota e para o Nível-2 por padrão.
O tipo de métrica é a métrica estreita por padrão. A métrica ampla é recomendada. A rota IS-ISv6 pode ser aprendida somente quando a multi-topologia é usada. O atributo de entidade IS-ISv6 é Level-1-2 por padrão.
IRMP (Aplicável somente ao modelo S3054G-B)
Visão geral
O IRMP (Internal Routing Message Protocol), compatível com o Cisco EIGRP, é um protocolo de roteamento dinâmico baseado no vetor de distância. O IRMP usa o DUAL (Diffusing Update Algorithm) para calcular a rota entre vários dispositivos em paralelo, garantindo a ausência de circuito em loop e convergência rápida. O IRMP supera a baixa velocidade de convergência do protocolo de roteamento baseado em vetor de distância. Além disso, ele não precisa do protocolo de roteamento de status do link para executar o algoritmo Dijkstra e os bancos de dados relacionados o fazem. não consumir enormes recursos de CPU ou memória.
O protocolo IRMP se aplica à rede de médio e pequeno porte e oferece suporte a vários sistemas autônomos. Os sistemas autônomos podem operar de forma independente sem interferir um no outro.
Configuração da função IRMP
Tabela 11 -1 lista de funções IRMP
| Tarefa de configuração | |
| Configurar a função básica do IRMP | Habilite o protocolo IRMP |
| Configurar a geração de rota IRMP | Configurar a redistribuição de IRMP |
| Configurar o controle de rota IRMP |
Configurar o resumo da rota IRMP
Configurar a distância administrativa do IRMP Configurar o balanceamento de carga do IRMP Configurar a filtragem de rota IRMP Configurar o deslocamento da métrica do IRMP Configurar o valor da métrica de rota IRMP |
| Configurar a otimização de rede IRMP |
Configurar a interface passiva do IRMP
Configurar o modo de stub do IRMP Configurar a consulta inteligente IRMP Configurar a divisão horizontal do IRMP Configurar o temporizador IRMP Configurar o vizinho estático do IRMP |
| Configurar a autenticação de rede IRMP | Configurar a autenticação IRMP |
Configurar a função básica do IRMP
Nas várias tarefas de configuração do IRMP, o protocolo IRMP deve ser ativado primeiro para tornar válidas as configurações de outros recursos de função.
Condição de configuração
Antes de configurar a função básica do IRMP, primeiro complete as seguintes tarefas:
- Configure o protocolo da camada de link para garantir a comunicação normal da camada de link.
- Configure o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
Ativar protocolo IRMP
Antes de utilizar o protocolo IRMP, primeiro o usuário deve realizar as seguintes configurações:
- Estabeleça o processo de IRMP.
- Configure o IRMP para cobrir o segmento de rede conectado diretamente.
Tabela 11 -2 Habilitar o protocolo IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Estabeleça o processo IRMP e entre no modo de configuração IRMP | router irmp autonomous-system-number | Obrigatório. Por padrão, o processo IRMP não está habilitado. |
| Configure o IRMP para cobrir o segmento de rede conectado diretamente | network ip-address [ wildcard-mask ] |
Obrigatório.
Por padrão, nenhuma rede conectada diretamente é coberta. Se a máscara curinga não for transportada, o endereço de rede classful será usado por padrão. |
Ao estabelecer o vizinho IRMP, os números do sistema autônomo devem ser consistentes. Caso contrário, a relação de vizinhança não pode ser estabelecida.
Configurar geração de rota IRMP
No IRM, o O comando network pode ser usado para cobrir o roteamento do segmento de rede conectado diretamente. O roteamento externo pode ser introduzido usando a redistribuição.
Condição de configuração
Antes de configurar a geração de rota IRMP, primeiro complete as seguintes tarefas:
- Configurar o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IRMP .
Configurar a redistribuição de IRMP
Apresente o roteamento gerado por outros protocolos ao IRMP configurando a redistribuição de roteamento . O roteamento de outros processos IRMP também pode ser introduzido.
Tabela 11 -3Configurar a redistribuição de IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IRMP | router irmp autonomous-system-number | - |
| Configurar a redistribuição de IRMP | redistribute protocol [ process-id ] [ route-map route-map-name / metric bandwidth delay reliability loading mtu ] | Obrigatório. Por padrão, o roteamento externo não é redistribuído. |
| Configure o valor da métrica padrão para o roteamento externo de redistribuição de IRMP | default-metric bandwidth delay reliability loading mtu | Opcional |
Quando o comando default-metric e o comando redistribute protocolo [ process-id ] comando métrico são configurados ao mesmo tempo, o comando posterior tem uma prioridade mais alta.
Configurar o controle de rota IRMP
Condição de configuração
Antes de configurar o controle de rota IRMP, primeiro conclua as seguintes tarefas:
- Configure o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IRMP.
Configurar resumo da rota IRMP
Tanto a rota agregada do IRMP quanto a rota detalhada original existem na tabela de roteamento local, mas apenas o roteamento agregado é informado ao vizinho. Assim, na rede de grande porte, a escala da tabela de roteamento vizinha reduz e a largura de banda da rede consumida pelos pacotes de protocolo também diminui.
O IRMP suporta o resumo automático e o resumo do endereço IP da interface. O valor métrico da rota agregada usa o valor métrico mínimo de todas as rotas detalhadas.
- Resumo automático
Nesse modo, a rota é agregada como o endereço de rede classful correspondente pela configuração não manual. O modo de rota automática agrega apenas a rota do segmento de rede conectado diretamente.
Tabela 11 -4 Configurar o resumo automático do IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IRMP | router irmp autonomous-system-number | - |
| Configurar o resumo automático do IRMP | auto-summary | Opcional. Por padrão, a função de resumo automático do IRMP está desabilitada. |
- Resumo da rota da interface
resumo da rota da interface precisa que o usuário configure a combinação de um par de endereço IP de destino e máscara. Esta combinação agrega as rotas que são cobertas neste segmento de rede.
Tabela 11 -5 Configurar o resumo da rota da interface IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o resumo do endereço IP da interface IRMP | ip summary-address irmp autonomous-system-number ip-address mask | Obrigatório |
O resumo automático apenas agrega as rotas do segmento de rede diretamente conectado e não faz com que todos os vizinhos sob o processo se restabeleçam. O resumo da rota da interface visa todas as rotas IRMP entregues da interface especificada e pode fazer com que os vizinhos na interface especificada sejam restabelecidos. O resumo da rota da interface é anterior ao resumo automático. O resumo da rota da interface é independente entre si. Ou seja, quando o resumo de rotas de interface 10.1.0.0/16 e 10.0.0.0/8 são configurados ao mesmo tempo, o IRMP anunciará as duas rotas de resumo simultaneamente.
Configurar a distância administrativa do IRMP
A distância administrativa executa a política de roteamento para o roteamento no mesmo aumento de rede a partir de protocolos diferentes. Quanto menor a distância administrativa, maior a prioridade do roteamento. Você pode alterar a distância administrativa do roteamento IRMP para afetar a política de roteamento.
Tabela 11 -6 Configurar a distância administrativa do IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a distância administrativa do IRMP | distance irmp internal-routes-distance external-routes-distance |
Opcional.
Por padrão, a distância administrativa para a rota interna do IRMP é 90 e para a rota externa é 170. |
Ao configurar a distância administrativa do IRMP, todos os vizinhos sob o processo podem ser restabelecidos.
Configurar balanceamento de carga IRMP
O IRMP suporta balanceamento de carga de custo igual e balanceamento de carga de custo desigual. Quando existem várias rotas com os mesmos valores de métrica para a rede de destino, o balanceamento de carga de custo igual é formado. Quando existem várias rotas com diferentes valores de métrica para a rede de destino, você pode executar o comando variance para alterar o fator de conversão e formar o balanceamento de carga de custo desigual.
A variação define um fator de conversão, que é usado para determinar o escopo do roteamento de balanceamento de carga de custo desigual. Quando o valor da métrica de um roteamento não ideal é menor que o valor da métrica do roteamento ideal multiplicando o valor da variação, esse roteamento é selecionado como o roteamento de balanceamento de carga de custo desigual.
O comando maximum-paths é usado para controlar o número máximo de roteamentos para balanceamento de carga IRMP, suportando um máximo de 16 caminhos para balanceamento de carga. Quando o número do caminho é definido como 1, a função de carregamento é cancelada. O número de caminhos para balanceamento de carga IRMP inclui o número de caminhos de balanceamento de carga de custo igual e caminhos de balanceamento de carga de custo desigual. O caminho selecionado para balanceamento de carga IRMP depende da variação do fator de conversão.
Tabela 11 -7 Configurar o balanceamento de carga IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IRMP | router irmp autonomous-system-number | - |
| Configure o fator de conversão do IRM para formar o balanceamento de carga desigual | variance number | Opcional. Por padrão, o fator de conversão é 1. |
| Configure o número máximo de caminhos para balanceamento de carga IRMP | maximum-paths path-number | Opcional. Por padrão, o número máximo de caminhos para balanceamento de carga IRMP é 4. |
Configurar filtragem de rota IRMP
Controle o roteamento recebido ou entregue configurando a ACL ou a lista de prefixos. A filtragem de roteamento de entrada e saída pode ser configurada na interface ao mesmo tempo.
Tabela 11 -8 Configurar a filtragem de rota IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IRMP | router irmp autonomous-system-number | - |
| Configurar a filtragem de rota IRMP | distribute-list { access-list-name | gateway prefix-list-name1 | prefix prefix-list-name2 [ gateway prefix-list-name3 ] } { in | out } [ interface-name ] | Obrigatório |
A filtragem de roteamento IRMP suporta apenas a ACL padrão. Você pode configurar a filtragem em todas as interfaces ou usar o nome da interface parâmetro para especificar a interface para configurar a filtragem. Quando os dois modos anteriores são configurados ao mesmo tempo, a configuração é válida quando as duas regras de filtragem anteriores são definidas para permitir.
Configurar o deslocamento da métrica do IRMP
Por padrão, o roteamento IRMP adota o valor métrico anunciado pelo vizinho. Em alguns cenários de aplicativos, o valor da métrica requer modificação. O usuário pode retificar o valor métrico de um roteamento especificado configurando o deslocamento métrico IRMP.
Se o deslocamento da métrica de entrada estiver configurado, o valor da métrica de roteamento será modificado, salvo na tabela de roteamento e, em seguida, anunciado ao vizinho ao receber o roteamento IRMP. Se o deslocamento da métrica de saída estiver configurado, apenas o valor da métrica anunciado para o roteamento vizinho será modificado e o valor da métrica local permanecerá inalterado.
Tabela 11 -9 Configurar o deslocamento métrico IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IRMP | router irmp autonomous-system-number | - |
| Configurar o deslocamento da métrica do IRMP | offset-list access-list-name { in | out } offset-value [ interface-name ] | Obrigatório |
O deslocamento métrico IRMP suporta apenas a ACL padrão. Ao configurar o deslocamento métrico do IRMP, todos os vizinhos sob o processo podem ser restabelecidos.
Configurar o valor da métrica de rota IRMP
O IRMP calcula um valor de métrica composta como o valor de métrica de rota com base nos recursos do link, como largura de banda, atraso, carga e confiabilidade do link. A fórmula de cálculo é a seguinte:
Métrica de rota = 256 x ([k1 x (10 /Largura de banda) + k2 x (10 /Largura de banda)/(256 – Carga) + k3 x (Atraso/10)] x [k5/(Confiabilidade + k4)])
Onde, a largura de banda está na unidade de kbit/s e o atraso está na unidade de microssegundo. Cada valor k indica o valor ponderado do recurso de link correspondente. Por padrão, o RMP usa a largura de banda e o atraso do link como o valor da métrica.
Tabela 11 -10 Configurar o valor da métrica de rota IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IRMP | router irmp autonomous-system-number | - |
| Configurar o valor da métrica de rota IRMP | metric weights tos k1 k2 k3 k4 k5 |
Obrigatório.
Tos indica o tipo de serviço, suportando apenas os serviços do tipo 0. Por padrão, k1 = k3 =1 e k2 = k4 = k5 =0. O valor K deve ser consistente ao estabelecer a relação de vizinhança. |
Configurar otimização de rede IRMP
Condição de configuração
Antes de configurar a otimização de rede IRMP, primeiro conclua as seguintes tarefas:
- Configure o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IRMP .
Configurar interface passiva IRMP
O protocolo de roteamento dinâmico adota a interface passiva para reduzir efetivamente a largura de banda da rede consumida pelo protocolo de roteamento. No protocolo IRMP, a interface passiva é configurada, o que pode suprimir o recebimento e transmissão de pacotes IRMP na interface especificada. Por exemplo, se o gigabitethernet 0 estiver configurado como interface passiva, o IRMP não receberá e transmitirá o pacote nesta interface mesmo que o O comando network é usado para cobrir o segmento de rede no qual a interface está localizada.
Tabela 11 -11 Configurar a interface passiva IR MP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IRMP | router irmp autonomous-system-number | - |
| Configurar a interface passiva do IRMP | passive interface interface-name | Obrigatório |
Configurar o modo de stub IRMP
Configurar o modo stub IRMP pode melhorar a estabilidade da rede IRMP e reduzir os recursos ocupados. A função Stub é usada na topologia de rede hub e spoke. Para habilitar a função Stub, você só precisa configurar o Stub no roteador spoke, mas não precisa alterar a configuração do roteador hub. O roteador spoke especifica o tipo de rota a ser anunciado por meio do comando stub irmp . O roteador de hub não envia os pacotes de consulta para o vizinho Stub.
Tabela 11 -12 Configurar Stub IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IRMP | router irmp autonomous-system-number | - |
| Configurar stub IRMP | irmp stub { receive-only } | { connected / summary / redistributed } | Obrigatório. Por padrão, não é o modo stub. |
Modificar a configuração do Stub resulta na reconexão de todos os vizinhos no processo.
Configurar a consulta inteligente do IRMP
Configurar a consulta inteligente IRMP para controlar o envio dos pacotes de consulta pode reduzir o número de pacotes trocados na rede, reduzindo os recursos ocupados. Se a função de consulta inteligente estiver habilitada, o dispositivo não envia os pacotes de consulta ao vizinho cancelando a rota, de modo a reduzir o número de pacotes de consulta e de resposta na rede.
Tabela 11 -13 Configurar Stub IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IRMP | router irmp autonomous-system-number | - |
| Configurar a consulta inteligente IRMP | smart-query infinity-update | Obrigatório. Por padrão, não habilite a consulta inteligente. |
Configurar divisão horizontal do IRMP
A divisão horizontal do IRMP indica que a rota aprendida pelo IRMP de uma determinada interface não será anunciada dessa interface para evitar a formação de um loop.
Tabela 11 -14 Configurar a divisão horizontal do IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a divisão horizontal do IRMP | ip split-horizon irmp autonomous-system-number | Opcional. Por padrão, a função de divisão horizontal está habilitada. |
Configurar temporizador IRMP
- Configure o temporizador keep-alive para o vizinho IRMP.
O pacote IRMP Hello é usado para descobrir o vizinho e mantê-lo vivo espalhando o pacote na rede usando o modo multicast periódico e não confiável com o endereço multicast como 224.0.0.10. O intervalo de entrega padrão para o pacote Hello é determinado pelo tipo de rede da interface de entrega. O intervalo de entrega padrão é de 5 segundos na interface de transmissão e ponto a ponto e de 60 segundos na interface NBMA.
O tempo de espera indica o intervalo inválido do vizinho IRMP. Quando um dispositivo recebe um pacote Hello de seu vizinho, este pacote contém um tempo de espera, que informa o tempo máximo válido do vizinho ao dispositivo. Se o pacote Hello não for recebido do vizinho quando atingir o tempo limite, isso indica que o vizinho não está acessível e o vizinho será removido. Por padrão, o tempo de espera é três vezes o intervalo de saudação.
Tabela 11 -15 Configurar o temporizador keep-alive para o vizinho IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o intervalo de hello do IRMP | ip hello-interval irmp autonomous-system hello-time |
Opcional.
Por padrão, o intervalo de saudação é definido como 5s ou 60s com base no tipo de rede. |
| Configurar o tempo de espera do IRMP | ip hold-time irmp autonomous-system-number hold-time | Opcional. Por padrão, o tempo de espera é três vezes o intervalo de saudação. |
- Configure o temporizador de rota IRMP.
O IRMP usa o DUAL (Diffusing Update Algorithm) para aprender o roteamento. Quando o DUAL inicia, o temporizador ativo é ativado. Se a resposta dos pacotes consultados não for recebida quando o temporizador expirar, os vizinhos sem resposta serão removidos da lista de vizinhos. A rota sem resposta defini como Ativa e a rota é considerada inalcançável.
Quando o IRMP recebe a solicitação do vizinho, se a rota local for aprendida de outros vizinhos, o IRMP não responderá imediatamente. Em vez disso, ative um temporizador de retenção e aguarde um período. No período, se o IRMP não receber o pacote de solicitação do vizinho, ele responde o pacote para evitar a formação do loop.
Tabela 11 -16 Configurar o temporizador de rota IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IRMP | router irmp autonomous-system-number | - |
| Configurar o tempo limite do timer ativo | timers active-time minutes | Opcional. Por padrão, o tempo limite do temporizador ativo é de 3 minutos. |
| Configurar o tempo limite de espera | timers holddown-time seconds | Opcional. Por padrão, o tempo limite de espera é de 5s. |
Ao configurar o timer de rota, todos os vizinhos sob o processo podem ser restabelecidos.
Configurar vizinho estático do IRMP
Configure o vizinho estático IRMP, onde todos os pacotes IRMP entre vizinhos adotam a interação unicast.
Para executar o protocolo de roteamento dinâmico IRMP no NBMA que não suporta a rede de transmissão, como X.25 e Frame, o vizinho estático precisa ser configurado em par. Caso contrário, o relacionamento com o vizinho falhará.
Tabela 11 -17 Configurar o vizinho estático IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração IRMP | router irmp autonomous-system-number | - |
| Configurar o vizinho estático do IRMP | neighbor neighbor-ip-address interface-name | Obrigatório |
Configurar autenticação de rede IRMP
Condição de configuração
Antes de configurar a autenticação IRMP, primeiro conclua as seguintes tarefas:
- Configure o endereço IP da interface para permitir que os nós vizinhos sejam alcançáveis na camada de rede.
- Habilite o protocolo IRMP .
Configurar autenticação IRMP
Execute a verificação de validade e verificação no pacote IRMP configurando a autenticação IRMP para melhorar a segurança da rede. O IRMP suporta apenas a autenticação MD5.
Tabela 11 -18Configurar a autenticação IRMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a função de autenticação IRMP | ip message-digest-key irmp autonomous-system-number key-id md5 { 0 | 7 } password | Obrigatório |
Quando o mesmo ID de chave e senha são configurados nas interfaces ao mesmo tempo, o relacionamento vizinho do IRMP pode ser estabelecido.
Monitoramento e Manutenção do IRMP
Tabela 11 -19 Monitoramento e Manutenção do IRMP
| Comando | Descrição |
| clear ip irmp error | Limpe as informações estatísticas do pacote de erro IRMP |
| clear ip irmp [ autonomous-system-number ] neighbors [ interface-name ] | Redefinir o vizinho IRMP |
| clear ip irmp traffic [ autonomous-system-number ] | Limpe as informações estatísticas para receber e transmitir o pacote IRMP |
| show ip irmp error | Exibe as informações estatísticas do pacote de erro IRMP |
| show ip irmp interface [ autonomous-system-number ] | [ interface-name ] | Exibir as informações da interface IRMP |
| show ip irmp neighbor [ autonomous-system-number | detail | interface-name ] | Exibir as informações do vizinho IRMP |
| show ip irmp topology [autonomous-system-number ] [ active | detail | summary | ip-address mask ] | tabela de topologia IRMP |
| show ip irmp traffic [ autonomous-system-number ] | Exibe as informações estatísticas de recebimento e transmissão do pacote IRMP |
Exemplo de configuração típica do IRMP
Configurar a função básica do IRMP
Requisitos de rede
- O IRMP opera entre Device1 e Device2, estabelecendo o vizinho e interagindo na rota.
Topologia de rede

Figura 11 – 1 Rede da função básica do IRMP
Etapas de configuração
- Passo 1: Configure o endereço IP das interfaces. (Omitido)
- Passo 2: Configure o IRMP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router irmp 100Device1(config-irmp)#network 1.0.0.0 0.0.0.255Device1(config-irmp)#network 100.0.0.0 0.0.0.255Device1(config-irmp)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router irmp 100Device2(config-irmp)#network 1.0.0.0 0.0.0.255Device2(config-irmp)#network 200.0.0.0 0.0.0.255Device2(config-irmp)#exit
- Passo 3: Confira o resultado.
# Veja as informações do vizinho IRMP do Device1.
Device1#show ip irmp neighborIP-IRMP neighbors for process 100 Total neighbor 1Address Interface Hold(s) Uptime SeqNum Srtt(ms) Rto(s)1.0.0.2 gigabitethernet1 14 00:00:47 7 0 2
# Veja as informações do vizinho IRMP do Device2.
Device2#show ip irmp neighborIP-IRMP neighbors for process 100 Total neighbor 1Address Interface Hold(s) Uptime SeqNum Srtt(ms) Rto(s)1.0.0.1 gigabitethernet0 11 00:00:43 4 3920 4
Pode ser visto que o vizinho IRMP é estabelecido entre Device1 e Device2 I
# Visualize a tabela de topologia e a tabela de roteamento do Device1.
Device1#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet1P >200.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet1P >100.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:27:02, gigabitethernet1E 200.0.0.0/24 [90/3072] via 1.0.0.2, 00:15:07, gigabitethernet1C 100.0.0.0/24 is directly connected, 00:27:14, gigabitethernet0C 127.0.0.0/8 is directly connected, 137:46:13, lo0
Device1 aprende o roteamento 200.0.0.0/24 anunciado pelo Device2.
# Visualize a tabela de topologia IRMP e a tabela de roteamento do Device2.
Device2#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >200.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet1P >100.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.1 (3072/2816), gigabitethernet0Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:20:12, gigabitethernet0C 200.0.0.0/24 is directly connected, 00:19:53, gigabitethernet1E 100.0.0.0/24 [90/3072] via 1.0.0.1, 00:08:41, gigabitethernet0C 127.0.0.0/8 is directly connected, 361:04:08, lo0
Device2 aprende o roteamento 100.0.0.0/24 anunciado pelo Device1.
Configurar redistribuição de IRMP
Requisitos de rede
- O vizinho OSPF é estabelecido entre Device3 e Device2 e os roteamentos 200.0.0.0/24 e 210.0.0.0/24 diretamente conectados à interface são anunciados para Device2.
- O vizinho IRMP é estabelecido entre Device1 e Device2. Quando Device2 redistribui o roteamento OSPF para o IRMP, somente o roteamento 200.0.0.0/24 em vez do roteamento 210.0.0.0/24 é anunciado para Device1 através do controle de política de roteamento.
Topologia de rede
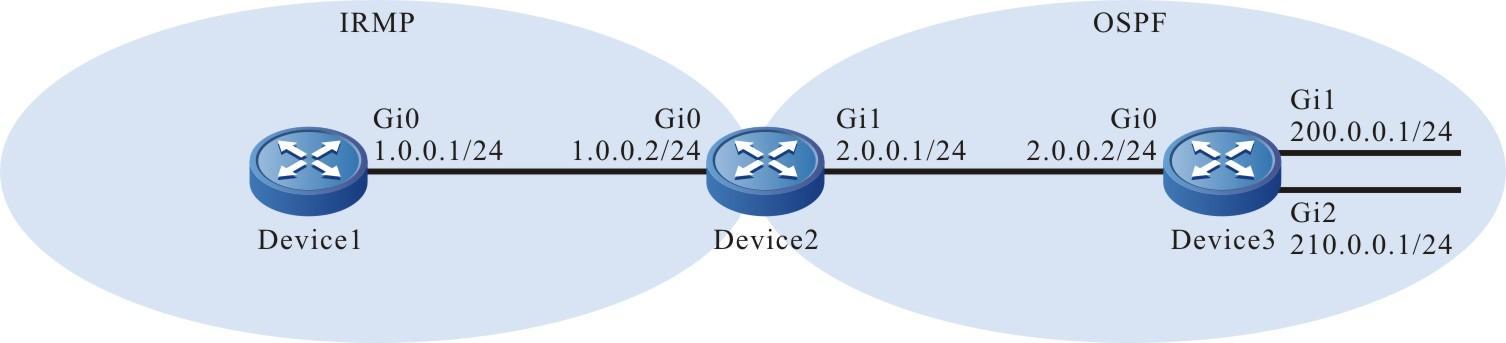
Figura 11 – 2 Networking da redistribuição da rota IRMP
Etapas de configuração
- Passo 1: Configure o endereço IP das interfaces. (Omitido)
- Passo 2: Configure o OSPF.
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 200.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 210.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
# Visualize a tabela de roteamento do Device2.
Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 07:39:21, gigabitethernet0C 2.0.0.0/24 is directly connected, 00:03:36, gigabitethernet1C 127.0.0.0/8 is directly connected, 57:04:58, lo0O 200.0.0.0/24 [110/2] via 2.0.0.2, 00:01:10, gigabitethernet1O 210.0.0.0/24 [110/2] via 2.0.0.2, 00:01:10, gigabitethernet1
Na tabela de roteamento, pode-se ver que Device2 aprende o roteamento OSPF 200.0.0.0/24 e 210.0.0.0/24 anunciado pelo Device3.
- Passo 3: Configure o IRMP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router irmp 100Device1(config-irmp)#network 1.0.0.0 0.0.0.255Device1(config-irmp)#exit
# Configurar dispositivo2.
Device2(config)#router irmp 100Device2(config-irmp)#network 1.0.0.0 0.0.0.255Device2(config-irmp)#exit
# Veja as informações do vizinho IRMP do Device1.
Device1#show ip irmp neighborIP-IRMP neighbors for process 100 Total neighbor 1Address Interface Hold(s) Uptime SeqNum Srtt(ms) Rto(s)1.0.0.2 gigabitethernet0 12 00:01:03 1 0 2
O vizinho IRMP é estabelecido com sucesso entre Device1 e Device2.
- Passo 4: Configure o IRMP para redistribuir o roteamento OSPF e para coordenar com a política de roteamento.
# Configure a política de roteamento para corresponder ao ACL permitindo apenas o roteamento 200.0.0.0/24 no Device2 e para coordenar com a política de roteamento quando o IRMP redistribui o roteamento OSPF.
Device2(config)#ip access-list standard 1Device2(config-std-nacl)#permit 200.0.0.0 0.0.0.255Device2(config-std-nacl)#exitDevice2(config)#route-map ospf_to_irmpDevice2(config-route-map)#match ip address 1Device2(config-route-map)#exitDevice2(config)#router irmp 100Device2(config-irmp)#redistribute ospf 100 route-map ospf_to_irmpDevice2(config-irmp)#exit
Ao configurar a política de roteamento, tanto a lista de prefixos quanto a ACL podem estabelecer a regra de correspondência. A diferença está em que a lista de prefixos pode corresponder com precisão à máscara de rota, mas a ACL não pode corresponder à máscara de rota.
- Passo 5: Confira o resultado.
# Visualize a tabela de topologia IRMP do Device2.
Device2#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P 200.0.0.0/24, 1 successors, FD is 2816via RedisOSPF 100 (2816/0)
Pode ser visto que Device2 distribui com sucesso o roteamento OSPF para o IRMP.
# Visualize a tabela de topologia e a tabela de roteamento do Device1.
Device1#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >200.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 07:47:01, gigabitethernet0C 127.0.0.0/8 is directly connected, 07:55:23, lo0Ex 200.0.0.0/24 [170/3072] via 1.0.0.2, 00:00:06, gigabitethernet0
Pode ser visto que Device1 aprende o roteamento 200.0.0.0/24 .
Na aplicação real, se houver dois ou mais roteadores de borda no sistema autônomo, é aconselhável não redistribuir rotas entre diferentes protocolos de roteamento. Se necessário, configure as políticas de controle de roteamento como filtragem e resumo no roteador de borda no sistema autônomo para evitar a geração de loop de roteamento.
Configurar deslocamento de métrica de IRMP
Requisitos de rede
- O protocolo IRMP opera entre Device1, Device2 , Device3 e Device4 para interconexão.
- Device1 aprende o roteamento 200.0.0.0/24 de Device2 e Device3 ao mesmo tempo.
- Configure o deslocamento métrico de roteamento na direção de recebimento em Device1 para permitir que Device1 escolha preferencialmente o roteamento anunciado por Device2.
Topologia de rede
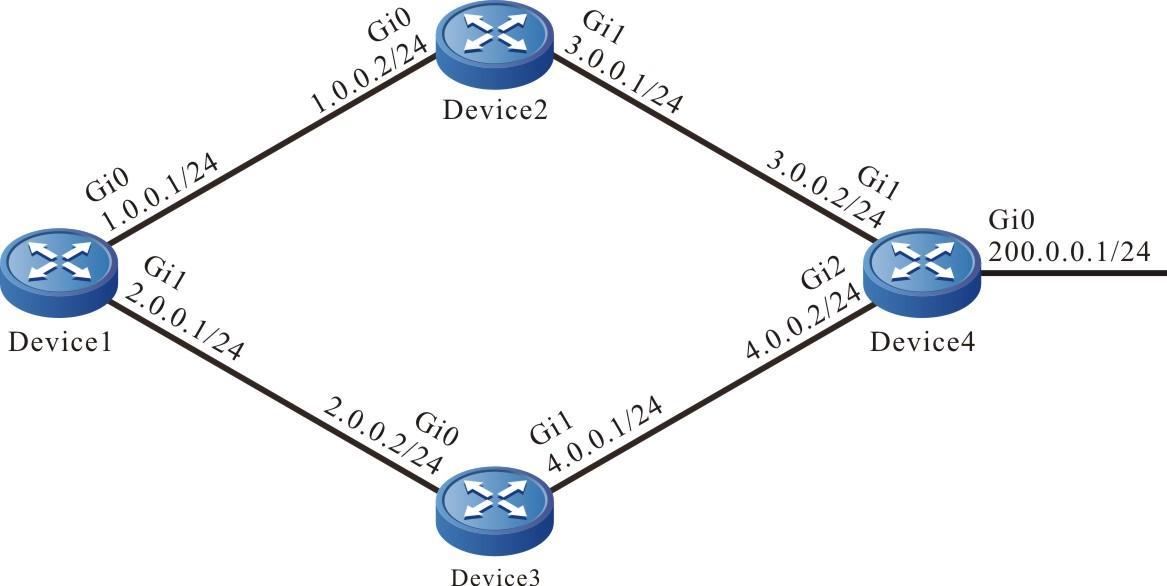
Figura 11 – 3 Rede do deslocamento métrico IRMP
Etapas de configuração
- Passo 1: Configure o endereço IP das interfaces. (Omitido)
- Passo 2: Configure o IRMP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router irmp 100Device1(config-irmp)#network 1.0.0.0 0.0.0.255Device1(config-irmp)#network 2.0.0.0 0.0.0.255Device1(config-irmp)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router irmp 100Device2(config-irmp)#network 1.0.0.0 0.0.0.255Device2(config-irmp)#network 3.0.0.0 0.0.0.255Device2(config-irmp)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router irmp 100Device3(config-irmp)#network 2.0.0.0 0.0.0.255Device3(config-irmp)#network 4.0.0.0 0.0.0.255Device3(config-irmp)#exit
# Configurar dispositivo4.
Device4#configure terminalDevice4(config)#router irmp 100Device4(config-irmp)#network 3.0.0.0 0.0.0.255Device4(config-irmp)#network 4.0.0.0 0.0.0.255Device4(config-irmp)#network 200.0.0.0 0.0.0.255Device4(config-irmp)#exit
# Visualize a informação do vizinho IRMP do Device1.
Device1#show ip irmp neighborIP-IRMP neighbors for process 100 Total neighbor 2Address Interface Hold(s) Uptime SeqNum Srtt(ms) Rto(s)1.0.0.2 gigabitethernet0 11 00:10:37 10 0 22.0.0.2 gigabitethernet1 12 00:10:15 9 0 2
# Visualize as informações do vizinho IRMP do Device4.
Device4#show ip irmp neighborIP-IRMP neighbors for process 100 Total neighbor 2Address Interface Hold(s) Uptime SeqNum Srtt(ms) Rto(s)3.0.0.1 gigabitethernet1 14 00:11:37 13 0 24.0.0.1 gigabitethernet2 12 00:10:45 12 0 2
Device1 estabelece com sucesso o vizinho IRMP com Device2 e Device3, respectivamente. Device4 estabelece com sucesso o vizinho IRMP com Device2 e Device3, respectivamente.
# Visualize a tabela de topologia e a tabela de roteamento do Device1.
Device1#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >2.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet1P >3.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0P >4.0.0.0/24, 1 successors, FD is 3072*via 2.0.0.2 (3072/512), gigabitethernet1P >200.0.0.0/24, 2 successors, FD is 3328*via 2.0.0.2 (3328/3072), gigabitethernet1 *via 1.0.0.2 (3328/3072), gigabitethernet0Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 13:16:35, gigabitethernet0C 2.0.0.0/24 is directly connected, 13:19:24, gigabitethernet1E 3.0.0.0/24 [90/3072] via 1.0.0.2, 00:03:22, gigabitethernet0E 4.0.0.0/24 [90/3072] via 2.0.0.2, 00:22:01, gigabitethernet1C 127.0.0.0/8 is directly connected, 22:27:25, lo0E 200.0.0.0/24 [90/3328] via 2.0.0.2, 00:21:22, gigabitethernet1[90/3328] via 1.0.0.2, 00:03:22, gigabitethernet0
Há dois roteamentos de balanceamento de carga para o segmento de rede 200.0.0.0/24 na tabela de roteamento Device1. Os caminhos de encaminhamento para o segmento de rede são Device1→Device2→Device4 e Device1→Device3→Device4.
- Passo 3: Configure o deslocamento métrico do IRMP.
# Configure a lista de deslocamentos em Device1. Adicione o valor de métrica 100 à interface conectada ao Device3 pelo roteamento especificado para permitir que o valor total da métrica que passa pelo Device3 seja maior do que aquele que passa pelo Device2 .
Device1(config)#ip access-list standard 1Device1(config-std-nacl)#permit 200.0.0.0 0.0.0.255Device1(config-std-nacl)#exitDevice1(config)#router irmp 100Device1(config-irmp)#offset-list 1 in 100 gigabitethernet1Device1(config-irmp)#exit
- Passo 4: Confira o resultado.
# Visualize a tabela de topologia e a tabela de roteamento do Device1.
Device1#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >2.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet1P >3.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0P >4.0.0.0/24, 1 successors, FD is 3072*via 2.0.0.2 (3072/512), gigabitethernet1P >200.0.0.0/24, 2 successors, FD is 3328*via 1.0.0.2 (3328/3072), gigabitethernet0 via 2.0.0.2 (3428/3172), gigabitethernet1Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 13:33:22, gigabitethernet0C 2.0.0.0/24 is directly connected, 13:36:11, gigabitethernet1E 3.0.0.0/24 [90/3072] via 1.0.0.2, 00:06:56, gigabitethernet0E 4.0.0.0/24 [90/3072] via 2.0.0.2, 00:05:43, gigabitethernet1C 127.0.0.0/8 is directly connected, 22:44:12, lo0E 200.0.0.0/24 [90/3328] via 1.0.0.2, 00:06:56, gigabitethernet0
Depois que o deslocamento métrico é configurado, Device1 escolhe o roteamento 200.0.0.0/24 anunciado pelo Device2.
A configuração da lista de deslocamento IRMP pode fazer com que o vizinho seja restabelecido.
Configurar filtragem de rota IRMP
Requisitos de rede
- O IRMP operou entre Device1 e Device2 para interação de roteamento.
- Device1 aprende dois roteamentos 2.0.0.0/24 e 3.0.0.0/24 anunciados por Device2 e Device1 só reserva as informações de roteamento de 2.0.0.0/24.
Topologia de rede
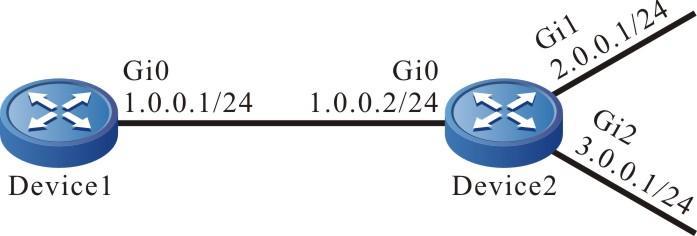
Figura 11 – 4 Rede de filtragem de rota IRMP
Etapas de configuração
- Passo 1: Configure o endereço IP das interfaces. (Omitido)
- Passo 2: Configure o IRMP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router irmp 100Device1(config-irmp)#network 1.0.0.0 0.0.0.255Device1(config-irmp)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router irmp 100Device2(config-irmp)#network 1.0.0.0 0.0.0.255Device2(config-irmp)#network 2.0.0.0 0.0.0.255Device2(config-irmp)#network 3.0.0.0 0.0.0.255Device2(config-irmp)#exit
# Visualize a informação do vizinho IRMP do Device1.
Device1#show ip irmp neighborIP-IRMP neighbors for process 100 Total neighbor 1Address Interface Hold(s) Uptime SeqNum Srtt(ms) Rto(s)1.0.0.2 gigabitethernet0 11 00:05:00 3 0 2
Pode ser visto que o vizinho IRMP é estabelecido com sucesso entre Device1 e Device2.
# Visualize a tabela de roteamento do Device1.
Device1#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >2.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0P >3.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:11:29, gigabitethernet0E 2.0.0.0/24 [90/3072] via 1.0.0.2, 00:07:43, gigabitethernet0E 3.0.0.0/24 [90/3072] via 1.0.0.2, 00:07:40, gigabitethernet0C 127.0.0.0/8 is directly connected, 00:19:50, lo0
Device1 aprende o roteamento 2.0.0.0/24 e 3.0.0.0/24.
- Passo 3: Configure a filtragem de rotas.
#Configure a regra ACL para permitir somente o roteamento 2.0.0.0/24 no Device1 e configure a lista de filtragem de entrada para coordenar com a ACL no IRMP.
Device1(config)#ip access-list standard 1Device1(config-std-nacl)#permit 2.0.0.0 0.0.0.255Device1(config-std-nacl)#exitDevice1(config)#router irmp 100Device1(config-irmp)#distribute-list 1 inDevice1(config-irmp)#exit
Ao configurar a filtragem de rotas, a lista de prefixos e a ACL podem estabelecer a regra de correspondência. A diferença está em que a lista de prefixos pode corresponder com precisão à máscara de rota, mas a ACL não pode corresponder à máscara de rota.
- Passo 4: Confira o resultado.
# Visualize a tabela de topologia e a tabela de roteamento do Device1.
Device1#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >2.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 00:22:33, gigabitethernet0E 2.0.0.0/24 [90/3072] via 1.0.0.2, 00:04:18, gigabitethernet0C 127.0.0.0/8 is directly connected, 00:30:55, lo0
Device1 só aprende o roteamento 2.0.0.0/24, mas o roteamento 3.0.0.0/24 é filtrado com sucesso.
Configurando o lista de distribuição comando pode fazer com que o vizinho IRMP seja restabelecido.
Configurar resumo da rota IRMP
Requisitos de rede
- O protocolo IRMP opera entre Device1, Device2 , Device3 e Device4 para interação de roteamento,
- Device1 aprende dois roteamentos 100.1.0.0/24 e 100.2.0.0/24 do Device. Para reduzir a escala da tabela de roteamento de Device1, é necessário que Device2 libere apenas o resumo de rota 100.0.0.0/14 para Device1.
Topologia de rede
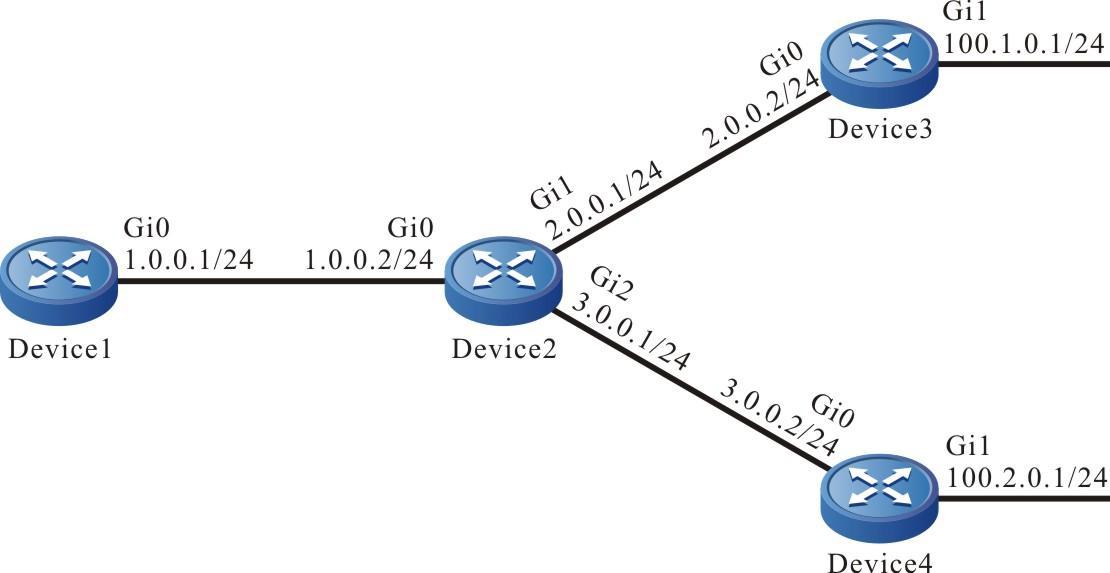
Figura 11 – 5 Rede do resumo da rota IRMP
Etapas de configuração
- Passo 1: Configure o endereço IP das interfaces. (Omitido)
- Passo 2: Configure o IRMP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router irmp 100Device1(config-irmp)#network 1.0.0.0 0.0.0.255Device1(config-irmp)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router irmp 100Device2(config-irmp)#network 1.0.0.0 0.0.0.255Device2(config-irmp)#network 2.0.0.0 0.0.0.255Device2(config-irmp)#network 3.0.0.0 0.0.0.255Device2(config-irmp)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router irmp 100Device3(config-irmp)#network 2.0.0.0 0.0.0.255Device3(config-irmp)#network 100.1.0.0 0.0.0.255Device3(config-irmp)#exit
# Configurar dispositivo4.
Device4#configure terminalDevice4(config)#router irmp 100Device4(config-irmp)#network 3.0.0.0 0.0.0.255Device4(config-irmp)#network 100.2.0.0 0.0.0.255Device4(config-irmp)#exit
# Visualize a informação do vizinho IRMP do Device2.
Device2#show ip irmp neighborIP-IRMP neighbors for process 100 Total neighbor 3Address Interface Hold(s) Uptime SeqNum Srtt(ms) Rto(s)1.0.0.1 gigabitethernet0 11 00:05:04 4 0 22.0.0.2 gigabitethernet0 14 00:04:42 3 16 23.0.0.2 gigabitethernet0 11 00:04:00 2 0 2
Device2 estabelece com sucesso o vizinho IRMP com Device1, Device3 e Device4, respectivamente.
#Visualize a tabela de topologia e a tabela de roteamento do Device2 .
Device2#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >2.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet1P >3.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet2P >100.1.0.0/24, 1 successors, FD is 3072*via 2.0.0.2 (3072/2816), gigabitethernet1P >100.2.0.0/24, 1 successors, FD is 3072*via 3.0.0.2 (3072/2816), gigabitethernet2Device2#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 08:12:36, gigabitethernet0C 2.0.0.0/24 is directly connected, 00:36:51, gigabitethernet1C 3.0.0.0/24 is directly connected, 00:12:06, gigabitethernet2E 100.1.0.0/24 [90/3072] via 2.0.0.2, 00:10:03, gigabitethernet1E 100.2.0.0/24 [90/3072] via 3.0.0.2, 00:00:08, gigabitethernet2C 127.0.0.0/8 is directly connected, 57:38:13, lo0
# Visualize a tabela de topologia e a tabela de roteamento do Device1.
Device1#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >2.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0P >3.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0P >100.1.0.0/24, 1 successors, FD is 3328*via 1.0.0.2 (3328/3072), gigabitethernet0P >100.2.0.0/24, 1 successors, FD is 3328*via 1.0.0.2 (3328/3072), gigabitethernet0Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 08:09:15, gigabitethernet0E 2.0.0.0/24 [90/3072] via 1.0.0.2, 00:13:19, gigabitethernet0E 3.0.0.0/24 [90/3072] via 1.0.0.2, 00:13:17, gigabitethernet0E 100.1.0.0/24 [90/3328] via 1.0.0.2, 00:12:53, gigabitethernet0E 100.2.0.0/24 [90/3328] via 1.0.0.2, 00:02:57, gigabitethernet0C 127.0.0.0/8 is directly connected, 08:17:36, lo0
Tanto o Device1 quanto o Device2 aprendem o roteamento 100.1.0.0/24 e 100.2.0.0/24.
- Passo 3: Configure o resumo da rota IRMP .
#Configure Device2 e configure o resumo da rota IRMP 100.0.0.0/14 na interface conectada ao Device1 .
Device2(config)#interface gigabitethernet0Device2(config-if-gigabitethernet0)#ip summary-address irmp 100 100.0.0.0 255.252.0.0Device2(config-if-gigabitethernet0)#exit
- Passo 4: Confira o resultado.
# Visualize a tabela de topologia IRMP do Device2.
Device2#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >2.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet1P >3.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet2P 100.0.0.0/14, 1 successors, FD is 3072via AddrSumm (3072/0)P >100.1.0.0/24, 1 successors, FD is 3072*via 2.0.0.2 (3072/2816), gigabitethernet1P >100.2.0.0/24, 1 successors, FD is 3072*via 3.0.0.2 (3072/2816), gigabitethernet2
Um resumo de rota 100.0.0.0/14 é gerado no Device2.
# Visualize a tabela de topologia e a tabela de roteamento do Device1.
Device1#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >2.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0P >3.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0P >100.0.0.0/14, 1 successors, FD is 3328*via 1.0.0.2 (3328/3072), gigabitethernet0Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 08:18:49, gigabitethernet0E 2.0.0.0/24 [90/3072] via 1.0.0.2, 00:04:54, gigabitethernet0E 3.0.0.0/24 [90/3072] via 1.0.0.2, 00:04:54, gigabitethernet0E 100.0.0.0/14 [90/3328] via 1.0.0.2, 00:04:54, gigabitethernet0C 127.0.0.0/8 is directly connected, 08:27:10, lo0
Pode ser visto que apenas o resumo da rota100.0.0.0/14 em vez da rota detalhada correspondente100.1.0.0/24 e 100.2.0.0/24 existe no Dispositivo1.
Configurar o resumo da rota IRMP no modo de interface pode fazer com que o vizinho seja restabelecido.
Configurar balanceamento de carga IRMP
Requisitos de rede
- O protocolo IRMP opera entre Device1, Device2 , Device3 e Device4 para interação de roteamento,
- Device1 aprende o roteamento 200.0.0.0/24 de Device2 e Device3 ao mesmo tempo. Modifique a largura de banda da interface gigabitethernet1 em Device1 para permitir que Device1 escolha preferencialmente o roteamento 200.0.0.0/24 aprendido de Device2.
- Device1 é necessário para transferir dados para o segmento de rede 200.0.0.0/24 simultaneamente nas linhas Device1→Device2→Device4 e Device1→Device3→Device4 .
Topologia de rede
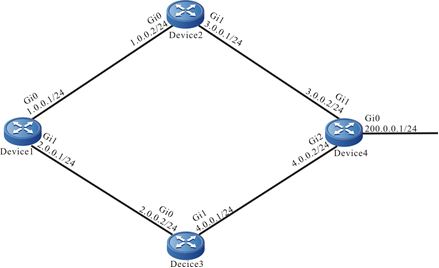
Figura 11 – 6 Rede do balanceamento de carga de custo desigual do IRMP
Etapas de configuração
- Passo 1: Configure o endereço IP das interfaces. (Omitido)
- Passo 2: Configure o IRMP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router irmp 100Device1(config-irmp)#network 1.0.0.0 0.0.0.255Device1(config-irmp)#network 2.0.0.0 0.0.0.255Device1(config-irmp)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router irmp 100Device2(config-irmp)#network 1.0.0.0 0.0.0.255Device2(config-irmp)#network 3.0.0.0 0.0.0.255Device2(config-irmp)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router irmp 100Device3(config-irmp)#network 2.0.0.0 0.0.0.255Device3(config-irmp)#network 4.0.0.0 0.0.0.255Device3(config-irmp)#exit
# Configurar dispositivo4.
Device4#configure terminalDevice4(config)#router irmp 100Device4(config-irmp)#network 3.0.0.0 0.0.0.255Device4(config-irmp)#network 4.0.0.0 0.0.0.255Device4(config-irmp)#network 200.0.0.0 0.0.0.255Device4(config-irmp)#exit
# Visualize a informação do vizinho IRMP do Device1.
Device1#show ip irmp neighborIP-IRMP neighbors for process 100 Total neighbor 2Address Interface Hold(s) Uptime SeqNum Srtt(ms) Rto(s)1.0.0.2 gigabitethernet0 11 00:10:37 10 0 22.0.0.2 gigabitethernet1 12 00:10:15 9 0 2
# Visualize as informações do vizinho IRMP do Device4.
Device4#show ip irmp neighborIP-IRMP neighbors for process 100 Total neighbor 2Address Interface Hold(s) Uptime SeqNum Srtt(ms) Rto(s)3.0.0.1 gigabitethernet1 14 00:11:37 13 0 24.0.0.1 gigabitethernet2 12 00:10:45 12 0 2
Device1 estabelece com sucesso o vizinho IRMP com Device2 e Device3, respectivamente. Device4 estabelece com sucesso o vizinho IRMP com Device2 e Device3, respectivamente.
# Visualize a tabela de topologia e a tabela de roteamento do Device1.
Device1#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >2.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet1P >3.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0P >4.0.0.0/24, 1 successors, FD is 3072*via 2.0.0.2 (3072/512), gigabitethernet1P >200.0.0.0/24, 2 successors, FD is 3328*via 2.0.0.2 (3328/3072), gigabitethernet1 *via 1.0.0.2 (3328/3072), gigabitethernet0Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 13:16:35, gigabitethernet0C 2.0.0.0/24 is directly connected, 13:19:24, gigabitethernet1E 3.0.0.0/24 [90/3072] via 1.0.0.2, 00:03:22, gigabitethernet0E 4.0.0.0/24 [90/3072] via 2.0.0.2, 00:22:01, gigabitethernet1C 127.0.0.0/8 is directly connected, 22:27:25, lo0E 200.0.0.0/24 [90/3328] via 2.0.0.2, 00:21:22, gigabitethernet1[90/3328] via 1.0.0.2, 00:03:22, gigabitethernet0
Há dois roteamentos de balanceamento de carga para o segmento de rede 200.0.0.0/24 na tabela de roteamento Device1. Os caminhos de encaminhamento para o segmento de rede são Device1→Device2→Device4 e Device1→Device3→Device4.
- Passo 3: Altere a largura de banda da interface.
#Mude a largura de banda da interface conectada ao Device1 e Device3 para 100.000 kbps.
Device1(config)#interface gigabitethernet1Device1(config-if-gigabitethernet1)#bandwidth 100000Device1(config-if-gigabitethernet1)#exit
# Visualize a tabela de topologia e a tabela de roteamento do Device1.
Device1#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >2.0.0.0/24, 1 successors, FD is 25856*via Connected (25856/0), gigabitethernet1P >3.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0P >4.0.0.0/24, 1 successors, FD is 26112*via 2.0.0.2 (26112/2816), gigabitethernet1P >200.0.0.0/24, 2 successors, FD is 3328*via 1.0.0.2 (3328/3072), gigabitethernet0 via 2.0.0.2 (26368/3072), gigabitethernet1Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 28:44:11, gigabitethernet0C 2.0.0.0/24 is directly connected, 00:14:05, gigabitethernet1E 3.0.0.0/24 [90/3072] via 1.0.0.2, 00:10:11, gigabitethernet0E 4.0.0.0/24 [90/28416] via 2.0.0.2, 00:07:57, gigabitethernet1C 127.0.0.0/8 is directly connected, 220:26:51, lo0E 200.0.0.0/24 [90/3328] via 1.0.0.2, 00:10:11, gigabitethernet0
Depois que o deslocamento métrico é configurado, Device1 escolhe preferencialmente o roteamento 200.0.0.0/24 anunciado pelo Device2.
- Passo 4: Configure o balanceamento de carga de custo desigual do IRMP.
#Configure Device1 e configure o fator de conversão do balanceamento de carga como 100.
Device1(config)#router irmp 100Device1(config-irmp)#variance 100Device1(config-irmp)#exit
Para obter detalhes sobre o fator de conversão do balanceamento de carga, consulte o capítulo de balanceamento de carga na configuração da função IRMP.
- Passo 5: Confira o resultado.
# Visualize a tabela de topologia e a tabela de roteamento do Device1.
Device1#show ip irmp topologyIP-IRMP Topology Table for process 100Codes: P - Passive, A - Active, H - Holddown, D - Hidden> - FIB route, * - FIB successorP >1.0.0.0/24, 1 successors, FD is 2816*via Connected (2816/0), gigabitethernet0P >2.0.0.0/24, 1 successors, FD is 28160*via Connected (28160/0), gigabitethernet1P >3.0.0.0/24, 1 successors, FD is 3072*via 1.0.0.2 (3072/2816), gigabitethernet0P >4.0.0.0/24, 1 successors, FD is 28416*via 2.0.0.2 (28416/2816), gigabitethernet1P >200.0.0.0/24, 2 successors, FD is 3328*via 1.0.0.2 (3328/3072), gigabitethernet0 *via 2.0.0.2 (26368/3072), gigabitethernet1Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 1.0.0.0/24 is directly connected, 28:47:15, gigabitethernet0C 2.0.0.0/24 is directly connected, 00:17:08, gigabitethernet1E 3.0.0.0/24 [90/3072] via 1.0.0.2, 00:13:15, gigabitethernet0E 4.0.0.0/24 [90/28416] via 2.0.0.2, 00:11:00, gigabitethernet1C 127.0.0.0/8 is directly connected, 220:29:54, lo0E 200.0.0.0/24 [90/3328] via 1.0.0.2, 00:13:15, gigabitethernet0 [90/26368] via 2.0.0.2, 00:00:12, gigabitethernet1
O roteamento 200.0.0.0/24 no Device1 forma o balanceamento de carga de custo desigual. Os dados serão transmitidos para balanceamento de carga nesses dois caminhos com base na razão inversa do valor da métrica.
BGP (Aplicável somente ao modelo S3054G-B)
Visão geral
O Border Gateway Protocol (BGP) é um protocolo de roteamento que troca informações de acessibilidade de camada de rede (NLRI) entre sistemas autônomos (ASs). Internal Gateway Protocols (IGPs), como Routing Information Protocol (RIP), Open Shortest Path First (OSPF) e Intermediate System-to-Intermediate System (IS-IS), concentram-se principalmente em encontrar caminhos precisos, tomando nós de rede (como roteadores, switches de camada 3, hosts multi-NIC) como unidades de roteamento. Diferente dos IGPs, os External Gateway Protocols (EGPs) concentram-se principalmente no controle da direção do roteamento, tomando as redes AS como unidades de roteamento.
BGP é usado para interconexão entre redes AS. Ele suporta a troca de informações de roteamento entre ASs. Geralmente é usado para agregação de rede em grande escala e núcleo de rede. Sua camada de aplicação determina que o BGI tenha as seguintes características quando comparado ao IGP:
- O BGP usa o protocolo TCP para transmitir pacotes através da porta de serviço 179. O TCP garante a confiabilidade da transmissão, portanto, o BGP não precisa fornecer uma política de controle de transmissão independente para transmissão confiável de informações.
- O BGP atualiza as rotas no modo incremental, ou seja, informa seus vizinhos sobre as alterações de rota somente quando as propriedades da rota são alteradas ou uma rota é adicionada ou excluída. Esse modo diminui bastante a largura de banda da rede ocupada pelo BGP nas rotas de transmissão.
- BGP é um protocolo de vetor de distância baseado em AS. Ele carrega propriedades de caminho AS em pacotes de roteamento para resolver o problema de loop de roteamento.
- As rotas BGP têm propriedades abundantes. Você pode modificar as propriedades aplicando uma política de roteamento. Desta forma, você pode controlar a filtragem de rotas e seleção livremente.
- O BGP tem dois tipos de vizinhos, o Interior Border Gateway Protocol (IBGP) e o External Border Gateway Protocol (EBGP). Entre diferentes tipos de vizinhos, diferentes anúncios de rota e políticas de roteamento são usados.
Configuração da função BGP
Tabela 12 -1Lista de funções BGP
| Tarefas de configuração | |
| Configure um vizinho BGP. |
Configure um vizinho IBGP.
Configure um vizinho EBGP. Configure um vizinho passivo BGP. Configure um vizinho MP-BGP. Configure a autenticação MD5 para vizinhos BGP. |
| Configure a geração de rotas BGP. |
Configure o BGP para anunciar rotas locais.
Configurando o BGP para redistribuir rotas. Configure o BGP para anunciar a rota padrão. |
| Configure o controle de rota BGP. |
Configure o BGP para anunciar rotas agregadas.
Configure a distância administrativa das rotas BGP. Configure as políticas de roteamento na direção de saída de um vizinho BGP. Configure uma política de roteamento na direção de entrada de um vizinho BGP. Configure o número máximo de rotas que um vizinho BGP recebe. Configure o número máximo de rotas de balanceamento de carga BGP. |
| Configure as propriedades da rota BGP. |
Configure o peso da rota BGP.
Configure a propriedade MED de uma rota BGP. Configure a propriedade Local-Preference de uma rota BGP. Configure a propriedade AS_PATH de uma rota BGP. Configure a propriedade NEXT-HOP de uma rota BGP. Configure a propriedade de comunidade de uma rota BGP. |
| Configure a otimização de rede BGP. |
Configure o tempo de atividade dos vizinhos BGP.
Configure o tempo de detecção de rota BGP. Configure a desconexão rápida de vizinhos EBGP. Configure a função de supressão de rota BGP. Configure o recurso de atualização do vizinho BGP. Configure o recurso de reinicialização suave do vizinho BGP. Configure a capacidade ORF dos vizinhos BGP. |
| Configure uma rede BGP de grande escala. |
Configure um grupo de pares BGP.
Configure um refletor de rota BGP. Configure uma confederação BGP. |
| Configurar BGP GR. | Configure um Auxiliar BGP GR. |
| Configure o BGP para coordenar com o BFD. | Configure o EBGP para coordenar com o BFD. Configure o IBGP para coordenar com o BFD. |
Configurar vizinho BGP
Condição de configuração
Antes de configurar um vizinho BGP, certifique-se de que:
- O protocolo da camada de link foi configurado para garantir a comunicação normal na camada de link.
- Os endereços da camada de rede das interfaces foram configurados para que os nós de rede adjacentes sejam alcançáveis na camada de rede.
Configurar um vizinho IBGP
1. Execute a configuração básica.
Ao configurar um vizinho IBGP, você precisa definir o AS do vizinho para ser o mesmo que o AS do dispositivo local. Você pode configurar um ID de roteador para um dispositivo. O Router ID é usado para identificar exclusivamente um dispositivo BGP na configuração de uma sessão BGP. Se nenhuma ID de roteador estiver configurada para um dispositivo, o dispositivo selecionará uma ID de roteador nos endereços de interface. As regras para a seleção são as seguintes:
- Selecione o maior endereço IP dos endereços IP da interface de loopback como o ID do roteador.
- Se nenhuma interface de loopback estiver configurada com um endereço IP, selecione o maior endereço IP dos endereços IP de outras interfaces como a ID do roteador.
- Somente quando uma interface está no status UP, o endereço IP da interface pode ser eleito como o Router ID.
Tabela 12 -2Configurar um vizinho IBGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite o protocolo BGP e entre no modo de configuração BGP. | router bgp autonomous-system | Obrigatório. Por padrão, o BGP está desabilitado. |
| Configure um ID de roteador para o dispositivo BGP. | bgp router-id router-id | Opcional. Por padrão, o dispositivo seleciona um Router ID dos endereços de interface. A interface de loopback e o endereço IP grande têm as prioridades. |
| Configure um vizinho IBGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho IBGP é criado. |
| Ative a capacidade de um vizinho IBGP na transmissão e recepção de rotas unicast IPv4. | neighbor { neighbor-address | peer-group-name } activate | Opcional. Por padrão, a capacidade do vizinho IBGP em transmitir e receber rotas unicast IPv4 é ativada automaticamente. |
| Configure uma descrição para um vizinho IBGP. | neighbor { neighbor-address | peer-group-name } description description-string | Opcional. Por padrão, nenhuma descrição é configurada para um vizinho IBGP. |
2. Configure o endereço de origem de uma sessão TCP.
O BGP usa o protocolo TCP para transmitir pacotes através da porta de serviço 179. O TCP apresenta transmissão confiável, garantindo que os pacotes do protocolo BGP possam ser transmitidos adequadamente para seus vizinhos.
Tabela 12 -3Configurar o endereço de origem de uma sessão TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite o protocolo BGP e entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um vizinho IBGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho IBGP é criado. |
| Configure o endereço de origem de uma sessão TCP de um vizinho IBGP. | neighbor { neighbor-address | peer-group-name } update-source { interface-name | ip-address } |
Obrigatório.
Por padrão, a sessão TCP seleciona automaticamente o endereço de uma interface de saída de roteamento como o endereço de origem. |
Se houver rotas de balanceamento de carga, os endereços de origem devem ser configurados para sessões TCP de vizinhos BGP. Se os endereços de origem da sessão TCP não estiverem configurados, se os vizinhos tiverem diferentes rotas ideais, eles poderão usar diferentes interfaces de saída como seus endereços de origem. Dessa forma, as sessões BGP podem falhar ao configurar dentro de um período de tempo.
Configurar um vizinho EBGP
1. Execute a configuração básica.
Ao configurar um vizinho EBGP, você precisa definir o AS do vizinho para ser diferente do AS do dispositivo local.
Tabela 12 -4Configurar um vizinho EBGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite o protocolo BGP e entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um vizinho EBGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho EBGP é criado. |
2. Configure um vizinho EBGP de conexão não direta
Os vizinhos EBGP estão localizados em redes de operação diferentes e geralmente são conectados por um link físico de conexão direta. Portanto, o valor TTL padrão para os pacotes IP entre vizinhos EBGP é 1. Em redes de operação de conexão não direta, você pode usar um comando para definir o valor TTL dos pacotes IP para configurar uma conexão BGP.
Tabela 12 -5Configurar um vizinho EBGP de conexão não direta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um vizinho EBGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho EBGP é criado. |
| Configure o endereço de origem de uma sessão TCP de um vizinho EBGP. | neighbor { neighbor-address | peer-group-name } update-source { interface-name | ip-address } | Opcional. Por padrão, a sessão TCP seleciona automaticamente o endereço de uma interface de saída de roteamento como o endereço de origem. |
| Permitir que vizinhos EBGP de conexão não direta estabeleçam uma conexão. | neighbor { neighbor-address | peer-group-name } ebgp-multihop [ ttl-value ] |
Obrigatório.
Por padrão, os dispositivos de conexão não direta não têm permissão para formar vizinhos EBGP. |
Configurar um vizinho passivo BGP
Em alguns ambientes de aplicativos especiais, a função de vizinho passivo BGP é necessária. Depois que a função de vizinho passivo é habilitada, o BGP não inicia a solicitação de conexão TCP para configurar uma relação de vizinho BGP; em vez disso, ele aguarda a solicitação de conexão do vizinho antes de estabelecer uma relação de vizinho. Por padrão, os vizinhos iniciam solicitações de conexão entre si. Se as conexões entrarem em conflito, eles selecionam uma conexão TCP ideal para formar uma sessão BGP. Antes de configurar um vizinho passivo BGP, você precisa configurar um vizinho BGP.
Tabela 12 -6Configurar um vizinho passivo BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um vizinho BGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho BGP é criado. |
| Configure um vizinho passivo BGP. | neighbor { neighbor-address | peer-group-name } passive | Obrigatório. Por padrão, nenhum vizinho passivo é ativado. |
Configurar um vizinho MP-BGP
Por padrão, os vizinhos BGP são ativados na família de endereços unicast IPv4 e têm a capacidade de transmitir e receber rotas unicast IPv4. Os vizinhos precisam ser habilitados usando um comando em outras famílias de endereços, como família de endereços multicast, família de endereços VRF e família unicast LS, para que tenham a capacidade de transmitir e receber as rotas necessárias. Antes de configurar um vizinho MP-BGP, você precisa configurar um vizinho BGP.
Tabela 12 -7Configurar um vizinho MP-BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um vizinho BGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho BGP é criado. |
| Entre no modo de configuração IPv4 do BGP. | address-family ipv4 multicast |
Obrigatório.
Por padrão, após entrar no modo de configuração BGP, o usuário está no modo de família de endereços unicast. |
| Ative os vizinhos na família de endereços multicast IPv4 do BGP. | neighbor { neighbor-address | peer-group-name } activate |
Obrigatório.
Por padrão, os vizinhos globais são desativados no modo de família de endereços multicast. |
| Saia do modo de configuração IPv4 do BGP. | exit-address-family | - |
| Entre no modo de configuração BGP IPv4 VRF. | address-family ipv4 vrf vrf-name | - |
| Configure vizinhos no modo de família de endereços BGP IPv4 VRF. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho BGP é criado. |
| Ative os vizinhos no modo de família de endereços IPv4 VRF. | neighbor { neighbor-address | peer-group-name } activate | Opcional. Por padrão, os vizinhos são ativados no modo de configuração BGP IPv4 VRF. |
| Saia do modo de configuração BGP IPv4 VRF. | exit-address-family | - |
| Entre no modo de configuração BGP LS. | address-family link-state unicast | - |
| Ative os vizinhos no modo de família de endereços unicast BGP LS. | neighbor { neighbor-address | peer-group-name } activate |
Obrigatório.
Por padrão, os vizinhos globais são desativados no modo de família de endereços VPN. |
| Saia do modo de configuração BGP LS. | exit-address-family | - |
Os vizinhos configurados no modo de configuração BGP IPv4 e no modo de configuração unicast BGP IPv4 são vizinhos globais, e os vizinhos configurados no modo de configuração BGP IPv4 VRF pertencem somente à família de endereços VRF.
Configurar autenticação MD5 para vizinhos BGP
O BGP suporta a configuração da autenticação MD5 para proteger a troca de informações entre vizinhos. A autenticação MD5 é implementada pelo protocolo TCP. Dois vizinhos devem ser configurados com a mesma senha de autenticação MD5 antes que uma conexão TCP possa ser configurada; caso contrário, se o protocolo TCP falhar na autenticação MD5, a conexão TCP não poderá ser configurada. Antes de configurar a autenticação MD5 para vizinhos BGP, você precisa configurar os vizinhos BGP.
Tabela 12 -8Configurar autenticação MD5 para vizinhos BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um vizinho BGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho BGP é criado. |
| Configure a autenticação MD5 para vizinhos BGP. | neighbor { neighbor-address | peer-group-name } password [ 0 | 7 ] password-string | Obrigatório. Por padrão, nenhuma autenticação MD5 é iniciada para vizinhos BGP. |
Configurar geração de rota BGP
Condição de configuração
Antes de configurar a geração de rotas BGP, certifique-se de que:
- O BGP está ativado.
- Os vizinhos BGP são configurados e uma sessão é configurada com sucesso.
Configurar o BGP para anunciar rotas locais
O BGP pode usar o comando network para introduzir as rotas da tabela de roteamento IP na tabela de roteamento BGP. Somente quando houver rotas que correspondam completamente à rede prefixo e máscara podem as rotas ser introduzidas na tabela de roteamento BGP e anunciadas.
Ao anunciar uma rota local, você pode aplicar um mapa de rota para a rota e também pode especificar a rota como a rota de backdoor. A rota backdoor usa rotas EBGP como rotas BGP locais e usa a distância administrativa das rotas locais. Isso permite que as rotas IGP tenham prioridades mais altas do que as rotas EBGP. Ao mesmo tempo, as rotas backdoor não serão anunciadas aos vizinhos EBGP.
Tabela 12 -9Configure o BGP para anunciar rotas locais
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para anunciar rotas locais. | network ip-address mask [ route-map rtmap-name [ backdoor ] | backdoor ] | Obrigatório. Por padrão, o BGP não anuncia rotas locais. |
O tipo de propriedade Origem das rotas locais anunciadas pelo BGP é IGP. Se você executar o backdoor de rede comando para uma rota EBGP, a distância administrativa da rota EBGP muda para a distância administrativa da rota local. (Por padrão, a distância administrativa da rota EBGP é 20 e a distância administrativa da rota local é 200.) Então, a distância administrativa da rota EBGP é menor que a distância administrativa da rota IGP padrão. Desta forma, a rota IGP é selecionada com prioridade, formando um link backdoor entre os vizinhos EBGP. O mapa de rotas aplicado às rotas locais anunciadas pelo BGP suporta opções de correspondência, incluindo as-path, community, e xtcommunity, ip address, ip nexthop e metric, e suporta as opções definidas, incluindo as-path, comm- lista, comunidade, extcommunity, ip next-hop, local-preference, métrica, origem e peso.
Configurar BGP para redistribuir rotas
O BGP não é responsável pelo aprendizado de rotas. Ele se concentra principalmente no gerenciamento das propriedades da rota para controlar a direção da rota. Portanto, o BGP redistribui as rotas IGP para gerar rotas BGP e anunciar as rotas BGP aos vizinhos. Quando o BGP redistribui rotas IGP, ele pode aplicar um diagrama de roteamento.
Tabela 12 -10Configure o BGP para redistribuir rotas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para redistribuir rotas IGP. | redistribute { connected | irmp as-number | isis [ area-tag ] [ match isis-level ] | ospf as-number [ match route-sub-type ] | rip | static } [ route-map map-name / metric value ] | Obrigatório. Por padrão, o BGP não redistribui rotas IGP. |
O tipo de propriedade Origem das rotas IGP anunciadas pelo BGP é INCOMPLETO. O mapa de rotas aplicado a outras rotas de protocolo que são redistribuídas pelo BGP suporta opções de correspondência, incluindo as-path, community, extcommunity, ip address, ip nexthop e metric, e suporta as opções definidas, incluindo as-path, comm-list , comunidade, extcommunity, ip next-hop, preferência local, métrica, origem e peso.
Configurar o BGP para anunciar a rota padrão
Antes que o BGP anuncie uma rota padrão aos vizinhos, a rota padrão precisa ser introduzida. Duas maneiras de introduzir as rotas padrão estão disponíveis: executando o comando neighbor default-originate para gerar uma rota padrão de BGP e executando o comando default-information origin para redistribuir a rota padrão de outro protocolo.
A rota padrão que é gerada executando o vizinho default-originate O comando é a rota 0.0.0.0/0 que é gerada automaticamente pelo BGP. A rota padrão que é redistribuída executando o comando default-information origin é a rota 0.0.0.0/0 do protocolo redistribuído introduzido pelo BGP.
Tabela 12 -11Configure o BGP para anunciar a rota padrão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para gerar a rota padrão. | neighbor { neighbor-address | peer-group-name } default-originate [ route-map rtmap-name ] | Obrigatório. Por padrão, o BGP não gera a rota padrão. |
| Configure a rota padrão de outro protocolo redistribuído pelo BGP. | default-information originate | Obrigatório. Por padrão, o BGP não redistribui a rota padrão de outro protocolo. |
Ao configurar o BGP para redistribuir a rota padrão de outro protocolo, você precisa configurar o BGP para redistribuir rotas. Ao configurar o BGP para gerar uma rota padrão, você pode aplicar um mapa de rotas à rota. O mapa de rotas aplicado à rota padrão gerada pelo BGP oferece suporte a opções definidas, incluindo como caminho, lista de comunicações, comunidade, comunidade externa, próximo salto ip, preferência local, métrica, origem e peso.
Configurar o controle de rota BGP
Condição de configuração
Antes de configurar o controle de rota BGP, certifique-se de que:
- O BGP está ativado.
- Os vizinhos BGP são configurados e uma sessão é configurada com sucesso.
Configurar o BGP para anunciar rotas agregadas
Em uma rede BGP de grande escala, para diminuir o número de rotas anunciadas aos vizinhos ou controlar efetivamente o roteamento BGP, você pode configurar uma rota agregada BGP.
Tabela 12 -12Configure o BGP para anunciar rotas agregadas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para anunciar rotas agregadas. | aggregate-address ip-address mask [ as-set / summary-only / route-map rtmap-name ] | Obrigatório. Por padrão, o BGP não agrega rotas. |
Ao configurar o BGP para anunciar rotas agregadas, você pode especificar a opção somente resumo para que o BGP anuncie apenas rotas agregadas. Isso diminui o número de rotas anunciadas. Você pode especificar o conjunto opção para gerar rotas de agregação com a propriedade AS_PATH. Você também pode aplicar um mapa de rotas às rotas de agregação para definir propriedades mais abundantes para as rotas de agregação.
Configurar a distância administrativa das rotas BGP
Na tabela de roteamento IP, cada protocolo controla a distância administrativa do roteamento. Quanto menor a distância administrativa, maior a prioridade. O BGP afeta o roteamento especificando as distâncias administrativas de segmentos de rede especificados. As distâncias administrativas das rotas que cobrem os segmentos de rede especificados serão modificadas. Enquanto isso, a ACL é aplicada para filtrar os segmentos de rede que são cobertos pelas rotas, ou seja, apenas as distâncias administrativas do segmento de rede permitidas pela ACL podem ser modificadas.
O comando distance bgp é usado para modificar as distâncias de gerenciamento de rotas BGP externas, internas e locais. O comando distance é usado apenas para modificar as distâncias administrativas de segmentos de rede especificados. O comando de distância tem uma prioridade mais alta do que o distância bgp comando. Os segmentos de rede cobertos pelo O comando distance usa a distância administrativa especificada pelo comando, enquanto os segmentos de rede que não são cobertos pelo comando distance usam a distância administrativa especificada pelo comando distance bgp .
Tabela 12 -13 Configurar a distância administrativa de uma rota BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para modificar a distância administrativa padrão. | distance bgp external-distance internal-distance local-distance | Opcional. Por padrão, a distância administrativa das rotas EBGP é 20, a distância administrativa das rotas IBGP é 200 e a distância administrativa das rotas locais é 200. |
| Configure a distância administrativa de um segmento de rede especificado. | distance administrative-distance ip-address mask [ acl-name ] |
Configurar políticas de roteamento na direção de saída de um vizinho BGP
O anúncio ou roteamento de rota BGP é implementado com base nas poderosas propriedades de roteamento. Ao anunciar rotas para vizinhos, você pode aplicar políticas de roteamento para modificar as propriedades da rota ou filtrar algumas rotas. Atualmente, as políticas de roteamento que podem ser aplicadas na direção de saída incluem:
- lista de distribuição: lista de distribuição.
- filter-list: lista de filtragem de propriedades AS_PATH.
- lista de prefixos: lista de prefixos de IP.
- mapa de rota: mapa de rota.
Tabela 12 -14 Configurar políticas de roteamento na direção de saída de um vizinho BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Aplique a lista de distribuição na direção de saída. | neighbor { neighbor-address | peer-group-name } distribute-list access-list-name out | Você pode selecionar várias opções. (No entanto, a lista de distribuição e a lista de prefixos IP não podem ser configuradas ao mesmo tempo.) Por padrão, nenhuma política de roteamento é configurada na direção de saída de um vizinho BGP. |
| Aplique a lista de filtragem de propriedade AS_PATH na direção de saída. | neighbor { neighbor-address | peer-group-name } filter-list aspath-list-name out | |
| Aplique a lista de prefixos IP na direção de saída. | neighbor { neighbor-address | peer-group-name } prefix-list prefix-list-name out | |
| Aplique um mapa de rotas na direção de saída. | neighbor { neighbor-address | peer-group-name } route-map rtmap-name out |
Depois de configurar a política de roteamento na direção de saída de um vizinho BGP, você precisa redefinir o vizinho para validar as configurações. Se você aplicar um mapa de rota na direção de saída de um refletor de rota, isso altera apenas a propriedade NEXT-HOP. Para saber como configurar uma lista de filtragem, consulte a seção "Configurar AS-PATH" do capítulo "Ferramentas de política de roteamento". Ao configurar políticas de roteamento na direção de saída de um vizinho BGP, você pode configurar várias políticas ao mesmo tempo. O BGP aplica políticas de roteamento na sequência de distribu-list , filter-list , prefix-list e route-map . Se uma política anterior for rejeitada, as últimas políticas não serão aplicadas. As informações de roteamento podem ser anunciadas somente após passarem por todas as políticas configuradas. O mapa de rotas aplicado na direção de saída de uma rota BGP suporta opções de correspondência, incluindo como caminho, comunidade, extcommunity, endereço IP, ip nexthop e métrica, e suporta as opções definidas, incluindo como caminho, comunicação. lista, comunidade, extcommunity, ip next-hop, local-preference, métrica, origem e peso.
Configurar políticas de roteamento na direção de entrada de um vizinho BGP
O BGP pode aplicar políticas de roteamento para filtrar as informações de roteamento recebidas ou modificar as propriedades da rota. Semelhante às políticas aplicadas nas direções de saída, quatro políticas são aplicadas nas direções de entrada:
- lista de distribuição: lista de distribuição.
- filter-list: lista de filtragem de propriedades AS_PATH.
- lista de prefixos: lista de prefixos de IP.
- mapa de rota: mapa de rota.
Tabela 12 -15 Configurar políticas de roteamento na direção de entrada de um vizinho BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Aplique a lista de distribuição na direção de entrada. | neighbor { neighbor-address | peer-group-name } distribute-list access-list-name in | Você pode selecionar várias opções. (No entanto, a lista de distribuição e a lista de prefixos IP não podem ser configuradas ao mesmo tempo.) Por padrão, nenhuma política é aplicada na direção de entrada. |
| Aplique a lista de filtragem de propriedade AS_PATH na direção de entrada. | neighbor { neighbor-address | peer-group-name } filter-list aspath-list-name in | |
| Aplique a lista de prefixos IP na direção de entrada. | neighbor { neighbor-address | peer-group-name } prefix-list prefix-list-name in | |
| Aplique um mapa de rota na direção de entrada. | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in |
Depois de configurar a política de roteamento na direção de entrada de um vizinho BGP, você precisa redefinir o vizinho para validar as configurações. Ao configurar políticas de roteamento na direção de entrada de um vizinho BGP, você pode configurar várias políticas ao mesmo tempo. O BGP aplica políticas de roteamento na sequência de distribu-list , filter-list , prefix-list e route-map . Se uma política anterior for rejeitada, as últimas políticas não serão aplicadas. Uma rota pode ser adicionada ao banco de dados após passar por todas as políticas configuradas. As políticas de roteamento aplicadas na direção de entrada de uma rota BGP suportam opções de correspondência, incluindo como caminho, comunidade, extcommunity, endereço IP, ip nexthop e métrica, e suportam as opções definidas, incluindo como caminho, lista de comunicações, comunidade, extcommunity, ip next-hop, preferência local, métrica, origem e peso.
Configurar o número máximo de rotas que um BGP recebe de um vizinho
Você pode limitar o número de rotas que um BGP recebe de um vizinho especificado. Quando o número de rotas que o BGP recebe do vizinho atinge um limite, um alarme é gerado ou o vizinho é desconectado.
Tabela 12 -16 Configure o número máximo de rotas que um BGP recebe de um vizinho
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o número máximo de rotas que um BGP recebe de um vizinho. | neighbor { neighbor-address | peer-group-name } maximum-prefix prefix-num [ threshold-value ] [ warning-only ] | Obrigatório. Por padrão, o número de rotas que um BGP recebe de um vizinho não é limitado. |
Se a opção somente aviso não for especificada, depois que o número de rotas que o BGP recebe do vizinho atingir o número máximo, a sessão BGP será desconectada automaticamente. Se a opção somente aviso for especificada, depois que o número de rotas que o BGP recebe do vizinho atingir o número máximo, uma mensagem de aviso será exibida, mas o aprendizado de rota continuará.
Configurar o número máximo de rotas de balanceamento de carga BGP
Em um ambiente de rede BGP, se vários caminhos com o mesmo custo estiverem disponíveis para alcançar o mesmo destino, você poderá configurar o número de rotas de balanceamento de carga BGP para balanceamento de carga.
Tabela 12 -17 Configure o número máximo de rotas de balanceamento de carga BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o número máximo de rotas de balanceamento de carga IBGP. | maximum-paths ibgp number | Obrigatório. Por padrão, o IBGP não suporta rotas de balanceamento de carga. |
| Configure o número máximo de rotas de balanceamento de carga EBGP. | maximum-paths number | Obrigatório. Por padrão, o EBGP não oferece suporte a rotas de balanceamento de carga. |
Depois que o número máximo de rotas de balanceamento de carga EBGP for configurado, o balanceamento de carga terá efeito somente quando as rotas EBGP forem selecionadas com prioridade. Em diferentes modos de configuração do BGP, os comandos para configurar o número máximo de rotas de balanceamento de carga são diferentes. Para obter detalhes, consulte a descrição dos caminhos máximos no manual técnico do BGP .
Configurar propriedades de rota BGP
Condição de configuração
Antes de configurar as propriedades da rota BGP, certifique-se de que:
- O BGP está ativado.
- Os vizinhos BGP são configurados e uma sessão é configurada com sucesso.
Configurar o peso da rota BGP
No roteamento BGP, a primeira regra é comparar os pesos das rotas. Quanto maior o peso de uma rota, maior a prioridade que ela tem. O peso de uma rota é propriedade local do dispositivo e não pode ser transferido para outros vizinhos BGP. O intervalo de valores de um peso de rota é 1-65535. Por padrão, o peso de uma rota que foi aprendida de um vizinho é 0 e os pesos de todas as rotas geradas pelo dispositivo local são todos 32768.
Tabela 12 -18Configurar o peso da rota BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o peso de uma rota de um vizinho ou grupo de pares. | neighbor { neighbor-address | peer-group-name } weight weight-num | Obrigatório. Por padrão, o peso de uma rota de um vizinho é 0. |
Configurar a propriedade MED de uma rota BGP
As propriedades do Multi-Exit Discriminator (MED) são usadas para selecionar a rota ideal para o tráfego que entra em um AS. Se as outras condições de roteamento forem as mesmas e o BGP aprender várias rotas com o mesmo destino de diferentes vizinhos EBGP, o BGP selecionará a rota com o valor MED mínimo como a entrada ideal.
O MED às vezes também é chamado de métrica externa. Ele é marcado como uma "métrica" na tabela de roteamento BGP. O BGP anuncia as propriedades MED das rotas que aprendeu de vizinhos para vizinhos IBGP, mas o BGP não anuncia as propriedades MED para vizinhos EBGP. Portanto, as propriedades MED são aplicáveis apenas a ASs adjacentes.
1. Configure o BGP para permitir a comparação de MEDs de rotas vizinhas de diferentes ASs.
Por padrão, o BGP implementa a seleção de rotas MED apenas entre as rotas que são do mesmo AS. No entanto, você pode executar o Comando bgp always-compare-med para permitir que o BGP ignore a limitação no mesmo AS na seleção de rota MED.
Tabela 12 -19 Configure o BGP para permitir a comparação de MEDs de rotas vizinhas de diferentes ASs
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para permitir a comparação de MEDs de rotas vizinhas de diferentes ASs. | bgp always-compare-med | Obrigatório. Por padrão, o BGP permite apenas comparar MEDs de rotas vizinhas do mesmo AS. |
2. Configure o BGP para classificar e selecionar MEDs de acordo com os grupos AS_PATH.
Por padrão, o BGP não está habilitado para classificar e selecionar MEDs de acordo com os grupos AS_PATH de rota. Para habilitar a função, execute o bgp deterministic-med comando. Na seleção de rotas, todas as rotas são organizadas com base em AS_PATHs. Em cada grupo AS_PATH, as rotas são classificadas com base nos valores MED. A rota com o valor MED mínimo é selecionada como a rota ideal no grupo.
Tabela 12 -20 Configure o BGP para classificar e selecionar MEDs de acordo com os grupos AS_PATH
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| BGP classifica e seleciona MEDs de acordo com os grupos AS _PATH | bgp deterministic-med |
Obrigatório.
Por padrão, não habilite o BGP para classificar e selecionar MEDs de acordo com os grupos AS _PATH da rota . |
3. Configure para comparar MEDs de rotas na confederação local.
Por padrão, os valores MED das rotas EBGP de diferentes ASs não são comparados. A configuração é válida para as rotas EBGP das confederações. Para habilitar a comparação de valores MED de rotas da confederação local, execute o comando bgp bestpath med confed .
Tabela 12 -21 Configure o BGP para comparar MEDs de rotas na confederação local
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para comparar os valores MED de rotas na confederação local. | bgp bestpath med confed |
Obrigatório.
Por padrão, os valores MED das rotas nas confederações locais não serão comparados. |
4. Configure um mapa de rotas para modificar as propriedades do MED.
Nas rotas de transmissão e recepção, você pode aplicar um mapa de rotas para modificar as propriedades do MED.
Tabela 12 -22 Configurar um mapa de rotas para modificar as propriedades do MED
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configurando um mapa de rotas para modificar as propriedades do MED. | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in | out | Obrigatório. Por padrão, nenhum mapa de rotas é aplicado a nenhum vizinho. |
Ao configurar um mapa de rotas para modificar uma propriedade MED, você pode usar o comando set metric para modificar a propriedade MED. Para obter detalhes, consulte a métrica de conjunto de ferramentas de política de roteamento - manual técnico . Após a configuração do comando neighbor attribute-unchanged , as propriedades MED dos vizinhos não podem ser alteradas pelo mapa de rotas aplicado.
Configurar a propriedade de preferência local de uma rota BGP
As propriedades de preferência local são transferidas apenas entre vizinhos IBGP. Local-Preference é usado para selecionar a saída ideal de um AS. A rota com a máxima preferência local será selecionada com prioridade.
O intervalo de valores de Local-Preference é 0-4294967295. Quanto maior o valor, maior a prioridade da rota . Por padrão, o valor Local-Preference de todas as rotas que são anunciadas aos vizinhos IBGP é 100. Você pode usar a preferência local padrão bgp comando ou o mapa de rotas para modificar o valor da propriedade Local-Preference.
1. Configure o BGP para modificar a propriedade de preferência local padrão.
Tabela 12 -23 Configure o BGP para modificar a propriedade de preferência local padrão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o valor padrão da propriedade BGP Local-Preference. | bgp default local-preference local-value | Opcional. Por padrão, o valor Local-Preference é 100. |
2. Configure o mapa de rotas para modificar a propriedade Local-Preference.
Tabela 12 -24 Configure o mapa de rotas para modificar a propriedade local-preference
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o mapa de rotas para modificar a propriedade Local-Preference. | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in | out | Obrigatório. Por padrão, o mapa de rotas não é aplicado a nenhum vizinho. |
Ao configurar um mapa de rotas para modificar a propriedade Local-Preference, você pode usar o set local-preference comando para modificar a propriedade Local-Preference. Para obter detalhes, consulte Ferramentas de Política de Roteamento - Manual Técnico - set local-preference .
Configurar a propriedade AS_PATH de uma rota BGP
1. Configure o BGP para ignorar AS_PATHs na seleção de rota.
Se as outras condições forem as mesmas, o BGP seleciona a rota com o AS-PATH mais curto na seleção de rota. Para cancelar a seleção de rota com base em AS_PATHs, execute o comando bgp bestpath as-path ignore .
Tabela 12 -25 Configure o BGP para ignorar AS_PATHs na seleção de rota
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para ignorar AS_PATHs na seleção de rota. | bgp bestpath as-path ignore | Obrigatório. Por padrão, os valores AS_PATH são comparados na seleção de rota. |
2. Configure o número de ASs locais que o BGP permite repetir.
Para evitar loops de roteamento, o BGP verifica as propriedades AS_PATH das rotas que são recebidas dos vizinhos, e as rotas que contêm o número AS local serão descartadas. No entanto, você pode executar o comando neighbor allowas-in para permitir que as propriedades AS_PATH das rotas que o BGP recebe contenham o número de AS local e você pode configurar o número de ASs que podem ser contidos.
Tabela 12 -26 Configure o número de ASs locais que o BGP permite repetir
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o número de ASs que podem ser repetidos. | neighbor { neighbor-address | peer-group-name } allowas-in [ as-num ] |
Obrigatório.
Por padrão, as propriedades AS_PATH das rotas recebidas dos vizinhos não permitem o número AS local. |
3. Configure o BGP para remover o número AS privado ao anunciar rotas para vizinhos.
Em uma rede BGP de grande escala, as propriedades AS_PATH das rotas contêm federação ou propriedade da comunidade. Por padrão, o BGP fornece as propriedades privadas do AS quando anuncia rotas para vizinhos. Para mascarar informações de rede privada, execute o vizinho remove-private-AS comando para remover o número AS privado.
Tabela 12 -27 Configure o BGP para remover o número Private AS ao anunciar rotas para vizinhos
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para remover o número AS privado ao anunciar rotas para vizinhos. | neighbor { neighbor-address | peer-group-name } remove-private-AS |
Obrigatório.
Por padrão, quando o BGP anuncia rotas para vizinhos, ele fornece o número AS privado. |
4. Configure para verificar a validade do primeiro número AS de uma rota EBGP.
Quando o BGP anuncia uma rota para os vizinhos EBGP, ele comprime o número do AS local na posição inicial do AS_PATH, e o AS que anuncia a rota primeiro fica localizado no final. Normalmente, o primeiro AS de uma rota que o EBGP recebe deve ser o mesmo número do AS vizinho; caso contrário, a rota será descartada.
Tabela 12 -28 Configure para verificar a validade do primeiro número AS de uma rota EBGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure para verificar a validade do primeiro número AS de uma rota EBGP. | bgp enforce-first-as | Obrigatório. Por padrão, o BGP não habilita o mecanismo de verificação do primeiro número AS. |
5. Configure um mapa de rotas para modificar as propriedades AS_PATH.
O BGP suporta a configuração de um mapa de rotas para modificar as propriedades AS_PATH. Você pode executar o prefixo set as-path comando para adicionar mais propriedades de roteamento para afetar o roteamento vizinho. Ao usar a função de prefixo set as-path , primeiro use o AS local para adicionar AS_PATH. Se você usar outro AS, o AS deve ser enfatizado para evitar que o AS rejeite as rotas anunciadas a ele.
Tabela 12 -29 Configure um mapa de rota para modificar as propriedades AS_PATH
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um mapa de rotas para modificar as propriedades AS_PATH. | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in | out | Obrigatório. Por padrão, nenhum mapa de rotas é aplicado a nenhum vizinho. |
Ao configurar um mapa de rotas para modificar uma propriedade AS_PATH, você pode usar o comando set as-path prepend para modificar a propriedade AS_PATH. Para obter detalhes, consulte Ferramentas de Política de Roteamento - Manual Técnico - set as-path .
Configurar a propriedade NEXT-HOP de uma rota BGP
Quando o BGP anuncia rotas para vizinhos IBGP, ele não altera as propriedades de roteamento (incluindo a propriedade NEXT-HOP). Quando o BGP anuncia as rotas que são aprendidas dos vizinhos EBGP para os vizinhos IBGP, você pode executar o comando next-hop-self para modificar a propriedade do próximo salto das rotas anunciadas aos vizinhos BGP para o endereço IP local. Você pode aplicar um mapa de rotas para modificar a propriedade do próximo salto.
1. Configure o BGP para usar o endereço IP local como o próximo salto de uma rota.
Tabela 12 -30 Configure o BGP para usar o endereço IP local como o próximo salto de uma rota
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para usar o endereço IP local como o próximo salto ao anunciar rotas. | neighbor { neighbor-address | peer-group-name } next-hop-self |
Obrigatório.
Por padrão, a propriedade do próximo salto das rotas anunciadas aos vizinhos EBGP é definida como o endereço IP local e a propriedade do próximo salto das rotas anunciadas aos vizinhos IBGP permanece inalterada. |
Quando o BGP é configurado para usar o endereço IP local como o próximo salto de uma rota, se você executar o comando neighbor update-source para configurar o endereço de origem de uma sessão TCP, o endereço de origem será usado como o endereço do próximo salto; caso contrário, o endereço IP da interface de saída do dispositivo de publicidade é selecionado como o endereço IP local.
2. Configure um mapa de rotas para modificar as propriedades do NEXT-HOP.
O BGP suporta a configuração de um mapa de rotas para modificar as propriedades do NEXT-HOP. Você pode executar o definir ip próximo salto comando para modificar a propriedade do próximo salto.
Tabela 12 -31 Configure um mapa de rotas para modificar as propriedades do NEXT-HOP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um mapa de rotas para modificar as propriedades do NEXT-HOP. | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in | out | Obrigatório. Por padrão, nenhum mapa de rotas é aplicado a nenhum vizinho. |
Ao configurar um mapa de rotas para modificar uma propriedade NEXT-HOP, você pode usar o comando set ip next-hop para modificar a propriedade NEXT-HOP. Para obter detalhes, consulte Ferramentas de Política de Roteamento- Manual Técnico -set ip next-hop .
Configurar a propriedade da comunidade de uma rota BGP
Quando o BGP anuncia rotas para vizinhos, ele pode ser configurado para enviar a propriedade da comunidade. Você pode aplicar um mapa de rotas a um vizinho especificado nas direções de entrada e saída para corresponder às propriedades da comunidade.
A propriedade de comunidade é usada para identificar um grupo de rotas para aplicar uma política de roteamento ao grupo de rotas. Dois tipos de propriedade comunitária estão disponíveis: padrão e estendido. A propriedade de comunidade padrão consiste em 4 bytes, fornecendo as propriedades como NO_EXPORT, LOCAL_AS, NO_ADVERTISE e INTERNET. A propriedade estendida consiste em oito bytes, fornecendo as propriedades Route Target (RT) e Route Origin (RO).
1. Configure o BGP para anunciar a propriedade da comunidade de rota aos vizinhos.
A comunidade de envio vizinha permite que você anuncie propriedade comunitária padrão ou propriedade comunitária estendida ou ambos os tipos de propriedade para os vizinhos.
Tabela 12 -32 Configure o BGP para anunciar a propriedade da comunidade de rota aos vizinhos
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para anunciar a propriedade da comunidade de rota aos vizinhos. | neighbor { neighbor-address | peer-group-name } send-community [ both | extended | standard ] | Obrigatório. Por padrão, a propriedade da comunidade não é anunciada a nenhum vizinho. |
Depois que os vizinhos são ativados na família de endereços VPNv4, as propriedades da comunidade padrão e estendida são automaticamente anunciadas aos vizinhos.
2. Configure um mapa de rotas para modificar a propriedade da comunidade.
O BGP oferece suporte à configuração de um mapa de rotas para modificar a propriedade da comunidade de rotas. Você pode usar o definir comunidade comandar a modificação da propriedade comunitária.
Tabela 12 -33 Configure um mapa de rotas para modificar a propriedade da comunidade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um mapa de rotas para modificar a propriedade da comunidade de rotas BGP | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in | out | Obrigatório. Por padrão, nenhum mapa de rotas é aplicado a nenhum vizinho. |
Ao configurar um mapa de rotas para modificar a propriedade da comunidade, você pode usar o comando set community para modificar a propriedade da comunidade. Para obter detalhes, consulte a comunidade de conjunto de ferramentas de política de roteamento - manual técnico .
Configurar otimização de rede BGP
Condição de configuração
Antes de configurar a otimização de rede BGP, certifique-se de que:
- O BGP está ativado.
- Os vizinhos BGP são configurados e uma sessão é configurada com sucesso.
Configurar o tempo de manutenção ativo dos vizinhos BGP
Depois que uma sessão BGP é configurada com sucesso, mensagens de manutenção ativa são enviadas periodicamente entre os vizinhos para manter a sessão BGP. Se nenhuma mensagem de manutenção ativa ou pacote de atualização for recebido do vizinho dentro do tempo de espera, a sessão BGP será desconectada devido ao tempo limite. O tempo de keep - alive é igual ou menor que 1/3 do tempo de h old.
Tabela 12 -34 Configure o tempo de manutenção de atividade dos vizinhos BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| tempo de atividade e o tempo de espera global do BGP . | timers bgp keepalive-interval holdtime-interval | Opcional. Por padrão, o temporizador de manutenção de atividade é de 60 segundos, o temporizador de retenção é de 180 segundos e o temporizador de reconexão de sessão é de 120 segundos. |
| Configure o tempo de atividade e o tempo de espera de um vizinho BGP ou grupo de pares. | neighbor { neighbor-address | peer-group-name } timers { keepalive-interval holdtime-interval | connect connect-interval } |
O tempo de manutenção e o tempo de espera definidos para um vizinho especificado têm prioridades mais altas do que o tempo de manutenção e o tempo de espera do BGP global. Os vizinhos negociam e, em seguida, tomam o tempo mínimo de espera como a espera da sessão BGP entre os vizinhos. Se o tempo de manutenção e o tempo de espera forem definidos como 0, a função de manutenção/retenção do vizinho será cancelada. Se o tempo de manutenção for maior que 1/3 do tempo de espera, a sessão BGP enviará pacotes de manutenção de atividade no intervalo de 1/3 do tempo de espera.
Configurar o tempo de detecção de rota BGP
O BGP visa principalmente a implementação de um processo de roteamento, com ASs como unidades de roteamento. Dentro de um AS, o IGP é usado para roteamento. Portanto, as rotas BGP geralmente dependem de rotas IGP. Se os próximos saltos ou interfaces de saída das rotas IGP nas quais o BGP depende mudarem, o BGP detectará as rotas IGP periodicamente para atualizar as rotas BGP. O BGP também atualiza as rotas BGP locais durante o intervalo de detecção.
Tabela 12 -35Configurar o tempo de detecção de rota BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o tempo de detecção de rota BGP. | bgp scan-time time | Opcional. Por padrão, o tempo de detecção de rota BGP é de 60 segundos. |
Se o tempo de detecção de rota BGP for muito pequeno, o BGP detecta rotas com frequência, afetando o desempenho do dispositivo.
Configurar a desconexão rápida de vizinhos EBGP
Depois que uma sessão BGP é configurada com sucesso, mensagens Keepalive são enviadas periodicamente entre os vizinhos para manter a sessão BGP. Se nenhuma mensagem Keepalive ou pacote de atualização for recebido do vizinho dentro do tempo de espera, a sessão BGP será desconectada devido ao tempo limite. Você pode configurar vizinhos EBGP de conexão direta para desconectar uma conexão BGP imediatamente depois que uma interface de conexão estiver inativa, sem aguardar o tempo limite de manutenção de atividade do BGP. Se a função de desconexão rápida do vizinho EBGP for cancelada, a sessão EBGP não responderá a um evento de inatividade da interface; em vez disso, a sessão BGP é desconectada após o tempo limite.
Tabela 12 -36Configure a desconexão rápida de vizinhos EBGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure a desconexão rápida de vizinhos EBGP. | bgp fast-external-failover | Opcional. Por padrão, a capacidade de processamento rápido do EBGP em responder ao evento de inatividade da interface de conexão direta está habilitada. |
Configurar a função de supressão de rota BGP
Rotas oscilantes em uma rede podem causar instabilidade da rede. Você pode configurar a atenuação de rota para amortecer esse tipo de rotas de modo a diminuir o efeito de rotas oscilantes na rede.
Uma rota frequentemente oscilante será atribuída com uma penalidade. Se a penalidade exceder o limite de supressão, a rota não será anunciada aos vizinhos. A penalidade não deve ser mantida além do tempo máximo de supressão. Se não ocorrer nenhuma oscilação na rota dentro do período de meia-vida, a penalidade será reduzida pela metade. Se a penalidade for menor que o valor limite, a rota poderá ser anunciada aos vizinhos novamente.
- Período de meia-vida: É o tempo em que a penalidade de uma rota é reduzida pela metade.
- Limite de reutilização: é o limite para a rota retomar o uso normal.
- Limite de supressão: É o limite para supressão de rota.
- Tempo máximo de supressão: É o tempo máximo de supressão da rota.
Tabela 12 -37Configure a função de supressão de rota BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o período de atenuação da rota BGP. | bgp dampening [ reach-half-life [ reuse-value suppress-value max-suppress-time [ unreach-half-life ] ] | route-map rtmap-name ] |
Obrigatório.
Por padrão, a função de supressão de rota está desabilitada. Depois que a função é habilitada, o período de meia-vida de supressão de rota padrão é de 15 minutos, o limite de reutilização de rota é de 750 segundos, o limite de supressão de rota é de 2.000 segundos, o tempo máximo de supressão de rota é de 60 minutos e a penalidade de rota inacessível meia- período de vida é de 15 minutos. |
O flapping de rota não apenas contém adição e exclusão de rotas, mas também contém alterações de propriedade de rota, como próximo salto e alterações de propriedade MED.
Configurar o recurso de atualização do vizinho BGP
Se a política de roteamento ou a política de seleção de rota aplicada a um vizinho BGP for alterada, a tabela de roteamento precisará ser atualizada. Uma maneira de atualizar a tabela de roteamento é redefinir a conexão BGP para redefinir a sessão BGP. No entanto, este modo pode resultar em oscilação da rota BGP, afetando os serviços normais. A outra maneira é mais elegante, ou seja, configurando o dispositivo BGP local para suportar o recurso de atualização de rota. Se um vizinho precisar redefinir uma rota, ele anunciará a mensagem Route-Refresh ao dispositivo local. Após receber a mensagem Route-Refresh, ele envia novamente a rota para o vizinho. Dessa forma, a tabela de roteamento é atualizada dinamicamente sem a necessidade de desconectar a sessão BGP.
Tabela 12 -38Configure o recurso de atualização do BGP Neighbor
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Habilite o recurso de atualização do vizinho BGP. | neighbor { neighbor-address | peer-group-name } capability route-refresh | Opcional. Por padrão, o recurso de atualização do vizinho BGP está habilitado. |
Configurar o recurso de reinicialização suave do vizinho BGP
Se a política de roteamento ou a política de seleção de rota aplicada a um vizinho BGP for alterada, a tabela de roteamento precisará ser atualizada. Uma maneira de atualizar a tabela de roteamento é redefinir a conexão BGP para redefinir a sessão BGP. No entanto, este modo pode resultar em oscilação da rota BGP, afetando os serviços normais. Outra maneira é mais elegante, ou seja, configurar o dispositivo BGP local para suportar o recurso de atualização de rota. Ainda há outra maneira, ou seja, habilitar o recurso de reinicialização por software do dispositivo BGP local. Por padrão, o dispositivo BGP reserva as informações de roteamento de cada vizinho. Depois de habilitar o recurso de reinicialização suave do vizinho, ele atualiza as rotas vizinhas que são mantidas no dispositivo local. Neste momento, as sessões BGP não são desconectadas.
Tabela 12 -39 Configurar o recurso de reinicialização suave do vizinho BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Habilite o recurso de reinicialização suave do vizinho BGP. | neighbor { neighbor-address | peer-group-name } soft-reconfiguration inbound | Obrigatório. Por padrão, a função de reinicialização suave do vizinho está desabilitada. |
Configurar a capacidade ORF de vizinhos BGP
O BGP implementa um controle de rota preciso por meio de propriedades de roteamento abundantes. Geralmente aplica políticas de roteamento nas direções de entrada e saída. Este modo é um comportamento local do BGP. O BGP também oferece suporte ao recurso ORF (Outbound Route Filtering). Ele anuncia a política de ingresso local para seus vizinhos por meio de pacotes de atualização de rota e, em seguida, os vizinhos aplicam a política quando anunciam rotas para o dispositivo BGP local. Isso diminui bastante o número de pacotes de atualização de rota trocados entre vizinhos BGP.
Para obter uma negociação bem-sucedida da capacidade ORF, certifique-se de que:
- A capacidade ORF está habilitada para ambos os vizinhos.
- "ORF send" e "ORF receive" devem corresponder. Ou seja, se uma extremidade for "ORF de envio", a outra extremidade deverá ser "ORF ambos" ou "ORF de recepção". Se uma extremidade for "ORF receber", a outra extremidade deve ser "ORF enviar" ou "ORF ambos".
- A extremidade "Envio ORF" deve ser configurada com uma lista de prefixos na direção de entrada.
Tabela 12 -40Configure a capacidade ORF dos vizinhos BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Aplique uma lista de prefixos na direção de entrada de um vizinho. | neighbor { neighbor-address | peer-group-name } prefix-list prefix-list-name in | Obrigatório. Por padrão, nenhuma lista de prefixos é aplicada a nenhum vizinho BGP. |
| Configure um vizinho para suportar o recurso ORF. | neighbor { neighbor-address | peer-group-name } capability orf prefix-list { both | receive | send } | Obrigatório. Por padrão, um vizinho não suporta o recurso ORF. |
Configurar rede BGP de grande escala
Condição de configuração
Antes de configurar uma rede BGP de grande escala, certifique-se de que:
- O BGP está ativado.
- Os vizinhos BGP são configurados e uma sessão é configurada com sucesso.
Configurar um grupo de pares do BGP
Um grupo de pares BGP é um grupo de vizinhos BGP configurados com a mesma política de configuração. Qualquer configuração executada em um grupo de pares BGP terá efeito em todos os membros do grupo de pares. Dessa forma, configurando o grupo de peers, você pode realizar gerenciamento e manutenção centralizados nos vizinhos.
Tabela 12 -41Configurar um grupo de peers BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Crie um grupo de pares BGP. | neighbor peer-group-name peer-group |
Obrigatório.
Por padrão, nenhum grupo de pares está configurado e um vizinho não está em nenhum grupo de pares. |
| Adicione um vizinho ao grupo de pares. | neighbor neighbor-address peer-group peer-group-name |
A configuração em um grupo de pares entra em vigor em todos os membros do grupo de pares. Depois que um vizinho é adicionado a um grupo de pares, se algumas configurações do vizinho forem iguais às configurações do grupo de pares, as configurações do vizinho serão excluídas. Se as políticas de roteamento forem configuradas nas direções de entrada e saída de um grupo de pares, depois que as políticas de roteamento forem alteradas, as alterações não terão efeito nos vizinhos que foram adicionados ao grupo de pares. Para aplicar as políticas de roteamento alteradas nos membros do grupo de pares, você precisa redefinir o grupo de pares.
Configurar um refletor de rota BGP
Em uma rede BGP de grande porte, é necessário que os vizinhos IBGP estejam totalmente conectados, ou seja, cada BGP precisa estabelecer conexões com todos os vizinhos IBGP. Desta forma, em uma rede que contém N vizinhos BGP, o número de conexões BGP é N*(N-1)/2. Quanto maior o número de conexões, maior o número de anúncios de rota. Configurar um BGP Route Reflector (RR) é um método para reduzir o número de conexões de rede. Vários IBGPs são categorizados em um grupo. Nesse grupo, um BGP é especificado para atuar como RR, enquanto outros BGPs atuam como clientes e BGPs que não estão no grupo atuam como não clientes. Os clientes estabelecem relações de pares apenas com o RR enquanto não estabelecem relações de pares com outros BGPs. Isso reduz o número de conexões IBGP obrigatórias e o número de conexões é N-1.
Os seguintes sapatos os princípios de roteamento do BGP RR:
- O RR reflete as rotas que ele aprende de vizinhos IBGP não clientes apenas para clientes.
- O RR reflete as rotas que ele aprende dos clientes para todos os clientes e não clientes, exceto os clientes que iniciam as rotas.
- O RR reflete as rotas que aprende dos vizinhos EBGP para todos os clientes e não clientes.
Tabela 12 -42Configurar um refletor de rota BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um ID de cluster RR. | bgp cluster-id { cluster-id-in-ip | cluster-id-in-num } | Obrigatório. Por padrão, o ID da rota é usado como o ID do cluster RR. |
| Configure um cliente como cliente do RR. | neighbor { neighbor-address | peer-group-name } route-reflector-client | Obrigatório. Por padrão, nenhum cliente é especificado como cliente do RR. |
| Configure a função de reflexão de rota entre vizinhos BGP. | bgp client-to-client reflection | Opcional. Por padrão, a função de reflexão de rota é habilitada entre clientes RR. |
Um ID de cluster RR é usado para identificar uma área RR. Uma área RR pode conter vários RRs e os RRs na área RR têm o mesmo ID de cluster RR.
Configurar uma Confederação BGP
Em uma rede BGP de grande porte, é necessário que os vizinhos IBGP estejam totalmente conectados, ou seja, cada BGP precisa estabelecer conexões com todos os vizinhos IBGP. Desta forma, em uma rede que contém N vizinhos BGP, o número de conexões BGP é N*(N-1)/2. Quanto maior o número de conexões, maior o número de anúncios de rota. A configuração de confederações BGP é outra maneira de reduzir o número de conexões de rede. Uma área AS é dividida em várias áreas sub-AS e cada área AS forma uma confederação. O IBGP é adotado dentro de uma confederação para fornecer conexões completas, e as áreas sub-AS da confederação são conectadas por meio de conexões EBGP. Isso reduz efetivamente o número de conexões BGP.
Ao configurar confederações BGP, você precisa atribuir um ID de confederação para cada confederação e especificar membros para a confederação. No caso de reflexão de rota, apenas o refletor de rota é necessário para suportar a reflexão de rota. No entanto, no caso de uma confederação, todos os membros de uma confederação devem apoiar a função de confederação.
Tabela 12 -43Configurar uma confederação BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Crie um ID de confederação BGP. | bgp confederation identifier as-number | Obrigatório. Por padrão, nenhum número AS é configurado para uma confederação. |
| Configure membros para a confederação. | bgp confederation peers as-number-list | Obrigatório. Por padrão, nenhum número sub-AS é configurado para uma confederação. |
Um ID de confederação é usado para identificar os sub-ASs da confederação. Os membros da Confederação são divididos em sub-ASs.
Configurar BGP GR
Graceful Restart (GR) é usado na alternância ativa/em espera entre dispositivos. Durante o GR, as informações de roteamento do dispositivo local e dos dispositivos vizinhos permanecem inalteradas na camada de encaminhamento, e o encaminhamento de dados não é afetado. Depois que a alternância é concluída e o novo dispositivo começa a ser executado, os dois dispositivos sincronizam as informações de roteamento na camada de protocolo e atualizam a camada de encaminhamento para que o encaminhamento de dados não seja interrompido durante o processo de alternância do dispositivo.
Funções envolvidas em um GR:
- GR Restarter: É o dispositivo que é reiniciado normalmente.
- GR Helper: É o dispositivo que auxilia no GR.
- Tempo GR: É o tempo máximo para reiniciar os GR-Restarters. GR Helper mantém a estabilidade das rotas durante o período de tempo.
Um dispositivo de controlador duplo pode atuar como um GR Restarter e um GR Helper, enquanto um dispositivo centralizado pode atuar apenas como um GR Helper, ajudando o GR Restarter a completar um GR. Quando o GR Restarter está no processo GR, o GR Helper mantém a estabilidade da rota até o tempo limite do GR Time. Depois que o GR Helper ajuda com o GR, ele sincroniza as informações de rota. Durante o processo, as rotas de rede e o encaminhamento de pacotes mantêm o status perante o GR, garantindo efetivamente a estabilidade da rede.
A relação BGP GR é estabelecida através da negociação de pacotes OPEN quando uma conexão é estabelecida entre vizinhos. Quando o GR Restarter reinicia o vizinho, a sessão BGP será desconectada, mas as rotas aprendidas do vizinho não serão excluídas. As rotas ainda são normalmente encaminhadas na tabela de roteamento IP. As rotas são rotuladas com as marcas Stale somente na tabela de roteamento BGP. Após a conclusão do GR, as rotas serão atualizadas.
O GR Restarter precisa estabelecer uma conexão com o GR Helper dentro do tempo máximo permitido; caso contrário, o GR Helper cancela a rota GR mantida e cancela o processo GR. Depois que o vizinho é reconectado, o GR Helper precisa receber um pacote de atualização com a marca End-Of-RIB do GR Restarter para concluir o processo GR; caso contrário, a rota GR que não for atualizada será excluída após o tempo máximo de retenção ( stalepath-time ) expirar e, em seguida, a relação GR será liberada.
Condição de configuração
Antes de configurar um BGP GR, certifique-se de que:
- O BGP está ativado.
- Os vizinhos BGP são configurados e uma sessão é configurada com sucesso.
Configurar o BGP GR Restarter
Tabela 12 -44 Configurar o reiniciador do BGP GR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Habilite o recurso BGP GR | bgp graceful-restart [ restart-time time | stalepath-time time ] |
Obrigatório.
Por padrão, o dispositivo BGP não habilita o recurso GR. Após habilitar o GR, o tempo máximo permitido para o vizinho reconfigurar a sessão é 120s, e o tempo máximo de espera da rota GR é 360s. |
| Configure a publicidade do recurso GR-Restarter para o vizinho | neighbor { neighbor-address | peer-group-name } capability graceful-restart | Obrigatório. Por padrão, não anuncie a capacidade do GR Restarter ao vizinho. |
Configurar um auxiliar BGP GR
Tabela 12 -45Configurar um auxiliar BGP GR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Habilite o recurso BGP GR. | bgp graceful-restart [ restart-time time | stalepath-time time ] |
Obrigatório.
Por padrão, o recurso GR está desabilitado para dispositivos BGP. Depois que o recurso GR é habilitado, o tempo máximo padrão permitido para reconfigurar uma sessão com o vizinho é 120s, e o tempo máximo de espera das rotas GR é 360s. |
Configurar BGP para coordenar com BFD
Normalmente, ainda existem alguns dispositivos intermediários entre os vizinhos BGP. Quando um dispositivo intermediário se torna defeituoso, a sessão BGP é normal dentro do tempo de espera e a falha de link causada pelo dispositivo intermediário não pode ser respondida a tempo. A detecção de encaminhamento bidirecional (BFD) fornece um método para detectar rapidamente o status de uma linha entre dois dispositivos. Depois que o BFD estiver habilitado para dispositivos BGP, se uma linha entre dois dispositivos estiver com defeito, o BFD pode encontrar rapidamente a falha de linha e notificar o BGP sobre a falha. Ele aciona o BGP para desconectar rapidamente a sessão e alternar rapidamente para a linha de backup, obtendo uma rápida alternância de rotas.
Condição de configuração
Antes de configurar o BGP para coordenar com o BFD, certifique-se de que:
- O BGP está ativado.
- Os vizinhos BGP são configurados e uma sessão é configurada com sucesso.
Configurar EBGP para coordenar com BFD
A coordenação entre EBGP e BFD é baseada em uma sessão BFD de salto único, e os parâmetros da sessão BFD precisam ser configurados no modo de interface.
Tabela 12 -46Configurar e EBGP para coordenar com BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o EBGP para coordenar com o BFD. | neighbor { neighbor-address | peer-group-name } fall-over bfd | Obrigatório. Por padrão, a função BFD está desabilitada para um vizinho. |
| Saia do modo de configuração BGP. | exit | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o intervalo mínimo de recebimento de uma sessão BFD. | bfd min-receive-interval milliseconds | Opcional. Por padrão, o intervalo mínimo de recebimento de uma sessão BFD é de 1000 m s. |
| Configure o intervalo mínimo de transmissão da sessão BFD. | bfd min-transmit-interval milliseconds | Opcional. Por padrão, o intervalo mínimo de transmissão de uma sessão BFD é de 1000 m s. |
| Configure o múltiplo de tempo limite de detecção de sessão BFD. | bfd multiplier number | Opcional. Por padrão, o múltiplo do tempo limite de detecção da sessão BFD é 5. |
Para a configuração relacionada do BFD, consulte o manual técnico do BFD da tecnologia de confiabilidade e o manual de configuração do BFD.
Configurar o reencaminhamento rápido do BGP
Condição de configuração
Antes de configurar o BGP para associar ao BFD, primeiro conclua a seguinte tarefa:
- Habilite o protocolo BGP.
- Configurar o vizinho BGP e configurar a sessão com sucesso.
Configurar o reencaminhamento rápido do BGP
Na rede BGP, devido à falha do link ou do dispositivo , os pacotes que passam pelo ponto de falha serão descartados ou será gerado um loop. A interrupção de tráfego causada por isso durará até que o protocolo convirja novamente, o que geralmente dura vários segundos. Para reduzir o tempo de interrupção do tráfego, o reencaminhamento rápido do BGP pode ser configurado. Através da aplicação do mapa de rotas, o próximo salto de backup é definido para a rota correspondente. Uma vez que o enlace principal falhe, o tráfego que passa pelo enlace principal será imediatamente comutado para o enlace de espera, de modo a atingir o objetivo de comutação rápida.
Tabela 12 -47 Configurar o reencaminhamento rápido do BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP | router bgp autonomous-system | - |
| Configurar o reencaminhamento rápido do BGP | fast-reroute route-map rtmap-name | opcional _ Por padrão, não habilite a função de reencaminhamento rápido. |
Após configurar o reencaminhamento rápido do BGP, é necessário redefinir o BGP, concluir a verificação inicial da rota e o backup. Caso contrário, apenas as rotas aprendidas após a configuração terão efeito. Depois de configurar o reencaminhamento rápido do BGP para aplicar para o mapa de rotas, defina o vizinho do BGP como o próximo salto de backup por meio do comando set fast-reroute backup-nexthop nexthop-address no mapa de roteamento. Se o vizinho não BGP estiver configurado como o próximo salto de backup, a função de reencaminhamento rápido não terá efeito.
Monitoramento e Manutenção de BGP
Tabela 12 -48Monitoramento e Manutenção de BGP
| Comando | Descrição |
| clear ip bgp { * [ vrf vrf-name ] | neighbor-address [ vrf vrf-name ] | as-number | peer-group peer-group-name | external } | Redefine o vizinho BGP. |
| clear ip bgp [ ipv4 unicast | ipv4 multicast ] dampening [ ip-address | ip-address/mask-length ] | Limpa rotas suprimidas. |
| clear ip bgp [ ipv4 unicast | ipv4 multicast ] flap-statistics [ ip-address | ip-address/mask-length ] | Limpa as estatísticas do flap de roteamento. |
| clear ip bgp { * | neighbor-address | as-number | peer-group peer-group-name | external } [ ipv4 unicast | ipv4 multicast | vpnv4 unicast | vrf vrf-name ] { [ soft ] [ in | out ] } | Soft redefine os vizinhos. |
| clear ip bgp { * | neighbor-address } in { ecomm | prefix-filter } | Anuncia ORF aos vizinhos. |
| show ip bgp [ vpnv4 { all | vrf vrf-name | rd route-distinguisher } ] [ ip-address | ip-address/mask-length ] | Exiba as informações de roteamento na família de endereços BGP relacionada. |
| show ip bgp attribute-info | Exiba os atributos de rota comum do BGP. |
| show ip bgp cidr-only | Exiba todas as rotas de rede classful do BGP. |
| show ip bgp community [community-number / aa:nn / exact-match / local-AS / no-advertise / no-export ] | Exiba as rotas que correspondem à propriedade de comunidade especificada. |
| show ip bgp community-info | Exiba todas as informações de propriedade da comunidade do BGP. |
| show ip bgp community-list community-list-name | Exiba a lista de comunidades que é aplicada às rotas. |
| show ip bgp [ vpnv4 { all | vrf vrf-name | rd route-distinguisher } ] dampening { dampened-paths | flap-statistics | parameters } | Exibe os detalhes da atenuação da rota. |
| show ip bgp filter-list filter-list-name [ exact-match ] | Exiba as rotas que correspondem à lista de filtros AS_PATH. |
| show ip bgp inconsistent-as | Exiba as rotas que estão em conflito com AS_PATH. |
| show ip bgp [ vpnv4 all ] neighbors [ ip-address ] | Exiba os detalhes dos vizinhos BGP. |
| show ip bgp orf ecomm | Exiba as informações ORF de todos os vizinhos BGP. |
| show ip bgp paths | Exiba as informações AS_PATH das rotas BGP. |
| show ip bgp prefix-list prefix-list-name | Exiba as rotas que correspondem à lista de filtros. |
| show ip bgp quote-regexp as-path-list-name | Exiba as rotas que correspondem à lista AS_PATH. |
| show ip bgp regexp as-path-list-name | Exiba as rotas que correspondem à lista AS_PATH. |
| show ip bgp route-map rtmap-name | Exiba as rotas que correspondem a um mapa de rotas. |
| show ip bgp scan | Exiba as informações de varredura BGP. |
| show ip bgp [ vpnv4 { all | vrf vrf-name | rd route-distinguisher } | vxlan] summary | Exiba o resumo dos vizinhos BGP. |
| show ip bgp vxlan local-remote [ ip-address | neighbor ip-address ] | Exiba as informações de sessão local anunciadas pelo BGP para o vizinho |
| show ip bgp vxlan session [ ip-address | active ] | Exibir as informações da sessão aprendidas pelo BGP |
Exemplo de configuração típica do BGP
Configurar funções básicas do BGP
Requisitos de rede
- Configure vizinhos EBGP entre Device1 e Device2 e configure vizinhos IBGP entre Device2 e Device3.
- Device1 aprende a rota direta de interface 200.0.0.0/24 de Device3, e Device3 aprende a rota direta de interface 100.0.0.0/24 de Device1.
Topologia de rede

Figura 12 - 1Rede para configurar funções básicas do BGP
Etapas de configuração
- Passo 1: Configure a VLAN e junte a interface à VLAN correspondente. (Omitido)
- Passo 2: Configure os endereços IP das interfaces. (Omitido)
- Passo 3: Configure o OSPF para que as rotas de loopback sejam alcançáveis entre os dispositivos.
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 10.0.0.1 0.0.0.0 area 0Device2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 20.0.0.1 0.0.0.0 area 0Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
#Consulte a tabela de roteamento do Device2.
Device2#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 20.0.0.1/32 [110/2] via 2.0.0.2, 00:27:09, vlan3
#Consulte a tabela de roteamento do Device3.
Device3#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 10.0.0.1/32 [110/2] via 2.0.0.1, 00:28:13, vlan2
De acordo com as informações consultadas, Device2 e Device3 aprenderam as rotas das interfaces de loopback de peer executando OSPF, preparando-se para configurar vizinhos IBGP nas interfaces de loopback de Device2 e Device3.
- Passo 4: Configurar BGP.
# Configurar dispositivo1.
Configure uma relação de peer EBGP de conexão direta com Device2. Introduza 100.0.0.0/24 ao BGP no modo de rede.
Device1#configure terminalDevice1(config)#router bgp 200Device1(config-bgp)#neighbor 1.0.0.2 remote-as 100Device1(config-bgp)#network 100.0.0.0 255.255.255.0Device1(config-bgp)#exit
# Configurar dispositivo2.
Configure uma relação de peer IBGP de conexão não direta com Device3 por meio de Loopback0 e defina o próximo salto da rota anunciada para o dispositivo local e configure uma relação de peer EBGP de conexão direta com Device1.
Device2(config)#router bgp 100Device2(config-bgp)#neighbor 20.0.0.1 remote-as 100Device2(config-bgp)#neighbor 20.0.0.1 update-source loopback0Device2(config-bgp)#neighbor 1.0.0.1 remote-as 200Device2(config-bgp)#neighbor 20.0.0.1 next-hop-selfDevice2(config-bgp)#exit
# Configurar dispositivo3.
Configure uma relação de peer IBGP de conexão não direta com Device2 por meio de Loopback0. Introduza 200.0.0.0/24 ao BGP no modo de rede.
Device3(config)#router bgp 100Device3(config-bgp)#neighbor 10.0.0.1 remote-as 100Device3(config-bgp)#neighbor 10.0.0.1 update-source loopback0Device3(config-bgp)#network 200.0.0.0 255.255.255.0Device3(config-bgp)#exit
Para evitar a oscilação de rota, os vizinhos IBGP são configurados por meio das interfaces de loopback e o OSPF precisa sincronizar as informações de roteamento das interfaces de loopback entre os vizinhos IBGP.
- Passo 5: Confira o resultado.
#No Device2, verifique o status do vizinho BGP.
Device2#show ip bgp summaryBGP router identifier 10.0.0.1, local AS number 100BGP table version is 22 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd1.0.0.1 4 200 3 3 1 0 0 00:00:29 120.0.0.1 4 100 5 4 2 0 0 00:02:13 1
De acordo com os números (Número de prefixos de rota recebidos dos vizinhos) exibidos na coluna State/PfxRcd, os vizinhos BGP foram configurados com sucesso entre o Dispositivo 2 e o Dispositivo 1 e o Dispositivo2 e o Dispositivo 3.
#Consulte a tabela de roteamento do Device1.
Device1#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 200.0.0.0/24 [20/0] via 1.0.0.2, 00:15:52, vlan3
#Consulte a tabela de roteamento do Device2.
Device2#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 100.0.0.0/24 [20/0] via 1.0.0.1, 00:14:11, vlan2B 200.0.0.0/24 [200/0] via 20.0.0.1, 00:17:12, vlan3
#Consulte a tabela de roteamento do Device3.
Device3#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 100.0.0.0/24 [200/0] via 10.0.0.1, 00:14:50, vlan2
Device1 aprendeu a rota direta de interface 200.0.0.0/24 de Device3, e Device3 aprendeu a rota direta de interface 100.0.0.0/24 de Device1.
Configurar BGP para redistribuir rotas
Requisitos de rede
- Configure vizinhos OSPF entre Device3 e Device2 e anuncie a rota de conexão direta da interface 200.0.0.0/24 para Device2.
- Configure vizinhos EBGP entre Device1 e Device2 e redistribua a rota OSPF que Device2 aprende para BGP e anuncie a rota para Device1.
Topologia de rede

Figura 12 - 2Rede para configurar o BGP para redistribuir rotas
Etapas de configuração
- Passo 1: Configure a VLAN e junte a interface à VLAN correspondente. (Omitido)
- Passo 2: Configure os endereços IP das interfaces. (Omitido)
- Passo 3: Configure o OSPF para que as rotas de loopback sejam alcançáveis entre os dispositivos.
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 200.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
#Consulte a tabela de roteamento do Device2.
Device2#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 200.0.0.0/24 [110/2] via 2.0.0.2, 00:01:45, vlan3
De acordo com a tabela de roteamento, Device2 aprendeu a rota OSPF 200.0.0.0/24 que foi anunciada pelo Device 3 .
- Passo 4: Configurar BGP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router bgp 200Device1(config-bgp)#neighbor 1.0.0.2 remote-as 100Device1(config-bgp)#exit
# Configurar dispositivo2.
Device2(config)#router bgp 100Device2(config-bgp)#neighbor 1.0.0.1 remote-as 200Device2(config-bgp)#exit
#No Device2, verifique o status do vizinho BGP.
Device2#show ip bgp summaryBGP router identifier 2.0.0.1, local AS number 100BGP table version is 21 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd1.0.0.1 4 200 2 2 2 0 0 00:00:42 0
Os vizinhos BGP foram configurados com sucesso entre Device2 e Device1.
- Passo 5: Configure o BGP para redistribuir a rota OSPF.
# Configurar dispositivo2.
Device2(config)#router bgp 100Device2(config-bgp)#redistribute ospf 100Device2(config-bgp)#exit
- Passo 6: Confira o resultado.
#Consulte a tabela de roteamento BGP do Device2.
Device2#show ip bgpBGP table version is 6, local router ID is 2.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[O]*> 2.0.0.0/24 0.0.0.0 1 32768 ?[O]*> 200.0.0.0/24 2.0.0.2 2 32768 ?
De acordo com as informações consultadas, as rotas OSPF foram redistribuídas com sucesso para o BGP.
#Consulte a tabela de roteamento do Device1.
Device1#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 2.0.0.0/24 [20/1] via 1.0.0.2, 00:06:14, vlan2B 200.0.0.0/24 [20/2] via 1.0.0.2, 00:06:14, vlan2
De acordo com as informações consultadas, Device1 aprendeu com sucesso as rotas 2.0.0.0/24 e 200.0.0.0/24.
Em um aplicativo real, se houver dois ou mais roteadores de limite AS, é recomendável não redistribuir rotas entre diferentes protocolos de roteamento. Se a redistribuição de rota precisar ser configurada, você deverá configurar políticas de controle de rota, como filtragem de rota e resumo de filtragem nos roteadores de limite AS para evitar loops de roteamento.
Configurar propriedades da comunidade BGP
Requisitos de rede
- Configure vizinhos EBGP entre Device1 e Device2.
- Device1 apresenta duas rotas de conexão direta 100.0.0.0/24 e 200.0.0.0/24 para BGP no modo de rede e define propriedades de comunidade diferentes para duas rotas anunciadas para Device2.
- Quando Device2 recebe rotas de Device1, ele aplica propriedades de comunidade na direção de entrada de um vizinho para filtrar a rota 100.0.0.0/24 e permitir a rota 200.0.0.0/24.
Topologia de rede
Figura 12 - 3Rede para configurar propriedades da comunidade BGP
Etapas de configuração
- Passo 1: Configure a VLAN e junte a interface à VLAN correspondente. (Omitido)
- Passo 2: Configure os endereços IP das interfaces. (Omitido)
- Passo 3: Configurar BGP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router bgp 100Device1(config-bgp)#neighbor 2.0.0.2 remote-as 200Device1(config-bgp)#network 100.0.0.0 255.255.255.0Device1(config-bgp)#network 200.0.0.0 255.255.255.0Device1(config-bgp)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router bgp 200Device2(config-bgp)#neighbor 2.0.0.1 remote-as 100Device2(config-bgp)#exit
#No Device1, verifique o status do vizinho BGP.
Device1#show ip bgp summaryBGP router identifier 200.0.0.1, local AS number 100BGP table version is 11 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd2.0.0.2 4 200 2 3 1 0 0 00:00:04 0
Os vizinhos BGP foram configurados com sucesso entre Device1 e Device2.
#Consulte a tabela de roteamento do Device2.
Device2#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 100.0.0.0/24 [20/0] via 2.0.0.1, 00:07:47, vlan2B 200.0.0.0/24 [20/0] via 2.0.0.1, 00:07:47, vlan2
De acordo com as informações consultadas, Device2 aprendeu com sucesso as rotas 100.0.0.0/24 e 200.0.0.0/24.
- Passo 4: Configure a ACL e a política de roteamento e defina as propriedades da comunidade BGP.
# Configurar dispositivo1.
Device1(config)#ip access-list standard 1Device1(config-std-nacl)#permit 100.0.0.0 0.0.0.255Device1(config-std-nacl)#commitDevice1(config-std-nacl)#exitDevice1(config)#ip access-list standard 2Device1(config-std-nacl)#permit 200.0.0.0 0.0.0.255Device1(config-std-nacl)#commitDevice1(config-std-nacl)#exitDevice1(config)#route-map CommunitySet 10Device1(config-route-map)#match ip address 1Device1(config-route-map)#set community 100:1Device1(config-route-map)#exitDevice1(config)#route-map CommunitySet 20Device1(config-route-map)#match ip address 2Device1(config-route-map)#set community 100:2Device1(config-route-map)#exit
Defina diferentes propriedades de comunidade para as rotas 100.0.0.0/24 e 200.0.0.0/24, respectivamente, configurando uma ACL e uma política de roteamento.
- Passo 5: Configure uma política de roteamento para BGP.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#neighbor 2.0.0.2 route-map CommunitySet outDevice1(config-bgp)#neighbor 2.0.0.2 send-communityDevice1(config-bgp)#exit
#Consulte a tabela de roteamento BGP do Device2.
Device2#show ip bgp 100.0.0.0BGP routing table entry for 100.0.0.0/24Paths: (1 available, best #1, table Default-IP-Routing-Table)Not advertised to any peer1002.0.0.1 (metric 10) from 2.0.0.1 (10.0.0.1)Origin IGP, metric 0, localpref 100, valid, external, bestCommunity: 100:1Last update: 00:01:06 agoDevice2#show ip bgp 200.0.0.0BGP routing table entry for 200.0.0.0/24Paths: (1 available, best #1, table Default-IP-Routing-Table)Not advertised to any peer1002.0.0.1 (metric 10) from 2.0.0.1 (10.0.0.1)Origin IGP, metric 0, localpref 100, valid, external, bestCommunity: 100:2Last update: 00:01:10 ago
De acordo com a tabela de roteamento BGP de Device2, a propriedade de comunidade da rota 100.0.0.0/24 é definida como 100:1 e as propriedades de comunidade da rota 200.0.0.0/24 são definidas como 100:2.
- Passo 6: Configure a filtragem de rota BGP.
# Configurar dispositivo2.
Device2(config)#ip community-list 1 permit 100:2Device2(config)#route-map communityfilterDevice2(config-route-map)#match community 1Device2(config-route-map)#exitDevice2(config)#router bgp 200Device2(config-bgp)#neighbor 2.0.0.1 route-map communityfilter inDevice2(config-bgp)#exit
- Passo 7: Confira o resultado.
#Consulte a tabela de roteamento do Device2.
Device2#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 200.0.0.0/24 [20/0] via 2.0.0.1, 00:00:53, vlan2
De acordo com a tabela de roteamento BGP do Device2, a rota 100.0.0.0/24 foi filtrada na direção de entrada e a rota 200.0.0.0/24 foi permitida.
Depois que uma política de roteamento é configurada no peer, o BGP deve ser redefinido para que a configuração entre em vigor. Você deve configurar o comando send-community para anunciar a propriedade da comunidade ao peer.
Configurar o refletor de rota BGP
Requisitos de rede
- Configure vizinhos EBGP entre Device3 e Device4 e configure Device4 para anunciar a rota 100.0.0.0/24.
- Configure vizinhos IBGP entre Device2 e Device3 e entre Device2 e Device1 respectivamente. Em Device2, configure Route Reflectors (RRs) e configure Device1 e Device3 como clientes, para que Device1 possa aprender a rota 100.0.0.0/24 anunciada por Device4.
Topologia de rede
Figura 12 - 4 Rede para configurar um refletor de rota BGP
Etapas de configuração
- Passo 1: Configure a VLAN e junte a interface à VLAN correspondente. (Omitido)
- Passo 2: Configure os endereços IP das interfaces. (Omitido)
- Passo 3: Configure o OSPF para que as rotas de loopback sejam alcançáveis entre os dispositivos.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 10.0.0.1 0.0.0.0 area 0Device1(config-ospf)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 20.0.0.1 0.0.0.0 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device2#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 30.0.0.1 0.0.0.0 area 0Device3(config-ospf)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 2.0.0.0/24 [110/2] via 1.0.0.2, 01:12:00, vlan2O 20.0.0.1/32 [110/2] via 1.0.0.2, 01:11:47, vlan2O 30.0.0.1/32 [110/3] via 1.0.0.2, 01:07:47, vlan2
#Consulte a tabela de roteamento do Device2.
Device2#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 10.0.0.1/32 [110/2] via 1.0.0.1, 01:13:02, vlan2O 30.0.0.1/32 [110/2] via 2.0.0.2, 01:08:58, vlan3
#Consulte a tabela de roteamento do Device3.
Device3#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 1.0.0.0/24 [110/2] via 2.0.0.1, 01:10:04, vlan2O 10.0.0.1/32 [110/3] via 2.0.0.1, 01:10:04, vlan2O 20.0.0.1/32 [110/2] via 2.0.0.1, 01:10:04, vlan2
De acordo com a tabela de roteamento, Device1, Device2 e Device3 aprenderam as rotas das interfaces de loopback um do outro.
- Passo 4: Configurar BGP.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#neighbor 20.0.0.1 remote-as 100Device1(config-bgp)#neighbor 20.0.0.1 update-source loopback0Device1(config-bgp)#exit
# Configurar dispositivo2.
Device2(config)#router bgp 100Device2(config-bgp)#neighbor 30.0.0.1 remote-as 100Device2(config-bgp)#neighbor 30.0.0.1 update-source loopback0Device2(config-bgp)#neighbor 10.0.0.1 remote-as 100Device2(config-bgp)#neighbor 10.0.0.1 update-source loopback0Device2(config-bgp)#exit
# Configurar dispositivo3.
Device3(config)#router bgp 100Device3(config-bgp)#neighbor 3.0.0.2 remote-as 200Device3(config-bgp)#neighbor 20.0.0.1 remote-as 100Device3(config-bgp)#neighbor 20.0.0.1 update-source loopback0Device3(config-bgp)#neighbor 20.0.0.1 next-hop-selfDevice3(config-bgp)#exit
# Configurar dispositivo4.
Device4#configure terminalDevice4(config)#router bgp 200Device4(config-bgp)#neighbor 3.0.0.1 remote-as 100Device4(config-bgp)#network 100.0.0.0 255.255.255.0Device4(config-bgp)#exit
#No Device2, verifique o status do vizinho BGP.
Device2#show ip bgp summaryBGP router identifier 20.0.0.1, local AS number 100BGP table version is 12 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd10.0.0.1 4 100 8 8 1 0 0 00:03:01 030.0.0.1 4 100 9 9 1 0 0 00:02:41 1
#No Device4, verifique o status do vizinho BGP.
Device4#show ip bgp summaryBGP router identifier 100.0.0.1, local AS number 200BGP table version is 11 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd3.0.0.1 4 100 19 19 1 0 0 00:05:40 0
De acordo com as informações consultadas, os vizinhos BGP foram configurados entre os dispositivos.
#Consulte a tabela de roteamento BGP do Device3.
Device3#show ip bgpBGP table version is 2, local router ID is 30.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 100.0.0.0/24 3.0.0.2 0 0 200 i
#Consulte a tabela de roteamento BGP do Device2.
Device2#show ip bgpBGP table version is 768, local router ID is 20.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*>i100.0.0.0/24 30.0.0.1 0 100 0 200 i
#Consulte a tabela de roteamento BGP de Device1.
Device1#show ip bgpBGP table version is 2, local router ID is 10.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path
De acordo com a tabela de roteamento, Device2 e Device3 aprenderam a rota 100.0.0.0/24 e Device2 não anunciou a rota para Device1.
- Passo 5: Configure um refletor de rota BGP.
# Configurar dispositivo2.
Device2(config)#router bgp 100Device2(config-bgp)#neighbor 10.0.0.1 route-reflector-clientDevice2(config-bgp)#neighbor 30.0.0.1 route-reflector-client
Device2(config-bgp)#exit
No Device2, Device1 e Device3 foram configurados como clientes RR.
- Passo 6: Confira o resultado.
#Consulte a tabela de roteamento do Device1.
Device1#show ip bgpBGP table version is 2, local router ID is 10.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*>i100.0.0.0/24 30.0.0.1 0 100 0 200 iDevice1#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 100.0.0.0/24 [200/0] via 30.0.0.1, 00:01:40, vlan2
No BGP de Device2, Device1 e Device3 foram configurados como clientes RR, e Device2 refletiu com sucesso a rota 100.0.0.0/24 para o cliente RR Device1.
Se você configurar um peer como cliente RR, o dispositivo e os vizinhos do peer serão redefinidos.
Configurar o resumo da rota BGP
Requisitos de rede
- Configure vizinhos OSPF entre Device1 e Device3 e configure Device3 para anunciar as rotas 100.1.0.0/24 e 100.2.0.0/24 para Device1.
- Configure vizinhos EBGP entre Device1 e Device2.
- Em Device1, agregue as rotas 100.1.0.0/24 e 100.2.0.0/24 na rota 100.0.0.0/14 e anuncie a rota agregada para Device2.
Topologia de rede
Figura 12 - 5Rede para configurar o resumo da rota BGP
Etapas de configuração
- Passo 1: Configure a VLAN e junte a interface à VLAN correspondente. (Omitido)
- Passo 2: Configure os endereços IP das interfaces. (Omitido)
- Passo 3: Configure o OSPF para que as rotas de loopback sejam alcançáveis entre os dispositivos.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 100.1.0.0 0.0.0.255 area 0Device3(config-ospf)#network 100.2.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 100.1.0.0/24 [110/2] via 2.0.0.2, 00:00:24, vlan3O 100.2.0.0/24 [110/2] via 2.0.0.2, 00:00:24, vlan3
De acordo com a tabela de roteamento, Device1 aprendeu as rotas 100.1.0.0/24 e 100.2.0.0/24 anunciadas pelo Device3.
- Passo 4: Configurar BGP.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#neighbor 1.0.0.2 remote-as 200Device1(config-bgp)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router bgp 200Device2(config-bgp)#neighbor 1.0.0.1 remote-as 100Device2(config-bgp)#exit
#No Device1, verifique o status do vizinho BGP.
Device1#show ip bgp summaryBGP router identifier 1.0.0.1, local AS number 100BGP table version is 21 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd1.0.0.2 4 200 2 2 2 0 0 00:00:42 0
Os vizinhos BGP foram configurados com sucesso entre Device1 e Device2.
- Passo 5: Configure o resumo da rota BGP.
Duas soluções estão disponíveis para satisfazer os requisitos de rede.
Solução 1: configure uma rota estática agregada direcionada a null0 para introduzir a rota estática agregada ao BGP.
# Configurar dispositivo1.
Device1(config)#ip route 100.0.0.0 255.252.0.0 null0Device1(config)#router bgp 100Device1(config-bgp)#network 100.0.0.0 255.252.0.0Device1(config-bgp)#exit
Confira o resultado.
#Consulte a tabela de roteamento BGP de Device1.
Device1#show ip bgpBGP table version is 2, local router ID is 10.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 100.0.0.0/14 0.0.0.0 32768 i
A rota agregada 100.0.0.0/14 foi gerada na tabela de roteamento BGP de Device1.
#Consulte a tabela de roteamento do Device2.
Device2#show ip bgpBGP table version is 3, local router ID is 20.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 100.0.0.0/14 1.0.0.1 0 0 100 iDevice2#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 100.0.0.0/14 [20/0] via 1.0.0.1, 01:39:30, vlan2
Device2 aprendeu com sucesso a rota agregada 100.0.0.0/14 que foi anunciada pelo Device 1 .
Solução 2: Primeiro, introduza rotas comuns no BGP e, em seguida, execute o comando agregador-endereço para agregar as rotas.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#redistribute ospf 100Device1(config-bgp)#aggregate-address 100.0.0.0 255.252.0.0 summary-onlyDevice1(config-bgp)#exit
Confira o resultado.
#Consulte a tabela de roteamento BGP de Device1.
Device1#show ip bgpBGP table version is 2, local router ID is 10.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 100.0.0.0/14 0.0.0.0 32768 i[B]s> 100.1.0.0/24 2.0.0.2 2 32768 i[B]s> 100.2.0.0/24 2.0.0.2 2 32768 i
A rota agregada 100.0.0.0/14 foi gerada na tabela de roteamento BGP de Device1.
#Consulte a tabela de roteamento do Device2.
Device2#show ip bgpBGP table version is 3, local router ID is 20.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 100.0.0.0/14 1.0.0.1 0 0 100 iDevice2#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 100.0.0.0/14 [20/0] via 1.0.0.1, 01:39:30, vlan2
Device2 aprendeu com sucesso a rota agregada 100.0.0.0/14 que foi anunciada pelo Device 1 .
Quando o comando agregado-endereço é usado para agregar rotas, se o comando estendido estiver configurado, o dispositivo anuncia apenas a rota agregada; caso contrário, as rotas comuns e as rotas agregadas são anunciadas.
Configurar a prioridade de seleção de rota BGP
Requisitos de rede
- Configure vizinhos IBGP entre Device1 e Device2 e entre Device1 e Device3, e configure vizinhos EBGP entre Device4 e Device2 e entre Device4 e Device3.
- Device1 anuncia duas rotas 55.0.0.0/24 e 65.0.0.0/24 para Device4 e Device4 anuncia duas rotas 75.0.0.0/24 e 85.0.0.0/24 para Device1.
- Modifique a propriedade Local-preference das rotas em Device2 e Device3 para que Device1 selecione a rota 75.0.0.0/24 anunciada por Device2 e a rota 85.0.0.0/24 anunciada por Device3 com prioridade.
- Modifique a propriedade MED das rotas em Device2 e Device3 para que Device4 selecione a rota 55.0.0.0/24 anunciada por Device2 e a rota 65.0.0.0/24 anunciada por Device3 com prioridade.
Topologia de rede
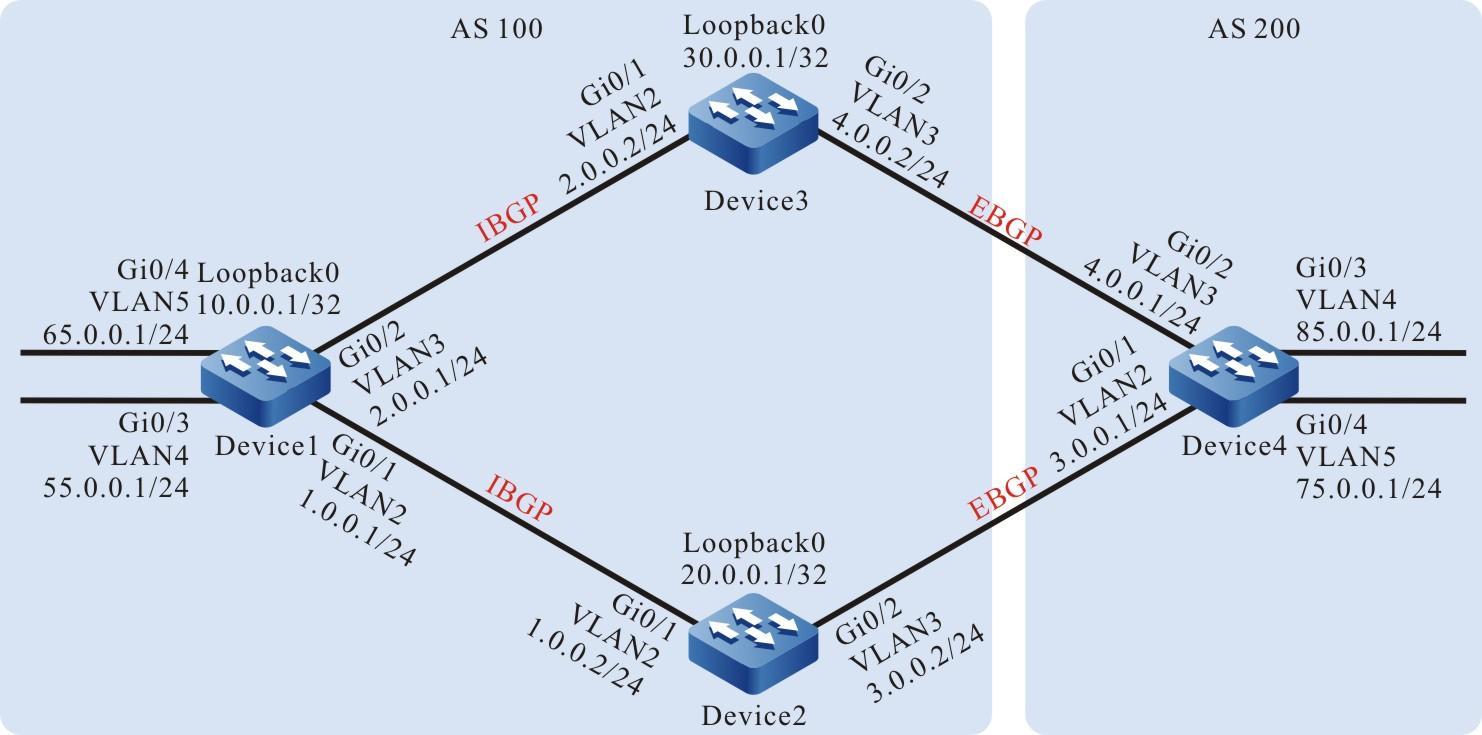
Figura 12 - 6 Rede para configurar a prioridade de seleção de rota BGP
Etapas de configuração
- Passo 1: Configure a VLAN e junte a interface à VLAN correspondente. (Omitido)
- Passo 2: Configure os endereços IP das interfaces. (Omitido)
- Passo 3: Configure o OSPF para que as rotas de loopback sejam alcançáveis entre os dispositivos.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 10.0.0.1 0.0.0.0 area 0Device1(config-ospf)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 20.0.0.1 0.0.0.0 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 30.0.0.1 0.0.0.0 area 0Device3(config-ospf)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 20.0.0.1/32 [110/2] via 1.0.0.2, 00:03:15, vlan2O 30.0.0.1/32 [110/2] via 2.0.0.2, 00:01:40, vlan3
#Consulte a tabela de roteamento do Device2.
Device2#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 2.0.0.0/24 [110/2] via 1.0.0.1, 00:03:54, vlan2O 10.0.0.1/32 [110/2] via 1.0.0.1, 00:03:54, vlan2O 30.0.0.1/32 [110/3] via 1.0.0.1, 00:02:14, vlan2
#Consulte a tabela de roteamento do Device3.
Device3#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 1.0.0.0/24 [110/2] via 2.0.0.1, 00:02:35, vlan2O 10.0.0.1/32 [110/2] via 2.0.0.1, 00:02:35, vlan2O 20.0.0.1/32 [110/3] via 2.0.0.1, 00:02:35, vlan2
De acordo com a tabela de roteamento, Device1, Device2 e Device3 aprenderam as rotas das interfaces de loopback um do outro.
- Passo 4: Configurar BGP.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#neighbor 20.0.0.1 remote-as 100Device1(config-bgp)#neighbor 20.0.0.1 update-source loopback0Device1(config-bgp)#neighbor 30.0.0.1 remote-as 100Device1(config-bgp)#neighbor 30.0.0.1 update-source loopback0Device1(config-bgp)#network 55.0.0.0 255.255.255.0Device1(config-bgp)#network 65.0.0.0 255.255.255.0Device1(config-bgp)#exit
# Configurar dispositivo2.
Device2(config)#router bgp 100Device2(config-bgp)#neighbor 10.0.0.1 remote-as 100Device2(config-bgp)#neighbor 10.0.0.1 update-source loopback0Device2(config-bgp)#neighbor 10.0.0.1 next-hop-selfDevice2(config-bgp)#neighbor 3.0.0.1 remote-as 200Device2(config-bgp)#exit
# Configurar dispositivo3.
Device3(config)#router bgp 100Device3(config-bgp)#neighbor 10.0.0.1 remote-as 100Device3(config-bgp)#neighbor 10.0.0.1 update-source loopback0Device3(config-bgp)#neighbor 10.0.0.1 next-hop-selfDevice3(config-bgp)#neighbor 4.0.0.1 remote-as 200Device3(config-bgp)#exit
# Configurar dispositivo4.
Device4#configure terminalDevice4(config)#router bgp 200Device4(config-bgp)#neighbor 3.0.0.2 remote-as 100Device4(config-bgp)#neighbor 4.0.0.2 remote-as 100Device4(config-bgp)#network 75.0.0.0 255.255.255.0Device4(config-bgp)#network 85.0.0.0 255.255.255.0Device4(config-bgp)#exit
#No Device1, verifique o status do vizinho BGP.
Device1#show ip bgp summaryBGP router identifier 10.0.0.1, local AS number 100BGP table version is 22 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd20.0.0.1 4 100 11 11 2 0 0 00:07:40 230.0.0.1 4 100 7 7 2 0 0 00:03:59 2
#No Device4, verifique o status do vizinho BGP.
Device4#show ip bgp summaryBGP router identifier 85.0.0.1, local AS number 200BGP table version is 22 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd3.0.0.2 4 100 5 6 2 0 0 00:02:24 24.0.0.2 4 100 6 5 2 0 0 00:02:24 2
Os vizinhos IBGP foram configurados entre Device1 e Device2 e entre Device2 e Device3, e os vizinhos EBGP foram configurados entre Device4 e Device2 e entre Device4 e Device3.
#Consulte a tabela de roteamento do Device1.
Device1#show ip bgpBGP table version is 2, local router ID is 10.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 55.0.0.0/24 0.0.0.0 0 32768 i[B]*> 65.0.0.0/24 0.0.0.0 0 32768 i[B]* i75.0.0.0/24 30.0.0.1 0 100 0 200 i[B]*>i 20.0.0.1 0 100 0 200 i[B]* i85.0.0.0/24 30.0.0.1 0 100 0 200 i[B]*>i 20.0.0.1 0 100 0 200 iDevice1#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 75.0.0.0/24 [200/0] via 20.0.0.1, 01:13:17, vlan2B 85.0.0.0/24 [200/0] via 20.0.0.1, 01:13:17, vlan2
De acordo com a tabela de roteamento, tanto a rota 75.0.0.0/24 quanto a rota 85.0.0.0/24 de Device1 selecionam Device2 como o dispositivo de próximo salto.
#Consulte a tabela de roteamento do Device4.
Device4#show ip bgpBGP table version is 2, local router ID is 85.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]* 55.0.0.0/24 3.0.0.2 0 0 100 i[B]*> 4.0.0.2 0 0 100 i[B]* 65.0.0.0/24 3.0.0.2 0 0 100 i[B]*> 4.0.0.2 0 0 100 i[B]*> 75.0.0.0/24 0.0.0.0 0 32768 i[B]*> 85.0.0.0/24 0.0.0.0 0 32768 iDevice4#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 55.0.0.0/24 [20/0] via 4.0.0.2, 01:25:19, vlan3B 65.0.0.0/24 [20/0] via 4.0.0.2, 01:25:19, vlan3
De acordo com a tabela de roteamento, tanto a rota 55.0.0.0/24 quanto a rota 65.0.0.0/24 de Device4 selecionam Device3 como o dispositivo de próximo salto.
- Passo 5: Configure uma ACL e uma política de roteamento para definir a métrica e a preferência local.
# Configurar dispositivo2.
Device2(config)#ip access-list standard 1Device2(config-std-nacl)#permit 75.0.0.0 0.0.0.255Device2(config-std-nacl)#commitDevice2(config-std-nacl)#exitDevice2(config)#ip access-list standard 2Device2(config-std-nacl)#permit 65.0.0.0 0.0.0.255Device2(config-std-nacl)#commitDevice2(config-std-nacl)#exitDevice2(config)#route-map SetPriority1 10Device2(config-route-map)#match ip address 1Device2(config-route-map)#set local-preference 110Device2(config-route-map)#exiDevice2(config)#route-map SetPriority1 20Device2(config-route-map)#exitDevice2(config)#route-map SetPriority2 10Device2(config-route-map)#match ip address 2Device2(config-route-map)#set metric 100Device2(config-route-map)#exitDevice2(config)#route-map SetPriority2 20Device2(config-route-map)#exit
No Device2, configure uma política de roteamento para definir a preferência local da rota 75.0.0.0/24 para 110 e defina a métrica da rota 65.0.0.0/24 para 100.
# Configurar dispositivo3.
Device3(config)#ip access-list standard 1Device3(config-std-nacl)#permit 85.0.0.0 0.0.0.255Device2(config-std-nacl)#commitDevice3(config-std-nacl)#exitDevice3(config)#ip access-list standard 2Device3(config-std-nacl)#permit 55.0.0.0 0.0.0.255Device2(config-std-nacl)#commitDevice3(config-std-nacl)#exitDevice3(config)#route-map SetPriority1 10Device3(config-route-map)#match ip address 1Device3(config-route-map)#set local-preference 110Device3(config-route-map)#exitDevice3(config)#route-map SetPriority1 20Device3(config-route-map)#exitDevice3(config)#route-map SetPriority2 10Device3(config-route-map)#match ip address 2Device3(config-route-map)#set metric 100Device3(config-route-map)#exitDevice3(config)#route-map SetPriority2 20Device3(config-route-map)#exit
No Device3, configure uma política de roteamento para definir a preferência local da rota 85.0.0.0/24 para 110 e defina a métrica da rota 55.0.0.0/24 para 100.
Ao configurar uma política de roteamento, você pode criar uma regra de filtragem com base em uma lista de prefixos ou ACL. A lista de prefixos pode corresponder precisamente às máscaras de roteamento, enquanto a ACL não pode corresponder às máscaras de roteamento.
- Passo 6: Configure uma política de roteamento para BGP.
# Configurar dispositivo2.
Device2(config)#router bgp 100Device2(config-bgp)#neighbor 10.0.0.1 route-map SetPriority1 outDevice2(config-bgp)#neighbor 3.0.0.1 route-map SetPriority2 outDevice2(config-bgp)#exit
No Device2, configure a direção de saída do vizinho 10.0.0.1 para modificar a preferência local da rota 75.0.0.0/24 e configure a direção de saída do vizinho 3.0.0.1 para modificar a métrica da rota 65.0.0.0/24.
# Configurar dispositivo3.
Device3(config)#router bgp 100Device3(config-bgp)#neighbor 10.0.0.1 route-map SetPriority1 outDevice3(config-bgp)#neighbor 4.0.0.1 route-map SetPriority2 outDevice3(config-bgp)#exit
No Device3, configure a direção de saída do vizinho 10.0.0.1 para modificar a preferência local da rota 85.0.0.0/24 e configure a direção de saída do vizinho 4.0.0.1 para modificar a métrica da rota 55.0.0.0/24.
Depois que uma política de roteamento é configurada no peer, o BGP deve ser redefinido para que a configuração entre em vigor.
- Passo 7: Confira o resultado.
#Consulte a tabela de roteamento do Device1.
Device1#show ip bgpBGP table version is 5, local router ID is 10.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 55.0.0.0/24 0.0.0.0 0 32768 i[B]*> 65.0.0.0/24 0.0.0.0 0 32768 i[B]* i75.0.0.0/24 30.0.0.1 0 100 0 200 i[B]*>i 20.0.0.1 0 110 0 200 i[B]*>i85.0.0.0/24 30.0.0.1 0 110 0 200 i[B]* i 20.0.0.1 0 100 0 200 iDevice1#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 75.0.0.0/24 [200/0] via 20.0.0.1, 00:01:34, vlan2B 85.0.0.0/24 [200/0] via 30.0.0.1, 00:00:51, vlan3
De acordo com a tabela de roteamento, a preferência local das rotas 75.0.0.0/24 e 85.0.0.0/24 é modificada com sucesso, e Device1 seleciona a rota 75.0.0.0/24 que é anunciada pelo Device2 e a rota 85.0.0.0/24 que é anunciada pelo Device3 com prioridade.
#Consulte a tabela de roteamento do Device4.
Device4#show ip bgpBGP table version is 4, local router ID is 85.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]* 55.0.0.0/24 4.0.0.2 100 0 100 i[B]*> 3.0.0.2 0 0 100 i[B]*> 65.0.0.0/24 4.0.0.2 0 0 100 i[B]* 3.0.0.2 100 0 100 i[B]*> 75.0.0.0/24 0.0.0.0 0 32768 i[B]*> 85.0.0.0/24 0.0.0.0 0 32768 iDevice4#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 55.0.0.0/24 [20/0] via 3.0.0.2, 00:15:02, vlan2B 65.0.0.0/24 [20/0] via 4.0.0.2, 00:14:55, vlan3
De acordo com a tabela de roteamento, a métrica das rotas 55.0.0.0/24 e 65.0.0.0/24 é modificada com sucesso, e Device4 seleciona a rota 55.0.0.0/24 que é anunciada por Device2 e a rota 65.0.0.0/24 que é anunciada por Device3 com prioridade.
Uma política de roteamento pode ser usada na direção de saída do anúncio de rota e também pode ser usada na direção de entrada de recebimento de rota.
Configurar Confederação BGP
Requisitos de rede
- Device2, Device3, Device4 e Device5 estão no mesmo BGP AS 200. Para reduzir o número de conexões completas IBGP, eles são divididos em dois ASs diferentes em uma confederação BGP.
- Configure vizinhos EBGP entre Device1 e Device2 e anuncie a rota 100.0.0.0/24 para AS 200.
Topologia de rede
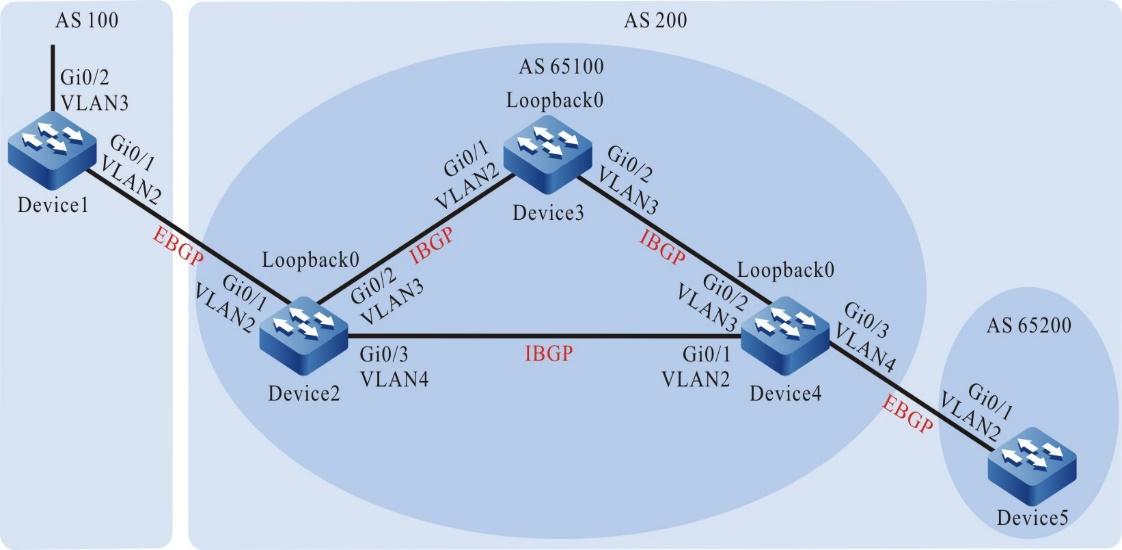
Figura 12 - 7Rede para configurar uma confederação BGP
| Dispositivo | Interface | VLAN | Endereço de IP |
| Dispositivo1 | Gi0/1 Gi0/2 |
2 3 |
1.0.0.1/24 100.0.0.1/24 |
| Dispositivo2 | Gi0/1 Gi0/2 Gi0/3 |
2 3 4 |
1.0.0.2/24 2.0.0.2/24 3.0.0.2/24 |
| Loopback0 | 20.0.0.1/32 | ||
| Dispositivo3 | Gi0/1 Gi0/2 |
2 3 |
2.0.0.1/24 4.0.0.1/24 |
| Loopback0 | 30.0.0.1/32 | ||
| Dispositivo 4 | Gi0/1 Gi0/2 Gi0/3 |
2 3 4 |
3.0.0.1/24 4.0.0.1/24 5.0.0.1/24 |
| Loopback0 | 40.0.0.1/32 | ||
| Dispositivo 5 | Gi0/1 | 2 | 5.0.0.2/24 |
Etapas de configuração
- Passo 1: Configure a VLAN e junte a interface à VLAN correspondente. (Omitido)
- Passo 2: Configure os endereços IP das interfaces. (Omitido)
- Passo 3: Configure o OSPF para que as rotas de loopback sejam alcançáveis entre os dispositivos.
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 20.0.0.1 0.0.0.0 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 30.0.0.1 0.0.0.0 area 0Device3(config-ospf)#exit
# Configurar dispositivo4.
Device4#configure terminalDevice4(config)#router ospf 100Device4(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device4(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Device4(config-ospf)#network 5.0.0.0 0.0.0.255 area 0Device4(config-ospf)#network 40.0.0.1 0.0.0.0 area 0Device4(config-ospf)#exit
# Configurar dispositivo5.
Device5#configure terminalDevice5(config)#router ospf 100Device5(config-ospf)#network 5.0.0.0 0.0.0.255 area 0Device5(config-ospf)#exit
#Consulte a tabela de roteamento do Device2.
Device2#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 4.0.0.0/24 [110/2] via 2.0.0.1, 00:02:42, vlan3[110/2] via 3.0.0.1, 00:02:11, vlan4O 30.0.0.1/32 [110/2] via 2.0.0.1, 00:02:32, vlan3O 40.0.0.1/32 [110/2] via 3.0.0.1, 00:02:05, vlan4
#Consulte a tabela de roteamento do Device3.
Device3#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 3.0.0.0/24 [110/2] via 2.0.0.2, 00:03:24, vlan2[110/2] via 4.0.0.2, 00:02:38, vlan3O 20.0.0.1/32 [110/2] via 2.0.0.2, 00:03:24, vlan2O 40.0.0.1/32 [110/2] via 4.0.0.2, 00:02:38, vlan3
#Consulte a tabela de roteamento do Device4.
Device4#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 2.0.0.0/24 [110/2] via 3.0.0.2, 00:03:42, vlan2[110/2] via 4.0.0.1, 00:03:42, vlan3O 20.0.0.1/32 [110/2] via 3.0.0.2, 00:03:42, vlan2O 30.0.0.1/32 [110/2] via 4.0.0.1, 00:03:42, vlan3
#Consulte a tabela de roteamento do Device5.
Device5#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 2.0.0.0/24 [110/3] via 5.0.0.1, 00:00:03, vlan2O 3.0.0.0/24 [110/2] via 5.0.0.1, 00:00:03, vlan2O 4.0.0.0/24 [110/2] via 5.0.0.1, 00:00:03, vlan2O 20.0.0.1/32 [110/3] via 5.0.0.1, 00:00:03, vlan2O 30.0.0.1/32 [110/3] via 5.0.0.1, 00:00:03, vlan2O 40.0.0.1/32 [110/2] via 5.0.0.1, 00:00:03, vlan2
De acordo com a tabela de roteamento, Device2, Device3 e Device4 aprenderam as rotas das interfaces de loopback um do outro.
- Passo 4: Configure conexões BGP em uma confederação.
Configure conexões IBGP em uma confederação.
# Configurar dispositivo2.
Device2(config)#router bgp 65100Device2(config-bgp)#neighbor 30.0.0.1 remote-as 65100Device2(config-bgp)#neighbor 30.0.0.1 update-source loopback0Device2(config-bgp)#neighbor 40.0.0.1 remote-as 65100Device2(config-bgp)#neighbor 40.0.0.1 update-source loopback0Device2(config-bgp)#neighbor 30.0.0.1 next-hop-selfDevice2(config-bgp)#neighbor 40.0.0.1 next-hop-selfDevice2(config-bgp)#exit
# Configurar dispositivo3.
Device3(config)#router bgp 65100Device3(config-bgp)#neighbor 20.0.0.1 remote-as 65100Device3(config-bgp)#neighbor 20.0.0.1 update-source loopback0Device3(config-bgp)#neighbor 40.0.0.1 remote-as 65100Device3(config-bgp)#neighbor 40.0.0.1 update-source loopback0Device3(config-bgp)#exit
# Configurar dispositivo4.
Device4(config)#router bgp 65100Device4(config-bgp)#neighbor 20.0.0.1 remote-as 65100Device4(config-bgp)#neighbor 20.0.0.1 update-source loopback0Device4(config-bgp)#neighbor 30.0.0.1 remote-as 65100Device4(config-bgp)#neighbor 30.0.0.1 update-source loopback0Device4(config-bgp)#exit
Configure conexões EBGP em uma confederação.
# Configurar dispositivo4.
Device4(config)#router bgp 65100Device4(config-bgp)#neighbor 5.0.0.2 remote-as 65200Device4(config-bgp)#exit
# Configurar dispositivo5.
Device5(config)#router bgp 65200Device5(config-bgp)#neighbor 5.0.0.1 remote-as 65100Device5(config-bgp)#exit
#No Device4, verifique o status do vizinho BGP.
Device4#show ip bgp summaryBGP router identifier 40.0.0.1, local AS number 65100BGP table version is 21 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd5.0.0.2 4 65200 15 15 2 0 0 00:09:40 020.0.0.1 4 65100 9 9 2 0 0 00:07:49 030.0.0.1 4 65100 7 7 2 0 0 00:05:39 0
Vizinhos IBGP foram configurados entre Device4 e Device2 e entre Device4 e Device3, e vizinhos EBGP foram configurados entre Device4 e Device5.
- Passo 5: Configure uma confederação BGP.
# Configurar dispositivo1.
Configure um par EBGP. O número AS do peer é confederação como ID 200.
Device1#configure terminalDevice1(config)#router bgp 100Device1(config-bgp)#neighbor 1.0.0.2 remote-as 200Device1(config-bgp)#network 100.0.0.0 255.255.255.0Device1(config-bgp)#exit
# Configurar dispositivo2.
Configure o ID de confederação BGP para 200 e configure um par EBGP. O número do peer AS é 100.
Device2(config)#router bgp 65100Device2(config-bgp)#bgp confederation identifier 200Device2(config-bgp)#neighbor 1.0.0.1 remote-as 100Device2(config-bgp)#exit
# Configurar dispositivo3.
Configure o ID da confederação BGP para 200.
Device3(config)#router bgp 65100Device3(config-bgp)#bgp confederation identifier 200Device3(config-bgp)#exit
# Configurar dispositivo4.
Configure o ID da confederação BGP para 200 e configure a confederação para conter a área 65100.
Device4#configure terminalDevice4(config)#router bgp 65100Device4(config-bgp)#bgp confederation identifier 200Device4(config-bgp)#bgp confederation peers 65200Device4(config-bgp)#exit
# Configurar dispositivo5.
Configure o ID da confederação BGP para 200 e configure a confederação para conter a área 65200.
Device5(config)#router bgp 65200Device5(config-bgp)#bgp confederation identifier 200Device5(config-bgp)#bgp confederation peers 65100Device5(config-bgp)#exit
- Passo 6: Confira o resultado.
#No Device1, verifique o status do vizinho BGP.
Device1#show ip bgp summaryBGP router identifier 100.0.0.1, local AS number 100BGP table version is 21 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd1.0.0.2 4 200 6 6 2 0 0 00:02:20 0
Os vizinhos EBGP foram configurados com sucesso entre Device1 e Device2.
#No Device5, consulte as informações da rota.
Device5#show ip bgpBGP table version is 49, local router ID is 5.0.0.2Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 100.0.0.0/24 20.0.0.1 0 100 0 (65100) 100 iDevice5#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 100.0.0.0/24 [200/0] via 20.0.0.1, 00:00:38, vlan2
Device5 aprendeu com sucesso a rota 100.0.0.0/24, e a propriedade do próximo salto da rota permanece inalterada enquanto a rota é transmitida na confederação. Device2, Device3, Device4 e Device5 pertencem à mesma confederação e não são necessárias conexões completas. Device5 obtém informações de rota externa por meio de Device4.
Configurar BGP para coordenar com BFD
Requisitos de rede
- Configure vizinhos EBGP entre Device1 e Device2 e entre Device1 e Device3, e configure vizinhos IBGP entre Device2 e Device3.
- Device1 aprende a rota EBGP 3.0.0.0/24 de Device2 e Device3, e Device1 seleciona para encaminhar dados para o segmento de rede 3.0.0.0/24 por meio de Device2.
- Em Device1 e Device2, configure EBGP para coordenar com BFD. Quando a linha entre Device1 e Device2 fica com defeito, o BFD pode detectar rapidamente a falha e notificar o BGP sobre a falha. Em seguida, Device1 seleciona para encaminhar dados para o segmento de rede 3.0.0.0/24 por meio de Device3.
Topologia de rede
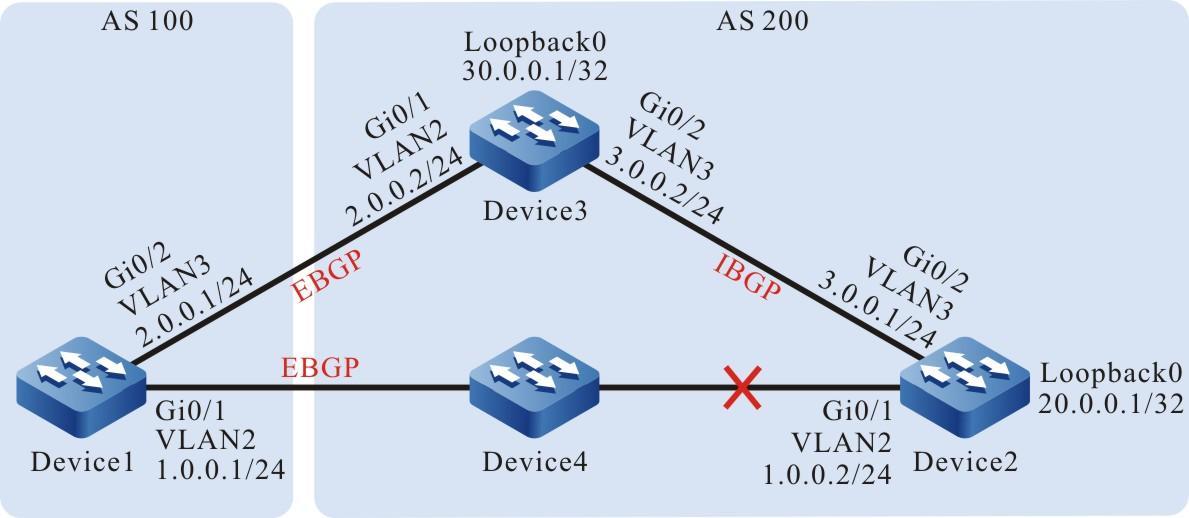
Figura 12 - 8Rede para configurar o BGP para coordenar com o BFD
Etapas de configuração
- Passo 1: Configure a VLAN e junte a interface à VLAN correspondente. (Omitido)
- Passo 2: Configure os endereços IP das interfaces. (Omitido)
- Passo 3: Configure o OSPF para que as rotas de loopback sejam alcançáveis entre os dispositivos.
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 20.0.0.1 0.0.0.0 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 30.0.0.1 0.0.0.0 area 0Device3(config-ospf)#exit
#Consulte a tabela de roteamento do Device2.
Device2#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 30.0.0.1/32 [110/2] via 3.0.0.2, 00:02:26, vlan3
#Consulte a tabela de roteamento do Device3.
Device3#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 20.0.0.1/32 [110/2] via 3.0.0.1, 00:03:38, vlan3
De acordo com a tabela de roteamento, Device2 e Device3 aprenderam as rotas das interfaces de loopback um do outro.
- Passo 4: Configure uma ACL e uma política de roteamento para definir a métrica de uma rota.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ip access-list standard 1Device1(config-std-nacl)#permit 3.0.0.0 0.0.0.255Device1(config-std-nacl)#commitDevice1(config-std-nacl)#exitDevice1(config)#route-map SetMetricDevice1(config-route-map)#match ip address 1Device1(config-route-map)#set metric 50Device1(config-route-map)#exit
A política de roteamento configurada no Device1 define a métrica da rota 3.0.0.0/24 para 50.
- Passo 5: Configure o BGP e configure o Device1 com uma política de roteamento.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#neighbor 1.0.0.2 remote-as 200Device1(config-bgp)#neighbor 2.0.0.2 remote-as 200Device1(config-bgp)#neighbor 2.0.0.2 route-map SetMetric inDevice1(config-bgp)#exit
# Configurar dispositivo2.
Device2(config)#router bgp 200Device2(config-bgp)#neighbor 1.0.0.1 remote-as 100Device2(config-bgp)#neighbor 30.0.0.1 remote-as 200Device2(config-bgp)#neighbor 30.0.0.1 update-source loopback0Device2(config-bgp)#network 3.0.0.0 255.255.255.0Device2(config-bgp)#exit
# Configurar dispositivo3.
Device3(config)#router bgp 200Device3(config-bgp)#neighbor 2.0.0.1 remote-as 100Device3(config-bgp)#neighbor 20.0.0.1 remote-as 200Device3(config-bgp)#neighbor 20.0.0.1 update-source loopback0Device3(config-bgp)#network 3.0.0.0 255.255.255.0Device3(config-bgp)#exit
Depois que uma política de roteamento é configurada no peer, o BGP deve ser redefinido para que a configuração entre em vigor.
#No Device1, verifique o status do vizinho BGP.
Device1#show ip bgp summaryBGP router identifier 2.0.0.1, local AS number 100BGP table version is 22 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd1.0.0.2 4 200 2 2 2 0 0 00:01:32 12.0.0.2 4 200 2 2 2 0 0 00:01:43 1
#No Device2, verifique o status do vizinho BGP.
Device2#show ip bgp summaryBGP router identifier 20.0.0.1, local AS number 200BGP table version is 21 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd1.0.0.1 4 100 2 2 2 0 0 00:02:52 030.0.0.1 4 200 3 3 2 0 0 00:02:45 1
Os vizinhos BGP entre Device1, Device2 e Device3 foram configurados com sucesso.
#Consulte a tabela de roteamento do Device1.
Device1#show ip bgpBGP table version is 3, local router ID is 1.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]* 3.0.0.0/24 2.0.0.2 50 0 200 i[B]*> 1.0.0.2 0 0 200 iDevice1#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 3.0.0.0/24 [20/0] via 1.0.0.2, 00:07:19, vlan2
De acordo com a tabela de roteamento, a rota 3.0.0.0/24 de Device1 seleciona Device2 como o dispositivo de próximo salto.
- Passo 6: Configure o BGP para coordenar com o BFD.
# Configurar dispositivo1.
Device1(config)#bfd fast-detectDevice1(config)#router bgp 100Device1(config-bgp)#neighbor 1.0.0.2 fall-over bfdDevice1(config-bgp)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#bfd min-receive-interval 500Device1(config-if-vlan2)#bfd min-transmit-interval 500Device1(config-if-vlan2)#bfd multiplier 4Device1(config-if-vlan2)#exit
# Configurar dispositivo2.
Device2(config)#bfd fast-detectDevice2(config)#router bgp 200Device2(config-bgp)#neighbor 1.0.0.1 fall-over bfdDevice2(config-bgp)#exitDevice2(config)#interface vlan2Device2(config-if-vlan2)#bfd min-receive-interval 500Device2(config-if-vlan20)#bfd min-transmit-interval 500Device2(config-if-vlan2)#bfd multiplier 4Device2(config-if-vlan2)#exit
O BFD está habilitado entre os vizinhos EBGP Device1 e Device2, e o intervalo mínimo de transmissão, intervalo mínimo de recebimento e múltiplo de tempo limite de detecção dos pacotes de controle BFD foram modificados.
- Passo 7: Confira o resultado.
#No Dispositivo1, consulte o status da sessão BFD.
Device1#show bfd sessionOurAddr NeighAddr LD/RD State Holddown interface1.0.0.1 1.0.0.2 2/2 UP 2000 valn2
No Device1, o status do BFD está ativo e o tempo de espera é negociado para ser 2000ms.
#Se a linha entre Device1 e Device2 estiver com defeito, a rota pode mudar rapidamente para a linha de backup.
#Consulte a tabela de roteamento do Device1.
Device1#show ip bgpBGP table version is 6, local router ID is 1.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 3.0.0.0/24 2.0.0.2 50 0 200 iDevice1#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 3.0.0.0/24 [20/50] via 2.0.0.2, 00:00:05, vlan3
O próximo salto da rota 3.0.0.0/24 é Device3.
IPv6 BGP (Aplicável somente ao modelo S3054G-B)
Visão geral
IPv6 BGP (BGP4 +) é estendido de BGP-4. O BGP-4 só pode gerenciar informações de roteamento IPv4. Para suportar o protocolo IPv6, o IETF estende o BGP-4 para formar o IPv6 BGP. O padrão IPv6 BGP atual é RFC 2858 (Multiprotocol Extensions for BGP-4).
O IPv6 BGP precisa refletir as informações do protocolo da camada de rede IPv6 nos atributos NLRI (Network Layer Reachability Information) e NEXT_HOP. Os dois atributos NLRI introduzidos no IPv6 BGP são:
- MP_REACH_NLRI: Multiprotocol Reachable NLRI, usado para liberar a rota alcançável e informações do próximo salto
- MP_UNREACH_NLRI: Multiprotocol Unreachable NLRI, usado para cancelar a rota inacessível
O atributo NEXT_HOP no IPv6 BGP é representado por um endereço IPv6, que pode ser um endereço unicast global IPv6 ou um endereço local de link.
O IPv6 BGP usa os atributos de extensão multiprotocolo do BGP para realizar o aplicativo na rede IPv6. O mecanismo de mensagem original e o mecanismo de roteamento do protocolo BGP não mudam.
Configuração da função IPv6 BGP
Tabela 13 -1 Lista de funções IPv6 BGP
| Tarefas de configuração | |
| Configure um vizinho IPv6 BGP. |
Configure um vizinho IBGP.
Configure um vizinho EBGP. Configure um vizinho passivo BGP. Configure um vizinho MP-BGP. Configure a autenticação MD5 para vizinhos BGP. |
| Configure a geração de rotas BGP. |
Configure o BGP para anunciar rotas locais.
Configurando o BGP para redistribuir rotas. Configure o BGP para anunciar a rota padrão. |
| Configure o controle de rota BGP. |
Configure o BGP para anunciar rotas agregadas.
Configure a distância administrativa das rotas BGP. Configure as políticas de roteamento na direção de saída de um vizinho BGP. Configure as políticas de roteamento na direção de entrada de um vizinho BGP. Configure o número máximo de rotas que um vizinho BGP recebe. Configure o número máximo de rotas de balanceamento de carga BGP. |
| Configure as propriedades da rota BGP. |
Configure o peso da rota BGP.
Configure a propriedade MED de uma rota BGP. Configure a propriedade Local-Preference de uma rota BGP. Configure a propriedade AS_PATH de uma rota BGP. Configure a propriedade NEXT-HOP de uma rota BGP. Configurar a propriedade de comunidade de uma rota BGP |
| Configure a otimização de rede BGP. |
Configure o tempo de atividade dos vizinhos BGP.
Configure o tempo de detecção de rota BGP. Configure a desconexão rápida de vizinhos EBGP. Configure a função de supressão de rota BGP. Configure o recurso de atualização do vizinho BGP. Configure o recurso de reinicialização suave do vizinho BGP. Configure a capacidade ORF dos vizinhos BGP. |
| Configure uma rede BGP de grande escala. |
Configure um grupo de pares BGP.
Configure um refletor de rota BGP. Configure uma confederação BGP. |
| Configurar BGP GR. | Configurar um reiniciador do BGP GR Configure um Auxiliar BGP GR. |
| Configure o BGP para coordenar com o BFD. | Configure o EBGP para coordenar com o BFD. Configure o IBGP para coordenar com o BFD. |
Configurar um vizinho IPv6 BGP
Condição de configuração
Antes de configurar um vizinho IPv6 BGP, certifique-se de que:
- O protocolo da camada de link foi configurado para garantir a comunicação normal na camada de link.
- Os endereços da camada de rede das interfaces foram configurados para que os nós de rede adjacentes sejam alcançáveis na camada de rede.
Configurar um vizinho IBGP
1. Execute a configuração básica.
Ao configurar um vizinho IBGP, você precisa definir o AS do vizinho para ser o mesmo que o AS do dispositivo local. Você pode configurar um ID de roteador para um dispositivo. O Router ID é usado para identificar exclusivamente um dispositivo BGP na configuração de uma sessão BGP. Se nenhuma ID de roteador estiver configurada para um dispositivo, o dispositivo selecionará uma ID de roteador nos endereços de interface. As regras para a seleção são as seguintes:
- Selecione o maior endereço IP dos endereços IP da interface de loopback como o ID do roteador.
- Se nenhuma interface de loopback estiver configurada com um endereço IP, selecione o maior endereço IP dos endereços IP de outras interfaces como a ID do roteador.
- Somente quando uma interface está no status UP, o endereço IP da interface pode ser eleito como o Router ID.
Tabela 13 -2 Configurar um vizinho IBGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite o protocolo BGP e entre no modo de configuração BGP. | router bgp autonomous-system | Obrigatório. Por padrão, o BGP está desabilitado. |
| Configure um ID de roteador para o dispositivo BGP. | bgp router-id router-id | Opcional. Por padrão, o dispositivo seleciona um Router ID dos endereços de interface. A interface de loopback e o endereço IP grande têm as prioridades. |
| Configure um vizinho IBGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | andatória. Por padrão, nenhum vizinho IBGP é criado. |
| Configure uma descrição para um vizinho IBGP. | neighbor { neighbor-address | peer-group-name } description description-string | Opcional. Por padrão, nenhuma descrição é configurada para um vizinho IBGP. |
| modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Ative a capacidade de um vizinho IBGP na transmissão e recepção de rotas unicast IPv6. | neighbor { neighbor-address | peer-group-name } activate | Opcional. Por padrão, a capacidade do vizinho IBGP em transmitir e receber rotas unicast IPv6 não está ativada. |
2. Configure o endereço de origem de uma sessão TCP.
O BGP usa o protocolo TCP como protocolo de transporte. O TCP apresenta transmissão confiável, garantindo que os pacotes do protocolo BGP possam ser transmitidos adequadamente para seus vizinhos.
Tabela 13 -3 Configurar o endereço de origem de uma sessão TCP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite o protocolo BGP e entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um vizinho IBGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho IBGP é criado. |
| Configure o endereço de origem de uma sessão TCP de um vizinho IBGP. | neighbor { neighbor-address | peer-group-name } update-source { interface-name | ipv6-address } |
Obrigatório.
Por padrão, a sessão TCP seleciona automaticamente o endereço de uma interface de saída de roteamento como o endereço de origem. |
Se houver rotas de balanceamento de carga, os endereços de origem devem ser configurados para sessões TCP de vizinhos BGP. Se os endereços de origem da sessão TCP não estiverem configurados, se os vizinhos tiverem diferentes rotas ideais, eles poderão usar diferentes interfaces de saída como seus endereços de origem. Dessa forma, as sessões BGP podem falhar ao configurar dentro de um período de tempo.
Configurar um vizinho EBGP
1. Execute a configuração básica.
Ao configurar um vizinho EBGP, você precisa definir o AS do vizinho para ser diferente do AS do dispositivo local.
Tabela 13 -4 Configurar um vizinho EBGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Habilite o protocolo BGP e entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um vizinho EBGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho EBGP é criado. |
2. Configure um vizinho EBGP de conexão não direta
Os vizinhos EBGP estão localizados em redes de operação diferentes e geralmente são conectados por um link físico de conexão direta. Portanto, o valor TTL padrão para os pacotes IP entre vizinhos EBGP é 1. Em redes de operação de conexão não direta, você pode usar um comando para definir o valor TTL dos pacotes IP para configurar uma conexão BGP.
Tabela 13 -5 Configurar um vizinho EBGP de conexão não direta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um vizinho EBGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho EBGP é criado. |
| Configure o endereço de origem de uma sessão TCP de um vizinho EBGP. | neighbor { neighbor-address | peer-group-name } update-source { interface-name | ipv6-address } | Opcional. Por padrão, a sessão TCP seleciona automaticamente o endereço de uma interface de saída de roteamento como o endereço de origem. |
| Permitir que vizinhos EBGP de conexão não direta estabeleçam uma conexão. | neighbor { neighbor-address | peer-group-name } ebgp-multihop [ ttl-value ] |
Obrigatório.
Por padrão, os dispositivos de conexão não direta não têm permissão para formar vizinhos EBGP. |
Configurar um vizinho passivo BGP
Em alguns ambientes de aplicativos especiais, a função de vizinho passivo BGP é necessária. Depois que a função de vizinho passivo é habilitada, o BGP não inicia a solicitação de conexão TCP para configurar uma relação de vizinho BGP; em vez disso, ele aguarda a solicitação de conexão do vizinho antes de estabelecer uma relação de vizinho. Por padrão, os vizinhos iniciam solicitações de conexão entre si. Se as conexões entrarem em conflito, eles selecionam uma conexão TCP ideal para formar uma sessão BGP. Antes de configurar um vizinho passivo BGP, você precisa configurar um vizinho BGP.
Tabela 13 -6 Configurar um vizinho passivo BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um vizinho BGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho BGP é criado. |
| Configure um vizinho passivo BGP. | neighbor { neighbor-address | peer-group-name } passive | Obrigatório. Por padrão, nenhum vizinho passivo é ativado. |
Configurar um vizinho MP-BGP
Por padrão, o vizinho BGP pode ter a capacidade de receber e enviar a rota correspondente quando a família de endereços VRF e a família de endereços VPN são ativadas. Antes de configurar um vizinho MP-BGP , você precisa configurar um vizinho BGP.
Tabela 13 -7 Configurar um vizinho MP-BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um vizinho BGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, não crie nenhum vizinho BGP. |
| Entre no modo de configuração BGP IPv6 VRF. | address-family ipv6 vrf vrf-name | - |
| Configure os vizinhos na família de endereços BGP IPv6 VRF | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, não crie nenhum vizinho BGP. |
| Ative os vizinhos na família de endereços IPv6 VRF . | neighbor { neighbor-address | peer-group-name } activate | Opcional. Por padrão, os vizinhos do modo de configuração BGP IPv6 VRF são ativados. |
| Saia do modo de configuração BGP IPv6 VRF . | exit-address-family | - |
Os vizinhos configurados no modo de configuração BGP IPv6 e no modo de configuração unicast BGP IPv6 são vizinhos globais, e os vizinhos configurados no modo de configuração BGP IPv6 VRF pertencem somente à família de endereços VRF.
Configurar autenticação MD5 para vizinhos BGP
O BGP suporta a configuração da autenticação MD5 para proteger a troca de informações entre vizinhos. A autenticação MD5 é implementada pelo protocolo TCP. Dois vizinhos devem ser configurados com a mesma senha de autenticação MD5 antes que uma conexão TCP possa ser configurada; caso contrário, se o protocolo TCP falhar na autenticação MD5, a conexão TCP não poderá ser configurada. Antes de configurar a autenticação MD5 para vizinhos BGP, você precisa configurar os vizinhos BGP.
Tabela 13 -8 Configurar autenticação MD5 para vizinhos BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um vizinho BGP. | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório. Por padrão, nenhum vizinho BGP é criado. |
| Configure a autenticação MD5 para vizinhos BGP. | neighbor { neighbor-address | peer-group-name } password [ 0 | 7 ] password-string | Obrigatório. Por padrão, nenhuma autenticação MD5 é iniciada para vizinhos BGP. |
Configurar geração de rota IPv6 BGP
Condição de configuração
Antes de configurar a geração de rota IPv6 BGP, certifique-se de que:
- O BGP está ativado.
- Os vizinhos IPv6 BGP são configurados e uma sessão é configurada com sucesso.
Configurar o BGP para anunciar rotas locais
O BGP pode usar o comando network para introduzir as rotas da tabela de rotas IPv6 na tabela de rotas BGP. Somente quando houver rotas que correspondam completamente à rede prefixo e máscara as rotas podem ser introduzidas na tabela de rotas BGP e anunciadas.
Ao anunciar uma rota local, você pode aplicar um mapa de rota para a rota e também pode especificar a rota como a rota de backdoor. A rota backdoor usa rotas EBGP como rotas BGP locais e usa a distância administrativa das rotas locais. Isso permite que as rotas IGP tenham prioridades mais altas do que as rotas EBGP. Ao mesmo tempo, as rotas backdoor não serão anunciadas aos vizinhos EBGP.
Tabela 13 -9 Configurar BGP para anunciar rotas locais
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o BGP para anunciar rotas locais. | network ipv6-prefix [ route-map rtmap-name [ backdoor ] | backdoor ] | Obrigatório. Por padrão, o BGP não anuncia rotas locais. |
O tipo de propriedade Origem das rotas locais anunciadas pelo BGP é IGP. Se você executar o backdoor de rede comando para uma rota EBGP, a distância administrativa da rota EBGP muda para a distância administrativa da rota local. (Por padrão, a distância administrativa da rota EBGP é 20 e a distância administrativa da rota local é 200.), menor que a distância administrativa padrão da rota IGP, de modo que a rota IGP seja selecionada primeiro, formando um link backdoor entre vizinhos EBGP . O mapa de rotas aplicado às rotas locais anunciadas pelo BGP suporta opções de correspondência, incluindo como caminho, comunidade, e xtcommunity, endereço ip v6, ipv6 nexthop e metric, e suporta as opções definidas, incluindo as-path, comm-list, community, extcommunity, ipv6 next-hop, local-preference, metric, origin e weight.
Configurar BGP para redistribuir rotas
O BGP não é responsável pelo aprendizado de rotas. Ele se concentra principalmente no gerenciamento das propriedades da rota para controlar a direção da rota. Portanto, o BGP redistribui as rotas IGP para gerar rotas BGP e anunciar as rotas BGP aos vizinhos. Quando o BGP redistribui rotas IGP, ele pode aplicar um diagrama de roteamento.
Tabela 13 -10 Configure o BGP para redistribuir rotas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o BGP para redistribuir rotas IGP. | redistribute { connected | isis [ area-tag ] [ match isis-level ] | ospf as-number [ match route-sub-type ] | rip process-id | static } [ route-map map-name / metric value ] | Obrigatório. Por padrão, o BGP não redistribui rotas IGP. |
O tipo de propriedade Origem das rotas IGP anunciadas pelo BGP é INCOMPLETO. O mapa de rotas aplicado a outras rotas de protocolo que são redistribuídas pelo BGP suporta opções de correspondência, incluindo como caminho, comunidade, extcommunity, endereço ipv6, ipv6 nexthop e métrica, e suporta as opções definidas, incluindo como caminho, comm-list, comunidade, extcommunity, próximo salto IPv6, preferência local, métrica, origem e peso.
Configurar o BGP para anunciar a rota padrão
Antes que o BGP anuncie uma rota padrão aos vizinhos, a rota padrão precisa ser introduzida. Duas maneiras de introduzir as rotas padrão estão disponíveis: executando o comando neighbor default-originate para gerar uma rota padrão de BGP e executando o comando default-information origin para redistribuir a rota padrão de outro protocolo.
A rota padrão que é gerada executando o vizinho default-originate O comando é route ::/ 0 que é gerado automaticamente pelo BGP. A rota padrão que é redistribuída executando o comando default-information origin é a rota 0::/0 do protocolo redistribuído introduzido pelo BGP.
Tabela 13 -11 Configure o BGP para anunciar a rota padrão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o BGP para gerar a rota padrão. | neighbor { neighbor-address | peer-group-name } default-originate [ route-map rtmap-name ] | Obrigatório. Por padrão, o BGP não gera a rota padrão. |
| Configure o BGP para redistribuir a rota padrão de outros protocolos | default-information originate | Obrigatório. Por padrão, o BGP não redistribui a rota padrão de outro protocolo. |
Ao configurar o BGP para redistribuir a rota padrão de outro protocolo, você precisa configurar o BGP para redistribuir rotas. Ao configurar o BGP para gerar uma rota padrão, você pode aplicar um mapa de rotas à rota. O mapa de rotas aplicado à rota padrão gerada pelo BGP oferece suporte a opções definidas, incluindo as-path, comm-list, community, extcommunity, ipv6 next-hop, local-preference, metric, origin e weight.
Configurar o controle de rota IPv6 BGP
Condição de configuração
Antes de configurar o controle de rota BGP, certifique-se de que:
- O BGP está ativado.
- Os vizinhos IPv6 BGP são configurados e uma sessão é configurada com sucesso.
Configurar o BGP para anunciar rotas agregadas
Em uma rede BGP de grande escala, para diminuir o número de rotas anunciadas aos vizinhos ou controlar efetivamente o roteamento BGP, você pode configurar uma rota agregada BGP.
Tabela 13 -12 Configurar BGP para anunciar rotas agregadas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o BGP para anunciar rotas agregadas. | aggregate-address ipv6-prefix [ as-set / summary-only / route-map rtmap-name ] | Obrigatório. Por padrão, o BGP não agrega rotas. |
Ao configurar o BGP para anunciar rotas agregadas, você pode especificar a opção somente resumo para que o BGP anuncie apenas rotas agregadas. Isso diminui o número de rotas anunciadas. Você pode especificar o conjunto opção para gerar rotas de agregação com a propriedade AS_PATH. Você também pode aplicar um mapa de rotas às rotas de agregação para definir propriedades mais abundantes para as rotas de agregação.
Configurar a distância administrativa das rotas BGP
Na tabela de roteamento IP, cada protocolo controla a distância administrativa do roteamento. Quanto menor a distância administrativa, maior a prioridade. O BGP afeta o roteamento especificando as distâncias administrativas de segmentos de rede especificados. As distâncias administrativas das rotas que cobrem os segmentos de rede especificados serão modificadas. Enquanto isso, a ACL é aplicada para filtrar os segmentos de rede que são cobertos pelas rotas, ou seja, apenas as distâncias administrativas do segmento de rede permitidas pela ACL podem ser modificadas.
O comando distance bgp é usado para modificar as distâncias de gerenciamento de rotas BGP externas, internas e locais. O comando distance é usado apenas para modificar as distâncias administrativas de segmentos de rede especificados. O comando de distância tem uma prioridade mais alta do que o distância bgp comando. Os segmentos de rede cobertos pelo O comando distance usa a distância administrativa especificada pelo comando, enquanto os segmentos de rede que não são cobertos pelo comando distance usam a distância administrativa especificada pelo comando distance bgp .
Tabela 13 -13 Configurar a distância administrativa de uma rota BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o BGP para modificar a distância administrativa padrão. | distance bgp external-distance internal-distance local-distance | Opcional. Por padrão, a distância administrativa das rotas EBGP é 20, a distância administrativa das rotas IBGP é 200 e a distância administrativa das rotas locais é 200. |
| Configure a distância administrativa de um segmento de rede especificado. | distance administrative-distance ipv6-prefix [ acl-num | acl-name ] |
Configurar políticas de roteamento na direção de saída de um vizinho BGP
A publicidade ou roteamento de rota BGP é implementado com base nas poderosas propriedades de roteamento. Ao anunciar rotas para vizinhos, você pode aplicar políticas de roteamento para modificar as propriedades da rota ou filtrar algumas rotas. Atualmente, as políticas de roteamento que podem ser aplicadas na direção de saída incluem:
- lista de distribuição: lista de distribuição.
- filter-list: lista de filtragem de propriedades AS_PATH.
- lista de prefixos: lista de prefixos de IP.
- mapa de rota: mapa de rota.
Tabela 13 -14 Configurar políticas de roteamento na direção de saída de um vizinho BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Aplique a lista de distribuição na direção de saída. | neighbor { neighbor-address | peer-group-name } distribute-list {access-list-num | access-list-name } out | Você pode selecionar várias opções. (No entanto, a lista de distribuição e a lista de prefixos IP não podem ser configuradas ao mesmo tempo.) Por padrão, nenhuma política de roteamento é configurada na direção de saída de um vizinho BGP. |
| Aplique a lista de filtragem de propriedade AS_PATH na direção de saída. | neighbor { neighbor-address | peer-group-name } filter-list aspath-list-name out | |
| Aplique a lista de prefixos IP na direção de saída. | neighbor { neighbor-address | peer-group-name } prefix-list prefix-list-name out | |
| Aplique um mapa de rotas na direção de saída. | neighbor { neighbor-address | peer-group-name } route-map rtmap-name out |
Depois de configurar a política de roteamento na direção de saída de um vizinho BGP, você precisa redefinir o vizinho para validar as configurações. Se você aplicar um mapa de rota na direção de saída de um refletor de rota, isso altera apenas a propriedade NEXT-HOP. Para saber como configurar uma lista de filtragem, consulte a seção "Configurar AS-PATH" do capítulo "Ferramentas de política de roteamento". Ao configurar políticas de roteamento na direção de saída de um vizinho BGP, você pode configurar várias políticas ao mesmo tempo. O BGP aplica políticas de roteamento na sequência de distribu-list , filter-list , prefix-list e route-map . Se uma política anterior for rejeitada, as últimas políticas não serão aplicadas. As informações de roteamento podem ser anunciadas somente após passarem por todas as políticas configuradas. O mapa de rotas que é aplicado na direção de saída de uma rota BGP oferece suporte a opções de correspondência, incluindo como caminho, comunidade, extcommunity, endereço ipv6, ip nexthop e métrica, e suporta as opções definidas, incluindo as-path, comm- lista, comunidade, extcommunity, próximo salto IPv6, preferência local, métrica, origem e peso.
Configurar políticas de roteamento na direção de entrada de um vizinho BGP
O BGP pode aplicar políticas de roteamento para filtrar as informações de roteamento recebidas ou modificar as propriedades da rota. Semelhante às políticas aplicadas nas direções de saída, quatro políticas são aplicadas nas direções de entrada:
- lista de distribuição: lista de distribuição.
- filter-list: lista de filtragem de propriedades AS_PATH.
- lista de prefixos: lista de prefixos IPv6.
- mapa de rota: mapa de rota.
Tabela 13 -15 Configurar políticas de roteamento na direção de entrada de um vizinho BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Aplique a lista de distribuição na direção de entrada. | neighbor { neighbor-address | peer-group-name } distribute-list { access-list-num | access-list-name } in | Você pode selecionar várias opções. (No entanto, a lista de distribuição e a lista de prefixos IP não podem ser configuradas ao mesmo tempo.) Por padrão, nenhuma política é aplicada na direção de entrada. |
| Aplique a lista de filtragem de propriedade AS_PATH na direção de entrada. | neighbor { neighbor-address | peer-group-name } filter-list aspath-list-name in | |
| Aplique a lista de prefixos IP na direção de entrada. | neighbor { neighbor-address | peer-group-name } prefix-list prefix-list-name in | |
| Aplique um mapa de rota na direção de entrada. | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in |
Depois de configurar a política de roteamento na direção de entrada de um vizinho BGP, você precisa redefinir o vizinho para validar as configurações. Ao configurar políticas de roteamento na direção de entrada de um vizinho BGP, você pode configurar várias políticas ao mesmo tempo. O BGP aplica políticas de roteamento na sequência de distribu-list , filter-list , prefix-list e route-map . Se uma política anterior for rejeitada, as últimas políticas não serão aplicadas. Uma rota pode ser adicionada ao banco de dados após passar por todas as políticas configuradas. As políticas de roteamento aplicadas na direção de entrada de uma rota BGP suportam opções de correspondência, incluindo como caminho, comunidade, extcommunity, endereço ipv6, ipv6 nexthop e métrica, e suportam as opções definidas, incluindo as-path, comm-list, comunidade, extcommunity, próximo salto IPv6, preferência local, métrica, origem e peso.
Configurar o número máximo de rotas que um BGP recebe de um vizinho
Você pode limitar o número de rotas que um BGP recebe de um vizinho especificado. Quando o número de rotas que o BGP recebe do vizinho atinge um limite, um alarme é gerado ou o vizinho é desconectado.
Tabela 13 -16 Configure o número máximo de rotas que um BGP recebe de um vizinho
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o número máximo de rotas recebidas pelo vizinho. | neighbor { neighbor-address | peer-group-name } maximum-prefix prefix-num [ threshold-value ] [ warning-only ] | Obrigatório. Por padrão, o número de rotas recebidas pelo vizinho. |
Se a opção somente aviso não for especificada, depois que o número de rotas que o BGP recebe do vizinho atingir o número máximo, a sessão BGP será desconectada automaticamente. Se a opção somente aviso for especificada, depois que o número de rotas que o BGP recebe do vizinho atingir o número máximo, uma mensagem de aviso será exibida, mas o aprendizado de rota continuará.
Configurar o número máximo de rotas de balanceamento de carga BGP
Em um ambiente de rede BGP, se vários caminhos com o mesmo custo estiverem disponíveis para alcançar o mesmo destino, você poderá configurar o número de rotas de balanceamento de carga BGP para balanceamento de carga.
Tabela 13 -17 Configure o número máximo de rotas de balanceamento de carga BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o número máximo de rotas de balanceamento de carga IBGP. | maximum-paths ibgp number | Obrigatório. Por padrão, o IBGP não suporta rotas de balanceamento de carga. |
| Configure o número máximo de rotas de balanceamento de carga EBGP. | maximum-paths number | Obrigatório. Por padrão, o EBGP não oferece suporte a rotas de balanceamento de carga. |
Depois que o número máximo de rotas de balanceamento de carga EBGP for configurado, o balanceamento de carga terá efeito somente quando as rotas EBGP forem selecionadas com prioridade. Em diferentes modos de configuração do BGP, os comandos para configurar o número máximo de rotas de balanceamento de carga são diferentes. Para obter detalhes, consulte a descrição dos caminhos máximos no manual técnico do BGP.
Configurar propriedades de rota IPv6 BGP
Condição de configuração
Antes de configurar as propriedades da rota BGP, certifique-se de que:
- O BGP está ativado.
- Os vizinhos IPv6 BGP são configurados e uma sessão é configurada com sucesso.
Configurar o peso da rota BGP
No roteamento BGP, a primeira regra é comparar os pesos das rotas. Quanto maior o peso de uma rota, maior a prioridade que ela tem. O peso de uma rota é propriedade local do dispositivo e não pode ser transferido para outros vizinhos BGP. O intervalo de valores de um peso de rota é 1-65535. Por padrão, o peso de uma rota que foi aprendida de um vizinho é 0 e os pesos de todas as rotas geradas pelo dispositivo local são todos 32768.
Tabela 13 -18 Configurar o peso da rota BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o peso de uma rota de um vizinho ou grupo de pares. | neighbor { neighbor-address | peer-group-name } weight weight-num | Obrigatório. Por padrão, o peso de uma rota de um vizinho é 0. |
Configurar a propriedade MED de uma rota BGP
As propriedades do Multi-Exit Discriminator (MED) são usadas para selecionar a rota ideal para o tráfego que entra em um AS. Se as outras condições de roteamento forem as mesmas e o BGP aprender várias rotas com o mesmo destino de diferentes vizinhos EBGP, o BGP selecionará a rota com o valor MED mínimo como a entrada ideal.
O MED às vezes também é chamado de métrica externa. Ele é marcado como uma "métrica" na tabela de rotas BGP. O BGP anuncia as propriedades MED das rotas que aprendeu de vizinhos para vizinhos IBGP, mas o BGP não anuncia as propriedades MED para vizinhos EBGP. Portanto, as propriedades MED são aplicáveis apenas a ASs adjacentes.
1. Configure o BGP para permitir a comparação de MEDs de rotas vizinhas de diferentes ASs.
Por padrão, o BGP implementa a seleção de rotas MED apenas entre as rotas que são do mesmo AS. No entanto, você pode executar o Comando bgp always-compare-med para permitir que o BGP ignore a limitação no mesmo AS na seleção de rota MED.
Tabela 13 -19 Configurar BGP para permitir a comparação de MEDs de rotas vizinhas de diferentes ASs
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para permitir a comparação de MEDs de rotas vizinhas de diferentes ASs. | bgp always-compare-med | Obrigatório. Por padrão, o BGP permite apenas comparar MEDs de rotas vizinhas do mesmo AS. |
2. Configure o BGP para classificar e selecionar MEDs de acordo com os grupos AS_PATH.
Por padrão, o BGP não está habilitado para classificar e selecionar MEDs de acordo com os grupos AS_PATH de rota. Para habilitar a função, execute o bgp deterministic-med comando. Na seleção de rotas, todas as rotas são organizadas com base em AS_PATHs. Em cada grupo AS_PATH, as rotas são classificadas com base nos valores MED. A rota com o valor MED mínimo é selecionada como a rota ideal no grupo.
Tabela 13 -20 Configurar BGP para classificar e selecionar MEDs de acordo com os grupos AS_PATH
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Compare MEDs de confederação na seleção de rota BGP. | bgp deterministic-med | Obrigatório. Por padrão, os MEDs da confederação não são comparados na seleção de rota BGP. |
3. Configure para comparar MEDs de rotas na confederação local.
Por padrão, os valores MED das rotas EBGP de diferentes ASs não são comparados. A configuração é válida para as rotas EBGP das confederações. Para habilitar a comparação de valores MED de rotas da confederação local, execute o comando bgp bestpath med confed .
Tabela 13 -21 Configure o BGP para comparar MEDs de rotas na confederação local
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para comparar os valores MED de rotas na confederação local. | bgp bestpath med confed |
Obrigatório.
Por padrão, os valores MED das rotas nas confederações locais não serão comparados. |
4. Configure um mapa de rotas para modificar as propriedades do MED.
Nas rotas de transmissão e recepção, você pode aplicar um mapa de rotas para modificar as propriedades do MED.
Tabela 13 -22 Configurar um mapa de rotas para modificar as propriedades do MED
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configurando um mapa de rotas para modificar as propriedades do MED. | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in | out | Obrigatório. Por padrão, nenhum mapa de rotas é aplicado a nenhum vizinho. |
Ao configurar um mapa de rotas para modificar uma propriedade MED, você pode usar o comando set metric para modificar a propriedade MED. Para obter detalhes, consulte a métrica de conjunto manual de ferramentas de política de roteamento . Após a configuração do comando neighbor attribute-unchanged , as propriedades MED dos vizinhos não podem ser alteradas pelo mapa de rotas aplicado.
Configurar a propriedade de preferência local de uma rota BGP
As propriedades de preferência local são transferidas apenas entre vizinhos IBGP. Local-Preference é usado para selecionar a saída ideal de um AS. A rota com a máxima preferência local será selecionada com prioridade.
O intervalo de valores de Local-Preference é 0-4294967295. Quanto maior o valor, maior a prioridade da rota. Por padrão, o valor Local-Preference de todas as rotas que são anunciadas aos vizinhos IBGP é 100. Você pode usar a preferência local padrão bgp comando ou o mapa de rotas para modificar o valor da propriedade Local-Preference.
1. Configure o BGP para modificar a propriedade de preferência local padrão.
Tabela 13 -23 Configurar o BGP para modificar a propriedade de preferência local padrão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o valor padrão da propriedade BGP Local-Preference. | bgp default local-preference local-value | Opcional. Por padrão, o valor Local-Preference é 100. |
2. Configure o mapa de rotas para modificar a propriedade Local-Preference.
Tabela 13 -24 Configure o mapa de rotas para modificar a propriedade local-preference
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o mapa de rotas para modificar a propriedade Local-Preference. | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in | out | Obrigatório. Por padrão, o mapa de rotas não é aplicado a nenhum vizinho. |
Ao configurar um mapa de rotas para modificar a propriedade Local-Preference, você pode usar o set local-preference comando para modificar a propriedade Local-Preference. Para obter detalhes, consulte a preferência local definida pelo manual de ferramentas de política de roteamento.
Configurar a propriedade AS_PATH de uma rota BGP
1. Configure o BGP para ignorar AS_PATHs na seleção de rota.
Se as outras condições forem as mesmas, o BGP seleciona a rota com o AS-PATH mais curto na seleção de rota. Para cancelar a seleção de rota com base em AS_PATHs, execute o comando bgp bestpath as-path ignore .
Tabela 13 -25 Configure o BGP para ignorar AS_PATHs na seleção de rota
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o BGP para ignorar AS_PATHs na seleção de rota. | bgp bestpath as-path ignore | Obrigatório. Por padrão, os valores AS_PATH são comparados na seleção de rota. |
2. Configure o número de ASs locais que o BGP permite repetir.
Para evitar loops de roteamento, o BGP verifica as propriedades AS_PATH das rotas que são recebidas dos vizinhos, e as rotas que contêm o número AS local serão descartadas. No entanto, você pode executar o comando neighbor allowas-in para permitir que as propriedades AS_PATH das rotas que o BGP recebe contenham o número de AS local e você pode configurar o número de ASs que podem ser contidos.
Tabela 13 -26 Configurar o número de ASs locais que o BGP permite repetir
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o número de ASs que podem ser repetidos. | neighbor { neighbor-address | peer-group-name } allowas-in [ as-num ] |
Obrigatório.
Por padrão, as propriedades AS_PATH das rotas recebidas dos vizinhos não permitem o número AS local. |
3. Configure o BGP para remover o número AS privado ao anunciar rotas para vizinhos.
Em uma rede BGP de grande escala, as propriedades AS_PATH das rotas contêm federação ou propriedade da comunidade. Por padrão, o BGP fornece as propriedades privadas do AS quando anuncia rotas para vizinhos. Para mascarar informações de rede privada, execute o vizinho remove-private-AS comando para remover o número AS privado.
Tabela 13 -27 Configure o BGP para remover o número Private AS ao anunciar rotas para vizinhos
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o BGP para remover o número AS privado ao anunciar rotas para vizinhos. | neighbor { neighbor-address | peer-group-name } remove-private-AS |
Obrigatório.
Por padrão, quando o BGP anuncia rotas para vizinhos, ele fornece o número AS privado. |
4. Configure para verificar a validade do primeiro número AS de uma rota EBGP.
Quando o BGP anuncia uma rota para os vizinhos EBGP, ele comprime o número do AS local na posição inicial do AS_PATH, e o AS que anuncia a rota primeiro fica localizado no final. Normalmente, o primeiro AS de uma rota que o EBGP recebe deve ser o mesmo número do AS vizinho; caso contrário, a rota será descartada.
Tabela 13 -28 Configure para verificar a validade do primeiro número AS de uma rota EBGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure para verificar a validade do primeiro número AS de uma rota EBGP. | bgp enforce-first-as | Obrigatório. Por padrão, o BGP não habilita o mecanismo de verificação do primeiro número AS. |
5. Configure um mapa de rotas para modificar as propriedades AS_PATH.
O BGP suporta a configuração de um mapa de rotas para modificar as propriedades AS_PATH. Você pode executar o prefixo set as-path comando para adicionar mais propriedades de roteamento para afetar o roteamento vizinho. Ao usar a função de prefixo set as-path , primeiro use o AS local para adicionar AS_PATH. Se você usar outro AS, o AS deve ser enfatizado para evitar que o AS rejeite as rotas anunciadas a ele.
Tabela 13 -29 Configure um mapa de rota para modificar as propriedades AS_PATH
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure um mapa de rotas para modificar as propriedades AS_PATH. | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in | out | Obrigatório. Por padrão, nenhum mapa de rotas é aplicado a nenhum vizinho. |
Ao configurar um mapa de rotas para modificar uma propriedade AS_PATH, você pode usar o comando set as-path prepend para modificar a propriedade AS_PATH. Para obter detalhes, consulte Ferramentas de Política de Roteamento-Manual de Comando- definir como caminho .
Configurar a propriedade NEXT-HOP de uma rota BGP
Quando o BGP anuncia rotas para vizinhos IBGP, ele não altera as propriedades de roteamento (incluindo a propriedade NEXT-HOP). Quando o BGP anuncia as rotas que são aprendidas dos vizinhos EBGP para os vizinhos IBGP, você pode executar o comando next-hop-self para modificar a propriedade do próximo salto das rotas anunciadas aos vizinhos BGP para o endereço IP local. Você pode aplicar um mapa de rotas para modificar a propriedade do próximo salto.
1. Configure o BGP para usar o endereço IP local como o próximo salto de uma rota.
Tabela 13 -30 Configure o BGP para usar o endereço IP local como o próximo salto de uma rota
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o BGP para usar o endereço IP local como o próximo salto ao anunciar rotas. | neighbor { neighbor-address | peer-group-name } next-hop-self |
Obrigatório.
Por padrão, a propriedade do próximo salto das rotas anunciadas aos vizinhos EBGP é definida para o endereço IP v6 local , e a propriedade do próximo salto das rotas anunciadas aos vizinhos IBGP permanece inalterada. |
Quando o BGP é configurado para usar o endereço IPv6 local como o próximo salto de uma rota, se você executar o comando neighbor update-source para configurar o endereço de origem de uma sessão TCP, o endereço de origem será usado como o endereço do próximo salto; caso contrário, o endereço IP da interface de saída do dispositivo de publicidade é selecionado como o endereço IPv6 local.
2. Configure um mapa de rotas para modificar as propriedades do NEXT-HOP.
O BGP suporta a configuração de um mapa de rotas para modificar as propriedades do NEXT-HOP. Você pode executar o definir o próximo salto IPv6 comando para modificar a propriedade do próximo salto.
Tabela 13 -31 Configurar um mapa de rotas para modificar as propriedades do NEXT-HOP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure um mapa de rotas para modificar as propriedades do NEXT-HOP. | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in | out | Obrigatório. Por padrão, nenhum mapa de rotas é aplicado a nenhum vizinho. |
Ao configurar um mapa de rotas para modificar uma propriedade NEXT-HOP, você pode usar o comando set ipv6 next-hop para modificar a propriedade NEXT-HOP. Para obter detalhes, consulte Ferramentas de política de roteamento-manual de comando- set ipv6 next-hop .
Configurar a propriedade da comunidade de uma rota BGP
Quando o BGP anuncia rotas para vizinhos, ele pode ser configurado para enviar a propriedade da comunidade. Você pode aplicar um mapa de rotas a um vizinho especificado nas direções de entrada e saída para corresponder às propriedades da comunidade.
A propriedade de comunidade é usada para identificar um grupo de rotas para aplicar uma política de roteamento ao grupo de rotas. Dois tipos de propriedade comunitária estão disponíveis: padrão e estendido. A propriedade de comunidade padrão consiste em 4 bytes, fornecendo as propriedades como NO_EXPORT, LOCAL_AS, NO_ADVERTISE e INTERNET. A propriedade estendida consiste em oito bytes, fornecendo as propriedades Route Target (RT) e Route Origin (RO).
1. Configure o BGP para anunciar a propriedade da comunidade de rota aos vizinhos.
A comunidade de envio vizinha permite que você anuncie propriedade comunitária padrão ou propriedade comunitária estendida ou ambos os tipos de propriedade para os vizinhos.
Tabela 13 -32 Configurar BGP para anunciar propriedade de comunidade de rota para vizinhos
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o BGP para anunciar a propriedade da comunidade de rota aos vizinhos. | neighbor { neighbor-address | peer-group-name } send-community [ both | extended | standard ] | Obrigatório. Por padrão, a propriedade da comunidade não é anunciada a nenhum vizinho. |
Depois que os vizinhos são ativados na família de endereços VPNv6, as propriedades da comunidade padrão e estendida são automaticamente anunciadas aos vizinhos.
2. Configure um mapa de rotas para modificar a propriedade da comunidade.
O BGP oferece suporte à configuração de um mapa de rotas para modificar a propriedade da comunidade de rotas. Você pode usar o definir comunidade comandar a modificação da propriedade comunitária.
Tabela 13 -33 Configurar um mapa de rotas para modificar a propriedade da comunidade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure um mapa de rotas para modificar a propriedade da comunidade de rotas BGP | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in | out | Obrigatório. Por padrão, nenhum mapa de rotas é aplicado a nenhum vizinho. |
Ao configurar um mapa de rotas para modificar a propriedade da comunidade, você pode usar o comando set community para modificar a propriedade da comunidade. Para obter detalhes, consulte a comunidade de conjunto de manuais de comando de ferramentas de política de roteamento .
Configurar a otimização de rede IPv6 BGP
Condição de configuração
Antes de configurar a otimização de rede BGP, certifique-se de que:
- O BGP está ativado.
- Os vizinhos IPv6 BGP são configurados e uma sessão é configurada com sucesso.
Configurar o tempo de manutenção ativo dos vizinhos BGP
Depois que uma sessão BGP é configurada com sucesso, mensagens de manutenção ativa são enviadas periodicamente entre os vizinhos para manter a sessão BGP. Se nenhuma mensagem de manutenção ativa ou pacote de atualização for recebido do vizinho dentro do tempo de espera, a sessão BGP será desconectada devido ao tempo limite. O tempo de keep - alive é igual ou menor que 1/3 do tempo de h old.
Tabela 13 -34 Configurar o tempo de manutenção de atividade dos vizinhos BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| tempo de atividade e o tempo de espera global do BGP . | timers bgp keepalive-interval holdtime-interval | Opcional. Por padrão, o temporizador de manutenção de atividade é de 60 segundos, o temporizador de retenção é de 180 segundos e o temporizador de reconexão de sessão é de 120 segundos. |
| Configure o tempo de atividade e o tempo de espera de um vizinho BGP ou grupo de pares. | neighbor { neighbor-address | peer-group-name } timers { keepalive-interval holdtime-interval | connect connect-interval } |
O tempo de manutenção e o tempo de espera definidos para um vizinho especificado têm prioridades mais altas do que o tempo de manutenção e o tempo de espera do BGP global. Os vizinhos negociam e, em seguida, tomam o tempo mínimo de espera como a espera da sessão BGP entre os vizinhos. Se o tempo de manutenção e o tempo de espera forem definidos como 0, a função de manutenção/retenção do vizinho será cancelada. Se o tempo de manutenção for maior que 1/3 do tempo de espera, a sessão BGP enviará pacotes de manutenção de atividade no intervalo de 1/3 do tempo de espera.
Configurar o tempo de detecção de rota BGP
O BGP visa principalmente a implementação de um processo de roteamento, com ASs como unidades de roteamento. Dentro de um AS, o IGP é usado para roteamento. Portanto, as rotas BGP geralmente dependem de rotas IGP. Se os próximos saltos ou interfaces de saída das rotas IGP nas quais o BGP depende mudarem, o BGP detectará as rotas IGP periodicamente para atualizar as rotas BGP. O BGP também atualiza as rotas BGP locais durante o intervalo de detecção.
Tabela 13 -35 Configurar tempo de detecção de rota BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure o tempo de detecção de rota BGP. | bgp scan-time time | Opcional. Por padrão, o tempo de detecção de rota BGP é de 60 segundos. |
Se o tempo de detecção de rota BGP for muito pequeno, o BGP detecta rotas com frequência, afetando o desempenho do dispositivo.
Configurar a desconexão rápida de vizinhos EBGP
Depois que uma sessão BGP é configurada com sucesso, mensagens Keepalive são enviadas periodicamente entre os vizinhos para manter a sessão BGP. Se nenhuma mensagem Keepalive ou pacote de atualização for recebido do vizinho dentro do tempo de espera, a sessão BGP será desconectada devido ao tempo limite. Você pode configurar vizinhos EBGP de conexão direta para desconectar uma conexão BGP imediatamente depois que uma interface de conexão estiver inativa, sem aguardar o tempo limite de manutenção de atividade do BGP. Se a função de desconexão rápida do vizinho EBGP for cancelada, a sessão EBGP não responderá a um evento de inatividade da interface; em vez disso, a sessão BGP é desconectada após o tempo limite.
Tabela 13 -36 Configure a desconexão rápida de vizinhos EBGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure a desconexão rápida de vizinhos EBGP. | bgp fast-external-failover | Opcional. Por padrão, a capacidade de processamento rápido do EBGP em responder ao evento de inatividade da interface de conexão direta está habilitada. |
Configurar a função de supressão de rota BGP
Rotas oscilantes em uma rede podem causar instabilidade da rede. Você pode configurar a atenuação de rota para amortecer esse tipo de rotas de modo a diminuir o efeito de rotas oscilantes na rede.
Uma rota frequentemente oscilante será atribuída com uma penalidade. Se a penalidade exceder o limite de supressão, a rota não será anunciada aos vizinhos. A penalidade não deve ser mantida além do tempo máximo de supressão. Se não ocorrer nenhuma oscilação na rota dentro do período de meia-vida, a penalidade será reduzida pela metade. Se a penalidade for menor que o valor limite, a rota poderá ser anunciada aos vizinhos novamente.
- Período de meia-vida: É o tempo em que a penalidade de uma rota é reduzida pela metade.
- Limite de reutilização: é o limite para a rota retomar o uso normal.
- Limite de supressão: É o limite para supressão de rota.
- Tempo máximo de supressão: É o valor limite máximo para uma penalidade de rota.
Tabela 13 -37 Configurar a função de supressão de rota BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o período de atenuação da rota BGP. | bgp dampening [ reach-half-life [ reuse-value suppress-value max-suppress-time [ unreach-half-life ] ] | route-map rtmap-name ] |
Obrigatório.
Por padrão, a função de supressão de rota está desabilitada. Depois que a função é habilitada, o período de meia-vida de supressão de rota padrão é de 15 minutos, o tempo de reutilização de rota é de 750 segundos, o tempo mínimo de supressão de rota é de 2000 segundos, o tempo máximo de supressão de rota é de 60 minutos e a penalidade de rota metade inacessível -período de vida é de 15 minutos. |
O flapping de rota não apenas contém adição e exclusão de rotas, mas também contém alterações de propriedade de rota, como próximo salto e alterações de propriedade MED.
Configurar o recurso de atualização do vizinho BGP
Se a política de roteamento ou a política de seleção de rota aplicada a um vizinho BGP for alterada, a tabela de rotas precisará ser atualizada. Uma maneira de atualizar a tabela de rotas é redefinir a conexão BGP para redefinir a sessão BGP. No entanto, este modo pode resultar em oscilação da rota BGP, afetando os serviços normais. A outra maneira é mais elegante, ou seja, configurando o dispositivo BGP local para suportar o recurso de atualização de rota. Se um vizinho precisar redefinir uma rota, ele anunciará a mensagem Route-Refresh ao dispositivo local. Após receber a mensagem Route-Refresh, ele envia novamente a rota para o vizinho. Dessa forma, a tabela de rotas é atualizada dinamicamente sem a necessidade de desconectar a sessão BGP.
Tabela 13 -38 Configure o recurso de atualização do BGP Neighbor
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Habilite o recurso de atualização do vizinho BGP. | neighbor { neighbor-address | peer-group-name } capability route-refresh | Opcional. Por padrão, o recurso de atualização do vizinho BGP está habilitado. |
Configurar o recurso de reinicialização suave do vizinho BGP
Se a política de roteamento ou a política de seleção de rota aplicada a um vizinho BGP for alterada, a tabela de rotas precisará ser atualizada. Uma maneira de atualizar a tabela de rotas é redefinir a conexão BGP para redefinir a sessão BGP. No entanto, este modo pode resultar em oscilação da rota BGP, afetando os serviços normais. Outra maneira é mais elegante, ou seja, configurar o dispositivo BGP local para suportar o recurso de atualização de rota. Ainda há outra maneira, ou seja, habilitar o recurso de reinicialização por software do dispositivo BGP local. Por padrão, o dispositivo BGP reserva as informações de roteamento de cada vizinho. Depois de habilitar o recurso de reinicialização suave do vizinho, ele atualiza as rotas vizinhas que são mantidas no dispositivo local. Neste momento, as sessões BGP não são desconectadas.
Tabela 13 -39 Configurar o recurso de reinicialização suave do vizinho BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Habilite o recurso de reinicialização suave do vizinho BGP. | neighbor { neighbor-address | peer-group-name } soft-reconfiguration inbound | Obrigatório. Por padrão, a função de reinicialização suave do vizinho está desabilitada. |
Configurar a capacidade ORF de vizinhos BGP
O BGP implementa um controle de rota preciso por meio de propriedades de roteamento abundantes. Geralmente aplica políticas de roteamento nas direções de entrada e saída. Este modo é um comportamento local do BGP. O BGP também oferece suporte ao recurso ORF (Outbound Route Filtering). Ele anuncia a política de ingresso local para seus vizinhos por meio de pacotes de atualização de rota e, em seguida, os vizinhos aplicam a política quando anunciam rotas para o dispositivo BGP local. Isso diminui bastante o número de pacotes de atualização de rota trocados entre vizinhos BGP.
Para obter uma negociação bem-sucedida da capacidade ORF, certifique-se de que:
- A capacidade ORF está habilitada para ambos os vizinhos.
- "ORF send" e "ORF receive" devem corresponder. Ou seja, se uma extremidade for "ORF de envio", a outra extremidade deverá ser "ORF ambos" ou "ORF de recepção". Se uma extremidade for "ORF receber", a outra extremidade deve ser "ORF enviar" ou "ORF ambos".
- A extremidade "Envio ORF" deve ser configurada com uma lista de prefixos na direção de entrada.
Tabela 13 -40 Configure a capacidade ORF dos vizinhos BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Aplique uma lista de prefixos na direção de entrada de um vizinho. | neighbor { neighbor-address | peer-group-name } prefix-list prefix-list-name in | Obrigatório. Por padrão, nenhuma lista de prefixos é aplicada a nenhum vizinho BGP. |
| Configure um vizinho para suportar o recurso ORF. | neighbor { neighbor-address | peer-group-name } capability orf prefix-list { both | receive | send } | Obrigatório. Por padrão, um vizinho não suporta o recurso ORF. |
Configurar rede IPv6 BGP de grande escala
Condição de configuração
Antes de configurar uma rede BGP de grande escala, certifique-se de que:
- O BGP está ativado.
- Os vizinhos IPv6 BGP são configurados e uma sessão é configurada com sucesso.
Configurar um grupo de pares do BGP
Um grupo de pares BGP é um grupo de vizinhos BGP configurados com a mesma política de configuração. Qualquer configuração executada em um grupo de pares BGP terá efeito em todos os membros do grupo de pares. Dessa forma, configurando o grupo de peers, você pode realizar gerenciamento e manutenção centralizados nos vizinhos.
Tabela 13 -41 Configurar um grupo de peers BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Crie um grupo de pares BGP. | neighbor peer-group-name peer-group |
Obrigatório.
Por padrão, nenhum grupo de pares está configurado e um vizinho não está em nenhum grupo de pares. |
| Adicione um vizinho ao grupo de pares. | neighbor neighbor-address peer-group peer-group-name |
A configuração em um grupo de pares entra em vigor em todos os membros do grupo de pares. Depois que um vizinho é adicionado a um grupo de pares, se algumas configurações do vizinho forem iguais às configurações do grupo de pares, as configurações do vizinho serão excluídas. Se as políticas de roteamento forem configuradas nas direções de entrada e saída de um grupo de pares, depois que as políticas de roteamento forem alteradas, as alterações não terão efeito nos vizinhos que foram adicionados ao grupo de pares. Para aplicar as políticas de roteamento alteradas nos membros do grupo de pares, você precisa redefinir o grupo de pares.
Configurar um refletor de rota BGP
Em uma rede BGP de grande porte, é necessário que os vizinhos IBGP estejam totalmente conectados, ou seja, cada BGP precisa estabelecer conexões com todos os vizinhos IBGP. Desta forma, em uma rede que contém N vizinhos BGP, o número de conexões BGP é N*(N-1)/2. Quanto maior o número de conexões, maior o número de anúncios de rota. Configurar um BGP Route Reflector (RR) é um método para reduzir o número de conexões de rede. Vários IBGPs são categorizados em um grupo. Nesse grupo, um BGP é especificado para atuar como RR, enquanto outros BGPs atuam como clientes e BGPs que não estão no grupo atuam como não clientes. Os clientes estabelecem relações de pares apenas com o RR enquanto não estabelecem relações de pares com outros BGPs. Isso reduz o número de conexões IBGP obrigatórias e o número de conexões é N-1.
Os seguintes sapatos os princípios de roteamento do BGP RR:
- O RR reflete as rotas que ele aprende de vizinhos IBGP não clientes apenas para clientes.
- O RR reflete as rotas que ele aprende dos clientes para todos os clientes e não clientes, exceto os clientes que iniciam as rotas.
- O RR reflete as rotas que aprende dos vizinhos EBGP para todos os clientes e não clientes.
Tabela 13 -42 Configurar um refletor de rota BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Configure um ID de cluster RR. | bgp cluster-id { cluster-id-in-ip | cluster-id-in-num } | Obrigatório. Por padrão, o ID da rota é usado como o ID do cluster RR. |
| Configure um vizinho como cliente do RR. | neighbor { neighbor-address | peer-group-name } route-reflector-client | Obrigatório. Por padrão, nenhum vizinho é especificado como cliente do RR. |
| Configure a função de reflexão de rota entre clientes BGP. | bgp client-to-client reflection | Opcional. Por padrão, a função de reflexão de rota é habilitada entre clientes RR. |
Um ID de cluster RR é usado para identificar uma área RR. Uma área RR pode conter vários RRs e os RRs na área RR têm o mesmo ID de cluster RR.
Configurar uma Confederação BGP
Em uma rede BGP de grande porte, é necessário que os vizinhos IBGP estejam totalmente conectados, ou seja, cada BGP precisa estabelecer conexões com todos os vizinhos IBGP. Desta forma, em uma rede que contém N vizinhos BGP, o número de conexões BGP é N*(N-1)/2. Quanto maior o número de conexões, maior o número de anúncios de rota. A configuração de confederações BGP é outra maneira de reduzir o número de conexões de rede. Uma área AS é dividida em várias áreas sub-AS, e cada área AS forma uma confederação. O IBGP é adotado dentro de uma confederação para fornecer conexões completas, e as áreas sub-AS da confederação são conectadas por meio de conexões EBGP. Isso reduz efetivamente o número de conexões BGP.
Ao configurar confederações BGP, você precisa atribuir um ID de confederação para cada confederação e especificar membros para a confederação. No caso de reflexão de rota, apenas o refletor de rota é necessário para suportar a reflexão de rota. No entanto, no caso de uma confederação, todos os membros de uma confederação devem apoiar a função de confederação.
Tabela 13 -43 Configurar uma confederação BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Crie um ID de confederação BGP. | bgp confederation identifier as-number | Obrigatório. Por padrão, nenhum número AS é configurado para uma confederação. |
| Configure membros para a confederação. | bgp confederation peers as-number-list | Obrigatório. Por padrão, nenhum número sub-AS é configurado para uma confederação. |
Um ID de confederação é usado para identificar os sub-ASs da confederação. Os membros da Confederação são divididos em sub-ASs.
Configurar IPv6 BGP GR
Graceful Restart (GR) é usado na alternância ativa/em espera entre dispositivos. Durante o GR, as informações de roteamento do dispositivo local e dos dispositivos vizinhos permanecem inalteradas na camada de encaminhamento, e o encaminhamento de dados não é afetado. Depois que a alternância é concluída e o novo dispositivo começa a ser executado, os dois dispositivos sincronizam as informações de roteamento na camada de protocolo e atualizam a camada de encaminhamento para que o encaminhamento de dados não seja interrompido durante o processo de alternância do dispositivo.
Funções envolvidas em um GR:
- GR Restarter: É o dispositivo que é reiniciado normalmente.
- GR Helper: É o dispositivo que auxilia no GR.
- Tempo GR: É o tempo máximo para reiniciar os GR-Restarters. GR Helper mantém a estabilidade das rotas durante o período de tempo.
Um dispositivo de controlador duplo pode atuar como um GR Restarter e um GR Helper, enquanto um dispositivo centralizado pode atuar apenas como um GR Helper, ajudando o GR Restarter a completar um GR. Quando o GR Restarter está no processo GR, o GR Helper mantém a estabilidade da rota até o tempo limite do GR Time. Depois que o GR Helper ajuda com o GR, ele sincroniza as informações de rota. Durante o processo, as rotas de rede e o encaminhamento de pacotes mantêm o status perante o GR, garantindo efetivamente a estabilidade da rede.
A relação BGP GR é estabelecida através da negociação de pacotes OPEN quando uma conexão é estabelecida entre vizinhos. Quando o GR Restarter reinicia o vizinho, a sessão BGP será desconectada, mas as rotas aprendidas do vizinho não serão excluídas. As rotas ainda são normalmente encaminhadas na tabela de rotas IP. As rotas são rotuladas com as marcas Stale somente na tabela de rotas BGP. Após a conclusão do GR, as rotas serão atualizadas.
O GR Restarter precisa estabelecer uma conexão com o GR Helper dentro do tempo máximo permitido ( restart-time ) ; caso contrário, o GR Helper cancela a rota GR mantida e cancela o processo GR. Depois que o vizinho é reconectado, o GR Helper precisa receber um pacote de atualização com a marca End-Of-RIB do GR Restarter para concluir o processo GR; caso contrário, a rota GR que não for atualizada será excluída após o tempo máximo de retenção ( stalepath-time ) expirar e, em seguida, a relação GR será liberada.
Condição de configuração
Antes de configurar um BGP GR, certifique-se de que:
- O BGP está ativado.
- Os vizinhos IPv6 BGP são configurados e uma sessão é configurada com sucesso.
Configurar o reiniciador do BGP GR
Tabela 13 -44 Configurar um reiniciador do BGP GR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Habilite o recurso BGP GR. | bgp graceful-restart [ restart-time time | stalepath-time time ] |
Obrigatório.
Por padrão, o recurso GR está desabilitado para dispositivos BGP. Depois que o recurso GR é habilitado, o tempo máximo padrão permitido para reconfigurar uma sessão com o vizinho é 120s, e o tempo máximo de espera das rotas GR é 360s. |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure a publicidade do recurso GR-Restarter para o vizinho | neighbor { neighbor-address | peer-group-name } capability graceful-restart | Obrigatório. Por padrão, não anuncie o recurso GR-Restarter ao vizinho. |
Configurar BGP GR Ajudante
Tabela 13 -45 Configurar um auxiliar BGP GR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Habilite o recurso BGP GR. | bgp graceful-restart [ restart-time time | stalepath-time time ] |
Obrigatório.
Por padrão, o recurso GR está desabilitado para dispositivos BGP. Depois que o recurso GR é habilitado, o tempo máximo padrão permitido para reconfigurar uma sessão com o vizinho é 120s, e o tempo máximo de espera das rotas GR é 360s. |
Configurar IPv6 BGP para coordenar com BFD
Normalmente, ainda existem alguns dispositivos intermediários entre os vizinhos BGP. Quando um dispositivo intermediário se torna defeituoso, a sessão BGP é normal dentro do tempo de espera e a falha de link causada pelo dispositivo intermediário não pode ser respondida a tempo. A detecção de encaminhamento bidirecional (BFD) fornece um método para detectar rapidamente o status de uma linha entre dois dispositivos. Depois que o BFD estiver habilitado para dispositivos BGP, se uma linha entre dois dispositivos estiver com defeito, o BFD pode encontrar rapidamente a falha de linha e notificar o BGP sobre a falha. Ele aciona o BGP para desconectar rapidamente a sessão e alternar rapidamente para a linha de backup, obtendo uma rápida alternância de rotas.
Condição de configuração
Antes de configurar o BGP para coordenar com o BFD, certifique-se de que:
- O BGP está ativado.
- Os vizinhos IPv6 BGP são configurados e uma sessão é configurada com sucesso.
Configurar EBGP para coordenar com BFD
A coordenação entre EBGP e BFD é baseada em uma sessão BFD de salto único, e os parâmetros da sessão BFD precisam ser configurados no modo de interface.
Tabela 13 -46 Configurar e EBGP para coordenar com BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o EBGP para coordenar com o BFD. | neighbor { neighbor-address | peer-group-name } fall-over bfd [single-hop] | Obrigatório. Por padrão, a função BFD está desabilitada para um vizinho. |
| Saia do modo de configuração unicast IPv6 do BGP | exit-address-family | - |
| Saia do modo de configuração BGP. | exit | - |
| Entre no modo de configuração da interface. | interface interface-name | - |
| Configure o intervalo mínimo de recebimento de uma sessão BFD. | bfd min-receive-interval milliseconds | Opcional. Por padrão, o intervalo mínimo de recebimento de uma sessão BFD é 1000s. |
| Configure o intervalo mínimo de transmissão da sessão BFD. | bfd min-transmit-interval milliseconds | Opcional. Por padrão, o intervalo mínimo de transmissão de uma sessão BFD é 1000s. |
| Configure o múltiplo de tempo limite de detecção de sessão BFD. | bfd multiplier number | Opcional. Por padrão, o múltiplo do tempo limite de detecção da sessão BFD é 5. |
Para a configuração relacionada do BFD, consulte o manual técnico do BFD da tecnologia de confiabilidade e o manual de configuração do BFD.
Configurar IBGP para coordenar com BFD
A coordenação entre IBGP e BFD é baseada em uma sessão BFD multi-hop, e os parâmetros da sessão BFD precisam ser configurados no modo BGP.
Tabela 13 -47 Configure o IBGP para coordenar com o BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| Entre no modo de configuração unicast IPv6 do BGP | address-family ipv6 unicast | - |
| Configure o IBGP para coordenar com o BFD. | neighbor { neighbor-address | peer-group-name } fall-over bfd [single-hop] | Obrigatório. Por padrão, a função BFD está desabilitada para um vizinho. |
| Configure o intervalo mínimo de recebimento da sessão BFD. | bfd min-receive-interval milliseconds | Opcional. Por padrão, o intervalo mínimo de recebimento de uma sessão BFD é 1000s. |
| Configure o intervalo mínimo de transmissão da sessão BFD. | bfd min-transmit-interval milliseconds | Opcional. Por padrão, o intervalo mínimo de transmissão de uma sessão BFD é 1000s. |
| Configure o múltiplo de tempo limite de detecção de sessão BFD. | bfd multiplier number | Opcional. Por padrão, o múltiplo do tempo limite de detecção da sessão BFD é 5. |
Configurar o reencaminhamento rápido do IPv6 BGP
Condição de configuração
Antes de configurar o reencaminhamento rápido de IPv6BGP, primeiro conclua as seguintes tarefas:
- Ao configurar o reencaminhamento rápido baseado no mapa de rotas, o mapa de rotas associado já está configurado.
- Habilite o protocolo IPv6 BGP.
Configurar o reencaminhamento rápido do BGP
Na rede IPv6BGP , devido a falha de link ou dispositivo, os pacotes que passam pelo ponto de falha serão descartados ou serão gerados loops. A interrupção de tráfego causada por isso durará vários segundos até que o protocolo convirja novamente. Para reduzir o tempo de interrupção do tráfego, o reencaminhamento rápido do IPv6BGP pode ser configurado. Através da aplicação do mapa de roteamento, o próximo salto de backup é definido para a rota correspondente. Uma vez que o enlace principal falhe, o tráfego que passa pelo enlace principal será imediatamente comutado para o enlace de espera, de modo a atingir o objetivo de comutação rápida.
Tabela 13 -48 Configurar o reencaminhamento rápido do IPv6 BGP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração BGP. | router bgp autonomous-system | - |
| unicast BGP IPv6 | address-family ipv6 unicast | - |
| Configurar o reencaminhamento rápido do BGP com base no mapa de rotas | fast-reroute route-map route-map-name |
Obrigatório.
Por padrão, não habilite a função de reencaminhamento rápido com base no mapa de rota. |
| Configurar o reencaminhamento rápido automático do BGP | pic | Obrigatório. Por padrão, não ative a função de redirecionamento rápido automático do BGP. |
Após configurar o reencaminhamento rápido do BGP, é necessário redefinir o BGP, concluir a verificação inicial da rota e o backup. Caso contrário, apenas as rotas aprendidas após a configuração terão efeito. Ao configurar o reencaminhamento rápido com base no mapa de rotas via set backup-nexthop auto , o protocolo executa o reencaminhamento rápido automático. Quando o modo pic é usado, o protocolo será redirecionado automaticamente rapidamente; As várias formas de reencaminhamento rápido são mutuamente exclusivas. Depois de configurar o reencaminhamento rápido do BGP para solicitar o mapa de rotas, defina o vizinho BGP como o próximo salto de backup por meio do comando set backup-nexthop nexthop-address no mapa de rotas. Se o vizinho não BGP estiver configurado como o próximo salto de backup, a função de reencaminhamento rápido não terá efeito.
Monitoramento e Manutenção de BGP IPv6
Tabela 13 -49 Monitoramento e manutenção de BGP IPv6
| Comando | Descrição |
| clear bgp ipv6 { * | as-number | peer-group peer-group-name | external | neighbor-address } [vrf vrf-name] | Redefine o vizinho BGP. |
| clear bgp [ipv6 unicast] dampening [ ipv6-address | ipv6-address/mask-length] | Limpa rotas suprimidas. |
| clear bgp [ipv6 unicast] flap-statistics [ ipv6-address | ipv6-address/mask-length] | Limpa as informações estatísticas do flap |
| clear bgp [ipv6] { * | as-number | peer-group peer-group-name | external | neighbor-address} [vrf vrf-name] { [ soft ] [ in | out ] } | Vizinhos de reinicialização suave. |
| clear bgp [ipv6] { * | neighbor-address | as-number | peer-group peer-group-name | external } [vrf vrf-name] in prefix-filter | Anuncia ORF aos vizinhos. |
| show bgp{ipv6 unicast | vpnv6 unicast { all | vrf vrf-name | rd route-distinguisher } } [ ipv6-address | ipv6-address/mask-length] | Exibe as informações de roteamento na família de endereços BGP relacionada. |
| show ip bgp attribute-info | Exibe os atributos de rota comum do BGP. |
| show bgp ipv6 unicast community [community-number / aa:nn / exact-match / local-AS / no-advertise / no-export ] | Exibe as rotas que correspondem à propriedade da comunidade especificada. |
| show bgp ipv6 unicast community-list community-list-name | Exibe a lista de comunidades que é aplicada às rotas. |
| show bgp {ipv6 unicast | vpnv6 unicast { all | vrf vrf-name | rd route-distinguisher } } dampening { dampened-paths | flap-statistics | parameters } | Exibe os detalhes da atenuação da rota. |
| show bgp ipv6 unicast filter-list filter-list-name [ exact-match ] | Exibe as rotas que correspondem à lista de filtros AS_PATH. |
| show bgp ipv6 unicast inconsistent-as | Exibe as rotas que estão em conflito com AS_PATH. |
| show bgp { ipv6 unicast | vpnv6 uicast { all | vrf vrf-name | rd route-distinguisher }} neighbors [ ipv6-address ] | Exibe os detalhes dos vizinhos BGP |
| show bgp ipv6 unicast prefix-list prefix-list-name | Exibe as rotas que correspondem à lista de prefixos |
| show bgp ipv6 unicast quote-regexp as-path-list-name | Exibe as rotas que correspondem à lista AS_PATH |
| show bgp ipv6 unicast regexp as-path-list-name | Exibe as rotas que correspondem à lista AS_PATH |
| show bgp ipv6 unicast route-map rtmap-name | Exibe as rotas que correspondem ao mapa de rotas |
| show ip bgp scan | Exibe as informações de varredura BGP. |
| show bgp {ipv6 unicast | vpnv6 { all | vrf vrf-name | rd route-distinguisher } } summary | Exibe o resumo dos vizinhos BGP. |
Exemplo de configuração típica de IPv6 BGP
Configurar funções básicas do IPv6 BGP
Requisitos de rede
- Configure vizinhos EBGP entre Device1 e Device2 e configure vizinhos IBGP entre Device2 e Device3.
- Device1 aprende a rota direta de interface 2001:4::/64 de Device3, e Device3 aprende a rota direta de interface 2001:1::/64 de Device1.
Topologia de rede
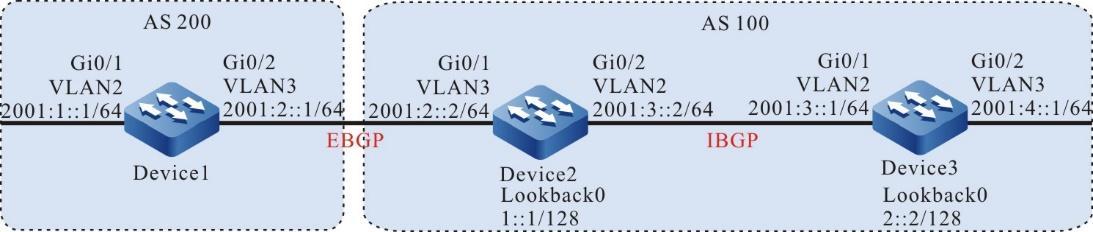
Figura 13 – 1 Rede para configurar as funções básicas do IPv6 BGP
Etapas de configuração
- Passo 1: Configure os endereços unicast globais IPv6 das interfaces. (Omitido)
- Passo 2: Configure o OSPFv3 para que as rotas de loopback sejam alcançáveis entre os dispositivos.
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface vlan 2Device2(config-if-vlan2)#ipv6 router ospf 100 area 0Device2(config-if-vlan2)#exitDevice2(config)#interface loopback 0Device2(config-if-loopback0)#ipv6 router ospf 100 area 0Device2(config-if-loopback0)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface vlan 2Device3(config-if-vlan2)#ipv6 router ospf 100 area 0Device3(config-if-vlan2)#exitDevice3(config)#interface loopback 0Device3(config-if-loopback0)#ipv6 router ospf 100 area 0Device3(config-if-loopback0)#exit
# Visualize a tabela de rotas do Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w1d:23:51:37, lo0LC 1::1/128 [0/0]via ::, 00:09:34, loopback0O 2::2/128 [110/2]via fe80::201:7aff:fec0:525a, 00:05:29, vlan2C 2001:2::/64 [0/0]via ::, 00:09:41, vlan3L 2001:2::2/128 [0/0]via ::, 00:09:39, vlan3C 2001:3::/64 [0/0]via ::, 00:08:55, vlan2L 2001:3::2/128 [0/0]via ::, 00:08:53, vlan2
# Visualize a tabela de rotas do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w5d:18:34:53, lo0O 1::1/128 [110/2]via fe80::201:7aff:fe5e:6d2e, 00:29:59, vlan2LC 2::2/128 [0/0]via ::, 00:32:36, loopback0C 2001:3::/64 [0/0]via ::, 00:32:59, vlan2L 2001:3::1/128 [0/0]via ::, 00:32:58, vlan2C 2001:4::/64 [0/0]via ::, 00:32:44, vlan3L 2001:4::1/128 [0/0]via ::, 00:32:43, vlan3
De acordo com as informações consultadas, Device2 e Device3 aprenderam as rotas das interfaces de loopback de peer executando OSPFv3, preparando-se para configurar vizinhos IBGP nas interfaces de loopback de Device2 e Device3.
- Passo 3: Configure as funções básicas do IPv6 BGP.
# Configurar dispositivo1.
Configure um peer EBGP de conexão direta com Device2. Introduza 2001:1::/64 ao BGP no modo de rede.
Device1#configure terminalDevice1(config)#router bgp 200Device1(config-bgp)#bgp router-id 1.1.1.1Device1(config-bgp)#address-family ipv6Device1(config-bgp-af)#neighbor 2001:2::2 remote-as 100Device1(config-bgp-af)#network 2001:1::/64Device1(config-bgp-af)#exit-address-familyDevice1(config-bgp)#exit
# Configurar dispositivo2.
Configure o peer EBGP de conexão direta com Device1, configure um peer IBGP de conexão não direta com Device3 por meio de Loopback0 e defina o próximo salto da rota anunciada para o dispositivo local.
Device2(config)#router bgp 100Device2(config-bgp)#bgp router-id 2.2.2.2Device2(config-bgp)#address-family ipv6Device2(config-bgp-af)#neighbor 2001:2::1 remote-as 200Device2(config-bgp-af)#neighbor 2::2 remote-as 100Device2(config-bgp-af)#neighbor 2::2 next-hop-selfDevice2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#neighbor 2::2 update-source loopback 0Device2(config-bgp)#exit
# Configurar dispositivo3.
Configure uma relação de peer IBGP de conexão não direta com Device2 por meio de Loopback0. Introduza 2001:4::/64 ao BGP no modo de rede.
Device3(config)#router bgp 100Device3(config-bgp)#bgp router-id 3.3.3.3Device3(config-bgp)#address-family ipv6Device3(config-bgp-af)#neighbor 1::1 remote-as 100Device3(config-bgp-af)#network 2001:4::/64Device3(config-bgp-af)#exit-address-familyDevice3(config-bgp)#neighbor 1::1 update-source loopback 0Device3(config-bgp)#exit
Para evitar a oscilação de rota, os vizinhos IBGP são configurados por meio das interfaces de loopback e o OSPFv3 precisa sincronizar as informações de roteamento das interfaces de loopback entre os vizinhos IBGP.
- Passo 4: Confira o resultado.
#No Device2, verifique o status do vizinho IPv6 BGP.
Device2#show bgp ipv6 unicast summaryBGP router identifier 2.2.2.2, local AS number 100BGP table version is 42 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd2::2 4 100 8 6 3 0 0 00:04:12 1 2001:2::1 4 200 15 15 3 0 0 00:11:17 1Total number of neighbors 2
De acordo com os números (Número de prefixos de rota recebidos dos vizinhos) exibidos na coluna State/PfxRcd, os vizinhos IPv6 BGP foram configurados com sucesso entre o Dispositivo 2 e o Dispositivo 1, Dispositivo 3.
# Visualize a tabela de rotas do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w2d:00:42:57, lo0C 2001:1::/64 [0/0]via ::, 00:02:59, vlan2L 2001:1::1/128 [0/0]via ::, 00:02:56, vlan2C 2001:2::/64 [0/0]via ::, 00:52:17, vlan3L 2001:2::1/128 [0/0]via ::, 00:52:16, vlan3B 2001:4::/64 [20/0]via 2001:2::2, 00:06:13, vlan3
# Visualize a tabela de rotas do Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w2d:00:34:53, lo0LC 1::1/128 [0/0]via ::, 00:52:49, loopback0O 2::2/128 [110/2]via fe80::201:7aff:fec0:525a, 00:48:45, vlan2B 2001:1::/64 [20/0]via 2001:2::1, 00:03:18, vlan3C 2001:2::/64 [0/0]via ::, 00:52:57, vlan3L 2001:2::2/128 [0/0]via ::, 00:52:55, vlan3C 2001:3::/64 [0/0]via ::, 00:52:10, vlan2L 2001:3::2/128 [0/0]via ::, 00:52:09, lo0B 2001:4::/64 [200/0]via 2::2, 00:07:27, vlan2
# Visualize a tabela de rotas do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w5d:18:54:38, lo0O 1::1/128 [110/2]via fe80::201:7aff:fe5e:6d2e, 00:49:44, vlan2LC 2::2/128 [0/0]via ::, 00:52:21, loopback0B 2001:1::/64 [200/0]via 1::1, 00:03:54, vlan2C 2001:3::/64 [0/0]via ::, 00:52:44, vlan2L 2001:3::1/128 [0/0]via ::, 00:52:43, vlan2C 2001:4::/64 [0/0]via ::, 00:52:29, vlan3L 2001:4::1/128 [0/0]via ::, 00:52:28, vlan3
Device1 aprendeu a rota de conexão direta de interface 2001:4::/64 de Device3, e Device3 aprendeu a rota de conexão direta de interface 2001:1::/64 de Device1.
Configurar IPv6 BGP para redistribuir rotas
Requisitos de rede
- Configure vizinhos OSPFv3 entre Device3 e Device2 e anuncie a rota de conexão direta da interface 2001:3::/64 para Device2.
- Configure vizinhos EBGP entre Device1 e Device2 e redistribua a rota OSPFv3 que Device2 aprende para BGP e anuncie a rota para Device1.
Topologia de rede

Figura 13 - 2 Rede para configurar IPv6 BGP para redistribuir rotas
Etapas de configuração
- Passo 1: Configure os endereços unicast globais IPv6 das interfaces. (Omitido)
- Passo 2: Configure o OSPFv3 para que Device2 possa aprender a rota de interface de conexão direta 2001:3::/64 para Device3.
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 router ospf 100 area 0Device2(config-if-vlan3)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface vlan 2Device3(config-if-vlan2)#ipv6 router ospf 100 area 0Device3(config-if-vlan2)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 router ospf 100 area 0Device3(config-if-vlan3)#exit
# Visualize a tabela de rotas do Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w2d:01:10:38, lo0C 2001:1::/64 [0/0]via ::, 00:06:25, vlan2L 2001:1::2/128 [0/0]via ::, 00:06:24, lo0C 2001:2::/64 [0/0]via ::, 00:05:46, vlan3L 2001:2::2/128 [0/0]via ::, 00:05:43, lo0O 2001:3::/64 [110/2]via fe80::201:7aff:fec0:525a, 00:02:41, vlan3
De acordo com a tabela de rotas, Device2 aprendeu a rota OSPFv3 2001:3::/64 que foi anunciada pelo Device 3 .
- Passo 3: Configure as funções básicas do IPv6 BGP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router bgp 100Device1(config-bgp)#bgp router-id 1.1.1.1Device1(config-bgp)#address-family ipv6Device1(config-bgp-af)#neighbor 2001:1::2 remote-as 200Device1(config-bgp-af)#exit-address-familyDevice1(config-bgp)#exit
# Configurar dispositivo2.
Device2(config)#router bgp 200Device2(config-bgp)#bgp router-id 2.2.2.2Device2(config-bgp)#address-family ipv6Device2(config-bgp-af)#neighbor 2001:1::1 remote-as 100Device2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#exit
#No Device2, verifique o status do vizinho IPv6 BGP.
Device2#show bgp ipv6 unicast summaryBGP router identifier 2.2.2.2, local AS number 200BGP table version is 11 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd2001:1::1 4 100 2 2 1 0 0 00:00:50 0Total number of neighbors 1
Os vizinhos IPv6 BGP foram configurados com sucesso entre Device2 e Device1.
- Passo 4: Configure o IPv6 BGP para redistribuir a rota OSPFv3.
# Configurar dispositivo2.
Device2(config)#router bgp 200Device2(config-bgp)#address-family ipv6Device2(config-bgp-af)#redistribute ospf 100Device2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#exit
- Passo 5: Confira o resultado.
# Veja a tabela de rotas IPv6 BGP de Device2.
Device2#show bgp ipv6 unicastBGP table version is 2, local router ID is 2.2.2.2Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[O]*> 2001:2::/64 :: 1 32768 ?[O]*> 2001:3::/64 :: 2 32768 ?
De acordo com as informações consultadas, as rotas OSPFv3 foram redistribuídas com sucesso para IPv6 BGP.
# Visualize a tabela de rotas do Device1.
Device1#show bgp ipv6 unicastBGP table version is 3, local router ID is 1.1.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 2001:2::/64 2001:1::2 1 0 200 ?[B]*> 2001:3::/64 2001:1::2 2 0 200 ?
De acordo com as informações consultadas, Device1 aprendeu com sucesso as rotas 2001:2::/64 e 2001:3::/64.
Em um aplicativo real, se houver dois ou mais roteadores de limite AS, é recomendável não redistribuir rotas entre diferentes protocolos de roteamento. Se a redistribuição de rota precisar ser configurada, você deverá configurar políticas de controle de rota, como filtragem de rota e resumo de filtragem nos roteadores de limite AS para evitar loops de roteamento.
Configurar propriedades da comunidade IPv6 BGP
Requisitos de rede
- Configure vizinhos EBGP entre Device1 e Device2.
- Device1 apresenta duas rotas de conexão direta 2001:1::/64 e 2001:2::/64 para BGP no modo de rede e defina propriedades de comunidade diferentes para duas rotas anunciadas para Device2.
- Quando Device2 recebe rotas de Device1, ele aplica propriedades de comunidade na direção de entrada de um vizinho para filtrar a rota 2001:1::/64 e permitir a rota 2001:2::/64.
Topologia de rede
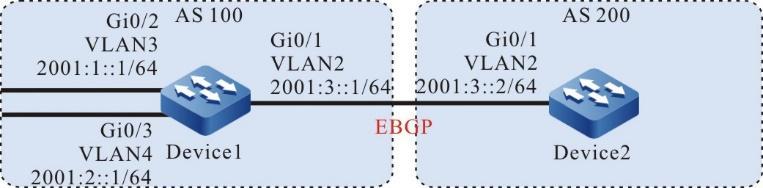
Figura 13 - 3 Rede para configurar as propriedades da comunidade IPv6 BGP
Etapas de configuração
- Passo 1: Configure os endereços unicast globais IPv6 das interfaces. (Omitido)
- Passo 2: Configure as funções básicas do IPv6 BGP.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router bgp 100Device1(config-bgp)#bgp router-id 1.1.1.1Device1(config-bgp)#address-family ipv6Device1(config-bgp-af)#neighbor 2001:3::2 remote-as 200Device1(config-bgp-af)#network 2001:1::/64Device1(config-bgp-af)#network 2001:2::/64Device1(config-bgp-af)#exit-address-familyDevice1(config-bgp)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router bgp 200Device2(config-bgp)#bgp router-id 2.2.2.2Device2(config-bgp)#address-family ipv6Device2(config-bgp-af)#neighbor 2001:3::1 remote-as 100Device2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#exit
#No Dispositivo1, verifique o status do vizinho IPv6 BGP.
Device1#show bgp ipv6 unicast summaryBGP router identifier 1.1.1.1, local AS number 100BGP table version is 11 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd2001:3::2 4 200 3 4 1 0 0 00:01:02 0Total number of neighbors 1
Os vizinhos IPv6 BGP foram configurados com sucesso entre Device1 e Device2.
#Consulte a tabela de rotas do Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w2d:05:45:34, lo0B 2001:1::/64 [20/0]via 2001:3::1, 00:01:35, vlan2B 2001:2::/64 [20/0]via 2001:3::1, 00:01:35, vlan2C 2001:3::/64 [0/0]via ::, 00:04:09, vlan2L 2001:3::2/128 [0/0]via ::, 00:04:08, lo0
De acordo com as informações consultadas, Device2 aprendeu com sucesso as rotas 2001:1::/64 e 2001:2::/64.
- Passo 3: Configure a ACL e a política de roteamento e defina as propriedades da comunidade IPv6 BGP.
# Configurar dispositivo1.
Device1(config)#ipv6 access-list extended 7001Device1(config-v6-list)#permit ipv6 2001:1::/64 anyDevice1(config-v6-list)#commitDevice1(config-v6-list)#exitDevice1(config)#ipv6 access-list extended 7002Device1(config-v6-list)#permit ipv6 2001:2::/64 anyDevice1(config-v6-list)#commitDevice1(config-v6-list)#exitDevice1(config)#route-map CommunitySet 10Device1(config-route-map)#match ipv6 address 7001Device1(config-route-map)#set community 100:1Device1(config-route-map)#exitDevice1(config)#route-map CommunitySet 20Device1(config-route-map)#match ipv6 address 7002Device1(config-route-map)#set community 100:2Device1(config-route-map)#exit
Defina diferentes propriedades da comunidade para rotas 2001:1::/64 e 2001:2::/64, respectivamente, configurando uma ACL e uma política de roteamento.
- Passo 4: Configure uma política de roteamento para IPv6 BGP.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#address-family ipv6Device1(config-bgp-af)#neighbor 2001:3::2 route-map CommunitySet outDevice1(config-bgp-af)#neighbor 2001:3::2 send-communityDevice1(config-bgp-af)#exit-address-familyDevice1(config-bgp)#exit
# Veja a tabela de rotas IPv6 BGP de Device2.
Device2#show bgp ipv6 unicast 2001:1::/64BGP routing table entry for 2001:1::/64Paths: (1 available, best #1, table Default-IP-Routing-Table)Not advertised to any peer1002001:3::1 (metric 10) from 2001:3::1 (1.1.1.1)Origin IGP, metric 0, localpref 100, valid, external, bestCommunity: 100:1Last update: 00:00:24 agoDevice2#show bgp ipv6 unicast 2001:2::/64BGP routing table entry for 2001:2::/64Paths: (1 available, best #1, table Default-IP-Routing-Table)Not advertised to any peer1002001:3::1 (metric 10) from 2001:3::1 (1.1.1.1)Origin IGP, metric 0, localpref 100, valid, external, bestCommunity: 100:2Last update: 00:00:30 ago
De acordo com a tabela de rotas IPv6 BGP de Device2, a propriedade da comunidade da rota 2001:1::/64 é definida como 100:1 e as propriedades da comunidade da rota 2001:2::/64 são definidas como 10 0:2.
- Passo 5: Configure a filtragem de rota IPv6 BGP.
# Configurar dispositivo2.
Device2(config)#ip community-list 1 permit 100:2Device2(config)#route-map CommunityFilterDevice2(config-route-map)#match community 1Device2(config-route-map)#exitDevice2(config)#router bgp 200Device2(config-bgp)#address-family ipv6Device2(config-bgp-af)#neighbor 2001:3::1 route-map CommunityFilter inDevice2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#exit
- Passo 6: Confira o resultado.
# Visualize a tabela de rotas do Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w2d:05:58:57, lo0B 2001:2::/64 [20/0]via 2001:3::1, 00:00:05, vlan2C 2001:3::/64 [0/0]via ::, 00:17:32, vlan2L 2001:3::2/128 [0/0]via ::, 00:17:30, lo0
De acordo com a tabela de rotas IPv6 BGP de Device2, a rota 2001:1::/64 foi filtrada na direção de entrada e a rota 2001:2::/64 foi permitida.
Depois que uma política de roteamento é configurada no vizinho IPv6 BGP, o IPv6 BGP deve ser redefinido para que a configuração entre em vigor. Você deve configurar o comando send-community para anunciar a propriedade da comunidade ao peer.
Configurar o refletor de rota IPv6 BGP
Requisitos de rede
- Configure vizinhos EBGP entre Device3 e Device4 e configure Device4 para anunciar a rota 2001:4::/64.
- Configure vizinhos IBGP entre Device2 e Device3 e entre Device2 e Device1 respectivamente. Em Device2, configure Route Reflectors (RRs) e configure Device1 e Device3 como clientes, para que Device1 possa aprender a rota 2001:4::/64 anunciada por Device4.
Topologia de rede

Figura 13 - 4 Rede para configurar um refletor de rota IPv6 BGP
Etapas de configuração
- Passo 1: Configure os endereços unicast globais IPv6 das interfaces. (Omitido)
- Passo 2: Configure o OSPFv3 para que as rotas de loopback sejam alcançáveis entre os dispositivos.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)#router-id 1.1.1.1Device1(config-ospf6)#exitDevice1(config)#interface vlan 2Device1(config-if-vlan2)#ipv6 router ospf 100 area 0Device1(config-if-vlan2)#exitDevice1(config)#interface loopback 0Device1(config-if-loopback0)#ipv6 router ospf 100 area 0Device1(config-if-loopback0)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface vlan 2Device2(config-if-vlan2)#ipv6 router ospf 100 area 0Device2(config-if-vlan2)#exitDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 router ospf 100 area 0Device2(config-if-vlan3)#exitDevice2(config)#interface loopback 0Device2(config-if-loopback0)#ipv6 router ospf 100 area 0Device2(config-if-loopback0)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 router ospf 100 area 0Device3(config-if-vlan3)#exitDevice3(config)#interface loopback 0Device3(config-if-loopback0)#ipv6 router ospf 100 area 0Device3(config-if-loopback0)#exit
# Visualize a tabela de rotas do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w2d:06:26:16, lo0LC 1::1/128 [0/0]via ::, 00:13:56, loopback0O 2::2/128 [110/2]via fe80::201:7aff:fec0:525a, 00:09:06, vlan2O 3::3/128 [110/3]via fe80::201:7aff:fec0:525a, 00:00:36, vlan2C 2001:1::/64 [0/0]via ::, 00:14:03, vlan2L 2001:1::1/128 [0/0]via ::, 00:14:02, lo0O 2001:2::/64 [110/2]via fe80::201:7aff:fec0:525a, 00:09:06, vlan2
# Visualize a tabela de rotas do Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w6d:00:46:09, lo0O 1::1/128 [110/2]via fe80::201:7aff:fe5e:6d2e, 00:10:05, vlan2LC 2::2/128 [0/0]via ::, 00:14:23, loopback0O 3::3/128 [110/2]via fe80::201:7aff:fe62:bb80, 00:01:44, vlan3C 2001:1::/64 [0/0]via ::, 00:14:48, vlan2L 2001:1::2/128 [0/0]via ::, 00:14:47, lo0C 2001:2::/64 [0/0]via ::, 00:14:41, vlan3L 2001:2::2/128 [0/0]via ::, 00:14:39, lo0
# Visualize a tabela de rotas do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w2d:06:37:24, lo0O 1::1/128 [110/3]via fe80::201:7aff:fec0:525b, 00:02:39, vlan3O 2::2/128 [110/2]via fe80::201:7aff:fec0:525b, 00:02:39, vlan3LC 3::3/128 [0/0]via ::, 00:14:45, loopback0O 2001:1::/64 [110/2]via fe80::201:7aff:fec0:525b, 00:02:39, vlan3C 2001:2::/64 [0/0]via ::, 00:15:03, vlan3L 2001:2::1/128 [0/0]via ::, 00:15:02, lo0C 2001:3::/64 [0/0]via ::, 00:14:55, vlan2L 2001:3::1/128 [0/0]via ::, 00:14:54, lo0
De acordo com a tabela de rotas, Device1, Device2 e Device3 aprenderam as rotas das interfaces de loopback um do outro.
- Passo 3: Configure as funções básicas do IPv6 BGP.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#bgp router-id 1.1.1.1Device1(config-bgp)#address-family ipv6Device1(config-bgp-af)#neighbor 2::2 remote-as 100Device1(config-bgp-af)#exit-address-familyDevice1(config-bgp)#neighbor 2::2 update-source loopback 0Device1(config-bgp)#exit
# Configurar dispositivo2.
Device2(config)#router bgp 100Device2(config-bgp)#bgp router-id 2.2.2.2Device2(config-bgp)#address-family ipv6Device2(config-bgp-af)#neighbor 1::1 remote-as 100Device2(config-bgp-af)#neighbor 3::3 remote-as 100Device2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#neighbor 1::1 update-source loopback 0Device2(config-bgp)#neighbor 3::3 update-source loopback 0Device2(config-bgp)#exit
# Configurar dispositivo3.
Device3(config)#router bgp 100Device3(config-bgp)#bgp router-id 3.3.3.3Device3(config-bgp)#address-family ipv6Device3(config-bgp-af)#neighbor 2::2 remote-as 100Device3(config-bgp-af)#neighbor 2::2 next-hop-selfDevice3(config-bgp-af)#neighbor 2001:3::2 remote-as 200Device3(config-bgp-af)#exit-address-familyDevice3(config-bgp)#neighbor 2::2 update-source loopback 0Device3(config-bgp)#exit
# Configurar Device4 .
Device4#configure terminalDevice4(config)#router bgp 200Device4(config-bgp)#bgp router-id 4.4.4.4Device4(config-bgp)#address-family ipv6Device4(config-bgp-af)#neighbor 2001:3::1 remote-as 100Device4(config-bgp-af)#network 2001:4::/64Device4(config-bgp-af)#exit-address-familyDevice4(config-bgp)#exit
#No Device2, verifique o status do vizinho IPv6 BGP.
Device2#show bgp ipv6 unicast summaryBGP router identifier 2.2.2.2, local AS number 100BGP table version is 22 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd1::1 4 100 10 10 2 0 0 00:07:18 03::3 4 100 10 9 2 0 0 00:06:53 1Total number of neighbors 2
#No Device4, verifique o status do vizinho IPv6 BGP.
Device4#show bgp ipv6 unicast summaryBGP router identifier 4.4.4.4, local AS number 200BGP table version is 21 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd2001:3::1 4 100 3 4 2 0 0 00:01:45 0Total number of neighbors 1
De acordo com as informações consultadas, os vizinhos IPv6 BGP foram configurados entre os dispositivos.
#Consulte a tabela de rotas IPv6 BGP de Device3.
Device3#show bgp ipv6 unicastBGP table version is 3, local router ID is 3.3.3.3Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 2001:4::/64 2001:3::2 0 0 200 i
# Veja a tabela de rotas IPv6 BGP de Device2.
Device2#show bgp ipv6 unicastBGP table version is 7, local router ID is 2.2.2.2Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*>i2001:4::/64 3::3 0 100 0 200 i
#Consulte a tabela de rotas IPv6 BGP de Device1.
Device1#show bgp ipv6 unicastDe acordo com o resultado acima, Device2 e Device3 aprenderam a rota 2001:4::/64 e Device2 não anunciou a rota para Device1.
- Passo 4: Configure um refletor de rota IPv6 BGP.
# Configurar dispositivo2.
Device2(config)#router bgp 100Device2(config-bgp)#address-family ipv6Device2(config-bgp-af)#neighbor 1::1 route-reflector-clientDevice2(config-bgp-af)#neighbor 3::3 route-reflector-clientDevice2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#exit
No Device2, Device1 e Device3 foram configurados como clientes RR.
- Passo 5: Confira o resultado.
# Visualize a tabela de rotas do Device1.
Device1#show bgp ipv6 unicastBGP table version is 2, local router ID is 1.1.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*>i2001:4::/64 3::3 0 100 0 200 iDevice1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w2d:06:48:52, lo0LC 1::1/128 [0/0]via ::, 00:36:32, loopback0O 2::2/128 [110/2]via fe80::201:7aff:fec0:525a, 00:31:42, vlan2O 3::3/128 [110/3]via fe80::201:7aff:fec0:525a, 00:23:12, vlan2C 2001:1::/64 [0/0]via ::, 00:36:39, vlan2L 2001:1::1/128 [0/0]via ::, 00:36:38, lo0O 2001:2::/64 [110/2]via fe80::201:7aff:fec0:525a, 00:31:42, vlan2B 2001:4::/64 [200/0]via 3::3, 00:01:16, vlan2
No BGP de Device2, Device1 e Device3 foram configurados como os clientes RR, e Device2 refletiu com sucesso a rota 2001:4::/64 para o cliente RR Device1.
Se você configurar um vizinho IPv6 BGP como um cliente RR, o vizinho será redefinido.
Configurar o resumo da rota IPv6 BGP
Requisitos de rede
- Configure vizinhos OSPFv3 entre Device1 e Device3 e configure Device3 para anunciar rotas 2002:1::/64 e 2002:2::/64 para Device1.
- Configure vizinhos EBGP entre Device1 e Device2.
- Em Device1, agregue as rotas 2002:1::/64 e 2002:2::/64 na rota 2002::/30 e anuncie a rota agregada para Device2.
Topologia de rede

Figura 13 – 5 Rede para configurar o resumo da rota IPv6 BGP
Etapas de configuração
- Passo 1: Configure os endereços unicast globais IPv6 das interfaces. (Omitido)
- Passo 2: Configure o OSPFv3 para que Device1 possa aprender as duas rotas 2002:1:/64 e 2002:2::/64 anunciados por Device3.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)#router-id 1.1.1.1Device1(config-ospf6)#exitDevice1(config)#interface vlan 2Device1(config-if-vlan2)#ipv6 router ospf 100 area 0Device1(config-if-vlan2)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface vlan 2Device3(config-if-vlan2)#ipv6 router ospf 100 area 0Device3(config-if-vlan2)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 router ospf 100 area 0Device3(config-if-vlan3)#exitDevice3(config)#interface gigabitethernet 0/2/2Device3(config-if-gigabitethernet0/2/2)#ipv6 router ospf 100 area 0Device3(config-if-gigabitethernet0/2/2)#exit
# Visualize a tabela de rotas do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w2d:07:35:38, lo0C 2001:1::/64 [0/0]via ::, 00:01:11, vlan2L 2001:1::2/128 [0/0]via ::, 00:01:10, lo0C 2001:2::/64 [0/0]via ::, 00:01:06, vlan3L 2001:2::2/128 [0/0]via ::, 00:01:04, lo0O 2002:1::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:01:54, vlan2O 2002:2::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:01:54, vlan2
De acordo com a tabela de rotas, Device1 aprendeu as rotas 2002:1:1::/64 e 2002:1:2::/64 anunciados por Device3.
- Passo 3: Configure as funções básicas do IPv6 BGP.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#bgp router-id 1.1.1.1Device1(config-bgp)#address-family ipv6Device1(config-bgp-af)#neighbor 2001:2::1 remote-as 200Device1(config-bgp-af)#exit-address-familyDevice1(config-bgp)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router bgp 200Device2(config-bgp)#bgp router-id 2.2.2.2Device2(config-bgp)#address-family ipv6Device2(config-bgp-af)#neighbor 2001:2::2 remote-as 100Device2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#exit
#No Dispositivo1, verifique o status do vizinho IPv6 BGP.
Device1#show bgp ipv6 unicast summaryBGP router identifier 1.1.1.1, local AS number 100BGP table version is 11 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd2001:2::1 4 200 3 3 1 0 0 00:01:16 0
Os vizinhos IPv6 BGP foram configurados com sucesso entre Device1 e Device2.
- Passo 4: Configure o resumo da rota IPv6 BGP.
Duas soluções estão disponíveis para completar os requisitos de rede.
Solução 1: Configure uma rota estática IPv6 direcionada a null0 para introduzir a rota estática ao BGP.
# Configurar dispositivo1.
Device1(config)#ipv6 route 2002::/30 null 0Device1(config)#router bgp 100Device1(config-bgp)#address-family ipv6Device1(config-bgp-af)#network 2002::/30Device1(config-bgp-af)#exit-address-familyDevice1(config-bgp)#exit
Confira o resultado.
# Visualize a tabela de rotas IPv6 BGP de Device1.
Device1#show bgp ipv6 unicastBGP table version is 2, local router ID is 1.1.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 2002::/30 :: 0 32768 i
Você pode ver que a rota agregada 2001::/16 é gerada na tabela de rotas IPv6 BGP do Device1 .
# Visualize a tabela de rotas do Device2.
Device2#show bgp ipv6 unicastBGP table version is 2, local router ID is 2.2.2.2Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 2002::/30 2001:2::2 0 0 100 iDevice2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w6d:03:14:01, lo0C 2001:2::/64 [0/0]via ::, 01:20:21, vlan3L 2001:2::1/128 [0/0]via ::, 01:20:20, lo0B 2002::/30 [20/0]via 2001:2::2, 00:00:44, vlan3
Device2 aprendeu com sucesso a rota agregada 2002::/30 que foi anunciada pelo Device 1 .
Solução 2: Primeiro, introduza rotas detalhadas no BGP e, em seguida, execute o comando agregador-endereço para agregar as rotas.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#address-family ipv6Device1(config-bgp-af)#redistribute ospf 100Device1(config-bgp-af)#aggregate-address 2002::/30 summary-onlyDevice1(config-bgp-af)#exit-address-familyDevice1(config-bgp)#exit
Confira o resultado.
#Consulte a tabela de rotas IPv6 BGP de Device1.
Device1#show bgp ipv6 unicastBGP table version is 4, local router ID is 1.1.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[O]*> 2001:1::/64 :: 1 32768 ?[B]*> 2002::/30 :: 32768 i[O]s> 2002:1::/64 :: 2 32768 ?[O]s> 2002:2::/64 :: 2 32768 ?
A rota agregada 2002::/30 foi gerada na tabela de rotas IPv6 BGP de Device1.
# Visualize a tabela de rotas do Device2.
Device2#show bgp ipv6 unicastBGP table version is 4, local router ID is 2.2.2.2Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 2001:1::/64 2001:2::2 1 0 100 ?[B]*> 2002::/30 2001:2::2 0 0 100 iDevice2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w6d:03:16:42, lo0B 2001:1::/64 [20/0]via 2001:2::2, 00:00:50, vlan2C 2001:2::/64 [0/0]via ::, 01:23:01, vlan2L 2001:2::1/128 [0/0]via ::, 01:23:00, lo0B 2002::/30 [20/0]via 2001:2::2, 00:00:50, vlan2
Device2 aprendeu com sucesso a rota agregada 2002::/30 que foi anunciada pelo Device 1 .
Quando o comando agregado-endereço é usado para agregar rotas, se o comando estendido summary-only estiver configurado, o dispositivo anuncia apenas a rota agregada; caso contrário, as rotas comuns e as rotas agregadas são anunciadas.
Configurar a prioridade de seleção de rota IPv6 BGP
Requisitos de rede
- Configure vizinhos IBGP entre Device1 e Device2 e entre Device1 e Device3, e configure vizinhos EBGP entre Device4 e Device2 e entre Device4 e Device3.
- Device1 anuncia duas rotas 2001:1::/64 e 2001:2::/64 para Device4, e Device4 anuncia duas rotas 2001:7::/64 e 2001:8::/64 para Device1.
- Modifique a propriedade Local-preference das rotas em Device2 e Device3 para que Device1 selecione a rota 2001:7::/64 anunciada por Device2 e a rota 2001:8::/64 anunciada por Device3 com prioridade.
- Modifique a propriedade MED das rotas em Device2 e Device3 para que Device4 selecione a rota 2001:1::/64 anunciada por Device3 e a rota 2001:2::/64 anunciada por Device2 com prioridade.
Topologia de rede
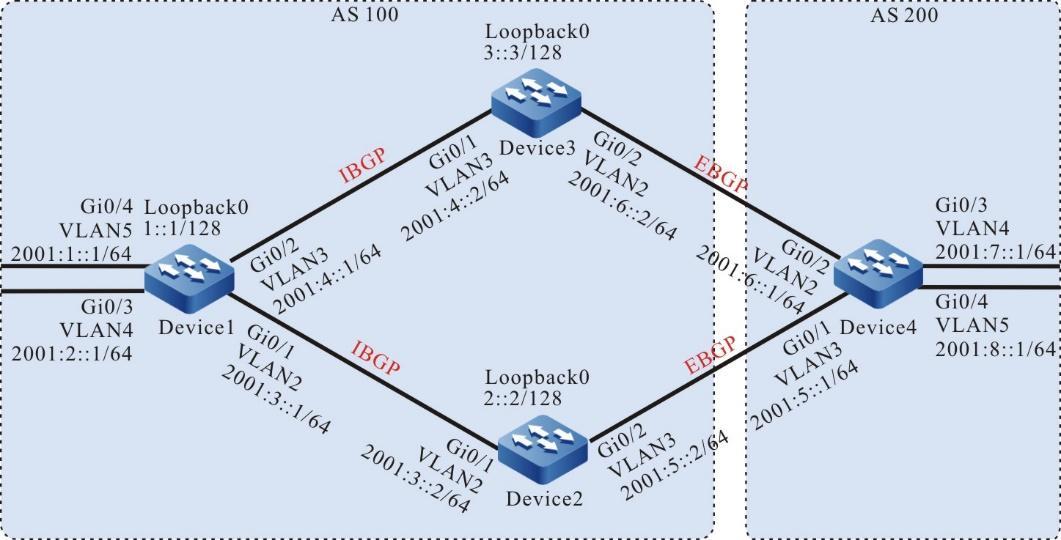
Figura 13 - 6 Rede para configurar a prioridade de seleção de rota IPv6 BGP
Etapas de configuração
- Passo 1: Configure os endereços unicast globais IPv6 das interfaces. (Omitido)
- Passo 2: Configure o OSPFv3 para que as rotas de loopback sejam alcançáveis entre os dispositivos.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)#router-id 1.1.1.1Device1(config-ospf6)#exitDevice1(config)#interface vlan 2Device1(config-if-vlan2)#ipv6 router ospf 100 area 0Device1(config-if-vlan2)#interface vlan3Device1(config-if-vlan3)#ipv6 router ospf 100 area 0Device1(config-if-vlan3)#interface loopback 0Device1(config-if-loopback0)#ipv6 router ospf 100 area 0Device1(config-if-loopback0)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface vlan 2Device2(config-if-vlan2)#ipv6 router ospf 100 area 0Device2(config-if-vlan2)#exitDevice2(config)#interface loopback 0Device2(config-if-loopback0)#ipv6 router ospf 100 area 0Device2(config-if-loopback0)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface vlan 2Device3(config-if-vlan2)#ipv6 router ospf 100 area 0Device3(config-if-vlan2)#exitDevice3(config)#interface loopback 0Device3(config-if-loopback0)#ipv6 router ospf 100 area 0Device3(config-if-loopback0)#exit
# Visualize a tabela de rotas do Device1.
Device1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w5d:04:03:11, lo0LC 1::1/128 [0/0]via ::, 00:08:39, loopback0O 2::2/128 [110/2]via fe80::201:7aff:fe5e:87da, 00:02:04, vlan2O 3::3/128 [110/2]via fe80::201:7aff:fec0:525b, 00:00:38, vlan3C 2001:1::/64 [0/0]via ::, 00:09:12, gigabitethernet0/2/3L 2001:1::1/128 [0/0]via ::, 00:09:11, lo0C 2001:2::/64 [0/0]via ::, 00:08:26, gigabitethernet0/2/2L 2001:2::1/128 [0/0]via ::, 00:08:26, gigabitethernet0/2/2C 2001:3::/64 [0/0]via ::, 00:09:01, vlan2L 2001:3::1/128 [0/0]via ::, 00:09:00, lo0C 2001:4::/64 [0/0]via ::, 00:08:55, vlan3L 2001:4::1/128 [0/0]via ::, 00:08:53, lo0
# Visualize a tabela de rotas do Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w4d:23:16:51, lo0O 1::1/128 [110/2]via fe80::201:7aff:fe62:bb7f, 00:04:25, vlan2LC 2::2/128 [0/0]via ::, 00:09:31, loopback0O 3::3/128 [110/3]via fe80::201:7aff:fe62:bb7f, 00:02:52, vlan2C 2001:3::/64 [0/0]via ::, 00:09:49, vlan2L 2001:3::2/128 [0/0]via ::, 00:09:48, lo0O 2001:4::/64 [110/2]via fe80::201:7aff:fe62:bb7f, 00:04:25, vlan2C 2001:5::/64 [0/0]via ::, 00:09:39, vlan3L 2001:5::2/128 [0/0]via ::, 00:09:38, lo0
# Visualize a tabela de rotas do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w1d:22:16:55, lo0O 1::1/128 [110/2]via fe80::201:7aff:fe62:bb80, 00:04:27, vlan2O 2::2/128 [110/3]via fe80::201:7aff:fe62:bb80, 00:04:27, vlan2LC 3::3/128 [0/0]via ::, 00:10:48, loopback0O 2001:3::/64 [110/2]via fe80::201:7aff:fe62:bb80, 00:04:27, vlan2C 2001:4::/64 [0/0]via ::, 00:11:55, vlan2L 2001:4::2/128 [0/0]via ::, 00:11:54, lo0C 2001:6::/64 [0/0]via ::, 00:11:48, vlan3L 2001:6::2/128 [0/0]via ::, 00:11:47, lo0
De acordo com a tabela de rotas, Device1, Device2 e Device3 aprenderam as rotas das interfaces de loopback um do outro.
- Passo 3: Configure as funções básicas do IPv6 BGP.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#bgp router-id 1.1.1.1Device1(config-bgp)#address-family ipv6Device1(config-bgp-af)#neighbor 2::2 remote-as 100Device1(config-bgp-af)#neighbor 3::3 remote-as 100Device1(config-bgp-af)#network 2001:1::/64Device1(config-bgp-af)#network 2001:2::/64Device1(config-bgp-af)#exit-address-familyDevice1(config-bgp)#neighbor 2::2 update-source loopback 0Device1(config-bgp)#neighbor 3::3 update-source loopback 0Device1(config-bgp)#exit
# Configurar dispositivo2.
Device2(config)#router bgp 100Device2(config-bgp)#bgp router-id 2.2.2.2Device2(config-bgp)#address-family ipv6Device2(config-bgp-af)#neighbor 1::1 remote-as 100Device2(config-bgp-af)#neighbor 1::1 next-hop-selfDevice2(config-bgp-af)#neighbor 2001:5::1 remote-as 200Device2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#neighbor 1::1 update-source loopback 0Device2(config-bgp)#exit
# Configurar dispositivo3.
Device3(config)#router bgp 100Device3(config-bgp)#bgp router-id 3.3.3.3Device3(config-bgp)#address-family ipv6Device3(config-bgp-af)#neighbor 1::1 remote-as 100Device3(config-bgp-af)#neighbor 1::1 next-hop-selfDevice3(config-bgp-af)#neighbor 2001:6::1 remote-as 200Device3(config-bgp-af)#exit-address-familyDevice3(config-bgp)#neighbor 1::1 update-source loopback 0Device3(config-bgp)#exit
# Configurar Device4 .
Device4#configure terminalDevice4(config)#router bgp 200Device4(config-bgp)#bgp router-id 4.4.4.4Device4(config-bgp)#address-family ipv6Device4(config-bgp-af)#neighbor 2001:5::2 remote-as 100Device4(config-bgp-af)#neighbor 2001:6::2 remote-as 100Device4(config-bgp-af)#network 2001:7::/64Device4(config-bgp-af)#network 2001:8::/64Device4(config-bgp-af)#exit-address-familyDevice4(config-bgp)#exit
#No Dispositivo1, verifique o status do vizinho IPv6 BGP.
Device1#show bgp ipv6 unicast summaryBGP router identifier 1.1.1.1, local AS number 100BGP table version is 42 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd2::2 4 100 9 10 4 0 0 00:06:18 23::3 4 100 7 8 4 0 0 00:04:29 2Total number of neighbors 2
#No Device4, verifique o status do vizinho IPv6 BGP.
Device4#show bgp ipv6 unicast summaryBGP router identifier 4.4.4.4, local AS number 200BGP table version is 42 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd2001:5::2 4 100 6 5 4 0 0 00:02:43 22001:6::2 4 100 5 6 4 0 0 00:02:32 2Total number of neighbors 2
Os vizinhos IBGP foram configurados entre Device1 e Device2 e entre Device2 e Device3, e os vizinhos EBGP foram configurados entre Device4 e Device2 e entre Device4 e Device3.
# Visualize a tabela de rotas do Device1.
Device1#show bgp ipv6 unicastBGP table version is 4, local router ID is 1.1.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 2001:1::/64 :: 0 32768 i[B]*> 2001:2::/64 :: 0 32768 i[B]* i2001:7::/64 3::3 0 100 0 200 i[B]*>i 2::2 0 100 0 200 i[B]*>i2001:8::/64 2::2 0 100 0 200 i[B]* i 3::3 0 100 0 200 iDevice1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w5d:04:20:19, lo0LC 1::1/128 [0/0]via ::, 00:25:47, loopback0O 2::2/128 [110/2]via fe80::201:7aff:fe5e:87da, 00:19:12, vlan2O 3::3/128 [110/2]via fe80::201:7aff:fec0:525b, 00:17:46, vlan3C 2001:1::/64 [0/0]via ::, 00:26:20, gigabitethernet0/2/3L 2001:1::1/128 [0/0]via ::, 00:26:19, lo0C 2001:2::/64 [0/0]via ::, 00:25:34, gigabitethernet0/2/2L 2001:2::1/128 [0/0]via ::, 00:25:34, gigabitethernet0/2/2C 2001:3::/64 [0/0]via ::, 00:26:09, vlan2L 2001:3::1/128 [0/0]via ::, 00:26:08, lo0C 2001:4::/64 [0/0]via ::, 00:26:03, vlan3L 2001:4::1/128 [0/0]via ::, 00:26:01, lo0B 2001:7::/64 [200/0]via 2::2, 00:03:21, vlan2B 2001:8::/64 [200/0]via 2::2, 00:02:57, vlan2
De acordo com a tabela de rotas, ambas as rotas 2001:7::/64 e rota 2001:8::/64 de Device1 selecione Device2 como o dispositivo de próximo salto.
#Consulte a tabela de rotas do Device4.
Device4#show bgp ipv6 unicastBGP table version is 4, local router ID is 4.4.4.4Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]* 2001:1::/64 2001:6::2 0 0 100 i[B]*> 2001:5::2 0 0 100 i[B]* 2001:2::/64 2001:6::2 0 0 100 i[B]*> 2001:5::2 0 0 100 i[B]*> 2001:7::/64 :: 0 32768 i[B]*> 2001:8::/64 :: 0 32768 iDevice4#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w5d:04:14:15, lo0B 2001:1::/64 [20/0]via 2001:5::2, 00:06:52, vlan2B 2001:2::/64 [20/0]via 2001:5::2, 00:06:52, vlan2C 2001:5::/64 [0/0]via ::, 00:26:17, vlan2L 2001:5::1/128 [0/0]via ::, 00:26:16, lo0C 2001:6::/64 [0/0]via ::, 00:26:24, vlan3L 2001:6::1/128 [0/0]via ::, 00:26:23, lo0C 2001:7::/64 [0/0]via ::, 00:25:53, gigabitethernet0/2/3L 2001:7::1/128 [0/0]via ::, 00:25:51, lo0C 2001:8::/64 [0/0]via ::, 00:25:40, gigabitethernet0/2/2L 2001:8::1/128 [0/0]via ::, 00:25:40, gigabitethernet0/2/2
Ambas as rotas 2001:1::/64 e 2001:2::/64 de Device4 seleciona Device3 como o dispositivo do próximo salto.
- Passo 4: Configure uma ACL e uma política de roteamento para definir a métrica e a preferência local.
# Configurar dispositivo2.
Device2(config)#ipv6 access-list extended 7001Device2(config-v6-list)#permit ipv6 2001:8::/64 anyDevice2(config-v6-list)#commitDevice2(config-v6-list)#exitDevice2(config)#ipv6 access-list extended 7002Device2(config-v6-list)#permit ipv6 2001:1::/64 anyDevice2(config-v6-list)#commitDevice2(config-v6-list)#exitDevice2(config)#route-map SetPriority1 10Device2(config-route-map)#match ipv6 address 7001Device2(config-route-map)#set local-preference 110Device2(config-route-map)#exitDevice2(config)#route-map SetPriority1 20Device2(config-route-map)#set local-preference 20Device2(config-route-map)#exitDevice2(config)#route-map SetPriority2 10Device2(config-route-map)#match ipv6 address 7002Device2(config-route-map)#set metric 100Device2(config-route-map)#exitDevice2(config)#route-map SetPriority2 20Device2(config-route-map)#set metric 20Device2(config-route-map)#exit
No Device2, configure uma política de roteamento para definir a preferência local da rota 2001:8::/64 para 110 e defina a métrica da rota 2001:1::/64 para 100.
# Configurar dispositivo3.
Device3(config)#ipv6 access-list extended 7001Device3(config-v6-list)#permit ipv6 2001:7::/64 anyDevice2(config-v6-list)#commitDevice3(config-v6-list)#exitDevice3(config)#ipv6 access-list extended 7002Device3(config-v6-list)#permit ipv6 2001:2::/64 anyDevice2(config-v6-list)#commitDevice3(config-v6-list)#exitDevice3(config)#route-map SetPriority1 10Device3(config-route-map)#match ipv6 address 7001Device3(config-route-map)#set local-preference 110Device3(config-route-map)#exitDevice3(config)#route-map SetPriority1 20Device3(config-route-map)#exitDevice3(config)#route-map SetPriority2 10Device3(config-route-map)#match ipv6 address 7002Device3(config-route-map)#set metric 100Device3(config-route-map)#exitDevice3(config)#route-map SetPriority2 20Device3(config-route-map)#exit
No Device3, configure uma política de roteamento para definir a preferência local da rota 2001:7::/64 para 110 e defina a métrica da rota 2001:2::/64 para 100.
Ao configurar uma política de roteamento, você pode criar uma regra de filtragem com base em uma lista de prefixos ou ACL. A lista de prefixos pode corresponder precisamente às máscaras de roteamento, enquanto a ACL não pode corresponder às máscaras de roteamento.
- Passo 5: Configure uma política de roteamento para IPv6 BGP.
# Configurar dispositivo2.
Device2(config)#router bgp 100Device2(config-bgp)#address-family ipv6Device2(config-bgp-af)#neighbor 1::1 route-map SetPriority1 outDevice2(config-bgp-af)#neighbor 2001:5::1 route-map SetPriority2 outDevice2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#exit
No Device2, configure a direção de saída do vizinho 1::1 para modificar a preferência local da rota 2001:8::/64 e configure a direção de saída do vizinho 2001:5::1 para modificar a métrica da rota 2001:1: :/64.
# Configurar dispositivo3.
Device3(config)#router bgp 100Device3(config-bgp)#address-family ipv6Device3(config-bgp-af)#neighbor 1::1 route-map SetPriority1 outDevice3(config-bgp-af)#neighbor 2001:6::1 route-map SetPriority2 outDevice3(config-bgp-af)# exit-address-familyDevice2(config-bgp)#exit
No Device3, configure a direção de saída do vizinho 10.0.0.1 para modificar a preferência local da rota 2001:7::/64 e configure a direção de saída do vizinho 2001:6::1 para modificar a métrica da rota2001:2::/ 64.
Depois que uma política de roteamento é configurada no vizinho, você precisa redefinir o vizinho.
- Passo 6: Confira o resultado.
# Visualize a tabela de rotas do Device1.
Device1#show bgp ipv6 unicastA versão da tabela BGP é 9, o ID do roteador local é 1.1.1.1Códigos de status: s suprimido, d amortecido, h histórico, * válido, > melhor, i - interno,S obsoletoCódigos de origem: i - IGP, e - EGP, ? - incompletoCaminho de peso da métrica do próximo salto da rede LocPrf[B]*> 2001:1::/64 :: 0 32768 i[B]*> 2001:2::/64 :: 0 32768 i[B]* i2001:7::/64 2::2 0 100 0 200i[B]**>i 3::3 0 110 0 200i[B]*>i2001:8::/64 2::2 0 110 0 200i[B]* i 3::3 0 100 0 200 iDevice1#show rota ipv6Códigos: C - Conectado, L - Local, S - estático, R - RIP, B - BGP, i-ISISU - Rota estática por usuárioO - OSPF, OE-OSPF Externo, M - GerenciamentoL ::1/128 [0/0]via ::, 1s5d:04:59:59, lo0LC 1::1/128 [0/0]via ::, 01:05:27, loopback0O 2::2/128 [110/2]via fe80::201:7aff:fe5e:87da, 00:58:52, vlan3O 3::3/128 [110/2]via fe80::201:7aff:fec0:525b, 00:57:26, gigabitethernet0/2/2C 2001:1::/64 [0/0]via ::, 01:06:00, vlan2L 2001:1::1/128 [0/0]via ::, 01:05:59, lo0C 2001:2::/64 [0/0]via ::, 01:05:14, loopback1L 2001:2::1/128 [0/0]via ::, 01:05:14, loopback1C 2001:3::/64 [0/0]via ::, 01:05:49, vlan3L 2001:3::1/128 [0/0]via ::, 01:05:48, lo0C 2001:4::/64 [0/0]via ::, 01:05:43, gigabitethernet0/2/2L 2001:4::1/128 [0/0]via ::, 01:05:41, lo0B 2001:7::/64 [200/0]via 3::3, 00:09:05, vlan3B 2001:8::/64 [200/0]via 2::2, 00:04:58, vlan2
De acordo com a tabela de rotas, preferência local das rotas 2001:7::/64 e 2001:8::/64 é modificado com sucesso, e Device1 seleciona a rota 2001:8::/64 que é anunciada por Device2 e route2001:7::/64 que é anunciada por Device3 com prioridade.
#Consulte a tabela de rotas do Device4.
Device4#show bgp ipv6 unicastBGP table version is 5, local router ID is 4.4.4.4Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]* 2001:1::/64 2001:5::2 100 0 100 i[B]*> 2001:6::2 0 0 100 i[B]*> 2001:2::/64 2001:5::2 0 0 100 i[B]* 2001:6::2 100 0 100 i[B]*> 2001:7::/64 :: 0 32768 i[B]*> 2001:8::/64 :: 0 32768 iDevice4#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w5d:04:53:45, lo0B 2001:1::/64 [20/0]via 2001:6::2, 00:12:10, vlan3B 2001:2::/64 [20/0]via 2001:5::2, 00:07:40, vlan2C 2001:5::/64 [0/0]via ::, 01:05:47, vlan2L 2001:5::1/128 [0/0]via ::, 01:05:46, lo0C 2001:6::/64 [0/0]via ::, 01:05:54, vlan3L 2001:6::1/128 [0/0]via ::, 01:05:52, lo0C 2001:7::/64 [0/0]via ::, 01:05:22, gigabitethernet0/2/3L 2001:7::1/128 [0/0]via ::, 01:05:21, lo0C 2001:8::/64 [0/0]via ::, 01:05:09, gigabitethernet0/2/2L 2001:8::1/128 [0/0]via ::, 01:05:09, gigabitethernet0/2/2
De acordo com a tabela de rotas, métrica de rotas 2001:1::/64 e 2001:2::/64 é modificado com sucesso, e Device4 seleciona a rota 2001:2::/64 que é anunciada por Device2 e a rota 2001:1::/64 que é anunciada por Device3 com prioridade.
Uma política de roteamento pode ser usada na direção de saída do anúncio de rota e também pode ser usada na direção de entrada de recebimento de rota.
Configurar IPv6 BGP para coordenar com BFD
Requisitos de rede
- Configure vizinhos EBGP entre Device1 e Device2 e entre Device1 e Device3, e configure vizinhos IBGP entre Device2 e Device3.
- Device1 aprende a rota EBGP 2001:3::/64 de Device2 e Device3, e Device1 seleciona para encaminhar dados para o segmento de rede 2001:3:: /64 por meio de Device2.
- Em Device1 e Device2, configure EBGP para coordenar com BFD. Quando a linha entre Device1 e Device2 fica com defeito, o BFD pode detectar rapidamente a falha e notificar o BGP sobre a falha. Em seguida, Device1 seleciona para encaminhar dados para o segmento de rede 2001:3::/64 por meio de Device3.
Topologia de rede
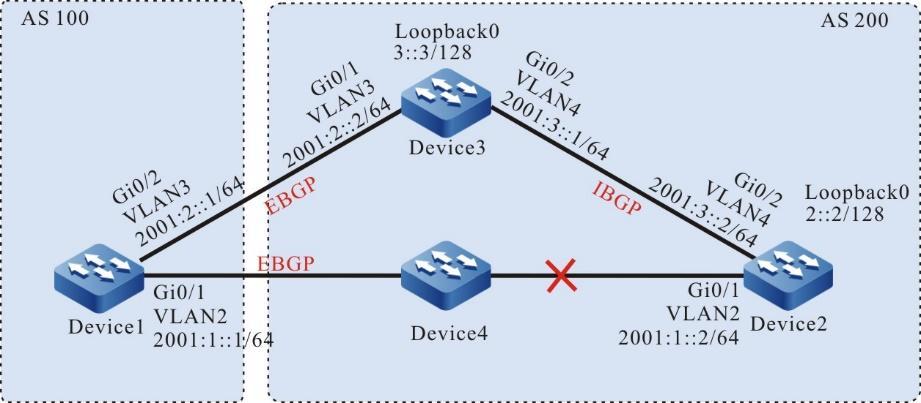
Figura 13 - 7 Rede para configurar IPv6 BGP para coordenar com BFD
Etapas de configuração
- Passo 1: Configure os endereços unicast globais IPv6 das interfaces. (Omitido)
- Passo 2: Configure o OSPFv3 para que as rotas de loopback sejam alcançáveis entre os dispositivos.
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)# interface vlan3Device2(config-if-vlan3)#ipv6 router ospf 100 area 0Device2(config-if-vlan3)#exitDevice2(config)#interface loopback 0Device2(config-if-loopback0)#ipv6 router ospf 100 area 0Device2(config-if-loopback0)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 router ospf 100 area 0Device3(config-if-vlan3)#exitDevice3(config)# interface loopback 0Device3(config-if-loopback0)#ipv6 router ospf 100 area 0Device3(config-if-loopback0)#exit
# Visualize a tabela de rotas do Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w2d:09:31:22, lo0LC 2::2/128 [0/0]via ::, 00:10:10, loopback0O 3::3/128 [110/1]via fe80::201:7aff:fec0:525a, 00:00:12, vlan3C 2001:1::/64 [0/0]via ::, 00:10:54, vlan2L 2001:1::2/128 [0/0]via ::, 00:10:53, lo0C 2001:3::/64 [0/0]via ::, 00:10:17, vlan3L 2001:3::2/128 [0/0]via ::, 00:10:16, lo0
# Visualize a tabela de rotas do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w6d:03:50:38, lo0O 2::2/128 [110/2]via fe80::201:7aff:fe5e:6d2e, 00:02:40, vlan3LC 3::3/128 [0/0]via ::, 00:00:49, loopback0C 2001:2::/64 [0/0]via ::, 00:03:03, vlan2L 2001:2::2/128 [0/0]via ::, 00:03:02, lo0C 2001:3::/64 [0/0]via ::, 00:03:18, vlan3L 2001:3::1/128 [0/0]via ::, 00:03:17, lo0
De acordo com a tabela de rotas, Device2 e Device3 aprenderam as rotas das interfaces de loopback um do outro.
- Passo 3: Configure uma ACL e uma política de roteamento para definir a métrica de uma rota.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 access-list extended 7001Device1(config-v6-list)#permit ipv6 2001:3::/64 anyDevice1(config-v6-list)#commitDevice1(config-v6-list)#exitDevice1(config)#route-map SetMetricDevice1(config-route-map)#match ipv6 address 7001Device1(config-route-map)#set metric 50Device1(config-route-map)#exit
A política de roteamento configurada em Device1 define a métrica da rota 2001:3::/64 para 50.
- Passo 4: Funções básicas do IPv6 BGP e associe Device1 à política de roteamento.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#bgp router-id 1.1.1.1Device1(config-bgp)#address-family ipv6Device1(config-bgp-af)#neighbor 2001:1::2 remote-as 200Device1(config-bgp-af)#neighbor 2001:2::2 remote-as 200Device1(config-bgp-af)#neighbor 2001:2::2 route-map SetMetric inDevice1(config-bgp-af)#exit-address-familyDevice1(config-bgp)#exit
# Configurar dispositivo2.
Device2(config)#router bgp 200Device2(config-bgp)#bgp router-id 2.2.2.2Device2(config-bgp)#address-family ipv6Device2(config-bgp-af)#neighbor 2001:1::1 remote-as 100Device2(config-bgp-af)#neighbor 3::3 remote-as 200Device2(config-bgp-af)#network 2001:3::/64Device2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#neighbor 3::3 update-source loopback 0Device2(config-bgp)#exit
# Configurar dispositivo3.
Device3(config)#router bgp 200Device3(config-bgp)#bgp router-id 3.3.3.3Device3(config-bgp)#address-family ipv6Device3(config-bgp-af)#neighbor 2001:2::1 remote-as 100Device3(config-bgp-af)#neighbor 2::2 remote-as 200Device3(config-bgp-af)#network 2001:3::/64Device3(config-bgp-af)#exit-address-familyDevice3(config-bgp)#neighbor 2::2 update-source loopback 0Device3(config-bgp)#exit
Depois que uma política de roteamento é configurada no peer, você precisa redefinir o peer.
#No Dispositivo1, verifique o status do vizinho IPv6 BGP.
Device1#show bgp ipv6 unicast summaryBGP router identifier 1.1.1.1, local AS number 100BGP table version is 22 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd2001:1::2 4 200 7 6 2 0 0 00:04:00 12001:2::2 4 200 5 5 2 0 0 00:02:03 1Total number of neighbors 2
#No Device2, verifique o status do vizinho IPv6 BGP.
Device2#show bgp ipv6 unicast summaryBGP router identifier 2.2.2.2, local AS number 200BGP table version is 21 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd3::3 4 200 5 5 2 0 0 00:02:10 12001:1::1 4 100 6 7 2 0 0 00:04:38 0Total number of neighbors 2
Os vizinhos IPv6 BGP entre Device1, Device2 e Device3 foram configurados com sucesso.
Device1#show bgp ipv6 unicastBGP table version is 2, local router ID is 1.1.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]* 2001:3::/64 2001:2::2 50 0 200 i[B]*> 2001:1::2 0 0 200 iDevice1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w2d:09:53:27, lo0C 2001:1::/64 [0/0]via ::, 00:24:05, vlan2L 2001:1::1/128 [0/0]via ::, 00:24:02, lo0C 2001:2::/64 [0/0]via ::, 00:25:21, vlan3L 2001:2::1/128 [0/0]via ::, 00:25:20, lo0B 2001:3::/64 [20/0]via 2001:1::2, 00:05:06, vlan2
De acordo com a tabela de rotas, a rota 2001:3::/64 de Device1 seleciona Device2 como o dispositivo de próximo salto.
- Passo 5: Configure IPv6 BGP para vincular com BFD.
# Configurar dispositivo1.
Device1(config)#router bgp 100Device1(config-bgp)#address-family ipv6Device1(config-bgp-af)#neighbor 2001:1::2 fall-over bfdDevice1(config-bgp-af)#exit-address-familyDevice1(config-bgp)#exitDevice1(config)#interface vlan 2Device1(config-if-vlan2)#bfd min-transmit-interval 500Device1(config-if-vlan2)#bfd min-receive-interval 500Device1(config-if-vlan2)#bfd multiplier 4Device1(config-if-vlan2)#exit
# Configurar dispositivo2.
Device2(config)#router bgp 200Device2(config-bgp)#address-family ipv6Device2(config-bgp-af)#neighbor 2001:1::1 fall-over bfdDevice2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#exitDevice2(config)#interface vlan 2Device2(config-if-vlan2)#bfd min-transmit-interval 500Device2(config-if-vlan2)#bfd min-receive-interval 500Device2(config-if-vlan2)#bfd multiplier 4Device2(config-if-vlan2)#exit
O BFD está habilitado entre os vizinhos EBGP Device1 e Device2, e o intervalo mínimo de transmissão, intervalo mínimo de recebimento e múltiplo de tempo limite de detecção dos pacotes de controle BFD foram modificados.
- Passo 6: Confira o resultado.
#No Dispositivo1, consulte o status da sessão BFD.
Device1#show bfd session ipv6OurAddr NeighAddr State Holddown Interface2001:1::1 2001:1::2 UP 2000 vlan2
No Device1, o status do BFD está ativo e o tempo de espera é negociado para ser 2000ms.
#Se a linha entre Device1 e Device2 estiver com defeito, a rota pode mudar rapidamente para a linha de backup.
# Visualize a tabela de rotas do Device1.
Device1#show bgp ipv6 unicastBGP table version is 3, local router ID is 1.1.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 2001:3::/64 2001:2::2 50 0 200 iDevice1#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 1w2d:10:06:30, lo0C 2001:1::/64 [0/0]via ::, 00:37:08, vlan2L 2001:1::1/128 [0/0]via ::, 00:37:04, lo0C 2001:2::/64 [0/0]via ::, 00:38:24, vlan3L 2001:2::1/128 [0/0]via ::, 00:38:23, lo0B 2001:3::/64 [20/0]via 2001:2::2, 00:00:16, vlan3
O próximo salto da rota 2001:3::/64 é Device3.
PBR
Visão geral
O PBR (policy-based routing) é um mecanismo de roteamento para encaminhar os pacotes com base na política definida pelo usuário . Quando o pacote é encaminhado na rota, o pacote pode ser correspondido com base na regra ACL, como o número do protocolo IP, o endereço IP de origem, o endereço de destino e o comprimento. Para os pacotes que correspondem às regras de correspondência, endereço IP de destino, número da porta TCP/UDP de origem, número TCP/UDP de destino, prioridade do pacote e identificador TCP. Para os pacotes que atendem à regra de correspondência, execute a operação de acordo com a política especificada. (defina o próximo salto para o pacote) Desta forma, o controle de encaminhamento dos pacotes é implementado.
O roteamento tradicional encaminha pacotes apenas com base nos endereços de destino. Comparado com o roteamento tradicional, o PBR é mais flexível. É um complemento eficaz e aprimoramento do mecanismo de roteamento tradicional.
Configuração da Função PBR
Tabela 14 -1 lista de configuração PBR
| Tarefa de configuração | |
| Configurar o PBR |
Configurar o endereço IP do próximo salto para encaminhar o pacote
Configurar o endereço IP do próximo salto em espera para encaminhar o pacote Configure o endereço IPv6 do próximo salto do encaminhamento de pacotes Configure o endereço IPv6 do próximo salto em espera do encaminhamento de pacotes Configurar o grupo de ação PBR para se ligar ao ACL Configurar o grupo de ação PBR para vincular com a regra ACL |
| Configurar o aplicativo PBR |
Configurar para aplicar o ACL com PBR à interface Ethernet L2/L3
Configurar para aplicar o ACL com PBR ao VLAN Configurar para aplicar o ACL com PBR para Interface VLAN Configurar para aplicar o ACL com PBR ao intervalo de vlan Configurar para aplicar o ACL com PBR ao intervalo de vlan de interface Configure para aplicar a ACL com PBR globalmente |
Configurar PBR
O PBR é alcançado dependendo da filtragem de pacotes pela regra ACL. A regra ACL primeiro filtra os pacotes qualificados e, em seguida, encaminha os pacotes para o próximo salto executando o PBR.
Condição de configuração
Antes de configurar a função PBR , primeiro complete a seguinte tarefa:
- Configure a ACL e a regra ACL .
Configurar o endereço IP do próximo salto para o pacote de encaminhamento
Configurar o endereço IP do próximo salto para o encaminhamento do pacote para especificar o endereço IP de destino do PBR.
Até 6 endereços IP de próximo salto podem ser especificados para encaminhar o pacote. Se o usuário configurar vários endereços IP do próximo salto simultaneamente e vários endereços IP do próximo salto estiverem acessíveis, o pacote escolherá o endereço IP do próximo salto para encaminhamento usando o modo de balanceamento de carga.
Tabela 14 -2 Configure o endereço IP do próximo salto para encaminhar o pacote
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do grupo de ação PBR | pbr-action-group pbr-action-group-name | - |
| Configure o endereço IP do próximo salto para encaminhar o pacote | redirect ipv4-nexthop ip-address [ip-address] [ip-address ] [ip-address ] [ip-address ] [ip-address ] [vrf vrf-name] |
Obrigatório.
Por padrão, o endereço IP do próximo salto para encaminhar o pacote não está configurado. |
Se todos os endereços IP do próximo salto configurados estiverem inacessíveis, a função PBR não terá efeito. O endereço IP do próximo salto não pode ser configurado como endereço IP local, endereço IP multicast e endereço IP de transmissão.
Configurar o endereço IP do próximo salto em espera para o pacote de encaminhamento
Configurar o endereço IP do próximo salto em espera para o encaminhamento do pacote para especificar o endereço IP de destino do PBR.
Quando o próximo salto ativo não for alcançável, se o endereço IP do próximo salto em espera for alcançável, o pacote será encaminhado para o endereço IP do próximo salto em espera. Se o próximo salto ativo for alcançável, o pacote continuará a ser encaminhado para o endereço IP do próximo salto ativo.
Tabela 14 -3 Configure o endereço IP do próximo salto em espera para encaminhar o pacote
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do grupo de ação PBR | pbr-action-group pbr-action-group-name | - |
| Configure o endereço IP do próximo salto em espera para encaminhar o pacote | redirect ipv4-nexthop backup ip-address [vrf vrf-name] |
Obrigatório.
Por padrão, o endereço IP do próximo salto em espera para encaminhar o pacote não está configurado. |
espera configurados estiverem inacessíveis, a função PBR não terá efeito. O endereço IP do próximo salto não pode ser configurado como endereço IP multicast e endereço IP de broadcast.
Configurar o endereço IPv6 do próximo salto do encaminhamento de pacotes
Configure o endereço IPv6 do próximo salto do encaminhamento de pacotes, para especificar o endereço de destino da rota de política.
Você pode especificar no máximo seis endereços IPv6 do próximo salto do encaminhamento de pacotes. Se o usuário configurar vários endereços IPv6 de próximo salto ao mesmo tempo e houver vários endereços IPv6 de próximo salto alcançáveis, o pacote adotará o modo de balanceamento de carga para especificar o endereço IPv6 de próximo salto para encaminhamento.
Tabela 14 -4 Configurar o endereço IPv6 do próximo salto do encaminhamento de pacotes
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do grupo de ação PBR | pbr-action-group pbr-action-group-name | - |
| Configure o endereço IPv6 do próximo salto do encaminhamento de pacotes | redirect ipv6-nexthop ipv6-address [ipv6-address] [ipv6-address ] [ipv6-address ] [ipv6-address ] [ipv6-address ] [vrf vrf-name] |
Obrigatório.
Por padrão, não configure o endereço IPv6 do próximo salto do encaminhamento de pacotes. |
Se os endereços IPv6 do próximo salto configurados estiverem inacessíveis, a função PBR não terá efeito. O endereço IP do próximo salto não pode ser configurado como endereço IP v6 local , endereço multicast ou endereço de transmissão.
Configurar o endereço IPv6 do próximo salto em espera para o pacote de encaminhamento
Configurar o endereço IPv6 do próximo salto em espera para o encaminhamento do pacote para especificar o endereço IP de destino do PBR.
Quando o próximo salto ativo não for alcançável, se o endereço IPv6 do próximo salto em espera for alcançável, o pacote será encaminhado para o endereço IPv6 do próximo salto em espera. Se o próximo salto ativo for alcançável, o pacote continuará a ser encaminhado para o endereço IPv6 do próximo salto ativo.
Tabela 14 -5 Configurar o endereço IPv6 do próximo salto em espera para encaminhar o pacote
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do grupo de ação PBR | pbr-action-group pbr-action-group-name | - |
| Configure o endereço IP v6 do próximo salto em espera para encaminhar o pacote | redirect ipv6-nexthop backup ipv6-address [vrf vrf-name] |
Obrigatório.
Por padrão, o endereço IPv6 do próximo salto em espera para encaminhar o pacote não está configurado. |
v6 do próximo salto em espera configurados estiverem inacessíveis, a função PBR não terá efeito. O endereço IPv6 do próximo salto não pode ser configurado como endereço IP multicast e endereço IP de transmissão.
Configurar o grupo de ação PBR para vincular com ACL
Configure o grupo de ação PBR para vincular com a ACL para alcançar todas as regras na ACL para associar às ações de execução PBR.
Após o grupo de ação PBR ser vinculado à ACL , todas as regras na ACL estabelecerão a associação com as ações de execução PBR. Se o pacote recebido pela interface corresponder à regra ACL, o pacote será encaminhado para o próximo salto.
Tabela 14 -6 Configure o grupo de ação PBR para vincular com a ACL
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o grupo de ação PBR para vincular com a ACL | ip pbr-action-group pbr-action-group-name access-list { access-list-number | access-list-name } |
Opcional.
Por padrão , o grupo de ação PBR não está vinculado ao IP ACL . O grupo de ação PBR oferece suporte à ligação IP ACL . A ACL IP contém a ACL padrão IP e a ACL estendida IP . |
| ipv6 pbr-action-group pbr-action-group-name access-list { access-list-number | access-list-name } |
Opcional.
Por padrão, não vincule o grupo de ação PBR com a ACL IPv6. O grupo de ação PBR oferece suporte à vinculação de ACL IPv6. A ACL IPv6 contém ACL padrão IPv6 e ACL estendida IPv6. |
Somente quando o endereço IP do próximo salto configurado é alcançável, o PBR pode entrar em vigor. O PBR pode entrar em vigor apenas para as regras permitidas na ACL.
Configurar o grupo de ação PBR para vincular a regra ACL
Configure o grupo de ação PBR para vincular com a regra ACL para alcançar a regra ACL para associar às ações de execução PBR.
Após o grupo de ação PBR ser vinculado à regra ACL , a regra ACL estabelecerá a associação com as ações de execução PBR. Se o pacote recebido pela interface corresponder à regra ACL, o pacote será encaminhado para o próximo salto especificado pelo grupo de ação.
Tabela 14 -7 Configure o grupo de ação PBR para vincular com a regra ACL
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o grupo de ação PBR para vincular com a regra ACL | Refer to the section "Configure IP standard ACL". Refer to the section "Configure IP extended ACL". Refer to “Configure IPv6 Standard ACL”. Refer to “Configure IPv6 Extended ACL”. | Nas regras de licenciamento do ACL padrão IP e ACL estendida , o grupo de ação PBR deve ser especificado para que o PBR entre em vigor. Ao configurar as regras de permissão da ACL padrão IPv6 e da ACL estendida, o grupo de ação PBR deve ser especificado para que a PBR entre em vigor. |
Somente quando o endereço IP do próximo salto configurado é alcançável, o PBR pode entrar em vigor. O PBR pode entrar em vigor apenas para as regras permitidas na ACL.
Configurar aplicativo PBR
A aplicação PBR na verdade é a aplicação do ACL com o PBR. A validação do PBR depende da regra ACL . A ACL pode ser aplicada à interface Ethernet L2/L3, VLAN, Interface VLAN , VLAN RANGE, Interface VLAN RANGE e globalmente.
ACL com o PBR é aplicada à interface Ethernet L2/L3, VLAN, Interface VLAN e globalmente , pode causar colisão. Neste caso , o PBR correspondente à prioridade alta entra em vigor e a prioridade na ordem decrescente é a seguinte: porta, VLAN /Interface VLAN , VLAN RANGE/Interface VLAN RANGE e global.
A correspondência ACL da interface L3 VLAN é sempre maior do que a da interface L2. Uma vez que o ACL da interface L3 VLAN combina, não combine mais o ACL do L2 VLAN.
Condição de configuração
Nenhum
Configure para aplicar ACL com PBR à interface Ethernet L2/L3
Após o ACL com o PBR ser aplicado à interface Ethernet L2/L3, a interface Ethernet L2/L3 correspondente terá a função PBR.
Mesa 14 -8 Configure para aplicar o PBR à interface Ethernet L2/L3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | Qualquer de configuração da interface Ethernet L2/L3, a configuração subsequente só pode ter efeito na interface atual. Após entrar no modo de configuração do grupo de agregação, a configuração subsequente só pode ter efeito no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | link-aggregation link-aggregation-id | |
| Configure para aplicar o PBR à interface | ip policy-based-route { access-list-number | access-list-name } | Opcional. Por padrão, a interface não aplica o IP ACL com PBR. |
| ipv6 policy-based-route { access-list-number | access-list-name } | Opcional. Por padrão, a interface não aplica o IPv6 ACL com PBR. |
Configurar para aplicar ACL com PBR ao VLAN
Depois que a ACL com PBR for aplicada à VLAN, todas as interfaces na VLAN correspondente terão a função PBR.
Tabela 14 -9 Configure para aplicar o PBR à VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no _ VLAN modo de configuração | vlan vlan-id | - |
| Aplique o PBR à VLAN | ip policy-based-route{ access-list-number | access-list-name } | Opcional. Por padrão, a VLAN não aplica o IP ACL com PBR. |
Configure para aplicar ACL com PBR para interfacear VLAN
Após o ACL com PBR ser aplicado à Interface VLAN, as interfaces Jnterface VLAN correspondentes terão a função PBR.
Tabela 14 -10 Configure para aplicar o PBR à Interface VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre na Interface VLAN _ modo de configuração | Interface vlan vlan-id | - |
| Configure para aplicar o PBR à interface VLAN | ip policy-based-route { access-list-number | access-list-name } | Opcional. Por padrão, a Interface VLAN não é aplicada ao IP ACL com o PBR. |
| ipv6 policy-based-route { access-list-number | access-list-name } | Opcional. Por padrão, a Interface VLAN não é aplicada ao IPv6 ACL com o PBR. |
Configurar para aplicar ACL com PBR para VLAN RANGE
Após o ACL com PBR ser aplicado ao VLAN RANGE , o VLAN RANGE correspondente terá a função PBR.
Tabela 14 -11 Configure para aplicar o PBR ao VLAN RANGE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure para aplicar o PBR ao VLAN RANGE | ip policy-based-route { access-list-number | access-list-name } vlan range <1-4094> | opcional _ Por padrão, o IP ACL com o PBR não é aplicado ao VLAN RANGE . |
| ipv6 policy-based-route { access-list-number | access-list-name } vlan range <1-4094> | Opção al Por padrão, o IPv6 ACL com o PBR não é aplicado ao VLAN RANGE . |
Configurar para Aplicar ACL com PBR para Interface VLAN RANGE
Após o ACL com PBR ser aplicado à Interface VLAN RANGE , a VLAN RANGE correspondente terá a função PBR.
Tabela 14 -12 Configure para aplicar o PBR à interface VLAN RANGE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure para aplicar o PBR para Interface VLAN RANGE | ip policy-based-route { access-list-number | access-list-name } interface vlan range <1-4094> | opcional _ Por padrão, o IP ACL com o PBR não é aplicado à Interface VLAN RANGE . |
| ipv6 policy-based-route { access-list-number | access-list-name }interface vlan range <1-4094> | Opção al Por padrão, o IPv6 ACL com o PBR não é aplicado à Interface VLAN RANGE . |
Configure para aplicar ACL com PBR globalmente
Depois que o ACL com PBR for aplicado globalmente, todas as interfaces no dispositivo terão a função PBR.
Tabela 14 -13 Configure para aplicar o PBR globalmente
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure para aplicar o PBR globalmente | global ip policy-based-route { access-list-number | access-list-name } | Obrigatório. Por padrão, o ACL com PBR não é aplicado globalmente. |
Monitoramento e Manutenção de PBR
Tabela 14 -14 Monitoramento e manutenção de PBR
| Comando | Descrição |
| show pbr-action-group [ pbr-action-group-name ] | Exiba as informações de configuração do PBR. |
| show policy-based-route object [ global | interface [ vlan | switchport | vlan-range ] | vlan | vlan-range ] | Exiba as informações de configuração do PBR. Se não especificar o parâmetro, exiba todas as informações do aplicativo PBR. |
Exemplo de configuração típica de PBR
Configurar PBR
Requisito de rede
- Device1 tem a rota padrão e o gateway é Device2.
- Configure o PBR no Device1 para permitir que o PC visite a rede 1.1.1.0/24 via Device3 e visite a rede 1.1.2.0/24 via Device2.
Topologia de rede
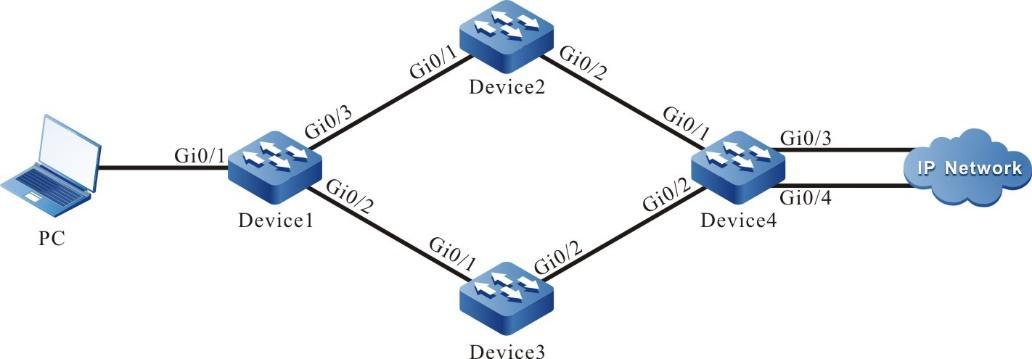
Figura 14 -1 Rede de configuração do PBR
| Dispositivo | Interface | VLAN | Endereço de IP |
| Computador | 10.1.1.1/24 | ||
| Dispositivo1 | Gi0/1 Gi0/2 Gi0/3 |
2 3 4 |
10.1.1.2/24 20.1.1.2/24 30.1.1.2/24 |
| Dispositivo2 | Gi0/1 Gi0/2 |
2 3 |
30.1.1.2/24 50.1.1.1/24 |
| Dispositivo3 | Gi0/1 Gi0/2 |
2 3 |
20.1.1.2/24 40.1.1.1/24 |
| Dispositivo 4 | Gi0/1 Gi0/2 Gi0/3 Gi0/4 |
2 3 4 5 |
50.1.1.2/24 40.1.1.2/24 1.1.1.1/24 1.1.2.1/24 |
Etapas de configuração
- Passo 1:Configure a VLAN e junte a interface à VLAN correspondente. (Omitido)
- Passo 2:Configure os endereços IP das interfaces. (Omitido)
- Passo 3:Configure a rota estática.
#Configurar dispositivo1 .
Device1#configure terminalDevice1(config)#ip route 0.0.0.0 0.0.0.0 30.1.1.2
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ip route 10.1.1.0 255.255.255.0 30.1.1.1Device2(config)#ip route 1.1.0.0 255.255.0.0 50.1.1.2
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ip route 10.1.1.0 255.255.255.0 20.1.1.1Device3(config)#ip route 1.1.0.0 255.255.0.0 40.1.1.2
# Configure Device4 .
Device4#configure terminalDevice4(config)#ip route 30.1.1.0 255.255.255.0 50.1.1.1Device4(config)#ip route 20.1.1.0 255.255.255.0 40.1.1.1Device4(config)#ip route 10.1.1.0 255.255.255.0 50.1.1.1Device4(config)#ip route 10.1.1.0 255.255.255.0 40.1.1.1
# Visualize a tabela de roteamento do Device1.
Device1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, Ex - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is 30.1.1.2 to network 0.0.0.0S 0.0.0.0/0 [1/100] via 30.1.1.2, 00:26:24, vlan4C 10.1.1.0/24 is directly connected, 00:00:59, vlan2C 20.1.1.0/24 is directly connected, 00:00:50, vlan3C 30.1.1.0/24 is directly connected, 00:00:39, vlan4C 127.0.0.0/8 is directly connected, 03:47:36, lo0
- Passo 4:Configure o PBR no Device1.
#Configure o grupo de ação PBR e redirecione o pacote para o próximo salto 20.1.1.2.
Device1(config)#pbr-action-group pbrDevice1(config-action-group)#redirect ipv4-nexthop 20.1.1.2Device1(config-action-group)#exit
# Visualize as informações do grupo de ação PBR no Device1.
Device1#show pbr-action-group pbrpbr-action-group pbr>redirect ipv4-nexthop 20.1.1.2(valid)
#Configure a ACL e vincule a regra ACL combinando o segmento de rede IP de destino 1.1.1.0/24 com o grupo de ação L3 pbr.
Device1(config)#ip access-list extended 1001Device1(config-std-nacl)#permit ip any 1.1.1.0 0.0.0.255 pbr-action-group pbrDevice1(config-std-nacl)#permit ip any 1.1.2.0 0.0.0.255Device1(config-std-nacl)#commitDevice1(config-std-nacl)#exit
#Visualize as informações de ACL de Device1.
Device1#show ip access-list 1001ip access-list standard 100110 permit ip any 1.1.1.0 0.0.0.255 l3-action-group pbr (active)20 permit ip any 1.1.2.0 0.0.0.255
- Passo 5:Aplique o ACL.
# Aplique o ACL 1001 na interface vlan2 do Dispositivo1.
Device1(config)#interface vlan2Device1(config-if-vlan2)#ip policy-based-route 1001Device1(config-if-vlan2)#exit
- Passo 6:Confira o resultado.
# Visualize o caminho que passará para chegar à entrada de destino 1.1.1.0/24 através do Traceroute no PC .
C:\Documents and Settings\Administrator>tracert 1.1.1.1Tracing route to 1.1.1.1 over a maximum of 30 hops1 1 ms 1 ms 1 ms 10.1.1.22 <1 ms <1 ms <1 ms 20.1.1.23 <1 ms <1 ms <1 ms 1.1.1.1Trace complete.
Pode-se ver que o PC passará Device1 , Device3 e Device4 para alcançar a rede 1.1.1.0/24.
# Visualize o caminho que passará para alcançar a rede de destino 1.1.2.0/24 através do Traceroute no PC .
C:\Documents and Settings\Administrator>tracert 1.1.2.1Tracing route to 1.1.2.1 over a maximum of 30 hops1 1 ms 1 ms 1 ms 10.1.1.22 <1 ms <1 ms <1 ms 30.1.1.23 <1 ms <1 ms <1 ms 1.1.2.1Trace complete.
Pode-se ver que o PC passará Device1 , Device2 e Device4 para alcançar a rede 1.1.2.0/24.
Combine de forma flexível os pacotes pela regra ACL. Você pode combinar o endereço IP de origem, o endereço IP de destino, a interface de origem , a interface de destino, o protocolo e as informações do identificador TCP do pacote. A ACL pode ser vinculada na interface Ethernet L2/L3, VLAN, Interface VLAN e globalmente .
Ferramentas PBR
Visão geral
Uma política de roteamento pode alterar as propriedades ou a acessibilidade de uma rota para alterar as informações de roteamento ou alterar os caminhos pelos quais o fluxo de dados passa. Uma política de roteamento é aplicada principalmente nos seguintes aspectos:
- Define as propriedades de rota: define as propriedades de rota necessárias para as rotas que correspondem à política de roteamento.
- Controla o anúncio de rota: quando um protocolo de roteamento anuncia uma rota, ele anuncia apenas as rotas que atendem aos requisitos.
- Controla o recebimento de rotas: Quando um protocolo de roteamento, recebe apenas as rotas que atendem aos requisitos para controlar o número de rotas e melhorar a segurança da rede.
- Controla a redistribuição de rotas: quando um protocolo de roteamento redistribui rotas externas, ele introduz apenas as rotas que atendem aos requisitos. Uma ferramenta de política de roteamento também pode ser usada para definir algumas propriedades para as rotas externas que são introduzidas.
Key-chain é uma ferramenta de gerenciamento de senha. Ele fornece senhas de autenticação para o protocolo de roteamento para pacotes de protocolo de autenticação.
Configurar ferramentas PBR
Tabela 15 -1Lista de ferramentas de política de roteamento
| Tarefas de configuração | |
| Configure uma lista de prefixos. | Configure uma lista de prefixos. |
| Configure uma lista AS-PATH. | Configure uma lista AS-PATH. |
| Configure uma lista de comunidade. | Configure uma lista de comunidade. |
| Configure uma lista Extcommunity. | Configure uma lista Extcommunity. |
| Configure um mapa de rotas. |
Crie um mapa de rotas.
Configure as cláusulas de correspondência de um mapa de rotas. Configure as cláusulas set de um mapa de rotas. |
| Configure um chaveiro. | Configure um chaveiro. |
Configurar lista de prefixos
Condição de configuração
Nenhum
Configurar uma lista de prefixos
A lista de prefixos filtra rotas com base em prefixos. A ACL é projetada primeiro para filtrar pacotes de dados e, em seguida, usada para filtrar rotas, enquanto a lista de prefixos é projetada para filtrar rotas. Através de alguma filtragem de rota as funções da ACL e da lista de prefixos são as mesmas, a lista de prefixos é mais flexível que a ACL.
Uma lista de prefixos é identificada por um nome de lista de prefixos. Cada lista de prefixos contém várias entradas e cada entrada pode especificar um intervalo correspondente de forma independente. Cada entrada tem um número de série, indicando a sequência na qual a lista de prefixos implementa verificações de correspondência.
As entradas de uma lista de prefixos estão na relação OR. Quando uma rota tenta corresponder a uma lista de prefixos, ela verifica as entradas na sequência de pequeno a grande. Quando a rota corresponder a uma entrada, ela passará pela filtragem da lista de prefixos e a próxima entrada não será mais verificada.
Tabela 15 -2Configurar uma lista de prefixos
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma lista de prefixos IPv4. | ip prefix-list prefix-list-name [ seq seq-value ] { deny | permit } network / length [ ge ge-value ] [ le le-value ] | Obrigatório. Por padrão, nenhuma lista de prefixos IPv4 é configurada. |
O intervalo de valores é 0<=comprimento
Configurar lista AS-PATH (Aplicável somente ao modelo S3054G-B)
Condição de configuração
Nenhum
Configurar uma lista AS-PATH
Uma lista AS-PATH é uma ferramenta para filtragem baseada em números AS. É usado para filtragem de rota BGP. A propriedade de caminho AS de uma rota BGP registra todos os ASs pelos quais a rota passa. Quando o BGP anuncia uma rota para uma rede fora do AS local, ele adiciona o número do AS local à propriedade do caminho do AS para registrar os caminhos do AS pelos quais a rota passa.
Uma lista AS-PATH contém várias entradas e as entradas estão na relação OR. Quando uma rota tenta corresponder a uma lista AS-PATH, ela verifica as entradas seguindo a sequência de configuração. Uma vez que a rota corresponde a uma entrada, ela passa pela filtragem da lista AS-PATH.
Tabela 15 -3Configurar uma lista AS- PATH
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma lista AS-PATH. | ip as-path access-list path-list-number { permit | deny } regular-expression | Obrigatório. Por padrão, nenhuma lista AS-PATH é configurada. |
Uma lista AS-PATH usa uma expressão regular para especificar uma coleção de propriedades AS que atendem ao requisito. Uma expressão regular consiste em alguns caracteres comuns e alguns metacaracteres. Caracteres comuns incluem caracteres maiúsculos e minúsculos e números, enquanto metacaracteres têm significados especiais, conforme mostrado na tabela a seguir.
Tabela 15 -4 Significados de metacaracteres em uma expressão regular
| Símbolo | Significado |
| . | Corresponde a qualquer caractere único. |
| * | Corresponde a uma sequência que consiste em 0 ou mais bits no modo. |
| + | Corresponde a uma sequência que consiste em 1 ou mais bits no modo. |
| ? | Corresponde a uma sequência que consiste em 0 ou 1 bit no modo. |
| ^ | Corresponde ao início da cadeia de caracteres inserida. |
| $ | Corresponde ao final da cadeia de caracteres inserida. |
| _ | Corresponde a vírgulas, colchetes, início e fim da cadeia de caracteres inserida e espaços em branco. |
| [] | Corresponde a caracteres únicos em um determinado intervalo. |
| - | Separa o ponto final de um intervalo. |
Configurar Comunidade - Lista (Aplicável somente ao modelo S3054G-B)
Condição de configuração
Nenhum
Configurar uma comunidade - Lista
Um Community - lista é usado para filtrar as propriedades da comunidade de rotas. Normalmente, uma rota consiste em duas partes: propriedades de prefixo e roteamento. As propriedades de roteamento são diferentes para diferentes protocolos de roteamento. O protocolo IGP geralmente fornece propriedades simples, como métrica, mas o protocolo BGP fornece propriedades complexas, como propriedade de comunidade. Uma lista de comunidade é usada para filtração.
A filtragem em uma lista de comunidade atua na rota na qual a propriedade da comunidade está configurada. Ou seja, se o resultado da filtragem for negado, a rota em vez da propriedade comunitária é filtrada.
Estão disponíveis dois tipos de listas comunitárias: lista comunitária normal e lista comunitária alargada. Uma lista de comunidade padrão filtra rotas BGP com base nas propriedades de AS local, internet, sem publicidade e sem exportação. Uma lista de comunidade estendida filtra rotas BGP com propriedades de comunidade com base em uma expressão regular.
Uma lista de comunidade pode ser usada para um protocolo de roteamento com propriedades de comunidade. No entanto, você precisa vincular a lista da comunidade a um mapa de rotas e, em seguida, aplicar o mapa de rotas ao protocolo de roteamento.
Uma lista de comunidade contém várias entradas e as entradas estão na relação OR. Quando uma rota tenta corresponder a uma lista de comunidade, ela verifica as entradas seguindo a seqüência de configuração. Assim que a rota corresponder a uma entrada da lista de comunidades, ela passará pela filtragem da lista de comunidades. Para o uso de uma expressão regular na configuração de uma lista de comunidade estendida , consulte " Configurar uma lista AS-PATH".
Tabela 15 -5Configurar uma lista de comunidade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma lista de comunidade padrão. | ip community-list { community-list-number | standard community-list-name } { permit | deny } [ community-number / aa:nn / local-AS / internet / no-advertise / no-export ] | Obrigatório. Por padrão, nenhuma lista de comunidade padrão é configurada. |
| Configure uma comunidade estendida - lista. | ip community-list { community-list-number | expanded community-list-name } { permit | deny } regular-expression | Obrigatório. Por padrão, nenhuma lista de comunidade estendida é configurada. |
Configurar Extcommunity - Lista (Aplicável somente ao modelo S3054G-B)
Condição de configuração
Nenhum
Configurar uma Extcommunity-List
Uma lista de comunidade estendida (Extcommunity-list) filtra as rotas BGP com base nas propriedades da comunidade estendida. A qualidade e o método de uso de uma lista de comunidade estendida (Extcommunity-list) são os mesmos de uma lista de comunidade padrão. A principal diferença é que as propriedades da comunidade estendida são usadas principalmente em uma rede privada virtual de camada 3 (L3VPN) de Multi Protocol Label Switching (MPLS), portanto, uma lista Extcommunity também é usada principalmente em um MPLS L3VPN.
Dois tipos de listas Extcommunity estão disponíveis: lista Extcommunity padrão e lista de comunidade Ex t estendida. A lista de Extcommunity padrão filtra as rotas BGP com base nas propriedades Destino do Roteador e Site ou Origem. Uma lista Extcommunity estendida filtra rotas BGP com propriedades de comunidade com base em uma expressão regular.
Uma lista Extcommunity contém várias entradas e as entradas estão na relação OR. Quando uma rota tenta corresponder a uma lista de Extcommunity, ela verifica as entradas seguindo a sequência de configuração. Uma vez que a rota corresponde a uma entrada, ela passa pela filtragem da lista Extcommunity. Para o uso de uma expressão regular na configuração de uma lista Extcommunity estendida, consulte "Configurar uma lista AS-PATH".
Tabela 15 -6Configurar uma lista de extcommunity
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure uma lista Extcommunity padrão. | ip extcommunity-list { extcommunity-list-number | standard extcommunity-list-name} { permit | deny } [ rt extcommunity-number / soo extcommunity-number ] | Obrigatório. Por padrão, nenhuma lista Extcommunity padrão é configurada. |
| Configure uma lista Extcommunity estendida. | ip extcommunity-list { extcommunity-list-number | expanded extcommunity-list-name } { permit | deny } regular-expression | Obrigatório. Por padrão, nenhuma lista Extcommunity estendida está configurada. |
Configurar mapa de rota
Um mapa de rotas é uma ferramenta para combinar rotas e definir propriedades de rota. Um mapa de rotas consiste em várias instruções, e cada instrução consiste em algumas cláusulas de correspondência e cláusulas de conjunto. As cláusulas de correspondência definem as regras de correspondência da instrução e as cláusulas de conjunto definem as ações de acompanhamento após uma rota corresponder às cláusulas de correspondência. As cláusulas de correspondência estão na relação OR, ou seja, uma rota deve corresponder a todas as cláusulas de correspondência da instrução.
As instruções do mapa de rotas estão na relação OR. Quando uma rota tenta corresponder a um mapa de rotas, ela verifica as entradas na sequência de pequeno a grande. Uma vez que uma rota corresponde a uma instrução, ela corresponde ao mapa de rotas e a próxima instrução não será mais verificada. Se uma rota não corresponder a uma instrução, ela não corresponderá ao mapa de rotas.
Condição de configuração
Antes de configurar um mapa de rotas, certifique-se de que:
- A ACL, lista de prefixos, AS-PATH e Community-list ou Extcommunity-list que são necessários para configurar um mapa de rotas foram configurados.
Criar um mapa de rotas
Ao criar um mapa de rotas, você pode especificar o modo de correspondência das instruções do mapa de rotas. Dois modos de jogo estão disponíveis: permitir e negar .
o permitir mode define o modo de correspondência das instruções do mapa de rotas para permitir, ou seja, se uma rota corresponder a todas as cláusulas de correspondência da instrução, a rota terá permissão para passar e, em seguida, as cláusulas set da instrução serão executadas. Se uma rota não corresponder às cláusulas de correspondência da instrução, ela começará a corresponder à próxima instrução do mapa de rotas.
A negação mode define o modo de correspondência das instruções do mapa de rotas para negar, ou seja, quando uma rota corresponde a todas as cláusulas de correspondência de uma instrução, a rota é negada e a rota não corresponderá à próxima instrução do mapa de rotas. No modo deny , as cláusulas set não serão executadas.
Tabela 15 -7Crie um mapa de rotas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Crie um mapa de rotas. | route-map map-name [ { permit | deny } [ seq-number ] ] | Obrigatório. Por padrão, nenhum mapa de rota é criado. |
Se você executar o comando route-map para criar um mapa de rotas, se você configurar apenas o nome do mapa de rotas, mas não configurar o modo de correspondência e o número de série da instrução, uma instrução cujo modo de correspondência é permitir e número de série é 10 é criada automaticamente. Se um mapa de rotas for aplicado ao protocolo de roteamento, mas o mapa de rotas não tiver sido configurado, todos os objetos não serão correspondentes.
Configurar as cláusulas de correspondência de um mapa de rota
As cláusulas de correspondência de uma instrução de mapa de rotas estão na relação OR, ou seja, uma rota deve corresponder a todas as cláusulas de correspondência antes de poder passar.
Tabela 15 -8Configure a cláusula match de um mapa de rotas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração do mapa de rotas. | route-map map-name [ { permit | deny } [ seq-number ] ] | - |
| Especifique a lista AS-PATH que corresponde ao mapa de rotas. | match as-path path-list-number | Opcional. Por padrão, nenhuma lista AS-PATH que corresponda ao mapa de rotas é especificada. |
| Especifique a lista da Comunidade BGP que corresponde ao mapa de rotas. | match community community-list-number / community-list-name [ exact-match ] | Opcional. Por padrão, nenhuma lista de comunidade BGP que corresponda ao mapa de rotas é especificada. |
| Especifique a lista BGP Extcommunity que o mapa de rotas corresponde. | match extcommunity extcommunity-list-number / extcommunity-list-name | Opcional. Por padrão, nenhuma lista BGP Extcommunity que o mapa de rotas corresponda é especificada. |
| Especifique a interface que corresponde ao mapa de rotas. | match interface interface-names | Opcional. Por padrão, nenhuma interface que corresponda ao mapa de rotas é especificada. |
| Especifique o prefixo de rota que corresponde ao mapa de rotas. | match ip address { access-list-number | access-list-name | prefix-list prefix-list-name } | Opcional. Por padrão, nenhum prefixo de rota que corresponda ao mapa de rotas é especificado. |
| Especifique o endereço do próximo salto que corresponde ao mapa de rotas. | match ip next-hop { access-list-name | prefix-list prefix-list-name } | Opcional. Por padrão, nenhum endereço de próximo salto que corresponda ao mapa de rotas é especificado. |
| Especifique o endereço da rota de origem que corresponde ao mapa de rotas. | match ip route-source { access-list-name | prefix-list prefix-list-name } | Opcional. Por padrão, nenhum endereço de rota de origem que corresponda ao mapa de rotas é especificado. |
| Especifique o valor da métrica de rota que corresponde ao mapa de rotas. | match metric metric-value [+-offset] | Opcional. Por padrão, nenhum valor de métrica de rota que corresponda ao mapa de rotas é especificado. |
| Especifique o tipo de roteamento que corresponde ao mapa de rotas. | match route-type { external / interarea / internal / level-1 / level-2 / nssa-external / type-1 / type-2 } | Opcional. Por padrão, nenhum tipo de roteamento que corresponda ao mapa de rotas é especificado. |
| Especifique o valor da etiqueta que corresponde ao mapa de rotas. | match tag tag-value | Opcional. Por padrão, nenhum valor de tag que o mapa de rotas corresponda é especificado. |
Se um mapa de rotas não estiver configurado com cláusulas de correspondência, todos os objetos poderão corresponder ao mapa de rotas com êxito. Quando a ACL e a lista de prefixos associados às cláusulas de correspondência não existem, nenhum objeto pode corresponder ao mapa de rotas.
Configurar as cláusulas de conjunto de um mapa de rota
Quando o modo de correspondência do mapa de rotas é permitido, se uma rota corresponder a todas as cláusulas de correspondência, as operações de conjunto serão executadas. Se o modo de correspondência for negado, as operações definidas não serão executadas.
Tabela 15 -9Configurar as cláusulas set de um mapa de rotas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Entre no modo de configuração do mapa de rotas. | route-map map-name [ { permit | deny } [ seq-number ] ] | - |
| Defina a propriedade do caminho AS de uma rota BGP. | set as-path prepend as-path-number | Opcional. Por padrão, a propriedade de caminho AS da rota BGP não está configurada. |
| Configure a propriedade da comunidade da rota BGP. | set communtiy { community-number | additive | local-AS | internet | no-advertise | no-export | none } | Opcional. Por padrão, a propriedade da comunidade da rota BGP não está configurada. |
| Exclua a lista da comunidade da rota BGP. | set comm-list { community-list-number / community-list-name } delete | Opcional. Por padrão, a propriedade da comunidade da rota BGP não é excluída. |
| Defina os parâmetros de atenuação da rota BGP. | set dampening half-life start-reusing start-suppress max-duration | Opcional. Por padrão, os parâmetros de atenuação da rota BGP não são definidos. |
| Defina as propriedades Extcommunity da rota MPLS L3VPN. | set extcommunity { rt | soo } extcommunity | Opcional. Por padrão, as propriedades Extcommunity do MPLS L3VPN não são configuradas. |
| Defina o próximo salto de backup | set fast-reroute [ backup-interface interface-names ] backup-nexthop nexthop-address | opcional _ Por padrão, não configure o próximo salto de backup de rota. |
| Defina o próximo salto para a rota . | set ip default next-hop ip-address | Opcional. Por padrão, o próximo salto da rota não está configurado . É usado para definir o próximo salto durante a redistribuição da rota OSPF |
| Defina o próximo salto para a rota | set ip next-hop ip-address | Opcional. Por padrão, o próximo salto da rota não está configurado . É usado para definir o próximo salto da rota para o mapa de rotas associado ao BGP. |
| Defina a prioridade local da rota BGP. | set local-preference value | Opcional. Por padrão, a prioridade local não está configurada para a rota BGP. |
| Defina o valor métrico da rota. | set metric { metric | +metric | -metric | bandwidth delay reliable loading mtu } | Opcional. Por padrão, o valor métrico da rota não está configurado. |
| Defina o tipo de métrica da rota. | set metric-type { external | internal | type-1 | type-2 } | Opcional. Por padrão, o tipo de métrica da rota não está configurado. |
| Configure a propriedade Origem da rota BGP. | set origin { egp as-number | igp | incomplete } | Opcional. Por padrão, a propriedade Origem da rota BGP não está configurada. |
| Defina o campo de opção de tag de rotas externas. | set tag tag-value | Opcional. Por padrão, o campo de opção de tag de rotas externas não está configurado . |
| Defina o peso da rota BGP. | set weight weight-value | Opcional. Por padrão, o peso da rota BGP não é configurado . |
Configurar chaveiro
Condição de configuração
Nenhum
Configurar um chaveiro
O chaveiro é uma ferramenta de gerenciamento de senhas. Ele fornece senhas de autenticação para o protocolo de roteamento para pacotes de protocolo de autenticação. Um chaveiro fornece senhas diferentes para transmitir e receber pacotes e fornece senhas diferentes para IDs de chave diferentes. Enquanto isso, um chaveiro pode alternar automaticamente as senhas de acordo com a duração da validade das chaves, ou seja, usa chaves diferentes em diferentes períodos de tempo. Isso aumenta muito a segurança da senha.
Você pode configurar vários IDs de chave para um chaveiro. Quando um protocolo usa o chaveiro para autenticação, ele obtém o ID da chave de acordo com as seguintes regras:
- As senhas de transmissão válidas mínimas dos IDs de chave são obtidas como senhas de transmissão.
- Entre os IDs de chave maiores que os IDs de chave especificados do protocolo, obtenha as senhas de recebimento válidas mínimas dos IDs de chave como as senhas de recebimento.
- Se um ID de chave estiver contido nos pacotes de protocolo recebidos, uma pesquisa pelas senhas de recebimento válidas será executada com base no ID de chave. Caso contrário, as senhas de recebimento válidas mínimas dos IDs de chave na cadeia de chaves local são usadas como a senha de recebimento.
Tabela 15 -10Configurar um chaveiro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global. | configure terminal | - |
| Configure um chaveiro. | key chain keychain-name | Obrigatório. Por padrão, o chaveiro não está configurado. |
| Configure um ID de chave. | key key-id | Obrigatório. Por padrão, o ID da chave não está configurado. |
| Configure uma senha. | key-string [ 0 | 7 ] password |
Obrigatório.
Por padrão, nenhuma senha é configurada. Um espaço em branco também é considerado um caractere de senha. Preste atenção a isso ao configurar uma senha. |
| Configure a duração válida na qual uma chave atua como a senha de recebimento. | accept-lifetime time-start { time-end | duration second | infinite } | Obrigatório. Por padrão, a senha de recebimento é sempre válida. |
| Configure a duração válida na qual uma chave atua como a senha de transmissão. | send-lifetime time-start { time-end | duration second | infinite } | Obrigatório. Por padrão, a senha de transmissão é sempre válida. |
Monitoramento e Manutenção da política de roteamento
Tabela 15 -11Monitoramento e manutenção da política de roteamento
| Comando | Descrição |
| clear ip prefix-list [ prefix-list-name network/length ] | Limpa as estatísticas da lista de prefixos. |
| show ip prefix-list [ prefix-list-name [ network/lenghter [ first-match | longer ] | seq sep_value ] | detail [ prefix-list-name ] | orf-prefix | summary [ prefix-list-name ] | Exiba as informações sobre uma lista de prefixos. |
| show ip as-path-access-list [ list-name ] | Exiba as informações sobre uma lista AS-PATH. |
| show ip community-list [ community-list-number | community-list-name] | Exiba as informações sobre uma lista da Comunidade. |
| show ip extcommunity-list [ extcommunity-list-number | extcommunity-list-name ] | Exiba as informações sobre uma lista Extcommunity. |
| show route-map [ route-map-name ] | Exibe as informações sobre um mapa de rotas. |
| show key chain [ keychain-name ] | Exiba as informações sobre um chaveiro. |
Exemplo de configuração típica da ferramenta PBT
Configurar a política de roteamento para configurar a redistribuição de rota
Requisitos de rede
- Execute o OSPF entre Device1 e Device2 e execute RIP entre Device2 e Device3.
- No Device2, configure o OSPF para redistribuir as rotas RIP e associe uma política de roteamento para modificar as propriedades da rota. É necessário que a propriedade tag da rota 100.1.1.0/24 seja alterada para 5, o valor métrico da rota v seja alterado para 50 e a propriedade da rota 120.1.1.0/24 permaneça inalterada.
Topologia de rede
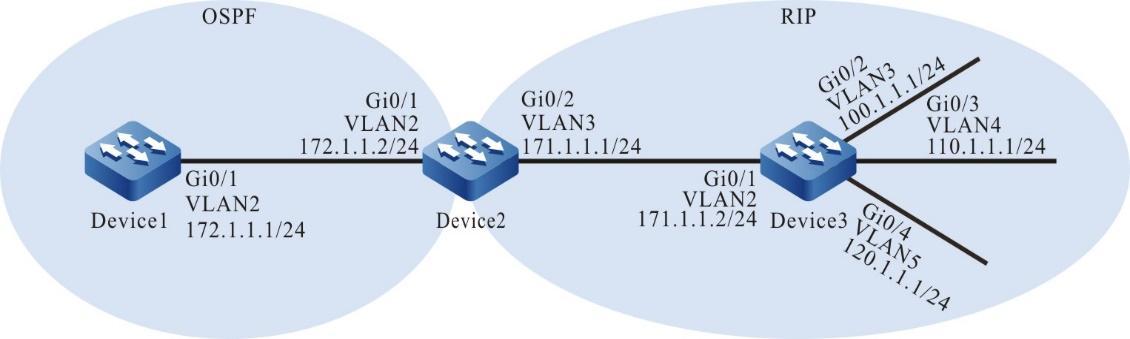
Figura 15 - 1 Configurando uma política de roteamento para configurar a redistribuição de rota
Etapas de configuração
- Passo 1:Configure a VLAN e junte a interface à VLAN correspondente. (Omitido)
- Passo 2:Configure os endereços IP das interfaces. (Omitido)
- Passo 3:Configurar OSPF.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 172.1.1.0 0.0.0.255 area 0Device1(config-ospf)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 172.1.1.0 0.0.0.255 area 0Device2(config-ospf)#exit
- Passo 4:Configurar RIP.
# Configurar dispositivo2.
Device2(config)#router ripDevice2(config-rip)#version 2Device2(config-rip)#network 171.1.1.0Device2(config-rip)#exit
# Configurar dispositivo3.
Device3(config)#configure terminalDevice3(config)#router ripDevice3(config-rip)#version 2Device3(config-rip)#network 171.1.1.0Device3(config-rip)#network 100.1.1.0Device3(config-rip)#network 110.1.1.0Device3(config-rip)#network 120.1.1.0Device3(config-rip)#exit
- Passo 5:Configure o OSPF para redistribuir as rotas RIP.
# Configurar dispositivo2.
Device2(config)#router ospf 100Device2(config-ospf)#redistribute ripDevice2(config-ospf)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalOE 100.1.1.0/24 [150/20] via 172.1.1.2, 02:22:08, vlan2OE 110.1.1.0/24 [150/20] via 172.1.1.2, 00:49:57, vlan2OE 120.1.1.0/24 [150/20] via 172.1.1.2, 02:22:08, vlan2OE 171.1.1.0/24 [150/20] via 172.1.1.2, 02:22:41, vlan2
De acordo com a tabela de roteamento de Device1, as rotas RIP 100.1.1.0/24, 110.1.1.0/24 e 120.1.1.0/24 são redistribuídas para o processo OSPF e anunciadas com sucesso para Device1.
- Passo 6:Configure uma ACL e uma política de roteamento.
# Configurar dispositivo2.
Configure uma ACL para permitir a passagem das rotas 100.1.1.0/24, 110.1.1.0/24 e 120.1.1.0/24.
Device2(config)#ip access-list standard 1Device2(config-std-nacl)#permit 100.1.1.0 0.0.0.255Device2(config-std-nacl)#commitDevice2(config-std-nacl)#exitDevice2(config)#ip access-list standard 2Device2(config-std-nacl)#permit 110.1.1.0 0.0.0.255Device2(config-std-nacl)#commitDevice2(config-std-nacl)#exitDevice2(config)#ip access-list standard 3Device2(config-std-nacl)#permit 120.1.1.0 0.0.0.255Device2(config-std-nacl)#commitDevice2(config-std-nacl)#exit
Configure a política de roteamento rip_to_ospf. Defina a propriedade de tag das rotas que correspondem à ACL 1, defina a propriedade de métrica das rotas que correspondem à ACL2 e não altere as propriedades de roteamento das rotas que correspondem à ACL 3.
Device2(config)#route-map rip_to_ospf 10Device2(config-route-map)#match ip address 1Device2(config-route-map)#set tag 5Device2(config-route-map)#exitDevice2(config)#route-map rip_to_ospf 20Device2(config-route-map)#match ip address 2Device2(config-route-map)#set metric 50Device2(config-route-map)#exitDevice2(config)#route-map rip_to_ospf 30Device2(config-route-map)#match ip address 3Device2(config-route-map)#exit
Ao configurar uma política de roteamento, você pode criar uma regra de correspondência com base em uma lista de prefixos ou ACL. A lista de prefixos pode corresponder precisamente às máscaras de roteamento, enquanto a ACL não pode corresponder às máscaras de roteamento.
- Passo 7:Configure o OSPF para redistribuir rotas RIP e associar uma política de roteamento.
# Configurar dispositivo2.
Device2(config)#router ospf 100Device2(config-ospf)#redistribute rip route-map rip_to_ospfDevice2(config-ospf)#exit
- Passo 8:Confira o resultado.
#Verifique o banco de dados OSPF de Device1.
Device1#show ip ospf database externalOSPF Router with ID (172.1.1.1) (Process ID 100)AS External Link StatesLS age: 1183Options: 0x22 (-|-|DC|-|-|-|E|-)LS Type: AS-external-LSALink State ID: 100.1.1.0 (External Network Number)Advertising Router: 172.1.1.2LS Seq Number: 80000006Checksum: 0xbcc0Length: 36Network Mask: /24Metric Type: 2 (Larger than any link state path)TOS: 0Metric: 20Forward Address: 0.0.0.0External Route Tag: 5LS age: 1233Options: 0x22 (-|-|DC|-|-|-|E|-)LS Type: AS-external-LSALink State ID: 110.1.1.0 (External Network Number)Advertising Router: 172.1.1.2LS Seq Number: 80000006Checksum: 0x0d4dLength: 36Network Mask: /24Metric Type: 2 (Larger than any link state path)TOS: 0Metric: 50Forward Address: 0.0.0.0External Route Tag: 0LS age: 1113Options: 0x22 (-|-|DC|-|-|-|E|-)LS Type: AS-external-LSALink State ID: 120.1.1.0 (External Network Number)Advertising Router: 172.1.1.2LS Seq Number: 80000005Checksum: 0x5f10Length: 36Network Mask: /24Metric Type: 2 (Larger than any link state path)TOS: 0Metric: 20Forward Address: 0.0.0.0External Route Tag: 0
#Consulte a tabela de roteamento do Device1.
Device1#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalOE 100.1.1.0/24 [150/20] via 172.1.1.2, 02:30:28, vlan2OE 110.1.1.0/24 [150/50] via 172.1.1.2, 00:58:17, vlan2OE 120.1.1.0/24 [150/20] via 172.1.1.2, 02:30:28, vlan2
De acordo com o banco de dados OSPF e a tabela de roteamento do Device1, a tag da rota 100.1.1.0/24 é 5, a métrica da rota 110.1.1.0/24 é 50 e as propriedades de roteamento da rota 120.1.1.0/24 não são alteradas.
Na redistribuição de rotas externas, as rotas das interfaces de conexão direta cobertas pelo processo RIP também serão redistribuídas no protocolo de destino.
Configurar a política de roteamento para BGP
Requisitos de rede
- Execute o protocolo IGP ISPF e configure vizinhos IBGP entre Device1 e Device2 e entre Device1 e Device3 , e configure vizinhos EBGP entre Device4 e Device2 e entre Device4 e Device3.
- Configure uma política de roteamento em Device2 e Device3 para que os dados de Device1 alcancem o segmento de rede 100.1.1.0/24 por meio de Device2, alcancem o segmento de rede 110.1.1.0/24 por Device3, alcancem o segmento de rede 120.1.1.0/24 por Device2 e alcancem a rede segmento 130.1.1.0/24 por meio de Device3.
Topologia de rede
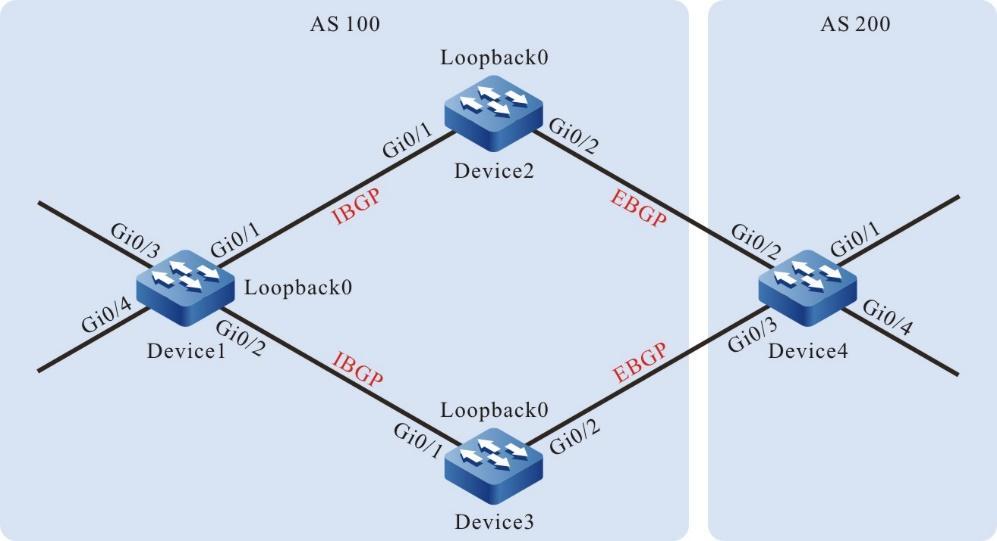
Figura 15 - 2Configurando uma política de roteamento para BGP
| Dispositivo | Interface | VLAN | Endereço de IP |
| Dispositivo1 | Gi0/1 Gi0/2 Gi0/3 Gi0/4 |
2 3 4 5 |
1.0.0.1/24 2.0.0.1/24 120.1.1.1/24 130.1.1.1/24 |
| Loopback0 | 38.1.1.1/32 | ||
| Dispositivo2 | Gi0/1 Gi0/2 |
2 3 |
1.0.0.2/24 3.0.0.1/24 |
| Loopback0 | 39.1.1.1/32 | ||
| Dispositivo3 | Gi0/1 Gi0/1 |
2 3 |
2.0.0.2/24 4.0.0.1/24 |
| Loopback0 | 40.1.1.1/32 | ||
| Dispositivo 4 | Gi0/1 Gi0/2 Gi0/3 Gi0/4 |
2 3 4 5 |
100.1.1.1/24 3.0.0.2/24 4.0.0.2/24 110.1.1.1/24 |
Etapas de configuração
- Passo 1:Configure a VLAN e junte a interface à VLAN correspondente. (Omitido)
- Passo 2:Configure os endereços IP das interfaces. (Omitido)
- Passo 3:Configure o OSPF para que as rotas de loopback sejam alcançáveis entre os dispositivos.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 38.1.1.1 0.0.0.0 area 0Device1(config-ospf)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 39.1.1.1 0.0.0.0 area 0Device2(config-ospf)#exit
# Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 40.1.1.1 0.0.0.0 area 0Device3(config-ospf)#exit
#Consulte a tabela de roteamento do Device1.
Device1#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 39.1.1.1/32 [110/2] via 1.0.0.2, 19:11:33, vlan2O 40.1.1.1/32 [110/2] via 2.0.0.2, 18:56:32, vlan3
#Consulte a tabela de roteamento do Device2.
Device2#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 2.0.0.0/24 [110/2] via 1.0.0.1, 19:19:10, vlan2O 38.1.1.1/32 [110/2] via 1.0.0.1, 19:09:43, vlan2O 40.1.1.1/32 [110/3] via 1.0.0.1, 18:56:49, vlan2
#Consulte a tabela de roteamento do Device3.
Device3#show ip route ospfCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalO 1.0.0.0/24 [110/2] via 2.0.0.1, 19:17:33, vlan2O 38.1.1.1/32 [110/2] via 2.0.0.1, 19:09:59, vlan2O 39.1.1.1/32 [110/3] via 2.0.0.1, 19:12:06, vlan2
Após a conclusão da configuração, Device1 pode configurar vizinhos OSPF respectivamente com Device2 e Device3 e os dispositivos podem aprender as rotas de Loopback da extremidade do peer.
- Passo 4:Configurar BGP.
# Configurar dispositivo1.
Configure Device1 para configurar vizinhos IBGP respectivamente com Device2 e Device3 por meio de interfaces Loopback e anuncie as rotas 120.1.1.0/24 e 130.1.1.0/24 para a tabela de roteamento BGP.
Device1(config)#router bgp 100Device1(config-bgp)#neighbor 39.1.1.1 remote-as 100Device1(config-bgp)#neighbor 39.1.1.1 update-source loopback0Device1(config-bgp)#neighbor 40.1.1.1 remote-as 100Device1(config-bgp)#neighbor 40.1.1.1 update-source loopback0Device1(config-bgp)#network 120.1.1.0 255.255.255.0Device1(config-bgp)#network 130.1.1.0 255.255.255.0Device1(config-bgp)#exit
# Configurar dispositivo2.
Device2(config)#router bgp 100Device2(config-bgp)#neighbor 38.1.1.1 remote-as 100Device2(config-bgp)#neighbor 38.1.1.1 update-source loopback0Device2(config-bgp)#neighbor 38.1.1.1 next-hop-selfDevice2(config-bgp)#neighbor 3.0.0.2 remote-as 200Device2(config-bgp)#exit
# Configurar dispositivo3.
Device3(config)#router bgp 100Device3(config-bgp)#neighbor 38.1.1.1 remote-as 100Device3(config-bgp)#neighbor 38.1.1.1 update-source loopback0Device3(config-bgp)#neighbor 38.1.1.1 next-hop-selfDevice3(config-bgp)#neighbor 4.0.0.2 remote-as 200Device3(config-bgp)#exit
# Configurar dispositivo4.
Configure Device4 para configurar vizinhos EBGP respectivamente com Device2 e Device3 e anuncie as rotas 100.1.1.0/24 e 110.1.1.0/24 para a tabela de roteamento BGP.
Device4#configure terminalDevice4(config)#router bgp 200Device4(config-bgp)#neighbor 3.0.0.1 remote-as 100Device4(config-bgp)#neighbor 4.0.0.1 remote-as 100Device4(config-bgp)#network 100.1.1.0 255.255.255.0Device4(config-bgp)#network 110.1.1.0 255.255.255.0Device4(config-bgp)#exit
#Consulte as informações de roteamento BGP do Device1.
Device1#show ip bgpBGP table version is 2, local router ID is 38.1.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*>i100.1.1.0/24 39.1.1.1 0 100 0 200 i[B]* i 40.1.1.1 0 100 0 200 i[B]*>i110.1.1.0/24 39.1.1.1 0 100 0 200 i[B]* i 40.1.1.1 0 100 0 200 i[B]*> 120.1.1.0/24 0.0.0.0 0 32768 i[B]*> 130.1.1.0/24 0.0.0.0 0 32768 i
#Consulte a tabela de roteamento do Device1.
Device1#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 100.1.1.0/24 [200/0] via 39.1.1.1, 19:03:19, vlan2B 110.1.1.0/24 [200/0] via 39.1.1.1, 19:03:19, vlan2
De acordo com a tabela de roteamento BGP do Device1, os dados direcionados aos segmentos de rede 100.1.1.0/24 e 110.1.1.0/24 têm duas rotas válidas, respectivamente. Como o ID do roteador de Device2 é menor, os dados BGP direcionados aos segmentos de rede 100.1.1.0/24 e 110.1.1.0/24 optam por passar Device2 por padrão.
#Consulte as informações de roteamento BGP do Device4.
Device4#show ip bgpBGP table version is 3, local router ID is 110.1.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 100.1.1.0/24 0.0.0.0 0 32768 i[B]*> 110.1.1.0/24 0.0.0.0 0 32768 i[B]* 120.1.1.0/24 4.0.0.1 0 0 100 i[B]*> 3.0.0.1 0 0 100 i[B]* 130.1.1.0/24 4.0.0.1 0 0 100 i[B]*> 3.0.0.1 0 0 100 i
#Consulte a tabela de roteamento do Device4.
Device4#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 120.1.1.0/24 [20/0] via 3.0.0.1, 19:25:05, vlan3B 130.1.1.0/24 [20/0] via 3.0.0.1, 19:25:05, vlan3
De acordo com a tabela de roteamento BGP do Device4, os dados direcionados aos segmentos de rede 120.1.1.0/24 e 130.1.1.0/24 têm duas rotas válidas. Como Device4 primeiro configura uma relação de vizinho com Device2, leva mais tempo para Device2 aprender as duas rotas, então os dados BGP que são direcionados aos segmentos de rede 120.1.1.0/24 e 130.1.1.0/24 escolhem passar Device2 por padrão .
- Passo 5:Configure uma lista de prefixos e uma política de roteamento.
# Configurar dispositivo2.
Configure uma lista de prefixos para permitir a passagem das rotas 100.1.1.0/24 e 130.1.1.0/24.
Device2(config)#ip prefix-list 1 permit 100.1.1.0/24Device2(config)#ip prefix-list 2 permit 130.1.1.0/24
Configure a política de roteamento lp para que a lista de prefixos 1 de Device2 permita definir a preferência local para rotas.
Device2(config)#route-map lp 10Device2(config-route-map)#match ip address prefix-list 1Device2(config-route-map)#set local-preference 200Device2(config-route-map)#exitDevice2(config)#route-map lp 20Device2(config-route-map)#exit
Configure a política de roteamento med para que a lista de prefixos 2 de Device2 permita definir a propriedade MED para rotas.
Device2(config)#route-map med 10Device2(config-route-map)#match ip address prefix-list 2Device2(config-route-map)#set metric 10Device2(config-route-map)#exitDevice2(config)#route-map med 20Device2(config-route-map)#exit
# Configurar dispositivo3.
Configure uma lista de prefixos para permitir a passagem das rotas 110.1.1.0/24 e 120.1.1.0/24.
Device3(config)#ip prefix-list 1 permit 110.1.1.0/24Device3(config)#ip prefix-list 2 permit 120.1.1.0/24
Configure a política de roteamento lp para que a lista de prefixos 1 de Device3 permita definir a preferência local para rotas.
Device3(config)#route-map lp 10Device3(config-route-map)#match ip address prefix-list 1Device3(config-route-map)#set local-preference 200Device3(config-route-map)#exitDevice3(config)#route-map lp 20Device3(config-route-map)#exit
Configure a política de roteamento med para que a lista de prefixos 2 de Device3 permita definir a propriedade MED para rotas.
Device3(config)#route-map med 10Device3(config-route-map)# match ip address prefix-list 2Device3(config-route-map)#set metric 10Device3(config-route-map)#exitDevice3(config)#route-map med 20Device3(config-route-map)#exit
Ao configurar uma política de roteamento, você pode criar uma regra de correspondência com base em uma lista de prefixos ou ACL. A lista de prefixos pode corresponder precisamente às máscaras de roteamento, enquanto a ACL não pode corresponder às máscaras de roteamento.
- Passo 6:Configure uma política de roteamento para BGP.
# Configurar dispositivo2.
Aplique a política de roteamento lp às rotas de saída do vizinho 38.1.1.1 e aplique a política de roteamento med às rotas de saída do vizinho 3.0.0.2.
Device2(config)#router bgp 100Device2(config-bgp)#neighbor 38.1.1.1 route-map lp outDevice2(config-bgp)#neighbor 3.0.0.2 route-map med outDevice2(config-bgp)#exit
# Configurar dispositivo3.
Aplique a política de roteamento lp às rotas de saída do vizinho 38.1.1.1 e aplique a política de roteamento med às rotas de saída do vizinho 4.0.0.2.
Device3(config)#router bgp 100Device3(config-bgp)#neighbor 38.1.1.1 route-map lp outDevice3(config-bgp)#neighbor 4.0.0.2 route-map med outDevice3(config-bgp)#exit
- Passo 7: Confira o resultado.
#Consulte as informações de roteamento BGP do Device1.
Device1#show ip bgpBGP table version is 9, local router ID is 38.1.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]* i100.1.1.0/24 40.1.1.1 0 100 0 200 i[B]*>i 39.1.1.1 0 200 0 200 i[B]*>i110.1.1.0/24 40.1.1.1 0 200 0 200 i[B]* i 39.1.1.1 0 100 0 200 i[B]*> 120.1.1.0/24 0.0.0.0 0 32768 i[B]*> 130.1.1.0/24 0.0.0.0 0 32768 i
#Consulte a tabela de roteamento do Device1.
Device1#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 100.1.1.0/24 [200/0] via 39.1.1.1, 02:58:12, vlan2B 110.1.1.0/24 [200/0] via 40.1.1.1, 02:58:10, vlan3
De acordo com a tabela de roteamento BGP do Device1, a rota 100.1.1.0/24 tem dois próximos saltos, 40.1.1.1 e 39.1.1.1. A preferência local da rota com o próximo salto 39.1.1.1 foi alterada para 200 para que os dados direcionados ao segmento de rede 100.1.1.0/24 escolham passar Device2 com prioridade . A rota 110.1.1.0/24 também tem dois próximos saltos, 40.1.1.1 e 39.1.1.1. A preferência local da rota com o próximo salto 40.1.1.1 foi alterada para 200 para que os dados direcionados ao segmento de rede 110.1.1.0/24 escolham passar o Device3 com prioridade.
#Consulte as informações de roteamento BGP do Device4.
Device4#show ip bgpBGP table version is 9, local router ID is 110.1.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 100.1.1.0/24 0.0.0.0 0 32768 i[B]*> 110.1.1.0/24 0.0.0.0 0 32768 i[B]* 120.1.1.0/24 4.0.0.1 10 0 100 i[B]*> 3.0.0.1 0 0 100 i[B]*> 130.1.1.0/24 4.0.0.1 0 0 100 i[B]* 3.0.0.1 10 0 100 i
#Consulte a tabela de roteamento do Device4.
Device4#show ip route bgpCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalB 120.1.1.0/24 [20/0] via 3.0.0.1, 03:05:39, vlan3B 130.1.1.0/24 [20/0] via 4.0.0.1, 03:05:37, vlan4
De acordo com a tabela de roteamento BGP do Device4, a rota 120.1.1.0/24 tem dois próximos saltos, 4.0.0.1 e 3.0.0.1. A métrica da rota com o próximo salto 4.0.0.1 foi alterada para 10 para que os dados direcionados ao segmento de rede 120.1.1.0/24 escolham passar o Device2 com prioridade. A rota 130.1.1.0/24 também tem dois próximos saltos, 4.0.0.1 e 3.0.0.1. A métrica da rota com o próximo salto 3.0.0.1 foi alterada para 10 para que os dados direcionados ao segmento de rede 130.1.1.0/24 escolham passar o Device3 com prioridade.
Se uma política de roteamento for aplicada a um peer ou grupo de peers de BGP, ela poderá ser aplicada na direção de recebimento ou anúncio do peer ou grupo de peers de BGP, e as configurações entrarão em vigor depois que o BGP for redefinido.
06 Multicast
Noções básicas de multicast L2
Visão geral
A principal tarefa da base multicast L2 é manter a tabela de encaminhamento multicast L2. Os módulos de aplicação do multicast L2 geram suas tabelas multicast L2 por configuração estática e aprendizado dinâmico, e então sincronizam as informações com os módulos básicos do multicast L2. Os módulos de base multicast L2 integram as informações para formar a tabela de encaminhamento multicast L2.
Configuração das funções básicas de multicast L2
Tabela 1 -1 Lista de configuração de noções básicas de multicast L2
| Tarefa de configuração | |
| Configure a política de encaminhamento de pacotes desconhecidos do multicast L2 | Configurar política de encaminhamento MAC de pacote desconhecido de multicast L2 |
| Configurar multicast estático L2 | Configurar multicast estático L2 |
Configurar a política de encaminhamento de pacote desconhecido de L2 Multicast
Os pacotes de serviço multicast desconhecidos têm dois tipos de diretivas de encaminhamento: descartar pacotes de serviço multicast desconhecidos ou inundar os pacotes de serviço multicast desconhecidos.
Condição de configuração
Antes de configurar a política de encaminhamento de pacotes desconhecidos do multicast L2, primeiro conclua a seguinte tarefa:
- Configurar VLAN correspondente
Configurar a política de encaminhamento de MAC de pacote desconhecido de L2 Multicast
No modo de encaminhamento MAC multicast L2, os pacotes de serviço multicast são encaminhados combinando VLAN e endereço MAC de destino. Quando o pacote de serviço multicast não corresponde à tabela de encaminhamento, é um pacote de serviço multicast desconhecido. O dispositivo tem dois tipos de políticas de encaminhamento para os pacotes de serviço multicast desconhecidos: descartar pacotes de serviço multicast desconhecidos ou inundar pacotes de serviço multicast desconhecidos.
Tabela 1 -2 Configurar política de encaminhamento MAC de pacote desconhecido de multicast L2
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração de VLAN | vlan vlan-id | - |
| Configurar a política de encaminhamento multicast L2 | l2-multicast drop-unknown | Opcional Por padrão, a função de descartar pacotes de serviço multicast desconhecidos não está habilitada na VLAN. |
Configurar multicast estático L2
O multicast estático L2 gera a tabela de encaminhamento multicast L2 por configuração estática. Ele é formado pelo usuário que especifica o endereço MAC multicast, VLAN e lista de portas (incluindo lista de portas de membros e lista de portas proibidas).
Condição de configuração
Antes de configurar o multicast estático L2, primeiro conclua a seguinte tarefa:
- Configurar VLAN correspondente
Configurar multicast estático L2
Tabela 1 -3 Configurar multicast estático L2
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Criar multicast estático L2 | l2-multicast mac-entry static mac-address vlan vlan-id | Obrigatório Por padrão, a entrada multicast estática L2 não está configurada. |
| Configurar a porta membro da entrada multicast estática L2 | interface link-aggregation link-aggregation-id { member | forbidden } | Opcional Por padrão, a porta membro da entrada multicast estática L2 não está configurada. |
| Configurar o grupo de agregação de membros da entrada multicast estática L2 | link-aggregation link-aggregation-id { member | forbidden } | Opcional Por padrão, o grupo de agregação de membros da entrada multicast estática L2 não está configurado. |
Monitoramento e manutenção da base de multicast L2
Tabela 1 -4 Monitoramento e manutenção da base multicast L2
| Comando | Descrição |
| show l2-multicast ha { phase batch | phase flat | statistics } | Exiba as informações de alta confiabilidade do multicast L2 |
| show l2-multicast ip-entry | Exiba as informações da tabela de encaminhamento de IP do multicast L2 |
| show l2-multicast l3-ip-entry | Exiba as informações da tabela de encaminhamento de IP L3 do multicast L2 |
| show l2-multicast mac-entry { all | forward | static } | Exibir a tabela multicast L2 |
| show l2-multicast vlan-setting { all | vlan-id } | Exiba as informações de multicast VLAN L2 |
Exemplo de configuração típico de multicast estático L2
Configurar multicast estático L2
Requisitos de rede
- Device1 configura o protocolo de roteamento multicast; Device2 configura multicast estático L2 em VLAN2; PC1 é o receptor do serviço multicast; PC2 e PC3 não são o receptor do serviço multicast.
- O Servidor Multicast envia pacotes de serviço multicast; PC1 pode receber pacotes de serviço multicast corretamente; PC2 e PC3 não podem receber pacotes de serviço multicast.
Topologia de rede
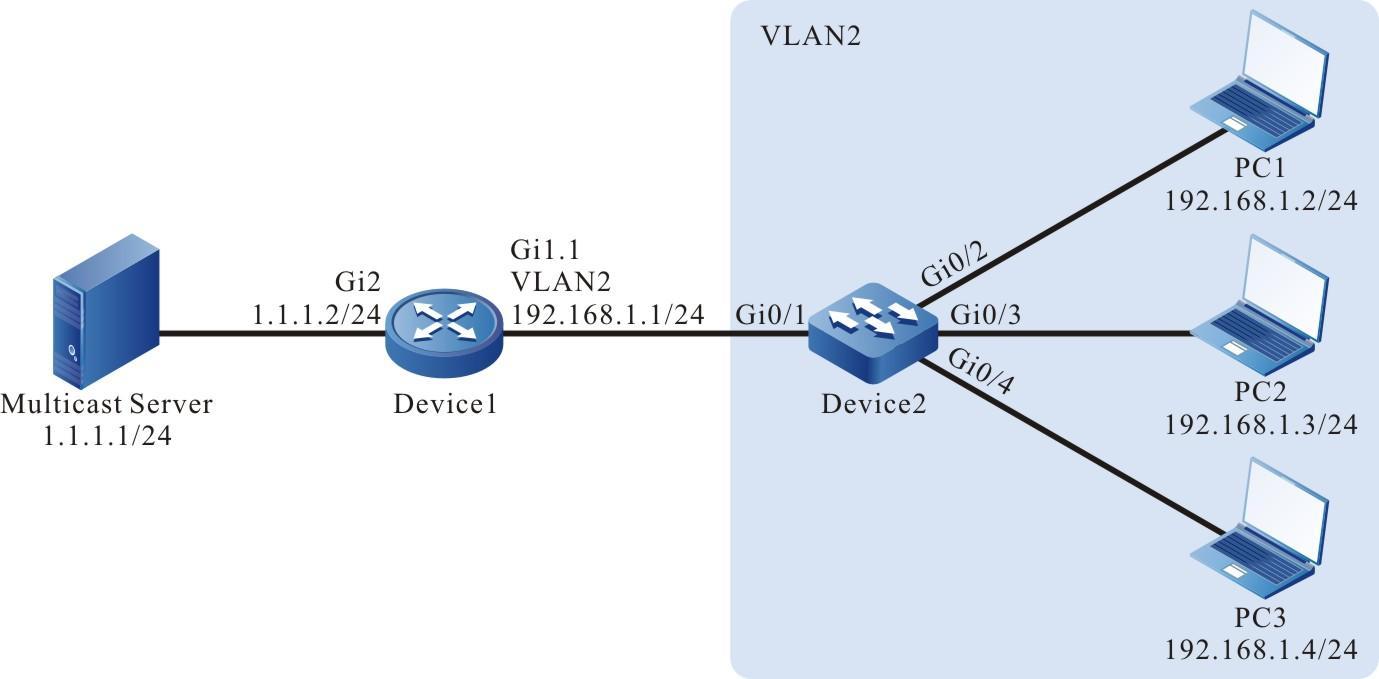
Figura 1 -1 Topologia de rede de configuração de multicast estático L2
Etapas de configuração
- Passo 1:Device1 configura o endereço IP da interface e habilita o protocolo de roteamento multicast. (omitido)
- Passo 2: Configurar dispositivo2.
#Criar VLAN2 no Dispositivo2.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/2 - gigabitethernet0/4 no Device2 como Access, permitindo a passagem dos serviços da VLAN2.
Device2(config)#interface gigabitethernet 0/2-0/4Device2(config-if-range)#switchport access vlan 2Device2(config-if-range)#exit
#Configure o tipo de link da porta gigabitethernet0/1 no Device2 como Trunk, permitindo a passagem dos serviços da VLAN2. Configure PVID como 1.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode trunkDevice2(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2Device2(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 1Device2(config-if-gigabitethernet0/1)#exit
# Habilite o descarte de multicast desconhecido na VLAN2.
Device2(config)#vlan 2Device2(config-vlan2)#l2-multicast drop-unknownDevice2(config-vlan2)#exit
#Configure os membros do grupo multicast estático L2.
Device2(config)#l2-multicast mac-entry static 0100.5E01.0101 vlan 2Device2(config-mcast)#interface gigabitethernet 0/2 memberDevice2(config-mcast)#exitDevice2(config)#l2-multicast mac-entry static 0100.5E01.0101 vlan 2Device2(config-mcast)#interface gigabitethernet 0/3 forbiddenDevice2(config-mcast)#exit
- Passo 3:Confira o resultado.
#Visualize a entrada multicast estática L2 do Device2.
Device2#show l2-multicast mac-entry staticCurrent L2 Static Multicast 2 entries---- -------- ------------------ ------------------------------NO. VID Group MAC address Interface Name---- -------- ------------------ ------------------------------1 2 0100.5E01.0101 [M] gi0/22 2 0100.5E01.0101 [F] gi0/3
#Multicast Server envia os pacotes de serviço multicast com endereço de destino 224.1.1.1. PC1 pode receber os pacotes de serviço multicast corretamente; PC2 e PC3 não podem receber pacotes de serviço multicast.
Configurar Multicast estático IPv6 L2
Requisitos de rede
- Device1 configura o protocolo de roteamento multicast IPv6; Device2 configura multicast estático IPv6 L2 em VLAN2; PC1 é o receptor do serviço multicast; PC2 e PC3 são os receptores do serviço não multicast.
- O Servidor Multicast envia pacotes de serviço multicast IPv6; PC1 pode receber pacotes de serviço multicast corretamente; PC2 e PC3 não podem receber pacotes de serviço multicast.
Topologia de rede
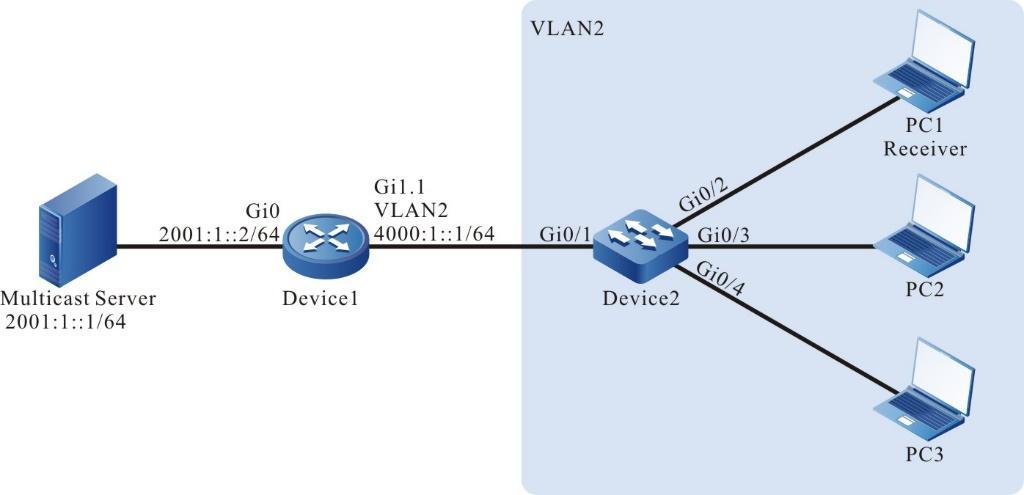
Figura 1 -2 Topologia de rede de configuração de multicast estático IPv6 L2
Etapas de configuração
- Passo 1:Device1 configura o endereço IP da interface e habilita o protocolo de roteamento multicast. (omitido)
- Passo 2:Configurar dispositivo2.
# Em Device2, crie VLAN2.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exit
#No Device2, configure o tipo de link das portas gigabitethernet0/2~gigabitethernet0/4 como Access, permitindo a passagem dos serviços da VLAN2.
Device2(config)#interface gigabitethernet 0/2-0/4Device2(config-if-range)#switchport access vlan 2Device2(config-if-range)#exit
# No Device2, configure o tipo de link da porta gigabitethernet0/ 1 como Trunk, permita que os serviços da VLAN2 passem e configure PVID como 1.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode trunkDevice2(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2Device2(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 1Device2(config-if-gigabitethernet0/1)#exit
# Em VLAN2, habilite o descarte multicast desconhecido.
Device2(config)#vlan 2Device2(config-vlan2)#l2-multicast drop-unknownDevice2(config-vlan2)#exit
# Configurar os membros do grupo multicast estático L2.
Device2(config)# l2-multicast mac-entry static 3333.0000.0001 vlan 2Device2(config-mcast)#interface gigabitethernet 0/2 memberDevice2(config-mcast)#interface gigabitethernet 0/3 forbiddenDevice2(config-mcast)#exit
- Passo 3:Confira o resultado.
# Consulta as entradas multicast estáticas IPv6 L2 de Device2.
Device2# show l2-multicast mac-entry staticCurrent L2 Static Multicast 1 entries---- -------- ------------------ ---------------------------------------------NO. VID Group MAC address Interface Name---- -------- ------------------ ---------------------------------------------1 2 3333.0000.0001 [M] gi0/2[F] gi0/3
#Multicast Server envia o pacote multicast com o endereço de destino ff10::1 . PC1 pode receber corretamente o pacote multicast, mas PC2 e PC3 não podem receber os pacotes multicast.
No multicast estático IPv6 L2, os pacotes multicast só podem ser encaminhados para a porta cuja função é membro. Para a porta proibida, mesmo sendo adicionado ao grupo multicast do grupo multicast estático pelo modo mld snooping, os pacotes multicast cujo endereço de destino seja o grupo multicast estático não serão encaminhados para a porta proibida. As portas não-membro e não proibidas podem ser adicionadas ao grupo multicast do grupo multicast estático pelo modo de espionagem mld, e o pacote multicasy cujo endereço de destino é o grupo multicast estático será encaminhado para a porta.
IGMP Snooping
Visão geral
IGMP Snooping (Internet Group Management Protocol snooping) é a função projetada para o dispositivo que não suporta IGMP para reduzir o alcance de espalhamento do pacote de serviço multicast e evitar que o pacote multicast seja espalhado para os segmentos de rede que não precisam do multicast pacote. Ele forma e mantém a lista de portas de membros downstream de cada grupo multicast no local ouvindo pacotes IGMP. Dessa forma, ao receber o pacote de serviço multicast, encaminhe na porta do membro downstream especificada. Enquanto isso, o IGMP Snooping pode ouvir os pacotes do protocolo IGMP e cooperar com o roteador multicast upstream para gerenciar e controlar os serviços multicast.
O IGMP Snooping realiza principalmente as seguintes funções:
- Ouça os pacotes IGMP para configurar as informações de multicast. O IGMP Snooping obtém as informações do receptor multicast downstream ouvindo pacotes IGMP, realizando o encaminhamento de pacotes de serviço multicast na porta membro especificada.
- Ouça os pacotes de protocolo IGMP. Desta forma, o roteador multicast upstream pode manter corretamente a tabela de relação de membros IGMP.
Configuração da função de espionagem IGMP
Tabela 2 -1 Lista de configuração da função de espionagem IGMP
| Tarefa de configuração | |
| Configurar funções básicas do IGMP Snooping |
Habilite a função IGMP Snooping
Configurar a versão de espionagem IGMP função de encaminhamento L2 de espionagem IGMP |
| Configurar consulta de espionagem IGMP |
Ativar o consultador de espionagem IGMP
Configure o endereço IP de origem do pacote de consulta IGMP Configurar intervalo de consulta geral do grupo Configure o tempo máximo de resposta Configure o intervalo de consulta do grupo especificado Configurar saída rápida |
| Configurar a porta do roteador de espionagem IGMP |
Configurar a porta do roteador de espionagem IGMP
Configure o tempo de idade da porta do roteador dinâmico de espionagem IGMP |
| Configurar evento TCN de espionagem IGMP |
Habilite a convergência rápida
Configurar o intervalo de consulta do evento TCN Configurar os tempos de consulta do evento TCN |
| Configurar a política de espionagem IGMP |
Configurar a regra de filtro de porta
Configurar itens máximos do grupo multicast de porta Configure a política de limitação superior do grupo multicast da porta |
| Configurar proxy de espionagem IGMP | Configurar o proxy de espionagem IGMP |
Configurar funções básicas de espionagem IGMP
Nas tarefas de configuração do IGMP snooping, você deve primeiro habilitar a função IGMP snooping para que a configuração das outras funções possa ter efeito.
Condição de configuração
Antes de configurar as funções básicas do IGMP snooping, primeiro complete a seguinte tarefa:
- Configurar VLAN
Ativar função de espionagem IGMP
Depois de habilitar a função de espionagem IGMP, o dispositivo pode executar a função de espionagem IGMP.
Tabela 2 -2 Ativar a função de espionagem IGMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar função de espionagem IGMP global | ip igmp snooping | Obrigatório Por padrão, a função de espionagem IGMP global não está habilitada. |
| Habilite a função de espionagem IGMP da VLAN especificada | ip igmp snooping vlan vlan-id | Obrigatório Por padrão, a função de espionagem IGMP não está habilitada na VLAN. |
função de espionagem IGMP global , você pode habilitar a função de espionagem IGMP da VLAN especificada.
Configurar a versão de espionagem IGMP
A versão de espionagem IGMP configurada e as regras de processamento dos pacotes de protocolo IGMP são as seguintes:
A versão de espionagem IGMP configurada é V3 e o dispositivo pode processar pacotes de protocolo IGMP de V1, V2 e V3;
A versão de espionagem IGMP configurada é V2 e o dispositivo pode processar os pacotes de protocolo IGMP de V1 e V2 e não processa pacotes de protocolo V3, mas faz com que os pacotes de protocolo V3 inundem na VLAN.
A versão de espionagem IGMP configurada é V1 e o dispositivo pode processar os pacotes de protocolo IGMP de V1 e não processa pacotes de protocolo V2 ou V3, mas faz com que os pacotes de protocolo V2 e V3 inundem na VLAN.
Tabela 2 -3 Configurar a versão de espionagem IGMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a versão de espionagem IGMP | ip igmp snooping vlan vlan-id version version-number | Opcional Por padrão, a versão de espionagem IGMP é 2. |
Encaminhamento L2 de espionagem IGMP
Normalmente, a espionagem IGMP encaminha o pacote de serviço multicast na VLAN de acordo com o endereço IP de origem multicast e o endereço IP de destino multicast . Depois de configurar o encaminhamento L2 do IGMP snooping, o IGMP snooping encaminha pacotes de serviço multicast na VLAN de acordo com o endereço MAC de destino multicast .
Tabela 2 -4 IGMP snooping encaminhamento L2
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ative a função de encaminhamento L2 multicast L2 na VLAN especificada | ip igmp snooping vlan vlan-id l2-forwarding | Obrigatório Por padrão, a função de encaminhamento de IP de VLAN IGMP snooping L2 multicast está habilitada. |
| Ative a função de encaminhamento de IP multicast L2 na VLAN especificada | ip igmp snooping vlan vlan-id ipmc l2-forwarding | Obrigatório Por padrão, a função de encaminhamento MAC do multicast L2 snooping IGMP na VLAN está habilitada. |
Como 32 endereços IP multicast correspondem a um endereço MAC multicast e o encaminhamento L2 não pode especificar o encaminhamento de origem multicast, pode haver vários grupos de origem multicast IP correspondentes ao mesmo grupo MAC . Neste momento, haverá conflito de encaminhamento .
Configurar o IGMP snooping Querier
Se não houver um dispositivo multicast L3 na rede, ele não poderá realizar as funções relacionadas do querier IGMP. Para resolver o problema, você pode configurar o IGMP snooping querier no dispositivo multicast L2 para realizar a função IGMP querier para que o dispositivo multicast L2 possa configurar e manter a entrada de encaminhamento multicast, de modo a encaminhar pacotes de serviço multicast normalmente.
Condição de configuração
Antes de configurar as funções básicas do IGMP snooping querier, primeiro complete a seguinte tarefa:
- função de espionagem IGMP global e VLAN
Ativar o Consultador de espionagem IGMP
Você deve primeiro habilitar a função IGMP snooping querier para que a configuração dos outros recursos do querier possa ter efeito.
Tabela 2 -5 Ativar consulta de espionagem IGMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar o consultador de espionagem IGMP | ip igmp snooping vlan vlan-id querier | Obrigatório Por padrão, o consultador de espionagem IGMP da VLAN especificada não está habilitado. |
Configurar o endereço IP do consultador
O consultador configurado com endereço IP participa da eleição do consultador IGMP na VLAN e o consultador preenche o endereço IP no campo de endereço IP de origem do pacote de consulta do grupo IGMP enviado.
Tabela 2 -6 Configurar o endereço IP do consultador
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o endereço IP do consultador | ip igmp snooping vlan vlan-id querier address ip-address | Obrigatório Por padrão, o endereço IP do consultador da VLAN especificada não está configurado. |
Quando o endereço IP do questionador não está configurado, o endereço IP de origem padrão do questionador é 0.0.0.0, mas o consultador não envia o pacote de consulta do grupo IGMP com o endereço IP de origem 0.0.0.0.
Configurar intervalo de consulta do grupo geral
O consultador IGMP envia periodicamente os pacotes de consulta do grupo geral para manter a relação de membro do grupo. Você pode modificar o intervalo de envio dos pacotes de consulta do grupo geral IGMP de acordo com a realidade da rede. Por exemplo, se o intervalo de consulta do grupo geral configurado for longo, pode-se reduzir o número de pacotes do protocolo IGMP na rede, evitando o congestionamento da rede.
Tabela 2 -7 Configurar intervalo de consulta do grupo geral
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar intervalo de consulta do grupo geral | ip igmp snooping vlan vlan-id querier query-interval interval-value | Opcional Por padrão, o intervalo de consulta do grupo geral é 125s. |
Na mesma VLAN, o intervalo de consulta configurado do grupo geral deve ser maior que o tempo máximo de resposta. Caso contrário, a configuração não será bem-sucedida.
Configurar máx. Tempo de resposta
O pacote de consulta de grupo geral enviado pelo consultador IGMPv2 contém o campo de tempo máximo de resposta. O receptor multicast envia os pacotes de relatório do membro dentro do intervalo máximo de resposta.
Tabela 2 -8 Configure o tempo máximo de resposta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o tempo máximo de resposta | ip igmp snooping vlan vlan-id querier max-response-time time-value | Opcional Por padrão, o tempo máximo de resposta é 10s. |
Em uma VLAN, o tempo de resposta máximo configurado deve ser menor que o intervalo de consulta do grupo geral. Caso contrário, a configuração não será bem-sucedida.
Configurar intervalo de consulta do grupo especificado
Quando o consultador IGMP recebe o pacote de saída de um grupo multicast, ele envia o pacote de consulta do grupo especificado para consultar o segmento do grupo multicast, para saber se a sub-rede possui o membro do grupo multicast. Se não estiver recebendo o pacote de relatório de membro do grupo multicast após aguardar o “ último período de vida ”, exclua as informações do grupo multicast.
Tabela 2 -9 Configurar intervalo de consulta do grupo especificado
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar intervalo de consulta do grupo especificado | ip igmp snooping vlan vlan-id last-member-query-interval interval-value | Opcional Por padrão, o intervalo de consulta do grupo especificado é de 1.000 ms. |
Configurar Saída Rápida
Se o dispositivo receber o pacote de saída de um grupo multicast após configurar a saída rápida, o dispositivo não enviará mais o pacote de consulta do grupo especificado para a porta e as informações do grupo multicast serão excluídas imediatamente.
Tabela 2 -10 Configurar saída rápida
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a saída rápida | ip igmp snooping vlan vlan-id immediate-leave | Obrigatório Por padrão, a função de saída rápida da VLAN especificada não está habilitada. |
Existem vários receptores do mesmo grupo multicast na porta do dispositivo ao mesmo tempo. Quando a porta recebe o pacote de saída IGMP do grupo multicast enviado por um receptor e se a saída rápida estiver configurada na VLAN da porta do dispositivo, os serviços multicast dos outros receptores são interrompidos.
Configurar porta do roteador de espionagem IGMP
A porta do roteador de espionagem IGMP é a porta que recebe os pacotes de consulta do grupo IGMP ou os pacotes do protocolo de roteamento multicast. Quando o dispositivo recebe o relatório do membro IGMP ou deixa o pacote, encaminhe o pacote pela porta do roteador de espionagem IGMP. Desta forma, o roteador conectado na parte superior pode manter a tabela de relação de membros IGMP corretamente.
A porta do roteador de espionagem IGMP pode ser aprendida dinamicamente ou configurada manualmente. A porta do roteador dinâmico de espionagem IGMP atualiza o tempo de idade recebendo regularmente os pacotes de consulta do grupo IGMP ou pacotes de protocolo de roteamento multicast. A porta do roteador estático de espionagem IGMP não envelhece.
Condição de configuração
Antes de configurar as funções da porta do roteador de espionagem IGMP, primeiro conclua as seguintes tarefas:
- função de espionagem IGMP global e VLAN
- Adicionar membro da porta na VLAN
Configurar porta de roteador estático de espionagem IGMP
Depois de configurar a porta do roteador estático de espionagem IGMP, o dispositivo pode encaminhar o pacote de protocolo IGMP através da porta, mesmo que a porta não receba o pacote de consulta de grupo IGMP ou o pacote de protocolo de roteamento multicast. Ele pode evitar o problema de que a porta do roteador envelhece porque os serviços do dispositivo multicast L3 conectado superior são interrompidos.
Tabela 2 -11 Configurar porta do roteador estático de espionagem IGMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a porta do roteador estático de espionagem IGMP | ip igmp snooping vlan vlan-id mrouter interface { interface-name | link-aggregation link-aggregation-id } | Obrigatório Por padrão, a porta do roteador estático de espionagem IGMP não está configurada. |
Configurar o tempo de idade da porta do roteador dinâmico de espionagem IGMP
Se o tempo de idade configurado da porta do roteador dinâmico de espionagem IGMP for maior, ele pode evitar o problema de que a porta do roteador do dispositivo multicast L3 conectado superior envelheceu rapidamente devido à interrupção do serviço.
Tabela 2 -12 Configurar o tempo de idade da porta do roteador dinâmico de espionagem IGMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o tempo de idade da porta do roteador dinâmico de espionagem IGMP | ip igmp snooping vlan vlan-id timer router-port expiry expiry-value | Opcional Por padrão, o tempo de idade da porta do roteador dinâmico de espionagem IGMP é 255s. |
Configurar evento TCN de espionagem IGMP
Condição de configuração
Antes de configurar a função de evento TCN de espionagem IGMP, primeiro conclua a seguinte tarefa:
- função de espionagem IGMP global e VLAN
Habilite a convergência rápida
Quando a topologia da rede muda, gere o evento TCN e a porta raiz da spanning tree envia ativamente os pacotes de licença IMGP globais (endereço do grupo: 0.0.0.0) para solicitar ao IGMP querier enviar o pacote geral de consulta do grupo, tornando a convergência rápida.
Depois de habilitar a convergência rápida do evento TCN de espionagem IGMP, a porta raiz da árvore não abrangente também envia ativamente o pacote de saída IGMP global (endereço do grupo: 0.0.0.0), tornando a convergência rápida.
Tabela 2 -13 Habilitar convergência rápida
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a convergência rápida | ip igmp snooping tcn query solicit | Obrigatório Por padrão, a convergência rápida não está habilitada no evento TCN. |
Configurar intervalo de consulta do evento TCN
Quando o evento TCN acontece, o IGMP snooping consultador envia a consulta geral do grupo de acordo com o intervalo de consulta do evento TCN.
Tabela 2 -14 Configurar intervalo de consulta do evento TCN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o intervalo de consulta do evento TCN | ip igmp snooping vlan vlan-id querier tcn query interval interval-value | Opcional Por padrão, o intervalo de consulta do evento TCN é 31s. |
Configurar tempos de consulta do evento TCN
Quando o evento TCN acontece, o IGMP snooping consultador envia a consulta geral do grupo de acordo com o intervalo de consulta do evento TCN. Depois que os tempos de envio atingirem os tempos de consulta configurados do evento TCN, restaure para o intervalo de consulta do grupo geral.
Tabela 2 -15 Configurar tempos de consulta do evento TCN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure os tempos de consulta do evento TCN | ip igmp snooping vlan vlan-id querier tcn query count count-number | Opcional Por padrão, os tempos de consulta do evento TCN são 2. |
Configurar política de espionagem IGMP
A política de espionagem IGMP é usada principalmente para controlar o receptor na porta, de modo a controlar o fluxo multicast e limitar a ação do receptor. No ambiente de encaminhamento de fluxo multicast L2 de configuração, você também pode aplicar a política de espionagem IGMP.
Condição de configuração
Antes de configurar a política de espionagem IGMP, primeiro conclua a seguinte tarefa:
- Ative a função de espionagem IGMP global e VLAN
Configurar regra de filtro de porta
Quando o receptor espera obter o serviço multicast, inicie ativamente o pacote de relatório do membro IGMP e o dispositivo julga de acordo com a regra de filtro de porta aplicada na porta: recuse o usuário a adicionar o grupo multicast de destino; permitir que o usuário adicione o grupo multicast de destino; limitar os tempos e o tempo do usuário adicionando o grupo multicast de destino.
Tabela 2 -16 Configurar regra de filtro de porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do perfil IGMP | ip igmp profile profile-id | - |
| Configure o intervalo do grupo multicast recusado | deny { all | low-ip-address [ high-ip-address ] } | Opcional Por padrão, o intervalo do grupo de multicasts recusados não está configurado. |
| Configure o intervalo do grupo multicast permitido | permit { all | low-ip-address [ high-ip-address ] } | Opcional Por padrão, o intervalo do grupo de multicasts permitido não está configurado. |
| Configurar a regra de grupo multicast de visualização | preview { all | low-ip-address [ high-ip-address ] | count count-number | interval interval-time | time time-duration } | Opcional Por padrão, a regra de grupo multicast de visualização não está configurada. |
| Retornar ao modo de configuração global | exit | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Você deve selecionar um deles. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entrar no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Na porta, aplique a regra de filtro de porta IGMP | ip igmp filter profile-number | Obrigatório Por padrão, a regra de filtro de porta IGMP não é aplicada na porta. |
O endereço do grupo multicast só pode estar em uma regra de filtro de perfil IGMP: negar, permitir e visualizar. A nova regra cobre a regra antiga. Redefinir o período de tempos de visualização > tempo de visualização × tempos de visualização + intervalo de visualização × (tempo de visualização – 1).
Configurar o número máximo de grupos de multicast de portas
O número máximo de grupos multicast de porta pode limitar o número de grupos multicast aos quais o receptor é adicionado.
Tabela 2 -17 Número máximo de grupos multicast de porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Você deve selecionar um deles. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entrar no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o número máximo de grupos multicast na porta | ip igmp max-groups number | Opcional Por padrão, o número máximo de grupos multicast aos quais a porta pode ser adicionada dinamicamente é 6144 . |
Configurar a política de limitação superior de grupos de multicast de porta
Quando o número de grupos multicast aos quais o receptor é adicionado excede o número máximo configurado de grupos multicast: Se a política de limitação superior do grupo multicast da porta for substituída, o novo grupo multicast adicionado no dispositivo substituirá automaticamente o grupo multicast existente ; se a política de limitação superior do grupo multicast da porta for recusar, recuse o novo grupo multicast adicionado.
Tabela 2 -18 Configurar política de limitação superior do grupo multicast de porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Você deve selecionar um deles. Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entrar no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure a política de limitação superior do grupo multicast da porta | ip igmp max-groups action { deny | replace } | Opcional Por padrão, a ação de processamento após o número de grupos multicast aos quais a porta é adicionada dinamicamente atinge o máximo é recusar. |
Configurar interface para controlar o pacote PIM JOIN
Após configurar a interface para controlar o pacote PIM JOIN, o pacote JOIN é encaminhado por software, não por hardware.
Tabela 2 -19 Configure a interface para controlar o pacote PIM JOIN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a interface para controlar o pacote PIM JOIN | ip igmp snooping vlan vlan-id ctrl-pim | Obrigatório Por padrão, não controle o pacote PIN JOIN da VLAN especificada. |
Antes de habilitar, inunde o pacote JOIN na VLAN. Após a habilitação, o pacote é encaminhado para a CPU, mas não inundará a VLAN.
Proxy Snooping IGMP
Quando houver muitos receptores do grupo multicast na rede, para reduzir o número do relatório do membro IGMP e deixar os pacotes recebidos pelo dispositivo multicast upstream e reduzir o custo do sistema, você pode configurar o proxy de espionagem IGMP no dispositivo.
espionagem IGMP delega o receptor downstream para enviar os pacotes de relatório do membro IGMP e deixar os pacotes para o dispositivo upstream e também pode responder ao pacote de consulta do grupo IGMP enviado pelo dispositivo multicast upstream e, em seguida, enviar o pacote de consulta do grupo IGMP para o dispositivo downstream.
Condição de configuração
Antes de configurar a função roxy snooping IGMP , primeiro complete a seguinte tarefa:
- função de espionagem IGMP global e VLAN
Configurar proxy de espionagem IGMP
Tabela 2 -20 Configurar proxy de espionagem IGMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar proxy de espionagem IGMP | ip igmp snooping proxy vlan vlan-id upstream interface { interface-name | link-aggregation link-aggregation-id } | Obrigatório Por padrão, a porta do agente IGMP não está configurada na VLAN. |
Configurar IGMP snooping Static Group
Grupo estático de espionagem IGMP é as entradas da tabela de grupos de espionagem IGMP estática geradas pela configuração estática. Ao configurar o grupo estático de espionagem IGMP, podemos efetivamente resolver o problema de envelhecimento do grupo multicast de aprendizado dinâmico de espionagem IGMP.
Quando o dispositivo está configurado com IGMP snooping grupo estático em VLAN, IGMP snooping querier e endereço do querier em VLAN, e IGMP snooping proxy port em VLAN, o dispositivo enviará IGMP member report packet para IGMP snooping proxy port in VLAN ao gerar IGMP snooping estático entrada da tabela de grupos. O endereço IP de origem do pacote de relatório do membro IGMP é o endereço de consulta configurado. Desta forma, o roteador uplink pode manter corretamente a tabela de associação IGMP. Quando a configuração de grupo estático de espionagem IGMP na VLAN é excluída, o dispositivo excluirá a entrada da tabela de grupo estático de espionagem IGMP correspondente e enviará o pacote de licença de membro IGMP para a porta proxy de espionagem IGMP na VLAN.
Condição de configuração
Antes de configurar a função de grupo estático de espionagem IGMP, primeiro conclua a seguinte tarefa :
- função de espionagem IGMP global e VLAN
- de porta na VLAN.
Configurar IGMP snooping Static Group
Tabela 2 -21 Configurar grupo estático de espionagem IGMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar grupo estático de espionagem IGMP | ip igmp snooping vlan vlan-id static-group group-ip-address { interface interface-name | interface link-aggregation link-aggregation-id } | Mandatório _ Por padrão, não configure o grupo estático de espionagem IGMP. |
Monitoramento e manutenção de espionagem IGMP
Tabela 2 -22 monitoramento e manutenção de espionagem IGMP
| Comando | Descrição |
| clear ip igmp snooping groups [ grp-addr ip-address | vlan vlan-id [ grp-addr ip-address-in-vlan ] ] | Limpar as informações do grupo de espionagem IGMP |
| clear ip igmp snooping statistics vlan vlan-id [ interface interface-name | interface link-aggregation link-aggregation-id ] | Limpe as informações de estatísticas do pacote do protocolo IGMP |
| show ip igmp snooping proxy member database [ vlan vlan-id ] | Exibir as informações do banco de dados do membro do proxy de espionagem IGMP |
| show ip igmp snooping proxy special query source-list [ vlan vlan-id ] | Exibir a lista de origem da consulta de origem especificada recebida pelo proxy de espionagem IGMP |
| show ip igmp snooping proxy upstream [ vlan vlan-id ] | Exibir as informações de execução do proxy de espionagem IGMP |
| show ip igmp snooping debugging | Exibir as informações de status de depuração de espionagem IGMP |
| show ip igmp snooping egress_table | Exibir a tabela de encaminhamento L2 do IGMP snooping |
| show ip igmp snooping groups [ vlan vlan-id ] grp-addr ip-address ] | Exiba as informações do grupo multicast de espionagem IGMP |
| show ip igmp snooping groups [ vlan vlan-id ] count | Exibe o número de grupos multicast de espionagem IGMP |
| show ip igmp snooping groups detail [ vlan vlan-id ] grp-addr ip-address ] | Exiba os detalhes do grupo multicast de espionagem IGMP |
| show ip igmp snooping interface statistics | Configure as informações estatísticas dos grupos multicast aos quais a porta de espionagem IGMP é adicionada |
| show ip igmp snooping l3_ip_table | Exiba a tabela de encaminhamento de IP L3 da espionagem IGMP |
| show ip igmp snooping mcast_table | Exibir a tabela de encaminhamento de espionagem IGMP |
| show ip igmp snooping mrouter [ vlan vlan-id ] | Exibir as informações da porta do roteador de espionagem IGMP |
| show ip igmp snooping querier [ vlan vlan-id ] | Exibir as informações do consultador de espionagem IGMP |
| show ip igmp snooping statistics vlan vlan-id [ interface interface-name | interface link-aggregation link-aggregation-id ] | Exiba as informações de estatísticas do pacote IGMP da porta de espionagem IGMP |
| show ip igmp snooping [ vlan vlan-id [ info ] ] | Exibir as informações de espionagem IGMP |
| show multicast control [ all-info | interface interface-name | interface link-aggregation link-aggregation-id ] | Exibir as informações do controle multicast L2 |
Exemplo de configuração típico de espionagem IGMP
Configurar espionagem IGMP
Requisitos de rede
- Device1 configura o protocolo de rota multicast; Device2 permite espionagem IGMP; PC1 e PC2 são os receptores do serviço multicast; PC3 é o receptor do serviço não multicast.
- O Servidor Multicast envia os pacotes de serviço multicast; PC1 e PC2 podem receber os pacotes de serviço multicast; PC3 não pode receber o pacote de serviço multicast.
Topologia de rede

Figura 2 -1 Topologia de rede de espionagem IGMP
Etapas de configuração
- Passo 1:Device1 configura o endereço IP da interface e habilita o protocolo de rota multicast. (omitido)
- Passo 2:Configurar dispositivo2.
#Criar VLAN2 no Dispositivo2.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/2-gigabitethernet0/4 no Device2 como Access, permitindo a passagem dos serviços da VLAN2.
Device2(config)#interface gigabitethernet 0/2-0/4Device2(config-if-range)#switchport access vlan 2Device2(config-if-range)#exit
# Configura o tipo de link da porta gigabitethernet0/1 no Device2 como Trunk, permitindo a passagem dos serviços da VLAN2; PVID está configurado como 1.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode trunkDevice2(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2Device2(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 1Device2(config-if-gigabitethernet0/1)#exit
# Habilite o descarte de multicast desconhecido na VLAN2.
Device2(config)#vlan 2Device2(config-vlan2)#l2-multicast drop-unknownDevice2(config-vlan2)#exit
#Ativar espionagem IGMP.
Device2(config)#ip igmp snoopingDevice2(config)#ip igmp snooping vlan 2
- Passo 3:Confira o resultado.
# PC1 e PC2 enviam pacote de relatório de membro IGMPv2 para adicionar o grupo multicast 224.1.1.1.
#Exibe a tabela de membros multicast do Device2.
Device2#show ip igmp snooping groupsVLAN ID Interface Name Group Address Expires Last Reporter V1 Expires V2 Expires Uptime_______ ___________________ _______________ ________ _______________ _________2 gi0/2 224.1.1.1 00:03:26 192.168.1.2 stopped 00:00:552 gi0/3 224.1.1.1 00:03:44 192.168.1.3 stopped 00:00:40
#Multicast Server envia o pacote de serviço multicast com endereço de destino 224.1.1.1; PC1 e PC2 podem receber corretamente o pacote de serviço multicast; PC3 não pode receber o pacote de serviço multicast.
Configurar o controle de recebimento multicast
Requisitos de rede
- Device1 configura o protocolo de roteamento multicast.
- O Device2 habilita o snooping IGMP, configura o controle de recebimento multicast e aplica-se à porta correspondente.
- Servidor Multicast envia o pacote de serviço multicast; PC1 e PC2 podem receber o pacote de serviço multicast.
Topologia de rede

Figura 2 -2 Topologia de rede para configurar o controle de recebimento multicast
Etapas de configuração
- Passo 1:Device1 configura o endereço IP da interface e habilita o protocolo de rota multicast. (omitido)
- Passo 2:Configurar dispositivo2.
#Criar VLAN2 no Dispositivo2.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/2-gigabitethernet0/4 no Device2 como Access, permitindo a passagem dos serviços da VLAN2.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exitDevice2(config)#interface gigabitethernet 0/2-0/4Device2(config-if-range)#switchport access vlan 2Device2(config-if-range)#exit
# Configura o tipo de link da porta gigabitethernet0/1 no Device2 como Trunk, permitindo a passagem dos serviços da VLAN2; PVID está configurado como 1.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode trunkDevice2(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2Device2(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 1Device2(config-if-gigabitethernet0/1)#exit
#Ativar espionagem IGMP.
Device2(config)#ip igmp snoopingDevice2(config)#ip igmp snooping vlan 2
# Configure o perfil1 da política de controle de recebimento multicast, permite adicionar o grupo multicast 224.1.1.1 e aplicar à porta gigabitethernet0/2.
Device2(config)#ip igmp profile 1Device2(config-igmp-profile)#permit 224.1.1.1Device2(config-igmp-profile)#exitDevice2(config)#interface gigabitethernet 0/2Device2(config-if-gigabitethernet0/2)#ip igmp filter 1Device2(config-if-gigabitethernet0/2)#exit
# Configure o perfil de política de controle de recebimento multicast2, visualize o grupo multicast 224.1.1.1 e aplique à porta gigabitethernet0/3.
Device2(config)#ip igmp profile 2Device2(config-igmp-profile)#preview 224.1.1.1Device2(config-igmp-profile)#exitDevice2(config)#interface gigabitethernet 0/3Device2(config-if-gigabitethernet0/3)#ip igmp filter 2Device2(config-if-gigabitethernet0/3)#exit
# Configure a política de controle de recebimento multicast profile3, recuse a adição ao grupo multicast 224.1.1.1 e aplique à porta gigabitethernet0/4.
Device2(config)#ip igmp profile 3Device2(config-igmp-profile)#permit allDevice2(config-igmp-profile)#deny 224.1.1.1Device2(config-igmp-profile)#exitDevice2(config)#interface gigabitethernet 0/4Device2(config-if-gigabitethernet0/4)#ip igmp filter 3Device2(config-if-gigabitethernet0/4)#exit
- Passo 3:Confira o resultado.
# PC1, PC2 e PC3 enviam pacote de relatório de membro IGMPv2 para adicionar ao grupo multicast 224.1.1.1.
#Ver tabela de membros multicast de Device2.
Device2#show ip igmp snooping groupsIGMP Snooping Group MembershipTotal 2 groupsVLAN ID Interface Name Group Address Expires Last Reporter V1 Expires V2 Expires Uptime___________________________________________________________________________________2 gi0/2 224.1.1.1 00:04:19 192.168.1.2 stopped 00:00:012 gi0/3 224.1.1.1 00:04:19 192.168.1.3 stopped 00:00:01
PC1 e PC2 podem adicionar ao grupo multicast 224.1.1.1; PC3 não adiciona ao grupo multicast 224.1.1.1.
# Multicast Server envia o pacote de serviço multicast com endereço de destino 224.1.1.1.
PC1 e PC2 podem receber corretamente o pacote de serviço multicast; PC3 não pode receber o pacote de serviço multicast.
# Depois de esperar 10s, veja a tabela de membros multicast de Device2 e multicast recebendo informações de controle de gigabitethernet0/ 3.
Device2#show ip igmp snooping groupsIGMP Snooping Group MembershipTotal1 groupVLAN ID Interface Name Group Address Expires Last Reporter V1 Expires V2 Expires Uptime___________________________________________________________________________________2 gi0/2 224.1.1.1 00:04:10 192.168.1.2 stopped 00:00:10Device2#show multicast control interface gigabitethernet 0/3ip multicast control gigabitethernet0/3 vlan 2 information---------------------------------------------profile: 2group right information:preview: 224.1.1.1preview information:preview count: 3preview count remain: 2preview time: 10 (s)preview interval: 60 (s)group information:group: 224.1.1.1uptime: 00:00:10next preview time remain: 00:00:60
Após a chegada do tempo de visualização da porta gigabitethernet0/3 (após 10s), a entrada do membro do grupo é excluída; PC1 pode receber corretamente o pacote de serviço multicast; PC2 e PC2 não podem receber o pacote de serviço multicast.
Configurar proxy de espionagem IGMP
Requisitos de rede
- Em Device1, configure o protocolo de roteamento multicast.
- Device2 , habilite IGMP snooping e GMP s nooping roxy .
- Servidor Multicast envia o pacote de serviço multicast; PC1, PC2 e PC3 podem receber corretamente o pacote de serviço multicast.
Topologia de rede
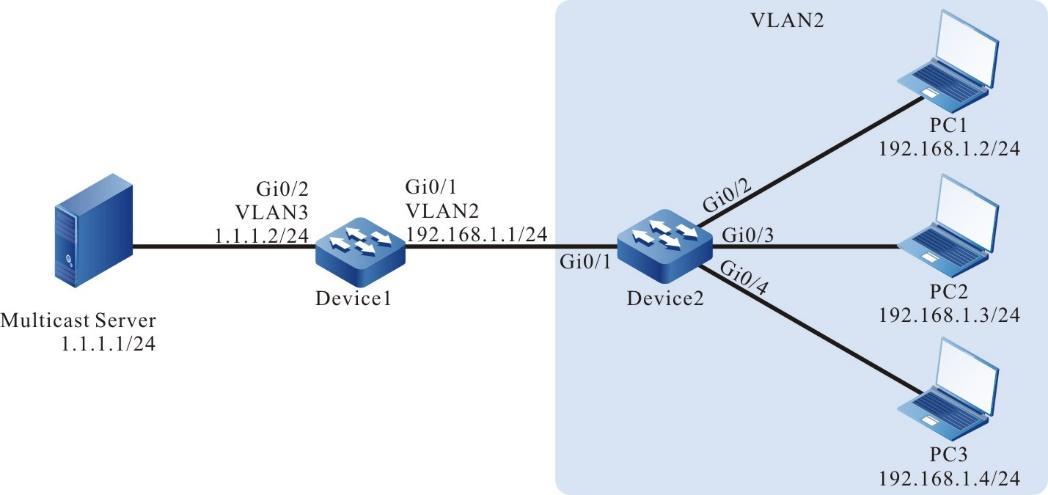
Figura 2 -3 Topologia de rede de configuração do proxy nooping do IGMP
Etapas de configuração
- Passo 1: Device1 configura o endereço IP da interface e habilita o protocolo de rota multicast.
n2)# ip pim sparse-modeDevice1(config-if-vlan2)# exitDevice1(config)#interface vlan 3Device1(config-if-vlan3)# ip address 1.1.1.2 255.255.255.0Device1(config-if-vlan3)# ip pim sparse-modeDevice1(config-if-vlan3)# exit
- Passo 2:Configurar dispositivo2.
#Criar VLAN2 no Dispositivo2.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/2-gigabitethernet0/4 no Device2 como Access, permitindo a passagem dos serviços da VLAN2.
Device2(config)#interface gigabitethernet 0/2-0/4Device2(config-if-range)#switchport access vlan 2Device2(config-if-range)#exit
# Configura o tipo de link da porta gigabitethernet0/1 no Device2 como Trunk, permitindo a passagem dos serviços da VLAN2; PVID está configurado como 1.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode trunkDevice2(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2Device2(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 1Device2(config-if-gigabitethernet0/1)#exit
#Ativar espionagem IGMP na VLAN2; configure o endereço de consulta do snooping IGMP como 192.168.1.254.
Device2(config)#ip igmp snoopingDevice2(config)#ip igmp snooping vlan 2Device2(config)#ip igmp snooping vlan 2 querierDevice2(config)#ip igmp snooping vlan 2 querier address 192.168.1.254
# Configure o proxy nooping do IGMP .
Device2(config)#ip igmp snooping proxy vlan 2 upstream interface gigabitethernet 0/1Device2(config)#exit
- Passo 3:Confira o resultado.
#PC1, PC2 e PC3 enviam sucessivamente pacotes de relatório de membro IGMPv2 para adicionar ao grupo multicast 224.1.1.1.
#Visualize as informações do proxy nooping do IGMP do Device2 .
Device2#show ip igmp proxy upstream vlan 2vlan 2 proxy upstream information:------------------------------upstream interface : gi0/1upstream querier compatmode version : 2upstream querier address : 192.168.1.1upstream report source address : 192.168.1.4upstream querier query interval : 125supstream querier query response interval: 10supstream querier LMQI : 1supstream querier LMQC : 2upstream querier robustness variable : 2upstream querier present timer : 00:02:50upstream V1 querier present timer : stoppedupstream V2 querier present timer : 00:02:55
#Visualize a tabela de membros multicast do proxy nooping Device2 e IGMP s banco de dados de membros.
Device2#show ip igmp snooping groupsIGMP Snooping Group MembershipTotal 3 groupsVLAN ID Interface Name Group Address Expires Last Reporter V1 Expires V2 Expires Uptime_________________________________________________________ ____________________________2 gi0/2 224.1.1.1 00:04:09 192.168.1.2 stopped 00:00:142 gi0/3 224.1.1.1 00:04:09 192.168.1.3 stopped 00:00:112 gi0/4 224.1.1.1 00:04:12 192.168.1.4 stopped 00:00:07
Você pode ver que PC1, PC2 e PC3 são adicionados ao grupo multicast 224.1.1.1.
Device2#show ip igmp snooping proxy member database vlan 2IGMP Snooping Proxy Member Database TableTotal 1 groupVLAN ID Group Address Mode Source Address------- --------------- ------- ---------------2 224.1.1.1 EXCLUDE *
#Exibe a tabela de membros multicast de Device1.
Device1#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires224.1.1.1 vlan 2 00:00:15 00:04:11 192.168.1.2 stopped
Você pode ver que quando o PC adiciona ao grupo multicast 224.1.1.1, Device2 só pode encaminhar o primeiro pacote de relatório do membro IGMPv2 para Device1 e os outros são todos descartados.
#Multicast Server envia o pacote de serviço multicast com endereço de destino 224.1.1.1; PC1, PC2 e PC3 podem receber corretamente o pacote de serviço multicast.
#PC1 e PC2 enviam pacote de saída IGMPv2 para deixar o grupo multicast 224.1.1.1.
Device2#show ip igmp snooping groupsIGMP Snooping Group MembershipTotal 1 groupVLAN ID Interface Name Group Address Expires Last Reporter V1 Expires V2 Expires Uptime_______________________________________________________________________________________2 gi0/4 224.1.1.1 00:03:54 192.168.1.4 stopped 00:06:37Device1#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires224.1.1.1 vlan 2 00:06:48 00:03:48 192.168.1.2 stopped
Depois que PC1 e PC2 saem do grupo multicast 224.1.1.1, PC3 não sai do grupo multicast, ainda há o membro do grupo PC3 na tabela de membros multicast. Portanto, Device2 não envia o pacote de licença do grupo multicast para Device1.
#PC3 envia o pacote de licença IGMPv2 para sair do grupo multicast 224.1.1.1; veja a tabela de membros multicast de Device2 e Device1.
Device2#show ip igmp snooping groups Você pode ver que não há nenhuma tabela de membros multicast no Device2.
Device1#show ip igmp groups Não há nenhum membro multicast no Device1. Quando o último membro do grupo PC3 deixa o grupo multicast, Device2 envia o pacote de saída do grupo multicast para Device1.
#PC1, PC2 e PC3 não podem receber o pacote de serviço multicast.
Configurar redirecionamento de multicast desconhecido
Requisitos de rede
- O dispositivo 2 configura o protocolo de roteamento multicast.
- O dispositivo 1 habilita o IGMP snooping , descarte de multicast desconhecido e redirecionamento de multicast desconhecido.
- Servidor Multicast envia o pacote de serviço multicast; PC1, PC2 e PC3 podem receber corretamente o pacote de serviço multicast.
Topologia de rede

Figura 2 -4 Topologia de rede de configuração de redirecionamento multicast desconhecido
Etapas de configuração
- Passo 1: Configure o endereço IP da interface Device2 e ative o protocolo de roteamento multicast. (omitido)
- Passo 2: Configure Device2 e Devoce1.
# No Device2, configure o tipo de link da porta gigabitethernet0/2 –gigabitethernet0/ 3 como Access, permitindo a passagem dos serviços VLAN 2 , configure o tipo de link da porta gigabitethernet0/1 como trunk, permitindo a passagem do serviço VLAN2 e configure o PVID como 1 .
Device2(config)#interface gigabitethernet 0/2-0/3Device2(config-if-range)#switchport access vlan 2Device2(config-if-range)#exitDevice2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode trunkDevice2(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2Device2(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 1Device2(config-if-gigabitethernet0/1)#exitDevice2(config-if-vlan2)# ip address 192.168.1.1 255.255.255.0Device1(config-if-vlan2)# ip pim sparse-modeDevice1(config-if-vlan2)# exit
# Em Device1, crie VLAN2 .
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exit
# No Device1, configure o tipo de link da porta gigabitethernet0/2 como Access, permitindo a passagem dos serviços VLAN2, configure o tipo de link da porta gigabitethernet0/1 como trunk, permitindo a passagem do serviço VLAN2 e configure o PVID como 1.
Device1(config)#interface gigabitethernet 0/2Device1(config-if-gigabitethernet0/2)# switchport access vlan 2Device1(config-if-gigabitethernet0/2)#exitDevice1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#switchport mode trunkDevice1(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2Device1(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 1Device1(config-if-gigabitethernet0/1)#exit
# Em VLAN2, habilite o descarte multicast desconhecido.
Device1(config)#vlan 2Device1(config-vlan2)#l2-multicast drop-unknownDevice1(config-vlan2)#exit
# Ative a espionagem IGMP.
Device1(config)#ip igmp snoopingDevice1(config)#ip igmp snooping vlan 2
# Em VLAN2, habilite o redirecionamento multicast desconhecido.
Device1(config)#vlan 2Device1(config-vlan2)#multicast mrouter-forwardingDevice1(config-vlan2)#exit
- Passo 3:Confira o resultado.
# PC1 e PC2 enviam pacotes de relatório de membro IGMPv2 para ingressar no grupo multicast 224.1.1.1.
# Consulta a tabela de membros multicast de Device2.
Device1#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires224.1.1.1 vlan2 00:21:02 00:03:47 192.168.1.2 stopped
O servidor #Multicast envia o pacote de serviço multicast cujo endereço de destino é 224.1.1.1.
#PC1 e PC2 podem receber corretamente os pacotes de serviço multicast.
Configurar IGMP snooping Static Group
Requisitos de rede
- O dispositivo 1 está configurado com protocolo de roteamento multicast. O dispositivo 2 habilita a espionagem IGMP na VLAN 2. PC1 e PC2 são receptores do serviço de grupo estático de espionagem IGMP e PC3 é o receptor do serviço não multicast.
- O servidor multicast envia pacotes de serviço multicast, PC1 e PC2 podem receber pacotes de serviço multicast corretamente e PC3 não pode receber pacotes de serviço multicast.
Topologia de rede
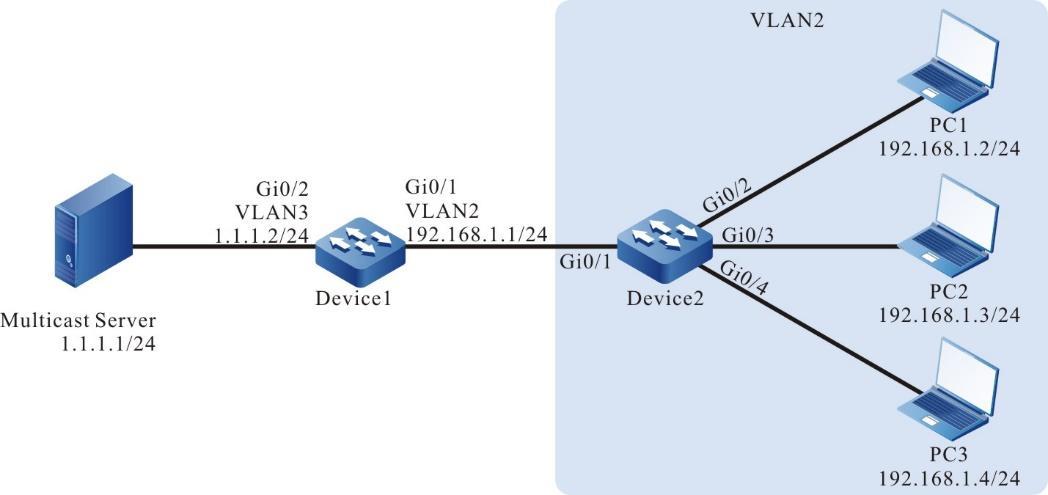
Figura 2 -5 Topologia de rede de configuração do grupo estático de espionagem IGMP
Etapas de configuração
- Passo 1:Em Device1, configure o endereço IP da interface e ative o protocolo de roteamento multicast (omitido).
- Passo 2:Configurar Dispositivo2.
#No Dispositivo2, crie VLAN2.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exit
# No Device2 , configure o tipo de link das portas gigabitethernet0/2~gigabitethernet0/4 como Acesso, permitindo a passagem dos serviços da VLAN2.
Device2(config)#interface gigabitethernet 0/2-0/4Device2(config-if-range)#switchport access vlan 2Device2(config-if-range)#exit
# No Device2 , configure o tipo de link das portas gigabitethernet0/1 como Trunk, permitindo a passagem dos serviços da VLAN2, e configure o PVID como 1.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode trunkDevice2(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2Device2(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 1Device2(config-if-gigabitethernet0/1)#exit
# Em VLAN2, habilite o descarte multicast desconhecido.
Device2(config)#vlan 2Device2(config-vlan2)#l2-multicast drop-unknownDevice2(config-vlan2)#l3-multicast drop-unknownDevice2(config-vlan2)#exit
# Ative o IGMP snooping e configure o grupo estático de IGMP snooping .
Device2(config)#ip igmp snoopingDevice2(config)#ip igmp snooping vlan 2Device2(config)#ip igmp snooping vlan 2 static-group 224.1.1.1 interface gigabitethernet 0/2Device2(config)#ip igmp snooping vlan 2 static-group 224.1.1.1 interface gigabitethernet 0/3Device2(config)#exit
- Passo 3:Confira o resultado.
# Visualize a tabela de membros multicast do Device2 .
Device2#show ip igmp snooping groupsIGMP Snooping Static Group MembershipTotal 2 groupVLAN ID Port Name Group Address Uptime_______ ___________________ _______________ __________2 gi0/2 224.1.1.1 00:00:482 gi0/3 224.1.1.1 00:00:45
#Multicast Server envia o pacote de serviço multicast com o endereço de destino 224.1.1.1. PC1 e PC2 podem receber os pacotes de serviço multicast corretamente e PC3 não pode receber os pacotes de serviço multicast.
Multicast VLAN
Visão geral
Para o modo tradicional de multicast sob demanda, quando no usuário sob demanda de diferentes VLANs, cada VLAN copia um fluxo multicast na VLAN. O modo multicast sob demanda desperdiça muita largura de banda.
Para resolver o problema, você pode configurar o modo multicast VLAN para fazer com que os usuários em diferentes VLANs compartilhem uma multicast VLAN . Depois que a função de multicast VLAN é habilitada, o fluxo multicast é transmitido apenas na multicast VLAN e a multicast VLAN é completamente separada da VLAN do usuário. Isso não apenas economiza a largura de banda, mas também garante a segurança.
Multicast VLAN tem dois tipos: MVR (Multicast VLAN Registration) e MVP (Multicast VLAN Plus).
Configuração de multicast VLAN
Tabela 3 -1 Lista de configuração de multicast VLAN
| Tarefa de configuração | |
| Configurar MVP | Configurar multicast VLAN MVP Ative a função MVP |
| Configurar MVR | Configurar multicast VLAN MVR Ative a função MVR |
Configurar MVP
O MVP é usado pela rede de borda. A porta membro da sub VLAN pode se conectar ao dispositivo multicast e também pode se conectar diretamente ao usuário. Ao conectar-se ao dispositivo multicast, a porta membro da sub VLAN envia o pacote multicast com a etiqueta VLAN; ao se conectar ao usuário, a porta membro da sub VLAN pode enviar pacotes multicast sem a etiqueta VLAN.
Condição de configuração
Antes de configurar a multicast VLAN do MVP, primeiro conclua a seguinte tarefa:
- Configurar VLAN
- função de espionagem IGMP global e VLAN
Configurar multicast VLAN MVP
Configure o MVP para realizar o pacote multicast de encaminhamento entre VLANs entre a multicast VLAN do MVP e a sub VLAN membro. A porta membro da multicast VLAN do MVP precisa ser consistente com a VLAN Tag do dispositivo upstream conectado; a porta do membro da sub VLAN do MVP precisa ser consistente com a etiqueta da VLAN do dispositivo downstream conectado.
Tabela 3 -2 Configurar multicast VLAN do MVP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o multicast VLAN do MVP | multicast-vlan mvlan-id subvlan subvlan-id | Obrigatório Por padrão, a multicast VLAN do MVP e a sub VLAN do membro não são configuradas. |
Ativar função MVP
Depois de habilitar a função MVP na multicast VLAN MVP, o pacote de encaminhamento entre VLANs entre a multicast VLAN MVP e a sub VLAN membro pode ser realizado.
Tabela 3 -3 Habilite a função MVP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração de VLAN | vlan vlan-id | - |
| Habilite a função MVP na VLAN | multicast-vlan enable | Obrigatório Por padrão, a função MVP está desabilitada na VLAN. |
Configurar MVR
MV R é usado pela rede de borda. A porta membro da multicast VLAN MVR só pode se conectar a usuários, e os pacotes multicast enviados da porta membro da VLAN não podem ter tag VLAN.
Condição de configuração
Antes de configurar a multicast VLAN do MV R , primeiro conclua a seguinte tarefa:
- Configurar VLAN
- Ative a função de espionagem IGMP global e VLAN
Configurar multicast VLAN MVR
Quando várias portas de usuário pertencem a diferentes VLANs, os usuários em diferentes VLANs podem compartilhar uma multicast VLAN adicionando essas portas à multicast VLAN MVR.
Tabela 3 -4 Configurar multicast VLAN MVR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar multicast VLAN MVR | mvr vlan vlan-id | Obrigatório Por padrão, não configure a multicast VLAN do MVR. |
Ative a função MVR
Quando a função MVR estiver habilitada, a configuração da multicast VLAN MVR entrará em vigor.
Tabela 3 -5 Habilite a função MVR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ative a função MVR | mvr enable | Obrigatório Por padrão, não ative a função MVR. |
Monitoramento e manutenção de multicast VLAN
Tabela 3 -6 Monitoramento e manutenção de multicast VLAN
| Comando | Descrição |
| show multicast-vlan vlan-id | Exiba as informações de multicast VLAN do MVP |
| show mvr | Exibir as informações do MVR |
Exemplo de configuração típico de multicast VLAN
Configurar MVP
Requisitos de rede
- Device1 configura o protocolo de rota multicast.
- Device2 habilita a espionagem IGMP e configura o MVP.
- O Servidor Multicast envia pacotes de serviço multicast; multicast VLAN2 pode copiar os pacotes de serviço multicast para sub VLAN4-VLAN5. PC1, PC2 e PC3 podem receber corretamente os pacotes de serviço multicast.
Topologia de rede
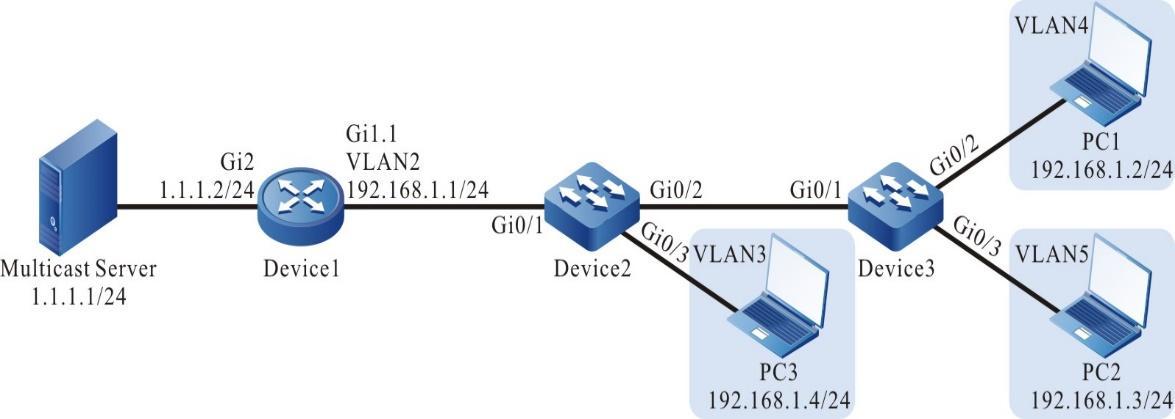
Figura 3 -1 rede de configuração típica do MVP
Etapas de configuração
- Passo 1:Device1 configura o endereço IP da interface e habilita o protocolo de rota multicast. (omitido)
- Passo 2:Configurar dispositivo2.
#Create VLAN2-VLAN5 no Device2.
Device2#configure terminalDevice2(config)#vlan 2-5
#Configure o tipo de link da porta gigabitethernet0/1 no Device2 como Trunk, permitindo a passagem dos serviços da VLAN2; PVID está configurado como 1.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode trunkDevice2(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2Device2(config-if-gigabitethernet0/1)# switchport trunk pvid vlan 1Device2(config-if-gigabitethernet0/1)#exit
#Configure o tipo de link da porta gigabitethernet0/2 no Device2 como Trunk, permitindo a passagem dos serviços de VLAN4-VLAN5; PVID está configurado como 1.
Device2(config)#interface gigabitethernet 0/2Device2(config-if-gigabitethernet0/2)#switchport mode trunkDevice2(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 4-5Device2(config-if-gigabitethernet0/2)# switchport trunk pvid vlan 1Device2(config-if-gigabitethernet0/2)#exit
#Configure o tipo de link da porta gigabitethernet0/3 no Device2 como Access, permitindo a passagem dos serviços da VLAN3.
Device2(config)#interface gigabitethernet 0/3Device2(config-if-gigabitethernet0/3)#switchport access vlan 3Device2(config-if-gigabitethernet0/3)#exit
#Configure a espionagem IGMP.
Device2(config)#ip igmp snoopingDevice2(config)#ip igmp snooping vlan 2Device2(config)#ip igmp snooping vlan 3Device2(config)#ip igmp snooping vlan 4Device2(config)#ip igmp snooping vlan 5
#Configure o MVP.
Device2(config)#multicast-vlan 2 subvlan 3-5Device2(config)#vlan 2Device2(config-vlan2)#multicast-vlan enableDevice2(config-vlan2)#exit
- Passo 3:Configurar dispositivo3.
#Create VLAN4-VLAN5 no Device3.
Device3#configure terminalDevice3(config)#vlan 4-5
#Configure o tipo de link da porta gigabitethernet0/1 no Device3 como Trunk, permitindo a passagem dos serviços de VLAN4-VLAN5; PVID está configurado como 1.
Device3(config)#interface gigabitethernet 0/1Device3(config-if-gigabitethernet0/1)#switchport mode trunkDevice3(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 4-5Device3(config-if-gigabitethernet0/1)# switchport trunk pvid vlan 1Device3(config-if-gigabitethernet0/1)#exit
#Configure o tipo de link da porta gigabitethernet0/2 no Device3 como Access, permitindo a passagem dos serviços da VLAN4.
Device3(config)#interface gigabitethernet 0/2Device3(config-if-gigabitethernet0/2)#switchport access vlan 4Device3(config-if-gigabitethernet0/2)#exit
# Configure o tipo de link da porta gigabitethernet0/3 no Device3 como Access, permitindo a passagem dos serviços da VLAN5.
Device3(config)#interface gigabitethernet 0/3Device3(config-if-gigabitethernet0/3)#switchport access vlan 5Device3(config-if-gigabitethernet0/3)#exit
- Passo 4:Confira o resultado.
#Visualize as informações do MVP.
Device2#show multicast-vlanMulticast Vlan Table---------------------------------VLAN ID: 2status: enablesubvlan count: 3subvlan: 3-5
#PC1, PC2 e PC3 enviam o relatório de relação de membro IGMPv2 para adicionar ao grupo multicast 224.1.1.1.
#Exibe a tabela de membros multicast do Device2.
Device2#show ip igmp snooping groupsIGMP Snooping Group MembershipTotal 3 groupsVLAN ID Interface Name Group Address Expires Last Reporter V1 Expires V2 Expires Uptime___________________________________________________________________________ __________3 gi0/3 224.1.1.1 00:03:54 192.168.1.4 stopped 00:01:184 gi0/2 224.1.1.1 00:04:17 192.168.1.2 stopped 00:00:075 gi0/2 224.1.1.1 00:03:54 192.168.1.3 stopped 00:01:21
#Visualize a tabela de encaminhamento multicast do Device2.
Device2#show ip igmp snooping l3_ip_tableTotal 1 entryFlags: M - L2 multicast, S - short of resources(*, 224.1.1.1)Ingress Vlan: 2Flags : ML2 Interface List: gigabitethernet0/1Egress Vlan Flags L3 Interface List3 M gigabitethernet0/34 M gigabitethernet0/25 M gigabitethernet0/2
#Multicast Server envia o pacote de serviço multicast com endereço de destino 224.1.1.1. PC1, PC2 e PC3 podem receber corretamente o pacote de serviço multicast.
Configurar MVR
Requisitos de rede
- Device1 configura o protocolo de rota multicast.
- Existem três VLANs em toda a rede, vlan2 - vlan4. A porta que conecta o PC se junta à VLAN correspondente no modo híbrido.
- Device2 habilita a espionagem IGMP e configura o MVP.
- O Servidor Multicast envia pacotes de serviço multicast; PC1, PC2 e PC3 podem receber corretamente os pacotes de serviço multicast.
Topologia de rede
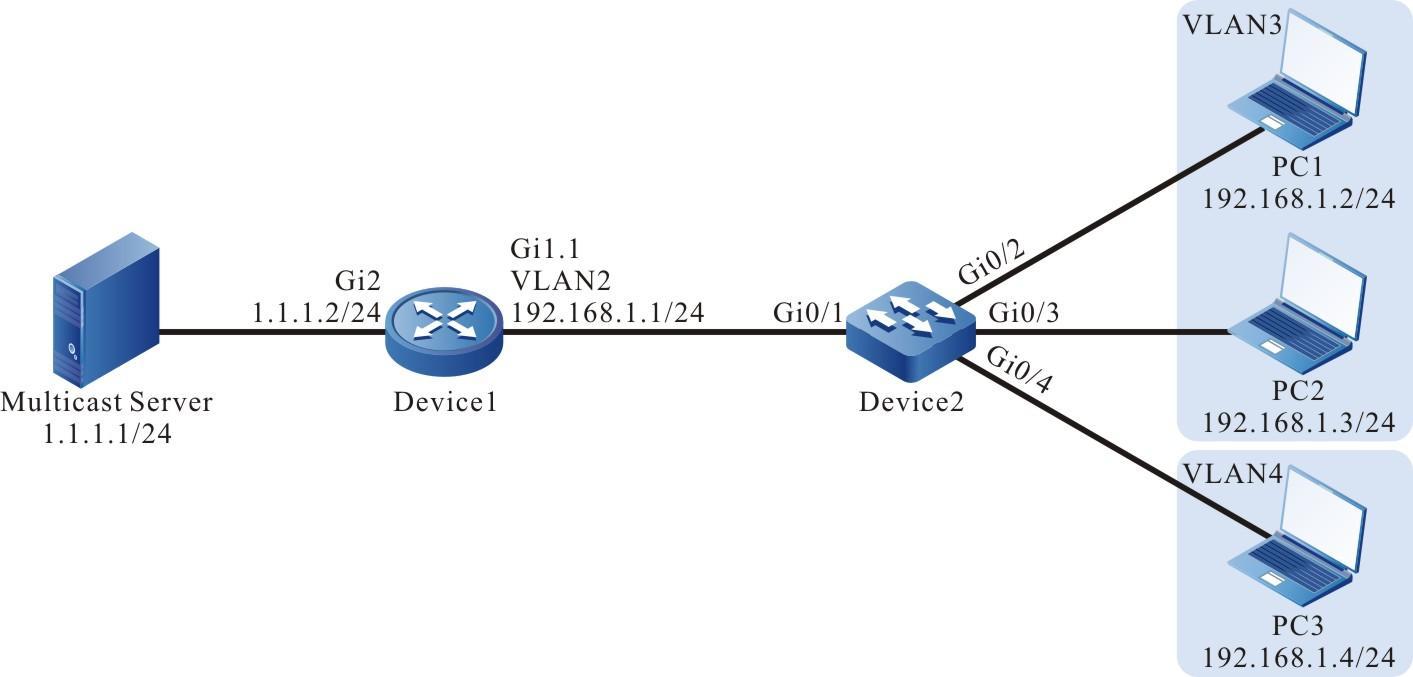
Figura 3 - 2 Rede de configuração típica de 2 MV R
Etapas de configuração
- Passo 1:Device1 configura o endereço IP da interface e habilita o protocolo de rota multicast. (omitido)
- Passo 2:Configurar dispositivo2 .
#Create VLAN2-VLAN 4 no Device2.
Device2#configure terminalDevice2(config)#vlan 2-4
#Configure o tipo de link da porta gigabitethernet0/1 no Device2 como Trunk, permitindo a passagem dos serviços da VLAN2; PVID está configurado como 1.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode hybridDevice2(config-if-gigabitethernet0/1)#switchport hybrid tagged vlan 2Device2(config-if-gigabitethernet0/1)# switchport trunk pvid vlan 1Device2(config-if-gigabitethernet0/1)#exit
#Configure o tipo de link da porta gigabitethernet0/ 2- gigabitethernet0/ 3 no Device2 como H ybrid, permitindo que os serviços de VLAN 2 -VLAN 3 passem; O PVID está configurado como 3 .
Device2(config)#interface gigabitethernet 0/2-0/3Device2(config-if-range)#switchport mode hybridDevice2(config-if-range)#switchport hybrid untagged vlan 2-3Device2(config-if-range)#switchport hybrid pvid vlan 3Device2(config-if-range)#exit
#Configure o tipo de link da porta gigabitethernet0/ 4 no Device2 como H ybrid, permitindo a passagem dos serviços de VLAN2 e VLAN4 ; O PVID está configurado como 4 .
Device2(config)#interface gigabitethernet 0/4Device2(config-if-gigabitethernet0/4)#switchport mode hybridDevice2(config-if-gigabitethernet0/4)#switchport hybrid untagged vlan 4Device2(config-if-gigabitethernet0/4)#switchport hybrid untagged vlan 2Device2(config-if-gigabitethernet0/4)#switchport hybrid pvid vlan 4Device2(config-if-gigabitethernet0/4)#exit
# Configure a espionagem IGMP.
Device2(config)#ip igmp snoopingDevice2(config)#ip igmp snooping vlan 2Device2(config)#ip igmp snooping vlan 3Device2(config)#ip igmp snooping vlan 4
# Configurar MV R.
Device2(config)#mvr vlan 2Device2(config)#mvr enableDevice2(config)#exit
- Passo 3:Confira o resultado.
#Consulte as informações do MVR.
Device2#show mvrMVR status:enablemulticast-vlan: 2
#PC1, PC2 e PC3 enviam o relatório de relação de membro IGMPv2 para adicionar ao grupo multicast 224.1.1.1.
#Exibe a tabela de membros multicast do Device2.
Device2#show ip igmp snooping groupsIGMP Snooping Group MembershipTotal 3 groupsVLAN ID Interface Name Group Address Expires Last Reporter V1 Expires V2 Expires Uptime________________________________________________________________________________________2 gi0/2 224.1.1.1 00:04:14 192.168.1.2 stopped 00:00:072 gi0/3 224.1.1.1 00:04:14 192.168.1.3 stopped 00:00:072 gi0/4 224.1.1.1 00:04:14 192.168.1.4 stopped 00:00:07
#Multicast Server envia o pacote de serviço multicast com endereço de destino 224.1.1.1. PC1, PC2 e PC3 podem receber corretamente o pacote de serviço multicast.
Noções básicas de multicast IPv4
Visão geral
O básico de multicast IPv4 é a base da execução do protocolo multicast IP e a parte comum de todos os protocolos multicast. Não importa qual protocolo de rota multicast seja executado, primeiro precisamos habilitar a função de encaminhamento multicast IP para que o dispositivo possa encaminhar os pacotes de serviço multicast.
Configuração básica da função do IPv4 Multicast
Tabela 4 -1 Lista de configuração de funções básicas de multicast IPv4
| Tarefa de configuração | |
| Ativar encaminhamento multicast IP | Habilite o encaminhamento multicast IP |
| Configurar regra de encaminhamento multicast IP |
Configurar a borda de gerenciamento de encaminhamento multicast
Configurar a limitação de entrada de encaminhamento multicast |
A interface Ethernet L3 não suporta Função de regra de encaminhamento multicast IP.
Não
Habilite a função de encaminhamento multicast IP para que o serviço multicast de encaminhamento possa ser executado normalmente.
Tabela 4 -2 Ativar encaminhamento multicast IP
Antes de configurar a borda de gerenciamento de encaminhamento multicast da interface, primeiro conclua a seguinte tarefa:
Após configurar a borda de gerenciamento, o dispositivo pode filtrar os pacotes de serviço multicast e os pacotes de serviço multicast que não correspondem às regras da lista de acesso não podem ser encaminhados da interface.
Tabela 4 -3 Configurar borda de gerenciamento de encaminhamento multicast
Configure o tempo limite da entrada de encaminhamento multicast. Após o tempo limite, exclua ou execute outras operações pela tag de entrada.
Tabela 4 -4 Configurar o tempo limite da entrada de encaminhamento multicast
Configure o número máximo de entradas de encaminhamento multicast. Após exceder o número máximo de entradas de encaminhamento multicast, a nova entrada de encaminhamento multicast não é criada.
Tabela 4 -5 Configurar limitação de entrada de encaminhamento multicast Tabela 4 -6 Monitoramento e manutenção de noções básicas de multicast IPv4
Ativar encaminhamento multicast IP
Condição de configuração
Ativar encaminhamento multicast IP
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Ativar encaminhamento multicast IP
ip multicast-routing [ vrf vrf-name ]
Obrigatório Por padrão, o encaminhamento multicast IP não está habilitado.
Configurar regra de encaminhamento multicast IP
Condição de configuração
Configurar a borda de gerenciamento de encaminhamento de multicast
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração da interface
interface interface-name
-
Configurar borda de gerenciamento de encaminhamento multicast
ip multicast boundary { access-list-number | access-list-name }
Obrigatório Por padrão, a borda de gerenciamento de encaminhamento multicast não está configurada.
Configurar o tempo limite de entrada de encaminhamento de multicast
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Configure o tempo limite da entrada de encaminhamento multicast
ip multicast mrt-timer timevalue
Opcional Por padrão, o tempo limite da entrada de encaminhamento multicast é de 180 segundos.
Configurar limitação de entrada de encaminhamento multicast
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Configurar limitação de entrada de encaminhamento multicast
ip multicast route-limit number-value [ vrf vrf-name ]
Opcional Por padrão, o número máximo de entradas de encaminhamento multicast é 9216. O intervalo de valores varia com a alteração do modo de trabalho do sistema.
Monitoramento e Manutenção de Noções Básicas de Multicast IPv4
Comando
Descrição
clear ip mcache [ source source-ip-address ] [ group group-ip-address ] [ all | vrf vrf-name ]
Limpar a entrada de rota multicast
show ip mcache [ source source-ip-address ] [ group group-ip-address ] [ vrf vrf-name ]
Exibir as informações da tabela de rotas multicast
show ip mnhp [ [ vrf vrf-name ] | [ vlan vlan-id ] ]
Exibir as informações do próximo salto multicast
show ip mrt-egressinfo[ [ group-ip-address [ source-ip-address ] ] [ vrf vrf-name ] | group-ip-address source-ip-address vrf-id vrf-id]
Exibir as informações da porta de encaminhamento multicast
show ip mvif [ vrf vrf-name ]
Exibir as informações da interface virtual multicast
show ip mvrf
Exiba as informações de VRF multicast
IGMP
Visão geral
IGMP (Internet Group Management Protocol) é o protocolo para gerenciar os membros multicast IP na pilha de protocolos TCP/IP, usado para configurar e manter a relação de membro do grupo multicast entre o host IP e o dispositivo multicast vizinho direto.
O IGMP tem três versões. Atualmente, o amplamente utilizado é o IGMPv2. O IGMPv2 possui três tipos de pacotes: pacotes de consulta, relatório de relação de membro do grupo e pacote de saída de membro do grupo.
O pacote de consulta inclui o pacote de consulta geral e o pacote de consulta de grupo especificado. O dispositivo fica sabendo quais membros existem na rede de conexão direta por meio dos pacotes de consulta geral e se existem membros de um grupo especificado na rede de conexão direta por meio dos pacotes de consulta de grupo especificados.
Relatório de relação do membro do grupo: Quando o host deseja adicionar em um grupo multicast, o host imediatamente envia o relatório de relação do membro do grupo para o grupo multicast desejado. Quando o host recebe um pacote de consulta, ele também envia o relatório de relação dos membros do grupo.
Pacote de saída de membro do grupo: Quando o host sai de um grupo multicast, envie um relatório de saída de um membro do grupo. Quando o dispositivo recebe o pacote de saída de membro do grupo, envie a consulta de grupo especificada para confirmar se um grupo especificado possui membros.
Configuração da função IGMP
Tabela 5 – 1 lista de configuração da função IGMP
| Tarefa de configuração | |
| Configurar funções básicas do IGMP |
Habilite o protocolo IGMP
Configurar a versão IGMP Configurar adição de grupo estático Configurar filtro de grupo multicast Configurar filtro de grupo multicast do SSM |
| Ajuste e otimize a rede IGMP |
Configure o intervalo de consulta do grupo geral
Configurar o fator de robustez Configure o tempo máximo de resposta Configurar a consulta de grupo especificada Configurar o tempo limite do outro consultador Configurar a saída rápida |
A interface Ethernet L3 não suporta a função IGMP.
Antes de configurar as funções básicas do IGMP, primeiro complete a seguinte tarefa: Tabela 5 – 2 Habilite o protocolo IGMP Tabela 5 – 3 Configurar a versão IGMP
Como a estrutura do pacote e os tipos de versões diferentes dos protocolos IGMP são diferentes, sugere-se configurar a mesma versão do IGMP para todos os dispositivos na mesma sub-rede.
Após configurar um grupo estático ou grupo de origem na interface, o dispositivo considera que a interface possui o receptor do grupo multicast ou grupo de origem.
Tabela 5 – 4 Configurar adição de grupo estático
A interface configurada com o filtro de grupo multicast IGMP filtra o relatório de relação de membro de grupo no segmento de acordo com as regras da ACL e somente o relatório de relação de membro de grupo permitido pela ACL é processado e o não permitido é descartado diretamente. Para o grupo multicast existente mas não permitido pelo ACL, exclua imediatamente as informações do grupo multicast.
Tabela 5 – 5 Configurar filtro de grupo multicast
grupo de acesso ip igmp O comando suporta apenas a ACL padrão.
Após configurar o intervalo dos grupos de origem recebidos pelo IGMP, filtre o relatório de relação de membro do grupo de origem recebido para limitar o intervalo do grupo de origem que a interface atende. Para os grupos pertencentes à faixa PIM-SSM, somente não pode ser aceito o relatório de relação de membro (IS_EX, TO_EX) do IGMPv3 permitido pela lista de acesso (S, G ).
Tabela 5 – 6 Configurar o filtro de grupo multicast do SSM
IP igmp grupo de acesso ssm pode ter efeito somente quando a interface habilita IGMPv3. IP igmp grupo de acesso ssm tem efeito apenas para os grupos de origem no intervalo PIM SSM. IP igmp ssm-access-group suporta apenas a ACL estendida.
Configurar funções básicas do IGMP
Condição de configuração
Ativar protocolo IGMP
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Habilite o encaminhamento multicast IP
ip multicast-routing
Obrigatório Por padrão, o encaminhamento multicast IP está desabilitado.
Entre no modo de configuração da interface
interface interface-name
-
Habilite o protocolo IGMP
ip pim sparse-mode
Obrigatório Por padrão, o IGMP está desabilitado. Quando a interface habilita o protocolo de rota multicast, habilite automaticamente o IGMP. Somente após habilitar o IGMP, todas as configurações do IGMP podem entrar em vigor.
Configurar versão IGMP
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração da interface
interface interface-name
-
Configurar a versão IGMP
ip igmp version version-number
Obrigatório Por padrão, a versão IGMP é 2.
Configurar adição de grupo estático
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração da interface
interface interface-name
-
Configurar a adição de grupo estático
ip igmp static-group group-ip-address [ source-ip-address ]
Obrigatório Por padrão, a interface não é adicionada a nenhum grupo multicast ou grupo de origem no modo estático.
Configurar filtro de grupo multicast
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração da interface
interface interface-name
-
Configurar o filtro de grupo multicast IGMP
ip igmp access-group { access-list-number | access-list-name }
Obrigatório Por padrão, o filtro de grupo multicast não está configurado.
Configurar filtro de grupo multicast do SSM
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração da interface
interface interface-name
-
Configurar o filtro de grupo multicast do SSM
ip igmp ssm-access-group { access-list-number | access-list-name }
Obrigatório Por padrão, não filtre para limitar os membros do grupo SSM.
Ajustar e otimizar a rede IGMP
Condição de configuração
Antes de ajustar e otimizar a rede IGMP, primeiro complete a seguinte tarefa:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Habilite o protocolo IGMP
Configurar intervalo de consulta do grupo geral
O consultador IGMP envia periodicamente os pacotes gerais de consulta do grupo para manter a relação do membro do grupo. Você pode modificar o intervalo de envio dos pacotes de consulta do grupo geral IGMP de acordo com a realidade da rede.
Tabela 5 – 7 Configure o intervalo de consulta do grupo geral
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o intervalo de consulta do grupo geral | ip igmp query-interval interval-value | Opcional Por padrão, o intervalo de envio dos pacotes de consulta de grupo geral IGMP é 125s. |
Os intervalos de consulta de gêneros dos dispositivos no mesmo segmento devem tentar manter a consistência. O intervalo geral de consulta do grupo deve ser maior que o tempo máximo de resposta. Caso contrário, a configuração não será bem-sucedida.
Configurar fator de robustez
Tabela 5 – 8 Configurar fator de robustez
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o fator de robustez | ip igmp robustness-variable variable-value | Opcional Por padrão, o fator de robustez do consultador IGMP é 2. |
Após configurar o fator de robustez, os seguintes parâmetros também mudam com os parâmetros de robustez: Timeout do membro do grupo = Fator de robustez * tempo geral de consulta do grupo + tempo máximo de resposta; Tempo limite de outra consulta = fator de robustez * tempo geral de consulta + tempo máximo de resposta/2; Quanto maior o fator de robustez, maior o tempo limite do membro do grupo IGMP e o tempo limite de outro consultador. O usuário define o valor de acordo com a realidade da rede.
Configurar tempo máximo de resposta
O pacote de consulta de grupo geral enviado pelo consultador IGMPv2 contém o campo de tempo máximo de resposta e o receptor envia o relatório de relação de membro do grupo dentro do intervalo máximo de resposta.
Tabela 5 – 9 Configure o tempo máximo de resposta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o tempo máximo de resposta | ip igmp query-max-response-time seconds | Opcional Por padrão, o tempo máximo de resposta da consulta de grupo geral IGMP é 10s. |
Configurar consulta de grupo especificada
Depois que o querier IGMP recebe o pacote de saída de um grupo multicast, envie os pacotes de consulta do grupo especificado dos “tempos de consulta do grupo especificados” para consultar o grupo multicast no segmento, para saber se a sub-rede possui os membros do multicast grupo. Se não receber o relatório de relação de membro do grupo multicast após aguardar o “ último período de vida ”, exclua as informações do grupo multicast.
Tabela 5 – 10 Configure a consulta de grupo especificada
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o intervalo de consulta do grupo especificado | ip igmp last-member-query-interval interval-value | Opcional Por padrão, o intervalo de envio dos pacotes de consulta de grupo especificados é de 1s. |
| Configure os tempos de consulta do grupo especificado | ip igmp last-member-query-count count-value | Opcional Por padrão, o tempo de envio dos pacotes de consulta de grupo especificados é 2. |
IP igmp intervalo de consulta do último membro e ip igmp last-member-query-count são inválidos no IGMPv1, porque o host IGMPv1 não envia pacotes de licença ao sair de um grupo multicast.
Configurar outro tempo limite de consulta
O dispositivo com o menor endereço em uma sub-rede é eleito como o querier e os outros dispositivos são chamados de não-querier. Nos não-consultores, defina um tempo limite como o cronômetro de “outros consultas de tempo limite” (os outros consultadores têm cronômetro) para o consultador. Quando o não-consultor receber o pacote de consulta do pesquisador, atualize o cronômetro. Quando o timer expira, isso indica que o consultador IGMP atual se torna inválido e você precisa reeleger o novo consultador.
Tabela 5 – 11 Configurar o tempo limite do outro consultador
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o tempo limite do outro consultador | ip igmp query-timeout seconds | Opcional Por padrão, o tempo limite do outro consultador é de 255s. |
Se o tempo limite de configuração de outro consultador for menor que o intervalo de consulta, o consultador na rede poderá ser alterado repetidamente.
Configurar Saída Rápida
O segmento final na rede só se conecta a um host para realizar a ação de comutação do grupo multicast com frequência. Para reduzir o atraso de saída, você pode configurar a saída rápida do grupo multicast no dispositivo.
Após configurar a saída rápida, o dispositivo recebe o pacote de saída de um grupo multicast e verifica se o grupo multicast pertence ao intervalo de saída rápida. Se sim, o dispositivo não envia mais o pacote de consulta do grupo especificado para o segmento e exclui as informações do grupo multicast imediatamente.
Tabela 5 – 12 Configurar a saída rápida
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o intervalo do grupo multicast da saída rápida | ip igmp immediate-leave group-list { access-list-number | access-list-name } | Obrigatório Por padrão, não permita a saída rápida do grupo multicast, aplicável ao IGMPv2. |
| Configure o intervalo do grupo de origem da licença rápida | ip igmp sg-immediate-leave sg-list { access-list-number | access-list-name } | Obrigatório Por padrão, não permita a saída rápida do grupo de origem, aplicável ao IGMPv3. |
Configurar mapeamento IGMP SSM
Condições de configuração
Antes de configurar o mapeamento IGMP SSM, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando alcançável a camada de rede do nó vizinho;
- Habilite o protocolo IGMP.
Configurar mapeamento IGMP SSM
Para fornecer o serviço PIM-SSM para o receptor que não suporta IGMPv3 na rede PIM-SSM, podemos configurar a função IGMP SSM Mapping no dispositivo.
O usuário pode configurar a regra de mapeamento IGMP SSM de acordo com a demanda do receptor da rede. O relatório de relação de membro de grupo permitido pela regra é convertido no relatório de relação de não membro IGMPv3 (IS_EX, TO_EX), e o endereço de origem multicast é o endereço de origem especificado pela regra de mapeamento IGMP SSM.
Tabela 5 -13 Configurar o mapeamento IGMP SSM
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite o mapeamento IGMP SSM | ip igmp ssm-map enable [ vrf vrf-name ] | Obrigatório Por padrão, não habilite o mapeamento IGMP SSM. |
| Configurar a regra de mapeamento IGMP SSM | ip igmp ssm-map static { access-list-number | access-list-name } source-ip-address [ vrf vrf-name ] | Obrigatório Por padrão, não há regra de mapeamento IGMP SSM. |
o IP igmp mapa ssm estático O comando suporta apenas a ACL padrão.
Monitoramento e manutenção de IGMP
Tabela 5 - 14 Monitoramento e manutenção do IGMP
| Comando | Descrição |
| clear ip igmp group [ group-ip-address ] [ interface-name ] [ vrf vrf-name ] | Limpe as informações do grupo multicast IGMP |
| clear ip igmp statistic interface interface-name [ vrf vrf-name ] | Limpe as informações de estatísticas do pacote IGMP na interface |
| show ip igmp groups [ [ static ] | [ interface-name ] [ group-ip-address ] [ detail ] ] [ vrf vrf-name ] | Exiba as informações do grupo multicast IGMP |
| show ip igmp interface [ interface-name ] [ vrf vrf-name ] | Exibir as informações IGMP da interface |
| show ip igmp statistic interface interface-name [ vrf vrf-name ] | Exiba as informações estatísticas dos pacotes IGMP |
Exemplo de configuração típica de IGMP
Configurar IGMP
Requisitos de rede
- Toda a rede executa o protocolo PIM-SM.
- Device1, Device2 e Receiver estão na mesma LAN e o Device 2 é o consultador.
- Receptor é um receptor da rede final Device1 e Device2.
- Execute o IGMPv2 entre Device1, Device2 e a rede final.
Topologia de rede
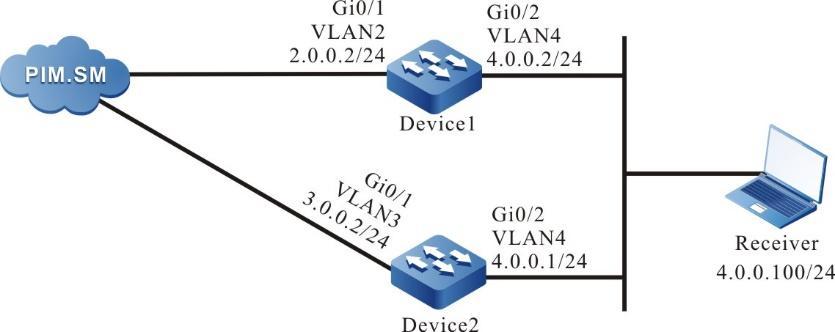
Figura 5 -1 Rede de configuração do IGMP
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (omitido)
- Passo 2:Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM na interface.
#Configurar dispositivo1.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device1(config)#configure terminalDevice1(config)#ip multicast-routingDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ip pim sparse-modeDevice1(config-if-vlan4)#exit
#Configurar dispositivo2.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device2(config)#configure terminalDevice2(config)#ip multicast-routingDevice2(config)#interface vlan3Device2(config-if-vlan3)#ip pim sparse-modeDevice2(config-if-vlan3)#exitDevice2(config)#interface vlan4Device2(config-if-vlan4)#ip pim sparse-modeDevice2(config-if-vlan4)#exit
- Passo 3:Confira o resultado.
#Visualize as informações da versão IGMP e o resultado da eleição do consultador da interface Device1 vlan 4 .
Device1#show ip igmp interface vlan4Interface vlan4 (Index 50331921)IGMP Active, Non-Querier (4.0.0.1, Expires: 00:02:15)Default version 2IP router alert option in IGMP V2 msgs: EXCLUDEInternet address is 4.0.0.2IGMP query interval is 125 secondsIGMP querier timeout is 255 secondsIGMP max query response time is 10 seconds configged, and 10 seconds is adoptedLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsIGMP robustness variable is 2
#Visualize as informações da versão IGMP e o resultado da eleição do consultador da interface Device2 vlan 4 .
Device2#show ip igmp interface vlan4Interface vlan4 (Index 50331921)IGMP Active, Querier (4.0.0.1)Default version 2IP router alert option in IGMP V2 msgs: EXCLUDEInternet address is 4.0.0.1IGMP query interval is 125 secondsIGMP querier timeout is 255 secondsIGMP max query response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsIGMP robustness variable is 2
#Receiver envia o relatório de relação de membro IGMPv2 para adicionar ao grupo multicast 225.1.1.1.
#Visualize a tabela de membros multicast de Device1.
Device1#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires225.1.1.1 vlan4 00:21:02 00:03:47 4.0.0.100 stopped
#Exibe a tabela de membros multicast do Device2.
Device2#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires225.1.1.1 vlan4 00:21:02 00:03:47 4.0.0.100 stopped
Após configurar o protocolo multicast na interface, habilite automaticamente a função IGMP e execute o IGMPv2 por padrão. Você pode configurar a versão IGMP em execução da interface através do comando ip igmp version . Quando vários dispositivos un IGMP em uma LAN, elege o IGMP querier e aquele com o menor endereço é eleito como o IGMP querier da LAN.
Configurar mapeamento IGMP SSM
Requisitos de rede
- Toda a rede executa o protocolo PIM-S S M.
- Receiver1 , Receiver2 , Receiver3 e Device2 estão todos em uma LAN.
- Execute o IGMPv 3 entre o Dispositivo 2 e a rede stub.
- Use o mapeamento IGMP SSM em Device2 para que Receiver2 e Receiver3 possam receber apenas os pacotes de serviço multicast enviados por Source1 .
Topologia de rede
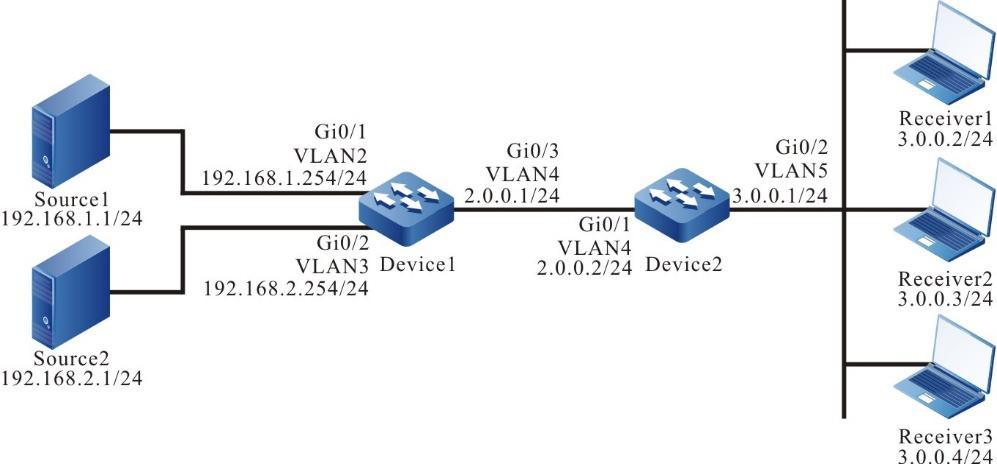
Figura 5 - 2 Rede de configuração do mapeamento IGMP SSM
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (omitido)
- Passo 2:Habilite o OSPF de roteamento unicast para que todos os dispositivos de rede na rede possam se comunicar uns com os outros.
#Configurar dispositivo1 .
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 192.168.1.0 0.0.0.255 area 0Device1(config-ospf)#network 192.168.2.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configurar dispositivo2 .
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Visualize a tabela de rotas do Device2.
Device2#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 00:16:05, vlan4C 3.0.0.0/24 is directly connected, 00:06:36, vlan5O 192.168.1.0/24 [110/2] via 2.0.0.1, 00:15:17, vlan4O 192.168.2.0/24 [110/2] via 2.0.0.1, 00:00:51, vlan4
O método de visualização do Device1 é o mesmo do Device2, portanto o processo de visualização é omitido.
- Passo 3:Habilite o encaminhamento multicast globalmente, configure o PIM-SSM globalmente e o intervalo do grupo multicast do serviço SSM é 232.0.0.0/8. Nas interfaces, habilite o protocolo multicast PIM-SM. A interface gigabitethernet1 do Device2 executa IGMPv3.
#Configurar dispositivo1.
Habilite o encaminhamento multicast globalmente, configure o PIM-SSM globalmente e habilite o protocolo multicast PIM-SM na interface.
Device1(config)#ip multicast-routingDevice1(config)#ip pim ssm defaultDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ip pim sparse-modeDevice1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ip pim sparse-modeDevice1(config-if-vlan4)#exit
#Configurar dispositivo2.
Habilite o encaminhamento multicast globalmente, configure o PIM-SSM globalmente e habilite o protocolo multicast PIM-SM na interface. A interface gigabitethernet1 roda IGMPv3.
Device2(config)#ip multicast-routingDevice2(config)#ip pim ssm defaultDevice2(config)#interface vlan4Device2(config-if-vlan40)#ip pim sparse-modeDevice2(config-if-vlan4)#exitDevice2(config)#interface vlan5Device2(config-if-vlan5)#ip pim sparse-modeDevice2(config-if-vlan5)#ip igmp version 3Device2(config-if-vlan5)#exit
#Visualize as informações IGMP da interface vlan5 no Device2.
Device2#show ip igmp interface vlan5Interface vlan5 (Index 50331921)IGMP Enabled, Active, Querier (3.0.0.1)Configured for version 3IP router alert option in IGMP V2 msgs: EXCLUDEInternet address is 3.0.0.1IGMP query interval is 125 secondsIGMP querier timeout is 255 secondsIGMP max query response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsIGMP robustness variable is 2
- Passo 4:Habilite o mapeamento IGMP SSM no Device2 e configure a regra de mapeamento IGMP SSM para que o Receptor 2 e o Receptor 3 possam receber apenas os pacotes de serviço multicast enviados por Source1.
#Configurar dispositivo2.
Habilite o mapeamento IGMP SSM, configure o intervalo do grupo multicast do IGMP SSM como 232.0.0.0~232.0.0.255 e o endereço de origem multicast é 192.168.1.1.
Device2(config)#ip access-list standard 1Device2(config-std-nacl)#permit 232.0.0.0 0.0.0.255Device2(config-std-nacl)#exitDevice2(config)#ip igmp ssm-map enableDevice2(config)#ip igmp ssm-map static 1 192.168.1.1
#Visualize a regra de mapeamento IGMP SSM de Device2.
Device2#show ip igmp ssm-mapIGMP SSM-MAP Information : enableacl-name source-addr--------------------------192.168.1.1
- Passo 5:Confira o resultado.
# Receiver1 envia o pacote de relatório do membro IGMPv3 do grupo de origem especificado para adicionar ao grupo multicast 232.1.1.1 e a origem multicast especificada é 192.168.2.1; Receiver2 envia o pacote de relatório do membro IGMPv2 para adicionar ao grupo multicast 232.1.1.2; Receiver3 envia o pacote de relatório do membro IGMPv1 para adicionar ao grupo multicast 232.1.1.3.
#Source1 e Source2 ambos enviam os pacotes de serviço multicast com grupos multicast 232.1.1.1, 232.1.1.2 e 232.1.1.3.
#Exibe a tabela de membros multicast.
Device2#show ip igmp groupsIGMP Connected Group MembershipTotal 3 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires232.1.1.1 vlan5 01:28:45 stopped 3.0.0.2 stopped stopped232.1.1.2 vlan5 01:29:01 stopped 3.0.0.3 stopped stopped232.1.1.3 vlan5 01:29:16 stopped 3.0.0.4 stopped stoppedDevice2#show ip igmp groups detailInterface:vlan5Group: 232.1.1.1Uptime: 01:30:44Group mode: IncludeLast reporter: 3.0.0.2TIB-A Count: 1TIB-B Count: 0Group source list: (R - Remote, M - SSM Mapping)Source Address Uptime v3 Exp M Exp Fwd Flags192.168.2.1 01:30:44 00:03:39 stopped Yes RInterface: vlan5Group: 232.1.1.2Uptime: 01:31:00Group mode: IncludeLast reporter: 3.0.0.3TIB-A Count: 1TIB-B Count: 0Group source list: (R - Remote, M - SSM Mapping)Source Address Uptime v3 Exp M Exp Fwd Flags192.168.1.1 01:31:00 stopped 00:03:38 Yes MInterface: vlan5Group: 232.1.1.3Uptime: 01:31:15Group mode: IncludeLast reporter: 3.0.0.4TIB-A Count: 1TIB-B Count: 0Group source list: (R - Remote, M - SSM Mapping)Source Address Uptime v3 Exp M Exp Fwd Flags192.168.1.1 01:31:15 stopped 00:03:42 Yes M
#Visualize a tabela de rotas multicast PIM-SM do Device2.
Device2#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 0 (*,G) entryTotal 3 (S,G) entriesTotal 0 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(192.168.2.1, 232.1.1.1)Up time: 01:32:51KAT time: 00:03:24RPF nbr: 2.0.0.1RPF idx: vlan4SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Vlan5Joined interface list:Asserted interface list:Outgoing interface list:Vlan5Packet count 19868613(192.168.1.1, 232.1.1.2)Up time: 01:33:07KAT time: 00:03:24RPF nbr: 2.0.0.1RPF idx: vlan4SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Vlan5Joined interface list:Asserted interface list:Outgoing interface list:Vlan5Packet count 19873645(192.168.1.1, 232.1.1.3)Up time: 01:33:22KAT time: 00:03:24RPF nbr: 2.0.0.1RPF idx: vlan4SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Vlan5Joined interface list:Asserted interface list:Outgoing interface list:Vlan5Packet count 19873645
# Receiver1 só pode receber os pacotes de serviço multicast enviados por Source2; Receiver2 e Receiver3 só podem receber os pacotes de serviço multicast enviados por Source1.
O método de visualização do Device1 é o mesmo do Device2, portanto o processo de visualização é omitido. O mapeamento IGMP SSM precisa ser usado com PIM-SSM; o intervalo do grupo multicast na regra de mapeamento IGMP SSM deve pertencer ao intervalo do grupo multicast PIM-SSM. O mapeamento IGMP SSM executa principalmente IGMPv1 ou IGMPv2 e não pode ser atualizado para o host receptor de IGMPv3 para fornecer suporte ao modelo SSM. O mapeamento IGMP SSM é inválido para o pacote de relatório do membro IGMPv3.
Configurar adição estática IGMP
Requisito de rede
- Toda a rede executa o protocolo PIM-SM.
- Receptor é um receptor da rede final do dispositivo.
- Execute o IGMPv2 entre o dispositivo e a rede final.
- A interface de dispositivo vlan3 adiciona ao grupo multicast 225.1.1.1 estaticamente.
Topologia de rede
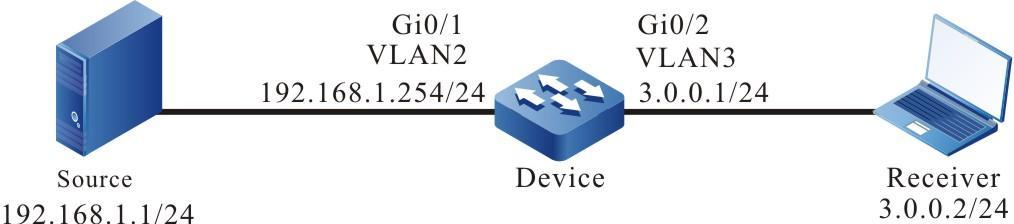
Figura 5 -3 Rede de configuração de adição estática IGMP
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (omitido)
- Passo 2:Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM na interface.
#Configurar dispositivo.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device(config)#configure terminalDevice(config)#ip multicast-routingDevice(config)#interface vlan2Device(config-if-vlan2)#ip pim sparse-modeDevice(config-if-vlan2)#exitDevice(config)#interface vlan3Device(config-if-vlan3)#ip pim sparse-modeDevice(config-if-vlan3)#exit
#Visualize as informações IGMP da interface do dispositivo vlan3.
Device#show ip igmp interface vlan3Interface vlan3 (Index 50331921)IGMP Active, Querier (3.0.0.1)Default version 2IP router alert option in IGMP V2 msgs: EXCLUDEInternet address is 3.0.0.1IGMP query interval is 125 secondsIGMP querier timeout is 255 secondsIGMP max query response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsIGMP robustness variable is 2
- Passo 3: A interface de dispositivo vlan3 adiciona ao grupo multicast 225.1.1.1 estaticamente.
#Configurar dispositivo.
A interface de dispositivo vlan3 adiciona ao grupo multicast 225.1.1.1 estaticamente.
Device(config)#interface vlan3Device(config-if-vlan3)#ip igmp static-group 225.1.1.1Device(config-if-vlan3)#exit
- Passo 4:Confira o resultado.
#Source envia o pacote multicast com o grupo multicast 225.1.1.1.
#Exibe a tabela de membros multicast de Device.
Device#show ip igmp groupsIGMP Static Group MembershipTotal 1 static groupsGroup Address Source Address Interface225.1.1.1 0.0.0.0 vlan3
#Visualize a tabela de rotas multicast do dispositivo.
Device#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 1 (S,G) entryTotal 1 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(*, 225.1.1.1)Up time: 00:08:12RP: 0.0.0.0RPF nbr: 0.0.0.0RPF idx: NoneFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan3Joined interface list:Asserted interface list:(192.168.1.1, 225.1.1.1)Up time: 00:07:24KAT time: 00:02:22RPF nbr: 0.0.0.0RPF idx: NoneSPT bit: TRUEFlags:JOIN DESIREDCOULD REGISTERUpstream State: JOINEDLocal interface list:Joined interface list:register_vif0Asserted interface list:Outgoing interface list:register_vif0vlan3Packet count 8646421(192.168.1.1, 225.1.1.1, rpt)Up time: 00:07:24RP: 0.0.0.0Flags:RPT JOIN DESIREDRPF SGRPT XG EQUALUpstream State: NOT PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:vlan3
#Receiver pode receber o pacote multicast com o grupo multicast 225.1.1.1 enviado por Source.
Configurar filtro de grupo multicast IGMP
Requisito de rede
- Toda a rede executa o protocolo PIM-SM.
- Receptor é um receptor da rede final do dispositivo.
- Execute o IGMPv2 entre o dispositivo e a rede final.
- A interface de dispositivo vlan3 filtra o grupo multicast; o intervalo dos grupos multicast que o Receptor pode adicionar é 225.1.1.0-225.1.1.255.
Topologia de rede
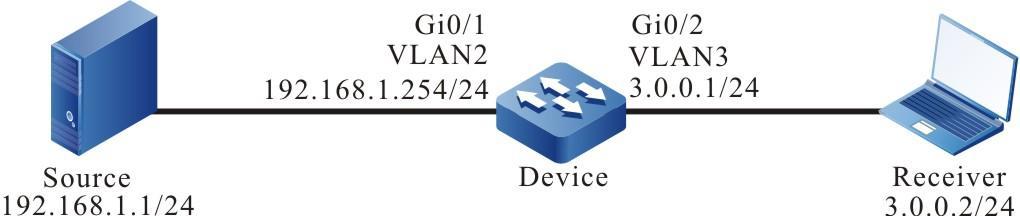
Figura 5 -4 Rede de configuração do filtro de grupo multicast IGMP
Etapas de configuração
- Passo 1: Configure o endereço IP da interface. (omitido)
- Passo 2: Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM na interface.
#Configurar dispositivo.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device(config)#configure terminalDevice(config)#ip multicast-routingDevice(config)#interface vlan2Device(config-if-vlan2)#ip pim sparse-modeDevice(config-if-vlan2)#exitDevice(config)#interface vlan3Device(config-if-vlan3)#ip pim sparse-modeDevice(config-if-vlan3)#exit
# Visualize as informações IGMP da interface do dispositivo vlan3.
Device#show ip igmp interface vlan3Interface vlan3 (Index 50331921)IGMP Enabled, Active, Querier (3.0.0.1)Default version 2IP router alert option in IGMP V2 msgs: EXCLUDEInternet address is 3.0.0.1IGMP query interval is 125 secondsIGMP querier timeout is 255 secondsIGMP max query response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsIGMP robustness variable is 2
- Passo 3:Configure o filtro de grupo multicast na interface do dispositivo vlan3.
#Configurar dispositivo.
Configure o filtro de grupo multicast na interface do dispositivo vlan3; o intervalo dos grupos multicast que o Receptor pode adicionar é 225.1.1.0-225.1.1.255.
Device(config)#ip access-list standard 1Device(config-std-nacl)#permit 225.1.1.0 0.0.0.255Device(config-std-nacl)#commitDevice(config-std-nacl)#exitDevice(config)#interface vlan3Device(config-if-vlan3)#ip igmp access-group 1Device(config-if-vlan3)#exit
- Passo 4:Confira o resultado.
#Receiver envia o relatório de relação de membro IGMPv2 para adicionar ao grupo multicast 225.1.1.1 e 226.1.1.1.
#Source envia os pacotes multicast com o grupo multicast 225.1.1.1 e 226.1.1.1.
#Exibe a tabela de membros multicast de Device.
Device#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires225.1.1.1 vlan3 03:14:59 00:03:05 3.0.0.2 stopped
#Visualize a tabela de rotas multicast do dispositivo.
Device#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 2 (S,G) entriesTotal 2 (S,G,rpt) entriesTotal 0 FCR entryUp timer/Expiry timer(*, 225.1.1.1)Up time: 00:00:56RP: 0.0.0.0RPF nbr: 0.0.0.0RPF idx: NoneFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan3Joined interface list:Asserted interface list:(192.168.1.1, 225.1.1.1)Up time: 00:00:15KAT time: 00:03:15RPF nbr: 0.0.0.0RPF idx: NoneSPT bit: TRUEFlags:JOIN DESIREDCOULD REGISTERUpstream State: JOINEDLocal interface list:Joined interface list:register_vif0Asserted interface list:Outgoing interface list:register_vif0vlan3Packet count 1(192.168.1.1, 225.1.1.1, rpt)Up time: 00:00:15RP: 0.0.0.0Flags:RPT JOIN DESIREDRPF SGRPT XG EQUALUpstream State: NOT PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:vlan3(192.168.1.1, 226.1.1.1)Up time: 00:00:15KAT time: 00:03:15RPF nbr: 0.0.0.0RPF idx: NoneSPT bit: TRUEFlags:JOIN DESIREDCOULD REGISTERUpstream State: JOINEDLocal interface list:Joined interface list:register_vif0Asserted interface list:Outgoing interface list:register_vif0Packet count 1(192.168.1.1, 226.1.1.1, rpt)Up time: 00:00:15RP: 0.0.0.0Flags:RPF SGRPT XG EQUALUpstream State: RPT NOT JOINEDLocal interface list:Pruned interface list:Outgoing interface list:
#Receiver só pode receber os pacotes de serviço multicast com o grupo multicast 225.1.1.1 enviado por Source.
Para filtrar com base no grupo de origem multicast, use o comando ip igmp ssm-access-group para realizar. Ao usar o comando, é necessário que o dispositivo execute o PIM-SSM e a interface execute o IGMPv3 .
PIM-DM
Visão geral
O PIM-DM (Protocol Independent Multicast-Dense Mode) é aplicável quando os membros do grupo estão relativamente concentrados e o intervalo é pequeno ou o recurso de largura de banda da rede é suficiente.
O PIM-DM não depende do protocolo de rota unicast especificado para a verificação de RPF.
O PIM-DM adota o “Push” para transmitir os pacotes multicast. Quando a origem multicast começar a enviar os pacotes multicast, suponha que todas as sub-redes no domínio multicast tenham os receptores multicast, de modo que os pacotes multicast sejam enviados para todos os nós da rede. O PIM-DM encaminha e remove o multicast sem o receptor. Quando o nó do nó de ramificação de encaminhamento multicast removido tem o receptor da fonte multicast, o PIM-DM usa o mecanismo de enxerto para restaurar ativamente o encaminhamento dos dados multicast.
O PIM-DM usa o mecanismo de atualização de status para atualizar o status downstream regularmente para que a ramificação removida não expire.
Configuração da Função PIM-DM
Tabela 6 -1 lista de configuração da função PIM-DM
| Tarefa de configuração | |
| Configurar funções básicas do PIM-DM | Configurar o protocolo PIM-DM |
| Configurar o vizinho PIM-DM |
Configure o período de envio dos pacotes HELLO
Configurar o tempo de atividade do vizinho PIM-DM Configurar filtro vizinho PIM-DM |
| Configurar os parâmetros de atualização de status | Configurar o intervalo de atualização do status do PIM-DM |
A interface Ethernet L3 não suporta a função PIM-DM.
Antes de configurar o PIM-DM, primeiro conclua as seguintes tarefas: Tabela 6 -2 Configurar o protocolo PIM-DM Antes de configurar o vizinho PIM-DM, primeiro conclua as seguintes tarefas:
A interface habilitada com o protocolo PIM-DM envia periodicamente os pacotes Hello para configurar e manter o vizinho PIM-DM.
Tabela 6 -3 Configure o período de envio de pacotes HELLO
Quando a interface recebe os pacotes Hello de um vizinho, registre o holdtime transportado no pacote Hello como o tempo keepalive do vizinho. Se não receber o pacote Hello do vizinho dentro do tempo de keepalive, considera-se que o vizinho se torna inválido.
Tabela 6 -4 Configure o tempo de atividade do vizinho PIM-DM
Para salvar os recursos do sistema, você pode usar a função de filtro vizinho para configurar o vizinho seletivamente, de modo a salvar os recursos do dispositivo.
Tabela 6 -5 Configurar o filtro vizinho PIM-DM
Antes de configurar os parâmetros de atualização de status do PIM-DM, primeiro conclua as seguintes tarefas:
O PIM-DM precisa definir o intervalo do roteador conectado diretamente à fonte gerando os pacotes de atualização de status
Tabela 6 -6 Configurar o intervalo de atualização do status do PIM-DM Tabela 6 -7 Monitoramento e manutenção do PIM-DM
Configurar funções básicas do PIM-DM
Condição de configuração
Configurar protocolo PIM-DM
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração da interface
interface interface-name
-
Habilite o protocolo PIM-DM.
ip pim dense-mode
ip pim dense-mode passive
Qualquer Por padrão, o PIM-DM está desabilitado na interface. Habilite o protocolo PIM-DM via modo denso ip pim passivo . A interface não envia os pacotes de saudação ao vizinho.
Configurar o vizinho PIM-DM
Condição de configuração
Configurar período de envio de pacotes HELLO
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração da interface
interface interface-name
-
Configure o período de envio dos pacotes Hello
ip pim dense-mode hello-interval interval-value
Opcional Por padrão, o período de envio dos pacotes Hello é de 30s.
Configurar o tempo de atividade do vizinho PIM-DM
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração da interface
interface interface-name
-
Configure o tempo de atividade do vizinho PIM-DM
ip pim dense-mode hello-holdtime holdtime-value
Opcional Por padrão, o tempo de atividade do vizinho PIM-DM é 105s.
Configurar filtro vizinho PIM-DM
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração da interface
interface interface-name
-
Configurar o filtro vizinho PIM-DM
ip pim dense-mode neighbor-filter { access-list-number | access-list-name }
Opcional Por padrão, não habilite a função de filtro vizinho PIM-DM.
Configurar parâmetros de atualização de status
Condição de configuração
Configurar o intervalo de atualização do status do PIM-DM
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração da interface
interface interface-name
-
Configurar o intervalo de atualização do status do PIM-DM
ip pim dense-mode state-refresh origination-interval interval-value
Opcional Por padrão, o intervalo de atualização do status do PIM-DM é de 60 segundos.
Monitoramento e manutenção do PIM-DM
Comando
Descrição
clear ip pim dense-mode mroute [ group-ip-address source-ip-address ] [ vrf vrf-name ]
Limpe as informações de rota multicast PIM-DM
show ip pim dense-mode interface [ detail ] [ vrf vrf-name ]
Exibir as informações da interface PIM-DM
show ip pim dense-mode neighbor [ detail ] [ vrf vrf-name ]
Exiba as informações do vizinho PIM-DM
show ip pim dense-mode nexthop [ source-ip-address ] [ vrf vrf-name ]
Exiba as informações do próximo salto unicast do PIM-DM para a fonte
show ip pim dense-mode mroute [ [ group group-ip-address [ source source-ip-address ] ]| [ source source-ip-address group group-ip-address ] ] [ vrf vrf-name ]
Exibir as informações da tabela de rotas do protocolo PIM-DM
Exemplo de configuração típica do PIM-DM
Configurar funções básicas do PIM-DM
Requisitos de rede
- Toda a rede habilita o protocolo PIM-DM.
- Receptor é um receptor da rede final Device2.
- Execute o IGMPv2 entre o Device2 e a rede final.
Topologia de rede

Figura 6 -1 Rede de configuração das funções básicas do PIM-DM
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (omitido)
- Passo 2:Configure o endereço IP da interface. (omitido)
- Passo 3:Habilite o protocolo de rota unicast OSPF para que todos os dispositivos na rede possam se comunicar uns com os outros.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 192.168.1.0 0.0.0.255 area 0Device1(config-ospf)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Visualize a tabela de rotas do Device2.
Device2#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, Ex - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 1.0.0.0/24 is directly connected, 00:07:30, vlan3C 2.0.0.0/24 is directly connected, 00:07:14, vlan4O 192.168.1.0/24 [110/2] via 1.0.0.1, 00:00:16, vlan3
O método de visualização da tabela de rotas do Device1 é o mesmo do Device2.
- Passo 4:Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-DM na interface.
#Configurar dispositivo1.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-DM na interface.
Device1(config)#ip multicast-routingDevice1(config)#interface vlan 2Device1(config-if-vlan2)#ip pim dense-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan 3Device1(config-if-vlan3)#ip pim dense-modeDevice1(config-if-vlan3)#exit
#Configurar dispositivo2.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-DM na interface.
Device2(config)#ip multicast-routingDevice2(config)#interface vlan 3Device2(config-if-vlan3)#ip pim dense-modeDevice2(config-if-vlan3)#exitDevice2(config)#interface vlan 4Device2(config-if-vlan4)#ip pim dense-modeDevice2(config-if-vlan4)#exit
# Visualize as informações da interface habilitada com o protocolo PIM-DM no Device2 e as informações do vizinho PIM-DM.
Device2#show ip pim dense-mode interfaceTotal 2 Interface entriesTotal 0 External Interface entryTotal 0 Sparse-Dense Mode Interface entryAddress Interface VIFIndex Ver/ Nbr VIFMode Count Flag1.0.0.2 vlan3 0 v2/D 1 UP2.0.0.1 vlan4 1 v2/D 0 UPDevice2#show ip pim dense-mode neighborPIM Dense-mode Neighbor Table:PIM Dense-mode VRF Name: DefaultTotal 1 Neighbor entriesNeighbor-Address Interface Uptime/Expires Ver1.0.0.1 vlan3 00:02:15/00:01:30 v2
#Visualize as informações IGMP da interface VLAN4 do Device2.
Device2#show ip igmp interface vlan 4Interface vlan4 (Index 65547)IGMP Active, Querier (2.0.0.1)Default version 2IP router alert option in IGMP V2 msgs: EXCLUDEInternet address is 2.0.0.1IGMP query interval is 125 secondsIGMP querier timeout is 255 secondsIGMP max query response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsIGMP robustness variable is 2
O método de visualização das informações do Device1 é o mesmo do Device2. Após configurar o protocolo multicast na interface, ative automaticamente a função IGMP e execute o IGMPv2 por padrão. Você pode configurar a versão IGMP em execução na interface executando o comando ip igmp version.
- Passo 5:Confira o resultado.
#Receiver envia o relatório de relação de membro IGMPv2 para adicionar ao grupo multicast 225.1.1.1.
#Source envia os pacotes multicast com o grupo multicast 225.1.1.1.
#Exibe a tabela de membros multicast do Device2.
Device2#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires225.1.1.1 vlan4 00:06:01 00:04:06 2.0.0.2 stopped
#Visualize a tabela de rotas multicast PIM-DM do Device2.
Device2#show ip pim dense-mode mroutePIM-DM Multicast Routing TableTotal 1 mroute entries(192.168.1.1, 225.1.1.1)Expire in: 00:02:35RPF Neighbor: 1.0.0.1, Nexthop: 1.0.0.1, vlan3Upstream IF: vlan3Upstream State: ForwardingAssert State: LoserDownstream IF List:vlan4, in 'olist':Downstream State: NoInfoAssert State: NoInfo
#Receiver pode receber os pacotes multicast com o grupo multicast 225.1.1.1 enviado por Source.
O método de visualização das informações do Device1 é o mesmo do Device2.
PIM-SM
Visão geral
PIM-SM (Protocol Independent Multicast, Sparse Mode) é aplicável quando os membros do grupo são relativamente dispersos e seu alcance é relativamente amplo ou o recurso de largura de banda da rede é relativamente limitado.
O PIM-SM não depende de nenhum protocolo de rota unicast específico. O dispositivo anuncia as informações de multicast para todos os roteadores PIM-SM enviando ativamente os pacotes para solicitar a configuração da árvore de distribuição de multicast (MDT) e definir RP (Ponto de Rendezvous) e BSR (Roteador Bootstrap). Quando o receptor adiciona a um grupo multicast, a extremidade receptora DR (Designated Router) envia o PIM adicionando pacote ao RP, construindo a árvore de compartilhamento-RPT com RP como root, enquanto o DR de origem registra a fonte multicast para RP, construindo a fonte árvore com a fonte multicast como raiz. Os pacotes de serviço multicast são transmitidos ao receptor ao longo da árvore de origem e da árvore de compartilhamento; a extremidade receptora DR envia o pacote de adição PIM para a fonte multicast. Por fim, mude de RPT para SPT baseado em fonte (Shortest-path Tree), de modo a reduzir o atraso da rede.
PIM SSM é a abreviação de Protocol Independent Multicast ---- Source Specific Multicast. PIM-SSM é o subconjunto do protocolo PIM-SM e deve ser executado com base no PIM-SM. O protocolo PIM-SSM define o endereço IPv4 232.0.0.0-232.255.255.255 para ser reservado para SSM. O PIM-SSM deve funcionar com IGMPv3, porque o IG MPv3 pode enviar o pacote de relatório de associação IGMP da origem e do grupo especificados.
Configuração da Função PIM-SM
Tabela 7 – 1 lista de configuração da função PIM-SM
| Tarefa de configuração | |
| Configure as funções básicas do PIM-SM | Habilite o protocolo PIM-SM |
| Configurar o roteador de agregação PIM-SM | Configurar C-RP Configurar RP estático |
| Configurar o roteador bootstrap PIM-SM | Configurar C-BSR Configurar a borda BSR |
| Configurar o registro de origem multicast PIM-SM |
Configurar a verificação de acessibilidade RP
Configure a taxa de envio dos pacotes de registro Configure a taxa de envio dos pacotes de parada de registro Configure o endereço de origem do pacote de registro Configurar filtro de pacote de registro |
| Configurar os parâmetros do vizinho PIM-SM |
Configure o período de envio dos pacotes Hello
Configure o tempo de atividade do vizinho Configurar o filtro vizinho Configurar a prioridade de DR |
| Configurar comutação PIM-SM SPT | Configurar a condição de comutação SPT |
| Configurar PIM-SSM | Configurar PIM-SSM |
| Configurar PIM-SDM | Ativar PIM-SDM |
A interface Ethernet L3 não suporta a função PIM-SM.
Configurar funções básicas do PIM-SM
Condição de configuração
Antes de configurar o PIM-SM, primeiro complete a seguinte tarefa:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
Ativar protocolo PIM-SM
Tabela 7 – 2 Habilite o protocolo PIM-SM
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite o encaminhamento multicast IP | ip multicast-routing | Obrigatório Por padrão, o encaminhamento multicast IP não está habilitado. |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite o protocolo PIM-SM | ip pim sparse-mode | Qualquer Por padrão, o PIM-SM está desabilitado na interface. |
| ip pim sparse-mode passive |
Após habilitar o protocolo PIM-SM, habilite automaticamente o protocolo IGMP. Após habilitar a função PIM-SM, todas as configurações do PIM-SM podem entrar em vigor.
Configurar roteador de agregação PIM-SM
Condição de configuração
Antes de configurar o RP, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Habilite o protocolo PIM-SM
Configurar C-RP
RP é gerado pela eleição C-RO. Depois que o BSR é eleito, todos os C-RPs (Candidate-Rendezvous Point) enviam regularmente o pacote C-RP unicast para o BSR. O BSR integra as informações do C-RP e transmite as informações para todos os dispositivos no domínio PIM-SM por meio do pacote de bootstrap.
Tabela 7 – 3 Configurar C-RP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar C-RP | ip pim rp-candidate interface-name [ [ priority-value [ interval-value [ group-list { access-list-number | access-list-name } ] ] ] | [ group-list { access-list-number | access-list-name } ] ] [ vrf vrf-name ] | Obrigatório Por padrão, não há C-RP. |
Regras de eleição do RP: Para o intervalo de grupo do serviço C-RP, execute a correspondência mais longa da máscara. Se a correspondência mais longa da máscara tiver vários C-RPs, compare a prioridade de C-RP. Quanto menor o valor, maior a prioridade. Aquele com maior prioridade vence. Se houver vários C-RPs com prioridade mais alta, execute o cálculo de HASH para o endereço e o grupo C-RP. Aquele com o maior valor de HASH vence. Se houver vários RPs com o maior HASH, o C-RP com o maior endereço IP vence.
Configurar RP estático
Para a rede PIM-SM simples, sugere-se usar o RP estático. Se estiver usando o RP estático, não precisa realizar a configuração do BSR, eliminando a frequente interação entre RP e BSR, de modo a economizar a largura de banda da rede.
Tabela 7 – 4 Configurar RP estático
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o RP estático | ip pim rp-addressess ip-address [ access-list-name | access-list-number ] [ override ] [ vrf vrf-name ] | Obrigatório Por padrão, não há RP estático. |
Todos os dispositivos no mesmo domínio PIM-SM devem ser configurados com o mesmo RP estático.
Configurar roteador Bootstrap PIM-SM
Condição de configuração
Antes de configurar o BSR, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Habilite o protocolo PIM-SM
Configurar C-BSR
Em um domínio PIM-SM, deve haver o BSR exclusivo. Vários C-BSRs (Candidate-Bootstrap Router) optam por gerar o BSR exclusivo por meio do pacote de bootstrap.
Tabela 7 – 5 Configurar C-BSR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar C-BSR | ip pim bsr-candidate interface_name [ hash-mask-length [ priority-value ] ] [ vrf vrf-name ] | Obrigatório Por padrão, não há C-BSR. |
Regras de eleição do BSR: Compare as prioridades. Quanto maior o valor, maior a prioridade. Aquele com maior prioridade vence. Se a prioridade for a mesma, vence aquele com o maior endereço IP.
Configurar borda BSR
O BSR é responsável por coletar as informações do C-RP e transmitir as informações para todos os dispositivos no domínio PIM-SM por meio do pacote de bootstrap. O intervalo BSR é o intervalo do domínio multicast. O pacote de bootstrap não pode passar pela interface configurada com a borda BSR. Os dispositivos fora da faixa de domínio multicast não podem participar do encaminhamento do pacote de serviço multicast no domínio multicast, de modo a realizar a divisão do domínio multicast.
Tabela 7 – 6 Configurar a borda BSR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a borda BSR | ip pim bsr-border | Obrigatório Por padrão, não há borda multicast. |
Configurar registro de origem multicast PIM-SM
Condição de configuração
Antes de configurar o registro de origem multicast, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Habilite o protocolo PIM-SM
Configurar verificação de acessibilidade de RP
Antes que o DR de origem envie o pacote de registro para o RP, primeiro execute a verificação de acessibilidade do RP. Se descobrir que a rota RP não é alcançável, não se registre no RP, de modo a reduzir o custo do DR.
Tabela 7 – 7 Configurar a verificação de acessibilidade RP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a verificação de acessibilidade RP | ip pim register-rp-reachability [ vrf vrf-name ] | Obrigatório Por padrão, antes de realizar o registro PIM, não verifique a acessibilidade do RP. |
Para reduzir o custo do DR de origem, sugere-se configurar o comando nos DRs de origem de todos os PIM-SMs.
Configurar taxa de envio de pacotes de registro
Quando o DR de origem recebe o pacote multicast, encapsule o pacote multicast para o pacote de registro e envie ao RP para o registro de origem até que o registro seja concluído.
Quando o DR de origem não completa o registro de origem multicast e o fluxo multicast é grande, gere muitos pacotes de registro, o que aumenta a carga do dispositivo RP. Mesmo RP não pode funcionar normalmente. O DR de origem não precisa transmitir todos os pacotes de registro de um fluxo para o RP, portanto, configurar a taxa de envio dos pacotes de registro no DR de origem pode não apenas atingir o objetivo do registro de origem, mas também reduzir a carga do RP.
Tabela 7 – 8 Configure a taxa de envio do pacote de registro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a taxa de envio do pacote de registro | ip pim register-rate-limit rate-limit-value [ vrf vrf-name ] | Obrigatório Por padrão, não limite a taxa de envio do pacote de registro. |
Para reduzir a carga de RP, sugere-se configurar a taxa de envio dos pacotes de registro de origem em todos os DRs de origem.
Configurar taxa de envio de pacotes de parada de registro
Após o RP receber o pacote de registro do DR de origem, envie o pacote de parada de registro ao DR de origem para concluir o registro. Quando o RP recebe muitos pacotes de registro, é necessário responder a todos os pacotes de registro (enviar pacote de parada de registro). Na verdade, há muitos pacotes repetidos nos pacotes de parada de registro. Você pode limitar a taxa de envio do pacote de parada de registro no RP para reduzir o custo do RP.
Tabela 7 – 9 Configure a taxa de envio do pacote de parada de registro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a taxa de envio do pacote de parada de registro | ip pim register-stop-rate-limit rate-limit-value [ vrf vrf-name ] | Obrigatório Por padrão, não limite a taxa de envio do pacote de parada de registro. |
Para melhorar a robustez de toda a rede PIM-SM, sugere-se limitar a taxa do pacote de parada do registrador de origem em todos os RPs.
Configurar o endereço de origem do pacote de registro
Quando o DR de origem realiza o registro de origem, o endereço de origem do pacote de registro utiliza o endereço IP da interface de registro registrado automaticamente pelo sistema. O comando pode especificar o endereço de origem do pacote de registro como o endereço IP de uma interface no dispositivo para atender a alguma demanda especial da rede.
Tabela 7 – 10 Configure o endereço de origem do pacote de registro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o endereço de origem do pacote de registro | ip pim register-source interface interface-name [ vrf vrf-name ] | Obrigatório Por padrão, use o endereço IP da interface de registro registrada automaticamente pelo sistema como o endereço de origem do pacote de registro. |
Configurar Filtro de Pacotes de Registro
Para evitar o ataque de registro de origem, você pode usar o ACL no RP para executar o filtro de origem multicast para o pacote de registro. Somente a fonte multicast permitida pelo ACL pode registrar-se com sucesso no RP.
Tabela 7 – 11 Configurar o filtro de pacotes de registro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o filtro de pacotes de registro | ip pim accept-register list { access-list-number | acees-list-name } [ vrf vrf-name ] | Obrigatório Por padrão, não filtre o pacote de registro. |
Configurar os parâmetros do vizinho PIM-SM
Condição de configuração
Antes de configurar os parâmetros do vizinho PIM-SM, primeiro complete as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Habilite o protocolo PIM-SM
Configurar período de envio de pacotes Hello
A interface habilitada com o protocolo PIM envia periodicamente os pacotes Hello para configurar e manter o vizinho PIM.
Tabela 7 – 12 Configure o período de envio do pacote Hello
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o período de envio do pacote Hello | ip pim hello-interval interval-value | Opcional Por padrão, o período de envio do pacote Hello é de 30s. |
Configurar o tempo de atividade do vizinho
Quando a interface recebe os pacotes Hello de um vizinho, registre o holdtime transportado no pacote Hello como o tempo keepalive do vizinho. Se não receber o pacote Hello do vizinho dentro do tempo de keepalive, considera-se que o vizinho se torna inválido.
Tabela 7 – 13 Configure o tempo de atividade do vizinho PIM-SM
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o tempo de atividade do vizinho PIM-SM | ip pim hello-holdtime holdtime-value | Opcional Por padrão, o tempo de atividade do vizinho PIM-SM é 105s. |
Configurar filtro vizinho
Se houver muitos vizinhos PIM em uma sub-rede, você pode usar a função de filtro vizinho para configurar o vizinho seletivamente, de modo a economizar os recursos do dispositivo.
Tabela 7 – 14 Configurar o filtro vizinho
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o filtro vizinho | ip pim neighbor-filter { access-list-number | acees-list-name } | Obrigatório Por padrão, não habilite a função de filtro vizinho. |
Configurar prioridade de DR
O DR desempenha um papel importante na rede PIM-SM, portanto, é importante selecionar o DR apropriado. Você pode selecionar o dispositivo apropriado como DR configurando a prioridade de DR.
Uma sub-rede PIM-SM permite apenas um DR. De acordo com a função, o DR pode ser dividido em DR de origem e DR de recebimento.
A principal função do DR de origem é realizar o registro de origem para RP.
A principal função do DR receptor é adicionar ao RP e configurar a comutação de RPT e SPT.
Tabela 7 – 15 Configurar a prioridade de DR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a prioridade de DR | ip pim dr-priority priority-value | Opcional Por padrão, a prioridade de DR é 1. |
Regras de eleição do DR: Compare as prioridades. Quanto maior o valor, maior a prioridade. Aquele com maior prioridade vence. Se a prioridade for a mesma, vence aquele com o maior endereço IP.
Configurar comutação PIM-SM SPT
Condição de configuração
Antes de configurar o SPT, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Habilite o protocolo PIM-SM
Configurar condição de comutação SPT
O DR da extremidade receptora não conhece o endereço da fonte multicast, portanto, só pode adicionar ao RP para formar o RPT. O DR de origem realiza o registro de origem para RP e forma a árvore de origem entre o DR de origem e o RP. Inicialmente, a direção do fluxo multicast é da fonte multicast para o RP e depois do RP para o receptor. Quando o DR da extremidade receptora recebe o primeiro pacote multicast, ele realiza a adição à fonte multicast, forma SPT e executa a poda para RPT. Isso é chamado de comutação SPT.
O comando é configurar a condição de comutação SPT na extremidade receptora DR.
Tabela 7 – 16 Configure a condição de comutação SPT
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a condição de comutação SPT | ip pim spt-threshold infinity [ group-list { access-list-number | acees-list-name } ] [ vrf vrf-name ] | Obrigatório Por padrão, todos os grupos multicast realizam a comutação SPT. |
Não configure o SPT nunca comutando no RP. Caso contrário, pode resultar na falha do encaminhamento multicast.
Configurar PIM-SSM
PIM-SSM é um subconjunto de PIM-SM. No PIM-SSM, não é necessário RP, BSR ou RPT, e não há comutação SPT, mas o DR da extremidade receptora adiciona diretamente à origem multicast e configura a árvore do caminho mais curto (SPT) com a origem como raiz.
Condição de configuração
Antes de configurar o PIM-SSM, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Habilite o protocolo PIM-SM em todas as interfaces que precisam de encaminhamento de rota multicast
Configurar PIM-SSM
Tabela 7 – 17 Configurar PIM-SSM
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar PIM-SSM | ip pim ssm { default | range { access-list-number | acees-list-name } } [ vrf vrf-name ] | Obrigatório Por padrão, a função SSM está desabilitada. |
Ao usar o PIM-SSM, a extremidade receptora deve habilitar o IGMPv3. Quando o receptor não pode ser atualizado para IGMPv3, você pode usar a função IGMP SSM Mapping para cooperar com o PIM-SSM. Certifique-se de que os intervalos de endereços do grupo multicast SSM configurados em todos os dispositivos no domínio sejam consistentes. Caso contrário, pode resultar na anormalidade do PIM-SS.
Configurar a política de controle do PIM-SM
Configurar a mudança de status de DR relacionada à interface
Não DR habilita o encaminhamento multicast L2 e interrompe o encaminhamento multicast L3. DR não é afetado.
Tabela 7 - 18 Configurar a prioridade de DR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a prioridade de DR | ip pim drchg-attention | Por padrão, é o encaminhamento multicast L3. |
Configurar a interface para suprimir o pacote PIM-JION
Configure a interface para suprimir o pacote PIM-JOIN.
Tabela 7 - 19 Configure a interface para suprimir o pacote PIM-JOIN.
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure a interface para suprimir o pacote PIM-JOIN. | ip pim join-suppression | Por padrão, não suprima o pacote PIM-JOIN da interface. |
Configurar PIM-SM BFD
Condições de configuração
Antes de configurar o PIM-SM BFD, primeiro complete a seguinte tarefa:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
Configurar PIM-SM BFD
Tabela 7 - 20 Configurar PIM-SM BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar PIM-SM BFD | ip pim bfd | Por padrão, não habilite a função PIM-SM BFD. |
Monitoramento e Manutenção do PIM-SM
Tabela 7 - 21 Monitoramento e manutenção do PIM-SM
| Comando | Descrição |
| clear ip pim bsr rp-set [ vrf vrf-name ] | Limpe as informações do conjunto RP do PIM-SM |
| clear ip pim mroute [ group-address [ source-address ] ] [ vrf vrf-name ] | Limpe as informações de rota multicast do PIM-SM |
| clear ip pim statistics [ interface interface-name | vrf vrf-name ] | Limpe as informações estáticas dos pacotes do protocolo PIM-SM |
| show ip pim bsr-router [ vrf vrf-name ] | Exibir as informações de rota de bootstrap do PIM-SM |
| show ip pim interface [ [ interface-name ] detail ] [ vrf vrf-name ] | Exibir as informações da interface PIM-SM |
| show ip pim local-members [ interface-name | vrf vrf-name ] | Exibir as informações do membro do grupo local PIM-SM |
| show ip pim mroute [ ssm | group group-ip-address [ source source-ip-address ] | source source-ip-address ] [ vrf vrf-name ] | Exiba as informações da tabela de rotas multicast PIM-SM |
| show ip pim neighbor [ detail ] [ vrf vrf-name ] | Exiba as informações do vizinho PIM-SM |
| show ip pim nexthop [ ip-address ] [ vrf vrf-name ] | Exiba as informações do roteador de próximo salto PIM-SM |
| show ip pim rp mapping [ vrf vrf-name ] | Exibir as informações do PIM-SM RP |
| show ip pim rp-hash group-address [ vrf vrf-name ] | Exiba a informação RP do mapeamento do grupo multicast |
| show ip pim statistics [ vrf vrf-name ] | Exibe as informações estatísticas dos pacotes do protocolo PIM-SM |
Exemplo de configuração típica do PIM-SM
Configurar funções básicas do PIM-SM
Requisitos de rede
- Toda a rede executa o protocolo PIM-SM.
- Receiver1 e Receiver2 são os dois receptores da rede final Device3.
- Device1 e Device2 são C-BSR e C-RP.
- Execute o IGMPv2 entre o Device3 e a rede final.
Topologia de rede
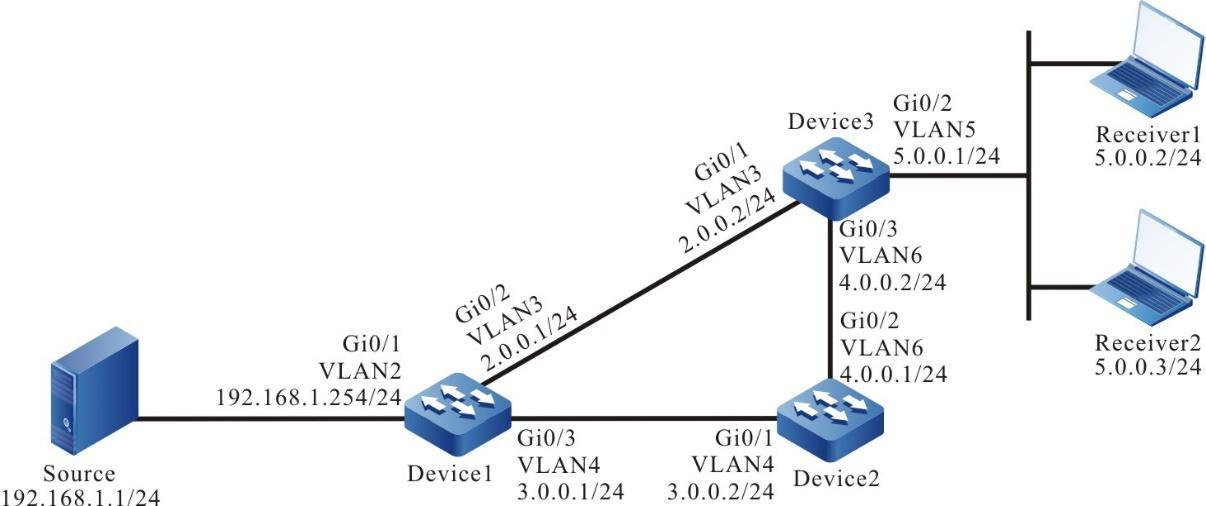
Figura 7 -1 Rede de configuração das funções básicas do PIM-SM
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (omitido)
- Passo 2:Habilite o protocolo de rota unicast OSPF para que todos os dispositivos na rede possam se comunicar uns com os outros.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 192.168.1.0 0.0.0.255 area 0Device1(config-ospf)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
#Visualize a tabela de rotas do Device3.
Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 14:48:47, vlan3O 3.0.0.0/24 [110/2] via 2.0.0.1, 14:31:14, vlan3[110/2] via 4.0.0.1, 14:31:04, vlan6C 4.0.0.0/24 is directly connected, 15:36:57, vlan6C 5.0.0.0/24 is directly connected, 14:09:18, vlan5O 192.168.1.0/24 [110/2] via 2.0.0.1, 00:30:55, vlan3
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 3:Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM na interface.
#Configurar dispositivo1.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device1(config)#ip multicast-routingDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ip pim sparse-modeDevice1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ip pim sparse-modeDevice1(config-if-vlan4)#exit
#Configurar dispositivo2.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device2(config)#ip multicast-routingDevice2(config)#interface vlan4Device2(config-if-vlan4)#ip pim sparse-modeDevice2(config-if-vlan4)#exitDevice2(config)#interface vlan6Device2(config-if-vlan6)#ip pim sparse-modeDevice2(config-if-vlan6)#exit
#Configurar dispositivo3.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device3(config)#ip multicast-routingDevice3(config)#interface vlan3Device3(config-if-vlan3)#ip pim sparse-modeDevice3(config-if-vlan3)#exitDevice3(config)#interface vlan5Device3(config-if-vlan5)#ip pim sparse-modeDevice3(config-if-vlan5)#exitDevice3(config)#interface vlan6Device3(config-if-vlan6)#ip pim sparse-modeDevice3(config-if-vlan6)#exit
# Visualize as informações da interface habilitada com o protocolo PIM-SM no Device3 e as informações do vizinho PIM-SM.
Device3#show ip pim interfacePIM Interface Table:PIM VRF Name: DefaultTotal 3 Interface entriesTotal 0 External Interface entryTotal 0 Sparse-Dense Mode Interface entryAddress Interface VIF Ver/ VIF Nbr DR DR BSR CISCO NeighborIndex Mode Flag Count Pri Border Neighbor Filter2.0.0.2 vlan3 0 v2/S UP 1 1 2.0.0.2 FALSE FALSE5.0.0.1 vlan5 2 v2/S UP 0 1 5.0.0.1 FALSE FALSE4.0.0.2 vlan6 3 v2/S UP 1 1 4.0.0.2 FALSE FALSEDevice3#show ip pim neighborPIM Neighbor Table:PIM VRF Name: DefaultTotal 2 Neighbor entriesNeighbor Interface Uptime/Expires Ver DRAddress Priority/Mode2.0.0.1 vlan3 01:12:00/00:01:39 v2 1 /4.0.0.1 vlan6 01:13:19/00:01:35 v2 1 /
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
#Visualize as informações IGMP da interface VLAN 5 do Device3.
Device3#show ip igmp interface vlan5Interface vlan5 (Index 50332250)IGMP Active, Querier (5.0.0.1)Default version 2IP router alert option in IGMP V2 msgs: EXCLUDEInternet address is 5.0.0.1IGMP query interval is 125 secondsIGMP querier timeout is 255 secondsIGMP max query response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsIGMP robustness variable is 2
Após configurar o protocolo multicast na interface, ative automaticamente a função IGMP e execute o IGMPv2 por padrão. Você pode configurar a versão IGMP em execução na interface executando o comando ip igmp version .
- Passo 4:Configure a interface vlan3 do Device1 como C-BSR e C-RP; configure a interface vlan 4 do Device2 como C-BSR e C-RP.
#Configurar dispositivo1.
Configure a interface vlan3 do Device1 como C-BSR e C-RP; a prioridade do C-BSR é 200; o intervalo do grupo multicast do serviço C-RP é 230.0.0.0/8.
Device1(config)#ip pim bsr-candidate vlan 3 10 200Device1(config)#ip access-list standard 1Device1(config-std-nacl)#permit 230.0.0.0 0.255.255.255Device1(config-std-nacl)#commitDevice1(config-std-nacl)#exitDevice1(config)#ip pim rp-candidate vlan 3 group-list 1
#Configurar dispositivo2.
Configure a interface vlan 4 do Device2 como C-BSR e C-RP; a prioridade de C-BSR é 0; o intervalo do grupo multicast do serviço C-RP do Device2 é 230.0.0.0/4.
Device2(config)#ip pim bsr-candidate vlan4Device2(config)#ip pim rp-candidate vlan4
#Visualize as informações de BSR e RP do Device3.
Device3#show ip pim bsr-routerPIMv2 Bootstrap informationPIM VRF Name: DefaultBSR address: 2.0.0.1BSR Priority: 200Hash mask length: 10Up time: 01:03:30Expiry time: 00:01:46Role: Non-candidate BSRState: Accept PreferredDevice3#show ip pim rp mappingPIM Group-to-RP Mappings Table:PIM VRF Name: DefaultTotal 2 RP set entriesTotal 2 RP entriesGroup(s): 224.0.0.0/4RP count: 1RP: 3.0.0.2Info source: 2.0.0.1, via bootstrap, priority 192Up time: 01:03:29Expiry time: 00:02:02Group(s): 230.0.0.0/8RP count: 1RP: 2.0.0.1Info source: 2.0.0.1, via bootstrap, priority 192Up time: 01:15:50Expiry time: 00:02:02
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido. Ao configurar vários C-BSRs em um domínio multicast, primeiro eleja o BSR de acordo com a prioridade e o C-BSR com a maior prioridade é eleito como BSR. Quando as prioridades dos C-BSRs são as mesmas, o C-BSR com o maior endereço IP é eleito como BSR. Ao configurar vários C-RPs em um domínio multicast e os intervalos do grupo multicast de serviço são os mesmos, calcule o RP do grupo multicast G de acordo com o algoritmo de hash. No domínio multicast, você pode configurar o RP por meio do comando ip pim rp-address , mas é necessário que os endereços RP estáticos configurados em todos os dispositivos no domínio multicast se mantenham consistentes.
- Passo 5:Confira o resultado.
# Receiver1 e Receiver2 enviam os relatórios de relação de membro IGMPv2 para adicionar ao grupo multicast 225.1.1.1, 230.1.1.1 respectivamente .
#Source envia os pacotes multicast com o grupo multicast 225.1.1.1, 230.1.1.1 .
#Exibe a tabela de membros multicast do Device3.
Device3#show ip igmp groupsIGMP Connected Group MembershipTotal 2 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires225.1.1.1 vlan5 00:56:48 00:02:39 5.0.0.2 stopped230.1.1.1 vlan5 00:56:48 00:02:46 5.0.0.3 stopped
#Visualize o RP do grupo multicast 225.1.1.1,230.1.1.1 no Device3.
Device3#show ip pim rp-hash 225.1.1.1PIM VRF Name: DefaultRP: 3.0.0.2Info source: 2.0.0.1, via bootstrapDevice3#show ip pim rp-hash 230.1.1.1PIM VRF Name: DefaultRP: 2.0.0.1Info source: 2.0.0.1, via bootstrap
#Visualize a tabela de rotas multicast do Device3.
Device3#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 2 (*,G) entriesTotal 2 (S,G) entriesTotal 2 (S,G,rpt) entriesTotal 0 FCR entryUp timer/Expiry timer(*, 225.1.1.1)Up time: 00:36:21RP: 3.0.0.2RPF nbr: 4.0.0.1RPF idx: vlan6Flags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan5Joined interface list:Asserted interface list:(192.168.1.1, 225.1.1.1)Up time: 00:36:02KAT time: 00:03:11RPF nbr: 4.0.0.1RPF idx: vlan6SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:vlan5Packet count 2517423(192.168.1.1, 225.1.1.1, rpt)Up time: 00:36:02RP: 3.0.0.2Flags:RPT JOIN DESIREDPRUNE DESIREDRPF SGRPT XG EQUALUpstream State: PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:vlan5(*, 230.1.1.1)Up time: 00:36:21RP: 2.0.0.1RPF nbr: 2.0.0.1RPF idx: vlan3Flags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan5Joined interface list:Asserted interface list:(192.168.1.1, 230.1.1.1)Up time: 00:36:02KAT time: 00:03:11RPF nbr: 2.0.0.1RPF idx: vlan3SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:vlan5Packet count 2517712(192.168.1.1, 230.1.1.1, rpt)Up time: 00:36:02RP: 2.0.0.1Flags:RPT JOIN DESIREDRPF SGRPT XG EQUALUpstream State: NOT PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:
#Receiver1 só pode receber o pacote de serviço multicast com o grupo multicast 225.1.1.1 enviado pela Origem. Receiver2 só pode receber o pacote de serviço multicast com o grupo multicast 230.1.1.1 enviado pela Origem.
O método de visualização de Device1 e Device2 é o mesmo de Device3, portanto o processo de visualização é omitido. Por padrão, o dispositivo habilita a comutação SPT.
Configurar PIM-SSM
Requisitos de rede
- Toda a rede executa o protocolo PIM-SSM.
- O receptor é um receptor da rede final Device3.
- Execute o IGMPv3 entre o Device3 e a rede final.
Topologia de rede
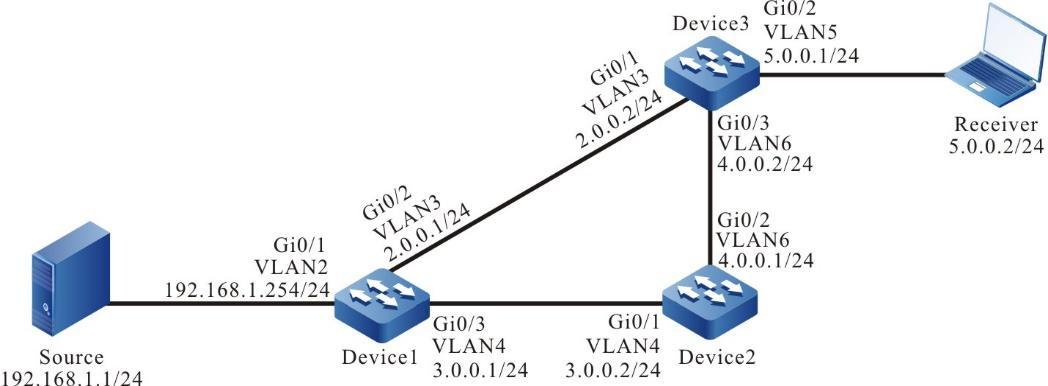
Figura 7 -2 Rede de configuração do PIM-SSM
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (omitido)
- Passo 2:Habilite o protocolo de rota unicast OSPF para que todos os dispositivos na rede possam se comunicar uns com os outros.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 192.168.1.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
#Visualize a tabela de rotas do Device3.
Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 14:48:47, vlan3O 3.0.0.0/24 [110/2] via 2.0.0.1, 14:31:14, vlan3[110/2] via 4.0.0.1, 14:31:04, vlan6C 4.0.0.0/24 is directly connected, 15:36:57, vlan6C 5.0.0.0/24 is directly connected, 14:09:18, vlan5O 192.168.1.0/24 [110/2] via 2.0.0.1, 00:30:55, vlan3
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 3:Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM na interface.
#Configurar dispositivo1.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device1(config)#ip multicast-routingDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ip pim sparse-modeDevice1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ip pim sparse-modeDevice1(config-if-vlan4)#exit
#Configurar dispositivo2.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device2(config)#ip multicast-routingDevice2(config)#interface vlan4Device2(config-if-vlan4)#ip pim sparse-modeDevice2(config-if-vlan4)#exitDevice2(config)#interface vlan6Device2(config-if-vlan6)#ip pim sparse-modeDevice2(config-if-vlan6)#exit
#Configurar dispositivo3.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device3(config)#ip multicast-routingDevice3(config)#interface vlan3Device3(config-if-vlan3)#ip pim sparse-modeDevice3(config-if-vlan3)#exitDevice3(config)#interface vlan5Device3(config-if-vlan5)#ip pim sparse-modeDevice3(config-if-vlan5)#exitDevice3(config)#interface vlan6Device3(config-if-vlan6)#ip pim sparse-modeDevice3(config-if-vlan6)#exit
# Visualize as informações da interface habilitada com o protocolo PIM-SM no Device3 e as informações do vizinho PIM-SM.
Device3#show ip pim interfacePIM Interface Table:PIM VRF Name: DefaultTotal 3 Interface entriesTotal 0 External Interface entryTotal 0 Sparse-Dense Mode Interface entryAddress Interface VIF Ver/ VIF Nbr DR DR BSR CISCO NeighborIndex Mode Flag Count Pri Border Neighbor Filter2.0.0.2 vlan3 3 v2/S UP 1 1 2.0.0.2 FALSE FALSE5.0.0.1 vlan5 0 v2/S UP 0 1 5.0.0.1 FALSE FALSE4.0.0.2 vlan6 2 v2/S UP 1 1 4.0.0.2 FALSE FALSEDevice3#show ip pim neighborPIM Neighbor Table:PIM VRF Name: DefaultTotal 2 Neighbor entriesNeighbor Interface Uptime/Expires Ver DRAddress Priority/Mode2.0.0.1 vlan3 01:12:00/00:01:39 v2 1 /4.0.0.1 vlan6 01:13:19/00:01:35 v2 1 /
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 4:Configure o PIM-SSM em todos os dispositivos; o intervalo do grupo multicast do serviço SSM é 232.0.0.0/8. vlan 5 de Device3 executa IGMPv3.
#Configurar dispositivo1.
Device1(config)#ip pim ssm default#Configurar dispositivo2.
Device2(config)#ip pim ssm default#Configurar dispositivo3.
Device3(config)#ip pim ssm defaultDevice3(config)#interface vlan5Device3(config-if-vlan5)#ip igmp version 3Device3(config-if-vlan5)#exit
# Visualize as informações IGMP da interface VLAN 5 do Device3.
Device3#show ip igmp interface vlan5Interface vlan5 (Index 50332250)IGMP Enabled, Active, Querier (5.0.0.1)Configured for version 3IP router alert option in IGMP V2 msgs: EXCLUDEInternet address is 5.0.0.1IGMP query interval is 125 secondsIGMP querier timeout is 255 secondsIGMP max query response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsIGMP robustness variable is 2
- Passo 5:Confira o resultado.
#Receiver envia o relatório de relação de membro IMGPv3 do grupo de origem especificado para adicionar ao grupo multicast 232.1.1.1; a fonte de multicast especificada é 192.168.1.1
#Source envia os pacotes multicast com o grupo multicast 232.1.1.1 .
#Exibe a tabela de membros multicast do Device3.
Device3#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires232.1.1.1 vlan5 00:11:14 stopped 5.0.0.2 stopped stoppedDevice3#show ip igmp groups detailInterface: vlan5Group: 232.1.1.1Uptime: 00:11:20Group mode: IncludeLast reporter: 5.0.0.2TIB-A Count: 1TIB-B Count: 0Group source list: (R - Remote, M - SSM Mapping)Source Address Uptime v3 Exp M Exp Fwd Flags192.168.1.1 00:11:20 00:03:28 stopped Yes R
#Visualize a tabela de rotas multicast do Device3.
Device3#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 0 (*,G) entryTotal 1 (S,G) entryTotal 0 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(192.168.1.1, 232.1.1.1)Up time: 12:59:27KAT time: 00:03:20RPF nbr: 2.0.0.1RPF idx: vlan3SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Vlan5Joined interface list:Asserted interface list:Outgoing interface list:Vlan5Packet count 109783214
# O receptor só pode receber o pacote de serviço multicast com o grupo multicast 232.1.1.1 enviado pela Origem.
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido. O intervalo de grupo multicast padrão do PIM-SSM é 232.0.0.0/8. Você pode modificar o intervalo do grupo multicast do serviço 232.0.0.0/8 por meio do comando ip pim ssm range . Para o grupo multicast G que atende à condição SSM, a tabela de rotas multicast não gera a entrada (*,G), mas apenas gera a entrada (S,G).
Configurar o controle de encaminhamento multicast PIM-SM
Requisitos de rede
- Toda a rede executa o protocolo PIM-SM.
- O receptor é um receptor da rede final Device3.
- Device2 é C-BSR e C-RP.
- Em Device2 e Device3, controle a fonte multicast, fazendo com que o Receiver receba apenas o pacote de serviço multicast enviado por Source1.
- Execute o IGMPv2 entre o Device3 e a rede final.
Topologia de rede
Figura 7 -3 Rede de configuração do controle de encaminhamento multicast PIM-SM
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (omitido)
- Passo 2:Habilite o protocolo de rota unicast OSPF para que todos os dispositivos na rede possam se comunicar uns com os outros.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 10.0.0.0 0.0.255.255 area 0Device1(config-ospf)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
#Visualize a tabela de rotas do Device3.
Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 15:51:07, vlan6O 3.0.0.0/24 [110/2] via 2.0.0.1, 15:33:34, vlan6[110/2] via 4.0.0.1, 15:33:24, vlan8C 4.0.0.0/24 is directly connected, 16:39:17, vlan8C 5.0.0.0/24 is directly connected, 15:11:38, vlan9O 10.0.0.0/24 [110/2] via 2.0.0.1, 00:06:32, vlan6O 10.0.1.0/24 [110/2] via 2.0.0.1, 00:06:32, vlan6O 10.0.2.0/24 [110/2] via 2.0.0.1, 00:06:32, vlan6O 10.0.3.0/24 [110/2] via 2.0.0.1, 00:06:32, vlan6
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 3:Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM na interface.
#Configurar dispositivo1.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device1(config)#ip multicast-routingDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ip pim sparse-modeDevice1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ip pim sparse-modeDevice1(config-if-vlan4)#exitDevice1(config)#interface vlan5Device1(config-if-vlan5)#ip pim sparse-modeDevice1(config-if-vlan5)#exitDevice1(config)#interface vlan6Device1(config-if-vlan6)#ip pim sparse-modeDevice1(config-if-vlan6)#exitDevice1(config)#interface vlan7Device1(config-if-vlan7)#ip pim sparse-modeDevice1(config-if-vlan7)#exit
#Configurar dispositivo2.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device2(config)#ip multicast-routingDevice2(config)#interface vlan7Device2(config-if-vlan7)#ip pim sparse-modeDevice2(config-if-vlan7)#exitDevice2(config)#interface vlan8Device2(config-if-vlan8)#ip pim sparse-modeDevice2(config-if-vlan8)#exit
#Configurar dispositivo3.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device3(config)#ip multicast-routingDevice3(config)#interface vlan6Device3(config-if-vlan6)#ip pim sparse-modeDevice3(config-if-vlan6)#exitDevice3(config)#interface vlan8Device3(config-if-vlan8)#ip pim sparse-modeDevice3(config-if-vlan8)#exitDevice3(config)#interface vlan9Device3(config-if-vlan9)#ip pim sparse-modeDevice3(config-if-vlan9)#exit
# Visualize as informações da interface habilitada com o protocolo PIM-SM no Device3 e as informações do vizinho PIM-SM.
Device3#show ip pim interfacePIM Interface Table:PIM VRF Name: DefaultTotal 3 Interface entriesTotal 0 External Interface entryTotal 0 Sparse-Dense Mode Interface entryAddress Interface VIF Ver/ VIF Nbr DR DR BSR CISCO NeighborIndex Mode Flag Count Priority Border Neighbor Filter2.0.0.2 vlan6 2 v2/S UP 1 1 2.0.0.2 FALSE FALSE4.0.0.2 vlan8 0 v2/S UP 1 1 4.0.0.2 FALSE FALSE5.0.0.1 vlan9 3 v2/S UP 0 1 5.0.0.1 FALSE FALSEDevice3#show ip pim neighborPIM Neighbor Table:PIM VRF Name: DefaultTotal 2 Neighbor entriesNeighbor Interface Uptime/Expires Ver DRAddress Priority/Mode2.0.0.1 vlan6 00:50:29/00:01:19 v2 1 /4.0.0.1 vlan8 00:57:58/00:01:33 v2 1 /
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 4:Configure a vlan 7 do Device2 como C-BSR e C-RP de toda a rede e o intervalo do grupo multicast do serviço C-RP é 224.0.0.0/4.
#Configurar dispositivo2.
Device2(config)#ip pim bsr-candidate vlan7Device2(config)#ip pim rp-candidate vlan7
#Visualize as informações de BSR e RP do Device3.
Device3#show ip pim bsr-routerPIMv2 Bootstrap informationPIM VRF Name: DefaultBSR address: 3.0.0.2 BSR Priority: 0Hash mask length: 10Up time: 00:10:37Expiry time: 00:01:33Role: Non-candidate BSRState: Accept PreferredDevice3#show ip pim rp mappingPIM Group-to-RP Mappings Table:PIM VRF Name: DefaultTotal 1 RP set entryTotal 1 RP entryGroup(s): 224.0.0.0/4RP count: 1RP: 3.0.0.2Info source: 3.0.0.2, via bootstrap, priority 192Up time: 03:59:59Expiry time: 00:01:49
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 5:Em Device2 e Device3, controle para a fonte multicast, fazendo com que o Receiver receba apenas o pacote de serviço multicast enviado por Source1
#No Device2, configure a lista de acesso de mensagens de registro aceitas, filtrando a mensagem de registro de Source4.
Device2(config)#ip access-list standard 1Device2(config-std-nacl)#deny 10.0.3.0 0.0.0.255Device2(config-std-nacl)#permit anyDevice2(config-std-nacl)#commitDevice2(config-std-nacl)#exitDevice2(config)#ip pim accept-register list 1
#Na interface vlan 6 e vlan 8 do Device3, configure o ingresso ACL , filtrando os pacotes de serviço multicast do Source3.
Device3(config)#ip access-list extended 1001Device3(config-ext-nacl)#deny ip 10.0.2.0 0.0.0.255 224.0.0.0 31.255.255.255Device3(config-ext-nacl)#permit igmp any anyDevice3(config-ext-nacl)#permit pim any anyDevice3(config-ext-nacl)#permit ospf any anyDevice3(config-ext-nacl)#permit ip any anyDevice2(config-std-nacl)#commitDevice3(config-ext-nacl)#exitDevice3(config)#interface vlan6Device3(config-if-vlan6)#ip access-group 1001 inDevice3(config-if-vlan6)#exitDevice3(config)#interface vlan8Device3(config-if-vlan8)#ip access-group 1001 inDevice3(config-if-vlan8)#exit
#Na interface vlan 9 do Device3, configure o ingresso ACL , filtrando os pacotes de serviço multicast do Source2.
Device3(config)#ip access-list extended 1002Device3(config-ext-nacl)#deny ip 10.0.1.0 0.0.0.255 224.0.0.0 31.255.255.255Device3(config-ext-nacl)#permit igmp any anyDevice3(config-ext-nacl)#permit pim any anyDevice3(config-ext-nacl)#permit ip any anyDevice3(config-ext-nacl)#commitDevice3(config-ext-nacl)#exitDevice3(config)#interface vlan9Device3(config-if-vlan9)#ip access-group 1002 outDevice3(config-if-vlan9)#exit
- Passo 6:Confira o resultado.
#Receiver envia o relatório de relação de membro IMGPv2 para adicionar ao grupo multicast 225.1.1.1.
# Source1, Source2, Source3 e Source4 enviam os pacotes multicast com o grupo multicast 225.1.1.1 .
#Exibe a tabela de membros multicast do Device2.
Device2#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires225.1.1.1 vlan9 00:00:38 00:03:45 5.0.0.2 stopped
#Visualize a tabela de rotas multicast do Device3.
Device3#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 2 (S,G) entriesTotal 2 (S,G,rpt) entriesTotal 0 FCR entryUp timer/Expiry timer(*, 225.1.1.1)Up time: 00:07:55RP: 3.0.0.2RPF nbr: 4.0.0.1RPF idx: vlan8Flags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Vlan9Joined interface list:Asserted interface list:(10.0.0.1, 225.1.1.1)Up time: 00:07:49KAT time: 00:03:17RPF nbr: 2.0.0.1RPF idx: vlan6SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:vlan9Packet count 268411(10.0.0.1, 225.1.1.1, rpt)Up time: 00:07:49RP: 3.0.0.2Flags:RPT JOIN DESIREDPRUNE DESIREDRPF SGRPT XG EQUALUpstream State: PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:Vlan9(10.0.1.1, 225.1.1.1)Up time: 00:07:49KAT time: 00:03:17RPF nbr: 2.0.0.1RPF idx: vlan6SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:Vlan9Packet count 268237(10.0.1.1, 225.1.1.1, rpt)Up time: 00:07:49RP: 3.0.0.2Flags:RPT JOIN DESIREDPRUNE DESIREDRPF SGRPT XG EQUALUpstream State: PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:Vlan9
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
#Visualize a correspondência de ACL no Device2.
Device2#show ip access-list 1ip access-list standard 110 deny 10.0.3.0 0.0.0.255 32 matches20 permit any 2767 matches
#Visualize a correspondência de ACL no Device3.
Device3#show ip access-list 1001ip access-list extended 100110 deny ip 10.0.2.0 0.0.0.255 224.0.0.0 31.255.255.255 671545 matches20 permit igmp any any 19 matches30 permit pim any any 119 matches40 permit ospf any any 252 matches50 permit ip any any 1343339 matchesDevice3#show ip access-list 1002ip access-list extended 100210 deny ip 10.0.1.0 0.0.0.255 224.0.0.0 31.255.255.255 672358 matches20 permit igmp any any 10 matches30 permit pim any any 40 matches40 permit ip any any 672532 matches
#Receive end só pode receber os pacotes de serviço multicast enviados por Source1.
Ao executar o controle de origem multicast, é melhor configurar primeiro o controle de origem multicast e, em seguida , a origem multicast sob demanda , porque, por padrão, após receber o pacote de serviço multicast, o DR final receptor executa a comutação SPT. Se primeiro a origem de multicast sob demanda e, em seguida, executar o controle de encaminhamento de multicast, o controle de encaminhamento de multicast não terá função. Para evitar que o controle de encaminhamento multicast não funcione , você pode configurar não permitir a comutação SPT na extremidade receptora DR.
Configurar a convergência de comutação DR de PIM-SM e BFD Linkage
Requisitos de rede
- Toda a rede executa o protocolo PIM-SM.
- O receptor é um receptor da rede final Device3.
- Device2 e device3 estão localizados na rede stub do receptor e device3 é o receptor DR.
- A linha entre device2 e device3 habilita o PIM BFD. Quando a linha entre o dispositivo3 e o receptor falhar, o Dispositivo2 mudará rapidamente para o receptor DR.
Topologia de rede
Figura 7 -4 Rede de configuração da convergência de comutação DR de ligação PIM-SM e BFD
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (omitido)
- Passo 2:Habilite o protocolo de roteamento unicast OSPF, para que todos os dispositivos na rede possam se comunicar uns com os outros.
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 192.168.1.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
# Consulta a tabela de rotas do Device3.
Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 14:48:47, vlan3O 3.0.0.0/24 [110/2] via 2.0.0.1, 14:31:14, vlan3[110/2] via 4.0.0.1, 14:31:04, vlan4C 4.0.0.0/24 is directly connected, 15:36:57, vlan4O 192.168.1.0/24 [110/2] via 2.0.0.1, 00:30:55, vlan3
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 3:Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM na interface.
#Configurar dispositivo1.
Habilite o encaminhamento multicast globalmente e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device1(config)#ip multicast-routingDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan 3Device1(config-if-vlan3)#ip pim sparse-modeDevice1(config-if-vlan3)#exitDevice1(config)#interface vlan 4Device1(config-if-vlan4)#ip pim sparse-modeDevice1(config-if-vlan4)#exit
#Configurar dispositivo2.
Habilite o encaminhamento multicast globalmente e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device2(config)#ip multicast-routingDevice2(config)#interface vlan 4Device2(config-if-vlan4)#ip pim sparse-modeDevice2(config-if-vlan4)#exitDevice2(config)#interface vlan 5Device2(config-if-vlan5)#ip pim sparse-modeDevice2(config-if-vlan5)#exit
#Configurar dispositivo3.
Habilite o encaminhamento multicast globalmente e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device3(config)#ip multicast-routingDevice3(config)#interface vlan 3Device3(config-if-vlan3)#ip pim sparse-modeDevice3(config-if-vlan3)#exitDevice3(config)#interface vlan 4Device3(config-if-vlan4)#ip pim sparse-modeDevice3(config-if-vlan4)#exit
#Visualize as informações da interface no Dispositivo 3 habilitado com o protocolo PIM-SM e as informações de vizinhos do PIM-SM.
Device3#show ip pim interfacePIM Interface Table:PIM VRF Name: DefaultTotal 2 Interface entriesTotal 0 External Interface entryTotal 0 Sparse-Dense Mode Interface entryAddress Interface VIF Ver/ VIF Nbr DR DR BSR CISCO NeighborIndex Mode Flag CountPri Border Neighbor Filter2.0.0.2 vlan3 2 v2/S UP 1 1 2.0.0.2 FALSE FALSE4.0.0.2 vlan4 0 v2/S UP 1 1 4.0.0.2 FALSE FALSEDevice3#show ip pim neighborPIM Neighbor Table:PIM VRF Name: DefaultTotal 2 Neighbor entriesNeighborInterface Uptime/Expires VerDRAddress Priority/Mode4.0.0.1 vlan4 00:11:26/00:01:19 v2 1 /2.0.0.1 vlan3 00:05:57/00:01:18 v2 1 /
# Você pode ver que Device3 é o receptor DR da rede stub onde o receptor está localizado.
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 4: Configure C-BSR e C-RP.
#Configurar dispositivo1.
Configure a VLAN2 do Device1 como C-BSR e C-RP de toda a rede, e o intervalo do grupo multicast do serviço C-RP é 224.0.0.0/8.
Device1(config)#ip pim bsr-candidate vlan 2Device1(config)#ip pim rp-candidate vlan 2
# Visualize as informações de BSR e RP do Device3 .
Device3#show ip pim bsr-routerPIMv2 Bootstrap informationPIM VRF Name: DefaultBSR address: 192.168.1.254BSR Priority: 0Hash mask length: 10Up time: 00:00:17Expiry time: 00:01:56Role: Non-candidate BSRState: Accept PreferredDevice3#show ip pim rp mappingPIM Group-to-RP Mappings Table:PIM VRF Name: DefaultTotal 1 RP set entryTotal 1 RP entryGroup(s): 224.0.0.0/4RP count: 1RP: 192.168.1.254Info source: 192.168.1.254, via bootstrap, priority 192Up time: 00:00:16Expiry time: 00:02:14
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 5:Em Device2 e Device3, configure a ligação PIM e BFD.
#Configurar dispositivo2.
Device2(config)#interface vlan 5Device2(config-if-vlan5)#ip pim bfdDevice2(config-if-vlan5)#exit
#Configurar dispositivo3.
Device3(config)#interface vlan 4Device3(config-if-vlan4)#ip pim bfdDevice3(config-if-vlan4)#exit
# Consulta as informações da sessão BFD do Device3.
Device3#show bfd session detailTotal session number: 1OurAddr NeighAddr LD/RD State Holddown Interface4.0.0.2 4.0.0.1 5/1 UP 5000 vlan4Type:ipv4 directLocal State:UP Remote State:UP Up for: 0h:6m:39s Number of times UP:1Send Interval:1000ms Detection time:3000ms(1000ms*3)Local Diag:0 Demand mode:0 Poll bit:0MinTxInt:1000 MinRxInt:1000 Multiplier:5Remote MinTxInt:10 Remote MinRxInt:10 Remote Multiplier:3Registered protocols:PIMAgent session info:Sender:slot 2 Recver:slot 2
#Você pode ver que o PIM está associado ao BFD com sucesso.
O método de visualização do Device2 é o mesmo do Device3, portanto o processo de visualização é omitido.
- Passo 6: Confira o resultado.
#Receiver envia o relatório de associação IGMPv2 para ingressar no grupo multicast 225.1.1.1, e Source envia o pacote de serviço multicast com o grupo multicast 225.1.1.1.
# Veja o membro multicast tabelas em Device2 e Device3.
Device2#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires225.1.1.1 vlan5 00:00:56 00:03:25 4.0.0.3 stoppedDevice3#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires225.1.1.1 vlan4 00:00:02 00:04:17 4.0.0.3 stopped
# Visualize as tabelas de rotas multicast PIM-SM em Device2 e Device3.
Device2#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 0 (S,G) entryTotal 0 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(*, 225.1.1.1)Up time: 00:04:27RP: 192.168.1.254RPF nbr: 0.0.0.0RPF idx: NoneFlags:Upstream State: NOT JOINEDLocal interface list:vlan5Joined interface list:Asserted interface list:Device3#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 1 (S,G) entryTotal 1 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(*, 225.1.1.1)Up time: 00:02:10RP: 192.168.1.254RPF nbr: 2.0.0.1RPF idx: vlan3Flags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan4Joined interface list:Asserted interface list:(192.168.1.1, 225.1.1.1)Up time: 00:00:37KAT time: 00:02:53RPF nbr: 2.0.0.1RPF idx: vlan3SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:vlan4Packet count 0(192.168.1.1, 225.1.1.1, rpt)Up time: 00:00:37RP: 192.168.1.254Flags:RPT JOIN DESIREDRPF SGRPT XG EQUALUpstream State: NOT PRUNEDLocal interface list:Pruned interface list:Outgoing interface list
#Pode ser visto que o estado upstream da tabela de roteamento multicast PIM-SM do Device2 é NOT JOINED , o estado upstream da rota multicast Device3 é JOINED , e os pacotes de serviço multicast são encaminhados ao Receiver através do Device3.
#Quando a linha entre o Device3 e o Receptor falha, o BFD detecta e notifica rapidamente o protocolo PIM-SM, e o Device2 muda rapidamente para o receptor Dr.
#Visualize as informações do vizinho PIM-SM, as informações da sessão BFD e a tabela de rotas multicast PIM-SM do Device2.
Device2#show ip pim neighborPIM Neighbor Table:PIM VRF Name: DefaultTotal 1 Neighbor entryNeighbor Interface Uptime/Expires Ver DRAddress Priority/Mode3.0.0.1 vlan4 01:12:27/00:01:31 v2 1 /Device2#show bfd session detailTotal session number: 0Device2#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 1 (S,G) entryTotal 1 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(*, 225.1.1.1)Up time: 00:01:03RP: 192.168.1.254RPF nbr: 3.0.0.1RPF idx: vlan4Flags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan5Joined interface list:Asserted interface list:(192.168.1.1, 225.1.1.1)Up time: 00:00:42KAT time: 00:02:48RPF nbr: 3.0.0.1RPF idx: vlan4SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:vlan5Packet count 0(192.168.1.1, 225.1.1.1, rpt)Up time: 00:00:42RP: 192.168.1.254Flags:RPT JOIN DESIREDRPF SGRPT XG EQUALUpstream State: NOT PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:
# Visualize o vizinho PIM-SM, a sessão BFD e a tabela de rotas multicast do Device3.
Device3#show ip pim neighborPIM Neighbor Table:PIM VRF Name: DefaultTotal 1 Neighbor entryNeighbor Interface Uptime/Expires Ver DRAddress Priority/Mode2.0.0.1 vlan3 00:12:27/00:01:20 v2 1 /Device3#show bfd session detailTotal session number: 0Device3#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 0 (*,G) entryTotal 0(S,G) entryTotal 0 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer
# Pode-se ver que depois que o DR Device3 do receptor falha, a sessão BFD responde imediatamente e o Device2 muda para o DR do receptor. o pacote de serviço multicast é encaminhado ao Receptor através do Device2.
A vinculação de BFD e PIM também é aplicável ao cenário de campanha de ativos no segmento de rede compartilhado. Quando a interface do Assert Winner falha, o Assert Loser pode responder rapidamente e recuperar o encaminhamento de pacotes multicast.
Configurar RPF Convergência de comutação de rota de ligação PIM-SM e BFD
Requisitos de rede
- Toda a rede executa o protocolo PIM-SM.
- Device2 é C-BSR e C-RP.
- Toda a rede usa OSPF para interagir com a rota unicast.
- As funções de detecção PIM BFD e OSPF BFD são habilitadas para a linha entre Device1 e Device3. Depois que a linha falha, o BFD pode detectar e notificar rapidamente os protocolos PIM e OSPF, para que o vizinho RPF do Device3 para a fonte multicast possa alternar rapidamente para o Device2.
Topologia de rede
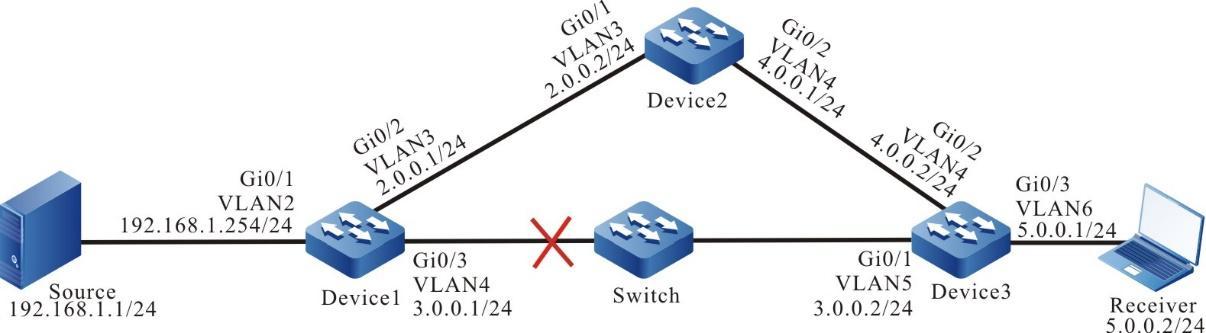
Figura 7 -5 Rede de configuração de comutação de rota RPF de ligação PIM-SM e BFD
Etapas de configuração
- Passo 1: Configure o endereço IP da interface. (omitido)
- Passo 2: Habilite o protocolo de roteamento unicast, para que todos os dispositivos na rede possam se comunicar uns com os outros.
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 192.168.1.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 5.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
# Consulta a tabela de rotas unicast de Device3.
Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 3.0.0.0/24 is directly connected, 00:01:40, vlan5C 4.0.0.0/24 is directly connected, 00:00:46, vlan4C 5.0.0.0/24 is directly connected, 03:45:18, vlan6C 127.0.0.0/8 is directly connected, 2d:08:42:01, lo0O 192.168.1.0/24 [110/2] via 3.0.0.1, 00:01:29, vlan5O 2.0.0.0/24 [110/2] via 4.0.0.1, 00:01:29, vlan4[110/2] via 3.0.0.1, 00:01:29, vlan5
Os métodos de visualização de Device1 e Device2 são os mesmos de Device3, portanto o processo de visualização é omitido.
- Passo 3:Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM na interface.
#Configurar dispositivo1.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device1(config)#ip multicast-routingDevice1(config)#interface vlan 2Device1(config-if-vlan2)#ip pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan 3Device1(config-if-vlan3)#ip pim sparse-modeDevice1(config-if-vlan3)#exitDevice1(config)#interface vlan 4Device1(config-if-vlan4)#ip pim sparse-modeDevice1(config-if-vlan4)#exit
#Configurar dispositivo2.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device2(config)#ip multicast-routingDevice2(config)#interface vlan 3Device2(config-if-vlan3)#ip pim sparse-modeDevice2(config-if-vlan3)#exitDevice2(config)#interface vlan 4Device2(config-if-vlan4)#ip pim sparse-modeDevice2(config-if-vlan4)#exit
#Configurar dispositivo3.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces relacionadas.
Device3(config)#ip multicast-routingDevice3(config)#interface vlan 4Device3(config-if-vlan4)#ip pim sparse-modeDevice3(config-if-vlan4)#exitDevice3(config)#interface vlan 6Device3(config-if-vlan6)#ip pim sparse-modeDevice3(config-if-vlan6)#exitDevice3(config)#interface vlan 5Device3(config-if-vlan5)#ip pim sparse-modeDevice3(config-if-vlan5)#exit
# Consulta as informações da interface no Device3 habilitado com o protocolo PIM-SM e as informações do vizinho PIM-SM.
Device3#show ip pim interfacePIM Interface Table:PIM VRF Name: DefaultTotal 3 Interface entriesTotal 0 External Interface entryTotal 0 Sparse-Dense Mode Interface entryAddress Interface VIF Ver/ VIF Nbr DR DR BSR CISCO NeighborIndex Mode Flag CountPri Border Neighbor Filter4.0.0.2 vlan4 0 v2/S UP 1 1 4.0.0.2 FALSE FALSE5.0.0.1 vlan6 2 v2/S UP 0 1 5.0.0.1 FALSE FALSE3.0.0.2 vlan5 3 v2/S UP 1 1 3.0.0.2 FALSE FALSEDevice3#show ip pim neighborPIM Neighbor Table:PIM VRF Name: DefaultTotal 2 Neighbor entriesNeighbor Interface Uptime/Expires Ver DRAddress Priority/Mode4.0.0.1 vlan4 00:05:26/00:01:20 v2 1 /3.0.0.1 vlan5 00:03:51/00:01:24 v2 1 /
- Passo 4: Configurar C-BSR e C-RP .
# Configurar dispositivo2.
Configure a VLAN3 do Device2 C-BSR e C-RP de toda a rede, e o intervalo do grupo multicast do serviço C-RP é 224.0.0.0/8.
Device2(config)#ip pim bsr-candidate vlan 3Device2(config)#ip pim rp-candidate vlan 3
# Consulta as informações de BSR e RP do Device3.
Device3#show ip pim bsr-routerPIMv2 Bootstrap informationPIM VRF Name: DefaultBSR address: 2.0.0.2BSR Priority: 0Hash mask length: 10Up time: 00:02:56Expiry time: 00:01:14Role: Non-candidate BSRState: Accept PreferredDevice3#show ip pim rp mappingPIM Group-to-RP Mappings Table:PIM VRF Name: DefaultTotal 1 RP set entryTotal 1 RP entryGroup(s): 224.0.0.0/4RP count: 1RP: 2.0.0.2Info source: 2.0.0.2, via bootstrap, priority 192Up time: 00:02:58Expiry time: 00:01:32
- Passo 5: Configure PIM, OSPF para vincular com BFD em Device1 e Device3.
# Configurar dispositivo1.
Device1(config)#interface vlan 4Device1(config-if-vlan4)#ip pim bfdDevice1(config-if-vlan4)#ip ospf bfdDevice1(config-if-vlan4)#exit
#Configurar dispositivo3.
Device3(config)#interface vlan 5Device3(config-if-vlan5)#ip pim bfdDevice3(config-if-vlan5)#ip ospf bfdDevice3(config-if-vlan5)#exit
# Consulta as informações da sessão BFD do Device3.
Device3#show bfd session detailTotal session number: 1OurAddr NeighAddr LD/RD State Holddown Interface3.0.0.2 3.0.0.1 5/2 UP 5000 vlan5Type:ipv4 directLocal State:UP Remote State:UP Up for: 0h:2m:35s Number of times UP:1Send Interval:1000ms Detection time:5000ms(1000ms*5)Local Diag:0 Demand mode:0 Poll bit:0MinTxInt:1000 MinRxInt:1000 Multiplier:5Remote MinTxInt:1000 Remote MinRxInt:1000 Remote Multiplier:5Registered protocols:OSPF PIMAgent session info:Sender:slot 1 Recver:slot 1
# Você pode ver que a sessão BFD entre Device1 e Device3 está estabelecida normalmente, e os protocolos OSPF e PIM estão associados com sucesso.
Os métodos de visualização do Device1 são os mesmos do Device3, portanto o processo de visualização é omitido.
- Passo 6: Confira o resultado.
#Receiver envia o relatório de associação IGMPv2 para ingressar no grupo multicast 225.1.1.1, e Source envia o pacote de serviço multicast com o grupo multicast 225.1.1.1.
# Veja o membro multicast tabela de Device3.
Device3#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires225.1.1.1 vlan6 02:55:24 00:04:18 5.0.0.3 stopped
# Consulta a tabela de rotas multicast PIM-SM do Device3 .
Device3#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 1 (S,G) entryTotal 1 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(*, 225.1.1.1)Up time: 02:57:30RP: 2.0.0.2RPF nbr: 4.0.0.1RPF idx: vlan4Flags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan6Joined interface list:Asserted interface list:(192.168.1.1, 225.1.1.1)Up time: 00:12:58KAT time: 00:03:03RPF nbr: 3.0.0.1RPF idx: vlan5SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:vlan6Packet count 620657(192.168.1.1, 225.1.1.1, rpt)Up time: 00:12:58RP: 2.0.0.2Flags:RPT JOIN DESIREDRPF SGRPT XG EQUALUpstream State: NOT PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:
##Você pode ver que o vizinho RPF do Device3 para a origem multicast é Device1, e a interface de entrada do pacote de serviço multicast é vlan5.
#Quando a linha entre Device1 e Device3 falha, o BFD detecta e notifica rapidamente os protocolos OSPF e PIM, o OSPF alterna a rota para Device2 para comunicação e notifica o protocolo PIM da mudança de rota unicast, o protocolo PIM alterna rapidamente para o vizinho RPF de fonte multicast.
#Visualize o vizinho PIM-SM e a tabela de rotas multicast do dispositivo3.
Apr 27 2016 06:59:26: %BFD-SESSION_DOWN-4: Session [destination address:3.0.0.1,source address:3.0.0.2,interface:vlan5,local-discriminator:4] DOWNDevice3#show ip pim neighborPIM Neighbor Table:PIM VRF Name: DefaultTotal 1 Neighbor entryNeighbor Interface Uptime/Expires Ver DRAddress Priority/Mode4.0.0.1 vlan4 00:34:40/00:01:37 v2 1 /Device3#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 1 (S,G) entryTotal 1 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(*, 225.1.1.1)Up time: 03:07:04RP: 2.0.0.2RPF nbr: 4.0.0.1RPF idx: vlan4Flags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan6Joined interface list:Asserted interface list:(192.168.1.1, 225.1.1.1)Up time: 00:22:32KAT time: 00:03:29RPF nbr: 4.0.0.1RPF idx: vlan4SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:vlan6Packet count 1127697(192.168.1.1, 225.1.1.1, rpt)Up time: 00:22:32RP:2.0.0.2Flags:RPT JOIN DESIREDRPF SGRPT XG EQUALUpstream State: NOT PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:vlan6
# Você pode ver que o vizinho RPF do Device3 para a fonte multicast é comutado para Device2, e a interface de entrada do pacote de serviço multicast é vlan4.
Como a convergência da rota RPF da ligação PIM e BFD depende da velocidade de convergência do roteamento unicast, o BFD também precisa se conectar com o protocolo de roteamento unicast OSPF relacionado.
MSDP
Visão geral
O RP na rede PIM-SM conhece apenas as informações de origem multicast no domínio multicast, mas na aplicação real, toda a rede é dividida em vários domínios multicast. No caso, o RP no domínio não pode saber as informações de origem multicast fora do domínio e o receptor não pode receber os pacotes multicast de outros domínios.
O MSDP (Multicast Source Discovery Protocol) fornece uma solução multicast entre domínios. O mecanismo MSDP transmite as informações de origem multicast do domínio multicast para o RP de outro domínio multicast, e o RP no outro domínio multicast pode iniciar a adição à fonte multicast do domínio multicast e configurar a árvore de distribuição multicast, de modo a realizar a transmissão entre domínios dos pacotes multicast.
Configuração da Função MSDP
Tabela 8 -1 lista de configuração da função MSDP
| Tarefa de configuração | |
| Configurar as funções básicas do MSDP | Configurar o par MSDP Desabilitar o peer MSDP |
| Configurar a conexão de peer MSDP | Configurar o par padrão do MSDP Configurar o grupo de malha MSDP |
| Configurar o pacote SA | Configurar o pacote de solicitação SA Configurar a política de filtro de pacote SA |
A interface Ethernet L3 não suporta a função MSDP .
Configure a conexão de peer MSDP através do peer MSDP entre os domínios multicast, formando um “mapa de interconexão MSDP”. Quando o ponto MSDP de um domínio perceber a nova origem multicast, encapsule as novas informações de origem multicast no pacote SA (Origem-Ativa) e envie para todos os pontos remotos configurando a conexão de ponto MSDP. Após o peer MSDP receber o pacote SA, o pacote SA que passa pelo RPF (Reverse Path Forwarding) é encaminhado. Com a retransmissão entre os peers MSDP, você pode transmitir a mensagem SA enviada por um RP para todos os outros RPs, realizando o compartilhamento das informações de origem multicast entre os domínios multicast.
Use o TCP como o protocolo de transmissão entre os peers MSDP. Use a confiabilidade do TCP para garantir que os pacotes do protocolo MSDP possam ser transmitidos ao peer remoto corretamente.
Antes de configurar o MSDP, primeiro conclua as seguintes tarefas:
Configure a conexão de peer MSDP entre o dispositivo local e o dispositivo remoto especificado. No dispositivo remoto, você também deve especificar o dispositivo local como o ponto de MSDP para que a conexão de mesmo nível possa ser configurada com êxito. Depois que a conexão de peer é configurada com sucesso, os peers interagem com os pacotes do protocolo MSDP por meio da conexão.
Tabela 8 -2 Configurar o peer MSDP
Ao configurar o primeiro peer MSDP, habilite automaticamente o protocolo MSDP.
O administrador pode desabilitar a conexão de peer MSDP especificada por meio do comando de acordo com a demanda da rede. Após desabilitar a conexão de peer MSDP, pare de interagir os pacotes de protocolo MSDP entre os peers MSDP.
Tabela 8 -3 Desabilitar o peer MSDP
Configurar par MSDP
Condição de configuração
Configurar par MSDP
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Configurar o par MSDP
ip msdp [ vrf vrf-name ] peer peer-ip-address [ connect-source interface-name ] [ remote-as as-number-value ]
Obrigatório Por padrão, o peer MSDP não está configurado.
Desabilitar peer MSDP
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Desabilitar o peer MSDP
ip msdp [ vrf vrf-name ] shutdown peer-ip-address
Obrigatório Por padrão, não desabilite o peer MSDP.
Configurar conexão de peer MSDP
Após o dispositivo receber o pacote SA, execute a verificação RPF. Os pacotes que passam na verificação são encaminhados para os outros peers que configuram a conexão de peer. Os pacotes que não passam na verificação RPF são descartados.
O peer padrão, grupo de malha pode omitir a especificação da verificação RPF do pacote SA entre os peers.
Condição de configuração
Antes de configurar o MSDP, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Configure o protocolo PIM-SM, realizando o multicast intra-domínio
- Configurar o par MSDP
Configurar o par padrão do MSDP
Ao especificar o peer MSDP padrão, você pode configurar o intervalo RP. Ao receber o pacote SA enviado pelo peer padrão e se o RP no pacote pertencer ao intervalo permitido, não execute a verificação RPF. Caso contrário, ainda execute a verificação RPF para o RP no pacote.
Tabela 8 -4 Configurar o par padrão do MSDP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o par padrão do MSDP | ip msdp [ vrf vrf-name ] default-peer peer-ip-address [ prefix-list prefix-list-name ] | Obrigatório Por padrão, o peer padrão do MSDP não está configurado. |
Configurar grupo de malha MSDP
Ao receber o pacote SA do peer no grupo, o dispositivo passa diretamente na verificação RPF e não encaminha o pacote SA para os outros peers do grupo, mas apenas encaminha para os peers fora do grupo. Isso pode reduzir a carga do dispositivo e evitar o encaminhamento repetido, de modo a economizar a largura de banda da rede.
Tabela 8 -5 Configurar o grupo de malha MSDP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o grupo de malha MSDP | ip msdp [ vrf vrf-name ] mesh-group mesh-group-name peer-ip-address | Obrigatório Por padrão, nenhum par é adicionado ao grupo de malha. |
Configurar pacote SA
Condição de configuração
Antes de configurar o MSDP, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Configure o protocolo PIM-SM, realizando o multicast intra-domínio
- Configurar o par MSDP
Configurar pacote de solicitação SA
Após configurar o pacote de solicitação SA no dispositivo, o dispositivo envia imediatamente o pacote de solicitação SA ao peer MSDP ao receber o novo pacote de adição do grupo multicast, de modo a reduzir o atraso de adição do grupo multicast.
Alguns RP não esperam ser conhecidos pelos receptores do outro domínio multicast não reconhecido. Você pode configurar a política de filtro do pacote de solicitação SA em todos os peers do domínio multicast ao qual o RP pertence. Responda apenas ao pacote de solicitação SA dos peers permitidos pela política.
Tabela 8 -6 Configurar o pacote de solicitação SA
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o envio do pacote de solicitação SA | ip msdp [ vrf vrf-name ] sa-request peer-ip-address | Obrigatório Por padrão, ao receber o novo pacote de adição do grupo multicast, o dispositivo não envia o pacote de solicitação SA ao peer MSDP, mas aguarda o pacote SA do próximo período. |
| Configure a política de filtro do pacote de solicitação SA recebido | ip msdp [ vrf vrf-name ] filter-sa-request peer-ip-address [ list access-list-number | access-list-name ] | Obrigatório Por padrão, não filtre o pacote de solicitação SA. |
ip msdp filter-sa-request suporta apenas a ACL padrão.
Configurar política de filtro de pacotes SA
Normalmente, o peer MSDP aceita os pacotes SA de todos os peers que passam na verificação RPF e encaminham para todos os peers fora do grupo de malha. O usuário pode configurar a política de filtro do pacote SA no peer conforme desejado, controlando os pacotes SA de ou enviados para o peer especificado. Ao receber ou encaminhar o pacote SA, o dispositivo filtra o grupo de origem multicast e o RP do pacote SA.
Tabela 8 -7 Configurar a política de filtro do pacote SA
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a política de filtro do pacote SA | ip msdp [ vrf vrf-name ] sa-filter { in | out } peer-ip-address [ list { access-list-name | access-list-number } ] [ rp-list { access-list-name | access-list-number } ] | Obrigatório Por padrão, não filtre o pacote SA. |
O parâmetro list de ip msdp sa-filter suporta apenas a ACL estendida. O parâmetro rp-list do ip msdp sa-filter suporta apenas a ACL padrão.
Monitoramento e manutenção do MSDP
Tabela 8 -8 Monitoramento e Manutenção do MSDP
| Comando | Descrição |
| clear ip msdp [ vrf vrf-name ] peer [ peer-ip-address ] | Limpar as informações do peer MSDP |
| clear ip msdp [ vrf vrf-name ] sa-cache [ group-ip-address ] | Limpe as informações do cache SA |
| clear ip msdp [ vrf vrf-name ] statistics [ peer-ip-address ] | Limpe as informações estatísticas dos pares MSDP |
| show ip msdp [ vrf vrf-name ] count [ as-number-value ] | Exiba as informações SA recebidas pelo MSDP do domínio AS |
| show ip msdp [ vrf vrf-name ] peer [ peer-ip-address [ accepted-SAs | advertised-SAs ] ] | Exibir as informações do peer MSDP |
| show ip msdp [ vrf vrf-name ] rpf [ peer-ip-address ] | Exibir as informações de rota do próximo salto do MSDP |
| show ip msdp [ vrf vrf-name ] sa-cache [ group-ip-address [ source-ip-address ] ] [ as-number-value ] | Exibir as informações de cache MSDP SA |
| show ip msdp [ vrf vrf-name ] summary | Exibir as informações de verão do par MSDP |
Exemplo de configuração típica do MSDP
Configurar Multicast de Domínio Inter-PIM-SM
Requisitos de rede
- Toda a rede inclui dois AS: AS100 e AS200. Execute o protocolo BGP entre Ass e use MBGP para interagir na rota multicast; no AS, execute o protocolo OSPF para interagir com a rota.
- O domínio multicast PIM-SM1 está localizado em AS100; o domínio multicast PIM-SM2 está localizado no AS200. Source é uma fonte multicast de PIM-SM1. Receptor é um receptor de PIM-SM2.
- Loopback1 de Device2 é C-BSR de PIM-SM1 e Loopback0 de Device2 é C-RP de PIM-SM1. Loopback1 de Device3 é C-BSR de PIM-SM2 e Loopback0 de Device3 é C-RP de PIM-SM2.
- Entre Device2 e Device3, configure a conexão de peer MSDP, de modo a realizar o encaminhamento entre domínios do pacote de serviço multicast, para que o Receptor possa receber o pacote de serviço multicast enviado pela Origem.
Topologia de rede
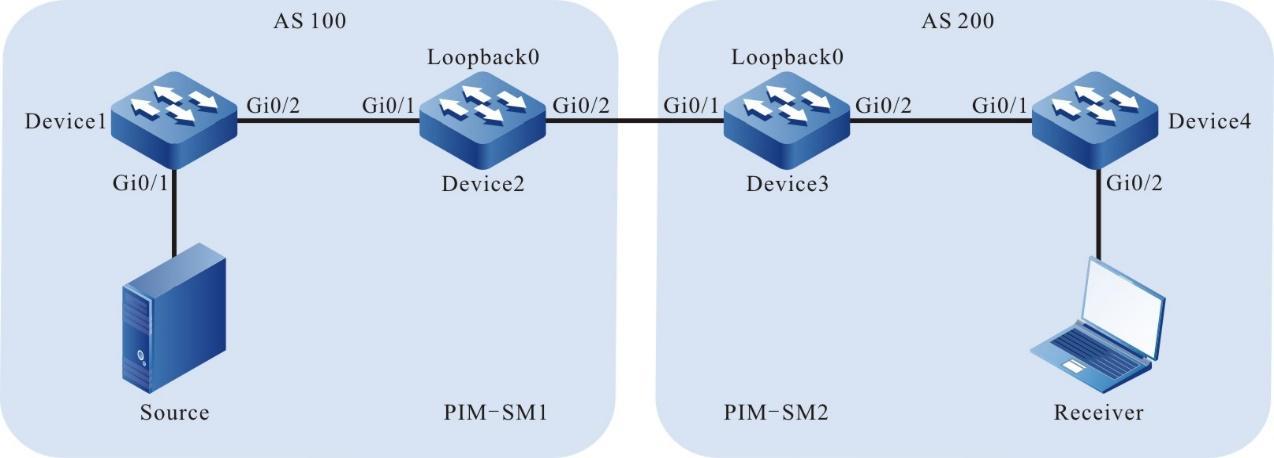
Figura 8 -1 Rede de configuração do multicast de domínio inter-PIM-SM
| Dispositivo | Interface | VLAN | Endereço de IP |
| Dispositivo1 | Gi0/1 Gi0/2 |
2 3 |
10.1.1.1/24 10.1.2.1/24 |
| Dispositivo2 | Gi0/1 | 3 | 10.1.2.2/24 |
| Dispositivo2 | Gi0/2 Loopback0 Loopback1 |
4 | 10.1.3.1/24 11.11.11.11/32 12.12.12.12/32 |
| Dispositivo3 | Gi0/1 Gi0/2 Loopback0 Loopback1 |
4 5 |
10.1.3.2/24 10.1.4.1/24 22.22.22.22/32 12.12.12.12/32 |
| Dispositivo 4 | Gi0/1 Gi0/2 |
5 6 |
10.1.4.2/24 10.1.5.1/24 |
| Fonte | 10.1.1.2/24 |
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. (omitido)
- Passo 2: Configure o endereço IP da interface. (omitido)
- Passo 3: Configure o OSPF para que todos os dispositivos no domínio AS possam se comunicar entre si.
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 10.1.1.0 0.0.0.255 area 0Device1(config-ospf)#network 10.1.2.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 10.1.2.0 0.0.0.255 area 0Device2(config-ospf)#network 11.11.11.11 0.0.0.0 area 0Device2(config-ospf)#network 12.12.12.12 0.0.0.0 area 0Device2(config-ospf)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 10.1.4.0 0.0.0.255 area 0Device3(config-ospf)#network 22.22.22.22 0.0.0.0 area 0Device3(config-ospf)#network 23.23.23.23 0.0.0.0 area 0Device3(config-ospf)#exit
#Configurar dispositivo4.
Device4#configure terminalDevice4(config)#router ospf 100Device4(config-ospf)#network 10.1.4.0 0.0.0.255 area 0Device4(config-ospf)#network 10.1.5.0 0.0.0.255 area 0Device4(config-ospf)#exit
#Visualize a tabela de rotas do Device1.
Device1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 10.1.1.0/24 is directly connected, 00:05:44, vlan2C 10.1.2.0/24 is directly connected, 22:24:35, vlan3O 11.11.11.11/32 [110/2] via 10.1.2.2, 01:21:25, vlan3O 12.12.12.12/32 [110/2] via 10.1.2.2, 01:19:25, vlan3
#Visualize a tabela de rotas do Device4.
Device4#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 10.1.4.0/24 is directly connected, 22:41:14, vlan5C 10.1.5.0/24 is directly connected, 00:08:11, vlan6O 22.22.22.22/32 [110/2] via 10.1.4.1, 01:23:33, vlan5O 23.23.23.23/32 [110/2] via 10.1.4.1, 01:19:33, vlan5
Você pode ver que Device1 e Device4 só aprendem as rotas do domínio AS pertencente.
O método de visualização de Device2 e Device3 é o mesmo de Device1, Device4, portanto o processo de visualização é omitido.
- Passo 4:Habilite globalmente o encaminhamento multicast, habilite o protocolo multicast PIM-SM na interface e configure C-BSR e C-RP.
#Configurar dispositivo1.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces.
Device1(config)#ip multicast-routingDevice1(config)#interface vlan 2Device1(config-if-vlan2)#ip pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan 3Device1(config-if-vlan3)#ip pim sparse-modeDevice1(config-if-vlan3)#exit
#Configurar dispositivo2.
Habilite globalmente o encaminhamento multicast, habilite o protocolo multicast PIM-SM na interface e configure Loopback 1 como C-BSR e Loopback0 como C-RP; o intervalo do grupo multicast do serviço C-RP é 224.0.0.0/4.
Device2(config)#ip multicast-routingDevice2(config)#interface loopback 0Device2(config-if-loopback0)#ip pim sparse-modeDevice2(config-if-loopback0)#exitDevice2(config)#interface loopback 1Device2(config-if-loopback1)#ip pim sparse-modeDevice2(config-if-loopback1)#exitDevice2(config)#interface vlan 3Device2(config-if-vlan3)#ip pim sparse-modeDevice2(config-if-vlan3)#exitDevice2(config)#interface vlan 4Device2(config-if-vlan4)#ip pim sparse-modeDevice2(config-if-vlan4)#exitDevice2(config)#ip pim bsr-candidate loopback1Device2(config)#ip pim rp-candidate loopback0
#Configurar dispositivo3.
Habilite globalmente o encaminhamento multicast, habilite o protocolo multicast PIM-SM na interface e configure Loopback 1 como C-BSR e Loopback 0 como C-RP; o intervalo do grupo multicast do serviço C-RP é 224.0.0.0/4.
Device3(config)#ip multicast-routingDevice3(config)#interface loopback 0Device3(config-if-loopback0)#ip pim sparse-modeDevice3(config-if-loopback0)#exitDevice3(config)#interface loopback 1Device3(config-if-loopback1)#ip pim sparse-modeDevice3(config-if-loopback1)#exitDevice3(config)#interface vlan 4Device3(config-if-vlan4)#ip pim sparse-modeDevice3(config-if-vlan4)#exitDevice3(config)#interface vlan 5Device3(config-if-vlan5)#ip pim sparse-modeDevice3(config-if-vlan5)#exitDevice3(config)#ip pim bsr-candidate loopback 1Device3(config)#ip pim rp-candidate loopback0
#Configurar dispositivo4.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM nas interfaces.
Device4(config)#ip multicast-routingDevice4(config)#interface vlan 5Device4(config-if-vlan5)#ip pim sparse-modeDevice4(config-if-vlan5)#exitDevice4(config)#interface vlan 6Device4(config-if-vlan6)#ip pim sparse-modeDevice4(config-if-vlan6)#exit
#Visualize as informações da interface habilitada com o protocolo PIM-SM no Device4 e as informações do vizinho PIM-SM.
Device4#show ip pim interfacePIM Interface Table:PIM VRF Name: DefaultTotal 3 Interface entriesTotal 0 External Interface entryTotal 0 Sparse-Dense Mode Interface entryAddress Interface VIF Ver/ VIF Nbr DR DR BSR CISCO NeighborIndex Mode Flag Count Pri Border Neighbor Filter10.1.4.2 register_vif0 1 v2/S UP10.1.4.2 vlan5 0 v2/S UP 1 1 10.1.4.2 FALSE FALSE10.1.5.1 vlan6 2 v2/S UP 0 1 10.1.5.1 FALSE FALSEDevice4#show ip pim neighborPIM Neighbor Table:PIM VRF Name: DefaultTotal 1 Neighbor entryNeighbor Interface Uptime/Expires Ver DRAddress Priority/Mode10.1.4.1 vlan5 23:03:12/00:01:20 v2 1 /
O método de visualização de Device1, Device2 e Device3 é o mesmo do Device4, portanto, o processo de visualização é omitido.
#Visualize as informações de BSR e RP do Device4.
Device4#show ip pim bsr-routerPIMv2 Bootstrap informationPIM VRF Name: DefaultBSR address: 23.23.23.23BSR Priority: 0Hash mask length: 10Up time: 01:57:44Expiry time: 00:01:28Role: Non-candidate BSRState: Accept PreferredDevice4#show ip pim rp mappingPIM Group-to-RP Mappings Table:PIM VRF Name: DefaultTotal 1 RP set entryTotal 1 RP entryGroup(s): 224.0.0.0/4RP count: 1RP: 22.22.22.22Info source: 23.23.23.23, via bootstrap, priority 192Up time: 01:57:45Expiry time: 00:01:47
#Visualize as informações de BSR e RP do Device1.
Device1#show ip pim bsr-routerPIMv2 Bootstrap informationPIM VRF Name: DefaultBSR address: 12.12.12.12BSR Priority: 0Hash mask length: 10Up time: 02:00:24Expiry time: 00:01:44Role: Non-candidate BSRState: Accept PreferredDevice1#show ip pim rp mappingPIM Group-to-RP Mappings Table:PIM VRF Name: DefaultTotal 1 RP set entryTotal 1 RP entryGroup(s): 224.0.0.0/4RP count: 1RP: 11.11.11.11Info source: 12.12.12.12, via bootstrap, priority 192Up time: 02:00:30Expiry time: 00:01:58
Você pode ver que há somente a informação BSR e RP do domínio multicast pertencente em Device4, Device1.
O método de visualização de Device2 e Device3 é o mesmo de Device1, Device4, portanto o processo de visualização é omitido.
- Passo 5: Configurar MP-EBGP. Configure o peer EBGP conectado diretamente entre Device2 e Device3 e use o MBGP para interagir com a rota multicast.
#Configurar dispositivo2.
Configure a configuração do peer EBGP conectado diretamente com Device3, habilite a pilha de endereços Multicast e anuncie a rota multicast.
Device2(config)#router bgp 100Device2(config-bgp)#neighbor 10.1.3.2 remote-as 200Device2(config-bgp)#address-family ipv4 multicastDevice2(config-bgp-af)#network 10.1.1.0 255.255.255.0Device2(config-bgp-af)#network 11.11.11.11 255.255.255.255Device2(config-bgp-af)#neighbor 10.1.3.2 activateDevice2(config-bgp-af)#exit-address-familyDevice2(config-bgp)#exit
#Configurar dispositivo3.
Configure a configuração do peer EBGP conectado diretamente com Device2, habilite a pilha de endereços Multicast e anuncie a rota multicast.
Device3(config)#router bgp 200Device3(config-bgp)#neighbor 10.1.3.1 remote-as 100Device3(config-bgp)#address-family ipv4 multicastDevice3(config-bgp-af)#network 10.1.5.0 255.255.255.0Device3(config-bgp-af)#network 22.22.22.22 255.255.255.255Device3(config-bgp-af)#neighbor 10.1.3.1 activateDevice3(config-bgp-af)#exit-address-familyDevice3(config-bgp)#exit
#Visualize o status do vizinho BGP do Device3.
Device3#show ip bgp summaryBGP router identifier 22.22.22.22, local AS number 200BGP table version is 22 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd10.1.3.1 4 100 114 111 2 0 0 01:35:00 0Total number of neighbors 1
De acordo com o número exibido na lista State/PfxRcd (o número dos prefixos de rota unicast recebidos do vizinho), podemos ver que o vizinho BGP está configurado com sucesso entre Device3 e Device2.
#Visualize a tabela de rotas BGP Multicast do Device3.
Device3#show bgp ipv4 multicastBGP table version is 9, local router ID is 22.22.22.22Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteNetwork Next Hop Metric LocPrf Weight Path[B]*> 10.1.1.0/24 10.1.3.1 2 0 100 i[B]*> 10.1.5.0/24 10.1.4.2 2 32768 i[B]*> 11.11.11.11/32 10.1.3.1 0 0 100 i[B]*> 22.22.22.22/32 0.0.0.0 0 32768 i
Você pode ver que Device3 aprende as rotas de origem e RP do domínio multicast PIM-SM1 e o próximo salto é o par MSDP 10.1.3.1.
O método de visualização do Device2 é o mesmo do Device3, portanto o processo de visualização é omitido.
- Passo 6: Configurar MSDP.
#Configurar dispositivo2.
Configure a configuração do peer EBGP conectado diretamente com Device3; habilitar a função de enviar ativamente o pacote de solicitação SA para o peer especificado; configure usando a regra RFC3618 para executar a verificação RPF do pacote MSDP.
Device2(config)#ip msdp peer 10.1.3.2 remote-as 200Device2(config)#ip msdp sa-request 10.1.3.2Device2(config)#ip msdp rpf rfc3618
#Configurar dispositivo3.
Configure a configuração do peer EBGP conectado diretamente com Device2; habilitar a função de enviar ativamente o pacote de solicitação SA para o peer especificado; configure usando a regra RFC3618 para executar a verificação RPF do pacote MSDP.
Device3(config)#ip msdp peer 10.1.3.1 remote-as 100Device3(config)#ip msdp sa-request 10.1.3.1Device3(config)#ip msdp rpf rfc3618
#Visualize o status de conexão do peer MSDP e os detalhes do Device3.
Device3#show ip msdp summaryMSDP Peer Status SummaryTotal 1 Peer entryPeer Address AS State Reset Uptime/Downtime10.1.3.1 100 Up 0 02:21:18Device3#show ip msdp peerMSDP Peer Table:Total 1 Peer entryMSDP Peer 10.1.3.1, AS 100 (configured AS)Connection status:State: Established, Resets: 0, Connection source: none configuredUptime(Downtime): 02:50:00, Message sent/received: 136/161Connection and counters cleared 02:13:25 agoLocal Address of connection: 10.1.3.2Remote Address of connection: 10.1.3.1Local Port: 639, Remote Port: 1179SA-Requests:Input filter: noneSending SA-Requests to peer: enabledSA:Input filter: noneMessage counters:RPF Failure count: 0SA Messages in/out: 47/0SA Requests in/out: 0/3SA Responses in/out: 3/0Data Packets in/out: 0/0
Você pode ver que a conexão de peer MSDP está configurada com sucesso entre Device3 e Device2.
O método de visualização do Device2 é o mesmo do Device3, portanto o processo de visualização é omitido.
- Passo 7: Confira o resultado.
#Receiver envia o pacote de relatório do membro IGMPv2 para adicionar ao grupo multicast 225.1.1.1; A origem envia o pacote de serviço multicast com o grupo multicast 225.1.1.1.
#Visualize a tabela de membros multicast no Device4.
Device4#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires225.1.1.1 vlan6 00:05:11 00:02:38 10.1.5.2 stopped
#Visualize as informações de cache MSDP SA do Device2.
Device2#show ip msdp sa-cacheMSDP Source-Active Cache - 1 entries(10.1.1.2, 225.1.1.1), RP 11.11.11.11, Originated, 00:11:45/00:05:39
Você pode ver que Device2 gera e armazena em cache o pacote SA. O endereço de origem multicast no pacote SA é 10.1.1.2; o endereço do grupo multicast é 225.1.1.1; o endereço RP é 11.11.11.11.
#Visualize as informações de cache MSDP SA e a tabela de verificação RPF do Device3.
Device3#show ip msdp sa-cacheMSDP Source-Active Cache - 1 entries(10.1.1.2, 225.1.1.1), RP 11.11.11.11, Recv From Peer 10.1.3.1, 00:08:39/00:05:21Device3#show ip msdp rpfDestination Nexthop Nexthop Nexthop Metric PrefAddress Address From RefCnt10.1.3.1 0.0.0.0 0.0.0.0 1 10 011.11.11.11 10.1.3.1 10.1.3.1 1 0 20
Você pode ver que Device3 recebe e armazena em cache o pacote SA. O pacote SA é do par 10.1.3.1. O endereço de origem multicast no pacote é 10.1.1.2; o endereço do grupo multicast é 225.1.1.1; o endereço RP é 11.11.11.11; o próximo salto no melhor caminho do Device3 para o RP final de origem (11.11.11.11) é 10.1.3.1.
#Visualize a tabela de rotas multicast PIM-SM do Device3.
Device3#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 1 (S,G) entryTotal 1 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(*, 225.1.1.1)Up time: 00:13:57RP: 22.22.22.22RPF nbr: 0.0.0.0RPF idx: NoneFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:vlan5 00:13:57/00:02:33Asserted interface list:(10.1.1.2, 225.1.1.1)Up time: 00:13:57KAT time: 00:03:28RPF nbr: 10.1.3.1RPF idx:vlan4SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:vlan5Packet count 6906038(10.1.1.2, 225.1.1.1, rpt)Up time: 00:13:57RP: 22.22.22.22Flags:RPT JOIN DESIREDPRUNE DESIREDRPF SGRPT XG EQUALUpstream State: PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:vlan5
#Receiver pode receber o pacote de serviço multicast com o grupo multicast 225.1.1.1 enviado por Source.
O método de visualização do Device2 é o mesmo do Device3, portanto o processo de visualização é omitido.
Configurar Anycast RP
Requisitos de rede
- Todo o domínio multicast PIM executa o protocolo PIM-SM.
- A interface Loopback0 do Device3 é C-BSR. As interfaces Loopback1 de Device2 e Device4 são C-RP e os endereços IP são os mesmos.
- Use o endereço IP de Loopback0 entre Device2 e Device4 para configurar a conexão de peer MSDP.
- No domínio, configure vários RPs com o mesmo endereço; dispositivo não RP seleciona o RP mais próximo usado para gerenciar a fonte e o receptor multicast. Os RPs trocam as informações de origem multicast via MSDP para que o serviço multicast de todo o domínio multicast possa interagir. Se um RP falhar, suas áreas gerenciadas serão compartilhadas por outros RPs.
Topologia de rede

Figura 8 -2 Rede de configuração do Anycast RP
| Dispositivo | Interface | VLAN | endereço de IP |
| Dispositivo1 | Gi0/1 Gi0/2 |
2 3 |
10.1.1.1/24 10.1.2.1/24 |
| Dispositivo2 | Gi0/1 Gi0/2 |
3 4 |
10.1.2.2/24 10.1.3.1/24 |
| Loopback0 | 11.11.11.11/32 | ||
| Loopback1 | 55.55.55.55/32 | ||
| Dispositivo3 | Gi0/1 Gi0/2 |
4 5 |
10.1.3.2/24 10.1.4.1/24 |
| Loopback0 | 44.44.44.44/32 | ||
| Dispositivo 4 | Gi0/1 Gi0/2 |
5 6 |
10.1.4.2/24 10.1.5.1/24 |
| Loopback0 | 22.22.22.22/32 | ||
| Loopback1 | 55.55.55.55/32 | ||
| Dispositivo 5 | Gi0/1 Gi0/2 |
6 7 |
10.1.5.2/24 10.1.6.1/24 |
| Fonte | - | 10.1.1.2/24 |
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (omitido)
- Passo 2:Configure o endereço IP da interface. (omitido)
- Passo 3:Configure o OSPF para que todos os dispositivos na rede possam se comunicar uns com os outros.
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 10.1.1.0 0.0.0.255 area 0Device1(config-ospf)#network 10.1.2.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 10.1.2.0 0.0.0.255 area 0Device2(config-ospf)#network 10.1.3.0 0.0.0.255 area 0Device2(config-ospf)#network 11.11.11.11 0.0.0.0 area 0Device2(config-ospf)#network 55.55.55.55 0.0.0.0 area 0Device2(config-ospf)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 10.1.3.0 0.0.0.255 area 0Device3(config-ospf)#network 10.1.4.0 0.0.0.255 area 0Device3(config-ospf)#network 44.44.44.44 0.0.0.0 area 0Device3(config-ospf)#exit
#Configurar dispositivo4.
Device4#configure terminalDevice4(config)#router ospf 100Device4(config-ospf)#network 10.1.4.0 0.0.0.255 area 0Device4(config-ospf)#network 10.1.5.0 0.0.0.255 area 0Device4(config-ospf)#network 22.22.22.22 0.0.0.0 area 0Device4(config-ospf)#network 55.55.55.55 0.0.0.0 area 0Device4(config-ospf)#exit
#Configurar dispositivo5.
Device5#configure terminalDevice5(config)#router ospf 100Device5(config-ospf)#network 10.1.5.0 0.0.0.255 area 0Device5(config-ospf)#network 10.1.6.0 0.0.0.255 area 0Device5(config-ospf)#exit
#Visualize a tabela de rotas do Device5.
Device5#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setO 10.1.1.0/24 [110/5] via 10.1.5.1, 04:04:37, vlan6O 10.1.2.0/24 [110/4] via 10.1.5.1, 04:05:13, vlan6O 10.1.3.0/24 [110/3] via 10.1.5.1, 04:17:36, vlan6O 10.1.4.0/24 [110/2] via 10.1.5.1, 18:19:08, vlan6C 10.1.5.0/24 is directly connected, 18:22:13, vlan6C 10.1.6.0/24 is directly connected, 04:32:51, vlan7O 11.11.11.11/32 [110/4] via 10.1.5.1, 04:17:36, vlan6O 22.22.22.22/32 [110/2] via 10.1.5.1, 03:56:25, vlan6O 44.44.44.44/32 [110/3] via 10.1.5.1, 04:13:23, vlan6O O 55.55.55.55/32 [110/2] via 10.1.5.1, 04:17:36, vlan6
O método de visualização de Device1, Device2, Device3 e Device4 é o mesmo do Device5, portanto o processo de visualização é omitido.
- Passo 4:Habilite globalmente o encaminhamento multicast, habilite o protocolo multicast PIM-SM na interface e configure C-BSR e C-RP.
#Configurar dispositivo1.
Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM na interface.
Device1(config)#ip multicast-routingDevice1(config)#interface vlan 2Device1(config-if-vlan2)#ip pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan 3Device1(config-if-vlan3)#ip pim sparse-modeDevice1(config-if-vlan3)#exit
#Configurar dispositivo2.
Habilite globalmente o encaminhamento multicast, habilite o protocolo multicast PIM-SM na interface e configure Loopback1 como C-RP; o intervalo do grupo multicast do serviço C-RP é 224.0.0.0/4.
Device2(config)#ip multicast-routingDevice2(config)#interface loopback0Device2(config-if-loopback0)#ip pim sparse-modeDevice2(config-if-loopback0)#exitDevice2(config)#interface loopback1Device2(config-if-loopback1)#ip pim sparse-modeDevice2(config-if-loopback1)#exitDevice2(config)#interface vlan 3Device2(config-if-vlan3)#ip pim sparse-modeDevice2(config-if-vlan3)#exitDevice2(config)#interface vlan 4Device2(config-if-vlan4)#ip pim sparse-modeDevice2(config-if-vlan4)#exitDevice2(config)#ip pim rp-candidate loopback1
#Configurar dispositivo3.
Habilite globalmente o encaminhamento multicast, habilite o protocolo multicast PIM-SM na interface e configure Loopback0 como C-BSR.
Device3(config)#ip multicast-routingDevice3(config)#interface loopback0Device3(config-if-loopback0)#ip pim sparse-modeDevice3(config-if-loopback0)#exitDevice3(config)#interface vlan 4Device3(config-if-vlan4)#ip pim sparse-modeDevice3(config-if-vlan4)#exitDevice3(config)#interface vlan 5Device3(config-if-vlan5)#ip pim sparse-modeDevice3(config-if-vlan5)#exitDevice3(config)#ip pim bsr-candidate loopback0
#Configurar dispositivo4.
Habilite globalmente o encaminhamento multicast, habilite o protocolo multicast PIM-SM na interface e configure Loopback1 como C-RP; o intervalo do grupo multicast do serviço C-RP é 224.0.0.0/4.
Device4(config)#ip multicast-routingDevice4(config)#interface loopback0Device4(config-if-loopback0)#ip pim sparse-modeDevice4(config-if-loopback0)#exitDevice4(config)#interface loopback1Device4(config-if-loopback1)#ip pim sparse-modeDevice4(config-if-loopback1)#exitDevice4(config)#interface vlan 5Device4(config-if-vlan5)#ip pim sparse-modeDevice4(config-if-vlan5)#exitDevice4(config)#interface vlan 6Device4(config-if-vlan6)#ip pim sparse-modeDevice4(config-if-vlan6)#exitDevice4(config)#ip pim rp-candidate loopback1
#Configurar dispositivo5. Habilite globalmente o encaminhamento multicast e habilite o protocolo multicast PIM-SM na interface.
Device5(config)#ip multicast-routingDevice5(config)#interface vlan 6Device5(config-if-vlan6)#ip pim sparse-modeDevice5(config-if-vlan6)#exitDevice5(config)#interface vlan 7Device5(config-if-vlan7)#ip pim sparse-modeDevice5(config-if-vlan7)#exit
#Visualize as informações da interface habilitada com o protocolo PIM-SM no Device5 e as informações do vizinho PIM-SM.
Device5#show ip pim interfacePIM Interface Table:PIM VRF Name: DefaultTotal 3 Interface entriesTotal 0 External Interface entryTotal 0 Sparse-Dense Mode Interface entryAddress Interface VIF Ver/ VIF Nbr DR DR BSR CISCO NeighborIndex Mode Flag Count Pri Border Neighbor Filter10.1.5.2 register_vif0 1 v2/S UP10.1.5.2 vlan6 0 v2/S UP 1 1 10.1.5.2 FALSE FALSE10.1.6.1 vlan7 2 v2/S UP 0 1 10.1.6.1 FALSE FALSEDevice5#show ip pim neighborPIM Neighbor Table:PIM VRF Name: DefaultTotal 1 Neighbor entryNeighbor Interface Uptime/Expires Ver DRAddress Priority/Mode10.1.5.1 vlan6 18:37:22/00:01:45 v2 1 /
#Visualize as informações de BSR e RP do Device5.
Device5#show ip pim bsr-routerPIMv2 Bootstrap informationPIM VRF Name: DefaultBSR address: 44.44.44.44BSR Priority: 0Hash mask length: 10Up time: 04:36:44Expiry time: 00:01:35Role: Non-candidate BSRState: Accept PreferredDevice5#show ip pim rp mappingPIM Group-to-RP Mappings Table:PIM VRF Name: DefaultTotal 1 RP set entryTotal 1 RP entryGroup(s): 224.0.0.0/4RP count: 1RP: 55.55.55.55Info source: 44.44.44.44, via bootstrap, priority 192Up time: 04:36:44Expiry time: 00:01:53
O método de visualização de Device1, Device2, Device3 e Device4 é o mesmo do Device5, portanto o processo de visualização é omitido.
- Passo 5:Configurar MSDP.
#Configurar dispositivo2.
Configure a configuração da conexão de peer MSDP de conexão não direta via Loopback0 com Loopback0 de Device4; habilitar a função de enviar ativamente o pacote de solicitação SA para o peer especificado; configure o endereço RP no pacote SA como o endereço IP de Loopback0; configure usando a regra RFC3618 para executar a verificação RPF do pacote MSDP.
Device2(config)#ip msdp peer 22.22.22.22 connect-source loopback0Device2(config)#ip msdp sa-request 22.22.22.22Device2(config)#ip msdp originator-id loopback0Device2(config)#ip msdp rpf rfc3618
#Configurar dispositivo4.
Configure a configuração da conexão de peer MSDP de conexão não direta via Loopback0 com Loopback0 de Device2; habilitar a função de enviar ativamente o pacote de solicitação SA para o peer especificado; configure o endereço RP no pacote SA como o endereço IP de Loopback0; configure usando a regra RFC3618 para executar a verificação RPF do pacote MSDP.
Device4(config)#ip msdp peer 11.11.11.11 connect-source loopback0Device4(config)#ip msdp sa-request 11.11.11.11Device4(config)#ip msdp originator-id loopback0Device4(config)#ip msdp rpf rfc3618
#Visualize o status da conexão do peer MSDP e os detalhes do Device4.
Device4#show ip msdp summaryMSDP Peer Status SummaryTotal 1 Peer entryPeer Address AS State Reset Uptime/Downtime11.11.11.11 ? Up 0 05:49:35Device4#show ip msdp peerMSDP Peer 11.11.11.11, AS ?Connection status:State: Established, Resets: 0, Connection source: loopback0Uptime(Downtime): 05:49:39, Message sent/received: 352/528Connection and counters cleared 05:53:24 agoLocal Address of connection: 22.22.22.22Remote Address of connection: 11.11.11.11Local Port: 639, Remote Port: 1053SA-Requests:Input filter: noneSending SA-Requests to peer: enabledSA:Input filter: noneMessage counters:RPF Failure count: 3SA Messages in/out: 348/0SA Requests in/out: 0/3SA Responses in/out: 2/0Data Packets in/out: 0/0
Você pode ver que Device4 e Device2 configuraram a conexão de peer MSDP com sucesso.
O método de visualização do Device2 é o mesmo do Device4, portanto o processo de visualização é omitido.
- Passo 6:Confira o resultado.
# Origem envia o pacote de serviço multicast com o grupo multicast 225.1.1.1.
#Visualize as informações de cache MSDP SA do Device2.
Device2#show ip msdp sa-cacheMSDP Source-Active Cache - 1 entries(10.1.1.2, 225.1.1.1), RP 55.55.55.55, Originated, 00:03:34/00:05:43
Você pode ver que Device2 gera e armazena em cache o pacote SA. O endereço de origem multicast no pacote SA é 10.1.1.2; o endereço do grupo multicast é 225.1.1.1; o endereço RP é 55.55.55.55.
#Visualize as informações de cache MSDP SA e a tabela de verificação RPF do Device4.
Device4#show ip msdp sa-cacheMSDP Source-Active Cache - 1 entries(10.1.1.2, 225.1.1.1), RP 11.11.11.11, Recv From Peer 11.11.11.11, 00:07:02/00:05:58Device4#show ip msdp rpfDestination Nexthop Nexthop Nexthop Metric PrefAddress Address From RefCnt10.1.4.1 0.0.0.0 0.0.0.0 1 10 011.11.11.11 10.1.4.1 55.55.55.55 3 3 11055.55.55.55 0.0.0.0 0.0.0.0 2 1 0
Você pode ver que Device4 recebe e armazena em cache o pacote SA. O pacote SA é do par 11.11.11.11. O endereço de origem multicast no pacote é 10.1.1.2; o endereço do grupo multicast é 225.1.1.1; o endereço RP é 11.11.11.11.
Se ip msdp originator-id estiver configurado no RP de origem e quando enviar o pacote SA para o peer MSDP, ele substituirá o endereço RP no pacote pelo endereço IP da interface especificada.
#Visualize a tabela de rotas multicast PIM-SM do Device2.
Device2#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 0 (*,G) entryTotal 1 (S,G) entryTotal 1 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(10.1.1.2, 225.1.1.1)Up time: 00:01:14KAT time: 00:03:23RPF nbr: 10.1.2.1RPF idx: vlan3SPT bit: FALSEFlags:Upstream State: NOT JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:Packet count 0(10.1.1.2, 225.1.1.1, rpt)Up time: 00:01:14RP: 55.55.55.55Flags:RPF SGRPT XG EQUALUpstream State: RPT NOT JOINEDLocal interface list:Pruned interface list:Outgoing interface list:
#Visualize a tabela de rotas multicast PIM-SM do Device4.
Device4#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 0 (*,G) entryTotal 0 (S,G) entryTotal 0 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer
Você pode ver que há (10.1.1.2, 225.1.1.1) entrada no Device2 e nenhuma entrada (10.1.1.2, 225.1.1.1) no Device4. Indica que Source inicia o registro PIM-SM para o RP mais próximo, ou seja, Device2.
#Receiver envia o pacote de relatório do membro IGMPv2 para adicionar ao grupo multicast 225.1.1.1.
#Visualize a tabela de membros multicast no Device5.
Device5#show ip igmp groupsIGMP Connected Group MembershipTotal 1 groupsGroup Address Interface Uptime Expires Last Reporter V1 Expires V2 Expires225.1.1.1 vlan7 00:00:12 00:04:12 10.1.6.2 stopped
#Visualize a tabela de rotas multicast PIM-SM do Device2.
Device2#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 0 (*,G) entryTotal 1 (S,G) entryTotal 1 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(10.1.1.2, 225.1.1.1)Up time: 00:19:01KAT time: 00:03:14RPF nbr: 10.1.2.1RPF idx: vlan3SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:vlan4 00:02:56/00:02:34Asserted interface list:Outgoing interface list:vlan4Packet count 1136269(10.1.1.2, 225.1.1.1, rpt)Up time: 00:19:01RP: 55.55.55.55Flags:RPF SGRPT XG EQUALUpstream State: RPT NOT JOINED
#Visualize a tabela de rotas multicast PIM-SM do Device4.
Device4#show ip pim mrouteIP Multicast Routing Table:PIM VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 1 (S,G) entryTotal 1 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(*, 225.1.1.1)Up time: 00:05:54RP: 55.55.55.55RPF nbr: 0.0.0.0RPF idx: NoneFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:vlan6 00:05:54/00:02:36Asserted interface list:(10.1.1.2, 225.1.1.1)Up time: 00:05:54KAT time: 00:03:22RPF nbr: 10.1.4.1RPF idx: vlan5SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:vlan6 00:05:54/00:02:37Asserted interface list:Outgoing interface list:vlan6Packet count 2172581(10.1.1.2, 225.1.1.1, rpt)Up time: 00:05:54RP: 55.55.55.55Flags:RPT JOIN DESIREDPRUNE DESIREDRPF SGRPT XG EQUALUpstream State: PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:vlan6
Você pode ver que há uma entrada (*,225.1.1.1) no Device4 e nenhuma entrada (*,225.1.1.1) no Device2. Indica que Source inicia o PIM-SM adicionando ao RP mais próximo, ou seja, Device4.
#Receiver pode receber o pacote de serviço multicast com o grupo multicast 225.1.1.1 enviado por Source.
MLD
Visão geral
MLD é a abreviação de Multicast Listener Discovery Protocol, usado para configurar e manter a relação de membro do grupo multicast entre o host IPv6 e seu dispositivo multicast vizinho direto.
O roteador MLD usa o endereço local do link unicast IPv6 como endereço de origem para enviar o pacote MLD. O MLD usa o tipo de pacote ICMPv6 (Internet Control Message Protocol for IPv6). Todos os pacotes MLD são limitados no link local e os saltos são 1.
MLD tem duas versões: MLDv1 n corresponde a IGMPv2 e MLDv 2 corresponde a IGMPv3.
Os tipos de pacotes do protocolo IGMP que adotam o protocolo IP número 2 são diferentes. O protocolo MLD adota o tipo de pacote ICMPv6 (o número do protocolo IP é 58), incluindo o pacote de consulta MLD (o valor do tipo é 130), o pacote de relatório MLDv1 (o valor do tipo é 131), o pacote de saída MLDv1 (o valor do tipo é 132) e o relatório MLDv2 pacote (o valor do tipo é 143). O protocolo MLD e o protocolo IGMP possuem formatos de pacotes diferentes, mas possuem as mesmas ações de protocolo.
Configuração da função MLD
Configurar funções básicas de MLD
Condição de configuração
Antes de configurar as funções básicas do MLD , primeiro complete a seguinte tarefa:
- Habilite a interface IPv6
- Habilite a interface MLD
Habilite o protocolo MLD
Tabela 9 -1 Habilitar o protocolo MLD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| encaminhamento multicast IPv6 | ipv6 multicast-routing [ vrf vrf-name ] | Obrigatório Por padrão, o encaminhamento multicast do IPv6 está desabilitado. |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite o protocolo MLD | ipv6 mld enable | Obrigatório Por padrão, não habilite o MLD. Após habilitar o MLD, todas as configurações do MLD podem entrar em vigor. |
Configurar a versão do MLD
Tabela 9 -2 Configurar a versão do MLD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a versão do MLD | ipv6 mld version version-number | Obrigatório Por padrão, a versão MLD é 2. |
Como a estrutura do pacote e os tipos de versões diferentes dos protocolos MLD são diferentes, sugere-se configurar a mesma versão do IGMP para todos os dispositivos na mesma sub-rede.
Configurar adição de grupo estático
Após configurar um grupo estático ou grupo de origem na interface, o dispositivo considera que a interface possui o receptor do grupo multicast ou grupo de origem.
Tabela 9 -3Configurar adição de grupo estático
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a adição de grupo estático | ipv6 mld static-group group-ipv6-address [ source-ipv6-address ] | Obrigatório Por padrão, a interface não é adicionada a nenhum grupo multicast ou grupo de origem no modo estático. |
Configurar filtro de grupo multicast
A interface configurada com o filtro de grupo multicast MLD filtra o relatório de relação de membro de grupo no segmento de acordo com as regras da ACL e somente o relatório de relação de membro de grupo permitido pela ACL é processado e o não permitido é descartado diretamente. Para o grupo multicast existente mas não permitido pelo ACL, exclua imediatamente as informações do grupo multicast.
Tabela 9 -4Configurar filtro de grupo multicast
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o filtro de grupo multicast IGMP | ipv6 mld access-group { access-list-number | access-list-name } | Obrigatório Por padrão, o filtro de grupo multicast não está configurado. |
O ipv6 mld grupo de acesso comando suporta apenas a ACL padrão.
Ajustar e otimizar a rede MLD
Condição de configuração
Antes de ajustar e otimizar a rede MLD , primeiro complete as seguintes tarefas :
- Habilite o protocolo IPv6
- Habilite o protocolo MLD na interface
Configurar intervalo de consulta do grupo geral
MLD envia periodicamente os pacotes gerais de consulta do grupo para manter a relação do membro do grupo. Você pode modificar o intervalo de envio dos pacotes de consulta do grupo geral MLD de acordo com a realidade da rede.
Tabela 9 -5Configurar o intervalo de consulta do grupo geral
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o intervalo de consulta do grupo geral | ipv6 mld query-interval interval-value | Opcional Por padrão, o intervalo de envio dos pacotes de consulta do grupo geral MLD é 125s. |
Os intervalos de consulta de gêneros dos dispositivos no mesmo segmento devem tentar manter a consistência. O intervalo geral de consulta do grupo deve ser maior que o tempo máximo de resposta. Caso contrário, a configuração não será bem-sucedida.
Configurar fator de robustez
O fator de robustez é usado para evitar a perda de pacotes.
Tabela 9 -6Configure o fator de robustez
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o fator de robustez | ipv6 mld robustness-variable variable-value | Opcional Por padrão, o fator de robustez do consultador MLD é 2. |
Após configurar o fator de robustez, os seguintes parâmetros também mudam com os parâmetros de robustez: Timeout do membro do grupo = Fator de robustez * tempo geral de consulta do grupo + tempo máximo de resposta; Tempo limite de outro consultador = Fator de robustez * tempo geral de consulta do grupo + tempo máximo de resposta/2; Quanto maior o fator de robustez, maior o tempo limite do membro do grupo MLD e o tempo limite de outro consultador. Defina o valor de acordo com a realidade da rede.
Configurar tempo máximo de resposta
O pacote de consulta de grupo geral enviado pelo consultador contém o campo de tempo máximo de resposta e o receptor envia o relatório de relação de membro do grupo dentro do intervalo máximo de resposta. Se o receptor não enviar o relatório de relação dos membros do grupo dentro do tempo máximo de resposta, o dispositivo considera que a sub-rede não possui o receptor do grupo multicast e exclui as informações do grupo multicast imediatamente.
Tabela 9 -7Configure o tempo máximo de resposta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o tempo máximo de resposta | ipv6 mld query-max-response-time seconds | Opcional Por padrão, o tempo máximo de resposta da consulta do grupo geral MLD é 10s. |
Configurar consulta de grupo especificada
Depois que o consultador MLD recebe o pacote de saída de um grupo multicast, envie o pacote de consulta do grupo especificado para consultar o grupo multicast no segmento . Os tempos de envio do pacote dependem dos “ Tempos de consulta de grupo especificados ” . Isto é para saber se a sub-rede tem os membros do grupo multicast. Se não receber o relatório de relação de membro do grupo multicast após aguardar o “tempo máximo de resposta”, exclua as informações do grupo multicast.
Tabela 9 -8Configurar a consulta de grupo especificada
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o intervalo de consulta do grupo especificado | ipv6 mld last-member-query-interval interval-value | Opcional Por padrão, o intervalo de envio dos pacotes de consulta de grupo especificados é de 1s. |
| Configure os tempos de consulta do grupo especificado | ipv6 mld last-member-query-count count-value | Opcional Por padrão, os tempos de enviar o pacotes de consulta de grupo especificados é 2. |
Configurar Saída Rápida
O segmento final da rede conecta-se apenas a um host , que executa com frequência a ação de comutação do grupo multicast. Para reduzir o atraso de saída, você pode configurar a saída rápida do grupo multicast no dispositivo.
Após configurar a saída rápida, o dispositivo recebe o pacote de saída de um grupo multicast e verifica se o grupo multicast pertence ao intervalo de saída rápida. Se sim, o dispositivo não envia mais o pacote de consulta do grupo especificado para o segmento e exclui as informações do grupo multicast imediatamente.
Tabela 9 -9Configurar a saída rápida
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o intervalo do grupo de origem da licença rápida | ipv6 mld immediate-leave { access-list-number | access-list-name } | Obrigatório Por padrão, não permita a saída rápida do grupo multicast |
Configurar o mapeamento MLD SSM
Condição de configuração
Antes de configurar o mapeamento MLD SSM, primeiro conclua as seguintes tarefas:
- Habilite a interface IPv6
- Habilite a interface MLD
Configurar o MLD Mapeamento SSM
Para fornecer o serviço IPv6 PIM-SM SSM para o receptor que não suporta MLD v 2 na rede IPv6 PIM-SM SSM, podemos configurar a função MLD SSM Mapping no dispositivo.
O usuário pode configurar a regra de mapeamento MLD SSM de acordo com a demanda do receptor da rede. O relatório de relação de membro de grupo permitido pela regra é convertido no relatório de relação de não-membro MLD (IS_EX, TO_EX), e o endereço de origem multicast é o endereço de origem especificado pela regra de mapeamento MLD SSM.
Tabela 9 -10 Configurar o mapeamento MLD SSM
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar mapeamento MLD SSM | ipv6 mld ssm-map enable [ vrf vrf-name ] | Obrigatório Por padrão, o mapeamento MLD SSM não está habilitado. |
| Configurar a regra de mapeamento MLD SSM | ipv6 mld ssm-map static { access-list-number | access-list-name } source-ipv6-address [ vrf vrf-name ] | Obrigatório Por padrão, não há regra de mapeamento MLD SSM . |
O ipv6 mld mapa ssm O comando estático suporta apenas a ACL estendida .
Monitoramento e manutenção de MLD
Tabela 9 -11 Monitoramento e manutenção de MLD
| Comando | Descrição |
| clear ipv6 mld group [ group-ipv6-address ] [ interface-name ] [ vrf vrf-name ] | Limpe as informações do grupo multicast MLD |
| clear ipv6 mld statistic interface interface-name | Limpe as informações de estatísticas do pacote MLD na interface |
| show ipv6 mld groups [ [ static ] | [ interface-name ] [ group-ipv6-address ] [ detail ] ] [ vrf vrf-name ] | Exiba as informações do grupo multicast MLD |
| show ipv6 mld interface [ interface-name ] [ vrf vrf-name ] | informações da interface MLD |
| show ipv6 mld statistic interface interface-name [ vrf vrf-name ] | Exiba as informações estatísticas dos pacotes MLD |
Exemplo de configuração típica de MLD
Configurar funções básicas de MLD
Requisitos de rede
- Toda a rede executa o protocolo IPv6 PIM-SM.
- Device1, Device2 e Receiver estão na mesma LAN e Device1 é o consultador.
- Receptor é um receptor da rede stub Device1 e Device2 .
- Execute o MLD v2 entre Device1, Device2 e rede stub .
Topologia de rede
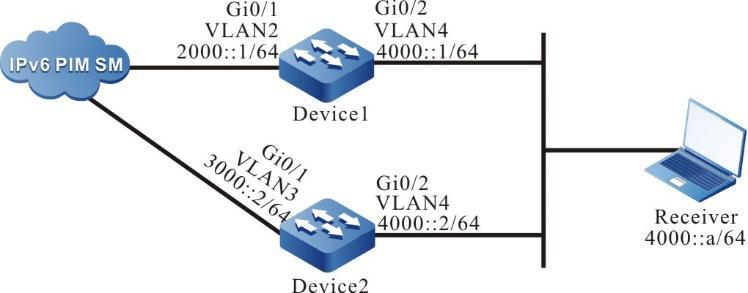
Figura 9 - 1Rede de configuração das funções básicas do MLD
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente (omitida).
- Passo 2:Configure o endereço IPv6 da interface (omitido).
- Passo 3:Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM na interface. Habilite o MLD na interface do Device1 e Device2 conectando o Receiver.
# Configurar dispositivo1.
Habilite globalmente o encaminhamento multicast IPv6 , habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas e habilite MLD na interface do Receptor de conexão .
Device1#configure terminalDevice1(config)#ipv6 multicast-routingDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ipv6 pim sparse-modeDevice1(config-if-vlan4)#ipv6 mld enableDevice1(config-if-vlan4)#exit
# Configurar dispositivo2.
Habilite globalmente o encaminhamento multicast IPv6 , habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas e habilite MLD na interface do Receptor de conexão .
Device2#configure terminalDevice2(config)#ipv6 multicast-routingDevice2(config)#interface vlan3Device2(config-if-vlan3)#ipv6 pim sparse-modeDevice2(config-if-vlan3)#exitDevice2(config)#interface vlan4Device2(config-if-vlan4)#ipv6 pim sparse-modeDevice2(config-if-vlan4)#ipv6 mld enableDevice2(config-if-vlan4)#exit
- Passo 4:Confira o resultado.
#Visualize as informações da versão do MLD e o resultado da eleição do consultador da interface Device1 vlan4 .
Device1#show ipv6 mld interface vlan4Interface vlan4 (Index 23)MLD Enabled, ActiveQuerier: fe80::201:2ff:fe03:406 (Self)Default version: 2Querier parameter:Query interval is 125 secondsQuerier timeout is 255 secondsQuery response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsRobustness variable is 2
#Visualize as informações da versão do MLD e o resultado da eleição do consultador da interface Device2 gigabitethernet0/0/1 .
Device2#show ipv6 mld interface vlan4Interface vlan4 (Index 50331674)MLD Enabled, ActiveQuerier: fe80::201:2ff:fe03:406Non-Querier: fe80::201:7aff:febc:662b Expires: 00:04:07Default version: 2Querier parameter:Query interval is 125 secondsQuerier timeout is 255 secondsQuery response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsRobustness variable is 2
# O receptor envia o pacote de relatório do membro MLD v2 para adicionar ao grupo multicast FF1E::1 .
#Visualize a tabela de membros multicast de Device1.
Device1#show ipv6 mld groupsMLD Connected Group MembershipTotal 1 Connected GroupsGroup Interface Uptime Expires V1-Expires Last Reporterff1e::1 vlan4 00:00:02 00:04:17 not used fe80::b
#Exibe a tabela de membros multicast do Device2.
Device2#show ipv6 mld groupsMLD Connected Group MembershipTotal 1 Connected GroupsGroup Interface Uptime Expires V1-Expires Last Reporterff1e::1 vlan4 00:00:02 00:04:17 not used fe80::b
Na interface , execute a versão MLDv2, seja compatível com o relatório de relação do membro MLDv1 e o pacote de licença do membro MLDv1 por padrão. Você pode configurar a versão MLD em execução da interface através do comando IPv6 versão mld . Quando vários dispositivos executam MLD em uma LAN, elege o consultador MLD e aquele com o menor endereço é eleito como o consultador MLD da LAN.
Configurar adição estática de MLD
Requisitos de rede
- Toda a rede executa o protocolo IPv6 PIM-SM.
- Receptor é um receptor da rede de stub do dispositivo.
- Execute o MLD v2 entre o dispositivo e a rede stub.
- A interface de dispositivo vlan3 adiciona ao grupo multicast FF1E::1 estaticamente.
Topologia de rede
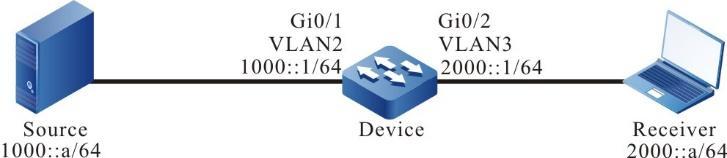
Figura 9 - 2Rede de configuração de adição estática de MLD
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente (omitida).
- Passo 2:Configure o endereço IPv6 da interface (omitido).
- Passo 3:Habilite globalmente o encaminhamento multicast IPv6 , habilite o protocolo multicast IPv6 PIM-SM na interface. Habilite o MLD na interface de conexão do Receptor.
#Configurar dispositivo .
Habilite globalmente o encaminhamento multicast IPv6 , habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas e habilite MLD na interface do Receptor de conexão .
Device#configure terminalDevice(config)#ipv6 multicast-routingDevice(config)#interface vlan2Device(config-if-vlan2)#ipv6 pim sparse-modeDevice(config-if-vlan2)#exitDevice(config)#interface vlan3Device(config-if-vlan3)#ipv6 pim sparse-modeDevice(config-if-vlan3)#ipv6 mld enableDevice(config-if-vlan3)#exit
#Visualize as informações de MLD da interface do dispositivo vlan3 .
Device#show ipv6 mld interface vlan3Interface vlan3 (Index 23)MLD Enabled, ActiveQuerier: fe80::201:2ff:fe03:406 (Self)Default version: 2Querier parameter:Query interval is 125 secondsQuerier timeout is 255 secondsQuery response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsRobustness variable is 2
- Passo 4:interface de dispositivo vlan3 adiciona ao grupo multicast FF1E::1 estaticamente.
#Configurar dispositivo .
A interface de dispositivo vlan3 adiciona ao grupo multicast FF1E::1 estaticamente.
Device(config)#interface vlan3Device(config-if-vlan3)#ipv6 mld static-group ff1e::1Device(config-if-vlan3)#exit
- Passo 5:Confira o resultado.
#Source envia o pacote multicast com o grupo multicast FF1E::1 .
#Exibe a tabela de membros multicast de Device.
Device#show ipv6 mld groupsMLD Static Group MembershipTotal 1 Static GroupsGroup Source Interfaceff1e::1 :: vlan3
#Visualize a tabela de rotas multicast do dispositivo.
Device#show ipv6 pim mrouteIP Multicast Routing Table:PIM6 VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 1 (S,G) entryTotal 1 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(*, ff1e::1)Up time: 00:01:06RP: ::RPF nbr: ::RPF idx: NoneFlags:Upstream State: NOT JOINEDLocal interface list:Vlan3Joined interface list:Asserted interface list:(1000::a, ff1e::1)Up time: 00:00:04KAT time: 00:03:26RPF nbr: ::RPF idx: NoneSPT bit: TRUEFlags:JOIN DESIREDCOULD REGISTERUpstream State: JOINEDLocal interface list:Joined interface list:register_vif0Asserted interface list:Outgoing interface list:register_vif0vlan3Packet count 1(1000::a, ff1e::1, rpt)Up time: 00:00:04RP: ::Flags:RPT JOIN DESIREDRPF SGRPT XG EQUALUpstream State: NOT PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:
O #Receiver pode receber o pacote multicast com o grupo multicast FF1E::1 enviado por Source.
Configurar mapeamento MLD SSM
Requisitos de rede
- Toda a rede executa o IPv6 PIM-SM protocolo SSM.
- Receiver1 , Receiver2 e Device2 estão todos em uma LAN.
- Execute o MLDv2 entre o dispositivo 2 e a rede stub .
- Use o mapeamento MLD SSM em Device2 para que Receiver2 possa receber apenas os pacotes de serviço multicast enviados por Source1 .
Topologia de rede
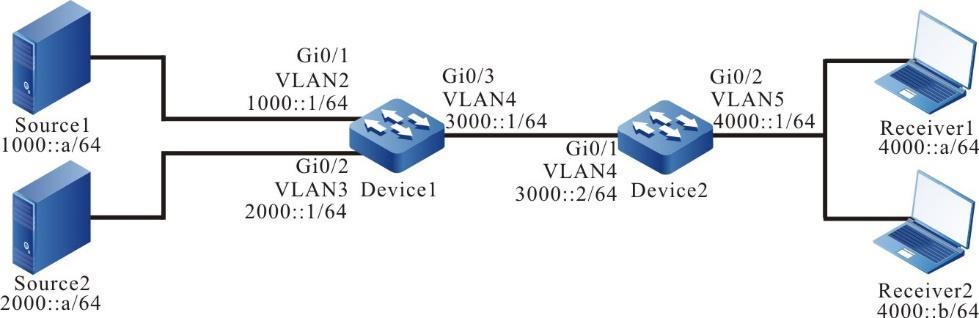
Figura 9 - 3 Rede de configuração do mapeamento MLD SSM
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente (omitida).
- Passo 2: Configure o endereço IPv6 da interface (omitido).
- Passo 3: Habilite o roteamento unicast IPv6 OSPFv3 para que todos os dispositivos de rede na rede possam se comunicar uns com os outros.
# Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)#router-id 1.1.1.1Device1(config-ospf6)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 router ospf 100 area 0Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 router ospf 100 area 0Device1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ipv6 router ospf 100 area 0Device1(config-if-vlan4)#exit
# Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface vlan4Device2(config-if-vlan4)#ipv6 router ospf 100 area 0Device2(config-if-vlan4)#exit
#Visualize a tabela de rotas do Device2.
Device2#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 05:20:37, lo0O 1000::/64 [110/2]via fe80::201:2ff:fe03:406, 00:35:30, vlan4O 2000::/64 [110/2]via fe80::201:2ff:fe03:406, 00:37:15, vlan4C 3000::/64 [0/0]via ::, 00:38:24, vlan4L 3000::2/128 [0/0]via ::, 00:38:22, lo0C 4000::/64 [0/0]via ::, 00:31:55, vlan5L 4000::2/128 [0/0]via ::, 00:31:53, lo0
O método de visualização do Device1 é o mesmo do Device2, portanto o processo de visualização é omitido.
- Passo 4:Habilite o encaminhamento multicast IPv6 globalmente, configure o IPv6 PIM-SM SSM globalmente e o intervalo do grupo multicast do serviço SSM é FF3X::/32 . Nas interfaces, habilite o protocolo multicast IPv6 PIM-SM. A interface vlan5 do Device2 executa o MLDv2 .
# Configurar dispositivo1.
Habilite o encaminhamento multicast IPv6 globalmente, configure o IPv6 PIM-SM SSM globalmente e habilite o protocolo multicast IPv6 PIM-SM na interface.
Device1(config)#ipv6 multicast-routingDevice1(config)#ipv6 pim ssm defaultDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 pim sparse-modeDevice1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ipv6 pim sparse-modeDevice1(config-if-vlan4)#exit
# Configurar dispositivo2.
Habilite o encaminhamento multicast IPv6 globalmente, configure o IPv6 PIM-SM SSM globalmente , habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas e execute MLDv2 na interface vlan5.
Device2(config)#ipv6 multicast-routingDevice2(config)#ipv6 pim ssm defaultDevice2(config)#interface vlan4Device2(config-if-vlan4)#ipv6 pim sparse-modeDevice2(config-if-vlan4)#exitDevice2(config)#interface vlan5Device2(config-if-vlan5)#ipv6 pim sparse-modeDevice2(config-if-vlan5)#ipv6 mld enableDevice2(config-if-vlan5)#exit
#Visualize as informações de MLD da interface vlan5 no Device2.
Device2#show ipv6 mld interface vlan5Interface vlan5 (Index 23)MLD Enabled, ActiveQuerier: fe80::201:2ff:fe03:406 (Self)Default version: 2Querier parameter:Query interval is 125 secondsQuerier timeout is 255 secondsQuery response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsRobustness variable is 2
- Passo 5: Habilite o mapeamento MLD SSM no Device2 e configure a regra de mapeamento MLD SSM para que o Receptor 1 e o Receptor 2 possam receber somente os pacotes multicast enviados por Source1.
# Configurar dispositivo2.
Habilite o mapeamento MLD SSM, configure o intervalo do grupo multicast do MLD SSM como FF3E::/64 e o endereço de origem multicast é 1000::a .
Device2(config)#ipv6 access-list extended 7001Device2(config-std-nacl)#permit ipv6 any ff3e::/64Device2(config-std-nacl)#commitDevice2(config-std-nacl)#exitDevice2(config)#ipv6 mld ssm-map enableDevice2(config)#ipv6 mld ssm-map static 7001 1000::a
- Passo 6: Confira o resultado.
# Receiver1 envia o pacote de relatório do membro MLDv2 do grupo de origem especificado para adicionar ao grupo multicast FF3E::1 e a origem multicast especificada é 2000::a ; Receiver2 envia o pacote de relatório do membro MLDv1 para adicionar ao grupo multicast FF3E::2 .
#Source1 e Source2 ambos enviam os pacotes de serviço multicast com grupos multicast FF3E::1 e FF3E::2 .
#Visualize a tabela de membros multicast de Device2 .
Device2#show ipv6 mld groupsMLD Connected Group MembershipTotal 2 Connected GroupsGroup Interface Uptime Expires V1-Expires Last Reporterff3e::1 vlan5 00:00:33 not used not used fe80::aff3e::2 vlan5 00:00:33 not used not used fe80::bDevice2#show ipv6 mld groups detailMLD Connected Group MembershipTotal 2 Connected GroupsGroup Interface Uptime Expires V1-Expires Last Reporterff3e::1 vlan5 00:00:36 not used not used fe80::aGroup mode : IncludeTIB-A Count: 1TIB-B Count: 0TIB-ASource list: (R - Remote, M - SSM Mapping)Source Uptime Expires Flags2000::a 00:00:36 00:03:49 Rff3e::2 vlan5 00:00:36 not used not used fe80::bGroup mode : IncludeTIB-A Count: 1TIB-B Count: 0TIB-ASource list: (R - Remote, M - SSM Mapping)Source Uptime Expires Flags1000::a 00:00:36 00:03:45 RM
#Visualize a tabela de rotas multicast do Device2.
Device2#show ipv6 pim mrouteIP Multicast Routing Table:PIM6 VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 0 (*,G) entryTotal 2 (S,G) entriesTotal 0 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(2000::a, ff3e::1)Up time: 00:01:36KAT time: 00:01:54RPF nbr: fe80::201:2ff:fe03:406RPF idx: vlan4SPT bit: FALSEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan5Joined interface list:Asserted interface list:Outgoing interface list:vlan5Packet count 0(1000::a, ff3e::2)Up time: 00:01:36KAT time: 00:01:54RPF nbr: fe80::201:2ff:fe03:406RPF idx: vlan4SPT bit: FALSEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan5Joined interface list:Asserted interface list:Outgoing interface list:vlan5Packet count 0
#Receiver1 só pode receber os pacotes de serviço multicast enviados por Source2; Receiver2 só pode receber os pacotes de serviço multicast enviados por Source1.
O método de visualização do Device1 é o mesmo do Device2, portanto o processo de visualização é omitido. MLD SSM precisa ser usado com IPv6 PIM-SM SSM ; o intervalo do grupo multicast na regra de mapeamento MLD SSM deve pertencer ao intervalo do grupo multicast IPv6 PIM-SM SSM . O mapeamento IGMP SSM executa principalmente o MLD v1 e não pode ser atualizado para o host receptor do MLD v 2 para fornecer suporte ao modelo SSM. O mapeamento MLD SSM é inválido para o pacote de relatório de membro MLD v 2 .
Configurar filtro de grupo multicast MLD
Requisitos de rede
- Toda a rede executa o protocolo IPv6 PIM-SM.
- Receptor é um receptor da rede de stub do dispositivo .
- Execute o MLD v2 entre o dispositivo e a rede stub .
- A interface do dispositivo gigabitethernet0/0/1 filtra o grupo multicast; o intervalo dos grupos multicast que o Receptor pode adicionar é ff10::/16 .
Topologia de rede

Figura 9 - 4 Rede de configuração do filtro de grupo multicast IGMP
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente (omitida).
- Passo 2: Configure o endereço IPv6 da interface (omitido).
- Passo 3: Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM na interface.
#Configurar dispositivo .
Habilite globalmente o encaminhamento multicast IPv6 , habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas e habilite MLD na interface do Receptor de conexão.
Device#configure terminalDevice(config)#ipv6 multicast-routingDevice(config)#interface vlan2Device(config-if-vlan2)#ipv6 pim sparse-modeDevice(config-if-vlan2)#exitDevice(config)#interface vlan3Device(config-if-vlan3)#ipv6 pim sparse-modeDevice(config-if-vlan3)#ipv6 mld enableDevice(config-if-vlan3)#exit
# Visualize as informações do MLD da interface do dispositivo vlan3 .
Device(config)#ipv6 access-list extended 7001Device(config-std-nacl)#permit ipv6 any ff10::/16Device(config-std-nacl)#commitDevice(config-std-nacl)#exitDevice(config)#interface vlan3Device(config-if-vlan3)#ipv6 mld access-group 7001Device(config-if-vlan3)#exit
- Passo 4:Configure o filtro de grupo multicast na interface do dispositivo vlan3.
#Configurar dispositivo .
Configure o filtro de grupo multicast na interface do dispositivo vlan3; o intervalo dos grupos multicast que o Receptor pode adicionar é ff10::/16 .
Device(config)#ipv6 access-list extended 7001Device(config-std-nacl)#permit ipv6 any ff10::/16Device(config-std-nacl)#commitDevice(config-std-nacl)#exitDevice(config)#interface vlan3Device(config-if-vlan3)#ipv6 mld access-group 7001Device(config-if-vlan3)#exit
- Passo 5:Confira o resultado.
pacote de relatório do membro IGMPv2 para adicionar ao grupo multicast FF10::1 e FF11::1 .
#Source envia os pacotes multicast com o grupo multicast FF10::1 e FF11::1 .
#Exibe a tabela de membros multicast de Device.
Device#show ipv6 mld groupsMLD Connected Group MembershipTotal 1 Connected GroupsGroup Interface Uptime Expires V1-Expires Last Reporterff10::1 vlan3 01:06:32 00:04:15 00:04:15 fe80::b
#Visualize a tabela de rotas multicast do dispositivo.
Device#show ipv6 pim mrouteIP Multicast Routing Table:PIM6 VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 2 (S,G) entriesTotal 2 (S,G,rpt) entriesTotal 0 FCR entryUp timer/Expiry timer(*, ff10::1)Up time: 00:01:00RP: ::RPF nbr: ::RPF idx: NoneFlags:Upstream State: NOT JOINEDLocal interface list:vlan3Joined interface list:Asserted interface list:(1000::a, ff10::1)Up time: 00:00:06KAT time: 00:03:24RPF nbr: ::RPF idx: NoneSPT bit: TRUEFlags:JOIN DESIREDCOULD REGISTERUpstream State: JOINEDLocal interface list:vlan3Joined interface list:register_vif0Asserted interface list:Outgoing interface list:register_vif0vlan3Packet count 1(1000::a, ff10::1, rpt)Up time: 00:00:06RP: ::Flags:RPT JOIN DESIREDRPF SGRPT XG EQUALUpstream State: NOT PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:(1000::a, ff11::1)Up time: 00:00:06KAT time: 00:03:24RPF nbr: ::RPF idx: NoneSPT bit: TRUEFlags:JOIN DESIREDCOULD REGISTERUpstream State: JOINEDLocal interface list:Joined interface list:register_vif0Asserted interface list:Outgoing interface list:register_vif0Packet count 1(1000::a, ff11::1, rpt)Up time: 00:00:06RP: ::Flags:RPF SGRPT XG EQUALUpstream State: RPT NOT JOINEDLocal interface list:Pruned interface list:Outgoing interface list:
#Receiver só pode receber os pacotes de serviço multicast com o grupo multicast FF10::1 enviado pela Origem.
Para filtrar com base no grupo de origem multicast, use o comando ipv6 mld access-group para realizar e configure o endereço de origem correspondente na ACL associada. Por exemplo, permitir ipv6 1000::/16 ff10::/16 indica permitir que o grupo de origem no intervalo de grupo FF10::/16 e o intervalo de origem especificado 1000::/16 sejam adicionados. Ao usar a função, é necessário que a interface execute o MLDv2.
MLD Snooping
Visão geral
MLD Snooping é a abreviação de Multicast Listener Discovery Snooping. É um mecanismo de restrição multicast IPv6 executado em dispositivos L2, usado para gerenciar e controlar grupos multicast IPv6.
MLD Snooping realiza principalmente as seguintes funções:
- Ouça os pacotes MLD para estabelecer informações de multicast. O MLD Snooping obtém informações sobre o receptor multicast downstream escutando pacotes MLD e encaminha pacotes de serviço multicast em portas membro designadas.
- Ouça os pacotes MLD. Desta forma, o roteador multicast upstream pode manter corretamente a tabela de relação de membro MLD.
Configuração da função de espionagem MLD
Tabela 10 -1 Lista de configuração da função de MLD snooping
| Tarefas de configuração | |
| Funções básicas de MLD snooping |
Ativar a função de MLD snooping
Configurar a versão de espionagem do MLD função de encaminhamento MAC de MLD snooping |
| Configurar consulta de MLD snooping |
Ativar o pesquisador de MLD snooping
Configure o endereço IPv6 de origem do pacote de consulta MLD Configure o intervalo de consulta do grupo comum Configure o tempo máximo de resposta Configure o intervalo de consulta do grupo especificado Configurar saída rápida |
| Configurar a porta do roteador de MLD snooping | a porta do roteador de MLD snooping porta do roteador dinâmico de MLD snooping |
| Configurar evento TCN de MLD snooping |
Habilite a convergência rápida
Configure o intervalo de consulta do evento TCN Configure os tempos de consulta do evento TCN |
Configurar funções básicas de MLD snooping
Nas tarefas de configuração do MLD snooping , primeiro habilite a função MLD snooping para que as configurações das outras funções tenham efeito.
Condição de configuração
Antes de configurar as funções básicas do MLD snooping , primeiro complete as seguintes tarefas:
- Configurar VLAN
Ativar função de MLD snooping
Depois que a função de MLD snooping é habilitada, a função de MLD snooping pode ser executada no dispositivo.
Tabela 10 -2 Ativar a função de espionagem MLD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| função de MLD snooping global | ipv6 mld snooping | Obrigatório Por padrão, não habilite a função de espionagem MLD global . |
| Habilite a função de MLD snooping da VLAN especificada | ipv6 mld snooping vlan vlan-id | Obrigatório Por padrão, não habilite a função de espionagem MLD na VLAN. |
Depois que a função de MLD snooping global é habilitada, a função de MLD snooping da VLAN especificada pode ser habilitada.
Configurar a versão de espionagem do MLD
A versão de MLD snooping configurada e as regras de processamento de pacotes do protocolo MLD são as seguintes:
MLD snooping configurada é V2, o dispositivo pode processar os pacotes de protocolo MLD de V1 e V2.
MLD snooping configurada é V1, o dispositivo pode processar os pacotes de protocolo MLD de V1, mas não processa os pacotes de protocolo V2, que inundam a VLAN.
Tabela 10 -3 Configurar a versão de espionagem do MLD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| versão de espionagem do MLD | ipv6 mld snooping vlan vlan-id version version-number | Opcional Por padrão, a versão do snooping MLD é 2. |
Ativar MLD espionando o encaminhamento MAC
U normalmente, MLD Snooping encaminha os pacotes multicast na VLAN de acordo com o endereço MAC de destino. Depois de configurar o encaminhamento MAC de rastreamento MLD, o rastreamento MLD encaminha os pacotes multicast na VLAN de acordo com o endereço MAC de origem multicast e o endereço MAC de destino multicast.
Tabela 10 -4 Ativar encaminhamento MAC de MLD snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função de encaminhamento MAC multicast L2 na VLAN especificada | ipv6 mld snooping vlan vlan-id l2-forwarding | Obrigatório Por padrão, habilite a função de encaminhamento de IP multicast L2 espionando MLD da VLAN. |
Configurar o Consultador de espionagem do MLD
Se não houver um dispositivo multicast L3 na rede, ele não poderá realizar as funções relacionadas do consultador MLD. Para resolver o problema, você pode configurar o MLD snooping querier no dispositivo multicast L2 para realizar a função MLD querier para que o dispositivo multicast L2 possa configurar e manter a entrada de encaminhamento multicast, de modo a encaminhar pacotes de serviço multicast normalmente.
Condição de configuração
Antes de configurar as funções básicas do MLD snooping , primeiro complete as seguintes tarefas:
- MLD snooping global e VLAN .
Ativar o Consulta de espionagem do MLD
Você deve primeiro habilitar a função de consulta de MLD snooping para que a configuração dos outros recursos do consultador possa ter efeito.
Tabela 10 -5 Ativar o pesquisador de espionagem MLD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar o pesquisador de MLD snooping | ipv6 mld snooping vlan vlan-id querier | Obrigatório Por padrão, não habilite o consultador de MLD snooping da VLAN especificada. |
Configurar o endereço IPv6 do consultador
O consultador configurado com endereço IPv6 participa da eleição do consultador MLD na VLAN e o consultador preenche o endereço IPv6 no campo de endereço IPv6 de origem do pacote de consulta do grupo MLD enviado.
Tabela 10 -6 Configurar o endereço IPv6 do consultador
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o endereço IPv6 do consultador | ipv6 mld snooping vlan vlan-id querier address ipv6-address | Obrigatório Por padrão, não configure o endereço IPv6 do consultador da VLAN especificada. |
Quando o endereço IPv6 do consultador não está configurado, o endereço IPv6 de origem padrão do consultador é 0 ::0 , mas o consultador não envia o pacote de consulta do grupo MLD com o endereço IPv6 de origem 0.0.0.0.
Configurar intervalo de consulta do grupo geral
MLD envia periodicamente os pacotes de consulta do grupo geral para manter a relação de membro do grupo. Você pode modificar o intervalo de envio dos pacotes de consulta do grupo geral MLD de acordo com a realidade da rede. Por exemplo, se o intervalo de consulta do grupo geral configurado for longo, pode-se reduzir o número de pacotes do protocolo MLD na rede, evitando o congestionamento da rede.
Tabela 10 -7 Configure o intervalo de consulta do grupo geral
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o intervalo de consulta do grupo geral | ipv6 mld snooping vlan vlan-id querier query-interval interval-value | Opcional Por padrão, o intervalo de consulta do grupo geral é 125s. |
Em uma VLAN, o intervalo de consulta configurado do grupo geral deve ser maior que o tempo máximo de resposta. Caso contrário, a configuração falhará.
Configurar máx. Tempo de resposta
O pacote de consulta de grupo geral enviado pelo consultador MLD contém o campo de tempo máximo de resposta. O receptor multicast envia os pacotes de relatório do membro dentro do intervalo máximo de resposta. Se o receptor multicast não enviar os pacotes de relatório do membro dentro do tempo máximo de resposta, o dispositivo considera que a sub-rede não possui o receptor do grupo multicast e, em seguida, exclui as informações do grupo multicast de uma só vez.
Tabela 10 -8 Configure o tempo máximo de resposta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o tempo máximo de resposta | ipv6 mld snooping vlan vlan-id querier max-response-time time-value | Opcional Por padrão, o tempo máximo de resposta é 10s. |
Em uma VLAN, o tempo de resposta máximo configurado deve ser menor que o intervalo de consulta do grupo geral. Caso contrário, a configuração falhará.
Configurar intervalo de consulta do grupo especificado
Quando o consultador MLD recebe o pacote de saída de um grupo multicast, ele envia o pacote de consulta do grupo especificado para consultar o segmento do grupo multicast, para saber se a sub-rede possui o membro do grupo multicast. Se não receber o pacote de relatório de membro do grupo multicast após aguardar o “tempo máximo de resposta”, exclua as informações do grupo multicast.
Tabela 10 -9 Configure o intervalo de consulta do grupo especificado
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o intervalo de consulta do grupo especificado | ipv6 mld snooping vlan vlan-id last-member-query-interval interval-value | Opcional Por padrão, o intervalo de consulta do grupo especificado é 1000ms. |
Configurar Saída Rápida
Se o dispositivo receber o pacote de saída de um grupo multicast após configurar a saída rápida, o dispositivo não enviará mais o pacote de consulta do grupo especificado para a porta e as informações do grupo multicast serão excluídas imediatamente.
Tabela 10 -10 Configurar saída rápida
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar saída rápida | ipv6 mld snooping vlan vlan-id immediate-leave | Obrigatório Por padrão, não habilite a função de saída rápida da VLAN especificada. |
Existem vários receptores do mesmo grupo multicast na porta do dispositivo ao mesmo tempo. Quando a porta recebe o pacote de saída MLD do grupo multicast enviado por um receptor e se a saída rápida estiver configurada na VLAN da porta do dispositivo, os serviços multicast dos outros receptores são interrompidos.
Configurar a porta do roteador de MLD snooping
A porta do roteador de MLD snooping é a porta que recebe os pacotes de consulta do grupo MLD ou os pacotes do protocolo de roteamento multicast. Quando o dispositivo recebe o relatório do membro MLD ou deixa o pacote, encaminhe o pacote pela porta do roteador de MLD snooping. Desta forma, o roteador conectado superior pode manter a tabela de relação de membro MLD corretamente.
A porta do roteador de MLD snooping pode ser aprendida dinamicamente ou configurada manualmente. A porta do roteador dinâmico de MLD snooping atualiza o tempo de idade recebendo regularmente os pacotes de consulta do grupo MLD ou os pacotes de protocolo de roteamento multicast. A porta do roteador estático de espionagem MLD não será envelhecida.
Condição de configuração
Antes de configurar as funções da porta do roteador de MLD snooping, primeiro conclua as seguintes tarefas:
- função de MLD snooping global e VLAN
- Adicionar membro da porta na VLAN
Configurar a porta do roteador estático de espionagem MLD
Depois de configurar a porta do roteador estático de MLD snooping, o dispositivo pode encaminhar o pacote de protocolo MLD através da porta, mesmo que a porta não receba o pacote de consulta de grupo MLD ou o pacote de protocolo de roteamento multicast. Ele pode evitar o problema de que a porta do roteador envelhece porque os serviços do dispositivo multicast L3 conectado superior são interrompidos.
Tabela 10 -11 Configurar porta do roteador estático de MLD snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a porta do roteador estático de MLD snooping | ipv6 mld snooping vlan vlan-id mrouter { interface interface-name | link-aggregation link-aggregation-id } | Obrigatório Por padrão, não configure a porta do roteador estático de MLD snooping. |
Configurar o tempo de idade da porta do roteador dinâmico de espionagem do MLD
Se o tempo de idade configurado da porta do roteador dinâmico de MLD snooping for maior, ele pode evitar o problema de que a porta do roteador do dispositivo multicast L3 conectado superior envelheceu rapidamente devido à interrupção do serviço.
Tabela 10 -12 Configurar o tempo de idade da porta do roteador dinâmico de espionagem MLD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o tempo de idade da porta do roteador dinâmico de MLD snooping | ipv6 mld snooping vlan vlan-id timer router-port expiry expiry-value | Opcional Por padrão, o tempo de idade da porta do roteador dinâmico de MLD snooping é 255s. |
Configurar evento TCN de MLD snooping
Condição de configuração
Antes de configurar a função de evento MLD snooping TCN, primeiro conclua a seguinte tarefa:
- função de MLD snooping global e VLAN
Ativar convergência rápida
Quando a topologia da rede muda, gere o evento TCN e a porta raiz da árvore de abrangência envia ativamente os pacotes de licença IMGP globais para solicitar que o consultador MLD envie o pacote de consulta geral do grupo, tornando a convergência rápida.
Depois de habilitar a convergência rápida do evento TCN de MLD snooping, a porta raiz da árvore não abrangente também envia ativamente o pacote de saída MLD global, tornando a convergência rápida.
Tabela 10 -13 Habilitar convergência rápida
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a convergência rápida | ipv6 mld snooping tcn query solicit | Obrigatório Por padrão, não habilite a convergência rápida no evento TCN. |
Configurar intervalo de consulta do evento TCN
Quando o evento TCN acontece, o consultador de espionagem MLD envia a consulta geral do grupo de acordo com o intervalo de consulta do evento TCN.
Tabela 10 -14 Configurar intervalo de consulta do evento TCN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar intervalo de consulta do evento TCN | ipv6 mld snooping vlan vlan-id querier tcn query interval interval-value | Opcional Por padrão, o intervalo de consulta do evento TCM é 31s. |
Configurar tempos de consulta do evento TCN
Quando o evento TCN acontece, o consultador de espionagem MLD envia a consulta geral do grupo de acordo com o intervalo de consulta do evento TCN. Depois que os tempos de envio atingirem os tempos de consulta configurados do evento TCN, restaure para o intervalo de consulta do grupo geral.
Tabela 10 -15 Configurar tempos de consulta do evento TCN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure os tempos de consulta do evento TCN | ipv6 mld snooping vlan vlan-id querier tcn query count count-number | Opcional Por padrão, os tempos de consulta do evento TCN são 2. |
Configurar funções básicas do IPv6 PIM-SM
Requisitos de rede
- Toda a rede executa o protocolo IPv6 PIM-SM.
- Receiver1 e Receiver2 são os dois receptores da rede stub Device3.
- Device1 e Device2 são C-BSR e C-RP.
- Execute o MLDv2 entre o Device3 e a rede stub.
Topologia de rede

Figura 10 - 1 Rede de configuração das funções básicas do IPv6 PIM-SM
Etapas de configuração
- Passo 1:Configure o endereço IPv6 da interface. (omitido)
- Passo 2:Habilite o protocolo de roteamento unicast OSPFv3 para que todos os dispositivos na rede possam se comunicar entre si.
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)#router-id 1.1.1.1Device1(config-ospf6)#exitDevice1(config)#interface gigabitethernet0/0/0Device1(config-if-gigabitethernet0/0/0)#ipv6 router ospf 100 area 0Device1(config-if-gigabitethernet0/0/0)#exitDevice1(config)#interface gigabitethernet0/0/1Device1(config-if-gigabitethernet0/0/1)#ipv6 router ospf 100 area 0Device1(config-if-gigabitethernet0/0/1)#exitDevice1(config)#interface gigabitethernet0/0/2Device1(config-if-gigabitethernet0/0/2)#ipv6 router ospf 100 area 0Device1(config-if-gigabitethernet0/0/2)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface gigabitethernet0/0/0Device2(config-if-gigabitethernet0/0/0)#ipv6 router ospf 100 area 0Device2(config-if-gigabitethernet0/0/0)#exitDevice2(config)#interface gigabitethernet0/0/1Device2(config-if-gigabitethernet0/0/1)#ipv6 router ospf 100 area 0Device2(config-if-gigabitethernet0/0/1)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface gigabitethernet0/0/0Device3(config-if-gigabitethernet0/0/0)#ipv6 router ospf 100 area 0Device3(config-if-gigabitethernet0/0/0)#exitDevice3(config)#interface gigabitethernet0/0/1Device3(config-if-gigabitethernet0/0/1)#ipv6 router ospf 100 area 0Device3(config-if-gigabitethernet0/0/1)#exitDevice3(config)#interface gigabitethernet0/0/2Device3(config-if-gigabitethernet0/0/2)#ipv6 router ospf 100 area 0Device3(config-if-gigabitethernet0/0/2)#exitDevice3(config)#interface gigabitethernet0/0/3Device3(config-if-gigabitethernet0/0/3)#ipv6 router ospf 100 area 0Device3(config-if-gigabitethernet0/0/3)#exit
#Visualize a tabela de rotas do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w6d:04:39:46, lo0O 2001:1::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:00:24, gigabitethernet0/0/0C 2001:2::/64 [0/0]via ::, 00:01:05, gigabitethernet0/0/0L 2001:2::1/128 [0/0]via ::, 00:01:04, lo0O 2001:3::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:00:24, gigabitethernet0/0/0[110/2]via fe80::201:7aff:fec0:525a, 00:00:04, gigabitethernet0/0/1C 2001:4::/64 [0/0]via ::, 00:00:49, gigabitethernet0/0/1L 2001:4::1/128 [0/0]via ::, 00:00:48, lo0C 2001:5::/64 [0/0]via ::, 00:00:43, gigabitethernet0/0/2L 2001:5::1/128 [0/0]via ::, 00:00:42, lo0C 2001:6::/64 [0/0]via ::, 00:00:43, gigabitethernet0/0/3L 2001:6::1/128 [0/0]via ::, 00:00:42, lo0
O método de visualização de Device1 e D evice2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 3:Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM na interface.
#Configurar dispositivo1.
Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas.
Device1(config)#ipv6 multicast-routingDevice1(config)#interface gigabitethernet0/0/0Device1(config-if-gigabitethernet0/0/0)#ipv6 pim sparse-modeDevice1(config-if-gigabitethernet0/0/0)#exitDevice1(config)#interface gigabitethernet0/0/1Device1(config-if-gigabitethernet0/0/1)#ipv6 pim sparse-modeDevice1(config-if-gigabitethernet0/0/1)#exitDevice1(config)#interface gigabitethernet0/0/2Device1(config-if-gigabitethernet0/0/2)#ipv6 pim sparse-modeDevice1(config-if-gigabitethernet0/0/2)#exit
#Configurar dispositivo2.
Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas.
Device2(config)#ipv6 multicast-routingDevice2(config)#interface gigabitethernet0/0/0Device2(config-if-gigabitethernet0/0/0)#ipv6 pim sparse-modeDevice2(config-if-gigabitethernet0/0/0)#exitDevice2(config)#interface gigabitethernet0/0/1Device2(config-if-gigabitethernet0/0/1)#ipv6 pim sparse-modeDevice2(config-if-gigabitethernet0/0/1)#exit
#Configurar dispositivo3.
Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas.
Device3(config)#ipv6 multicast-routingDevice3(config)#interface gigabitethernet0/0/0Device3(config-if-gigabitethernet0/0/0)#ipv6 pim sparse-modeDevice3(config-if-gigabitethernet0/0/0)#exitDevice3(config)#interface gigabitethernet0/0/1Device3(config-if-gigabitethernet0/0/1)#ipv6 pim sparse-modeDevice3(config-if-gigabitethernet0/0/1)#exitDevice3(config)#interface gigabitethernet0/0/2Device3(config-if-gigabitethernet0/0/2)#ipv6 pim sparse-modeDevice3(config-if-gigabitethernet0/0/2)#exitDevice3(config)#interface gigabitethernet0/0/3Device3(config-if-gigabitethernet0/0/3)#ipv6 pim sparse-modeDevice3(config-if-gigabitethernet0/0/3)#exit
# Visualize as informações da interface habilitada com o protocolo IPv6 PIM-SM no Device3 e as informações do vizinho IPv6 PIM-SM.
Device3#show ipv6 pim interfacePIM6 Interface Table:PIM6 VRF Name: DefaultTotal 5 Interface entriesTotal 0 External Interface entryTotal 0 Sparse-Dense Mode Interface entryInterface VIF Ver/ VIF Nbr DR BSR CISCO NeighborIndex Mode Flag Count Pri Border Neighbor Filterregister_vif0 2 v2/S UPAddress : fe80::201:7aff:fe5e:6d2d Global Address: ::gigabitethernet0/0/0 1 v2/S UP 1 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d2d Global Address: 2001:2::1 DR: fe80::201:7aff:fe62:bb7egigabitethernet0/0/1 3 v2/S UP 1 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d2e Global Address: 2001:4::1 DR: fe80::201:7aff:fec0:525agigabitethernet0/0/2 4 v2/S UP 0 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d2f Global Address: 2001:5::1 DR: fe80::201:7aff:fe5e:6d2fgigabitethernet0/0/3 5 v2/S UP 0 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d30 Global Address: 2001:6::1 DR: fe80::201:7aff:fe5e:6d30Device3#show ipv6 pim neighborPIM6 Neighbor Table:PIM6 VRF Name: DefaultTotal 2 Neighbor entriesNeighbor Interface Uptime/Expires Ver DRAddress Priority/Modefe80::201:7aff:fe62:bb7e gigabitethernet0/0/0 00:04:01/00:01:29 v2 1 / DRfe80::201:7aff:fec0:525a gigabitethernet0/0/1 00:04:03/00:01:39 v2 1 / DR
Os métodos de visualização de Device1 e Device2 são os mesmos de Device3, portanto o processo de visualização é omitido.
- Passo 4:Habilite o MLD em gigabitethernet0/0/ 2 e gigabitethernet0/0/ 3 de Device3.
# Configurar dispositivo3.
Habilite o MLD em gigabitethernet0/0/ 2 e gigabitethernet0/0/ 3 de Device3.
Device3(config)#interface gigabitethernet0/0/2Device3(config-if-gigabitethernet0/0/2)#ipv6 mld enableDevice3(config-if-gigabitethernet0/0/2)#exitDevice3(config)#interface gigabitethernet0/0/3Device3(config-if-gigabitethernet0/0/3)#ipv6 mld enableDevice3(config-if-gigabitethernet0/0/3)#exit
# Consulta as informações de MLD da interface Device3 gigabitethernet0/0/2 e gigabitethernet0/0/3.
Device3#show ipv6 mld interfaceInterface gigabitethernet0/0/2 (Index 11)MLD Enabled, ActiveQuerier: fe80::201:7aff:fe5e:6d2f (Self)Default version: 2Querier parameter:Query interval is 125 secondsQuerier timeout is 255 secondsQuery response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsRobustness variable is 2Interface gigabitethernet0/0/3 (Index 12)MLD Enabled, ActiveQuerier: fe80::201:7aff:fe5e:6d30 (Self)Default version: 2Querier parameter:Query interval is 125 secondsQuerier timeout is 255 secondsQuery response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsRobustness variable is 2
Você pode configurar a versão do MLD em execução na interface através do comando ipv6 mld version.
- Passo 5: Configure a interface gigabitethernet0/0/1 de Device1 como C-BSR e C-RP e configure a interface gigabitethernet0/0/0 de Device2 como C-BSR e C-RP .
#Configurar dispositivo1.
Configure a interface gigabitethernet0/0/1 do Device1 como C-BSR e C-RP; a prioridade do C-BSR é 200; o intervalo do grupo multicast do serviço C-RP é FF10::/16 .
Device1(config)#ipv6 pim bsr-candidate gigabitethernet0/0/1 10 200Device1(config)#ipv6 access-list extended 7001Device1(config-v6-list)#permit ipv6 any ff10::/16Device1(config-v6-list)#exitDevice1(config)#ipv6 pim rp-candidate gigabitethernet0/0/1 group-list 7001
#Configurar dispositivo2.
Configure a interface gigabitethernet0/0/0 do Device2 como C-BSR e C-RP; a prioridade de C-BSR é 0; o intervalo do grupo multicast do serviço C-RP do Device2 é FF 00::/8.
Device2(config)#ipv6 pim bsr-candidate gigabitethernet0/0/0Device2(config)#ipv6 pim rp-candidate gigabitethernet0/0/0
#Visualize as informações de BSR e RP do Device3.
Device3#show ipv6 pim bsr-routerPIM6v2 Bootstrap informationPIM6 VRF Name: DefaultBSR address: 2001:2::2BSR Priority: 200Hash mask length: 10Up time: 00:03:04Expiry time: 00:02:06Role: Non-candidate BSRState: Accept PreferredDevice3#show ipv6 pim rp mappingPIM6 Group-to-RP Mappings Table:PIM6 VRF Name: DefaultTotal 2 RP set entriesTotal 2 RP entriesGroup(s): ff00::/8RP count: 1RP: 2001:3::1Info source: 2001:2::2, via bootstrap, priority 192Up time: 00:21:30Expiry time: 00:02:24Group(s): ff10::/16RP count: 1RP: 2001:2::2Info source: 2001:2::2, via bootstrap, priority 192Up time: 00:04:31Expiry time: 00:02:24
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido. Ao configurar vários C-BSRs em um domínio multicast, primeiro eleja o BSR de acordo com a prioridade e o C-BSR com a maior prioridade é eleito como BSR. Quando as prioridades dos C-BSRs são as mesmas, o C-BSR com o maior endereço IP é eleito como BSR. Ao configurar vários C-RPs em um domínio multicast e os intervalos do grupo multicast de serviço são os mesmos, calcule o RP do grupo multicast G de acordo com o algoritmo de hash. No domínio multicast, você pode configurar o RP através do comando ipv6 pim rp-address , mas é necessário que os endereços RP estáticos configurados em todos os dispositivos no domínio multicast se mantenham consistentes.
- Passo 6:Confira o resultado.
#PC1 e PC2 enviam o pacote de relatório do membro MLDv2 para adicionar ao grupo multicast FF10::1 e FF50::1 respectivamente.
#Source envia os pacotes multicast com o grupo multicast FF10::1, FF50::1 .
#Exibe a tabela de membros multicast do Device3.
Device3#show ipv6 mld groupsMLD Connected Group MembershipTotal 2 Connected GroupsGroup Interface Uptime Expires V1-Expires Last Reporterff10::1 gigabitethernet0/0/2 00:00:09 00:04:13 not used fe80::210:94ff:fe00:1ff50::1 gigabitethernet0/0/3 00:00:09 00:04:14 not used fe80::210:94ff:fe00:2
#Visualize o RP do grupo multicast FF10::1, FF50::1 no Dispositivo3.
Device3#show ipv6 pim rp-hash ff10::1PIM6 VRF Name: DefaultRP: 2001:2::2Info source: 2001:2::2, via bootstrapDevice3#show ipv6 pim rp-hash ff50::1PIM6 VRF Name: DefaultRP: 2001:3::1Info source: 2001:2::2, via bootstrap
#Visualize a tabela de rotas multicast do Device3.
Device3#show ipv6 pim mrouteIP Multicast Routing Table:PIM6 VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 2 (*,G) entriesTotal 2 (S,G) entriesTotal 2 (S,G,rpt) entriesTotal 0 FCR entryUp timer/Expiry timer(*, ff10::1)Up time: 00:00:06RP: 2001:2::2RPF nbr: fe80::201:7aff:fe62:bb7eRPF idx: gigabitethernet0/0/0Flags:JOIN DESIREDUpstream State: JOINEDLocal interface list:gigabitethernet0/0/2Joined interface list:Asserted interface list:(2001:1::1, ff10::1)Up time: 00:00:05KAT time: 00:03:25RPF nbr: fe80::201:7aff:fe62:bb7eRPF idx: gigabitethernet0/0/0SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:gigabitethernet0/0/2Packet count 0(2001:1::1, ff10::1, rpt)Up time: 00:00:05RP: 2001:2::2Flags:RPT JOIN DESIREDRPF SGRPT XG EQUALUpstream State: NOT PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:(*, ff50::1)Up time: 00:00:06RP: 2001:3::1RPF nbr: fe80::201:7aff:fec0:525aRPF idx: gigabitethernet0/0/1Flags:JOIN DESIREDUpstream State: JOINEDLocal interface list:gigabitethernet0/0/3Joined interface list:Asserted interface list:(2001:1::1, ff50::1)Up time: 00:00:05KAT time: 00:03:27RPF nbr: fe80::201:7aff:fe62:bb7eRPF idx: gigabitethernet0/0/0SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:gigabitethernet0/0/3Packet count 1(2001:1::1, ff50::1, rpt)Up time: 00:00:05RP: 2001:3::1Flags:RPT JOIN DESIREDPRUNE DESIREDRPF SGRPT XG EQUALUpstream State: PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:gigabitethernet0/0/3
#PC1 só pode receber o pacote de serviço multicast com o grupo multicast FF10::1 enviado pelo Multicast Server . O PC2 só pode receber o pacote de serviço multicast com o grupo multicast FF50::1 enviado pelo Multicast Server .
O método de visualização de Device1 e Device2 é o mesmo de Device3, portanto o processo de visualização é omitido. Por padrão, o dispositivo habilita a comutação SPT.
Exemplo de configuração típica de espionagem de MLD
Configurar a espionagem do MLD
Requisitos de rede
- Device1 configura o protocolo de roteamento multicast IPv6; Device2 habilita a espionagem de MLD; PC1 e PC2 são os receptores do serviço multicast; PC3 é o receptor do serviço não multicast.
- O Servidor Multicast envia os pacotes de serviço multicast; PC1 e PC2 podem receber os pacotes de serviço multicast; PC3 não pode receber o pacote de serviço multicast.
Topologia de rede

Figura 10 -2 Rede de configuração de espionagem MLD
Etapas de configuração
- Passo 1:Device1 configura o endereço IPv6 da interface e habilita o protocolo de roteamento multicast IPv6. (omitido)
- Passo 2:Configurar dispositivo2.
# Cria VLAN2 no Dispositivo 2.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exit
# No Device2, configure o tipo de link das portas gigabitethernet0/2~gigabitethernet0/4 como acesso e permita a passagem dos serviços da VLAN2.
Device2(config)#interface gigabitethernet 0/2-0/4Device2(config-if-range)#switchport access vlan 2Device2(config-if-range)#exit
# No Device2, configure o tipo de link da porta gigabitethernet0/1 como Trunk e permita a passagem dos serviços da VLAN2. Configure PVID como 1.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode trunkDevice2(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2Device2(config-if-gigabitethernet0/1)#switchport trunk pvid vlan 1Device2(config-if-gigabitethernet0/1)#exit
# Em VLAN2, habilite o descarte multicast desconhecido.
Device2(config)#vlan 2Device2(config-vlan2)#l2-multicast drop-unknownDevice2(config-vlan2)#l3-multicast ipv6 drop-unknownDevice2(config-vlan2)#exit
# Habilite a espionagem de MLD e habilite a função de aprendizado dinâmico da porta de roteamento da VLAN2.
Device2(config)#ipv6 mld snoopingDevice2(config)#ipv6 mld snooping vlan 2Device2(config)#ipv6 mld snooping vlan 2 mrouter-learning
- Passo 3:Confira o resultado.
#PC1 e PC2 enviam pacote de relatório do membro MLDv1 para adicionar o grupo multicast IPv6 FF10::1 .
# Consulta a tabela de membros multicast de Device2.
Device2#show ipv6 mld snooping groupsMLD Snooping Group MembershipTotal 2 groupsVLAN ID Port Name Group Address Expires Last Reporter V1 Expires Uptime_______ ___________ ____________ ________ _________ __________ __________2 gi0/2 ff10::1 00:03:59 fe80::b stopped 00:00:162 gi0/3 ff10::1 00:03:59 fe80::c stopped 00:00:16
# Servidor multicast envia o pacote multicast IPv6 cujo endereço de destino é FF10 ::1 , PC2 e PC2 podem receber o pacote de serviço multicast e PC3 não pode receber o pacote de serviço multicast.
Noções básicas de multicast IPv6
Visão geral
Noções básicas de multicast IPv6 é a base da execução do protocolo multicast IPv6 e a parte comum de todos os protocolos multicast. Não importa qual protocolo de rota multicast seja executado, primeiro precisamos habilitar a função de encaminhamento multicast IPv6 para que o dispositivo possa encaminhar os pacotes de serviço multicast.
Configuração das funções básicas do IPv6 Multicast
Tabela 11 -1 Lista de configuração de funções básicas de multicast IPv6
| Tarefa de configuração | |
| Habilite o encaminhamento multicast IPv6 | Habilite o encaminhamento multicast IPv6 |
Ativar encaminhamento multicast IPv6
IPv6 é o módulo básico do encaminhamento multicast. O dispositivo pode encaminhar os pacotes de serviço multicast IPv6 somente após habilitar a função de encaminhamento multicast IPv6 . Tanto o encaminhamento multicast IPv6 geral quanto o encaminhamento rápido multicast IPv6 são controlados pela ativação do encaminhamento multicast IPv6 .
O encaminhamento rápido multicast IPv6 é uma tecnologia de encaminhamento multicast rápido IPv64 projetada para melhorar o desempenho de encaminhamento dos pacotes de serviço. Ele completa a seleção de rotas e o processamento do serviço por um tempo, de modo a reduzir o consumo de recursos causado pela comutação entre as tarefas internas do sistema e o gerenciamento de cache de pacotes. Por fim, melhore o desempenho de encaminhamento de dados de todo o sistema.
Condição de configuração
Antes de configurar a função de encaminhamento multicast IPv6 , primeiro conclua a seguinte tarefa:
- Configure o endereço IPv6 da interface, tornando alcançável a camada de rede do nó vizinho;
- Configure qualquer protocolo de roteamento unicast, tornando as rotas no domínio alcançáveis;
- Configure qualquer protocolo de roteamento multicast.
Ativar encaminhamento multicast IPv6
O dispositivo pode encaminhar os pacotes de serviço multicast IPv6 somente após habilitar a função de encaminhamento multicast IPv6 .
Tabela 11 -2 Habilitar o encaminhamento multicast IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite o encaminhamento multicast IPv6 | ipv6 multicast-routing [ vrf vrf-name ] | Obrigatório Por padrão, o encaminhamento multicast do IP v6 não está habilitado. |
Configurar regra de encaminhamento multicast IPV6
Condição de configuração
Antes de configurar a função de encaminhamento multicast IPv6 , primeiro conclua a seguinte tarefa:
- Configure o endereço IPv6 da interface, tornando alcançável a camada de rede do nó vizinho;
- Configure qualquer protocolo de roteamento unicast IPv6, tornando as rotas no domínio alcançáveis;
- Habilite o encaminhamento multicast IPv6;
- Configure qualquer protocolo de roteamento multicast IPv6.
Configurar Limitação da Tabela de Rota Multicast IPV6
Configure o limite máximo de entradas da tabela de roteamento multicast IPv6. Após exceder o limite máximo de entradas da tabela de roteamento IPv6 Multicast, não crie mais uma nova tabela de roteamento IPv6 Multicast.
Tabela 11 -3 Configurar a limitação da tabela de rotas multicast IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a limitação da tabela de rotas multicast IPv6 | ipv6 multicast route-limit number-value [ vrf vrf-name ] | opcional _ da tabela de rotas multicast são 8192. |
Monitoramento e Manutenção de Noções Básicas de Multicast IPv6
Tabela 11 -4 Monitoramento e manutenção de noções básicas de multicast IPv6
| Comando | Descrição |
| clear ipv6 mroute [ source source-ipv6-address ] [ group group-ipv6-address ] [ vrf vrf-name ] | Limpar a tabela de rotas do núcleo multicast |
| show ipv6 mroute [ source source-ipv6-address ] [ group group-ipv6-address ] [ vrf vrf-name ] | Exibir as informações da tabela de rotas do núcleo multicast |
| show ipv6 multicast-if [ vrf vrf-name ] | Exibir as informações da interface virtual multicast |
IPv6 PIM-SM
Visão geral
O protocolo IPv6 PIM e o protocolo IPv4 PIM têm os mesmos comportamentos, exceto a estrutura de endereço IP no pacote. Consulte a breve introdução do PIM-SM.
Configuração da Função IPv6 PIM-SM
Tabela 12 -1Lista de configuração da função IPv6 PIM-SM
| Tarefa de configuração | |
| Configurar as funções básicas do IPv6 PIM-SM | Habilite o protocolo IPv6 PIM-SM |
| Configurar o roteador de agregação IPv6 PIM-SM | Configurar C-RP Configurar RP estático |
| Configurar o roteador de bootstrap IPv6 PIM-SM | Configurar C-BSR Configurar a borda BSR |
| Configurar o registro de origem multicast IPv6 PIM-SM |
Configurar a verificação de acessibilidade RP
Configure a taxa de envio dos pacotes de registro Configure a taxa de envio dos pacotes de parada de registro Configure o endereço de origem do pacote de registro Configurar filtro de pacote de registro |
| Configurar parâmetros vizinhos IPv6 PIM-SM |
Configure o período de envio dos pacotes Hello
Configure o tempo de atividade do vizinho Configurar o filtro vizinho Configurar a prioridade de DR |
| Configurar comutação IPv6 PIM-SM SPT | Configurar a condição de comutação SPT |
| Configurar IPv6 PIM-SSM | Configurar IPv6 PIM-SSM |
Configurar funções básicas do IPv6 PIM-SM
Condições de configuração
Antes de configurar o IPv6 PIM-SM, primeiro conclua a seguinte tarefa:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
Ativar protocolo IPv6 PIM-SM
Tabela 12 -2Habilite o protocolo IPv6 PIM-SM
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite o encaminhamento multicast IPv6 | ipv6 multicast-routing | Obrigatório Por padrão, o encaminhamento multicast IPv6 não está habilitado. |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite o protocolo IPv6 PIM-SM | ipv6 pim sparse-mode | Qualquer Por padrão, o IPv6 PIM-SM está desabilitado na interface. |
| ipv6 pim sparse-mode passive |
Após habilitar a função IPv6 PIM-SM, todas as configurações IPv6 PIM-SM podem entrar em vigor.
Configurar roteador de agregação IPv6 PIM-SM
Condição de configuração
Antes de configurar o RP, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Habilite o protocolo IPv6 PIM-SM
Configurar C-RP
RP é gerado pela eleição C-RP. Depois que o BSR é eleito, todos os C-RPs (Candidate-Rendezvous Point) regularmente fazem o unicast do pacote C-RP para o BSR. O BSR integra as informações do C-RP e transmite as informações para todos os dispositivos no domínio IPv6 PIM-SM por meio do pacote de bootstrap.
Tabela 12 -3Configurar C-RP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar C-RP | ipv6 pim rp-candidate interface-name [ [ priority-value [ interval-value [ group-list { access-list-number | access-list-name } ] ] ] | [ group-list { access-list-number | access-list-name } ] ] [ vrf vrf-name ] | Obrigatório Por padrão, não há C-RP. |
Regras de eleição do RP: Para o intervalo de grupo do serviço C-RP, execute a correspondência mais longa da máscara. Se a correspondência mais longa da máscara tiver vários C-RPs, compare a prioridade de C-RP. Quanto menor o valor, maior a prioridade. Aquele com maior prioridade vence. Se houver vários C-RPs com prioridade mais alta, execute o cálculo de HASH para o endereço e o grupo C-RP. Aquele com o maior valor de HASH vence. Se houver vários RPs com o maior HASH, o C-RP com o maior endereço IPv6 vence.
Configurar RP estático
Para a rede IPv6 PIM-SM simples, sugere-se usar o RP estático. Se estiver usando o RP estático, não precisa realizar a configuração do BSR, eliminando a frequente interação entre RP e BSR, de modo a economizar a largura de banda da rede.
Tabela 12 -4Configurar RP estático
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o RP estático | ipv6 pim rp-address ipv6-address [ access-list-name | access-list-number ] [ override ] [ vrf vrf-name ] | Obrigatório Por padrão, não há RP estático. |
Todos os dispositivos no mesmo domínio IPv6 PIM-SM devem ser configurados com o mesmo RP estático.
Configurar roteador de inicialização IPv6 PIM-SM
Condições de configuração
Antes de configurar o BSR, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Habilite o protocolo IPv6 PIM-SM
Configurar C-BSR
Em um domínio IPv6 PIM-SM, deve haver o BSR exclusivo. Vários C-BSRs (Candidate-Bootstrap Router) optam por gerar o BSR exclusivo por meio do pacote de bootstrap.
Tabela 12 -5Configurar C-BSR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar C-BSR | ipv6 pim bsr-candidate interface_name [ hash-mask-length [ priority-value ] ] [ vrf vrf-name ] | Obrigatório Por padrão, não há C-BSR. |
Regras de eleição do BSR: Compare as prioridades. Quanto maior o valor, maior a prioridade. Aquele com maior prioridade vence. Se a prioridade for a mesma, vence aquele com o maior endereço IPv6.
Configurar borda BSR
O BSR é responsável por coletar as informações do C-RP e transmitir as informações para todos os dispositivos no domínio IPv6 PIM-SM por meio do pacote de bootstrap. O intervalo BSR é o intervalo do domínio multicast. O pacote de bootstrap não pode passar pela interface configurada com a borda BSR. Os dispositivos fora da faixa de domínio multicast não podem participar do encaminhamento do pacote de serviço multicast no domínio multicast, de modo a realizar a divisão do domínio multicast.
Tabela 12 -6Configurar a borda BSR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a borda BSR | ipv6 pim bsr-border | Obrigatório Por padrão, não há borda multicast. |
Configurar registro de origem multicast IPv6 PIM-SM
Condição de configuração
Antes de configurar o registro de origem multicast, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Habilite o protocolo IPv6 PIM-SM
Configurar verificação de acessibilidade de RP
Antes que o DR de origem envie o pacote de registro para o RP, primeiro execute a verificação de acessibilidade do RP. Se descobrir que a rota RP não é alcançável, não se registre no RP, de modo a reduzir o custo do DR.
Tabela 12 -7Configurar a verificação de acessibilidade RP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a verificação de acessibilidade RP | ipv6 pim register-rp-reachability [ vrf vrf-name ] | Obrigatório Por padrão, antes de realizar o registro PIM, não verifique a acessibilidade do RP. |
Para reduzir o custo do DR de origem, sugere-se configurar o comando nos DRs de origem de todos os PIM-SMs IPv6.
Configurar taxa de envio de pacotes de registro
Quando o DR de origem recebe o pacote multicast, encapsule o pacote multicast para o pacote de registro e envie ao RP para o registro de origem até que o registro seja concluído.
Quando o DR de origem não completa o registro de origem multicast e o fluxo multicast é grande, gere muitos pacotes de registro, o que aumenta a carga do dispositivo RP. Mesmo RP não pode funcionar normalmente. O DR de origem não precisa transmitir todos os pacotes de registro de um fluxo para o RP, portanto, configurar a taxa de envio dos pacotes de registro no DR de origem pode não apenas atingir o objetivo do registro de origem, mas também reduzir a carga do RP.
Tabela 12 -8Configure a taxa de envio do pacote de registro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a taxa de envio do pacote de registro | ipv6 pim register-rate-limit rate-limit-value [ vrf vrf-name ] | Obrigatório Por padrão, não limite a taxa de envio do pacote de registro. |
Para reduzir a carga de RP, sugere-se configurar a taxa de envio dos pacotes de registro de origem em todos os DRs de origem.
Configurar taxa de envio de pacotes de parada de registro
Após o RP receber o pacote de registro do DR de origem, envie o pacote de parada de registro ao DR de origem para concluir o registro. Quando o RP recebe muitos pacotes de registro, é necessário responder a todos os pacotes de registro (enviar pacote de parada de registro). Na verdade, há muitos pacotes repetidos nos pacotes de parada de registro. Você pode limitar a taxa de envio do pacote de parada de registro no RP para reduzir o custo do RP.
Tabela 12 -9 Configure a taxa de envio do pacote de parada de registro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a taxa de envio do pacote de parada de registro | ipv6 pim register-stop-rate-limit rate-limit-value [ vrf vrf-name ] | Obrigatório Por padrão, não limite a taxa de envio do pacote de parada de registro. |
Para melhorar a robustez de toda a rede IPv6 PIM-SM, sugere-se limitar a taxa do pacote de parada de registro de origem em todos os RPs.
Configurar o endereço de origem do pacote de registro
Quando o DR de origem realiza o registro de origem, o endereço de origem do pacote de registro utiliza o endereço IPv6 da interface de registro registrado automaticamente pelo sistema. O comando pode especificar o endereço de origem do pacote de registro como o endereço IPv6 de uma interface no dispositivo para atender a alguma demanda especial da rede.
Tabela 12 -10Configure o endereço de origem do pacote de registro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o endereço de origem do pacote de registro | ipv6 pim register-source interface interface-name [ vrf vrf-name ] | Obrigatório Por padrão, use o endereço IPv6 da interface de registro registrada automaticamente pelo sistema como o endereço de origem do pacote de registro. |
Configurar Filtro de Pacotes de Registro
Para evitar o ataque de registro de origem, você pode usar o ACL no RP para executar o filtro de origem multicast para o pacote de registro. Somente a fonte multicast permitida pelo ACL pode registrar-se com sucesso no RP.
Tabela 12 -11Configurar o filtro de pacotes de registro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o filtro de pacotes de registro | ipv6 pim accept-register list { access-list-number | access-list-name } [ vrf vrf-name ] | Obrigatório Por padrão, não filtre o pacote de registro. |
Configurar parâmetros vizinhos IPv6 PIM-SM
Condição de configuração
Antes de configurar os parâmetros do vizinho IPv6 PIM-SM, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Habilite o protocolo IPv6 PIM-SM
Configurar período de envio de pacotes Hello
A interface habilitada com o protocolo IPv6 PIM-SM envia periodicamente os pacotes Hello para configurar e manter o vizinho PIM.
Tabela 12 -12Configure o período de envio do pacote Hello
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o período de envio do pacote Hello | ipv6 pim hello-interval interval-value | Opcional Por padrão, o período de envio do pacote Hello é de 30s. |
Configurar o tempo de atividade do vizinho
Quando a interface recebe os pacotes Hello de um vizinho, registre o holdtime transportado no pacote Hello como o tempo keepalive do vizinho. Se não receber o pacote Hello do vizinho dentro do tempo de keepalive, considera-se que o vizinho se torna inválido.
Tabela 12 -13 Configurar o tempo de atividade do vizinho IPv6 PIM-SM
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o tempo de atividade do vizinho IPv6 PIM-SM | ipv6 pim hello-holdtime holdtime-value | Opcional Por padrão, o tempo de atividade do vizinho IPv6 PIM-SM é 105s. |
Configurar filtro vizinho
Se houver muitos vizinhos PIM em uma sub-rede, você pode usar a função de filtro vizinho para configurar o vizinho seletivamente, de modo a economizar os recursos do dispositivo.
Tabela 12 -14Configurar o filtro vizinho
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o filtro vizinho | ipv6 pim neighbor-filter { access-list-number | access-list-name } | Obrigatório Por padrão, não habilite a função de filtro vizinho. |
Configurar prioridade de DR
O DR desempenha um papel importante na rede IPv6 PIM-SM, portanto, é importante selecionar o DR apropriado. Você pode selecionar o dispositivo apropriado como DR configurando a prioridade de DR.
Uma sub-rede IPv6 PIM-SM permite apenas um DR. De acordo com a função, o DR pode ser dividido em DR de origem e DR de recebimento.
A principal função do DR de origem é realizar o registro de origem para RP.
A principal função do DR receptor é adicionar ao RP e configurar a comutação de RPT e SPT.
Tabela 12 -15Configurar a prioridade de DR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar a prioridade de DR | ipv6 pim dr-priority priority-value | Opcional Por padrão, a prioridade de DR é 1. |
Regras de eleição do DR: Compare as prioridades. Quanto maior o valor, maior a prioridade. Aquele com maior prioridade vence. Se a prioridade for a mesma, vence aquele com o maior endereço IPv6.
Configurar comutação IPv6 PIM-SM SPT
Condição de configuração
Antes de configurar o SPT, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Habilite o protocolo IPv6 PIM-SM
Configurar condição de comutação SPT
O DR da extremidade receptora não conhece o endereço da fonte multicast, portanto, só pode adicionar ao RP para formar o RPT. O DR de origem realiza o registro de origem para RP e forma a árvore de origem entre o DR de origem e o RP. Inicialmente, a direção do fluxo multicast é da fonte multicast para o RP e depois do RP para o receptor. Quando o DR da extremidade receptora recebe o primeiro pacote multicast, ele realiza a adição à fonte multicast, forma SPT e executa a poda para RPT. Isso é chamado de comutação SPT.
O comando é configurar a condição de comutação SPT na extremidade receptora DR.
Tabela 12 -16Configurar a condição de comutação SPT
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a condição de comutação SPT | ipv6 pim spt-threshold { infinity | threshold [ group-list {access-list-number | access-list-name } ] [ vrf vrf-name ] | Obrigatório Por padrão, todos os grupos multicast realizam a comutação SPT. |
Não configure o SPT nunca comutando no RP. Caso contrário, pode resultar na falha do encaminhamento multicast.
Configurar IPv6 PIM-SSM
IPv6 PIM-SSM é um subconjunto de IPv6 PIM-SM. No IPv6 PIM-SSM, não é necessário RP, BSR ou RPT, e não há comutação SPT, mas o DR da extremidade receptora adiciona diretamente à origem multicast e configura a árvore do caminho mais curto (SPT) com a origem como raiz.
Condição de configuração
Antes de configurar o IPv6 PIM-SSM, primeiro conclua as seguintes tarefas:
- Configure o endereço da camada de rede da interface, tornando a camada de rede do nó vizinho alcançável
- Configure qualquer protocolo de rota unicast, tornando a rota intradomínio alcançável
- Habilite o protocolo IPv6 PIM-SM em todas as interfaces que precisam de encaminhamento de rota multicast
Configurar IPv6 PIM-SSM
Tabela 12 -17Configurar IPv6 PIM-SSM
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar PIM-SSM | ipv6 pim ssm { default | range { access-list-number | access-list-name } } | Obrigatório Por padrão, a função SSM está desabilitada. |
Ao usar IPv6 PIM-SSM, a extremidade receptora deve habilitar MLDv2 . Quando o receptor não pode ser atualizado para MLDv2 , você pode usar a função IGMP SSM Mapping para cooperar com IPv6 PIM-SSM. Certifique-se de que os intervalos de endereços do grupo multicast SSM configurados em todos os dispositivos no domínio sejam consistentes. Caso contrário, pode resultar na anormalidade do IPv6 PIM-SS.
Monitoramento e manutenção do IPv6 PIM-SM
Tabela 12 -18Monitoramento e manutenção de IPv6 PIM-SM
| Comando | Descrição |
| clear ipv6 pim bsr rp-set [ vrf vrf-name ] | Limpe as informações do conjunto RP do IPv6 PIM-SM |
| clear ipv6 pim mroute [ group-address [ source-address ] ] [ vrf vrf-name ] | Limpe as informações de rota multicast do IPv6 PIM-SM |
| clear ipv6 pim statistics [ [ interface interface-name | [ vrf vrf-name ] | Limpe as informações estáticas dos pacotes do protocolo IPv6 PIM-SM |
| show ipv6 pim bsr-router [ vrf vrf-name ] | Exiba as informações de rota de bootstrap IPv6 PIM-SM |
| show ipv6 pim interface [ interface-name detail | detail ] [ vrf vrf-name ] | Exibir as informações da interface IPv6 PIM-SM |
| show ipv6 pim local-members interface-name [ vrf vrf-name ] | Exiba as informações do membro do grupo local IPv6 PIM-SM |
| show ipv6 pim mroute [| ssm | group group-address [ source source-address ] | source source-address ] [ vrf vrf-name ] | Exiba as informações da tabela de rotas multicast IPv6 PIM-SM |
| show ipv6 pim neighbor [ detail ] [ vrf vrf-name ] | Exiba as informações do vizinho IPv6 PIM-SM |
| show ipv6 pim nexthop [ ipv6-address ] [ vrf vrf-name ] | Exiba as informações do roteador de próximo salto IPv6 PIM-SM |
| show ipv6 pim rp mapping [ vrf vrf-name ] | Exiba as informações do IPv6 PIM-SM RP |
| show ipv6 pim rp-hash group-address [ vrf vrf-name ] | Exiba a informação RP do mapeamento do grupo multicast |
| show ipv6 pim statistics [ vrf vrf-name ] | Exiba as informações estatísticas dos pacotes do protocolo IPv6 PIM-SM |
Exemplo de configuração típica do IPv6 PIM-SM
Configurar as funções básicas do IPv6 PIM-SM
Requisitos de rede
- Toda a rede executa o protocolo IPv6 PIM-SSM.
- PC1 e PC2 são os dois receptores da rede stub Device3.
- Device1 e Device2 são C-BSR e C-RP .
- Execute o MLDv2 entre o Device3 e a rede stub.
Topologia de rede

Figura 12 -1 Rede de configuração das funções básicas do IPv6 PIM-SM
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente (omitida).
- Passo 2:Configure o endereço IPv6 da interface. (omitido)
- Passo 3:Habilite o protocolo de roteamento unicast OSPFv3 para que todos os dispositivos na rede possam se comunicar entre si.
#Configurar dispositivo1 .
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)#router-id 1.1.1.1Device1(config-ospf6)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 router ospf 100 area 0Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 router ospf 100 area 0Device1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ipv6 router ospf 100 area 0Device1(config-if-vlan4)#exit
# Configure o Dispositivo 2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface vlan4Device2(config-if-vlan4)#ipv6 router ospf 100 area 0Device2(config-if-vlan4)#exitDevice2(config)#interface vlan5Device2(config-if-vlan5)#ipv6 router ospf 100 area 0Device2(config-if-vlan5)#exit
# Configure o Dispositivo 3.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 router ospf 100 area 0Device3(config-if-vlan3)#exitDevice3(config)#interface vlan5Device3(config-if-vlan5)#ipv6 router ospf 100 area 0Device3(config-if-vlan5)#exitDevice3(config)#interface vlan6Device3(config-if-vlan6)#ipv6 router ospf 100 area 0Device3(config-if-vlan6)#exitDevice3(config)#interface vlan7Device3(config-if-vlan7)#ipv6 router ospf 100 area 0Device3(config-if-vlan7)#exit
# Consulta a tabela de rotas do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w6d:04:39:46, lo0O 2001:1::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:00:24, vlan3C 2001:2::/64 [0/0]via ::, 00:01:05, vlan3L 2001:2::1/128 [0/0]via ::, 00:01:04, lo0O 2001:3::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:00:24, vlan3[110/2]via fe80::201:7aff:fec0:525a, 00:00:04, vlan5C 2001:4::/64 [0/0]via ::, 00:00:49, vlan5L 2001:4::1/128 [0/0]via ::, 00:00:48, lo0C 2001:5::/64 [0/0]via ::, 00:00:43, vlan6L 2001:5::1/128 [0/0]via ::, 00:00:42, lo0C 2001:6::/64 [0/0]via ::, 00:00:43, vlan7L 2001:6::1/128 [0/0]via ::, 00:00:42, lo0
Os métodos de consulta de Device1 e Device2 são os mesmos de Device3, portanto, o processo de consulta é omitido.
- Passo 4: Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM na interface.
# Configurar Device1 .
Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM na interface relacionada.
Device1(config)#ipv6 multicast-routingDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 pim sparse-modeDevice1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ipv6 pim sparse-modeDevice1(config-if-vlan4)#exit
# Configure o Dispositivo 2.
Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM na interface relacionada.
Device2(config)#ipv6 multicast-routingDevice2(config)#interface vlan4Device2(config-if-vlan4)#ipv6 pim sparse-modeDevice2(config-if-vlan4)#exitDevice2(config)#interface vlan5Device2(config-if-vlan5)#ipv6 pim sparse-modeDevice2(config-if-vlan5)#exit
# Configure o Dispositivo 3.
Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM na interface relacionada.
Device3(config)#ipv6 multicast-routingDevice3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 pim sparse-modeDevice3(config-if-vlan3)#exitDevice3(config)#interface vlan5Device3(config-if-vlan5)#ipv6 pim sparse-modeDevice3(config-if-vlan5)#exitDevice3(config)#interface vlan6Device3(config-if-vlan6)#ipv6 pim sparse-modeDevice3(config-if-vlan6)#exitDevice3(config)#interface vlan7Device3(config-if-vlan7)#ipv6 pim sparse-modeDevice3(config-if-vlan7)#exit
# Consulta as informações sobre a interface habilitada com o protocolo IPv6 PIM-SM no Device3 e as informações do vizinho IPv6 PIM-SM .
Device3#show ipv6 pim interfacePIM6 Interface Table:PIM6 VRF Name: DefaultTotal 5 Interface entriesTotal 0 External Interface entryTotal 0 Sparse-Dense Mode Interface entryInterface VIF Ver/ VIF Nbr DR BSR CISCO NeighborIndex Mode Flag Count Pri Border Neighbor Filterregister_vif0 2 v2/S UPAddress : fe80::201:7aff:fe5e:6d2d Global Address: ::vlan3 1 v2/S UP 1 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d2d Global Address: 2001:2::1 DR: fe80::201:7aff:fe62:bb7evlan5 3 v2/S UP 1 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d2e Global Address: 2001:4::1 DR: fe80::201:7aff:fec0:525avlan6 4 v2/S UP 0 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d2f Global Address: 2001:5::1 DR: fe80::201:7aff:fe5e:6d2fvlan7 5 v2/S UP 0 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d30 Global Address: 2001:6::1 DR: fe80::201:7aff:fe5e:6d30Device3#show ipv6 pim neighborPIM6 Neighbor Table:PIM6 VRF Name: DefaultTotal 2 Neighbor entriesNeighbor Interface Uptime/Expires Ver DRAddress Priority/Modefe80::201:7aff:fe62:bb7e vlan3 00:04:01/00:01:29 v2 1 / DRfe80::201:7aff:fec0:525a vlan5 00:04:03/00:01:39 v2 1 / DR
Os métodos de consulta de Device1 e Device2 são os mesmos de Device3 e o processo de consulta é omitido.
- Passo 5: Em vlan6 e vlan7 de Device3, habilite o MLD.
# Configure o Dispositivo 3.
Em vlan6 e vlan7 de Device3, habilite o MLD.
Device3(config)#interface vlan6Device3(config-if-vlan6)#ipv6 mld enableDevice3(config-if-vlan6)#exitDevice3(config)#interface vlan7Device3(config-if-vlan7)#ipv6 mld enableDevice3(config-if-vlan7)#exit
# Consulta as informações de MLD da interface vlan6 e vlan7 no Device3.
Device3#show ipv6 mld interfaceInterface vlan6 (Index 11)MLD Enabled, ActiveQuerier: fe80::201:7aff:fe5e:6d2f (Self)Default version: 2Querier parameter:Query interval is 125 secondsQuerier timeout is 255 secondsQuery response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsRobustness variable is 2Interface vlan7 (Index 12)MLD Enabled, ActiveQuerier: fe80::201:7aff:fe5e:6d30 (Self)Default version: 2Querier parameter:Query interval is 125 secondsQuerier timeout is 255 secondsQuery response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsRobustness variable is 2
Você pode configurar a versão do MLD em execução na interface por meio do comando IPv6 mld version .
- Passo 6: Configure a interface vlan3 do Device1 como C-BSR e C-RP e configure a interface vlan4 do Device2 como C-BSR e C-RP.
# Configurar Device1 .
Configure a interface vlan3 de Device1 como C-BSR e C-RP , a prioridade de C-BSR é 200 e o intervalo do grupo multicast do serviço C-RP é FF10::/16 .
Device1(config)#ipv6 pim bsr-candidate vlan3 10 200Device1(config)#ipv6 access-list extended 7001Device1(config-v6-list)#permit ipv6 any ff10::/16Device1(config-v6-list)#commitDevice1(config-v6-list)#exitDevice1(config)#ipv6 pim rp-candidate vlan3 group-list 7001
# Configure o Dispositivo 2.
Configure a interface vlan 4 do dispositivo 2 como C-BSR e C-RP , a prioridade de C-BSR é 0 e o intervalo do grupo multicast do serviço C-RP é FF 00::/8.
Device2(config)#ipv6 pim bsr-candidate vlan4Device2(config)#ipv6 pim rp-candidate vlan4
#Consulte as informações de BSR e RP do Device3.
Device3#show ipv6 pim bsr-routerPIM6v2 Bootstrap informationPIM6 VRF Name: DefaultBSR address: 2001:2::2 BSR Priority: 200Hash mask length: 10Up time: 00:03:04Expiry time: 00:02:06Role: Non-candidate BSRState: Accept PreferredDevice3#show ipv6 pim rp mappingPIM6 Group-to-RP Mappings Table:PIM6 VRF Name: DefaultTotal 2 RP set entriesTotal 2 RP entriesGroup(s): ff00::/8RP count: 1RP: 2001:3::1Info source: 2001:2::2, via bootstrap, priority 192Up time: 00:21:30Expiry time: 00:02:24Group(s): ff10::/16RP count: 1RP: 2001:2::2Info source: 2001:2::2, via bootstrap, priority 192Up time: 00:04:31Expiry time: 00:02:24
Os métodos de consulta de Device1 e Device2 são os mesmos de Device3 e o processo de consulta é omitido. Ao configurar vários C-BSRs em um domínio multicast, o BSR será selecionado primeiro de acordo com a prioridade e o C-BSR com a prioridade mais alta será selecionado como BSR. Quando as prioridades dos C-BSRs são as mesmas, o C-BSR com o maior endereço IP é selecionado como BSR. Quando vários C-RPs são configurados em um domínio multicast e o intervalo do grupo multicast do serviço é o mesmo, o RP correspondente do grupo multicast G será calculado de acordo com o algoritmo de hash. No domínio multicast, você pode configurar o RP pelo comando ipv6 pim rp-address , mas os endereços RP estáticos configurados em todos os dispositivos de todo o domínio multicast devem ser consistentes.
- Passo 7:Confira o resultado.
#PC1 e PC2 respectivamente enviam relatório de relação de membro MLDv2 para adicionar ao grupo multicast FF10::1 e FF50::1 .
#Multicast Server envia o pacote de serviço multicast do grupo multicast FF10::1, FF50::1 .
#Consulte a tabela de membros multicast no Device3.
Device3#show ipv6 mld groupsMLD Connected Group MembershipTotal 2 Connected GroupsGroup Interface Uptime Expires V1-Expires Last Reporterff10::1 vlan6 00:00:09 00:04:13 not used fe80::210:94ff:fe00:1ff50::1 vlan7 00:00:09 00:04:14 not used fe80::210:94ff:fe00:2
#Consulte o RP do grupo multicast FF10::1, FF50::1 no Dispositivo3.
Device3#show ipv6 pim rp-hash ff10::1PIM6 VRF Name: DefaultRP: 2001:2::2Info source: 2001:2::2, via bootstrapDevice3#show ipv6 pim rp-hash ff50::1PIM6 VRF Name: DefaultRP: 2001:3::1Info source: 2001:2::2, via bootstrap
#Consulte a tabela de rotas multicast do Device3.
Device3#show ipv6 pim mrouteIP Multicast Routing Table:PIM6 VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 2 (*,G) entriesTotal 2 (S,G) entriesTotal 2 (S,G,rpt) entriesTotal 0 FCR entryUp timer/Expiry timer(*, ff10::1)Up time: 00:00:06RP: 2001:2::2RPF nbr: fe80::201:7aff:fe62:bb7eRPF idx: vlan3Flags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan6Joined interface list:Asserted interface list:(2001:1::1, ff10::1)Up time: 00:00:05KAT time: 00:03:25RPF nbr: fe80::201:7aff:fe62:bb7eRPF idx: vlan3SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:vlan6Packet count 0(2001:1::1, ff10::1, rpt)Up time: 00:00:05RP: 2001:2::2Flags:RPT JOIN DESIREDRPF SGRPT XG EQUALUpstream State: NOT PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:(*, ff50::1)Up time: 00:00:06RP: 2001:3::1RPF nbr: fe80::201:7aff:fec0:525aRPF idx: vlan5Flags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan7Joined interface list:Asserted interface list:(2001:1::1, ff50::1)Up time: 00:00:05KAT time: 00:03:27RPF nbr: fe80::201:7aff:fe62:bb7eRPF idx: vlan3SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:vlan7Packet count 1(2001:1::1, ff50::1, rpt)Up time: 00:00:05RP: 2001:3::1Flags:RPT JOIN DESIREDPRUNE DESIREDRPF SGRPT XG EQUALUpstream State: PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:vlan7
# PC1 só pode receber pacotes de serviço multicast enviados pelo Multicast Server, cujo grupo multicast é FF10::1. O PC2 só pode receber pacotes de serviço multicast enviados pelo Multicast Server, cujo grupo multicast é FF50::1.
Os métodos de consulta de Device1 e Device2 são os mesmos de Device3, portanto, o método de consulta é omitido. Por padrão, o dispositivo habilita a comutação SPT.
Configurar IPv6 PIM-SSM
Requisitos de rede
- Toda a rede executa o protocolo IPv6 PIM-SSM.
- O PC é um receptor da rede stub Device3.
- Execute o MLDv2 entre o Device3 e a rede stub.
Topologia de rede

Figura 12 - 2Rede de configuração do IPv6 PIM-SSM
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente (omitida).
- Passo 2:Configure o endereço IPv6 da interface. (omitido)
- Passo 3:Habilite o protocolo de roteamento unicast OSPFv3 para que todos os dispositivos na rede possam se comunicar entre si.
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router ospf 1 00Device1(config-ospf6)#router-id 1.1.1.1Device1(config-ospf6)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 router ospf 100 area 0Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 router ospf 100 area 0Device1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ipv6 router ospf 100 area 0Device1(config-if-vlan4)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface vlan4Device2(config-if-vlan4)#ipv6 router ospf 100 area 0Device2(config-if-vlan4)#exitDevice2(config)#interface vlan5Device2(config-if-vlan5)#ipv6 router ospf 100 area 0Device2(config-if-vlan5)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 router ospf 100 area 0Device3(config-if-vlan3)#exitDevice3(config0)#interface vlan5Device3(config-if-vlan5)#ipv6 router ospf 100 area 0Device3(config-if-vlan5)#exitDevice3(config)#interface vlan6Device3(config-if-vlan6)#ipv6 router ospf 100 area 0Device3(config-if-vlan6)#exit
#Visualize a tabela de rotas do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 2w6d:04:39:46, lo0O 2001:1::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:00:24, vlan3C 2001:2::/64 [0/0]via ::, 00:01:05, vlan3L 2001:2::2/128 [0/0]via ::, 00:01:04, lo0O 2001:3::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:00:24, vlan3[110/2]via fe80::201:7aff:fec0:525a, 00:00:04, vlan5C 2001:4::/64 [0/0]via ::, 00:00:49, vlan5L 2001:4::1/128 [0/0]via ::, 00:00:48, lo0C 2001:5::/64 [0/0]via ::, 00:00:43, vlan6L 2001:5::1/128 [0/0]via ::, 00:00:42, lo0
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 4:Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM na interface.
#Configurar dispositivo1.
Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas.
Device1(config)#ipv6 multicast-routingDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 pim sparse-modeDevice1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ipv6 pim sparse-modeDevice1(config-if-vlan4)#exit
#Configurar dispositivo2.
Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas.
Device2(config)#ipv6 multicast-routingDevice2(config)#interface vlan4Device2(config-if-vlan4)#ipv6 pim sparse-modeDevice2(config-if-vlan4)#exitDevice2(config)#interface vlan5Device2(config-if-vlan5)#ipv6 pim sparse-modeDevice2(config-if-vlan5)#exit
#Configurar dispositivo3.
Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas.
Device3(config)#ipv6 multicast-routingDevice3(config)#interface vlan3Device3(config-if-vlan3)#ipv6 pim sparse-modeDevice3(config-if-vlan3)#exitDevice3(config)#interface vlan5Device3(config-if-vlan5)#ipv6 pim sparse-modeDevice3(config-if-vlan5)#exitDevice3(config)#interface vlan6Device3(config-if-vlan6)#ipv6 pim sparse-modeDevice3(config-if-vlan6)#exit
# Visualize as informações da interface habilitada com o protocolo IPv6 PIM-SM no Device3 e as informações do vizinho IPv6 PIM-SM.
Device3#show ipv6 pim interfacePIM6 Interface Table:PIM6 VRF Name: DefaultTotal 4 Interface entriesTotal 0 External Interface entryTotal 0 Sparse-Dense Mode Interface entryInterface VIF Ver/ VIF Nbr DR BSR CISCO NeighborIndex Mode Flag Count Pri Border Neighbor Filterregister_vif0 2 v2/S UPAddress : fe80::201:7aff:fe5e:6d2d Global Address: ::vlan3 1 v2/S UP 1 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d2d Global Address: 2001:2::2 DR: fe80::201:7aff:fe62:bb7evlan5 3 v2/S UP 1 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d2e Global Address: 2001:4::1 DR: fe80::201:7aff:fec0:525avlan6 4 v2/S UP 0 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d2f Global Address: 2001:5::1 DR: fe80::201:7aff:fe5e:6d2fDevice3#show ipv6 pim neighborPIM6 Neighbor Table:PIM6 VRF Name: DefaultTotal 2 Neighbor entriesNeighbor Interface Uptime/Expires Ver DRAddress Priority/Modefe80::201:7aff:fe62:bb7e vlan3 00:04:01/00:01:29 v2 1 / DRfe80::201:7aff:fec0:525a vlan5 00:04:03/00:01:39 v2 1 / DR
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 5:Habilite o MLD em gigabitethernet0/0/ 2 do Device3.
# Configure o Dispositivo 3.
Habilite o MLD na vlan6 do Device3.
Device3(config)#interface vlan6Device3(config-if-vlan6)#ipv6 mld enableDevice3(config-if-vlan6)#exit
# Visualize as informações de MLD da interface Device3 vlan6.
Device3#show ipv6 mld interface vlan6Interface vlan6 (Index 11)MLD Enabled, ActiveQuerier: fe80::201:7aff:fe5e:6d2f (Self)Default version: 2Querier parameter:Query interval is 125 secondsQuerier timeout is 255 secondsQuery response time is 10 secondsLast member query response interval is 1 secondsLast member query count is 2Group Membership interval is 260 secondsRobustness variable is 2
Você pode configurar a versão do MLD em execução na interface via versão ipv6 mld.
- Passo 6: Configure IPv6 PIM-SSM em todos os dispositivos; o intervalo do grupo multicast do serviço SSM é FF3X::/32.
#Configurar dispositivo1.
Device1(config)#ipv6 pim ssm default#Configurar dispositivo2.
Device2(config)#ipv6 pim ssm default#Configurar dispositivo3.
Device3(config)#ipv6 pim ssm default- Passo 7:Confira o resultado.
#PC envia o relatório de relação de membro MLDv2 do grupo de origem especificado para adicionar ao grupo multicast FF30::1 ; a fonte de multicast especificada é 2001:1::1 .
# Multicast Server envia os pacotes multicast com o grupo multicast FF30::1 .
#Exibe a tabela de membros multicast do Device3.
Device3#show ipv6 mld groups detailMLD Connected Group MembershipTotal 1 Connected GroupsGroup Interface Uptime Expires V1-Expires Last Reporterff30::1 vlan6 00:26:42 not used not used fe80::210:94ff:fe00:1Group mode : IncludeTIB-A Count: 1TIB-B Count: 0TIB-ASource list: (R - Remote, M - SSM Mapping)Source Uptime Expires Flags2001:1::1 00:05:55 00:03:41 R
#Visualize a tabela de rotas multicast do Device3.
Device3#show ipv6 pim mrouteIP Multicast Routing Table:PIM6 VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 0 (*,G) entryTotal 1 (S,G) entryTotal 0 (S,G,rpt) entryTotal 0 FCR entryUp timer/Expiry timer(2001:1::1, ff30::1)Up time: 00:06:48KAT time: 00:02:30RPF nbr: fe80::201:7aff:fe62:bb7eRPF idx: vlan3SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan6Joined interface list:Asserted interface list:Outgoing interface list:vlan6Packet count 275560
# O PC só pode receber o pacote de serviço multicast com o grupo multicast FF30::1 enviado pela Origem.
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido. O intervalo de grupo multicast padrão do IPv6 PIM-SSM é FF3X::/32. Você pode modificar o intervalo do grupo multicast do serviço IPv6 PIM-SSM por meio do comando IPv6 pim ssm range . Para o grupo multicast G que atende à condição SSM, a tabela de rotas multicast não gera a entrada (*,G), mas apenas gera a entrada (S,G).
Configurar o controle de encaminhamento multicast IPv6 PIM-SM
Requisitos de rede
- Toda a rede executa o protocolo IPv6 PIM-SM.
- Receptor é um receptor da rede stub Device3.
- Device2 é C-BSR e C-RP.
- Em Device2 e Device3, controle para a fonte multicast, fazendo com que o PC receba apenas o pacote de serviço multicast enviado pelo Multicast Server 1 .
- Execute o MLDv2 entre o Device3 e a rede stub.
Topologia de rede
Figura 12 - 3 Rede de configuração do controle de encaminhamento multicast IPv6 PIM-SM
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente (omitida).
- Passo 2:Configure o endereço IPv6 da interface. (omitido)
- Passo 3:Habilite o protocolo de roteamento unicast OSPFv3 para que todos os dispositivos na rede possam se comunicar entre si.
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#ipv6 router ospf 100Device1(config-ospf6)#router-id 1.1.1.1Device1(config-ospf6)#exitDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 router ospf 100 area 0Device1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 router ospf 100 area 0Device1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ipv6 router ospf 100 area 0Device1(config-if-vlan4)#exitDevice1(config)#interface vlan5Device1(config-if-vlan5)#ipv6 router ospf 100 area 0Device1(config-if-vlan5)#exitDevice1(config)#interface vlan6Device1(config-if-vlan6)#ipv6 router ospf 100 area 0Device1(config-if-vlan6)#exitDevice1(config)#interface vlan7Device1(config-if-vlan7)#ipv6 router ospf 100 area 0Device1(config-if-vlan7)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#ipv6 router ospf 100Device2(config-ospf6)#router-id 2.2.2.2Device2(config-ospf6)#exitDevice2(config)#interface vlan7Device2(config-if-vlan7)#ipv6 router ospf 100 area 0Device2(config-if-vlan7)#exitDevice2(config)#interface vlan8Device2(config-if-vlan8)#ipv6 router ospf 100 area 0Device2(config-if-vlan8)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#ipv6 router ospf 100Device3(config-ospf6)#router-id 3.3.3.3Device3(config-ospf6)#exitDevice3(config)#interface vlan6Device3(config-if-vlan6)#ipv6 router ospf 100 area 0Device3(config-if-vlan6)#exitDevice3(config)#interface vlan8Device3(config-if-vlan8)#ipv6 router ospf 100 area 0Device3(config-if-vlan8)#exitDevice3(config)#interface vlan9Device3(config-if-vlan9)#ipv6 router ospf 100 area 0Device3(config-if-vlan9)#exit
#Visualize a tabela de rotas do Device3.
Device3#show ipv6 routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementL ::1/128 [0/0]via ::, 3w2d:05:13:23, lo0O 2001:1::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:00:24, vlan6O 2001:2::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:00:24, vlan6O 2001:3::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:00:24, vlan6O 2001:4::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:00:24, vlan6C 2001:5::/64 [0/0]via ::, 00:01:52, vlan6L 2001:5::2/128 [0/0]via ::, 00:01:50, lo0O 2001:6::/64 [110/2]via fe80::201:7aff:fe62:bb7e, 00:00:24, vlan6[110/2]via fe80::201:7aff:fec0:525a, 00:00:24, vlan8C 2001:7::/64 [0/0]via ::, 00:01:25, vlan8L 2001:7::2/128 [0/0]via ::, 00:01:24, lo0C 2001:8::/64 [0/0]via ::, 00:01:16, vlan9L 2001:8::1/128 [0/0]via ::, 00:01:14, lo0
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 4:Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM na interface.
#Configurar dispositivo1.
Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast Device1(config)#ipv6 multicast-routing
Device1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 pim sparse-modeDevice1(config-if-vlan2)#exitDevice1(config)#interface vlan3Device1(config-if-vlan3)#ipv6 pim sparse-modeDevice1(config-if-vlan3)#exitDevice1(config)#interface vlan4Device1(config-if-vlan4)#ipv6 pim sparse-modeDevice1(config-if-vlan4)#exitDevice1(config)#interface vlan5Device1(config-if-vlan5)#ipv6 pim sparse-modeDevice1(config-if-vlan5)#exitDevice1(config)#interface vlan6Device1(config-if-vlan6)#ipv6 pim sparse-modeDevice1(config-if-vlan6)#exitDevice1(config)#interface vlan7Device1(config-if-vlan7)#ipv6 pim sparse-modeDevice1(config-if-vlan7)#exit
#Configurar dispositivo2.
Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas.
Device2(config)#ipv6 multicast-routingDevice2(config)#interface vlan7Device2(config-if-vlan7)#ipv6 pim sparse-modeDevice2(config-if-vlan7)#exitDevice2(config)#interface vlan8Device2(config-if-vlan8)#ipv6 pim sparse-modeDevice2(config-if-vlan8)#exit
#Configurar dispositivo3.
Habilite globalmente o encaminhamento multicast IPv6 e habilite o protocolo multicast IPv6 PIM-SM nas interfaces relacionadas.
Device3(config)#ipv6 multicast-routingDevice3(config)#interface vlan6Device3(config-if-vlan6)#ipv6 pim sparse-modeDevice3(config-if-vlan6)#exitDevice3(config)#interface vlan8Device3(config-if-vlan8)#ipv6 pim sparse-modeDevice3(config-if-vlan8)#exitDevice3(config)#interface vlan9Device3(config-if-vlan9)#ipv6 pim sparse-modeDevice3(config-if-vlan9)#exit
# Visualize as informações da interface habilitada com o protocolo IPv6 PIM-SM no Device3 e as informações do vizinho IPv6 PIM-SM.
Device3#show ipv6 pim interfacePIM6 Interface Table:PIM6 VRF Name: DefaultTotal 4 Interface entriesTotal 0 External Interface entryTotal 0 Sparse-Dense Mode Interface entryInterface VIF Ver/ VIF Nbr DR BSR CISCO NeighborIndex Mode Flag Count Pri Border Neighbor Filterregister_vif0 2 v2/S UPAddress : fe80::201:7aff:fe5e:6d2d Global Address: ::vlan6 1 v2/S UP 1 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d2d Global Address: 2001:5::2 DR: fe80::201:7aff:fe62:bb7evlan8 4 v2/S UP 1 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d2e Global Address: 2001:7::2 DR: fe80::201:7aff:fec0:525avlan9 3 v2/S UP 0 1 FALSE FALSEAddress : fe80::201:7aff:fe5e:6d2f Global Address: 2001:8::1 DR: fe80::201:7aff:fe5e:6d2fDevice3#show ipv6 pim neighborPIM6 Neighbor Table:PIM6 VRF Name: DefaultTotal 2 Neighbor entriesNeighbor Interface Uptime/Expires Ver DRAddress Priority/Modefe80::201:7aff:fe62:bb7e vlan6 00:07:08/00:01:25 v2 1 / DRfe80::201:7aff:fec0:525a vlan8 00:00:18/00:01:27 v2 1 / DR
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 5:Configure gigabitethernet 0/0/0 de Device2 como o C-BSR e C-RP de toda a rede e o intervalo do grupo multicast do serviço C-RP é FF 00::/8 .
#Configurar dispositivo2.
Device2(config)#ipv6 pim bsr-candidate vlan7Device2(config)#ipv6 pim rp-candidate vlan7
#Visualize as informações de BSR e RP do Device3.
Device3#show ipv6 pim bsr-routerPIM6v2 Bootstrap informationPIM6 VRF Name: DefaultBSR address: 2001:6::2BSR Priority: 0Hash mask length: 126Up time: 00:00:21Expiry time: 00:01:54Role: Non-candidate BSRState: Accept PreferredDevice3#show ipv6 pim rp mappingPIM6 Group-to-RP Mappings Table:PIM6 VRF Name: DefaultTotal 1 RP set entryTotal 1 RP entryGroup(s): ff00::/8RP count: 1RP: 2001:6::2Info source: 2001:6::2, via bootstrap, priority 192Up time: 00:00:28Expiry time: 00:02:02
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
- Passo 6:Em Device2 e Device3, controle para a fonte multicast, fazendo com que o PC receba apenas o pacote de serviço multicast enviado pelo Multicast Server 1 .
#No Device2, configure a lista de acesso de mensagens de registro aceitas, filtrando a mensagem de registro do Servidor Multicast 4 .
Device2(config)#ipv6 access-list extended 7001Device2(config-std-nacl)#deny ipv6 host 2001:4::2 anyDevice2(config-std-nacl)#permit ipv6 any anyDevice2(config-std-nacl)#commitDevice2(config-std-nacl)#exitDevice2(config)#ipv6 pim accept-register list 7001
#Na interface valn6 e vlan8 do Device3, configure o ingresso IPv6 acl, filtrando os pacotes de serviço multicast do Multicast Server 3 .
Device3(config)#ipv6 access-list extended 7001Device3(config-v6-list)#deny ipv6 host 2001:3::2 anyDevice3(config-v6-list)#permit ipv6 any anyDevice3(config-v6-list)#commitDevice3(config-v6-list)#exitDevice3(config)#interface vlan6Device3(config-if-vlan6)#ipv6 access-group 7001 inDevice3(config-if-vlan6)#exitDevice3(config)#interface vlan8Device3(config-if-vlan8)#ipv6 access-group 7001 inDevice3(config-if-vlan8)#exit
#Na interface vlan9 do Device3, configure o ingresso IPv6 acl, filtrando os pacotes de serviço multicast do Multicast Server 2 .
Device3(config)#ipv6 access-list extended 7002Device3(config-v6-list)#deny ipv6 host 2001:2::2 anyDevice3(config-v6-list)#permit ipv6 any anyDevice3(config-v6-list)#commitDevice3(config-v6-list)#exitDevice3(config)#interface vlan9Device3(config-if-vlan9)#ipv6 access-group 7002 outDevice3(config-if-vlan9)#exit
- Passo 7:Confira o resultado.
#PC envia o relatório de relação de membro MLDv2 para adicionar ao grupo multicast FF10::1 .
# Servidor multicast 1, Servidor multicast 2, Servidor Multicast 3 e Servidor Multicast 4 todos enviam os pacotes multicast do grupo multicast FF10::1 .
#Visualize a tabela de membros multicast do Dispositivo 3 .
Device3#show ipv6 mld groupsMLD Connected Group MembershipTotal 1 Connected GroupsGroup Interface Uptime Expires V1-Expires Last Reporterff10::1 vlan9 00:35:31 00:03:31 not used fe80::210:94ff:fe00:1
#Visualize a tabela de rotas multicast do Device3.
Device3#show ipv6 pim mrouteIP Multicast Routing Table:PIM6 VRF Name: DefaultTotal 0 (*,*,RP) entryTotal 1 (*,G) entryTotal 2 (S,G) entriesTotal 2 (S,G,rpt) entriesTotal 0 FCR entryUp timer/Expiry timer(*, ff10::1)Up time: 00:04:25RP: 2001:6::2RPF nbr: fe80::201:7aff:fec0:525aRPF idx: vlan8Flags:JOIN DESIREDUpstream State: JOINEDLocal interface list:vlan9Joined interface list:Asserted interface list:(2001:1::2, ff10::1)Up time: 00:03:33KAT time: 00:01:51RPF nbr: fe80::201:7aff:fe62:bb7eRPF idx: vlan6SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:vlan9Packet count 159075(2001:1::2, ff10::1, rpt)Up time: 00:03:33RP: 2001:6::2Flags:RPT JOIN DESIREDPRUNE DESIREDRPF SGRPT XG EQUALUpstream State: PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:vlan9(2001:2::2, ff10::1)Up time: 00:03:33KAT time: 00:01:51RPF nbr: fe80::201:7aff:fe62:bb7eRPF idx: vlan6SPT bit: TRUEFlags:JOIN DESIREDUpstream State: JOINEDLocal interface list:Joined interface list:Asserted interface list:Outgoing interface list:vlan9Packet count 156062(2001:2::2, ff10::1, rpt)Up time: 00:03:33RP: 2001:6::2Flags:RPT JOIN DESIREDPRUNE DESIREDRPF SGRPT XG EQUALUpstream State: PRUNEDLocal interface list:Pruned interface list:Outgoing interface list:vlan9
O método de visualização de Device1 e device2 é o mesmo de Device3, portanto o processo de visualização é omitido.
#Visualize a correspondência de IPv6 ACL no Device2.
Device2#show ipv6 access-list 7001ipv6 access-list extended 700110 deny ipv6 host 2001:4::2 any 14 matches20 permit ipv6 any any 51 matches
#Visualize a correspondência de IPv6 ACL no Device3.
Device3#show ipv6 access-list 7001ipv6 access-list extended 700110 deny ipv6 host 2001:3::2 any 10760 matches20 permit ipv6 any any 4089685 matchesDevice3#show ipv6 access-list 7002ipv6 access-list extended 700210 deny ipv6 host 2001:2::2 any 2046914 matches20 permit ipv6 any any 2049595 matches
O #PC end só pode receber os pacotes de serviço multicast enviados pelo Multicast Server 1 .
Ao executar o controle de origem multicast, é melhor configurar primeiro o controle de origem multicast e, em seguida , a origem multicast sob demanda , porque, por padrão, após receber o pacote de serviço multicast, o DR final receptor executa a comutação SPT. Se primeiro a origem de multicast sob demanda e, em seguida, executar o controle de encaminhamento de multicast, o controle de encaminhamento de multicast não terá função. Para evitar que o controle de encaminhamento multicast não funcione , você pode configurar não permitir a comutação SPT na extremidade receptora DR.
07 QoS
QoS
Visão geral
Fundo
Na rede IP tradicional, o dispositivo de encaminhamento trata todos os pacotes igualmente, adota “First in, first out” (FIFO) para processar todos os pacotes e tenta o melhor esforço para transmitir o pacote ao destino, portanto, não pode fornecer nenhuma garantia de confiabilidade. e atraso da transmissão do pacote.
No entanto, com o desenvolvimento da rede IP, surgem cada vez mais novas aplicações baseadas na rede IP, que apresentam novos requisitos para a qualidade de serviço da rede IP, especialmente a demanda por pacotes de serviço com alta exigência de tempo real é mais óbvio. Por exemplo, a mídia de fluxo de rede, VoIP e outros serviços em tempo real apresentam alta exigência para o atraso de transmissão dos pacotes. Se o atraso de transmissão do pacote for longo, o usuário não poderá aceitar (relativamente, os serviços de e-mail e FTP não são sensíveis ao atraso de transmissão). Para suportar os serviços de comunicação com diferentes requisitos de qualidade de serviço, é necessário que a rede possa distinguir de forma inteligente os diferentes tipos de comunicação, de modo a fornecer o serviço correspondente.
A capacidade de distinguir os tipos de comunicação é a premissa básica de fornecer diferentes qualidades de serviço para diferentes comunicações, de modo que o modo de serviço de melhor esforço da rede IP tradicional não pode atender aos requisitos da aplicação de rede IP atual. A tecnologia QoS (Quality of Service) tem como objetivo solucionar o problema, de modo a atender aos diferentes requisitos de qualidade de serviço dos usuários da rede.
Modelo de serviço
A QoS fornece os três tipos de modelos de serviço a seguir, ou seja, serviço de melhor esforço, serviço integrado e serviço diferenciado (DiffServ para abreviar).
Best-Effort é um modelo de serviço único e também o modelo de serviço mais simples. O programa aplicativo pode enviar qualquer quantidade de pacotes a qualquer momento sem obter permissão ou informar a rede com antecedência. Para o serviço de melhor esforço, a rede tenta enviar os pacotes da melhor forma, mas não fornece garantias de atraso de transmissão e confiabilidade dos pacotes. Best-Effort é o modelo de serviço padrão da Internet e é aplicável à maioria dos aplicativos de rede, como FTP e E-Mail. É realizado através do mecanismo de fila FITO.
IntServ é um modelo de serviço que pode fornecer vários tipos de serviço. Ele pode atender a vários requisitos de QoS. Antes de enviar pacotes, o modelo de serviço precisa solicitar os recursos de serviço especificados da rede. A solicitação é concluída através da sinalização RSVP. O RSVP aplica-se aos recursos de rede para o aplicativo antes que o programa aplicativo comece a enviar pacotes, portanto, ele pertence à sinalização fora da banda. Antes de enviar dados, o programa aplicativo primeiro informa à rede seus próprios parâmetros de tráfego e a solicitação de qualidade de serviço especificada necessária, incluindo largura de banda, atraso e assim por diante. Após receber a solicitação de recurso do programa aplicativo, a rede executa a verificação de distribuição de recursos, ou seja, julga se deve distribuir recursos para o programa aplicativo com base na aplicação de recursos do programa aplicativo e nos recursos presentes da rede. Uma vez que a rede confirma a distribuição de recursos para o programa aplicativo, a rede mantém um estado para o fluxo especificado (Fluxo, confirmado pelos endereços IP, números de porta e números de protocolo dos dois lados) e executa a classificação de pacotes, monitoramento de tráfego, enfileiramento e agendamento com base no estado. Após receber as informações de confirmação da rede (ou seja, confirmar que a rede já reserva recursos para os pacotes do programa aplicativo), o programa aplicativo pode enviar pacotes. Desde que os pacotes do programa aplicativo sejam controlados dentro da faixa descrita pelos parâmetros de tráfego, a rede se comprometerá a atender aos requisitos de QoS do programa aplicativo.
O DiffServ classifica as comunicações de acordo com os requisitos do serviço e, em seguida, processa os pacotes de entrada e saída de acordo com o resultado da classificação, de modo a garantir que a rede esteja sempre em bom estado de conexão de comunicação. É um modelo de serviço multicanal e pode atender aos requisitos de QoS de diferentes fluxos. A maior diferença com o IntServ é que o DiffServ pode reservar recursos na rede sem troca de sinalização. Ele funciona apenas em uma porta de um dispositivo de transmissão na rede, processando os pacotes de entrada e saída da porta. O DiffServ não precisa manter as informações de status para cada tipo de comunicação. Ele distingue o nível de QoS de cada pacote de acordo com o mecanismo de QoS configurado e fornece o serviço para o pacote de acordo com o nível. Portanto, o mecanismo que fornece o esquema de QoS também é chamado de CoS. Existem muitos métodos de classificação e os modos comuns são classificar de acordo com a prioridade do pacote IP, classificar de acordo com a origem, endereço de destino e porta do pacote, classificar de acordo com o protocolo do pacote, classificar de acordo com o tamanho do pacote e o pacote porta de entrada, e assim por diante.
Mapeamento de prioridade, classificação de fluxo, monitoramento de tráfego, modelagem de tráfego, gerenciamento de congestionamento e prevenção de congestionamento são os principais componentes do DiffServ. A classificação de fluxo identifica os pacotes de acordo com algumas regras de correspondência e é a base e premissa do DiffServ; monitoramento de tráfego, modelagem de tráfego, gerenciamento de congestionamento e prevenção de congestionamento distribuem e programam os recursos para o tráfego de rede de diferentes aspectos e são a personificação da idéia DiffServ.
Introdução às funções de QoS
Mapeamento de prioridade
O mapeamento de prioridade inclui o mapeamento de entrada e o mapeamento de saída. O mapeamento de ingresso mapeia para a prioridade local (LP) de acordo com a prioridade 802.1p e o valor DSCP no pacote; mapeamento de saída mapeia para a prioridade 802.1pe valor DSCP de acordo com a prioridade local (LP) do pacote. O mapeamento de prioridade serve para agendamento de filas e controle de congestionamento.
O dispositivo suporta quatro tipos de mapeamento de prioridade: mapear o pacote DSCP para a prioridade local (LP); mapear a prioridade 802.1p do pacote para a prioridade local (LP); mapear a prioridade local (LP) do pacote para a prioridade de saída 802.1p do pacote; mapeie a prioridade local (LP) do pacote para o valor DSCP de saída do pacote. O diagrama da relação de mapeamento de prioridade é o seguinte:
Figura 1 -1 Diagrama da relação de mapeamento de prioridade
Classificação de fluxo
A classificação de fluxo adota alguma regra para identificar os pacotes que atendem a um recurso, divide os pacotes de recursos diferentes em várias classes e, em seguida, usa o mecanismo de QoS correspondente para fornecer serviços diferentes para classes diferentes. Portanto, a classificação de fluxos é a premissa e base da prestação de diferentes serviços.
A classificação de fluxo inclui contador, medidor, espelho de fluxo, redirecionamento e remarcação.
Contador e medidor realizam as ações de contagem e medição de acordo com o resultado da classificação de vazão.
O espelho de fluxo significa espelhar os pacotes correspondentes nas portas especificadas.
Redirecionamento significa redirecionar os pacotes correspondentes para a porta especificada ou para o próximo salto especificado.
Remarcar significa definir ou modificar os atributos de um tipo de pacote. Depois de dividir os pacotes em diferentes tipos por meio da classificação de fluxo, a remarcação pode modificar os atributos do pacote. Prepare - se para o processamento subsequente do pacote.
Monitoramento de tráfego
O monitoramento de tráfego limita a velocidade dos pacotes de entrada por meio do token bucket. Para garantir que a sobrecarga não aconteça com o tráfego que passa pela rede e provoque o congestionamento, o dispositivo fornece a limitação de taxa com base na direção de recebimento da porta, limitando a taxa total na direção de recebimento da porta. O tráfego em alta velocidade é descartado.
Modelagem de tráfego
A função típica da modelagem de tráfego é limitar o tráfego de saída de uma rede, fazendo com que os pacotes sejam enviados com uma taxa média. Normalmente, ele é dividido em modelagem de tráfego de porta e modelagem de tráfego de fila. Quando a taxa de envio dos pacotes excede a taxa de modelagem, os pacotes de alta velocidade são armazenados em buffer na fila e, em seguida, são enviados com uma taxa média. A diferença entre a modelagem de tráfego e o monitoramento de tráfego: Ao usar o monitoramento de tráfego para controlar o tráfego de pacotes, os pacotes de velocidade não são armazenados em buffer, mas são descartados diretamente, enquanto a modelagem de tráfego armazena em buffer os pacotes de velocidade, reduzindo os pacotes descartados causados pela rajada tráfego. No entanto, a modelagem de tráfego pode aumentar o atraso, enquanto o monitoramento de tráfego quase não aumenta o atraso.
Gerenciamento de congestionamento
Quando a carga de tráfego do dispositivo é leve, não gere congestionamento e os pacotes são encaminhados ao atingir a porta. Quando a taxa de chegada dos pacotes é maior que a taxa de envio da porta e excede o limite de processamento da porta ou os recursos do dispositivo não são suficientes, ocorre congestionamento no dispositivo. O congestionamento pode tornar a comunicação de toda a rede não confiável. O atraso de ponta a ponta, o jitter e a taxa de perda de pacotes usados para medir a qualidade do serviço de rede aumentam. Se habilitar o gerenciamento de congestionamento e quando o congestionamento ocorrer, os pacotes serão enfileirados na porta e aguardarão o encaminhamento da porta. O gerenciamento de congestionamento geralmente adota a tecnologia de filas e a porta determina em qual fila o pacote deve ser colocado de acordo com a prioridade do pacote e o mecanismo de fila e como agendar e encaminhar os pacotes.
A programação comum inclui SP (Prioridade Estrita), RR (Round Robin), WRR (Round Robin Ponderado) e WDRR (Round Robin do Déficit Ponderado).
SP (Prioridade Estrita) : Existem oito filas na porta, fila 0-7. A fila 7 tem a prioridade mais alta e a fila 0 tem a prioridade mais baixa.
RR (Round Robin): Após uma fila agendar um pacote, volte para a próxima fila.
WRR (Weighted Round Robin) : É o escalonamento ponderado baseado em pacote. Você pode configurar o número de pacotes agendados por cada fila antes de passar para a próxima fila.
WDRR ( Weighted Deficit Round Robin) : É a melhoria para o algoritmo WRR. O algoritmo é baseado em duas variáveis, ou seja, quantum e contador de crédito. O quantum significa o peso na unidade de byte e é um parâmetro configurável. O contador de crédito significa o acúmulo e consumo do quantum, que é um parâmetro de status e não pode ser configurado. No estado inicial, o contador de crédito de cada fila é igual ao quantum. Toda vez que a fila enviar um pacote, subtraia o número de bytes do pacote do contador de crédito. Quando o contador de crédito for inferior a 0, interrompa o agendamento da fila. Quando todas as filas pararem de agendar, complemente o quantum para todas as filas.
Prevenção de congestionamento
A tecnologia de prevenção de congestionamento monitora a carga de comunicação da rede, de modo a evitar o congestionamento antes que o congestionamento da rede aconteça. A tecnologia comumente usada é WRED ( Weighted Random Early Detection). A diferença com o método tail drop é que o WRED seleciona o pacote descartado de acordo com a prioridade DSCP ou IP e pode fornecer diferentes recursos de desempenho para diferentes tipos de dados de serviço. Também pode evitar a sincronização global TCP.
No algoritmo WRED, o ponto inicial do pacote de descarte da fila é marcado como DropStartPoint e o ponto final do descarte é marcado como DropEndPoint. Quando o comprimento médio da fila está entre DropStartPoint e DropEndPoint, o WRED descarta o pacote aleatoriamente pela taxa de queda correspondente, enquanto quando o comprimento da fila excede DropEndPoint, descarta o pacote em 100%. Quando o comprimento da fila é menor que DropStartPoint, o WRED não descarta o pacote.
O seguinte é o diagrama do WRED:
Figura 1 -2 diagrama WRED
Função do Grupo de Ação
Para suportar a classificação de fluxo e controle de tráfego, o dispositivo estende a ACL tradicional para que a ACL e a regra da ACL possam ser vinculadas a um grupo de ação respectivamente, adotando a ação correspondente para o pacote correspondente. O grupo de ação contém as configurações do contador, medidor, espelho de fluxo, redirecionamento e remarcação.
Para várias ACLs e regras de ACL sendo usadas em diferentes domínios de função, as configurações dos grupos de ação são diferentes. Para o ingresso ACL, o grupo de ação usado do IP ACL é o grupo de ação L3 e o grupo de ação usado do MAC ACL é o grupo de ação L2. O grupo de ação de saída é usado na direção de saída da ACL. O grupo de ação VFP é usado para realizar o QinQ baseado em fluxo. Cada ACL pode ser vinculada a vários grupos de ação, mas o efetivo depende do domínio de função vinculado à ACL. Por exemplo, uma regra de IP ACL é configurada com grupo de ação L3, grupo de ação de saída e grupo de ação VFP ao mesmo tempo. Quando o IP ACL é aplicado na direção de entrada, a ação no grupo de ação L3 entra em vigor e as ações nos outros dois grupos de ação não têm efeito.
A rota de política no grupo de ação é um mecanismo de encaminhamento de pacotes para roteamento flexível com base na rede de destino. A rota de política classifica os pacotes por meio do Content Aware Processor e encaminha o fluxo de dados que está de acordo com a regra de classificação de acordo com o próximo salto especificado. Quando algum pacote é roteado por outro caminho, mas não pelo caminho mais curto, podemos habilitar a rota de política. A prioridade da rota de política é maior do que qualquer outra rota. Portanto, uma vez que o usuário configura a habilitação da rota da política, o envio do pacote é processado de acordo com a rota da política. Somente quando a correspondência da lista de acesso falhar, podemos continuar a encaminhar de acordo com o resultado da pesquisa da tabela de encaminhamento. Caso contrário, encaminhe o pacote de acordo com as informações de próximo salto especificadas da política de rota. O próximo salto especificado da rota de política deve ser o próximo salto conectado diretamente . Para o endereço de próximo salto não conectado diretamente, o sistema permite configurar, mas na verdade é inválido.
Configuração da função de QoS
Tabela 1 -1 A lista de configuração da função de QoS
| Tarefa de configuração | |
| Configurar o mapeamento de prioridade | Configurar o mapeamento de prioridade Configurar o mapeamento de prioridade padrão |
| Configurar a classificação de fluxo |
Configurar o contador
Configurar o medidor Configurar o espelho de fluxo Configurar o redirecionamento Configurar remarcação de prioridade l2 Configurar remarcação de prioridade l3 |
| Configurar o monitoramento de tráfego | Configurar a limitação de taxa baseada em porta |
| Configurar a modelagem de tráfego |
Configurar a modelagem de tráfego baseada em fila
Configurar a modelagem de tráfego baseada em porta |
| Configurar o gerenciamento de congestionamento | Configure a política de agendamento da fila de portas |
| Configurar a prevenção de congestionamento | Configurar o modo de soltar |
| Configurar o grupo de ação do VFP |
Configure o processamento para o pacote com uma tag VLAN de camada única
Configure o processamento para o pacote com tag VLAN de camada dupla Configure o processamento para o pacote sem tag VLAN Configure o VRF de vinculação no grupo de ação do VFP |
Configurar mapeamento de prioridade
O mapeamento de prioridade é o mapeamento entre a prioridade 802.1p, o valor DSCP e a prioridade local (LP) no pacote. Modifique ou distribua o campo de prioridade do pacote para servir para evitar congestionamento e gerenciamento de congestionamento.
Condição de configuração
Nenhum
Configurar mapeamento de prioridade
O mapeamento de prioridade inclui o mapeamento de entrada e o mapeamento de saída. O mapeamento de ingresso mapeia para a prioridade local (LP) de acordo com a prioridade 802.1p e o valor DSCP no pacote; o mapeamento de saída mapeia para a prioridade 802.1pe valor DSCP de acordo com a prioridade local (LP).
Tabela 1 -2 Configurar o mapeamento de prioridade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o perfil de mapeamento de prioridade | qos map-table {ingress | egress } template-name | Obrigatório Configure o perfil de prioridade de saída e entrada. |
| Entre na visualização de perfil | { dot1p-lp | dscp-lp | lp- dot1p | lp-dscp } index to value | Opcional Por padrão, o mapeamento de prioridade no perfil é a relação de mapeamento padrão. |
| B ind a porta com o perfil de mapeamento de prioridade | map-table template- name { ingress | egress } | Obrigatório Por padrão, não vincule o perfil de mapeamento de prioridade. |
Para o pacote com a prioridade especificada entrando na fila, é melhor não deixar o pacote entrar na fila 7, porque todos os pacotes enviados da CPU entram na fila 7. Se a fila 7 tiver muitos pacotes, os pacotes da CPU podem ser descartados . O mapeamento dscp-Ip e dotlp-lp são configurados no perfil ao mesmo tempo. O dscp-lp tem prioridade mais alta e entra em vigor primeiro.
Depois de habilitar o mapeamento dot1p-lp de ingresso, a prioridade 802.1p do pacote encaminhado não é modificada de acordo com a prioridade local (LP) por padrão. Por exemplo, a relação de mapeamento dot1p-lp é de 1 a 5; depois de combinar o 802.1p da VLAN Tag no pacote de entrada com 1, a prioridade 802.1p do pacote encaminhado com a VLAN Tag ainda é 1.
O mapeamento de prioridade não tem efeito para o pacote observado pelo grupo de ação. Primeiro, observe a prioridade local (LP) no grupo de ação de ingresso e, em seguida, o mapeamento para a prioridade 802.1p e o valor DSCP do pacote por meio da prioridade local (LP) na saída entra em vigor. Observe a prioridade 802.1p no ingresso e, em seguida, mapeie a prioridade local e o valor DSCP por meio da prioridade 802.1p não tem efeito, mas a observação da própria prioridade 802.1p entra em vigor. O mapeamento de acordo com a prioridade 802.1p do pacote original também tem efeito, ou seja, a remarcação tem efeito separadamente, o mapeamento de prioridade tem efeito separadamente e o mapeamento de prioridade de acordo com o valor remarcado não tem efeito.
Se a função QINQ estiver habilitada na porta e o perfil vinculado da porta contiver mapeamentos dot1p-lp e dscp-lp, talvez você não consiga obter o resultado de mapeamento desejado. Portanto, é recomendável não habilitar a função de mapeamento de prioridade de ligação de porta de QINQ em uma porta ao mesmo tempo. Depois de configurar o mapeamento lp-dscp, o mapeamento padrão de lp-dscp é 0 a 0, 1 a 8, 2 a 16, 3 a 24, 4 a 32, 5 a 40, 6 a 48 e 7 a 56.
Configurar mapeamento de prioridade padrão
O mapeamento de prioridade padrão, o mesmo que o mapeamento de prioridade, possui o mapeamento de entrada e saída. A diferença está em que o mapeamento de prioridade padrão mapeia as entradas não configuradas com mapeamento de prioridade para o valor padrão.
Tabela 1 -3 Configurar o mapeamento de prioridade padrão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o perfil de mapeamento de prioridade | qos map-table {ingress | egress } template-name | Obrigatório Configure o perfil de prioridade de entrada e saída. |
| Configurar o mapeamento de prioridade padrão | { dot1p-lp | dscp-lp | lp- dot1p | lp-dscp } default value | Obrigatório Por padrão, não configure o mapeamento de prioridade padrão. |
Configurar classificação de fluxo
A classificação de fluxo adota alguma regra para identificar os pacotes que atendem a um recurso, divide os pacotes de recursos diferentes em várias classes e, em seguida, usa o mecanismo de QoS correspondente para fornecer serviços diferentes para classes diferentes. Portanto, a classificação de fluxos é a premissa e base da prestação de diferentes serviços.
Condição de configuração
Antes de configurar a classificação de fluxo, primeiro conclua a seguinte tarefa:
- Configure a ACL.
Configurar contador
A configuração da ação de contagem no grupo de ação visa contar o número de pacotes correspondentes.
Tabela 1 -4 Configurar o contador
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o grupo de ação L3 e entre no modo de configuração do grupo de ação L3 | l3-action-group l3-action-group-name | Qualquer Depois de entrar no modo de configuração do grupo de ação L3, a configuração subsequente apenas entra em vigor no grupo de ação L3 atual; Após entrar no modo de configuração do grupo de ação L2, a configuração subsequente apenas entra em vigor no grupo de ação L2 atual; Depois de entrar no modo de configuração do grupo de ações de saída, a configuração subsequente apenas entra em vigor no grupo de ações de saída atual |
| Configure o grupo de ação L2 e entre no modo de configuração do grupo de ação L2 | l2-action-group l2-action-group-name | |
| Configure o grupo de ações de saída e entre no modo de configuração do grupo de ações de saída | egr-action-group egr-action-group-name | |
| Configurar o contador | count { all-colors } | Obrigatório Por padrão, os pacotes não são contados no grupo de ação. |
Configurar medidor
Configure o medidor no grupo de ação para limitar a taxa ou marcar os pacotes correspondentes. Ao configurar um medidor inexistente, o medidor entra em vigor imediatamente quando o medidor especificado é configurado. Quando nenhum medidor é configurado no grupo de ação, todos os pacotes correspondentes são considerados como pacotes verdes. Quando um medidor for configurado no grupo de ação para colorir os pacotes, os pacotes serão marcados em verde e amarelo de acordo com o tráfego de pacotes, e então o contador contará o número de pacotes de cores diferentes.
Tabela 1 -5 configurar o medidor
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o medidor e entre no modo medidor | traffic-meter traffic-meter-name | Obrigatório Por padrão, os pacotes em amarelo são descartados e o modo medidor não está configurado. Após entrar na configuração do medidor, uma configuração completa do medidor contém ações do medidor para pacotes em amarelo e configuração do modo medidor. Uma configuração incompleta não terá efeito. |
| Configurar as ações do medidor | meter action yellow { drop | transmit } | Opcional Por padrão, os pacotes em amarelo são descartados. |
| Configurar o modo do medidor | meter mode { srtcm cir cbs ebs | trtcm cir cbs pir pbs } | Obrigatório Por padrão, o modo do medidor não está configurado. |
| Entre no modo de configuração global | exit | - |
| Configure o grupo de ação L3 e entre no modo de configuração do grupo de ação L3 | l3-action-group l3-action-group-name | Qualquer Depois de entrar no modo de configuração do grupo de ação L3, a configuração subsequente apenas entra em vigor no grupo de ação L3 atual; Após entrar no modo de configuração do grupo de ação L2, a configuração subsequente apenas entra em vigor no grupo de ação L2 atual; Depois de entrar no modo de configuração do grupo de ações de saída, a configuração subsequente apenas entra em vigor no grupo de ações de saída atual |
| Configure o grupo de ação L2 e entre no modo de configuração do grupo de ação L2 | l2-action-group l2-action-group-name | |
| Configure o grupo de ações de saída e entre no modo de configuração do grupo de ações de saída | egr-action-group egr-action-group-name | |
| Configurar o medidor de vinculação | meter traffic-meter-name | Obrigatório Por padrão, nenhum medidor está vinculado. |
Se a ACL vinculada aos objetos estiver configurada com o grupo de ação e o grupo de ação estiver configurado com um medidor para limitar a taxa, podem existir ações de limitação de taxa conflitantes. Quando a limitação de taxa é aplicada, os pacotes em vermelho e amarelo são descartados. Por exemplo, a porta 0/1 pertence à VLAN1, a ACL na porta 0/1 permite que os pacotes do endereço IP de origem 1.1.1.1 passem e o tráfego é configurado dentro de 5 Mbps. A ACL da VLAN1 permite que os pacotes do endereço IP de origem 1.1.1.1 passem e o tráfego seja configurado dentro de 1 Mbps.
Nesta situação, a taxa mínima no canal de pacotes entrará em vigor e o tráfego será configurado dentro de 1 Mbps. Especialmente, devido à limitação de hardware, o tráfego real para limitação de taxa multinível será menor que a taxa mínima no canal de pacotes. Portanto, a limitação de taxa em vários níveis não é recomendada quando é necessária uma limitação de taxa precisa. O medidor no grupo de ações de saída não oferece suporte à ação remark lp ou remark dotlp-lp.
Você não pode marcar novamente o pacote amarelo. O medidor é baseado nos chips. Ou seja, o medidor em cada chip limita a taxa de tráfego na porta. Se o medidor existir em dois chips diferentes sob a porta de agregação de link, existe um medidor em cada chip e, portanto, a limitação de taxa tem o efeito duas vezes do efeito de limitação de taxa esperado. Se um medidor for aplicado à VLAN, o medidor entrará em vigor para cada chip em cada placa de linha. Os objetos VLAN são limitados a 10 Mbps. Se existirem cinco placas de linha de núcleo único no dispositivo, o tráfego de 10 Mbps terá efeito para um par de placas de linha. Ou seja, o tráfego em cada placa de linha em conformidade com a limitação de taxa de VLAN é de 10 Mbps. Se existirem dois chips em uma placa de linha, o tráfego para cada chip na placa de linha será de 10 Mbps.
Configurar espelho de fluxo
A configuração do espelho de fluxo no grupo de ação visa especificar o pacote correspondente à porta.
Tabela 1 -6 Configurar o espelho de fluxo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o grupo de ação L3 e entre no modo de configuração do grupo de ação L3 | l3-action-group l3-action-group-name | Qualquer Depois de entrar no modo de configuração do grupo de ação L3, a configuração subsequente apenas entra em vigor no grupo de ação L3 atual; Depois de entrar no modo de configuração do grupo de ação L2, a configuração subsequente apenas entra em vigor no grupo de ação L2 atual. |
| Configure o grupo de ação L2 e entre no modo de configuração do grupo de ação L2 | l2-action-group l2-action-group-name | |
| Configurar o espelho de fluxo | mirror interface interface-name | Obrigatório Por padrão, o espelho de fluxo não está configurado. |
Configurar redirecionamento
A configuração do redirecionamento de pacotes no grupo de ação visa redirecionar os pacotes correspondentes para a porta especificada ou o próximo salto especificado.
Tabela 1 -7 Configure o redirecionamento
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o grupo de ação L3 e entre no modo de configuração do grupo de ação L3 | l3-action-group l3-action-group-name | Qualquer Depois de entrar no modo de configuração do grupo de ação L3, a configuração subsequente apenas entra em vigor no grupo de ação L3 atual; Depois de entrar no modo de configuração do grupo de ação L2, a configuração subsequente apenas entra em vigor no grupo de ação L2 atual. |
| Configure o grupo de ação L2 e entre no modo de configuração do grupo de ação L2 | l2-action-group l2-action-group-name | |
| Configurar o redirecionamento | redirect { interface interface-name |interface link-aggregation link-aggregation-id} | Obrigatório Por padrão, o redirecionamento de pacote não está configurado. |
Configurar remarcação de prioridade l2
A configuração da remarcação de pacotes no grupo de ação visa classificar os pacotes combinados para facilitar aos usuários a adoção de diferentes políticas de QoS nas comunicações de dados subsequentes.
Tabela 1 -8 Configurar remarcação de prioridade l2
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o grupo de ação L3 e entre no modo de configuração do grupo de ação L3 | l3-action-group l3-action-group-name | Qualquer Depois de entrar no modo de configuração do grupo de ação L3, a configuração subsequente apenas entra em vigor no grupo de ação L3 atual; Após entrar no modo de configuração do grupo de ação L2, a configuração subsequente apenas entra em vigor no grupo de ação L2 atual; Depois de entrar no modo de configuração do grupo de ações de saída, a configuração subsequente apenas entra em vigor no grupo de ações de saída atual |
| Configure o grupo de ação L2 e entre no modo de configuração do grupo de ação L2 | l2-action-group l2-action-group-name | |
| Configure o grupo de ações de saída e entre no modo de configuração do grupo de ações de saída | egr-action-group egr-action-group-name | |
| Configurar remarcação de prioridade l2 | remark l2-priority { dscp dscp-value |{{ dot1p | dot1p-lp | lp } { priority-value | precedence }}} | Obrigatório Por padrão, a remarcação de prioridade l2 não está configurada. |
No grupo de ação, o campo de prioridade no TOS do pacote IP não pode ser usado para remarcar a prioridade 802.1p na tag VLAN. O grupo de ação de saída não oferece suporte à ação de observação.
Configurar remarcação de prioridade l3
A configuração da remarcação de pacotes no grupo de ação visa classificar os pacotes combinados para facilitar aos usuários a adoção de diferentes políticas de QoS nas comunicações de dados subsequentes.
Tabela 1 -9 Configurar remarcação de prioridade l3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o grupo de ação L3 e entre no modo de configuração do grupo de ação L3 | l3-action-group l3-action-group-name | Qualquer Depois de entrar no modo de configuração do grupo de ação L3, a configuração subsequente apenas entra em vigor no grupo de ação L3 atual; Depois de entrar no modo de configuração do grupo de ações de saída, a configuração subsequente apenas entra em vigor no grupo de ações de saída atual. |
| Configure o grupo de ações de saída e entre no modo de configuração do grupo de ações de saída | egr-action-group egr-action-group-name | |
| Configurar remarcação de prioridade l3 | remark l3-priority { dscp dscp-value | precedence { priority-value | dot1p } } | Obrigatório Por padrão, a remarcação de prioridade l3 não está configurada. |
Se a ACL vinculada aos objetos estiver configurada com o grupo de ação, pode haver conflito de remarcação. Por exemplo, a porta 0/1 pertence a VLAN1, a ACL na porta 0/1 permite que os pacotes do endereço IP de origem 1.1.1.1 passem e a ação para remarcar o campo DSCP como 5 é configurada. O ACL de VLAN1 permite que os pacotes do endereço IP de origem 1.1.1.1 passem e a ação para remarcar o campo DSCP como 4 é configurada. Nesta situação, esta situação é tratada com base na porta > VLAN > global e MAC ACL > IP ACL por prioridade e o valor de remarcação final é 5. Se a ACL vinculada aos objetos estiver configurada com o grupo de ação, poderá existir uma ação de remarcação sem conflito. Por exemplo, a porta 0/1 pertence a VLAN1, a ACL na porta 0/1 permite que os pacotes do endereço IP de origem 1.1.1.1 passem e a ação para remarcar o campo DSCP como 5 é configurada. A ACL de VLAN1 permite que os pacotes do endereço IP de origem 1.1.1.1 passem e a prioridade 802.1p é remarcada como 4. Para a ação de remarcação sem conflito, o pacote DSCP será marcado como 5 e o 802.1 p prioridade será marcada como 4. No grupo de ação, a prioridade 802.1p na etiqueta de VLAN não pode ser usada para remarcar o campo de prioridade no TOS do pacote IP. O grupo de ação de saída não oferece suporte à ação de observação.
Configurar monitoramento de tráfego
Para garantir que a sobrecarga não aconteça com o tráfego que passa pela rede e provoque o congestionamento, o dispositivo fornece a limitação de taxa com base na direção de recebimento da porta, limitando a taxa total na direção de recebimento da porta. O tráfego em alta velocidade é descartado.
Condição de configuração
Nenhum
Configurar limitação de taxa baseada em porta
Para fornecer diferentes limitações de taxa para portas em diferentes períodos de tempo, cada porta é configurada com oito limitações de taxa de diferentes prioridades. Cada taxa é limitada e então vinculada a um domínio de tempo. Para as entradas que entram em vigor ao mesmo tempo, determine qual entrada entra em vigor por prioridade. O número 0 indica a prioridade mais alta e o número 7 indica a prioridade mais baixa. A limitação de taxa sobre a porta pode ser configurada diretamente sem o domínio do tempo.
Tabela 1 -10 Configurar limitação de taxa baseada em porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | - |
| Configurar limitação de taxa baseada em porta | rate-limit { default rate burst-size | priority rate burst-size [ time-range time-range-name ] } | Obrigatório Por padrão, a limitação de taxa na porta não está configurada. |
Configurar modelagem de tráfego
A modelagem de tráfego permite que os pacotes sejam enviados a uma taxa média. A diferença entre modelagem de tráfego e monitoramento de tráfego: o monitoramento de tráfego tem efeito na direção de entrada e a modelagem de tráfego tem efeito na direção de saída. O tráfego excessivo na direção de entrada será descartado, mas o tráfego excessivo na direção de saída será armazenado em cache.
Condição de configuração
Nenhum
Configurar modelagem de tráfego baseada em fila
A modelagem de tráfego baseada em fila permite que o tráfego na fila seja enviado a uma taxa média. Diferentes formas de tráfego podem ser executadas para diferentes filas, conforme necessário.
Tabela 1 -11 Configurar modelagem de tráfego baseada em fila
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | - |
| Configurar modelagem de tráfego baseada em fila | traffic-shape queue queue-id { { cir cir [cbs cbs] pir pir [pbs pbs] } | { cir cir [cbs cbs]} | { pir pir [pbs pbs] } } | Obrigatório Por padrão, a modelagem de tráfego baseada em fila não está configurada. |
Configurar modelagem de tráfego baseada em porta
A modelagem de tráfego baseada em porta permite que a vinculação de domínio de tempo alcance diferentes larguras de banda em diferentes períodos de tempo. Cada porta é configurada com oito formatos de tráfego de diferentes prioridades e cada formato de tráfego está vinculado a um domínio de tempo. Para as entradas que entram em vigor ao mesmo tempo, determine qual entrada entra em vigor por prioridade. O número 0 indica a prioridade mais alta e o número 7 indica a prioridade mais baixa.
Tabela 1 -12 Configurar a modelagem de tráfego baseada em porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configurar a modelagem de tráfego baseada em porta | traffic-shape{ {pir rate [pbs burst-size] } | { priority pir rate [pbs burst-size][time-range range-name] } } | Obrigatório Por padrão, a modelagem de tráfego baseada em porta não está configurada. |
Configurar gerenciamento de congestionamento
Em uma rede complexa, o congestionamento é comum porque a largura de banda atual não pode satisfazer o encaminhamento normal. O congestionamento pode causar uma série de problemas negativos da seguinte forma: o sistema quebra devido aos recursos de rede abundantes, o utilitário de recursos de rede é baixo devido à diminuição da taxa de transferência da rede e o atraso na transmissão de pacotes e o aumento do jitter. A política de agendamento para a fila da porta é um método para gerenciar o congestionamento.
Condição de configuração
Nenhum
Configurar a política de agendamento da fila de portas
A política de agendamento baseada em fila envia o tráfego classificado por um determinado algoritmo de nível de prioridade. Cada algoritmo de fila resolve um determinado problema de tráfego de rede e tem grande influência na alocação de recursos de largura de banda, atraso e jitter. O escalonamento de filas processa os pacotes de diferentes prioridades em níveis. Um pacote com alta prioridade será enviado preferencialmente.
A programação comum inclui SP (Prioridade Estrita), RR (Round Robin), WRR (Round Robin Ponderado) e WDRR (Round Robin do Déficit Ponderado).
SP (Prioridade Estrita): Existem oito filas na porta, fila 0-7. A fila 7 tem a prioridade mais alta e a fila 0 tem a prioridade mais baixa.
RR (Round Robin):Após uma fila agendar um pacote, volte para a próxima fila.
WRR (Weighted Round Robin): É o escalonamento ponderado baseado em pacote. Você pode configurar o número de pacotes agendados por cada fila antes de passar para a próxima fila.
WDRR (Weighted Deficit Round Robin): É a melhoria para o algoritmo WRR. O algoritmo é baseado em duas variáveis, ou seja, quantum e contador de crédito. O quantum significa o peso na unidade de byte e é um parâmetro configurável. O contador de crédito significa o acúmulo e consumo do quantum, que é um parâmetro de status e não pode ser configurado. No estado inicial, o contador de crédito de cada fila é igual ao quantum. Toda vez que a fila enviar um pacote, subtraia o número de bytes do pacote do contador de crédito. Quando o contador de crédito for inferior a 0, interrompa o agendamento da fila. Quando todas as filas pararem de agendar, complemente o quantum para todas as filas.
Tabela 1 -13 Configurar a política de agendamento para a fila da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | - |
| Configure a política de agendamento para a fila de portas | queue-schedule { sp | rr | { { wrr | wdrr } weight0 weight1 weight2 weight3 weight4 weight5 weight6 weight7} } | Obrigatório Por padrão, a política de agendamento para a fila de portas é o SP. |
Configurar prevenção de congestionamento
A tecnologia de prevenção de congestionamento monitora o utilitário de recursos da rede e a carga de comunicação da rede, de modo a evitar o congestionamento descartando ativamente os pacotes antes que o congestionamento da rede aconteça ou piore. O congestionamento excessivo prejudica muito os recursos da rede e, portanto, uma determinada medida deve ser adotada para aliviar o congestionamento. A medida comum é configurar o modo de descarte de pacotes.
Condição de configuração
Nenhum
Configurar o modo de soltar
Tail drop e WRED ( Weighted Random Early Detection) são dois modos comuns de descarte de pacotes.
Tail drop: É uma política tradicional de descarte de pacotes. Quando o comprimento da fila atinge o valor máximo, todos os novos pacotes serão descartados. Essa política de descarte de pacotes pode causar sincronização global TCP. Quando os pacotes conectados por vários TCPs são descartados em uma fila, várias conexões TCP entrarão no status de prevenção de congestionamento e inicialização lenta para diminuir e ajustar o tráfego e, em seguida, o pico de tráfego poderá ocorrer simultaneamente. Repetidamente, o tráfego e a rede ficam instáveis.
WRED: Quando o comprimento da fila excede seu próprio comprimento, os pacotes são descartados em 100%. Quando o comprimento da fila for menor que o valor inicial, não descarte nenhum pacote. Quando o comprimento da fila for maior que o valor inicial, descarte os pacotes aleatoriamente de acordo com o valor configurado. O número aleatório gerado pelo WRED é baseado na prioridade. O WRED introduz a prioridade IP para distinguir da política de descarte de pacotes. O pacote com alta prioridade é considerado para seu benefício e este pacote será descartado em uma probabilidade relativamente baixa.
Tabela 1 -14 Configurar o modo de descarte de pacote
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configurar o modo de soltar | drop-mode cos-value { tail-drop | wred drop-start start-value drop-rate drop-rate-value [ only-tcp | all ] } | Obrigatório Por padrão, o modo de descarte de pacotes para a fila de portas é o modo de descarte de cauda. |
Configurar grupo de ação VFP
O grupo de ação VFP (VLAN Filter Processor) classifica os pacotes e especifica o pacote com a etiqueta de VLAN de camada única, o pacote com etiqueta de VLAN de camada dupla e o pacote sem etiqueta de VLAN.
Condição de configuração
Antes de configurar o grupo de ação do VFP, primeiro conclua a seguinte tarefa:
- Configure a ACL.
Configurar o processamento para o pacote com tag VLAN de camada única
No grupo de ação VFP, configure o processamento para o pacote com a tag VLAN de camada única, especialmente para combinar e processar a prioridade 802.1p e os números VLAN na tag VLAN.
Tabela 1 -15 Configure o processamento para o pacote com tag VLAN de camada única
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o grupo de ação do VFP e entre no modo de configuração do grupo de ação do VFP | vfp-action-group vfp-action-group-name | Obrigatório Por padrão, o grupo de ação do VFP não está configurado. |
| Configure o processamento para o pacote com tag VLAN de camada única | one-tag { match-vlan { any | vlan-id } | ovlan-act { add-ovlan vlan-id [ priority priority-value ] } | replace-vlan vlan-id } | Obrigatório Por padrão, o processamento do pacote com tag VLAN de camada única não está configurado. |
Configurar processamento para pacote com etiqueta de VLAN de camada dupla
No grupo de ação VFP, configure o processamento para o pacote com a etiqueta de VLAN de camada dupla, especialmente para corresponder e processar a prioridade 802.1p e os números de VLAN na etiqueta de VLAN interna e externa.
Tabela 1 -16 Configure o processamento para o pacote com tag VLAN de camada dupla
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o grupo de ação do VFP e entre no modo de configuração do grupo de ação do VFP | vfp-action-group vfp-action-group-name | Obrigatório Por padrão, o grupo de ação CFP não está configurado. |
| Configure o processamento para o pacote com tag VLAN de camada dupla | double-tag { invlan-act { delete-invlan | replace-invlan vlan-id } | match-invlan { any | vlan-id } | match-ovlan { any | vlan-id } | ovlan-act replace-ovlan vlan-id } | Obrigatório Por padrão, o processamento do pacote com tag VLAN de camada dupla não está configurado. |
Configurar processamento para pacote sem etiqueta de VLAN
No grupo de ação VFP, configure o processamento para o pacote sem tag VLAN, especialmente para adicionar a tag VLAN interna e externa.
Tabela 1 -17 Configure o processamento para o pacote sem tag VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o grupo de ação do VFP e entre no modo de configuração do grupo de ação do VFP | vfp-action-group vfp-action-group-name | Obrigatório Por padrão, o grupo de ação do VFP não está configurado. |
| Configure o processamento para o pacote sem tag VALN | untag { invlan-act add-invlan vlan-id } | ovlan-act add-ovlan vlan-id | Obrigatório Por padrão, o processamento do pacote sem tag VLAN não está configurado. |
Configurar VRF de ligação no grupo de ação VFP
Tabela 1 -18 Configurar VRF de ligação no grupo de ação VFP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o grupo de ação do VFP e entre no modo de configuração do grupo de ação do VFP | vfp-action-group vfp-action-group-name | Obrigatório Por padrão, o grupo de ação do VFP não está configurado. |
| Configure o VRF de vinculação no grupo de ação do VFP | vrfset vrf-name | Obrigatório Por padrão, o VRF obrigatório no grupo de ação do VFP não está configurado. |
Configurar controle de fluxo baseado em prioridade
Controle de fluxo baseado em prioridade, que adota controle de fluxo baseado em prioridade para controlar o tráfego de encaminhamento salto a salto, de modo a perceber que vários tipos de tráfego em execução no link Ethernet não são afetados um pelo outro
Condição de configuração
Nenhum
Configurar controle de fluxo baseado em prioridade
PFC ( Priority-based Flow Control) realiza o controle de tráfego com base na prioridade salto a salto. Quando o dispositivo encaminha o pacote, ele entra na fila correspondente ao relacionamento de mapeamento de acordo com a prioridade do pacote para agendamento e encaminhamento. Quando a taxa de envio dos pacotes de uma prioridade excede a taxa de recebimento, resultando em espaço insuficiente de buffer de dados disponível do receptor, o receptor enviará o quadro de pausa PFC para o dispositivo do salto anterior. O dispositivo do salto anterior parará de enviar os pacotes da prioridade após receber o pacote do quadro de pausa, e a transmissão do tráfego não poderá ser retomada até que o quadro PFC XON seja recebido ou após um certo tempo de envelhecimento. Através do uso da função PFC, um tipo de congestionamento de tráfego não afetará o encaminhamento normal de outros tipos de tráfego, de modo que diferentes tipos de pacotes no mesmo link não afetem uns aos outros.
Tabela 1 -19 20 Configurar o controle de tráfego baseado em prioridade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| L2 /L3 | interface interface-name | - |
| Habilite a função PFC da fila de portas | priority-flow-control cos-vlue | cos-vlue : número da fila da porta |
Configurar para exibir a notificação de congestionamento
A notificação de congestionamento explícita é usada para exibir a notificação de congestionamento. Quando o dispositivo está congestionado, o domínio ECN do cabeçalho do pacote IP é marcado e o pacote CNP (pacote de notificação de congestionamento) é enviado da extremidade receptora para a extremidade emissora, de modo a diminuir o congestionamento do dispositivo e realizar o -fim de gerenciamento de congestionamento.
Condição de configuração
Nenhum
Configurar para exibir a notificação de congestionamento
ECN ( Explicit Congestion Notification ) define um controle de fluxo e mecanismo de notificação de congestionamento de ponta a ponta baseado na camada IP e na camada de transporte. O ECN usa o domínio DS no cabeçalho IP para marcar o status de congestionamento no caminho de transmissão. O dispositivo terminal que suporta esta função pode avaliar o congestionamento no caminho de transmissão pelo conteúdo do pacote, de modo a ajustar o modo de envio do pacote e evitar aumentar o congestionamento.
Tabela 1 -21 Configurar o dispositivo para exibir a notificação de congestionamento
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função de exibir a notificação de congestionamento | explicit-congestion-notification | - |
Monitoramento e manutenção de QoS
Tabela 1 -22 Monitoramento e manutenção de QoS
| Comando | Descrição |
| show drop-mode [ interface interface-name ] | Exiba o modo de descarte da fila de portas |
| show egr-action-group [ egr-action-group-name ] | Exibir informações de configuração relacionadas do grupo de ações de saída |
| show l2-action-group [ l2-action-group-name ] | Exiba as informações de configuração relacionadas do grupo de ação L2 |
| show l3-action-group [ l3-action-group-name ] | Exiba as informações de configuração relacionadas do grupo de ação L3 |
| show map-table user-name [ template name {ingress | egress} ] | Exibir as informações do perfil de mapeamento de prioridade |
| show queue-schedule [ interface interface-name ] | Exiba a política de agendamento da fila de portas |
| show rate-limit [ interface interface-name ] | Exibir as informações de limitação de taxa da porta |
| show traffic-count { inst-all | inst-global | inst-vlan-range | inst-interface-vlan-range | { inst-interface interface-name | inst-interface-vlan vlan-id | inst-link-aggregation link-aggregation-id | inst-vlan vlan-id } { ip-in | ip-out | ipv6-in | ipv6-out | mac-in | mac-out }} | Exibe as informações do contador da ACL aplicada ao objeto especificado |
| show traffic-meter [ traffic-meter-name ] | Exibir todas as informações do contador |
| show traffic-shape [ interface interface-name ] | Exiba as informações de modelagem de tráfego na porta e na fila |
| show vfp-action-group [ vfp-action-group-name ] | Exibir informações de configuração relacionadas no grupo de ação do VFP |
Exemplo de configuração típico de QoS
Configurar mapeamento de prioridade
Requisitos de rede
- Existem dois servidores na rede, ou seja, servidor de vídeo e servidor de dados.
- O valor de DSCP no pacote de tráfego de vídeo é 34 e o valor de DSCP no pacote de tráfego de dados é 38.
- Configure a função de mapeamento de prioridade, percebendo que a prioridade 802.1p do pacote de tráfego de vídeo é 5 e a prioridade 802.1p do pacote de tráfego de dados é 1.
Topologia de rede
Figura 1 -3 Rede de configuração do mapeamento de prioridade
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
# Configure o tipo de link da porta gigabitethernet0/1 como Access e permita que os serviços da VLAN2 passem.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2
# Configure o tipo de link da porta gigabitethernet0/2 como Trunk e permita a passagem dos serviços da VLAN2.
Device(config-if-gigabitethernet0/1)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode trunkDevice(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/2)#exit
- Passo 2:Configure a função de mapeamento de prioridade.
#Configure a função de mapeamento de prioridade globalmente , mapeie o pacote com valor DSCP 34 para a fila 2 e mapeie o pacote com valor DSCP 38 para a fila 3.
Device(config)#qos map-table ingress aDevice(config-maptable-ingress)#dscp-lp 34 to 2Device(config-if-gigabitethernet0/1)# dscp-lp 38 to 3
# Configure globalmente a função de mapeamento de prioridade, mapeie a prioridade 802.1p do pacote na fila 2 para 5 e mapeie a prioridade 802.1p do pacote na fila 3 para 1.
Device(config)#qos map-table egress bDevice(config-maptable-egress)#lp-dot1p 2 to 5Device(config- maptable-egress)# lp-dot1p 3 to 1
# Na porta, vincule o perfil e configure a confiança.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)# map-table a ingressDevice(config-if-gigabitethernet0/1)#qos map-table trust dscp ingressDevice(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)# map-table b egressDevice(config-if-gigabitethernet0/2)#qos map-table trust dot1p egress
- Passo 3:Confira o resultado.
#Depois que o tráfego de vídeo e o tráfego de dados são processados pelo dispositivo, a prioridade 802.1p do pacote de tráfego de vídeo enviado da porta gigabitethernet0/2 é 5 e a prioridade 802.1p do pacote de tráfego de dados é 1.
Configurar observação
Requisitos de rede
- Existem dois servidores na rede, ou seja, servidor de vídeo e servidor de dados.
- Configure a função de remarcação, percebendo que a prioridade 802.1p do pacote de tráfego de vídeo está marcada como 5 e a prioridade 802.1p do pacote de tráfego de dados não muda.
Topologia de rede
Figura 1 -4 Rede de configuração da remarcação
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como acesso e permita a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2
#Configure o tipo de link da porta gigabitethernet0/2 como Trunk e permita a passagem dos serviços da VLAN2.
Device(config-if-gigabitethernet0/1)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode trunkDevice(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/2)#exit
- Passo 2:Configure o grupo de ação L3.
#Configure o grupo de ação L3 chamado remark e a ação é marcar a prioridade 802.1p do pacote como 5.
Device(config)#l3-action-group remarkDevice(config-action-group)#remark l2-priority dot1p 5Device(config-action-group)#exit
- Passo 3:Configure a ACL padrão IP.
#Configure a ACL padrão IP com o número de série 1 no dispositivo.
Device(config)#ip access-list standard 1#Configure a vinculação da regra com o grupo de ação L3 chamado remark, percebendo que a prioridade 802.1p do pacote de tráfego de vídeo é marcada como 5.
Device(config-std-nacl)#permit host 100.0.0.1 l3-action-group remark#Configure a regra, permitindo a passagem do tráfego de dados e não modificando a prioridade 802.1p do pacote.
Device(config-std-nacl)#permit host 100.0.0.2Device(config-std-nacl)#commitDevice(config-std-nacl)#exit
- Passo 4:Configure aplicando a ACL padrão IP.
#Aplique a ACL padrão IP com número de série 1 na direção de entrada da porta gigabitethernet0/1 no dispositivo.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ip access-group 1 inDevice(config-if-gigabitethernet0/1)#exit
#Visualize a informação da ACL aplicada à porta no dispositivo.
Device#show acl-object interface-----------Interface-----Bind-----Instance--------------Interface----------------Direction----AclType----AclNamegi0/1 IN IP 1
- Passo 5:Confira o resultado.
#Depois que o tráfego de vídeo e o tráfego de dados são processados pelo Dispositivo, a prioridade 802.1p do pacote de tráfego de vídeo enviado da porta gigabitethernet0/2 é modificada para 5 e a prioridade 802.1p do pacote de tráfego de dados não muda.
Configurar modelagem de tráfego
Requisitos de rede
- Existem dois servidores na rede, ou seja, servidor de vídeo e servidor de dados.
- Configure a função de modelagem de tráfego; verifique se a taxa de tráfego de vídeo é de 20.000 kbps, mas não pode exceder 20.000 kbps; o total da taxa de tráfego de vídeo e a taxa de tráfego de dados não excede 50.000 kbps. Quando a taxa de tráfego de vídeo for maior que 20.000 kbps, limite a taxa de tráfego de vídeo a 20.000 kbps; quando a taxa de tráfego de vídeo é menor que 20.000 kbps, a largura de banda restante é ocupada pelo tráfego de dados.
Topologia de rede
Figura 1 -5 Rede de configuração da modelagem de tráfego
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como acesso e permita a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2
#Configure o tipo de link da porta gigabitethernet0/2 como Trunk e permita a passagem dos serviços da VLAN2.
Device(config-if-gigabitethernet0/1)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode trunkDevice(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/2)#exit
- Passo 2:Configure o grupo de ação L3.
#Configure o grupo de ação L3 chamado LP7 e a ação é observar o pacote na fila 7.
Device(config)#l3-action-group LP7Device(config-action-group)#remark l2-priority 1p 7Device(config-action-group)#exit
#Configure o grupo de ação L3 chamado LP6 e a ação é observar o pacote na fila 6.
Device(config)#l3-action-group LP6Device(config-action-group)#remark l2-priority 1p 6Device(config-action-group)#exit
- Passo 3:Configure a ACL padrão IP.
#Configure a ACL padrão IP com o número de série 1 no dispositivo.
Device(config)#ip access-list standard 1#Configure a vinculação da regra com o grupo de ação L3 chamado LP7, percebendo que o pacote de tráfego de vídeo é remarcado para a fila 7.
Device(config-std-nacl)#permit host 100.0.0.1 l3-action-group LP7#Configure a vinculação da regra com o grupo de ação L3 chamado LP6, percebendo que o pacote de tráfego de vídeo é remarcado para a fila 6.
Device(config-std-nacl)#permit host 100.0.0.2 l3-action-group LP6Device(config-std-nacl)#commitDevice(config-std-nacl)#exit
- Passo 4:Configure aplicando a ACL padrão IP.
#Aplique a ACL padrão IP com número de série 1 na direção de entrada da porta gigabitethernet0/1 no dispositivo.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ip access-group 1 inDevice(config-if-gigabitethernet0/1)#exit
#Visualize a informação da ACL aplicada à porta no dispositivo.
Device#show acl-object interface-----------Interface-----Bind-----Instance--------------Interface----------------Direction----AclType----AclNamegi0/1 IN IP 1
- Passo 5:Configure a função de modelagem de tráfego.
#Configure a modelagem de tráfego baseada em fila na porta gigabitethernet0/2 e limite a taxa de tráfego na fila de 7 a 20.000 kbps.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#traffic-shape queue 7 cir 20000 pir 20000
#Configure a modelagem de tráfego baseada em porta na porta gigabitethernet0/2 e limite a taxa de tráfego da porta a 50.000 kbps.
Device(config-if-gigabitethernet0/2)#traffic-shape pir 50000Device(config-if-gigabitethernet0/2)#exit
- Passo 6:Confira o resultado.
# Depois que o tráfego de vídeo e o tráfego de dados são processados pelo dispositivo, o total da taxa de tráfego de vídeo e a taxa de tráfego de dados enviados da porta gigabitethernet0/2 não excede 50.000 kbps. Quando a taxa de tráfego de vídeo for maior que 20.000 kbps, limite a taxa de tráfego de vídeo a 20.000 kbps; quando a taxa de tráfego de vídeo é menor que 20.000 kbps, a largura de banda restante pode ser ocupada pelo tráfego de dados.
Configurar limitação de taxa
Requisitos de rede
- Existem dois servidores na rede, ou seja, servidor de vídeo e servidor de dados.
- Configure a função de limitação de taxa e limite o total da taxa de tráfego de vídeo e a taxa de tráfego de dados para não exceder 50.000 kbps. A taxa de tráfego de dados não excede 20.000 kbps.
Topologia de rede
Figura 1 -6 Rede de configuração da limitação de taxa
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como acesso e permita a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2
#Configure o tipo de link da porta gigabitethernet0/2 como Trunk e permita a passagem dos serviços da VLAN2.
Device(config-if-gigabitethernet0/1)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode trunkDevice(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/2)#exit
- Passo 2:Configure a função de limitação de taxa.
#Configure a limitação de taxa baseada em porta na porta gigabitethernet0/1 e limite a taxa de tráfego a 50 000 kbps.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#rate-limit default 50000 4096Device(config-if-gigabitethernet0/1)#exit
- Passo 3:Configure a função do medidor.
#Configure o medidor chamado data_stream e limite a taxa de tráfego a 20 000kbps.
Device(config)#traffic-meter data_streamDevice(config-meter)#meter mode srtcm 20000 4096 4096Device(config-meter)#exit
- Passo 4:Configure o grupo de ação de saída.
#Configure o grupo de ações de saída chamado data_stream e aplique o medidor no grupo de ações de saída.
Device(config)#egr-action-group data_streamDevice(config-egract-group)#meter data_streamDevice(config-egract-group)#exit
- Passo 5:Configure a ACL padrão IP.
#Configure a ACL padrão IP com o número de série 1 no dispositivo.
Device(config)#ip access-list standard 1#Configure a vinculação da regra com o grupo de ações de saída chamado data_stream e limite a taxa de tráfego de dados a 20.000 kbps.
Device(config-std-nacl)#permit host 100.0.0.2 egr-action-group data_stream#Configure a regra e permita a passagem do tráfego de vídeo.
Device(config-std-nacl)#permit host 100.0.0.1Device(config-std-nacl)#commitDevice(config-std-nacl)#exit
- Passo 6:Configure aplicando a ACL padrão IP.
#Aplique a ACL padrão IP com número de série 1 na direção de saída da porta gigabitethernet0/2 no dispositivo.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#ip access-group 1 outDevice(config-if-gigabitethernet0/2)#exit
#Visualize a informação da ACL aplicada à porta no dispositivo.
Device#show acl-object interface-----------Interface-----Bind-----Instance--------------Interface----------------Direction----AclType----AclNamegi0/2 OUT IP 1
- Passo 7:Confira o resultado.
#Depois que o tráfego de vídeo e o tráfego de dados são processados pelo dispositivo, o total da taxa de tráfego de vídeo e o tráfego de dados enviado da porta gigabitethernet0/2 não excede 50.000 kbps e a taxa de tráfego de dados não excede 20.000 kbps.
Configurar WRED
Requisitos de rede
- Muitos terminais baixam arquivos do servidor FTP.
- Configure a função WRED no dispositivo, evitando que a sincronização global TCP resulte na conexão FTP intermitente.
Topologia de rede
Figura 1 -7 Rede de configuração do WRED
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como acesso e permita a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2
#Configure o tipo de link da porta gigabitethernet0/2 como Trunk e permita a passagem dos serviços da VLAN2.
Device(config-if-gigabitethernet0/1)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode trunkDevice(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/2)#exit
- Passo 2:Configure a função WRED.
#Configure o valor de drop start do pacote na fila 0 na porta gigabitethernet0/2 como 80 e a taxa de drop como 45.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#drop-mode 0 wred drop-start 80 drop-rate 45
Device(config-if-gigabitethernet0/2)#exit
Os pacotes enviados do PC são todos pacotes Untag e entram na fila 0 por padrão.
- Passo 3:Confira o resultado.
#Quando muitos terminais baixam arquivos do servidor FTP, a conexão FTP intermitente não acontece.
Configurar SP
Requisitos de rede
- Há servidor de autenticação (servidor AAA), servidor de vídeo e um dispositivo terminal (PC) na rede.
- Configure a função SP. Quando o tráfego da porta de saída estiver congestionado, primeiro garanta o tráfego do servidor de autenticação, depois o tráfego de vídeo e, por último, o tráfego do terminal.
Topologia de rede
Figura 1 -8 Rede de configuração do SP
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como acesso e permita a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2
#Configure o tipo de link da porta gigabitethernet0/2 como Trunk e permita a passagem dos serviços da VLAN2.
Device(config-if-gigabitethernet0/1)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode trunkDevice(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/2)#exit
- Passo 2:Configure o grupo de ação L3.
#Configure o grupo de ação L3 chamado LP7 e a ação é observar os pacotes na fila 7.
Device(config)#l3-action-group LP7Device(config-action-group)#remark l2-priority 1p 7Device(config-action-group)#exit
#Configure o grupo de ação L3 chamado LP6 e a ação é observar os pacotes na fila 6.
Device(config)#l3-action-group LP6Device(config-action-group)#remark l2-priority 1p 6Device(config-action-group)#exit
#Configure o grupo de ação L3 chamado LP5 e a ação é observar os pacotes na fila 5.
Device(config)#l3-action-group LP5Device(config-action-group)#remark l2-priority 1p 5Device(config-action-group)#exit
- Passo 3:Configure a ACL padrão IP.
#Configure a ACL padrão IP com o número de série 1 no dispositivo.
Device(config)#ip access-list standard 1#Configure a vinculação da regra com o grupo de ação L3 chamado LP7, percebendo que os pacotes de tráfego de autenticação são remarcados para a fila 7.
Device(config-std-nacl)#permit host 100.0.0.1 l3-action-group LP7#Configure a vinculação da regra com o grupo de ação L3 denominado LP6, percebendo que os pacotes de tráfego de autenticação são remarcados para a fila 6.
Device(config-std-nacl)#permit host 100.0.0.2 l3-action-group LP6#Configure a vinculação da regra com o grupo de ação L3 denominado LP5, percebendo que os pacotes de tráfego de autenticação são remarcados para a fila 5.
Device(config-std-nacl)#permit host 100.0.0.3 l3-action-group LP5Device(config-std-nacl)#commitDevice(config-std-nacl)#exit
- Passo 4:Configure aplicando a ACL padrão IP.
#Aplique a ACL padrão IP com número de série 1 na direção de entrada da porta gigabitethernet0/1 no dispositivo.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ip access-group 1 inDevice(config-if-gigabitethernet0/1)#exit
#Visualize a informação da ACL aplicada à porta no dispositivo.
Device#show acl-object interface-----------Interface-----Bind-----Instance--------------Interface----------------Direction----AclType----AclNamegi0/1 IN IP 1
- Passo 5:Configure a função SP.
#Configure a função SP na porta gigabitethernet0/2 e execute o escalonamento de prioridade estrita para o pacote.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#queue-schedule spDevice(config-if-gigabitethernet0/2)#exit
- Passo 6:Confira o resultado.
#Quando o tráfego da porta de saída gigabitethernet0/2 estiver congestionado, primeiro permita a passagem do tráfego de autenticação, depois o tráfego de vídeo e, por último, o tráfego do terminal.
Configurar WDRR
Requisitos de rede
- Há servidor de autenticação (servidor AAA), servidor de vídeo e um dispositivo terminal (PC) na rede.
- Configure a função WDRR. Quando o tráfego da porta de saída estiver congestionado, perceba que o tráfego do terminal, o tráfego de vídeo e o tráfego de autenticação passam por alguma proporção especificada.
Topologia de rede
Figura 1 -9 Rede de configuração do WDRR
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como acesso e permita a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2
#Configure o tipo de link da porta gigabitethernet0/2 como Trunk e permita a passagem dos serviços da VLAN2.
Device(config-if-gigabitethernet0/1)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode trunkDevice(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/2)#exit
- Passo 2:Configure o grupo de ação L3.
#Configure o grupo de ação L3 chamado LP7 e a ação é observar o pacote na fila 7.
Device(config)#l3-action-group LP7Device(config-action-group)#remark l2-priority 1p 7Device(config-action-group)#exit
#Configure o grupo de ação L3 chamado LP6 e a ação é observar o pacote na fila 6.
Device(config)#l3-action-group LP6Device(config-action-group)#remark l2-priority 1p 6Device(config-action-group)#exit
#Configure o grupo de ação L3 chamado LP5 e a ação é observar o pacote na fila 5.
Device(config)#l3-action-group LP5Device(config-action-group)#remark l2-priority 1p 5Device(config-action-group)#exit
- Passo 3:Configure a ACL padrão IP.
#Configure a ACL padrão IP com o número de série 1 no dispositivo.
Device(config)#ip access-list standard 1#Configure a vinculação da regra com o grupo de ação L3 chamado LP7, percebendo que os pacotes de tráfego de autenticação são remarcados para a fila 7.
Device(config-std-nacl)#permit host 100.0.0.1 l3-action-group LP7#Configure a vinculação da regra com o grupo de ação L3 denominado LP6, percebendo que os pacotes de tráfego de autenticação são remarcados para a fila 6.
Device(config-std-nacl)#permit host 100.0.0.2 l3-action-group LP6#Configure a vinculação da regra com o grupo de ação L3 denominado LP5, percebendo que os pacotes de tráfego de autenticação são remarcados para a fila 5.
Device(config-std-nacl)#permit host 100.0.0.3 l3-action-group LP5Device(config-std-nacl)#commitDevice(config-std-nacl)#exit
- Passo 4:Configure aplicando a ACL padrão IP.
#Aplique a ACL padrão IP com número de série 1 na direção de entrada da porta gigabitethernet0/1 no dispositivo.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ip access-group 1 inDevice(config-if-gigabitethernet0/1)#exit
#Visualize a informação da ACL aplicada à porta no dispositivo.
Device#show acl-object interface-----------Interface-----Bind-----Instance--------------Interface----------------Direction----AclType----AclNamegi0/1 IN IP 1
- Passo 5:Configure a função WDRR.
#Configure a função WDRR na porta gigabitethernet0/2, agendando os pacotes da fila 5, fila 6 e fila 7 na proporção de 1:2:3.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#queue-schedule wdrr 1 1 1 1 1 1 2 3Device(config-if-gigabitethernet0/2)#exit
- Passo 6:Confira o resultado.
#Quando o tráfego da porta de saída gigabitethernet0/2 está congestionado e os bytes do pacote são consistentes, o tráfego do terminal, o tráfego de vídeo e o tráfego de autenticação passam na proporção de 1:2:3; quando os bytes do pacote não são consistentes, o tráfego do terminal, o tráfego de vídeo e o tráfego de autenticação passam na proporção de (1*os bytes do pacote de autenticação): (2*os bytes dos bytes de vídeo):(3*os bytes de o pacote terminal).
Configurar SP+WRR
Requisitos de rede
- Há servidor de autenticação (servidor AAA), servidor de vídeo e um dispositivo terminal (PC) na rede.
- Configure a função SP+WRR. Quando o tráfego da porta de saída estiver congestionado, primeiro certifique-se de que todo o tráfego do servidor de autenticação possa passar e que o tráfego do terminal e o tráfego de vídeo possam passar na proporção de 1:2.
Topologia de rede
Figura 1 -10 Rede de configuração do SP+WRR
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como acesso e permita a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2
#Configure o tipo de link da porta gigabitethernet0/2 como Trunk e permita a passagem dos serviços da VLAN2.
Device(config-if-gigabitethernet0/1)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode trunkDevice(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2Device(config-if-gigabitethernet0/2)#exit
- Passo 2:Configure o grupo de ação L3.
#Configure o grupo de ação L3 chamado LP7 e a ação é observar o pacote na fila 7.
Device(config)#l3-action-group LP7Device(config-action-group)#remark l2-priority 1p 7Device(config-action-group)#exit
#Configure o grupo de ação L3 chamado LP6 e a ação é observar o pacote na fila 6.
Device(config)#l3-action-group LP6Device(config-action-group)#remark l2-priority 1p 6Device(config-action-group)#exit
#Configure o grupo de ação L3 chamado LP5 e a ação é observar o pacote na fila 5.
Device(config)#l3-action-group LP5Device(config-action-group)#remark l2-priority 1p 5Device(config-action-group)#exit
- Passo 3:Configure a ACL padrão IP.
#Configure a ACL padrão IP com o número de série 1 no dispositivo.
Device(config)#ip access-list standard 1#Configure a vinculação da regra com o grupo de ação L3 chamado LP7, percebendo que os pacotes de tráfego de autenticação são remarcados para a fila 7.
Device(config-std-nacl)#permit host 100.0.0.1 l3-action-group LP7#Configure a vinculação da regra com o grupo de ação L3 denominado LP6, percebendo que os pacotes de tráfego de autenticação são remarcados para a fila 6.
Device(config-std-nacl)#permit host 100.0.0.2 l3-action-group LP6#Configure a vinculação da regra com o grupo de ação L3 denominado LP5, percebendo que os pacotes de tráfego de autenticação são remarcados para a fila 5.
Device(config-std-nacl)#permit host 100.0.0.3 l3-action-group LP5Device(config-std-nacl)#commitDevice(config-std-nacl)#exit
- Passo 4:Configure aplicando a ACL padrão IP.
#Aplique a ACL padrão IP com número de série 1 na direção de entrada da porta gigabitethernet0/1 no dispositivo.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ip access-group 1 inDevice(config-if-gigabitethernet0/1)#exit
#Visualize a informação da ACL aplicada à porta no dispositivo.
Device#show acl-object interface-----------Interface-----Bind-----Instance--------------Interface----------------Direction----AclType----AclNamegi0/1 IN IP 1
- Passo 5: Configure a função SP + WRR.
#Configure a função SP+WRR na porta gigabitethernet0/2, permitindo a passagem de todos os pacotes da fila 7 e escalonando os pacotes da fila 5 e da fila 6 na proporção de 1:2.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#queue-schedule wrr 1 1 1 1 1 1 2 0Device(config-if-gigabitethernet0/2)#exit
- Passo 6:Confira o resultado.
#Quando o tráfego da porta gigabitethernet0/2 está congestionado, todo o tráfego de autenticação passa primeiro. O tráfego do terminal e o tráfego de vídeo passam na proporção de 1:2.
Configurar espelho de fluxo
Requisitos de rede
- PC1, PC2 e PC3 estão conectados com o Dispositivo; PC1 e PC2 se comunicam em VLAN2.
- Configure a função de espelhamento de fluxo no Dispositivo, percebendo que o PC3 monitora os pacotes recebidos pela porta gigabitethernet 0/1 do Dispositivo.
Topologia de rede
Figura 1 -11 Rede de configuração do espelho de fluxo
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta.
#Criar VLAN2 no dispositivo.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 e gigabitethernet0/2 no dispositivo como acesso e permita a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1-0/2Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
- Passo 2:Configure a função de espelho de fluxo.
#Configure o grupo de ação L3 chamado mirror e espelhe o pacote na porta gigabitethernet0/3.
Device(config)#l3-action-group mirrorDevice(config-action-group)#mirror interface gigabitethernet 0/3Device(config-action-group)#exit
- Passo 3:Configure a função do contador.
#Configure o grupo de ações de saída chamado count, contando o número de pacotes.
Device(config)#egr-action-group countDevice(config-egract-group)#count all-colorsDevice(config-egract-group)#exit
- Passo 4:Configure a ACL padrão IP.
#Configure a ACL padrão IP com o número de série 1 no dispositivo.
Device(config)#ip access-list standard 1#Configure a vinculação da regra com o grupo de ação L3 chamado mirror, percebendo que todos os pacotes são espelhados na porta gigabitethernet0/3.
Device(config-std-nacl)#permit any l3-action-group mirrorDevice(config-std-nacl)#commitDevice(config-std-nacl)#exit
# Configure a ACL padrão IP com número de série 2 no dispositivo.
Device(config)#ip access-list standard 2#Configure a vinculação da regra com o grupo de ações de saída chamado count, contando todos os pacotes.
Device(config-std-nacl)#permit any egr-action-group countDevice(config-std-nacl)#commitDevice(config-std-nacl)#exit
- Passo 5:Configure aplicando a ACL padrão IP.
#Aplique a ACL padrão IP com número de série 1 na direção de entrada da porta gigabitethernet0/1 no dispositivo.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ip access-group 1 inDevice(config-if-gigabitethernet0/1)#exit
#Aplique a ACL padrão IP com número de série 2 na direção de saída da porta gigabitethernet0/3 no dispositivo.
Device(config)#interface gigabitethernet 0/3Device(config-if-gigabitethernet0/3)#ip access-group 2 outDevice(config-if-gigabitethernet0/3)#exit
#Visualize a informação da ACL aplicada à porta no dispositivo.
Device#show acl-object interface-----------Interface-----Bind-----Instance--------------Interface----------------Direction----AclType----AclNamegi0/1 IN IP 1gi0/3 OUT IP 2
- Passo 6: Confira o resultado.
#Quando PC1 e PC2 se comunicam, podemos capturar os pacotes recebidos pela porta gigabitethernet0/1 no PC3.
#Visualize o número de pacotes medidos pelo contador no dispositivo.
Device#show traffic-count inst-interface gigabitethernet 0/3 ip-outInterface Instance_type Acl_name Frame_gapgigabitethernet0/3 Ip Acl Bind Interface Out 2 No-----------------------------------------------------------------------seq : 10counter_mode : count all colorall packets number : 5all packets byte : 640-----------------------------------------------------------------------
Podemos ver que existem cinco pacotes medidos na direção de saída da porta gigabitethernet0/3.
08 Segurança
ARP Check
Visão geral
ARP Check é uma função de verificar a validade do pacote ARP, evitando que o pacote ARP inválido passe e melhorando a segurança da rede.
A verificação de validade do pacote ARP é baseada na entrada de ligação de porta. A entrada de ligação inclui dois tipos:
Entrada de ligação estática: entrada de ligação estática configurada manualmente;
Entrada de ligação dinâmica: gerada dinamicamente pela entrada válida da função DHCP Snooping e função 802.1X.
O princípio de verificação do ARP Check é o seguinte:
No pacote ARP recebido pela porta, verifique o endereço IP de envio, o endereço MAC de origem para corresponder à entrada de ligação ARP Check da porta. Se corresponder, o pacote ARP é um pacote válido e é encaminhado diretamente. Caso contrário, o pacote ARP é um pacote inválido e é descartado.
Configuração da função de verificação ARP
Tabela 1 -1 Lista de configuração da função ARP Check
| Tarefa de configuração | |
| Habilite a função de verificação de porta ARP | Habilite a função de verificação de porta ARP |
| Vincule a entrada estática ARP Check | Vincule a entrada estática ARP Check |
| Reinstale a entrada que não consegue gravar o hardware | Reinstale a entrada que não consegue gravar o hardware |
Ativar função de verificação de porta ARP
Condição de configuração
Nenhum
Ativar função de verificação de porta ARP
Depois de habilitar a função ARP Check da porta, o ARP Check obtém dinamicamente a entrada no banco de dados DHCP Snooping e grava no hardware ACL.
Tabela 1 -2 Habilite a função de verificação ARP da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a função ARP Check da porta | arp-check enable | Obrigatório Por padrão, a função Port ARP Check não está habilitada. |
Vincular entrada estática de verificação ARP
Condição de configuração
Nenhum
Vincular entrada estática de verificação ARP
Tabela 1 -3 Bind ARP Verifique a entrada estática
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Vincule a entrada estática ARP Check | arp-check binding mac-address ip-address [ rate limit-value ] | Obrigatório Por padrão, não configure a entrada de ligação estática ARP Check |
Reinstale a entrada de verificação ARP não bem-sucedida na gravação do hardware
Condição de configuração
Nenhum
Reinstale a entrada de verificação ARP não bem-sucedida na gravação do hardware
Tabela 1 -4 Reinstalar a entrada de verificação ARP não bem-sucedida na gravação do hardware
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Reinstale a entrada de verificação ARP não bem-sucedida na gravação do hardware | arp-check install | Obrigatório Por padrão, não instale ARP Check Entry Not Succeeded in Writing Hardware |
Monitoramento e Manutenção de ARP Check
Tabela 1 -5 Monitoramento e manutenção do ARP Check
| Comando | Descrição |
| show arp-check [ active | brief | inactive | interface interface-name | interface link-aggregation link-aggregation-id ] | Exibir as informações na entrada ARP Check |
Exemplo de configuração típica de verificação ARP
Configurar funções básicas da verificação ARP
Requisitos de rede
- PC1 e PC2 estão conectados à rede IP via dispositivo.
- Configure a função básica ARP Check, percebendo que o PC1 pode acessar a rede IP normalmente e o PC2 não pode acessar a rede IP.
Topologia de rede

Figura 1 – 1 Rede de configuração das funções básicas do ARP Check
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
# Configure o tipo de link da porta gigabitethernet0/1 como Access e permita a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2Device(config-if-gigabitethernet0/1)#exit
- Passo 2:Configure a função ARP Check no dispositivo.
#Ative a função ARP Check na porta gigabitethernet0/1 e configure a entrada de ligação ARP Check com o endereço MAC 0012.0100.0002 e o endereço IP 192.168.1.2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#arp-check enableDevice(config-if-gigabitethernet0/1)#arp-check binding 0012.0100.0002 192.168.1.2 rate 10Device(config-if-gigabitethernet0/1)#exit
- Passo 3:Confira o resultado.
#Visualize as informações de configuração do ARP Check.
Device#show arp-check brief-------------------------------------------------------Interface Name Status Binding Table-------------------------------------------------------gi0/1 Enable Yes……
Você pode ver que a porta gigabitethernet0/1 está habilitada com a função ARP Check, e há a entrada ARP Check.
#Exibe a entrada de ligação de verificação ARP da porta.
Device#show arp-check interface gigabitethernet0/1--------------------------ARP Check Table------------------------------------FLAG Codes:-----------------------------------------------------------------------------------------------Interface-Name Status MAC-Address IP-Address Rate PolicySource SetHardware----------------------------------------------------------------------------gi0/1 enable 0012.0100.0002 192.168.1.2 10 STATIC activetotal number: 1
#PC1 pode acessar a rede IP normalmente, mas o PC2 não pode acessar a rede IP.
Combine ARP Check com DHCP Snooping
Requisitos de rede
- PC1 e PC2 estão conectados à rede IP via dispositivo; O PC1 usa o endereço IP estático e o PC2 obtém o endereço IP via DHCP.
- O dispositivo configura a função DHCP Snooping e ARP Check, percebendo que o PC2 pode acessar a rede IP normalmente e o PC1 não pode acessar a rede IP.
Topologia de rede
Figura 1 -2 Rede de combinar ARP Check com DHCP Snooping
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1, gigabitethernet0/2 e gigabitethernet0/3 como acesso, todos permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1-0/3Device(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
- Passo 2: Configure a função DHCP Snooping no dispositivo.
#Habilite a função DHCP Snooping e configure a porta gigabitethernet0/2 como porta de confiança.
Device(config)#dhcp-snoopingDevice(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#dhcp-snooping trustDevice(config-if-gigabitethernet0/2)#exit
- Passo 3: Configure a função ARP Check no dispositivo.
#Habilite a função ARP Check na porta gigabitethernet0/1.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#arp-check enableDevice(config-if-gigabitethernet0/1)#exit
- Passo 4: Confira o resultado.
#Depois que o PC2 obtiver o endereço IP com sucesso, visualize a entrada dinâmica do DHCP Snooping no dispositivo.
Device#show dhcp-snooping databasedhcp-snooping database:database entries count:1database entries delete time :300---------------------------------macAddr ipAddr transtion-id vlan interface leaseTime(s) status0013.0100.0001 192.168.1.100 2 2 gi0/1 107990 active------
#Visualize a entrada de ligação ARP Check da porta gigabitethernet0/1.
Device#show arp-check interface gigabitethernet0/1--------------------------ARP Check Table------------------------------------FLAG Codes:-----------------------------------------------------------------------------------------------Interface-Name Status MAC-Address IP-Address Rate PolicySource SetHardware----------------------------------------------------------------------------gi0/1 enable 0013.0100.0001 192.168.1.100 15 DHCPSP activetotal number: 1
Combine ARP Check com 802.1X
Requisitos de rede
- O PC1 está conectado à rede IP via dispositivo e o dispositivo adota o controle de acesso 802.1X.
- O modo de autenticação adota a autenticação RADIUS.
- PC1 não pode acessar a rede se não for autenticado com sucesso. Depois de passar a autenticação, o PC1 tem permissão para acessar a rede IP.
- O usuário autenticado pode gerar a entrada arp-check para realizar a detecção de validade do pacote arp do usuário autenticado.
Topologia de rede
Figura 1 -3 Rede de combinar ARP Check com 802.1X
Etapas de configuração
- Passo 1:No dispositivo, configure o tipo de link da VLAN e da porta.
#No dispositivo, crie VLAN2~VLAN4.
Device#configure terminalDevice(config)#vlan 2-4Device(config)#exit
#Configure o tipo de link da porta gigabitethernet 0/2 como acesso, permitindo a passagem dos serviços da VLAN2. Device(config)#interface gigabitethernet 0/2
Device(config-if-gigabitethernet0/2)#switchport access vlan 2Device(config-if-gigabitethernet0/2)#exit
#No gigabitethernet 0/3-gigabitethernet 0/4 do Dispositivo, configure o tipo de link da porta como Acesso, permitindo que os serviços de VLAN3-VLAN4 passem respectivamente (omitido).
- Passo 2:Configure o endereço IP da interface do Dispositivo.
#Configure o endereço IP da VLAN4 como 130.255.167.1/24.
Device(config)#interface vlan 4Device(config-if-vlan4)#ip address 130.255.167.1 255.255.255.0Device(config-if-vlan4)#exit
- Passo 3: Configure a autenticação AAA.
#No dispositivo, habilite a autenticação AAA, adote o modo de autenticação RADIUS, a chave do servidor é admin, a prioridade é 1 e o endereço do servidor RADIUS é 130.255.167.167/24.
Device(config)#aaa new-modelDevice(config)#aaa authentication connection default radiusDevice(config)#radius-server host 130.255.167.167 priority 1 key admin
- Passo 4:Configure o servidor AAA.
#No servidor AAA, configure o nome de usuário, a senha e o valor da chave como admin (omitido).
- Passo 5:Configure a autenticação 802.1X.
#Ative a autenticação 802.1X na porta e configure o modo de autenticação como Macbased.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#dot1x port-control enableDevice(config-if-gigabitethernet0/2)#authentication port-method macbasedDevice(config-if-gigabitethernet0/2)#exit
- Passo 6:No Dispositivo, configure a função ARP Check.
#Ative a função ARP Check na porta gigabitethernet0/2.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#arp-check enableDevice(config-if-gigabitethernet0/2)#exit
- Passo 7:Autentique com sucesso.
#Antes de passar a autenticação, o PC1 não pode acessar a rede.
#Após iniciar a autenticação e ser autenticado com sucesso, o PC1 pode acessar a rede IP.
Device#show dot1x user--------------------NO 1 : MAC_ADDRESS= 3883.45ef.7984 STATUS= Authorized USER_NAME= adminVLAN= 2 INTERFACE= gi0/2 USER_TYPE= DOT1XAUTH_STATE= AUTHENTICATED BACK_STATE= IDLE IP_ADDRESS= 199.0.0.1IPV6_ADDRESS= UnknownOnline time: 0 week 0 day 0 hours 0 minute 51 secondsTotal: 1 Authorized: 1 Unauthorized/guest/critical: 0/0/0 Unknown: 0
- Passo 8:Confira o resultado.
Device#show arp-check interface gigabitethernet0/2--------------------------ARP Check Table------------------------------------FLAG Codes:-----------------------------------------------------------------------------------------------Interface-Name Status MAC-Address IP-Address Rate PolicySource SetHardware----------------------------------------------------------------------------gi0/2 enable 3883.45ef.7984 199.0.0.1 15 DOT1X activetotal number: 1
#Se o pacote arp enviado pelo PC1 corresponder completamente à entrada, encaminhe-o e limite a velocidade normalmente. Se não corresponder, solte-o diretamente.
CPU Protection
Visão geral
Existem muitos pacotes de protocolo no dispositivo que precisam ser enviados à CPU para processamento e precisamos especificar a fila para cada tipo de pacote de protocolo. A função de CPU Protection classifica os pacotes de protocolo enviados à CPU e os pacotes entram em diferentes filas da CPU de acordo com as diferentes prioridades de protocolo. Podemos definir a limitação de taxa de cada fila.
O dispositivo possui totalmente oito filas, numeradas de 0 a 7. Elas adotam as prioridades estritas. Quanto menor o número, menor a prioridade. Ou seja, a prioridade da fila 0 é a mais baixa e a prioridade da fila 7 é a mais alta. Os pacotes na fila c
Enquanto isso, o dispositivo pode executar a limitação de taxa para os pacotes que entram em cada fila da CPU, evitando que o ataque de pacote de protocolo vicioso na rede cause uma utilização muito alta da CPU do dispositivo e resulte no funcionamento anormal do dispositivo.
Configuração da função de CPU Protection
Tabela 2 -1 A lista de configuração da função de CPU Protection
| Tarefa de configuração | |
| Configure a fila de CPU do pacote de protocolo | Configure a fila de CPU do pacote de protocolo |
| Configure a limitação de taxa da fila da CPU |
Configure a limitação de taxa total de todas as filas de CPU
Configure a limitação de taxa de cada fila de CPU |
| Configure o pacote de protocolo personalizado para ser processado pela CPU |
Configure a regra de correspondência do pacote de protocolo personalizado a ser processado pela CPU
Configure o modo do pacote de protocolo personalizado a ser processado pela CPU |
Configurar fila de CPU de pacotes de protocolo
Condição de configuração
Nenhum
Configurar fila de CPU de pacotes de protocolo
O dispositivo possui totalmente oito filas e o usuário pode configurar diferentes pacotes de protocolo para entrar em diferentes filas. O dispositivo envia os pacotes de protocolo para a CPU para processamento em ordem de fila de alta prioridade para fila de baixa prioridade de acordo com a configuração do usuário. Se os pacotes de protocolo estiverem na fila com alta prioridade, eles primeiro obterão o processamento da CPU. Além disso, o usuário também pode especificar o pacote importante para entrar na fila de alta prioridade, garantindo que os pacotes importantes sejam enviados primeiro à CPU para processamento. Por padrão, diferentes pacotes de protocolo entram na fila padrão da CPU. Além disso, também podemos usar o comando para modificar o pacote para entrar na fila de CPU especificada.
Tabela 2 -2 Configure a fila da CPU do pacote de protocolo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a fila de CPU que os pacotes de protocolo inserem | cpu-packet protocol cos cos-value | Obrigatório Por padrão, diferentes pacotes de protocolo entram na fila padrão da CPU. |
Configurar a limitação de taxa total de todas as filas de CPU
Condição de configuração
Nenhum
Configurar a limitação de taxa total de todas as filas de CPU
Para evitar que o ataque vicioso na rede cause uma utilização muito alta da CPU e o dispositivo não possa ser executado, o usuário pode configurar a limitação de taxa total de todas as filas da CPU. Se houver ataque e a taxa total de pacotes em todas as filas exceder a taxa total limitada, os pacotes serão descartados, evitando causar uma utilização muito alta da CPU.
Tabela 2 -3 Configure a limitação de taxa total de todas as filas de CPU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a limitação de taxa total de todas as filas de CPU | cpu-packet cos global pps pps-value | Obrigatório Por padrão, a taxa limitada total de todas as filas é 2000PPS. |
Configurar a limitação de taxa de cada fila de CPU
Condição de configuração
Nenhum
Configurar a limitação de taxa de cada fila de CPU
Para evitar que o ataque vicioso na rede cause uma utilização muito alta da CPU e o dispositivo não possa ser executado, o usuário pode configurar a limitação de taxa de cada fila da CPU. Se houver ataque e a taxa de pacotes na fila exceder a taxa limitada da fila, o pacote será descartado, evitando causar uma utilização muito alta da CPU. Por padrão, diferentes filas de CPU definem diferentes taxas limitadas. O usuário pode modificar a taxa limitada da fila da CPU conforme desejado.
Tabela 2 -4 Configure a limitação de taxa de cada fila de CPU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a limitação de taxa de cada fila de CPU | cpu-packet cos cos-value pps pps-value | Obrigatório Por padrão, a limitação de taxa de cada fila é diferente. |
Configure o pacote de protocolo personalizado para ser processado pela CPU
Condição de configuração
Nenhum
Configurar regra de correspondência de Pacote de protocolo personalizado a ser processado pela CPU
A regra de correspondência configurada do pacote de protocolo personalizado a ser processado pela CPU deve ser usada com o modo do pacote de protocolo personalizado a ser processado pela CPU. Ele executa o processamento da ação correspondente para o pacote que atende à regra de correspondência. A regra de correspondência inclui dst-mac (endereço MAC de destino), ingresso (interface), vlan-id (ID VLAN), tipo ether (tipo Ethernet), IP (IPV4), IPV6, 0x0000 (tipo Ethernet personalizado), ip- protocolo (protocolo IP, como IGMP e TCP), dst-ip (IP de destino), src-port (porta de origem) e dst-port. O usuário pode combinar as regras de correspondência acima para usar conforme desejado.
Tabela 2 -5 Configure a regra de correspondência do pacote de protocolo personalizado a ser processado pela CPU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a regra de correspondência do protocolo personalizado | cpu-packet user-define user-id match { dst-mac dst-mac | ether-type { ether-type-value | ip [ dst-ip dst-ip-address | dst-mac dst-mac | ingress ingress-interface | ip-protocol protocol-type | vlan-id vlan-id [ dst-ip dst-ip-address | ingress ingress-interface | ip-protocol protocol-type ] ] | arp [src-mac src-mac | dst-mac dst-mac | target-ip target-ip | request | reply ] | ipv6 [ dst-ip6 dst-ipv6-address | dst-mac dst-mac | ingress ingress-interface | ip-protocol protocol-type | vlan-id vlan-id [ dst-ip dst-ip-address | ingress ingress-interface | ip-protocol protocol-type ] ] } | ingress ingress-interface | vlan-id vlan-id [ ingress ingress-interface ] } | Obrigatório Por padrão, não há nenhuma regra de correspondência. |
O pedido não é suportado. resposta não é suportada.
Configurar o modo de pacote de protocolo personalizado a ser processado pela CPU
A regra de correspondência configurada do pacote de protocolo personalizado a ser processado pela CPU deve ser usada com o modo do pacote de protocolo personalizado a ser processado pela CPU. Ele executa o processamento da ação correspondente para o pacote que atende à regra de correspondência. Por exemplo, se o modo configurado for cópia, não altere o processo de encaminhamento original do pacote, mas copie o pacote para a CPU para processamento; se o modo configurado for drop, não permita enviar o pacote à CPU para processamento, mas descarte o pacote; se o modo configurado for remark, modifique a prioridade do pacote a ser processado pela CPU; se o modo configurado for trap, altere o processo de encaminhamento original do pacote enviando apenas o pacote para a CPU para processamento em vez de encaminhar o pacote.
Tabela 2 -6 Configure o modo de envio do pacote de protocolo personalizado para CPU
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a ação do pacote de protocolo personalizado a ser processado pela CPU | cpu-packet user-define user-id action { drop | { copy | remark | trap } cos cos-value } | Obrigatório Por padrão, não execute nenhuma ação para o pacote que atende à regra de correspondência. Quando os modos de processamento do pacote de protocolo personalizado pela CPU são copy, remark e trap, você pode especificar o valor COS. |
ação de observação não é suportada
Monitoramento e manutenção da CPU Protection
Tabela 2 -7 Monitoramento e manutenção da CPU Protection
| Comando | Descrição |
| show cpu-packet protocol-config-table | Exibe as informações de configuração de todos os pacotes de protocolo enviados à CPU |
| show cpu-packet cos | Exibe as informações de fila atuais e padrão dos pacotes de protocolo a serem processados pela CPU |
| show cpu-packet pps | Exiba as informações de limitação de taxa de cada fila de CPU |
| show cpu-packet udf-table | Exiba todas as informações de entrada de ACL personalizadas definidas por meio do módulo de CPU Protection |
Exemplo de configuração típico de proteção de CPU
Configurar funções básicas de CPU Protection
Requisitos de rede
- O PC está conectado à rede IP via dispositivo.
- Configure o pacote DHCP para enfileirar 5 no dispositivo para que o pacote DHCP que chega ao dispositivo local possa primeiro obter o processamento da CPU.
- Execute a limitação de taxa para a fila ARP no dispositivo para que quando a utilização da CPU do dispositivo for muito alta, o pacote com baixa prioridade possa ser processado normalmente.
Topologia de rede
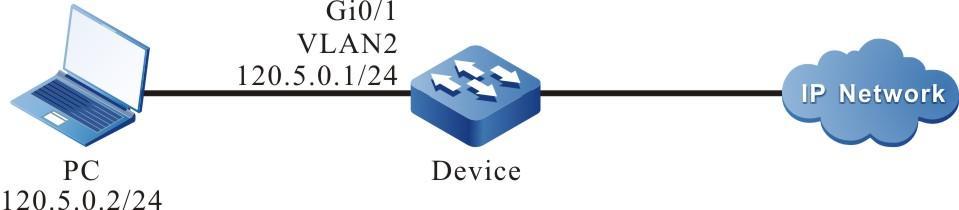
Figura 2 – 1 Rede de configuração das funções básicas de CPU Protection
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Configure a fila da CPU do pacote DHCP.
# Configure o pacote DHCP para enfileirar 5 no dispositivo.
Device#configure terminalDevice(config)#cpu-packet dhcp cos 5
- Passo 4:Configure a limitação de taxa da fila da CPU.
# Configure a taxa limitada da fila da CPU no dispositivo como 50pps.
Device(config)#cpu-packet cos 1 pps 100- Passo 5:Confira o resultado.
#Visualize a fila de CPU dos pacotes de protocolo no dispositivo.
Device#show cpu-packet cosType Current-CoS [Default-CoS]-------------------------------------------------------random 0 [0]ipv6-all 0 [0]pppoe 0 [0]udp-broadcast 0 [0]icmp 0 [0]ip-e-packet 0 [0]ipsec-esp 0 [0]ipsec-ah 0 [0]ip 0 [0]mpls-unicast 0 [0]mpls-multicast 0 [0]LBD_l2-src-miss 0 [0]ipaddr-0 0 [0]ipaddr-127 0 [0]ipv4-all 0 [0]src-martian-addr 0 [0]arp 1 [1]ip6-solicited-node 1 [1]host-group 1 [1]router-group 1 [1]ND 1 [1]trill-oam 1 [1]lldp 2 [2]dot1x 2 [2]dhcp 5 [2]dhcpv6 2 [2]http 2 [2]svi-ip 2 [2]pim 3 [3]pim6 3 [3]igmp-dvmrp 3 [3]ip6-interface-multicast 3 [3]ike 3 [3]ntp 3 [3]mld 3 [3]rsvp 4 [4]ospf 4 [4]ospfv3 4 [4]irmp 4 [4]rip 4 [4]ripng 4 [4]is-is 4 [4]bgp 4 [4]ldp 4 [4]mlag-pts 4 [4]mlag-keep-alive 4 [4]mvst 5 [5]l2-interface-unicast 5 [5]gvrp 5 [5]mvst-inspection 5 [5]ulfd 5 [5]l2pt 5 [5]svi-icmp 5 [5]ethernet-cfm 5 [5]ethernet-lmi 5 [5]bfd 6 [6]vbrp 6 [6]vrrp 6 [6]vrrp3 6 [6]telnet 6 [6]ssh 6 [6]loopback-detect 6 [6]slow-protocols 6 [6]stp-bpdu 6 [6]radius 6 [6]trill 6 [6]mlag 6 [6]eips 7 [7]ulpp 7 [7]mad-fast-hello 7 [7]erps 7 [7]Device#
Você pode ver que a fila da CPU do DHCP no dispositivo é ajustada da fila padrão 2 para a fila 5.
# Visualize a limitação de taxa da fila no dispositivo.
Device#show cpu-packet ppsCoS Current-PPS [Default-PPS]---------------------------------0 250 [250]1 100 [250]2 500 [500]3 500 [500]4 1000 [1000]5 400 [400]6 400 [400]7 100 [100]TOTAL 2000 [2000]
Você pode ver que a taxa limitada da fila 1 de ARP no dispositivo é modificada do padrão 250pps para 100pps.
Configurar regra personalizada de proteção de CPU
Requisitos de rede
- O dispositivo está conectado diretamente ao PC1 e ao PC2.
- Configure a regra personalizada da CPU Protection no dispositivo e intercepte o pacote que corresponde à condição da CPU para processamento e insira a fila correspondente.
Topologia de rede

Figura 2 – 2 Networking de configuração da regra customizada de proteção da CPU
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Configure a regra personalizada de CPU Protection.
#Configure a regra personalizada e intercepte o pacote IP com endereço de destino 121.5.0.2 para CPU para processamento e defina o valor de COS como 5.
Device#configure terminalDevice(config)#cpu-packet user-define 1 match ether-type ip dst-ip host 121.5.0.2Device(config)#cpu-packet user-define 1 action trap cos 5
- Passo 4:Confira o resultado.
#Visualize a regra personalizada no dispositivo.
Device#show cpu-packet udf-tableuser-define 1ether-type: 0x0800(IPv4)dst-ip: host 121.5.0.2location: globalvalid: yesaction: trapCoS: 5
# Quando o PC1 acessa o PC2, a regra personalizada da regra da CPU entra em vigor e intercepta o pacote IP com o endereço de destino 121.5.0.2 no dispositivo para a CPU para processamento e entra na fila 5.
Quando a regra personalizada corresponder a outra condição e executar outros modos, consulte a configuração.
Port Security
Visão geral
Visão geral da Port Security
A Port Security é o mecanismo de segurança de controle dos dispositivos conectados à rede. Ele é aplicado à camada de acesso e pode limitar os hosts de usar a porta do dispositivo, permitindo que alguns hosts especificados acessem a rede, enquanto os outros hosts não podem acessar a rede.
A função de Port Security pode vincular o endereço MAC do usuário, endereço IP, ID da VLAN e número da porta, impedindo que o usuário inválido acesse a rede, de modo a garantir a segurança dos dados da rede e o usuário válido pode obter largura de banda suficiente.
Regra de Port Security
A regra de Port Security é dividida em quatro tipos:
Regra MAC: Controle se o host pode se comunicar de acordo com o endereço MAC do host. O modo de ligação da regra MAC contém ligação MAC, ligação MAC+VLAN, ligação MAC+IP e ligação MAC+IPv6.
Regra de IP: Controle se o host pode se comunicar de acordo com o endereço IP do host. A regra de IP pode ser para a vinculação de um único endereço IP e também pode ser para a vinculação do segmento de endereço IP.
Regras IPv6: controle se o host pode se comunicar de acordo com o endereço IPv6 do host. As regras IPv6 podem ser vinculadas a um único endereço IPv6 ou a segmentos de endereço IPv6;
Regra MAX: Limite o número de endereços MAC que podem ser aprendidos livremente pela porta para controlar a comunicação do host. O número das entradas de endereço MAC não contém as entradas de endereço MAC válidas geradas pela regra MAC, regra IP e ligação IPv6
Regra STICKY: Controla se o host pode se comunicar de acordo com o endereço MAC do host. O modo de ligação da regra STICKY contém a ligação MAC, ligação MAC+VLAN, ligação MAC+IP e ligação MAC + IPv6. A regra STICKY pode aprender automaticamente e também configurar manualmente, e é salva na configuração em execução. Se salvar a configuração em execução antes do dispositivo reiniciar, não é necessário configurar novamente após o dispositivo reiniciar e a regra STICKY entrar em vigor automaticamente. Ao habilitar a função STICKY na porta e o modo de aprendizado STICKY for o modo MAC, converta a entrada MAC dinâmica aprendida pela regra MAX para a regra STICKY e salve na configuração em execução.
Regras de VOICE VLAN: Controla principalmente a comunicação do host de acordo com se o endereço MAC do host pertence ao OUI configurado pelo VOICE-VLAN. Esses endereços MAC não incluem a lista de endereços MAC legítimos gerados por regras MAC, regras IP e vinculação IPv6.
Princípio de Trabalho de Port Security
Se apenas habilitar a Port Security, a Port Security descartará todos os pacotes recebidos na porta. As regras de Port Security dependem dos pacotes ARP e dos pacotes IP do dispositivo a serem acionados. Quando o dispositivo recebe o pacote ARP e o pacote IP, a Port Security extrai várias informações do pacote e combina com a regra configurada. A ordem de correspondência é primeiro corresponder à regra MAC, depois corresponder à regra STICKY, depois corresponder à regra IP e, por último, corresponder à regra MAX e controlar a tabela de encaminhamento L2 da porta de acordo com o resultado correspondente, de modo a controlar o encaminhamento ação da porta para o pacote. O pacote válido que corresponde à regra MAX ou à regra STICKY é encaminhado. Para o pacote que corresponde à regra MAC ou regra IP, se a ação da regra para o pacote for permitida, o pacote pertence ao pacote válido e é encaminhado. Caso contrário, o pacote é inválido e descartado.
A ação é a regra MAC permitida e a regra IP. Depois de entrar em vigor, grave o endereço MAC da regra na tabela de encaminhamento L2 para que o encaminhamento L2 possa ser executado para os pacotes que correspondem à regra. Se a ação for a regra Mac recusada e a regra IP, o MAC correspondente não é gravado na tabela de encaminhamento L2 e o pacote precisa ser descartado por meio da Port Security.
Após a regra MAC e a regra STICKY entrarem em vigor, escreva nas entradas do endereço MAC para formar as entradas efetivas, fazendo com que o pacote execute o encaminhamento L2. O processamento do pacote IPv6 é semelhante.
Configuração da função de Port Security
Tabela 3 -1 Lista de configuração de funções básicas da segurança da porta
| Tarefa de configuração | |
| Configure as funções básicas da Port Security | Ative a função de Port Security |
| Configurar a regra de Port Security |
Configurar a regra MAC
Configurar a regra de IP Configurar a regra IPv6 Configurar a regra MAX Configurar a regra STICKY Configurar a regra VOICE VLAN |
| Configure o modo de aprendizado da regra STICKY | Configure o modo de aprendizado da regra STICKY |
| Configure a função de envelhecimento do endereço MAC estático |
Habilite a função de envelhecimento do endereço MAC estático
Configure o tempo de idade do endereço MAC estático |
| Configure o modo de processamento ao receber o pacote inválido | Configure o modo de processamento ao receber o pacote inválido |
| Configure o intervalo de envio de log ao receber o pacote inválido | Configure o intervalo de envio de log ao receber o pacote inválido |
| Configure a Port Security para usar a função ACL | Configure a Port Security para usar a função ACL |
Configurar funções básicas de Port Security
Nas tarefas de configuração da Port Security, deve-se primeiro habilitar a Port Security para que a configuração das demais funções tenha efeito.
Condição de configuração
Nenhum
Ativar função de Port Security
Depois de habilitar a Port Security e se não configurar nenhuma regra de Port Security, a porta não pode aprender o endereço MAC.
Tabela 3 -2 Configure as funções básicas da Port Security
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Ative a função de Port Security | port-security enable | Obrigatório Por padrão, a função de Port Security não está habilitada. |
A regra IP e a regra MAX da Port Security e 802.1x não podem ser usadas em uma porta ao mesmo tempo. A regra IP e a regra MAX da Port Security e a autenticação do endereço MAC não podem ser usadas em uma porta ao mesmo tempo. A função de Port Security e autenticação de canal seguro não pode ser usada em uma porta ao mesmo tempo. A Port Security e o DAI (Dynamic ARP Inspection) não podem ser usados em uma porta ao mesmo tempo.
Configurar o modo de aprendizado da regra STICKY
Condição de configuração
Antes de configurar o modo de aprendizagem da regra STICKY, primeiro complete a seguinte tarefa:
- Ative a função de Port Security
Configurar o modo de aprendizado da regra STICKY
Se o usuário espera realizar o aprendizado STICKY por MAC ou MAC + VLAN, você pode configurar o modo de aprendizado da regra STICKY como modo MAC. Se o usuário espera realizar o aprendizado da regra STICKY por MAC+IP, você pode configurar o modo de aprendizado da regra STICKY como modo MAC+IP.
Tabela 3 -9 Configure o modo de aprendizado da regra STICKY
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o modo de aprendizado da regra STICKY | port-security permit mac-address sticky mode { mac | mac-ip } | Obrigatório Por padrão, o modo de aprendizado da regra STICKY é o modo MAC. |
Configurar a função de envelhecimento do endereço MAC estático
Condição de configuração
Antes de configurar a função de envelhecimento do endereço MAC estático, primeiro conclua a seguinte tarefa:
- Ative a função de Port Security
Ativar função de envelhecimento do endereço MAC estático
Para detectar se o terminal da entrada efetiva da regra MAC ou regra IP está online, o usuário pode habilitar a função de envelhecimento do endereço MAC estático. Após a função de envelhecimento do endereço MAC estático e se for detectado que o terminal está offline, a entrada efetiva do terminal é excluída para que os recursos do chip possam ser liberados.
Tabela 3 -10 Habilite a função de envelhecimento do endereço MAC estático
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação , a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a função de envelhecimento do endereço MAC estático | port-security aging static | Obrigatório Por padrão, a função de envelhecimento do endereço MAC estático está desabilitada. |
Configurar o tempo de idade do endereço MAC estático
O usuário pode configurar o tempo de idade razoável de acordo com a configuração real do ambiente de rede. Na aplicação geral, apenas mantenha o valor padrão.
Tabela 3 -11 Configure o tempo de idade do endereço MAC estático
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o tempo de idade do endereço MAC estático | port-security aging time time-value | Obrigatório Por padrão, o tempo de duração do endereço MAC estático é de 1 minuto. |
Configurar o modo de processamento ao receber pacote inválido
Condição de configuração
Antes de configurar o modo de processamento ao receber o pacote inválido , primeiro complete a seguinte tarefa:
- Ative a função de Port Security
Configurar o modo de processamento ao receber pacote inválido
A Port Security fornece três tipos de modos de processamento para o pacote inválido, ou seja, proteger, restringir e desligar. O usuário pode selecionar de acordo com o requisito de segurança. As funções específicas dos três modos de processamento são as seguintes:
- protect: Após receber o pacote inválido, descarte o pacote.
- restringir : Depois de receber o pacote inválido, descarte o pacote e intercepte as informações para o NMS.
- shutdown : Após receber o pacote inválido, descarte o pacote, desabilite a porta que está recebendo o pacote e intercepte as informações para o NMS.
Tabela 3 -12 Configure o modo de processamento ao receber o pacote inválido
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o modo de processamento do pacote inválido | port-security violation { protect | restrict | shutdown } | Obrigatório Por padrão, o modo de processamento quando a Port Security recebe o pacote inválido é protegido . |
Configurar intervalo de envio de log ao receber pacote inválido
Condição de configuração
Antes de configurar o intervalo de envio de log ao receber o pacote inválido, primeiro conclua a seguinte tarefa:
- Ative a função de segurança da interface.
Configurar intervalo de envio de log ao receber pacote inválido
O usuário pode configurar o intervalo de envio de log com base no pacote inválido realmente recebido. Na aplicação geral, basta reservar o valor padrão.
Tabela 3 -13 Configure o intervalo de envio de log ao receber o pacote inválido
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o intervalo de envio de log ao receber o pacote inválido | port-security violation log-interval log-interval-value | Obrigatório Por padrão, o intervalo de envio de log quando a interface recebe o pacote inválido com segurança é de 5 s. |
Configurar a Port Security para usar a função ACL
Condição de configuração
Antes de configurar a Port Security para usar a função ACL, primeiro conclua a seguinte tarefa:
- Ative a função de Port Security
Configurar a Port Security para usar a ACL
Os usuários podem configurar se a Port Security usa ACL de acordo com as necessidades reais. Ao usar as regras ACL, MAC+IP, MAC+IPv6, STICKY MAC+IP e STICKY MAC+IPv6 podem corresponder com precisão o endereço MAC de origem e o endereço IP/IPv6 de origem do usuário, evitando o acesso ilegal do usuário com correspondência de endereço MAC de origem e incompatibilidade de endereço IP/IPv6 de origem.
Tabela 3 -14 Configurar regra MAC+IP para usar ACL
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure a Port Security para a ACL do usuário | port-security use-acl | Obrigatório Por padrão, a Port Security não usa ACL. |
Monitoramento e Manutenção da Port Security
Tabela 3 -15 Monitoramento e manutenção da Port Security
| Comando | Descrição |
| clear port-security statistics | Limpe as informações estatísticas dos pacotes enviados e recebidos |
| show port-security | Exiba as informações de resumo da porta configurada com a Port Security |
| show port-security ip-address | Exibir a regra de IP configurada |
| show port-security ipv6-address | Exibir a regra IPv6 configurada |
| show port-security mac-address | Exiba a regra MAC configurada e a regra STICKY |
| show port-security active-address | Exibir as informações de todas as entradas efetivas |
| show port-security detect-mac | Exibir a nova entrada MAC atualmente detectada |
| show port-security violation log-interval | Exibe o período de impressão do log quando a entrada MAC inválida é detectada atualmente |
| show port-security violation-mac | Exibir a entrada MAC inválida atualmente detectada |
| show port-security statistics | Exibe as informações estatísticas dos pacotes enviados e recebidos |
Exemplo de configuração típico de Port Security
Configurar regra MAC e IP de Port Security
Requisitos de rede
- PC1, PC2 e a impressora de rede são conectados ao servidor via Device.
- Configure a função de Port Security no dispositivo, permitindo a passagem de PC1 e recusando a passagem de PC2; permitir que a impressora de rede execute as tarefas de impressão entregues pelo servidor e pelo usuário do PC1.
Topologia de rede

Figura 3 – 1 Rede de configuração de Port Security MAC e regra de IP
Etapas de configuração
- Passo 1:Configurar VLAN.
#Criar VLAN.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link de porta em gigabitethernet0/1-gigabitethernet0/3 do dispositivo como acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1-0/3Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
- Passo 2:Configure a função de Port Security.
#Configure a regra MAC+IP no gigabitethernet0/1 do Device, permitindo a passagem do PC1; configurar a regra de IP, recusando a passagem de PC2.
Device#config terminalDevice(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#port-security enableDevice(config-if-gigabitethernet0/1)#port-security permit mac-address 3883.45ef.7984 ip-address 199.0.0.1Device(config-if-gigabitethernet0/1)#port-security deny ip-address 199.0.0.2Device(config-if-gigabitethernet0/1)#exit
#Configure a regra MAC em gigabitethernet0/2 do dispositivo, permitindo que a impressora de rede acesse a rede.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#port-security enableDevice(config-if-gigabitethernet0/2)#port-security permit mac-address 3883.45ef.f395Device(config-if-gigabitethernet0/2)#exit
- Passo 3:Confira o resultado.
#Visualize as entradas efetivas da Port Security no dispositivo. O usuário pode ver que os MACs do PC1 e da impressora de rede são gravados nas entradas efetivas da Port Security.
Device#show port-security active-address-----------------------------------------------------------------------------------------Entry Interface MAC address VID IP/IPv6 Addr Derivation Age(Sec)-----------------------------------------------------------------------------------------1 gi0/1 38:83:45:EF:79:84 2 199.0.0.1 MAC+IP 02 gi0/2 38:83:45:EF:F3:95 2 199.0.0.3 MAC 0
#Com a detecção, podemos ver que o PC1 pode acessar o servidor e a impressora da rede pode executar a tarefa de impressão entregue pelo PC1 e o servidor.
#Com a detecção, podemos ver que o PC2 não consegue pingar o servidor ou a impressora da rede.
Configurar regra MAC de Port Security
Requisitos de rede
- PC1, PC2 e PC3 são conectados ao servidor via Device; O PC e o servidor estão na mesma LAN.
- Configure a regra de Port Security no dispositivo, permitindo que PC1 e PC2 acessem o servidor e recusando o acesso de PC3 ao servidor.
Topologia de rede
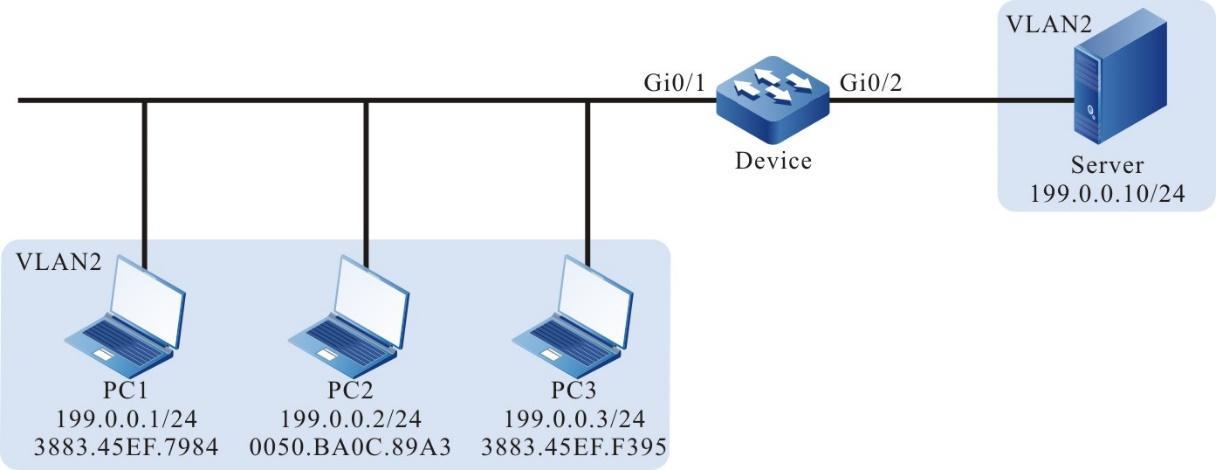
Figura 3 – 2 Networking de configuração da regra MAX da segurança da porta
Etapas de configuração
- Passo 1:Configurar VLAN.
#Criar VLAN.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link de porta em gigabitethernet0/1-gigabitethernet0/2 do dispositivo como acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1-0/2Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
- Passo 2:Configure a regra de Port Security no dispositivo.
#Configure a regra MAX em gigabitethernet0/1 do dispositivo. O número máximo de regras MAC é 3.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#port-security enableDevice(config-if-gigabitethernet0/1)#port-security maximum 3Device(config-if-gigabitethernet0/1)exit
#Recusar PC3 para acessar o servidor em giabitethernet0/1 do dispositivo.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#port-security deny mac-address 3883.45ef.f395Device(config-if-gigabitethernet0/1)exit
- Passo 3:Confira o resultado.
#Os três PCs tentam se comunicar com o servidor respectivamente. Você pode ver que PC1 e PC2 podem acessar o servidor e PC3 não pode acessar o servidor. Visualize as entradas efetivas da Port Security em gigabitethernet0/1 do dispositivo e você poderá ver que os endereços MAC de PC1 e PC2 são gravados nas entradas efetivas da Port Security.
Device#show port-security active-address-----------------------------------------------------------------------------------------Entry Interface MAC address VID IP/IPv6 Addr Derivation Age(Sec)-----------------------------------------------------------------------------------------1 gi0/1 00:50:ba:0c:89:a3 2 --- FREE 02 gi0/1 38:83:45:EF:79:84 2 --- FREE 0Total Mac Addresses for this criterion: 2
Configurar regra STICKY de Port Security
Requisitos de rede
- PC1, PC2 e PC3 são conectados ao servidor via Device; eles estão na mesma LAN que o servidor.
- Configure a regra de Port Security no Dispositivo, permitindo a passagem de dois PCs.
- Depois de salvar a configuração e reiniciar o dispositivo, a regra STICKY pode entrar em vigor imediatamente.
Topologia de rede
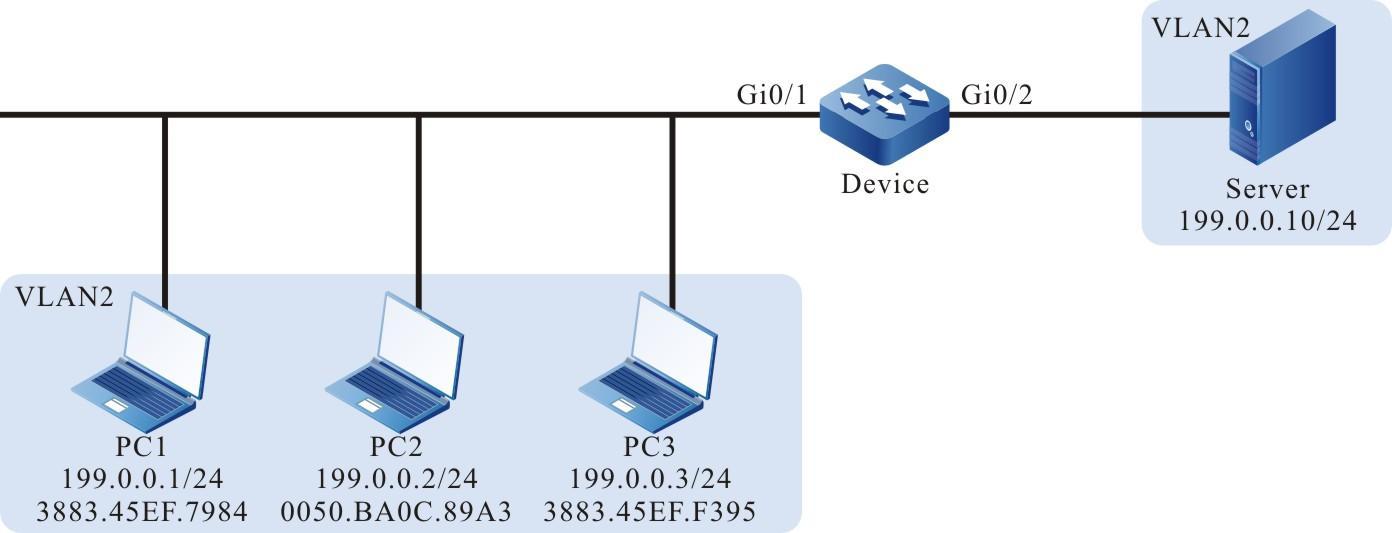
Figura 3 – 3 Networking de configuração da regra STICKY da segurança da porta
Etapas de configuração
- Passo 1:Configurar VLAN.
#Criar VLAN.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link de porta em gigabitethernet0/1-gigabitethernet0/2 do dispositivo como acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1-0/2Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
- Passo 2:Configure a regra MAX da Port Security no dispositivo.
#Configure a regra MAX em gigabitethernet0/1 do dispositivo. O número máximo de regras MAX é 2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#port-security enableDevice(config-if-gigabitethernet0/1)#port-security maximum 2Device(config-if-gigabitethernet0/1)exit
- Passo 3:Configure a regra STICKY da Port Security no dispositivo.
#Ative a função STICKY no gigabitethernet0/1 do dispositivo.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#port-security permit mac-address stickyDevice(config-if-gigabitethernet0/1)#exit
- Passo 4:Confira o resultado.
#PC1, PC2 e PC3 tentam se comunicar com o servidor. Veja as entradas efetivas da Port Security em gigabitethernet0/1 do dispositivo e você pode ver que o tipo de regra em gigabitethernet0/1 é STICKY.
Device#show port-security active-address-----------------------------------------------------------------------------------------Entry Interface MAC address VID IP/IPv6 Addr Derivation Age(Sec)-----------------------------------------------------------------------------------------1 gi0/1 38:83:45:EF:79:84 2 199.0.0.1 STICKY 02 gi0/1 38:83:45:EF:F3:95 2 199.0.0.3 STICKY 0Total Mac Addresses for this criterion: 2
#Após salvar a configuração e reiniciar o dispositivo, a regra STICKY existe e entra em vigor.
Device#show port-security active-address-----------------------------------------------------------------------------------------Entry Interface MAC address VID IP/IPv6 Addr Derivation Age(Sec)-----------------------------------------------------------------------------------------1 gi0/1 38:83:45:EF:79:84 2 199.0.0.1 STICKY 02 gi0/1 38:83:45:EF:F3:95 2 199.0.0.3 STICKY 0Total Mac Addresses for this criterion: 2
IP Source Guard
Visão geral
A função IP Source Guard é uma função de filtro de pacotes e pode filtrar e controlar os pacotes encaminhados pela porta, evitando que os pacotes inválidos passem pela porta e melhorando a Port Security. A função pode ser dividida em dois tipos:
- A função Port IP Source Guard filtra os pacotes IP recebidos pela porta especificada. O modo de filtro inclui IP, MAC e IP+MAC. Os modos de processamento específicos são os seguintes:
- Modo IP: Se o endereço IP de origem e o ID da VLAN no pacote forem os mesmos que o endereço IP e o ID da VLAN registrados nas entradas vinculadas, a porta encaminhará o pacote. Caso contrário, solte-o.
- Modo MAC: Se o MAC de origem no pacote for o mesmo que o endereço MAC, número de VLAN registrado na tabela de ligação, a porta encaminhará o pacote. Caso contrário, solte-o.
- Modo IP+MAC: Se o endereço IP de origem, o endereço MAC de origem e o ID da VLAN no pacote forem os mesmos que o endereço IP, o endereço MAC e o ID da VLAN registrados nas entradas vinculadas, a porta encaminhará o pacote. Caso contrário, descarte o pacote.
- Entradas vinculadas estáticas, entradas vinculadas estáticas do IP Source Guard de porta configurada manualmente
- Entradas vinculadas dinâmicas, geradas dinamicamente pelas entradas válidas da função DHCP Snooping.
- A função Global IP Source Guard filtra os pacotes recebidos por todas as portas, incluindo pacotes ARP e IP. Os modos de filtro específicos são os seguintes:
- Se o endereço IP de origem no pacote IP for igual ao endereço IP nas entradas vinculadas do IP Source Guard global, mas o endereço MAC de origem for diferente ou o endereço MAC de origem no pacote IP for igual ao endereço MAC em as entradas globais vinculadas ao IP Source Guard, mas o ID do endereço IP de origem é diferente, descarte o pacote.
- Se o endereço IP de envio no pacote ARP for o mesmo que o endereço IP nas entradas vinculadas, mas o endereço MAC de origem for diferente ou o endereço MAC de origem no pacote ARP for o mesmo que o endereço MAC nas entradas vinculadas, mas o endereço IP de envio é diferente, descarte o pacote.
A configuração do tipo de filtro tem efeito apenas para a entrada de associação dinâmica, não afetando a entrada de associação estática.
As entradas vinculadas do IP Source Guard da porta incluem dois tipos:
Configuração da função de IP Source Guard
Tabela 4 -1 A lista de configuração da função IP Source Guard
| Tarefa de configuração | |
| Configure as entradas vinculadas estáticas da porta IP Source Guard | Configure as entradas vinculadas estáticas da porta IP Source Guard |
| Configure a função IP Source Guard da porta |
Configure a função IP Source Guard da porta
Configure o tipo de pacote de filtro da porta IP Source Guard |
| Configurar a função global do IP Source Guard | Configurar a função global do IP Source Guard |
Configurar entradas de limite estático do IP Source Guard da porta
Condição de configuração
Antes de configurar as entradas de limite estático do IP Source Guard da porta, primeiro conclua a seguinte tarefa:
- Habilite a função IP Source Guard da porta ou habilite a função Dynamic ARP Inspection da porta
Configurar entradas de limite estático do IP Source Guard da porta
As entradas vinculadas estáticas da porta IP Source Guard são a base da filtragem dos pacotes IP recebidos pela porta especificada.
Quando a função Inspeção ARP Dinâmica da porta está habilitada, somente as entradas estáticas configuradas com mac, ip e vlan podem servir como base para a detecção de validade dos pacotes ARP.
Tabela 4 -2 Configure as entradas vinculadas estáticas da porta IP Source Guard
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure as entradas vinculadas estáticas da porta IP Source Guard | ip source binding { ip-address ip-address [ mac-address mac-address [ vlan vlan-id ] | vlan vlan-id ] | mac-address mac-address [ vlan vlan-id ] } | Obrigatório Por padrão, não há entrada de limite estático da porta IP Source Guard. |
Para a função de Inspeção de ARP Dinâmico da porta, consulte o capítulo Inspeção de ARP Dinâmico do manual de configuração.
Configurar a função de IP Source Guard da porta
Condição de configuração
Nenhum
função de IP Source Guard da porta
Depois de habilitar a função Port IP Source Guard, primeiro grave a entrada vinculada à porta no chip, incluindo a entrada vinculada estática e a entrada vinculada dinâmica. A entrada de limite estático é gravada primeiro. E então realizar o controle de segurança dos pacotes IP recebidos pela porta de acordo com as entradas escritas no chip, melhorando a segurança.
Tabela 4 -3 Configurar a função IP Source Guard da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a função IP Source Guard da porta | ip verify source | Obrigatório Por padrão, a função IP Source Guard da porta está desabilitada. |
Após habilitar a função de IP Source Guard da porta, as entradas vinculadas da IP Source Guard da porta são gravadas no chip. O número de entradas gravadas no chip depende dos recursos de entrada de chip disponíveis. Se os recursos de entrada do chip estiverem esgotados e for necessário adicionar entradas vinculadas ou habilitar a função IP Source Guard da porta na outra porta, precisamos excluir as entradas vinculadas relacionadas de alguns recursos de entrada do chip. Se algumas entradas vinculadas do IP Source Guard não puderem ser gravadas no chip porque os recursos de entrada do chip não são suficientes, o sistema tentará automaticamente gravar as entradas vinculadas no chip novamente a cada 60 segundos até que todas as entradas vinculadas sejam gravadas no chip ou excluídas. Se as funções do IP Source Guard da porta e do IP Source Guard global forem usadas ao mesmo tempo, o pacote IP recebido pela porta precisa corresponder às entradas vinculadas do IP Source Guard da porta e do IP Source Guard global para que possa ser encaminhado. Caso contrário, é descartado. Antes de habilitar a função IP Source Guard da porta e se o dispositivo terminal conectado à porta não for um cliente DHCP, ou o dispositivo terminal for o cliente DHCP, mas o dispositivo local não habilitar a função DHCP Snooping, precisamos configurar o MAC endereço, endereço IP e o ID de VLAN do dispositivo terminal como a entrada de ligação estática do IP Source Guard da porta, de modo a garantir que depois de habilitar a função, o dispositivo terminal se comunique normalmente. Para a função DHCP Snooping, consulte o capítulo DHCP Snooping do manual de configuração.
Configurar o tipo de pacote filtrado de IP Source Guard da porta
Condição de configuração
Antes de configurar o tipo de pacote filtrado da porta IP Source Guard, primeiro conclua a seguinte tarefa:
- Habilite a função IP Source Guard da porta
Configurar o tipo de pacote filtrado de IP Source Guard da porta
Após habilitar a função Port IP Source Guard, o pacote IP é filtrado por meio de ip. Quando o endereço IP de origem e o número da VLAN do pacote IPv4 recebido pela porta são os mesmos que o endereço IP de origem e o número da VLAN na entrada de ligação do IP Source Guard da porta, a porta encaminha o pacote; se algum for diferente, descarte o pacote.
Após habilitar a função Port IP Source Guard, os pacotes IP são filtrados por meio do ip-mac. Quando o endereço MAC de origem, o endereço IP de origem e o número da VLAN do pacote IP recebido pela porta são os mesmos que o endereço MAC, o endereço IP e o número da VLAN nas entradas de ligação do IP Source Guard da porta, a porta encaminha o pacote; se algum for diferente, descarte o pacote.
Após habilitar a função Port IP Source Guard, os pacotes IP são filtrados por meio do mac. Quando o endereço MAC de origem e o número da VLAN do pacote IP recebido pela porta são os mesmos que o endereço MAC, o endereço IP e o número da VLAN nas entradas de ligação do IP Source Guard da porta, a porta encaminha o pacote; se algum for diferente, descarte o pacote.
Tabela 4 -4 Configure o tipo de pacote filtrado da porta IP Source Guard
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite o tipo de pacote de filtro do IP Source Guard da porta | ip verify source type {ip | ip-mac | mac} | Obrigatório Por padrão, o modo de filtro é do tipo filtro IP, tendo efeito apenas para a entrada dinâmica. |
Configurar a função de ligação de entrada estática da porta MAC
Condição de configuração
Antes de configurar a função de ligação de entrada estática do MAC da porta, primeiro conclua a seguinte tarefa:
- Habilite a função IP Source Guard da porta
Configurar a função de ligação de entrada estática da porta MAC
Depois de configurar a função de ligação de entrada estática MAC da porta, obtenha o endereço mac correspondente, o número da vlan e o número da porta das entradas estáticas do IP Source Guard configuradas e as entradas dinâmicas na porta, e entregue a entrada MAC estática correspondente.
Tabela 4 -5 Configurar a função de ligação de entrada estática MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar a função de ligação de entrada estática MAC | ip source sticky-mac | Obrigatório Por padrão, a função de ligação de entrada estática do MAC da porta está desabilitada. |
Configurar a função de IP Source Guard global
Condição de configuração
Nenhum
Configurar a função de IP Source Guard global
Para proteger a segurança do endereço IP do usuário e impedir que outro usuário use seu próprio endereço IP, podemos configurar a função IP Source Guard global para vincular o endereço IP do usuário e o endereço MAC. As entradas vinculadas ao IP Source Guard globais do endereço IP do usuário configurado e do endereço MAC são gravadas diretamente no chip, de modo a filtrar os pacotes IP e ARP inválidos.
Ao habilitar a função Global Dynamic ARP Inspection, as entradas vinculadas do IP Source Guard globais configuradas servem como base para a detecção de validade da função global Dynamic ARP Inspection para os pacotes ARP.
Tabela 4 -6 Configurar a função global do IP Source Guard
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Configurar a função global do IP Source Guard | source binding mac-address ip-address | Obrigatório Por padrão, não há entrada vinculada ao IP Source Guard global e a função está desabilitada. O comando habilita a função global do IP Source Guard. Enquanto isso, uma entrada vinculada ao IP Source Guard global é configurada. |
Se a ACL estendida híbrida for aplicada à entrada global (todas as portas), precisamos cancelar o aplicativo para que a função IP Source Guard global possa ser configurada. Caso contrário, a configuração falha. Consulte o capítulo ACL do manual de configuração. As entradas globais vinculadas ao IP Source Guard suportam no máximo 40. Após exceder 40, a configuração falha. As entradas vinculadas do IP Source Guard globais configuradas são gravadas diretamente no chip. O número de entradas vinculadas gravadas no chip depende dos recursos de entrada de chip disponíveis. Se os recursos de entrada do chip estiverem esgotados e for necessário adicionar as entradas vinculadas do IP Source Guard global, precisamos excluir as entradas vinculadas relacionadas de alguns recursos de entrada do chip. Se as funções do IP Source Guard da porta e do IP Source Guard global forem usadas ao mesmo tempo, o pacote IP recebido pela porta precisa corresponder às entradas vinculadas do IP Source Guard da porta e do IP Source Guard global para que possa ser encaminhado. Caso contrário, é descartado.
Para a função de Inspeção de ARP Dinâmico da porta, consulte o capítulo Inspeção de ARP Dinâmico do manual de configuração.
Monitoramento e manutenção do IP Source Guard
Tabela 4 -7 Monitoramento e manutenção do IP Source Guard
| Comando | Descrição |
| show ip binding table [ interface interface-name | link-aggregation link-aggregation-id | slot | summary ] | Exiba as informações estatísticas das entradas vinculadas do IP Source Guard da porta e a quantidade de entrada vinculada |
| show ip source guard [ interface interface-name | link-aggregation link-aggregation-id ] | Exibe as informações de configuração da função IP Source Guard da porta |
| show source binding | Exiba as informações estáticas das entradas vinculadas do IP Source Guard global e a quantidade de entrada |
Exemplo de configuração típico do IP Source Guard
Configurar a função de IP Source Guard de porta efetiva com base em entradas dinâmicas de DHCP snooping
Requisitos de rede
- PC1 e PC2 estão conectados à rede IP via dispositivo.
- Configure a função global de espionagem de IP.
- Configure a função IP Source Guard da porta, para que o PC2 possa acessar a rede IP normalmente e o PC2 não possa acessar a rede IP.
Topologia de rede
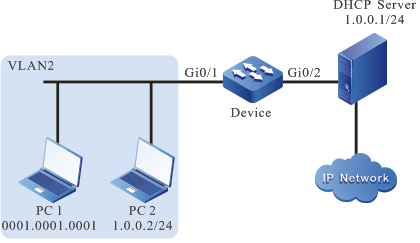
Figura 4 – 1 Rede de configuração da função IP Source Guard da porta efetiva com base nas entradas dinâmicas do DHCP Snooping
Etapas de configuração
- Passo 1:Em Dispositivo, configure a VLAN e o tipo de link de porta.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como Acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2Device(config-if-gigabitethernet0/1)#exit
- Passo 2:No dispositivo, habilite a função DHCP Snooping global e configure giga bitthernet0/2 conectado ao servidor DHCP como a porta confiável.
Device(config)#dhcp snooping enableDevice(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#dhcp snooping trustDevice(config-if-gigabitethernet0/2)#exit
- Passo 3:Configure o pool de endereços do servidor DHCP como 1.0.0.0/24. (omitido)
- Passo 4:No dispositivo, configure a função IP Source Guard da porta.
#Na porta gigabitethernet0/1, habilite a função IP Source Guard baseada em porta.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ip verify sourceDevice(config-if-gigabitethernet0/1)#exit
- Passo 5:Confira o resultado.
# Visualize as informações de configuração do DHCP Snooping.
Device#show dhcp-snoopingdhcp-snooping configuration information:dhcp-snooping status:enabledhcp-snooping option82 information status:disabledhcp-snooping option82 information policy:replacedhcp-snooping option82 information format:defaultdhcp-snooping option82 information remote id:default(mac address)dhcp-snooping information relay-address :Nonedhcp-snooping binding agent save mode :auto-flashdhcp-snooping binding agent save delay :1800dhcp-snooping binding agent save pool :30dhcp-snooping interface information :-------------------------------------------------------------interface trust-status rate-limit(pps) circuit-Idgi0/0/1 untrust 40 default(vlan-mod-interface)gi0/0/2 trust ---- default(vlan-mod-interface)gi0/0/3 untrust 40 default(vlan-mod-interface)gi0/0/4 untrust 40 default(vlan-mod-interface)gi0/0/5 untrust 40 default(vlan-mod-interface)……
#Visualize as informações de configuração do IP Source Guard.
Device#show ip source guard-----------------------------------------IP source guard interfaces on slot 0 :Total number of enabled interfaces : 1-------------------------------------------------------Interface Name Status Verify Type L2 Status-------------------------------------------------------gi0/1 Enabled ip Disabledgi0/2 Disabled ip Disabledgi0/3 Disabled ip Disabledgi0/4 Disabled ip Disabledgi0/5 Disabled ip Disabled……
Você pode ver que a porta gigabitethernet0/1 está habilitada com a função IP Source Guard e o tipo de verificação é ip. Portanto, no exemplo acima, as entradas dinâmicas são efetivadas com base em ip+vlan.
#Visualize as entradas vinculadas ao IP Source Guard da porta.
Device#show ip binding table---------------------------------------------IP Source Guard binding table on slot 0Total binding entries : 1Static binding entries : 0Dynamic binding entries : 1Dynamic not write entries : 0PCE writing entries : 1-----------------------------------------------------------------------------------------Interface-Name MAC-Address IP-Address VLAN-ID Type-Flag Writing-Flag L2-Flag-----------------------------------------------------------------------------------------gi0/1 0001.0001.0001 1.0.0.2 2 dynamic Write Not Write
#PC1 pode acessar a rede IP normalmente e o PC2 não pode acessar a rede IP.
Configurar a função de IP Source Guard da porta com base em entradas estáticas
Requisitos de rede
- PC1 e PC2 estão conectados à rede IP via dispositivo.
- Configure a função IP Source Guard da porta efetiva com base em entradas estáticas, para que o PC2 possa acessar a rede IP normalmente e o PC2 não possa acessar a rede IP.
Topologia de rede
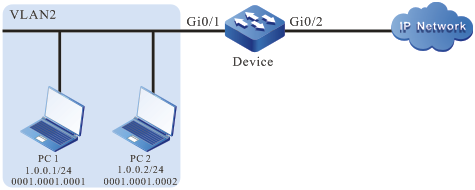
Figura 4 – 2 Rede de configuração da função IP Source Guard da porta efetiva com base em entradas estáticas
Etapas de configuração
- Passo 1:Em Dispositivo, configure a VLAN e o tipo de link de porta.
# Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como Acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2Device(config-if-gigabitethernet0/1)#exit
- Passo 2:No dispositivo, configure a função IP Source Guard da porta.
#Na porta gigabitethernet0/1, habilite a função IP Source Guard com base no modo de filtragem MAC+VLAN e configure o endereço IP como 1.0.0.1 e as entradas de ligação do IP Source Guard da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ip verify sourceDevice(config-if-gigabitethernet0/1)#ip source binding ip-address 1.0.0.1 vlan 2Device(config-if-gigabitethernet0/1)#exit
- Passo 3:Confira o resultado.
#Visualize as informações de configuração do IP Source Guard.
Device#show ip source guard-----------------------------------------IP source guard interfaces on slot 0 :Total number of enabled interfaces : 1-------------------------------------------------------------Interface Name Status Verify Type L2 Status-------------------------------------------------------------gi0/1 Enabled IP Disabledgi0/2 Disabled IP Disabledgi0/3 Disabled IP Disabledgi0/4 Disabled IP Disabled……
Você pode ver que a porta gigabitethernet0/1 está habilitada com a função IP Source Guard. As entradas estáticas do IP Source Guard entram em vigor de acordo com as entradas IP+VLAN configuradas, não relacionadas com o valor Verify Type. Portanto, no exemplo acima, as entradas dinâmicas são efetivadas com base em ip+vlan.
#Visualize as entradas vinculadas ao IP Source Guard da porta.
Device #show ip binding table-----------------------------------------IP Source Guard binding table on slot 0Total binding entries : 1Static binding entries : 1Dynamic binding entries : 0Dynamic not write entries : 0PCE writing entries : 1-----------------------------------------------------------------------------------------Interface-Name MAC-Address IP-Address VLAN-ID Type-Flag Writing-Flag L2-Flag-----------------------------------------------------------------------------------------gi0/1 --- 1.0.0.1 2 Static Write Not Write
# PC1 pode acessar a rede IP normalmente e o PC2 não pode acessar a rede IP.
IPv6 Source Guard
Visão geral
A função IPv6 Source Guard é uma função de filtro de pacotes e pode filtrar e controlar os pacotes encaminhados pela porta, evitando que os pacotes inválidos passem pela porta e melhorando a Port Security. A função pode ser dividida em dois tipos:
- A função Port IPv6 Source Guard filtra os pacotes IPv6 recebidos pela porta especificada. O modo de filtro inclui IP, IP+MAC e MAC. Os modos de processamento específicos são os seguintes:
- Modo IP: Se o endereço IPv6 de origem e o ID de VLAN no pacote forem os mesmos que o endereço IPv6 e o ID de VLAN registrados nas entradas vinculadas, a porta encaminhará o pacote. Caso contrário, solte-o.
- Modo IP+MAC+VLAN: Se o endereço IPv6 de origem, o endereço MAC de origem e o ID da VLAN no pacote forem os mesmos que o endereço IPv6, o endereço MAC e o ID da VLAN registrados nas entradas vinculadas, a porta encaminhará o pacote. Caso contrário, descarte o pacote.
- Modo MAC+VLAN: Se o endereço MAC de origem e o ID de VLAN no pacote forem os mesmos que o endereço MAC e o ID de VLAN registrados nas entradas vinculadas, a porta encaminhará o pacote. Caso contrário, descarte o pacote.
- Entradas estáticas vinculadas, portas configuradas manualmente IPv6 Source Guard entradas estáticas vinculadas
- Entradas vinculadas dinâmicas, geradas dinamicamente pelas entradas válidas da função DHCPv6 Snooping.
- A função Global IPv6 Source Guard filtra os pacotes recebidos por todas as portas. Os modos de filtro específicos são os seguintes:
- Se o endereço IPv6 de origem ou o endereço MAC no pacote IPv6 for diferente do endereço IPv6 ou do endereço MAC de origem nas entradas vinculadas do IPv6 Source Guard global, mas o endereço MAC de origem for diferente, descarte o pacote.
A configuração do tipo de filtro tem efeito apenas para a entrada de associação dinâmica, não afetando a entrada de associação estática.
As entradas vinculadas da porta IPv6 Source Guard incluem dois tipos:
Configuração da função de IPv6 Source Guard
Tabela 5 -1 A lista de configuração da função IPv6 Source Guard
| Tarefas de configuração | |
| Configure as funções básicas da porta IPv6 Source Guard |
Habilite a função de proteção de fonte IPv6 da porta
Configure as entradas vinculadas da porta IPv6 Source Guard |
| Configure o tipo de pacote filtrado da porta IPv6 Source Guard | Configure o tipo de pacote filtrado da porta IPv6 Source Guard |
| Configure as entradas vinculadas estáticas da porta IPv6 Source Guard | Configure as entradas vinculadas estáticas da porta IPv6 Source Guard |
| Configure a função de ligação de entrada estática MAC da porta | Configure a função de ligação de entrada estática MAC da porta |
| Configurar a função global de IPv6 Source Guard | Configurar a função global de IPv6 Source Guard |
Ativar função de proteção de fonte IPv6 da porta
Condição de configuração
Nenhum
Ativar função de proteção de fonte IPv6 da porta
Depois de habilitar a função de proteção de fonte IPv6 da porta, grave as entradas vinculadas na porta (incluindo entradas estáticas e entradas dinâmicas) no chip e os pacotes que correspondem completamente aos recursos de entrada vinculada podem ser encaminhados. Caso contrário, solte-o. Depois de habilitar o IPv6 Source Guard, permita que os pacotes DHCPv6 e os pacotes ND na porta passem por padrão.
Tabela 5 -2 Habilite a função de IPv6 Source Guard da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a função de proteção de fonte IPv6 da porta | ipv6 verify source | Obrigatório Por padrão, a função de IPv6 Source Guard da porta está desabilitada. |
Configurar máx. Entradas vinculadas do IPv6 Source Guard da porta
Condição de configuração
Antes de configurar o número máximo de entradas vinculadas ao Source Guard IPv6 da porta, primeiro conclua a seguinte tarefa:
- Habilite a função de proteção de fonte IPv6 da porta
Configurar máx. Número de entradas de IPv6 Source Guard da porta
O número máximo de entradas vinculadas (incluindo entradas vinculadas estáticas e dinâmicas) suportadas pela porta impede que uma porta seja atacada e ocupe os recursos do dispositivo.
Tabela 5 -3 Configure o número máximo de entradas vinculadas ao Source Guard IPv6 da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o número máximo de entradas vinculadas ao Source Guard IPv6 da porta | ipv6 verify source max-entries number | Obrigatório Por padrão, cada porta pode ser configurada com 536 entradas vinculadas. |
Configurar o tipo de pacote filtrado de IPv6 Source Guard da porta
Condição de configuração
Antes de configurar o tipo de pacote filtrado da porta IPv6 Source Guard, primeiro conclua a seguinte tarefa:
- Habilite a função de proteção de fonte IPv6 da porta
Configurar o tipo de pacote filtrado de IPv6 Source Guard da porta
Após habilitar a função de proteção de fonte IPv6 da porta, filtre os pacotes IPv6 pelo modo ip. Quando o endereço IPv6 de origem e o número de VLAN no pacote IPv6 recebido pela porta são os mesmos que o endereço IPv6 de origem e o número de VLAN nas entradas vinculadas do Source Guard IPv6 da porta, a porta encaminha o pacote. Se algum for diferente, solte-o.
Após habilitar a função de proteção de fonte IPv6 da porta, filtre o pacote IPv6 pelo modo ip-mac. Quando o endereço MAC de origem, o endereço IPv6 de origem e o número VLAN no pacote IPv6 recebido pela porta são os mesmos que o endereço MAC, o endereço IPv6 e o número VLAN na entrada vinculada do Source Guard da porta IPv6, a porta encaminha o pacote. Se algum for diferente, solte-o.
Após habilitar a função de proteção de fonte IPv6 da porta, filtre o pacote IPv6 pelo modo mac. Quando o endereço MAC de origem e o número da VLAN no pacote IPv6 recebido pela porta são os mesmos que o endereço MAC, o endereço IPv6 e o número da VLAN na entrada vinculada do Source Guard da porta IPv6, a porta encaminha o pacote. Se algum for diferente, solte-o.
Tabela 5 -4 Configure o tipo de pacote filtrado da porta IPv6 Source Guard
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o tipo de pacote filtrado da porta IPv6 Source Guard | ipv6 verify source type {ip | ip-mac | mac} | Obrigatório Por padrão, a porta filtra os pacotes pelo modo ip. |
Depois de habilitar a função de proteção de fonte IPv6 da porta, as entradas vinculadas da proteção de fonte IPv6 da porta são gravadas no chip. O número de entradas gravadas no chip depende dos recursos de entrada de chip disponíveis. Se os recursos de entrada do chip estiverem esgotados e for necessário adicionar entradas vinculadas ou habilitar a função de IPv6 Source Guard da porta na outra porta, precisamos excluir as entradas vinculadas relacionadas de alguns recursos de entrada do chip. Se algumas entradas vinculadas do Source Guard IPv6 não puderem ser gravadas no chip porque os recursos de entrada do chip não são suficientes, o sistema tentará automaticamente gravar as entradas vinculadas no chip novamente a cada 60 segundos até que todas as entradas vinculadas sejam gravadas no chip ou excluídas. Configure o tipo de pacote de filtro de IPv6 Source Guard da porta válido apenas para entrada dinâmica gerada pela espionagem DHCPv6
Configurar entradas vinculadas estáticas do IPv6 Source Guard da porta
Condição de configuração
Antes de configurar as entradas de limite estático da porta IPv6 Source Guard, primeiro conclua a seguinte tarefa:
- Habilite a função de proteção de fonte IPv6 da porta
Configurar entradas vinculadas estáticas do IPv6 Source Guard da porta
As entradas vinculadas estáticas da porta IPv6 Source Guard são a base da filtragem dos pacotes IPv6 recebidos pela porta especificada.
Tabela 5 -5 Configure as entradas vinculadas estáticas da porta IPv6 Source Guard
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure as entradas vinculadas estáticas da porta IPv6 Source Guard | ipv6 source binding { ipv6-address ipv6-address [ mac-address mac-address [ vlan vlan-id ] | vlan vlan-id ] | mac-address mac-address [ vlan vlan-id ] } | Obrigatório Por padrão, não há entrada de limite estático da porta IPv6 Source Guard. |
Configurar a função de ligação de entrada estática da porta MAC
Condição de configuração
Antes de configurar a função de ligação de entrada estática da porta IPv6 Source Guard, primeiro conclua a seguinte tarefa:
- Habilite a função de proteção de fonte IPv6 da porta
Configurar a função de ligação de entrada estática da porta MAC
Depois de configurar a função de ligação de entrada estática MAC da porta, obtenha o endereço mac correspondente, o número da vlan e o número da porta das entradas estáticas do IP Source Guard configuradas e as entradas dinâmicas na porta, e entregue a entrada MAC estática correspondente.
Tabela 5 -6 Configurar a função de ligação de entrada estática MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar a função de ligação de entrada estática MAC | Ipv6 source sticky-mac | Obrigatório função de ligação de entrada estática do MAC da porta está desabilitada. |
Configurar a função de proteção de origem do IPv6 global
Condição de configuração
Nenhum
Configurar a função de IPv6 Source Guard global
Para proteger a segurança do endereço IPv6 do usuário e impedir que outro usuário use seu próprio endereço IPv6, podemos configurar a função IPv6 Source Guard global para vincular o endereço IPv6 do usuário e o endereço MAC. As entradas vinculadas ao IP Source Guard globais do endereço IPv6 do usuário configurado e do endereço MAC são gravadas diretamente no chip, de modo a filtrar os pacotes IPv6 inválidos.
Tabela 5 -7 Configurar a função global de proteção de origem IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Configurar a função global de IPv6 Source Guard | ipv6 source binding mac-address mac-address ipv6-address ipv6_address | Obrigatório Por padrão, não há entrada vinculada ao IPv6 Source Guard global e a função está desabilitada. |
As entradas vinculadas ao IPv6 Source Guard globais suportam no máximo 40. Após exceder 40, a configuração falha. As entradas vinculadas do IPv6 Source Guard globais configuradas são gravadas diretamente no chip. O número de entradas vinculadas gravadas no chip depende dos recursos de entrada de chip disponíveis. Se os recursos de entrada do chip estiverem esgotados e for necessário adicionar as entradas vinculadas do IPv6 Source Guard globais, precisamos excluir as entradas vinculadas relacionadas de alguns recursos de entrada do chip. Se as funções IPv6 Source Guard da porta e IPv6 Source Guard global estiverem habilitadas ao mesmo tempo, o pacote IP recebido pela porta precisa corresponder às entradas vinculadas da porta IPv6 Source Guard e IPv6 Source Guard global ao mesmo tempo para que pode ser encaminhado. Caso contrário, é descartado.
Monitoramento e manutenção do IPv6 Source Guard
Tabela 5 -8 Monitoramento e manutenção do IPv6 Source Guard
| Comando | Descrição |
| show ipv6 binding table [ dynamic | static | interface interface-name | slot | summary ] | Exiba as informações estatísticas das entradas vinculadas do IPv6 Source Guard e a quantidade de entrada vinculada |
| show ipv6 source guard [ interface interface-name] | Exibe as informações de configuração da função de proteção de origem IPv6 da porta |
Exemplo de configuração típico do IPv6 Source Guard
Configurar a função de IPv6 Source Guard da porta com base em entradas dinâmicas de DHCPv6 snooping
Requisitos de rede
- PC1 e PC2 estão conectados à rede IPv6 via dispositivo.
- Configure a função global de DHCPv6 snooping.
- Configure a função de IPv6 Source Guard da porta para que o PC1 possa acessar a rede IPv6 normalmente e o PC2 não possa acessar a rede IPv6.
Topologia de rede
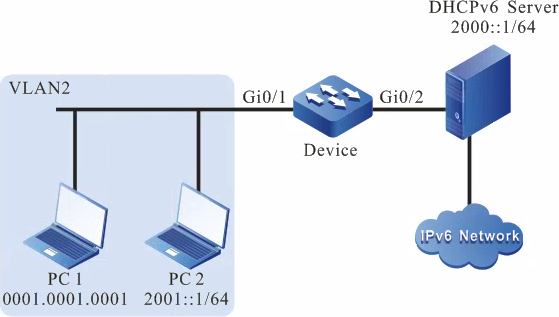
Figura 5 – 1 Rede de configuração da função de proteção de origem IPv6 da porta efetiva com base em entradas dinâmicas de espionagem DHCPv6
Etapas de configuração
- Passo 1:Configure o tipo de link de VLAN e porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
# Configura o tipo de link da porta gigabitethernet 0/1 como Acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2Device(config-if-gigabitethernet0/1)#exit
- Passo 2:No dispositivo, habilite a função de DHCPv6 snooping global e configure giga bitthernet0/2 conectado ao servidor DHCP como a porta confiável.
Device(config)#ipv6 dhcp snooping enableDevice(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#ipv6 dhcp snooping trustDevice(config-if-gigabitethernet0/2)#exit
- Passo 3:Configure o pool de endereços do servidor DHCPv6 como 2000::2/64. (omitido)
- Passo 4:No dispositivo, configure a função IPv6 Source Guard da porta.
#Na porta gigabitethernet0/1, habilite a função de IPv6 Source Guard baseada em porta.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ipv6 verify sourceDevice(config-if-gigabitethernet0/1)#exit
- Passo 5:Confira o resultado.
#Visualize as informações de configuração do DHCPv6 Snooping.
Device#show ipv6 dhcp snoopingdhcpv6-snooping configuration information:dhcpv6-snooping status:enabledhcpv6-snooping entry aged time:300dhcpv6-snooping binding agent save delay time:1800dhcpv6-snooping binding agent save type :FLASHdhcpv6-snooping binding agent save file :dhcpv6sp_binding.dbdhcpv6-snooping binding agent save pool time:30dhcpv6-snooping interface information :-------------------------------------------------------------interface trust-status max-learning-num option-policy option18-status option37-statusgi0/1 untrust 1024 keep disable disablegi0/2 trust 1024 keep disable disablegi0/3 untrust 1024 keep disable disablegi0/4 untrust 1024 keep disable disablegi0/5 untrust 1024 keep disable disable……
# Visualize as informações de configuração do IPv6 Source Guard.
Device#show ipv6 source guard-----------------------------------------IPv6 source guard interfaces on slot 0 :Total number of enabled interfaces : 1-------------------------------------------------------Interface Name Status Verify Type L2 Status Max Entry-------------------------------------------------------gi0/1 Enabled ip Disabled 536gi0/2 Disabled ip Disabled 536gi0/3 Disabled ip Disabled 536gi0/4 Disabled ip Disabled 536gi0/5 Disabled ip Disabled 536……
Podemos ver que a função IPv6 Source Guard está habilitada na porta gigabitethernet0/1. Verifique se o tipo é ip. Portanto, no exemplo acima, as entradas dinâmicas são efetivadas com base em IP+VLAN.
# Exibe a entrada vinculada ao IPv6 Source Guard da porta.
Device#show ipv6 binding table----------------------------global Ipv6 and mac binding entry -----------------------------total :0-----------------------------------------------------------------------------------------------------------------------------------IPv6 Source Guard binding table on slot 0Total binding entries : 1Static binding entries : 0Static not write entries : 0Dynamic binding entries : 1Dynamic not write entries : 0PCE writing entries : 1-----------------------------------------------------------------------------------------Interface-Name MAC-Address VLAN-ID Type-Flag Writing-Flag L2-Flag IP-Address-----------------------------------------------------------------------------------------gi0/1 0001.0001.0001 2 dynamic Write Not Write 2000::2
#PC1 pode acessar a rede IPv6 normalmente e o PC2 não pode acessar a rede IPv6.
Configurar a função de IPv6 Source Guard da porta efetiva com base em entradas estáticas
Requisitos de rede
- PC1 e PC2 estão conectados à rede IPv6 via dispositivo.
- Configure a função de IPv6 Source Guard da porta com base em entradas estáticas, para que o PC1 possa acessar a rede IPv6 normalmente e o PC2 não possa acessar a rede IP.
Topologia de rede
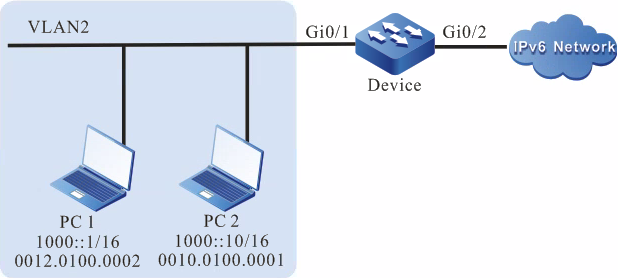
Figura 5 – 2 Rede de configuração da função de proteção de origem IPv6 da porta efetiva com base em entradas estáticas
Etapas de configuração
- Passo 1:Configure o tipo de link de VLAN e porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
# Configure o tipo de link da porta gigabitethernet0/1 como Access, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2Device(config-if-gigabitethernet0/1)#exit
- Passo 2:Configure a função de IPv6 Source Guard da porta no dispositivo.
# Habilite a função de proteção de fonte IPv6 da porta com base no modo de filtragem MAC+VLAN na porta gigabitethernet0/1 e configure o endereço IP como 1000::1 e a entrada vinculada da proteção de fonte IPv6 da porta da VLAN 2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ipv6 verify sourceDevice(config-if-gigabitethernet0/1)#ipv6 source binding ip-address 1000::1 vlan 2Device(config-if-gigabitethernet0/1)#exit
- Passo 3:Confira o resultado.
# Visualize as informações de configuração do IPv6 Source Guard.
Device#show ipv6 source guard-----------------------------------------IP source guard interfaces on slot 0 :Total number of enabled interfaces : 1-------------------------------------------------------------Interface Name Status Verify Type L2 Status-------------------------------------------------------------gi0/1 Enabled IP Disabledgi0/2 Disabled IP Disabledgi0/3 Disabled IP Disabledgi0/4 Disabled IP Disabled……
Podemos ver que a função IPv6 Source Guard está habilitada na porta gigabitethernet0/1. A entrada estática do IPv6 Source Guard entra em vigor de acordo com a entrada MAC+VLAN configurada, não relacionada com o valor Verify Type. Portanto, o exemplo acima tem efeito com base em MAC+VLAN.
# Exibe a entrada vinculada ao IPv6 Source Guard da porta.
Device #show ipv6 binding table----------------------------global Ipv6 and mac binding entry -----------------------------total :0-----------------------------------------------------------------------------------------------------------------------------------IPv6 Source Guard binding table on slot 0Total binding entries : 1Static binding entries : 1Static not write entries : 0Dynamic binding entries : 0Dynamic not write entries : 0PCE writing entries : 1-----------------------------------------------------------------------------------------Interface-Name MAC-Address VLAN-ID Type-Flag Writing-Flag L2-Flag IP-Address-----------------------------------------------------------------------------------------gi0/1 --- 2 Static Write Not Write 1000::1
#PC1 pode acessar a rede IPv6 normalmente e o PC2 não pode acessar a rede IPv6.
ND Snooping
Visão geral
ND Snooping
ND snooping é um recurso de segurança do IPv6 ND (descoberta de vizinhos), que é usado no ambiente de rede de comutação L2. A tabela de vinculação dinâmica do ND snooping é estabelecida ouvindo o pacote de solicitação de vizinho NS (solicitação de vizinho) no processo de detecção de DAD (detecção de endereço duplicado) de usuários, de modo a registrar o endereço IPv6 de origem, endereço MAC de origem, VLAN, ingresso porta e outras informações do pacote, de modo a evitar o subsequente ataque de pacotes ND de usuários falsificados e gateway.
Interface confiável/não confiável do ND Snooping
Interface de confiança do ND Snooping: Este tipo de interface é usado para conectar nós IPv6 confiáveis. Para os pacotes ND recebidos desse tipo de interface, o dispositivo encaminha normalmente.
Interface não confiável do ND Snooping: Este tipo de interface é usado para conectar nós IPv6 não confiáveis. Para pacotes RA e pacotes de redirecionamento recebidos desse tipo de interface, o dispositivo os considera como pacotes ilegais e os descarta diretamente. Para pacotes NA/NS/RS recebidos, se a VLAN onde esta interface ou interface está localizada habilitar a função de verificação de validade do pacote ND, o dispositivo usará a tabela de ligação dinâmica ND Snooping para realizar a verificação de correspondência da tabela de ligação para NA/NS/ pacotes RS. Quando o pacote não está de acordo com o relacionamento da tabela de vinculação, o pacote é considerado o pacote de usuário ilegal e descartado diretamente; para outros tipos de pacotes ND recebidos, o dispositivo encaminha normalmente.
Tabela de ligação ND Snooping
Depois que a função ND snooping é configurada, o dispositivo estabelece a tabela de vinculação dinâmica ND Snooping ouvindo o pacote NS usado pelo usuário para detecção de endereço repetido. As entradas incluem o endereço IPv6 de solicitação, endereço MAC de origem, VLAN, interface de entrada e outras informações no pacote DAD. A tabela de ligação dinâmica ND snooping pode ser usada para realizar a verificação de correspondência da tabela de ligação para pacotes NA/NS/RS recebidos de interfaces não confiáveis, de modo a filtrar pacotes NA/NS/RS ilegais.
Configuração da função ND Snooping
Tabela 6 -1 Lista de configuração da função ND Snooping
| Tarefa de configuração | |
| Ative a função ND Snooping | Ative a função ND Snooping |
| Especifique a interface de confiança do ND Snooping | Especifique a interface de confiança do ND Snooping |
| Configurar entrada de ligação estática do ND Snooping | Configurar entrada de ligação estática do ND Snooping |
| Configurar a função de detecção da tabela de vinculação dinâmica do ND Snooping | Configurar a função de detecção da tabela de vinculação dinâmica do ND Snooping |
| Ativar a função de log de detecção de ataque ND Snooping | Ativar a função de log de detecção de ataque ND Snooping |
Ativar função ND Snooping
Condição de configuração
Nenhum
Ativar função ND Snooping
Tabela 6 -2 Ativar a função ND Snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar a função global ND Snooping | nd snooping enable | Obrigatório Por padrão, a função global ND Snooping está desabilitada. |
| Entre no modo de configuração L2 VLAN | vlan vlan-id | Obrigatório Depois de entrar no modo de configuração L2 VLAN, a configuração subsequente entra em vigor apenas na VLAN atual. |
| Habilite a função ND Snooping na VLAN | nd snooping enable | Obrigatório Por padrão, a função ND Snooping não está habilitada na VLAN. |
Especificar a interface de confiança do ND Snooping
Condição de configuração
Nenhum
Especificar a interface de confiança do ND Snooping
Tabela 6 -3 Especificar a interface de confiança do ND Snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar a função global ND Snooping | nd snooping enable | Obrigatório Por padrão, a função global ND Snooping está desabilitada. |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Obrigatório Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas para a porta atual. |
| Especifique a interface de confiança do ND Snooping | nd snooping trusted | Obrigatório Por padrão, a interface é a interface não confiável. |
Configurar entrada de ligação estática do ND Snooping
Condição de configuração
Nenhum
Configurar entrada de ligação estática do ND Snooping
Tabela 6 -4 Configurar entrada de ligação estática do ND Snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar a função global ND Snooping | nd snooping enable | Obrigatório Por padrão, a função global ND Snooping está desabilitada. |
| Configurar entrada de ligação estática do ND Snooping | nd snooping user-bind ipv6-address mac-address vlan vlan-id interface interface-name | Opcional Por padrão, não configure a entrada de ligação estática do ND snooping. Quando a entrada de associação estática estiver configurada, primeiro corresponda à entrada de associação estática. Quando a entrada de ligação estática não estiver configurada, use diretamente a entrada de ligação dinâmica. |
Configurar a função de detecção da tabela de ligação dinâmica ND Snooping
Condição de configuração
Nenhum
Configurar a função de detecção da tabela de ligação dinâmica ND Snooping
Tabela 6 -5 Configurar a função de detecção da tabela de ligação dinâmica ND Snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar a função global ND Snooping | nd snooping enable | Obrigatório Por padrão, a função global ND Snooping está desabilitada. |
| Configurar a função de detecção da tabela de vinculação dinâmica do ND Snooping | nd snooping detect retransmit retransmits-times interval time | Obrigatório Por padrão, a função de detecção da tabela de ligação dinâmica do ND Snooping não está habilitada. |
Ativar a função de registro de detecção de ataque ND Snooping
Condição de configuração
Nenhum
Ativar a função de registro de detecção de ataque ND Snooping
Tabela 6 -6 Ativar a função de registro de detecção de ataque ND Snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar a função global ND Snooping | nd snooping enable | Obrigatório Por padrão, a função global ND Snooping está desabilitada. |
| Ative a função de registro de detecção de ataque do ND Snooping | nd snooping attack-log enable | Obrigatório Por padrão, a função de registro de detecção de ataque do ND Snooping está desabilitada. |
Monitoramento e Manutenção de ND
Tabela 6 -7 Monitoramento e Manutenção de ND
| Comando | Descrição |
| clear nd fast-response statistics | Limpe as estatísticas de resposta rápida do ND |
| clear nd snooping dynamic-user-bind | Excluir entradas de vinculação dinâmica do ND snooping |
| clear nd snooping prefix | Excluir entrada de prefixo de espionagem ND |
| clear nd snooping statistics | Limpar informações estatísticas de espionagem ND |
| show nd fast-response statistics | Exibir as estatísticas de resposta rápida do ND |
| show nd proxy address | Exibe o endereço com ND como resposta do módulo externo |
| show nd snooping prefix | Exibir a entrada do prefixo de espionagem ND |
| show nd snooping user-bind | Exibir a entrada de ligação do ND snooping |
| show nd snooping statistics | Exibir as informações de estatísticas de espionagem do ND |
Exemplo de configuração típica do ND Snooping
Configurar a função básica do ND Snooping
Requisitos de rede
- O dispositivo 1 está conectado ao dispositivo de gateway 2 por meio de gigabitothernet0/3.
- O dispositivo 2 habilita o serviço RA (habilita a função de envio de pacotes RA).
- O dispositivo 1 habilita a função de espionagem ND. Quando um invasor envia pacotes NS/NA/RS/RA ilegais na rede, o Device1 descarta esses pacotes ND inválidos para garantir a comunicação entre o usuário válido e o gateway.
Topologia de rede

Figura 6 - 1 Rede de configuração das funções básicas do ND Snooping
Etapas de configuração
- Passo 1:Em Device1, configure a VLAN e o tipo de link de porta.
#Cria VLAN2.
Device1#configure terminalDevice1(config)#vlan 2Device1(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1-gigabitethernet0/3 como Acesso, permitindo a passagem dos serviços da VLAN2.
Device1(config)#interface gigabitethernet 0/1-0/3Device1(config-if-range)#switchport mode accessDevice1(config-if-range)#switchport access vlan 2Device1(config-if-range)#exit
- Passo 2:Na interface L3 gigabitethernet0/2/1 do dispositivo de gateway Device2, configure o endereço IPv6.
Device2(config)#interface gigabitethernet 0/2/1Device2 (config-if-gigabitethernet0/2/1)#ipv6 address 10::1/64Device2 (config-if-gigabitethernet0/2/1)#exit
- Passo 3:No dispositivo de gateway Device2, habilite o serviço RA (habilite a função de envio de pacotes RA).
Device2(config)#interface gigabitethernet 0/2/1Device2 (config-if-gigabitethernet0/2/1)#no ipv6 nd suppress-ra periodDevice2 (config-if-gigabitethernet0/2/1)#no ipv6 nd suppress-ra responseDevice2 (config-if-gigabitethernet0/2/1)#exit
- Passo 4:Em Device1, configure a função ND Snooping.
#Ative globalmente a função ND Snooping.
Device1(config)#nd snooping enable#VLAN2 habilita a função ND Snooping.
Device1(config)#vlan 2Device1(config-vlan2)#nd snooping enableDevice1(config-vlan2)#exit
#Configure a porta gigabitethernet0/3 como interface de confiança.
Device1(config)#interface gigabitethernet 0/3Device1(config-if-gigabitethernet0/3)#nd snooping trustedDevice1(config-if-gigabitethernet0/3)#exit
- Passo 5:Confira o resultado.
#Veja que Device1 obtém as informações de prefixo enviadas pelo dispositivo de gateway Device2.
Device1#show nd snooping prefixprefix length valid-time preferred-time-------------------------------------------------------------------------------------10:: 64 2592000 604800Total number: 1
#Após PC1 configurar o endereço IPv6 10::3 no intervalo de gerenciamento do prefixo 10::/64, visualize a entrada ND Snooping no dispositivo.
Device1#show nd snooping user-bind dynamicipv6-address mac-address vlan interface type10::3 0857.00da.4715 2 gi0/1 dynamic
No Device1, gere a entrada ND Snooping do IP, MAC, VLAN, acesse as informações da porta do PC1.
#Attacker simula o IP do PC1 para enviar pacotes NS, NA e RS ao gateway. O dispositivo recebe os pacotes NS, NA, RS do invasor, julga que é inconsistente com a entrada de espionagem de ND gravada, descarta-a e faz registros relevantes nas informações estatísticas de espionagem de ND.
Device1#show nd snooping statisticsStatistics for lpu 0 nd snooping:lladdrInvalid: 0dadPacketDeal: 0nsPacketPass: 0nsPacketDrop: 1naPacketPass: 0naPacketDrop: 1 rsPacketDrop: 1rsPacketPass: 0raPacketPass: 0raPacketDrop: 0rdPacketDrop: 0rdPacketPass: 0sendDtPktFail: 0sendDtPktOk: 0
#Attacker simula o gateway para enviar o pacote RA para PC1. O dispositivo recebe o pacote RA do invasor, julga que o pacote RA é recebido do pacote não confiável, descarta-o e faz os registros relacionados nas informações estatísticas do ND Snooping.
Device1#show nd snooping statisticsStatistics for lpu 0 nd snooping:lladdrInvalid: 0dadPacketDeal: 0nsPacketPass: 0nsPacketDrop: 0naPacketPass: 0naPacketDrop: 0rsPacketDrop: 0rsPacketPass: 0raPacketPass: 0raPacketDrop: 1rdPacketDrop: 0rdPacketPass: 0sendDtPktFail: 0sendDtPktOk: 0
DHCP Snooping
Visão geral
Visão geral das funções básicas do DHCP Snooping
O DHCP Snooping é um recurso de segurança do DHCP (Dynamic Host Configuration Protocol) e tem as duas funções a seguir:
- Registre a relação correspondente do endereço MAC e endereço IP do cliente DHCP:
Considerando a segurança, o administrador da rede pode precisar registrar o endereço IP utilizado quando o usuário acessa a rede, confirmando a relação correspondente do endereço IP do host do usuário e o endereço IP obtido do servidor DHCP.
O DHCP Snooping escuta o pacote de solicitação DHCP e o pacote de resposta DHCP recebido pela porta confiável e registra o endereço MAC do cliente DHCP e o endereço IP obtido. O administrador pode visualizar as informações de endereço IP obtidas pelo cliente DHCP por meio da entrada vinculada registrada pelo DHCP Snooping.
- Certifique-se de que o cliente obtenha o endereço IP do servidor válido
Se houver um servidor DHCP não autorizado na rede, o cliente DHCP pode obter o endereço IP errado, resultando em anormalidade de comunicação ou riscos de segurança. Para garantir que o cliente DHCP possa obter o endereço IP do servidor DHCP válido, a função DHCP Snooping permite configurar a porta como porta confiável ou porta não confiável:
- Porta de confiança é a porta conectada direta ou indiretamente ao servidor DHCP válido. A porta de confiança encaminha o pacote de resposta DHCP recebido normalmente, para garantir que o cliente DHCP possa obter o endereço IP correto.
- Porta não confiável é a porta não conectada direta ou indiretamente ao servidor DHCP válido. Se a porta não confiável receber o pacote de resposta DHCP enviado pelo servidor DHCP, descarte-o para evitar que o cliente DHCP obtenha o endereço IP errado.
Breve introdução da opção de DHCP snooping 82
O DHCP Snooping suporta a adição, encaminhamento e gerenciamento para o Option82. Option82 é uma opção de pacote DHCP. A opção é utilizada para registrar as informações de localização do cliente DHCP e o administrador pode localizar o cliente DHCP de acordo com a opção, de modo a realizar algum controle de segurança. Por exemplo, controle o número de endereços IP que podem ser distribuídos para uma porta ou VLAN. O modo de processamento de Option82 varia com o tipo de pacote DHCP:
- Após o dispositivo receber o pacote de solicitação DHCP, processe o pacote de acordo com se o pacote contém a Option82, a política de processamento configurada pelo usuário e o formato de preenchimento e, em seguida, encaminhe o pacote processado para o servidor DHCP.
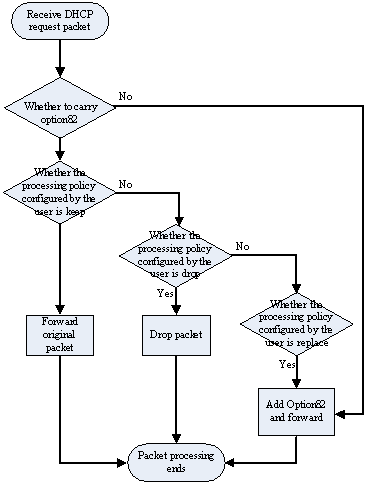
Figura 7 -1 Fluxo de processamento da Opção 82
- Quando o dispositivo receber o pacote de resposta do servidor DHCP e se o pacote contiver a Option82, exclua a Option82 e encaminhe para o cliente DHCP; se o pacote não contiver o Option82, encaminhe diretamente para o cliente DHCP.
Configuração da função de DHCP snooping
Tabela 7 -1 Lista de configuração da função DHCP Snooping
| Tarefa de configuração | |
| Configurar as funções básicas do DHCP Snooping |
Configurar a função DHCP Snooping
Configurar o status de confiança da porta Configurar a função de limitação de taxa de DHCP snooping |
| Configurar a opção de DHCP snooping 82 |
Configure a política de processamento de Option82
Configurar o conteúdo do ID remoto Configurar o conteúdo do Circuit ID Configure o formato de preenchimento do Option82 Configure a política de processamento do pacote Option82 |
| Configure o armazenamento das entradas vinculadas do DHCP Snooping |
Configure o armazenamento automático da entrada vinculada do DHCP Snooping
Configure o armazenamento manual da entrada vinculada do DHCP Snooping |
Configurar funções básicas de DHCP snooping
As funções básicas do DHCP Snooping incluem habilitar a função DHCP Snooping, configurar o status de confiança da porta e limitar a taxa dos pacotes DHCP.
Condição de configuração
Nenhum
Configurar função de DHCP snooping
Após habilitar a função DHCP Snooping, monitore os pacotes DHCP recebidos por todas as portas do dispositivo:
- Para o pacote de solicitação recebido, gere a entrada vinculada correspondente de acordo com as informações no pacote
- Para o pacote de resposta recebido do pacote de confiança, atualize o status e o tempo de concessão da entrada vinculada
- Para o pacote de resposta recebido da porta não confiável, descarte-o diretamente
Tabela 7 -2 Configurar a função DHCP Snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função DHCP Snooping | dhcp-snooping | Obrigatório Por padrão, a função DHCP Snooping está desabilitada. |
Configurar o status de confiança da porta
Para evitar que o cliente DHCP obtenha o endereço do servidor DHCP inválido, podemos configurar a porta conectada direta ou indiretamente ao servidor válido como a porta confiável.
Depois que a porta for configurada como a porta confiável, permita o encaminhamento normal do pacote de resposta DHCP. Caso contrário, descarte o pacote de resposta DHCP.
Tabela 7 -3 Configurar o status de confiança da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar o status de confiança da porta | dhcp-snooping trust | Obrigatório Por padrão, todas as portas são portas não confiáveis. |
A porta conectada ao servidor DHCP precisa ser configurada como a porta confiável. Caso contrário, o cliente DHCP não poderá obter o endereço. Depois que a porta for configurada como a porta confiável, não limite a taxa dos pacotes DHCP que passam pela porta. Depois de alterar o status da porta confiável para a porta não confiável, o limite superior da taxa de porta é o padrão 40.
Configurar limitação de taxa de DHCP snooping
A configuração da função de limitação de taxa DHCP Snooping pode limitar o número de pacotes DHCP processados a cada segundo, evitando que outros pacotes de protocolo não possam ser processados a tempo porque o sistema processa os pacotes DHCP por um longo tempo.
Quando o número de pacotes DHCP recebidos em um segundo excede a limitação de taxa, os pacotes DHCP subsequentes são descartados. Se os pacotes DHCP recebidos pela porta por 20 segundos sucessivos excederem a limitação de taxa, desative a porta para isolar a fonte de impacto do pacote.
Tabela 7 -4 Configurar a função de limitação de taxa de DHCP snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar a função de limitação de taxa de DHCP snooping | dhcp-snooping rate-limit limit-value | Obrigatório Por padrão, o limite de taxa superior dos pacotes DHCP é 40pps. |
Depois de configurar o limite de taxa dos pacotes DHCP no modo de configuração do grupo de agregação, o limite de taxa de pacote DHCP de cada porta membro do grupo de agregação é o valor. A função de limitação de taxa de pacote DHCP só tem efeito para a porta não confiável e não tem efeito para a porta confiável. Depois que a porta for desabilitada automaticamente, podemos configurar Error-Disable para habilitar a porta automaticamente. Por padrão, a função de desativação automática da porta está habilitada; se os pacotes DHCP recebidos pela porta por 20s sucessivos excederem a limitação de taxa, mas não puderem desabilitar a porta automaticamente, precisamos visualizar a configuração de Error-Disable. Para a função Error-Disable, consulte o capítulo Error-Disable do manual de configuração.
Configurar a opção de DHCP snooping 82
A função DHCP Snooping suporta Option82. Option82 pode conter no máximo 255 subopções. O dispositivo suporta duas subopções, ou seja, Circuit ID e Remote ID.
Condição de configuração
Antes de configurar DHCP Snooping Option82, primeiro complete a seguinte tarefa:
- Habilite a função DHCP Snooping
Configurar a política de processamento de Option82
Depois que a porta é configurada com as informações de desabilitação, qualquer que seja o pacote de opções que a porta receba, ele será encaminhado como está.
Tabela 6 -5 Configurar a política de processamento de Option82
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a Option82 da função DHCP Snooping | dhcp-snooping information enable | Obrigatório Por padrão, a Option82 da função DHCP Snooping está desabilitada. |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure a política de processamento de Option82 | dhcp-snooping information disable | Opcional Por padrão, a política de processamento para o pacote de solicitação DHCP com Option82 é substituir, ou seja, encaminhar após a substituição. |
Configurar ID remoto
O conteúdo do Remote ID inclui conteúdo padrão e conteúdo não padrão. O formato de preenchimento do conteúdo padrão do Remote ID é o seguinte:

Figura 7 -2 O formato de preenchimento do conteúdo padrão do Remote ID
O conteúdo não padrão inclui cadeia de caracteres e nome de dispositivo personalizados e precisa ser configurado para ter efeito no formato de configuração do usuário. O formato de preenchimento do conteúdo não padrão do Remote ID é o seguinte:

Figura 7 -3 O formato de preenchimento do conteúdo não padrão do Remote ID
Tabela 7 -5 Configurar o conteúdo do Remote ID
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o conteúdo do Remote ID | dhcp-snooping information format remote-id { string | default | hostname } | Obrigatório Por padrão, o conteúdo do Remote ID é o conteúdo padrão, ou seja, o endereço MAC da porta do dispositivo. |
Configurar ID do Circuito
O conteúdo do Circuit ID inclui conteúdo padrão e conteúdo não padrão. O formato de preenchimento do conteúdo padrão do Circuit ID é o seguinte:
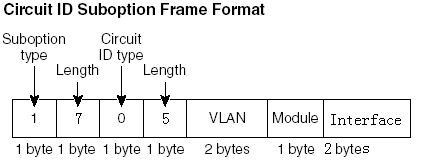
Figura 7 -4 O formato de preenchimento do conteúdo padrão do Circuit ID
O conteúdo não padrão precisa ser configurado para ter efeito no formato de configuração do usuário. O formato de preenchimento do conteúdo não padrão do Circuit ID é o seguinte:

Figura 7 -5 O formato de preenchimento do conteúdo não padrão do Circuit ID
Tabela 7 -6 Configure o conteúdo do Circuit ID
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar o conteúdo do Circuit ID | dhcp-snooping information format circuit-id { string | default } | Obrigatório Por padrão, o conteúdo do Circuit ID é o conteúdo padrão. |
Configurar Formato de Preenchimento da Opção 82
O formato de preenchimento do Option82 inclui o formato padrão e o formato de configuração do usuário.
Quando o formato de preenchimento é o formato padrão, o conteúdo de Remote ID e Circuit ID são ambos o conteúdo padrão; somente após o formato de preenchimento ser configurado como o formato de configuração do usuário, o conteúdo não padrão de Remote ID e Circuit ID pode entrar em vigor.
Tabela 7 -7 Configure o formato de preenchimento da Opção 82
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o formato de preenchimento de Option82 | dhcp-snooping information format { default | user-config } | Obrigatório Por padrão, o formato de preenchimento é o formato padrão. |
Configurar a Política de Processamento de Pacotes da Opção 82
Configure a política de processamento de pacotes de Option82. Podemos adotar diferentes políticas de encaminhamento para o pacote de solicitação DHCP contendo Option82.
Tabela 7 -8 Configurar a política de processamento de pacotes de Option82
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a política de processamento de pacotes de Option82 | dhcp-snooping information policy { drop | keep | replace } | Obrigatório Por padrão, a política de processamento é substituir. |
Configurar o armazenamento de entradas vinculadas de espionagem de DHCP
A função DHCP Snooping suporta o armazenamento automático ou manual no caminho especificado das entradas vinculadas. Se o dispositivo reiniciar, as entradas vinculadas armazenadas podem ser restauradas, evitando afetar a comunicação porque as entradas vinculadas são perdidas.
O caminho especificado pode ser dispositivo FLASH, servidor FTP ou servidor TFTP.
Condição de configuração
Antes de configurar o caminho de armazenamento das entradas vinculadas como o servidor FTP/TFTP, primeiro conclua a seguinte tarefa:
- Servidor FTP/TFTP, ative a função do servidor FTP/TFTP normalmente
- O dispositivo pode executar ping no endereço IP do servidor FTP/TFTP.
Configurar o armazenamento automático de entradas vinculadas de DHCP snooping
As entradas vinculadas do DHCP Snooping podem ser configuradas como o modo de armazenamento automático, ou seja, o sistema armazena automaticamente as entradas vinculadas regularmente.
O sistema atualiza periodicamente as entradas vinculadas, detectando se as entradas vinculadas são atualizadas. Se sim, precisamos armazenar as entradas atualizadas no caminho especificado após a chegada do atraso de armazenamento. O atraso de armazenamento pode prevenir e controlar o armazenamento frequente do sistema porque as entradas são atualizadas continuamente.
Tabela 7 -9 Configurar o armazenamento automático de entradas vinculadas ao DHCP Snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o armazenamento automático das entradas vinculadas do DHCP Snooping | dhcp-snooping database savetype auto { flash file-name | ftp dest-ip-address ftp-username ftp-password file-name | tftp dest-ip-address file-name } | Obrigatório Por padrão, o modo de armazenamento das entradas vinculadas é o modo automático, o caminho de armazenamento é flash e o nome do arquivo de armazenamento é dhcpsp_binding.db. |
| Configure o atraso de armazenamento das entradas vinculadas | dhcp-snooping database savedelay seconds | Opcional Por padrão, o atraso de armazenamento das entradas vinculadas é de 1800s. |
| Configure o intervalo de atualização das entradas vinculadas | dhcp-snooping database savepool seconds | Opcional Por padrão, o intervalo de atualização das entradas vinculadas é de 30 segundos. |
Configurar o armazenamento manual de entradas vinculadas de DHCP snooping
As entradas vinculadas do DHCP Snooping podem ser configuradas como o modo de armazenamento manual, ou seja, execute o comando store para concluir o armazenamento das entradas vinculadas.
Tabela 7 -10 Configure o armazenamento manual das entradas vinculadas do DHCP Snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o armazenamento manual das entradas vinculadas do DHCP Snooping | dhcp-snooping database savetype manual { flash file-name | ftp dest-ip-address ftp-username ftp-password file-name | tftp dest-ip-address file-name } | Obrigatório Por padrão, o modo de armazenamento das entradas vinculadas é o modo automático, o caminho de armazenamento é flash e o nome do arquivo de armazenamento é dhcpsp_binding.db. |
| Configurar o arquivo vinculado ao armazenamento | dhcp-snooping database save | Obrigatório Armazene as entradas vinculadas ao caminho especificado. Por padrão, as entradas vinculadas não são armazenadas no caminho especificado. |
Monitoramento e manutenção de DHCP snooping
Tabela 7 -11 Monitoramento e manutenção do DHCP Snooping
| Comando | Descrição |
| clear dhcp-snooping database { interface { interface-list | link-aggregation link-aggregation-id } | ip-address ip-address | mac-address mac-address | vlan vlan-id | all } | Limpar as entradas vinculadas |
| clear dhcp-snooping packet statistics [ interface { interface-name | link-aggregation link-aggregation-id } ] | Limpe as informações estatísticas dos pacotes DHCP enviados e recebidos |
| show dhcp-snooping [ interface { interface-name | link-aggregation link-aggregation-id } | save | detail ] | Exibir as informações de configuração do DHCP Snooping |
| show dhcp-snooping database [ | { { begin | exclude | include } expression | redirect { file file-name | ftp [ vrf vrf-name ] { hostname | dest-ip-address } ftp-username ftp-password file-name } } ] [ interface { interface-name | link-aggregation link-aggregation-id } | ip-address ip-address | vlan vlan-id| mac-address mac-address [ | { { begin | exclude | include } expression | redirect { file file-name | ftp [ vrf vrf-name ] { hostname | dest-ip-address } ftp-username ftp-password file-name } } ] | detail ] | Exibir as informações de entrada vinculada do DHCP Snooping |
| show dhcp-snooping packet statistics [ interface { interface-name | link-aggregation link-aggregation-id } ] | Exibe as informações estatísticas dos pacotes DHCP enviados e recebidos |
Exemplo de configuração típico de DHCP snooping
Configurar funções básicas de DHCP snooping
Requisitos de rede
- DHCP Server1 é o servidor DHCP válido; DHCP Server2 é o servidor DHCP inválido.
- Depois de configurar a função DHCP Snooping, o PC1 e o PC2 podem obter o endereço do DHCP Server1.
Topologia de rede
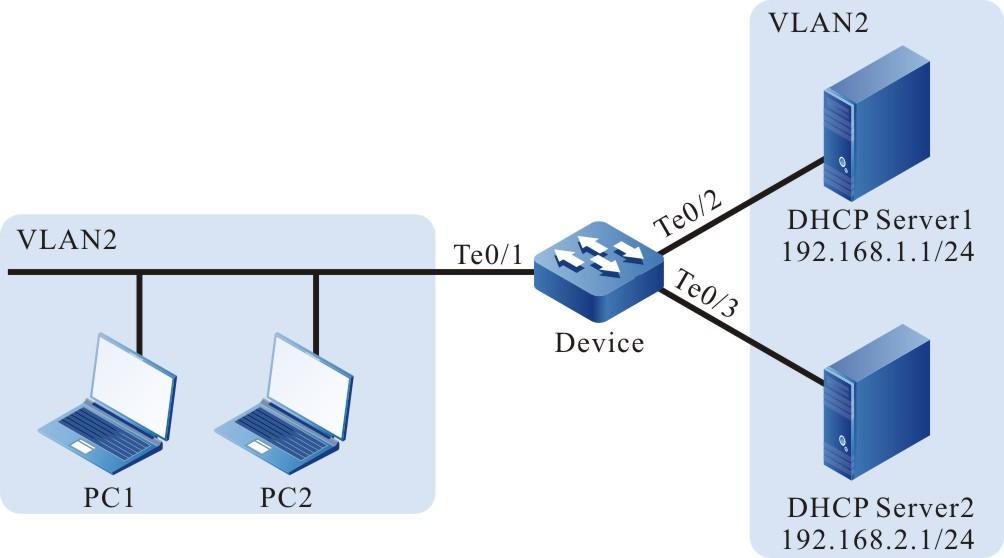
Figura 7 -6 Rede de configuração das funções básicas do DHCP Snooping
Etapas de configuração
- Passo 1:Configure o tipo de link de VLAN e porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta dez gigabitethernet 0/1-ten gigabitethernet 0/3 como Acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface tengigabitethernet 0/1-0/3Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
- Passo 2:Configure o pool de endereços do DHCP Server1 como 192.168.1.100-192.168.1.199 e o pool de endereços do DHCP Server2 como 192.168.2.100-192.168.2.199. (Omitido)
- Passo 3:Configure a função DHCP Snooping no dispositivo.
#Ative a função DHCP Snooping.
Device(config)#dhcp-snoopinga porta dez gigabitethernet 0/2 como porta de confiança.
Device(config)#interface tengigabitethernet 0/2Device(config-if-tengigabitethernet0/2)#dhcp-snooping trustDevice(config-if-tengigabitethernet0/2)#exit
- Passo 4:Confira o resultado.
#Depois que o PC1 e o PC2 obtiverem o endereço com sucesso, visualize as entradas do DHCP Snooping no dispositivo.
Device#show dhcp-snooping databasedhcp-snooping database:database entries count:2database entries delete time :300---------------------------------macAddr ipAddr transtion-id vlan interface leaseTime(s) status0013.0100.0002 192.168.1.101 1 2 te0/1 107990 active------0013.0100.0001 192.168.1.100 0 2 te0/1 107989 active------Total valid DHCP Client binding table for this criterion: 2
PC1 e PC2 podem obter endereços do DHCP Server1.
DHCPv6 Snooping
Visão geral
Introdução às funções básicas de DHCPv6 snooping
A DHCPv6 snooping é um recurso de segurança do DHCPv6 (Dynamic Host Configuration Protocol for IPv6) e tem as duas funções a seguir:
- Registre a relação correspondente do endereço MAC e do endereço IPv6 do cliente DHCPv6:
Considerando a segurança, o administrador da rede pode precisar registrar o endereço IPv6 utilizado quando o usuário acessa a rede, confirmando a relação correspondente do endereço IPv6 do host do usuário e o endereço IPv6 obtido do servidor DHCPv6.
A DHCPv6 snooping escuta o pacote de solicitação DHCPv6 e o pacote de resposta DHCPv6 recebido pela porta confiável e registra o endereço MAC do cliente DHCPv6 e o endereço IPv6 obtido. O administrador pode visualizar as informações de endereço IPv6 obtidas pelo cliente DHCPv6 por meio da entrada vinculada registrada pela DHCPv6 snooping.
- Certifique-se de que o cliente obtenha o endereço IPv6 do servidor válido
Se houver um servidor DHCPv6 não autorizado na rede, o cliente DHCPv6 poderá obter o endereço IPv6 incorreto, resultando em anormalidade de comunicação ou riscos de segurança. Para garantir que o cliente DHCPv6 possa obter o endereço IPv6 do servidor DHCPv6 válido, a função de DHCPv6 snooping permite configurar a porta como porta confiável ou porta não confiável:
- Porta de confiança é a porta conectada direta ou indiretamente ao servidor DHCPv6 válido. A porta de confiança encaminha o pacote de resposta DHCPv6 recebido normalmente, para garantir que o cliente DHCPv6 possa obter o endereço IP correto.
- Porta não confiável é a porta não conectada direta ou indiretamente ao servidor DHCPv6 válido. Se a porta não confiável receber o pacote de resposta DHCPv6 enviado pelo servidor DHCPv6, descarte-o para evitar que o cliente DHCPv6 obtenha o endereço IPv6 errado.
Breve introdução da opção de DHCPv6 snooping 18/37
Para fazer com que o servidor DHCPv6 obtenha as informações de localização física do cliente DHCPv6, você pode adicionar Option18 e Option37 ao pacote de solicitação DHCPv6.
Quando o dispositivo detecta o pacote DHCPv6, ele pode adicionar algumas informações do dispositivo do usuário ao pacote de solicitação DHCPv6 pelo modo de opção DHCPv6. A opção 18 registra as informações de interface do cliente e é chamada de opção de ID de interface (ID de interface). A opção37 registra as informações do endereço MAC do cliente e é chamada de opção de ID remoto (ID remoto).
Quando o Option18/37 estiver habilitado e após o dispositivo receber o pacote de solicitação DHCPv6, forneça o seguinte processamento de acordo com a política de processamento e o modo de preenchimento do Option18/37 configurado pelo usuário.
Tabela 8 -1 A política de processamento do pacote de solicitação DHCPv6
| Pacote de solicitação DHCPv6 | Política de processamento | Modo de enchimento | Princípio de Processamento de Pacotes |
| Sem Opção 18/37 | Adicionar Adicionar |
Formato de preenchimento padrão Formato de preenchimento estendido |
Preencha e encaminhe de acordo com o formato padrão
Preencha e encaminhe de acordo com o formato personalizado do usuário |
| Com Opção 18/37 | Manter Substituir |
Não preencha Formato de preenchimento padrão Formato de preenchimento estendido |
Encaminhar sem processar Opção 18/37
Substitua o conteúdo original da Option18/37 e encaminhe de acordo com o formato padrão Substitua o conteúdo original da Option18/37 e encaminhe de acordo com o formato personalizado do usuário |
Configuração da função de DHCPv6 snooping
Tabela 8 -2 Lista de configuração da função de espionagem DHCPv6
| Tarefa de configuração | |
| Configurar funções básicas de DHCPv6 snooping |
Ativar DHCPv6 snooping
Configurar o status de confiança da porta Configure o número das entradas vinculadas à porta |
| Configurar a opção de DHCPv6 snooping 18/37 |
Configurar Opção 18
Configurar Opção 37 Configure a política de processamento do pacote Option18/37 |
| Configure o tempo de atraso de exclusão da entrada inválida de DHCPv6 snooping | Configure o tempo de atraso de exclusão da entrada inválida de DHCPv6 snooping |
| Configure o armazenamento das entradas vinculadas de DHCPv6 snooping | Configure o armazenamento das entradas vinculadas de DHCPv6 snooping |
Configurar funções básicas de DHCPv6 snooping
As funções básicas de DHCPv6 snooping incluem habilitar a função de DHCPv6 snooping, configurar o status de confiança da porta e configurar o número de entradas vinculadas de espionagem DHCPv6 da porta.
Condição de configuração
Nenhum
Ativar DHCPv6 snooping
Após habilitar a função de DHCPv6 snooping, monitore os pacotes DHCPv6 recebidos por todas as portas do dispositivo.
- Para o pacote de solicitação DHCPv6 recebido, gere a entrada vinculada correspondente de acordo com as informações no pacote
- Para o pacote de resposta recebido pela porta confiável, atualize o status e o tempo de concessão das entradas vinculadas correspondentes
- Para o pacote de resposta recebido pela porta não confiável, descarte-o diretamente
Tabela 8 -3 Ativar DHCPv6 snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ative a função de DHCPv6 snooping | ipv6 dhcp snooping enable | Qualquer Por padrão, a função de DHCPv6 snooping está desabilitada. |
| Habilite a função de DHCPv6 snooping da VLAN especificada | ipv6 dhcp snooping vlan vlanlist |
Configurar o status de confiança da porta
Para evitar que o cliente DHCPv6 obtenha o endereço do servidor DHCPv6 inválido, você pode configurar a porta conectada direta ou indiretamente ao servidor válido como a porta confiável.
Depois que a porta for configurada como a porta confiável, permita que o pacote de resposta DHCPv6 seja encaminhado normalmente. Caso contrário, descarte o pacote de resposta DHCPv6.
Tabela 8 -4 Configurar o status de confiança da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar o status de confiança da porta | ipv6 dhcp snooping trust | Obrigatório Por padrão, todas as portas são portas não confiáveis. |
A porta conectada ao servidor DHCPv6 precisa ser configurada como a porta confiável. Caso contrário, o cliente DHCPv6 não poderá obter o endereço.
Configurar o número de entradas vinculadas de espionagem da porta DHCPv6
A configuração do número de entradas vinculadas de espionagem DHCPv6 pode limitar o número máximo de entradas dinâmicas que podem ser aprendidas pela porta, evitando ocupar muitos recursos do sistema.
Tabela 8 -5 Configure o número das entradas vinculadas de DHCPv6 snooping da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o número de entradas vinculadas de espionagem DHCPv6 | ipv6 dhcp snooping max-learning-num number | Obrigatório Por padrão, o número de entradas vinculadas que podem ser aprendidas pela porta é 1024. |
Configurar a opção de DHCPv6 snooping 18/37
A função de DHCPv6 snooping suporta Option18 e Option37. Option18 e Option37 suportam o formato de preenchimento padrão e o formato de preenchimento estendido.
Condição de configuração
Antes de configurar o snooping DHCP Option18 e Option37, primeiro conclua a seguinte tarefa:
- Ative a função de DHCPv6 snooping
Configurar Opção 18
O conteúdo do ID da interface inclui o formato de preenchimento padrão e o formato de preenchimento estendido. O formato de preenchimento de conteúdo padrão do ID da interface é o seguinte:

Figura 8 -1 O formato de preenchimento de conteúdo padrão da Interface ID
O formato de preenchimento estendido precisa que o formato de preenchimento seja configurado para ter efeito no formato de configuração do usuário. O formato de preenchimento estendido do ID da interface é o seguinte:
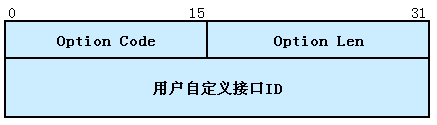
Figura 8 -2 O formato de preenchimento estendido de Interface ID
Tabela 8 -6 Configurar Opção 18
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Ativar a função Opção 18 | ipv6 dhcp snooping option interface-id enable | Obrigatório Por padrão, a Opção18 está desabilitada. |
| Configurar o conteúdo do ID da interface | ipv6 dhcp snooping option format interface-id string | Opcional Por padrão, o conteúdo do ID da interface em Option18 é o formato do ID da interface – duid. |
Configurar Opção 37
O conteúdo do Remote ID inclui o formato de preenchimento padrão e o formato de preenchimento estendido. O formato de preenchimento de conteúdo padrão do Remote ID é o seguinte:
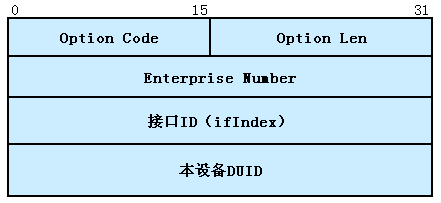
Figura 8 -3 O formato de preenchimento de conteúdo padrão do Remote ID
O formato de preenchimento estendido precisa que o formato de preenchimento seja configurado para ter efeito no formato de configuração do usuário. O formato de preenchimento estendido do Remote ID é o seguinte:
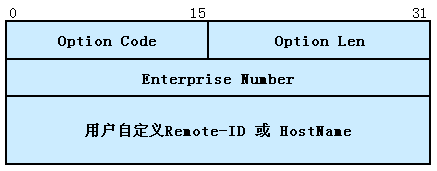
Figura 8 -4 O formato de preenchimento de conteúdo não padrão do Remote ID
Tabela 8 -7 Configurar Opção 37
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Ativar a função Option37 | ipv6 dhcp snooping option remote-id enable | Obrigatório Por padrão, a função Option37 está desabilitada. |
| Configurar o conteúdo do Remote ID | ipv6 dhcp snooping option format remote-id { string | hostname } | Obrigatório Por padrão, o conteúdo do Remote ID em Option37 é o formato enterprise num - interface id –duid. |
Configurar a política de processamento do pacote Option18/37
Após configurar a política de processamento do pacote Option18/37, você pode adotar diferentes políticas de processamento para o pacote de solicitação DHCPv6 com Option18/37.
Tabela 8 -8 Configurar a política de processamento do pacote Option18/37
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure a política de processamento do pacote Option18/37 | ipv6 dhcp snooping option policy replace | Obrigatório Por padrão, não substitua o conteúdo Option18/37 no pacote de solicitação DHCPv6. |
Configurar tempo de atraso de exclusão de entrada inválida de DHCPv6 snooping
Condição de configuração
Antes de configurar o tempo de atraso para excluir a entrada inválida de DHCPv6 snooping, primeiro conclua a seguinte tarefa:
- Ative a função de DHCPv6 snooping
Configurar tempo de atraso de exclusão de entrada inválida de DHCPv6 snooping
Após excluir o relacionamento de ligação, a entrada vinculada é atualizada para inválida. A entrada inválida não é excluída imediatamente, mas é excluída após exceder o tempo de atraso. Durante o período, caso o cliente renove a concessão, a entrada vinculada pode ser ativada, mas não é necessário redefinir a entrada vinculada.
Tabela 8 -9 Configure o tempo de atraso de exclusão da entrada inválida de DHCPv6 snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o tempo de atraso de exclusão da entrada inválida de DHCPv6 snooping | ipv6 dhcp snooping database timeout seconds | Obrigatório Por padrão, o tempo de atraso de exclusão da entrada inválida de DHCPv6 snooping é de 300s. |
Configurar o armazenamento de entradas vinculadas de espionagem DHCPv6
A função de DHCPv6 snooping suporta o armazenamento automático ou manual no dispositivo FLASH. Se o dispositivo reiniciar, as entradas vinculadas armazenadas podem ser restauradas, evitando afetar a comunicação porque as entradas vinculadas são perdidas.
Condição de configuração
Antes de configurar o armazenamento das entradas vinculadas de DHCPv6 snooping, primeiro conclua a seguinte tarefa:
- Ative a função de DHCPv6 snooping
Configurar o armazenamento de entradas vinculadas de espionagem DHCPv6
O sistema atualiza periodicamente as entradas vinculadas de espionagem do DHCPv6, detectando se as entradas vinculadas são atualizadas. Se sim, precisamos armazenar as entradas atualizadas no caminho especificado após a chegada do atraso de armazenamento. Enquanto isso, você também pode armazenar as entradas vinculadas ao dispositivo FLASH imediatamente.
Tabela 8 -10 Configurar o armazenamento das entradas vinculadas de DHCPv6 snooping
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o intervalo de atualização das entradas vinculadas de DHCPv6 snooping | ipv6 dhcp snooping database save pool seconds | Opcional Por padrão, o intervalo de atualização das entradas vinculadas de DHCPv6 snooping é de 30 segundos. |
| Configure o atraso de armazenamento das entradas vinculadas de DHCPv6 snooping | ipv6 dhcp snooping database save interval seconds | Opcional Por padrão, o atraso de armazenamento das entradas vinculadas de DHCPv6 snooping é 1800s. |
| Configure o armazenamento das entradas vinculadas imediatamente | ipv6 dhcp snooping database save now | Opcional Por padrão, o atraso de armazenamento da entrada vinculada é de 1800s. |
| Configure o armazenamento das entradas vinculadas de DHCPv6 snooping para o arquivo especificado | ipv6 dhcp snooping database save filename string | Obrigatório Por padrão, o nome do arquivo de armazenamento é /flash/dhcpv6sp_binding.db. |
Monitoramento e manutenção de DHCPv6 snooping
Tabela 8 -11 Monitoramento e manutenção de espionagem DHCPv6
| Comando | Descrição |
| clear ipv6 dhcp snooping database [ interface { interface-list } | ipv6-address ipv6-address | mac-address | vlan vlan-id ] | Limpe a entrada de ligação do DHCPv6 Snooping |
| clear ipv6 dhcp snooping statistics [ interface { interface-name } ] | Limpe as informações estatísticas dos pacotes DHCPv6 recebidos e enviados |
| show ipv6 dhcp snooping [ interface { interface-name } ] | Exiba as informações de configuração do DHCPv6 Snooping na interface especificada |
| show ipv6 dhcp snooping database [ | { { begin | exclude | include } expression | redirect { file file-name | ftp [ vrf vrf-name ] { hostname | dest-ip-address } ftp-username ftp-password file-name } } ] [ interface { interface-name } | ipv6-address ipv6-address | mac-address mac-address | vlan vlan-id] [ | { { begin | exclude | include } expression | redirect { file file-name | ftp [ vrf vrf-name ] { hostname | dest-ip-address } ftp-username ftp-password file-name } } ] ] | Exiba as informações de entrada vinculada do DHCPv6 Snooping |
| show ipv6 dhcp snooping statistics [ interface { interface-name } ] | Exiba as informações estatísticas dos pacotes DHCPv6 recebidos e enviados |
Exemplo de configuração típico de DHCPv6 snooping
Configurar funções básicas de DHCPv6 snooping
Requisitos de rede
- DHCPv6 Server1 é o servidor DHCPv6 válido; DHCPv6 Server2 é o servidor DHCPv6 inválido.
- Depois de configurar a função de DHCPv6 snooping, PC1 e PC2 podem obter o endereço do DHCPv6 Server1.
Topologia de rede
Figura 8 -5 Rede de configuração das funções básicas de DHCPv6 snooping
Etapas de configuração
- Passo 1:Configure o tipo de link de VLAN e porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
# Configura o tipo de link da porta tengigabitethernet0/1-tengigabitethernet0/3 como acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface tengigabitethernet 0/1-0/3Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
- Passo 2:Configure o pool de endereços do DHCPv6 Server1 como 1000::2/64 e o pool de endereços do DHCPv6 Server2 como 2000::2/64. (Omitido)
- Passo 3:Configure a função de DHCPv6 snooping no dispositivo.
# Habilite a função de DHCPv6 snooping.
Device(config)#ipv6 dhcp snooping enable# Configure a porta tengigabitethernet0/2 como porta confiável.
Device(config)#interface tengigabitethernet 0/2Device(config-if-tengigabitethernet0/2)#ipv6 dhcp snooping trustDevice(config-if-tengigabitethernet0/2)#exit
- Passo 4:Confira o resultado.
# Após PC1 e PC2 obterem o endereço com sucesso, visualize as entradas de DHCPv6 snooping no dispositivo.
Device#show ipv6 dhcp snooping databaseInterface-Name MAC-Address VLAN-ID ValidTime AgedTime IP-Addresste0/1 0001.0001.0008 2 120 0 1000::2te0/1 0001.0001.0007 2 120 0 1000::3
PC1 e PC2 podem obter endereços do DHCPv6 Server1.
Inspeção ARP Dinâmica
Visão geral
A inspeção ARP dinâmica é chamada de DAI para abreviar. Descubra e previna o ataque de falsificação ARP verificando a validade do pacote ARP, melhorando a segurança da rede. A função DAI é dividida em dois tipos:
- Função Port DAI: Verifica a validade do pacote ARP recebido pela porta especificada, de forma a descobrir e prevenir o ataque de spoofing ARP;
A base para verificar a validade do pacote ARP é a entrada de ligação do IP Source Guard da porta. O princípio de verificação específico é o seguinte:
Se o endereço IP de envio, o endereço MAC de origem e o ID da VLAN no pacote ARP recebido corresponderem à entrada de ligação do IP Source Guard da porta, o pacote ARP será um pacote válido e será encaminhado. Caso contrário, o pacote ARP é um pacote inválido, descarte-o e registre as informações de log.
- Função global DAI: Verifique a validade dos pacotes ARP recebidos por todas as portas, para evitar que usuários falsos enviem pacotes ARP forjados, resultando em entradas ARP incorretas.
A detecção de validade da mensagem ARP é baseada na entrada de ligação de proteção de origem IP global. O princípio de detecção específico é o seguinte:
Quando no pacote ARP recebido, o endereço IP do remetente é o mesmo que o endereço IP na entrada de ligação do protetor de origem IP global, mas o endereço MAC de origem é diferente, julgue o pacote ARP como um pacote forjado e descarte sem gravar as informações de log.
A função DAI da porta, global DAI também verifica a eficácia do pacote ARP. O princípio de verificação específico é o seguinte:
Quando o endereço MAC de origem no pacote ARP recebido for diferente do endereço MAC de envio, o pacote é um pacote ineficaz, descarte-o e não registre as informações de log.
- Detecção de Ataque ARP de Interface: Não execute a detecção de validação para o pacote ARP recebido na interface especificada. Registre apenas as informações de log, que são usadas para detectar o ataque ARP.
Configuração da Função de Inspeção ARP Dinâmica
Tabela 9 -1 A lista de configuração da função de Inspeção ARP Dinâmica
| Tarefa de configuração | |
| Configurar a função de inspeção ARP dinâmica da porta | Configurar a função de inspeção ARP dinâmica da porta |
| Configurar a função global Dynamic ARP Inspection | Configurar a função global Dynamic ARP Inspection |
Configurar a função de inspeção ARP dinâmica da porta
Condição de configuração
Antes de configurar a função de Inspeção ARP Dinâmica da porta, primeiro conclua a seguinte tarefa:
- Configure a entrada de ligação do IP Source Guard da porta
Configurar Inspeção ARP Dinâmica de Porta
Após habilitar a função DAI da porta, o sistema verifica a validade do pacote ARP recebido pela porta de acordo com a entrada de ligação do IP Source Guard. O pacote inválido é descartado e registrado nos logs.
O conteúdo registrado nos logs inclui VLAN ID, porta de recebimento, endereço IP de envio, endereço IP de destino, endereço MAC de envio, endereço MAC de destino e o número dos mesmos pacotes ARP inválidos. O usuário pode analisar ainda mais de acordo com as informações de log gravadas, como localizar o host que inicia o pacote ARP.
Por padrão, as informações de log são emitidas periodicamente. Podemos controlar a gravação, saída e envelhecimento do pacote configurando o intervalo de saída do log. O intervalo de saída do log serve como base dos seguintes parâmetros de log:
- Período de atualização do log: usado para avaliar se os logs precisam ser gerados e antigos. Se o intervalo de saída do log configurado for menor que 5s, o período de atualização do log será igual a 1s. Caso contrário, o período de atualização do log é igual a 1/5 do intervalo de saída do log.
- Tempo de idade do log: Após o tempo limite de idade, os logs são excluídos. O tempo de idade do log é o intervalo de saída do log.
- Token de log: no período de atualização de log, o número máximo de logs permitidos para gravação. O número de tokens de log é 15 múltiplos do período de atualização do log.
Após habilitar a função port DAI, podemos configurar também a função port ARP rate limit, ou seja, limitar o número de pacotes ARP que são processados a cada segundo, evitando que os demais pacotes do protocolo não possam ser processados a tempo porque o sistema processa muitos pacotes de pacotes ARP por um longo tempo.
A função de limitação de taxa de porta ARP é limitar o número de pacotes ARP que são processados a cada segundo, evitando que os outros pacotes de protocolo não possam ser processados a tempo porque o sistema processa muitos pacotes ARP por um longo tempo. Depois que o número de pacotes ARP recebidos em um segundo excede o limite de taxa, os pacotes ARP recebidos subsequentes são descartados. Se os pacotes ARP recebidos pela porta em 20 segundos sucessivos excederem a taxa, desabilite a porta para isolar a fonte de impacto do pacote.
Tabela 9 -2 Configurar a função de inspeção ARP dinâmica da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a função DAI da porta | ip arp inspection | Obrigatório Por padrão, a função DAI da porta está desabilitada. |
| Configure o limite superior dos pacotes ARP processados pela porta | ip arp inspection rate-limit limit-value | Opcional Por padrão, o limite superior dos pacotes ARP processados pela porta é 15pps. |
| Retornar ao modo de configuração global | exit | - |
| Configure o número de logs em buffer | ip arp inspection log-buffer buffer-size | Opcional Por padrão, o sistema pode armazenar em buffer 32 logs. Se estiver configurado como 0, indica que os logs não estão em buffer, ou seja, após detectar o pacote ARP inválido, os logs são enviados diretamente para o terminal. |
| Configurar o intervalo de saída do log | ip arp inspection log-interval seconds | Opcional Por padrão, o intervalo de saída do log é 20s. Se estiver configurado como 0, indica que os logs não estão em buffer, ou seja, após detectar o pacote ARP inválido, os logs são enviados diretamente para o terminal. |
| Configurar o nível de saída do log | ip arp inspection log-level log-level | Opcional Por padrão, o nível de saída do log é 6. |
Depois que a função DAI da porta é habilitada, todos os pacotes ARP recebidos pela porta (broadcast ARP e unicast ARP) são redirecionados para a CPU para detecção, encaminhamento de software, gravação de log e assim por diante. Quando o número de pacotes ARP é grande, eles consomem seriamente os recursos da CPU, portanto, quando o dispositivo se comunica normalmente, não é sugerido habilitar a função DAI da porta. Quando há dúvida de que há ataque de falsificação de ARP na rede, é necessário habilitar a função DAI da porta para detectar e localizar. Em uma porta, a função DAI da porta não pode ser usada com a função de Port Security ao mesmo tempo. Depois de configurar o limite de taxa da porta que processa os pacotes ARP no modo de configuração do grupo de agregação, o limite de taxa de pacote ARP de cada porta membro do grupo de agregação é o valor. Se os pacotes ARP recebidos pela porta em 20s sucessivos ultrapassarem o limite superior, mas a porta não for desabilitada automaticamente, é necessário consultar o capítulo Error-Disable do manual de configuração.
Configurar a função de inspeção ARP dinâmica global
Condição de configuração
Antes de configurar a função global Dynamic ARP Inspection, primeiro complete a seguinte tarefa:
- Configurar a entrada vinculada do IP Source Guard global
Configurar a função de inspeção ARP dinâmica global
Após habilitar a função DAI global, o sistema realizará a verificação de validade do pacote ARP recebido de acordo com a entrada vinculada do IP Source Guard global. Se for o pacote inválido, descarte-o diretamente e não registre o log.
Tabela 9 -3 Configure a função global Dynamic ARP Inspection
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar função DAI global | arp-security | Obrigatório Por padrão, a função DAI global está desabilitada. |
Configurar inspeção dinâmica de ataque ARP
Condição de configuração
Nenhum
Configurar inspeção dinâmica de ataque ARP
Depois que a detecção dinâmica de ataque ARP for habilitada, o sistema não realizará a inspeção de validação para o pacote ARP recebido, mas apenas registrará o log.
Mesa 9 -4 Configurar a inspeção dinâmica de ataque ARP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente só pode ter efeito na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente só pode ter efeito no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Permita a detecção de ataque A RP na interface | ip arp inspection attack | Obrigatório Por padrão, a detecção de ataque ARP não está habilitada na interface. |
Monitoramento e Manutenção da Inspeção ARP Dinâmica
Tabela 9 -5 Monitoramento e manutenção de inspeção ARP dinâmica
| Comando | Descrição |
| clear ip arp inspection { log-information | log-statistics | pkt-statistics [ interface { interface-name | link-aggregation link-aggregation-id } ] } | Exclua as informações estatísticas registradas pela função DAI |
| show arp-security | Exibir o status global da função DAI |
| show ip arp inspection [ interface { interface-name | link-aggregation link-aggregation-id } ] | Exibe as informações de configuração da função DAI da porta |
| show ip arp inspection log-information | Exibe as informações de log gravadas pela função DAI da porta |
| show ip arp inspection log-statistics | Exibir as informações estatísticas dos logs |
| show ip arp inspection pkt-statistics [ interface { interface-name | link-aggregation link-aggregation-id } ] | Exiba as informações estatísticas dos pacotes ARP |
Exemplo de configuração típica de DAI
Configurar função básica DAI
Requisitos de rede
- PC1 e PC2 estão conectados à rede IP via dispositivo.
- Em Device, configure a função DAI da porta, evitando o ataque ARP e spoofing.
Topologia de rede
Figura 9 -1 Rede de configuração das funções básicas da DAI
Etapas de configuração
- Passo 1:Em Dispositivo, configure a VLAN e o tipo de link de porta.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta tengigabitethernet0/1 como Acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface tengigabitethernet 0/1Device(config-if-tengigabitethernet0/1)#switchport mode accessDevice(config-if-tengigabitethernet0/1)#switchport access vlan 2Device(config-if-tengigabitethernet0/1)#exit
- Passo 2:Configure a função DAI da porta no dispositivo.
#Ative a função DAI da porta na porta tengigabitethernet0/1 e configure o limite superior da porta tengigabitethernet0/1 processando pacotes ARP como 30pps.
Device(config)#interface tengigabitethernet 0/1Device(config-if-tengigabitethernet0/1)#ip arp inspectionDevice(config-if-tengigabitethernet0/1)#ip arp inspection rate-limit 30Device(config-if-tengigabitethernet0/1)#exit
- Passo 3:Em Dispositivo, configure a entrada de ligação.
#Na porta tengigabitethernet0/1, configure o endereço MAC como 0012.0100.0001, o endereço IP como 192.168.1.2 e a entrada de ligação do IP Source Guard da porta da VLAN2.
Device(config)#interface tengigabitethernet 0/1Device(config-if-tengigabitethernet0/1)#ip source binding ip-address 192.168.1.2 mac-address 0012.0100.0001 vlan 2Device(config-if-tengigabitethernet0/1)#exit
- Passo 4:Confira o resultado.
#Consulte as informações de configuração relacionadas à DAI.
Device#show ip arp inspectionDynamic ARP Inspection information:Dynamic ARP Inspection log buffer size: 30Dynamic ARP Inspection log Interval: 20Dynamic ARP Inspection log Level: 6Dynamic ARP Inspection interface information :-------------------------------------------interface status rate-limit(pps) attackte0/1 enable 30 OFFte0/2 disable 15 OFF……
#Quando a taxa de recebimento de pacotes ARP pela porta tengigabitothernet0/1 exceder 30pps, o dispositivo descartará os pacotes que excederem a taxa e emitirá a seguinte mensagem de prompt.
Jan 1 02:21:06: The rate on interface tengigabitethernet0/1 too fast ,the arp packet drop!#Quando a taxa de recebimento de pacotes ARP pela porta tengigabitothernet0/1 exceder 30pps e durar 20 segundos, o dispositivo fechará a porta tengigabitothernet0/1 e emitirá as seguintes informações de prompt.
Jan 1 02:21:26: %LINK-INTERFACE_DOWN-4: interface tengigabitethernet0/1, changed state to downJan 1 02:21:26: The rate of arp packet is too fast,dynamic arp inspection shut down the tengigabitethernet0/1 !
#Quando os pacotes ARP recebidos pela porta tengigabitothernet0/1 são inconsistentes com a entrada de ligação, o dispositivo registra as informações ilegais no seguinte formato no log DAI e as envia regularmente.
Jan 1 07:19:49: SEC-7-DARPLOG: sender IP address: 192.168.1.3 sender MAC address:0011.0100.0001 target IP address: 0.0.0.0 target MAC address:0000.0000.0000 vlan ID:2 interface ID: tengigabitethernet0/1 record packet :32 packet(s) #Visualize o registro DAI.
Device#show ip arp inspection log-informationLogCountInBuffer:1SEC-7-DARPLOG: sender IP address: 192.168.1.3 sender MAC address:0011.0100.0001 target IP address: 0.0.0.0 target MAC address:0000.0000.0000 vlan ID:2 interface ID: tengigabitethernet0/1 record packet :0 packet(s)
DAI Combinando com DHCP Snooping
Requisitos de rede
- PC1 e PC2 estão conectados à rede IP via dispositivo; PC2 é o cliente DHCP; Device2 é o relé DHCP.
- O Device1 configura a função DHCP Snooping e porta DAI, percebendo que o PC2 pode acessar a rede IP normalmente e o PC1 não pode acessar a rede IP.
Topologia de rede

Figura 9 – 1 Rede de combinação de DAI com DHCP Snooping
Etapas de configuração
- Passo 1:Configure o tipo de link de VLAN e porta no Device1.
#Criar VLAN3.
Device1#configure terminalDevice1(config)#vlan 3Device1(config-vlan3)#exit
#Configure o tipo de link de porta tengigabitethernet 0/1 e tengigabitethernet 0/2 como acesso, permitindo a passagem dos serviços da VLAN3.
Device1(config)#interface tengigabitethernet 0/1-0/2Device1(config-if-range)#switchport access vlan 3Device1(config-if-range)#exit
- Passo 2:Configure o tipo de link de VLAN e porta no Device2.
#Cria VLAN2 e VLAN3.
Device2#configure terminalDevice2(config)#vlan 2-3
#Configure o tipo de link da porta tengigabitethernet 0/1 e tengigabitethernet 0/2 como acesso; a porta tengigabitethernet 0/1 permite a passagem dos serviços da VLAN2; a porta tengigabitethernet 0/2 permite a passagem dos serviços da VLAN3.
Device2(config)#interface tengigabitethernet 0/1Device2(config-if-tengigabitethernet0/1)#switchport mode accessDevice2(config-if-tengigabitethernet0/1)#switchport access vlan 2Device2(config-if-tengigabitethernet0/1)#exitDevice2(config)#interface tengigabitethernet 0/2Device2(config-if-tengigabitethernet0/2)#switchport mode accessDevice2(config-if-tengigabitethernet0/2)#switchport access vlan 3Device2(config-if-tengigabitethernet0/2)#exit
- Passo 3:Configure a interface VLAN e o endereço IP em Device1 e Device2. (Omitido)
- Passo 4:Configure a função DHCP Snooping no Device1.
#Ative a função DHCP Snooping e configure a porta tengigabitethernet0/2 como porta confiável.
Device1(config)#dhcp-snoopingDevice1(config)#interface tengigabitethernet 0/2Device1(config-if-tengigabitethernet0/2)#dhcp-snooping trustDevice1(config-if-tengigabitethernet0/2)#exit
- Passo 5:Configure a função DAI da porta no Device1.
#Ative a função DAI da porta na porta tengigabitethernet0/1.
Device1(config)#interface tengigabitethernet 0/1Device1(config-if-tengigabitethernet0/1)#ip arp inspectionDevice1(config-if-tengigabitethernet0/1)#exit
- Passo 6:Configure o endereço IP do servidor de retransmissão DHCP no Device2.
#Configure o endereço IP do servidor de retransmissão DHCP como 198.168.2.1.
Device2(config-if-vlan3)ip dhcp relayDevice2(config-if-vlan3)ip dhcp relay server-address 192.168.2.1
- Passo 7:Confira o resultado.
#Depois que o PC2 obtiver o endereço com sucesso; veja as entradas dinâmicas do DHCP Snooping no Device1.
Device1#show dhcp-snooping databasedhcp-snooping database:database entries count:1database entries delete time :300---------------------------------macAddr ipAddr transtion-id vlan interface leaseTime(s) status0013.0100.0001 192.168.1.100 2 2 te0/1 107990 active------
# O PC2 pode acessar a Rede IP normalmente e o PC1 não pode acessar a Rede IP.
Host Guard
Visão geral
A função Host Guard é usada principalmente para os dispositivos da camada de acesso, evitando que os pacotes ARP forjados pelo invasor danifiquem a tabela ARP no dispositivo terminal. O endereço IP do host protegido pelo Host Guard geralmente é aplicado aos endereços IP do dispositivo de gateway na rede e no servidor importante.
Na função Host Guard, existem dois conceitos:
- Grupo de guarda de host: compreende uma série de regras de grupo de guarda de host, ou seja, o conjunto de endereços IP de host protegidos;
- Regra do grupo Host Guard: um endereço IP de host protegido
O princípio de trabalho da função Host Guard é o seguinte:

Figura 10 – 1 O breve diagrama da função Host Guard
Conforme mostrado na figura acima, o Atacante pode utilizar o endereço IP 192.168.1.1 do Servidor para forjar o pacote ARP e encaminhar para o PC via Dispositivo, danificando a tabela ARP no PC. Como resultado, o PC não pode acessar o Servidor normalmente.
No Dispositivo, após aplicar o endereço IP do Servidor 192.168.1.1 como uma regra de grupo de guarda de host à porta te0/2, quando o endereço IP de envio no pacote ARP recebido pelo Dispositivo for o mesmo que o endereço IP do Servidor e se o a porta é te0/2, o pacote pode ser processado normalmente; se a porta de recebimento não for te0/2, o pacote será descartado. Ou seja, o pacote ARP enviado pelo Servidor só pode ser encaminhado pela porta te0/2. O pacote ARP forjado pelo atacante é descartado.
Configuração da Função do Host Guard
Tabela 10 -1 A lista de configuração da função Host Guard
| Tarefa de configuração | |
| Configurar a função Host Guard | Configurar o grupo de proteção do host Configurar o aplicativo do grupo de proteção do host |
Configurar a função de proteção do host
Condição de configuração
Nenhum
Configurar grupo de guarda de host
O grupo de guarda de host compreende uma série de regras de grupo de guarda de host. Podemos configurar os endereços IP do gateway e servidor importante na rede conforme as regras no grupo de guarda de host.
Tabela 10 -2 Configurar o grupo de guarda do host
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Crie o grupo de guarda do host | host-guard group group-name | Obrigatório Por padrão, não crie nenhum grupo de guarda de host. |
| Configurar a regra do grupo de guarda do host | permit host ip-address | Obrigatório Por padrão, não configure a regra do grupo de guarda do host. |
Cada grupo de guarda de host suporta no máximo 128 regras de grupo de guarda de host.
Configurar aplicativo do grupo de guarda de host
Aplique o grupo de guarda do host à porta. Podemos monitorar os pacotes ARP recebidos, realizando a proteção para a tabela ARP.
Tabela 10 -3 Configurar o aplicativo do host guard group
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o aplicativo do grupo de guarda do host | host-guard binding group-name | Obrigatório Por padrão, não há grupo de guarda de host aplicado na porta ou grupo de agregação. |
Monitoramento e manutenção do Host Guard
Tabela 10 -4 Monitoramento e manutenção do Host Guard
| Comando | Descrição |
| show host-guard binding [ interface interface-id | link-aggregation link-aggregation-id ] | Exibir as informações do aplicativo do grupo de guarda do host |
| show host-guard group [ group-name ] | Exiba as informações de configuração do grupo de guarda do host e das regras |
AAA
Visão geral
AAA refere-se a Autenticação, Autorização e Contabilidade. Desde que a rede apareceu, o mecanismo de autenticação, autorização e contabilidade tornou-se a base da operação da rede. O uso dos recursos na rede precisa ser gerenciado por Autenticação, Autorização e Contabilidade. AAA adota a arquitetura cliente/servidor. O cliente roda em NAS (Network Access Server) e o servidor gerencia as informações do usuário de forma centralizada. Para o usuário, NAS é o servidor; para o servidor, NAS é o cliente.
Autenticação significa autenticar o usuário ao utilizar os recursos do sistema de rede. Durante o processo, obtenha as informações de ID interagindo com o usuário e, em seguida, envie para o servidor de autenticação; o último verifica e processa as informações do ID com as informações do usuário salvas no banco de dados e, em seguida, confirma se o ID do usuário está correto de acordo com o resultado do processamento. Autorização significa que o usuário autorizado do sistema de rede usa seus recursos pelo modo especificado. O processo especifica os serviços e autoridades que o usuário autenticado pode usar e possuir após estar conectado à rede, como o endereço IP autorizado. Contabilidade significa que o sistema de rede coleta e registra o uso do usuário para os recursos da rede, de modo a cobrar do usuário pela rede usando taxas ou usado para auditoria.
RADIUS é um protocolo da arquitetura C/S. Seu cliente é o servidor NAS em primeiro lugar. O mecanismo de autenticação do protocolo RADIUS é flexível e pode adotar o modo de autenticação de login PAP, CHAP ou Unix. RADIUS é um protocolo expansível e todo o seu trabalho é baseado no vetor de Attribute-Length-Value. O princípio básico de trabalho do RADIUS é: O usuário está conectado ao NAS; O NAS usa o pacote Access-Require para enviar as informações do usuário ao servidor RADIUS, incluindo nome de usuário, senha e assim por diante. A senha do usuário é criptografada via MD5. As duas partes usam a chave de compartilhamento, que não é distribuída pela rede. O servidor RADIUS verifica a validade do nome de usuário e senha e fornece um desafio, se necessário, exigindo a autenticação adicional do usuário. Também podemos realizar a autenticação semelhante para NAS. Se válido, devolva o pacote Access-Accept ao NAS, permitindo que o usuário execute o próximo trabalho. Caso contrário, devolva o pacote Access-Reject, recusando o acesso do usuário. Se permitir o acesso, o NAS inicia a solicitação de estatísticas Account-Require ao servidor RADIUS. O servidor RADIUS responde Account-Accept, iniciando as estatísticas para o usuário. Enquanto isso, o usuário pode realizar suas próprias operações.
TACACS é um protocolo de autenticação antigo para a rede Unix. Ele permite que o servidor de acesso remoto transite a senha de login do usuário para o servidor de autenticação. O servidor de autenticação decide se o usuário pode efetuar login no sistema. O TACACS é um protocolo de criptografia, mas sua segurança é inferior ao TACACS+ e RADIUS. Na verdade, o TACACS+ é um novo protocolo. TACACS+ e RADIUS substituem o protocolo anterior na rede atual. TACACS+ usa TCP, enquanto RADIUS usa UDP. O RADIUS combina a autenticação e autorização do aspecto do usuário, enquanto o TACACS+ separa as duas operações.
Configuração de função AAA
Tabela 11 -1 A lista de configuração da função AAA
| Tarefa de configuração | |
| Configurar o domínio AAA | Configurar domínio ISP |
| Configure a função de autenticação no domínio AAA | Configure os métodos de autenticação padrão, login, dot1x e portal no domínio ISP |
| Configure a função de autorização no domínio AAA | Configure os métodos de autorização padrão, login e comandos no domínio ISP |
| Configure a função de contabilidade no domínio AAA | Configure os métodos de contabilidade padrão, login, dot1x, portal e comandos no domínio ISP |
| Digite o método de autenticação do modo privilegiado | Digite o método de autenticação do modo privilegiado |
| Configure a habilitação da autorização CLI | Configure a habilitação da autorização CLI Configurar habilitar a autorização do console |
| Configurar a função de estatísticas do sistema | Configure o método de estatísticas do evento do sistema |
| Configurar os atributos de estatísticas |
Configure a desativação das estatísticas de nome de usuário vazias
Configurar o envio do pacote de atualização de estatísticas Configurar o envio do modo de processamento de falha de estatísticas |
| Configurar o esquema RADIUS |
Configurar o servidor RADIUS
Configurar os atributos RADIUS Configure o endereço de origem do envio do pacote RADIUS |
| Configurar o esquema TACACS | Configurar o servidor TACACS Configure o endereço de origem do envio do pacote TACAS |
Configurar o domínio AAA
Domínio : o gerenciamento de usuários NAS é baseado no domínio ISP (Internet Service Provider), e cada usuário pertence a um domínio ISP. Em geral, o domínio ISP ao qual o usuário pertence é determinado pelo nome de usuário fornecido quando o usuário efetua login. Há um domínio do sistema por padrão. No domínio, você pode configurar o método de autenticação, autorização e contabilidade de cada usuário de acesso.
A solução do usuário baseado em domínio e gerenciamento de AAA é descrita da seguinte forma:
O gerenciamento de dispositivos NAS para usuários é baseado no domínio ISP. Geralmente, o domínio ISP ao qual o usuário pertence é determinado pelo nome de usuário fornecido quando o usuário efetua login.
"Inserir nome de usuário "= "Nome de usuário entendido pelo dispositivo"+ "Nome de domínio"
Ao autenticar usuários, os dispositivos determinam seus domínios na seguinte ordem e, em seguida, executam políticas AAA nos domínios:
- (Opcional) Faça login/acesse o módulo para configurar o domínio de autenticação designado;
- Domínio ISP especificado no nome de usuário;
- O domínio ISP padrão do sistema
Condição de configuração
Nenhum
Configurar o domínio ISP
Tabela 11 -2 Configurar o domínio AAA
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre na visualização de domínio do ISP | domain isp-name | Opcional Por padrão, o sistema possui um domínio ISP denominado system. |
| Retornar ao modo de configuração global | exit | - |
| Configurar o domínio ISP padrão | domain default enable isp-name | Opcional Por padrão, o domínio ISP padrão do sistema é o domínio do sistema. |
Configure a função de autenticação no domínio AAA
AAA fornece uma série de métodos de autenticação para garantir a segurança de dispositivos e serviços de rede. Por exemplo, autenticar o login do usuário para evitar que usuários ilegais operem dispositivos; autenticar usuários no modo privilegiado para restringir as autoridades de uso dos usuários para o dispositivo; autenticar conexões de sessão PPP para restringir a configuração das conexões ilegais.
Condição de configuração
Nenhum
Configurar o método de autenticação no domínio ISP
O AAA pode autenticar um usuário quando ele tenta fazer login em um domínio ISP específico. Os usuários que falham na autenticação não podem fazer login no domínio ISP especificado.
Tabela 11 -3 Configurar a lista de métodos de autenticação no domínio ISP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre na visualização de domínio do ISP | domain isp-name | Obrigatório Por padrão, o sistema possui um domínio ISP denominado system. |
| Configure o método de autenticação padrão no domínio ISP | aaa authentication default { none / local / radius-group group-name / tacacs-group group-name } | Opcional Por padrão, o método de autenticação padrão no domínio ISP é local. |
| Configure o método de autenticação de login do usuário no domínio ISP | aaa authentication login { none / enable / local / radius-group group-name / tacacs-group group-name } | Opcional Por padrão, não configure o método de autenticação de login, mas adote o método de autenticação padrão no domínio. |
| Configure o método de autenticação portal|dot1x no domínio ISP | aaa authentication {portal | dot1x}{ none / local /radius-group group-name / tacacs -group group-name } | Opcional Por padrão, não configure o Portal, método de autenticação dot1x, mas adote o método de autenticação padrão no domínio. |
Configure a função de autorização no domínio AAA
Após a autenticação bem-sucedida, a função de autorização do AAA pode controlar os direitos dos usuários administradores para recursos do dispositivo e acesso para recursos de rede, restringir administradores a executar comandos não autorizados e restringir o acesso de usuários a recursos de rede não autorizados.
Condição de configuração
Ao configurar a autorização de linha de comando no domínio, primeiro configure a autorização de habilitação da linha de comando para que a autorização de linha de comando configurada no domínio possa ter efeito.
Configurar o método de autorização no domínio ISP
Quando um usuário executa um item de autorização em um domínio ISP específico, o AAA pode autorizar o usuário, conceder ao usuário certas autoridades e proibir o usuário não autorizado de executar o item de autorização no domínio.
Tabela 11 -4 Configurar a lista de métodos de autorização no domínio ISP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre na visualização de domínio do ISP | domain isp-name | Obrigatório Por padrão, o sistema possui um domínio ISP denominado system. |
| Configure o método de autorização padrão no domínio ISP | aaa authorization default { if-authenticated / local / none / radius-group group-name / tacacs-group group-name } | Opcional Por padrão, o método de autorização no domínio ISP é nenhum. |
| Configure o método de autorização de comandos no domínio ISP | aaa authorization commands cmd-lvl { if-authenticated / none / radius-group group-name / tacacs-group group-name } | Opcional Por padrão, não configure o método de autorização de comandos no domínio ISP e o método de autorização no domínio é nenhum. A função de autorização de comando deve estar habilitada para que a configuração tenha efeito. |
| Configure o método de autorização do usuário que faz login no dispositivo no domínio ISP | aaa authorization login { if-authenticated / local / none / radius-group group-name / tacacs-group group-name } | Opcional Por padrão, não configure o método de autorização de login no domínio ISP, mas adote o método de autorização padrão no domínio. |
Os comandos de autorização AAA e os comandos config-commands de autorização aaa são configurados em nenhuma sequência.
Configure a função de contabilidade no domínio AAA
Os métodos personalizados podem ser usados para medir o comando, a sessão de login, o serviço de rede e os eventos do sistema no dispositivo. Os resultados estatísticos podem ser usados como base para cobrança dos usuários.
Condição de configuração
Nenhum
Configurar o método de contabilidade no domínio ISP
Quando um usuário efetua login com sucesso em um domínio ISP, o AAA pode contar o usuário, incluindo a hora de início do login, a hora de término do login, os comandos inseridos e assim por diante.
Tabela 11 -5 Configurar o método de contabilidade no domínio ISP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre na visualização de domínio do ISP | domain isp-name | Obrigatório Por padrão, o sistema possui um domínio ISP denominado system. |
| Configure o método de estatísticas de comando no domínio ISP | aaa accounting commands cmd-lvl { [ broadcast ] tacacs-group group-name } | Opcional Por padrão, não configure o método de estatísticas de comando e não execute as estatísticas de comando. |
| Configure o método de estatísticas padrão no domínio ISP | aaa accounting default { none | { start-stop | stop-only | wait-start [ broadcast ] { radius-group group-name / tacacs-group group-name }}} | Opcional Por padrão, o método de estatísticas no domínio ISP é nenhum. |
| Configure o método de contabilidade do usuário que faz login no dispositivo no domínio ISP | aaa accounting login{ none | { start-stop | stop-only | wait-start [ broadcast ] { radius-group group-name / tacacs-group group-name } } } | Opcional Por padrão, não configure o método de contabilidade do usuário que faz login no dispositivo no domínio ISP, mas use o método de contabilidade padrão no domínio ISP. |
| Configure o método de contabilidade portal|dot1x no domínio ISP | aaa accounting { portal | dot1x } { none | { start-stop | stop-only | wait-start [ broadcast ] { radius-group group-name / tacacs-group group-name } } } | Opcional Por padrão, não configure o portal, método de contabilidade dot1x no domínio ISP, mas use o método de contabilidade padrão no domínio ISP. |
Digite o Método de Autenticação do Modo Privilegiado
Depois que o usuário fizer login com sucesso no dispositivo, o AAA poderá autenticar o usuário que está entrando no modo privilegiado digitando o comando enable e proibir o usuário de entrar no modo privilegiado se a autenticação falhar.
Condição de configuração
Nenhum
Configurar o método de autenticação do modo privilegiado
Tabela 11 -6 Configure o método de autenticação do modo privilegiado
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o método de autenticação do modo privilegiado | aaa authentication enable-method { none / enable / radius-group group-name / tacacs-group group-name } | Opcional Por padrão, o método de autenticação do modo privilegiado é habilitado. |
Ao usar o método de autenticação RADIUS, a senha do nome de usuário no formato $enabLEVEL$ é usada como senha de autenticação, onde LEVEL representa o nível de usuário inserido pelo usuário atual e o intervalo de valores é 0-15, e o o nível mais alto é 15.
Ativar autorização de comando
Condição de configuração
Nenhum
Ativar autorização de comando
O dispositivo possui comandos de 0 a 15 níveis. A autorização de comando é determinar o nível de comandos usados pelos usuários pelo método de autorização e restringir os usuários a usar os comandos acima do nível atual.
Tabela 11 -7 Habilitar a autorização do comando no modo global
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a autorização de comando | aaa authorization config-commands | Obrigatório Por padrão, desative a função de autorização de comando. |
Ativar autorização do console
Para executar a restrição de acesso para a porta do console, você pode habilitar a autorização da porta do console e precisa habilitar a função de autorização do comando. E então, o dispositivo autorizará os comandos executados pela porta do console.
Tabela 11 -8 Habilitar a autorização do console
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a autorização do console | aaa authorization console | Obrigatório Por padrão, não ative a autorização do console. |
Configurar a função de estatísticas de eventos do sistema
Os usuários podem enviar eventos, como inicialização e reinicialização do sistema, ao servidor para obter estatísticas, configurando o método de estatísticas de eventos do sistema.
Condição de configuração
Nenhum
Configurar o método de estatísticas de eventos do sistema
Tabela 11 -9 Configurar a lista de métodos de estatísticas de eventos do sistema
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o método de estatísticas de eventos do sistema | aaa accounting system { none / { start-stop [broadcast ] { tacacs-group group-name } } } | Obrigatório Por padrão, não conta os eventos do sistema. |
As estatísticas de eventos do sistema suportam apenas o protocolo TACACS, mas não suportam o protocolo RADIUS.
Configurar os atributos de contabilidade
Condição de configuração
Nenhum
Desativar contabilidade de nome de usuário nulo
O usuário pode desabilitar a contabilidade de nome de usuário nulo AAA configurando o comando aaa contabilidade suprimir nome de usuário nulo . Por padrão, habilite a contabilidade de nome de usuário nulo AAA.
Tabela 11 -10 Desabilitar a contabilidade de nome de usuário nulo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Desabilite a contabilidade de nome de usuário nulo | aaa accounting suppress null-username | Obrigatório Por padrão, habilite a contabilidade de nome de usuário nulo. |
Enviar pacote de atualização de contabilidade
O usuário pode configurar o modo de envio do pacote de atualização contábil, incluindo principalmente envio em tempo real e envio periódico.
Tabela 11 -11 Envie o pacote de atualização de contabilidade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Envie o pacote de atualização de contabilidade | aaa accounting update periodic interval | Obrigatório Por padrão, não envie o pacote de atualização de contabilidade. |
Configurar o modo de processamento de envio de falha de contabilidade
Tabela 11 -12 Enviar o modo de processamento de envio de falha de contabilidade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o modo de processamento de envio de falha de contabilidade | aaa accounting start-fail {online | offline} | Opcional Por padrão, se a inicialização da contabilidade falhar, o usuário não poderá ficar online. |
Configurar o esquema RADIUS
Para configurar o esquema RADIUS, você precisa configurar os principais parâmetros do servidor.
Condição de configuração
Nenhum
Configurar o servidor RADIUS
Quando o AAA precisa usar o método RADIUS para autenticação, autorização e contabilidade, é necessário configurar os parâmetros do servidor RADIUS, incluindo endereço IP do servidor, porta de autenticação/autorização, porta de contabilidade e informações de chave compartilhada.
Antes de entrar no servidor RADIUS, precisamos configurar o grupo de servidores RADIUS. Referencie o nome do grupo de servidores ao configurar a lista de métodos, e podemos usar o grupo de servidores RADIUS para autenticar, autorizar e contar os usuários.
Tabela 11 -13 Configurar o servidor RADIUS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o nome do grupo de servidores RADIUS (o comando também pode entrar no modo de configuração do grupo de servidores RADIUS) | aaa server group radius group-name | Obrigatório Por padrão, não configure o nome do grupo de servidores RADIUS. |
| Configurar o servidor RADIUS | server {ip-address|ipv6 ip-address} [ acc-port acc-port-num ] [ auth-port auth-port-num ] [ priority priority ] { key [ 0 | 7 ] key } | Obrigatório Por padrão, não configure o servidor RADIUS. |
| Configurar o tempo morto do RADIUS | dead-time dead-time | Opcional Por padrão, o tempo morto do servidor RADIUS é 0, indicando que não está morto. |
| Configure os tempos máximos de retransmissão de RADIUS | retransmit retries | Opcional Por padrão, os tempos máximos de retransmissão do servidor RADIUS são três vezes. |
| Configure o tempo limite de resposta do servidor RADIUS | timeout timeout | Opcional Por padrão, o tempo limite de espera pela resposta do servidor RADIUS é de 5s. |
| Configure não verificar TAG ao resolver o atributo de túnel entregue pelo servidor RADIUS | tunnel without-tag | Opcional Por padrão, precisa do TAG ao resolver o atributo de túnel entregue pelo servidor RADIUS. |
| Configure o VRF do grupo de servidores RADIUS | ip vrf forwarding vrf-name | Opcional Por padrão, o grupo de servidores RADIUS pertence ao VRF global. |
Os dispositivos selecionam a ordem em que os servidores RADIUS são usados de acordo com o valor de prioridade configurado. O tempo morto significa que o dispositivo marca os servidores RADIUS que não respondem às solicitações de autenticação como indisponíveis e nenhuma solicitação é enviada a esses servidores durante o tempo morto. As chaves de compartilhamento configuradas no dispositivo e no servidor RADIUS devem ser consistentes.
Configurar os atributos RADIUS
Tabela 11 -14 Configurar os atributos RADIUS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o valor do tipo de serviço do atributo no pacote RADIUS da autenticação de login | radius login service-type attr-value | Opcional Por padrão, o valor do tipo de serviço no pacote RADIUS é 7. |
| Configure o máximo de pacotes simultâneos do dispositivo NAS e do servidor RADIUS | radius control-speed pck-num | Opcional Por padrão, o máximo de pacotes simultâneos do dispositivo NAS e do servidor RADIUS é 100. |
Configure o endereço de origem do envio do pacote RADIUS
Tabela 11 -15 Configure o endereço de origem de envio do pacote RADIUS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a interface selecionada pelo endereço de origem RADIUS | ip radius source-interface interface-name [ vrf vrf-name ] | Opcional Por padrão, o dispositivo seleciona automaticamente a interface de origem. |
Configurar a função de contabilidade do RADIUS
A função account-on é usada principalmente para designar todos os usuários online no servidor RADIUS quando o processo AAA é ativado pela primeira vez. Por padrão, a função de contabilização está desabilitada; quando a função account-on está habilitada, o intervalo de retransmissão padrão é de 6 segundos e o tempo máximo de retransmissão é de 50 vezes; devido ao tempo de inicialização lento do cartão de serviço do dispositivo de última geração, é recomendável que os usuários definam os tempos de retransmissão e o tempo de intervalo não inferiores aos valores padrão, tanto quanto possível.
Tabela 11 -16 Configurar a função de contabilização do RADIUS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de grupo de servidores RADIUS | aaa server group radius group-name | - |
| Configure a conta na função de RADIUS | accounting-on enable [interval seconds | send send-times] | Opcional Por padrão, a função de contabilização está desabilitada. |
Configurar o esquema TACACS
Para configurar o esquema TACACS, é necessário configurar os parâmetros chave do servidor.
Condição de configuração
Nenhum
Configurar o servidor TACACS
Se o AAA precisar usar o método TACACS para autenticação, autorização e contabilidade após configurar o servidor TACACS, ele precisará configurar os parâmetros do servidor TACACS, incluindo endereço IP do servidor, chave compartilhada, número da porta do servidor e outras informações de configuração.
O grupo de servidores TACACS pode ser usado para autenticar, autorizar e contabilizar usuários consultando o nome do grupo de servidores ao configurar o método.
Tabela 11 -17 Configurar o servidor TACACS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o nome do grupo de servidores TACACS (o comando também pode entrar no modo de configuração do grupo de servidores TACAS) | aaa server group tacacs group-name | Obrigatório Por padrão, não configure o nome do grupo de servidores TACAS. |
| Configurar o servidor TACACS | server {ip-address|ipv6 ip-address} [ port port-num ] [ priority priority ] { key [ 0 | 7 ] key} | Obrigatório Por padrão, não configure o servidor membro do grupo de servidores TACAS. |
| Configure o tempo limite de resposta do servidor TACAS | timeout timeout | Opcional Por padrão, o tempo limite de espera pela resposta do servidor TACAS é de 5s. |
| Configure o atributo VRF do grupo de servidores TACAS | ip vrf forwarding vrf-name | Opcional Por padrão, o grupo de servidores TACAS pertence ao VRF global. |
servidor de comando { endereço IP | endereço IP ipv6 } [ porta port-num ] [ prioridade prioridade ] { chave [ 0 | 7 ] tecla } várias vezes para configurar vários servidores TACAS no grupo de servidores Tacas. O dispositivo seleciona o servidor para autenticação de acordo com a ordem de configuração. Quando um servidor falha, o dispositivo seleciona automaticamente o próximo servidor. As chaves de compartilhamento configuradas no dispositivo e no servidor TACAS devem ser consistentes.
Configurar o endereço de origem do envio do pacote TACAS
Tabela 11 -18 Configure o endereço de origem do envio do pacote TACAS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a interface selecionada pelo endereço de origem TACAS | ip tacacs source-interface interface-name [ vrf vrf-name ] | Opcional Por padrão, o dispositivo seleciona automaticamente a interface de origem. |
Monitoramento e Manutenção AAA
Tabela 11 -19 Monitoramento e manutenção de AAA
| Comando | Descrição |
| debug aaa { authentication | authorization | accounting | event | error | all } | Habilite as informações de depuração AAA |
| debug radius [details] | Habilite as informações de depuração RADIUS |
| debug tacacs | Habilite as informações de depuração do TACAS |
| show aaa configuration | Exiba as informações de configuração AAA |
| show aaa module [dot1x | shell | shell-cmd | shell-web ] | Exiba os módulos de função AAA e o resultado sobre o módulo operando AAA pela última vez |
| show aaa server [ radius | tacacs ] | Indique a configuração do servidor RADIUS/TACACS e o status de AAA |
| show aaa session [dot1x | portal | shell | shell-web ] | Exibir a sessão de estatísticas AAA |
| show aaa source-address | Exibe o endereço de origem usado por AAA |
Exemplo de configuração típica AAA
Configurar o login do usuário Telnet para usar a autenticação local
Requisito de rede
Configure o dispositivo para usar a autenticação local para login de usuário Telnet
Topologia de rede

Figura 11 - 1 Rede de configuração de login de usuário Telnet para usar autenticação local
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. (omitido)
- Passo 2: Configure o endereço IP da interface. (Omitido)
- Passo 3: Configurar dispositivo.
# Configure o nome de usuário como admin1 e a senha como admin1.
Device#configure terminalDevice(config)#local-user admin1 class managerDevice(config-user-manager-admin1)#service-type telnetDevice(config-user-manager-admin1)#password 0 admin1Device(config-user-manager-admin1)#exit
#Configure o modo de autenticação AAA como a autenticação local.
Device(config)#domain systemDevice(config-isp-system)#aaa authentication login localDevice(config-isp-system)#exit
#Configure a sessão Telnet e habilite a autenticação local AAA.
Device(config)#line vty 0 15Device(config-line)#login aaaDevice(config-line)#exit
- Passo 4:Confira o resultado.
Quando o cliente efetuar login no dispositivo via Telnet, insira o nome de usuário admin1 e a senha admin1 de acordo com o prompt e, em seguida, efetue login na interface de usuário do Shell do dispositivo com êxito.
Configure o login do usuário Telnet para usar autenticação, autorização e estatísticas RADIUS
Requisitos de rede
- O dispositivo está conectado ao servidor Telnet e RADIUS e a rota IP está disponível.
- O endereço IP do servidor RADIUS é 2.0.0.2/24, a porta de autenticação/autorização é 1812, a porta de estatísticas é 1813 e a chave de compartilhamento é admin.
- Quando o usuário Telnet faz login no dispositivo, é necessário autenticar/autorizar e medir através do servidor RADIUS.
- Quando o servidor RADIUS falhar, use a autenticação e autorização locais.
Topologia de rede
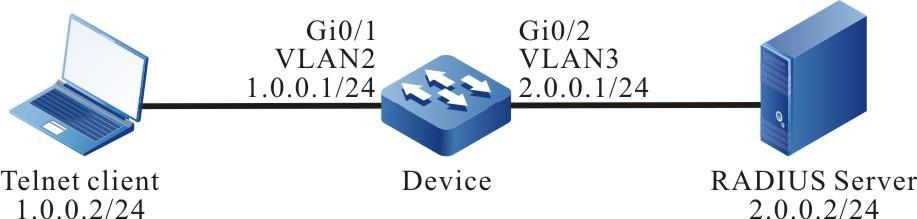
Figura 11 - 2 Rede de configuração de login de usuário Telnet para usar autenticação/autorização RADIUS e contabilidade
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Configurar dispositivo.
# Configure o AAA e use a autenticação/autorização RADIUS e a contabilidade.
A autenticação e a autorização primeiro usam o primeiro método na lista de métodos. Use o segundo método para autenticar e autorizar quando o servidor falhar.
Device#configure terminalDevice(config)#domain systemDevice(config-isp-system)#aaa authentication login radius-group radius-group localDevice(config-isp-system)#aaa authorization login radius-group radius-group localDevice(config-isp-system)#aaa accounting login start-stop radius-group radius-groupDevice(config-isp-system)#exit
#Configure o servidor RADIUS, a porta de autenticação é 1812, a porta de estatísticas é 1813 e a chave de compartilhamento é admin.
Device(config)#aaa server group radius radius-groupDevice(config-sg-radius-radius-group)#server 2.0.0.2 auth-port 1812 acct-port 1813 key adminDevice(config-sg-radius-radius-group)#exit
#Configure a sessão Telnet e habilite a autenticação/autorização RADIUS e estatísticas.
Device(config)#line vty 0 15Device(config-line)#login aaaDevice(config-line)#exit
- Passo 4:Configure o servidor RADIUS.
Para a configuração da interface do servidor RADIUS, consulte o documento de ajuda do servidor. A seguir, listamos as principais etapas.
#Adicione o usuário admin no servidor RADIUS, defina a senha como admin e configure o rótulo do usuário como 15.
#Defina o endereço IP do servidor como 2.0.0.2, compartilhe a chave como admin, a porta de autenticação como 1812 e a porta de estatísticas como 1813.
#Defina o endereço IP do cliente como 2.0.0.1 e a chave de compartilhamento como admin.
- Passo 5:Verifique o resultado e verifique a autenticação/autorização e estatísticas.
# Depois que o usuário Telnet fizer login no dispositivo, autorize com sucesso e use o show comando de privilégio para visualizar a prioridade do usuário 15.
#Podemos visualizar as informações de estatísticas de login e desconexão no servidor RADIUS.
Configurar a comutação de nível de usuário Telnet para usar a autenticação RADIUS
Requisitos de rede
- O dispositivo está conectado ao servidor Telnet e RADIUS e a rota IP está disponível.
- O endereço IP do servidor RADIUS é 2.0.0.2/24, a porta de autenticação/autorização é 1812 e a chave de compartilhamento é admin.
- Quando o nível de usuário muda de 1 para 3 depois que o usuário Telnet faz login no dispositivo, é necessário autenticar via servidor RADIUS.
Topologia de rede
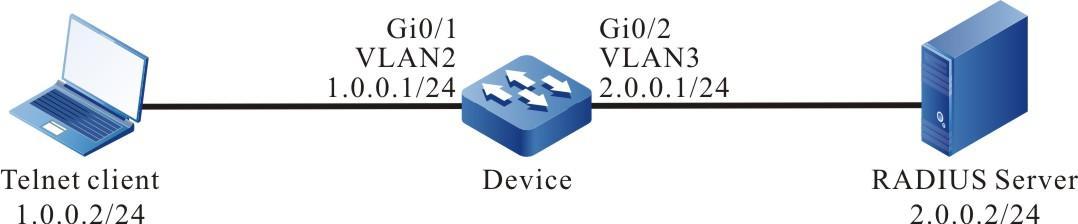
Figura 3 - 5 Rede de configuração de comutação de nível de usuário Telnet para usar autenticação RADIUS
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Configurar dispositivo.
#Configure a comutação de nível de usuário para usar a autenticação RADIUS.
Device#configure terminalDevice(config)#aaa authentication enable-method radius-group radius-groupDevice(config)#domain systemDevice(config-isp-system)#aaa authentication login radius-group radius-group localDevice(config-isp-system)#exit
#Configure o servidor RADIUS, a porta de autenticação é 1812 e a chave de compartilhamento é admin.
Device(config)#aaa server group radius radius-groupDevice(config-sg-radius-radius-group)#server 2.0.0.2 auth-port 1812 acct-port 1813 key adminDevice(config-sg-radius-radius-group)#exitDevice(config)#line vty 0 15Device(config-line)#login aaaDevice(config-line)#exit
- Passo 4:Configure o servidor RADIUS.
Para a configuração da interface do servidor RADIUS, consulte o documento de ajuda do servidor. A seguir, listamos as principais etapas.
#Adicione o nome de usuário $enab3$ com o nível de usuário 3 e defina a senha como admin.
A alternância de nível de usuário é corrigida para usar o nome de usuário no formato $enabLEVEL$ para autenticação. LEVEL é o nível para o qual o usuário deseja alternar. Quando o nível de usuário é reduzido, não precisa de autenticação.
- Passo 5:Confira o resultado.
Após o usuário Telnet inserir o nome de usuário e a senha para efetuar login de acordo com o prompt, o nível de usuário é 1 por padrão. Após executar o comando enable 3, insira a senha admin. Após ser autenticado pelo servidor RADIUS com sucesso, o nível de usuário é alterado para 3.
Configurar autorização TACACS e estatísticas do comando Shell
Requisitos de rede
- O dispositivo está conectado ao servidor Telnet e RADIUS e a rota IP está disponível.
- O endereço IP do servidor RADIUS é 2.0.0.2/24, a porta de serviço é 49 e a chave de compartilhamento é admin.
- Após o cliente Telnet efetuar login no dispositivo, o comando shell operado com nível de usuário 15 deve ser autorizado através do servidor TACACS e registrar o comando shell no servidor TACACS.
Topologia de rede

Figura 11 – 3 Rede de configuração da autorização TACACS e contabilidade do comando Shell
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Configurar dispositivo.
#Configure a autorização e a contabilidade do comando TACACS.
A autenticação deve ser bem-sucedida antes da autorização e contabilização.
Device#configure terminalDevice(config)#domain systemDevice(config-isp-system)#aaa authentication login tacacs-group tacacs-group localDevice(config-isp-system)#aaa authorization commands 15 tacacs-group tacacs-groupDevice(config-isp-system)#aaa accounting commands 15 tacacs-group tacacs-groupDevice(config-isp-system)#exitDevice(config)#aaa authorization config-commands
# Configure o servidor TACACS, a porta de serviço é 49 e a chave de compartilhamento é admin.
Device(config)#aaa server group tacacs tacacs-groupDevice(config-sg-tacacs-tacacs-group)#server 2.0.0.2 port 49 key adminDevice(config-sg-tacacs-tacacs-group)#exit
#Configure a sessão Telnet e habilite a autorização e a contabilidade TACACS.
Device(config)#line vty 0 15Device(config-line)#login aaaDevice(config-line)#exit
- Passo 4:Configure o servidor TACACS.
Para a configuração da interface do servidor TACACS , consulte o documento de ajuda do servidor. A seguir, listamos as principais etapas.
#Adicione o cliente 2.0.0.1 no servidor, a chave de compartilhamento é admin e selecione a autenticação “TACACS+(Cisco IOS)”.
#Defina a autorização do comando Shell para o administrador do usuário Telnet. Permitir os comandos configure terminal , roteador ospf e router rip e recuse os outros comandos.
- Passo 5:Confira o resultado.
#Depois que o usuário Telnet fizer login no dispositivo, execute o comando Shell. O comando autorizado pode ser executado com sucesso e a autorização do comando não autorizado falhou.
Device#configure terminal% Enter configuration commands, one per line. End with CNTL+Z.Device(config)#router ospf 100Device(config-ospf)#exitDevice(config)#router ripDevice(config-rip)#exitDevice(config)#interface fastethernet 0/1Command authorization failedDevice(config)#router bgp 100Command authorization failed
#Visualize as informações de estatísticas do comando Shell.
No servidor TACACS, podemos ver as informações estatísticas do comando Shell.
802.1X
Visão geral
802.1X
O 802.1X é uma solução de autenticação de acesso de banda larga apresentada pelo IEEE em junho de 2001. Ele define o controle de acesso à rede baseado em porta. Ao utilizar os recursos de acesso físico da LAN do IEEE 802 LAN, o 802.1X fornece um conjunto de métodos para autenticar e autorizar o acesso de dispositivos conectados às portas LAN via ponto a ponto.
O sistema 802.1X é a estrutura cliente/servidor típica, conforme mostrado na figura a seguir, incluindo três entidades: sistema suplicante (cliente), sistema de autenticação (dispositivo de autenticação) e sistema de servidor de autenticação (servidor de autenticação).

Figura 12 - 1 Arquitetura do sistema 802.1X
- A instalação do cliente suporta o software cliente da autenticação 802.1X, enviando a solicitação de autenticação para o dispositivo de autenticação. Se autenticar com sucesso, conecte-se à rede normalmente.
- O dispositivo de autenticação está entre o cliente e o servidor de autenticação, controlando o acesso à rede do cliente interagindo com o servidor.
- Normalmente, o servidor de autenticação é o servidor RADIUS (Remote Authentication Dial-In User Service), utilizado para verificar a validade do cliente e informar o resultado da autenticação ao dispositivo de autenticação. O dispositivo de autenticação controla o acesso à rede do cliente de acordo com o resultado da autenticação.
EAP (Extensible Authentication Protocol) usado pela autenticação 802.1X é um protocolo geral de autenticação PPP, usado para interagir as informações de autenticação entre o cliente, dispositivo de autenticação e servidor de autenticação. O protocolo 802.1X utiliza o formato de encapsulamento de quadro EAPOL (EAP Over LAN) para encapsular o pacote EAP, realizando a interação entre o cliente e o dispositivo de autenticação. De acordo com os diferentes cenários de aplicação, o protocolo 802.1X encapsula o pacote EAP nos diferentes formatos de quadro, realizando a interação entre o dispositivo de autenticação e o servidor de autenticação. No modo de autenticação de retransmissão, o pacote EAP é encapsulado no formato de quadro EAPOR (EAP Over RADIUS); no modo de autenticação de terminação, o pacote EAP é encapsulado no formato de quadro RADIUS padrão.
O modo de autenticação 802.1X inclui o modo de autenticação de retransmissão e o modo de autenticação final.
O fluxo de autenticação de retransmissão é o seguinte:
Figura 12 – 2 fluxo de autenticação de retransmissão 802.1X
O fluxo de autenticação de retransmissão é o seguinte:
- Quando o usuário tiver o requisito de acesso à rede, habilite o programa cliente 802.1X, insira o nome de usuário e a senha válidos registrados no servidor de autenticação e inicie a solicitação de autenticação (pacote EAPOL-Start). Aqui, o programa cliente envia o pacote de autenticação de solicitação para o dispositivo de autenticação e inicia um processo de autenticação.
- Após o dispositivo de autenticação receber o quadro de dados de solicitação de autenticação, envie um quadro de solicitação (pacote de solicitação/identidade EAP) para solicitar que o programa cliente do usuário envie o nome de usuário de entrada.
- O programa cliente responde à solicitação enviada pelo dispositivo de autenticação, enviando as informações do nome de usuário para o dispositivo de autenticação através do quadro de dados (EAP-Response/Pacote de identidade). O dispositivo de autenticação encapsula o quadro de dados enviado pelo cliente no pacote (pacote de solicitação de acesso RADIUS) e envia para o servidor de autenticação para processamento.
- Depois que o servidor RADIUS recebe as informações de nome de usuário encaminhadas pelo dispositivo de autenticação, compare as informações com a tabela de nomes de usuário no banco de dados, encontre as informações correspondentes do nome de usuário e use uma palavra de criptografia gerada aleatoriamente para criptografá-la. Enquanto isso, envie a palavra criptografada para o dispositivo de autenticação por meio do pacote RADIUS Access-Challenge; o dispositivo de autenticação o encaminha para o programa cliente.
- Após o programa cliente receber a palavra criptografada encaminhada pelo dispositivo de autenticação (pacote EAP-Request/MD5 Challenge), use a palavra criptografada para criptografar a senha (o algoritmo de criptografia é irreversível, gerando o pacote EAP-Response/MD5 Challenge) e encaminhar para o servidor de autenticação através do dispositivo de autenticação.
- O servidor de autenticação RADIUS compara as informações de senha criptografada recebidas (pacote de solicitação de acesso RADIUS) com as informações de senha criptografada local. Se forem iguais, considere o usuário como usuário válido e realimenta a mensagem de passagem da autenticação (pacote RADIUS Access-Accept e pacote EAP-Success);
- Após o dispositivo de autenticação receber a mensagem de aprovação da autenticação, altere a porta para o estado autorizado, permitindo que o usuário acesse a rede através da porta.
- O cliente também pode enviar o pacote EAPOL-Logoff para o dispositivo de autenticação, solicitando ativamente offline. O dispositivo de autenticação altera o status da porta de autorizada para não autorizada e envia o pacote EAP-Failure ao cliente.
A autenticação precisa do dispositivo de autenticação e do servidor de autenticação para suportar o protocolo EAP.
O fluxo de autenticação de encerramento é o seguinte:

Figura 12 - 3 802.1X terminando o fluxo de autenticação
- A diferença entre o modo de autenticação final e o modo de autenticação de retransmissão é: A palavra de criptografia aleatória usada para criptografar as informações de senha do usuário é gerada pelo dispositivo de autenticação. E o dispositivo de autenticação envia o nome de usuário, palavra de criptografia aleatória e informações de senha criptografadas pelo cliente para o servidor RADIUS para autenticação.
O modo de autenticação final é usado pelo servidor de autenticação implantado anteriormente e não oferece suporte ao protocolo EAP.
O dispositivo de autenticação suporta dois modos de controle de acesso:
- Modo de controle de acesso baseado em porta (Portbased): Depois que o primeiro usuário na porta é autenticado com sucesso, os outros usuários de acesso podem acessar a rede sem autenticação, mas depois que o primeiro usuário fica offline, os outros usuários também são recusados a acessar a rede .
- Modo de controle de acesso baseado em usuário (baseado em Mac): Todos os usuários de acesso na porta precisam ser autenticados separadamente. Depois que um usuário fica offline, apenas o usuário não pode acessar a rede e os outros usuários ainda podem acessar a rede.
A VLAN automática também é chamada de VLAN atribuída. Quando o cliente passa a autenticação do servidor, o servidor entrega as informações de VLAN autorizadas ao dispositivo de autenticação. Se a VLAN fornecida existir no dispositivo de autenticação e for válida, a porta de autenticação será adicionada à VLAN fornecida . Depois que o cliente fica offline, a porta é restaurada para o estado não autenticado, a porta é excluída da Auto VLAN e o valor padrão da porta é restaurado para a VLAN configurada anteriormente.
Após habilitar a Guest VLAN, o usuário pode e somente pode acessar os recursos na VLAN sem autenticação. Depois que o usuário é autenticado com sucesso, a porta sai da Guest VLAN e o usuário pode acessar outros recursos da rede. Normalmente, o usuário pode obter o software cliente 802.1X no Guest VLAN para atualizar o cliente ou executar outro programa aplicativo (como software antivírus, patch do sistema operacional). Após habilitar a autenticação 802.1x e configurar corretamente a VLAN convidada, a porta será adicionada à VLAN convidada no modo sem etiqueta. Neste momento, o usuário sob a porta na VLAN convidada inicia a autenticação. Se a autenticação falhar, a porta ainda está na VLAN convidada. Se a autenticação for bem-sucedida, ela pode ser dividida nos dois casos a seguir:
- Se o servidor de autenticação entregar uma VLAN, a porta deixará a VLAN convidada e ingressará na VLAN distribuída. Depois que o usuário estiver offline, a porta retornará à VLAN convidada;
- Se o servidor de autenticação não entregar a VLAN, a porta deixa a VLAN convidada e se junta à VLAN de configuração configurada no dispositivo de autenticação. Depois que o usuário estiver offline, a porta retornará à VLAN convidada.
Autenticação de canal seguro
Com base na função de autenticação 802.1X, a função de autenticação de canal seguro pode alcançar a autenticação 802.1X e abrir um canal seguro para os usuários finais especificados. Assim, o usuário final pode visitar os recursos na rede especificada no modo de não autenticação ou especificar um usuário final para visitar os recursos da rede sem autenticação.
Autenticação de endereço MAC
Na rede real, além de muitos usuários finais, pode haver alguns terminais de rede (como impressora de rede). Os terminais não carregam ou não podem instalar o software de cliente de autenticação 802.1X e podem usar o modo de autenticação de cliente livre para acessar a rede. O método de autenticação não precisa que o usuário instale nenhum software cliente de autenticação 802.1X. Depois que o dispositivo de autenticação detecta o endereço MAC do usuário pela primeira vez, o dispositivo de autenticação usa o nome de usuário e a senha configurados ou o endereço MAC do usuário como nome de usuário e senha para enviar ao servidor de autenticação para autenticação.
O formato de nome de usuário e senha usado pela autenticação de endereço MAC tem dois casos:
O endereço MAC serve como nome de usuário e senha: Use o endereço MAC do usuário autenticado como nome de usuário e senha;
Nome de usuário e senha fixos: Use o nome de usuário e a senha configurados no dispositivo de autenticação.
Configuração da Função 802.1X
Tabela 12 – 1 lista de configuração da função 802.1X
| Tarefa de configuração | |
| Configurar a função de autenticação 802.1X | Habilite a autenticação 802.1X |
| Configurar a autenticação de canal seguro | Ative a função de autenticação de canal seguro Configurar e aplicar o canal seguro |
| Configure a autenticação 802.1X e a propriedade de autenticação de canal seguro |
Configurar o modo de autenticação da porta
Configurar a função de disparo multicast Configurar a função de reautenticação Configure os tempos máximos de falha de autenticação da porta Configure a função de omitir o campo IP no nome de usuário Configurar a função de transmissão transparente de pacote Configurar a função keepalive Configure a função de não aguardar a resposta do servidor |
| Configurar a autenticação de endereço MAC |
Habilite a função de autenticação de endereço MAC
Configurar o formato de nome de usuário de autenticação de endereço MAC |
| Configurar os atributos públicos |
Configurar a direção controlada
Configurar a lista de hosts autenticáveis Configurar a função de autorização de IP Configure os tempos máximos de envio do pacote de solicitação de autenticação Configure os tempos máximos de envio do pacote de autenticação Configure a função de registro de log da falha de autenticação Configurar a função keepalive ARP Configure o máximo de usuários da porta Configurar o nome do prefixo IP ACL LAN padrão válida Configure permitindo que o usuário não autenticado se comunique na VLAN pertencente ao PVID Configurar o modo de controle de acesso à porta Configurar VLAN de convidado Configurar ACL de convidado Configurar VLAN crítica Configurar a função de movimentação de autenticação do usuário Configure os parâmetros do temporizador Configuração padrão da porta Configurar a etapa de registro de log |
Configurar função de autenticação 802.1X
A autenticação 802.1X e a autenticação de endereço MAC podem ser configuradas simultaneamente na mesma interface.
- Se a autenticação for bem-sucedida quando o usuário final realizar a autenticação de endereço MAC pela primeira vez, a autenticação 802.1X iniciada pelo usuário final não será processada. Caso contrário, a autenticação 802.1X iniciada pelo usuário final será processada normalmente.
- Quando o usuário final inicia a autenticação 802.1X pela primeira vez , não execute a autenticação de endereço MAC .
Condição de configuração
Nenhum
Ativar autenticação 802.1X
Para habilitar a função de autenticação 802.1X, o usuário final precisa instalar o software cliente com a função de autenticação 802.1X.
Tabela 12 – 2 Ativar 802.1X
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilitar autenticação global 802.1X | dot1x { enable | disable } | Opcional Por padrão, a função de autenticação global 802.1X está habilitada. |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a autenticação 802.1X | dot1x port-control { enable | disable } | Obrigatório Por padrão, a função de autenticação 802.1X na porta está desabilitada. |
Não ative a função de autenticação 802.1X e a função de autenticação de canal seguro simultaneamente em uma porta. Suporta habilitação da função de autenticação 802.1X e função de Port Security em uma porta ao mesmo tempo, mas há a seguinte limitação: Não permite configurar a regra de IP de Port Security ou regra MAX. Se a Port Security estiver configurada com a regra MAC relacionada quando a função de autenticação 802.1X for usada com a função de Port Security, o 802.1X não processará os pacotes enviados e solicitações de autenticação do terminal, que são processados pela segurança da porta.
Configure o pacote ARP/IP para acionar a geração do usuário 802.1X
Após habilitar a função de autenticação 802.1X na porta, se o usuário do terminal quiser visualizar as informações do usuário do terminal no dispositivo de autenticação sem iniciar a autenticação, ele precisa configurar o pacote ARP/IP para acionar a geração do usuário 802.1X.
Habilite a função de autenticação 802.1X e a função de disparo do pacote ARP/IP gerando o usuário 802.1X em uma porta. Quando o dispositivo de autenticação recebe o pacote ARP ou IP do usuário do terminal na porta, ele pode gerar o usuário 802.1X.
Tabela 12 - 3 Habilitar a função de acionamento do pacote ARP/IP gerando o usuário 802.1X
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure a função de acionamento do pacote ARP/IP gerando o usuário 802.1X | dot1x arp-ip-auth { enable | disable } | Obrigatório Por padrão, a função de acionamento do pacote ARP/IP que gera o usuário 802.1X está desabilitada na porta. |
| Configure o tempo limite do acionamento do pacote ARP/IP gerando o usuário 802.1X | dot1x arp-ip-auth timeout timeout-value | Opcional Por padrão, o tempo limite do disparo do pacote ARP/IP gerando o usuário 802.1X é de 5 minutos. |
Configurar autenticação de canal seguro
Condição de configuração
Nenhum
Ativar autenticação de canal seguro
Com base na função de autenticação 802.1X, a função de autenticação de canal seguro pode alcançar a autenticação 802.1X e abrir um canal seguro para os usuários finais especificados. Assim, o usuário final pode visitar os recursos na rede especificada no modo de não autenticação ou especificar um usuário final para visitar os recursos da rede sem autenticação.
Tabela 12 – 4 Habilite a autenticação de canal seguro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente só pode ter efeito na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente só pode ter efeito no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a autenticação de canal seguro | dot1x free-ip | Obrigatório Por padrão, a função de autenticação de canal seguro na interface está desabilitada. |
Não ative a função de autenticação de canal seguro e a função de Port Security simultaneamente em uma porta. Não ative a função de autenticação 802.1X e a função de autenticação de canal seguro simultaneamente em uma interface. Não ative a função de autenticação de endereço MAC e a função de autenticação de canal seguro simultaneamente em uma interface. Quando a função de autenticação de canal seguro está habilitada na interface, mas a regra de canal seguro não é aplicada ou a regra de canal seguro não está configurada, a função de autenticação de canal seguro e a função de autenticação 802.1X são idênticas. Durante a autenticação do canal seguro, quando a autenticação do usuário for bem-sucedida, ela ocupará os recursos do chip. Se os recursos do chip forem insuficientes, causará falha na autenticação do usuário.
Configurar e aplicar canal seguro
Depois que a autenticação de canal seguro for habilitada na interface, espera-se que o usuário final possa visitar os recursos na rede especificada quando o usuário final não estiver autenticado ou especificar um usuário final para visitar os recursos da rede sem autenticação. Neste caso, configure e aplique o canal seguro.
As regras para configurar o canal seguro podem ser classificadas nos seguintes tipos:
- Configure para permitir que o usuário final visite os recursos de rede especificados.
- Configure o usuário final especificado para visitar os recursos de rede.
Tabela 12 -5 Aplicar canal seguro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o canal seguro | hybrid access-list advanced { access-list-number | access-list-name } | Obrigatório Por padrão, o canal seguro não está configurado no dispositivo. |
| Configurar a regra de canal seguro | [ sequence ] permit [ether-ipv6] protocol { any | source-ip-addr source-wildcard | host source-ip-addr } { any | source-mac-addr source-wildcard | host source-mac-addr } { any | destination-ip-addr destination-wildcard | host destination-ip-addr } { any | destination-mac-addr destination-wildcard | host destination-mac-addr } | Obrigatório Por padrão, a regra de canal seguro não está configurada no canal seguro. |
| Aplicar o canal seguro | global security access-group { access-group-number | access-group-name } | Obrigatório Por padrão, nenhum canal seguro é aplicado no sistema. |
O dispositivo pode ser configurado com vários canais seguros. Um canal seguro pode ser configurado com várias regras de canal seguro. O tipo de canal seguro só pode ser a ACL avançada híbrida . Apenas um canal seguro pode ser aplicado ao dispositivo.
Configurar função de URL de redirecionamento
Se a URL de redirecionamento estiver configurada no dispositivo de autenticação e quando o usuário acessar a rede de segmento não livre da autenticação sem passar a autenticação ou não ser autenticado, o dispositivo de autenticação redirecionará o endereço da URL acessada pelo usuário para o redirecionamento configurado. endereço URL direto. Na interface de URL especificada, o usuário pode baixar/atualizar o cliente de autenticação, atualizar o software e assim por diante.
Tabela 12 -6 Configurar a função de redirecionamento de URL
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o canal seguro | hybrid access-list advanced { access-list-number | access-list-name } | Obrigatório Por padrão, o dispositivo não está configurado com o canal seguro. |
| Configurar a regra de canal seguro | [ sequence ] permit [ether-ipv6] protocol { any | source-ip-addr source-wildcard | host source-ip-addr } { any | source-mac-addr source-wildcard | host source-mac-addr } { any | destination-ip-addr destination-wildcard | host destination-ip-addr } { any | destination-mac-addr destination-wildcard | host destination-mac-addr } | Obrigatório Por padrão, o canal seguro não está configurado com a regra de canal seguro. |
| Aplicar o canal seguro | global security access-group { access-group-number | access-group-name } | Obrigatório Por padrão, nenhum canal seguro é aplicado no sistema. |
| Configurar a função de redirecionamento de URL | dot1x url url-redirect-string | Obrigatório Por padrão, o endereço de URL de redirecionamento não está configurado no dispositivo. |
O segmento livre da autenticação precisa incluir o endereço IP do servidor DNS e o endereço IP do link de URL de redirecionamento. Quando o cliente precisa solicitar o endereço do servidor DHCP, e o dispositivo de autenticação não é o servidor DHCP, é necessário habilitar a função DHCP RELAY no dispositivo de autenticação, para garantir que o cliente possa obter o endereço IP normalmente .
Configurar autenticação 802.1X e propriedade de autenticação de canal seguro
Se a função de autenticação 802.1X ou a função de autenticação de canal seguro não estiver habilitada na interface, a propriedade relacionada configurada não terá efeito.
Configurar o modo de autenticação de porta
O modo de autenticação 802.1X inclui o modo de autenticação de retransmissão e o modo de autenticação final.
O sistema de autenticação 802.1X compreende cliente, dispositivo de autenticação e servidor de autenticação. O protocolo 802.1X padrão define que o cliente e o servidor de autenticação interagem por meio do pacote EAP. O dispositivo de autenticação desempenha o papel de “retransmissor” durante a interação. O dispositivo de autenticação encapsula os dados EAP enviados pelo cliente em outro protocolo, como o protocolo RADIUS, e envia para o servidor de autenticação. Da mesma forma, o dispositivo de autenticação encapsula os dados EAP enviados pelo servidor de autenticação no pacote EAPOL e encaminha para o cliente. O modo de interação é chamado de modo de autenticação de retransmissão. O modo de autenticação de retransmissão requer que o servidor de autenticação suporte o protocolo EAP. A configuração do mecanismo de autenticação suportado pelo modo de autenticação de retransmissão EAP depende do cliente e do servidor de autenticação.
O servidor de autenticação implantado anteriormente pode não oferecer suporte ao protocolo EAP e precisa ser configurado como o modo de autenticação final. O pacote EAP do cliente não é enviado diretamente ao servidor de autenticação, mas o dispositivo de autenticação completa o pacote EAP interagindo com o cliente. Depois de obter as informações de autenticação do usuário suficientes, o dispositivo de autenticação envia as informações de autenticação ao servidor de autenticação para autenticação.
O modo de autenticação de finalização EAP suporta autenticação PAP (Protocolo de autenticação de senha) e autenticação CHAP (Protocolo de autenticação de handshake de desafio).
Tabela 12 - 7 Configurar o modo de autenticação da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação , a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar o modo de autenticação da porta | dot1x eap-relay { enable | disable } | Obrigatório Por padrão, o modo de autenticação na porta é o modo de autenticação final. |
A configuração do modo de autenticação de encerramento suporta apenas a autenticação EAP baseada em MD5 (Message Digest Algorithm). A função de autenticação 802.1x e a função de autenticação de canal seguro suportam o modo de retransmissão e autenticação final. Quando o cliente adota a autenticação de certificado, a porta de autenticação precisa ser configurada como o modo de autenticação de retransmissão. A autenticação de endereço MAC só pode suportar o modo de autenticação de terminação.
Configurar a função de acionamento de multicast
Alguns terminais são instalados com o cliente de autenticação 802.1X, mas o cliente não inicia a autenticação ativamente. O processo de autenticação só pode depender do dispositivo de autenticação para ser acionado. O dispositivo de autenticação envia periodicamente o pacote multicast solicitando o nome de usuário para a porta configurada com o disparo multicast. Após receber o pacote, o cliente responde a solicitação de autenticação do dispositivo de autenticação e inicia a autenticação 802.1X.
Tabela 12 – 8 Configurar a função de disparo multicast
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2 , a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Ativar o gatilho multicast | dot1x multicast-trigger | Obrigatório Por padrão, a função de disparo multicast na porta está desabilitada. |
| Configurar o período de disparo do multicast | dot1x multicast-period multicast-period-value | Opcional Por padrão, o tempo de disparo multicast na porta é 15s. |
Se o cliente não suportar a função de disparo multicast, a exibição do adaptador do cliente pode estar anormal. Enquanto isso, pode causar a falha de reautenticação.
Configurar função de reautenticação
Para verificar se o cliente está online, evitar o travamento anormal do cliente afetando a exatidão da contabilidade do usuário e impedir que o cliente seja usado por outros, o dispositivo de autenticação inicia periodicamente a solicitação de reautenticação para o cliente. Durante o processo, o usuário não precisa inserir o nome de usuário ou a senha novamente.
Tabela 12 - 9 Configurar a função de reautenticação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2 , a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar a reautenticação | dot1x reauthentication | Obrigatório Por padrão, a função de reautenticação está habilitada na porta. |
Configurar tempos máximos de falha de autenticação
Depois que os tempos de falha de autenticação do cliente atingem o limite, o cliente entra no estado morto. Durante o tempo morto, o dispositivo de autenticação não responde mais à solicitação de autenticação iniciada pelo cliente.
Tabela 12 – 10 Configure os tempos máximos de falha de autenticação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| tempos máximos de falha de autenticação de porta | dot1x max-authfail max-authfail-value | Obrigatório Por padrão, o tempo máximo de falha de autenticação da porta é 1. |
Configurar função de transmissão transparente de pacote
No ambiente de aplicação real, o terminal de autenticação e o dispositivo de autenticação podem cruzar o dispositivo intermediário. Se o dispositivo intermediário não puder transmitir o pacote EAPOL de forma transparente, a autenticação não poderá ser realizada normalmente. Para que a autenticação seja feita normalmente, precisamos habilitar a função de transmitir o pacote EAPOL de forma transparente na porta do dispositivo intermediário que recebe o pacote EAPOL e configurar uma porta de uplink para a porta. Se a porta habilitada com a função de transmissão do pacote EAPOL receber o pacote EAPOL de forma transparente, envie o pacote da porta uplink configurada. Se o dispositivo conectado diretamente à porta de uplink for um dispositivo de autenticação, o dispositivo de autenticação processa após receber o pacote EAPOL.
Tabela 12 – 11 Configurar a função de transmissão transparente de pacote
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure a função de transmissão transparente de pacote | dot1x eapol-relay { enable | disble } | Obrigatório Por padrão, a função de transmitir o pacote de forma transparente na porta está desabilitada. |
| Configurar a porta de uplink | dot1x eapol-relay uplink { interface interface-name | link-aggregation link-aggregation-id } | Obrigatório Por padrão, a porta não está configurada com a porta de uplink. |
Configurar função Keepalive
Para detectar se o cliente está online, o dispositivo de autenticação envia periodicamente o pacote EAP-Request/Identity ao cliente. Se estiver recebendo o pacote EAP-Response/Identity do cliente, envie o pacote EAP-Request/MD5 Challenge para o cliente. Se o sistema de autenticação receber o pacote EAP-Response/MD5 Challenge, confirme se o cliente está online normalmente e envie o pacote EAP-Success para informar o cliente sobre o sucesso do keepalive.
Tabela 12 – 12 Configurar a função keepalive
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar a função keepalive | dot1x keepalive { enable | disable } | Obrigatório Por padrão, a função keepalive na porta está desabilitada. |
| Configurar o tempo de manutenção | dot1x keepalive period period-value | Opcional Por padrão, o período keepalive na porta é de 60 segundos. |
| Configure os tempos de retransmissão do pacote keepalive | dot1x keepalive retries retries-value | Opcional Por padrão, o tempo máximo de atividade na porta é 3. |
| Configurar o tipo keepliave | dot1x keepalive type { request-identity | request-md5} | Opcional Por padrão, o tipo keepalive na porta é o keeplive padrão. |
A função keepalive precisa ser suportada pelo software cliente de autenticação 802.1X (como o cliente TC). Se o cliente não oferecer suporte, isso pode resultar na falha do keepalive e o usuário ficar offline.
Configurar não aguardando resposta do servidor
No modo de autenticação de retransmissão, o cliente pode enviar alguns pacotes que o servidor não responde. Os pacotes fazem com que o canal de sessão entre o dispositivo de autenticação e o servidor de autenticação seja ocupado e, como resultado, a autenticação do cliente subsequente falha. Podemos habilitar a função de não aguardar a resposta do servidor na porta para evitar o problema.
Tabela 12 - 13 Configure a função de não aguardar a resposta do servidor
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| resposta do servidor | dot1x nowait-result | Obrigatório Por padrão, a função de não aguardar a resposta do servidor está desabilitada. |
Configurar autenticação de endereço MAC
A autenticação 802.1X e a autenticação de endereço MAC podem ser configuradas simultaneamente na mesma interface.
- Se a autenticação for bem-sucedida quando o usuário final realizar a autenticação de endereço MAC pela primeira vez, a autenticação 802.1X iniciada pelo usuário final não será processada. Caso contrário, a autenticação 802.1X iniciada pelo usuário final será processada normalmente.
- Quando o usuário final inicia a autenticação 802.1X pela primeira vez , não execute a autenticação de endereço MAC .
Condição de configuração
Nenhum
Ativar função de autenticação de endereço MAC
A autenticação de endereço MAC também é chamada de autenticação de cliente livre. O modo de autenticação é aplicável ao terminal que não pode instalar o software cliente para autenticação e também ao usuário final que não instala o software cliente, mas pode autenticar sem inserir o nome de usuário e a senha.
Ao configurar os parâmetros de autenticação de endereço MAC na porta do dispositivo de autenticação e se a porta não habilitar a função de autenticação de endereço MAC, a função configurada não tem efeito.
Tabela 12 - 14 Habilite a função de autenticação de endereço MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a função de autenticação de endereço MAC | dot1x mac-authentication { enable | disable } | Obrigatório Por padrão, a função de autenticação de endereço MAC na porta está desabilitada. |
Suporte habilitando a função de autenticação de endereço MAC e função de Port Security em uma porta ao mesmo tempo, mas há limitação: não permite configurar a regra de IP de segurança de porta ou regra MAX. Não ative a função de autenticação de endereço MAC e a função de autenticação de canal de segurança em uma porta ao mesmo tempo.
Configurar o formato de nome de usuário de autenticação de endereço MAC
O formato de nome de usuário e senha usado pela autenticação de endereço MAC inclui dois casos: formato fixo de nome de usuário e senha e formato de nome de usuário e senha de endereço MAC.
Formato fixo de nome de usuário e senha: Ao receber os pacotes do usuário final, o dispositivo de autenticação envia o nome de usuário e a senha configurados ao servidor de autenticação para autenticação.
Formato de nome de usuário e senha do endereço MAC: O dispositivo de autenticação usa o endereço MAC do usuário final como nome de usuário e senha. O formato do endereço MAC como nome de usuário e senha inclui dois casos: Um é com o hífen, como 00-01-7a-00-00-01; o outro não é com hífen, como 00017a000001.
Tabela 12 – 15 Configurar o formato de nome de usuário de autenticação de endereço MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar o formato de nome de usuário de autenticação de endereço MAC | dot1x mac-authentication user-name-format { fixed account account-value password password-value | mac-address [ with-hyphen | without-hyphen ] } | Obrigatório Por padrão, a autenticação de endereço MAC adota o endereço MAC com hífen como nome de usuário e senha. |
Configurar delimitador de nome de domínio
O dispositivo de autenticação pode gerenciar o usuário com base no domínio. Se o nome de usuário de autenticação tiver o nome de domínio, o dispositivo usará o servidor no grupo de servidores AAA para autenticar, autorizar e contabilizar o usuário. Se o nome de usuário de autenticação não tiver o nome de domínio, use o servidor de autenticação configurado padrão no sistema para autenticar. Portanto, o dispositivo de autenticação precisa analisar corretamente o nome de usuário e o nome de domínio, desempenhando a função decisiva para que o usuário forneça o serviço de autenticação. Diferentes clientes suportam diferentes delimitadores de nome de usuário e nome de domínio. Para gerenciar e controlar melhor o acesso do usuário de diferentes formatos de nome de usuário, é necessário especificar o delimitador de nome de domínio suportado no dispositivo de autenticação.
Atualmente, os delimitadores de nome de domínio com suporte incluem @, / e \.
Quando o delimitador de nome de domínio é @, o formato de nome de usuário autenticado é username@domain .
Quando o delimitador de nome de domínio é /, o formato de nome de usuário autenticado é username/domain .
Quando o delimitador de nome de domínio é \, o formato de nome de usuário autenticado é domain\username .
Aqui, nome de usuário é o nome de usuário puro e domínio é o nome de domínio. Se o nome de usuário contiver vários delimitadores de nome de domínio, o dispositivo de autenticação identificará apenas o primeiro delimitador de nome de domínio como o delimitador de nome de domínio usado real e os outros caracteres como uma parte do nome de domínio.
Tabela 12 - 16 Configurar o delimitador de nome de domínio
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar o delimitador de nome de domínio | dot1x domain-delimiter domain-delimiter-type | Obrigatório Por padrão, o delimitador de nome de domínio na porta é @. |
Ao usar o nome de usuário com o nome de domínio para autenticação, é necessário configurar o grupo de servidores de autenticação correspondente no dispositivo de autenticação.
Configurar o formato de nome de usuário de autenticação
O usuário de autenticação é nomeado pelo formato username@domain. O nome de domínio está atrás do delimitador de nome de domínio @. O dispositivo de autenticação decide qual grupo de servidores de autenticação autentica o usuário analisando o nome de domínio. O servidor inicial não pode aceitar o nome de usuário com o nome de domínio, portanto, o dispositivo de autenticação precisa excluir o nome de domínio contido no nome de usuário e apenas enviar o nome de usuário de autenticação para o servidor. Você pode selecionar se o nome de usuário de autenticação enviado ao dispositivo de autenticação carrega o nome de domínio configurando o formato do nome de usuário de autenticação.
Atualmente, o delimitador de nome de domínio compatível inclui @, \, /.
Tabela 12 - 17 Configurar o formato do nome de usuário de autenticação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o formato do nome de usuário de autenticação | dot1x user-name-format { with-domain | without-domain } | Obrigatório Por padrão, envie o nome de usuário de autenticação com o nome de domínio para o servidor de autenticação. |
Configure a porta de envio do nome de usuário de autenticação sem nome de domínio para o servidor de autenticação para não dar suporte à autenticação de certificado.
Configurar o modo de interação do pacote de autenticação
No cenário de aplicação real, depois que a maioria dos clientes inicia a autenticação, o dispositivo de autenticação e o cliente suportam o modo de interação de autenticação unicast/multicast, mas ainda existem clientes de autenticação que podem identificar apenas o pacote de autenticação multicast, ou seja, o pacote de autenticação com o endereço MAC de destino 0180.C200.0003. Aqui, você pode configurar o modo de interação da autenticação multicast na porta.
Para a maioria dos clientes de autenticação, após o dispositivo de autenticação receber o pacote EAP respondido pelo servidor pela primeira vez e interagir com o cliente e o servidor de autenticação, fique sujeito ao identificador no pacote de serviço. Apenas alguns clientes de autenticação precisam estar sujeitos ao identificador gerado pelo dispositivo de autenticação. Para o caso, é necessário configurar a função referente ao identificador no pacote de autenticação EAP na porta.
Tabela 12 -18 Configurar o modo de interação do pacote de autenticação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar o modo de interação de autenticação | dot1x auth-mac { multicast | unicast } | Obrigatório Por padrão, a porta adota o modo de interação do pacote de autenticação unicast. |
| Refere-se ao identificador no pacote de autenticação EAP | dot1x identifier { match | ignore } | Opcional Por padrão, não se preocupe com o identificador no pacote de autenticação EAP. |
Apenas alguns clientes precisam se preocupar com o identificador do pacote que interagiu com a autenticação. A menos que haja uma demanda clara, tente evitar configurar a função.
Configurar atributos públicos
Ao configurar os parâmetros de atributo público e se a função de autenticação 802.1X, autenticação de canal seguro ou função de autenticação de endereço MAC não estiver habilitada na porta, a função configurada não terá efeito.
Condição de configuração
Ao configurar a função de autorização IP na porta, você precisa configurar a função keepalive ARP ao mesmo tempo.
Configurar direção controlada
A direção controlada da porta inclui controle bidirecional e controle unidirecional.
- Controlado bidirecional: A porta proíbe receber e encaminhar pacotes.
- Controlado unidirecional: Proíbe o recebimento de pacotes do cliente, mas permite o encaminhamento de pacotes para o cliente.
A função é usada com a função WOL (Wake On Lan). Algum terminal está no estado inativo, mas sua placa de rede ainda pode processar alguns pacotes especiais, como pacotes WOL. Depois que a placa de rede receber os pacotes WOL, habilite o dispositivo terminal e entre no estado de funcionamento.
Quando a porta de acesso do terminal inativo habilita a função de autenticação, você pode configurar a porta como controlada unidirecional, garantindo que os pacotes WOL possam ser encaminhados ao terminal normalmente. Depois que o terminal for iniciado, ele poderá iniciar a autenticação. Após passar a autenticação, ele pode acessar os recursos da rede normalmente.
Ao enviar os pacotes WOL através do segmento, é necessário configurar a entrada de encaminhamento ARP no dispositivo de autenticação.
Tabela 12 -19 Configurar a direção controlada
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Configurar a direção controlada | dot1x control-direction { both | in } | Obrigatório Por padrão, a porta é controlada bidirecionalmente. |
Configurar lista de hosts autenticados
Depois de habilitar a função de lista de hosts autenticáveis, apenas permita que o usuário cujo endereço MAC esteja na lista de hosts autenticáveis se autentique e as autenticações iniciadas pelos outros usuários são recusadas.
Tabela 12 -20 Configurar a lista de hosts autenticáveis
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar a lista de hosts autenticáveis | dot1x auth-address { enable | disable | mac-address } | Obrigatório Por padrão, a lista de hosts autenticáveis na porta está desabilitada. |
Configurar função de autorização de IP
Ao habilitar a função de autorização de IP na porta e se descobrir que o endereço IP do usuário de autenticação muda, force o usuário offline, incluindo os seguintes modos:
Desabilitar: No modo, não detecta o endereço IP do usuário.
dhcp-server: Ao configurar o modo, é necessário configurar a função DHCP Snooping no dispositivo. Depois que o usuário de autenticação obtiver o endereço IP do servidor DHCP, registre a relação de ligação do usuário de autenticação e o endereço IP no dispositivo. Se descobrir que o endereço IP do usuário foi alterado, force o usuário offline.
servidor radius: o servidor RADIUS encapsula o endereço IP usado encapsulando o usuário de autenticação no campo Endereço IP do Quadro no pacote RADIUS e o dispositivo de autenticação registra a relação de ligação do usuário e o endereço IP. Se descobrir que o endereço IP do usuário foi alterado, force o usuário offline.
Suplicante: Depois que o usuário passa pela primeira autenticação, o dispositivo registra a relação de vinculação do usuário de autenticação e do endereço IP. Se descobrir que o endereço IP do usuário foi alterado, force o usuário offline.
bind-mac-ip: Modo de ligação MAC+IP, após o usuário de autenticação passar pela primeira autenticação, uma entrada de ligação MAC+IP será gerada e a configuração da entrada será salva. Mais tarde, apenas o endereço IP nas entradas de ligação geradas quando a primeira autenticação é passada pode ser usada para acessar a rede.
Tabela 12 -21 Configurar a função de autorização de IP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar a função de autorização de IP | dot1x authorization ip-auth-mode { disable | dhcp-server | radius-server | supplicant | bind-mac-ip } | Obrigatório Por padrão, a função de autorização de IP está desabilitada na porta. |
Configurar máx. Envio de pacotes de solicitação de tempos de autenticação
Após o dispositivo de autenticação receber os pacotes EAPOL-Start enviados pelo cliente, envie o pacote de solicitação de autenticação EAP-Request/Identity ao cliente. Se o dispositivo de autenticação não receber o pacote de resposta, retransmita o pacote. A função é utilizada para configurar os tempos máximos de envio do pacote EAP-Request/Identity. Se os tempos de envio excederem o valor máximo configurado, o dispositivo de autenticação julga que o cliente está desconectado e encerra a autenticação.
O processo de retransmissão do pacote EAP-Request/Identity é o seguinte:

Figura 12 -4 Retransmitir pacotes de solicitação/identidade EAP
Tabela 12 -22 Configure os tempos máximos de envio dos pacotes de solicitação de autenticação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure os tempos máximos de envio dos pacotes de solicitação de autenticação | dot1x max-reauth count | Obrigatório Por padrão, os tempos máximos de envio do pacote de solicitação de autenticação na porta são 3. |
Configurar máx. Envio do pacote de tempos de autenticação
Durante a autenticação, o dispositivo de autenticação envia os outros pacotes EAP-Request, exceto os pacotes EAP-Request/Identity para o cliente, como o pacote de desafio EAP-Request/MD5. Se o dispositivo de autenticação não receber o pacote de resposta, retransmita o pacote. A função é utilizada para configurar os tempos máximos de envio do pacote. Se os tempos de envio excederem o valor máximo configurado, o dispositivo de autenticação julga que a autenticação do cliente falhou.
O processo de retransmissão do pacote EAP-Request é o seguinte:

Figura 12 -5 Retransmitir o pacote EAP-Request
Tabela 12 -23 Configure os tempos máximos de envio do pacote de autenticação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2 , a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure os tempos máximos de envio do pacote de autenticação | dot1x max-req count | Obrigatório Por padrão, os tempos máximos de envio do pacote de autenticação na porta são 2. |
Configurar a função de log de registro de falha de autenticação
Após habilitar a função de registro de falha de autenticação, o dispositivo de autenticação registrará as informações sobre a falha de autenticação, de modo a detectar o motivo da falha.
Tabela 12 - 24 Configurar a função de log de registro de falha de autenticação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar a função de registro de dados de gravação | dot1x logging security-data {abnormal-logoff | failed-login | normal-logoff | successful-login }* | Obrigatório Por padrão, a função de registro de dados de registro não está habilitada na porta. |
Configurar a função ARP Keepalive
Para verificar se o usuário está online após o usuário do terminal passar pela autenticação, o dispositivo de autenticação envia os pacotes de solicitação ARP para o usuário autenticado. O dispositivo de autenticação confirma se o usuário está online ao receber o pacote de resposta ARP do usuário.
Tabela 12 -25 Configurar a função keepalive ARP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar a função keepalive ARP | dot1x client-probe { enable | disable } | Obrigatório Por padrão, a função keepalive ARP na porta está desabilitada. |
O dispositivo de autenticação pode acionar a função keepalive ARP normalmente somente após obter o endereço IP do usuário autenticado. Se não estiver recebendo o pacote de resposta ARP do dispositivo de autenticação durante o período de proteção, force o usuário a ficar offline.
Configurar o máximo de usuários de uma porta
Após o número de usuários autenticados na porta atingir o limite configurado, o sistema de autenticação não responde à nova solicitação de autenticação iniciada pelo usuário.
Tabela 12 – 26 Configurar o máximo de usuários da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o máximo de usuários da porta | authentication max-user-num max-uer-num-value | Obrigatório Por padrão, o número máximo de usuários permitidos para conexão na porta é 256. |
A porta precisa ser configurada como o modo de controle de acesso baseado no usuário (baseado em Mac). Caso contrário, os usuários de acesso configurados não podem entrar em vigor.
Configurar o nome do prefixo IP ACL
Após a autenticação do usuário final ser bem-sucedida, quando o servidor envia o IP ACL com o número maior que 2000 , é necessário configurar o IP ACL com o nome " IP ACL prefix name + ACL number" no dispositivo . Por exemplo, o servidor envia a ACL com o número 2001 e então configura a ACL IP com o nome " assignacl-2001" no dispositivo.
Tabela 12 -27 Configurar o nome do prefixo IP ACL
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o nome do prefixo IP ACL | dot1x number-acl-prefix number-acl-prefix-name | Obrigatório Por padrão, o nome do prefixo IP ACL é " assignacl-". |
Quando o modo de controle de acesso é configurado como modo multi-host baseado em porta (multi-hosts em modo host baseado em porta), a entrega da função ACL não tem efeito.
Configurar VLAN válida padrão
Quando o servidor não envia a VLAN (Auto VLAN), esta configuração pode ser usada para especificar a VLAN se espera -se que os usuários autenticados se comuniquem na VLAN especificada .
Tabela 12 -28 Configure a VLAN válida padrão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| VLAN válida padrão | dot1x default-active-vlan default-active-vlan-id | Obrigatório Por padrão, a VLAN válida padrão não está configurada. |
A prioridade do relacionamento de ligação após a autenticação do usuário é na seguinte ordem: servidor enviando a VLAN, VLAN válida padrão, VLAN na qual o PVID da interface se localiza. Quando a porta é configurada com base no modo de controle de acesso do usuário (macbased), a VLAN efetiva padrão entrará em vigor quando a porta atender ao modo VLAN do modo híbrido e a condição MAC VLAN estiver habilitada.
Configure para permitir que o usuário não autenticado se comunique na VLAN que o PVID localiza no
Quando várias interfaces acessam a interface, cada terminal precisa realizar o controle de acesso. Alguns terminais que não podem iniciar a autenticação 802.1X também esperam visitar os recursos da rede e você pode habilitar o comando. Depois que a função é habilitada, o usuário final não autenticado pode normalmente se comunicar na VLAN na qual o PVID está localizado.
Esta função deve atender às seguintes funções para garantir o funcionamento normal.
- Habilite a autenticação 802.1X ou a autenticação de endereço MAC na interface.
- O modo de controle de acesso da interface é o modo de controle de acesso baseado no usuário (Macbased).
- O modo VLAN da porta é o modo híbrido.
- A função de receber apenas o pacote Untag precisa ser habilitada na interface.
Tabela 12 -29 Configure para permitir que o usuário não autenticado se comunique na VLAN que o PVID localiza em
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure para permitir que o usuário não autenticado se comunique na VLAN na qual o PVID localiza | dot1x native-vlan-free | Obrigatório Por padrão, a função de permitir que o usuário não autenticado se comunique na VLAN em que o PVID se localiza está desabilitada, |
Depois que a função é habilitada na interface, a função de apenas receber o pacote untag precisa ser habilitada na interface configurando o comando switchport accept frame-type untag na interface para garantir que o pacote enviado pelo usuário não autenticado possa apenas ser encaminhado na VLAN em que o PVID se localiza. Recomenda-se que esta função seja usada em conjunto com a VLAN enviada pelo servidor ou a VLAN válida padrão. A função não suporta a autenticação de canal seguro.
Configurar o modo de controle de acesso à porta
Existem dois tipos de modos de controle de acesso à porta: modo de controle de acesso baseado em porta e modo de autenticação de controle de acesso baseado em usuário.
Modo de controle de acesso baseado em porta (Portbased): Na porta, apenas permita a passagem de uma autenticação de usuário;
Modo de controle de acesso baseado em usuário (baseado em Mac): Na porta, permita que a autenticação multiusuário seja aprovada. Os usuários na porta precisam passar a autenticação respectivamente para que possam acessar a rede.
O modo de controle de acesso baseado em porta inclui dois tipos: modo multi-host e modo de host único.
Modo multi-host (Multi-hosts): Depois que um usuário na porta passa pela autenticação, os outros usuários na porta podem acessar a rede sem autenticação.
Modo Single-host (Single-host): Na porta, permite apenas que um usuário passe a autenticação e acesse a rede; os outros usuários não podem acessar a rede e também não podem passar na autenticação.
Tabela 12 - 30 Configurar o modo de controle de acesso à porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar o modo de controle de acesso | authentication port-method { macbased | portbased } | Obrigatório Por padrão, habilite o modo de autenticação do usuário na porta. |
| Configurar o modo de controle de acesso baseado em porta | authentication port-method portbased host-mode { multi-hosts | single-host } | Opcional Por padrão, habilite o modo de autenticação multi-host na porta. |
Ao configurar o modo de host do modo de controle de acesso baseado em porta, precisamos garantir que o modo de controle de acesso esteja configurado como o modo de controle de acesso baseado em porta ( Portbased).
Configurar VLAN de convidado
O usuário pode obter o software cliente 802.1X no Guest VLAN para atualizar o cliente ou executar outro programa aplicativo (como software antivírus e patch do sistema operacional).
Tabela 12 - 31 Configurar VLAN de convidado
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar VLAN de convidado | authentication guest-vlan guest-vlan-id | Obrigatório Por padrão, a Guest VLAN não está configurada na porta; o intervalo de valores é 1-4094. |
A VLAN convidada da porta não pode ser aplicada à VLAN dinâmica. Se o ID de VLAN especificado pelo Guest VLAN for o VLAN criado automaticamente pelo GVRP, o Guest VLAN poderá ser configurado com sucesso, mas não terá efeito. Para garantir que as funções possam ser usadas normalmente, distribua diferentes IDs de VLAN para VLAN de Voz, VLAN Privada e VLAN de Convidado.
Configurar ACL de convidado
Se o usuário não passar na autenticação, podemos configurar a Guest ACL na porta para limitar os recursos acessados pelo usuário na Guest VLAN.
Tabela 12 - 32 Configurar ACL de convidado
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar ACL de convidado | authentication guest-acl guest-acl-name | Obrigatório Por padrão, o Guest ACL não está configurado na porta. |
Se o Guest VLAN não estiver configurado na porta, o Guest ACL configurado não terá efeito. A ACL de convidado pode ter efeito apenas no modo de controle de acesso baseado no usuário (baseado em Mac). A regra ACL é configurada no dispositivo de autenticação.
Configurar VLAN crítica
Quando o usuário adota a autenticação RADIUS, o servidor de autenticação não fica disponível e, como resultado, a autenticação falha. Permita que o usuário acesse os recursos na VLAN especificada e a VLAN é chamada de VLAN Crítica.
Quando a porta está configurada como o modo de controle de acesso baseado em porta e há usuário para autenticar na porta, mas todos os servidores de autenticação não estão disponíveis, a porta é adicionada à VLAN crítica e todos os usuários sob a porta podem acessar os recursos na VLAN crítica.
Quando a porta está configurada como modo de controle de acesso baseado em usuário e há usuário para autenticar na porta, mas todos os servidores de autenticação não estão disponíveis, o usuário só tem permissão para acessar os recursos na VLAN Crítica.
Se a porta estiver configurada como o modo de controle de acesso baseado no usuário, ela deverá atender às seguintes condições para funcionar normalmente:
- O modo VLAN da porta é o modo híbrido
- A porta habilita a função MAC VLAN. O usuário na VLAN crítica inicia a autenticação. Se o servidor de autenticação ainda não estiver disponível, o usuário ainda está na VLAN Crítica. Se o servidor de autenticação estiver disponível, o usuário sairá da VLAN crítica com o resultado da autenticação.
Após a porta ser adicionada à VLAN crítica e se o dispositivo de autenticação estiver configurado com a função de detecção AAA, é detectado que o servidor de autenticação está disponível. Se a reinicialização da recuperação de vlan crítica estiver configurada:
- Se a porta for o modo de controle de acesso baseado em mac, a porta adicionada à VLAN crítica enviará o pacote unicast a todos os usuários na VLAN crítica ativamente, acionando a reautenticação do usuário.
- Se a porta for o modo de controle de acesso baseado em porta, a porta adicionada à VLAN crítica enviará ativamente o pacote multicast, acionando o usuário para reautenticar.
Tabela 12 -33 Configurar VLAN Crítica
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar VLAN crítica | authentication critical-vlan critical-vlan-id | Obrigatório Por padrão, não configure a VLAN crítica na porta. O intervalo de valores é 1-4094. |
| Configure a recuperação de porta e acione a autenticação | authentication critical-vlan recovery-action reinitialize | Opcional Por padrão, depois que o servidor de autenticação é detectado como disponível, a porta só sai da VLAN Crítica. |
A função suporta apenas a autenticação RADIUS. Se a função radius e escape estiverem configuradas no dispositivo, ou seja, configure a autenticação aaa dot1x radius none e critical vlan , quando o usuário autenticar, o servidor de autenticação não estará disponível e o usuário não entrará na Critical VLAN, mas escapará diretamente. Se apenas a função escape estiver configurada, ou seja, configurar a autenticação aaa dot1x none e critical vlan , quando o usuário autenticar, a função escape entrará em vigor. Ao configurar apenas a função Guest VLAN na porta, o usuário não conseguiu autenticar está na Guest VLAN. Quando a função Guest VLAN e Critical VLAN são configuradas na porta ao mesmo tempo, o usuário não consegue autenticar porque o servidor de autenticação não está disponível e entra na Critical VLAN. Se o usuário falhar por outro motivo, ele entrará na Guest VLAN. Para a função de detecção AAA, consulte a configuração da seção AAA.
Configurar a função de transferência de autenticação do usuário
A função de transferência de autenticação de usuário se aplica ao cenário em que o mesmo usuário (distinguir com base no endereço MAC do terminal) transfere de uma porta de autenticação do mesmo dispositivo para outra. Quando a função de transferência de autenticação do usuário está desabilitada, o usuário não tem permissão para iniciar a autenticação em outra porta de autenticação do dispositivo após ser autenticado em uma porta do dispositivo; quando a função de transferência de autenticação do usuário está habilitada e depois que o usuário é autenticado em uma porta, o dispositivo primeiro exclui as informações de autenticação na porta original após detectar que o usuário transfere para outra porta de autenticação e, em seguida, permite que o usuário inicie a autenticação na nova porta de autenticação
Independentemente de a função de transferência de autenticação do usuário estar habilitada ou não, o dispositivo gravará o log ao detectar que o usuário transfere entre as portas de autenticação.
Tabela 12 -34 Configurar a função de transferência de autenticação do usuário
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar a função de transferência de autenticação do usuário | authentication station-move { enable | disable } | Obrigatório Por padrão, a função de transferência de autenticação do usuário está desabilitada. |
Configurar parâmetros do temporizador
Os parâmetros do temporizador na porta contêm: temporizador de reautenticação, temporizador silencioso, temporizador de tempo limite do servidor, temporizador de tempo limite do cliente, temporizador de verificação offline do usuário de autenticação de endereço MAC.
Temporizador de reautenticação ( re-authperiod): Após configurar a função de reautenticação na porta, o dispositivo de autenticação inicia regularmente a solicitação de reautenticação ao cliente, aplicável à autenticação 802.1X.
Temporizador de silêncio (período de silêncio): Quando o cliente atinge os tempos máximos de falha de autenticação, o dispositivo de autenticação pode responder à solicitação de autenticação do cliente novamente após o tempo de silêncio expirar, aplicável à autenticação 802.1X e à autenticação de endereço MAC.
Temporizador de timeout do servidor (server-timeout): Se o dispositivo de autenticação não receber o pacote de resposta do servidor dentro do tempo especificado, ele é considerado desconectado do servidor, aplicável à autenticação 802.1X e autenticação de endereço MAC.
Timer timeout do cliente (supp-timeout): Se o dispositivo de autenticação não receber o pacote de resposta do cliente 802.1X dentro do tempo especificado, considera-se desconectado do usuário, aplicável à autenticação 802.1X.
Temporizador de verificação offline do usuário de autenticação de endereço MAC (detecção offline): Depois de habilitar a autenticação de endereço MAC, a porta detecta periodicamente se o usuário está online, aplicável à autenticação de endereço MAC.
Tabela 12 - 35 Configurar os parâmetros do temporizador
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure os parâmetros do temporizador | dot1x timeout { re-authperiod re-authperiod-value | quiet-period quiet-period-value | server-timeout server-timeout-value | supp-timeout supp-timeout-value | offline-detect offline-detect-value } | Obrigatório Por padrão, o tempo de reautenticação na porta é 3600s; o intervalo de valores é 5-65535; O tempo de silêncio é de 60 anos; o intervalo de valores é 1-65535; O tempo limite do servidor é de 30 segundos; o intervalo de valores é 5-3600; O tempo limite do cliente é de 30 segundos; o intervalo de valores é 5-3600; O tempo de verificação offline do cliente é de 300 segundos; o intervalo de valores é 5-3600; |
Configurar função MAB
Quando o terminal passa pela autenticação de endereço MAC e precisa passar pela autenticação do cliente para usar direitos de acesso mais altos, esta função pode ser habilitada.
Tabela 12 - 36 Habilitar a função MAB
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a autenticação 802.1X | dot1x port-control { enable | disable } | Obrigatório Por padrão, a função de autenticação 802.1X está desabilitada na porta. |
| Habilite a função de autenticação de endereço MAC | dot1x mac-authentication { enable | disable } | Obrigatório Por padrão, a função de autenticação de endereço MAC está desabilitada na porta. |
| Ative a função MAB | dot1x after-mac-auth { enable | disable } | Obrigatório Por padrão, a função MAB está desabilitada na porta. |
Restaurar a configuração padrão da porta
Restaure a configuração padrão da autenticação 802.1X e a autenticação de endereço MAC na porta.
Tabela 12 – 37 Restaurar a configuração padrão da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Restaurar a configuração padrão da porta | dot1x default | Obrigatório Na porta, desative a autenticação 802.1X e a função de autenticação de endereço MAC; os parâmetros de configuração relacionados são restaurados para os valores padrão e os parâmetros de configuração padrão não entram em vigor. |
O comando show dot1x é usado para visualizar os parâmetros de configuração padrão de autenticação detalhada.
Configurar a função de domínio de autenticação forçada da porta
Você pode habilitar essa função quando precisar atribuir à força os usuários autenticados na porta a um domínio especificado para autenticação.
Por padrão, o domínio de autenticação obrigatória da porta não está configurado. O domínio usado para autenticação do usuário usa o domínio carregado pelo nome do usuário. Se o usuário não carrega o domínio, o domínio padrão do módulo aaa é usado.
Após a configuração na porta, a prioridade do domínio utilizado pelo usuário é: domínio configurado na porta > domínio transportado pelo usuário > domínio padrão do módulo aaa.
Tabela 12 – 38 Ativar a função de domínio de autenticação forçada
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Ativar a função de domínio de autenticação forçada 802.1X | dot1x authentication domain domain-name | Obrigatório Por padrão, não configure o domínio de autenticação forçada na porta. |
802.1X Monitoramento e Manutenção
Tabela 12 - 39 Monitoramento e manutenção do 802.1X
| Comando | Descrição |
| clear dot1x statistic [ interface interface-name | interface link-aggregation link-aggregation-id | mac { mac-address | all } ] | Limpar as informações de estatísticas de autenticação |
| clear dot1x auth-fail-user history [ mac mac-address ] | Limpe as informações do registro de falha de autenticação |
| show authentication user [ interface interface-name | interface link-aggregation link-aggregation-id | mac mac-address | summary ] | Exibir as informações do usuário de gerenciamento de autenticação |
| show authentication intf-status [ interface interface-name | interface link-aggregation link-aggregation-id ] | Exibir as informações de status de autenticação |
| show dot1x | Exiba as informações de configuração padrão da autenticação |
| show dot1x auth-fail-user history [ recent | mac mac-address ] | Exibir as informações de falha de autenticação |
| show dot1x auth-address [ mac-address | interface interface-name | interface link-aggregation link-aggregation-id ] | Exibir as informações da lista de hosts autenticáveis |
| show dot1x config [ interface interface-name | interface link-aggregation link-aggregation-id ] | Exibir as informações de configuração de autenticação |
| show dot1x free-ip | Exibir as informações de configuração do canal seguro |
| show dot1x global config | Exibir as informações de configuração global |
| show dot1x statistic [ interface interface-name | interface link-aggregation link-aggregation-id | mac { mac-address | all } ] | Exibir as informações de estatísticas de autenticação |
| show dot1x user [ interface interface-name | interface link-aggregation link-aggregation-id | summary ] | Exibir as informações do usuário |
Exemplo de configuração típica de 802.1X
Configurar autenticação baseada em porta 802.1X
Requisitos de rede
- O usuário PC1 e PC2 em uma VLAN estão conectados à rede IP via dispositivo. No Dispositivo, habilite o controle de acesso 802.1X;
- O modo de autenticação adota a autenticação RADIUS;
- Quando o usuário não passar na autenticação, apenas permita o acesso ao Update Server; após o usuário passar na autenticação, permitir o acesso à Rede IP;
- Depois que um usuário na LAN passa pela autenticação, os outros usuários na VLAN podem acessar a rede IP sem autenticação.
Topologia de rede
Figura 12 – 6 Rede de configuração da autenticação baseada em porta 802.1X
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e a interface no dispositivo.
#Create VLAN2–Vlan5 no dispositivo.
Device#configure terminalDevice(config)# vlan 2-5
Device(config)#exit
# Configura o tipo de link da interface gigabitethernet 0/2 como Access , permitindo que os serviços da VLAN2 passem
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode accessDevice(config-if-gigabitethernet0/2)#switchport access vlan 2Device(config-if-gigabitethernet0/2)#exit
#Configure o tipo de link de porta em gigabitethernet0/3~gigabitethernet0/5 do dispositivo como acesso, permitindo que os serviços de VLAN3-VLAN5 passem respectivamente. (Omitido)
- Passo 2:Configure o endereço IP da interface do Dispositivo.
#Configure o endereço IP da VLAN5 como 130.255.167.1/24.
Device(config)#interface vlan 5Device(config-if-vlan5)#ip address 130.255.167.1 255.255.255.0Device(config-if-vlan5)#exit
- Passo 3:Configure a autenticação AAA.
#Habilite a autenticação AAA no dispositivo e adote o modo de autenticação RADIUS. A chave do servidor é admin, a prioridade é 1 e o endereço do servidor RADIUS é 130.255.167.167/24.
Device(config)#domain systemDevice(config-isp-system)# aaa authentication dot1x radius-group radiusDevice(config-isp-system)#exitDevice(config)#aaa server group radius radiusDevice(config-sg-radius-radius)#server 130.255.167.167 priority 1 key admin
- Passo 4:Configure o servidor AAA.
#Configure o nome de usuário, senha e chave como admin no servidor AAA. (Omitido)
#No servidor AAA, configure o RADIUS para entregar os três atributos de Auto VLAN: 64 é VLAN, 65 é 802 e 81 é VLAN3. (Omitido)
- Passo 5:Configure a autenticação da porta 802.1X.
#Ative a autenticação 802.1X na porta e o modo de autenticação é baseado em porta.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#dot1x port-control enableDevice(config-if-gigabitethernet0/2)# authentication port-method portbasedDevice(config-if-gigabitethernet0/2)#exit
#Configure Guest VLAN da porta como VLAN4.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)# authentication guest-vlan 4Device(config-if-gigabitethernet0/2)#exit
- Passo 6:Confira o resultado.
#Antes de passar a autenticação, gigabitethernet0/2 é adicionado ao Guest VLAN. Aqui, os usuários PC1 e PC2 estão na VLAN4 e permitem acessar o Servidor de Atualização.
Device#show vlan 4---- ---- -------------------------------- ------- --------- -----------------------------NO. VID VLAN-Name Owner Mode Interface---- ---- -------------------------------- ------- --------- -----------------------------1 4 VLAN0004 static Untagged gi0/2 gi0/4
#Verifique se o PC1 pode passar na autenticação; o servidor de autenticação entrega VLAN3. Aqui, os usuários PC1 e PC2 estão na VLAN3 e podem acessar a rede IP.
Device#show dot1x user--------------------NO 1 : MAC_ADDRESS= 3883.45ef.7984 STATUS= Authorized USER_NAME= adminVLAN= 3 INTERFACE= gi0/2 USER_TYPE= DOT1XAUTH_STATE= AUTHENTICATED BACK_STATE= IDLE IP_ADDRESS= UnknownIPV6_ADDRESS= UnknownOnline time: 0 week 0 day 0 hours 0 minute 51 secondsTotal: 1 Authorized: 1 Unauthorized/guest/critical: 0/0/0 Unknown: 0
Configurar autenticação baseada em Mac 802.1X
Requisitos de rede
- O usuário PC1 e PC2 em uma VLAN estão conectados à rede IP via dispositivo. O dispositivo adota o controle de acesso 802.1X;
- O modo de autenticação adota a autenticação RADIUS;
- Quando o PC não passar na autenticação, apenas permita o acesso ao Servidor de Atualização; após passar a autenticação, só permitir o acesso à Rede IP;
- Depois que um usuário na LAN passar pela autenticação, os outros usuários na VLAN ainda não poderão acessar a rede IP sem passar pela autenticação.
Topologia de rede
Figura 12 - 7 Rede de configuração da autenticação baseada em Mac 802.1X
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e interface no dispositivo .
#Create VLAN2–VLAN5 no dispositivo.
Device#configure terminalDevice(config)#vlan 2-5Device(config)#exit
#Configure o tipo de link da interface gigabitethernet 0/2 como Híbrido , permitindo a passagem de serviços de VLAN2 . Configure PVID como 2 . Device(config)#interface gigabitethernet 0/2
Device(config-if-gigabitethernet0/2)#switchport hybrid untagged vlan 2Device(config-if-gigabitethernet0/2)#switchport hybrid pvid vlan 2Device(config-if-gigabitethernet0/2)#exit
#Configure o tipo de link de porta em gigabitethernet0/3-gigabitethernet0/5 do dispositivo como acesso, permitindo que os serviços de VLAN3-VLAN5 passem respectivamente. (Omitido)
- Passo 2:Configure o endereço IP da interface do Dispositivo.
#Configure o endereço IP da VLAN5 como 130.255.167.1/24.
Device(config)#interface vlan 5Device(config-if-vlan5)#ip address 130.255.167.1 255.255.255.0Device(config-if-vlan5)#exit
- Passo 3:Configure a autenticação AAA.
#Ative a autenticação AAA no dispositivo, adote o modo de autenticação RADIUS, a chave do servidor é admin, a prioridade é 1 e o endereço do servidor RADIUS é 130.255.167.167/24.
Device(config)#domain systemDevice(config-isp-system)# aaa authentication dot1x radius-group radiusDevice(config-isp-system)#exitDevice(config)#aaa server group radius radiusDevice(config-sg-radius-radius)#server 130.255.167.167 priority 1 key admin
- Passo 4:Configure o servidor AAA.
#Configure o nome de usuário, senha e chave como admin no servidor AAA. (Omitido)
#No servidor AAA, configure o RADIUS para entregar os três atributos de Auto VLAN: 64 é VLAN, 65 é 802 e 81 é VLAN3. (Omitido)
- Passo 5:Configure a autenticação 802.1X.
#Ative a autenticação 802.1X na porta e configure o modo de autenticação como Macbased.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#dot1x port-control enableDevice(config-if-gigabitethernet0/2)#authentication port-method macbasedDevice(config-if-gigabitethernet0/2)#exit
#Enable MAC VLAN de gigabitethernet0/2.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#mac-vlan enableDevice(config-if-gigabitethernet0/2)exit
#Configure Guest VLAN da porta como VLAN4.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)# authentication guest-vlan 4Device(config-if-gigabitethernet0/2)#exit
- Passo 6:Confira o resultado.
#Antes de passar a autenticação, gigabitethernet0/2 é adicionado ao Guest VLAN. Aqui. PC1 e PC2 estão em VLAN4, e PC1 e PC2 podem acessar o servidor de atualização.
Device#show vlan 4---- ---- -------------------------------- ------- --------- -----------------------------NO. VID VLAN-Name Owner Mode Interface---- ---- -------------------------------- ------- --------- -----------------------------1 4 VLAN0004 static Untagged gi0/2 gi0/4
#Depois que o usuário PC1 inicia a autenticação e passa a autenticação, o usuário PC1 está em Auto VLAN3 e pode acessar a rede IP. Aqui, o PC2 ainda não pode acessar a rede IP sem autenticação.
Device#show dot1x user--------------------NO 1 : MAC_ADDRESS= 3883.45ef.7984 STATUS= Authorized USER_NAME= adminVLAN= 3 INTERFACE= gi0/2 USER_TYPE= DOT1XAUTH_STATE= AUTHENTICATED BACK_STATE= IDLE IP_ADDRESS= UnknownIPV6_ADDRESS= UnknownOnline time: 0 week 0 day 0 hours 0 minute 51 secondsTotal: 1 Authorized: 1 Unauthorized/guest/critical: 0/0/0 Unknown: 0
#Após o usuário do PC2 inserir o nome de usuário ou senha errados e falhar na autenticação, o usuário do PC2 está na VLAN4 do Convidado e pode acessar o Servidor de Atualização.
Device#show dot1x user--------------------NO 1 : MAC_ADDRESS= 3883.45ef.f395 STATUS= Unauth(guest) USER_NAME= adminVLAN= 4 INTERFACE= gi0/2 USER_TYPE= DOT1XAUTH_STATE= GUEST_HELD BACK_STATE= IDLE IP_ADDRESS= UnknownIPV6_ADDRESS= UnknownTotal:1 Authorized: 0 Unauthorized/guest/critical: 0/1/0 Unknown: 0
Configurar o modo de transmissão transparente 802.1X
Requisitos de rede
- O PC está conectado ao Device2 habilitado com o controle de acesso 802.1X via Device1 e conectado à rede IP.
- Device1 habilita a função de transmissão transparente; Device2 usa o modo de autenticação RADIUS .
- Depois de passar a autenticação, o PC pode acessar a rede IP.
Topologia de rede
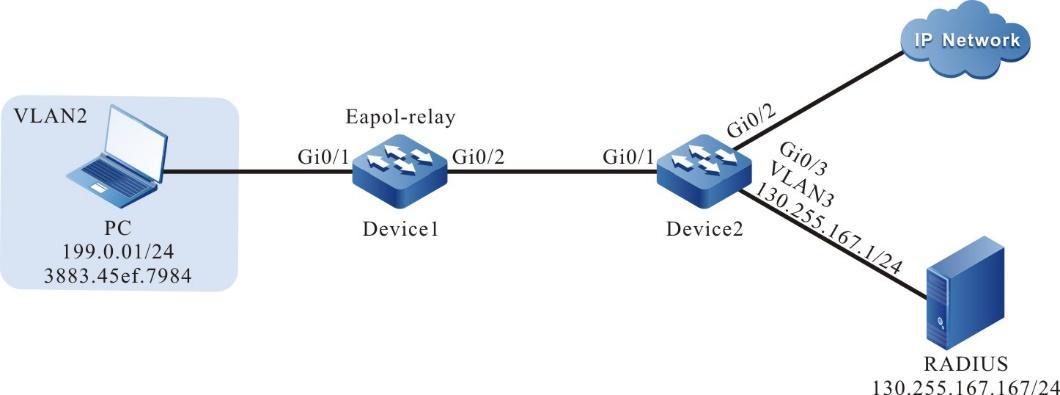
Figura 12 - 8 Rede de configuração do modo de transmissão transparente 802.1X
Etapas de configuração
- Passo 1:Configure o tipo de link de VLAN e interface no Device2.
#Create VLAN2–VLAN3 no Device2.
Device2#configure terminalDevice2(config)#vlan 2-3Device2(config)#exit
#Configure o tipo de link da interface gigabitethernet 0/1 como Access , permitindo a passagem de serviços da VLAN2 .
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode accessDevice2(config-if-gigabitethernet0/1)#switchport access vlan 2Device2(config-if-gigabitethernet0/1)#exit
#Configure o tipo de link de porta em gigabitethernet0/2–gigabitethernet0/3 do Device2 como Access, permitindo que os serviços de VLAN2–VLAN3 passem. (Omitido)
- Passo 2:Configure o endereço IP da interface do Device2.
#Configure o endereço IP da VLAN3 como 130.255.167.1/24.
Device2(config)#interface vlan 3Device2(config-if-vlan3)#ip address 130.255.167.1 255.255.255.0Device2(config-if-vlan3)#exit
- Passo 3:Configure a autenticação AAA.
#Habilite a autenticação AAA no Device2 e adote o modo de autenticação RADIUS. A chave do servidor é admin, a prioridade é 1 e o endereço do servidor RADIUS é 130.255.167.167/24.
Device(config)#domain systemDevice(config-isp-system)# aaa authentication dot1x radius-group radiusDevice(config-isp-system)#exitDevice(config)#aaa server group radius radiusDevice(config-sg-radius-radius)#server 130.255.167.167 priority 1 key admin
- Passo 4:Configure o servidor AAA.
#Configure o nome de usuário, a senha e a chave como admin no servidor AAA. (Omitido)
- Passo 5:Configure a porta VLAN do Device1.
#Configure o tipo de link de porta em gigabitethernet0/1-gigabitethernet0/2 do Device1 como Access, permitindo que os serviços da VLAN2 passem. (Omitido)
- Passo 6:Habilite a função de transmissão transparente 802.1X no Device1.
#Configure o modo de transmissão transparente 802.1X em gigabitethernet0/1 de Device1 e a porta de uplink é gigabitethernet0/2.
Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#dot1x eapol-relay enableDevice1(config-if-gigabitethernet0/1)#dot1x eapol-relay uplink interface gigabitethernet 0/2Device1(config-if-gigabitethernet0/1)#exit
- Passo 7:Configure o modo de autenticação 802.1X no Device2.
#Ative a autenticação 802.1X de gigabitethernet0/1 e o modo de autenticação de porta é baseado em porta.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#dot1x port-control enableDevice2(config-if-gigabitethernet0/1)# authentication port-method portbasedDevice2(config-if-gigabitethernet0/1)#exit
- Passo 8:Confira o resultado.
O usuário do #PC pode ser autenticado com sucesso e acessar a rede IP.
Device2#show dot1x user--------------------NO 1 : MAC_ADDRESS= 3883.45ef.7984 STATUS= Authorized USER_NAME= adminVLAN= 2 INTERFACE= gi0/1 USER_TYPE= DOT1XAUTH_STATE= AUTHENTICATED BACK_STATE= IDLE IP_ADDRESS= UnknownIPV6_ADDRESS= UnknownOnline time: 0 week 0 day 0 hours 0 minute 51 secondsTotal: 1 Authorized: 1 Unauthorized/guest/critical: 0/0/0 Unknown: 0
Configurar autenticação de cliente livre 802.1X
Requisitos de rede
- A impressora de rede está conectada à rede IP via dispositivo; O dispositivo adota o controle de acesso 802.1X;
- O dispositivo executa regularmente a detecção offline para a impressora de rede.
- Use o modo de autenticação RADIUS.
- Depois de passar a autenticação, a impressora de rede pode executar a tarefa de impressão da rede IP.
Topologia de rede

Figura 12 - 9 Rede de configuração da autenticação de cliente livre 802.1X
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e interface no dispositivo .
# Crie VLAN2–VLAN3 no dispositivo.
Device#configure terminalDevice(config)#vlan 2-3Device(config)#exit
# Configure o tipo de link da interface gigabitethernet 0/1 como Access , permitindo a passagem de serviços de VLAN2 .
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2Device(config-if-gigabitethernet0/1)#exit
#Configure o tipo de link de porta em gigabitethernet0/2–gigabitethernet0/3 do dispositivo como acesso, permitindo que os serviços de VLAN2–VLAN3 passem. (Omitido)
- Passo 2:Configure o endereço IP da interface do Dispositivo.
#Configure o endereço IP da VLAN3 como 130.255.167.1/24.
Device(config)#interface vlan 3Device(config-if-vlan3)#ip address 130.255.167.1 255.255.255.0Device(config-if-vlan3)#exit
- Passo 3:Configure a autenticação AAA.
#Habilite a autenticação AAA no Device2 e adote o modo de autenticação RADIUS. A chave do servidor é admin, a prioridade é 1 e o endereço do servidor RADIUS é 130.255.167.167/24.
Device(config)#domain systemDevice(config-isp-system)# aaa authentication dot1x radius-group radiusDevice(config-isp-system)#exitDevice(config)#aaa server group radius radiusDevice(config-sg-radius-radius)#server 130.255.167.167 priority 1 key admin
- Passo 4:Configure o servidor AAA.
#Configure o nome de usuário, a senha e a chave como admin no servidor AAA. (Omitido)
- Passo 5:Configure a autenticação 802.1X.
#Configure o modo de autenticação de cliente livre 802.1X e use o endereço MAC da impressora de rede como nome de usuário e senha.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#dot1x mac-authentication enableDevice(config-if-gigabitethernet0/1)#exit
#Configure Dispositivo para realizar a detecção offline da impressora a cada 120 segundos.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#dot1x timeout offline-detect 120Device(config-if-gigabitethernet0/1)#exit
- Passo 6:Confira o resultado.
#A impressora de rede pode passar a autenticação e pode executar a tarefa de impressão da rede IP.
Device#show dot1x user--------------------NO 1 : MAC_ADDRESS= 3883.45ef.f395 STATUS= Authorized USER_NAME= 38-83-45-ef-f3-95VLAN= 2 INTERFACE= gi0/1 USER_TYPE= DOT1XAUTH_STATE= AUTHENTICATED BACK_STATE= IDLE IP_ADDRESS= 199.0.0.3IPV6_ADDRESS= UnknownOnline time: 0 week 0 day 0 hours 1 minutes 6 secondsTotal: 1 Authorized: 1 Unauthorized/guest/critical: 0/0/0 Unknown: 0
Configurar canal seguro
Requisitos de rede
- Os usuários PC1 e PC2 na mesma VLAN acessam a rede IP através do Device. Habilite o controle de acesso ao canal seguro no dispositivo.
- A autenticação adota a autenticação RADIUS.
- O PC1 tem permissão para visitar o Servidor de Atualização antes do sucesso da autenticação e tem permissão para visitar o Servidor de Atualização e a Rede IP após o sucesso da autenticação.
- O PC2 tem permissão para visitar o servidor de atualização e a rede IP sem autenticação.
Topologia de rede

Figura 8–8 Rede de configuração de canal seguro
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da interface na interface.
#Crie VLAN2 e VLAN5 no dispositivo.
Device#configure terminalDevice(config)#vlan 2,5Device(config)#exit
#Configure o tipo de link da interface gigabitethernet0/2 como Acesso, permitindo a passagem de serviços de VLAN2.
Device#configure terminalDevice(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)# switchport mode accessDevice(config-if-gigabitethernet0/2)# switchport access vlan 2Device(config-if-gigabitethernet0/2)#end
#Configura o tipo de link da interface gigabitethernet 0/3–gigabitethernet 0/4 como Access on Device, permitindo a passagem de serviços de VLAN2. Configure o tipo de link da interface gigabitethernet 0/5 como Acesso, permitindo a passagem de serviços de VLAN5. (Omitido)
- Passo 2:Configure o endereço IP da interface do Dispositivo.
#Configure o endereço IP da VLAN5 como 130.255.167.1/24.
Device#configure terminalDevice(config)#interface vlan 5Device(config-if-vlan5)#ip address 130.255.167.1 255.255.255.0Device(config-if-vlan5)#end
- Passo 3:Configure a autenticação AAA.
#Ative a autenticação AAA no dispositivo e adote o modo de autenticação RADIUS. Configure a chave do servidor como admin, a prioridade como 1 e o endereço IP do servidor RADIUS como 130.255.167.167/24.
Device(config)#domain systemDevice(config-isp-system)# aaa authentication dot1x radius-group radiusDevice(config-isp-system)#exitDevice(config)#aaa server group radius radiusDevice(config-sg-radius-radius)#server 130.255.167.167 priority 1 key admin
- Passo 4:Configure o servidor AAA.
#Configure o nome de usuário, a senha e o valor da chave no servidor AAA como administrador. (Omitido)
- Passo 5:Configure o canal seguro.
#Habilite o controle de acesso ao canal seguro na interface gigabitethernet 0/2 .
Device#configure terminalDevice(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#dot1x free-ipDevice(config-if-gigabitethernet0/2)#exit
#Configure um canal seguro chamado channel e configure para permitir que o PC1 visite o Servidor de Atualização e configure para permitir que o PC2 visite o Servidor de Atualização e a Rede IP .
Device#configure terminal
Device(config)#hybrid access-list advanced channelDevice (config-adv-hybrid-nacl)#permit ip any any host 199.0.0.10 anyDevice(config-adv-hybrid-nacl)#permit ip host 199.0.0.2 any any any
#Aplica o canal seguro chamado channel .
Device#configure terminalDevice(config)#global security access-group channelDevice(config)#exit
- Passo 6:Confira o resultado.
#Visualize as informações de configuração do canal seguro.
Device#show dot1x free-ip802.1X free-ip Enable Interface (num:1): gi0/2global security access-group channelTotal free-ip user number : 0Device#show hybrid access-list channelhybrid access-list advanced channel10 permit ip any any host 199.0.0.10 any
20 permit ip host 199.0.0.2 any any any
Pode-se ver que o canal seguro está habilitado na interface gigabitethernet 0/2 e a interface está vinculada à regra de canal seguro do canal.
#PC1 pode visitar o servidor de atualização e não pode visitar outros recursos de rede antes do sucesso da autenticação.
#Visualize as informações de autenticação do usuário após o usuário PC1 iniciar a autenticação e a autenticação for bem-sucedida.
Device#show dot1x user--------------------NO 1 : MAC_ADDRESS= 3883.45ef.7984 STATUS= Authorized USER_NAME= adminVLAN= 2 INTERFACE= gi0/2 USER_TYPE= DOT1XAUTH_STATE= AUTHENTICATED BACK_STATE= IDLE IP_ADDRESS= 199.0.0.1IPV6_ADDRESS= UnknownOnline time: 0 week 0 day 0 hours 0 minute 51 secondsTotal: 1 Authorized: 1 Unauthorized/guest/critical: 0/0/0 Unknown: 0
Pode ser visto que o usuário PC1 passou na autenticação e então o PC1 pode visitar o Servidor de Atualização e a Rede IP.
#PC2 pode visitar o servidor de atualização e a rede IP sem autenticação.
Configurar o modo de servidor DHCP de autorização de IP
Requisitos de rede
- O PC está conectado à Rede IP via Dispositivo; Dispositivo habilita o controle de acesso 802.1X;
- O modo de autenticação adota a autenticação RADIUS.
- O PC1 obtém o endereço IP por meio do servidor DHCP especificado e pode acessar a rede IP.
- Após ser configurado para realizar a autenticação de endereço IP estático, o PC2 não pode acessar a rede IP.
Topologia de rede

Figura 12 -10 Rede de configuração de autorização de IP 802.1X Modo de servidor DHCP
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e a interface no dispositivo.
#Crie VLAN2 e VLAN4 no dispositivo, configure o tipo de link de porta como Híbrido em gigabitethernet0/2, permita que os serviços de VLAN2 passem e configure PVID como 2.
Device#configure terminalDevice(config)#vlan 2,4Device(config)#intergice gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode hybridDevice(config-if-gigabitethernet0/2)#switchport hybrid untagged vlan 2Device(config-if-gigabitethernet0/2)#switchport hybrid pvid vlan 2Device(config-if-gigabitethernet0/2)#exit
#No gigabitethernet0/5 do dispositivo, configure o tipo de link da porta como acesso, permita a passagem dos serviços da VLAN2 (omitido).
#Configure o tipo de link de porta como Acesso em gigabitethernet0/4 do Dispositivo, permita que os serviços de VLAN4 passem (omitidos).
- Passo 2:Configure o endereço IP da interface do Dispositivo.
#Configure o endereço IP das VLANs 4 a130.255.167.1/24.
Device(config)#intergice vlan 4Device(config-if-vlan4)#ip address 130.255.167.1 255.255.255.0Device(config-if-vlan4)#exit
- Passo 3:Configure a autenticação AAA.
#Ative a autenticação AAA no dispositivo, adote o modo de autenticação RADIUS, a chave do servidor é admin, a prioridade é 1 e o endereço do servidor RADIUS é 130.255.167.167/24.
Device(config)#domain systemDevice(config-isp-system)# aaa authentication dot1x radius-group radiusDevice(config-isp-system)#exitDevice(config)#aaa server group radius radiusDevice(config-sg-radius-radius)#server 130.255.167.167 priority 1 key admin
- Passo 4:Configure o servidor AAA.
#No servidor AAA, configure o nome de usuário e a senha e o valor da chave como admin (omitido).
- Passo 5:Configure o servidor DHCP.
#No servidor DHCP, configure o segmento de endereço IP distribuído como 199.0.0.2-199.0.0.10 e a máscara de sub-rede como 255.255.255.0 (omitido).
- Passo 6:Habilite a função DHCP Snooping no dispositivo e configure a porta gigabitethernet0/5 do dispositivo como porta confiável.
Device(config)#dhcp-snoopingDevice(config)#intergice gigabitethernet 0/5Device(config-if-gigabitethernet0/5)#dhcp-snooping trustDevice(config-if-gigabitethernet0/5)#exit
- Passo 7:Configure a autenticação 802.1X no dispositivo.
#Ative a autenticação 802.1X de gigabitethernet0/2.
Device(config)#intergice gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#dot1x port-control enableDevice(config-if-gigabitethernet0/2)#exit
#Configure a autorização de IP de gigabitethernet0/2 como modo de servidor DHCP.
Device(config)#intergice gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#dot1x authorization ip-auth-mode dhcp-serverDevice(config-if-gigabitethernet0/2)#exit
#Ative o keepalive ARP de gigabitethernet0/2.
Device(config)#intergice gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#dot1x client-probe enableDevice(config-if-gigabitethernet0/2)#exit
- Passo 8:Confira o resultado.
O usuário #PC1 pode autenticar com sucesso e pode obter o endereço IP do servidor DHCP e acessar a rede IP.
Device#show dot1x user--------------------NO 1 : MAC_ADDRESS= 3883.45ef.7984 STATUS= Authorized USER_NAME= adminVLAN= 2 INTERFACE= gi0/2 USER_TYPE= DOT1XAUTH_STATE= AUTHENTICATED BACK_STATE= IDLE IP_ADDRESS= 199.0.0.3IPV6_ADDRESS= UnknownOnline time: 0 week 0 day 0 hours 0 minutes 36 secondsTotal: 1 Authorized: 1 Unauthorized/guest/critical: 0/0/0 Unknown: 0
#Após a autenticação do usuário PC2, ele está no estado GET-IP e não pode obter o endereço IP.
NO 1 : MAC_ADDRESS= 3883.45ef.f381 STATUS= Unauthorized USER_NAME= adminVLAN= 2 INTERFACE= gi0/2 USER_TYPE= DOT1XAUTH_STATE= GET_IP BACK_STATE= IDLE IP_ADDRESS= UnknownIPV6_ADDRESS= UnknownOnline time: 0 week 0 day 0 hour 0 minute 34 secondsTotal: 1 Authorized: 0 Unauthorized/guest/critical: 1/0/0 Unknown: 0
#Após a verificação, o PC2 não pode acessar a rede IP.
Configurar VLAN crítica 802.1X
Requisitos de rede
- O PC está conectado à Rede IP via Dispositivo; Dispositivo habilita o controle de acesso 802.1X;
- O modo de autenticação adota a autenticação RADIUS.
- Quando o PC falha ao autenticar porque o servidor não está disponível, permita apenas o acesso ao Update Server.
Topologia de rede
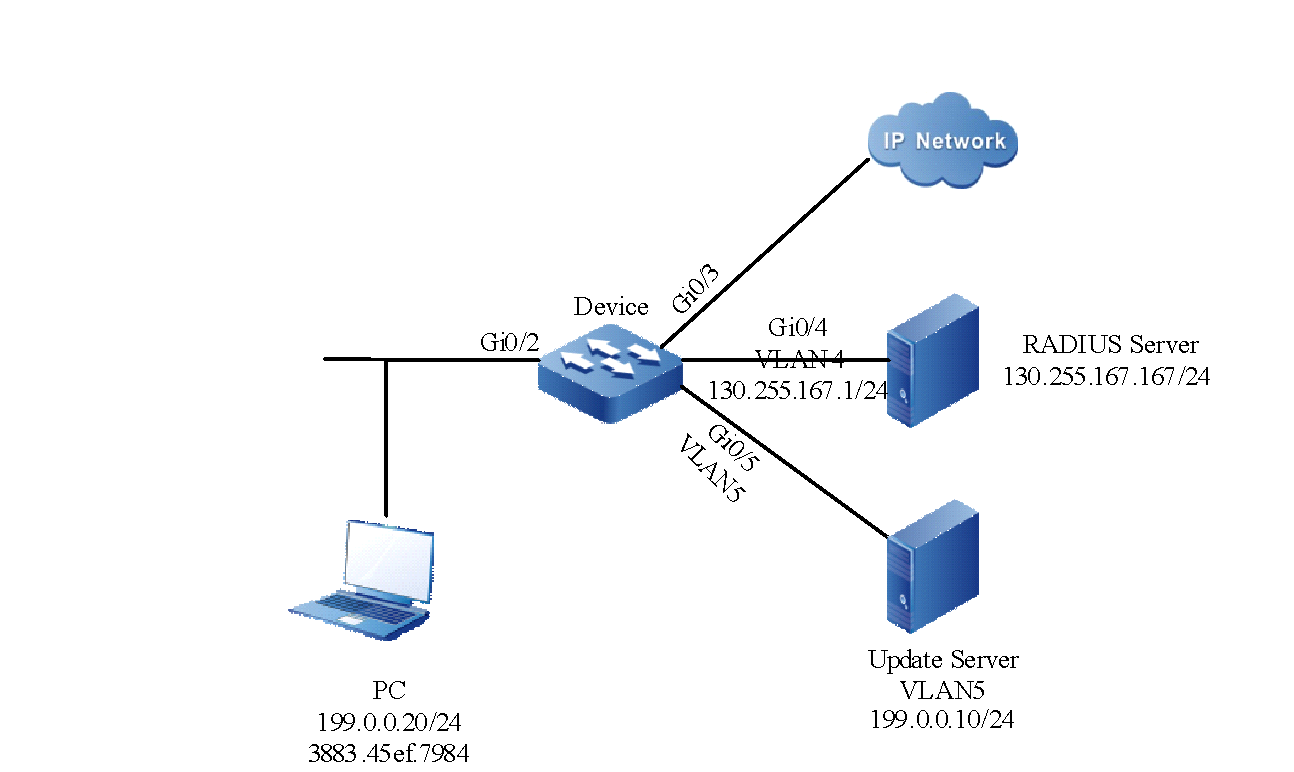
Figura 12 -11 Rede de configuração da VLAN crítica 802.1X
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e a interface no dispositivo.
#Crie VLAN2, VLAN4 e VLAN5 no dispositivo, configure o tipo de link de porta como Híbrido em gigabitethernet0/2, permita que os serviços de VLAN2 passem e configure PVID como 2.
Device#configure terminalDevice(config)#vlan 2,4,5Device(config)#intergice gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode hybridDevice(config-if-gigabitethernet0/2)#switchport hybrid untagged vlan 2Device(config-if-gigabitethernet0/2)#switchport hybrid pvid vlan 2Device(config-if-gigabitethernet0/2)#exit
#No gigabitethernet0/5 do dispositivo, configure o tipo de link da porta como acesso, permita que os serviços da VLAN5 passem (omitido).
#Configure o tipo de link de porta como Acesso em gigabitethernet0/4 do Dispositivo, permita que os serviços de VLAN4 passem (omitidos).
- Passo 2:Configure o endereço IP da interface do Dispositivo.
#Configure o endereço IP da VLAN4 como 130.255.167.1/24.
Device(config)#intergice vlan 4Device(config-if-vlan4)#ip address 130.255.167.1 255.255.255.0Device(config-if-vlan4)#exit
- Passo 3:Configure a autenticação AAA.
#Ative a autenticação AAA no dispositivo, adote o modo de autenticação RADIUS, a chave do servidor é admin, a prioridade é 1 e o endereço do servidor RADIUS é 130.255.167.167/24.
Device(config)#domain systemDevice(config-isp-system)# aaa authentication dot1x radius-group radiusDevice(config-isp-system)#exitDevice(config)#aaa server group radius radiusDevice(config-sg-radius-radius)#server 130.255.167.167 priority 1 key admin
- Passo 4:Configure o servidor AAA.
#No servidor AAA, configure o nome de usuário e a senha e o valor da chave como admin (omitido).
- Passo 5:Configure a autenticação 802.1X no dispositivo.
#Ative a autenticação 802.1X de gigabitethernet 0/2.
Device(config)#intergice gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#dot1x port-control enableDevice(config-if-gigabitethernet0/2)#exit
#Enable MAC VLAN de gigabitethernet0/2.
Device(config)#intergice gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#mac-vlan enableDevice(config-if-gigabitethernet0/2)exit
#Configure VLAN crítica da porta como VLAN5.
Device(config)#intergice gigabitethernet 0/2Device(config-if-gigabitethernet0/2)# authentication critical-vlan 5Device(config-if-gigabitethernet0/2)#exit
- Passo 6:Confira o resultado.
#Como o servidor está anormal, o dispositivo não pode executar ping no servidor. Como resultado, a autenticação do usuário falha porque o servidor não está disponível. O usuário do PC está na VLAN Crítica e pode acessar o Servidor de Atualização.
Device#show dot1x user--------------------NO 1 : MAC_ADDRESS= 3883.45ef.7984 STATUS= Unauth(critical) USER_NAME= adminVLAN= 5 INTERFACE= gi0/2 USER_TYPE= DOT1XAUTH_STATE= CRITICAL_HELD BACK_STATE= IDLE IP_ADDRESS= UnknownIPV6_ADDRESS= UnknownTotal: 1 Authorized: 0 Unauthorized/guest/critical: 0/0/1 Unknown: 0
#A porta gigabitethernet0/2 é adicionada à VLAN crítica.
Device#show vlan 5---- ---- -------------------------------- ------- --------- -----------------------------NO. VID VLAN-Name Owner Mode Intergice---- ---- -------------------------------- ------- --------- -----------------------------1 5 VLAN5 static Untagged gi0/2 gi0/5
Configurar usando 802.1x com Port Security
Requisitos de rede
- O PC está conectado à Rede IP via Dispositivo; O dispositivo habilita o controle de acesso 802.1X e a Port Security;
- O modo de autenticação adota a autenticação RADIUS.
- Configure a regra de Port Security de não corresponder ao endereço MAC do PC1, e o PC1 pode passar a autenticação e acessar a rede IP.
- Configure a regra de negação de Port Security para corresponder ao endereço MAC do PC2, e o PC2 não pode passar na autenticação.
Topologia de rede
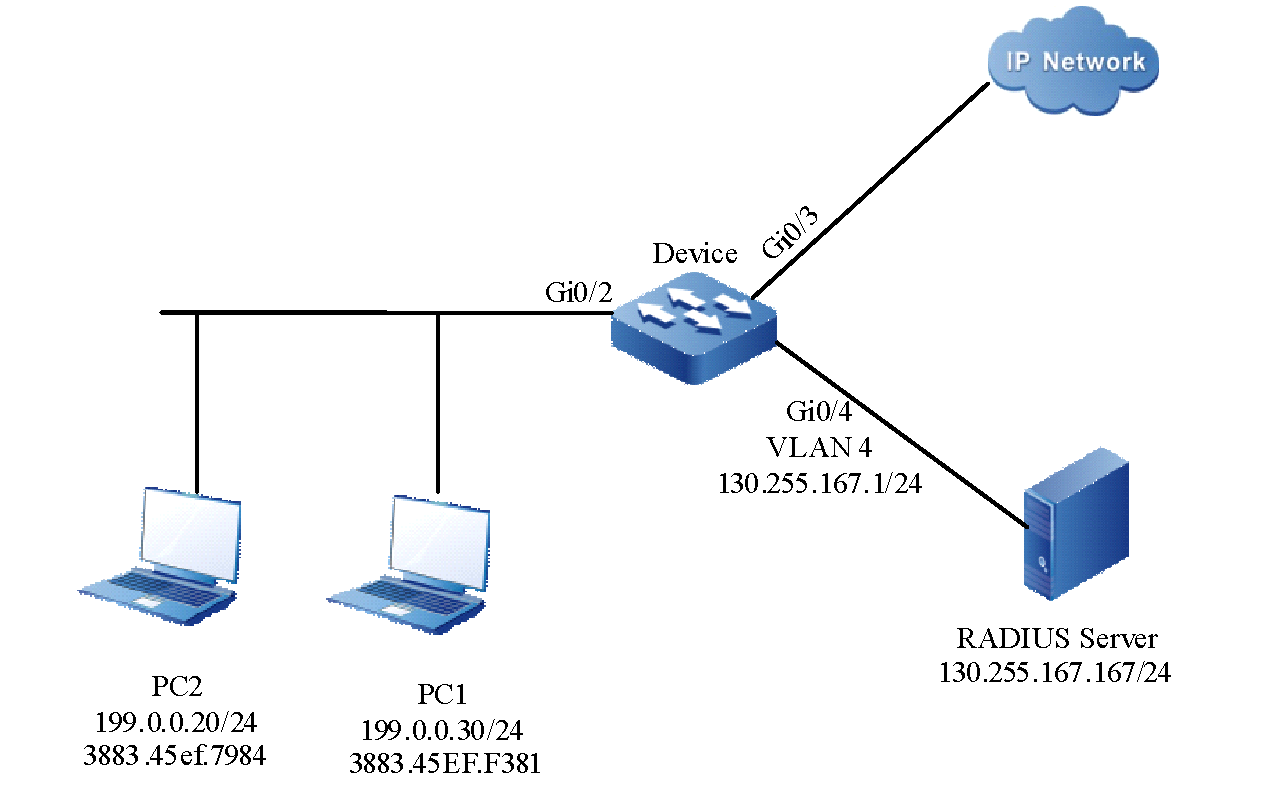
Figura 12 -12 Rede de configuração usando 802.1X com Port Security
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e a interface no dispositivo.
#Crie VLAN2, VLAN4 e VLAN5 no dispositivo, configure o tipo de link de porta como Híbrido em gigabitethernet0/2, permita que os serviços de VLAN2 passem e configure PVID como 2.
Device#configure terminalDevice(config)#vlan 2,4Device(config)#intergice gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode hybridDevice(config-if-gigabitethernet0/2)#switchport hybrid untagged vlan 2Device(config-if-gigabitethernet0/2)#switchport hybrid pvid vlan 2Device(config-if-gigabitethernet0/2)#exit
#No gigabitethernet0/4 do dispositivo, configure o tipo de link da porta como acesso, permita que os serviços da VLAN4 passem (omitido).
- Passo 2:Configure o endereço IP da interface do Dispositivo.
#Configure o endereço IP da VLAN4 como 130.255.167.1/24.
Device(config)#intergice vlan 4Device(config-if-vlan4)#ip address 130.255.167.1 255.255.255.0Device(config-if-vlan4)#exit
- Passo 3:Configure a autenticação AAA.
#Ative a autenticação AAA no dispositivo, adote o modo de autenticação RADIUS, a chave do servidor é admin, a prioridade é 1 e o endereço do servidor RADIUS é 130.255.167.167/24.
Device(config)#domain systemDevice(config-isp-system)# aaa authentication dot1x radius-group radiusDevice(config-isp-system)#exitDevice(config)#aaa server group radius radiusDevice(config-sg-radius-radius)#server 130.255.167.167 priority 1 key admin
- Passo 4:Configure o servidor AAA.
#No servidor AAA, configure o nome de usuário e a senha e o valor da chave como admin (omitido).
- Passo 5:Configure a autenticação 802.1X no dispositivo.
#Habilite a autenticação 802.1X em gigabitethernet0/2.
Device(config)#intergice gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#dot1x port-control enableDevice(config-if-gigabitethernet0/2)#exit
- Passo 6:Configure a Port Security no dispositivo.
#Ative a Port Security na porta gigabitethernet0/2.
Device(config)#intergice gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#port-security enableDevice(config-if-gigabitethernet0/2)exit
#Configure a regra de Port Security na porta gigabitethernet0/2.
Device(config)#intergice gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#port-security deny mac-address 3883.45EF.7984Device(config-if-gigabitethernet0/2)exit
- Passo 7:Confira o resultado.
O usuário #PC1 pode autenticar com sucesso e acessar a rede IP após passar a autenticação.
Device#show dot1x user--------------------NO 1 : MAC_ADDRESS= 3883.45ef.f381 STATUS= Authorized USER_NAME= adminVLAN= 2 INTERFACE= gi0/2 USER_TYPE= DOT1XAUTH_STATE= AUTHENTICATED BACK_STATE= IDLE IP_ADDRESS= UnknownIPV6_ADDRESS= UnknownOnline time: 0 week 0 day 0 hour 0 minute 1 secondTotal: 1 Authorized: 1 Unauthorized/guest/critical: 0/0/0 Unknown: 0
O usuário #PC2 não consegue autenticar com sucesso e não consegue acessar a rede.
PORTAL
Visão geral
Visão geral do portal
A autenticação do portal também é conhecida como autenticação da Web, ou seja, autentica o usuário aceitando o nome de usuário e a senha inseridos pelo usuário por meio da página da Web. A tecnologia de autenticação do Portal fornece um método de controle de acesso flexível. Sem instalar o cliente, o controle de acesso pode ser implementado na camada de acesso e na entrada de dados chave que precisa ser protegida. O site de autenticação do portal é geralmente chamado de site do portal.
Quando usuários não autenticados acessam a rede, o dispositivo força os usuários a acessar um site específico, ou seja, o servidor do Portal. Sem autenticação, os usuários podem acessar os serviços gratuitamente, como atualização de programas de aplicativos (como software antivírus e patches do sistema operacional). Quando os usuários precisam utilizar outros recursos na Internet, eles devem autenticar sua identidade na página de autenticação do Portal fornecida pelo servidor do Portal. Eles podem usar os recursos de rede somente depois de passar a autenticação.
Além da flexibilidade de autenticação, o Portal também pode fornecer funções de gerenciamento convenientes. Na página de autenticação do Portal, você pode realizar serviços personalizados como publicidade e notificação.
Composição do Sistema Portal
O método de rede típico do Portal é mostrado na figura a seguir. Ele consiste em quatro elementos: Portal Client, Authentication Device, Portal Server (servidor Portal) e AAA Server (autenticação/autorização/servidor de estatísticas, referido como servidor AAA).
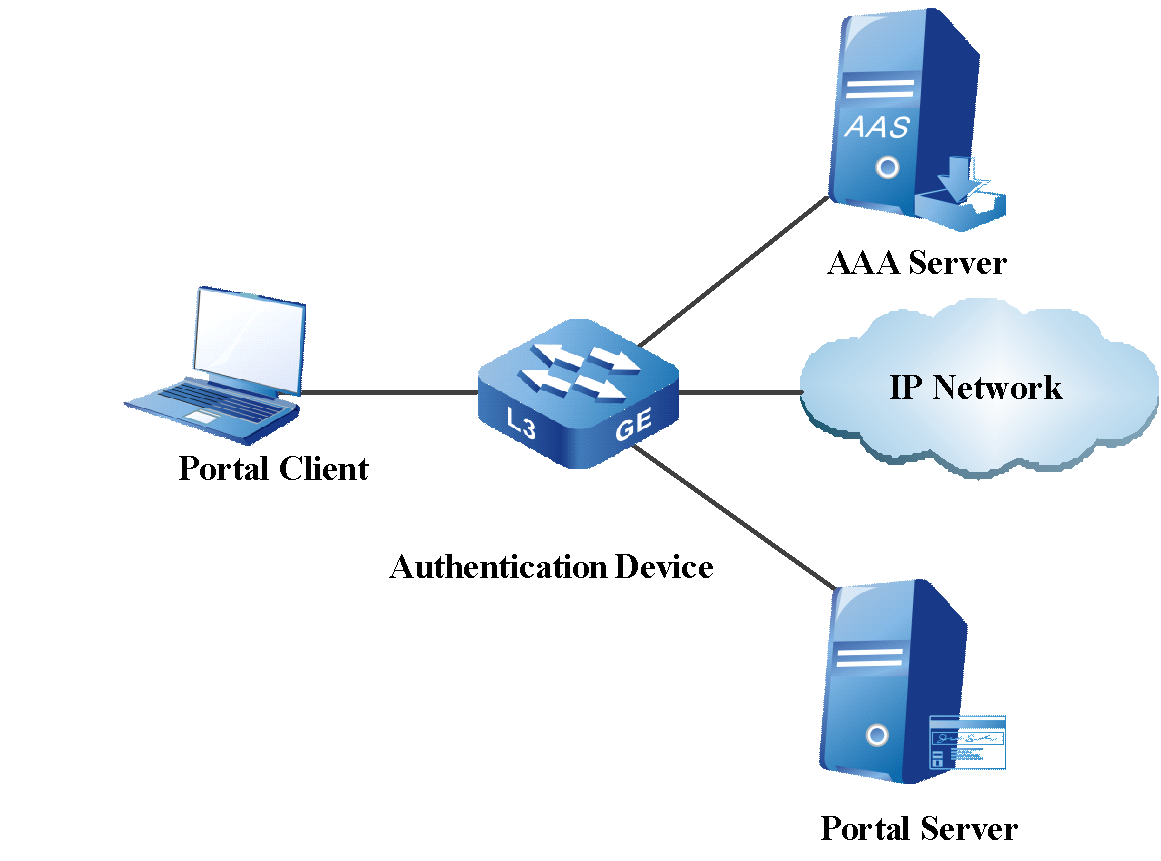
Figura 13 -1 Composição do sistema do portal
- Cliente Autenticado: Normalmente, é o navegador que executa o protocolo HTTP, e também pode ser o software proprietário do Portal.
- Dispositivo de autenticação: O dispositivo de autenticação está localizado entre o cliente e o servidor de autenticação. Ele controla o acesso à rede do cliente interagindo com o servidor Portal e o servidor AAA.
- Servidor do Portal: O sistema do lado do servidor que recebe solicitações de autenticação de clientes de autenticação, fornece serviços de portal gratuitos e interface de autenticação baseada na Web. O Portal Server aceita solicitações de autenticação de clientes de autenticação, extrai as informações de autenticação, interage com dispositivos de autenticação por meio do protocolo do Portal e notifica os clientes de autenticação sobre os resultados da autenticação.
- Servidor AAA: Normalmente, é o servidor RADIUS (Remote Authentication Dial-In User Service), utilizado para verificar a validade do cliente e notificar o resultado da autenticação ao dispositivo de autenticação. O dispositivo de autenticação controla o acesso à rede do cliente de acordo com o resultado da autenticação.
Modos de autenticação do portal
Em diferentes modos de rede, os modos de autenticação do Portal disponíveis são diferentes, diferenciados pelas camadas de rede que implementam a autenticação do Portal na rede. Os modos de autenticação do Portal são divididos em dois tipos: modo de autenticação L2 e modo de autenticação L3.
- Modo de autenticação L2
Suporte a ativação da função de autenticação do Portal na interface L2 do dispositivo de autenticação que conecta o usuário. Os usuários só podem acessar o servidor do Portal configurando manualmente ou DHCP para obter diretamente um endereço IP antes da autenticação; após a autenticação, eles podem acessar os recursos da rede. O modo de autenticação L2 é baseado no controle MAC de origem, que permite que os pacotes com o endereço MAC de origem válido passem após a autenticação.
- Modo de autenticação L3
Suporte para habilitar a função de autenticação do Portal na interface L3 do dispositivo de autenticação que conecta o usuário. O modo de autenticação L3 pode ser dividido em modo de autenticação L3 comum e modo de autenticação de atribuição de endereço secundário.
- Modo de autenticação L3 comum
Os usuários só podem acessar o servidor Portal e o endereço de acesso livre configurando manualmente ou DHCP para obter diretamente um endereço IP antes da autenticação; após a autenticação, eles podem acessar os recursos da rede. O modo de autenticação L3 comum tem dois modos de controle:
- Controle baseado no IP de origem: Permitir que o pacote com o IP de origem válido passe após passar a autenticação
- Controle baseado no IP de origem + MAC de origem: permite que o pacote com o IP de origem válido e o MAC de origem passem após passar a autenticação
Processo de autenticação do portal
Existem dois modos de interação de autenticação entre o servidor do Portal e o dispositivo de autenticação:
- Interação de autenticação CHAP (Challenge Handshake Authentication Protocol): O nome de usuário e a senha são criptografados para transmitir, com alta segurança
- Interação de autenticação PAP (Password Authentication Protocol): O nome de usuário e a senha são transmitidos em texto simples, com baixa segurança
Para adotar a interação de autenticação CHAP, o servidor do Portal executará a verificação de handshake de consulta. O desafio é gerado aleatoriamente quando o dispositivo de autenticação recebe o pacote de desafio de solicitação, o comprimento é de 16 bytes e é entregue ao servidor do Portal com o pacote de resposta de desafio.
O processo de autenticação do L2 Portal é o mesmo que o processo normal de autenticação do L3 Portal. O processo de autenticação do Portal da atribuição de endereço secundário possui dois processos de atribuição de endereço, portanto, seu processo de autenticação é diferente dos outros dois modos de autenticação.
- O fluxo de autenticação L2 Portal e autenticação L3 Portal comum
O fluxograma é o seguinte:

Figura 13 -2 fluxograma CHAP de autenticação L2/L3 comum Portal

Figura 13 -3 O fluxograma PAP de autenticação do Portal L2/L3 comum
O fluxo da autenticação do Portal L2 e da autenticação do Portal L3 comum:
- Os usuários do portal iniciam solicitações de autenticação por meio do protocolo HTTP quando precisam acessar a rede. Quando o pacote HTTP passa pelo dispositivo de autenticação, o dispositivo autenticado permite que o pacote HTTP acesse o servidor do Portal ou com o endereço de acesso livre definido para passar; para o pacote HTTP que acessa outros endereços, o dispositivo de autenticação o intercepta e o redireciona para o servidor do Portal. O servidor Portal fornece a página da Web para que os usuários insiram os nomes de usuário e senhas válidos registrados no servidor de autenticação para iniciar um processo de autenticação.
- O servidor do Portal adota a interação de autenticação CHAP para verificar o handshake de consulta e o servidor do Portal solicita o Desafio do dispositivo de autenticação. Adote a interação de autenticação PAP para executar diretamente a etapa (4).
- O dispositivo de autenticação gera aleatoriamente o desafio ao receber o pacote de desafio de solicitação , envia o pacote de sucesso de desafio de solicitação e entrega o desafio ao servidor do Portal. Adote a interação de autenticação PAP para executar diretamente a etapa (4).
- O servidor do Portal monta o nome de usuário e a senha inseridos pelo usuário em um pacote de autenticação de solicitação e o envia ao dispositivo de autenticação para solicitar a autenticação. Ao mesmo tempo, ative o temporizador para aguardar a resposta de autenticação.
- Interaja com o pacote de protocolo RADIUS entre o dispositivo de autenticação e o servidor RADIUS.
- O dispositivo de autenticação envia o pacote de sucesso de autenticação para o servidor do Portal.
- O servidor do Portal envia o pacote de passagem de autenticação para o cliente de autenticação, informando ao usuário sobre o sucesso da autenticação.
- O servidor do Portal envia o pacote de confirmação de sucesso da autenticação para o dispositivo de autenticação.
- O fluxo de autenticação do Portal da atribuição de endereço secundário
O fluxograma é o seguinte:

Figura 13 -4 O fluxograma CHAP de atribuição de endereço secundário Autenticação do portal
Figura 13 -5 O fluxograma PAP de atribuição de endereço secundário Autenticação do portal
O fluxograma de autenticação do Portal da atribuição de endereço secundário:
- Os usuários do portal iniciam solicitações de autenticação por meio do protocolo HTTP quando precisam acessar a rede. Quando o pacote HTTP passa pelo dispositivo de autenticação, o dispositivo autenticado permite que o pacote HTTP acesse o servidor do Portal ou com o endereço de acesso livre definido para passar; para o pacote HTTP que acessa outros endereços, o dispositivo de autenticação o intercepta e o redireciona para o servidor do Portal. O servidor Portal fornece a página da Web para que os usuários insiram os nomes de usuário e senhas válidos registrados no servidor de autenticação para iniciar um processo de autenticação.
- O servidor do Portal adota a interação de autenticação CHAP para verificar o handshake de consulta e o servidor do Portal solicita o Desafio do dispositivo de autenticação. Adote a interação de autenticação PAP para executar diretamente a etapa (4).
- O dispositivo de autenticação gera o desafio aleatoriamente ao receber o pacote de desafio de solicitação, envia o pacote de sucesso do desafio de solicitação e entrega o desafio ao servidor do Portal. Adote a interação de autenticação PAP para executar diretamente a etapa (4).
- O servidor do Portal monta o nome de usuário e a senha inseridos pelo usuário em um pacote de autenticação de solicitação e o envia ao dispositivo de autenticação para solicitar a autenticação. Ao mesmo tempo, ative o temporizador para aguardar a resposta de autenticação.
- Interaja com o pacote de protocolo RADIUS entre o dispositivo de autenticação e o servidor RADIUS.
- O dispositivo de autenticação envia o pacote de sucesso de autenticação para o servidor do Portal.
- O servidor do Portal envia o pacote de passagem de autenticação para o cliente de autenticação, informando ao usuário sobre o sucesso da autenticação.
- Após receber o pacote de senha de autenticação, o cliente obtém o novo endereço IP público via DHCP e informa ao servidor do Portal que o usuário obteve o novo endereço IP.
- O dispositivo de autenticação descobre a alteração do endereço IP do usuário detectando a entrada DHCP Snooping, modifica o endereço IP do usuário e envia o pacote de alteração do endereço IP do usuário para informar que o servidor do Portal detectou a alteração do IP do usuário.
- O servidor do Portal informa ao cliente que ficou online com sucesso.
- O servidor do Portal envia o pacote de confirmação de alteração de endereço IP do usuário para o dispositivo de autenticação.
Suporte para entrega de ACL
ACL (Access Control List) fornece a função de controlar o acesso do usuário aos recursos da rede e restringir a autoridade de acesso dos usuários. Quando o usuário estiver online, e se a ACL autorizada estiver configurada no servidor, o dispositivo controlará o fluxo de dados da porta do usuário de acordo com a ACL autorizada emitida pelo servidor. Antes de configurar a ACL autorizada no servidor, é necessário configurar as regras correspondentes no dispositivo. A autenticação L2 Portal suporta a entrega da ACL padrão IP e ACL estendida IP, e a autenticação L3 Portal suporta a entrega da ACL estendida IP, mas os itens correspondentes das regras ACL configuradas suportam a adição de “IP de origem + MAC de origem”.
Configuração da Função do Portal
Tabela 13 – 1 Lista de configuração da função do Portal
| Tarefa de configuração | |
| Configurar o servidor e os atributos do Portal |
Criar um servidor de portal
Configurar o tipo de servidor do Portal Configurar a função de detecção do servidor do Portal Configure a interface de origem usada enviando o pacote do Portal Configure o número da porta UDP de destino para enviar o pacote offline forçado pelo usuário |
| Configure a função de autenticação do Portal L2 | Habilite a função de autenticação do Portal L2 |
| Configure os atributos de autenticação do Portal L2 | Configurar o modo de controle de acesso à porta |
| Configure a função de autenticação do Portal L3 | Habilite a função de autenticação do Portal L3 comum Configurar e aplicar canal seguro |
| Configurar os atributos públicos |
Configurar o máximo de usuários da interface
Configurar a função de migração de autenticação do usuário Configure se deseja carregar o nome de domínio Configure os parâmetros do temporizador Configurar a lista de métodos de autenticação Configurar a lista de métodos de estatísticas |
Configurar o Portal Server e os Atributos
Condição de configuração
Nenhum
Criar um servidor de portal
Crie um servidor do Portal e especifique os parâmetros relacionados do servidor do Portal, incluindo o endereço IP do servidor, chave criptografada compartilhada, número da porta do servidor e URL do servidor (o endereço da página de autenticação do servidor).
Tabela 13 – 2 Criar um servidor de Portal
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Criar um servidor de portal | portal server server-name ip ip-address key [ 0 | 7 ] key-string [ port udp-port-num | url url-string ] | Opcional Por padrão, não crie um servidor do Portal. |
O protocolo do Portal suporta apenas o protocolo IPv4. Até 5 servidores do Portal são criados no dispositivo de autenticação. Os parâmetros do servidor Portal configurados podem ser excluídos ou modificados somente quando o servidor Portal não é referenciado pela interface. As chaves de compartilhamento configuradas no dispositivo de autenticação e no servidor do Portal devem ser consistentes.
Configurar o tipo de servidor do portal
A configuração do tipo de servidor do Portal tem dois aspectos de funções:
- Diferentes servidores do Portal fazem algumas expansões nas especificações do protocolo padrão do Portal.
- Quando o servidor do Portal não está configurado com a URL do servidor, o servidor do Portal usa a URL do servidor padrão do tipo correspondente para redirecionar.
Os seguintes tipos de servidor podem ser especificados:
aas : O servidor AAS, URL do servidor padrão: http://IP-ADDRESS/portal/Login.do
imc : O servidor IMC, URL do servidor padrão: http://IP-ADDRES:8080/porta
definido pelo usuário: servidor definido pelo usuário. O formato de URL do servidor padrão segue a especificação de protocolo
Tabela 13 – 3 Configurar o tipo de servidor do Portal
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o tipo de servidor do Portal | portal server server-name type { aas | imc | user-defined } | Opcional Por padrão, o tipo de servidor é AAS. |
Configurar a função de detecção do servidor do portal
No processo de autenticação do Portal, se a comunicação entre o dispositivo de autenticação e o servidor do Portal for interrompida, os novos usuários não poderão ficar online e os usuários do Portal online existentes não poderão ficar offline normalmente. Para resolver esses problemas, é necessário que o dispositivo de autenticação possa detectar a tempo a mudança do estado alcançável do servidor do Portal e acionar as operações correspondentes para lidar com o impacto da mudança. Por exemplo, quando um servidor do Portal especificado não estiver acessível, todos os usuários que se autenticarem usando o servidor do Portal serão forçados a passar a autenticação para acessar os recursos da rede, que é comumente chamada de função de escape do Portal.
Com a função de detecção, o dispositivo de autenticação pode detectar o status alcançável do servidor do Portal. A configuração específica é a seguinte:
- O intervalo para detectar se o servidor está acessível
- A ação quando o status alcançável do servidor muda
- Gravar o log: Grave as informações de log quando o status alcançável do servidor do Portal for alterado
- Limitação do usuário aberto: Quando o status alcançável do servidor do Portal for alterado, registre as informações de log. Quando o servidor do Portal especificado estiver inacessível, todos os usuários que utilizam o servidor do Portal para autenticação são forçados a passar a autenticação. Quando o servidor do Portal estiver acessível novamente, force o usuário que é forçado a passar na autenticação usando o servidor do Portal a ficar offline.
Tabela 13 – 4 Configurar a função de detecção do servidor do Portal
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o intervalo de detecção do servidor do Portal | portal server server-name detect-interval detect-interval-value | Opcional Por padrão, o intervalo de detecção do servidor do Portal é de 60 segundos e o intervalo de valores é de 20 a 600 segundos ou 0. Quando configurado como 0, não detecta o servidor do Portal. |
| Configure a ação quando o status alcançável do servidor do Portal for alterado | portal server server-name failover { log | permit } | Opcional Por padrão, registre as informações de log quando o status alcançável do servidor do Portal for alterado. |
Configurar a interface de origem usada enviando o pacote do portal
Especifique a interface de origem usada enviando o pacote do Portal. O endereço IP mestre configurado na interface de origem é o endereço de origem usado pelo dispositivo de autenticação para enviar o pacote do Portal ao servidor do Portal. Se não houver endereço IP mestre na interface de origem, a comunicação falhará.
Tabela 13 – 5 Configure a interface de origem usada enviando o pacote do Portal
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a interface de origem usada enviando o pacote do Portal | portal server server-name source-interface interface-name | Opcional Por padrão, não especifique a interface de origem usada ao enviar o pacote do Portal, ou seja, considere a interface de conexão do usuário como a interface de origem do envio do pacote do Portal. |
Configurar o número da porta UDP de destino do pacote offline forçado pelo usuário
O número da porta de algum servidor para receber o pacote offline forçado pelo usuário é o número da porta UDP especificado, portanto, é necessário configurar o número da porta UDP de destino do pacote offline forçado pelo usuário.
Tabela 13 – 6 Configure o número da porta UDP de destino do pacote offline forçado pelo usuário
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o número da porta UDP de destino do pacote offline forçado pelo usuário | portal server server-name ntf-logout-port udp-port-num | Opcional Por padrão, não especifique o número da porta UDP de destino do pacote offline forçado pelo usuário, mas adote o número da porta do servidor como o número da porta UDP de destino do pacote offline forçado pelo usuário. |
Configurar a função de autenticação do portal L2
Condição de configuração
Para habilitar a função de autenticação L2 Portal, é necessário atender às seguintes condições:
- O servidor do Portal é criado no dispositivo de autenticação
Ativar a função de autenticação do portal L2
Habilite a autenticação do Portal L2 na porta de conexão do usuário no dispositivo de autenticação. A autenticação do Portal L2 controla com base no MAC de origem, permitindo a passagem do pacote autenticado com o endereço MAC de origem válido.
Tabela 13 – 7 Habilite a função de autenticação do Portal L2
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a função de autenticação do Portal L2 | portal server server-name method layer2 | Obrigatório Por padrão, a função de autenticação L2 Portal da porta está desabilitada. |
O modo de autenticação L2 Portal não suporta a entrega de VLAN. Em uma porta, você não pode configurar a autenticação L2 Portal ou a função 802.1X Free-IP ao mesmo tempo. Quando a autenticação L2 Portal está habilitada em uma porta, a interface VLAN correspondente não pode habilitar a autenticação L3 Portal. Caso contrário, a configuração falha. Quando a porta habilitada com a autenticação L2 Portal for adicionada à interface VLAN habilitada com a autenticação L3 Portal, limpe a configuração de autenticação L2 Portal da porta automaticamente e registre o log de autolimpeza da configuração ao mesmo tempo.
Configurar atributos de autenticação do portal L2
Condição de configuração
Nenhum
Configurar o modo de controle de acesso à porta
Existem dois modos de controle de acesso à porta: modo de controle de acesso baseado em porta e modo de controle de acesso baseado em usuário.
Modo de controle de acesso baseado em porta (Portbased): Permitir apenas que um usuário passe a autenticação na porta
Modo de controle de acesso baseado em usuário (Macbased): Na porta, permite que vários usuários passem pela autenticação; os usuários na porta podem acessar a rede somente após passar a autenticação.
O modo de controle de acesso baseado em porta é dividido em dois tipos: modo multi-host e modo de host único.
Modo multi-host (Multi-hosts): Depois que um usuário na porta passa pela autenticação, os outros usuários na porta podem acessar a rede sem autenticação.
Modo de host único (Single-host): Na porta, permite apenas que um usuário passe a autenticação e acesse a rede, e os outros usuários não podem acessar a rede e não podem passar a autenticação.
Tabela 13 – 8 Configurar o modo de controle de acesso à porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar o modo de controle de acesso | authentication port-method { macbased | portbased } | Obrigatório Por padrão, habilite o modo de autenticação do usuário na porta. |
| Modo de controle de acesso baseado em porta | authentication port-method portbased host-mode { multi-hosts | single-host } | Opcional Por padrão, habilite o modo de autenticação multi-host na porta. |
Ao configurar o modo de host no modo de controle de acesso baseado em porta, é necessário garantir que o modo de controle de acesso tenha sido configurado como modo de controle de acesso baseado em porta (Portbased).
Configurar a função de autenticação do portal L3
Condição de configuração
Para habilitar a função de autenticação do Portal L3, é necessário atender à seguinte condição:
- O servidor do Portal é criado no dispositivo de autenticação
Ativar a função de autenticação do portal L3 comum
Na interface L3 do dispositivo de autenticação que conecta o usuário, ative a função de autenticação do Portal L3 comum. O modo de autenticação L3 comum tem dois modos de controle:
- Controle baseado no IP de origem: Permitir que o pacote autenticado com o IP de origem válido passe
- Controle baseado no IP de origem + MAC de origem: permite a passagem do pacote autenticado com o IP de origem válido e o endereço MAC de origem
Tabela 13 – 9 Habilitar a função de autenticação do Portal L3 comum
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite a função de autenticação do Portal L3 comum | portal server server-name method layer3 [ ip | ip-mac ] | Obrigatório Por padrão, a função de autenticação do Portal L3 comum está desabilitada. |
Você não pode habilitar a autenticação 802.1X e a função de autenticação MAC na porta que está habilitada com a autenticação L3 Portal comum. Você não pode habilitar a função de autenticação L2 Portal na porta que está habilitada com a autenticação L3 Portal comum. Quando a porta habilitada com a autenticação L2 Portal é adicionada à interface VLAN habilitada com a autenticação L3 Portal comum, a autenticação L2 Portal será desabilitada.
Habilite a função de autenticação do portal de atribuição de endereço secundário
Habilite a função de autenticação do Portal da atribuição de endereço secundário na interface L3 do usuário de autenticação que conecta o usuário. A função de autenticação do Portal da atribuição de endereço secundário controla com base no IP de origem + MAC de origem, permitindo a passagem do pacote autenticado com o IP de origem válido e o endereço MAC de origem.
Para configurar a função de autenticação do Portal de atribuição de endereço secundário, é necessário atender às seguintes condições:
- Configure os endereços IP ativos e em espera na interface
- As funções DHCP Relay e DHCP Snooping precisam ser configuradas no dispositivo de autenticação.
Tabela 13 – 10 Habilite a função de autenticação do Portal da atribuição de endereço secundário
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite a função de autenticação do Portal da atribuição de endereço secundário | portal server server-name method redhcp | Obrigatório Por padrão, a função de autenticação do Portal da atribuição de endereço secundário é desativada na interface. |
Você não pode habilitar a autenticação 802.1X e a função de autenticação MAC na porta que está habilitada com a interface de autenticação do Portal da atribuição de endereço secundário. Você não pode ativar a função de autenticação do Portal L2 na porta que está ativada com a interface de autenticação do Portal da atribuição de endereço secundário. Quando a porta habilitada com a autenticação L2 Portal é adicionada à interface VLAN habilitada com a autenticação Portal da atribuição de endereço secundário, a autenticação L2 Portal será desabilitada. O modo de autenticação do Portal da atribuição de endereço secundário precisa ser suportado pelo cliente do Portal e pelo servidor do Portal ao mesmo tempo. Caso contrário, a autenticação não pode ser feita.
Configurar e aplicar canal seguro
Depois de habilitar a função de autenticação L3 na interface L3, é necessário configurar e aplicar o canal seguro se espera permitir que os usuários do terminal acessem os recursos na rede especificada sem autenticação ou especificar os usuários do terminal específico para acessar os recursos da rede sem autenticação.
A configuração das regras de canal seguro pode ser dividida nos seguintes tipos:
- Configure o usuário do terminal para permitir o acesso aos recursos de rede especificados
- Configure o usuário do terminal especificado para permitir o acesso aos recursos da rede
Tabela 13 – 11 Aplicar o canal seguro
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o canal seguro | hybrid access-list advanced { access-list-number | access-list-name } | Obrigatório Por padrão, o canal seguro não está configurado no dispositivo. |
| Configurar as regras de canal seguro | [ sequence ] permit protocol { any | source-ip-addr source-wildcard | host source-ip-addr } { any | source-mac-addr source-wildcard | host source-mac-addr } { any | destination-ip-addr destination-wildcard | host destination-ip-addr } { any | destination-mac-addr destination-wildcard | host destination-mac-addr } | Obrigatório Por padrão, não há regra de canal seguro no canal seguro. |
| Aplicar o canal seguro | global security access-group { access-group-number | access-group-name } | Obrigatório Por padrão, não aplique nenhum canal seguro no sistema. |
O dispositivo pode configurar vários canais seguros e um canal seguro pode ser configurado com várias regras de canal seguro. O tipo de canal seguro só pode ser a ACL avançada mista. No dispositivo, permita apenas a aplicação de um canal seguro.
Configurar atributos públicos
Condição de configuração
Nenhum
Configurar máx. Usuários da interface
Se os usuários autenticados na interface atingirem o limite configurado, o sistema de autenticação não responderá às solicitações de autenticação dos novos usuários. O intervalo de valores do máximo de usuários da interface L2 é 1-4096. O intervalo de valores do máximo de usuários da interface L3 é de 1 a 500.
Tabela 13 – 12 Configurar o máximo de usuários da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. Depois de entrar no modo de configuração de interface, a configuração subsequente apenas entra em vigor na interface atual. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Entre no modo de configuração da interface | interface interface-name | |
| Configurar o máximo de usuários da interface | authentication max-user-num max-user-num-value | Obrigatório Por padrão, o número máximo de usuários permitidos para conexão na interface é 256. |
Na interface L2, é necessário configurar como o modo de controle de acesso baseado no usuário (Macbased). Caso contrário, o número configurado de usuários que podem se conectar não terá efeito.
Configurar a função de transferência de autenticação do usuário
A função de transferência de autenticação do usuário se aplica ao cenário em que o mesmo usuário transfere de uma porta de autenticação do mesmo dispositivo para outra. Quando a função de transferência de autenticação do usuário está desabilitada, o usuário não tem permissão para iniciar a autenticação em outra porta de autenticação do dispositivo após ser autenticado em uma porta do dispositivo; quando a função de transferência de autenticação do usuário está habilitada e depois que o usuário é autenticado em uma porta, o dispositivo primeiro exclui as informações de autenticação na porta original após detectar que o usuário transfere para outra porta de autenticação e, em seguida, permite que o usuário inicie a autenticação na nova porta de autenticação
Independentemente de a função de transferência de autenticação do usuário estar habilitada ou não, o dispositivo gravará o log ao detectar que o usuário transfere entre as portas de autenticação.
Tabela 13 -13 Configurar a função de transferência de autenticação do usuário
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. Depois de entrar no modo de configuração de interface, a configuração subsequente apenas entra em vigor na interface atual. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Entre no modo de configuração da interface | interface interface-name | |
| Configurar a função de migração de autenticação do usuário | authentication station-move { enable | disable } | Obrigatório Por padrão, a função de migração de autenticação do usuário está desabilitada. |
Configurar se deve levar o nome de domínio
Em alguns cenários, quando o cliente inicia a autenticação, o nome de usuário carrega automaticamente o nome de domínio e o usuário que carrega o nome de domínio não consegue se autenticar no servidor de autenticação. Para evitar esse caso, o dispositivo de autenticação pode configurar se o formato de nome de usuário de autenticação enviado ao servidor de autenticação carrega o nome de domínio.
Tabela 13 – 14 Configure se deve levar o nome de domínio
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. Depois de entrar no modo de configuração de interface, a configuração subsequente apenas entra em vigor na interface atual. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Entre no modo de configuração da interface | interface interface-name | |
| Configure se deseja carregar o nome de domínio | portal user-name-format { with-domain | without-domain } | Obrigatório Por padrão, carregue o nome de domínio. |
Configurar parâmetros do temporizador
Na interface, os parâmetros do temporizador contêm temporizador de tempo limite de autenticação, temporizador de tempo limite autenticado, temporizador de detecção de inatividade e temporizador de silêncio.
Temporizador de tempo limite de autenticação (período de autenticação): Ao detectar que existe o pacote do cliente, habilite o temporizador de tempo limite de autenticação. Após o timer expirar e se não houver resultado de autenticação, o cliente será excluído.
Temporizador de tempo limite autenticado (autenticado-período): quando o cliente for autenticado com sucesso, habilite o temporizador de tempo limite autenticado. Após o tempo limite do temporizador, force a exclusão das informações do cliente autenticado.
Temporizador de detecção de inatividade (período de inatividade): Quando o cliente for autenticado com sucesso, habilite o temporizador de detecção de inatividade. Após detectar que o cliente está offline, force a exclusão das informações do cliente autenticado.
Temporizador de silêncio (período de silêncio): após a falha na autenticação do cliente, habilite o temporizador de silêncio. Após o tempo limite do temporizador de silêncio, o dispositivo de autenticação responde à solicitação de autenticação do cliente novamente.
Os novos horários só podem ser válidos para o usuário de autenticação online subsequente, não são válidos para o usuário de autenticação online.
Tabela 13 - 15 Configurar os parâmetros do temporizador
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. Depois de entrar no modo de configuração de interface, a configuração subsequente apenas entra em vigor na interface atual. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Entre no modo de configuração da interface | interface interface-name | |
| Configure os parâmetros do temporizador | portal timeout { authenticating-period authenticating-period-value | authenticated-period authenticated-period-value | idle-period idle-period-value | quiet-period quiet-period-value } | Obrigatório Por padrão, o tempo do timer de tempo limite de autenticação é 120s e o intervalo de valores é 15-300; o tempo do timer de tempo limite autenticado é 3600s e o intervalo de valores é 300-864000; o tempo do temporizador de detecção de inatividade é 300s, 0 ou 180-1800; o tempo de silêncio é 60 e o intervalo de valores é 15-3600. |
Configurar lista de métodos de autenticação
Configure a lista de métodos de autenticação usada pelo usuário do Portal. Quando o nome de usuário do usuário do Portal carrega o nome de domínio, use a lista de métodos de autenticação especificada pelo nome de domínio. Quando o nome de usuário do usuário do Portal não possuir o nome de domínio, use a lista de métodos de autenticação configurados.
Tabela 13 - 16 Configurar a lista de métodos de autenticação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a lista de métodos de autenticação de conexão | portal authentication method-list { default | list-name } | Opcional Por padrão, use a lista de métodos de autenticação padrão. |
Configurar lista de métodos de estatísticas
Configure a lista de métodos de estatísticas usada pelo usuário do Portal. Quando o nome de usuário do usuário do Portal carrega o nome de domínio, use a lista de métodos de estatísticas especificada pelo nome de domínio; quando o nome de usuário do usuário do Portal não possuir o nome de domínio, use a lista de métodos de estatísticas configuradas.
Tabela 13 - 17 Configurar a lista de métodos de estatísticas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a lista de métodos de estatísticas de conexão | portal accounting method-list { default | list-name } | Opcional Por padrão, use a lista de métodos de estatísticas padrão. |
Monitoramento e manutenção do portal
Tabela 13 - 18 Monitoramento e manutenção do portal
| Comando | Descrição |
| clear portal user { ip ip-address | mac mac-address | all | interface interface-name | link-aggregation link-aggregation-id } | Forçar o usuário do Portal offline |
| clear portal auth-fail-user history [ ip ip-address ] | Limpe as informações do registro de falha de autenticação |
| clear portal statistic [ interface interface-name | link-aggregation link-aggregation-id ] | Limpar as informações de estatísticas de autenticação |
| show authentication user [ip ip-address | mac mac-address | all | interface interface-name | link-aggregation link-aggregation-id | summary ] | Exibir as informações do usuário de gerenciamento de autenticação |
| show authentication intf-status [ interface interface-name | link-aggregation link-aggregation-id ] | Exibir as informações de status de autenticação |
| show portal | Exibir as informações de configuração padrão autenticadas |
| show portal auth-fail-user history [ ip ip-address | recent ] | Exibir as informações de falha de autenticação |
| show portal config [ interface interface-name | link-aggregation link-aggregation-id ] | Exibir as informações de configuração de autenticação |
| show portal global config | Exibir as informações de configuração global |
| show portal server | Exibir as informações do servidor do Portal |
| show portal statistic [ interface interface-name | link-aggregation link-aggregation-id ] | Exibir as informações de estatísticas de autenticação |
| show portal user [ ip ip-address | mac mac-address | interface interface-name | link-aggregation link-aggregation-id | summary ] | Exibir as informações do usuário |
Exemplo de configuração típica do portal
Configurar a autenticação baseada em porta da autenticação do portal L2
Requisitos de rede
- PC1 e PC2 em uma LAN são conectados à rede IP via Device, habilitam a função de autenticação L2 Portal no Device e configuram o modo de autenticação como Portabased.
- O modo de autenticação adota a autenticação RADIUS.
- O usuário não autenticado pode acessar apenas o Portal Server e o usuário autenticado pode acessar a Rede IP.
- Depois que um usuário na LAN passa pela autenticação, os outros usuários na LAN podem acessar a rede IP sem autenticação.
Topologia de rede
Figura 13 -6 Rede de configuração da autenticação baseada em porta da autenticação L2 Portal
Etapas de configuração
- Passo 1:Configure a VLAN e o tipo de link de porta no dispositivo.
#Criar VLAN129 no dispositivo.
Device#configure terminalDevice(config)#vlan 129Device(config)#exit
#Configure o tipo de link da porta gigabitethernet0/2 como Acesso, permitindo a passagem dos serviços da VLAN129.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode accessDevice(config-if-gigabitethernet0/2)#switchport access vlan 129Device(config-if-gigabitethernet0/2)#exit
#Configure o tipo de link de porta em gigabitethernet 0/3-gigabitethernet 0/5 do Dispositivo como Acesso, permitindo a passagem dos serviços da VLAN129 (omitido).
- Passo 2:Configure o endereço IP da interface do Dispositivo.
#Configure o endereço IP da VLAN129 como 129.255.43.10/24.
Device(config)#interface vlan 129Device(config-if-vlan129)#ip address 129.255.43.10 255.255.255.0Device(config-if-vlan129)#exit
- Passo 3:Configure a autenticação AAA.
#No dispositivo, habilite a autenticação AAA, adote o modo de autenticação RADIUS, o endereço do servidor RADIUS é 129.255.43.90/24, o valor da chave é admin e a prioridade é 1.
Device#configure terminalDevice(config)#aaa new-modelDevice(config)#aaa authentication connection default radiusDevice(config)#radius-server host 129.255.43.90 priority 1 key admin
- Passo 4:Configure o servidor AAA.
#Configure o nome de usuário, a senha e o valor da chave como admin no servidor AAA (omitido).
- Passo 5:Configure a autenticação do Portal L2.
#No Dispositivo, configure o servidor do Portal denominado server1.
Device(config)# portal server server1 ip 129.255.43.99 key admin url http://129.255.43.99:8080/portal#No dispositivo, habilite a autenticação do portal L2 e o modo de autenticação é Portased.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#portal server server1 method layer2Device(config-if-gigabitethernet0/2)#authentication port-method portbasedDevice(config-if-gigabitethernet0/2)#exit
- Passo 6:Configure o servidor do Portal.
#No servidor do Portal, configure o endereço IP, o endereço do dispositivo e a chave do PC1 como admin (omitido).
- Passo 7:Confira o resultado.
#Antes de passar a autenticação, tanto o PC1 quanto o PC2 podem acessar apenas o Portal Server.
#PC1 pode passar a autenticação. Tanto o PC1 quanto o PC2 podem acessar a rede IP.
Device#show portal user--------------------NO 1 : IP_ADDRESS= 129.255.43.1 STATUS= Authorized USER_NAME= adminINTERFACE= gi0/2 CTRL_METHOD= L2_MAC AUTH_STATE= AUTHENTICATEDBACK_STATE= AAA_SM_IDLE VLAN= 129 MAC_ADDRESS= 00E0.4C47.01DBTotal: 1 Authorized: 1 Unauthorized/Guest/Critical: 0/0/0
Configurar autenticação baseada em Mac da autenticação do portal L2
Requisitos de rede
- PC1 e PC2 em uma LAN estão conectados à rede IP via dispositivo, habilitam a função de autenticação L2 Portal no dispositivo e configuram o modo de autenticação como baseado em Mac.
- O modo de autenticação adota a autenticação RADIUS.
- O usuário não autenticado pode acessar apenas o Portal Server e o usuário autenticado pode acessar a Rede IP.
- Depois que um usuário na LAN passa a autenticação, o usuário pode acessar a rede IP e os outros usuários na LAN podem acessar a rede IP depois de passar a autenticação.
Topologia de rede
Figura 13 -7 Rede de configuração da autenticação baseada em Mac da autenticação L2 Portal
Etapas de configuração
- Passo 1:Configure a VLAN e o tipo de link de porta no dispositivo.
#Criar VLAN129 no dispositivo.
Device#configure terminal
Device(config)#vlan 129
Device(config)#exit#Configure o tipo de link da porta gigabitethernet0/2 como Acesso, permitindo a passagem dos serviços da VLAN129.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode accessDevice(config-if-gigabitethernet0/2)#switchport access vlan 129Device(config-if-gigabitethernet0/2)#exit
#Configure o tipo de link de porta em gigabitethernet 0/3-gigabitethernet 0/5 do Dispositivo como Acesso, permitindo a passagem dos serviços da VLAN129 (omitido).
- Passo 2:Configure o endereço IP da interface do Dispositivo.
#Configure o endereço IP da VLAN129 como 129.255.43.10/24.
Device(config)#interface vlan 129Device(config-if-vlan129)#ip address 129.255.43.10 255.255.255.0Device(config-if-vlan129)#exit
- Passo 3:Configure a autenticação AAA.
#No dispositivo, habilite a autenticação AAA, adote o modo de autenticação RADIUS, o endereço do servidor RADIUS é 129.255.43.90/24, o valor da chave é admin e a prioridade é 1.
Device#configure terminalDevice(config)#aaa new-modelDevice(config)#aaa authentication connection default radiusDevice(config)#radius-server host 129.255.43.90 priority 1 key admin
- Passo 4:Configure o servidor AAA.
#Configure o nome de usuário, a senha e o valor da chave como admin no servidor AAA (omitido).
- Passo 5:Configure a autenticação do portal L2.
#No Dispositivo, configure o servidor do Portal denominado server1.
Device(config)# portal server server1 ip 129.255.43.99 key admin url http://129.255.43.99:8080/portal#No dispositivo, habilite a autenticação do portal L2 e o modo de autenticação é baseado em Mac.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#portal server server1 method layer2Device(config-if-gigabitethernet0/2)#authentication port-method macbasedDevice(config-if-gigabitethernet0/2)#exit
- Passo 6:Configure o servidor do Portal.
#No servidor do Portal, configure o endereço IP, o endereço do dispositivo e a chave do PC1 como admin (omitido).
- Passo 7:Confira o resultado.
#Antes de passar a autenticação, tanto o PC1 quanto o PC2 podem acessar apenas o Portal Server.
#PC1 pode passar a autenticação. O PC1 pode acessar a rede IP e o PC2 não pode acessar a rede IP.
Device#show portal user--------------------NO 1 : IP_ADDRESS= 129.255.43.1 STATUS= Authorized USER_NAME= adminINTERFACE= gi0/2 CTRL_METHOD= L2_MAC AUTH_STATE= AUTHENTICATEDBACK_STATE= AAA_SM_IDLE VLAN= 129 MAC_ADDRESS= 00E0.4C47.01DBTotal: 1 Authorized: 1 Unauthorized/Guest/Critical: 0/0/0
Configurar autenticação de portal L3 comum
Requisitos de rede
- PC1 e PC2 em uma LAN estão conectados à rede IP via dispositivo e habilitam a autenticação normal do portal L3 no dispositivo.
- O modo de autenticação adota a autenticação RADIUS.
- Antes de passar a autenticação, o PC1 só pode acessar o Servidor de Atualização. Depois de passar a autenticação, o PC1 pode acessar a rede IP.
- PC2 pode acessar o servidor de atualização.
Topologia de rede

Figura 13 -8 Rede de configuração da autenticação do Portal L3 comum
Etapas de configuração
- Passo 1: Crie as VLANs
#No dispositivo, crie VLAN128, VLAN129, VLAN130 e VLAN131.
Device#configure terminal
Device(config)#vlan 128,129,130,131Device(config)#exit
#Configure o tipo de link da porta gigabitethernet0/2 como Acesso, permitindo a passagem dos serviços da VLAN128.
Device#configure terminal
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode accessDevice(config-if-gigabitethernet0/2)#switchport access vlan 128Device(config-if-gigabitethernet0/2)#end
#Configure o tipo de link de porta em gigabitethernet0/1 do Dispositivo como Acesso, permitindo a passagem dos serviços da VLAN131. Configure o tipo de link de porta em gigabitethernet0/3 do Dispositivo como Acesso, permitindo a passagem dos serviços da VLAN130. Configure o tipo de link de porta em gigabitethernet0/4-gigabitethernet 0/5 do dispositivo como acesso, permitindo a passagem dos serviços da VLAN129. (omitido)
- Passo 2:Configure o endereço IP da interface do Dispositivo, garantindo que a rota de rede seja alcançável.
#Configure o endereço IP da VLAN128 como 128.255.36.10/24.
Device#configure terminalDevice(config)#interface vlan 128Device(config-if-vlan128)#ip address 128.255.36.10 255.255.255.0Device(config-if-vlan128)#end
#Configure o endereço IP da VLAN129 como 129.255.43.10/24.
Device#configure terminalDevice(config)#interface vlan 129Device(config-if-vlan129)#ip address 129.255.43.10 255.255.255.0Device(config-if-vlan129)#end
#Configure o endereço IP da VLAN130 como 130.255.28.10/24.
Device#configure terminalDevice(config)#interface vlan 130Device(config-if-vlan130)#ip address 130.255.28.10 255.255.255.0Device(config-if-vlan130)#end
#Configure o endereço IP da VLAN131 como 131.255.28.10/24.
Device#configure terminalDevice(config)#interface vlan 131Device(config-if-vlan131)#ip address 131.255.28.10 255.255.255.0Device(config-if-vlan131)#end
- Passo 3:Configure a autenticação AAA.
#No dispositivo, habilite a autenticação AAA, adote o modo de autenticação RADIUS, o endereço do servidor RADIUS é 129.255.43.90/24, o valor da chave é admin e a prioridade é 1.
Device#configure terminalDevice(config)#aaa new-modelDevice(config)#aaa authentication connection default radiusDevice(config)#radius-server host 129.255.43.90 priority 1 key admin
- Passo 4:Configure o servidor AAA.
#No servidor AAA, configure o nome de usuário, a senha e o valor da chave como admin (omitido).
- Passo 5:Configure a autenticação do Portal L3 comum.
#No Dispositivo, configure o servidor do Portal denominado server1.
Device(config)# portal server server1 ip 129.255.43.99 key admin url http://129.255.43.99:8080/portal#No Dispositivo, habilite a autenticação do Portal L3 comum.
Device#configure terminalDevice(config)#interface vlan 128Device(config-if-vlan128)#portal server server1 method layer3 ipDevice(config-if-vlan128)#exit
#Configure um canal seguro denominado canal, permitindo que PC1 e PC2 acessem o Servidor de Atualização.
Device#configure terminal
Device(config)#hybrid access-list advanced channelDevice(config-adv-hybrid-nacl)#permit ip any any host 130.255.28.20 any
#Aplica o canal seguro chamado channel.
Device#configure terminalDevice(config)#global security access-group channelDevice(config)#exit
- Passo 6:Configure o servidor do Portal.
#No servidor do Portal, configure o endereço IP, os adders do dispositivo e o valor da chave do PC1 como admin (omitido).
- Passo 7:Confira o resultado.
#Consulte as informações de configuração do canal seguro.Device#show portal global config
portal global configuration information:authentication method list : defaultaccounting method list : defaultglobal security access-group : channel
#Antes de passar a autenticação, o PC1 pode acessar o servidor de atualização e não pode acessar a rede IP.
#PC1 pode passar a autenticação e pode acessar o servidor de atualização e a rede IP. PC2 pode acessar o servidor de atualização e não pode acessar a rede IP.
Device#show portal user--------------------NO 1:IP_ADDRESS= 128.255.36.1 STATUS= Authorized USER_NAME= adminINTERFACE= vlan128 CTRL_METHOD= L3_IP AUTH_STATE= AUTHENTICATEDBACK_STATE= AAA_SM_IDLETotal: 1 Authorized: 1 Unauthorized/Guest/Critical: 0/0/0
Acesso a dispositivos confiáveis
Visão geral
Para proteger a rede principal de ser acessada ilegalmente, o dispositivo de borda da rede principal deve ter alta segurança. Isso requer que outros dispositivos de rede conectados ao dispositivo de borda da rede principal sejam um dispositivo claramente confiável. A função de acesso a dispositivos confiáveis é baseada em um protocolo 802.1X maduro para impedir que dispositivos não autorizados acessem a rede principal. A topologia de rede básica, conforme mostrado na Figura 7-1, inclui três entidades: o Dispositivo de Acesso, o Sistema de Autenticação e o Sistema Servidor de Autenticação.
Figura 14 -1 O diagrama de topologia de acesso do dispositivo confiável
O método específico de acesso ao dispositivo confiável é o seguinte:
- Ative a função de acesso do dispositivo confiável no dispositivo de acesso e configure as credenciais de identidade necessárias e os parâmetros relacionados no dispositivo de acesso e no servidor de autenticação.
- Habilite a função de autenticação do dispositivo 802.1X no dispositivo de autenticação, a porta conectada ao dispositivo de acesso torna-se a porta controlada aguardando o acesso do dispositivo de acesso.
- O dispositivo de acesso inicia automaticamente a autenticação 802.1X após conectar o dispositivo de autenticação. Depois de passar a autenticação 802.1X, o dispositivo de autenticação abre a porta controlada e o dispositivo de acesso é conectado à rede com sucesso.
- O dispositivo de acesso executa regularmente a autenticação de manutenção de atividade para o dispositivo de autenticação ao definir o período de manutenção de atividade do dispositivo de autenticação.
Configuração da função de acesso a dispositivos confiáveis
Tabela 14 – 1 Lista de configuração da função de acesso de dispositivo confiável
| Tarefa de configuração | |
| Configure o acesso do dispositivo confiável |
Configure o nome de usuário e a senha do acesso ao dispositivo confiável
Configure o formato do nome de usuário do acesso ao dispositivo confiável Configure o período de disparo do acesso ao dispositivo confiável Ative a função de acesso do dispositivo confiável |
| Configure a autenticação do dispositivo 802.1X |
Habilite a função de autenticação do dispositivo 802.1X
Configure o período keepalive da autenticação do dispositivo 802.1X |
Configurar acesso a dispositivos confiáveis
Condição de configuração
Nenhum
Configurar nome de usuário e senha de acesso a dispositivos confiáveis
Para conectar o dispositivo de acesso à rede com sucesso, você precisa configurar o nome de usuário e a senha do acesso do dispositivo confiável na porta conectada ao dispositivo de autenticação. O nome de usuário e a senha configurados são enviados ao dispositivo de autenticação para autenticação como credencial de autenticação do dispositivo de acesso através do protocolo 802.1X (modo MD5-Challenge)
Tabela 14 – 2 Configure o nome de usuário e a senha de acesso ao dispositivo confiável
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente só pode ter efeito na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente só pode ter efeito no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o nome de usuário e a senha do acesso ao dispositivo confiável | dot1x client user username password 0 password | Obrigatório Por padrão, a porta não está configurada com o nome de usuário ou senha de acesso ao dispositivo confiável. |
Em uma porta, você pode configurar apenas um nome de usuário e senha para o acesso ao dispositivo. Em uma porta, o novo nome de usuário e senha cobrirão o nome de usuário e a senha originais na porta.
Configurar o formato do nome de usuário de acesso do dispositivo confiável
A autenticação 802.1X determina se o peer que inicia a autenticação é um dispositivo ou um terminal se o pacote de protocolo EAP-Response/Identity carrega o ID do dispositivo. Quando o nome de usuário de acesso do dispositivo confiável em uma porta carrega o ID do dispositivo, a autenticação iniciada pela porta é a autenticação do dispositivo 802.1X. Quando o nome de usuário de acesso do dispositivo confiável em uma porta não carrega o ID do dispositivo, a autenticação iniciada pela porta é a autenticação do terminal 802.1X.
Tabela 14 – 3 Configure o formato do nome de usuário do acesso ao dispositivo confiável
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente só pode ter efeito na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente só pode ter efeito no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o formato do nome de usuário do acesso ao dispositivo confiável | dot1x client user-name-format { with-dev-flag | without-dev-flag } | Obrigatório Por padrão, o nome de usuário do acesso do dispositivo confiável na porta carrega o ID do dispositivo. |
Configurar período de acionamento de acesso a dispositivos confiáveis
Antes de passar a autenticação, o dispositivo acessado inicia ativamente o pacote EAPoL-Start para realizar a autenticação do dispositivo 802.1X de acordo com o período de disparo de acesso configurado, garantindo que o dispositivo acessado possa se conectar à rede rapidamente.
Tabela 14 – 4 Configure o período de disparo do acesso ao dispositivo confiável
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente só pode ter efeito na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente só pode ter efeito no grupo de agregação. |
| modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o período de disparo do acesso ao dispositivo confiável | dot1x client auth-interval interval-value | Obrigatório Por padrão, o período de disparo do acesso do dispositivo confiável na porta é de 15s. |
Ativar função de acesso do dispositivo confiável
Depois de habilitar a função de acesso do dispositivo, o dispositivo acessado executa ativamente a autenticação do dispositivo 802.1X antes de passar pela autenticação. Depois de passar a autenticação do dispositivo 802.1X, o dispositivo autenticado habilita a porta controlada e o dispositivo acessado conecta-se com sucesso à rede.
Tabela 14 – 5 Habilite a função de acesso do dispositivo confiável
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente só pode ter efeito na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente só pode ter efeito no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Ative a função de acesso do dispositivo confiável | dot1x client { enable | disable } | Obrigatório Por padrão, a função de acesso do dispositivo confiável na porta está desabilitada. |
Você não pode habilitar a função de acesso e a função de autenticação 802.1X do dispositivo confiável em uma porta ao mesmo tempo. Você não pode habilitar a função de acesso e a função de autenticação de endereço MAC do dispositivo confiável em uma porta ao mesmo tempo. Você não pode habilitar a função de acesso e a função de autenticação de canal seguro do dispositivo confiável em uma porta ao mesmo tempo.
Configurar autenticação de dispositivo 802.1X
Condição de configuração
Nenhum
Ative a função de autenticação do dispositivo 802.1X
Para que a função de autenticação do dispositivo 802.1X entre em vigor no dispositivo de autenticação, você precisa habilitar a autenticação 802.1X e a função de autenticação do dispositivo 802.1X ao mesmo tempo. Depois que a autenticação do dispositivo entra em vigor, a porta conectada do dispositivo de autenticação e o dispositivo de acesso tornam-se a porta controlada. Depois que a autenticação do dispositivo for bem-sucedida, o dispositivo de autenticação habilitará a porta controlada e o dispositivo de acesso conectará a rede com sucesso.
Tabela 14 – 6 Habilite a função de autenticação do dispositivo 802.1X
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente só pode ter efeito na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente só pode ter efeito no grupo de agregação. |
| modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a autenticação 802.1X | dot1x port-control { enable | disable } | Obrigatório Por padrão, a função de autenticação 802.1X em uma porta está desabilitada. |
| Habilite a autenticação do dispositivo 802.1X | dot1x device-auth { enable | disable } | Obrigatório Por padrão, a função de autenticação de dispositivo 802.1X em uma porta está desabilitada. |
Você não pode habilitar a função de autenticação e a função de autenticação de endereço MAC do dispositivo 802.1X em uma porta ao mesmo tempo. Você não pode habilitar a função de autenticação e a função de autenticação de canal seguro do dispositivo 802.1X em uma porta ao mesmo tempo.
Configurar o período Keepalive da autenticação do dispositivo 802.1X
Para detectar se o dispositivo de acesso está online, após passar pela autenticação, o dispositivo de autenticação entrega o período de manutenção da atividade da autenticação do dispositivo 802.1X configurado para o dispositivo de acesso e o dispositivo de acesso inicia a autenticação de manutenção de atividade pelo período de manutenção de atividade. Se o dispositivo de autenticação não receber a autenticação keepalive do dispositivo de acesso dentro de três vezes do período keepalive, considera-se que o dispositivo de acesso não está online e altera o status da porta para o estado controlado.
Tabela 14 – 7 Configure o período keepalive da autenticação do dispositivo 802.1X
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente só pode ter efeito na interface atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente só pode ter efeito no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o período keepalive da autenticação do dispositivo 802.1X | dot1x device-auth keepalive period-value | Obrigatório Por padrão, o período keepalive da autenticação do dispositivo 802.1X em uma porta é de 600 segundos. |
Monitoramento e manutenção de acesso a dispositivos confiáveis
Tabela 14 – 8 Monitoramento e manutenção do acesso ao dispositivo confiável
| Comando | Descrição |
| show dot1x client config { interface interface-name | link-aggregation link-aggregation-id } | Exibir as informações de configuração |
| show dot1x client user { interface interface-name | link-aggregation link-aggregation-id } | Exibir as informações de acesso |
| show dot1x user [ mac-address | auth-type {device | user } | interface interface-name | link-aggregation link-aggregation-id | summary ] | Exibir as informações do usuário |
Exemplo de configuração típico de acesso a dispositivos confiáveis
Requisitos de rede
- O dispositivo de acesso Device1 está conectado à rede IP através do dispositivo de autenticação Device2; Device2 adota o controle de acesso de autenticação do dispositivo.
- O dispositivo de acesso Device1 inicia regularmente a autenticação keepalive.
- Durante a autenticação, use o modo de autenticação RADIUS.
- Depois de passar a autenticação do dispositivo de acesso, o PC permite o acesso à rede.
Topologia de rede

Figura 14 -2 Rede de configuração de acesso a dispositivos confiáveis
Etapas de configuração
- Passo 1:Em Device1, configure o tipo de link da VLAN e da porta.
#No gigabitethernet 0/2 do Device1, configure o tipo de link da porta como Access, permitindo a passagem dos serviços da VLAN2.
Device1(config)#interface gigabitethernet 0/2Device1(config-if-range)#switchport mode accessDevice1(config-if-range)#switchport access vlan 2Device1(config-if-range)#exit
#No gigabitethernet 0/1 do Device1, configure o tipo de link de porta como Híbrido, e a porta é adicionada à VLAN2 no modo Tagged.
Device1(config)#interface gigabitethernet 0/1Device1(config-if-range)#switchport mode hybridDevice1(config-if-range)#switchport hybrid tagged vlan 2Device1(config-if-range)#exit
- Passo 2:No Device2, configure o tipo de link da VLAN e da porta.
#No Dispositivo2, crie VLAN2~VLAN3.
Device2#configure terminalDevice2(config)#vlan 2-3Device2(config)#exit
#No gigabitethernet 0/1 do Device2, configure o tipo de link da porta como Híbrido, e a porta será adicionada à VLAN2 no modo Tagged.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-range)#switchport mode hybridDevice2(config-if-range)# switchport hybrid tagged vlan 2Device2(config-if-range)#exit
#No gigabitethernet 0/2-gigabitethernet 0/3 do Device2, configure o tipo de link da porta como Access, permitindo que os serviços de VLAN2~VLAN3 passem. (omitido)
- Passo 3:Configure o endereço IP da interface do Device2.
#No Device2, configure o endereço IP da VLAN3 como 130.255.167.1/24.
Device2(config)#interface vlan 3Device2(config-if-vlan3)#ip address 130.255.167.1 255.255.255.0Device2(config-if-vlan3)#exit
- Passo 4:No Device, configure a autenticação AAA.
#No Device2, habilite a autenticação AAA, adote o modo de autenticação RADIUS, a chave do servidor é admin, a prioridade é 1 e o endereço do servidor RADIUS é 130.255.167.167/24.
Device2(config)#aaa new-modelDevice2(config)#aaa authentication connection default radiusDevice2(config)#radius-server host 130.255.167.167 priority 1 key admin
- Passo 5:Configure o servidor AAA.
# No servidor AAA, configure o nome de usuário, senha e chave como admin. (Omitido)
- Passo 6:Em Device1, configure o acesso ao dispositivo confiável.
#No Dispositivo1, configure o nome de usuário e a senha da autenticação de acesso ao dispositivo confiável.
Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#dot1x client user admin password 0 adminDevice1(config-if-gigabitethernet0/1)#exit
#No Device1, configure iniciando o pacote eapol-start ativamente com um intervalo de 10s para realizar a autenticação do dispositivo 802.1X.
Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#dot1x client auth-interval 10Device1(config-if-gigabitethernet0/1)#exit
#No Dispositivo1, habilite a função de acesso do dispositivo confiável.
Device1(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#dot1x client enableDevice2(config-if-gigabitethernet0/1)#exit
- Passo 7:Em Device2, configure a autenticação do dispositivo 802.1X.
#No Dispositivo2, habilite a autenticação 802.1X.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#dot1x port-control enableDevice2(config-if-gigabitethernet0/1)#exit
#No Dispositivo2, habilite a autenticação do dispositivo 802.1X.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#dot1x device-auth enableDevice2(config-if-gigabitethernet0/1)#exit
#No Device2, configure o período keepalive da autenticação do dispositivo 802.1X como 120s.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#dot1x device-auth keepalive 120Device2(config-if-gigabitethernet0/1)#exit
- Passo 8:Confira o resultado.
#Antes de passar a autenticação do dispositivo de acesso, o PC não pode acessar a rede. Depois de passar a autenticação, o PC pode acessar a rede normalmente.
Device1#show dot1x client userInterface : gi0/1Status : AuthorizedState Machine State : AUTHENTICATEDKeep Alive Interval : 120 sec (802.1X Server)Device2#show dot1x user auth-type device--------------------NO 1 : MAC_ADDRESS= 3883.45ef.7984 STATUS= Authorized USER_NAME= adminVLAN= 2 INTERFACE= gi0/1 USER_TYPE= DOT1XAUTH_STATE= AUTHENTICATED BACK_STATE= IDLE IP_ADDRESS= UnknownOnline time: 0 week 0 day 0 hour 0 minute 53 secondsTotal: 1 Authorized: 1 Unauthorized/guest/critical: 0/0/0 Unknown: 0
Configuração de ACL
Visão geral
Visão geral da ACL
Uma ACL (Access Control List) compreende uma série de regras. Cada regra é uma sentença de permissão, recusa ou observação, indicando a condição e ação correspondentes. A regra ACL filtra os pacotes combinando algum campo no pacote.
ACL pode incluir várias regras. O conteúdo correspondente especificado por cada regra é diferente e o conteúdo correspondente em regras diferentes pode se sobrepor ou entrar em conflito. A correspondência de regras de ACL obedece estritamente à ordem da sequência de pequeno a grande. A regra com sequência menor entra em vigor mais cedo. Sequência significa o número de ordem da regra na ACL while.
Existe uma regra de recusar todos os pacotes ocultos após a última regra da ACL e a sequência é maior do que todas as outras regras da ACL. A regra oculta é invisível e descarta os pacotes que não correspondem às regras anteriores, ou seja, quando o pacote não corresponde às regras anteriores, ele corresponde à regra padrão e é descartado.
De acordo com o uso da ACL, podemos dividir a ACL em sete tipos, ou seja, ACL padrão IP, ACL estendida IP, ACL padrão MAC, ACL estendida MAC, ACL estendida híbrida, ACL padrão IPv6 e ACL estendida IPv6. O nome da ACL pode usar o número e também pode usar a cadeia de caracteres personalizada. Quando o nome da ACL usa o número, o tipo de ACL correspondente e o intervalo de valores numéricos são os seguintes:
- ACL padrão IP: 1-1000;
- ACL estendida de IP: 1001-2000;
- ACL padrão MAC: 2001-3000;
- MAC ACL estendido: 3001-4000;
- ACL estendida híbrida: 5001-6000.
- ACL estendida IPv6: 7001-8000
- ACL padrão MPLS: 8001-9000
Quando o nome da ACL adota a cadeia de caracteres personalizada, todas as ACLs compartilham um espaço de nome, ou seja, se a ACL padrão IP usar um nome, os outros tipos de ACL não poderão usar o nome.
ACL também pode executar o grupo de ação correspondente de acordo com a correspondência. Para obter detalhes, consulte o “Manual de configuração de QoS”.
Visão geral do domínio do tempo
O domínio do tempo é o conjunto dos segmentos de tempo. Um domínio de tempo pode conter de zero a vários segmentos de tempo. O intervalo de tempo do domínio do tempo é a união dos segmentos de tempo.
O segmento de tempo tem os dois tipos a seguir:
- Segmento de tempo periódico: Segmento de tempo periódico significa selecionar um dia ou vários dias de segunda a domingo, e o ponto de tempo inicial até o ponto de tempo final como o segmento de tempo, tendo efeito todas as semanas repetidamente.
- Segmento de tempo absoluto: O segmento de tempo absoluto significa entrar em vigor dentro do intervalo de data e hora especificado
O usuário geralmente tem as seguintes demandas:
O PC de um segmento de rede pode acessar o servidor apenas no horário de trabalho do dia de trabalho (exceto em todos os feriados); na tarde de sábado, permitir que todos os PCs se comuniquem com a Internet externa.
As demandas de controle de comunicação com base no tempo podem ser atendidas vinculando o domínio do tempo na regra ACL ou ACL.
Configuração da função ACL
Tabela 15 - 1 lista de configuração da função ACL
| Tarefa de configuração | |
| Configurar a ACL padrão IP | Configurar a ACL padrão IP Configure a ACL padrão IP nomeada por números |
| Configurar a ACL estendida IP | Configurar a ACL estendida IP Configure a ACL estendida IP nomeada por números |
| Configurar a ACL padrão MAC | Configurar a ACL padrão MAC Configure a ACL padrão MAC nomeada por números |
| Configurar a ACL estendida MAC | Configurar a ACL estendida MAC Configure a ACL estendida MAC nomeada por números |
| Configurar a ACL estendida híbrida | Configurar a ACL estendida híbrida Configure a ACL estendida híbrida nomeada por números |
| Configurar a ACL padrão IPv6 | Configurar a ACL padrão IPv6 Configure a ACL padrão IPv6 nomeada por números |
| Configurar ACL estendida IPv6 | Configurar ACL estendida IPv6 Configurar ACL estendida IPv6 nomeada por números |
| Configure a limitação de quantidade das regras de ACL | Configure a limitação de quantidade das regras de ACL |
| Configurar o domínio do tempo |
Configurar o domínio do tempo
Configurar o segmento de tempo periódico Configurar o segmento de tempo absoluto Configurar o período de atualização Configurar o deslocamento máximo de tempo Configure o domínio de tempo a ser vinculado à regra ACL Configure o domínio de tempo a ser vinculado à ACL |
| Configurar o aplicativo ACL |
Configure o IP ACL a ser aplicado à porta
Configure o MAC ACL a ser aplicado à porta Configure o IP ACL a ser aplicado à VLAN Configure o IP ACL para ser aplicado globalmente Configure a ACL híbrida para ser aplicada globalmente Configure o IP ACL a ser aplicado à interface Configure o MAC ACL para ser aplicado à interface Configure o IPv6 ACL a ser aplicado à porta Configure o IPv6 ACL para ser aplicado à interface |
Configurar ACL padrão IP
A ACL padrão IP faz as regras de acordo com o endereço IP de origem para filtrar os pacotes.
Condição de configuração
Nenhum
Configurar ACL padrão IP
O nome ACL padrão IP pode usar o número e também pode usar a cadeia de caracteres personalizada. Se o nome da ACL padrão IP adotar os números, podemos configurar a limitação de quantidade máxima da ACL; se adotar a cadeia de caracteres personalizada, não há limitação para a quantidade máxima de ACL. O usuário pode selecionar o nome da ACL conforme desejado.
Tabela 15 -2 Configurar a ACL padrão IP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a ACL padrão IP | ip access-list standard { access-list-number | access-list-name } | Obrigatório Por padrão, a ACL padrão IP não está configurada. O intervalo de números da ACL padrão IP é 1-1000. |
| Configurar a regra de permissão da ACL | [ sequence ] permit { any | source-addr source-wildcard | host source-addr } [ time-range time-range-name ] [log] [ pbr-action-group pbr-action-group-name ] [ l3-action-group l3-action-group-name ] [ egr-action-group egr-action-group-name ] [ vfp-action-group vfp-action-group-name ] | Opcional Por padrão, a regra de permissão ACL não está configurada. |
| Configure a regra de recusa de ACL | [ sequence ] deny { any | source-addr source-wildcard | host source-addr } [ time-range time-range-name ] [log] [ pbr-action-group pbr-action-group-name ] [ l3-action-group l3-action-group-name ] [ egr-action-group egr-action-group-name ] [ vfp-action-group vfp-action-group-name ] | Opcional Por padrão, a regra de recusa do ACL não está configurada. |
| Configurar as observações da ACL | [ sequence ] remark comment | Opcional Por padrão, as observações da regra ACL não são configuradas. |
Ao usar o ip lista de acesso padrão comando para criar a ACL padrão IP, a ACL pode ser criada somente após configurar as regras no modo de configuração ACL padrão IP. Sequência significa o número de ordem da regra na ACL. ACL combina e filtra o pacote estritamente de acordo com a ordem da sequência pequena para a sequência grande. A regra com a sequência pequena entra em vigor primeiro. Quando todas as regras não corresponderem, execute a ação de descarte padrão, ou seja, todos os pacotes não autorizados a passar são descartados.
Configurar IP padrão ACL nomeado por números
A ACL padrão IP nomeada por números pode permitir que o usuário identifique o tipo da ACL rapidamente. No entanto, a ACL padrão IP nomeada por números tem algumas limitações. Por exemplo, a quantidade de ACL é limitada.
Tabela 15 -3 Configurar a ACL padrão IP nomeada por números
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a ACL padrão IP nomeada por números | access-list access-list-number { permit | deny } { any | source-addr source-wildcard | host source-addr } [ time-range time-range-name ] [log] [ pbr-action-group pbr-action-group-name ] [ l3-action-group l3-action-group-name ] [ egr-action-group egr-action-group-name ] [ vfp-action-group vfp-action-group-name ] | Obrigatório Por padrão, a ACL padrão IP nomeada por números não está configurada. O intervalo de sequência da ACL padrão IP é 1-1000. |
| Configure as observações da ACL padrão IP nomeada por números | access-list access-list-number remark comment | Opcional Por padrão, as observações da ACL padrão IP nomeada por números não são configuradas. |
Se a ACL com a sequência especificada não existir, crie uma nova ACL e adicione novas regras. Se a ACL com o número especificado existir, basta adicionar novas regras.
Configurar ACL estendida de IP
A ACL estendida de IP pode fazer a regra de classificação de acordo com o número do protocolo IP, endereço IP de origem, endereço IP de destino, número da porta TCP/UDP de origem, número da porta TCP/UDP de destino, prioridade do pacote, tag TCP e tag de fragmento para filtrar os pacotes .
Condição de configuração
Nenhum
Configurar ACL estendida de IP
O nome da ACL estendida de IP pode usar o número e também pode usar a cadeia de caracteres personalizada. Se o nome da ACL estendida IP adotar os números, podemos configurar a limitação de quantidade máxima da ACL; se adotar a cadeia de caracteres personalizada, não há limitação para a quantidade máxima de ACL. O usuário pode selecionar o nome da ACL conforme desejado. A ACL estendida de IP é mais rica, mais correta e mais flexível do que o conteúdo definido pela ACL padrão de IP.
Tabela 15 -4 Configurar a ACL estendida de IP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a ACL estendida IP | ip access-list extended { access-list-number | access-list-name } | Obrigatório Por padrão, a ACL estendida de IP não está configurada. O intervalo de sequência da ACL estendida de IP é 1001-2000. |
| Configurar a regra de permissão da ACL | [ sequence ] permit protocol { any | source-addr source-wildcard | host source-addr } [ operator source-port ] { any | destination-addr destination-wildcard | host destination-addr } [ operator destination-port ] [ ack | fin | psh | rst | syn | urg ] [ precedence precedence ] [ tos tos ] [ dscp dscp ] [fragments] [log] [ time-range time-range-name ] [ pbr-action-group pbr-action-group-name ] [ l3-action-group l3-action-group-name ] [ egr-action-group egr-action-group-name ] [ vfp-action-group vfp-action-group-name ] | Opcional Por padrão, a regra de permissão do ACL não está configurada. |
| Configure a regra de recusa de ACL | [ sequence ] deny protocol { any | source-addr source-wildcard | host source-addr } [ operator source-port ] { any | destination-addr destination-wildcard | host destination-addr } [ operator destination-port ] [ ack | fin | psh | rst | syn | urg ] [ precedence precedence ] [ tos tos ] [ dscp dscp ] [fragments] [log] [ time-range time-range-name ] [ pbr-action-group pbr-action-group-name ] [ l3-action-group l3-action-group-name ] [ egr-action-group egr-action-group-name ] [ vfp-action-group vfp-action-group-name ] | Opcional Por padrão, a regra de recusa do ACL não está configurada. |
| Configurar as observações da ACL | [ sequence ] remark comment | Opcional Por padrão, as observações da ACL não são configuradas. |
Ao usar o ip lista de acesso estendido comando para criar a ACL estendida de IP, a ACL pode ser criada somente após configurar as regras no modo de configuração da ACL estendida de IP. Sequência significa o número de ordem da regra na ACL. ACL combina e filtra o pacote estritamente de acordo com a ordem da sequência pequena para a sequência grande. A regra com a sequência pequena entra em vigor primeiro. Quando todas as regras não corresponderem, execute a ação de descarte padrão, ou seja, todos os pacotes não autorizados a passar são descartados.
Configurar ACL estendida IP nomeada por números
A ACL estendida de IP nomeada por números pode permitir que o usuário identifique o tipo da ACL rapidamente. No entanto, a ACL estendida de IP nomeada por números tem algumas limitações. Por exemplo, a quantidade de ACL é limitada. A ACL estendida de IP é mais rica, mais correta e mais flexível do que o conteúdo definido pela ACL padrão de IP.
Tabela 15 -5 Configurar a ACL estendida de IP nomeada por números
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a ACL estendida IP nomeada por números | access-list access-list-number { permit | deny } protocol { any | source-addr source-wildcard | host source-addr } [ operator source-port ] { any | destination-addr destination-wildcard | host destination-addr } [ operator destination-port ] [ ack | fin | psh | rst | syn | urg ] [ precedence precedence ] [ tos tos ] [ dscp dscp ] [fragments] [log] [ time-range time-range-name ] [ pbr-action-group pbr-action-group-name ] [ l3-action-group l3-action-group-name ] [ egr-action-group egr-action-group-name ] [ vfp-action-group vfp-action-group-name ] | Obrigatório Por padrão, a ACL estendida de IP nomeada por números não está configurada. O intervalo de sequência da ACL estendida de IP é 1001-2000. |
| Configure as observações da ACL estendida IP nomeada por números | access-list access-list-number remark comment | Opcional Por padrão, as observações da ACL estendida IP nomeada por números não são configuradas. |
Se a ACL com a sequência especificada não existir, crie uma nova ACL e adicione novas regras. Se a ACL com o número especificado existir, basta adicionar novas regras.
Configurar ACL padrão MAC
O padrão MAC ACL faz as regras de acordo com o endereço MAC de origem para filtrar os pacotes.
Condição de configuração
Nenhum
Configurar ACL padrão MAC
O nome ACL padrão MAC pode usar o número e também pode usar a cadeia de caracteres personalizada. Se o nome da ACL padrão MAC adotar os números, podemos configurar a limitação de quantidade máxima da ACL; se adotar a cadeia de caracteres personalizada, não há limitação para a quantidade máxima de ACL. O usuário pode selecionar o nome da ACL conforme desejado.
Tabela 15 -6 Configurar a ACL padrão MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a ACL padrão MAC | mac access-list standard { access-list-number | access-list-name } | Obrigatório Por padrão, a ACL padrão MAC não está configurada. O intervalo de sequência da ACL padrão MAC é 2001-3000. |
| Configurar a regra de permissão da ACL | [ sequence ] permit { any | source-addr source-wildcard | host source-addr } [ time-range time-range-name ] [log] [ l2-action-group l2-action-group-name ] [ egr-action-group egr-action-group-name ] [ vfp-action-group vfp-action-group-name ] | Opcional Por padrão, a regra de permissão do ACL não está configurada. |
| Configure a regra de recusa de ACL | [ sequence ] deny { any | source-addr source-wildcard | host source-addr } [ time-range time-range-name ] [log] [ l2-action-group l2-action-group-name ] [ egr-action-group egr-action-group-name ] [ vfp-action-group vfp-action-group-name ] | Opcional Por padrão, a regra de recusa do ACL não está configurada. |
| Configurar as observações da ACL | [ sequence ] remark comment | Opcional Por padrão, as observações do ACL não são configuradas. |
Ao usar o mac lista de acesso comando padrão para criar a ACL padrão MAC, a ACL pode ser criada somente após configurar as regras no modo de configuração ACL padrão MAC. Sequência significa o número de ordem da regra na ACL. ACL combina e filtra o pacote estritamente de acordo com a ordem da sequência pequena para a sequência grande. A regra com a sequência pequena entra em vigor primeiro. Quando todas as regras não corresponderem, execute a ação de descarte padrão, ou seja, todos os pacotes não autorizados a passar são descartados.
Configurar a ACL padrão MAC nomeada por números
A ACL padrão MAC nomeada por números pode permitir que o usuário identifique rapidamente o tipo da ACL. No entanto, a ACL padrão MAC nomeada por números tem algumas limitações. Por exemplo, a quantidade de ACL é limitada.
Tabela 15 -7 Configure a ACL padrão MAC nomeada por números
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a ACL padrão MAC nomeada por números | access-list access-list-number { permit | deny } { any | source-addr source-wildcard | host source-addr } [ time-range time-range-name ] [log] [ l2-action-group l2-action-group-name ] [ egr-action-group egr-action-group-name ] [ vfp-action-group vfp-action-group-name ] | Obrigatório Por padrão, a ACL padrão MAC nomeada por números não está configurada. O intervalo de sequência da ACL padrão MAC é 2001-3000. |
| Configure as observações da ACL padrão MAC nomeada por números | access-list access-list-number remark comment | Opcional Por padrão, as observações da ACL padrão MAC nomeada por números não são configuradas. |
Se a ACL com a sequência especificada não existir, crie uma nova ACL e adicione novas regras. Se a ACL com o número especificado existir, basta adicionar novas regras.
Configurar ACL Estendido MAC
A ACL estendida MAC pode fazer a regra de classificação de acordo com o tipo de protocolo Ethernet, endereço MAC de origem, endereço MAC de destino, ID de VLAN e prioridade 802.1p, para filtrar os pacotes.
Condição de configuração
Nenhum
Configurar ACL Estendido MAC
O nome da ACL estendida MAC pode usar o número e também pode usar a cadeia de caracteres personalizada. Se o nome da ACL estendida MAC adotar os números, podemos configurar a limitação de quantidade máxima da ACL; se adotar a cadeia de caracteres personalizada, não há limitação para a quantidade máxima de ACL. O usuário pode selecionar o nome da ACL conforme desejado. A ACL estendida MAC é mais rica, correta e flexível do que o conteúdo definido pela ACL padrão MAC.
Tabela 15 -8 Configurar a ACL estendida MAC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a ACL estendida MAC | mac access-list extended { access-list-number | access-list-name } | Obrigatório Por padrão, a ACL estendida MAC não está configurada. O intervalo de sequência da ACL estendida MAC é 3001-4000. |
| Configurar a regra de permissão da ACL | [ sequence ] permit { any | source-addr source-wildcard | host source-addr } { any | destination-addr destination-wildcard | host destination-addr } [ ether-type type ] [ cos cos ] [ vlan-id vlan ] [ time-range time-range-name ] [log] [ l2-action-group l2-action-group-name ] [ egr-action-group egr-action-group-name ] [ vfp-action-group vfp-action-group-name ] | Opcional Por padrão, a regra de permissão do ACL não está configurada. |
| Configure a regra de recusa de ACL | [ sequence ] deny { any | source-addr source-wildcard | host source-addr } { any | destination-addr destination-wildcard | host destination-addr } [ ether-type type ] [ cos cos ] [ vlan-id vlan ] [ time-range time-range-name ] [log] [ l2-action-group l2-action-group-name ] [ egr-action-group egr-action-group-name ] [ vfp-action-group vfp-action-group-name ] | Opcional Por padrão, a regra de recusa do ACL não está configurada. |
| Configurar as observações da ACL | [ sequence ] remark comment | Opcional Por padrão, as observações do ACL não são configuradas. |
Ao usar o Mac lista de acesso estendido comando para criar o MAC Extended ACL, o ACL pode ser criado somente após configurar as regras no modo de configuração MAC Extended ACL. Sequência significa o número de ordem da regra na ACL. ACL combina e filtra o pacote estritamente de acordo com a ordem da sequência pequena para a sequência grande. A regra com a sequência pequena entra em vigor primeiro. Quando todas as regras não corresponderem, execute a ação de descarte padrão, ou seja, todos os pacotes não autorizados a passar são descartados.
Configurar ACL estendida MAC nomeada por números
A ACL estendida MAC nomeada por números pode permitir que o usuário identifique o tipo da ACL rapidamente. No entanto, a ACL estendida MAC nomeada por números tem algumas limitações. Por exemplo, a quantidade de ACL é limitada. A ACL estendida MAC é mais rica, correta e flexível do que o conteúdo definido pela ACL padrão MAC.
Tabela 15 -9 Configurar a ACL estendida MAC nomeada por números
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a ACL estendida MAC nomeada por números | access-list access-list-number { permit | deny } { any | source-addr source-wildcard | host source-addr } { any | destination-addr destination-wildcard | host destination-addr } [ ether-type type ] [ cos cos ] [ vlan-id vlan ] [ time-range time-range-name ] [log] [ l2-action-group l2-action-group-name ] [ egr-action-group egr-action-group-name ] [ vfp-action-group vfp-action-group-name ] | Obrigatório Por padrão, a ACL estendida MAC nomeada por números não está configurada. O intervalo de sequência da ACL estendida MAC é 3001-4000. |
| Configure as observações da ACL estendida MAC nomeada por números | access-list access-list-number remark comment | Opcional Por padrão, as observações da ACL estendida MAC nomeada por números não são configuradas. |
Se a ACL com a sequência especificada não existir, crie uma nova ACL e adicione novas regras. Se a ACL com o número especificado existir, basta adicionar novas regras. Depois de configurar o comando acl match ipv6 packet , o pacote ipv6 pode ser combinado.
Configurar ACL estendida híbrida
A ACL estendida híbrida pode fazer a regra de classificação de acordo com o endereço MAC de origem, endereço MAC de destino, tipo de Ethernet, tipo de protocolo IP, endereço IP de origem, endereço IP de destino, prioridade de pacote, ID de VLAN e prioridade 802.1p, de modo a filtrar o pacotes.
Condição de configuração
Nenhum
Configurar ACL estendida híbrida
híbrida pode usar o número e também a cadeia de caracteres personalizada. Se o nome da ACL estendida Híbrida adotar os números, podemos configurar a limitação de quantidade máxima da ACL; se adotar a cadeia de caracteres personalizada, não há limitação para a quantidade máxima de ACL. O usuário pode selecionar o nome da ACL conforme desejado. A ACL estendida híbrida é mais rica, mais correta e mais flexível do que usar o conteúdo definido por IP ACL e MAC ACL separadamente .
Tabela 15 -10 Configurar a ACL estendida híbrida
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a ACL estendida híbrida | hybrid access-list extended { access-list-number | access-list-name } | Obrigatório Por padrão, a ACL estendida híbrida não está configurada. A faixa de sequência da ACL estendida híbrida é 5001-6000. |
| Configurar a regra de permissão da ACL | [ sequence ] permit { any | source-mac -addr source-wildcard | host source-mac-addr } { any | destination-mac-addr destination-wildcard | host destination-mac-addr } [ cos cos ] [ vlan-id vlan ] [ time-range time-range-name ] [egr-action-group egr-action-group-name] [ethter-type] { etherne-type | ipv4 protocol } { any | source-ip-addr source-wildcard | host source-ip-addr } { any | destination -ip-addr destination -wildcard | host destination-ip-addr }[ precedence precedence ] [ tos tos ] [ dscp dscp ] [fragments ] [ time-range time-range-name ] [egr-action-group egr-action-group-name] | Opcional Por padrão, a regra de permissão do ACL não está configurada. |
| Configure a regra de recusa de ACL | [ sequence ] deny { any | source-mac -addr source-wildcard | host source-mac-addr } { any | destination-mac-addr destination-wildcard | host destination-mac-addr } [ cos cos ] [ vlan-id vlan ] [ time-range time-range-name ] [egr-action-group egr-action-group-name] [ethter-type] { etherne-type | ipv4 protocol } { any | source-ip-addr source-wildcard | host source-ip-addr } { any | destination -ip-addr destination -wildcard | host destination-ip-addr }[ precedence precedence ] [ tos tos ] [ dscp dscp ] [fragments ] [ time-range time-range-name ] [egr-action-group egr-action-group-name] | Opcional Por padrão, a regra de recusa do ACL não está configurada. |
| Configurar as observações da ACL | [ sequence ] remark comment | Opcional Por padrão, as observações do ACL não são configuradas. |
Ao usar o híbrido lista de acesso comando estendido para criar a ACL estendida híbrida, a ACL pode ser criada somente após a configuração das regras no modo de configuração da ACL estendida híbrida. Sequência significa o número de ordem da regra na ACL. ACL combina e filtra o pacote estritamente de acordo com a ordem da sequência pequena para a sequência grande. A regra com a sequência pequena entra em vigor primeiro. Quando todas as regras não corresponderem, execute a ação de descarte padrão, ou seja, todos os pacotes não autorizados a passar são descartados.
Configurar ACL estendida híbrida nomeada por números
A ACL estendida híbrida nomeada por números pode permitir que o usuário identifique o tipo da ACL rapidamente. No entanto, a ACL estendida híbrida nomeada por números tem algumas limitações. Por exemplo, a quantidade de ACL é limitada.
Tabela 15 -11 Configurar a ACL estendida híbrida nomeada por números
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a ACL estendida híbrida nomeada por números | access-list access-list-number { permit | deny } { any | source-mac -addr source-wildcard | host source-mac-addr } { any | destination-mac-addr destination-wildcard | host destination-mac-addr } [ cos cos ] [ vlan-id vlan ] [ time-range time-range-name ] [egr-action-group egr-action-group-name] [ethter-type] { etherne-type | ipv4 protocol } { any | source-ip-addr source-wildcard | host source-ip-addr } { any | destination -ip-addr destination -wildcard | host destination-ip-addr }[ precedence precedence ] [ tos tos ] [ dscp dscp ] [fragments ] [ time-range time-range-name ] [egr-action-group egr-action-group-name] | Obrigatório Por padrão, a ACL estendida híbrida nomeada por números não está configurada. A faixa de sequência da ACL estendida híbrida é 5001-6000. |
| Configure as observações da ACL estendida híbrida nomeada por números | access-list access-list-number remark comment | Opcional Por padrão, as observações da ACL estendida híbrida nomeada por números não são configuradas. |
Se a ACL com a sequência especificada não existir, crie uma nova ACL e adicione novas regras. Se a ACL com o número especificado existir, basta adicionar novas regras.
Configurar ACL padrão IPv6
A ACL padrão IPv6 faz as regras de classificação de acordo com o endereço IPv6 de origem para filtrar os pacotes.
Condição de configuração
Nenhum
Configurar ACL padrão IPv6
O nome ACL padrão IP pode usar os números e também pode usar a cadeia de caracteres personalizada. Ao usar os números, você pode configurar o número máximo de ACLs. Ao adotar a cadeia de caracteres personalizada, não há limitação para a quantidade máxima de ACL. O usuário pode selecionar o nome da ACL conforme desejado.
Tabela 15 -12 Configurar a ACL padrão IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a ACL padrão IPv6 | ipv6 access-list standard { access-list-number | access-list-name } | Obrigatório Por padrão, a ACL padrão IPv6 não está configurada. |
| Configurar a regra de permissão da ACL | [ sequence ] permit { any | source-addr/source-wildcard | host source-addr } [ time-range time-range-name ] [ pbr-action-group pbr-action-group-name ] [ l3-action-group l3-action-group-name ] [ egr-action-group egr-action-group-name ] | Opcional Por padrão, a regra de permissão ACL não está configurada. |
| Configure a regra de recusa de ACL | [ sequence ] deny { any | source-addr/source-wildcard | host source-addr } [ time-range time-range-name ] [ l3-action-group l3-action-group-name ] [ egr-action-group egr-action-group-name ] [ pbr-action-group pbr-action-group-name ] | Opcional Por padrão, não configure a regra de recusa ACL. |
| Configurar as observações da ACL | [ sequence ] remark comment | Opcional Por padrão, não configure as observações da regra ACL. |
Ao usar o comando ipv6 access-list standard para criar a ACL padrão IPv6, a ACL pode ser criada somente após configurar as regras no modo de configuração ACL padrão IPv6. Sequência significa o número de ordem da regra na ACL. ACL combina e filtra o pacote estritamente de acordo com a ordem da sequência pequena para a sequência grande. A regra com a sequência pequena entra em vigor primeiro. Quando todas as regras não corresponderem, execute a ação de descarte padrão, ou seja, todos os pacotes não autorizados a passar são descartados.
Configurar a ACL padrão IPv6 nomeada por números
A ACL padrão IPv6 nomeada por números pode permitir que o usuário identifique rapidamente o tipo da ACL. No entanto, a ACL padrão IPv6 nomeada por números tem algumas limitações. Por exemplo, a quantidade de ACL é limitada.
Tabela 15 -13 Configurar a ACL padrão IPv6 nomeada por números
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a ACL padrão IPv6 nomeada por números | access-list access-list-number { permit | deny } { any | source-addr/source-wildcard | host source-addr } [ time-range time-range-name ] [ l3-action-group l3-action-group-name ] [ egr-action-group egr-action-group-name ] [ pbr-action-group pbr-action-group-name ] | Obrigatório Por padrão, a ACL padrão IPv6 nomeada por números não está configurada. O intervalo de sequência da ACL padrão do IPv6 é 6001-7000. |
| Configure as observações da ACL padrão do IPv6 nomeada por números | access-list access-list-number remark comment | Opcional Por padrão, as observações da ACL padrão IPv6 nomeada por números não são configuradas. |
Se a ACL com a sequência especificada não existir, crie uma nova ACL e adicione novas regras. Se a ACL com o número especificado existir, basta adicionar novas regras.
Configurar ACL estendida IPv6
A ACL estendida IPv6 pode fazer a regra de classificação de acordo com o número do protocolo IPv6, endereço IPv6 de origem, endereço IPv6 de destino, número da porta TCP/UDP de origem, número da porta TCP/UDP de destino, prioridade do pacote, tag de fragmento e tag TCP, de modo a filtrar os pacotes.
Condição de configuração
Nenhum
Configurar ACL estendida IPv6
O nome da ACL estendida IPv6 pode usar o número e também pode usar a cadeia de caracteres personalizada. Se o nome da ACL estendida IPv6 adotar os números, podemos configurar a limitação de quantidade máxima de ACL; se adotar a cadeia de caracteres personalizada, não há limitação para a quantidade máxima de ACL. O usuário pode selecionar o nome da ACL conforme desejado.
Tabela 15 -14 Configurar a ACL estendida IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a ACL estendida IPv6 | ipv6 access-list extended { access-list-number | access-list-name } | Obrigatório Por padrão, a ACL estendida do IPv6 não está configurada. |
| Configurar a regra de permissão da ACL | [ sequence ] permit protocol { any | source-addr/source-wildcard | host source-addr } [ operator source-port ] { any | destination-addr/destination-wildcard | host destination-addr } [ operator destination-port ] [ ack / fin / psh / rst / syn / urg ] [ precedence precedence ] [ tos tos ] [ dscp dscp ] [fragments] [ time-range time-range-name ] [ pbr-action-group pbr-action-group-name ] [ l3-action-group l3-action-group-name ] [ egr-action-group egr-action-group-name ] | Opcional Por padrão, a regra de permissão do ACL não está configurada. |
| Configure a regra de recusa de ACL | [ sequence ] deny protocol { any | source-addr/source-wildcard | host source-addr } [ operator source-port ] { any | destination-addr/destination-wildcard | host destination-addr } [ operator destination-port ] [ ack / fin / psh / rst / syn / urg ] [ precedence precedence ] [ tos tos ] [ dscp dscp ] [fragments] [ time-range time-range-name ] [ pbr-action-group pbr-action-group-name ] [ l3-action-group l3-action-group-name ] [ egr-action-group egr-action-group-name ] | Opcional Por padrão, a regra de recusa do ACL não está configurada. |
| Configurar as observações da ACL | [ sequence ] remark comment | Opcional Por padrão, as observações da ACL não são configuradas. |
Ao usar o IPv6 lista de acesso estendido comando para criar a ACL estendida do IPv6, a ACL pode ser criada somente após a configuração das regras no modo de configuração da ACL estendida do IPv6. Sequência significa o número de ordem da regra na ACL. ACL combina e filtra o pacote estritamente de acordo com a ordem da sequência pequena para a sequência grande. A regra com a sequência pequena entra em vigor primeiro. Quando todas as regras não corresponderem, execute a ação de descarte padrão, ou seja, todos os pacotes não autorizados a passar são descartados.
Configurar ACL estendida IPv6 nomeada por números
A ACL estendida IPv6 nomeada por números pode permitir que o usuário identifique rapidamente o tipo da ACL. No entanto, a ACL estendida IPv6 nomeada por números tem algumas limitações. Por exemplo, a quantidade de ACL é limitada.
Tabela 15 -15 Configurar a ACL estendida IPv6 nomeada por números
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a ACL estendida IPv6 nomeada por números | access-list access-list-number { permit | deny } protocol { any | source-addr/source-wildcard | host source-addr } [ operator source-port ] { any | destination-addr/destination-wildcard | host destination-addr } [ operator destination-port ] [ ack / fin / psh / rst / syn / urg ] [ precedence precedence ] [ tos tos ] [ dscp dscp ] [fragments] [ time-range time-range-name ] [ pbr-action-group pbr-action-group-name ] [ l3-action-group l3-action-group-name ] [ egr-action-group egr-action-group-name ] | Obrigatório Por padrão, a ACL estendida IPv6 nomeada por números não está configurada. O intervalo de sequência da ACL estendida do IPv6 é 7001-8000. |
| Configure as observações da ACL estendida IPv6 nomeada por números | access-list access-list-number remark comment | Opcional Por padrão, as observações da ACL estendida IPv6 nomeada por números não são configuradas. |
Se a ACL com a sequência especificada não existir, crie uma nova ACL e adicione novas regras. Se a ACL com o número especificado existir, basta adicionar novas regras.
Configurar operação de confirmação
O comando de operação de confirmação serve para confirmar as regras ACL configuradas e confirmar se as regras adicionadas ou excluídas entram em vigor. Depois de adicionar ou excluir regras de ACL, você deve executar a operação de confirmação. Caso contrário, as regras adicionadas ou excluídas não terão efeito. Ao salvar a configuração, as regras não confirmadas não serão salvas no arquivo de inicialização.
Condição de configuração
Configurar ACL
Configurar operação de confirmação
Depois de configurar a regra de ACL, você precisa executar a operação de confirmação para enviar as regras de ACL adicionadas ou excluídas.
Tabela 15 -16 Configurar a operação de confirmação da regra ACL
| Etapa | Comando | Descrição |
| Entre no modo de configuração ACL | ip access-list standard { access-list-number | access-list-name } | Obrigatório Por padrão, não configure a ACL padrão IP. O intervalo de números da ACL padrão IP é 1-1000. O modo de configuração da ACL não está limitado à ACL padrão IP, e a operação de confirmação suporta todos os modos de configuração da ACL. |
| Envie a operação de regra ACL | commit | Obrigatório Por padrão, a regra adicionada ou excluída não é Commit. |
Configurar limitação de quantidade de regras de ACL
Condição de configuração
Nenhum
Configurar limitação de quantidade de regras de ACL
Depois de habilitar a limitação de quantidade de regras de ACL, o número máximo de regras que podem ser configuradas em uma ACL é 1024.
Tabela 15 -17 Configurar a limitação de quantidade da regra ACL
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Desabilitar/habilitar a limitação de quantidade da regra ACL | access-list rule-limit { enable | disable } | Obrigatório Por padrão, está desabilitado, ou seja, o número máximo de regras que podem ser configuradas em uma ACL não se limita a 1024. |
Configurar domínio de tempo
O domínio do tempo é o conjunto dos segmentos de tempo. Um domínio de tempo pode conter de zero a vários segmentos de tempo. O intervalo de tempo do domínio do tempo é a união dos segmentos de tempo. O domínio de tempo pode ser vinculado com a regra ACL ou ACL, pois a condição de se a regra ACL ou ACL entra em vigor.
Condição de configuração
Antes de configurar a função de domínio do tempo, primeiro conclua a seguinte tarefa:
- Configurar ACL
Configurar domínio de tempo
Configure se o objeto de aplicativo do domínio de tempo é limitado pelo domínio de tempo. Quando habilitado, o objeto do aplicativo é limitado pelo domínio do tempo. Pelo contrário, não é limitado pelo domínio do tempo.
Tabela 15 -18 Configurar o domínio do tempo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar desabilitar/habilitar o domínio do tempo | set time-range { disable | enable } | Obrigatório Por padrão, está habilitada. |
Configurar segmento de tempo periódico
Segmento de tempo periódico: Segmento de tempo periódico significa selecionar um dia ou vários dias de segunda a domingo, e o ponto de tempo inicial até o ponto de tempo final como o segmento de tempo, tendo efeito todas as semanas repetidamente.
Tabela 15 -19 Configurar o segmento de tempo periódico
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o domínio do tempo | time-range time-range-name | Obrigatório Por padrão, não configure o domínio de tempo. |
| Configurar o segmento de tempo periódico | [ sequence ] periodic [ day-of-the-week ] [ hh: mm [ : ss ] ] to [ day-of-the-week ] [ hh: mm [ : ss ] ] | Qualquer Por padrão, não configure o segmento de tempo periódico. O comando anterior pode especificar o intervalo de tempo como um dia (como segunda-feira) ou vários dias (como segunda-feira, sexta-feira). O último comando pode especificar o intervalo de tempo como todos os dias, fins de semana ou dias úteis. |
| [ sequence ] periodic { weekdays | weekend | daily } [ hh: mm [ : ss ] ] to [ hh: mm [ : ss ] ] |
Configurar segmento de tempo absoluto
O segmento de tempo absoluto significa entrar em vigor dentro do intervalo de data e hora especificado.
Tabela 15 -20 Configurar o segmento de tempo absoluto
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o domínio do tempo | time-range time-range-name | Obrigatório Por padrão, não configure o domínio de tempo. |
| Configure o segmento de tempo absoluto do domínio do tempo | [ sequence ] absolute start hh: mm [ : ss ] [ day [ month [ year ] ] ] end hh: mm [ : ss ] [ day [ month [ year ] ] ] | Obrigatório Por padrão, não configure o segmento de tempo absoluto do domínio de tempo. |
Configurar período de atualização
O status do domínio do tempo inclui efetivo e ineficaz. O período de atualização de status do domínio de tempo é de 1 minuto por padrão. Atualizar automaticamente de acordo com a hora atual do sistema. Portanto, ao atualizar o status, pode haver um atraso de 0 a 60 segundos em comparação com a hora do sistema.
Tabela 15 -21 Configurar o período de atualização
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o período de atualização do domínio de tempo | set time-range frequency { frequency-min | seconds frequency-sec} | Obrigatório O valor padrão é 1 minuto. O período de atualização é o intervalo entre duas atualizações e a unidade é minuto ou segundo. |
Configurar compensação de tempo máximo
O deslocamento máximo significa o deslocamento máximo entre o tempo de acumulação do contador e o tempo do sistema. Quando as estatísticas de tempo excederem o deslocamento, rejulgue o status do domínio de tempo e atualize durante a próxima atualização para que as estatísticas de tempo sejam mais corretas.
Tabela 15 -22 Configurar o deslocamento de tempo máximo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o deslocamento de tempo máximo do domínio de tempo | set time-range max-offset max-offset-number | Obrigatório O valor padrão é 100. A unidade do deslocamento de tempo é o segundo e o intervalo de valores é de 1 a 300. |
Configurar domínio de tempo e vinculação de regras de ACL
Quando for necessário controlar um usuário para acessar os recursos da rede dentro do segmento de tempo especificado, podemos definir a regra ACL com base no domínio do tempo para filtrar os pacotes. Se o domínio de tempo entra em vigor afeta diretamente a regra ACL associada.
Tabela 15 -23 Configure o domínio de tempo a ser vinculado à regra ACL
| Etapa | Comando | Descrição |
| Configure a vinculação com a regra de ACL padrão de IP | Refer to “Configure IP Standard ACL” | - |
| Configure a vinculação com a regra de ACL estendida de IP | Refer to “Configure IP Extended ACL” | - |
| Configure a ligação com a regra ACL padrão MAC | Refer to “Configure MAC Standard ACL” | - |
| Configure a ligação com a regra de ACL estendida MAC | Refer to “Configure MAC Extended ACL” | - |
| Configurar a vinculação com a regra de ACL estendida híbrida | Refer to “Configure Hybrid Extended ACL” | - |
| Configure a vinculação com a regra de ACL padrão IPv6 | Refer to “Configure IPv6 standard ACL” | - |
| Configure a vinculação com a regra de ACL estendida IPv6 | Refer to “Configure IPv6 extended ACL” | - |
Quando o domínio de tempo vinculado à regra ACL não existe, a regra ACL está no estado efetivo.
Configurar domínio de tempo e vinculação de ACL
Quando for necessário controlar um usuário para acessar os recursos da rede dentro do segmento de tempo especificado, podemos definir a regra ACL com base no domínio do tempo para filtrar os pacotes. Se o domínio do tempo entra em vigor afeta diretamente as regras contidas em toda a ACL.
Tabela 15 -24 Configurar o domínio de tempo e a ligação ACL
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o domínio de tempo a ser vinculado com IP ACL | ip time-range time-range-name access-list { access-list-number | access-list-name } | Obrigatório Por padrão, não configure o domínio de tempo para ser vinculado ao IP ACL. |
| Configure o domínio de tempo a ser vinculado com MAC ACL | mac time-range time-range-name access-list { access-list-number | access-list-name } | Obrigatório Por padrão, não configure o domínio de tempo para ser vinculado com MAC ACL. |
| Configure o domínio de tempo a ser vinculado à ACL híbrida | hybrid time-range time-range-name access-list { access-list-number | access-list-name } | Obrigatório Por padrão, não configure o domínio de tempo para ser vinculado à ACL híbrida. |
| Configure o domínio de tempo a ser vinculado com IPv6 ACL | ipv6 time-range time-range-name access-list { access-list-number | access-list-name } | Obrigatório Por padrão, não configure o domínio de tempo para ser vinculado à ACL IPv6. |
Quando o domínio de tempo vinculado à regra ACL não existe, a regra ACL está no estado efetivo.
Configurar aplicativo ACL
ACL pode ser aplicado globalmente, para VLAN, VLAN RANGE, porta e interface. MAC ACL, IP ACL e IPV6 ACL podem ser aplicados globalmente, VLAN, IPV6 ACL, entrada e saída da porta e interface; A ACL híbrida só pode ser aplicada globalmente.
Se a ACL for aplicada globalmente, filtre todos os pacotes de entrada da porta do dispositivo; se a ACL for aplicada à VLAN, filtre todos os pacotes de entrada da porta na VLAN e os pacotes de encaminhamento de saída; Se a ACL for aplicada à VLAN RANGE, ela entrará em vigor para as VLANs na VLAN RANGE; se o ACL for aplicado à porta, filtre todos os pacotes de entrada da porta e os pacotes de encaminhamento de saída; se o ACL for aplicado à interface, filtre os pacotes de encaminhamento L3.
A correspondência de ACL tem a ordem de prioridade. A prioridade de alta para baixa deve ser aplicada à porta, aplicada à VLAN e aplicada globalmente.
Se as ACLs aplicadas a VLAN e VLAN RANGE existirem ao mesmo tempo, as regras de ACL aplicadas à VLAN serão combinadas primeiro. Depois que as regras aplicadas à VLAN forem correspondidas, as regras no intervalo da VLAN não serão mais correspondentes. Se as ACLs aplicadas à VLAN e à VLAN da interface L3 existirem ao mesmo tempo, as regras da ACL da VLAN da interface L3 serão combinadas primeiro. Depois que as regras aplicadas à VLAN da interface L3 corresponderem, as regras na VLAN não serão mais correspondentes.
Se o pacote corresponder à regra ACL de aplicação à porta, VLAN e globalmente ao mesmo tempo, o pacote cujo resultado do filtro de alta prioridade é permitir é encaminhado para a ACL de próxima prioridade para filtragem. O pacote cujo resultado do filtro de alta prioridade é negado é descartado diretamente e não é mais encaminhado para a ACL de próxima prioridade para processamento.
Condição de configuração
Antes de configurar a função do aplicativo ACL, primeiro conclua a seguinte tarefa:
- Configurar ACL
Configurar IP ACL para ser aplicado à porta
Aplique IP ACL à porta. O pacote que passa pela porta é analisado e processado de acordo com o IP ACL.
Tabela 15 -25 Configure o IP ACL a ser aplicado à porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure a aplicação de IP ACL à porta | ip access-group { access-list-number | access-list-name } { in | out | vfp} | Obrigatório Por padrão, o IP ACL não é aplicado à porta. |
Se a ACL aplicada à porta não existir, todos os pacotes que passam pela porta são permitidos.
Configurar MAC ACL para ser aplicado à porta
Aplique MAC ACL à porta. O pacote que passa pela porta é analisado e processado de acordo com o MAC ACL.
Tabela 15 -26 Configure o MAC ACL a ser aplicado à porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o MAC ACL a ser aplicado à porta | mac access-group { access-list-number | access-list-name } { in | out| vfp } | Obrigatório Por padrão, o MAC ACL não é aplicado à porta. |
Se a ACL aplicada à porta não existir, todos os pacotes que passam pela porta são permitidos. A MAC ACL só pode corresponder ao pacote IPv4 e não pode corresponder a outros tipos de pacotes.
Configurar IP ACL para ser aplicado à VLAN
Aplique IP ACL à VLAN. O pacote que passa pela porta é analisado e processado de acordo com o IP ACL.
Tabela 15 -27 Configurar IP ACL a ser aplicado à VLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração VLAN | vlan vlan-id | - |
| Configure o IP ACL a ser aplicado à VLAN | ip access-group { access-list-number | access-list-name } { in | out | vfp } | Obrigatório Por padrão, a VLAN não é aplicada ao IP ACL. |
Se a ACL aplicada à VLAN não existir, todos os pacotes que passam pela VLAN são permitidos.
Configurar MAC ACL para ser aplicado ao VLAN RANGE
Aplique MAC ACL ao VLAN RANGE. Os pacotes que passam VLAN RANGE são analisados e processados de acordo com MAC ACL.
Tabela 15 -28 Configurar MAC ACL a ser aplicado ao VLAN RANGE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o MAC ACL para ser aplicado ao VLAN RANGE | mac access-group { access-list-number | access-list-name } { in | out } vlan range <1-4094> | Obrigatório Por padrão, o MAC ACL não é aplicado ao VLAN RANGE. |
Se o ACL aplicado ao VLAN RANGE não existir, todos os pacotes que passam pelo VLAN RANGE são permitidos.
Configurar IP ACL para ser aplicado ao VLAN RANGE
Aplique IP ACL ao VLAN RANGE. Os pacotes que passam VLAN RANGE são analisados e processados de acordo com o IP ACL.
Tabela 15 -29 Configurar IP ACL a ser aplicado ao VLAN RANGE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o IP ACL a ser aplicado ao VLAN RANGE | ip access-group { access-list-number | access-list-name } { in | out } vlan range <1-4094> | Obrigatório Por padrão, o IP ACL não é aplicado ao VLAN RANGE. |
Se o ACL aplicado ao VLAN RANGE não existir, todos os pacotes que passam pelo VLAN RANGE são permitidos.
Configurar IPv6 ACL para ser aplicado ao VLAN RANGE
Aplique IPv6 ACL ao VLAN RANGE. Os pacotes que passam VLAN RANGE são analisados e processados de acordo com IPv6 ACL.
Tabela 15 -30 Configurar IPv6 ACL a ser aplicado ao VLAN RANGE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o IPv6 ACL para ser aplicado ao VLAN RANGE | ipv6 access-group { access-list-number | access-list-name } { in | out } vlan range <1-4094> | Obrigatório Por padrão, o IPv6 ACL não é aplicado ao VLAN RANGE. |
Se o ACL aplicado ao VLAN RANGE não existir, todos os pacotes que passam pelo VLAN RANGE são permitidos.
Configure o MAC ACL para ser aplicado à L3 Interface VLAN RANGE
Aplique MAC ACL ao intervalo de VLAN da interface L3. Os pacotes que passam pela interface L3 VLAN RANGE são analisados e processados de acordo com o MAC ACL.
Tabela 15 -31 Configurar MAC ACL a ser aplicado à interface L3 VLAN RANGE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o MAC ACL para ser aplicado à interface L3 VLAN RANGE | mac access-group { access-list-number | access-list-name } { in | out } interface vlan range <1-4094> | Obrigatório Por padrão, o MAC ACL não é aplicado ao VLAN RANGE da interface L3. |
Se a ACL aplicada à interface L3 VLAN RANGE não existir, todos os pacotes que passam pela VLAN RANGE são permitidos.
Configure o IP ACL para ser aplicado à L3 Interface VLAN RANGE
Aplique IP ACL ao intervalo de VLAN da interface L3. Os pacotes que passam pela interface L3 VLAN RANGE são analisados e processados de acordo com o IP ACL.
Tabela 15 -32 Configurar IP ACL a ser aplicado à interface L3 VLAN RANGE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o IP ACL a ser aplicado à interface L3 VLAN RANGE | ip access-group { access-list-number | access-list-name } { in | out } interface vlan range <1-4094> | Obrigatório Por padrão, o IP ACL não é aplicado ao VLAN RANGE da interface L3. |
Se a ACL aplicada à interface L3 VLAN RANGE não existir, todos os pacotes que passam pela VLAN RANGE são permitidos.
Configurar IPv6 ACL para ser aplicado ao L3 Interface VLAN RANGE
Aplique IPv6 ACL a L3 interface VLAN RANGE. Os pacotes que passam pela interface L3 VLAN RANGE são analisados e processados de acordo com o IPv6 ACL.
Tabela 15 -33 Configurar IPv6 ACL a ser aplicado à interface L3 VLAN RANGE
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure IPv6 ACL para ser aplicado à interface L3 VLAN RANGE | ipv6 access-group { access-list-number | access-list-name } { in | out } interface vlan range <1-4094> | Obrigatório Por padrão, o IPv6 ACL não é aplicado ao VLAN RANGE da interface L3. |
Se a ACL aplicada à interface L3 VLAN RANGE não existir, todos os pacotes que passam pela VLAN RANGE são permitidos.
Configurar IP ACL para ser aplicado globalmente
Aplique IP ACL globalmente. Os pacotes que passam por todas as portas são analisados e processados de acordo com o IP ACL.
Tabela 15 -34 Configure o IP ACL para ser aplicado globalmente
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o IP ACL para ser aplicado globalmente | global ip access-group { access-list-number | access-list-name } in | Obrigatório Por padrão, o IP ACL não é aplicado globalmente. |
Se a ACL aplicada globalmente não existir e todas as portas não estiverem configuradas com ACL, todos os pacotes que passarem pela porta serão permitidos.
Configurar a ACL híbrida para ser aplicada globalmente
Aplique a ACL híbrida globalmente. Os pacotes que passam por todas as portas são analisados e processados de acordo com o Hybrid ACL.
Tabela 15 -35 Configure a ACL híbrida para ser aplicada globalmente
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a ACL híbrida para ser aplicada globalmente | global hybrid access-group { access-list-number | access-list-name } in | Obrigatório Por padrão, a ACL híbrida não é aplicada globalmente. |
Se a ACL aplicada globalmente não existir e todas as portas não estiverem configuradas com ACL, todos os pacotes que passarem por todas as portas serão permitidos. Ao configurar o Hybrid ACL para ser aplicado globalmente, a função global do IP Source Guard precisa ser desabilitada.
Configurar IP ACL para ser aplicado a uma interface
Aplique IP ACL a uma interface. O pacote que passa pela porta é analisado e processado de acordo com o IP ACL.
Tabela 15 -36 Configurar IP ACL a ser aplicado à interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o IP ACL a ser aplicado à interface | ip access-group { access-list-number | access-list-name } { in | out | self } | Obrigatório Por padrão, o IP ACL não é aplicado à interface. |
Se a ACL aplicada à interface não existir, todos os pacotes que passam pela interface são permitidos.
Configurar MAC ACL para ser aplicado a uma interface
Aplique MAC ACL a uma interface. O pacote que passa pela porta é analisado e processado de acordo com o MAC ACL.
Tabela 15 -37 Configure o MAC ACL para ser aplicado à interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o MAC ACL para ser aplicado à interface | mac access-group { access-list-number | access-list-name } { in | out } | Obrigatório Por padrão, o MAC ACL não é aplicado à interface. |
Se a ACL aplicada à interface não existir, todos os pacotes que passam pela interface são permitidos.
Configurar IPv6 ACL para ser aplicado a uma porta
Aplique IPv6 ACL a uma porta. O pacote que passa pela porta é analisado e processado de acordo com o IPv6 ACL.
Tabela 15 -38 Configurar IPv6 ACL para ser aplicado a uma porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | link-aggregation link-aggregation-id | |
| Configure o IPv6 ACL para ser aplicado a uma porta | ipv6 access-group { access-list-number | access-list-name } { in | out } | Obrigatório Por padrão, a ACL IPv6 não é aplicada à porta. |
Se a ACL aplicada à porta não existir, todos os pacotes que passam pela porta são permitidos.
Configurar IPv6 ACL para ser aplicado a uma interface
Aplique IPv6 ACL a uma interface. O pacote que passa pela interface é analisado e processado de acordo com o IPv6 ACL.
Tabela 15 -39 Configurar IPv6 ACL para ser aplicado a uma interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Aplicar IPv6 ACL a uma interface | ipv6 access-group { access-list-number | access-list-name } { in | out } | Obrigatório Por padrão, a ACL IPv6 não é aplicada à interface. |
Se a ACL aplicada à interface não existir, todos os pacotes que passam pela interface são permitidos.
Configurar o modo ACL
Há dois modos quando a mesma ACL é aplicada a portas diferentes. Um é o modo de porta. No modo Porta, a mesma ACL usa recursos ACL diferentes em portas diferentes e o tráfego de portas diferentes usa recursos diferentes para corresponder. O outro é o modo bitmap. No modo bitmap, a mesma ACL usa os mesmos recursos ACL em portas diferentes, a correspondência de portas é realizada por bitmap e o tráfego de portas diferentes é correspondido por recursos relacionados. Dessa forma, o modo bitmap pode economizar recursos. Por padrão, o ACL está no modo de porta.
Condição de configuração
Nenhum
Configurar o modo ACL
Quando a mesma ACL é usada em portas diferentes, o modo pode ser usado para ajustar se a ACL entrega recursos separadamente nas portas ou se os recursos são compartilhados pelo BitMap.
Tabela 15 -40 Configurar o modo ACL
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o modo ACL | acl mode { port | bitmap } | Obrigatório Por padrão, a ACL está no modo Porta. |
Monitoramento e manutenção de ACL
Tabela 15 -41 Monitoramento e Manutenção de ACL
| Comando | Descrição |
| show access-list [ access-list-number | access-list-name ] | Exiba as informações de configuração da ACL |
| show acl-object [ global | interface [ vlan [ in | out ] | switchport [ in | out | vfp ]] | vlan [ in | out ] | vlan-range [ in | out ] ] | Exiba a VLAN, porta, ACL global aplicada, VLAN de interface, VLAN RANGE e informações de VLAN de interface . |
| show ip access-list [ access-list-number | access-list-name ] | Exiba as informações de configuração do IP ACL |
| show hybrid access-list [ access-list-number | access-list-name ] | Exibe as informações de configuração da ACL estendida e avançada do Hybird |
| show ip interface list | Exiba as informações do IP ACL aplicado à interface |
| show ipv6 access-list [ access-list-number | access-list-name ] | Exiba as informações de configuração da ACL IPv6 |
| show mac access-list [ access-list-number | access-list-name ] | Configure as informações de configuração do MAC ACL |
| show mac interface list | Exiba as informações do MAC ACL aplicado à interface |
| show time-range [ time-range-name ] | Exibir as informações de configuração e status do domínio de tempo |
| show time-range-state [ time-range-name ] | Exibir as informações de status do domínio do tempo |
| show acl mode | Exibir as informações do modo ACL |
Exemplo de configuração típica de ACL
Configurar ACL padrão IP
Requisitos de rede
- PC1, PC2 e PC3 estão conectados à rede IP via dispositivo.
- Configure a regra ACL padrão IP, percebendo que PC1 pode acessar a rede IP, PC2 e PC3 não podem acessar a rede IP.
Topologia de rede
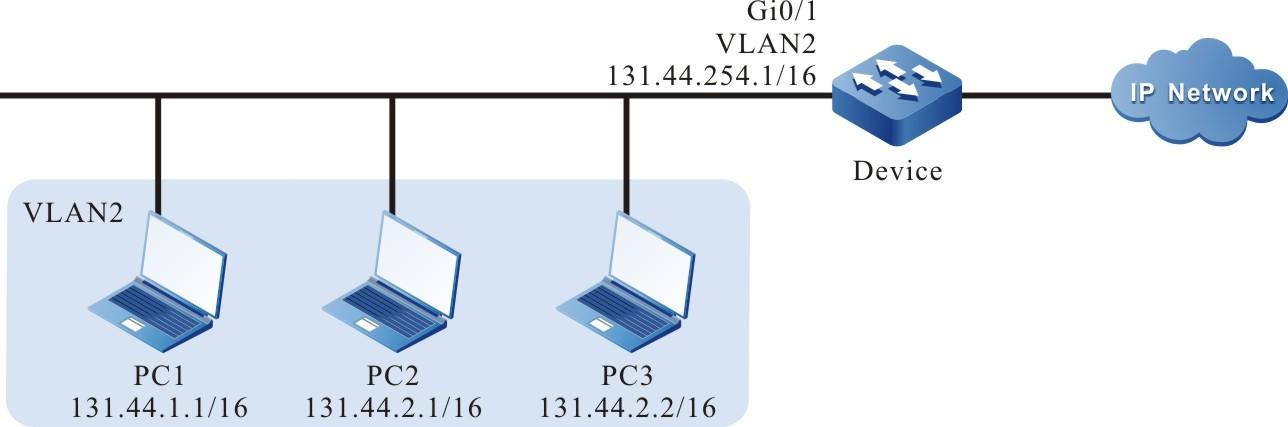
Figura 15 – 1 Rede de configuração da ACL padrão IP
Etapas de configuração
- Passo 1:Configure o tipo de link de VLAN e porta no dispositivo.
#Criar VLAN.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como Acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2Device(config-if-gigabitethernet0/1)#exit
- Passo 2:Configure a interface VLAN correspondente e o endereço IP no dispositivo. (Omitido)
- Passo 3:Configure a ACL padrão IP.
#Configure a ACL padrão IP com o número de série 1 no dispositivo.
Device(config)#ip access-list standard 1# Configure a regra, permitindo que PC1 acesse a rede IP.
Device(config-std-nacl)#permit host 131.44.1.1#Configure a regra, evitando que o segmento de rede 131.44.2.0/24 acesse a Rede IP.
Device(config-std-nacl)#deny 131.44.2.0 0.0.0.255#Envie a regra configurada
Device(config-std-nacl)#commitDevice(config-std-nacl)#exit
#Visualize as informações da ACL com número de série 1 no dispositivo.
Device#show ip access-list 1ip access-list standard 110 permit host 131.44.1.120 deny 131.44.2.0 0.0.0.255
- Passo 4:Configure a aplicação da ACL padrão IP.
#Aplique a ACL padrão IP com número de série 1 à entrada da porta gigabitethernet0/1 no dispositivo.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ip access-group 1 inDevice(config-if-gigabitethernet0/1)#exit
#Visualize a informação da ACL aplicada à porta no dispositivo.
Device#show acl-object interface-----------Interface-----Bind-----Instance--------------Interface----------------Direction----AclType----AclNamegi0/1 IN IP 1-----------Interface-----Bind-----Instance--------------Interface VlanId---------Direction----AclType----AclNameDevice#
- Passo 5:Confira o resultado.
# PC1 pode acessar a rede IP; PC e PC3 não podem acessar a rede IP.
Configurar ACL estendida de IP com domínio de tempo
Requisitos de rede
- PC1, PC2 e PC3 estão conectados à rede IP via dispositivo.
- Configure a regra de ACL estendida de IP, percebendo que o PC1 pode acessar a rede IP dentro do tempo especificado, o PC2 pode acessar o serviço FTP na rede IP e o PC3 não pode acessar a rede IP.
Topologia de rede
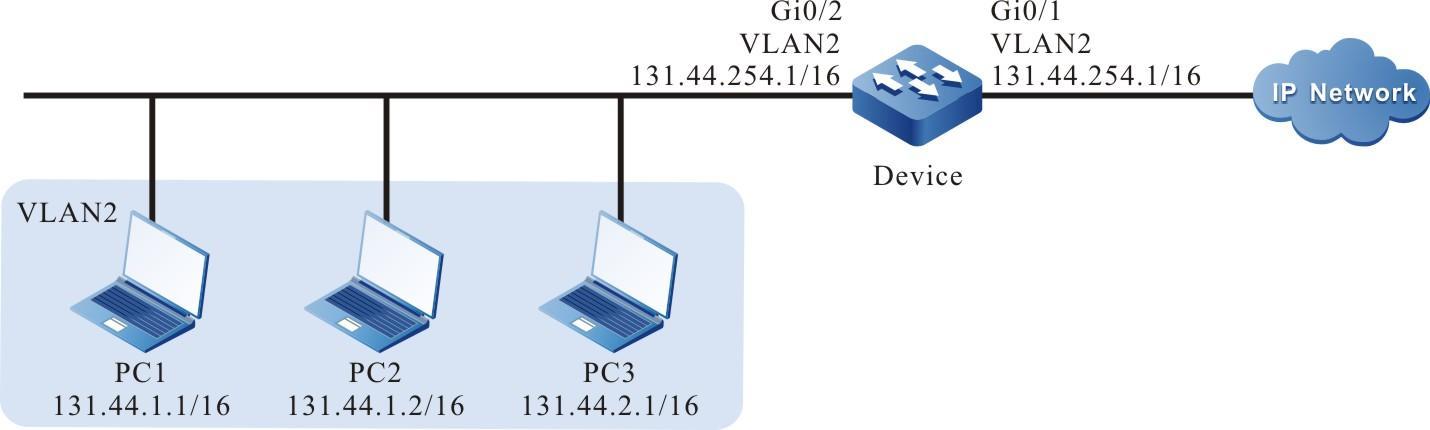
Figura 15 – 2 Rede de configuração de ACL estendida de IP com domínio de tempo
Etapas de configuração
- Passo 1:Configure o tipo de link de VLAN e porta no dispositivo.
#Criar VLAN.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1, gigabitethernet0/2 como acesso, permitindo os serviços de VLAN2 para passar.
Device(config)#interface gigabitethernet 0/1,0/2Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
- Passo 2:Configure a interface VLAN correspondente e o endereço IP no dispositivo. (Omitido)
- Passo 3:Configure o domínio do tempo.
#Configure o domínio de tempo “time-range-work” no dispositivo e o intervalo é das 08:00:00 às 18:00:00 todos os dias.
Device(config)#time-range time-range-work
Device(config-time-range)#periodic daily 08:00:00 to 18:00:00Device(config-time-range)#exit
#Visualize a hora atual do sistema no dispositivo.
Device#show clockUTC FRI APR 05 15:26:31 2013
#Visualize as informações do domínio de tempo definido “ time-range-work” no dispositivo.
Device#show time-range time-range-workTimerange name:time-range-work (STATE:active)10 periodic daily 08:00:00 to 18:00:00 (active)
- Passo 4:Configure a ACL estendida IP.
#Configure a ACL estendida de IP com o número de série 1001 no dispositivo.
Device(config)#ip access-list extended 1001#Configure a regra, evitando que o segmento de rede 131.44.2.0/24 acesse a Rede IP.
Device(config-ext-nacl)#deny ip 131.44.2.0 0.0.0.255 any#Configure a regra, permitindo que o PC2 acesse o serviço FTP da Rede IP.
Device(config-ext-nacl)#permit tcp host 131.44.1.2 any eq ftpDevice(config-ext-nacl)#permit tcp host 131.44.1.2 any eq ftp-data
#Configure a regra, permitindo que o PC1 acesse a rede IP no domínio de tempo definido “ time-range-work” intervalo.
Device(config-ext-nacl)#permit ip host 131.44.1.1 any time-range time-range-work#Envie a regra configurada
Device(config-ext-nacl)#commitDevice(config-ext-nacl)#exit
#Visualize as informações da ACL com número de série 1001 no dispositivo.
Device#show ip access-list 1001ip access-list extended 100110 deny ip 131.44.2.0 0.0.0.255 any20 permit tcp host 131.44.1.2 any eq ftp30 permit tcp host 131.44.1.2 any eq ftp-data40 permit ip host 131.44.1.1 any time-range time-range-work (active)
- Passo 5:Configure a aplicação da ACL estendida de IP.
#Aplique a ACL estendida de IP com número de série 1001 à saída da porta gigabitethernet0/1 no dispositivo.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ip access-group 1001 outDevice(config-if-gigabitethernet0/1)#exit
#Visualize a informação da ACL aplicada à porta no dispositivo.
Device#show acl-object interface-----------Interface-----Bind-----Instance--------------Interface----------------Direction----AclType----AclNamegi0/1 OUT IP 1001-----------Interface-----Bind-----Instance--------------Interface VlanId---------Direction----AclType----AclName
- Passo 6:Confira o resultado.
#PC1 pode acessar a Rede IP das 08:00 às 18:00 de todos os dias; PC2 pode acessar qualquer servidor FTP em Rede IP; PC3 não pode acessar a rede IP.
Configurar ACL padrão MAC
Requisitos de rede
- PC1, PC2 e PC3 estão conectados à rede IP via dispositivo.
- Configure a regra ACL padrão MAC, percebendo que PC1 pode acessar a rede IP, PC2 e PC3 não podem acessar a rede IP.
Topologia de rede

Figura 15 – 3 Rede de configuração da ACL padrão MAC
Etapas de configuração
- Passo 1:Configure o tipo de link de VLAN e porta no dispositivo.
#Criar VLAN.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/2 como Acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode accessDevice(config-if-gigabitethernet0/2)#switchport access vlan 2Device(config-if-gigabitethernet0/2)#exit
- Passo 2:Configure a interface VLAN correspondente e o endereço IP no dispositivo. (Omitido)
- Passo 3:Configure a ACL padrão MAC.
#Configure a ACL padrão MAC com número de série 2001 no dispositivo.
Device(config)#mac access-list standard 2001# Configure a regra, permitindo que PC1 acesse a rede IP.
Device(config-std-mac-nacl)#permit host 0001.0001.0001#Configure a regra, impedindo que o segmento de rede com endereço MAC 0002.0002.0000 e máscara ffff.ffff.0000 acesse a rede IP.
Device(config-std-mac-nacl)#deny 0002.0002.0000 0000.0000.ffff#Envie a regra configurada
Device(config-ext-nacl)#commit#Visualize as informações da ACL com número de série 2001 no dispositivo.
Device#show mac access-list 2001mac access-list standard 2001
10 permit host 0001.0001.000120 deny 0002.0002.0000 0000.0000.ffff
- Passo 4:Configure a aplicação da ACL padrão MAC.
#Aplique a ACL padrão MAC com número de série 2001 ao ingresso da porta gigabitethernet0/2 no dispositivo.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#mac access-group 2001 inDevice(config-if-gigabitethernet0/2)#exit
#Visualize a informação da ACL aplicada à porta no dispositivo.
Device#show acl-object interface-----------Interface-----Bind-----Instance--------------Interface----------------Direction----AclType----AclNamegi0/2 IN MAC 2001-----------Interface-----Bind-----Instance--------------Interface VlanId---------Direction----AclType----AclName
- Passo 5:Confira o resultado.
# PC1 pode acessar a rede IP; PC2 e PC3 não podem acessar a rede IP.
Configurar ACL Estendido MAC
Requisitos de rede
- PC1, PC2 e Telefone IP estão conectados à Rede IP via Dispositivo1.
- Configure a regra de ACL estendida MAC no Device2, percebendo que o usuário da VLAN2 não pode acessar a rede IP e, exceto os usuários de voz, todos os outros usuários da VLAN3 podem acessar a rede IP.
Topologia de rede

Figura 15 – 4 Rede de configuração da ACL estendida MAC
Etapas de configuração
- Passo 1:Configure o tipo de link de VLAN e porta no Device2.
#Cria VLAN2 e VLAN3.
Devic2e#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exit
Device2#configure terminalDevice2(config)#vlan 3Device2(config-vlan3)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como Trunk, permitindo a passagem dos serviços de VLAN2 e VLAN3.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode trunkDevice2(config-if-gigabitethernet0/1)#switchport trunk vlan 2-3Device2(config-if-gigabitethernet0/1)#exit
- Passo 2:Configure a interface VLAN correspondente e o endereço IP em Device1 e Device2. (Omitido)
- Passo 3:Configure o Voice-VLAN para definir o valor COS do pacote do Telefone IP como 7 no Dispositivo1. (Omitido)
- Passo 4:Configure a ACL estendida MAC.
#Configure o MAC Extended ACL com o número de série 3001 no Device2.
Device2(config)#mac access-list extended 3001# Configure a regra, evitando que os usuários da VLAN2 acessem a rede IP.
Devic2(config-ext-mac-nacl)#deny any any vlan-id 2#Configure a regra, evitando que os usuários de voz na VLAN3 acessem a rede IP.
Device2(config-ext-mac-nacl)#deny any any cos 7 vlan-id 3#Configure a regra, permitindo que os demais usuários da VLAN3 acessem a rede IP.
Device2(config-ext-mac-nacl)#permit any any vlan-id 3#Envie a regra configurada
Device2(config-ext-nacl)#commit#Visualize as informações da ACL com número de série 3001 no Device2.
Device2#show access-list 3001mac access-list extended 300110 deny any any vlan-id 220 deny any any cos 7 vlan-id 330 permit any any vlan-id 3
- Passo 5:Configure a aplicação da ACL estendida MAC.
#Aplique o MAC Extended ACL com número de série 3001 ao ingresso da porta gigabitethernet0/1 no Device2.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#mac access-group 3001 inDevice2(config-if-gigabitethernet0/1)#exit
#Visualize as informações da ACL aplicada à porta no Device2.
Device#show acl-object interface-----------Interface-----Bind-----Instance--------------Interface----------------Direction----AclType----AclNamegi0/1 IN MAC 3001-----------Interface-----Bind-----Instance--------------Interface VlanId---------Direction----AclType----AclName
- Passo 6:Confira o resultado.
# PC2 pode acessar a rede IP; O PC1 e o Telefone IP não podem acessar a Rede IP.
Para a configuração do Voice-VLAN, consulte o capítulo Voice-VLAN do manual de configuração.
Configurar ACL estendida híbrida
Requisitos de rede
- PC1, PC2 e PC3 estão conectados à rede IP via dispositivo.
- Configure a regra de ACL estendida híbrida, percebendo que PC1 pode acessar a rede IP dentro do tempo especificado, PC2 e PC3 não podem acessar a rede IP.
Topologia de rede

Figura 15 - 5 Rede de configuração de ACL estendida híbrida
Etapas de configuração
- Passo 1:Configure o tipo de link de VLAN e porta no dispositivo.
#Criar VLAN.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como Acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode accessDevice(config-if-gigabitethernet0/1)#switchport access vlan 2Device(config-if-gigabitethernet0/1)#exit
- Passo 2:Configure a interface VLAN correspondente e o endereço IP no dispositivo. (Omitido)
- Passo 3:Configure o domínio do tempo.
#Configure o domínio de tempo “time-range-work” no dispositivo e o intervalo é das 08:00 às 18:00 todos os dias.
Device(config)#time-range time-range-workDevice(config-time-range)#periodic daily 08:00 to 18:00Device(config-time-range)#exit
#Visualize a hora atual do sistema no dispositivo.
Device#show clockUTC FRI APR 05 15:26:31 2013
#Visualize as informações do domínio de tempo definido “time-range-work” no dispositivo.
Device#show time-range time-range-work
Timerange name:time-range-work (STATE:active)10 periodic daily 08:00 to 18:00 (active)
- Passo 4:Configure a lista de ACL estendida híbrida.
#Configure a ACL estendida híbrida com o número de série 5001 no dispositivo.
Device(config)#hybrid access-list extended 5001#Configure a regra, permitindo que o PC1 acesse a rede IP no domínio de tempo definido “ time-range-work” intervalo.
Device(config-hybrid-nacl)# permit host 0001.0001.0001 any ether-type ipv4 ip any any time-range time-range-work#Configure a regra, evitando que o segmento 131.44.0.0/16 acesse a Rede IP.
Device(config-hybrid-nacl)# deny any any ether-type ipv4 ip 131.44.0.0 0.0.255.255 any#Configure a regra, permitindo que todos os pacotes da Rede IP passem pelo Device.
Device(config-hybrid-nacl)# permit any any ether-type ipv4 ip any any#Envie a regra configurada
Device(config-hybrid-nacl)#commitDevice(config-hybrid-nacl)#exit
#Visualize as informações da ACL com número de série 5001 no dispositivo.
Device#show hybrid access-list 5001hybrid access-list extended 500110 permit host 0001.0001.0001 any ether-type ipv4 ip any any time-range time-range-work (active)20 deny any any ether-type ipv4 ip 131.44.0.0 0.0.255.255 any30 permit any any ether-type ipv4 ip any any
- Passo 5:Configure a aplicação da ACL estendida híbrida.
#Aplique a ACL estendida híbrida com número de série 5001 ao ingresso globalmente.
Device(config)#global hybrid access-group 5001 in#Visualize as informações da ACL aplicada globalmente no dispositivo.
Device#show acl-object global----------------Global-----Bind-----Instance-----------Global-------------------Direction----AclType----AclNameglobal IN HYBRID 5001
- Passo 6:Confira o resultado.
#PC1 pode acessar a rede IP das 08:00 às 18:00 todos os dias; PC2 e PC3 não podem acessar a rede IP.
URPF
Visão geral
Na Internet atual, muitos ataques de rede usam o pacote de ataque de endereço IP de origem falsa. Por um lado, pode evitar que o próprio endereço IP seja rastreado; por outro lado, o endereço IP de origem do pacote, como ataque Land e Smurf, é o endereço IP do objeto de ataque. Para limitar o dano causado pelo ataque de endereço de origem falso e rastrear a origem do ataque, avance para filtrar o tráfego de endereço IP de origem falso no ISP ou dispositivo de acesso à rede de borda em rfc2827 e rfc3704, suprimindo o ataque na fonte de geração do pacote de ataque .
A principal função do URPF (Unicast Reverse Path Forwarding) é impedir a ação de ataque à rede com base na falsificação de endereço de origem falso. Durante o encaminhamento de pacotes, execute a tabela de rota reversa procurando o endereço de origem do pacote e julgue se permite a passagem do pacote de acordo com o resultado da pesquisa da tabela de rotas, de modo a evitar o spoofing do endereço IP, especialmente válido para o Ataque DoS (Denial of Service) do endereço de origem falso. A verificação URPF tem dois modos, ou seja, estrito e solto.
O ataque à rede já causa a séria ameaça à segurança da rede. O URPF filtra o pacote de ataque de rede do endereço IP de origem falso no ISP ou dispositivo de acesso de borda, para suprimir o dano causado pelo pacote de ataque de rede. É um método válido de prevenir o ataque à rede.
Configuração da função URPF
Tabela 16 -1 lista de configuração da função UPPF
| Tarefa de configuração | |
| Configurar a função URPF | Configurar a verificação de URPF |
Configurar função URPF
Condição de configuração
Nenhum
Configurar verificação de URPF
Configurando o URPF, verifique-o para filtrar o pacote de ataque com base no endereço IP de origem falso na interface de recebimento. O URPF suporta os modos estrito e solto. No modo solto, o URPF executa a tabela de rotas procurando o endereço IP de origem do pacote recebido. Se encontrar a rota, permitir que o pacote passe, enquanto no modo estrito, não precisamos apenas encontrar a rota, mas também a interface de saída e a interface de recebimento de pacotes precisam ser as mesmas para que o pacote possa passar .
Tabela 16 -2 Configurar a verificação de URPF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a verificação global de URPF | ip urpf [ allow-default-route ] | Obrigatório |
| Entre no modo de configuração da porta | interface interface-name | - |
| Habilite a verificação de URPF da porta | ip urpf { loose | strict } | Obrigatório Por padrão, a porta não habilita a verificação de URPF. A verificação de URPF da porta pode ter efeito somente após habilitar a verificação de URPF global. |
Habilitar a função URPF fará com que o número máximo de tabelas de rotas suportadas por todo o dispositivo seja reduzido pela metade.
Monitoramento e Manutenção de URPF
Tabela 16 -3 Monitoramento e Manutenção de URPF
| Comando | Descrição |
| show ip urpf brief | Exibir as informações de configuração do URPF |
| show ip urpf config | Exiba as informações de configuração de URPF globais e de interface |
Exemplo de configuração típica de URPF
Configurar o modo estrito de URPF
Requisitos de rede
- O PC está conectado à Rede IP via Dispositivo; configure o modo estrito URPF no dispositivo.
- O PC simula o invasor para enviar o pacote inválido com o endereço de origem falso para acessar a rede IP. A função URPF do dispositivo descarta o pacote.
Topologia de rede

Figura 16 – 1 Rede de configuração do modo estrito de URPF
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP e a rota da interface; é necessário que o PC possa acessar a rede IP via dispositivo. (Omitido)
- Passo 3:Configure o modo estrito de URPF.
#Ative a função URPF no dispositivo e configure o modo estrito do URPF na porta gigabitethernet0/1.
Device#configure terminalDevice(config)#ip urpfDevice(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#ip urpf strictDevice(config-if-gigabitethernet0/1)#exit
- Passo 4:Confira o resultado.
#PC acessa a rede IP via dispositivo e o endereço de origem é 120.5.0.2.
Há a rota para 120.5.0.2 ao dispositivo e a interface de saída da rota é VLAN2. A interface de saída de rota para o endereço de origem e a interface para receber o pacote são a mesma interface VLAN2. Após passar na verificação estrita do URPF, o pacote é encaminhado pelo dispositivo e o PC pode acessar a rede IP.
#PC simula que o invasor envie o pacote inválido com o endereço de origem falso; acessar Rede IP via Dispositivo; o endereço de origem é 120.10.0.2.
Não há rota para 120.10.0.2 no Dispositivo; O URPF descarta o pacote e o PC não pode acessar a rede IP.
Configurar o modo solto URPF
Requisitos de rede
- PC1 acessa PC2 via Device1, Device2 e Device 3 inno ambiente de rede; o pacote de resposta do PC2 chega ao PC1 via Device3 e Device1.
- Configure o modo solto URPF no Device3.
- O PC1 simula o invasor para enviar o pacote inválido com o endereço de origem falso para acessar o PC2. A função URPF do Device3 descarta o pacote.
Topologia de rede
Figura 16 - 2 Rede de configuração do modo solto URPF
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Configure a rota estática na rede, fazendo com que o PC1 acesse o PC2 via Device1, Device2 e Device3; o pacote de resposta do PC2 chega ao PC1 via Device3 e Device1.
#Configure a rota estática de Device1, Device2 e Device3; construir o ambiente de rede nos requisitos de rede.
Device1#configure terminalDevice1(config)#ip route 120.1.0.0 255.255.255.0 120.3.0.2Device1(config)#ip route 120.2.0.0 255.255.255.0 120.3.0.2
Device2#configure terminalDevice2(config)#ip route 120.1.0.0 255.255.255.0 120.2.0.2
Device3#configure terminalDevice3(config)#ip route 120.5.0.0 255.255.255.0 120.4.0.1
#Visualize as tabelas de rotas de Device1, Device2 e Device3.
Device1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setS 120.1.0.0/24 [1/10] via 120.3.0.2, 00:10:49, vlan3S 120.2.0.0/24 [1/10] via 120.3.0.2, 00:11:19, vlan3
C 120.3.0.0/24 is directly connected, 00:19:15, vlan3C 120.4.0.0/24 is directly connected, 00:15:00, vlan4C 120.5.0.0/24 is directly connected, 00:07:36, vlan2C 127.0.0.0/8 is directly connected, 357:23:02, lo0Device2#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setS 120.1.0.0/24 [1/10] via 120.2.0.2, 00:15:37, vlan3
C 120.2.0.0/24 is directly connected, 00:17:17, vlan3
C 120.3.0.0/24 is directly connected, 00:25:21, vlan2C 127.0.0.0/8 is directly connected, 00:38:29, lo0Device3#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 120.1.0.0/24 is directly connected, 00:17:01, vlan4C 120.2.0.0/24 is directly connected, 00:19:13, vlan2C 120.4.0.0/24 is directly connected, 00:18:50, vlan3S 120.5.0.0/24 [1/10] via 120.4.0.1, 00:17:19, vlan3C 127.0.0.0/8 is directly connected, 00:26:16, lo0
- Passo 4:Configure o modo solto URPF no Device3.
#Habilite a função URPF no Device3 e configure o modo solto URPF na porta gigabitethernet0/1.
Device3#configure terminalDevice3(config)#ip urpfDevice3(config)#interface gigabitethernet 0/1Device3(config-if-gigabitethernet0/1)#ip urpf looseDevice3(config-if-gigabitethernet0/1)#exit
- Passo 5:Confira o resultado.
#PC1 pingar PC2
O pacote de solicitação de ping do PC1 chega ao PC2 via Device1, Device2 e Device3; o pacote de resposta de ping do PC2 chega ao PC1 via Device3 e Device1.
#PC1 acessa PC2 e o endereço de origem é 120.5.0.2.
Há a rota para 120.5.0.2 no Device3 e a interface de saída da rota é VLAN3. A interface de saída de rota para o endereço de origem VLAN3 e a interface para receber o pacote VLAN2 não são a mesma interface, mas após a verificação de URPF, o pacote é encaminhado pelo Device3, o PC1 pode acessar o PC2 e o pacote de resposta do PC2 chega ao PC1 via Dispositivo3 e Dispositivo1.
#PC1 simula o invasor enviar o pacote inválido com o endereço de origem falso para acessar o PC2 e o endereço de origem é 120.10.0.2.
Não há rota para 120.10.0.2 no Device3; URPF descarta o pacote; PC1 não pode acessar PC2.
O descarte de pacote gerado pela detecção não gera as informações de log ou estatísticas. A diferença dos modos estrito e solto do URPF: No modo solto, o URPF executa a tabela de rotas procurando o endereço IP de origem do pacote recebido. Se encontrar a rota, permitir que o pacote passe, enquanto no modo estrito, não precisamos apenas encontrar a rota, mas também a interface de saída e a interface de recebimento de pacotes precisam ser as mesmas para que o pacote possa passar . Geralmente aplica o modo estrito. O modo solto é aplicado ao ambiente de rede do caso semelhante “A rota de chegada e a rota de retorno são inconsistentes”.
Detecção de Ataque
Visão geral
A detecção de ataques é uma função importante para manter a segurança da rede. Ele analisa o conteúdo do pacote processado pelo dispositivo, avalia se o pacote possui o recurso de ataque e executa algumas precauções para o pacote com o recurso de ataque de acordo com a configuração, como interceptar o pacote de ataque e registrar o log do pacote de ataque. Configurar a função de detecção de ataque no dispositivo, por um lado, pode evitar que o dispositivo se torne anormal devido ao ataque à rede, melhorando a capacidade anti-ataque do dispositivo; por outro lado, pode interceptar o tráfego de ataque encaminhado pelo dispositivo, evitando que os demais dispositivos da rede não funcionem normalmente por terem sido atacados.
Configuração da função de detecção de ataque
Tabela 17 -1 A lista de configuração da função de detecção de ataque
| Tarefa de configuração | |
| Configure a função de detecção de ataque de software |
Configure a interceptação do pacote com comprimento de IP muito pequeno
Configure a interceptação dos pacotes de fragmentos irracionais Configure a interceptação do pacote de ataque Land Configure a interceptação do pacote de ataque Fraggle Configure a interceptação do pacote de ataque de inundação ICMP Configure a interceptação do pacote de ataque de inundação TCP SYN Configure a interceptação do pacote de ataque de varredura de endereço e porta Configurar a gravação do log de detecção de ataque de software |
| Configurar a função de detecção de ataque de hardware |
Configure a interceptação do pacote de fragmento ICMP do protocolo IPv4&6
Configure a interceptação do pacote com o mesmo MAC de origem e destino Configure a interceptação do pacote com o mesmo IP de origem e destino Configure a interceptação do pacote TCP com a mesma porta de origem e destino Configure a interceptação do pacote UDP com a mesma porta de origem e destino Configure a interceptação do pacote IPv4&6 com o campo de controle TCP (flags) e o número de série seq como 0 Configure a interceptação do ataque IPv4&6 com TCP FIN, URG e PSH como 1, mas sequência como 0 Configure a interceptação do pacote IPv4&6 com os sinalizadores TCP SYN e FIN definidos ao mesmo tempo |
A função de detecção de ataque de software é válida apenas para o pacote para o dispositivo local; a função de detecção de ataque de hardware é válida para todos os pacotes recebidos pela porta de comutação. A detecção de ataque de software suporta as estatísticas e a gravação de log para os empacotadores descartados; a detecção de ataque de hardware é realizada pelo chip de comutação e não suporta as estatísticas e a gravação de log para os pacotes descartados.
A função de detecção de ataque de software é realizada adotando o modo de software, realizando a detecção de ataque apenas para o pacote com o endereço de destino como o próprio dispositivo, para evitar que o dispositivo receba o ataque de rede.
Antes de configurar as funções de interceptação de inundação ICMP e detecção de ataque de inundação TCP SYN, primeiro conclua as seguintes tarefas:
Quando o dispositivo recebe o pacote IP com o comprimento IP (incluindo o cabeçote IP e a carga) menor que o comprimento configurado, descarte o pacote.
Tabela 17 -2 Configure a interceptação do pacote com comprimento de IP muito pequeno
Após configurar o comando, o pacote BFD pode ser descartado.
Quando o dispositivo receber o pacote de fragmento IP e o deslocamento do fragmento mais seu próprio comprimento de carga exceder o comprimento configurado, descarte o pacote.
Tabela 17 -3 Configurar interceptação de pacote de fragmento irracional Quando o dispositivo receber o pacote ICMP especificado para filtrar, descarte-o. Tabela 17 -4 Configurar a interceptação do pacote ICMP especificado Quando o dispositivo receber os pacotes ICMP_ECHO, ICMP_MASKREQ e ICMP_TSTAMP, descarte-os. Tabela 17 -5 Configure a interceptação do pacote não zero de código ICMP
O ataque terrestre adota o mesmo IP e porta de origem e destino para enviar o pacote TCP SYN para a máquina alvo, fazendo com que o sistema alvo com o furo crie uma conexão TCP vazia consigo mesmo, resultando até mesmo na quebra do sistema alvo.
Quando o dispositivo recebe o pacote TCP SYN com o mesmo IP de origem e destino e a mesma porta de origem e destino, descarte o pacote.
Tabela 17 -6 Configurar interceptação do pacote de ataque Land O ataque Fraggle usa a porta de destino 19 ou 7 do pacote UDP para atacar.
Quando o dispositivo recebe o pacote UDP e a porta de destino é 19 ou 7, ele é considerado o pacote de ataque Fraggle e é descartado.
Tabela 17 -7 Configurar interceptação do pacote de ataque Fraggle
O ataque de inundação ICMP envia muitas solicitações de eco ICMP ao host de destino para bloquear a rede do host de destino. O host de destino consome muitos recursos para responder e não pode fornecer serviços normalmente.
Quando o número de pacotes ICMP com o mesmo IP de destino recebido pelo dispositivo em um segundo excede o limite, os pacotes que excedem o limite são descartados.
Tabela 17 -8 Configurar interceptação do pacote de ataque de inundação ICMP
Ao configurar a interceptação do pacote de ataque de inundação ICMP, primeiro é necessário criar a ACL, usada para especificar o fluxo de dados protegido. Verificamos se é o pacote de ataque de inundação ICMP apenas para o fluxo de dados permitido pela ACL. Caso contrário, permita que o pacote passe.
O ataque TCP SYN Flood envia muitas solicitações TCP SYN para o host de destino, mas não responde à mensagem ACK. Como resultado, o host de destino tem muitas semi-conexões aguardando o recebimento da mensagem ACK do solicitante, que ocupam os recursos disponíveis do host de destino. Como resultado, o host de destino não pode fornecer os serviços de rede normais.
Quando o número de pacotes TCP SYN com o mesmo IP de destino recebido pelo dispositivo em um segundo excede o limite, os pacotes que excedem o limite são descartados.
Tabela 17 -9 Configurar interceptação do pacote de ataque de inundação TCP SYN
Ao configurar a interceptação do pacote de ataque de inundação TCP SYN, primeiro é necessário criar a ACL, usada para especificar o fluxo de dados protegido. Verificamos se é o pacote de ataque de inundação TCP SYN apenas para o fluxo de dados permitido pela ACL. Caso contrário, permita que o pacote passe.
O ataque de varredura de endereço significa que o invasor envia os pacotes CMP para detectar o host ativo na rede, enquanto a varredura de porta significa que o invasor envia o pacote TCP ou UDP para detectar a porta habilitada do host ativo na rede. Com a varredura de endereço e porta, o invasor pode obter as informações do host ativo na rede. Normalmente, a varredura de endereço e porta é o presságio do invasor iniciando o ataque à rede.
Quando o número de pacotes ICMP com o mesmo IP e IPs de destino diferentes recebidos pelo dispositivo em um segundo excede o limite, é considerado o ataque de varredura de endereço e os pacotes que excedem o limite são descartados. Quando o número de pacotes TCP ou UDP com o mesmo IP de origem e diferentes portas de destino recebidos pelo dispositivo dentro de um segundo excede o limite, é considerado o ataque de varredura de porta e os pacotes que excedem o limite são descartados.
Tabela 17 -10 Configurar interceptação do pacote de ataque de varredura de endereço e porta
Quando a detecção de ataque de software do dispositivo interceptar o pacote de ataque, registre as informações de log.
Tabela 17 -11 Configurar a gravação do log de detecção de ataque de software
Configurar a função de detecção de ataque de software
Condição de configuração
Configurar pacote de interceptação com comprimento de IP muito pequeno
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Configure a interceptação do pacote com comprimento de IP muito pequeno
anti-attack drop small-packet [ length ]
Obrigatório Por padrão, não configure a função de interceptar o pacote com comprimento de IP muito pequeno. Após configurar a função e se não especificar o comprimento, intercepte o pacote com comprimento de IP menor que 64 bytes por padrão.
Configurar pacote de fragmento irracional de interceptação
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
de pacote de fragmento irracional
anti-attack drop fragment [ max-off length ]
Obrigatório Por padrão, não configure a função de interceptar o pacote de fragmento não razoável. Depois de configurar a função e se não especificar o comprimento, intercepte o fragmento cujo deslocamento mais seu próprio comprimento de carga excede 65535 por padrão.
Configurar Interceptação de Pacote ICMP Especificado
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Configure a interceptação do pacote ICMPv4 do tipo especificado para o dispositivo local
anti-attack drop icmp type{ ECHOREPLY | UNREACH | SOURCEQUENCH | REDIRECT | ECHO | ROUTERADVERT | ROUTERSOLICIT | TIMXCEED | PARAMPROB | TSTAMP | TSTAMPREPLY | IREQ | IREQREPLY | MASKREQ | MASKREPLY}
Obrigatório Por padrão, não configure a interceptação do pacote ICMPv4 do tipo especificado para o dispositivo local.
Configurar o código ICMP de interceptação do pacote diferente de zero
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Interceptar o pacote de solicitação ICMP com o campo de código diferente de zero para o dispositivo local
anti-attack drop icmp code none-zero
Obrigatório Por padrão, não configure a interceptação do pacote de solicitação ICMP com o campo de código diferente de zero para o dispositivo local.
Configurar pacote de ataque terrestre de interceptação
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Configure a interceptação do pacote de ataque Land
anti-attack detect tcp-land
Obrigatório Por padrão, não configure a interceptação do pacote de ataque Land.
Configurar pacote de ataque Fraggle de interceptação
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Configure a interceptação do pacote de ataque Fraggle
anti-attack detect fraggle access-list-name } [ masklen length ]
Obrigatório Por padrão, não configure a função de interceptação do pacote de ataque Fraggle.
Configurar pacote de ataque de inundação ICMP de interceptação
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Configure a interceptação do pacote de ataque de inundação ICMP
anti-attack flood icmp list { access-list-number | access-list-name } [ maxcount number ]
Obrigatório Por padrão, não configure a função de interceptação do pacote de ataque de inundação ICMP. Após configurar a função e se não especificar o limite, o valor padrão é 500.
Configurar o pacote de ataque de inundação TCP SYN de interceptação
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Configure a interceptação do pacote de ataque de inundação TCP SYN
anti-attack flood tcp list { access-list-number | access-list-name } [ maxcount number ]
Obrigatório Por padrão, não configure a função de interceptar o pacote de ataque de inundação TCP SYN. Após configurar a função e se não especificar o limite, o valor padrão é 500.
Configurar o pacote de ataque de varredura de endereço e porta de interceptação
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração da interface
interface interface-name
-
Configure a interceptação do pacote de ataque de varredura de endereço e porta
anti-attack scanprotect { default | interval { default | interval-value } addr-limit { default | max-addr-value } port-limit { default | max-port-value } ban-timeout { default | max-ban-timeout } }
Obrigatório Por padrão, não configure a função de interceptar os pacotes de ataque de varredura de endereço e porta. Depois de configurar a função, o intervalo padrão é 1s, o limite de varredura de endereço padrão é 10 IPs diferentes e o limite de varredura de porta padrão é 10 portas de destino diferentes.
Configurar gravação de log de detecção de ataque de software
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Configurar a gravação do log de detecção de ataque de software
anti-attack log
Obrigatório Por padrão, não configure a função de log de detecção de ataque de software.
Configurar a função de detecção de ataque de hardware
Condições de configuração
Nenhum
Configurar pacote de fragmento ICMP de interceptação do protocolo IPv4 e 6
Quando o dispositivo receber o pacote de fragmento ICMP do protocolo IPv4&6, descarte o pacote.
Tabela 17 -12 Configurar interceptando o pacote de fragmento ICMP do protocolo IPv4&6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a interceptação do pacote de fragmento ICMP do protocolo IPv4&6 | anti-attack detect frag-icmp | Obrigatório Por padrão, não configure a interceptação do pacote de fragmento ICMP do protocolo IPv4&6. |
Configurar pacote de interceptação com o mesmo MAC de origem e destino
Quando a porta de comutação do dispositivo recebe o pacote com o mesmo MAC de origem e destino, descarte o pacote.
Tabela 17 -13 Configure a interceptação do pacote com o mesmo MAC de origem e destino
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a interceptação do pacote com o mesmo MAC de origem e destino | anti-attack detect src-dst-mac-equal | Obrigatório Por padrão, não configure a função de interceptar o pacote com o mesmo MAC de origem e destino |
Configurar pacote de interceptação com o mesmo IP de origem e destino
Quando a porta de comutação do dispositivo receber o pacote com o mesmo IP de origem e destino, descarte o pacote.
Tabela 17 -14 Configure a interceptação do pacote com o mesmo IP de origem e destino
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a interceptação do pacote com o mesmo IP de origem e destino | anti-attack detect src-dst-ip-equal | Obrigatório Por padrão, não configure a função de interceptar o pacote com o mesmo IP de origem e destino . |
Configurar o pacote TCP/UDP de interceptação com a mesma porta de origem e destino
Quando a porta de comutação do dispositivo recebe o pacote TCP/UDP com a mesma porta de origem e destino, descarte o pacote.
Tabela 17 -15 Configure a interceptação do pacote TCP/UDP com a mesma porta de origem e destino
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a interceptação do pacote TCP/UDP com a mesma porta de origem e destino | anti-attack detect src-dst-port-equal | Obrigatório Por padrão, não configure a função de interceptação do pacote TCP/UDP com a mesma porta de origem e destino . |
Configurar o pacote de interceptação IPv4 e v6 com campo de controle TCP (flags) e número de série (seq) como 0
Quando a porta do switch do dispositivo recebe o pacote IPv4&6 com o campo de controle TCP (flags) e o número de série (seq) como 0, descarte o pacote.
Tabela 17 -16 Configure a interceptação do pacote IPv4&v6 com o campo de controle TCP (flags) e o número de série (seq) como 0
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a interceptação do pacote IPv4&v6 com o campo de controle TCP (flags) e o número de série (seq) como 0 | anti-attack detect tcp-flag-seq-zero | Obrigatório Por padrão, não configure a interceptação do pacote IPv4&v6 com o campo de controle TCP (flags) e o número de série (seq) como 0. |
Configurar interceptação de ataque IPv4 e 6 com TCP FIN, URG e PSH como 1, mas sequência como 0
Quando a porta do switch do dispositivo recebe o pacote de ataque IPv4&6 com TCP FIN, URG e PSH como 1, mas sequência como 0, descarte o pacote.
Tabela 17 -17 Configure a interceptação do pacote de ataque IPv4&6 com TCP FIN, URG e PSH como 1, mas sequência como 0
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a interceptação do pacote de ataque IPv4&6 com o TCP FIN, URG e PSH como 1, mas a sequência como 0 | anti-attack detect tcp-invalid-flag | Obrigatório Por padrão, não configure a interceptação do pacote de ataque IPv4&6 com o TCP FIN, URG e PSH como 1, mas a sequência como 0. |
Configurar a interceptação do pacote IPv4&6 com os sinalizadores TCP SYN e FIN definidos ao mesmo tempo
Quando a porta do switch do dispositivo recebe o pacote IPv4&6 com sinalizadores SYN FIN no TCP configurados ao mesmo tempo, descarte o pacote.
Tabela 17 -18 Configure a interceptação do pacote IPv4&6 com sinalizadores SYN FIN em TCP configurados ao mesmo tempo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a interceptação do pacote IPv4 e 6 com sinalizadores SYN FIN no TCP configurados ao mesmo tempo | anti-attack detect tcp-syn-fin | Obrigatório Por padrão, não configure a interceptação do pacote IPv4&6 com sinalizadores SYN FIN no TCP configurados ao mesmo tempo. |
Monitoramento e manutenção da detecção de ataques
Tabela 17 -19 Monitoramento e manutenção de detecção de ataque
| Comando | Descrição |
| clear anti-attack statistic | Limpe as informações de estatísticas de detecção de ataque de software |
| show anti-attack config | Exibir o software de detecção de ataque e as informações de configuração de hardware |
| show anti-attack statistic | Exibir as informações de estatísticas de detecção de ataque de software |
| show anti-attack scanprotect config | Exibir as informações de configuração de detecção de ataque de varredura |
| show anti-attack scanprotect monitor | Exibir as informações de estatísticas de detecção de ataque de varredura |
| clear anti-attack scanprotect | Limpar as informações de estatísticas de verificação de ataque de varredura |
Exemplo de configuração típico de detecção de ataque
Configurar detecção de ataque anti-DDOS
Requisitos de rede
- O dispositivo está conectado à rede IP via porta gigabitethernet0/1.
- O dispositivo configura a função de detecção de ataque anti-DDOS. Ao encontrar o pacote de ataque, alarme e descarte o pacote de ataque, tomando como exemplo o ataque SYN Flood comum, o ataque Ping Flood e o ataque Land.
Topologia de rede
Figura 17 - 1 Rede de configuração da detecção de ataque anti-DDOS
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Configure a regra ACL.
#Configure a regra ACL padrão, correspondendo ao endereço do dispositivo a ser protegido.
Device#configure terminalDevice(config)#ip access-list standard 1Device(config-std-nacl)#permit host 100.0.0.1Device(config-std-nacl)#exit
- Passo 4:Configure a função de detecção de ataque e ative a função de gravação de log.
#Configure a função de detecção de ataque SYN Flood, Ping Flood e Land no dispositivo.
Device(config)# anti-attack detect tcp-landDevice(config)# anti-attack flood icmp list 1 maxcount 100Device(config)# anti-attack flood tcp list 1 maxcount 100
#Ative a função de gravação de log de detecção de ataque anti-DDOS no dispositivo.
Device(config)#anti-attack log- Passo 5:Confira o resultado.
#Quando o dispositivo recebe o ataque SYN Flood, gera as seguintes informações de log:
%FW FLOOD_WARN-4: vlan2 gigabitethernet0/1 SYN flood attack detected, destination IP 100.0.0.1, overflow 100 packets/second.#Quando o dispositivo recebe o ataque Ping Flood, produza as seguintes informações de log:
%FW-FLOOD_WARN-4: vlan2 gigabitethernet0/1 ICMP flood attack detected, destination IP 100.0.0.1, overflow 100 packets/second..#Quando o dispositivo recebe o ataque Land, produza as seguintes informações de log:
%FW-LAND_WARN-4: LAND attack detected at vlan2 gigabitethernet0/1, source IP equals destination IP 100.0.0.1, source port equals destination port 1024.#Visualize as informações de estatísticas do pacote de detecção de ataque no dispositivo:
IP attack Drops-------------------- ----------Small IP 0Fragment 0Tcp-land 6256Fraggle 0SYN Flood 6200ICMP Flood 4893
A função de detecção de ataque DDOS é válida apenas para os pacotes processados pela CPU.
Configurar o ataque de interceptação com o mesmo endereço IP de origem e destino
Requisitos de rede
- O dispositivo configura a função de detecção de interceptar o ataque com o mesmo endereço IP de origem e destino, detectando o pacote de ataque e descartando-o.
Topologia de rede

Figura 17 – 2 Rede de configuração de interceptação do ataque com o mesmo endereço IP de origem e destino
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Configure a função de detecção de ataque.
#Configure a função de detecção de interceptação do ataque com o mesmo endereço IP de origem e destino.
Device#configure terminalDevice(config)# anti-attack detect src-dst-ip-equal
- Passo 4:Confira o resultado.
#Quando o invasor inicia o ataque de pacote com o mesmo endereço IP de origem e destino para o PC, não podemos capturar o pacote de ataque no PC.
A função de detecção de interceptação do ataque com o mesmo endereço IP de origem e destino é válida para os pacotes processados pela CPU e os pacotes de serviço. Quando a função de detecção de interceptar o ataque com o mesmo endereço IP de origem e destino descarta o pacote, não gere as informações de log ou estatísticas.
AARF
Introdução AARF
AARF é a abreviação de Anti Attack Resilient Framework.
Visão geral da AARF
No ambiente de rede, os switches são frequentemente atacados por pacotes maliciosos (ARP, ICMP, etc.). Esses ataques mal-intencionados impõem cargas pesadas ao sistema do switch e tornam o sistema incapaz de continuar em execução. Normalmente, um grande número de pacotes consumirá a utilização da CPU, memória, entradas de tabela ou outros recursos do switch. Como resultado, os outros pacotes de protocolo normais e pacotes de gerenciamento não podem ser processados pelo sistema, ou mesmo toda a rede não pode ser executada.
O AARF pode efetivamente identificar e impedir que o switch seja afetado por esses ataques. Ele pode garantir o funcionamento normal do sistema e proteger a CPU de carga excessiva quando o switch for atacado, para que toda a rede possa funcionar normalmente.
Princípios da AARF
De um modo geral, o princípio do protocolo anti-ataque de pacotes é contar os pacotes enviados para a CPU, calcular a taxa de envio deles e comparar com o limite de ataque definido. Se a taxa atingir o limite de ataque, considera-se que o pacote de protocolo tem comportamento de ataque, e então, realizar algumas restrições para o host com comportamento de ataque, como descarte de CPU, limite de velocidade e filtragem, de forma a proteger a CPU .
De fato, do ponto de vista da implementação, diferentes funções anti-ataque de pacotes de protocolo têm o mesmo método de implementação para estatísticas de pacotes, identificação, aplicação de política de ataque e assim por diante. Abstraímos o mesmo processamento, construímos uma estrutura e formamos o AARF. O AARF é usado para implementar alguns mecanismos de processamento comuns do módulo anti-ataque, de modo a melhorar a escalabilidade do módulo anti-ataque e reduzir a carga de trabalho de desenvolvimento do novo módulo anti-ataque do protocolo.
Atualmente, o AARF suporta o ARP guard (arp-guard).
ARP Anti-Ataque
ARP guard (arp-guard) é uma função de monitoramento em tempo real dos pacotes ARP para a CPU, evitando que um grande número de pacotes ARP afete a CPU e melhorando a segurança do dispositivo.
A proteção ARP inclui proteção ARP baseada em host, proteção ARP baseada em porta e identificação de varredura ARP.
O guarda ARP baseado em host conta os pacotes ARP recebidos e, em seguida, compara o valor das estatísticas com o limite definido. Se exceder o limite, é identificado como excesso de velocidade ou ataque. As estatísticas e a identificação são baseadas no endereço IP de origem/ID da VLAN/porta e no endereço MAC de origem da camada de link/ID da VLAN/porta.
O protetor ARP baseado em porta conta o número de pacotes ARP recebidos pela porta sem ataque ao host. Se exceder o limite definido pela porta, é identificado como excesso de velocidade ou ataque. As estatísticas de porta não incluem os pacotes ARP que foram identificados como ataques de host (as entradas da tabela de host são geradas e as políticas de proteção contra ataques são aplicadas).
A identificação de varredura ARP pode identificar dois tipos de varredura ARP: a varredura ARP com endereço MAC de origem fixo e IP de origem variável e a varredura ARP com MAC de origem fixo e IP de origem e IP de destino variável.
Configuração da Função ARP Guard
Tabela 18 -1 lista de configuração da função de guarda ARP
| Tarefas de configuração | |
| Configure as funções básicas do guarda ARP | Habilite a função de guarda ARP global Habilite a função de guarda ARP na porta |
| Configure a política do monitor do guarda ARP | Configurar a política de monitor global Configure a política do monitor na porta |
Configurar as funções básicas do ARP Guard
A função de proteção ARP baseada em porta pode entrar em vigor somente após a função de proteção ARP global ser habilitada.
Condição de configuração
Nenhum
Ativar função de proteção ARP global
Tabela 18 -2 Habilitar a função de guarda ARP global
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração AARF | aarf | - |
| Habilite a função de guarda ARP global | arp-guard enable | Obrigatório Por padrão, não habilite a função de guarda ARP globalmente. |
Ativar função de proteção ARP da porta
Tabela 18 -3 Habilitar a função de guarda ARP da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | link-aggregation link-aggregation-id | |
| Habilite a função de guarda ARP da porta | aarf arp-guard enable | Obrigatório Por padrão, não habilite a função de guarda ARP na porta. |
Configurar a política do monitor do ARP Guard
Condição de configuração
Nenhum
Configure a política de monitor do Global ARP Guard
Tabela 18 -4 Configurar a política do monitor da função de guarda ARP global
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração AARF | aarf | - |
| Configure a política de monitor do guarda ARP global | arp-guard policy { filter | monitor | punish macbased} | Por padrão, a política do monitor do protetor ARP global é monitor. |
Configurar a política do monitor do protetor ARP da porta
Tabela 18 -5 Configurar a política do monitor do protetor ARP da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente apenas entra em vigor na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente apenas entra em vigor no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | link-aggregation link-aggregation-id | |
| Configure a política do monitor do protetor ARP da porta | aarf arp-guard policy { filter | monitor | punish macbased} | Por padrão, a política do monitor do protetor ARP da porta não está configurada e a política do monitor do protetor ARP global entra em vigor. |
O comando aarf arp-guard policy filter é uma política de proteção para filtrar os hosts aplicados ao host ou porta com ataque ARP sob a porta. Após configurar a política de filtragem, gere o alarme de ataque após detectar o host com excesso de velocidade ARP ou comportamento de ataque sob a porta e, se a velocidade do host que envia pacotes ARP estiver entre o limite de velocidade e o limite de ataque, a velocidade do ARP pacotes para a CPU serão limitados ao limite de velocidade. Os pacotes ARP na direção de encaminhamento serão encaminhados na velocidade de envio do host; se a velocidade do host que envia pacotes ARP exceder o limite de ataque, os pacotes ARP para a CPU serão descartados. Se detectar que a porta tem overspend ou comportamento de ataque (ou seja, a taxa total da porta que recebe os pacotes ARP de todos os hosts sem ataque é maior ou igual ao limite de velocidade da porta ou limite de ataque), gere o alarme de ataque. Se a taxa total da porta que recebe os pacotes ARP dos hosts sem ataque estiver entre o limite de velocidade da porta e o limite de ataque da porta, a taxa total da porta que recebe os pacotes ARP dos hosts sem ataque limita a velocidade do Os pacotes ARP para a CPU pelo limite de velocidade da porta, e os pacotes ARP a serem encaminhados são encaminhados pela velocidade inicial. Se a taxa total da porta que recebe os pacotes ARP de hosts sem ataque for maior ou igual ao limite de ataque da porta, todos os pacotes ARP recebidos pela porta serão descartados na direção de encaminhamento e não serão enviados à CPU.
O comando aarf arp-guard policy monitor é uma política de proteção de monitoramento do host aplicado ao host ou porta com o ataque ARP sob a porta. Após configurar a política de monitoramento, gere o alarme de ataque após detectar o pacote host ou porta com velocidade ARP ou comportamento de ataque detectado na porta, mas o pacote será enviado para a CPU na taxa do limite de velocidade e o ARP pacote além do limite de velocidade será descartado pela CPU; o pacote ARP a ser encaminhado será encaminhado na taxa inicial.
O comando aarf arp-guard policy punir macbased é uma política de proteção de punir o limite de velocidade aplicado aos hosts MAC com os ataques ARP sob a porta. Após configurar a política de punição do limite de velocidade, gere o alarme de ataque ao detectar o pacote host MAC com velocidade ARP ou comportamento de ataque sob a porta. Se a taxa dos pacotes enviados pelo host MAC estiver entre o limite de velocidade e o limite de ataque, a política do monitor entrará em vigor. Se a taxa de pacotes ARP for maior ou igual ao limite de ataque, os pacotes MAC que atacam o host serão enviados à CPU e encaminhados na metade da taxa do limite de velocidade MAC. Se o ataque parar ou a taxa cair abaixo do limite de velocidade MAC, remova a política de proteção do host quando o período de envelhecimento chegar. Além disso, neste modo de política, tanto a porta quanto o host IP usam a política do monitor.
Monitoramento e manutenção do ARP Guard
Tabela 18 -6 Monitoramento e manutenção de guarda ARP
| Comando | Descrição |
| show aarf arp-guard configure | Exibir as informações de configuração do guarda ARP |
| show aarf arp-guard hosts | Exibir as informações do host monitorado |
| show aarf arp-guard ports | Exibir as informações da porta monitorada |
| show aarf arp-guard scan | Exibir as informações do host digitalizadas |
AARF ARP-Guard Exemplo de Configuração Típica
Configurar as funções básicas do AARF ARP-GUARD
Requisitos de rede
- PC1, PC2 e PCs são conectados à rede IP via dispositivo.
- O PC1 envia o pacote ARP para atacar o dispositivo, o dispositivo habilita o AARF ARP-Guard, o dispositivo normalmente identifica o excesso de velocidade do ARP, o ataque ARP, a varredura ARP MAC, a varredura ARP MAC-IP e a política AARF ARP-Guard normalmente entra em vigor.
Topologia de rede
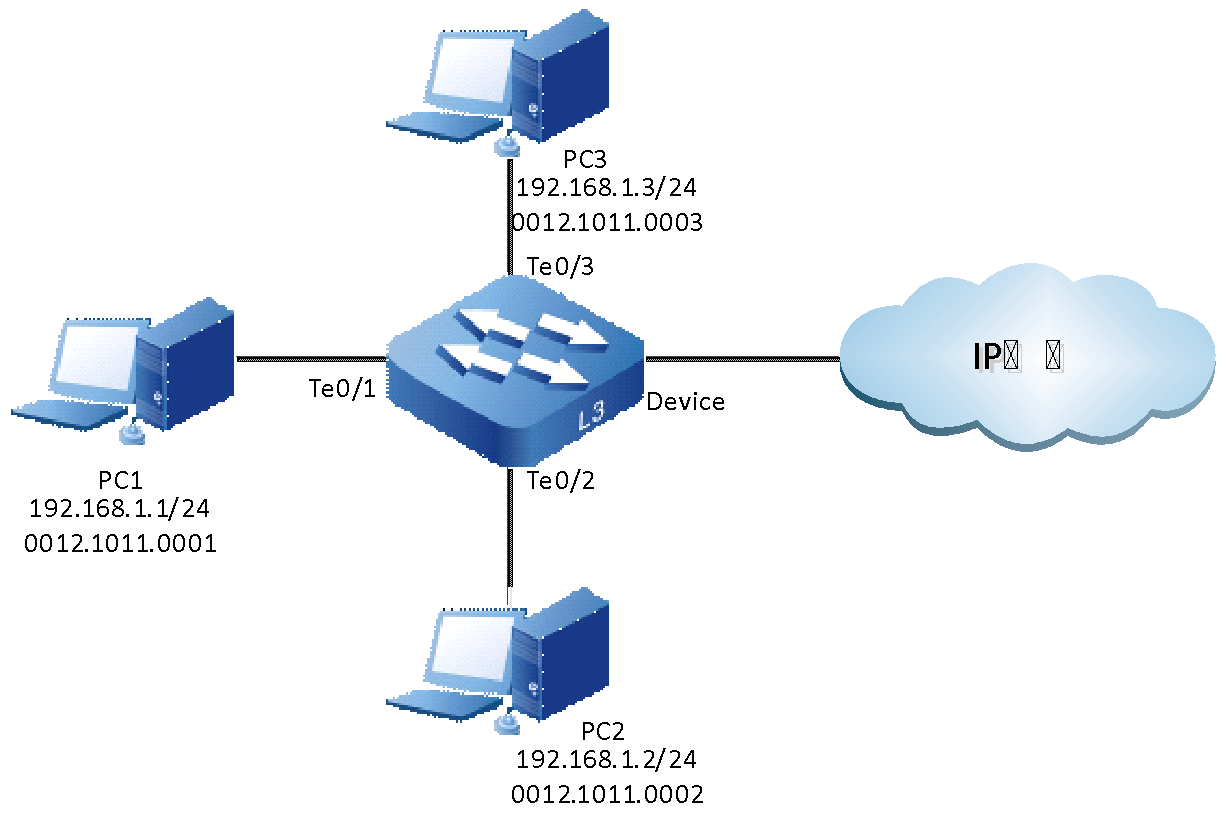
Figura 18 – 1 Rede para configurar a função de guarda ARP
Etapas de configuração
- Passo 1:Configure a VLAN e o tipo de link de porta no dispositivo.
#Cria VLAN2.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta tengigabitethernet0/1, tengigabitethernet0/2 e tengigabitethernet0/3 como acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface tengigabitethernet 0/1-0/3Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2
- Passo 2:Configure os gateways de PC1, PC2 e PC3 no dispositivo.
#Configure a interface VLAN 2 como gateway de PC1, PC2 e PC3.
Device(config)#interface vlan 2Device(config-if-vlan2)#ip address 192.168.1.254 24
- Passo 3:Ative o AARF ARP-Guard no dispositivo.
#Ativar AARF ARP-Guard globalmente.
Device(config)#aarfDevice(config-aarf)#arp-guard enable
#Ative AARF ARP-Guard na porta tengigabitethernet0/1, os limites relacionados são os valores padrão e configure a política como filtro.
Device(config-if-tengigabitethernet0/1)# aarf arp-guard enableDevice(config-if-tengigabitethernet0/1)# aarf arp-guard policy filter
- Passo 4:Confira o resultado.
#Consulte as informações de configuração do AARF ARP-Guard.
Device#show aarf arp-guard configure interface tengigabitethernet 0/1(Format of column Rate-limit and Attack-threshold is per-src-ip/per-src-mac/per-interface.)-----------------------------------------------------------------------------------------Interface/Global Status Rate-limit Attack-threshold Scan-threshold Attack-policy-----------------------------------------------------------------------------------------te0/1 Enabled 4/4/100 8/8/200 15 filter
#Quando a taxa de PC1 enviando o pacote de solicitação ARP para solicitar o endereço IP do gateway de dispositivo for maior ou igual ao limite de velocidade baseado em host 4pps e menor que o limite de ataque baseado em host 8pps, forme as entradas da tabela relacionada e produza o informações de registro. O dispositivo reconhece que o pacote ARP baseado em host está com excesso de velocidade.
Device#show aarf arp-guard hosts--------------------------------------------------------------------------------Interface Vlan IP MAC Action Policy---------------------------------------------------------------------------------te0/1 2 192.168.1.1 - overspeed monitorte0/1 2 - 0012.1011.0001 overspeed monitorTotal: 2 record(s).
#O log de saída é:
Dec 20 2016 03:45:28: %AARF-INTERFACE-3:<arp-guard>There are overspeed, attack or scan detected on interface te0/1.(TUE DEC 20 03:45:25 2016)Dec 20 2016 03:45:28: %AARF-DETECTED-3:<arp-guard>Host<IP=N/A,MAC=0012.1011.0001,interface= te0/1,VLAN=2> overspeed was detected.(TUE DEC 20 03:45:25 2016)Dec 20 2016 03:45:28: %AARF-DETECTED-3:<arp-guard>Host<IP=192.168.1.1,MAC=N/A,interface= te0/1,VLAN=2> overspeed was detected.(TUE DEC 20 03:45:25 2016)
#Quando a taxa de PC1 enviando o pacote de solicitação ARP para solicitar o endereço IP do gateway do dispositivo é maior que o limite de ataque baseado em host 8pps, o dispositivo filtra o pacote ARP, forma as entradas da tabela relacionada e gera as informações de log. O dispositivo identifica o ataque de pacote ARP baseado em host.
Device#show aarf arp-guard hosts--------------------------------------------------------------------------------
Interface Vlan IP MAC Action Policy
--------------------------------------------------------------------------------te0/1 2 192.168.1.1 - attack filterte0/1 2 - 0012.1011.0001 attack filterTotal: 2 record(s).
#O log de saída é:
Dec 20 2016 04:30:33: %AARF-INTERFACE-3:<arp-guard>There are overspeed, attack or scan detected on interface te0/1.(TUE DEC 20 04:30:30 2016)Dec 20 2016 04:30:33: %AARF-FILTER-3:<arp-guard>Host<IP=N/A,MAC=0012.1011.0001,interface=te0/1,VLAN=2> attack was filter.(TUE DEC 20 04:30:30 2016)Dec 20 2016 04:30:33: %AARF-FILTER-3:<arp-guard>Host<IP=192.168.1.2,MAC=N/A,interface=te0/1,VLAN=2> attack was filter.(TUE DEC 20 04:30:30 2016)
#Quando o PC1 envia vários pacotes de solicitação ARP sem ataque e a taxa de envio é maior ou igual ao limite de velocidade baseado em porta 100 e menor que o limite de ataque baseado em porta 200, o dispositivo forma as entradas da tabela relacionada e emite o informações de registro. O dispositivo identifica o excesso de velocidade ARP baseado em porta.
Device#show aarf arp-guard ports-----------------------------------------------------------------------------------------Interface Hosts Scan Action Policy-----------------------------------------------------------------------------------------te0/1 0 0 overspeed monitor
#O log de saída é:
Dec 22 2016 06:36:32: %AARF-INTERFACE-3:<arp-guard>Interface te0/1 was overspeed.(THU DEC 22 06:36:29 2016) #Quando o PC1 envia vários pacotes de solicitação ARP sem ataque e a taxa de envio é maior ou igual ao limite de ataque baseado em porta 200, o dispositivo filtra todos os pacotes ARP da porta, forma as entradas da tabela relacionada e gera as informações de log. O dispositivo identifica o ataque ARP baseado em porta.
Device#show aarf arp-guard ports-----------------------------------------------------------------------------------------Interface Hosts Scan Action Policy-----------------------------------------------------------------------------------------te0/1 0 0 attack filter
#O log de saída é:
Dec 22 2016 06:46:58: %AARF-INTERFACE-3:<arp-guard>Interface te0/1 was filter.(THU DEC 22 06:46:57 2016)#Quando o PC1 envia o pacote de solicitação ARP com o MAC fixo e o IP do remetente crescente, e o número de pacotes de solicitação ARP enviados em 10 segundos excede 15, forme as entradas da tabela relacionada e produza as informações de log. O dispositivo identifica a varredura MAC ARP.
Device#show aarf arp-guard scan-----------------------------------------------------------------------------------------Interface Vlan IP MAC Time-stamp-----------------------------------------------------------------------------------------te0/1 2 N/A 0012.1011.0001 THU DEC 22 03:16:30 2016Total: 1 record(s).
#O log de saída é:
Dec 22 2016 03:16:19: %AARF-INTERFACE-3:<arp-guard>There are overspeed, attack or scan detected on interface te0/1.(THU DEC 22 03:16:16 2016)Dec 22 2016 03:16:19: %AARF-SCAN-4:<arp-guard>Host<IP=N/A,MAC=0012.1011.0001,interface=te0/1,VLAN=2> scan was detected.(THU DEC 22 03:16:16 2016)
#Quando o PC1 envia o pacote de solicitação ARP com o MAC fixo e o IP do remetente, e o IP de destino crescente, e o número de pacotes de solicitação ARP enviados em 10s excede 15, forme as entradas da tabela relacionada e produza as informações de log. O dispositivo identifica a varredura MAC-IP ARP.
Device#show aarf arp-guard scan-----------------------------------------------------------------------------------------------Interface Vlan IP MAC Time-stamp-----------------------------------------------------------------------------------------------te0/1 2 192.168.1.254 0012.1011.0001 THU DEC 22 03:38:52 2016Total: 1 record(s).
#O log de saída é:
Dec 22 2016 03:37:33: %AARF-INTERFACE-3:<arp-guard>There are overspeed, attack or scan detected on interface te0/1.(THU DEC 22 03:37:30 2016)Dec 22 2016 03:37:33:%AARF-SCAN-4:<arp-guard>Host<IP=192.168.1.254,MAC=0012.1011.0001,interface=te0/1,VLAN=2> scan was detected.(THU DEC 22 03:37:30 2016)
PPPoE+
Visão geral
PPPoE+ (protocolo ponto-ponto sobre Ethernet plus) é o processo de obtenção do pacote de solicitação PPPoE enviado pelo cliente PPPoE, adicionando informações de porta acessadas pelo host do usuário do terminal em seu campo de carga e, em seguida, encaminhando-o para o servidor PPPoE, que realiza -to-point binding entre o terminal do usuário e o servidor.
PPPoE + Princípios
O PPPoE+ obtém o pacote PADI enviado pelo cliente PPPoE, adiciona um ou mais conteúdos de tag PPPoE no campo de informações de carga do pacote e então o envia para o servidor PPPoE por inundação. Quando o servidor receber o pacote PADI com tag, ele enviará um pacote PADO para o cliente PPPoE. Quando o cliente PPPoE receber o pacote PADO, ele enviará um pacote PADR. Neste momento, PPPoE+ obtém o pacote PADR e adiciona um ou mais conteúdos de tag PPPoE no campo de informações de carga do pacote, e então consulta a tabela FDB de acordo com o endereço de destino no pacote e encaminha para o servidor PPPoE. Quando o servidor PPPoE receber o pacote com tag, ele irá gerar aleatoriamente um ID de sessão, que será adicionado no campo PADS packet e enviado ao cliente PPPoE. Dessa forma, a negociação PPP e a interação do pacote PPPoE com os clientes podem ser realizadas.
Breve introdução ao TAG de identificação do fornecedor do pacote PPPoE
Para permitir que o servidor PPPoE obtenha as informações de localização física do cliente PPPoE, a etiqueta de identificação do fornecedor pode ser adicionada ao pacote de solicitação do PPPoE.
Quando o dispositivo interage com o pacote PPPoE, ele pode adicionar algumas informações do dispositivo relacionadas ao usuário ao pacote de solicitação PPPoE na forma de etiqueta de identificação do fornecedor. A opção de tag de ID do fornecedor registra as informações da interface do cliente. O ID do circuito é o ID do circuito e o ID remoto é o ID remoto
Quando o switch PPPoE + enable é ligado, após o dispositivo receber o pacote de solicitação PPPoE, ele pode fornecer o seguinte processamento de acordo com a estratégia de processamento e método de preenchimento da tag de identificação do fornecedor do pacote PPPoE configurado pelo usuário:
Tabela 19 -1 Política de processamento do pacote de solicitação PPPoE
| Pacote de solicitação PPPoE | Política de processamento | Modo de enchimento | Princípio de processamento de pacotes |
| Não contém TAG de ID de fornecedor | adicionar adicionar |
Modo de preenchimento padrão Modo de enchimento estendido |
Preencha e encaminhe de acordo com o formato padrão
Preencha e encaminhe pelo formato personalizado |
| Conter TAG de ID de fornecedor | Manter Filtro Substituir |
Não preencher
Solte o pacote Formato de preenchimento padrão Modo de enchimento estendido |
Não processe ou encaminhe o pacote PPPoE
Solte o pacote PPPoE Substitua o conteúdo original da TAG do ID do fornecedor e encaminhe pelo formato padrão Substitua o pacote TAG original do ID do fornecedor e encaminhe pelo formato personalizado |
PPPoE + Configuração básica de funções
Tabela 19 -2 PPPoE + lista de configuração de funções
| Tarefas de configuração | |
| Configurar o PPPoE + função | Habilite o PPPoE + função da porta |
| Configure a política de processamento para o PPPoE + pacote | Configure a política de processamento da porta para o PPPoE + pacote |
| Configure o política de preenchimento para o pacote PPPoE | Configure o política de preenchimento para o pacote PPPoE |
| Configure a política de preenchimento para o circuit-id | Configure a política de preenchimento para o circuit-id |
| Configure a política de preenchimento para remote-id | Configure a política de preenchimento para remote-id |
| Configure o valor do ID do fornecedor da porta | Configure o valor do ID do fornecedor da porta |
Habilitar/Desabilitar PPPoE + Função
Condição de configuração
Interface Ethernet L2 ou modo de grupo de agregação
Tabela 19 -3 Habilitar/desabilitar o PPPoE + função
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de interface Ethernet L2 | interface interface name | Habilitar/desabilitar o PPPoE + função no modo de porta |
| Insira o grupo de agregação de portas | interface link-aggregation link-aggregation-id | Habilitar/desabilitar o PPPoE + função no modo de grupo de agregação |
| Habilitar/desabilitar o PPPoE + função | pppoe relay enable/no pppoe relay enable | Por padrão, desative o PPPoE + função |
Configurar a política de processamento do PPoE + Função para o pacote PPPoE com tag vendor-id
Condição de configuração
Interface Ethernet L2 ou modo de grupo de agregação
Tabela 19 -4 Configure a política de processamento para o pacote PPPoE com tag vendor-id
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de interface Ethernet L2 | interface interface name | A configuração tem efeito no modo de porta. |
| Insira o grupo de agregação de portas | interface link-aggregation link-aggregation-id | A configuração entra em vigor no modo de grupo de agregação. |
| Configure a política de processamento para o pacote PPPoE com tag vendor-id | pppoe relay information policy {keep|drop|replace} | Por padrão, substitua as informações do pacote pela tag vendor-id e encaminhe-a |
O comando pppoe relay information policy keep é manter o pacote PPPoE com tag vendor-id no modo porta/grupo de agregação e encaminhá-lo.
O comando pppoe relay information policy drop é filtrar o pacote PPPoE com tag vendor-id no modo port/aggregation group.
O comando pppoe relay information policy replace é substituir o conteúdo da tag vendor-id do pacote PPPoE pela tag vendor-id no modo de grupo de porta/agregação e encaminhá-lo.
Configure a identificação do circuito do campo da tag de identificação do fornecedor
Condição de configuração
Interface Ethernet L2 ou modo de grupo de agregação
Tabela 19 -5 Configure o conteúdo do circuit-id do campo de tag vendor-id
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de interface Ethernet L2 | interface interface name | A configuração tem efeito no modo de porta. |
| Insira o grupo de agregação de portas | interface link-aggregation link-aggregation-id | A configuração entra em vigor no modo de grupo de agregação. |
| Configure o conteúdo do circuit-id do campo de tag vendor-id | pppoe relay information format circuit-id{LINE|default} | Por padrão, preencha Vlan -interface no pacote |
O comando pppoe relay information format circuit-id LINE é usado pelo usuário para personalizar o conteúdo do circuit-id.
O comando pppoe relay information format circuit-id default é usado para configurar a porta para preencher o circuit-id como vlan-interface.
Configurar remote-id do campo de tag vendor-id
Condição de configuração
Interface Ethernet L2 ou modo de grupo de agregação
Tabela 19 -6 Configurar remote-id do campo de tag vendor-id
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de interface Ethernet L2 | interface interface name | A configuração tem efeito no modo de porta. |
| Insira o grupo de agregação de portas | interface link-aggregation link-aggregation-id | A configuração entra em vigor no modo de grupo de agregação. |
| Configurar o conteúdo do ID remoto | pppoe relay infotmation format remote-id{LINE|default } | Por padrão, preencha o endereço MAC da porta do dispositivo no pacote |
O comando pppoe relay information format remote-id LINE é usado pelo usuário para personalizar o conteúdo do remote-id.
O comando pppoe relay information format remote-id default é usado para configurar a porta para preencher remote-id como switch-mac.
Configurar a política de preenchimento para o pacote com tag vendor-id
Condição de configuração
Interface Ethernet L2 ou modo de grupo de agregação
Tabela 19 -7 Configure a política de preenchimento para o pacote com tag vendor-id
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de interface Ethernet L2 | interface interface name | A configuração tem efeito no modo de porta. |
| Insira o grupo de agregação de portas | interface link-aggregation link-aggregation-id | A configuração entra em vigor no modo de grupo de agregação. |
| Configurar o número de subopções da tag do ID do fornecedor | pppoe relay information encapsulation {circuit-id|remote-id|both} | Por padrão, preencha o circuit-id e o remote-id. |
Configurar o valor do ID do fornecedor de preenchimento na tag do ID do fornecedor
Condição de configuração
Interface Ethernet L2 ou modo de grupo de agregação
Tabela 19 -8 Configurar o preenchimento do valor do ID do fornecedor na tag do ID do fornecedor
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de interface Ethernet L2 | interface interface name | A configuração tem efeito no modo de porta. |
| Insira o grupo de agregação de portas | interface link-aggregation link-aggregation-id | A configuração entra em vigor no modo de grupo de agregação. |
| Configurar o valor do ID do fornecedor | pppoe relay information vendor-id vendor-id | O intervalo de valores é 0-4294967295. Por padrão, o ID do fornecedor é 2011. |
09 Alta Disponibilidade
HA (Alta disponibilidade)
Visão geral
HA (High Availability) é uma plataforma de gerenciamento de alta disponibilidade no dispositivo, proporcionando a detecção regular de algumas falhas do sistema, garantindo que os serviços não sejam interrompidos.
Configuração da função HA
Monitoramento e manutenção de HA
Tabela 1 - 1 Monitoramento e manutenção de HA
| Comando | Descrição |
| show ham job | Exibir a tabela de nós de processamento de tarefas de HA do dispositivo local |
ULFD
Visão geral
Na Ethernet tradicional, geralmente usamos a fibra e outro meio físico para conectar os dispositivos. Na rede real, a conexão cruzada de fibra (Figura 2-1 ), ou uma fibra não conectada ou desconectada (Figura 2-2 ) pode resultar na comunicação unidirecional. Esse tipo de link defeituoso é chamado de link unidirecional. O link unidirecional causa uma série de problemas. Por exemplo, a falha de detecção de spanning tree resulta no erro de cálculo de topologia.
Figura 2 -1 Conexão cruzada de fibra

Figura 2 -2 Uma fibra não está conectada ou desconectada
ULFD (Detecção de Falha de Link Unidirecional) pode monitorar se a fibra ou o par trançado tem o link unidirecional. Quando o ULFD detecta o link unidirecional, ele é responsável por fechar a conexão unidirecional física e lógica, enviando as informações de alarme ao usuário e bloqueando a falha de outros protocolos.
Função ULFD
Tabela 2 - 1 lista de configuração da função ULFD
| Tarefa de configuração | |
| Configurar as funções básicas do ULFD | Ativar função ULFD global Habilite a função ULFD da interface Ethernet |
| Configurar os parâmetros ULFD |
Configure o período de envio dos pacotes de detecção ULFD
Configure a interface Ethernet desabilitada por ULFD |
Configurar funções básicas do ULFD
Condição de configuração
Antes de configurar as funções básicas do ULFD, primeiro complete a seguinte tarefa:
- Certifique-se de que a porta de detecção ULFD esteja conectada normalmente
Ativar função ULFD global
O ULFD possui dois modos de trabalho, ou seja, normal e agressivo. Para os dois modos, a base de julgamento do link unidirecional é diferente. O modo normal é frequentemente usado para verificar a unidireção causada pela conexão de cruzamento. O modo agressivo é usado para verificar a conexão unidirecional causada pela conexão ou desconexão cruzada.
Tabela 2 – 2 Ativar a função ULFD global
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar função ULFD global | ulfd { aggressive | enable } | Obrigatório Por padrão, não habilite a função ULFD global. |
Ativar função ULFD da interface Ethernet
A detecção ULFD precisa habilitar a função de detecção ULFD global e a função de detecção ULFD da interface Ethernet . Se a função ULFD não estiver habilitada globalmente, mas apenas habilitada na interface Ethernet , a função ULFD não terá efeito.
Se o modo de detecção ULFD ativado globalmente e o modo de detecção ULFD ativado pela interface Ethernet forem inconsistentes, o modo de detecção ULFD da interface Ethernet entrará em vigor primeiro.
Tabela 2 – 3 Habilite a função ULFD da interface Ethernet
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 /L3 | interface interface-name | - |
| Habilite a função ULFD da interface Ethernet | ulfd port [ aggressive ] | Obrigatório Por padrão, não habilite a função ULFD da interface Ethernet . |
Para alternar o modo de trabalho ULFD na interface Ethernet , primeiro cancele o modo de trabalho anterior e depois configure o novo modo. Ao habilitar a função ULFD na interface Ethernet , certifique-se de que a interface Ethernet vizinha também esteja configurada com a função ULFD e funcione no mesmo modo de detecção.
Configurar parâmetros ULFD
Condição de configuração
Antes de configurar os parâmetros ULFD, primeiro complete a seguinte tarefa:
- Ative a função ULFD
Configurar o período de envio do pacote de detecção ULFD
O ULFD envia periodicamente os pacotes de detecção para detectar se a rede possui o link unidirecional. Podemos modificar o período de envio dos pacotes de detecção de acordo com a realidade da rede. O período de envio dos pacotes de detecção é de 7 a 90 segundos. Por padrão, é 15s.
Tabela 2 – 4 Configure o período de envio do pacote de detecção ULFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o período de envio do pacote ULFD | ulfd message time time-value | Opcional Por padrão, o período de envio do pacote de detecção unidirecional é de 15s. |
Redefinir interface Ethernet desabilitada por ULFD
Se o ULFD detectar a unidireção e desabilitar a interface Ethernet, para reativar a função de detecção ULFD da interface Ethernet , o usuário precisa realizar a operação de reset manualmente. A operação configura a interface Ethernet para UP e reativa a detecção ULFD.
Tabela 2 – 5 Redefinir a interface Ethernet desabilitada por ULFD
| Etapa | Comando | Descrição |
| Redefina a interface Ethernet desabilitada por ULFD | ulfd reset [ interface interface-name ] | Opcional Por padrão, não execute a operação de reset automaticamente após a interface Ethernet ser desabilitada. |
Monitoramento e Manutenção ULFD
Tabela 2 - 6 Monitoramento e manutenção do ULFD
| Comando | Descrição |
| show ulfd [ all | interface interface-name [ detail ] ] | Exibir as informações de configuração global do ULFD e todas as informações de configuração do ULFD da interface Ethernet /especificada |
Monitoramento e Manutenção ULFD
Tabela 2 - 6 Monitoramento e manutenção do ULFD
| Comando | Descrição |
| show ulfd [ all | interface interface-name [ detail ] ] | Exibir as informações de configuração global do ULFD e todas as informações de configuração do ULFD da interface Ethernet /especificada |
Configurar a função básica ULFD
Requisitos de rede
- Device1 e Device2 são conectados através da fibra.
- Configure o modo agressivo ULFD para desabilitar a porta ao detectar o link unidirecional.
Topologia de rede

Figura 2 -3 Rede de configuração da função básica ULFD
Etapas de configuração
- Passo 1:Configurar a função ULFD
#Habilite a função ULFD no Device1 e configure o modo de trabalho ULFD como modo agressivo na porta gigabitethernet0/1.
Device1#configure terminalDevice1(config)#ulfd aggressiveDevice1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#ulfd port aggressiveDevice1(config-if-gigabitethernet0/1)#exit
#Habilite a função ULFD no Device2 e configure o modo de trabalho ULFD na porta gigabitethernet0/1 como modo agressivo .
Device2#configure terminalDevice2(config)#ulfd aggressiveDevice2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#ulfd port aggressiveDevice2(config-if-gigabitethernet0/1)#exit
#Visualize as informações ULFD da porta gigabitethernet0/1 no Device1.
Device1#show ulfd interface gigabitethernet 0/1Interface name : gigabitethernet0/1ULFD config mode : AggressiveULFD running mode : AggressiveLink status : Link UpLink direction : BidirectionalULFD fsm status : AdvertisementNeighbors number : 1----------Device ID : 00017a787878Interface name : gigabitethernet0/1Device Name : Device2Message Interval : 15Timeout Interval : 5Link Direction : BidirectionalAging Time : 40Time to Die : 36-------------------------------------
O método de visualização das informações da porta ULFD no Device2 é o mesmo do Device1. (Omitido)
- Passo 2:Confira o resultado.
#No ambiente de rede real (consulte a Figura 2-1 e Figura 2-2), quando as fibras estão conectadas de forma cruzada ou uma fibra não está conectada, desconectada, isso resulta na comunicação unidirecional. Após configurar a função ULFD, a porta gigabitethernet0/1 é desabilitada ao detectar a conexão unidirecional no Device1 e as seguintes informações de log são emitidas:
%ULFD_LOG_WARN: gigabitethernet0/1: detected Unidirectional neighbor: device ID[00017a787878], device name[Device2], interface name[gigabitethernet0/1]!%LINK-INTERFACE_DOWN-3: interface gigabitethernet0/1, changed state to down%ULFD-UNDIR_LINK_ERR_V3-4: ULFD shutdown interface gigabitethernet0/1 successful
#Visualize o status da porta gigabitethernet0/1 e podemos ver que a porta está desabilitada.
Device1#show interface gigabitethernet 0/1gigabitethernet0/1 configuration informationDescription :Status : EnabledLink : Down (Err-disabled)Set Speed : AutoAct Speed : UnknownSet Duplex : AutoAct Duplex : UnknownSet Flow Control : OffAct Flow Control : OffMdix : NormalMtu : 1824Port mode : LANPort ability : 100M FD,1000M FDLink Delay : No DelayStorm Control : Unicast DisabledStorm Control : Broadcast DisabledStorm Control : Multicast DisabledStorm Action : NonePort Type : NniPvid : 1Set Medium : FiberAct Medium : FiberMac Address : 0000.1111.2224
Ao configurar a função ULFD, certifique-se de que o ULFD configurado nos dois lados do link funcione no mesmo modo de detecção. Quando o modo de trabalho comum ULFD é o modo normal, consulte o método de configuração. O modo normal suporta apenas a detecção de passagem única causada pela conexão cruzada da fibra.
EIPS
Visão geral
Na rede Ethernet L2, STP é adotado para confiabilidade da rede. O STP é um protocolo de proteção de anel padrão desenvolvido pelo IEEE e amplamente aplicado, mas é restrito pela capacidade real da rede e o tempo de convergência é afetado pela topologia da rede. O tempo de convergência STP está na unidade de segundo e um diâmetro de rede maior resulta em maior tempo de convergência.
Para reduzir o tempo de convergência e eliminar o impacto da capacidade da rede, surge o EIPS (Ethernet Intelligent Protection Switching). O EIPS é um protocolo de camada de enlace aplicado ao anel Ethernet e pode prevenir a tempestade de broadcast causada pelo enlace de dados. Quando um link no anel Ethernet é desconectado, um link de backup pode ser usado imediatamente para recuperar as comunicações entre os diferentes nós da rede em anel. Comparado com o STP, o EIPS é caracterizado por uma velocidade de convergência de topologia mais rápida (menor que 50s) e tempo de convergência irrelevante com o número de nós na rede em anel.
O EIPS suporta os modos sub-anel e hierárquico. No modo de sub-anel, dois anéis de interseção são divididos em um anel principal e um sub-anel. Existe uma ligação comum entre o anel principal e o subanel. No modo hierárquico, um anel principal é selecionado dos anéis de interseção. O link de baixo nível é formado pelo anel conectado ao anel principal excluindo o link comum com o anel principal. Geralmente, o modo de sub-anel divide os anéis de interseção no anel principal e no sub-anel, e o modo hierárquico divide os anéis de interseção no anel principal e no link de baixo nível. Em ambos os modos, há apenas um anel principal e vários subanéis ou vários links de baixo nível.
Conceitos Básicos
Para entender melhor os conceitos básicos apresentados nesta seção, consulte as legendas das topologias típicas do modo sub-anel e modo hierárquico.
-
Domínio EIPS
Um domínio EIPS é construído por dispositivos interconectados com o mesmo ID de domínio e a mesma VLAN de controle. Ele pode conter vários anéis EIPS. Um é o anel principal e os outros são os anéis secundários. Um domínio EIPS consiste em anel EIPS, VLAN de controle EIPS , nó principal, nó de transmissão, nó de controle de borda e nó assistente de borda.
-
Anel EIPS
Um anel EIPS é identificado por um ID inteiro, correspondendo fisicamente a uma topologia Ethernet em um anel. O anel EIPS inclui um anel principal e vários subanéis. Um sub-anel é interceptado com o anel principal por meio do nó de borda e é interceptado com os outros sub-anéis por meio do anel principal. O nível de um anel principal é 0 e o nível de um subanel é maior que 0.
- Nó EIPS
- VLAN de controle EIPS
- Porta EIPS
- Nível de topologia
- Segmento de topologia
Os comutadores no anel EIPS são chamados de nós. Cada nó possui um ID de domínio e um ID de anel exclusivos e está conectado ao anel por duas portas, uma porta primária e uma porta secundária especificada pelo usuário.
Nó mestre: inicia o polling do status do anel Ethernet e implementa as medidas quando o status da topologia da rede muda. Apenas um nó mestre está disponível em um anel.
Nó de transmissão: especifica os nós excluindo o nó mestre no anel principal do EIPS. Ele monitora o status do link conectado diretamente ao nó e relata as alterações de status ao nó mestre por meio dos pacotes do protocolo EIPS. E então, o nó mestre decide como lidar com essa situação.
Os dois nós interceptados pelo sub-anel e pelo anel principal são chamados de nós de borda (também chamados de nó de transmissão no anel principal). Os nós de borda incluem o nó de controle de borda e o nó assistente de borda, que devem ser usados em par para detectar a integridade e o status de falha do anel principal.
Uma VLAN de controle é usada para transferir os pacotes do protocolo EIPS. Todas as portas no anel EIPS devem ser configuradas com VLANs de controle. As interfaces VLAN de controle não podem ser configuradas com endereços IP. No modo de anel secundário, as portas do anel principal devem ser adicionadas à VLAN de controle do anel principal e à VLAN de controle dos anéis secundários, mas as portas do anel secundário só podem ser adicionadas à VLAN de controle do anel secundário. sub-anéis. No modo hierárquico, as VLANs de controle podem ser as mesmas no anel principal e nos links de baixo nível.
A porta EIPS é uma concepção abstrata, correspondendo a um link que forma o anel EIPS. Esse link pode ser um único link físico ou uma porta de agregação formada por vários links físicos. Cada nó EIPS possui duas portas conectadas ao anel EIPS. Devido à interseção do anel EIPS, uma porta EIPS pode pertencer a vários nós EIPS.
Porta EIPS primária e porta EIPS secundária: As portas no nó mestre e no nó de transmissão são divididas em porta primária e porta secundária. A porta principal no nó mestre envia o pacote Hello e a porta secundária recebe esse pacote. Este método é usado para garantir a integridade do anel. Se o anel estiver completo, a VLAN de dados da porta secundária será bloqueada. Para um nó de transmissão, uma porta primária e uma porta secundária não possuem significados especiais.
O nível de topologia refere-se à divisão hierárquica dos anéis no domínio EIPS. O domínio EIPS compreende um anel ou vários anéis de interseção. Quando o domínio EIPS consiste em apenas um único anel, o anel é o anel de nível principal e é numerado como 0; quando o domínio EIPS compreende vários anéis de interseção, um anel é selecionado como o anel de nível principal e é numerado 0. O link de segmento de baixo nível refere-se ao anel conectado ao anel de nível principal excluindo o link comum que cruza com o anel principal. anel nivelado.
O link de baixo nível refere-se ao conjunto de links excluindo o link comum conectado à camada superior.
O anel de nível principal é numerado 0 (o nível mais alto). Quanto menor o nível, maior o número do nível.
Em um EIPS hierárquico, o número do segmento é usado para identificar diferentes links de baixo nível da mesma camada. Vários links de baixo nível podem existir no mesmo nível do domínio EIPS e são definidos por diferentes números de segmento. O número do segmento do anel de nível principal é 0.
Depois que o domínio EIPS é dividido por níveis e segmentos, o anel correspondente ou link de baixo nível de cada nível e segmento em todo o domínio é identificado por um número de nível único e número de segmento, que é chamado de segmento de nível. Os links de baixo nível que definem o número do nível e o número do segmento são chamados de segmento de baixo nível.
Mecanismo Operacional
- Mecanismo de sondagem
- Mecanismo de alarme de link-down
- Mecanismo de recuperação de anel
- Mecanismo de balanceamento de carga
- Mecanismo de nó em espera
O mecanismo de polling é um mecanismo que o nó mestre do anel EIPS detecta ativamente a integridade do anel.
O nó mestre envia o pacote Hello da porta primária periodicamente e os pacotes são transmitidos por todos os nós de transmissão. Se o anel estiver íntegro, a porta secundária no nó mestre receberá o pacote Hello antes do tempo limite e o nó mestre manterá a porta secundária no estado bloqueado. Se o anel estiver quebrado, a porta secundária no nó mestre não poderá receber o pacote Hello antes do tempo limite e o nó mestre desbloqueará as VLANs de dados na porta secundária e enviará o pacote COMM-FLUSH-FDB para todos os nós de transmissão para atualizar suas próprias entradas da tabela de encaminhamento.
Quando qualquer porta no nó de transmissão ou no nó de borda estiver inativa no anel EIPS, ele enviará o pacote Link-Down para o nó mestre de uma só vez. Quando o nó mestre recebe o pacote Link-Down, ele desbloqueia as VLANs de dados em sua porta secundária e envia o pacote COMM-FLUSH-FDB para todos os nós de transmissão e nós de borda para atualizar suas próprias entradas da tabela de encaminhamento. Depois que os nós atualizam suas entradas da tabela de encaminhamento, o fluxo de dados é comutado para um link normal.
Quando qualquer porta no nó de transmissão ou no nó de borda estiver Ativa novamente no anel EIPS, o nó mestre poderá descobrir a recuperação do anel após um período de tempo. A rede pode formar um anel temporário e gerar uma tempestade de broadcast para VLANs de dados.
Para evitar a geração de um anel temporário, quando o nó de espera descobre que sua porta conectada ao anel está Ativa novamente, o nó de espera bloqueia temporariamente a porta (somente os pacotes de VLANs de controle têm permissão para passar). Quando tiver certeza de que nenhum loop será causado, a porta será desbloqueada.
Vários domínios EIPS são configurados no mesmo anel Ethernet e enviam o tráfego de diferentes VLANs de dados. Ou seja, diferentes tráfegos de VLAN são encaminhados por caminhos diferentes, resultando em balanceamento de carga.
O nó de transmissão conectado diretamente à porta secundária no nó mestre é considerado um nó em espera. Quando o nó mestre opera normalmente, o nó standby funciona como um nó de transmissão; quando o nó mestre quebra, o nó em espera funciona como um nó mestre.
Topologia típica para o modo de subanel
- Topologia típica para o anel único
O EIPS Domain1 inclui um EIPS Ring1, Master, Transit1, Transit2 e Transit3, conforme mostrado na Figura 3-1.
Figura 3 -1 Topologia para o anel único
Esta topologia é caracterizada com resposta rápida e tempo de convergência curto para mudanças de topologia.
- Topologia típica para o anel de interseção
O EIPS Domain1 inclui dois anéis, Ring1 como anel principal e Ring2 como subanel. Ring1 consiste em Master, Transit1 e Transit2; Ring2 consiste em controle de borda (Transit3) , assistente de borda (Transit4) , Sub Transit1 e Sub Transit2. Tanto o controle de borda quanto o assistente de borda são nós de transmissão de Ring1 , conforme mostrado na Figura 3-2.
Figura 3 -2 Topologia para o anel de interseção
Essa topologia é aplicada principalmente ao cenário em que um sub-anel é dual homing para o uplink por meio de dois nós de borda, fornecendo backup de uplink.
Topologia típica para o modo hierárquico
- Topologia típica para o anel único
EIPS Domain1 inclui Ring1, Master, Transit1, Transit2 e Transit3. A porta primária (Primária) e a porta secundária (Escravo) são configuradas no nó mestre . EIPS Domain1 tem apenas Ring1. Este único anel é definido como o anel de nível principal com nível numerado 0 e segmento numerado 0. Quando o anel de nível principal não está com defeito, as VLANs de dados na porta Slave são bloqueadas. , conforme mostrado na Figura 3-3.
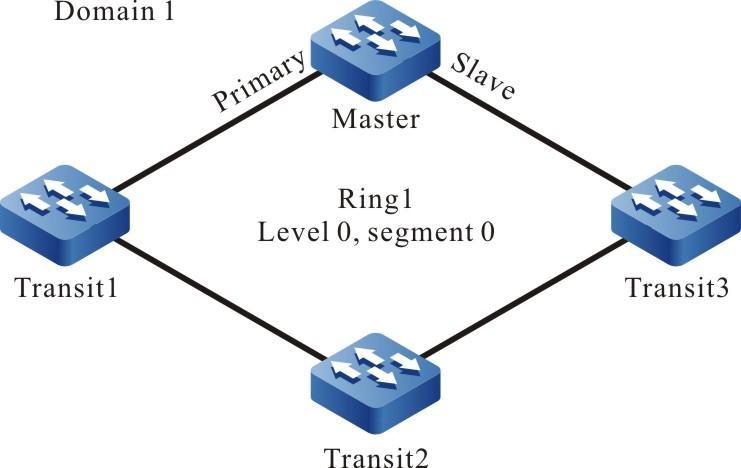
Figura 3 -3 Topologia para o anel único no modo hierárquico
- Topologia típica para o anel de interseção
Domain1 é dividido em uma estrutura hierárquica com um anel de nível principal e um segmento de baixo nível. O Anel1 é definido com o nível numerado 0 e o segmento numerado 0. O anel cruzado com o Anel1 exclui as partes comuns causadas pela interseção Trânsito2 e Trânsito3 e forma um segmento de baixo nível com o nível numerado 1 e o segmento numerado 1. O anel de nível principal (Nível 0 e segmento 0) inclui Master, Transit1, Transit2, Transit3 e Transit4. O anel de nível principal é um único anel.
O segmento de baixo nível (Nível 1 e segmento 1) inclui Controle de borda (Trânsito2) e Assistente de borda (Trânsito3) , Trânsito5 e Trânsito6.
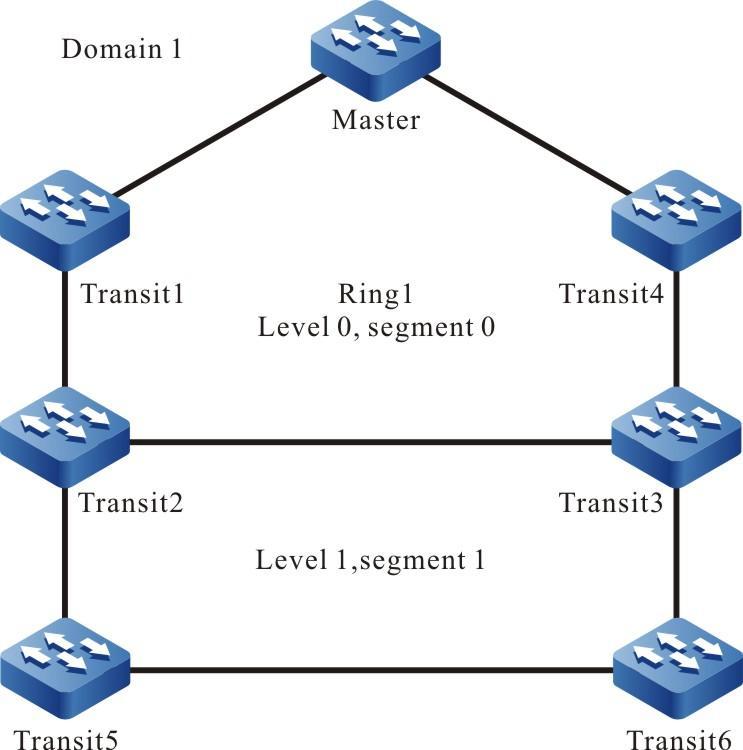
Figura 3 -4 Topologia para o anel de interseção no modo hierárquico
Configuração da função EIPS
Tabela 3 – 1 Lista de configuração das funções EIPS
| Tarefa de configuração | |
| Configurar anel EIPS |
Configure o nó mestre EIPS.
Configure o nó de transmissão EIPS. Configure o nó de controle de borda EIPS. Configure o nó do assistente de borda EIPS. Configure o domínio EIPS. Configure a VLAN de controle EIPS. Configure o número do nível EIPS. Configure o número do segmento EIPS. Configure a instância de dados EIPS. |
| Configurar a confiabilidade do EIPS | Configure o nó de espera EIPS. Configure a detecção unidirecional de EIPS. |
| Configurar temporizador EIPS | Configure o temporizador EIPS. |
O EIPS suporta o modo de sub-anel e o modo hierárquico. O modo hierárquico é recomendado. A configuração no modo hierárquico difere ligeiramente da configuração no modo sub-anel. O segmento de parâmetro e o número do segmento EIPS são obrigatórios para a criação de nós EIPS no modo hierárquico.
Antes de configurar o anel EIPS, configure as portas nos nós que serão conectados ao anel EIPS e os nós no anel.
Antes de configurar o anel EIPS, primeiro conclua as seguintes tarefas: Execute as seguintes configurações no dispositivo que será configurado como o nó mestre. Tabela 3 – 2 Configurar o nó mestre EIPS
No modo de anel secundário, todas as portas do anel principal devem ser adicionadas à VLAN de controle do anel secundário.
Execute as seguintes configurações no dispositivo que será configurado como nó de transmissão. Tabela 3 – 3 Configurar o nó de transmissão EIPS
Execute as seguintes configurações no dispositivo que será configurado como o nó de controle de borda.
Tabela 3 – 4 Configurar o nó de controle de borda EIPS
Execute as seguintes configurações no dispositivo que será configurado como o nó do assistente de borda.
Tabela 3 – 5 Configurar o nó do assistente de borda EIPS
O domínio EIPS especifica o domínio ao qual pertence o anel EIPS ou o segmento de nível. Todos os nós no mesmo domínio EIPS devem ser configurados com o mesmo ID de domínio.
Tabela 3 – 6 Configurar domínio EIPS
Configure a VLAN de controle para um anel EIPS ou o segmento de nível antes de iniciar o protocolo EIPS. Todos os nós no mesmo anel EIPS devem ser configurados com a mesma VLAN de controle. Portanto, ao configurar a VLAN de controle, escolha a VLAN que foi criada, mas não utilizada por outros protocolos L2. Caso contrário, a configuração falha.
A VLAN de controle EIPS transfere pacotes de protocolo EIPS em vez de pacotes de dados. Tabela 3 – 7 Configurar VLAN de controle EIPS
O número do nível EIPS é um símbolo importante para distinguir o anel principal do subanel ou segmento de baixo nível. O número do nível de todos os anéis principais é 0 e o número do nível do subanel de nível 1 ou do segmento de nível de nível 1 é 1. O resto pode ser feito da mesma maneira. Todos os nós nos subanéis devem ser configurados e o número do subanel do mesmo nível ou o número do nível do mesmo segmento de nível deve ser o mesmo.
Tabela 3 – 8 Configurar o número do nível EIPS
O número do segmento EIPS é um símbolo importante no modo hierárquico. O número do segmento do anel principal é 0 e o número do segmento no segmento de baixo nível é definido pelo usuário. O número do segmento deve ser configurado para o segmento de nível com número de nível maior que 0. Enquanto isso, o número do segmento para os nós no mesmo segmento de nível deve ser o mesmo.
Tabela 3 – 9 Configurar o número do segmento EIPS
A instância de dados deve ser configurada antes de configurar o anel EIPS ou o segmento de nível. As VLANs de dados que podem passar na porta EIPS devem estar contidas na instância de dados EIPS. A mesma instância de dados deve ser configurada em todos os nós no mesmo domínio EIPS.
A instância de dados é configurada usando o MSTP (Multiple Spanning Tree Protocol Instance). Portanto, antes de configurar o anel EIPS ou o segmento de nível, configure a instância MSTP e a relação de mapeamento entre o MSTP e a VLAN contida no MATP.
Tabela 3 – 10 Configurar a instância de dados EIPS
Quando as configurações anteriores forem concluídas, execute os comandos a seguir para iniciar o protocolo EIPS.
Tabela 3 – 11 Inicie o protocolo no nó EIPS
Configurar anel EIPS
Condições de configuração
Configurar o nó mestre EIPS
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Crie o nó mestre EIPS
eips ring ring-id master [ segment ]
Obrigatório Por padrão, o nó mestre EIPS não está configurado. Recomenda-se que o parâmetro segment seja utilizado para especificar o anel EIPS no modo hierárquico. Caso contrário, o anel EIPS está no modo de subanel.
Configure a porta primária no nó mestre
primary interface interface-name
Obrigatório Por padrão, a porta primária no nó mestre não está configurada.
Configurar a porta secundária do nó mestre
secondary interface interface-name
Obrigatório Por padrão, a porta secundária no nó mestre não está configurada.
Configurar a instância de dados para o nó mestre
instance instance-id
Obrigatório Por padrão, a instância de dados do nó mestre não está configurada. As VLANs de dados que podem passar na porta EIPS devem estar contidas na instância de dados EIPS. A mesma instância de dados deve ser configurada em todos os nós no mesmo domínio EIPS.
Configurar nó de transmissão EIPS
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Crie o nó de transmissão EIPS
eips ring ring-id transit [ segment ]
Obrigatório Por padrão, o nó de transmissão EIPS não está configurado. Recomenda-se que o segmento parâmetro ser usado para especificar o anel EIPS no modo hierárquico. Caso contrário, o anel EIPS está no modo de subanel.
Configure a porta primária no nó de transmissão
primary interface interface-name
Obrigatório Por padrão, a porta primária no nó de transmissão não está configurada.
Configure a porta secundária no nó de transmissão
secondary interface interface-name
Obrigatório Por padrão, a porta secundária no nó de transmissão não está configurada.
Configure a instância de dados para o nó de transmissão
instance instance-id
Obrigatório Por padrão, a instância de dados para o nó de transmissão não está configurada. As VLANs de dados que podem passar na porta EIPS devem estar contidas na instância de dados EIPS. A mesma instância de dados deve ser configurada em todos os nós no mesmo domínio EIPS.
Configurar o nó de controle de borda EIPS
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Configurar o nó de controle de borda
eips ring ring-id edge [ segment ]
Obrigatório Por padrão, o nó de controle de borda não está configurado. Recomenda-se que o parâmetro segment seja utilizado para especificar o anel EIPS no modo hierárquico. Caso contrário, o anel EIPS está no modo de subanel.
Associar o nó de controle de borda ao nó de transmissão
transit ring ring-id
Obrigatório Por padrão, o nó de controle de borda não está associado ao nó de transmissão. Somente quando o nó de controle de borda está associado ao nó de transmissão, o segmento de baixo nível ou sub-anel pode coordenar com o anel principal.
Configure a porta de borda no nó de controle de borda
edge interface interface-name
Obrigatório Por padrão, a porta de borda para o nó de controle de borda não é especificada. A porta de borda conecta um segmento de baixo nível ou subanel ao anel principal.
Controlar a instância de dados para o nó de controle de borda
instance instance-id
Obrigatório Por padrão, a instância de dados para o nó de controle de borda não está configurada. As VLANs de dados que podem passar na porta EIPS devem estar contidas na instância de dados EIPS. A mesma instância de dados deve ser configurada em todos os nós no mesmo domínio EIPS.
Configurar o nó do EIPS Edge Assistant
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Configurar nó do assistente de borda
eips ring ring-id assistant [ segment ]
Obrigatório Por padrão, o nó do assistente de borda não está configurado, Recomenda-se que o parâmetro segment seja utilizado para especificar o anel EIPS no modo hierárquico. Caso contrário, o anel EIPS está no modo de subanel.
Associe o nó assistente de borda ao nó de transmissão
transit ring ring-id
Obrigatório Por padrão, o nó assistente de borda não está associado ao nó de transmissão. Somente quando o nó assistente de borda está associado ao nó de transmissão, o segmento de baixo nível ou subanel pode coordenar com o anel principal.
Configure a porta de borda no nó do assistente de borda
edge interface interface-name
Obrigatório Por padrão, a porta de borda no nó do assistente de borda não está configurada. A porta de borda conecta um segmento de baixo nível ou subanel ao anel principal.
Configure a instância de dados para o nó do assistente de borda
instance instance-id
Obrigatório Por padrão, a instância de dados para o nó do assistente de borda não está configurada. As VLANs de dados que podem passar na porta EIPS devem estar contidas na instância de dados EIPS. A mesma instância de dados deve ser configurada em todos os nós no mesmo domínio EIPS.
Configurar domínio EIPS
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração EIPS
eips ring ring-id { master | transit | edge | assistant } [ segment ]
-
Configurar o domínio EIPS
domain id domain-id
Obrigatório Por padrão, o domínio EIPS não está configurado.
Configurar VLAN de controle EIPS
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração EIPS
eips ring ring-id { master | transit | edge | assistant } [ segment ]
-
Configurar a VLAN de controle EIPS
control vlan vlan-id
Obrigatório Por padrão, a VLAN de controle EIPS não está configurada.
Configurar o número do nível EIPS
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração EIPS
eips ring ring-id { master | transit | edge | assistant } [ segment ]
-
Configurar o número do sub-anel ou segmento de nível
level level-id
Obrigatório Por padrão, o número de nível para o subanel ou segmento de nível não está configurado.
Configurar o número do segmento EIPS
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração EIPS
eips ring ring-id { master | transit | edge | assistant } [ segment ]
-
Configurar o número do segmento EIPS
segment segment-id
Obrigatório Por padrão, o número do segmento para o segmento de nível não está configurado. Este comando é dedicado ao modo hierárquico EIPS e não está disponível para o modo subanel. O número do segmento é configurado no nó de controle de borda, nó assistente de transmissão e nó de transmissão para o segmento de baixo nível.
Configurar instância de dados EIPS
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração MSTP
spanning-tree mst configuration
-
Configurar a instância MSTP
instance instance-id vlan vlan-range
Obrigatório Por padrão, o MSTP cria a instância 0 que contém todas as VLANs. Configure a instância MSTP e mapeie o MSTP com a VLAN de dados correspondente.
Entre no modo de configuração global
exit
-
Entre no modo de configuração EIPS
eips ring ring-id { master | transit | edge | assistant } [ segment ]
-
Configurar a instância de dados EIPS
instance instance-id
Obrigatório Por padrão, a instância de dados EIPS não está configurada.
Iniciar protocolo EIPS
Etapa
Comando
Descrição
Entre no modo de configuração global
configure terminal
-
Entre no modo de configuração EIPS
eips ring ring-id { master | transit | edge | assistant } [ segment ]
-
Inicie o protocolo EIPS
eips start
Obrigatório Por padrão, o protocolo EIPS nos nós não é iniciado.
Configurar a confiabilidade do EIPS
Condição de configuração
Não
Configurar nó de espera EIPS
Para melhorar a confiabilidade do anel EIPS, o nó em espera funciona substituindo o nó mestre quando o nó mestre quebra.
O nó em espera é configurado no nó de transmissão que está conectado diretamente ao nó mestre.
Tabela 3 – 12 Configurar nó de espera EIPS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração EIPS | eips ring ring-id { master | transit | edge | assistant } [ segment ] | - |
| Configure o nó de transmissão especificado como nó de espera | backup master | Obrigatório Por padrão, o nó em espera não está configurado. |
Configurar detecção unidirecional EIPS
Habilite a função de detecção unidirecional na porta ou no grupo de portas.
Tabela 3 – 13 Configure a detecção unidirecional EIPS na porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configure a detecção unidirecional EIPS na porta | eips udld interval [ value ] | Obrigatório Por padrão, a função de detecção unidirecional na porta não está habilitada. |
Configurar temporizador EIPS
Condição de configuração
Antes de configurar o temporizador EIPS, primeiro conclua a seguinte tarefa:
- Configure as funções básicas do EIPS.
Configurar temporizador EIPS
Para os nós mestres e nós de controle de borda no modo hierárquico, um temporizador é usado para controlar a frequência de envio e o tempo limite para recebimento do pacote Hello. Para os nós de transmissão, um temporizador de bloco é usado para controlar a duração do nó de transmissão que transita do status de recuperação de falha para o status completo.
Tabela 3 – 14 Configurar temporizador EIPS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração EIPS | eips ring ring-id { master | transit | edge | assistant } [ segment ] | - |
| Configurar o temporizador para o nó EIPS | timer { hello | receive | block } timer-value | Obrigatório Por padrão, o tempo limite do timer de saudação é 1s; para o temporizador de recepção, são 5s; para o temporizador de bloqueio, é 10s. |
O temporizador para envio do pacote hello pode ser configurado apenas nos nós mestres ou nos nós de controle de borda e o temporizador de bloqueio pode ser configurado apenas nos nós de transmissão.
Se os nós em espera estiverem configurados, a duração do tempo limite para o cronômetro Hello nos nós mestres não poderá ser configurada como 0.
Monitoramento e manutenção de EIPS
Tabela 3 – 15 Monitoramento e manutenção de EIPS
| Comando | Descrição |
| clear eips { interface [ interface-name ] | link-aggregation [ link-aggregation-number ] | ring [ ring-id ] | udld } | Limpe as informações de estatísticas relacionadas ao EIPS |
| show eips { config [ ring-id ] | interface [ interface-name ] | link-aggregation [ link-aggregation-number ] | mac-control-table | ring [ ring-id ] | topology [ ring ring-id ] | topology-summary [ ring ring-id ] | udld [ interface interface-name ] } | Exiba as informações de configuração, status e estatísticas do EIPS, incluindo a porta EIPS, porta de agregação, tabela de endereços, nó, topologia e informações relacionadas ao áudio unidirecional UDLD |
Exemplo de configuração típico de EIPS
Configurar o anel único EIPS no modo hierárquico
Requisitos de rede
- Quatro dispositivos na LAN estão dentro do anel EIPS 1. Configure o modo de segmento EIPS e bloqueie a porta secundária gigabitethernet 0/2 no mestre para obter a proteção do anel.
- Quando o link entre o nó de transmissão Transit1 e Transit2 for desconectado, desbloqueie o status STP bloqueado para gigabitethernet0/2 no nó mestre para obter a alternância de dados e garantir que as comunicações na LAN não sejam afetadas.
Topologia de rede

Figura 3 -5 Rede de configuração do anel único EIPS no modo hierárquico
Etapas de configuração
- Passo 1:Configure a VLAN e o tipo de link de porta.
#Criar VLAN2 e VLAN3 no Master e configurar o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN2 e VLAN3. Configure o PVID como 1.
Master#configure terminalMaster(config)#vlan 2-3Master(config)#interface gigabitethernet 0/1-0/2Master(config-if-range)#switchport mode trunkMaster(config-if-range)#switchport trunk allowed vlan add 2-3Master(config-if-range)#switchport trunk pvid vlan 1
#Mapeie VLAN2 e VLAN3 no mestre para a instância STP 0. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2.
Master(config-if-range)#no spanning-tree enableMaster(config-if-range)#exit
#Crie VLAN2 e VLAN3 no Transit1 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2. (Omitido)
#Crie VLAN2 e VLAN3 no Transit2 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2. (Omitido)
#Crie VLAN2 e VLAN3 no Transit3 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2. (Omitido)
VLAN2 é a VLAN de controle, que é usada apenas para transferir os pacotes do protocolo EIPS. VLAN3 é a VLAN de dados, que é usada para transferir serviços. Para habilitar a função EIPS, a VLAN de controle e a VLAN de dados do EIPS devem ser mapeadas para a instância STP correspondente e a função STP na porta deve ser desabilitada.
- Passo 2:Configurar o modo hierárquico EIPS
#Cria o nó mestre do anel principal Ring1 no modo hierárquico no mestre. Configure o número do nível do anel EIPS como 0, número do segmento como 0, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
Master(config)#eips ring 1 master segmentMaster(config-eips)#control vlan 2Master(config-eips)#level 0Master(config-eips)#segment 0Master(config-eips)#instance 0Master(config-eips)#primary interface gigabitethernet 0/1Master(config-eips)#secondary interface gigabitethernet 0/2Master(config-eips)#eips startMaster(config-eips)#exit
#Cria o nó de transmissão Ring1 no modo hierárquico no Transit1. Configure o número do nível do anel EIPS como 0, número do segmento como 0, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
Transit1(config)#eips ring 1 transit segmentTransit1(config-eips)#control vlan 2Transit1(config-eips)#level 0Transit1(config-eips)#segment 0Transit1(config-eips)#instance 0Transit1(config-eips)#primary interface gigabitethernet 0/1Transit1(config-eips)#secondary interface gigabitethernet 0/2Transit1(config-eips)#eips startTransit1(config-eips)#exit
#Cria o nó de transmissão Ring1 no modo hierárquico no Transit2. Configure o número do nível do anel EIPS como 0, número do segmento como 0, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
Transit2(config)#eips ring 1 transit segmentTransit2(config-eips)#control vlan 2Transit2(config-eips)#level 0Transit2(config-eips)#segment 0Transit2(config-eips)#instance 0Transit2(config-eips)#primary interface gigabitethernet 0/1Transit2(config-eips)#secondary interface gigabitethernet 0/2Transit2(config-eips)#eips startTransit2(config-eips)#exit
#Cria o nó de transmissão Ring3 no modo hierárquico no Transit3. Configure o número do nível do anel E IPS como 0, número do segmento como 0, instância como 0, VLAN de controle como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
Transit3(config)#eips ring 1 transit segmentTransit3(config-eips)#control vlan 2Transit3(config-eips)#level 0Transit3(config-eips)#segment 0Transit3(config-eips)#instance 0Transit3(config-eips)#primary interface gigabitethernet 0/1Transit3(config-eips)#secondary interface gigabitethernet 0/2Transit3(config-eips)#eips startTransit3(config-eips)#exit
- Passo 3:Confira o resultado
#Execute o mostrar eips topologia-resumo comando nos quatro dispositivos. Podemos ver que o status do anel EIPS é redondo e as informações de topologia são consistentes.
Master#show eips topology-summaryring ID : 1topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit3 0000.0000.008b transit gi0/2 UP gi0/1 UP NO2 Transit2 0001.7a22.2224 transit gi0/2 UP gi0/1 UP YES3 Transit1 0000.0010.0017 transit gi0/2 UP gi0/1 UP YES4 Master 0001.7a54.5d71 master gi0/1 UP gi0/2 UP NOTransit3#show eips topology-summaryring ID : 1topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Master 0001.7a54.5d71 master gi0/2 UP gi0/1 UP NO2 Transit1 0000.0010.0017 transit gi0/1 UP gi0/2 UP YES3 Transit2 0001.7a22.2224 transit gi0/1 UP gi0/2 UP YES4 Transit3 0000.0000.008b transit gi0/1 UP gi0/2 UP NOTransit1#show eips topology-summaryring ID : 1topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit2 0001.7a22.2224 transit gi0/1 UP gi0/2 UP YES2 Transit3 0000.0000.008b transit gi0/1 UP gi0/2 UP NO3 Master 0001.7a54.5d71 master gi0/2 UP gi0/1 UP NO4 Transit1 0000.0010.0017 transit gi0/1 UP gi0/2 UP YESTransit2#show eips topology-summaryring ID : 1topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit3 0000.0000.008b transit gi0/1 UP gi0/2 UP NO2 Master 0001.7a54.5d71 master gi0/2 UP gi0/1 UP NO3 Transit1 0000.0010.0017 transit gi0/1 UP gi0/2 UP YES4 Transit2 0001.7a22.2224 transit gi0/1 UP gi0/2 UP YES
#Run the show eips topologia comando nos quatro dispositivos. Podemos ver que a porta secundária gigabitethernet0/2 no Master está bloqueada e outras portas estão desbloqueadas.
Master#show eips topologyring ID : 1topo status : roundtopo index 1 :host name : Transit3eips type : transiteips status : COMPLETEborder : NObase MAC : 0000.0000.008bsys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/2MAC : 0000.0000.008brole : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0000.0000.008brole : primaryblock-status : unblocklink-status : UPtopo index 2 :host name : Transit2eips type : transiteips status : COMPLETEborder : YESbase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/2MAC : 0001.7a22.2224role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0001.7a22.2224role : primaryblock-status : unblocklink-status : UPtopo index 3 :host name : Transit1eips type : transiteips status : COMPLETEborder : YESbase MAC : 0000.0010.0017sys oid : 1.3.6.1.4.1.5651.1.102.140interface1 : gi0/2MAC : 0000.0010.0017role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0000.0010.0017role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Mastereips type : mastereips status : COMPLETEborder : NObase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/1MAC : 0001.7a54.5d71role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a54.5d71role : secondblock-status : blocklink-status : UP
#Quando o link entre Transit1 e Transit2 estiver desconectado, execute o show eips comando de topologia novamente. Podemos ver que o status do anel muda para não redondo, o status do EIPS é FALHA e a porta secundária gigabitethernet0/2 no mestre muda para desbloqueio. Transit1 se comunica com Transit2 via Master, o que garante comunicações ininterruptas entre Transit1 e Transit2.
Master#show eips topologyring ID : 1topo status : not roundtopo index 1 :host name : Transit1eips type : transiteips status : FAULTborder : YESbase MAC : 0000.0010.0017sys oid : 1.3.6.1.4.1.5651.1.102.140interface1 : gi0/2MAC : 0000.0010.0017role : secondblock-status : blocklink-status : DOWNinterface2 : gi0/1MAC : 0000.0010.0017role : primaryblock-status : unblocklink-status : UPtopo index 2 :host name : Mastereips type : mastereips status : FAULTborder : NObase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/1MAC : 0001.7a54.5d71role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a54.5d71role : secondblock-status : unblocklink-status : UPtopo index 3 :host name : Transit3eips type : transiteips status : FAULTborder : NObase MAC : 0000.0000.008bsys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/2MAC : 0000.0000.008brole : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0000.0000.008brole : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit2eips type : transiteips status : FAULTborder : YESbase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/2MAC : 0001.7a22.2224role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0001.7a22.2224role : primaryblock-status : block link-status : DOWN
Configurar anéis de interseção EIPS no modo hierárquico
Requisitos de rede
- Seis dispositivos na LAN formam anéis de interseção de dois níveis. Configure o modo hierárquico EIPS para bloquear a porta secundária gigabitethernet 0/2 no mestre e a porta de borda gigabitethernet 0/3 no trânsito 1 para obter a proteção do anel.
- Quando o link entre Transit1 e Transit2 for desconectado, desbloqueie o status STP bloqueado para gigabitethernet0/2 no mestre do anel principal para obter a alternância de dados e garantir que as comunicações no anel1 não sejam afetadas.
- Quando o link entre sTransit1 e sTransit2 for desconectado, desbloqueie o status STP bloqueado para gigabitethernet 0/3 em Transit1 para obter a alternância de dados e garantir que as comunicações no Ring2 não sejam afetadas.
Topologia de rede
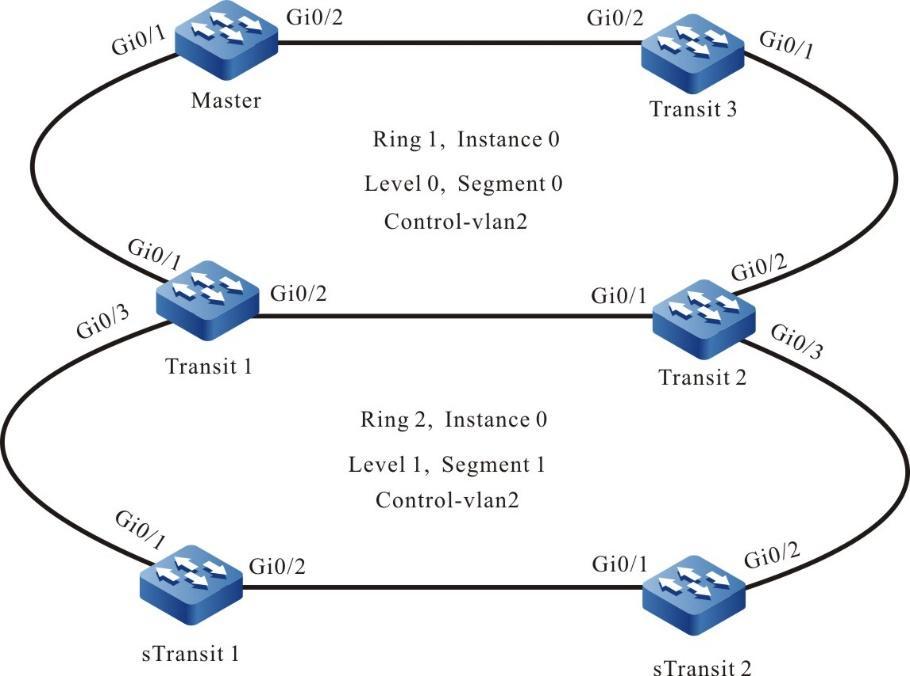
Figura 3 -6 Rede de configuração do anel de interseção EIPS no modo hierárquico
Etapas de configuração
- Passo 1: Configure a VLAN e o tipo de link de porta.
#Crie VLAN2 e VLAN3 no mestre.
Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como
Trunk, permitindo a passagem dos serviços de VLAN2 e VLAN3. Configure o PVID como 1.
Master#configure terminalMaster(config)#vlan 2-3Master(config)#interface gigabitethernet 0/1-0/2Master(config-if-range)#switchport mode trunkMaster(config-if-range)#switchport trunk allowed vlan add 2-3Master(config-if-range)#switchport trunk pvid vlan 1
Configurar anéis de interseção EIPS no modo hierárquico
Requisitos de rede
- Seis dispositivos na LAN formam anéis de interseção de dois níveis. Configure o modo hierárquico EIPS para bloquear a porta secundária gigabitethernet 0/2 no mestre e a porta de borda gigabitethernet 0/3 no trânsito 1 para obter a proteção do anel.
- Quando o link entre Transit1 e Transit2 for desconectado, desbloqueie o status STP bloqueado para gigabitethernet0/2 no mestre do anel principal para obter a alternância de dados e garantir que as comunicações no anel1 não sejam afetadas.
- Quando o link entre sTransit1 e sTransit2 for desconectado, desbloqueie o status STP bloqueado para gigabitethernet 0/3 em Transit1 para obter a alternância de dados e garantir que as comunicações no Ring2 não sejam afetadas.
Topologia de rede
Figura 3 -6 Rede de configuração do anel de interseção EIPS no modo hierárquico
Etapas de configuração
- Passo 1: Configure a VLAN e o tipo de link de porta.
#Crie VLAN2 e VLAN3 no mestre.
Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN2 e VLAN3. Configure o PVID como 1.
Master#configure terminalMaster(config)#vlan 2-3Master(config)#interface gigabitethernet 0/1-0/2Master(config-if-range)#switchport mode trunkMaster(config-if-range)#switchport trunk allowed vlan add 2-3Master(config-if-range)#switchport trunk pvid vlan 1
#Mapeie VLAN2 e VLAN3 no mestre para a instância STP 0. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2.
Master(config-if-range)#no spanning-tree enableMaster(config-if-range)#exit
#Mapeie VLAN2 e VLAN3 no mestre para a instância STP 0. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2.
Master(config-if-range)#no spanning-tree enableMaster(config-if-range)#exit
#Crie VLAN2 e VLAN3 no Transit1 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1-gigabitethernet0/3 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1-gigabitethernet0/3. (Omitido)
#Crie VLAN2 e VLAN3 no Transit2 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1-gigabitethernet0/3 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1-gigabitethernet0/3. (Omitido)
#Crie VLAN2 e VLAN3 no Transit3 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2. (Omitido)
#Crie VLAN2 e VLAN3 no sTransit1 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2. (Omitido)
#Crie VLAN2 e VLAN3 no sTransit2 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link de gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2. (Omitido)
VLAN2 é a VLAN de controle, que é usada apenas para transferir os pacotes do protocolo EIPS. VLAN3 é a VLAN de dados, que é usada para transferir serviços. Para habilitar a função EIPS, a VLAN de controle e a VLAN de dados do EIPS devem ser mapeadas para a instância STP correspondente e a função STP na porta deve ser desabilitada.
- Passo 2 :Configurar Anel1.
#Cria o nó mestre Ring1 no modo hierárquico no mestre. Configure o número do nível do anel EIPS como 0, número do segmento como 0, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
Master(config)#eips ring 1 master segmentMaster(config-eips)#control vlan 2Master(config-eips)#level 0Master(config-eips)#segment 0Master(config-eips)#instance 0Master(config-eips)#primary interface gigabitethernet 0/1Master(config-eips)#secondary interface gigabitethernet 0/2Master(config-eips)#eips startMaster(config-eips)#exit
#Crie VLAN2 e VLAN3 no Transit1 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1-gigabitethernet0/3 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1-gigabitethernet0/3. (Omitido)
#Crie VLAN2 e VLAN3 no Transit2 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1-gigabitethernet0/3 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1-gigabitethernet0/3. (Omitido)
#Crie VLAN2 e VLAN3 no Transit3 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2. (Omitido)
#Crie VLAN2 e VLAN3 no sTransit1 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2. (Omitido)
#Crie VLAN2 e VLAN3 no sTransit2 e mapeie VLAN2 e VLAN3 para a instância STP 0. Configure o tipo de link de gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2 e VLAN3 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2. (Omitido)
VLAN2 é a VLAN de controle, que é usada apenas para transferir os pacotes do protocolo EIPS. VLAN3 é a VLAN de dados, que é usada para transferir serviços. Para habilitar a função EIPS, a VLAN de controle e a VLAN de dados do EIPS devem ser mapeadas para a instância STP correspondente e a função STP na porta deve ser desabilitada.
- Passo 2 :Configurar Anel1.
#Cria o nó mestre Ring1 no modo hierárquico no mestre. Configure o número do nível do anel EIPS como 0, número do segmento como 0, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
Master(config)#eips ring 1 master segmentMaster(config-eips)#control vlan 2Master(config-eips)#level 0Master(config-eips)#segment 0Master(config-eips)#instance 0Master(config-eips)#primary interface gigabitethernet 0/1Master(config-eips)#secondary interface gigabitethernet 0/2Master(config-eips)#eips startMaster(config-eips)#exit
#Cria o nó de transmissão Ring1 no modo hierárquico no Transit1. Configure o número do nível do anel EIPS como 0, número do segmento como 0, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS. (Omitido)
# Cria o nó de transmissão Ring1 no modo hierárquico em Transit2. Configure o número do nível do anel EIPS como 0, número do segmento como 0, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS. (Omitido)
# Cria o nó de transmissão Ring1 no modo hierárquico em Transit3. Configure o número do nível do anel EIPS como 0, número do segmento como 0, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS. (Omitido)
- Passo 3: Configurar Ring2
#Cria o nó de borda Ring2 no modo hierárquico em Transit1. Configure o número do nível do anel EIPS como 1, número do segmento como 1, instância como 0, controle VLAN como VLAN2, porta de borda como gigabitethernet0/3 e Ring1 como seu nó de Transit1(config)#eips ring 2 edge segment
Transit1(config-eips)#control vlan 2Transit1(config-eips)#level 1Transit1(config-eips)#segment 1Transit1(config-eips)#instance 0Transit1(config-eips)#transit ring 1Transit1(config-eips)#edge interface gigabitethernet0/3Transit1(config-eips)#eips startTransit1(config-eips)#exit
#Cria o nó de transmissão Ring1 no modo hierárquico no Transit1. Configure o número do nível do anel EIPS como 0, número do segmento como 0, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS. (Omitido)
# Cria o nó de transmissão Ring1 no modo hierárquico em Transit2. Configure o número do nível do anel EIPS como 0, número do segmento como 0, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS. (Omitido)
# Cria o nó de transmissão Ring1 no modo hierárquico em Transit3. Configure o número do nível do anel EIPS como 0, número do segmento como 0, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS. (Omitido)
- Passo 3: Configurar Ring2
#Cria o nó de borda Ring2 no modo hierárquico em Transit1. Configure o número do nível do anel EIPS como 1, número do segmento como 1, instância como 0, controle VLAN como VLAN2, porta de borda como gigabitethernet0/3 e Ring1 como seu nó de Transit1(config)#eips ring 2 edge segment
Transit1(config-eips)#control vlan 2Transit1(config-eips)#level 1Transit1(config-eips)#segment 1Transit1(config-eips)#instance 0Transit1(config-eips)#transit ring 1Transit1(config-eips)#edge interface gigabitethernet0/3Transit1(config-eips)#eips startTransit1(config-eips)#exit
#Cria o nó de borda Ring2 no modo hierárquico em Transit2. Configure o número do nível do anel EIPS como 1, número do segmento como 1, instância como 0, controle VLAN como VLAN2, porta de borda como gigabitethernet0/3 e Ring1 como seu nó de transmissão associado. Habilite o EIPS.
Transit2(config)#eips ring 2 assistant segmentTransit2(config-eips)#control vlan 2Transit2(config-eips)#level 1Transit2(config-eips)#segment 1Transit2(config-eips)#instance 0Transit2(config-eips)#transit ring 1Transit2(config-eips)#edge interface gigabitethernet0/3Transit2(config-eips)#eips startTransit2(config-eips)#exit
#Cria o nó de borda Ring2 no modo hierárquico em Transit2. Configure o número do nível do anel EIPS como 1, número do segmento como 1, instância como 0, controle VLAN como VLAN2, porta de borda como gigabitethernet0/3 e Ring1 como seu nó de transmissão associado. Habilite o EIPS.
Transit2(config)#eips ring 2 assistant segmentTransit2(config-eips)#control vlan 2Transit2(config-eips)#level 1Transit2(config-eips)#segment 1Transit2(config-eips)#instance 0Transit2(config-eips)#transit ring 1Transit2(config-eips)#edge interface gigabitethernet0/3Transit2(config-eips)#eips startTransit2(config-eips)#exit
#Cria o nó de transmissão Ring2 no modo hierárquico em sTransit1. Configure o número do nível do anel EIPS como 1, número do segmento como 1, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta sTransit1(config)#eips ring 2 transit segment
sTransit1(config-eips)#control vlan 2sTransit1(config-eips)#level 1sTransit1(config-eips)#segment 1sTransit1(config-eips)#instance 0sTransit1(config-eips)#primary interface gigabitethernet 0/1sTransit1(config-eips)#secondary interface gigabitethernet 0/2sTransit1(config-eips)#eips startsTransit1(config-eips)#exit
#Cria o nó de transmissão Ring2 no modo hierárquico em sTransit1. Configure o número do nível do anel EIPS como 1, número do segmento como 1, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta sTransit1(config)#eips ring 2 transit segment
sTransit1(config-eips)#control vlan 2sTransit1(config-eips)#level 1sTransit1(config-eips)#segment 1sTransit1(config-eips)#instance 0sTransit1(config-eips)#primary interface gigabitethernet 0/1sTransit1(config-eips)#secondary interface gigabitethernet 0/2sTransit1(config-eips)#eips startsTransit1(config-eips)#exit
# Crie o nó de transmissão Ring2 no modo hierárquico em sTransit2. Configure o número do nível do anel EIPS como 1, número do segmento como 1, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
sTransit2(config)#eips ring 2 transit segmentsTransit2(config-eips)#control vlan 2sTransit2(config-eips)#level 1sTransit2(config-eips)#segment 1sTransit2(config-eips)#instance 0sTransit2(config-eips)#primary interface gigabitethernet 0/1sTransit2(config-eips)#secondary interface gigabitethernet 0/2sTransit2(config-eips)#eips startsTransit2(config-eips)#exit
# Crie o nó de transmissão Ring2 no modo hierárquico em sTransit2. Configure o número do nível do anel EIPS como 1, número do segmento como 1, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
sTransit2(config)#eips ring 2 transit segmentsTransit2(config-eips)#control vlan 2sTransit2(config-eips)#level 1sTransit2(config-eips)#segment 1sTransit2(config-eips)#instance 0sTransit2(config-eips)#primary interface gigabitethernet 0/1sTransit2(config-eips)#secondary interface gigabitethernet 0/2sTransit2(config-eips)#eips startsTransit2(config-eips)#exit
- Passo 4: Confira o resultado.
# Execute o mostrar eips topologia-resumo comando no nó de borda e no nó assistente. Podemos ver que o status EIPS do anel principal e dos subanéis é redondo e as informações de topologia são consistentes.
Transit1#show eips topology-summaryring ID : 1topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit2 0001.7a22.2224 transit gi0/1 UP gi0/2 UP YES2 Transit3 0000.0000.008b transit gi0/1 UP gi0/2 UP NO3 Master 0014.0000.1202 master gi0/2 UP gi0/1 UP NO4 Transit1 0001.7a54.5d71 transit gi0/1 UP gi0/2 UP YESring ID : 2topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit2 0001.7a22.2224 assistant ---- ---- gi0/3 UP NO2 sTransit2 2012.1209.1728 transit gi0/2 UP gi0/1 UP NO3 sTransit1 0000.0010.0017 transit gi0/2 UP gi0/1 UP NO4 Transit1 0001.7a54.5d71 edge gi0/3 UP ---- ---- NOTransit2#show eips topology-summaryring ID : 1topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit3 0000.0000.008b transit gi0/1 UP gi0/2 UP NO2 Master 0014.0000.1202 master gi0/2 UP gi0/1 UP NO3 Transit1 0001.7a54.5d71 transit gi0/1 UP gi0/2 UP YES4 Transit2 0001.7a22.2224 transit gi0/1 UP gi0/2 UP YESring ID : 2topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit1 0001.7a54.5d71 edge ---- ---- gi0/3 UP NO2 sTransit1 0000.0010.0017 transit gi0/1 UP gi0/2 UP NO3 sTransit2 2012.1209.1728 transit gi0/1 UP gi0/2 UP NO4 Transit2 0001.7a22.2224 assistant gi0/3 UP ---- ---- NO
- Passo 4: Confira o resultado.
# Execute o mostrar eips topologia-resumo comando no nó de borda e no nó assistente. Podemos ver que o status EIPS do anel principal e dos subanéis é redondo e as informações de topologia são consistentes.
Transit1#show eips topology-summaryring ID : 1topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit2 0001.7a22.2224 transit gi0/1 UP gi0/2 UP YES2 Transit3 0000.0000.008b transit gi0/1 UP gi0/2 UP NO3 Master 0014.0000.1202 master gi0/2 UP gi0/1 UP NO4 Transit1 0001.7a54.5d71 transit gi0/1 UP gi0/2 UP YESring ID : 2topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit2 0001.7a22.2224 assistant ---- ---- gi0/3 UP NO2 sTransit2 2012.1209.1728 transit gi0/2 UP gi0/1 UP NO3 sTransit1 0000.0010.0017 transit gi0/2 UP gi0/1 UP NO4 Transit1 0001.7a54.5d71 edge gi0/3 UP ---- ---- NOTransit2#show eips topology-summaryring ID : 1topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit3 0000.0000.008b transit gi0/1 UP gi0/2 UP NO2 Master 0014.0000.1202 master gi0/2 UP gi0/1 UP NO3 Transit1 0001.7a54.5d71 transit gi0/1 UP gi0/2 UP YES4 Transit2 0001.7a22.2224 transit gi0/1 UP gi0/2 UP YESring ID : 2topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit1 0001.7a54.5d71 edge ---- ---- gi0/3 UP NO2 sTransit1 0000.0010.0017 transit gi0/1 UP gi0/2 UP NO3 sTransit2 2012.1209.1728 transit gi0/1 UP gi0/2 UP NO4 Transit2 0001.7a22.2224 assistant gi0/3 UP ---- ---- NO
#Execute o mostrar eips topologia comando na porta de borda. Podemos ver que a porta secundária gigabitethernet0/2 no Master e a porta de borda gigabitethernet0/3 no T ransit1 estão bloqueadas e as outras portas estão desbloqueadas. O status EIPS do anel principal e dos subanéis é COMPLETO .
Transit1#show eips topologyring ID : 1topo status : roundtopo index 1 :host name : Transit2eips type : transiteips status : COMPLETEborder : YESbase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface1 : gi0/1MAC : 0001.7a22.2224role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a22.2224role : secondblock-status : unblocklink-status : UPtopo index 2 :host name : Transit3eips type : transiteips status : COMPLETEborder : NObase MAC : 0000.0000.008bsys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/1MAC : 0000.0000.008brole : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0000.0000.008brole : secondblock-status : unblocklink-status : UPtopo index 3 :host name : Mastereips type : mastereips status : COMPLETEborder : NObase MAC : 0014.0000.1202sys oid : 1.3.6.1.4.1.5651.1.102.127interface1 : gi0/2MAC : 0014.0000.1202role : secondblock-status : blocklink-status : UPinterface2 : gi0/1MAC : 0014.0000.1202role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : transiteips status : COMPLETEborder : YESbase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/1MAC : 0001.7a54.5d71role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a54.5d71role : secondblock-status : unblocklink-status : UPring ID : 2topo status : roundtopo index 1 :host name : Transit2eips type : assistanteips status : COMPLETEborder : NObase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface2 : gi0/3MAC : 0001.7a22.2224role : edgeblock-status : unblocklink-status : UPtopo index 2 :host name : sTransit2eips type : transiteips status : COMPLETEborder : NObase MAC : 2012.1209.1728sys oid : 1.3.6.1.4.1.5651.1.102.126interface1 : gi0/2MAC : 2012.1209.1728role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 2012.1209.1728role : primaryblock-status : unblocklink-status : UPtopo index 3 :host name : sTransit1eips type : transiteips status : COMPLETEborder : NObase MAC : 0000.0010.0017sys oid : 1.3.6.1.4.1.5651.1.102.140interface1 : gi0/2MAC : 0000.0010.0017role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0000.0010.0017role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : edgeeips status : COMPLETEborder : NObase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/3MAC : 0001.7a54.5d71role : edgeblock-status : blocklink-status : UP
#Execute o mostrar eips topologia comando na porta de borda. Podemos ver que a porta secundária gigabitethernet0/2 no Master e a porta de borda gigabitethernet0/3 no T ransit1 estão bloqueadas e as outras portas estão desbloqueadas. O status EIPS do anel principal e dos subanéis é COMPLETO .
Transit1#show eips topologyring ID : 1topo status : roundtopo index 1 :host name : Transit2eips type : transiteips status : COMPLETEborder : YESbase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface1 : gi0/1MAC : 0001.7a22.2224role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a22.2224role : secondblock-status : unblocklink-status : UPtopo index 2 :host name : Transit3eips type : transiteips status : COMPLETEborder : NObase MAC : 0000.0000.008bsys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/1MAC : 0000.0000.008brole : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0000.0000.008brole : secondblock-status : unblocklink-status : UPtopo index 3 :host name : Mastereips type : mastereips status : COMPLETEborder : NObase MAC : 0014.0000.1202sys oid : 1.3.6.1.4.1.5651.1.102.127interface1 : gi0/2MAC : 0014.0000.1202role : secondblock-status : blocklink-status : UPinterface2 : gi0/1MAC : 0014.0000.1202role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : transiteips status : COMPLETEborder : YESbase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/1MAC : 0001.7a54.5d71role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a54.5d71role : secondblock-status : unblocklink-status : UPring ID : 2topo status : roundtopo index 1 :host name : Transit2eips type : assistanteips status : COMPLETEborder : NObase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface2 : gi0/3MAC : 0001.7a22.2224role : edgeblock-status : unblocklink-status : UPtopo index 2 :host name : sTransit2eips type : transiteips status : COMPLETEborder : NObase MAC : 2012.1209.1728sys oid : 1.3.6.1.4.1.5651.1.102.126interface1 : gi0/2MAC : 2012.1209.1728role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 2012.1209.1728role : primaryblock-status : unblocklink-status : UPtopo index 3 :host name : sTransit1eips type : transiteips status : COMPLETEborder : NObase MAC : 0000.0010.0017sys oid : 1.3.6.1.4.1.5651.1.102.140interface1 : gi0/2MAC : 0000.0010.0017role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0000.0010.0017role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : edgeeips status : COMPLETEborder : NObase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/3MAC : 0001.7a54.5d71role : edgeblock-status : blocklink-status : UP
#Quando o link entre Transit1 e Transit2 estiver desconectado, execute o show eips topologia comando novamente. Podemos ver que o status do Ring1 muda para não redondo, o status do EIPS muda para FALHA, gigabitethernet0/2 no mestre muda para desbloqueio. Transit1 se comunica com Transit2 via Master, o que garante comunicações ininterruptas entre Transit1 e Transit2. O status do Ring2 ainda é redondo, o status do EIPS ainda é COMPLETE e gigabitethernet0/3 no Transit1 ainda está bloqueado.
Transit1#show eips topology ring 1ring ID : 1topo status : not roundtopo index 1 :host name : Transit2eips type : transiteips status : FAULTborder : YESbase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface1 : gi0/1MAC : 0001.7a22.2224role : primaryblock-status : blocklink-status : DOWNinterface2 : gi0/2MAC : 0001.7a22.2224role : secondblock-status : unblocklink-status : UPtopo index 2 :host name : Transit3eips type : transiteips status : FAULTborder : NObase MAC : 0000.0000.008bsys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/1MAC : 0000.0000.008brole : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0000.0000.008brole : secondblock-status : unblocklink-status : UPtopo index 3 :host name : Mastereips type : mastereips status : FAULTborder : NObase MAC : 0014.0000.1202sys oid : 1.3.6.1.4.1.5651.1.102.127interface1 : gi0/2MAC : 0014.0000.1202role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0014.0000.1202role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : transiteips status : FAULTborder : YESbase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/1MAC : 0001.7a54.5d71role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a54.5d71role : secondblock-status : blocklink-status : DOWNTransit1#show eips topology ring 2ring ID : 2topo status : roundtopo index 1 :host name : Transit2eips type : assistanteips status : COMPLETEborder : NObase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface2 : gi0/3MAC : 0001.7a22.2224role : edgeblock-status : unblocklink-status : UPtopo index 2 :host name : sTransit2eips type : transiteips status : COMPLETEborder : NObase MAC : 2012.1209.1728sys oid : 1.3.6.1.4.1.5651.1.102.126interface1 : gi0/2MAC : 2012.1209.1728role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 2012.1209.1728role : primaryblock-status : unblocklink-status : UPtopo index 3 :host name : sTransit1eips type : transiteips status : COMPLETEborder : NObase MAC : 0000.0010.0017sys oid : 1.3.6.1.4.1.5651.1.102.140interface1 : gi0/2MAC : 0000.0010.0017role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0000.0010.0017role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : edgeeips status : COMPLETEborder : NObase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/3MAC : 0001.7a54.5d71role : edgeblock-status : blocklink-status : UP
#Quando o link entre Transit1 e Transit2 estiver desconectado, execute o show eips topologia comando novamente. Podemos ver que o status do Ring1 muda para não redondo, o status do EIPS muda para FALHA, gigabitethernet0/2 no mestre muda para desbloqueio. Transit1 se comunica com Transit2 via Master, o que garante comunicações ininterruptas entre Transit1 e Transit2. O status do Ring2 ainda é redondo, o status do EIPS ainda é COMPLETE e gigabitethernet0/3 no Transit1 ainda está bloqueado.
Transit1#show eips topology ring 1ring ID : 1topo status : not roundtopo index 1 :host name : Transit2eips type : transiteips status : FAULTborder : YESbase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface1 : gi0/1MAC : 0001.7a22.2224role : primaryblock-status : blocklink-status : DOWNinterface2 : gi0/2MAC : 0001.7a22.2224role : secondblock-status : unblocklink-status : UPtopo index 2 :host name : Transit3eips type : transiteips status : FAULTborder : NObase MAC : 0000.0000.008bsys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/1MAC : 0000.0000.008brole : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0000.0000.008brole : secondblock-status : unblocklink-status : UPtopo index 3 :host name : Mastereips type : mastereips status : FAULTborder : NObase MAC : 0014.0000.1202sys oid : 1.3.6.1.4.1.5651.1.102.127interface1 : gi0/2MAC : 0014.0000.1202role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0014.0000.1202role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : transiteips status : FAULTborder : YESbase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/1MAC : 0001.7a54.5d71role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a54.5d71role : secondblock-status : blocklink-status : DOWNTransit1#show eips topology ring 2ring ID : 2topo status : roundtopo index 1 :host name : Transit2eips type : assistanteips status : COMPLETEborder : NObase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface2 : gi0/3MAC : 0001.7a22.2224role : edgeblock-status : unblocklink-status : UPtopo index 2 :host name : sTransit2eips type : transiteips status : COMPLETEborder : NObase MAC : 2012.1209.1728sys oid : 1.3.6.1.4.1.5651.1.102.126interface1 : gi0/2MAC : 2012.1209.1728role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 2012.1209.1728role : primaryblock-status : unblocklink-status : UPtopo index 3 :host name : sTransit1eips type : transiteips status : COMPLETEborder : NObase MAC : 0000.0010.0017sys oid : 1.3.6.1.4.1.5651.1.102.140interface1 : gi0/2MAC : 0000.0010.0017role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0000.0010.0017role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : edgeeips status : COMPLETEborder : NObase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/3MAC : 0001.7a54.5d71role : edgeblock-status : blocklink-status : UP
#Quando apenas o link entre sTransit1 e sTransit2 estiver desconectado, execute o mostrar eips comando de topologia no nó de borda e no nó assistente de borda. Podemos ver que o status do Ring2 muda para não redondo, o status do EIPS muda para FALHA, gigabitethernet0/3 no Transit1 muda para desbloqueio. sTransit1 se comunica com sTransit2 via Transit1, o que garante comunicações ininterruptas entre sTransit1 e sTransit2. O status do Ring1 ainda é redondo, o status do EIPS ainda é COMPLETE e gigabitethernet0/2 no Master ainda está bloqueado.
Transit1#show eips topology ring 2ring ID : 2topo status : not roundtopo index 1 :host name : sTransit1eips type : transiteips status : FAULTborder : NObase MAC : 0000.0010.0017sys oid : 1.3.6.1.4.1.5651.1.102.140interface1 : gi0/2MAC : 0000.0010.0017role : secondblock-status : blocklink-status : DOWNinterface2 : gi0/1MAC : 0000.0010.0017role : primaryblock-status : unblocklink-status : UPtopo index 2 :host name : Transit1eips type : edgeeips status : FAULTborder : NObase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/3MAC : 0001.7a54.5d71role : edgeblock-status : unblocklink-status : UPTransit2#show eips topology ring 2ring ID : 2topo status : not roundtopo index 1 :host name : sTransit2eips type : transiteips status : FAULTborder : NObase MAC : 2012.1209.1728sys oid : 1.3.6.1.4.1.5651.1.102.126interface1 : gi0/1MAC : 2012.1209.1728role : primaryblock-status : blocklink-status : DOWNinterface2 : gi0/2MAC : 2012.1209.1728role : secondblock-status : unblocklink-status : UPtopo index 2 :host name : Transit2eips type : assistanteips status : FAULTborder : NObase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface1 : gi0/3MAC : 0001.7a22.2224role : edgeblock-status : unblocklink-status : UPTransit1#show eips topology ring 1ring ID : 1topo status : roundtopo index 1 :host name : Transit2eips type : transiteips status : COMPLETEborder : YESbase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface1 : gi0/1MAC : 0001.7a22.2224role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a22.2224role : secondblock-status : unblocklink-status : UPtopo index 2 :host name : Transit3eips type : transiteips status : COMPLETEborder : NObase MAC : 0000.0000.008bsys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/1MAC : 0000.0000.008brole : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0000.0000.008brole : secondblock-status : unblocklink-status : UPtopo index 3 :host name : Mastereips type : mastereips status : COMPLETEborder : NObase MAC : 0014.0000.1202sys oid : 1.3.6.1.4.1.5651.1.102.127interface1 : gi0/2MAC : 0014.0000.1202role : secondblock-status : blocklink-status : UPinterface2 : gi0/1MAC : 0014.0000.1202role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : transiteips status : COMPLETEborder : YESbase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/1MAC : 0001.7a54.5d71role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a54.5d71role : secondblock-status : unblock
#Quando apenas o link entre sTransit1 e sTransit2 estiver desconectado, execute o mostrar eips comando de topologia no nó de borda e no nó assistente de borda. Podemos ver que o status do Ring2 muda para não redondo, o status do EIPS muda para FALHA, gigabitethernet0/3 no Transit1 muda para desbloqueio. sTransit1 se comunica com sTransit2 via Transit1, o que garante comunicações ininterruptas entre sTransit1 e sTransit2. O status do Ring1 ainda é redondo, o status do EIPS ainda é COMPLETE e gigabitethernet0/2 no Master ainda está bloqueado.
Transit1#show eips topology ring 2ring ID : 2topo status : not roundtopo index 1 :host name : sTransit1eips type : transiteips status : FAULTborder : NObase MAC : 0000.0010.0017sys oid : 1.3.6.1.4.1.5651.1.102.140interface1 : gi0/2MAC : 0000.0010.0017role : secondblock-status : blocklink-status : DOWNinterface2 : gi0/1MAC : 0000.0010.0017role : primaryblock-status : unblocklink-status : UPtopo index 2 :host name : Transit1eips type : edgeeips status : FAULTborder : NObase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/3MAC : 0001.7a54.5d71role : edgeblock-status : unblocklink-status : UPTransit2#show eips topology ring 2ring ID : 2topo status : not roundtopo index 1 :host name : sTransit2eips type : transiteips status : FAULTborder : NObase MAC : 2012.1209.1728sys oid : 1.3.6.1.4.1.5651.1.102.126interface1 : gi0/1MAC : 2012.1209.1728role : primaryblock-status : blocklink-status : DOWNinterface2 : gi0/2MAC : 2012.1209.1728role : secondblock-status : unblocklink-status : UPtopo index 2 :host name : Transit2eips type : assistanteips status : FAULTborder : NObase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface1 : gi0/3MAC : 0001.7a22.2224role : edgeblock-status : unblocklink-status : UPTransit1#show eips topology ring 1ring ID : 1topo status : roundtopo index 1 :host name : Transit2eips type : transiteips status : COMPLETEborder : YESbase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface1 : gi0/1MAC : 0001.7a22.2224role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a22.2224role : secondblock-status : unblocklink-status : UPtopo index 2 :host name : Transit3eips type : transiteips status : COMPLETEborder : NObase MAC : 0000.0000.008bsys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/1MAC : 0000.0000.008brole : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0000.0000.008brole : secondblock-status : unblocklink-status : UPtopo index 3 :host name : Mastereips type : mastereips status : COMPLETEborder : NObase MAC : 0014.0000.1202sys oid : 1.3.6.1.4.1.5651.1.102.127interface1 : gi0/2MAC : 0014.0000.1202role : secondblock-status : blocklink-status : UPinterface2 : gi0/1MAC : 0014.0000.1202role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : transiteips status : COMPLETEborder : YESbase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/1MAC : 0001.7a54.5d71role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a54.5d71role : secondblock-status : unblock
link-status : UP
link-status : UP
Configurar anéis de interseção EIPS no modo de subanel
Requisitos de rede
- Seis dispositivos na LAN formam anéis de interseção de dois níveis. Configure o modo de sub-anel EIPS para bloquear a porta secundária gigabitethernet 0/2 no mestre e a porta secundária gigabitethernet 0/2 no sMaster para obter a proteção do anel.
- Quando o link entre Transit1 e Transit2 for desconectado, desbloqueie o status STP bloqueado para gigabitethernet0/2 no mestre do anel principal para obter a alternância de dados e garantir que as comunicações no anel1 não sejam afetadas.
- Quando o link entre sTransit1 e sTransit2 for desconectado, desbloqueie o status STP bloqueado para gigabitethernet 0/2 no sMaster para obter a alternância de dados e garantir que as comunicações no Ring2 não sejam afetadas.
Topologia de rede
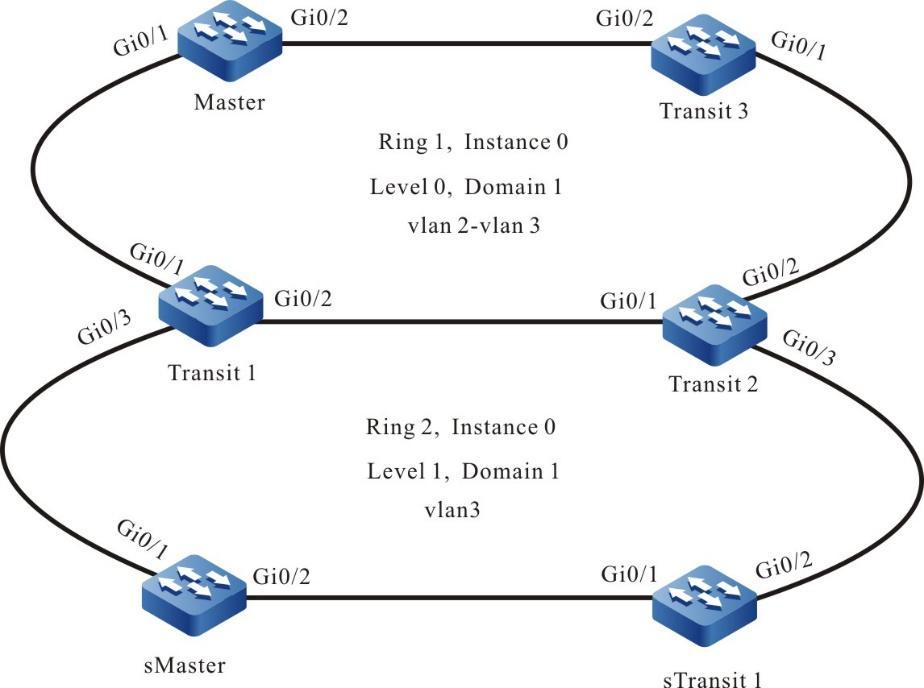
Figura 3 -7 Rede de configuração do anel de interseção EIPS no modo de sub-anel
Etapas de configuração
- Passo 1: Configure a VLAN e o tipo de link de porta.
#Cria VLAN2-VLAN4 no Mestre.
Configure o tipo de link de gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2-VLAN4 passem. Configure o PVID como 1.
Master#configure terminalMaster(config)#vlan 2-4Master(config)#interface gigabitethernet 0/1-0/2Master(config-if-range)#switchport mode trunkMaster(config-if-range)#switchport trunk allowed vlan add 2-4Master(config-if-range)#switchport trunk pvid vlan 1
#Mape VLAN2-VLAN4 no mestre para a instância STP 0. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2.
Master(config-if-range)#no spanning-tree enableMaster(config-if-range)#exit
#Crie VLAN2-VLAN4 no Transit1 e mapeie VLAN2-VLAN4 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2-VLAN4 passem. Configure o PVID como 1.
Configure o tipo de link da porta gigabitethernet0/3 como Trunk, permitindo a passagem dos serviços de VLAN3 e VLAN4. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1- gigabitethernet0/3. (Omitido)
#Crie VLAN2-VLAN4 no Transit2 e mapeie VLAN2-VLAN4 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2-VLAN4 passem. Configure o PVID como 1.
Configure o tipo de link da porta gigabitethernet0/3 como Trunk, permitindo a passagem dos serviços de VLAN3 e VLAN4. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1-gigabitethernet0/3. (Omitido)
#Crie VLAN2-VLAN4 em Transit3 e mapeie VLAN2-VLAN4 para a instância STP 0.
Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo que os serviços de VLAN2-VLAN4 passem. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2. (Omitido)
#Crie VLAN3 e VLAN4 no sMa ster e mapeie VLAN3 por meio de VLAN4 para a instância STP 0.
Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN3 e VLAN4. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2. (Omitido)
#Crie VLAN3 e VLAN4 em sTransit1 e mapeie VLAN3 e VLAN4 para a instância STP 0. Configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN3 e VLAN4. Configure o PVID como 1. Desabilite o STP nas portas gigabitethernet0/1 e gigabitethernet0/2. (Omitido)
VLAN2 é a VLAN de controle para o anel principal e VLAN3 é a VLAN de controle para o subanel, que é usada apenas para transferir os pacotes do protocolo EIPS. VLAN4 é a VLAN de dados, que é usada para transferir serviços. Para habilitar a função EIPS, a VLAN de controle e a VLAN de dados do EIPS devem ser mapeadas para a instância STP correspondente e a função STP na porta deve ser desabilitada. A VLAN de controle do sub-anel deve ser a VLAN de dados do anel principal. Ao usar o cenário de aplicação do anel principal que cruza o subanel, a instância de mapeamento EIPS só pode ser configurada como instância 0.
- Passo 2: Configurar Anel1.
#Cria o nó mestre Ring1 no modo sub ring no Master. Configure o número de nível do anel EIPS como 0, número de domínio como 0, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
Master(config)#eips ring 1 masterMaster(config-eips)#control vlan 2Master(config-eips)#level 0Master(config-eips)#domain id 1Master(config-eips)#instance 0Master(config-eips)#primary interface gigabitethernet 0/1Master(config-eips)#secondary interface gigabitethernet 0/2Master(config-eips)#eips startMaster(config-eips)#exit
#Cria o nó de transmissão Ring1 no modo sub ring em Transit1. Configure o número de nível do anel EIPS como 0, número de domínio como 1, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
Transit1(config)#eips ring 1 transitTransit1(config-eips)#instance 0Transit1(config-eips)#control vlan 2Transit1(config-eips)#domain id 1Transit1(config-eips)#level 0Transit1(config-eips)#primary interface gigabitethernet0/1Transit1(config-eips)#secondary interface gigabitethernet0/2Transit1(config-eips)#eips startTransit1(config-eips)#exit
#Cria o nó de transmissão Ring1 no modo sub ring em Transit2. Configure o número de nível do anel EIPS como 0, número de domínio como 1, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
Transit2(config-eips)#instance 0Transit2(config-eips)#domain id 1Transit2(config-eips)#control vlan 2Transit2(config-eips)#level 0Transit2(config-eips)#primary interface gigabitethernet0/1Transit2(config-eips)#secondary interface gigabitethernet0/2Transit2(config-eips)#eips startTransit2(config-eips)#exit
#Cria o nó de transmissão Ring1 no modo sub ring em Transit3. Configure o número de nível do anel EIPS como 0, número de domínio como 1, instância como 0, controle VLAN como VLAN2, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
Transit3(config)#eips ring 1 transitTransit3(config-eips)#control vlan 2Transit3(config-eips)#level 0Transit3(config-eips)#domain id 1Transit3(config-eips)#instance 0Transit3(config-eips)#primary interface gigabitethernet 0/1Transit3(config-eips)#secondary interface gigabitethernet 0/2Transit3(config-eips)#eips startTransit3(config-eips)#exit
- Passo 3: Configurar Ring2.
#Cria o nó de borda Ring2 no modo de sub-anel em Transit1. Configure o número de nível do anel EIPS como 0, número de domínio como 1, instância como 0, controle VLAN como VLAN3, porta de borda como gigabitethernet0/3 e Ring1 como seu nó de transmissão associado. Habilite o EIPS.
Transit1(config)#eips ring 2 edgeTransit1(config-eips)#control vlan 3Transit1(config-eips)#level 1Transit1(config-eips)#domain id 1Transit1(config-eips)#instance 0Transit1(config-eips)#transit ring 1Transit1(config-eips)#edge interface gigabitethernet0/3Transit1(config-eips)#eips startTransit1(config-eips)#exit
#Cria o nó de borda Ring2 no modo de sub-anel em Transit2. Configure o número de nível do anel EIPS como 1, número de domínio como 1, instância como 0, controle VLAN como VLAN3, porta de borda como gigabitethernet0/3 e Ring1 como seu nó de transmissão associado. Habilite o EIPS.
Transit2(config)#eips ring 2 assistantTransit2(config-eips)#control vlan 3Transit2(config-eips)#level 1Transit2(config-eips)#domain id 1Transit2(config-eips)#instance 0Transit2(config-eips)#transit ring 1Transit2(config-eips)#edge interface gigabitethernet0/3Transit2(config-eips)#eips startTransit2(config-eips)#exit
#Cria o nó mestre Ring2 no modo de sub-anel no sMaster. Configure o número de nível do anel EIPS como 1, número de domínio como 1, controle VLAN como VLAN3, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
sMaster(config)#eips ring 2 mastersMaster(config-eips)#level 1sMaster(config-eips)#domain id 1sMaster(config-eips)#instance 0sMaster(config-eips)#control vlan 3sMaster(config-eips)#primary interface gigabitethernet 0/1sMaster(config-eips)#secondary interface gigabitethernet 0/2sMaster(config-eips)#eips startsMaster(config-eips)#exit
# Crie o nó de transmissão Ring2 no modo de sub-anel em sTransit1. Configure o número de nível do anel EIPS como 1, número de domínio como 1, instância como 0, controle VLAN como VLAN3, porta primária como gigabitethernet0/1 e porta secundária como gigabitethernet0/2. Habilite o EIPS.
sTransit1(config)#eips ring 2 transitsTransit1(config-eips)#control vlan 3sTransit1(config-eips)#level 1sTransit1(config-eips)#domain id 1sTransit1(config-eips)#instance 0sTransit1(config-eips)#primary interface gigabitethernet 0/1sTransit1(config-eips)#secondary interface gigabitethernet 0/2sTransit1(config-eips)#eips startsTransit1(config-eips)#exit
- Passo 4: Confira o resultado.
#Execute o mostrar eips comando topology-summary no nó de borda e no nó assistente de borda. Podemos ver que o status EIPS do anel principal e dos subanéis é redondo e as informações de topologia são consistentes.
Transit1#show eips topology-summaryring ID : 1topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit2 0001.7a22.2224 transit gi0/1 UP gi0/2 UP YES2 Transit3 0000.0000.008b transit gi0/1 UP gi0/2 UP NO3 Master 0014.0000.1202 master gi0/2 UP gi0/1 UP NO4 Transit1 0001.7a54.5d71 transit gi0/1 UP gi0/2 UP YESring ID : 2topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit2 0001.7a22.2224 assistant ---- ---- gi0/3 UP NO2 sTransit1 2012.1209.1728 transit gi0/2 UP gi0/1 UP NO3 sMaster 0000.0010.0017 master gi0/2 UP gi0/1 UP NO4 Transit1 0001.7a54.5d71 edge gi0/3 UP ---- ---- NOTransit2#show eips topology-summaryring ID : 1topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit3 0000.0000.008b transit gi0/1 UP gi0/2 UP NO2 Master 0014.0000.1202 master gi0/2 UP gi0/1 UP NO3 Transit1 0001.7a54.5d71 transit gi0/1 UP gi0/2 UP YES4 Transit2 0001.7a22.2224 transit gi0/1 UP gi0/2 UP YESring ID : 2topo status : roundseq host-name mac type interface1 link interface2 link isBorder----------------------------------------------------------------------------------------------------------------1 Transit1 0001.7a54.5d71 edge ---- ---- gi0/3 UP NO2 sMaster 0000.0010.0017 master gi0/1 UP gi0/2 UP NO3 sTransit1 2012.1209.1728 transit gi0/1 UP gi0/2 UP NO4 Transit2 0001.7a22.2224 assistant gi0/3 UP ---- ---- NO
#Execute o mostrar eips comando de topologia no nó de borda. Podemos ver que gigabitethernet0/2 no Master e gigabitethernet0/2 no sMaster estão bloqueados e as outras portas estão desbloqueadas. O status EIPS de Master no anel principal e sMaster no subanel é COMPLETE e o status EIPS das outras portas é LINK-UP .
Transit1#show eips topologyring ID : 1topo status : roundtopo index 1 :host name : Transit2eips type : transiteips status : LINK-UPborder : YESbase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface1 : gi0/1MAC : 0001.7a22.2224role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a22.2224role : secondblock-status : unblocklink-status : UPtopo index 2 :host name : Transit3eips type : transiteips status : LINK-UPborder : NObase MAC : 0000.0000.008bsys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/1MAC : 0000.0000.008brole : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0000.0000.008brole : secondblock-status : unblocklink-status : UPtopo index 3 :host name : Mastereips type : mastereips status : COMPLETEborder : NObase MAC : 0014.0000.1202sys oid : 1.3.6.1.4.1.5651.1.102.127interface1 : gi0/2MAC : 0014.0000.1202role : secondblock-status : blocklink-status : UPinterface2 : gi0/1MAC : 0014.0000.1202role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : transiteips status : LINK-UPborder : YESbase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/1MAC : 0001.7a54.5d71role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a54.5d71role : secondblock-status : unblocklink-status : UPring ID : 2topo status : roundtopo index 1 :host name : Transit2eips type : assistanteips status : LINK-UPborder : NObase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface2 : gi0/3MAC : 0001.7a22.2224role : edgeblock-status : unblocklink-status : UPtopo index 2 :host name : sTransit1eips type : transiteips status : LINK-UPborder : NObase MAC : 2012.1209.1728sys oid : 1.3.6.1.4.1.5651.1.102.126interface1 : gi0/2MAC : 2012.1209.1728role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 2012.1209.1728role : primaryblock-status : unblocklink-status : UPtopo index 3 :host name : sMastereips type : mastereips status : COMPLETEborder : NObase MAC : 0000.0010.0017sys oid : 1.3.6.1.4.1.5651.1.102.140interface1 : gi0/2MAC : 0000.0010.0017role : secondblock-status : blocklink-status : UPinterface2 : gi0/1MAC : 0000.0010.0017role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : edgeeips status : LINK-UPborder : NObase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/3MAC : 0001.7a54.5d71role : edgeblock-status : unblocklink-status : UP
#Quando o link entre Transit1 e Transit2 estiver desconectado, execute o show eips topologia comando no nó de borda novamente. Podemos ver que o status de Ring1 muda para não redondo e o status EIPS de Transit1 e Transit2 muda para LINK-DOWN. O status EIPS do mestre no anel principal muda para FALHA e gigabitethernet0/2 no mestre muda para desbloqueio. Transit1 se comunica com Transit2 via Master, o que garante comunicações ininterruptas entre Transit1 e Transit2. O status de Ring2 ainda é redondo, o status de EIPS de sMaster ainda é COMPLETO e gigabitethernet0/2 de sMaster ainda está bloqueado.
Transit1#show eips topology ring 1ring ID : 1topo status : not roundtopo index 1 :host name : Transit2eips type : transiteips status : LINK-DOWNborder : YESbase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface1 : gi0/1MAC : 0001.7a22.2224role : primaryblock-status : blocklink-status : DOWNinterface2 : gi0/2MAC : 0001.7a22.2224role : secondblock-status : unblocklink-status : UPtopo index 2 :host name : Transit3eips type : transiteips status : LINK-UPborder : NObase MAC : 0000.0000.008bsys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/1MAC : 0000.0000.008brole : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0000.0000.008brole : secondblock-status : unblocklink-status : UPtopo index 3 :host name : Mastereips type : mastereips status : FAULTborder : NObase MAC : 0014.0000.1202sys oid : 1.3.6.1.4.1.5651.1.102.127interface1 : gi0/2MAC : 0014.0000.1202role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0014.0000.1202role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : transiteips status : LINK-DOWNborder : YESbase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/1MAC : 0001.7a54.5d71role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a54.5d71role : secondblock-status : blocklink-status : DOWNTransit1#show eips topology ring 2ring ID : 2topo status : roundtopo index 1 :host name : Transit2eips type : assistanteips status : LINK-UPborder : NObase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface2 : gi0/3MAC : 0001.7a22.2224role : edgeblock-status : unblocklink-status : UPtopo index 2 :host name : sTransit1eips type : transiteips status : LINK-UPborder : NObase MAC : 2012.1209.1728sys oid : 1.3.6.1.4.1.5651.1.102.126interface1 : gi0/2MAC : 2012.1209.1728role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 2012.1209.1728role : primaryblock-status : unblocklink-status : UPtopo index 3 :host name : sMastereips type : mastereips status : COMPLETEborder : NObase MAC : 0000.0010.0017sys oid : 1.3.6.1.4.1.5651.1.102.140interface1 : gi0/2MAC : 0000.0010.0017role : secondblock-status : blocklink-status : UPinterface2 : gi0/1MAC : 0000.0010.0017role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : edgeeips status : LINK-UPborder : NObase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/3MAC : 0001.7a54.5d71role : edgeblock-status : unblocklink-status : UP
#Quando apenas o link entre sTransit1 e Transit2 estiver desconectado, execute o show eips comando de topologia novamente em Transit1 e Transit2. Podemos ver que o status do Ring2 muda para não redondo, o status EIPS do sMaster muda para FALHA e gigabitethernet0/2 do sMaster muda para desbloqueio. sTransit1 se comunica com Transit2 via sMaster, o que garante comunicações ininterruptas entre sTransit1 e Transit2. O status do Ring1 ainda é redondo, o status do EIPS ainda é COMPLETE e gigabitethernet0/2 no Master ainda está bloqueado.
Transit1#show eips topology ring 2ring ID : 2topo status : not roundtopo index 1 :host name : sTransit1eips type : transiteips status : LINK-DOWNborder : NObase MAC : 2012.1209.1728sys oid : 1.3.6.1.4.1.5651.1.102.126interface1 : gi0/2MAC : 2012.1209.1728role : secondblock-status : blocklink-status : DOWNinterface2 : gi0/1MAC : 2012.1209.1728role : primaryblock-status : unblocklink-status : UPtopo index 2 :host name : sMastereips type : mastereips status : FAULTborder : NObase MAC : 0000.0010.0017sys oid : 1.3.6.1.4.1.5651.1.102.140interface1 : gi0/2MAC : 0000.0010.0017role : secondblock-status : unblocklink-status : UPinterface2 : gi0/1MAC : 0000.0010.0017role : primaryblock-status : unblocklink-status : UPtopo index 3 :host name : Transit1eips type : edgeeips status : LINK-UPborder : NObase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/3MAC : 0001.7a54.5d71role : edgeblock-status : unblocklink-status : UPTransit2#show eips topology ring 2ring ID : 2topo status : not roundtopo index 1 :host name : Transit2eips type : assistanteips status : LINK-DOWNborder : NObase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface1 : gi0/3MAC : 0001.7a22.2224role : edgeblock-status : blocklink-status : DOWNTransit1#show eips topology ring 1ring ID : 1topo status : roundtopo index 1 :host name : Transit2eips type : transiteips status : LINK-UPborder : YESbase MAC : 0001.7a22.2224sys oid : 1.3.6.1.4.1.5651.1.0.0interface1 : gi0/1MAC : 0001.7a22.2224role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a22.2224role : secondblock-status : unblocklink-status : UPtopo index 2 :host name : Transit3eips type : transiteips status : LINK-UPborder : NObase MAC : 0000.0000.008bsys oid : 1.3.6.1.4.1.5651.1.102.146interface1 : gi0/1MAC : 0000.0000.008brole : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0000.0000.008brole : secondblock-status : unblocklink-status : UPtopo index 3 :host name : Mastereips type : mastereips status : COMPLETEborder : NObase MAC : 0014.0000.1202sys oid : 1.3.6.1.4.1.5651.1.102.127interface1 : gi0/2MAC : 0014.0000.1202role : secondblock-status : blocklink-status : UPinterface2 : gi0/1MAC : 0014.0000.1202role : primaryblock-status : unblocklink-status : UPtopo index 4 :host name : Transit1eips type : transiteips status : LINK-UPborder : YESbase MAC : 0001.7a54.5d71sys oid : 1.3.6.1.4.1.5651.1.102.145interface1 : gi0/1MAC : 0001.7a54.5d71role : primaryblock-status : unblocklink-status : UPinterface2 : gi0/2MAC : 0001.7a54.5d71role : secondblock-status : unblocklink-status : UP
ULPP e Monitoramento de Link
Visão geral
O modo de rede dual-uplink é um modo de rede comum da rede principal. O modo de rede melhora a confiabilidade da rede através do link redundante. A solução comum de remover o link redundante é usar o STP, mas o tempo de convergência do STP não pode atender ao requisito Ethernet de classe de operadora. Neste caso, surge o ULPP (Up l ink Protect Protocol).
O ULPP atende ao requisito de desempenho do usuário para a convergência rápida do link e realiza o backup redundante do link ativo/standby e a comutação rápida do tráfego, mas também simplifica a configuração de forma eficiente. Isso torna a implantação e a manutenção mais convenientes e melhora a eficiência do trabalho da equipe de implantação e manutenção.
O Monitor Link fornece uma tecnologia de gerenciamento de link da mudança de status do link. As portas no grupo Monitor Link incluem uma porta de uplink e várias portas de downlink. A porta de uplink é monitorada em tempo real. Quando o status da porta de uplink mudar, defina as portas de downlink ao mesmo tempo , de modo a informar de forma síncrona o status da porta do dispositivo de uplink para o dispositivo de downlink rapidamente. Isso é útil para os módulos STP e ULPP responderem à mudança de rede e alternar o tráfego.
Configuração da função ULPP
Tabela 4 – 1 lista de configuração da função ULPP
| Tarefa de configuração | |
| Configurar as funções básicas do ULPP | Configurar o grupo ULPP Configurar a porta de uplink ULPP |
| Configure o modo compatível com ULPP | Configure o modo compatível do grupo ULPP Configure o modo compatível da porta de uplink ULPP |
| Configurar a função básica do Monitor Link | Configurar o grupo Monitor Link |
Configurar funções básicas do ULPP
Condição de configuração
Antes de configurar a função básica ULPP, primeiro complete a seguinte tarefa:
- Configure o mapeamento de instância de spanning tree do grupo ULPP
- Ao configurar a VLAN de controle do grupo ULPP, é necessário que a VLAN seja criada
- A porta membro do grupo ULPP deve ser adicionada à VLAN de controle
Configurar grupo ULPP
O grupo ULPP contém duas portas, ou seja, porta mestre e porta escrava. O grupo ULPP possui dois modos de trabalho, ou seja, backup de link e balanceamento de carga. No modo backup de link, apenas uma das portas mestre ou escrava do grupo ULPP está no estado de encaminhamento; o outro está bloqueado e no estado de espera. Quando o link de porta de encaminhamento normal falha, o grupo ULPP bloqueia automaticamente a porta e alterna a porta de espera bloqueada para o estado de encaminhamento. No mecanismo de balanceamento de carga, o grupo ULPP suporta o tráfego da instância spanning tree em diferentes VLANs de acordo com a relação de ligação da instância spanning tree e da porta configurada na porta mestre/escravo.
Tabela 4 – 2 Configurar o grupo ULPP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Crie o grupo ULPP e entre no modo de configuração ULPP | ulpp-group group-id | Obrigatório Por padrão, não crie o grupo ULPP. |
| Configure a porta mestre do ULPP | master { interface interface-name | link-aggregation link-aggregation-id } | Obrigatório Por padrão, não configure a porta master do grupo ULPP. |
| Configure a porta escrava do grupo ULPP | slave { interface interface-name | link-aggregation link-aggregation-id } | Obrigatório Por padrão, não configure a porta escrava do grupo ULPP. |
| Configure a instância do grupo ULPP | instance group instance-number { master | slave } | Obrigatório Por padrão, não configure a instância do grupo ULPP. As instâncias de spanning tree da porta mestre e da porta escrava não podem se cruzar. |
| Configure a VLAN de controle do grupo ULPP | control-vlan vlan-id | Obrigatório Por padrão, não configure a VLAN de controle do grupo ULPP. |
| Configurar habilitando o grupo ULPP | enable | Obrigatório Por padrão, não configure a habilitação do grupo ULPP |
| Habilite a função do ULPP enviando o pacote FLUSH | flush enable | Opcional Por padrão, não habilite a função do grupo ULPP enviando o pacote FLUSH |
| Configure o modo de trabalho do grupo ULPP | mode { load-balance | backup } | Opcional Por padrão, o grupo ULPP é o modo mestre/escravo (backup). |
| Configure a função de preempção de função do grupo ULPP | preemption mode role | Opcional Por padrão, não configure a preempção de função do grupo ULPP. Quando o modo de trabalho do grupo ULPP é o modo de backup de link, a função de preempção de função pode ser configurada. |
A porta membro do grupo ULPP deve desabilitar a função de detecção de EIPS, STP e loopback. A porta membro do grupo ULPP não pode ser a porta membro do grupo ULPP e do grupo Monitor Link. A VLAN de controle do grupo ULPP não pode ser usada para encaminhar os dados do serviço. Um grupo ULPP pode ter apenas uma VLAN de controle; uma VLAN de controle só pode pertencer a um grupo ULPP. Após desabilitar o grupo ULPP, todas as portas membro são bloqueadas em todas as instâncias de spanning tree.
Configurar porta de uplink ULPP
Quando a comutação de link acontece com o grupo ULPP, o grupo ULPP envia os pacotes FLUSH para informar outros dispositivos para atualizar a tabela de endereços, de modo a garantir a comutação rápida do tráfego do serviço na rede. A porta uplink não apenas recebe o pacote FLUSH, mas também encaminha o pacote FLUSH na VLAN de controle do dispositivo.
Tabela 4 – 3 Configure a VLAN de controle de porta de uplink do grupo ULPP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da porta | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente terá efeito apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | link-aggregation link-aggregation-id | |
| Configure a VLAN de controle de porta de uplink do grupo ULPP | ulpp flush control-vlan vlan-list | Obrigatório Por padrão, não configure a VLAN de controle de porta de uplink do grupo ULPP |
Configurar o modo compatível com ULPP
Condição de configuração
Antes de configurar o modo compatível com ULPP, primeiro complete as seguintes tarefas:
- Para configurar o modo compatível do grupo ULPP, precisamos configurar as funções básicas do grupo ULPP
- Para configurar o modo de configuração da porta de uplink ULPP, precisamos configurar primeiro a VLAN de controle de porta de uplink ULPP
Configurar o modo compatível com o grupo ULPP
O grupo ULPP pode ser compatível com três modos, ou seja, flexlink, smartlink e modo multicast de smartlink.
Tabela 4 – 4 Configurar o modo compatível do grupo ULPP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração ULPP | ulpp-group group-id | - |
| Configure o modo compatível com o grupo ULPP | compatible { flexlink | smartlink | smartlink multicast-mode } | Obrigatório Por padrão, não configure o modo compatível com o grupo ULPP |
Configurar o modo compatível com a porta de uplink ULPP
A porta de uplink ULPP pode ser compatível com três modos, ou seja, flexlink, smartlink e modo multicast de smartlink.
Tabela 4 – 5 Configure o modo compatível com a porta de uplink ULPP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente terá efeito apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | link-aggregation link-aggregation-id | |
| Configure o modo compatível com a porta de uplink ULPP | ulpp compatible { flexlink | smartlink | smartlink multicast-mode } | Obrigatório Por padrão, não configure o modo compatível com a porta de uplink do grupo ULPP. |
A porta de uplink do grupo ULPP pode configurar o modo compatível somente após desabilitar a árvore geradora.
Configurar funções básicas do grupo de monitoramento de links
Condição de configuração
Nenhum
Configurar grupo de monitoramento de links
Pode haver apenas uma porta de uplink do grupo Monitor Link. Pode ser porta, grupo de agregação ou grupo ULPP. Pode haver várias portas de downlink do grupo Monitor Link. Pode ser porta ou grupo de agregação, mas não pode ser grupo ULPP.
Tabela 4 – 6 Configurar o grupo Monitor Link
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Crie o grupo Monitor Link e entre no modo de configuração Monitor Link | mtlk-group group-id | Obrigatório Por padrão, não crie o grupo Monitor Link. |
| Configure a porta de uplink do grupo Monitor Link | uplink { interface interface-name | link-aggregation link-aggregation-id | ulpp-group group-id } | Opcional Por padrão, não configure a porta de uplink do grupo Monitor Link. |
| Configure a porta de downlink do grupo Monitor Link | downlink { interface interface-name | link-aggregation link-aggregation-id } | Opcional Por padrão, não configure a porta de downlink do grupo Monitor Link. |
Monitoramento e Manutenção da ULPP
Tabela 4 - 7 Monitoramento e manutenção do ULPP
| Comando | Descrição |
| clear ulpp message flush { receive | send group group-id | transmit } | Limpe as informações estatísticas dos pacotes FLUSH do grupo ULPP |
| show ulpp group group-id | Exibir as informações de configuração do grupo ULPP |
| show ulpp instance group group-id | Exibe o status da árvore de abrangência nascida pela porta do membro mestre/em espera do grupo ULPP |
| show ulpp message flush { send group group-id | receive | transmit } | Exibe as informações estatísticas dos pacotes FLUSH processados pelo grupo ULPP |
| show ulpp assi | Exiba as informações de configuração da porta de uplink do grupo ULPP |
| show mtlk group group-id | Exibir as informações de configuração do grupo Monitor Link |
Exemplo de configuração típico de ULPP e monitoramento de link
Configurar ULPP
Requisitos de rede
- Quatro dispositivos formam a rede dual-uplink. Os dispositivos de uplink são Device1, Device2 e Device3; o dispositivo de downlink é Device4.
- Configure a função ULPP no dispositivo de downlink para que a porta normalmente carregue ou comute os serviços na instância de spanning tree associada.
Topologia de rede
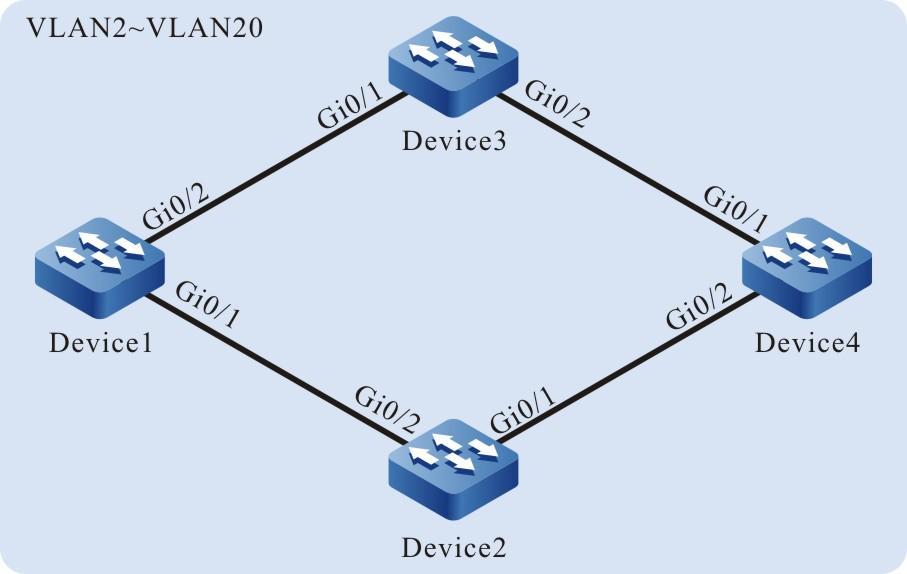
Figura 4 -1 Rede de configuração do grupo ULPP
Etapas de configuração
# Crie VLAN2-VLAN20 no Device1, configure o tipo de link da porta gigabiteternet0/1, gigabiteternet0/2 no Device1 como Trunk; permitir que os serviços de VLAN2-VLAN20 passem.
Device1#configure terminalDevice1(config)#vlan 2-20Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#switchport mode trunkDevice1(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2-20Device1(config-if-gigabitethernet0/1)#exitDevice1(config)#interface gigabitethernet 0/2Device1(config-if-gigabitethernet0/2)#switchport mode trunkDevice1(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2-20Device1(config-if-gigabitethernet0/2)#exit
A configuração da VLAN, porta e tipo de link de Device2, Device3 e Device4 é a mesma do Device1. (Omitido)
- Passo 2: Configure a instância de spanning tree no Device4.
#Configure a instância de spanning tree; instância 1 mapeia VLAN3-VLAN10; instância 2 mapeia VLAN11-VLAN20.
Device4(config)#spanning-tree mst configurationDevice4(config-mst)#region-name adminDevice4(config-mst)#revision-level 1Device4(config-mst)#instance 1 vlan 3-10Device4(config-mst)#instance 2 vlan 11-20#Enable the spanning tree instance.Device4(config-mst)#active configuration pendingDevice4(config-mst)#exit
- Passo 3: Configure a função ULPP no Device4.
#Cria o grupo ULPP.
Device4(config)#ulpp-group 1#Configure a porta master gigabitethernet0/1 e a porta slave gigabitethernet0/2 do grupo ULPP.
Device4(config-ulpp-1)#master interface gigabitethernet 0/1Device4(config-ulpp-1)#slave interface gigabitethernet 0/2
#Configure a porta master gigabitethernet0/1 para vincular com a instância 1 da spanning tree e a porta escrava gigabitethernet0/2 para vincular com a instância 2 da spanning tree.
Device4(config-ulpp-1)#instance group 1 masterDevice4(config-ulpp-1)#instance group 2 slave
#Configure o modo de trabalho do grupo ULPP como backup do link.
Device4(config-ulpp-1)#mode backup#Configure a VLAN de controle do grupo ULPP como VLAN2.
Device4(config-ulpp-1)#control-vlan 2# Habilite o mecanismo de envio do pacote ULPP Flush.
Device4(config-ulpp-1)#flush enable# Habilita o grupo ULPP.
Device4(config-ulpp-1)#enableDevice4(config-ulpp-1)#exit
Após a VLAN2 ser configurada como VLAN de controle, somente os pacotes Flush podem passar na VLAN, mas os outros pacotes de serviço não podem.
- Passo 4: Configure o dispositivo de uplink Device1, Device2 e Device3.
# Configure o mecanismo de recebimento e envio dos pacotes Flush no Device1.
Device1(config)#interface gigabitethernet 0/1-0/2Device1(config-if-range)#ulpp flush control-vlan 2Device1(config-if-range)#exit
O mecanismo de recebimento e encaminhamento de Device2 e Device3 é o mesmo do Device1. (Omitido)
- Passo 5: Confira o resultado.
#Visualize o status do grupo ULPP no Device4.
Device4#show ulpp group 1--------------------------------------ulpp-group 1 configuration information--------------------------------------Current status : MASSWork type : BackupControl vlan : 2Flush function : EnablePreemtion mode : DisableMaster interface name : gi0/1Slave interface name : gi0/2Master interface status : ActiveSlave interface status : StandbyMaster interface instance : 1Slave interface instance : 2Flexlink compatible : DisableSmartlink compatible : DisableSmartlink mcast compatible : DisableEnable status : Enable
#Visualize o status da instância de spanning tree associada da porta mestre e escrava no Device4.
Device4#show ulpp instance group 1--------------------------------------ulpp-group 1 instance status--------------------------------------Master forwarding instance : 1-2Master block instance : NoneSlave forwarding instance : NoneSlave block instance : 1-2
#Depois que a porta gigabitethernet0/1 do Device4 falhar, alterne o status do grupo ULPP. Visualize o status do grupo ULPP no Device4.
Device4#show ulpp group 1--------------------------------------ulpp-group 1 configuration information--------------------------------------Current status : MNSAWork type : BackupControl vlan : 2Flush function : EnablePreemtion mode : DisableMaster interface name : gi0/1Slave interface name : gi0/2Master interface status : DownSlave interface status : ActiveMaster interface instance : 1Slave interface instance : 2Flexlink compatible : DisableSmartlink compatible : DisableSmartlink mcast compatible : DisableEnable status : Enable
A porta master gigabitethernet0/1 muda de Active para Down; a porta slave gigabitethernet0/2 muda de Standby para Active; os serviços na instância de spanning tree são encaminhados normalmente via gigabitethernet0/2.
#O dispositivo de uplink Device1 e Device2 imprime as seguintes informações.
19:26:10: [tUlpp]%ULPP-ASSI: Receive flush message from gigabitethernet0/2 success, the receive sequence number is 1, vlan id is 2O impresso é a informação do pacote Flush recebido pelo dispositivo de uplink Device1 e Device2 quando o status do grupo ULPP muda.
Configurar Monitoramento de Link
Requisitos de rede
- Quatro dispositivos formam a rede dual-uplink. Os dispositivos de uplink são Device1, Device2 e Device3; o dispositivo de downlink é Device4.
- Configure a função Monitor Link no Device3, realizando o monitoramento da falha do link.
- Quando a porta de uplink do grupo Monitor Link falhar, desabilite a porta de downlink, causando a alternância do link mestre/escravo do grupo ULPP e garantindo a conectividade da rede.
Topologia de rede
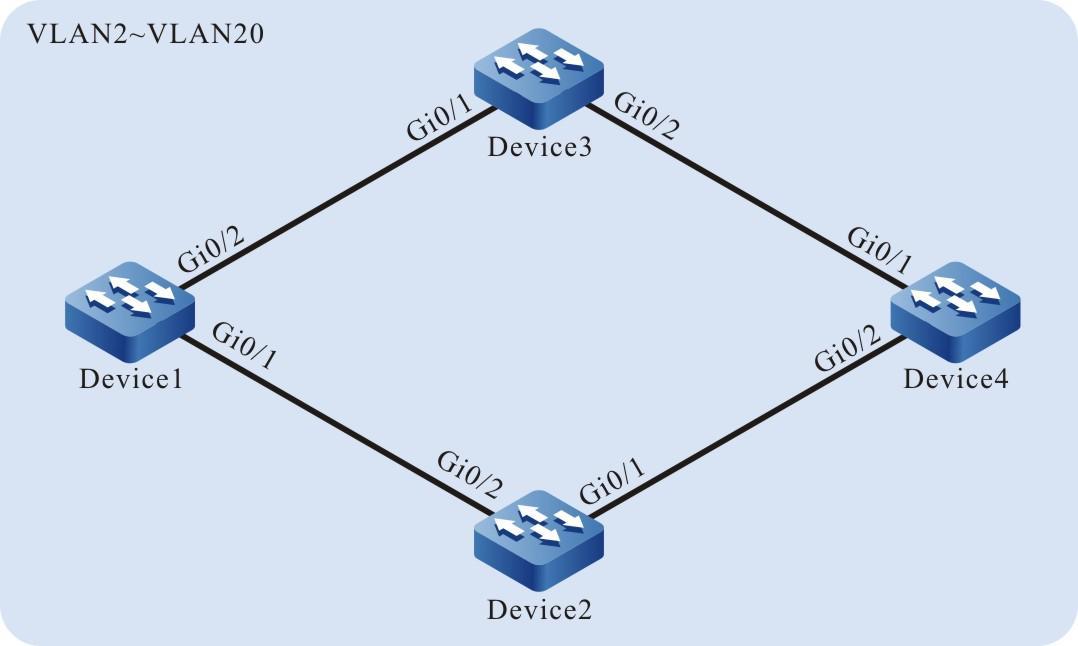
Figura 4 -2 Rede de configuração do Monitor Link
Etapas de configuração
- Passo 1: Configure o tipo de link da VLAN e da porta.
# Crie VLAN2-VLAN20 no Device1, configure o tipo de link da porta gigabiteternet0/1, gigabiteternet0/2 no Device1 como Trunk; permitir que os serviços de VLAN2-VLAN20 passem.
Device1#configure terminalDevice1(config)#vlan 2-20Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#switchport mode trunkDevice1(config-if-gigabitethernet0/1)#switchport trunk allowed vlan add 2-20Device1(config-if-gigabitethernet0/1)#exitDevice1(config)#interface gigabitethernet 0/2Device1(config-if-gigabitethernet0/2)#switchport mode trunkDevice1(config-if-gigabitethernet0/2)#switchport trunk allowed vlan add 2-20Device1(config-if-gigabitethernet0/2)#exit
A configuração da porta e do tipo de link de Device2, Device3 e Device4 é a mesma do Device1. (Omitido)
- Passo 2: Configure a instância de spanning tree no Device4.
#Configure a instância de spanning tree; instância 1 mapeia VLAN3-VLAN10; instância 2 mapeia VLAN11-VLAN20.
Device4(config)#spanning-tree mst configurationDevice4(config-mst)#region-name adminDevice4(config-mst)#revision-level 1Device4(config-mst)#instance 1 vlan 3-10Device4(config-mst)#instance 2 vlan 11-20#Enable the spanning tree instance.Device4(config-mst)#active configuration pendingDevice4(config-mst)#exit
- Passo 3: Configure a função ULPP no Device4.
Device4(config)#ulpp-group 1Device4(config-ulpp-1)#master interface gigabitethernet 0/1Device4(config-ulpp-1)#slave interface gigabitethernet 0/2Device4(config-ulpp-1)#instance group 1 masterDevice4(config-ulpp-1)#instance group 2 slaveDevice4(config-ulpp-1)#mode backupDevice4(config-ulpp-1)#control-vlan 2Device4(config-ulpp-1)#flush enableDevice4(config-ulpp-1)#enableDevice4(config-ulpp-1)#exit
Após a VLAN2 ser configurada como VLAN de controle, somente os pacotes Flush podem passar na VLAN, mas os outros pacotes de serviço não podem.
- Passo 4: Configure o dispositivo de uplink Device1, Device2 e Device3.
# Configure o mecanismo de recebimento e envio dos pacotes Flush no Device1.
Device1(config)#interface gigabitethernet 0/1-0/2Device1(config-if-range)#ulpp flush control-vlan 2Device1(config-if-range)#exit
O mecanismo de recebimento e encaminhamento de Device2 e Device3 é o mesmo do Device1. (Omitido)
- Passo 5: Configure o grupo Monitor Link.
#Crie o grupo Monitor Link no Device3.
Device3(config)#mtlk-group 1#Configure gigabitethernet0/1 como a porta de uplink do grupo Monitor Link no Device3.
Device3(config-mtlk-1)#uplink interface gigabitethernet 0/1#Configure gigabitethernet0/2 como a porta de downlink do grupo Monitor Link no Device3.
Device3(config-mtlk-1)#downlink interface gigabitethernet 0/2#Visualize o grupo Monitor Link.
Device3#show mtlk group 1--------------------------------------mtlk-group 1 configuration information--------------------------------------Uplink interface : gi0/1Uplink type : no-ulppUplink status : upDownlink interface : gi0/2
- Passo 6: Confira o resultado.
#Depois que a porta de uplink gigabitethernet0/1 do dispositivo de uplink Device3 falha, o status da porta de downlink gigabitethernet0/2 mantém a ligação com o status da porta de uplink gigabitethernet0/1. A porta de downlink é forçada a ser desabilitada.
#Exibe o status da porta de downlink gigabitethernet0/2.
Device3#show interface gigabitethernet 0/2gigabitethernet0/2 configuration informationDescription : downlinkStatus : EnabledLink : Down (Err-disabled)Set Speed : AutoAct Speed : UnknownSet Duplex : AutoAct Duplex : UnknownSet Flow Control : OffAct Flow Control : OffMdix : AutoMtu : 1824Port mode : LANPort ability : 10M HD,10M FD,100M HD,100M FD,1000M FDLink Delay : No DelayStorm Control : Unicast DisabledStorm Control : Broadcast DisabledStorm Control : Multicast DisabledStorm Action : NonePort Type : NniPvid : 1Set Medium : CopperAct Medium : CopperMac Address : 0001.7a58.000b
A porta de downlink gigabitethernet0/2 está desabilitada, causando a alternância do link mestre/escravo do grupo ULPP do Device4 e garantindo a conectividade da rede.
VRRP
Visão geral
VRRP (Virtual Router Redundancy Protocol) é um protocolo de tolerância a falhas. Ele garante que, quando o dispositivo do próximo salto do host falhar, ele possa ser substituído por outro dispositivo a tempo, de modo a garantir a continuidade e a confiabilidade da comunicação. Para fazer o VRRP funcionar, primeiro crie um endereço IP virtual e um endereço MAC. Desta forma, adicione um dispositivo virtual na rede. No entanto, quando o host na rede se comunica com o dispositivo virtual, não precisa saber de nenhuma informação do dispositivo físico na rede. Um dispositivo virtual compreende um host (mestre) e vários dispositivos escravos (backup). O dispositivo mestre realiza a função de encaminhamento real. Quando o dispositivo mestre falha, o dispositivo escravo se torna o novo dispositivo mestre e assume seu trabalho.
O dispositivo mestre mencionado no texto a seguir é substituído por “Mestre” e o dispositivo escravo é substituído por “Backup”.
Configuração da função VRRP
Tabela 5 - 1 lista de configuração da função VRRP
| Tarefa de configuração | |
| Configurar as funções básicas do VRRP |
Habilite o protocolo VRRP
Configurar a prioridade VRRP Configurar o modo de preempção de VRRP Configure o endereço MAC real do VRRP |
| Configurar o grupo de associação VRRP | Configurar o grupo de associação VRRP |
| Configurar a autenticação de rede VRRP | Configurar a autenticação de texto simples VRRP |
| Configure o VRRP para vincular com o Track |
Configure o VRRP para se conectar com o Track para monitorar a linha de uplink mestre
Configure o VRRP para vincular com o Track para monitorar a linha de interconexão Master e Backup |
Configurar funções básicas do VRRP
Nas tarefas de configuração do VRRP, primeiro habilite o protocolo VRRP e o endereço IP virtual do grupo VRRP precisa estar no mesmo segmento que o endereço IP da interface para que as outras funções configuradas possam ter efeito.
Condição de configuração
Antes de configurar as funções básicas do VRRP, primeiro complete a seguinte tarefa:
- Configurar o endereço IP da interface
Ativar protocolo VRRP
Para habilitar a função VRRP, você precisa criar o grupo VRRP e configurar o endereço IP virtual na interface.
Tabela 5 – 2 Habilite o protocolo VRRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configurar o grupo VRRP | vrrp vrid ip ip-address | Obrigatório Habilite o protocolo VRRP. VRID é o número do grupo VRRP; ip-address é o endereço IP virtual. |
Configurar prioridade de VRRP
Após configurar o VRRP e não definir a prioridade, a prioridade padrão é 100. O dispositivo com alta prioridade é eleito como Mestre para encaminhar o pacote e o outro torna-se Backup. Se as prioridades de todos os dispositivos forem iguais, escolha de acordo com o endereço IP da interface do dispositivo. Aquele com endereço IP de interface grande torna-se Mestre. Podemos definir a prioridade do VRRP conforme desejado. Quanto maior o valor , maior a prioridade .
Tabela 5 – 3 Configure a prioridade VRRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure a prioridade do grupo VRRP | vrrp vrid priority priority | Obrigatório Configure a prioridade do VRRP; a prioridade padrão é 100. |
No modo MAC virtual, quando o endereço IP da interface é igual ao endereço IP virtual, ele imediatamente se torna o estado Init e a prioridade permanece inalterada. Caso o usuário precise configurar o endereço IP virtual igual ao endereço IP da interface, é necessário alterar o modo MAC virtual para o modo MAC real.
Configurar o modo de preempção de VRRP
Após configurar o VRRP, no modo de preempção, quando outro dispositivo do grupo VRRP descobre que sua prioridade é maior que a do Mestre atual, ele se torna Mestre; no modo de não preempção, desde que o Mestre não falhe, mesmo que o outro dispositivo tenha prioridade mais alta, ele não pode se tornar Mestre.
Tabela 5 – 4 Configurar o modo de preempção de VRRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o grupo VRRP como o modo de preempção | vrrp vrid preempt | Obrigatório Por padrão, habilite o modo de preempção |
Configurar o endereço MAC real do VRRP
Um dispositivo virtual no grupo VRRP tem um endereço MAC virtual. De acordo com a RFC2338, o formato do endereço MAC virtual é 00-00-5E-00-01-{vrid}. Quando o dispositivo virtual responde à solicitação ARP, a resposta é o endereço MAC virtual, mas não o endereço MAC real da interface. Por padrão, o usado é o endereço MAC virtual da interface.
Tabela 5 – 5 Configure o endereço MAC real do VRRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o VRRP para usar o endereço MAC real | vrrp vrid use-bia | Obrigatório Por padrão, use o endereço MAC virtual. |
Por padrão, após configurar o VRRP, o usado é o endereço MAC virtual. Após configurar o comando, use o MAC real . Ou seja, quando o host envia o pacote, encaminhe pelo endereço MAC real; após excluir o comando, use o endereço MAC virtual . Ou seja, quando o host envia o pacote, use o endereço MAC virtual para encaminhar.
Configurar grupo de links VRRP
O grupo de links VRRP pode reduzir a interação dos pacotes VRRP e a carga da rede e atinge o switchover da classe ms . Adicione vários grupos VRRP comuns a um grupo de links VRRP e diferentes grupos VRRP desempenham funções diferentes no grupo de links, como ativo ou não ativo. O grupo Ativo no grupo de links é responsável por enviar o pacote , enquanto o grupo não Ativo não envia . O status do grupo não ativo mantém-se consistente com o status do grupo ativo, ou seja, comutadores de status do grupo ativo, e o status do grupo não ativo também alterna, de modo a reduzir a interação do pacote de protocolo. Além disso, o grupo de enlaces pode configurar o período de envio do pacote VRRP para ms -class , de modo a alcançar o switchover rápido.
Condição de configuração
Antes de configurar o grupo de links VRRP, primeiro conclua a seguinte tarefa:
- Configurar vários grupos VRRP
Configurar grupo de links VRRP
Para configurar o grupo de links VRRP, primeiro crie o grupo de links VRRP e, em seguida, adicione o grupo VRRP comum configurado ao grupo de links criado. O grupo VRRP comum pode ser adicionado ao grupo de links no formato de grupo ativo ou não ativo, mas um grupo de links deve ter apenas um grupo ativo.
Tabela 5 – 6 Configurar o grupo de links VRRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o grupo de links | vrrp linkgroup lgid [ interval Interval-time ] | Obrigatório Por padrão, o valor do intervalo de tempo é 1000ms |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Adicione o grupo geral VRRP ao grupo de links pelo modo ativo | vrrp vrid linkgroup lgid [ active ] | Obrigatório Se não estiver selecionando ativo, adicione pelo modo não ativo. |
Além do grupo de links, vários grupos VRRP também podem realizar o balanceamento de carga. Para obter detalhes, consulte o capítulo “Configurar o balanceamento de carga do VRRP” em “Exemplo de configuração típica do VRRP”. No grupo de enlaces, após a adição do grupo geral VRRP, o timer do grupo geral torna-se inválido, ou seja, o período de envio dos pacotes VRRP do grupo geral toma como referência o timer do grupo de enlaces.
Configurar autenticação de rede VRRP
O VRRP suporta a autenticação de texto simples. O comprimento definido da autenticação de texto não pode ser uma palavra de autenticação de 8 bits.
Condição de configuração
Antes de configurar a autenticação de rede VRRP, primeiro conclua a seguinte tarefa:
- Configurar um grupo VRRP
Configurar autenticação de texto simples VRRP
Tabela 5 – 7 Configurar a autenticação de texto simples VRRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configurar a autenticação de texto simples VRRP | vrrp vrid authentication text string | Obrigatório Por padrão, não ative a função de autenticação de texto simples. A senha de autenticação pode ter no máximo 8 caracteres. |
Configure o VRRP para vincular com a faixa
O VRRP pode monitorar o status da linha de uplink e da linha de interconexão Master, Backup para melhorar a confiabilidade do VRRP.
Condição de configuração
Antes de configurar o VRRP para vincular ao Track, primeiro conclua a seguinte tarefa:
- Configurar um grupo VRRP
Configure o VRRP para Link com Track para Monitorar a Linha de Uplink Master
No Master, configure a vinculação com Track. Ele pode associar com a interface via Track, ou associar com BFD, RTR para torná-lo referente ao status da interface uplink. Depois que a interface de uplink está inativa, o VRRP pode reduzir a prioridade do mestre por meio do decréscimo configurado. Aqui, após o recebimento do Backup, ele muda automaticamente para Master (observe que a prioridade do Master é menor que a prioridade do Backup). Se for necessário alternar o Backup rapidamente, podemos configurar o recebimento do comando de comutação rápida de baixa prioridade no Backup. Para obter detalhes, consulte a figura a seguir.
Figura 5 – 1 Configure o VRRP para fazer o link com o Track para monitorar a linha de uplink mestre
Configure o VRRP para vincular com a trilha para associar à interface de uplink
Associe o VRRP com a interface de uplink em questão via Track. Quando a interface de uplink está inativa, o Master reduz automaticamente sua própria prioridade. Aqui, o Backup recebe o pacote VRRP de baixa prioridade e alterna para Master. Se o usuário estiver configurado com “Receive low-priority packet fast switching”, ou seja, função low-pri-master, Backup fast alterna para Master.
Tabela 5 – 8 Configure o VRRP para vincular com o Track para associar à interface de uplink (configure no Master)
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o VRRP para associar à interface de uplink | vrrp vrid track interface-name [ decrement ] | Obrigatório Por padrão, o decréscimo de prioridade é 10. |
| Configure o VRRP recebendo a função de comutação rápida de pacotes de baixa prioridade | vrrp vrid switchover low-pri-master | Opcional O comando é configurado no Backup para alternar rapidamente quando a prioridade do Mestre é reduzida. |
Configure o VRRP para vincular com trilha (vinculação de trilha com BFD, RTR e assim por diante)
Se Track estiver associado a BFD, RTR e assim por diante, o Master pode associar diretamente a Track, para monitorar a linha. Quando a linha falha, o Mestre reduz sua própria prioridade. Aqui, o Backup recebe o pacote VRRP de baixa prioridade e alterna para Master. Se o usuário estiver configurado com “Receive low-priority packet fast switching”, ou seja, função low-pri-master, Backup fast alterna para Master.
Tabela 5 – 9 Configure o Master para vincular com Track (Track linking com BFD, RTR e assim por diante)
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o VRRP para associar à interface de uplink | vrrp vrid track track-id [ decrement ] | Obrigatório Por padrão, o decréscimo de prioridade é 10. |
| Configure o VRRP recebendo a função de comutação rápida de pacotes de baixa prioridade | vrrp vrid switchover low-pri-master | Opcional O comando é configurado no Backup para alternar rapidamente quando a prioridade do Mestre é reduzida. |
Para o método de configuração de criação de trilha, trilha associada a BFD ou RTR, consulte o manual de configuração de trilha. Se a função low-pri-master estiver configurada e quando o Backup receber o pacote de baixa prioridade, mesmo que seja o modo sem preempção, ele também alternará rapidamente. Se a função não estiver configurada ao receber o pacote de baixa prioridade, o Backup alterna após o próximo tempo limite. Se o requisito de tempo de comutação não for rigoroso, não é necessário configurar a função low-pri-master, mas se o requisito de tempo de comutação for rigoroso, a função pode fazer com que o tempo de comutação atinja o nível ms.
Configure o VRRP para associar com a trilha para monitorar a linha de interconexão mestre e de backup
Configure o VRRP para associar à trilha para monitorar a linha de interconexão Master e Backup. Se a linha entre Master e Backup estiver desativada, o Backup alternará rapidamente para Master. Para obter detalhes, consulte a figura a seguir.

Figura 5 – 2 Configure o VRRP para associar à trilha para monitorar a linha de interconexão Master e Backup
Tabela 5 – 10 Configure o VRRP para associar à trilha para monitorar a linha de interconexão Master e Backup
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure a função de comutação rápida quando o dispositivo VRRP de backup descobrir que a linha entre o mestre e o backup está desativada | vrrp vrid track track-id switchover | Obrigatório |
Para a configuração de Track associando BFD e RTR, consulte o Manual de Configuração de Track. Track pode se associar ao BFD para monitorar o status da linha entre Master e Backup.
Monitoramento e manutenção de VRRP
Tabela 5 - 11 Monitoramento e manutenção de VRRP
| Comando | Descrição |
| show vrrp [brief ] | [interface interface-name] | [group [linkgroup-number ]] | Exiba as informações de configuração do VRRP, incluindo informações de endereço IP virtual, informações de endereço MAC virtual, status do dispositivo, prioridade do dispositivo, endereço de interface do dispositivo dependente, informações do grupo de links e assim por diante. |
Exemplo de configuração típica de VRRP
Configurar grupo de backup único VRRP
Requisitos de rede
- Em Device1 e Device2, crie um único grupo de backup VRRP para que Device1 e Device2 compartilhem um endereço IP virtual, realizando o backup para o gateway padrão do host do usuário e reduzindo o tempo de interrupção da rede.
Topologia de rede
Figura 5 -3 Rede de configuração do grupo de backup único VRRP
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2: Configure o endereço IP da interface. (Omitido)
- Passo 3: Crie o grupo VRRP.
#No Dispositivo1, configure o grupo 1 do VRRP, o endereço IP virtual é 10.1.1.3 e configure a prioridade como 110.
Device1#configure terminalDevice1(config)#interface vlan 2Device1(config-if-vlan2)#vrrp 1 ip 10.1.1.3Device1(config-if-vlan2)#vrrp 1 priority 110Device1(config-if-vlan2)#exit
# No Device2, configure o VRRP group1 e o endereço IP virtual é 10.1.1.3.
Device2#configure terminalDevice2(config)#interface vlan 2Device2(config-if-vlan2)#vrrp 1 ip 10.1.1.3Device2(config-if-vlan2)#exit
- Passo 4: Confira o resultado.
# Visualize o status do VRRP do Device1.
Interface vlan2 (Flags 0x1)Pri-addr : 10.1.1.1Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01 , installed into HWDepend prefix:10.1.1.1/24State : MasterNormal priority : 110Currnet priority : 110Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
# Visualize o status do VRRP do Device2.
Device2#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 10.1.1.2Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01Depend prefix:10.1.1.2/24State : BackupMaster addr : 10.1.1.1Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
Podemos ver que o status do VRRP do Device1 é Master e o status do VRRP do Device2 é Cópia de segurança. Device1 e Device2 compartilham um endereço IP virtual. O host se comunica com a rede através do endereço. Quando Device1 falha, Device2 muda para Master imediatamente para encaminhar dados.
O princípio de eleição do status VRRP é por prioridade. Aquele com grande prioridade é o Mestre. Se as prioridades forem as mesmas, compare de acordo com o endereço IP da interface. Aquele com endereço IP grande é o Master. Por padrão, o VRRP funciona no modo de preempção. A prioridade padrão é 100.
Configurar grupo de links VRRP
Requisitos de rede
- Na interface Device1 e Device2, habilite o VRRP e adicione ao grupo de links. Somente o grupo ativo no grupo de links interage com os pacotes de protocolo.
- O status do VRRP do não ativo mantém-se consistente com o status do VRRP do grupo ativo. Quando o status do grupo ativo muda, o grupo não ativo também muda.
Topologia de rede
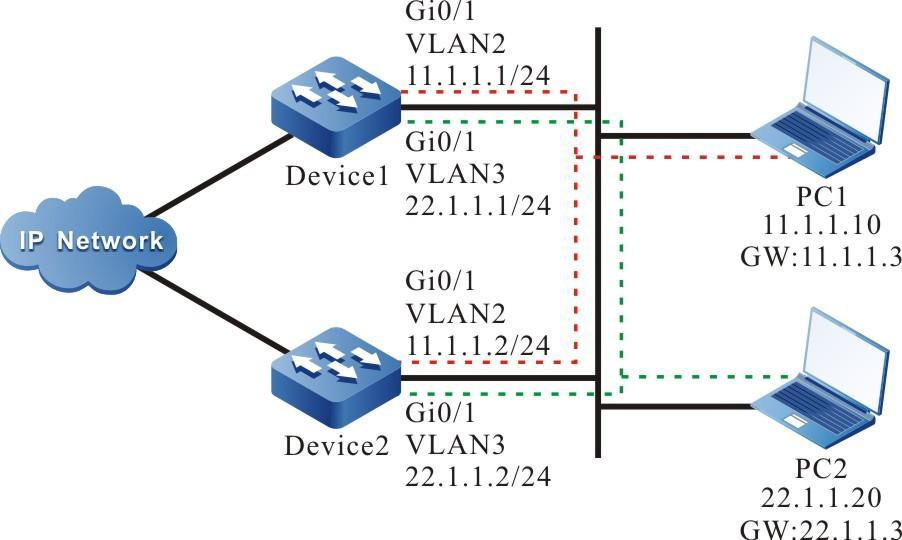
Figura 5 -4 Rede de grupo de backup múltiplo VRRP
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2: Configure o endereço IP da interface. (Omitido)
- Passo 3: Crie um grupo de links VRRP.
# Configure o grupo de links VRRP 1 no Device1.
Device1#configure terminalDevice1(config)#vrrp linkgroup 1
# Configure o grupo de links VRRP 1 no Device2.
Device2#configure terminalDevice2(config)#vrrp linkgroup 1
- Passo 4: Crie o grupo VRRP.
# Configure o endereço IP virtual do grupo VRRP 1 como 11.1.1.3 na interface Device1.
Device1(config)#interface vlan 2Device1(config-if-vlan2)#vrrp 1 ip 11.1.1.3Device1(config-if-vlan2)#exit
# Configure o endereço IP virtual do grupo VRRP 2 como 22.1.1.3 na interface Device1.
Device1(config)#interface vlan 3Device1(config-if-vlan3)#vrrp 2 ip 22.1.1.3Device1(config-if-vlan3)#exit
# Configure o endereço IP virtual do grupo VRRP 1 como 11.1.1.3 na interface Device2.
Device2(config)#interface vlan 2Device2(config-if-vlan2)#vrrp 1 ip 11.1.1.3Device2(config-if-vlan2)#exit
# Configure o endereço IP virtual do grupo VRRP 2 como 22.1.1.3 na interface Device2.
Device2(config)#interface vlan 3Device2(config-if-vlan3)#vrrp 2 ip 22.1.1.3Device2(config-if-vlan3)#exit
- Passo 5: Configure o VRRP para adicionar ao grupo de links.
# No Device1, o grupo VRRP 1 é adicionado ao grupo de links no modo Ativo.
Device1(config)#interface vlan 2Device1(config-if-vlan2)#vrrp 1 linkgroup 1 activeDevice1(config-if-vlan2)#exit
# No Device1, o grupo VRRP 2 é adicionado ao grupo de links no modo não ativo.
Device1(config)#interface vlan 3Device1(config-if-vlan3)#vrrp 2 linkgroup 1Device1(config-if-vlan3)#exit
# No Device2, o grupo 1 do VRRP é adicionado ao grupo de links no modo Ativo.
Device2(config)#interface vlan 2Device2(config-if-vlan2)#vrrp 1 linkgroup 1 activeDevice2(config-if-vlan2)#exit
# No Device2, o grupo VRRP 2 é adicionado ao grupo de links no modo não ativo.
Device2(config)#interface vlan 3Device2(config-if-vlan3)#vrrp 2 linkgroup 1Device2(config-if-vlan3)#exit
- Passo 6: Confira o resultado.
#Visualize o status do VRRP no Device1.
Device1#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 11.1.1.1Vrf : 0Virtual router : 1Linkgroup : 1Active : TRUEVirtual IP address : 11.1.1.3Virtual MAC address : 00-00-5e-00-01-01Depend prefix:11.1.1.1/24State : BackupMaster addr : 11.1.1.2Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : NoneInterface vlan3 (Flags 0x1)Pri-addr : 22.1.1.1Vrf : 0Virtual router : 2Linkgroup : 1Active : FALSEVirtual IP address : 22.1.1.3Virtual MAC address : 00-00-5e-00-01-02Depend prefix:22.1.1.1/24State : BackupMaster addr : 0.0.0.0Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
# Visualize o status do VRRP no Device2.
Device2#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 11.1.1.2Vrf : 0Virtual router : 1Linkgroup : 1Active : TRUEVirtual IP address : 11.1.1.3Virtual MAC address : 00-00-5e-00-01-01 , installed into HWDepend prefix:11.1.1.2/24State : MasterNormal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : NoneInterface vlan3 (Flags 0x1)Pri-addr : 22.1.1.2Vrf : 0Virtual router : 2Linkgroup : 1Active : FALSEVirtual IP address : 22.1.1.3Virtual MAC address : 00-00-5e-00-01-02 , installed into HWDepend prefix:22.1.1.2/24State : MasterNormal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
Podemos ver que o status VRRP do grupo não ativo e do grupo ativo se mantém consistente.
- Passo 7: Configure a prioridade da interface VLAN2 no Device1 como 110, alterando o status.
Device1(config)#interface vlan 2Device1(config-if-vlan2)#vrrp 1 priority 110Device1(config-if-vlan2)#exit
#Visualize o status do VRRP no Device1.
Device1#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 11.1.1.1Vrf : 0Virtual router : 1Linkgroup : 1Active : TRUEVirtual IP address : 11.1.1.3Virtual MAC address : 00-00-5e-00-01-01 , installed into HWDepend prefix:11.1.1.1/24State : MasterNormal priority : 110Currnet priority : 110Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : NoneInterface vlan3 (Flags 0x1)Pri-addr : 22.1.1.1Vrf : 0Virtual router : 2Linkgroup : 1Active : FALSEVirtual IP address : 22.1.1.3Virtual MAC address : 00-00-5e-00-01-02 , installed into HWDepend prefix:22.1.1.1/24State : MasterNormal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
#Visualize o status do VRRP no Device2.
Device2#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 11.1.1.2Vrf : 0Virtual router : 1Linkgroup : 1Active : TRUEVirtual IP address : 11.1.1.3Virtual MAC address : 00-00-5e-00-01-01Depend prefix:11.1.1.2/24State : BackupMaster addr : 11.1.1.1Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : NoneInterface vlan3 (Flags 0x1)Pri-addr : 22.1.1.2Vrf : 0Virtual router : 2Linkgroup : 1Active : FALSEVirtual IP address : 22.1.1.3Virtual MAC address : 00-00-5e-00-01-02Depend prefix:22.1.1.2/24State : BackupMaster addr : 0.0.0.0Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
Podemos ver que quando o status do grupo Ativo muda, o grupo não Ativo também muda e se mantém consistente com o grupo Ativo. O grupo Ativo no grupo de links é responsável por enviar os pacotes de protocolo, mas o grupo não Ativo não envia os pacotes. Isso pode reduzir a interação dos pacotes de protocolo e a carga da rede.
A granularidade do intervalo de envio pode ser menor. O mínimo pode ser configurado para o nível ms, de modo a atingir a comutação rápida.
Configure o VRRP para vincular com a faixa
Requisitos de rede
- Habilite o VRRP entre Device1 e Device2; Device1 e Device2 compartilham um endereço IP virtual, realizando o backup do gateway padrão do host do usuário.
- Device1 monitora o status da interface VLAN3 via Track. Quando a porta de uplink VLAN3 do Device1 está inativa, o VRRP pode sentir e alternar o status, fazendo com que o Backup se torne um novo mestre para encaminhar dados.
Topologia de rede
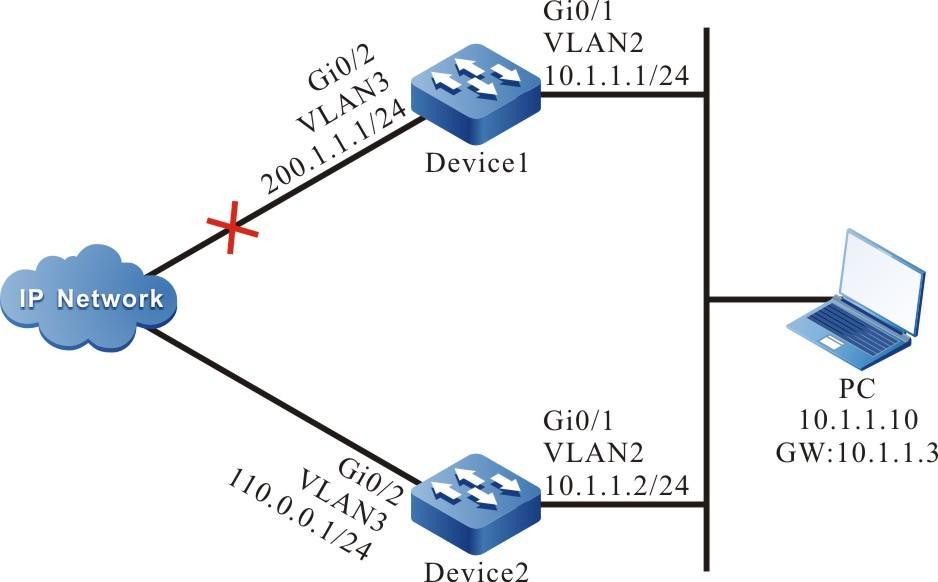
Figura 5 -5 Networking de VRRP vinculando com Track
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2: Configure o endereço IP da interface. (Omitido)
- Passo 3: Crie o grupo VRRP.
# Configure o grupo VRRP 1 no Device1; o endereço IP virtual é 10.1.1.3 e a prioridade é 110.
Device1#configure terminalDevice1(config)#interface vlan 2Device1(config-if-vlan2)#vrrp 1 ip 10.1.1.3Device1(config-if-vlan2)#vrrp 1 priority 110Device1(config-if-vlan2)#exit
# Configure o grupo VRRP 1 no Device2; o endereço IP virtual é 10.1.1.3.
Device2#configure terminalDevice2(config)#interface vlan 2Device2(config-if-vlan2)#vrrp 1 ip 10.1.1.3Device2(config-if-vlan2)#exit
# Visualize o status do VRRP do Device1.
Device1#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 10.1.1.1Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01 , installed into HWDepend prefix:10.1.1.1/24State : MasterNormal priority : 110Currnet priority : 110Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
# Visualize o status do VRRP do Device2.
Device2#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 10.1.1.2Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01Depend prefix:10.1.1.2/24State : BackupMaster addr : 10.1.1.1Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
- Passo 4: Configure o VRRP para vincular com o Track.
#No Device1, configure o VRRP para link com Track e monitore a interface uplink VLAN3; configure o decremento de prioridade como 20.
Device1(config)#interface vlan 2Device1(config-if-vlan2)#vrrp 1 track vlan3 20Device1(config-if-vlan2)#exit
# Visualize o status do VRRP do Device1.
Device1#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 10.1.1.1Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01 , installed into HWDepend prefix:10.1.1.1/24State : MasterNormal priority : 110Currnet priority : 110Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : NoneTrack interface : vlan3Reduce : 20Reduce state : NO
Quando a interface de uplink VLAN3 do Device1 está inativa, a prioridade do VRRP é reduzida em 20. Aqui, a prioridade do Device2 é alta, então o status muda.
# Visualize o status do VRRP do Device1.
Device1#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 10.1.1.1Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01Depend prefix:10.1.1.1/24State : BackupMaster addr : 10.1.1.2Normal priority : 110Currnet priority : 90Priority reduced : 20Preempt-mode : YESAdvertise-interval : 1Authentication Mode : NoneTrack interface : vlan3Reduce : 20Reduce state : YES
# Visualize o status do VRRP do Device2.
Device2#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 10.1.1.2Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01 , installed into HWDepend prefix:10.1.1.2/24State : MasterNormal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
Se a associação de VRRP e Track precisar atingir a comutação rápida, podemos configurar o switchover low-pri-master no Backup.
Configurar VRRP para vincular com BFD
Requisitos de rede
- Habilite o VRRP entre Device1 e Device2.
- O tempo de comutação do status VRRP do Device1 e Device2 precisa de pelo menos 3s e o serviço o tempo de interrupção é longo. É necessário configurar a associação VRRP e BFD em Device1 e Device2, realizando a comutação de nível ms.
Topologia de rede
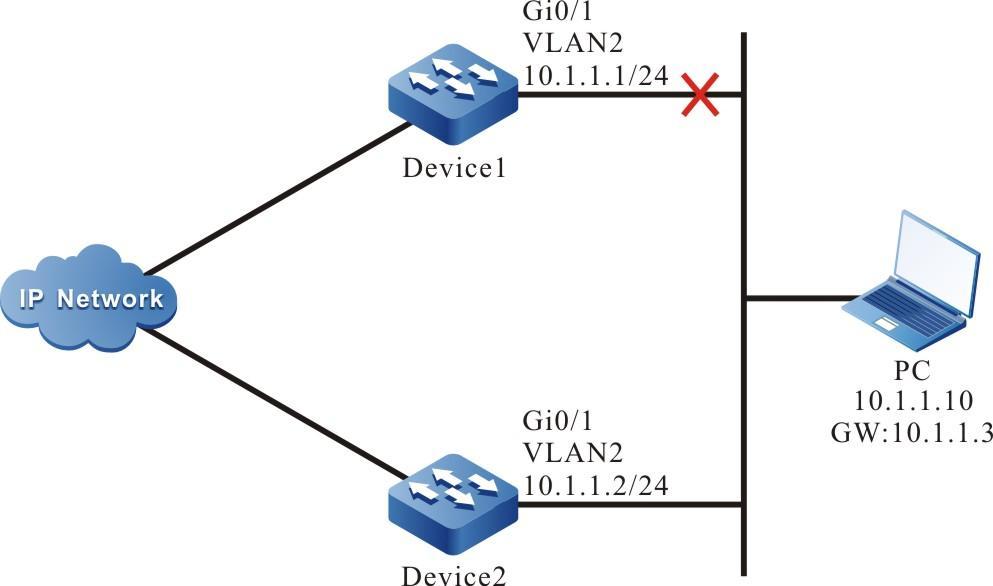
Figura 5 -6 Rede de ligação VRRP com BFD
Etapas de configuração
# Configure o grupo VRRP 1 no Device1; o endereço IP virtual é 10.1.1.3 e a prioridade é 105.
Device1#configure terminalDevice1(config)#interface vlan 2Device1(config-if-vlan2)#vrrp 1 ip 10.1.1.3Device1(config-if-vlan2)#vrrp 1 priority 105Device1(config-if-vlan2)#exit
# Configure o grupo VRRP 1 no Device2; o endereço IP virtual é 10.1.1.3.
Device2#configure terminalDevice2(config)#interface vlan 2Device2(config-if-vlan2)#vrrp 1 ip 10.1.1.3Device2(config-if-vlan2)#exit
# Visualize o status do VRRP do Device1.
Device1#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 10.1.1.2Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01 , installed into HWDepend prefix:10.1.1.2/24State : MasterNormal priority : 105Currnet priority : 105Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
# Visualize o status do VRRP do Device2.
Device2#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 10.1.1.2Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01Depend prefix:10.1.1.2/24State : BackupMaster addr : 10.1.1.1Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
# Configure Track para vincular com BFD no Device1.
Device1(config)#track 1Device1(config-track)#bfd interface vlan2 remote-ip 10.1.1.2 local-ip 10.1.1.1Device1(config-track)#exit
# Configure Track para vincular com BFD no Device2.
Device2#configure terminalDevice2(config)#track 1Device2(config-track)#bfd interface vlan2 remote-ip 10.1.1.1 local-ip 10.1.1.2Device2(config-track)#exit
#Visualize o status do BFD no Dispositivo1.
Device1#show bfd sessionOurAddr NeighAddr LD/RD State Holddown interface10.1.1.1 10.1.1.2 6/7 UP 5000 vlan2
#Visualize o status do BFD no Device2.
Device2#show bfd sessionOurAddr NeighAddr LD/RD State Holddown interface10.1.1.2 10.1.1.1 7/6 UP 5000 vlan2
#Configure o VRRP para vincular ao Track on Device2 e configure a alternância.
Device2(config)#interface vlan 2Device2(config-if-vlan2)#vrrp 1 track 1 switchoverDevice2(config-track)#exit
#Visualize o status do VRRP no Device2.
Device2#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 10.1.1.1Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01Depend prefix:10.1.1.1/24State : BackupMaster addr : 10.1.1.2Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : NoneTrack object : 1Switchover state : NO
Quando a linha Device1 falha, a sessão BFD é inativa e o Track também fica inativo. Device2 sente de uma vez e muda para dados de encaminhamento mestre.
Device2#show bfd sessionOurAddr NeighAddr LD/RD State Holddown interface10.1.1.2 10.1.1.1 7/0 DOWN 5000 vlan2Device2#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 10.1.1.2Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01 , installed into HWDepend prefix:10.1.1.2/24State : MasterNormal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : NoneTrack object : 1Switchover state : YES
Quando o VRRP é vinculado ao Track, o Switchover precisa ser configurado no Backup. Depois de encontrar Track down, mude para Master imediatamente.
Configurar o balanceamento de carga do VRRP
Requisitos de rede
- Device1 e Device2 pertencem a dois grupos VRRP ao mesmo tempo; Device1 é Mestre no grupo1 e Backup no grupo2; Device2 é Backup no grupo1 e Mestre no grupo2.
- PC1 encaminha dados via Device1 e PC2 encaminha dados via Device2, realizando o balanceamento de carga.
Topologia de rede

Figura 5 -7 Rede de balanceamento de carga VRRP
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2: Configure o endereço IP da interface. (Omitido)
- Passo 3: Crie o grupo VRRP 1.
# Configure o grupo VRRP 1 no Device1; o endereço IP virtual é 10.1.1.3 e a prioridade é 110.
Device1#configure terminalDevice1(config)#interface vlan 2Device1(config-if-vlan2)#vrrp 1 ip 10.1.1.3Device1(config-if-vlan2)#vrrp 1 priority 110Device1(config-if-vlan2)#exit
# Configure o grupo VRRP 1 no Device2; o endereço IP virtual é 10.1.1.3.
Device2#configure terminalDevice2(config)#interface vlan 2Device2(config-if-vlan2)#vrrp 1 ip 10.1.1.3Device2(config-if-vlan2)#exit
- Passo 4: Crie o grupo VRRP 2
#Configure o endereço IP virtual do VRRP group2 como 10.1.1.4 no Device1.
Device1(config)#interface vlan 2Device1(config-if-vlan2)#vrrp 2 ip 10.1.1.4Device1(config-if-vlan2)#exit
#Configure o endereço IP virtual do VRRP group2 como 10.1.1.4 no Device2 e configure a prioridade como 110.
Device2(config)#interface vlan 2Device2(config-if-vlan2)#vrrp 2 ip 10.1.1.4Device2(config-if-vlan2)#vrrp 2 priority 110Device2(config-if-vlan2)#exit
- Passo 5: Confira o resultado.
#Visualize o status do VRRP no grupo1 e no grupo2 no Dispositivo1.
Device1#show vrrpInterface vlan2 (Flags 0x1)Pri-addr : 10.1.1.1Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01 , installed into HWDepend prefix:10.1.1.1/24State : MasterNormal priority : 110Currnet priority : 110Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : NoneVirtual router : 2Virtual IP address : 10.1.1.4Virtual MAC address : 00-00-5e-00-01-02Depend prefix:10.1.1.1/24State : BackupMaster addr : 10.1.1.2Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
#Visualize o status do VRRP no grupo1 e no grupo2 no Dispositivo2.
Interface vlan2 (Flags 0x1)Pri-addr : 10.1.1.2Vrf : 0Virtual router : 1Virtual IP address : 10.1.1.3Virtual MAC address : 00-00-5e-00-01-01Depend prefix:10.1.1.2/24State : BackupMaster addr : 10.1.1.1Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : NoneVirtual router : 2Virtual IP address : 10.1.1.4Virtual MAC address : 00-00-5e-00-01-02 , installed into HWDepend prefix:10.1.1.2/24State : MasterNormal priority : 110Currnet priority : 110Priority reduced : 0Preempt-mode : YESAdvertise-interval : 1Authentication Mode : None
Podemos ver que Device1 serve como Master of VRRP group1 e Backup of VRRP group2. Em contraste com Device1, Device2 serve como mestre do grupo VRRP 2 e backup do grupo VRRP 1. Quando um dispositivo falha, dois PCs encaminham dados através do outro dispositivo. Isso realiza o balanceamento de carga e o backup um do outro.
VRRPv3
Visão geral
VRRP v3 (abreviação de Virtual Router Redundancy Protocol Version 3 ) é um protocolo de tolerância a falhas. Ele garante que, quando o dispositivo do próximo salto do host falhar, ele possa ser substituído por outro dispositivo a tempo, de modo a garantir a continuidade e a confiabilidade da comunicação. Para fazer o VRRP v3 funcionar, primeiro crie um endereço IP virtual e um endereço MAC. Desta forma, adicione um dispositivo virtual na rede. No entanto, quando o host na rede se comunica com o dispositivo virtual, não precisa saber de nenhuma informação do dispositivo físico na rede. Um dispositivo virtual compreende um host (mestre) e vários dispositivos escravos (backup). O dispositivo mestre realiza a função de encaminhamento real. Quando o dispositivo mestre falha, o dispositivo escravo se torna o novo dispositivo mestre e assume seu trabalho.
O dispositivo mestre mencionado no texto a seguir é substituído por “Mestre” e o dispositivo escravo é substituído por “Backup”.
função VRRPv3
Tabela 6 -1 lista de configuração da função VRRPv3
| Tarefa de configuração | |
| Configurar funções básicas do VRRPv3 |
Habilite o protocolo VRRPv3
Configurar a prioridade VRRPv3 Configurar o modo de preempção do VRRPv3 Configure o endereço MAC virtual do VRRPv3 |
| Configure o VRRP v3 para vincular com o Track |
Configure o VRRP v3 para vincular com o Track para monitorar a linha de uplink mestre
Configure o VRRP v3 para vincular com o Track para monitorar a linha de interconexão Master e Backup |
Configurar funções básicas do VRRP v3
Nas tarefas de configuração do VRRP v3 , primeiro habilite o protocolo VRRP v3 e o endereço IP virtual v6 do grupo VRRP v3 precisa estar no mesmo segmento que o link local do IP v6 endereço da interface para que as outras funções configuradas possam ter efeito.
Condição de configuração
Antes de configurar as funções básicas do VRRP v3 , primeiro conclua a seguinte tarefa:
- Habilite o endereço local de link IPv6 da interface
Ativar protocolo VRRP v3
Para habilitar a função VRRP v3 , você precisa criar o grupo VRRP e configurar o link local IPv6 endereço virtual na interface. Para configurar o endereço virtual global, o segmento do endereço virtual deve estar no mesmo segmento que o endereço real global na interface.
Tabela 6 -2 Habilitar o protocolo VRRP v3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o endereço virtual link-local do grupo VRRPv3 | ipv6 vrrp vrid ip ip-address link-local | Obrigatório Por padrão, não habilite o VRRPv3. |
| Configure o endereço virtual global do grupo VRRPv3 | ipv6 vrrp vrid ip ip-address | Opcional O endereço virtual global configurado deve estar no mesmo segmento que o endereço real global na interface. Por padrão, não habilite o endereço virtual global. |
Configurar prioridade VRRPv3
Após configurar o VRRP v3 e não definir a prioridade, a prioridade padrão é 100. O dispositivo com alta prioridade é eleito como Mestre para encaminhar o pacote e o outro torna-se Backup. Se as prioridades de todos os dispositivos forem iguais, eleja de acordo com a interface IPv6 link-local endereço do dispositivo. Aquele com o endereço de link local IPv6 de interface grande torna-se mestre. Podemos definir a prioridade do VRRP v3 conforme desejado. Quanto maior o valor , maior a prioridade .
Tabela 6 -3 Configurar a prioridade do VRRP v3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure a prioridade do grupo VRRPv3 | ipv6 vrrp vrid priority priority | Obrigatório Por padrão, a prioridade do VRRPv3 é 100. |
Configurar o modo de preempção do VRRP v3
Após configurar o VRRP v3 , no modo de preempção, quando outro dispositivo do grupo VRRP v3 descobre que sua prioridade é maior que a do mestre atual, ele se torna mestre; no modo de não preempção, desde que o Mestre não falhe, mesmo que o outro dispositivo tenha prioridade mais alta, ele não pode se tornar Mestre.
Tabela 6 -4 Configurar o modo de preempção do VRRP v3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o grupo VRRP v3 como o modo de preempção | ipv6 vrrp vrid preempt | Obrigatório Por padrão , ative a função de preempção. |
Configurar o endereço MAC virtual do VRRP v3
Um roteador virtual no grupo VRRP v3 tem um endereço MAC virtual. De acordo com RFC5798, o formato do endereço MAC virtual é 00-00-5E-00-02-{vrid}. Por padrão, o usado é o endereço MAC real da interface.
Tabela 6 -5 Configure o endereço MAC virtual do VRRP v3
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o VRRP v3 para usar o endereço MAC virtual | ipv6 vrrp vrid use-vmac | Obrigatório Por padrão, VRRPv3 use s o endereço MAC real . |
Por padrão, após configurar o VRRP v3 , o endereço MAC real é usado . Após configurar o comando desta seção , utilize o MAC virtual , ou seja, quando o host enviar o pacote, encaminhe pelo endereço MAC virtual ; após excluir o comando desta seção , use o endereço MAC real , ou seja, quando o host enviar o pacote, use o endereço MAC real para encaminhar.
Configure o VRRP v3 para vincular com a faixa
O VRRP v3 pode monitorar o status da linha de uplink e do mestre, linha de interconexão de backup para melhorar a confiabilidade do VRRP v3 .
Condição de configuração
Antes de configurar o VRRP v3 para vincular ao Track, primeiro conclua a seguinte tarefa:
- Configurar um grupo VRRP v3
Configure o VRRP v3 para Link com Track para monitorar a linha de uplink mestre
No Master, configure a vinculação com Track. Ele pode se conectar com a interface via Track, ou se conectar com BFD, RTR para que se refira ao status da interface de uplink. Depois que a interface de uplink estiver inativa, o VRRP v3 pode reduzir a prioridade do mestre por meio do decremento configurado. Aqui, após o recebimento do Backup, ele muda automaticamente para Master (observe que a prioridade do Master é menor que a prioridade do Backup). Se for necessário alternar o Backup rapidamente, podemos configurar o recebimento do comando de comutação rápida de baixa prioridade no Backup. Para obter detalhes, consulte a figura a seguir.
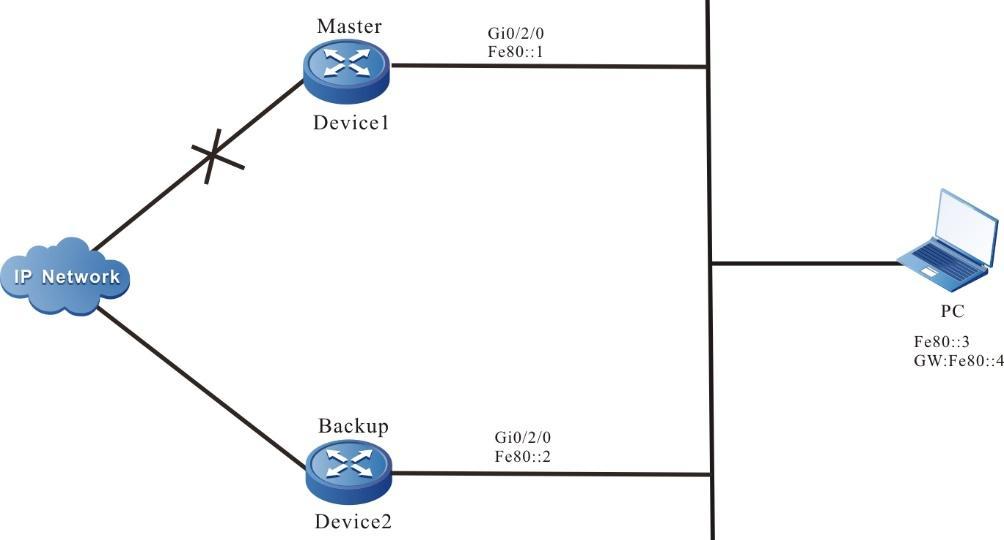
Figura 6 -1 Configure o VRRP v3 para vincular com Track para monitorar a linha de uplink mestre
Configurar VRRP v3 para Link com Track to Link com Interface de Uplink
Associe o VRRP v3 com a interface de uplink em questão via Track. Quando a interface de uplink está inativa, o Master reduz automaticamente sua própria prioridade. Aqui, o Backup recebe o pacote VRRP v3 de baixa prioridade e alterna para Master. Se o usuário estiver configurado com “Receive low-priority packet fast switching”, ou seja, função low-pri-master, Backup fast alterna para Master.
Tabela 6 -6 Configure o VRRP v3 para vincular com Track to link with uplink interface (configure no Master)
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o VRRP v3 para vincular com a interface de uplink | ipv6 vrrp vrid track interface-name [ decrement ] | Obrigatório Por padrão, o VRRPv3 não é vinculado ao Track. |
| Configure a função de comutação rápida quando o VRRP v3 receber o pacote de baixa prioridade | ipv6 vrrp vrid switchover low-pri-master | Opcional Por padrão, não habilite a função low-pri-master . O comando é configurado no Backup para alternar rapidamente quando a prioridade do Mestre é reduzida. |
Configure o VRRP v3 para Link com Track (Track Linking com BFD, RTR e assim por diante)
Se Track estiver associado a BFD, RTR e assim por diante, o Master pode se conectar diretamente com Track, de modo a monitorar a linha. Quando a linha falha, o Mestre reduz sua própria prioridade. Aqui, o Backup recebe o pacote VRRP v3 de baixa prioridade e alterna para Master. Se o usuário estiver configurado com “Receive low-priority packet fast switching”, ou seja, função low-pri-master, Backup fast alterna para Master.
Tabela 6 -7 Configurar Master para vincular com Track (Track linking com BFD, RTR e assim por diante)
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o VRRP v3 para vincular com a interface de uplink | ipv6 vrrp vrid track track-id [ decrement ] | Obrigatório Por padrão, o VRRPv3 não é vinculado ao Track. |
| Configure a função de comutação rápida quando o VRRP v3 receber pacotes de baixa prioridade | ipv6 vrrp vrid switchover low-pri-master | Opcional Por padrão, não habilite a função low-pri-master . O comando é configurado no Backup para alternar rapidamente quando a prioridade do Mestre é reduzida. |
Para o método de configuração de criação de trilha, trilha associada a BFD ou RTR, consulte o manual de configuração de trilha. Se a função low-pri-master estiver configurada e quando o Backup receber o pacote de baixa prioridade, ele alternará rapidamente. Se a função não estiver configurada ao receber o pacote de baixa prioridade, o Backup alterna após o próximo tempo limite. Se o requisito de tempo de comutação não for rigoroso, não é necessário configurar a função low-pri-master, mas se o requisito de tempo de comutação for rigoroso, a função pode fazer com que o tempo de comutação atinja o nível ms.
Configure o VRRP v3 para vincular com a trilha para monitorar a linha de interconexão mestre e de backup
Configure o VRRP v3 para vincular com a trilha para monitorar a linha de interconexão Master e Backup. Se a linha entre Master e Backup estiver desativada, o Backup alternará rapidamente para Master. Para obter detalhes, consulte a figura a seguir.

Figura 6 -2 Configure o VRRP v3 para vincular com a trilha para monitorar a linha de interconexão mestre e de backup
Tabela 6 -8 Configure o VRRP v3 para vincular com a trilha para monitorar a linha de interconexão mestre e de backup
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure a função de comutação rápida quando o dispositivo Backup VRRP v3 descobrir que a linha entre o mestre e o backup está desativada | ipv6 vrrp vrid track track-id switchover | Obrigatório Por padrão, o VRRPv3 não é vinculado ao Track . |
Para a configuração de Track associando BFD e RTR, consulte o Manual de Configuração de Track. Track pode se conectar com BFD para monitorar o status da linha entre Master e Backup.
VRRPv3 Monitoramento e manutenção
Tabela 6 -9 Monitoramento e manutenção do VRRP v3
| Comando | Descrição |
| show ipv6 vrrp [ interface interface-name ] | [brief] | Exiba as informações de configuração do VRRP v3 , incluindo informações de endereço IP virtual, informações de endereço MAC virtual, status do dispositivo, prioridade do dispositivo, endereço de interface do dispositivo dependente, informações do grupo de links e assim por diante. |
Exemplo de configuração típica de VRRPv3
Configurar grupo de backup único VRRP baseado em IPv6
Requisitos de rede
- Em Device1 e Device2, crie um único grupo de backup VRRP baseado em IPv6 para que Device1 e Device2 compartilhem o mesmo endereço local de link IPv6 virtual e endereço global , realizando o backup para o gateway padrão do host do usuário e reduzindo o tempo de interrupção do rede.
Topologia de rede
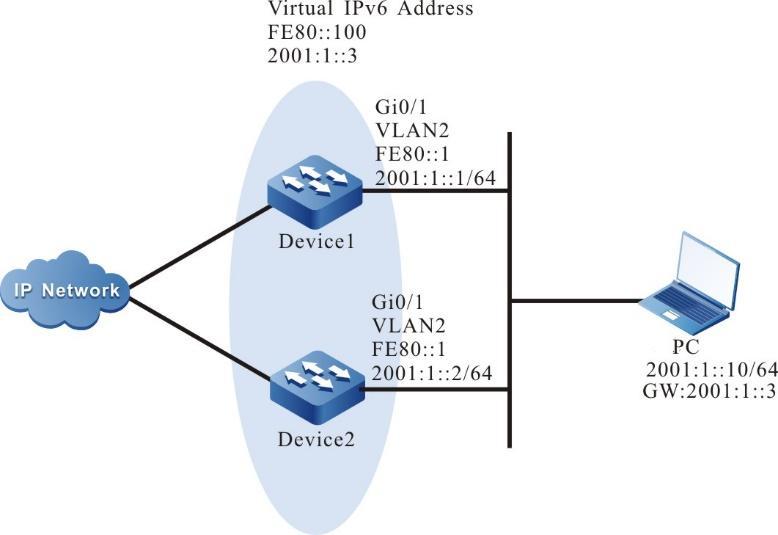
Figura 6 -3 Rede de configuração de grupo de backup único VRRP baseado em IPv6
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente (omitida).
- Passo 2: Configure o endereço IP v6 da interface. Habilite o switch da resposta RA e envio periódico RA
Device1#configure terminalDevice1(config-if-vlan2)#ipv6 address fe80::1 link-localDevice1(config-if-vlan2)#ipv6 address 2001:1::1/64Device1(config-if-vlan2)#no ipv6 nd suppress-ra periodDevice1(config-if-vlan2)#no ipv6 nd suppress-ra responseDevice1(config-if-vlan2)#exitDevice2#configure terminalDevice2(config-if-vlan2)#ipv6 address fe80::2 link-localDevice2(config-if-vlan2)#ipv6 address 2001:1::2/64Device2(config-if-vlan2)#no ipv6 nd suppress-ra periodDevice2(config-if-vlan2)#no ipv6 nd suppress-ra responseDevice2(config-if-vlan2)#exit
- Passo 3: Crie o grupo VRRP baseado em IPv6 .
#No Device1, configure o grupo 1 do VRRP v3 , o endereço IP virtual é 2001:1::3 e fe80::100 e configure a prioridade como 110.
Device1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 vrrp 1 ip fe80::100 link-localDevice1(config-if-vlan2)#ipv6 vrrp 1 ip 2001:1::3Device1(config-if-vlan2)#ipv6 vrrp 1 priority 110Device1(config-if-vlan2)#exit
# No Device2, configure o VRRP v3 group1 e o endereço IP virtual é 2001:1::3 e fe80::100 .
Device2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 vrrp 1 ip fe80::100 link-localDevice2(config-if-vlan2)#ipv6 vrrp 1 ip 2001:1::3Device2(config-if-vlan2)#exit
- Passo 4: Confira o resultado.
# Visualize o status do IPv6 VRRP do Device1.
Device1#show ipv6 vrrpInterface vlan2 (Flags 0x9)Pri-addr : fe80::1Vrf : 0Pri-matchaddr : fe80::1Virtual router : 1Mac mode: real mac modeVirtual IP address : fe80::100Global address count:1Global Match address : 2001:1::1Global Virtual IP address : 2001:1::3Virtual MAC address : 00-00-5e-00-02-01State : MasterNormal priority : 110Currnet priority : 110Priority reduced : 0Preempt-mode : YESAdvertise-interval : 100Authentication Mode : None
# Visualize o status do IPv6 VRRP do Device2.
Device2#show ipv6 vrrpInterface vlan2 (Flags 0x9)Pri-addr : fe80::2Vrf : 0Pri-matchaddr : fe80::2Virtual router : 1Mac mode: real mac modeVirtual IP address : fe80::100Global address count:1Global Match address : 2001:1::2Global Virtual IP address : 2001:1::3Virtual MAC address : 00-00-5e-00-02-01State : BackupMaster addr : fe80::1Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 100Authentication Mode : None
Podemos ver que o status do VRRP v3 do Device1 é Master e o status do VRRP v3 do Device2 é Cópia de segurança. Device1 e Device2 compartilham um endereço IP virtual. O host se comunica com a rede através do endereço. Quando Device1 falha, Device2 muda para Master imediatamente para encaminhar dados.
O princípio de eleição do status VRRP v3 é por prioridade. Aquele com grande prioridade é o Mestre. Se as prioridades forem as mesmas, compare de acordo com o endereço local do link IP da interface. Aquele com endereço IP grande é o Master. Por padrão, o VRRP v3 funciona no modo de preempção. A prioridade padrão é 100.
Configurar VRRP baseado em IPv6 para vincular com track
Requisitos de rede
- Em Device1 e Device2 , crie um grupo de backup único IPv6 VRRP ; Device1 e Device2 compartilham um endereço local de link IPv6 virtual e um endereço global virtual , realizando o backup do gateway padrão do host do usuário , de modo a reduzir o tempo de interrupção da rede.
- Device1 monitora o status da interface VLAN3 via Track. Quando a porta de uplink VLAN3 do Device1 está inativa, o VRRP v3 pode sentir o evento inativo da interface do monitor e reduzir sua própria prioridade, fazendo com que o Backup se torne o novo mestre e continue a encaminhar os dados.
Topologia de rede
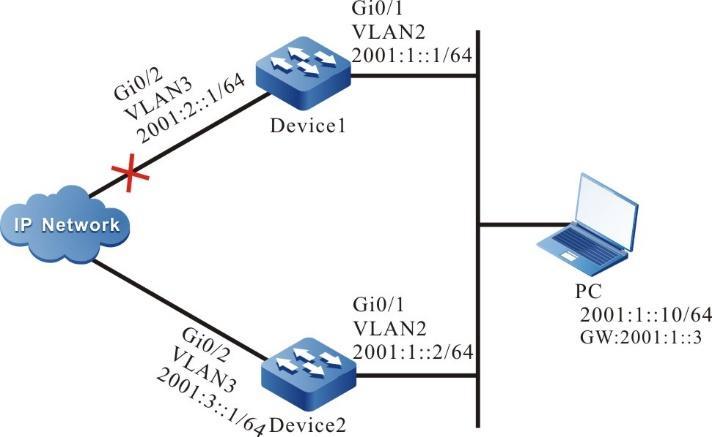
Figura 6 -4 Networking de IPv6 VRRP vinculando com Track
Etapas de configuração
Device1#configure terminalDevice1(config-if-vlan2)#ipv6 address fe80::1 link-localDevice1(config-if-vlan2)#ipv6 address 2001:1::1/64Device1(config-if-vlan2)#no ipv6 nd suppress-ra periodDevice1(config-if-vlan2)#no ipv6 nd suppress-ra responseDevice1(config-if-vlan2)#exitDevice2#configure terminalDevice2(config-if-vlan2)#ipv6 address fe80::2 link-localDevice2(config-if-vlan2)#ipv6 address 2001:1::2/64Device2(config-if-vlan2)#no ipv6 nd suppress-ra periodDevice2(config-if-vlan2)#no ipv6 nd suppress-ra responseDevice2(config-if-vlan2)#exit
# No Device1, configure o grupo 1 do VRRP v3, o endereço IP virtual é 2001:1::3 e fe80::100 e configure a prioridade como 110.
Device1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 vrrp 1 ip fe80::100 link-localDevice1(config-if-vlan2)#ipv6 vrrp 1 ip 2001:1::3Device1(config-if-vlan2)#ipv6 vrrp 1 priority 110Device1(config-if-vlan2)#exit
# No Device2, configure o grupo 1 do VRRP v3 e o endereço IP virtual é 2001:1::3 e fe80::100 .
Device2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 vrrp 1 ip fe80::100 link-localDevice2(config-if-vlan2)#ipv6 vrrp 1 ip 2001:1::3Device2(config-if-vlan2)#exit
#Visualize o status do IPv6 VRRP do Device1.
Device1# show ipv6 vrrpInterface vlan2 (Flags 0x9)Pri-addr : fe80::1Vrf : 0Pri-matchaddr : fe80::1Virtual router : 1Mac mode: real mac modeVirtual IP address : fe80::100Global address count:1Global Match address : 2001:1::1Global Virtual IP address : 2001:1::3Virtual MAC address : 00-00-5e-00-02-01State : MasterNormal priority : 110Currnet priority : 110Priority reduced : 0Preempt-mode : YESAdvertise-interval : 100Authentication Mode : None
# Visualize o status do IPv6 VRRP do Device2.
Device2#show ipv6 vrrpInterface vlan2 (Flags 0x9)Pri-addr : fe80::2Vrf : 0Pri-matchaddr : fe80::2Virtual router : 1Mac mode: real mac modeVirtual IP address : fe80::100Global address count:1Global Match address : 2001:1::2Global Virtual IP address : 2001:1::3Virtual MAC address : 00-00-5e-00-02-01State : BackupMaster addr : fe80::1Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 100Authentication Mode : None
# No Device1, configure o VRRP v3 para link com Track, monitore a interface de uplink vlan3 e configure o valor reduzido da prioridade como 20.
Device1#configure o terminal
Device1(config)#interface vlan2
Device1(config-if-vlan2)#ipv6 vrrp 1 faixa gigabitethernet 1 20
Device1(config-if-vlan2)#exit
# Visualize o status do IPv6 VRRP do Device1.
Device1#configure terminalDevice1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 vrrp 1 track gigabitethernet 1 20Device1(config-if-vlan2)#exit#View the IPv6 VRRP status of Device1.Device1#show ipv6 vrrpInterface vlan2 (Flags 0x9)Pri-addr : fe80::1Vrf : 0Pri-matchaddr : fe80::1Virtual router : 1Mac mode: real mac modeVirtual IP address : fe80::100Global address count:1Global Match address : 2001:1::1Global Virtual IP address : 2001:1::3Virtual MAC address : 00-00-5e-00-02-01State : MasterNormal priority : 110Currnet priority : 110Priority reduced : 0Preempt-mode : YESAdvertise-interval : 100Authentication Mode : NoneTrack interface : vlan3Reduce : 20Reduce state : NO
Quando a interface do monitor vlan3 do Device1 está inativa, a prioridade do VRRP v3 é reduzida em 20. Aqui, a prioridade do Device2 é alta e se antecipa como Master, e o status muda.
# Visualize o status do IPv6 VRRP do Device1.
Device1#show ipv6 vrrpInterface vlan2 (Flags 0x9)Pri-addr : fe80::1Vrf : 0Pri-matchaddr : fe80::1Virtual router : 1Mac mode: real mac modeVirtual IP address : fe80::100Global address count:1Global Match address : 2001:1::1Global Virtual IP address : 2001:1::3Virtual MAC address : 00-00-5e-00-02-01State : BackupMaster addr : fe80::2Normal priority : 110Currnet priority : 90Priority reduced : 20Preempt-mode : YESAdvertise-interval : 100Authentication Mode : NoneTrack interface : vlan3Reduce : 20Reduce state : YES
# Visualize o status do IPv6 VRRP do Device2 .
Device2#show ipv6 vrrpInterface vlan2 (Flags 0x9)Pri-addr : fe80::2Vrf : 0Pri-matchaddr : fe80::2Virtual router : 1Mac mode: real mac modeVirtual IP address : fe80::100Global address count:1Global Match address : 2001:1::2Global Virtual IP address : 2001:1::3Virtual MAC address : 00-00-5e-00-02-01State : MasterNormal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 100Authentication Mode : None
Configurar o balanceamento de carga do VRRP baseado em IPv6
Requisitos de rede
- Em Device1 e Device2 , crie dois grupos de backup IPv6 VRRP ; Device1 e Device2 pertencem a dois grupos VRRPv3 ao mesmo tempo. Device1 é Mestre no grupo1 e Backup no grupo 2; Device2 é Backup no grupo 1 e Mestre no grupo 2.
- PC1 encaminha dados via Device1 e PC2 encaminha dados via Device2, realizando o balanceamento de carga.
Topologia de rede
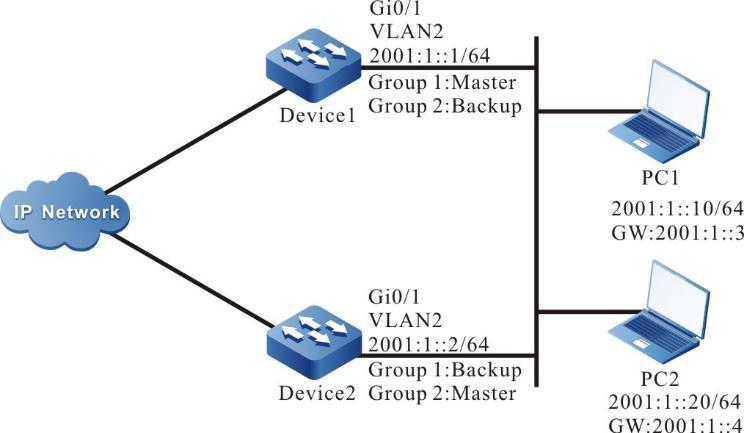
Figura 6 -5 Rede de balanceamento de carga IPv6 VRRP
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente (omitida).
- Passo 2: Configure o endereço IPv6 da interface e habilite o switch da resposta RA e o envio periódico RA
Device1#configure terminalDevice1(config-if-vlan2)#ipv6 address fe80::1 link-localDevice1(config-if-vlan2)#ipv6 address 2001:1::1/64Device1(config-if-vlan2)#no ipv6 nd suppress-ra periodDevice1(config-if-vlan2)#no ipv6 nd suppress-ra responseDevice1(config-if-vlan2)#exitDevice2#configure terminalDevice2(config-if-vlan2)#ipv6 address fe80::2 link-localDevice2(config-if-vlan2)#ipv6 address 2001:1::2/64Device2(config-if-vlan2)#no ipv6 nd suppress-ra periodDevice2(config-if-vlan2)#no ipv6 nd suppress-ra responsDevice2(config-if-vlan2)#exit
- Passo 3: Criar grupo IPv6 VRRP 1.
# No Device1, configure o grupo 1 do VRRP v3, o endereço IP virtual é 2001:1::3 e fe80::100 e configure a prioridade como 110.
Device1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 vrrp 1 ip fe80::100 link-localDevice1(config-if-vlan2)#ipv6 vrrp 1 ip 2001:1::3Device1(config-if-vlan2)#ipv6 vrrp 1 priority 110Device1(config-if-vlan2)#exit
# No Device1, configure o grupo 1 do VRRP v3 e o endereço IP virtual é 2001:1::3 e fe80::100 .
Device2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 vrrp 1 ip fe80::100 link-localDevice2(config-if-vlan2)#ipv6 vrrp 1 ip 2001:1::3Device2(config-if-vlan2)#exit
- Passo 4: Crie o grupo IPv6 VRRP 2.
# No Device1, configure VRRPv3 group2 e o endereço IP virtual é 2001:1::4 e fe80::200 .
Device1(config)#interface vlan2Device1(config-if-vlan2)#ipv6 vrrp 2 ip fe80::200 link-localDevice1(config-if-vlan2)#ipv6 vrrp 2 ip 2001:1::4Device1(config-if-vlan2)#exit
# No Device2, configure VRRPv3 group2, o endereço IP virtual é 2001:1::4 e fe80::200 e configure a prioridade como 110.
Device2(config)#interface vlan2Device2(config-if-vlan2)#ipv6 vrrp 2 ip fe80::200 link-localDevice2(config-if-vlan2)#ipv6 vrrp 2 ip 2001:1::4Device2(config-if-vlan2)#ipv6 vrrp 2 priority 110Device2(config-if-vlan2)#exit
- Passo 5: Confira o resultado
# No Device1, visualize o status do grupo 1 e do grupo 2 do IPv6 VRRP.
Device1#show ipv6 vrrpInterface vlan2 (Flags 0x9)Pri-addr : fe80::1Vrf : 0Pri-matchaddr : fe80::1Virtual router : 1Mac mode: real mac modeVirtual IP address : fe80::100Global address count:1Global Match address : 2001:1::1Global Virtual IP address : 2001:1::3Virtual MAC address : 00-00-5e-00-02-01State : MasterNormal priority : 110Currnet priority : 110Priority reduced : 0Preempt-mode : YESAdvertise-interval : 100Authentication Mode : NonePri-matchaddr : fe80::1Virtual router : 2Mac mode: real mac modeVirtual IP address : fe80::200Global address count:1Global Match address : 2001:1::1Global Virtual IP address : 2001:1::4Virtual MAC address : 00-00-5e-00-02-02State : BackupMaster addr : fe80::2Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 100Authentication Mode : None
# No Device2, visualize o status do grupo 1 e do grupo 2 do IPv6 VRRP.
Device2#show ipv6 vrrpInterface vlan2 (Flags 0x9)Pri-addr : fe80::2Vrf : 0Pri-matchaddr : fe80::2Virtual router : 1Mac mode: real mac modeVirtual IP address : fe80::100Global address count:1Global Match address : 2001:1::2Global Virtual IP address : 2001:1::3Virtual MAC address : 00-00-5e-00-02-01State : BackupMaster addr : fe80::1Normal priority : 100Currnet priority : 100Priority reduced : 0Preempt-mode : YESAdvertise-interval : 100Authentication Mode : NonePri-matchaddr : fe80::2Virtual router : 2Mac mode: real mac modeVirtual IP address : fe80::200Global address count:1Global Match address : 2001:1::2Global Virtual IP address : 2001:1::4Virtual MAC address : 00-00-5e-00-02-02State : MasterNormal priority : 110Currnet priority : 110Priority reduced : 0Preempt-mode : YESAdvertise-interval : 100Authentication Mode : None
Você pode ver que o Device1 serve como mestre do grupo 1 do VRRPv3 e se torna o backup do grupo 2 do VRRPv3, enquanto o Device2 serve como o mestre do grupo 2 do VRRPv3 e o backup do grupo 1 do VRRPv3. Quando um dispositivo falha, dois PCs encaminham os dados pelo outro dispositivo. Isso não apenas afeta o balanceamento de carga, mas também realiza o backup mútuo.
VBRP
Visão geral
O VBRP (Virtual Backup Router Protocol) fornece uma função de backup para o gateway, usada por vários roteadores para manter o encaminhamento contínuo do gateway virtual. O VBRP mapeia os vários roteadores referidos para um roteador virtual e garante que haja apenas um roteador para representar para o roteador virtual encaminhar pacotes. Quando o roteador para encaminhamento de dados não pode funcionar normalmente por algum motivo, outro roteador em espera substitui o roteador virtual para encaminhar pacotes, enquanto o roteador que não pode funcionar normalmente não suporta mais a tarefa de encaminhamento. O processo de comutação é curto e transparente para o host na LAN, de modo a alcançar a função de backup do gateway.
O dispositivo ativo mencionado no texto a seguir é substituído por “Ativo” e o dispositivo em espera é substituído por “Em espera”.
Configuração da função VBRP
Tabela 7 – 1 lista de configuração da função VBRP
| Tarefa de configuração | |
| Configurar as funções básicas do VBRP |
Habilite o protocolo VBRP
Habilite a prioridade VBRP Habilite o modo de preempção VBRP Configurar o endereço MAC real do VBRP |
| Configurar a autenticação de rede VBRP | Configurar a autenticação de texto simples VBRP Configurar a autenticação VBRP MD5 |
| Configure o VBRP para vincular ao Track para associar à interface de uplink | Configure o VBRP para vincular ao Track para associar à interface de uplink |
Configurar funções básicas do VBRP
Nas tarefas de configuração do VBRP, primeiro habilite a função VBRP e o endereço IP virtual do grupo VBRP precisa estar no mesmo segmento que o endereço IP da interface para que as outras funções configuradas possam ter efeito.
Condição de configuração
Antes de configurar as funções básicas do VBRP, primeiro complete a seguinte tarefa:
- Configurar o endereço IP da interface
Habilitar protocolo VBRP
Para habilitar a função VBRP, precisamos criar o grupo VBRP na interface e adicionar o roteador VBRP ao grupo.
Tabela 7 – 2 Habilite o protocolo VBRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configurar o grupo VBRP | standby [ group-number ] ip [ ip-address ] | Obrigatório Configure o roteador a ser adicionado ao grupo VBRP; por padrão, o número do grupo é 0 e o endereço IP é o endereço IP virtual. |
Configurar prioridade VBRP
Após configurar o VBRP e não definir a prioridade, a prioridade padrão é 100. O dispositivo com alta prioridade é eleito como Ativo para encaminhar o pacote e o outro fica em Standby. Se as prioridades de todos os dispositivos forem iguais, escolha de acordo com o endereço IP da interface do dispositivo. Aquele com endereço IP de interface grande torna-se ativo. Podemos definir a prioridade VBRP conforme desejado. Quanto maior o valor , maior a prioridade .
Tabela 7 – 3 Configurar a prioridade VBRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure a prioridade do grupo VBRP | standby [ group-number ] priority value | Obrigatório Configure a prioridade VBRP; por padrão, a prioridade é 100. |
Configurar o modo de preempção de VBRP
No modo de preempção, uma vez que outro dispositivo do grupo VBRP descobre que sua prioridade é maior que a do Ativo atual, ele se torna Ativo; no modo de não preempção, desde que o Ativo não falhe, mesmo que o outro dispositivo tenha prioridade mais alta, ele não pode se tornar Ativo.
Tabela 7 – 4 Configurar o modo de preempção do VBRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o grupo VBRP como o modo de preempção | standby [ group-number ] preempt [ delay delay-time ] | Obrigatório Configure o VBRP como o modo de preempção. Por padrão, é o modo de não preempção. |
Configurar o endereço MAC real do VBRP
Após configurar o VBRP e se for necessário fazer com que o grupo VBRP use o endereço MAC real, precisamos usar o seguinte comando para configurar. Quando o dispositivo virtual responde à solicitação ARP, o endereço MAC respondido é real, mas não o endereço MAC virtual da interface. Por padrão, o usado é o endereço MAC virtual.
Tabela 7 – 5 Configurar o MAC real do VBRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o VBRP como o MAC real | standby [ group-number ] use-bia | Obrigatório Por padrão, use o endereço MAC virtual. |
Por padrão, após configurar o VBRP, o usado é o endereço MAC virtual. Depois de configurar o comando standby use-bia , use o MAC real . Ou seja, quando o host envia o pacote, encaminhe pelo endereço MAC real; depois de configurar o comando no espera use-bia , use o endereço MAC virtual da interface, ou seja, quando o host enviar o pacote, use o endereço MAC virtual para encaminhar.
Configurar autenticação de rede VBRP
O VBRP possui dois modos, ou seja, autenticação de texto simples e autenticação MD5. O comprimento definido da autenticação de texto simples não pode exceder oito palavras de autenticação. O comprimento definido da autenticação MD5 é a palavra de autenticação que não excede 64 bits.
Condição de configuração
Antes de configurar as funções básicas do VBRP, primeiro complete a seguinte tarefa:
- Configurar o grupo VBRP
Configurar autenticação de texto simples VBRP
Configure a autenticação VBRP para verificar e verificar a validade do pacote VBRP. Podemos usar o seguinte comando para configurar o modo de autenticação de texto simples VBRP.
Tabela 7 – 6 Configurar a autenticação de texto simples VBRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configurar a autenticação de texto simples VBRP | standby group-number authentication { string } | Obrigatório A palavra de autenticação configurada é string e o comprimento não pode exceder a palavra de autenticação de 8 bits. Por padrão, não ative a autenticação de texto simples. |
Configurar autenticação VBRP MD5
Configure a autenticação VBRP para verificar e verificar a validade do pacote VBRP. Podemos usar o seguinte comando para configurar o modo de autenticação VBRP MD5
Tabela 7 – 7 Configurar a autenticação VBRP MD5
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configurar a autenticação VBRP MD5 | standby group-number authentication { md5 { key-id key-identifier key-string key-string } | { key-string key-string } } | Obrigatório Configure a autenticação de rede MD5 e o comprimento não pode exceder a palavra de autenticação de 8 bits. Por padrão, não habilite a autenticação MD5. |
Configurar VBRP para Link com Track
Associe o VBRP à interface de uplink em questão via Track. Quando a interface de uplink está inativa, o Active reduz automaticamente sua própria prioridade. Aqui, Standby recebe o pacote de baixa prioridade e muda para Active. Para obter detalhes, consulte a figura a seguir.
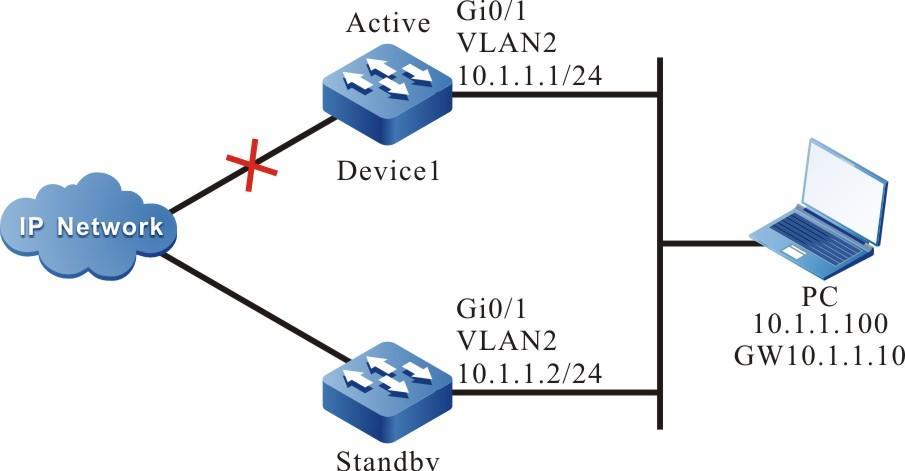
Figura 6 – 1 Configure o VBRP para vincular com o Track para monitorar a linha de uplink ativo
Condição de configuração
Antes de configurar as funções básicas do VBRP, primeiro complete a seguinte tarefa:
- Configurar o grupo VBRP
Configure o VBRP para vincular com a faixa para associar à interface de uplink
Associe o VBRP à interface de uplink em questão via Track. Quando a interface de uplink está inativa, o Active reduz automaticamente sua própria prioridade. Aqui, Standby recebe o pacote de baixa prioridade e muda para Active.
Tabela 7 – 8 Configure o VBRP para vincular com o Track para associar à interface de uplink
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o VBRP para vincular ao Track para associar à interface de uplink | standby [ group-number ] track { { interface-name} | track-id } [ decrement ] | Obrigatório Configure a associação com a interface interface-name . Quando a interface está inativa, a prioridade é reduzida em decréscimo. Por padrão, reduza a prioridade para 10. |
Configurar VBRP para Link com Track para Associar com BFD e RTR
Se Track estiver associado a BFD, RTR e assim por diante, Active pode associar-se diretamente ao grupo Track, de modo a monitorar a linha. Quando a linha falha, o Active reduz sua própria prioridade. Aqui, o Standby recebe o pacote VBRP de baixa prioridade, alterna para Ativo.
Tabela 7 – 9 Configure o VBRP para vincular ao Track para associar ao BFD e RTR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o VBRP para vincular ao Track para associar à interface de uplink | standby [ group-number ] track { track-id } [ decrement ] | Obrigatório Configure a associação com Track track-id. A trilha está associada a BFD, RTR e assim por diante. Por padrão, a prioridade é reduzida em 10. |
Para o método de configuração de associação de trilha com BFD, RTR e assim por diante, consulte o Manual de configuração de trilha.
Monitoramento e manutenção de VBRP
Tabela 7 – 10 monitoramento e manutenção de VBRP
| Comando | Descrição |
| Show standby [brief] | [ all ] | [ interface interface-name group gid] | Exiba as informações de configuração do VBRP, incluindo informações de endereço IP virtual, informações de endereço MAC virtual, status do dispositivo, prioridade do dispositivo, endereço de interface do dispositivo dependente, informações do grupo de links e assim por diante. |
Exemplo de configuração típica de VBRP
Configurar o modo básico VBRP
Requisitos de rede
- Habilite o VBRP entre Device1 e Device2; Device1 e Device2 compartilham um endereço IP virtual, realizando o backup para o gateway padrão do host do usuário e reduzindo o tempo de interrupção da rede.
Topologia de rede

Figura 7 -2 Rede do modo básico VBRP
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2: Configure o endereço IP da interface. (Omitido)
- Passo 3: Crie o grupo VBRP.
#Configure o grupo 1 do VBRP no Device1; o endereço IP virtual é 10.1.1.10; habilitar o modo de preempção; configure a prioridade como 110.
Device1#configure terminalDevice1(config)#interface vlan 2Device1(config-if-vlan2)#standby 1 ip 10.1.1.10Device1(config-if-vlan2)#standby 1 preemptDevice1(config-if-vlan2)#standby 1 priority 110
#Configurar o grupo 1 do VBRP no Dispositivo2; o endereço IP virtual é 10.1.1.10; habilitar o modo de preempção;
Device2#configure terminalDevice1(config-if-vlan2)#standby 1 ip 10.1.1.10Device1(config-if-vlan2)#standby 1 preemptDevice1(config-if-vlan2)#standby 1 priority 110
- Passo 4: Confira o resultado.
Device1#show standbyInterface vlan2Primary address 10.1.1.1, state upGroup 1State is ActiveVirtual IP address is 10.1.1.10Refer to local IP prefix 193.168.1.1/24Local virtual MAC address is 0000.0c07.ac01Current MAC type VMAC, installed into HWHello time 3 sec, hold time 10 secNext hello sent in 0.633348 secsPreemption enabled, delay 0 secActive router is localStandby router is 10.1.1.2,priority 100 (expires in 8.466648 secs)Priority 110 (configured 110)
# Visualize o status do VBRP do Device2.
Device2#show standbyInterface vlan2Primary address 10.1.1.2, state upGroup 1State is StandbyVirtual IP address is 10.1.1.10Refer to local IP prefix 10.1.1.2/24Local virtual MAC address is 0000.0c07.ac01Current MAC type VMACHello time 3 sec, hold time 10 secNext hello sent in 0.450022 secsPreemption enabled, delay 0 secActive router is 10.1.1.1, priority 110 (expires in 7.266656 secs)Standby router is localPriority 100 (configured 100)
A partir do status VBRP, podemos ver que a prioridade VBRP do Device1 é 110, o status é Ativo e o status VBRP de Device2 é Standby. Após a falha do Dispositivo1, o Dispositivo2 muda automaticamente para Ativo para encaminhar dados.
O princípio de eleição do status VRRP é por prioridade. Aquele com grande prioridade é Ativo. Se as prioridades forem as mesmas, compare de acordo com o endereço IP da interface. Aquele com endereço IP grande está ativo. Por padrão, o VBRP funciona no modo sem preempção. O modo de preempção precisa ser configurado manualmente. Recomenda-se configurar como modo de preempção. A prioridade padrão do VBRP é 100.
Configurar VBRP para Link com Track
Requisitos de rede
- Habilite o VBRP entre Device1 e Device2.
- Device1 monitora o status da interface VLAN3 via Track. Quando a porta de uplink VLAN3 do Device1 está inativa, o VBRP pode sentir e alternar o status, fazendo com que o Standby se torne um novo Ativo para o encaminhamento de dados.
Topologia de rede
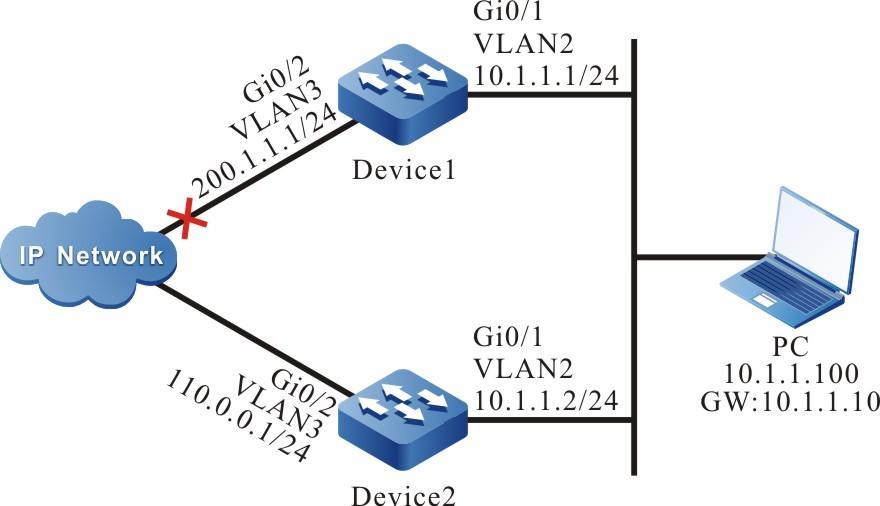
Figura 7 -3 Rede de configuração do VBRP para vincular com o Track
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2: Configure o endereço IP da interface. (Omitido)
- Passo 3: Crie o grupo VBRP.
#Configure o endereço IP virtual do grupo VBRP 1 no Device1 como 10.1.1.10, habilite a função de preempção e configure a prioridade como 110.
Device1#configure terminalDevice1(config)#interface vlan 2Device1(config-if-vlan2)#standby 1 ip 10.1.1.10Device1(config-if-vlan2)#standby 1 preemptDevice1(config-if-vlan2)#standby 1 priority 110
#Configure o endereço IP virtual do VBRP group1 no Device2 como 10.1.1.10 e habilite a função de preempção.
Device2#configure terminalDevice2(config)#interface vlan 2Device2(config-if-vlan2)#standby 1 ip 10.1.1.10Device2(config-if-vlan2)#standby 1 preempt#View the VBRP status of Device1.Device1#show standbyInterface vlan2Primary address 10.1.1.1, state upGroup 1State is ActiveVirtual IP address is 10.1.1.10Refer to local IP prefix 10.1.1.1/24Local virtual MAC address is 0000.0c07.ac01Current MAC type VMAC, installed into HWHello time 3 sec, hold time 10 secNext hello sent in 0.533352 secsPreemption enabled, delay 0 secActive router is localStandby router is 10.1.1.2, priority 100 (expires in 9.283362 secs)Priority 110 (configured 110)
# Visualize o status do VBRP do Device2.
Device2#show standbyInterface vlan2Primary address 10.1.1.2, state upGroup 1State is StandbyVirtual IP address is 10.1.1.10Refer to local IP prefix 10.1.1.2/24Local virtual MAC address is 0000.0c07.ac01Current MAC type VMACHello time 3 sec, hold time 10 secNext hello sent in 2.516646 secsPreemption enabled, delay 0 secActive router is 10.1.1.1, priority 110 (expires in 9.516646 secs)Standby router is localPriority 100 (configured 100)
- Passo 4: Configure o VBRP para vincular ao Track.
#No Device1, configure o VBRP para link com Track, monitore a interface de uplink VLAN3 e configure o decremento de prioridade como 20.
evice1(config)#interface vlan 2Device1(config-if-vlan2)#standby 1 track vlan 3 20
#Visualize o status do VBRP do Device1.
Device1#show standbyInterface vlan2Primary address 10.1.1.1, state upGroup 1State is ActiveVirtual IP address is 10.1.1.10Refer to local IP prefix 10.1.1.1/24Local virtual MAC address is 0000.0c07.ac01Current MAC type VMAC, installed into HWHello time 3 sec, hold time 10 secNext hello sent in 0.533352 secsPreemption enabled, delay 0 secActive router is localStandby router is 10.1.1.2, priority 100 (expires in 9.283362 secs)Priority 110 (configured 110)Track interface vlan3 state Up decrement 20
#Quando a porta de uplink VLAN3 do Device1 está inativa, a prioridade VBRP é reduzida em 20. Aqui, a prioridade do Device2 é alta, então o status muda.
#Visualize o status do VBRP do Device1.
Device1#show standbyInterface vlan2Primary address 10.1.1.1, state upGroup 1State is StandbyVirtual IP address is 10.1.1.10Refer to local IP prefix 10.1.1.1/24Local virtual MAC address is 0000.0c07.ac01Current MAC type VMACHello time 3 sec, hold time 10 secNext hello sent in 0.800008 secsPreemption enabled, delay 0 secActive router is 10.1.1.2, priority 100 (expires in 7.766676 secs)Standby router is localPriority 90 (configured 110)Track interface vlan3 state Down decrement 20#View the VBRP status on Device2.Device2#show standbyInterface vlan2Primary address 10.1.1.2, state upGroup 1State is ActiveVirtual IP address is 10.1.1.10Refer to local IP prefix 10.1.1.2/24Local virtual MAC address is 0000.0c07.ac01Current MAC type VMAC, installed into HWHello time 3 sec, hold time 10 secNext hello sent in 0.533352 secsPreemption enabled, delay 0 secActive router is localStandby router is 10.1.1.1, priority 90 (expires in 9.283362 secs)Priority 100 (configured 100)
Configurar o modo de balanceamento de carga VBRP
Requisitos de rede
- Device1 e Device2 pertencem a dois grupos VBRP ao mesmo tempo; Device1 está ativo no grupo1 e em espera no grupo2; Device2 está em espera no grupo1 e ativo no grupo2.
- PC1 encaminha dados via Device1 e PC2 encaminha dados via Device2, realizando o balanceamento de carga.
Topologia de rede
Figura 7 -4 Rede de balanceamento de carga VBRP
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2: Configure o endereço IP da interface. (Omitido)
- Passo 3: Criar grupo VBRP1.
# Configure o endereço IP virtual do grupo VBRP 1 no Device1 como 10.1.1.10, habilite a função de preempção e configure a prioridade como 110.
Device1#configure terminalDevice1(config)#interface vlan 2Device1(config-if-vlan2)#standby 1 ip 10.1.1.10Device1(config-if-vlan2)#standby 1 preemptDevice1(config-if-vlan2)#standby 1 priority 110#Configure the virtual IP address of VBRP group1 on Device2 as 10.1.1.10 and enable the preemption function.Device2#configure terminalDevice2(config)#interface vlan 2Device2(config-if-vlan2)#standby 1 ip 10.1.1.10Device2(config-if-vlan2)#standby 1 preempt
- Passo 4: Criar grupo VBRP2.
# Configure o endereço IP virtual do grupo VBRP 2 no Device1 como 10.1.1.11 e habilite a função de preempção.
Device1(config)#interface vlan 2Device1(config-if-vlan2)#standby 2 ip 10.1.1.11Device1(config-if-vlan2)#standby 2 preempt
# Configure o endereço IP virtual do grupo VBRP 1 no Device2 como 10.1.1.11, habilite a função de preempção e configure a prioridade como 120.
Device2(config)#interface vlan 2Device2(config-if-vlan2)#standby 2 ip 10.1.1.11Device2(config-if-vlan2)#standby 2 preemptDevice2(config-if-vlan2)#standby 2 priority 120
- Passo 5: Confira o resultado.
#Visualize o status do VBRP no grupo 1 e no grupo 2 no Device1.
Device1#show standbyInterface vlan2Primary address 10.1.1.1, state upGroup 1State is ActiveVirtual IP address is 10.1.1.10Refer to local IP prefix 10.1.1.1/24Local virtual MAC address is 0000.0c07.ac01Current MAC type VMAC, installed into HWHello time 3 sec, hold time 10 secNext hello sent in 0.633348 secsPreemption enabled, delay 0 secActive router is localStandby router is 10.1.1.2, priority 100 (expires in 7.83370 secs)Priority 110 (configured 110)Group 2State is StandbyVirtual IP address is 10.1.1.11Refer to local IP prefix 10.1.1.1/24Local virtual MAC address is 0000.0c07.ac02Current MAC type VMACHello time 3 sec, hold time 10 secNext hello sent in 0.950002 secsPreemption enabled, delay 0 secActive router is 10.1.1.2, priority 120 (expires in 7.300028 secs)Standby router is localPriority 100 (configured 100)#View the status of VBRP in group 1 and group 2 on Device2.Device2#show standbyInterface vlan2Primary address 10.1.1.2, state upGroup 1State is StandbyVirtual IP address is 10.1.1.10Refer to local IP prefix 10.1.1.2/24Local virtual MAC address is 0000.0c07.ac01Current MAC type VMACHello time 3 sec, hold time 10 secNext hello sent in 0.600016 secsPreemption enabled, delay 0 secActive router is 10.1.1.1, priority 110 (expires in 7.700012 secs)Standby router is localPriority 100 (configured 100)Group 2State is ActiveVirtual IP address is 10.1.1.11Refer to local IP prefix 10.1.1.2/24Local virtual MAC address is 0000.0c07.ac02Current MAC type VMAC, installed into HWHello time 3 sec, hold time 10 secNext hello sent in 0.816674 secsPreemption enabled, delay 0 secActive router is localStandby router is 10.1.1.1, priority 100 (expires in 8.33332 secs)Priority 120 (configured 120)
Podemos ver que Device1 serve como Ativo do grupo VBRP1 e Standby do grupo VBRP2. Em contraste com Device1, Device2 serve como Active do grupo VBRP 2 e Standby do grupo VBRP 1. Quando um dispositivo falha, dois PCs encaminham dados através do outro dispositivo. Isso realiza o balanceamento de carga e o backup um do outro.
Protocolo de balanceamento de carga VRRP
Visão geral
O protocolo de balanceamento de carga VRRP (Protocolo de Redundância de Roteador Virtual de Balanço de Carga ) suporta os clientes configurados com o mesmo gateway para serem carregados dinamicamente sob a condição de exportação de vários gateways na LAN. Enquanto isso, leva em consideração o recurso de backup de redundância.
Os principais dispositivos mencionados abaixo são substituídos por "Master" e os dispositivos de backup são substituídos por "Backup".
Configuração da função do protocolo de balanceamento de carga VRRP
Tabela 8 -1 lista de configuração de função de protocolo de balanceamento de carga VRRP
| Tarefas de configuração | |
| Configurar o modo atual do VRRP | Habilite o modo de balanceamento de carga VRRP |
| Configure as funções básicas do protocolo de balanceamento de carga VRRP |
Habilite o protocolo de balanceamento de carga VRRP
Configure a prioridade do protocolo de balanceamento de carga VRRP Configure o endereço MAC virtual do protocolo de balanceamento de carga VRRP |
| Configure o temporizador do protocolo de balanceamento de carga VRRP |
Configure o intervalo de período do pacote Hello
Configure o intervalo de período do pacote Keep Configure o temporizador zumbi do endereço mac virtual Configure o temporizador de idade do terminal de encaminhamento Configure o temporizador de detecção do terminal de encaminhamento |
Configurar o modo atual do protocolo de balanceamento de carga VRRP
Nas tarefas de configuração do protocolo de balanceamento de carga VRRP, o modo de protocolo de balanceamento de carga VRRP deve ser habilitado, que é mutuamente exclusivo com o protocolo padrão VRRP.
Condições de configuração
Nenhum
Ativar VRRP Load - Balance Protocol Mode
Tabela 8 -2 Habilite o modo de protocolo de balanceamento de carga VRRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | vrrp mode load-balance | Obrigatório |
Configurar as funções básicas do protocolo de balanceamento de carga VRRP
Nas tarefas de configuração do protocolo de balanceamento de carga VRRP, o protocolo de balanceamento de carga VRRP deve ser habilitado primeiro e o endereço IP virtual do grupo de protocolos de balanceamento de carga VRRP precisa estar no mesmo segmento de rede que o endereço IP do interface, para que as outras funções configuradas possam ter efeito.
Condições de configuração
Antes de configurar as funções básicas do VRRP, primeiro conclua as seguintes tarefas:
- Configurar o endereço IP da interface
Habilite o protocolo de balanceamento de carga VRRP
Para habilitar a função de protocolo de balanceamento de carga VRRP, é necessário criar um grupo de protocolos de balanceamento de carga VRRP na interface e configurar o endereço IP virtual.
Tabela 8 -3 Habilite o protocolo VRRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configurar o grupo de protocolos de balanceamento de carga VRRP | vrrp vrid ip ip-address | Obrigatório Habilite o protocolo de balanceamento de carga VRRP. Aqui, vrid é o número do grupo de protocolos de balanceamento de carga VRRP e ip-address é o endereço IP virtual. |
No modo de protocolo de balanceamento de carga VRRP, você não pode configurar o IP virtual para ser o mesmo que o IP da interface.
Configurar a Prioridade do Protocolo de Balanço de Carga VRRP
Se a prioridade não for configurada após a configuração do protocolo de balanceamento de carga VRRP, sua prioridade padrão será 100; o dispositivo de alta prioridade será eleito como Master responsável pelo encaminhamento de pacotes, e os demais serão Backup; se as prioridades de todos os dispositivos forem iguais, eleja de acordo com o endereço IP da interface de cada dispositivo, e a interface com o endereço IP grande será a Master; você pode definir a prioridade do protocolo de balanceamento de carga VRRP de acordo com a necessidade. Quanto maior o valor de prioridade, maior a prioridade.
Tabela 8 -4 Configure a prioridade do grupo de protocolos de balanceamento de carga VRRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| grupo de protocolos de balanceamento de carga VRRP | vrrp vrid priority priority | Obrigatório Por padrão, a prioridade é 100. |
Configurar autenticação de texto simples do protocolo de balanceamento de carga VRRP
Após a configuração do protocolo de balanceamento de carga VRRP, se a autenticação de texto simples não estiver definida, a função de autenticação de texto simples não será habilitada por padrão; somente quando a autenticação é consistente no grupo de protocolos de balanceamento de carga VRRP, o vizinho pode ser estabelecido com sucesso e o estado pode ser negociado.
Tabela 8 -5 Configurar a autenticação de texto simples do protocolo de balanceamento de carga VRRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configurar a autenticação de texto simples do protocolo de balanceamento de carga VRRP | vrrp vrid authentication text string | Mandatório _ Por padrão, não ative a função de autenticação de texto simples. A senha de autenticação tem no máximo oito caracteres. |
Configure o endereço MAC real do protocolo de balanceamento de carga VRRP
Cada roteador virtual em um grupo de protocolos de balanceamento de carga VRRP tem um endereço MAC virtual. De acordo com os regulamentos do protocolo de balanceamento de carga VRRP, o formato do endereço MAC virtual é 00.01.7a.00. {vrid}. {mid}, e o valor médio é atribuído pelo mestre. Quando um roteador virtual responde a uma solicitação ARP, o retornado é o endereço MAC virtual, não o endereço MAC real da interface. Por padrão, o endereço MAC virtual da interface é usado.
Tabela 8 -6 Configure o endereço MAC real do protocolo de balanceamento de carga VRRP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o protocolo de balanceamento de carga VRRP para usar o endereço MAC real | vrrp vrid use-bia | Obrigatório Por padrão, use o endereço MAC virtual . |
Por padrão, adote o endereço MAC virtual após configurar o VRRP. Após configurar o comando desta seção, utilize o MAC real na interface correspondente, ou seja, o host encaminha o pacote pelo endereço MAC real; após excluir o comando desta seção, utilize o endereço MAC virtual da interface correspondente, ou seja, o host envia o pacote pelo endereço MAC virtual.
Configurar o temporizador do protocolo de balanceamento de carga VRRP
No protocolo de balanceamento de carga VRRP, execute as ações correspondentes de acordo com o temporizador correspondente, de modo a manter o estado relevante.
Condições de configuração
Antes de configurar o temporizador do protocolo de balanceamento de carga VRRP, primeiro conclua as seguintes tarefas:
- Alterne o modo VRRP para o modo de protocolo de balanceamento de carga VRRP
- Habilite o grupo de protocolos de balanceamento de carga VRRP
Configurar o intervalo de período do pacote Hello
O pacote Hello é o principal responsável por anunciar algumas informações aos vizinhos e manter o relacionamento entre os vizinhos, por isso é necessário manter os períodos de envio dos pacotes Hello consistentes entre os vizinhos do mesmo grupo.
Tabela 8 -7 Configure o intervalo de período do pacote Hello
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o intervalo de período do pacote Hello do protocolo de balanceamento de carga VRRP grupo | vrrp vrid timers hello Hello–time [ hold Hold–time [preserved Preserved–time [delay-vote Delay-vote–time]]] | Obrigatório Configure o intervalo de período do pacote Hello. Aqui, vrid é o número do grupo VRRP; Hello – time especifica o período de envio do pacote Hello do grupo VRRP; Hold – tempo especifica o tempo de espera do vizinho do grupo VRRP; Preservado – tempo especifica o tempo de reserva do MAC virtual do grupo VRRP; Delay-vote – time especifica o tempo de eleição de atraso do grupo VRRP. |
Configurar o intervalo do período do pacote Keep
O pacote Keep é responsável por anunciar o endereço MAC virtual do roteador virtual para o switch L2 e atualizar as entradas MAC L2 do switch .
Tabela 8 -8 Configure o intervalo de período do pacote Keep
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o intervalo de período do pacote Keep do grupo de protocolos de balanceamento de carga VRRP | vrrp vrid timers keep keep-time | Obrigatório Configure o intervalo de período do pacote Keep. Aqui, vrid é o número do grupo VRRP; Keep -time especifica o período de envio do pacote Keep do grupo de protocolos de balanceamento de carga VRRP. |
Configurar o temporizador do zumbi do endereço MAC virtual
Depois que o proprietário do MAC virtual falhar, o MAC virtual experimentará o estado reservado e atingirá o estado zumbi. A configuração do estado zumbi precisa do temporizador maior que o tempo de idade do ARP do terminal inferior.
Tabela 8 -9 Configure o temporizador zumbi do endereço MAC virtual
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o tempo de zumbi do endereço MAC virtual do grupo de protocolos de balanceamento de carga VRRP | vrrp vrid timers zombie zombie-time | Obrigatório Configure o temporizador zumbi do endereço MAC virtual. Aqui, vrid é o número do grupo de protocolos de balanceamento de carga VRRP e Zombie -time especifica o tempo zumbi do MAC virtual do grupo de protocolos de balanceamento de carga VRRP. |
Configurar o temporizador de idade do terminal de encaminhamento
Se o terminal não estiver online por muito tempo ao gerenciar o terminal na camada de encaminhamento, ele será envelhecido para liberar os recursos ocupados pelo terminal, atualizando assim os itens da tabela de terminais do grupo.
Tabela 8 -10 Configure o temporizador de idade do terminal na camada de encaminhamento
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configurar o temporizador de idade do terminal de encaminhamento do grupo de protocolos de balanceamento de carga VRRP | vrrp vrid timers forwarding ageing forwarding-ageing-time | Obrigatório Configure o tempo de idade do terminal na camada de encaminhamento. Aqui, vrid é o número do grupo VRRP e forwarding-ageing-time especifica o tempo de idade do terminal na camada de encaminhamento no grupo VRRP. |
Configure o temporizador de detecção do terminal na camada de encaminhamento
Ao gerenciar o terminal na camada de encaminhamento, detecte o estado online do terminal regularmente, de modo a atualizar o estado do terminal no local.
Tabela 8 -11 Configure o temporizador de detecção do terminal na camada de encaminhamento
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | Obrigatório |
| Configure o temporizador de detecção do terminal na camada de encaminhamento no grupo de protocolos de balanceamento de carga VRRP | vrrp vrid timers forwarding dtct forwarding-dtct-time | Obrigatório Configurar o temporizador de detecção do terminal na camada de encaminhamento. Aqui, vrid é o número do grupo de protocolos de balanceamento de carga VRRP, e forwarding- dtct -time especifica o tempo de detecção do terminal na camada de encaminhamento no grupo de protocolos de balanceamento de carga VRRP. |
Monitoramento e manutenção do protocolo de balanceamento de carga VRRP
Tabela 8 -12 Monitoramento e manutenção de VRRP
| Comando | Descrição |
| Show vrrp [ interface interface-name ] | Exiba as informações de configuração do protocolo de balanceamento de carga do VRRP, incluindo informações de endereço IP virtual, informações de endereço MAC virtual, status do dispositivo, prioridade do dispositivo, endereço de interface do dispositivo dependente, informações do grupo de ligação, etc. |
Exemplo de configuração típica de balanceamento de carga de VRRP
Configurar as funções básicas do protocolo de balanceamento de carga VRRP
Requisitos de rede
- Em Device1 e Device2, crie um grupo de backup de balanceamento de carga VRRP, fazendo com que Device1 e Device2 compartilhem um endereço IP virtual e realize o backup para o gateway padrão do host do usuário, de modo a reduzir o tempo de interrupção da rede.
- O protocolo de balanceamento de carga VRRP realiza a função de carga distribuindo o tráfego de diferentes hosts de usuários para diferentes dispositivos VRRP em um grupo. A diferença significativa do VRRP comum é que os dispositivos de backup no protocolo de balanceamento de carga VRRP também podem encaminhar o tráfego, o que permite que os usuários configurem o mesmo endereço de gateway para todos os hosts na rede para obter o balanceamento de carga.
Topologia de rede
Figura 8 -1 Rede de configuração das funções básicas do protocolo de balanceamento de carga VRRP
Etapas de configuração
- Passo 1: Configure o endereço IPv4 da interface (omitido).
- Passo 2: Configure o dispositivo como o modo de protocolo de balanceamento de carga VRRP.
# Configure o Dispositivo 1.
Device1#configure terminalDevice1(config)#vrrp mode load-balance
# Configure o Dispositivo 2.
Device2#configure terminalDevice2(config)#vrrp mode load-balance
# Consulta o protocolo VRRP modo de Dispositivo1.
Device1#show vrrp-pub modeCurrent mode:load_balanceCurrent switch:0
# Consulta o protocolo VRRP modo de Device2.
Device2#show vrrp-pub modeCurrent mode:load_balanceCurrent switch:0
Você pode ver que Device1 e Device2 são executados no modo de protocolo de balanceamento de carga VRRP.
- Passo 3: Crie um grupo de backup de protocolo de balanceamento de carga VRRP.
# No Device1, crie o grupo de backup 1. O endereço IP virtual é 10.1.1.3 e configure a prioridade como 110.
Device1(config)#interface gigabitethernet 0/2/0Device1(config-if-gigabitethernet0/2/0)#vrrp 1 ip 10.1.1.3Device1(config-if-gigabitethernet0/2/0)#vrrp 1 priority 110Device1(config-if-gigabitethernet0/2/0)#exit
# No dispositivo 2 , crie o grupo de backup 1 e o endereço IP virtual é 10.1.1.3
Device2(config)#interface gigabitethernet 0/2/0Device2(config-if-gigabitethernet0/2/0)#vrrp 1 ip 10.1.1.3Device2(config-if-gigabitethernet0/2/0)#exit
- Passo 4: Consulte o status do protocolo de balanceamento de carga VRRP.
# Consulta a tabela vizinha do protocolo de balanceamento de carga VRRP do Device1.
Device1#show vrrp neighborGid Neighbor Priority Uid Virtual-ip Master Hold-time Interface1 10.1.1.2 100 412780 10.1.1.3 10.1.1.1 36 gigabitethernet0/2/0
Do campo Neighbor, você pode ver que Device1 configura com sucesso o vizinho com Device2 .
# Consulta a tabela vizinha do protocolo de balanceamento de carga VRRP do Device2.
Device2#show vrrp neighborGid Neighbor Priority Uid Virtual-ip Master Hold-time Interface1 10.1.1.1 110 348619 10.1.1.3 10.1.1.1 33 gigabitethernet0/2/0
Do campo Neighbor, você pode ver que Device2 também configura o vizinho com Device1 com sucesso .
# Consulta o status do protocolo de balanceamento de carga VRRP do Device1.
Device1#show vrrpInterface gigabitethernet0/2/0Vrf:0Virtual router : 1Mac mode: real mac modeForwording mac :00.01.7a.7c.72.26Virtual IP address : 10.1.1.3Match address : 10.1.1.1State : MasterPriority : 110Hello interval(sec) : 10next hello in 3 secsHold time(sec) : 40Delay vote time(sec) : 40Delay delete time(sec) : 20Preserve time(sec) : 40Keep(min) : 15Zombie(min) : 10Uid : 348619Terminal number : 0/1000
partir do campo State, você pode ver que Device1 é eleito como Master .
#Consulte o status do protocolo de balanceamento de carga VRRP do Device2.
Device2#show vrrpInterface gigabitethernet0/2/0Vrf:0Virtual router : 1Mac mode: real mac modeForwording mac :00.01.7a.ff.ff.00Virtual IP address : 10.1.1.3Match address : 10.1.1.2State : Backupmaster:10.1.1.1Priority : 100Hello interval(sec) : 10next hello in 6 secsHold time(sec) : 40Delay vote time(sec) : 40Delay delete time(sec) : 20Preserve time(sec) : 40Keep(min) : 15Zombie(min) : 10Uid : 412780Terminal number : 0
No campo State, você pode ver que Device2 se torna Backup.
#No Dispositivo1, consulte o protocolo de balanceamento de carga VRRP encaminhando a tabela de distribuição de endereços MAC.
Device1# show vrrp fmacGid Virtual-ip Forwarding-mac Owner Backup Owner-state Timeout Interface1 10.1.1.3 0001.7a7c.7226 10.1.1.1 - Active - gigabitethernet0/2/0 1 10.1.1.3 0001.7aff.ff00 10.1.1.2 - Active - gigabitethernet0/2/0
Somente o Master tem a função de distribuir o endereço MAC de encaminhamento. Da relação correspondente entre Owner e Forwarding-mac, pode-se ver que o endereço MAC de encaminhamento alocado para 10.1.1.1 é 0001.7a7c.7226, e o endereço MAC de encaminhamento alocado para 10.1.1.2 é 0001.7aff.ff00.
O protocolo de balanceamento de carga VRRP só pode funcionar no modo não antecipado. O protocolo de balanceamento de carga VRRP inicia o temporizador de eleição de atraso no estado de inicialização e, por padrão, é quatro vezes o intervalo Hello. Escolha após o tempo limite. O protocolo de balanceamento de carga VRRP elege de acordo com a prioridade. Aquele com maior prioridade é eleito como Mestre. Se as prioridades forem as mesmas, compare os endereços IP das interfaces. Aquele com o maior endereço IP é eleito como Master e os demais são Backup.
- Passo 5: Confira o resultado.
#No PC1 e PC2, execute ping no gateway para testar a conectividade. Em Device1, consulte o endereço MAC de encaminhamento de gateway distribuído pelo Master para o host.
gateway forwarding MAC address distributed by Master for the host.Device1#show vrrp terminalGid Virtual-ip Terminal Forwarding-mac Interface1 10.1.1.3 10.1.1.10 0001.7a7c.7226 gigabitethernet0/2/01 10.1.1.3 10.1.1.20 0001.7aff.ff00 gigabitethernet0/2/0
Conforme mostrado na tabela acima, os terminais de host PC1 e PC2 são atribuídos com diferentes endereços MAC de encaminhamento de gateway. Combinado com os endereços MAC de encaminhamento alocados pelo Mestre para o Dispositivo 1 e Dispositivo 2 na Etapa 4, pode-se ver que o tráfego de PC1 e PC2 é encaminhado pelo Dispositivo 1 e Dispositivo 2, respectivamente, para obter o balanceamento de carga.
# No Device2, consulte a tabela de distribuição de endereços MAC de encaminhamento do gateway do terminal de backup.
Device2#show vrrp terminalGid Virtual-ip Terminal Forwarding-mac Interface1 10.1.1.3 10.1.1.10 0001.7a7c.7226 gigabitethernet0/2/01 10.1.1.3 10.1.1.20 0001.7aff.ff00 gigabitethernet0/2/0
tabela de distribuição de endereços MAC de encaminhamento do gateway do terminal para todos os dispositivos VRRP.
Track
Visão geral
Track pode ser usado para monitorar algumas informações quando o sistema é executado. Os outros módulos de serviço podem ser associados ao Track para que o módulo de serviço possa monitorar a mudança quando o sistema for executado. Depois que o módulo de serviço é associado ao Track e quando as informações monitoradas pelo Track mudam, o Track informa o módulo de serviço para que o módulo de serviço possa processar de forma correspondente. Por exemplo, na aplicação real, o VRRP e o VBRP frequentemente monitoram o status da interface de uplink e a disponibilidade da rede associando-se ao Track e ajustando sua própria prioridade de acordo com as informações, de modo a realizar a alternância ativa/em espera.
Configuração da função de track
Tabela 9 – 1 Lista de configuração da função de trilha
| Tarefa de configuração | |
| Configurar o grupo Track | Configurar o grupo Track |
| Configurar o objeto de monitor |
Configurar o status da interface do monitor
Configure o monitoramento do status da interface Ethernet L2 Configure o monitoramento da rota direta da interface Configurar rota de monitoramento alcançável Configurar o monitoramento do grupo RTR Configurar o monitoramento do status do grupo de agregação Configurar o monitoramento da sessão BFD |
Configurar grupo de track
Condição de configuração
Nenhum
Configurar grupo de track
O sistema pode configurar vários grupos de trilhas. Cada grupo de faixas é independente um do outro. Um grupo Track pode incluir vários objetos de monitor.
O grupo Track possui duas lógicas, ou seja, “e”, “ou”:
- Quando a lógica do grupo Track for “e”, todos os objetos de monitor no grupo Track precisam estar ativos para que o grupo Track possa estar ativo; em contraste, está para baixo.
- Quando a lógica do grupo Track for “ou”, enquanto um objeto de monitor no grupo Track estiver ativo, o status do objeto Track pode estar ativo; em contraste, está para baixo.
Tabela 9 – 2 Configure o grupo Track
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Crie o grupo Faixa | track group-id | Obrigatório |
| Configurar lógica de grupo de track | logic operator { AND | OR } | Opcional AND : lógica “e” OR : lógico “ou” Por padrão, a lógica do grupo de track é “ou”. |
Quando o módulo de serviço precisa monitorar alguma informação via Track, além de configurar o objeto monitor no grupo Track, também precisamos consultar o manual de configuração do módulo de serviço e configurar o módulo de serviço para associar ao grupo Track.
Configurar objeto do track
Condição de configuração
Antes de configurar o objeto do track, primeiro conclua a seguinte tarefa:
- Configurar o grupo Track
Configurar o status da interface de monitoramento
Podemos configurar o objeto do track como o status da interface no grupo Track. Quando o protocolo da camada de rede da interface está ativo, o status do objeto do track está ativo; quando o protocolo da camada de rede da interface está inativo, o status do objeto do track está inativo.
Tabela 9 – 3 Configurar o status da interface de monitoramento
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da trilha | track group-id | Obrigatório |
| Configurar o status da interface de monitoramento | interface interface-name line-protocol interface interface-name line-ipv6-protocol | Obrigatório |
Configurar Monitoramento do Status da Interface Ethernet L2
Podemos configurar o objeto do track como o status da interface Ethernet L2 no grupo Track. Quando a interface Ethernet L2 está ativa, o status do objeto do track está ativo; quando a interface Ethernet L2 está inativa, o status do objeto do track está inativo.
Tabela 9 – 4 Configure o monitoramento do status da interface Ethernet L2
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da trilha | track group-id | Obrigatório |
| Configure o monitoramento do status da interface Ethernet L2 | switchport interface name | Obrigatório |
Configurar monitoramento de rota direta de interface
Podemos configurar o objeto do track como a rota direta da interface no grupo Track. Quando a interface tem endereço IP e o status está ativo, o status do objeto do track está ativo; quando a interface não tem endereço IP ou o status está inativo, o status do objeto do track está inativo.
Tabela 9 – 5 Configure o monitoramento da rota direta da interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da trilha | track group-id | Obrigatório |
| Configure o monitoramento da rota direta da interface | interface interface-name ip-routing interface interface-name ipv6-routing | Obrigatório |
Configurar rota de monitoramento alcançável
Podemos configurar o objeto do track como a rota alcançável no grupo Track. Quando existe a rota da rede configurada, o status do objeto do track é up; quando não há rota da rede configurada, o status do objeto do track é inativo.
Tabela 9 – 6 Configurar rota de monitoramento alcançável
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da trilha | track group-id | Obrigatório |
| Configurar rota de monitoramento alcançável | ip-route network mask [ vrf vrf-name ] [ metric metric-value ] ipv6-route network mask [ vrf vrf-name ] [ metric metric-value ] | Obrigatório Quando há a opção metric , a métrica de rota para a rede precisa ser menor que o valor configurado para que o status do objeto do track possa estar ativo. |
Configurar grupo RTR de monitoramento
Podemos configurar o objeto do track como o grupo RTR no grupo Track. Quando o status do grupo RTR é alcançável, o status do objeto do track é ativo; quando o status do grupo RTR é inacessível, o status do objeto do track é inativo. RTR (Response Time Reporter) é uma ferramenta de detecção e monitoramento da rede. Track pode monitorar o grupo RTR para monitorar a comunicação de rede.
Tabela 9 – 7 Configure o monitoramento do grupo RTR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da trilha | track group-id | Obrigatório |
| Configurar o monitoramento do grupo RTR | rtr rtr-group-id | Obrigatório |
Para a configuração do grupo RTR, consulte o Manual de configuração do SLA.
Configurar o status do grupo de agregação de monitoramento
Podemos configurar o objeto do trackado no grupo Track como o status do grupo de agregação. Quando o status do grupo de agregação está ativo, o estado do objeto do trackado está ativo; quando o estado do grupo de agregação está inativo, o estado do objeto do trackado está inativo.
Tabela 9 – 8 Configurar o monitoramento do status do grupo de agregação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da trilha | track group-id | Obrigatório |
| Configurar o monitoramento da sessão BFD | link-aggregation link-aggregation-id | Mandatório _ |
Configurar sessão BFD de monitoramento
Podemos configurar o objeto do track como a sessão BFD no grupo Track. Quando o status da sessão BFD está ativo, o status do objeto do track está ativo; quando o status da sessão BFD está inativo, o status do objeto do track está inativo. O protocolo BFD é um conjunto de mecanismo de detecção unificado padrão, usado para detectar rapidamente, monitorar o caminho na rede ou o status da conexão do encaminhamento de rota IP. O status da conexão de rede pode ser monitorado indiretamente monitorando a sessão BFD.
Tabela 9 – 9 Configure o monitoramento da sessão BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da trilha | track group-id | Obrigatório |
| Configurar o monitoramento da sessão BFD | bfd interface interface-name remote-ip ip-address local-ip ip-address bfd interface interface-name remote-ipv6 ipv6-address local-ipv6 ipv6-address | Obrigatório Ao configurar o monitoramento da sessão BFD, ele precisa ser configurado nos dois lados da sessão BFD. Caso contrário, a sessão BFD não pode ser configurada com sucesso. |
Monitoramento e manutenção de track
Tabela 9 – 10 Monitoramento e manutenção da trilha
| Comando | Descrição |
| show track object group-id | Exibe as informações do grupo Track. |
| show track bfd-session | Exibe as informações da sessão BFD monitorada pelo Track. |
BFD
Visão geral
O protocolo BFD (Bidirectional Forwarding Detection) é um conjunto de mecanismo de detecção padrão e unificado, usado para detectar e monitorar o caminho na rede ou o status de conexão de encaminhamento de rota IP rapidamente. Ele fornece um mecanismo de detecção rápida de falhas universal, padrão, independente de meio e independente de protocolo. Ele pode detectar rapidamente a falha de linha entre dois dispositivos para os protocolos da camada superior, como protocolo de roteamento e MPLS.
O BFD pode fornecer a detecção de falhas em qualquer tipo de caminho entre os sistemas. Uma sessão BFD é configurada com base na demanda específica do aplicativo. Se vários protocolos de aplicativo corresponderem ao mesmo caminho, você poderá usar uma sessão BFD para detectar.
O fluxo de processamento do protocolo BFD e do protocolo de aplicação superior inclui:
O protocolo de aplicação superior envia as informações do vizinho (incluindo o endereço IP do peer, endereço IP local, interface e assim por diante) para o protocolo BFD.
O protocolo BFD consulta se existe a sessão correspondente. Se não, crie a sessão correspondente de acordo com as informações do vizinho recebido e, em seguida, a sessão BFD envia o pacote de controle BFD para conduzir o funcionamento da máquina de status. O pacote de controle BFD completa a sessão por meio do mecanismo de handshake de três tempos, experimentando a transferência de Down para Init e de Init para Up. Ao configurar a sessão, os parâmetros da sessão são negociados, incluindo o intervalo de envio de pacotes e intervalo de detecção.
Após a configuração da sessão, envie os pacotes de detecção periodicamente para detectar o status do caminho. Se os pacotes de controle BFD do dispositivo peer não forem recebidos dentro do intervalo de detecção, o protocolo BFD considera que o caminho possui falha e informa a informação da falha ao protocolo de aplicação superior.
Após o protocolo de aplicação superior receber o relatório de falha, informe o protocolo BFD para deletar a sessão ao desabilitar ou deletar o vizinho. Se nenhum outro protocolo de camada superior precisar detectar o link de sessão, exclua a sessão correspondente.
De acordo com o tipo de caminho de detecção, ele inclui a detecção de caminho IP de salto único vizinho ao terminal local e ao par, e a detecção de caminho IP multi-hop não vizinho ao terminal e ponto local. Atualmente, vincular os protocolos OSPF, RIP, EBGP, ISIS, LDP, RSVP-TE, TRACK e de rota estática com BFD pertence à detecção de caminho IP de salto único. A vinculação de IBGP com BFD pertence à detecção de caminho IP multi-hop.
Configuração da função BFD
Tabela 10 – 1 lista de configuração da função BFD
| Tarefa de configuração | |
| Configurar as funções básicas do BFD |
Configure o intervalo mínimo de envio dos pacotes de controle BFD
Configure o intervalo mínimo de recebimento dos pacotes de controle BFD Configure os múltiplos de tempo limite de detecção da sessão BFD |
Configurar funções básicas do BFD
Condição de configuração
Antes de configurar as funções básicas do BFD, primeiro complete as seguintes tarefas:
- Configure o endereço IP da interface, tornando a camada de rede do nó vizinho acessível
- Configure o aplicativo de camada superior associado ao BFD
Configurar o intervalo mínimo de envio de pacotes de controle BFD
Tabela 10 – 2 Configure o intervalo mínimo de envio de pacotes de controle BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o intervalo mínimo de envio de pacotes de controle BFD | bfd min-transmit-interval value | Opcional Por padrão, o intervalo mínimo de envio de pacotes de controle BFD é de 1000ms. |
O intervalo de envio real dos pacotes BFD locais = MAX (intervalo mínimo de envio dos pacotes de controle BFD locais, intervalo mínimo de recebimento dos pacotes de controle BFD peer) No modo interface, configure o intervalo mínimo de envio do pacote de controle BFD para ter efeito apenas para a sessão IP de salto único.
Configurar o intervalo mínimo de recebimento de pacotes de controle BFD
Tabela 10 – 3 Configure o intervalo mínimo de recebimento do pacote de controle BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure o intervalo mínimo de recebimento do pacote de controle BFD | bfd min-receive-interval value | Opcional Por padrão, o intervalo mínimo de recebimento dos pacotes de controle BFD é de 1000ms. |
O intervalo de envio real dos pacotes de controle do peer BFD = MAX (intervalo mínimo de envio dos pacotes de controle do peer BFD, o intervalo mínimo de recebimento dos pacotes de controle do BFD local) No modo interface, configure o intervalo mínimo de recebimento do pacote de controle BFD para ter efeito apenas para a sessão IP de salto único.
Configurar Múltiplos de Tempo Limite de Detecção da Sessão BFD
Tabela 10 – 4 Configure os múltiplos de tempo limite de detecção da sessão BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configure os múltiplos de tempo limite de detecção da sessão BFD | bfd multiplier value | Opcional Por padrão, os múltiplos de tempo limite de detecção da sessão BFD são 5. |
Para garantir a validade da detecção de sessão BFD, tenha o cuidado de configurar o mínimo dos múltiplos de tempo limite de detecção BFD. Tempo de detecção real de BFD local = os múltiplos de tempo limite de detecção da sessão BFD de peer × o intervalo de envio real do pacote BFD de peer No modo de interface, configure os múltiplos de tempo limite de detecção do pacote de controle BFD para ter efeito apenas para a sessão IP de salto único.
Configurar a função de detecção rápida da sessão BFD
Tabela 10 – 5 Configure a função de detecção rápida da sessão BFD
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a função de detecção rápida da sessão BFD | bfd fast-detect | Opcional Por padrão, a função de detecção rápida da sessão BFD está desabilitada. |
Monitoramento e manutenção de BFD
Tabela 10 - 6 Monitoramento e manutenção de BFD
| Comando | Descrição |
| clear bfd drop statistics | Limpe as informações de estatísticas do pacote de erro BFD |
| clear bfd error-statistics | Limpe as informações de estatísticas de erro do BFD |
| show bfd | Exiba os parâmetros BFD suportados pelo dispositivo |
| show bfd client | Exibir as informações do cliente BFD |
| show bfd discriminator | Exiba as informações do discriminador BFD |
| show bfd drop statistics | Exibir as informações de estatísticas do pacote de erro BFD |
| show bfd error-statistics | Exibir as informações de estatísticas de erro BFD |
| show bfd session [ neighbor-ipv4-address ] [ detail ] | Exiba as informações da sessão BFD IPv4 |
| show bfd session ipv6 [ neighbor-ipv6-address [ interface-name ] ] [ detail ] | Exiba as informações da sessão BFD IPv6 |
Exemplo de configuração típica de BFD
Configurar funções básicas do BFD
Requisitos de rede
- Device4 é o dispositivo de conexão e apenas transmite os dados de forma transparente.
- Device1, Device2 e Device3 executam o protocolo OSPF; Device1 e Device3 configuram a função de detecção BFD.
- Modifique os parâmetros BFD. Quando a linha entre Device4 e Device3 falha, os dados de serviço entre Device1 e Device3 podem realizar a comutação de nível de ms.
Topologia de rede
Figura 10 -1 Rede de configuração das funções básicas do BFD
Etapas de configuração
- Passo 1: Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2: Configure o endereço IP da interface. (Omitido)
- Passo 3: Configurar OSPF.
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#router-id 1.1.1.1Device1(config-ospf)#network 10.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 20.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 200.0.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configurar dispositivo2.
Terminal Device2#configure
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#router-id 2.2.2.2Device2(config-ospf)#network 20.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 30.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#router-id 3.3.3.3Device3(config-ospf)#network 10.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 30.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 201.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
- Passo 4: Configure o OSPF para vincular com o BFD.
#Configurar dispositivo1.
Device1(config)#bfd fast-detectDevice1(config)#interface vlan2Device1(config-if-vlan2)#ip ospf bfdDevice1(config-if-vlan2)#exit
# Configurar dispositivo3.
Device3(config)#bfd fast-detectDevice3(config)#interface vlan2Device3(config-if-vlan2)#ip ospf bfdDevice3(config-if-vlan2)#exit
#Visualize a sessão BFD do Device1.
Device1#show bfd session detailTotal session number: 1OurAddr NeighAddr LD/RD State Holddown interface10.0.0.1 10.0.0.2 12/19 UP 5000 vlan2Type:directLocal State:UP Remote State:UP Up for: 0h:10m:57s Number of times UP:1Send Interval:1000ms Detection time:5000ms(1000ms*5)Local Diag:0 Demand mode:0 Poll bit:0MinTxInt:1000 MinRxInt:1000 Multiplier:5Remote MinTxInt:1000 Remote MinRxInt:1000 Remote Multiplier:5Registered protocols:OSPF
Podemos ver que o OSPF enlaça com BFD com sucesso, a sessão está configurada normalmente e o tempo limite de detecção é de 5s.
#Visualize a tabela de rotas do Device1.
Device1#show ip route
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:20:01, vlan2C 20.0.0.0/24 is directly connected, 00:25:22, vlan3O 30.0.0.0/24 [110/2] via 20.0.0.2, 00:12:31, vlan3[110/2] via 10.0.0.2, 00:11:20, vlan2C 127.0.0.0/8 is directly connected, 00:31:09, lo0C 200.0.0.0/24 is directly connected, 00:20:10, vlan4O 201.0.0.0/24 [110/2] via 10.0.0.2, 00:11:30, vlan2
Na tabela de rotas, podemos ver que a rota 201.0.0.0/24 seleciona primeiro a linha entre Device1 e Device3 para se comunicar.
- Passo 5: Configure os parâmetros BFD.
#Configurar dispositivo1. Modifique o intervalo mínimo de envio e o intervalo mínimo de recebimento dos pacotes de controle BFD para 100ms. Os múltiplos de tempo limite de detecção são 3.
Device1(config)#interface vlan2Device1(config-if-vlan2)#bfd min-transmit-interval 100Device1(config-if-vlan2)#bfd min-receive-interval 100Device1(config-if-vlan2)#bfd multiplier 3Device1(config-if-vlan2)#exit
#Configurar dispositivo3. Modifique o intervalo mínimo de envio e o intervalo mínimo de recebimento dos pacotes de controle BFD para 100ms. Os múltiplos de tempo limite de detecção são 3.
DDevice3(config)#interface vlan2
Device3(config-if-vlan2)#bfd min-transmit-interval 100Device3(config-if-vlan2)#bfd min-receive-interval 100Device3(config-if-vlan2)#bfd multiplier 3Device3(config-if-vlan2)#exit
- Passo 6: Confira o resultado.
#Visualize a sessão BFD do Device1.
Device1#show bfd session detail
#View the BFD session of Device1.Device1#show bfd session detailTotal session number: 1OurAddr NeighAddr LD/RD State Holddown interface10.0.0.1 10.0.0.2 12/19 UP 300 vlan2Type:directLocal State:UP Remote State:UP Up for: 0h:11m:27s Number of times UP:1Send Interval:100ms Detection time:300ms(100ms*3)Local Diag:0 Demand mode:0 Poll bit:0MinTxInt:100 MinRxInt:100 Multiplier:3Remote MinTxInt:100 Remote MinRxInt:100 Remote Multiplier:3Registered protocols:OSPF
Após a modificação dos parâmetros do BFD, o tempo limite de detecção do BFD é negociado de 5s a 300ms.
#Quando a linha entre Device1 e Device3 falha, o BFD detecta rapidamente a falha e informa o OSPF, e então o OSPF muda a rota para Device2 para comunicação. Veja a tabela de rotas de Device1.
Device1#show ip routeCodes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management, E - IRMP, EX - IRMP externalC 10.0.0.0/24 is directly connected, 00:25:00, vlan2C 20.0.0.0/24 is directly connected, 00:30:33, vlan3O 30.0.0.0/24 [110/2] via 20.0.0.2, 00:17:32, vlan3C 127.0.0.0/8 is directly connected, 00:36:10, lo0C 200.0.0.0/24 is directly connected, 00:25:11, vlan4O 201.0.0.0/24 [110/3] via 20.0.0.2, 00:00:10, vlan3
Comparado com a tabela de rotas na Etapa 3, podemos ver que a rota 201.0.0.0/24 já está mudou para Device2 para comunicação.
O modo de processamento BFD no Device3 é semelhante ao Device1.
ERPS
Visão geral
STP (Spanning Tree Protocol) é geralmente usado para confiabilidade de rede em redes Ethernet L2, mas STP (Spanning Tree Protocol) geralmente converge em segundos, e o tempo de convergência é maior quando o diâmetro da rede é maior. Para diminuir o tempo de convergência e eliminar a influência do tamanho da rede, surgiu a tecnologia ERPS (Ethernet Ring Protection Switching). ERPS (Ethernet Ring Protection Switching) é um padrão de protocolo L2 definido pelo ITU-T, e o número do protocolo padrão é ITU-T G.8032/Y1344, também conhecido como G.8032. G. 8032 é uma tecnologia de camada de link de rede em anel Ethernet com alta confiabilidade e estabilidade. Ele pode evitar a tempestade de transmissão causada pelo loop de dados quando a rede de anel Ethernet estiver intacta. Quando o link da rede em anel Ethernet falha, ele pode restaurar rapidamente o caminho de comunicação entre os nós na rede em anel e possui uma alta velocidade de convergência. Enquanto isso, se os equipamentos dos fabricantes na rede em anel suportarem o protocolo, eles poderão se comunicar entre si.
Conceitos relacionados ao ERPS:
- Anel ERPS (Ethernet Ring Protection Switching): Anel ERPS é a unidade básica do protocolo ERPS. Consiste em um grupo de dispositivos de rede interconectados com o mesmo controle VLAN (Virtual Local Area Network). Os anéis ERPS são divididos em anéis principais e subanéis. Os anéis principais são anéis fechados e os anéis secundários são anéis não fechados. Os atributos dos anéis principais e secundários são determinados pelo usuário.
- Função de porta: Existem três tipos de funções de porta especificadas no protocolo ERPS: porta proprietária RPL, porta vizinha RPL e porta comum, entre as quais o tipo de porta vizinha RPL é suportado apenas pela versão ERPSv2.
- Porta do proprietário do RPL: Um anel ERPS possui apenas uma porta do proprietário do RPL, que é especificada pela configuração do usuário. O protocolo ERPS impede que o link gere loops bloqueando o status de encaminhamento da porta proprietária do RPL. O link onde a porta do proprietário do RPL está localizada é o RPL (Ring Protection Link).
- Porta vizinha RPL: A porta vizinha RPL refere-se à porta do nó diretamente conectada à porta do proprietário RPL. Normalmente, as portas proprietárias RPL e as portas vizinhas RPL são bloqueadas para evitar loops. Quando a rede em anel ERPS falha, a porta do proprietário RPL e a porta vizinha RPL serão abertas.
- Porta comum: No anel ERPS, todas as portas, exceto a porta proprietária RPL e a porta vizinha RPL, são portas comuns. As portas comuns são responsáveis por monitorar seu próprio status de link conectado diretamente e notificar oportunamente outras portas de nó sobre alterações de status de link.
- VLAN de Controles ERPS: Usado para transmitir pacotes do protocolo ERPS. A VLAN de controle é especificada pelo usuário. A VLAN utilizada como VLAN de controle ERPS não pode ser utilizada por outros serviços. A VLAN de controle de cada loop ERPS é diferente.
- Instância de dados ERPS: A instância de dados do mapeamento de VLAN de dados que precisa da proteção do anel ERPS.
Função ERPS
Tabela 11 -1 lista de configuração da função ERPS
| Tarefas de configuração | |
| Configurar o anel ERPS | Configurar o anel ERPS Habilite o protocolo ERPS |
| Configurar o temporizador de toque do ERPS | Configurar o temporizador de toque do ERPS |
| Configurar a otimização da rede ERPS |
Configure o modo de comutação do bloqueio de porta ERPS
Limpe os pontos de bloqueio da configuração do ERPS Configure a notificação da mudança de topologia ERPS Configurar a função de limitação do ERPS TC |
| Configure o ERPS para associar ao CFM | Configure o ERPS para associar ao CFM |
Configurar o anel ERPS
Ao configurar o anel ERPS, é necessário configurar as portas em cada nó que acessam o anel ERPS e os nós no anel.
- Condições de configuração
- Crie uma VLAN de controle
- Feche o protocolo de rede em anel das portas em anel
- Configure a porta do anel como o modo de tronco
- Adicione as portas do anel à VLAN de controle do anel
- Configure a instância MSTP e a relação de mapeamento das VLANs contidas
-
Configurar o anel ERPS
Configure as funções básicas do anel ERPS.
Tabela 11 -2 Configurar o anel ERPS
Etapa Comando Descrição Entre no modo de configuração global configure terminal - Criar um anel ERPS erps ring ring-id Obrigatório Por padrão, não crie um anel ERPS e o intervalo de valores do anel é de 1 a 64. Configurar a VLAN de controle de anel ERPS control vlan vlan-id Obrigatório Por padrão, não configure a VLAN de controle do anel ERPS. Configurar a instância de dados de anel do ERPS instance instance-list Obrigatório Por padrão, não configure a instância de dados do ERPS. Configurar a porta de anel ERPS PORT0 port0 { interface interface-name | interface link-aggregation link-aggregation-id } [ rpl { owner | neighbour } ] Obrigatório Por padrão, não configure o ERPS port0 . rpl owner: Indique que a porta é a porta proprietária do RPL rpl vizinho: Indica que a porta é a porta vizinha do RPL. Se não estiver configurando o rpl, indique que a porta é a comum porta. Configure a porta de anel ERPS PORT1 port1 { interface interface-name | interface link-aggregation link-aggregation-id } [ rpl { owner | neighbour } ] Obrigatório Por padrão, não configure o ERPS port1. rpl proprietário : Indica que a porta é a porta proprietária do RPL rpl neighbor : Indica que a porta é a porta vizinha de RPL. Se não estiver configurando o rpl, indique que a porta é a porta comum. Configure as informações de versão do anel ERPS version { v1 | v2 } Opcional Por padrão, a versão é V2. Configure o valor mel do pacote ERPS r i ng mel level-id Opcional Por padrão, o valor mel é 7 e o intervalo de valores é 0-7. Configurar o anel ERPS é o subanel sub-ring Opcional Por padrão, o anel ERPS é o anel principal. Configure o anel ERPS para o modo sem retorno revertive disable Opcional _ Por padrão, o ERPS é o modo switchback. Configure o canal virtual do subanel ERPS virtual-channel enable Opcional _ Por padrão, o ERPS é o canal não virtual. A VLAN de controle ERPS só pode ser usada para transmitir os pacotes do protocolo ERPS, não para outros serviços. Todos os nós no mesmo anel ERPS precisam configurar o mesmo valor Mel. O canal virtual de subanel não é recomendado no ambiente de rede em anel de interseção.
- Habilitar o Protocolo ERPS
Antes de configurar o anel ERPS, primeiro conclua as seguintes tarefas:
Após a conclusão da configuração acima, use o comando para habilitar o protocolo ERPS.
Tabela 11 -3 Habilite o protocolo no anel ERPS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do ERPS | erps ring ring-id | - |
| Habilite o protocolo ERPS | erps enable | Obrigatório Por padrão, o anel não habilita o protocolo ERPS. |
Configurar o temporizador de toque ERPS
- Condições de configuração
- Configurar o anel ERPS
- Configurar o temporizador de toque do ERPS
Antes de configurar o temporizador ERPS, primeiro complete a seguinte tarefa:
Para evitar a oscilação da rede, o temporizador de toque do ERPS será habilitado para reduzir o tempo de interrupção do tráfego após a recuperação da falha do equipamento do nó ou link no anel do ERPS.
Tabela 11 -4 Configurar o temporizador ERPS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do ERPS | erps ring ring-id | - |
| Configure o temporizador Guard do anel ERPS | guard-timer time-value | Obrigatório Por padrão, o tempo limite do timer Guard é de 500ms e o intervalo do timer Guard é de 10-2000ms. |
| Configure o temporizador Hold-off do anel ERPS | holdoff-timer time-value | Obrigatório Por padrão, o tempo limite do timer de espera é 0ms e o intervalo do timer de espera é 0-10 000ms. |
| Configure o temporizador WTR do anel ERPS | wtr-timer time-value | Obrigatório Por padrão, o tempo limite do temporizador WTR é de 5 minutos e o intervalo do temporizador WTR é de 1 a 12 minutos . |
Configurar a otimização de rede ERPS
- Condições de configuração
Antes de configurar a otimização da rede ERPS, primeiro conclua a seguinte tarefa:
- Configurar o anel ERPS
-
Configurar o modo de comutação do bloqueio de porta ERPS
Uma vez que a largura de banda do link onde a porta do proprietário do RPL está localizada pode ser capaz de transportar mais tráfego do usuário, é possível considerar o bloqueio do link com largura de banda baixa para que o tráfego do usuário possa ser transmitido de volta ao RPL.
Tabela 11 -5 Configurar o modo de comutação do bloqueio da porta ERPS
Etapa Comando Descrição Configure o modo de comutação do bloqueio de porta ERPS erps ring ring-id { interface interface-name | interface link-aggregation link-aggregation-id } switch { force | manual } Obrigatório Por padrão, não configure o modo de comutação do ponto de bloqueio da porta do anel ERPS. -
Limpe os pontos de bloqueio da configuração do ERPS
Limpe os pontos de bloqueio da configuração do anel ERPS.
Tabela 11 -6 Limpe os pontos de bloqueio da configuração do ERPS
Etapa Comando Descrição Limpe os pontos de bloqueio da configuração do ERPS clear erps ring ring-id Obrigatório - Configurar a notificação de mudança de topologia ERPS
- Configurar Função Limite ERPS TC
Quando a topologia do loop ERPS muda e a rede L2 superior não é notificada a tempo, a tabela de endereços MAC da rede L2 superior ainda retém as entradas da tabela de endereços MAC antes que a topologia da rede downstream mude, o que causará a interrupção do usuário tráfego. Para garantir a comunicação normal do tráfego do usuário, é necessário selecionar o objeto de notificação do loop ERPS de acordo com a rede real do usuário.
Tabela 11 -7 Configurar a notificação da mudança de topologia do anel ERPS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do ERPS | erps ring ring-id | - |
| Configure a notificação da alteração da topologia do anel ERPS | tc-notify erps ring ring-list | Obrigatório Por padrão, não notifique a mudança da topologia do ERPS. |
A notificação frequente de mudança de topologia levará ao declínio da capacidade de processamento da CPU, e os pacotes FDB de descarga frequentemente atualizados no anel ERPS ocupam a largura de banda da rede. Para evitar esta situação, é necessário suprimir os pacotes de notificação de mudança de topologia. Ao configurar o intervalo de proteção da mudança de topologia ERPS e o limite máximo dos pacotes de mudança de topologia processados no intervalo de proteção da mudança de topologia, suprima a notificação de mudança de topologia e evite excluir frequentemente as entradas de endereço MAC e entradas ARP, de modo a proteger o equipamento.
Tabela 11 -8 Configurar a função de limite ERPS TC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do ERPS | erps ring ring-id | - |
| Configure a habilitação do limite de TC da mudança de topologia do ERPS | tc-limit enable | Obrigatório Por padrão, não habilite a função de limite TC. |
| Configure o intervalo do limite TC da mudança de topologia ERPS | tc-limit interval interval-value | Opcional O intervalo padrão é de 2 segundos e o intervalo de valores é de 1 a 500 segundos. |
| Configure o limite do limite TC da mudança de topologia ERPS | tc-limit threshold threshold-value | Opcional O valor padrão é 3 e o intervalo de valores é 1-64. |
Configurar o ERPS para vincular com o CFM
- Condições de configuração
ERPS para se conectar com o CFM (Connectivity Fault Management), primeiro complete a seguinte tarefa:
- Configurar as funções básicas do ERPS
- Configurar a função CFM
- Configurar o ERPS para vincular com o CFM
Após configurar a função Ethernet CFM linkage na porta do anel adicionada ao anel ERPS, você pode acelerar a detecção de falhas, percebendo a rápida convergência da topologia e reduzindo o tempo de interrupção do tráfego.
Tabela 11 -9 Configurar ERPS para vincular com CFM
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual; depois de entrar no modo de configuração do grupo de agregação, o configuração tem efeito apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o ERPS para vincular com o CFM | erps ring ring-id track cfm md md-name ma ma-name mep mep-id remote-mep rmep-id | Obrigatório Por padrão, a porta não está vinculada ao CFM. |
Monitoramento e Manutenção de ERPS
Tabela 11 -10 Monitoramento e manutenção do ERPS
| Comando | Descrição |
| clear erps [ring ring-id ] statistics | Limpar as informações estatísticas relacionadas ao ERPS |
| show erps [ ring ring-id ] config | Exibir as informações de configuração do ERPS |
| show erps [ring ring-id] detail | Exibir as informações detalhadas do ERPS |
| show erps [ring ring-id] statistics | Exibir as informações de estatísticas do ERPS |
Exemplo de configuração típica de ERPS
Configurar funções básicas do ERPS
Requisitos de rede
- Todos os dispositivos estão em uma rede L2.
- Todos os dispositivos habilitam o ERPS e adotam o ERPS para cortar os anéis de link na rede.
Topologia de rede

Figura 11 -1 Configurar funções básicas do ERPS
Etapas de configuração
- Passo 1: Configure vlan e tipo de link de porta.
#No Device1, crie VLAN2, VLAN100~VLAN200 respectivamente, e configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN2, vlan100~VLAN200.
Device1#configure terminalDevice1(config)#vlan 2,100-200Device1(config)# interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#shutdownDevice1(config-if-gigabitethernet0/1)# switchport mode trunkDevice1(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device1(config-if-gigabitethernet0/1)#exitDevice1(config)# interface gigabitethernet 0/2Device1(config-if-gigabitethernet0/1)# switchport mode trunkDevice1(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device1(config-if-gigabitethernet0/1)#end
#No Device2, crie VLAN2, VLAN100~VLAN200 respectivamente, e configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN2, vlan100~VLAN200.
Device1#configure terminalDevice1(config)#vlan 2,100-200Device1(config)# interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#shutdownDevice1(config-if-gigabitethernet0/1)# switchport mode trunkDevice1(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device1(config-if-gigabitethernet0/1)#exitDevice1(config)# interface gigabitethernet 0/2Device1(config-if-gigabitethernet0/1)# switchport mode trunkDevice1(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device1(config-if-gigabitethernet0/1)#end
#No Device3, crie VLAN2, VLAN100~VLAN200 respectivamente, e configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN2, vlan100~VLAN200.
Device1#configure terminalDevice1(config)#vlan 2,100-200Device1(config)# interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#shutdownDevice1(config-if-gigabitethernet0/1)# switchport mode trunkDevice1(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device1(config-if-gigabitethernet0/1)#exitDevice1(config)# interface gigabitethernet 0/2Device1(config-if-gigabitethernet0/1)# switchport mode trunkDevice1(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device1(config-if-gigabitethernet0/1)#end
#No Device4, crie VLAN2, VLAN100~VLAN200 respectivamente, e configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN2, vlan100~VLAN200.
Device1#configure terminalDevice1(config)#vlan 2,100-200Device1(config)# interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#shutdownDevice1(config-if-gigabitethernet0/1)# switchport mode trunkDevice1(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device1(config-if-gigabitethernet0/1)#exitDevice1(config)# interface gigabitethernet 0/2Device1(config-if-gigabitethernet0/1)# switchport mode trunkDevice1(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device1(config-if-gigabitethernet0/1)#end
- Passo 2: Configure a instância do MST.
# No Device1, configure a instância 1 do MST para mapear vlan100-200 e ative a instância.
Device1#configure terminalDevice1(config)# spanning-tree mst configurationDevice1(config-mst)# instance 1 vlan 100-200Device1(config-mst)# active configuration pendingDevice1(config-mst)#end
# No dispositivo 2 , configure a instância 1 do MST para mapear vlan100-200 e ative a instância.
Device1#configure terminalDevice1(config)# spanning-tree mst configurationDevice1(config-mst)# instance 1 vlan 100-200Device1(config-mst)# active configuration pendingDevice1(config-mst)#end
# No dispositivo 3 , configure a instância 1 do MST para mapear vlan100-200 e ative a instância.
#On Device3, configure MST instance 1 to map vlan100-200, and activate the instance.Device1#configure terminalDevice1(config)# spanning-tree mst configurationDevice1(config-mst)# instance 1 vlan 100-200Device1(config-mst)# active configuration pendingDevice1(config-mst)#end
# No dispositivo 4 , configure a instância 1 do MST para mapear vlan100-200 e ative a instância.
Device1#configure terminalDevice1(config)# spanning-tree mst configurationDevice1(config-mst)# instance 1 vlan 100-200Device1(config-mst)# active configuration pendingDevice1(config-mst)#end
- Passo 3: Configurar ERPS .
# No Device1, configure o ERPS ring1, configure a vlan2 como VLAN de controle do ring1, configure gigabitethernet0/1 como a porta normal do ring1, configure gigabitethernet0/2 como a porta proprietária do ring1, configure a instância 1 como VLAN de dados do ring1 e habilite o ERPS função do anel1.
Device1# configure terminalDevice1(config)#erps ring 1Device1(config-erps1)# control vlan 2Device1(config-erps1)# port0 interface g0/1Device1(config-erps1)# port1 interface g0/2 rpl ownerDevice1(config-erps1)# instance 1Device1(config-erps1)# erps enableDevice1(config-erps1)# exitDevice1(config)# interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#no shutdownDevice1(config-if-gigabitethernet0/1)# end
# No Device2, configure o ERPS ring1, configure a vlan2 como VLAN de controle do ring1, configure gigabitethernet0/1 como a porta normal do ring1, configure gigabitethernet0/2 como a porta normal do ring1, configure a instância 1 como VLAN de Device2# configure terminal
Device2(config)#erps ring 1Device2(config-erps1)# control vlan 2Device2(config-erps1)# port0 interface g0/1Device2(config-erps1)# port1 interface g0/2Device2(config-erps1)# instance 1Device2(config-erps1)# erps enableDevice2(config-erps1)# exitDevice2(config)# interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#no shutdownDevice2(config-if-gigabitethernet0/1)# end
# No Device3, configure o ERPS ring1, configure vlan2 como VLAN de controle do ring1, configure gigabitethernet0/1 como a porta vizinha do ring1, configure gigabitethernet0/2 como a porta normal do ring1, configure a instância 1 como VLAN de dados do ring1 e habilite o ERPS função do anel1.
Device3# configure terminalDevice3(config)#erps ring 1Device3(config-erps1)# control vlan 2Device3(config-erps1)# port0 interface g0/1 rpl neighborDevice3(config-erps1)# port1 interface g0/2Device3(config-erps1)# instance 1Device3(config-erps1)# erps enableDevice3(config-erps1)# exitDevice3(config)# interface gigabitethernet 0/1Device3(config-if-gigabitethernet0/1)#no shutdownDevice3(config-if-gigabitethernet0/1)# end
# No Device4, configure o ERPS ring1, configure vlan2 como VLAN de controle do ring1, configure gigabitethernet0/1 como a porta normal do ring1, configure gigabitethernet0/2 como a porta normal do ring1, configure a instância 1 como VLAN de dados do ring1 e habilite o ERPS função do anel1.
Device4# configure terminalDevice4(config)#erps ring 1Device4(config-erps1)# control vlan 2Device4(config-erps1)# port0 interface g0/1Device4(config-erps1)# port1 interface g0/2Device4(config-erps1)# instance 1Device4(config-erps1)# erps enableDevice4(config-erps1)# exitDevice4(config)# interface gigabitethernet 0/1Device4(config-if-gigabitethernet0/1)#no shutdownDevice4(config-if-gigabitethernet0/1)# end
- Passo 4: Confira o resultado.
# Depois que a topologia da rede se tornar estável, consulte as informações do ERPS do Dispositivo e tome o dispositivo1 como exemplo.
#Consulte as informações do ERPS do Device1.
Device1# show erps ring 1 detailRing ID : 1Version : v2R-APS mel : 7Instance : 1 vlans mapped : 100-200Control VLAN : 2Node role : OwnerNode state : idleGuard timer : 500 ms Running : 0 msHoldoff timer : 0 ms Running : 0 msWTR timer : 5 min Running : 0 sWTB timer : 7 s Running : 0 sSubring : NoTc-limit enable : NoTc-limit Interval : 2Tc-limit Threshold : 3Revertive operation : RevertiveR-APS channel : Non-Virtual channelEnable status : EnableGigabitethernet0/1 Flush LogicRemote Node ID : 0000-0000-0000Remote BPR : 0Gigabitethernet0/1 track CFMMD Name :MA Name :MEP ID : 0RMEP ID : 0CFM State : 0Gigabitethernet0/2 Flush LogicRemote Node ID : 0000-0000-0000Remote BPR : 0Gigabitethernet0/2 track CFMMD Name :MA Name :MEP ID : 0RMEP ID : 0CFM State : 0Port Name PortRole SwitchType PortStatus SignalStatus----------------------------------------------------------------------------------------------Port0 gigabitethernet0/1 Normal -- Forwarding Non-failedPort1 gigabitethernet0/2 Owner -- Blocking Non-failed
Antes de configurar o ERPS, certifique-se de que o status do link de pelo menos um ponto na rede em anel esteja inativo. Caso contrário, causará loop.
Configurar a carga do ERPS
Requisitos de rede
- Todos os dispositivos estão em uma rede L2.
- O tráfego de dados de data1 é transmitido via device2-device1, e o tráfego de dados de Data2 é transmitido via device4-device3, realizando o balanceamento de carga e fornecendo o backup do link.
Topologia de rede
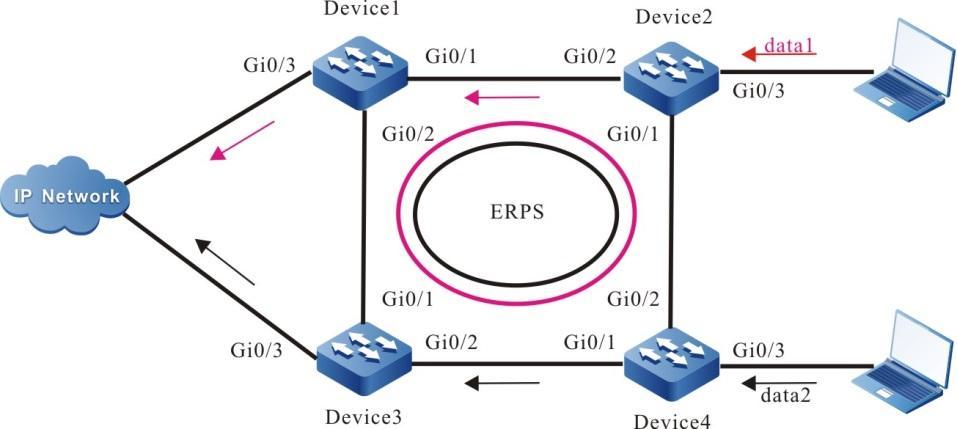
Figura _ 11 -2 Configurar a carga do ERPS
Etapas de configuração
- Passo 1: Configure vlan e tipo de link de porta.
#No Dispositivo1, crie VLAN2 - VLAN3, VLAN100 - VLAN200 e VLAN300 - VLAN400 e configurar o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo os serviços de VLAN2 - VLAN3 , VLAN100 - VLAN200 e VLAN300 - VLAN400 para passar.
Device1#configure terminalDevice1(config)#vlan 2,100-200Device1(config)# interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#shutdownDevice1(config-if-gigabitethernet0/1)# switchport mode trunkDevice1(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,300-400Device1(config-if-gigabitethernet0/1)#exitDevice1(config)# interface gigabitethernet 0/2Device1(config-if-gigabitethernet0/1)# switchport mode trunkDevice1(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,300-400Device1(config-if-gigabitethernet0/1)#end
#No dispositivo 2 , crie VLAN2 - VLAN3, VLAN100 - VLAN200 e VLAN300 - VLAN400 e configurar o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo os serviços de VLAN2 - VLAN3 , VLAN100 - VLAN200 e VLAN300 - VLAN400 para passar.
Device2#configure terminalDevice2(config)#vlan 2,100-200Device2(config)# interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#shutdownDevice2(config-if-gigabitethernet0/1)# switchport mode trunkDevice2(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice2(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device2(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,300-400Device2(config-if-gigabitethernet0/1)#exitDevice2(config)# interface gigabitethernet 0/2Device2(config-if-gigabitethernet0/1)# switchport mode trunkDevice2(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice2(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device2(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,300-400Device2(config-if-gigabitethernet0/1)#end
#No dispositivo 3 , crie VLAN2 - VLAN3, VLAN100 - VLAN200 e VLAN300 - VLAN400 e configurar o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo os serviços de VLAN2 - VLAN3 , VLAN100 - VLAN200 e VLAN300 - VLAN400 para passar.
Device3#configure terminalDevice3(config)#vlan 2,100-200Device3(config)# interface gigabitethernet 0/1Device3(config-if-gigabitethernet0/1)#shutdownDevice3(config-if-gigabitethernet0/1)# switchport mode trunkDevice3(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice3(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device3(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,300-400Device3(config-if-gigabitethernet0/1)#exitDevice3(config)# interface gigabitethernet 0/2Device3(config-if-gigabitethernet0/1)# switchport mode trunkDevice3(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice3(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device3(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,300-400Device3(config-if-gigabitethernet0/1)#end
#No dispositivo 4 , crie VLAN2 - VLAN3, VLAN100 - VLAN200 e VLAN300 - VLAN400 e configurar o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo os serviços de VLAN2 - VLAN3 , VLAN100 - VLAN200 e VLAN300 - VLAN400 para passar.
Device4#configure terminalDevice4(config)#vlan 2,100-200Device4(config)# interface gigabitethernet 0/1Device4(config-if-gigabitethernet0/1)#shutdownDevice4(config-if-gigabitethernet0/1)# switchport mode trunkDevice4(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice4(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device4(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,300-400Device4(config-if-gigabitethernet0/1)#exitDevice4(config)# interface gigabitethernet 0/2Device4(config-if-gigabitethernet0/1)# switchport mode trunkDevice4(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice4(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device4(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,300-400Device4(config-if-gigabitethernet0/1)#end
- Passo 2: Configure a instância do MST.
# No Device1, configure a instância 1 do MST para mapear vlan100-200, configure a instância 2 do MST para mapear vlan300-400 e ative a instância.
Device1#configure terminalDevice1(config)# spanning-tree mst configurationDevice1(config-mst)# instance 1 vlan 100-200Device1(config-mst)# instance 2 vlan 300-400Device1(config-mst)# active configuration pendingDevice1(config-mst)#end
# No dispositivo 2 , configure a instância 1 do MST para mapear vlan100-200, configure a instância 2 do MST para mapear vlan300-400 e ative a instância.
Device2#configure terminalDevice2(config)# spanning-tree mst configurationDevice2(config-mst)# instance 1 vlan 100-200Device2(config-mst)# instance 2 vlan 300-400Device2(config-mst)# active configuration pendingDevice2(config-mst)#end
# No dispositivo 3 , configure a instância 1 do MST para mapear vlan100-200, configure Device3#configure terminal
Device3(config)# spanning-tree mst configurationDevice3(config-mst)# instance 1 vlan 100-200Device3(config-mst)# instance 2 vlan 300-400Device3(config-mst)# active configuration pendingDevice3(config-mst)#end
# No dispositivo 4 , configure a instância 1 do MST para mapear vlan100-200, configure a instância 2 do MST para mapear vlan300-400 e ative a instância.
Device4#configure terminalDevice4(config)# spanning-tree mst configurationDevice4(config-mst)# instance 1 vlan 100-200Device4(config-mst)# instance 2 vlan 300-400Device4(config-mst)# active configuration pendingDevice4(config-mst)#end
- Passo 3: Configurar ERPS .
# No Device1, configure o ERPS ring1, configure a vlan2 como VLAN de controle do ring1, configure gigabitethernet0/1 como a porta normal do ring1, configure gigabitethernet0/2 como a porta normal do ring1, configure a instância 1 como VLAN de dados do ring1 e habilite o ERPS função do anel1.
Device1# configure terminalDevice1(config)#erps ring 1Device1(config-erps1)# control vlan 2Device1(config-erps1)# port0 interface g0/1Device1(config-erps1)# port1 interface g0/2Device1(config-erps1)# instance 1Device1(config-erps1)# erps enableDevice1(config-erps1)# end
# No Device1, configure o ERPS ring2, configure a vlan3 como VLAN de controle do ring2, configure gigabitethernet0/1 como a porta normal do ring2, configure gigabitethernet0/2 como a porta normal do ring2, configure a instância 2 como VLAN de dados do ring2 e habilite o Função ERPS de ring2.
Device1# configure terminalDevice1(config)#erps ring 2Device1(config-erps1)# control vlan 3Device1(config-erps1)# port0 interface g0/1Device1(config-erps1)# port1 interface g0/2Device1(config-erps1)# instance 2Device1(config-erps1)# erps enableDevice1(config-erps1)# exitDevice1(config)# interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#no shutdownDevice1(config-if-gigabitethernet0/1)# end
# No Device2, configure o ERPS ring1, configure vlan2 como VLAN de controle do ring1, configure gigabitethernet0/1 como a porta proprietária do ring1, configure gigabitethernet0/2 como a porta normal do ring1, configure a instância 1 como VLAN de dados do ring1 e habilite o ERPS função do anel1.
Device2# configure terminalDevice2(config)#erps ring 1Device2(config-erps1)# control vlan 2Device2(config-erps1)# port0 interface g0/1 rpl ownerDevice2(config-erps1)# port1 interface g0/2Device2(config-erps1)# instance 1Device2(config-erps1)# erps enableDevice2(config-erps1)# exit
# No Device2, configure o ERPS ring2, configure a vlan3 como VLAN de controle do ring2, configure gigabitethernet0/1 como a porta vizinha do ring2, configure gigabitethernet0/2 como a porta normal do ring2, configure a instância 2 como VLAN de dados do ring2 e habilite o Função ERPS de ring2.
Device2# configure terminalDevice2(config)#erps ring 1Device2(config-erps1)# control vlan 3Device2(config-erps1)# port0 interface g0/1 rpl neighborDevice2(config-erps1)# port1 interface g0/2Device2(config-erps1)# instance 2Device2(config-erps1)# erps enableDevice2(config-erps1)# exitDevice2(config)# interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#no shutdownDevice2(config-if-gigabitethernet0/1)# end
# No Device3, configure o ERPS ring1, configure a vlan2 como VLAN de controle do ring1, configure gigabitethernet0/1 como a porta normal do ring1, configure gigabitethernet0/2 como a porta normal do ring1, configure a instância 1 como VLAN de dados do ring1 e habilite o ERPS função do anel1.
Device3# configure terminalDevice3(config)#erps ring 1Device3(config-erps1)# control vlan 2Device3(config-erps1)# port0 interface g0/1 rpl neighborDevice3(config-erps1)# port1 interface g0/2Device3(config-erps1)# instance 1Device3(config-erps1)# erps enableDevice3(config-erps1)# exit
# No Device3, configure o ERPS ring2, configure a vlan3 como VLAN de controle do ring2, configure gigabitethernet0/1 como a porta vizinha do ring2, configure gigabitethernet0/2 como a porta normal do ring2, configure a instância 2 como VLAN de dados do ring2 e habilite o Função ERPS de ring2.
Device3# configure terminalDevice3(config)#erps ring 2Device3(config-erps1)# control vlan 3Device3(config-erps1)# port0 interface g0/1Device3(config-erps1)# port1 interface g0/2Device3(config-erps1)# instance 2Device3(config-erps1)# erps enableDevice3(config-erps1)# exitDevice3(config)# interface gigabitethernet 0/1Device3(config-if-gigabitethernet0/1)#no shutdownDevice3(config-if-gigabitethernet0/1)# end
# No Device4, configure o ERPS ring1, configure a vlan2 como VLAN de controle do ring1, configure gigabitethernet0/1 como a porta normal do ring1, configure gigabitethernet0/2 como a porta vizinha do ring1, configure a instância 1 como VLAN de dados do ring1 e habilite o ERPS função do anel1.
Device4# configure terminalDevice4(config)#erps ring 1Device4(config-erps1)# control vlan 2Device4(config-erps1)# port0 interface g0/1Device4(config-erps1)# port1 interface g0/2 rpl neighbourDevice4(config-erps1)# instance 1Device4(config-erps1)# erps enableDevice4(config-erps1)# exit
# No Device4, configure o ERPS ring2, configure a vlan3 como VLAN de controle do ring2, configure gigabitethernet0/1 como a porta normal do ring2, configure gigabitethernet0/2 como a porta proprietária do ring2, configure a instância 2 como VLAN de dados do ring2 e habilite o Função ERPS de ring2.
Device4# configure terminalDevice4(config)#erps ring 2Device4(config-erps1)# control vlan 3Device4(config-erps1)# port0 interface g0/1Device4(config-erps1)# port1 interface g0/2 rpl ownerDevice4(config-erps1)# instance 2Device4(config-erps1)# erps enableDevice4(config-erps1)# exitDevice4(config)# interface gigabitethernet 0/1Device4(config-if-gigabitethernet0/1)#no shutdownDevice4(config-if-gigabitethernet0/1)# end
- Passo 4: Confira o resultado.
# Depois que a topologia da rede se estabilizar, consulte as informações do ERPS do dispositivo e tome o dispositivo 2 como exemplo.
#Consulte as informações do ERPS do Dispositivo 2 .
Device2# show erps ring 1 detailRing ID : 1Version : v2R-APS mel : 7Instance : 1 vlans mapped : 100-200Control VLAN : 2Node role : OwnerNode state : idleGuard timer : 500 ms Running : 0 msHoldoff timer : 0 ms Running : 0 msWTR timer : 5 min Running : 0 sWTB timer : 7 s Running : 0 sSubring : NoTc-limit enable : NoTc-limit Interval : 2Tc-limit Threshold : 3Revertive operation : RevertiveR-APS channel : Non-Virtual channelEnable status : EnableGigabitethernet0/1 Flush LogicRemote Node ID : 0000-0000-0000Remote BPR : 0Gigabitethernet0/1 track CFMMD Name :MA Name :MEP ID : 0RMEP ID : 0CFM State : 0Gigabitethernet0/2 Flush LogicRemote Node ID : 0000-0000-0000Remote BPR : 0Gigabitethernet0/2 track CFMMD Name :MA Name :MEP ID : 0RMEP ID : 0CFM State : 0Port Name PortRole SwitchType PortStatus SignalStatus----------------------------------------------------------------------------------------------Port0 gigabitethernet0/1 Owner -- Blocking Non-failedPort1 gigabitethernet0/2 Normal -- Forwarding Non-failedDevice2# show erps ring 2 detailRing ID : 2Version : v2R-APS mel : 7Instance : 1 vlans mapped : 100-200Control VLAN : 3Node role : NeighbourNode state : idleGuard timer : 500 ms Running : 0 msHoldoff timer : 0 ms Running : 0 msWTR timer : 5 min Running : 0 sWTB timer : 7 s Running : 0 sSubring : NoTc-limit enable : NoTc-limit Interval : 2Tc-limit Threshold : 3Revertive operation : RevertiveR-APS channel : Non-Virtual channelEnable status : EnableGigabitethernet0/1 Flush LogicRemote Node ID : 0000-0000-0000Remote BPR : 0Gigabitethernet0/1 track CFMMD Name :MA Name :MEP ID : 0RMEP ID : 0CFM State : 0Gigabitethernet0/2 Flush LogicRemote Node ID : 0000-0000-0000Remote BPR : 0Gigabitethernet0/2 track CFMMD Name :MA Name :MEP ID : 0RMEP ID : 0CFM State : 0Port Name PortRole SwitchType PortStatus SignalStatus----------------------------------------------------------------------------------------------Port0 gigabitethernet0/1 Neighbour -- Blocking Non-failedPort1 gigabitethernet0/2 Normal -- Forwarding Non-failed
Ao carregar, vários anéis lógicos em um anel físico não podem ser configurados com a mesma instância de dados.
Configurar ERPS Intersected Ring
Requisitos de rede
- Todos os dispositivos estão em uma rede L2.
- Device1-device2-device4-device3 e device3-device5-device6-device4 formam dois loops físicos respectivamente, e todos os dispositivos habilitam ERPS para o loop de link.
Topologia de rede

Figura 11 -3 _ Configurar o anel de interseção do ERPS
Etapas de configuração
- Passo 1: Configure vlan e tipo de link de porta
#No Device1, crie VLAN2 e VLAN100 - VLAN200 e configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN2 e VLAN100 - VLAN200 .
Device1#configure terminalDevice1(config)#vlan 2,100-200Device1(config)# interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#shutdownDevice1(config-if-gigabitethernet0/1)# switchport mode trunkDevice1(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device1(config-if-gigabitethernet0/1)#exitDevice1(config)# interface gigabitethernet 0/2Device1(config-if-gigabitethernet0/1)# switchport mode trunkDevice1(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice1(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device1(config-if-gigabitethernet0/1)#end
#No dispositivo 2 , crie VLAN2 e VLAN100 - VLAN200 e configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN2 e VLAN100 - VLAN200 .
Device2#configure terminalDevice2(config)#vlan 2,100-200Device2(config)# interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#shutdownDevice2(config-if-gigabitethernet0/1)# switchport mode trunkDevice2(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice2(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device2(config-if-gigabitethernet0/1)#exitDevice2(config)# interface gigabitethernet 0/2Device2(config-if-gigabitethernet0/1)# switchport mode trunkDevice2(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice2(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device2(config-if-gigabitethernet0/1)#end
#No dispositivo 3 , crie VLAN2 -VLAN3 e VLAN100 - VLAN200 e configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN2 e VLAN100 - VLAN200 . Configure o tipo de link da porta gigabitethernet0/3 como Trunk, permitindo a passagem dos serviços de VLAN3, vlan100 - VLAN200 .
Device3#configure terminalDevice3(config)#vlan 2,100-200Device3(config)# interface gigabitethernet 0/1Device3(config-if-gigabitethernet0/1)#shutdownDevice3(config-if-gigabitethernet0/1)# switchport mode trunkDevice3(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice3(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device3(config-if-gigabitethernet0/1)#exitDevice3(config)# interface gigabitethernet 0/2Device3(config-if-gigabitethernet0/1)# switchport mode trunkDevice3(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice3(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device3(config-if-gigabitethernet0/1)#endDevice3(config)# interface gigabitethernet 0/3Device3(config-if-gigabitethernet0/1)#shutdownDevice3(config-if-gigabitethernet0/1)# switchport mode trunkDevice3(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice3(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,100-200Device3(config-if-gigabitethernet0/1)#exit
#No dispositivo 4 , crie VLAN2 -VLAN3 e VLAN100 - VLAN200 e configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN2 e VLAN100 - VLAN200 . Configure o tipo de link da porta gigabitethernet0/3 como Trunk, permitindo a passagem dos serviços de VLAN3, vlan100 - VLAN200 .
Device4#configure terminalDevice4(config)#vlan 2,100-200Device4(config)# interface gigabitethernet 0/1Device4(config-if-gigabitethernet0/1)#shutdownDevice4(config-if-gigabitethernet0/1)# switchport mode trunkDevice4(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice4(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device4(config-if-gigabitethernet0/1)#exitDevice4(config)# interface gigabitethernet 0/2Device4(config-if-gigabitethernet0/1)# switchport mode trunkDevice4(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice4(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 2,100-200Device4(config-if-gigabitethernet0/1)#endDevice4(config)# interface gigabitethernet 0/3Device4(config-if-gigabitethernet0/1)#shutdownDevice4(config-if-gigabitethernet0/1)# switchport mode trunkDevice4(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice4(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,100-200Device4(config-if-gigabitethernet0/1)#exit
#No dispositivo 5 , crie VLAN3 e VLAN100 - VLAN200 e configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos serviços de VLAN 3 e VLAN100 - VLAN200 .
Device5#configure terminalDevice5(config)#vlan 2,100-200Device5(config)# interface gigabitethernet 0/1Device5(config-if-gigabitethernet0/1)#shutdownDevice5(config-if-gigabitethernet0/1)# switchport mode trunkDevice5(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice5(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,100-200Device5(config-if-gigabitethernet0/1)#exitDevice5(config)# interface gigabitethernet 0/2Device5(config-if-gigabitethernet0/1)# switchport mode trunkDevice5(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice5(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,100-200Device5(config-if-gigabitethernet0/1)#end
#No dispositivo 6 , crie VLAN3 e VLAN100 - VLAN200 e configure o tipo de link das portas gigabitethernet0/1 e gigabitethernet0/2 como Trunk, permitindo a passagem dos Device3#configure terminal
Device3(config)#vlan 3,100-200Device3(config)# interface gigabitethernet 0/1Device3(config-if-gigabitethernet0/1)#shutdownDevice3(config-if-gigabitethernet0/1)# switchport mode trunkDevice3(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice3(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,100-200Device3(config-if-gigabitethernet0/1)#exitDevice3(config)# interface gigabitethernet 0/2Device3(config-if-gigabitethernet0/1)# switchport mode trunkDevice3(config-if-gigabitethernet0/1)# no switchport trunk allowed vlan allDevice3(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3,100-200Device3(config-if-gigabitethernet0/1)#end
- Passo 2: Configure a instância do MST.
# No Device1, configure a instância 1 do MST para mapear vlan100-200 e ative a Device1(config)# spanning-tree mst configuration
Device1(config-mst)# instance 1 vlan 100-200Device1(config-mst)# active configuration pendingDevice1(config-mst)#end
# No dispositivo 2 , configure a instância 1 do MST para mapear vlan100-200 e ative a instância.
Device2#configure terminalDevice2(config)# spanning-tree mst configurationDevice2(config-mst)# instance 1 vlan 100-200Device2(config-mst)# active configuration pendingDevice2(config-mst)#end
# No dispositivo 3 , configure a instância 1 do MST para mapear vlan100-200 e ative a instância.
Device3#configure terminalDevice3(config)# spanning-tree mst configurationDevice3(config-mst)# instance 1 vlan 100-200Device3(config-mst)# active configuration pendingDevice3(config-mst)#end
# No dispositivo 4 , configure a instância 1 do MST para mapear vlan100-200 e ative a instância.
Device4#configure terminalDevice4(config)# spanning-tree mst configurationDevice4(config-mst)# instance 1 vlan 100-200Device4(config-mst)# active configuration pendingDevice4(config-mst)#end
# No dispositivo 5 , configure a instância 1 do MST para mapear vlan100-200 e ative a instância.
Device5#configure terminalDevice5(config)# spanning-tree mst configurationDevice5(config-mst)# instance 1 vlan 100-200Device5(config-mst)# active configuration pendingDevice5(config-mst)#end
# No dispositivo 6 , configure a instância 1 do MST para mapear vlan100-200 e ative a instância.
Device6#configure terminalDevice6(config)# spanning-tree mst configurationDevice6(config-mst)# instance 1 vlan 100-200Device6(config-mst)# active configuration pendingDevice6(config-mst)#end
- Passo 3: Configurar ERPS
# No Device1, configure o ERPS ring1, configure a vlan2 como VLAN de controle do ring1, configure gigabitethernet0/1 como a porta normal do ring1, configure gigabitethernet0/2 como a porta proprietária do ring1, configure a instância 1 como VLAN de dados do ring1 e habilite o ERPS função do anel1.
Device1# configure terminalDevice1(config)#erps ring 1Device1(config-erps1)# control vlan 2Device1(config-erps1)# port0 interface g0/1Device1(config-erps1)# port1 interface g0/2 rpl ownerDevice1(config-erps1)# instance 1Device1(config-erps1)# erps enableDevice1(config-erps1)# endDevice1(config)# interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#no shutdownDevice1(config-if-gigabitethernet0/1)# end
# No Device2, configure o ERPS ring1, configure a vlan2 como VLAN de controle do ring1, configure gigabitethernet0/1 como a porta vizinha do ring1, configure gigabitethernet0/2 como a porta normal do ring1, configure a instância 1 como VLAN de dados do ring1 e habilite o ERPS função do anel1.
Device2# configure terminalDevice2(config)#erps ring 1Device2(config-erps1)# control vlan 2Device2(config-erps1)# port0 interface g0/1 rpl neighbourDevice2(config-erps1)# port1 interface g0/2Device2(config-erps1)# instance 1Device2(config-erps1)# erps enableDevice2(config-erps1)# exitDevice2(config)# interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#no shutdownDevice2(config-if-gigabitethernet0/1)# end
# No Device3, configure o ERPS ring1, configure a vlan2 como VLAN de controle do ring1, configure gigabitethernet0/1 como a porta normal do ring1, configure gigabitethernet0/2 como a porta normal do ring1, configure a instância 1 como VLAN de dados do ring1 e habilite o ERPS função do anel1.
Device3# configure terminalDevice3(config)#erps ring 1Device3(config-erps1)# control vlan 2Device3(config-erps1)# port0 interface g0/1Device3(config-erps1)# port1 interface g0/2Device3(config-erps1)# instance 1Device3(config-erps1)# erps enableDevice3(config-erps1)# exitDevice2(config)# interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#no shutdownDevice2(config-if-gigabitethernet0/1)# end
# No Device3, configure o ERPS ring2, configure a vlan3 como VLAN de controle do ring2, configure gigabitethernet0/ 3 como a porta normal do ring2, configure a instância 1 como VLAN de dados do ring2, configure o ring2 como subanel e habilite a função ERPS do ring2.
Device3# configure terminalDevice3(config)#erps ring 2Device3(config-erps1)# control vlan 3Device3(config-erps1)# port0 interface g0/3Device3(config-erps1)# instance 1Device3(config-erps1)# sub-ringDevice3(config-erps1)# erps enableDevice3(config-erps1)# exitDevice3(config)# interface gigabitethernet 0/3Device3(config-if-gigabitethernet0/1)#no shutdownDevice3(config-if-gigabitethernet0/1)# end
# No Device4, configure o ERPS ring1, configure a vlan2 como VLAN de controle do ring1, configure gigabitethernet0/ 1 como a porta normal do ring1, configure gigabitethernet0/2 como a porta normal do ring1, configure a instância 1 como VLAN de dados do ring1 e habilite o Função ERPS de ring1.
Device4# configure terminalDevice4(config)#erps ring 1Device4(config-erps1)# control vlan 2Device4(config-erps1)# port0 interface g0/1Device4(config-erps1)# port1 interface g0/2Device4(config-erps1)# instance 1Device4(config-erps1)# erps enableDevice4(config-erps1)# exitDevice4(config)# interface gigabitethernet 0/1Device4(config-if-gigabitethernet0/1)#no shutdownDevice4(config-if-gigabitethernet0/1)# end
# No Device4, configure o ERPS ring2, configure o vlan3 como VLAN de controle do ring2, configure gigabitethernet0/ 3 como a porta normal do ring2, configure a instância 1 como VLAN de dados do ring2, configure o ring2 como subanel e habilite a função ERPS do ring2.
Device4# configure terminalDevice4(config)#erps ring 2Device4(config-erps1)# control vlan 3Device4(config-erps1)# port0 interface g0/3Device4(config-erps1)# instance 1Device4(config-erps1)# sub-ringDevice4(config-erps1)# erps enableDevice4(config-erps1)# exitDevice4(config)# interface gigabitethernet 0/3Device4(config-if-gigabitethernet0/1)#no shutdownDevice4(config-if-gigabitethernet0/1)# end
# No Device5, configura o ERPS ring2, configura a vlan3 como VLAN de controle do ring2, configura gigabitethernet0/ 2 como a porta normal de ring2, configure gigabitethernet0/ 1 como a porta proprietária de ring2, configure a instância 1 como VLAN de dados de ring2, configure ring2 como sub-anel e habilite a função ERPS de ring2.
Device4# configure terminalDevice4(config)#erps ring 2Device4(config-erps1)# control vlan 3Device4(config-erps1)# port0 interface g0/1 rpl ownerDevice4(config-erps1)# port0 interface g0/2Device4(config-erps1)# instance 1Device4(config-erps1)# sub-ringDevice4(config-erps1)# erps enableDevice4(config-erps1)# exitDevice4(config)# interface gigabitethernet 0/1Device4(config-if-gigabitethernet0/1)#no shutdownDevice4(config-if-gigabitethernet0/1)# end
# No Device6, configurar ERPS ring2, configurar vlan3 como VLAN de controle de ring2, configurar gigabitethernet0/ 2 como porta vizinha de ring2, configurar gigabitethernet0/ 1 como porta normal de ring2, configurar instância 1 como VLAN de dados de ring2, configurar ring2 como sub-anel e habilite a função ERPS de ring2.
Device4# configure terminalDevice4(config)#erps ring 2Device4(config-erps1)# control vlan 3Device4(config-erps1)# port0 interface g0/1Device4(config-erps1)# port0 interface g0/2 rpl neighbourDevice4(config-erps1)# instance 1Device4(config-erps1)# sub-ringDevice4(config-erps1)# erps enableDevice4(config-erps1)# exitDevice4(config)# interface gigabitethernet 0/1Device4(config-if-gigabitethernet0/1)#no shutdownDevice4(config-if-gigabitethernet0/1)# end
- Passo 4: Confira o resultado.
# Após a estabilização da topologia da rede , consulte as informações do ERPS do Dispositivo e tome o dispositivo 3 como exemplo.
#Consulte as informações do ERPS do Dispositivo 3 .
Device3# show erps ring 1 detailRing ID : 1Version : v2R-APS mel : 7Instance : 1 vlans mapped : 100-200Control VLAN : 2Node role : NormalNode state : idleGuard timer : 500 ms Running : 0 msHoldoff timer : 0 ms Running : 0 msWTR timer : 5 min Running : 0 sWTB timer : 7 s Running : 0 sSubring : NoTc-limit enable : NoTc-limit Interval : 2Tc-limit Threshold : 3Revertive operation : RevertiveR-APS channel : Non-Virtual channelEnable status : EnableGigabitethernet0/1 Flush LogicRemote Node ID : 0000-0000-0000Remote BPR : 0Gigabitethernet0/1 track CFMMD Name :MA Name :MEP ID : 0RMEP ID : 0CFM State : 0Gigabitethernet0/2 Flush LogicRemote Node ID : 0000-0000-0000Remote BPR : 0Gigabitethernet0/2 track CFMMD Name :MA Name :MEP ID : 0RMEP ID : 0CFM State : 0Port Name PortRole SwitchType PortStatus SignalStatus----------------------------------------------------------------------------------------------Port0 gigabitethernet0/1 Normal -- Forwarding Non-failedPort1 gigabitethernet0/2 Normal -- Forwarding Non-failedDevice3# show erps ring 2 detailRing ID : 2Version : v2R-APS mel : 7Instance : 1 vlans mapped : 100-200Control VLAN : 3Node role : NormalNode state : idleGuard timer : 500 ms Running : 0 msHoldoff timer : 0 ms Running : 0 msWTR timer : 5 min Running : 0 sWTB timer : 7 s Running : 0 sSubring : NoTc-limit enable : NoTc-limit Interval : 2Tc-limit Threshold : 3Revertive operation : RevertiveR-APS channel : Non-Virtual channelEnable status : EnableGigabitethernet0/3 Flush LogicRemote Node ID : 0000-0000-0000Remote BPR : 0Gigabitethernet0/1 track CFMMD Name :MA Name :MEP ID : 0RMEP ID : 0CFM State : 0Port Name PortRole SwitchType PortStatus SignalStatus----------------------------------------------------------------------------------------------Port0 gigabitethernet0/3 Normal -- Forwarding Non-failed
10 Gerenciamento e Monitoramento
Teste de rede e diagnóstico de falhas
Visão geral
Com a ferramenta de teste de rede e diagnóstico de falhas, podemos verificar o status da conexão de rede e diagnosticar a falha do sistema. Na manutenção diária, quando é necessário verificar a conexão de rede, podemos utilizar a função ping e a função traceroute. Quando for necessário diagnosticar a falha do sistema, podemos abrir as informações de depuração do sistema para diagnosticar a falha do sistema.
Aplicativo de teste de rede e diagnóstico de falhas
Tabela 1 -1 Lista de aplicativos de teste de rede e diagnóstico de falhas
| Funções do aplicativo | |
| Pingfunção | ping ping ip Ping interativo grupo ping |
| Função traceroute | Traceroute Traceroute interativo |
| Função de depuração do sistema | Depuração do sistema |
Função Ping
A função ping é usada para verificar o status da conexão de rede e se o host está acessível. A função ping envia o pacote de solicitação de eco ICMP para o host e aguarda a resposta de eco ICMP, usada para avaliar se o destino é alcançável. Pingpode testar o tempo de retorno da origem ao destino.
Condição de configuração
Nenhum
ping
Tabela 1 -2 ping
| Etapa | Comando | Descrição |
| Verifique se o endereço de destino especificado está acessível | ping [ vrf vrf-name ] {[ip host-name | ip-address] | [ ipv6 host-name | ipv6-address] | host-name | ip-address | ipv6-address } [ -l packet-length ] [ -w wait-time ] [ -n packet-number | -t ] | Obrigatório |
Ping interativo
Se você precisar usar rota de origem solta, rota de origem estrita, rota de registro, registro de data e hora e outras opções, ou precisar saber o tamanho máximo do pacote ICMP suportado pelo dispositivo de mesmo nível, você pode usar o ping interativo para conseguir.
Tabela 1 -3 Ping interativo
| Etapa | Comando | Descrição |
| Entre no modo interativo de ping | ping [ vrf vrf-name ] | Obrigatório No modo de usuário privilegiado, execute o comando para entrar no modo interativo de ping. |
| Configurar o tipo de protocolo de rede | Protocol [ ip ]:[ ip | ipv6] | Opcional Por padrão, use o protocolo IPv4. |
| Configure o endereço IP de destino ou o nome do host | Target IP address or hostname:{ ip-address | host-name } | Obrigatório |
| Configure os horários de envio do pacote de solicitação ICMP | Repeat count [5]:[ repeat-count ] | Opcional Por padrão, envie por 5 vezes. |
| Configurar o comprimento do pacote de solicitação ICMP | Datagram size [76]:[ datagram-size ] |
Opcional
O comprimento do pacote é o tamanho de todo o pacote IP. Por padrão, o comprimento do pacote é de 76 bytes. |
| Configure o tempo limite para aguardar a resposta ICMP | Timeout in seconds [2]:[ timeout ] | Opcional Por padrão, o tempo limite é de 2s. |
| Ative a opção estendida | Extended commands [no]:[ yes | no ] |
Opcional
Após habilitar a opção estendida, o comando de configuração da opção estendida fica disponível. Por padrão, não ative a opção estendida. |
| Configure a opção estendida, o endereço IP de origem ou a interface de saída do pacote de solicitação ICMP | Source address or interface:{ ip-address | interfacename } |
Opcional
Após habilitar a opção estendida, o comando pode ser configurado. Por padrão, não especifique o endereço de origem e a interface de saída do pacote de solicitação. |
| Configure a seleção estendida, o tipo de serviço do pacote de solicitação ICMP | Type of service [0]:[ tos ] |
Opcional
. Apenas o protocolo IPv4 suporta o comando. Após habilitar a opção estendida, o comando pode ser configurado. Por padrão, o valor TOS é 0. |
| Configure a opção estendida, definindo não permitindo o fragmento | Set DF bit in IP header? [ no ]:[ yes | no ] |
Opcional
. Apenas o protocolo IPv4 suporta o comando. Após habilitar a opção estendida, o comando pode ser configurado. Por padrão, não defina o sinalizador DF, permitindo fragmento. |
| Configure a opção estendida, validando o conteúdo de dados do pacote de resposta | Validate reply data? [ no ]:[ yes | no ] |
Opcional
. Apenas o protocolo IPv4 suporta o comando. Após habilitar a opção estendida, o comando pode ser configurado. Por padrão, não valide o conteúdo dos dados. |
| Configure a opção estendida, o conteúdo de dados do pacote de solicitação ICMP | Data pattern [abcd]:[ data-pattern ] |
Opcional
Após habilitar a opção estendida, o comando pode ser configurado. Por padrão, o perfil de conteúdo de dados é “abcd”. |
| Configure a opção estendida, opção de rota de origem solta, opção de rota de origem estrita, rota de registro, registro de data e hora, detalhes de exibição | Loose, Strict, Record, Timestamp, Verbose[ none ]:[ l | s ] [ r / t / v ] |
Opcional
, apenas o protocolo IPv4 suporta o comando. Após habilitar a opção estendida, o comando pode ser configurado. Por padrão, não configure a opção estendida. |
| Habilitar a varredura do pacote de solicitação ICMP enviado | Sweep range of sizes [ no ]:[ yes | no ] |
Opcional
, apenas o protocolo IPv4 suporta o comando. Por padrão, a varredura do pacote enviado está desabilitada. |
| Configure o valor inicial da verificação | Sweep min size [36]:[ min-szie ] |
Opcional
, apenas o protocolo IPv4 suporta o comando. Após habilitar a varredura do pacote enviado, o comando pode ser configurado. Por padrão, o valor inicial da varredura é 36. |
| Configure o valor final da digitalização | Sweep max size [18024]:[ max-size ] |
Opcional
, apenas o protocolo IPv4 suporta o comando. Após habilitar a varredura do pacote enviado, o comando pode ser configurado. Por padrão, o valor final da varredura é 18024 |
| Configurar o valor incremental de verificação | Sweep interval [1]:[ interval ] |
Opcional
, apenas o protocolo IPv4 suporta o comando. Após habilitar a varredura do pacote enviado, o comando pode ser configurado. Por padrão, o valor incremental de varredura é 1. |
groupping
O dispositivo suporta o envio de várias solicitações de eco ICMP de uma só vez e obtém um status de conexão de rede mais preciso de acordo com o número de pacotes de resposta ICMP retornados pelo host de destino.
Tabela 1 -4 agrupamento
| Etapa | Comando | Descrição |
| Envie vários grupos de pacotes de solicitação ICMP, verificando se o endereço de destino é alcançável | groupping [ vrf vrf-name ] { hostname | ip-address } [ [ -l packet-length ] [ -g packet-group ] [ -w wait-time ] [ -n packet-number ] [ -t ] | Obrigatório |
Ao executar ping no nome do host de destino, primeiro configure a função DNS. Caso contrário, o ping falhará. Para configuração de DNS, consulte “Configuração de DNS” em “Configuração do protocolo de rede IP”.
Função Traceroute
A função traceroute é usada para visualizar os gateways passados pelo pacote da origem ao destino. É usado principalmente para verificar se o destino é alcançável e analisar o nó de rede com defeito. O processo de execução do traceroute é: Primeiro envie um pacote IP com TTL 1 para o host de destino; o gateway de primeiro salto descarta o pacote e retorna um pacote de erro de tempo limite ICMP. Dessa forma, o traceroute obtém o primeiro endereço de gateway no caminho. E então o traceroute envia um pacote com TTL 2. Dessa forma, obtenha o endereço do gateway de segundo salto. Continue o processo até chegar ao host de destino. O número da porta UDP do pacote traceroute é o número da porta do destino que não pode ser usado por nenhum programa aplicativo. Após o destino receber o pacote, retorne um pacote de erro da porta inalcançável. Dessa forma, obtenha todos os endereços de gateway no caminho.
Condição de configuração
Nenhum
traçar rota
Tabela 1 -5 traceroute
| Etapa | Comando | Descrição |
| Visualize os gateways passados pelo pacote da origem ao destino | traceroute [vrf vrf-name ] {{ip host-name | ip-address} | {ipv6 host-name | ipv6-address} | host-name | ip-address | ipv6-address } [ -f start-ttl] [ -w wait-time] [ -m max-ttl] | Obrigatório |
Traceroute interativo
Tabela 1 -6 Traceroute interativo
| Etapa | Comando | Descrição |
| Entre no modo interativo do traceroute | traceroute [ vrf vrf-name ] | Obrigatório No modo de usuário privilegiado, execute o comando para entrar no modo interativo traceroute. |
| Configurar o tipo de protocolo de rede | Protocol [ ip ]:[ ip | ipv6] | Opcional Por padrão, use o protocolo IPv4. |
| Configure o endereço IP de destino ou o nome do host | Target IP address or hostname:{ ip-address | host-name } | Obrigatório |
| Configure o endereço IP de origem ou a interface de saída do pacote traceroute | Source address or interface:{ ip-address | interface-name } | Opcional Por padrão, não especifique o endereço IP de origem ou a interface de saída do pacote |
| Configure o tempo limite de espera para cada resposta do pacote de detecção | Timeout in seconds [3]:timeout | Opcional Por padrão, tempo limite após 3s. |
| Configure os horários de envio do pacote de detecção com o mesmo valor TTL | Probe count [3]:probe-count | Opcional Por padrão, envie por três vezes. |
| Configure o valor mínimo de TTL do pacote de detecção | Minimum Time to Live [1]:min-ttl | Opcional Por padrão, o valor mínimo de TTL é 1. |
| Configure o valor máximo de TTL do pacote de detecção | Maximum Time to Live [30]:max-ttl | Opcional Por padrão, o valor máximo de TTL é 30. |
| Configure o número da porta UDP de destino do pacote de detecção | Port Number [33434]:port-number | Opcional Por padrão, o número da porta de destino é 33434. |
| Configure a opção estendida, opção de rota de origem solta, opção de rota de origem estrita, rota de registro, registro de data e hora, detalhes de exibição | Loose, Strict, Record, Timestamp, Verbose[ none ]:[ l | s ] [ r / t / v ] | Opcional , apenas o protocolo IPv4 suporta o comando. Por padrão, não configure a opção. |
Função de depuração do sistema
Para ajudar o usuário a diagnosticar o problema, a maioria dos módulos de função do dispositivo fornecem a função de depuração.
A função de depuração tem dois controles de chave:
- A chave de depuração do módulo, controlando se deve gerar as informações de depuração do módulo
- O interruptor de saída da tela, controlando a saída das informações de depuração para o terminal
Condição de configuração
Nenhum
Depuração do sistema
Tabela 1 -7 Depuração do sistema
| Etapa | Comando | Descrição |
| Abra a chave de saída da tela de depuração do sistema de login remoto | terminal monitor |
Opcional
O login remoto inclui telnet, ssh e assim por diante. Por padrão, a chave está fechada. |
| Entre no modo de configuração global | configure terminal | - |
| Abra a chave de saída da tela de depuração do sistema do console | logging console | Opcional Por padrão, o switch está aberto. |
| Sair do modo de configuração global | exit | - |
| Abra a chave de depuração do módulo de função do sistema | debug { all | module-name [ option ] } |
Opcional
Por padrão, todas as chaves de depuração dos módulos de função do sistema estão fechadas. |
As informações de depuração podem ser exibidas no terminal somente após a configuração de depuração opção de nome de módulo, terminal monitor ou registro consola ao mesmo tempo. A geração e saída das informações de depuração afetam o desempenho do sistema, portanto, quando necessário, é melhor usar o comando debug module-name option para abrir o switch de depuração especificado. A depuração tudo comando abre todas as opções de depuração, então é melhor não usar. Após o término da depuração, feche o comutador de depuração correspondente a tempo ou use o botão não depurar all comando para fechar todas as opções de depuração.
Monitoramento e manutenção de teste de rede e diagnóstico de falhas
Tabela 1 -8 Monitoramento e manutenção do teste do sistema e diagnóstico de falhas
| Comando | Descrição |
| show debugging | Exiba as informações do módulo de função da chave de depuração aberta no sistema. |
Exemplo de configuração típico de teste de rede e diagnóstico de falhas
PingInscrição
Requisito de rede
- Device1 falha ao fazer login no Device3 por telnet do endereço IP e precisamos confirmar se a rota IP entre Device1 e Device3 é alcançável.
- Device1 falha ao fazer login no Device3 enviando telnet para o endereço IPv6 e precisamos confirmar se a rota IPv6 entre Device1 e Device3 é alcançável.
Topologia de rede

Figura 1 -1 rede de aplicativos de ping
Etapas de configuração
- Passo 1:Configure o endereço IP e o endereço unicast global IPv6 da interface . (Omitido)
- Passo 2:Use o comando ping para ver se a rota entre Device1 e Device3 é alcançável.
#Ver se Device1 pode pingar o endereço IP 2.0.0.2 do Device3.
Device1#ping 2.0.0.2Press key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to 2.0.0.2 , timeout is 2 seconds:.....Success rate is 0% (0/5).
#Ver se Device1 pode pingar o endereço IPv6 2001:2::2 de Device3.
Device1#ping 2001:2::2Press key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to 2001:2::2 , timeout is 2 seconds:.....Success rate is 0% (0/5).
- Passo 3:Use o comando ping para ver se a rota entre Device1 e Device2 é alcançável.
#Ver se Device1 pode pingar o endereço IP 1.0.0.2 do Device2.
Device1#ping 1.0.0.2Press key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to 1.0.0.2 , timeout is 2 seconds:!!!!!Success rate is 100% (5/5). Round-trip min/avg/max = 0/0/0 ms.
#Ver se Device1 pode pingar o endereço IPv6 2001:1::2 de Device2.
Device1#ping 2001:1::2Press key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to 2001:1::2 , timeout is 2 seconds:!!!!!Success rate is 100% (5/5). Round-trip min/avg/max = 0/0/0 ms.
- Passo 4:Use o comando ping para ver se a rota entre Device2 e Device3 é alcançável.
#Ver se o Device2 pode fazer ping no endereço IP 2.0.0.2 do Device3.
Device2#ping 2.0.0.2Press key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to 2.0.0.2 , timeout is 2 seconds:!!!!!Success rate is 100% (5/5). Round-trip min/avg/max = 0/0/0 ms.
#Ver se Device2 pode pingar o endereço IPv6 2001: 2 ::2 de Device3.
Device2#ping 2001:2::2Press key (ctrl + shift + 6) interrupt it.Sending 5, 76-byte ICMP Echos to 2001:2::2 , timeout is 2 seconds:!!!!!Success rate is 100% (5/5). Round-trip min/avg/max = 0/176/883 ms.
A partir do resultado acima, podemos ver que Device1 e Device2 podem se comunicar entre si, Device2 e Device3 podem se comunicar entre si e o problema aparece entre Device1 e Device3. Mais tarde, podemos verificar a configuração da rota ou usar o debug IP ICMP e depurar icmp ipv6 comandos para ver se o conteúdo do pacote ICMP e do pacote ICMPv6 está correto. Também podemos usar o traceroute descrito na próxima seção para confirmar o nó de rede com defeito.
Traceroute
Requisito de rede
- Device1 falha ao fazer login no Device3 por telnet do endereço IP e precisamos confirmar se a rota IP entre Device1 e Device3 é alcançável. Se a rota estiver inacessível, precisamos confirmar o nó de rede com defeito.
- Device1 falha ao fazer login no Device3 enviando telnet para o endereço IPv6 e precisamos confirmar se a rota IPv6 entre Device1 e Device3 é alcançável. Se a rota estiver inacessível, precisamos confirmar o nó de rede com defeito.
Topologia de rede

Figura 1 -2 Rede de aplicativos Traceroute
Etapas de configuração
- Passo 1:Configure o endereço IP e o endereço unicast global IPv6 da interface . (Omitido)
- Passo 2:Use o traçar rota comando para confirmar o ponto de falha entre Device1 e Device3.
#Use o traçar rota comando para confirmar o ponto de falha IPv4 entre Device1 e Device3.
Device1#traceroute 2.0.0.2Type escape sequence to abort.Tracing the route to 2.0.0.2 , min ttl = 1, max ttl = 30 .1 1.0.0.2 0 ms 0 ms 0 ms2 * * *3 * * *4 * * *5 * * *6
#Use o traçar rota comando para confirmar o ponto de falha IPv6 entre Device1 e Device3.
Device1#traceroute 2001:2::2Type escape sequence to abort.Tracing the route to 2001:2::2 , min ttl = 1, max ttl = 30 .1 2001:1::2 0 ms 0 ms 0 ms2 * * *3 * * *4 * * *5 * * *6
A partir do resultado acima, o pacote traceroute enviado pelo Device1 pode chegar ao Device2. O pacote traceroute de Device2 não pode alcançar Device3. Mais tarde, precisamos verificar a configuração da rota entre Device2 e Device3 e a linha, ou usar o debug IP ICMP e depurar ipv6 ICMP comando para ver se o conteúdo do pacote ICMP e do pacote ICMPv6 está correto. Também podemos usar o ping descrito na última seção para detectar a conexão entre Device2 e Device3.
Gateway Keepalive
Visão geral
Keepalive gateway configura a interface Ethernet para enviar o pacote keepalive para o endereço de gateway especificado, usado para monitorar a acessibilidade do gateway de destino. Quando o gateway estiver inacessível, feche a camada de protocolo IP da interface.
Depois de configurar o gateway keepalive em uma interface, a interface envia regularmente o pacote de solicitação ARP para o endereço do gateway configurado. Quando a interface não recebe o pacote de resposta ARP por N vezes sucessivas (N são os tempos de repetição configurados para o usuário), feche a camada de protocolo IP da interface. Até receber novamente o pacote de resposta ARP, habilite a camada de protocolo IP da interface.
Configuração da Função Keepalive do Gateway
Tabela 2 – 1 Lista de configuração da função keepalive do gateway
| Tarefa de configuração | |
| Configurar a função de gateway de manutenção de atividade |
Configurar a função básica do gateway de manutenção de atividade
Configure os parâmetros de envio do pacote keepalive Configurar a função keepalive do gateway associado ao IPv6 |
Configurar a função Keepalive do gateway
Condição de configuração
Antes de configurar a função keepalive do gateway, primeiro conclua a seguinte tarefa:
- Configurar o endereço IP da interface
Configurar a função básica Keepalive do gateway
Tabela 2 – 2 Configurar a função básica keepalive do gateway
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Configurar o Keepalive do gateway | keepalive gateway ip-address [interval | msec interval ] [ retry-count ] | Obrigatório Por padrão, não ative a função keepalive do gateway. |
Configurar parâmetros de envio do pacote Keepalive
Ao configurar os parâmetros de envio do pacote keepalive, podemos controlar a taxa de envio do pacote keepalive do gateway. Quando a taxa de envio do pacote keepalive atingir o valor configurado, faça uma pausa pelo tempo configurado e continue a enviar os pacotes keepalive.
Tabela 2 – 3 Configure os parâmetros de envio do pacote keepalive
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a taxa de envio do pacote keepalive | keepalive gateway disperse pkt-rate packet-rate | Opcional Por padrão, a taxa máxima de envio do pacote keepalive é 100pps. |
| Configure o tempo de pausa no envio do pacote keepalive | keepalive gateway disperse pause-time pause-time | Opcional Por padrão, o tempo de pausa no envio do pacote keepalive é de 100ms. |
Configurar a função Keepalive do gateway associado ao IPv6
Após a configuração da função keepalive do gateway associado ao IPv6, a camada de protocolo IPv6 da interface será fechada ao mesmo tempo em que o gateway não estiver acessível.
Tabela 2 -4 Configurar a função keepalive do gateway associado ao IPv6
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a taxa de envio dos pacotes keepalive | keepalive gateway ipv6-respond-ipv4 | Opcional Por padrão, a função keepalive do gateway associado ao IPv6 está desabilitada . |
Monitoramento e manutenção do gateway Keepalive
Tabela 2 – 5 Monitoramento e manutenção do gateway keepalive
| Comando | Descrição |
| clear keepalive gateway statistics [ interface-name ] | Limpe as informações de estatísticas de envio e recebimento do gateway keepalive |
| show keepalive gateway [ interface-name ] | Visualize a interface habilitada com o gateway keepalive e sua configuração |
| show keepalive gateway disperse | Veja a configuração do parâmetro de envio do pacote keepalive do gateway |
| show keepalive gateway statistics [ interface-name ] | Visualize as informações de estatísticas do gateway keepalive |
Exemplo de configuração típico do Gateway Keepalive
Configurar Gateway Keepalive
Requisitos de rede
- Device4 é o dispositivo de conexão, apenas transmitindo dados de forma transparente.
- Execute o protocolo OSPF em Device1, Device2 e Device3 para realizar a interação da rota.
- O fluxo de dados de Device1 para o segmento 201.0.0.0/24 primeiro seleciona Device3.
- A linha entre Device1 e Device3 usa a função keepalive do gateway. Quando a linha entre Device1 e Device3 falha, o gateway keepalive detecta rapidamente a falha e modifica o status da interface para inativo. Depois que o OSPF sentir a mudança de status da interface, mude a rota para Device2 para comunicação.
Topologia de rede

Figura 2 – 1 Rede de configuração do gateway keepalive
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Configure o processo OSPF.
# Configurar dispositivo 1 .
Device1#configure terminalDevice1(config)#router ospf 100Device1(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device1(config-ospf)#network 200.0.0.0 0.0.0.255 area 0Device1(config-ospf)#exit
#Configurar dispositivo2.
Device2#configure terminalDevice2(config)#router ospf 100Device2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Device2(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device2(config-ospf)#exit
#Configurar dispositivo3.
Device3#configure terminalDevice3(config)#router ospf 100Device3(config-ospf)#network 1.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Device3(config-ospf)#network 201.0.0.0 0.0.0.255 area 0Device3(config-ospf)#exit
#Visualize a tabela de rotas do Device1.
Device1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, Ex - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 1.0.0.0/24 is directly connected, 00:20:17, vlan3C 2.0.0.0/24 is directly connected, 13:01:32, vlan2O 3.0.0.0/24 [110/2] via 2.0.0.2, 01:11:40, vlan2[110/2] via 1.0.0.2, 00:02:00, vlan3C 200.0.0.0/24 is directly connected, 01:31:58, vlan4O 201.0.0.0/24 [110/2] via 1.0.0.2, 00:02:00, vlan3
# O fluxo de dados de Device1 para o segmento 201.0.0.0/24 primeiro seleciona Device3.
O método de visualização de Device2 e Device3 é o mesmo de Device1, portanto o processo de visualização é omitido aqui.
- Passo 4:Configure o Keepalive do gateway.
#Configurar dispositivo1.
Device1(config)#interface vlan 3Device1(config-if-vlan3)#keepalive gateway 1.0.0.2Device1(config-if-vlan3)#exit
#Configurar dispositivo3.
Device3(config)#interface vlan 3Device3(config-if-vlan3)#keepalive gateway 1.0.0.1Device3(config-if-vlan3)#exit
#Visualize as informações de manutenção de atividade do gateway do Device1.
Device1#show keepalive gatewayinterface vlan3 gateway 1.0.0.2 time 10s retry 3 remain 3 now UP
#Visualize as informações de manutenção de atividade do gateway do Device3.
Device3#show keepalive gatewayinterface vlan3 gateway 1.0.0.1 time 10s retry 3 remain 3 now UP
- Passo 5:Confira o resultado.
#Após a linha entre Device1 e Device3 falhar, o gateway keepalive detecta rapidamente a falha e modifica o status da interface VLAN3 para down.
Device1#show keepalive gatewayinterface vlan3 gateway 1.0.0.2 time 10s retry 3 remain 0 now DOWN
# Após o OSPF sentir a mudança de status da interface VLAN3, mude a rota para Device2 para comunicação.
Device1# show ip ospf interface vlan3VLAN3 is down, line protocol is downOSPF is enabled, but not running on this interfaceDevice1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, Ex - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 13:16:40, vlan2O 3.0.0.0/24 [110/2] via 2.0.0.2, 00:01:25, vlan2C 200.0.0.0/24 is directly connected, 00:10:53, vlan4O 201.0.0.0/24 [110/3] via 2.0.0.2, 00:00:18, vlan2
#Podemos ver que o fluxo de dados de Device1 para o segmento 201.0.0.1/24 primeiro seleciona Device2.
SLA
Visão geral
SLA(Service Level Agreements) calcula os parâmetros relacionados de acordo com a transmissão do pacote e emite o relatório por último . SLA, também chamado de RTR (Response Time Reporter), é uma ferramenta de detecção e monitoramento de rede. SLAenvia regularmente os pacotes do protocolo especificado para detectar e monitorar a comunicação da rede. SLApode diagnosticar diferentes aplicativos de rede e produzir o resultado do teste configurando diferentes tipos de entidades RTR e ajustando.
SLAConceitos Básicos:
- Entidade RTR: Entidade RTR é um conceito universal e não relacionado com o tipo específico de entidade RTR. Os tipos de entidade RTR atuais do sistema incluem: a entidade ICMP-echo, a entidade ICMP-path-echo, a entidade ICMP-path-jitter e a entidade UDP-echo usada para detectar a comunicação de rede; a entidade VoIP-jitter usada para detectar a rede transmitindo os pacotes VoIP; a entidade FLOW-statistics usada para detectar o tráfego de interface .
- L SP-ping entidade: Usado para detectar a comunicação de rede MPLS
- Grupo RTR: Um grupo de entidades RTR é o conjunto de uma ou várias entidades;
- Respondente RTR: O respondedor RTR é configurado no destino, usado principalmente para configurar a conexão com a origem e responder ao pacote de detecção enviado pela origem. A maioria das entidades não precisa configurar o respondente, mas ao usar a entidade UDP-echo e a entidade VoIP-jitter, devemos configurar o respondente.
- Agendamento RTR: Se estiver apenas configurando a entidade RTR ou o grupo de entidades RTR, não podemos detectar, mas devemos iniciar o agendamento para que a detecção possa ser concluída.
SLAConfiguração da função
Tabela 3 -1 SLAlista de configuração de funções
| Tarefa de configuração | |
| Ativar RTR | Ativar RTR |
| Configurar a entidade RTR |
Criar a entidade RTR
Configurar a entidade ICMP-echo Configurar a entidade ICMPv6-echo Configurar a entidade ICMP-path-echo Configurar a entidade ICMP-path-jitter Configurar a entidade VoIP-jitter Configurar a entidade UDP-echo Configurar a entidade FLOW-statistics Configure a configuração comum da entidade |
| Configurar o grupo de entidades RTR | Configurar o grupo de entidades RTR |
| Configurar o respondedor RTR | Configurar o respondedor RTR |
| Configurar a programação RTR | Configurar a programação RTR |
| Configurar pausar o agendamento da entidade | Configurar pausar o agendamento da entidade |
| Configurar o agendamento de restauração da entidade | Configurar o agendamento de restauração da entidade |
Ativar RTR
Nas tarefas de configuração do RTR, primeiro habilite o RTR para que a configuração das demais funções tenha efeito.
Condição de configuração
Nenhum
Ativar RTR
Tabela 3 -2 Ativar RTR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar RTR | rtr enable | Obrigatório Por padrão, não habilite o RTR. |
Configurar entidade RTR
Condição de configuração
Antes de configurar a entidade RTR, primeiro conclua a seguinte tarefa:
- Ativar RTR.
Criar Entidade RTR
Uma entidade corresponde a um tipo de detecção. Após criar a entidade RTR e entrar no modo de configuração da entidade, podemos configurar os parâmetros da entidade.
Tabela 3 -3 Crie a entidade RTR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Criar a entidade RTR | rtr entity-id entity-type | Obrigatório |
Configurar entidade ICMP-echo
A entidade ICMP-echo é para detectar a comunicação de rede. Ele envia regularmente o pacote de solicitação de eco ICMP para um endereço de destino na rede, de modo a obter o atraso e a perda de pacotes da transmissão do pacote da extremidade de detecção para a extremidade de destino. Em um período de detecção, desde que a entidade ICMP-echo receba um pacote de resposta de solicitação de eco ICMP, o status da entidade é alcançável.
Todos os dispositivos de rede gerais suportam ping, de modo que a entidade possa ter efeito na detecção da comunicação de rede. Com as políticas de agendamento ricas e a função de gravação de log, podemos permitir que o administrador da rede conheça o status da comunicação da rede e as informações do histórico a tempo e reduza a entrada do comando ping comum com frequência ao mesmo tempo.
Tabela 3 -4 Configurar a entidade ICMP-echo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da entidade ICMP-echo | rtr entity-id [ icmpecho ] | Obrigatório |
| Configurar o atributo de detecção | set [ vrf vrf-name ] target-ip-address [ npacket ] [ data-size ] [ timeout ] [ frequency-value ] [ extend source-ip-address [ tos ] [ set-DF ] [ verify-data ] ] | Obrigatório Por padrão, não configure o atributo de detecção da entidade. |
| Configure o valor RTT como base de julgamento para detectar se a entidade é alcançável | status-care rtt | Opcional Por padrão, o valor RTT não é usado para determinar se é alcançável. |
| Configure a configuração comum da entidade | Consulte “Configurar a configuração comum da entidade” | Opcional |
O intervalo de agendamento (valor de frequência) da entidade ICMP-echo precisa atender ao seguinte requisito: intervalo de agendamento > npacket * timeout Se estiver configurando o agendador para a entidade, o tempo de duração do agendador deve ser maior que o intervalo de agendamento da entidade.
Configurar Entidade ICMPV6 -echo
A função da entidade de eco ICMPv6 é detectar a comunicação básica da rede. Ele envia regularmente o pacote de solicitação de eco ICMP para um endereço de destino na rede, de modo a obter o atraso e a perda de pacotes da transmissão de pacotes da detecção final ao destino. Em um ciclo de detecção, desde que um pacote de resposta de solicitação de eco ICMP seja recebido por uma entidade de eco ICMP V6, o status da entidade é alcançável.
Como os dispositivos de rede gerais suportam ping, essa entidade pode desempenhar um papel na detecção da comunicação básica da rede. Por meio de políticas de agendamento abundantes e funções de registro, os administradores de rede podem conhecer a situação de comunicação da rede e informações históricas a tempo e reduzir a entrada tediosa do comando ping comum.
Tabela 3 -5 Configurar o ICMP V6 -echo entidade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da entidade ICMP-echo | rtr entity-id [ icmpv6echo ] | - |
| Configurar os atributos de detecção | set [ vrf vrf-name ] target-ip-address [ npacket ] [ data-size ] [ timeout ] [ frequency-value ] [ extend source-ip-address [ tos ] [ verify-data ] ] | Mandatório Por padrão, não configure o atributo de detecção da entidade. |
| Configure o valor RTT como base de julgamento para detectar se a entidade é alcançável | status-care rtt | Opcional Por padrão, o valor RTT não é usado para determinar se é alcançável. |
| Configure a configuração comum da entidade | Consulte “Configurar a configuração comum da entidade” | Opcional |
O intervalo de agendamento (valor de frequência) da entidade ICMPv6-echo precisa atender ao seguinte requisito: intervalo de agendamento > npacket * timeout Se estiver configurando o agendador para a entidade, o tempo de duração do agendador deve ser maior que o intervalo de agendamento da entidade.
Configurar entidade ICMP-path-echo
A entidade ICMP-path-echo é para detectar a comunicação de rede. Ele envia regularmente o pacote de solicitação de eco ICMP para um endereço de destino na rede, de modo a obter o atraso e a perda de pacotes da transmissão de pacotes da extremidade de detecção para a extremidade de destino, bem como o atraso e a perda de pacotes entre a extremidade de detecção e os dispositivos intermediários da extremidade de detecção ao destino. Em um período de detecção, desde que a entidade ICMP-path-echo receba um pacote de resposta de solicitação de eco ICMP, o status da entidade é alcançável.
Todos os dispositivos de rede gerais suportam ping, de modo que a entidade possa ter efeito na detecção da comunicação de rede. Com as políticas de agendamento ricas e a função de gravação de log, podemos permitir que o administrador da rede conheça o status da comunicação da rede (por exemplo, qual dispositivo de rede no caminho tem um atraso sério) e as informações do histórico no tempo.
Tabela 3 -6 Configurar a entidade ICMP-path-echo
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema | configure terminal | - |
| Entre no modo de configuração da entidade ICMP-path-echo | rtr entity-id [ icmp-path-echo ] | Obrigatório |
| Configurar o atributo de detecção | set dest-ipaddr target-ip-address [ source-ipaddr source-ip-address ] | Obrigatório |
| Configure a seleção de rota de origem solta | lsr-path [ hop-ip-address-list | none ] | Opcional Por padrão, não configure a seleção de rota de origem solta. |
| Configure detectando apenas o status da rede da origem ao destino | targetOnly [ true | false ] |
Opcional
Por padrão, se targetOnly for true, detectará apenas o status da rede da origem ao destino. Se targetOnly for false, detecte o status da rede da origem ao destino, salto por salto. |
| Configure se deseja verificar o conteúdo do pacote de resposta | verify-data [ true | false ] | Opcional Por padrão, não verifique o conteúdo dos dados. |
| Configure a configuração comum da entidade | Consulte “Configurar a configuração comum da entidade” | Opcional |
Configurar entidade ICMP-path-jitter
A entidade ICMP-path-jitter é para detectar a comunicação de rede. Ele envia regularmente o pacote de solicitação de eco ICMP para um endereço de destino na rede, de modo a obter o atraso, o jitter e a perda de pacotes da transmissão do pacote da extremidade da detecção para a extremidade do destino, bem como o atraso, jitter e pacote perda entre a extremidade de detecção e os dispositivos intermediários da extremidade de detecção ao destino. Em um período de detecção, desde que a entidade ICMP-path-jitter receba um pacote de resposta de solicitação de eco ICMP, o status da entidade é alcançável.
Todos os dispositivos de rede gerais suportam ping, de modo que a entidade possa ter efeito na detecção da comunicação de rede. Com as políticas de agendamento ricas e a função de gravação de log, podemos permitir que o administrador da rede conheça o status da comunicação da rede (por exemplo, qual dispositivo de rede no caminho tem um atraso sério) e as informações do histórico no tempo.
Tabela 3 -7 Configurar a entidade ICMP-path-jitter
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema | configure terminal | - |
| Entre no modo de configuração ICMP-path-jitter | rtr entity-id [ icmp-path-jitter ] | Obrigatório |
| Configurar o atributo de detecção | set dest-ipaddr target-ip-address [ pkt-number ] [ pkt-interval ] [ source-ipaddr source-ip-address ] | Obrigatório |
| Configure o endereço IP da seleção de rota de origem solta | lsr-path [ hop-ip-address-list | none ] | Opcional Por padrão, não configure a seleção de rota de origem solta. |
| Configure detectando apenas o status da rede da origem ao destino | targetOnly [ true | false ] |
Opcional
Por padrão, se targetOnly for true, detectará apenas o status da rede da origem ao destino. Se targetOnly for false, detecte o status da rede da origem ao destino, salto por salto. |
| Configure o limite de jitter e a regra de excesso de limite | threshold-jitter jitter direction { be | se } | Opcional Por padrão, o limite de jitter é 6000ms e a regra de excesso de limite é be. |
| Configure se deseja verificar o conteúdo do pacote de resposta | verify-data [ true | false ] | Opcional Por padrão, não verifique o conteúdo dos dados. |
| Configure a configuração comum da entidade | Consulte “Configurar a configuração comum da entidade” | Opcional |
Quando a regra do excesso é ser e o valor real é maior ou igual ao limite, é julgado como acima do limite; quando a regra do excesso é se e o valor real é menor ou igual ao limite, é julgado como acima do limite.
Configurar entidade VoIP-jitter
A entidade VoIP-jitter é a entidade RTR usada para medir a qualidade de transmissão do pacote VoIP na rede IP geral.
A entidade VoIP-jitter pode simular a lei G .711 A, a lei G.711 mu e .729Ao codec G ou os códigos personalizados para enviar o pacote UDP com a taxa correspondente, intervalo e tamanho do pacote do dispositivo de origem para o dispositivo de destino, medir o retorno tempo, perda de pacote unidirecional e atraso unidirecional do pacote e calcula o valor ICPIF com base nas informações estatísticas. Por fim, estime o valor MOS de acordo com o valor ICPIF. No período de detecção, desde que a entidade VoIP-jitter receba um pacote de resposta de detecção, o status da entidade é alcançável.
Tabela 3 -8 Configurar a entidade VoIP-jitter
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema | configure terminal | - |
| Entre no modo de configuração VoIP-jitter | rtr entity-id [ jitter ] | Obrigatório Se a entidade já existir, entre diretamente no modo de configuração da entidade. |
| Configurar o atributo de detecção | set dest-ipaddr target-ip-address dest-port target-port { g711alaw | g711ulaw | g729a | user_defined packet-size packet-number packet-interval schedule-interval } [ source-ipaddr source-ip-address ] [ source-port source-port ] | Obrigatório |
| Configure o limite de atraso unidirecional da origem ao destino e a regra de excesso de limite | threshold-sd-delay sd-delay direction { be | se } | Opcional Por padrão, o limite de atraso sd é 5000ms e a regra de excesso de limite é be. |
| Configure o limite de jitter unidirecional da origem ao destino e a regra de excesso de limite | threshold-sd-jitter sd-jitter direction { be | se } | Opcional Por padrão, o limite de jitter sd é 6000ms e a regra de excesso de limite é be. |
| Configure o limite de perda de pacotes e a regra de excesso de limite da origem ao destino | threshold-sd-pktloss sd-packet direction { be | se } |
Opcional
Por padrão, o limite de perda de pacotes SD é 60.000 e a regra de excesso de limite é be. |
| Configure o limite de atraso unidirecional do destino para a origem e a regra de excesso de limite | threshold-ds-delay ds-delay direction { be | se } | Opcional Por padrão, o limite de atraso ds é 5000ms e a regra de excesso de limite é be. |
| Configure o limite de jitter unidirecional do destino para a regra de origem e excesso de limite | threshold-ds-jitter ds-jitter direction { be | se } |
Opcional
Por padrão, o limite de jitter direcional da unidade ds é 6000ms e a regra de excesso de limite é be. |
| Configure o limite de perda de pacote do destino para a origem e a regra de excesso de limite | threshold-ds-pktloss ds-packet direction { be | se } |
Opcional
Por padrão, o limite de perda de pacote ds é 60.000 e a regra de excesso de limite é be. |
| Configure o limite icpif e a regra de excesso de limite | threshold-icpif icpif-value direction { be | se } | Opcional Por padrão, o limite icpif é 100000000 e a regra de excesso de limite é be. |
| Configure o limite mos e a regra de excesso de limite | threshold-mos mos-value direction { be | se } | Opcional Por padrão, o limite mos é 10000000 e a regra de excesso de limite é be. |
| Configure a configuração comum da entidade | Consulte “Configurar a configuração comum da entidade” | Opcional |
Ao usar a detecção de entidade VoIP-jitter, além de configurar a entidade VoIP-jitter, também precisamos configurar o respondente RTR no destino. Por padrão, a entidade VoIP-jitter envia muitos pacotes, que ocupam a largura de banda da rede, portanto, quando a configuração da entidade exceder uma hora, o shell avisa. Quando a entidade VoIP-jitter detecta a rede transmitindo o pacote VoIP, os relógios da origem e do destino precisam ser consistentes, portanto, antes de agendar a entidade VoIP-jitter, também precisamos configurar o servidor NTP no destino e o cliente NTP na fonte. Depois que os relógios estiverem sincronizados, configure o respondedor RTR e, por fim, configure o agendador. Para a configuração do NTP, consulte o Manual de configuração do NTP. Quando a regra do excesso é ser e o valor real é maior ou igual ao limite, é julgado como acima do limite; quando a regra do excesso é se e o valor real é menor ou igual ao limite, é julgado como acima do limite.
Configurar entidade UDP-echo
A entidade UDP-echo detecta principalmente o pacote UDP transmitido na rede IP. Na entidade, precisamos especificar o endereço de destino e a porta do pacote enviado. Podemos monitorar a transmissão do pacote UDP na rede IP agendando a entidade. Em um período de detecção, desde que a entidade UDP-echo receba um pacote de resposta de detecção, o status da entidade é alcançável.
A entidade UDP-echo pode monitorar eficientemente para registrar o atraso de retorno, perda de pacotes e outras informações do pacote UDP na rede IP, até mesmo gravar as informações do histórico monitorado por logs para que o administrador da rede possa conhecer a comunicação da rede e corrigir a culpa.
Tabela 3 -9 Configurar a entidade UDP-echo
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema | configure terminal | - |
| Entre no modo de configuração da entidade UDP-echo | rtr entity-id [ udpecho ] | Obrigatório Se a entidade já existir, entre diretamente no modo de configuração da entidade. |
| Configurar o atributo de detecção | set dest-ipaddr target-ip-address dest-port target-port [ source-ipaddr source-ip-address ] [ source-port source-port ] | Obrigatório Por padrão, não configure o atributo de detecção. |
| Configure o conteúdo de enchimento do pacote | data-pattern pad | Opcional Por padrão, o conteúdo de preenchimento é “ABCD”. |
| Configure a configuração comum da entidade | Consulte “Configurar a configuração comum da entidade” | Opcional |
Ao usar a detecção de entidade UDP-echo, além de configurar a entidade UDP-echo, também precisamos configurar o respondente RTR no destino.
Configurar entidade de estatísticas de FLUXO
A entidade FLOW-statistics deve detectar o tráfego de interface e uma entidade corresponde a uma interface. Podemos monitorar o tráfego na interface agendando a entidade. Em um período de detecção, enquanto houver pacotes passando pela interface monitorada pela entidade FLOW-statistics, o status da entidade é alcançável.
O intervalo da entidade FLOW-statistics que monitora o tráfego da interface é de 10s-10min. Podemos registrar as informações de valor de pico de tráfego na interface por monitoramento, até mesmo registrar as informações de histórico das estatísticas de tráfego durante cada monitoramento, de modo a fazer com que o administrador da rede conheça o status da comunicação da rede e corrija a falha.
Tabela 3 -10 Configurar a entidade FLOW-statistics
| Etapa | Comando | Descrição |
| Entre no modo de configuração do sistema | configure terminal | - |
| Entre no modo de configuração da entidade FLOW-statistics | rtr entity-id [ flow-statistics ] | Obrigatório Se a entidade já existir, entre diretamente no modo de configuração da entidade. |
| Configurar o atributo de detecção | flow-statistics interface interface-name interval interval | Obrigatório |
| Configure o limite de tráfego recebido pela interface e a regra de excesso de limite | threshold-inflow flow-value direction { be | se } |
Opcional
Por padrão, o limite de tráfego recebido pela interface é 200000000bps (bit/s) e a regra de over-limit é be. |
| Configure o limite dos pacotes recebidos pela interface e a regra de excesso de limite | threshold-inpacket packet-value direction { be | se } |
Opcional
Por padrão, o limite dos pacotes recebidos pela interface é 200000000 e a regra de over-limit é be. |
| Configure o limite do tráfego recebido pela interface e a regra de excesso de limite | threshold-outflow flow-value direction { be | se } |
Opcional
Por padrão, o limite de tráfego enviado pela interface é 200000000 bps (bit/s) e a regra de over-limit é be. |
| Configure o limite dos pacotes recebidos pela interface e a regra de excesso de limite | threshold-outpacket packet-value direction { be | se } |
Opcional
Por padrão, o limite dos pacotes recebidos pela interface é 200000000 e a regra de over-limit é be. |
| Configure a configuração comum da entidade | Consulte “Configurar a configuração comum da entidade” | Opcional |
Quando a regra do excesso é ser e o valor real é maior ou igual ao limite, é julgado como acima do limite; quando a regra do excesso é se e o valor real é menor ou igual ao limite, é julgado como acima do limite.
Configurar configuração comum de entidades
Tabela 3 -11 Configurar a configuração comum das entidades
| Etapa | Comando | Descrição |
| Configurar o tipo de alarme | alarm-type [ log | log-and-trap | trap | none ] | Opcional Por padrão, o modo de alarme é nenhum, ou seja, não alarme. |
| Configure o número de registros de histórico salvos | number-of-history-kept history-number | Opcional Por padrão, salve um registro de histórico. |
| Configure o período de salvamento dos registros do histórico | periods periods | Opcional Por padrão, após o término de cada agendamento, salve um registro de histórico. |
| Configurar o tempo limite | timeout timeout |
Opcional
Por padrão, o tempo limite é: Entidade ICMP-path-echo 5000ms Entidade ICMP-path-jitter 5000ms Entidade VoIP-jitter 50000ms Entidade de eco UDP 5000ms A entidade que não suporta o comando: Entidade de eco ICMP Entidade de eco ICMPv6 Entidade de estatísticas de FLUXO |
| Configure o valor TOS do pacote | tos tos-value |
Opcional
Por padrão, o valor TOS é 0. A entidade que não suporta o comando: Entidade de eco ICMP Entidade de eco ICMPv6 |
| Configure o atributo VRF da entidade | vrf vrf-name |
Opcional
Por padrão, não configure o atributo VRF da entidade. As entidades que não suportam o comando: Entidade de eco ICMP Entidade de eco ICMPv6 Entidade de estatísticas de FLUXO |
| Configurar o intervalo de agendamento da entidade | frequency seconds |
Opcional
Por padrão, o intervalo de agendamento é: Entidade ICMP-path-echo 60s Entidade ICMP-path-jitter 60s Entidade UDP-eco 60s As entidades que não suportam o comando: Entidade de eco ICMP Entidade de eco ICMPv6 entidade VoIP-jitter Entidade de estatísticas de FLUXO |
| Configurar o comprimento do pacote de detecção | request-data-size data-size |
Opcional
Por padrão, o comprimento do pacote de detecção: Entidade ICMP-path-echo 70 bytes Entidade ICMP-path-jitter 70 bytes Entidade UDP-echo 16 bytes As entidades que não suportam o comando: Entidade de eco ICMP Entidade de eco ICMPv6 entidade VoIP-jitter Entidade de estatísticas de FLUXO |
| Configure o limite de perda de pacote e a regra de excesso de limite | threshold-pktloss pktloss direction { be | se } |
Opcional
Por padrão, o limite de perda de pacotes: Entidade de eco ICMP 150 Entidade de eco ICMPv6 150 Entidade ICMP-path-echo 1 Entidade ICMP-path-jitter 100 Entidade de eco UDP 1 A regra do excesso de limite é ser. As entidades que não suportam o comando: entidade VoIP-jitter Entidade de estatísticas de FLUXO |
| Configure o limite de atraso bidirecional e a regra de excesso de limite | threshold-rtt rtt direction { be | se } |
Opcional
Por padrão, o limite de atraso bidirecional é: Entidade de eco ICMP 9000ms Entidade de eco ICMPv6 9000ms Entidade ICMP-path-echo 9000ms ICMP-path -jitter entidade 9000ms Entidade VoIP-jitter 9000ms Entidade UDP-eco 9000ms A regra do excesso de limite é ser. As entidades que não suportam o comando: Entidade de estatísticas de FLUXO |
Se a entidade RTR já existir e a entidade estiver no estado não agendado, execute o rtr ID da entidade comando para entrar diretamente no modo de configuração da entidade. Quando a regra do excesso é ser e o valor real é maior ou igual ao limite, é julgado como acima do limite; quando a regra do excesso é se e o valor real é menor ou igual ao limite, é julgado como acima do limite. O intervalo de agendamento da entidade ICMP-path-echo precisa atender ao seguinte requisito: intervalo de agendamento > tempo limite. O intervalo de agendamento da entidade ICMP-path-jitter precisa atender ao seguinte requisito: intervalo de agendamento > tempo limite; timeout precisa atender ao seguinte requisito: timeout > pkt-number * pkt-interval; Para o parâmetro pkt-number e o parâmetro pkt-interval, consulte o comando set da entidade ICMP-path-echo. Quando o intervalo de agendamento da entidade VoIP-jitter seleciona simulando G.711ALaw, G.711muLaw e .729Acodec G, é necessário atender ao seguinte requisito: intervalo de agendamento > timeout + 5; ao selecionar o codec personalizado, é necessário atender ao seguinte requisito: intervalo de agendamento > intervalo de agendamento + 5; schedule-interval precisa atender ao seguinte requisito: schedule-interval > packet-number * packet-interval; para os parâmetros de intervalo de agendamento, número de pacote e intervalo de pacote, consulte o comando set da entidade VoIP-jitter. O intervalo de agendamento da entidade UDP-echo precisa atender ao seguinte requisito: intervalo de agendamento > tempo limite + 5.
Configurar grupo de entidades RTR
Um grupo de entidades RTR é o conjunto de um ou vários grupos de entidades RTR. Uma entidade RTR pode pertencer a vários grupos de entidades RTR e o grupo não pode se tornar membro do grupo. Um grupo só pode conter um membro uma vez. O grupo de entidades RTR é identificado exclusivamente pelo ID do grupo e o nome do grupo é gerado automaticamente pelo sistema.
O grupo de entidades RTR é principalmente para agendar um conjunto RTR. O agendamento para o grupo de entidades RTR é equivalente ao agendamento para todas as entidades RTR no grupo de entidades RTR. O resultado da detecção é salvo nos registros de histórico da entidade RTR.
Condição de configuração
Antes de configurar o grupo de entidades RTR, primeiro conclua a seguinte tarefa:
- Ativar RTR.
Configurar grupo de entidades RTR
Tabela 3 -12 Configurar o grupo de entidades RTR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do grupo de entidades RTR | rtr group group-id | Obrigatório Se o grupo de entidades RTR não existir, crie automaticamente o grupo de entidades. |
| Adicione os membros no grupo de entidades RTR | member entity-list | Opcional Por padrão, o grupo de entidades RTR não contém nenhum membro. |
| Configure as opções do grupo de entidades RTR | option { or | and } |
Opcional
Por padrão, a opção de status do grupo de entidades RTR é e (quando todas as entidades do grupo são alcançáveis, o status do grupo pode ser alcançado) |
| Configure o intervalo de agendamento entre os membros no grupo de entidades RTR | interval interval | Opcional Por padrão, o intervalo de agendamento dos membros do grupo é 0s. |
| Configure o grupo de entidades RTR para gerar o agendador automaticamente | group probe |
Opcional
Por padrão, não configure o grupo de entidades RTR para gerar o planejador automaticamente. |
Uma entidade VoIP-jitter ou entidade UDP-echo não pode ser adicionada a vários grupos para agendamento. Caso contrário, o resultado do agendamento pode estar errado. O método de cálculo para o intervalo de agendamento do grupo de entidades RTR é o seguinte: intervalo de agendamento = o máximo de todos os intervalos de agendamento dos membros + (quantidade de membros – 1) * intervalo de agendamento entre os membros.
Configurar o RTR Responder
O respondedor RTR é usado principalmente para configurar a conexão com a extremidade de origem e responder aos pacotes de detecção enviados pela extremidade de origem, de modo a garantir que o resultado da detecção esteja correto. A entidade VoIP-jitter e a entidade UDP-echo precisam configurar a conexão com a extremidade de destino, portanto, devemos configurar o respondedor RTR na extremidade de destino.
Condição de configuração
Antes de configurar o respondedor RTR, primeiro conclua a seguinte tarefa:
- Ativar RTR.
Configurar o RTR Responder
Tabela 3 -13 Configurar o respondedor RTR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o respondedor RTR | rtr responder | Obrigatório Por padrão, não configure o respondedor RTR. |
Configurar o Agendador RTR
O escalonador RTR é a política de detecção de escalonamento para a entidade ou grupo RTR. O escalonador RTR pode usar um membro de entidade como objeto e também pode usar um grupo de entidades RTR como objeto, mas não pode usar o grupo e a entidade como objeto juntos. O escalonador RTR é identificado exclusivamente pelo ID do escalonamento e não relacionado com o tipo de entidade RTR, mas o intervalo de escalonamento deve considerar os atributos da entidade RTR escalonada ou os membros do grupo de entidades RTR. O agendador RTR fornece políticas de agendamento ricas e pode selecionar agendar de uma só vez ou iniciar a agenda após algum tempo, até mesmo definir o tempo absoluto de início do agendamento. Além disso, o agendador pode encerrar automaticamente após os horários de agendamento definidos e também pode sempre existir.
Condição de configuração
Antes de configurar o planejador RTR, primeiro conclua a seguinte tarefa:
- Configure a entidade RTR desejada ou o grupo de entidades RTR
Configurar o Agendador RTR
Tabela 3 -14 Configurar o agendador RTR
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o agendador RTR, agendando uma entidade ou grupo | rtr schedule schedule-id { entity entity-id | group group-id } start { hh:mm [ :ss ] date month year | after hh:mm [ :ss ] | now } ageout ageout-time life { forever | life-time repeat repeat-times } | Obrigatório Por padrão, não configure o agendador RTR. |
O tempo de idade do agendador RTR deve ser maior que o intervalo de agendamento do objeto de agendamento. Caso contrário, após um agendamento, o agendador será excluído devido ao vencimento e ao tempo limite.
Configurar pausar entidade de agendamento
Para a entidade que está sendo agendada, podemos configurar pausando o agendamento da entidade.
Condição de configuração
Antes de configurar o agendamento de pausa da entidade, primeiro conclua a seguinte tarefa:
- A entidade está sendo agendada
Configurar pausar entidade de agendamento
Tabela 3 -15 Configurar pausar o agendamento da entidade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar pausar o agendamento da entidade | rtr entity-id halt | Opcional Por padrão, não pause a entidade no estado de agendamento. |
Apenas uma entidade pode configurar o rtr parar . Se a entidade for membro do grupo de entidades RTR, não podemos configurar o rtr parar. Depois de configurar o rtr parar e se ainda não estiver configurando o rtr retomar antes do término do período de agendamento, o agendador de agendamento da entidade será excluído devido ao vencimento e ao tempo limite.
Configurar a restauração da entidade de agendamento
Para o agendamento pausado da entidade, podemos configurar o agendamento de restauração da entidade.
Condição de configuração
Antes de configurar o agendamento de restauração da entidade, primeiro conclua a seguinte tarefa:
- A entidade está no estado de agendamento pausado
Configurar a restauração da entidade de agendamento
Tabela 3 -16 Configurar o agendamento de restauração da entidade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o agendamento de restauração da entidade | rtr entity-id resume | Opcional |
SLAMonitoramento e manutenção
Tabela 3 -17 SLAMonitoramento e manutenção
| Comando | Descrição |
| show rtr entity [ entity-id ] | Exibir as informações da entidade RTR |
| show rtr group [ group-id ] | Exibir as informações do grupo de entidades RTR |
| show rtr history entity-id | Exibe as informações de registro de histórico da entidade RTR especificada |
| show rtr schedule [ schedule-id ] | Exibir as informações do agendador RTR |
Exemplo de configuração típico SLA
Configurar entidade ICMP-echo para detectar comunicação de rede básica
Requisito de rede
- Use a entidade ICMP-echo em Device1, detectando a comunicação básica da rede de Device1 para Device3.
Topologia de rede

Figura 3 – 1 Rede de configuração da entidade ICMP-echo
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP e a rota da interface, fazendo com que o Device1 se comunique com o Device3. (Omitido)
- Passo 3:Configure a entidade ICMP-echo e adicione os parâmetros de atributo.
#Configurar dispositivo1.
Device1#config terminalDevice1(config)#rtr enableDevice1(config)#rtr 1 icmpechoDevice1(config-rtr-icmpecho)#set 132.1.1.1 5 70 2 12 extend 131.1.1.1 0 TRUE FALSEDevice1(config-rtr-icmpecho)#alarm-type logDevice1(config-rtr-icmpecho)#number-of-history-kept 255Device1(config-rtr-icmpecho)#threshold-pktLoss 10 direction beDevice1(config-rtr-icmpecho)#threshold-rtt 1000 direction beDevice1(config-rtr-icmpecho)#exit
#Visualize os parâmetros da entidade ICMP-echo.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:IcmpEcho1 Created:TRUE****************type:ICMPECHO****************CreatedTime:WED OCT 31 14:49:31 2012LatestModifiedTime:WED OCT 31 14:53:53 2012Times-of-schedule:0TargetIp:132.1.1.1Transmit-packets:5Totally-send-packets:0Packet-size:70Timeout:2(s)Alarm-type:logThreshold-of-rtt:1000(ms) direction:beThreshold-of-packet-loss:10 direction:beNumber-of-history-kept:255Periods:1Extend parameters:sourceIp:131.1.1.1 tos:0 DF(DON'T FRAG):TRUE Verify-data:FALSEIn-scheduling:FALSESchedule frequency:12(s)Status:DEFAULT
O resultado mostra que os parâmetros da entidade são consistentes com a configuração.
In-scheduling:FALSEDescription entidade não está agendada.
Status:DEFAULT O status da entidade de descrição é DEFAULT.
Quando a entidade não está agendada, o status é DEFAULT; quando a entidade é agendada e se a entidade é alcançável, o status é REACHABLE; se a entidade estiver inacessível, o status será INACESSÍVEL.
- Passo 4:Agende a entidade ICMP-echo definida e defina os parâmetros de atributo do agendamento.
#Configurar dispositivo1
Device1(config)#rtr schedule 1 entity 1 start now ageout 100 life forever- Passo 5:Confira o resultado.
Quando a conectividade de rede de Device1 para Device3 é normal:
#Visualize o status da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:IcmpEcho1 Created:TRUE****************type:ICMPECHO****************CreatedTime:WED OCT 31 14:49:31 2012LatestModifiedTime:WED OCT 31 14:53:53 2012Times-of-schedule:1Time-of-last-schedule:WED OCT 31 14:54:07 2012TargetIp:132.1.1.1Transmit-packets:5Totally-send-packets:5Packet-size:70Timeout:2(s)Alarm-type:logThreshold-of-rtt:1000(ms) direction:beThreshold-of-packet-loss:10 direction:beNumber-of-history-kept:255Periods:1Extend parameters:sourceIp:131.1.1.1 tos:0 DF(DON'T FRAG):TRUE Verify-data:FALSEIn-scheduling:TRUESchedule frequency:12(s)Status:REACHABLE
In-scheduling: TRUE indica que a entidade está sendo agendada;
Status:REACHABLE indica que o status da entidade é alcançável, ou seja, a conexão de rede do Dispositivo1 para o Dispositivo3 está normal.
- Quando a conectividade de rede de Device1 para Device3 está com defeito:
O modo de alarme é configurado como log, portanto, quando a rede for desconectada, imprima as informações do alarme no dispositivo, conforme abaixo:
Oct 31 14:54:46: [tRtrIcmpRcv]Rtr 1 (ICMPECHO) rtt [9000ms] was exceeded(>=) threshold [1000ms].#Visualize o status da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:IcmpEcho1 Created:TRUE****************type:ICMPECHO****************CreatedTime:WED OCT 31 14:49:31 2012LatestModifiedTime:WED OCT 31 14:53:53 2012Times-of-schedule:4Time-of-last-schedule:WED OCT 31 14:54:43 2012TargetIp:132.1.1.1Transmit-packets:5Totally-send-packets:20Packet-size:70Timeout:2(s)Alarm-type:logThreshold-of-rtt:1000(ms) direction:beThreshold-of-packet-loss:10 direction:beNumber-of-history-kept:255Periods:1Extend parameters:sourceIp:131.1.1.1 tos:0 DF(DON'T FRAG):TRUE Verify-data:FALSEIn-scheduling:TRUESchedule frequency:12(s)Status:UNREACHABLE
In-scheduling: TRUED indica que a entidade está sendo agendada;
Status:UNREACHABLE indica que o status da entidade está inacessível, ou seja, a conexão de rede do Dispositivo1 para o Dispositivo3 está inacessível.
#Visualize o conteúdo do registro do histórico.
Device1#show rtr history 1--------------------------------------------------------------ID:1 Name:IcmpEcho1 CurHistorySize:4 MaxHistorysize:255History recorded as following:WED OCT 31 14:54:46 2012PktLoss:5 ,Rtt:invalidWED OCT 31 14:54:32 2012PktLoss:0 ,Rtt:11 (ms)WED OCT 31 14:54:20 2012PktLoss:0 ,Rtt:2 (ms)WED OCT 31 14:54:07 2012PktLoss:0 ,Rtt:2 (ms)
Nos registros do histórico, registre a perda de pacotes e o atraso de cada agendamento; se Rtt for inválido, indica que há falha na rede e a rede é alcançável.
Configurar a entidade ICMP-path-echo para detectar a comunicação de rede
Requisito de rede
- Use a entidade ICMP-path-echo em Device1, detectando a comunicação de rede do caminho de Device1 para Device3.
Topologia de rede

Figura 3 – 2 Rede de configuração da entidade ICMP-path-echo
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP e a rota da interface, fazendo com que Device1, Device2 e Device3 se comuniquem entre si. (Omitido)
- Passo 3:Configure a entidade ICMP-path-echo e adicione os parâmetros de atributo.
#Configurar dispositivo1.
Device1#config terminalDevice1(config)#rtr enableDevice1(config)#rtr 1 icmp-path-echoDevice1(config-rtr-icmppathecho)#set dest-ipaddr 192.0.0.2 source-ipaddr 110.1.0.1Device1(config-rtr-icmppathecho)#number-of-history-kept 255Device1(config-rtr-icmppathecho)#targetOnly falseDevice1(config-rtr-icmppathecho)#exit
# Visualize os parâmetros da entidade ICMP-path-echo.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:IcmpPathEcho1 Created:TRUE****************type:ICMPPATHECHO****************CreatedTime:WED OCT 24 10:18:02 2012LatestModifiedTime:WED OCT 24 10:19:09 2012Times-of-schedule:0TargetIp:192.0.0.2SourceIp:110.1.0.1Transmit-packets:1 (each hop)Request-data-size:70Timeout:5000(ms)Frequency:60(s)TargetOnly:FALSEVerify-data:FALSEAlarm-type:noneThreshold-of-rtt:9000(ms) direction:beThreshold-of-pktloss:1 direction:beNumber-of-history-kept:255Periods:1In-scheduling:FALSEStatus:DEFAULT--------------------------------------------------------------
O resultado mostra que os parâmetros da entidade são consistentes com a configuração.
In-scheduling:FALSE indica que a entidade não está agendada.
Status:DEFAULT indica que o status da entidade é DEFAULT.
- Passo 4:Agende a entidade ICMP-path-echo definida e defina os parâmetros de atributo do agendamento.
#Configurar dispositivo1.
Device1(config)#rtr schedule 1 entity 1 start now ageout 100 life 600 repeat 10- Passo 5:Confira o resultado.
#Visualize o status da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:IcmpPathEcho1 Created:TRUE****************type:ICMPPATHECHO****************CreatedTime:WED OCT 24 10:18:02 2012LatestModifiedTime:WED OCT 24 10:19:09 2012Times-of-schedule:1Time-of-last-schedule:WED OCT 24 10:20:01 2012TargetIp:192.0.0.2SourceIp:110.1.0.1Transmit-packets:1 (each hop)Request-data-size:70Timeout:5000(ms)Frequency:60(s)TargetOnly:FALSEVerify-data:FALSEAlarm-type:noneThreshold-of-rtt:9000(ms) direction:beThreshold-of-pktloss:1 direction:beNumber-of-history-kept:255Periods:1In-scheduling:TRUEStatus:REACHABLE
In-scheduling:TRUE indica que a entidade está sendo agendada.
Status:REACHABLE indica que o status da entidade é alcançável, ou seja, a conexão de rede do Dispositivo1 para o Dispositivo3 está normal.
#Visualize o conteúdo do registro do histórico.
Device1#show rtr history 1--------------------------------------------------------------ID:1 Name:IcmpPathEcho1History of hop-by-hop:110.1.0.2 PktLoss:0 ,Rtt:2 (ms)192.0.0.2 PktLoss:0 ,Rtt:1 (ms)History of record from source to dest:CurHistorySize:1 MaxHistorysize:255WED OCT 24 10:20:01 2012PktLoss:0 ,Rtt:1 (ms)
Nos registros do histórico, registre a perda de pacotes e o atraso de cada agendamento.
#Aguarde algum tempo e após agendar 10 vezes, visualize o status da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:IcmpPathEcho1 Created:TRUE****************type:ICMPPATHECHO****************CreatedTime:WED OCT 24 10:18:02 2012LatestModifiedTime:WED OCT 24 10:19:09 2012Times-of-schedule:10Time-of-last-schedule:WED OCT 24 10:29:01 2012TargetIp:192.0.0.2SourceIp:110.1.0.1Transmit-packets:1 (each hop)Request-data-size:70Timeout:5000(ms)Frequency:60(s)TargetOnly:FALSEVerify-data:FALSEAlarm-type:noneThreshold-of-rtt:9000(ms) direction:beThreshold-of-pktloss:1 direction:beNumber-of-history-kept:255Periods:1In-scheduling:FALSEStatus:DEFAULT
Após o agendamento por 10 vezes, o agendamento é interrompido e o status da entidade é DEFAULT.
Configurar caminho ICMP - Entidade jitter para detectar comunicação de rede
Requisito de rede
- Use a entidade ICMP-path-jitter em Device1, detectando a comunicação de rede do caminho de Device1 para Device3.
Topologia de rede

Figura 3 – 3 Rede de configuração da entidade ICMP-path-jitter
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP e a rota da interface, fazendo com que Device1, Device2 e Device3 se comuniquem entre si. (Omitido)
- Passo 3:Configure a entidade ICMP-path-jitter e adicione os parâmetros de atributo.
#Configurar dispositivo1.
Device1#config terminalDevice1(config)#rtr enableDevice1(config)#rtr 1 icmp-path-jitterDevice1(config-rtr-icmppathjitter)#set dest-ipaddr 192.0.0.2 10 20 source-ipaddr 110.1.0.1Device1(config-rtr-icmppathjitter)#number-of-history-kept 255Device1(config-rtr-icmppathjitter)#targetOnly falseDevice1(config-rtr-icmppathjitter)#exit
#Visualize os parâmetros da entidade ICMP-path-jitter.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:IcmpPathJitter1 Created:TRUE****************type:ICMPPATHJITTER****************CreatedTime:WED OCT 24 10:54:31 2012LatestModifiedTime:WED OCT 24 10:56:12 2012Times-of-schedule:0TargetIp:192.0.0.2SourceIp:110.1.0.1Transmit-packets:10 (each hop)Packets-interval:20(ms)Request-data-size:70Timeout:5000(ms)Frequency:60(s)TargetOnly:FALSEVerify-data:FALSEAlarm-type:noneThreshold-of-rtt:9000(ms) direction:beThreshold-of-pktLoss: 200000000 direction:beThreshold-of-jitter:6000(ms) direction:beNumber-of-history-kept:255Periods:1In-scheduling:FALSEStatus:DEFAULT--------------------------------------------------------------
O resultado mostra que os parâmetros da entidade são consistentes com a configuração.
In-scheduling:FALSE indica que a entidade não está agendada.
Status:DEFAULT indica que o status da entidade é DEFAULT.
- Passo 4:Agende a entidade ICMP-path-jitter definida e defina os parâmetros de atributo do agendamento.
#Configurar dispositivo1.
Device1(config)#rtr schedule 1 entity 1 start now ageout 100 life foreve- Passo 5:Confira o resultado.
#Visualize o status da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:IcmpPathJitter1 Created:TRUE****************type:ICMPPATHJITTER****************CreatedTime:WED OCT 24 10:54:31 2012LatestModifiedTime:WED OCT 24 10:56:12 2012Times-of-schedule:4Time-of-last-schedule:WED OCT 24 11:00:25 2012TargetIp:192.0.0.2SourceIp:110.1.0.1Transmit-packets:10 (each hop)Packets-interval:20(ms)Request-data-size:70Timeout:5000(ms)Frequency:60(s)TargetOnly:FALSEVerify-data:FALSEAlarm-type:noneThreshold-of-rtt:9000(ms) direction:beThreshold-of-pktLoss: 200000000 direction:beThreshold-of-jitter:6000(ms) direction:beNumber-of-history-kept:255Periods:1In-scheduling:TRUEStatus:REACHABLE--------------------------------------------------------------
Em agendamento: TRUE indica que a entidade está sendo agendada.
Status:REACHABLE indica que o status da entidade é alcançável, ou seja, a conexão de rede do Dispositivo1 para o Dispositivo3 está normal.
#Visualize o conteúdo do registro do histórico.
Device1#show rtr history 1--------------------------------------------------------------ID:1 Name:IcmpPathJitter1History of hop-by-hop:110.1.0.2 PktLoss:0 Rtt:1 (ms),Jitter:0 (ms)192.0.0.2 PktLoss:0 Rtt:0 (ms),Jitter:0 (ms)History of record from source to dest:CurHistorySize:4 MaxHistorysize:255WED OCT 24 11:00:25 2012PktLoss:0 ,Rtt:1 (ms),Jitter:0 (ms)WED OCT 24 10:59:25 2012PktLoss:0 ,Rtt:0 (ms),Jitter:0 (ms)WED OCT 24 10:58:25 2012PktLoss:0 ,Rtt:0 (ms),Jitter:0 (ms)WED OCT 24 10:57:25 2012PktLoss:0 ,Rtt:0 (ms),Jitter:0 (ms)--------------------------------------------------------------
Nos registros do histórico, registre a perda de pacotes, atraso e jitter de cada agendamento.
Configurar a entidade VoIP-jitter para detectar pacotes VoIP de transmissão de rede
Requisito de rede
- Use a entidade VoIP-jitter em Device1 e detecte a rede transmitindo pacotes VoIP de Device1 para Device3 .
Topologia de rede

Figura 3 – 4 Rede de configuração da entidade VoIP-jitter
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP e a rota da interface, fazendo com que o Device1 se comunique com o Device3. (Omitido)
- Passo 3:Configure o ntp e sincronize o relógio.
#Configurar dispositivo3.
Device3#config terminalDevice3(config)#ntp master
#Configurar dispositivo1.
Device1(config)#ntp server 192.0.0.2#Ver que Device3 se torna o servidor de relógio com sucesso e avisar que o relógio está sincronizado.
Device3#show ntp statusCurrent NTP status informationClock is synchronized, stratum 8, reference is 127.127.8.10reference time is D4321EF4.7BBBBB68 (08:01:56.483 Wed Oct 24 2012)
#Ver que Device1 se torna o cliente do relógio com sucesso, avisar que o relógio está sincronizado e exibir o endereço do servidor.
Device1#show ntp statusCurrent NTP status informationClock is synchronized, stratum 9, reference is 192.0.0.2reference time is D43222C1.91110F31 (08:18:09.566 Wed Oct 24 2012)
- Passo 4:Configure o respondedor no Device3 como o final do respondente.
#Configurar dispositivo3
Device3(config)#rtr enableDevice3(config)#rtr responder
- Passo 5:Configure a entidade VoIP-jitter em Device1 e adicione os parâmetros de atributo.
#Configurar dispositivo1.
Device1#config terminalDevice1(config)#rtr enableDevice1(config)#rtr 1 jitterDevice1(config-rtr-jitter)#set dest-ipaddr 192.0.0.2 dest-port 1234 g711alaw source-ipaddr 110.1.0.1 source-port 1234Device1(config-rtr-jitter)#number-of-history-kept 255Device1(config-rtr-jitter)#exit
#Visualize o parâmetro da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:Jitter1 Created:TRUE****************type:JITTER****************CreatedTime:WED OCT 24 16:02:32 2012LatestModifiedTime:WED OCT 24 16:02:58 2012Times-of-schedule:0Entry-state:PendTargetIp:192.0.0.2 targetPort:1234Codec:G.711 A-Law Packet-size:172 Packet-number:1000Packet-transmit-interval:20(ms)frequency:60(s)SourceIp:110.1.0.1 Soure-port:1234TimeOut:50000(ms)Alarm-type:noneThreshold-of-dsDelay:5000(ms) direction:beThreshold-of-dsJitter:6000(ms) direction:beThreshold-of-dsPktLoss:200000000 direction:beThreshold-of-sdDelay:5000(ms) direction:beThreshold-of-sdJitter:6000(ms) direction:beThreshold-of-sdPktLoss:200000000 direction:beThreshold-of-rtt:9000(ms) direction:beThreshold-of-mos:10000000 direction:beThreshold-of-icpif:100000000 direction:beNumber-of-history-kept:255Periods:1Status:DEFAULT--------------------------------------------------------------
O resultado mostra que os parâmetros da entidade são consistentes com a configuração.
Status:DEFAULT indica que o status da entidade é DEFAULT.
- Passo 6:Agende a entidade VoIP-jitter definida e defina os parâmetros de atributo do agendamento.
#Configurar dispositivo1.
Device1(config)#rtr schedule 1 entity 1 start now ageout 100 life 600 repeat 10- Passo 7:Confira o resultado.
#Visualize o status da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:Jitter1 Created:TRUE****************type:JITTER****************CreatedTime:WED OCT 24 16:02:32 2012LatestModifiedTime:WED OCT 24 16:06:02 2012Times-of-schedule:3Time-of-last-schedule:WED OCT 24 16:08:29 2012Entry-state:TransmitTargetIp:192.0.0.2 targetPort:1234Codec:G.711 A-Law Packet-size:172 Packet-number:1000Packet-transmit-interval:20(ms)frequency:60(s)SourceIp:110.1.0.1 Soure-port:1234TimeOut:50000(ms)Alarm-type:noneThreshold-of-dsDelay:5000(ms) direction:beThreshold-of-dsJitter:6000(ms) direction:beThreshold-of-dsPktLoss:200000000 direction:beThreshold-of-sdDelay:5000(ms) direction:beThreshold-of-sdJitter:6000(ms) direction:beThreshold-of-sdPktLoss:200000000 direction:beThreshold-of-rtt:9000(ms) direction:beThreshold-of-mos:10000000 direction:beThreshold-of-icpif:100000000 direction:beNumber-of-history-kept:255Periods:1Status:REACHABLE--------------------------------------------------------------
Estado de entrada:Transmitir indica que a entidade está sendo agendada.
Status: REACHABLE indica que o status da entidade é alcançável e a rede de Device1 para Device3 transmite os pacotes VoIP normalmente.
#Visualize o conteúdo do registro do histórico.
Device1#show rtr history 1--------------------------------------------------------------ID:1 Name:Jitter1 CurHistorySize:3 MaxHistorysize:255History recorded as following:WED OCT 24 16:08:46 2012SdPktLoss:0 ,DsPktLoss:0 ,Rtt:185 (ms),SdDelay:14 (ms),DsDelay:178 (ms),SdJitter:8 (ms),DsJitter:183 (ms),Mos:5.000000 ,icpif:0.000000WED OCT 24 16:07:45 2012SdPktLoss:0 ,DsPktLoss:0 ,Rtt:14 (ms),SdDelay:16 (ms),DsDelay:7 (ms),SdJitter:10 (ms),DsJitter:13 (ms),Mos:5.000000 ,icpif:0.000000WED OCT 24 16:06:46 2012SdPktLoss:0 ,DsPktLoss:0 ,Rtt:17 (ms),SdDelay:16 (ms),DsDelay:9 (ms),SdJitter:11 (ms),DsJitter:13 (ms),Mos:5.000000 ,icpif:0.000000--------------------------------------------------------------
Nos registros do histórico, registre a perda de pacote unidirecional, atraso de retorno, atraso unidirecional e jitter unidirecional de cada agendamento.
Antes de configurar a entidade VoIP-jitter, precisamos configurar o serviço NTP para realizar a sincronização do relógio da rede e configurar o comando rtr responder no destino como o respondente. Observe que, se o relógio não estiver sincronizado ou não estiver configurando a extremidade do respondente, o resultado do agendamento está errado.
Configurar a entidade UDP-echo para detectar pacotes UDP de transmissão de rede
Requisito de rede
- Use a entidade UDP-echo em Device1 e detecte a rede transmitindo pacotes UDP de Device1 para Device3 .
Topologia de rede

Figura 3 – 5 Rede de configuração da entidade UDP-echo
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP e a rota da interface, fazendo com que o Device1 se comunique com o Device3. (Omitido)
- Passo 3:Configure o respondedor no Device3 como o final do respondente.
#Configurar dispositivo3
Device3#config terminalDevice3(config)#rtr enableDevice3(config)#rtr responder
- Passo 4:Configure a entidade UDP-echo em Device1 e adicione os parâmetros de atributo.
#Configurar dispositivo1.
Device1#config terminalDevice1(config)#rtr enableDevice1(config)#rtr 1 udpechoDevice1(config-rtr-udpecho)#set dest-ipaddr 192.0.0.2 dest-port 1001 source-ipaddr 110.1.0.1 source-port 1001Device1(config-rtr-udpecho)#number-of-history-kept 255Device1(config-rtr-udpecho)#frequency 10Device1(config-rtr-udpecho)#exit
#Visualize o parâmetro da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:UdpEcho1 Created:TRUE****************type:UDPECHO****************CreatedTime:WED OCT 24 16:36:45 2012LatestModifiedTime:WED OCT 24 16:37:44 2012Times-of-schedule:0Entry-state:PendTargetIp:192.0.0.2 TargetPort:1001SourceIp:110.1.0.1 SourePort:1001TimeOut:5000(ms)request-data-size:16Frequecy:10(s)Alarm-type:noneThreshold-of-rtt:9000(ms) direction:beThreshold-of-pktloss:1 direction:beNumber-of-history-kept:255Periods:1Status:DEFAULT--------------------------------------------------------------
O resultado mostra que os parâmetros da entidade são consistentes com a configuração.
Status: DEFAULT indica que o status da entidade é DEFAULT.
- Passo 5:Agende a entidade UDP-echo definida e defina os parâmetros de atributo do agendamento.
#Configurar dispositivo1.
Device1(config)#rtr schedule 1 entity 1 start now ageout 100 life forever- Passo 6:Confira o resultado.
#Visualize o status da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:UdpEcho1 Created:TRUE****************type:UDPECHO****************CreatedTime:WED OCT 24 16:36:45 2012LatestModifiedTime:WED OCT 24 16:37:44 2012Times-of-schedule:5Time-of-last-schedule:WED OCT 24 16:39:50 2012Entry-state:PendTargetIp:192.0.0.2 TargetPort:1001SourceIp:110.1.0.1 SourePort:1001TimeOut:5000(ms)request-data-size:16Frequecy:10(s)Alarm-type:noneThreshold-of-rtt:9000(ms) direction:beThreshold-of-pktloss:1 direction:beData-pattern:ABCDNumber-of-history-kept:255Periods:1Status:REACHABLE--------------------------------------------------------------
Status: REACHABLE indica que o status da entidade é alcançável, ou seja, a rede de Device1 para Device2 pode transmitir os pacotes UDP normalmente.
#Visualize o conteúdo do registro do histórico.
Device1#show rtr history 1--------------------------------------------------------------ID:1 Name:UdpEcho1 CurHistorySize:5 MaxHistorysize:255History recorded as following:WED OCT 24 16:39:54 2012PktLoss:0 ,Rtt:1 (ms)WED OCT 24 16:39:44 2012PktLoss:0 ,Rtt:1 (ms)WED OCT 24 16:39:33 2012PktLoss:0 ,Rtt:2 (ms)WED OCT 24 16:39:23 2012PktLoss:0 ,Rtt:2 (ms)WED OCT 24 16:39:13 2012PktLoss:0 ,Rtt:2 (ms)--------------------------------------------------------------
Nos registros do histórico, registre a perda de pacotes e o atraso de cada agendamento.
Antes de configurar a entidade UDP-echo, precisamos configurar o comando rtr responder na extremidade de destino como o respondente. Se a extremidade do respondente não estiver configurada, o resultado do agendamento está errado.
Configurar a entidade FLOW-statistics para detectar o tráfego de interface
Requisito de rede
- Use a entidade FLOW-statistics no Device1 e detecte o fluxo da interface vlan2.
Topologia de rede
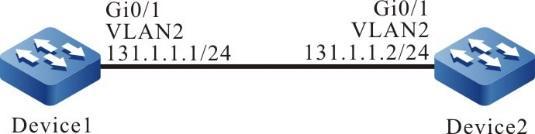
Figura 3 -6 Rede de configuração da entidade FLOW-statistics
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (omitido)
- Passo 2:Device1 , configure a entidade FLOW-statistics e adicione os parâmetros de atributo.
#Configurar dispositivo1.
Device1#config terminalDevice1(config)#rtr enableDevice1(config)#rtr 1 flow-statisticsDevice1(config-rtr-flowsta)#flow-statistics interface vlan 2 interval 60Device1(config-rtr-flowsta)#number-of-history-kept 255Device1(config-rtr-flowsta)#exit
#Visualize os parâmetros da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:flow-statistics1 Created:TRUE****************type:FLOWSTATISTICS****************CreatedTime:THU OCT 25 09:57:43 2012LatestModifiedTime:THU OCT 25 09:58:03 2012Times-of-schedule:0Alarm-type:noneThreshold-of-inputPkt:200000000 direction:beThreshold-of-inputFlow:200000000 direction:beThreshold-of-outputPkt:200000000 direction:beThreshold-of-outputFlow:200000000 direction:beInterface: vlan2Statistics-interval:60(s)Number-of-history-kept:255Periods:1Status:DEFAULT--------------------------------------------------------------
O resultado mostra que o parâmetro entidade é consistente com a configuração.
Status:DEFAULT indica que o status da entidade é DEFAULT.
- Passo 3:Agende a entidade de estatísticas de fluxo definida e defina os parâmetros de atributo do planejamento.
#Configurar dispositivo1.
Device1(config)#rtr schedule 1 entity 1 start now ageout 100 life 600 repeat 10- Passo 4:Confira o resultado.
- Quando há o fluxo de dados recebido na interface vlan2 :
#Visualize o status da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:flow-statistics1 Created:TRUE****************type:FLOWSTATISTICS****************CreatedTime:THU OCT 25 09:57:43 2012LatestModifiedTime:THU OCT 25 09:58:03 2012Times-of-schedule:2Time-of-last-schedule:THU OCT 25 10:02:11 2012Alarm-type:noneThreshold-of-inputPkt:200000000 direction:beThreshold-of-inputFlow:200000000 direction:beThreshold-of-outputPkt:200000000 direction:beThreshold-of-outputFlow:200000000 direction:beInterface: vlan 2Statistics-interval:60(s)Number-of-history-kept:255Periods:1Status:REACHABLE--------------------------------------------------------------
Status:REACHABLE indica que o status da entidade é alcançável, ou seja, há pacotes entrando/saindo da interface vlan2.
- Quando não há fluxo entrando/saindo da interface vlan2 :
#Visualize o status da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:flow-statistics1 Created:TRUE****************type:FLOWSTATISTICS****************CreatedTime:THU OCT 25 09:57:43 2012LatestModifiedTime:THU OCT 25 09:58:03 2012Times-of-schedule:5Time-of-last-schedule:THU OCT 25 10:05:11 2012Alarm-type:noneThreshold-of-inputPkt:200000000 direction:beThreshold-of-inputFlow:200000000 direction:beThreshold-of-outputPkt:200000000 direction:beThreshold-of-outputFlow:200000000 direction:beInterface: vlan 2Statistics-interval:60(s)Number-of-history-kept:255Periods:1Status:UNREACHABLE--------------------------------------------------------------
Status:UNREACHABLE indica que nenhum fluxo entra/sai da interface vlan2 e o status da entidade é inacessível.
# Visualize o conteúdo do registro do histórico.
Device1#show rtr history 1--------------------------------------------------------------ID:1 Name:flow-statistics1 CurHistorySize:5 MaxHistorysize:255History recorded as following:THU OCT 25 10:05:11 2012Input pkt:0 (packets/s),Input flow:0 (bits/s),Output pkt:0 (packets/s),Output flow:0 (bits/s)THU OCT 25 10:04:11 2012Input pkt:209 (packets/s),Input flow:214000 (bits/s),Output pkt:0 (packets/s),Output flow:0 (bits/s)THU OCT 25 10:03:11 2012Input pkt:8460 (packets/s),Input flow:8663000 (bits/s),Output pkt:0 (packets/s),Output flow:0 (bits/s)THU OCT 25 10:02:11 2012Input pkt:8460 (packets/s),Input flow:8663000 (bits/s),Output pkt:0 (packets/s),Output flow:0 (bits/s)THU OCT 25 10:01:12 2012Input pkt:6456 (packets/s),Input flow:6610000 (bits/s),Output pkt:0 (packets/s),Output flow:0 (bits/s)--------------------------------------------------------------
A taxa (baseada em quantidade e baseada em bits) de entrada/saída da interface vlan2 durante cada agendamento é registrada em detalhes nos registros do histórico.
A acessibilidade da entidade FLOW-statistics é definida como: quando a entidade está em escalonamento, desde que haja tráfego de entrada ou saída da interface, o status da entidade é alcançável e, se não houver tráfego, é inacessível.
Configurar a entidade IPv6 ICMP-echo para detectar a comunicação de rede
Requisito de rede
- Use a entidade ICMP echo IPv6 em Device1 para detectar a comunicação de rede básica entre Device1 e Device3.
Topologia de rede

Figura 3 -7 Rede de configuração da entidade IPv6 ICMP-echo
Etapas de configuração
- Passo 1:Configure o endereço IPv6, rota da interface, para que Device1 e Device3 possam se comunicar entre si. (omitido)
- Passo 2:Configurar a entidade IPv6 ICMP-echo e adicionar os parâmetros de atributo.
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#rtr enableDevice1(config)#rtr 1 icmpv6echoDevice1(config-rtr-icmpv6echo)#set 2136::2 5 70 2 12 extend 2135::1 0 TRUEDevice1(config-rtr-icmpv6echo)#alarm-type logDevice1(config-rtr-icmpv6echo)#number-of-history-kept 255Device1(config-rtr-icmpv6echo)#threshold-pktLoss 10 direction beDevice1(config-rtr-icmpv6echo)#threshold-rtt 1000 direction beDevice1(config-rtr-icmpv6echo)#exit
# Visualize os parâmetros da entidade IPv6 ICMP-echo.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:Icmpv6Echo1 Created:TRUE****************type:ICMPV6ECHO****************CreatedTime:Tue Sep 17 10:05:52 2019LatestModifiedTime:Tue Sep 17 10:21:06 2019Times-of-schedule:0TargetIpv6:2136::2Transmit-packets:5Totally-send-packets:0Packet-size:70Timeout:2(s)Alarm-type:logThreshold-of-rtt:1000(ms) direction:beThreshold-of-packet-loss:10 direction:beNumber-of-history-kept:255Periods:1Extend parameters:sourceIpv6:2135::1 tos:0 Verify-data:TRUEIn-scheduling:FALSESchedule frequency:12(s)Status:DEFAULT--------------------------------------------------------------
O resultado mostra que os parâmetros da entidade são consistentes com a configuração.
In-scheduling:FALSE indica que a entidade não agenda.
Status:DEFAULT indica que o status da entidade é DEFAULT.
Quando a entidade não está agendada, o status é DEFAULT; quando a entidade é agendada e se a entidade é alcançável, o status é REACHABLE; se a entidade não for alcançável, o status será UNREACHABLE.
- Passo 3:Agende a entidade IPv6 ICMP-echo definida e defina os parâmetros de atributo do agendamento.
#Configurar dispositivo1.
Device1(config)#rtr schedule 1 entity 1 start now ageout 20 life forever- Passo 4:Confira o resultado.
- Quando a conectividade de rede entre Device1 e Device3 é normal :
#Visualize o status da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:Icmpv6Echo1 Created:TRUE****************type:ICMPV6ECHO****************CreatedTime:Tue Sep 17 10:05:52 2019LatestModifiedTime:Tue Sep 17 10:21:06 2019Times-of-schedule:2Time-of-last-schedule:Tue Sep 17 10:24:08 2019TargetIpv6:2136::2Transmit-packets:5Totally-send-packets:10Packet-size:70Timeout:2(s)Alarm-type:logThreshold-of-rtt:1000(ms) direction:beThreshold-of-packet-loss:10 direction:beNumber-of-history-kept:255Periods:1Extend parameters:sourceIpv6:2135::1 tos:0 Verify-data:TRUEIn-scheduling:TRUESchedule frequency:12(s)Status:REACHABLE--------------------------------------------------------------
In-scheduling:TRUE indica que a entidade está em agendamento.
Status: REACHABLE indica que o status da entidade é alcançável, ou seja, a conectividade de rede entre Device1 e Device3 é normal.
- Quando a conectividade de rede entre Device1 e Device3 falha :
Como os parâmetros da entidade estão configurados com o modo de alarme de log, ao atingir ou ultrapassar o valor limite, imprima as informações de alarme da seguinte forma:
%SLA-4:Rtr 1 (ICMPV6ECHO) rtt [9000ms] was exceeded(>=) threshold [1000ms].#Visualize o status da entidade.
Device1#show rtr entity 1--------------------------------------------------------------ID:1 name:Icmpv6Echo1 Created:TRUE****************type:ICMPV6ECHO****************CreatedTime:Tue Sep 17 10:05:52 2019LatestModifiedTime:Tue Sep 17 10:21:06 2019Times-of-schedule:21Time-of-last-schedule:Tue Sep 17 10:28:08 2019TargetIpv6:2136::2Transmit-packets:5Totally-send-packets:105Packet-size:70Timeout:2(s)Alarm-type:logThreshold-of-rtt:1000(ms) direction:beThreshold-of-packet-loss:10 direction:beNumber-of-history-kept:255Periods:1Extend parameters:sourceIpv6:2135::1 tos:0 Verify-data:TRUEIn-scheduling:TRUESchedule frequency:12(s)Status:UNREACHABLE--------------------------------------------------------------
In-scheduling:TRUE indica que a entidade está em agendamento.
Status: UN REACHABLE indica que o status da entidade é inacessível, ou seja, a conectividade de rede entre Device1 e Device3 está inacessível.
#Visualize o conteúdo do registro do histórico.
Device1#show rtr history 1--------------------------------------------------------------ID:1 Name:Icmpv6Echo1 CurHistorySize:4 MaxHistorysize:255History recorded as following:Tue Sep 17 10:24:42 2019PktLoss:5 ,Rtt:invalidTue Sep 17 10:24:29 2019PktLoss:1 ,Rtt:400 (ms)Tue Sep 17 10:24:17 2019PktLoss:0 ,Rtt:1 (ms)Tue Sep 17 10:24:05 2019PktLoss:0 ,Rtt:0 (ms)--------------------------------------------------------------
A perda de pacotes e o atraso de cada agendamento são registrados em detalhes no registro do histórico; O RTT é inválido, o que indica que a rede não está acessível devido à falha na rede.
Configurar TRACK para vincular com SLA
Requisito de rede
- TRACK links com SLA. Julgue a validade da rota estática no Device1 por meio do status da entidade.
Topologia de rede

Figura 3 – 7 Rede de configuração do TRACK para se conectar comSLA
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Configure a entidade ICMP-echo em Device1 para detectar a conectividade de rede de Device1 para Device2 e adicione a entidade ao grupo de entidades.
#Configurar dispositivo1.
Device1#config terminalDevice1(config)#rtr enableDevice1(config)#rtr 1 icmpechoDevice1(config-rtr-icmpecho)#set 110.1.0.2 5 70 2 12 extend 110.1.0.1 0 true falseDevice1(config-rtr-icmpecho)#number-of-history-kept 255Device1(config-rtr-icmpecho)#exitDevice1(config)#rtr group 1Device1(config-rtr-group)#member 1Device1(config-rtr-group)#exit
- Passo 4:Defina TRACK e associe com LSA.
#Configurar dispositivo1.
Device1(config)#track 1Device1(config-track)#rtr 1
- Passo 5:Adicione a rota estática e associe TRACK.
#Configurar dispositivo1.
Device1(config)#ip route 192.0.0.0 255.255.255.0 110.1.0.2 track 1- Passo 6:Agende a entidade e verifique a validade da rota estática.
#Configurar dispositivo1.
Device1(config)#rtr schedule 1 group 1 start now ageout 100 life forever- Passo 7:Confira o resultado.
Quando a conectividade de rede de Device1 para Device2 é normal:
#Exibe o status do grupo de entidades.
Device1#show rtr group 1----------------------------------------------ID:1 name:rtrGroup1 Members schedule interval:0Option: AND Status:REACHABLE*****************************type:SINGLE Entity Id :1
O status do grupo de entidades é REACHABLE.
#Na tabela de rotas do Device1, visualize a rota do segmento 192.0.0.0/24.
Device1#show ip route 192.0.0.0Codes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setS 192.0.0.0/24 [1/10] via 110.1.0.2, 00:00:09, vlan2
O resultado mostra que existe a rota para o segmento 192.0.0.0/24, indica que quando o status do grupo de entidades for RECHABLE, julgue que a rota estática é válida.
- Quando a conectividade de rede de Device1 para Device2 está com defeito:
#Visualize o status do grupo de entidades:
Device1#show rtr group 1----------------------------------------------ID:1 name:rtrGroup1 Members schedule interval:0Option: AND Status:UNREACHABLE*****************************type:SINGLE Entity Id :1
O status do grupo de entidades é UNREACHEABLE.
#Na tabela de rotas do Device1, visualize a rota do segmento 192.0.0.0/24.
Device1#show ip route 192.0.0.2Codes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not set
O resultado mostra que não há rota para o segmento 192.0.0.0/24, indica que quando o status do grupo de entidades for UNREACHABLE, julgue que a rota estática é inválida.
Configurar TRACK to Link com ICMP-echo ipv6
Requisito de rede
- RASTREIE links com SLA. Julgue a validade da rota estática no Device1 por meio do status da entidade.
Topologia de rede

Figura 3 – 8 Rede de configuração do TRACK para link com icmp-echo ipv6
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (omitido)
- Passo 2:Em Device1, configure a entidade IPv6 ICMP-echo para detectar a conectividade de rede entre Device1 e Device2 e adicione a entidade ao grupo de entidades.
#Configure Device1 .
Device1#config terminalDevice1(config)#rtr enableDevice1(config)#rtr 1 icmpv6echoDevice1(config-rtr-icmpv6echo)# set 2135::2 5 70 2 12 extend 2135::1 0 FALSEDevice1(config-rtr-icmpv6echo)#number-of-history-kept 255Device1(config-rtr-icmpv6echo)#exitDevice1(config)#rtr group 1Device1(config-rtr-group)#member 1Device1(config-rtr-group)#exit
- Passo 3:Defina TRACK e associe SLA.
#Configurar dispositivo1.
Device1(config)#track 1Device1(config-track)#rtr 1Device1(config-track)#exit
- Passo 4:Adicione rota estática e associe TRACK.
#Configurar dispositivo1.
Device1(config)#ipv6 route 2136::/64 2135::2 track 1- Passo 5:Agende o grupo de entidades.
#Configurar dispositivo1.
Device1(config)#rtr schedule 1 group 1 start now ageout 20 life forever- Passo 6:Confira o resultado.
Quando a conectividade de rede entre Device1 e Device2 é normal:
# Visualize o status do grupo de entidades.
Device1#show rtr group 1----------------------------------------------ID:1 name:rtrGroup1 Members schedule interval:0Option: AND Status:REACHABLE*****************************type:SINGLE Entity Id :1
O status do grupo de entidades é REACHABLE.
# Na tabela de rotas do Device1 , visualize a rota do segmento de rede 2136::/64.
Device1#show ipv6 route 2136::/64Codes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - ManagementS 2136::/64 [1/0]via 2135::2 [0], 00:50:17, vlan1002135::2 [0], vlan100
O resultado mostra que existe a rota para o segmento 2136::/64, indicando que quando o status do grupo de entidades for REACHABLE, julgue que a rota estática associada é válida.
- Quando a conectividade de rede entre Device1 e Device2 falha :
# Visualize o status do grupo de entidades.
Device1#show rtr group 1----------------------------------------------ID:1 name:rtrGroup1 Members schedule interval:0Option: AND Status:UNREACHABLE*****************************type:SINGLE Entity Id :1
O status do grupo de entidades é INACEITÁVEL..
# Na tabela de rotas do Device1 , visualize a rota do segmento de rede 21 36::/64.
Device1#show ipv6 route 2136::/64Codes: C - Connected, L - Local, S - static, R - RIP, B - BGP, i-ISISU - Per-user Static routeO - OSPF, OE-OSPF External, M - Management
O resultado mostra que não há rota para o segmento 2136::/64, indicando que quando o status do grupo de entidades for UNREACHABLE, julgue que a rota estática associada é inválida.
NTP
Visão geral
NTP (Network Time Protocol) é o protocolo padrão da Internet usado para sincronizar a hora na Internet. NTP é sincronizar a hora do dispositivo com a hora padrão. Atualmente, o padrão de tempo adotado é o UTC (Universal Time Coordinated).
O design do NTP considera totalmente a complexidade da sincronização de tempo na Internet. O NTP fornece o mecanismo estrito, prático e válido, aplicável aos ambientes de Internet com várias escalas e velocidades. O NTP não apenas corrige a hora atual, mas também rastreia continuamente a mudança de hora e pode ajustar automaticamente . Mesmo que a rede falhe, ela pode manter a estabilidade do tempo . O custo de rede gerado pelo NTP é pequeno e tem as medidas de garantir a segurança da rede. As medidas podem fazer com que o NTP obtenha a sincronização de tempo confiável e correta na Internet.
No aplicativo real, selecione o modo de trabalho NTP apropriado de acordo com a implantação da rede, para atender ao requisito de sincronização do relógio da rede em diferentes ambientes. O NTP suporta os três modos de trabalho a seguir:
- Modo cliente/servidor
No modo cliente/servidor, o cliente envia o pacote de sincronização do relógio com o campo Modo 3 (modo cliente) para o servidor. Após receber o pacote, o servidor trabalha automaticamente no modo servidor e envia o pacote de resposta com o campo Modo 4 (modo servidor). Após receber o pacote de resposta, o cliente sincroniza o relógio do sistema. No modo, o cliente pode sincronizar o relógio do servidor, enquanto o servidor não pode sincronizar o relógio do cliente.
- Modo de par
No modo peer, o peer ativo e o peer passivo primeiro interagem o pacote NTP com o campo Mode 3 (modo cliente) e 4 (modo servidor). E então, o peer ativo envia o pacote de sincronização do relógio com o campo Mode 1 (o modo de peer ativo) para o peer passivo. Após receber o pacote, o peer passivo trabalha automaticamente no modo de peer passivo e envia o pacote de sincronização do relógio com o campo Mode 2 (modo de peer passivo). Desta forma, o modo peer é configurado. No modo, o peer ativo e o peer passivo sincronizam o relógio mutuamente. Se os relógios das duas partes já estiverem sincronizados , fique sujeito ao relógio com camadas menores.
- Modo de transmissão
No modo de transmissão, o servidor de transmissão envia periodicamente o pacote de sincronização de relógio com o campo Modo 5 (modo de servidor de transmissão) para o endereço de transmissão 255.255.255.255, e o cliente de transmissão monitora o pacote de transmissão do servidor de transmissão. Quando o cliente de transmissão recebe o primeiro pacote de transmissão , o cliente de transmissão e o servidor de transmissão interagem o pacote NTP com o campo Modo 3 (modo cliente) e 4 (modo de servidor), de modo a obter o atraso de rede do cliente de transmissão e do servidor de transmissão . E então, o cliente de broadcast continua a monitorar o pacote de broadcast e sincroniza o relógio do sistema de acordo com o pacote de broadcast recebido.
Configuração da função NTP
Tabela 4 -1 lista de configuração da função NTP
| Tarefa de configuração | |
| Configurar as funções básicas do NTP |
Configurar o modo cliente/ servidor NTP
Configurar o modo de peer NTP Configurar o modo de transmissão NTP |
| Configurar os parâmetros opcionais NTP |
Configurar o relógio de referência NTP
Configure a interface de origem do pacote NTP Configure o controle de recebimento e envio do pacote NTP Configure a quantidade de sessões dinâmicas NTP |
| Configurar as funções de autenticação NTP |
Configurar a autenticação de cliente/servidor NTP
Configurar a autenticação de peer NTP Configurar a autenticação de transmissão NTP |
| Configurar o controle de acesso NTP | Configurar o controle de acesso NTP |
Configurar funções básicas do NTP
Condição de configuração
Antes de configurar as funções básicas do NTP, primeiro complete a seguinte tarefa:
- Configure o endereço da camada de rede da interface, tornando acessível a camada de rede entre o solicitante do serviço de relógio NTP e o provedor de serviço de relógio .
- O provedor de serviços de relógio NTP habilita o NTP.
Configurar o modo cliente/servidor NTP
Ao utilizar o modo cliente/servidor NTP, não precisa de configuração especial no servidor, mas é necessário garantir que o relógio do servidor esteja sincronizado e as camadas de relógio do servidor sejam menores que as camadas de relógio do cliente.
Execute a seguinte configuração no cliente NTP.
Tabela 4 -2 Configurar o cliente NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Especifique o servidor NTP | ntp server [ vrf vrf-name ] { ip-address | ipv6 ipv6-address | domain-name } [ version version-number | key key-number | source interface-name ]* | Obrigatório Por padrão, não especifique o servidor NTP. |
O endereço IP parâmetro é um endereço unicast, mas não pode ser o endereço de broadcast, endereço multicast ou endereço IP do dispositivo local. O endereço IPv6 parâmetro é um endereço unicast global ou endereço Link-Local, mas não pode ser o endereço multicast. Depois de especificar a interface de origem do pacote do cliente via source nome-da-interface , o endereço IP mestre da interface ou o primeiro endereço IPv6 unicast global é definido como o endereço IP de origem do pacote enviado pelo cliente . Se o endereço do servidor configurado for IPv6 Link-local address, você deve especificar a interface de origem. Você pode especificar vários servidores configurando o servidor ntp ou servidor ntp ipv6 comando várias vezes. Você pode especificar no máximo 64 servidores (o total de nomes de domínio ipv4+ipv6+ ) .
Configurar o modo de par NTP
Ao usar o modo NTP peer, não precisa de configuração especial no peer passivo, mas é necessário garantir que o peer passivo possa receber e enviar o pacote NTP. Você pode habilitar o NTP configurando o ntp enable (ipv6 ) comando no peer passivo ou qualquer comando NTP em “1 .2.1 Configurar funções básicas do NTP ” .
Execute a seguinte configuração no peer NTP ativo.
Tabela 4 -3 Configurar o peer ativo NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Especifique o par passivo NTP | ntp peer [ vrf vrf-name ] { ip-address | ipv6 ipv6-address | domain-name } [ version version-number | key key-number | source interface-name ] * | Obrigatório Por padrão, não especifique o peer passivo NTP. |
O endereço IP parâmetro é um endereço unicast, mas não pode ser o endereço de broadcast, endereço multicast ou endereço IP do dispositivo local. O endereço ip v6 O parâmetro é um endereço unicast global ou endereço Link-Local , mas não pode ser o endereço multicast. Depois de especificar a interface de origem de envio do pacote de peer ativo via source interface-name , o endereço IP mestre da interface ou o primeiro endereço IPv6 unicast global é definido como o endereço IP de origem do pacote enviado pelo peer ativo. Se o endereço de peer configurado for o endereço IPv6 Link-local, você deve especificar a interface de origem. Você pode especificar vários pares passivos configurando o servidor ntp ou ntp peer ipv6 comando várias vezes. Você pode especificar no máximo 64 peers passivos (o total de IPv4+IPv6 +nome de domínio).
Configurar o modo de transmissão NTP
Ao usar o modo de transmissão NTP, o servidor de transmissão e o cliente de transmissão precisam ser configurados e é necessário garantir que o relógio do servidor de transmissão esteja sincronizado e as camadas de relógio sejam menores que as camadas de relógio do cliente de transmissão. É necessário especificar uma interface para envio do pacote de broadcast NTP no servidor de broadcast e uma interface para recebimento do pacote de broadcast NTP no cliente de broadcast, assim a configuração do modo de broadcast somente pode ser realizada no modo de interface específico.
Execute a seguinte configuração no cliente de difusão NTP.
Tabela 4 -4 Configurar o cliente de transmissão NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite o cliente de transmissão NTP na interface | ntp broadcast client | Obrigatório Por padrão, a interface não habilita o cliente de transmissão NTP. |
Execute a seguinte configuração no servidor de transmissão NTP.
Tabela 4 -5 Configurar o servidor de transmissão NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface | interface interface-name | - |
| Habilite o servidor de broadcast NTP na interface | ntp broadcast-server [ key key-number | version version-number ]* | Obrigatório Por padrão, a interface não habilita o servidor de transmissão NTP. |
Configurar parâmetros opcionais de NTP
Condição de configuração
Nenhum
Relógio Relógio de referência NTP
O NTP pode sincronizar a hora do sistema através dos dois modos a seguir:
- Sincronize com o relógio local, ou seja, adote o relógio local como relógio de referência NTP
- Sincronize com a outra fonte de relógio na rede, ou seja, use qualquer um dos três modos de trabalho NTP mencionados anteriormente.
Tabela 4 -6 Configure o relógio local como o relógio de referência NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o relógio local como o relógio de referência NTP | ntp master [ stratum-number ] | Obrigatório Por padrão, não configure o relógio local como o relógio de referência NTP. |
Depois de configurar o relógio local como o relógio de referência NTP, o NTP não pode sincronizar o relógio da outra fonte de relógio na rede. Após configurar o relógio local como relógio de referência NTP, o dispositivo local pode servir como fonte de relógio para sincronizar o outro dispositivo na rede. Por favor, use a configuração com cuidado, para evitar o erro de relógio de outro dispositivo na rede.
Configurar a interface de origem do pacote NTP
Se a interface de origem do pacote NTP estiver configurada e quando o dispositivo enviar o pacote NTP ativamente, selecione o endereço IP mestre da interface de origem especificada como o endereço IP de origem do pacote.
Tabela 4 -7 Configure a interface de origem do pacote NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a interface de origem do pacote NTP | ntp source interface-name | Obrigatório Por padrão, não configure a interface de origem do pacote NTP. |
Se estiver usando o comando ntp server ou ntp peer para especificar a interface de origem, primeiro use a interface de origem especificada pelo comando ntp server ou ntp peer . Se o ntp broadcast estiver configurado no modo de interface, a interface de origem do pacote de broadcast NTP será a interface configurada com o comando acima. Se a interface de origem do pacote NTP especificado estiver inativa, restaure o endereço mestre da interface de roteamento padrão ou o primeiro endereço unicast global para encapsular o endereço de origem do NTP. Se a interface de origem do pacote NTP especificado não estiver configurada com endereço e estiver no estado ativo, mas não houver um endereço IPv4 ou IPv6 correspondente, restaure o endereço mestre da interface de roteamento padrão ou o primeiro endereço unicast global para encapsular o endereço de origem do NTP .
Configurar o controle de recebimento e envio do pacote NTP
Por padrão, o dispositivo não receberá e enviará todos os pacotes NTP. Você pode configurar o controle de recebimento e envio do pacote NTP para habilitar o recebimento e envio do pacote NTP.
Tabela 4 -8 Configure o controle de recebimento e envio do pacote NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite o recebimento e envio do pacote NTP | ntp enable [ipv6] | Obrigatório Por padrão, não proíba o recebimento e envio do pacote NTP. |
Após configurar o comando no ntp enable , será proibido receber e enviar todos os pacotes NTP do IPv4. Se estiver configurando o comando ntp enable , ele habilitará o recebimento e envio dos pacotes NTP do IPv4. Após configurar o comando no ntp enable ipv6 , será proibido receber e enviar todos os pacotes NTP IPv6 . Se configurar o comando ntp enable ipv6 , ele habilitará o recebimento e envio de pacotes NTP IPv6 .
Configurar o número de sessões dinâmicas NTP
Defina o número máximo de conexões dinâmicas NTP permitidas localmente configurando o número de sessões dinâmicas NTP.
Tabela 4 -9 Configurar o número de sessões dinâmicas NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Defina o número máximo de conexões dinâmicas NTP permitidas localmente | ntp max-dynamic-sessions number | Mandatório Por padrão, o número de sessões NTP dinâmicas que podem ser configuradas é 100. |
Configurar a função de autenticação NTP
Na rede com alta exigência de segurança, ao executar o protocolo NTP, é necessário habilitar a função de autenticação. Autentique o pacote interagido pelo solicitante do serviço de relógio NTP e pelo provedor de serviço de relógio para garantir que o solicitante do serviço de relógio esteja sincronizado com a hora válida, melhorando a segurança da rede.
Condição de configuração
Para configurar a função de autenticação NTP, primeiro conclua a seguinte tarefa:
- Configure o endereço da camada de rede da interface, tornando acessível a camada de rede entre o solicitante do serviço de relógio NTP e o provedor de serviço de relógio .
- O provedor de serviços de relógio NTP habilita o NTP.
Configurar autenticação de cliente/servidor NTP
Ao configurar a autenticação de cliente/servidor NTP, é necessário habilitar a função de autenticação no cliente e no servidor, configurar a chave de autenticação, definir a chave de autenticação como a chave confiável e especificar a chave associada ao servidor no cliente.
Execute a seguinte configuração no cliente NTP.
Tabela 4 -10 Configurar a autenticação do cliente NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função de autenticação NTP | ntp authenticate | Obrigatório Por padrão, não ative a função de autenticação NTP. |
| Configurar a chave de autenticação | ntp authentication-key key-number md5 {0 plain-key | 7 cipher-key} | Obrigatório Por padrão, não configure a chave de autenticação. |
| Configure a chave especificada como a chave confiável | ntp trusted-key key-number | Obrigatório Por padrão, não especifique a chave confiável. |
| Especifique a chave associada ao servidor | ntp server [ vrf vrf-name ] { ip-address | domain-name | ipv6 ipv6-address } [ version version | source interface-name ] key key-number | Obrigatório |
Execute a seguinte configuração no servidor NTP.
Tabela 4 -11 Configurar a autenticação do servidor NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função de autenticação NTP | ntp authenticate | Obrigatório Por padrão, não ative a função de autenticação NTP. |
| Configurar a chave de autenticação | ntp authentication-key key-number md5 {0 plain-key | 7 cipher-key} | Obrigatório Por padrão, não configure a chave de autenticação. |
| Especifique a chave como a chave confiável | ntp trusted-key key-number | Obrigatório Por padrão, não especifique a chave confiável. |
O servidor e o cliente precisam ser configurados com a mesma chave de autenticação.
Configurar autenticação de peer NTP
Ao configurar a autenticação NTP peer, é necessário habilitar a função de autenticação no peer ativo e no peer passivo, configurar a chave de autenticação, definir a chave de autenticação como a chave confiável e especificar a chave associada ao peer passivo no peer ativo .
Execute a seguinte configuração no peer NTP ativo.
Tabela 4 -12 Configurar a autenticação de peer ativo NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função de autenticação NTP | ntp authenticate | Obrigatório Por padrão, não ative a função de autenticação NTP. |
| Configurar a chave de autenticação | ntp authentication-key key-number md5 {0 plain-key | 7 cipher-key} | Obrigatório Por padrão, não configure a chave de autenticação. |
| Especifique a chave como a chave confiável | ntp trusted-key key-number | Obrigatório Por padrão, não especifique a chave confiável. |
| Especifique a chave associada ao par passivo | ntp peer [ vrf vrf-name ] ip-address | domain-name | ipv6 ipv6-address [ version version | source interface-name ] key key-number | Obrigatório |
Execute a seguinte configuração no peer passivo NTP.
Tabela 4 -13 Configurar a autenticação de peer passivo NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função de autenticação NTP | ntp authenticate | Obrigatório Por padrão, não ative a função de autenticação NTP. |
| Configurar a chave de autenticação | ntp authentication-key key-number md5 {0 plain-key | 7 cipher-key} | Obrigatório Por padrão, não configure a chave de autenticação. |
| Especifique a chave como a chave confiável | ntp trusted-key key-number | Obrigatório Por padrão, não especifique a chave confiável |
O peer ativo e o peer passivo precisam ser configurados com a mesma chave de autenticação.
Configurar autenticação de transmissão NTP
Ao configurar a autenticação de difusão NTP, é necessário habilitar a função de autenticação no cliente de difusão e no servidor de difusão, configurar a chave de autenticação, definir a chave de autenticação como a chave confiável e especificar a chave associada ao servidor de difusão.
Execute a seguinte configuração no cliente de difusão NTP.
Tabela 4 -14 Configurar a autenticação do cliente de transmissão NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função de autenticação NTP | ntp authenticate | Obrigatório Por padrão, não ative a função de autenticação NTP. |
| Configurar a chave de autenticação | ntp authentication-key key-number md5 {0 plain-key | 7 cipher-key} | Obrigatório Por padrão, não configure a chave de autenticação. |
| Especifique a chave como a chave confiável | ntp trusted-key key-number | Obrigatório Por padrão, não especifique a chave confiável. |
Execute a seguinte configuração no servidor de transmissão NTP.
Tabela 4 -15 Configurar a autenticação do servidor de transmissão NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função de autenticação NTP | ntp authenticate | Obrigatório Por padrão, não ative a função de autenticação NTP. |
| Configurar a chave de autenticação | ntp authentication-key key-number md5 {0 plain-key | 7 cipher-key} | Obrigatório Por padrão, não configure a chave de autenticação. |
| Especifique a chave como a chave confiável | ntp trusted-key key-number | Obrigatório Por padrão, não especifique a chave confiável. |
| Entre no modo de configuração da interface | interface interface-name | - |
| Especifique a chave associada ao servidor de transmissão | ntp broadcast-server [ version version-number ] key key-number | Obrigatório |
O servidor de transmissão e o cliente de transmissão precisam ser configurados com a mesma chave de autenticação.
Configurar controle de acesso NTP
Condição de configuração
Para configurar o controle de acesso NTP, primeiro conclua a seguinte tarefa:
- Configure a ACL associada ao controle de acesso
Configurar controle de acesso NTP
O NTP pode limitar o acesso ao servidor NTP local associando-se à ACL.
Tabela 4 -16 Configurar o controle de acesso NTP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o controle de acesso NTP | ntp access-control list access-list-name | Obrigatório Por padrão, não configure o controle de acesso NTP. |
Monitoramento e manutenção de NTP
Tabela 4 -17 Monitoramento e manutenção de NTP
| Comando | Descrição |
| show ntp associations [ipv6] | Exibir as informações da sessão NTP |
| show ntp status | Exibir as informações de status NTP |
| snmp-server enable traps ntp [stratum-change | sync-lost | sync-success]* | Ativar a função Trap do NTP |
Exemplo de configuração típica de NTP
Configurar servidor/cliente NTP IPv4
Requisitos de rede
- Device1 é o servidor NTP e Device2 é o cliente NTP.
- Device1 e Device2 são interconectados através de suas interfaces VLAN2 e a rota é alcançável.
- O servidor NTP é a fonte do relógio e o cliente obtém o relógio do servidor.
Topologia de rede

Figura 4 -1 Rede de configuração do servidor e cliente NTP
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (Omitido)
- Passo 2:Configure o servidor NTP Device1.
#Ative o NTP IPv4 do dispositivo1, configure o fuso horário como fuso horário de Pequim, o relógio local como relógio de referência e o número de camadas de relógio como 3.
Device1#configure terminalDevice1(config)#ntp enableDevice1(config)#clock timezone BINJING 8Device1(config)#ntp master 3Device1(config)#exit
- Passo 3:Configure o cliente NTP Device2.
#Ative o NTP IPv4 do dispositivo2 e configure o fuso horário como o fuso horário de Pequim.
Device2#configure terminalDevice2(config)#ntp enableDevice2(config)#clock timezone BINJING 8
#Especifique o dispositivo1 do servidor NTP e o endereço IP é 1.0.0.1.
Device2(config)#ntp server 1.0.0.1Device2(config)#exit
- Passo 4:Confira o resultado.
#Executar o show ntp status comando no cliente Device2, e visualizar o status de sincronização do relógio, indicando que o cliente e o servidor NTP Device1 estão sincronizados e as camadas de clock são 4, maiores que Device1.
Device2#show ntp statusCurrent NTP status informationNTP ipv4 is enabledNTP ipv6 is disabledClock is synchronized, stratum 4, reference is 1.0.0.1reference time is D442EB0E.432F29BD (01:49:02.262 Tue Nov 06 2012)
#Executar o show comando clock para visualizar o relógio do dispositivo no cliente Device2.
Device2#show clockBEIJING(UTC+08:00) TUE NOV 06 09:49:30 2012
Configurar servidor NTP IPv4/modo de cliente de vários níveis
Requisito de rede
- Device1 é o servidor NTP; Device2 e Device3 são os clientes NTP .
- Device2 são interconectados com Device1 e Device 3 via interface vlan2, vlan3; a rota é alcançável.
- Device1 fornece o relógio para Device2; Device2 fornece o relógio para Device3.
Topologia de rede

Figura 4 -2 Rede de configuração do servidor NTP e clientes multinível
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (Omitido)
- Passo 2:Configure o servidor NTP Device1.
#Ative o NTP IPv4 do dispositivo1, configure o fuso horário como fuso horário de Pequim, o relógio local como relógio de referência e o número de camadas de relógio como 3.
Device1#configure terminalDevice1(config)#ntp enableDevice1(config)#clock timezone BINJING 8Device1(config)#ntp master 3Device1(config)#exit Device1(config)#ntp master 3
- Passo 3:Configure o cliente NTP Device2.
# Habilite a função NTP IPv4 do Device2 e configure o fuso horário como fuso horário de Pequim.
Device2#configure terminalDevice2(config)#ntp enableDevice2(config)#clock timezone BINJING 8
#Especifique o dispositivo1 do servidor NTP e o endereço IP é 1.0.0.1.
Device2(config)#ntp server 1.0.0.1- Passo 4:Configure o cliente NTP Device3.
#Ative a função NTP IPv4 do Device3 e configure o fuso horário como o fuso horário de Pequim.
Device3#configure terminalDevice3(config)#ntp enableDevice3(config)#clock timezone BINJING 8
#Especifique o servidor NTP Device2 e o endereço IP é 2.0.0.1.
Device2(config)#ntp server 2.0.0.1- Passo 5:Verifique o resultado, visualizando as informações de sincronização do relógio em Device2 e Device3.
#Executa o mostrar ntp comando status no cliente Device2 e visualize o status de sincronização do relógio, indicando que Device2 e o servidor NTP Device1 estão sincronizados e as camadas de clock são 4, maiores que Device1.
Device2#show ntp statusCurrent NTP status informationNTP ipv4 is enabledNTP ipv6 is disabledClock is synchronized, stratum 4, reference is 1.0.0.1reference time is D44CC35E.BAA6A190 (13:02:22.729 Tue Nov 13 2012)
#Executa o mostrar relógio comando para visualizar o relógio do dispositivo no cliente Device2.
Device2#show clockBEIJING(UTC+08:00) TUE NOV 13 21:02:24 2012
#Executar o show ntp status comando no cliente Device3, e veja o relógio status de sincronização, indicando que Device3 e Device2 estão sincronizados e as camadas de clock são 5, maiores que Device1.
Device3#show ntp statusCurrent NTP status informationNTP ipv4 is enabledNTP ipv6 is disabledClock is synchronized, stratum 5, reference is 2.0.0.1reference time is D44CC365.5CC8C4C8 (13:02:29.362 Tue Nov 13 2012)
#Executa o mostrar relógio comando para visualizar o relógio do dispositivo no cliente Device3.
Device3#show clockBEIJING(UTC+08:00) TUE NOV 13 21:02:36 2012
Configurar o servidor e cliente NTP com autenticação MD5
Requisito de rede
- Device1 é o servidor NTP; Device2 é o cliente NTP , e eles adotam a autenticação do algoritmo MD5.
- Dispositivo 1 está interconectado com o Dispositivo 2 por meio de sua interface vlan2 ; a rota é alcançável.
- O servidor NTP é a fonte do relógio e o cliente obtém o relógio do servidor .
Topologia de rede

Figura 4 -3 Rede de configuração do servidor e cliente NTP com autenticação MD5
Etapas de configuração
- Passo 1:Configurar o endereço IP da interface (omitido).
- Passo 2:Configurar o servidor NTP.
# Habilite o NTP IPv4 do Device1, configure o fuso horário como fuso horário de Pequim, o relógio local como o relógio de referência e as camadas do relógio como 3.
Device1#configure terminalDevice1(config)#ntp enableDevice1(config)#clock timezone BINJING 8Device1(config)#ntp master 3Device1(config)#exit
# E habilite a autenticação.
Device1(config)#ntp authenticate# Configurar o nº da chave de autenticação como 1, algoritmo como MD5 e chave como admin.
Device1(config)#ntp authentication-key 1 md5 0 admin# Configurar chave 1 para ser confiável.
Device1(config)#ntp trusted-key 1- Passo 3:Configurar o cliente NTP.
#Ative o NTP IPv4 do Device2 e configure o fuso horário como o fuso horário de Pequim,
Device2#configure terminalDevice2(config)#ntp enableDevice2(config)#clock timezone BINJING 8
# Especifique o servidor NTP para o cliente e o endereço IP é 1.0.0.1.
Device2(config)#ntp server 1.0.0.1# E habilite a autenticação.
Device2(config)#ntp authenticate# Configurar o nº da chave de autenticação como 1, algoritmo como MD5 e chave como admin.
Device2(config)#ntp authentication-key 1 md5 0 admin# Configurar chave 1 para ser confiável.
Device2(config)#ntp trusted-key 1- Passo 4:Confira o resultado.
#Executar o show ntp comando status no cliente Device2 para visualizar o status de sincronização do relógio e outras informações, indicando que o cliente e o servidor NTP device1 foram sincronizados, e o número de camadas de relógio é 4, maior que o do Device1 por 1.
Device2#show ntp statusCurrent NTP status informationNTP ipv4 is enabledNTP ipv6 is disabledClock is synchronized, stratum 4, reference is 1.0.0.1reference time is D442ECE1.8BB7B219 (01:56:49.545 Tue Nov 06 2012)
# No Device2 , execute o show comando clock para visualizar o relógio do dispositivo.
Device2#show clockBEIJING(UTC+08:00) TUE NOV 06 09:56:52 2012
O número de série de autenticação do cliente e servidor NTP deve ser o mesmo e a chave deve ser a mesma.
Configurar o modo de peer NTP IPv4
Requisitos de rede
- Device1 , Device2 e Device3 são interconectados por meio de suas interfaces; a rota é alcançável.
- Device1 define o relógio local como o relógio de referência e o número de camadas é 3.
- Device2 é o cliente NTP; defina Device1 para o servidor NTP.
- Device3 define Device2 como o peer, Device3 é o peer ativo e Device2 é o peer passivo.
Topologia de rede

Figura 4 -4 Rede de configuração do modo NTP peer
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (omitido)
- Passo 2:Em Device1, habilite NTP IPv4 e configure o fuso horário como fuso horário de Pequim e o número das camadas de relógio local como 3.
Device1#configure terminalDevice1(config)#ntp enableDevice1(config)#clock timezone BINJING 8Device1(config)#ntp master 3
- Passo 3:Device2 especifica Device1 como o servidor NTP.
#No Devie2, habilite NTP IPv4 e configure o fuso horário como Beijing Timezone.
Device2#configure terminalDevice2(config)#ntp enableDevice2(config)#clock timezone BEIJING 8
# Especifique o endereço IP do servidor NTP como 1.0.0.254.
Device2(config)#ntp server 1.0.0.254- Passo 4:Device3 define Device2 como o par.
#No Dispositivo3, habilite o NTP IPv4 e configure o fuso horário como horário de Pequim zona.
Device3#configure terminalDevice3(config)#ntp enableDevice3(config)#clock timezone BEIJING 8
# Especifique o endereço IP do peer NTP como 1.0.0.1.
Device3(config)#ntp peer 1.0.0.1- Passo 5:Confira o resultado.
# Execute o comando show ntp status no cliente Device2 e visualize as informações de status de sincronização do relógio.
Device2#show ntp statusCurrent NTP status informationNTP ipv4 is enabledNTP ipv6 is disabledClock is synchronized, stratum 4, reference is 1.0.0.254reference time is D8E9785D.221F1F5 (03:09:17.8 Tue Apr 28 2015)
As camadas do relógio Device2 são 4, maiores que Device1 por 1, e o endereço do servidor de relógio de referência é 1.0.0.254, indicando que o Device2 cliente já está sincronizado com o Device1 servidor.
#Execute o comandoshow clockpara ver o relógio do dispositivo no cliente Device2.
>Device2#show clock BEIJING(UTC+08:00) TUE APR 28 11:10:36 2015
#Execute o comando show ntp status no peer ativo Device3 e visualize as informações de status de sincronização do relógio.
Device3#show ntp statusCurrent NTP status informationNTP ipv4 is enabledNTP ipv6 is disabledClock is synchronized, stratum 5, reference is 1.0.0.1reference time is D8E9795C.29835CC9 (03:13:32.162 Tue Apr 28 2015)
As camadas do relógio Device3 são 5, maiores que Device2 por 1, e o endereço do servidor de relógio de referência é 1.0.0.1, indicando que o Device3 de peer ativo já está sincronizado com o Device2 de peer passivo.
#Execute o comandoshow clockpara ver o relógio do dispositivo no cliente Device3.
Device3#show clockBEIJING(UTC+08:00) TUE APR 28 11:16:19 2015
Configurar o modo de transmissão NTP
Requisitos de rede
- Device1 , Device2 e Device3 são interconectados por meio de suas interfaces; a rota é alcançável.
- Device1 define o relógio local como o relógio de referência e o número de camadas é 3.
- Device1 é o servidor de broadcast NTP e envia o pacote de broadcast NTP da interface vlan2 .
- Device2 e Device3 são o cliente de broadcast NTP, monitorando o pacote de broadcast NTP em sua interface vlan2 .
Topologia de rede
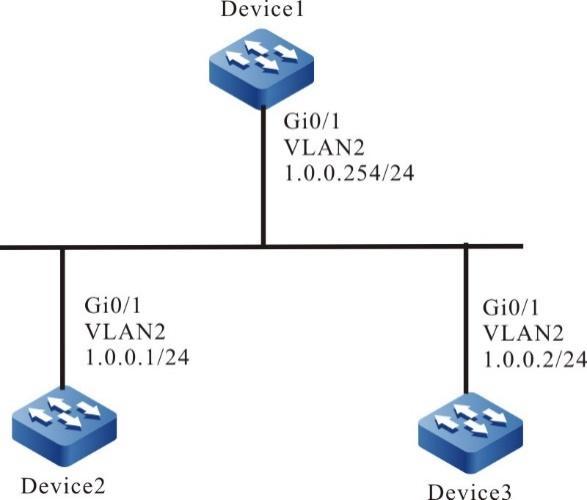
Figura 4 -5 Rede de configuração do modo de transmissão NTP
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (omitido)
- Passo 2:Device1 define o relógio local como o relógio de referência e o número de camadas é Passo 3:Configure Device1 como servidor de broadcast NTP, enviando o pacote de broadcast NTP da interface vlan2 .
# No Device1 , habilite o NTP IPv4 e configure o fuso horário como fuso horário de Pequim e o número das camadas de relógio local como 3.
Device1#configure terminalDevice1(config)#ntp enableDevice1(config)#clock timezone BINJING 8Device1(config)#ntp master 3
#Configure Device1 como servidor de broadcast NTP, enviando o pacote de broadcast NTP do interface vlan2.
Device1(config)#interface vlan2Device1(config-if-vlan2)#ntp broadcast-server
- Passo 3:Configure Device2 como o cliente de difusão NTP, monitorando o pacote de difusão NTP no interface vlan2 .
Device2#configure terminalDevice2(config)#ntp enableDevice2(config)#clock timezone BINJING 8Device2(config)#interface vlan2Device2(config-if- vlan2)#ntp broadcast-client
- Passo 4:Configure Device3 como o cliente de broadcast NTP, monitorando o pacote de broadcast NTP na interface vlan2 .
Device3#configure terminalDevice3(config)#ntp enableDevice3(config)#clock timezone BINJING 8Device3(config)#interface vlan2Device3(config-if- vlan2)#ntp broadcast-client
- Passo 5:Confira o resultado.
# Execute o comando show ntp status no cliente Device2 e visualize as informações de status de sincronização do relógio.
Device2#show ntp statusCurrent NTP status informationNTP ipv4 is enabledNTP ipv6 is disabledClock is synchronized, stratum 4, reference is 1.0.0.254reference time is D8E97C99.5110D9FE (03:27:21.316 Tue Apr 28 2015)
O número de camadas de relógio Device2 é 4, maior que Device1 por 1, e o endereço do servidor de relógio de referência é 1.0.0.254, indicando que o cliente Device2 já está sincronizado com o servidor Device1.
#Execute o comando show clock para ver o relógio do dispositivo no cliente Device2.
Device2#show clockBEIJING(UTC+08:00) TUE APR 28 11:27:22 2015
# Execute o comando show ntp status no peer ativo Device3 e visualize as informações de status de sincronização do relógio.
Device3#show ntp statusCurrent NTP status informationNTP ipv4 is enabledNTP ipv6 is disabledClock is synchronized, stratum 4, reference is 1.0.0.254reference time is D8E97CAC.78F42CA6 (03:27:40.472 Tue Apr 28 2015)
As camadas do relógio Device3 são 4, maiores que Device1 por 1, e o endereço do servidor de relógio de referência é 1.0.0.254, indicando que o Device3 de mesmo nível ativo já está sincronizado com o servidor Device1.
#Execute o comandoshow clockpara ver o relógio do dispositivo no cliente Device3.
Device3#show clockBEIJING(UTC+08:00) TUE APR 28 11:27:41 2015
Configurar servidor e cliente NTP IPV6
Requisitos de rede
- Device1 é o servidor NTP e Device2 é o cliente NTP.
- Device1 e Device2 são interconectados através de suas interfaces VLAN2 e a rota é alcançável.
- O servidor NTP é a fonte do relógio e o cliente obtém o relógio do servidor.
Topologia de rede

Figura 4 -6 Rede de configuração do NTP Servidor e cliente IPV6
Etapas de configuração
- Passo 1:Configure o endereço IPv6 da interface. (Omitido)
- Passo 2:Configure o servidor NTP Device1.
#Ative o NTP IPv6 do dispositivo1, configure o fuso horário como fuso horário de Pequim, o relógio local como relógio de referência e o número de camadas de relógio como 3.
Device1#configure terminalDevice1(config)#ntp enable ipv6Device1(config)#clock timezone BINJING 8Device1(config)#ntp master 3Device1(config)#exit
- Passo 3:Configurar o cliente NTP Device2.
# Habilite o NTP IPv6 do Device2 e configure o fuso horário como o fuso horário de Pequim.
Device2#configure terminalDevice2(config)#ntp enable ipv6Device2(config)#clock timezone BINJING 8
# Especifique o Device1 do servidor NTP e o endereço IPv6 como 10:1::121.
Device2(config)#ntp server ipv6 10:1::121Device2(config)#exit
- Passo 4:Confira o resultado.
#Executar o show ntp status comando no cliente Device2, e visualizar o status de sincronização do relógio, indicando que o cliente e o servidor NTP Device1 estão sincronizados e as camadas de clock são 4, maiores que Device1.
Device2#show ntp statusCurrent NTP status informationNTP ipv4 is disabledNTP ipv6 is enabledClock is synchronized, stratum 4, reference is 10:1::121reference time is D442EB0E.432F29BD (01:49:02.262 Tue Nov 06 2012)
#No Client Device2, execute o show clock comando para visualizar o relógio do dispositivo.
Device2#show clockBEIJING(UTC+08:00) TUE NOV 06 09:49:30 2012
Configurar NTP IPV6 Peer Mode
Requisitos de rede
- Device1 , Device2 e Device3 são interconectados por meio de suas interfaces; a rota é alcançável.
- Device1 define o relógio local como o relógio de referência e o número de camadas é 3.
- Device2 é o cliente NTP; defina Device1 para o servidor NTP.
- Device3 define Device2 como o peer, Device3 é o peer ativo e Device2 é o peer passivo.
Topologia de rede
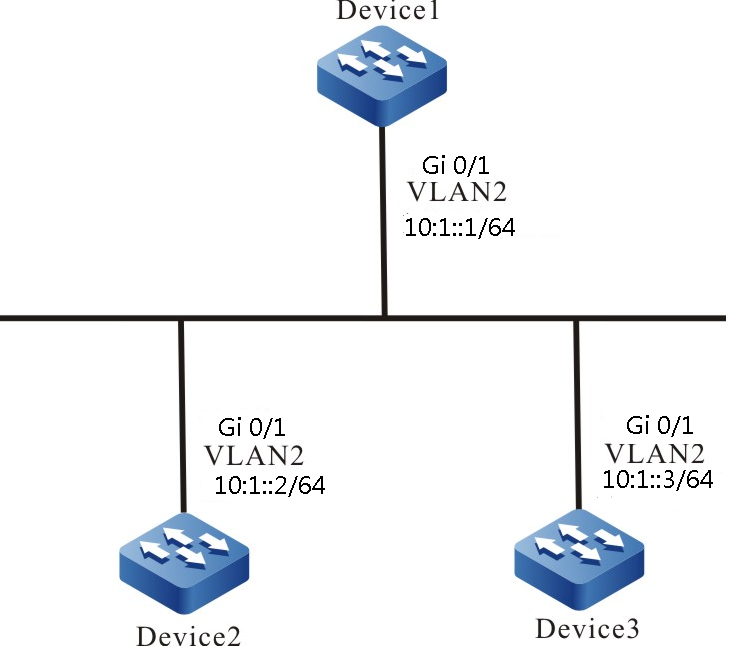
Figura 4 -7 Rede de configuração do modo NTP IPv6 peer
Etapas de configuração
- Passo 1:Configure o endereço IP v6 da interface. (omitido)
- Passo 2:Em Device1, habilite NTP IPv6 e configure o fuso horário como fuso horário de Pequim e o número das camadas de relógio local como 3.
Device1#configure terminalDevice1(config)#ntp enable ipv6Device1(config)#clock timezone BINJING 8Device1(config)#ntp master 3
- Passo 3:Device2 especifica Device1 como o servidor NTP.
#No Devie2, habilite o NTP IPv6 e configure o fuso horário como horário de Pequim zona.
Device2#configure terminalDevice2(config)#ntp enable ipv6Device2(config)#clock timezone BEIJING 8
# Especifique o endereço IP v6 do servidor NTP como 10:1::1 .
Device2(config)#ntp server ipv6 10:1::1- Passo 4:Device3 define Device2 como o par.
#No Dispositivo3, habilite o NTP IPv6 e configure o fuso horário como horário de Pequim zona.
Device3#configure terminalDevice3(config)#ntp enable ipv6Device3(config)#clock timezone BEIJING 8
# Especifique o endereço IP v6 do peer NTP como 10:1:: 2.
Device3(config)#ntp peer ipv6 10:1::2- Passo 5:Confira o resultado.
# Execute o comando show ntp status no cliente Device2 e visualize as informações de status de sincronização do relógio.
Device2#show ntp statusCurrent NTP status informationNTP ipv4 is disabledNTP ipv6 is enabledClock is synchronized, stratum 4, reference is 10:1::1reference time is D8E9785D.221F1F5 (03:09:17.8 Tue Apr 28 2015)
As camadas do relógio Device2 são 4, maiores que Device1 por 1, e o endereço do servidor de relógio de referência é 10:1::1 , indicando que o Device2 cliente já está sincronizado com o Device1 servidor.
#Execute o comandoshow clockpara ver o relógio do dispositivo no cliente Device2.
Device2#show clockBEIJING(UTC+08:00) TUE APR 28 11:10:36 2015
#Execute o comando show ntp status no peer ativo Device3 e visualize as informações de status de sincronização do relógio.
Device3#show ntp statusCurrent NTP status informationNTP ipv4 is disabledNTP ipv6 is enabledClock is synchronized, stratum 5, reference is 10:1::2reference time is D8E9795C.29835CC9 (03:13:32.162 Tue Apr 28 2015)
As camadas do relógio Device3 são 5, maiores que Device2 por 1, e o endereço do servidor de relógio de referência é 10:1:: 2, indicando que o Device3 de peer ativo já está sincronizado com o Device2 de peer passivo.
#Execute o comandoshow clockpara ver o relógio do dispositivo no cliente Device3.
Device3#show clockBEIJING(UTC+08:00) TUE APR 28 11:16:19 2015
Port Mirror
Visão geral
Introdução ao Port Mirror
O espelho de porta, também chamado de SPAN (Switched Port Analyzer), é um modo de gerenciamento usado para monitorar o fluxo de dados da porta do dispositivo. SPAN inclui SPAN local, SPAN remoto , SPAN remoto encapsulado e SPAN de VLAN .
Conceitos Básicos
SPAN Sessão
Sessão SPAN significa espelhar o fluxo de dados de uma ou várias portas de monitor no dispositivo e enviar para a porta de destino. O fluxo de dados espelhado pode ser o fluxo de dados de entrada e também pode ser o fluxo de dados de saída ou espelhar o fluxo de dados de entrada e saída ao mesmo tempo. Podemos configurar o SPAN para a porta desabilitada e a sessão SPAN não entra em vigor, mas enquanto a porta relacionada estiver habilitada, o SPAN entrará em vigor.
SPAN local
O SPAN local suporta o espelho de porta em um dispositivo. Todas as portas espelhadas e de destino estão no mesmo dispositivo.
SPAN remoto
O SPAN remoto, também chamado de RSPAN (Remote Switched Port Analyzer), suporta que a porta espelhada pode não estar em um dispositivo, realizando o monitoramento remoto através da rede L2. Na VLAN RSPAN especificada, cada Sessão RSPAN faz com que os pacotes espelhados sejam encaminhados na rede L2. RSPAN inclui Sessão de Origem RSPAN, VLAN RSPAN e Sessão de Destino RSPAN. Precisamos configurar a sessão de origem RSPAN e a sessão de destino RSPAN em dispositivos diferentes. Ao configurar a sessão de origem RSPAN, precisamos especificar uma ou várias portas espelhadas e uma ou várias VLANs RSPAN. Os dados espelhados pela porta do monitor são enviados para RSPAN VLAN. Para configurar a sessão de destino RSPAN em outro dispositivo, precisamos especificar a porta de destino e uma VLAN RSPAN. A sessão de destino RSPAN envia dados RSPAN VLAN para a porta de destino.
SPAN remoto encapsulado
O SPAN remoto encapsulado, também chamado de ERSPAN (Encapsulated Remote Switched Port Analyzer), encapsula os pacotes espelhados através do túnel especificado, atravessando a rede L3, de modo a espelhar os dados. Ao configurar a sessão ERSPAN, precisamos especificar uma ou várias portas espelhadas, o endereço IP de origem e o endereço IP de destino.
VLAN SPAN
VLAN SPAN suporta o espelho de VLAN em um dispositivo. Espelhe um ou vários monitores de fluxo de dados de VLAN e envie para a porta de destino. O fluxo de dados espelhado pode ser o fluxo de dados de entrada e também pode ser o fluxo de dados de saída ou espelhar o fluxo de entrada e saída ao mesmo tempo.
Tipo de tráfego
O tipo de tráfego inclui Receber (Rx) (o tráfego recebido da porta espelhada, Transmitir (Tx) (o tráfego encaminhado da porta espelhada e Ambos (o tráfego recebido e encaminhado da porta espelhada).
SPAN Source Port
A porta de origem SPAN também é chamada de porta monitorada. Seus dados são monitorados para análise de rede. O fluxo de dados monitorado pode estar na direção de entrada, na direção de saída ou em ambas. Pode funcionar em diferentes VLANs. A porta de origem pode ser uma porta geral ou um grupo de agregação. Uma porta de origem só pode pertencer a uma sessão SPAN.
SPAN Destination Port
A porta de destino SPAN só pode ser uma porta física real separada ou um grupo de agregação. Uma porta de destino só pode ser usada em uma sessão SPAN. A porta de destino pode ser uma porta geral ou um grupo de agregação.
O dispositivo suporta tomar a porta de destino como a porta de encaminhamento geral, mas para universalidade e para que os dados monitorados não sejam interferidos por outro fluxo de dados, sugere-se excluir a porta de destino de todas as VLANs.
A porta de destino não deve ser conectada a outro dispositivo. Caso contrário, pode resultar no loop de rede. A porta de destino não pode mais suportar outros serviços. A porta de destino deve ser maior ou igual à largura de banda da porta espelhada. Caso contrário, pode haver perda de pacotes. A porta de destino não pode habilitar o LACP (Link Aggregation Control Protocol), para evitar que os dados espelhados sejam afetados. As portas de destino de uma sessão podem ser no máximo quatro. De acordo com o chip, diferentes cartões podem suportar diferentes números de portas de destino.
RSPAN VLAN
A VLAN RSPAN deve ser uma VLAN ociosa, especialmente usada pelo RSPAN. Podemos selecionar uma VLAN ociosa durante a configuração, mas devemos garantir que os outros dispositivos no caminho da porta espelhada para a porta de destino estejam todos configurados com a VLAN e adicionar as portas correspondentes dos outros dispositivos no caminho para a VLAN.
Configuração da função SPAN
Tabela 5 -1 lista de configuração da função SPAN
| Tarefa de configuração | |
| Configurar SPAN local | Configurar sessão de SPAN local |
| Configurar RSPAN | Configurar VLAN RSPAN Configurar sessão de origem RSPAN Configurar sessão de destino RSPAN |
| Configurar ERSPAN | Configurar sessão de origem ERSPAN |
| Configurar VLAN SPAN | Configurar a sessão VLAN SPAN |
Configurar SPAN local
O SPAN local é usado para analisar o fluxo de dados da porta do dispositivo local.
Condição de configuração
Nenhum
Configurar sessão de SPAN local
A sessão de SPAN local copia os pacotes recebidos ou encaminhados de uma ou várias portas de origem e encaminha para fora da porta de destino sem afetar o encaminhamento de serviço normal da porta de origem.
Tabela 5 -2 Configurar a sessão de SPAN local
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Configurar o fim de origem da sessão de SPAN local | monitor session session-number source { interface interface-list | interface link-aggregation link-aggregation-id } [ both | tx | rx] | Obrigatório Por padrão, não configure a extremidade de origem da sessão de SPAN local. |
| Configure a extremidade de destino da sessão de SPAN local | monitor session session-number destination { interface interface- list | interface link-aggregation link-aggregation-id } | Obrigatório Por padrão, não configure a extremidade de destino da sessão de SPAN local. |
Ao configurar o fim da origem da sessão e especificar a porta habilitada com o espelho como o grupo de agregação, o grupo de agregação especificado já deve estar criado. Se o grupo de agregação não for criado, a configuração falhará. Da mesma forma, ao configurar o final de destino da sessão e especificar a porta de encaminhamento do pacote espelho como o grupo de agregação, o grupo de agregação especificado também já deve estar criado. Se o grupo de agregação não for criado, a configuração falhará. Uma porta não pode ser a porta de origem e a porta de destino de uma sessão ao mesmo tempo. Uma porta não pode existir em várias sessões ao mesmo tempo. A origem da sessão do espelho de porta não pode ser a mesma que a origem do espelho de fluxo.
Configurar RSPAN
A sessão RSPAN é usada para analisar o fluxo de dados da porta de origem do dispositivo remoto alcançável na rede L2. A sessão RSPAN inclui a sessão de origem RSPAN e a sessão de destino RSPAN.
Condição de configuração
Nenhum
Configurar VLAN RSPAN
O RSPAN faz com que o pacote espelho atravesse a rede L2 rotulando a tag RSPAN LAN no pacote espelho.
Tabela 5 -3 Configurar VLAN RSPAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração VLAN | vlan vlan-id | - |
| Configure a VLAN como RSPAN VLAN | remote-span | Obrigatório Por padrão, não configure RSPAN VLAN. |
A VLAN RSPAN não deve suportar outros serviços, mas pode suportar apenas o tráfego RSPAN. RSPAN VLAN proíbe habilitar a função de aprendizado de endereço MAC. Exceto para as portas usadas para suportar o tráfego RSPAN, não configure nenhuma porta para RSPAN VLAN.
Configurar sessão de origem RSPAN
Depois de configurar a sessão de origem RSPAN, rotule a tag RSPAN VLAN no pacote espelho e, em seguida, encaminhe-a da porta de destino da sessão de origem RSPAN.
Tabela 5 -4 Configurar a sessão de origem RSPAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a extremidade de origem da sessão de origem RSPAN | monitor session session-number source { interface interface-list | interface link-aggregation link-aggregation-id } [ both | tx | rx ] | Obrigatório Por padrão, não configure a extremidade de origem da sessão de origem do RSPAN. |
| Configure a extremidade de destino da sessão de origem RSPAN | monitor session session-number destination remote vlan vlan-id interface interface-name | Obrigatório Por padrão, não configure a extremidade de destino da sessão de origem RSPAN. |
Ao configurar o fim da origem da sessão e especificar a porta habilitada com o espelho como o grupo de agregação, o grupo de agregação especificado já deve estar criado. Se o grupo de agregação não for criado, a configuração falhará. A VLAN especificada deve ser definida como RSPAN VLAN antes da sessão de origem RSAPN. Uma porta não pode ser a porta de origem e a porta de destino de uma sessão ao mesmo tempo. Uma porta não pode existir em várias sessões ao mesmo tempo. A extremidade de destino da sessão de origem RSPAN só pode ser a porta geral, mas não pode ser o grupo de agregação. A sessão de origem RSPAN suporta apenas uma porta de destino.
Configurar sessão de destino RSPAN
Quando a sessão de destino do RSPAN receber o pacote, identifique o pacote espelho de acordo com a tag RSPAN VLAN e encaminhe o pacote espelho para o dispositivo de análise.
Tabela 5 -5 Configurar a sessão de destino RSPAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a extremidade de origem da sessão de destino RSPAN | monitor session session-number source remote vlan vlan-id | Obrigatório Por padrão, não configure a extremidade de origem da sessão de destino RSPAN. |
| Configure a extremidade de destino da sessão de destino RSPAN | monitor session session-number destination { interface interface- list | interface link-aggregation link-aggregation-id } | Obrigatório Por padrão, não configure a extremidade de destino da sessão de destino RSPAN. |
A VLAN especificada deve ser definida como RSPAN VLAN antes da sessão de destino RSAPN. Uma porta não pode existir em várias sessões ao mesmo tempo. O tipo de porta de destino da sessão de destino RSPAN deve ser Híbrido.
Configurar ERSPAN
A sessão ERSPAN é usada para analisar o fluxo de dados que passa pela porta de dispositivo remoto alcançável da rede L3.
Condição de configuração
Nenhum
Configurar sessão ERSPAN
A extremidade de destino da sessão de origem ERSPAN é usada para especificar o endereço IP de origem encapsulado, o endereço IP de destino, a tag VLAN, o valor TTL e a prioridade TOS da sessão de origem ERSPAN. Após ser encapsulado com o cabeçote IP, o pacote espelho pode atravessar a rede L3.
Tabela 5 -6 Configurar a sessão de origem ERSPAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Configure a extremidade de origem da sessão de origem ERSPAN | monitor session session-number source { interface interface-list | interface link-aggregation link-aggregation-id } [ both | tx | rx ] | Obrigatório Por padrão, não configure a extremidade de origem da sessão de origem ERSPAN. |
| Configure a extremidade de destino da sessão de origem ERSPAN | monitor session session-number destination type erspan-source source-ip source-ip-addr destination-ip destination-ip-addr [ vrf vrf-name] [ ttl ttl] [ tos tos] | Obrigatório Por padrão, não configure o destino final da sessão de origem ERSPAN. |
Ao configurar o fim da sessão de destino e especificar a porta de encaminhamento do pacote espelho como o grupo de agregação, o grupo de agregação especificado já deve estar criado. Se o grupo de agregação não for criado, a configuração falhará. Uma porta não pode existir em várias sessões ao mesmo tempo. O endereço IP de origem pode procurar diretamente o endereço MAC correspondente do endereço IP. O endereço IP de origem especificado é configurado no dispositivo. A porta de saída do próximo salto não pode pertencer ao grupo de agregação. Os IPs de origem das sessões ERSPAN que suportam várias portas de destino podem ser iguais ou diferentes, mas o IP de destino deve ser diferente. A origem da sessão do espelho de porta não pode ser a mesma que a origem do espelho de fluxo.
Configurar VLAN SPAN
A sessão VLAN SPAN é usada para analisar o fluxo de dados da VLAN especificada.
Condição de configuração
Nenhum
Configurar sessão VLAN SPAN
O VLAN SPAN é semelhante ao SPAN local. A sessão VLAN SPAN copia o pacote recebido ou encaminhado por uma ou várias VLANs de origem e encaminha da porta de destino. Enquanto isso, não afeta o encaminhamento de serviço normal da VLAN de origem.
Tabela 5 -7 Configurar a sessão VLAN SPAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Configure a VLAN de origem da sessão VLAN SPAN | monitor session session-number source vlan [ both | tx | rx ] | Obrigatório Por padrão, não configure a VLAN de origem da sessão VLAN SPAN. |
| Configure o destino da sessão VLAN SPAN | monitor session session-number destination interface interface- list | Obrigatório Por padrão, não configure o destino da sessão VLAN SPAN. |
A porta de destino da sessão VLAN SPAN não pode ser a porta membro da VLAN de origem da sessão VLAN SPAN. A porta de destino da sessão VLAN SPAN só pode ser a porta geral, mas não pode ser o grupo de agregação. A porta membro da VLAN de origem da sessão VLAN SPAN não pode estar em várias sessões ao mesmo tempo. Ao configurar a VLAN de origem da sessão VLAN SPAN e se as portas membro da VLAN de origem já pertencerem a outras sessões , essas sessões excluirão ativamente as portas. O sistema suporta apenas uma sessão VLAN SPAN.
SPAN Monitoramento e Manutenção
Tabela 5 -8 Monitoramento e Manutenção de SPAN
| Comando | Descrição |
| show monitor rspan-vlan | Exibir RSPAN VLAN. |
| show monitor session { session-number | all | local | remote | erspan } | Exiba as informações de configuração da sessão SPAN. |
Exemplo de configuração típico de espelho de porta
Configurar SPAN local
Requisito de rede
- PC1, PC2 e PC3 estão conectados com o Dispositivo; PC1 e PC2 se comunicam na VLAN2.
- Configurar SPAN Local no Dispositivo; a porta de origem é gigabitethernet0/1; a porta de destino é gigabitethernet0/3; PC3 monitora os pacotes recebidos e enviados pela porta gigabitethernet0/1 do Dispositivo.
Topologia de rede
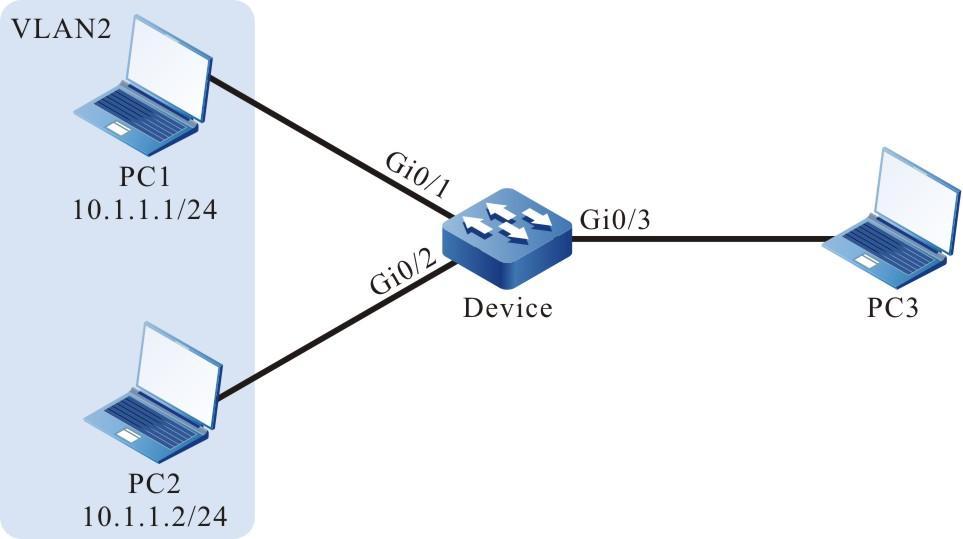
Figura 5 -1 Rede de configuração do SPAN local
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta.
#Criar VLAN2 no dispositivo.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 e gigabitethernet0/2 no dispositivo como acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1-0/2Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
- Passo 2:Configurar SPAN local.
#Configure o SPAN local no dispositivo, a sessão de origem do espelho é a porta gigabitethernet0/1 e a sessão de destino é a porta gigabitethernet0/3.
Device(config)#monitor session 1 source interface gigabitethernet 0/1 bothDevice(config)#monitor session 1 destination interface gigabitethernet 0/3
#Visualize as informações da sessão do SPAN local no dispositivo.
Device#show monitor session all----------------------------------------------------------Session 1Type : SPAN Local SessionDestination Interface : gigabitethernet0/3Source Interface(both): gi0/1
- Passo 3:Confira o resultado.
#Quando o PC1 e o PC2 se comunicam, os pacotes enviados e recebidos pela porta gigabitethernet0/1 podem ser obtidos no PC3.
Configurar RSPAN
Requisitos de rede
- PC1 e PC2 estão conectados ao Device1 e se comunicam na VLAN2; PC3 está conectado com Device2.
- Configurar RSPAN em Device1 e Device2; PC3 monitora os pacotes recebidos e enviados pela porta gigabitethernet0/1 do Device1 via RSPAN VLAN3.
Topologia de rede
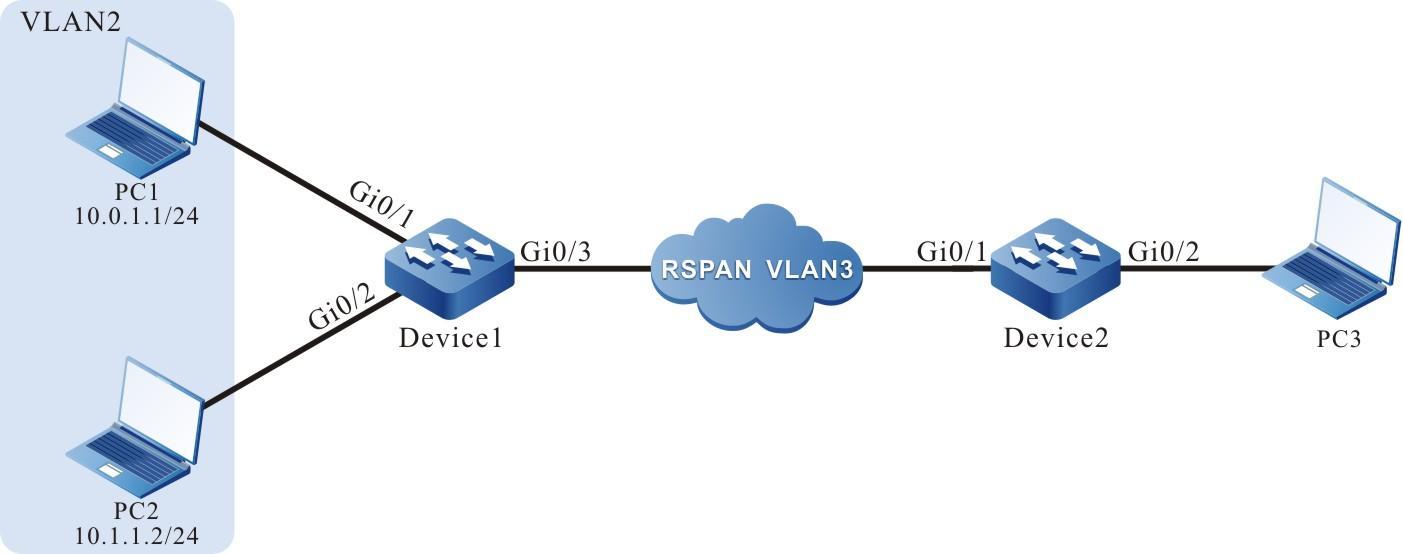
Figura 5 -2 Rede de configuração do RSPAN
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta.
#Criar VLAN2 no Dispositivo1.
Device1#configure terminalDevice1(config)#vlan 2Device1(config-vlan2)#exit
#Configure o tipo de link da porta gigabitethernet0/1 e gigabitethernet0/2 no Device1 como Access, permitindo a passagem dos serviços da VLAN2.
Device1(config)#interface gigabitethernet 0/1-0/2Device1(config-if-range)#switchport mode accessDevice1(config-if-range)#switchport access vlan 2Device1(config-if-range)#exit
#Configure o tipo de link da porta gigabitethernet0/3 como Trunk no Device1.
Device1(config)#interface gigabitethernet 0/3Device1(config-if-gigabitethernet0/3)#switchport mode trunkDevice1(config-if-gigabitethernet0/3)#exit
#Configure o tipo de link da porta gigabitethernet0/1 como Trunk no Device2.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#switchport mode trunkDevice2(config-if-gigabitethernet0/1)#exit
#Configure o tipo de link da porta gigabitethernet0/2 como Hybrid no Device2.
Device2(config)#interface gigabitethernet 0/2Device2(config-if-gigabitethernet0/2)#switchport mode hybridDevice2(config-if-gigabitethernet0/2)#exit
- Passo 2: Configure RSPAN em Device1 e Device2.
#Configure a VLAN3 como RSPAN VLAN no Device1 e configure a porta gigabitethernet0/3 para permitir a passagem dos serviços da VLAN3.
Device1(config)#vlan 3Device1(config-vlan3)#remote-spanDevice1(config-vlan3)#exitDevice1(config)#interface gigabitethernet 0/3Device1(config-if-gigabitethernet0/3)#switchport trunk allowed vlan add 3Device1(config-if-gigabitethernet0/3)#exit
#Configure RSPAN no Device1, a sessão de origem do espelho é a porta gigabitethernet0/1 e sessão de destino é a porta gigabitethernet0/3.
Device1(config)#monitor session 1 source interface gigabitethernet 0/1 bothDevice1(config)#monitor session 1 destination remote vlan 3 interface gigabitethernet 0/3
#Visualize as informações da sessão RSPAN no Device1.
Device1#show monitor session all----------------------------------------------------------Session 1Type : RSPAN Source SessionRSPAN VLAN : 3Destination Interface : gigabitethernet0/3Source Interface(both): gi0/1
VLAN 3 aRSPAN da VLAN no Device2 e configure a porta gigabitethernet0/1 para permitir a passagem dos serviços da VLAN3.
Device2(config)#vlan 3Device2(config-vlan3)#remote-spanDevice2(config-vlan3)#exitDevice2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)# switchport trunk allowed vlan add 3Device2(config-if-gigabitethernet0/1)#exit
#Configure RSPAN no Device2, a sessão de origem do espelho é RSPAN VLAN3 e a sessão de destino é a porta gigabitethernet0/2.
Device2(config)#monitor session 1 source remote vlan 3Device2(config)#monitor session 1 destination interface gigabitethernet 0/2
#Visualize as informações da sessão RSPAN no Device2.
Device2#show monitor session all----------------------------------------------------------Session 1Type : RSPAN Destination SessionRSPAN VLAN : 3Destination Interface : gigabitethernet0/2
- Passo 3:Confira o resultado.
#Quando o PC1 e o PC2 se comunicam, os pacotes enviados e recebidos pela porta gigabitethernet0/1 do Device1 podem ser obtidos no PC3.
Configurar ERSPAN
Requisitos de rede
- PC1 e PC2 estão conectados com Device1 e se comunicam entre si na VLAN2.
- PC3 se comunica com o dispositivo via rede IP.
- Configurar ERSPAN no Dispositivo; o endereço IP de origem é 192.168.1.1/24; o endereço IP de destino é 192.168. 1.100 /24; PC3 monitora os pacotes recebidos e enviados pela porta gigabitethernet0/1 do Dispositivo.
Topologia de rede
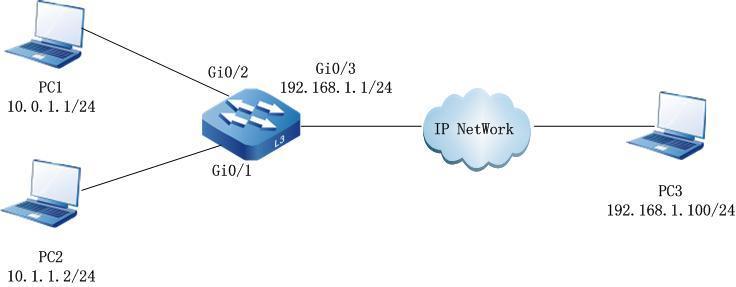
Figura 5 -3 Rede de configuração do ERSPAN
Etapas de configuração
- Passo 1:Configure VLAN, tipo de link de porta e endereço de interface.
#Crie VLAN2 e VLAN3 no dispositivo.
Device#configure terminalDevice(config)#vlan 2-3
#Configure o tipo de link da porta gigabitethernet0/1 e gigabitethernet0/2 no dispositivo como acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1-0/2Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
#Configure o tipo de link da porta gigabitethernet0/3 no dispositivo como acesso, permitindo a passagem dos serviços da VLAN3.
Device(config)#interface gigabitethernet 0/3Device(config-if-gigabitethernet0/3)#switchport mode accessDevice(config-if-gigabitethernet0/3)#switchport access vlan 3Device(config-if-gigabitethernet0/3)#exit
#Configure o endereço IP da interface no dispositivo.
Device(config)#interface vlan 3Device(config-if-vlan3)#ip address 192.168.1.1 255.255.255.0Device(config-if-vlan3)#exit
- Passo 2:Configure o ERSPAN no dispositivo.
#Configure ERSPAN no dispositivo, a porta da sessão de origem do espelho é gigabitethernet0/1, o endereço IP de origem da sessão de destino é 192.168.1.1 e o endereço IP de destino é 192.168. 1.100 .
Device(config)#monitor session 1 source interface gigabitethernet 0/1 bothDevice(config)#monitor session 1 destination type erspan-source source-ip 192.168.1.1 destination-ip 192.168.1.100 vlan 3
#Visualize as informações da sessão ERSPAN no dispositivo.
Device#show monitor session all----------------------------------------------------------Session 1Type : ERSPAN Source SessionDestination Interface : gigabitethernet0/3Source IP Address: 192.168.1.1Destination IP Address: 192.168.1.100Source Mac Address: 0001.7a54.5c94Next Hop Mac Address: 0000.1100.0001Erspan L2 Vlan:3Source Interface(both): gi0/1
- Passo 3:Confira o resultado.
#Quando o PC1 e o PC2 se comunicam, os pacotes enviados e recebidos pela porta gigabitethernet0/1 podem ser obtidos no PC3.
Configurar VLAN SPAN
Requisitos de rede
- PC1, PC2 e PC3 estão conectados ao Dispositivo; PC1 e PC2 se comunicam em VLAN2.
- Configure o VLAN SPAN no Dispositivo, a vlan de origem é vlan2, e a porta de destino é g igabitethernet 0/3, percebendo que o PC3 monitora os pacotes recebidos e enviados pela VLAN2 do Dispositivo.
Topologia de rede
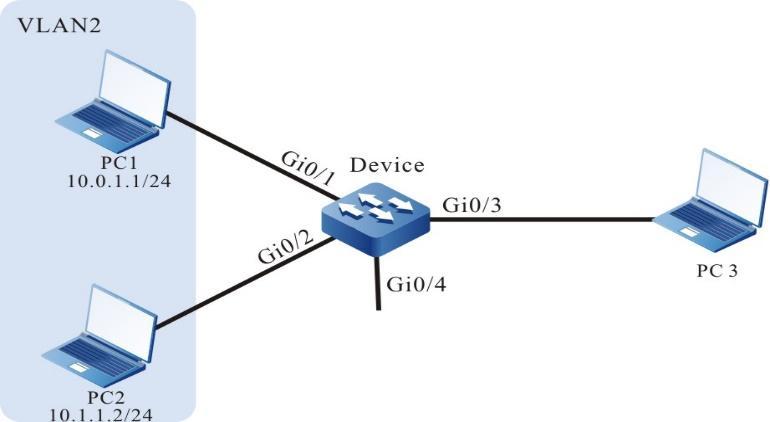
Figura 5 -4 Rede de configuração de VLAN SPAN
Etapas de configuração
- Passo 1:Configure o tipo de link da VLAN e da porta.
#Criar VLAN2 no dispositivo.
Device#configure terminalDevice(config)#vlan 2Device(config-vlan2)#exit
# Em Device, configure o tipo de link da porta g igabitethernet 0/1 e g igabitethernet 0/2 como Acesso, permitindo a passagem dos serviços da VLAN2.
Device(config)#interface gigabitethernet 0/1-0/2Device(config-if-range)#switchport mode accessDevice(config-if-range)#switchport access vlan 2Device(config-if-range)#exit
- Passo 2:Configurar VLAN SPAN.
# Configure o VLAN SPAN no dispositivo, a sessão de origem do espelho é vlan2 e a sessão de destino é a porta g igabitethernet 0/3.
Device(config)#monitor session 1 source vlan 2 bothDevice(config)# monitor session 1 destination interface gigabitethernet0/3Device#show monitor session all----------------------------------------------------------Session 1Type : SPAN Local VLAN SessionDestination Interface : gi0/3Source VLAN(both): 2
- Passo 3:Confira o resultado.
#Quando o PC1 e o PC2 se comunicam, você pode capturar os pacotes recebidos e enviados pela VLAN2 no PC3.
sFlow
Visão geral
O sFlow é uma tecnologia usada para amostrar e monitorar o tráfego de rede, em conformidade com o padrão RFC3176. O sFlow realiza diferentes amostragens de acordo com diferentes configurações. O processo de amostragem é: Primeiro, analise a cabeça do pacote do pacote amostrado, encapsule como o pacote sFlow de acordo com a definição padrão e envie para o receptor de terceiros, o que é conveniente para o usuário analisar e monitorar o tráfego que entra no dispositivo através do receptor de terceiros.
O sFlow inclui os dois modos de amostragem a seguir:
- Modo de amostragem do amostrador: É um modo de amostragem fornecido pelo chip de comutação, amostrando o tráfego que entra na porta aleatoriamente;
- Modo de amostragem Poller: É um modo de amostragem de software, usado para coletar regularmente as informações de estatísticas de pacotes e tráfego da porta.
O sFlow define os dois papéis a seguir:
- Papel do agente: É o agente sFlow no dispositivo, utilizado para gerenciar os dois modos de amostragem do sFlow e executar a tarefa de amostragem;
- Função do receptor: É o mapeamento do receptor de terceiros que suporta o protocolo sFlow no dispositivo local, usado para salvar as informações do receptor de terceiros (como endereço IP e número da porta UDP) e enviar regularmente os pacotes sFlow armazenados em buffer no dispositivo para o receptor de terceiros.
Configuração da função sFlow
Tabela 6 -1 lista de configuração da função sFlow
| Tarefa de configuração | |
| Configurar as funções básicas do sFlow | Criar a função de agente Criar a função de receptor |
| Configurar o modo de amostragem do sFlow | Configurar o modo de amostragem do amostrador Configurar o modo de amostragem do poller |
Configurar funções básicas do sFlow
Condição de configuração
Nenhum
Criar função de agente
A função de agente é usada para configurar e gerenciar a amostragem. Atualmente, o tipo de endereço de rede suportado pela função de agente só pode ser IPv4.
Tabela 6 -2 Crie a função do agente
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Criar a função de agente | sflow agent ip ip-address | Obrigatório Por padrão, não crie a função de agente. |
Criar função de receptor
A função de receptor é usada para salvar as informações do receptor de terceiros e enviar os pacotes sFlow armazenados em buffer no dispositivo para o receptor de terceiros por meio do modo UDP. As condições de disparo do envio de pacotes incluem as duas seguintes:
- Quando a área de buffer especificada estiver cheia e não puder ser preenchida com novas informações de amostragem de sFlow, primeiro encapsule a parte em buffer para o pacote sFlow, envie para o receptor de terceiros e, em seguida, preencha a nova parte na área de buffer. Isso pode reduzir o número de pacotes sFlow enviados pelo dispositivo para o receptor de terceiros, obviamente.
- Encapsule as informações de amostragem de sFlow armazenadas em buffer como o pacote sFlow periodicamente e envie para o receptor de terceiros. Isso pode evitar que a parte armazenada em buffer não possa ser encapsulada como o pacote sFlow e enviada ao receptor de terceiros por não receber novas informações de amostragem de sFlow por um longo tempo.
Tabela 6 -3 Criar a função de receptor
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Criar a função de receptor | sflow receiver receiver-index owner owner-name ip ip-address [ packet-size packet-size-value ] [ timeout timeout-value ] [ udp-port udp-port-number ] | Obrigatório Por padrão, não crie a função de receptor. |
Configurar o modo de amostragem do sFlow
Condição de configuração
Antes de configurar o modo de amostragem do sFlow, primeiro conclua a seguinte tarefa:
- Criar a função de agente
- Criar a função de receptor
Configurar o modo de amostragem do amostrador
No modo de amostragem do amostrador, ou seja , amostragem de fluxo de interface , o chip de comutação amostra o tráfego recebido pela interface aleatoriamente. Depois de obter o pacote de amostra, primeiro copie as informações do cabeçalho do pacote, resolva o conteúdo copiado, obtenha as informações de amostra desejadas e, por fim, encapsule as informações de amostra e envie para o receptor de terceiros correspondente da função de receptor.
Tabela 6 -4 Configurar o modo de amostragem do amostrador de interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configurar o modo de amostragem do amostrador | sflow sampler receiver receiver-index [ header-size header-size-value ] [ sample-rate sample-rate-value ] [ direction direction-value ] [ type type-value ] | Obrigatório Por padrão, não configure o modo de amostragem do amostrador. |
Configurar o modo de amostragem do poller
O modo de amostragem de poller, que é a amostragem de polling regular de interface , é para encapsular regularmente as informações de estatísticas de tráfego e pacote na interface dentro do período e enviar para o receptor de terceiros correspondente da função de receptor.
Tabela 6 -5 Configurar o modo de amostragem do poller
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configurar o modo de amostragem do poller | sflow poller poller-index receiver receiver-index [ interval interval-value ] [ type type-value ] | Obrigatório Por padrão, não configure o modo de amostragem do poller. |
sFlow Monitoramento e Manutenção
Tabela 6 -6 Monitoramento e manutenção de sFlow
| Comando | Descrição |
| clear sflow receiver receiver-index statistics | Limpe as informações de estatísticas de amostragem do sFlow relacionadas à função de receptor especificada |
| show sflow | Exiba a configuração do sFlow e as informações de execução |
| show sflow agent | Exiba a configuração e as informações de execução da função do agente |
| show sflow poller [ interface interface-name | local ] | Exiba a configuração e as informações de execução do modo de amostragem do poller na interface |
| show sflow receiver [ receiver-index [ statistics ] ] | Exiba as informações de estatísticas de amostragem do sFlow, configuração e informações de execução relacionadas à função do receptor |
| show sflow sampler [ interface interface-name | local ] | Exibe a configuração e as informações de execução do modo do amostrador na interface |
Exemplo de configuração típica do sFlow
Configurar funções básicas do sFlow
Requisitos de rede
- Device é o dispositivo do agente sFlow e a rota com o servidor NMS é alcançável.
- O servidor NMS monitora o tráfego de dados da interface do dispositivo via sFlow.
Topologia de rede

Figura 6 -1 Rede de configuração das funções básicas do sFlow
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a interface à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Configure a função sFlow.
#Ative o agente sFlow.
Device#configure terminalDevice(config)#sflow agent ip 1.1.1.1
#Configure o endereço IP de destino e o número da interface UDP de destino do pacote de saída de estatísticas do sFlow, o intervalo de envio do pacote é de 5s e o tamanho do buffer é de 1400 bytes.
Device(config)#sflow receiver 1 owner 1 ip 129.255.151.10 timeout 5 udp-port 6343 packet-size 1400#Realize a amostragem do amostrador para o fluxo de entrada da interface gigabitethernet0/1 e a frequência de amostragem é 10.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#sflow sampler receiver 1 sample-rate 10 direction rx
#Realize a amostragem do poller para o fluxo de entrada da interface gigabitethernet0/1 e o período de polling é de 20s.
Device(config-if-gigabitethernet0/1)#sflow poller 1 receiver 1 interval 20Device(config-if-gigabitethernet0/1)#exit
- Passo 4:Confira o resultado.
#Visualize as informações do sFlow no dispositivo.
Device#show sflowsFlow Agent Configuration: (Interval = 120, Current Tick = 0x002a6476)Address Receivers Samplers PollersVersion Id Type Net Address Socket Number Number Number Boot Time / Exec Time--------- ---- ------- ----------------- -------- ----------- ----------- ----------- -----------/-----------1.3 1 IPv4 1.1.1.1 0x1c 1/78 1/156 1/156 0x00000ab2/0x002a644csFlow Receivers Configuration: (Reset Delta = 18000, Current Tick = 0x002a6476)Datagram MaximumIndex Owner Net Address Port Version Datagram Timeout Reset Time /Expire Time------- ------------------------- ----------------- ------- -------- -------- ------- -----------/-----------1 1 129.255.151.10 6343 5 1400 5 0x002a644c/0x002a6578sFlow Samplers Configuration:Sampling Types: H - raw packet header E - ethernet packetF - IPv4 packet S - IPv6 packetReceiver Sampling Sampling Maximum Sampling Pkts NumberInterface Index Rate Direction Header Types (Curr/Last)------------- -------- -------- --------- ------- -------- ---------------gi0/1 1 10 rx 128 H 0x0000/0x0001sFlow Pollers Configuration: (Current Tick = 0x002a6476)Sampling Types: G - generic counterE - ethernet counterReceiver SamplingInterface Instance Index Types Interval Countdown------------- -------- -------- -------- -------- ------------gi0/1 1 1 G 10 0x002a65b4
#No NMS, podemos visualizar as informações de fluxo de entrada da interface gigabitethernet0/1 no dispositivo.
LLDP
Visão geral
Visão geral do protocolo LLDP
LLDP (Link Layer Discovery Protocol) é o protocolo de camada de link definido no padrão IEEE 802.1ab. Ele organiza as informações do dispositivo local para TLV (Tipo/Comprimento/Valor), encapsula em LLDPDU (Link Layer Discovery Protocol Data Unit) e envia para o dispositivo vizinho conectado diretamente. Enquanto isso, ele salva o LLDPDU recebido do dispositivo vizinho no modo padrão MIB (Management Information Base). Com o LLDP, o dispositivo pode salvar e gerenciar suas próprias informações de dispositivos vizinhos conectados diretamente para que o sistema de gerenciamento de rede consulte e julgue o status de comunicação do link.
Informações do tipo TLV
O TLV que o LLDP pode encapsular inclui o TLV básico, o TLV definido pela organização e o TLV MED (Media Endpoint Discovery). TLV básico é um grupo de TLV considerado como a base do gerenciamento de dispositivos de rede. TLV definido pela organização e MED TLV é o TLV definido pela organização padrão e outras instituições, usado para fortalecer o gerenciamento dos dispositivos de rede. Podemos configurar se deseja liberar em LLDPDU de acordo com a demanda real.
TLV básico
No TLV básico, existem vários tipos de TLV, que são obrigatórios para a realização da função LLDP, ou seja, devem ser liberados em LLDPDU, conforme tabela a seguir.
Tabela 1 - 1 Descrição do TLV básico
| Tipo TLV | Descrição | Seja para liberar |
| Fim do LLDPDU TLV | Indica o fim do LLDPDU | Sim |
| ID do chassi TLV | O endereço MAC do dispositivo de envio | Sim |
| ID de porta TLV | Usado para identificar a porta da extremidade de envio do LLDPDU; quando o dispositivo não envia MED TLV, o conteúdo é o nome da porta; ao selecionar enviar MED TLV, o conteúdo é o endereço MAC da porta. | Sim |
| Tempo de Vida TLV | O tempo ao vivo das informações do dispositivo local no dispositivo vizinho | Sim |
| Descrição da porta TLV | A cadeia de caracteres de descrição da porta | Não |
| Nome do sistema TLV | O nome do dispositivo | Não |
| Descrição do sistema TLV | A descrição do sistema | Não |
| Capacidades do sistema TLV | As principais funções do sistema e quais funções podem ser habilitadas | Não |
| Endereço de gerenciamento TLV | Endereço de gerenciamento, número de interface correspondente e oid (identificador de objeto). O endereço de gerenciamento pode ser um endereço IP configurado manualmente; Se não estiver configurado, selecione o endereço IP primário da porta de gerenciamento do dispositivo; Se a interface de gerenciamento não estiver configurada, selecione o endereço IP primário que a interface permite passar pela VLAN; Se alguma VLAN não estiver configurada com o endereço IP primário, o endereço de gerenciamento será nulo. Por padrão, envie o TLV. | Sim |
TLV Definido pela Organização
O TLV definido pela organização inclui o TLV definido pela Organização 802.1 e o TLV definido pela Organização 802.3, conforme mostrado na tabela a seguir.
Tabela 1 - 2 Descrição do TLV definido pela organização 802.1
| Tipo TLV | Descrição | Seja para liberar |
| Porta VLAN ID TLV | ID da VLAN da porta | Não |
| Porta e protocolo VLAN ID TLV | ID da VLAN do protocolo de porta | Não |
| Nome da VLAN TLV | Nome da porta VLAN | Não |
| Identidade de protocolo TLV | O tipo de protocolo suportado pela porta. O dispositivo local não suporta o envio de identidade de protocolo TLV, mas pode receber este tipo de TLV | Não |
Tabela 1 - 3 Descrição do TLV definido pela organização 802.3
| Tipo TLV | Descrição | Seja para liberar |
| Configuração MAC/PHY/Status TLV | A taxa e o status duplex da porta, se a negociação automática de taxa de porta é suportada, se a função de negociação automática está habilitada e a taxa atual e o status duplex | Não |
| Energia via MDI TLV | Capacidade de alimentação da porta | Não |
| TLV de agregação de links | Se a porta suporta agregação de link e se deve habilitar a agregação de link | Não |
| Tamanho Máximo do Quadro TLV | O comprimento máximo de quadro suportado é o MTU (unidade máxima de transmissão) configurado pela porta | Não |
MED TLV
As informações do MED TLV são mostradas na tabela a seguir.
Tabela 1 - 4 A descrição do MED TLV
| Tipo TLV | Descrição | Seja para liberar |
| Capacidades LLDP-MED TLV | O tipo de dispositivo MED do dispositivo e o tipo LLDP MED TLV que pode ser encapsulado em LLDPDU | Não |
| Política de rede TLV | ID da VLAN da porta, aplicativos suportados (como voz e vídeo), prioridade dos aplicativos e políticas usadas | Não |
| Estendido Power-via-MDI TLV | A capacidade de alimentação do dispositivo | Não |
| Revisão de Hardware TLV | A versão de hardware do dispositivo | Não |
| Revisão de Firmware TLV | A versão do firmware do dispositivo | Não |
| Revisão de Software TLV | A versão do software do dispositivo | Não |
| Número de série TLV | O número de série do dispositivo | Não |
| Nome do fabricante TLV | O fabricante do dispositivo | Não |
| Nome do modelo TLV | O nome do módulo do dispositivo | Não |
| ID do recurso TLV | O ID do ativo do dispositivo para gerenciamento de diretório e rastreamento de ativos | Não |
| Identificação do local TLV | As informações de ID de localização do dispositivo conectado, usadas por outros dispositivos no aplicativo com base na localização | Não |
Mecanismo de Trabalho LLDP
Modo de trabalho LLDP
A porta inclui os quatro modos de trabalho LLDP a seguir:
- RxTx : envia e recebe LLDPDU;
- Tx: enviar apenas LLDPDU;
- Rx: só recebe LLDPDU;
- Desabilitar: não envia nem recebe LLDPDU.
Mecanismo de envio LLDP
O mecanismo de envio LLDP:
- Quando a porta funciona no modo RxTx ou Tx , envie regularmente LLDPDU para o dispositivo vizinho de acordo com o período de envio do pacote LLDP;
- Depois que a porta habilitar a função de pesquisa, pesquise regularmente se a configuração relacionada ao LLDP no dispositivo local muda. Se a configuração mudar, envie o LLDPDU imediatamente. Para evitar que a alteração frequente das informações locais cause muitos LLDPDU enviados, é necessário atrasar e aguardar algum tempo e, em seguida, continuar a enviar o próximo LLDPDU ao enviar um LLDPDU todas as vezes.
- Quando alguma configuração relacionada ao LLDP do dispositivo local for alterada (por exemplo, selecione o tipo de TLV liberado), ou se encontrar a alteração de configuração após habilitar a função de polling, habilite o mecanismo de envio rápido, ou seja, envie imediatamente o LLDPDU da quantidade especificada continuamente e, em seguida, restaure o período normal de envio de pacotes LLDP.
- Quando a função LLDP global estiver desabilitada ou a porta habilitada com LLDP executar shutdown, adicionar ao grupo de agregação e desabilitar o LLDP, assim como reiniciar o dispositivo, envie um LLDPDU com CLOSE TLV para informar o dispositivo vizinho.
Mecanismo de Recebimento LLDP
Quando a porta funciona no modo RxTx ou Rx, verifique a validade do LLDPDU recebido e do TLV transportado. Depois de passar na verificação de validade, salve as informações do vizinho no dispositivo local e defina o tempo de idade das informações do vizinho no dispositivo local de acordo com o TTL (Time To Live) transportado em LLDPU. Se o valor TTL no LLDPDU recebido for 0, envelheça as informações do vizinho de uma só vez. A capacidade de armazenamento do protocolo LLDP para o vizinho é limitada. Se os vizinhos atingirem o limite, mais pacotes de publicidade de vizinhos serão descartados e não poderão ser salvos.
Configuração da Função LLDP
Tabela 1 - 5 lista de configuração da função LLDP
| Tarefa de configuração | |
| Configurar as funções básicas do LLDP |
Habilite a função LLDP global
Habilite a função LLDP da porta Ativar a função de vizinho de aprendizado baseado em porta LLDP |
| Configurar o modo de trabalho LLDP | Configurar o modo de trabalho LLDP |
| Configure o TLV que o LLDP permite liberar |
Configure o TLV básico permitido para liberação
Configure o TLV definido pela organização com permissão para liberar Configure o MED TLV com permissão para liberar |
| Configurar os parâmetros LLDP |
Configurar o tempo ao vivo do vizinho
Configurar o atraso de envio de pacotes Configurar o período de envio de pacotes Configure o número de pacotes enviados rapidamente Configurar o atraso de reinicialização Configure o período de verificação da configuração do LLDP |
Configurar funções básicas do LLDP
Habilite a função LLDP global e a função LLDP da porta ao mesmo tempo para que o LLDP possa funcionar normalmente. O dispositivo local obtém as informações do dispositivo vizinho interagindo LLDPDU com outro dispositivo.
Condição de configuração
Nenhum
Ativar função LLDP global
Tabela 1 - 6 Habilitar a função LLDP global
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função LLDP global | lldp run | Obrigatório Por padrão, não ative a função LLDP global. |
Ativar função LLDPe Po
Tabela 1 - 7 Habilite a função LLDP da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre na interface Ethernet L2/L3/modo de configuração da porta de gerenciamento fora de banda | interface interface-name | E também Depois de entrar no modo de configuração da interface Ethernet l2/l3/porta de gerenciamento fora de banda, a configuração subsequente terá efeito apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a função LLDP da porta | lldp enable | Obrigatório Por padrão, a interface habilita a função LLDP. |
Ativar a função de vizinho de aprendizagem baseada em porta LLDP
Depois de configurar a função de vizinho de aprendizado baseado em porta LLDP, ele pode aprender e exibir vizinhos com base na única porta do dispositivo. Por padrão, os dispositivos aprendem e exibem os vizinhos com base nas portas e nas portas do grupo de agregação.
Tabela 1 - 8 Habilite a função de vizinho de aprendizado baseado em porta LLDP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar a função de vizinho de aprendizado baseado em porta LLDP | lldp mode-ap | Opcional Por padrão, a função está desabilitada. |
Configurar o modo de trabalho LLDP
Condição de configuração
Nenhum
Configurar o modo de trabalho LLDP
O usuário pode definir diferentes modos de trabalho de acordo com a função do dispositivo na rede. Se for o dispositivo seed (o dispositivo central coletado pela topologia de rede), sugere-se configurar o modo de trabalho LLDP como Rx. Caso contrário, sugere-se configurar o modo de trabalho LLDP como Tx.
Tabela 1 - 9 Configurar o modo de trabalho LLDP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | E também Depois de entrar no modo de configuração da interface Ethernet l2/l3, a configuração subsequente terá efeito apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure o modo de trabalho LLDP como Rx | lldp receive |
Opcional
Por padrão, o modo de trabalho LLDP é RxTx . O modo de trabalho LLDP é decidido pelos comandos lldp receber e lldp transmite. |
| Configure o modo de trabalho LLDP como Tx | lldp transmit |
Configurar TLV Permitido pelo LLDP para Liberar
O dispositivo vizinho pode conhecer os detalhes do dispositivo local liberando o TLV.
Condição de configuração
Nenhum
Configurar TLV Básico Permitido pelo LLDP para Liberar
O usuário pode liberar diferentes TLVs básicos de acordo com a demanda real da aplicação.
Tabela 1 - 10 Configure o TLV básico permitido pelo LLDP para liberar
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | E também Depois de entrar no modo de configuração da interface Ethernet l2/l3, a configuração subsequente terá efeito apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure as permissões básicas do TLV LLDP para liberar | lldp tlv-select { basic-tlv { all | port-description | system-capability | system-description | system-name } } | Opcional Por padrão, permita liberar todos os TLVs básicos. |
Configurar permissões de TLV LLDP definidas pela organização para liberar
O usuário pode liberar diferentes TLVs definidos pela organização de acordo com a demanda real do aplicativo.
Tabela 1 - 11 Configure as permissões de TLV LLDP definidas pela organização para liberar
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | E também Depois de entrar no modo de configuração da interface Ethernet l2/l3, a configuração subsequente terá efeito apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure as permissões de TLV LLDP definidas pela organização para liberar | lldp tlv-select { dot1-tlv { all | port-vlan-id | protocol-vlan-id | vlan-name } | dot3-tlv { all | link-aggregation | mac-physic | max-frame-size | power } } | Opcional Por padrão, permita liberar todos os TLVs definidos pela organização. |
Configurar permissões MED TLV LLDP para liberação
O usuário pode liberar diferentes MED TLVs de acordo com a demanda real do aplicativo.
Tabela 1 - 12 Configurar as permissões do MED TLV LLDP para liberar
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | E também Depois de entrar no modo de configuração da interface Ethernet l2/l3, a configuração subsequente terá efeito apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configure as permissões do MED TLV LLDP para liberar | lldp med-tlv-select { all | capability | location-id elin-address phonenum | network-policy | power-via-mdi | inventory } | Opcional Por padrão, não permita a liberação de todos os MED TLVs. |
Configurar parâmetros LLDP
Condição de configuração
Nenhum
Configurar tempo de vida do vizinho
Especifique o tempo de vida das informações do dispositivo local no dispositivo vizinho configurando o TTL vizinho para que o dispositivo vizinho possa excluir as informações do dispositivo local após a chegada do TTL do dispositivo local.
Tabela 1 - 13 Configure o tempo de vida do vizinho
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o tempo de vida do dispositivo local no dispositivo vizinho | lldp holdtime holdtime-value |
Opcional
Por padrão, o tempo de vida do dispositivo local no dispositivo vizinho é de 120 segundos. |
Configurar o atraso de envio de pacotes
A configuração do atraso de envio de pacotes pode impedir que a alteração frequente das informações locais faça com que muitos LLDPDU sejam enviados.
Tabela 1 - 14 Configurar o atraso de envio de pacotes
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o atraso de envio dos pacotes LLDP | lldp transmit-delay transmit-delay-value | Opcional Por padrão, o atraso de envio dos pacotes LLDP é de 2s. |
Configurar período de envio de pacotes
O dispositivo local envia regularmente o pacote LLDP para o dispositivo vizinho configurando o período de envio dos pacotes para que as informações do dispositivo local no dispositivo vizinho não sejam envelhecidas.
Tabela 1 - 15 Configurar o período de envio de pacotes
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o período de envio dos pacotes LLDP | lldp transmit-interval transmit-interval-value | Opcional Por padrão, o período de envio dos pacotes LLDP é de 30s. |
Configurar a quantidade de pacotes enviados rapidamente
Quando alguma configuração de LLDP do dispositivo local (por exemplo, selecione o tipo de TLV liberado) é alterada, ou quando o mecanismo de pesquisa descobre que as informações de configuração relacionadas ao LLDP no dispositivo local são alteradas após habilitar a função de pesquisa, para fazer com que outros dispositivos descubram a alteração do dispositivo local o mais rápido possível, habilite o mecanismo de envio rápido, ou seja, envie continuamente os LLDPDUs da quantidade especificada (é 3 por padrão) de uma só vez e, em seguida, restaure o período normal de envio.
Tabela 1 - 16 Configurar a quantidade de pacotes enviados rapidamente
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o número de pacotes enviados rapidamente | lldp fast-count fast-count-value | Opcional Por padrão, o número de pacotes enviados rapidamente é 3. |
Configurar atraso de reinicialização
Quando o modo de trabalho da porta mudar, reinicialize a máquina de status do protocolo da porta. Para evitar que a mudança frequente do modo de trabalho da porta reinicie continuamente a máquina de status do protocolo da porta, podemos configurar o atraso de reinicialização da porta.
Tabela 1 - 17 Configurar o atraso de reinicialização
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o atraso de reinicialização | lldp reinit reinit-value | Opcional Por padrão, o atraso de reinicialização é de 2s. |
Configurar o período de verificação de configuração LLDP
Para informar o dispositivo vizinho a tempo após a alteração da configuração do LLDP, podemos configurar o período de verificação da configuração do LLDP.
Tabela 1 - 18 Configure o período de verificação da configuração do LLDP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | E também Depois de entrar no modo de configuração da interface Ethernet l2/l3, a configuração subsequente terá efeito apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Habilite a função de sondagem e configure o período de sondagem | lldp check-change-interval check-change-interval-value | Opcional Por padrão, a função de sondagem está desabilitada. |
Configurar os parâmetros TLV da política de rede LLDP MED
Configure a política de rede LLDP MED TLV para que a política de rede LLDP MED TLV possa configurar parâmetros de acordo com os requisitos do usuário e enviá-los por meio de pacotes.
Tabela 1 - 19 Configurar a política de rede LLDP MED TLV
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | E também Depois de entrar no modo de configuração da interface Ethernet l2/l3, a configuração subsequente terá efeito apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | interface link-aggregation link-aggregation-id | |
| Configurar a política de rede LLDP MED TLV | lldp med network-policy [ voice | voice-signaling ] [ tag | untag ] tag-id l2-priority l2-priorit-value dscp dscp-value |
Opcional
Por padrão, o parâmetro TLV da política de rede LLDP MED no pacote não está configurado. tag-id : O intervalo de valores é 1~4094. l2-priorit-value : O intervalo de valores é 0~7. dscp -value : O intervalo de valores é de 0 a 63. |
Monitoramento e manutenção do LLDP
Tabela 1 - 20 Monitoramento e Manutenção do LLDP
| Comando | Descrição |
| clear lldp neighbors [ interface interface-name | interface link-aggregation link-aggregation-id ] | Limpar as informações do vizinho |
| show lldp neighbors [ detail | interface interface-name [ detail ] | interface link-aggregation link-aggregation-id [ detail ] ] | Exibir as informações do vizinho |
| show lldp neighbors oui [ interface interface-name | interface link-aggregation link-aggregation-id ] | Exibir informações de endereço OUI vizinho e gravar o status de entrada da tabela OUI de Voz-VLAN |
| clear lldp statistics | Limpe as informações de estatísticas do pacote LLDP |
| show lldp statistics { interface interface-name | interface link-aggregation link-aggregation-id } | Exibe as informações de estatísticas de pacotes LLDP recebidos e enviados da porta especificada |
| show lldp | Exibir as informações de configuração global do LLDP |
| show lldp interface interface-name | Exiba o modo de trabalho LLDP da porta especificada e o período de pesquisa de verificação da alteração da configuração LLDP |
| show lldp interface link-aggregation link-aggregation-id | Exiba o modo de trabalho LLDP do grupo de agregação especificado e o ciclo de pesquisa para verificar as alterações de configuração do LLDP |
| show lldp tlv-select [ interface interface-name | interface link-aggregation link-aggregation-id ] | Exiba as informações básicas de configuração de TLV e TLV definidas pela organização |
| show lldp voice neighbors [ detail | interface interface-name [ detail ] | interface link-aggregation link-aggregation-id [ detail ] ] | D isplay as informações do vizinho de voz |
| show lldp med network-policy local [ interface link-aggregation link-aggregation-id | interface interface-name ] | Exiba as informações do parâmetro TLV da política de rede local |
Exemplo de configuração típica do LLDP
Configurar funções básicas do LLDP
Requisito de rede
- Configure a função LLDP em Device1, Device2 e Device3, realizando a descoberta do vizinho da camada de link.
Topologia de rede

Figura 1 - 1 Rede de configuração das funções básicas do LLDP
Etapas de configuração
- Passo 1:Habilite a função LLDP no dispositivo.
# Habilite a função LLDP no Device1.
Device1#configure terminalDevice1(config)#lldp run
# Habilite a função LLDP no Device2.
Device2#configure terminalDevice2(config)#lldp run
# Habilite a função LLDP no Device3.
Device3#configure terminalDevice3(config)#lldp run
- Passo 2:Configure a função LLDP na porta.
#Habilite a função LLDP na porta gigabitethernet 0/1 do Device1.
Device1(config)#interface gigabitethernet 0/1Device1(config-if-gigabitethernet0/1)#lldp enableDevice1(config-if-gigabitethernet0/1)#exit
# Habilite a função LLDP na interface gigabitethernet 0/1 , gigabitethernet 0 /2 de Device2.
Device2(config)#interface gigabitethernet 0/1Device2(config-if-gigabitethernet0/1)#lldp enableDevice2(config-if-gigabitethernet0/1)#exitDevice2(config)#interface gigabitethernet 0/2Device2(config-if-gigabitethernet0/2)#lldp enableDevice2(config-if-gigabitethernet0/2)#exit
# Habilite a função LLDP na porta gigabitethernet0 /1 do Device3.
Device3(config)#interface gigabitethernet 0/1Device3(config-if-gigabitethernet0/1)#lldp enableDevice3(config-if-gigabitethernet0/1)#exit
- Passo 3:Confira o resultado.
#Visualize as informações do vizinho no Device1.
Device1#show lldp neighborsCapability codes:(R) Router, (B) Bridge, (T) Telephone, (C) DOCSIS Cable Device(W) WLAN Access Point, (P) Repeater, (S) Station, (O) OtherIndex Local Intf Hold-time Capability Peer Intf Device ID1 gi0/1 120 P,R, gi0/1 Device2
Device1 descobre o vizinho Device2.
# Visualize as informações de detalhes do vizinho Device1 .
Device1#show lldp neighbors detailBasic informationChassis ID : 0001.7a54.5d0bInterface ID : gi0/1Interface Description : gigabitethernet0/1System Name : Device2System Description : MyPower (R) Operating System SoftwareCopyright (C) 2013 Intelbras Communication Technology Co.,Ltd.All Rights Reserved.Time Remaining : 111 secondsSystem Capabilities : P,R,Enabled Capabilities : P,R,Management Addresses : IP,10.0.0.1802.1 organizationally informationPort VLAN ID : 1Port And Protocol VLAN ID : 0VLAN Name Of VLAN 1 : DEFAULT802.3 organizationally informationAuto Negotiation : Supported, EnabledPMD Auto Negotiation Advertised : 10BASE-T,10BASE-TFD,100BASE-TX,100BASE-TXFD,FDX-PAUSE,1000BASE-TFD,Media Attachment Unit Type : 1000BaseTFD,Port Class : PSEPSE Power : Supported, EnabledPSE Pairs Control Ability : NoPower Pairs : 1Power Class : 1Link Aggregation : Supported, DisabledLink Aggregation ID : 0Max Translate Unit : 1824MED organizationally informationCapabilities : Not SupportedClass Type : Not SupportedApplication Type : Not SupportedPolicy : Not SupportedVLAN Tagged : Not SupportedVLAN ID : Not SupportedL2 Priority : Not SupportedDSCP Value : Not SupportedLocation ID : Not SupportedPower Type : Not SupportedPower Source : Not SupportedPower Priority : Not SupportedPower Value : Not SupportedHardwareRev : Not SupportedFirmwareRev : Not SupportedSoftwareRev : Not SupportedSerialNum : Not SupportedManufacturer Name : Not SupportedModel Name : Not SupportedAsset Tracking Identifier : Not Supported---------------------------------------------Total entries displayed: 1
Para ver as informações do vizinho de Device2 e Device3, consulte Device1.
Configurar a função LLDP-MED
Requisitos de rede
- Configurar a função LLDP MED no dispositivo e configurar o lldp do telefone para usar a política de rede correspondente para transmissão.
Topologia de rede

Figura 1 - 2 _ Rede de configuração da função LLDP -MED
Etapas de configuração
- Passo 1: Vlan e habilite a função LLDP.
Device#configure terminalDevice(config)#vlan 100Device(config-vlan100)#name PCDevice(config-vlan100)#exitDevice(config)#Device(config)#vlan 200Device(config-vlan200)#name IP PhoneDevice(config-vlan200)#exitDevice(config)#lldp run
- Passo 2:Configure a função LLDP na porta.
Na porta gigabitethernet0/1 do dispositivo, modifique o modo de interface como híbrido e adicione à vlan correspondente.
Device(config)#interface gigabitethernet 0/1Device(config-if-gigabitethernet0/1)#switchport mode hybridDevice(config-if-gigabitethernet0/1)#switchport hybrid pvid vlan 100Device(config-if-gigabitethernet0/1)#switchport hybrid untagged vlan 100Device(config-if-gigabitethernet0/1)#switchport hybrid tagged vlan 200Device(config-if-gigabitethernet0/1)#exit
Na porta gigabitethernet0 /1 do Dispositivo, configure os parâmetros da função LLDP-MED.
Device(config-if-gigabitethernet0/1)#lldp med network-policy voice tag 200 l2-priority 5 dscp 30Device(config-if-gigabitethernet0/1)#lldp med-tlv-select all
- Passo 3:Confira o resultado.
# Visualize as informações do parâmetro TLV da política de rede local do LLDP-MED.
Device#show lldp med network-policy localPort Name: gigabitethernet0/11. LLDP_MED Network policyApplication Type : VoicePolicy : DefinedVLAN Tagged : YesVLAN ID : 200L2 Priority : 5DSCP Value : 30
# Visualize as informações do vizinho no dispositivo.
Device#show lldp neighborsCapability codes:(R) Router, (B) Bridge, (T) Telephone, (C) DOCSIS Cable Device(W) WLAN Access Point, (P) Repeater, (S) Station, (O) OtherIndex Local Intf Hold-time Capability Peer Intf Device ID1 gi0/1 20 B,T ccd8.1f0f.32f3 VEP620E
O dispositivo descobre o vizinho VEP620E .
#Visualize as informações detalhadas do vizinho do dispositivo.
Device# show lldp neighbors interface gigabitethernet 0/1 detailNeighbor 1:1. Basic informationChassis ID : 192.168.99.2Interface ID : ccd8.1f0f.32f3Interface Description : WAN Port 10M/100M/1000MSystem Name : VEP620ESystem Description : :14.0.0.4.r1Time Remaining : 13 secondsSystem Capabilities : B,TEnabled Capabilities : B,TManagement Addresses : IP,192.168.99.22. 802.1 organizationally informationPort VLAN ID : Not SupportedPort And Protocol VLAN ID : Not SupportedVLAN Name Of VLAN : Not Supported3. 802.3 organizationally informationAuto Negotiation : Not SupportedOperMau : Not SupportedPort Class : PDPSE Power : Not Supported, DisabledPSE Pairs Control Ability : NoPower Pairs : 1Power Class : 1Link Aggregation : Not SupportedLink Aggregation ID : Not SupportedMax Translate Unit : Not Supported4. MED organizationally informationCapabilities : LLDP-MED Capabilities,Network Policy,MED Class Type : Endpoint Class IIIApplication Type : VoicePolicy : DefinedVLAN Tagged : YesVLAN ID : 200L2 Priority : 5DSCP Value : 30Location ID : Not SupportedPower Type : Not SupportedPower Source : Not SupportedPower Priority : Not SupportedPower Value : Not SupportedHardwareRev : V2.0FirmwareRev : Not SupportedSoftwareRev : 14.0.0.4.r1SerialNum : 000000000000000000000C0600ccd81f0f32f3Manufacturer Name : Not SupportedModel Name : VEP620EAsset Tracking Identifier : Not Supported---------------------------------------------Total entries displayed
NDSP
Visão geral
Visão geral do NDSP Protocolo
NDSP (Network Devices Searching Protocol) é um protocolo de descoberta de dispositivos baseado em pacote multicast , que pode descobrir dispositivos conectados diretamente. Ele organiza as informações do dispositivo local em TLV (tipo/comprimento/valor), que é encapsulado em NDSPPDU (dispositivos de rede buscando unidade de dados de protocolo) e enviado ao dispositivo vizinho diretamente conectado. Ao mesmo tempo, ele também analisa o NDSPPDU recebido do dispositivo vizinho e armazena em cache as informações do dispositivo conectado diretamente ao local. Por meio do NDSP, o dispositivo pode salvar e gerenciar as informações de si mesmo e dos dispositivos vizinhos diretamente conectados para que o sistema de gerenciamento de rede consulte e julgue o status de comunicação do link.
O NDSP tem apenas uma tabela – tabela vizinha conectada direta. Para redes gerais, há apenas um vizinho conectado direto em uma interface, portanto, o número de entradas da tabela não excederá o número de interfaces.
Configuração da função NDSP
Tabela 8 -1 lista de configuração da função NDSP
| Tarefa de configuração | |
| Configurar funções básicas do NDSP | Ativar a função NDSP global NDSP da porta |
| Configurar os parâmetros LLDP | Configurar o tempo de atividade do vizinho Configurar o período de envio do pacote |
Configurar as funções básicas do NDSP
A função NDSP global e a função NDSP de porta devem ser habilitadas ao mesmo tempo para que o NDSP possa funcionar corretamente. O dispositivo local encontra vizinhos e obtém informações do dispositivo vizinho interagindo NDSPPDU com outros dispositivos.
Condições de configuração
Nenhum
NDSP global
Tabela 8 -2 Habilite a função NDSP global
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ativar a função NDSP global | ndsp run | Mandatório Por padrão, não ative a função NDSP global . |
NDSP da porta
Tabela 8 -3 Habilite a função NDSP da porta
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2/L3, a configuração subsequente terá efeito apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente entra em vigor apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | Interface link-aggregation link-aggregation-id | |
| NDSP da porta | ndsp enable | Mandatório Por padrão, a porta não habilita a função NDSP . |
Configurar os Parâmetros NDSP
Condições de configuração
Nenhum
Configurar Keepalive Time of the Neighbor
O TTL é configurado para especificar o tempo de manutenção das informações do dispositivo local no dispositivo vizinho, para que o dispositivo vizinho possa excluir as informações do dispositivo local após a expiração da vida útil do dispositivo local.
Tabela 8 -4 Configurar o tempo de keepalive do vizinho
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o tempo de atividade do dispositivo local no dispositivo vizinho | ndsp holdtime holdtime-value | Opcional Por padrão, o tempo de atividade do dispositivo local no dispositivo vizinho é de 30s. |
Configurar o Período de Envio do Pacote
Ao configurar o período de envio do pacote, o dispositivo local enviará o pacote NDSP para o dispositivo vizinho regularmente, para que as informações do dispositivo local no dispositivo vizinho não sejam envelhecidas.
Tabela 8 -5 Configura o período de envio do pacote
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o período de envio do pacote NDSP | ndsp timer value | Opcional Por padrão, o período de envio do pacote NDSP é de 10s . |
Monitoramento e manutenção de NDSP
Tabela 8 -6 NDSP monitoramento e manutenção
| Etapa | Comando | Descrição |
| show ndsp neighbors [ detail] | Exiba as informações do vizinho |
Exemplo de configuração típica de NDSP
Configurar as funções básicas do NDSP
Requisitos de rede
- Em Device1 e Device2, configure a função NDSP, realizando a descoberta do vizinho da camada de enlace.
Topologia de rede

Figura 8 -1 Rede de configuração das funções básicas do NDSP
Etapas de configuração
- Passo 1:No Dispositivo, habilite a função NDSP.
#No Dispositivo1, habilite a função NDSP.
Device1#configure terminalDevice1(config)#ndsp run
# No Device2 , habilite a função NDSP.
Device2#configure terminalDevice2(config)# ndsp run
- Passo 2:Na porta, configure a função NDSP.
# Na agregação de link de porta 1 de Device1, habilite a função NDSP .
Device1(config)# interface link-aggregation 1Device1(config-if-link-aggregation1)# ndsp enableDevice1(config-if-link-aggregation1)#exit
# Na agregação de link de porta 2 do Device2 , habilite a função NDSP.
Device2(config)# interface link-aggregation 2Device2(config-if-link-aggregation2)# ndsp enableDevice2(config-if-link-aggregation2)#exit
- Passo 3:Confira o resultado.
# Visualize as informações do vizinho no Device1 .
Device1#show ndsp neighborsCapability Codes: R - Router, T - Trans Bridge, B - Source Route BridgeS - Switch, H - Host, I - IGMP, r - RepeaterDevice ID Local Interface Holdtime Capability Neighbor Interface Platform00017a6a01f2 link-agg1 30 S link-agg2 MyPower S4230-52TXF (V1)-switch
Device1 descobre o vizinho Device2.
# Visualize as informações detalhadas do vizinho Device1 .
Device1#show ndsp neighbors detail-------------------------Device ID: 00017a6a01f2Platform: S4230-52TXF (V1), Capabilities: SwitchPort: link-agg1, Port ID (outgoing port): link-agg2Holdtime : 26 secVersion :MyPower (R) Operating System Software S4230 Software, Version 9.5.0.2(26)(integrity) RELEASE SOFTWARE Copyright (C) 2019 Intelbras Communication Technology Co.,Ltd.All Rights Reserved. Intelbras Communication Technology Co.,Ltd.Compiled Feb 27 2020, 17:00:44Native VLAN : 1
Para a informação do vizinho de Device2, refira Device1.
SNMP
Visão geral
O SNMP (Simple Network Management Protocol) é um protocolo padrão de gerenciamento de dispositivos da Internet. Ele garante que as informações de gerenciamento possam ser transmitidas entre o Network Management Station e o agente SNMP do dispositivo gerenciado. É conveniente que o administrador do sistema gerencie o sistema de rede.
O SNMP é um protocolo de camada de aplicação no modo cliente/servidor. Ele inclui principalmente três partes:
- NMS (Estação de Gerenciamento de Rede)
- agente SNMP
- MIB (Base de Informações Gerenciais).
O conjunto de estruturas de todos os objetos gerenciados mantidos pelo dispositivo é chamado de MIB. Os objetos gerenciados são organizados de acordo com a estrutura de árvore hierárquica. MIB define as informações de gerenciamento de rede obtidas por um dispositivo. Para ser consistente com o protocolo de gerenciamento de rede padrão, cada dispositivo deve usar o formato definido no MIB para exibir as informações. Um subconjunto de ISO ASN.1 define a sintaxe para MIB. Cada MIB usa a estrutura em árvore definida em ASN.1 para organizar todas as informações disponíveis. Cada informação é um nó com pontuação e cada nó contém um ID de objeto e uma breve descrição de texto.
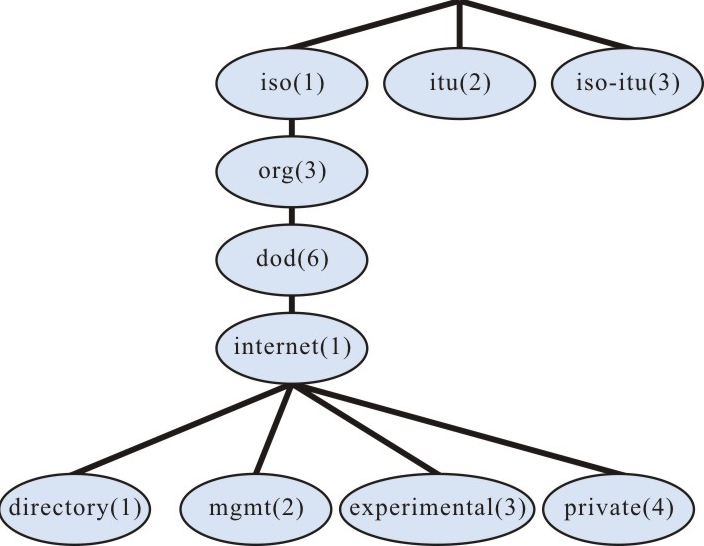
Figura 8 – 1 diagrama de árvore ASN.1 de gerenciamento de rede
As versões do protocolo SNMP incluem SNMPv1, SNMPv2 e SNMPv3.
- SNMPv1: A primeira versão do protocolo SNMP. As desvantagens: problema de segurança, desperdício de largura de banda, falta de capacidade de comunicação entre gerentes, o protocolo fornece apenas as operações limitadas;
- SNMPv2: Faz algumas melhorias com base no SNMPv1, tornando as funções mais fortes e a segurança melhor;
- SNMPv3: identidade original, integridade da informação e alguns aspectos de proteção de retransmissão, confidencialidade de conteúdo, autorização e controle de processo, configuração remota e capacidade de gerenciamento necessária para os três recursos acima;
Portanto, o desenvolvimento do SNMPv3 está centralizado em dois objetivos, ou seja, fornecer a plataforma de segurança viável na arquitetura aprimorada e manter a consistência do sistema de gerenciamento de rede.
O protocolo SNMP inclui principalmente as seguintes operações:

Figura 8 – 2 Diagrama de operação de gerenciamento SNMP
- Get-request: a estação de trabalho da rede SNMP obtém um ou vários parâmetros do agente SNMP.
- Get-next-request: a estação de trabalho da rede SNMP obtém o próximo parâmetro de um ou vários parâmetros do agente SNMP.
- Get-bulk: a estação de trabalho de rede SNMP obtém os parâmetros de lote do agente SNMP.
- Set-request: A estação de trabalho da rede SNMP define um ou vários parâmetros do agente SNMP.
- Get-response: o agente SNMP retorna um ou vários parâmetros e é a operação de resposta do agente SNMP para as três operações acima.
- Trap: O pacote enviado pelo agente SNMP ativamente, informando que algo está acontecendo com a estação de trabalho da rede SNMP.
SNMPv1 e SNMPv2 usam o nome de autenticação para verificar se têm o direito de usar o objeto MIB, portanto, somente quando o nome de autenticação da estação de trabalho da rede for consistente com um nome de autenticação definido no dispositivo, podemos gerenciar o dispositivo.
O nome de autenticação tem os dois atributos a seguir:
- Somente leitura: A autoridade de leitura da estação de trabalho de rede autorizada para todos os objetos MIB do dispositivo;
- Read-write: A autoridade de leitura e gravação da estação de trabalho de rede autorizada para todos os objetos MIB do dispositivo.
O SNMPv3 determina qual mecanismo de segurança deve ser adotado para processar os dados pelo modelo de segurança e pelo nível de segurança. Existem três modelos de segurança: SNMPv1, SNMPv 2ce SNMPv3.
Tabela 8 – 1 Modelo de segurança compatível e nível de segurança
| Modelo de segurança | Nível de segurança | Autenticação | Criptografia | Descrição |
| SNMPv1 | NoAuthNoPriv | Nome de autenticação | Nenhum | Confirme a validade dos dados por meio do nome de autenticação. |
| SNMPv2c | NoAuthNoPriv | Nome de autenticação | Nenhum | Confirme a validade dos dados por meio do nome de autenticação. |
| SNMPv3 | NoAuthNoPriv | Nome de usuário | Nenhum | Confirme a validade dos dados através do nome de usuário. |
| SNMPv3 | AuthNoPriv | MD5/SHA | Nenhum | Use o modo de autenticação de dados HMAC-MD5/HMAC-SHA. |
| SNMPv3 | AuthPriv | MD5/SHA | DES | Use o modo de autenticação de dados HMAC-MD5/HMAC-SHA e o modo de criptografia de dados CBC-DES. |
Configuração da função SNMP
Tabela 8 – 2 lista de configuração de funções SNMP
| Tarefa de configuração | |
| Configurar as funções básicas do SNMP |
Habilite o serviço SNMP
Configurar a visualização MIB Configurar as informações de contato do gerente Configure as informações de localização física do dispositivo |
| Configurar SNMPv1/v2 | Configurar o nome da comunidade SNMP Configurar as funções de interceptação SNMP |
| Configurar SNMPv3 |
Configurar o grupo de usuários SNMP
Configurar o usuário SNMP Configurar publicidade SNMP Configurar o encaminhamento do agente SNMP |
Configurar funções básicas do SNMP
Condição de configuração
Nenhum
Ativar serviço SNMP
Se o dispositivo estiver habilitado com o serviço SNMP, o dispositivo pode gerenciar e configurar através do software de gerenciamento de rede SNMP.
Tabela 8 – 3 Habilite o serviço SNMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Habilite o serviço SNMP | snmp-server start [ rfc ] | Obrigatório Por padrão, o serviço SNMP está desabilitado. |
Configurar visualização MIB
Use o modelo de controle de acesso baseado em exibição para julgar se o objeto de gerenciamento associado de uma operação é permitido pela exibição. Somente os objetos de gerenciamento permitidos pela exibição podem ter permissão de acesso.
Tabela 8 – 4 Configurar a visualização MIB
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Configurar a visualização MIB | snmp-server view view-name oid-string { include | exclude } | Obrigatório Por padrão, o nome da visualização SNMP é Padrão. |
| Configurar o tipo de hora de inicialização do sistema obtido no MIB | snmp-server mib2 sysuptime { snmp-agent-uptime | system-uptime } | Mandatório Por padrão, é tempo de atividade do sistema . |
Configurar informações de contato do gerente
As informações de contato do gerente são um nó de informações no protocolo SNMP. O software de gerenciamento de rede pode obter as informações via SNMP.
Tabela 8 – 5 Configurar o modo de contato do gerente
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Configurar as informações de contato do gerente | snmp-server contact contact-line | Obrigatório |
Configurar informações de localização física do dispositivo
As informações de localização física do dispositivo são um nó de informações no protocolo SNMP. O software de gerenciamento de rede pode obter as informações via SNMP.
Tabela 8 – 6 Configure as informações de localização física do dispositivo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Configure as informações de localização física do dispositivo | snmp-server location location | Obrigatório |
Configurar SNMPv1/v2
Condição de configuração
Antes de configurar o SNMPv1/v2, primeiro conclua a seguinte tarefa:
- Configure o protocolo da camada de link, garantindo a comunicação normal da camada de link
- Configure o endereço IP da interface, tornando alcançável a camada de rede dos nós vizinhos
Criar nome de comunidade SNMP
O SNMPv1/SNMPv 2cadota o esquema de segurança baseado no nome da comunidade. O nome da comunidade SNMP pode ser considerado como a senha entre o NMS e o proxy SNMP, ou seja, o proxy SNMP aceita apenas as operações de gerenciamento do mesmo nome de comunidade e o SNMP de um nome de comunidade diferente não é respondido e é descartado diretamente.
Tabela 8 – 7 Configurar o nome da comunidade
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Configure o nome da comunidade do proxy SNMP | snmp-server community community-name [ view view-name ] { ro | rw } [ access-list-number | access-list-name] | Obrigatório Por padrão, o nome da comunidade é público. |
Configurar SNMPv3
Condições de configuração
Antes de configurar o SNMPv3, primeiro conclua a seguinte tarefa:
- Configure o protocolo da camada de link, garantindo a comunicação normal da camada de link
- Configure o endereço IP da interface, tornando alcançável a camada de rede dos nós vizinhos
Criar grupo de usuários SNMP
Durante o controle, podemos associar algum usuário a um grupo. Os usuários de um grupo têm a mesma autoridade de acesso.
- Podemos configurar um grupo para associar à visualização. Existem três tipos de visualizações, ou seja, visualização somente leitura, visualização de gravação e visualização de notificação.
- Podemos configurar o nível de segurança do grupo, configurando se precisa de autenticação e criptografia.
Tabela 8 – 8 Crie o grupo de usuários SNMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Crie o grupo de usuários SNMP | snmp-server group group-name v3 { authnopriv | authpriv | noauth } [ notify notify-view | read read-view | write write-view ] | Obrigatório Authnopriv: autentica, mas não criptografa Authpriv: autenticar e criptografar Noauth: não autentica ou criptografa |
Criar usuário SNMP
Execute o gerenciamento de segurança por meio do modelo de segurança baseado no usuário. A estação de trabalho da rede pode se comunicar com o proxy SNMP somente após usar o usuário válido. O usuário válido precisa ser configurado.
Para SNMPv3, também podemos especificar o nível de segurança, algoritmo de autenticação (MD5 ou SHA), senha de autenticação, algoritmo de criptografia (DES) e senha de criptografia.
Tabela 8 – 9 Configurar o usuário
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Crie o usuário SNMP | snmp-server user user-name group-name [ remote ip-address port-num ] v3 [ auth { md5 | sha| SM3 } password [ encrypt {des | aes | SM4 } password ] ] [access access-list-number | access-list-name | Ipv6 access-list-number] | Obrigatório |
Configure o usuário SNMPv3 com base no modelo de segurança do usuário (USM), salve as informações de autenticação e criptografia de cada usuário. Observe que somente após configurar o protocolo de autenticação, podemos configurar o protocolo de criptografia. Para o usuário remoto (o chamado remoto é relativo à entidade SNMPv3 local. Se a entidade SNMPv3 local precisar se comunicar com outra entidade SNMPv3, a outra entidade SNMPv3 é chamada de entidade SNMPv3 remota. Isso é mencionado em notificação e proxy), também precisamos especificar o endereço IP e o número da porta UDP do usuário remoto. Ao configurar o usuário remoto, devemos primeiro configurar o engineID da entidade SNMP remota do usuário. Além disso, cada usuário deve corresponder a um grupo para que possamos mapear um modelo de segurança e um nome de segurança para um nome de grupo por meio do controle de acesso baseado em visualização. Ao configurar o encaminhamento de proxy automático e podemos não saber o endereço IP do dispositivo delegado, precisamos apenas inserir 0.0.0.0 no endereço IP. Além disso, o encaminhamento de proxy automático deve ser combinado com o mecanismo de manutenção de atividade.
Configurar notificação SNMP
A configuração de notificação SNMPv3 contém os vários tipos a seguir:
- Configuração de notificação SNMPv3: Configure a notificação SNMPv3 e especifique o tipo de mensagem de notificação como inform;
- Configuração do filtro de notificação SNMPv3: Filtro de notificação significa o filtro usado para determinar se uma mensagem de notificação deve ser enviada para um endereço de destino.
- Configuração da tabela de mapa de endereços de notificação SNMPv3: Associe o endereço de notificação a uma tabela de filtros.
Tabela 8 – 10 Configure a notificação
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Configurar a notificação SNMP | snmp-server notify notify notify-name taglist inform | Obrigatório |
| Configurar o filtro de notificação SNMP | snmp-server notify filter filter-name oid-subtree { exclude | include } | Obrigatório Excluir: Filtre as notificações de todos os objetos na subárvore MIB. Incluir: Informa todos os objetos na subárvore MIB. |
| Configure os parâmetros de endereço SNMP | snmp-server AddressParam { address-name | paramIn } v3 user-name { noauth | authpriv | authnopriv } | Obrigatório |
| Configurar a tabela de mapa de filtro de notificação SNMP | snmp-server notify profile filter-name address-param | Obrigatório filter-name : Especifique o nome do filtro de notificação a ser mapeado address-param : Especifique o nome do parâmetro de endereço a ser mapeado. |
Configurar encaminhamento de proxy SNMP
Se a estação de trabalho da rede não puder acessar diretamente o proxy SNMP gerenciado, o dispositivo intermediário precisará oferecer suporte ao encaminhamento de proxy. Atualmente, apenas o SNMPv3 oferece suporte ao encaminhamento de proxy.
Tabela 8 – 11 Configurar o encaminhamento de proxy
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Configurar o ID do mecanismo remoto SNMP | snmp-server engineID remote ip-address port-num [ vrf vrf-name ] engine-id [ group-name ] | Obrigatório Configure o ID do mecanismo da entidade SNMP que precisa do encaminhamento de proxy |
| Configure os parâmetros de endereço SNMP | snmp-server AddressParam [ address-name | paramIn ] v3 user-name { noauth | authpriv | authnopriv } | Obrigatório |
| Configurar o endereço de notificação SNMP | snmp-server TargetAddress target-name ip-address port-num address-param taglist time-out retry-num | Obrigatório |
| Configurar o encaminhamento de proxy SNMP | snmp-server proxy proxy-name { inform | trap | read | write } { engineId | auto } engineId address-param target-addr [ context-name ] | Obrigatório |
Configurar trap SNMP
Trap são as informações que os agentes SNMP enviam ativamente para as estações de trabalho da rede para relatar eventos específicos. Os pacotes Trap podem ser divididos em Trap geral e Trap personalizado. A Trap Geral inclui Autenticação, Linkdown, Linkup, Coldstart, Warmstart, crc-error, out-packet-error , out-usage-rate , in-packet-error e in -usage -rate . O Custom Trap é gerado de acordo com os requisitos de cada módulo.
Tabela 8 - 12 Configurar trap
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite o trap da interface do link para baixo ou para cima | snmp-server enable traps snmp [ linkup | linkdown ] | Obrigatório Por padrão, a interceptação SNMP está desabilitada. |
| Entre no modo de configuração da interface | interface interface-type interface-num | Opcional |
| Configure o trap da mudança de status da interface | snmp trap link-status | Opcional |
| Configurar o host de destino do Trap | snmp-server host { ip-address | host-name } traps {community community-name version { 1 | 2 } | user username authnopriv | authpriv | noauth version 3 }[ port port-num | vrf vrf-name ] | Obrigatório É necessário especificar o endereço IP como o endereço IP da estação de trabalho da rede. |
| Configure o endereço de origem do pacote Trap | snmp-server trap-source ip-address | Opcional |
Normalmente, há muitas informações de traps, portanto, elas ocuparão os recursos do equipamento e afetarão o desempenho do equipamento. Portanto, é recomendado que a função Trap dos módulos especificados seja habilitada conforme necessário, nem todos os módulos estão habilitados.
Monitoramento e manutenção de SNMP
Tabela 8 – 13 Monitoramento e manutenção de SNMP
| Comando | Descrição |
| show snmp-server | Visualize as informações de estatísticas do pacote do protocolo SNMP |
| show snmp-server AddressParams | Visualize as informações do parâmetro de endereço do proxy SNMP |
| show snmp-server community | Veja as informações da comunidade de proxy SNMP |
| show snmp-server contact | Ver o contato do gerenciador de dispositivos |
| show snmp-server context | Veja o contexto SNMPv3 |
| show snmp-server engineGroup | Exiba as informações do grupo de mecanismo de proxy SNMP |
| show snmp-server engineID | Exiba as informações do ID do mecanismo de proxy SNMP |
| show snmp-server group | Visualize as informações do grupo de usuários do proxy SNMP |
| show snmp-server Host | Exiba as informações do host de interceptação de proxy SNMP |
| show snmp-server location | Visualize as informações de localização do dispositivo |
| show snmp-server notify filter | Exibir as informações do filtro de notificação do proxy SNMP |
| show snmp-server notify notify | Exiba as informações da notificação do proxy SNMP |
| show snmp-server notify profile | Exiba as informações associadas da notificação de proxy SNMP |
| show snmp-server port | Exibe o número da porta configurada pelo protocolo SNMP |
| show snmp-server proxy | Visualize as informações de encaminhamento de proxy SNMP |
| show snmp-server reg-list | Visualize as informações do módulo do MIB registrado no SNMP |
| show snmp-server TargetAddress | Visualize as informações de entrada de endereço do proxy SNMP |
| show snmp-server user | Visualize as informações do usuário SNMP |
| show snmp-server view | Ver as informações de visualização SNMP |
Exemplo de configuração típica de SNMP
servidor proxy SNMP v1/v2c
Requisitos de rede
- Device é o dispositivo SNMP Agent e a rota com o servidor NMS é alcançável.
- O NMS monitora e gerencia o Dispositivo via SNMP v1 ou SNMP v 2c; quando o dispositivo falha, ele reporta ativamente ao NMS.
Topologia de rede
Figura 8 -3 Rede de configuração do 2cservidor proxy SNMP v1/v
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Habilite o proxy SNMP no dispositivo e configure o nome da comunidade SNMP.
#Configurar dispositivo.
Habilite o proxy SNMP; configure o nome da visualização do nó como padrão, o nome da comunidade somente leitura como público e o nome da comunidade leitura-gravação como público.
Device#configure terminalDevice(config)#snmp-server startDevice(config)#snmp-server view default 1.3.6.1 includeDevice(config)#snmp-server community public view default roDevice(config)#snmp-server community public view default rw
- Passo 4:Configure o dispositivo para enviar os pacotes Trap para a estação de trabalho da rede (NMS) ativamente e use o nome da comunidade como público.
#Configurar dispositivo.
Device(config)#snmp-server enable trapsDevice(config)#snmp-server host 129.255.140.1 traps community public version 2
A versão SNMP especificada no snmp-server O comando host deve ser consistente com a versão do SNMP em execução no NMS.
- Passo 5:Configurar NMS.
#No NMS usando SNMP v1/v 2c, precisamos definir “nome da comunidade somente leitura” e “nome da comunidade leitura-gravação”. Além disso, também precisamos definir "tempo limite" e "tempos de repetição". O usuário consulta e configura o dispositivo via NMS.
Ao usar o nome da comunidade somente leitura, o usuário só pode consultar o dispositivo via NMS. Ao usar o nome da comunidade de leitura e gravação, o usuário pode consultar e configurar o dispositivo via NMS.
- Passo 6:Confira o resultado.
#NMS pode consultar e configurar alguns parâmetros do dispositivo através do nó MIB. O NMS pode receber várias informações de Trap do dispositivo, como interface para cima, para baixo do dispositivo, a mudança de rota causada pela oscilação da rede. O dispositivo gera as informações de Trap correspondentes e as envia ao NMS.
Configurar servidor proxy SNMP v3
Requisitos de rede
- Device é o dispositivo SNMP Agent e a rota com o servidor NMS é alcançável.
- O NMS gerencia o dispositivo via SNMPv3.
Topologia de rede

Figura 8 -4 Rede de configuração do servidor proxy SNMP v3
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido).
- Passo 3:Habilite o proxy SNMP no dispositivo e configure as informações básicas do SNMPv3.
#Configurar dispositivo.
Habilite o proxy SNMP; configure o nome da visualização do nó como padrão e ele poderá acessar todos os objetos no nó 1.3.6.1.
Device#configure terminalDevice(config)#snmp-server startDevice(config)#snmp-server view default1.3.6.1 include
Configure o grupo de usuários como público e o nível de segurança como authpriv; a visualização de leitura e gravação e a visualização de notificação usam o padrão; configurar o nome de usuário como public, pertencente ao grupo de usuários public, algoritmo de autenticação como MD5, senha de autenticação como admin, algoritmo de criptografia como DES e senha de criptografia como admin.
Device(config)#snmp-server group public v3 authpriv read default write default notify defaultDevice(config)#snmp-server user public public v3 auth md5 admin encrypt des admin
Configure o nome do texto como público.
Device(config)#snmp-server context public- Passo 4:Configurar NMS.
#No NMS usando SNMP v3, precisamos definir o nome de usuário e selecionar o nível de segurança. De acordo com diferentes níveis de segurança, precisamos definir o algoritmo de autenticação, senha de autenticação, algoritmo de criptografia, senha de criptografia e assim por diante. Além disso, também precisamos definir "tempo limite" e "tempos de repetição". O usuário consulta e configura o dispositivo via NMS.
- Passo 5:Confira o resultado.
# No NMS, podemos consultar e definir alguns parâmetros do Device através do nó MIB.
Configurar SNMP trap v3 Notificar
Requisitos de rede
- Device é o dispositivo SNMP Agent e a rota com o servidor NMS é alcançável.
- O NMS monitora o dispositivo via SNMPv3. Quando o dispositivo falha ou tem algo errado, ele reporta ativamente ao NMS.
Topologia de rede

Figura 8 -5 Rede de configuração de notificação de interceptação SNMPv3
Etapas de configuração
- Passo 1:Configure o endereço IP da interface. (Omitido).
- Passo 2:Habilite o proxy SNMP no dispositivo e configure as informações básicas do SNMPv3.
#Configurar dispositivo.
Habilite o proxy SNMP; configure o nome da visualização do nó como padrão e você poderá acessar todos os objetos no nó de acesso 1.3.6.1.
Device#configure terminalDevice(config)#snmp-server startDevice(config)#snmp-server view default 1.3.6.1 include
Configure o grupo de usuários como público, o nível de segurança como authpriv, a visualização de leitura e gravação e a visualização de notificação, todos usam o padrão; configurar nome de usuário como público, pertencente ao grupo de usuários público, algoritmo de autenticação como MD5, senha de autenticação como Admin, algoritmo de criptografia como DES e senha de criptografia como Admin.
Device(config)#snmp-server group public v3 authpriv read default write default notify defaultDevice(config)#snmp-server user public public v3 auth md5 Admin encrypt des Admin
Configure o dispositivo para enviar todas as informações do Trap.
Device(config)#snmp-server enable traps- Passo 3:Configure o dispositivo para enviar o pacote de interceptação SNMP v3 para o NMS.
#Configurar dispositivo.
Configure o nome de usuário do trap SNMP v3 como público no NSM e o nível de segurança como authpriv.
Device(config)#snmp-server host 129.255.140.1 version 3 user public authpriv- Passo 4:Configurar NMS .
#No NMS, é necessário configurar o nome de usuário e a senha consistentes com o proxy SNMP, executar o software de gerenciamento de rede e monitorar o número da porta UDP 162.
- Passo 5:Confira o resultado.
#NMS pode receber vários tipos de informações de Trap do dispositivo, como mudança de rota causada pela interface do dispositivo para cima e para baixo, flap de rede. O dispositivo irá gerar as informações de Trap correspondentes e enviá-las ao NMS.
Configurar SNMP v3 informar Notificar
Requisitos de rede
- Device é o dispositivo SNMP Agent e a rota com o servidor NMS é alcançável.
- O NMS monitora o dispositivo via SNMPv3. Quando o dispositivo falha ou tem algo errado, ele reporta ativamente ao NMS.
Topologia de rede
Figura 8 -6 Rede de configuração de notificação SNMPv3
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido).
- Passo 3:Habilite o proxy SNMP no dispositivo e configure as informações básicas do SNMPv3.
#Configurar dispositivo.
Habilite o proxy SNMP; configure o nome da visualização do nó como padrão e ele poderá acessar todos os objetos no nó 1.3.6.1.
Device#configure terminalDevice(config)#snmp-server startDevice(config)#snmp-server view default 1.3.6.1 include
Configure o grupo de usuários como group1 e o nível de segurança como authpriv; a visualização de leitura e gravação e a visualização de notificação usam o padrão.
Device(config)#snmp-server group group1 v3 authpriv read default write default notify defaultConfigure o grupo de usuários como user2, pertencente ao grupo de usuários group1, algoritmo de autenticação como MD5, senha de autenticação como admin, algoritmo de criptografia como DES e senha de criptografia como admin.
Device(config)#snmp-server user user2 group1 public v3 auth md5 admin encrypt des adminConfigure o nome do texto como público.
Device(config)#snmp-server context public- Passo 4:Configure o dispositivo para enviar uma mensagem de notificação ao NMS.
#Configurar dispositivo.
Configure o endereço IP e o ID do mecanismo do usuário remoto, ou seja, NMS.
Device(config)#snmp-server engineID remote 129.255.140.1 162 bb87654321Configure o nome de usuário remoto como user1, pertencente ao grupo de usuários group1, algoritmo de autenticação como MD5, senha de autenticação como admin, algoritmo de criptografia como DES e senha de criptografia como admin.
Device(config)#snmp-server user user1 group1 remote 129.255.140.1 162 v3 auth md5 adminencrypt des adminConfigure o nome do parâmetro de endereço local como param-user1; configure o nome do endereço de destino como target-user1; use o parâmetro de endereço param-user1; o nome da lista de endereços de destino é target-user1.
Device(config)#snmp-server AddressParam param-user1 v3 user1 authprivDevice(config)#snmp-server TargetAddress target-user1 129.255.140.1 162 param-user1 tag-user1 10 3
Configure a entidade de notificação como notify-user1; configurar a entidade filtro de notify como filter-user1, contendo a notificacao de todos os objetos do nodo 1.3.6.1; configure a tabela de configuração de notificação e deixe a entidade de filtro fileter-user1 se associar ao parâmetro de endereço param-user1.
Device(config)#snmp-server notify notify notify-user1 tag-user1 informDevice(config)#snmp-server notify filter filter-user1 1.3.6.1 includeDevice(config)#snmp-server notify profile filter-user1 param-user1
- Passo 5:Configurar NMS.
#Você precisa definir o nome de usuário e selecionar o nível de segurança ao usar o NMS da versão SNMP V3. De acordo com os diferentes níveis de segurança, é necessário definir o algoritmo de autenticação, senha de autenticação, algoritmo de criptografia, senha de criptografia, etc., e monitorar a porta UDP número 162.
- Passo 6:Confira o resultado.
#NMS pode receber várias informações de Trap do Dispositivo, como interface up, down of Device, a mudança de rota causada pela oscilação da rede. O dispositivo gera as informações de Trap correspondentes e as envia ao NMS.
Configurar o encaminhamento de proxy SNMP v3
Requisitos de rede
- A rota do Device2 para o servidor NMS é alcançável.
- Device2 é o agente do dispositivo proxy; Device1 é o dispositivo delegado.
- Em Device1 e Device2, execute SNMPv3.
- No NMS, execute SNMPv3. O NMS gerencia Device1 e Device2 via SNMP v3.
Topologia de rede

Figura 8 -7 Rede de configuração do encaminhamento de proxy SNMP v3
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido) .
- Passo 3:No dispositivo proxy Device2, habilite o proxy SNMP e configure as informações básicas do SNMPv3.
#Configurar dispositivo2.
Habilite o proxy SNMP; configure o nome da visualização do nó como padrão e ele poderá acessar todos os objetos no nó 1.3.6.1.
Device2#configure terminalDevice2(config)#snmp-server startDevice1(config)#snmp-server view default 1.3.6.1 include
Configure o grupo de usuários como group-local e o nível de segurança como authpriv ; a visualização de leitura e gravação e a visualização de notificação usam o padrão; configurar o nome de usuário como user1, pertencente ao grupo de usuários group-local, algoritmo de autenticação como MD5, senha de autenticação como proxy, algoritmo de criptografia como DES e senha de criptografia como proxy.
Device1(config)#snmp-server group group-local v3 authpriv read default write default notify defaultDevice1(config)#snmp-server user user1 group-local v3 auth md5 admin encrypt des admin
- Passo 4:No dispositivo delegado Device1, habilite o proxy SNMP e configure a visualização SNMP.
#Configurar dispositivo1.
Device1#configure terminalDevice1(config)#snmp-server startDevice1(config)#snmp-server view default 1.3.6.1 include
- Passo 5:Configure as informações do dispositivo delegado no dispositivo proxy Device2.
#Configurar dispositivo2.
Configure o endereço IP e o ID do mecanismo do dispositivo delegado.
Device2(config)#snmp-server engineID remote 150.1.2.2 161 800016130300017a000137Configure o grupo de usuários do dispositivo delegado como grupo-usuário, nível de segurança como authpriv; tanto a visualização de leitura quanto a visualização de notificação usam o padrão.
Device2(config)#snmp-server group group-user v3 authpriv read default write default notify defaultConfigure o nome de usuário como re-usuário, pertencente ao grupo de usuários group-user, algoritmo de autenticação como MD5, senha de autenticação como admin, algoritmo de criptografia como DES e senha de criptografia como admin.
Device2(config)#snmp-server user re-user group-user remote 150.1.2.2 161 v3 auth md5 admin encrypt des adminConfigure o nome do parâmetro de endereço local como plocal e o nome do parâmetro de endereço remoto como pusher; configure o nome do endereço de destino como tuser e use o parâmetro de endereço puuser.
Device2(config)#snmp-server AddressParam plocal v3 user1 authprivDevice2(config)#snmp-server AddressParam puser v3 re-user authprivDevice2(config)#snmp-server TargetAddress tuser 150.1.2.2 161 puser taguser 10 2
Configure o nome de encaminhamento de proxy como proxy-re-user, a autoridade de operação como write , o engin e ID do dispositivo delegado como 800016130300017a000137, o parâmetro de endereço usado plocal, o endereço de destino usado tuser; configure o nome do contexto como proxyuser.
Device2(config)#snmp-server proxy proxy-re-user write 800016130300017a000137 plocal tuser proxyuserDevice2(config)#snmp-server context proxyuser
#Visualize as informações de ID do motor do Device2 .
Device2#show snmp-server engineIDLocal engine ID: 80001613030000000052fdIPAddress: 150.1.2.2 remote port: 161 remote engine ID: 800016130300017a000137
O ID do mecanismo do dispositivo remoto deve ser consistente com o dispositivo delegado. O motor e ID do dispositivo pode ser visualizado através do show servidor SNMP ID do motor comando. O protocolo de monitoramento do dispositivo delegado é UDP e a porta é 161.
- Passo 6:Execute a configuração relacionada do SNMPv3 no dispositivo delegado Device1.
#Configurar dispositivo1.
Configure o grupo de usuários como g1 e o nível de segurança como authpriv; a visualização de leitura e gravação e a visualização de notificação usam o padrão; configure o nome de usuário como re-usuário, algoritmo de autenticação como MD5, senha de autenticação como admin, algoritmo de criptografia como DES e senha de criptografia como admin.
Device1(config)#snmp-server group g1 v3 authpriv read default write default notify defaultDevice1(config)#snmp-server user re-user g1 v3 auth md5 admin encrypt des adminDevice1(config)#snmp-server context proxyuser
- Passo 7:Configurar NMS.
#SNMP v3 adota o mecanismo de segurança de autenticação e criptografia. No NMS, precisamos definir o nome de usuário e selecionar o nível de segurança. De acordo com diferentes níveis de segurança, precisamos definir o algoritmo de autenticação, senha de autenticação, algoritmo de criptografia, senha de criptografia e assim por diante. Além disso, também precisamos definir "tempo limite" e "tempos de repetição". O usuário pode consultar e configurar o dispositivo via NMS. Quando for necessário consultar ou configurar o dispositivo delegado, também precisamos definir o engin e ID do encaminhamento de proxy como o engin e ID do dispositivo delegado no NMS.
- Passo 8:Confira o resultado.
#No NMS, podemos consultar e definir alguns parâmetros de Device2 e Device1 através do nó MIB.
RMON
Visão geral
Uma função importante do gerenciamento de rede é monitorar o desempenho dos elementos da rede. No modo de gerenciamento de rede SNMP tradicional, a iniciativa do gerenciamento é dominada principalmente pela estação de gerenciamento de rede. Normalmente, a estação de trabalho de gerenciamento de rede consulta regularmente os dados do dispositivo e, em seguida, mede e analisa no sistema de gerenciamento de rede, para obter as informações desejadas do administrador. Nesse modo, a estação de trabalho de gerenciamento de rede precisa enviar e receber muitos pacotes para os dispositivos de rede. Quando há muitos dispositivos na rede, isso causa a carga adicional para a rede. Enquanto isso, o bloqueio de rede e outros fatores levam vários acidentes ao funcionamento do sistema de gerenciamento de rede. Para isso, apresentamos o conceito RMON (Remote Network Monitoring).
A realização do RMON ainda precisa do suporte do protocolo SNMP. Na verdade, é um grupo de MIBs, distribuído no MIB-2, e o ID do objeto é 1.3.6.1.2.1.16. Comparado com outras MIBs gerais, o RMON adiciona o cálculo no Agente durante a realização, ou seja, coloca o processamento, como estatísticas de desempenho no dispositivo. Isso realiza o processamento distribuído em toda a rede, reduzindo as desvantagens trazidas pelo polling da estação de trabalho de gerenciamento da rede.
O RMON precisa realizar muitas funções de cálculo, então o proxy RMON anterior (também chamado de Probe) é acionado por um dispositivo especial, distribuído na rede para monitorar o alvo correspondente. Com a melhoria da capacidade de processamento do dispositivo de rede, o RMON é gradualmente integrado aos dispositivos de rede, de modo a realizar o requisito RMON com alta eficiência. No entanto, isso também apresenta requisitos de desempenho mais altos para os dispositivos de rede . Afinal, os cálculos do RMON ocupam muitos recursos do sistema, reduzindo o desempenho do sistema . Este é também o custo adicional trazido pelo gerenciamento, então o RMON é realizado principalmente no hardware com capacidade de processamento de rede, como chip de comutação.
RMON MIB tem 10 grupos:
- estatísticas: Meça todas as interfaces Ethernet do dispositivo, como broadcast e conflito;
- histórico: Registre as amostras das informações estatísticas periódicas que são retiradas do grupo de estatísticas;
- alarme: permite que o usuário do console de administração configure o intervalo de amostragem e o alarme quando os valores de quaisquer contadores ou inteiros (registrados pelo proxy RMON) excederem o valor limite;
- host: Inclua os tráfegos de entrada/saída de vários tipos de hosts aderentes à sub-rede;
- hostTopN: Contém as informações de estatísticas armazenadas dos hosts, alguns parâmetros nas tabelas de hosts desses hosts são os mais altos;
- matriz: Indique as informações de erro e utilização na forma de matriz, para que o operador possa utilizar qualquer par de endereços para buscar as informações;
- filtro: permite que o monitor monitore os pacotes combinados com o filtro;
- capture: Os grupos capturados configuram um grupo de área de buffer, usado para armazenar os grupos capturados do canal.
- event: Apresenta a tabela de todos os eventos gerados pelo proxy RMON;
- tokenRing: mantém as informações estatísticas e de configuração de uma sub-rede que é um token ring
Configuração da Função RMON
Tabela 9 -1 lista de configuração da função RMON
| Tarefa de configuração | |
| Habilite a função RMON | Habilite a função RMON |
| Configurar o grupo de alarme RMON | Configurar a instância de alarme RMON |
| Configurar o grupo de eventos RMON | Configurar o evento de disparo RMON |
| Configurar o grupo de histórico do RMON | Configurar a instância do grupo de histórico do RMON |
| Configurar o grupo de estatísticas RMON | Configurar a função de gerenciamento de estatísticas RMON |
Ativar função RMON
Condição de configuração
Nenhum
Ativar função RMON
Ativar o RMON é fornecer o recurso relacionado para a função de monitoramento do RMON. As fontes podem entrar em vigor somente após a configuração da função do grupo de monitoramento RMON.
Tabela 9 -2 Habilitar a função RMON
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função RMON | rmon | Obrigatório |
Configurar grupo de alarme RMON
A função de grupo de alarme RMON significa configurar vários alarmes e cada alarme monitora uma instância de alarme. Dentro do intervalo de amostragem, quando o valor dos dados da instância do alarme for alterado e exceder o limite crescente ou o limite decrescente, acione o evento de alarme. De acordo com o modo de processamento definido pelo grupo de eventos de alarme, processe os alarmes. Quando o valor dos dados exceder o limite continuamente, alarme somente para o primeiro excesso.
Condição de configuração
Antes de configurar o grupo de alarme RMON, primeiro complete a seguinte tarefa:
- Habilite a função de proxy SNMP
- Habilite a função TRAP do RMON no SNMP
Configurar instância de alarme RMON
Tabela 9 -3 Configurar a instância de alarme RMON
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função RMON | rmon | Opcional |
| Configurar o grupo de alarme RMON | rmon alarm alarm-num OID interval { absolute | delta } risingthreshold rising-threshold [ rising-event ] fallingthreshold falling-threshold [ falling-event ] [ owner owner ] | Obrigatório Por padrão, o grupo de eventos de disparo de alarme é 1. Por padrão, o proprietário do grupo de alarmes é config. |
Configurar Grupo de Alarme Estendido RMON
O grupo de alarme estendido RMON pode calcular a variável de alarme e, em seguida, comparar o resultado do cálculo com o valor de limite definido, realizando a função de alarme mais rica.
Condição de configuração
Antes de configurar o grupo de alarme RMON, primeiro complete a seguinte tarefa:
- Habilite a função de proxy SNMP
- Habilite a função TRAP do RMON no SNMP
- Configurar um grupo de estatísticas
Configurar Grupo de Alarme Estendido RMON
Tabela 9 -4 Configurar o grupo de alarme estendido RMON
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função RMON | rmon | Opcional |
| Configurar um grupo de estatísticas | rmon statistics ethernet statistics-num OID [ owner owner ] | Mandatório Por padrão, o proprietário do grupo de estatísticas é config. |
| Configurar grupo de alarme RMON | rmon prialarm alarm-num WORD interval { absolute | delta } risingthreshold rising-threshold rising-event fallingthreshold falling-threshold falling-event entrytype forever [ ownerowner ] | Obrigatório Por padrão, o proprietário do grupo de alarmes é config. |
Configurar grupo de eventos RMON
Configurar a função do grupo de eventos RMON significa configurar vários eventos, definindo o número de série do evento e o modo de processamento de cada evento. O evento possui os seguintes modos de processamento: O evento é registrado no log; o evento envia a mensagem TRAP para o sistema de gerenciamento de rede; registre o evento no log e envie a mensagem TRAP para o sistema de gerenciamento de rede, mas não processe.
Condição de configuração
Antes de configurar o grupo de eventos RMON, primeiro conclua a seguinte tarefa:
- Habilite a função de proxy SNMP
- Habilite a função TRAP do RMON no SNMP
Configurar evento de disparo RMON
O evento de disparo RMON é usado principalmente para processar os eventos quando o alarme RMON acontece.
Tabela 9 -5 Configurar o evento de disparo RMON
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função RMON | rmon | Opcional |
| Configurar o grupo de eventos RMON | rmon event event-num [ description event-description / log max-num / owner owner / trap communit ] | Obrigatório Por padrão, o proprietário do grupo de eventos é config. |
Configurar evento de histórico do RMON
Configurar a função do grupo de histórico do RMON significa configurar vários grupos de histórico. O grupo de histórico RMON armazena os dados de sub-rede obtidos por amostragem com intervalo fixo. O grupo compreende a tabela de controle do histórico e os dados do histórico. A tabela de controle define o número de série da interface de sub-rede amostrada, o intervalo de amostragem e muitos dados a serem amostrados a cada vez, enquanto a tabela de dados é usada para armazenar os dados obtidos durante a amostragem.
Condição de configuração
Antes de configurar o grupo de histórico do RMON, primeiro conclua a seguinte tarefa:
- Habilite a função de proxy SNMP
Configurar a instância do grupo de histórico RMON
O grupo de histórico do RMON configura principalmente o objeto de monitor da tabela de controle de histórico, intervalo de amostragem, muitos dados a serem amostrados e assim por diante.
Tabela 9 -6 Configurar a instância do grupo de histórico RMON
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função RMON | rmon | Opcional |
| Configurar o grupo de histórico do RMON | rmon history control history-num OID buckets-num [ interval interval ] [ owner owner ] | Obrigatório Por padrão, o intervalo de amostragem é 1800s. Por padrão, o proprietário do grupo de histórico é config. |
Configurar grupo de estatísticas RMON
Configurar a função do grupo de estatísticas RMON é configurar o objeto monitor como as informações estatísticas da interface Ethernet. O grupo de estatísticas fornece uma tabela e cada linha da tabela indica as informações estatísticas de uma sub-rede. O administrador de rede pode obter várias informações estatísticas de um segmento da tabela (o tráfego de um segmento, a distribuição de vários tipos de pacotes, vários tipos de pacotes de erro e o número de colisões e assim por diante).
Condição de configuração
Antes de configurar o grupo de estatísticas RMON, primeiro conclua a seguinte tarefa:
- Habilite a função RMON
- Habilite a função de proxy SNMP
Configurar a função de gerenciamento de estatísticas
Tabela 9 -7 Configurar a função de gerenciamento de estatísticas RMON
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função RMON | rmon | Obrigatório |
| Configurar o grupo de estatísticas RMON | rmon statistics ethernet statistics-num OID [ owner owner ] | Obrigatório Por padrão, o proprietário do grupo de estatísticas é config. |
RMON Monitoramento e Manutenção
Tabela 9 -8 Monitoramento e Manutenção de RMON
| Comando | Descrição |
| show rmon alarm | Exibe os alarmes RMON configurados no dispositivo |
| show rmon alarm supportVariable | Exibir os objetos de monitor suportados no dispositivo |
| show rmon event | Exibe o evento RMON configurado no dispositivo |
| show rmon history { control | ethernet control-num } | Exiba o grupo de histórico RMON configurado no dispositivo |
| show rmon prialarm | Exibe o alarme estendido RMON configurado no dispositivo |
| show rmon statistics ethernet | Exiba o grupo de estatísticas RMON configurado no dispositivo |
Exemplo de configuração típica de RMON
Configurar funções básicas do RMON
Requisitos de rede
- Device é o dispositivo proxy RMON e a rota com o servidor NMS é alcançável;
- Monitore e gerencie os grupos de eventos, grupos de alarmes, grupos de histórico e grupos de estatísticas do RMON via NMS.
Topologia de rede

Figura 9 -1 Rede de configuração das funções básicas do RMON
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente. (Omitido)
- Passo 2:Configure o endereço IP da interface. (Omitido)
- Passo 3:Configure o proxy SNMP.
#Ative o proxy SNMP e configure o nó de visualização do nó como padrão e o nome da comunidade somente leitura como público.
Device#configure terminalDevice(config)#snmp-server startDevice(config)#snmp-server view default 1.3.6.1 includeDevice(config)#snmp-server community public view default ro
#Ative a função SNMP Trap e configure o endereço de destino e o nome de comunidade usado do pacote Trap.
Device(config)#snmp-server enable trapsDevice(config)#snmp-server host 129.255.151.1 traps community public
- Passo 4:Configure o grupo de eventos RMON, grupo de alarmes, grupo de histórico e grupo de estatísticas do dispositivo.
#Ative o proxy RMON.
Device(config)#rmon#Configure o número de série do grupo de eventos como 1 e registre os pacotes de entrada da porta gigabitethernet0/1.
Device(config)#rmon event 1 description gigabitethernet0/1_in_octes log 100 trap public#Configurar o grupo de eventos de alarme; o objeto do monitor é ifInOctets.1; configurar a amostragem do valor relativo; o intervalo de amostragem é de 10s. Configure o limite crescente e decrescente como 100; configure o evento acionado de atingir o valor limite como event1.
Device(config)#rmon alarm 1 ifInOctets.1 10 delta risingthreshold 100 1 fallingthreshold 100 1 owner 1#Configure o grupo de estatísticas RMON.
Device(config)#rmon statistics ethernet 1 ifIndex.1#Configure o grupo de histórico do RMON.
Device(config)#rmon history control 1 ifIndex.1 10 A porta correspondente do índice de instância ifInOctets.1 é g ig abitethernet0/1 no dispositivo. Você pode usar o comando show interface switchport snmp ifindex para exibir os valores de índice snmp de todas as portas L2; o comando show interface snmp ifindex exibe o valor do índice snmp de todas as portas L3; o comando show interface switchport XXXX snmp ifindex exibe o valor de índice snmp da porta L2 especificada; o comando show interface XXXX snmp ifindex exibe o valor do índice snmp da porta L3 especificada. O índice de instância de objeto monitorado remoto precisa ser lido na tabela de interface ifEntry do MIB-2.
- Passo 5:Configurar NMS.
#No NMS usando SNMP v1/v 2c, precisamos definir “Nome da comunidade somente leitura”, “tempo limite” e “Tempos de repetição”.
- Passo 6:Confira o resultado.
# Visualize a configuração de entrada do grupo de eventos RMON do dispositivo.
Device#sh rmon eventEvent 1 is active, owned by configDescription : gigabitethernet_0/1_in_octesEvent firing causes: log and trap, last fired at 11:38:07Current log entries:logIndex logTime Description----------------------------------------------------------------1 11:38:07 gigabitethernet_0/1_in_octes
# Configure a configuração de entrada de alarme RMON do dispositivo.
Device#show rmon alarmAlarm 1 is active, owned by 1Monitoring variable: ifInOctets.1, Sample interval: 10 second(s)Taking samples type: delta, last value was 4225 Rising threshold : 100, assigned to event: 1 Falling threshold : 100, assigned to event: 1
# Configure a configuração de entrada do grupo de estatísticas RMON do dispositivo.
Device#sh rmon statistics ethernet-------------------------------Ethernet statistics table information:Index: 1Data Source: ifIndex.1Owner: configStatus: Valid------------------------------ifIndex.1 statistics information:------------------------------DropEvents:0Octets: 26962295Pkts:252941BroadcastPkts:156943MulticastPkts:62331CRCAlignErrors:51UndersizePkts:0OversizePkts:0Fragments:0Jabbers:0Collisions:0Pkts64Octets:167737Pkts65to127Octets:47962Pkts128to255Octets:22497Pkts256to511Octets:9967Pkts512to1023Octets:4032Pkts1024to1518Octets:745
# Visualize a configuração de entrada do grupo de histórico RMON do dispositivo.
Device#show rmon history control----------------------------------RMON history control entry index: 1Data source: IfIndex.1Buckets request: 10Buckets granted: 2Interval: 1800Owner: configEntry status: Valid----------------------------------
#NMS pode consultar as informações de histórico, eventos e estatísticas no dispositivo via MIB.
O NMS pode receber as informações de interceptação do evento de alarme do dispositivo. Por exemplo, quando a taxa de alteração do tráfego de entrada da interface do monitor é maior que o limite crescente ou menor que o limite decrescente, o dispositivo gera as informações de interceptação correspondentes e as envia para o NMS.
CWMP
Visão geral
CWMP (CPE WAN Management Protocol) é um protocolo desenvolvido pela BroadBandForum.org para gerenciar e configurar o CPE (Customer Premise Equipment), também chamado de TR-069. Ele define o quadro de protocolo geral, padrão de mensagem, modo de gerenciamento e modelo de dados para gerenciar o CPE que se conecta à rede de acesso de banda larga à Internet da operadora.
O CWMP pode ser descrito como um modelo de quadro de dados, que descreve a comunicação entre o dispositivo como roteador de banda larga e o ACS (Auto-Configuration Server). Ele é usado para executar a configuração e o gerenciamento centralizados remotos do CPE (como roteador de banda larga, switch, dispositivo de gateway de Internet e STB) do lado do usuário.
CWMP protocolo é um protocolo da camada de aplicação acima da camada IP. Este protocolo pode ser aplicado amplamente e não tem restrição quanto ao modo de acesso. CPEs baseados nos seguintes modos de acesso, como ADSL- ( Asymmetrical Dig 2w ital Subscriber Loop ), rede Ethernet e PON ( Passive Optical Network) , podem utilizar este protocolo. A arquitetura do sistema baseada no TR069 é mostrada na Figura 10-1 . A arquitetura de ponta a ponta do protocolo CWMP possui os seguintes recursos:
- Com o modelo de conexão elástica, tanto o CPE quanto o ACS podem acionar o estabelecimento da conexão. Isso evita manter a conexão entre o CPE e o ACS.
- Ele pode ser descoberto automaticamente entre o CPE e o ACS .
- O ACS pode configurar e monitorar dinamicamente o CPE .
Figura 11 -1 Arquitetura CPE e ACS
Para o CPE, o CWMP conclui principalmente os quatro aspectos de trabalho a seguir:
- Configure o CPE automaticamente e configure o serviço dinâmico . Para o ACS , cada CPE pode se marcar no protocolo , como modelo e versão. De acordo com a regra definida, o ACS pode enviar a configuração para um determinado CPE ou para um grupo de CPEs . O CPE pode solicitar automaticamente as informações de configuração do ACS quando é ligado e o ACS pode iniciar ativamente a configuração a qualquer momento . Através desta função, ele pode alcançar a função "instalação de configuração zero" do CPE ou controlar a mudança dinâmica do parâmetro de serviço do lado da rede.
- Gerencie o arquivo de versão e o arquivo de configuração do CPE . O CWMP fornece o gerenciamento e download para o arquivo de versão e arquivo de configuração no CPE . O ACS pode identificar o número da versão do dispositivo do usuário e determinar se deve atualizar remotamente a versão do software do dispositivo. O ACS pode saber se a atualização foi bem-sucedida após a conclusão da atualização. O CPE pode fazer backup através do upload do arquivo de configuração e recuperar através do download do arquivo de configuração sob o controle do ACS .
- Configure a atualização remota para o CPE . É uma função iniciada pelo ACS para configurar a atualização remota para o CPE. Atualmente, o ACS executa a atualização remota à configuração do CPE no modo hierárquico.
- Alcance o gerenciamento seguro da interface do dispositivo. Através do modo RPC definido pelo CWM (remote process invoking) , ele pode realizar o gerenciamento seguro da interface do dispositivo, incluindo a desativação , ativação, ligação automática, desvinculação automática, interface 802.1x e desativação da função 802.1x
Certifique-se de que o dispositivo com Flash como 16M não desligue ou reinicialize ao atualizar a versão usando o CWMP e assegure a correção da versão de atualização. Caso contrário, o sistema pode não ser inicializado.
Quando o dispositivo funciona no modo VST, o dispositivo não suporta a função CWMP.
Configuração da função CWMP
Tabela 11 -1 lista de configuração da função CWMP
| Tarefa de configuração | |
| Configurar a função básica do CWMP |
Entre no modo de configuração CWMP
Habilite o proxy CWMP Configurar as informações relacionadas ao servidor ACS Configurar a interface do dispositivo WAN Configure o CWMP para enviar periodicamente o pacote INFORM Configure o per i od do CWMP enviando o pacote INFORM Configurar o download do arquivo CWMP Configure a função de retomada do ponto de interrupção do arquivo CWMP Configure o código de provisão do CWMP |
| Configure a função de autenticação e criptografia CWMP |
Configurar as informações de autenticação CWMP
Configure o certificado ACS do CWMP Configure a impressão digital do certificado ACS do CWMP |
| Configurar a função estendida CWMP | Configure o endereço IP especificado do CWMP Configurar o backup do link CWMP |
Configurar a função básica do CWMP
Condição de configuração
Antes de configurar a função básica do proxy CWMP, primeiro entre no modo de configuração global e, em seguida, configure a função básica do proxy CWMP.
Entre no modo de configuração do CWMP
Para a configuração relacionada ao proxy CWMP , primeiro entre no modo de configuração do proxy CWMP .
Tabela 11 -2 Entre no modo de configuração CWMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do proxy CWMP | cwmp agent | Obrigatório |
Ativar proxy CWMP
Se o dispositivo estiver habilitado com a função de proxy CWMP, o dispositivo poderá interagir com o CS por meio do proxy CWMP para configurar e gerenciar remotamente o dispositivo.
Tabela 11 -3 Habilitar o proxy CWMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do proxy CWMP | cwmp agent | Obrigatório |
| Habilite o proxy CWMP | enable | Obrigatório Por padrão, o proxy CWMP está no estado desabilitado. |
Configurar informações relacionadas ao servidor ACS
Ao configurar as informações relacionadas ao ACS, incluindo o endereço de conexão do servidor ACS, o dispositivo pode se comunicar com o servidor ACS.
Tabela 11 -4 Configurar as informações relacionadas ao servidor ACS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do proxy CWMP | cwmp agent | Obrigatório |
| Habilite o proxy CWMP | enable | Obrigatório Por padrão, o proxy CWMP está no estado desabilitado. |
| Configurar informações relacionadas ao ACS | management server url url-string | Obrigatório Por padrão, o dispositivo não está configurado com o parâmetro relacionado ao ACS . Para o modo não criptografado, url-string usa o http protocolo . Para o modo de criptografia, url-string usa o protocolo https . |
| Configure o nome de usuário do dispositivo que inicia a conexão com o ACS | management server user-name |
Opcional
Por padrão , o dispositivo não está configurado com o parâmetro relacionado ao ACS . Se o nome de usuário não estiver configurado no ACS , não é necessário configurar o nome de usuário. |
| Configure o nome de usuário e a senha correspondente do dispositivo que inicia a conexão com o ACS | management server password |
Opcional
Por padrão , o dispositivo não está configurado com o parâmetro relacionado ao ACS . Se o nome de usuário e a senha correspondente não estiverem configurados no ACS , não é necessário configurar o nome de usuário e a senha. |
Configurar interface de dispositivo WAN
Especifique a interface como a interface de dispositivo WAN padrão no modo de interface. Se o dispositivo WAN padrão não for especificado, isso fará com que o proxy CWMP não possa enviar o pacote Informar para conectar o servidor ACS .
Tabela 11 -5 Configurar a interface do dispositivo WAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre na interface L3 a ser usada | interface interface-name | Obrigatório Deve ser configurado no modo de interface L3. |
| Configurar o dispositivo WAN padrão | cwmp wan default | Obrigatório Por padrão, a interface do dispositivo WAN do proxy CWMP não é especificada. |
Se o dispositivo WAN padrão não for especificado, pode fazer com que o CWMP não possa enviar o pacote Informar para conectar o ACS. Deve ficar claro o nome do parâmetro e o endereço IP do dispositivo WAN conectado à Internet no sistema atual ao organizar o pacote Inform. Depois que uma interface for especificada como o dispositivo WAN padrão, se o endereço IP da WAN não estiver configurado no modo CWMP e a interface estiver configurada com o endereço IP, a URL de solicitação de conexão será gerada usando o endereço IP da interface.
Configure o CWMP para enviar periodicamente o pacote INFORM
Configurando o CWMP para enviar periodicamente o pacote Inform , o dispositivo pode enviar periodicamente o pacote Inform ao ACS . Após o ACS receber o pacote Inform enviado pelo dispositivo, manipule o pacote com base na pré-configuração.
Tabela 11 -6 Configure o CWMP para enviar periodicamente o pacote INFORM
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do proxy CWMP | cwmp agent | Obrigatório |
| Habilite o proxy CWMP | enable | Obrigatório Por padrão, o proxy CWMP está desabilitado. |
| Configure o CWMP para enviar periodicamente o pacote INFORM | enable inform | Obrigatório Por padrão, a função do CWMP que envia periodicamente a função INFORM está habilitada. |
Configurar o período de envio do pacote INFORM CWMP
Após configurar o CWMP para enviar periodicamente o pacote INFORM, você pode configurar o período do proxy CWMP enviando o pacote Inform. O período de envio padrão é 43200s (12h).
Tabela 11 -7 Configure o periodo do CWMP enviando o pacote INFORM
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração CWMP | cwmp agent | Obrigatório |
| Habilite o proxy CWMP | enable | Obrigatório Por padrão, o proxy CWMP está desabilitado. |
| Configure o CWMP para enviar periodicamente o pacote INFORM | enable inform | Obrigatório Por padrão, a função do CWMP que envia periodicamente o pacote INFORM está habilitada, |
| Configure o per i od do CWMP enviando o pacote INFORM | inform interval inform-interval | Obrigatório Por padrão, o intervalo para o dispositivo que envia automaticamente o pacote de informações é 43200s. |
Após configurar a função do proxy CWMP que envia o pacote Inform e não configurar o período de envio do pacote Inform , o CWMP envia o pacote Inform ao ACS em 43200 s (12h) por padrão. Depois que o intervalo de envio periódico do pacote Inform for modificado, o intervalo modificado só poderá entrar em vigor quando o último intervalo expirar. Se você quiser que o intervalo modificado entre em vigor imediatamente , você pode reinicializar o proxy CWMP . W aqui, para habilitar e não habilitar , consulte o capítulo relacionado no CWMP manual de comando .
Configurar download do arquivo CWMP
Quando a função do proxy CWMP que suporta o download do arquivo for necessária para baixar o arquivo de versão e o arquivo de configuração , configure a função de download do arquivo proxy CWMP com antecedência.
Tabela 11 -8 Configurar o download do arquivo CWMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do proxy CWMP | cwmp agent | Obrigatório |
| Habilite o proxy CWMP | enable | Obrigatório Por padrão, o proxy CWMP está desabilitado. |
| função de download do arquivo CWMP | enable download | Obrigatório Por padrão, a função de download de arquivo do CWMP não está habilitada. |
Configurar a função de resumo do ponto de interrupção do arquivo CWMP
Depois que a função de download do arquivo CWMP for configurada e o CWMP for necessário para dar suporte à função de retomada do ponto de interrupção, você poderá configurar a função.
Tabela 11 -9 Configure a função de retomada do ponto de interrupção do arquivo CWMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do proxy CWMP | cwmp agent | Obrigatório |
| Habilite o proxy CWMP | enable | Obrigatório Por padrão, o proxy CWMP está desabilitado. |
| Configure a função de download do arquivo CWMP | enable download | Obrigatório Por padrão, a função de download de arquivo do CWMP não está habilitada. |
| Configure a função de retomada do ponto de interrupção do arquivo CWMP | enable download resume | Obrigatório Por padrão, a função de retomada do ponto de interrupção do arquivo do CWMP não está habilitada. |
Antes que a função de retomada do ponto de interrupção do arquivo CWMP seja configurada, a função de download de arquivo do CWMP deve ser configurada. Se a função de download de arquivo não estiver configurada inicialmente, a função de retomada do ponto de interrupção do arquivo não terá efeito mesmo se a função de retomada de arquivo estiver configurada.
Configurar código de provisão CWMP
Esta função é usada para configurar o CWMP código de provisão que é usado para marcar as informações básicas de serviço fornecidas pelo CWMP .
Tabela 11 -10 Configurar CWMP código de provisão
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do proxy CWMP | cwmp agent | Obrigatório |
| Habilite o proxy CWMP | enable | Obrigatório Por padrão, o proxy CWMP está desabilitado. |
| Configurar o código de provisão CWMP | provision code provision-code | Obrigatório Por padrão, o CWMP não está configurado com o código de provisão. |
Configurar autenticação CWMP e função de criptografia
Condição de configuração
Antes de configurar a função de autenticação e criptografia CWMP, primeiro conclua a seguinte tarefa:
- A configuração básica do proxy CWMP é concluída, incluindo a configuração de habilitação do proxy CWMP e a configuração de informações ACS do proxy CWMP .
- Ao configurar a função de criptografia , prepare o certificado e ele requer importação manual.
Configurar a função de autenticação CWMP
Quando o ACS requer iniciar a conexão com o dispositivo, configure o proxy CWMP para autenticar a solicitação de conexão enviada do ACS em termos de segurança.
Tabela 11 -11 Configurar a função de autenticação CWMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do proxy CWMP | cwmp agent | Obrigatório |
| Habilite o proxy CWMP | enable | Obrigatório Por padrão, o proxy CWMP está desabilitado. |
| Configure o nome de usuário para o CPE que autentica o pedido de conexão do ACS | connection request username user-name | Obrigatório Por padrão, o nome de usuário não está configurado. |
| Configure a senha para o CPE que autentica o pedido de conexão do ACS | connection request password password | Obrigatório Por padrão, a senha não está configurada. |
Configurar nome de domínio de confiança CWMP PKI
Visualizando a partir da segurança, quando o dispositivo se conecta ao ACS através do modo HTTPS, você precisa especificar o nome de domínio de confiança do KPI do proxy CWMP, para verificar a validade do certificado ACS.
Tabela 11 -12 Configurar o CWMP Certificado ACS
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do proxy CWMP | cwmp agent | Obrigatório |
| Habilite o proxy CWMP | enable | Obrigatório Por padrão, o proxy CWMP está desabilitado. |
| Configurar o nome de domínio de confiança do KPI do proxy CWMP | secure-identity ca-name | Obrigatório Por padrão, o proxy CWMP não tem o nome de domínio de confiança do KPI. |
Configurar a função estendida CWMP
Condição de configuração
Antes de configurar a função estendida do CWMP , primeiro conclua as seguintes tarefas:
- Conclua as configurações básicas do CWMP , incluindo a configuração de habilitação do proxy CWMP, a configuração de informações do proxy CWMP ACS .
- Configure o endereço IP da interface para permitir que as camadas de rede dos nós vizinhos sejam alcançáveis.
- Quando a função de backup do link é necessária, a interface configurada como backup deve estar normal, incluindo o endereço IP configurado e a interface no estado UP .
Configurar o endereço IP de origem especificado do CWMP
Quando o endereço IP de origem é configurado, o ACS pode se comunicar diretamente com o endereço IP especificado.
Tabela 11 -13 Configurar o endereço IP de origem especificado pelo CWMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração do proxy CWMP | cwmp agent | Obrigatório |
| Habilite o proxy CWMP | enable | Obrigatório Por padrão, o proxy CWMP está desabilitado. |
| Configure o endereço IP de origem especificado pelo proxy CWMP | ip source ip-address | Obrigatório Por padrão, o endereço IP de origem do pacote não é especificado quando o dispositivo estabelece link com o ACS e o endereço IP de origem do pacote é a interface de saída do pacote. |
Configurar backup de link CWMP
Quando a função de backup de link é configurada no modo de interface, há uma interface WAN padrão e outras são interfaces WAN de backup quando o dispositivo é configurado com várias interfaces WAN. O endereço IP da interface WAN padrão é usado para gerar a URL de solicitação de conexão e então enviá-la ao ACS . Quando a interface WAN padrão está inativa , uma interface é escolhida da interface WAN de backup e é considerada como a interface WAN atual . Então , seu endereço IP é usado para gerar a URL de solicitação de conexão,
Tabela 11 -14 Configurar o backup do link CWMP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre na interface L3 que requer backup de configuração | interface interface-name | Obrigatório |
| Configure a interface de backup do proxy CWMP | cwmp wan backup | Obrigatório Por padrão, a interface de backup do dispositivo WAN do proxy CWMP não é especificada. |
Cada dispositivo só pode ser configurado com uma interface padrão CWMP WAN e uma interface de backup CWMP WAN.
Monitoramento e manutenção de CWMP
Tabela 11 -15 Monitoramento e manutenção do CWMP
| Comando | Descrição |
| show cwmp agent | Exiba as informações relacionadas do proxy CWMP. |
| show cwmp session | Exiba as informações da sessão do proxy CWMP. |
| show cwmp methods | Exiba o RPC ( chamada de procedimento remoto) ) suportado pelo proxy CWMP |
| show cwmp parameter all | Exiba todos os nomes de parâmetros do proxy CWMP |
| show cwmp parameter para-string | Exiba as informações detalhadas do parâmetro do proxy CWMP especificado |
| show cwmp parameter notify { active | all | forceactive | passive } | Exiba o nome do parâmetro notificado do proxy CWMP |
| show cwmp parameter values [ para-string | error ] | Exiba as informações detalhadas do parâmetro do proxy CWMP especificado |
Exemplo de configuração típica do CWMP
Configurar a função de autenticação CWMP
Requisitos de rede
- Dispositivo visita o ACS através da Rede e habilita a função CWMP no Dispositivo . Configurar a função de autenticação tanto no dispositivo quanto no ACS .
- Após a aprovação da autenticação, o dispositivo executará as tarefas de atualização de versão, restauração de configuração, backup de configuração e atualização de configuração enviadas pelo ACS .
Topologia de rede
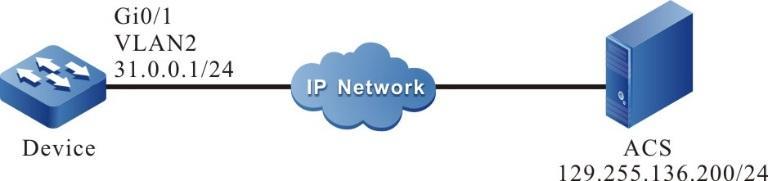
Figura 11 -2 Rede da função de autenticação CWMP
Etapas de configuração
- Passo 1:Configurar a VLAN e adicionar a porta à VLAN correspondente (omitido).
- Passo 2:Configure o endereço IP e a rota da interface. (Omitido)
- Passo 3:Configure o CWMP.
# Habilite o proxy CWMP e a função de download de arquivos no dispositivo e configure a URL do ACS.
Device#configure terminalDevice(config)#cwmp agentDevice(config-cwmp)#enableDevice(config-cwmp)#management server url http://129.255.136.200:8080/openacs/acsDevice(config-cwmp)#enable downloadDevice(config-cwmp)#exit
#Configure a interface VLAN2 como o dispositivo WAN padrão.
Device(config)#interface vlan 2Device(config-if-vlan2)#cwmp wan defaultDevice(config-if-vlan2)#exit
- Passo 4:Configure o servidor ACS .
# Crie o modelo de fragmento no ACS e configure o nome de usuário de autenticação e a senha como admin . (Omitido)
# Crie a tarefa de upgrade de configuração no ACS e escolha o modelo de fragmento a ser criado. Entregue a tarefa de configuração ao Dispositivo . (Omitido)
O ACS envia o nome de usuário e a senha de autenticação ao Dispositivo através da configuração da tarefa de atualização para garantir que o ACS possa passar pela autenticação do Dispositivo .
# Criar tarefa de atualização de versão, tarefa de restauração e tarefa de backup no ACS .
- Passo 5:Confira o resultado.
# Executa o show running-config comando no Dispositivo e pode-se ver que o ACS envia o nome de usuário e senha do Dispositivo .
cwmp agentmanagement server url http://129.255.136.200:8080/openacs/acsconnection request username adminconnection request password adminenable downloadenableexit
#Device pode executar com sucesso a tarefa de atualização de versão. Configure a tarefa de restauração e a tarefa de backup enviadas pelo ACS .
Configurar o endereço IP de origem especificado pelo CWMP
Requisitos de rede
- O dispositivo visita o ACS através da rede e habilita a função CWMP no dispositivo .
- Especifique o endereço IP de origem do CWMP como 1.0.0.1 . permitir que o dispositivo visite o ACS através do firewall e execute as tarefas de atualização de versão, restauração de configuração e backup de configuração enviadas pelo ACS.
Topologia de rede
Figura 11 -3 Rede de configuração do endereço IP de origem especificado pelo CWMP
Etapas de configuração
- Passo 1:Configurar a VLAN e adicionar a porta à VLAN correspondente (omitido).
- Passo 2:Configure o endereço IP e o roteador das interfaces. (Omitido)
- Passo 3:Configure o CWMP .
# Ative o proxy CWMP e a função de download de arquivos no dispositivo. Configurar a URL do ACS e o endereço IP de origem do CWMP como 1.0.0.1 .
Device#configure terminalDevice(config)#cwmp agentDevice(config-cwmp)#enableDevice(config-cwmp)#management server url http://129.255.136.200:8080/openacs/acsDevice(config-cwmp)#enable downloadDevice(config-cwmp)#ip source 1.0.0.1Device(config-cwmp)#exit
# Configure a interface Loopback0 como o dispositivo WAN padrão .
Device(config)#interface loopback 0Device(config-if-loopback0)#cwmp wan defaultDevice(config-if-loopback0)#exit
- Passo 4:Configure o firewall.
# O firewall rejeita o pacote com o endereço IP de origem como 43.0.0.1 para passar e permite que o pacote com o endereço IP de origem como 1.0.0.1 passe.
- Passo 5:Configure o servidor ACS .
# Crie a tarefa de atualização de versão e a tarefa de restauração de configuração e a tarefa de backup de configuração no ACS .
- Passo 6:Confira o resultado.
# Executa o show running-config comando no dispositivo e o endereço IP de origem configurado podem ser visualizados.
cwmp agentmanagement server url http://129.255.136.200:8080/openacs/acsenable downloadenableip source 1.0.0.1exit
#O dispositivo pode executar com sucesso a tarefa de atualização de versão e a tarefa de restauração de configuração e a tarefa de backup de configuração enviadas pelo ACS .
Configurar backup de link CWMP
Requisitos de rede
- O dispositivo pode visitar o ACS através de dois links. A interface gigabitethernet 0 é selecionada por prioridade para se comunicar com o ACS.
- Quando a interface vlan2 está com defeito, o dispositivo pode se comunicar com o ACS através da interface vlan3 . Quando a interface gigabitethernet 0 se recupera, o dispositivo pode se comunicar com o ACS através da interface vlan2 .
Topologia de rede
Figura 11 -4 Rede de configuração do backup do link CWMP
Etapas de configuração
- Passo 1:Configurar a VLAN e adicionar a porta à VLAN correspondente (omitido).
- Passo 2:Configure o endereço IP e a rota das interfaces. (Omitido)
- Passo 3:Configure o CWMP .
#Habilite o proxy CWMP e a função de download de arquivo no dispositivo e configure a URL do ACS .
Device#configure terminalDevice(config)#cwmp agentDevice(config-cwmp)#enableDevice(config-cwmp)#management server url http://129.255.136.200:8080/openacs/acsDevice(config-cwmp)#enable downloadDevice(config-cwmp)#exit
#Configure a interface vlan2 como a interface WAN padrão.
Device(config)#interface vlan2Device(config-if-vlan2)#cwmp wan defaultDevice(config-if-vlan2)#exit
# Configure a interface vlan3 como o dispositivo WAN de backup .
Device(config)#interface vlan3Device(config-if-vlan3)#cwmp wan backupDevice(config-if-vlan3)#exit
- Passo 4:Confira o resultado.
#Visualize as informações do proxy CWMP no dispositivo.
Device#show cwmp agentAgent status: EnabledPeriodic Inform: EnabledDownload files: EnabledInform interval: 43200ACS URL: http://129.255.136.200:8080/openacs/acsACS user name:ACS user password:Connection request URL: http://42.0.0.1:7547/00017A/MyPower-S4320/00017a136922/cwmpConnection request user name:Connection request password:Default WAN device: vlan2Current WAN device: vlan2CA certificate: /flash/tr069/ca.pem
Pode -se ver que o dispositivo WAN padrão é VLAN2 e o dispositivo WAN atual é VLAN2 . Pode ser visto na página de gerenciamento ACS que o endereço IP correspondente do Dispositivo é 42.0.0.1 .
# Quando a interface VLAN2 no dispositivo estiver com defeito, visualize as informações do proxy CWMP .
Device#show cwmp agentAgent status: EnabledPeriodic Inform: EnabledDownload files: EnabledInform interval: 43200ACS URL: http://129.255.136.200:8080/openacs/acsACS user name:ACS user password:Connection request URL: http://43.0.0.1:7547/00017A/MyPower-S4320/00017a136922/cwmpConnection request user name:Connection request password:Default WAN device: vlan2Current WAN device: vlan3CA certificate: /flash/tr069/ca.pem
Pode-se ver que o dispositivo WAN padrão é vlan2 e o dispositivo WAN atual é vlan3 . Pode ser visto na página de gerenciamento do ACS que o endereço IP correspondente do Dispositivo é 43.0.0.1 .
# Quando a interface vlan2 no dispositivo for recuperada, visualize as informações do proxy CWMP . Pode-se ver que tanto o dispositivo WAN padrão quanto o dispositivo WAN atual são vlan2 . Pode ser visto na página de gerenciamento ACS que o endereço IP correspondente do Dispositivo é 42.0.0.1 .
NETCONF
Visão geral
NETCONF (Network Configuration Protocol) é um tipo de protocolo de gerenciamento de rede baseado em XML. Ele fornece um método programável para configurar e gerenciar dispositivos de rede. Com este protocolo, os usuários podem definir parâmetros, obter valores de parâmetros, obter informações estatísticas, etc. O pacote NETCONF usa o formato XML e possui uma poderosa capacidade de filtragem. Cada item de dados possui um nome de elemento fixo e localização, o que faz com que diferentes dispositivos de um mesmo fabricante tenham o mesmo modo de acesso e modo de apresentação de resultados. Os dispositivos de diferentes fabricantes também podem obter o mesmo efeito mapeando XML, o que o torna muito conveniente no desenvolvimento do software de terceiros, é fácil desenvolver um software de gerenciamento de rede personalizado especial no ambiente de mistura de diferentes fabricantes e diferentes dispositivos. Com a ajuda de tal software de gerenciamento de rede, o uso da função NETCONF tornará o gerenciamento de configuração do equipamento de rede mais simples e eficiente.
Configuração básica da função NETCONF
Tabela 12 -1 Lista de configuração de funções básicas NETCONF
| Tarefas de configuração | |
| Configurar as funções do servidor NETCONF |
Habilite a função do servidor NETCONF
Configurar o tempo limite de desconexão do cliente NETCONF Configurar o máximo de sessões de NETCONF |
Configurar funções do servidor NETCONF
Condições de configuração
Antes de configurar as funções do servidor NETCONF, primeiro complete as seguintes tarefas:
- Configure o protocolo da camada de link e assegure a comunicação normal da camada de link.
- Configure o endereço da camada de rede da interface e certifique-se de que o nó cliente NETCONF esteja acessível na camada de rede.
Ativar a função do servidor NETCONF
Tabela 12 -2 Habilite a função do servidor NETCONF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função global NETCONF | netconf server enable | Mandatório Por padrão, a função NETCONF não está habilitada . |
Configurar a função de desconexão de tempo limite do cliente NETCONF
Tabela 12 -3 Configurar o tempo limite de desconexão do cliente NETCONF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função global NETCONF | netconf client idle-time | Mandatório Por padrão, o tempo limite de desconexão do cliente NETCONF é 3600s . |
Configurar Max. Sessões do NETCONF
Tabela 12 -4 Configurar o número máximo de sessões NETCONF
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o máximo de sessões de NETCONF | netconf server max-session session-num | Opcional Por padrão, o máximo de sessões suportadas pelo servidor NETCONF é 4 . |
Configurar NETCONF CALL-HOME Função
Condições de configuração
Antes de configurar a função do servidor NETCONF, primeiro complete as seguintes tarefas :
- Configure o protocolo da camada de link e assegure a comunicação normal da camada de link.
- Configure o endereço da camada de rede da interface e certifique-se de que o nó cliente NETCONF esteja acessível na camada de rede.
Configurar NETCONF CALL-HOME Função
O terminal call-home configurado pode se conectar automaticamente ao terminal configurado após o serviço NETCONF ser habilitado, de modo a estabelecer uma conexão SSH do NETCONF sem que o cliente se conecte ativamente ao servidor NETCONF.
Tabela 12 -5 Configurar NETCONF CALL-HOME função
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar NETCONF CALL-HOME função | netconf call-home client client-name ssh endpoint-name address host-name [ port port-num ] | Mandatório Por padrão, não há termimal de call-home. |
Monitoramento e Manutenção NETCONF
Tabela 12 -5 Monitoramento e manutenção do NETCONF
| Comando | Descrição |
| debug netconf [ all | cmf | conf | database | dbm | plugin | server | ssh | yang ] | Abra a chave de depuração NETCONF |
| show netconf session | D isplay as informações da sessão conectada do cliente NETCONF |
Telemetria
Visão geral
A telemetria é uma tecnologia de coleta de dados de dispositivos de rede remotamente com alta velocidade. Ele usa o "modo push" para obter em tempo hábil dados de monitoramento ricos dos dispositivos de rede, de modo a perceber rapidamente a localização de falhas na rede e a operação e manutenção inteligentes eficientes da rede.
Com a escala crescente da rede e a baixa eficiência de gerenciamento dos métodos tradicionais de monitoramento de rede (como SNMP e CLI), ele não pode atender às necessidades de monitoramento de rede de alto desempenho. Após o surgimento da tecnologia de telemetria, ela pode obter maior precisão e coleta de dados de monitoramento mais em tempo real para redes de grande escala e localizar e resolver rapidamente problemas de rede, de modo que forneça uma importante plataforma de big data para otimização da qualidade da rede e fornece um forte suporte para os requisitos e desenvolvimento de operação e manutenção de rede inteligente no futuro.
A função de telemetria inclui principalmente duas partes:
- Assinatura estática
A assinatura estática de telemetria indica que o dispositivo atua como cliente, o coletor atua como servidor e o dispositivo inicia ativamente a conexão com o coletor para coleta e envio de dados
- Assinatura dinâmica
A assinatura dinâmica de telemetria indica que o dispositivo atua como servidor, o coletor atua como cliente para iniciar a conexão com o dispositivo e o dispositivo coleta e transmite dados.
Configuração da função de telemetria
Tabela 13 -1 Lista de configuração da função de telemetria
| Tarefas de configuração | |
| Configurar função de assinatura estática de telemetria | Configurar o sensor Configurar o coletor Configurar assinatura Habilitar assinatura |
| Configurar a função de assinatura dinâmica de telemetria | Configurar o servidor GRPC |
Configurar a função de assinatura estática de telemetria
Condições de configuração
Nenhum
Configurar sensor
Ao configurar os dados de amostragem de assinatura estática de telemetria, você precisa criar um grupo de sensores de amostragem, especificar as informações do caminho de amostragem e configurar o caminho de amostragem necessário do sensor de acordo com as informações do caminho de amostragem especificadas.
Tabela 13 -2 Configurar o sensor
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de grupo de sensores | telemetry sensor-group sensor-name |
Mandatório
Se o grupo não existir, crie um grupo diretamente e entre no modo de grupo. Caso contrário, entre diretamente no modo de grupo. |
| Configurar o caminho do sensor | sensor-path path-name | Mandatório |
Configurar o Coletor de Alvos
Ao configurar os dados de amostragem de assinatura estática de telemetria, você precisa criar um grupo de destino de entrega e, em seguida, especificar o coletor de destino ao qual os dados de amostragem são entregues.
Tabela 13 -3 Configurar o coletor de destino
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de grupo de sensores | telemetry destination-group destination-name | Mandatório Se o grupo existir, entre diretamente no modo de grupo. |
| Configurar o endereço de destino | ipv4-address [vrf vrf-name] ip-address port port-num | Mandatório Por padrão, vrf usa global e o intervalo de valores da porta é 1-65535. |
Criar assinatura
Ao configurar a assinatura estática de telemetria para dados de amostra, você precisa criar uma assinatura para associar o grupo de destino de entrega configurado ao grupo de sensores de amostragem e concluir a entrega de dados.
Tabela 13 -4 Criar assinatura
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de grupo de assinatura | telemetry subscription subscription-name | Mandatório |
| Configurar a interface de origem de envio da assinatura | source-interface interface-name |
Opcional
Por padrão, a interface de saída para transmissão será determinada de acordo com a rota, e o endereço IP ativo da interface de saída será usado como endereço IP de origem para transmissão |
| Configurar para associar o grupo de sensores | sensor-group sensor-name [ sample-interval sample-interval ] |
Mandatório
Se o grupo de sensores não existir, você precisa primeiro configurar o grupo de sensores. O valor padrão de sample-interval é 10000 milissegundos |
| Configurar grupo-alvo de entrega associado | destination-group destination-name |
Mandatório
Se o grupo de destino não existir, você precisará configurar primeiro o grupo de destino de entrega. |
| Habilitar assinatura | subscription enable | Mandatório Após habilitar, conclua a entrega dos dados. |
Configurar a função de assinatura dinâmica de telemetria
Condições de configuração
Nenhum
Habilite o Servidor GRPC
Para assinatura dinâmica, o lado do dispositivo atua como um servidor, portanto, ative a função de servidor GRPC do dispositivo. Se você precisar concluir o envio de dados de assinatura dinâmica, precisará estabelecer uma conexão entre o coletor como cliente e o dispositivo.
Tabela 13 -5 Configurar servidor GRPC
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite o servidor GRPC | grpc server [port port-num] | Mandatório O valor padrão da porta é 51700. |
Monitoramento e manutenção de telemetria
Tabela 13 -6 Monitoramento e manutenção de telemetria
| Comando | Descrição |
| show telemetry sensor-group [ sensor-name ] | Exiba as informações do sensor de amostragem, incluindo as informações do caminho de amostragem configurado |
| show telemetry destination [ destination-name ] | Exibir as informações do grupo de destino de entrega, incluindo as informações de endereço de destino de entrega configuradas |
| show telemetry subscription [ subscription-name ] | Exiba as informações de assinatura, incluindo o grupo de sensores associado configurado e as informações do grupo-alvo |
| show telemetry sensor-path | Exiba o caminho de amostragem do sensor de telemetria, incluindo as informações do caminho de amostragem com suporte |
| show telemetry dynamic-subscription [ dynamic-subscription-name ] | Exiba as estatísticas de assinatura dinâmica de Telemetria, incluindo informações de caminho do sensor de assinatura dinâmica. |
Exemplo de configuração típica de telemetria
Configurar a função de assinatura estática de telemetria
Requisitos de rede
- O dispositivo atua como cliente de telemetria para entregar ativamente os dados ao servidor.
- Habilite o serviço de Telemetria no Servidor e monitore ativamente a porta 30000.
Topologia de rede

Figura 13 -1 Rede de configuração da assinatura estática de telemetria
Etapas de configuração
- Passo 1:No Servidor, habilite o serviço de Telemetria e monitore a porta 30000 (omitida).
- Passo 2:Configure a função de assinatura estática de telemetria.
#Crie um sensor de grupo de amostragem e configure o caminho de amostragem como dmm/memInfo abaixo para contar dados como utilização de memória.
Device#configure terminalDevice(config)#telemetry sensor-group sensorDevice(config-telemetry-sensor-group-sensor)#sensor-path dmm/memInfoDevice(config-telemetry-sensor-group-sensor)#exit
#Crie um grupo de destino, configure o endereço de destino como o endereço do servidor e configure a porta como a porta monitorada pelo Servidor.
Device(config)#telemetry destination-group destDevice(config-telemetry-destination-group-dest)#ipv4-address 1.1.1.2 port 30000Device(config-telemetry-destination-group-dest)#exit
#Configure o grupo de assinatura, faça referência ao grupo alvo da combinação de sensores configurado acima e ative a função de assinatura.
Device(config)#telemetry subscription subDevice(config-telemetry-subscription-sub)#sensor-group sensor sample-interval 10000Device(config-telemetry-subscription-sub)#destination-group destDevice(config-telemetry-subscription-sub)#subscription enable
- Passo 3:Confira o resultado.
#O coletor pode receber as estatísticas de memória enviadas pelo dispositivo por meio de Telemetria a cada 10s.
Figura 13 -2 Estatísticas de uso de memória recebidas pelo coletor
Configurar a função de assinatura dinâmica de telemetria
Requisitos de rede
- Como um cliente de telemetria, o Cliente é usado para enviar uma solicitação de dados de telemetria ao dispositivo e exibir os dados respondidos pelo dispositivo
- Como servidor de telemetria, o De vice é usado para responder às solicitações do dispositivo
Topologia de rede

Figura 13 -3 Rede de configuração da assinatura dinâmica de telemetria
Etapas de configuração
- Passo 1:Habilite o serviço GRPC no dispositivo.
Device#configure terminalDevice(config)#grpc server
- Passo 2:No Cliente, entregue a solicitação de dados de Telemetria ( omitida).
- Passo 3:Confira o resultado.
# No dispositivo, mostre as informações de conexão de assinatura dinâmica.
Device#show telemetry dynamic-subscription1.Telemetry dynamic-subscription Information:-----------------------------------------------------------------Subscription-name : dynSubs96183Subscription-id : 96183Request-id : 3874318141Encoding : JSONSample-interval(ms): : 10000Subscription-state: : Subscribed-----------------------------------------------------------------Sensor group information:-----------------------------------------------------------------Sample-interval(ms) Sample-path-----------------------------------------------------------------10000 dmm/memInfo-----------------------------------------------------------------
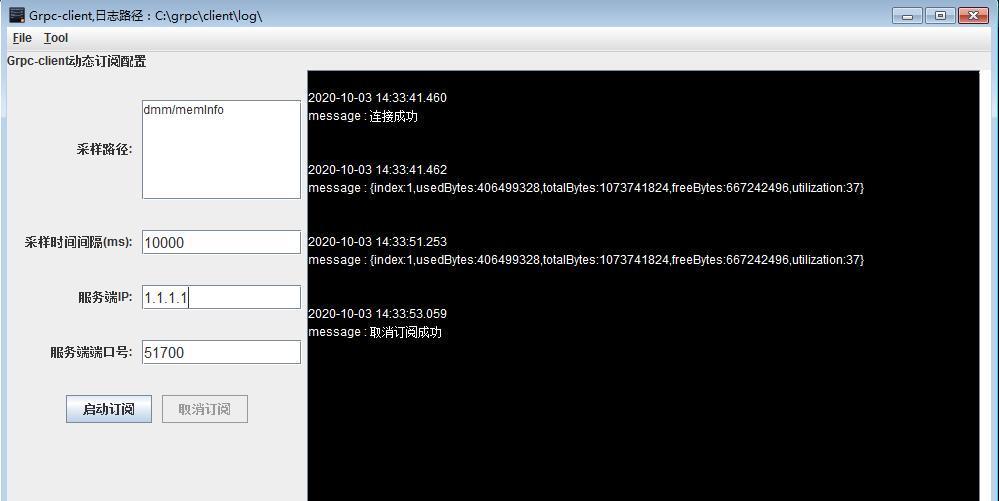
Figura 13 -4 Cliente enviando dados
DYINGGASP
Visão geral
DYINGGASP ( Dying Gasp ) é uma função que o dispositivo envia automaticamente mensagens de alarme para o servidor quando a tensão de entrada não consegue atender ao funcionamento normal do sistema. O DYINGGASP requer que a alimentação do dispositivo ainda possa ser mantida por um período de tempo após a falha de energia para enviar mensagens de alarme. DYINGGASP pode enviar mensagens de alarme através de syslog e SNMP trap.
básica da função DYINGGASP
Tabela 13 -1 Lista de configuração de funções básicas do DYINGGASP
| Tarefas de configuração | |
| Configurar a função DYINGGASP | Ative a função DYINGGASP |
Configurar a função DYINGGASP
Condições de configuração
Antes de configurar a função DYINGGASP, primeiro complete as seguintes tarefas :
- Configurar o SNMP, servidor Syslog
- Configure o endereço da camada de rede da interface, garantindo que o servidor SNMP e Syslog esteja acessível na camada de rede
Habilite o DYINGGASP Função
Tabela 13 -2 Habilite a função DYINGGASP
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Ative a função DYINGGASP | dying-gasp primary {syslog | snmp-trap} [secondary {syslog | snmp-trap}] | Obrigatório Por padrão, a função DYINGGASP não está habilitada. |
DYINGGASP Monitoramento e Manutenção
Tabela 13 -3 Monitoramento e manutenção da DYINGGASP
| Comando | Descrição |
| show dying-gasp status | Exibe a configuração atual do DYINGGASP, trap SNMP, Syslog e outras informações |
| show dying-gasp capability | Exibe se o dispositivo no sistema suporta o envio de mensagens DYINGGASP por meio de trap SNMP e syslog |
11 Virtualização
VST
Visão geral
Com a crescente exigência do usuário para reduzir o custo e melhorar a confiabilidade do dispositivo, a apresenta uma tecnologia de combinação de vários switches físicos para formar um switch virtual, que é a Tecnologia de Comutação Virtual , chamada VST.
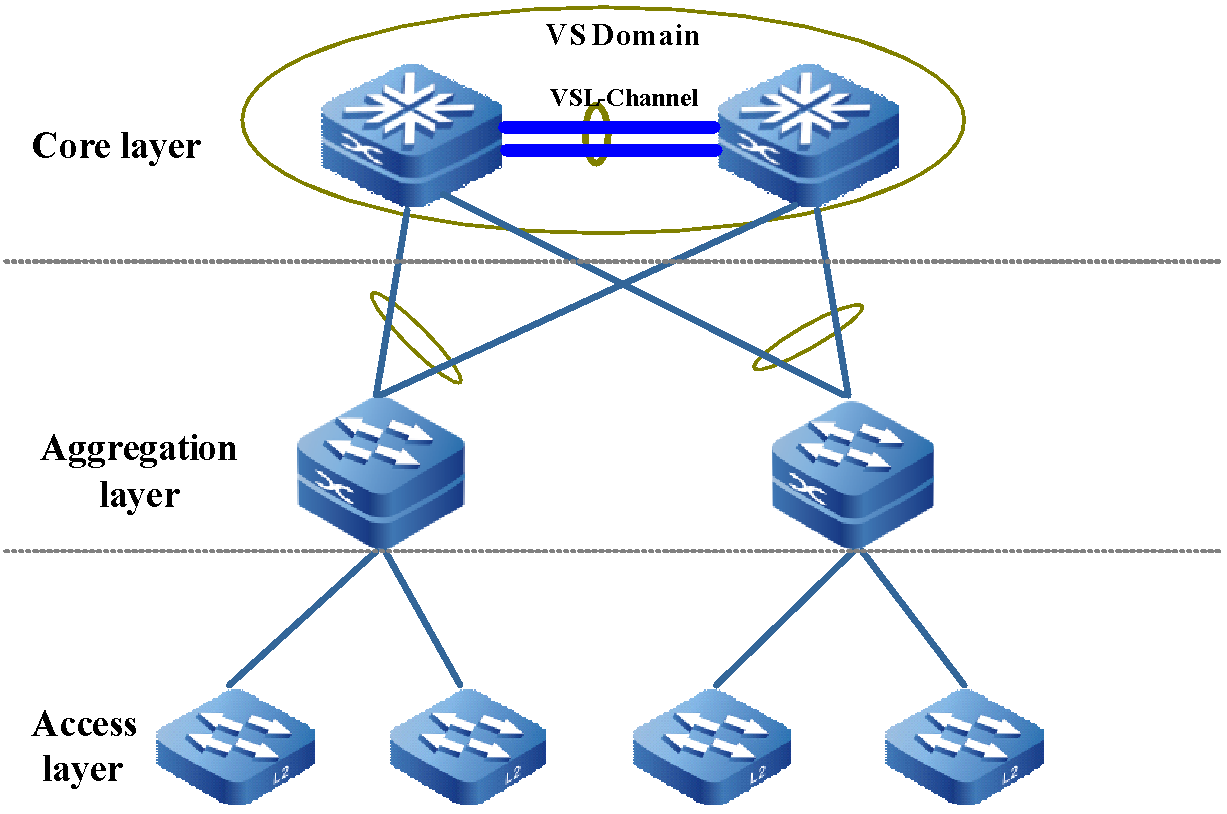
Figura 1 -1 Visualização da rede física VST
Conforme mostrado na figura 1-1, dois dispositivos da camada núcleo são conectados através da interface VSL, formando um VS Domain (domínio de comutação virtual, também chamado de sistema de empilhamento). O dispositivo da camada de agregação é vinculado ao VS Domain por meio da agregação de link. O Domínio VS da camada principal é um dispositivo virtual para os outros dispositivos de rede.
Comparado com a tradicional árvore geradora L2 e a tecnologia L3 VRRP/VBRP, o VST tinha as seguintes vantagens:
- A largura de banda aumenta multiplicativamente e é usada de forma eficaz
Como a tecnologia tradicional executa STP/RSTP/MSTP, um dos dois links de uplink anteriores está no estado de encaminhamento e o outro está no estado de espera. Depois de usar o VST, vários dispositivos se tornam um dispositivo lógico, portanto, não é necessário bloquear alguns links. Dois enlaces formam um grupo de agregação e ambos podem ser usados para encaminhar dados, de forma a aproveitar a largura de banda dos enlaces de forma eficiente, evitando o desperdício de recursos de largura de banda. Além disso, o link de agregação entre dispositivos e placas cruzadas pode fornecer os links redundantes e também pode realizar o balanceamento de carga dinâmico, fazendo uso de todas as larguras de banda de forma eficiente.
- Alta fiabilidade
O virtual sistema de comutação é formado por vários dispositivos membros. O dispositivo de controle é responsável pela operação, gerenciamento e manutenção de todo o sistema de comutação virtual e os outros dispositivos membros estão no estado de espera. Uma vez que o dispositivo de controle falhe e não dependa da convergência de STP/RSTP/MSTP, VRRP/VBRP, o sistema elege um novo dispositivo de controle dos dispositivos membros em espera , garantindo que os serviços do sistema de comutação virtual não sejam interrompidos e melhorando a confiabilidade quando o dispositivo membro falha.
- Simplifique a topologia de rede
O dispositivo virtual formado pelo VST equivale a um dispositivo na rede, conectado aos dispositivos ao redor através do link de agregação. Não há loop L2, portanto não é necessário configurar o protocolo STP/RSTP/MSTP. Os protocolos da camada de controle são executados em um dispositivo virtual, reduzindo a troca de muitos pacotes de protocolo entre os dispositivos e diminuindo o tempo de convergência da rota.
- Gerenciamento unificado
Depois que dois ou mais dispositivos formam o sistema de empilhamento, a plataforma de controle dos dispositivos membros no sistema de comutação virtual está no estado de espera, mas a plataforma de dados está ativa. O usuário pode fazer login no sistema de comutação virtual pela porta de qualquer dispositivo membro e gerenciar todo o dispositivo virtual de maneira unificada, mas não precisa se conectar a cada dispositivo membro para gerenciamento.
Conceitos Básicos
Domínio de comutação virtual
O domínio de comutação virtual é formado por um ou vários dispositivos membros. As configurações de número de domínio dos dispositivos membros em um domínio de comutação virtual devem ser as mesmas. O número de domínio determina exclusivamente um domínio de comutação virtual. Quando o endereço MAC do domínio de comutação virtual usa o modo de endereço MAC virtual para obter, o número do domínio de comutação virtual decide exclusivamente o endereço MAC, portanto, em uma LAN, os números de domínio entre vários sistemas de empilhamento não podem ser os mesmos.
Dispositivo Membro de Comutação Virtual
Cada dispositivo físico no domínio de comutação virtual também é chamado de dispositivo membro de comutação virtual . Em um domínio de empilhamento, o número do membro determina exclusivamente um dispositivo membro.
Interface VSL eMember Ports
Vincule várias portas físicas com a capacidade de empilhamento para formar um canal de link de comutação virtual (VSL-Channel). O VSL-Channel é o canal de link lógico de troca de pacotes de protocolo e encaminhamento de dados de serviço entre dispositivos membros. A porta física é chamada de porta membro do link de comutação virtual.
Os dispositivos membros são adicionados a um domínio de comutação virtual e são interconectados através do canal VSL, formando um dispositivo virtual.
LMP
O LMP (Link Manage Protocol) é usado para gerenciar o canal VSL e as portas membro.
PVP
O RRP (Role Resolution Protocol) é usado para eleger a função do dispositivo membro no sistema de empilhamento.
TDP
O TDP (Topology Discovery Protocol) é usado para anunciar as informações do dispositivo membro no sistema de empilhamento, garantindo a consistência de todas as informações do dispositivo membro no sistema de empilhamento.
Configuração da função VST
Tabela 1 -1 lista de configuração da função VST
| Tarefas de configuração | |
| Configurar o dispositivo membro de comutação virtual |
Configurar o número de domínio do dispositivo membro de comutação virtual
Configurar o número do dispositivo do membro de comutação virtual Configurar a prioridade do dispositivo membro de comutação virtual |
| Configurar a interface VSL | Criar uma interface VSL Configure a porta para adicionar à interface VSL |
| Configurar o modo de execução do dispositivo | Configurar o modo de execução do dispositivo |
| Configurar o número máximo de dispositivos suportados pelo sistema de empilhamento | Configurar o número máximo de dispositivos suportados pelo sistema de empilhamento |
Configurar dispositivo membro de comutação virtual
Antes de o dispositivo ser adicionado ao domínio de empilhamento de comutação virtual ou após ser adicionado ao domínio de empilhamento de comutação virtual, você pode configurar o dispositivo, incluindo seu número de membro, número de domínio e prioridade.
No modo VST, após modificar o número do membro ou o número de domínio do dispositivo membro de comutação virtual, o novo número de membro ou número de domínio configurado não entra em vigor imediatamente, mas entra em vigor somente após o dispositivo membro de comutação virtual salvar a configuração e reiniciar .
Condição de configuração
Nenhum
Configurar o número de domínio do dispositivo membro de comutação virtual
Tabela 1 -2 Configurar o número de domínio do dispositivo membro de comutação virtual
| Etapa | Comando | Descrição |
| Entre no modo de configuração do membro de comutação virtual | switch virtual member member-id | - |
| Configure o número do domínio do dispositivo membro de comutação virtual | domain domain-id | Obrigatório Por padrão, o número do dispositivo membro de comutação virtual é 100. |
No modo VST, ao adicionar o dispositivo membro de comutação virtual ao domínio de comutação virtual, certifique-se de que os números de domínio dos dispositivos membros de comutação virtuais sejam os mesmos. Caso contrário, os dispositivos de membro de comutação virtual não podem ser adicionados a um domínio de comutação virtual. No modo VST, depois de modificar o número de domínio, o novo número de domínio não entra em vigor imediatamente, mas entra em vigor somente após o dispositivo membro de comutação virtual salvar a configuração e reiniciar.
Configurar o número do dispositivo do membro de comutação virtual
A configuração do número do dispositivo membro de comutação virtual inclui dois casos:
- O dispositivo nunca é configurado com o número do dispositivo membro de comutação virtual e você precisa configurar um número de dispositivo membro de comutação virtual ;
- O dispositivo é configurado com o número do dispositivo membro de comutação virtual e você precisa modificar para o novo número do dispositivo membro de comutação virtual.
Portanto, existem dois comandos para configurar o número do dispositivo membro de comutação virtual: Um é para configurar o número do dispositivo membro de comutação virtual e o outro é para modificar o número do dispositivo membro de comutação virtual, conforme mostrado na Tabela 1- 3.
Tabela 1 -3 Configurar o número do dispositivo membro VST
| Etapa | Comando | Descrição |
| Entre no modo global | configure terminal | - |
| Configurar o número do dispositivo do membro de comutação virtual | switch virtual member member-id | Obrigatório Por padrão, o dispositivo não possui o número do dispositivo do membro de comutação virtual. |
| Modifique o número do dispositivo do membro de comutação virtual | switch virtual member member-id rename member-id-new | Opcional |
No modo VST, após modificar o número do dispositivo membro de comutação virtual, salve a configuração e reinicie o sistema para que o novo número do dispositivo membro de comutação virtual possa entrar em vigor. Em um domínio de comutação virtual, o número de membro de cada dispositivo membro de comutação virtual é exclusivo. Caso contrário, o dispositivo membro de comutação virtual não pode empilhar normalmente.
prioridade de dispositivo do membro de comutação virtual
Quando vários dispositivos de membro de comutação virtual são adicionados a um domínio de comutação virtual, você pode configurar a prioridade do dispositivo de membro de comutação virtual para melhorar a possibilidade de o dispositivo de membro de comutação virtual ser eleito como o dispositivo de controle. Quanto maior o valor de prioridade, maior a possibilidade.
Tabela 1 -4 Configurar a prioridade do dispositivo membro de comutação virtual
| Etapa | Comando | Descrição |
| Entre no modo de configuração do membro de comutação virtual | switch virtual member member-id | - |
| Configure a prioridade do dispositivo membro de comutação virtual | priority priority-num | Obrigatório Por padrão, a prioridade do dispositivo membro de comutação virtual é 100. |
A regra de eleição do dispositivo de controle de comutação virtual no domínio de comutação virtual: O dispositivo de controle de comutação virtual é anterior; quando houver vários dispositivos de controle de comutação virtual, compare de acordo com a etapa 2. Se não houver dispositivo de controle de comutação virtual, compare de acordo com a etapa 3. Caso contrário, encerre a comparação . O dispositivo de controle de comutação virtual com maior tempo de execução é anterior; se o tempo de execução for o mesmo, compare conforme o passo 3. Caso contrário, encerre a comparação. Aquele com maior prioridade é o anterior. Se a prioridade for a mesma, compare de acordo com a etapa 4. Caso contrário, encerre a comparação. Aquele com o menor número de membro é o anterior.
Configurar canal VSL
O VSL-Channel é uma interface lógica e vincula várias interfaces físicas que suportam o empilhamento para gerenciar as portas físicas de maneira unificada. Qualquer operação para o VSL-Channel funciona em cada porta membro física.
Condição de configuração
Nenhum
Criar canal VSL
Tabela 1 -5 Criar Canal VSL
| Etapa | Comando | Descrição |
| Entre no modo global | configure terminal | - |
| Criar canal VSL | vsl-channel vsl-channel-id | Obrigatório No modo autônomo , vsl-channel-id é um valor de uma dimensão, indicando o número da interface do link de comutação virtual; no modo VST, é o valor bidimensional. A primeira dimensão é o número do membro de comutação virtual e a segunda dimensão é o número da interface de link de comutação virtual. |
Ao excluir a interface do link de comutação virtual, todas as portas membro no canal VSL saem do canal VSL e todas as configurações da porta membro são restauradas para o estado padrão. Antes de excluir o canal VSL, confirme se não há loop na rede após a exclusão.
Configurar porta para adicionar ao canal VSL
Tabela 1 -7 Configurar uma porta para adicionar ao canal VSL
| Etapa | Comando | Descrição |
| Entre no modo global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configure a porta para adicionar ao canal VSL | vsl-channel vsl-channel-id mode on [ type extern ] | Obrigatório |
Os níveis de capacidade de porta de todas as portas membro no canal VAL devem ser os mesmos.
Configurar o modo de execução do dispositivo
O dispositivo atual suporta dois modos de execução, ou seja, modo autônomo e modo de empilhamento. O dispositivo pode formar um domínio de comutação virtual com os outros dispositivos membros de comutação virtual somente quando executado no modo VST.
Condição de configuração
Nenhum
Configurar o modo de execução do dispositivo
Tabela 1 -7 Configure o modo de execução do dispositivo
| Etapa | Comando | Descrição |
| Entre no modo de usuário privilegiado | enable | - |
| Configurar o modo de execução do dispositivo | switch mode { stand-alone | virtual } | Obrigatório Por padrão, o dispositivo é executado no modo autônomo . |
Depois que o modo de execução do dispositivo for alterado, o dispositivo será reiniciado e executado pelo novo modo de configuração após a reinicialização. Diferentes modos de execução dos dispositivos correspondem aos seus próprios arquivos de configuração de inicialização independentes. Antes que o dispositivo mude para ser executado no modo VST, certifique-se de que o número do dispositivo do membro de comutação virtual esteja configurado. Caso contrário, ele não pode mudar.
Configurar Max. Dispositivos suportados pelo sistema de empilhamento
Um sistema de empilhamento consiste em vários dispositivos. Há um limite no número de dispositivos em um sistema de empilhamento. O valor limite definido é o número máximo de dispositivos suportados pelo sistema de empilhamento.
Condições de configuração
Nenhum
Configurar Max. Dispositivos suportados pelo sistema de empilhamento
Tabela 1 -8 Configura o número máximo de dispositivos suportados pelo sistema de empilhamento
| Etapa | Comando | Descrição |
| Entre no modo global | configure terminal | - |
| Configurar o número máximo de dispositivos suportados pelo sistema de empilhamento | switch virtual max-number number | Mandatório _ Por padrão, o número máximo de dispositivos suportados pelo sistema de empilhamento é 8. |
Depois de modificar o número máximo de dispositivos suportados pelo sistema de empilhamento, você deve salvar a configuração e reiniciar o sistema antes que ela entre em vigor.
Monitoramento e manutenção de VST
Tabela 1 -9 Monitoramento e manutenção de VST
| Comando | Descrição |
| show switch virtual | Exiba as informações básicas do domínio de comutação virtual |
| show switch virtual local config | Exiba as informações básicas de configuração do dispositivo membro de comutação virtual local |
| show switch virtual local current | Exiba as informações básicas de execução do dispositivo membro de comutação virtual local |
| show switch virtual member member-id [ config | current ] | Exibir as informações básicas do dispositivo membro de comutação virtual |
| show switch virtual topo | Exiba as informações do caminho de encaminhamento do dispositivo membro de comutação virtual local para os outros dispositivos membros de comutação virtual no domínio de comutação virtual |
| show switch vsl-channel [ vsl-channel-id ] | Exiba as informações do canal VSL no domínio de comutação virtual |
Exemplo de configuração típica de VST
Configurar dispositivos para formar o sistema de empilhamento de links
Requisito de rede
- Device0 e Device1 formam o sistema de empilhamento de links; Device0 torna-se o dispositivo de controle.
Topologia de rede

Figura 1 -2 Configurar dispositivos para formar o sistema de empilhamento de links
Etapas de configuração
- Passo 1:Configure Device0.
# No Device0, configure o número do dispositivo do membro de comutação virtual como 0, configure o número do domínio como 10 e a prioridade é 255.
Device0#configure terminalDevice0(config)#switch virtual member 0Do you want to modify member id(Yes|No)?y% Member ID 0 config will take effect only after the exec command 'switch mode virtual' is issuedDevice0(config-vst-member-0)#domain 10% Domain ID 10 config will take effect only after the exec command 'switch mode virtual' is issuedDevice0(config-vst-member-0)#priority 255Device0(config-vst-member-0)#exit
# No Device0, crie a interface de link de switch virtual 1 e adicione a porta tengigabitethernet1/1 e tengigabitethernet1/ 2 à interface de link de switch virtual 1.
Device0(config)#vsl-channel 1Device0(config-vsl-channel-1)#exitDevice0(config)#interface tengigabitethernet 1/1-1/2Device0(config-if-range)#vsl-channel 1 mode onDevice0(config-if-range)#exit
# Salve a configuração em Device0.
Device0#writeAre you sure to overwrite /flash/startup (Yes|No)?yBuilding Configuration...doneWrite to startup file ... OKWrite to mode file... OK
- Passo 2:Configurar dispositivo1.
# No Device1, configure o número do dispositivo do membro de comutação virtual como 1, configure o número do domínio como 10 e a prioridade é 200.
Device1#configure terminalDevice1(config)#switch virtual member 1Do you want to modify member id(Yes|No)?y% Member ID 1 config will take effect only after the exec command 'switch mode virtual' is issuedDevice1(config-vst-member-1)#domain 10% Domain ID 10 config will take effect only after the exec command 'switch mode virtual' is issuedDevice1(config-vst-member-1)#priority 200Device1(config-vst-member-1)#exit
# No Device1, crie a interface de link de switch virtual 1 e adicione a porta tengigabitethernet0/1 e tengigabitethernet0/ 2 à interface de link de switch virtual 1.
Device1(config)#vsl-channel 1Device1(config-vsl-channel-1)#exitDevice1(config)#interface tengigabitethernet 0/1-0/2Device1(config-if-range)#vsl-channel 1 mode onDevice1(config-if-range)#exit
# No Device1, salve a configuração.
Device1#writeAre you sure to overwrite /flash/startup (Yes|No)?yBuilding Configuration...doneWrite to startup file ... OKWrite to mode file... OK
- Passo 3:Configure o modo de execução de Device0 e Device1 como o modo VST.
# Configure o modo de execução do Device0 como o modo VST.
Device0#switch mode virtualThis command will convert all interface names to naming convention "interface-type member-number/slot/interface" ,Please make sure to save current configuration.Do you want to proceed? (yes|no)?yConverting interface names Building configuration...Copying the startup configuration to backup file named "startup-backupalone"...Please wait...system reloading is in progress!okReset system!Jul 30 2014 17:36:14: %SYS-5-RELOAD: Reload requested
# Configure o modo de execução do Device1 como o modo VST.
Device1#switch mode virtualThis command will convert all interface names to naming convention "interface-type member-number/slot/interface" ,Please make sure to save current configuration.Do you want to proceed? (yes|no)?yConverting interface names Building configuration...Copying the startup configuration to backup file named "startup-backupalone"...Please wait...system reloading is in progress!okReset system!Jul 30 2014 17:36:20: %SYS-5-RELOAD: Reload requested
- Passo 4:Confira o resultado
# No Device0, o sistema VST é formado e Device0 é o dispositivo mestre.
Device0#show switch virtualCodes: L - local-device,I - isolate-deviceVirtual Switch Mode : VIRTUALVirtual Switch DomainId : 10Virtual Switch mac-address : 0001.7a6a.001b--------------- VST MEMBER INFORMATION ------------------CODE MemberID Role Pri LocalVsl RemoteVsl---- -------- ------ ---- --------------- ---------------L 0 Master 255 vsl-channel 0/1 vsl-channel 1/11 Member 200 vsl-channel 1/1 vsl-channel 0/1
MAD
Visão geral
Quando o canal VSL no sistema de empilhamento falha, o sistema de empilhamento é dividido em vários domínios de comutação virtual e há vários dispositivos de controle de comutação virtual com a mesma configuração global (chamado de dispositivo de controle abreviado). Isso é chamado de multi-ativo. A configuração global do dispositivo lógico dividido é a mesma do dispositivo lógico anterior, portanto, há conflito de configuração de rede, resultando na anormalidade do tráfego. Para evitar a influência para os serviços, surge o MAD (Multi-Active Detection).
O sistema de empilhamento atual suporta dois modos MAD: MAD LACP e MAD Fast-Hello, atendendo a diferentes requisitos de rede.
O status MAD inclui dois tipos: Ativo e Recuperação. Ativo indica o estado de funcionamento normal e Recuperação indica o estado de desabilitação. No estado de recuperação, todas as interfaces Ethernet L2/L3 e interfaces VLAN, exceto as portas membro VSL e as portas reservadas, são desabilitadas porMAD.
Quando o dispositivo recebe os pacotes de detecção MAD, compare os dados no pacote com os dados do dispositivo lógico local. Se o VS Domain ID no pacote (número de domínio de comutação virtual da extremidade de envio) for o mesmo do dispositivo lógico local, e o Master ID no pacote (o número de membro do dispositivo de controle no domínio de comutação virtual de a extremidade de envio) é diferente do dispositivo lógico local, considera-se que o multi-ativo acontece e inicia a eleição multi-ativa. De acordo com algumas regras de eleição, em um domínio de comutação virtual, basta reservar um dispositivo lógico para manter Ativo e os outros dispositivos lógicos entrarão no estado de Recuperação.
Durante a rede MAD LACP, use o dispositivo intermediário; durante a rede MAD Fast-Hello, você pode usar o dispositivo intermediário e também pode adotar a conexão direta. Se estiver adotando o modo de conexão direta, você precisa garantir que haja uma linha de conexão direta entre quaisquer dois dispositivos membros de comutação virtual para o MAD, ou seja, é necessário garantir a conexão completa.
Configuração da função MAD
Tabela 2 -1 lista de configuração da função MAD
| Tarefas de configuração | |
| Configurar a função MAD LACP | Configurar a função MAD LACP |
| Configurar a função MAD Fast-Hello | Configurar a função MAD Fast-Hello |
| Configurar a porta reservada | Configurar a porta reservada |
| Configure a restauração do status MAD para Ativo | Configure a restauração do status MAD para Ativo |
Configurar a função MAD LACP
O MAD LACP realiza a detecção e a eleição multiativas expandindo o campo de pacote do protocolo LACP.
Condição de configuração
Nenhum
Configurar a função MAD LACP
Tabela 2 -2 Configurar a função MAD LACP
| Etapa | Comando | Descrição |
| Entre no modo global | configure terminal | - |
| Criar um grupo de agregação dinâmico | link-aggregation link-aggregation-id mode lacp | Obrigatório Por padrão, não crie o grupo de agregação especificado. |
| Entre no modo de configuração do grupo de agregação | link-aggregation link-aggregation-id | - |
| Habilite a função MAD LACP | mad enable | Obrigatório Por padrão, não habilite a função MAD LACP. |
O grupo de agregação dinâmica suporta a ativação da função MAC LACP. O dispositivo intermediário usado pela rede deve ser um dispositivo que suporte a função de transmissão transparente do pacote LACP.
Configurar a função MAD Fast-Hello
Os pacotes de protocolo do MAD Fast-Hello são definidos pelo e carregam diretamente os dados necessários ao MAD e eleição.
Condição de configuração
Nenhum
Configurar a função MAD Fast-Hello
Tabela 2 -3 Configurar a função MAD Fast-Hello
| Etapa | Comando | Descrição |
| Entre no modo global | configure terminal | - |
| Configure o período de envio dos pacotes MAD Fast-Hello no modo normal | mad fast-hello normal interval interval-time | Opcional Por padrão, o período de envio dos pacotes MAD Fast-Hello no modo normal é de 2000ms. |
| Configure o período de envio dos pacotes MAD Fast-Hello no modo agressivo | mad fast-hello aggressive interval interval-time | Opcional Por padrão, o período de envio dos pacotes MAD Fast-Hello no modo agressivo é de 500ms. |
| Configure a direção do modo agressivo | mad fast-hello aggressive duration duration-time | Opcional Por padrão, a duração do modo agressivo é de 120 segundos. |
| Entre no modo de configuração VLAN | vlan vlan-id | - |
| Configurar a VLAN de controle | mad fast-hello control-vlan | Obrigatório Por padrão, não configure a VLAN de controle. |
| Entre no modo global | exit | - |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | - |
| Configure o tipo de link da porta como Trunk | switchport mode trunk | Obrigatório Por padrão, o tipo de link de porta é Acesso. |
| Desabilite a função spanning tree da porta | no spanning-tree enable | Obrigatório Por padrão, a porta habilita a função spanning tree. |
| Configurar a porta de controle | mad fast-hello vlan vlan-id | Obrigatório Por padrão, não configure a porta de controle. |
A VLAN de controle e a porta de controle do MAD Fast-Hello só podem ser usadas para o MAD Fast-Hello e não podem mais configurar outros serviços. No controle port of MAD Fast-Hello, desative a função spanning tree da porta.
Configurar porta reservada
Quando o status do MAD muda para Recovery, a porta reservada não é desabilitada pelo MAD e você pode configurar a porta, interface (porta do console) que tem o uso especial e precisa manter UP como a porta reservada.
Condição de configuração
Nenhum
Configurar porta reservada
Tabela 2 -4 Configurar a porta reservada
| Etapa | Comando | Descrição |
| Entre no modo global | configure terminal | - |
| Entre no modo de configuração da interface Ethernet L2/L3 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2 /L3 , a configuração subsequente terá efeito apenas na interface atual ; depois de entrar no modo de configuração do grupo de agregação, a configuração subsequente terá efeito apenas no grupo de agregação ; depois de entrar no modo de configuração de interface, a configuração subsequente apenas entra em vigor na interface atual. |
| Entre no modo de configuração do grupo de agregação | link-aggregation link-aggregation-id | |
| Entre no modo de configuração da interface | interface vlan vlan-id | |
| Configurar a porta reservada | mad exclude recovery | Obrigatório Por padrão, não configure a porta reservada. |
O grupo de agregação habilitado com a função MAD LACP não pode ser configurado como a porta reservada.
Configurar a recuperação do status MAD para ativo
Condição de configuração
Nenhum
Configurar a recuperação do status MAD para ativo
Tabela 2 -5 Configure a recuperação do status MAD para Ativo
| Etapa | Comando | Descrição |
| Entre no modo global | configure terminal | - |
| Configure a recuperação do status MAD para Ativo | mad restore | Obrigatório Por padrão, o status MAD muda para Ativo. |
Quando o status do MAD muda para Recuperação, para a porta e interface desabilitadas, o MAD não é processado. Quando o status MAD mudar para Ativo, basta habilitar a porta e a interface desabilitada porMAD.
MAD Monitoramento e Manutenção
Tabela 2 -6 Monitoramento e manutenção do MAD
| Comando | Descrição |
| show mad exclude recovery interface [ switchport | vlan ] | Exibir a porta reservada configurada |
| show mad fast-hello | Exibir as informações do MAD Fast-Hello |
| show mad lacp | Exibir as informações do MAD LACP |
| show mad status | Exibir o status MAD |
Exemplo de configuração típica do MAD
Configurar a função MAD LACP
Requisitos de rede
- Device0 e Device1 formam o sistema de empilhamento com Device0 como dispositivo de controle. PC1 acessa a rede IP através do sistema de empilhamento.
- Configure a função MAD LACP para que o PC1 possa acessar a rede IP normalmente após o Device1 ser separado do sistema de empilhamento devido à falha do canal VSL e os serviços não se tornarem anormais devido ao conflito de configuração da rede.
Topologia de rede

Figura 2 -1 Rede de configuração da função MAD LACP
Etapas de configuração
- Passo 1:Faça Device0 e Device1 formar o sistema de empilhamento com Device0 como o dispositivo de controle.
Omitido
- Passo 2:Configure a função MAD LACP no Device0.
# Crie VLAN2 no Device0, crie o grupo de agregação dinâmica 1, configure o tipo de link do grupo de agregação 1 como Trunk e permita que os serviços de VLAN2 passem.
Device0#configure terminalDevice0(config)#vlan 2Device0(config-vlan2)#exitDevice0(config)#link-aggregation 1 mode lacpDevice0(config)#link-aggregation 1Device0(config-link-aggregation1)#switchport mode trunkDevice0(config-link-aggregation1)#switchport trunk allowed vlan add 2Device0(config-link-aggregation1)#exit
# Em Device0, adicione a porta dez gigabitethernet0/0/1, dez gigabitethernet1/0/1 ao grupo de agregação 1.
Device0(config)#interface tengigabitethernet 0/0/1,1/0/1Device0(config-if-range)#link-aggregation 1 activeDevice0(config-if-range)#exit
# Habilite a função MAD LACP no grupo de agregação 1 do Device0.
Device0(config)#link-aggregation 1Device0(config-link-aggregation1)#mad enableDevice0(config-link-aggregation1)#exit
- Passo 3:Configurar dispositivo2.
#No Device2, crie a VLAN2 e configure o tipo de link da porta dez gigabitethernet0 /1, dez gigabitethernet0 /2, permitindo a passagem dos serviços da VLAN2.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exitDevice2(config)#interface tengigabitethernet 0/1,0/2Device2(config-if-range)#switchport mode trunkDevice2(config-if-range)#switchport trunk allowed vlan add 2Device2(config-if-range)#exit
# No Device2, desative a função spanning tree da porta dez gigabitethernet0/1, dez gigabitethernet 0/2.
Device2(config)#interface tengigabitethernet 0/1,0/2Device2(config-if-range)#no spanning-tree enableDevice2(config-if-range)#exit
- Passo 4:Confira o resultado.
# Visualize as informações do MAD LACP no Device0.
Device0#show mad lacp------------MAD-LACP INFORMATION--------------Link-aggregation Mad state----------------- -----------------1 enable
# Após Device1 ser separado do sistema de empilhamento devido à falha do canal VSL, o status MAD do sistema de empilhamento com Device0 como dispositivo de controle é Ativo e o status MAD do sistema de empilhamento com Device1 como dispositivo de controle é Recovery.
Device0#show mad statusMAD status: activeDevice1#show mad statusMAD status: recovery
#PC1 pode acessar a rede IP.
Configurar a função MAD Fast-Hello
Requisitos de rede
- Device0 e Device1 formam o sistema de empilhamento com Device0 como dispositivo de controle.
- Configure a função MAD Fast-Hello para que os serviços não se tornem anormais devido ao conflito de configuração de rede após Device1 ser dividido do sistema de empilhamento devido à falha do canal VSL.
Topologia de rede

Figura 2 -2 Rede de configuração do MAD Fast-Hello
Etapas de configuração
- Passo 1:Faça Device0 e Device1 formar o sistema de empilhamento com Device0 como o dispositivo de controle.
Omitido
- Passo 2:Configure a função MAD Fast-Hello no Device0.
# Crie VLAN2 no Device0 e configure como VLAN de controle do MAD Fast-Hello.
Device0#configure terminalDevice0(config)#vlan 2Device0(config-vlan2)#mad fast-hello control-vlanDevice0(config-vlan2)#exit
# No Device0, configure o tipo de link da porta gigabitethernet0/0/1,gigabitethernet1/0/1 como Trunk e adicione ao controle VLAN do MAD Fast-Hello.
Device0(config)#interface tengigabitethernet 0/0/1,1/0/1Device0(config-if-range)#switchport mode trunkDevice0(config-if-range)#mad fast-hello vlan 2Device0(config-if-range)#exit
# Desabilite a função spanning tree da porta gigabitethernet0/0/1, gigabitethernet1/0/1 no dispositivo0.
Device0(config)#interface tengigabitethernet 0/0/1,1/0/1Device0(config-if-range)#no spanning-tree enableDevice0(config-if-range)#exit
- Passo 3:Configurar dispositivo2.
# Crie VLAN2 no Device2, configure o tipo de link da porta gigabitethernet0 /1, gigabitethernet0 /2 como Trunk, e permita que os serviços de VLAN2 passem.
Device2#configure terminalDevice2(config)#vlan 2Device2(config-vlan2)#exitDevice2(config)#interface tengigabitethernet 0/1,0/2Device2(config-if-range)#switchport mode trunkDevice2(config-if-range)#switchport trunk allowed vlan add 2Device2(config-if-range)#exit
# Desabilite a função spanning tree da porta gigabitethernet0/1,gigabitethernet 0/2 no Device2.
Device2(config)#interface tengigabitethernet 0/1,0/2Device2(config-if-range)#no spanning-tree enableDevice2(config-if-range)#exit
- Passo 4:Confira o resultado.
# Visualize a habilitação do MAD Fast-Hello no Device0.
Device0#show mad fast-helloMAD Fast-Hello Information:Normal interval : 2000 ms(default: 2000)Aggressive interval : 500 ms(default: 500)Aggressive duration : 120 s (default: 120)Control vlan : 2-------------- -------------Interface Control vlan-------------- -------------te0/0/1 2te1/0/1 2
# Após Device1 ser separado do sistema de empilhamento devido à falha do canal VSL, o status MAD do sistema de empilhamento com Device0 como dispositivo de controle é Ativo e o status MAD do sistema de empilhamento com Device1 como dispositivo de controle é Recovery.
Device0#show mad statusMAD status: activeDevice1# show mad statusMAD status: recovery
MVST
Visão geral
Atualmente, a tecnologia VST (tecnologias de comutação virtual, que combina vários dispositivos físicos horizontais em um dispositivo virtual) tornou-se gradualmente uma tecnologia de rede necessária para LAN devido à sua alta confiabilidade e fácil gerenciamento. A tecnologia VST realiza o gerenciamento unificado de vários dispositivos em um mesmo nível, mas ainda existe o problema do gerenciamento descentralizado de dispositivos em rede multinível. Especialmente na LAN típica de duas camadas, a camada de acesso usa um grande número de dispositivos de acesso, que são grandes em número e fortes em dispersão, e precisam ser mantidos e gerenciados um por um. A gestão é muito trabalhosa. Além disso, atribuir um endereço IP a esses dispositivos consumirá muitos recursos de endereço IP, o que sem dúvida é um desperdício devido à atual escassez de recursos de endereço IP.
Para resolver os problemas acima, é proposta a tecnologia MVST (mix virtual switching technology). Conforme mostrado na figura abaixo, a camada central da LAN adota a tecnologia VST para virtualizar vários dispositivos em um dispositivo lógico, enquanto a tecnologia MVST (mix virtual switching technology) é usada verticalmente, o que torna todos os dispositivos da LAN virtuais como um dispositivo lógico. dispositivo, formando um domínio de gerenciamento unificado (domínio MVST). O domínio de gerenciamento fornece um endereço IP de gerenciamento para o exterior e fornece a capacidade de gerenciamento e acesso para cada dispositivo na LAN. Ele realmente percebe que "uma rede, uma máquina", uma rede, um IP e um dispositivo podem gerenciar facilmente toda a LAN, simplificando bastante o gerenciamento.
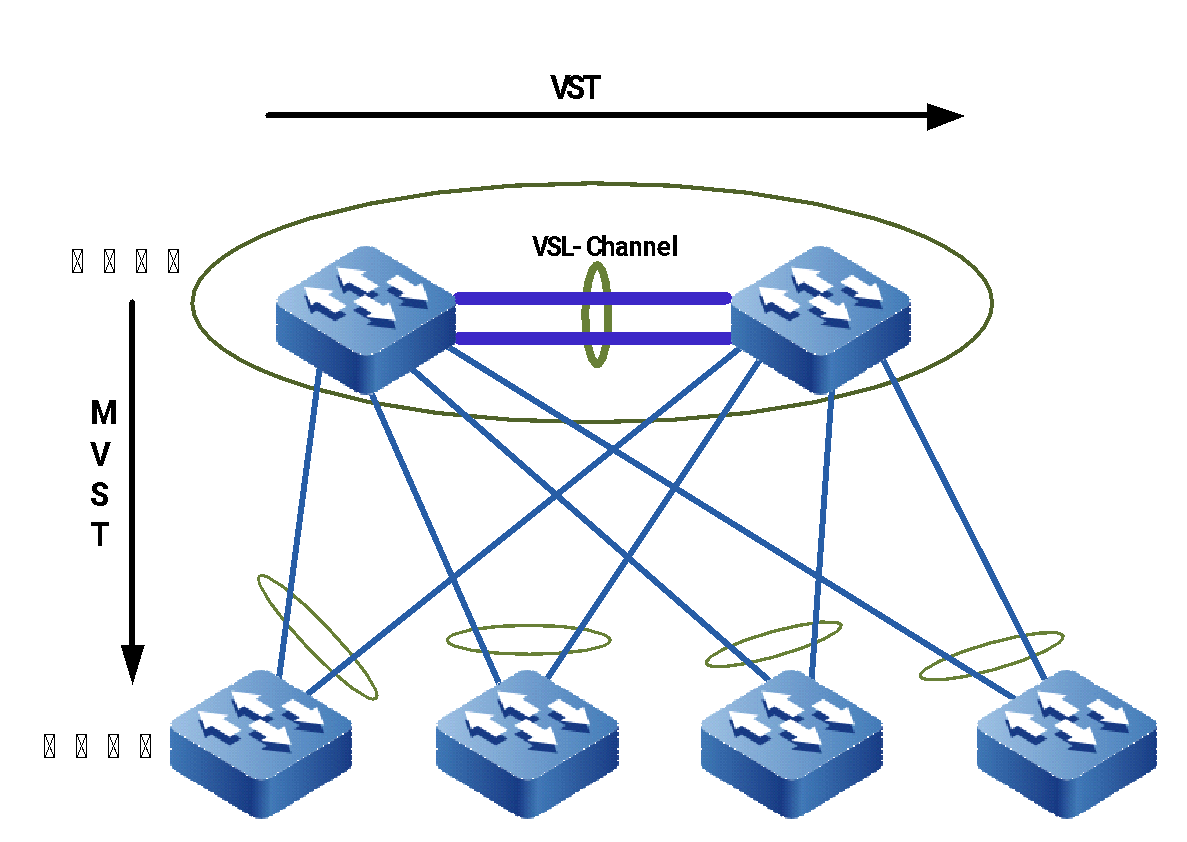
Figura 3 -1 visualização da rede física MVST
De acordo com a localização e função do dispositivo na LAN, o MVST define três funções de dispositivo:
- MVST ): Responsável por configurar, gerenciar e monitorar todos os dispositivos da LAN.
- Cartão estendido (slot MVST Slave): O cartão estendido na LAN, aceitando a configuração unificada e o gerenciamento do dispositivo mestre.
- Cartão candidato (MVST C andidate ): Não é adicionado ao domínio MVST, mas tem as condições de se tornar o cartão estendido.
O dispositivo mestre no domínio MVST descobre a placa estendida por meio do protocolo de detecção MVST, coleta as informações de cada placa estendida no domínio MVST por meio do protocolo de coleta de topologia MVST e desenha a visualização da topologia da LAN. O dispositivo mestre adiciona o dispositivo de acesso ao domínio MVST de acordo com a visualização da topologia.
Depois que o cartão estendido é adicionado ao domínio MVST, o usuário pode fazer login na interface de controle do dispositivo mestre através do endereço IP do dispositivo mestre, realizando o gerenciamento unificado de toda a LAN. Além da configuração e gerenciamento geral, a tecnologia MVST oferece as seguintes funções:
- Configuração do modelo
No cenário de aplicação, se alguma configuração pertencer à configuração básica pública e todas as placas estendidas no domínio MVST precisarem aplicar a configuração, você pode editar a configuração para o modelo de configuração e o dispositivo mestre entrega o modelo de configuração para a placa estendida, que completa a configuração básica pública.
- Configuração automática
O dispositivo mestre faz backup do arquivo de configuração de inicialização do cartão estendido para a mídia de armazenamento local. Quando a placa estendida falha e precisa ser substituída por uma nova placa estendida, a nova placa estendida não precisa de nenhuma configuração, mas acessa diretamente a LAN através de uma interface e o dispositivo mestre entrega automaticamente o arquivo de configuração de backup para a placa estendida. Desta forma, a placa estendida completa a configuração e a rede se recupera rapidamente.
- Configuração de uma chave
O dispositivo mestre pode habilitar as funções Dot1x, controle de tempestade, DHCP Snooping e Arp-check de todas as placas estendidas no domínio MVST por uma chave.
- Atualização automática
O dispositivo mestre prepara antecipadamente o IOS da placa estendida. Quando a placa estendida é adicionada ao domínio MVST, o dispositivo mestre detecta automaticamente se a versão em execução da placa estendida é consistente com a versão de atualização automática. Se não for consistente, o plano de fundo executa a atualização automática. Na interface visível do usuário, imprima as informações do log. Quando o cartão estendido é atualizado, o usuário ainda pode gerenciar o dispositivo mestre ou o cartão estendido.
- Gerenciamento dinâmico de senhas
No domínio MVST, as senhas de login de todas as placas estendidas são geradas dinamicamente pelo dispositivo mestre. Depois que o cartão estendido é adicionado ao domínio MVST com sucesso, o dispositivo mestre gera a senha dinâmica e entrega a senha ao cartão estendido. Se a placa estendida precisar fazer login via console diretamente durante a execução, a senha de login só poderá ser obtida pelo dispositivo mestre, reforçando a segurança da LAN.
Configuração da função MVST
Tabela 3 -1 lista de configuração da função MVST
| Tarefa de configuração | |
| Configurar funções básicas do MVST | Configurar o dispositivo mestre Configurar o cartão estendido |
| Configurar parâmetros MVST |
Configure o intervalo de envio do pacote de detecção
Configurar o tempo de idade do vizinho Configure o intervalo de atividade do cartão estendido Configure o tempo limite do status da conexão do cartão estendido Configurar os parâmetros de topologia |
| Configurar as funções do recurso MVST |
Configurar a função de atualização
Configurar a função de perfil Configurar a função de configuração de vinculação automática Configure a configuração individual Configurar a função do grupo de dispositivos Configurar a função de registro |
Configurar funções básicas do MVST
Ao esperar gerenciar os dispositivos em um domínio por meio da tecnologia MVST, o usuário pode configurar o MVST. Nas tarefas de configuração do MVST, primeiro habilite a função MVST para que a configuração da outra função tenha efeito.
Condição de configuração
Nenhum
Configurar dispositivo mestre
O dispositivo mestre é o centro nervoso do MVST. Ele fornece um canal de gerenciamento para o domínio MVST. O administrador gerencia os dispositivos do domínio especificado de forma unificada através do canal.
Tabela 3 -2 Configurar o dispositivo mestre
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função MVST | mvst enable | Obrigatório Por padrão, a função MVST está desabilitada. |
| Configure o dispositivo especificado como o dispositivo mestre do domínio MVST | mvst master | Obrigatório Por padrão, não especifique o dispositivo mestre. |
| Configurar o nome de domínio MVST | mvst domain-name domain-name | Opcional Por padrão, o nome de domínio MVST é mvst-1. |
| Crie a porta de agregação privada MVST | mvst link-aggregation | Crie a porta de agregação de link MVST |
| Adicionar os membros do grupo de agregação | mvst interface interface-name join link-aggregation link-aggregation-id active | uma porta membro ao grupo de agregação MVST |
| Entre no modo de configuração da interface Ethernet L2 | interface interface-name | Qualquer Depois de entrar no modo de configuração da interface Ethernet L2, a configuração subsequente entra em vigor apenas na porta atual. Depois de entrar no modo de configuração do grupo de agregação , a configuração subsequente entra em vigor apenas no grupo de agregação. |
| Entre no modo de configuração do grupo de agregação | link-aggregation link-aggregation-id | |
| Habilite a detecção de MVST na porta | mvst inspection | Obrigatório Por padrão, a função de detecção MVST da porta está desabilitada. |
Configurar cartão estendido
Ao esperar gerenciar um dispositivo via MVST, o usuário pode configurar o dispositivo como o cartão estendido do domínio MVST. Depois que o dispositivo de caixa habilita a função MVST, as duas últimas portas do dispositivo atual formam um grupo de agregação como a porta de uplink privada do MVST.
Tabela 3 -3 Configurar o cartão estendido
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Habilite a função MVST | mvst enable | Obrigatório Por padrão, a função MVST está desabilitada. |
Configurar parâmetros MVST
Condição de configuração
Antes de configurar os parâmetros do MVST, primeiro conclua a seguinte tarefa:
- Configurar o dispositivo mestre
Configurar o intervalo de envio do pacote de detecção
O dispositivo habilitado com a função MVST envia periodicamente o pacote de detecção para descobrir o dispositivo conectado e extrair as informações chave do pacote de detecção para formar sua própria tabela de informações do dispositivo vizinho.
Tabela 3 -4 Configure o intervalo de envio do pacote de detecção
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o intervalo de envio do pacote de detecção MVST | mvst inspection timer timer-value | Obrigatório Por padrão, o intervalo de envio do pacote de detecção MVST é de 10s. |
Configurar o tempo de idade do vizinho
O tempo de idade do vizinho indica o tempo de vida das informações do dispositivo local no dispositivo vizinho para que o dispositivo vizinho possa excluir as informações do dispositivo local após a chegada do tempo de vida do dispositivo local.
Tabela 3 -5 Configure o tempo de idade do vizinho
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o tempo de idade das informações do dispositivo local no dispositivo vizinho | mvst inspection aging-time aging-time-value | Obrigatório Por padrão, o tempo de duração das informações do dispositivo local no dispositivo vizinho é de 30 segundos. |
Configurar o intervalo Keepalive do cartão estendido
Depois que o cartão estendido é adicionado ao domínio MVST, o dispositivo mestre e o cartão estendido começam a trocar os pacotes de manutenção de atividade. Por padrão, o pacote keepalive é trocado a cada 8s. Se o dispositivo mestre não receber três pacotes keepalive do cartão estendido sucessivamente, altere o status Ativo do cartão estendido para o status Connect.
Tabela 3 -6 Configure o intervalo keepalive do cartão estendido
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o intervalo de atividade do cartão estendido | mvst handtime handtime-value | Obrigatório Por padrão, o intervalo keepalive do cartão estendido é 8s. |
Configurar o tempo limite do status de conexão do cartão estendido
Se o dispositivo mestre receber o pacote keepalive enviado pelo cartão estendido dentro do tempo válido do status de conexão, altere o status de Conexão do cartão estendido para o status Ativo. Se não estiver recebendo o pacote keepalive enviado pelo cartão estendido, altere o status Connect do cartão estendido para o status Disconnect.
O dispositivo mestre não envia mais o pacote keepalive para o cartão estendido no status Disconnect até receber novamente o pacote keepalive enviado pelo cartão estendido.
Tabela 3 -7 Configure o tempo limite do status de conexão da placa estendida
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o tempo limite de status de conexão do cartão estendido | mvst holdtime holdtime-value | Obrigatório Por padrão, o tempo limite do status de conexão da placa estendida é de 80 segundos. |
Configurar parâmetros de topologia
Após a configuração do domínio MVST, o dispositivo mestre coleta regularmente as informações de topologia de todo o domínio MVST por meio do pacote de solicitação de topologia. Quando o pacote de solicitação de topologia está se espalhando na rede, muitos dispositivos de rede receberão o pacote de solicitação de topologia ao mesmo tempo e enviarão o pacote de resposta de topologia, o que pode causar o bloqueio da rede. Para reduzir o fenômeno, a segunda porta começa a encaminhar o pacote de solicitação de topologia após o dispositivo mestre aguardar o tempo de atraso de cada porta encaminhando o pacote de solicitação de coleta de topologia ... ..até que a última porta complete o encaminhamento do pacote de solicitação de topologia.
Tabela 3 -8 Configurar os parâmetros de topologia
| Etapa | Comando | Descrição |
| modo de configuração global | configure terminal | - |
| Configurar o período de coleta de topologia | mvst topo hello-time hello-time-value | Obrigatório Por padrão, o período de coleta de topologia é de 30 segundos. |
| Configure o tempo de atraso da porta do dispositivo mestre que coleta a topologia | mvst topo port-delay-time port-delay-time-value | Opcional Por padrão, o tempo de atraso da porta do dispositivo mestre que coleta a topologia é de 100ms. |
Configurar funções MVST
Condição de configuração
Antes de configurar as funções do MVST, primeiro complete a seguinte tarefa:
- Configurar as funções básicas do MVST
Configurar a função de atualização
A função de atualização indica que o dispositivo mestre atualiza o arquivo espelho do sistema ou o arquivo Monitor da placa estendida.
Existem dois modos de atualização do arquivo espelho do sistema ou do arquivo Monitor da placa estendida:
- Atualização automática: Depois que a placa estendida é adicionada ao domínio MVST com sucesso, o dispositivo mestre detecta automaticamente se a versão em execução da placa estendida é consistente com a versão de atualização automática. Se não for consistente, atualize a placa estendida automaticamente.
- Atualização manual: O usuário atualiza o arquivo espelho do sistema ou o arquivo Monitor da placa estendida em tempo real através do modo de linha de comando de acordo com a demanda em tempo real.
Tabela 3 -9 Configurar a função de atualização
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar a atualização automática | mvst auto update image { path/image-name | image-name } [ ip-address { ftp user-name user-password | tftp } [reload [write ]] | Obrigatório Por padrão, nenhuma configuração de atualização automática. |
| Entre no modo de usuário privilegiado | exit | - |
| Configure a atualização do cartão estendido manualmente | mvst update slave-slot slave-slot-id { image | bootloader } { path/filename | filename } [ ip-address { ftp user-name user-password | tftp } [ reload ] | reload ]或 mvst update device-group device-group-id { image | bootloader } { path/filename | filename } [ ip-address { ftp user-name user-password | tftp } [ reload ] | reload ] | Opcional |
Antes de configurar a atualização automática, é necessário garantir que o arquivo de versão já exista.
Configurar a função de modelo
A função de modelo pode concluir a configuração e o gerenciamento do lote, o que é conveniente para a manutenção da rede. O usuário edita a configuração básica pública para um arquivo txt de acordo com os requisitos de operação e manutenção da rede e, em seguida, o dispositivo mestre entrega o arquivo ao cartão estendido. O cartão estendido completa a configuração básica pública.
Tabela 3 -10 Configurar a função de modelo
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Especifique o modelo de configuração | mvst configure template template-name | Obrigatório Por padrão, não especifique o modelo de configuração. |
| Configure o dispositivo mestre para entregar o modelo de configuração ao cartão estendido | mvst apply configure template {service-group service-group-id | slave-slot { slave-slot-id | all } } | Opcional |
Depois que o dispositivo mestre entregar o modelo de configuração ao cartão estendido, execute a gravação do slot escravo ou gravação do grupo de dispositivos comando para fazer com que todas as placas estendidas salvem as informações de configuração no arquivo de configuração de inicialização.
Configurar a função de configuração de ligação automática
O dispositivo mestre faz backup do arquivo de configuração de inicialização de todas as placas estendidas no domínio MVST para a mídia de armazenamento local por meio da configuração de vinculação automática. Quando o cartão estendido precisa ser alterado devido a falhas e outros motivos, o novo cartão estendido pode concluir a configuração automaticamente por meio do arquivo de configuração de inicialização de backup.
Tabela 3 -11 Configurar a função de configuração de vinculação automática
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure a porta para vincular com o arquivo de configuração de inicialização | mvst bind startup interface {interface-list | link-aggregation link-aggregation-id} | all | Obrigatório Por padrão, a porta não está vinculada ao arquivo de configuração de inicialização. |
Configurar configuração individual
As placas estendidas no domínio MVST terão diferentes serviços de rede devido ao ambiente de rede, portanto, a configuração da placa estendida precisa ser individual . O administrador pode fazer login na interface de configuração virtual do cartão estendido por meio do dispositivo mestre e concluir o gerenciamento de configuração do cartão estendido.
Tabela 3 -12 Configure a configuração individual
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o cartão estendido | configure slave-slot slave-slot-id | Obrigatório Faça login na interface de configuração virtual do cartão estendido |
| Entre no modo de usuário privilegiado | exit | - |
| Configure o cartão estendido para salvar as informações de configuração atuais no arquivo de configuração de inicialização | write slave-slot slave-slot-id | Opcional |
Configurar a função do grupo de dispositivos
Quando todas as placas estendidas no grupo de dispositivos precisam realizar a mesma função, você pode configurar o grupo de dispositivos para realizar o gerenciamento de configuração em lote. O administrador pode fazer login na interface de configuração virtual da amostra de configuração do grupo de dispositivos por meio do dispositivo mestre e concluir o gerenciamento de configuração do grupo de dispositivos.
Tabela 3 -13 Configurar a função do grupo de dispositivos
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o grupo de dispositivos | configure device-group device-group-id slave-slot slave-slot-id | Obrigatório O administrador efetua login na interface de configuração virtual da amostra de configuração do grupo de dispositivos. |
| Entre no privilegiado modo de usuário | exit | - |
| Configure todas as placas estendidas no grupo de dispositivos para salvar as informações de configuração atuais no arquivo de configuração de inicialização | write device-group { device-group-id | all } | Opcional |
Configurar a Função do Grupo de Serviços
Quando todos os cartões estendidos no grupo de serviço precisam atingir a mesma função, o gerenciamento de configuração em lote pode ser concluído configurando o grupo de serviço, como configurar o mesmo modelo de configuração. O administrador pode efetuar login na interface do grupo de serviços por meio do dispositivo de gerenciamento para gerenciar a configuração do grupo de serviços.
Tabela 3 -14 Configurar a função do grupo de serviço
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o grupo de serviço | mvst service-group device-group-id | Mandatório _ C rie e insira o grupo de serviço |
| Anúncio do membro | In the service configuration mode slave-slot slave-slot-id | Mandatório _ cartão estendido ao grupo de serviço |
| Especifique o modelo de configuração do grupo de serviço | configure template /flash/filepath | opcional _ Especifique todas as placas estendidas no grupo de serviço para executar o mesmo modelo de configuração |
| Entre no modo de usuário privilegiado | exit | - |
Configurar a função de registro
A função de registro do MVST indica que o cartão estendido envia as informações de registro do dispositivo local para o dispositivo mestre. O administrador pode modificar o tom do nível de log enviado pelo cartão estendido ao dispositivo mestre de acordo com os requisitos do ambiente de rede.
Tabela 3 -15 Configurar a função de log
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o nível de log enviado pelo cartão estendido ao dispositivo mestre | mvst slave-slot logging [ logging-level1 logging-level2 ] | Obrigatório Por padrão, o nível de log enviado pelo cartão estendido ao dispositivo mestre é 0-5. |
Monitoramento e manutenção de MVST
Tabela 3 -16 Monitoramento e manutenção do MVST
| Comando | Descrição |
| show mvst auto-update config | Exibir as informações de configuração de atualização automática |
| show mvst device-group [device-group-id ] | Exibe as informações de execução de configuração do grupo de dispositivos especificado |
| show mvst servcie-group [servcie -group-id ] | Exiba o grupo de serviço e especifique as informações do grupo de serviço |
| show mvst inspection | Exibir as informações do vizinho do dispositivo |
| show mvst inspection opened | Exibe a porta habilitada com a função de detecção MVST |
| show mvst inspection queue | Exibir as informações da fila de detecção do MVST |
| show mvst slave-slot | Exibir as informações do cartão estendido no domínio MVST |
| show mvst slave-slot slave-slot-id command | Exibe algumas informações principais de execução do cartão estendido especificado |
| show mvst slave-slot logging | Exibe o tom do nível de log enviado pelo cartão estendido ao mestre |
| show mvst slave-slot password | Exibir a tabela de senhas de login do cartão estendido |
| show mvst slave-slot { slave-slot-id use–info | use-info } | Exibir as informações de uso do número do cartão estendido |
| show mvst startup bind info | Exibir as informações de ligação de porta |
| show mvst statistics | Exibe as informações estatísticas dos pacotes MVST enviados e recebidos |
| show mvst summary | Exibir as informações abstratas do domínio MVST |
| show mvst topo config | Exibir as informações de configuração dos parâmetros de topologia |
| show mvst topo information [ slave-slot slave-slot-id ] | Exibir as informações de topologia |
| show mvst tunnel | Exiba as informações do canal entre o dispositivo mestre e a placa estendida no domínio MVST |
| show mvst upgrade-information { device-group device-group-id | slave-slot { all | slave-slot-id } } | Exibir as informações de status de atualização do cartão estendido |
| show mvst write-information device-group { { device-group-id | all } | slave-slot slave-slot-id } | Exibe as informações de status do cartão estendido salvando a configuração atual |
| show running-config slave-slot slave-slot-id | Exibe as informações de configuração atuais do cartão estendido |
| show startup-config slave-slot slave-slot-id | Exiba o conteúdo do arquivo de configuração de inicialização do cartão estendido |
Exemplo de configuração típica do MVST
Configurar atualização de detecção automática
Requisito de rede
- Device1 e Device2 formam o sistema de empilhamento e servem como dispositivo mestre MVST; Device3, Device 4 e Device 5 servem como placa estendida e as últimas portas da placa estendida são conectadas ao dispositivo mestre MVST.
- O dispositivo mestre configura a atualização de detecção automática. Quando Device 3 , Device 4 e Device5 são adicionados ao domínio MVST como a placa estendida, a placa estendida pode ser atualizada automaticamente.
Topologia de rede

Figura 3 -2 Configurar a atualização de detecção automática
Etapas de configuração
- Passo 1:Configure o sistema VST.
# No Device1 , configure o número do dispositivo membro do switch virtual para 1 e o número do domínio para 10 e a prioridade para 255.
Device1#configure terminalDevice1(config)#switch virtual member 1Do you want to modify member id(Yes|No)?y% Member ID 1 config will take effect only after the exec command 'switch mode virtual' is issuedDevice1(config-vst-member-1)#domain 10% Domain ID 10 config will take effect only after the exec command 'switch mode virtual' is issuedDevice1(config-vst-member-1)#priority 255Device1(config-vst-member-1)#exit
# No Device1, crie a interface de link de switch virtual 1 e adicione as portas tentengigabitethernet 0/1 e tentengigabitethernet 0/2 à interface de link de switch virtual 1 .
Device1(config)#vsl-channel 1Device1(config-vsl-channel-1)#exitDevice1(config)#interface tentengigabitethernet 0/1Device1(config-if-tentengigabitethernet0/1)#vsl-channel 1 mode onDevice1(config-if-tentengigabitethernet0/1)#exitDevice1(config)#interface tentengigabitethernet 0/2Device1(config-if-tentengigabitethernet0/2)#vsl-channel 1 mode onDevice1(config-if-tentengigabitethernet0/2)#exit
# No Dispositivo 1, salve a configuração.
Device1#writeAre you sure to overwrite /flash/startup (Yes|No)?yBuilding Configuration...doneWrite to startup file ... OKWrite to mode file... OK
# No Device2 , configure o número do dispositivo membro do switch virtual para 2 e o número do domínio para 10 e a prioridade para 200.
Device2#configure terminalDevice2(config)#switch virtual member 2Do you want to modify member id(Yes|No)?y% Member ID 2 config will take effect only after the exec command 'switch mode virtual' is issuedDevice2(config-vst-member-2)#domain 10% Domain ID 10 config will take effect only after the exec command 'switch mode virtual' is issuedDevice2(config-vst-member-2)#priority 200Device2(config-vst-member-2)#exit
# No Device2 , crie a interface de link de switch virtual 1 e adicione a porta tentengigabitethernet1/1 à interface de link de switch virtual 1.
Device2(config)#vsl-channel 1Device2(config-vsl-channel-1)#exitDevice2(config)#interface tentengigabitethernet 0/1Device2(config-if-tentengigabitethernet0/1)#vsl-channel 1 mode onDevice2(config-if-tentengigabitethernet0/1)#exitDevice2(config)#interface tentengigabitethernet 0/2Device2(config-if-tentengigabitethernet0/2)#vsl-channel 1 mode onDevice2(config-if-tentengigabitethernet0/2)#exit
# No Device2 , salve a configuração.
Device2#writeAre you sure to overwrite /flash/startup (Yes|No)?yBuilding Configuration...doneWrite to startup file ... OKWrite to mode file... OK
# Configurar o modo de execução do Device1 para o modo de empilhamento.
Device1#switch mode virtualThis command will convert all interface names to naming convention "interface-type member-number/slot/interface" ,Please make sure to save current configuration.Do you want to proceed? (yes|no)?yConverting interface names Building configuration...Copying the startup configuration to backup file named "startup-backupalone"...Please wait...system reloading is in progress!okReset system!%SYS-5-RELOAD: Reload requested
# Configurar o modo de execução do Device2 para o modo de empilhamento.
Device2#switch mode virtualThis command will convert all interface names to naming convention "interface-type member-number/slot/interface" ,Please make sure to save current configuration.Do you want to proceed? (yes|no)?yConverting interface names Building configuration...Copying the startup configuration to backup file named "startup-backupalone"...Please wait...system reloading is in progress!okReset system!%SYS-5-RELOAD: Reload requested
# Após a reinicialização, vista em Device1, o sistema de empilhamento é formado, e Device1 é o dispositivo mestre do sistema de empilhamento.
Device1#show switch virtualCodes: L - local-device,I - isolate-deviceVirtual Switch Mode : VIRTUALVirtual Switch DomainId : 10Virtual Switch mac-address : 0001.7a6a.0255--------------- VST MEMBER INFORMATION ------------------CODE MemberID Role Pri LocalVsl RemoteVsl------------------------------------------------------------------------------L 1 Master 255 vsl-channel 1/1 vsl-channel 2/12 Member 200 vsl-channel 2/1 vsl-channel 1/1
- Passo 2:Configurar as funções básicas do MVST.
#No Device1, configure o sistema de empilhamento como o dispositivo de gerenciamento MVST.
Device1(config)#mvst enable%MVST-NOTIFY-5: MVST is enabled !Device1(config)#mvst masterDevice1(config)#mvst domain-name test
# No Device1 , configure a agregação de links do sistema de empilhamento e habilite a detecção de MVST.
Device1(config)#mvst link-aggregation 1 mode lacpDevice1(config)# mvst interface tengigabitethernet 1/1/1,2/1/1 join link-aggregation 1 activeDevice1(config)#interface link-aggregation 1Device1(config-link-aggregation1)#mvst inspectionDevice1(config-link-aggregation1)#exitDevice1(config)#mvst link-aggregation 2 mode lacpDevice1(config)# mvst interface tengigabitethernet 1/1/2,2/1/2 join link-aggregation 2 activeDevice1(config)#interface link-aggregation 2Device1(config-link-aggregation2)#mvst inspectionDevice1(config-link-aggregation2)#exitDevice1(config)#mvst link-aggregation 3 mode lacpDevice1(config)# mvst interface tengigabitethernet 1/1/3,2/1/3 join link-aggregation 3 activeDevice1(config)#interface link-aggregation 3Device1(config-link-aggregation3)#mvst inspectionDevice1(config-link-aggregation3)#exit
# No Device3 , habilite a função MVST.
Device3#configure terminalDevice3#configure terminalDevice3(config)#mvst enable%MVST-NOTIFY-5: MVST is enabled !Device3(config)#mvst link-aggregation 1 mode lacpDevice3(config)# mvst interface tengigabitethernet 2/1,2/2 join link-aggregation 1 activeDevice3(config)#interface link-aggregation 1Device3(config-link-aggregation1)#mvst inspectionDevice3(config-link-aggregation1)#exit%MVST-NOTIFY-5: interface tengigabitethernet2/1 and interface tengigabitethernet2/2 join link-aggregation 1 successfully.
# No Device4 , habilite a função MVST.
Device4#configure terminalDevice4(config)#mvst enable%MVST-NOTIFY-5: MVST is enabled !Device4(config)#mvst link-aggregation 2 mode lacpDevice4(config)# mvst interface tengigabitethernet 2/1,2/2 join link-aggregation 2 activeDevice4(config)#interface link-aggregation 2Device4(config-link-aggregation2)#mvst inspectionDevice4(config-link-aggregation2)#exit%MVST-NOTIFY-5: interface tengigabitethernet2/1 and interface tengigabitethernet2/2 join link-aggregation 2 successfully.
# No Device5 , habilite a função MVST.
Device5#configure terminalDevice5(config)#mvst enable%MVST-NOTIFY-5: MVST is enabled !Device5(config)#mvst link-aggregation 3 mode lacpDevice5(config)# mvst interface tengigabitethernet 2/1,2/2 join link-aggregation 3 activeDevice5(config)#interface link-aggregation 3Device5(config-link-aggregation3)#mvst inspectionDevice5(config-link-aggregation3)#exit%MVST-NOTIFY-5: interface tengigabitethernet2/1 and interface tengigabitethernet2/2 join link-aggregation 3 successfully.
- Passo 3:Configure a detecção de atualização automática.
#No Device1, configure a detecção de atualização automática, especifique a versão de atualização da placa estendida e adicione os parâmetros clear, reload e write.
Device1(config)# mvst auto update image /flash/sp26-g-9.6.0.1(R).pck reload write# No Device1 , verifique o resultado da configuração.
----------------------------------------------------------------------------------------------------------------OPTION Codes:R -- Reload slave slot when update slave slot successfullyW -- Save slave slot current configuration to startup-config--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ID OPTION IMAGE-NAME IMAGE-PATH----------------------------------------------------------------------------------------------------------------1 None sp25-g-9.6.1.1(R).pck /flash/sp25-g-9.6.1.1(R).pck2 R sp23-g-9.6.1.1(R).pck /flash/sp23-g-9.6.1.1(R).pck3 RW sp26-g-9.6.0.1(R).pck /flash/sp26-g-9.6.0.1(R).pck
- Passo 4:Conecte as placas estendidas Device3 , Device4 e Device5 ao domínio MVST e detecte que a versão de Device3 não é consistente com a versão de atualização, portanto, atualize automaticamente. Se detectar que as versões de Device4 e Device5 são consistentes, não atualize automaticamente.
#Conecte Device3, Device4 e Device5 ao domínio MVST e, em seguida, verifique o resultado do MVST no Device1.
#Verifique os resultados do MVST no Device1. Você pode ver que Device3, Device4 e Device5 ingressam no domínio MVST na forma de um cartão estendido. Os slots são Slave-slot0, Slave-slot1 e Save-slot2, e seus nomes de host mudam para switch-ss0, switch-ss1 e switch-ss2.
Device1#show mvst topo information---------------------------------------------------------------------------------------------------------------------------------role domain-name interface mac device-type host-name---------------------------------------------------------------------------------------------------------------------------------Slave-slot test link-aggregation 1 0001.7a63.bd76 NSS4330-56TXF(V1) switch-ss0Slave-slot test link-aggregation 2 0001.7a64.72aa NSS4330-56TXF(V1) switch-ss1Slave-slot test link-aggregation 3 0001.7a63.bd43 NSS4330-56TXF(V1) switch-ss2Master test 0001.7a6a.0258 NSS5810-50TXFP(V1) Device1
#O status de atualização do cartão estendido pode ser verificado em tempo real no Device1. Device3 está no estado de atualização. Após a atualização do Device3 ser bem-sucedida, o sistema é reiniciado, mas Device4 e Device5 não são atualizados.
Device1#show mvst upgrade-information slave-slot allSlave slot upgrade information:---------------------------------------------------------------------------------------------------------------------------------ss-id upgrade-type upgrade-status start-time over-time hostname---------------------------------------------------------------------------------------------------------------------------------0 image downloading JAN/27/2015 14:58:24 switch-ss0 1 none none switch-ss1 2 none none switch-ss2
#O dispositivo foi atualizado com sucesso. Salve a configuração e reinicie.
Device1#%MVST-UPDATE_NOTIFY-5: Update slave slot 0 image successfully.%MVST-WRITE_RESULT-5: The slave slot 0 write to startup file successfully.%MVST-NOTIFY_RELOAD-3: Slave slot 0 mpu is going to reload.
Configurar entrega automática de modelo público
Requisitos de rede
- Device1 e Device2 formam o sistema de empilhamento e servem como dispositivo de gerenciamento MVST, e Device 3, Device 4 e Device 5 são usados como placas estendidas, e as duas últimas portas da placa estendida são conectadas ao dispositivo de gerenciamento MVST;
- Configure Device3 como um switch de modelo e sua configuração serve como uma configuração de modelo público. Quando Device4 e Device5 estiverem conectados ao domínio MVST, entregue automaticamente o modelo de configuração;
- Altere a configuração de Devce3, colete-a como modelo de configuração pública e force a distribuição para Device4 e Device5.
Topologia de rede
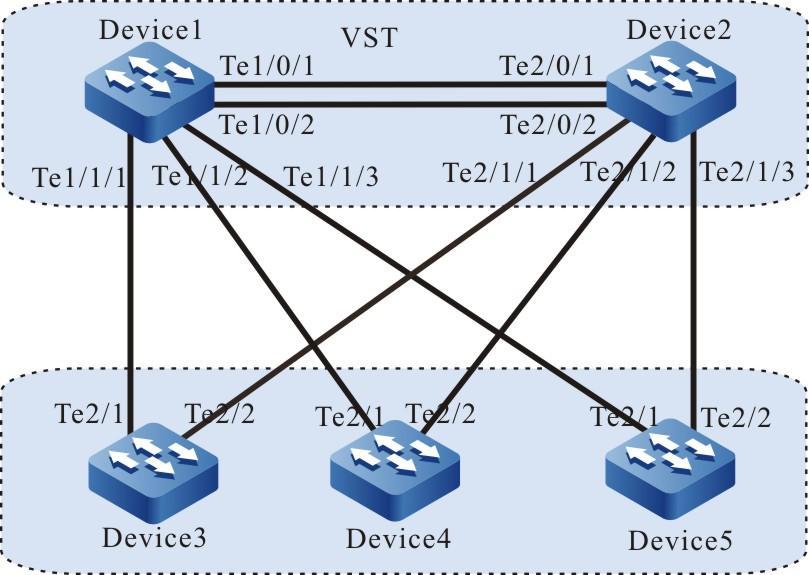
Figura 3 -3 Configure a entrega automática do modelo público
Etapas de configuração
- Passo 1:Configurar o sistema VST.
# No Device1 , configure o No. do dispositivo membro do switch virtual como 1, e o No. do domínio como 10, e a prioridade como 255.
Device1#configure terminalDevice1(config)#switch virtual member 1Do you want to modify member id(Yes|No)?y% Member ID 1 config will take effect only after the exec command 'switch mode virtual' is issuedDevice1(config-vst-member-1)#domain 10% Domain ID 10 config will take effect only after the exec command 'switch mode virtual' is issuedDevice1(config-vst-member-1)#priority 255Device1(config-vst-member-1)#exit
# No Device1, crie a interface de link de switch virtual 1 e adicione as portas tentengigabitethernet 0/1 e tentengigabitethernet 0/2 à interface de link de switch virtual 1 .
Device1(config)#vsl-channel 1Device1(config-vsl-channel-1)#exitDevice1(config)#interface tentengigabitethernet 0/1Device1(config-if-tentengigabitethernet0/1)#vsl-channel 1 mode onDevice1(config-if-tentengigabitethernet0/1)#exitDevice1(config)#interface tentengigabitethernet 0/2Device1(config-if-tentengigabitethernet0/2)#vsl-channel 1 mode onDevice1(config-if-tentengigabitethernet0/2)#exit
# No Device1 , salve a configuração.
Device1#writeAre you sure to overwrite /flash/startup (Yes|No)?yBuilding Configuration...doneWrite to startup file ... OKWrite to mode file... OK
# No Device2 , configure o nº do dispositivo membro do switch virtual como 2, o nº do domínio como 10 e a prioridade como 200.
Device2#configure terminalDevice2(config)#switch virtual member 2Do you want to modify member id(Yes|No)?y% Member ID 2 config will take effect only after the exec command 'switch mode virtual' is issuedDevice2(config-vst-member-2)#domain 10% Domain ID 10 config will take effect only after the exec command 'switch mode virtual' is issuedDevice2(config-vst-member-2)#priority 200Device2(config-vst-member-2)#exit
# No Device2 , crie a interface de link de switch virtual 1 e adicione a porta tentengigabitethernet1/ 1 à interface de link de switch virtual 1.
Device2(config)#vsl-channel 1Device2(config-vsl-channel-1)#exitDevice2(config)#interface tentengigabitethernet 0/1Device2(config-if-tentengigabitethernet0/1)#vsl-channel 1 mode onDevice2(config-if-tentengigabitethernet0/1)#exitDevice2(config)#interface tentengigabitethernet 0/2Device2(config-if-tentengigabitethernet0/2)#vsl-channel 1 mode onDevice2(config-if-tentengigabitethernet0/2)#exit
#No Device2, salve a configuração.
Device2#writeAre you sure to overwrite /flash/startup (Yes|No)?yBuilding Configuration...doneWrite to startup file ... OKWrite to mode file... OK
# Configurar o modo de execução do Device1 como modo de empilhamento.
Device1#switch mode virtualThis command will convert all interface names to naming convention "interface-type member-number/slot/interface" ,Please make sure to save current configuration.Do you want to proceed? (yes|no)?yConverting interface names Building configuration...Copying the startup configuration to backup file named "startup-backupalone"...Please wait...system reloading is in progress!okReset system!%SYS-5-RELOAD: Reload requested
# Configurar o modo de execução do Device2 como modo de empilhamento.
Device2#switch mode virtualThis command will convert all interface names to naming convention "interface-type member-number/slot/interface" ,Please make sure to save current configuration.Do you want to proceed? (yes|no)?yConverting interface names Building configuration...Copying the startup configuration to backup file named "startup-backupalone"...Please wait...system reloading is in progress!okReset system!%SYS-5-RELOAD: Reload requested
# Visualize Device1 , o sistema de empilhamento é formado, e Device1 é o dispositivo mestre do sistema de empilhamento.
Device1#show switch virtualCodes: L - local-device,I - isolate-deviceVirtual Switch Mode : VIRTUALVirtual Switch DomainId : 10Virtual Switch mac-address : 0001.7a6a.0255--------------- VST MEMBER INFORMATION ------------------CODE MemberID Role Pri LocalVsl RemoteVsl----------------------------------------------------------------------------L 1 Master 255 vsl-channel 1/1 vsl-channel 2/12 Member 200 vsl-channel 2/1 vsl-channel 1/1
- Passo 2: Configurar as funções básicas do MVST.
# Configurar o sistema de empilhamento como dispositivo de gerenciamento MVST.
Device1(config)#mvst enable%MVST-NOTIFY-5: MVST is enabled !Device1(config)#mvst masterDevice1(config)#mvst domain-name test
# Configurar a agregação de links do sistema de empilhamento e habilitar a detecção de MVST.
Device1(config)#mvst link-aggregation 1 mode lacpDevice1(config)# mvst interface tengigabitethernet 1/1/1,2/1/1 join link-aggregation 1 activeDevice1(config)#interface link-aggregation 1Device1(config-link-aggregation1)#mvst inspectionDevice1(config-link-aggregation1)#exitDevice1(config)#mvst link-aggregation 2 mode lacpDevice1(config)# mvst interface tengigabitethernet 1/1/2,2/1/2 join link-aggregation 2 activeDevice1(config)#interface link-aggregation 2Device1(config-link-aggregation2)#mvst inspectionDevice1(config-link-aggregation2)#exitDevice1(config)#mvst link-aggregation 3 mode lacpDevice1(config)# mvst interface tengigabitethernet 1/1/3,2/1/3 join link-aggregation 3 activeDevice1(config)#interface link-aggregation 3Device1(config-link-aggregation3)#mvst inspectionDevice1(config-link-aggregation3)#exit
# No Device3 , habilite a função MVST.
Device3#configure terminalDevice3#configure terminalDevice3(config)#mvst enable%MVST-NOTIFY-5: MVST is enabled !Device3(config)#mvst link-aggregation 1 mode lacpDevice3(config)# mvst interface tengigabitethernet 2/1,2/2 join link-aggregation 1 activeDevice3(config)#interface link-aggregation 1Device3(config-link-aggregation1)#mvst inspectionDevice3(config-link-aggregation1)#exit%MVST-NOTIFY-5: interface tengigabitethernet2/1 and interface tengigabitethernet2/2 join link-aggregation 1 successfully.
# No Device4 , habilite a função MVST.
Device4#configure terminalDevice4(config)#mvst enable%MVST-NOTIFY-5: MVST is enabled !Device4(config)#mvst link-aggregation 2 mode lacpDevice4(config)# mvst interface tengigabitethernet 2/1,2/2 join link-aggregation 2 activeDevice4(config)#interface link-aggregation 2Device4(config-link-aggregation2)#mvst inspectionDevice4(config-link-aggregation2)#exit%MVST-NOTIFY-5: interface tengigabitethernet2/1 and interface tengigabitethernet2/2 join link-aggregation 2 successfully.
# No dispositivo5, habilite a função MVST .
Device5#configure terminalDevice5(config)#mvst enable%MVST-NOTIFY-5: MVST is enabled !Device5(config)#mvst link-aggregation 3 mode lacpDevice5(config)# mvst interface tengigabitethernet 2/1,2/2 join link-aggregation 3 activeDevice5(config)#interface link-aggregation 3Device5(config-link-aggregation3)#mvst inspectionDevice5(config-link-aggregation3)#exit%MVST-NOTIFY-5: interface tengigabitethernet2/1 and interface tengigabitethernet2/2 join link-aggregation 3 successfully.
#Adicione Device3 ao domínio MVST como um cartão estendido. Verifique os resultados do MVST no Device1 depois que o dispositivo for adicionado.
#Verifique os resultados do MVST no Device1. Você pode ver que Device3 se junta ao domínio MVST na forma de um cartão estendido. Seu slot é Slave-slot0 e seu nome de host muda para switch-ss0.
Device1#show mvst topo information--------------------------------------------------------------------------------------------------------------------------------role domain-name interface mac device-type host-name--------------------------------------------------------------------------------------------------------------------------------Slave-slot test link-aggregation 1 0001.7a63.bd76 NSS4330-56TXF(V1) switch-ss0Master test 0001.7a6a.0258 NSS5810-50TXFP(V1) Device1
- Passo 3: Tome Device3 como o switch de modelo e colete o modelo de configuração pública.
#Configurar Device3.
Device1(config)#configure slave-slot 0switch-ss0(config)#snmp-server host 1.1.1.1switch-ss0(config)#snmp-server start%SNMP-WARMSTART-5 SNMP agent on host switch-ss0 is undergoing a warm startswitch-ss0(config)#snmp-server enable traps vlanswitch-ss0(config)#link-aggregation 1switch-ss0(config-link-aggregation1)#description management linkswitch-ss0(config-link-aggregation1)#exitswitch-ss0(config)#vlan 100,200,300
#No Device1, verifique a configuração do cartão estendido Device3.
Device1#show running-config slave-slot 0hostname switch-ss0vlan 100,200,300link-aggregation 1description management linkno spanning-tree enablemvst inspectionexitsnmp-server startsnmp-server view default 1.2 includesnmp-server view default 1.0.8802 includesnmp-server view default 1.1.2 includesnmp-server view default 1.3.111 includesnmp-server view default 1.3.6.1 includesnmp-server community public view default rosnmp-server enable traps vlansnmp-server host 1.1.1.1 traps community public version 2
# No Device1, salve a configuração do Device3 .
Device1#write slave-slot 0Are you sure to overwrite slave slot 0 /flash/startup (Yes|No)?yDevice1#Jan 9 2015 16:32:34: %MVST-WRITE_RESULT-5: The slave slot 0 write to startup file successfully.
- Passo 4:Use a configuração do Device3 como o modelo de configuração pública para entregar automaticamente .
#On Device1, configure a configuração pública para entregar automaticamente.
Device1(config)#mvst configure template slave-slot 0Are you sure to overwrite configure template /flash/mvst-template (Yes|No)?yGet the slave slot 0 startup-config...OKWrite to /flash/mvst-template ....OK.Device1(config)#
- Passo 5: Adicione o cartão estendido ao domínio MVST para carregar o modelo de configuração automaticamente.
#Conecte o cartão estendido Device4 e Device5 ao domínio MVST, e você poderá ver as informações de impressão da entrega automática do modelo de configuração no Device1.
Device1#%MVST-Slave_slot_add-5:Slave slot 1 add to the MVST%MVST-Slave_slot_add-5:Slave slot 2 add to the MVST.%MVST-EXECUTE_COFNIG-5:Slave slot 1 is going to execute configure template /flash/mvst-template.%MVST-EXECUTE_COFNIG-5:Slave slot 1 execute configure file successfully!%MVST-EXECUTE_COFNIG-5:Slave slot 2 is going to execute configure template /flash/mvst-template.%MVST-EXECUTE_COFNIG-5:Slave slot 2 execute configure file successfully!
# Em Device1, verifique o resultado do MVST e os nomes de host de Device4 e Device5 são adicionados com o sufixo ss1 e ss2, ou seja, switch-ss1 e switch-ss2 .
Device1#show mvst topo information--------------------------------------------------------------------------------------------------------------------------------role domain-name interface mac device-type host-name---------------------------------------------------------------------------------------------------------------------------------Slave-slot test link-aggregation 1 0001.7a63.bd76 NSS4330-56TXF(V1) switch-ss0Slave-slot test link-aggregation 2 0001.7a64.72aa NSS4330-56TXF(V1) switch-ss1Slave-slot test link-aggregation 3 0001.7a63.bd43 NSS4330-56TXF(V1) switch-ss2Master test 0001.7a6a.0258 NSS5810-50TXFP(V1) Device1
#On Device1, verifique a configuração do Device4, e a configuração é entregue com sucesso.
Device1#show running-config slave-slot 1hostname switch-ss1vlan 100,200,300link-aggregation 1description management linkno spanning-tree enablemvst inspectionexitsnmp-server startsnmp-server view default 1.2 includesnmp-server view default 1.0.8802 includesnmp-server view default 1.1.2 includesnmp-server view default 1.3.111 includesnmp-server view default 1.3.6.1 includesnmp-server community public view default rosnmp-server enable traps vlansnmp-server host 1.1.1.1 traps community public version 2
#On Device1, verifique a configuração do Device5, e a configuração é entregue com sucesso.
Device1#show running-config slave-slot 2hostname switch-ss2vlan 100,200,300link-aggregation 1description management linkno spanning-tree enablemvst inspectionexitsnmp-server startsnmp-server view default 1.2 includesnmp-server view default 1.0.8802 includesnmp-server view default 1.1.2 includesnmp-server view default 1.3.111 includesnmp-server view default 1.3.6.1 includesnmp-server community public view default rosnmp-server enable traps vlansnmp-server host 1.1.1.1 traps community public version 2
- Passo 6: Forçar a entrega do modelo de configuração pública.
#Modifique a configuração do Device3 e adicione a configuração ACL.
Device1(config)#configure slave-slot 0switch-ss0(config)#ip access-list extended testswitch-ss0(config-ext-nacl)#permit ip 192.168.0.1 0.0.0.255 anyswitch-ss0(config-ext-nacl)#permit ip any anyswitch-ss0(config-ext-nacl)#exitswitch-ss0(config)#endswitch-ss0#show access-listip access-list extended test10 permit ip 192.168.0.0 0.0.0.255 any20 permit ip any any
# No Device1, salve a configuração do Device3 .
Device1#write slave-slot 0Are you sure to overwrite slave slot 0 /flash/startup (Yes|No)?yDevice1#%MVST-WRITE_RESULT-5: The slave slot 0 write to startup file successfully.%MVST-COLLECT_STARTUP-5: Collect slave slot 0 startup begin.%MVST-COLLECT_STARTUP-5: Collect slave slot 0 startup OK.
#No Debive 1, Device3 como o novo modelo de configuração pública.
Device1(config)#mvst configure template slave-slot 0Are you sure to overwrite configure template /flash/mvst-template (Yes|No)?yGet the slave slot 0 startup-config...OKWrite to /flash/mvst-template ....OK.
# Em Device1, força a distribuição do template de configuração pública para Device4, e há a informação de impressão de distribuição bem sucedida.
Device1(config)#mvst apply configure template slave-slot 1%MVST-EXECUTE_COFNIG-5: Slave slot 1 is going to execute configure template /flash/ mvst-template%MVST-EXECUTE_COFNIG-5: Slave slot 1 execute configure file successfully!
#Verifique se a configuração do Device4 contém a configuração ACL mais recente.
Device1(config)#configure slave-slot 1switch-ss1#show access-listip access-list extended test10 permit ip 192.168.0.0 0.0.0.255 any20 permit ip any any
Configurar configuração de entrega automática vinculada
Requisitos de rede
- Device1 e Device2 formam o sistema de empilhamento e servem como dispositivo de gerenciamento MVST, e Device 3, O dispositivo 4 e o dispositivo 5 são usados como placas estendidas e as duas últimas portas da placa estendida são conectadas ao dispositivo de gerenciamento MVST;
- Execute a configuração diferenciada para Device3, Device4 e Device5, e vincule a configuração das placas estendidas correspondentes à agregação de link 1, agregação de link 2 e convergência de link 3 ao dispositivo de gerenciamento MVST;
- Após simular a falha do Device3, substitua um novo dispositivo (Device6) e o dispositivo de gerenciamento MVST pode emitir automaticamente a configuração do Device3 coletada anteriormente.
- É simulado que quando a agregação de link 1 do dispositivo de gerenciamento MVST falha, a agregação de link 4 precisa ser criada e a configuração do Device3 vinculado ao grupo de agregação de link 1 é migrada para a agregação de link 4.
Topologia de rede
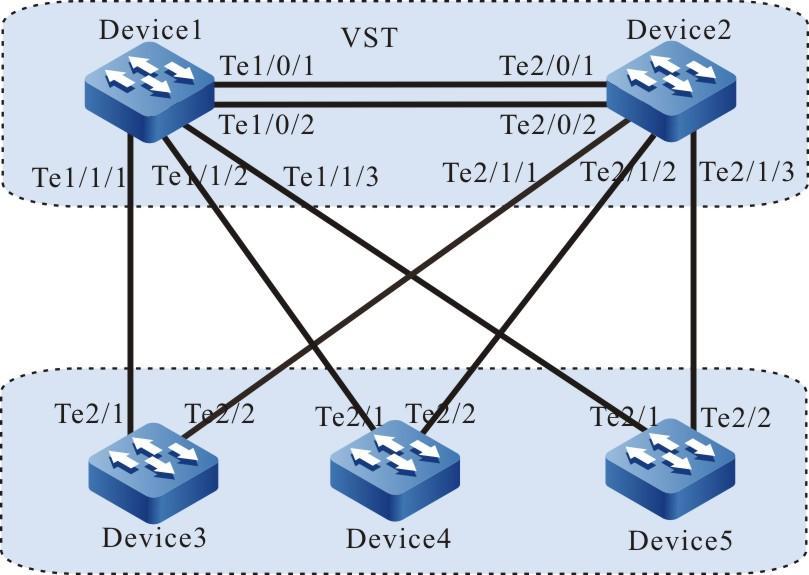
Figura 3 -4 Configurar entrega automática da configuração vinculada
Etapas de configuração
- Passo 1: Configurar o sistema VST.
#Configure o número do dispositivo do membro do switch virtual como 1, o número do domínio como 10 e a prioridade como 255 no Device1.
Device1#configure terminalDevice1(config)#switch virtual member 1Do you want to modify member id(Yes|No)?y% Member ID 1 config will take effect only after the exec command 'switch mode virtual' is issuedDevice1(config-vst-member-1)#domain 10% Domain ID 10 config will take effect only after the exec command 'switch mode virtual' is issuedDevice1(config-vst-member-1)#priority 255Device1(config-vst-member-1)#exit
# No Device1, crie a interface de link de switch virtual 1 e adicione as portas tentengigabitethernet 0/1 e tentengigabitethernet 0/2 à interface de link de switch virtual 1 .
Device1(config)#vsl-channel 1Device1(config-vsl-channel-1)#exitDevice1(config)#interface tentengigabitethernet 0/1Device1(config-if-tentengigabitethernet0/1)#vsl-channel 1 mode onDevice1(config-if-tentengigabitethernet0/1)#exitDevice1(config)#interface tentengigabitethernet 0/2Device1(config-if-tentengigabitethernet0/2)#vsl-channel 1 mode onDevice1(config-if-tentengigabitethernet0/2)#exit
# No Device1 , salve a configuração.
Device1#writeAre you sure to overwrite /flash/startup (Yes|No)?yBuilding Configuration...doneWrite to startup file ... OKWrite to mode file... OK
#Configure o número do dispositivo do membro do switch virtual como 2, o número do domínio como 10 e a prioridade como 255 no Device2.
Device2#configure terminalDevice2(config)#switch virtual member 2Do you want to modify member id(Yes|No)?y% Member ID 2 config will take effect only after the exec command 'switch mode virtual' is issuedDevice2(config-vst-member-2)#domain 10% Domain ID 10 config will take effect only after the exec command 'switch mode virtual' is issuedDevice2(config-vst-member-2)#priority 200Device2(config-vst-member-2)#exit
# No Device2 , crie a interface de link de switch virtual 1 e adicione as portas tentengigabitethernet1/1 à interface de link de switch virtual 1.
Device2(config)#vsl-channel 1Device2(config-vsl-channel-1)#exitDevice2(config)#interface tentengigabitethernet 0/1Device2(config-if-tentengigabitethernet0/1)#vsl-channel 1 mode onDevice2(config-if-tentengigabitethernet0/1)#exitDevice2(config)#interface tentengigabitethernet 0/2Device2(config-if-tentengigabitethernet0/2)#vsl-channel 1 mode onDevice2(config-if-tentengigabitethernet0/2)#exit
# No Device2 , salve a configuração.
Device2#writeAre you sure to overwrite /flash/startup (Yes|No)?yBuilding Configuration...doneWrite to startup file ... OKWrite to mode file... OK
# Configurar o modo de execução do Device1 como modo de empilhamento.
Device1#switch mode virtualThis command will convert all interface names to naming convention "interface-type member-number/slot/interface" ,Please make sure to save current configuration.Do you want to proceed? (yes|no)?yConverting interface names Building configuration...Copying the startup configuration to backup file named "startup-backupalone"...Please wait...system reloading is in progress!okReset system!%SYS-5-RELOAD: Reload requested
# Configurar o modo de execução do Device2 como modo de empilhamento.
Device2#switch mode virtualThis command will convert all interface names to naming convention "interface-type member-number/slot/interface" ,Please make sure to save current configuration.Do you want to proceed? (yes|no)?yConverting interface names Building configuration...Copying the startup configuration to backup file named "startup-backupalone"...Please wait...system reloading is in progress!okReset system!%SYS-5-RELOAD: Reload requested
# Visualize Device1 , o sistema de empilhamento é formado, e Device1 é o dispositivo mestre do sistema de empilhamento.
Device1#show switch virtualCodes: L - local-device,I - isolate-deviceVirtual Switch Mode : VIRTUALVirtual Switch DomainId : 10Virtual Switch mac-address : 0001.7a6a.0255--------------- VST MEMBER INFORMATION ---------------------CODE MemberID Role Pri LocalVsl RemoteVsl--------------------------------------------------------------------------------L 1 Master 255 vsl-channel 1/1 vsl-channel 2/12 Member 200 vsl-channel 2/1 vsl-channel 1/1
- Passo 2:Configurar as funções básicas do MVST.
# Configurar o sistema de empilhamento como dispositivo de gerenciamento MVST.
Device1(config)#mvst enable%MVST-NOTIFY-5: MVST is enabled !Device1(config)#mvst masterDevice1(config)#mvst domain-name test
# Configurar a agregação de links do sistema de empilhamento e habilitar a detecção de MVST.
Device1(config)#mvst link-aggregation 1 mode lacpDevice1(config)# mvst interface tengigabitethernet 1/1/1,2/1/1 join link-aggregation 1 activeDevice1(config)#interface link-aggregation 1Device1(config-link-aggregation1)#mvst inspectionDevice1(config-link-aggregation1)#exitDevice1(config)#mvst link-aggregation 2 mode lacpDevice1(config)# mvst interface tengigabitethernet 1/1/2,2/1/2 join link-aggregation 2 activeDevice1(config)#interface link-aggregation 2Device1(config-link-aggregation2)#mvst inspectionDevice1(config-link-aggregation2)#exitDevice1(config)#mvst link-aggregation 3 mode lacpDevice1(config)# mvst interface tengigabitethernet 1/1/3,2/1/3 join link-aggregation 3 activeDevice1(config)#interface link-aggregation 3Device1(config-link-aggregation3)#mvst inspectionDevice1(config-link-aggregation3)#exit
# No Device3 , habilite a função MVST.
Device3#configure terminalDevice3#configure terminalDevice3(config)#mvst enable%MVST-NOTIFY-5: MVST is enabled !Device3(config)#mvst link-aggregation 1 mode lacpDevice3(config)# mvst interface tengigabitethernet 2/1,2/2 join link-aggregation 1 activeDevice3(config)#interface link-aggregation 1Device3(config-link-aggregation1)#mvst inspectionDevice3(config-link-aggregation1)#exit%MVST-NOTIFY-5: interface tengigabitethernet2/1 and interface tengigabitethernet2/2 join link-aggregation 1 successfully.
# No Device4 , habilite a função MVST.
Device4#configure terminalDevice4(config)#mvst enable%MVST-NOTIFY-5: MVST is enabled !Device4(config)#mvst link-aggregation 2 mode lacpDevice4(config)# mvst interface tengigabitethernet 2/1,2/2 join link-aggregation 2 activeDevice4(config)#interface link-aggregation 2Device4(config-link-aggregation2)#mvst inspectionDevice4(config-link-aggregation2)#exit%MVST-NOTIFY-5: interface tengigabitethernet2/1 and interface tengigabitethernet2/2 join link-aggregation 2 successfully.
# No Device5 , habilite a função MVST.
Device5#configure terminalDevice5(config)#mvst enable%MVST-NOTIFY-5: MVST is enabled !Device5(config)#mvst link-aggregation 3 mode lacpDevice5(config)# mvst interface tengigabitethernet 2/1,2/2 join link-aggregation 3 activeDevice5(config)#interface link-aggregation 3Device5(config-link-aggregation3)#mvst inspectionDevice5(config-link-aggregation3)#exit%MVST-NOTIFY-5: interface tengigabitethernet2/1 and interface tengigabitethernet2/2 join link-aggregation 3 successfully.
#Conecte Device3, Device4 e Device5 ao domínio MVST e, em seguida, verifique o resultado do MVST após a conexão dos dispositivos.
#Verifique os resultados do MVST no Device1. Você pode ver que Device3, Device4 e Device5 ingressam no domínio MVST na forma de um cartão estendido. Os slots são Slave-slot0, Slave-slot1 e Save-slot2, e seus nomes de host mudam para switch-ss0, switch-ss1 e switch-ss2.
Device1#show mvst topo information---------------------------------------------------------------------------------------------------------------------------------role domain-name interface mac device-type host-name---------------------------------------------------------------------------------------------------------------------------------Slave-slot test link-aggregation 1 0001.7a63.bd76 NSS4330-56TXF(V1) switch-ss0Slave-slot test link-aggregation 2 0001.7a64.72aa NSS4330-56TXF(V1) switch-ss1Slave-slot test link-aggregation 3 0001.7a63.bd43 NSS4330-56TXF(V1) switch-ss2Master test 0001.7a6a.0258 NSS5810-50TXFP(V1) Device1
- Passo 3:Configure a função de entrega automática da configuração vinculada.
#Execute a configuração diferenciada para Device3, Device4 e Device5.
Device1(config)#configure slave-slot 0switch-ss0(config)#vlan 100switch-ss0(config)#exitswitch-ss0#exitswitch-ss0>exitDevice1(config)#configure slave-slot 1switch-ss1(config)#vlan 200switch-ss1(config)#exitswitch-ss1#exitswitch-ss1>exitDevice1(config)#configure slave-slot 2switch-ss2(config)#vlan 300switch-ss2(config)#exitswitch-ss2#exitswitch-ss2>exit
#On Device1, salve as configurações de Device3, Device4 e Device5.
Device1#write slave-slot 0Are you sure to overwrite slave slot 0 /flash/startup (Yes|No)?yDevice1#Jan 9 2015 16:32:34: %MVST-WRITE_RESULT-5: The slave slot 0 write to startup file successfully.Device1#write slave-slot 1Are you sure to overwrite slave slot 0 /flash/startup (Yes|No)?yDevice1#Jan 9 2015 16:32:34: %MVST-WRITE_RESULT-5: The slave slot 1 write to startup file successfully.Device1#write slave-slot 2Are you sure to overwrite slave slot 0 /flash/startup (Yes|No)?yDevice1#Jan 9 2015 16:32:34: %MVST-WRITE_RESULT-5: The slave slot 2 write to startup file successfully.
# Configure a função de entrega automática da configuração vinculada no Device1. A inicialização das placas estendidas correspondentes ao grupo de agregação de link 1, grupo de agregação de link 2 e grupo de agregação de link 3 é coletada para o dispositivo de gerenciamento MVST.
Device1(config)#mvst bind startup link-aggregation 1Device1(config)#Jan 9 2015 15:25:16: %MVST-COLLECT_STARTUP-5: Collect slave slot 0 startup begin.Jan 9 2015 15:25:16: %MVST-COLLECT_STARTUP-5: Collect slave slot 0 startup OK.Device1(config)#mvst bind startup link-aggregation 2Device1(config)#Jan 9 2015 15:25:16: %MVST-COLLECT_STARTUP-5: Collect slave slot 1 startup begin.Jan 9 2015 15:25:16: %MVST-COLLECT_STARTUP-5: Collect slave slot 1 startup OK.Device1(config)#mvst bind startup link-aggregation 3Device1(config)#Jan 9 2015 15:25:16: %MVST-COLLECT_STARTUP-5: Collect slave slot 2 startup begin.Jan 9 2015 15:25:16: %MVST-COLLECT_STARTUP-5: Collect slave slot 2 startup OK.
# Visualize os resultados da entrega automática da configuração vinculada no Device1. A inicialização das placas estendidas 0, 1 e 2 são coletadas nos arquivos startup-lag1, startup-lag2 e startup-lag3 em USB.
Device1#show mvst startup bind info---------------------------------------------------Interface Bind-file-name---------------------------------------------------link-aggregation 1 /usb/startup-lag1link-aggregation 2 /usb/startup-lag2link-aggregation 3 /usb/startup-lag3
# Depois de habilitar a função MVST em um novo dispositivo (Device6), o grupo de agregação de link 1 do dispositivo de gerenciamento MVST é adicionado ao domínio MVST para substituir Device3. Device6 é adicionado ao domínio MVST na forma de um cartão estendido. O slot é Slave-slot3, e há as informações de impressão da configuração de entrega automática de startup-lag1.
Device1#Jan 9 2015 16:54:46: %MVST-Slave_slot_add-5:Slave slot 3 add to the MVST.Jan 9 2015 16:54:47: %MVST-EXECUTE_COFNIG-5: Slave slot 3 is going to execute configure file /usb/ startup-lag1.Jan 9 2015 16:54:48: %MVST-EXECUTE_COFNIG-5: Slave slot 3 execute configure file successfully!
#Verifique os resultados do MVST no Device1. Device6 junta-se ao domínio MVST na forma de um cartão estendido. Seu slot é Slave-slot3 e seu nome de host é switch-ss3.
Device1#show mvst topo information-----------------------------------------------------------------------------------------------------------------------------role domain-name interface mac device-type host-name-----------------------------------------------------------------------------------------------------------------------------Slave-slot test link-aggregation 4 0001.7a63.bd89 NSS4330-56TXF(V1) switch-ss3Slave-slot test link-aggregation 2 0001.7a64.72aa NSS4330-56TXF(V1) switch-ss1Slave-slot test link-aggregation 3 0001.7a63.bd43 NSS4330-56TXF(V1) switch-ss2Master test 0001.7a6a.0258 NSS5810-50TXFP(V1) Device1
#Verifique a configuração do Device6, Device6 carrega a configuração do Device3 e VLAN100 é criada.
Device1#show run slave-slot 3vlan 100
- Passo 4:Configurar a função de migração da configuração vinculada entregue automaticamente.
# No Device1, configure a agregação de links 4.
Device1(config)#interface tengigabitethernet 1/1/1,2/1/1Device1(config-if-range)#link-aggregation 4 activeDevice1(config-if-range)#exit
# Configure a migração da configuração vinculada entregue automaticamente no Device1, migrando a configuração coletada pela agregação de link 1 para a agregação de link 4.
Device1(config)#mvst bind startup link-aggregation 4Device1(config)#mvst relocate configure interface link-aggregation 1 interface link-aggregation 4interface link-aggregation1 file will cover interface link-aggregation4 file, are you sure to do it(Yes|No)?y
#No Device1, verifique se a configuração resultante foi migrada com sucesso, e existe o arquivo de configuração denominado startup-lag4 em USB.
Device1(config-fs)#cd /usbDevice1(config-fs)#dir7256 JAN-09-2015 17:58:16 startup-lag4
#Delete a inicialização do Device6, reinicie o Device6 sem salvar a configuração. Depois que o dispositivo é iniciado, você pode ver que a configuração de startup-lag4 é carregada no Device6, o que é consistente com a configuração de startup-lag1 antes da migração.
Device1#show run slave-slot 3vlan 100
12 Data Center Features
(Aplicável somente ao modelo S3054G-B)
VxLAN
Visão geral
Plano de fundo
Para obter alta confiabilidade e implantação redundante, a maioria das redes corporativas e seus data centers cruzam vários locais físicos em diferentes locais físicos e implantam serviços semelhantes nesses locais. Para integrar os recursos do data center e reduzir o custo de gerenciamento, os recursos do data center geralmente são virtualizados. A tecnologia de virtualização do data center inclui principalmente virtualização de rede, virtualização de armazenamento e virtualização de servidor. Entre eles, a virtualização de servidores consiste em usar um software especial de virtualização para virtualizar várias máquinas virtuais em um servidor físico. Cada máquina virtual é executada de forma independente e possui seu próprio sistema operacional, programa aplicativo e ambiente de hardware virtual. Para realizar a alocação e o gerenciamento dinâmicos de recursos entre sites, as máquinas virtuais devem ser capazes de migrar livremente entre os data centers. Como o processo de migração das máquinas virtuais é transparente para os usuários, o endereço IP não pode ser alterado. Portanto, é necessário que as redes antes e depois da migração das máquinas virtuais estejam na mesma rede L2. Portanto, é necessário realizar a interligação de redes L2 entre sites distribuídos em diferentes locais.
VxLAN é um tipo de tecnologia "MAC in IP", que é usada para realizar a grande interconexão L2 baseada na rede IP core. O VxLAN mantém apenas o endereço MAC e as informações de encaminhamento nos dispositivos de borda do site, sem alterar a rede interna e a estrutura de rede principal do site.
uso de VxLAN como a grande tecnologia de interconexão de rede L2 tem as seguintes vantagens:
- A VxLAN encapsula os pacotes enviados pela máquina virtual em UDP e usa o endereço IP/MAC da rede física como cabeçalho externo para encapsular, que mostra apenas os parâmetros encapsulados. Portanto, o requisito da grande rede L2 para a especificação do endereço MAC é bastante reduzido. Além dos dispositivos de borda de rede vxlan , os outros dispositivos da rede não precisam identificar o endereço MAC da máquina virtual, o que reduz a pressão de aprendizado do endereço MAC e melhora o desempenho do dispositivo.
- O VxLAN introduz um ID de usuário semelhante ao ID de VLAN, que é chamado de identificador de rede VxLAN VNI. É composto por 24 bits e suporta até 16777215 segmentos VxLAN, para atender a um grande número de IDs de usuários.
- Ao usar MAC no encapsulamento UDP para estender a rede L2, a rede física e a rede virtual são desacopladas. Os locatários podem planejar sua própria rede virtual sem considerar as limitações do endereço IP da rede física e do domínio de transmissão, o que reduz bastante a dificuldade de gerenciamento da rede.
Conceitos básicos
Nó de Borda Virtual da Rede
NVE (borda de virtualização de rede) é uma entidade de rede que realiza a função de virtualização de rede. Depois que o pacote é encapsulado e transformado pela entidade de rede NVE, a rede VxLAN virtual pode ser estabelecida entre o NVE com base na rede básica de três camadas.
Ponto final do túnel VxLAN
VTEP ( VxLAN Tunnel End Point ) é um dispositivo de comutação localizado na borda do site. Ele opera como um dispositivo de camada 2 na rede local e um dispositivo L3 na rede central. Ele fornece principalmente interconexão de duas camadas entre redes de sites. Ele conclui o encapsulamento de pacotes da rede local para a rede central e o desencapsulamento de pacotes da rede central para a rede local.
Interface de rede principal: a interface L3 no dispositivo de borda conectado à rede principal, ou seja, Porta de rede .
Interface interna do site: a interface L2 no dispositivo de borda conectado ao dispositivo interno do site, ou seja, Porta Interna .
VxLAN Sessão
VxLAN é estabelecer o túnel VxLAN por meio de configuração manual ou negociação de protocolo e associar a instância VxLAN para formar uma instância de encaminhamento efetiva entre VTEP s. Esta instância é chamada de sessão VxLAN . Os dados só podem ser encaminhados se a sessão vxlan for válida.
EVPN
EVPN (Ethernet Virtual Private Network) é uma tecnologia L2 VPN. A tecnologia EVPN usa o MP-BGP estendido para espalhar as informações do host na rede do usuário entre diferentes sites e usa o plano de controle para substituir o plano de dados para concluir o aprendizado do endereço MAC entre sites na rede do usuário.
VXLAN é apenas um protocolo de encapsulamento de dados. Não define o plano de controle. A aprendizagem de endereços MAC entre sites é completada pela inundação de tráfego do plano de dados tradicional. A maior desvantagem desse método é que há muito tráfego de inundação na rede de rolamentos do data center. A fim resolver este problema, VXLAN introduz EVPN como o plano de controle. Ao trocar rotas BGP EVPN entre VTEPs, realiza a descoberta automática de VTEP e a notificação mútua de informações do host, de modo a evitar inundações de dados desnecessárias.
Especificações do protocolo
- RFC7348: Virtual eXtensible Local Area Network ( VxLAN ): Um Framework para sobreposição de redes de camada 2 virtualizadas em redes de camada 3.
- RFC 7432 : VPN Ethernet baseada em BGP MPLS
- RFC 8365 -- Uma solução de sobreposição de virtualização de rede usando Ethernet VPN (EVPN)
- draft-ietf-bess-evpn-inter-subnet-forwarding-05
- draft-ietf-bess-evpn-prefix-advertisement-11
- draft-malhotra-bess-evpn-irb-extended-mobility-03
função VxLAN
Tabela 2 -1 Lista de configuração da função VxLAN
| Tarefas de configuração | |
| Configurar funções básicas de VxLAN |
Configurar instância VxLAN
Configurar informações de descrição da instância VxLAN Configurar a interface VxLAN L3 Configurar aprendizado entre sites Configurar NVE |
| Configurar o VxLAN estático | Configure a lista de cópias do cabeçalho estático VxLAN |
| Configurar EVPN VxLAN |
Configure o NVE para habilitar o EVPN
Configure os atributos EVPN da instância VxLAN Configure os atributos EVPN da instância VRF (opcional) Configure o BGP para habilitar o EVPN Configure a política de vizinho BGP (opcional) Configurar o mapa de rotas VxLAN (opcional) |
Configurar VxLAN Instância
Condição de configuração
Nenhum
Configurar VxLAN Instância
Cada instância de VxLAN é uma área de trabalho independente. Por meio do isolamento VNID , diferentes instâncias de VxLAN não podem se comunicar entre si. A mesma instância de VxLAN pode se comunicar entre si. O dispositivo oferece suporte à configuração de até 4.096 instâncias de VxLAN .
Tabela 2 -2 Configurar o VxLAN instância
| Etapa | Comando | Descrição |
| Modo de configuração global | configure terminal | - |
| configuração VxLAN | vxlan vxlan-id | Obrigatório Por padrão, não crie nenhuma VxLAN . |
| Configurar VxLAN VNID | vxlan vnid vnid | Por padrão, ele não está configurado. |
O VNID da instância VxLAN deve ser configurado em prioridade . Caso contrário , outras configurações de serviço não terão efeito.
Configurar informações de descrição da instância VxLAN
Para ser conveniente para memória e gerenciamento, as informações de descrição do VxLAN podem ser configuradas de acordo com o tipo de serviço, função e conexão do VxLAN .
Tabela 2 -3 Configure as informações de descrição de VxLAN
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração VxLAN | vxlan vxlan-id | Obrigatório Após entrar no modo de configuração VxLAN , o VxLAN informações de descrição podem ser configuradas. |
| Configurar VxLAN informações de descrição | description description-name | Opcional Por padrão, VxLAN não possui as informações de descrição. |
Acesso ao serviço de instância VxLAN
O VxLAN não contém nenhum ponto de acesso de serviço quando foi criado inicialmente. As máquinas virtuais são conectadas à rede VxLAN usando diferentes métodos de acesso, de modo a realizar o encaminhamento de rede VxLAN para serviços de máquina virtual. O modo de acesso é o seguinte:
Tabela 2 -4 Configurar o modo de ponto de serviço
| Modo | Descrição |
| vlan | Este tipo de interface recebe apenas os pacotes com tag VLAN e a tag VLAN externa que corresponde à tag VLAN especificada; Quando esse tipo de interface encapsula o pacote original com VXLAN, a tag VLAN mais externa será removida; Ao desencapsular o pacote VXLAN , a tag VLAN especificada será adicionada antes do encaminhamento. Neste modo, as portas físicas precisam ser adicionadas à VLAN correspondente e a VLAN global precisa ser criada Este modo suporta o encaminhamento L2 e o encaminhamento L3. |
| qinq | Este tipo de interface recebe apenas os pacotes com duas camadas especificadas de tag VLAN; Quando esse tipo de interface encapsula o pacote original com VXLAN, as duas camadas mais externas de tags VLAN serão removidas; Ao descapsular o pacote VXLAN, as duas camadas especificadas de tags VLAN serão adicionadas antes do encaminhamento. Neste modo, a porta física deve ser adicionada à VLAN externa correspondente e a VLAN global precisa ser criada Este modo suporta o encaminhamento L2 e o encaminhamento L3. |
| desmarcar | tipo de interface só recebe os pacotes sem Tag VLAN . O modo suporta encaminhamento L2 e encaminhamento L3 ao mesmo tempo. |
| predefinição | A interface tem permissão para receber todos os pacotes, independentemente de haver tag VLAN no pacote. Esse tipo de interface não realizará nenhum processamento de tag VLAN para o pacote original, incluindo adição, substituição ou remoção, seja o pacote VLAN encapsulado ou desencapsulado. Este modo suporta apenas o encaminhamento L2 e não suporta o encaminhamento entre VLANs. |
A instância VxLAN não contém nenhum ponto de acesso de serviço quando é criada inicialmente. Você precisa configurá-lo manualmente da seguinte maneira.
Tabela 2 -5 Configurar o ponto de serviço
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o modo de porta | interface tengigabitethernet 0/1 | Obrigatório Após entrar no modo de porta, você pode configurar a porta a ser adicionada à instância VxLAN e oferecer suporte à porta de agregação. |
| Configurar o modo de acesso da instância VxLAN | vxlan vxlan-id encapsulation { vlan vlan-id | qinq svlan svlan-id cvlan cvlan-id | untag | default } | Obrigatório Por padrão, nenhuma porta é adicionada ao VxLAN . a porta for adicionada à VxLAN , a função VxLAN poderá entrar em vigor na porta. |
Quando o modo de acesso é untag e defaul , várias instâncias vxlan não podem ser adicionadas à mesma porta ao mesmo tempo. Quando o modo de acesso é o modo VLAN, a porta de acesso vxlan precisa ser configurada como acesso de tag.
Configurar a interface VxLAN L3
Na função L3 VxLAN , você deve configurar a interface VxLAN L3 e especificar o IP.
Tabela 2 -6 Configurar o VxLAN interface
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configurar o VxLAN interface | interface vxlan vxlan-id | M andatpry padrão, não configure a interface VxLAN . Ao habilitar a função L3 VxLAN , ela deve ser configurada. |
| Configurar a interface VxLAN para associar com VRF | ip vrf forwarding vrf-name | opcional _ Por padrão, a interface VxLAN não está associada ao VRF. |
| Configurar o endereço IP da interface VxLAN | ip address X.X.X.X | Mandatório _ Por padrão, a interface VxLAN não está configurada com o endereço IP. Ao habilitar a função L3 VxLAN , ela deve ser configurada. |
Habilite o Aprendizado de Rota
Depois que o VxLAN habilita a função de aprendizado entre sites, o pacote de solicitação ARP, o pacote de resposta ARP e o pacote ARP livre recebido na porta interna gerarão a rota EVPN local e notificarão os vizinhos através do protocolo BGP EVPN para realizar o aprendizado de rota entre os VTEPs .
Tabela 2 -7 Habilite o aprendizado de rota
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Entre no modo de configuração VxLAN | vxlan vxlan-id | Obrigatório |
| Habilite o aprendizado de rota | vxlan local-mac advertise vxlan local-ip advertise | Obrigatório Por padrão, está habilitado. |
Configurar NVE
NVE (borda de virtualização de rede) é uma entidade de rede que realiza a função de virtualização de rede. Após o pacote ser encapsulado e transformado pela entidade de rede NVE, a rede VxLAN virtual pode ser estabelecida entre os NVEs com base na rede básica L3.
Tabela 2 -8 Configurar nve
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Crie uma interface nve | interface nve nve-number | Obrigatório Por padrão, não crie a interface NVE no dispositivo. |
| Configurar o endereço IP de origem | source ip-address | Obrigatório VTEP não é configurado na interface NVE. |
Configurar Static VxLAN Túnel
Condição de configuração
Nenhum
Configurar a lista de cópia de cabeçalho estático de VxLAN Instância
O cabeçalho refere-se ao nó de ingresso do túnel VxLAN , e a lista de cópias refere-se a que quando o nó de entrada do túnel VxLAN recebe o pacote BUM ( Broadcast & Unknown-unicast & Multicast ), ele copiará o pacote e o enviará para todos os VTEP s em a lista. A lista de cópias de cabeçalho é a lista de endereços IP do VTEP remoto usado para guiar o nó de ingresso do túnel VxLAN para copiar e enviar o pacote BUM.
A lista de cópias de cabeçalho, também conhecida como túnel BUM VxLAN , copia o pacote BUM recebido de acordo com a lista VTEP e o envia para todos os VTEPs pertencentes ao mesmo VNI através da interface NVE de origem da lista de cópias de cabeçalho.
Tabela 2 -9 Configurar a lista de cópias do cabeçalho estático VxLAN
| Etapa | Comando | Descrição |
| Modo de configuração global | configure terminal | - |
| Modo de configuração da interface NVE | interface nve nve-number | Obrigatório |
| Configure a lista de cópias do cabeçalho estático VxLAN especificado | vxlan vxlan-id ingress-replication peer ip-address | Obrigatório Por padrão, não configure a lista de cópias do cabeçalho estático. |
Mesmo que o VTEP de origem corresponda apenas a um VTEP remoto , é necessário executar o comando para especificar o endereço VTEP correspondente e configurar a lista de cópias de cabeçalho.
Configurar EVPN VxLAN Túnel
Condição de configuração
Antes de configurar o modo BGP EVPN para implantar o serviço VxLAN , primeiro conclua as seguintes tarefas:
- Configure o protocolo da camada de link, garantindo a comunicação normal da camada de link
- Configure o endereço da camada de rede da interface, tornando o nó de rede vizinho acessível na camada de rede
Configurar o NVE para habilitar o protocolo EVPN
Após o NVE ativar o EVPN, negocie e configure automaticamente o túnel VxLAN entre VTEPs por meio do protocolo BGP EVPN.
Tabela 2 -10 Configurar o túnel VxLAN dinâmico
| Etapa | Comando | Descrição |
| Modo de configuração global | configure terminal | - |
| Modo de configuração da interface NVE | interface nve nve-number | Obrigatório |
| Configurar a instância VxLAN especificada para associar NVE | vxlan vxlan-id | Obrigatório Por padrão, não associe . |
| Especifique a instância VxLAN para usar EVPN para configurar a lista de cópias de cabeçalho | vxlan vxlan-id ingress-replication protocol bgp | Opcional Por padrão, não especifique. |
Configure os atributos EVPN da instância VxLAN
RD é usado para identificar rotas EVPN geradas por diferentes VxLANs , de modo a obter o isolamento entre diferentes VxLANs ; route-target é usado para controlar a importação e exportação de rotas EVPN . Quando o VTEP inicia rotas EVPN , ele carrega o atributo Export RT. Quando o VTEP decide para qual VxLAN a rota EVPN é importada, o atributo Export RT carregado pela rota é usado para corresponder ao Import RT do VxLAN local .
Tabela 2 -11 Configurar os atributos VxLAN EVPN
| Etapa | Comando | Descrição |
| Modo de configuração global | configure terminal | - |
| Modo de configuração da instância VxLAN | vxlan vxlan-id | Obrigatório No modo de configuração VxLAN , você pode entrar no modo de configuração EVPN. |
| configuração VxLAN EVPN | address-family evpn | Obrigatório Após entrar no modo VxLAN EVPN , você pode configurar os atributos VxLAN EVPN . |
| Configurar VxLAN rd | rd route-distinguisher | Obrigatório Por padrão, não configure VxLAN RD . |
| Configurar destino de rota VxLAN | route-target [both|export|import] { ASN:nn|IP-address:nn} | Obrigatório padrão, não configure os atributos Exportar, Importar RT de VxLAN . |
Configurar os atributos EVPN da instância VRF ( opcional)
Somente quando o gateway distribuído é implantado, o atributo EVPN da instância VRF precisa ser configurado. Essa configuração é ignorada na implantação de gateway centralizado.
Tabela 2 -12 Configurar os atributos EVPN da instância VRF
| Etapa | Comando | Descrição |
| Modo de configuração global | configure terminal | - |
| Entre no modo de configuração VRF | ip vrf vrf-name | Obrigatório |
| Configurar rd | rd route-distinguisher | Mandatório _ Por padrão, não configure rd. |
| Configurar L3VNID | l3vnid vnid-number | Obrigatório Por padrão, não está configurado.L3VNID. |
| no modo de configuração da família de endereços VRF EVPN | address-family evpn | Obrigatório |
| Configure o destino de rota do VRF EVPN | route-target [ both | export | import ] { ASN:nn|IP-address:nn} | Obrigatório Por padrão, não configure o atributo Importar e Exportar . |
| Um ssociate VRF EVPN com a política de rota de saída. | export map route-map-name | Opcional padrão, o VRF EVPN não está associado à política de rota de saída. |
| Um ssociate VRF EVPN com a política de rota de ingresso. | import map route-map-name | Opcional padrão, o VRF EVPN não está associado à política de rota de ingresso. |
Configurar BGP para habilitar EVPN
BGP habilita o recurso EVPN, fazendo com que o BGP aprenda a rota EVPN, crie um túnel VxLAN dinâmico, forme a sessão VxLAN e adicione à tabela de encaminhamento e guie o encaminhamento de pacotes VxLAN .
Tabela 2 -13 Configurar BGP EVP N para habilitar EVPN
| Etapa | Comando | Descrição |
| Modo de configuração global | configure terminal | - |
| Habilite o protocolo BGP e entre no modo de configuração BGP | router bgp autonomous-system | Obrigatório Por padrão, não está habilitado. |
| Configurar o BGP vizinho | neighbor { neighbor-address | peer-group-name } remote-as as-number | Obrigatório Por padrão, não crie nenhum vizinho BGP. |
| Configurar o endereço de origem da sessão TCP do vizinho BGP | neighbor { neighbor-address | peer-group-name } update-source { interface-name | ip-address } | Opcional Por padrão, as sessões TCP selecionam automaticamente o endereço da interface de saída de rota como o endereço de origem. |
| Entre no modo de configuração BGP EVPN | address-family l2vpn evpn | Obrigatório |
| Ativar o recurso EVPN | neighbor { neighbor-address | peer-group-name } activate | Obrigatório Por padrão, não está ativado. |
| Configurar o refletor EVPN | neighbor { neighbor-address | peer-group-name } route-reflector-client | Opcional Por padrão, não habilite o refletor. |
| modo de configuração BGP IPV4 VRF | address-family ipv4 vrf vrf-name | Opcional |
| Configure a rota unicast VRF para redistribuir para EVPN e formar cinco tipos de rotas | advertise-l2vpn-evpn | Opcional Essa configuração é necessária para a implantação do gateway distribuído. |
| Entre no modo de configuração BGP EVPN | address-family l2vpn evpn | Mandatório _ |
| Quando o BGP é configurado para anunciar rotas para vizinhos ou grupos de pares, não altere os valores de atributo as path, Med e next hop da rota. | neighbor attribute-unchanged[ as-path | med | next-hop ] | Opcional Essa configuração só é necessária ao implantar uma rede VXLAN entre data centers de ponta a ponta. |
Configurar a política de vizinho BGP ( opcional)
Ao vincular o mapa de rotas nos vizinhos BGP EVPN , você pode filtrar efetivamente as rotas com o VNI especificado recebido na direção de entrada ou impedir a publicidade de algumas rotas com o VNI especificado aos vizinhos na direção de saída.
Tabela 2 -14 Configurar a política EVPN do vizinho BGP
| Etapa | Comando | Descrição |
| Modo de configuração global | configure terminal | - |
| Habilite o protocolo BGP e entre no modo de configuração BGP | router bgp autonomous-system | Obrigatório Por padrão, não habilite o BGP. |
| Entre no modo de configuração BGP EVPN | address-family l2vpn evpn | Obrigatório |
| Configurar o vizinho para aplicar o mapa de rotas na direção de ingresso | neighbor { neighbor-address | peer-group-name } route-map rtmap-name in | Obrigatório Por padrão, não aplique o mapa de rota na direção de entrada. |
| Configurar o vizinho para aplicar o mapa de rotas na direção de saída | neighbor { neighbor-address | peer-group-name } route-map rtmap-name out | Obrigatório Por padrão, não aplique o mapa de rota na direção de saída. |
Configurar o mapa de rotas VxLAN ( opcional )
Ao configurar a política de VxLAN vizinha , é necessário vincular o mapa de rotas e usar o mapa de rotas para corresponder ao número VxLAN local , ao próximo salto da rota e outros itens correspondentes para controlar as rotas de entrada e saída.
Tabela 2 -15 Configurar o VxLAN mapa de rotas
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| C rie o mapa de rotas | route-map map-name [ { permit | deny } [ seq-number ] ] | Obrigatório Por padrão, não crie o mapa de rotas. |
| Combine vxlan -id | match vxlan vxlan-id | Opcional padrão, não corresponde ao VxLAN No. |
Monitoramento e manutenção de VxLAN
Tabela 2 -16 VxLAN monitoramento e manutenção
| Comando | Descrição |
| show bgp l2vpn evpn { all | rd route-distinguisher | vxlan-id } { all-type | type { 2 [eth-tag-id:ip-addr-len:ip-address] | 3 [eth-tag-id:mac-addr-len:mac-addr:ip-addr-len:ip-addr]}} | 5 [eth-tag-id:ip-addr-len:ip-addr] | Exiba as informações de rota na família de endereços BGP MVPN |
| show bgp l2vpn evpn conf | Exiba as informações de configuração do EVPN |
| show bgp l2vpn evpn {vxlan vxlan-id | vrf vrf-name} | Exiba as informações EVPN VxLAN /VRF |
| show bgp l2vpn evpn { all | rd route-distinguisher |vxlan-id } neignbors ip-address { advertised-routes | received-routes | routes}{ all-type | type 2 | type 3| type 5 } | Exiba as informações de rota do vizinho especificado sob o cluster de endereços BGP EVPN |
| show bgp l2vpn evpn vxlan-id statistics | Exiba as estatísticas de roteamento do VxLAN especificado no cluster de endereços BGP EVPN |
| show bgp l2vpn evpn summary | Exibir informações de resumo do vizinho do BGP EVPN |
| show vxlan vxlan-id arp-auto-reply | Exiba as informações da tabela de resposta arp da instância VxLAN especificada |
| show vxlan vxlan-id config | Exiba as informações de configuração para uma instância VxLAN especificada |
| show vxlan vxlan-id instance | D isplay as informações de instância do VxLAN especificado |
| show vxlan vxlan-id internal | Exiba o ponto de acesso de serviço da instância VxLAN especificada |
| show vxlan vxlan-id session | Exibe todas as informações de sessão associadas à instância VxLAN especificada |
| show vxlan arp-auto-reply | Exibir informações da tabela de resposta ARP da instância VxLAN |
| show vxlan config | Exiba as informações globais de VxLAN |
| show vxlan instance | Exiba as informações da instância VxLAN |
| show vxlan internal [interface interface-num | interface link-aggregation link-aggregation-id ] | Exiba o ponto de sucesso do serviço VxLA |
| show vxlan tunnel | Exiba as informações do túnel VxLAN |
| show vxlan session | D isplay as informações da sessão VxLAN |
Exemplo de configuração típica de VXLAN
Configurar Static VXLAN para realizar a intercomunicação L2
Requisitos de rede
- Leaf1 e leaf2 servem como VTEP para criar a instância VXLAN .
- Leaf1 e Leaf2 configuram o túnel VXLAN estático por meio da interface de loopback.
- O túnel VXLAN é estabelecido para realizar o interfuncionamento da VM entre o servidor 1 e o servidor2 do mesmo segmento de rede.
Topologia de rede

Figura 2 -1 Rede de configuração da VXLAN estática para realizar a intercomunicação L2
Etapas de configuração
- Passo 1:Configure a VLAN e adicione a porta à VLAN correspondente (omitida).
- Passo 2:Configure o endereço IP da interface.
#Configure Leaf1.
Leaf1(config)#interface loopback 0Leaf1(config-if-loopback0)#ip address 10.0.0.1 255.255.255.255Leaf1(config-if-loopback0)#exitLeaf1(config)#interface vlan 3Leaf1(config-if-vlan3)#ip address 2.0.0.1 255.255.255.0Leaf1(config-if-vlan3)#exit
#Configure Leaf2 .
Leaf2(config)#interface loopback 0Leaf2(config-if-loopback0)#ip address 20.0.0.1 255.255.255.255Leaf2(config-if-loopback0)#exitLeaf2(config)#interface vlan 3Leaf2(config-if-vlan3)#ip address 2.0.0.2 255.255.255.0Leaf2(config-if-vlan3)#exit
- Passo 3:Configurar o OSPF, tornando as rotas de Loopback entre os dispositivos alcançáveis.
#Configure Leaf1 .
Leaf1#configure terminalLeaf1(config)#router ospf 100Leaf1(config-ospf)#network 10.0.0.1 0.0.0.0 area 0Leaf1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Leaf1(config-ospf)#exit
#Configure Leaf2 .
Leaf2#configure terminalLeaf2(config)#router ospf 100Leaf2(config-ospf)#network 20.0.0.1 0.0.0.0 area 0Leaf2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Leaf2(config-ospf)#exit
# Visualize a tabela de rotas de Leaf1 .
Leaf1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 00:05:40, vlan3C 127.0.0.0/8 is directly connected, 1d:21:38:36, lo0C 10.0.0.1/32 is directly connected, 00:06:34, loopback0O 20.0.0.1/32 [110/2] via 2.0.0.2, 00:00:05, vlan3
# Visualize a tabela de rotas do Leaf2 .
Leaf2#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 00:06:43, vlan3C 127.0.0.0/8 is directly connected, 1w3d:03:35:57, lo0O 10.0.0.1/32 [110/2] via 2.0.0.1, 00:02:36, vlan3C 20.0.0.1/32 is directly connected, 00:07:07, loopback0
Pode-se ver que leaf1 e leaf2 aprendem a rota da porta de loop de pares executando o protocolo OSPF, que é preparado para leaf1 e leaf2 estabelecerem vizinhos IBGP através da porta de loopback.
- Passo 4:Configure VXLAN e associe VNID para adicionar portas de leaf1 e leaf2 a VXLAN .
#Configure Leaf1 .
Leaf1(config)# vxlan 100Leaf1(config-vxlan-100)#vxlan vnid 100Leaf1(config-vxlan-100)#exitLeaf1(config)# interface tengigabitethernet 0/1Leaf1(config-if-tengigabitethernet0/1)# vxlan 100 encapsulation vlan 2Leaf1(config-if-tengigabitethernet0/1)#exit
#Configure Leaf2 .
Leaf2(config)# vxlan 100Leaf2(config-vxlan-100)#vxlan vnid 100Leaf2(config-vxlan-100)#exitLeaf2(config)# interface tengigabitethernet 0/1Leaf2(config-if-tengigabitethernet0/1)# vxlan 100 encapsulation vlan 2Leaf2(config-if-tengigabitethernet0/1)#exit
# Visualize as informações VXLAN de Leaf1.
Leaf1#show vxlan 100 configvxlan 100vxlan vnid 100exitLeaf1#show running-config interface te0/1interface tengigabitethernet0/1switchport mode trunkswitchport trunk allowed vlan add 2switchport trunk pvid vlan 1vxlan 100 encapsulation vlan 2exit
# Visualize as informações de VXLAN do Leaf2.
Leaf2#show vxlan 100 configvxlan 100vxlan vnid 100exitLeaf2#show running-config interface te0/1interface tengigabitethernet0/1switchport mode trunkswitchport trunk allowed vlan add 2switchport trunk pvid vlan 1vxlan 100 encapsulation vlan 2exit
- Passo 5:Configurar o túnel VXLAN estático.
#Configure a interface NVE de Leaf1 e os membros de replicação de cabeçalho estático da VXLAN correspondente .
Leaf1(config)#interface nve 1Leaf1(config-if-nve1)#source 10.0.0.1Leaf1(config-if-nve1)#vxlan 100 ingress-replication peer 20.0.0.1Leaf1(config-if-nve1)#exit
#Configure a interface NVE de Leaf2 e os membros de replicação de cabeçalho estático da VXLAN correspondente .
Leaf2(config)#interface nve 1Leaf2(config-if-nve1)#source 20.0.0.1Leaf2(config-if-nve1)#vxlan 100 ingress-replication peer 10.0.0.1Leaf2(config-if-nve1)#exit
# Visualize as informações do túnel e a sessão VXLAN de Leaf1.
Leaf1# show vxlan tunnelNumber of vxlan tunnel: 1---- ---------- ------------------- ------------------- ----------NO. TunnelID Source Destination State---- ---------- ------------------- ------------------- ----------1 32768 10.0.0.1 20.0.0.1 up
Você pode ver que o túnel VXLAN em Leaf1 foi estabelecido com sucesso e está no estado ativo.
Leaf1#show vxlan sessionNumber of vxlan session: 1---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 100 32768 32768 10.0.0.1 20.0.0.1 up
Você pode ver que a sessão VXLAN com VXLAN -ID 100 em leaf1 liga com sucesso o túnel com a identificação de túnel 32768 e o status está ativo.
# Visualize as informações de VXLAN do Leaf2.
Leaf2# show vxlan tunnelNumber of vxlan tunnel: 1---- ---------- ------------------- ------------------- ----------NO. TunnelID Source Destination State---- ---------- ------------------- ------------------- ----------1 32768 20.0.0.1 10.0.0.1 up
VXLAN no Leaf2 foi configurado com sucesso e o status é UP.
Leaf2#show vxlan sessionNumber of vxlan session: 1---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 100 32768 32768 20.0.0.1 10.0.0.1 up
Você pode ver que a sessão VXLAN com VXLAN -ID 100 em leaf2 liga com sucesso o túnel com a ID de túnel 32768 e o status está ativo.
- Passo 6:Confira o resultado
# VM1 no Server1 faz ping em VM1 no Server2.
C:\Documents and Settings\ Server 1> ping 1.0.0.2Pinging 1.0.0.2 with 32 bytes of data:Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Ping statistics for 1.0.0.2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0m
Pode ser visto que Server1 e server2 podem cruzar a rede L3 entre leaf1 e leaf2 para realizar a intercomunicação.
Configurar BGP EVPN VXLAN para realizar a intercomunicação L2
Requisitos de rede
- Leaf1 e leaf2 servem como VTEP para criar a instância VXLAN .
- Leaf1 e Leaf 2 criam o túnel BGP EVPN VXLAN, realizando a intercomunicação do Server1 e Server2 no mesmo segmento.
Topologia de rede

Figura 2 -2 Rede de configuração do BGP EVPN VXLAN para realizar a intercomunicação L2
Etapas de configuração
- Passo 1:Configurar a VLAN e adicionar as portas à VLAN correspondente (omitido).
- Passo 2:Configurar o endereço IP da interface.
#Configure a Folha1 .
Leaf1(config)#interface loopback 0Leaf1(config-if-loopback0)#ip address 10.0.0.1 255.255.255.255Leaf1(config-if-loopback0)#exitLeaf1(config)#interface vlan 3Leaf1(config-if-vlan3)#ip address 2.0.0.1 255.255.255.0Leaf1(config-if-vlan3)#exit
#Configure Leaf2 .
Leaf2(config)#interface loopback 0Leaf2(config-if-loopback0)#ip address 20.0.0.1 255.255.255.255Leaf2(config-if-loopback0)#exitLeaf2(config)#interface vlan 3Leaf2(config-if-vlan3)#ip address 2.0.0.2 255.255.255.0Leaf2(config-if-vlan3)#exit
- Passo 3:Configurar o OSPF, tornando a rota Loopback entre dispositivos alcançável.
#Configure Leaf1 .
Leaf1#configure terminalLeaf1(config)#router ospf 100Leaf1(config-ospf)#network 10.0.0.1 0.0.0.0 area 0Leaf1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Leaf1(config-ospf)#exit
#Configure Leaf2 .
Leaf2#configure terminalLeaf2(config)#router ospf 100Leaf2(config-ospf)#network 20.0.0.1 0.0.0.0 area 0Leaf2(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Leaf2(config-ospf)#exit
# Visualize a tabela de rotas de Leaf1 .
Leaf1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 00:05:40, vlan3C 127.0.0.0/8 is directly connected, 1d:21:38:36, lo0C 10.0.0.1/32 is directly connected, 00:06:34, loopback0O 20.0.0.1/32 [110/2] via 2.0.0.2, 00:00:05, vlan3
# Visualize a tabela de rotas do Leaf2 .
Leaf2#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 00:06:43, vlan3C 127.0.0.0/8 is directly connected, 1w3d:03:35:57, lo0O 10.0.0.1/32 [110/2] via 2.0.0.1, 00:02:36, vlan3C 20.0.0.1/32 is directly connected, 00:07:07, loopback0
Podemos ver que leaf1 e leaf2 aprenderam a rota da porta de loopback de peer executando o protocolo OSPF.
- Passo 4:Configure o VXLAN e associe o VNID e configure a família de endereços EVPN para adicionar portas de leaf1 e leaf2 ao VXLAN .
#Configure Leaf1 .
Leaf1(config)# vxlan 100Leaf1(config-vxlan-100)#vxlan vnid 100Leaf1(config-vxlan-100)#address-family evpnLeaf1(config-vxlan-evpn)#rd 100:1Leaf1(config-vxlan-evpn)#route-target both 100:1Leaf1(config-vxlan-evpn)#exitLeaf1(config-vxlan-100)#exitLeaf1(config)# interface tengigabitethernet 0/1Leaf1(config-if-tengigabitethernet0/1)# vxlan 100 encapsulation vlan 2Leaf1(config-if-tengigabitethernet0/1)#exit
#Configure Leaf2 .
Leaf2(config)# vxlan 100Leaf2(config-vxlan-100)#vxlan vnid 100Leaf2(config-vxlan-100)#address-family evpnLeaf2(config-vxlan-evpn)#rd 100:1Leaf2(config-vxlan-evpn)#route-target both 100:1Leaf2(config-vxlan-evpn)#exitLeaf2(config-vxlan-100)#exitLeaf2(config)# interface tengigabitethernet 0/1Leaf2(config-if-tengigabitethernet0/1)# vxlan 100 encapsulation vlan 2Leaf2(config-if-tengigabitethernet0/1)#exit
# Visualize as informações VXLAN de Leaf1.
Leaf1#show vxlan 100 configvxlan 100vxlan vnid 100address-family evpnrd 100:1route-target import 100:1route-target export 100:1exitexitLeaf1#show running-config interface te0/1interface tengigabitethernet0/1switchport mode trunkswitchport trunk allowed vlan add 2switchport trunk pvid vlan 1vxlan 100 encapsulation vlan 2exit
# Visualize as informações de VXLAN do Leaf2.
Leaf2#show vxlan 100 configvxlan 100vxlan vnid 100address-family evpnrd 100:1route-target import 100:1route-target export 100:1exitexitLeaf2#show running-config interface te0/1interface tengigabitethernet0/1switchport mode trunkswitchport trunk allowed vlan add 2switchport trunk pvid vlan 1vxlan 100 encapsulation vlan 2exit
- Passo 5:Configurar BGP.
#Configure Leaf1 .
Configure para estabelecer um peer EBGP conectado diretamente com leaf2 e ative o recurso de notificação na família de endereços EBGP .
Leaf1(config)#router bgp 100Leaf1(config-bgp)#neighbor 2.0.0.2 remote-as 200Leaf1(config-bgp)#address-family l2vpn evpnLeaf1(config-bgp-af)#neighbor 2.0.0.2 activateLeaf1(config-bgp-af)#exit-address-familyLeaf1(config-bgp)#exit
#Configure Leaf2 .
Configure para estabelecer um peer EBGP conectado diretamente com leaf2 e ative o recurso de notificação na família de endereços EVPN .
Leaf2(config)#router bgp 200Leaf2(config-bgp)#neighbor 2.0.0.1 remote-as 100Leaf2(config-bgp)#address-family l2vpn evpnLeaf2(config-bgp-af)#neighbor 2.0.0.1 activateLeaf2(config-bgp-af)#exit-address-familyLeaf2(config-bgp)#exit
# Visualize o vizinho BGP EVPN de Leaf1 .
Leaf1#show bgp l2vpn evpn summaryBGP router identifier 10.0.0.1, local AS number 100BGP table version is 51 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd2.0.0.2 4 200 52 50 4 0 0 00:42:18 0Total number of neighbors 1
# Visualize o vizinho BGP EVPN de Leaf2 .
Leaf2#show bgp l2vpn evpn summaryBGP router identifier 20.0.0.1, local AS number 200BGP table version is 51 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd2.0.0.1 4 100 52 53 5 0 0 00:43:20 0Total number of neighbors 1
Podemos ver que leaf1 e leaf2 estabeleceram com sucesso vizinhos BGP EVPN
- Passo 6:Configurar a interface NVE .
#Configure a interface NVE de Leaf1 e configure a VXLAN correspondente , e use o protocolo BGP para construir o túnel L2 dinamicamente.
Leaf1(config)#interface nve 1Leaf1(config-if-nve1)#source 10.0.0.1Leaf1(config-if-nve1)#vxlan 100 ingress-replication protocol bgpLeaf1(config-if-nve1)#exit
#Configure a interface NVE do Leaf2 e configure o VXLAN correspondente , e use o protocolo BGP para construir o túnel L2 dinamicamente.
Leaf2(config)#interface nve 1Leaf2(config-if-nve1)#source 20.0.0.1Leaf2(config-if-nve1)#vxlan 100 ingress-replication protocol bgpLeaf2(config-if-nve1)#exit
# Visualize as informações do túnel e a sessão VXLAN de Leaf1.
Leaf1# show vxlan tunnelNumber of vxlan tunnel: 1---- ---------- ------------------- ------------------- ----------NO. TunnelID Source Destination State---- ---------- ------------------- ------------------- ----------1 32768 10.0.0.1 20.0.0.1 upLeaf1#show vxlan sessionNumber of vxlan session: 1---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 100 32768 32768 10.0.0.1 20.0.0.1 up
# Visualize as informações do túnel e a sessão VXLAN do Leaf2.
Leaf2# show vxlan tunnelNumber of vxlan tunnel: 1---- ---------- ------------------- ------------------- ----------NO. TunnelID Source Destination State---- ---------- ------------------- ------------------- ----------1 32768 20.0.0.1 10.0.0.1 upLeaf2#show vxlan sessionNumber of vxlan session: 1---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 100 32768 32768 20.0.0.1 10.0.0.1 up
Das informações acima, podemos ver que o túnel está ativo e a sessão multicast dinâmica VXLAN entre Leaf1 e Leaf2 pode ser estabelecida normalmente. Até agora, o tráfego L2 BUM pode ser encaminhado entre Leaf1 e Leaf2.
- Passo 7:V M1 do Server1 e VM1 od Server pingam os diferentes endereços de diferentes segmentos , respectivamente , e visualizam a sessão VXLAN de Leaf1 e Leaf2.
# Visualize a sessão VXLAN de Leaf1.
Leaf1#show vxlan session 20.0.0.1vxlan session 32768state: upsource IP: 10.0.0.1destination IP: 20.0.0.1source mac: 0001.7a00.5278destination mac: 0001.7a21.81e7interface: vlan3switchport: tengigabitethernet0/2vxlan list: 100vxlan unicast list: 100vxlan multicast list: 100
# Visualize a sessão VXLAN do Leaf2.
Leaf2#show vxlan session 10.0.0.1vxlan session 32768state: upsource IP: 20.0.0.1destination IP: 10.0.0.1source mac: 0001.7a21.81e7destination mac: 0001.7a00.5278interface: vlan3switchport: tengigabitethernet0/2vxlan list: 100vxlan unicast list: 100vxlan multicast list: 100
Pode-se ver que as sessões dinâmicas de unicast foram estabelecidas e o tráfego de unicast L2 pode ser encaminhado.
- Passo 8:Confira o resultado
# VM1 do Server1 pinga VM1 do Server2.
C:\Documents and Settings\ Server 1> ping 1.0.0.2Pinging 1.0.0.2 with 32 bytes of data:Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Ping statistics for 1.0.0.2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0m
Você pode ver que Server1 e Server2 podem cruzar a rede L3 entre Leaf1 e Leaf2 para realizar a intercomunicação.
BGP EVPN suporta IBGP e EBGP. Depois que o BGP habilita o recurso EVPN VXLAN, o vizinho BGP será redefinido automaticamente.
Configurar o gateway VXLAN centralizado estático
Requisitos de rede
- Crie instâncias VXLAN em Leaf1, Spine1 e Leaf2, respectivamente
- Leaf1, Spine1 e Leaf2 estabelecem um túnel VXLAN estático por meio da interface de loopback e atuam como gateway centralizado VXLAN na espinha1 para realizar interfuncionamento entre servidores do mesmo segmento de rede Server1 e Server3 e servidores de diferentes segmentos de rede server2 e Server3.
Topologia de rede
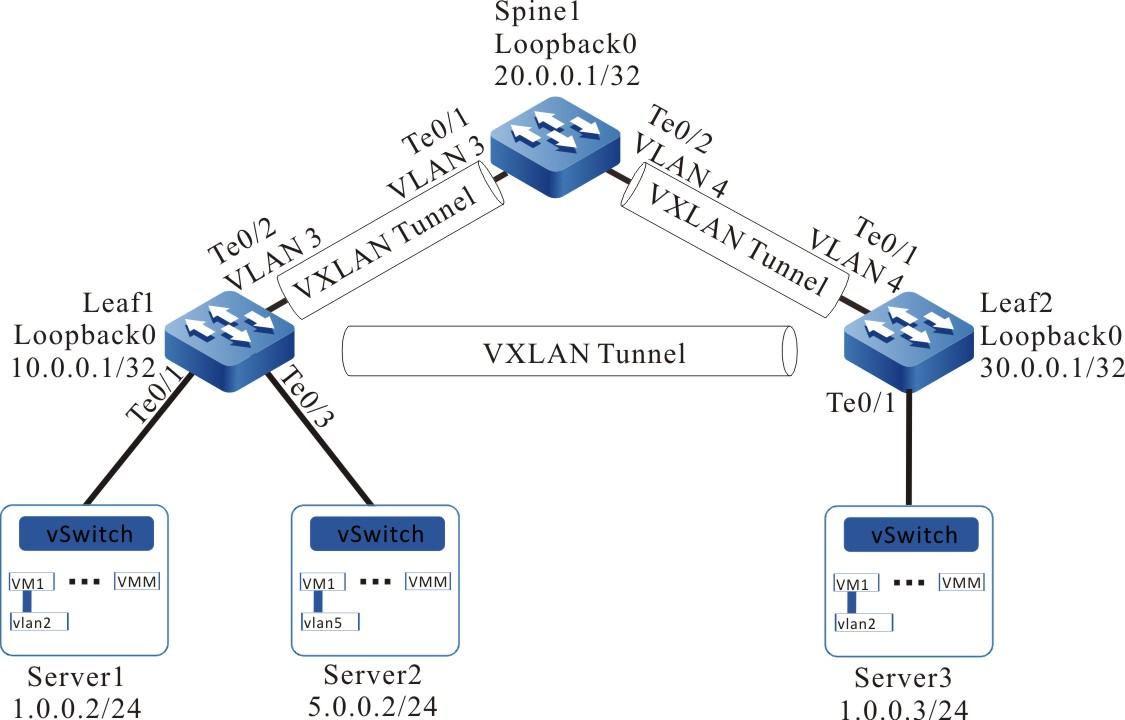
Figura 2 -3 Rede de configuração do gateway VXLAN centralizado estático
Etapas de configuração
- Passo 1:Configure a VLAN e adicione as portas à VLAN correspondente (omitida).
- Passo 2:Configure o endereço IP da interface.
#Configure Leaf1.
Leaf1(config)#interface loopback 0Leaf1(config-if-loopback0)#ip address 10.0.0.1 255.255.255.255Leaf1(config-if-loopback0)#exitLeaf1(config)#interface vlan 3Leaf1(config-if-vlan3)#ip address 2.0.0.1 255.255.255.0Leaf1(config-if-vlan3)#exit
#Configure Spine1.
Spine1(config)#interface loopback 0Spine1(config-if-loopback0)#ip address 20.0.0.1 255.255.255.255Spine1(config-if-loopback0)#exitSpine1(config)#interface vlan 3Spine1(config-if-vlan3)#ip address 2.0.0.2 255.255.255.0Spine1(config-if-vlan3)#exitSpine1(config)#interface vlan 4Spine1(config-if-vlan4)#ip address 3.0.0.1 255.255.255.0Spine1(config-if-vlan4)#exit
#Configure Leaf2.
Leaf2(config)#interface loopback 0Leaf2(config-if-loopback0)#ip address 30.0.0.1 255.255.255.255Leaf2(config-if-loopback0)#exitLeaf2(config)#interface vlan 4Leaf2(config-if-vlan4)#ip address 3.0.0.2 255.255.255.0Leaf2(config-if-vlan4)#exit
- Passo 3:Configure o OSPF, tornando a rota de Loopback entre dispositivos alcançável.
#Configure Leaf1 .
Leaf1#configure terminalLeaf1(config)#router ospf 100Leaf1(config-ospf)#network 10.0.0.1 0.0.0.0 area 0Leaf1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Leaf1(config-ospf)#exit
#Configure Spine1 .
Spine1#configure terminalSpine1(config)#router ospf 100Spine1(config-ospf)#network 20.0.0.1 0.0.0.0 area 0Spine1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Spine1(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Spine1(config-ospf)#exit
#Configure Leaf2 .
Leaf2#configure terminalLeaf2(config)#router ospf 100Leaf2(config-ospf)#network 30.0.0.1 0.0.0.0 area 0Leaf2(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Leaf2(config-ospf)#exit
#Visualize a tabela de rotas da Folha 1.
Leaf1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 00:28:27, vlan3O 3.0.0.0/24 [110/2] via 2.0.0.2, 00:00:05, vlan3C 127.0.0.0/8 is directly connected, 2d:23:06:31, lo0C 10.0.0.1/32 is directly connected, 1d:01:34:29, loopback0O 20.0.0.1/32 [110/2] via 2.0.0.2, 00:00:05, vlan3O 30.0.0.1/32 [110/3] via 2.0.0.2, 00:00:05, vlan3
#Visualize a tabela de rotas do Spine 1.
Spine1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 07:04:46, vlan3C 3.0.0.0/24 is directly connected, 00:23:50, vlan4C 127.0.0.0/8 is directly connected, 1w4d:05:02:08, lo0O 10.0.0.1/32 [110/2] via 2.0.0.1, 00:00:57, vlan3C 20.0.0.1/32 is directly connected, 1d:01:33:17, loopback0O 30.0.0.1/32 [110/2] via 3.0.0.2, 00:01:33, vlan4
#Visualize a tabela de rotas da Folha 2.
Leaf2#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setO 2.0.0.0/24 [110/2] via 3.0.0.1, 00:02:43, vlan4C 3.0.0.0/24 is directly connected, 00:22:14, vlan4C 30.0.0.0/24 is directly connected, 00:23:24, loopback0C 127.0.0.0/8 is directly connected, 4d:00:16:59, lo0O 10.0.0.1/32 [110/3] via 3.0.0.1, 00:02:07, vlan4O 20.0.0.1/32 [110/2] via 3.0.0.1, 00:02:43, vlan4
Podemos ver que Leaf1, Spine1 e Leaf2 aprenderam a rota da porta de loopback de peer executando o protocolo OSPF.
- Passo 4:Configure o VXLAN e associe o VNID para fazer com que as portas de Leaf1 e Spine1 sejam adicionadas ao VXLAN.
#Configure Leaf1.
Leaf1(config)#vxlan 100Leaf1(config-vxlan-100)#vxlan vnid 100Leaf1(config-vxlan-100)#exitLeaf1(config)# interface tengigabitethernet 0/1Leaf1(config-if-tengigabitethernet0/1)# vxlan 100 encapsulation vlan 2Leaf1(config-if-tengigabitethernet0/1)#exitLeaf1(config)#vxlan 200Leaf1(config-vxlan-200)#vxlan vnid 200Leaf1(config-vxlan-200)#exitLeaf1(config)# interface tengigabitethernet 0/3Leaf1(config-if-tengigabitethernet0/3)# vxlan 200 encapsulation vlan 5Leaf1(config-if-tengigabitethernet0/3)#exit
#Configure Spine1 .
Spine1(config)#vxlan 100Spine1(config-vxlan-100)#vxlan vnid 100Spine1(config-vxlan-100)#exitSpine1(config)# vxlan 200Spine1(config-vxlan-200)#vxlan vnid 200Spine1(config-vxlan-200)#exit
#Configure Leaf2 .
Leaf2(config)#vxlan 100Leaf2(config-vxlan-100)#vxlan vnid 100Leaf2(config-vxlan-100)#exitLeaf2(config)# interface tengigabitethernet 0/1Leaf2(config-if-tengigabitethernet0/1)# vxlan 100 encapsulation vlan 2Leaf2(config-if-tengigabitethernet0/1)#exit
# Visualize as informações de VXLAN de Leaf1..
Leaf1#show vxlan configvxlan 100vxlan vnid 100exitvxlan 200vxlan vnid 200exitLeaf1#show running-config interface te0/1interface tengigabitethernet0/1switchport mode trunkswitchport trunk allowed vlan add 2switchport trunk pvid vlan 1vxlan 100 encapsulation vlan 2exitLeaf1#show running-config interface te0/3interface tengigabitethernet0/3switchport mode trunkswitchport trunk allowed vlan add 5switchport trunk pvid vlan 1vxlan 100 encapsulation vlan 5exit
# Veja as informações de VXLAN do Spine1..
Spine1#show vxlan configvxlan 100vxlan vnid 100exitvxlan 200vxlan vnid 200exit
# Visualize as informações de VXLAN de Leaf2..
Leaf2#show vxlan configvxlan 100vxlan vnid 100exitLeaf1#show running-config interface te0/1interface tengigabitethernet0/1switchport mode trunkswitchport trunk allowed vlan add 2switchport trunk pvid vlan 1vxlan 100 encapsulation vlan 2exit
- Passo 5:Configure o túnel VXLAN estático.
#Configurar a interface nve de Leaf1 e configurar o membro de cópia de cabeçalho estático da VXLAN correspondente.
Leaf1(config)#interface nve 1Leaf1(config-if-nve1)#source 10.0.0.1Leaf1(config-if-nve1)#vxlan 100 ingress-replication peer 20.0.0.1Leaf1(config-if-nve1)#vxlan 100 ingress-replication peer 30.0.0.1Leaf1(config-if-nve1)#vxlan 200 ingress-replication peer 20.0.0.1Leaf1(config-if-nve1)#exit
#Configurar a interface nve do Spine1 e configurar o membro de cópia de cabeçalho estático da VXLAN correspondente.
Spine1(config)#interface nve 1Spine1(config-if-nve1)#source 20.0.0.1Spine1(config-if-nve1)#vxlan 100 ingress-replication peer 10.0.0.1Spine1(config-if-nve1)#vxlan 100 ingress-replication peer 30.0.0.1Spine1(config-if-nve1)#vxlan 200 ingress-replication peer 10.0.0.1Spine1(config-if-nve1)#exit
#Configurar a interface nve do Leaf2 e configurar o membro da cópia do cabeçalho estático da VXLAN correspondente.
Leaf2(config)#interface nve 1Leaf2(config-if-nve1)#source 30.0.0.1Leaf2(config-if-nve1)#vxlan 100 ingress-replication peer 10.0.0.1Leaf2(config-if-nve1)#vxlan 100 ingress-replication peer 20.0.0.1Leaf2(config-if-nve1)#exit
# Veja as informações do túnel de Leaf1 e a sessão VXLAN.
Leaf1# show vxlan tunnelNumber of vxlan tunnel: 2---- ---------- ------------------- ------------------- ----------NO. TunnelID Source Destination State---- ---------- ------------------- ------------------- ----------1 32768 10.0.0.1 20.0.0.1 up2 32769 10.0.0.1 30.0.0.1 upLeaf1#show vxlan sessionNumber of vxlan session: 3---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 100 32768 32768 10.0.0.1 20.0.0.1 up2 100 32769 32769 10.0.0.1 30.0.0.1 up3 200 32768 32768 10.0.0.1 20.0.0.1 up
Você pode ver que as sessões VXLAN com VXLAN-ID 100 e 200 compartilham o mesmo túnel com Tunnel ID 32768 .
# Visualize as informações do túnel e a sessão VXLAN do Spine1.
Spine1# show vxlan tunnelNumber of vxlan tunnel: 2---- ---------- ------------------- ------------------- ----------NO. TunnelID Source Destination State---- ---------- ------------------- ------------------- ----------1 32768 20.0.0.1 10.0.0.1 up2 32769 20.0.0.1 30.0.0.1 upSpine1#show vxlan sessionNumber of vxlan session: 3---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 100 32768 32768 20.0.0.1 10.0.0.1 up2 100 32769 32769 20.0.0.1 30.0.0.1 up3 200 32768 32768 20.0.0.1 10.0.0.1 up
# Visualize as informações do túnel da sessão Leaf2 e VXLAN.
Leaf2# show vxlan tunnelNumber of vxlan tunnel: 2---- ---------- ------------------- ------------------- ----------NO. TunnelID Source Destination State---- ---------- ------------------- ------------------- ----------1 32768 30.0.0.1 10.0.0.1 up2 32769 30.0.0.1 20.0.0.1 upLeaf2#show vxlan sessionNumber of vxlan session: 2---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 100 32768 32768 30.0.0.1 10.0.0.1 up2 100 32769 32769 30.0.0.1 20.0.0.1 up
A informação acima indica que o túnel está UP, o status da sessão VXLAN está ativo e está corretamente associado ao VXLAN.
- Passo 6:No Spine1, configure o gateway VXLAN L3.
Spine1(config)#interface vxlan 100Spine1(config-if-vxlan100)#ip address 1.0.0.1 24Spine1(config-if-vxlan100)#exitSpine1(config)#int vxlan 200Spine1(config-if-vxlan200)#ip address 5.0.0.1 24Spine1(config-if-vxlan200)#exit
# Veja a interface VXLAN e a tabela de rotas do Spine1.
Spine1#show interface vxlan 100vxlan100:line protocol is upFlags: (0xc008063) BROADCAST MULTICAST ARP RUNNINGType: ETHERNET_CSMACDInternet address: 1.0.0.1/24Broadcast address: 1.0.0.255Metric: 0, MTU: 1500, BW: 100000 Kbps, DLY: 100 usec, VRF: globalReliability 255/255, Txload 1/255, Rxload 1/255Ethernet address is 0001.7a21.81e75 minutes input rate 0 bits/sec, 0 packets/sec5 minutes output rate 0 bits/sec, 0 packets/sec1 packets received; 2 packets sent1 multicast packets received2 multicast packets sent0 input errors; 0 output errors0 collisions; 0 droppedUnknown protocol 0Spine1#show interface vxlan 200vxlan200:line protocol is upFlags: (0xc008063) BROADCAST MULTICAST ARP RUNNINGType: ETHERNET_CSMACDInternet address: 5.0.0.1/24Broadcast address: 5.0.0.255Metric: 0, MTU: 1500, BW: 100000 Kbps, DLY: 100 usec, VRF: globalReliability 255/255, Txload 1/255, Rxload 1/255Ethernet address is 0001.7a21.81e75 minutes input rate 0 bits/sec, 0 packets/sec5 minutes output rate 0 bits/sec, 0 packets/sec0 packets received; 2 packets sent0 multicast packets received2 multicast packets sent0 input errors; 0 output errors0 collisions; 0 droppedUnknown protocol 0Spine1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 1.0.0.0/24 is directly connected, 00:02:08, vxlan100C 2.0.0.0/24 is directly connected, 07:51:05, vlan3C 3.0.0.0/24 is directly connected, 01:10:08, vlan4C 5.0.0.0/24 is directly connected, 00:01:58, vxlan200C 127.0.0.0/8 is directly connected, 1w4d:05:48:26, lo0O 10.0.0.1/32 [110/2] via 2.0.0.1, 00:47:15, vlan3C 20.0.0.1/32 is directly connected, 1d:02:19:36, loopback0O 30.0.0.1/32 [110/2] via 3.0.0.2, 00:47:51, vlan4
- Passo 7:Confira o resultado.
#No Server1, Server2 e Server3, configure o gateway.
# O n Server3, ping Server1.
C:\Documents and Settings\ Server 3> ping 1.0.0.2Pinging 1.0.0.2 with 32 bytes of data:Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Ping statistics for 1.0.0.2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0m
Server3 podem cruzar a rede L3 entre Leaf1, Spine1 e Leaf2 para realizar a intercomunicação.
# No Server3, ping Server2.
C:\Documents and Settings\ Server 3> ping 5.0.0.2Pinging 5.0.0.2 with 32 bytes of data:Reply from 5.0.0.2: bytes=32 time<1ms TTL=255Reply from 5.0.0.2: bytes=32 time<1ms TTL=255Reply from 5.0.0.2: bytes=32 time<1ms TTL=255Reply from 5.0.0.2: bytes=32 time<1ms TTL=255Ping statistics for 5.0.0.2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0m
Server3 podem cruzar a rede L3 entre Leaf1, Spine1 e Leaf2 para realizar a intercomunicação.
Configurar o gateway dual-ativo centralizado BGP EVPN VXLAN
Requisitos de rede
- Crie instâncias VXLAN em Leaf1 , Leaf2, Spine1 e Spine2, respectivamente
- Leaf1, Leaf2, Spine1 e Spine2 conectam a rota EVPN através do MP-IBGP , criam o túnel I BGP EVPN VXLAN e criam o gateway centralizado VXLAN em Spine1 e Spine2 para realizar o interfuncionamento entre VM1 de Server1 e VM1 de server2 em diferentes segmentos de rede.
Topologia de rede
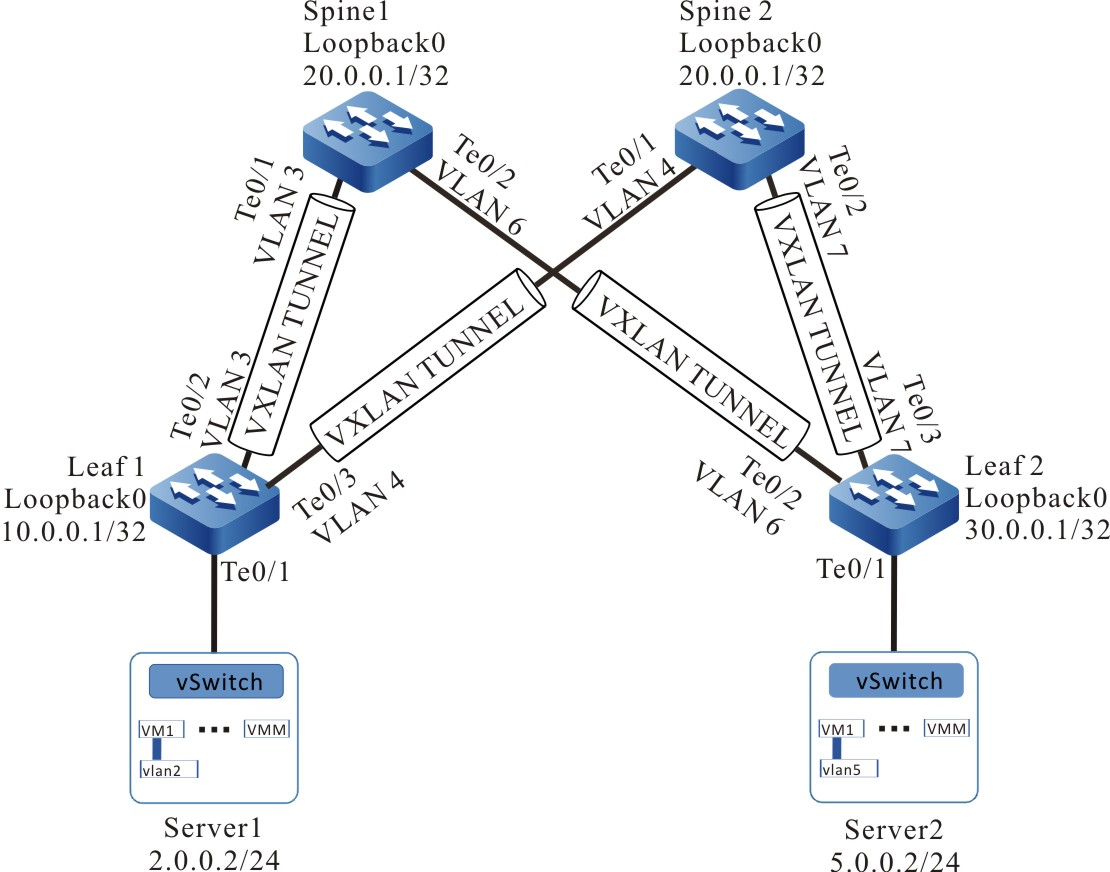
Figura 2 -4 Rede de configuração do gateway dual-active centralizado BGP EVPN VXLAN
Etapas de configuração
- Passo 1:Configure a VLAN e adicione as portas à VLAN correspondente (omitida).
- Passo 2:Configure o endereço IP da interface.
#Configure Leaf1.
Leaf1(config)#interface loopback 0Leaf1(config-if-loopback0)#ip address 10.0.0.1 255.255.255.255Leaf1(config-if-loopback0)#exitLeaf1(config)#interface vlan 3Leaf1(config-if-vlan3)#ip address 3.0.0.1 255.255.255.0Leaf1(config-if-vlan3)#exitLeaf1(config)#interface vlan 4Leaf1(config-if-vlan4)#ip address 4.0.0.1 255.255.255.0Leaf1(config-if-vlan4)#exit
#Configure Leaf2.
Leaf2(config)#interface loopback 0Leaf2(config-if-loopback0)#ip address 30.0.0.1 255.255.255.255Leaf2(config-if-loopback0)#exitLeaf2(config)#interface vlan 6Leaf2(config-if-vlan6)#ip address 6.0.0.2 255.255.255.0Leaf2(config-if-vlan6)#exitLeaf2(config)#interface vlan 7Leaf2(config-if-vlan7)#ip address 7.0.0.2 255.255.255.0Leaf2(config-if-vlan7)#exit
#Configure Spine1.
Spine1(config)#interface loopback 0Spine1(config-if-loopback0)#ip address 20.0.0.1 255.255.255.255Spine1(config-if-loopback0)#exitSpine1(config)#interface loopback 1Spine1(config-if-loopback1)#ip address 20.0.1.1 255.255.255.255Spine1(config-if-loopback1)#exitSpine1(config)#interface vlan 3Spine1(config-if-vlan3)#ip address 3.0.0.2 255.255.255.0Spine1(config-if-vlan3)#exitSpine1(config)#interface vlan 6Spine1(config-if-vlan6)#ip address 6.0.0.2 255.255.255.0Spine1(config-if-vlan6)#exit
#Configurar Spine2.
Spine2(config)#interface loopback 0Spine2(config-if-loopback0)#ip address 20.0.0.1 255.255.255.255Spine2(config-if-loopback0)#exitSpine2(config)#interface loopback 1Spine2(config-if-loopback1)#ip address 20.0.2.1 255.255.255.255Spine2(config-if-loopback1)#exitSpine2(config)#interface vlan 4Spine2(config-if-vlan4)#ip address 4.0.0.2 255.255.255.0Spine2(config-if-vlan4)#exitSpine2(config)#interface vlan 7Spine2(config-if-vlan7)#ip address 7.0.0.2 255.255.255.0Spine2(config-if-vlan7)#exit
- Passo 3:Configure o OSPF, tornando a rota de Loopback entre dispositivos alcançável.
#Configure Leaf1.
Leaf1#configure terminalLeaf1(config)#router ospf 100Leaf1(config-ospf)#network 10.0.0.1 0.0.0.0 area 0Leaf1(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Leaf1(config-ospf)#network 4.0.0.0 0.0.0.255 area 0Leaf1(config-ospf)#exit
#F ou a configuração de Leaf2, Spine1 e Spine2, consulte Leaf1.
#Visualize a tabela de rotas de Leaf1.
Leaf1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 3.0.0.0/24 is directly connected, 02:47:02, vlan3C 4.0.0.0/24 is directly connected, 02:46:43, vlan4O 6.0.0.0/24 [110/2] via 3.0.0.2, 02:32:02, vlan3O 7.0.0.0/24 [110/2] via 4.0.0.2, 02:31:22, vlan4C 127.0.0.0/8 is directly connected, 21:16:50, lo0C 10.0.0.1/32 is directly connected, 02:51:55, loopback0O 20.0.0.1/32 [110/2] via 3.0.0.2, 02:32:02, vlan3[110/2] via 4.0.0.2, 02:31:32, vlan4O 20.0.1.1/32 [110/2] via 3.0.0.2, 01:51:02, vlan3O 20.0.2.1/32 [110/2] via 4.0.0.2, 01:53:11, vlan4O 30.0.0.1/32 [110/3] via 3.0.0.2, 02:32:02, vlan3[110/3] via 4.0.0.2, 02:31:22, vlan4
Você pode ver que Leaf1 aprendeu a rota da porta de loopback de peer executando o protocolo OSPF.
- Passo 4:Configure o VXLAN e associe o VNID e configure o cluster de endereços EVPN para fazer com que as portas da Folha 1 e da Folha 2 se unam à VXLAN .
#Configure Leaf1.
Leaf1(config)# vxlan 100Leaf1(config-vxlan-100)#vxlan vnid 100Leaf1(config-vxlan-100)#address-family evpnLeaf1(config-vxlan-evpn)#rd 100:1Leaf1(config-vxlan-evpn)#route-target both 100:1Leaf1(config-vxlan-evpn)#exitLeaf1(config-vxlan-100)#exitLeaf1(config)# interface tengigabitethernet 0/1Leaf1(config-if-tengigabitethernet0/1)# vxlan 100 encapsulation vlan 2Leaf1(config-if-tengigabitethernet0/1)#exit
#Configure Leaf2.
Leaf2(config)# vxlan 200Leaf2(config-vxlan-200)# vxlan vnid 200Leaf2(config-vxlan-200)#address-family evpnLeaf2(config-vxlan-evpn)#rd 200:1Leaf2(config-vxlan-evpn)#route-target both 200:1Leaf2(config-vxlan-evpn)#exitLeaf2(config-vxlan-200)#exitLeaf2(config)# interface tengigabitethernet 0/1Leaf2(config-if-tengigabitethernet0/1)# vxlan 200 encapsulation vlan 5Leaf2(config-if-tengigabitethernet0/1)#exit
#Configure Spine1.
Spine1(config)# vxlan 100Spine1(config-vxlan-100)#vxlan vnid 100Spine1(config-vxlan-100)#address-family evpnSpine1(config-vxlan-evpn)#rd 100:1Spine1(config-vxlan-evpn)#route-target both 100:1Spine1(config-vxlan-evpn)#exitSpine1(config-vxlan-100)#exitSpine1(config)# vxlan 200Spine1(config-vxlan-200)# vxlan vnid 200Spine1(config-vxlan-200)#address-family evpnSpine1(config-vxlan-evpn)#rd 200:1Spine1(config-vxlan-evpn)#route-target both 200:1Spine1(config-vxlan-evpn)#exitSpine1(config-vxlan-200)#exit
#Configurar Spine2.
Spine2(config)# vxlan 100Spine2(config-vxlan-100)#vxlan vnid 100Spine2(config-vxlan-100)#address-family evpnSpine2(config-vxlan-evpn)#rd 100:1Spine2(config-vxlan-evpn)#route-target both 100:1Spine2(config-vxlan-evpn)#exitSpine2(config-vxlan-100)#exitSpine2(config)# vxlan 200Spine2(config-vxlan-200)# vxlan vnid 200Spine2(config-vxlan-200)#address-family evpnSpine2(config-vxlan-evpn)#rd 200:1Spine2(config-vxlan-evpn)#route-target both 200:1Spine2(config-vxlan-evpn)#exitSpine2(config-vxlan-200)#exit
# Visualize as informações de VXLAN de Leaf1..
Leaf1#show vxlan configvxlan 100vxlan vnid 100address-family evpnrd 100:1route-target import 100:1route-target export 100:1exitexitLeaf1#show running-config interface te0/1interface tengigabitethernet0/1switchport mode trunkswitchport trunk allowed vlan add 2switchport trunk pvid vlan 1vxlan 100 encapsulation vlan 2exit
# Visualize as informações de VXLAN de Leaf2..
Leaf2#show vxlan configvxlan 200vxlan vnid 200address-family evpnrd 200:1route-target import 200:1route-target export 200:1exitexitLeaf2#show running-config interface te0/1interface tengigabitethernet0/1switchport mode trunkswitchport trunk allowed vlan add 5switchport trunk pvid vlan 1vxlan 200 encapsulation vlan 5exit
# Veja as informações de VXLAN do Spine1..
Spine1#show vxlan configvxlan 100vxlan vnid 100address-family evpnrd 100:1route-target import 100:1route-target export 100:1exitexitvxlan 200vxlan vnid 200address-family evpnrd 200:1route-target import 200:1route-target export 200:1exitexit
# Visualize as informações de VXLAN do Spine2.
Spine2#show vxlan configvxlan 100vxlan vnid 100address-family evpnrd 100:1route-target import 100:1route-target export 100:1exitexitvxlan 200vxlan vnid 200address-family evpnrd 200:1route-target import 200:1route-target export 200:1exitexit
- Passo 5:Configurar BGP.
#Configure Leaf1.
Configure o peer IBGP com Spine1 e Spine2 e ative o recurso de notificação na família de endereços EVPN .
Leaf1(config)#router bgp 100Leaf1(config-bgp)#neighbor 20.0.1.1 remote-as 100Leaf1(config-bgp)#neighbor 20.0.1.1 update-source loopback0Leaf1(config-bgp)#neighbor 20.0.2.1 remote-as 100Leaf1(config-bgp)#neighbor 20.0.1.1 update-source loopback0Leaf1(config-bgp)#address-family l2vpn evpnLeaf1(config-bgp-af)#neighbor 20.0.1.1 activateLeaf1(config-bgp-af)#neighbor 20.0.2.1 activateLeaf1(config-bgp-af)#exit-address-familyLeaf1(config-bgp)#exit
#Configure Spine1.
Configure o peer IBGP com Leaf1 e Leaf2 e ative o recurso de notificação e o cliente refletor na família de endereços EVPN .
Spine1(config)#router bgp 100Spine1(config-bgp)#neighbor 10.0.0.1 remote-as 100Spine1(config-bgp)#neighbor 10.0.0.1 update-source loopback1Spine1(config-bgp)#neighbor 30.0.0.1 remote-as 100Spine1(config-bgp)#neighbor 30.0.0.1 update-source loopback1Spine1(config-bgp)#address-family l2vpn evpnSpine1(config-bgp-af)#neighbor 10.0.0.1 activateSpine1(config-bgp-af)#neighbor 10.0.0.1 route-reflector-clientSpine1(config-bgp-af)#neighbor 30.0.0.1 activateSpine1(config-bgp-af)#neighbor 30.0.0.1 route-reflector-clientSpine1(config-bgp-af)#exit-address-familySpine1(config-bgp)#exit
#Configure Leaf2 para estabelecer o peer IBGP com Spine1 e Spine2 e ative a capacidade de notificação na família de endereços EVPN . Para a configuração de Leaf2, consulte Leaf1.
#Configure o Spine para estabelecer o peer IBGP com Leaf1 e Leaf2 e ative o recurso de notificação na família de endereços EVPN . Para a configuração do Spine2, consulte Spine1.
# Visualize o vizinho BGP EVPN de Leaf1 .
Leaf1#show bgp l2vpn evpn summaryBGP router identifier 10.0.0.1, local AS number 100BGP table version is 11 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd20.0.1.1 4 100 12 12 1 0 0 00:09:05 020.0.2.1 4 100 2 2 1 0 0 00:00:21 0Total number of neighbors 2
# Visualize o vizinho BGP EVPN de Spine1 .
Spine1#show bgp l2vpn evpn summaryBGP router identifier 20.0.1.1, local AS number 100BGP table version is 11 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd10.0.0.1 4 100 12 12 1 0 0 00:09:17 030.0.0.1 4 100 3 3 1 0 0 00:01:14 0Total number of neighbors 2
- Passo 6:Configurar a interface NVE e a VM para acionar o ARP de aprendizado.
#Configurar a interface NVE de Leaf1, e configurar a VXLAN correspondente para usar o protocolo BGP para configurar o túnel VXLAN dinamicamente.
Leaf1(config)#interface nve 1Leaf1(config-if-nve1)#source 10.0.0.1Leaf1(config-if-nve1)#vxlan 100 ingress-replication protocol bgpLeaf1(config-if-nve1)#exit
#Configure a interface NVE do Leaf2 e configure a VXLAN correspondente para usar o protocolo BGP para configurar o túnel VXLAN dinamicamente.
Leaf2(config)#interface nve 1Leaf2(config-if-nve1)#source 30.0.0.1Leaf2(config-if-nve1)#vxlan 200 ingress-replication protocol bgpLeaf2(config-if-nve1)#exit
#Configurar a interface NVE do Spine1 e configurar o VXLAN correspondente para usar o protocolo BGP para configurar o túnel VXLAN dinamicamente.
Spine1(config)#interface nve 1Spine1(config-if-nve1)#source 20.0.0.1Spine1(config-if-nve1)#vxlan 100,200 ingress-replication protocol bgpSpine1(config-if-nve1)#exit
#Configurar a interface NVE do Spine2 e configurar a VXLAN correspondente para usar o protocolo BGP para configurar o túnel VXLAN dinamicamente.
Spine2(config)#interface nve 1Spine2(config-if-nve1)#source 20.0.0.1Spine2(config-if-nve1)#vxlan 100,200 ingress-replication protocol bgpSpine2(config-if-nve1)#exit
# VM1 no Server1 e VM1 no Server2 pingam os endereços inexistentes do mesmo segmento de rede, respectivamente.
- Passo 7:Spine1 e Spine2, crie o gateway VXLAN L3.
#On Spine1, crie o gateway VXLAN L3.
Spine1(config)#interface vxlan 100Spine1(config-if-vxlan100)#ip address 2.0.0.1 24Spine1(config-if-vxlan100)#mac-address 0000.5e00.0101Spine1(config-if-vxlan100)#exitSpine1(config)#int vxlan 200Spine1(config-if-vxlan200)#ip address 5.0.0.1 24Spine1(config-if-vxlan200)#mac-address 0000.5e00.0102Spine1(config-if-vxlan200)#exit
# No Spine2 , crie o gateway VXLAN L3.
Spine2(config)#interface vxlan 100Spine2(config-if-vxlan100)#ip address 2.0.0.1 24Spine2(config-if-vxlan100)#mac-address 0000.5e00.0101Spine2(config-if-vxlan100)#exitSpine2(config)#int vxlan 200Spine2(config-if-vxlan200)#ip address 5.0.0.1 24Spine2(config-if-vxlan200)#mac-address 0000.5e00.0102Spine2(config-if-vxlan200)#exit
#Veja a interface VXLAN e a tabela de rotas do Spine1.
Spine1#show interface vxlan 100vxlan100:line protocol is upFlags: (0xc008063) BROADCAST MULTICAST ARP RUNNINGType: ETHERNET_CSMACDInternet address: 2.0.0.1/24Broadcast address: 2.0.0.255Metric: 0, MTU: 1500, BW: 100000 Kbps, DLY: 100 usec, VRF: globalReliability 255/255, Txload 1/255, Rxload 1/255Ethernet address is 0000.5e00.01015 minutes input rate 0 bits/sec, 0 packets/sec5 minutes output rate 0 bits/sec, 0 packets/sec0 packets received; 1 packets sent0 multicast packets received1 multicast packets sent0 input errors; 0 output errors0 collisions; 0 droppedUnknown protocol 0Spine1#show interface vxlan 200vxlan200:line protocol is upFlags: (0xc008063) BROADCAST MULTICAST ARP RUNNINGType: ETHERNET_CSMACDInternet address: 5.0.0.1/24Broadcast address: 5.0.0.255Metric: 0, MTU: 1500, BW: 100000 Kbps, DLY: 100 usec, VRF: globalReliability 255/255, Txload 1/255, Rxload 1/255Ethernet address is 0000.5e00.01025 minutes input rate 0 bits/sec, 0 packets/sec5 minutes output rate 0 bits/sec, 0 packets/sec0 packets received; 1 packets sent0 multicast packets received1 multicast packets sent0 input errors; 0 output errors0 collisions; 0 droppedUnknown protocol 0Spine1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 00:31:28, vxlan100C 3.0.0.0/24 is directly connected, 04:05:05, vlan3O 4.0.0.0/24 [110/2] via 3.0.0.1, 03:47:46, vlan3C 5.0.0.0/24 is directly connected, 00:04:32, vxlan200C 6.0.0.0/24 is directly connected, 04:04:53, vlan6O 7.0.0.0/24 [110/2] via 6.0.0.1, 03:47:35, vlan6C 127.0.0.0/8 is directly connected, 3d:19:46:04, lo0O 10.0.0.1/32 [110/2] via 3.0.0.1, 03:52:27, vlan3C 20.0.0.1/32 is directly connected, 04:05:42, loopback0C 20.0.1.1/32 is directly connected, 03:07:49, loopback1O 20.0.2.1/32 [110/3] via 3.0.0.1, 03:09:24, vlan3[110/3] via 6.0.0.1, 03:09:24, vlan6O 30.0.0.1/32 [110/2] via 6.0.0.1, 03:52:27, vlan6
#Veja a interface VXLAN e a tabela de rotas do Spine2.
Spine2#show interface vxlan 100vxlan100:line protocol is upFlags: (0xc008063) BROADCAST MULTICAST ARP RUNNINGType: ETHERNET_CSMACDInternet address: 2.0.0.1/24Broadcast address: 2.0.0.255Metric: 0, MTU: 1500, BW: 100000 Kbps, DLY: 100 usec, VRF: globalReliability 255/255, Txload 1/255, Rxload 1/255Ethernet address is 0000.5e00.01015 minutes input rate 0 bits/sec, 0 packets/sec5 minutes output rate 0 bits/sec, 0 packets/sec0 packets received; 1 packets sent0 multicast packets received1 multicast packets sent0 input errors; 0 output errors0 collisions; 0 droppedUnknown protocol 0Spine2#show interface vxlan 200vxlan200:line protocol is upFlags: (0xc008063) BROADCAST MULTICAST ARP RUNNINGType: ETHERNET_CSMACDInternet address: 5.0.0.1/24Broadcast address: 5.0.0.255Metric: 0, MTU: 1500, BW: 100000 Kbps, DLY: 100 usec, VRF: globalReliability 255/255, Txload 1/255, Rxload 1/255Ethernet address is 0000.5e00.01025 minutes input rate 0 bits/sec, 0 packets/sec5 minutes output rate 0 bits/sec, 0 packets/sec0 packets received; 1 packets sent0 multicast packets received1 multicast packets sent0 input errors; 0 output errors0 collisions; 0 droppedUnknown protocol 0Spine2#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 02:35:05, vxlan100O 3.0.0.0/24 [110/2] via 4.0.0.1, 00:45:30, vlan4C 4.0.0.0/24 is directly connected, 06:08:19, vlan4C 5.0.0.0/24 is directly connected, 02:08:45, vxlan200O 6.0.0.0/24 [110/2] via 7.0.0.1, 05:51:24, vlan7C 7.0.0.0/24 is directly connected, 06:08:01, vlan7C 127.0.0.0/8 is directly connected, 1d:00:42:19, lo0O 10.0.0.1/32 [110/2] via 4.0.0.1, 05:51:24, vlan4C 20.0.0.1/32 is directly connected, 06:09:57, loopback0O 20.0.1.1/32 [110/3] via 7.0.0.1, 05:11:01, vlan7[110/3] via 4.0.0.1, 00:00:21, vlan4C 20.0.2.1/32 is directly connected, 05:13:31, loopback1O 30.0.0.1/32 [110/2] via 7.0.0.1, 05:51:24, vlan7
- Passo 8:a rota BGP EVPN e as informações da sessão VXLAN.
#Visualize as informações de rota BGP EVPN de Leaf1.
Leaf1#show bgp l2vpn evpn all all-typeBGP local router ID is 10.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteEVPN Information for Route Distinguisher:100:1MAC/IP Advertisement Routes:Network(ETID:MAC:IP) Next Hop Metric LocPrf Weight Path[B]*>i0:48:0000.5e00.0101:0:0.0.0.0/96 20.0.0.1 0 100 0 i[B]* i 20.0.0.1 0 100 0 i[B]*> 0:48:0010.9400.0002:0:0.0.0.0/96 0.0.0.0 0 32768 i[B]*>i0:48:0000.5e00.0101:32:2.0.0.1/128 20.0.0.1 0 100 0 i[B]* i 20.0.0.1 0 100 0 i[B]*> 0:48:0010.9400.0002:32:2.0.0.2/128 0.0.0.0 0 32768 iInclusive Multicast Ethernet Tag Routes:Network(Originating IP Addr) Next Hop Metric LocPrf Weight Path[B]*> 0:32:10.0.0.1/72 0.0.0.0 0 32768 i[B]*>i0:32:20.0.0.1/72 20.0.0.1 0 100 0 i[B]* i 20.0.0.1 0 100 0 i
#Visualize as informações de rota BGP EVPN de Leaf2.
Leaf2#show bgp l2vpn evpn all all-typeBGP local router ID is 30.0.0.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteEVPN Information for Route Distinguisher:200:1MAC/IP Advertisement Routes:Network(ETID:MAC:IP) Next Hop Metric LocPrf Weight Path[B]*>i0:48:0000.5e00.0102:0:0.0.0.0/96 20.0.0.1 0 100 0 i[B]* i 20.0.0.1 0 100 0 i[B]*> 0:48:0010.9400.0001:0:0.0.0.0/96 0.0.0.0 0 32768 i[B]*>i0:48:0000.5e00.0102:32:5.0.0.1/128 20.0.0.1 0 100 0 i[B]* i 20.0.0.1 0 100 0 i[B]*> 0:48:0010.9400.0001:32:5.0.0.2/128 0.0.0.0 0 32768 iInclusive Multicast Ethernet Tag Routes:Network(Originating IP Addr) Next Hop Metric LocPrf Weight Path[B]*>i0:32:20.0.0.1/72 20.0.0.1 0 100 0 i[B]* i 20.0.0.1 0 100 0 i[B]*> 0:32:30.0.0.1/72 0.0.0.0 0 32768 i
#Visualize as informações de rota BGP EVPN de Spine1.
Spine1#show bgp l2vpn evpn all all-typeBGP local router ID is 20.0.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteEVPN Information for Route Distinguisher:100:1MAC/IP Advertisement Routes:Network(ETID:MAC:IP) Next Hop Metric LocPrf Weight Path[B]*> 0:48:0000.5e00.0101:0:0.0.0.0/96 0.0.0.0 0 32768 i[B]*>i0:48:0010.9400.0002:0:0.0.0.0/96 10.0.0.1 0 100 0 i[B]*> 0:48:0000.5e00.0101:32:2.0.0.1/128 0.0.0.0 0 32768 i[B]*>i0:48:0010.9400.0002:32:2.0.0.2/128 10.0.0.1 0 100 0 iInclusive Multicast Ethernet Tag Routes:Network(Originating IP Addr) Next Hop Metric LocPrf Weight Path[B]*>i0:32:10.0.0.1/72 10.0.0.1 0 100 0 i[B]*> 0:32:20.0.0.1/72 0.0.0.0 0 32768 iEVPN Information for Route Distinguisher:200:1MAC/IP Advertisement Routes:Network(ETID:MAC:IP) Next Hop Metric LocPrf Weight Path[B]*> 0:48:0000.5e00.0102:0:0.0.0.0/96 0.0.0.0 0 32768 i[B]*>i0:48:0010.9400.0001:0:0.0.0.0/96 30.0.0.1 0 100 0 i[B]*> 0:48:0000.5e00.0102:32:5.0.0.1/128 0.0.0.0 0 32768 i[B]*>i0:48:0010.9400.0001:32:5.0.0.2/128 30.0.0.1 0 100 0 iInclusive Multicast Ethernet Tag Routes:Network(Originating IP Addr) Next Hop Metric LocPrf Weight Path[B]*> 0:32:20.0.0.1/72 0.0.0.0 0 32768 i[B]*>i0:32:30.0.0.1/72 30.0.0.1 0 100 0 i
#Veja as informações do túnel e as informações da sessão VXLAN de Leaf1.
Leaf1# show vxlan tunnelNumber of vxlan tunnel: 1---- ---------- ------------------- ------------------- ----------NO. TunnelID Source Destination State---- ---------- ------------------- ------------------- ----------1 32768 10.0.0.1 20.0.0.1 upLeaf1#show vxlan sessionNumber of vxlan session: 1---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 100 32768 32768 10.0.0.1 20.0.0.1 upLeaf1#show vxlan session 20.0.0.1vxlan session 32768state: upsource IP: 10.0.0.1destination IP: 20.0.0.1source mac: 0001.7a91.2de8destination mac: 0001.7a21.8203interface: vlan4switchport: tengigabitethernet0/3source mac: 0001.7a91.2de8destination mac: 0001.7a21.81e7interface: vlan3switchport: tengigabitethernet0/2vxlan list: 100vxlan unicast list: 100vxlan multicast list: 100
Pode ser visto que Leaf1 estabelece sessões dinâmicas de unicast e multicast VXLAN com Spine1 e Spine2.
#Visualize as informações do túnel e as informações da sessão VXLAN do Leaf2.
Leaf2# show vxlan tunnelNumber of vxlan tunnel: 1---- ---------- ------------------- ------------------- ----------NO. TunnelID Source Destination State---- ---------- ------------------- ------------------- ----------1 32768 30.0.0.1 20.0.0.1 upLeaf2#show vxlan sessionNumber of vxlan session: 1---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 200 32768 32768 30.0.0.1 20.0.0.1 upLeaf2#show vxlan session 20.0.0.1vxlan session 32768state: upsource IP: 30.0.0.1destination IP: 20.0.0.1source mac: 0001.7a00.5278destination mac: 0001.7a21.81e7interface: vlan6switchport: tengigabitethernet0/2source mac: 0001.7a00.5278destination mac: 0001.7a21.8203interface: vlan7switchport: tengigabitethernet0/3vxlan list: 200vxlan unicast list: 200vxlan multicast list: 200
Pode ser visto que Leaf2 estabelece sessões dinâmicas de unicast e multicast VXLAN com Spine1 e Spine2.
- Passo 9:Confira o resultado.
# No Server1 e Server2, configure o gateway.
#No Server1, ping Server2.
C:\Documents and Settings\ Server 1> ping 5.0.0.2Pinging 5.0.0.2 with 32 bytes of data:Reply from 5.0.0.2: bytes=32 time<1ms TTL=255Reply from 5.0.0.2: bytes=32 time<1ms TTL=255Reply from 5.0.0.2: bytes=32 time<1ms TTL=255Reply from 5.0.0.2: bytes=32 time<1ms TTL=255Ping statistics for 5.0.0.2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0m
Server1 e Server2 podem cruzar a rede L3 para realizar a intercomunicação.
Configurar BGP EVPN VXLAN Gateway distribuído
Requisitos de rede
- Crie instâncias VXLAN em Leaf1, Leaf2, Spine1 e Spine2, respectivamente
- Leaf1, Spine1 e Leaf2 conectam a rota EVPN através do MP-IBGP . Folha1 e Leaf2 criam o túnel IBGP EVPN VXLAN; crie a instância VRF e o gateway distribuído VXLAN em Leaf1 e Leaf2 para realizar o interfuncionamento entre server1 e server3 no mesmo segmento de rede e server2 e server3 em diferentes segmentos de rede.
- Na família de endereços BGP VRF em Leaf1 e Leaf2, habilite a importação da rota para a família de endereços EVPN, realizando a intercomunicação entre a rede VXLAN e a rede IP comum
Topologia de rede

Figura 2 -5 Rede de configuração do gateway distribuído BGP EVPN VXLAN
Etapas de configuração
- Passo 1:Configure a VLAN e adicione as portas à VLAN correspondente (omitida).
- Passo 2:Configure o endereço IP da interface.
#Configure Leaf1.
Leaf1(config)#interface loopback 0Leaf1(config-if-loopback0)#ip address 10.0.0.1 255.255.255.255Leaf1(config-if-loopback0)#exitLeaf1(config)#interface loopback 1Leaf1(config-if-loopback1)#ip address 10.0.1.1 255.255.255.255Leaf1(config-if-loopback1)#exitLeaf1(config)#interface vlan 3Leaf1(config-if-vlan3)#ip address 2.0.0.1 255.255.255.0Leaf1(config-if-vlan3)#exit
#Configure Spine1.
Spine1(config)#interface loopback 0Spine1(config-if-loopback0)#ip address 20.0.0.1 255.255.255.255Spine1(config-if-loopback0)#exitSpine1(config)#interface loopback 1Spine1(config-if-loopback1)#ip address 20.0.1.1 255.255.255.255Spine1(config-if-loopback1)#exitSpine1(config)#interface vlan 3Spine1(config-if-vlan3)#ip address 2.0.0.2 255.255.255.0Spine1(config-if-vlan3)#exitSpine1(config)#interface vlan 4Spine1(config-if-vlan4)#ip address 3.0.0.1 255.255.255.0Spine1(config-if-vlan4)#exit
#Configure Leaf2.
Leaf2(config)#interface loopback 0Leaf2(config-if-loopback0)#ip address 30.0.0.1 255.255.255.255Leaf2(config-if-loopback0)#exitLeaf2(config)#interface loopback 1Leaf2(config-if-loopback1)#ip address 30.0.1.1 255.255.255.255Leaf2(config-if-loopback1)#exitLeaf2(config)#interface vlan 4Leaf2(config-if-vlan4)#ip address 3.0.0.2 255.255.255.0Leaf2(config-if-vlan4)#exit
- Passo 3:Configure o OSPF, tornando a rota de Loopback entre dispositivos alcançável.
#Configure Leaf1.
Leaf1#configure terminalLeaf1(config)#router ospf 100Leaf1(config-ospf)#network 10.0.0.1 0.0.0.0 area 0Leaf1(config-ospf)#network 10.0.1.1 0.0.0.0 area 0Leaf1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Leaf1(config-ospf)#exit
#Configure Spine1.
Spine1#configure terminalSpine1(config)#router ospf 100Spine1(config-ospf)#network 20.0.0.1 0.0.0.0 area 0Spine1(config-ospf)#network 20.0.1.1 0.0.0.0 area 0Spine1(config-ospf)#network 2.0.0.0 0.0.0.255 area 0Spine1(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Spine1(config-ospf)#exit
#Configure Leaf2.
Leaf2#configure terminalLeaf2(config)#router ospf 100Leaf2(config-ospf)#network 30.0.0.1 0.0.0.0 area 0Leaf2(config-ospf)#network 30.0.1.1 0.0.0.0 area 0Leaf2(config-ospf)#network 3.0.0.0 0.0.0.255 area 0Leaf2(config-ospf)#exit
#Visualize a tabela de rotas da Folha 1.
Leaf1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 00:56:51, vlan3O 3.0.0.0/24 [110/2] via 2.0.0.2, 00:56:00, vlan3C 10.0.1.0/24 is directly connected, 00:08:30, loopback1C 127.0.0.0/8 is directly connected, 3d:03:23:29, lo0C 10.0.0.1/32 is directly connected, 00:56:51, loopback0O 20.0.0.1/32 [110/2] via 2.0.0.2, 00:56:00, vlan3O 20.0.1.1/32 [110/2] via 2.0.0.2, 00:05:22, vlan3O 30.0.0.1/32 [110/3] via 2.0.0.2, 00:55:52, vlan3O 30.0.1.1/32 [110/3] via 2.0.0.2, 00:05:44, vlan3
#Visualize a tabela de rotas do Spine 1..
Spine1#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 2.0.0.0/24 is directly connected, 01:01:05, vlan3C 3.0.0.0/24 is directly connected, 01:01:05, vlan4C 20.0.1.0/24 is directly connected, 00:12:40, loopback1C 127.0.0.0/8 is directly connected, 1w4d:09:22:41, lo0O 10.0.0.1/32 [110/2] via 2.0.0.1, 01:00:21, vlan3O 10.0.1.1/32 [110/2] via 2.0.0.1, 00:08:04, vlan3C 20.0.0.1/32 is directly connected, 01:01:05, loopback0O 30.0.0.1/32 [110/2] via 3.0.0.2, 01:00:13, vlan4O 30.0.1.1/32 [110/2] via 3.0.0.2, 00:10:05, vlan4
#Visualize a tabela de rotas do Leaf 2..
Leaf2#show ip routeCodes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setO 2.0.0.0/24 [110/2] via 3.0.0.1, 01:04:02, vlan4C 3.0.0.0/24 is directly connected, 01:04:44, vlan4C 30.0.0.0/24 is directly connected, 01:04:44, loopback0C 30.0.1.0/24 is directly connected, 00:15:47, loopback1C 127.0.0.0/8 is directly connected, 4d:04:40:07, lo0O 10.0.0.1/32 [110/3] via 3.0.0.1, 01:04:02, vlan4O 10.0.1.1/32 [110/3] via 3.0.0.1, 00:11:49, vlan4O 20.0.0.1/32 [110/2] via 3.0.0.1, 01:04:02, vlan4O 20.0.1.1/32 [110/2] via 3.0.0.1, 00:13:28, vlan4
Você pode ver que Leaf1 , Spine1 e Leaf2 aprenderam as rotas para as portas de loopback de peer executando o protocolo OSPF.
- Passo 4:Configure VXLAN e associe VNID , e configure a família de endereços EVPN para fazer as portas de Leaf1 e Leaf2 se juntarem a VXLAN .
#Configure Leaf1 .
Leaf1(config)#vxlan 100Leaf1(config-vxlan-100)#vxlan vnid 100Leaf1(config-vxlan-100)#address-family evpnLeaf1(config-vxlan-evpn)#rd 100:1Leaf1(config-vxlan-evpn)#route-target both 100:1Leaf1(config-vxlan-evpn)#exitLeaf1(config-vxlan-100)#exitLeaf1(config)# interface tengigabitethernet 0/1Leaf1(config-if-tengigabitethernet0/1)# vxlan 100 encapsulation vlan 2Leaf1(config-if-tengigabitethernet0/1)#exitLeaf1(config)# vxlan 200Leaf1(config-vxlan-200)#vxlan vnid 200Leaf1(config-vxlan-200)#address-family evpnLeaf1(config-vxlan-evpn)#rd 200:1Leaf1(config-vxlan-evpn)#route-target both 200:1Leaf1(config-vxlan-evpn)#exitLeaf1(config-vxlan-200)#exitLeaf1(config)# interface tengigabitethernet 0/3Leaf1(config-if-tengigabitethernet0/3)# vxlan 200 encapsulation vlan 5Leaf1(config-if-tengigabitethernet0/3)#exit
#Configure Spine1 .
Spine1(config)#vxlan 100Spine1(config-vxlan-100)#vxlan vnid 100Spine1(config-vxlan-100)#address-family evpnSpine1(config-vxlan-evpn)#rd 100:1Spine1(config-vxlan-evpn)#route-target both 100:1Spine1(config-vxlan-evpn)#exitSpine1(config-vxlan-100)#exitSpine1(config)#vxlan 200Spine1(config-vxlan-200)#vxlan vnid 200Spine1(config-vxlan-200)#address-family evpnSpine1(config-vxlan-evpn)#rd 200:1Spine1(config-vxlan-evpn)#route-target both 200:1Spine1(config-vxlan-evpn)#exitSpine1(config-vxlan-200)#exit
#Configure Leaf2 .
Leaf2(config)#vxlan 100Leaf2(config-vxlan-100)#vxlan vnid 100Leaf2(config-vxlan-100)#address-family evpnLeaf2(config-vxlan-evpn)#rd 100:1Leaf2(config-vxlan-evpn)#route-target both 100:1Leaf2(config-vxlan-evpn)#exitLeaf2(config-vxlan-100)#exitLeaf2(config)# interface tengigabitethernet 0/1Leaf2(config-if-tengigabitethernet0/1)# vxlan 100 encapsulation vlan 2Leaf2(config-if-tengigabitethernet0/1)#exit
# Visualize as informações de VXLAN de Leaf1..
Leaf1#show vxlan configvxlan 100vxlan vnid 100address-family evpnrd 100:1route-target import 100:1route-target export 100:1exitexitvxlan 200vxlan vnid 200address-family evpnrd 200:1route-target import 200:1route-target export 200:1exitexitLeaf1#show running-config interface te0/1interface tengigabitethernet0/1switchport mode trunkswitchport trunk allowed vlan add 2switchport trunk pvid vlan 1vxlan 100 encapsulation vlan 2exitLeaf1#show running-config interface te0/3interface tengigabitethernet0/3switchport mode trunkswitchport trunk allowed vlan add 5switchport trunk pvid vlan 1vxlan 200 encapsulation vlan 5exit
# Veja as informações de VXLAN do Spine1..
Spine1#show vxlan configvxlan 100vxlan vnid 100address-family evpnrd 100:1route-target import 100:1route-target export 100:1exitexitvxlan 200vxlan vnid 200address-family evpnrd 200:1route-target import 200:1route-target export 200:1exitexit
# Visualize as informações de VXLAN de Leaf2..
Leaf2#show vxlan configvxlan 100vxlan vnid 100address-family evpnrd 100:1route-target import 100:1route-target export 100:1exitexitLeaf1#show running-config interface te0/1interface tengigabitethernet0/1switchport mode trunkswitchport trunk allowed vlan add 2switchport trunk pvid vlan 1vxlan 100 encapsulation vlan 2exit
- Passo 5:Configurar BGP.
#Configure Leaf1 .
Configure o peer IBGP com Spine1 e ative o recurso de notificação na família de endereços EVPN.
Leaf1(config)#router bgp 100Leaf1(config-bgp)#neighbor 20.0.1.1 remote-as 100Leaf1(config-bgp)#neighbor 20.0.1.1 update-source loopback 1Leaf1(config-bgp)#address-family l2vpn evpnLeaf1(config-bgp-af)#neighbor 20.0.1.1 activateLeaf1(config-bgp-af)#exit-address-familyLeaf1(config-bgp)#exit
#Configure Spine1 .
Leaf1 e Leaf2 respectivamente, e ative o recurso de notificação e configure o refletor na família de endereços EVPN.
Spine1(config)#router bgp 100Spine1(config-bgp)#neighbor 10.0.1.1 remote-as 100Spine1(config-bgp)#neighbor 10.0.1.1 update-source loopback 1Spine1(config-bgp)#neighbor 30.0.1.1 remote-as 100Spine1(config-bgp)#neighbor 30.0.1.1 update-source loopback 1Spine1(config-bgp)#address-family l2vpn evpnSpine1(config-bgp-af)#neighbor 10.0.1.1 activateSpine1(config-bgp-af)#neighbor 10.0.1.1 route-reflector-clientSpine1(config-bgp-af)#neighbor 30.0.1.1 activateSpine1(config-bgp-af)#neighbor 30.0.1.1 route-reflector-clientSpine1(config-bgp-af)#exit-address-familySpine1(config-bgp)#exit
#Configure Leaf2 .
Spine1 e ative o recurso de notificação na família de endereços EVPN.
Leaf2(config)#router bgp 100Leaf2(config-bgp)#neighbor 20.0.1.1 remote-as 100Leaf2(config-bgp)#neighbor 20.0.1.1 update-source loopback 1Leaf2(config-bgp)#address-family l2vpn evpnLeaf2(config-bgp-af)#neighbor 20.0.1.1 activateLeaf2(config-bgp-af)#exit-address-familyLeaf2(config-bgp)#exit
# Visualize o vizinho BGP EVPN de Leaf1 .
Leaf1#show bgp l2vpn evpn summaryBGP router identifier 10.0.1.1, local AS number 100BGP table version is 11 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd20.0.1.1 4 100 2 2 1 0 0 00:00:28 0Total number of neighbors 1
# Visualize o vizinho BGP EVPN de Spine1 .
Spine1#show bgp l2vpn evpn summaryBGP router identifier 20.0.1.1, local AS number 100BGP table version is 11 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd10.0.1.1 4 100 3 3 1 0 0 00:01:34 030.0.1.1 4 100 2 2 1 0 0 00:00:02 0Total number of neighbors 2
# Visualize o vizinho BGP EVPN de Leaf2 .
Leaf2#show bgp l2vpn evpn summaryBGP router identifier 30.0.1.1, local AS number 100BGP table version is 11 BGP AS-PATH entries0 BGP community entriesNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd20.0.1.1 4 100 3 3 1 0 0 00:01:10 0Total number of neighbors 1
- Passo 6:Configurar a instância VRF.
#Configure a instância VRF de Leaf1 .
Leaf1(config)#ip vrf 1Leaf1(config-vrf)#rd 100:2Leaf1(config-vrf)#l3vnid 1Leaf1(config-vrf)#address-family evpnLeaf1(config-vrf-evpn)#route-target both 100:2Leaf1(config-vrf-evpn)#exitLeaf1(config-vrf)#exit
#Configure a instância VRF de Leaf2 .
Leaf2(config)#ip vrf 1Leaf2(config-vrf)#rd 100:2Leaf2(config-vrf)#l3vnid 1Leaf2(config-vrf)#address-family evpnLeaf2(config-vrf-evpn)#route-target both 100:2Leaf2(config-vrf-evpn)#exitLeaf2(config-vrf)#exit
- Passo 7:Configurar a interface NVE.
#Configure a interface NVE de Leaf1 e configure a VXLAN correspondente para usar o protocolo BGP para configurar o túnel L2 dinamicamente.
Leaf1(config)#interface nve 1Leaf1(config-if-nve1)#source 10.0.0.1Leaf1(config-if-nve1)#vxlan 100,200 ingress-replication protocol bgpLeaf1(config-if-nve1)#exit
#Configure a interface NVE do Leaf2 e configure o VXLAN correspondente para usar o protocolo BGP para configurar o túnel L2 dinamicamente.
Leaf2(config)#interface nve 1Leaf2(config-if-nve1)#source 30.0.0.1Leaf2(config-if-nve1)#vxlan 100 ingress-replication protocol bgpLeaf2(config-if-nve1)#exit
- Passo 8:Configurar o gateway VXLAN L3 e vincular a instância VRF correspondente.
#Configure o gateway L3 de Leaf1 e vincule a instância VRF correspondente.
Leaf1(config)#interface vxlan 200Leaf1(config-if-vxlan200)#ip vrf forwarding 1Leaf1(config-if-vxlan200)#vxlan distribute-gatewayLeaf1(config-if-vxlan200)#ip address 5.0.0.1 24Leaf1(config-if-vxlan200)#exit
#Configure o gateway L3 do Leaf2 e vincule a instância VRF correspondente.
Leaf2(config)#interface vxlan 100Leaf2(config-if-vxlan100)#ip vrf forwarding 1Leaf2(config-if-vxlan100)#vxlan distribute-gatewayLeaf2(config-if-vxlan100)#ip address 1.0.0.1 24Leaf2(config-if-vxlan100)#exit
#Visualize a interface VXLAN e a tabela de rotas de Leaf1.
Leaf1#show interface vxlan 200vxlan200:line protocol is upFlags: (0xc008063) BROADCAST MULTICAST ARP RUNNINGType: ETHERNET_CSMACDInternet address: 5.0.0.1/24Broadcast address: 5.0.0.255Metric: 0, MTU: 1500, BW: 100000 Kbps, DLY: 100 usec, VRF: 1Reliability 255/255, Txload 1/255, Rxload 1/255Ethernet address is 0001.7a00.52785 minutes input rate 0 bits/sec, 0 packets/sec5 minutes output rate 0 bits/sec, 0 packets/sec94 packets received; 88 packets sent0 multicast packets received5 multicast packets sent0 input errors; 0 output errors0 collisions; 0 droppedUnknown protocol 0Leaf1#show ip route vrf 1Codes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 5.0.0.0/24 is directly connected, 00:01:13, vxlan200
#Veja a interface VXLAN e a tabela de rotas do Leaf2.
Leaf2#show interface vxlan 100vxlan100:line protocol is upFlags: (0xc008063) BROADCAST MULTICAST ARP RUNNINGType: ETHERNET_CSMACDInternet address: 1.0.0.1/24Broadcast address: 1.0.0.255Metric: 0, MTU: 1500, BW: 100000 Kbps, DLY: 100 usec, VRF: 1Reliability 255/255, Txload 1/255, Rxload 1/255Ethernet address is 0001.7a6a.00425 minutes input rate 0 bits/sec, 0 packets/sec5 minutes output rate 0 bits/sec, 0 packets/sec0 packets received; 2 packets sent0 multicast packets received2 multicast packets sent0 input errors; 0 output errors0 collisions; 0 droppedUnknown protocol 0Leaf2#show ip route vrf 1Codes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 1.0.0.0/24 is directly connected, 00:02:15, vxlan100
#Veja as informações do túnel e a sessão VXLAN de Leaf1.
Leaf1# show vxlan tunnelNumber of vxlan tunnel: 1---- ---------- ------------------- ------------------- ----------NO. TunnelID Source Destination State---- ---------- ------------------- ------------------- ----------1 32768 10.0.0.1 30.0.0.1 upLeaf1#show vxlan sessionNumber of vxlan session: 1---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 100 32768 32768 10.0.0.1 30.0.0.1 upLeaf1#show vxlan session l3Number of vxlan session: 1---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 4097 32768 32768 10.0.0.1 30.0.0.1 up
#Visualize as informações do túnel e a sessão VXLAN do Leaf2.
Leaf2# show vxlan tunnelNumber of vxlan tunnel: 1---- ---------- ------------------- ------------------- ----------NO. TunnelID Source Destination State---- ---------- ------------------- ------------------- ----------1 32768 30.0.0.1 10.0.0.1 upLeaf2#show vxlan sessionNumber of vxlan session: 1---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 100 32768 32768 30.0.0.1 10.0.0.1 upLeaf2#show vxlan session l3Number of vxlan session: 1---- ---------- ---------- ---------- ------------------- ------------------- ----------NO. VXLAN-ID SessionID TunnelID Source Destination State---- ---------- ---------- ---------- ------------------- ------------------- ----------1 4097 32768 32768 30.0.0.1 10.0.0.1 up
VXLAN pode ser configurada normalmente.
- Passo 9:Configure a rota unicast VRF e habilite a função de melhorar a rota para a família de endereços EVPN sob a família de endereços BGP VRF.
#Configure Leaf1 .
Leaf1(config)#interface loopback 2Leaf1(config-if-loopback2)#ip vrf forwarding 1Leaf1(config-if-loopback2)#ip address 11.0.0.1 255.255.255.255Leaf1(config-if-loopback2)#exitLeaf1(config)#router bgp 100Leaf1(config-bgp)#address-family ipv4 vrf 1Leaf1(config-bgp-af)#advertise-l2vpn-evpnLeaf1(config-bgp-af)#network 11.0.0.1 255.255.255.255Leaf1(config-bgp-af)#exit-address-familyLeaf1(config-bgp)#exit
#Configure Leaf2 .
Leaf2(config)#interface loopback 2Leaf2(config-if-loopback2)#ip vrf forwarding 1Leaf2(config-if-loopback2)#ip address 31.0.0.1 32Leaf2(config-if-loopback2)#exitLeaf2(config)#router bgp 100Leaf2(config-bgp)#address-family ipv4 vrf 1Leaf2(config-bgp-af)#advertise-l2vpn-evpnLeaf2(config-bgp-af)#network 31.0.0.1 255.255.255.255Leaf2(config-bgp-af)#exit-address-familyLeaf2(config-bgp)#exit
# Servidor1, Server2 e Server3 enviam arp.
BGP EVPN Classe 2 e 5 e rotas unicast VRF de Leaf1.
Leaf1#show bgp l2vpn evpn all type 2BGP local router ID is 10.0.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteEVPN Information for Route Distinguisher:100:1MAC/IP Advertisement Routes:Network(ETID:MAC:IP) Next Hop Metric LocPrf Weight Path[B]*>i0:48:0001.7a6a.0042:0:0.0.0.0/96 30.0.0.1 0 100 0 i[B]*> 0:48:0010.9400.104c:0:0.0.0.0/96 0.0.0.0 0 32768 i[B]*>i0:48:0010.9400.104e:0:0.0.0.0/96 30.0.0.1 0 100 0 i[B]*>i0:48:0001.7a6a.0042:32:1.0.0.1/128 30.0.0.1 0 100 0 i[B]*> 0:48:0010.9400.104c:32:1.0.0.2/128 0.0.0.0 0 32768 i[B]*>i0:48:0010.9400.104e:32:1.0.0.3/128 30.0.0.1 0 100 0 iEVPN Information for Route Distinguisher:100:2MAC/IP Advertisement Routes:Network(ETID:MAC:IP) Next Hop Metric LocPrf Weight Path[B]*>i0:48:0001.7a6a.0042:32:1.0.0.1/128 30.0.0.1 0 100 0 i[B]*>i0:48:0010.9400.104e:32:1.0.0.3/128 30.0.0.1 0 100 0 iEVPN Information for Route Distinguisher:200:1MAC/IP Advertisement Routes:Network(ETID:MAC:IP) Next Hop Metric LocPrf Weight Path[B]*> 0:48:0001.7a00.5278:0:0.0.0.0/96 0.0.0.0 0 32768 i[B]*> 0:48:0010.9400.104d:0:0.0.0.0/96 0.0.0.0 0 32768 i[B]*> 0:48:0001.7a00.5278:32:5.0.0.1/128 0.0.0.0 0 32768 i[B]*> 0:48:0010.9400.104d:32:5.0.0.2/128 0.0.0.0 0 32768 iLeaf1#show bgp l2vpn evpn all type 5BGP local router ID is 10.0.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteEVPN Information for Route Distinguisher:100:2IP Prefix Routes:Network(ETID:IP) Next Hop Metric LocPrf Weight Path[B]*> 0:32:11.0.0.1/72 0.0.0.0 0 32768 i[B]*>i0:32:31.0.0.1/72 30.0.0.1 0 100 0 iLeaf1#show ip route vrf 1Codes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 5.0.0.0/24 is directly connected, 00:09:00, vxlan200B 1.0.0.1/32 [200/0] via 30.0.0.1, 00:06:31, vxlan4097B 1.0.0.3/32 [200/0] via 30.0.0.1, 00:01:48, vxlan4097C 11.0.0.1/32 is directly connected, 00:08:47, loopback2B 31.0.0.1/32 [200/0] via 30.0.0.1, 00:06:17, vxlan4097
# Veja a rota BGP EVPN Classe 2 e 5 e rotas unicast VRF de Leaf2.
Leaf2#show bgp l2vpn evpn all type 2BGP local router ID is 30.0.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteEVPN Information for Route Distinguisher:100:1MAC/IP Advertisement Routes:Network(ETID:MAC:IP) Next Hop Metric LocPrf Weight Path[B]*> 0:48:0001.7a6a.0042:0:0.0.0.0/96 0.0.0.0 0 32768 i[B]*>i0:48:0010.9400.104c:0:0.0.0.0/96 10.0.0.1 0 100 0 i[B]*> 0:48:0010.9400.104e:0:0.0.0.0/96 0.0.0.0 0 32768 i[B]*> 0:48:0001.7a6a.0042:32:1.0.0.1/128 0.0.0.0 0 32768 i[B]*>i0:48:0010.9400.104c:32:1.0.0.2/128 10.0.0.1 0 100 0 i[B]*> 0:48:0010.9400.104e:32:1.0.0.3/128 0.0.0.0 0 32768 iEVPN Information for Route Distinguisher:100:2MAC/IP Advertisement Routes:Network(ETID:MAC:IP) Next Hop Metric LocPrf Weight Path[B]*>i0:48:0001.7a00.5278:32:5.0.0.1/128 10.0.0.1 0 100 0 i[B]*>i0:48:0010.9400.104d:32:5.0.0.2/128 10.0.0.1 0 100 0 iEVPN Information for Route Distinguisher:200:1MAC/IP Advertisement Routes:Network(ETID:MAC:IP) Next Hop Metric LocPrf Weight Path[B]*>i0:48:0001.7a00.5278:32:5.0.0.1/128 10.0.0.1 0 100 0 i[B]*>i0:48:0010.9400.104d:32:5.0.0.2/128 10.0.0.1 0 100 0 iLeaf2#show bgp l2vpn evpn all type 5BGP local router ID is 30.0.1.1Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,S StaleOrigin codes: i - IGP, e - EGP, ? - incompleteEVPN Information for Route Distinguisher:100:2IP Prefix Routes:Network(ETID:IP) Next Hop Metric LocPrf Weight Path[B]*>i0:32:11.0.0.1/72 10.0.0.1 0 100 0 i[B]*> 0:32:31.0.0.1/72 0.0.0.0 0 32768 iLeaf2#Leaf2#show ip rouLeaf2#show ip route vrf 1Codes: C - connected, S - static, R - RIP, O - OSPF, OE-OSPF External, M - ManagementD - Redirect, E - IRMP, EX - IRMP external, o - SNSP, B - BGP, i-ISISGateway of last resort is not setC 1.0.0.0/24 is directly connected, 00:09:10, vxlan100B 5.0.0.1/32 [200/0] via 10.0.0.1, 00:08:31, vxlan4097B 5.0.0.2/32 [200/0] via 10.0.0.1, 00:08:31, vxlan4097B 11.0.0.1/32 [200/0] via 10.0.0.1, 00:08:31, vxlan4097C 31.0.0.1/32 is directly connected, 00:09:14, loopback2
A informação acima mostra que o dispositivo aprende a rota unicast VRF através da rota EVPN .
- Passo 10:Confira o resultado.
#On Server3, ping Server1.
C:\Documents and Settings\ Server 3> ping 1.0.0.2Pinging 1.0.0.2 with 32 bytes of data:Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Reply from 1.0.0.2: bytes=32 time<1ms TTL=255Ping statistics for 1.0.0.2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0m
Pode-se ver que Server1 e Server3 podem cruzar a rede L3 entre Leaf1, Spine1 e Leaf2 para realizar a intercomunicação.
#On Server3, ping Server2.
C:\Documents and Settings\ Server 3> ping 5.0.0.2Pinging 5.0.0.2 with 32 bytes of data:Reply from 5.0.0.2: bytes=32 time<1ms TTL=255Reply from 5.0.0.2: bytes=32 time<1ms TTL=255Reply from 5.0.0.2: bytes=32 time<1ms TTL=255Reply from 5.0.0.2: bytes=32 time<1ms TTL=255Ping statistics for 5.0.0.2:Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:Minimum = 0ms, Maximum = 0ms, Average = 0m
Pode-se ver que o Servidor 2 e Server3 podem cruzar a rede L3 entre Leaf1, Spine1 e Leaf2 para realizar a intercomunicação.
Configurar o BGP EVPN no Data Center Distributed Gateway
Requisitos de rede
- Execute o protocolo IGP entre Spine1, Spine2, Device1 e Devcie2 para conectar a rota.
- Execute o protocolo EBGP entre Spine1 e Spine2 para conectar a rota EVPN e execute o protocolo IBGP entre Spine1 e Leaf1, Spine2 e Leaf2 para conectar a rota EVPN.
- Como VTEP, Leaf1 e Leaf2 criam o túnel IBGP EVPN VXLAN , e criam a instância VRF e o gateway distribuído vxlan em Leaf1 e Leaf2, de modo a realizar a intercomunicação entre Server1 e Server3, Server2 e Server4 no mesmo segmento de rede, Server1 e Server4 , Server2 e Server3 nos diferentes segmentos de rede.
- Na família de endereços BGP VRF em Leaf1 e Leaf2, habilite a importação da rota para a família de endereços EVPN, de modo a realizar a intercomunicação da rede VXLAN e da rede IP comum.
Topologia de rede

Figura 2 -6 Rede de configuração do BGP EVPN no gateway distribuído do data center
Etapas de configuração
- Passo 1:Configure a VLAN e adicione as portas à VLAN correspondente (omitida).
- Passo 2:Configure o endereço IP da interface. (omitido)
- Passo 3:Configure o OSPF, tornando a rota de Loopback entre dispositivos alcançável. (omitido)
- Passo 4:Leaf1 e Leaf2, configure VXLAN e associe VNID, e configure a família de endereços EVPN, de modo a fazer com que as portas de Leaf1 e Leaf2 sejam adicionadas à VXLAN. (omitido)
- Passo 5:Configurar BGP.
#Configurar Leaf1 e Spine1, Leaf2 e Spine1 para configurar o vizinho IBGP e ativar o recurso de publicidade na família de endereços EVPN (omitido).
#Configurar Spine1 e Spine2 para configurar o vizinho EBGP e ativar o recurso de publicidade na família de endereços EVPN e configurar a função de não alterar o atributo de rota ao anunciar a rota para o vizinho (omitido).
- Passo 6:Configure a instância VRF.
#Configure a instância VRF de Leaf1 e Folha2 (omitido).
- Passo 7:Configure a interface NVE.
#Configurar a interface NVE de Leaf1 e Leaf2 e configurar a VXLAN correspondente para usar o protocolo BGP para configurar dinamicamente o túnel L2 (omitido).
- Passo 8:Leaf1 e Leaf2, configure o gateway VXLAN L3 e vincule a instância VRF correspondente (omitida).
- Passo 9:Leaf1 e Leaf2, configure a rota unicast VRF e habilite a função de importar a rota para a família de endereços EVPN (omitido).
- Passo 10:Confira o resultado.
#No Server1, ping Server3.
que Server1 e Server3 podem cruzar a rede L3 entre Leaf1, Spine1 e Leaf2 para realizar a intercomunicação.
#No Server1, ping Server4.
que Server1 e Server3 podem cruzar a rede L3 entre Leaf1, Spine1 e Leaf2 para realizar a intercomunicação.
Para todas as configurações e verificação de resultados na seção, você pode consultar o conteúdo da seção 2.3.5.
NLB
Visão geral
NLB é um recurso de balanceamento de carga de cluster de vários servidores desenvolvido pela Microsoft no Windows Server. Quando o switch está conectado ao cluster de servidor NLB, o servidor NLB requer que o switch envie o pacote cujo endereço IP de destino é o endereço IP do cluster de servidor NLB para cada servidor no cluster de servidor NLB.
Configuração da função NLB
Tabela 2 -1 Lista de configuração da função NLB
| Tarefa de configuração | |
| Configurar a função NLB |
Configurar o grupo de reflexão
Configure o ARP estático para vincular o grupo de reflexão Configurar a multiporta MAC estática |
Configurar NLB
Condição de configuração
Nenhum
Configurar o ARP estático para vincular o grupo de reflexão
Tabela 2 -2 Configurar o ARP estático para ligar o grupo reflectio
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | configure terminal | - |
| Configure o ARP estático para vincular o grupo de reflexão | arp [ vrf vrf-name ] { ip-address | host-name } mac-address vlan vlan-id serviceloop-group serviceloop-group-id | Obrigatório |
Ao usar a função NLB, você precisa desabilitar o arp smac -check multicast.
Configure Static MAC Multi-Port
Depois de configurar a entrada da tabela de endereços MAC de encaminhamento estático de várias portas de saída, quando a porta recebe o pacote na VLAN correspondente, ela corresponde ao endereço MAC de destino do pacote com a entrada da tabela de endereços MAC de encaminhamento estático configurada no dispositivo. Se a correspondência for bem-sucedida, o pacote será encaminhado das várias portas de saída especificadas. Essa função pode enviar pacotes com mais flexibilidade para várias portas de saída para obter vários encaminhamentos de tráfego.
Tabela 2 -3 Configurar o endereço MAC de encaminhamento estático vinculado às várias portas de saída
| Etapa | Comando | Descrição |
| Entre no modo de configuração global | config terminal | - |
| Configure o endereço MAC de encaminhamento estático vinculado ao grupo de agregação | mac-address multiport mac-address-valu vlan vlan-id interface { interface-name1 [ to interface-name2 ] } | Obrigatório Por padrão, não configure o endereço MAC de encaminhamento estático de várias portas de saída no dispositivo. |
Monitoramento e manutenção de NLB
Tabela 2 -4 Monitoramento e manutenção de NLB
| Comando | Descrição |
| show mac-address multiport | Exiba as informações de várias portas MAC |
| show arp | Exibir as informações do ARP |
| show serviceloop-group | Exibir as informações do grupo de reflexão |
Exemplo de configuração típica de NLB
Requisitos de rede
- Após configurar o grupo de reflexão, MAC multiporta, ARP estático, o pacote enviado pelo PC será enviado para todos os servidores NLB.
Topologia de rede
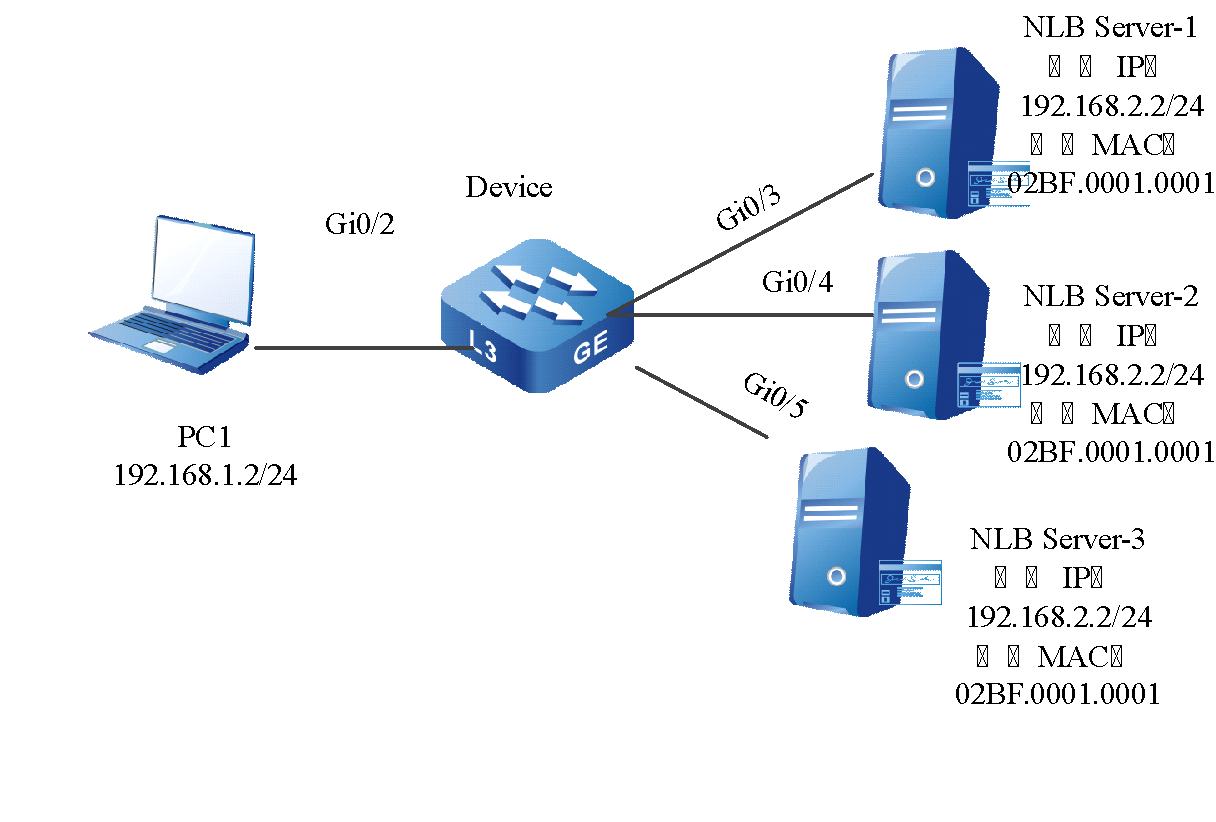
Figura 2-1 Rede de configuração do NLB
Etapas de configuração
- Passo 1:No dispositivo, configure a VLAN e o tipo de link de porta e o endereço IP .
# No dispositivo, crie VLAN2 e 3 .
Device#configure terminalDevice(config)#vlan 2,3
#Configure o tipo de link da porta gigabitethernet0/ 2 para acessar, permita que os serviços da VLAN2 passem, habilite a interação VLAN2 e configure o endereço IP para 192.168.1.1/24.
Device(config)#interface gigabitethernet 0/2Device(config-if-gigabitethernet0/2)#switchport mode accessDevice(config-if-gigabitethernet0/2)#switchport access vlan 2Device(config-if-gigabitethernet0/2)#exitDevice(config)#interface vlan 2Device(config-if-vlan2)#ip address 192.168.1.1 255.255.255.0Device(config-if-vlan2)#exit
o tipo de link de porta em gigabitethernet 0/3 – gigabitethernet 0/5 do Device to Access, permita a passagem dos serviços da VLAN2, habilite a interface VLAN2 e configure o endereço IP para 192.168.1.1/24 (omitido).
- Passo 2:Configurar o grupo de reflexão.
#Configure o grupo de reflexão 1 e selecione qualquer porta do dispositivo para adicionar ao grupo de reflexão.
Device(config)#serviceloop-group 1Device (config)# interface gigabitethernet 0/6Device(config-if-gigabitethernet0/6)#serviceloop-group 1 activeDevice(config-if-gigabitethernet0/6)#exit
- Passo 3:Configurar multiportas MAC.
#No dispositivo, configure a multiporta MAC e especifique a porta de saída como gi0/3-gi0/5 .
Device#configure terminalDevice(config)#mac-address multiport 02BF.1.1 vlan 3 interface gigabitethernet 0/3,0/4,0/5Device(config)#exit
- Passo 4:Configurar o ARP estático .
# No dispositivo, configure o ARP estático e vincule o grupo de reflexão.
Device#configure terminalDevice(config)# arp 192.168.2.2 02bf.1.1 vlan 3 serviceloop-group 1Device(config)#exit
- Passo 5:Confira o resultado .
#Visualize o grupo de reflexão.
Device# show serviceloop-groupserviceloop group 1Description:Number of ports in total: 1serviceloop port: gigabitethernet0/6
#Visualize a multiporta MAC.
Device# show mac-address multiportmac vlan interface02BF.0001.0001 3 gi0/3-0/5
#Visualizar ARP . _
Device# show arpProtocol Address Age (min) Hardware Addr Type Interface SwitchportInternet 192.168.1.1 - 0001.7a6a.011e ARPA vlan2 ---Internet 192.168.2.1 - 0001.7a6a.011e ARPA vlan3 ---Internet 192.168.2.2 - 02bf.0001.0001 ARPA vlan3 gigabitethernet0/3Internet 192.168.2.2 - 02bf.0001.0001 ARPA vlan3 gigabitethernet0/4Internet 192.168.2.2 - 02bf.0001.0001 ARPA vlan3 gigabitethernet0/5
# Ao acessar o IP do cluster do servidor NLB do PC, cada servidor pode receber o pacote.
Termo de garantia
Para a sua comodidade, preencha os dados abaixo, pois, somente com a apresentação deste em conjunto com a nota fiscal de compra do produto, você poderá utilizar os benefícios que lhe são assegurados.
Nome do cliente:
Assinatura do cliente:
Nº da nota fiscal:
Data da compra:
Modelo:
Nº de série:
Revendedor:
Fica expresso que esta garantia contratual é conferida mediante as seguintes condições:
1. Todas as partes, peças e componentes do produto são garantidos contra eventuais defeitos de fabricação, que porventura venham a apresentar, pelo prazo de 3 (três) anos – sendo 3 (três) meses de garantia legal e 33 (trinta e três) meses de garantia contratual –, contado a partir da data de entrega do produto ao Senhor Consumidor, conforme consta na nota fiscal de compra do produto, que é parte integrante deste Termo em todo o território nacional. Esta garantia contratual compreende a troca gratuita de partes, peças e componentes que apresentarem defeito de fabricação, incluindo a mão de obra utilizada nesse reparo. Caso não seja constatado defeito de fabricação, e sim defeito(s) proveniente(s) de uso inadequado, o Senhor Consumidor arcará com essas despesas.
2. A instalação do produto deve ser feita de acordo com o Manual do Produto e/ou Guia de Instalação. Caso seu produto necessite a instalação e configuração por um técnico capacitado, procure um profissional idôneo e especializado, sendo que os custos desses serviços não estão inclusos no valor do produto.
3. Na eventualidade de o Senhor Consumidor solicitar atendimento domiciliar, deverá encaminhar-se ao Serviço Autorizado mais próximo para consulta da taxa de visita técnica. Caso seja constatada a necessidade da retirada do produto, as despesas decorrentes de transporte e segurança de ida e volta do produto ficam sob a responsabilidade do Senhor Consumidor.
4. Na eventualidade de o Senhor Consumidor solicitar atendimento domiciliar, deverá encaminhar-se ao Serviço Autorizado mais próximo para consulta da taxa de visita técnica. Caso seja constatada a necessidade da retirada do produto, as despesas decorrentes, como as de transporte e segurança de ida e volta do produto, ficam sob a responsabilidade do Senhor Consumidor.
5. A garantia perderá totalmente sua validade na ocorrência de quaisquer das hipóteses a seguir: a) se o vício não for de fabricação, mas sim causado pelo Senhor Consumidor ou por terceiros estranhos ao fabricante; b) se os danos ao produto forem oriundos de acidentes, sinistros, agentes da natureza (raios, inundações, desabamentos, etc.), umidade, tensão na rede elétrica (sobretensão provocada por acidentes ou flutuações excessivas na rede), instalação/uso em desacordo com o manual do usuário ou decorrentes do desgaste natural das partes, peças e componentes; c) se o produto tiver sofrido influência de natureza química, eletromagnética, elétrica ou animal (insetos, etc.); d) se o número de série do produto tiver sido adulterado ou rasurado; e) se o equipamento tiver sido violado.
6. Esta garantia não cobre perda de dados, portanto, recomenda-se, se for o caso do produto, que o Consumidor faça uma cópia de segurança regularmente dos dados que constam no produto.
7. A Intelbras não se responsabiliza pela instalação deste produto, e também por eventuais tentativas de fraudes e/ou sabotagens em seus produtos. Mantenha as atualizações do software e aplicativos utilizados em dia, se for o caso, assim como as proteções de rede necessárias para proteção contra invasões (hackers). O equipamento é garantido contra vícios dentro das suas condições normais de uso, sendo importante que se tenha ciência de que, por ser um equipamento eletrônico, não está livre de fraudes e burlas que possam interferir no seu correto funcionamento.
A garantia contratual deste termo é complementar à legal, portanto, a Intelbras S/A reserva-se o direito de alterar as características gerais, técnicas e estéticas de seus produtos sem aviso prévio.
Sendo estas as condições deste Termo de Garantia complementar, a Intelbras S/A se reserva o direito de alterar as características gerais, técnicas e estéticas de seus produtos sem aviso prévio.
Todas as imagens deste manual são ilustrativas.

Suporte a clientes:(48) 2106 0006
Fórum: forum.intelbras.com.br
Suporte via chat: intelbras.com.br/suporte-tecnico
Suporte via e-mail: suporte@intelbras.com.br
SAC:0800 7042767
Onde comprar? Quem instala?:0800 7245115
Intelbras S/A – Indústria de Telecomunicação Eletrônica Brasileira
Rodovia SC 281, km 4,5 – Sertão do Maruim – São José/SC - 88122-001
CNPJ 82.901.000/0014-41 - www.intelbras.com.br
Indústria Brasileira